
Submitted:
31 August 2023
Posted:
31 August 2023
You are already at the latest version
Abstract
As a high-quality forestry product with excellent performance, particleboard is widely used in many fields and has great market potential. At present, it is a research difficulty to accurately identify small, fine and different shapes of defects on the whole particleboard through machine vision technology. The application of image super-resolution reconstruction technology on particleboard can improve the surface image quality of particleboard, which is conducive to the subsequent improvement of defect detection accuracy. In this study, super-resolution dense attention generative adversarial network (SRDAGAN) model was improved to solve the problem that super-resolution generative adversarial network (SRGAN) reconstructed image would produce artifacts and its performance needed to be improved. The Batch Normalization (BN) layer was removed, the convolutional block attention module (CBAM) was optimized to construct dense block, and the dense blocks were constructed by densely skip connection. Then, the corresponding 52400 image blocks with high resolution and low resolution were trained, verified and tested according to the ratio of 3:1:1. The model was comprehensively evaluated from the effect of image reconstruction and the two indexes of PSNR and SSIM. It was found that compared with BICUBIC and SRGAN, PSNR index of SRDAGAN increased by 4.88dB and 3.25dB respectively, and SSIM increased by 0.0507 and 0.1122 respectively. The reconstructed images not only had clearer texture, but also had more realistic expression of various features, and the performance of the model had been greatly improved. At the same time, this study also emphatically discussed on the image reconstruction effect with defects. The result showed that the SRDAGAN proposed in this study can complete the super-resolution reconstruction of particleboard images with high quality. In the future, it can also be further combined with defect detection for actual production to improve the quality of forestry products and increase economic benefits.
Keywords:
particleboard
; super-resolution reconstruction
; generate adversarial networks
; defect
1. Introduction
Particleboard is a kind of wood-based nonstructural composite manufactured using a compressed mixture of wood particles of various size and resin [1,2]. As an important forestry product, particleboard can greatly save forest resources, reduce deforestation and promote low-carbon development by reusing wood processing residues. Because the particleboard has the advantages of low price, easy processing, good sound insulation and thermal insulation [3,4], it is used in a variety of applications including furniture manufacture and construction [5]. According to IMARC Group [6], the global particleboard market size reached 22.2 Billion dollars in 2022, and is expected to achieve a compound annual growth rate of 3.7% in the next six years.
However, defects often appear on the surface of panels either from problems in manufacturing or handling, these include glue spots, sanding defects, staining (from oil or rust), indentations and scratches [7]. At present, many researchers use machine vision technology [8] to collect particleboard surface images and use intelligent defect detection instead of manual screening. Zhao et al. [9] used Ghost Bottleneck module, SELayer module and DWConv module to improve the You Only Look Once v5 (YOLOv5) model ,which obtained a lightweight model to detect particleboard defects. Then, this team [10] proposed a YOLO v5-Seg-Lab-4 model to detect particleboards defects. The results showed that Mean Average Precision of the model was 93.20%, and Mean Intersection over Union was 76.63%, which improved detection performance. Wang et al. [11] used an improved Capsule Network Model to solve the small sample classification problem of particleboards defects. The research on defect detection of particleboard has not been applied to enterprise production, and the defect detection of the whole particleboard still needs to be further explored.
In the actual production process, the size of the whole particleboard is 1220mm×2440mmm. The surface area of particleboard is large and the texture details are complex and diverse, while the surface defects of particleboard are mostly small in area, and some defects are only 10 sq. mm. When the whole particleboard is photographed with an industrial camera with a resolution of 2k, the 1mm has only 1-2 pixels, resulting in less image feature information, blurred defect contours and difficult to identify and detect. When using a more detailed camera, the cost of the enterprise investment will be greatly increased. Therefore, how to accurately identify the small, fine and different shapes of defects on the full particleboard has become a research difficulty. The application of image super-resolution reconstruction technology on particleboard can extract image detail features, improve the surface image quality of particleboard, which is of great significance to study the image information of particleboard and serve for subsequent defect detection.
Image super-resolution reconstruction is to reconstruct the low-resolution image into the corresponding high-resolution image through a specific algorithm to improve the image quality and make it closer to the actual situation. In the image reconstruction, the traditional interpolation algorithm will have the problems of blurred image edge and lack of feature information expression, so the reconstruction effect is not ideal. For this reason, many researchers used deep learning algorithms to complete image super-resolution reconstruction tasks, such as SRResnet, EDSR, EPSR, DBPN and other methods [12]. Dong et al. [13] proposed a three-layer convolution neural network algorithm SRCNN for super-resolution reconstruction, which is the first work of deep learning method in the field of super-resolution reconstruction. Ledig et al. [14] proposed a residual network structure, which is used to construct SRGAN. The ability of model reconstruction is improved by antagonistic training between generator and discriminator, which makes the image more real, but there are also artifacts. After that, Zhang et al [15] introduced channel attention module for super-resolution reconstruction for the first time, which solved the difficult problem of deep network training. Many researchers continue to explore SRGAN deeply. Xiong et al. [16] modified the loss function and network structure to apply it to remote sensing images to improve the stability of the model and reconstruction performance. In order to solve the problem that the reconstructed image is too smooth and the details are lost, Zhong et al. [17] introduced the residual channel attention module to reconstruct the infrared image of insulators through the improved SRGAN in order to better realize the classification of insulator defects. Liang et al. [18] proposed a SwinIR model to restore high-quality images, which consisted of shallow feature extraction, deep feature extraction and high-quality image reconstruction. SRGAN has good performance in many fields, and we can obtain more real images, but it has not been explored in the image of particleboard at present. This task has certain exploratory significance and broad prospects.
The main contributions of this study are as follows: (1) in order to solve the problem of artifacts generated by SRGAN and the reconstruction performance needs to be improved, we constructed SRDAGAN by optimizing it. We removed the BN layer, improved the CBAM to build dense block and used densely skip connection. After fully extracting image feature information, the network realized the artifact removal and improved the super-resolution reconstruction performance of the model. (2) the improved SRDAGAN was applied to the super-resolution reconstruction of the particleboard images, so that the research of particleboard was no longer a single defect detection in visual inspection. We further dug out the detailed information of the particleboard image, which was a very interesting and meaningful research task.
2. Materials and Methods
2.1. Image Acquisition
During the experiment, the surface image of particleboard is obtained by self-built image acquisition system, which is shown in Figure 1. The specific parameters of linear camera, lens, adapter ring and light source selected by the particleboard image acquisition system are shown in Table 1. In this experiment, the particleboard specimens provided by China Dare Wood Industrial (Jiangsu) Co., Ltd. were selected. The specific product parameters of the particleboards are shown in Table 2.
We put the particleboard specimens on the conveyor belt, set up the light source and adjusted the position of the camera so that the lens was 1100mm away from the surface of the particleboard, so that the whole particleboard could be photographed. Lighting was provided only through the linear light sources. A pair of photoelectric trigger switches was set up, and then the conveyor belt was turned on to transport the particleboards. The color linear camera received the trigger signal and started to collect the surface images of the particleboards line by line and save it. The camera completed the data transmission through the Gige interface, and finally obtained the RGB images of the whole particleboards [19].
2.2. Establishment of Dataset
The pixel size of the original images of particleboards was 8192×16800. The original images were preprocessed, the black edge was cut by threshold segmentation, and the tilt problem of particleboard caused by uneven placement was solved with the help of rectangular correction. Considering that too large images will increase the complexity of network computing and occupy more memory, all images were cut into image blocks with the size of 128 ×128 pixels. Then, the bicubic interpolation down-sampling method was used to obtain the corresponding low-resolution image blocks of particleboards, the proportional coefficient is ×4, that is, the low-resolution image blocks were the size of 32×32, and finally 52400 high-resolution and low-resolution image blocks were obtained. According to the proportion of 3:1:1, the training set, verification set and test set were divided, that is, the number of images in the training set was 31440, and the number of images in the verification set and test set was 10480 each.
In the established dataset, the particleboard image blocks contained big shavings, scratches, staining and other defects, and some of the particleboard image blocks are shown in Figure 2.
2.3. Improvement of Image Processing Algorithm
Traditional interpolation methods often have the problem that the edge information of the image is not clear and some details are smoothed when reconstructing the image. Therefore, this study adopted an improved SRGAN structure, which included two main parts: the generator and the discriminator. The algorithm flow is shown in Figure 3. The down-sampled low-resolution image was input into the trained generator to generate the super-resolution image , and then the generated super-resolution image and the corresponding high-resolution image were input into the discriminator at the same time. The result is between 0 and 1, and the closer the value is to 1, the higher the reality of the image restoration. In the process of generating adversarial network training, the model iteratively adjusted the parameters according to the discrimination situation. The parameters of the generator were adjusted and optimized if the judgment is correct, and the parameters of the discriminator were adjusted and optimized if the judgment is incorrect. The generator and the discriminator carried out adversarial learning, alternate training, and then improved performance. Finally, the super-resolution image generated by the generator was closer to the real image. The discriminant performance of the discriminator had also been greatly improved, which can accurately judge whether the image is correct [20].
In order to fully mine the features of the particleboard images and enhance the image expression, we proposed the SRDAGAN, which removed the Batch Normalization (BN) layers to improve the network reconstruction performance and reduce training time, designed an improved CBAM [21]. Fully mining the detailed features of the image and using dense jump connections enable the network to learn more high-frequency features.
2.3.1. Removed Batch Normalization
In the neural network structure, the BN layer mainly plays the role of normalization of data information, which speeds up the convergence of model training and reduces the dependence of the network on the initial value of data [22]. However, for the task of super-resolution reconstruction of particleboard images, there are many texture details on the surface image, and because there is a certain density deviation of particleboard products within the allowable range of technology, then there will inevitably be some differences in the feature information of different positions on the whole particleboard, and there will also be slight differences in the fineness and color characteristics of the particle fragments. This puts forward higher requirements for the ability of the network to extract information. When the image data is normalized by the BN layer, the same operation will be performed on the output of the upper layer, and the feature information in the image will be ignored to a certain extent, which greatly reduces the ability of the network to extract feature information, and the BN layer plays a limited role in the process of image super-resolution reconstruction.
Therefore, we removed the BN layer, on the one hand, it can greatly reduce the computational cost and improve the stability of the model, on the other hand, it can prevent it from smoothing the color, texture, contrast and other information in the image, and restrain the generation of artifacts. In addition, after reducing the BN layer, we can more easily design and improve the network structure, add attention modules to improve the performance of the model, and make the image reconstruction of particleboard more clear and real.
2.3.2. Improved Convolutional Block Attention Module
The attention module focuses on the specific information of the image with reference to human vision, and selectively extracts and processes the high-frequency information of this part. In this study, CBAM was optimized to extract the channel information and spatial information of the particleboard images at the same time, focusing on the details of the particleboard image. CBAM mainly included channel attention module (CAM) [23] and spatial attention module (SAM) [24]. In this study, CAM and SAM were built into a tandem structure in the order of before and after, as shown in Figure 4.
In the CAM structure part, only the spatial dimension information is compressed and the channel information of the feature image is fully extracted. When the input data is the feature image of C×H×W (C is the number of channels, H is the height of the image, and W is the width of the image), it is subjected to average pooling and maximum pooling [25] respectively, and then through the convolution layer [26] compresses the amount of channels C to the original 1/R (R takes 16), the activate function selects Relu, and then combines the two data to form a feature mapping in the form of addition [27]. Through a convolutional layer and a sigmoid layer, the feature mapping range is between 0 and 1, which enhances the expression of the high-frequency information and suppresses the expression of the useless information. The calculation equation is shown in equation (1), where and are weights, is sigmoid function. Then multiply the output result by the original image to get , so that the feature image returns to the size of C×H×W.
In the SAM structure part, only the channel dimension information is compressed and the spatial information of the feature image is fully extracted. The calculated input data was input into average pooling and maximum pooling, and the two data are combined in the form of concat to complete the splicing. The convolution with a size of 7×7 is used to reduce the dimension of the image to 1×H×W, and then the mapping is completed through a convolution layer and a sigmoid layer. The calculation equation is shown in equation (2), where represents a convolution operation with a size of 7×7. The output result is multiplied by the feature image to get , and the feature image returns to the size of C×H×W again.
CBAM can not only fully learn the channel and spatial information of the image and extract important features, but also as a lightweight attention module, it has less computation and strong general performance, so it can be better embedded in the neural network structure, and then improve the overall reconstruction performance of the model.
2.3.3. Construction of Generator
As shown in Figure 5(a), the common dense block consists of a BN layer, a convolution layer and a Relu layer, which has a large amount of computation and can not fully extract the details of the image [28]. As shown in Figure 5(b), an improved dense block was designed in this study. We combined a convolution layer, a Relu layer and a CBAM into a Bottleneck at the same time, and then connected the image features extracted from each layer to each layer after it through concat connection, and four Bottlenecks were connected to form a dense block. This method fully extracted the complex detail features of the particleboard surface, carried on the deep mining according to the particleboard image information, and played a better role in restoring.
As shown in Figure 6, in the generator of SRDAGAN, the low-resolution image block is input through the convolution layer, and the original size of each image block is 3×W×H. After the input of the convolution layer, the size becomes C×W×H. The information of the three channels of RGB in the particleboard image block is mapped to C channel components, and the low frequency features in the image are extracted.
Then n dense blocks (n takes 8) process the image data by densely skip connection, extract the high frequency features in the images, and let the neural network fully learn the color, texture and other feature information of the particleboard images. After the image is output by dense block, all the features are connected in series, resulting in a large amount of computation, so a convolution layer with the size of 1×1 is used to reduce the number of channels. The deconvolution layer is used to learn up-sampling and output a feature image with 256 channels. The reconstruction layer magnifies the image proportionally and outputs it to the output layer. The output layer consists of a convolution layer, which reduces the amount of channels of the feature image to 3, and finally outputs the super-resolution image .
2.3.4. Construction of Discriminator
In SRGAN structure, the discriminator of the standard GAN is used to distinguish the generated super-resolution image [29]. The closer the value is to 1, the closer the .is to the real high-resolution image , as shown in equation (3):
where is the evaluation value of the discriminant result, and is the output of the untransformed discriminator.
In this study, for the discriminator in SRDAGAN, we used the discriminator based on relative mean, as shown equation (4) and equation (5):
where the real high-resolution image and the reconstructed super-resolution image are respectively represented by and , and the mean value operation of the images in a small batch is represented by respectively.
2.3.5. Loss Function
In the super-resolution task, the loss function [30] provides guidance for model training by evaluating the difference between the super-resolution image of the model output and the original high- resolution image . The loss function of the model generator is the comprehensive loss function , as indicated by the equation (6):
where is the perceptual loss, is the generative adversarial loss, is the content loss, and λ and are the balance coefficients between each loss function .
The loss function LD of the model discriminator is shown in equation (7):
where and represent the mean value operation of all real high-resolution images and all reconstructed super-resolution images in a small batch, respectively.
3. Results
3.1. Evaluation index
In the task of super-resolution reconstruction of particleboard images, in order to accurately analyze the quality of the generated super-resolution images, we used three evaluation indexes: peak signal-to-noise ratio (PSNR) [31], structural similarity index measure (SSIM) [32], and learned perceptual image patch similarity (LPIPS) [33]. At the same time, using the three indexes to calculate can better analyze the image quality and objectively evaluate the super-resolution reconstruction performance of the model.
PSNR index is calculated based on the mean squared error (MSE) [34], which represents the ratio relation of the maximum pixel value MAX of the image to the MSE of the image. The higher the value, the higher the image quality. The quality evaluation is mainly based on the difference between image pixels, as shown in Equations (8) and (9):
SSIM evaluates the structural similarity between the reference image and the target image through the correlation of the parameters of each pixel in the image. SSIM comprehensively considers the mean value of luminance, the standard deviation of contrast and the covariance of the structure in the image to form the evaluation results. The value of SSIM is between 0 and 1. The closer the value is, the higher the quality of image reconstruction is. It mainly evaluates the degree of similarity between image pixels, which is more consistent with the sensory evaluation of human eyes, as shown in Equations (10), (11), (12) and (13).
where and are reference images and target images, , and are luminance, contrast and structure respectively, and represent the average value of and , and represent the standard deviation of and , represents the covariance of and , and and take constants.
LPIPS is used to measure the differences between two images, which can better evaluate the differences of perceptual quality. Input the generated image and the real image into L layers of convolutional neural network, extract the features through each layer, normalize them, calculate the L2 distance [35] after weighting the features of each layer, and finally get the LPIPS value by averaging. The smaller the value of LPIPS, the smaller the difference between the two images and the more realistic the generated image, as shown in equation (14).
where represents the distance between and , is the vector that reduces the number of active channels, and and represent the normalized image after the feature extraction of the l layer, respectively.
3.2. Experimental results
In this study, experiments were carried out under the same hardware and software conditions, and the specific parameters of the experimental configuration are shown in Table 4. We used Adam optimizer [36] to update the weight parameters of the network, the initial learning rate of the network was and the learning rate of every 50000 epoches was halved. The attenuation rate parameter was set to 0.9 and was set to 0.999. The feature weight was 1, the amount of feature image was 64 and the batchsize was set to 32, and the balance coefficients λ and of the discriminator are 5×10-3 and 1×10-2, respectively.
The images of the particleboards were input into the trained model for reconstruction, and the super-resolution images of the particleboards were obtained. In order to compare the details of the image restoration more clearly, we showed and compared the contrast images of the same part of the particleboard, as shown in Figure 7. From left to right are the images of the corresponding parts of LR, BICUBIC, SRGAN, SWINIR and SRDAGAN. Obviously, with the deepening of image information mining [37], the effect of super-resolution reconstruction was gradually improved, the texture details were richer, and the feature performance was more obvious. SRDAGAN can fully reflect some texture and color information which can not be well restored by BICUBIC, SRGAN and SWINIR. In order to study the impact of the improvement points in our study on the performance of the model, we take the ablation experiments to gradually modify the model and compare it on the evaluation indexes, as shown in Table 4 The average results of PSNR, SSIM and LPIPS evaluation on the test set are shown in Table 5.
From the perspective of image reconstruction effect, the quality of the particleboard image generated by the traditional BICUBIC was poor, and the characteristic information of the particleboard could not be well represented. The simple data processing method caused the image restoration details to be blurred and the texture was not clear enough, which could not meet the requirements of the particleboard reconstruction. Compared with the texture details of the particleboard image reconstructed by BICUBIC, the texture details of the particleboard image were better represented by SRGAN, the edges were sharper and more obvious, and the features of the images were better restored, but it inevitably produces artifacts, which will restrain the real information expression of the image itself and affect the image perception. From the point of view of human vision, the reconstruction quality still needed to be further improved. In this study, the images reconstructed by SRDAGAN made up for the shortcomings of the existing network structure, and efficiently reconstructed a variety of feature information such as the color, texture distribution and fineness of the particle fragments., while avoiding artifacts that reduced the image quality. At the same time, there were a few wood particles with great difference in color, and the SRDAGAN proposed in this study had a good ability to restore and characterize particle fragments of different colors, make differences obvious, and the sensory effect was better. In the comparison of the state-of-the-art method, although the SWINIR model can restore the feature information of the particleboard to a better extent, it is still not as good as the image restored by SRDAGAN. In this study, image information was fully mined by removing BN, improving CBAM, and using densely skip connection. After comparison, we found that the images reconstruct by SRDAGAN were more real and the details were clearer.
From the perspective of image evaluation index, when facing the PSNR index, BICUBIC was 25.83dB, the effect was not good. SRGAN improved 1.63dB than BICUBIC, image reconstruction had achieved a certain effect, and the restoration of pixel is more reasonable. Traditional BICUBIC obviously limited the ability to mine image feature information because of the simple processing and calculation. SRDAGAN method could achieved 30.71dB. Compared with BICUBIC, SRGAN and SWINIR, its PSNR index increased by 4.88dB, 3.25dB and 2.68dB, respectively. The details of each pixel of the particleboard images were better restored, the low frequency information could be preserved and repaired, and the high frequency information could be deeply mined.
When facing the SSIM index, BICUBIC, SRGAN, SWINIR and SRDAGAN were 0.6517, 0.7024, 0.7498 and 0.8146 respectively. SRGAN was 0.0507 higher than BICUBIC, although it was improved to a certain extent, but due to the existence of artifacts, there was still room for improvement in similarity with the real image. By improving the network structure, SRDAGAN fully extracted important information. Compared with the former three methods, SSIM was increased by 0.1629, 0.1122 and 0.0648 respectively, and the performance of the super-resolution reconstruction model was significantly improved. Due to the gradual optimization of data processing, the reconstructed images were more and more close to the real high-resolution images, and the differences caused by image reconstruction were getting smaller and smaller.
When facing the LPIPS index, BICUBIC, SRGAN, SWINIR and SRDAGAN were 0.4829, 0.3946, 0.3530 and 0.2881 respectively. Compared with the former three methods, our method has an advantage of 0.1948, 0.1065 and 0.0639. Compared with the unmodified SRGAN, the performance of the images restored by SRDAGAN had also been improved to a better extent, and the differences with the real images had been greatly reduced. LPIPS index further illustrated the excellent performance of SRDAGAN model.
4. Discussion
In the actual production process of the factory, the particleboards often appear small defects with various shapes, which affect the quality of the board [38]. Through super-resolution reconstruction of the particleboard images, we can explore its help for the subsequent defect detection. For the particleboard images with defective parts, we compared and analyzed and discussed its reconstruction in depth. The defects of particleboards were shown in Figure 8.
In Figure 8, from top to bottom are big shaving, handwriting, glue spot, staining, and scratch of particleboards, and from left to right are the images corresponding to LR, BICUBIC, SRGAN, SWINIR, SRDAGAN, and HR. By comparison, it was found that the reconstruction ability of traditional BICUBIC for various defects is obviously insufficient, and there was a problem that the reconstruction of defect contours was not clear and not sharp. SRGAN had been able to extract the contour features of each defect to a certain extent in image super-resolution reconstruction, and the edges of the reconstructed defect images were clearer and sharper, especially on the three defects of big shaving, handwriting and scratch, the contour details of defects performed better. However, this method had a shortcoming that could not be ignored. Due to the existence of the BN layer and the network structure, artifacts and image color information would be severely suppressed. The particleboard images reconstructed by the algorithm could not accurately restore the true color features. This would inevitably cause interference to the subsequent detection. During intelligent detection, it is very likely that glue spots will be recognized as dust spots and staining will be recognized as sand leakage, resulting in errors in particleboard detection and grading. For the state-of-the-art method SWINIR, the performance of this model had been improved, and the detail recovery was better. However, the contour reduction of big shavings, handwriting and scratches was still not clear enough, and the performance of the model needed to be further improved.
For the SRDAGAN algorithm proposed in this study, it better improved the shortcomings of SRGAN. This method could not only fully learn the defect details, but also improved the performance of the model through mutual training of the generator and the discriminator, and finally generate artifact-free and high-quality super-resolution images. At the same time, compared with other methods, when SRDAGAN reconstructed images, the color features, contour shapes, and information expressions of multiple defects had been significantly improved. Not only was the particleboard image reconstruction effect improved, but also the generated super-resolution images were closer to the real high-resolution images, and the defect features could be distinguished from the normal particle features, which can be further and better applied to actual engineering.
In terms of method innovation, the SRDAGAN method proposed in this study removed the BN layer, improved CBAM to form dense block, built a generator through densely skip connection, and combined the discriminator with the generative adversarial idea to achieve model improvement. From the experimental results, the SRDAGAN we proposed greatly enhanced the expressiveness and authenticity of super-resolution reconstructed images. Compared with the common methods and the state-of-the-art method, the performance of SRDAGAN had been improved to a better extent, and the performance was better. After removing the BN layer, it can correctly express the real color information and eliminate artifacts. The improved generator can mine and extract texture details, defect features and other information, and finally completed high quality image reconstruction. Moreover, by applying a suitable super-resolution method in the industrial detection process of particleboard products, a lower-resolution industrial camera can be selected for image acquisition, and super-resolution images can be obtained under the condition of reducing economic costs for defect detection, improving the level of intelligence in the forestry field.
5. Conclusions
In this study, aiming at the problems such as poor reconstruction effect of traditional interpolation methods, artifacts in SRGAN reconstruction images, and reconstruction performance to be improved, an improved SRDAGAN method was designed, which finally improved the super-resolution reconstruction image quality of particleboards and made images more clear and real.
Firstly, we acquired the surface images of the whole particleboards through the self-built image acquisition system, and then divided the training set, verification set and test set according to the ratio of 3:1:1 after image processing. Then, for the SRDAGAN model, BN layer was removed, CBAM was optimized to build dense block, dense blocks were formed into the generator by densely skip connection, and generator and discriminator were trained at the same time. Then, the particleboard images were input into the trained model for testing, and the performance of different algorithms was compared on the test set. The SRDAGAN proposed by our study has the best performance, with PSNR, SSIM and LPIPS reaching 30.71dB, 0.8146 and 0.2881 respectively. Compared with BICUBIC, it improved 4.88dB, 0.1629 and 0.1948. Compared with SRGAN, it improved 3.25dB, 0.1122 and 0.1065. Compared with SWINIR, it improved 2.68dB, 0.0648 and 0.0639. At the same time, from the perspective of image quality, the texture details, color features and other information of super-resolution reconstructed images were evaluated comprehensively, especially the reconstruction effect of particleboard images with defects was discussed. We found that SRDAGAN can overcome the problems of low quality and artifacts, and can generate high quality, clearer and more realistic particleboard super-resolution reconstructed images.
For further work, our team will expand the dataset to supplement the particleboard defect images such as soft and edge breakage, make the dataset more diverse, and verify the reconstruction performance of the model on images with other defects. At the same time, we will also combine super-resolution reconstruction algorithm and defect detection algorithm, use economical cameras to realize the defect detection of particleboard, and set up a super-resolution reconstruction detection system in line with the actual production to improve the quality of forestry products and increase economic benefits.
Author Contributions
Conceptualization, W.Y. and Y.L.; methodology, W.Y. and Y.L.; software, W.Y. and Y.L.; validation, W.Y., H.Z. and Y.L.; formal analysis, Y.Y. and Y.S.; investigation, W.Y; resources, Y.L.; data curation, Y.L.; writing—original draft preparation, W.Y.; writing—review and editing, Y.L.; visualization, Y.Y. and Y.S.; supervision, Y.L.; project administration, Y.L. and W.Y.; funding acquisition, Y.L. and W.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Postgraduate Research and Practice Innovation Program of Jiangsu Province ‘Research on Intelligent Detection System of Particleboard Surface Defects’, grant number SJCX23_0321, and Central Financial Forestry Science and Technology Promotion Demonstration Project 'Demonstration and Promotion of Key Technology of Particleboard Appearance Quality Inspection', grant number Su[2023]TG06. It was also funded by the 2019 Jiangsu Province Key Research and Development Plan by the Jiangsu Province Science and Technology, grant number BE2019112.
Data Availability Statement
The data are not publicly available because this study is still in progress with the company.
Acknowledgments
The authors would like to express their most sincere thanks for the support of experimental materials and consultation given by China Dare Wood Industrial (Jiangsu) Co., Ltd.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Baharuddina, M.N.M.; Zain, N.M.; Harunc, W.S.W.; Roslina, E.N.; Ghazali, F.A.; Som, S.N.M. Development and performance of particleboard from various types of organic waste and adhesives: A review. Int J Adhes Adhes 2023, 124. [Google Scholar] [CrossRef]
- Lee, S.H.; Lum, W.C.; Boon, J.G.; Kristak, L.; Antov, P.; Pedzik, M.; Rogozinski, T.; Taghiyari, H.R.; Lubis, M.A.R.; Fatriasari, W.; et al. Particleboard from agricultural biomass and recycled wood waste: a review. J Mater Res Technol 2022, 20, 4630–4658. [Google Scholar] [CrossRef]
- Ferrandez-Garcia, C.E.; Ferrandez-Garcia, A.; Ferrandez-Villena, M.; Hidalgo-Cordero, J.F.; Garcia-Ortuno, T.; Ferrandez-Garcia, M.T. Physical and Mechanical Properties of Particleboard Made from Palm Tree Prunings. Forests 2018, 9. [Google Scholar] [CrossRef]
- Copak, A.; Jirouš-Rajković, V.; Španić, N.; Miklečić, J. The Impact of Post-Manufacture Treatments on the Surface Characteristics Important for Finishing of OSB and Particleboard. Forests 2021, 12. [Google Scholar] [CrossRef]
- Owodunni, A.A.; Lamaming, J.; Hashim, R.; Taiwo, O.F.A.; Hussin, M.H.; Kassim, M.H.M.; Bustami, Y.; Sulaiman, O.; Amini, M.H.M.; Hiziroglu, S. Adhesive application on particleboard from natural fibers: A review. Polym Composite 2020, 41, 4448–4460. [Google Scholar] [CrossRef]
- Particle Board Market: Global Industry Trends, Share, Size, Growth, Opportunity and Forecast 2023-2028. Available online: https://www.imarcgroup.com/particle-board-market.
- Iswanto, A.H.; Sucipto, T.; Suta, T.F. Effect of Isocyanate Resin Level on Properties of Passion Fruit Hulls (PFH) Particleboard. Iop C Ser Earth Env 2019, 270. [Google Scholar] [CrossRef]
- Shu, Y.; Xiong, C.; Fan, S. Interactive design of intelligent machine vision based on human–computer interaction mode. Microprocessors and Microsystems 2020, 75. [Google Scholar] [CrossRef]
- Zhao, Z.; Yang, X.; Zhou, Y.; Sun, Q.; Ge, Z.; Liu, D. Real-time detection of particleboard surface defects based on improved YOLOV5 target detection. Scientific Reports 2021, 11. [Google Scholar] [CrossRef]
- Zhao, Z.; Ge, Z.; Jia, M.; Yang, X.; Ding, R.; Zhou, Y. A Particleboard Surface Defect Detection Method Research Based on the Deep Learning Algorithm. Sensors 2022, 22. [Google Scholar] [CrossRef]
- Wang, C.C.; Liu, Y.Q.; Wang, P.Y.; Lv, Y.L. Research on the Identification of Particleboard Surface Defects Based on Improved Capsule Network Model. Forests 2023, 14. [Google Scholar] [CrossRef]
- Ye, S.; Zhao, S.; Hu, Y.; Xie, C. Single-Image Super-Resolution Challenges: A Brief Review. Electronics 2023, 12, 2975. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.G.; He, K.M.; Tang, X.O. Learning a Deep Convolutional Network for Image Super-Resolution. Lect Notes Comput Sc 2014, 8692, 184–199. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.H.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. Proc Cvpr Ieee 2017, 105–114. [Google Scholar] [CrossRef]
- Zhang, Y.L.; Li, K.P.; Li, K.; Wang, L.C.; Zhong, B.N.; Fu, Y. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. Computer Vision - Eccv 2018, Pt Vii 2018, 11211, 294–310. [Google Scholar] [CrossRef]
- Xiong, Y.; Guo, S.; Chen, J.; Deng, X.; Sun, L.; Zheng, X.; Xu, W. Improved SRGAN for Remote Sensing Image Super-Resolution Across Locations and Sensors. Remote Sensing 2020, 12. [Google Scholar] [CrossRef]
- Zhong, Z.; Chen, Y.; Hou, S.; Wang, B.; Liu, Y.; Geng, J.; Fan, S.; Wang, D.; Zhang, X. Super-resolution reconstruction method of infrared images of composite insulators with abnormal heating based on improved SRGAN. IET Generation, Transmission & Distribution 2022, 16, 2063–2073. [Google Scholar] [CrossRef]
- Liang, J.Y.; Cao, J.Z.; Sun, G.L.; Zhang, K.; Van Gool, L.; Timofte, R. SwinIR: Image Restoration Using Swin Transformer. Ieee Int Conf Comp V 2021, 1833–1844. [Google Scholar] [CrossRef]
- Xie, W.; Wei, S.; Yang, D. Morphological measurement for carrot based on three-dimensional reconstruction with a ToF sensor. Postharvest Biology and Technology 2023, 197. [Google Scholar] [CrossRef]
- Çelik, G.; Talu, M.F. Resizing and cleaning of histopathological images using generative adversarial networks. Physica A: Statistical Mechanics and its Applications 2020, 554. [Google Scholar] [CrossRef]
- Woo, S.H.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. Computer Vision - Eccv 2018, Pt Vii 2018, 11211, 3–19. [Google Scholar] [CrossRef]
- Song, Y.; Li, J.W.; Hu, Z.Z.; Cheng, L.X. DBSAGAN: Dual Branch Split Attention Generative Adversarial Network for Super-Resolution Reconstruction in Remote Sensing Images. Ieee Geosci Remote S 2023, 20. [Google Scholar] [CrossRef]
- Zhang, W.; Ke, W.; Yang, D.; Sheng, H.; Xiong, Z. Light field super-resolution using complementary-view feature attention. Comput Vis Media 2023. [CrossRef]
- Liu, J.; Zhang, W.J.; Tang, Y.T.; Tang, J.; Wu, G.S. Residual Feature Aggregation Network for Image Super-Resolution. 2020 Ieee/Cvf Conference on Computer Vision and Pattern Recognition (Cvpr) 2020, 2356-2365. [CrossRef]
- Qian, H.; Zheng, J.C.; Wang, Y.S.; Jiang, D. Fatigue Life Prediction Method of Ceramic Matrix Composites Based on Artificial Neural Network. Appl Compos Mater 2023. [Google Scholar] [CrossRef]
- Jin, X.J.; McCullough, P.E.; Liu, T.; Yang, D.Y.; Zhu, W.P.; Chen, Y.; Yu, J.L. A smart sprayer for weed control in bermudagrass turf based on the herbicide weed control spectrum. Crop Prot 2023, 170. [Google Scholar] [CrossRef]
- Lu, E.M.; Hu, X.X. Image super-resolution via channel attention and spatial attention. Appl Intell 2022, 52, 2260–2268. [Google Scholar] [CrossRef]
- Brahimi, S.; Ben Aoun, N.; Benoit, A.; Lambert, P.; Ben Amar, C. Semantic segmentation using reinforced fully convolutional densenet with multiscale kernel. Multimed Tools Appl 2019, 78, 22077–22098. [Google Scholar] [CrossRef]
- Esmaeilpour, M.; Chaalia, N.; Abusitta, A.; Devailly, F.X.; Maazoun, W.; Cardinal, P. Bi-discriminator GAN for tabular data synthesis. Pattern Recogn Lett 2022, 159, 204–210. [Google Scholar] [CrossRef]
- Tohokantche, A.T.A.; Cao, W.M.; Mao, X.D.; Wu, S.; Wong, H.S.; Li, Q. alpha beta-GAN: Robust generative adversarial networks. Inform Sciences 2022, 593, 177–200. [Google Scholar] [CrossRef]
- Mohammad-Rahimi, H.; Vinayahalingam, S.; Mahmoudinia, E.; Soltani, P.; Berge, S.J.; Krois, J.; Schwendicke, F. Super-Resolution of Dental Panoramic Radiographs Using Deep Learning: A Pilot Study. Diagnostics 2023, 13. [Google Scholar] [CrossRef] [PubMed]
- Gourdeau, D.; Duchesne, S.; Archambault, L. On the proper use of structural similarity for the robust evaluation of medical image synthesis models. Med Phys 2022, 49, 2462–2474. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. 2018 Ieee/Cvf Conference on Computer Vision and Pattern Recognition (Cvpr) 2018, 586-595. [CrossRef]
- Li, Z.; Wang, D.; Zhu, T.; Ni, C.; Zhou, C. SCNet: A deep learning network framework for analyzing near-infrared spectroscopy using short-cut. Infrared Physics & Technology 2023, 132, 104731. [Google Scholar] [CrossRef]
- Xue, F.Y.; Zhou, M.; Zhang, C.J.; Shao, Y.H.; Wei, Y.P.; Wang, M.L. Rt-swinir: an improved digital wallchart image super-resolution with attention-based learned text loss. Visual Comput 2023. [CrossRef]
- Chang, Z.H.; Zhang, Y.; Chen, W.B. Electricity price prediction based on hybrid model of adam optimized LSTM neural network and wavelet transform. Energy 2019, 187. [Google Scholar] [CrossRef]
- Xie, C.; Tang, H.; Fei, L.; Zhu, H.; Hu, Y. IRNet: An Improved Zero-Shot Retinex Network for Low-Light Image Enhancement. Electronics 2023, 12. [Google Scholar] [CrossRef]
- Rofii, M.N.; Yumigeta, S.; Kojima, Y.; Suzuki, S. Utilization of High-density Raw Materials for PanelProduction and Its Performance. Procedia Environ Sci 2014, 20, 315–320. [Google Scholar] [CrossRef]
Figure 1.
Image acquisition system for particleboard.

Figure 2.
Particleboard image blocks: (a) without defects; (b) big shaving; (c) scratch; (d) staining.
Figure 2.
Particleboard image blocks: (a) without defects; (b) big shaving; (c) scratch; (d) staining.

Figure 3.
Algorithm flow.
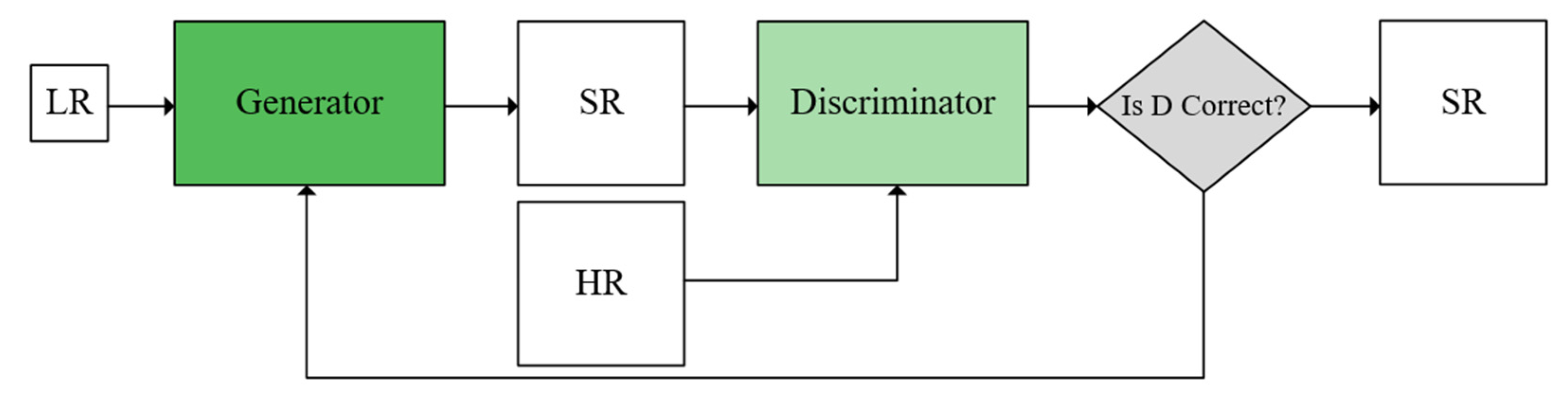
Figure 4.
Improved convolutional block attention module.
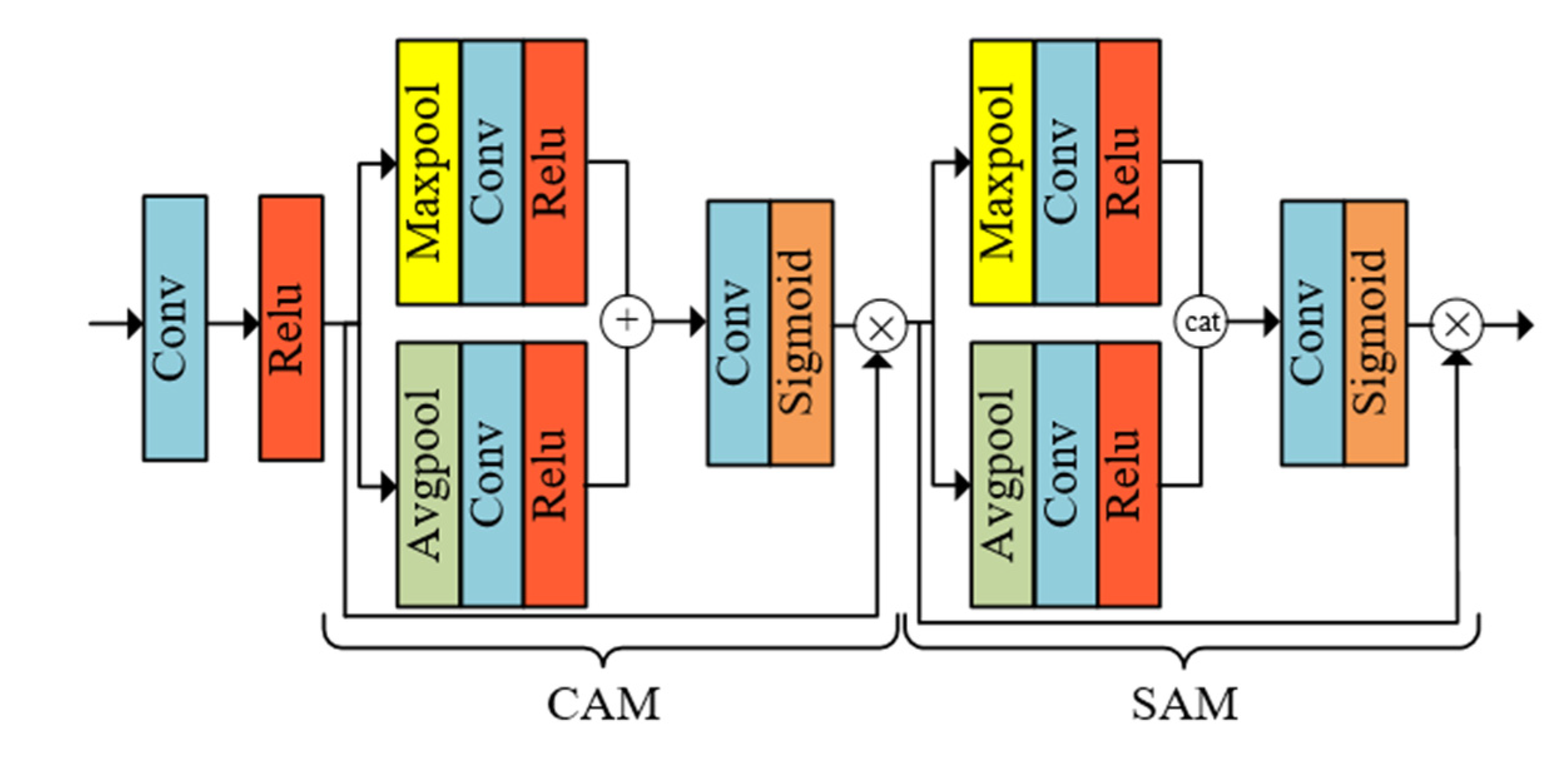
Figure 5.
Comparison of dense blocks: (a) common dense block; (b) improved dense block.
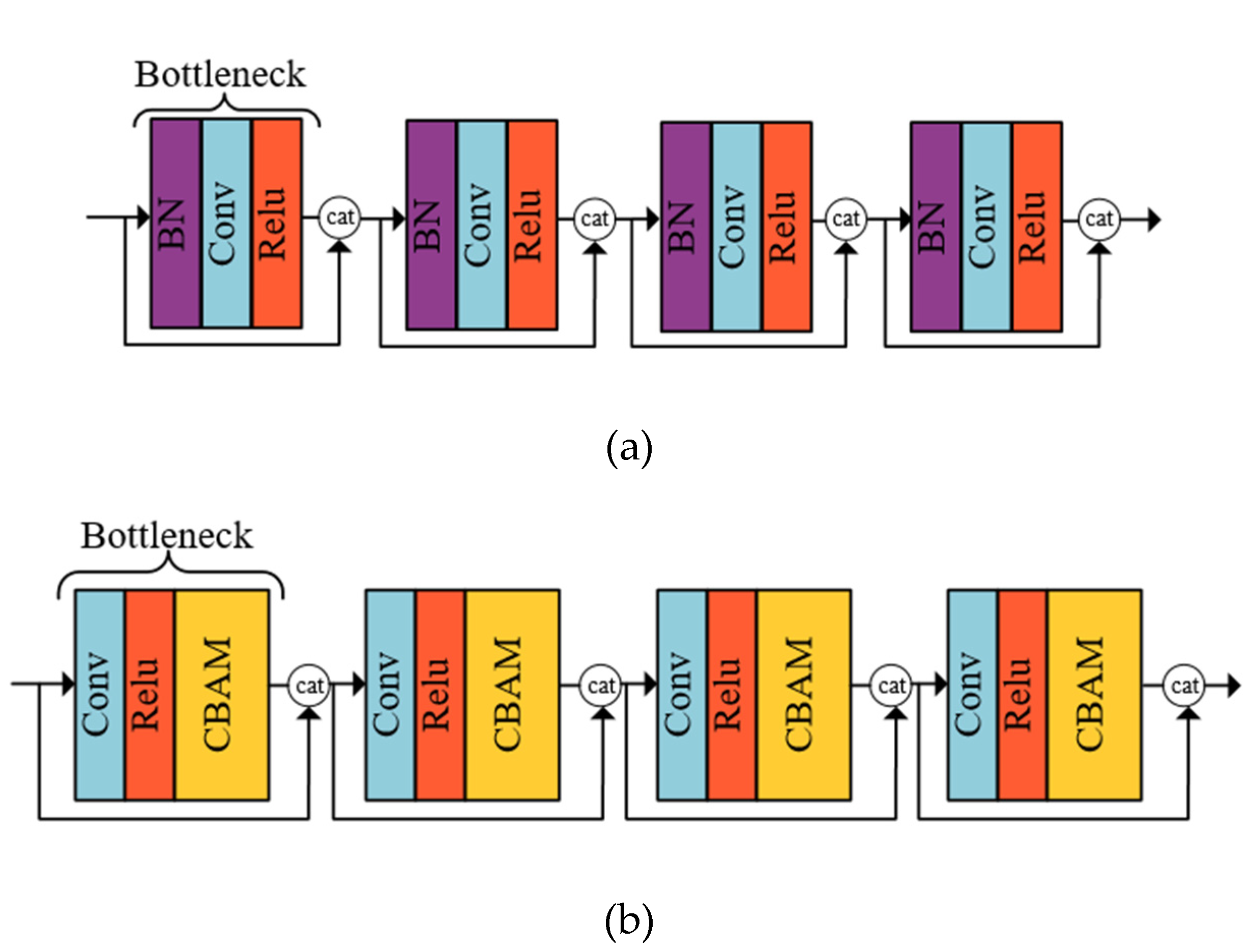
Figure 6.
Generator of SRDAGAN.
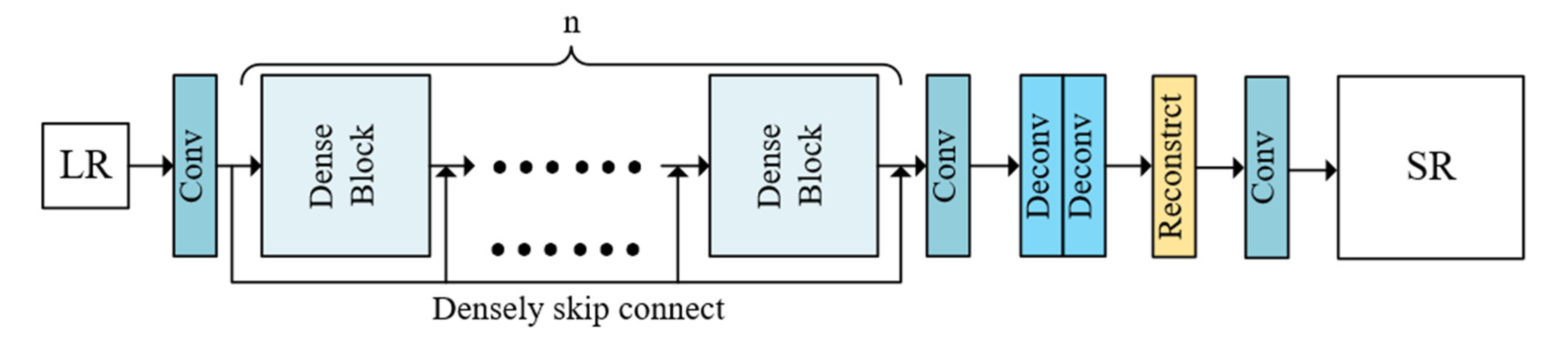
Figure 7.
Comparison of super-resolution reconstruction images of particleboards.

Figure 8.
Comparison of the reconstruction effect of particleboard images with defective parts.


Table 1.
Equipment parameters of image acquisition system.
| Device | Item | Parameter |
|---|---|---|
| Camera | Product Model | HIKROBOT MV-CL086-91GC |
| Resolution | 8192×6 pixel | |
| Pixel Size | 5µm | |
| Maximum Line Frequency | 4.7kHz | |
| Sensor Type | CMOS | |
| Spectrum | Color | |
| Exposure Time | 3μs-10ms | |
| Data Interface | Gige | |
| Lens | Product Model | LD21S01 |
| Focus Distance | 35mm±5% | |
| Aperture | F2.8-F16 | |
| Adapter ring | Product Model | M72-F T34.5 |
| Light Source | Product Model | HIKROBOT MV-LTHS-1300-W |
| Overall Dimension | 1370mm×58mm×90.1mm | |
| Type | Linear light source | |
| Power | 576W | |
| Color Temperature | 6000-7000K |
Table 2.
Particleboard product parameters.
| Item | Parameter |
|---|---|
| Size | 12200mm*24400mm*18mm |
| Raw Material Tree Species | Pine |
| Adhesive | Urea-formaldehyde resin |
| Density Deviation | <4% |
| Hot-pressing Temperature | 160-200℃ |
Table 3.
Experimental configuration parameters.
| Configuration Platform | Item | Parameter |
|---|---|---|
| Hardware Configuration | System | Windows 10 ×64 |
| CPU | Intel(R) Core(TM) I9 9900K@3.60 GHz | |
| GPU | NVIDIA GeForce RTX 2080 Ti | |
| Memory | KHX2666C16/16G×2 | |
| Software Configuration | IDE | PyCharm Community Edition |
| Programing Language | Python3.7 | |
| Computing Platform | CUDA10.1 | |
| GPU Accelerate library | CuDNN7604 |
Table 4.
Ablation experiments.
| Improvements and indexes | 1st | 2nd | 3rd | 4th |
|---|---|---|---|---|
| BN | √ | × | × | × |
| Improved CBAM | × | × | √ | √ |
| Densely skip connection | × | × | × | √ |
| PSNR(dB) ↑ | 27.46 | 28.12 | 29.66 | 30.71 |
| SSIM ↑ | 0.7024 | 0.7371 | 0.7832 | 0.8146 |
| LPIPS ↓ | 0.3946 | 0.3527 | 0.3035 | 0.2881 |
Table 5.
Evaluation index results of different algorithms.
| Algorithm | PSNR(dB) ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|
| BICUBIC | 25.83 | 0.6517 | 0.4829 |
| SRGAN | 27.46 | 0.7024 | 0.3946 |
| SWINIR | 28.03 | 0.7498 | 0.3530 |
| SRDAGAN | 30.71 | 0.8146 | 0.2881 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



