Submitted:
06 September 2023
Posted:
07 September 2023
You are already at the latest version
Abstract
The construction safety risks (such as landslides or slumps) of the high-fill subgrade are characterized by uncertainty and variability. In order to ensure the construction safety of the high-fill subgrade of the expressway, a comprehensive risk assessment model of high-fill subgrade construction according to the combination weighting method based on game theory was established. Firstly, settlement rate, lateral differential settlement, horizontal displacement at the foot of the slope, deep horizontal displacement, and excess pore pressure were selected as evaluation indicators, and an evaluation index system of high-fill subgrade was constructed. Secondly, the subjective and objective weights were obtained via the analytic hierarchy process and entropy method. Furthermore, the optimized weights were obtained by introducing game theory, and the construction risk of the high-fill subgrade was evaluated and analyzed using the fuzzy comprehensive evaluation method. Finally, based on the high-fill section of the Zhijiang-Tongren Expressway in Hunan Province (China), the evaluation model was validated through field measurement data. The results show that the safety scores obtained using the three methods of analytic hierarchy process, entropy method, and combination weighting method based on game theory are similar. The combination weighting evaluation model can correct the evaluation result error caused by a single weight and avoid information delay caused by the manual processing and analysis of monitoring data. The high-fill subgrade safety evaluation grade based on the combination weighting method and game theory is consistent with the engineering situation, and its fault tolerance range is within 20%. The evaluation model proposed in this study can scientifically and effectively evaluate the safety risks of high-fill subgrade construction, significantly improving the safety and reliability during the construction process.
Keywords:
subgrade engineering
; risk assessment
; game theory
; approximate comprehensive evaluation method
1. Introduction
Highway construction is often faced with various kinds of topography and geomorphology, especially in mountainous areas, which are characterized by high-fill subgrades and cut-and-fill subgrades. In this study, high-fill subgrades are defined as embankments with fill heights exceeding 20 meters. With the emergence of a large number of high-fill embankments, the settlement and stability control of high-fill embankments are particularly important. Improper treatment of high-fill subgrades will have a large impact on the road quality and driving comfort and may lead to engineering problems [1,2,3]. Therefore, monitoring subgrade engineering, through multiple means, is of the utmost importance for the ensured stability of these high-fill subgrades [4]. However, there is no unified standard method for safety risk assessment of high-fill subgrade, and different evaluation methods yield different conclusions, resulting in an unscientific classification of engineering risk levels. Moreover, since engineers need to measure and process data from the monitoring equipment, the monitoring reports are usually issued monthly, which may lead to a lag in the engineering safety assessment. The uncertainty of safety assessment for high-fill subgrade and the untimely detection data dramatically increase the risk probability during construction.
In the field of improving the reliability and real-time performance of engineering construction risk assessment, international research on engineering risk assessment is mainly carried out by combining qualitative and quantitative analysis methods, such as the grey system theory [5,6], cloud model [7,8], and the set pair analysis (SPA) method [9,10,11]. Zhang et al. used a fuzzy Bayesian network (FBN) and fuzzy analytic hierarchy process (FAHP) for the dynamic risk analysis of foundation pit collapse risks during construction [12]. It provided effective decision support for planners and engineers. Wang et al. proposed a combined method involving a rank-sum ratio (RSR), a criteria importance through intercriteria correlation (CRITIC), and a least squares support vector machine (LVSSM) to establish a traffic safety risk index system and a risk assessment model of ordinary arterial highways [13]. Gebrehiwet et al. presented an approach for evaluating the risks in the case of schedule delays by using the similarity to the ideal solution (TOPSIS) and fuzzy synthetic evaluation of the various lifecycles of the construction projects [14].
Furthermore, Yu et al. proposed a comprehensive evaluation method that was based on the improved entropy–TOPSIS method [15]. Li et al. used the cloud entropy weight method and cloud model theory to conduct a risk assessment, and the cloud model images were able to directly determine the overall risk level of the bridge construction and the level of risk indicators [16]. Alawad et al. used computer vision and pattern recognition to perform risk management in railway systems, in which a convolutional neural network (CNN) was applied as a supervised machine learning model to identify risks [17]. Isah et al. presented a neural network approach by developing a deep neural network (DNN) model for assessing the risk impact on the project schedule and cost performance of road projects [18]. Lai et al. used an assessment model that was based on the fuzzy comprehensive evaluation (FCE) method to evaluate the flood risks in the Dongjiang River Basin. A combination of subjective weights and objective weights, which were based on game theory [19], was then used. This assessment model has, since then, been gradually used for risk assessment in various fields [20,21]. Islam et al. and Hegde et al. summarized current research trends and application areas of fuzzy and hybrid methods and machine learning methods to engineering risk assessment [22,23]. It is easy to find that game theory and fuzzy comprehensive evaluation methods are increasingly widely used in engineering risk assessment and have achieved excellent assessment results.
In addition, uncertainty is expected in high-fill subgrade engineering, and technical personnel will encounter uncertainty at all stages of the engineering, such as poor site selection or unexposed weaknesses in geology; insufficient investigation of site material characteristics; the parameter values to be determined are unclear; the accuracy of important numerical values obtained through analysis will have an impact on the stability and construction safety of high-fill subgrade. During the construction of the high-fill subgrade, the data of various monitoring projects can characterize the stability impact of the high-fill subgrade. Therefore, selecting detection indicators is crucial for the risk assessment of subgrade construction. Currently, the evaluation index system, which has been established in most of the subgrade risk assessment studies, usually takes the geometry of the subgrade, construction process, and soil conditions as the evaluation factors for the subgrade stability [24,25,26]. Taskiran T examined the influence of rainfall, hydraulic conductivity, and slope inclination on the stability of unsaturated soil slopes during rainy seasons, highlighting the factors contributing to slope instabilities [27]. Wu D et al. proposed a three-dimensional limit analysis method considering pore water pressures and nonlinear strength envelope for slope stability evaluation, highlighting their importance in slope engineering design and landslide prevention[28]. Li Z et al. examined the impact of lateral deformation on subgrade settlement and introduces a revised model that incorporates lateral strain, highlighting the significance of accounting for lateral deformation in settlement analysis [29]. K. Raja et al. analyzed the relationship between soil properties, subgrade strength, and settlement characteristics. Soil samples from the Kangeyam block in the southern region were tested, and their properties were evaluated. The results were mapped using GIS for assessing safety and future considerations of subgrade qualities [30]. However, most of these evaluation models are not suitable for the evaluation of the dynamic changes in subgrade stability during subgrade construction, which are generated by the surrounding environment, climate, etc.
The purpose of this study is to propose a scientifically reliable method for evaluating the safety risks of subgrade construction. First, the settlement rate, lateral differential settlement, horizontal displacement at the foot of the slope, deep horizontal displacement, and excess pore pressure were combined to employ an index evaluation system. Second, a comprehensive evaluation model was established based on the game theory combination of the analytic hierarchy process and entropy method. Third, taking the Zhitong Expressway in Hunan Province as an example, the monitoring data of the project were calculated to derive the corresponding evaluation results. Finally, based on the result scores, stability analysis of the model was conducted to prove the model’s validity and the error tolerance range.
2. Construction of a Risk Assessment Index System for High-Fill Subgrade Constructions
The deformation monitoring and stress monitoring of a high-fill subgrade are important means to ensure the subgrade stability and driving safety. During the construction of a high-fill subgrade, the influencing factors for the subgrade stability are directly shown by various types of monitoring data. According to the principles of scientificity, systematicity, independence, and comparability, combined with the monitoring items and indexes of high-fill subgrade engineering, five evaluation factors were selected here to establish an evaluation factor set: U = {u1, u2, u3, u4, u5} (as shown in Figure 1).
Figure 1.
Risk assessment index of a high-fill subgrade construction.
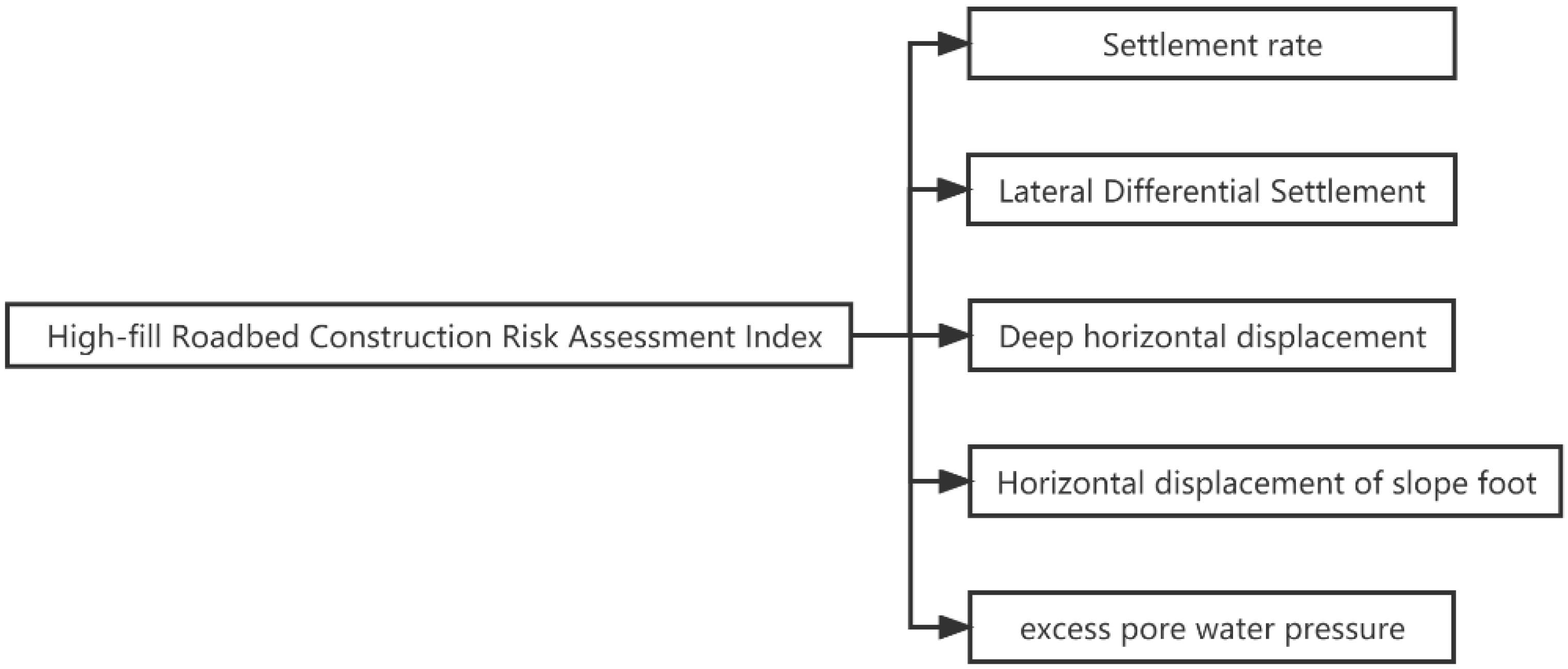
According to the “Guideline for safety risk assessment of highway and waterway engineering construction” (JT/T 1375.1-2022), the high-fill subgrade construction risks are divided into four levels: level I (safe), level II (relatively safe), level III (less safe), and level IV (unsafe). The monitoring warning value can be classified into different warning levels according to 70%, 85%, and 100% of the maximum allowable control value. According to the specifications and earlier research and summaries on various control indexes, the index intervals of various evaluation indexes and risk levels were constructed after a comprehensive analysis (as shown in Table 1 and Table 2). In addition, the index requirements for high-fill subgrades of the reference specification in this study apply to non-specialized soil high-fill subgrades and high-fill subgrades on soft soil foundations.

Table 1.
Risk level evaluation standards for high-fill subgrade constructions.
| Index | Meaning | Monitoring alert value |
|---|---|---|
| u1 | Settlement rate (mm/d) |
According to the “Technical Guidelines for Design and Construction of Highway Embankment on Soft Ground” (JTG/T D31-02-2013), the alert value of the settlement on the top surface of the fill layer should be set to 10 mm/d. |
| u2 | Lateral differential settlement (cm) | According to references [31] and [32], the maximum allowable horizontal differential settlement should be set to 7 cm. |
| u3 | Deep horizontal displacement | According to the inflection point method proposed by “Standard for Monitoring of Subgrade on Soft Ground” (GB/T 51275-2017), a danger warning is required when the displacement curve has an inflection point, and the slope after the inflection point is larger than twice the slope before the inflection point. |
| u4 | Horizontal displacement of the slope foot (mm/d) | According to the “Technical Specification for Monitoring of Highway Subgrades” (DB45/T 2364-2021), the alert value of the horizontal displacement of the slope foot should be set to 5 mm/d. |
| u5 | Excess pore water pressure (%) | According to the “Specification for Pore Pressure Measurement” (CECS55-93) and the “Code for Investigation of Geotechnical Engineering” (GB 50021-2001), the maximum allowable value of excess pore water pressure should be set to 0.6 times the overlying effective stress. Also, the index should be set to the ratio of excess pore water pressure to the maximum allowable value of excess pore water pressure at the corresponding monitoring position. |
Table 2.
Index ranges of each risk level for evaluation indicators.
| Risk Index | Risk Level | |||
|---|---|---|---|---|
| I | II | III | IV | |
| u1 (mm/d) | ≤7 | (7, 8.5] | (8.5, 10] | >10 |
| u2 (cm) | ≤3 | (3, 5] | (5, 7] | >7 |
| u3 (times) | ≤1.4 | (1.4, 1.7] | (1.7, 2] | >2 |
| u4 (mm/d) | ≤3.5 | (3.5, 4.25] | (4.25, 5] | >5 |
| u5 (%) | ≤0.7 | (0.7, 0.85] | (0.85, 1] | >1 |
3. Comprehensive Risk Evaluation Model Based on the Combination weighting method based on game theory
3.1. Combination weighting method based on game theory
1. Weighting with the AHP method
The AHP method required multiple experts to compare and assess the importance degree of the evaluation indexes by virtue of their academic research and engineering experience. The subjective weight can be determined after concluding consultations and after the result has passed the consistency check. For the AHP method, the calculation steps were as follows:
Step 1: The reciprocal 1-9 scale method [33] was used to determine the quantitative scale for each pair of indexes (as shown in Table 3). The scales 2, 4, 6, and 8 indicated the corresponding importance of the relative scale. The reciprocal of these values indicated the opposite importance (i.e., j was more important than i), and it was possible to construct the judgment matrix A=(aij)n×n, where aij is the importance of the index pairs and n is the total number of indexes.
Table 3.
Relationship between scales and meanings.
| Scales | Meanings |
|---|---|
| 1 | i is as important as j |
| 3 | i is slightly more important than j |
| 5 | i is more important than j |
| 7 | i is even more important than j |
| 9 | i is really more important than j |
Step 2: The product normalization was adopted to obtain the weight vector wj, where is the proportion of weights for the j-th indexes and n is the number of indexes:
Step 3: The λmax (judgment matrix eigenvalue), (consistency index), and CR (random consistency ratio) were calculated and determined, and the consistency of the judgment matrix was acceptable for CR < 0.1.
2. The entropy method
According to the influence of the degree of relative change in each index on the system as a whole, the entropy method was a way to determine the index weight coefficient by calculating the information entropy of the observed value of each index. Furthermore, according to the characteristics of the monitoring index data, the high-fill embankments of the Zhijiang-Tongren expressway were divided into several sections, which were used as different sample data. Based on the entropy method, the process of calculations was as follows:
Step 1: The dimensionless treatment of the data matrix of each monitoring index of high-fill subgrade was carried out. It was assumed that there were m objects to be evaluated with n evaluation indexes, and the data matrix was transformed into a standardized matrix B=(bij) m×n.
Step 2: The entropy, ej, of index j at the i-th section was, thereafter, calculated:
where the characteristic specific gravity .
Step 3: The weight, w , of each index was then calculated:
3. Optimized combination weighting method based on game theory
The optimized weighting game theory is a method in which the Nash equilibrium is used as the synergistic target in looking for similarities and achieving an average of each weight. That is, one has to look for the vectors that differ the least from the vectors of each basic index weight [34,35]. The combination weighting steps that were based on game theory are as follows:
Step 1: Under the assumption that the k groups of the weight vectors can be obtained by using k subjective and objective weighting methods, the basic weight vectors can be expressed as wk={wk1, wk2, , wkn}, where n denotes the number of indicators and k is the number of different assignment methods. In this paper, k=2. The random linear combination of z groups of weight vectors is as follows:
where ak* is the linear combination coefficient of the k-th weight, and w* is the comprehensive weight vector of the k weight vectors wk.
Step 2: The linear combination weight coefficient was optimized according to the synergistic targets of the Nash equilibrium in achieving the minimum deviation among each group of weights, so as to obtain the optimal combination weight. The model could be deduced as follows:
where ak is the weight coefficient; wkT is the transpose matrix of the basic weight vector set.
It could be obtained from the differential properties of the matrix, and the optimized first derivative condition of the above equation was as follows:
Its corresponding linear system of equations could be expressed as follows:
Step 3: The linear combination coefficient ak* could be obtained according to the above equations, and the linear coefficient was obtained as follows through normalization of the results:
The optimal combination weight, w*, was then finally obtained.
3.2. Establishment of a comprehensive risk evaluation model for the construction of a high-fill subgrade
The fuzzy comprehensive analysis method is often used to evaluate the engineering risks during the risk evaluation practice of engineering projects [36,37]. The reason is that it comprehensively considers the influence degree of all risk factors on risk events, describing the importance degree of each risk factor by adopting optimized weight game theory. It calculates various risk probabilities based on the constructed mathematical model. In the present study, the steps for the method are as follows:
Step 1: The fuzzy comment set V was determined. The fuzzy comment set was a collection of various evaluation results of risk factors. It was determined as V={v1, v2, v3, v4}= (level I, level II, level III, level IV). There were, thus, four risk levels.
Step 2: The fuzzy membership matrix was, thereafter, determined. According to the approximate evaluation index set U and comment set V (that were well established), n was set as the number of U elements in the index set, and m was set as the number of V elements in the comment set. Since the approximate evaluation elements were interval values, a trapezoidal membership function could be adopted (as shown in Table 4). According to the data characteristics of each monitoring item of a high-fill subgrade, the comprehensive membership matrix of a certain road section was calculated as R= (rij)n×m.
Table 4.
Expression of ladder membership functions.
| Type of function | Partial small membership function | Intermediate type membership function | Partial large membership function |
|---|---|---|---|
| Trapezoidal membership function |
Step 3: A comprehensive evaluation was then conducted. The weight of the evaluation factors was set to w*, which was a comprehensive weight value based on game theory. The approximate comprehensive evaluation result B was obtained as follows:
where ∘ is the approximate synthesis operator, which is the weighted average from which (M(∙, ⊕)) was selected; Ri is the fuzzy evaluation matrix of the i-th road section; and rinm is denoted as the affiliation of the n-th indicator of the i-th road section at the m-th risk level.
The analysis was mainly conducted by adopting the maximum membership principle. This means that the risk level that corresponds to the maximum value in the integrated affiliation matrix B was used as the risk assessment result of the evaluated object. The comprehensive evaluation result of the construction risk at the i-th section of high-fill subgrade was:
4. Case Study
Section 5 of the Zhijiang-Tongren expressway was monitored with each monitoring unit from October 2020 to September 2022, and the high-fill subgrade of this section was divided into three subsections (L1, L2, and L3) according to the construction risk evaluation index system of high-fill subgrade.
4.1. Data selection and processing
The monitoring equipment (including the settlement plate, inclinometer tube, side pile, and pore water pressure gauge) was used to monitor the data of each index (Figure 1), and the equipment was buried, as shown in Figure 2. To better evaluate the stability of the high-fill subgrade, the worst index value in the past monitoring data was adopted according to the most unfavorable principle for the single index monitoring of a certain road section. The corresponding index value was obtained by calculating and processing the original monitoring data of the equipment (as shown in Table 6).
Figure 2.
Schematic diagram of the buried position of the monitoring equipment.
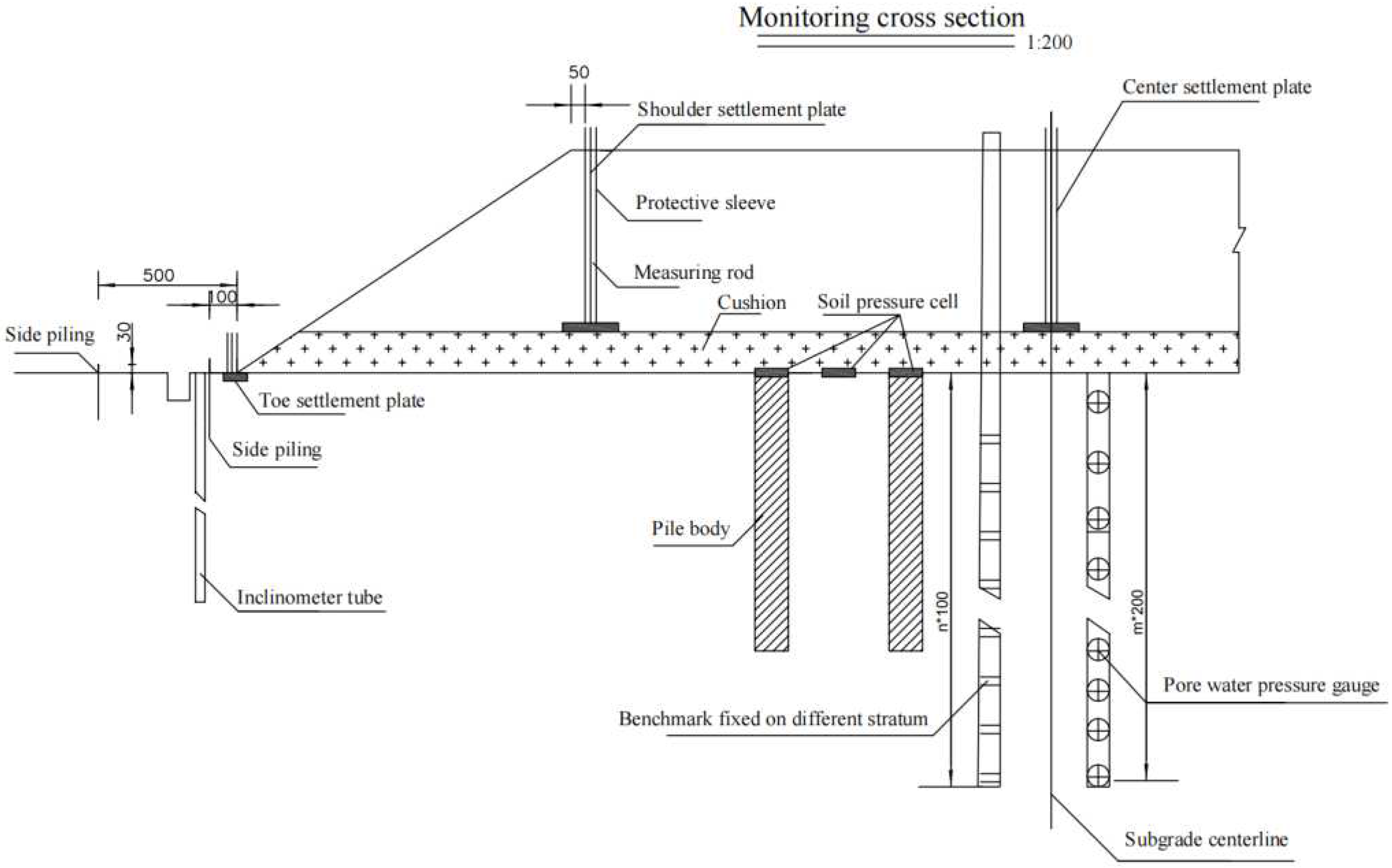
Table 5.
Breakdown of effective measurement points for high fill roadbed monitoring.
| Road section | Construction stake number | Shoulder settlement plate | Central settlement plate | Inclino-meter | Border Pile | Vibrating wire piezometer | Earth pressure cell |
|---|---|---|---|---|---|---|---|
| L1 | K27+060~ K27+707 |
4 | 2 | 3 | 3 | 3 | 3 |
| L2 | ZK31+730~ ZK31+810 |
4 | 2 | 3 | 3 | 3 | 3 |
| L3 | ZK31+830~ ZK32+100 |
4 | 2 | 2 | 3 | 3 | 3 |
Table 6.
Sampled data of evaluation indexes for the Zhitong Expressway.
| Road section |
u1 (mm/d) |
u2 (cm) |
u3 |
u4 (mm/d) |
u5 (%) |
|---|---|---|---|---|---|
| L1 | 4.333 | 6.47 | 1.9 | 0.500 | 0.541 |
| L2 | 0.717 | 2.21 | 1.5 | 0.428 | 0.560 |
| L3 | 2.667 | 3.37 | 1.6 | 0.571 | 0.209 |
It could be analyzed and concluded from Table 6 that the sedimentation rate, lateral differential settlement, and deep horizontal displacement of L1 were the highest, while all indexes of L2 were the lowest, with the exception of the excess pore water pressure. It could also be seen from the risk level classification of the evaluation indexes that the original values of each index in the above table belonged to the minimization indexes and did not have to be made consistent. Since each index unit and evaluation scale differed, the proportional transformation method was adopted to carry out a dimensionless treatment of the original index data (as shown in eq. 12).
where is the original data of the j-th index at the i-th road section, and is the data after a dimensionless treatment of the original data. After that, the data in Table 6 were substituted into and , and the standardized matrix M was obtained as follows:
Table 7.
Value of the standardized matrix M.
| Road section | u1 | u2 | u3 | u4 | u5 |
|---|---|---|---|---|---|
| L1 | 0.165 | 0.342 | 0.789 | 0.856 | 0.386 |
| L2 | 1 | 1 | 1 | 1 | 0.373 |
| L3 | 0.269 | 0.656 | 0.938 | 0.750 | 1 |
4.2. Establishment of optimized combination weights
To evaluate the importance of the monitoring indexes of high-fill subgrades, 14 experts and engineers in the field of road engineering were invited to grade the importance of each indicator. Thus, 10 of the 14 experts and engineers had intermediate and higher-level titles, which ensured the authority of the survey results. In the research study, the questionnaire format was used to collect data, which used a Likert five-scale method to rate each monitoring indicator to assess its importance to the safety of high-fill subgrade. The experts rated each indicator on a scale of 1-5 depending on their academic experience. Higher scores represent a higher level of importance of the indicator to the stability of high-fill roadbeds.
SPSS (Statistical Product Service Solutions) were used to test the reliability of the survey data. After completing the questionnaire data collection, the validity and reliability tests of the questionnaire results from 14 experts were considered to ensure the reliability and validity of the data. According to the results of the validity test, the KMO (Kaiser–Meyer–Olkin) is 0.702, which is greater than 0.7, indicating that the validity of the data in this study is better and, therefore, suitable information to extract. Bartlett’s spherical test p-value is 0.001, which is less than 0.05, indicating that the data form the questionnaire passed the validity test. According to the results of the reliability test, the corresponding Cronbach Alpha coefficient was 0.809, and the CITC (corrected item-total correlation) values were 0.546, 0.819, 0.494, 0.579, and 0.618; all the CITC values were greater than 0.3, which indicated that the data in this study were reliable, with a high degree of credibility and validity.
Furthermore, it was shown that the high-fill subgrade construction risk index system, which was established in the present study, is reasonable. The average score of each indicator was calculated based on the score of each indicator of the questionnaire, and then the judgment matrix was obtained based on the average score of each indicator, as shown in Table 8 and Table 9.
Table 8.
Evaluation of assessment indexes by experts.
| Risk Index | u1 | u2 | u3 | u4 | u5 |
|---|---|---|---|---|---|
| Mean | 3.571 | 2.571 | 3.071 | 3.714 | 2.429 |
The index judgment matrix A that was constructed using the 1-9 scale method is as follows:
Table 9.
Value of the index judgment matrix A.
| A | u1 | u2 | u3 | u4 | u5 |
| u1 | 1 | 3 | 2 | 1/2 | 4 |
| u2 | 1/3 | 1 | 1/2 | 1/4 | 2 |
| u3 | 1/2 | 2 | 1 | 1/3 | 3 |
| u4 | 2 | 4 | 3 | 1 | 5 |
| u5 | 1/4 | 1/2 | 1/3 | 1/5 | 1 |
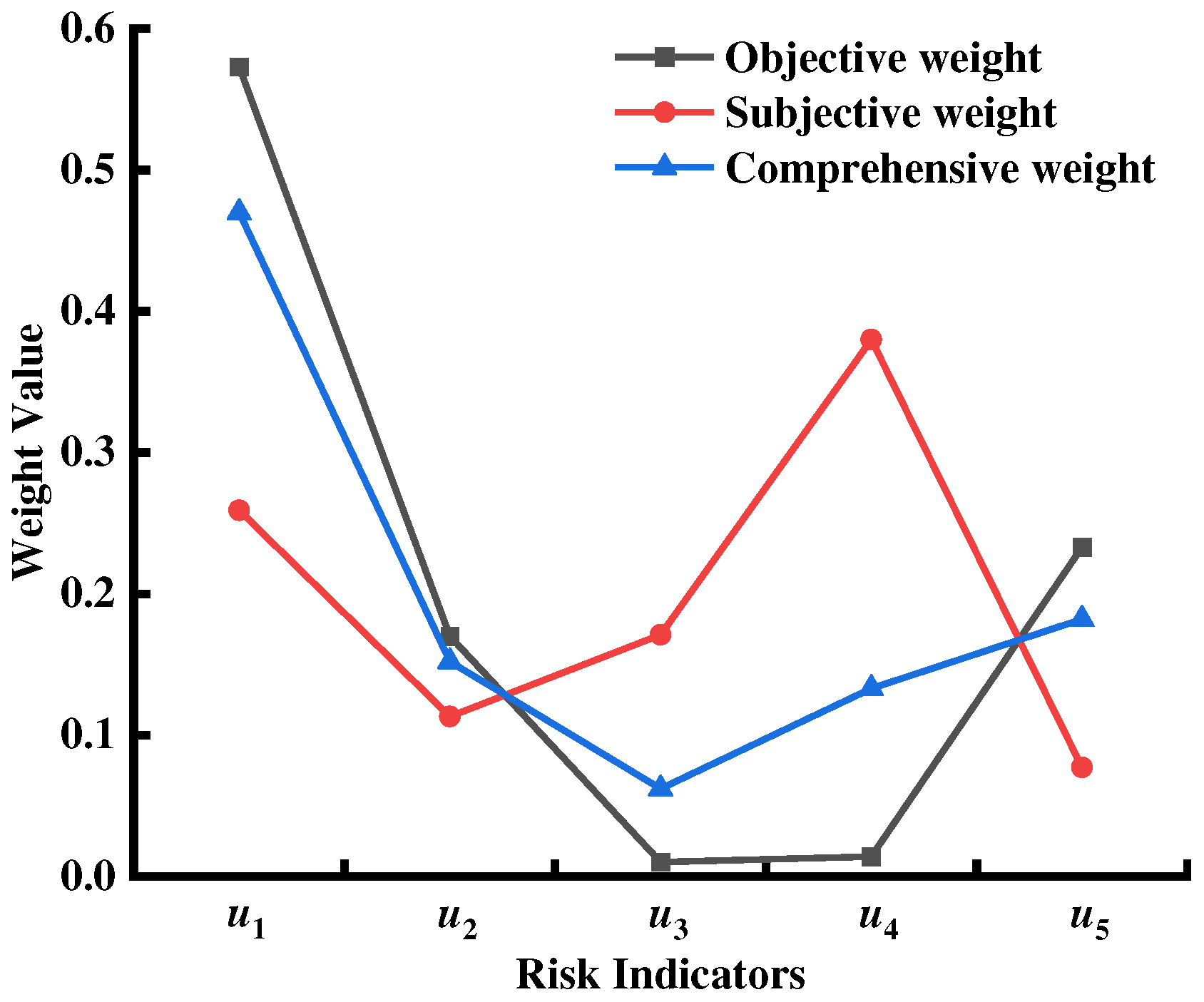
As a result of the calculation steps in the AHP method, the CR value of the evaluation index set was 0.027, which was less than 0.1. It, thus, indicated that the judgment matrix passed the consistency test and that the weighting was reasonable. Furthermore, the calculations of eqs. 1 and 2 showed that the subjective weight was w1 = 0.259, 0.113, 0.171, 0.380, and 0.077 for risk indicators u1, u2, u3, u4, and u5, respectively. In addition, the calculations of the standardized matrix, M, showed that the objective weight was w2 = 0.573, 0.170, 0.010, 0.014, and 0.233 for risk indicators u1, u2, u3, u4, and u5, respectively. According to the entropy method, the standardized matrix was obtained from the monitoring of the data processing of road sections L1, L2, and L3.
It was also found that the linear optimal coefficients a1 and a2 were 0.326 and 0.674, respectively. According to game theory, these values were based on the weight vector of the subjective and objective weighting method. And, finally, the optimized combination weight value was w* = 0.470, 0.152, 0.062, 0.133, and 0.182 for risk indicators u1, u2, u3, u4, and u5, respectively. As can be seen in Figure 3, the comprehensive weight factor w* was positioned between the subjective weight factor and the objective weight factor for each risk indicator, which indicated that the designed comprehensive weight method undermined the deviation degree of some indexes according to the entropy weight method. In addition, it also reduced the subjective influence of the AHP method, making the calculation results more accurate.
Figure 3.
Comparison of the three weights factors for the risk indicator system.
4.3. Comprehensive assessment
By substituting the index data in Table 2 into a trapezoidal membership function, the approximate matrix for L1, L2, and L3 was calculated as follows:
Table 10.
Results of each index membership matrix of road sections.
| Membership matrix | Evaluation index | Risk Level | |||
|---|---|---|---|---|---|
| I | II | III | IV | ||
| R1 | u1 | 0.374 | 0.626 | 0 | 0 |
| u2 | 0 | 0.653 | 0.815 | 0 | |
| u3 | 0.063 | 0.533 | 0.831 | 0 | |
| u4 | 0.700 | 0.300 | 0 | 0 | |
| u5 | 0.218 | 0.782 | 0 | 0 | |
| R2 | u1 | 0.802 | 0.198 | 0 | 0 |
| u2 | 0.231 | 0.769 | 0 | 0 | |
| u3 | 0.010 | 0.990 | 0.251 | 0 | |
| u4 | 0.678 | 0.322 | 0 | 0 | |
| u5 | 0.232 | 0.768 | 0 | 0 | |
| R3 | u1 | 0.657 | 0.343 | 0 | 0 |
| u2 | 0.090 | 0.910 | 0.109 | 0 | |
| u3 | 0.027 | 0.973 | 0.451 | 0 | |
| u4 | 0.674 | 0.326 | 0 | 0 | |
| u5 | 0.343 | 0.657 | 0 | 0 | |
The Bi (i=1,2,3) was obtained as follows according to the comprehensive membership evaluation Equation (10):
Table 11.
Results of comprehensive membership.
| Comprehensive membership | Risk Level | |||
|---|---|---|---|---|
| I | II | III | IV | |
| B1 | 0.313 | 0.609 | 0.175 | 0 |
| B2 | 0.545 | 0.455 | 0.016 | 0 |
| B3 | 0.477 | 0.523 | 0.045 | 0 |
Based on the traditional AHP method and the entropy weight method, the results of the comprehensive membership of the three high-fill road sections (L1, L2, and L3) are shown in Table 12. In these results, the w1 factor was calculated using the traditional AHP method, and the w2 factor was calculated according to the entropy weight method and eq. 10.
Table 12.
Evaluation results using the AHP method and the entropy method.
| Road section | AHP method | Entropy method |
|---|---|---|
| L1 | [0.390 0.501 0.234 0] | [0.275 0.662 0.147 0] |
| L2 | [0.511 0.489 0.043 0] | [0.562 0.438 0.002 0] |
| L3 | [0.468 0.532 0.089 0] | [0.481 0.519 0.023 0] |
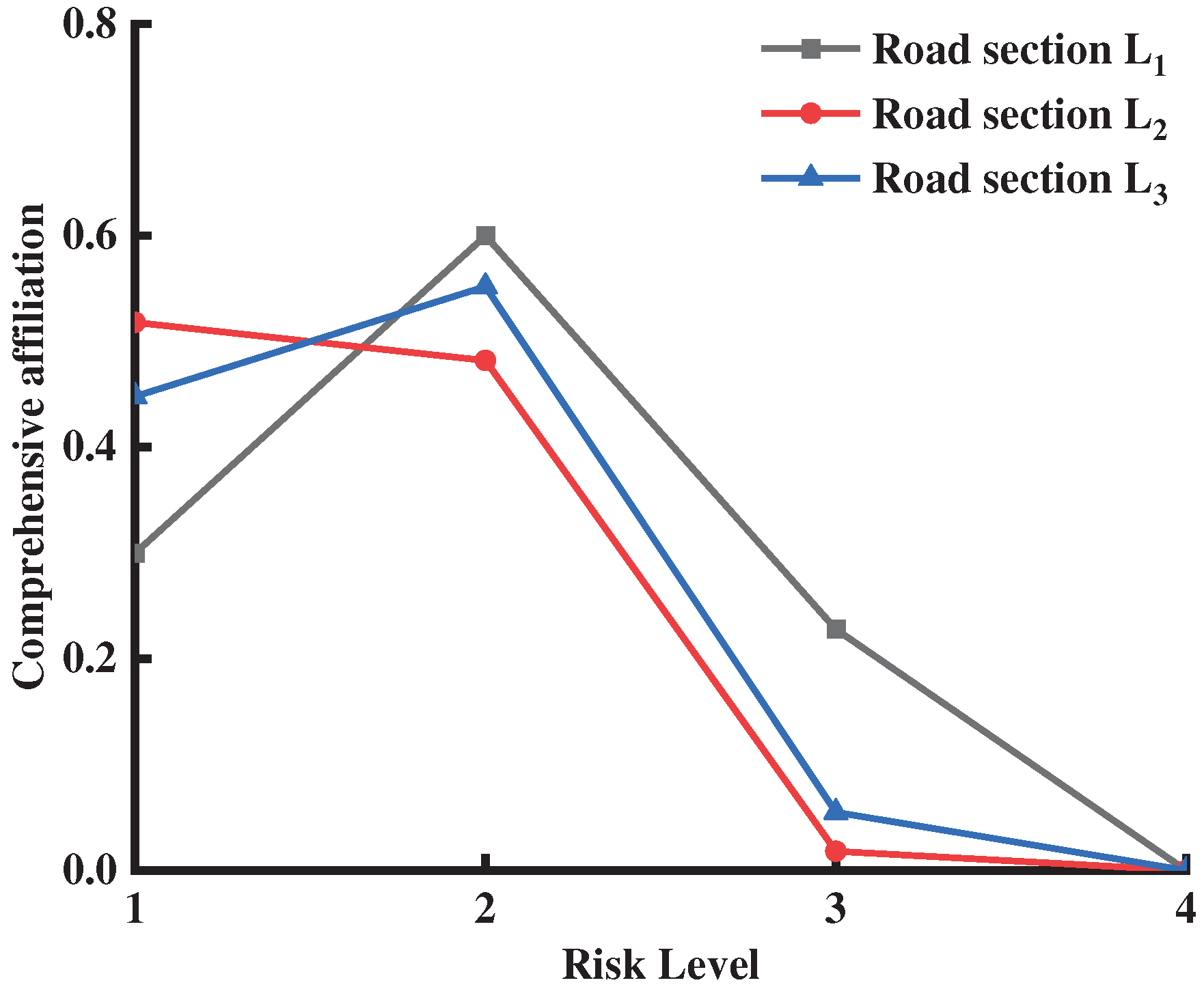
The membership of the three road sections (L1, L2, and L3) of the Zhijiang-Tongren expressway, which was calculated and obtained according to the evaluation model, is shown in Figure 4. According to the maximum membership principle, L2 had a maximum membership of 0.545 and belonged to level I (safe), while L1 and L3 had a maximum membership of 0.609 and 0.523, respectively, and belonged to level II (relatively safe). The results of the three evaluation methods were consistent, indicating that the high-fill embankments were in a safe state as a whole. Among these, the lateral differential settlement and deep horizontal displacement of L1 were at level III (less safe), which indicated that L1 was the most unstable among the three road sections. Thus, it required concentrated monitoring, while the other two were in a stage of steady state.
The comprehensive membership matrix of each road section was normalized. The weighted average method was then used to score the safety condition of each road section as a percentage, as shown in Eqs. 13-14. The results from the scoring of each road section, as derived from each assignment method, are shown in Table 13.
where Bi’ denotes the comprehensive membership matrix of the i-th road section after normalization; bij denotes the affiliation of the i-th road section at the j-th risk level; and m is the risk level.
Table 13.
Results from the scoring of each road segment for each assignment method.
| Road section | Combined method | AHP method | Entropy method |
|---|---|---|---|
| L1 | 78.145 | 78.467 | 77.952 |
| L2 | 88.017 | 86.218 | 88.972 |
| L3 | 85.335 | 83.701 | 86.193 |
Through a comparison of the evaluation results of the above three methods, it could be concluded that it is difficult to ensure weight scientificity and accuracy using the traditional AHP method since the level of expertise is uneven. It is also difficult to reflect the importance of each index in the actual setting using the entropy weight method. In the present study, the Nash equilibrium of game theory was used to initially combine the subjective and objective indexes in the consideration of the importance of various risk factors as scientifically as possible. As can be concluded from the results presented in Table 13, the comprehensive safety evaluation results of the three road sections, as calculated using the three assignment methods, were L2 > L3 > L1, and the evaluation results did not change much. It basically maintained a trend for each road section in the comprehensive score ranking. The evaluation results were compared with the sample data of the three road sections in Table 6. It can be understood from Table 6 that the L2 road section performed the best and the L1 road section performed the worst for the sample data. This fully indicates that the model evaluation results were both accurate and valid.
Figure 4.
The comprehensive membership of each road section at various risk levels.
4.4. Model stability analysis
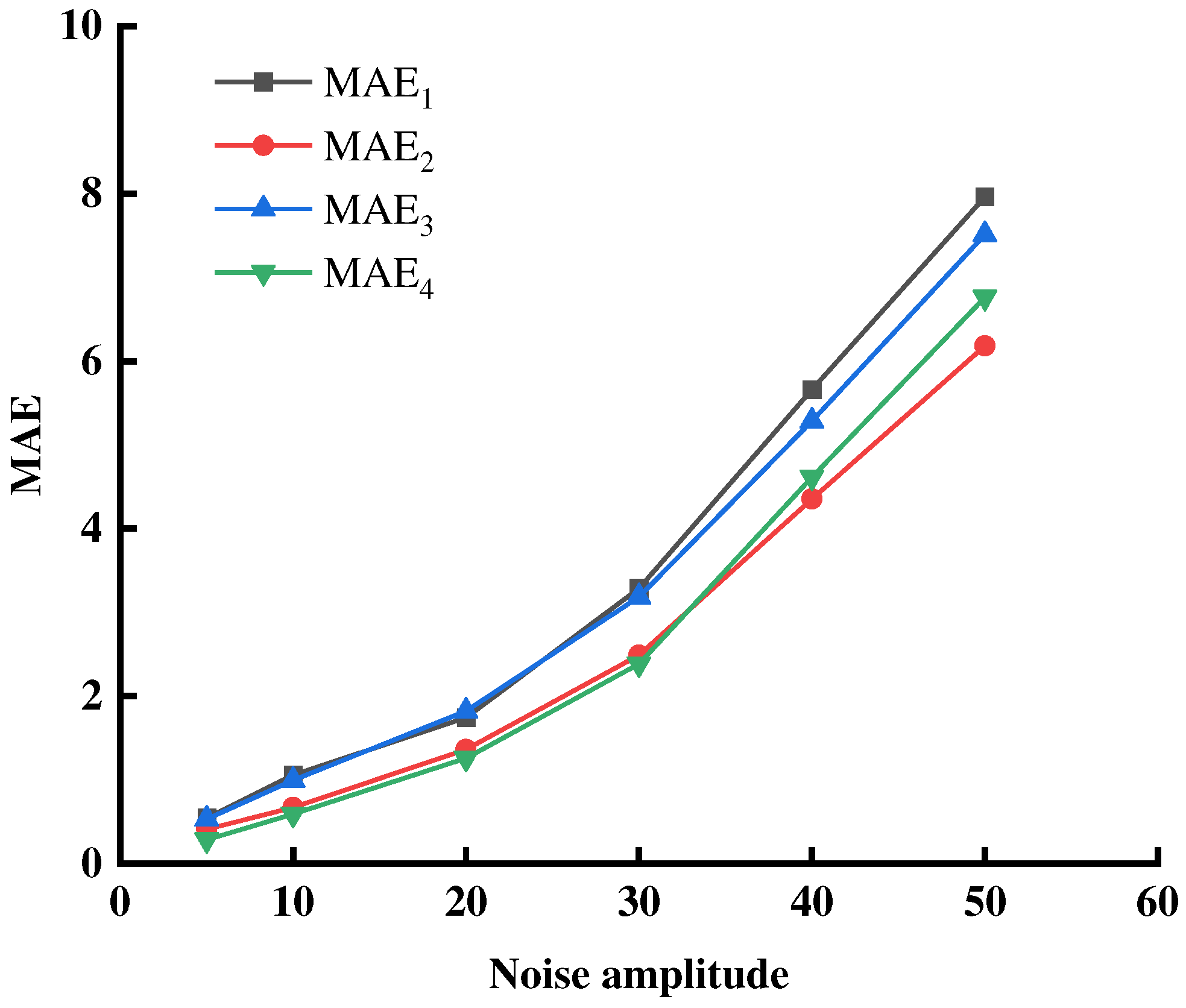
Deviations were inevitable in the process of field monitoring or data statistics. Although the model had a certain fault tolerance, it was impossible to know the fault tolerance range of the model for some specific data. In the present study, the data noise test was used to add a certain range of noise to the monitoring data. Furthermore, the model performance was analyzed to obtain the fault-tolerant range of the model with respect to the data. The data reliability was, thereafter, evaluated. First, the sample data were added with different amplitudes of noise, and the specific experimental scheme was as follows: the S sample feature data were randomly selected to add different degrees of noise, and ε was the upper bound of the ratio of noise value to the original number. The values of the ratio of noise were: 5%, 10%, 20%, 30%, 40%, and 50%. Data set C after adding noise was as follows: C’=C·(1+ε). When the scale of noise data exceeded 40% of the total data, the monitoring data did not reflect the actual pattern well. Therefore, noise scale S was selected to be less than or equal to 40%, and the noise amplitude ε was selected to be less than or equal to 50%.
The processed data were, thereafter, used for the model calculations in the derivation of safety scores for each road segment and for a comparison of original scores for each road segment. MAE (mean absolute error) and MAPE (mean absolute percentage error) were selected as error evaluation indicators to measure the superiority of the model results under different noise addition amplitudes. The model results without noise are denoted as . The model results under noise addition are denoted as . The MAE and MAPE can be represented as Eqs. 15-16, and the results are shown in Table 14.
Table 14.
Error situations under different noise amplitudes.
| Random number | Error index | Noise amplitude (%) | |||||
|---|---|---|---|---|---|---|---|
| 5 | 10 | 20 | 30 | 40 | 50 | ||
| 1 | MAE | 0.545 | 1.057 | 1.742 | 3.289 | 5.661 | 7.964 |
| MAPE | 0.616 | 1.191 | 1.967 | 3.777 | 6.663 | 9.685 | |
| 2 | MAE | 0.410 | 0.671 | 1.363 | 2.490 | 4.354 | 6.182 |
| MAPE | 0.465 | 0.760 | 1.574 | 2.871 | 5.050 | 7.345 | |
| 3 | MAE | 0.531 | 0.996 | 1.821 | 3.187 | 5.287 | 7.512 |
| MAPE | 0.598 | 1.126 | 2.104 | 3.721 | 6.275 | 9.156 | |
| 4 | MAE | 0.287 | 0.590 | 1.258 | 2.385 | 4.616 | 6.764 |
| MAPE | 0.319 | 0.657 | 1.482 | 2.864 | 5.577 | 8.388 | |
Experimentally, due to the addition of noise to the whole sample data, it could be seen that the model error index behaved differently for different noise amplitudes. With an increase in the noise amplitude, the values of MAE and MAPE gradually increased. This indicated that after the addition of noise, the evaluation results of the model gradually became inaccurate with an increase in noise amplitude. In addition, the error also increased. At the same time, it could be seen that the increase in random times had little effect on the error index. That is, the evaluation results of the model were relatively stable. According to the MAE curve in Figure 5, when the experimental data deviated from the true value by 20%, the growth trend of the error value clearly became faster. This indicated that the reliability of the evaluation results was reduced, the stability was weakened, and the overall performance of the model was reduced. When the noise amplitude was 20%, the MAPE values were all within 3%. This indicated that when the noise amplitude was 20%, the deviation of the evaluation results was within 3%, which had a small influence on the model evaluation results. Therefore, when the error range of the monitoring data index set was less than 20%, the evaluation model was able to provide the correct feedback for the evaluation results. When the deviation reached more than 20% of the true value, it was necessary to check the experimental data and eliminate the problem data.
Figure 5.
The MAE results for different noise amplitudes.
5. Conclusions
In this study, an approximate comprehensive evaluation model that is based on the game theory combination assignment was used to make a comprehensive assessment of the subgrade stability during the construction period of high-fill subgrade from the perspective of different monitoring indicators. The main findings obtained are as follows:
- (1)
- Combining the combination weighting method of Nash equilibrium thought in Game theory, the centralized unification of subjective and objective weighting of indicators is realized. This method considers the empirical judgments of experts on indicators and the objective attributes of evaluation indicators, avoiding the one-sidedness caused by single subjective or objective weighting.
- (2)
- The trapezoidal membership function was conducted as the membership function to evaluate each indicator level, and the fuzzy comprehensive evaluation method using the maximum membership principle and weighted average principle ensured the effectiveness of the evaluation results.
- (3)
- Applying the monitoring data of Zhitong Expressway for the evaluation model, it was found that the three methods yielded similar safety rating results for each section. The combined weighted evaluation model can correct the evaluation result error caused by a single weight, and the monitoring index error is within 20%.
- (4)
- The evaluation method proposed in this study provides a quick reference for construction safety management and safety warning. It can avoid information lag caused by the manual processing and analysis of monitoring data. However, the subgrade monitoring indexes will change for different engineering situations, so the universality and promotion value should be investigated in future cases.
- (5)
- The index requirements for high-fill subgrades of the reference specification in this study apply to non-specialized soil high-fill subgrades and high-fill subgrades on soft soil foundations, and other special soil subgrades can be borrowed for reference. However, their applicability needs to be further demonstrated.
Author Contributions
Conceptualization, Y.L. and T.H.; methodology, Y.L.; validation, Y.L. and T.H.; formal analysis, T.H.; investigation, T.H.; resources, Y.L.; data curation, T.H.; writing—original draft preparation, T.H.; writing—review and editing, T.H.; visualization, T.H.; supervision, Y.L.; project administration, Y.L.; funding acquisition, Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Science and Technology Progress and Innovation Program of Department of Transportation of Hunan Province, grant number 201707, and funded by the Open Fund of Hunan Province University Key Laboratory of Bridge Engineering (Changsha University of Science & Technology), grant number 15KA02.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors would like to express their gratitude to EditSprings (https://www.editsprings.cn) for the expert linguistic services provided.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Chen, D.; Ling, J.; Li, D.; Zheng, C. Monitoring and evaluating techniques of highway subgrade safety in the operation period. Road Materials and Pavement Design 2017, 18(sup3), 215–225. [Google Scholar] [CrossRef]
- Le Kouby, A.; Guimond-Barrett, A.; Reiffsteck, P.; Pantet, A.; Mosser, J.-F.; Calon, N. Improvement of existing railway subgrade by deep mixing. European Journal of Environmental and Civil Engineering 2020, 24(8), 1229–1244. [Google Scholar] [CrossRef]
- Lei, G.; Qiu-Yue, Z.; Xiang-Juan, Y.; Zhi-Hui, C. Analysis and model prediction of subgrade settlement for Linhai highway in China. Electronic Journal of Geotechnical Engineering 2014, 19, 11–21. [Google Scholar]
- Jia, L.; Guo, J.; Yao, K. In Situ Monitoring of the Long-Term Settlement of High-Fill Subgrade. Advances in Civil Engineering 2018, 2018, 1–9. [Google Scholar] [CrossRef]
- Bakhat, R.; Rajaa, M. Risk Assessment of a Wind Turbine Using an AHP-MABAC Approach with Grey System Theory: A Case Study of Morocco. Mathematical Problems in Engineering 2020, 2020, 1–22. [Google Scholar] [CrossRef]
- Wu, Z.; Shen, R. Safety Evaluation Model of Highway Construction based on Fuzzy Grey Theory. Procedia Engineering 2012, 45, 64–69. [Google Scholar] [CrossRef]
- Lin, C. J.; Zhang, M.; Li, L. P.; Zhou, Z. Q.; Liu, S.; Liu, C.; Li, T. Risk Assessment of Tunnel Construction Based on Improved Cloud Model. Journal of Performance of Constructed Facilities 2020, 34(3). [Google Scholar] [CrossRef]
- Luo, D.; Li, H.; Wu, Y.; Li, D.; Yang, X.; Yao, Q. Cloud model-based evaluation of landslide dam development feasibility. PLOS ONE 2021, 16(5), e0251212. [Google Scholar] [CrossRef]
- Wang, R.; Zhao, Q.; Sun, H.; Zhang, X.; Wang, Y. Risk Assessment Model Based on Set Pair Analysis Applied to Airport Bird Strikes. Sustainability 2022, 14(19), 12877. [Google Scholar] [CrossRef]
- Zhang, L.; Li, H. Construction Risk Assessment of Deep Foundation Pit Projects Based on the Projection Pursuit Method and Improved Set Pair Analysis. Applied Sciences 2022, 12(4), 1922. [Google Scholar] [CrossRef]
- Chen, W.; Zhang, G.; Jiao, Y.; Wang, H. Unascertained Measure-Set Pair Analysis Model of Collapse Risk Evaluation in Mountain Tunnels and Its Engineering Application. KSCE Journal of Civil Engineering 2020, 25(2), 451–467. [Google Scholar] [CrossRef]
- Zhang, G.; Wang, C.; Jiao, Y.; Wang, H.; Qin, W.; Chen, W.; Zhong, G. Collapse Risk Analysis of Deep Foundation Pits in Metro Stations Using a Fuzzy Bayesian Network and a Fuzzy AHP. Mathematical Problems in Engineering 2020, 2020, 1–18. [Google Scholar] [CrossRef]
- Wang, J.; Ma, C.; Wang, S.; Lu, X.; Li, D. Risk Assessment Model and Sensitivity Analysis of Ordinary Arterial Highways Based on RSR-CRITIC-LVSSM-EFAST. Sustainability 2022, 14(23), 16096. [Google Scholar] [CrossRef]
- Gebrehiwet, T.; Luo, H. Risk Level Evaluation on Construction Project Lifecycle Using Fuzzy Comprehensive Evaluation and TOPSIS. Symmetry 2018, 11(1), 12. [Google Scholar] [CrossRef]
- Yu, X.; Suntrayuth, S.; Su, J. A Comprehensive Evaluation Method for Industrial Sewage Treatment Projects Based on the Improved Entropy-TOPSIS. Sustainability 2020, 12(17), 6734. [Google Scholar] [CrossRef]
- Li, Q.; Zhou, J.; Feng, J. Safety Risk Assessment of Highway Bridge Construction Based on Cloud Entropy Power Method. Applied Sciences 2022, 12(17), 8692. [Google Scholar] [CrossRef]
- Alawad, H.; Kaewunruen, S.; An, M. A Deep Learning Approach Towards Railway Safety Risk Assessment. IEEE Access 2020, 8, 102811–102832. [Google Scholar] [CrossRef]
- Isah, M. A.; Kim, B.-S. Assessment of Risk Impact on Road Project Using Deep Neural Network. KSCE Journal of Civil Engineering 2021, 26(3), 1014–1023. [Google Scholar] [CrossRef]
- Lai, C.; Chen, X.; Chen, X.; Wang, Z.; Wu, X.; Zhao, S. A fuzzy comprehensive evaluation model for flood risk based on the combination weight of game theory. Natural Hazards 2015, 77(2), 1243–1259. [Google Scholar] [CrossRef]
- Li, H.; Chen, L.; Tian, F.; Zhao, L.; Tian, S. Comprehensive Evaluation Model of Coal Mine Safety under the Combination of Game Theory and TOPSIS. Mathematical Problems in Engineering 2022, 2022, 1–15. [Google Scholar] [CrossRef]
- Tang, J.; Wang, D.; Ye, W.; Dong, B.; Yang, H. Safety Risk Assessment of Air Traffic Control System Based on the Game Theory and the Cloud Matter Element Analysis. Sustainability 2022, 14(10), 6258. [Google Scholar] [CrossRef]
- Hegde, J.; Rokseth, B. Applications of machine learning methods for engineering risk assessment – A review. Safety Science 2020, 122, 104492. [Google Scholar] [CrossRef]
- Islam, M. S.; Nepal, M. P.; Skitmore, M.; Attarzadeh, M. Current research trends and application areas of fuzzy and hybrid methods to the risk assessment of construction projects. Advanced Engineering Informatics 2017, 33, 112–131. [Google Scholar] [CrossRef]
- Bao, X.; Li, H. Construction Risk Analysis of Subgrade Engineering in Perilous Mountainous Areas. Journal of Railway Engineering Society 2022, 39(07), 109-115+121. [Google Scholar]
- Guo, Q.; Li, Y.; Meng, X.; Guo, G.; Lv, X. Instability risk assessment of expressway construction site above an abandoned goaf: a case study in China. Environmental Earth Sciences 2019, 78(20), 588. [Google Scholar] [CrossRef]
- Zhang, Q.; Su, Q.; Liu, B.; Pei, Y.; Zhang, Z.; Chen, D. Comprehensive performance evaluation of high embankments in heavy-haul railways using an improved extension model with attribute reduction algorithm. Journal of Intelligent & Fuzzy Systems 2023, 44(2), 2673–2692. [Google Scholar] [CrossRef]
- Taskiran, T.; Fidan, A. A. Investigation of the Parameters Affecting the Stability of Unsaturated Soil Slope Subjected to Rainfall. TEKNIK DERGI 2019, 30(5), 9483–9506. [Google Scholar]
- Wu, D.; Wang, Y.; Zhang, F.; Qiu, Y. Influences of Pore-Water Pressure on Slope Stability considering Strength Nonlinearity. Advances in Civil Engineering 2021, 2021, 8823899. [Google Scholar] [CrossRef]
- Li, Z.; Guan, C.; Han, M.; Jia, J.; Liu, L.; Li, W. Estimation of Settlement in Loess-Filled Subgrade with Consideration of Lateral Deformation. Arabian Journal for Science and Engineering 2022, 47(4), 4713–4729. [Google Scholar] [CrossRef]
- Raja, K.; Vishnuvardhan, K.; Venkatachalam, S.; Richard, P. D.; Ramu, T.; RamKumar, S. Strength and settlement of subgrade soil in southern part of Kangeyam block. Materials Today: Proceedings 2022, 65, 1930–1938. [Google Scholar] [CrossRef]
- Yan, Q.; Zhi, X.; Liu, B. standard of differential settlement for highway subgrade. Journal of Chang’an University(Natural Science Edition) 2013, 33(02), 16–21. [Google Scholar]
- Xingxin, C.; Xuancang, W.; Zhiwei, G. Control criterion of subgrade differential settlement based on pavement damage response. Journal of Chang’an University(Natural Science Edition) 2010, 30(05), 31–34. [Google Scholar]
- Hummel, J. M.; Bridges, J. F. P.; Ijzerman, M. J. Group Decision Making with the Analytic Hierarchy Process in Benefit-Risk Assessment: A Tutorial. The Patient - Patient-Centered Outcomes Research 2014, 7(2), 129–140. [Google Scholar] [CrossRef] [PubMed]
- Abedian, M.; Amindoust, A.; Maddahi, R.; Jouzdani, J. A Nash equilibrium based decision-making method for performance evaluation: a case study. Journal of Ambient Intelligence and Humanized Computing 2021, 13(12), 5563–5579. [Google Scholar] [CrossRef]
- He, H.; Tian, C.; Jin, G.; An, L. An Improved Uncertainty Measure Theory Based on Game Theory Weighting. Mathematical Problems in Engineering 2019, 2019, 1–8. [Google Scholar] [CrossRef]
- Koulinas, G. K.; Marhavilas, P. K.; Demesouka, O. E.; Vavatsikos, A. P.; Koulouriotis, D. E. Risk analysis and assessment in the worksites using the fuzzy-analytical hierarchy process and a quantitative technique – A case study for the Greek construction sector. Safety Science 2019, 112, 96–104. [Google Scholar] [CrossRef]
- Wang, G.; Liu, Y.; Hu, Z.; Lyu, Y.; Zhang, G.; Liu, J.; Liu, Y.; Gu, Y.; Huang, X.; Zheng, H.; Zhang, Q.; Tong, Z.; Hong, C.; Liu, L. Flood Risk Assessment Based on Fuzzy Synthetic Evaluation Method in the Beijing-Tianjin-Hebei Metropolitan Area, China. Sustainability 2020, 12(4), 1451. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



