
Submitted:
27 February 2023
Posted:
27 February 2023
You are already at the latest version
Abstract
Using geometric considerations, we provide a clear derivation of the integral representation for the error function, known as the Craig formula. We calculate the corresponding power series expansion and prove the convergence. The same geometric means finally help to systematically derive handy formulas that approximate the inverse error function. Our approach can be used for applications in e.g. high-speed Monte Carlo simulations where this function is used extensively.
Keywords:
error function
; analytic function
; inverse error function
; approximations
MSC: 62E15; 62E17; 60E15; 26D15
1. Introduction
High-speed Monte Carlo simulations are used for a large spectrum of applications from mathematics to economy. As input for such simulations, the probability distribution are usually generated by pseudo-random number sambling, a method going back to a work of John von Neumann from 1951 [1]. In the era of “big data” such methods have to be fast and reliable, a sign of such neccessity being the release of the very first randomness Quside processing unit in 2023 [2]. Still, these samblings need to be cross-checked by exact methods, and for these the knowledge of analytical functions to describe the stochastic processes, among those the error function, are of tremendous importance.
By definition, a function is called analytic if it locally given by a converging Taylor series expansion. Even if a function itself turns out not to be analytic, its inverse can be analytic. The error function can be given analytically, one of these analytic expressions is the integral representation given by Craig in 1991 [3]. Craig mentioned this representation only in passing and did not give a derivation of it. In the following, there have been a couple of derivations of this formula [4,5,6]. In Sec. 2 we add a further one which is based on the same geometric considerations as employed in Ref. [7]. In Sec. 3 we give the series expansion for Craig’s integral representation and show the fast convergence of this series.
For the inverse error function, handbooks for special functions (cf. e.g., Ref. [8]) do not unveil such an analytic property. Instead, this function have to be approximated. Known approximations are dating back to the late 1960s and early 1970s [9,10]) and reach up to semi-analytical approximations by asymptotic expansion (cf., e.g., Refs. [11,12,13,14,15,16]. Using the same geometric considerations, in Sec. 4 we develop a couple of handy approximations which can easily be implemented in different computer languages, indicating the deviations from an exact treatment. In Sec. 5 we test the CPU time and give our conclusions.
2. Derivation of Craig’s integral representation
Ref. [7] provides an approximation for the Gaussian normal distribution obtained by geometric considerations. The same considerations apply to the error function which is given by the normal distribution via
Translating the results of Ref. [7] to the error function, one obtains the approximation of order p to be
where the values () are found in the intervals between and and can be optimised. In Ref. [7] it is shown that
for , and with times larger precision
where , . For the parameters taking the values of the upper limits of those intervals, it can be shown that the deviation is given by
Given the values with , in the limit the sum over n in Equation (2) can be replaced by an integral with measure to obtain
3. Power series expansion
The integral in Equation (6) can be expanded into a power series in ,
with
where . The coefficients can be expressed by the hypergeometric function, , also known as Barnes’ extended hypergeometric function. On the other hand, we can derive a constraint for the explicit finite series expression for that renders the series in Equation (7) to be convergent for all values of t. In order to be self-contained, intermediate steps to derive this constraint and to show the convergence are shown in the following. Necessary is Pascal’s rule
and the sum over the rows of Pascal’s triangle,
which can be shown by mathematical induction. The base case is obvious, as . For the induction step from n to we write the first and last elements and separately and use Pascal’s rule to obtain
This proves Equation (10). Returning to Equation (8), one has and, therefore,
For the result in Equation (8) this means that
i.e., the existence of a real number between and 1 such that . One has
and because of there is again a real number in the corresponding open interval so that
As the latter is the power series expansion of which is convergent for all values of t, also the original series is convergent and, therefore, with the limiting value shown in Equation (7). A more compact form of the power series expansion is given by
4. Approximations for the inverse error function
Based on the geometric approach from Ref. [7], in the following we describe how to find simple, handy formulas that, guided by higher and higher orders of the approximation (2) for the error function lead to more and more advanced approximation of the inverse error function. Starting point is the degree , i.e., the approximation in Equation (3). Inverting leads to , and using the parameter from Equation (3) gives
For the relative deviation from the exact value t is less than , for the deviation is less than . Therefore, for a more precise formula has to be used. As such higher values for E appear only in of the cases, this will not essentially influence the CPU time.
Continuing with , we insert into Equation (2) to obtain
where and are the same as for Equation (4). Taking the derivative of Equation (1) and approximating this by the difference quotient, one obtains
leading to . In this case, for in the larger interval the relative deviation is less than . Using instead of and inserting instead of one obtains with a relative deviation of maximally for the same interval. The results are shown in Figure 1.
The method to can be optimised by a method similar to the shooting method in boundary problems, giving dynamics to the calculation. Suppose that following one of the previous methods, for a particular argument E we have found an approximation for the value of the inverse error function at this argument. Using , one can adjust the improved result
by inserting and and calculating A for . In general, this procedure gives a vanishing deviation close to . In this case and for , in the interval the maximal deviation is slightly larger than while up to the deviation is restricted to . A more general ansatz
can be adjusted by inserting for and , and the system of equations
with , can be solved for A and B to obtain
For one obtains a relative deviation of , for the maximal deviation is . Finally, the adjustment of
leads to
where . For the relative deviation is restricted to while up to the maximal relative deviation is . The results for the deviations of () for linear, quadratic and cubic dynamical approximation are shown in Figure 2.
5. Conclusions
In order to test the feasibility and speed, we have coded our algorithm in the computer language C under Slackware 15.0 on an ordinary hp laptop. The dependence of the CPU time for the calculation is estimated by calculating the value times in sequence. The speed of the calculation of course turns does not depend on the value for E, as the precision is not optimised. This would have to be neccessary for a practical application. For an arbitrary starting value we perform this test, and the results are given in Table 1. An analysis of the table shows that a further step in the degree p doubles the run time while the dynamics for increasing n adds a constant value of approximately seconds to the result. Despite the fact the increase of the dynamics needs the solution of a linear system of equations and the coding of the result, this endeavour is justified, as by using the dynamics one can increase the precision of the result without loosing calculational speed.
Author Contributions
Conceptualization, D.M.; methodology, D.M. and S.G.; writing—original draft preparation, D.M.; writing—review and editing, S.G. and D.M.; visualization, S.G.; All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the European Regional Development Fund under Grant No. TK133.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- von Neumann, J.; von Neumann, J. Various Techniques Used in Connection with Random Digits. in Householder, A.S.; Forsythe, G.E.; and Germond, H.H. (eds.). Monte Carlo Methods. National Bureau of Standards Applied Mathematics Series 1951, 12, 36–38. [Google Scholar]
- Available online: https://quside.com/quside-unveils-the-worlds-first-randomness-processing-unit.
- Craig, J.W. A new, simple and exact result for calculating the probability of error for two-dimensional signal constellations. Proceedings of the 1991 IEEE Military Communication Conference 1991, 2, 571–575. [Google Scholar]
- Lever, K.V. New derivation of Craig’s formula for the Gaussian probability function. Electronics Letters 1998, 34, 1821–1822. [Google Scholar] [CrossRef]
- Tellambura, C; Annamalai, A. Derivation of Craig’s formula for Gaussian probability function. Electronics Letters 1999, 35, 1424–1425. [CrossRef]
- Stewart, S.M. Some alternative derivations of Craig’s formula. The Mathematical Gazette 2017, 101, 268–279. [Google Scholar] [CrossRef]
- Martila, D.; Groote, S. Evaluation of the Gauss Integral. Stats 2022, 5, 538–545. [Google Scholar] [CrossRef]
- Andrews, L.C. Special functions of mathematics for engineers. SPIE Press 1998, 110. [Google Scholar]
- Strecok, A.J. On the Calculation of the Inverse of the Error Function. Math. Comp. 1968, 22, 144–158. [Google Scholar]
- Blair, J. M; Edwards, C.A.; Johnson, J.H. Rational Chebyshev Approximations for the Inverse of the Error Function. Math. Comp. 1976, 30, 827–830. [Google Scholar] [CrossRef]
- Bergsma, W.P. A new correlation coefficient, its orthogonal decomposition and associated tests of independence. arXiv:math/0604627 [math.ST].
- Dominici, D. Asymptotic analysis of the derivatives of the inverse error function. arXiv:math/0607230 [math.CA].
- Dominici, D; Knessl, C. Asymptotic analysis of a family of polynomials associated with the inverse error function. arXiv:0811.2243 [math.CA].
- Winitzki, S. A handy approximation for the error function and its inverse. Available online: https://www.academia.edu/9730974/.
- Giles, M. Approximating the erfinv function. GPU Computing Gems Jade Edition, 2011; 109–116. [Google Scholar]
- Soranzo, A; Epure, E. Simply Explicitly Invertible Approximations to 4 Decimals of Error Function and Normal Cumulative Distribution Function. arXiv:1201.1320 [stat.CO].
Figure 1.
Relative deviations for the statical approximations
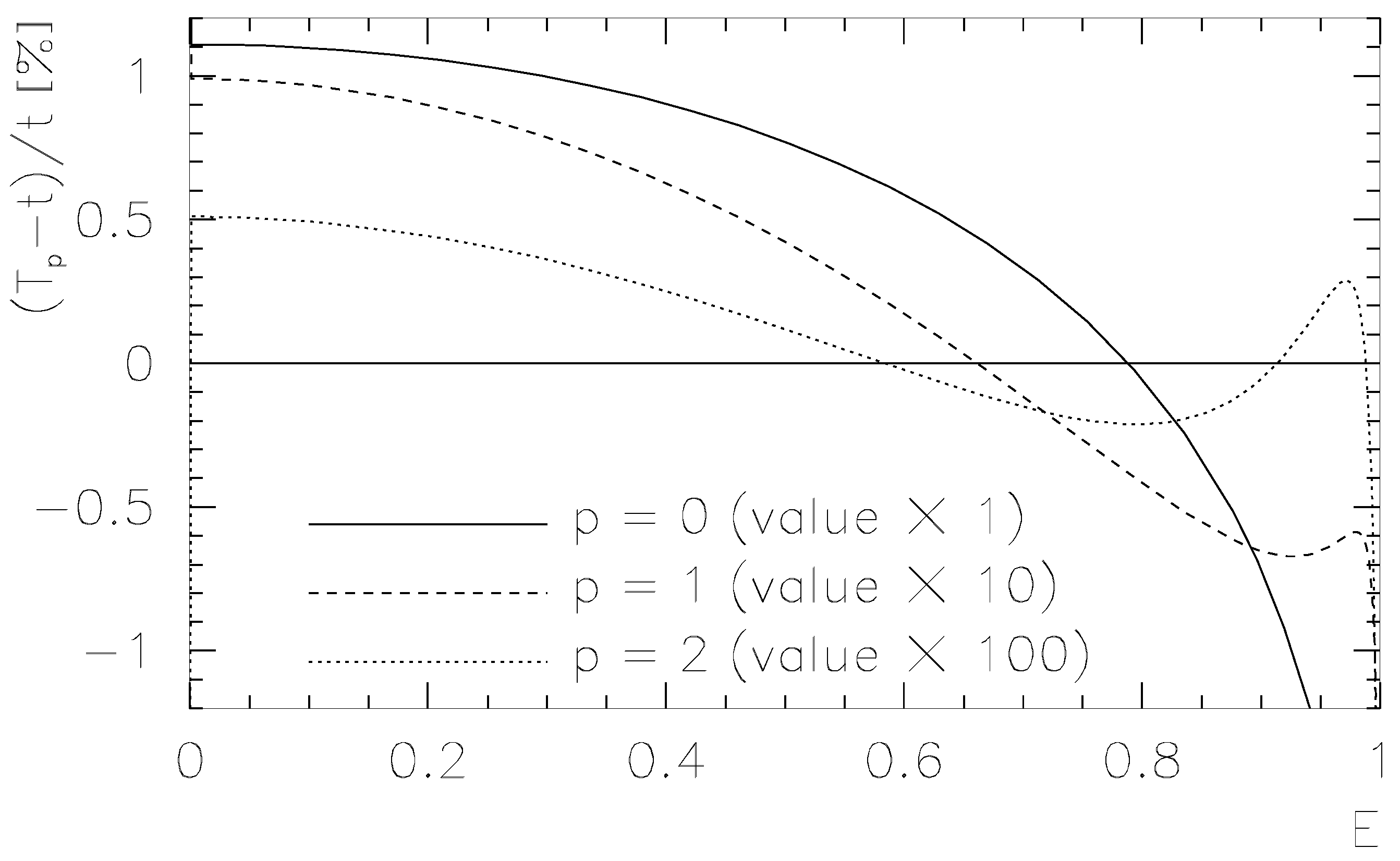
Figure 2.
Relative deviation for the dynamical approximations (the degree is chosen to be )
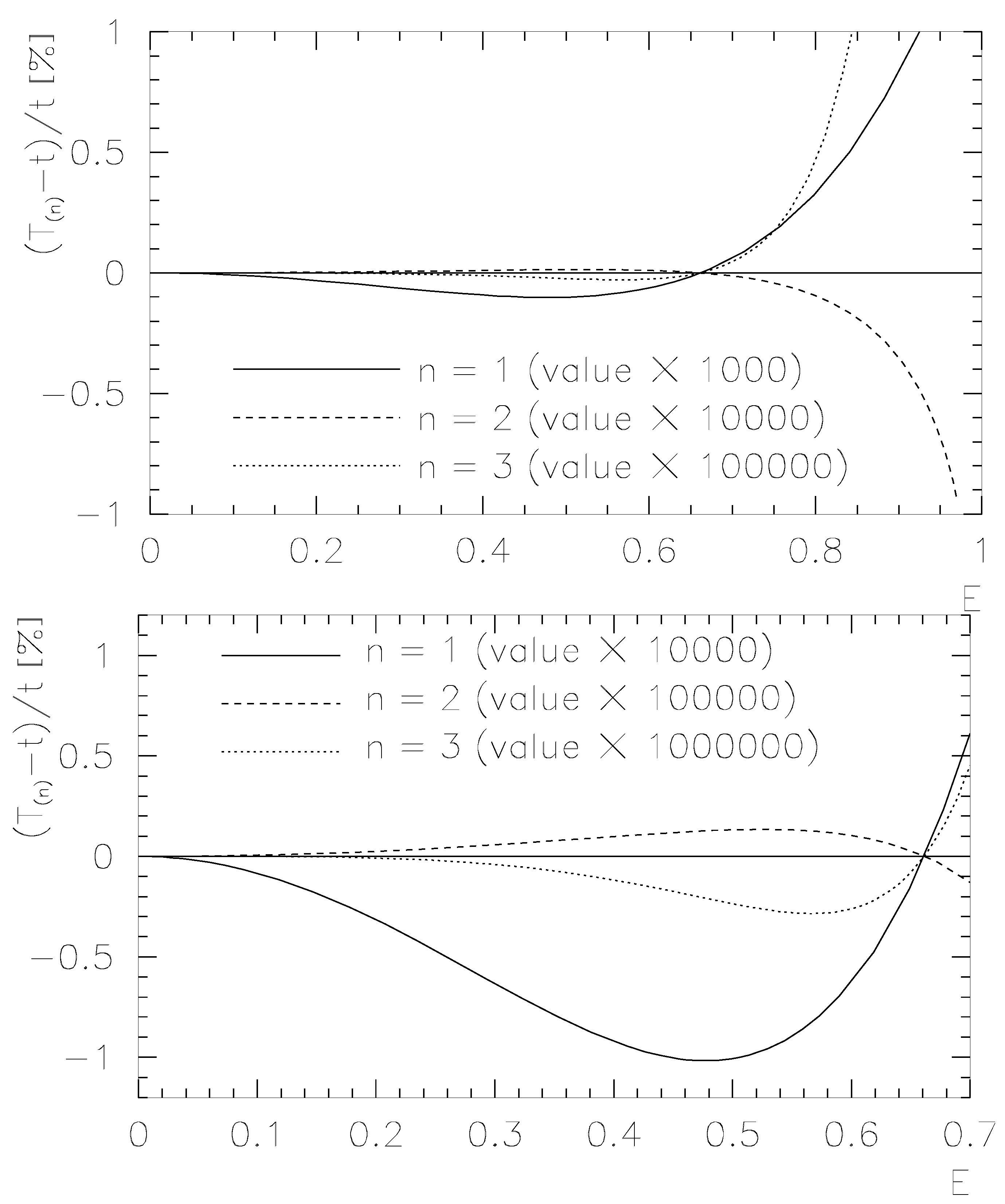

Table 1.
Run time experiment for our algorithm under C for and different values of n and p (CPU time in seconds). As indicated, the errors are in the last displayed digit, i.e., seconds.
Table 1.
Run time experiment for our algorithm under C for and different values of n and p (CPU time in seconds). As indicated, the errors are in the last displayed digit, i.e., seconds.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



