Submitted:
07 September 2023
Posted:
15 September 2023
Read the latest preprint version here
Abstract
The extent of single and multi-cropping systems in any region, and potential changes to it, have consequences on food and resource use raising important policy questions. However, addressing these questions is limited by a lack of reliable data on multi-cropping practices at a high spatial resolution, especially in areas with high crop diversity. In this paper, we describe a relatively low-cost and scalable method to identify double cropping at the field-scale using satellite (Landsat) imagery. The process combines machine learning methods with expert labeling. We demonstrate the process by measuring double cropping extent in a portion of Washington State in the Pacific Northwest United States--- a region with significant production of more than 60 distinct types of crops including hay, fruits, vegetables, and grains in irrigated settings. Our results indicate that the current state-of-the-art methods for identifying cropping intensity---that apply rule-based thresholds on vegetation indices---do not work well in regions with high-crop-diversity. Our deep learning model was able to capture the diverse nuances and achieve a high accuracy (99\% overall accuracy and 0.92 Kappa coefficient). Our expert labeling process worked well and has potential as a relatively low-cost, scalable approach for remote sensing applications. The product developed here is valuable to inform several policy questions related to food production and resource use.
Keywords:
double cropping
; multi cropping
; cropping intensity
; Landsat
; NDVI
; remote sensing
; machine learning
1. Introduction
Spatially-explicit characterization of land cover and land use, and how it changes over time is key to long-term agricultural, environmental, and natural resources planning and management. One land use characteristic that is becoming increasingly relevant for a wide range of policy questions is the extent of single-cropping versus multi-cropping systems; the latter refers to multiple crops grown and harvested in the same field in the same year. For example, government subsidized insurance for farmers that multi-crop has been proposed as a way to increase production and keep food prices down (Whitehouse Briefing 2022). Additionally, climate change has the potential to disrupt single-cropping systems in positive and negative ways. On the positive side, longer growing seasons under warming can allow cooler regions that historically could only single-crop to transition into multi-cropping systems (Seifert and Lobell 2015) and increase total food production and make farming more profitable. On the negative side, such a switch can increase crop irrigation water demands exacerbating water security concerns (Meza et al. 2008). It may also increase fertilizer use, exacerbating nutrient loading problems in water bodies, and negatively affecting soil health in general (Lal 2002; Jankowski et al. 2018).
Over the last decade, several studies have utilized satellite imagery and mapped cropping intensities, where an intensity of 1, 2 and 3 are indicative of single-, double- and triple-cropping, respectively. While earlier work utilized coarse-spatial-resolution imagery at 0.5 to several kilometer resolution (Yan et al. 2014; Li et al. 2014; Ding et al. 2015; Biradar and Xiao 2011), recent work has focused on Landsat or Sentinel data at finer spatial resolutions of 30m to 10m (Liu et al. 2020ab; Pan et al. 2021; Zhang et al. 2021). With the exception of Zhang et al. (2021)—a global spatially-explicit product building on methodology from Liu et al. (2020a)—work has primarily focused on geographic regions with high current multi-cropping-extent such as part of China, India and Indonesia. Regions such as the irrigated Western United States (US) where the multi-cropping practice is less prevalent historically but has potential to increase under a changing climate, are largely ignored. Additionally, crop diversity in the irrigated Western US is very high (hundreds of crops) as compared to the handful crop types typically referenced in existing work. It is unclear if the methodology used in the existing work will translate well into areas of high crop diversity.
The typical methodologies used in quantifying cropping intensities are rule based. They use a vegetation time series, apply threshold rules to identify peaks and troughs or starts and ends of the season, and count the number of crop cycles. Please note that by time series, we refer to the sequence of vegetation index over a given year. Given that these vegetation index thresholds can vary by crop and region, some modifications to generalize the process are considered. This includes standardization practices that replace the direct use of a vegetation-index time series with standardized values (Liu et al. 2020a; Zhang et al. 2021). Additional enhancements to disregard spurious growth cycles are sometimes considered. For example, spectral indices indicative of bare soil such as the Land Surface Water Index (LSWI) are used to double check the start and ends of the season (Biradar and Xiao 2011; Liu et al. 2020b), especially when water-logged rice cropping systems are involved. A minimum crop-cycle-length constraint is also applied in some cases (Liu et al. 2020a; Zhang et al. 2021). A key advantage of these methods is that training data is not necessary.
Machine learning (ML) model applications—which require training data—are rare (Rafif et al. 2021; He et al. 2021) and absent in larger regional-scale applications. However, these methods can be potentially helpful to learn important nuances in high-crop-diversity environments where vegetation thresholds and cycle lengths vary significantly by crop, soil characteristics, and farming practices (e.g. herbicide applications). The challenge in exploring ML methods is lack of ground truthed data (spatially-explicit labelled cropping intensity) across a range of cropping systems for training the models. While all labeling exercises are time and labor extensive, some applications such as the single-crop versus multi-crop distinction, are prohibitively so. For example, labeling images with irrigation canals or apples on a tree, can be performed by a human investigating the image directly, and with relatively minimal training. In contrast, labeling fields as single- or multi-cropped requires hiring enough personnel to visit fields multiple times within a season, which quickly becomes time and cost prohibitive.
Our objective is to address the gap in field-scale single- and multi-cropped land use data availability in regions with high crop diversity. We address this by: (a) labeling a ground-truth dataset in a relatively low-cost and scalable manner, (b) developing and evaluating ML classification methods for single- and multi-cropped fields that are crop-agnostic and at a field-scale, and (c) comparing the performance of the ML models with the simpler rule-based methods that are typically used. By low-cost we mean the relatively lower cost in terms of time and labor needs compared to drive-by/windshield surveys which are prohibitively expensive for our use case and not scalable to large areas. Finally, we will apply our best performing method to the irrigated agricultural extent of eastern Washington State in the Pacific Northwest US (Figure 1), as a case study. In this regional context, multi-cropping is essentially double-cropping and the rest of the paper uses this more specific terminology.
Our study region is a good test-bed for several reasons. Even though double-cropping is practiced, single-cropping dominates, posing a challenge for identifying double-cropped fields. It is located in the northern latitudes, and as the climate warms and the growing season lengthens, conditions could become more conducive for double-cropping. Additionally, it relies on surface water for irrigation, and there are important field-scale water management challenges associated with increased double-cropping, necessitating spatially-explicit information. This relates not just to the magnitude of additional irrigation water that might be needed, but also to the timing. Water law in the states in the Western US generally specifies that water rights are associated with a specific “place and season of use” and a new extended “season of use” brings in a regulatory burden on the water rights holder (farmer or irrigation district) and the managing agency (e.g. Washington State Department of Ecology) to modify the water right specifications accordingly. This is a time- and cost-intensive process as changes need to be verified under the stipulations of the Western Water Law and Prior Appropriation Doctrine (Hutchins 1971; Wiel 1911).
While recent cropping-intensity studies have leveraged data from the Sentinel mission—providing a 10m spatial resolution with a 5-day revisit (Drusch et al. 2012), we intentionally utilize data from the Landsat mission (Lauer et al. 1997; Wulder et al. 2019) at a 30m spatial resolution and a 8-day (when two concurrent Landsat products are combined) revisit. This is to leverage the Landsat time-series going back several decades—invaluable to understand trends, drivers and impacts of adopting double-cropping.
For a low-cost labeling process that does not involve drive-by surveys multiple times within a season, we leverage satellite imagery and the knowledge of regional experts who are familiar with the cropping systems and fields. While this labeled dataset may not be as good as that from a drive-by survey, we expect that it will provide an adequate policy-relevant level of accuracy for identifying single- versus double-cropped extent. We develop and evaluate four ML models, and compare them with a traditional rule-based method that does not require ground-truthing to assess the importance of the labeling process. This is an important result for applying this method to other crop-diverse regions.
The products that come out of this research can inform many policy questions. Additionally, learnings from this case study can be applied more broadly to the development of land use datasets under the challenging contexts of prohibitively expensive costs in developing ground-truth data sets.
2. Methods and data
The overall workflow components described in the this study are summarized in Figure 2. We first finalize the field-scale smoothed NDVI time series. This data along with other information is provided to the expert labeling process that creates the labeled ground-truth dataset. Classification models are then trained on the NDVI data and evaluated with the test set. Crop-specific summaries are also created for the test set. Finally, the models are applied over the full study area to obtain annual spatial-explicit maps of double-cropping.
2.1. Training, evaluation and application datasets
Model training, evaluation, and application are performed at a field-scale. The input data includes a time series of a commonly used vegetation index—Normalized Difference Vegetation Index (NDVI) (Huang et al. 2021; Kriegler 1969)— generated from multi-spectral observations at a 30m spatial resolution from 2015 to 2018 (Table 1) from Landsat missions 7 and 8. With two concurrent missions running at a staggered temporal resolution of 16 days, we get a combined finer temporal resolution of ∼8 days—important for capturing the quick succession of harvest and planting cycles in double-cropped systems. A field-scale NDVI time series is obtained by averaging values across all pixels contained within a field. More details of the time series construction are provided in Section 2.3.
Field boundaries were obtained from the WSD (forthcoming). This dataset was created via drive-by surveys by WSDA covering approximately a third of the state each year. That is, sections of the study area (Figure 1) were surveyed at least once over a three-year period. Each year’s dataset has the field boundary, crop type, irrigation system, and the date the field was last surveyed. The crop type recorded is just the main crop that was observed at the time of the annual drive-by survey. That is, information on double-cropping is not present in this dataset as that would require multiple drive-by passes by the same field each year.
For the ground-truth data used for classifying, we only consider fields that were surveyed in a given year to have accurate field boundaries (based on the last surveyed date). This also ensures that the crop type is correct when labeling (see Section 2.2 for the labeling process). We used data from the years 2015 to 2018, which resulted in 44,850 fields. Fields smaller than 10 acres were removed from the analysis to avoid edge-effects, which result in a noisy vegetation index signal. These smaller fields comprise less than 8% of the total area that we consider, and are rarely double-cropped according to the experience of our experts. Therefore, their exclusion will likely have a minimal impact on our analysis. We also filtered out crop types with minimal irrigated acreage (less than 2874.57 acres—11.63 km) in the study area. We selected 10% of the fields from each crop for labeling, and added additional fields by crop as necessary to ensure that we have at least 50 fields per crop (if available) in the labeled ground-truth dataset.
For the final model application, we covered the entire irrigated extent in our counties of interest using data from 2015-2018 (Table 1).
2.2. Expert labeling process
We collaborated with three individuals with extensive knowledge of cropping patterns in the region of study based on extensive time on the ground directly observing production. These individuals are professionals with university Extension and governmental agricultural agencies. Such experts are present in many agriculturally intensive production regions, which adds to the repeatability of our approach to other areas.1
We had a three-step process for interacting with the expert panel. First, was a meeting that allowed for a more open ended discussion to identify crops and regions most associated with double-cropping, the timing of planting and harvesting of the first and second crop, and potential complications such as cover crops or hay crops that are harvested multiple times in the growing season. Such open ended meetings are valuable for narrowing the scope of the analysis, although it is important to not allow existing perceptions that may be partially incorrect to over determine the analysis. In our case, we took a nuanced position to cover crops. While cover crops are generally not considered a double crop, since production is not harvested, we made an exception for the yellow-mustard cover crop and categorized it as a double-crop because our interest is in the water footprint. Other cover crops are planted very late in the season requiring minimal or no irrigation. In contrast, yellow mustard is planted early enough to require significant irrigation. A research question focused on total production of food and fiber, but not on resource use intensity, may result in a different categorization. It is also important to recognize that it may not be possible to differentiate a double-crop from a mustard cover-crop given expected similarities in their time series signatures of vegetation indices.
To provide some additional context on the type of issues that may be discussed at this phase, the following are examples of topics raised. Certain crops (e.g., buckwheat, beans, peas, sweet corn, seed crops, sudangrass, triticale in some regions, and alfalfa) are more prevalent in double cropping systems and therefore it would be good to know the crop type for the labeling process. Certain irrigation systems (e.g., flood) are not typically seen in double-cropped fields and the irrigation system would also be useful information for the labeling process. Additionally, double-cropping is prevalent in some areas and with some growers, and having a mapped location of the field will assist the expert in labeling by leveraging their local knowledge. In a double-cropping system, the second crop is typically planted by early August at the latest, and any indication of a second planting much after that is either a fall planted crop for the following year or a cover crop which should be considered a single-crop system for our purposes.
The second phase of the expert panel interaction was asynchronous labeling. For each field that we wanted to label, we provided the vegetation index time series, the crop type, irrigation system, and a google map link to the field location in a Google Form format. The form had five choices for labels: “single crop”, “double crop”, “mustard crop”, “either double or mustard crop”, and “unsure”. Before finalizing the ground-truth set to be sent to the expert panel, four other team members labeled easy to categorize crops—including crops that were clearly single cropped from a clean vegetation index time series, and perennial tree crops and berries which we know cannot be double-cropped—and checked for agreement across team members. The remaining observations, that constitute the more difficult cases, were labeled by experts asynchronously with each field labeled by at least two experts.
We flagged the fields where the experts were not in agreement and resolved discrepancies during a final synchronous meeting. Some challenging discrepancies could not be resolved and 15 fields were left as unsure and omitted from our dataset. The final labeled dataset consisted of 3,160 fields across four years (2015-2018) and representative of 63 crops Table 2 and five counties Table 1. The labeling process was guided by more information than just the vegetation time series, which is the only training input to the models. This additional information was necessary to get the labeling right, but unfortunately infeasible to provide for the whole spatial extent and across years from a model building and application perspective. The hope was that ML model would learn some of these nuances from the way they impact the shape of the vegetation index time series itself.
2.3. Vegetation index time series
Crops have distinct spectral reflectance signatures related to their growth and phenological stages. In remote sensing applications, this is typically captured via vegetation indices that capture growth condition, phenology, and canopy cover of plants as the season progresses. While many vegetation indices exist, a commonly used one in agricultural contexts is the Normalized Difference Vegetation Index (NDVI) (Liu et al. 2020a; Pan et al. 2021; Ghosh et al. 2022) which is calculated from spectrometric reflectances in the red and near-infrared bands (Eq. 1). NDVI steadily increases after planting and decreases with senescence leading to harvest. We used the Google Earth Engine (GEE)—a geospatial processing platform that helps access the large suite of publicly available satellite imagery —to obtain field-scale NDVI time series. We used Landsat Level 2, Collection 2, Tier 1 products that contain atmospherically corrected surface reflectance bands2.
The NDVI values are averaged over all cloud-free pixels contained within a field boundary. The data are typically noisy and irregular so they need to be processed to obtain a smooth time series that can be provided as input to models. This process is described below.
Satellite images are negatively affected by poor atmospheric conditions such as clouds or snow. These adverse effects typically lead to lower values of NDVI. As a part of data collection from GEE, we remove the cloudy pixels and then compute the average field-scale NDVI using the remaining clean pixels. Taking the average across pixels is a standard and routine practice (Belgiu and Csillik 2018; Huete et al. 2002). After fetching the data we remove noise from time-series to smooth the bumps and kinks that could throw off the detection of the crop growth cycle. There are numerous ways of smoothing including weighted moving averages, Fourier and wavelet techniques, asymmetric Gaussian function fitting, and the double logistic techniques. For comparison of different smoothing methods please see (Atkinson et al. 2012; Cai et al. 2017; Geng et al. 2014; Kandasamy et al. 2013; Hird and McDermid 2009). Performance of these methods depends on the data, the vegetation type, the data source, and the task at hand (Cai et al. 2017; Geng et al. 2014). We use Savitzky-Golay (SG) (Cai et al. 2017; Savitzky and Golay 1964) which is a commonly used polynomial regression fit based on a moving window. By varying the degree of polynomial and the size of window one can adjust level of smoothness.
Positive values of NDVI are indicative of greenness and negative values represent lack of vegetation where NDVI varies between -1 and 1.
The following steps are performed for denoising.
- Correct big jumps. The process of growing, and consequently the temporal pattern of greenness cannot have abrupt increases within a short period of time. Therefore, if the NDVI increases too quickly from time t to , a correction is required. In such cases, we assume NDVI at time t is affected negatively and therefore, we replace it via linear interpolation. In our study, we used a threshold of as the maximum NDVI growth allowed per day.
- Set negative NDVIs to zero. Negative NDVI values are an indication of lack of vegetation. In our scenario, the magnitude of such NDVIs are irrelevant. The negative NDVIs with high magnitudes adversely affect the NDVI-ratio method for classification (described in the Models section) and therefore the negative values are set to zero. Assume there is only one erroneous NDVI value that is negative and large in magnitude; e.g. -0.9, while all other values are positive. Then, the NDVI-ratio method which looks at normalized NDVI values will have a large value in its denominator and this single point affects the other points’ standardized values which can throw off the NDVI-ratio method. Under this scenario, the NDVI-ratio at the time of trough will be pushed up which leads to missing the harvest and re-planting in the middle of a growing season.
- Regularize the data. In this step, we regularize the data so that the data points are equidistant. In every 10-day time period, we pick the maximum NDVI as representative of those 10 days. The maximum is chosen because NDVI is negatively affected by poor atmospheric conditions (Kobayashi and Dye 2005; Liu and Huete 1995).
- Smooth the time series. As the last step, the SG filter is applied to time-series to smooth them even further. SG filtering is a local method that fits the data with a polynomial using the least square method. The parameters used in this study are 3 for the degree of polynomial and 7 for the size of moving window; i.e. a polynomial of degree 3 is fitted to 7 data points.
2.4. Models
With the labeled data and vegetation index time-series, we develop and evaluate 5 models to classify fields as single- or double-cropped. This includes the NDVI-ratio method used in prior related work (Liu et al. 2020a; Zhang et al. 2021), and four ML models; random forest (RF), support vector machine (SVM), k-nearest neighbors (kNN), and deep learning (DL).
-
NDVI-ratio method. One widely used approach for detecting the start of the season (SOS) and end of season (EOS) is the so-called NDVI-ratio method of White et al. (1997). NDVI-ratio is defined bywhere is NDVI at a given time, and are minimum and maximum of NDVI over a year, respectively. When this ratio crosses a given threshold, (Liu et al. 2020a; Zhang et al. 2021), then there is a SOS or EOS event. One pair of (SOS, EOS) event in a season is indicative of single cropping, and two pairs are indicative of double cropping. The following rules are applied under the NDVI-ratio method scenario.
- If the range of NDVI during the months of May through October (inclusively) is less than or equal to 0.3, then this field is labeled as single-cropped. This step was motivated by the low and flat time series of vegetation indices exhibited by orchards during visual inspection of figures.
- Determine SOS and EOS by -ratio method.
- If an SOS is detected for which there is no EOS in a given year, we nullify such SOS. Such event occurs for winter wheat for example. Similarly, if we detect one EOS over the year with no corresponding SOS, we drop the EOS and consider it as a single-cropping cycle. Example is winter wheat that is planted in the previous year.
- A growing cycle cannot be less than 40 days.
-
Machine learning models. We build three statistical learning models—SVM, RF, and kNN—as well as a DL model for classification. Given that the kNN model computes the distance between two vectors (NDVI at multiple points in time), the vectors need to be comparable. Planting dates may vary by field, and therefore, the measurement for distance should take the time shift into account. This is accomplished by using dynamic time warping as the distance measure for the kNN model. For deep learning (transfer learning) we have used the pre-trained VGG16 model provided by Keras and trained only the last layer.While the SVM, RF, and kNN models are provided with a vector of NDVI values as input, the DL model is provided with NDVI time-series images (time on the x axis and NDVI on the y axis) as inputs. This means that our approach to DL falls under the category of time-series image classification. While time-series data are not usually analyzed in this manner (Ismail Fawaz et al. 2020), it allows for nuances in the shape of the time series that other models may not capture, potentially resulting in better performance.Given that there are fewer double-cropped than single-cropped fields, we oversampled the double-cropped instances (the minority class) to address the class imbalance in the dataset. After oversampling, number of instances in the minority class was less than 50% of number of instances in majority class. Oversampling more than 50% led to lower performance. The problem, of course, is not the “imbalanced-ness”. The problem is that each class invades the space of the other class (Prati, Ronaldo C and Batista, Gustavo EAPA and Monard, Maria Carolina 2009; Azhar et al. 2023) and overdoing oversampling contributed to lowering the performance in our case. Please note that there is no oversampling in the NDVI-ratio method, since there is no training involved and the rules in NDVI-ratio method are pre-defined. These rules are applied to each individual field independent of other fields. In ML, however, all data points play a role in determining the shape of the classifier. Thus, oversampling is an attempt to tilt the weight in favor of the minority class.The training process was optimized using 5 fold cross-validation. The models are implemented using the Python (v3.9.16), scikit-learn package (v1.2.1) for RF, SVM, and kNN. For deep learning we have used TensorFlow (v2.9.1) and Keras (v2.9.0). For DTW metric dtaidistance v2.3.9 is used3.
3. Results
In this section, we compare the performance of the ML models against the NDVI-ratio method. We present crop-specific and regional summaries on the test dataset, and apply the DL model to all the fields in the study region for specific years (Table 1) reflective of “current” double-cropping extent .
3.1. Accuracy statistics across methods
The four ML models that require labeled training data, outperform the NDVI-ratio method with overall accuracies of 96% to 99% as opposed to 80% (Table 3) and a high kappa coefficient of 0.92 as compared to 0.005. The DL and SVM models have the best performance in identifying double-cropped fields while the other models struggle. The DL model outperforms all other models in classifying both “single-cropped” and “double-cropped” fields, and overall works best. Moreover, for double-cropped class the DL model has user accuracy of 0.92, and producer accuracy of 0.93 (Table 3).
Figure 3 shows NDVI time series for four fields labeled by the DL model. Two fields are labeled correctly (Figure 3a,b) and two are labeled incorrectly (Figure 3c,d). For the field shown in Figure 3c the model has missed the fact that the second crop’s cycle is a bit too late in the season (starting in September). In Figure 3d, where the model incorrectly labeled a double-cropped field as a single-crop, the noise in the raw data (red dots), seems to have resulted in an over-smoothing (blue line) misleading the model.
While results are not reported here, we also assessed the performance of using the Enhanced Vegetation Index (EVI) and did not notice a performance difference between EVI or NDVI. EVI is widely reported in the literature as not having vegetation index saturation issues associated with NDVI (Xu et al. 2019; Qiu et al. 2014; Jain et al. 2013). However, that issue did not reflect in performance improvements for our application.
3.2. Fraction of double-cropped acres by crop
In our initial meetings with the experts, the following were identified as common double-cropped crops: buckwheat, beans, peas, sweet corn, seed crops, sudangrass, triticale (in some regions), and alfalfa. Based on our crop-wise classification statistics on the test dataset (Figure 4), the crops with relatively higher fractions match with this list, except for alfalfa. Alfalfa is a perennial crop with a 3- to 4-year cycle where double cropping is a possibility only in the final year of the cycle. Given this, our labeling in the training set skewed toward classifying it as a single crop, and we may be underestimating the double-cropped acres for this crop.
The high percentages of buckwheat and yellow mustard are in agreement with the local knowledge that buckwheat is almost always double-cropped, and that yellow mustard primarily is a cover-crop following a potato crop. This is in contrast with the mustard crop type that is grown as a seed crop with a low double-cropped fraction. Moreover, perennial tree fruit and berries such as apples and blueberries cannot be double-cropped and the model performs well in capturing them as single-crops (only 2 out of 8,429 fields were incorrectly labeled). While all models are generally in agreement across crops, the differences across models are larger for some crops (e.g., triticale hay, mustard, and buckwheat).
3.3. Regional summary and spatial distribution of double-cropped fields
Over the 6 counties analyzed, around 10% of the total irrigated extent was double-cropped. While we do not have the ground truth data to compare this overall number, it is in qualitative agreement with the anecdotal expectation and local experts’ knowledge that the region has some but not a lot of double-cropped extent.
The majority of double-cropped fields are in the United States Bureau of Reclamation’s Columbia Basin Irrigation Project area that covers parts of Franklin, Adams, and Grant counties. The lowest rate of adoption is in Yakima county (Figure 5a,b). This is also in agreement with the experts’ expectations, and our knowledge of water rights security in the region (Weber and Lee 2021; of Ecology). Water use associated with growing two crops requires secure senior water rights, and the Columbia Basin Irrigation Project region has the water rights that can facilitate this. In contrast, a region like Yakima county has a large fraction of junior water rights holders for whom water rights restrictions may constrain the ability to adopt double-cropping.
4. Discussion
Two metrics indicate that our approach to identifying double versus single cropped fields works well and could be extended to other regions with crop diversity. The first is the high test accuracy of our DL model (overall accuracy of 99% and kappa coefficient of 0.92). The second is the qualitative evidence that we are getting the overall double-cropped crop types, and spatial extent in line with experts’ expectations. It is important to recognize that the greatest confidence would be provided by comparing results to ground-truth data to evaluate our estimated 10% overall double-cropped extent for all of our study area.
While the adjusted NDVI-ratio method (with augmented auxiliary algorithms) performed well in identifying double and triple cropped fields in other work (Liu et al. 2020a), its performance was poor in our case (only 8 out of 59 fields in the test set were identified correctly). This could potentially be attributed to the diversity of crops grown in our area, each of which has different canopy cover and vegetation index characteristics, rendering one threshold value to be inadequate in capturing this diversity. The ML models would be more appropriate in these contexts, highlighting the need to explore relatively lower-cost and scalable (to large regions) labeling options for remote sensing applications.
We also compared our results with the recently published global spatially-explicit cropping-intensity product at a 30m resolution (Zhang et al. 2021). This product does not distinguish between irrigated and dryland acres and is missing data in a significant part of one of our counties of interest: Yakima county. Therefore, to make an appropriate comparison, we masked out pixels from the global product that coincide with the field boundaries of our irrigated extent and excluded Yakima county. The resulting multi-cropped extent (primarily double-cropped) was ≈1,015.76km compared to our DL model’s estimate of ≈ 437.06km. Therefore, while the Zhang et al. (2021) global product is expected to be a conservative estimate in general, we find that it may be significantly overestimating the cropping intensity in our irrigated study area, and perhaps all of Western US irrigated extent. We hypothesize that this could be due to several reasons. First, the Zhang et al. (2021) methodology is based on an NDVI-ratio process which, as we demonstrated, does not work well in our highly diverse irrigated cropping environment. Additionally, our comparison highlighted that the Zhang et al. (2021) product seems to have erroneously classified a significant acreage of perennial crops (e.g., tree-fruit, berries, alfalfa) as double-cropped instead of single-cropped. Moreover, dryland production areas in our region are not double-cropped (based on expert’s opinion) while the global product does show double-cropping in this extent. This highlights that there is scope to integrate ML methods and regional insights into the global products to enhance their utility, especially in regions such as ours that are not well covered and tested in the cropping-intensity mapping literature.
The expert labeling process we describe here is much less burdensome than extensive drive-by surveys for land use labeling. The challenge is in identifying the right set of local experts for the application under consideration. At least in the United States agricultural context, the Land Grant University County Extension system has an established network of local experts that are familiar with the area, the fields, the growers, and their practices and are an excellent source of knowledge that should be leveraged more in developing labeled datasets that can aid remote sensing applications. While the precision of a drive-by survey may not be achievable, useful information for informing policy can be developed as demonstrated in this work.
This method has a number of potential extensions and applications. The first is extending the geographic scope of this work. While the model we have developed is publicly shared and can be directly applied, some additional labeling and retraining would likely be necessary, especially for regions where the cropping intensity can be larger than two crops in a year. Even in this scenario, our DL model can be used for transfer-learning approaches, which can shorten the training time. The models can be continually retrained and refined as new labeled data are created.
The second is to apply the proposed method and develop a historical time-series of double-cropped extent. This would allow a trend analysis that could be used to identify drivers of increased or decreased double-cropping including changing climatic patterns and agricultural commodity market conditions (Borchers et al. 2014). Further analysis would be needed to isolate the climatic drivers of trends, but the methods and dataset developed here are an important first step in generating data that will facilitate these analyses. Climatic relationships, once established, can be be extrapolated in a climate-change context to quantify the potential for increased double-cropping in the future. When coupled with a cross-sectional analysis of historical double-cropping trends across diverse regions, climatic thresholds at which double-cropping becomes infeasible (e.g., because the summers are too hot to double-crop) can also be identified. This will provide a realistic upper bound of the potential for increased double-cropping.
Finally, from a water footprint perspective, this spatially-explicit dataset can be a valuable input to crop models (e.g., VIC-CropSyst Malek et al. (2017)) to quantify irrigation demands under current and future conditions of double-cropping adoption. Existing studies on climate change impacts on irrigation demands do not account for double-cropping, and this addition will address an important missing component in the climate-change-impacts literature. This can inform the planning efforts of various stakeholders; irrigation districts planning for infrastructure management based on the season length, water rights management agencies planning for change requests, water management agencies planning for minimizing scarcity issues or changes to reservoir operations.
There are several other policy questions and trade offs that can be informed by utilizing such spatially-explicit datasets (along with other data and models). For example, how much of the growing global food demands can multi-cropping meet? Are the environmental outcomes of increased food production though intensification on existing land better or worse than outcomes from expanding agricultural land? What are the impacts on fertilizer inputs on the land or carbon sequestration potential? As stewards of our natural resources, it is important for us to address the broad range of trade offs that accompany any land use change trends and equip ourselves with datasets that help answer them.
5. Conclusion
The rule-based methods that are widely used to map cropping intensity did not work for our irrigated high-crop-diversity context. In contrast, ML models, especially the DL model, was able to learn crop-specific nuances and achieved overall accuracy of over 99% while also identifying double-cropping in the right crop groups and locations based on expert knowledge. Given that these models require labeled ground-truth data, low-cost labeling efforts that leverage satellite imagery and experts’ knowledge will be key to expanding the availability of such land use data sets at global scales. Given that these labeling efforts are likely to be local/regional endeavours, a centralized mechanism to publicly share these labeled datasets will allow the research community to make continued advancements in modeling the environment via remote sensing approaches.
Author Contributions
writing, H.N., K.R., S.S., and M.B.; review and editing, H.N., K.R., S.S., M.B., M.L., P.B., T.W., and A.M.; project administration, K.R. and M.B.; formal analysis, H.N., K.R., S.S., and M.B.; investigation, H.N., K.R., M.L., S.S., and M.B. methodology, H.N., K.R., M.B., P.B., A.M, T.W.; data curation, H.N.; visualization, H.N., S.S.; funding acquisition, M.B. and K.R.;
Funding
This research was funded by the National Aeronautics and Space Administration’s Western Water Applications Office (NASA WWAO) under Award Number 1667355 and the U.S. Geological Survey Award No. G16AP00090-0006 administered by the Washington State Water Research Center.
Data Availability Statement
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
Acknowledgments
We thank the Washington State Department of Ecology, the Washington State Department of Agriculture, and the Oregon Water Resources Department for supporting this research. We thank Siddharth Chaudhary, Bhupinderjeet Singh, Amin Norouzi Kandelati, Sienna Alicea, and Daniel Chadez for assistance with field surveys.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Whitehouse Briefing. FACT SHEET: President Biden Announces New Actions to Address Putin’s Price Hike, Make Food More Affordable, and Lower Costs for Farmers. https://www.whitehouse.gov/briefing-room/statements-releases/2022/05/11/fact-sheet-president-biden-announces-new-actions-to-address-putins-price-hike-make-food-more-affordable-and-lower-costs-for-farmers/, 2022. [Online; September 15, 2023].
- Seifert, C.A.; Lobell, D.B. Response of double cropping suitability to climate change in the United States. Environmental Research Letters 2015, 10, 024002. [CrossRef]
- Meza, F.J.; Silva, D.; Vigil, H. Climate change impacts on irrigated maize in Mediterranean climates: evaluation of double cropping as an emerging adaptation alternative. Agricultural systems 2008, 98, 21–30. [CrossRef]
- Lal, R. Soil carbon dynamics in cropland and rangeland. Environmental pollution 2002, 116, 353–362. [CrossRef]
- Jankowski, K.; Neill, C.; Davidson, E.A.; Macedo, M.N.; Costa Jr, C.; Galford, G.L.; Maracahipes Santos, L.; Lefebvre, P.; Nunes, D.; Cerri, C.E.; others. Deep soils modify environmental consequences of increased nitrogen fertilizer use in intensifying Amazon agriculture. Scientific reports 2018, 8, 13478. [CrossRef]
- Yan, H.; Xiao, X.; Huang, H.; Liu, J.; Chen, J.; Bai, X. Multiple cropping intensity in China derived from agro-meteorological observations and MODIS data. Chinese Geographical Science 2014, 24, 205–219. [CrossRef]
- Li, L.; Friedl, M.A.; Xin, Q.; Gray, J.; Pan, Y.; Frolking, S. Mapping crop cycles in China using MODIS-EVI time series. Remote Sensing 2014, 6, 2473–2493. [CrossRef]
- Ding, M.; Li, L.; Zhang, Y.; Sun, X.; Liu, L.; Gao, J.; Wang, Z.; Li, Y. Start of vegetation growing season on the Tibetan Plateau inferred from multiple methods based on GIMMS and SPOT NDVI data. Journal of Geographical Sciences 2015, 25, 131–148. [CrossRef]
- Biradar, C.M.; Xiao, X. Quantifying the area and spatial distribution of double- and triple-cropping croplands in India with multi-temporal MODIS imagery in 2005. International Journal of Remote Sensing 2011, 32, 367–386, [https://doi.org/10.1080/01431160903464179]. [CrossRef]
- Liu, C.; Zhang, Q.; Tao, S.; Qi, J.; Ding, M.; Guan, Q.; Wu, B.; Zhang, M.; Nabil, M.; Tian, F.; others. A new framework to map fine resolution cropping intensity across the globe: Algorithm, validation, and implication. Remote Sensing of Environment 2020, 251, 112095. [CrossRef]
- Liu, L.; Xiao, X.; Qin, Y.; Wang, J.; Xu, X.; Hu, Y.; Qiao, Z. Mapping cropping intensity in China using time series Landsat and Sentinel-2 images and Google Earth Engine. Remote Sensing of Environment 2020, 239, 111624. [CrossRef]
- Pan, L.; Xia, H.; Yang, J.; Niu, W.; Wang, R.; Song, H.; Guo, Y.; Qin, Y. Mapping cropping intensity in Huaihe basin using phenology algorithm, all Sentinel-2 and Landsat images in Google Earth Engine. International Journal of Applied Earth Observation and Geoinformation 2021, 102, 102376. [CrossRef]
- Zhang, M.; Wu, B.; Zeng, H.; He, G.; Liu, C.; Tao, S.; Zhang, Q.; Nabil, M.; Tian, F.; Bofana, J.; others. GCI30: a global dataset of 30 m cropping intensity using multisource remote sensing imagery. Earth System Science Data 2021, 13, 4799–4817. [CrossRef]
- Rafif, R.; Kusuma, S.S.; Saringatin, S.; Nanda, G.I.; Wicaksono, P.; Arjasakusuma, S. Crop intensity mapping using dynamic time warping and machine learning from multi-temporal PlanetScope data. Land 2021, 10, 1384. [CrossRef]
- He, Y.; Dong, J.; Liao, X.; Sun, L.; Wang, Z.; You, N.; Li, Z.; Fu, P. Examining rice distribution and cropping intensity in a mixed single- and double-cropping region in South China using all available Sentinel 1/2 images. International Journal of Applied Earth Observation and Geoinformation 2021, 101, 102351. [CrossRef]
- Hutchins, W.A. Water rights laws in the nineteen western states; Number 1, Natural Resource Economics Division, Economic Research Service, US Department of Agriculture, 1971.
- Wiel, S.C. Water Rights in the Western States: The Law of Prior Appropriation of Water as Applied Alone in Some Jurisdictions, and As, in Others, Confined to the Public Domain, with the Common Law of Riparian Rights for Waters Upon Private Lands. Federal, California and Oregon Statutes in Full, with Digest of Statutes of Alaska, Arizona, Colorado, Hawaii, Idaho, Kansas, Montana, Nebraska, Nevada, New Mexico, North Dakota, Oklahoma, Oregon, Philippine Islands, South Dakota, Texas, Utah, Washington and Wyoming; Vol. 2, Bancroft-Whitney, 1911.
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; others. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote sensing of Environment 2012, 120, 25–36. [CrossRef]
- Lauer, D.T.; Morain, S.A.; Salomonson, V.V. The Landsat program: Its origins, evolution, and impacts. Photogrammetric Engineering and Remote Sensing 1997, 63, 831–838.
- Wulder, M.A.; Loveland, T.R.; Roy, D.P.; Crawford, C.J.; Masek, J.G.; Woodcock, C.E.; Allen, R.G.; Anderson, M.C.; Belward, A.S.; Cohen, W.B.; others. Current status of Landsat program, science, and applications. Remote sensing of environment 2019, 225, 127–147. [CrossRef]
- Huang, S.; Tang, L.; Hupy, J.P.; Wang, Y.; Shao, G. A commentary review on the use of normalized difference vegetation index (NDVI) in the era of popular remote sensing. Journal of Forestry Research 2021, 32, 1–6. [CrossRef]
- Kriegler, F. Preprocessing transformations and their effects on multspectral recognition. Proceedings of the Sixth International Symposium on Remote Sesning of Environment, 1969, pp. 97–131.
- Washington State Department of Agriculture’s (WSDA) Agricultural Land Use Geodatabase. Accessed: September 15, 2023.
- Ghosh, A.; Nanda, M.K.; Sarkar, D. Assessing the spatial variation of cropping intensity using multi-temporal Sentinel-2 data by rule-based classification. Environment, Development and Sustainability 2022, 24, 10829–10851. [CrossRef]
- USGS Landsat 7 Level 2, Collection 2, Tier 1. https://developers.google.com/earth-engine/datasets/catalog/LANDSAT_LE07_C02_T1_L2/. [Online; September 15, 2023].
- USGS Landsat 8 Level 2, Collection 2, Tier 1. https://developers.google.com/earth-engine/datasets/catalog/LANDSAT_LC08_C02_T1_L2/. [Online; September 15, 2023].
- Belgiu, M.; Csillik, O. Sentinel-2 cropland mapping using pixel-based and object-based time-weighted dynamic time warping analysis. Remote Sensing of Environment 2018, 204, 509–523. [CrossRef]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.; Gao, X.; Ferreira, L. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sensing of Environment 2002, 83, 195–213. [CrossRef]
- Atkinson, P.M.; Jeganathan, C.; Dash, J.; Atzberger, C. Inter-comparison of four models for smoothing satellite sensor time-series data to estimate vegetation phenology. Remote Sensing of Environment 2012, 123, 400–417. [CrossRef]
- Cai, Z.; Jönsson, P.; Jin, H.; Eklundh, L. Performance of smoothing methods for reconstructing NDVI time-series and estimating vegetation phenology from MODIS data. Remote Sensing 2017, 9, 1271. [CrossRef]
- Geng, L.; Ma, M.; Wang, X.; Yu, W.; Jia, S.; Wang, H. Comparison of Eight Techniques for Reconstructing Multi-Satellite Sensor Time-Series NDVI Data Sets in the Heihe River Basin, China. Remote Sensing 2014, 6, 2024–2049. [CrossRef]
- Kandasamy, S.; Baret, F.; Verger, A.; Neveux, P.; Weiss, M. A comparison of methods for smoothing and gap filling time series of remote sensing observations-application to MODIS LAI products. Biogeosciences 2013, 10, 4055–4071. [CrossRef]
- Hird, J.N.; McDermid, G.J. Noise reduction of NDVI time series: An empirical comparison of selected techniques. Remote Sensing of Environment 2009, 113, 248–258. [CrossRef]
- Savitzky, A.; Golay, M.J. Smoothing and differentiation of data by simplified least squares procedures. Analytical chemistry 1964, 36, 1627–1639. [CrossRef]
- Kobayashi, H.; Dye, D.G. Atmospheric conditions for monitoring the long-term vegetation dynamics in the Amazon using normalized difference vegetation index. Remote Sensing of Environment 2005, 97, 519–525. [CrossRef]
- Liu, H.Q.; Huete, A. A feedback based modification of the NDVI to minimize canopy background and atmospheric noise. IEEE Transactions on Geoscience and Remote Sensing 1995, 33, 457–465. [CrossRef]
- White, M.A.; Thornton, P.E.; Running, S.W. A continental phenology model for monitoring vegetation responses to interannual climatic variability. Global Biogeochemical Cycles 1997, 11, 217–234. [CrossRef]
- Ismail Fawaz, H.; Lucas, B.; Forestier, G.; Pelletier, C.; Schmidt, D.F.; Weber, J.; Webb, G.I.; Idoumghar, L.; Muller, P.A.; Petitjean, F. Inceptiontime: Finding AlexNet for time series classification. Data Mining and Knowledge Discovery 2020, 34, 1936–1962. [CrossRef]
- Prati, Ronaldo C and Batista, Gustavo EAPA and Monard, Maria Carolina. Data mining with imbalanced class distributions: concepts and methods. IICAI, 2009, pp. 359–376.
- Azhar, N.A.; Pozi, M.S.M.; Din, A.M.; Jatowt, A. An Investigation of SMOTE Based Methods for Imbalanced Datasets With Data Complexity Analysis. IEEE Transactions on Knowledge and Data Engineering 2023, 35, 6651–6672. [CrossRef]
- Xu, W.; Jin, J.; Jin, X.; Xiao, Y.; Ren, J.; Liu, J.; Sun, R.; Zhou, Y. Analysis of Changes and Potential Characteristics of Cultivated Land Productivity Based on MODIS EVI: A Case Study of Jiangsu Province, China. Remote Sensing 2019, 11. [CrossRef]
- Qiu, B.; Zhong, M.; Tang, Z.; Wang, C. A new methodology to map double-cropping croplands based on continuous wavelet transform. International Journal of Applied Earth Observation and Geoinformation 2014, 26, 97–104. [CrossRef]
- Jain, M.; Mondal, P.; DeFries, R.S.; Small, C.; Galford, G.L. Mapping cropping intensity of smallholder farms: A comparison of methods using multiple sensors. Remote Sensing of Environment 2013, 134, 210–223. [CrossRef]
- Weber, E.; Lee, B. Columbia basin project water authorizations. The Water Report 2021.
- of Ecology, W.S.D. Washington State Water Rights. https://appswr.ecology.wa.gov/waterrighttrackingsystem/WaterRights/Map/WaterResourcesExplorer.aspx. [Accessed; September 15, 2023].
- Borchers, A.; Truex-Powell, E.; Wallander, S.; Nickerson, C. Multi-cropping practices: recent trends in double-cropping 2014.
- Malek, K.; Stöckle, C.; Chinnayakanahalli, K.; Nelson, R.; Liu, M.; Rajagopalan, K.; Barik, M.; Adam, J.C. VIC–CropSyst-v2: A regional-scale modeling platform to simulate the nexus of climate, hydrology, cropping systems, and human decisions. Geoscientific Model Development 2017, 10, 3059–3084. [CrossRef]
| 1 | McGuire and Waters are county Extension professionals from our region of interest and Beale initiated and currently manages WSDA’s agricultural land use mapping efforts. All experts have strong familiarity with fields, cropping practices, and growers in the region. |
| 2 | GEE datasets used in this study are LE07/C02/T1_L2 ( ), and LC08/C02/T1_L2 ( ). |
| 3 | Data processing and visualization is done using multiple Python packages. Scripts are accessible at https://github.com/HNoorazar/NASA_WWAO_DoubleCropping/tree/main. |
Figure 1.
Case study region: eastern Washington State in the Pacific Northwest US. We focus on five counties with anecdotal evidence of double-cropping; Adams, Benton, Franklin, Grant, Walla Walla, and Yakima.
Figure 1.
Case study region: eastern Washington State in the Pacific Northwest US. We focus on five counties with anecdotal evidence of double-cropping; Adams, Benton, Franklin, Grant, Walla Walla, and Yakima.
Figure 2.
The overall workflow used for classifying the fields from fetching the data to the final classification approaches is provided here. First we read satellite images on GEE, then compute VIs, then remove noise and smooth their time-series. These steps are followed by creation of ground-truth dataset, and finally we apply ML methods to classify them.
Figure 2.
The overall workflow used for classifying the fields from fetching the data to the final classification approaches is provided here. First we read satellite images on GEE, then compute VIs, then remove noise and smooth their time-series. These steps are followed by creation of ground-truth dataset, and finally we apply ML methods to classify them.
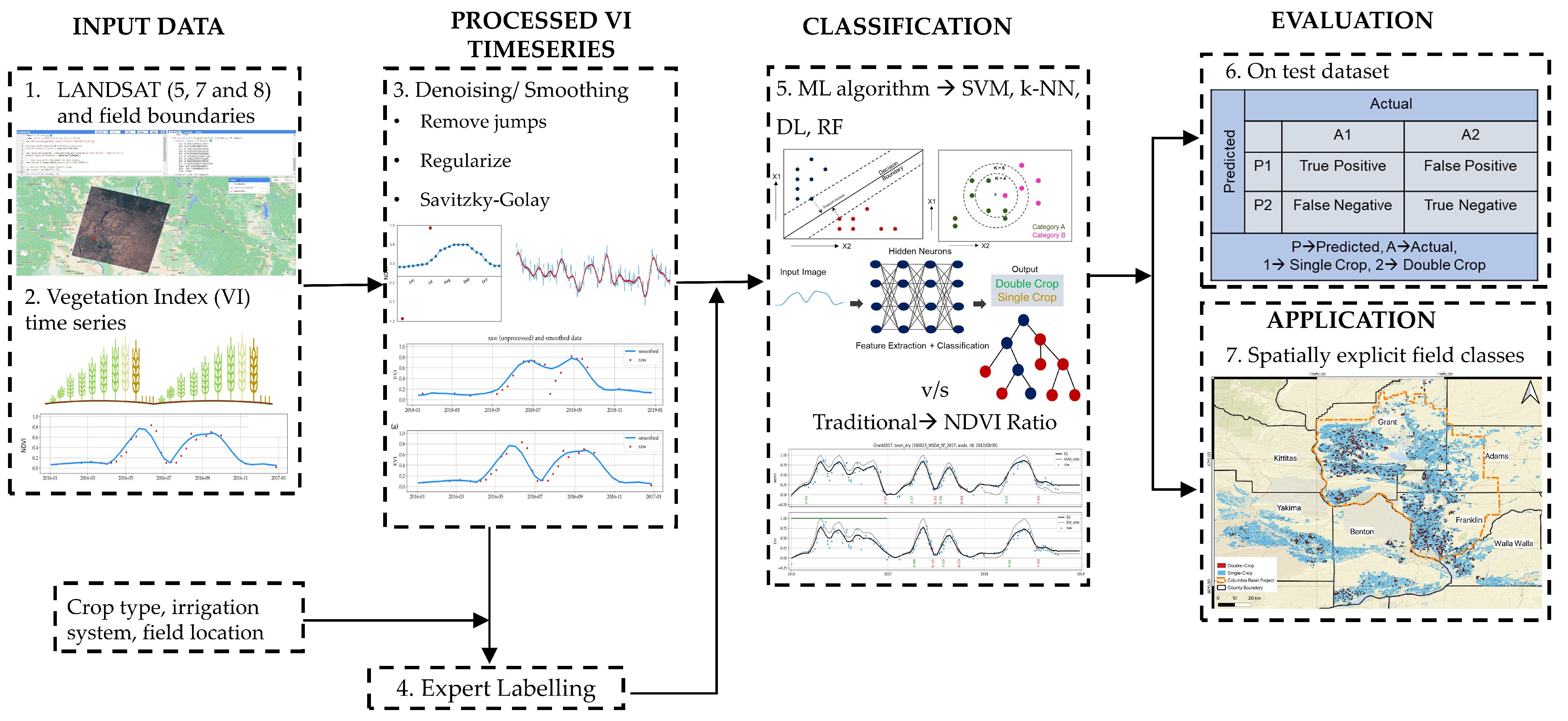
Figure 3.
Examples of raw and smoothed time-series from each group in the confusion matrix for the DL column of Table 3.
Figure 3.
Examples of raw and smoothed time-series from each group in the confusion matrix for the DL column of Table 3.
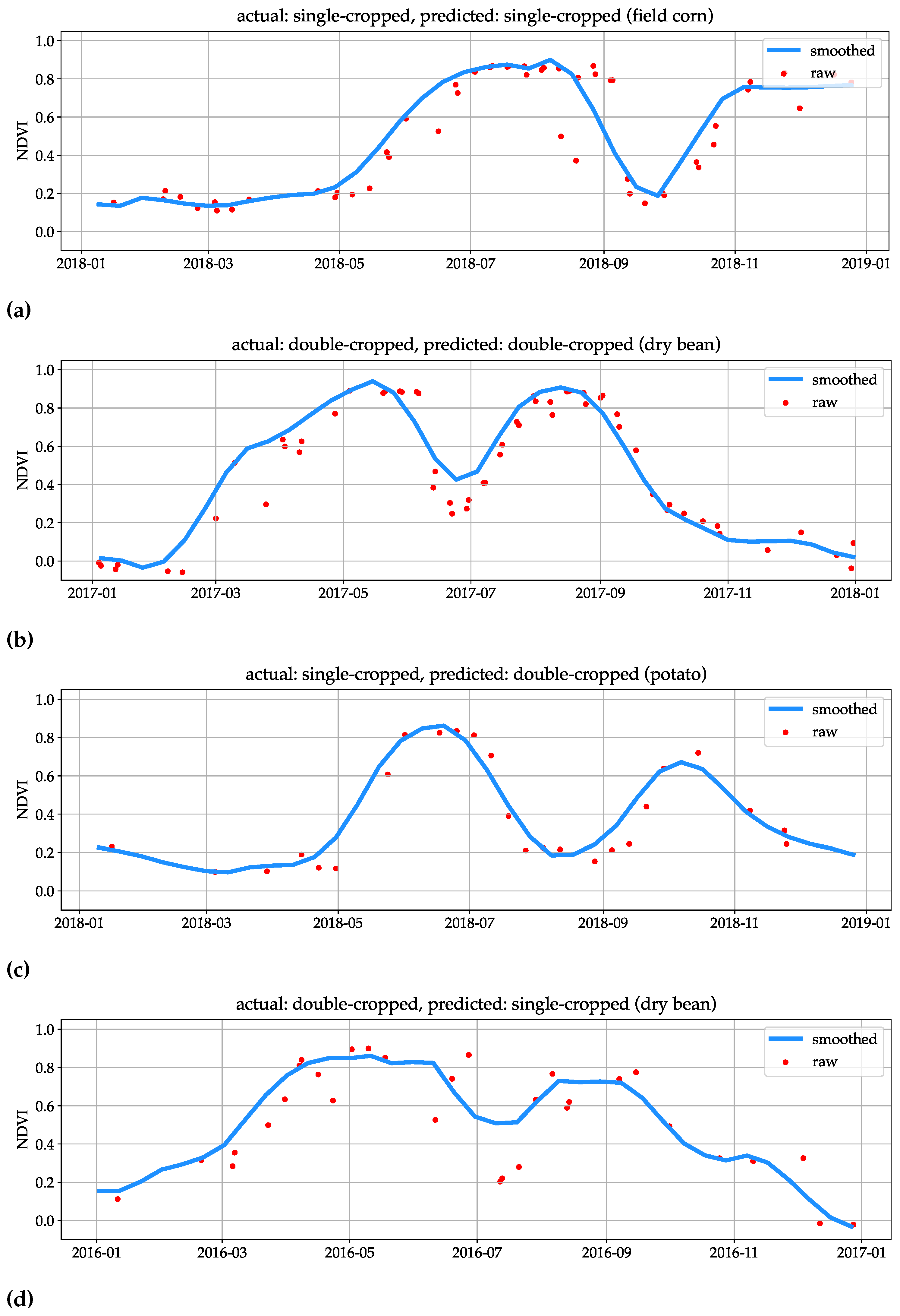
Figure 4.
Fraction (in %) of each crop’s acreage that is classified as a double-cropped. This is based on the test dataset. Perennial crops such as apples, that cannot be double cropped would have bar heights very close to zero are not displayed in this figure for visual clarity.
Figure 4.
Fraction (in %) of each crop’s acreage that is classified as a double-cropped. This is based on the test dataset. Perennial crops such as apples, that cannot be double cropped would have bar heights very close to zero are not displayed in this figure for visual clarity.
Figure 5.
Spatial distribution of classes of fields is presented in this figure along side the double-cropped area as percentage in each of the counties.
Figure 5.
Spatial distribution of classes of fields is presented in this figure along side the double-cropped area as percentage in each of the counties.

Table 1.
Field boundaries filtered for the different counties based on the last surveyed date.
| county | Adams | Benton | Franklin | Grant | Walla Walla | Yakima |
| survey year | 2016 | 2016 | 2018 | 2017 | 2015 | 2018 |
Table 2.
Crop varieties in the ground-truth set used for training the models.
| alfalfa hay | carrot | grass seed | pea, dry | sugar beet seed |
| alfalfa seed | carrot seed | hops | pea, green | sunflower |
| apple | cherry | market crops | pear | sunflower seed |
| apricot | corn seed | medicinal herb | pepper | timothy |
| asparagus | corn, field | mint | plum | triticale |
| barley | corn, sweet | mustard | poplar | triticale hay |
| barley hay | fallow | nectarine/peach | potato | watermelon |
| bean, dry | fallow, idle | oat hay | pumpkin | wheat |
| bean, green | fallow, tilled | onion | ryegrass seed | wheat fallow |
| blueberry | fescue seed | onion seed | sod farm | wildlife feed |
| bluegrass seed | grape, juice | orchard, unknown | squash | yellow mustard |
| buckwheat | grape, wine | pasture | sudangrass | |
| canola | grass hay | pea seed | sugar beet |
Table 3.
Classification results from the test set. User and producer accuracies reported in this table are for double-cropped class.
Table 3.
Classification results from the test set. User and producer accuracies reported in this table are for double-cropped class.
| actual | predicted | SVM | DL | kNN | RF | NDVI-ratio |
|---|---|---|---|---|---|---|
| single | single | 562 | 568 | 559 | 565 | 499 |
| double | double | 55 | 55 | 48 | 44 | 8 |
| single | double | 11 | 5 | 14 | 8 | 74 |
| double | single | 4 | 4 | 11 | 15 | 51 |
| # errors | 15 | 9 | 25 | 23 | 125 | |
| accuracy | 98% | 99% | 96% | 96% | 80% | |
| user acc. | 0.83 | 0.92 | 0.77 | 0.85 | 0.1 | |
| producer acc. | 0.93 | 0.93 | 0.81 | 0.75 | 0.14 | |
| kappa coeff. | 0.87 | 0.92 | 0.77 | 0.77 | 0.005 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



