Submitted:
10 June 2023
Posted:
12 June 2023
You are already at the latest version
Abstract
Depressive disorder is a disease that causes a decrease in daily function, and the prevalence of depressive disorder in Korea is the highest among OECD countries. However, due to lack of manpower and negative social awareness, timely treatment is not being performed properly. As a solution to this, AI counseling chatbots are emerging, and it is essential to use labeled datasets to create chatbots. Currently, many countries around the world, including Korea, use the Diagnostic and Statistical Manual of Mental Disorders Fifth Edition, DSM-5, but there are no nine labeled datasets according to the DSM-5 depression disorder diagnosis criteria. This study collects sympathetic datasets, analyzes morphemes using Kind Korean Morpheme Analyzer and augments and builds a word dictionary using Word2Vec. As a result, we have labeled the dataset with nine criteria for diagnosing DSM-5 depressive disorder, which will enhance the performance of the counseling chatbot.
Keywords:
DSM-5
; Natural Language Processing
; Morphological analysis
; labeling
; classification
; Embedding
; depressive disorders
1. Introduction
Depressive disorder is a disease that causes various cognitive and mental and physical symptoms, resulting in a decrease in daily function. Severe depressive disorder can lead to suicidal thoughts as well as repetitive thoughts of death [1]. The prevalence of depressive disorders in Korea is 36.8%, and 4 of every 10 people in Korea suffer from depressive disorders or depression, which is the highest among OECD countries [2].
The fifth edition of the Diagnostic and Statistical Manual of Mental Disorders Fifth Edition (DSM-5) is the official reference of the American Psychiatric Association (APA). The DSM-5 is also used around the world, and depressive disorders are included in its classification of mental disorders. Depressive disorders are determined by comprehensively considering the nine diagnostic criteria of the DSM-5, psychiatrists’ clinical experiences, clinical interviews, psychological test results, and treatment progress.
Fear caused by negative social perceptions of mental disorders can prevent counselors, including psychiatrists, from being treated for depressive disorders. In addition, it can be difficult to intervene in a timely manner due to the lack of infrastructure to cope with depressive disorders when they are accompanied by a physical disease [3]. Accordingly, natural language processing–based artificial intelligence (AI) services that can be consulted in a timely manner are emerging [4,5]. Among them, conversational AI agents known as chatbots can help predict mental illness conditions by consulting a counselor’s textual records.
The term chatbot refers to a robot that can converse with users. Natural-language processing and machine learning are essential for chatbots to carry on meaningful and complex conversations. In this case, supervised machine learning is the primary tool, and it is essential to label datasets to ensure correct answer are used during training sessions. In addition, because perceived empathy with users can lead to a positive evaluation of a chatbot’s responses, it is effective to use empathy datasets [6].
This paper labels an empathetic dataset according to DSM-5 depressive disorder diagnostic criteria. A wellness consultation dataset provided by AI Hub [7] and a dataset obtained by crawling the depression subreddit channel of the Reddit internet forum were used. In addition, the corresponding datasets were classified and labeled through the use of a word dictionary that classifies words expressing the elements of depressive disorders according to nine criteria.
Currently, none of the datasets on the market are labeled according to the DSM-5 depressive disorder diagnostic criteria. Accordingly, this paper labeled the dataset using DSM-5 depression disorder diagnostic criteria, which are widely used by the medical community in various fields. In medicine, the accuracy of diagnosis can be improved through the use of corresponding datasets and machine-learning models, and in natural-language processing, the criteria can be used in chatbots programmed for depression counseling. For chatbots specifically, empathy datasets and actual counseling datasets can help elicit positive evaluations by revealing an empathetic attitude toward the user.
2. Previous Research
Kang Seung-sik et al. [8] analyzed the vocabulary usage characteristics of the short messaging service (SMS) character corpus, which is a spoken corpus, the Naver movie review corpus, and the Korean written primitive corpus, which is a written corpus. To measure the strength of the performance, a discriminatory performance vocabulary analysis methodology was used, and adjectives that appear mainly in the spoken and written forms were identified. In addition, a word-embedding technique was used to automatically build an emotional vocabulary dictionary based on adjectives with high performance intensity. A total of 343,603 emotional vocabulary dictionaries were automatically constructed using this technique. However, related research has not been able to manually select a large number of automatically constructed professional vocabularies.
Kim et al. [9] proposed a machine learning–based emotional-analysis system that detects user depression through SMS messages. Using an emotion dictionary of words related to depression and other emotions, search keywords were selected from text data on Twitter to build a learning dataset consisting of 1,297 sentences that express depression-related emotions and 1,032 sentences without them. Finally, a circulatory neural network, short- and long-term memory, and gate circulation units were compared and evaluated. Among them, a model based on gate circulation units achieved an accuracy of 92.2%. However, Kim et al. limited depression-related emotions to “sadness.”
Seo et al. [10] collected conversation datasets from 2016 to February 2019 from users who tended to be depressed and those who were not, and analyzed the subject and vocabulary characteristics of the dataset. The periods before and after the depression trend were compared, and the depression trend was analyzed by period. In addition, topic modeling, simultaneous word analysis, and emotional analysis were used to identify the characteristics and differences among topics of conversation of users with respect to depression and non-depression trends, and to analyze the vocabulary used. However, the Seo et al. team’s biased thoughts may have affected the outcome when classifying words associated with depression and non-depression.
Chin et al. [11] collected conversation datasets related to depressed emotions in chats between people and chatbots. They analyzed their data using text-mining techniques to identify conversation topics related to depression-related emotions. In addition, through qualitative analysis, the types of depression that users described when confiding in chatbots were categorized and classified, and differences were identified by comparing them with depression-related data on Twitter.
3. Related Techniques
This section may be divided by subheadings. It should provide a concise and precise description of the experimental results, their interpretation, as well as the experimental conclusions that can be drawn.
3.1. Kind Korean Morpheme Analyzer
Morphological analysis refers to classifying sentences into morphemes and grasping the linguistic structure, and can distinguish roots, prefixes, suffixes, and parts of speech. The little morpheme analyzer [12] is a Korean morpheme analyzer that is less sensitive to spacing errors. For speed, an adjacent condition-inspection method using a mood dictionary was used, and for quality, a probability model based on the Heuristic and Hidden Markov Model was used. In the case of a heuristic model, morphemes were analyzed by considering the characteristics of the language, such as the part-verb of the previous word and the part-verb of the next word. Morpheme analysis results were then sorted to ensure the most appropriate information was obtained. A hidden Markov model is a probability model with both hidden and observed states. In the little morpheme analyzer, each morpheme is modeled as a hidden state and the parts of the morpheme are modeled as observable. Morpheme analysis estimates the probability of the appearance of morphemes. Figure 1 depicts an example of the morpheme analysis process using a little morpheme analyzer.
3.2. Word2Vec
Word2Vec [13] is a word-embedding technology presented by Google in 2013. Word2Vec distributes the meaning of a word across multiple dimensions, expresses it as a vector, and calculates the similarity between word vectors. At this time, analysis of words that appear in similar contexts assumes that they are similar. In addition, after making the word blank, the researchers guessed the word to place in the blank using the word adjacent to the blank in the sentence and one of two methods. Continuous bag of words (CBOW) methods leave the surrounding words and middle words blank, and Skip-Gram methods predict surrounding blank words as intermediate words. An example of the Word2Vec expression is shown in Figure 2.
3.3. Dataset Labeling and Classification
Dataset labeling provides information about the data, and dataset classification assigns data to groups. In general, machine-learning models use labeled datasets to solve classification problems. For machine-learning models to learn efficiently and perform predictions, high-quality labeled datasets are required. Datasets can be labeled manually or automatically. Manual labeling assigns datasets to experts and other categories and is often highly accurate, but can be costly, both in terms of money and time. Semi-graphic learning combines hand-labeled and non-labeled data, which can reduce labeling costs at the expense of mislabeled or missing data.
4. Dataset
4.1. Dataset Description
“Wellness counseling data” were created by processing records of mental health counseling at Severance Hospital in Sinchon. Only data related to mental symptoms were used. A total of 5,231 questions and 1,034 responses were included. The “intent” column has 19 labels: depression, sadness, loneliness, anger, lethargy, emotional control abnormalities, loss, loss of appetite, appetite, insomnia, anxiety, fatigue, guilt, concentration, self-confidence, despair, suicide impulse, and anxiety.
In the wellness counseling data, the average length of a counselor’s utterance is 28 characters (minimum 2, maximum 117), and the average length of a counselor’s utterance is 31 characters (minimum 5, maximum 67). Figure 3 shows the results of visualizing words that mainly appear in each counselor’s speeches and responses as a word cloud.
Data from the r/depression subreddit channel were extracted from Reddit, a mega-social community site in the United States. In this paper, 30,000 posts and comment data from 2010 to 2016 were randomly extracted. In the “depression” subreddit, any violation of the notice and detailed rules will be deleted regardless of the number of recommendations. The notice and detailed rules are shown in Figure 4.
Users of r/depression can only ask for help with depressive disorders for themselves or someone close to them, and all answers should be sympathetic. In addition, answers to posts asking for help are only allowed in public comments, and personal answers and posts are not allowed. Responses without meaningful content are not allowed, and responders should not pose as a role model or some with a superior perspective. Meaningless encouragement, promises that cannot be kept, and medical knowledge, advocacy, and opposition to treatments are also not permitted. In addition, it is impossible to certify self-harm methods and self-destructive content, and content that deviates from the subject or goes against the rules should not be encouraged. Finally, it is impossible to request and provide discussions, unauthorized surveys, self-promotion, and money, goods, services, etc.
4.2. Dataset Preprocessing
In the case of wellness counseling data, the “utterance” column, which involves counselors’ utterances, and the “response” column, which involves counselors’ responses, were used. After that, the missing value was deleted. In the case of r/depression data, sentences containing adjectives on either side of a “/”, such as “depressed/anxious,” were deleted. An example of a sentence is shown in Figure 5.
Translations were made using the Google Translate API [14]. An example of a translation result is shown in Figure 6.
5. Dictionary of Expression Words
A word dictionary was created based on the nine DSM-5 diagnostic criteria for depressive disorder. Medical staff working in the Department of Mental Health Medicine collected expressions for each of the nine depressive disorder criteria and generated a dictionary, as shown in Figure 7.
The number of words in the word dictionary for each criterion is 59, 45, 44, 33, 37, 27, 45, 26, and 47. Figure 8 provides an example of the first of the nine criteria: “most of the day, almost daily depressed mood.”
6. Methodology
6.1. Morphological Analysis
Each sentence of the preprocessed data was analyzed using a little morpheme analyzer. The preprocessed word dictionary was also morphemically analyzed and stored for each of the nine criteria. An example of each result is shown in Figure 9.
An example of the results of morphological analysis of the entire word dictionary is shown in Figure 10.
6.2. Morphological Screening
The results of the DSM-5 morpheme analysis were applied to the part-time tag table of the little morpheme analyzer (Figure 11). To extract only words with specific meanings, only parts, general adverbs, and body-language prefixes corresponding to body language, proverbs, and roots were selected.
6.3. Data Classification
Each sentence of the consultation dataset was searched to determine if the words were included in the dictionary, and automatic classification was performed accordingly in a cloud-based Jupiter laptop environment using a Tesla T4 graphical processing unit accelerator. An example of the classification process is shown in Figure 12.
6.4. Data Labeling
Classified data sets were labeled according to the DSM-5 depression disorder diagnostic criteria. For example, if the word dictionary for the third diagnostic criterion, “loss or gain weight without diet, loss or increase of appetite almost every day,” contained a “pig” in the counseling dataset sentence, the sentence was given a label of number 3. Figure 13 shows the results of labeling wellness consultation data according to the nine diagnostic criteria and visualizing the frequency.
6.5. Data Evaluation
In 5.4, it was confirmed that the number of datasets belonging to diagnostic criteria 3, 4, 6, 7, and 8 was small. The similarity of words for the corresponding diagnostic criteria was therefore searched using Word2Vec. In the case of Word2Vec’s hyperparameter, the window was set to 5, and the five words to the left and right of the word were predicted using the context. In addition, the min_count parameter specified the minimum frequency to be used for learning, and words that appeared fewer than 5 times were excluded from learning. Finally, the CBOW algorithm was used by assigning a value of 0 to sg, which is a parameter for designating the algorithm. Figure 14 shows the results of searching for words similar to “lonely,” “terrible,” and other terms.
The words and results of visualizations similar to “tough” are shown in Figure 15.
Similar words printed in this way were secondarily selected, and the same process was performed by adding them to the DSM-5 expression word dictionary.
7. Result
7.1. Comparing the Frequency of Each of the 9 Criteria
Figure 16 compares the frequency of wellness counseling data before and after word pre-augmentation, and Figure 17 compares the frequency of r/depression data from Reddit before and after augmentation.
Combining the wellness consultation data and Reddit data produced the following frequency visualization.
7.2. Frequency Result Inference
No significant difference was evident in the visualization results before and after augmentation of the word dictionary because many words were not added during dictionary enhancement. In addition, there was no significant difference in the counseling dataset collected in this study due to the lack of data corresponding to the label.
However, criteria 1 and 2 are “most of the day, almost every day of depression,” and “most of the day, almost every day of interest or pleasure in almost all daily activities is significantly reduced.” This indicates that the expression words are more ambiguous than other criteria and are often used. Compared with other criteria, the number of expressions such as “loss or gain weight without diet control, loss or increase of appetite almost every day” is small, but clear. However, diagnostic criteria 1 include “tears,” “sad,” and “disappointed,” which are ambiguous and frequently used in other contexts. As a result, we concluded that the number of data is inevitably high when the expression word is an ambiguous and widely used label.
8. Conclusions
This paper proposes a methodology for classifying and labeling datasets based on DSM-5 diagnostic criteria for depressive disorder. Wellness counseling data and Reddit crawling data consisting of empathy-related content were used to augment AI services for depressive counseling. A word dictionary built on medical knowledge was used and we analyzed the dataset and word dictionary using a little morpheme analyzer, with the resulting dataset labeled 1 to 9. In addition, if the number of words was insufficient, the word dictionary was augmented using Word2Vec.
A word dictionary built by medical staff and based on the DSM-5 depression disorder diagnosis criteria used by the APA was employed in this study. The proposed methodology can therefore be used in both medical care and natural language processing. By using datasets classified by proven diagnostic criteria, useful answers can be expected from natural language processing–based AI services such as chatbots. In addition, this approach can lead to a combination of AI and medical services that may be able to help solve problems related to the lack of counselors and difficulty supplying timely intervention.
Author Contributions
Conceptualization, methodology, experiment, visualization, formal analysis, GJ.L.; writing and editing, DB.P; supervision, HY.O. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Research Foundation of Korea grant funded by the Korea government (No. NRF-2022R1F1A1074696)
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Na-ju National Hospital. Depression [Internet]. Available: http://www.najumh.go.kr/html/content.do?depth=fc&menu_cd=02_02_00_01.
- Organisation for Economic Co-operation and Development, A New Benchmark for Mental Health Systems: Tackling the Social and Economic Costs of Mental Ill-Health, Paris, France: OECD Publishing. 2021.
- S.Y. Kim, J. E. Kim and H. W. Lee, “A Report of the Survey on the Current State of the Psychiatric Emergency Response in Seoul,” The Mental Health, vol. 11, no. 0, pp. 38-54, Dec. 2021. UCI: I410-ECN-0102-2022-500-001026410.
- G. H. Song, M. K. Kim and A. S. Park, “Promising Services Based on AI for Mental Health,” Electronics and Telecommunications Trends, vol. 35, no. 6, pp. 12-23, Dec. 2020. [CrossRef]
- M. Adam, M. Wessel and A. Benlian, “AI-based chatbots in customer service and their effects on user compliance,” Electron Markets, vol. 31, no. 2, pp. 427-445, Mar. 2020. [CrossRef]
- H. Rashkin, E. M. Smith, M. Li and Y. L. Boureau, “Towards Empathetic Open-domain Conversation Models: a New Benchmark and Dataset,” in Proceeding of the 57th Annual Meeting of the Association for Computational Linguistics, Florence: Italy, pp. 5370-5381, 2019.
- AI Hub. Wellness conversation dataset [Internet]. Available: https://aihub.or.kr/opendata/keti-data/recognition-laguage/KETI-02-006.
- S. S. Kang, H. J. Won and M. H. Lee, “Analyzing Vocabulary Characteristics of Colloquial Style Corpus and Automatic Construction of Sentiment Lexicon,” Smart Media Journal, vol. 9, no. 4, pp. 144-151, Dec. 2020. [CrossRef]
- K. R. Kim, J. H. Moon and U. R. Oh, “Analysis and Recognition of Depressive Emotion through NLP and Machine Learning,” The Journal of the Convergence on Culture Technology, vol. 6, no. 2, pp. 449-454, May. 2020. [CrossRef]
- H. R. Seo and M. Song, “An Analysis of the Discourse Topics of Users who Exhibit Symptoms of Depression on Social Media,” Journal of the Korean Society for Information Management, vol. 36, no. 4, pp. 207-226, Dec. 2019. [CrossRef]
- H. J. Chin, G. H. Baek, C. Y. Cha, J. H. Choi, H. S. Im and M. Y. Cha, “A study on the categories and characteristics of depressive moods in chatbot data”, in Proceeding of the Korea Information Processing Society Conference, Yeosu: Korea, pp. 993-996, 2021.
- Kind Korean Morpheme Analyzer [Internet]. Available: http://kkma.snu.ac.kr/.
- T. Mikolov, K. Chen, G. Corrado and J. Dean, “Efficient Estimation of Word Representations in Vector Space,” in Proceeding of Workshop at International Conference on Learning Representations, 2013.
Figure 1.
Example of the Kind Korean Morpheme Analyzer.

Figure 2.
Magnetization as a function of applied field.
Figure 3.
Wordcloud of ‘utterance (2차) ’column and ‘response (공감)’ column.

Figure 4.
Community basics and rules of r/depression.

Figure 5.
r/depression data examples including “depressed/anxious.”.

Figure 6.
Translation examples of r/depression data.
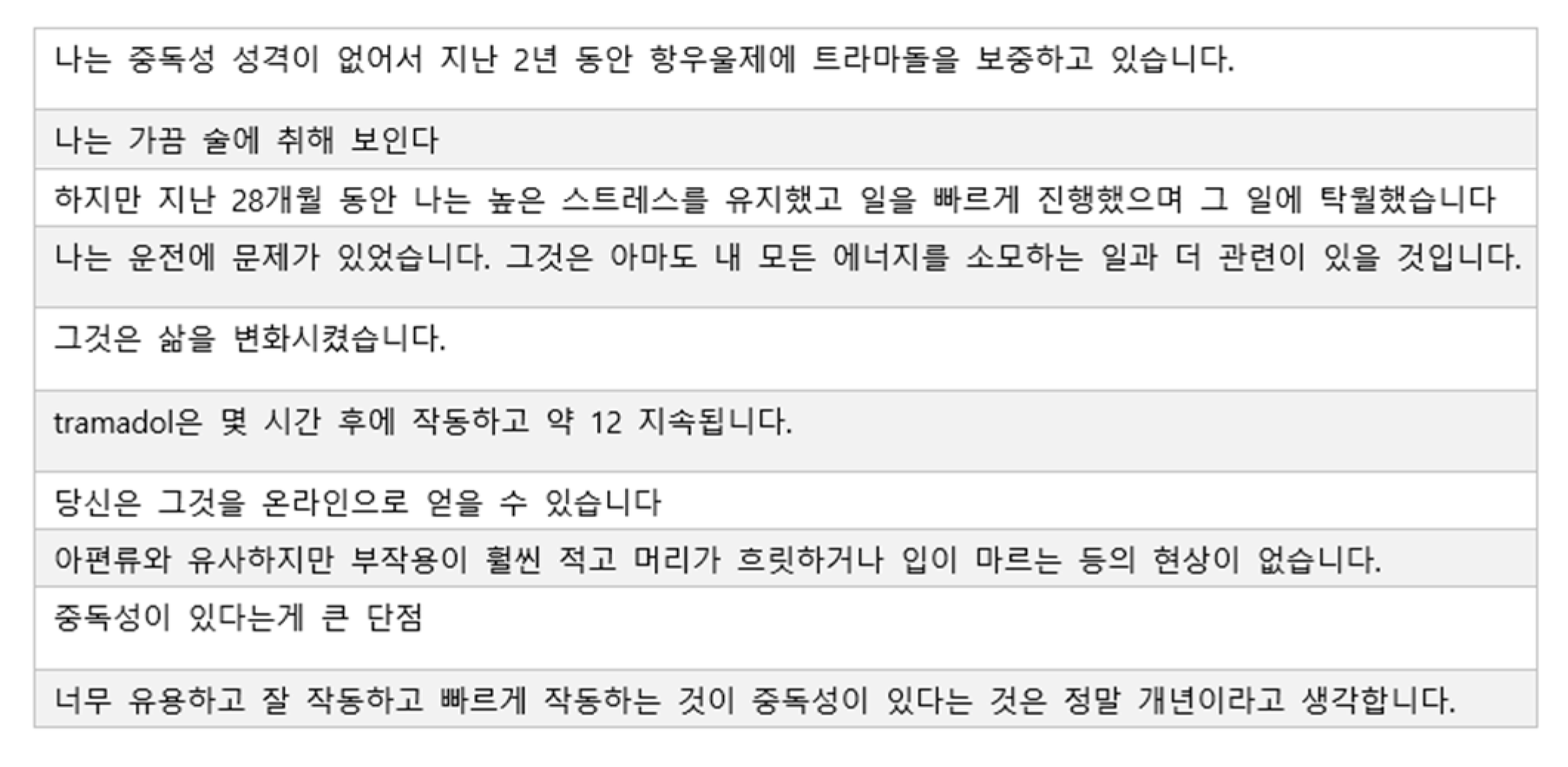
Figure 7.
DSM-5 diagnosis criteria for depressive disorder.

Figure 8.
Example of the word dictionary of the first DSM-5 diagnosis criteria for depressive disorder.
Figure 8.
Example of the word dictionary of the first DSM-5 diagnosis criteria for depressive disorder.
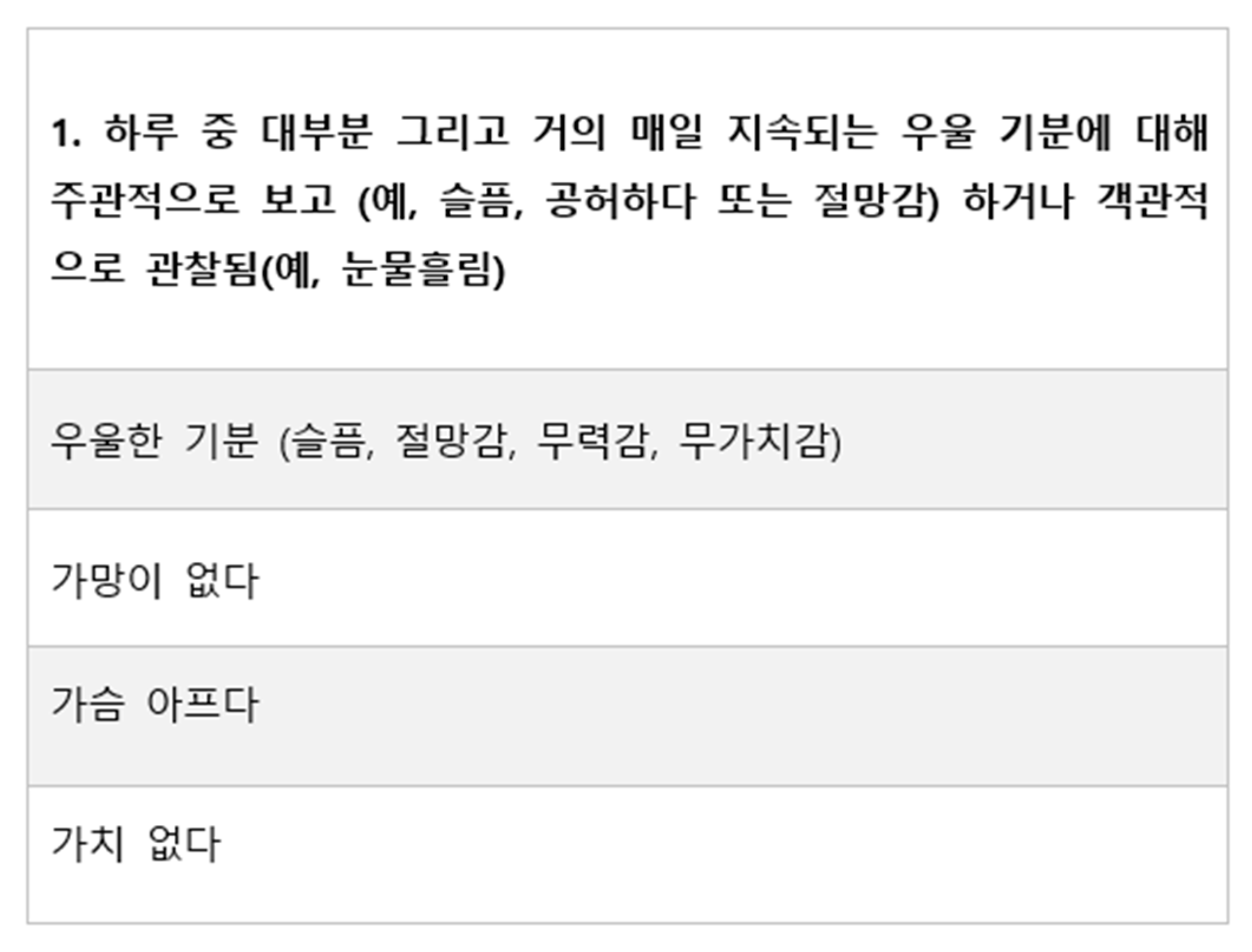
Figure 9.
Results of morphological analysis of datasets and word dictionaries.

Figure 10.
Results of morphological analysis of word dictionaries.

Figure 11.
Tag table of KKMA.
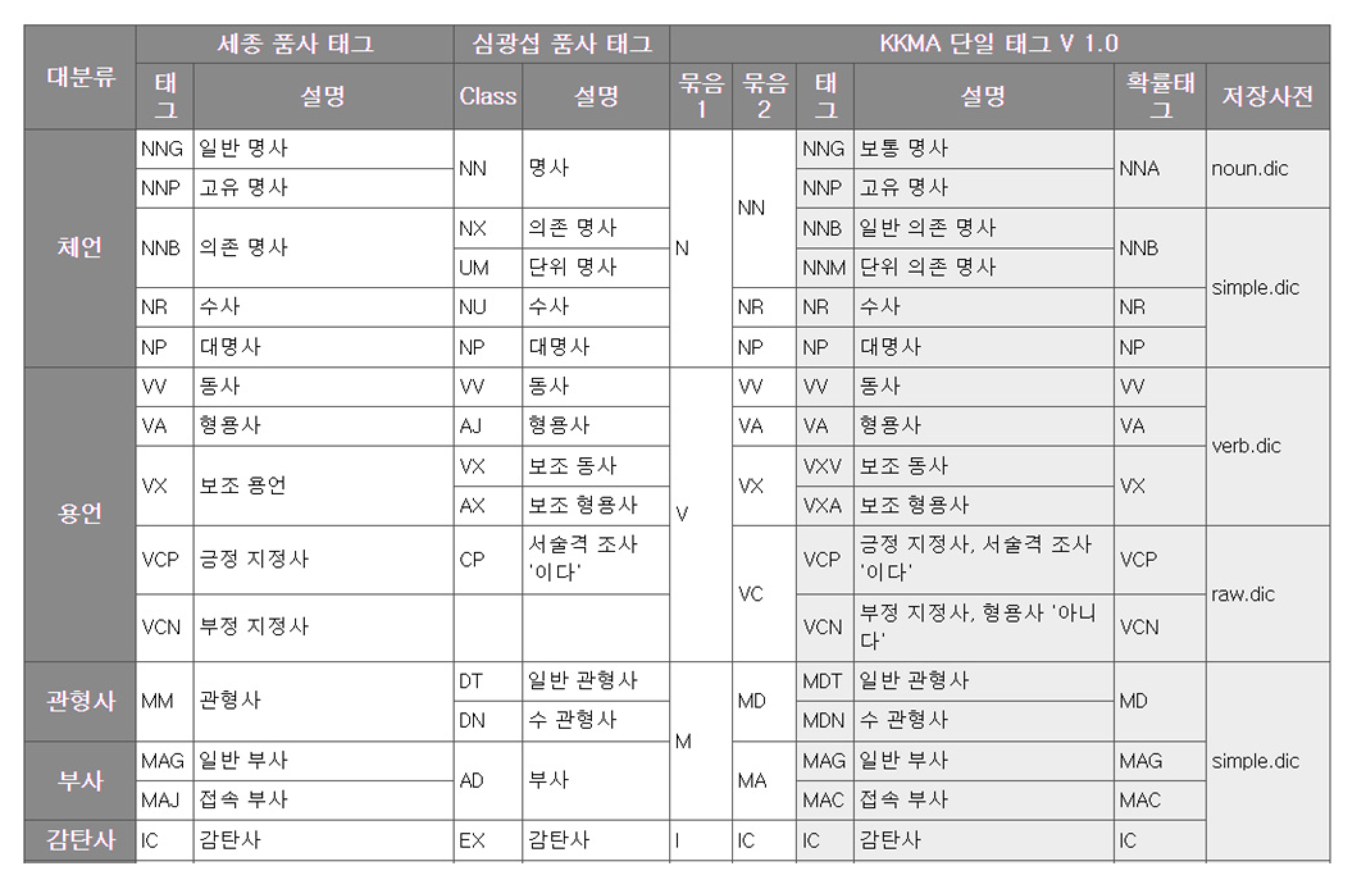
Figure 12.
Example of a classification process.
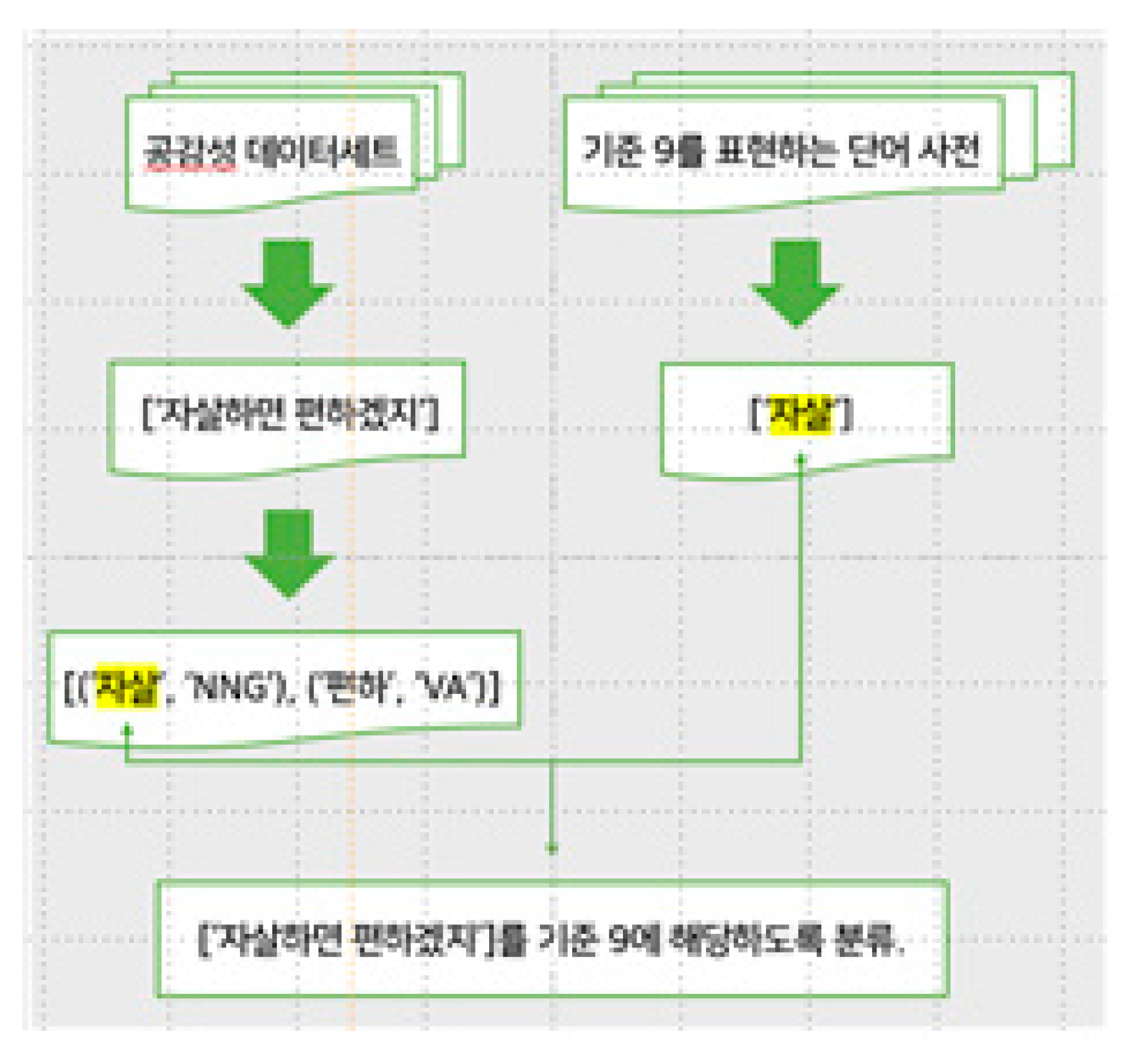
Figure 13.
Visualization of dataset classification.
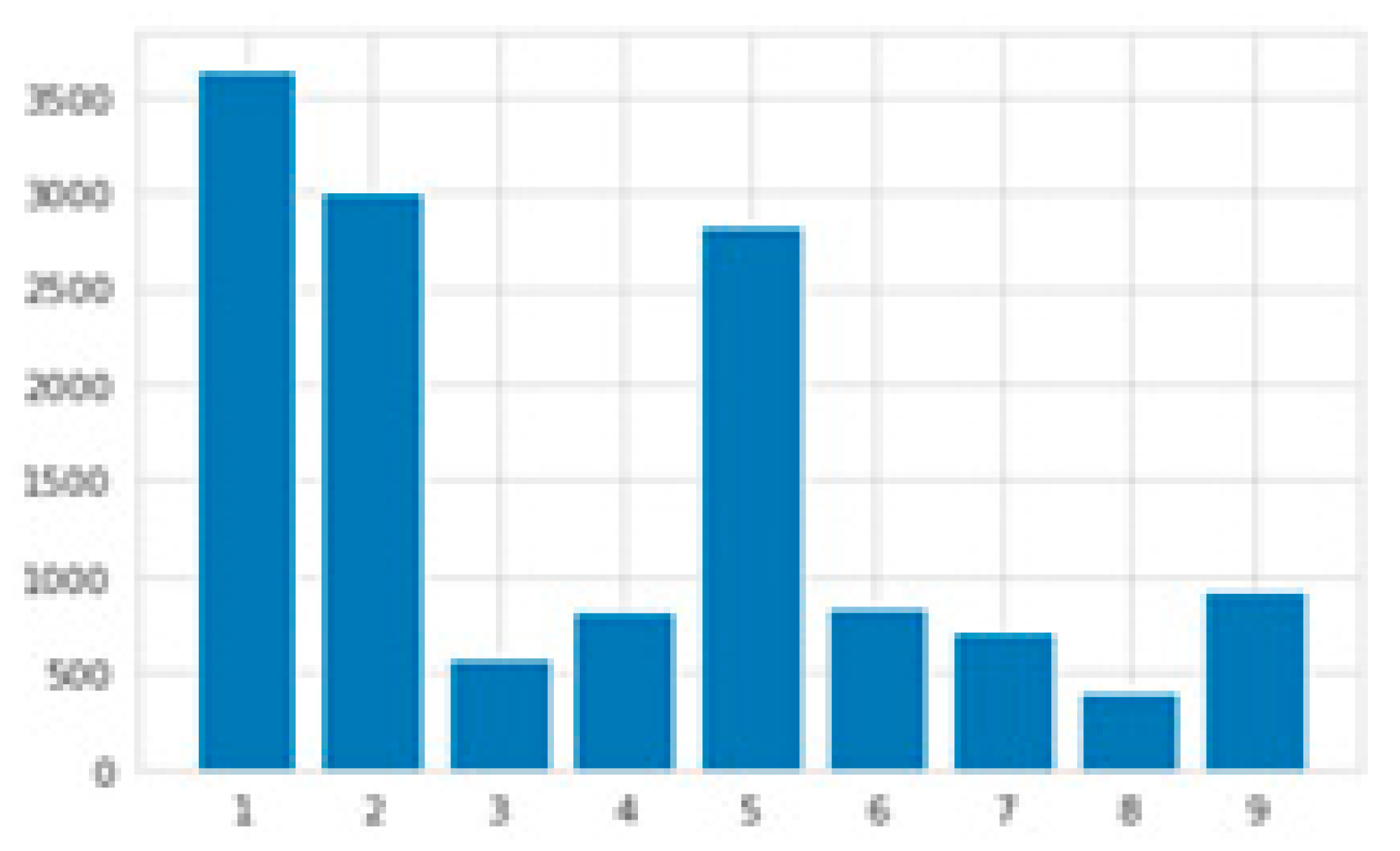
Figure 14.
Words similar to “lonely” and “terrible.”.
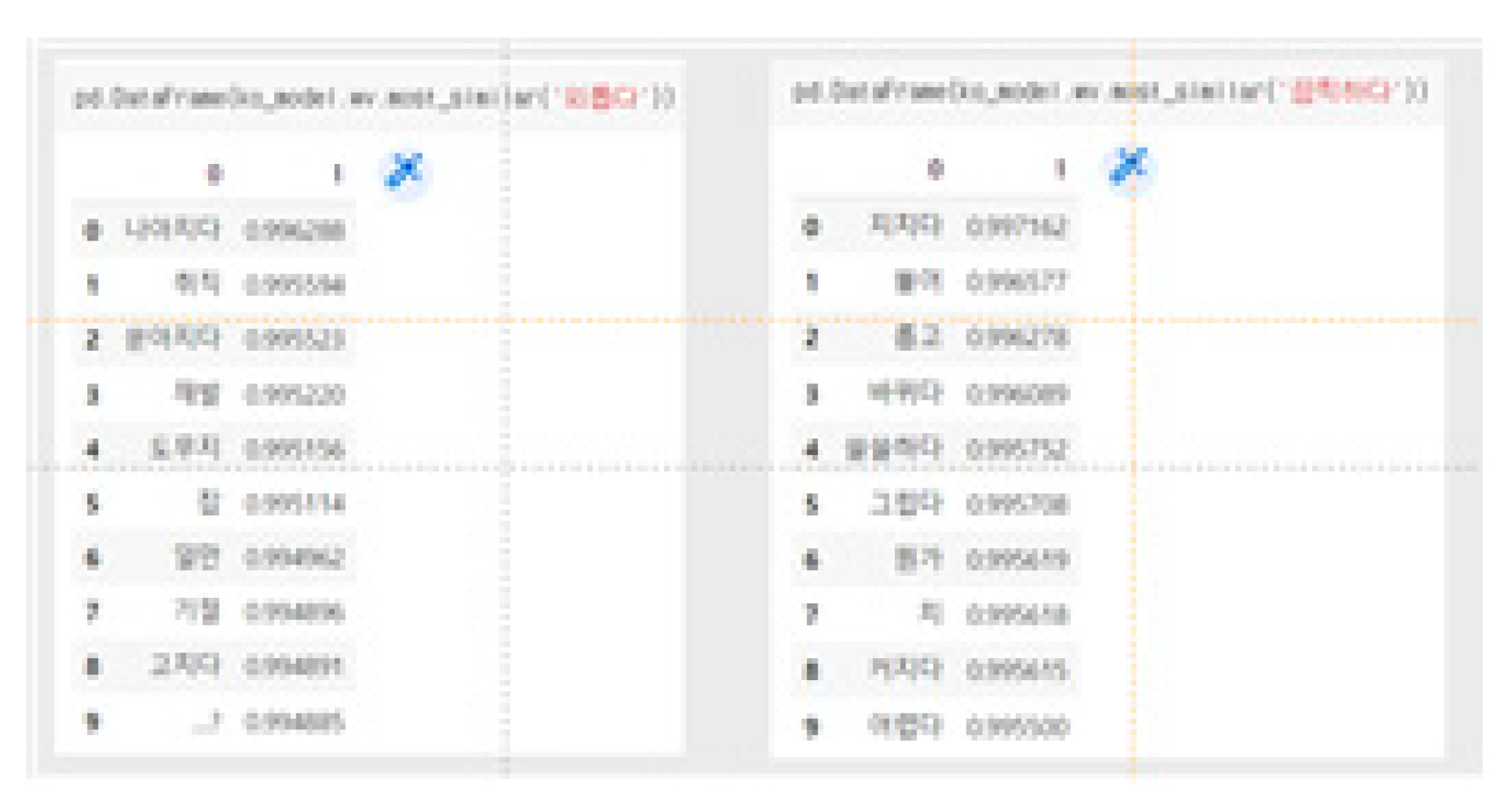
Figure 15.
Visualization and words similar to “tough.”.
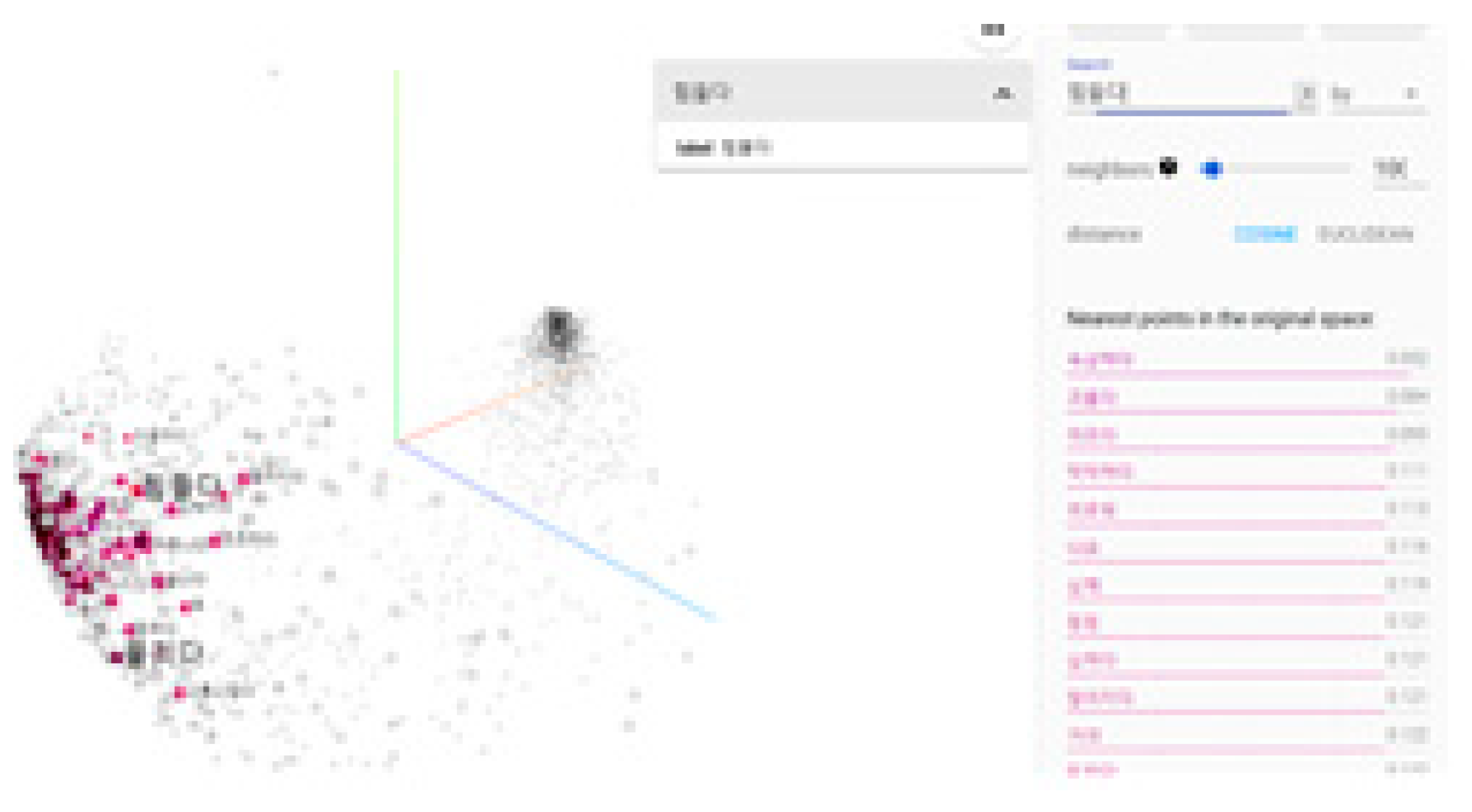
Figure 16.
Comparison of the wellness dataset classification.
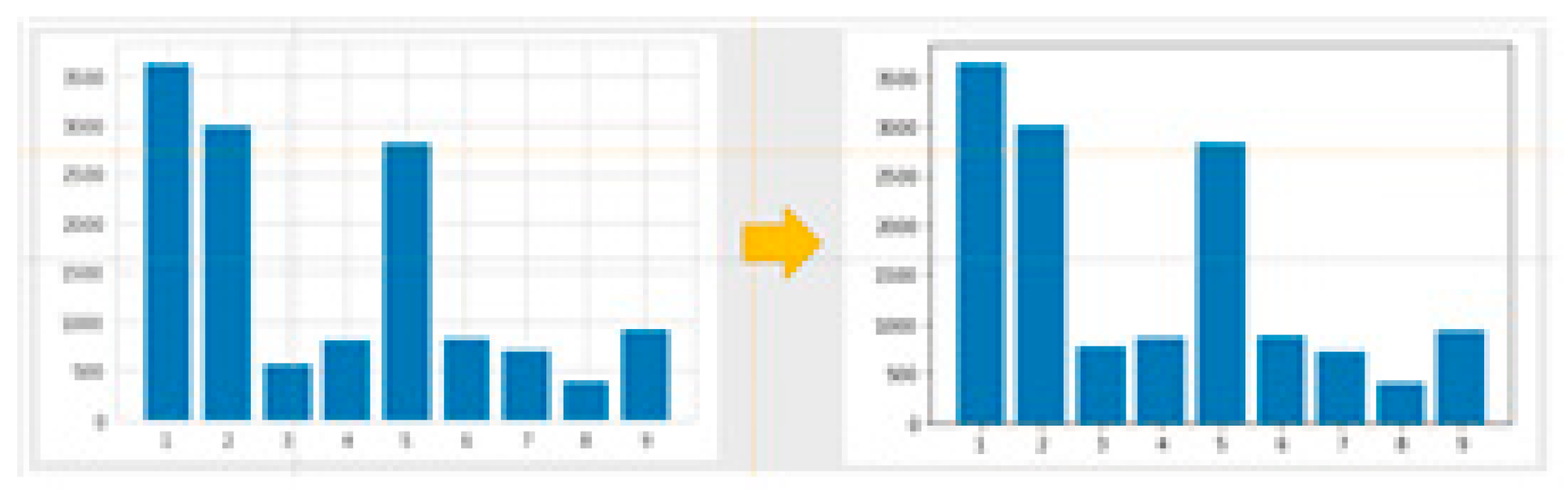
Figure 17.
Comparison of the Reddit dataset classification.

Figure 18.
Comparison of entire dataset classification.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



