
Submitted:
31 May 2023
Posted:
01 June 2023
You are already at the latest version
Abstract
Soccer is type of sport that carries a high risk of injury. Injury is not only cause in the unlucky soccer carrier and also team performance as well as financial effects can be worse since soccer is a team-based game. The duration of recovery from a soccer injury typically relies on its type and severity. Therefore, we conduct this research in order to predict the probability of players injury type using machine learning technologies in this paper. Furthermore, we compare different machine learning models to find the best fit model. Supervised classification machine learning models are applied in this paper. We gathered information about 54 professional soccer players who are playing in the top five European leagues based on their career history.
Keywords:
Soccer
; data analysis
; soccer injury type
; classification machine learning models
1. Introduction
Football, also known as soccer, is a sport that has captured the hearts and minds of people all around the world. Due to its physical nature, soccer can be challenging to participate in and as a team all players are under pressure of different types of injuries ranging from head to toe since it requires from players multifunctioning such as: running, sprinting, jogging, etc. [18]. The type of injury can vary and may be either common or uncommon, depending on the specific type of injury [26]. Machine learning is a component of artificial intelligence that can be used in the field of sports medicine. By using machine learning models, it is feasible to predict and avoid injuries by taking into account various risk factors such as the player’s past injury record, the number of games played, the significance of the competition, etc. [1]. Numerous academic papers and articles have explored the utilization of machine learning models within the field of sports science, particularly in soccer, to address various injury-related challenges. These include tasks such as detecting injuries, assessing injury risks, monitoring performance, predicting injuries, and guiding rehabilitation processes [1,21,22,24,25]. For example, a multi-dimensional approach combining GPS data and machine learning has been developed for injury forecasting in soccer. This approach strikes a balance between accuracy and interpretability [8]. Moreover, in that approach compares the performance of Decision Tree (DT) with Random Forest (RF), Logistic Regression (LR), Autoencoder-Stacked WaveNet Regression (ASWR), Multi-Stacked WaveNet Regression (MSWR), forecasters, as well as four baseline methods [8]. In a soccer injury pre-diction study that utilized GPS technology and wearable devices a combination of rule-based and fuzzy rule-based approaches, along with the XGBoost algorithm as a machine learning baseline, was implemented [25].
Numerous academic articles examining the prediction of soccer injuries have predominantly emphasized the collection of data via GPS technology or similar electronic devices. Nevertheless, challenges arise in acquiring consistent data using GPS technology for soccer teams due to limitations, permission from soccer teams, time-intensive procedures, and potentially prohibitive cost of such devices, rendering them unsuitable for all teams. Furthermore, there is a need for further research to focus on predicting specific types of injuries.
One of the main objectives of this paper is to showcase the potential of collecting data through professional soccer websites that data readily available on the web as an alternative to using GPS technology or other mechanical devices. Additionally, this paper introduces a method for predicting specific types of soccer injuries among players. In order to achieve this goal, we evaluate and compare different classification machine learning models in our experiment. The results of our study provide valuable insights into the key factors that contribute to injury occurrences. This information can be advantageous not only for the future careers of soccer players but also for coaches, scouts, team directors, and even fans who aspire to witness their favorite players perform without interruptions.
2. Related Work
Research conducted in the past has demonstrated that soccer is associated with a high incidence of injuries and injury rates comparing with other sport types such as hockey, volleyball, handball, rugby, and even combat sports such as judo and boxing, which primarily involve physical combat and close contact between opponents [2,3]. Moreover, it is studied that soccer injury has negative effects, one of them is decreasing the number of active times in the field and other is significant medical expenses and time consuming [4,5]. Numerous studies have been conducted to identify different types of sports-related injuries; however, the large volume of data involved in these researches have posed a significant challenge in terms of data management and analysis. Fortunately, the advent of machine learning technologies has made data collection and handling significantly more manageable, allowing researchers to more effectively analyze large volumes of data related to sports injuries. While machine learning is a relatively new area of study within the fields of sports science and sports medicine, its potential applications are rapidly gaining recognition as a powerful tool for analyzing and addressing various aspects of sports performance and injury prevention.
In 2014, one of the earliest studies on the use of machine learning in soccer was published, with a primary focus on the evaluation of the technical and tactical abilities of teams during the UEFA EURO2012 tournament [6]. Machine learning has found numerous applications in the field of sports science, including predicting club performance, forecasting game outcomes, and estimating club attendance [6,10,11,12,13]. In addition, machine learning has also been used in sports medicine, with a focus on predicting and preventing soccer injuries [7,8,9]. Moreover, machine learning models have the potential to enhance the productivity and effectiveness of professional soccer clubs, particularly in terms of training methodologies and developing more cohesive game strategies [14,29,30]. To realize these objectives, professionals in the field are utilizing cutting-edge technologies such as GPS tracking systems and inertial movement sensors (IMU sensors) along with markers for assessing fatigue and psychological well-being, and screening tests [8,25,27]. Additionally, the best analytical methods are being employed to make sense of the vast amounts of data generated through data collecting technologies [8,21,25,27].
3. Data for Predicting Soccer Injury
In this section, we present the data used in this paper. Additionally, we provide information on the soccer injury types and features.
3.1. Data Introduction
Data is a crucial component in every machine learning model. The effectiveness and accuracy of the model heavily rely on the quality and quantity of the data utilized for training. Machine learning algorithms learn through the data they receive, which emphasizes the importance of proper data selection.
This paper focuses on the analysis of 54 professional soccer players who have been playing in the highest-ranking European football leagues, including the English Premier League, Spanish La Liga, Italian Serie A, German Bundesliga, French League 1. The dataset we utilized comprised of soccer players who have a significant impact on game outcomes. There are 54 players included in the dataset, and they occupy various positions in the game. The dataset consists of 54 players, with 20 players identified as center-forwards, 10 as left-wingers, 5 as right-wingers, 3 as second-strikers, 6 as attacking midfielders, and the remaining 10 as central midfielders.
Additionally, in order to acquire information on the career and injury records of the players, we made use of a specialized website for soccer player’s information [19]. The website is a useful resource to gain significant knowledge about professional soccer players, including their career statistics, transfer history, market value, and injury records.
3.2. Data for Soccer Injury
A soccer injury is defined as any physical ailment that resulted in a player being taken out of a game, sitting out a game, or being sufficiently impaired to require medical attention [20]. A soccer injury is defined as any physical ailment that resulted in a player being taken out of a game, sitting out a game, or being sufficiently impaired to require medical attention [28]. Moreover, contact injuries and non-contact injuries are the two main types of soccer injuries. Contact injuries are caused by collisions with objects or other players, whereas non-contact injuries result from factors such as repetitive strain, poor technique, or sudden changes in movement. The primary objective of this paper is to concentrate on the four predominant injury types that are commonly experienced by professional soccer players. These four types of injuries include thigh injury, ankle injury, muscle injury, and knee injury. Our research paper utilized the career and injury history data of soccer players from our dataset.
Table 1 shows an example of dataset that depicts the career and injury history of professional soccer players, as examined in our study. Our dataset consists of a total of 12 columns. The “Player” column displays the names of the players in accordance with the season of their career, which is indicated in the “Season” column. The other columns are as follows: “Total” indicates the total number of games played in a particular season, while “Minutes” represents the total number of minutes played across all the games in that season. Our dataset encompasses FIFA, UEFA, and team games in the top five leagues due to their significant influence on the occurrence of soccer injuries among players.
FIFA games, including renowned tournaments like the World Cup, Continental Cup, and Olympic Games, hold significant importance for several reasons. These rea-sons include the opportunity for players to represent their country, evoke national pride, enjoy fan support, and engage in high-level competition. Moreover, in top leagues, matches typically take place on weekends, while UEFA games are scheduled for Tuesdays and Wednesdays. This arrangement results in players having to play at least 2 or 3 games per week. Consequently, the UEFA games can increase the risk of soccer players getting injured due to the added workload and potential overexertion. Furthermore, considering the factors mentioned above matches in FIFA, UEFA, and the top five leagues are deemed important and can have an impact on the likelihood of getting injured. The number of games played in these competitions is reflected in the “Important” column of the table. The “Injury” column indicates the type of injury, while the “Past4” to “Past1” columns indicate the type of injuries the player had in the past.
Furthermore, we used various machine learning models, which we compared in order to identify the optimal fit for predicting different types of soccer injuries. Our objective is to enhance our comprehension of the elements that contribute to such injuries, with the ultimate goal of devising more efficacious tactics for preventing injuries among soccer players
4. Machine Learning Models and Comparative Evaluation
This section presents a summary of the machine learning models and their categories that are applicable in the prediction of soccer injuries. Moreover, our study involved the comparison of numerous machine learning models to determine the most suitable one for predicting different types of soccer injuries.
4.1. Machine Learning Models
Machine learning models are algorithms that can automatically learn from data without being explicitly programmed. These models use statistical techniques to identify patterns in data, and with sufficient training, can make accurate predictions or decisions on new data. Machine learning can be classified into different types depending on the nature of the problem being addressed, the type of data available, and the learning process involved. These types of machine learning encompass supervised learning, unsupervised learning, semi-supervised learning, reinforcement learning, and deep learning.
In our study, we employed a supervised machine learning model. This is because supervised machine learning models are trained using labeled data, which indicates that the input data is provided with corresponding output values. However, supervised machine learning can be divided into two main categories: classification and regression. Classification is used to predict which category or class a new data point belongs to, based on its features. Regression, on the other hand, is used to predict a numerical value, such as a price or a score, based on the input features. However, this type of model is used when the output variable is continuous and cannot be classified into categories. Therefore, we utilized supervised classification machine learning models in our study due to the characteristics of our dataset and the objectives of our research. We employe a range of machine learning models, including Decision Tree, Random Forest, K-Nearest Neighbors (KNN), and Naive Bayes. Each of these classification models possesses its own set of strengths and weaknesses, and the selection of which one to utilize hinges upon the characteristics of the data and the specific problem being addressed. Decision trees employ a hierarchical structure to represent decisions and their potential out-comes. Conversely, random forests are ensemble methods that combine multiple decision trees to enhance accuracy and mitigate overfitting. K-Nearest Neighbors (KNN) is a non-parametric technique that assigns data points to classes based on the classes of their nearest neighbors in the feature space. KNN can be applied for both classification and regression tasks. Naive Bayes is a probabilistic model that leverages Bayes’ theorem to estimate the probability of a sample belonging to a particular class.
4.2. Comparative Evaluation
Classification is one of the fundamental problems in machine learning, and it involves assigning a class or category to a given data point. In this context, we used various classification machine learning models to classify data points based on their features.
As part of our study, we employed a data splitting approach to effectively assess the performance of our machine learning model. In order to achieve this, we utilized the `train_test_split` function from the `sklearn. model selection` module. By specifying a test size of 30%, we ensured that a significant portion of our dataset was dedicated to evaluating the model’s generalization capabilities.
Consequently, 70% of the data was allocated for training the model. This larger portion allowed the model to learn patterns and relationships within the data, facilitating its ability to make accurate predictions or classifications when exposed to new, unseen instances.
By dividing our data into separate training and testing sets, we were able to train the model on the training data, fine-tuning its parameters and optimizing its performance. The testing data, on the other hand, served as an independent benchmark to evaluate how well the model generalized to new, unseen data. The precise separation of data into training and testing subsets plays a vital role in objectively assessing the model’s performance, identifying overfitting, and validating its capability to handle real-life situations. It guarantees that the model is dependable and proficient when confronted with unfamiliar data outside of its training set.
Our study involved a comparison of the aforementioned models, utilizing two different approaches. The first approach involved applying three distinct types of injuries, whereas the second approach utilized four different types of injuries. We conducted this comparison to assess the performance of each model under different injury scenarios and to determine which model is better suited for each type of approaches.
Figure 1 depicts the representation of the first approach and second approaches, which included three and four different types of injury categories. The graph shows the variation of machine learning models with respect to their accuracy scores. In the first approach, the K-Nearest Neighbors (KNN) model performed the best on our dataset, achieving an accuracy score of 70%. The second-best model was the Decision Tree model, which achieved an accuracy score of 69%. The Random Forest model achieved an accuracy score of 66%, whereas the Naive Bayes model had the lowest accuracy score of 58% compared to the other models.
In the second approach it is evident that the second approach involved four different injury categories, and illustrates the disparities in accuracy scores among the various machine learning models. The KNN and Decision models obtained the highest accuracy scores of 70%, followed by the Random Forest model with an accuracy score of 62%. Among the models, the Naive Bayes model had the lowest accuracy score of 56%.
5. Experimental Evaluation
In the Comparative Evaluation subsection, four different machine learning models were compared using two different approaches. It was determined that KNN was the most suitable machine learning model for our dataset in both approaches.
In this section, the KNN model is utilized to determine the probability of each class. The model is specifically designed for 3 classes, as it has been found to have a higher accuracy compared to when it is used with 4 classes. In our study, we implemented a novel approach to predict injury types for individual players. We leveraged the historical injury data available to public and organized the players into groups based on their injury history. By analyzing the frequency of specific injury types, we aimed to identify patterns and tendencies within the dataset.
For instance, if a player had experienced a higher number of ankle injuries compared to other players, our analysis indicated that there was a higher likelihood of that player sustaining an ankle injury in the upcoming season. This information enabled us to make predictions regarding the potential injury risks faced by individual players.
Finally, the decision is made based on the probabilities of each class and the groupings of players.
5.1. Probability of Classes
Initially, we utilize three categories of injury and leverage the scikit-learn library, which is accessible in Python, to determine the probability of each injury type. Moreover, we analyzed three categories of injuries: non-injury, ankle injury, and muscle injury. The probability values for each category are shown in Table 2. We observed that the class with the highest probability among the others is non-injury, which has a probability of 60%. Moreover, ankle and muscle injury have the same probability, which is 20% respectively.
In addition to displaying the probability of each injury type, we have also included a classification report in Table 3. The scikit-learn library, which is a widely used Python library, was utilized to generate a classification report that would enable us to evaluate the effectiveness of our model.
This report provided us with a comprehensive overview of the model’s performance by presenting a variety of metrics such as precision, recall, and F1-score for each injury category. By examining these metrics, we were able to identify areas where the model performed well and where it fell short. This information can be used to refine and improve the model’s performance in future iterations. The use of scikit-learn library for generating the classification report made the evaluation process efficient and streamlined, enabling us to gain insights into the model’s performance with ease.
Moreover, Precision was used to evaluate the true positive rate among the total predicted positives for each injury category. The precision score for “non-injury” was 0.74, indicating that only 74% of predicted non-injury cases were actually correct. Recall, or sensitivity, was also computed for each category to measure the proportion of true positives among all actual positives. For “non-injury,” the recall score was 0.89, which means the model could only identify 89% of actual non-injury cases. The F1-score, a comprehensive measure of the model’s accuracy that combines precision and recall, was also calculated and resulted in 81%. Finally, the support column listed the number of instances of each injury type in the dataset, revealing insights into the dataset’s composition. It was found that the number of “non-injury” instances was 171. These metrics are crucial for evaluating the model’s performance and determining its ability to accurately detect various types of injuries.
5.2. Injury Susceptibility Assessment
In the above subsection, we have successfully calculated the probability for each class, using the KNN machine learning model, which we determined to be the most appropriate for our dataset.
In the following subsection, we will utilize the probability information obtained to identify players who may be susceptible to specific types of injuries in our dataset of 54 professional soccer players. To accomplish this, we will divide the players into three groups based on the three classes previously established and we consider the number of cases that players got injury with that specific type. Our model will be used to select the top five players who have already sustained injuries with those specific types. The top five players who have already suffered injuries with those specific types will be prioritized, as they have the highest risk of being injured again.
Table 4 presents the top five players in our dataset who are the least likely to sustain injuries. Additionally, the table reveals that the count column represents the number of instances where players did not suffer any injuries over the course of their career.
Based on the probability information obtained, all five players listed in the table have a 60% chance of not getting injured according to our model. Moreover, it is worth mentioning that based on the count column data, P. Aubameyang has the lowest probability of getting injured with 20 non-injury cases, whereas among the top five players with the least likelihood of sustaining injuries, T. Muller has the highest probability with only 15 non-injury instances.
By utilizing the method that we employed, we generated a group for class 2, which comprises players who have sustained ankle injuries.
Table 5 displays information on the top five players who have experienced the highest number of ankle injuries in our dataset, in comparison to other players. The data in Table 2, combined with the probability data obtained earlier, suggests that M. Reus and J. Felix are the players with the highest chance of suffering an ankle injury among those listed with 7 ankle injury cases, as there have been seven instances of ankle injuries and a 20% likelihood for both players. Furthermore, our model predicts that P. Pogba, H. Kane, and G. Bale have a reduced likelihood of experiencing an ankle injury compared to the other players, as there are only five instances of ankle injury associated with them.
Finally, we employed the same methodology to create a group of players who have suffered from muscle injuries. Table 6 shows the top five players who have experienced the highest number of muscle injuries, when compared to the other players in our dataset.
Moreover, based on Table 6 and the probability information gathered earlier, it can be inferred that M. Reus is the player most prone to muscle injuries, with a probability of 20% and 13 instances of muscle injuries compared to other players. Conversely, P. Dybala is the player with the least probability of sustaining a muscle injury among the top five players mentioned in the table, as there are only seven instances of muscle injuries associated with him.
6. Discussion
This section will focus on examining the outcomes that were obtained through our experiments, identifying potential directions for future studies, and contemplating the broader impacts and limitations of our work.
6.1. Interpretation of Results
The objective of our research was to propose a method for predicting the types of soccer injuries by using classification machine learning models. We conducted a study to identify the most suitable machine learning models for our data by comparing the performance of four different models: Decision Tree, Naive Bayes, Random Forest, and KNN. After evaluating the models, we found that KNN was the most effective model for our analysis.
Using KNN, we were able to provide the probability of each injury type, including non-injury, ankle injury, and muscle injury. Additionally, we provided a classification report to assess the effectiveness of the model. Finally, we were able to identify the injury types for individual players based on the model’s predictions.
6.2. Limitations
While our study showed promising results, it is important to acknowledge several limitations that could impact the interpretation and generalizability of our findings.
Firstly, we did not use any data collection devices, such as GPS or sensors, to gather information on the players. Additionally, the dataset was collected from a single professional soccer website [19], which may have introduced biases and may not be representative of other websites or sources of data.
Secondly, our model relied on a limited set of features, which could have limited its ability to capture more complex relationships in the data. Furthermore, the feature selection process may have missed relevant features that could have improved the accuracy of our model.
Lastly, our dataset did not include all possible variables that could impact the outcome of interest, such as individual player characteristics, environmental factors, and player behavior. As a result, the accuracy and generalizability of our model may have been limited.
6.3. Future Works
Although our study has provided some promising results, there are still limitations that should be addressed in future research. In the previous subsection, we discussed the limitations of our research. However, we plan to address these limitations in future work to improve our ability to predict a wider range of injury types beyond the three types considered in our study. By doing so, we can enhance the usefulness and applicability of our research for injury prevention and management in soccer players. For example, we used data from only one professional soccer website, which may have introduced biases and limited the generalizability of our findings. Therefore, future research could incorporate data from multiple sources, including different leagues and levels of play, to improve the representativeness of the data.
Additionally, the use of data collection devices such as GPS and sensors could provide more accurate and detailed information about player movements and injury risk. Therefore, incorporating such devices in future studies could help to develop more comprehensive injury prediction models.
Another possible area for future research is to explore alternative feature selection methods and include a broader range of variables in the models. This could help to capture more complex relationships in the data and improve the accuracy of the models.
Overall, by addressing these limitations and exploring new avenues for research, we can improve our understanding of injury prediction in soccer and develop more effective injury prevention strategies for players.
7. Conclusions
The application of machine learning technologies in the domains of sports science and sport medicine has been increasing significantly in recent years. These technologies have been leveraged to improve various aspects of sports performance, injury prevention, and rehabilitation. One of the sports that have been benefiting from machine learning technologies in soccer.
The main goal of this paper is to ascertain the chances of different types of injuries that professional soccer players may encounter during the forthcoming season.
Ultimately, we managed to forecast the likelihood of each of the three injury categories, with non-injury having a 60% probability, while ankle and muscle injuries both having a 20% probability. Furthermore, our findings revealed that P. Aubameyang had the lowest probability of sustaining an injury compared to other players in our dataset, with a 60% chance of not getting injured. On the other hand, M. Reus and J. Felix had the highest likelihood of experiencing an ankle injury among all soccer players in our dataset, with a 20% chance of injury. Additionally, our results indicated that M. Reus had the highest probability of suffering a muscle injury, with a 20% chance of getting injured.
The practical implications of our research are significant for soccer teams, as it provides useful insights into injury prevention strategies. Our work can help medical and data analytics staff gain a better understanding of the likelihood of different injury types occurring among their players. This knowledge can be used to create tailored injury prevention programs and regulations that address the specific needs and risks of each team member, thereby promoting player safety. The models we developed can be used to identify players who are at a higher risk of injury and provide them with targeted interventions. Coaches can also use this information to adjust their training routines and strategies to minimize the risk of injuries. Furthermore, sports organizations can utilize this information to develop regulations aimed at reducing the likelihood of certain types of injuries, such as head injuries, through equipment requirements or rule changes.
References
- Sigurdson, H.; Chan, H. Machine Learning applications to Sports Injury. In Proceedings of the 9th International Conference on Sport Sciences Research and Technology Support (icSPORTS 2021); pp. 157–168, ISBN 978-989-758-539-5, ISSN 2184-3201.
- Soccer injury rates continue five-year climb. The NCAA News 1993, 5.
- Rahnama, N.; Reilly, T.; Lees, A. Injury risk associated with playing actions during competitive soccer. Br J Sports Med 2002, 36, 354–359. [Google Scholar] [CrossRef]
- Yde, J.; Nielsen, A.B. Sports injuries in adolescents’ ball games: Soccer, handball and basketball. Br J Sports Med 1990, 24, 51. [Google Scholar] [CrossRef] [PubMed]
- Pritchett, J.W. Cost of high school soccer injuries. Am J Sports Med 1981, 9, 64–66. [Google Scholar] [CrossRef] [PubMed]
- Wang, M. Evaluating technical and tactical abilities of football teams in Euro 2012 based on improved information entropy model and SOM neural networks. Int J Multimedia Ubiquitous Eng. 2014, 9, 293–302. [Google Scholar] [CrossRef]
- Ayala, F.; López-Valenciano, A.; Gámez Martín, J.A.; De Ste Croix, M.; Vera-Garcia, F.J.; García-Vaquero, M.D.P.; Ruiz-Pérez, I.; Myer, G.D. A preventive model for hamstring injuries in professional soccer: Learning algorithms. Int J Sports Med. 2019, 40, 344–353. [Google Scholar] [CrossRef]
- Rossi, A.; Pappalardo, L.; Cintia, P.; Iaia, F.M.; Fernàndez, J.; Medina, D. Effective injury forecasting in soccer with GPS training data and machine learning. PLoS ONE 2018, 13, e0201264. [Google Scholar] [CrossRef]
- Oliver, J.L.; Ayala, F.; De Ste Croix, M.B.A.; Lloyd, R.S.; Myer, G.D.; Read, P.J. Using machine learning to improve our understanding of injury risk and prediction in elite male youth football players. J Sci Med Sport. 2020, 23, 1044–1048. [Google Scholar] [CrossRef]
- Goes, F.R.; Brink, M.S.; Elferink-Gemser, M.T.; Kempe, M.; Lemmink, K.A.P.M. The tactics of successful attacks in professional association football: Large-scale spatiotemporal analysis of dynamic subgroups using position tracking data. J Sports Sci. 2021, 39, 523–532. [Google Scholar] [CrossRef]
- Dick, U.; Brefeld, U. Learning to Rate Player Positioning in Soccer. Big Data 2019, 7, 71–82. [Google Scholar] [CrossRef]
- Şahin, M.; Erol, R. Prediction of Attendance Demand in European Football Games: Comparison of ANFIS, Fuzzy Logic, and ANN. Comput Intell. 2018, 7, 5714872. [Google Scholar] [CrossRef]
- Montoliu, R.; Martín-Félez, R.; Torres-Sospedra, J.; Martínez-Usó, A. Team activity recognition in Association Football using a Bag-of-Words-based method. Hum Mov Sci. 2015, 41, 465–478. [Google Scholar] [CrossRef] [PubMed]
- Gabbett, H.T.; Windt, J.; Gabbett, T.J. Cost-benefit analysis underlies training decisions in elite sport. Br J Sports Med. 2016, 50, 1291–1292. [Google Scholar] [CrossRef] [PubMed]
- Gabbett, T.J.; Nassis, G.P.; Oetter, E.; Pretorius, J.; Johnston, N.; Medina, D.; Rodas, G.; Myslinski, T.; Howells, D.; Beard, A.; Ryan, A. The athlete monitoring cycle: A practical guide to interpreting and applying training monitoring data. Br J Sports Med. 2017, 51, 1451–1452. [Google Scholar] [CrossRef] [PubMed]
- Nassis, G.P.; Massey, A.; Jacobsen, P.; Brito, J.; Randers, M.B.; Castagna, C.; Mohr, M.; Krustrup, P. Elite football of 2030 will not be the same as that of 2020: Preparing players, coaches and support staff for the evolution. Scand J Med Sci Sports 2020, 30, 962–964. [Google Scholar] [CrossRef]
- Paul, D.J.; Nassis, G.P. Testing strength and power in soccer players: The application of conventional and traditional methods of assessment. J Strength Cond Res. 2015, 29, 1748–1758. [Google Scholar] [CrossRef]
- Wong, P.; Hong, Y. Soccer Injury in the lower extremities. Br J Sports Med 2005, 39, 473–482. [Google Scholar] [CrossRef]
- Transfermarkt GmbH &, Co. KG 2000-2023, Wandsbeker Zollstraße 5a, 22041 Hamburg, 2022–2023. Available online: https://www.transfermarkt.com/.
- Kibler, W.B. Injuries in adolescent and preadolescent soccer players. Med SciSports Exerc 1993, 25, 1330–1332. [Google Scholar] [CrossRef]
- Catapult. Catapult: Provider of Wearable Technology for the Management of Athletes, 2022. Available online: https://www.catapultsports.com/.
- Rossi, A.; Pappalardo, L.; Cintia, P. A Narrative Review for a Machine Learning Application in Sports: An Example Based on Injury Forecasting in Soccer. Sports 2021, 10, 5. [Google Scholar] [CrossRef]
- Bengtsson, H.; Ekstrand, J.; Hägglund, M. Muscle injury rates in professional football increase with fixture congestion: An 11-year follow-up of the UEFA Champions League injury study. Br. J. Sports Med. 2013, 47, 743–747. [Google Scholar] [CrossRef]
- Lyubovsky, A.; Liu, Z.; Watson, A.; Kuehn, S.; Korem, E.; Zhou, G. A Pain Free Nociceptor: Predicting Football Injuries with Machine Learning. Smart Health. Available online: https://www.sciencedirect.com/journal/smart-health.
- Piłka, T.; Grzelak, B.; Sadurska, A.; Górecki, T.; Dyczkowski, K. Predicting Injuries in Football Based on Data Collected from GPS-Based Wearable Sensors. Sensors 2023, 23, 1227. [Google Scholar] [CrossRef] [PubMed]
- SOCCER INTER-ACTION SL © 2017, European Regional Development Fund, 2022–2023. Available online: https://soccerinteraction.com/the-most-serious-injuries-in-football.
- Majumdar, A.; Bakirov, R.; Hodges, D.; Scott, S.; Rees, T. Machine Learning for Understanding and Predicting Injuries in Football. Sports Medicine - Open 2022, 8, 73. [Google Scholar] [CrossRef] [PubMed]
- Gabbett, T.J. The training-injury prevention paradox: Should athletes be training smarter and harder? Br. J. Sports Med. 2016, 50, 273–280. [Google Scholar] [CrossRef] [PubMed]
- Hägglund, M.; Waldén, M.; Hedevik, H.; Kristenson, K.; Bengtsson, H.; Ekstrand, J. Injuries affect team performance negatively in professional football: An 11-year follow-up of the UEFA Champions League injury study. Br. J. Sports Med. 2013, 47, 738–742. [Google Scholar] [CrossRef]
- Eliakim, E.; Morgulev, E.; Lidor, R.; Meckel, Y. Estimation of injury costs: Financial damage of English Premier League teams’ underachievement due to injuries. BMJ Open Sport Exerc. Med. 2020, 6, e000675. [Google Scholar] [CrossRef]
Figure 1.
Representation of first and second approaches.
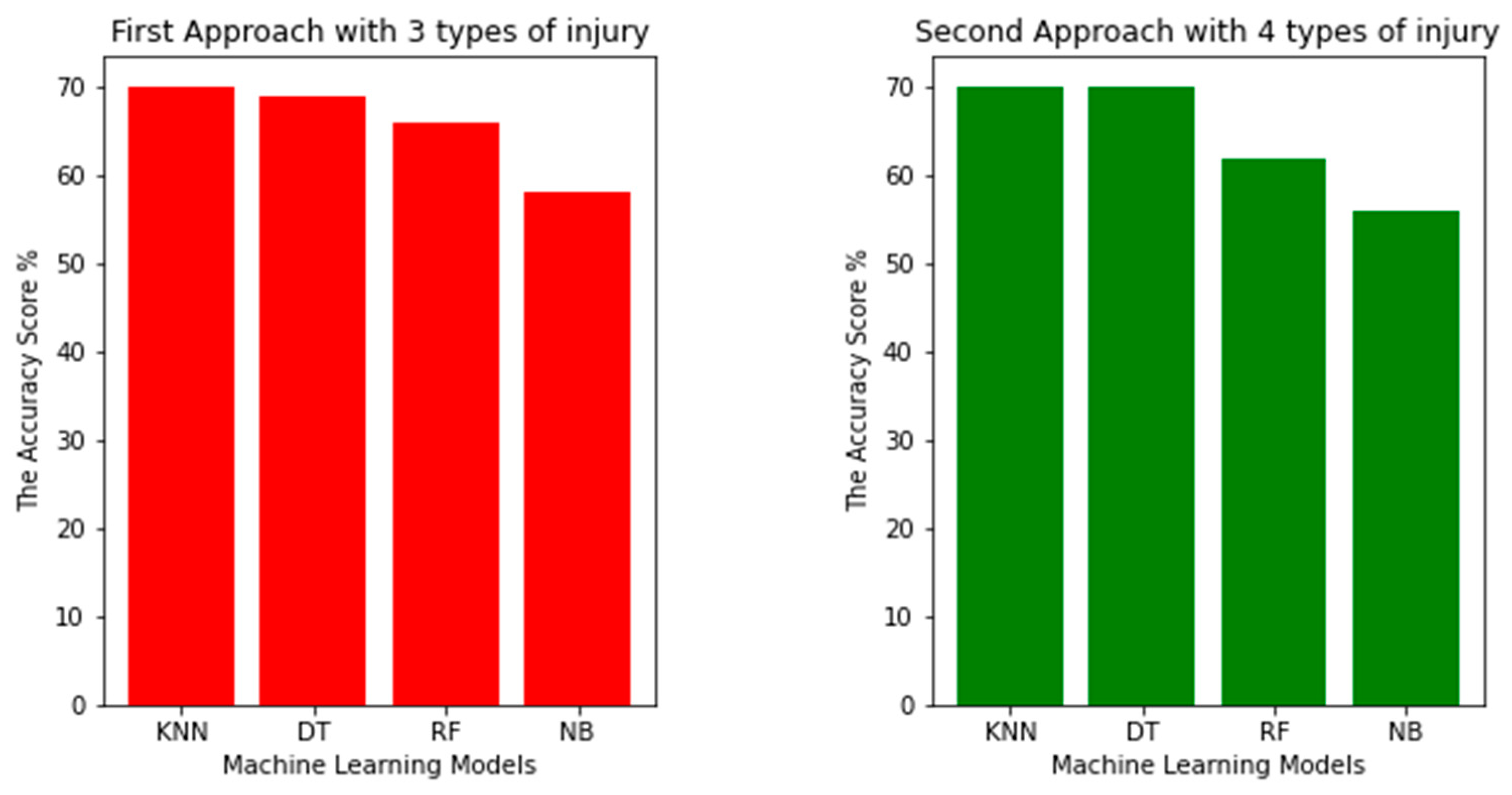

Table 1.
Example of Soccer Players Dataset.
| Player | Season | Total | Minutes | FIFA | CHL/EL | Important | Past4 | Past3 | Past2 | Past1 | Injury |
|---|---|---|---|---|---|---|---|---|---|---|---|
| G. Bale | 2006-2007 | 46 | 3948 | 3 | 0 | 39 | 0 | 0 | 0 | 0 | 0 |
| G. Bale | 2015-2016 | 38 | 2941 | 7 | 8 | 37 | 1 | 0 | 2 | 2 | 2 |
| C.Immobile | 2020-2021 | 56 | 4349 | 15 | 5 | 46 | 0 | 0 | 2 | 0 | 0 |
| C.Immobile | 2021-2022 | 41 | 3433 | 1 | 7 | 39 | 0 | 1 | 0 | 1 | 0 |
| E. Hazard | 2017-2018 | 63 | 4661 | 11 | 8 | 48 | 2 | 2 | 0 | 1 | 0 |
Note. 0: Non-injury, 1: Ankle-injury, 2: Muscle-injury.
Table 2.
Probability of Injury Type.
 |
Table 3.
Classification report.
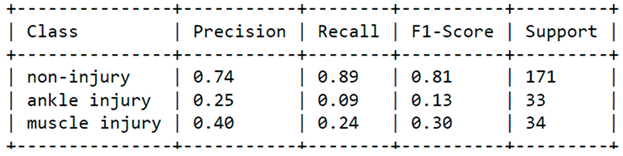 |
Table 4.
Top-5 non-injury players.
 |
Table 5.
Top-5 Ankle Injury players.
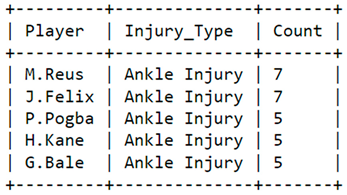 |
Table 6.
Top-5 Muscle Injury players.
 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



