Submitted:
27 July 2023
Posted:
28 July 2023
You are already at the latest version
Abstract
Reading is a complex cognitive task involving processes from different systems. The present work aims to identify some points of divergence reported in the reading literature and discuss them in a new experimental paradigm framework. Inspired by the paradigms of perceptual identification and rapid parallel presentation (RPVP), we emphasize that the originality of our experimental paradigm lies in the recruitment of multi-stable Arabic percepts within the region where low-level processing occurs (i.e., the visual span area). With good flexibility, the current paradigm has reached higher-order processing levels. In agreement with previous works highlighting the parafoveal-on-foveal effect, results suggest parallel word processing. Furthermore, they suggest a rapid extraction of syntactic and semantic information from words in sentences while attributing an advantage to semantic processing in the emergence of the sentence superiority effect.
Keywords:
reading
; recognition
; multi-stable perception
; higher-order processing
1. Introduction
Reading is a cognitive task that decodes visual signs (words) to derive meaning. The reading task may seem simple, but it involves various processes from different systems (e.g., visual and ocular control, attention, memory, phonology, semantics, and syntax). As these systems interact continuously throughout the learning process, determining their contributions and the different interactions becomes very difficult, making comprehension of the reading task difficult. In this respect, the literature has proposed some fundamental questions that are the subject of ongoing debate, which we have briefly summarized into four main points.
1.1. One Glance, Three Spans
Among the points of divergence in the reading literature, we find the amount of information extracted in a single fixation. Three spans were proposed. The visual span refers to the area on either side of the fixation point in which recognition of adjacent letters (in a line of text) occurs without any contribution from high-level processes [1]. Using the trigram task, where trigrams (sequences of three letters randomly generated from the letters of the alphabet) were presented briefly (100 ms) at different eccentricities, the authors estimate that the visual span size is around ten letters (five letters to the right and left of the fixation point). The visual attention span refers to the number of distinct elements an observer could process simultaneously [2]. The visual attention span paradigm is based on two tasks. In the free recall task, participants report letters regardless of location [3,4]. In the partial report task [3,5], participants must report only the cued letter after the stimulus has disappeared. In contrast, in an ecological reading situation, studies using the eye recording techniques and the masking window paradigm have introduced the concept of the perceptual span as the limited region from which visual, linguistic, and contextual information is acquired [6,7]. The perceptual span extends from 4 letters to the left, and 15 letters to the right of the fixation point [7,8] for text read from left to right [9]. A reversal of perceptual span asymmetry has similarly been demonstrated when reading Arabic [10], Hebrew [11], and Urdu [12] texts. At the same time, works on perceptual span asymmetry gave rise to the parafoveal preview benefit [13]. This phenomenon proposes that readers pre-process the parafoveal word (n) when processing the foveal word (n+1).
1.2. Written Word Recognition between Phonology and Semantics
Many works have emphasized the integration of information coming from the para-foveal word, such as orthographic code [14], phonological code [13], the abstract representation of letters [15], and semantic information [16]. These findings have contributed to the re-injection of the debate around the primacy of phonology or semantics in the written word recognition process. Proponents of the phonological mediation hypothesis argue that access to the mental lexicon can only be achieved with a phonological code [17,18]. In support of this, other works highlight the contribution of phonology to semantic categorization task [19,20]. For example, results from the category membership judgment task (e.g., for the category tree) propose that the presentation of homophones (e.g., beach) generated significant latencies and errors compared to the presentation of words (e.g., beech) [20]. In contrast, Spinelli and Ferrand have indicated that patients with phonological deficits access semantic representations by relying solely on spelling [21]. Similarly, Taha [22] proposes that Arabic written word recognition relies on activating semantic representations in the first order.
1.3. Higher Order Processing between Syntax and Semantics
The sentence superiority effect [23] suggests better word recognition when words are presented in a correct sentence (legal context) than in a scrambled sentence (illegal context). Although this effect has been well supported, the debate around its nature has pitted two streams against each other. The first one supports the syntactic consistency’s effect, while the second postulates semantic relatedness’s effect on the emergence of the sentence superiority effect (SSE). For example, Snell and colleagues [24] reported very short latencies when syntactically congruent words flanked foveal target words. In good agreement, other work has highlighted the role of syntax in the word identification process [23,25]. Controversially, Asano and Yokasawa [26] further suggest that parallel word processing allows for simultaneous activation of semantic representations of words in the sentence, which contributes to constructing a rapid primitive representation called proto-context. The results of their study indicate that the process of identifying words within the sentence relies, in the first instance, on semantic relatedness rather than on syntactic consistency.
1.4. Written Word Recognition between Sequential and Parallel Processing
Another fundamental question is whether the words are processed simultaneously or one by one while reading texts. A first current postulates a sequential shift of attention from word (n) to word (n+1) (Sequential Attention Shift-SAS). For example, the EZ-Reader model [27] suggests a decoupling between attention shift and saccade programming. According to its authors, the attention shift can only occur after completing the word identification phase (second phase - L2), and the saccade programming can be done after the completion of the phase of familiarity verification (first phase - L1) of the foveal word. In contrast, the second current proposes parallel word processing (Guidance by Attentional Gradient-GAG). For example, the SWIFT model [28] postulates that within the field of effective vision, attention is manifested by a Gaussian distribution allowing for parallel processing of several words at once. The model accounts for decreased visual acuity and predicts reduced activation of words far from the fixation point. Saccade triggering is based on sampling from a random distribution, while saccade target selection is based on lexical salience. As a result, the recognition of a word resets its activation and will not be a candidate for the next saccade. Although the EZ-Reader and SWIFT models differ in design, they agree on the word as the basic processing unit. Both conceive the saccade programming in two phases of constant duration, a "labile" phase and a "non-labile" phase. Saccade cancellation is always possible in the "labile" phase, while no cancellation is possible in the " non-labile " phase. As a comparison between the two streams, we point out that proofs are accumulating more and more in favor of parallel word processing. Works have revealed phenomena such as the parafoveal-on-foveal effect [29,30], and simultaneous extraction of the syntactic categories of words in the sentence [24].
2. Methodology
2.1. Participants
Twenty-eight university Arabic students (14 female) gave written informed consent to their participation in this experiment. All participants reported no suffering from learning disabilities and had a normal or corrected-to-normal vision.
2.2. Design and Materials
We used the Rapid Parallel Visual Presentation (RPVP) [23] pardigm with forced-choice perceptual identification task -2AFC [31,32]. We used four types of stimuli, correct sentences (CS), incorrect sentences (Ins), non-word lists (Nw), and correct sentences with scrambled targets (Css). For non-word list (Nw), incorrect sentence (Ins) and correct sentences (Cs), the alternatives (the trigrams) differed only in the central letter. For the correct sentence (Cs) and sentence with scrambled targets (Css), the first alternative was semantically and syntactically congruent while the second was syntactically congruent and semantically incongruent (see Table 1). For correct (CS), incorrect(Ins) and non-word(Nw) stimuli, three display positions (initial, median, and final) were tested. For the sentences with scambled words (Css), only the median position was tested. All stimuli were short and contained three words (or non-words). The location of each trigram was indexed by the middle letter. The middle trigram occupied the foveal region (the central letter was placed at eccentricity 0), whereas the trigrams displayed in the para-foveal regions moved away from the fixation point with a distance subtending a visual angle of 1.25°. A total of one hundred and twenty trials were played. Thirty trials for each type, ten trials per position.
2.3. Appartus and Procedure
The letter size subtended approximately a visual angle of 0.27°. The stimulus presentation time was 200 milliseconds. Participants sat in front of the screen in a dark room at a distance of 50 cm. Each trial started with a presentation (500ms) of a mask composed of 9 horizontal hash marks (’#’). After its disappearance, the stimulus presentation took place. After stimulus termination, a second mask appears with the two alternatives above and below the location of the target. The presentation of the stimuli and target locations was randomized. Using a mouse, participants chose one of the alternatives. Before moving to the test phase, participants were familiarized with a session of 20 training trials using only non-word trigrams.
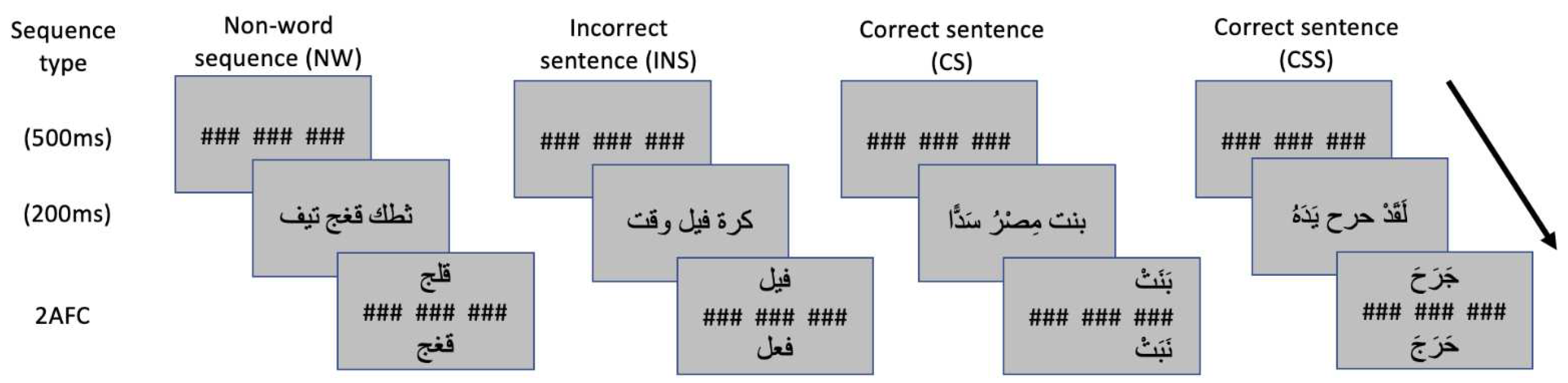
Figure 1.
Schmatic diagram of RPVP paradigm. Cs, Ins, Nw and Css correspond to correct sentences, incorrect sentences, non word lists and sentences with scrambled target, respectively.
Figure 1.
Schmatic diagram of RPVP paradigm. Cs, Ins, Nw and Css correspond to correct sentences, incorrect sentences, non word lists and sentences with scrambled target, respectively.
2.4. Data Analysis
Data analysis focuses on the probability of correct response and response time. The analysis of response time focused only on trials where the response was correct and the response time was less than 1000 milliseconds.
3. Results
3.1. The First Analysis
The first analysis focused on participants’ performance in correct and incorrect sentences and non-word stimuli. Analysis of the probability correct responses (binary data) was done using generalized linear mixed models (GLMMs) with stimulus type and position as fixed effects and participants as random effects [33]. We used the glmer function from the lme4 package [34] in the statistical computing environment R. Results showed an effect of sequence type () and position ( 0.001) on target identification. Pairwise comparison indicated that the probabilities of correct responses for non-word stimuli (Nw) were lower than those for words in either correct (Cs) (Estimate= -1.0115, SE= 0.114, z=-8.843) or incorrect (Ins) (Estimate=-0.7791, SE= 0.1103, z= -7.062) sentences. No difference was revealed in the probability of correct responses between correct (Cs) and incorrect sentences (Ins) (Estimate=-0.2324, SE=0.1209, z=-1.922). For the effect of position, pairwise comparison shows that the probabilities of correct responses were higher in the median position (P2) compared to those of the initial (P1) (Estimate=0.7102, SE=0.1225, z=5.799) and final (P3) (Estimate=-1.1622, SE=0.1194, z=-9.733) positions. Performances in the initial position (P1) were higher than those in the final (P3) positions (Estimate=-0.4520, SE=0.1069, z=-4.227).
For response time analysis, the linear mixed effects model (LMM) using the lmer function in the lme4 package [34] with stimulus type and position as fixed effects and participants as random effects [33] show significant effects of sequence type ( 0.01) and position ( 0.01) on normalized reaction time (RTnorm). Pairwise comparisons indicated that normalized reaction time (RTnorm) for non-word stimuli was lower than that for correct sentences (Cs) (Estimate=-0.145, SE=0.032, t=-4.43), and incorrect sentences (Ins) (Estimate=-0.108, SE=0.034, t=-3.16). No difference was revealed in normalized reaction time (RTnorm) between correct sentences (Cs) and incorrect sentences (Ins) (Estimate=0.036, SE=0.034, t=1.04). For the position effect, pairwise comparisons show that normalized reaction time (RTnorm) was lower on the median position compared to that on the initial position (P1) (Estimate=0.104, SE=0.034, t=3.00) and the final position (P3) (Estimate=-0.080, SE=0.033, t=-2.41). No significant difference was revealed between the final (P3) and initial (P1) positions (Estimate=0.023, SE=0.038, t=0.62).
3.2. The Second Analysis
The second analysis focused on participants’ performance in non-word stimuli, correct (Cs), incorrect (Ins) sentences, and sentences with scrambled words (Css) at the median position (P2). Generalized linear mixed model (GLMM) showed sequence type ( 0.001) on the probability of correct responses. Pairwise comparisons indicated that the probability of correct responses in non-word stimuli was lower than those in correct sentences (Cs)(Estimate=-0.841, SE=0.226, z=-3.71) and incorrect sentences (Ins) (Estimate=-0.93, SE=0.232, z=-4.00). Similarly, the probability of correct responses in sentences with scrambled targets (Css) was lower than those in correct sentences (Cs)(Estimate=-0.482, SE=0.235, z=-2.05), incorrect sentences (Ins)(Estimate=-0.571, SE=0.240, z=-2.37). No significant difference was revealed between non-word stimuli and sentences with scrambled targets (Css)(Estimate=-0.2288, SE=0.1199, z=-1.908).
For response time analysis, a linear mixed effects model (LMM) with stimulus type as fixed effects and participants as random effects [33] showed effects of sequence type ( 0.001) on normalized reaction time (RTnorm). Pairwise comparisons indicated that normalized reaction time (RTnorm) for non-word stimuli was lower than that for correct sentences (Cs) (Estimate=-0.217, SE=0.053, t=-4.05), incorrect sentences (Ins) (Estimate=-0.123, SE=0.054, t=-2.25), and sentences with scrambled words (Css) (Estimate=-0.185, SE=0.062, t=-2.97). No difference in normalized reaction time (RTnorm) between correct sentences (Cs), incorrect sentences (Ins), and sentences with scrambled target (Css), was revealed (see Table 3).
4. Discussion
The Paradigm
As mentioned in the introductory section, several points of divergence have been reported in the reading literature. In this regard, we would like to emphasize the need for more flexibility in experimental paradigms, not only in the reading context but also in different subjects that occupy the attention of cognitive sciences (e.g., episodic vs. semantic memory [35], multistable perception [36], memory vs. perception [37,38,39]). Indeed, the current paradigms have contributed significantly to a reasonably good understanding of many cognitive tasks. However, it should be mentioned that the crisis does not lie in the paradigms but in the stimuli and percepts. What we mean by this is that the question ’how do we create knowledge’ can only be answered if we use certain stimuli that are ’known and unknown at the same time’. In the present study, our paradigm proposes to put everything in the same bath. We have focused on the visual span area (conceived as a sensory limitation) [1], which is, in turn, embodied in the perceptual span [6,7,8] where high-level linguistic and contextual processing occurs. The exclusive character of our paradigm lies in the Arabic percepts used in the sentences with scrambled targets (Css). These are multistable percepts belonging to the original Arabic language and are not scrambled words, as introduced in the methodology section. As mentioned by a body of work, bi or multistable perceptual phenomena occur when an observer perceives the same stimulus differently [40]. Indeed, the alphabet of the original Arabic language was not dotted and contained only 18 letters, and the words in the texts were neither dotted nor vowelled [41]. By relying on the context, Arabic readers can remove the ambiguity of words [42]. In light of this, we emphasize that using such percepts will contribute to studying context-related effects, not only in the task of reading but also in other issues that confront cognitive sciences. For example, the isolated word /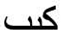 / could be expressed in the Schrödinger sense as:
/ could be expressed in the Schrödinger sense as:
/ could be expressed in the Schrödinger sense as: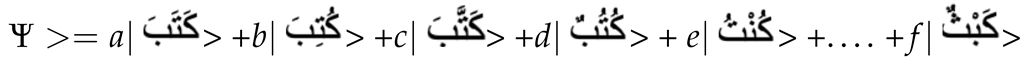
In good consistency with previous work, the first analysis on the probability correct responses for the three types of stimuli (correct, incorrect, and non-word) points to a word superiority effect [31]. As shown in Figure 2, words were better recognized than non-words. However, reaction time analyses show that non-words were recognized faster than words at the median (P2) and final (P3) positions (see Figure 2 (bottom)) and contradict the proposals of previous work [43]. Although this result represents a discrepancy, it indicate the initiation of additional processing. In addition to lexical processing, it is possible that the parallel presentation of words contributed to the initiation of higher-order processing (i.e., syntax and semantics) for correct (Cs) and incorrect (Ins) sentences and that the lack of lexical information in the case of non-word stimuli did not necessitate this kind of processing. Controversially to our postulates and work supporting the sentence superiority effect (SSE) [23], our analyses revealed no differences in the probability of correct response and reaction times between correct (Cs) and incorrect (Ins) sentences (see Table 2). These preliminary results run counter to primitive extraction of semantic representations [26] or extraction of the syntactic category [24] of words in the sentence. In this respect, we hypothesized (HP) that responses at the level of correct (Cs) and incorrect (Ins) sentences were stereotyped, and word recognition relied solely on visual and lexical information and occurred without any contribution from higher-order processing (at the sentence level). To test our hypothesis’s (HP) validity, we analyzed our data by including the sentences with the scrambled targets. This analysis suggests two results that require particular attention. The first one underlines similar performances in correct sentences(Cs) and incorrect sentences (Ins) (Estimate=0.088, SE=0.258, z=-0.343). The second indicates similar performances in the sentences with scrambled targets (Css) and non-word stimuli (Nw/baseline condition)(Estimate=- 0.2288, SE=0.1199, z=-1.908). Moreover, reaction time analyses showed no significant differences in normalized reaction(RTnorm) times between correct (Cs), incorrect (Ins) sentences and sentences with scrambled target (Css) (see Table 3). These results thus propose the higher-order processing contribution in scrambled word recognition and underline our hypothesis’s (HP) validity.

Table 2.
Proportion correct and mean normalized reaction time analyses.
| Proportion Correct | Normalized RT | |||||
|---|---|---|---|---|---|---|
| Condition | Estimate | SE | z | Estimate | SE | t |
| (Intercept) | 1.372 | 0.110 | 12.413 | 0.6493 | 0.0340 | 21.019 |
| Median | 0.710 | 0.122 | 5.799 | -0.0503 | 0.0186 | -3.014 |
| Final | -0.452 | 0.106 | -4.227 | -0.0232 | 0.0205 | -0.623 |
| Incorrect | -0.232 | 0.120 | -1.922 | 0.0307 | 0.0185 | -1.047 |
| Non-word | -1.011 | 0.114 | -8.843 | -0.0744 | 0.0197 | -4.439 |
* Fixed effects were deemed reliable if z and t values are greater than 1.96.
Table 3.
Parameters of pairwise comparisons between stimulus types in the three positions.
| Proportion Correct | Normalized RT | |||||
|---|---|---|---|---|---|---|
| Condition | Estimate | SE | z | Estimate | SE | t |
| Initial(P1) | ||||||
| Nw vs Cs | -1.098 | 0.197 | -5.576 | -0.0296 | 0.0609 | -0.485 |
| Nw vs Ins | -0.726 | 0.185 | -3.923 | -0.0600 | 0.0706 | -0.8491 |
| Cs vs Ins | 0.372 | 0.207 | 1.801 | -0.0304 | 0.0645 | -0.471 |
| Median(P2) | ||||||
| Nw vs Cs | -0.841 | 0.226 | -3.712 | -0.217 | 0.053 | -4.050 |
| Nw vs Ins | -0.930 | 0.232 | -4.005 | -0.123 | 0.054 | -2.255 |
| Nw vs Css | 0.359 | 0.206 | 1.742 | -0.185 | 0.062 | -2.975 |
| Cs vs Css | -0.482 | 0.235 | -2.051 | 0.031 | 0.062 | 0.505 |
| Ins vs Css | -0.571 | 0.240 | -2.374 | -0.062 | 0.064 | -0.969 |
| Cs vs Ins | 0.088 | 0.258 | 0.343 | 0.093 | 0.055 | 1.675 |
| Final (P3) | ||||||
| Nw vs Cs | -1.052 | 0.179 | -5.870 | -0.1036 | 0.0566 | -1.829 |
| Nw vs Ins | -0.767 | 0.174 | -4.407 | -0.1219 | 0.0566 | -2.154 |
| Cs vs Ins | 0.285 | 0.184 | 1.553 | -0.0183 | 0.0638 | -0.287 |
* Fixed effects were deemed reliable if z and t values are greater than 1.96.
Figure 2.
Probability correct responses and mean normalized reaction time (bottom) as a function of position (P1, P2 and P3) and stimuli type (Cs, Ins and Nw). Cs, Ins and Nw correspond to correct (red line), incorrect sentence (green line), and non-word stimuli (blue line). Error bars indicate 95% confidence intervals.
Figure 2.
Probability correct responses and mean normalized reaction time (bottom) as a function of position (P1, P2 and P3) and stimuli type (Cs, Ins and Nw). Cs, Ins and Nw correspond to correct (red line), incorrect sentence (green line), and non-word stimuli (blue line). Error bars indicate 95% confidence intervals.
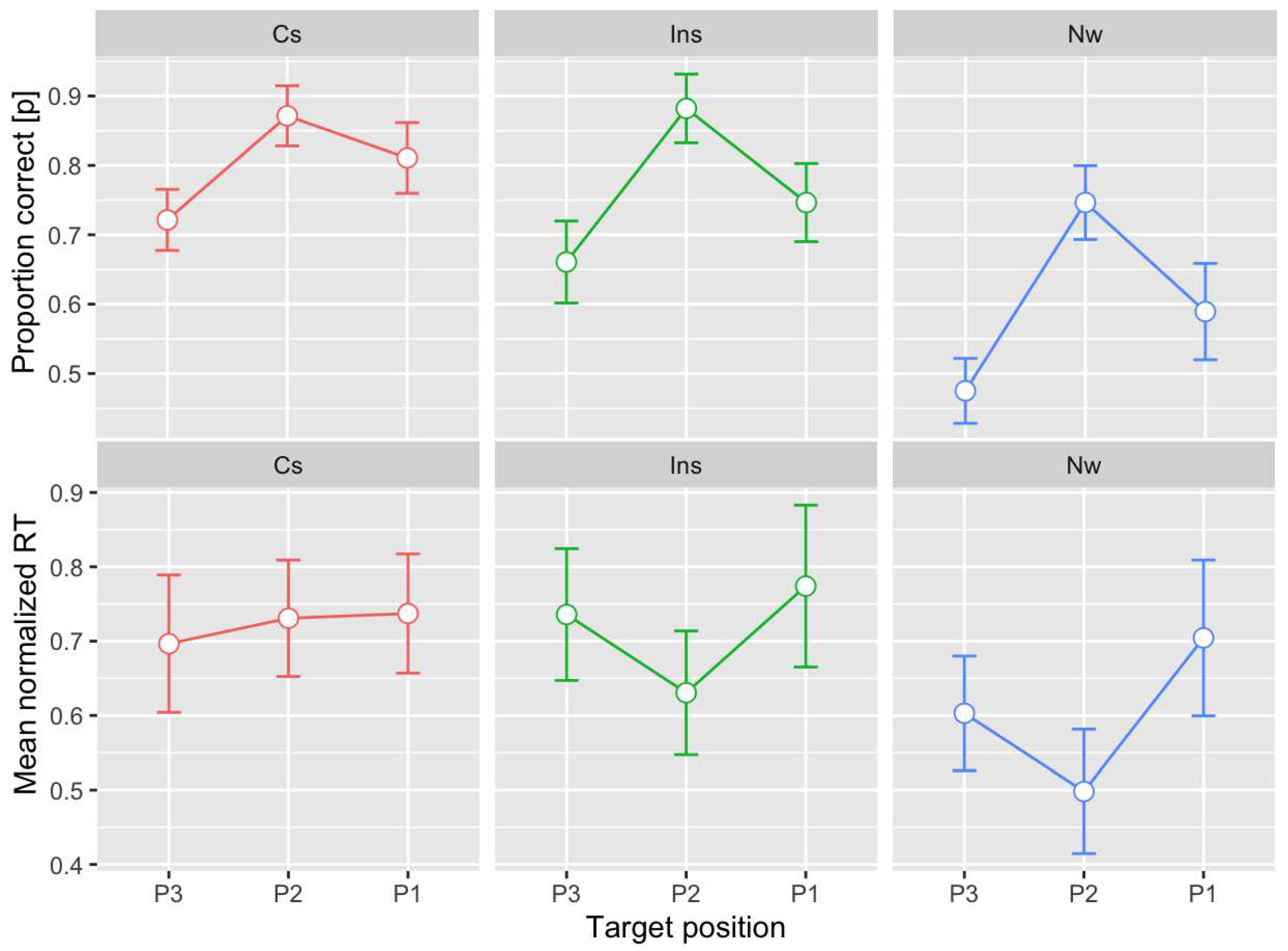
Figure 3.
Probability correct response (left) and mean normalized reaction time (right) at the median position (P2) for sentences with scrambled word (green bar), non-word stimuli (purple bar), correct sentences (red bar), and incorrect sentences (aqua green bar). Error bars indicate 95% confidence intervals.
Figure 3.
Probability correct response (left) and mean normalized reaction time (right) at the median position (P2) for sentences with scrambled word (green bar), non-word stimuli (purple bar), correct sentences (red bar), and incorrect sentences (aqua green bar). Error bars indicate 95% confidence intervals.
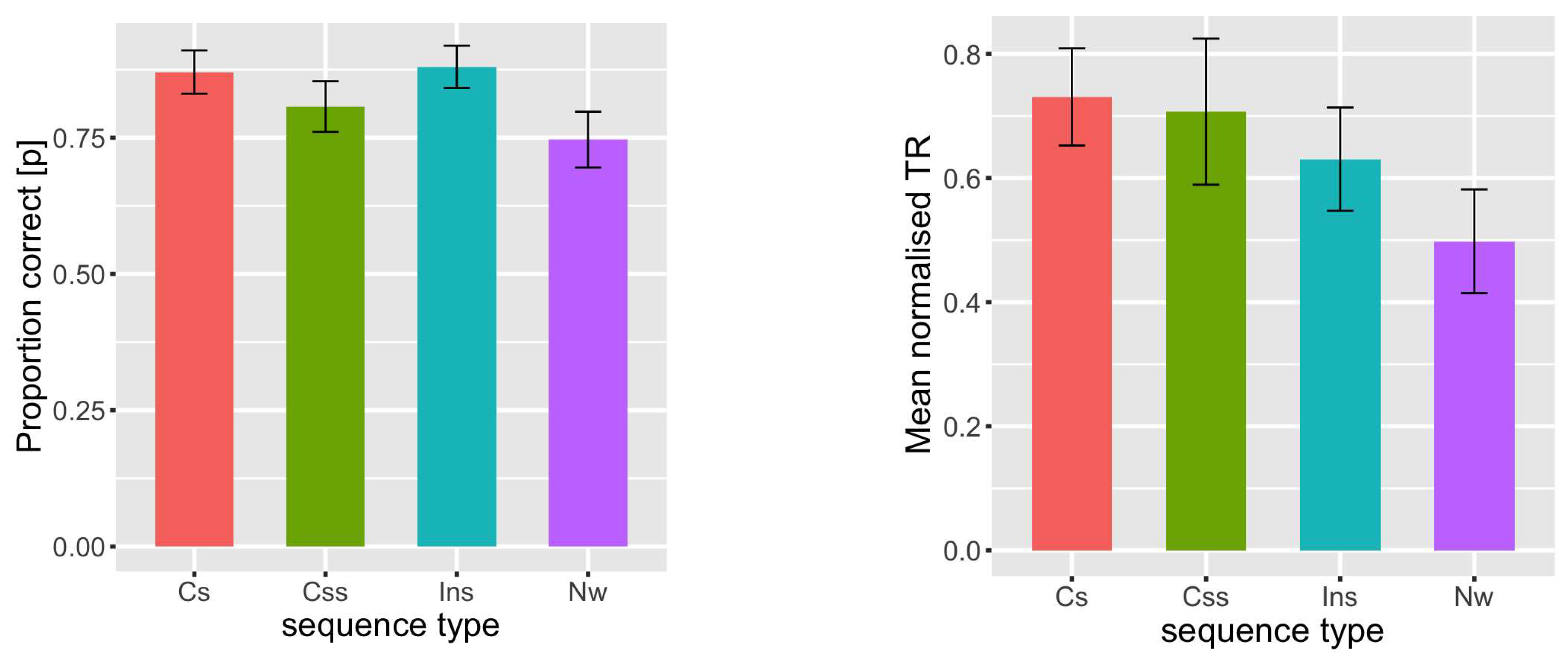
As the results show, analyses of the probabilities of correct responses suggest an effect of position on word recognition. The targets presented in the initial position were better recognized than those presented in the final position (see Figure 2-top) [26]. This observation can be interpreted, in the first place, by effects related to reading habits (the right-left direction for languages read from right to left) [26]. It is possible that our participants looked at the initial position (P1) or a location between the initial position (P1) and median position (P2) (HP2). Controversially, our analyses suggest a significant difference between the initial (P1) and median (P2) positions on the probability of correct responses (see, Table 2). If our hypothesis (HP2) were true, our participants would have a high chance of predicting the targets presented in the final position (P3) (the predictability effect) in the correct sentences (Cs). This observation support our hypothesis (HP) suggesting that our participants relied on visual and lexical information in the recognition of words in the correct sentences (Cs). Moreover, If our hypothesis (HP2) were true, we should observe, at least, a decrease in reaction time at the initial position (P1). Analysis of reaction time showed no significant difference between initial (P1) and final (P3) positions (Estimate=0.023, SE=0.038, t=0.62), which means that words were processed simultaneously. Two possible explanation for the reduced performance in the final position (P3). The first one points to poor visual attention skills in Arab readers [3]. The second point to a deployment of visual attention extend to the beginning of sequence. Controversially to the sequential sentence word processing, our results showed no difference in the probabilities of correct responses at the median position (P2) between sentences with scrambled target stimuli (Css) and non-word stimuli (Nw) (see Table 3). In good agreement, our finding corroborates studies’ proposals suggesting a parafoveal-on-foveal effect [29,30]. To identify the foveal scrambled word (P2), participants had to extract information from words in the final (P3) and initial (P1) positions. In light of this, we support the hypotheses of parallel processing and the extraction of semantic and syntactic information of multiple words at once [26,44]. Based on the propositions of Asano and Yokasawa [26] suggesting primitive extraction of a semantic representation and those of Snell et al. [44] suggesting parallel extraction of semantic information from the words of the sentence, the present results, therefore, attribute an advantage to semantic processing in the emergence of the sentence superiority effect. If the syntax has directly contributed to the emergence of the sentence superiority effect (SSE) in sentences with scrambled targets (Css), we must first reveal its effects in the correct sentences (Cs). After all, all three words in the correct sentences (Cs) were within the visual span area. In other words, although the syntactic word information (word location) was accessible [45], no significant difference was revealed between correct and incorrect sentences. For more visibility, let us take the example of the following sentence " ". In this example, it is clear that multistable percepts cannot be read without interaction between semantic and syntactic processing. First, we need elementary units of meaning (words) to perform computations (i.e., syntax) to generate the sentence’s overall meaning. Similarly, when presenting words with dots and vowels (
". In this example, it is clear that multistable percepts cannot be read without interaction between semantic and syntactic processing. First, we need elementary units of meaning (words) to perform computations (i.e., syntax) to generate the sentence’s overall meaning. Similarly, when presenting words with dots and vowels ( / It was said that an elephant was killed), the same interaction between the two levels (syntactic and semantic) will occur. The only difference is that the semantic information of the words in the sentence is available, which makes it easier to extract the primitive semantic representation. Paradigms using isolated words have yet to provide concrete answers to questions concerning the access code to the mental lexicon and the primacy of phonology or semantics in recognition of written words. Three streams have discussed the place of phonology in the reading task [46]. The first one suggest direct access to the mental lexicon without recourse to phonological coding [47]. The second proposes a phonological mediation to access the mental lexicon [17,18]. In contrast, dual root models [48,49]suggest that reading relies on two roots. The sub-lexical root calls on the grapheme-phoneme conversion system while presenting pseudowords and new words. The lexical root provides faster access to the mental lexicon, when a known word is presented. It should be noted that grapheme-phoneme conversion is costly in processing time. We put three hypotheses to the test based on our paradigm and findings. The first hypothesis (HC1) assumes the non-contribution of phonological coding in written word recognition, particularly in silent reading. Given Abu-Rabiaa’s proposal [42], suggesting that Arabic readers rely on context to deduce words’ phonological form when reading texts, we reject the hypothesis (HC1). A second hypothesis (HC2) assumes that recognition of scrambled words relied on early activation of the semantic representation. Kintsch and Mangalath [50] propose that word meaning results from the interaction between the various decontextualized semantic representations of words in long-term memory and the sentence’s overall meaning (semantic context). The problem with this proposal is that the orthographic and semantic representations of the percepts used in our paradigm do not exist in long-term memory. Our percepts are new stimuli for the reading system. Note that our results cannot be explained by the multi-trace memory model proposals [37]. What do exist are orthographic, phonological, and semantic representations of percept’s states (see equation 1). Since our percepts are qualified as new stimuli (i.e., new words), a third hypothesis (HC3) inspired by dual root model proposals [48,49] assumes an early phonological coding. We also reject this hypothesis (HC3) in two respects: first, because our results suggest a rapid parallel processing of the words sentence. Second, the grapheme-phoneme conversion process is a slow serial process. Given the multistable nature of scrambled words and the letters that form them, any attempt at early phonological encoding would be even more costly. Rejecting hypothesis (HC3) in no way implies the validity of hypothesis (HC2). We suggest that the recognition of multi-stable Arabic percepts may reflect the co-occurrence of learning (creation of the memory trace) and retrieval. Although the present paradigm supports the interaction between perception and memory [39], we should keep in mind that the multi-stable Arabic percepts used in the present study did not basically exist in episodic memory.
/ It was said that an elephant was killed), the same interaction between the two levels (syntactic and semantic) will occur. The only difference is that the semantic information of the words in the sentence is available, which makes it easier to extract the primitive semantic representation. Paradigms using isolated words have yet to provide concrete answers to questions concerning the access code to the mental lexicon and the primacy of phonology or semantics in recognition of written words. Three streams have discussed the place of phonology in the reading task [46]. The first one suggest direct access to the mental lexicon without recourse to phonological coding [47]. The second proposes a phonological mediation to access the mental lexicon [17,18]. In contrast, dual root models [48,49]suggest that reading relies on two roots. The sub-lexical root calls on the grapheme-phoneme conversion system while presenting pseudowords and new words. The lexical root provides faster access to the mental lexicon, when a known word is presented. It should be noted that grapheme-phoneme conversion is costly in processing time. We put three hypotheses to the test based on our paradigm and findings. The first hypothesis (HC1) assumes the non-contribution of phonological coding in written word recognition, particularly in silent reading. Given Abu-Rabiaa’s proposal [42], suggesting that Arabic readers rely on context to deduce words’ phonological form when reading texts, we reject the hypothesis (HC1). A second hypothesis (HC2) assumes that recognition of scrambled words relied on early activation of the semantic representation. Kintsch and Mangalath [50] propose that word meaning results from the interaction between the various decontextualized semantic representations of words in long-term memory and the sentence’s overall meaning (semantic context). The problem with this proposal is that the orthographic and semantic representations of the percepts used in our paradigm do not exist in long-term memory. Our percepts are new stimuli for the reading system. Note that our results cannot be explained by the multi-trace memory model proposals [37]. What do exist are orthographic, phonological, and semantic representations of percept’s states (see equation 1). Since our percepts are qualified as new stimuli (i.e., new words), a third hypothesis (HC3) inspired by dual root model proposals [48,49] assumes an early phonological coding. We also reject this hypothesis (HC3) in two respects: first, because our results suggest a rapid parallel processing of the words sentence. Second, the grapheme-phoneme conversion process is a slow serial process. Given the multistable nature of scrambled words and the letters that form them, any attempt at early phonological encoding would be even more costly. Rejecting hypothesis (HC3) in no way implies the validity of hypothesis (HC2). We suggest that the recognition of multi-stable Arabic percepts may reflect the co-occurrence of learning (creation of the memory trace) and retrieval. Although the present paradigm supports the interaction between perception and memory [39], we should keep in mind that the multi-stable Arabic percepts used in the present study did not basically exist in episodic memory.
". In this example, it is clear that multistable percepts cannot be read without interaction between semantic and syntactic processing. First, we need elementary units of meaning (words) to perform computations (i.e., syntax) to generate the sentence’s overall meaning. Similarly, when presenting words with dots and vowels (/ It was said that an elephant was killed), the same interaction between the two levels (syntactic and semantic) will occur. The only difference is that the semantic information of the words in the sentence is available, which makes it easier to extract the primitive semantic representation. Paradigms using isolated words have yet to provide concrete answers to questions concerning the access code to the mental lexicon and the primacy of phonology or semantics in recognition of written words. Three streams have discussed the place of phonology in the reading task [46]. The first one suggest direct access to the mental lexicon without recourse to phonological coding [47]. The second proposes a phonological mediation to access the mental lexicon [17,18]. In contrast, dual root models [48,49]suggest that reading relies on two roots. The sub-lexical root calls on the grapheme-phoneme conversion system while presenting pseudowords and new words. The lexical root provides faster access to the mental lexicon, when a known word is presented. It should be noted that grapheme-phoneme conversion is costly in processing time. We put three hypotheses to the test based on our paradigm and findings. The first hypothesis (HC1) assumes the non-contribution of phonological coding in written word recognition, particularly in silent reading. Given Abu-Rabiaa’s proposal [42], suggesting that Arabic readers rely on context to deduce words’ phonological form when reading texts, we reject the hypothesis (HC1). A second hypothesis (HC2) assumes that recognition of scrambled words relied on early activation of the semantic representation. Kintsch and Mangalath [50] propose that word meaning results from the interaction between the various decontextualized semantic representations of words in long-term memory and the sentence’s overall meaning (semantic context). The problem with this proposal is that the orthographic and semantic representations of the percepts used in our paradigm do not exist in long-term memory. Our percepts are new stimuli for the reading system. Note that our results cannot be explained by the multi-trace memory model proposals [37]. What do exist are orthographic, phonological, and semantic representations of percept’s states (see equation 1). Since our percepts are qualified as new stimuli (i.e., new words), a third hypothesis (HC3) inspired by dual root model proposals [48,49] assumes an early phonological coding. We also reject this hypothesis (HC3) in two respects: first, because our results suggest a rapid parallel processing of the words sentence. Second, the grapheme-phoneme conversion process is a slow serial process. Given the multistable nature of scrambled words and the letters that form them, any attempt at early phonological encoding would be even more costly. Rejecting hypothesis (HC3) in no way implies the validity of hypothesis (HC2). We suggest that the recognition of multi-stable Arabic percepts may reflect the co-occurrence of learning (creation of the memory trace) and retrieval. Although the present paradigm supports the interaction between perception and memory [39], we should keep in mind that the multi-stable Arabic percepts used in the present study did not basically exist in episodic memory.5. Conclusion
In short, the new paradigm has highlighted the contribution of context effects to the "reading" of Arabic multistable percepts. The use of Arabic multistable percepts has made it possible to reach higher-order processing levels than we can achieve with normal words and to propose a distinction between a recognition task and a reading task while unveiling the hidden side of reading. If reading used to be seen as a process for accessing meaning, the present work suggests that reading is a process that creates meaning by reconstructing the perception. In light of this, we will devote an other paper to a more in-depth discussion of this work’s contribution to the fundamental questions surrounding perception and memory.
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki, and approved by the Comité d’Ethique pour la Recherche Biomédicale Université Mohammed V – Rabat Faculté de Médecine et de Pharmacie de Rabat Faculté de Médecine Dentaire de Rabat (protocol code CERB 61-22 and date of approval: February 20, 2023).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study to publish this paper.
Acknowledgments
The authors wish to thank the people that participated in the current studies.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Legge, G.E.; Mansfield, J.S.; Chung, S.T. Psychophysics of reading: XX. Linking letter recognition to reading speed in central and peripheral vision. Vision research 2001, 41, 725–743. [Google Scholar] [CrossRef]
- Frey, A.; Bosse, M.L. Perceptual span, visual span, and visual attention span: Three potential ways to quantify limits on visual processing during reading. Visual Cognition 2018, 26, 412–429. [Google Scholar] [CrossRef]
- Awadh, F.H.; Phénix, T.; Antzaka, A.; Lallier, M.; Carreiras, M.; Valdois, S. Cross-language modulation of visual attention span: an Arabic-French-Spanish comparison in skilled adult readers. Frontiers in psychology 2016, 7, 307. [Google Scholar] [CrossRef] [PubMed]
- Sperling, G. The information available in brief visual presentations. Psychological monographs: General and applied 1960, 74, 1. [Google Scholar] [CrossRef]
- Averbach, E.; Coriell, A.S. Short-term memory in vision. The Bell System Technical Journal 1961, 40, 309–328. [Google Scholar] [CrossRef]
- McConkie, G.W.; Rayner, K. The span of the effective stimulus during a fixation in reading. Perception & Psychophysics 1975, 17, 578–586. [Google Scholar]
- Rayner, K.; McConkie, G.W. What guides a reader’s eye movements? Vision research 1976, 16, 829–837. [Google Scholar] [CrossRef] [PubMed]
- Rayner, K.; Bertera, J.H. Reading without a fovea. Science 1979, 206, 468–469. [Google Scholar] [CrossRef]
- Rayner, K.; Well, A. Pollatsek a Asymmetry of the effective visual field in reading. Percept Psychophys 1980, 27, 537–44. [Google Scholar] [CrossRef]
- Jordan, T.R.; Almabruk, A.A.; Gadalla, E.A.; McGowan, V.A.; White, S.J.; Abedipour, L.; Paterson, K.B. Reading direction and the central perceptual span: Evidence from Arabic and English. Psychonomic bulletin & review 2014, 21, 505–511. [Google Scholar]
- Pollatsek, A.; Bolozky, S.; Well, A.D.; Rayner, K. Asymmetries in the perceptual span for Israeli readers. Brain and language 1981, 14, 174–180. [Google Scholar] [CrossRef] [PubMed]
- Paterson, K.B.; McGowan, V.A.; White, S.J.; Malik, S.; Abedipour, L.; Jordan, T.R. Reading direction and the central perceptual span in Urdu and English. PloS one 2014, 9, e88358. [Google Scholar] [CrossRef] [PubMed]
- Pollatsek, A.; Lesch, M.; Morris, R.K.; Rayner, K. Phonological codes are used in integrating information across saccades in word identification and reading. Journal of Experimental Psychology: Human perception and performance 1992, 18, 148. [Google Scholar] [CrossRef] [PubMed]
- Rayner, K.; Well, A.D.; Pollatsek, A.; Bertera, J.H. The availability of useful information to the right of fixation in reading. Perception & Psychophysics 1982, 31, 537–550. [Google Scholar]
- Johnson, R.L.; Perea, M.; Rayner, K. Transposed-letter effects in reading: evidence from eye movements and parafoveal preview. Journal of Experimental psychology: Human perception and performance 2007, 33, 209. [Google Scholar] [CrossRef]
- Hohenstein, S.; Kliegl, R. Semantic preview benefit during reading. Journal of Experimental Psychology: Learning, Memory, and Cognition 2014, 40, 166. [Google Scholar] [CrossRef]
- Rubenstein, H.; Lewis, S.S.; Rubenstein, M.A. Evidence for phonemic recoding in visual word recognition. Journal of verbal learning and verbal behavior 1971, 10, 645–657. [Google Scholar] [CrossRef]
- Perfetti, C.A.; Zhang, S. Phonological processes in reading Chinese characters. Journal of Experimental Psychology: Learning, Memory, and Cognition 1991, 17, 633. [Google Scholar] [CrossRef]
- Van Orden, G.C. A ROWS is a ROSE: Spelling, sound, and reading. Memory & cognition 1987, 15, 181–198. [Google Scholar]
- Rayner, K.; Pollatsek, A.; Schotter, E.R. Reading: Word identification and eye movements. 2013.
- Spinelli, E. Psychologie du langage: l’écrit et le parlé, du signal à la signification; Armand Colin, 2005.
- Taha, H. The role of semantic activation during word recognition in Arabic. Cognitive Processing 2019, 20, 333–337. [Google Scholar] [CrossRef]
- Snell, J.; Grainger, J. The sentence superiority effect revisited. Cognition 2017, 168, 217–221. [Google Scholar] [CrossRef] [PubMed]
- Snell, J.; Meeter, M.; Grainger, J. Evidence for simultaneous syntactic processing of multiple words during reading. PloS one 2017, 12, e0173720. [Google Scholar] [CrossRef] [PubMed]
- Massol, S.; Grainger, J. The sentence superiority effect in young readers. Developmental Science 2021, 24, e13033. [Google Scholar] [CrossRef] [PubMed]
- Asano, M.; Yokosawa, K. Rapid extraction of gist from visual text and its influence on word recognition. The Journal of general psychology 2011, 138, 127–154. [Google Scholar] [CrossRef] [PubMed]
- Reichle, E.; Pollatsek, A. & Rayner, K.(2006) E–Z Reader: A cognitive-control, serial-attention model of eye-movement behavior during reading. Cognitive Systems Research, 7.
- Engbert, R.; Nuthmann, A.; Richter, E.M.; Kliegl, R. SWIFT: a dynamical model of saccade generation during reading. Psychological review 2005, 112, 777. [Google Scholar] [CrossRef]
- Kennedy, A. Parafoveal processing in word recognition. The Quarterly Journal of Experimental Psychology Section A 2000, 53, 429–455. [Google Scholar] [CrossRef]
- Murray, W.S. Parafoveal pragmatics. In Eye guidance in reading and scene perception; Elsevier, 1998; pp. 181–199.
- Reicher, G.M. Perceptual recognition as a function of meaningfulness of stimulus material. Journal of experimental psychology 1969, 81, 275. [Google Scholar] [CrossRef]
- Wheeler, D.D. Processes in word recognition. Cognitive Psychology 1970, 1, 59–85. [Google Scholar] [CrossRef]
- Baayen, R. Analyzing Linguistic Data: A Practical Introduction to Statistics Using R. Cambridge University Press 2008. [Google Scholar]
- Bates, D.; Maechler, M.; Bolker, B.; Walker, S. Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67: 1–48, 2015.
- Rousset, S. Les conceptions" système unique" de la mémoire: aspects théoriques. Revue de neuropsychologie 2000, 10, 27–51. [Google Scholar]
- Rodríguez-Martínez, G.A.; Castillo-Parra, H. Bistable perception: neural bases and usefulness in psychological research. International Journal of Psychological Research 2018, 11, 63–76. [Google Scholar] [CrossRef] [PubMed]
- Hintzman, D.L. MINERVA 2: A simulation model of human memory. Behavior Research Methods, Instruments, & Computers 1984, 16, 96–101. [Google Scholar]
- Hintzman, D.L. " Schema abstraction" in a multiple-trace memory model. Psychological review 1986, 93, 411. [Google Scholar] [CrossRef]
- Versace, R.; Vallet, G.T.; Riou, B.; Lesourd, M.; Labeye, É.; Brunel, L. Act-In: An integrated view of memory mechanisms. Journal of Cognitive Psychology 2014, 26, 280–306. [Google Scholar] [CrossRef]
- Dieter, K.C.; Brascamp, J.; Tadin, D.; Blake, R. Does visual attention drive the dynamics of bistable perception? Attention, Perception, & Psychophysics 2016, 78, 1861–1873. [Google Scholar]
- Awadh, F.H.R. Caractérisation et rôle de l’empan visuo-attentionnel chez les lecteurs arabophones adultes et enfants (experts et dyslexiques développementales). Theses, Université Grenoble Alpes, 2016.
- Abu-Rabia, S. Reading in Arabic orthography: The effect of vowels and context on reading accuracy of poor and skilled native Arabic readers. Reading and Writing 1997, 9, 65–78. [Google Scholar] [CrossRef]
- Jordan, T.R.; Paterson, K.B.; Almabruk, A.A. Revealing the superior perceptibility of words in Arabic. Perception 2010, 39, 426–428. [Google Scholar] [CrossRef]
- Snell, J.; Declerck, M.; Grainger, J. Parallel semantic processing in reading revisited: Effects of translation equivalents in bilingual readers. Language, Cognition and Neuroscience 2018, 33, 563–574. [Google Scholar] [CrossRef]
- Snell, J.; van Leipsig, S.; Grainger, J.; Meeter, M. OB1-reader: A model of word recognition and eye movements in text reading. Psychological review 2018, 125, 969. [Google Scholar] [CrossRef]
- Ferrand, L. Psychologie cognitive de la lecture (De Boeck ed.), 2007.
- Davis, C.J. The spatial coding model of visual word identification. Psychological review 2010, 117, 713. [Google Scholar] [CrossRef]
- Coltheart, M.; Rastle, K.; Perry, C.; Langdon, R.; Ziegler, J. DRC: a dual route cascaded model of visual word recognition and reading aloud. Psychological review 2001, 108, 204. [Google Scholar] [CrossRef] [PubMed]
- Perry, C.; Ziegler, J.C.; Zorzi, M. Beyond single syllables: Large-scale modeling of reading aloud with the Connectionist Dual Process (CDP++) model. Cognitive psychology 2010, 61, 106–151. [Google Scholar] [CrossRef] [PubMed]
- Kintsch, W.; Mangalath, P. The construction of meaning. Topics in cognitive science 2011, 3, 346–370. [Google Scholar] [CrossRef] [PubMed]
Table 1.
Examples of correct sentences (Cs), incorrect sentences (Ins), and sentences with scrambled targets (Css).
Table 1.
Examples of correct sentences (Cs), incorrect sentences (Ins), and sentences with scrambled targets (Css).
| Sequence Type | Sequence | Translation | Correct Alternative | False Alternative |
|---|---|---|---|---|
| Ins (incorrect) |  |
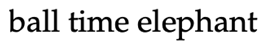 |
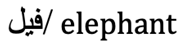 |
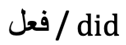 |
| Cs (correct) |  |
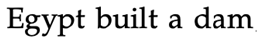 |
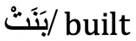 |
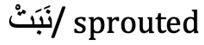 |
| Css(scrambled) | 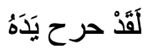 |
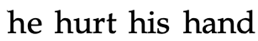 |
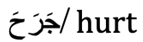 |
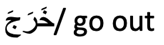 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



