
Submitted:
06 September 2023
Posted:
07 September 2023
You are already at the latest version
Abstract
In this study, deep neural network (DNN) and transfer learning (TL) techniques were employed to predict the viscous resistance and wake distribution based on the positions of flow control fins (FCFs) applied to containerships of various sizes. Both methods utilized data collected through Computational Fluid Dynamics (CFD) analysis. The position of the flow control fin (FCF) and hull-form information were utilized as input data, and the output data included viscous resistance coefficients and components of propeller axial velocity. The base DNN model was trained and validated using a source dataset from a 1000 TEU containership. Grid search cross-validation technique was employed to optimize the hyperparameters of the base DNN model. Then, transfer learning was applied to predict the viscous resistance and wake distribution for containerships of varying sizes. To enhance the accuracy of feature prediction with a limited amount of dataset, learning rate optimization was conducted. Transfer learning involves retraining and reconfiguring the base DNN model, and the accuracy was verified based on the fine-tuning method of the learning model. The results of this study can provide hull designers for containerships with performance evaluation information by predicting wake distribution, without relying on CFD analysis.
Keywords:
Flow Control Fin (FCF)
; Deep Neural Network (DNN)
; Transfer Learning (TL)
; containership
; viscous resistance coefficients
; wake flow distributions
1. Introduction
The severity of environmental issues resulting from industrial development has become a global concern, spanning various sectors, including the shipbuilding industry. As a result, various related regulations are being formulated or strengthened. In 2018, the International Maritime Organization (IMO) announced a strategy to reduce the total greenhouse gas emissions from ships by 50% and the Carbon Intensity Indicator (CII) by 70% by the year 2050, compared to the levels in 2008. As one of the initial strategies, the implementation of the EEXI (Energy Efficiency eXisting Ship Index) and the CII (Carbon Intensity Index) rating system is already in place. This represents a significant strengthening of energy efficiency regulations for existing ships. The efforts to meet EEXI compliance and achieve higher CII ratings are tasks assigned to the existing ships. Among several strategies for this purpose, one approach is to enhance resistance performance, and this can be achieved through the application of Energy Saving Devices (ESDs). The application of ESDs involves installing relatively small-scale devices that can lead to significant effects. Because of this, ESDs are utilized in various ways, not only for existing ships but also for the design of new ships.
Samsung Heavy Industries registered a patent in 2007 [1] for SAVER (SAmsung Vibration and Energy Reduction) Fins. These FCFs are designed to control the inflow fluid dynamics above and below the propeller of ships, to improve pressure resistance and reduce vibrations. Lee et al. [2] applied the SAVER Fins in combination with rudder bulb to a 35k DWT bulk carrier and confirmed a power-saving effect of 7.4% through model tests and sea trials. Kim et al. [3] attached vertical plates to the stern of a 24K tanker and confirmed improvements in resistance performance and wake distribution through Computational Fluid Dynamics (CFD) analysis. Lee et al. [4] investigated the changes in resistance performance and wake characteristics based on the position of FCF and the angle with the streamline using CFD analysis, focusing on an 80K bulk carrier. Recently, Park et al. [5] demonstrated through model tests and CFD that FCF can reduce the total resistance of a 6.5K DWT tanker by 4.3%. Many studies have been conducted on FCF design, and the effects of FCF are predominantly verified through model tests and CFD simulations. Furthermore, research has advanced to predict or optimize the effects of FCF using artificial intelligence techniques as a basis. A neural network was trained based on hull-form data and then used to predict the wake distribution [6]. Another example is Kim and Moon [7], who used a neuro-fuzzy technique to predict wake distribution. Wie and Kim [8] carried out optimal FCF design for the Kriso 300K VLCC using Genetic Algorithm (GA) and NLPQL (Non-Linear Programming by Quadratic Lagrangian).
In the previous paper by author’s [9], optimal FCF design was performed for a small containership using two strategies: neural network-based machine learning and optimization techniques. The objective of this current study is to predict the resistance performance and propeller inflow characteristics for containerships of various sizes, not just for a single containership. Initially, a Deep Neural Network (DNN) model is employed to predict the performance of a single containership with a substantial dataset available. The hyperparameters required for model configuration are optimized using grid search cross-validation. Subsequently, based on the base DNN model, Transfer Learning (TL) is utilized to predict performance for the remaining containerships with limited data. In this study, a small number of hull-forms are applied to transfer learning to predict the fluid dynamic performance based on the FCF position. This can be utilized as foundational research for expanding the applicability of fluid dynamic performance prediction techniques to containerships of various sizes and even to different types of vessels. Additionally, it is considered that the combination of transfer learning-based performance prediction and appropriate optimization algorithms can be extended to the FCF design of containerships of various sizes.
The paper organization is as follows: Section 2 presents the target ships and FCF specifications, and formulates the numerical methods to prepare for the data; Section 3 describes the theoretical background of deep neural networks and transfer learning, detailing the specific processes applied in this study. Subsequently, Section 4 presents the performance prediction results for containerships of various sizes. Finally, Section 5 discusses the main conclusions and findings.
2. Problem descriptions
2.1. Target ship and flow control fins
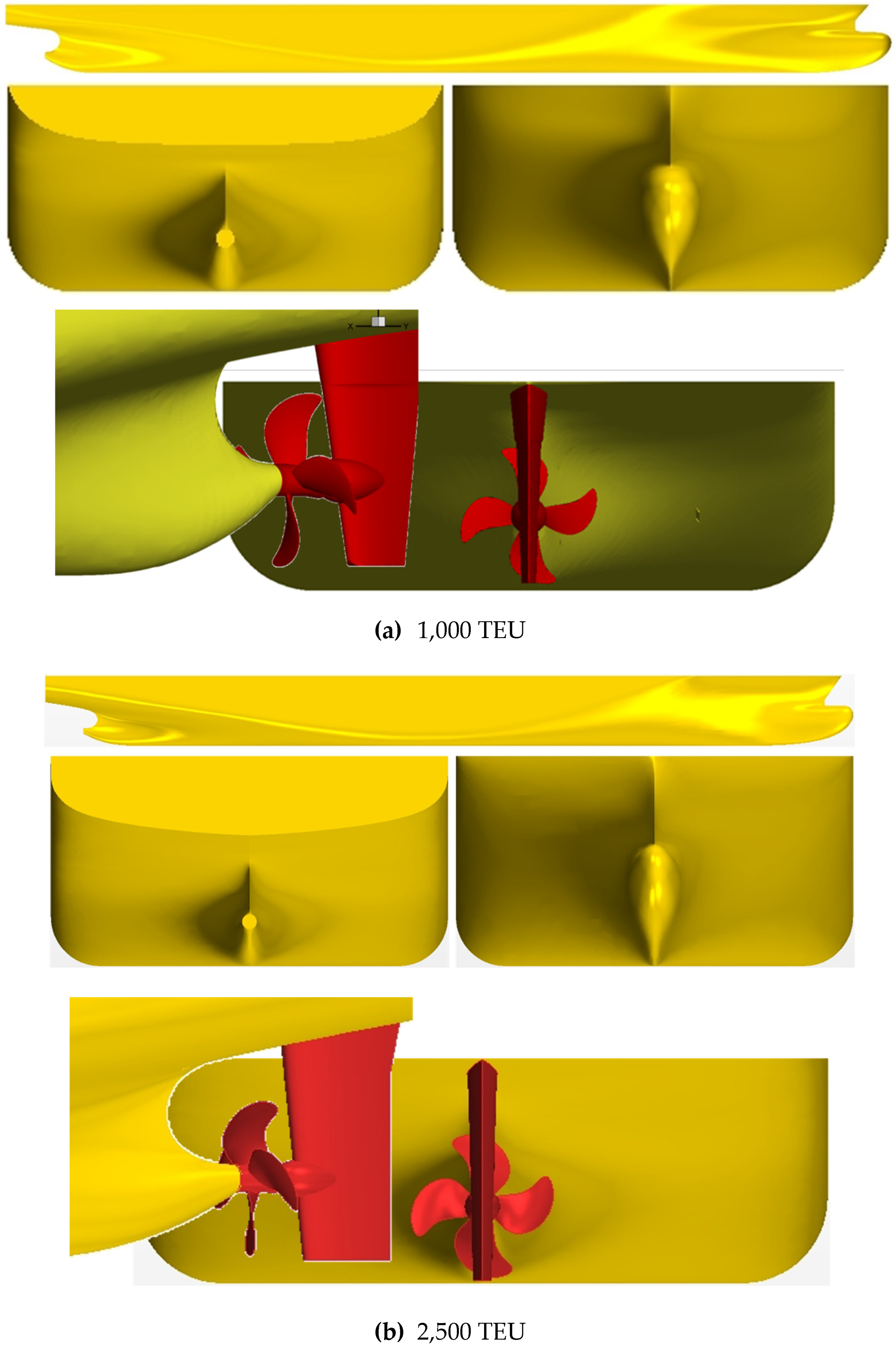
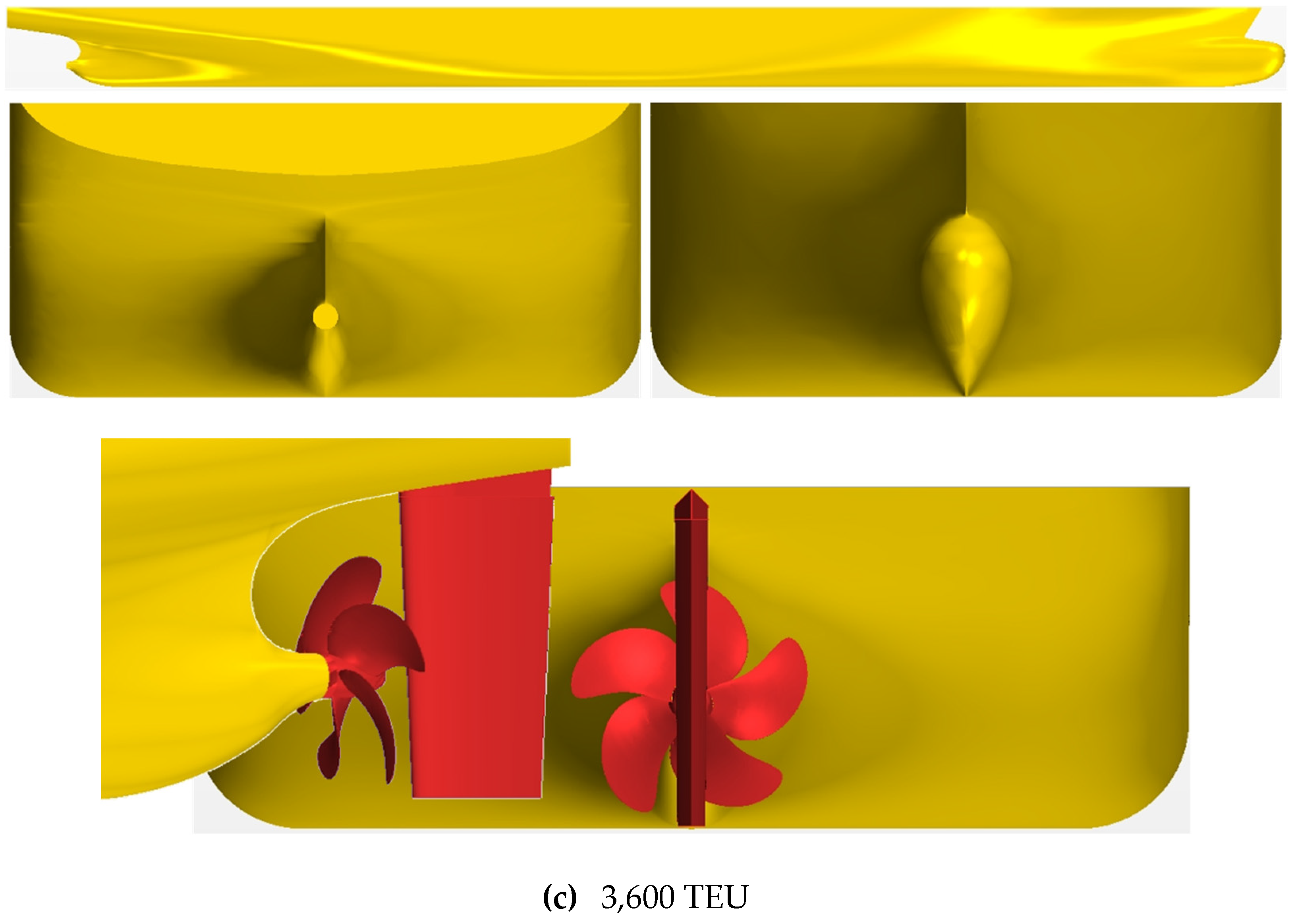
The base DNN used for predicting wake distribution and resistance is trained using data from the author’s previous paper. A relatively substantial amount of data used for training the DNN model comes from a 1,000 TEU containership constructed by Daesun Shipbuilding & Engineering Co. Ltd. This was associated with the presence of reliable CFD data. A model with a scale ratio was selected for numerical simulation. The data used for the transfer learning model consists of different-sized vessels: 2,500 TEU and 3,600 TEU (KCS; KRISO Containership) containerships. For these ships, models with each scale ratio of and were considered. The principal dimensions of target hulls and propellers are given in Table 1. Figure 1 presents the three-dimensional views of target hull forms and propellers.

Table 1.
Principal particulars of 1,000TEU containership.
| Class | Designation | Symbol (unit) | Full-scale ship |
|---|---|---|---|
| 1,000 TEU | Length bet. Perpendicular | (m) | 137.5 |
| Breadth | (m) | 23.6 | |
| Draft | (m) | 7.4 | |
| Block coefficient | 0.595 | ||
| Propeller Diameter | (m) | 5.5 | |
| 2,500 TEU | Length bet. Perpendicular | (m) | 185.0 |
| Breadth | (m) | 32.26 | |
| Draft | (m) | 10.0 | |
| Block coefficient | 0.640 | ||
| Propeller Diameter | (m) | 6.8 | |
| 3,600 TEU | Length bet. Perpendicular | (m) | 230.0 |
| Breadth | (m) | 32.2 | |
| Draft | (m) | 10.8 | |
| Block coefficient | 0.651 | ||
| Propeller Diameter | (m) | 7.9 |
Figure 1.
3D volumetric views of target hulls and propellers: (a) 1,000 TEU; (b) 2,500 TEU; (c) 3,600 TEU.
Figure 1.
3D volumetric views of target hulls and propellers: (a) 1,000 TEU; (b) 2,500 TEU; (c) 3,600 TEU.
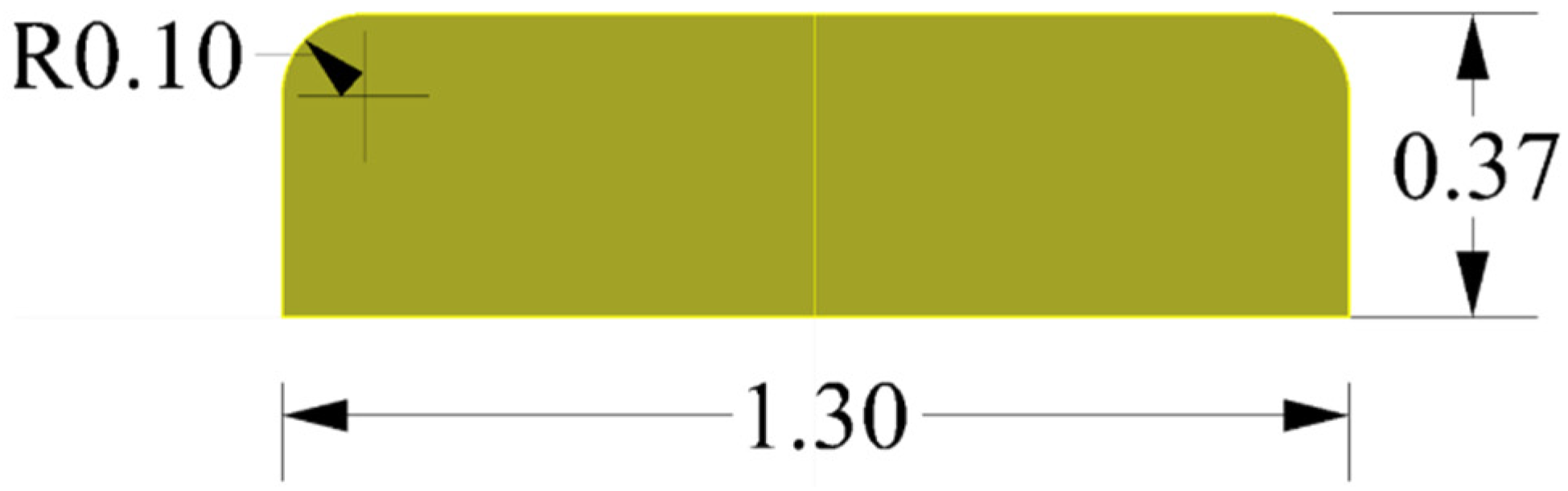
The Flow Control Fin (FCF) used in this study is in rectangular shape with two rounded corners (see Figure 2). The dimensions of full-scale FCF were 1.30 m long, 0.37m high, and 0.03m thick. When normalized by the propeller diameter , these correspond to (length) × (height) × (thickness). Generally, FCFs are attached in pair(s) at the same locations on the port and starboard sides. The design variables for the FCF are the longitudinal and vertical positions of FCF, inclination angle, and hull-form information. Here, the position of the FCF is located at the midpoint of the baseline, and the angle of inclination refers to the angle between the FCF baseline and the ship baseline. The hull-form information applies the derivatives representing the gradient of each tangent at the midpoint of the FCF in the directions of the station, waterline, and buttock line. In more detail, when the derivative is small in the station direction, it indicates that when observing the hull-form in the body plan, the shape resembles a V type. Similarly, when the derivatives are small in the waterline and buttock line directions, they represent hull-form that changes smoothly in the half-breadth and shear plan, respectively.
Figure 2.
Geometry of FCF.
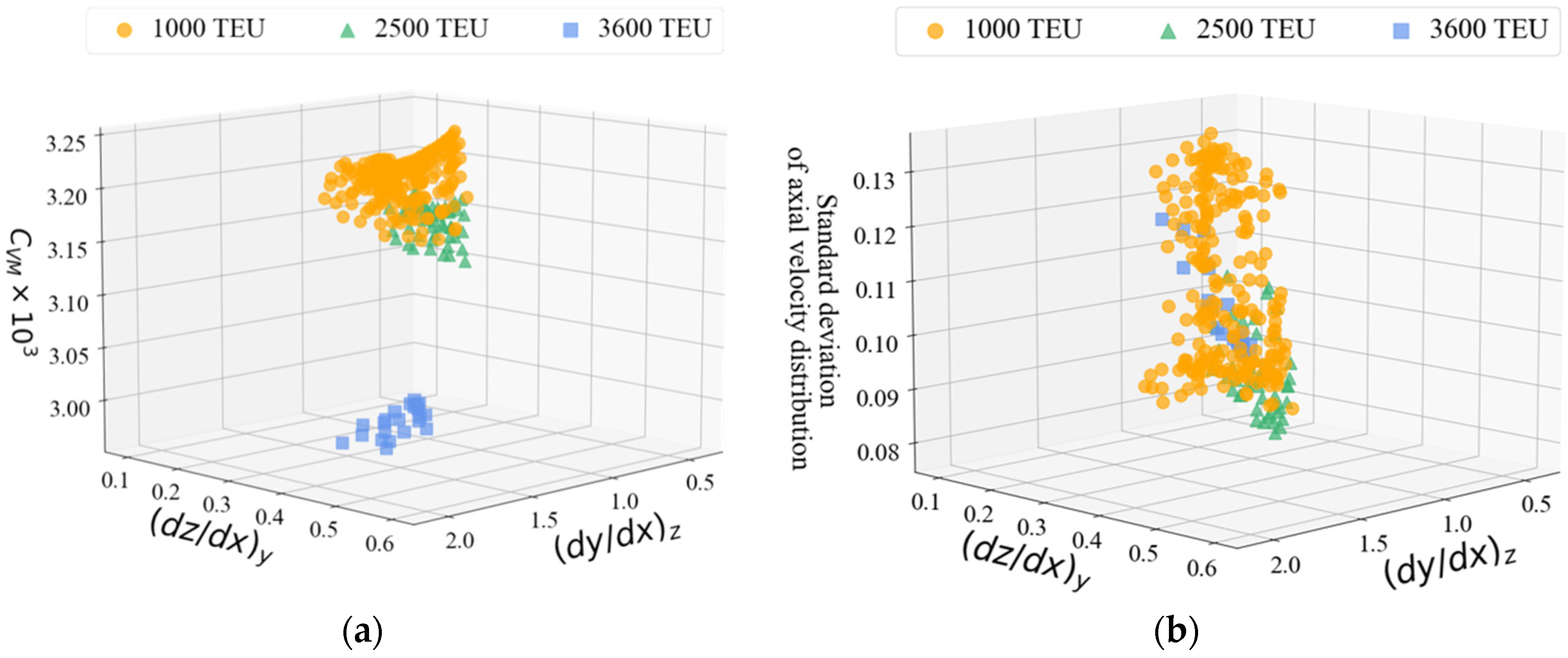
Indeed, even within the same type of vessel, differences in main particulars, hull-form, and the position of the FCF can result in variations in the characteristics of the propeller inflow velocity distribution. Figure 3 illustrates the distribution of the viscous resistance coefficient and the standard deviation of axial velocity distribution based on derivatives in the waterline and buttock line directions. The orange symbols represent the viscosity resistance coefficients and standard deviation for 1,000 TEU, the green symbols for 2,500 TEU, and the blue symbols for 3,600 TEU. Transfer learning was employed to predict values with varying characteristics across different ship sizes.
Figure 3.
Features distribution for each containership: (a) distribution of viscous resistance coefficient; (b) standard deviation of axial velocity distribution.
Figure 3.
Features distribution for each containership: (a) distribution of viscous resistance coefficient; (b) standard deviation of axial velocity distribution.
2.2. CFD simulation to obtain training data
In this study, 693 datasets were prepared by the CFD analysis to train, validate, and test the base DNN model. Each data corresponded to a combination of design parameters, including 11 longitudinal positions vertical positions inclination angles . Here, Refers to the station length, which is 1/20 of the length between perpendicular . Around 150 target datasets for 2,500 TEU and 3,600 TEU were obtained through CFD analysis for transfer learning. The target datasets were randomly selected within the same longitudinal and vertical position ranges as the source datasets. Similarly, the inclination angles were also randomly specified.
It is necessary to emphasize the importance of automation in such preprocessing steps as modeling and mesh generation, as it significantly enhances the overall computational efficiency for the entire set of 843 simulation cases. The processes including three-dimensional modeling of hull-forms with varying FCF positions, mesh generation, and creation of CFD setups was carried out using OptHull® software, a professional hull form design software. Then, the commercial CFD S/W STAR-CCM+ was configured and the numerical analysis were automatically controlled by an in-house javascript code. By using a 140 CPU (Intel Xeon 2.6GHz)-parallel computing cluster, approximately 419 hours were required to complete the preparation of data for the 843 simulations.
2.2.1. Governing equations
The STAR-CCM+ v.15.06 was used for the CFD analysis of the flow around the ship. The governing equations consist of the continuity equation for mass conservation and the Reynolds-Averaged Navier-Stokes (RANS) equations for momentum and energy conservation. These equations are given in the following tensor notation;
where is the velocity component in direction, while and are the static pressure, fluid density, absolute viscosity of fluid, Reynolds stress, and gravitational acceleration in the -direction, respectively.
The Reynolds stress turbulent model, being excellent in resolving bilge vortex and capable of high-accuracy prediction of flow around the ship [10], was employed in the numerical analysis. The transport equation for the Reynolds stress is described as follows;
where is the Kronecker delta and , and correspond to the diffusion, production, and pressure strain terms which are expressed as follows;
Here, , and are turbulent model constants. Additionally, and respectively represent turbulent kinetic energy and dissipation rate.
2.2.2. Computational domain and boundary conditions
Figure 4 illustrates the computational domain, which is rectangular, set within the range of , and . Since the computational domain is symmetric with respect to the center plane , only half domain was considered. In addition, a double-body simulation, in which the underwater hull was mirrored with respect to the free surface , was performed for all cases. This approach allows the neglect of wave generation by the ship hull and the resulting wave-making resistance. However, due to the deep submergence of the FCF, which prevents its influence on the free surface, complex issues in analyzing the various effects of FCF design on the flow field are avoided. The double-body simulation significantly reduces the computational time by omitting computationally intensive free-surface calculations, which is crucial for this study encompassing various test cases. The boundary conditions for the computational domain surfaces shown in Figure 4 are summarized in Table 2.
Figure 4.
Computational domain for double-body simulation.
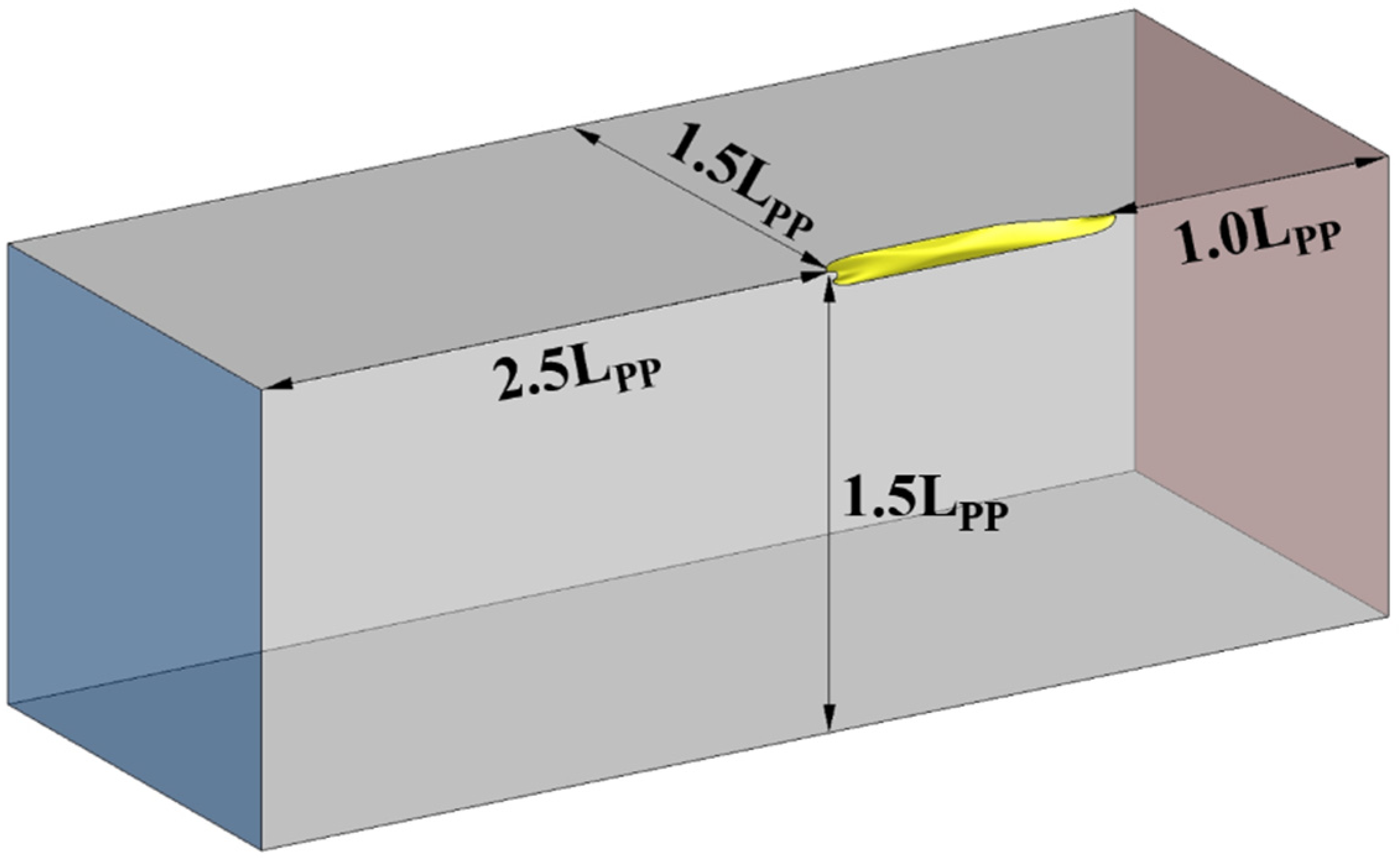
Table 2.
Boundary conditions for Figure 6.
Table 2.
Boundary conditions for Figure 6.
| Boundary surface | Type |
|---|---|
| Inlet | Velocity inlet |
| Outlet | Pressure outlet |
| Top, Bottom, Side, Centerplane | Symmetry |
| Ship | Wall |
2.2.3. Uncertainty analysis in CFD verification methodology
The validation of CFD analysis used to acquire 839 data points is unavoidable. In this study, a double body analysis was conducted to reduce data collection time. As a result, validation with model tests could not be carried out. Therefore, the verification of the grid system used in the analysis was performed following the procedures and guidelines recommended by ITTC [11]. To verify specific parameters used in the CFD analysis, numerical error and uncertainty of the simulation are evaluated. A parameter convergence study is performed by varying the input parameter while keeping all other parameters constant, using multiple solutions with systematic parameter refinement. The input parameter is varied based on the refinement ratio defined in Equation (7).
At least three values of the input parameter are required for evaluating convergence, and the convergence ratio is defined as Equation (8).
Here, represents the difference in simulation solutions and is defined as the changes between the medium-fine and coarse-medium . The convergence conditions are defined into three categories based on the convergence ratio as follows.
In case , the generalized Richardson Extrapolation (RE) method is employed to estimate the numerical error and uncertainty. In case , numerical uncertainty is estimated using the following equation.
Here, and represent the maximum and minimum values among the oscillating trends in the analysis results. In case , it is not possible to estimate numerical error and uncertainty since the analysis results exhibit a diverging tendency.
Subsequently, detailed explanations for the numerical error () and uncertainty () calculated through the generalized RE method are based on the ITTC Recommended Procedures and Guidelines for Uncertainty Analysis. In this study, the estimation results for numerical error and uncertainty of the grid system used in data acquisition through simulations are thoroughly described in Section 4.
3. Methodology
The present study can be divided into two main steps. Firstly, utilizing Deep Neural Networks, it predicts the viscous resistance coefficients and wake distributions for the 1,000 TEU container vessel, which has a substantial dataset. Secondly, building upon the results of the DNN training, it employs Transfer Learning to predict the viscous resistance coefficients and wake distributions for the 2,500 TEU and 3,600 TEU container vessels, which have relatively smaller datasets.
3.1. Deep Neural Network (DNN)
A deep Neural Network is a supervised learning technique that involves training and predicting based on input and output data. The number of hidden layers and the number of neurons in each layer connecting input and output data are determined according to the designer’s needs. The weights between layers are initialized and then continuously adjusted during the training process [12]. Figure 5 illustrates the general structure of a DNN, where represents input data. The outputs of each neuron in the first and second hidden layers are calculated using the following equations;
Here, represents the activation function, stands for bias, and represent the weights of neurons in the input layer and hidden layer, respectively. Furthermore, represents the normalized input value of the input layer, and is the output of neurons in the hidden layer. The final output of the last output layer is calculated in the same way as the output of the hidden layer. The calculated output value of the DNN model is then used to compute the loss function by comparing it with the actual values. Subsequently, an optimization algorithm is used to minimize the loss function and adjust the values of weights and biases. In this study, hyperparameters such as batch size, epochs, and learning rate were determined using the grid search cross-validation method. Table 3 represents the basic configuration of the hidden layers, activation function, and optimizer used for applying the grid search.
Figure 5.
The general architecture of the DNN model.
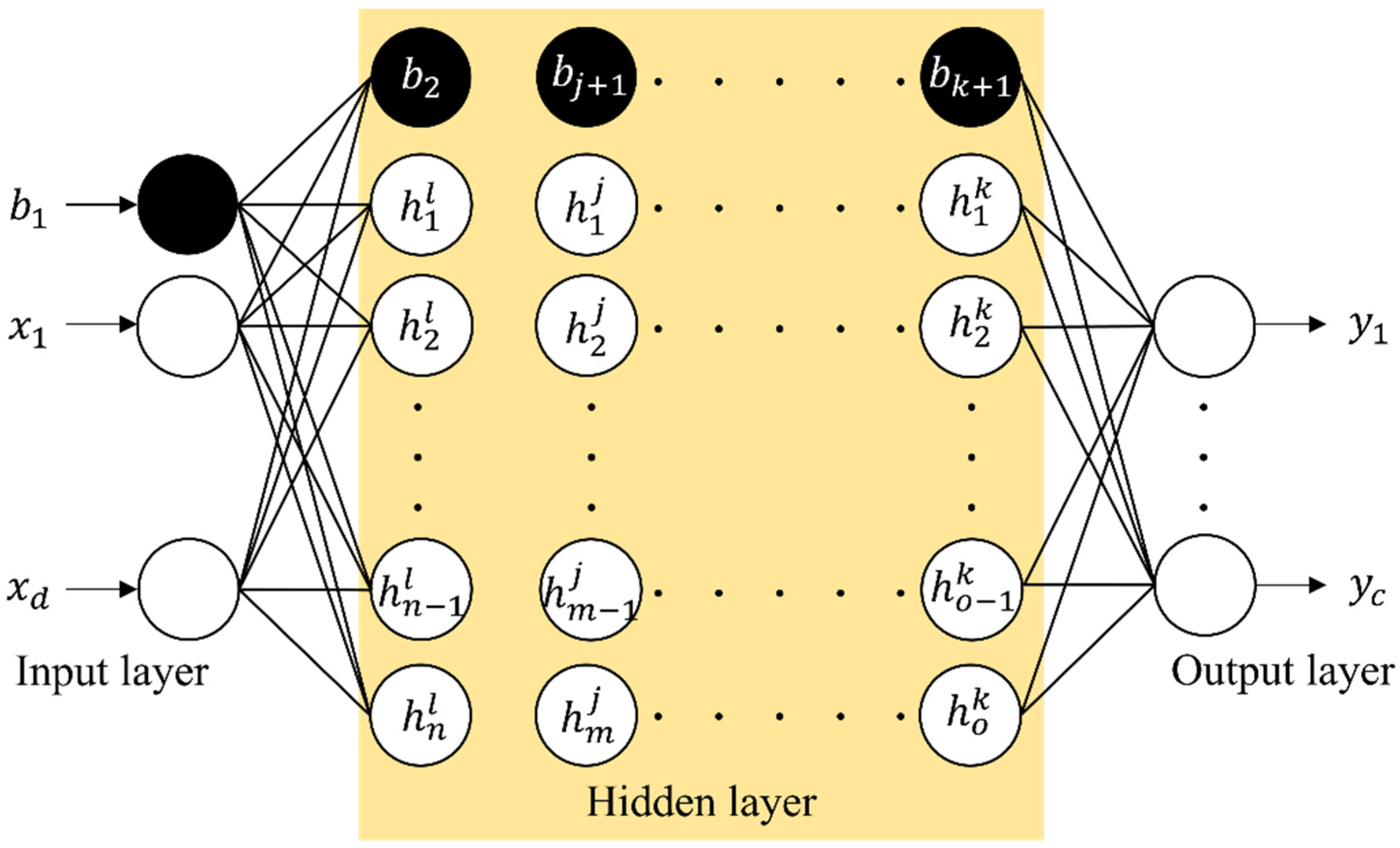
Table 3.
Hyper-parameters of the ANN.
| Layers | Neurons | Activation function | Optimizer |
|---|---|---|---|
| 1st hidden layer | 11 | ReLU | Adam |
| 2nd hidden layer | 22 | ||
| 3rd hidden layer | 44 | ||
| 4th hidden layer | 66 | ||
| 5th hidden layer | 89 |
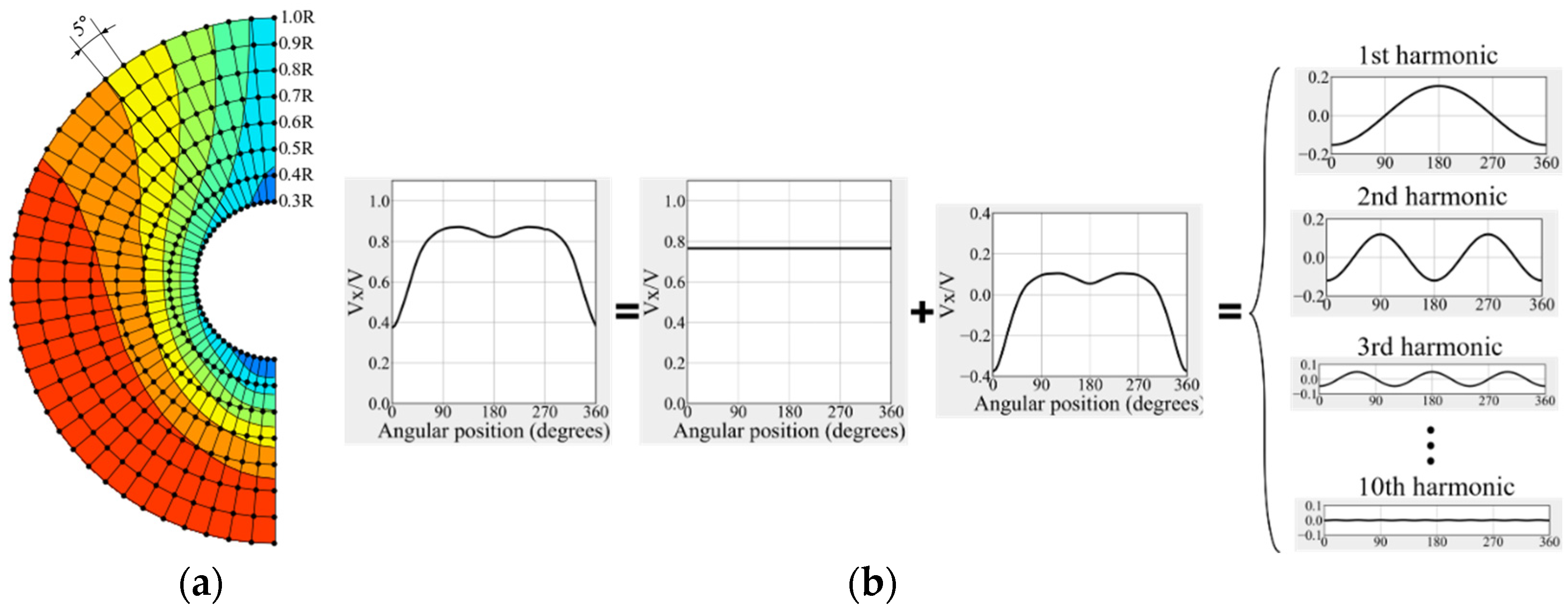
In this study, the DNN was employed to predict the axial velocity distribution in the propeller plane based on the input design variables of the Flow Control Fin (FCF). Thus, the input for the DNN consisted of the design variables , and the flow distribution became the outputs. Here, the angle of attack () was defined as the angle between the local streamline for the baseline hull without the FCF and the baseline of FCF. , and represent the derivatives of the station line (constant ), waterline (constant ), and buttock line (constant ), respectively. These derivatives indicate the inclinations of the hull in each direction relative to the center point where the FCF is attached. In order to enhance the training efficiency, it was essential to align the dimensions of the neural network’s input and output as closely as possible without compromising the detailed representation of the velocity distribution. To obtain the Fourier series coefficients for the axial velocity distribution in the form of polar array (Figure 6) of the propeller plane, harmonic analysis was performed. Specifically, the circumferential distribution of the axial velocity was expressed using a Fourier series up to the 10th order for eight radial positions within the range .
The symmetry of the wake flow distribution makes the sine coefficients , resulting in the utilization of the remaining cosine coefficients as the output of the base DNN model. This Fourier analysis preprocessing was found to improve training efficiency compared to cases without preprocessing. The 693 source datasets used for the base DNN model were divided into 415 training sets, 139 validation sets, and 139 test sets. When individual data sizes significantly differ, the training often fails. To mitigate this, all data was normalized using a Min-Max scaler to ensure sizes ranged from 0 to 1.
Figure 6.
Preprocessing of output data for the neural network: (a) bisecting the propeller plane; (b) harmonic analysis.
Figure 6.
Preprocessing of output data for the neural network: (a) bisecting the propeller plane; (b) harmonic analysis.
3.2. Transfer Learning (TL)
The machine learning algorithms of the data-centric learning method assume that they are trained by the same distribution of train and test datasets [13]. However, in real-world applications, this assumption may not hold. When the dataset changes, machine learning algorithms need to be retrained based on a substantial amount of newly collected training data, which can be time-consuming and costly [14]. To address these issues, transfer learning can be applied, allowing efficient learning with a small amount of new data. Transfer learning involves transferring the weights of a pre-trained neural network model to a new neural network for learning, thereby facilitating the construction of a model with a small amount of newly applied data [15]. The main objective of this study is to apply Deep Neural Networks (DNN) and Transfer Learning (TL) for estimating viscous resistance and wake distribution on various sizes of container ships using the position of flow control fin and hull-form information as input features. Figure 7 provides a brief overview of how transfer learning is applied.
Figure 7.
Overview of the transfer learning.
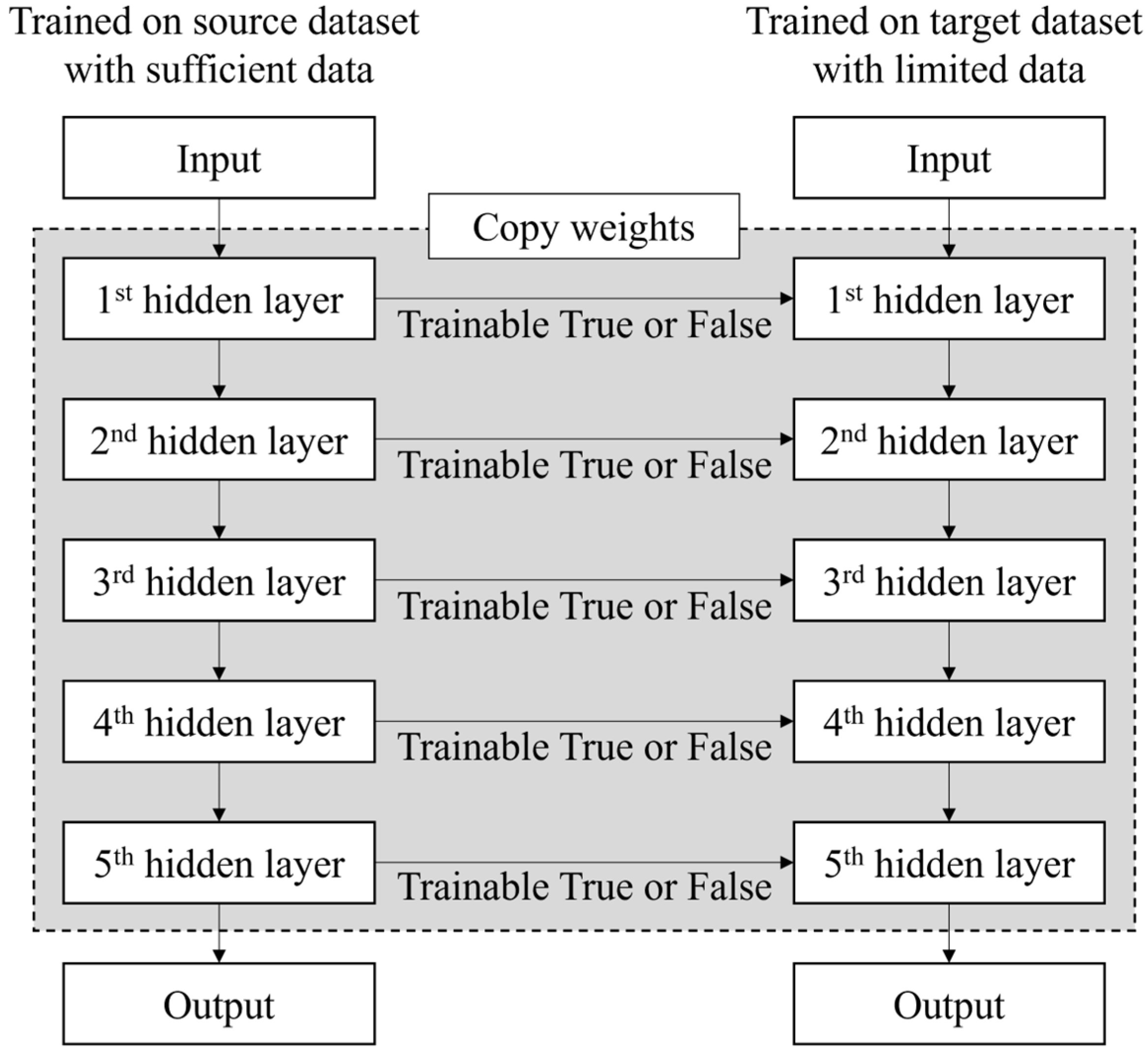
First, the base DNN model is trained and validated using the source dataset (1,000 TEU). Then, a new model is reconfigured (retrained and validated) based on a subset of the target dataset (2,500 TEU and 3,600 TEU), where the knowledge from the base DNN model is transferred. The remaining part of the target dataset is used in the testing phase of the reconfigured model.
3.3. Model application details
Figure 8 illustrates the structure of the algorithm for predicting viscous resistance and wake distribution of new sizes of container ships using transfer learning.
Figure 8.
Workflow of transfer learning.
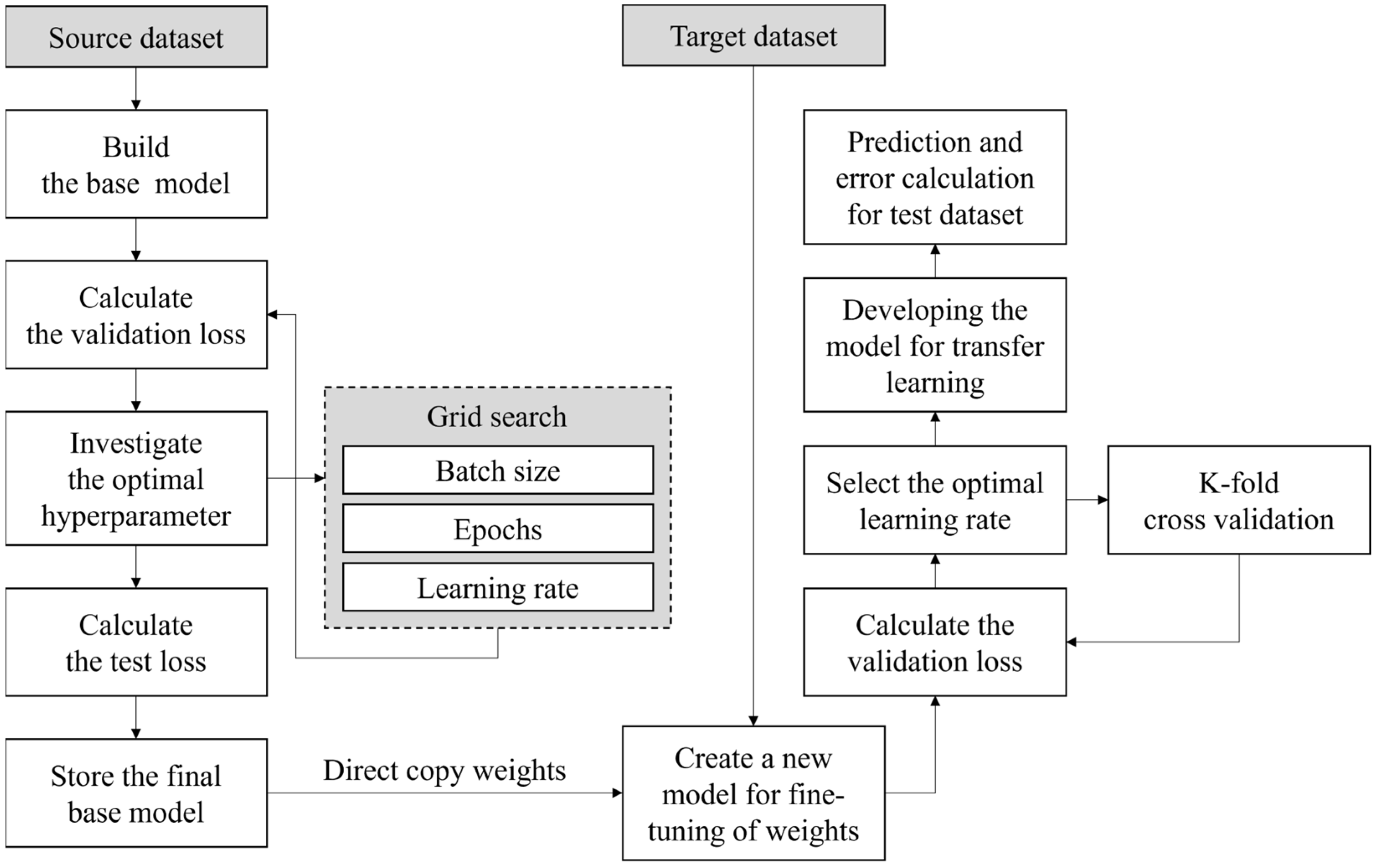
In this study, the source dataset used for training and validation of the base DNN model consists of viscous resistance and wake characteristics based on the flow control fin applied to a 1,000 TEU container ship. When training the DNN model, there are various hyperparameters that the designer needs to set, including batch size, the number of epochs, and the learning rate. The choice of the batch size used in mini-batch gradient descent affects the learning speed and the tracking of the global minimum point of the cost function. The number of epochs, which indicates how many times the entire dataset is iterated over during training, can lead to issues of overfitting and underfitting. Furthermore, selecting an appropriate optimizer and the corresponding learning rate is crucial based on the learning model and dataset used. To optimize these various hyperparameters, a grid search cross-validation method was applied, which involves exploring the optimal parameters by combining multiple settings specified by the designer. The loss function for optimizing the hyperparameters was the Mean Square Error (MSE). The base DNN model constructed with the optimal hyperparameters was then used to evaluate the learning performance on the test dataset.
Using the well-constructed base DNN model as a foundation, transfer learning was applied to create a restructured DNN model for knowledge transfer to 2,500 TEU and 3,600 TEU (KCS) as target datasets. For the reconstruction of the model through transfer learning, it’s necessary to fine-tune the weights of the base DNN model using a smaller learning rate compared to the original learning rate. To determine an appropriate learning rate for the small amount of target data, K-fold cross-validation was performed to assess the general prediction performance with varying learning rates. Subsequently, the effect of fixing the number of layers during the reconstruction of the DNN through transfer learning was investigated. Exactly, the study adopted transfer learning with fine-tuning, which involves adjusting or maintaining the weights of specific layers among the hidden layers of the base DNN model. This was done by training on various cases and comparing the results for each case. In this study, the application of transfer learning using a small dataset for container ships of different sizes demonstrates the potential for predicting resistance and wake distribution based on FCF position with sufficient accuracy.
3.4. Accuracy evaluation
The performance evaluation metrics used for the proposed model are as follows.
-
Mean Squared Error; MSE estimates the standard deviation of the random component in the data and is used to optimize the validation loss during model training. It is defined as follows:where is the true value of the sample, is the estimated output of thesample and is the number of samples.
-
Mean Absolute Percentage Error; MAPE is used to compare the accuracy of predictions and is defined as follows:Here, , and have the same meanings as mentioned in the previous descriptions. A lower MAPE indicates better predictions.
- Coefficient of Determination; The coefficient of determination, or , is defined to demonstrate how well the model predicts the variability of the observed and unobserved samples. The best possible value is 1, and it can also be negative, indicating that the model cannot follow the true datasets. is defined as follows:
Here, represents the mean of the actual samples, and the other variables have the same meanings as explained earlier.
4. Results
4.1. Uncertainties analysis in CFD verification
In this study, CFD analyses were conducted on a total of three grid systems by increasing and decreasing the grid size with a refinement ratio of . The total number of cells and model-scale viscous resistance for each grid system corresponding to the three different sizes of containerships are presented in Table 4. Due to the use of unstructured grids in CFD analysis, the randomness in grid generation leads to a limitation in precisely controlling the total number of cells.
Table 4.
Cell number of the grid system.
| Class | Fineness | # of grid cells | Rvm [N] |
|---|---|---|---|
| 1,000 TEU | Coarse | 398,208 | 26.05 |
| Medium | 1,047,619 | 26.19 | |
| Fine | 2,923,468 | 26.31 | |
| 2,500 TEU | Coarse | 400,585 | 27.35 |
| Medium | 1,080,754 | 27.55 | |
| Fine | 3,074,301 | 27.72 | |
| 3,600 TEU | Coarse | 391,605 | 33.99 |
| Medium | 913,245 | 34.09 | |
| Fine | 2,533,138 | 34.27 |
The results of numerical error and uncertainty assessment for the three different sizes of containerships are summarized in Table 5. Since all the convergence ratios are between 0 and 1, it can be assumed that the model-scale viscous resistance () converges monotonically. Therefore, numerical error and uncertainty were estimated using the generalized Richardson Extrapolation (RE) method. The results show that when performing double body analysis for the three containerships, it can be expected numerical uncertainty of Rvm due to grid effects to be within 2% for all cases. Based on the uncertainty results, data collection for machine learning was carried out using the medium grid system for all cases. The coarse grid system faced difficulties in generating a smooth flow control fin due to its thin structure. The fine grid system had a high number of cells, leading to extended analysis time. Consequently, the medium grid system was chosen to strike a balance between accuracy and computational efficiency.
Table 5.
Results of numerical error and uncertainty analysis for .
| Class | |||||||
|---|---|---|---|---|---|---|---|
| 1,000 TEU | -0.127 | -0.138 | 0.919 | -0.127 | 0.359 | 1.37 | |
| 2,500 TEU | -0.176 | -0.195 | 0.903 | -0.176 | 0.489 | 1.77 | |
| 3,600 TEU | -0.178 | -0.106 | 0.907 | -0.178 | 0.496 | 1.46 |
The subscript ‘G’ refers to grid size.
4.2. Prediction results using source dataset (the base DNN model)
The results of the grid search cross-validation for hyperparameter optimization of the DNN model using a total of 690 source data (1,000 TEU) are presented in Figure 9. The Mean Squared Error (MSE) was used to assess the prediction accuracy for each hyperparameter. In this study, three hyperparameters were optimized, and the optimal values for each parameter are as follows; 1) batch size: [4, 8, 16, 32, 64, 128], 2) epochs: [100, 500, 1000, 2000, 3000] and 3) learning rate: [0.001, 0.005, 0.01, 0.05, 0.1].
Figure 9.
Grid search results for DNN model using source dataset.
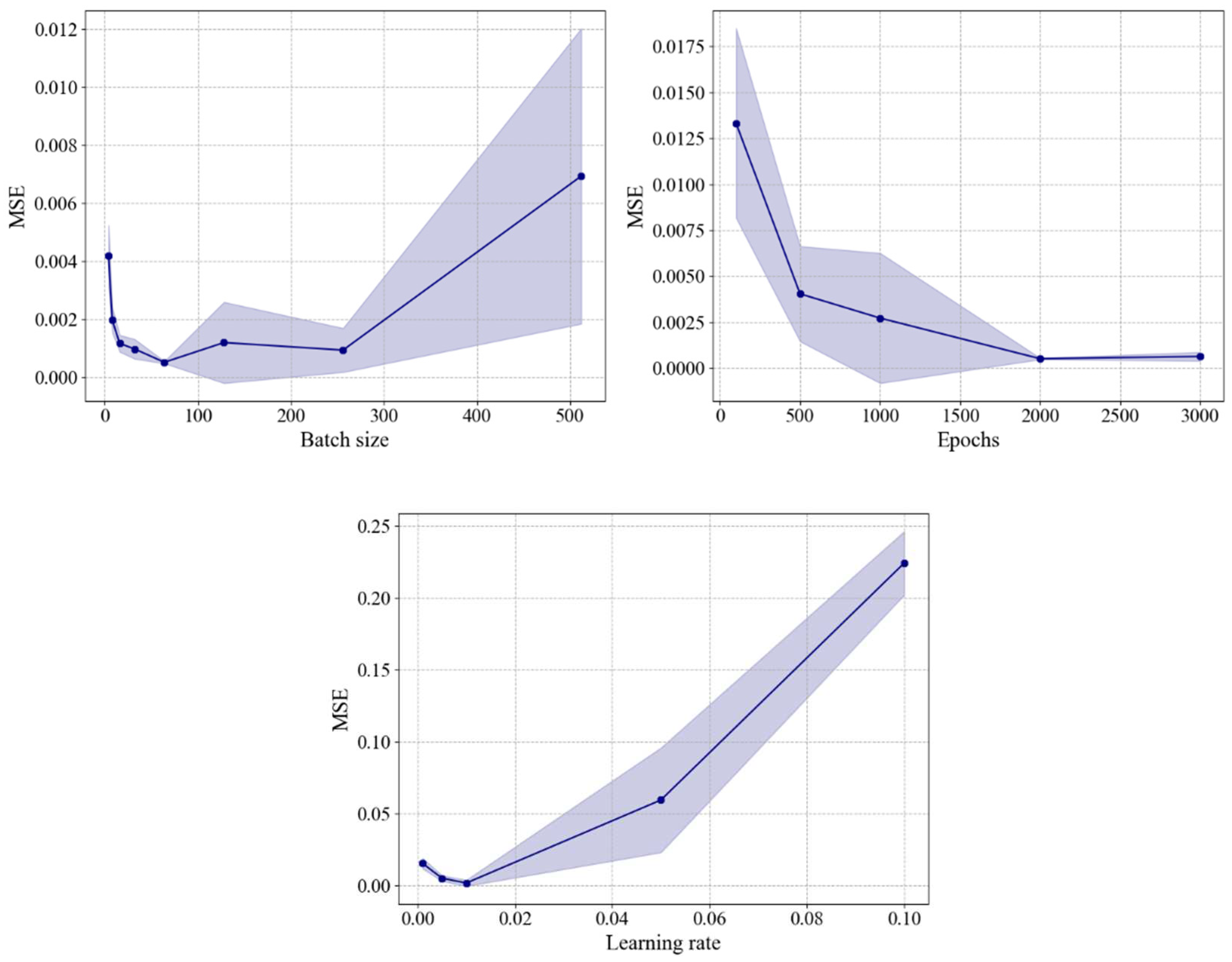
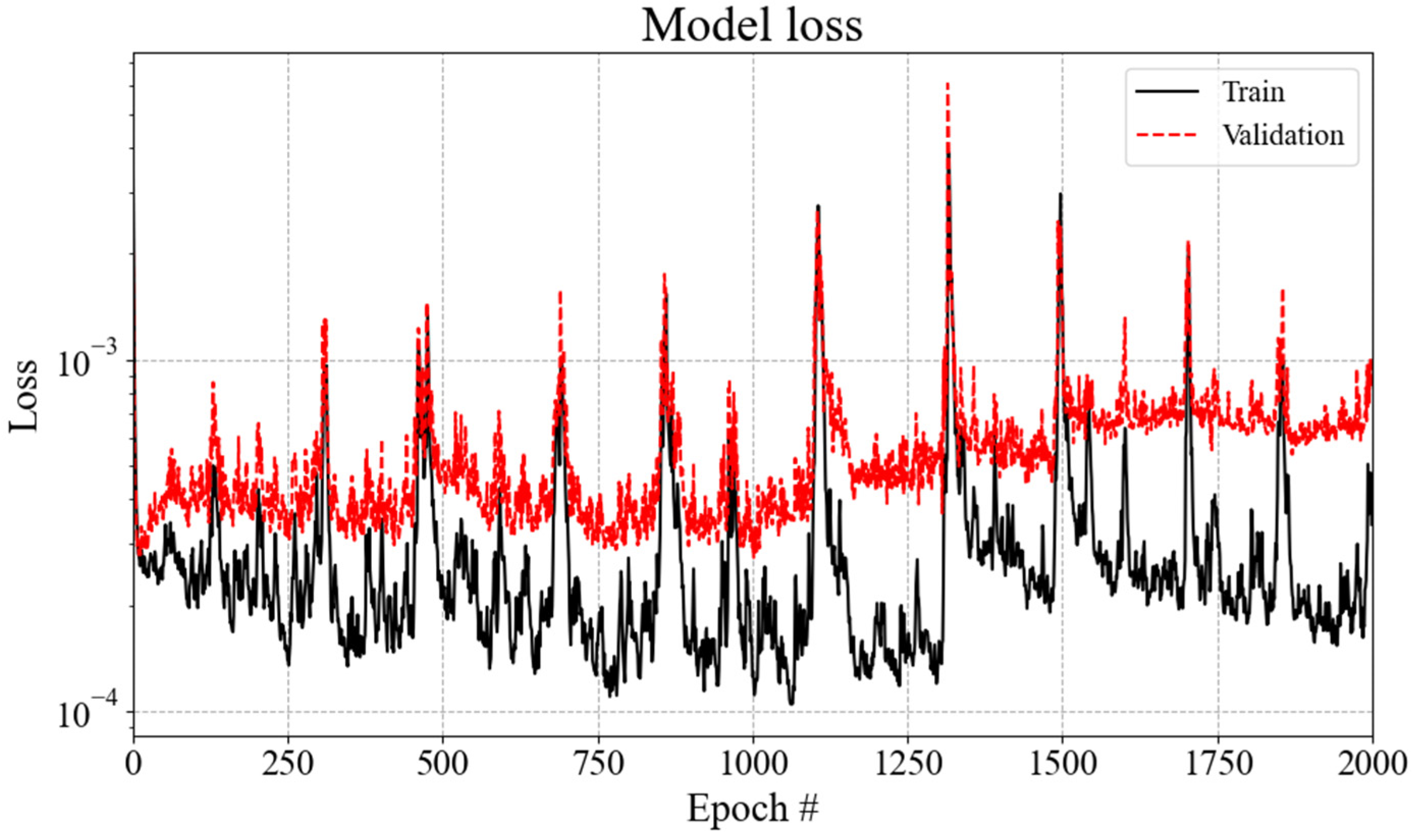
The final hyperparameters determined for the Base DNN model were chosen based on the consideration of a small mean squared error value while considering the training speed. The training hyperparameters for the base DNN model were set as follows: batch size = 64, epochs = 2000, and learning rate = 0.01. Using this combination of selected hyperparameters, the model was trained for a total of 18,000 iterations on the 1000 TEU containership dataset. The prediction accuracy of the base DNN training model is quantified by an MSE of approximately 0.0008, as shown in Figure 10. The peak of the loss typically occurs during mini-batch training with split data.
Figure 10.
Loss for the base DNN models.
The prediction accuracy for the test dataset not used during training was evaluated to validate the learning level of the base DNN model. Table 6 presents the evaluation metrics for the test dataset of the source data, which is the 1,000 TEU containership. MSE and MAPE indicate higher prediction accuracy as their values become smaller, and an value closer to 1 signifies that the test dataset not used in training is being well predicted. The DNN model can accurately predict viscous resistance and wake distribution in the propeller plane, as evidenced by the high level of accuracy. Figure 11 displays the predicted viscous resistance results for the two above-mentioned test cases. The average error of the viscous resistance coefficient of model is significantly small, being , which is less than 0.005% of the target value. Figure 12 compares the true data obtained from CFD analysis with the results predicted by the DNN. The true wake distribution is given on the left, and the predicted data is shown on the right. The true data for the circumferential distribution of the axial velocity component is depicted as black dashed lines, while the predicted data is represented by red symbols and solid lines. As observed in Figure 12, the true and predicted data closely match with high accuracy. The DNN model is capable of accurately predicting not only wake distribution but also viscosity resistance. The neural network that serves as the basis for transfer learning on a small amount of dataset requires sufficient prediction accuracy. Given the results above, it can be concluded that the base DNN model can effectively capture the design variables of the FCF and establish a strong association with both the viscous resistance coefficient and wake distribution, demonstrating high accuracy in its predictions.
Table 6.
MSE, MAPE and values for the base DNN model
| .MSE | MAPE [%] | |
|---|---|---|
| 0.00081 | 7.16 | 0.98 |
Figure 11.
Evaluation of prediction accuracy by the viscous resistance coefficient for the base DNN model.
Figure 11.
Evaluation of prediction accuracy by the viscous resistance coefficient for the base DNN model.
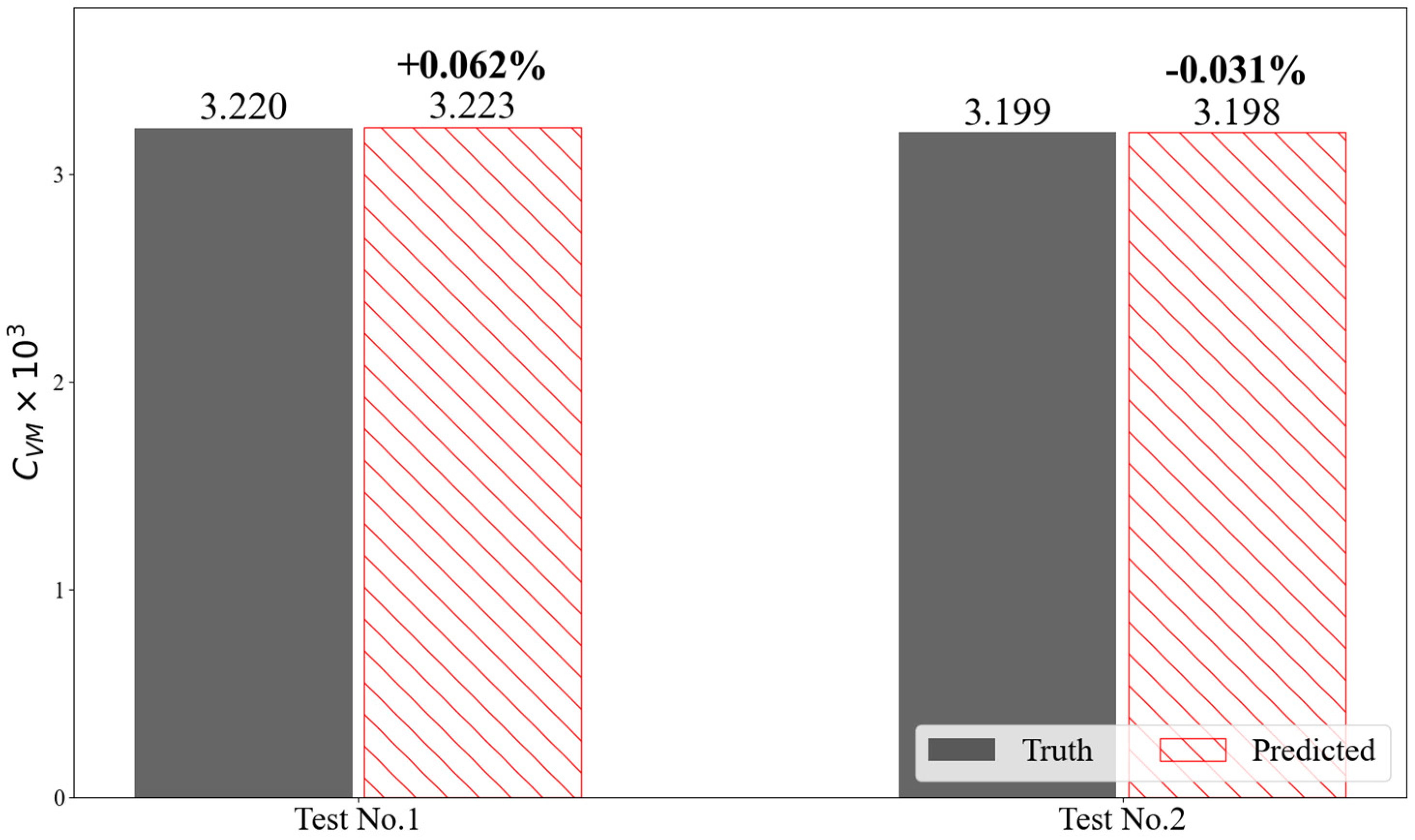
Figure 12.
Evaluation of prediction accuracy by harmonic wake distribution and axial wake distribution for the base DNN model: (a) Test data no.1; (b) Test data no.2.
Figure 12.
Evaluation of prediction accuracy by harmonic wake distribution and axial wake distribution for the base DNN model: (a) Test data no.1; (b) Test data no.2.
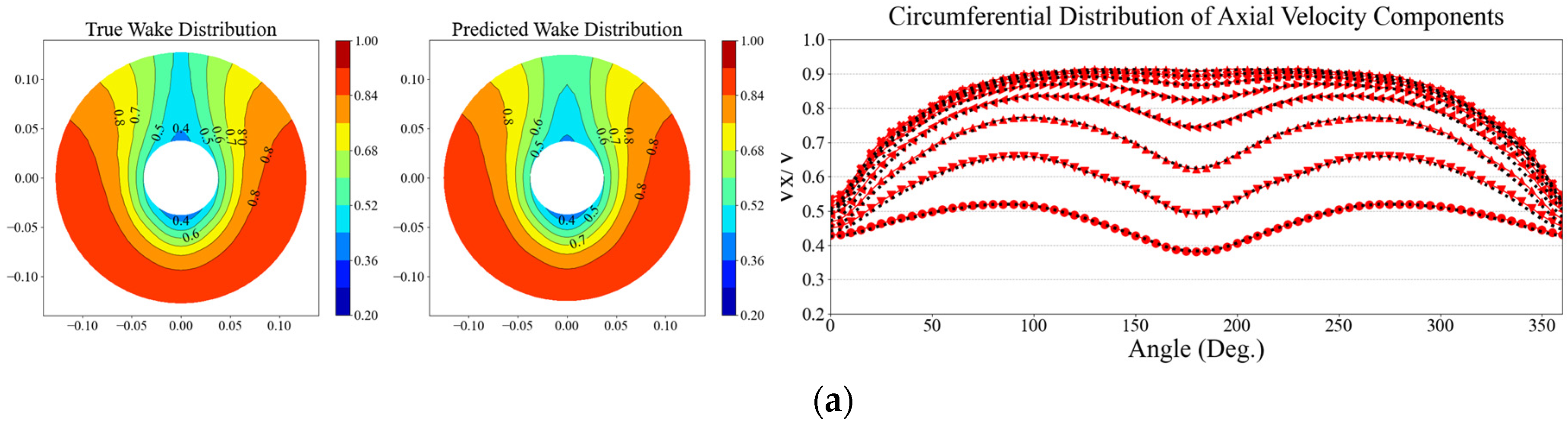
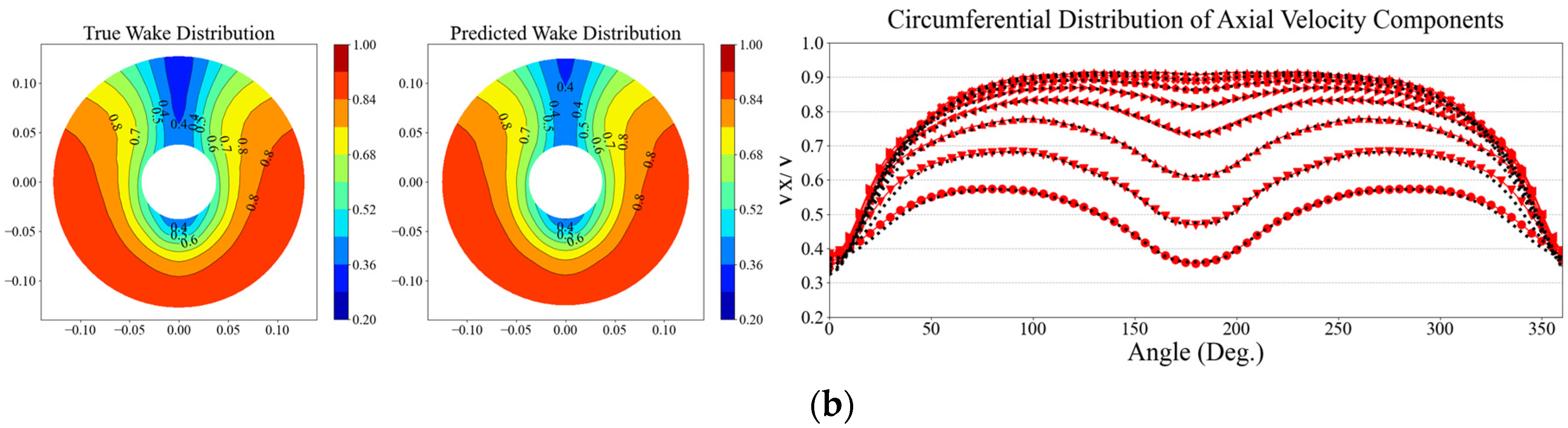
4.3. Prediction results using target dataset (DNN-TL model)
The DNN-TL model is reconstructed and retrained based on the weights of the previously trained DNN model, using only the target dataset. Since the size of the target dataset is considerably smaller (150 datasets) compared to the source dataset, a smaller learning rate is necessary to ensure training accuracy. Therefore, it is necessary to find the optimal learning rate value for the training dataset of the DNN-TL model The optimization was performed with learning rates [0.00001, 0.00005, 0.0001, 0.0005, 0.001, 0.005, 0.01], and the comparison of MSE values for each value is shown in Figure 13. In this study, the optimal learning rate value for predicting the viscous resistance and wake distribution of the target dataset (2,500 TEU and 3,600 TEU) is determined to be 0.0005. Based on this, the parameters of the DNN-TL model were constructed. To verify the prediction of viscous resistance and wake distribution based on transfer learning, different configurations were tested: DNN-TL models with 1, 4, and 5 fixed layers, as well as a DNN-TL model without any fixed layers (Table 7). Fine-tuning was performed on each of these configurations, and their performances were compared. In the DNN-TL model, the weights of neurons are initialized based on the previously trained base model, and the model is retrained and reconstructed using the training dataset from the target dataset.
Figure 13.
Optimization of the learning rate for DNN-TL model using target dataset.
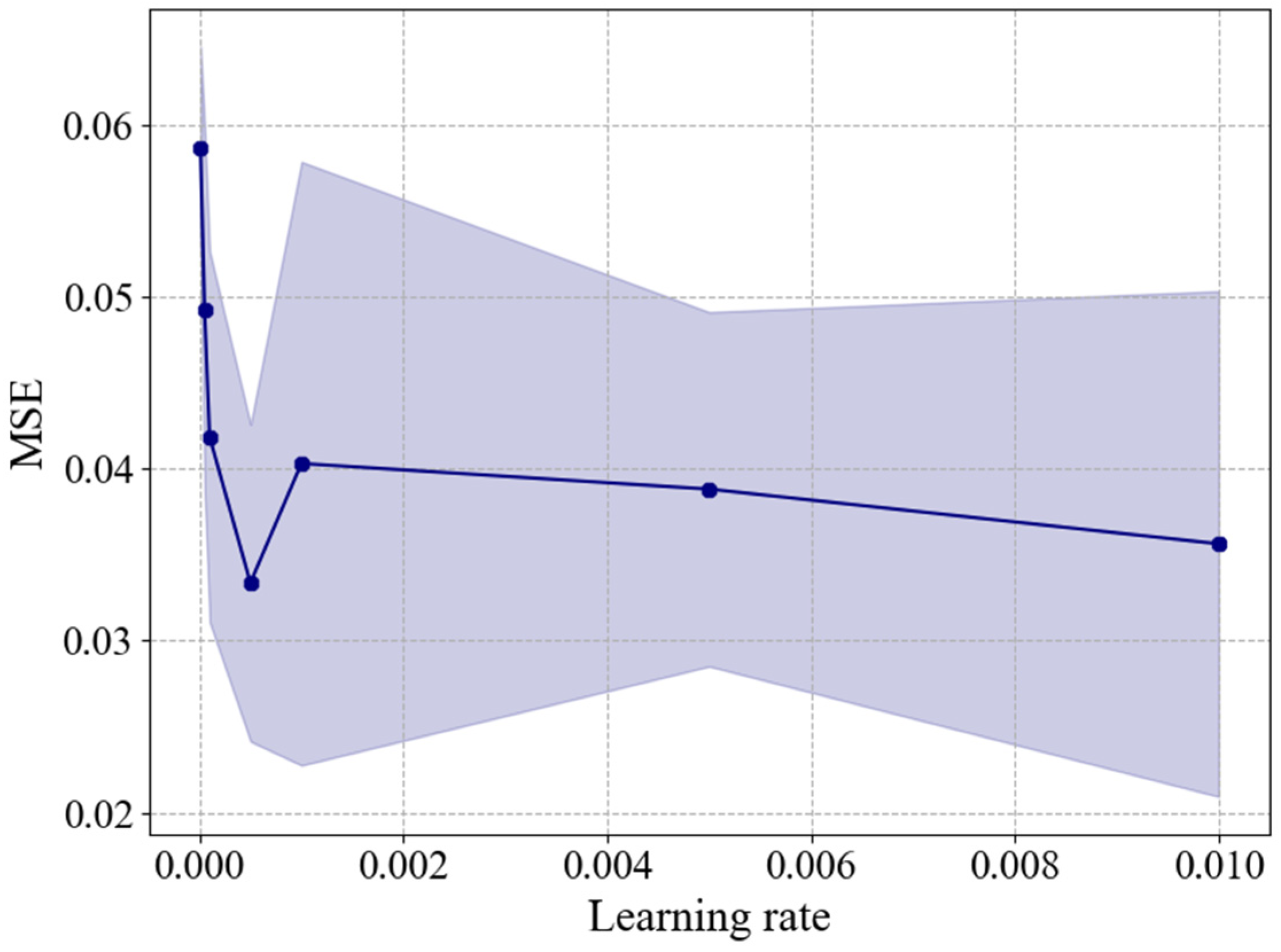
Table 7.
Fine-tuning for DNN-TL.
| 1st hidden layer | 2nd hidden layer | 3rd hidden layer | 4th hidden layer | 5th hidden layer | |
|---|---|---|---|---|---|
| All fixed layer | Fixed | Fixed | Fixed | Fixed | Fixed |
| Fixed 4 layer | Fixed | Fixed | Fixed | Fixed | Train |
| Fixed 1 layer | Fixed | Train | Train | Train | Train |
| No fixed layer | Train | Train | Train | Train | Train |
The prediction accuracy based on fine-tuning of hidden layer weights was evaluated to verify the level of learning. Figure 14 compares the predicted viscous resistance coefficients of the model ship for each fine-tuning condition. The black-filled bar chart represents the true values obtained from CFD analysis, while the red dashed-filled bars represent the predicted results from each fine-tuning condition. The viscosity resistance performance was compared using one test data for each of the 2,500 TEU and 3,600 TEU containerships. Figure 15 and Figure 16 illustrate the comparison of predicted results for harmonic wake distribution and circumferential distribution of axial velocity components for both 2,500 TEU and 3,600 TEU. The left figure shows the harmonic wake distribution obtained from CFD analysis, and the middle part displays the predicted wake distribution from each fine-tuning condition. In the case where the weights of all five hidden layers are fixed (All fixed layer case), there is an error of 18% specifically in the viscosity resistance coefficient () for the 3,600 TEU containership. The accuracy of predicting the axial velocity distribution in the propeller plane is also quite low, and it can be observed that it is trying to follow the wake distribution characteristics of the 1,000 TEU used in the base DNN model. In the case of ‘Fixed 4 layer’, where only the weights of the last layer among the layers were trained, for 2,500 TEU and 3,600 TEU show errors of 0.38% and -3.6% respectively. This indicates an improvement in prediction accuracy compared to the ‘All fixed layer’ case. In Figure 15(b) and Figure 16(b), compared to the ‘All fixed layer’, there is an attempt to capture the characteristics of each hull-form. This indicates that the weights of the last hidden layer among the hidden layers play a role in conveying a certain level of knowledge about the target datasets (2,500 TEU and 3,600 TEU). The prediction results for the Fixed 1 layer, where only the weights of the first hidden layer are not retrained, and the No fixed layer, where all layers are retrained, show a quite similar trend. The prediction results for both 2,500 TEU and 3,600 TEU exhibit errors within 0.5%. When observing the wake distribution and axial velocity components figures, it is evident that the characteristics of each linear component are sufficiently captured.
Figure 14.
Evaluation of prediction accuracy by the viscous resistance coefficient for the target dataset (2,500 TEU and 3,600 TEU) between each fine-tuning condition.
Figure 14.
Evaluation of prediction accuracy by the viscous resistance coefficient for the target dataset (2,500 TEU and 3,600 TEU) between each fine-tuning condition.
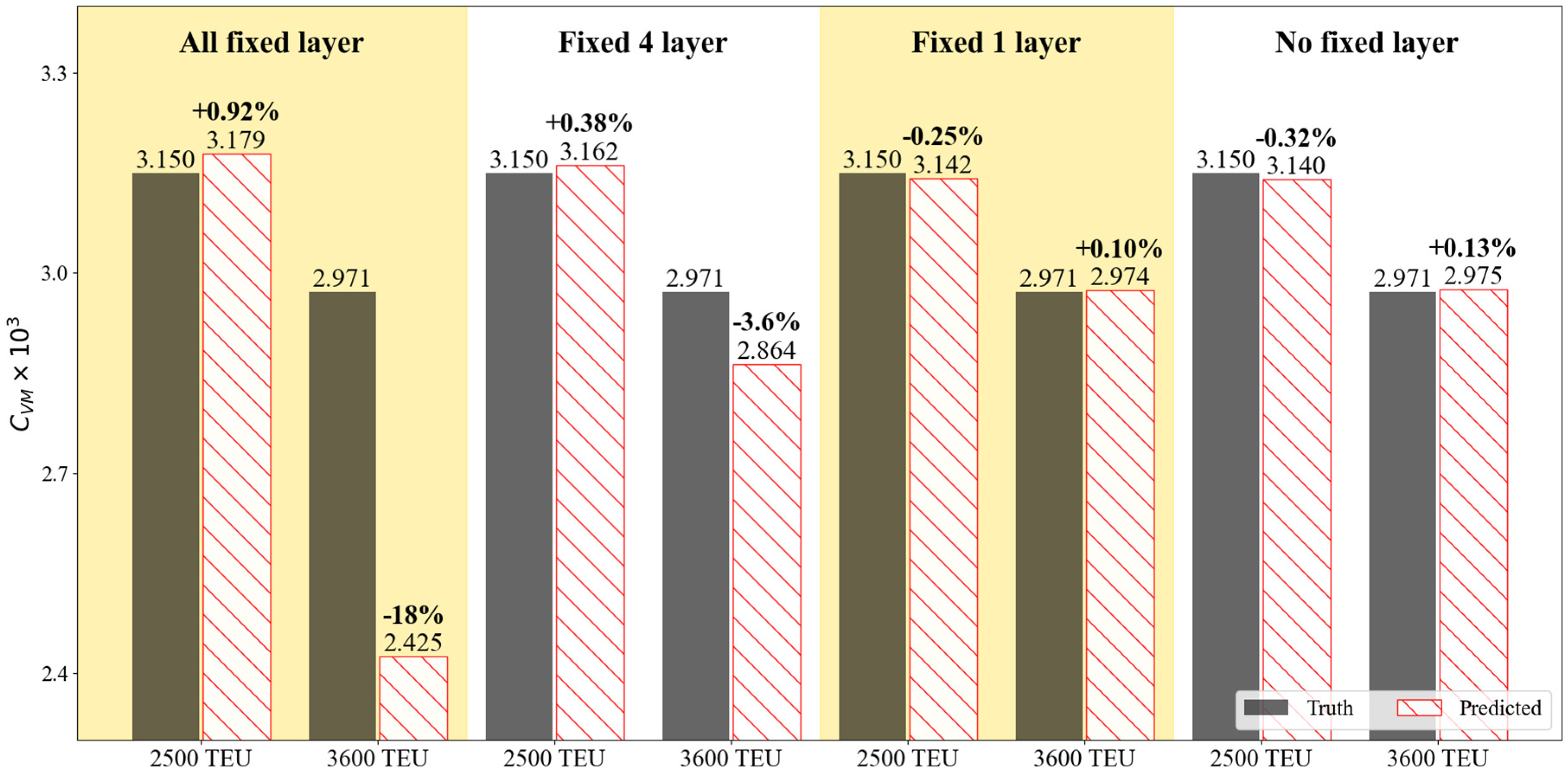
Figure 15.
Evaluation of prediction accuracy by harmonic wake distribution and axial wake distribution for 2,500 TEU between each fine-tuning condition: (a) All fixed; (b) Fixed 4 layer; (c) Fixed 1 layer; (d) No fixed layer.
Figure 15.
Evaluation of prediction accuracy by harmonic wake distribution and axial wake distribution for 2,500 TEU between each fine-tuning condition: (a) All fixed; (b) Fixed 4 layer; (c) Fixed 1 layer; (d) No fixed layer.
Figure 16.
Evaluation of prediction accuracy by harmonic wake distribution and axial wake distribution for 3,600 TEU between each fine-tuning condition: (a) All fixed; (b) Fixed 4 layer; (c) Fixed 1 layer; (d) No fixed layer.
Figure 16.
Evaluation of prediction accuracy by harmonic wake distribution and axial wake distribution for 3,600 TEU between each fine-tuning condition: (a) All fixed; (b) Fixed 4 layer; (c) Fixed 1 layer; (d) No fixed layer.
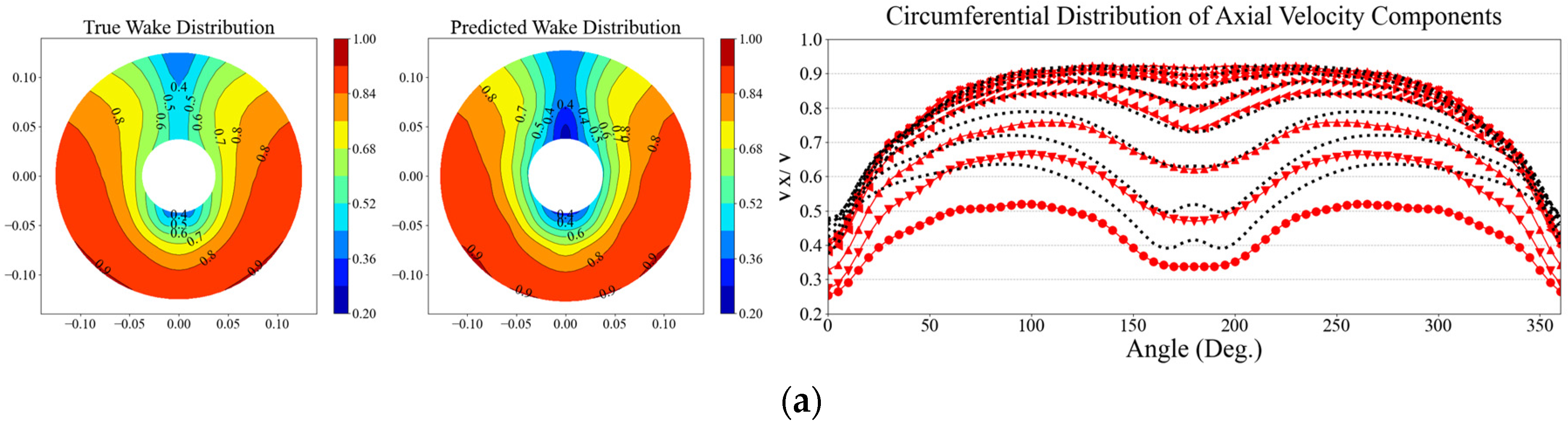
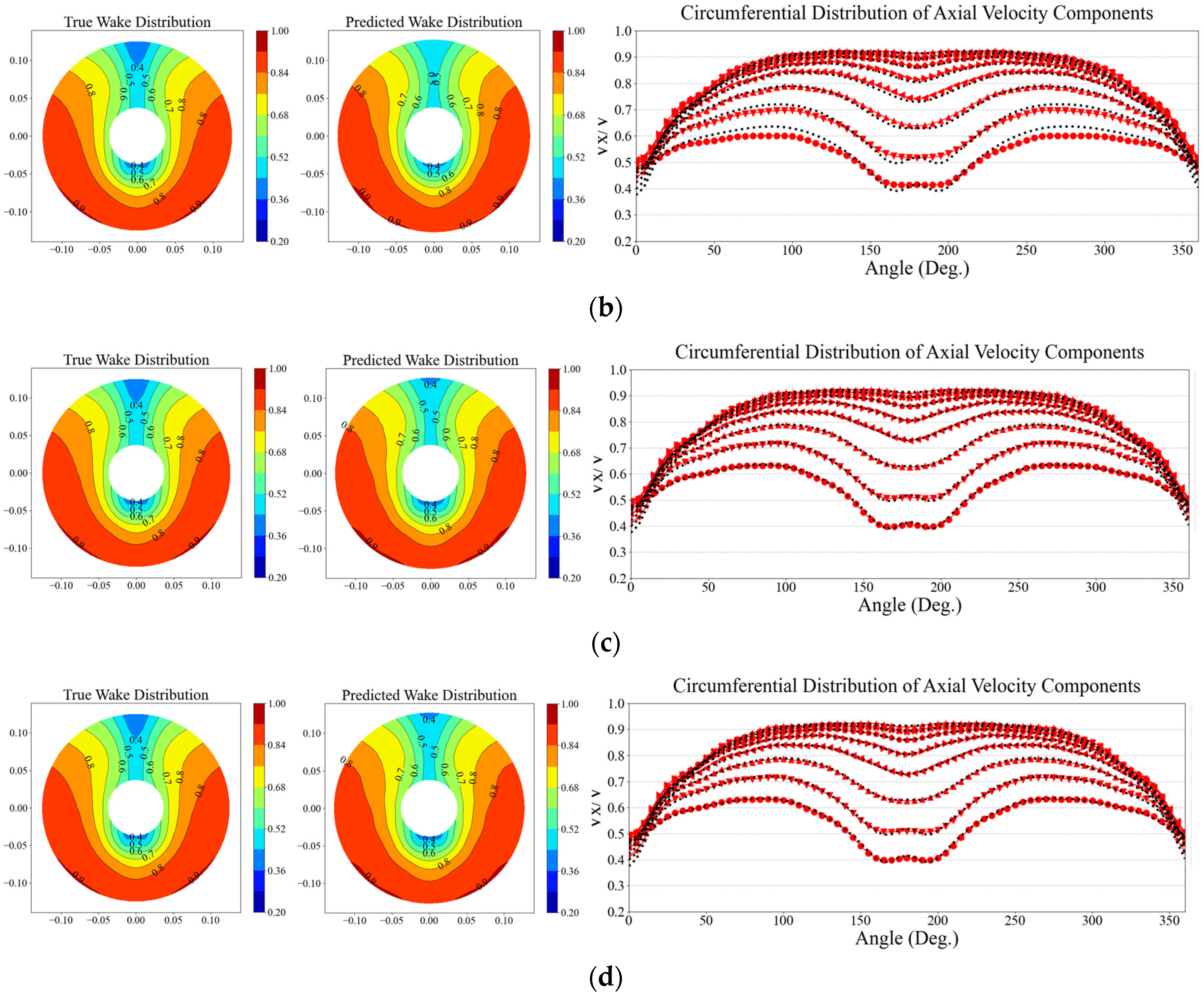
Table 8 presents the prediction accuracy metrics for the test dataset that was not used in the training process under each fine-tuning condition. MSE and MAPE are metrics where lower values indicate higher accuracy in predictions. , on the other hand, is a measure of how well the model explains the variance in the data. A higher value, closer to 1, indicates a better predictive performance. Generally, when , it is considered to have a reasonably good predictive accuracy, while indicates moderate predictive performance, and suggests poor predictive performance [16]. The score for the ‘All fixed layer’ case is -4.163, indicating no prediction capability on the test dataset. Conversely, when the first hidden layer is fixed, it exhibits the highest scores across all accuracy metrics. It is considered that the weights of the first layer in the previously trained base DNN model were tailored to capture the characteristics of the viscous resistance coefficient on containership and the axial velocity on the propeller plane. The remaining hidden layers seem to have been designed to understand the fluid characteristics by hull-form. To assess the level of prediction accuracy in this study, the performance was compared to accuracy metrics from other literature that used transfer learning for predictions. Solis and Calvo-Valverde [17] applied DNN and TL to time series prediction, and their optimal prediction model achieved a MAPE value of approximately 9%. Zhou et al. [18] predicted the dynamic behavior of a gas turbine engine using transfer learning, and in their optimal prediction model, they achieved MSE and values of 0.00466 and 0.881, respectively. The MSE, MAPE, and values in this paper all fall within a similar range, indicating that the prediction model applied with transfer learning is at a satisfactory level of accuracy.
Table 8.
MSE, MAPE and values for each fine-tuning conditions
| . | MSE | MAPE [%] | |
|---|---|---|---|
| All fixed layer | 0.3083 | 182.4 | -4.163 |
| Fixed 4 layer | 0.0307 | 24.88 | 0.499 |
| Fixed 1 layer | 0.0086 | 13.89 | 0.854 |
| No fixed layer | 0.0185 | 18.40 | 0.703 |
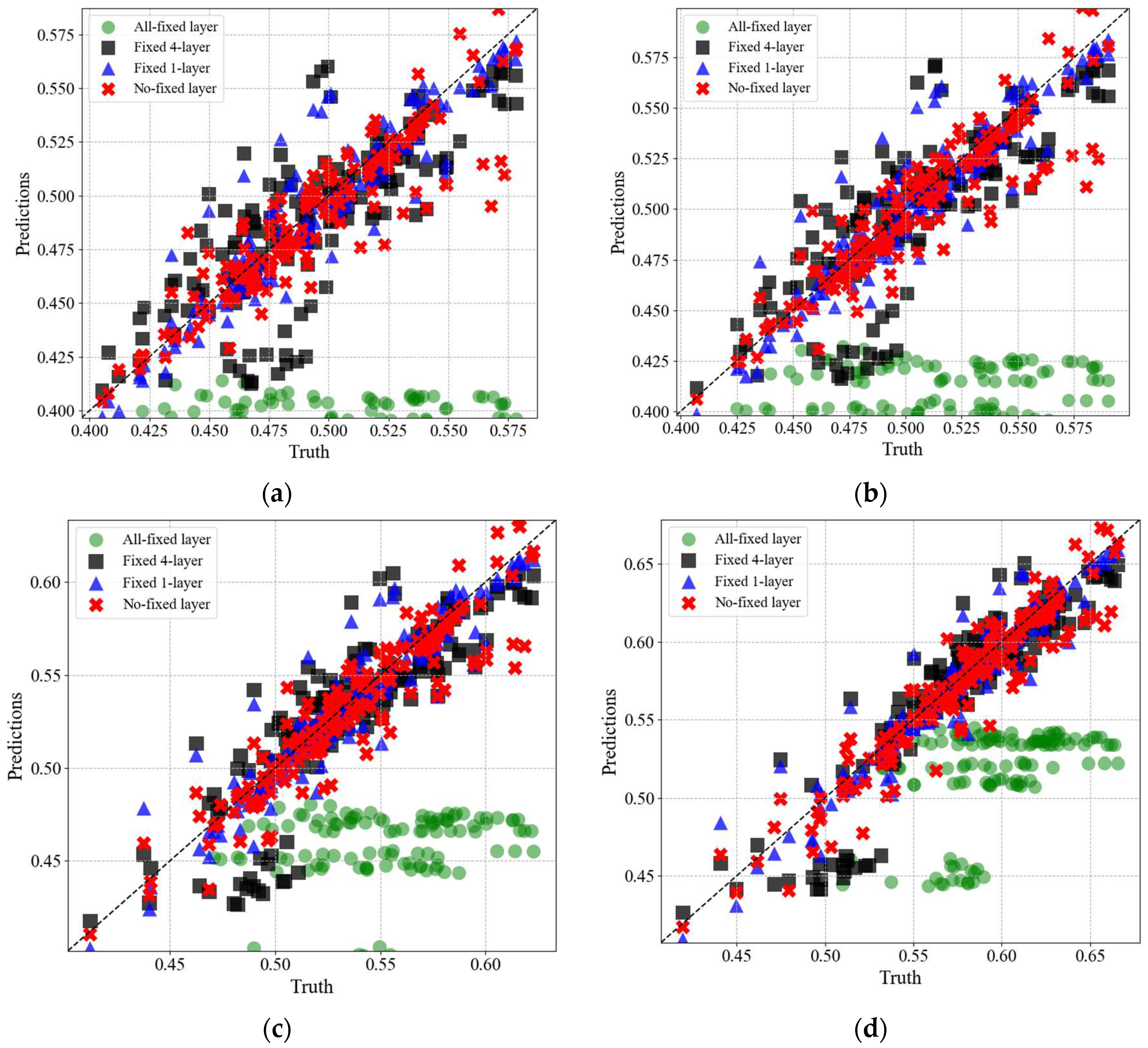
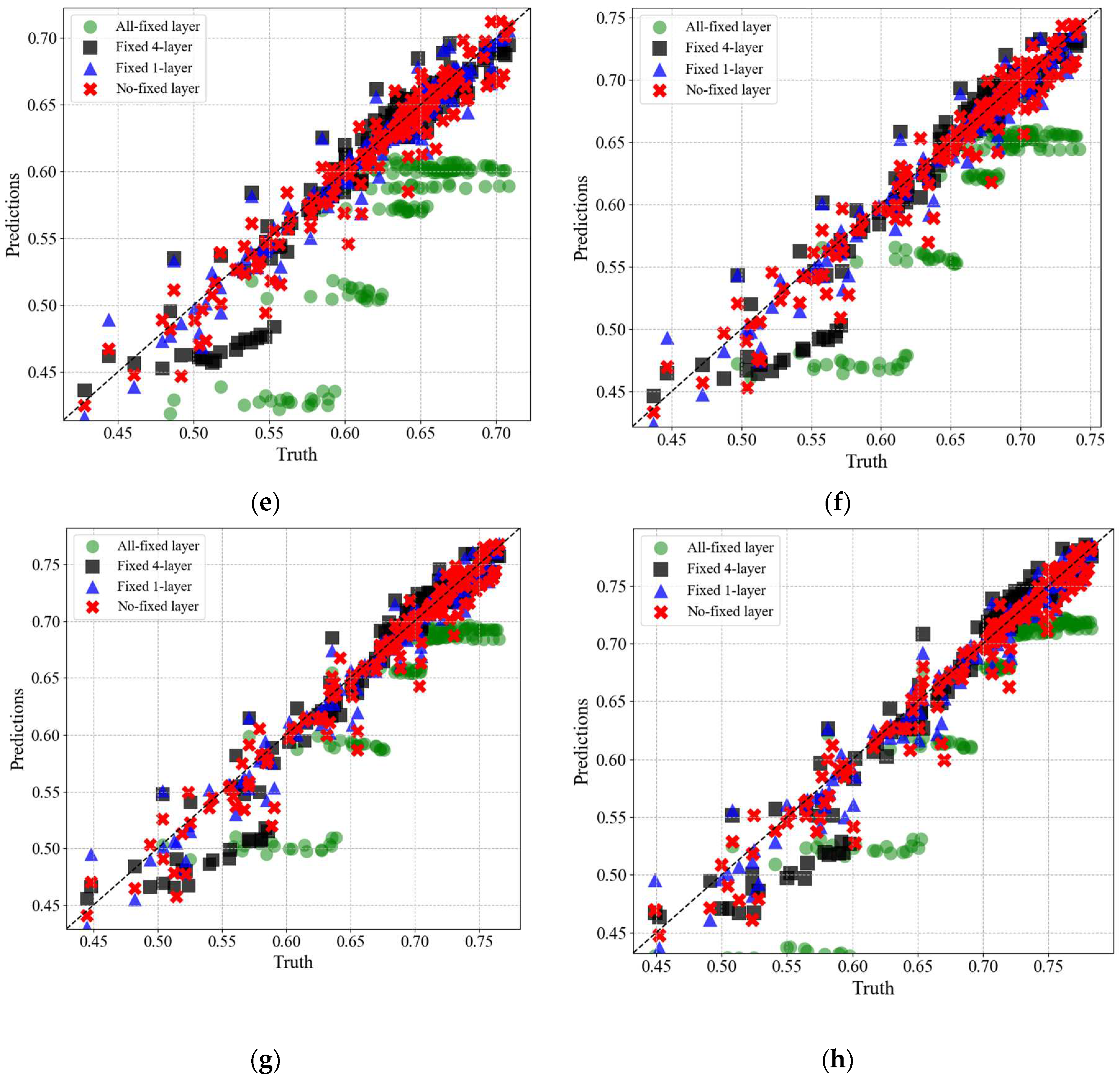
Figure 17 compares the predicted radial profiles of axial velocity components from the four tuning cases with their true values. The green circles represent the predictions from the ‘All fixed layer’ condition, the black squares are from the case where the first four layers were fixed (Fixed 4 layer), the blue triangles represent the condition where only the first layer was fixed (Fixed 1 layer), and the red ‘X’ symbols depict the predictions from the ‘No fixed layer’ condition. In the case of ‘All fixed layer’, significant discrepancies are observed between the predicted values and the true values across all radii. On the other hand, for the ‘Fixed 1 layer’ and ‘No fixed layer’ cases, it can be observed that the predicted values closely follow the trends of the true values.
Figure 17.
Predictions for the circumferential distribution of axial velocity components for each radius: (a) R=0.30; (b) R=0.40; (c) R=0.50; (d) R=0.60; (e) R=0.70; (f) R=0.80; (g) R=0.90; (h) R=1.00.
Figure 17.
Predictions for the circumferential distribution of axial velocity components for each radius: (a) R=0.30; (b) R=0.40; (c) R=0.50; (d) R=0.60; (e) R=0.70; (f) R=0.80; (g) R=0.90; (h) R=1.00.
5. Conclusions
This paper proposes a novel methodology for predicting the resistance performance and wake distribution of Flow Control Fins (FCFs) on containerships of various sizes using Deep Neural Network (DNN) through transfer learning. The main contribution of this paper lies in introducing DNN to predict the outcomes in a shorter time compared to traditional Computational Fluid Dynamics (CFD) simulations, which are used to assess the performance based on the locations of FCFs on containerships of different sizes. Another novel aspect is the utilization of Transfer Learning (TL) to enhance the efficiency of training using a limited amount of data. Firstly, a base DNN model is constructed based on a relatively large source dataset of 690 cases (1,000 TEU). Then, transfer learning is applied to predict the performance of smaller target datasets (2,500 TEU and 3,600 TEU) using the base DNN model as a foundation. Furthermore, fine-tuning between layers in the transfer learning process is employed to identify the conditions that yield the highest learning accuracy.
As a result, the first layer of the base DNN model was fixed, and the rest of the layers were retrained and reconfigured conditions showed higher scores in accuracy metrics. When evaluated using the test dataset not involved in the transfer learning training, the MSE, MAPE, and were found to be 0.0086, 13.89%, and 0.854, respectively, indicating the highest accuracy. Additionally, in terms of the viscous resistance coefficient (), the accuracy was within 0.5%. This study demonstrates the procedure in which machine learning techniques, particularly transfer learning, can contribute to the advancement of computational design technology. The current application of transfer learning-based predictive capabilities is not limited to specific case studies. By adopting the optimization techniques, it could be extended to the optimal design of FCFs’ positions for various types of containerships, which will be the topic of future study.
Author Contributions
Conceptualization, I.L.; methodology, M.L.; software, M.L.; validation, I.L.; formal analysis, M.L.; investigation, M.L.; resources, M.L.; data curation, M.L.; writing—original draft preparation, M.L.; writing—review and editing, I.L.; visualization, M.L.; supervision, I.L.; project administration, I.L.; funding acquisition, I.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Ministry of Science and ICT of Korea (No. 2022R1A2C2010821).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no competing interests.
References
- Samsung Heavy Industry (2007), Flow control appendages for improvement of pressure resistance and hull vibration, Korean patent 0 B 1007.
- Lee, H. D.; Hong, C. B.; Kim, H. T.; Choi, S. H.; Han, J. M.; Kim, B.; Lee, J. H. Development and application of energy saving devices to improve resistance and propulsion performance. The Twenty-fifth International Ocean and Polar Engineering Conference, Kona, Big Island, Hawaii, USA, 21-26 June 201. 26 June.
- Kim, D. J.; Oh, W. J.; Park, J. W.; Jeong, S. M. A Study on Flow Characteristics due to Dimension Variations of the Vertical Plate for Controlling the Ship Stern Flow. Journal of the Korean Society of Marine Environment & Safety 2016, 22(5), 576–582. [Google Scholar]
- Lee, J.; Kim, I.; Park, D. W. A Study on the Resistance Performance and Flow Characteristic of Ship with a Fin Attached on Stern Hull. Journal of the Korean Society of Marine Environment & Safety 2021, 27(7), 1106–1115. [Google Scholar]
- Park, Y.; Hwangbo, S. M.; Yu, J-W.; Cho, Y.; Lee, J. H.; Lee, I. Development of a small-sized tanker with reduced greenhouse gas emission under in-service condition based on CFD simulation. Ocean Engineering 2022, 286, 115588.
- Hwangbo, S.; Shin, H. Statistical prediction of wake fields on propeller plane by neural network using back-propagation. Journal of Ship and Ocean Technology 2000, 4(3), 1–12. [Google Scholar]
- Kim, S.-Y.; Moon, B. Wake distribution prediction on the propeller plane in ship design using artificial intelligence. Ships and Offshore Structures 2006, 1(2), 89–98. [Google Scholar] [CrossRef]
- Wie, D.-E.; Kim, D.-J. The Design Optimization of a Flow Control Fin Using CFD. Journal of the Society of Naval Architects of Korea 2012, 49(2), 174–181. [Google Scholar] [CrossRef]
- Lee, M-K. ; Lee, I. Optimal Design of Flow Control Fins for a Small Container Ship Based on Machine Learning. Journal of Marine Science and Engineering 2023, 11(6), 1149. [Google Scholar] [CrossRef]
- Kim, J. H.; Choi, J. E.; Choi, B. J.; Chung, S. H.; Seo, H. W. Development of energy-saving devices for a full slow-speed ship through improving propulsion performance. International Journal of Naval Architecture and Ocean Engineering 2015, 7(2), 390–398. [Google Scholar] [CrossRef]
- ITTC. Uncertainty Analysis in CFD, Verification and Validation Methodology and Procedures, Recommended Procedures and Guidelines. International Towing Tank Conference 2017, 7.5-03-01-01, 4–8.
- Qiao, J.; Liu, X.; Chen, Z. Prediction of the remaining useful life of lithium-ion batteries based on empirical mode decomposition and deep neural networks. IEEE Access 2020, 8, 42760–42767. [Google Scholar] [CrossRef]
- Babaeiyazdi, I.; Rezaei-Zare, A.; Shokrzadeh, S. Transfer Learning With Deep Neural Network for Capacity Prediction of Li-Ion Batteries Using EIS Measurement. IEEE Transactions on Transportation Electrification 2022, 9(1), 886–895. [Google Scholar] [CrossRef]
- Shen, S.; Sadoughi, M.; Li, M.; Wang, Z.; Hu, C. Deep convolutional neural networks with ensemble learning and transfer learning for capacity estimation of lithium-ion batteries. Applied Energy 2020, 260, 114296. [Google Scholar] [CrossRef]
- Park, K. M. Machine classification in ship engine rooms using transfer learning. Journal of the Korean Society of Marine Environment & Safety 2021, 27(2), 363–368. [Google Scholar]
- Chin, W. W.; Marcolin, B. L.; Newsted, P. R. A partial least squares latent variable modeling approach for measuring interaction effects: Results from a Monte Carlo simulation study and an electronic-mail emotion/adoption study. Information systems research 2003, 14(2), 189–217. [Google Scholar] [CrossRef]
- Solís, M.; Calvo-Valverde, L. A. A. Performance of Deep Learning models with transfer learning for multiple-step-ahead forecasts in monthly time series. arXiv preprint arXiv:2203.11196 2022. arXiv:2203.11196 2022.
- Zhou, D.; Hao, J.; Huang, D.; Jia, X.; Zhang, H. Dynamic simulation of gas turbines via feature similarity-based transfer learning. Frontiers in Energy 2020, 14, 817–835. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



