Submitted:
27 August 2020
Posted:
28 August 2020
You are already at the latest version
Abstract
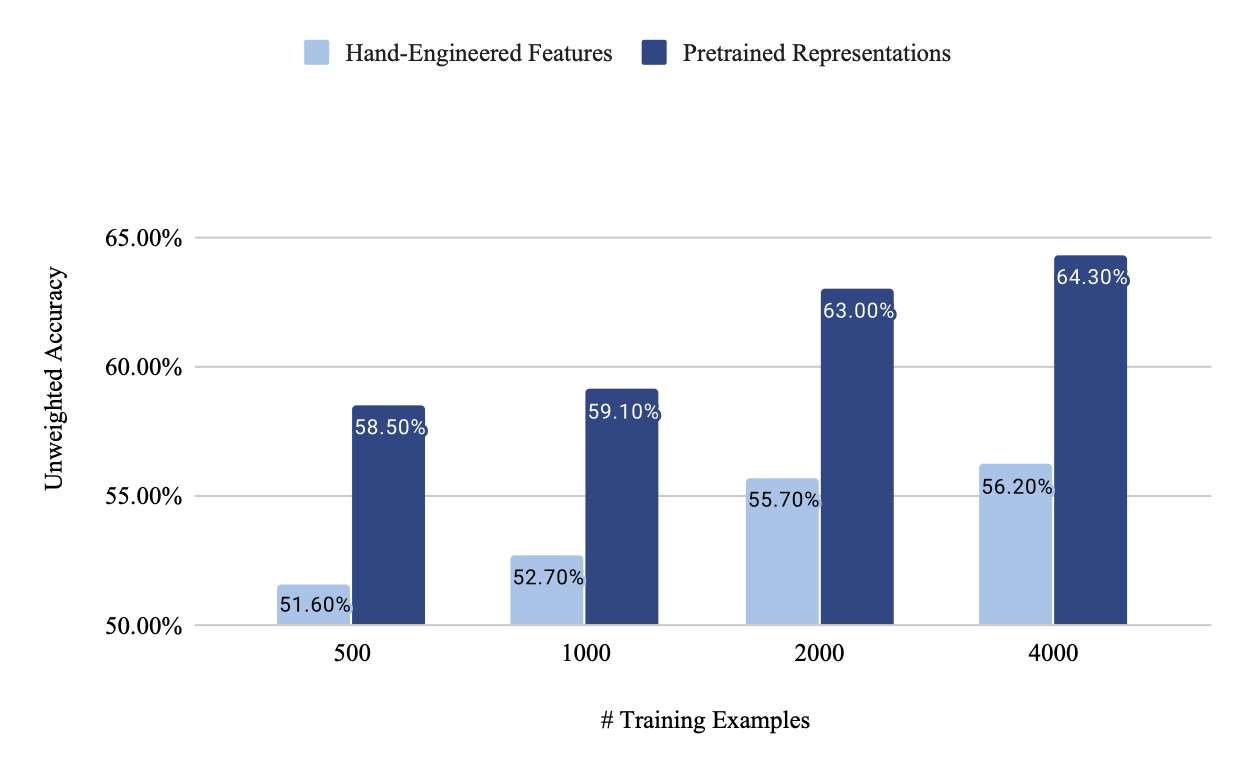
We propose a novel transfer learning method for speech emotion recognition allowing us to obtain promising results when only few training data is available. With as low as 125 examples per emotion class, we were able to reach a higher accuracy than a strong baseline trained on 8 times more data. Our method leverages knowledge contained in pre-trained speech representations extracted from models trained on a more general self-supervised task which doesn’t require human annotations, such as the wav2vec model. We provide detailed insights on the benefits of our approach by varying the training data size, which can help labeling teams to work more efficiently. We compare performance with other popular methods on the IEMOCAP dataset, a well-benchmarked dataset among the Speech Emotion Recognition (SER) research community. Furthermore, we demonstrate that results can be greatly improved by combining acoustic and linguistic knowledge from transfer learning. We align acoustic pre-trained representations with semantic representations from the BERT model through an attention-based recurrent neural network. Performance improves significantly when combining both modalities and scales with the amount of data. When trained on the full IEMOCAP dataset, we reach a new state-of-the-art of 73.9% unweighted accuracy (UA).
Keywords:
Speech Emotion Recognition
; Emotion AI
; Self-Supervised Learning
; Transfer Learning
; Low Resource Training
; wav2vec
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



