
Submitted:
24 July 2023
Posted:
24 July 2023
You are already at the latest version
Abstract
Vegetation classifications on large geographic scales are necessary to inform conservation decisions and monitor keystone, invasive, and endangered species. These classifications are often effectively achieved by applying models to imaging spectroscopy, a type of remote sensing, data, but such undertakings are often limited in spatial extent. Here we provide accurate, high-resolution spatial data on the keystone species Metrosideros polymorpha, a highly polymorphic tree species distributed across bioclimatic zones and environmental gradients on Hawai'i island, using airborne imaging spectroscopy and LiDAR. We compare two tree species classification techniques, support vector machine (SVM) and spectral mixture analysis (SMA), to assess their ability to map M. polymorpha over 28,000 square kilometers where differences in topography, background vegetation, sun angle relative to the aircraft, and day of data collection, among others, challenge accurate classification. To capture spatial variability in model performance, we applied gaussian process classification (GPC) to estimate the spatial probability density of M. polymorpha occurrence using only training sample locations. We found that, while SVM and SMA models exhibit similar raw score accuracy over the test set (96.0% and 93.4%, respectively), SVM better reproduces the spatial distribution of M. polymorpha than SMA. We developed a final 2 m x 2 m M. polymorpha presence dataset and a 30 m x 30 m M. polymorpha density dataset using SVM classifications that have been made publicly available for use in conservation applications. Accurate, large-scale species classifications are achievable, but metrics for model performance assessments must account for spatial variation of model accuracy.
Keywords:
Imaging spectroscopy
; Metrosideros polymorpha
; species classification
; support vector machine
; spectral unmixing
; gaussian process classification
1. Introduction
Conservation decision making relies on the quantification and monitoring of forested ecosystem health across large landscapes. Spatially mapping rare, endangered, keystone, or invasive tree species is necessary to understand habitat quality, model future forest assemblages, protect a particular species, and manage ecosystem services, among other conservation goals. While the number of studies reporting tree species classifications are increasing, few classify species across large geographic extents [1]. Large-scale species classifications have many logistical considerations that challenge accurate species mapping such as intraspecific variation [1], canopy and understory species turnover [2,3], subcanopy shading [4,5], date of image acquisition [4], and computational limitations [6]. Further, traditional metrics for evaluating model performance do not capture the spatial variability of model accuracy [7,8] and are therefore impractical for classifications on large geographic scales. Due to the pressing need for these data in conservation applications, it is important to address these challenges associated with tree species classifications over large geographic extents.
Metrosideros polymorpha ('ōhi'a lehua) is an ideal overstory tree species to address these challenges due to its prevalence in many bioclimatic zones, high intra-specific variation, and the need for accurate spatial data of this keystone species endemic to Hawai'i (Figure S1). Approximately half of the vegetative biomass [9] and 80% of native forest basal area [10] in Hawai'i is M. polymorpha. As a major component of native Hawaiian forests, M. polymorpha provides habitat to many endemic plants and animals [11], is culturally important to Native Hawaiians [12,13], and sustains vital ecosystem services such as groundwater recharge [14]. M. polymorpha, and therefore native Hawaiian forests, is in decline due to the introduction of invasive species and Rapid 'Ohi'a Dead (ROD), a widespread disease that has led to millions of M. polymorpha crown mortalities [15]. M. polymorpha not only represents a keystone species in decline, but its existence across multiple ecosystems from sea level to 7,150 m elevation and on a range of soil substrates from bare lava flows to late successional flows [16] allows us to investigate methods of mapping a single species across diverse landscapes. While studies have compared the spectral similarity of plants across ecosystems, they largely investigate the effect of species turnover on spectral variation [6,17]. The M. polymorpha model system [18] allows us to assess the intraspecific variation of one species across bioclimatic zones. Further, M. polymorpha is highly polymorphic, exhibiting heritable morphological and chemical differences across environmental gradients [19,20,21,22,23]. On Hawai'i Island, M. polymorpha has four described varieties, many of which hybridize naturally, that exist in specific habitats and have distinct morphologic, chemical, and spectral characteristics [22,23,24].
Despite the prominence of M. polymorpha on the landscape, spatial data of M. polymorpha does not exist at the resolution necessary to inform many native forest conservation decision-making processes. For example, the Hawai'i Gap Analysis Project (HI-GAP) developed spatial data of forest classes including M. polymorpha and mixed M. polymorpha stands, but these data were developed in 2001 using 30 m Landsat imagery [25]. While this map is useful to approximate locations where M. polymorpha may exist, the resolution is too coarse for detailed spatial analyses, and it includes many classification errors due to the lack of high spatial and spectral information inherent in Landsat data. Current, high-resolution spatial information of M. polymorpha is needed for watershed-level decision-making models being developed for Hawai'i Island [26,27,28], refining ROD monitoring methods, and defining a baseline species distribution of M. polymorpha to track future range shifts.
To develop novel and high-resolution (2 m x 2 m) spatial data of M. polymorpha in support of these conservation efforts, we used a fusion of airborne imaging spectroscopy and light detection and ranging (LiDAR) data. Imaging spectroscopy is a process of image formation that captures reflectance across a continuous portion of the visible to short-wave infrared (VSWIR) spectrum in short wavelength intervals (~10 nm). This high-spectral resolution data captures surface chemistry [29,30], and because each species has a unique chemical fingerprint [31], imaging spectroscopy allows for accurate species classifications [2,32,33,34,35,36,37]. LiDAR, which uses pulsed lasers to quantify surface structure, has been fused with imaging spectroscopy data to reduce the spectral influence of canopy shading [38,39].
Using airborne imaging spectroscopy and LiDAR data processed over 28,000 km2 of area at 2 m spatial resolution, we developed a spatial dataset of M. polymorpha canopies across Hawai'i Island with two classification techniques, support vector machine (SVM) and spectral mixture analysis (SMA). We assessed how well these methods can classify a single highly polymorphic tree species across a large geographic area. Classification performance was assessed by test set accuracy metrics and comparison to estimated spatial probability densities calculated with gaussian process classification (GPC). The final products include an accurate, high-resolution dataset of a keystone species available to conservationists and decision-makers seeking to protect native Hawaiian forests.
2. Materials and Methods
Imaging spectroscopy data were collected across Hawai'i Island by the Global Airborne Observatory (GAO) in January 2019, with some regions filled in with the most recent data from previous campaigns in January 2016, July 2017, and January 2018 [38]. In addition to the high-fidelity imaging spectrometer (380-2510 nm), the GAO houses a boresight aligned dual-laser LiDAR scanner. LiDAR data were used to generate a surface elevation map and precise time-synced position and orientation data that were used to orthorectify VSWIR spectroscopy data to 2 m x 2 m spatial resolution. After orthorectification, VSWIR data were corrected for atmospheric effects and processed to retrieve hemispherical-direction reflectance values with ACORN v6.0 (Atmospheric CORrection Now; AIG LLC; Boulder, CO) [40,41]. Cloud-free mosaics were developed by first removing clouds and cloud shadows from individual flight line level reflectance maps using a mixture of automated cloud detection provided by a trained neural network model and manual revision of the produced cloud and cloud shadow outlines. The cleaned flight line maps were then manually layered based on minimizing flight line edge artifacts as observed in red, green, blue composites. Mosaics were developed based on this layer order. VSWIR surface reflectance data across Hawai'i Island were then brightness normalized by dividing each VSWIR channel by the vector norm of the entire VSWIR spectrum for each pixel after removing bands affected by atmospheric water absorption features. Regions where differences between flight lines caused erroneous classifications were further processed using bidirectional reflectance distribution function (BRDF) adjustments. BRDF effects result from anisotropic scattering of remote sensing targets, when basic atmospheric correction model assumes a flat, evenly diffuse surface. Empirical kernel models were fit to the reflectance and observation angle data, and spectra were adjusted to a standard observation angle using the difference between the observed spectra and their modeled BRDF-spectra [42]. Brightness normalization is a means to control for variation in reflectance caused by properties not related to foliar chemistry such as subpixel shade, leaf orientation relative to viewing and sun angles, and leaf volume [43]. Next, the data were filtered to obtain pixels representing photosynthetic vegetation. Normalized difference vegetation index (NDVI) data were calculated using bands at 650 nm and 860 nm of the VSWIR data, and all pixels under a 0.7 NDVI threshold were removed. Understory and shaded portions of the canopy were filtered from the data using top-of-canopy height (TCH) surface maps generated from LiDAR and a shade mask generated using a ray tracing technique on the LiDAR-derived surface elevation map [38,44]. TCH surface maps were used to remove pixels below two meters.
2.1. Training Data Collection
In the summer of 2022 through spring 2023, 5366 canopies were delineated and identified as either M. polymorpha or “other vegetation” (Figure 1; Figure S2). 1713 crowns represented M. polymorpha canopies, and 3653 were of other species. Crowns of other species were grouped together and represent all the background vegetation spectra that the classification models discriminated from M. polymorpha. Field data were collected using Garmin Glo GPS connected to tablets with GAO TCH, true and false color composites, and preliminary M. polymorpha classifications developed using a support vector machine (SVM). These data were brought into the field to increase crown delineation accuracy. Data were collected using a combination of field excursions, helicopter surveys, and Google Street view. While data were collected across elevation and soil substrate age gradients, observations were primarily concentrated along roadways and other easily accessible sites (Figure 1). In addition to canopy data collected specifically for the M. polymorpha mapping effort, canopy delineations from Balzotti et al. [32] and Weingarten et al. [45] were included in the training data as they used similar methods of delineating crowns in 2019 GAO data. Canopy spectra were generated by averaging all pixels from the filtered reflectance data within each tree crown (Figure S2).
2.2. Species Classification
We compared the performance of two classification algorithms -- support vector machine (SVM) and spectral mixture analysis (SMA) -- in distinguishing M. polymorpha from other vegetation across Hawai'i Island. For both classification algorithms, crown data were randomly separated into training (70%) and test (30%) datasets to assess model performance.
SMA assumes that an image pixel spectrum is the linear combination of the abundant materials weighted by their fractional coverage, and that this mixed signal can be unmixed using combinations of “pure” endmember spectra representing different thematic classes. This method has been successfully used for forest species classifications across many ecosystems [33,34], including those in Hawai'i [36]. We used Multiple Endmember Spectral Mixture Analysis [46] on the full VSWIR spectra with automatic band selection, which allows endmembers and the number of classes used for SMA to change on a per-pixel basis. We used a two endmember MESMA model, which assumes that each pixel is either M. polymorpha or other vegetation plus a shade fraction [46,47]. Because we brightness normalized the data, no shade was used in the fitting procedure.
As computational time increases with the number of possible endmember combinations and endmembers from the same class are often spectrally similar, we pruned the spectral library by clustering training spectra and creating new endmember spectra from the mean reflectance of similar endmembers. Endmember similarity was determined using hierarchical clustering of the spectra within the training data, with a distance matrix computed using the spectral angle. To determine the optimal maximum inter-cluster distance, we tested a range of distances and used the one that achieved the highest accuracy on the test dataset. For clusters with endmembers representing both M. polymorpha and other vegetation, we averaged spectra within the cluster based on their classification to create multiple endmembers. Other parameters within MESMA such as maximum RMSE and shade threshold did not affect accuracy. The MESMA model used to classify GAO data across Hawai'i Island included a spectral library developed by reducing all the training data available into 2238 training points via the hierarchical clustering described above. While most pixels were classified as entirely M. polymorpha or other vegetation due to the high resolution of the imaging spectroscopy dataset (2 m x 2 m), we used a threshold of 0.5 to develop a binary M. polymorpha presence/absence dataset.
Like spectral unmixing, SVM classifiers are commonly used in imaging spectroscopy applications [2,32,48]. SVMs efficiently handle highly dimensional datasets by maximizing the distance between training data and decision boundaries between the two categories in feature space [2,49,50]. SVMs typically outperform other supervised classifiers such as random forest in imaging spectroscopy classification applications [48,51,52]. We optimized hyperparameter selection (kernel coefficient and regulation parameter) of a radial kernel SVM using a grid search in the scikit-learn package (version 0.24.1) [53] in Python (version 3.6.9). We used Youden’s J statistic, which uses the sensitivity and specificity of the model, to determine the optimal classification threshold [54].
Throughout the model training process, we noted that traditional classification metrics such as accuracy did not sufficiently describe model performance, particularly with respect to the spatial distribution of the model predictions. To characterize the spatial variability in model performance, we compared SVM- and spectral unmixing- derived M. polymorpha maps with an independently trained spatial probability density map estimated using gaussian process classification (GPC) in scikit-learn with a radial kernel [53]. GPC is a probabilistic classification technique that is used to assign expected class probabilities with Bayes theorem [55]. The GPC estimates the probability of observing M. polymorpha as a function of the x- and y-coordinates of the habitat range, providing a benchmark to validate the spatial accuracy of the spectral models (Figure S3). While the GPC as a predictor for M. polymorpha presence is limited by the sampling design, it is a useful tool for validating the SVM and spectral unmixing results as it can identify areas that have high and low M. polymorpha presence probability based on the training dataset. In regions without training data, the GPC has a middle probability (50/50) of M. polymorpha presence. The GPC trained on the training dataset achieved a 94% accuracy on the test dataset.
SVM and spectral unmixing were then applied to reflectance data filtered to excluded shaded portions of the canopy, non-photosynthetic features, and vegetation less than 2 m. To fill gaps in the canopy resulting from the shade masking, classification data were interpolated using the inverse distance weighting technique available in the rasterio package fill module v. 1.2.10. We then compared the accuracies of the two models as well as their island-wide classifications of M. polymorpha relative to the Bayesian GPC. The best M. polymorpha classification was used to develop a high resolution (2 m x 2 m) canopy map. This high-resolution map was then down sampled into a coarse density product by aggregating the 2m x 2m binary pixels onto a 30m x 30m grid via the mean function.
3. Results
3.1. Model Performance
We compared two classification techniques to assess their performance on the test dataset and 2 m x 2 m GAO data across Hawai'i Island (Figure 2; Table 1). The results showed that SVM outperformed spectral unmixing. The spectral unmixing model achieved an accuracy of 93.4% and precision of 88.7%,while the SVM achieved an accuracy of 96.0% and precision of 91.9% (Table 1). Further, the false positive rate was 1.5 percent higher for spectral unmixing (5.6%) than SVM (4.1%). Applied to the entire island, this two percent difference led to over 684 million more misclassified pixels for spectral unmixing than SVM (Figure 2). Interestingly, these misclassifications were often observed in geographically distinct regions from where the SVM predicted M. polymorpha to exist, often at lower elevations (Figure 2c). Moreover, false positives from spectral unmixing frequently occurred in regions with a low probability of M. polymorpha existing according to the Bayesian GPC (Fig 2c). Disagreement between the models was spatially arranged; 30.8% of pixels classified as M. polymorpha by spectral unmixing and not by SVM were in regions of low M. polymorpha according to the Bayesian GCP probability (<0.33). Only 13.9% of pixels classified as M. polymorpha by SVM but not spectral unmixing were in these regions of low M. polymorpha probability according to the GCP (Table 2).
Spectral unmixing was also more likely to misclassify M. polymorpha canopies as the true positive rate for spectral unmixing (91.2%) was 3.6% lower than that of the SVM (94.8%; Table 1). These false negatives most often occurred where M. polymorpha forests were predicted to be densest by the SVM (Figure 2c) and where Bayesian GPC indicated that M. polymorpha was most likely to occur. 47.5% of the pixels predicted as M. polymorpha by SVM but not spectral unmixing were in regions of high M. polymorpha likelihood (>0.66). In these regions, SVM predicted denser M. polymorpha forests than spectral unmixing. Given the superior performance of SVM over spectral unmixing, the results obtained from SVM classification were utilized to generate the final M. polymorpha classification products. These include a high-resolution (2 m x 2 m) canopy map (Figure 2a) and a 30 m x 30 m canopy density map (Figure 3).
3.2. Metrosideros polymorpha Distribution
Hawai'i Island spans 10,430 km2, 2739 km2 of which is forested, and 1626 km2 of these forests are M. polymorpha. According to the SVM, M. polymorpha comprises 59.4% of forest canopies on Hawaii Island. We compared the existing HI-GAP M. polymorpha coverage map (Figure S4) with our updated M. polymorpha canopy density map. According to HI-GAP, M. polymorpha covered 2346 km2 in 2001. 2063 km2 of the HI-GAP M. polymorpha coverage map overlapped with our density map. In these overlapping regions, our density map had a mean and median coverage of 0.84% and 0.98%, respectively. Using the density of M. polymorpha canopies in this area, we calculated that approximately 1743 km2 of M. polymorpha canopies exist in this region of overlap. Regions that were not included in the HI-GAP map had lower M. polymorpha canopy densities, mean and median percent coverage of 0.53 and 0.54, respectively. This region included 751 km2 of M. polymorpha canopies. We assume that most of these canopies existed 18 years prior to GAO data collection and the difference is largely a result of higher spatial (2 m x 2 m scaled to 30 m x 30 m) and spectral resolution afforded by airborne imaging spectroscopy as compared to the multispectral 30 m x 30 m spaceborne Landsat sensor.
4. Discussion
4.1. High Resolution Model Comparison
In classifying a single, highly polymorphic species across a large geographic extent, SVM outperformed spectral unmixing. Not only did the SVM have higher performance metrics in this and other Hawai'i-based imaging spectroscopy classification studies [15,32], but when evaluated in our study, spectral unmixing resulted in many false positives outside the current range of M. polymorpha. Spectral unmixing was included in this study as it has been suggested as a means of circumventing issues related to background signals and mixed pixels [1,3] and therefore is especially useful when classifying species across a broad range of ecosystems. The relatively poor performance of spectral unmixing may be attributed to the reduced variability in the spectral library [3]. While we attempted to include much of the spectral variability of the initial training dataset through hierarchical clustering, the MESMA spectral library included less variability than the original training data used by the SVM. By collecting a large training dataset that included M. polymorpha crowns with different vegetation understories and stand compositions, the SVM learned many of the possible M. polymorpha reflectance signatures and was therefore able to achieve a higher accuracy and precision than spectral unmixing. Aggregating training data using hierarchical clustering for the spectral unmixing model likely removed much of the variation in M. polymorpha pixels and may have exacerbated noise from show-through and mixed pixels. Here, we needed to balance model performance with computation time as the full spectral library of 5366 crowns was too computationally expensive to run MESMA even using a supercomputer.
4.2. Considerations for Future Large-Scale Modeling Efforts
As imaging spectroscopy technology advances and becomes more widely available via spaceborne sensors [56,57,58,59], it will become increasingly important to address challenges associated with large-scale vegetation classifications. Many of these challenges were present in this mapping effort as differences in topography, background vegetation, sun angle relative to the aircraft, and day of data collection, among others, challenged accurate classification of M. polymorpha as they have for other species [1,4]. While we used atmospheric correction, brightness normalization, shade masking, and bidirectional reflectance distribution function because these techniques reduce variation in reflectance spectra between mosaiced flight lines [4,38], we still needed to adjust our field sampling to capture the reflectance variation across flight lines. Yet sampling across flight lines in the field was not possible in all regions due to accessibility issues, and this will likely be the case for classifications of other species, especially in tropical regions. In future spaceborne applications, differences in reflectance resulting from satellite passes will need to be addressed to achieve seamless classification maps, especially as some techniques like shade masking will likely not be possible due to lower spatial resolutions.
Differences in background vegetation and stand characteristics across the study area as well as morphological and spectral variation of M. polymorpha across environmental gradients [19,20,60,61] challenged the development of this large-scale M. polymorpha spatial distribution dataset. Here, we attempted to classify M. polymorpha growing on lava flows and manicured lawns as well as individuals existing in largely alien forests and in M. polymorpha-dominated stands. While the high spatial resolution (2 m x 2 m) of our imaging spectroscopy data helped circumvent this issue, mixed pixels at the edges of canopies challenged our classifications. Further, stands dominated by M. polymorpha have different understory vegetation across Hawai'i Island, from the invasive Psidium cattleianum (strawberry guava) to the native Dicranopteris linearis (Uluhe fern). Differences in understory can cause classification inaccuracies due to show-through [62]. As differences in canopy density and species dominance within a stand are another factor in spectral separability [3,35], the diverse canopy structure and density of M. polymorpha across the island likely led to different accuracies based on stand structure.
Another challenge to mapping M. polymorpha across Hawai'i Island was in assessing model performance across a large geographic region. Both the SVM and spectral unmixing models achieved high classification accuracies (>93%), but conservationists referencing results from the spectral unmixing model would waste valuable time in geographic regions with high false positive rates of M. polymorpha. We employed Bayesian GPC to address this shortcoming of traditional model metrics and assess model performance spatially. While the GPC, like the spectral classification models, was biased based on our crown sampling locations, it provided a means to determine where and how the classification models were erroneous. For example, we were able to assess disagreements between the SVM and spectral unmixing outside the training dataset. While the training dataset was extensive, it biased our ability to fully assess model performance as we could not entirely capture the variability of M. polymorpha nor that of the other vegetation. We believe that employing spatial validation techniques such as the Bayesian GPC model, while not routinely used for species classification validation currently, will improve future large-scale classification efforts.
5. Conclusion
Large-scale vegetation classifications have many practical uses in conservation decision-making [63,64,65,66]. For example, this island-wide dataset of the keystone species M. polymorpha can be used to improve disease tracking models and as input for watershed-level decision-making models [26,27,28]. Until recently, these decision-making processes relied on a mapping effort from 2001, and while these data were useful for approximating M. polymorpha across Hawai'i Island, especially in regions with dense M. polymorpha stands, it did not include up to 316 km2 of M. polymorpha canopies, that are typically found in regions with low M. polymorpha canopy density. To achieve routine species classifications at large spatial scales, we need to address not only the issues discussed above, but also questions of spatial resolution [70] and training data collection [48]. The upcoming spaceborne imaging spectrometers will collect data at 30 m x 30 m resolution while the data used here were 2 m x 2 m. Further, this project required extensive fieldwork to collect over 5,000 training points, but designing better methods of planning sampling schemes across ecosystems and environmental gradients that would require less fieldwork but lead to similar results would make mapping projects like this more feasible.
Supplementary Materials
The following supporting information can be downloaded at the website of this paper posted on Preprints.org. Figure S1: Metrosideros polymorpha ('ohi'a lehua) in bloom.; Figure S2: Mean spectra of Metrosideros polymorpha and other vegetation in spectral library; Figure S3: Location of the 5366 crowns collected across Hawai'i Island to train the classification models; Figure S4: 2001 HI-GAP Metrosideros polymorpha extent as estimated using Landsat data
Author Contributions
Conceptualization, MMS, GPA, and REM; methodology, all authors; data curation, NRV; fieldwork, MMS; code development, MMS, BS, MK; formal analysis, MMS, BS; writing—original draft preparation, MMS; writing—review and editing, all authors; funding acquisition, MMS and GPA. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Science Foundation Doctoral Dissertation Improvement Grant (Award Number 2218932).
Data Availability Statement
Crown data used for model training and all M. polymorpha data products are openly available in Figshare at xxxxx.
Acknowledgments
The Global Airborne Observatory (GAO) is managed by the Center for Global Discovery and Conservation Science at Arizona State University. The GAO is made possible by support from private foundations, visionary individuals, and Arizona State University.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Fassnacht FE, Latifi H, Stereńczak K, Modzelewska A, Lefsky M, Waser LT, et al. Review of studies on tree species classification from remotely sensed data. Remote Sensing of Environment. 2016 Dec 1;186:64–87. [CrossRef]
- Baldeck CA, Asner GP, Martin RE, Anderson CB, Knapp DE, Kellner JR, et al. Operational Tree Species Mapping in a Diverse Tropical Forest with Airborne Imaging Spectroscopy. Kumar L, editor. PLoS ONE. 2015 Jul 8;10(7):e0118403. [CrossRef]
- Roth KL, Roberts DA, Dennison PE, Alonzo M, Peterson SH, Beland M. Differentiating plant species within and across diverse ecosystems with imaging spectroscopy. Remote Sensing of Environment. 2015 Sep 15;167:135–51. [CrossRef]
- Laybros A, Schläpfer D, Féret JB, Descroix L, Bedeau C, Lefevre MJ, et al. Across Date Species Detection Using Airborne Imaging Spectroscopy. Remote Sensing. 2019 Jan;11(7):789. [CrossRef]
- Lopatin J, Dolos K, Kattenborn T, Fassnacht FE. How canopy shadow affects invasive plant species classification in high spatial resolution remote sensing. Remote Sensing in Ecology and Conservation. 2019;5(4):302–17. [CrossRef]
- Roth KL, Dennison PE, Roberts DA. Comparing endmember selection techniques for accurate mapping of plant species and land cover using imaging spectrometer data. Remote Sensing of Environment. 2012 Dec 1;127:139–52. [CrossRef]
- Comber A, Fisher P, Brunsdon C, Khmag A. Spatial analysis of remote sensing image classification accuracy. Remote Sensing of Environment. 2012 Dec 1;127:237–46. [CrossRef]
- Yu Q, Gong P, Tian Y, Pu R, Yang J. Factors Affecting Spatial Variation of Classification Uncertainty in an Image Object-based Vegetation Mapping. Photogrammetric Engineering and Remote Sensing. 2008 Mar 29;74:1007–18. [CrossRef]
- Mortenson LA, Hughes RF, Friday JB, Keith LM, Barbosa JM, Friday NJ, et al. Assessing spatial distribution, stand impacts and rate of Ceratocystis fimbriata induced ‘ōhi‘a (Metrosideros polymorpha) mortality in a tropical wet forest, Hawai‘i Island, USA. Forest Ecology and Management 377: 83-92. 2016;377:83–92. [CrossRef]
- Loope L, Hughes F, Keith L, Harrington R, Hauff R, Friday JB, et al. Guidance document for Rapid Ohia Death: background for the 2017-2019 ROD Strategic Response Plan. University of Hawaii: College of Tropical Agriculture and Human Resources. 2016.
- Pratt T, Atkinson C, Banko PC, Jacobi J, Woodworth B. Conservation Biology of Hawaiian Forest Birds [Internet]. Yale University Press; 2009 [cited 2022 Aug 4]. Available from: https://yalebooks.yale.edu/9780300141085/conservation-biology-of-hawaiian-forest-birds.
- Chow, ET. The Sovereign Nation of Hawai’i: Resistance in the Legacy of “Aloha 'Oe.” SUURJ: Seattle University Undergraduate Research Journal. 2018;2(15):15.
- Westervelt, WD. Hawaiian Legends of Volcanoes (mythology). Ellis Press; 1916. 284 p.
- Kagawa A, Sack L, Duarte K, James S. Hawaiian native forest conserves water relative to timber plantation: species and stand traits influence water use. Ecol Appl. 2009 Sep;19(6):1429–43. [CrossRef]
- Vaughn NR, Asner GP, Brodrick PG, Martin RE, Heckler JW, Knapp DE, et al. An Approach for High-Resolution Mapping of Hawaiian Metrosideros Forest Mortality Using Laser-Guided Imaging Spectroscopy. Remote Sensing. 2018 Apr;10(4):502. [CrossRef]
- Wagner WL, Herbst DR, Sohmer SH. Manual of the Flowering Plants of Hawai’i [Internet]. Manual of the Flowering Plants of Hawai’i. University of Hawaii Press; [cited 2023 Apr 20]. Available from: https://www.degruyter.com/document/isbn/9780824885779/html?lang=en.
- Somers B, Asner GP. Invasive Species Mapping in Hawaiian Rainforests Using Multi-Temporal Hyperion Spaceborne Imaging Spectroscopy. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing. 2013 Apr;6(2):351–9. [CrossRef]
- Vitousek, PM. Nutrient Cycling and Limitation: Hawai’i as a Model System [Internet]. Princeton University Press; 2004 [cited 2022 Sep 23]. Available from: http://www.jstor.org/stable/j.ctv39x77c.
- Cordell S, Goldstein G, Mueller-Dombois D, Webb D, Vitousek PM. Physiological and morphological variation in Metrosideros polymorpha, a dominant Hawaiian tree species, along an altitudinal gradient: the role of phenotypic plasticity. Oecologia. 1998 Jan 1;113(2):188–96. [CrossRef]
- Joel G, Aplet G, Vitousek PM. Leaf Morphology Along Environmental Gradients in Hawaiian Metrosideros Polymorpha. Biotropica. 1994;26(1):17–22. [CrossRef]
- Martin RE, Asner GP, Sack L. Genetic variation in leaf pigment, optical and photosynthetic function among diverse phenotypes of Metrosideros polymorpha grown in a common garden. Oecologia. 2007 Mar 1;151(3):387–400. [CrossRef]
- Stacy EA, Johansen JB, Sakishima T, Price DK, Pillon Y. Incipient radiation within the dominant Hawaiian tree Metrosideros polymorpha. Heredity. 2014 Oct;113(4):334–42. [CrossRef]
- Stacy EA, Johansen JB, Sakishima T, Price DK. Genetic analysis of an ephemeral intraspecific hybrid zone in the hypervariable tree, Metrosideros polymorpha, on Hawai‘i Island. Heredity. 2016 Sep;117(3):173–83. [CrossRef]
- Seeley MM, Stacy EA, Martin RE, Asner GP. Foliar functional and genetic variation in a keystone Hawaiian tree species estimated through spectroscopy. Oecologia [Internet]. 2023 May 12 [cited 2023 May 17]. [CrossRef]
- U.S. Geological Survey Gap Analysis Program. GAP/LANDFIRE National Terrestrial Ecosystems 2011: U.S. Geological Survey [Internet]. 2011. (20160513). [CrossRef]
- Pascual A, Giardina CP, Povak NA, Hessburg PF, Asner GP. Integrating ecosystem services modeling and efficiencies in decision-support models conceptualization for watershed management. Ecological Modelling. 2022 Apr 1;466:109879.
- Pascual A, Giardina CP, Povak NA, Hessburg PF, Heider C, Salminen E, et al. Optimizing invasive species management using mathematical programming to support stewardship of water and carbon-based ecosystem services. Journal of Environmental Management. 2022 Jan 1;301:113803. [CrossRef]
- Povak NA, Hessburg PF, Giardina CP, Reynolds KM, Heider C, Salminen E, et al. A watershed decision support tool for managing invasive species on Hawai‘i Island, USA. Forest Ecology and Management. 2017 Sep;400:300–20. [CrossRef]
- Boardman JW, Green RO. Exploring the spectral variability of the Earth as measured by AVIRIS in 1999. 2000 Dec [cited 2023 Jan 3]; Available from: https://trs.jpl.nasa.gov/handle/2014/16602.
- Green RO, Boardman JW. Exploration of the relationship between information content and signal-to-noise ratio and spatial resolution in AVIRIS spectral data. Spectrum. 2000;7(8).
- Asner GP, Martin RE. Airborne spectranomics: mapping canopy chemical and taxonomic diversity in tropical forests. Frontiers in Ecology and the Environment. 2009;7(5):269–76. [CrossRef]
- Balzotti CS, Asner GP, Adkins ED, Parsons EW. Spatial drivers of composition and connectivity across endangered tropical dry forests. Journal of Applied Ecology. 2020;57(8):1593–604. [CrossRef]
- Chakravortty S, Shah E, Chowdhury AS. Application of Spectral Unmixing Algorithm on Hyperspectral Data for Mangrove Species Classification. In: Gupta P, Zaroliagis C, editors. Applied Algorithms. Cham: Springer International Publishing; 2014. p. 223–36. (Lecture Notes in Computer Science). [CrossRef]
- Pontius J, Hanavan RP, Hallett RA, Cook BD, Corp LA. High spatial resolution spectral unmixing for mapping ash species across a complex urban environment. Remote Sensing of Environment. 2017 Sep 15;199:360–9. [CrossRef]
- Shang X, Chisholm LA. Classification of Australian Native Forest Species Using Hyperspectral Remote Sensing and Machine-Learning Classification Algorithms. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing. 2014 Jun;7(6):2481–9. [CrossRef]
- Somers B, Asner GP. Tree species mapping in tropical forests using multi-temporal imaging spectroscopy: Wavelength adaptive spectral mixture analysis. International Journal of Applied Earth Observation and Geoinformation. 2014 Sep 1;31:57–66. [CrossRef]
- Torabzadeh H, Leiterer R, Hueni A, Schaepman ME, Morsdorf F. Tree species classification in a temperate mixed forest using a combination of imaging spectroscopy and airborne laser scanning. Agricultural and Forest Meteorology. 2019 Dec 15;279:107744. [CrossRef]
- Asner GP, Knapp DE, Boardman J, Green RO, Kennedy-Bowdoin T, Eastwood M, et al. Carnegie Airborne Observatory-2: Increasing science data dimensionality via high-fidelity multi-sensor fusion. Remote Sensing of Environment. 2012 Sep 1;124:454–65. [CrossRef]
- Féret JB, Asner GP. Mapping tropical forest canopy diversity using high-fidelity imaging spectroscopy. Ecological Applications. 2014;24(6):1289–96. [CrossRef]
- Miller, CJ. Performance assessment of ACORN atmospheric correction algorithm. In: Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery VIII [Internet]. SPIE; 2002 [cited 2021 Dec 21]. p. 438–49. Available from: https://www.spiedigitallibrary.org/conference-proceedings-of-spie/4725/0000/Performance-assessment-of-ACORN-atmospheric-correction-algorithm/10.1117/12.478777.full.
- Schaepman-Strub G, Schaepman M, Martonchik J, Schaaf C. Whats in a Satellite Albedo Product? IEEE. 2006;2848–52.
- Colgan MS, Baldeck CA, Féret JB, Asner GP. Mapping Savanna Tree Species at Ecosystem Scales Using Support Vector Machine Classification and BRDF Correction on Airborne Hyperspectral and LiDAR Data. Remote Sensing. 2012 Nov;4(11):3462–80. [CrossRef]
- Feilhauer H, Asner GP, Martin RE, Schmidtlein S. Brightness-normalized Partial Least Squares Regression for hyperspectral data. Journal of Quantitative Spectroscopy and Radiative Transfer. 2010 Aug 1;111(12):1947–57. [CrossRef]
- Asner GP, Knapp DE, Kennedy-Bowdoin T, Jones MO, Martin RE, Boardman JW, et al. Carnegie Airborne Observatory: in-flight fusion of hyperspectral imaging and waveform light detection and ranging for three-dimensional studies of ecosystems. JARS. 2007;1(1):013536. [CrossRef]
- Weingarten E, Martin R, Hughes F, Vaughn N, Schafron E, Asner GP. Early Detection of a Tree Pathogen using Airborne Remote Sensing. Ecological Applications. 2021;21(2). [CrossRef]
- Crabbé AH, Somers B, Roberts DA, Halligan K, Dennison P, Dudley K. MESMA QGIS Plugin [Internet]. 2020. Available from: https://bitbucket.org/kul-reseco/mesma.
- Roberts DA, Gardner M, Church R, Ustin S, Scheer G, Green RO. Mapping Chaparral in the Santa Monica Mountains Using Multiple Endmember Spectral Mixture Models. Remote Sensing of Environment. 1998 Sep 1;65(3):267–79. [CrossRef]
- Feret JB, Asner GP. Tree Species Discrimination in Tropical Forests Using Airborne Imaging Spectroscopy. IEEE Transactions on Geoscience and Remote Sensing. 2013 Jan;51(1):73–84. [CrossRef]
- Camps-Valls G, Gomez-Chova L, Calpe-Maravilla J, Martin-Guerrero JD, Soria-Olivas E, Alonso-Chorda L, et al. Robust support vector method for hyperspectral data classification and knowledge discovery. IEEE Transactions on Geoscience and Remote Sensing. 2004 Jul;42(7):1530–42. [CrossRef]
- Melgani F, Bruzzone L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Transactions on Geoscience and Remote Sensing. 2004 Aug;42(8):1778–90. [CrossRef]
- Dalponte M, Bruzzone L, Gianelle D. Tree species classification in the Southern Alps based on the fusion of very high geometrical resolution multispectral/hyperspectral images and LiDAR data. Remote Sensing of Environment. 2012 Aug 1;123:258–70. [CrossRef]
- Dalponte M, Ørka HO, Gobakken T, Gianelle D, Næsset E. Tree Species Classification in Boreal Forests With Hyperspectral Data. IEEE Transactions on Geoscience and Remote Sensing. 2013 May;51(5):2632–45. [CrossRef]
- Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, et al. Scikit-learn: Machine Learning in Python. MACHINE LEARNING IN PYTHON. :6.
- Youden WJ. Index for rating diagnostic tests. Cancer. 1950;3(1):32–5. [CrossRef]
- Rasmussen, CE. Gaussian Processes in Machine Learning. In: Bousquet O, von Luxburg U, Rätsch G, editors. Advanced Lectures on Machine Learning [Internet]. Berlin, Heidelberg: Springer Berlin Heidelberg; 2004 [cited 2023 Apr 19]. p. 63–71. (Lecture Notes in Computer Science; vol. 3176). Available from: http://link.springer.com/10.1007/978-3-540-28650-9_4. [CrossRef]
- Culver T, Rydeen A, Dix M, Camello M, Gallaher M, Lapidus D, et al. SBG user needs and valuation study. RTI Innovation Advisors; 2020.
- Iwasaki A, Tanii J, Kashimura O, Ito Y. Prelaunch Status of Hyperspectral Imager Suite (Hisui). In: IGARSS 2019 - 2019 IEEE International Geoscience and Remote Sensing Symposium. 2019. p. 5887–90.
- Lopinto E, Ananasso C. The Prisma Hyperspectral Mission. :12.
- Müller R, Alonso K, Krawczyk H, Bachmann M, Cerra D, Krutz D, et al. Overview and Status of the DESIS Mission. In Amsterdam, Netherlands; 2018 [cited 2021 Jan 5]. Available from: https://elib.dlr.de/123992/.
- Martin RE, Asner GP. Leaf Chemical and Optical Properties of Metrosideros polymorpha across Environmental Gradients in Hawaii. Biotropica. 2009;41(3):292–301. [CrossRef]
- Seeley MM, Martin RE, Vaughn NR, Thompson DR, Dai J, Asner GP. Quantifying the Variation in Reflectance Spectra of Metrosideros polymorpha Canopies across Environmental Gradients. Remote Sensing. 2023 Jan;15(6):1614. [CrossRef]
- Jensen RR, Hardin PJ, Hardin AJ. Classification of urban tree species using hyperspectral imagery. Geocarto International. 2012 Aug 1;27(5):443–58. [CrossRef]
- Callaghan J, McAlpine C, Mitchell D, Thompson J, Bowen M, Rhodes J, et al. Ranking and mapping koala habitat quality for conservation planning on the basis of indirect evidence of tree-species use: a case study of Noosa Shire, south-eastern Queensland. Wildl Res. 2011 Apr 20;38(2):89–102. [CrossRef]
- Fremout T, Thomas E, Gaisberger H, Van Meerbeek K, Muenchow J, Briers S, et al. Mapping tree species vulnerability to multiple threats as a guide to restoration and conservation of tropical dry forests. Global Change Biology. 2020;26(6):3552–68. [CrossRef]
- Jonsson M, Bengtsson J, Gamfeldt L, Moen J, Snäll T. Levels of forest ecosystem services depend on specific mixtures of commercial tree species. Nature Plants. 2019 Feb;5(2):141–7. [CrossRef]
- Maciel EA, Martins FR. Rarity patterns and the conservation status of tree species in South American savannas. Flora. 2021 Dec 1;285:151942. [CrossRef]
- Roth KL, Roberts DA, Dennison PE, Peterson SH, Alonzo M. The impact of spatial resolution on the classification of plant species and functional types within imaging spectrometer data. Remote Sensing of Environment. 2015 Dec 15;171:45–57. [CrossRef]
Figure 1.
Location of the 5366 crowns collected across Hawai'i Island to train the classification models. Red represents all Metrosideros polymorpha canopies, and blue are all other vegetation types.
Figure 1.
Location of the 5366 crowns collected across Hawai'i Island to train the classification models. Red represents all Metrosideros polymorpha canopies, and blue are all other vegetation types.
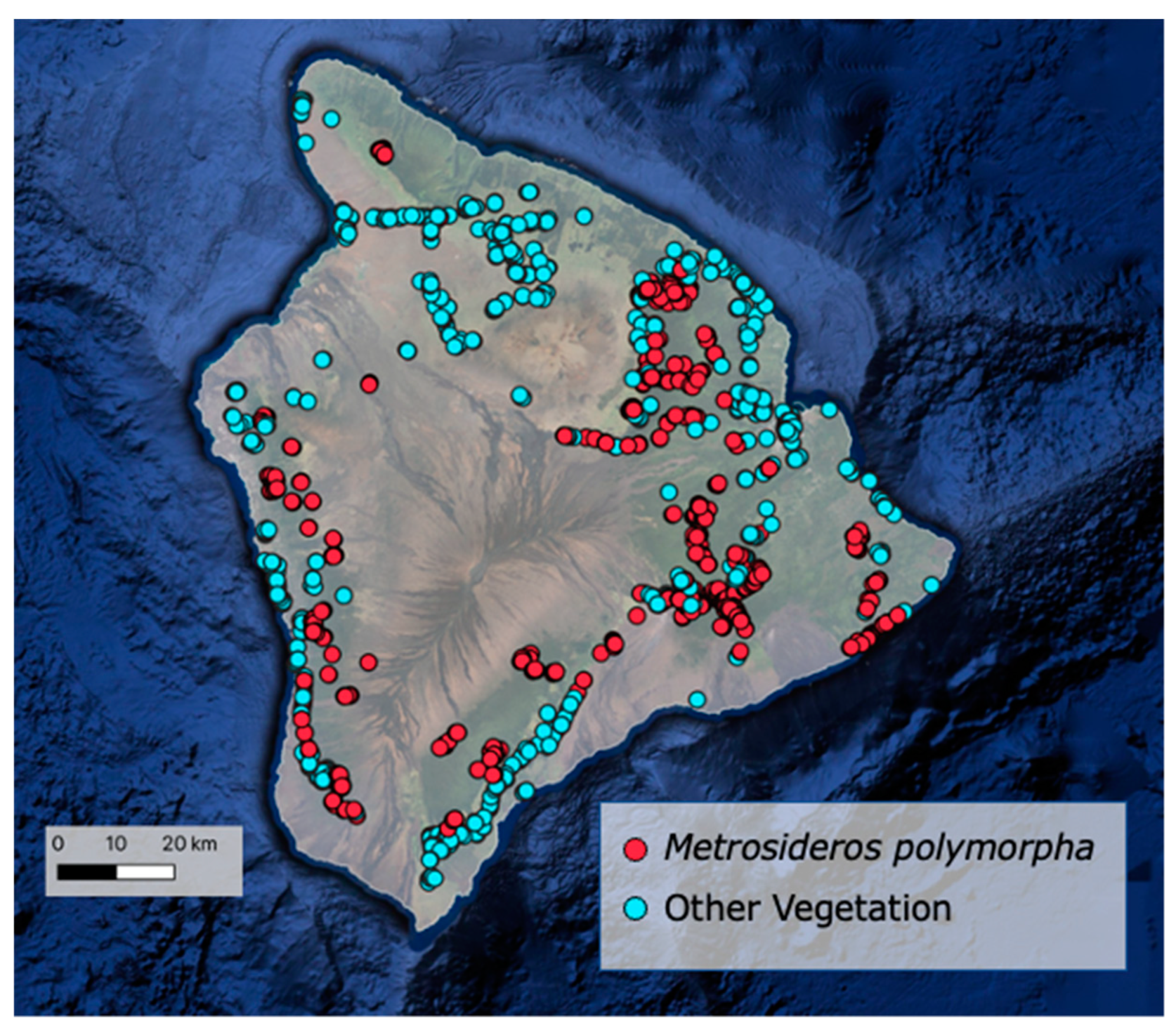
Figure 2.
Metrosideros polymorpha classifications: a) SVM, b) spectral unmixing. Red indicates where M. polymorpha canopies are located according to each model. c) Comparison of SVM and spectral unmixing classifications. Yellow: SVM only, Blue: spectral unmixing only. Gaussian process classification heatmap and contour lines indicating M. polymorpha likelihood (white: unlikely, darker: high likelihood).
Figure 2.
Metrosideros polymorpha classifications: a) SVM, b) spectral unmixing. Red indicates where M. polymorpha canopies are located according to each model. c) Comparison of SVM and spectral unmixing classifications. Yellow: SVM only, Blue: spectral unmixing only. Gaussian process classification heatmap and contour lines indicating M. polymorpha likelihood (white: unlikely, darker: high likelihood).
Figure 3.
Metrosideros polymorpha density map. Resolution is 30 m x 30 m.

Table 1.
Confusion matrix for the spectral unmixing and support vector machine (SVM) classifications of M. polymorpha on test datasets (2 m x 2 m).
Table 1.
Confusion matrix for the spectral unmixing and support vector machine (SVM) classifications of M. polymorpha on test datasets (2 m x 2 m).
| Predicted | |||||
|---|---|---|---|---|---|
| Spectral Unmixing | SVM | ||||
| M. polymorpha | Other Vegetation | M. polymorpha | Other Vegetation | ||
| Actual | M. polymorpha | 478 | 46 | 497 | 27 |
| Other Vegetation | 61 | 1025 | 44 | 1042 | |
Table 2.
Island-wide assessment of support vector machine (SVM) and spectral unmixing classification relative to Bayesian GPC spatial classification. Values indicate the percentage 2 m x 2 m pixels that were classified as M. polymorpha by one model and not the other in regions of high (>0.66), low (<0.33), and medium probability of M. polymorpha according to Bayesian GPC based on training data spatial information.
Table 2.
Island-wide assessment of support vector machine (SVM) and spectral unmixing classification relative to Bayesian GPC spatial classification. Values indicate the percentage 2 m x 2 m pixels that were classified as M. polymorpha by one model and not the other in regions of high (>0.66), low (<0.33), and medium probability of M. polymorpha according to Bayesian GPC based on training data spatial information.
| High M. polymorpha Likelihood | Low M. polymorpha Likelihood | Medium M. polymorpha Likelihood | |
|---|---|---|---|
| SVM | 47.5 | 13.9 | 38.9 |
| Spectral Unmixing | 29.4 | 30.6 | 39.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



