
Submitted:
10 August 2023
Posted:
10 August 2023
You are already at the latest version
Abstract
To estimate the degree of quantum entanglement, it is important to understand
the statistical behavior of functions of spectrum of density matrices such as von
Neumann entropy, quantum purity, and entanglement capacity. These entangle-
ment metrics over different generic state ensembles have been studied intensively
in the literature. As an alternative metric, in this work we study sum of square
root spectrum of density matrices, which is relevant to negativity and fidelity in
quantum information processing. In particular, we derive the exact mean and vari-
ance of sum of square root spectrum over the Bures-Hall generic state ensemble
extending known results obtained recently over the Hilbert-Schmidt ensemble.
Keywords:
quantum entanglement
; negativity
; fidelity
; Bures-Hall ensemble
; random matrix theory
1. Introduction and Main Results
1.1. Square Root Spectrum and Applications
The sum of square root of spectrum of density matrices is defined as
where m is the dimension of the density matrix and the set is its spectrum. The random variable (1) is closely related to the negativity (2) and fidelity (3) as discussed below.
Negativity is introduced in [1] as a computable measure of entanglement. For a pure state with and , the negativity is defined as
where is the trace norm (also known as the Schatten 1-norm) and refers to the partial transpose of . Moreover, it has a uniqueness property that suppose is a weak entanglement monotone that is a symmetric function of negative eigenvalues of , then is a nondecreasing function of , and for some constant in the case that it is additive, see [2].
Fidelity [3] refers to a measure of the similarity or overlap between two quantum states. It quantifies how closely one quantum state resembles another. It is defined as:
In this work, we only consider the case that , which is the maximum mixed state, and is the the density matrix corresponding to Bures-Hall ensemble. In this case, we have
The case of Hilbert-Schmidt is computed in [4].
1.2. Description of Bures-Hall Ensemble
The Bures-Hall ensemble is described as follows [5,6]. Consider a composite(bipartite) system that consists of two subsystems A and B of Hilbert space(complex vector space) with dimensions m and n, respectively. The Hilbert space . A random pure state of the composite system is defined as a linear combination of the random coefficients and the complete basis and of and [5],
where each follows the standard Gaussian distribution. We now consider a superposition of the state (5),
where U is an unitary random matrix with the measure proportional to [7]. The corresponding density matrix of the pure state (6) is
which has the natural probability constraint
Without loss of generality, we assume that . The reduced density matrix of the smaller subsystem A is computed by partial tracing (purification) of the full density matrix (7) over the other subsystem B (environment) as
The resulting density of the eigenvalues of () is the (generalized) complex Bures-Hall measure [7,8,9,10],
where the parameter takes half-integer values,
and the constant C is
For convenience, we need to define the random variable below:
Then, the negativity and fidelity are defined, respectively, as
1.3. Main Results
Proposition 1.1 The exact mean of the random variable defined in (13) valid for any subsystem dimensions under the Bures-Hall ensemble (10) is obtained as
where d is
The proof of Proposition 1.1 is given in Sec. 2.2.
Proposition 1.2 The exact second moment of in (13) valid for any subsystem dimensions under the Bures-Hall ensemble (10) is obtained as
where we denote
Therefore, the mean of negativity and fidelity, valid for any subsystem dimensions , are obtained, respectively, as
where the expectation is taken over the Bures-Hall ensemble (10). The exact variance of the first moment under the Bures-Hall ensemble is given by
The proof of these results is given in Sec. 2.3.
2. Computing Moments of Sum of Square Root Statistics
2.1. Ensemble Conversion
We calculate the random variables under the original ensemble by covering it to unconstrained ensemble. The unconstrained ensemble of the Bures-Hall measure is
where , i=1,...,m, and the constant C’ depends on the constant (12) as
with d denoting
The density of trace
is obtained as
where we have applied the change of variables
implies that is factored as [13]
which shows is independent of each .
2.2. Calculation of the Mean of
Following the formulas for [14, Eq. (26) to (48)], with the same notation, letting
letting instead of , we obtain
Applying the identity of Gamma function:
we are able to write the result as
Therefore, the mean of is given by
2.3. Calculation of the Second Moment
By (35), now it suffices to calculate .
where
where
where we denote
The kernal functions above((39) and (42) to (44)) are obtained in [15,16] , which were successfully used in calculating the mean and variance of von Neumann entropy under Bures-Hall ensemble [11].
So we can calculate five integrals separately to get the result:
2.3.1. Calculation of and
The evaluation of and could also be obtained by the formula for [11] with and respectively. Denoting
where
Notice that when , , so we get another expression of and :
By changing the order of integrals, and can be calculated as
2.3.2. Calculation of and
Calculation of and follows almost the same procedure. It starts from the fact that the kernels (43) as well as finite sum representation [14,17] of the Meijer G-functions . Directly evaluate the integrals over t by the identity [18]
This leads and to
where we denote
As
we get
Applying the identity of Gamma function (38), can be rewritten as
Define that
we get
2.3.3. Calculation of
3. Conclusions
In this work, we compute the exact mean values of negativity and fidelity over the Bures-Hall ensemble via computing the first two moments of sum of square root spectrum of density matrices. The results are obtained by making use of known formulas of correlation functions of Bures-Hall ensemble and the corresponding special functions. Future works include the computation of higher-order moments of sum of square root spectrum as well as obtaining its asymptotic distributions. .
Acknowledgments
This work is supported in part by the U.S. National Science Foundation (#2306968 and #2150486).
References
- Vidal, G.; Werner, R.F. Computable measure of entanglement. Phys. Rev. A 2002, 65, 032314. [Google Scholar] [CrossRef]
- Zhu, H.; Hayashi, M.; Chen, L. Axiomatic and operational connections between the l1-norm of coherence and negativity. Phys. Rev. A 2018, 97, 022342. [Google Scholar] [CrossRef]
- Jozsa, R. Fidelity for Mixed Quantum States. Journal of Modern Optics 1994, 41, 2315–2323. [Google Scholar] [CrossRef]
- Laha, A.; Kumar, S. Random density matrices: Analytical results for mean fidelity and variance of squared Bures distance. Phys. Rev. E 2023, 107, 034206. [Google Scholar] [CrossRef] [PubMed]
- Akemann, G.; Baik, J.; Di Francesco, P. (Eds.) The Oxford Handbook of Random Matrix Theory; Oxford University Press: United Kingdom, 2011. [Google Scholar] [CrossRef]
- Bengtsson, I.; Zyczkowski, K. Geometry of Quantum States: An Introduction to Quantum Entanglement. Geometry of Quantum States: An Introduction to Quantum Entanglement 2006. [Google Scholar] [CrossRef]
- Zhu, H.; Hayashi, M.; Chen, L. Axiomatic and operational connections between the l1-norm of coherence and negativity. Phys. Rev. A 2018, 97, 022342. [Google Scholar] [CrossRef]
- Hall, M.J. Random quantum correlations and density operator distributions. Physics Letters A 1998, 242, 123–129. [Google Scholar] [CrossRef]
- Zyczkowski, K.; Sommers, H.J. Induced measures in the space of mixed quantum states. Journal of Physics A: Mathematical and General 2001, 34, 7111. [Google Scholar] [CrossRef]
- Sommers, H.J.; Zyczkowski, K. Bures volume of the set of mixed quantum states. Journal of Physics A: Mathematical and General 2003, 36, 10083. [Google Scholar] [CrossRef]
- Wei, L. Exact variance of von Neumann entanglement entropy over the Bures-Hall measure. Phys. Rev. E 2020, 102, 062128. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Wei, L. Second-order statistics of fermionic Gaussian states. Journal of Physics A: Mathematical and Theoretical 2022, 55, 105201. [Google Scholar] [CrossRef]
- Page, D.N. Average entropy of a subsystem. Phys. Rev. Lett. 1993, 71, 1291–1294. [Google Scholar] [CrossRef] [PubMed]
- Wei, L. Proof of Sarkar–Kumar’s conjectures on average entanglement entropies over the Bures–Hall ensemble. Journal of Physics A: Mathematical and Theoretical 2020, 53, 235203. [Google Scholar] [CrossRef]
- Bertola, M.; Gekhtman, M.; Szmigielski, J. Cauchy–Laguerre Two-Matrix Model and the Meijer-G Random Point Field. Communications in Mathematical Physics 2014, 326, 111–144. [Google Scholar] [CrossRef]
- Forrester, P.J.; Kieburg, M. Relating the Bures Measure to the Cauchy Two-Matrix Model. Communications in Mathematical Physics 2016, 342, 151–187. [Google Scholar] [CrossRef]
- Bertola, M.; Gekhtman, M.; Szmigielski, J. Cauchy–Laguerre Two-Matrix Model and the Meijer-G Random Point Field. Communications in Mathematical Physics 2012, 326, 111–144. [Google Scholar] [CrossRef]
- Prudnikov, A.; Brychkov, Y.; Marichev, O. Integrals and Series. Volume 3: More Special Functions.; 1989.
Figure 1.
Simulated distribution of when , .
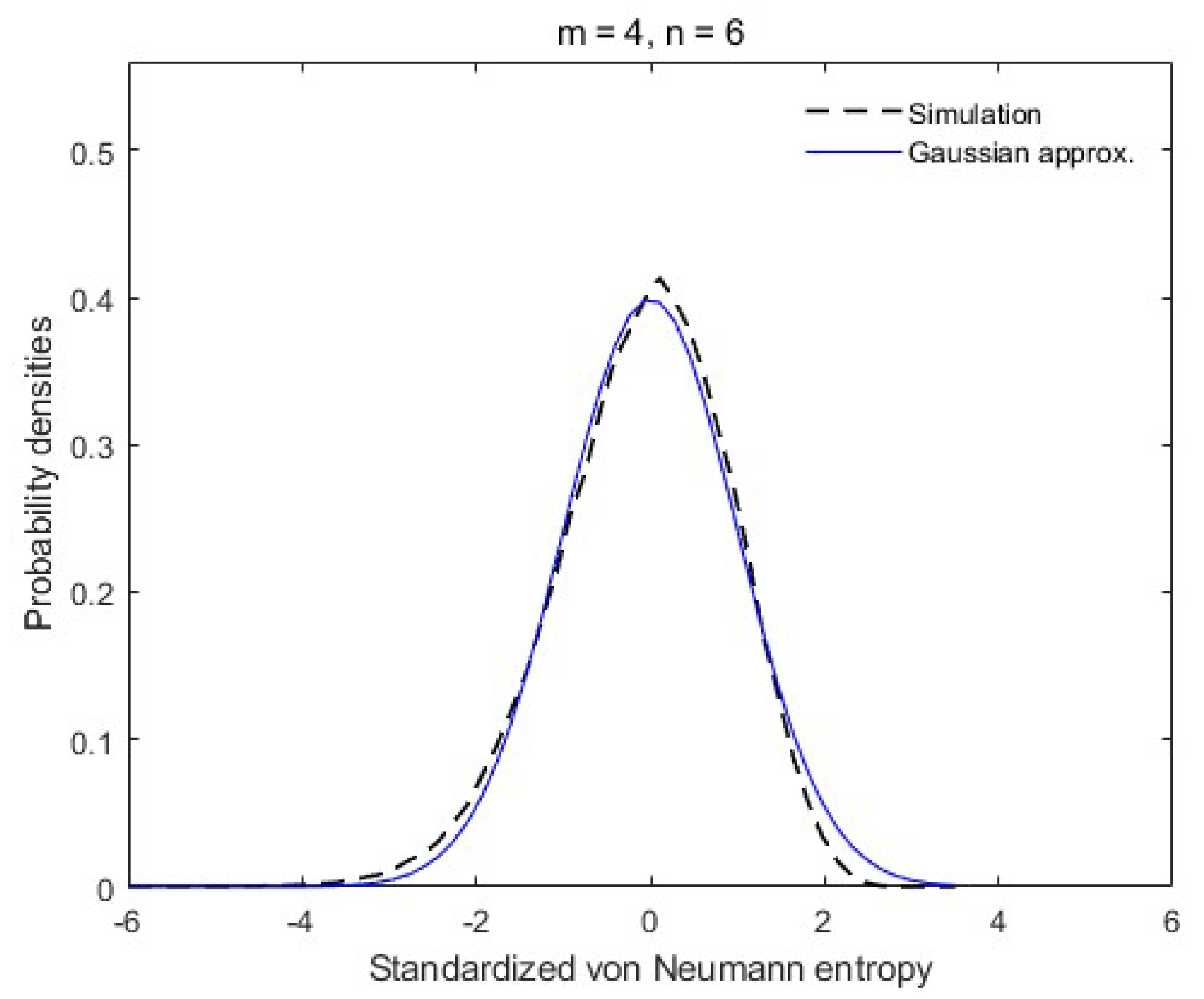
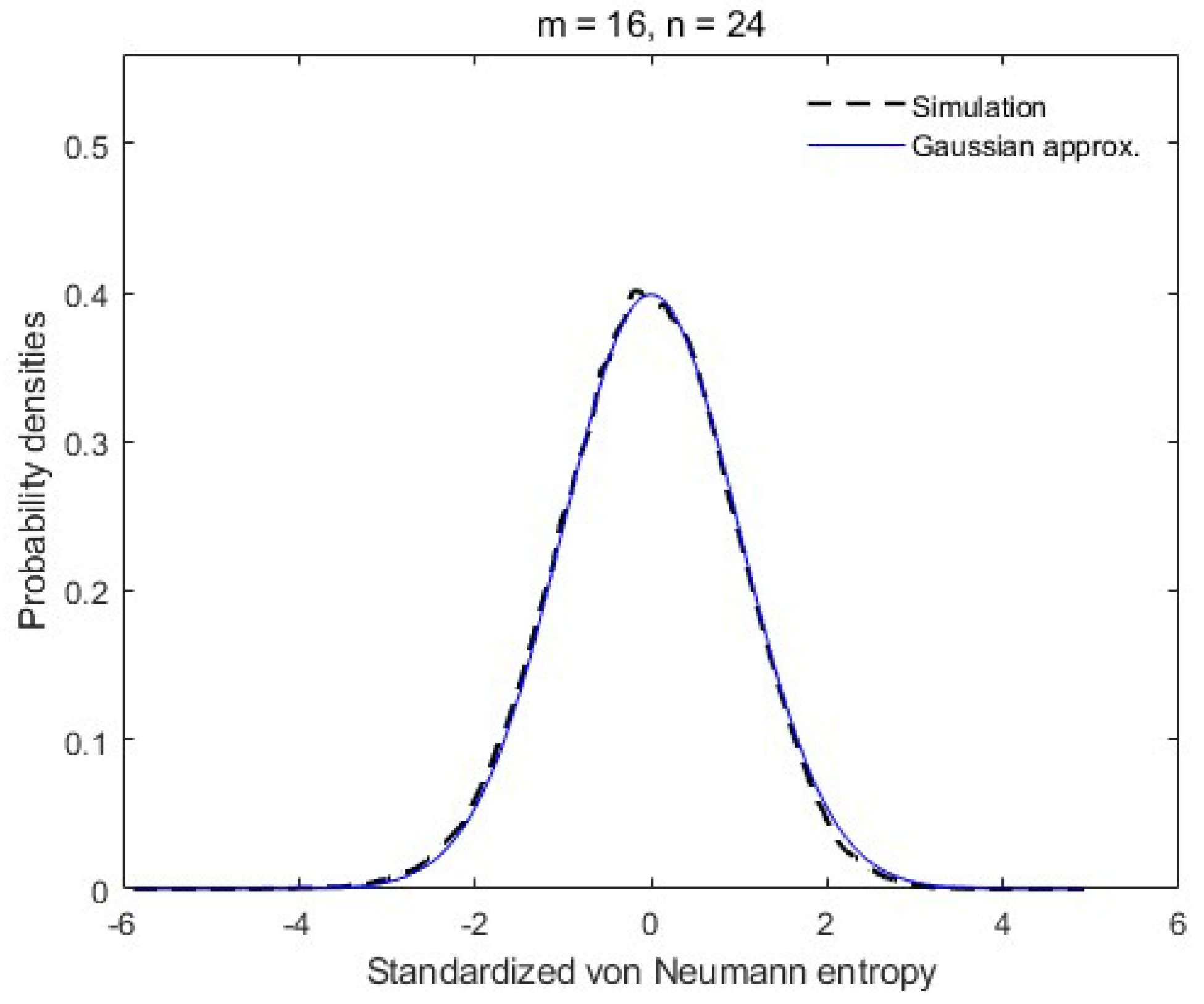
Figure 2.
Simulated distribution of when , .
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



