
Submitted:
20 July 2023
Posted:
21 July 2023
You are already at the latest version
Abstract
Prediction markets are heralded as powerful forecasting tools, but models to describe them often fail to capture the full complexity of the underlying mechanisms that drive price dynamics. To address this issue, we propose a model in which agents belong in a social network, have an opinion about the probability of a particular event to occur, and bet on the prediction market accordingly. Agents update their opinions about the event by interacting with their neighbours in the network, following the Deffuant model of opinion dynamics. Our results suggest that a simple market model that takes into account opinion formation dynamics is capable to replicate the empirical properties of historical prediction market time series, including volatility clustering and fat-tailed distribution of returns. Interestingly, the best results are obtained when there is the right level of variance in the opinions of the agents. Moreover, this paper provides a new way to indirectly validate opinion dynamics models against real data by using historical data obtained from PredictIt, an exchange platform whose data has never been used before to validate models of opinion diffusion.
Keywords:
opinion dynamics
; econophysics
; prediction markets
; complex networks
; agent-based modelling
1. Introduction
Futures contracts have long been used in finance to harness the wisdom of the crowd and make predictions about the future value of an asset by exploiting people’s aggregate expectations. Prediction markets are one of the most recent forms of futures and, although they were originally only meant to forecast the outcomes of important political events, nowadays they are used in a number of different contexts. For instance, alongside public markets that allow betting on political or sports events, there exist private prediction markets that are used by companies such as Google, Intel, and General Electric to gather people’s beliefs about business activities such as sales forecasts or the likelihood of a team meeting certain performance goals [1,2]. Although prediction markets are often heralded as an effective mechanism to make highly accurate predictions [3,4], it has been shown that they are prone to bias [5] and manipulation [6], and that these phenomena can spread to financial markets with dreadful consequences [6,7].
To better understand prediction markets and consequently account for these adverse events, thereby limiting their impact outside the prediction market itself, there is the need for models that realistically reproduce the underlying processes that drive price and opinion formation. This can be achieved by building adequately complex frameworks that can be validated against real-world data. That is, models that are simple enough to be understood and controlled, but complex enough to allow the emergence of realistic and complex dynamics generated by simple interactions between agents. Despite the vast amount of existing models of prediction markets [5,8,9,10], there is little work on modelling prediction market exchange platforms, arguably the most important type of prediction market.
To address this gap, in this paper we propose a model that matches the empirical properties (often referred to as stylized facts) of historical price and volume time series of political prediction markets. To achieve this, we consider a social network where agents possess an opinion about the probability of a given event occurring, and either buy or sell contracts on a prediction market exchange based on their opinion. To model the opinion dynamics process, we use the Deffuant model [11]. Opinion dynamics have long been a topic on which a number of physicists applied statistical physics tools to better understand human interactions and the complex phenomena that emerge from them (see, for example, [11,12,13,14,15] for seminal opinion dynamics models and [16] for a thorough review of the topic). Research has also been done using opinion dynamics models with binary opinions to model agents in the stock market [17,18,19,20]. Among the many models proposed to describe opinion diffusion in social networks, we choose to follow the Deffuant model, which has three features that make it especially suitable to represent the underlying opinion propagation process that determines prices in prediction markets. First, the Deffuant model considers continuous opinions bounded by arbitrary values. This makes it perfect to describe the diffusion of opinions about the probability of an event to occur, as the opinion can be bounded between 0 and 1 and take any value in this range. Second, since it has only two free parameters, the Deffuant model has the merit of being extremely simple, which allows us to gain deeper insights on what drives price properties in prediction markets. This also guarantees a good degree of realism without having to make assumptions on other parameters in the model, which have otherwise to be fine-tuned, a common (and often necessary) practice for models of financial markets [21,22]. Third, similar to other bounded confidence models of opinion diffusion, in the Deffuant model only people with similar opinions update their beliefs after interacting, which allows the possibility of not reaching consensus at equilibrium. This property enable us to analyze the similarity of our results to historical data depending on the number of opinion clusters that coexist at equilibrium.
This paper makes three important contributions. First, we introduce a model of prediction markets that uses opinion dynamics in social networks as its underlying mechanism. This model has the merit of being particularly simple, since it possesses only two free parameters, but highly robust at the same time, as it is capable of generating price time series that match the stylized facts of historical data for any combination of the two free parameters. Second, we show that our model reproduces historical data best when opinions are heterogeneous but revolve around a single opinion cluster. This suggests that participants in prediction markets tend to have a similar, yet not identical view on the outcome, especially in markets that have a limited duration. Third, our results support the presence of Deffuant-like opinion dynamics. This contribution helps tackling an important challenge that Sobkowitz posed by arguing that opinion dynamics models are often disconnected from the real world and lack of empirical validation [23]. Since his paper, the explosion of popularity social media experienced has certainly offered means of compelling validation [24,25]. However, the availability and popularity of such vast data sets resulted in most opinion dynamics models being validated only on social media data, potentially introducing a bias. In this paper, we use market data to provide evidence a continuous opinion diffusion models, and specifically the Deffuant model, is compatible with the exchange of opinions in prediction markets. To achieve this, we use data from PredictIt, a political prediction market exchange platform, and show that the Deffuant model provides an excellent representation of the underlying opinion diffusion process in social networks when opinions are scalar.
The remainder of the paper is organized as follows. In Section 2 we define the model of opinion formation and market exchange. In Section 3 we explain the experimental setting we used to run agent-based simulations of our model and discuss our findings, showing that our model provides a qualitatively good description of historical price and volume time series even in the worst case scenario. Finally, we conclude with a short discussion and outline future work in Section 4.
2. Model
In this section we describe the price formation model and argue why it is appropriate to represent prediction markets. We start by describing how prediction markets work, also defining normalized prices and true probabilities, and then we describe the model dynamics in detail.
Prediction markets are time-limited markets in which contracts are traded on the outcomes of a given event, , where i denotes the i-th event, and can take only two values: if i occurs, and 0 otherwise. Markets for which multiple options are available, e.g., Who will win the presidential elections? can be seen as markets in which there are N events, where N is the number of candidates running for president. The payoff of a contract on the i-th event is 1 if the corresponding event occurs and 0 otherwise. Let us denote with the price of the contract on the event . Since, in prediction markets, , where is the turnaround (e.g., spread, bookmaker fees, etc.), for our analysis we consider normalized prices , which give a better representation of the corresponding realization probabilities. Also, if a prediction market is completely efficient, the normalized price of a security reflects exactly the probability of the corresponding outcome to happen, i.e., , where is referred to as true probability.
To model the opinion diffusion process we follow the Deffuant model [11]. We start by considering a population of N agents, who belong in an undirected, unweighted social network . Without loss of generality, we assume that there is only one event with two possible outcomes and . Then, agent j possesses an opinion , which can take any real value and corresponds to its subjective probability the agent attaches to the outcome . The opinion update process is iterative: at each time step, agents may discuss the event with their neighbors, and update their opinion. To model this process, every round an agent i is randomly chosen from the network to discuss with agent j, which is, in turn, randomly chosen among agent i’s neighbors. If their opinions are too different, they refuse to update their beliefs. More precisely, the agent pair interacts only if , where is the threshold of this process and can take any real value between 0 and 1. If the agent pair interacts, they update their opinions as following:
where is the convergence parameter, and .
In this model, represents the open-mindedness of agents which would discuss with, or listen to other agents, only if their opinions are sufficiently close. In this paper we follow the basic Deffuant model and consider constant among all agents, but there exist other versions of this model in which agents have heterogeneous open-mindedness [26,27]. In general, affects the number of clusters at equilibrium (i.e., the number of opinions that coexist), while drives the convergence time [11].
To reflect the temporal volume dynamics observed by Restocchi et al. [28], each agent has a probability to participate in the market, where T is the duration of the market (in days), represents the number of days elapsed from the beginning of the market (with ), and is a scaling parameter, estimated on the same dataset [28]. If agent i is chosen to participate in the market, they can either buy or short sell a contract, whose payoff is 1 if and 0 otherwise. For sake of simplicity, we assume that there exists only one event, with two possible outcomes. Since agent i believes that , they will buy a contract only if the current price , and sell (or short sell) it if . They will neither buy or sell if . Following influential agent-based models of financial markets, we assume that price is purely driven by excess demand. Agents can only buy/sell at the current trading price and contracts are created whenever necessary. The demand of agent i, , is proportional to the distance between their opinion and the price, and is described by
That is, the more mispriced the agent believes the contract is, the more they will trade. The excess demand (ED) is simply the sum of each agent’s demand, multiplied by a noise term , as follows:
where, following [29], . The reason we choose to model the process with a multiplicative (cf. additive) noise term is that, to ensure that the price does not go beyond the boundaries too often, we need a quenching term. To ensure that this decision does not affect the model’s robustness, we run extensive simulations where the equation for the excess demand is . We found that, for , the two models return qualitatively similar results. However, adding such a quenching term would require us to run additional calibration and optimization, eventually risking to overfit our model. By adding a multiplicative noise, we avoid this issue. Importantly, below we show that the empirical properties of the time series obtained by running our simulations heavily depend on and , suggesting that the noise term has little impact on the emerging properties of the model. At each trading round, the price gets updated depending only on . Since prices are bounded between 0 and 1, they are set to 0 or 1 if they become less than 0 or greater than 1, respectively, following an update. Therefore, takes the following values:
where, without loss of generality, we have included the equation for the price update for in the first case (i.e., ).
3. Results
In this section we describe the experimental setting we use to run agent-based simulations of the model, and the results we obtained from such experiments. The simulations are run with all possible combinations of and , which are the only two free parameters in our model, within the ranges and , which represent the whole possible space for the Deffuant model, with a precision of 0.02 units. Our results show that this model provides a particularly accurate and robust description of prediction markets, because even under the worst-performing conditions, the synthetic time series produced by our simulations capture (at least to some degree) the emerging properties of prediction markets, such as volatility clustering and absence of autocorrelation of returns [30].
We tested the model on three different network topologies: a random network, a scale-free network, and a complete graph. We show results obtained on a complete graph (i.e. any agent is free to exchange opinions with any other agent), since we find that these replicate historical data more accurately. However, we do not find any significant difference in qualitative behaviour of the results, suggesting that i) price formation does not heavily depend on the network structure and that ii) our model is robust to topological changes. Results on the other two network topologies are shown in Appendix A.
Although it has been demonstrated that, at least under some circumstances, diffusion processes display finite-size effects [14,31], we decide to run experiments with 1000 agents to reflect the scarce liquidity prediction markets usually exhibit [28], with a median of approximately 300 trades per day per market. In fact, if any finite-size effect exists, this must be displayed by real prediction markets and, therefore, by keeping the number of participants low, we can capture such an effect in our simulations. We leave a detailed analysis of the relation between network size and price formation in prediction markets to future work. The choice of using Barabasi-Albert networks for our model is motivated by the fact that social networks exhibit hubs and that network topology does not have an influence on the equilibria of the Deffuant model [32].
To specify the other parameters of the simulations, we follow [28,30], who provide a comprehensive quantitative analysis of the empirical properties of prediction markets using the same data set from PredictIt. Specifically, for each combination of , , we run simulations, which is the number of markets used by Restocchi et al. [28,30] in their analysis, and the duration T of each market is randomly drawn from the empirical distribution of durations observed among these markets. In this way, our simulations will produce time series which are directly comparable with historical data on prediction markets. We initialised our agents with a uniform opinion distribution with an average of . This is for three reasons: First, these are the initial conditions that were first used in the paper that introduced the Deffuant model, and are the most widely used in practice. Second, we believe that a uniform distribution with an average of constitutes the most “uninformative prior”, and as such, it should not introduce a bias in our model. That is, other assumptions, and especially those with a different average opinion, could change the results. Given the impossibility to calibrate the initial opinion distribution with the existing dataset, we decided to remove what would have been another free parameter of the model. Third, for sake of simplicity, we assume that the true probability is equal to and is constant throughout the market. This assumption reflects the fact that, on PredictIt and other prediction markets exchange platforms, it is possible to bet on an event and on its opposite (i.e., there is the possibility to buy and sell contracts on the event Will happen? but also on the event Will not happen?).
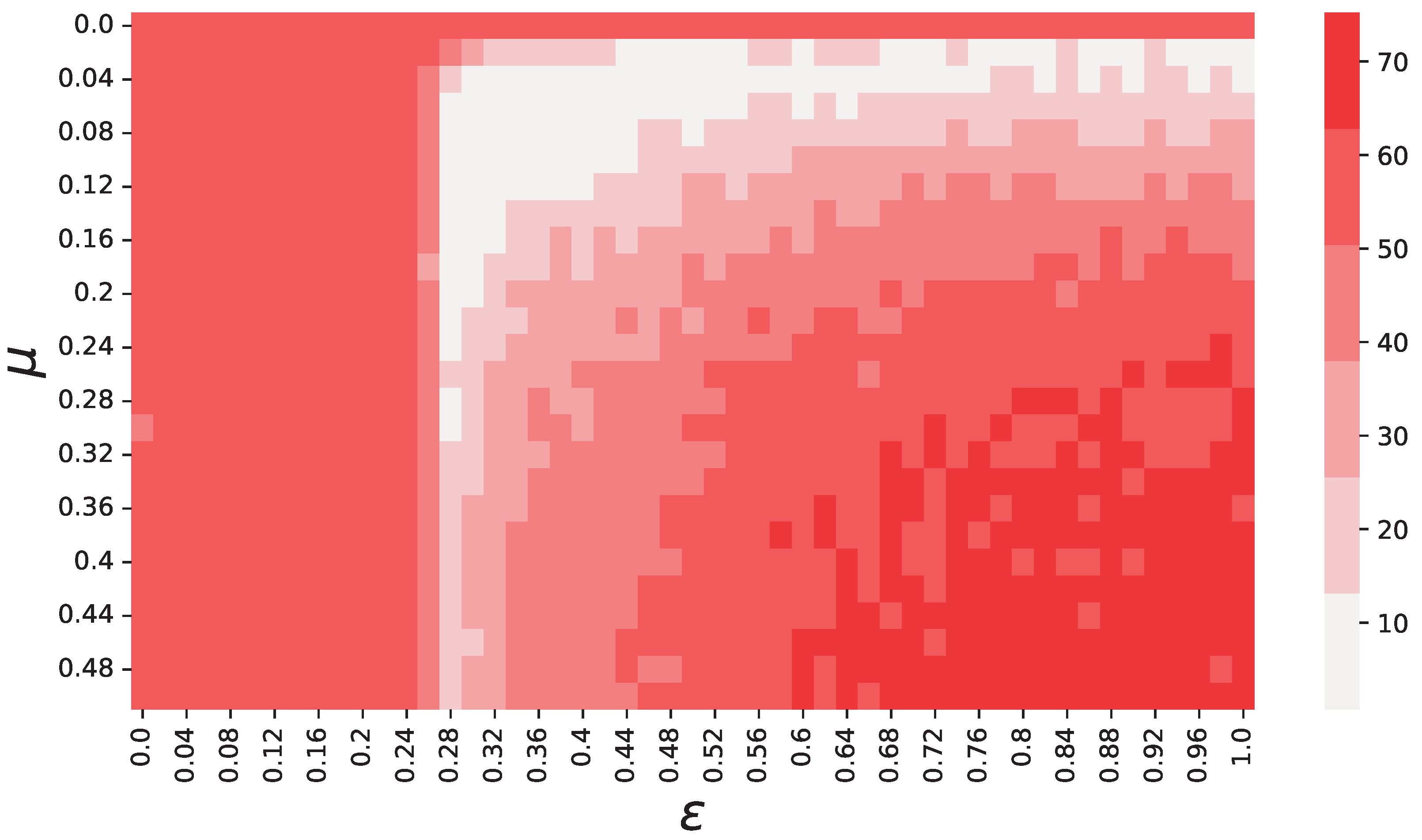
Figure 1.
Objective function values (see Equation (5)) depending on and . These results show that there is a region, approximately delimited by the area , where the objective function f reaches its minima. Each color used in this figure represents an interval of 12.5 for f, starting with . We chose to discretize the colors to smooth our results over noise, and make the regions easily recognizable.
Figure 1.
Objective function values (see Equation (5)) depending on and . These results show that there is a region, approximately delimited by the area , where the objective function f reaches its minima. Each color used in this figure represents an interval of 12.5 for f, starting with . We chose to discretize the colors to smooth our results over noise, and make the regions easily recognizable.
To find the optimal values for the pair , , we follow [33] and define the following objective function:
where and represent the kurtosis value of the distribution of the returns of all 3385 markets, for simulated and historical data, respectively. For the second term, rather than using the value of ARCH(1), i.e., the first autoregressive term of the time series, as suggested by Gilli and Winker, we use the value of the scaling parameter that describes the power-law decay of the autocorrelation function of absolute returns. Since the two terms in (5) can significantly differ in magnitude, to ensure that no component in the objective function outweighs the other, Gilli and Winker suggest that the second term, in our case , is multiplied by a constant that rescales its magnitude. For our data set, Restocchi et al. [30] found that and , from which we derive . We choose to use , instead of the first-order autocorrelation term a, because we believe this gives the calibration a better accuracy. Specifically, we also tried to calibrate the model by using two different functions, namely , where , and , and found that exhibits a qualitatively similar behavior to f, without adding information. Also, we found that by using , as suggested by Gilli and Winker, reduces the sensitivity of the objective function to and , and generates two regions of local minima in which values are not significantly different. These results are shown by Figure 2.
The objective function values computed from our simulations for each pair , are displayed by the heatmap in Figure 1. It is clear to see from this figure that there exists one region, approximately within the interval where f is significantly lower than in the rest of the space. This region also includes the global minimum, which is found in and .
It is also interesting to note that f displays a regular behavior when varying and . To better visualize this, in Figure 3 we cut the objective function space in slices and show the behavior of f separately depending on (), for a few () around its optimal value. By observing these two figures, it is easy to see two regularities. First, from the right-hand side plot one can note that, in the range , there is a sharp transition from high values of f to low ones, and that this behavior does not depend on (apart from ). Second, the left-hand side plot shows that f has always a minimum approximately in the range , but, depending on , this minimum is more or less pronounced, and it almost disappears for .
These results suggest that both and have a significant impact on the objective function, i.e., both parameters contribute in shaping the statistical properties of the time series generated by the model. This is expected, since, within short time horizons, they both contribute towards the emergence of consensus, and the speed at which this happens. For instance, for high values of and , consensus is reached too soon, and the generated time series become less accurate, as suggested by the high value of f in the region . However, our results suggest that has a greater impact on f than . Specifically, we observe that there is one region, delimited by , for which the objective function value becomes particularly high. Interestingly, this is the same value of below which consensus on a single opinion is not reached in the Deffuant model, and two or more opinions coexist at equilibrium [11], suggesting a relation between the accuracy of our model and whether there coexist one or more opinion clusters in the underlying opinion dynamics model. These results suggest that the quantitative accuracy at reproducing and heavily depends on whether there is a single opinion cluster existing at equilibrium, and on the time it takes for opinions to converge. Further evidence is represented by the results shown in Figure 4, in which we show the dependence of k and (Figure 4b) on and .
The results shown in Figure 4a suggest that the kurtosis of the distribution of raw returns is affected both by and , but loses its dependence on for low values of , approximately for , that is, in the region where multiple opinions coexist at equilibrium. However, the dependence on when suggests that, when only one opinion exists at equilibrium, the kurtosis highly depends on the time it takes to reach consensus. Not surprisingly, the shorter the time to reach consensus, the higher the kurtosis, as once consensus is reached only few agents trade, and those who trade have low absolute values of demand, since their opinion is closer to the mean. Similarly, Figure 4b shows that seems to depend mostly on , but exhibits a far sharper phase transition around than k, significantly decreasing its value for . Also, Figure 4b shows that, similarly to k, in the region , depends mainly on , and its value becomes the larger the faster opinions converge.
These results are further evidence that the accuracy of our model depends on whether there is a single opinion cluster or more, except for the region approximately delimited by , where consensus is reached early in the market and little or no trading exists after a certain point. Finally, Figure 4 shows that, for any pair , the time series generated by our simulations exhibit excess kurtosis and volatility clustering, which are the two main features of prediction markets time series we want to replicate. This is important because the optimal values of and can significantly change depending on the data set used for calibration, but our results suggest that our model is capable to reproduce, at least qualitatively, the empirical properties of prediction markets regardless the value of its parameters. However, it is important to note that combinations of parameters far from the optimum still show the emergence of the discussed stylized facts, but these are quantitatively far off from those observed in historical data.
Figure 5 shows two comparisons between historical data and simulation results, obtained with both the best and worst configurations, found for the pairs with and , respectively. The comparisons are based on the autocorrelation of absolute return and the probability density function of absolute returns, which are commonly used metrics to describe time series in financial markets [30,34]. From this figure we observe that the both the best and worst configurations generate distributions of returns which are similar to the historical one, only with slightly heavier tails. Results displayed in Figure 5 suggest that, whereas time series generated by the best configuration perfectly match the decay slope of the absolute return autocorrelation function, those generated by the worst configuration do not match historical data accurately. Indeed, although even in this case the decay of the autocorrelation function exhibits a long tail, its values quickly drop when the lag considered is greater than 10 days. This is because, for the pair of values , the underlying opinion dynamics process converges to one opinion cluster far earlier than the end of the market for most market durations. This causes price changes to be very small or zero, in contrast to the beginning of the market, when price changes are larger due to the higher heterogeneity of opinions.
4. Conclusions
In this paper we propose a model that is able to capture salient features of price formation in prediction markets. To achieve this, we propose an exchange market model in which participants are part of a social network, and exchange opinions about the realization of a particular event following the Deffuant model. Depending on their opinion, agents buy or sell contracts on a prediction market exchange. By running agent-based simulations, we show that our model generates price time series whose statistical properties closely mimic those of historical data on prediction markets. Interestingly, our findings show that even in the worst-case scenario our model reproduces prediction markets qualitatively, generating price time series that display volatility clustering and fat-tailed return distributions. These results suggest that a model of prediction markets in which agents interact with each other by sharing and updating their beliefs about an event is suitable to represent prediction markets. At the same time, using historical data, our findings corroborate the validity of the Deffuant model as a representation of real-world phenomena such as opinion formation with continuous opinions. Additionally, our results show that prediction markets are best reproduced by our model when opinions are scattered around a single opinion cluster. Conversely, when two or more opinions exist at equilibrium () or all agents have exactly the same opinion (large values of , for which consensus is reached early), the model yields quantitatively worse results. This suggests that, most of the times, single participants in prediction markets do not reach perfect consensus on the outcome, but still get close to it. This supports empirical evidence of mispricing in prediciton markets, which tends to decrease over time and is higher when market duration is shorter [35]. Our results suggest that this might be a consequence of market participants not having enough time to reach consensus, so that their opinions are scattered around a cluster.
However, our model has some limitations that should be addressed further in future work: most importantly, our model does not include shocks. The availability of new information during a financial market can have a significant impact on prices, and this is true for prediction markets too. The analysis of the impact of shocks on the underlying opinion dynamics process and their impact on price would be of great interest to understand how prediction markets can be made more stable, therefore improving their predictive power and reducing market manipulation. Finally, some of the model’s assumptions were made to simplify this initial exploration of the impact of opinion dynamics on price formation in prediction markets. Although all our assumptions were consistent with the literature, we believe that a thorough stress test could improve the understanding of price formation in prediction markets and perhaps lead to the creation of ad hoc opinion dynamics models for prediction markets.
Author Contributions
Conceptualization, V.R, F.M. and E.G.; methodology, V.R., E.G.; software, V.R.; validation, All authors; formal analysis, V.R.; data curation, V.R.; writing—original draft preparation, V.R.; writing—review and editing, All authors.; visualization, V.R.; All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding
Data Availability Statement
The data was provided by PredictIt and are available for academic research from PredictIt upon request. The code will be made publicly available on www.comses.net upon publication.
Acknowledgments
The authors would like to thank Claudio J. Tessone, Pietro Panzarasa, and Tiejun Ma for their feedback and insightful discussions.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
In this section, we present results obtained by using different network topologies for the opinion dynamics process. Specifically, we have tested our model on a random network (ER), built by following the Erdos-Rényi algorithm with , and on a scale-free network (BA), built by following the Barabasi-Albert preferential attachment algorithm [36], with each node forming 4 links when added to the network.
Here we show that our model, when agents are connected through a network, still displays the same qualitative behaviour. However, the main difference between these and the model on a complete graph, is that the latter gives a better minimum of the fitness function.
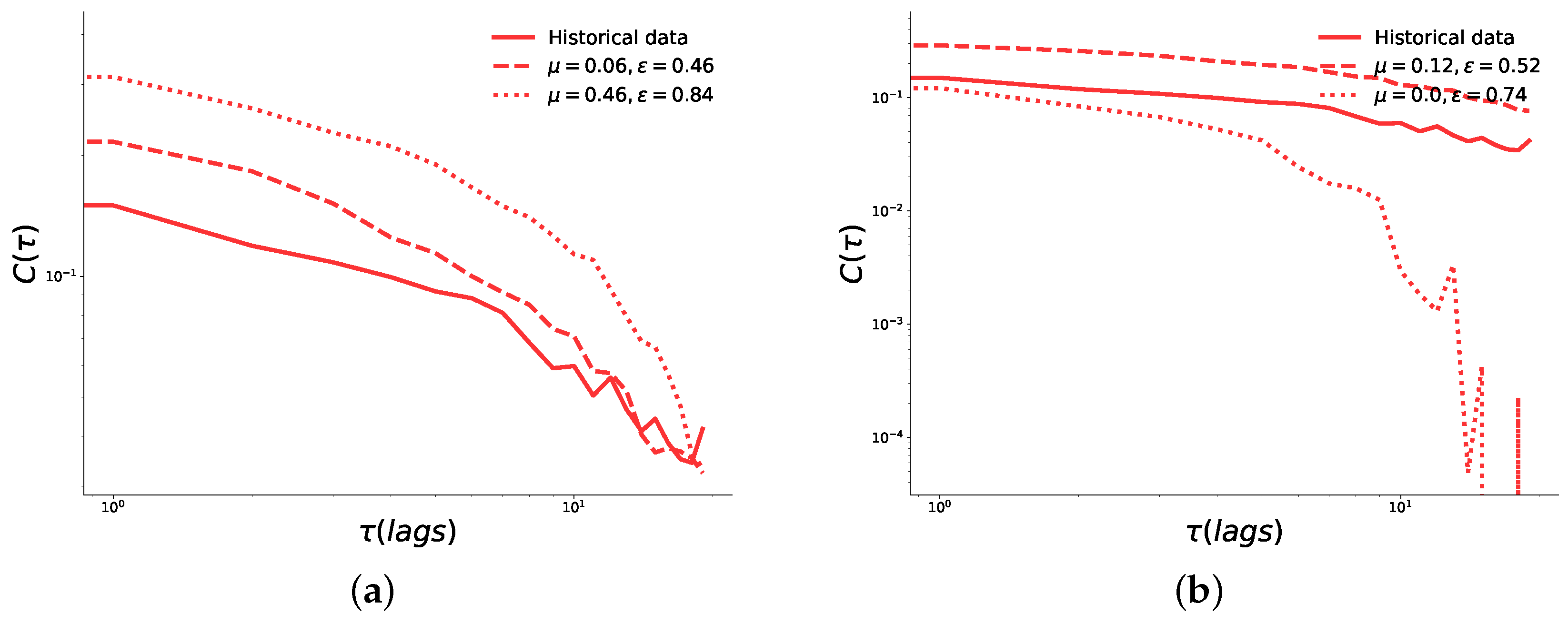
First, Figure A1 shows the objective function values for the model using a BA and a ER network. The regions in which the model best fits historical data remain approximately the same as with the model on the complete graph we presented in the main text. However, results on networks are worse than for the case of a complete graph case, as is evident from the higher minimum value and worse average fitness. The distributions of returns displayed in Figure A2 suggest that the model on a BA network yields realistic results for both the best and worst fit of and , whereas on the ER network the worst performing pair of parameters does not seem to follow the historical data accurately (see Figure 2b). Finally, the autocorrelation functions seem to decay with a similar exponent to that of the historical data for both networks. However, this is not the case for the worst-fit combinations, which follow a different path and, after a lag of 10 days, decay much more rapidly.
The presented results for small connectivity suggest that sparse networks are less suitable to reproduce price formation in prediction markets than a complete graph.
Figure A1.
Heatmaps for the objective function . The left-hand side figure has been obtained using a BA network, whereas the right-hand side figure has been obtained using a ER network.
Figure A1.
Heatmaps for the objective function . The left-hand side figure has been obtained using a BA network, whereas the right-hand side figure has been obtained using a ER network.
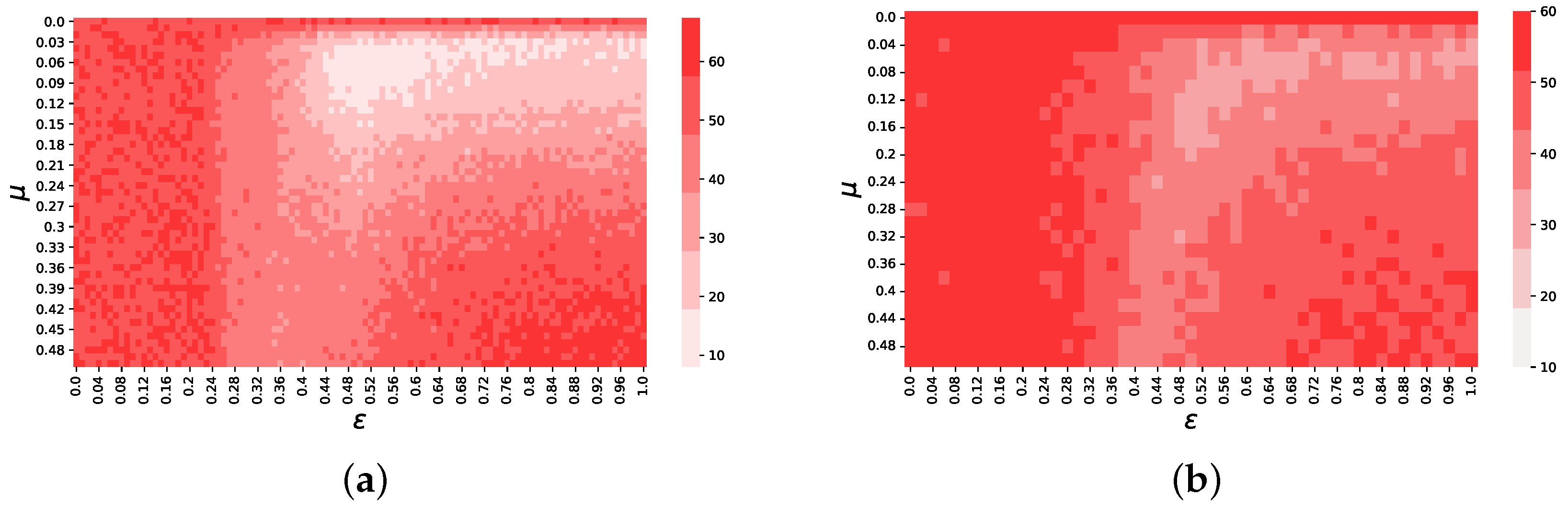
Figure A2.
Comparisons of the distribution of returns for simulations run using a BA network (left-hand side), and a ER network (right-hand side). For each network, the figures show both the best and worst fit pair of values and .
Figure A2.
Comparisons of the distribution of returns for simulations run using a BA network (left-hand side), and a ER network (right-hand side). For each network, the figures show both the best and worst fit pair of values and .
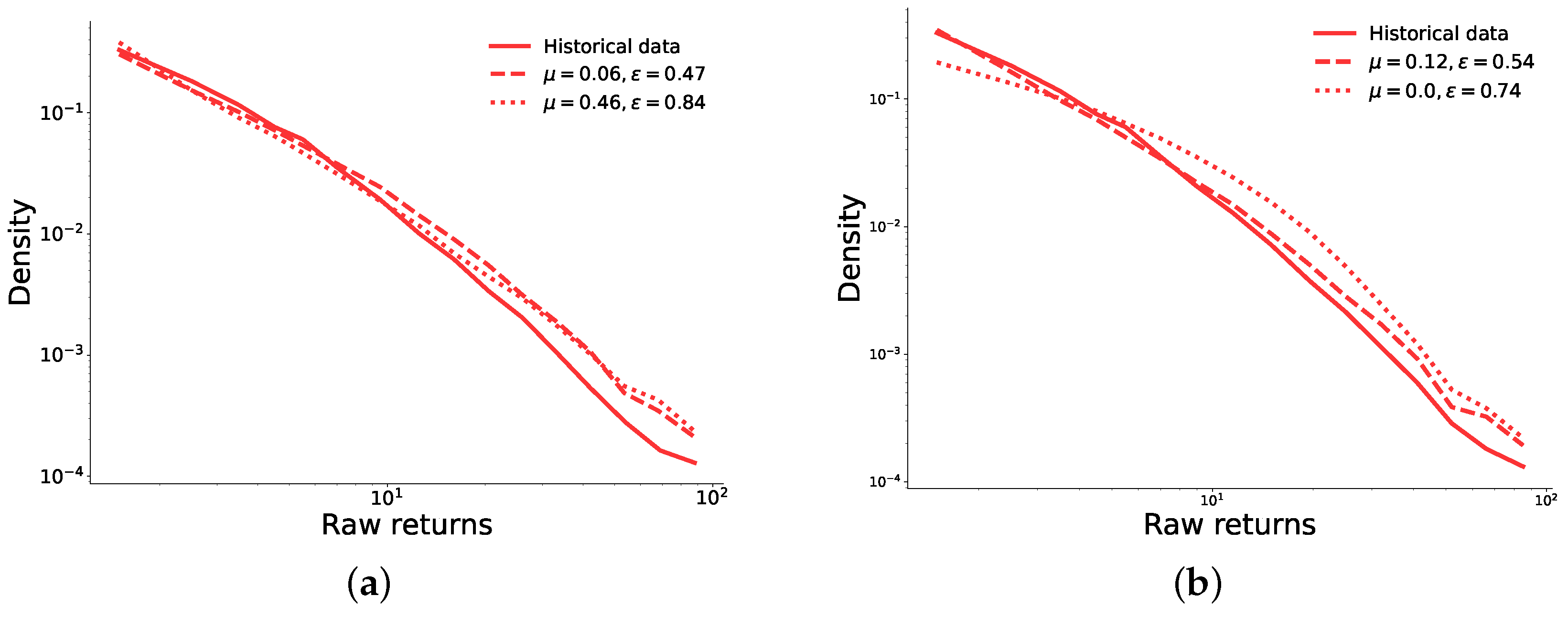
Figure A3.
Comparisons the behavior of the autocorrelation function of absolute returns, on a BA network (left-hand side), and on a ER network (right-hand side).
Figure A3.
Comparisons the behavior of the autocorrelation function of absolute returns, on a BA network (left-hand side), and on a ER network (right-hand side).
Appendix B
Figure A4.
Historical time series of raw returns (left-hand side panes), and time series of raw returns generated by our model with and (right-hand side panes). These represent a market duration of 23 days.
Figure A4.
Historical time series of raw returns (left-hand side panes), and time series of raw returns generated by our model with and (right-hand side panes). These represent a market duration of 23 days.
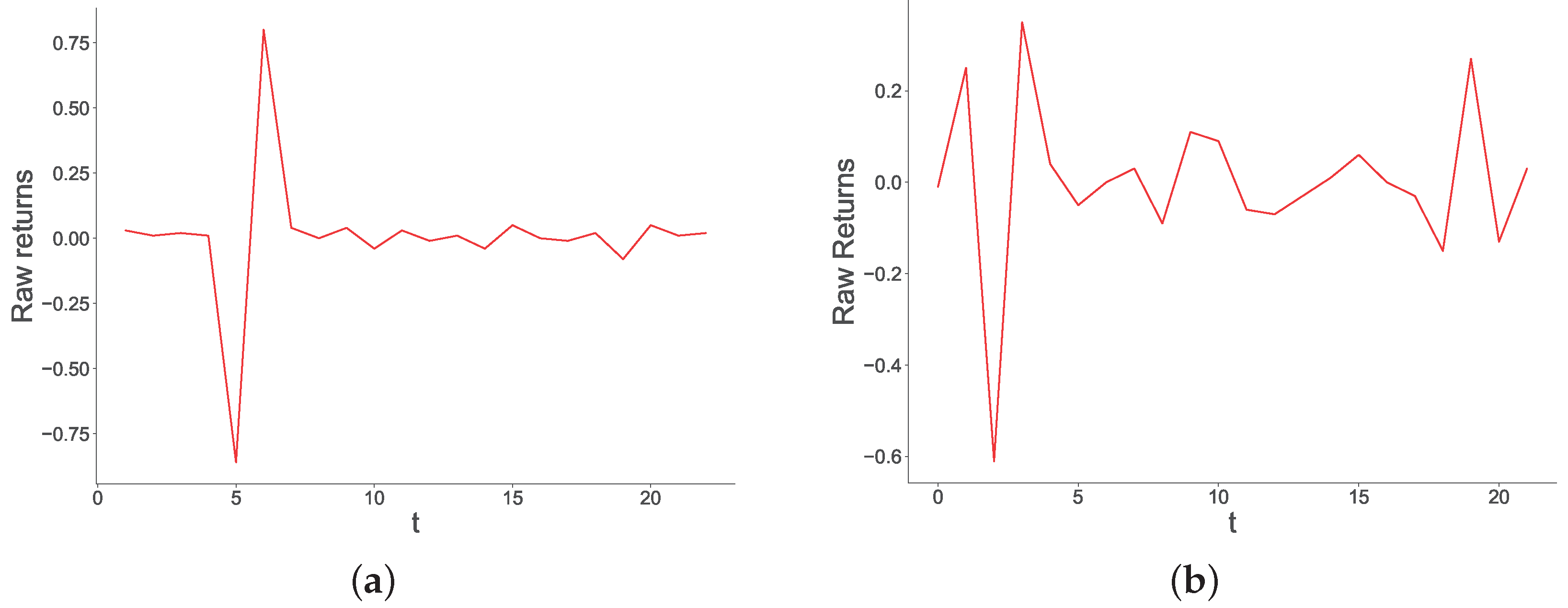
Figure A5.
Historical time series of raw returns (left-hand side panes), and time series of raw returns generated by our model with and (right-hand side panes). These represent a market duration of 40 days.
Figure A5.
Historical time series of raw returns (left-hand side panes), and time series of raw returns generated by our model with and (right-hand side panes). These represent a market duration of 40 days.
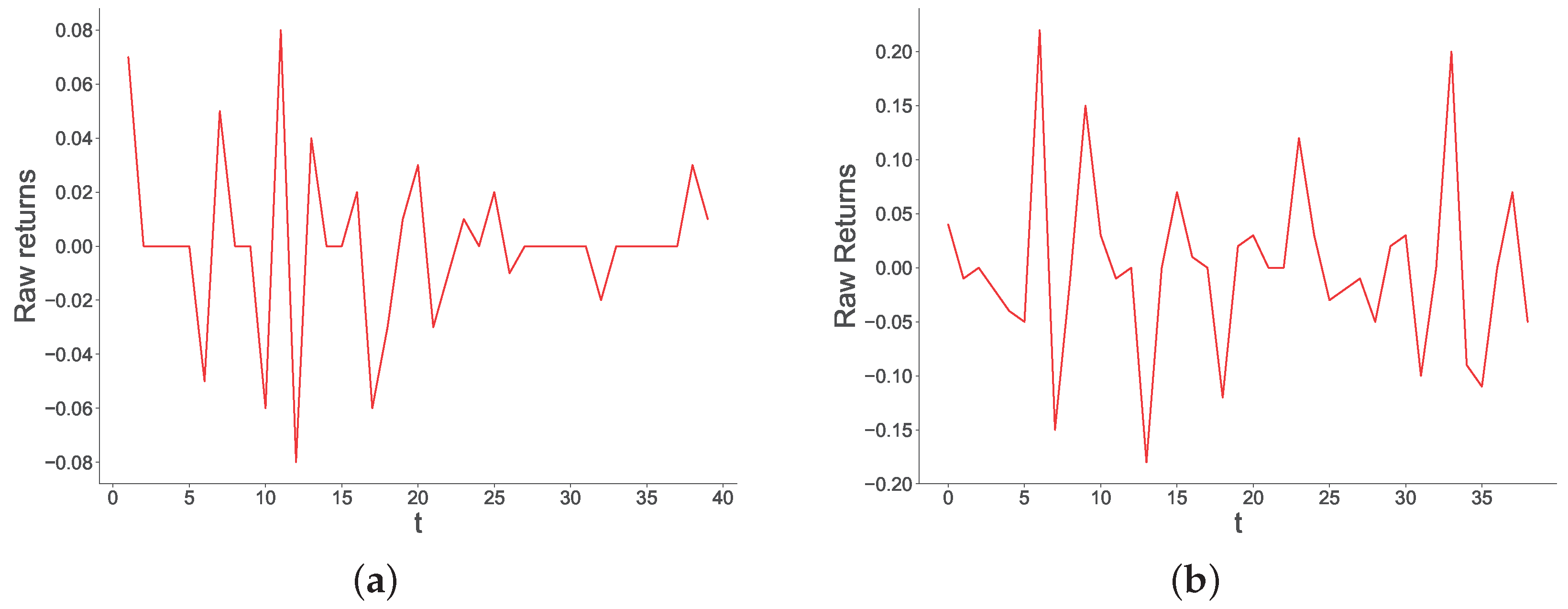
Figure A6.
Historical time series of raw returns (left-hand side panes), and time series of raw returns generated by our model with and (right-hand side panes). These represent a market duration of 80 days.
Figure A6.
Historical time series of raw returns (left-hand side panes), and time series of raw returns generated by our model with and (right-hand side panes). These represent a market duration of 80 days.
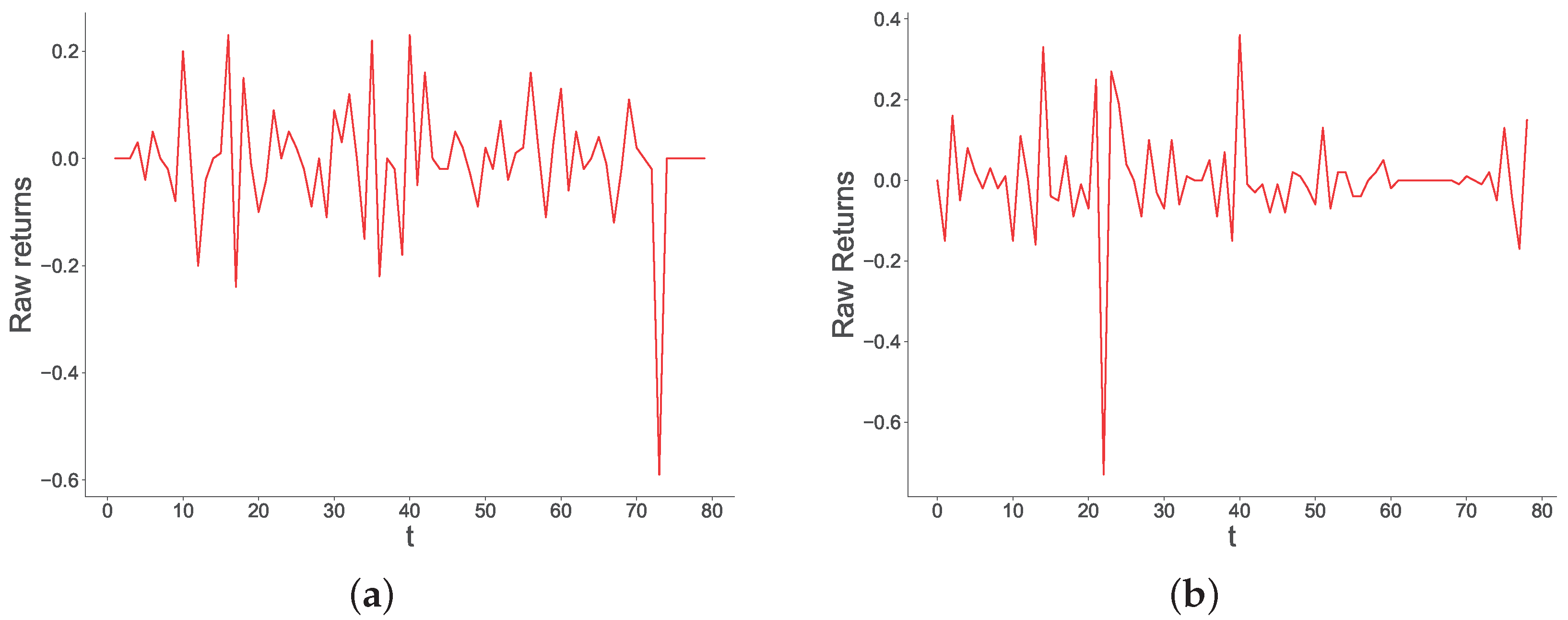
Figure A7.
Historical time series of raw returns (left-hand side panes), and time series of raw returns generated by our model with and (right-hand side panes). These represent a market duration of 158 days.
Figure A7.
Historical time series of raw returns (left-hand side panes), and time series of raw returns generated by our model with and (right-hand side panes). These represent a market duration of 158 days.
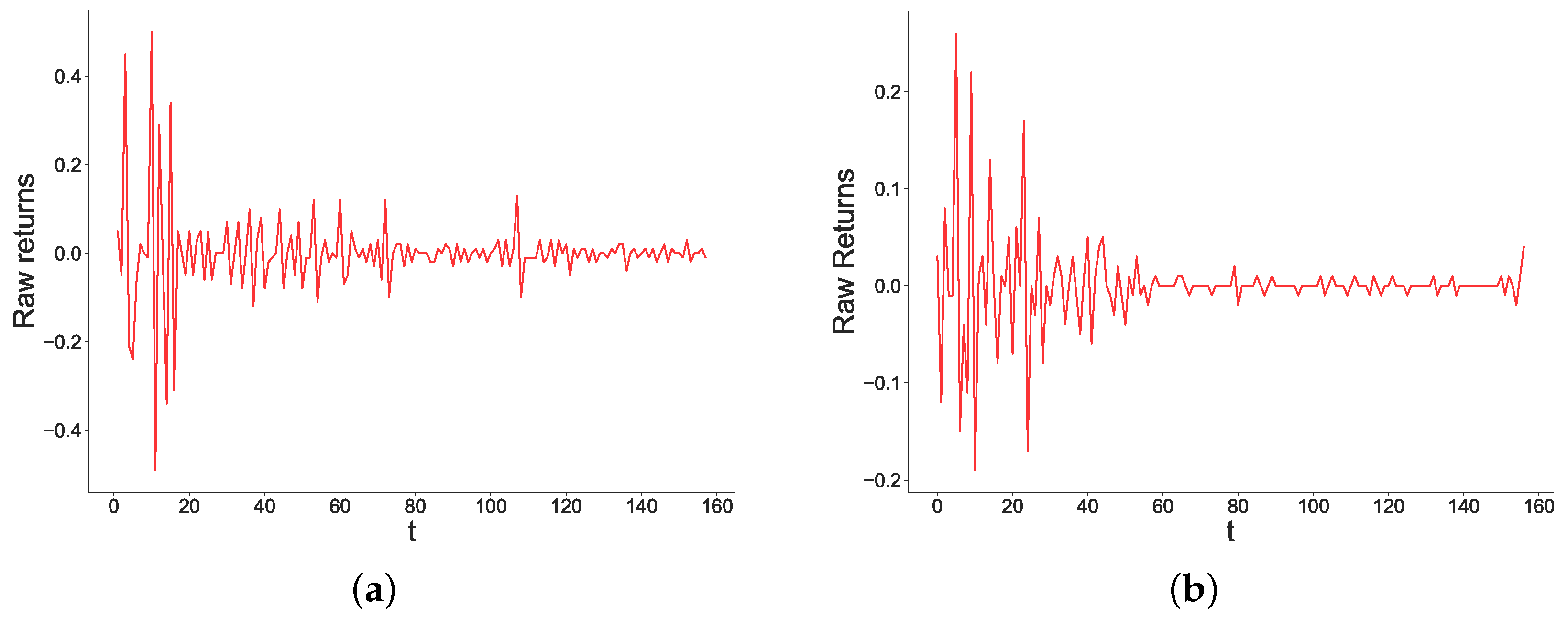
In this section, we show some historical trajectories of price changes together with similar trajectories generated by our model. Consistent with the financial literature, and especially with literature on agent-based models for financial markets, we focus on the time series of returns. To select time series, we employed the following procedure: First, to give a good illustration of different timespans, we selected four market durations, namely . Second, we randomly picked a historical market whose duration is within 5 days from the selected durations. In doing so, we selected the following time series:
- Will Mary Landrieu be defeated in the Louisiana Senate election? (duration days, Figure A4b)
- Will Rick Perry win the 2015 Iowa Straw Poll? (duration days, Figure A5a)
- Will Ed Miliband be Prime Minister after the next British election? (duration days, Figure A6a)
- Will the Republican party win Barbara Boxer’s Senate seat in California in 2016? (duration days, Figure A7a)
Third, for each duration T, we generated time series from our model. We did so 10 times for each T, and chose the time series that minimized the mse with the historical time series of same duration. Results are presented in Figure A4–Figure A7. From this figure, we see that our model generates realistic time series that exhibit similar trajectories to those observed in historical markets. Figure A4a (historical) and Figure A4b (simulated) show that, for markets with short durations, price changes tend to be stable, with occasional bursts of much higher magnitude than the rest of the time series. This can be explained by the low volumes short-term markets attract (short-term markets tend to be about less important events), which can give rise to such high volatility. Occasional bursts are also observed in markets with duration days, shown by Figure A6a (historical) and Figure A6b (simulated). The main difference of these markets with the ones with duration is that they display a higher volatility throughout. In contrast, longer-term markets, such as the ones displayed in Figure A7a (historical) and Figure A7b (simulated), display a high volatility at the beginning, where volumes are low, to then stabilize later on in the market, thanks to the participation of more traders.
References
- Plott, C.; Chen, K. Information Aggregation Mechanism: Concept, Design, and Implementation for a Sales Forecasting Problem; California Institute of Technology: Pasadena, CA, USA, 2002. [Google Scholar]
- Cowgill, B.; Wolfers, J.; Zitzewitz, E. Using prediction markets to track information flows evidence from Google. In Auctions, Market Mechanisms and Their Applications; Das, S., Ostrovsky, M., Pennock, D., Szymanski, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Berg, J.; Nelson, F.; Rietz, T. Prediction market accuracy in the long run. Int. J. Forecast. 2008, 24, 285–300. [Google Scholar] [CrossRef]
- Arnesen, S.; Bergfjord, O. Prediction markets vs pollsâan examination of accuracy for the 2008 and 2012 elections. J. Predict. Mark. 2014, 8, 24–33. [Google Scholar] [CrossRef]
- Restocchi, V.; McGroarty, F.; Gerding, E.; Johnson, J.E. It Takes All Sorts: A Heterogeneous Agent Explanation for Prediction Market Mispricing. Eur. J. Oper. Res. 2018, 270, 556–569. [Google Scholar]
- Goodell, J.; McGroarty, F.; Urquhart, A. Political uncertainty and the 2012 US presidential election: A cointegration study of prediction markets, polls and a stand-out expert. Int. Rev. Financ. Anal. 2015, 42, 397–410. [Google Scholar]
- Goodell, J.W.; Bodey, R.A. Price-earnings changes during US presidential election cycles: Voter uncertainty and other determinants. Public Choice 2012, 150, 633–650. [Google Scholar] [CrossRef]
- Shin, H.S. Measuring the Incidence of Insider Trading in a Market for State-Contingent Claims. Econ. J. 1993, 103, 1141–1153. [Google Scholar] [CrossRef]
- Ottaviani, M.; Sørensen, P.N. The Favorite-Longshot Bias: An Overview of the Main Explanations. In Handbook of Sports and Lottery Markets; Hausch, D.B., Ziemba, W.T., Eds.; North-Holland: Amsterdam, The Netherlands, 2008. [Google Scholar]
- Snowberg, E.; Wolfers, J. Explaining the FavoriteâLong Shot Bias: Is it Risk-Love or Misperceptions? J. Political Econ. 2010, 118, 723–746. [Google Scholar] [CrossRef]
- Deffuant, G.; Neau, D.; Amblard, F.; Weisbuch, G. Mixing beliefs among interacting agents. Adv. Complex Syst. 2000, 87, 11. [Google Scholar] [CrossRef]
- Sznajd-Weron, K.; Sznajd, J. Opinion evolution in closed community. Int. J. Mod. Phys. C 2000, 11, 1157. [Google Scholar]
- Clifford, P.; Sudbury, A. Minority Opinion Spreading in Random Geometry. Eur. Phys. J. B 2002, 25, 403–406. [Google Scholar]
- Tessone, C.J.; Toral, R.; Amengual, P.; Wio, H.S.; Miguel, M.S. Neighborhood models of minority opinion spreading. Eur. Phys. J. B 2004, 39, 535–544. [Google Scholar] [CrossRef]
- Baronchelli, A.; Dall’Asta, L.; Barrat, A.; Loreto, V. Topology Induced Coarsening in Language Games. Phys. Rev. E 2006, 73, 015102. [Google Scholar] [CrossRef] [PubMed]
- Castellano, C.; Fortunato, S.; Loreto, V. Statistical physics of social dynamics. Rev. Mod. Phys. 2009, 81, 591–646. [Google Scholar] [CrossRef]
- Galam, S. The invisible hand and the rational agent are behind bubbles and crashes. Chaos Solitons Fractals 2016, 88, 209–217. [Google Scholar] [CrossRef]
- Vilela, A.L.; Wang, C.; Nelson, K.P.; Stanley, H.E. Majority-vote model for financial markets. Phys. A: Stat. Mech. Its Appl. 2019, 515, 762–770. [Google Scholar] [CrossRef]
- Kononovicius, A.; Gontis, V. Agent based reasoning for the non-linear stochastic models of long-range memory. Phys. A: Stat. Mech. Its Appl. 2012, 391, 1309–1314. [Google Scholar] [CrossRef]
- Alfarano, S.; Lux, T.; Wagner, F. Estimation of Agent-Based Models: The Case of an Asymmetric Herding Model. Comput. Econ. 2005, 26, 19–49. [Google Scholar] [CrossRef]
- Lux, T.; Marchesi, M. Scaling and criticality in a stochastic multi-agent model of a Financial market. Nature 1999, 397, 498–500. [Google Scholar] [CrossRef]
- Zhou, W.X.; Sornette, D. Self-fulfilling Ising Model of Financial Markets. Eur. Phys. J. Vol. 2005, 181, 175–181. [Google Scholar]
- Sobkowicz, P. Modelling opinion formation with physics tools: Call for closer link with reality. J. Artif. Soc. Soc. Simul. 2009, 12, 11. [Google Scholar]
- Del Vicario, M.; Bessi, A.; Zollo, F.; Petroni, F.; Scala, A.; Caldarelli, G.; Stanley, H.E.; Quattrociocchi, W. The spreading of misinformation online. Proc. Natl. Acad. Sci. USA 2016, 113, 554–559. [Google Scholar] [CrossRef]
- Del Vicario, M.; Zollo, F.; Caldarelli, G.; Scala, A.; Quattrociocchi, W. Mapping social dynamics on Facebook: The Brexit debate. Soc. Netw. 2017, 50, 6–16. [Google Scholar] [CrossRef]
- Weisbuch, G.; Deffuant, G.; Amblard, F.; Nadal, J.P. Interacting Agents and Continuous Opinions Dynamics. In Lecture Notes in Economics and Mathematical Systems-No. 521; Fandel, G., Trockel, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 225–242. [Google Scholar]
- Lorenz, J. Managing Complexity: Insights, Concepts, Applications; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Restocchi, V.; McGroarty, F.; Gerding, E. Statistical properties of volume and calendar effects in prediction markets. Phys. A Stat. Mech. Its Appl. 2018, 523, 1150–1160. [Google Scholar] [CrossRef]
- Lux, T.; Marchesi, M. Volatility Clustering in Financial Markets: A Microsimulation of Interacting Agents. Int. J. Theor. Appl. Financ. 2000, 03, 675–702. [Google Scholar] [CrossRef]
- Restocchi, V.; McGroarty, F.; Gerding, E. The stylized facts of prediction markets: Analysis of price changes. Phys. A Stat. Mech. Its Appl. 2018, 515, 159–170. [Google Scholar] [CrossRef]
- Toral, R.; Tessone, C.J. Finite size effects in the dynamics of opinion formation. Commun. Comput. Phys. 2006, 2, 177–195. [Google Scholar]
- Fortunato, S. Universality of the Threshold for Complete Consensus for the Opinion Dynamics of Deffuant et al. Int. J. Mod. Phys. C 2004, 15, 1301–1307. [Google Scholar] [CrossRef]
- Gilli, M.; Winker, P. A global optimization heuristic for estimating agent based models. Comput. Stat. Data Anal. 2003, 43, 299–312. [Google Scholar] [CrossRef]
- Chakraborti, A.; Toke, I. Econophysics review: II. Agent-based models. Quant. Financ. 2011, 1041, 1013–1041. [Google Scholar] [CrossRef]
- Restocchi, V.; McGroarty, F.; Gerding, E. The temporal evolution of mispricing in prediction markets. Financ. Res. Lett. 2019, 29, 303–307. [Google Scholar] [CrossRef]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 5439, 509–512. [Google Scholar] [CrossRef] [PubMed]
Figure 2.
Heatmaps for the objective functions and , respectively. These figures show that including a in the objective function f does not add information (Figure 2a), whereas removing reduces the granularity of f (Figure 2b).
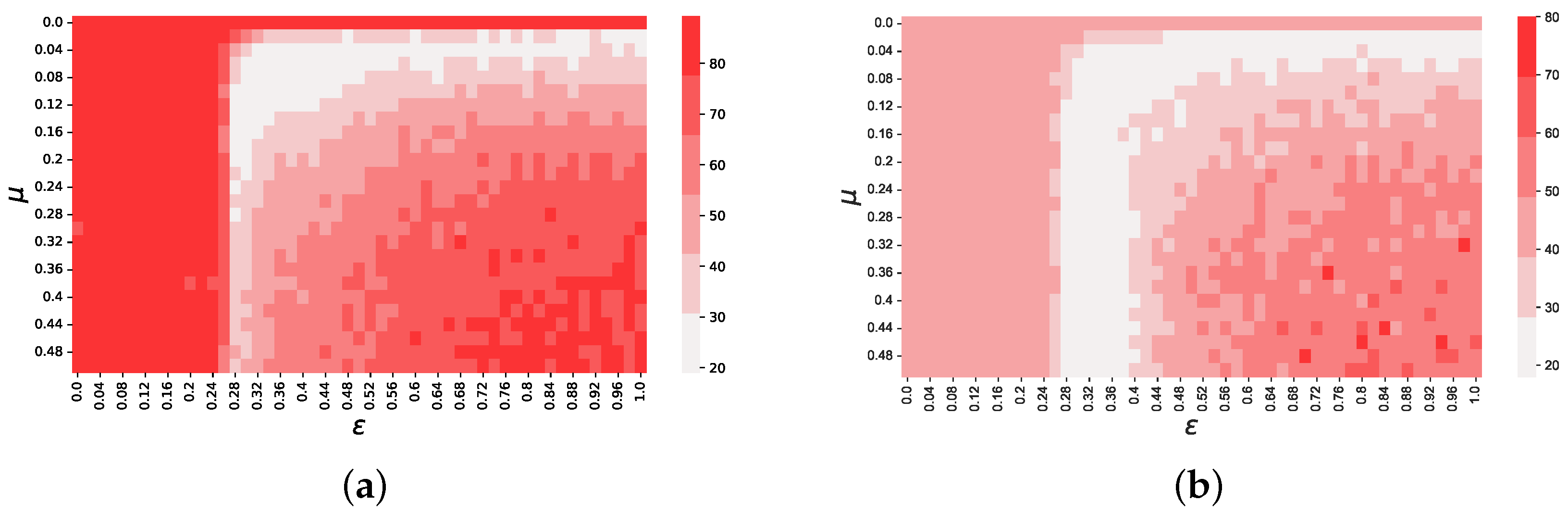
Figure 3.
Detailed view of the objective function f values, depending on (), for five values of () in the neighborhood of the optimal values. The objective function shows strong dependence on both and , but these figures suggest that has a greater impact on f than . Importantly, we can see that for all values of except from , there is a phase transition in the value of f in the region around , which is the threshold after which the Deffuant model starts converging to a single opinion cluster.
Figure 3.
Detailed view of the objective function f values, depending on (), for five values of () in the neighborhood of the optimal values. The objective function shows strong dependence on both and , but these figures suggest that has a greater impact on f than . Importantly, we can see that for all values of except from , there is a phase transition in the value of f in the region around , which is the threshold after which the Deffuant model starts converging to a single opinion cluster.
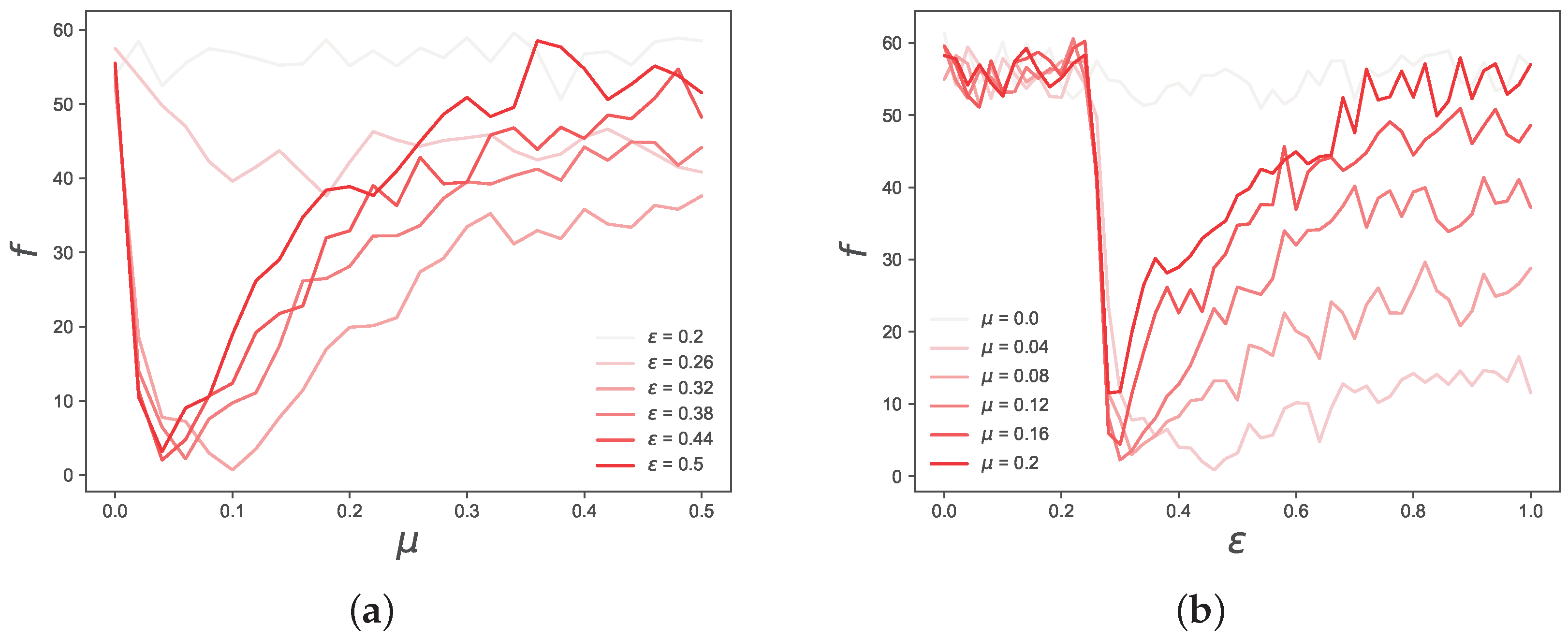
Figure 4.
Values of k (panel (a)) and (panel (b)) depending on and . These figures show that the kurtosis of the return distribution depends on both and equally, but that the value of is heavily affected by , suggesting a link with the number of coexisting opinions at equilibrium.
Figure 4.
Values of k (panel (a)) and (panel (b)) depending on and . These figures show that the kurtosis of the return distribution depends on both and equally, but that the value of is heavily affected by , suggesting a link with the number of coexisting opinions at equilibrium.
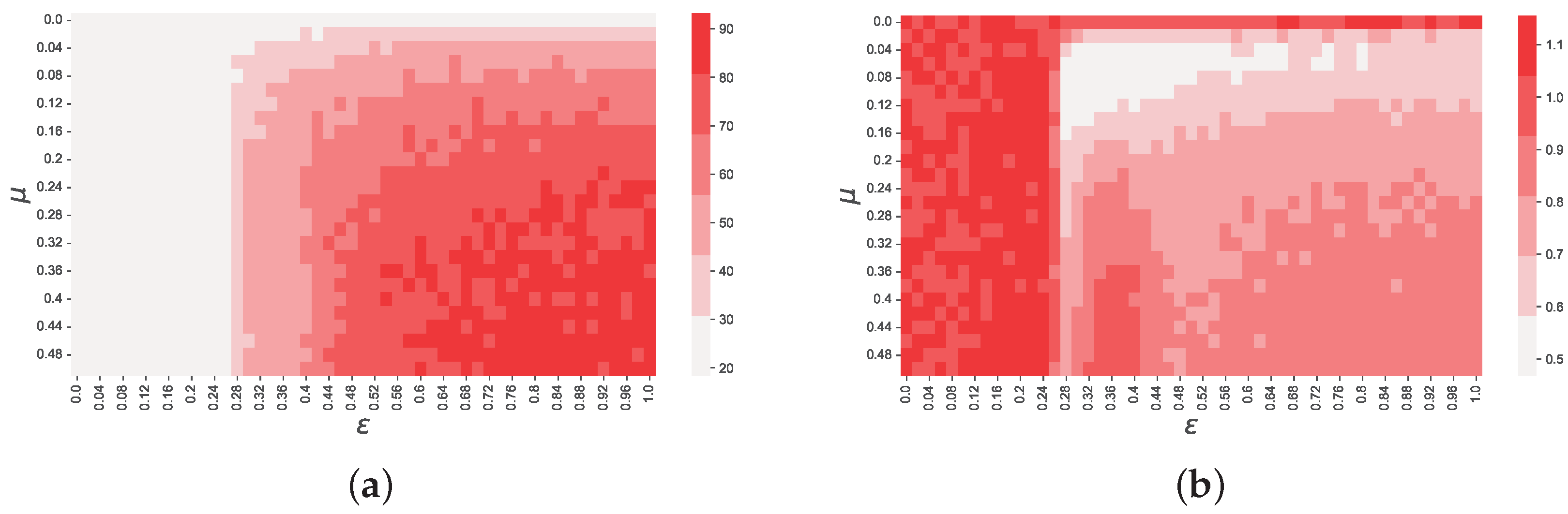
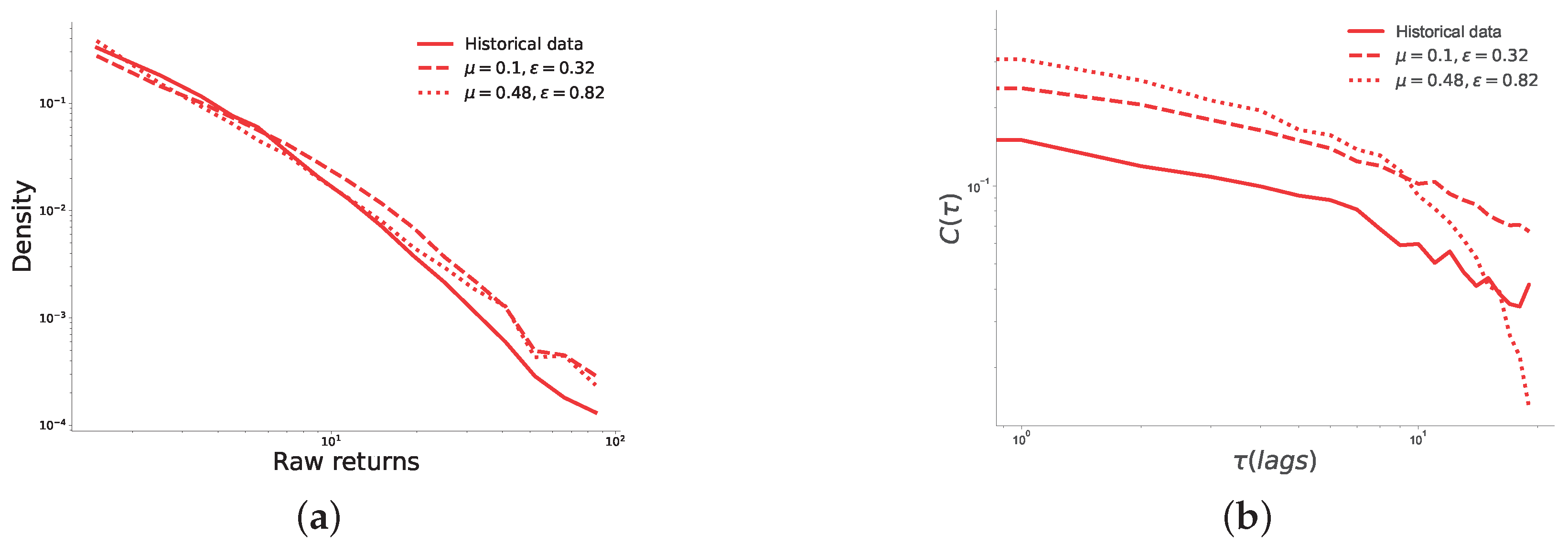
Figure 5.
Comparison between historical data and simulation data generated by the best and worst pairs of . Figure 5a shows the comparison between the probability density distributions of the distributions of raw returns. We note that the distribution of returns spans two decades. This is the maximum range for prediction markets in our data, since the minimum price increment is 0.01 [30], and prices are between 0 and 1. Also, this limits the negative impact of the time series being non-stationary, since large price changes are not allowed by default. Figure 5b shows the decay of the autocorrelation functions. These figures show that the both the best and worst fit of our model generate realistic returns, and that the best fit of our model also generates an autocorrelation of returns function that decays with the same exponent as the historical data .
Figure 5.
Comparison between historical data and simulation data generated by the best and worst pairs of . Figure 5a shows the comparison between the probability density distributions of the distributions of raw returns. We note that the distribution of returns spans two decades. This is the maximum range for prediction markets in our data, since the minimum price increment is 0.01 [30], and prices are between 0 and 1. Also, this limits the negative impact of the time series being non-stationary, since large price changes are not allowed by default. Figure 5b shows the decay of the autocorrelation functions. These figures show that the both the best and worst fit of our model generate realistic returns, and that the best fit of our model also generates an autocorrelation of returns function that decays with the same exponent as the historical data .
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



