
Submitted:
11 December 2023
Posted:
13 December 2023
You are already at the latest version
Abstract
This paper offers a comprehensive examination of the process involved in developing and automating supervised end-to-end machine learning workflows for forecasting and classification purposes. It offers a complete overview of the components (i.e. feature engineering, model selection, etc), principles (i.e. bias-variance decomposition, model complexity, overfitting, model sensitivity to feature assumptions and scaling, output interpretability, etc), models (i.e. neural networks, regression models, etc), methods (i.e. Cross-Validation, data augmentation, etc), metrics (i.e. Mean Squared Error, F1-score, etc) and tools that rule most supervised learning applications with numerical and categorical data, as well as their integration, automation, and deployment. The end goal and contribution of this paper is the education and guidance of the non-AI expert academic community over complete and rigorous machine learning pipelines and data science practices, from problem scoping to design and state-of-the-art automation tools, including basic principles and reasoning in the choice of methods. The paper delves into the critical stages of supervised machine learning workflow development, many of which are often omitted by researchers due to brevity, and covers foundational concepts essential for understanding and optimizing a functional machine learning workflow, thereby offering a holistic view of task-specific application development for applied researchers who are not AI experts.
Keywords:
Machine learning workflow
; Supervised learning
; Numerical data
; Categorical data
; Data engineering
; Extraction
; loading
; transformation
; Feature engineering
; Automated feature extraction
; Machine learning engineering
; Training
; validation
; evaluation
; Test-driven development
; Automated machine learning
; Model deployment
1. Introduction
Several machine learning applications are implemented as a workflow, that starts with data collection and ends with a model evaluation and simulations or software development. Examples of fields that introduce custom machine learning workflow solutions, include but are not limited to, malware detection and classification [1], software development with adversarial attack classification [2], task fault prediction in workflows developed with cloud services [3], pipeline optimization [4], classification of forest stand species via remote sensing [5], detection of mechanical discontinuities in materials and prediction of martensitic transformation peak temperature of alloys [6,7], optimization of metabolic pathways and ranking of miRNAs retards insulin gene transcription in human islets [8,9], large-scale crop yield forecasting [10], classification and forecasting in chemical engineering [11], predictive modeling in medicine [12], protein engineering/biophysical screening in pharmaceutical sciences [13], forecasting of oil uptake in batter for food science [14], vegetation height classification, forecasting fractured coal seams, and climate-related forecasting in environmental sciences [15,16,17], energy systems controlled by occupancy detection or energy demand forecasting [18,19,20,21,22], as well as environmental impact estimation from commercial aviation and aerospace requirements engineering [23,24,25,26,27]. Specifically in Artificial Intelligence (AI), machine learning frameworks have been proposed for a variety of data-driven expert systems, such as recommendation systems [28], decision support systems [29], fault diagnosis [30,31], crowdsourcing [32], as well as, generic data science [33], and big data [34] applications. Machine learning workflows or workflow sub-modules are often automated, i.e. automated classification [35], Automated Machine Learning (AutoML) in healthcare [36], aviation [37,38], biology [39] and agriculture [40,41].
Many researchers, including non-AI experts, develop machine learning workflows for a specific application, as the previous references clearly suggest. Therefore, they could benefit from guidance on how to develop rigorous and functional end-to-end machine learning workflows without missing important components or making decisions without considering fundamental AI principles, and also from understanding the state-of-the-art automation tools that can optimize their pipeline design and parameterization. Related work, such as [42,43,44], addressed critical components of a machine learning workflow, but without a focus on supervised cases with numerical and categorical data, while they were not very thorough on the interconnection of the sub-modules, and lacked the explanation of the basic principles required for the development of the workflow. Moreover, the references of [42] are mostly websites and blogs, as opposed to scientific papers. On the other hand, relative books in pipeline development focus more on coding using a specific language and often lack important concept explanations, such as the bias-variance decomposition [45,46,47]. Other review papers focus entirely on the automation of a very specific machine learning area, such as time series forecasting automation [48], and lack the explanation of basic AI principles and workflow sub-module operation, interconnection and development for the education and guidance of a non-AI researcher, seeking to understand and complete their manual workflow development before automating. Last, there are some machine learning workflow automation papers [41,49], that focus on a very specific application, i.e. biology or computer networks, that are however relatively incomplete, missing important AI principles, as well as references of methods outside of what has been published for that specific application under consideration, making them appropriate to guide researchers only on the specific application, and not on the broader spectrum of supervised learning with numerical and categorical data.
The contributions of this paper are threefold. First, this work introduces a methodology for the development and thorough understanding of end-to-end supervised machine learning workflows with numerical and categorical data. Second, this methodology is accompanied by all the workflow sub-modules, methods, principles, models, and algorithms, as well as their integration into the workflow, to guide and inform the non-AI researcher on developing rigorous pipelines. Third, it provides state-of-the-art tools for automated machine learning, including but not limited to automated Feature Engineering, architecture search, hyperparameter search, etc. A systematic and in-depth explanation of machine learning workflow sub-modules and interconnection allows researchers and non-AI professionals to fully comprehend, improve, and excel in machine learning workflow development and automation.
The rest of this paper is organized as follows. Section 2 provides an overview of the end-to-end machine learning workflow architecture. Section 3 presents the data engineering sub-module and Section 4 the machine learning sub-module which includes models and algorithms, as well as, training, validation, and evaluation methods. Section 5 analyzes the model deployment step, Section 6 presents the state-of-the-art automation methods in machine learning workflows and related coding practices, and Section 8 provides conclusions.
2. End-to-End Architecture of Machine Learning Workflows
The workflow of every machine learning (ML) project broadly consists of four stages: scoping of the problem, data engineering, modeling, and deployment of the model. In order to deploy and maintain machine learning models in production reliably and efficiently, a set of practices is necessary to automate the machine learning workflow while meeting business and regulatory requirements, known as Machine Learning Operations (MLOps) [50]. MLOps is considered to be the cross-section of Development Operations (DevOps), data engineering, and Machine Learning Engineering [50]. DevOps is another set of practices that combine software development (Dev) and IT operations (Ops), in order to develop useful software and maintain all data resources in data centers. The core principle of DevOps is automation and therefore Continuous Integration Continuous Delivery or Deployment (CI/CD) is a very important component, so that any software updates from developers are integrated and delivered to the latest software version [51]. CI/CD requires: continuous development, continuous testing (passing a series of predefined tests, see Section 5 for more details), continuous integration, continuous deployment, and continuous monitoring. Expertise in all three areas shown in Figure 1, is required for a machine learning workflow to transition into a product.
A machine learning workflow begins with scoping the problem to be solved, examining the available resources, and deciding upon the feasibility of the project. Then, the objectives and requirements are set and the project is initiated. As Figure 2 shows, data engineering, machine learning model engineering, and model development (production code) are the subsequent stages that will be continuously updated in an automated way, every time new data arrives. This workflow will be incorporated into production code and be subject to testing (Section 5) before every new version deployment as well as continuous monitoring and maintenance of the entire life cycle.
3. Data Engineering
This section provides a detailed explanation of the various stages involved in data engineering.
3.1. Data Pipeline: Extraction, Loading and Transformation
Data can be extracted and fed into a machine learning workflow from several sources, including databases (DB), documents, sensors, and simulations, as shown in Figure 2a. Loading and integrating this data can be challenging and it is an ongoing process, even after the machine learning model has been deployed and an initial master database has been constructed (continuous integration). All this data is in raw format and requires transformation (cleaning), i.e. treating missing values (i.e. imputation [52,53], complete entry removal, matrix completion [54,55,56,57,58] depending on the randomness in the missing data pattern or by producing the missing data with simulations [59]), correcting for data formats (mathematical representation of numbers, time stamps, inconsistent text format, size and resolution of images, etc), de-duplicating [60] (with or without a unique key per real-world entry) or removing redundant data, dealing with contradicting data, removing outliers (point outliers, collective or contextual outliers), etc. Current industry practices for data engineering, include ELT tools (Extract, Load, Transform) [61], which offer data extraction, data integration, and data transformation functions via some Application Programming Interface (API). ELT is currently preferred, as opposed to the previously followed approach ETL (Extract, Transform, Load) [62], because the data is integrated and saved before any transformations occur (data lake implementation). This way, the same data can be accessed by several analysts, scientists, and engineers before any transformations take place, and the scalability of transformation scripts, as the data set increases, is no longer an issue. These transformations are version-controlled and therefore historical transformations can be re-created by rolling back commits in ELT, while data and models can be easily tested. ELT has been growing quickly due to the following enablers: the development of modern data lakes, access to products that can load code and store data in data lakes, and the necessity to open the ELT process to anyone who has Structured Query Language (SQL) knowledge [63].
3.2. Feature Engineering
Feature engineering consists of feature generation, feature transformation, feature selection, and automated feature extraction for Deep Learning, as shown in Figure 2b.
3.2.1. Feature Generation
Feature generation refers to the process of creating new features for the purpose of improving the success metric which validates the machine learning model (Figure 2a), and therefore it is a very important step in the machine learning workflow. To extract new features, data visualization, and domain expertise [18,64] are necessary, but when unavailable or too complicated, Deep Learning neural network architectures can automatically extract features with additional layers which are trained to simulate the appropriate feature transformations that optimize training and generalization errors [65,66]. However, for a researcher with a deeper understanding of the underlying problem feature engineering will result in producing features by generating, combining, or transforming existing features (feature transformation explained next), in the direction of machine learning model performance improvement, given an appropriate evaluation metric (section 4.3). However, it is important to consider a priori a machine learning model in terms of feature learning capabilities. For example, linear regression models are able to learn sums and differences easily but a complex relationship between inputs and outputs would not be learned easily due to model linearity, and therefore such a model could benefit from generated features that explicitly capture that complicated non-linear relationship [67], or by linearizing these relationships. On the other hand, it is wise to be careful regarding generated features such as ratios, because they can be harder to learn by most machine learning models. Moreover, trees are more capable of capturing complex relationships between the inputs and outputs (numerical or categorical) but could still benefit from explicit features generated to capture those [68]. They can also benefit from group aggregate features, such as counts (features that count the total number of times a binary value is present), minimum and maximum feature values, and mean and standard deviation, while they are often used for feature selection, a by-product of the tree training [69]. However, trees can be sensitive to noisy inputs, so it is recommended to remove irrelevant input information, either by removing a feature or by removing a feature’s component (i.e. higher frequency noise) [70].
3.2.2. Feature Transformation
Feature transformation includes feature scaling and the application of deterministic transformations and its significance in the machine learning workflow is explained here. Feature scaling is an important part of the machine learning workflow since models that are smooth functions of the input, such as Linear Regression, Logistic Regression (LR), Neural Networks (NN), and other matrix-based models can be affected by the feature scale (values), given that the parameter vector which is updated via the Stochastic Gradient Descent method will be biased towards specific features [71]. Stochastic Gradient Descent algorithms also converge faster [72] with scaled feature values and with smaller derivatives during back-propagation (a by-product of feature scaling). Feature scaling is also necessary for Principal Component Analysis (PCA), used for dimensionality reduction, which may also be biased since the direction of maximum variance can be affected by large feature values. This issue has been bypassed by creating features with unit variance via scaling with the standard deviation [73]. On the other hand, distance-based algorithms, such as k-Nearest Neighbors (kNN), k-Means, and Support Vector Machines (SVM) are mostly affected by the range of values because they use distances between data points to determine their similarity, therefore, imposing scaling methods that keep the range the same for all features, such as Min-Max, can provide improved results [74]. Moreover, tree-based supervised algorithms such as Classification and Regression Trees (CART), Random Forests (RF), Gradient Boosted Decision Trees [70], are not affected by either the scale or the range of the feature values [75], because most splitting criteria utilize one feature at a time and monotonic feature transformations, do not affect the order of the data points [70]. Hence, the same data point (threshold) will eventually be selected to split the specific node of the tree, whether the data points were scaled or not [75]. Last, Graphical classifiers like Naive Bayes or Fisher Linear Discriminant Analysis (LDA) that rely on variable distributions do not require feature scaling either. The most common feature scaling methods are summarized in Table 1, where is some feature. For an example of the effect of different scaling methods on different supervised classification models and algorithms, the reader is referred to [74], which provides performance index values for a heart disease data set using different scaling methods on different machine learning models and algorithms. It is up to the researcher to evaluate the impact of different scaling methods on the workflow and decide the best way to move forward based on Table 1 recommendations, as well as, by following a similar approach to the heart disease example in [74].
To better understand the effect of scaling methods, it is worth mentioning that the principle behind any scaling method in Table 1 that divides by a normalization constant, is that the feature is scaled without changing the shape of the single-feature distribution (see Figure 2-18 in [75]). For example, if the data distribution is not Gaussian before Standardization, then it will not become Gaussian after. It will, however, have a mean of 0 and a standard deviation of 1, as mentioned in [75]. The interested researcher, however, should be careful in choosing a scaling method in terms of sparsity in the original features. For example, although Min-Max scaling bounds the scaled feature in the range, that is not the case with Standardization and -Normalization. Min-Max and Standardization, both subtract a value from the original feature which may or may not be zero. In the case where the original feature was sparse, doing so, may result in a dense scaled feature if the subtracted value is not zero and that may further burden a classifier model [75].
Feature transformation also includes the application of deterministic, usually invertible, transformations on numerical data. Following data visualization, transformations can be applied to improve feature interpretability (for example, removing high-frequency noise, introducing lag features, feature derivatives, etc. [48]) or conform with assumptions of machine learning models, such as linear regression (linearity, residual independence, homoscedasticity, and residual normality). For example, in order for a researcher to use linear regression models, a linear relationship between the independent variable and the target variable is required, something not necessary if a neural network architecture was selected. If that relationship is visualized to be non-linear, then a transformation can be decided to improve the linearity between the transformed independent variable and the target [76]. A common family of such transformations is the power transformations (power monotonic functions), with special cases the log transformation, the square root transformation, and the multiplicative inverse transformation (reciprocal transformation), all for non-zero data. The power transformations are parameterized by a non-negative value , which can be found via statistical estimation methods. When feature values vary in both the positive and negative range, other transformations such as the multiplicative inverse transformation, the Yeo-Johnson transformation [77], and the inverse hyperbolic sine transformation, can be applied. However, for transformations that assume non-negative data, constant offsets can be applied first to the feature values to shift all values in the positive reals. Another reason behind feature transformation is the principle of variance stabilization which removes the dependency of a population variance from the population mean (for example the reader is referred to Figure 2-11 in [75]). Common variance stabilizing transformations are the Fisher transformation [78] for the sample correlation coefficient, the square root transformation or Anscombe transform [79] for Poisson data (count data), the Box–Cox transformation [80] for regression analysis, and the arcsine square root transformation or angular transformation for proportions (binomial data) [81].
Feature transformation is also required for categorical features for the same range and value size reasons as in the numerical data case above. The most common transformation techniques for categorical features are summarized in Table 2 and their advantages and disadvantages are stated here. Researchers should be cautious in using Ordinal Encoding because of its disadvantage in generating ordered numerical features when no order was present in the original categorical data and that may affect the machine learning algorithm or model [75]. On the other hand, One-Hot Encoding does not have that effect, it clearly assigns one value to each category, leaving the 0 category free for missing data. However, it has a sum of 1 amongst the k new features which implies a linear dependency between those transformed features. That can lead to issues with training linear models since different linear combinations of the dependent features can produce the same predicted target value [75]. By removing one of the degrees of freedom, One-Hot Encoding becomes Dummy Encoding, where the reference category (missing category) is represented by all zeros, which does not allow for easy missing data representation. Moreover, in terms of interpretation, if a linear regression model is used, in the case of One-Hot Encoding, the intercept represents the target variable’s mean, while with Dummy Encoding, the intercept refers to the mean value of the target variable for the reference category [75]. Last, with Effect Coding, the resulting linear regression models are easier to interpret because the intercept represents the mean of the target variable. On the other hand, the dense -1 representation of the reference category can be expensive in terms of storage and computation. Since all the aforementioned encoding methods are not scalable for large data sets, scalability is only possible via feature compression. Feature compression is translated into either feature hashing (linear and kernel models) or bin counting (linear models and trees), where instead of the categorical feature, the conditional probability of the target variable under that value is used. The back-off method [75] or the count-min sketch [82] methods are available in the literature for rare categories in large data sets that were previously transformed with bin counting [75].
To summarize the feature transformation sub-module, the interested researcher is encouraged to also consider multivariate feature transformations, which transform several features at a time and may have superior performance in specific circumstances where i.e. the features are correlated [83] and high correlation can lead to feature redundancy. One such example is whitening transformations (linear) which lead to uncorrelated features with an identity covariance matrix [83]. The covariance matrix may first be expressed in a decomposed form, via i.e. Cholesky decomposition [84], before the whitening transformation is applied. Other similar transformations include: decorrelation, which removes the correlations but leaves variances intact [83], standardization, which sets the variances to 1 but leaves the correlations intact and coloring, which turns a random a vector of white random variables (with identity covariance) into a random vector with a pre-specified covariance matrix.
3.2.3. Feature Selection
Feature selection is another crucial sub-module of the machine learning workflow, often omitted due to brevity or lack of expertise in this area. However, the lack of features can lead to machine learning model underfitting and redundancy to overfitting, and therefore proper feature selection is important [71], following the feature generation and transformation steps. Feature selection can remove redundant features that are irrelevant to the target variables (adding "noise") by either selecting a subset of the features or by creating a lower dimensional representation (embedding) of the feature set, which adequately summarizes the necessary information contained in the original feature space [75] but unfortunately without the physical interpretation of the original features (dimensionality reduction is traded for interpretability). Moreover, feature selection serves the purpose of dimensionality reduction [85] which can remove the computational burden from the machine learning model, by removing linearly dependent features. A very common method of dimensionality reduction is PCA, which is also a whitening transformation, in the sense that the transformed features are no longer correlated [75]. In PCA, the dimensionality k of the embedding is subject to user choice but the operational cost of PCA can be very high for over a thousand features since it involves Singular Value Decomposition (SVD) of the original feature matrix [75]. A very interesting application of PCA is anomaly detection in time series data [86]. Since PCA projects the features to a linear subspace via linear projection, it is not ideal when the data lies in a nonlinear manifold. It is also not ideal when feature interpretability is necessary. In contrast, k-Means can perform feature selection when data lies in a nonlinear manifold, by clustering features together and selecting one feature to survive from each cluster (representative), while the rest are being discarded [75]. Another approach to dimensionality reduction is autoencoders [87], which, however, suffer from a lack of feature interpretability as well.
Unsupervised feature selection methods can be categorized as follows (a taxonomy is provided in Figure 1 of [88]). Attention is required to whether the method can directly incorporate categorical features or not.
-
Filter methods [88,89,90]: In this category of methods, feature selection is a pre-processing step to the machine learning model training and these methods are time efficient,
- a)
- Statistical/Information-based: these methods maximize feature relevance by maximizing a dependence measure, such as variance, covariance, entropy [90], linear correlation [91], Laplacian score [92] and mutual information. Representative methods include Feature Selection with Feature Similarity (FSFS) [91] based on Maximal Information Compression Index (MICI) and Relevance Redundancy Feature Selection (RRFS) [93]. Fisher’s criterion [94] is only used in Supervised Learning.
- b)
- Spectral/Sparsity Learning: these methods perform spectral analysis or combine spectral analysis with spectral learning. They find a trade-off between Goodness-of-Fit and a feature similarity measure. Representative methods include Multi-Cluster Feature Selection (MCFS) [95], Unsupervised Discriminative Feature Selection (UDFS) [96] and Non-negative Discriminative Feature Selection (NDFS) [89].
-
Wrapper methods [88,89,90]: In this category, feature selection is intertwined with the machine learning model training and hence evaluated by the model performance. These methods are more accurate than Filter methods but less time efficient,
- a)
- Sequential methods: these methods perform clustering on each feature subset and evaluate the clustering results based on some criterion. They can be based on Expectation Maximization or Trace Criterion [97], or on min/max of intra/inter-cluster variance [98] and then make a decision based on a score that provides feature ranking. Another alternative is the Simplified Silhouette Sequential Forward Selection (SS-SFS) proposed in [99].
- b)
- Iterative methods: [100] performs clustering and feature selection simultaneously by evaluating feature weights called feature saliences. Other iterative methods include Local Learning-based Clustering with Feature Selection (LLC-fs) [101], Embedded Unsupervised Feature Selection (EUFS) [102] and Dependence Guided Unsupervised Feature Selection (DGUFS) [103].
- Embedded methods: In this category, feature selection is part of the machine learning model training process [104].
Supervised feature selection methods include the deployment of a supervised machine learning model when target variables are available. After training a supervised machine learning model, a feature ranking process is used to select the most important features that adequately describe the outputs (one or more target variables). Three main approaches in supervised feature selection are explained below. A more thorough overview of feature selection methods can be found in the book [104] and in chapter 19 of the book [105].
- Shrinkage-based methods [106]: single-output or multi-output regression models with - or -regularization, can be trained via k-fold Cross-Validation (CV), to optimize a shrinkage parameter which trades-off model bias for variance. Penalization of the model weights with an norm is appropriate for feature selection because it can introduce feature sparsity (Lasso estimator [107]) when penalization with an norm (Ridge Regression [68]) does not force feature weights to zero. The combination of the two is called Elastic Net, which is useful when there is a group of features with high pairwise correlations [108]. Multi-output regression models perform better when outputs are correlated, i.e. when multi-task learning is desired, instead of independent task learning [109,110]. Multi-output models utilize an norm penalization term which either includes or excludes a feature from the model for all outputs [111]. In the multi-output case, the average weight of a feature across all outputs is obtained and then these average weights are normalized in the range (relative importance) with the Min-Max scaling method so that a rank of feature relative importance is derived [23].
- Tree-based methods: CART can be trained in a supervised sense and provide feature ranking as a by-product of the training process [70], in single-output or multi-output Decision Trees (DT) [112]. DTs are over-sensitive to the training set, irrelevant information, and noise, and therefore, prior unsupervised feature selection is strongly encouraged, via one of the methods proposed above. Moreover, DTs are known to overfit, and hence, ensembles of DTs [112], such as Bagging (bootstrap aggregation) [113], Boosted Trees [114] and Rotation Forests, are constructed to cope with overfitting. The RF, a characteristic example of Bagging, can generate diverse trees by bootstrap sampling and/or randomly selecting a subset of the features during learning [115,116]. Although an RF is faster and easier to train than a boosted tree [117,118,119], it is less accurate and sacrifices the intrinsic interpretability (explanation of output value and feature ranking) present in DTs [68]. In particular, feature selection happens inherently in single-output and multi-output DTs as the tree is being constructed, since the splitting criteria used at each node select the feature which performs the most successful separation of the remaining examples [70]. Therefore, in RFs, feature ranking is either impurity-based, such as the Mean Decrease in Impurity (MDI), or permutation-based, such as Permutation Importance [115]. MDI is a.k.a. Mean Decrease Gini or Gini Importance.
- Permutation Importance [115] is not only useful in RFs which have lost the inherent feature ranking mechanism of the tree but in other supervised machine learning models as well. Permutation Importance is better than MDI because it is not computed on the training set, but on the Out-of-Bag (OoB) sample, and is therefore, more useful to inform on the feature importance for predictions [115]. Moreover, MDI significantly favors numerical features over categorical ones as well as high cardinality categorical features (many categories) over low cardinality ones [115], something that does not happen with Permutation Importance. The Permutation Importance of a feature is calculated as the difference between the original error and the average permuted error of this feature, over a number of specified repetitions [115]. The permuted error of each feature (the OoB error) occurs when that feature is permuted (shuffled). Permutation is a mechanism that breaks the relationship between that feature and the target variables, revealing the importance of a feature to the model training accuracy [120]. In trees and other supervised methods which use a feature ranking approach to feature selection, the least performing features in terms of relative importance can be excluded from the feature set.
3.2.4. Automated Feature Extraction
An important note on feature engineering is that as the number of features and samples increases, data engineering, feature engineering, and Machine Learning Engineering methods, require scaling and modification to adjust to the new challenges. This concept was first introduced by Richard Bellman, as the Curse of Dimensionality (CoD) [121]. This principle is important to understand the need behind automated feature engineering.
CoD is associated with several challenges. First, the data representation in higher dimensions can be very sparse, since the data tends to concentrate in lower dimensional spaces and therefore the sample size necessary for learning a statistical or machine learning model, grows exponentially [122]. Second, the pairwise distances of the data points in higher dimensional spaces increase and they become more homogeneous hence observations may appear to be equally distanced from each other [123]. Two additional challenges related to CoD arise in the case of high-dimensional data clustering and anomaly detection. Those are the relevant attribute identification, i.e. the difficulty of describing the relevant quantitative locality of data instances in the high-dimensional space, and hubness, which refers to the tendency of high-dimensional data to contain data points that appear frequently in nearest neighbor clusters, known as hubs [124].

Table 3.
Summary of most common automated feature engineering tools for high-dimensional data.
| Automated F.E. Tool | Operation | Tool Tested On | Developer | Paper |
|---|---|---|---|---|
| ExploreKit | Feature generation & ranking | DT, SVM, RF | UC Berkeley | [125] |
| One Button Machine | Feature discovery in relational DBs | RF, XGBOOST | IBM | [126] |
| AutoLearn | Feature generation & selection | kNN, LR, SVM, RF, Adaboost, NN, DT | IIIT | [127] |
| GeP Feature Construction | Feature generation from GeP on DTs | kNN, DT, Naive Bayes | Wellington Uni. | [128] |
| Cognito | Feature generation & selection | N/A | IBM | [129] |
| RLFE | Feature generation & selection | RF | IBM | [130] |
| LFE | Feature transformation | LR, RF | IBM | [131] |
The last component of feature engineering is automated feature extraction which removes human intervention. This component is very useful in high-dimensional data that suffer from CoD, big data, and Deep Learning. Common examples of high-dimensional big data are time series, images (chapter 8 in [75]), video data [132], and finance applications [133,134], while extracted features are saved and organized in feature stores (structured data in Figure 2a), for accessibility and re-usability. Core approaches in automated feature extraction include the Multi-Relational Decision Tree Learning (MRDTL) [135], Deep Feature Synthesis (DFS) [136] and methods/models such as Deep Neural Networks (DNN) [137], Adaptive Linear Approximation (ALA), PCA, extraction of Best Fourier Coefficients (BFC) and Best Daubechies Wavelet Coefficients (BDW) and statistical moments [138]. Once the features are extracted, then feature selection can be performed via an unsupervised or supervised method, appropriate for the problem dimensions. Recursive Feature Elimination Support Vector Machines (REFSVM) and RELIEFF algorithms were proposed in [138] for feature selection and they can take into account feature interaction (correlation) for up to 500 features. For more features, the Pearson correlation coefficient is used to remove highly correlated features before any of the two aforementioned algorithms is applied. Other methods for automated feature extraction are Genetic Programming (GeP) [139], Reconstruction Independent Component Analysis (RICA) [140] which generates sparse representations of whitened data, Sparse Filtering [141] which minimizes an objective function via a standard limited memory Broyden-Fletcher-Goldfarb-Shanno (LBFGS) quasi-Newton optimizer [142] and Wavelet Scattering networks [143,144,145,146] which apply wavelet and scattering filters to produce low-variance features from time series and image data in Deep Learning applications. Features extracted by Wavelet Scattering networks are insensitive to input translations on an invariance scale, in the 1-D case [145] and insensitive to rotations, in the 2-D case. Invariance to input transformations, such as measurement noise and image rotation and translation, is desired so that the performance of the machine learning model is unaffected. The interested reader is also encouraged to review additional automated feature engineering tools, such as ExploreKit [125], One Button Machine [126], AutoLearn [127], GeP Feature Construction [128], Cognito [129], RLFE [130], and LFE [131].
4. Machine Learning Engineering
4.1. Models and Algorithms for Supervised Learning with Numerical and Categorical Data
Since the area of machine learning models and algorithms is very broad, it would be impossible to cover in one paper and therefore, this section focuses only on some basic supervised models and algorithms for the purposes of representing this workflow sub-module and its integration with the others. Supervised Learning is possible when target variable values are present in regression (continuous range target values) or classification problems (pre-specified target values indicative of a class). Machine learning models are characterized as parametric if they have a specific function form with parameters, whose values can be determined by a data set [122]. The most commonly used machine learning models and algorithms for supervised learning are summarized in Table 4. Note that DNN can be modeled as Gaussian Processes (GP) [66] and hence are considered non-parametric as well. The choice of the problem model or algorithm is not trivial and highly depends on the scalability desired as well as the features collected (dimensionality, linearity, signal-to-noise ratio, probabilistic assumptions, correlation, etc.), as explained in the feature engineering section. Often, researchers will experiment with multiple models/algorithms, but it is wise to narrow down the search for practical purposes. Table 4 summarizes basic criteria for guiding the choice of a model/algorithm, with each individual having additional assumptions that need to be taken into consideration.
4.2. Model Training and Validation
It is important to ensure that the machine learning model is not overfitting during the training process so that better model generalization is achieved in the testing phase and future use of this model. Common approaches to prevent model overfitting include validation, CV [165], data augmentation, removal of features, early stopping of training before optimality, regularization, and ensembling (Bootstrap [166], Bootstrap Aggregating, a.k.a. Bagging [113,167] and Boosting [168]). Although, CV and Bootstrap include efficient sample re-use [68], other validation methods can be analytical, such as Akaike Information Criterion (AIC), Bayesian Information Criterion (BIC), Minimum Description Length (MDL), and Structural Risk Minimization (SRM) [68]. Different validation methods provide a different test error estimate, which can be a more or less unbiased estimate of the true underlying test error, as mentioned by the authors in [68].
To explain the model validation principle and the model complexity choice better to applied researchers developing pipelines in their field, train and test error estimates are summarized in Figure 4a. The light blue and red lines, correspond to the train and test error estimates for different data sets of equal size. The dark blue and red lines, are the averages of the train and test error estimates of the light red and blue lines. The left half of Figure 4a (left of the red line minimum point), corresponds to higher error bias and lower error variance and is a sign of model underfitting, due to the limited model’s capacity. The right half of the same figure refers to higher model complexity, with higher error variance and lower error bias. That is the region of overfitting and happens when random noise in the data is modeled. The middle part which corresponds to the minimum of the test error (red line), is the ideal model complexity so that the best model generalization is achieved. The test error estimate is further decomposed into its components in Figure 4b. In supervised learning, the test error estimate is calculated by comparing the model’s predictive capability with the ground truth. In unsupervised learning, model selection is often conducted by selecting the point of maximum absolute second derivative on the train error curve, a.k.a. the elbow-method [169], commonly used in k-Means. For other validation and evaluation metrics, including CV in unsupervised learning, the interested researcher is referred to the following papers [170,171,172].
All the errors in Figure 4a are estimates based on some data set. Since the bias-variance decomposition is the most fundamental principle in machine learning, this section will dive deeper into the mathematical proof to substantiate the results shown in Figure 4a,b, and help the interested researcher optimize their pipelines. The test error is decomposed in Figure 4b, according to Equation (1). Assume for simplicity that , where is the target variable, is the machine learning model, is the model input, is noise with mean and variance and is the fitted model to a specific training set. Then, the expected test error is decomposed as follows, with the help of the identity ,
where the cross-terms are zero due to being deterministic, i.e. , the independence of and and the assumption that ,
The first term in (1), corresponds to the variance of the target variable around its true mean since and cannot be avoided. The second term, the squared bias, shows how the average of the estimate differs from the true mean, i.e. . The third term describes the variance of , i.e. the expected squared deviation of from its mean [68].
Having observed the behavior of the expected test error on testing data in Figure 4b, it is suggested to perform model selection on the best bias-variance trade-off point. Another set, the validation set, that was not used for training, is used for model selection and the model performance is then evaluated on the testing set, as explained in Section 4.3. Common ways of splitting the data set are: 70% or 50% for the train set, 20% or 25% for the validation set, and 10% or 25% for the test set [68]. When splitting includes random sampling, then the model may generalize better. However, it is advised to avoid random sampling (shuffling) in time series data, because of the signal autocorrelation. Moreover, it is suggested to use stratified training data in the case of classification, to ensure that all classes are equally represented in the training set so that the classifier is not biased towards a specific class. Although in the case of big data or Deep Learning, the previous splitting approach would be sufficient (chapter 7 in [68]), in small data sets with a higher danger of overfitting, it would not. Hence, different forms of CV are suggested to prevent bias and overfitting, by re-using the data set multiple times. CV is avoided in Deep Learning because training can become computationally intractable and therefore overfitting is managed in different ways. In big data sets, following training, the model performance is evaluated on the validation set. The validation set is used to tune model hyperparameters and prevent overfitting by early stopping, regularization, etc. The model performance is tested on the testing set that was not used for training or validation.
In cases where the data set is small, some form of CV is utilized as a way to avoid overfitting to that particular data set (Table 5). The first category of CV is Exhaustive CV. The data set of size n is split into a training set of size and a validation set of size p, in all possible ways. Every time, a model is fit and a validation error occurs. The average validation error across all validation sets is estimated for each hyperparameter value so that the optimal value can be selected at the minimum average error. Other variations of Exhaustive CV, include the case, which is less computationally heavy than the p case, or which is an almost unbiased method for estimating the area under the Receiver Operating Characteristic (ROC) curve, for binary classifiers [173].
The second category of CV, includes the Non-Exhaustive methods, an approximation of the Exhaustive Leave-p-out CV, which are computationally tractable. The most popular method, k-fold CV, requires splitting the data set randomly in k sets, and keeping a different set for validation every time, as shown in Figure 5. Again, the average error is calculated and utilized for hyperparameter estimation, by constructing a plot of average kfold CV error vs hyperparameter values. Popular choices for k are 5, 10, and 20. It is worth mentioning that the Leave-1-out CV has low bias and high variance, whereas the kfold CV with or , is a better compromise [174,175]. The next type of Non-Exhaustive CV method is the Holdout method, which randomly assigns p points in the training set and points in the testing set. It involves a single iteration and may be considered the same as the simple validation approach [175,176]. The last Non-Exhaustive CV method is the Repeated Random Sub-Sampling Validation, a.k.a. Monte Carlo CV, which is similar to the k-fold CV process, only with random validation sets, which means that some observations may never be part of the validation set [105].
The third category of CV methods is the Nested CV, where CV is used for hyperparameter tuning and error estimation simultaneously. Nested CV methods consider a testing set, in additionally to the training and validation sets of the previous categories. The k*l-fold CV splits the data set into k sets and iteratively each of the k sets is split into l sets, where are used for training and the other for validation. The inner sets are used to train the model and tune its hyperparameters and the outer is used for testing, in order to provide an unbiased evaluation of the model fit. A special case of k*l-fold CV, is the k-fold CV with validation and testing set, for . One by one, a testing set is selected and one by one, one of the remaining sets is used as a validation set while the other sets are used as training sets until all possible combinations have been evaluated.
4.3. Model Evaluation
Following the training and tuning of the model on the training and validation sets explained in Section 4.2, comes model evaluation. This step includes methods and metrics to evaluate that the model indeed performs adequately for the purpose it was developed. This step includes utilizing a training set based on which prediction is performed and the evaluation of performance indices. Moreover, evaluation refers to the verification of the model’s assumptions, after the predicted values are collected. One such example are linear regression models, the assumptions of which are summarized below [177].
- Linear relationship between each feature and each target variable. This assumption can be verified in the testing set by constructing scatter plots of each output vs each feature.
- Homoscedasticity, i.e. constant residual variance for all the values of a feature. This assumption can be verified by plotting the residuals vs each feature in the testing set.
- Independence of residual observations which is the same as independence of target variable observations (commonly violated in time series data). This can be verified by checking that the autocorrelation of the residual observations is non-zero with the Durbin-Watson test since that would indicate sample dependence.
- Normality of the target variable observations. This can be verified by constructing QQ plots of the residuals against the theoretical normal distribution and observing the straightness of the produced line.
It is worth mentioning that if some of the above assumptions do not hold, feature transformations can be applied to satisfy them, such as the ones explained in Section 3.2 of this dissertation. For additional solutions in order to conform with the linear regression model assumptions, the reader is referred to [177]. After model training, the assumptions above should also be verified on the testing set.
Supervised regression and classification models are not only evaluated based on their modeling assumptions but also based on performance metrics. Some commonly used performance indices in supervised learning are summarized in Table 6, where the following shortcuts are used: True Positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN). TPs/TNs are when the model predicts an observation to belong/not belong to a class and it does/does not indeed belong to that class. Equivalently, FPs/FNs are when the model predicts that an observation belongs/does not belong to a class and it does not/does belong to that class. Note that N is the number of samples, k is the number of independent variables, is an observed value, is a predicted value and is the sample average of the observed data.
The choice of the evaluation metric is of great importance, as the wrong choice can lead to the optimization of an irrelevant objective or the introduction of bias, as for example in the case of using Accuracy, instead of Balanced Accuracy, when the data set is unbalanced in terms of number of data points from each class [178]. The interested researcher may look into [179] for an empirical analysis of different model performance criteria.
5. Model Deployment
The final phase in the machine learning workflow of Figure 2a is the model deployment where businesses aim to harness its value. The model deployment process encompasses a series of steps undertaken before, during, and after the model is put into production, effectively facilitating the productization of the model. Model deployment steps include implementing best practices for deploying a model to production involves the standardization of code (TDD [180], Object-Oriented Programming (OOP) or Functional Programming paradigms, and the application of Design Patterns [181,182]), rigorous testing (bug identification, performance testing, integration testing, robustness testing, A/B testing [183], etc.), and ensuring the security (deploying in a private network or Virtual Private Cloud (VPC) [184]) and monitoring of the deployed ML model (for the model or data drifts, bugs, failures, etc.). Subsequently, the deployment undergoes continuous updates which include the integration of new data, additional data resources, transformations, models, etc., into the workflow, with new model versions being continuously delivered and deployed into the product. The inherent complexity of large-scale systems necessitates the implementation of workflows with sound design principles and robust testing. The next subsections provide all the steps involved in transitioning a model into a production environment.
5.1. Testing
This subsection describes the different types of testing that are performed before a model is put into production.
5.1.1. Unit Testing
Testing is a very important component of a machine learning workflow deployment into production for industry purposes and begins with unit testing. Unit testing verifies that software subprograms function as expected in isolation [185] and focuses on scrutinizing components within the software stack rather than predicting the model’s output, given its inherent unpredictability. Various testing frameworks like Pytest [186], Unittest [187], JUnit [188], Mockito [189], etc., can help generate dummy data sets and test expected outputs. Multiple scripted scenarios, encompassing both success and failure cases, are executed in the programming language to assess functionality and identify bugs. A comprehensive suite of unit tests is run during each deployment to ensure the code behaves as intended.
5.1.2. Performance Testing
In addition to unit testing, performance testing is frequently employed to assess the time required for training and gather details about the hardware configurations involved in the training process. This information has been proven to be crucial for future development and testing endeavors. Performance tests also evaluate the model’s response time under normal and peak loads, ensuring adherence to the Service Level Agreement (SLA) [190] and preventing compromise in availability due to request timeouts. Collecting statistics on the ML model’s responsiveness under varying workloads aids in identifying potential issues and guarantees that the system performs within specified operational parameters.
5.1.3. Integration Testing
The next level of testing is integration testing, a vital component of CI/CD, which tests the integration between a new or updated ML model and the rest of the code within the software stack before promoting it to production. Integration testing verifies the interaction between software components [185] by testing them together based on functional threads or exhaustively all with all (a.k.a. "big bang" testing). For example, an ML model that predicts the number of neighborhood houses sold must seamlessly interact with gateways, web servers, databases, and other networking layers [191]. Therefore, integration tests would be performed in this case to ensure that the interaction of the model with these services goes as expected. This rigorous integration testing helps identify and rectify potential issues, reducing the risk of disruptions in the live system.
5.1.4. System Testing
Most functional failures must have been identified during the unit and integration testing. System testing examines the behavior of the entire system for the purposes of system security, speed, accuracy, and reliability (non-functional requirements) and for proper interfacing with other applications, utilities, hardware devices, and the operating environment [185]. Installation testing is one form of system testing, that may appear in software systems that host an ML model [185]. System and acceptance testing are tests used across software engineering, whether ML is involved or not, but they are not always present in the ML pipeline testing process.
5.1.5. Acceptance Testing
Acceptance testing checks the system behavior against the customer’s requirements and the customers undertake, or specify, typical tasks to check that their requirements have been met or that the organization has identified these for the software’s target market. The developers of the system may or may not be involved in this testing level [185].
5.1.6. A/B Testing
Organizations derive value from making data-driven decisions regarding a model’s real-world performance. A/B testing [192] serves the understanding of the relationship between changes made to the model and the actual outcomes observed in user behavior. The model users are divided into the control group A and the treatment group B. The control group responds to the existing model and the treatment group to the new/modified model. User responses are recorded, and metrics are subsequently computed and compared. This comparison helps to assess the model’s performance before deploying it to the entire user base.
5.2. Model Deployment
After successfully completing various tests in the CI/CD pipeline, the approved changes are deployed to the production environment. The deployed model can be executed either through a scheduled process or triggered by certain events. Scheduled model execution, for example, includes generating an overnight report predicting sales for the next day which runs to provide up-to-date predictions for business planning. Trigger-based execution, on the other hand, involves responding to specific events such as user recommendations triggered by a user’s search keywords, in order to deliver real-time, personalized results, thus enhancing the user’s experience.
5.3. Monitoring and Maintenance
The consideration of model and data drift is of paramount importance during the protracted phases of model monitoring and maintenance. Model drift [193], driven by alterations in the statistical properties of the target variable over time, can result in a degradation of the model’s predictive performance. Simultaneously, data drift [194] pertains to variations in the distribution of input features, posing challenges to the model’s generalization capabilities. In the lifecycle of an ML model after deployment, sustained vigilance entails regular assessment of performance metrics, and juxtaposing them against benchmarks established during the model’s training phase. In the context of contemporary MLOps, the automation of drift detection and response mechanisms is increasingly pivotal to upholding model efficacy and alignment with evolving data dynamics.
5.4. Security Considerations
The infrastructure in which the ML model operates often faces threats, attacks, and risks that can jeopardize assets and availability. Therefore, it is imperative to assess and prepare for these scenarios by regularly applying software patches to known vulnerabilities. Organizations conduct thorough audits of open-source code for any vulnerabilities before incorporating it into production. A recommended strategy to mitigate risk is the creation of internally approved repositories for various versions of software used in building the model and the overall software stack. This centralized control over software versions ensures that only vetted and secure components are employed, reducing the likelihood of vulnerabilities compromising the system. If the ML model is exclusively serving customers within the organization, it is advisable to deploy the code in a private network or a VPC when hosted in the cloud. Adhering to the Principle of Least Privilege (PoLP) [195] is crucial when configuring both the software and ML model, regardless of whether the audience is internal or external. By implementing PoLP, access permissions are restricted to the minimum necessary for users or systems to perform their intended tasks. This helps reduce the potential attack surface and enhances overall security. In addition, monitoring usage patterns helps detect and mitigate any potential Distributed Denial-of-Service (DDoS) [196] attacks on the system. By closely observing network traffic and user interactions, abnormal patterns indicative of a DDoS attack can be identified and appropriate measures are taken to ensure the continued availability and performance of the ML model.
To conclude, model production code is developed via TDD which continuously creates tests to fail the system’s operation and then upgrades the system to pass the test [180]. This is a slow process but it leads to fewer bugs and re-usable code through various levels of testing [185,197], as shown in Figure 2c. Testing, deployment, monitoring, maintenance, and security follow the development. For comprehensive insights into both static and dynamic testing, the book by Lewis [198] is highly recommended. For guidance on adhering to good coding practices, it is advised to consult the works of Martin [199] and Thomas et al. [200]. These references offer valuable resources for researchers seeking in-depth knowledge in the domains of coding and testing practices for software development.
6. Automation in Machine Learning Workflows
Section 3.2.4, analyzed automation of feature extraction. This section focuses on the automation of the entire machine learning workflow and optimization of pipeline hyperparameters and is often referred to as AutoML. According to [201], AutoML makes decisions in a data-driven, objective, and automated way, with the user only providing the data and AutoML automatically determining the best approach. AutoML is particularly useful, for domain scientists which do not focus on learning in-depth machine learning practices, as well as, big data and Deep Learning applications [201]. Automation of AI expert systems, i.e. AI software with task-specific machine learning workflow for decision-making in the place of a human, is also possible via AutoML. The focal points of automation encompass various facets such as data engineering, feature engineering, model selection, ensembling, algorithm selection, hyperparameter optimization, as well as considerations of time, memory, and complexity constraints within the pipeline. Additionally, automation extends to the determination of evaluation and validation metrics. It is noteworthy that while certain aspects are more commonly automated, the spectrum of automated processes is diverse, catering to the nuanced requirements of the machine learning pipeline.
6.1. AutoML Methods
AutoML methods are utilized for tuning machine learning workflow hyperparameters, a.k.a. Automated Hyperparameter Optimization (AHO), including those decided before training and those decided during training. For example, the number of layers and neurons in a NN is tuned before training, while the NN weights are tuned during training. Although hyperparameter optimization has been considered an art, AutoML aims to automate this part of the machine learning workflow to make machine learning more accessible to non-technical professionals [36], and help optimize the functionality of developed pipelines.
According to [201], AHO can be very useful because it reduces the human effort necessary for machine learning and improves machine learning algorithm performance [202,203] and reproducibility of scientific results [204,205]. Hyperparameter optimization is a very challenging problem because: a) function evaluations can be extremely expensive for large models (i.e. DNN), large data sets, or very complex machine learning workflows, b) the configuration space can be complex (continuous, discrete, conditional hyperparameters) and high-dimensional, c) access to the loss function’s gradient with respect to the hyperparameters is often impossible, and d) generalized optimization is not possible as it depends on the data set size which varies [36]. The most common methods for hyperparameter optimization are summarized below.
-
Black-box hyperparameter optimization:
- a)
- Model-free black-box optimization methods include grid search in a finite range, which however suffers from the CoD and random search, where random search samples configurations at random until a certain budget for the search is exhausted [206]. This works better than grid search when some hyperparameters are much more important than others, which is very often the case [206]. Covariance Matrix Adaption Evolutionary Strategy (CMA-ES) [207], is one of the most competitive black-box optimization algorithms.
- b)
- Bayesian optimization has gained interest due to DNN tuning for image classification [203,208], speech recognition [209] and neural language modeling [202]. For an in-depth introduction to Bayesian optimization, the interested reader is referred to [210,211]. Many recent advances in Bayesian optimization do not treat hyperparameter tuning as a black-box anymore, i.e. multi-fidelity hyperparameter turning, Bayesian optimization with meta-learning, and Bayesian optimization taking the pipeline structure into account [212,213].
- Multi-fidelity optimization: these methods are less costly than black-box optimization methods which approximately assess the quality of hyperparameter settings. Multi-fidelity methods introduce heuristics inside an algorithm, using low-fidelity approximations of the actual loss function to reduce runtime. Such heuristics include hyperparameter tuning on a small data subset or feature subset and training for a few iterations by using CV or down-sampled images. Learning curve-based prediction for early stopping is used, as well as, Bandit-based (successive halving [214] and Hyperband [215]) algorithms for algorithm selection based on low-fidelity algorithm approximations. Moreover, Bayesian Optimization Hyperband (BOHB) [216] combines Bayesian optimization and HyperBand to achieve a combination of strong anytime performance (quick improvements in the beginning by using low fidelities in HyperBand) and strong final performance (good performance in the long run by replacing HyperBand’srandom search by Bayesian optimization). For adaptive fidelity options see [36].
Another AutoML family of methods, besides AHO, is meta-learning. This family aims to systematize the developer’s experience based on which a new model is built. First, meta-data needs to be collected that describe previously learned tasks and models and include algorithm configurations and hyperparameter values, workflow architectures, model evaluations (accuracy and training time), optimal model parameters, and meta-features. Second, learning from meta-data needs to take place in order to extract knowledge that can guide future optimal models and tasks. Examples of such methods are transfer learning [217] and few-shot learning [218]. For more related content on learning from model evaluations, task properties, and prior models, please see [36]. A very popular example of AutoML and the aforementioned methods is Neural Architecture Search (NAS), which aims to automate the discovery of new NN architectures [219]. Core approaches to NAS can be found in Table 7.
Scalability of AHO is an open-ended research topic that seems to concern multi-fidelity optimization, gradient-based methods, and meta-learning methods [36]. Parallel computing is expected to play an important role in the scalability of AHO, with parallel Bayesian optimization already implemented [239]. With the only exception being DNN [203,208,210,216,240,241,242,243], Bayesian optimization has not yet been applied successfully to data sets larger than a few thousand data points. For solutions related to overfitting, generalization, and arbitrary pipeline sizes, the reader is referred to [36]. State-of-the-art approaches to scalable AutoML with data privacy include federated learning [244].
6.2. AutoML Systems
AutoML systems, a.k.a. pipeline optimizers, are popular software that try to automate the machine learning workflow. An overview of available AutoML systems is provided in Table 8. For a complete overview of machine learning algorithms and coding languages supported by these systems, the reader is referred to [245]. Semi-automated pipeline optimizers AutoComplete [246] and PennAI are also mentioned in [245]. A performance comparison for AutoML systems is provided in [247].
7. A Supervised Classification Workflow Example
An example of supervised classification machine learning workflow, based on this paper’s methodology, is presented in Figure 6 and describes the approach taken by the IARPA-funded researchers in [18] to classify a room as occupied or empty (binary classification) from one CO2 and one temperature sensor measurement. Applications include energy efficiency, indoor air quality, emergency evacuation, and other applications. The data streams collected from the two sensors were saved locally, where the data engineering code treated the incoming values for missing data and timestamp consistency. Target variable values (occupancy class 0 or 1) were collected from the humans involved in the experiment, for model training and validation. Following that, a new feature, the HVAC state, was generated from the application of a domain-expertise deterministic transformation on the CO2 and temperature data, which helps enrich the input-output correlations by introducing additional information to this poor-input experiment (limited sensors and limited data set challenge). Additional feature transformation took place, by locally smoothing high-frequency noise on the CO2 data with a Savitky-Golay (FIR) filter [263], and feature extraction by producing the numerical derivatives of the smoothed CO2 signal, and lagged inputs, in real-time. All the input invariant features were utilized for training a supervised binary classifier, thus skipping any feature selection, in this feature-poor application, where all features were proved highly important. Although automated feature extraction methods proposed in this paper may have revealed better features, or the extraction of the same features with less human labor, this opportunity was not taken advantage of in the [18] project, and would remain as future work for the authors. A feed-forward neural network was trained on all the aforementioned features, with its architecture optimized manually via tracking of the training, validation, and testing errors, according to the bias-variance decomposition principle analyzed in this paper, as opposed to AutoML methods now available and presented in Section 6. The model evaluation took place via several classification metrics, including accuracy, balanced accuracy, F1-score, and custom application-related metrics (success rate, average detection delay, etc.). Model deployment was missing from this academic project. A rigorous methodology similar to the one presented in this paper was followed in [18], and resulted in highly accurate and mathematically rigorous results.
8. Discussion
This work provides an all-inclusive supervised machine learning workflow development and automation methodology for numerical and categorical data, along with an adequate literature review and associated industry practices. The machine learning workflow is analyzed from the early project brainstorming and scoping stage to data engineering, feature engineering, machine learning model engineering, workflow automation, and model deployment. Guidance is provided to the non-AI expert on how to develop and integrate the pieces of a rigorous, complete, functional, and optimized machine learning workflow for their application, without missing important sub-modules. Important AI principles (i.e. bias-variance decomposition, curse of dimensionality, model complexity, overfitting, model sensitivity to feature assumptions and scaling, output interpretability, etc.) are explained and their utilization in making important algorithm or tuning choices in the workflow is emphasized. State-of-the-art tools on feature extraction automation, neural architecture search, model selection, hyperparameter tuning, algorithm selection, model compression, etc. are provided and explained (i.e. Bayesian optimization, Genetic Programming, random grid search, etc.) for the optimization of the machine learning workflow under development.
Author Contributions
Conceptualization: S.I.K., and D.N.M.; Methodology: S.I.K.; Investigation: S.I.K., and A.T.R.; Writing: S.I.K., A.T.R., and A.P.B.; Visualization: S.I.K.; Supervision: O.J.P.F., and D.N.M.; Project administration: D.N.M.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AHO | Automated Hyperparameter Optimization |
| AIC | Akaike Information Criterion |
| ALA | Adaptive Linear Approximation |
| API | Application Programming Interface |
| AUC | Area Under Curve |
| Auto-WEKA | Automatic Model Selection & Hyperparameter Optimization |
| BDW | Best Daubechies Wavelet Coefficients |
| BFC | Best Fourier Coefficients |
| BIC | Bayesian Information Criterion |
| BOHB | Bayesian Optimization Hyperband |
| CART | Classification and Regression Tree |
| CASH | Combined Algorithm Selection & Hyperparameter optimization |
| CI/CD | Continuous Integration Continuous Delivery or Deployment |
| CMA-ES | Covariance Matrix Adaption Evolutionary Strategy |
| CoD | Curse of Dimensionality |
| CV | Cross-Validation |
| DB | Database |
| DDoS | Distributed Denial-of-Service |
| DevOps | Development Operations |
| DFS | Deep Feature Synthesis |
| DGUFS | Dependence Guided Unsupervised Feature Selection |
| DNN | Deep Neural Network |
| DT | Decision Tree |
| ELT | Extract, Load, Transform |
| ETL | Extract, Transform, Load |
| EUFS | Embedded Unsupervised Feature Selection |
| FIR | Finite Impulse Response |
| FN | False Negative |
| FP | False Positive |
| FSFS | Feature Selection with Feature Similarity |
| GeP | Genetic Programming |
| GP | Gaussian Process |
| HVAC | Heating Ventilation and Air Conditioning |
| IARPA | Intelligence Advanced Research Projects Activity |
| KDD | Knowledge Discovery from Data |
| kNN | k-Nearest Neighbors |
| LARS | Lasso Regression |
| LBFGS | Broyden-Fletcher-Goldfarb-Shanno |
| LDS | Linear Discriminant Analysis |
| LLC-fs | Local Learning-based Clustering with feature selection |
| LR | Logistic Regression |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| MCFS | Multi-Cluster Feature Selection |
| MDI | Mean Decrease in Impurity |
| MDL | Minimum Description Length |
| MICI | Maximal Information Compression Index |
| ML | Machine Learning |
| MLOps | Machine Learning Operations |
| MRDTL | Multi-Relational Decision Tree Learning |
| MSE | Mean Squared Error |
| NAS | Neural Automated Search |
| NDFS | Non-negative Discriminative Feature Selection |
| NN | Neural Network |
| NNI | Neural Network Intelligence |
| OLS | Ordinary Least Squares |
| OoB | Out-of-Bag |
| OOP | Object Oriented Programming |
| PoLP | Principle of Least Privilege |
| PCA | Principal Component Analysis |
| REFSVM | Recursive Feature Elimination Support Vector Machines |
| RF | Random Forest |
| RICA | Reconstruction Independent Component Analysis |
| RMSE | Root Mean Squared Error |
| ROC | Receiver Operating Characteristic |
| RRFS | Relevance Redundancy Feature Selection |
| SLA | Service Level Agreement |
| SQL | Structured Query Language |
| SRM | Structural Risk Minimization |
| SS-SFS | Simplified Silhouette Sequential Forward Selection |
| SVD | Singular Value Decomposition |
| SVM | Support Vector Machines |
| TDD | Test-Driven Development |
| TN | True Negative |
| TOC | Total Operating Characteristic |
| TP | True Positive |
| TPOT | Tree-based Pipeline Optimization Tool |
| UDFS | Unsupervised Discriminative Feature Selection |
| VPC | Virtual Private Cloud |
References
- Gibert, D.; Mateu, C.; Planes, J. The rise of machine learning for detection and classification of malware: Research developments, trends and challenges. Journal of Network and Computer Applications 2020, 153, 102526. [Google Scholar] [CrossRef]
- Bravo-Rocca, G.; Liu, P.; Guitart, J.; Dholakia, A.; Ellison, D.; Falkanger, J.; Hodak, M. Scanflow: A multi-graph framework for Machine Learning workflow management, supervision, and debugging. Expert Systems with Applications 2022, 202, 117232. [Google Scholar] [CrossRef]
- Bala, A.; Chana, I. Intelligent failure prediction models for scientific workflows. Expert Systems with Applications 2015, 42, 980–989. [Google Scholar] [CrossRef]
- Quemy, A. Two-stage optimization for machine learning workflow. Information Systems 2020, 92, 101483. [Google Scholar] [CrossRef]
- Grabska, E.; Frantz, D.; Ostapowicz, K. Evaluation of machine learning algorithms for forest stand species mapping using Sentinel-2 imagery and environmental data in the Polish Carpathians. Remote Sensing of Environment 2020, 251, 112103. [Google Scholar] [CrossRef]
- Liu, R.; Misra, S. A generalized machine learning workflow to visualize mechanical discontinuity. Journal of Petroleum Science and Engineering 2022, 210, 109963. [Google Scholar] [CrossRef]
- He, S.; Wang, Y.; Zhang, Z.; Xiao, F.; Zuo, S.; Zhou, Y.; Cai, X.; Jin, X. Interpretable machine learning workflow for evaluation of the transformation temperatures of TiZrHfNiCoCu high entropy shape memory alloys. Materials & Design 2023, 225, 111513. [Google Scholar]
- Zhou, Y.; Li, G.; Dong, J.; Xing, X.h.; Dai, J.; Zhang, C. MiYA, an efficient machine-learning workflow in conjunction with the YeastFab assembly strategy for combinatorial optimization of heterologous metabolic pathways in Saccharomyces cerevisiae. Metabolic engineering 2018, 47, 294–302. [Google Scholar] [CrossRef]
- Wong, W.K.; Joglekar, M.V.; Saini, V.; Jiang, G.; Dong, C.X.; Chaitarvornkit, A.; Maciag, G.J.; Gerace, D.; Farr, R.J.; Satoor, S.N.; others. Machine learning workflows identify a microRNA signature of insulin transcription in human tissues. Iscience 2021, 24. [Google Scholar] [CrossRef] [PubMed]
- Paudel, D.; Boogaard, H.; de Wit, A.; Janssen, S.; Osinga, S.; Pylianidis, C.; Athanasiadis, I.N. Machine learning for large-scale crop yield forecasting. Agricultural Systems 2021, 187, 103016. [Google Scholar] [CrossRef]
- Haghighatlari, M.; Hachmann, J. Advances of machine learning in molecular modeling and simulation. Current Opinion in Chemical Engineering 2019, 23, 51–57. [Google Scholar] [CrossRef]
- Reker, D. Practical considerations for active machine learning in drug discovery. Drug Discovery Today: Technologies 2019, 32, 73–79. [Google Scholar] [CrossRef]
- Narayanan, H.; Dingfelder, F.; Butté, A.; Lorenzen, N.; Sokolov, M.; Arosio, P. Machine learning for biologics: opportunities for protein engineering, developability, and formulation. Trends in pharmacological sciences 2021, 42, 151–165. [Google Scholar] [CrossRef] [PubMed]
- Jeong, S.; Kwak, J.; Lee, S. Machine learning workflow for the oil uptake prediction of rice flour in a batter-coated fried system. Innovative Food Science & Emerging Technologies 2021, 74, 102796. [Google Scholar]
- Li, W.; Niu, Z.; Shang, R.; Qin, Y.; Wang, L.; Chen, H. High-resolution mapping of forest canopy height using machine learning by coupling ICESat-2 LiDAR with Sentinel-1, Sentinel-2 and Landsat-8 data. International Journal of Applied Earth Observation and Geoinformation 2020, 92, 102163. [Google Scholar] [CrossRef]
- Lv, A.; Cheng, L.; Aghighi, M.A.; Masoumi, H.; Roshan, H. A novel workflow based on physics-informed machine learning to determine the permeability profile of fractured coal seams using downhole geophysical logs. Marine and Petroleum Geology 2021, 131, 105171. [Google Scholar] [CrossRef]
- Gharib, A.; Davies, E.G. A workflow to address pitfalls and challenges in applying machine learning models to hydrology. Advances in Water Resources 2021, 152, 103920. [Google Scholar] [CrossRef]
- Kampezidou, S.I.; Ray, A.T.; Duncan, S.; Balchanos, M.G.; Mavris, D.N. Real-time occupancy detection with physics-informed pattern-recognition machines based on limited CO2 and temperature sensors. Energy and Buildings 2021, 242, 110863. [Google Scholar] [CrossRef]
- Fu, H.; Kampezidou, S.; Sung, W.; Duncan, S.; Mavris, D.N. A Data-driven Situational Awareness Approach to Monitoring Campus-wide Power Consumption. 2018 International Energy Conversion Engineering Conference, 2018, p. 4414.
- Kampezidou, S.; Wiegman, H. Energy and power savings assessment in buildings via conservation voltage reduction. 2017 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT). IEEE, 2017, pp. 1–5.
- Kampezidou, S.I.; Romberg, J.; Vamvoudakis, K.G.; Mavris, D.N. Scalable Online Learning of Approximate Stackelberg Solutions in Energy Trading Games with Demand Response Aggregators. arXiv preprint arXiv:2304.02086 2023. [Google Scholar]
- Kampezidou, S.I.; Romberg, J.; Vamvoudakis, K.G.; Mavris, D.N. Online Adaptive Learning in Energy Trading Stackelberg Games with Time-Coupling Constraints. 2021 American Control Conference (ACC). IEEE, 2021, pp. 718–723.
- Gao, Z.; Kampezidou, S.I.; Behere, A.; Puranik, T.G.; Rajaram, D.; Mavris, D.N. Multi-level aircraft feature representation and selection for aviation environmental impact analysis. Transportation Research Part C: Emerging Technologies 2022, 143, 103824. [Google Scholar] [CrossRef]
- Tikayat Ray, A.; Cole, B.F.; Pinon Fischer, O.J.; White, R.T.; Mavris, D.N. aeroBERT-Classifier: Classification of Aerospace Requirements Using BERT. Aerospace 2023, 10. [Google Scholar] [CrossRef]
- Tikayat Ray, A.; Pinon Fischer, O.J.; Mavris, D.N.; White, R.T.; Cole, B.F. , aeroBERT-NER: Named-Entity Recognition for Aerospace Requirements Engineering using BERT. In AIAA SCITECH 2023 Forum. [CrossRef]
- Tikayat Ray, A. Standardization of Engineering Requirements Using Large Language Models. PhD thesis, Georgia Institute of Technology, 2023. [CrossRef]
- Tikayat Ray, A.; Cole, B.F.; Pinon Fischer, O.J.; Bhat, A.P.; White, R.T.; Mavris, D.N. Agile Methodology for the Standardization of Engineering Requirements Using Large Language Models. Systems 2023, 11. [Google Scholar] [CrossRef]
- Shrivastava, R.; Sisodia, D.S.; Nagwani, N.K. Deep neural network-based multi-stakeholder recommendation system exploiting multi-criteria ratings for preference learning. Expert Systems with Applications 2023, 213, 119071. [Google Scholar] [CrossRef]
- van Dinter, R.; Catal, C.; Tekinerdogan, B. A decision support system for automating document retrieval and citation screening. Expert Systems with Applications 2021, 182, 115261. [Google Scholar] [CrossRef]
- Li, X.; Zheng, J.; Li, M.; Ma, W.; Hu, Y. One-shot neural architecture search for fault diagnosis using vibration signals. Expert Systems with Applications 2022, 190, 116027. [Google Scholar] [CrossRef]
- Kim, J.; Comuzzi, M. A diagnostic framework for imbalanced classification in business process predictive monitoring. Expert Systems with Applications 2021, 184, 115536. [Google Scholar] [CrossRef]
- Jin, Y.; Carman, M.; Zhu, Y.; Xiang, Y. A technical survey on statistical modelling and design methods for crowdsourcing quality control. Artificial Intelligence 2020, 287, 103351. [Google Scholar] [CrossRef]
- Boeschoten, S.; Catal, C.; Tekinerdogan, B.; Lommen, A.; Blokland, M. The automation of the development of classification models and improvement of model quality using feature engineering techniques. Expert Systems with Applications 2023, 213, 118912. [Google Scholar] [CrossRef]
- Zhang, Y.; Kwong, S.; Wang, S. Machine learning based video coding optimizations: A survey. Information Sciences 2020, 506, 395–423. [Google Scholar] [CrossRef]
- Moniz, N.; Cerqueira, V. Automated imbalanced classification via meta-learning. Expert Systems with Applications 2021, 178, 115011. [Google Scholar] [CrossRef]
- Waring, J.; Lindvall, C.; Umeton, R. Automated machine learning: Review of the state-of-the-art and opportunities for healthcare. Artificial intelligence in medicine 2020, 104, 101822. [Google Scholar] [CrossRef] [PubMed]
- Kefalas, M.; Baratchi, M.; Apostolidis, A.; van den Herik, D.; Bäck, T. Automated machine learning for remaining useful life estimation of aircraft engines. 2021 IEEE International conference on prognostics and health management (ICPHM). IEEE, 2021, pp. 1–9.
- Tikayat Ray, A.; Bhat, A.P.; White, R.T.; Nguyen, V.M.; Pinon Fischer, O.J.; Mavris, D.N. Examining the Potential of Generative Language Models for Aviation Safety Analysis: Case Study and Insights Using the Aviation Safety Reporting System (ASRS). Aerospace 2023, 10. [Google Scholar] [CrossRef]
- Hayashi, M.; Tamai, K.; Owashi, Y.; Miura, K. Automated machine learning for identification of pest aphid species (Hemiptera: Aphididae). Applied entomology and zoology 2019, 54, 487–490. [Google Scholar] [CrossRef]
- Espejo-Garcia, B.; Malounas, I.; Vali, E.; Fountas, S. Testing the Suitability of Automated Machine Learning for Weeds Identification. Ai 2021, 2, 34–47. [Google Scholar] [CrossRef]
- Koh, J.C.; Spangenberg, G.; Kant, S. Automated machine learning for high-throughput image-based plant phenotyping. Remote Sensing 2021, 13, 858. [Google Scholar] [CrossRef]
- Warnett, S.J.; Zdun, U. Architectural design decisions for the machine learning workflow. Computer 2022, 55, 40–51. [Google Scholar] [CrossRef]
- Khalilnejad, A.; Karimi, A.M.; Kamath, S.; Haddadian, R.; French, R.H.; Abramson, A.R. Automated pipeline framework for processing of large-scale building energy time series data. PloS one 2020, 15, e0240461. [Google Scholar] [CrossRef]
- Michael, N.; Cucuringu, M.; Howison, S. OFTER: An Online Pipeline for Time Series Forecasting. arXiv preprint arXiv:2304.03877 2023. [Google Scholar] [CrossRef]
- Hapke, H.; Nelson, C. Building machine learning pipelines; O’Reilly Media, 2020.
- Kolodiazhnyi, K. Hands-On Machine Learning with C++: Build, train, and deploy end-to-end machine learning and deep learning pipelines; Packt Publishing Ltd, 2020.
- El-Amir, H.; Hamdy, M. Deep learning pipeline: building a deep learning model with TensorFlow; Apress, 2019.
- Meisenbacher, S.; Turowski, M.; Phipps, K.; Rätz, M.; Müller, D.; Hagenmeyer, V.; Mikut, R. Review of automated time series forecasting pipelines. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 2022, 12, e1475. [Google Scholar] [CrossRef]
- Wang, M.; Cui, Y.; Wang, X.; Xiao, S.; Jiang, J. Machine learning for networking: Workflow, advances and opportunities. Ieee Network 2017, 32, 92–99. [Google Scholar] [CrossRef]
- Kreuzberger, D.; Kühl, N.; Hirschl, S. Machine learning operations (mlops): Overview, definition, and architecture. IEEE Access 2023. [Google Scholar] [CrossRef]
- di Laurea, I.S. Mlops-standardizing the machine learning workflow. PhD thesis, University of Bologna Bologna, Italy, 2021.
- Allison, P.D. Missing data; Sage publications, 2001.
- Little, R.J.; Rubin, D.B. Statistical analysis with missing data; Vol. 793, John Wiley & Sons, 2019.
- Candes, E.; Recht, B. Exact matrix completion via convex optimization. Communications of the ACM 2012, 55, 111–119. [Google Scholar] [CrossRef]
- Candès, E.J.; Tao, T. The power of convex relaxation: Near-optimal matrix completion. IEEE Transactions on Information Theory 2010, 56, 2053–2080. [Google Scholar] [CrossRef]
- Candes, E.J.; Plan, Y. Matrix completion with noise. Proceedings of the IEEE 2010, 98, 925–936. [Google Scholar] [CrossRef]
- Johnson, C.R. Matrix completion problems: a survey. Matrix theory and applications, 1990, Vol. 40, pp. 171–198.
- Recht, B. A simpler approach to matrix completion. Journal of Machine Learning Research 2011, 12. [Google Scholar]
- Kennedy, A.; Nash, G.; Rattenbury, N.; Kempa-Liehr, A.W. Modelling the projected separation of microlensing events using systematic time-series feature engineering. Astronomy and Computing 2021, 35, 100460. [Google Scholar] [CrossRef]
- Elmagarmid, A.K.; Ipeirotis, P.G.; Verykios, V.S. Duplicate record detection: A survey. IEEE Transactions on knowledge and data engineering 2006, 19, 1–16. [Google Scholar] [CrossRef]
- Hlupić, T.; Oreščanin, D.; Ružak, D.; Baranović, M. An overview of current data lake architecture models. 2022 45th Jubilee International Convention on Information, Communication and Electronic Technology (MIPRO). IEEE, 2022, pp. 1082–1087.
- Vassiliadis, P. A survey of extract–transform–load technology. International Journal of Data Warehousing and Mining (IJDWM) 2009, 5, 1–27. [Google Scholar] [CrossRef]
- Vassiliadis, P.; Simitsis, A. Extraction, Transformation, and Loading. Encyclopedia of Database Systems 2009, 10. [Google Scholar]
- Dash, T.; Chitlangia, S.; Ahuja, A.; Srinivasan, A. A review of some techniques for inclusion of domain-knowledge into deep neural networks. Scientific Reports 2022, 12, 1–15. [Google Scholar] [CrossRef]
- Dara, S.; Tumma, P. Feature extraction by using deep learning: A survey. 2018 Second international conference on electronics, communication and aerospace technology (ICECA). IEEE, 2018, pp. 1795–1801.
- Lee, J.; Bahri, Y.; Novak, R.; Schoenholz, S.S.; Pennington, J.; Sohl-Dickstein, J. Deep neural networks as gaussian processes. arXiv preprint arXiv:1711.00165 2017. [Google Scholar]
- Benoit, K. Linear regression models with logarithmic transformations. London School of Economics, London 2011, 22, 23–36. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The elements of statistical learning: data mining, inference, and prediction; Vol. 2, Springer, 2009.
- Piryonesi, S.M.; El-Diraby, T.E. Role of data analytics in infrastructure asset management: Overcoming data size and quality problems. Journal of Transportation Engineering, Part B: Pavements 2020, 146, 04020022. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and regression trees; Routledge, 2017.
- Grus, J. Data science from scratch: first principles with python; O’Reilly Media, 2019.
- Sharma, V. A Study on Data Scaling Methods for Machine Learning. International Journal for Global Academic & Scientific Research 2022, 1, 23–33. [Google Scholar]
- Leznik, M.; Tofallis, C. Estimating invariant principal components using diagonal regression 2005.
- Ahsan, M.M.; Mahmud, M.P.; Saha, P.K.; Gupta, K.D.; Siddique, Z. Effect of data scaling methods on machine learning algorithms and model performance. Technologies 9 (3): 52, 2021.
- Zheng, A.; Casari, A. Feature engineering for machine learning: principles and techniques for data scientists; " O’Reilly Media, Inc.", 2018.
- Neter, J.; Kutner, M.H.; Nachtsheim, C.J.; Wasserman, W. ; others. Applied linear statistical models 1996. [Google Scholar]
- Yeo, I.K.; Johnson, R.A. A new family of power transformations to improve normality or symmetry. Biometrika 2000, 87, 954–959. [Google Scholar] [CrossRef]
- Fisher, R.A. Frequency distribution of the values of the correlation coefficient in samples from an indefinitely large population. Biometrika 1915, 10, 507–521. [Google Scholar] [CrossRef]
- Anscombe, F.J. The transformation of Poisson, binomial and negative-binomial data. Biometrika 1948, 35, 246–254. [Google Scholar] [CrossRef]
- Box, G.E.; Cox, D.R. An analysis of transformations. Journal of the Royal Statistical Society: Series B (Methodological) 1964, 26, 211–243. [Google Scholar] [CrossRef]
- Holland, S. Transformations of proportions and percentages, 2015.
- Cormode, G.; Muthukrishnan, S. An improved data stream summary: the count-min sketch and its applications. Journal of Algorithms 2005, 55, 58–75. [Google Scholar] [CrossRef]
- Kessy, A.; Lewin, A.; Strimmer, K. Optimal whitening and decorrelation. The American Statistician 2018, 72, 309–314. [Google Scholar] [CrossRef]
- Higham, N.J. Analysis of the Cholesky decomposition of a semi-definite matrix 1990.
- Jain, A.K.; Duin, R.P.W.; Mao, J. Statistical pattern recognition: A review. IEEE Transactions on pattern analysis and machine intelligence 2000, 22, 4–37. [Google Scholar] [CrossRef]
- Lakhina, A.; Crovella, M.; Diot, C. Diagnosing network-wide traffic anomalies. ACM SIGCOMM computer communication review 2004, 34, 219–230. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Zhang, C.; Li, C.; Xu, C. Autoencoder inspired unsupervised feature selection. 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018, pp. 2941–2945.
- Solorio-Fernández, S.; Carrasco-Ochoa, J.A.; Martínez-Trinidad, J.F. A review of unsupervised feature selection methods. Artificial Intelligence Review 2020, 53, 907–948. [Google Scholar] [CrossRef]
- Li, Z.; Yang, Y.; Liu, J.; Zhou, X.; Lu, H. Unsupervised feature selection using nonnegative spectral analysis. Proceedings of the AAAI conference on artificial intelligence, 2012, Vol. 26, pp. 1026–1032.
- Yu, L.; Liu, H. Feature selection for high-dimensional data: A fast correlation-based filter solution. Proceedings of the 20th international conference on machine learning (ICML-03), 2003, pp. 856–863.
- Mitra, P.; Murthy, C.; Pal, S.K. Unsupervised feature selection using feature similarity. IEEE transactions on pattern analysis and machine intelligence 2002, 24, 301–312. [Google Scholar] [CrossRef]
- He, X.; Cai, D.; Niyogi, P. Laplacian score for feature selection. Advances in neural information processing systems 2005, 18. [Google Scholar]
- Ferreira, A.J.; Figueiredo, M.A. An unsupervised approach to feature discretization and selection. Pattern Recognition 2012, 45, 3048–3060. [Google Scholar] [CrossRef]
- Park, C.H. A feature selection method using hierarchical clustering. In Mining intelligence and knowledge exploration; Springer, 2013; pp. 1–6.
- Cai, D.; Zhang, C.; He, X. Unsupervised feature selection for multi-cluster data. Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining, 2010, pp. 333–342.
- Yi Yang et al. “ 2, 1-norm regularized discriminative feature selection for unsupervised learning”. In: IJCAI 1062 international joint conference on artificial intelligence. 2011.
- Dy, J.G.; Brodley, C.E. Feature selection for unsupervised learning. Journal of machine learning research 2004, 5, 845–889. [Google Scholar]
- Breaban, M.; Luchian, H. A unifying criterion for unsupervised clustering and feature selection. Pattern Recognition 2011, 44, 854–865. [Google Scholar] [CrossRef]
- Hruschka, E.R.; Covoes, T.F. Feature selection for cluster analysis: an approach based on the simplified Silhouette criterion. International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce (CIMCA-IAWTIC’06). IEEE, 2005, Vol. 1, pp. 32–38.
- Law, M.H.; Figueiredo, M.A.; Jain, A.K. Simultaneous feature selection and clustering using mixture models. IEEE transactions on pattern analysis and machine intelligence 2004, 26, 1154–1166. [Google Scholar] [CrossRef]
- Zeng, H.; Cheung, Y.m. Feature selection and kernel learning for local learning-based clustering. IEEE transactions on pattern analysis and machine intelligence 2010, 33, 1532–1547. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Pedrycz, W.; Zhu, Q.; Zhu, W. Unsupervised feature selection via maximum projection and minimum redundancy. Knowledge-Based Systems 2015, 75, 19–29. [Google Scholar] [CrossRef]
- Guo, J.; Zhu, W. Dependence guided unsupervised feature selection. Proceedings of the AAAI Conference on Artificial Intelligence, 2018, Vol. 32.
- Liu, H.; Motoda, H. Feature extraction, construction and selection: A data mining perspective; Vol. 453, Springer Science & Business Media, 1998.
- Kuhn, M.; Johnson, K.; others. Applied predictive modeling; Vol. 26, Springer, 2013.
- Hastie, T.; Tibshirani, R.; Wainwright, M. Statistical learning with sparsity. Monographs on statistics and applied probability 2015, 143, 143. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Methodological) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. Journal of the royal statistical society: series B (statistical methodology) 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Obozinski, G.; Taskar, B.; Jordan, M. Multi-task feature selection. Statistics Department, UC Berkeley, Tech. Rep 2006, 2, 2. [Google Scholar]
- Argyriou, A.; Evgeniou, T.; Pontil, M. Multi-task feature learning. Advances in neural information processing systems 2006, 19. [Google Scholar]
- Yuan, M.; Lin, Y. Model selection and estimation in regression with grouped variables. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 2006, 68, 49–67. [Google Scholar] [CrossRef]
- Kocev, D.; Vens, C.; Struyf, J.; Džeroski, S. Ensembles of multi-objective decision trees. European conference on machine learning. Springer, 2007, pp. 624–631.
- Breiman, L. Bagging predictors. Machine learning 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. Journal of animal ecology 2008, 77, 802–813. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Machine learning 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Kocev, D.; Džeroski, S.; White, M.D.; Newell, G.R.; Griffioen, P. Using single-and multi-target regression trees and ensembles to model a compound index of vegetation condition. Ecological Modelling 2009, 220, 1159–1168. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. Boosting and additive trees. In The elements of statistical learning; Springer, 2009; pp. 337–387.
- Madeh Piryonesi, S.; El-Diraby, T.E. Using machine learning to examine impact of type of performance indicator on flexible pavement deterioration modeling. Journal of Infrastructure Systems 2021, 27, 04021005. [Google Scholar] [CrossRef]
- Piryonesi, S.M.; El-Diraby, T.E. Data analytics in asset management: Cost-effective prediction of the pavement condition index. Journal of Infrastructure Systems 2020, 26, 04019036. [Google Scholar] [CrossRef]
- Segal, M.; Xiao, Y. Multivariate random forests. Wiley interdisciplinary reviews: Data mining and knowledge discovery 2011, 1, 80–87. [Google Scholar] [CrossRef]
- Page, E.S. Journal of the Royal Statistical Society. Series A (General) 1962, 125, 161–162. [CrossRef]
- Bishop, C.M. Pattern recognition and machine learning; Springer, 2006.
- Gao, Z. Representative Data and Models for Complex Aerospace Systems Analysis. PhD thesis, Georgia Institute of Technology, 2022.
- Thudumu, S.; Branch, P.; Jin, J.; Singh, J.J. A comprehensive survey of anomaly detection techniques for high dimensional big data. Journal of Big Data 2020, 7, 1–30. [Google Scholar] [CrossRef]
- Katz, G.; Shin, E.C.R.; Song, D. Explorekit: Automatic feature generation and selection. 2016 IEEE 16th International Conference on Data Mining (ICDM). IEEE, 2016, pp. 979–984.
- Lam, H.T.; Thiebaut, J.M.; Sinn, M.; Chen, B.; Mai, T.; Alkan, O. One button machine for automating feature engineering in relational databases. arXiv preprint arXiv:1706.00327 2017. [Google Scholar]
- Kaul, A.; Maheshwary, S.; Pudi, V. Autolearn: automated feature generation and selection. 2017 IEEE International Conference on data mining (ICDM). IEEE, 2017, pp. 217–226.
- Tran, B.; Xue, B.; Zhang, M. Genetic programming for feature construction and selection in classification on high-dimensional data. Memetic Computing 2016, 8, 3–15. [Google Scholar] [CrossRef]
- Khurana, U.; Turaga, D.; Samulowitz, H.; Parthasrathy, S. Cognito: Automated feature engineering for supervised learning. 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW). IEEE, 2016, pp. 1304–1307.
- Khurana, U.; Samulowitz, H.; Turaga, D. Feature engineering for predictive modeling using reinforcement learning. Proceedings of the AAAI Conference on Artificial Intelligence, 2018, Vol. 32.
- Nargesian, F.; Samulowitz, H.; Khurana, U.; Khalil, E.B.; Turaga, D.S. Learning Feature Engineering for Classification. Ijcai, 2017, Vol. 17, pp. 2529–2535.
- Li, H.; Chutatape, O. Automated feature extraction in color retinal images by a model based approach. IEEE Transactions on biomedical engineering 2004, 51, 246–254. [Google Scholar] [CrossRef]
- Dang, D.M.; Jackson, K.R.; Mohammadi, M. Dimension and variance reduction for Monte Carlo methods for high-dimensional models in finance. Applied Mathematical Finance 2015, 22, 522–552. [Google Scholar] [CrossRef]
- Donoho, D.L.; others. High-dimensional data analysis: The curses and blessings of dimensionality. AMS math challenges lecture 2000, 1, 32. [Google Scholar]
- Atramentov, A.; Leiva, H.; Honavar, V. A multi-relational decision tree learning algorithm–implementation and experiments. International Conference on Inductive Logic Programming. Springer, 2003, pp. 38–56.
- Kanter, J.M.; Veeramachaneni, K. Deep feature synthesis: Towards automating data science endeavors. 2015 IEEE international conference on data science and advanced analytics (DSAA). IEEE, 2015, pp. 1–10.
- Weimer, D.; Scholz-Reiter, B.; Shpitalni, M. Design of deep convolutional neural network architectures for automated feature extraction in industrial inspection. CIRP annals 2016, 65, 417–420. [Google Scholar] [CrossRef]
- Schneider, T.; Helwig, N.; Schütze, A. Industrial condition monitoring with smart sensors using automated feature extraction and selection. Measurement Science and Technology 2018, 29, 094002. [Google Scholar] [CrossRef]
- Laird, P.; Saul, R. Automated feature extraction for supervised learning. Proceedings of the First IEEE Conference on Evolutionary Computation. IEEE World Congress on Computational Intelligence. IEEE, 1994, pp. 674–679.
- Le, Q.; Karpenko, A.; Ngiam, J.; Ng, A. ICA with reconstruction cost for efficient overcomplete feature learning. Advances in neural information processing systems 2011, 24. [Google Scholar]
- Ngiam, J.; Chen, Z.; Bhaskar, S.; Koh, P.; Ng, A. Sparse filtering. Advances in neural information processing systems 2011, 24. [Google Scholar]
- Nocedal, J.; Wright, S.J. Numerical optimization; Springer, 1999.
- Mallat, S. Group invariant scattering. Communications on Pure and Applied Mathematics 2012, 65, 1331–1398. [Google Scholar] [CrossRef]
- Bruna, J.; Mallat, S. Invariant scattering convolution networks. IEEE transactions on pattern analysis and machine intelligence 2013, 35, 1872–1886. [Google Scholar] [CrossRef] [PubMed]
- Andén, J.; Mallat, S. Deep scattering spectrum. IEEE Transactions on Signal Processing 2014, 62, 4114–4128. [Google Scholar] [CrossRef]
- Mallat, S. Understanding deep convolutional networks. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 2016, 374, 20150203. [Google Scholar] [CrossRef]
- Rizk, Y.; Hajj, N.; Mitri, N.; Awad, M. Deep belief networks and cortical algorithms: A comparative study for supervised classification. Applied computing and informatics 2019, 15, 81–93. [Google Scholar] [CrossRef]
- Rifkin, R.M.; Lippert, R.A. Notes on regularized least squares 2007.
- Yin, R.; Liu, Y.; Wang, W.; Meng, D. Sketch kernel ridge regression using circulant matrix: Algorithm and theory. IEEE transactions on neural networks and learning systems 2019, 31, 3512–3524. [Google Scholar] [CrossRef] [PubMed]
- Efron, B.; Hastie, T.; Johnstone, I.; Tibshirani, R. Least angle regression 2004.
- Bulso, N.; Marsili, M.; Roudi, Y. On the complexity of logistic regression models. Neural computation 2019, 31, 1592–1623. [Google Scholar] [CrossRef] [PubMed]
- Belyaev, M.; Burnaev, E.; Kapushev, Y. Exact inference for Gaussian process regression in case of big data with the Cartesian product structure. arXiv preprint arXiv:1403.6573 2014. [Google Scholar]
- Serpen, G.; Gao, Z. Complexity analysis of multilayer perceptron neural network embedded into a wireless sensor network. Procedia Computer Science 2014, 36, 192–197. [Google Scholar] [CrossRef]
- Jain, A.K.; Mao, J.; Mohiuddin, K.M. Artificial neural networks: A tutorial. Computer 1996, 29, 31–44. [Google Scholar] [CrossRef]
- Fleizach, C.; Fukushima, S. A naive bayes classifier on 1998 kdd cup. Dept. Comput. Sci. Eng., University of California, Los Angeles, CA, USA, Tech. Rep 1998.
- Jensen, F.V.; Nielsen, T.D. Bayesian networks and decision graphs; Vol. 2, Springer, 2007.
- Claesen, M.; De Smet, F.; Suykens, J.A.; De Moor, B. Fast prediction with SVM models containing RBF kernels. arXiv preprint arXiv:1403.0736 2014. [Google Scholar]
- Cardot, H.; Degras, D. Online principal component analysis in high dimension: Which algorithm to choose? International Statistical Review 2018, 86, 29–50. [Google Scholar] [CrossRef]
- Veksler, O. Nonparametric density estimation nearest neighbors, KNN, 2013.
- Raschka, Sebastian. STAT 479: Machine Learning Lecture Notes. 2018. Online: https://sebastianraschka.%20com/pdf/lecture-notes/stat479fs18/07_ensembles_notes.%20pdf.%20Citado%20na%20p%C3%A1g.%20viii.
- Sani, H.M.; Lei, C.; Neagu, D. Computational complexity analysis of decision tree algorithms. Artificial Intelligence XXXV: 38th SGAI International Conference on Artificial Intelligence, AI 2018, Cambridge, UK, December 11–13, 2018, Proceedings 38. Springer, 2018, pp. 191–197.
- Buczak, A.L.; Guven, E. A survey of data mining and machine learning methods for cyber security intrusion detection. IEEE Communications surveys & tutorials 2015, 18, 1153–1176. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Advances in neural information processing systems 2017, 30. [Google Scholar]
- Cai, D.; He, X.; Han, J. Training linear discriminant analysis in linear time. 2008 IEEE 24th international conference on data engineering. IEEE, 2008, pp. 209–217.
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-validation. Encyclopedia of database systems 2009, 5, 532–538. [Google Scholar]
- Efron, B.; Tibshirani, R.J. An introduction to the bootstrap; CRC press, 1994.
- Efron, B. Bootstrap methods: another look at the jackknife. In Breakthroughs in statistics; Springer, 1992; pp. 569–593.
- Breiman, L. Bias, variance, and arcing classifiers. Technical report, Tech. Rep. 460 Statistics Department University of California Berkeley, 1996.
- Syakur, M.; Khotimah, B.; Rochman, E.; Satoto, B.D. Integration k-means clustering method and elbow method for identification of the best customer profile cluster. IOP conference series: materials science and engineering. IOP Publishing, 2018, Vol. 336, p. 012017.
- Palacio-Niño, J.O.; Berzal, F. Evaluation metrics for unsupervised learning algorithms. arXiv preprint arXiv:1905.05667 2019. [Google Scholar]
- Halkidi, M.; Batistakis, Y.; Vazirgiannis, M. On clustering validation techniques. Journal of intelligent information systems 2001, 17, 107–145. [Google Scholar] [CrossRef]
- Perry, P.O. Cross-validation for unsupervised learning; Stanford University, 2009.
- Airola, A.; Pahikkala, T.; Waegeman, W.; De Baets, B.; Salakoski, T. An experimental comparison of cross-validation techniques for estimating the area under the ROC curve. Computational Statistics & Data Analysis 2011, 55, 1828–1844. [Google Scholar]
- Breiman, L.; Spector, P. Submodel selection and evaluation in regression. The X-random case. International statistical review/revue internationale de Statistique 1992, pp. 291–319.
- Kohavi, R.; others. A study of cross-validation and bootstrap for accuracy estimation and model selection. Ijcai. Montreal, Canada, 1995, Vol. 14, pp. 1137–1145.
- Arlot, S.; Celisse, A. A survey of cross-validation procedures for model selection. Statistics surveys 2010, 4, 40–79. [Google Scholar] [CrossRef]
- McCulloch, C.E.; Searle, S.R. Generalized, linear, and mixed models; John Wiley & Sons, 2004.
- Kühl, N.; Hirt, R.; Baier, L.; Schmitz, B.; Satzger, G. How to conduct rigorous supervised machine learning in information systems research: the supervised machine learning report card. Communications of the Association for Information Systems 2021, 48, 46. [Google Scholar] [CrossRef]
- Caruana, R.; Niculescu-Mizil, A. Data mining in metric space: an empirical analysis of supervised learning performance criteria. Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining, 2004, pp. 69–78.
- Beck, K. Test-driven development: by example; Addison-Wesley Professional, 2003.
- Washizaki, H.; Uchida, H.; Khomh, F.; Guéhéneuc, Y.G. Studying Software Engineering Patterns for Designing Machine Learning Systems. 2019 10th International Workshop on Empirical Software Engineering in Practice (IWESEP), 2019, pp. 49–495. [CrossRef]
- Gamma, E.; Helm, R.; Johnson, R.; Johnson, R.E.; Vlissides, J.; others. Design patterns: elements of reusable object-oriented software; Pearson Deutschland GmbH, 1995.
- Kohavi, R.; Longbotham, R. Online Controlled Experiments and A/B Testing. Encyclopedia of machine learning and data mining 2017, 7, 922–929. [Google Scholar]
- Rajasoundaran, S.; Prabu, A.; Routray, S.; Kumar, S.S.; Malla, P.P.; Maloji, S.; Mukherjee, A.; Ghosh, U. Machine learning based deep job exploration and secure transactions in virtual private cloud systems. Computers & Security 2021, 109, 102379. [Google Scholar] [CrossRef]
- Abran, A.; Moore, J.W.; Bourque, P.; Dupuis, R.; Tripp, L. Software engineering body of knowledge. IEEE Computer Society, Angela Burgess 2004, p. 25.
- pytest. pytest: helps you write better programs. URL: https://docs.pytest.org/en/7.4.x/. 1236.
- unittest. unittest— Unit testing framework. URL: https://docs.python.org/3/library/unittest.html. 1237.
- JUnit. JUnit. URL: https://junit.org/junit5/. 1238.
- mockito. mockito. URL: https://site.mockito.org/.
- Ardagna, C.A.; Bena, N.; Hebert, C.; Krotsiani, M.; Kloukinas, C.; Spanoudakis, G. Big Data Assurance: An Approach Based on Service-Level Agreements. Big Data 2023. 2023. [Google Scholar]
- Mili, A.; Tchier, F. Software testing: Concepts and operations; John Wiley & Sons, 2015.
- Li, P.L.; Chai, X.; Campbell, F.; Liao, J.; Abburu, N.; Kang, M.; Niculescu, I.; Brake, G.; Patil, S.; Dooley, J. ; others. Evolving software to be ML-driven utilizing real-world A/B testing: experiences, insights, challenges. 2021 IEEE/ACM 43rd International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 2021, pp. 170–179.
- Manias, D.M.; Chouman, A.; Shami, A. Model Drift in Dynamic Networks. IEEE Communications Magazine 2023. [Google Scholar] [CrossRef]
- Wani, D.; Ackerman, S.; Farchi, E.; Liu, X.; Chang, H.w.; Lalithsena, S. Data Drift Monitoring for Log Anomaly Detection Pipelines. arXiv preprint arXiv:2310.14893 2023. [Google Scholar]
- Schneider, F. Least privilege and more [computer security]. IEEE Security & Privacy 2003, 1, 55–59. [Google Scholar] [CrossRef]
- Mahjabin, T.; Xiao, Y.; Sun, G.; Jiang, W. A survey of distributed denial-of-service attack, prevention, and mitigation techniques. International Journal of Distributed Sensor Networks 2017, 13, 1550147717741463. [Google Scholar] [CrossRef]
- Certified Tester Foundation Level (CTFL) Syllabus. Technical report, International Software Testing Qualifications Board, Version 2018 v3.1.1.
- Lewis, W.E. Software testing and continuous quality improvement; Auerbach publications, 2004.
- Martin, R.C. Clean code: a handbook of agile software craftsmanship; Pearson Education, 2009.
- Thomas, D.; Hunt, A. The Pragmatic Programmer: your journey to mastery; Addison-Wesley Professional, 2019.
- Hutter, F.; Kotthoff, L.; Vanschoren, J. Automated machine learning: methods, systems, challenges; Springer Nature, 2019.
- Melis, G.; Dyer, C.; Blunsom, P. On the state of the art of evaluation in neural language models. arXiv preprint arXiv:1707.05589 2017. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. Advances in neural information processing systems 2012, 25. [Google Scholar]
- Bergstra, J.; Yamins, D.; Cox, D. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. International conference on machine learning. PMLR, 2013, pp. 115–123.
- Sculley, D.; Snoek, J.; Wiltschko, A.; Rahimi, A. Winner’s curse? On pace, progress, and empirical rigor 2018.
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. Journal of machine learning research 2012, 13. [Google Scholar]
- Hansen, N. The CMA evolution strategy: a comparing review. Towards a new evolutionary computation: Advances in the estimation of distribution algorithms 2006, pp. 75–102.
- Snoek, J.; Rippel, O.; Swersky, K.; Kiros, R.; Satish, N.; Sundaram, N.; Patwary, M.; Prabhat, M.; Adams, R. Scalable bayesian optimization using deep neural networks. International conference on machine learning. PMLR, 2015, pp. 2171–2180.
- Dahl, G.E.; Sainath, T.N.; Hinton, G.E. Improving deep neural networks for LVCSR using rectified linear units and dropout. 2013 IEEE international conference on acoustics, speech and signal processing. IEEE, 2013, pp. 8609–8613.
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; De Freitas, N. Taking the human out of the loop: A review of Bayesian optimization. Proceedings of the IEEE 2015, 104, 148–175. [Google Scholar] [CrossRef]
- Brochu, E.; Cora, V.M.; De Freitas, N. A tutorial on Bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. arXiv preprint arXiv:1012.2599 2010. [Google Scholar]
- Zeng, X.; Luo, G. Progressive sampling-based Bayesian optimization for efficient and automatic machine learning model selection. Health information science and systems 2017, 5, 1–21. [Google Scholar] [CrossRef]
- Zhang, Y.; Bahadori, M.T.; Su, H.; Sun, J. FLASH: fast Bayesian optimization for data analytic pipelines. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016, pp. 2065–2074.
- Jamieson, K.; Talwalkar, A. Non-stochastic best arm identification and hyperparameter optimization. Artificial intelligence and statistics. PMLR, 2016, pp. 240–248.
- Li, L.; Jamieson, K.; DeSalvo, G.; Rostamizadeh, A.; Talwalkar, A. Hyperband: A novel bandit-based approach to hyperparameter optimization. The Journal of Machine Learning Research 2017, 18, 6765–6816. [Google Scholar]
- Falkner, S.; Klein, A.; Hutter, F. BOHB: Robust and efficient hyperparameter optimization at scale. International Conference on Machine Learning. PMLR, 2018, pp. 1437–1446.
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Transactions on knowledge and data engineering 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. International conference on learning representations, 2017.
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural architecture search: A survey. The Journal of Machine Learning Research 2019, 20, 1997–2017. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 8697–8710.
- Zela, A.; Klein, A.; Falkner, S.; Hutter, F. Towards automated deep learning: Efficient joint neural architecture and hyperparameter search. arXiv preprint arXiv:1807.06906 2018. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Aging evolution for image classifier architecture search. AAAI conference on artificial intelligence, 2019, Vol. 2, p. 2.
- Runge, F.; Stoll, D.; Falkner, S.; Hutter, F. Learning to design RNA. arXiv preprint arXiv:1812.11951 2018. [Google Scholar]
- Swersky, K.; Snoek, J.; Adams, R.P. Freeze-thaw Bayesian optimization. arXiv preprint arXiv:1406.3896 2014. [Google Scholar]
- Domhan, T.; Springenberg, J.T.; Hutter, F. Speeding up automatic hyperparameter optimization of deep neural networks by extrapolation of learning curves. Twenty-fourth international joint conference on artificial intelligence, 2015.
- Klein, A.; Falkner, S.; Springenberg, J.T.; Hutter, F. Learning curve prediction with Bayesian neural networks. International conference on learning representations, 2016.
- Baker, B.; Gupta, O.; Raskar, R.; Naik, N. Accelerating neural architecture search using performance prediction. arXiv preprint arXiv:1705.10823 2017. [Google Scholar]
- Real, E.; Moore, S.; Selle, A.; Saxena, S.; Suematsu, Y.L.; Tan, J.; Le, Q.V.; Kurakin, A. Large-scale evolution of image classifiers. International conference on machine learning. PMLR, 2017, pp. 2902–2911.
- Elsken, T.; Metzen, J.H.; Hutter, F. Simple and efficient architecture search for convolutional neural networks. arXiv preprint arXiv:1711.04528 2017. [Google Scholar]
- Elsken, T.; Metzen, J.H.; Hutter, F. Efficient multi-objective neural architecture search via lamarckian evolution. arXiv preprint arXiv:1804.09081 2018. [Google Scholar]
- Cai, H.; Chen, T.; Zhang, W.; Yu, Y.; Wang, J. Efficient architecture search by network transformation. Proceedings of the AAAI Conference on Artificial Intelligence, 2018, Vol. 32.
- Cai, H.; Yang, J.; Zhang, W.; Han, S.; Yu, Y. Path-level network transformation for efficient architecture search. International Conference on Machine Learning. PMLR, 2018, pp. 678–687.
- Saxena, S.; Verbeek, J. Convolutional neural fabrics. Advances in neural information processing systems 2016, 29. [Google Scholar]
- Pham, H.; Guan, M.; Zoph, B.; Le, Q.; Dean, J. Efficient neural architecture search via parameters sharing. International conference on machine learning. PMLR, 2018, pp. 4095–4104.
- Bender, G.; Kindermans, P.J.; Zoph, B.; Vasudevan, V.; Le, Q. Understanding and simplifying one-shot architecture search. International conference on machine learning. PMLR, 2018, pp. 550–559.
- Liu, H.; Simonyan, K.; Yang, Y. Darts: Differentiable architecture search. arXiv preprint arXiv:1806.09055 2018. [Google Scholar]
- Cai, H.; Zhu, L.; Han, S. Proxylessnas: Direct neural architecture search on target task and hardware. arXiv preprint arXiv:1812.00332 2018. [Google Scholar]
- Xie, S.; Zheng, H.; Liu, C.; Lin, L. SNAS: stochastic neural architecture search. arXiv preprint arXiv:1812.09926, 2018. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. Advances in neural information processing systems 2011, 24. [Google Scholar]
- Desautels, T.; Krause, A.; Burdick, J.W. Parallelizing exploration-exploitation tradeoffs in gaussian process bandit optimization. Journal of Machine Learning Research 2014, 15, 3873–3923. [Google Scholar]
- Ginsbourger, D.; Le Riche, R.; Carraro, L. Kriging is well-suited to parallelize optimization. Computational intelligence in expensive optimization problems 2010, pp. 131–162.
- Hernández-Lobato, J.M.; Requeima, J.; Pyzer-Knapp, E.O.; Aspuru-Guzik, A. Parallel and distributed Thompson sampling for large-scale accelerated exploration of chemical space. International conference on machine learning. PMLR, 2017, pp. 1470–1479.
- Hutter, F.; Hoos, H.H.; Leyton-Brown, K. Parallel algorithm configuration. Learning and Intelligent Optimization: 6th International Conference, LION 6, Paris, France, January 16-20, 2012, Revised Selected Papers. Springer, 2012, pp. 55–70.
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowledge-Based Systems 2021, 216, 106775. [Google Scholar] [CrossRef]
- Nagarajah, T.; Poravi, G. A review on automated machine learning (AutoML) systems. 2019 IEEE 5th International Conference for Convergence in Technology (I2CT). IEEE, 2019, pp. 1–6.
- Thakur, A.; Krohn-Grimberghe, A. Autocompete: A framework for machine learning competition. arXiv preprint arXiv:1507.02188 2015. [Google Scholar]
- Ferreira, L.; Pilastri, A.; Martins, C.M.; Pires, P.M.; Cortez, P. A comparison of AutoML tools for machine learning, deep learning and XGBoost. 2021 International Joint Conference on Neural Networks (IJCNN). IEEE, 2021, pp. 1–8.
- Thornton, C.; Hutter, F.; Hoos, H.H.; Leyton-Brown, K. Auto-WEKA: Combined selection and hyperparameter optimization of classification algorithms. Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining, 2013, pp. 847–855.
- Kotthoff, L.; Thornton, C.; Hoos, H.H.; Hutter, F.; Leyton-Brown, K. Auto-WEKA: Automatic model selection and hyperparameter optimization in WEKA. Automated machine learning: methods, systems, challenges 2019, pp. 81–95.
- Komer, B.; Bergstra, J.; Eliasmith, C. Hyperopt-sklearn: automatic hyperparameter configuration for scikit-learn. ICML workshop on AutoML. Citeseer Austin, TX, 2014, Vol. 9, p. 50.
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.; Blum, M.; Hutter, F. Efficient and robust automated machine learning. Advances in neural information processing systems 2015, 28. [Google Scholar]
- Feurer, M.; Eggensperger, K.; Falkner, S.; Lindauer, M.; Hutter, F. Auto-sklearn 2.0: Hands-free automl via meta-learning. J Machine Learn Res 2020, 23, 1–61. [Google Scholar]
- Olson, R.S.; Moore, J.H. TPOT: A tree-based pipeline optimization tool for automating machine learning. Workshop on automatic machine learning. PMLR, 2016, pp. 66–74.
- Zimmer, L.; Lindauer, M.; Hutter, F. Auto-pytorch: Multi-fidelity metalearning for efficient and robust autodl. IEEE Transactions on Pattern Analysis and Machine Intelligence 2021, 43, 3079–3090. [Google Scholar] [CrossRef] [PubMed]
- Jin, H.; Song, Q.; Hu, X. Auto-keras: An efficient neural architecture search system. Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 2019, pp. 1946–1956.
- Peng, H.; Du, H.; Yu, H.; Li, Q.; Liao, J.; Fu, J. Cream of the Crop: Distilling Prioritized Paths For One-Shot Neural Architecture Search. Advances in Neural Information Processing Systems 2020, 33. [Google Scholar]
- Microsoft Research. NNI Related Publications. Online: https://nni.readthedocs.io/en/latest/notes/research_ 1371publications.html.
- Erickson, N.; Mueller, J.; Shirkov, A.; Zhang, H.; Larroy, P.; Li, M.; Smola, A. Autogluon-tabular: Robust and accurate automl for structured data. arXiv preprint arXiv:2003.06505 2020. [Google Scholar]
- Parul Pandey. A Deep Dive into H2O’s AutoML. Online: https://h2o.ai/blog/2019/a-deep-dive-into-h2os-automl/.
- Wang, C.; Wu, Q.; Weimer, M.; Zhu, E. Flaml: A fast and lightweight automl library. Proceedings of Machine Learning and Systems 2021, 3, 434–447. [Google Scholar]
- Shchur, O.; Turkmen, C.; Erickson, N.; Shen, H.; Shirkov, A.; Hu, T.; Wang, Y. AutoGluon-TimeSeries: AutoML for Probabilistic Time Series Forecasting. arXiv preprint arXiv:2308.05566 2023. [Google Scholar]
- Khider, D.; Zhu, F.; Gil, Y. autoTS: Automated machine learning for time series analysis. AGU Fall Meeting Abstracts, 2019, Vol. 2019, pp. PP43D–1637.
- Schafer, R.W. What is a Savitzky-Golay filter?[lecture notes]. IEEE Signal processing magazine 2011, 28, 111–117. [Google Scholar] [CrossRef]
Figure 1.
MLOps: the cross-section of machine learning engineering, DevOps, and data engineering.
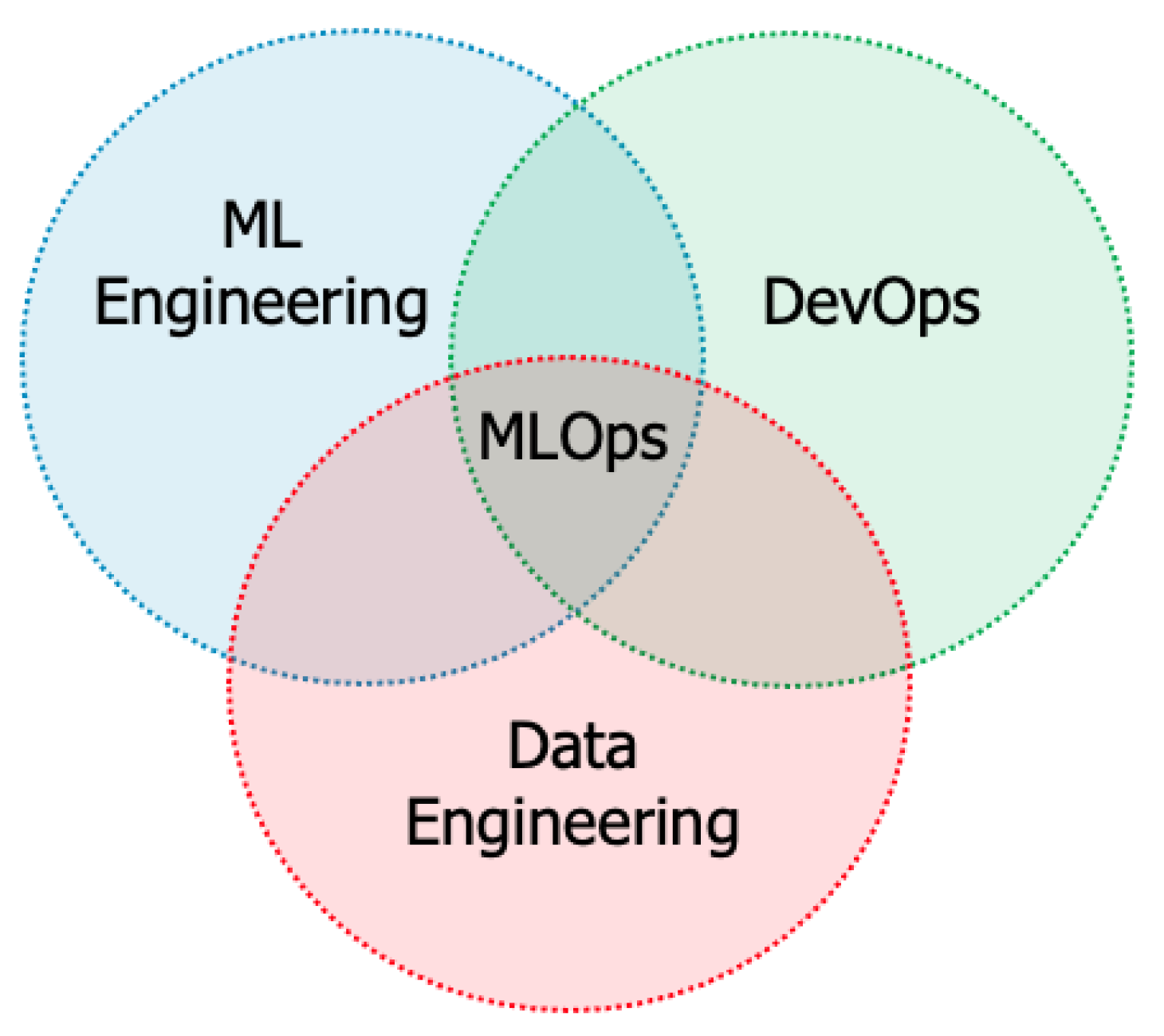
Figure 2.
(2a) The machine learning workflow, (2b) components of feature engineering and (2c) the testing levels of Test-Driven Development (TDD).
Figure 2.
(2a) The machine learning workflow, (2b) components of feature engineering and (2c) the testing levels of Test-Driven Development (TDD).

Figure 3.
Taxonomy of feature selection methods.

Figure 4.
Train error and test error estimates: (4a) behavior of train and test error estimates as the model complexity varies, figure imported and modified from [68], (4b) decomposition of test error estimate in its components, according to Equation (1).
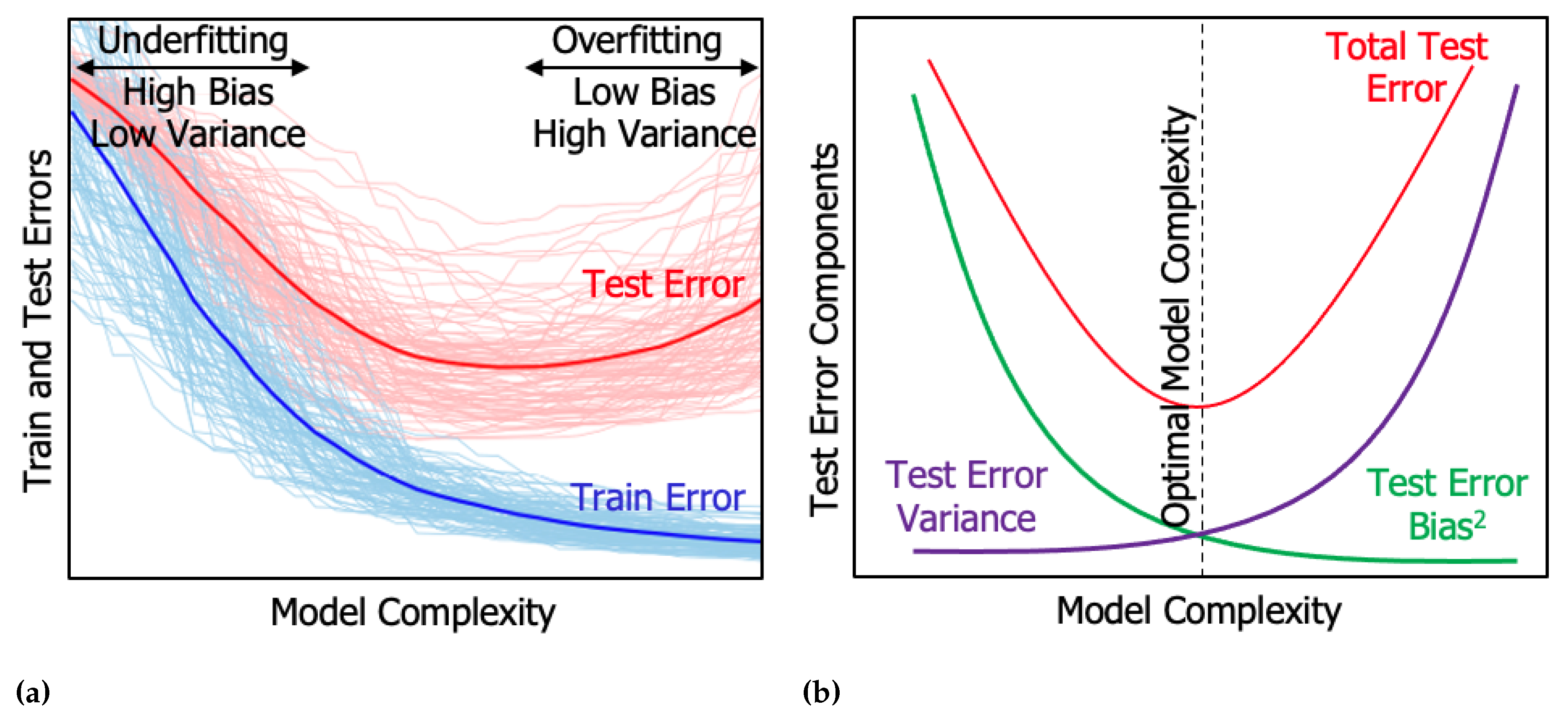
Figure 5.
Overview of k-fold CV method, for .

Figure 6.
Machine learning workflow example developed by academic researchers for occupancy detection, based on the methodology proposed in this paper. Model deployment and automation were not part of this academic work [18].
Figure 6.
Machine learning workflow example developed by academic researchers for occupancy detection, based on the methodology proposed in this paper. Model deployment and automation were not part of this academic work [18].
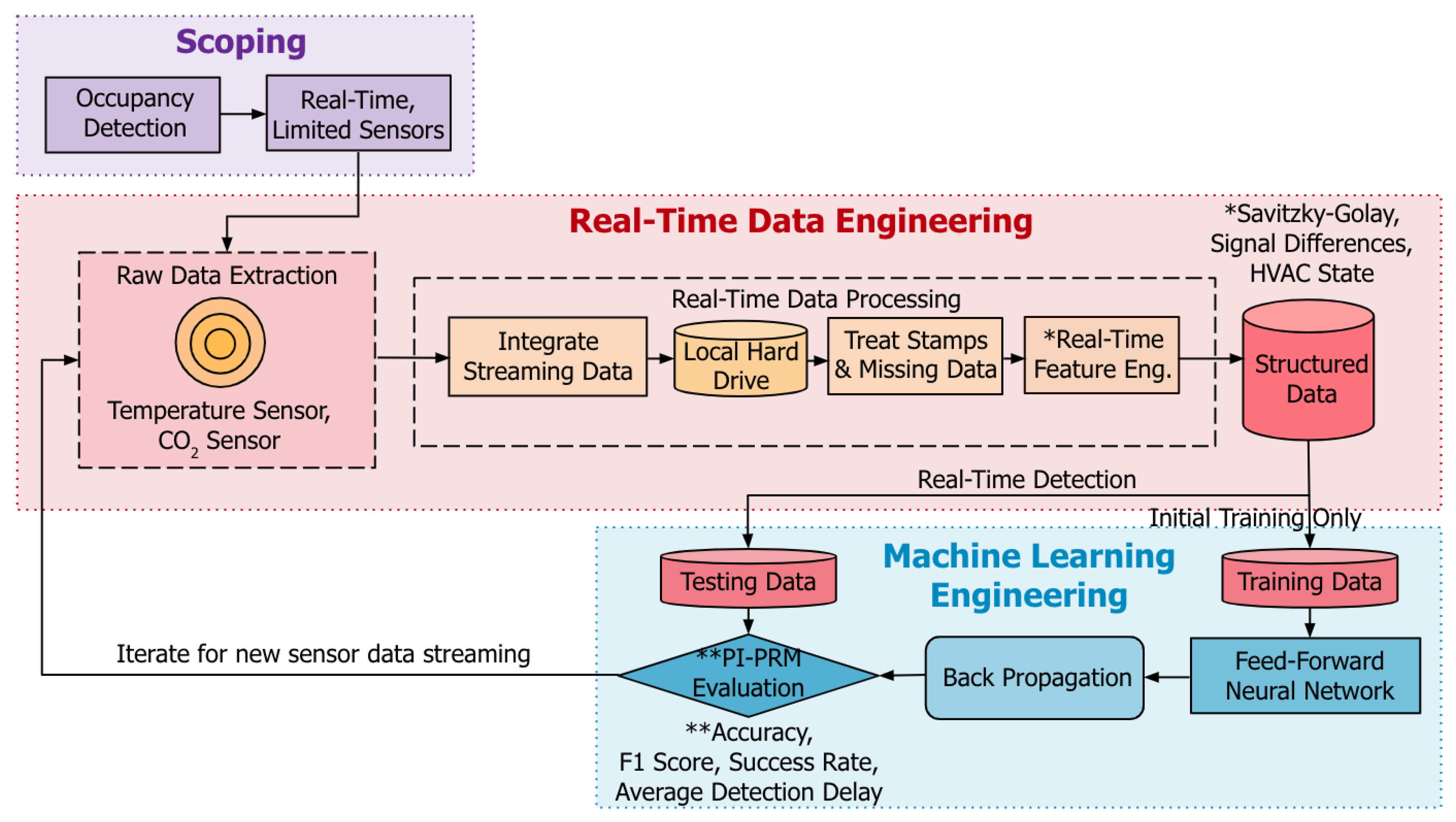
Table 1.
Summary of most common numerical feature scaling methods.
| Scaling Method | Scaled Feature | Scaling Effect | ML Algorithm/Model |
|---|---|---|---|
| Min-Max | k-Means, kNN, SVM | ||
| Standardization (z-score) | , | Linear/Logistic Regression, NN | |
| l2-Normalization | Vector Space Model |
Table 2.
Summary of most common methods for encoding categorical features.
| Encoding Method | Original Feature | Transformed Features | Result |
|---|---|---|---|
| Ordinal Encoding | string1, string2, ... | 1, 2, ... | Nonordinal categorical data becomes ordinal |
| One-Hot Encoding | string1, string2, ... | 001, 010, ... | k features for k categories, only one bit is "on" |
| Dummy Encoding | string1, string2, ... | 001, 010, ..., (000) | features for k categories, reference category is 0 |
| Effect Encoding | string1, string2, ... | 001, 010, ..., (-1-1-1) | k features for k categories, reference category is -1 |
Table 4.
Summary of common supervised machine learning models and standard algorithm complexity. Symbols: n: samples, p: features, s: support vectors, k: neighbors or trees in a model, d: nodes in a tree, q: maximum number of bins and : constant. The star ★ indicates that complexity varies with architecture (neurons, layers, connections, activation function [147]) and algorithm (type, epochs). Typically, Gradient Descent has running complexity of .
Table 4.
Summary of common supervised machine learning models and standard algorithm complexity. Symbols: n: samples, p: features, s: support vectors, k: neighbors or trees in a model, d: nodes in a tree, q: maximum number of bins and : constant. The star ★ indicates that complexity varies with architecture (neurons, layers, connections, activation function [147]) and algorithm (type, epochs). Typically, Gradient Descent has running complexity of .
| ML Model/Algorithm | Parametric | Linear | Train, Test, Space Complexity | Paper |
|---|---|---|---|---|
| Ordinary Least Squares (OLS) | ✓ | ✓ | , , | [148] |
| Kernel Ridge Regression | ✓ | ✓ | , -, | [149] |
| Lasso Regression (LARS) | ✓ | ✓ | , -, - | [150] |
| Elastic Net | ✓ | ✓ | , -, - | [108] |
| Logistic Regression | ✓ | ✓ | , , | [151] |
| GP Regression | ✗ | ✗ | , -, | [152] |
| Multi-Layer Perceptron | ✓ | ✗ | ★ | [153,154] |
| RNN/LSTM | ✓ | ✗ | ★ | - |
| CNN | ✓ | ✗ | ★ | - |
| Transformers | ✓ | ✗ | ★ | - |
| Radial Basis Function NN | ✗ | ✗ | ★ | - |
| DNN | ✓ | ✗ | ★ | - |
| Naive Bayes Classifier | ✓ | ✓ | , , | [155] |
| Bayesian Network | ✗ | ✗ | ★ | [156] |
| Bayesian Belief Network | ✓ | ✗ | ★ | - |
| SVM | ✗ | ✓ | , , | [157] |
| PCA | ✗ | ✓ | , -, | [158] |
| kNN | ✗ | ✗ | , , | [159,160] |
| CART | ✗ | ✗ | , , | [161] |
| RF | ✗ | ✗ | , , | [162] |
| Gradient Boost Decision Tree | ✗ | ✗ | , , | [163] |
| LDA | ✓ | ✓ | , -, , | [164] |
Table 5.
Summary of CV methods.
| CV Category | Specific CV Method | Result |
|---|---|---|
| Exhaustive CV | · Leave-p-out CV | models trained |
| · Leave-one-out CV | models trained | |
| Non-Exhaustive CV | · k-fold CV | k models trained |
| · Holdout | 1 model trained | |
| · Repeated Random Sub-Sampling | k models trained | |
| Validation (a.k.a. Monte Carlo CV) | ||
| Nested CV | · k*l-fold CV | models trained |
| · k-fold CV with validation and test set | k models trained with test set |
Table 6.
Summary of most common performance indices commonly used to evaluate the performance of regression and classification models.
Table 6.
Summary of most common performance indices commonly used to evaluate the performance of regression and classification models.
| Performance Index | Formula | Purpose |
|---|---|---|
| Mean Squared Error (MSE) | Regression | |
| Root Mean Squared Error (RMSE) | Regression | |
| Mean Absolute Error (MAE) | Regression | |
| Mean Absolute Percentage Error (MAPE) | Regression | |
| Coefficient of Determination () | Regression | |
| Adjusted Coefficient of Determination (A-) | Regression | |
| Confusion Matrix | TP, TN, FP, FN | Classification |
| Accuracy | Classification | |
| Balanced Accuracy | Classification | |
| Missclassification | Classification | |
| F1-Score | Classification | |
| F-Score | Classification | |
| Receiver Operating Characteristic (ROC) | Graphical | Classification |
| Area Under Curve (AUC) | Graphical | Classification |
| Total Operating Characteristic (TOC) | Graphical | Classification |
Table 7.
Overview of main NAS methods in AutoML.
| Method | Approach to Speed-Up | Paper |
|---|---|---|
| Lower fidelity estimates | Less epochs, data subsets, downscaled models/data, etc. | [215,216,220,221,222,223] |
| Learning curve extrapolation | Performance extrapolated after few epochs | [224,225,226,227] |
| Weight inheritance/network morphisms | Models warm-started with inherited weights | [228,229,230,231,232] |
| One-Shot models/weight sharing | One-shot model’s weights shared across architectures | [233,234,235,236,237,238] |
Table 8.
Overview of available AutoML systems (DE=Data Engineering, FE=Feature Engineering).
| Software | Problem Automated | AutoML Method | Paper |
|---|---|---|---|
| Auto-WEKA | CASH | Bayesian optimization | [248] |
| Auto-WEKA 2.0 | CASH with parallel runs | Bayesian optimization | [249] |
| Hyperopt-Sklearn | Space search of random hyperparameters | Bayesian otimization | [250] |
| Auto-Sklearn | Improved CASH with algorithm ensembles | Bayesian optimization | [251,252] |
| TPOT | Classification with FE | GeP | [253] |
| Auto-Net | Automates DNN tuning | Bayesian optimization | [36] |
| Auto-Net 2.0 | Automates DNN tuning | BOHB | [36] |
| Automatic Statistician | Automates data science | Various | [36] |
| AutoPytorch | Algo. selection, ensemble constr., hyperpar. tuning | Bayesian opt., meta-learn. | [254] |
| AutoKeras | NAS, hyperpar. tuning in DNN | Bayesian opt. guides network morphism | [255] |
| NNI | NAS, hyperpar. tuning, model compression, FE | One-shot modes, etc. | [256,257] |
| TPOT | Hyperpar. tuning, model selection | GeP | [253] |
| AutoGluon | Hyperpar. tuning | - | [258] |
| H2O | DE, FE, hyperpar. tuning, ensemble model selection | Random grid search, Bayesian opt. | [259] |
| FEDOT | Hyperparameter tuning | Evolutionary algorithms | - |
| Auto-Sklearn 2 | Model selection | Meta-learning, bandit strategy | [252] |
| FLAML | Algorithm selection, hyperpar. tuning | Search strategies | [260] |
| AutoGluon-TS | Ensemble constr. for time-series forecasting | Probabilistic time-series | [261] |
| AutoTS | Time-series data analysis | Various | [262] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



