Submitted:
02 July 2023
Posted:
04 July 2023
You are already at the latest version
Abstract
This report gives a comprehensive summary of two problems about graph convolutional networks (GCNs): over-smoothing and heterophily challenges, and outlines future directions to explore.
Keywords:
Graph Neural Networks
; Reinforcement Learning
; Over-smoothing
; Heterophily
1. Introduction
Many real-world problems can be modeled as graphs. Recently, neural network based approaches have achieved significant progress for solving large, complex, graph-structured problems [9,12,17,21,24,34,50]. Inspired by the success of Convolutional Neural Networks (CNNs) [31] in computer vision [33], graph convolution defined on the graph Fourier domain stands out as the key operator and one of the most powerful tools for using machine learning to solve graph problems. Although with high expressive power, GCNs still suffer from several difficulties, e.g. the over-smoothing problem limits deep GCNs to sufficiently exploit multi-scale information, heterophily problem makes the graph-aware models underperform the graph-agnostic models. This report summarizes the methods we have proposed to address those challenges and puts forward some research problems we will investigate.
To fully explain the above problems, in Section 1.1, we will first introduce the notation and background knowledge of graph networks. In Section 2, we introduce the loss of expressive power of deep graph neural networks (GNNs) and propose snowball and truncated Krylov architecture to address it; in Section 3, we analyze heterophily problems for the existing GNNs and propose Adaptive Channel Mixing (ACM) architecture to address it.
Main Contribution
In Section 2, we first point out that the output of deep GCN with ReLU activation function will suffer from loss of rank problem under certain conditions and this can cause deep GCN lose expressive power. We then prove that Tanh is better at preserving the rank of the output and verify this claim with numerical tests. Then we find a way to deepen GCN in block Krylov form and propose snowball and truncated Krylov networks which perform better than state-of-the-arts (SOTA) model on semi-supervised node classification tasks on 3 benchmark datasets. Besides, we point out that finding a specifically tailored weight initialization scheme for GCNs can be an promising direction to address over-smoothing efficiently in Section 2.2. In Section 3, we first illustrate the insufficiency of the current homophily metrics and propose aggregation homophily based on a new similarity matrix. We then show the advantage of the new homophily metric over the existing ones on synthetic graph. Based on the similarity matrix, we define diversification distinguishability of a node and demonstrate why high-pass filters can help to address heterophily problem. To include both low-pass and high-pass in GNNs, we extend filterbank method and propose ACM and ACMII frameworks that can boost the performance of baseline GNNs on heterophilous graphs.
1.1. Notation and Background Knowledge
Suppose we have an undirected graph , where is the node set with ; is the edge set without self-loop; is the symmetric adjacency matrix with if and only if , otherwise ; D is the diagonal degree matrix, i.e. and is the neighborhood set of node i. A graph signal is a vector defined on , where is defined on the node i. We also have a feature matrix whose columns are graph signals and each node i has a corresponding feature vector with dimension F, which is the i-th row of X. We denote as label encoding matrix, where is the one hot encoding of the label of node i and C is the total number of classes.
The (combinatorial) graph Laplacian is defined as , which is a Symmetric Positive Semi-Definite (SPSD) matrix [7]. Its eigendecomposition gives , where the columns of are orthonormal eigenvectors, namely the graph Fourier basis, with , and these eigenvalues are also called frequencies. The graph Fourier transform of the graph signal is defined as , where is the component of in the direction of .
Some graph Laplacian variants are commonly used, e.g. the symmetric normalized Laplacian and the random walk normalized Laplacian . The eigenvalues of and are the same and are in , and their corresponding eigenvectors satisfy .
The affinity (transition) matrices can be derived from the Laplacians, e.g. , . Then . Renormalized affinity and Laplacian matrices are introduced in [24] as , , where and it essentially adds a self-loop and is widely used in Graph Convolutional Network (GCN) as follows:
where and are parameter matrices. GCN can learn by minimizing the following cross entropy loss
The random walk renormalized matrix can also be applied to GCN and it has the same eigenvalues as . The corresponding Laplacian is defined as Specifically, the nature of random walk matrix makes behaves as a mean aggregator which is applied in [17] and is important to bridge the gap between spatial- and spectral-based graph convolution methods.
2. Loss of Expressive Power of Deep Graph Neural Networks
One major problem of the existing GCNs is the low expressive power limited by their shallow learning mechanisms [61,66]. There are mainly two reasons why an architecture that is scalable in depth has not been achieved yet. First, this problem is difficult: considering graph convolution as a special form of Laplacian smoothing [32], networks with multiple convolutional layers will suffer from an over-smoothing problem that makes the representation of even distant nodes indistinguishable [66]. Second, some people think it is unnecessary: for example, [4] states that it is not necessary for the label information to totally traverse the entire graph and one can operate on the multi-scale coarsened input graph and obtain the same flow of information as GCNs with more layers. Acknowledging the difficulty, we hold on to the objective of deepening GCNs since the desired compositionality1 will yield easy articulation and consistent performance for problems with different scales.
In Section 2.1, we first analyze the limits of deep GCNs brought by over-smoothing and the activation functions. Then, we show that any graph convolution with a well-defined analytic spectral filter can be written as a product of a block Krylov matrix and a learnable parameter matrix in a special form. Based on this, we propose two GCN architectures that leverage multi-scale information in different ways and are scalable in depth, with stronger expressive powers and abilities to extract richer representations of graph-structured data. For empirical validation, we test different instances of the proposed architectures on multiple node classification tasks. The results show that even the simplest instance of the architectures achieves state-of-the-art performance, and the complex ones achieve surprisingly higher performance. In Section 2.2, we propose to study an over-smoothing problem and give some ideas.
2.1. A Stronger Multi-Scale Deep GNN with Truncated Krylov Architecture
For this architecture, without considering the ReLU activation function, [32] shows that will converge to a space spanned by the eigenvectors of with eigenvalue 1. Taking activation function into consideration, our analyses on (3) can be summarized in the following theorems (see proof in the appendix of [44]).
Theorem 1.
Suppose that has k connected components. Let be any feature matrix and let be any non-negative parameter matrix with for . If has no bipartite components, then in (3), as , .
Theorem 2.
Suppose the n-dimensional and are independently sampled from a continuous distribution and the activation function is applied to pointwisely, then
Theorem 1 shows that, even considering ReLU, if we simply deepen GCN as (3), the extracted features will degrade under certain conditions, i.e. only contains the stationary information of the graph structure and loses all the local information in node for being smoothed. In addition, from the proof we see that the pointwise ReLU transformation is a conspirator. Theorem 2 tells us that Tanh is better at keeping linear independence among column features. We design a numerical experiment on synthetic data to test, under a 100-layer GCN architecture, how activation functions affect the rank of the output in each hidden layer during the feedforward process. As Figure 1a shows, the rank of hidden features decreases rapidly with ReLU, while having little fluctuation under Tanh, and even the identity function performs better than ReLU. So we propose to replace ReLU by Tanh.
Besides activation function, to find a way to deepen GCN, we first show that any graph convolution with well-defined analytic spectral filter defined on can be written as a product of a block Krylov matrix with a learnable parameter matrix in a specific form. Based on this, we propose snowball network and truncated Krylov network.
We take . Given a set of block vectors , the -span of is defined as . Then, the order-m block Krylov subspace with respect to the matrix , the block vector and the vector space , and its corresponding block Krylov matrix are respectively defined as
It is shown in [11,15] that there exists a smallest m such that for any , , where m depends on A and B.
Let denote the spectrum radius of and suppose where R is the radius of convergence for a real analytic scalar function g. Based on the above definitions and conclusions, the graph convolution can be written as
where for are parameter matrix blocks and . Then, a graph convolutional layer can generally be written as
where is a parameter matrix, and . The essential number of learnable parameters is .
The block Krylov form provides an insight about why an architecture that concatenates multi-scale features in each layer will boost the expressive power of GCN. Based on this idea, we propose the snowball and truncated Block Krylov architectures [44] shown in Figure 2, where we stack multi-scale information in each layer. From the performance comparison on semi-supervised node classification tasks with different label percentage in Table 1, we can see that the proposed models consistently perform better than the state-of-the-art models, especially when there are less labeled nodes. See detailed experimental results in [44].

Table 1.
Accuracy without Validation. For each (column), the greener the cell, the better the performance. The redder, the worse. If our methods achieve better performance than all others, the corresponding cell will be in bold.
Table 1.
Accuracy without Validation. For each (column), the greener the cell, the better the performance. The redder, the worse. If our methods achieve better performance than all others, the corresponding cell will be in bold.
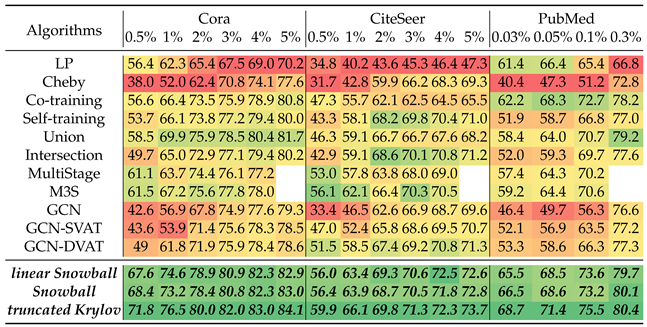 |
2.2. Future Works on Over-Smoothing
2.2.0.2. Weight Initialization for GNNs
Even without aggregation in each hidden layer, an NN with deep architecture still suffers from vanishing activation variances and back-propagated gradients variance problem [13], which make the training of deep NN hard. In last decade, designing new parameter initialization methods is proved to be effective [13,18] to address the variance reduction problem during feedforward and backpropagation process. This motivates us to investigate the variance propagation in GNNs and analyze if the current weight initialization methods are suitable for GNNs or not. To this end, we can show that the vanishing variance caused by aggregation operation in GNNs is more serious than NN. Designing a new parameter initialization scheme for GNNs is potentially a feasible way to address this problem and empirically achieves promising performance [45]. we will propose a new method in this subsection.
The current initialization scheme of GNNs still follows the Xavier initialization [13], i.e. , or He (or Kaiming) initialization [18], i.e., which is designed for traditional multilayer perceptron (MLP) , where is the parameter matrix of layer i and is the number of hidden units of layer i. These two initialization methods are derived by studying the variance propagation between layers during feedforward and backpropagation process. These two processes are different in GNNs by an extra multiplication of aggregation operator . To analyze the variance propagation, we use deep GCN as an example, use and decompose it as follows,
where , ; is the ground truth matrix with one-hot label vector. Then the gradient propagates in the following way,
2.2.0.3. Variance Analysis: Forward View
Consider element in matrix during the feed-forward process in (6),
Suppose we have linear activation function such as that proposed in [60]; each element in is i.i.d.initialized with ; and all elements in are independent 2. Then, can be written as
Suppose each element in shares the same variance denoted as . To prevent variance vanishing between layers, i.e., from (8) we can approximately have (see computation in Appendix A.2.1)
This tells us that the variance of depends on the degree of a node, but since the parameter matrix is shared by all nodes, we cannot design a node specified initialization scheme. Thus, we make a compromise between nodes as follows
Another way is to use weighted average by considering the node degree as the weight of each node. Through this way, we have
Variance Analysis: Backward View
Under the same assumption as feedforward view and suppose each element in and are independent to each other and has zero mean, from (7) we can approximately (see computation in Appendix A.2.2)
Then,
Thus,
Combined with (11), we can set the variance of the parameter matrix as
Thus, each element in can be drawn from .
Adaptive ReLU (AdaReLU) Activation Function
To satisfy the assumption that the activation function is linear at the beginning of training process and to still learn a nonlinear function during training, we design the following adaptive ReLU (AdaReLU) activation function
where and are learnable parameters and are initialized to be 1. If and for all i, we have channel-shared AdaReLU, otherwise we have channel-wise AdaReLU 3. From the preliminary experimental results, channel-wise works better than channel-shared AdaReLU.
3. GNNs on Heterophily Graphs
GNNs are considered as an extension of basic Neural Networks (NNs) by additionally making use of graph structure based on the relational inductive bias (homophily assumption), rather than treating the nodes as collections of independent and identically distributed (i.i.d.) samples. Though GNNs are believed to outperform basic NNs in real-world tasks, it is found that in some cases, the graph-aware models have little performance gain or even underperform graph-agnostic models [6,46,51,69,71]. One of the main reasons for the performance degradation is believed to be heterophily, i.e. when the connected nodes tend to have different labels [69,71]. Heterophily challenge has received attention recently and there are increasing number of models being put forward to analyze [39,43] and address this problem [6,36,41,42,64,69,70].
In this section , we first introduce the most commently used homophily metrics in Section 3.1. Then, we show that not all cases of heterophily are harmful for GNNs and propose new metrics based on a similarity matrix which considers the influence of both graph structure and input features on GNNs in Section 3.2. The metrics demonstrate advantages over the commonly used homophily metrics by tests on synthetic graphs. From the metrics and the observations, we find some cases of harmful heterophily can be addressed by diversification operation and its effectiveness can be proved in Section 3.3. With this fact and knowledge of filterbanks, we propose the Adaptive Channel Mixing (ACM) framework in Section 3.4 to adaptively exploit aggregation, diversification and identity channels in each GNN layer to address harmful heterophily. We validate the ACM-augmented baselines with real-world node classification tasks. They consistently achieve significant performance gain and exceed the state-of-the-art GNNs on most of the tasks without incurring significant computational burden. In Section 3.5, we introduce some prior work on addressing heterophily problems and explain their differences with ACM framework. The limitation of diversification operation and remaining challenges of heterophily problems are discussed in Section 3.6
3.1. Metrics of Homophily
The metrics of homophily are defined by considering different relations between node labels and graph structures defined by adjacency matrix. There are three commonly used homophily metrics: edge homophily [1,70], node homophily [51], and class homophily [35] 4 defined as follows:
where ; is the class-wise homophily metric [35]. They are all in the range of and a value close to 1 corresponds to strong homophily while a value close to 0 indicates strong heterophily. measures the proportion of edges that connect two nodes in the same class; evaluates the average proportion of edge-label consistency of all nodes; tries to avoid the sensitivity to imbalanced class, which can cause misleadingly large. The above definitions are all based on the graph-label consistency and imply that the inconsistency will cause harmful effect to the performance of GNNs. With this in mind, we will show a counter example to illustrate the insufficiency of the above metrics and propose new metrics in the following subsection.
3.2. Analysis of Heterophily and Aggregation Homophily Metric
Heterophily is believed to be harmful for message-passing based GNNs [6,51,70] because intuitively features of nodes in different classes will be falsely mixed and this will lead nodes indistinguishable [70]. Nevertheless, it is not always the case, e.g. the bipartite graph shown in Figure 3 is highly heterophilous according to the homophily metrics in (20), but after mean aggregation, the nodes in classes 1 and 2 only exchange colors and are still distinguishable. Authors in [6] also point out the insufficiency of by examples to show that different graph typologies with the same can carry different label information.
To analyze to what extent the graph structure can affect the output of a GNN, we first simplify the GCN by removing its nonlinearity as [60]. Let denote a general aggregation operator. Then, Equation (1) can be simplified as,
After each gradient decent step , where is the learning rate, the update of will be,
where is a post-aggregation node similarity matrix, is the prediction error matrix. The update direction of node i is essentially a weighted sum of the prediction error, i.e..
To study the effect of heterophily, we first define the aggregation similarity score as follows.
Definition 1.
Aggregation similarity score
where takes the average over u of a given multiset of values or variables.
measures the proportion of nodes that will put relatively larger similarity weights on nodes in the same class than in other classes after aggregation. It is easy to see that . But in practice, we observe that in most datasets, we will have . Based on this observation, we rescale (23) to the following modified aggregation similarity for practical usage,
In order to measure the consistency between labels and graph structures without considering node features and make a fair comparison with the existing homophily metrics in (20), we define the graph () aggregation () homophily and its modified version as
In practice, we will only check when . As Figure 3 shows, when , . Thus, this new metric reflects the fact that nodes in classes 1 and 2 are still highly distinguishable after aggregation, while other metrics mentioned before fail to capture the information and misleadingly give value 0. This shows the advantage of and by additionally considering information from aggregation operator and the similarity matrix.
Comparison of Homophily Metrics on Synthetic Graphs
To comprehensively compare with the metrics in (20) in terms of how they reveal the influence of graph structure on the GNN performance, we generate synthetic graphs (d-regular graphs with edge homophily varied from to ) and evaluate SGC with 1-hop aggregation (SGC-1) [60] and GCN [24] on them.
The performance of SGC-1 and GCN are expected to be monotonically increasing with a proper and informative homophily metric. However, Figure 4a–c show that the performance curves under and are U-shaped 5, while Figure 2d reveals a nearly monotonic curve only with a little numerical perturbation around 1. This indicates that can describe how the graph structure affects the performance of SGC-1 and GCN more appropriately and adequately than the existing metrics.
3.3. How Diversification Operation Helps with Harmful Heterophily
We first consider the example shown in Figure 5. From , nodes 1,3 assign relatively large positive weights to nodes in class 2 after aggregation, which will make node 1,3 hard to be distinguished from nodes in class 2. Despite the fact, we can still distinguish between nodes 1,3 and 4,5,6,7 by considering their neighborhood difference: nodes 1,3 are different from most of their neighbors while nodes 4,5,6,7 are similar to most of their neighbors. This indicates, in some cases, although some nodes become similar after aggregation, they are still distinguishable via their surrounding dissimilarities. This leads us to use diversification operation, i.e. high-pass (HP) filter [10] (will be introduced in the next subsection) to extract the information of neighborhood differences and address harmful heterophily. As in Figure 5 shows, nodes 1,3 will assign negative weights to nodes 4,5,6,7 after diversification operation, i.e. nodes 1,3 treat nodes 4,5,6,7 as negative samples and will move away from them during backpropagation. Base on this example, we first propose diversification distinguishability as follows to measures the proportion of nodes that diversification operation is potentially helpful for,
Definition 2.
Diversification Distinguishability (DD) based on .
Given , a node v is diversification distinguishable if the following two conditions are satisfied at the same time,
Then, graph diversification distinguishability value is defined as
We can see that . The effectiveness of diversification operation can be proved for binary classification problems under certain conditions based on definition 2, leading us to:
Theorem 3.
Suppose . Then, for a binary classification problem, i.e. , all nodes are diversification distinguishable, i.e.. Theorem 3 theoretically demonstrates the importance of diversification operation to extract high-frequency information of graph signal [10]. Combined with aggregation operation, which is a low-pass filter [10,48], we can get a filterbank which uses both aggregation and diversification operations to distinctively extract the low- and high-frequency information from graph signals. We will introduce filterbank in the next subsection.
3.4. Filterbank and Adaptive Channel Mixing(ACM) GNN Framework
Filterbank
For the graph signal defined on , a 2-channel linear (analysis) filterbank [10]6 includes a pair of low-pass(LP) and high-pass(HP) filters , where and retain the low-frequency and high-frequency content of , respectively. Filterbanks with will not lose any information of the input signal, i.e. perfect reconstruction property [10].
However, most existing GNNs are under uni-channel filtering architecture [17,24,58] with either or channel that only partially preserves the input information. Generally, the Laplacian matrices (, , , ) can be regarded as HP filters [10] and affinity matrices (, , , ) can be treated as LP filters [16,48]. Moreover, we consider MLPs as owing a special identity filterbank with matrix I that satisfies .
Filterbank in Spatial Form
Filterbank methods can also be extended to spatial GNNs. Formally, on the node level, left multiplying and on performs as aggregation and diversification operations, respectively. For example, suppose and , then for node i we have
where is the connection weight between two nodes. To leverage HP and identity channels in GNNs, we propose the Adaptive Channel Mixing (ACM) framework which can be applied to lots of baseline GNN. We use GCN as an example and introduce ACM framework in matrix form. We use and to represent general LP and HP filters. The ACM framework includes 3 steps as follows,
The framework with option 1 in step 1 is ACM framework and with option 2 is ACMII framework. ACM(II)-GCN first implement distinct feature extractions for 3 channels, respectively. After processed by a set of filterbanks, 3 filtered components are obtained. Different nodes may have different needs for the information in the 3 channels, e.g. in Figure 5, nodes 1,3 demand high-frequency information while node 2 only needs low-frequency information. To adaptively exploit information from different channels, ACM(II)-GCN learns row-wise (node-wise) feature-conditioned weights to combine the 3 channels. ACM(II) can be easily plugged into spatial GNNs by replacing and by aggregation and diversification operations as shown in (28).
Complexity
Number of learnable parameters in layer l of ACM(II)-GCN is , while it is in GCN. The computation of step 1-3 takes flops, while GCN layer takes flops, where is the number of non-zero elements.
Performance Comparison
We implement SGC [60] with 1 hop and 2 hops (SGC-1, SGC-2), GCNII [5], GCNII[5], GCN [24] and snowball networks with 2 and 3 layers (snowball-2, snowball-3) and apply them in ACM or ACMII framework: we use as LP filter and the corresponding HP filter is . We compare them with several baseline and SOTA GNN models: MLP with 2 layers (MLP-2), GAT [58], APPNP [25], GPRGNN [6], HGCN [70], MixHop [1], GCN+JK [24,35,63], GAT+JK [35,58,63], FAGCN [2] GraphSAGE [17] and Geom-GCN [51]. Besides the 9 benchmark datasets Cornell, Wisconsin, Texas, Film, Chameleon, Squirrel, Cora, Citeseer and Pubmed used in [51], we further test the above models on a new benchmark dataset, Deezer-Europe, that is proposed in [35]. On each dataset used in [51], we test the models 10 times following the same early stopping strategy, the same random data splitting method and Adam [23] optimizer as used in GPRGNN [6]. For Deezer-Europe, we test the above models 5 times with the same early stopping strategy, the same fixed splits and AdamW [37] used in [35].
To better visualize the performance boost and the comparison with SOTA models, in Figure 6, we plot the bar charts of the test accuracy of SOTA models, 3 selected baselines (GCN, snowball-2, snowball-3) and their ACM and ACMII augmented models on 6 most commonly used benchmark heterophily datasets (See [40] for the full results and comparison). We can see that after being applied in ACM or ACMII framework, the performance of the 3 baseline models are significantly boosted on all tasks and can achieve SOTA performance. Especially on Cornell, Texas, Film and Squirrel, the augmented models significantly outperform the current SOTA models. Overall, It suggests that ACM or ACMII framework can help GNNs to generalize better on node classification tasks on heterophilous graphs.
3.5. Prior Work
We discuss relevant work of GNNs on addressing heterophily challenge in this part. Authors in [1] acknowledge the difficulty of learning on graphs with weak homophily and propose MixHop to extract features from multi-hop neighborhood to get more information. Geom-GCN [51] precomputes unsupervised node embeddings and uses graph structure defined by geometric relationships in the embedding space to define the bi-level aggregation process. Authors in [20] propose measurements based on feature smoothness and label smoothness that are potentially helpful to guide GNNs on dealing with heterophilous graphs. HGCN [70] combines 3 key designs to address heterophily: (1) ego- and neighbor-embedding separation; (2) higher-order neighborhoods; (3) combination of intermediate representations. CPGNN [69] models label correlations by the compatibility matrix, which is beneficial for heterophily settings, and propagates a prior belief estimation into GNNs by the compatibility matrix. FBGNN [47] first proposes to use filterbank to address heterophily problem, but it does not fully explain the insights behind HP filters and does not contain identity channel and node-wise channel mixing mechanism. FAGCN [2] learns edge-level aggregation weights as GAT [58] but allows the weights to be negative which enables the network to capture the high-frequency components in graph signals. GPRGNN [6] uses learnable weights that can be both positive and negative for feature propagation, it allows GRPGNN to adapt heterophily structure of graph and is able to handle both high- and low-frequency parts of the graph signals.
3.6. Future Work
Limitation of Diversification Operation
Diversification operation does not work well in all harmful heterophily cases. For example, consider an imbalanced dataset where several small clusters with distinctive labels are densely connected to a large cluster. In this case, the surrounding differences of nodes in small clusters are similar, i.e. the neighborhood differences are mainly from their connection to the same large cluster, and this possibly makes diversification operation fail to discriminate them. Thus, it is obvious that ACM framework is not able to handle all heterophily cases.
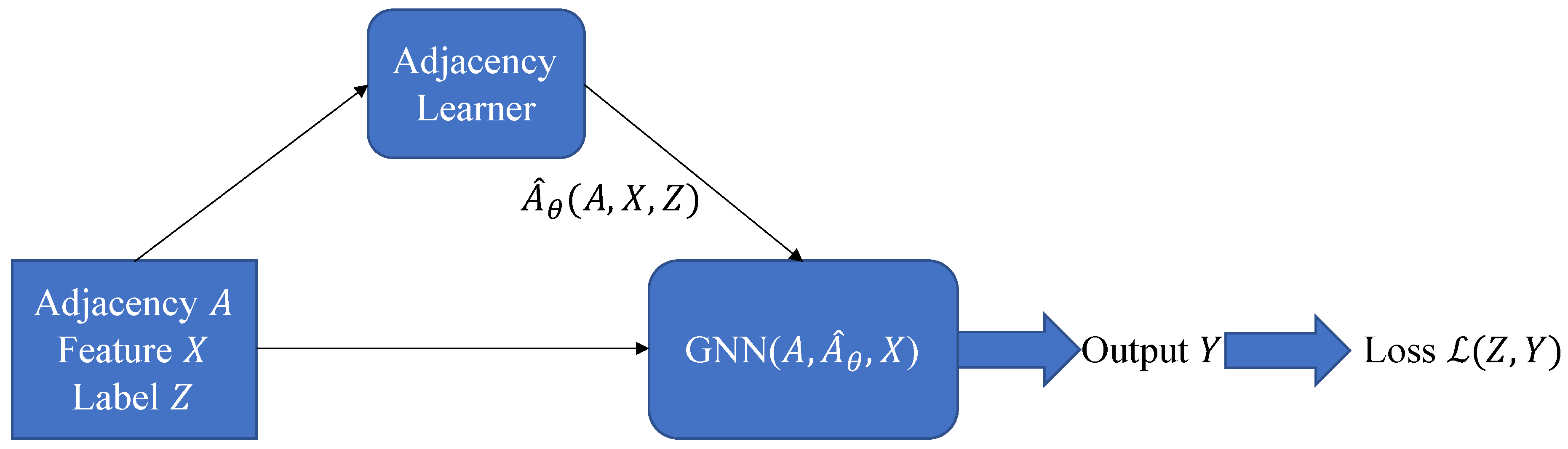
From Figure 4, we can see that GNNs consistently perform well in the high homophily area. This reveals the fact that all homophily cases are helpful. This reminds us that instead of using a fixed adjacency matrix, we can learn a new adjacency matrix with different homophily level. With this in mind, we design an architecture with additional adjacency learner as shown in Figure 7: instead of using a fixed predefined adjacency matrix, we will learn an adjacency matrix with edges that can reveal the label similarity between nodes, i.e. homophily. . This adjacency learner should ideally be trained end-to end. From some preliminary experimental results (not included in this report) of a GCN with a pretrained adjacency learner, this method is promising although there are some stability issues need to be fixed.
3.6.0.12. Exploring Different Ways for Adjacency Candidate Selection
Some tricks can be explored when we are selecting the adjacency candidates for the adjacency learner:
- Sample or select (top-) nodes from complementary graph, put them together with the pre-defined neighborhood set to form adjacency candidate set, then sample or select (top-) adjacency candidates for training. Try to train it end-to-end.
- Consider modeling the candidate selection process as a multi-armed bandit problem. Find an efficient way to learn to select good candidates from complementary graph. Can use pseudo count to prevent selecting the same nodes repeatedly.
4. Graph Representation Learning for Reinforcement Learning
4.1. Markov Decision Process (MDP)
MDP is a framework to model the learning process that the agent learns from the interaction with the environment[56,67,68]. The interaction happens in discrete time steps, . At step t, given a state , the agent picks an action according to a policy , which is a rule of choosing actions given a state. Then, at time , the environmental dynamics take the agent to a new state and provide a numerical reward . Such a sequence of interaction gives us a trajectory . The objective is to find an optimal policy to maximize the expected long-term discounted cumulative reward for each state s, where is the discount factor.
For a given policy , solving its value function is equivalent to solving the following linear system,
where . The state transition matrix essentially defines a graph structure over states and the reward vector is a signal defines on graph. Thus, solving value function can be considered as a (supervised or semi-supervised) node regression tasks over graph. Besides solving , the graph structure can also be used for reward propagation and representation learning in Reinforcement Learning (RL) [26,27,28].
4.2. Graph Representation Learning for MDP
Treating MDP as a graph is an old but never outdated idea. Traditional methods use graph Laplacian for a fixed policy to estimate , e.g. proto-value function [49]. In addition to value function estimation, [28] proposes to use GCN to learn potential-based reward shaping, which can accelerate the learning process of the agent.
The above methods both construct the graph from the sampled trajectory data. With modern Graph Representation Learning (GRL) methods e.g. node embedding methods [3], link prediction methods [52,54,57], we can learn to reconstruct the underlying graph (adjacency matrix) from sampled data more efficiently. And label propagation [53], which is a commonly used algorithm for graph semi-supervised learning, can be helpful for efficient reward propagation. In Section 4.3, we will introduce the potential of using GRL for reward propagation and representation learning in reinforcement learning.
4.3. Reinforcement Learning with Graph Representation Learning
In this section, we will draw how to represent Markov Decision Process (MDP) with graph and introduce two possible ways of using graph representation learning to address the problems defined on MDP.
Each state can be treated as a node on a graph, the transition probability between each pair of nodes (an element in state transition matrix) can be represented by the edge (or weight) between them and value function is a function defined on each node of the graph. The details (for finite MDP) are introduced in matrix form as follows [38,59]:
- Denote environment transition matrix as P, whereand , , for all . Note that P is not a square matrix.
- We rewrite the policy by an matrix , where , otherwise 0:where is an -dimensional row vector. From this definition, one can quickly verify that the matrix product gives the state-to-state transition matrix (asymmetric) induced by the policy in the environment P, and the matrix product gives the state-action-to-state-action transition matrix (asymmetric) induced by policy in the environment P.
- We denote the reward vector as , whose entry specifies the reward obtained when taking action a in state s, i.e.
- The state value function and state-action value function can be represented by
4.3.1. Learn Reward Propagation as Label Propagation
The sampling process from an MDP can be considered as a random walk defined on a graph, because the relation (edge) between each pair of states is essentially a transition probability 7. Discovering the underlying graph of a MDP can help us to leverage the correlation between states to learn value function or do to efficient exploration in sparse reward environment.
Usually, the graph is constructed from the trajectory data, i.e. the pairwise state transition data. But once we update the policy, we need to reconstruct the graph. With graph embedding methods for link prediction tasks, e.g., Deepwalk [52], node2vec [14], Line[57], we are able to learn graph reconstruction by inferring some unobserved transition. To be more specifically, instead of learning for a fixed policy , we can learn the state-action transition probability , which is independent of . In this way, we can take use of trajectory data in all history no matter the policy changes or not. And once we are given a policy, we can infer the graph by combining and .
4.3.2. Graph Embedding as Auxiliary Task for Representation Learning
Learning auxiliary tasks is showed to be helpful for state representation learning [22], which is critical to learn a good policy for agents. Among the methods, successor representation is showed to be theoretically and empirically important for learning a good state representations [8,29]. Modeling the successor triplet for MDP is essentially equivalent to modeling the triplet in knowledge graph. And there exist a lot of algorithms in knowledge graph embedding community to address triplet embedding problem, e.g., TransE [3], RotateE [55], QuatE [65] and DihEdral [62]. These methods can be borrowed to learn richer representation for RL tasks.
Appendix A. Calculation of Variances
Appendix A.1. Background
We first decompose the deep GCN architecture as follows
where , ; is the ground truth matrix with one-hot label vector in each row, C is number of classes; L is the scalar loss. Then the gradient propagates in the following way
where ⊙ is the Hadamard product. The gradient propagation of GCN differs from that of multi-layer perceptron (MLP) by an extra multiplication of when the gradient signal flows through .
Appendix A.2. Variance Analysis
Appendix A.2.1. Forward View
Suppose the activation function is identity function such as [60], all element in W share the same variance and each element in are independent and share the same variance, and , can be written as
Then, if we want we will have
Since the parameter matrix is shared by all nodes, we cannot design a node specified initialization scheme for the W. Thus, we initialize each element in W by the average values as follows
If we relax the assumption and assume it nonzero, as shown in [18], if we use ReLU activation function, we will have
If we consider the correlation between nodes and keep the assumption that each dimension of the feature (columns in ) is independent and , we will have
Since
we can have several reasonable assumptions over to get different results
- The adjacency matrix with self-loop can be considered as a prior covariance matrix and thus a reasonable assumption is .
- Consider symmetric normalized as a prior covariance matrix and we have
These assumptions all lead us to
Thus we have
Thus
Suppose and , since , we have and we assume . Then,
Thus,
can be considered as the effective degree of node i and an estimation is
Appendix A.2.2. Backward View
Under linear assumption, we have and
We have
And
From (A4), can be approximately written as
Then
Appendix A.3. Energy Analysis
Another way to design weight initialization is from the flow of energy perspective. Under the linear assumption and suppose we can do QR factorization of the weight matrices to make them orthogonal and , then we have
Suppose all and are equal, then
If we use ReLU activation function, we have
References
- S. Abu-El-Haija, B. Perozzi, A. Kapoor, N. Alipourfard, K. Lerman, H. Harutyunyan, G. Ver Steeg, and A. Galstyan. Mixhop: Higher-order graph convolutional architectures via sparsified neighborhood mixing. In international conference on machine learning, pages 21–29. PMLR, 2019.
- D. Bo, X. Wang, C. Shi, and H. Shen. Beyond low-frequency information in graph convolutional networks. arXiv preprint, arXiv:2101.00797, 2021.
- A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, and O. Yakhnenko. Translating embeddings for modeling multi-relational data. In Advances in neural information processing systems, pages 2787–2795, 2013.
- M. M. Bronstein, J. Bruna, Y. LeCun, A. Szlam, and P. Vandergheynst. Geometric deep learning: Going beyond euclidean data. arXiv, abs/1611.08097, 2016.
- M. Chen, Z. Wei, Z. Huang, B. Ding, and Y. Li. Simple and deep graph convolutional networks. arXiv preprint, arXiv:2007.02133.2020.
- E. Chien, J. Peng, P. Li, and O. Milenkovic. Adaptive universal generalized pagerank graph neural network. In International Conference on Learning Representations. https://openreview. net/forum, 2021.
- F. R. Chung and F. C. Graham. Spectral graph theory Number 92. American Mathematical Soc., 1997.
- P. Dayan. Improving generalization for temporal difference learning: The successor representation. Neural Computation, 5(4):613–624. 1993.
- M. Defferrard, X. Bresson, and P. Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. arXiv, abs/1606.09375, 2016.
- V. N. Ekambaram. Graph structured data viewed through a fourier lens. University of California, Berkeley, 2014.
- A. Frommer, K. Lund, and D. B. Szyld. Block Krylov subspace methods for functions of matrices. Electronic Transactions on Numerical Analysis. 47:100–126, 2017.
- J. Gilmer, S. S. Schoenholz, P. F. Riley, O. Vinyals, and G. E. Dahl. Neural message passing for quantum chemistry. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 1263–1272. JMLR. org, 2017.
- X. Glorot and Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, pages 249–256, 2010.
- A. Grover and J. Leskovec. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining, pages 855–864. ACM, 2016.
- M. H. Gutknecht and T. Schmelzer. The block grade of a block krylov space. Linear Algebra and its Applications, 430(1):174–185, 2009.
- W. L. Hamilton. Graph representation learning. Synthesis Lectures on Artifical Intelligence and Machine Learning, 14(3):1–159. 2020.
- W. L. Hamilton, R. Ying, and J. Leskovec. Inductive representation learning on large graphs. arXiv, abs/1706.02216, 2017.
- K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE international conference on computer vision, pages 1026–1034, 2015.
- G. E. Hinton, S. Osindero, and Y.-W. Teh. A fast learning algorithm for deep belief nets. Neural computation, 18(7):1527–1554, 2006.
- Y. Hou, J. Zhang, J. Cheng, K. Ma, R. T. Ma, H. Chen, and M.-C. Yang. Measuring and improving the use of graph information in graph neural networks. In International Conference on Learning Representations, 2019.
- C. Hua, S. Luan, Q. Zhang, and J. Fu. Graph neural networks intersect probabilistic graphical models: A survey. arXiv preprint, arXiv:2206.06089, 2022.
- M. Jaderberg, V. Mnih, W. M. Czarnecki, T. Schaul, J. Z. Leibo, D. Silver, and K. Kavukcuoglu. Reinforcement learning with unsupervised auxiliary tasks. arXiv preprint, arXiv:1611.05397.2016.
- D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint, arXiv:1412.6980.2014.
- T. N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks. arXiv, abs/1609.02907, 2016.
- J. Klicpera, A. Bojchevski, and S. Günnemann. Predict then propagate: Graph neural networks meet personalized pagerank. arXiv preprint, arXiv:1810.05997.2018.
- M. Klissarov and D. Precup. Diffusion-based approximate value functions. In the 35th international conference on Machine learning ECA Workshop, 2018.
- M. Klissarov and D. Precup. Graph convolutional networks as reward shaping functions. In ICLR 2019, Representation Learning on Graphs and Manifolds Workshop, 2019.
- M. Klissarov and D. Precup. Reward propagation using graph convolutional networks. arXiv preprint, arXiv:2010.02474.2020.
- T. D. Kulkarni, A. Saeedi, S. Gautam, and S. J. Gershman. Deep successor reinforcement learning. arXiv preprint, arXiv:1606.02396.2016.
- Y. LeCun, Y. Bengio, and G. Hinton. Deep learning. nature, 521(7553):436, . 2015.
- Y. LeCun, L. Bottou, Y. Bengio, P. Haffner, et al. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- Q. Li, Z. Han, and X.Wu. Deeper insights into graph convolutional networks for semi-supervised learning. arXiv, abs/1801.07606, 2018.
- R. Li, S. Wang, F. Zhu, and J. Huang. Adaptive graph convolutional neural networks. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
- R. Liao, Z. Zhao, R. Urtasun, and R. S. Zemel. Lanczosnet: Multi-scale deep graph convolutional networks. arXiv, abs/1901.01484, 2019.
- D. Lim, X. Li, F. Hohne, and S.-N. Lim. New benchmarks for learning on non-homophilous graphs. arXiv preprint, arXiv:2104.01404.2021.
- M. Liu, Z. Wang, and S. Ji. Non-local graph neural networks. arXiv preprint, arXiv:2005.14612.2020.
- I. Loshchilov and F. Hutter. Decoupled weight decay regularization. arXiv preprint, arXiv:1711.05101.2017.
- S. Luan, X.-W. Chang, and D. Precup. Revisit policy optimization in matrix form. arXiv preprint, arXiv:1909.09186.2019.
- S. Luan, C. Hua, Q. Lu, J. Zhu, X.-W. Chang, and D. Precup. When do we need gnn for node classification? arXiv preprint, arXiv:2210.16979.2022.
- S. Luan, C. Hua, Q. Lu, J. Zhu, M. Zhao, S. Zhang, X.-W. Chang, and D. Precup. Is heterophily a real nightmare for graph neural networks on performing node classification?
- S. Luan, C. Hua, Q. Lu, J. Zhu, M. Zhao, S. Zhang, X.-W. Chang, and D. Precup. Is heterophily a real nightmare for graph neural networks to do node classification? arXiv preprint, arXiv:2109.05641.2021.
- S. Luan, C. Hua, Q. Lu, J. Zhu, M. Zhao, S. Zhang, X.-W. Chang, and D. Precup. Revisiting heterophily for graph neural networks. Advances in neural information processing systems, 35:1362–1375, 2022.
- S. Luan, C. Hua, M. Xu, Q. Lu, J. Zhu, X.-W. Chang, J. Fu, J. Leskovec, and D. Precup. When do graph neural networks help with node classification: Investigating the homophily principle on node distinguishability. arXiv preprint, arXiv:2304.14274.2023.
- S. Luan, M. Zhao, X.-W. Chang, and D. Precup. Break the ceiling: Stronger multi-scale deep graph convolutional networks. Advances in neural information processing systems, 32, 2019.
- S. Luan, M. Zhao, X.-W. Chang, and D. Precup. Training matters: Unlocking potentials of deeper graph convolutional neural networks. arXiv preprint, arXiv:2008.08838.2020.
- S. Luan, M. Zhao, C. Hua, X.-W. Chang, and D. Precup. Complete the missing half: Augmenting aggregation filtering with diversification for graph convolutional networks. arXiv preprint, arXiv:2008.08844.2020.
- S. Luan, M. Zhao, C. Hua, X.-W. Chang, and D. Precup. Complete the missing half: Augmenting aggregation filtering with diversification for graph convolutional neural networks. arXiv preprint, arXiv:2212.10822.2022.
- T. Maehara. Revisiting graph neural networks: All we have is low-pass filters. arXiv preprint, arXiv:1905.09550.2019.
- S. Mahadevan. Proto-value functions: Developmental reinforcement learning. In Proceedings of the 22nd international conference on Machine learning, pages 553–560. ACM, 2005.
- F. Monti, D. Boscaini, J. Masci, E. Rodola, J. Svoboda, and M. M. Bronstein. Geometric deep learning on graphs and manifolds using mixture model cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5115–5124, 2017.
- H. Pei, B. Wei, K. C.-C. Chang, Y. Lei, and B. Yang. Geom-gcn: Geometric graph convolutional networks. arXiv preprint, arXiv:2002.05287.2020.
- B. Perozzi, R. Al-Rfou, and S. Skiena. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 701–710. ACM, 2014.
- U. N. Raghavan, R. Albert, and S. Kumara. Near linear time algorithm to detect community structures in large-scale networks. Physical review E, 76(3):036106, 2007.
- L. F. Ribeiro, P. H. Saverese, and D. R. Figueiredo. struc2vec: Learning node representations from structural identity. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pages 385–394, 2017.
- Z. Sun, Z.-H. Deng, J.-Y. Nie, and J. Tang. Rotate: Knowledge graph embedding by relational rotation in complex space. arXiv preprint, arXiv:1902.10197.2019.
- R. S. Sutton and A. G. Barto. Reinforcement learning: An introduction, MIT press,. 2018.
- J. Tang, M. Qu, M. Wang, M. Zhang, J. Yan, and Q. Mei. Line: Large-scale information network embedding. In Proceedings of the 24th international conference on world wide web, pages 1067–1077. International World Wide Web Conferences Steering Committee, 2015.
- P. Velickovic, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y. Bengio. Graph attention networks. arXiv, abs/1710.10903, 2017.
- T. Wang, M. Bowling, and D. Schuurmans. Dual representations for dynamic programming and reinforcement learning. In 2007 IEEE International Symposium on Approximate Dynamic Programming and Reinforcement Learning, pages 44–51. IEEE, 2007.
- F. Wu, T. Zhang, A. H. d. Souza Jr, C. Fifty, T. Yu, and K. Q. Weinberger. Simplifying graph convolutional networks. arXiv preprint, arXiv:1902.07153.2019.
- Z.Wu, S. Pan, F. Chen, G. Long, C. Zhang, and P. S. Yu. A comprehensive survey on graph neural networks. arXiv, abs/1901.00596, 2019.
- C. Xu and R. Li. Relation embedding with dihedral group in knowledge graph. arXiv preprint, arXiv:1906.00687.2019.
- K. Xu, C. Li, Y. Tian, T. Sonobe, K.-i. Kawarabayashi, and S. Jegelka. Representation learning on graphs with jumping knowledge networks. In J. Dy and A. Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 5453–5462. PMLR, 10–15 Jul 2018.
- Y. Yan, M. Hashemi, K. Swersky, Y. Yang, and D. Koutra. Two sides of the same coin: Heterophily and oversmoothing in graph convolutional neural networks. arXiv preprint, arXiv:2102.06462.2021.
- S. Zhang, Y. Tay, L. Yao, and Q. Liu. Quaternion knowledge graph embedding. arXiv preprint, arXiv:1904.10281.2019.
- S. Zhang, H. Tong, J. Xu, and R. Maciejewski. Graph convolutional networks: Algorithms, applications and open challenges. In International Conference on Computational Social Networks, pages 79–91. Springer, 2018.
- M. Zhao, Z. Liu, S. Luan, S. Zhang, D. Precup, and Y. Bengio. A consciousness-inspired planning agent for model-based reinforcement learning. Advances in neural information processing systems, 34:1569–1581, 2021.
- M. Zhao, S. Luan, I. Porada, X.-W. Chang, and D. Precup. Meta-learning state-based eligibility traces for more sample-efficient policy evaluation. arXiv preprint, arXiv:1904.11439.2019.
- J. Zhu, R. A. Rossi, A. Rao, T. Mai, N. Lipka, N. K. Ahmed, and D. Koutra. Graph neural networks with heterophily. arXiv preprint, arXiv:2009.13566.2020.
- J. Zhu, Y. Yan, L. Zhao, M. Heimann, L. Akoglu, and D. Koutra. Beyond homophily in graph neural networks: Current limitations and effective designs. Advances in Neural Information Processing Systems, 33, 2020.
- J. Zhu, Y. Yan, L. Zhao, M. Heimann, L. Akoglu, and D. Koutra. Generalizing graph neural networks beyond homophily. arXiv preprint, arXiv:2006.11468.2020.
| 1 | |
| 2 | For simplicity, the independence assumption is directly borrowed from [13], but theoretically it is too strong for GNNs. We will try to relax this assumption in the future. |
| 3 | The words "channel-shared" and "channel-wise" are borrowed from [18], which indicate if we share the same learning parameter between each feature dimension or not. |
| 4 | The authors in [35] did not name this homophily metric. We name it class homophily based on its definition. |
| 5 | A similar J-shaped curve is found in [70], though using different data generation processes. It does not mention the insufficiency of edge homophily. |
| 6 | In graph signal processing, an additional synthesis filter [10] is required to form the 2-channel filterbank. But synthesis filter is not needed in our framework, so we do not introduce it in our paper. |
| 7 | From this perspective, we should not treat the trajectory as sequential data, because we do not necessarily have an ordered relation between states on a graph, even for directed graph. Although the observation seems to have an order in it, we actually only have transition relation. |
Figure 1.
Changes in the number of independent features with the increment of network depth.
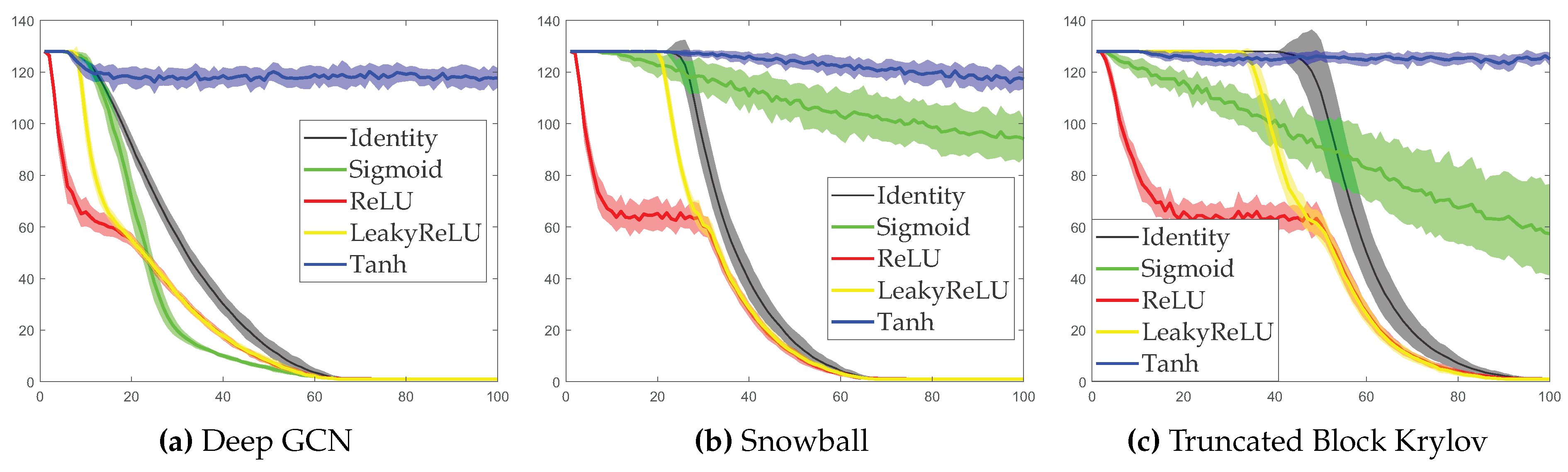
Figure 2.
Snowball and Truncated Krylov Architectures
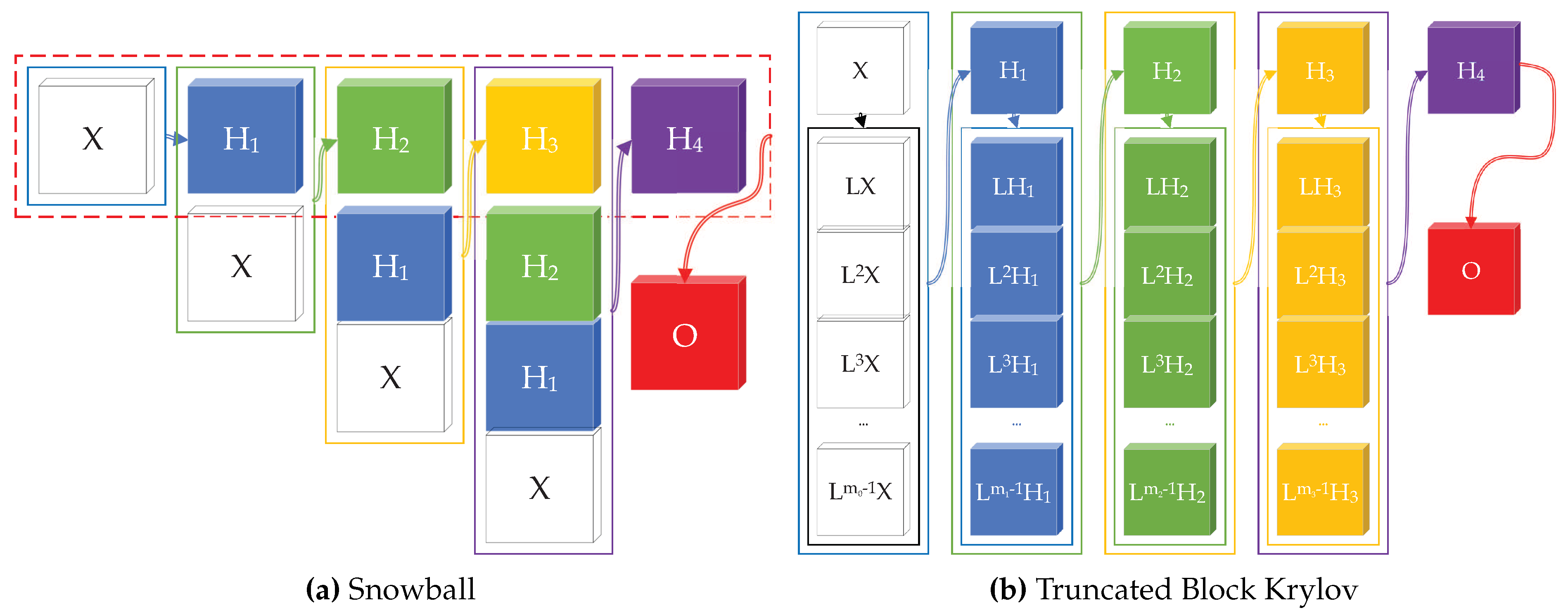
Figure 3.
Example of harmless heterophily
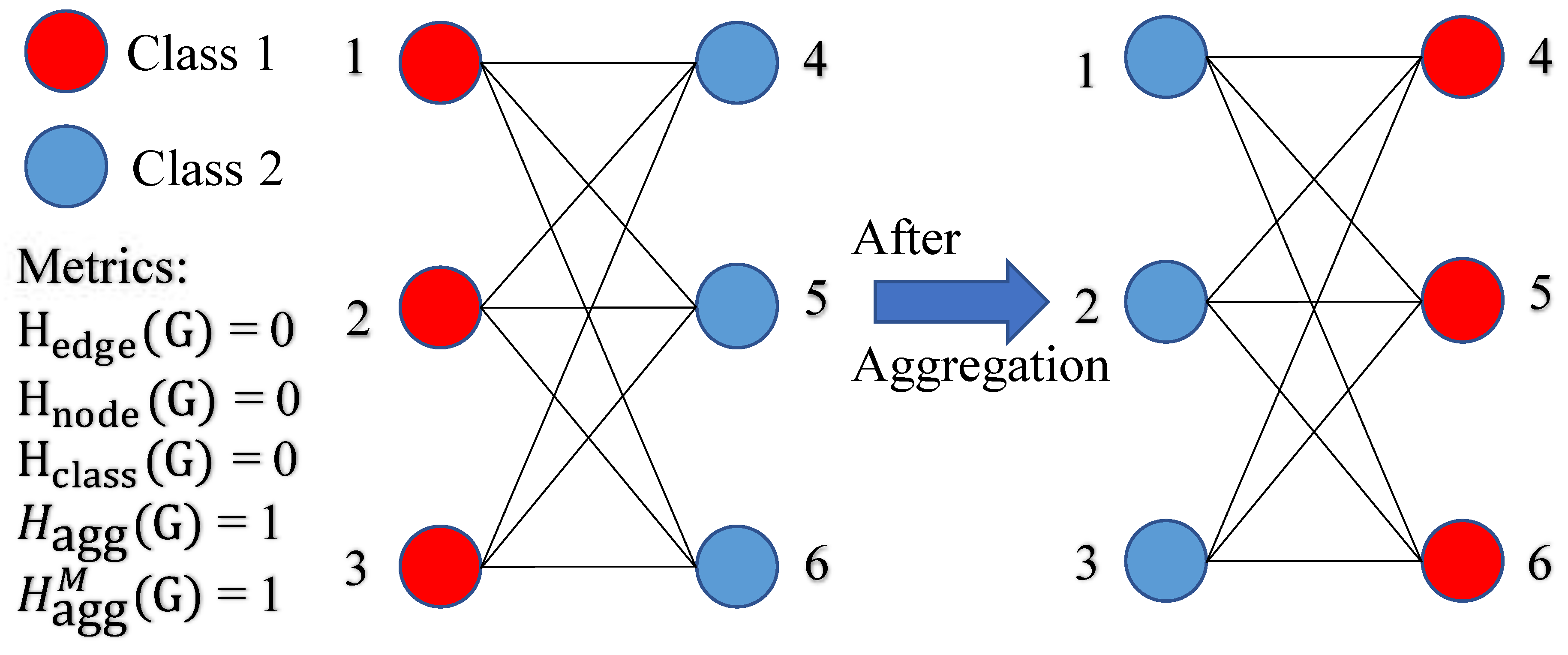
Figure 4.
Comparison of baseline performance under different homophily metrics.
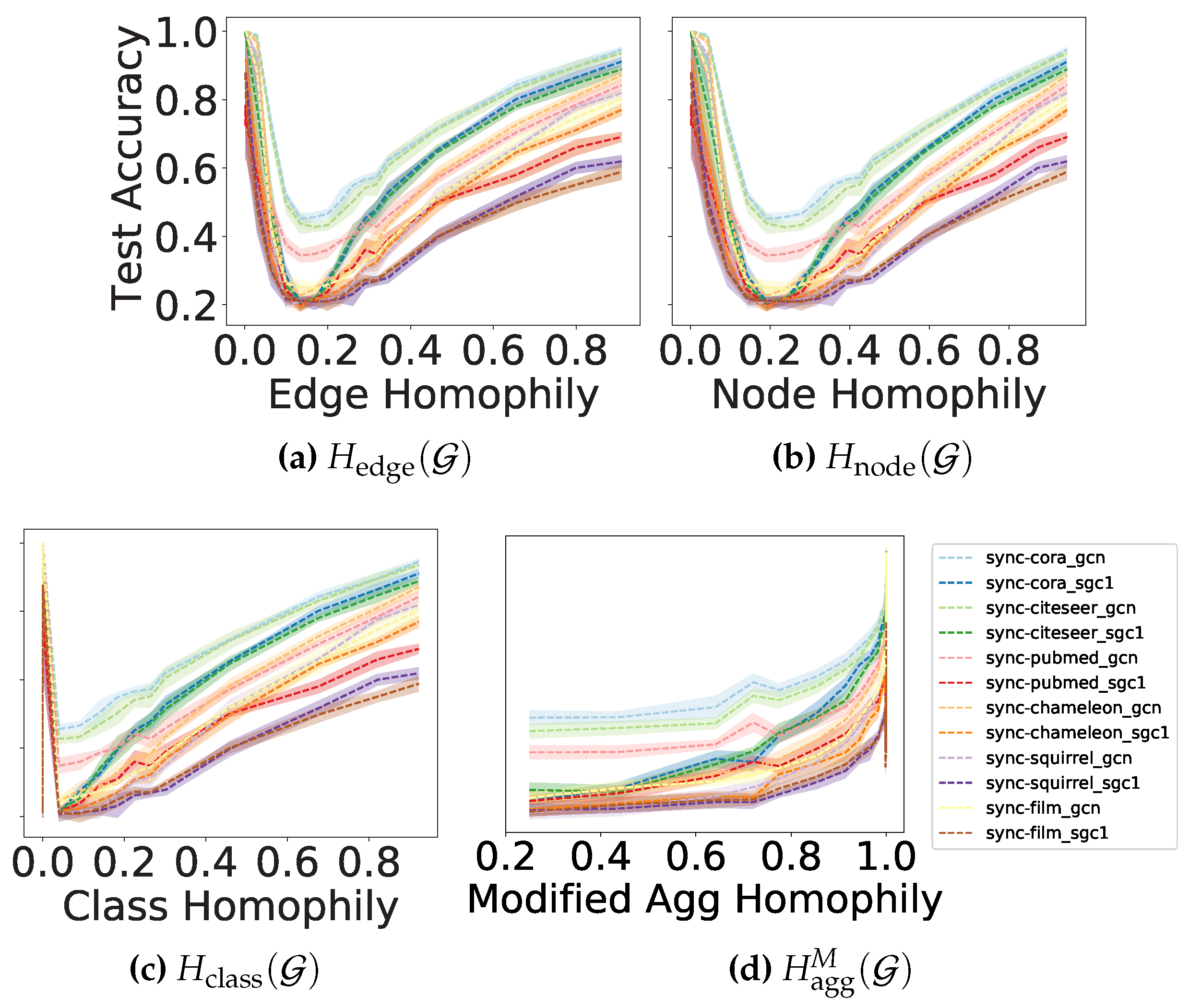
Figure 5.
Example of how HP filter addresses harmful heterophily.
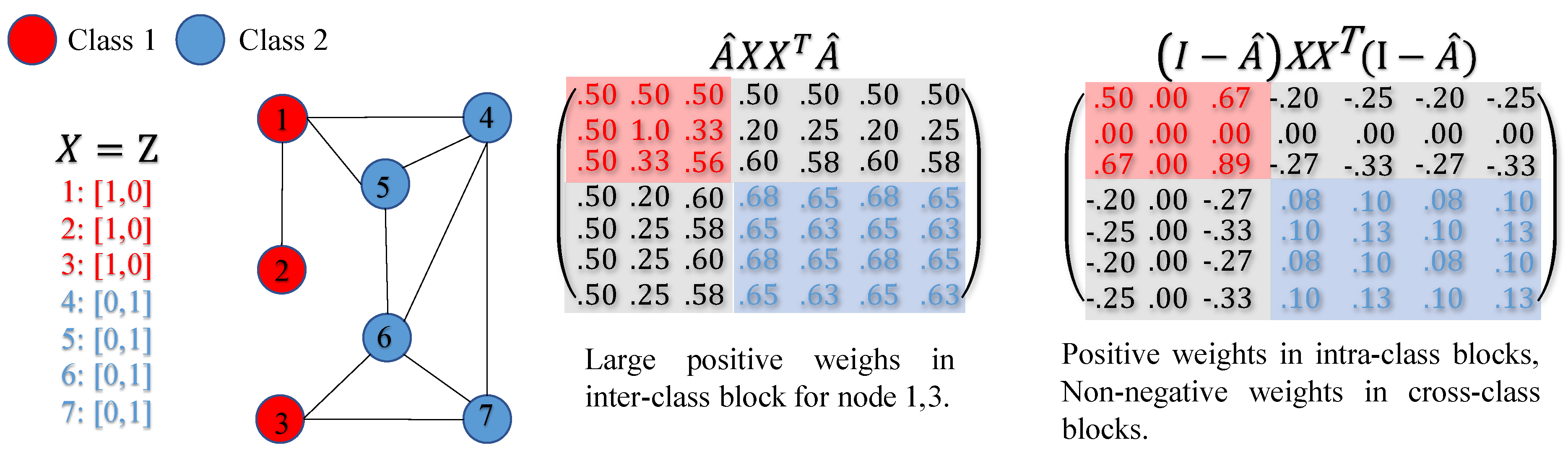
Figure 6.
Comparison of SOTA models (magenta), selected baseline GNNs (red) and their ACM (green) and ACMII (blue) augmented models on 6 selected datasets. The black line and the error bar indicate the standard deviation. The symbol “↑” means the amount of improvement of the best ACM-baseline and ACM-baseline over the SOTA models.
Figure 6.
Comparison of SOTA models (magenta), selected baseline GNNs (red) and their ACM (green) and ACMII (blue) augmented models on 6 selected datasets. The black line and the error bar indicate the standard deviation. The symbol “↑” means the amount of improvement of the best ACM-baseline and ACM-baseline over the SOTA models.
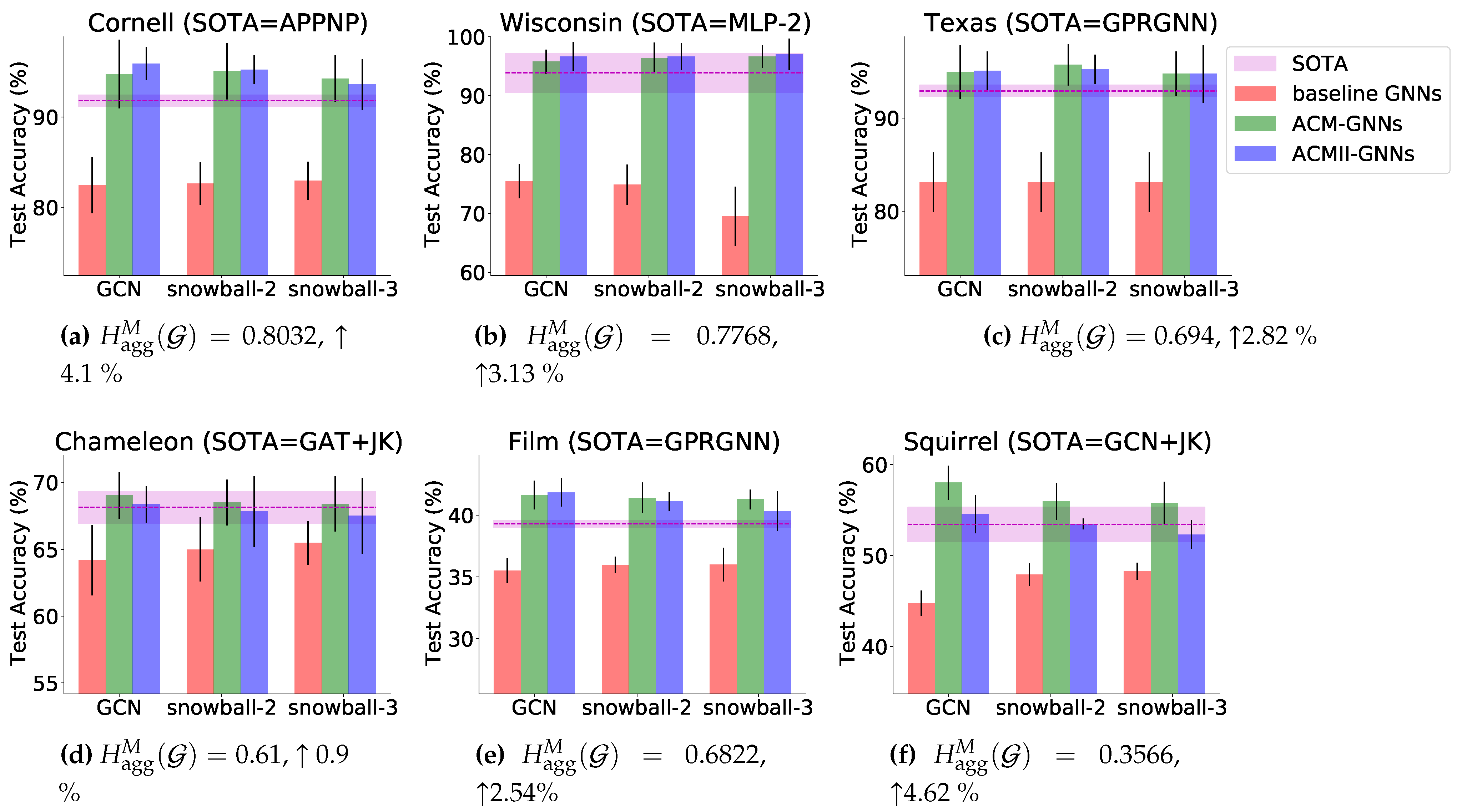
Figure 7.
GNN with adjacency learner.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



