
Submitted:
23 November 2018
Posted:
26 November 2018
You are already at the latest version
Abstract
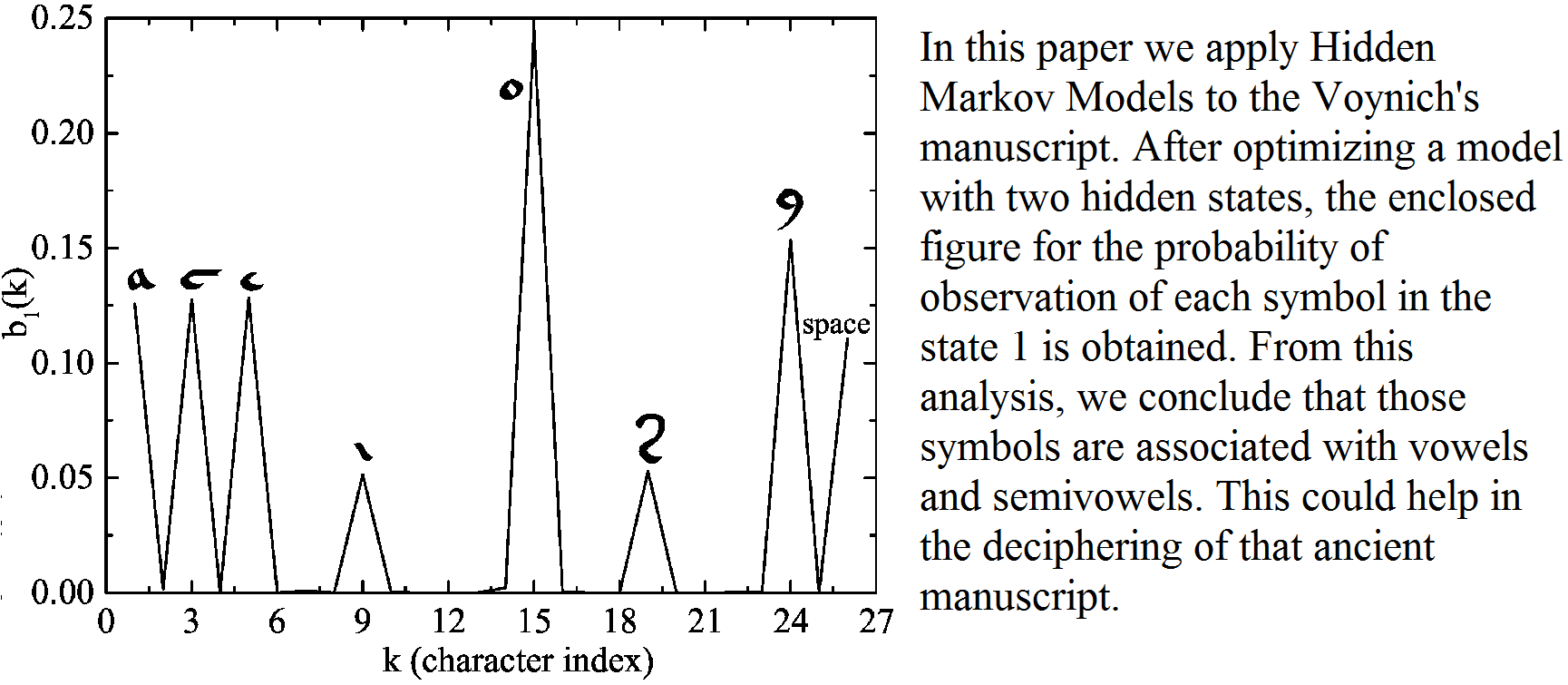
Hidden markov models are a very useful tool in the modelling of time series and any sequence of data. In particular, they have been successfully applied to the field of mathematical linguistics. In this paper, we apply a hidden markov model to analyze the underlying structure of an ancient and complex manuscript, known as Voynich's manuscript, that remains still undeciphered. By assuming a certain number of internal states representations for the symbols of the manuscript we train the network by means of the $\alpha$ and $\beta$-pass algorithms to optimize the model. By this procedure, we are able to obtain the so-called transition and observation matrices in order to compare with known languages concerning the frequency of consonant and vowel sounds. From this analysis, we conclude that transitions occur between the two states with similar frequencies to other languages. Moreover, the identification of the vowel and consonant sounds matches some previous tentative bottom-up approaches to decode the manuscript.
Keywords:
Hidden Markov Models
; Mathematical Linguistics
; Voynich Manuscript
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



