
Submitted:
27 October 2022
Posted:
01 November 2022
You are already at the latest version
Abstract
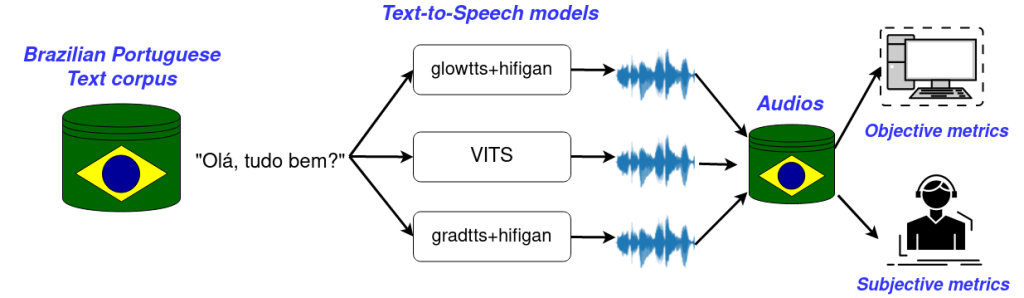
This paper compares the performance of three text-to-speech (TTS) models released from June 2021 to January 2022 in order to establish a baseline for Brazilian Portuguese. Those models were trained using dataset for Brazilian Portuguese. The experimental setup considers tts-portuguese dataset to fine-tune the following TTS models: VITS end-to-end model; glowtts and gradtts acoustic models both using hifi-gan vocoder. Performance metrics are arranged into objective and subjective metrics. As subjective metrics, the naturalness and intelligibility are measured based on the mean opinion score (MOS). Results shows that gradtts+hifigan model achieved naturalness of 4.07 MOS, close to performance of current commercial models.
Keywords:
text-to-speech
; naturalness
; intelligibility
; Brazilian Portuguese
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



