
Submitted:
20 December 2023
Posted:
21 December 2023
You are already at the latest version
Abstract
Moving object detection plays a crucial role in various applications, particularly in traffic surveillance and collision warning systems. However, the high cost of training and slow detection pose significant challenges to the practicality and real-time performance of existing methods. These challenges hinder the practicality and real-time performance of existing methods. The need for a reliable and efficient moving object detection system prompts the search for cost-effective strategies. Enhancing detection speed without sacrificing accuracy is crucial for real-time applications. Overcoming these challenges is essential to advance the field of moving object detection and improve its applicability in various domains. This paper presents a comprehensive review of the literature on moving object detection, proposes novel strategies to overcome the challenges of high training costs and slow detection. The study emphasizes the importance of reliable speed monitoring systems and advancements in control systems to enhance driver assistance on urban highways. Each frame in the dataset undergoes YOLOv6 processing to detect and classify objects, generating bounding box predictions and class probabilities. Optical flow, specifically the Lucas-Kanade method, is then utilized to compute motion vectors between consecutive frames. These motion vectors facilitate object tracking across frames, enabling refined bounding box positions and improving overall object tracking accuracy. The results demonstrate the effectiveness of the proposed technique in reducing training costs, improving detection speed, and maintaining a high level of accuracy when compared to existing methods. The paper concludes by summarizing the findings and highlighting the potential of the proposed strategy for precise and reliable moving object recognition in real-world traffic scenarios
Keywords:
moving object detection
; deep learning algorithms
; YOLO
; optical flow
; object tracking
; fusion techniques
; performance evaluation
1. Introduction
Automobiles play an important role in our daily lives because they have become an intrinsic part of our existence. A number of important factors contribute to the occurrence of traffic accidents. Excessive speed, distracted driving, the presence of objects on the road, poor signaling, the quality of the road infrastructure, and insufficient illumination are among these concerns. When assessing the causes of road accidents, speeding is an important issue to take into account. As a result, research on vehicular traffic concentrates on analyzing the variables that affect this part of a road section. We require a reliable speed monitoring system. Furthermore, developments in control systems that aim to aid drivers while traversing urban highways have occurred. Machine learning and deep learning are the topics that may accommodate a wide range of research projects, notably in the identification of objects. Object detection is crucial in recognizing items in films, for instance, the number of automobiles on a route in a certain region. Both deep learning algorithms had been used to make a lot of detections.
The automobile is a major player in the traffic environment, making it an important object to recognize and detect in the environment perception task, according to the research [1]. The rapid advancement of computer technology and sensor hardware has led to the employment of numerous unique methodologies and technologies in recent years for vehicle identification [1]. In order to estimate speed using a monocular camera, we must coordinate data collecting, tracking, and detection of the cars across the road while taking into account the lanes and space between vehicles, as shown in the study of [2]. In order to locate the automobiles on each frame by removing each frame from the backdrop picture, objects from the background must first be differentiated. Recent developments in object detection, notably YOLO, Yolov2 and Yolov3, have been employed in a number of scenarios with good accuracy, nevertheless. According to Yolo [2], the problem of object detection in frames is a regression to bounding boxes with spatial separations and related class probabilities. The research [3] arranges the survey in chronological order to highlight the connections between the suggested approaches and offers a thorough analysis of the current ones. For better understanding, the paper describes the respective architectures of Faster R-CNN, YOLO, and their suggested variants in detail. In order to advance the development of more precise and reliable vehicle detection, the study intends to give an extensive assessment of the current approaches for automatic moving vehicle detection and tracking in intelligent traffic surveillance [3]. The suggested method of [4] entails using a mask region-based convolutional neural network (Mask R-CNN) to segment vehicle instances from traffic surveillance video frames and using the acquired vehicle silhouette and three orthogonal vanishing points in the observed traffic scene, a 3D bounding box is created for each occurrence of a vehicle. Thus, the height of the vehicle image is directly related to the vertical edges of the created 3D bounding box. An evaluation of the suggested method's performance in the field shows that it is capable of overcoming the height estimate interferences caused by vehicles, shadows, and irregular appearance that are present in image-based approaches currently in use. Overall, the study shows the potential of the suggested strategy for elevated automobile recognition and collision warning in actual traffic situations, offering a more precise and reliable method of addressing the issue of over height vehicle collisions [4]. The authors of [5] recognize the difficulties in amassing traffic data at scale due to cost and availability, and they propose a novel morphology-based vehicle detection method that uses multispectral photos with an average frequency of 7.1 days from November 2019 to September 2020 to assess traffic density in various cities. According to the study, this approach successfully detects vehicle density in the majority of photos with an accuracy of 68.26% [5].
In this paper we do a systematic review of the research literature. First, a search protocol was created, then systematic searches were carried out in accordance with it. These searchers were guided by strings that were created in accordance with the determined research question. After that, a search method was developed to group all of the searches into categories based on the search journals. Also, research publications were filtered based on their title, abstract, and objectives as well as included in accordance with their inclusion criteria. In accordance with a searching protocol, papers published throughout a four-year period (2020, 2021, 2022, and 2023) were chosen for searching. Also, three databases (IEEE, Springer, and Google Scholar) were considered. All papers from journals were included according to an inclusion criterion. In title-based filtering any publications that did not address the current issue were removed. In abstract-based filtering all of the chosen databases did not include any papers whose abstracts did not address the issue. In objective-based filtering a table was created showing papers organized by their objectives after all of the papers were filtered according to their objectives. The goals of the research papers were determined and grouped into clusters following the title and abstract-based clustering. The categories of objectives were as follows: Performance (P), Applicability (App), Efficiency (E), Accuracy(A), Effectiveness (Eff), Robustness(R), Safety(S), Cost-Effective (CE), Sensitivity (SE) and F-Score (FS).
Yolo approach employed in [1] has low recall and a higher localization error when compared to two stage object detectors. These are the two main drawbacks of this YOLO variation. When compared to RetinaNet, YOLOv3 is slower and less accurate [6]. Numerous issues with DeepSORT exist, such as ID changes, poor occlusion handling, motion blur, and many others [6]. Training for R-CNN is expensive in terms of both money and time. Additionally, detection is quite slow [3]. YOLOv4 has a lesser recall and a larger localization error when compared to Faster R CNN. It is challenging to identify close items when there are just two recommended bounding boxes per grid [7]. CNN does not consider the object's position or orientation while producing predictions [8]. SSD might not provide advanced characteristics, which is bad for little items. More training data are needed [9]. The SVM algorithm does not do well with large data sets. It performs worse when there is more noise in the data collection [10]. Security and privacy concerns are raised in relation to UAV technology in [11]. PSD requires a stationary signal and responds slowly to windowing, making it difficult to comprehend. Deep neural networks are challenging to train with backpropagation because of the problem of vanishing gradient, which impacts the amount of time needed for training and reduces accuracy [11]. The influence of considerable pixel intensity fluctuations on the final image is a disadvantage of pixel-based approaches [12]. Window support and symbolic loops are absent from TensorFlow [12].
A visual instance of a vehicle detection is shown in Figure 1 [13]. The system can distinguish distinct cars from the background with high accuracy, enabling reliable assessments of vehicle size and motion patterns.
Figure 1.
Vehicle Detection Image.
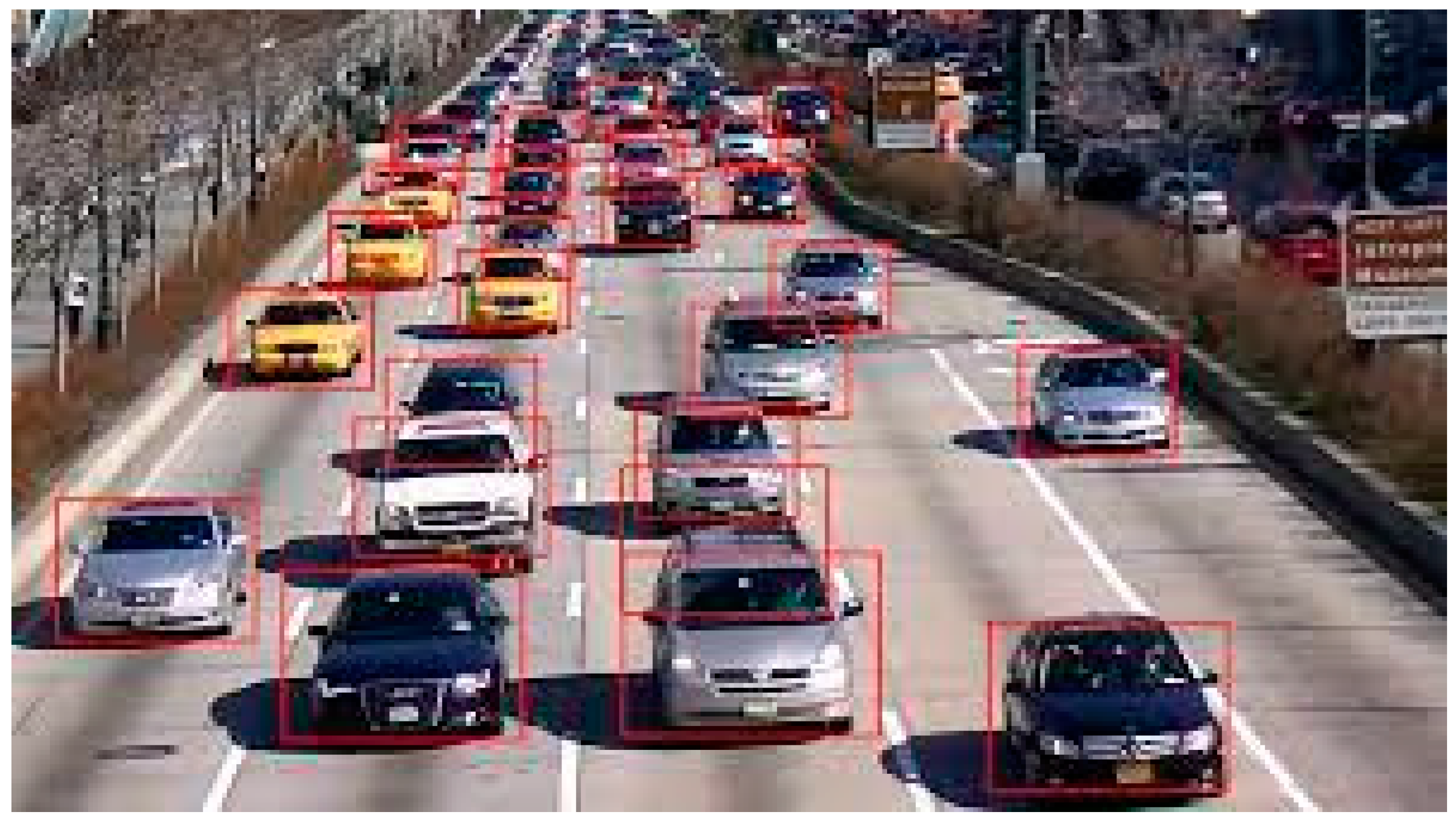
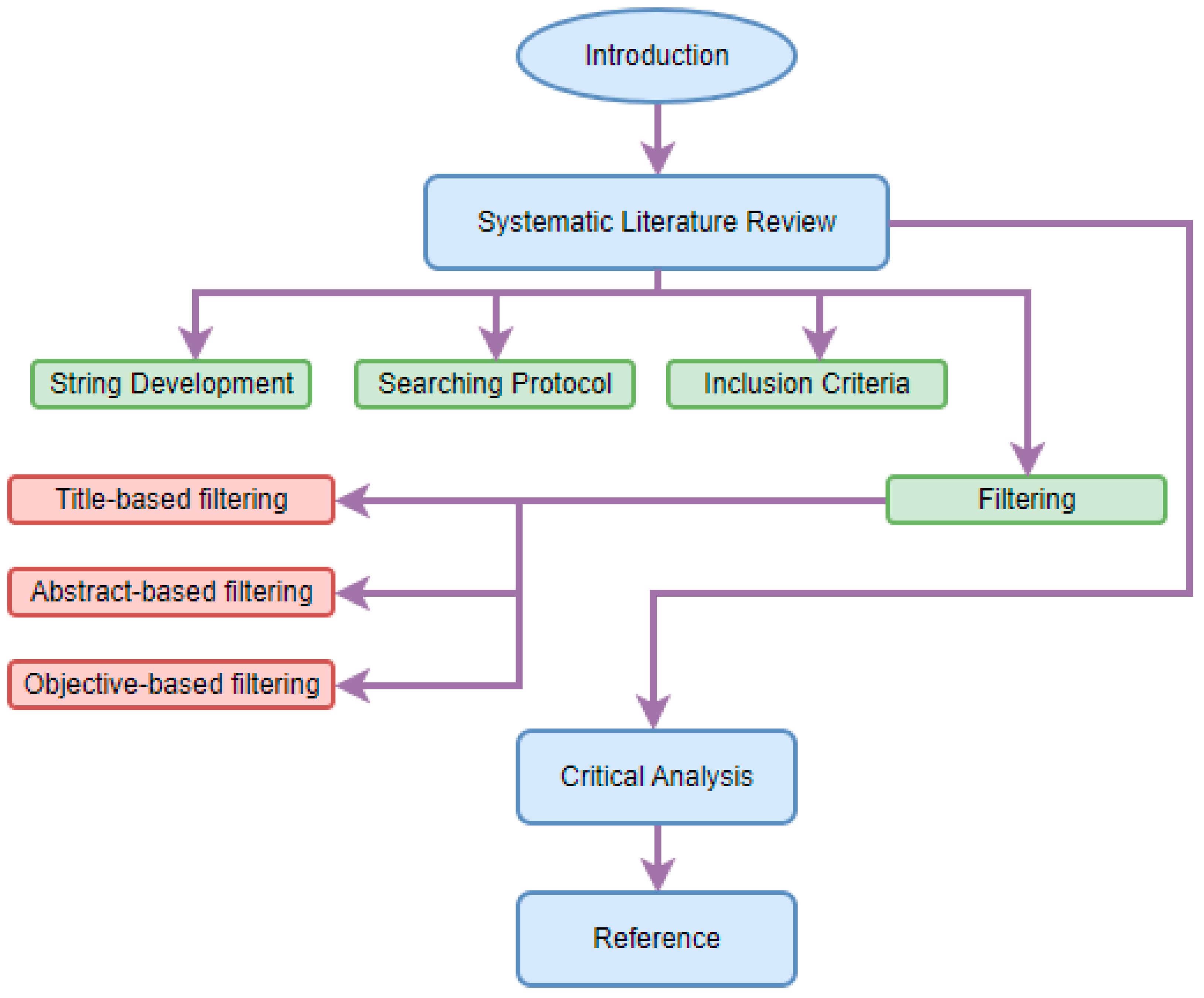
Figure 2.
Organization of paper.
The Table.1 summarizes the key points and contributions of various surveys in the area of tracking moving objects. It also draws attention to the improvements our paper makes over these earlier publications.

Table 1.
A summary of studies on query reformulation techniques.
| Ref. | Main Focus | Major Contribution | Enhancement in our paper |
|---|---|---|---|
| [1] | Analysis of vehicle detection techniques and how they're used in smart vehicle systems | Summarized more than 300 study contributions, comparing the effectiveness of old and new methods, and using a variety of vehicle detecting sensors. | Improving the model's generalisation and resilience by enhancing and preprocessing the dataset to increase the performance of our moving object identification system. |
| [2] | Studies of traffic flow and road safety using monocular cameras and AI | By comparing five statistical and three machine learning methods with a system that creates a dataset of vehicle speed estimation from monocular camera videos, we can demonstrate the effectiveness of the Linear Regression Model (LRM) for real-time speed estimation with potential hardware implementation. | Investigate the use of parallel processing and distributed computing approaches to speed up the detection process. |
| [3] | Using deep neural, automatic vehicle detection and tracking networks | Presenting a thorough analysis of existing Faster R-CNN and YOLO-based vehicle detection and tracking techniques, classifying them chronologically based on the architectures of their underlying algorithms, outlining the architectures of Faster R-CNN and YOLO and their variants, analyzing the current works' limitations, and highlighting the uncharted regions and potential future directions of research in this field. | Investigate methods for hardware acceleration to quicken the detecting process to improve our system's performance and effectiveness. |
| [4] | Crashes involving over height vehicles | Proposed a deep learning and view geometry-based method for autonomous vehicle height estimation. Vehicle instance segmentation and the creation of 3D boundary boxes were done using Mask R-CNN. | Investigate methods for hardware acceleration to quicken the detecting process to improve our system's performance and effectiveness. |
| [5] | Monitoring human mobility change during the COVID-19 pandemic using remote-sensing images | High temporal Planet multi-spectral pictures (from November 2019 to September 2020, on average 7.1 days of frequency) were used to propose a morphology-based vehicle detection approach to measure traffic density in various cities. It was shown that in the majority of the illustrations, the suggested approach reached a detection level with an efficiency of 68.26%, and that the general patterns of the observations match those of the public data already available (lockdown period, traffic volume, etc.), demonstrating that high temporal Planet data with world-wide coverage can provide traffic specifics for trend evaluation to further support informed decision-making for global extreme occurrences. | Improving the generalization and robustness of the model by enhancing and preprocessing the dataset to increase the performance of our moving object identification system. |
2. Systematic Literature Review
This report does a systematic review of the research literature. First, a search protocol was created, then systematic searches were carried out in accordance with it. These searchers were guided by strings that were created in accordance with the determined research question. After then, a search method was developed to group all of the searches into categories based on the search journals. Also, research publications were filtered based on their title, abstract, and objectives as well as included in accordance with their inclusion criteria.
2.1. String Development
Three synonyms for each term were used to create the strings.
Research Question: Moving Object Detection Using Deep Learning Algorithms
Table 1.
Research Synonyms.
| Words | Synonym #01 | Synonym #02 | Synonym #03 |
|---|---|---|---|
| Moving Object | Vehicle | Carrier | Transport |
| Detection | Observing | Identification | Distiguishing |
| Algorithms | Design | Method | Innovation |
Table 2.
Research Strings.
| Query 1: Moving Object Detection Using Deep Learning Algorithms |
| Query 2: Vehicle Detection Using Deep Learning Algorithms |
| Query 3: Carrier Object Detection Using Deep Learning Algorithms |
| Query 4: Transport Detection Using Deep Learning Algorithms |
| Query 5: Moving Object Observing Using Deep Learning Algorithms |
| Query 6: Moving Object Identification Using Deep Learning Algorithms |
| Query 7: Moving Object Distinguishing Using Deep Learning Algorithms |
| Query 8: Moving Object Detection Using Deep Learning Design |
| Query 9: Moving Object Detection Using Deep Learning Method |
| Query 10: Moving Object Detection Using Deep Learning Innovation |
2.2. Searching Protocols
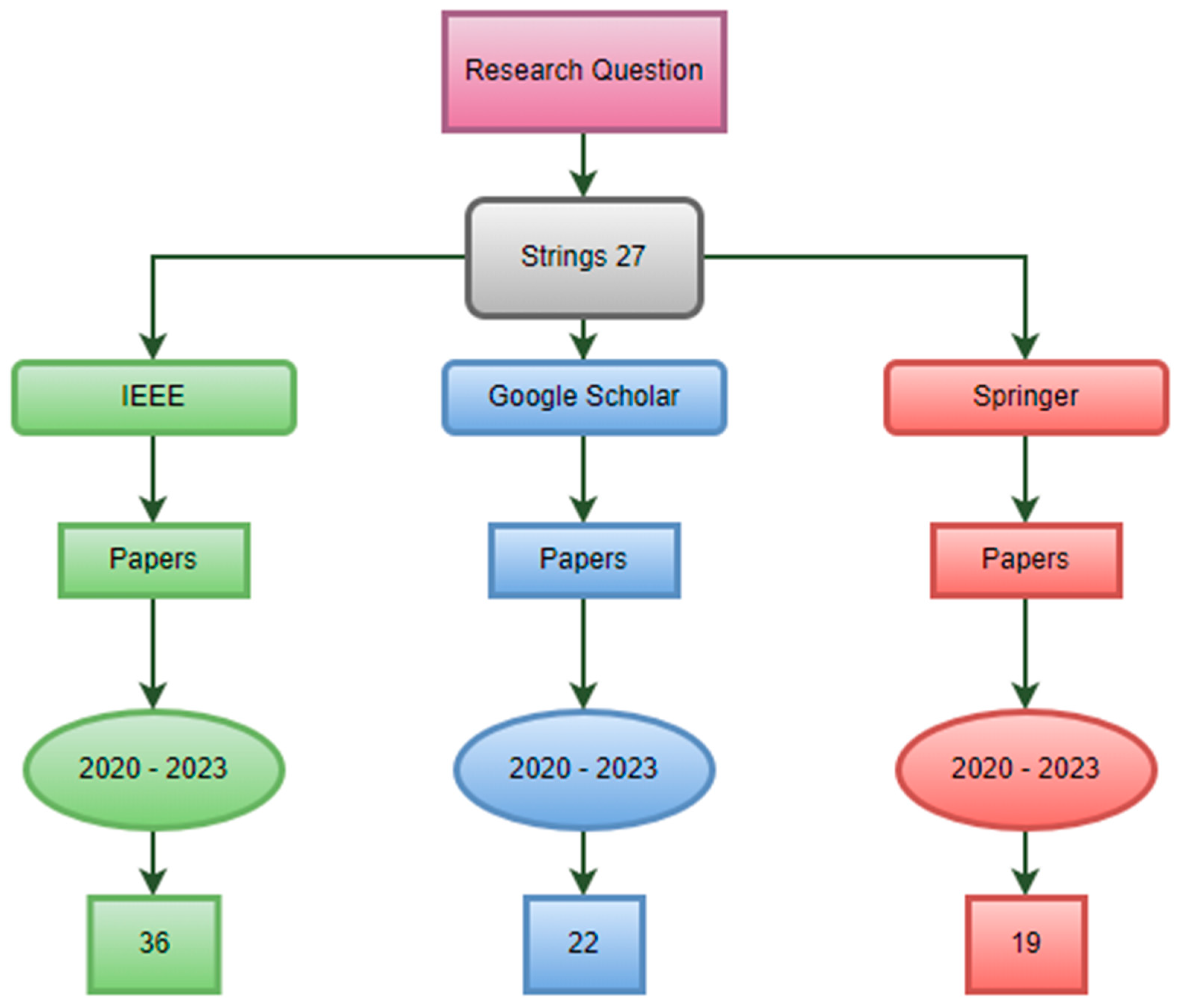
In accordance with a searching protocol, papers published throughout a four-year period (2020, 2021, 2022, and 2023) were chosen for searching. Also, three databases (IEEE, Springer, and Google Scholar) and three synonyms of each phrase were considered in the search. There were only seven papers chosen for each string. In Figure 1, the search tactics are shown.
Figure 1.
Search Approach using different Database.
2.3. Inclusion Criteria
All papers from journals were included according to an inclusion criterion that was created. There were no white papers present. The papers which were not published yet are not included.
2.4. Filtering
Figure 2 illustrates the first stage of the filtering process, which was title-based filtering. Any publications that did not address the current issue were removed from the databases that were chosen.
Abstract-based filtering was done in the second section. All of the chosen databases did not include any papers whose abstracts did not address the issue. As depicted in Figure 2, objective-based filtering was used in the third stage of the filtering. A table was created showing papers organized by their objectives after all of the papers were filtered according to their objectives.
The goals of the research papers were determined and grouped into clusters following the title and abstract-based clustering. This objective-based screening is given in Table 3. The categories of objectives were as follows: Performance (P), Applicability (App), Efficiency (E), Accuracy(A), Effectiveness (Eff), Robustness(R), Safety(S), Cost-Effective (CE), Sensitivity (SE) and F-Score (FS).
Table 3.
Notations and their definitions.
| Acronyms | Definition |
|---|---|
| P | Performance |
| App | Applicability |
| E | Efficiency |
| A | Accuracy |
| Eff | Effectiveness |
| R | Robustness |
| S | Safety |
| CE | Cost-Effectiveness |
| SE | Sensitivity |
| FS | F-Score |
An essential component of a systematic literature review or meta-analysis is objective-based screening. Researchers can locate all pertinent studies that satisfy a set of criteria by identifying particular study questions or objectives and developing inclusion and exclusion criteria. In order to give a summary of the evidence relevant to the study purpose, the procedure entails conducting an extensive search across numerous databases, screening studies for eligibility and quality, and synthesizing the results. Figure 2 describing the phases involved in objective-based screening of research papers to better illustrate this procedure.
Figure 2.
Objective-based screening of research papers.
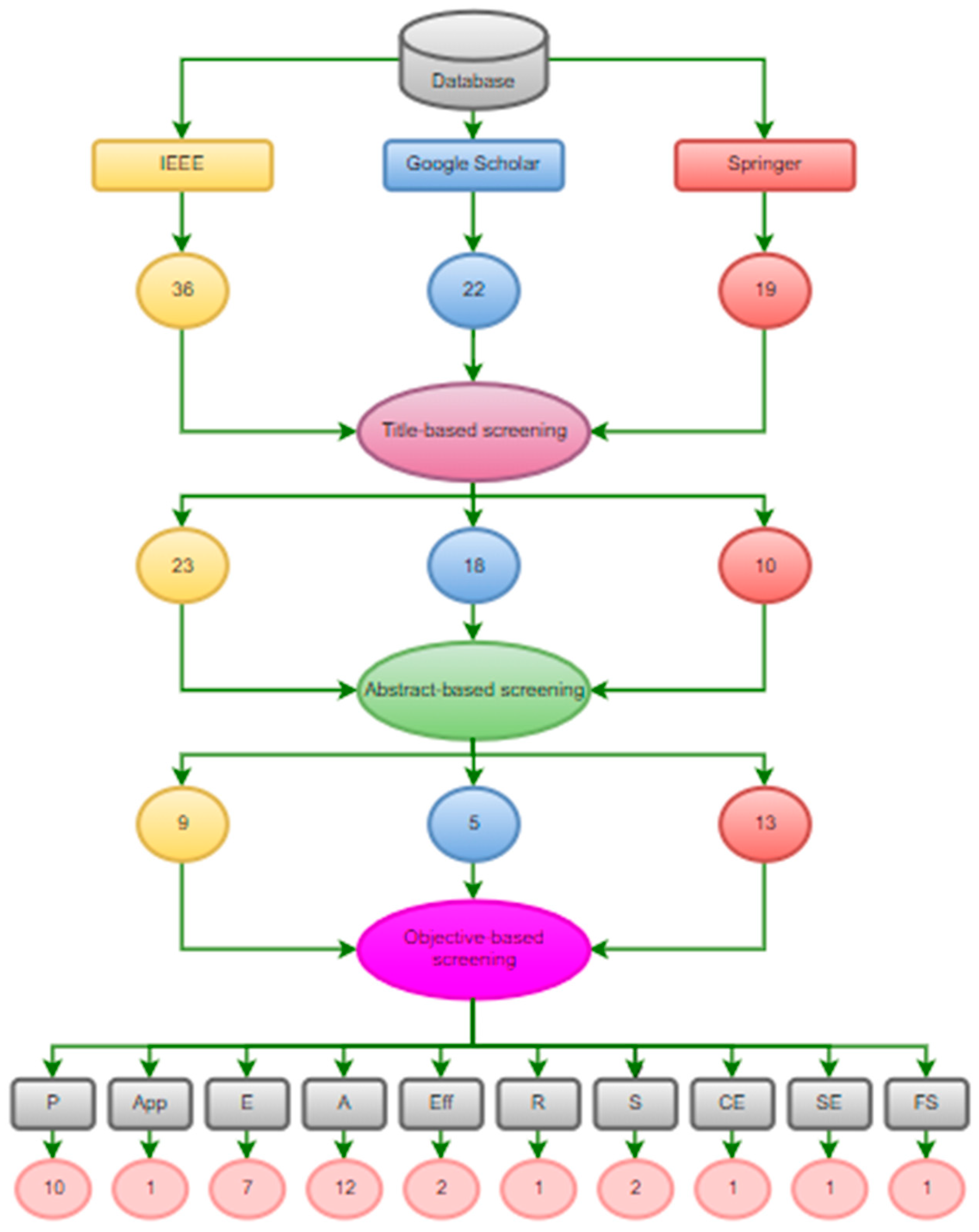
Table 4 lists some typical inclusion and exclusion criteria used in systematic literature reviews to assist researchers in understanding the essential criteria that can be utilized to conduct objective-based screening. When conducting objective-based screening, using this table as a guide can help to guarantee that all pertinent studies are found and taken into account in the analysis.
Table 4.
Objective Based Screening.
| Ref. | P | App | E | A | Eff | R | S | CE | SE | FS |
|---|---|---|---|---|---|---|---|---|---|---|
| [1] | ✓ | ✓ | – | – | – | – | – | – | – | – |
| [6] | – | – | ✓ | ✓ | – | – | – | – | – | – |
| [3] | ✓ | – | – | – | – | – | – | – | – | – |
| [7] | – | – | ✓ | ✓ | ✓ | – | – | – | – | – |
| [8] | ✓ | – | – | ✓ | – | – | – | – | – | – |
| [14] | ✓ | – | – | ✓ | – | ✓ | – | – | – | – |
| [15] | – | – | – | – | – | – | ✓ | – | – | – |
| [16] | – | – | – | ✓ | – | – | – | – | – | – |
| [9] | ✓ | – | – | – | – | – | – | – | – | – |
| [17] | – | – | ✓ | ✓ | – | – | – | – | – | – |
| [18] | ✓ | – | – | ✓ | – | – | – | – | – | – |
| [10] | – | – | – | ✓ | – | – | – | – | – | – |
| [11] | – | – | ✓ | ✓ | – | – | – | ✓ | – | – |
| [19] | ✓ | – | ✓ | ✓ | – | – | – | – | – | – |
| [20] | ✓ | – | ✓ | ✓ | – | – | ✓ | – | ✓ | ✓ |
| [12] | ✓ | – | ✓ | ✓ | – | – | – | – | – | – |
| [21] | ✓ | – | – | – | ✓ | – | – | – | – | – |
Several computer vision and video analytics applications, like traffic monitoring and autonomous driving, depend on the ability to detect moving vehicles. To tackle this challenge, a variety of techniques have been put out in the literature, each with advantages and disadvantages. Table 5 describing the methodology of numerous moving vehicle detection systems to aid researchers and practitioners in understanding the many approaches to moving vehicle detection. The important characteristics of each approach are summarized in this table, including the type of input data used, the algorithmic strategy used, and the performance metrics mentioned in the literature. It might be a useful resource for academics and professionals involved in the study of moving vehicle detection.
Table 5.
Summary of methodologies of moving vehicle detection techniques.
| Ref. | Technique | Methodology |
|---|---|---|
| [1] |
YOLO |
To identify the 2-D object bounding boxes in the colour image, DM, and RM, three YOLO-based object detectors were independently ran on every mode. After that, the detection results were combined using the evaluation function and nonmaximum suppression. |
| [6] |
YOLOv3, DeepSORT |
YOLOv3 makes advantage of a network with more volume. The network is known as Darknet-53 since it has 53 convolutional layers. It incorporates continuous convolutional layers from YOLOv2, Darknet-19, and other new residual networks. This paper combined fast enhanced DeepSORT MOT algorithm with appearance information of object candidates from object-detection CNNs to extract motion features and compute trajectories in lab workstation. DeepSORT, the real-time MOT method, is used for tracking, state estimation, and frame-by-frame data association. |
| [3] |
YOLO, R-CNN |
This article provides a thorough analysis of current vehicle recognition and tracking techniques based on YOLO and Faster R-CNN. It has largely concentrated on vehicle detection techniques based on deep neural networks, such as Faster R-CNN and YOLO network. |
| [7] |
YOLOv4, DeepSORT |
Deep learning algorithms will be used in DeepSORT to decrease the large number of identity shifts and increase the effectiveness of tracking through SORT algorithm occlusions. This vehicle detection and tracking technique leverages the Yolov4 model-based DeepSORT algorithm from the TensorFlow library. |
| [8] |
CNN |
CNNs pick up basic low-level aspects of vehicles in the first layers, then more intricate intermediate and high-level feature representations in the deeper layers, which are used to classify the vehicles. They involve learnable parameters that correspond to the weights and biases. |
| [14] |
YOLOv3-tiny |
Using yolov3-tiny, First, a second detection layer is created and added to the original yolov3-tiny network for the purpose of detecting small vehicles. Second, a set of side-way blocks are added to extract and combine features in several layers. |
| [15] |
YOLOv3 |
This article addresses the object detection issue and seeks to enhance it using the YOLOv3 approach. |
| [16] |
YOLO, R-CNN |
It is intended to compare the accuracy training process accomplishments using the YoloV4 and Faster-RCNN. Data sets with photographs chosen from various weather, land conditions, and time periods of the day are established for use in the training and testing phases. |
| [9] |
YOLOv3, SSD, R-CNN |
Algorithms for quick and high-performance object detection quicker R-CNN and YOLOv3 used for analyzing images captured by UAVs, tiny and SSD algorithms to identify cars. The positions of moving vehicles in traffic are determined automatically. |
| [17] |
YOLOv3-tiny |
This research suggests a YOLOv3-tiny-based deep learning approach for target vehicle detection. For feature extraction, YOLOv3 utilizes the darknet 53 convolutional layer. |
| [18] |
Z10TIRM, YOLOv4 |
Z10TIRM camera has the ability to record images not only in the traditional RGB image format but also in the infrared range. YOLOv4 model has been refined to have 148 layers, 94 of which are convolutional layers. Modifications were made to a few so-called route layers, restoring the neural network's prior connectivity. |
| [10] |
SVM, YOLOv3 |
By bringing together only perceptually similar images, the HOG offers a good generalization, in contrast to several regularly used representations. This results in the decision-making function that can accurately differentiate between object and non-object models using SVM. Compared to CNN and its offshoots, YOLOv3 is a more adaptive algorithm with regards to performance. |
| [11] |
UAV, PSD, DNN |
RF signals sent from the UAV to the controller are used in this paper's proposed UAV detection and identification process. By comparing the PSD to PSD models that have been trained, they were able to further determine the type of UAV. They have determined the kind of UAV if it fits one of the previously taught PSD models; if not, they record the spectrum as an unidentified kind of PSD into the database for subsequent human marking as training data to construct a new PSD model. They utilized the learned parameters and network topology as a model for prediction after training a DNN. However, the goal of training a DNN is to make use of its parameters. |
| [19] |
YOLO, Deep SORT |
To identify, track, and categorize the vehicles, the recorded video is passed to a deep learning framework built on the YOLO framework. All the items in video frames are identified and counted by YOLO. To track the objects in video frames, Deep SORT tracker is given the output of YOLO. All types of roadside objects could be counted successfully using the YOLOv3 and Deep SORT algorithms. |
| [20] |
YOLOv3, SVM |
To distinguish between various environmental categories, the non-leaf nodes of the decision tree are supplemented by the SVM classifier. Compare YOLOv3 and SPEED for the accuracy classification of ambulances, buses, fire trucks, conventional automobiles, and police cars. |
| [12] |
FE-CNN, TensorFlow Deep learning framework |
By determining the ideal number of convolution kernels, the weight and bias in the neural network are maximised during CNN training. As a result, FE-CNN accomplishes the recognition precision of GoogleLeNet in less time. The model outperforms GoogleLeNet because its precision is stable. Based on the generated computation graph, TensorFlow locates all the nodes that are reliant on E. |
| [21] |
R-CNN, SSD |
Both models Faster R-CNN and SSD are displaying multiple detections in some scenes, which means the same object is being picked up by both models at the same time and produces inaccurate results. |
3. Detailed Literature Review
The research of [1] presented YOLO(You Only Look Once) algorithm to identify the 2-D object bounding boxes in the colour image, DM, and RM, three YOLO-based object detectors were independently ran on each modality. After that, the detection results were combined using the evaluation function and nonmaximum suppression.
The research of [6] presented YOLOv3 and DeepSORT algorithms, YOLOv3 makes advantage of a network with more volume. The network is known as Darknet-53 since it has 53 convolutional layers. It incorporates continuous convolutional layers from YOLOv2, Darknet-19, and other new residual networks.
This paper combined fast enhanced DeepSORT MOT algorithm with appearance information of object candidates from object-detection CNNs to extract motion features and compute trajectories in lab workstation. DeepSORT—the real-time MOT method—is used for tracking, state estimation, and frame-by-frame data association.
The research of [3] presented YOLO and R-CNN (Faster Region- based Convolutional Neural Networks) techniques. It provides a thorough analysis of current vehicle recognition and tracking techniques based on YOLO and Faster R-CNN. It has largely concentrated on vehicle detection techniques based on deep neural networks, such as Faster R-CNN and YOLO network.
The research of [7] presented YOLOv4 and DeepSORT. Deep learning algorithms will be used in DeepSORT to decrease the large number of identity shifts and increase the effectiveness of tracking through SORT algorithm occlusions. This vehicle detection and tracking technique leverages the Yolov4 model-based DeepSORT algorithm from the TensorFlow library.
The research of [8] presented CNN. CNNs pick up basic low-level aspects of vehicles in the first layers, then more intricate intermediate and high-level feature representations in the deeper layers, which are used to classify the vehicles. They involve learnable parameters that correspond to the weights and biases.
The research of [14] presented YOLOv3-tiny. Using yolov3-tiny, First, a second detection layer is created and added to the original yolov3-tiny network for the purpose of detecting small vehicles. Second, a set of side-way blocks are added to extract and combine features in several layers.
The article of [15] addresses the object detection issue and seeks to enhance it using the YOLOv3 approach.
The research of [16] presented YOLO and R-CNN. It is intended to compare the accuracy training process accomplishments using the YoloV4 and Faster-RCNN. Data sets with photographs chosen from various weather, land conditions, and time periods of the day are established for use in the training and testing phases.
The research of [9] presented algorithms for quick and high-performance object detection quicker R-CNN and YOLOv3 used for analyzing images captured by UAVs, tiny and SSD algorithms to identify cars. The positions of moving vehicles in traffic are determined automatically.
This research [17] suggests a YOLOv3-tiny-based deep learning approach for target vehicle detection. For feature extraction, YOLOv3 utilizes the darknet 53 convolutional layer.
The research of [18] presented Z10TIRM and YOLOv4. Z10TIRM camera has the ability to record images not only in the traditional RGB image format but also in the infrared range. YOLOv4 model has been refined to have 148 layers, 94 of which are convolutional layers. Modifications were made to a few so-called route layers, restoring the neural network's prior connectivity.
Research of [10] presented SVM (Support Vector Machine) classifier and YOLOv3. The HOG provides a good generalization by grouping only perceptually comparable images, in contrast to several regularly used representations. Using SVM, this results in a decision-making function that can reliably differentiate between object and non-object models. In terms of performance, YOLOv3 is likewise a more adaptive algorithm than CNN and its offshoots. The research of [11] presented UAV, PSD (power spectrum density) Model and DNN (deep neural network) Model. RF signals sent from the UAV to the controller are used in this paper's proposed UAV detection and identification process. By comparing the PSD to PSD models that have been trained, they were able to further determine the type of UAV. They have determined the kind of UAV if it fits one of the previously taught PSD models; if not, they record the spectrum as an unidentified kind of PSD into the database for subsequent human marking as training data to construct a new PSD model. They utilized the learned parameters and network topology as a model for prediction after training a DNN. However, the goal of training a DNN is to make use of its parameters.
The research of [19] presented YOLO and Deep SORT. To identify, track, and categorize the vehicles, the recorded video is passed to a deep learning framework built on the YOLO framework. All the items in video frames are identified and counted by YOLO. To track the objects in video frames, Deep SORT tracker is given the output of YOLO. All types of roadside objects could be counted successfully using the YOLOv3 and Deep SORT algorithms.
The research of [20] presented YOLOv3 and SVM. To distinguish between various environmental categories, the non-leaf nodes of the decision tree are supplemented by the SVM classifier. Compare YOLOv3 and SPEED for the accuracy classification of ambulances, buses, fire trucks, conventional automobiles, and police cars.
The research of [12] presented FE-CNN (Fused Edge feature) and TensorFlow Deep learning framework. By determining the ideal number of convolution kernels, the weight and bias in the neural network are maximised during CNN training. As a result, FE-CNN accomplishes the recognition precision of GoogleLeNet in less time. The model outperforms GoogleLeNet because its precision is stable. Based on the generated computation graph, TensorFlow locates all the nodes that are reliant on E.
The research of [21] presented R-CNN and SSD (single-shot detector). Both models Faster R-CNN and SSD are displaying multiple detections in some scenes, which means the same object is being picked up by both models at the same time and produces inaccurate results. In our exploration of moving object detection using deep learning algorithms, our research draws upon foundational insights presented in [46,47,48,49,50,51,52,53,54,55,56,57,58].
4. Performance Analysis
4.1. Critical analysis
The critical study of moving objects detection techniques is summarized in Table 6. There is a list of all the schemes' objectives as well as their limitations.
High localization error and lower recall in comparison with two stage object detectors may be viewed as the two primary downsides of this version of YOLO [22]. The speed and accuracy of using YOLOv3 is less as compared to RetinaNet [23]. DeepSORT contains numerous flaws, including ID changes, poor handling of occlusion, motion blur, and many others [24]. In R-CNN training is costly both in terms of money and time. Moreover, detection is rather slow [25]. Compared to Faster R CNN, YOLOv4 has a lower recall and higher localization error. Having only two proposed bounding boxes per grid makes it difficult to recognize nearby objects [26]. The location and orientation of the object are not taken into account by CNN when making predictions [27]. SSD may not generate high level features, worse for small objects. Need more training data [28]. Compared to Faster R CNN, YOLOv4 has a lower recall and higher localization error. Having only two proposed bounding boxes per grid makes it difficult to recognize nearby objects [26]. Large data sets are not a good fit for the SVM algorithm. When there is more noise in the data set, it does not perform as well [29]. In UAV technique, there is issue of security and privacy [30]. PSD can be challenging to understand, needs a stationary signal, reacts slowly to windowing [31]. Due to the issue of vanishing gradient, which affects the amount of time required for training and decreases accuracy, deep neural networks are difficult to train with backpropagation [32]. The drawback of pixel-based techniques is the impact of significant pixel intensity changes on the final image [33]. TensorFlow has no window support and missing symbolic loops [34].
Table 6.
Summary of shortcomings of moving vehicle detection techniques.
| Ref. | Techniques | Shortcoming |
| [1] |
YOLO |
The two main drawbacks of this form of YOLO may be considered as high localization error and lower recall in compared to two stage object detectors [22]. |
| [6] |
YOLOv3, DeepSORT |
The speed and accuracy of using YOLOv3 is less as compared to RetinaNet [23] DeepSORT contains numerous flaws, including ID changes, poor handling of occlusion, motion blur, and many others [24] |
| [3] |
YOLO, R-CNN |
High localization error and lower recall primary downsides of this version of YOLO [22] In R-CNN training is costly both in terms of money and time. Moreover, detection is rather slow [25] |
| [7] |
YOLOv4, DeepSORT |
Compared to Faster R CNN, YOLOv4 has a lower recall and higher localization error. Having only two proposed bounding boxes per grid makes it difficult to recognize nearby objects [26] DeepSORT contains numerous flaws, including ID changes, poor handling of occlusion, motion blur, and many others [24] |
| [8] |
CNN |
The location and orientation of the object are not taken into account by CNN when making predictions [27] |
| [14] |
YOLOv3-tiny |
The speed and accuracy of using YOLOv3 is less as compared to RetinaNet [23] |
| [15] |
YOLOv3 |
The speed and accuracy of using YOLOv3 is less as compared to RetinaNet [23] |
| [16] |
YOLO, R-CNN |
The two main drawbacks of this form of YOLO may be considered as high localization error and lower recall in compared to two stage object detectors [22]. In R-CNN training is costly both in terms of money and time. Moreover, detection is rather slow [25] |
| [9] |
YOLOv3, SSD, R-CNN |
The speed and accuracy of using YOLOv3 is less as compared to RetinaNet [23] SSD may not generate high level features, worse for small objects. Need more training data [28] In R-CNN training is costly both in terms of money and time. Moreover, detection is rather slow [25] |
| [17] |
YOLOv3-tiny |
The speed and accuracy of using YOLOv3 is less as compared to RetinaNet [23] |
| [18] |
YOLOv4 |
Compared to Faster R CNN, YOLOv4 has a lower recall and higher localization error. Having only two proposed bounding boxes per grid makes it difficult to recognize nearby objects [26] |
| [10] |
SVM, YOLOv3 |
Large data sets are not a good fit for the SVM algorithm. When there is more noise in the data set, it does not perform as well [29] The speed and accuracy of using YOLOv3 is less as compared to RetinaNet [23] |
| [11] |
UAV, PSD, DNN |
In UAV technique, there is issue of security and privacy [30] PSD can be challenging to understand, needs a stationary signal, reacts slowly to windowing [31] Due to the issue of vanishing gradient, which affects the amount of time required for training and decreases accuracy, deep neural networks are difficult to train with backpropagation [32] |
| [19] |
YOLO, DeepSORT |
The two main drawbacks of this form of YOLO may be considered as high localization error and lower recall in compared to two stage object detectors [22]. DeepSORT contains numerous flaws, including ID changes, poor handling of occlusion, motion blur, and many others [24] |
| [20] |
YOLOv3, SVM |
The speed and accuracy of using YOLOv3 is less as compared to RetinaNet [23] Large data sets are not a good fit for the SVM algorithm. When there is more noise in the data set, it does not perform as well [29] |
| [12] |
FE-CNN, TensorFlow Deep learning framework |
The drawback of pixel-based techniques is the impact of significant pixel intensity changes on the final image [33] TensorFlow has no window support and missing symbolic loops [34] |
| [21] |
R-CNN, SSD |
In R-CNN training is costly both in terms of money and time. Moreover, detection is rather slow [25] SSD may not generate high level features, worse for small objects. Need more training data [28] |
The research gaps in the area of tracking moving objects are shown in the Table 7, along with the solutions that address each one. The table offers a thorough summary of the present difficulties faced by researchers in this field and sheds light on the cutting-edge strategies being used to close these gaps. The table provides a quick review of the ongoing work in moving object detection research by looking at each gap and its corresponding solution.
Table 7.
Research Gaps.
| Ref. | Research Gaps | Solution |
|---|---|---|
| [1] [3] [7] [16] [18] [19] |
High localization error |
With the use of superior training methods, YOLO performance has considerably improved. For object detection networks, a variety of training methods can be applied, including image fusion with geometry preserved alignment, cosine learning rate scheduler, synchronized batch normalization, data augmentation, and label smoothing [35]. |
| [6] [14] [15] [9] [17] [10] [20] |
Low speed and less accuracy |
To speed up the YOLOv3 algorithm, we can drop the output layers. When the discarding strategy is used, the extra computation is removed. 59 convolutional layers are used to find large scale objects in a feed-forward fashion [36]. |
| [6] [7] [19] |
Numerous flaws of DeepSORT |
We can correct everything using the newest algorithms. FairMOT and CentreTrack are two recent methods that can drastically lower ID switches and efficiently handle occlusions. Test other hypotheses, use different YOLOv5 model iterations, or use DeepSORT on a customer object detector [24]. |
| [3] [16] [9] [21] | Costly training and slow detection |
The MobileNet architecture can be utilized to build the fundamental R-CNN network. The duplicate proposal problem can be solved using the Soft-NMS method after the region proposal network [37]. |
| [9] [10] [11] [20] | Low performance and need more training data |
Increasing the input image resolution can fix the SSD's low performance issue [38]. |
| [11] | Issue of security and privacy | Using blockchain technology, UAVs may communicate securely with one another. It is necessary to build a secure and reliable UAV adhoc network as well as smart contracts [39]. |
| [12] | Intensity changes |
High-pass filters are used to detect abrupt changes in intensity across a defined area. Therefore, a high-pass filter will highlight areas in a small patch of pixels when light and dark pixels alternate (and vice versa) [40]. |
| [11] [12] | No window support and missing symbolic loops | Symbolic tensors can be executed in a while loop without preventing Eager execution [41]. |
| [8] | No location and orientation of object | A feature map, at the corresponding place of the output tensor, can be created by computing an element-wise product between each element of the kernel and the input tensor at each point of the tensor and summing it [42]. |
Dataset
| Ref. | Dataset description |
| [15] | MSCOCO, BDD100K, and self-generated image datasets for capturing vehicles |
| [14] | FLIR Dataset |
| [43] | Constructed their own dataset by using Anuj Shah Custom, Peltarion Custom and Hemil Patel Custom datasets |
| [9] | Images taken from UAV dataset |
| [16] | Images and records are taken from UAVs dataset |
| [10] | They used two famous datasets for detection, which are KITTI and GTI |
| [44] | Dataset collected by obtaining videos of emergency vehicle on YouTube |
| [45] | Kaggle dataset was used for both training and testing |
Conclusion
In this study, a practical solution to the problems of expensive training and delayed detection in moving object identification was proposed. To increase both the detection speed and accuracy, the suggested method combines the YOLOv6 algorithm with optical flow-based object tracking. We were able to locate and classify objects by applying YOLOv6 to each frame of the dataset and generating bounding box predictions and class probabilities. We estimated the motion vectors between successive frames using the optical flow approach, more precisely Lucas-Kanade, in order to increase the detection speed without sacrificing accuracy. The bounding box coordinates were then adjusted based on the motion data collected from optical flow to track the detected items across frames using these motion vectors.
Using fusion methods such weighted averaging, the refined object detections produced by the combination of YOLOv6 and optical flow-based tracking were further enhanced. Duplicate or overlapped detections were eliminated using post-processing techniques, such as non-maximum suppression. On the frames or video sequence, the final recognised objects and their paths may be seen. Metrics like accuracy, precision, recall, and F1 score were used to assess the performance of the combined YOLOv6 and optical flow technique. The findings showed that our suggested technique is successful in lowering training costs and enhancing detection speed while retaining a high degree of accuracy when compared to existing methods. Based on the evaluation results, adjustments and optimisations were made to the YOLOv6 and optical flow approaches' parameters and algorithms, which led to further gains in performance. The results of the study pave the way for additional investigation and advancement in the area of quick and effective moving object recognition.
References
- Z. Wang, J. Zhan, C. Duan, X. Guan, P. Lu, and K. Yang, “A Review of Vehicle Detection Techniques for Intelligent Vehicles,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–21, 2022 . [CrossRef]
- H. Rodríguez-Rangel, L. A. Morales-Rosales, R. Imperial-Rojo, M. A. Roman-Garay, G. E. Peralta-Peñuñuri, and M. Lobato-Báez, “Analysis of Statistical and Artificial Intelligence Algorithms for Real-Time Speed Estimation Based on Vehicle Detection with YOLO,” Applied Sciences, vol. 12, no. 6, Art. no. 6, Jan. 2022. [CrossRef]
- M. Maity, S. Banerjee, and S. Sinha Chaudhuri, “Faster R-CNN and YOLO based Vehicle detection: A Survey,” in 2021 5th International Conference on Computing Methodologies and Communication (ICCMC), Apr. 2021, pp. 1442–1447. [CrossRef]
- “Automated visual surveying of vehicle heights to help measure the risk of overheight collisions using deep learning and view geometry - Lu - 2023 - Computer-Aided Civil and Infrastructure Engineering - Wiley Online Library.” https://onlinelibrary.wiley.com/doi/full/10.1111/mice.12842 (accessed Feb. 24, 2023) .
- Y. Chen, R. Qin, G. Zhang, and H. Albanwan, “Spatial Temporal Analysis of Traffic Patterns during the COVID-19 Epidemic by Vehicle Detection Using Planet Remote-Sensing Satellite Images,” Remote Sensing, vol. 13, no. 2, Art. no. 2, Jan. 2021. [CrossRef]
- C. Chen, B. Liu, S. Wan, P. Qiao, and Q. Pei, “An Edge Traffic Flow Detection Scheme Based on Deep Learning in an Intelligent Transportation System,” IEEE Transactions on Intelligent Transportation Systems, vol. 22, no. 3, pp. 1840–1852, Mar. 2021. [CrossRef]
- M. A. Bin Zuraimi and F. H. Kamaru Zaman, “Vehicle Detection and Tracking using YOLO and DeepSORT,” in 2021 IEEE 11th IEEE Symposium on Computer Applications & Industrial Electronics (ISCAIE), Apr. 2021, pp. 23–29. [CrossRef]
- A. Bouguettaya, H. Zarzour, A. Kechida, and A. M. Taberkit, “Vehicle Detection From UAV Imagery With Deep Learning: A Review,” IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 11, pp. 6047–6067, Nov. 2022. [CrossRef]
- M. Böyük, R. Duvar, and O. Urhan, “Deep Learning Based Vehicle Detection with Images Taken from Unmanned Air Vehicle,” in 2020 Innovations in Intelligent Systems and Applications Conference (ASYU), Oct. 2020, pp. 1–4. [CrossRef]
- A. S. Abdullahi Madey, A. Yahyaoui, and J. Rasheed, “Object Detection in Video by Detecting Vehicles Using Machine Learning and Deep Learning Approaches,” in 2021 International Conference on Forthcoming Networks and Sustainability in AIoT Era (FoNeS-AIoT), Dec. 2021, pp. 62–65. [CrossRef]
- H. Liu, “Unmanned Aerial Vehicle Detection and Identification Using Deep Learning,” in 2021 International Wireless Communications and Mobile Computing (IWCMC), Jun. 2021, pp. 514–518. [CrossRef]
- “Deep learning-based algorithm for vehicle detection in intelligent transportation systems | SpringerLink.” https://link.springer.com/article/10.1007/s11227-021-03712-9 (accessed Feb. 28, 2023) .
- “Vehicle detection in intelligent transport system under a hazy environment: a survey - Husain - 2020 - IET Image Processing - Wiley Online Library.” https://ietresearch.onlinelibrary.wiley.com/doi/full/10.1049/iet-ipr.2018.5351# (accessed May 21, 2023) .
- Y. Lu, Q. Yang, J. Han, and C. Zheng, “A Robust Vehicle Detection Method in Thermal Images Based on Deep Learning,” in 2021 IEEE International Conference on Power, Intelligent Computing and Systems (ICPICS), Jul. 2021, pp. 386–390. [CrossRef]
- Z.-H. Huang, C.-M. Wang, W.-C. Wu, and W.-S. Jhang, “Application of Vehicle Detection Based On Deep Learning in Headlight Control,” in 2020 International Symposium on Computer, Consumer and Control (IS3C), Nov. 2020, pp. 178–180. [CrossRef]
- E. Bayhan, Z. Ozkan, M. Namdar, and A. Basgumus, “Deep Learning Based Object Detection and Recognition of Unmanned Aerial Vehicles,” in 2021 3rd International Congress on Human-Computer Interaction, Optimization and Robotic Applications (HORA), Jun. 2021, pp. 1–5. [CrossRef]
- L. Li and Y. Liang, “Deep Learning Target Vehicle Detection Method Based on YOLOv3-tiny,” in 2021 IEEE 4th Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Jun. 2021, pp. 1575–1579. [CrossRef]
- M. Kiac, K. Říha, J. Přinosil, and J. Mrnuštík, “Object Detection in Unmanned Aerial Vehicle Camera Stream Using Deep Neural Network,” in 2022 14th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), Oct. 2022, pp. 80–84. [CrossRef]
- R. Kejriwal, R. H J, A. Arora, and Mohana, “Vehicle Detection and Counting using Deep Learning basedYOLO and Deep SORT Algorithm for Urban Traffic Management System,” in 2022 First International Conference on Electrical, Electronics, Information and Communication Technologies (ICEEICT), Feb. 2022, pp. 1–6. [CrossRef]
- “An intelligent traffic detection approach for vehicles on highway using pattern recognition and deep learning | SpringerLink.” https://link.springer.com/article/10.1007/s00500-022-07375-3 (accessed Feb. 28, 2023) .
- “Vehicle detection and traffic density estimation using ensemble of deep learning models | SpringerLink.” https://link.springer.com/article/10.1007/s11042-022-13659-5 (accessed Feb. 28, 2023) .
- T. Diwan, G. Anirudh, and J. V. Tembhurne, “Object detection using YOLO: challenges, architectural successors, datasets and applications,” Multimed Tools Appl, vol. 82, no. 6, pp. 9243–9275, Mar. 2023. [CrossRef]
- V. Meel, “YOLOv3: Real-Time Object Detection Algorithm (Guide),” viso.ai, Jan. 02, 2022. https://viso.ai/deep-learning/yolov3-overview/ (accessed Mar. 24, 2023) .
- “Understanding Multiple Object Tracking using DeepSORT,” Jun. 21, 2022. https://learnopencv.com/understanding-multiple-object-tracking-using-deepsort/ (accessed Mar. 25, 2023) .
- A. Mohan, “Review on Fast RCNN,” Medium, May 22, 2020. https://medium.datadriveninvestor.com/review-on-fast-rcnn-202c9eadd23b (accessed Mar. 24, 2023) .
- madrasresearchorg, “YOLOV4: OPTIMAL SPEED AND ACCURACY OF OBJECT DETECTION,” MSRF|NGO, Oct. 15, 2021. https://www.madrasresearch.org/post/yolov4-optimal-speed-and-accuracy-of-object-detection (accessed Mar. 25, 2023) .
- “Drawbacks of Convolutional Neural Networks.” https://www.linkedin.com/pulse/drawbacks-convolutional-neural-networks-sakhawat-h-sumit (accessed Mar. 25, 2023) .
- H. Gao, “Understand Single Shot MultiBox Detector (SSD) and Implement It in Pytorch,” Medium, Jul. 19, 2018. https://medium.com/@smallfishbigsea/understand-ssd-and-implement-your-own-caa3232cd6ad (accessed Mar. 26, 2023) .
- A. Raj, “Everything About Support Vector Classification — Above and Beyond,” Medium, Aug. 06, 2022. https://towardsdatascience.com/everything-about-svm-classification-above-and-beyond-cc665bfd993e (accessed Mar. 26, 2023) .
- S. A. H. Mohsan, N. Q. H. Othman, Y. Li, M. H. Alsharif, and M. A. Khan, “Unmanned aerial vehicles (UAVs): practical aspects, applications, open challenges, security issues, and future trends,” Intel Serv Robotics, vol. 16, no. 1, pp. 109–137, Mar. 2023. [CrossRef]
- “OpenStax | Free Textbooks Online with No Catch.” https://openstax.org/ (accessed Mar. 26, 2023) .
- “Deep Neural Network - an overview | ScienceDirect Topics.” https://www.sciencedirect.com/topics/computer-science/deep-neural-network (accessed Mar. 26, 2023) .
- “Image Fusion - an overview | ScienceDirect Topics.” https://www.sciencedirect.com/topics/computer-science/image-fusion (accessed Mar. 28, 2023) .
- “Advantages and Disadvantages of TensorFlow - Javatpoint,” www.javatpoint.com. https://www.javatpoint.com/advantage-and-disadvantage-of-tensorflow (accessed Mar. 28, 2023) .
- “How to Improve YOLOv3,” Paperspace Blog, Jun. 29, 2020. https://blog.paperspace.com/improving-yolo/ (accessed May 10, 2023) .
- I. Martinez-Alpiste, G. Golcarenarenji, Q. Wang, and J. M. Alcaraz-Calero, “A dynamic discarding technique to increase speed and preserve accuracy for YOLOv3,” Neural Comput & Applic, vol. 33, no. 16, pp. 9961–9973, Aug. 2021. [CrossRef]
- “Improving Faster R-CNN Framework for Fast Vehicle Detection.” https://www.hindawi.com/journals/mpe/2019/3808064/#conclusions (accessed May 16, 2023) .
- “Understanding SSD MultiBox — Real-Time Object Detection In Deep Learning | by Eddie Forson | Towards Data Science.” https://towardsdatascience.com/understanding-ssd-multibox-real-time-object-detection-in-deep-learning-495ef744fab (accessed May 17, 2023) .
- H. Sachdeva, S. Gupta, A. Misra, K. Chauhan, and M. Dave, “Improving Privacy and Security in Unmanned Aerial Vehicles Network using Blockchain.” arXiv, Jun. 27, 2022. [CrossRef]
- A. Anand, “Introduction to CNN,” DataX Journal, Jul. 21, 2020. https://medium.com/data-science-community-srm/introduction-to-cnn-f3aaa8d79891 (accessed May 21, 2023) .
- “Eager execution prevents using while loops on Keras symbolic tensors · Issue #31848 · tensorflow/tensorflow,” GitHub. https://github.com/tensorflow/tensorflow/issues/31848 (accessed May 21, 2023) .
- R. Yamashita, M. Nishio, R. K. G. Do, and K. Togashi, “Convolutional neural networks: an overview and application in radiology,” Insights Imaging, vol. 9, no. 4, Art. no. 4, Aug. 2018. [CrossRef]
- M. H. Khan, M. Z. Hussein Sk Heerah, and Z. Basgeeth, “Automated Detection of Multi-class Vehicle Exterior Damages using Deep Learning,” in 2021 International Conference on Electrical, Computer, Communications and Mechatronics Engineering (ICECCME), Oct. 2021, pp. 01–06. [CrossRef]
- S. Sathruhan, O. K. Herath, T. Sivakumar, and A. Thibbotuwawa, “Emergency Vehicle Detection using Vehicle Sound Classification: A Deep Learning Approach,” in 2022 6th SLAAI International Conference on Artificial Intelligence (SLAAI-ICAI), Dec. 2022, pp. 1–6. [CrossRef]
- O. G. Abdulateef, A. I. Abdullah, S. R. Ahmed, and M. S. Mahdi, “Vehicle License Plate Detection Using Deep Learning,” in 2022 International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Oct. 2022, pp. 288–292. [CrossRef]
- Shahid, H., Ashraf, H., Javed, H., Humayun, M., Jhanjhi, N. Z., & AlZain, M. A. (2021). Energy optimised security against wormhole attack in iot-based wireless sensor networks. Comput. Mater. Contin, 68(2), 1967-81 .
- Wassan, S., Chen, X., Shen, T., Waqar, M., & Jhanjhi, N. Z. (2021). Amazon product sentiment analysis using machine learning techniques. Revista Argentina de Clínica Psicológica, 30(1), 695 .
- Almusaylim, Z. A., Zaman, N., & Jung, L. T. (2018, August). Proposing a data privacy aware protocol for roadside accident video reporting service using 5G in Vehicular Cloud Networks Environment. In 2018 4th International conference on computer and information sciences (ICCOINS) (pp. 1-5). IEEE .
- Ghosh, G., Verma, S., Jhanjhi, N. Z., & Talib, M. N. (2020, December). Secure surveillance system using chaotic image encryption technique. In IOP conference series: materials science and engineering (Vol. 993, No. 1, p. 012062). IOP Publishing .
- Humayun, M., Alsaqer, M. S., & Jhanjhi, N. (2022). Energy optimization for smart cities using iot. Applied Artificial Intelligence, 36(1), 2037255 .
- Hussain, S. J., Ahmed, U., Liaquat, H., Mir, S., Jhanjhi, N. Z., & Humayun, M. (2019, April). IMIAD: intelligent malware identification for android platform. In 2019 International Conference on Computer and Information Sciences (ICCIS) (pp. 1-6). IEEE .
- Diwaker, C., Tomar, P., Solanki, A., Nayyar, A., Jhanjhi, N. Z., Abdullah, A., & Supramaniam, M. (2019). A new model for predicting component-based software reliability using soft computing. IEEE Access, 7, 147191-147203 .
- Gaur, L., Afaq, A., Solanki, A., Singh, G., Sharma, S., Jhanjhi, N. Z., ... & Le, D. N. (2021). Capitalizing on big data and revolutionary 5G technology: Extracting and visualizing ratings and reviews of global chain hotels. Computers and Electrical Engineering, 95, 107374 .
- Nanglia, S., Ahmad, M., Khan, F. A., & Jhanjhi, N. Z. (2022). An enhanced Predictive heterogeneous ensemble model for breast cancer prediction. Biomedical Signal Processing and Control, 72, 103279 .
- Kumar, T., Pandey, B., Mussavi, S. H. A., & Zaman, N. (2015). CTHS based energy efficient thermal aware image ALU design on FPGA. Wireless Personal Communications, 85, 671-696 .
- Gaur, L., Singh, G., Solanki, A., Jhanjhi, N. Z., Bhatia, U., Sharma, S., ... & Kim, W. (2021). Disposition of youth in predicting sustainable development goals using the neuro-fuzzy and random forest algorithms. Human-Centric Computing and Information Sciences, 11, NA .
- Lim, M., Abdullah, A., & Jhanjhi, N. Z. (2021). Performance optimization of criminal network hidden link prediction model with deep reinforcement learning. Journal of King Saud University-Computer and Information Sciences, 33(10), 1202-1210 .
- Adeyemo Victor Elijah, Azween Abdullah, NZ JhanJhi, Mahadevan Supramaniam and Balogun Abdullateef O, “Ensemble and Deep-Learning Methods for Two-Class and Multi-Attack Anomaly Intrusion Detection: An Empirical Study” International Journal of Advanced Computer Science and Applications(IJACSA), 10(9), 2019 . [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



