Submitted:
22 December 2023
Posted:
22 December 2023
You are already at the latest version
Abstract
In this paper, we shall introduce the interval-valued spatial error model. Based on the idea of least square method of single-valued case, we give the parameter estimator for interval-valued spatial error model. The theoretical properties of the proposed estimator are proved. Finally, we give the numerical analysis and a real example.
Keywords:
Interval-valued random variable
; Spatial error model
; Parameter estimator
1. Introduction
It is well known that classical linear regression model and time series models are most widely used in statistical inference, including medical treatment, education, finance, science, technology and many other fields. Most of the cases, these models are used for single-valued random variables. In the real world, there are plenty of random phenomenas cannot be characterized by single-valued random variables. Taking the price of a stock on a given day for example, it is clearly unreasonable to use a single-valued data to decribe the stock price. If only single-valued data such as stock closing price or opening price are used, the fluctuation information in the process of stock trading is ignored and the resulting analysis results provided to decision-makers are also one-sided. Moreover, people will pay more attention to the data in a certain range, such as the temperature for a given day, instead of knowing the temperature at a certain time of one day, people care more about the maximum and minimum temperature of one day. In economic forecasting, economists mostly give a prediction range of economic growth rate. In the process of medical impact diagnosis, the impact result is usually a two-dimensional plan, and it is not a single value. Therefor, the interval-valued data are more appropriate and valuable in these cases because they provide more information. Thus it is necessary to consider the interval-valued statistical models and statictical inference problems.
Interval-valued random variables are special set-valued random variables. In mid twentith century, Aumann and Debreu first used set-valued mapping when studying economic phenomena. Aumann [1] gave the integral of set-valued random variables in 1965. Hiai and Umegaki [6] gave the concept of conditional expectation of set-valued random variables in 1978. Lyashenko [11,12] discussed the properties of set-valued random variables in Euclidean space, introduced the definition of set-valued Gaussian random variables, and gave the definition of variance for set-valued random variables. Vitale [16] studied the properties of distance. In 2005, Xuhua Yang and Shoumei Li [17] gave the definitions of variance and covariance for set-valued random variables under the distance, and obtained excellent properties. In 2008, Blanco et. al. defined the variance and studied the properties of interval valued random variables under a new distance in [2]. Hess [5], Papageorgiou [14,15], Shoumei Li et. al. [7,8,9] explored the convergence theory of set-valued random variables under different conditions. Molchanov in [13], Shoumei Li et. al. in [10] systematically summarized the theory of set-valued random variables. The above research promoted the development of set-valued random variable theory.
For interval-valued statistical models, Billard and Diday [3] established a linear regression model by using the midpoint of interval-valued random variables in 2000. In 2002, Billard and Diday [4] established linear regression models by using the two endpoints of interval-valued random variables respectively. In 2008, Lima Neto and de Carvalho [19] established linear regression models by using the center and radius of interval-valued random variables. In 2010, Lima Neto and de Carvalho [20] imposed non-negative constraints on the regression coefficients of radius on the basis of [19]. Wang [22] in 2012 proposed the complete information method to deal with the interval-valued linear regression model. Souza [23] introduced the parametrization method to linear regression model in 2017. In 2015, Wang Xun et. al. in [24] used set-valued theory to study linear regression problems, and gave the least square estimaor and the related properties. All the above research works are about the linear regression models of interval-valued random variables. The research on interval-valued spatial regression models and spatial error models are still blank.
As for the single-valued spatial error model, Anselin gave the maximum likelihood estimation method in [26] in 1988. Prucha proposed the generalized moment estimation method in [27] in 1999. In 2020, Yildirim [25] systematically summarized the methods of parameter estimation of spatial error model and proposed a new parameter estimation method based on likelihood equation. Many scholars have studied the classical linear regression and time series models of interval-valued random variables and achieved wonderful research results. We are considering the interval-valued spatial error models.
This paper attempts to extend the classical spatial error model to interval-valued case. The orginazation of this paper is as follows: in Section 2, we mainly introduce the notations and basic concepts of interval-valued random theory. In Section 3, we mainly discuss the interval-valued spatial error model, give the least square estimator of parameter obtain a series of digital characteristics and consistency of parameter estimation; In Section 4, the effectiveness of the method is illustrated by numerical simulation; In Section 5, gives an application of the model by studying the relationship between temperature and latitude in major cities of China.
2. Preliminaries on interval-valued random variables
2.1 distance and distance
Throughout this paper, we assume that is a complete probability space. is a d-dimensional Euclidean space, and are the norm and inner product in respectively, and the family of compact convex subsets in is . When , is abbreviated as , then is a family of nonempty bounded closed intervals in , that is
Where, and are the left and right endpoints of interval A respectively. In addition, interval A is also denoted as center radius form , where and are the center and radius of interval A respectively. For any set A, B, the addition and multiplication operations are defined as:
Interval is a special case of set, for , , the addition and multiplication operations are defined as:
Note that if set A does not degenerate to a point, . Then is not a linear space with respect to addition and multiplication.
For any set A, B in , the subtraction operation is defined as: . As a special case of set value, for interval , the definition of subtraction operation is derived as follows:
The support function of set is defined as
The distance is defined as follows: for any , the distance between set A and B is
where, is the unit sphere of , is a measure on , in particular, take on . Further, from Yang and Li [17], is a complete separable space. Specially, for interval and , the distance is
In particular, if ,
Call set-valued mapping be a set-valued random variable, if for any closed sets ,
Let denote the family of set-valued random variables in . The expression of distance between set-valued random variables and is
Similarly, for interval-valued random variables, the distance between interval value random variables and is
Further, from Yang and Li [17], is a complete separable distance space. In particular, if ,
2.2 Moment of set-valued random variables
The expectation of set-valued random variable is given by Aumann in [1],
where is the integrable selection set of F, that is,
Yang and Li in [17] introduced the variance and covariance of set-valued random variables based on distance. For set-valued random variable , the variance is defined as follows:
For two set-valued random variables , the covariance is defined as follows
If is an interval-valued random variable, then
The covariance of interval-valued random variables is
Through calculation, we can easily have
The variance and covariance of interval-valued random variables will be used in Section 3. For more information about the variance and covariance of set-valued random variables, readers can refer to [17].
3. Interval-valued spatial error model
Consider the classical spatial error model with the following form, where X is the explanatory variable, Y is the explained variable, is the unknown parameter, error term u, and are single point values, and W is a known space weight matrix, is a spatial autoregressive coefficient parameter,
the error item , is an identity matrix. By transforming, model (3.1) becomes,
denoted by
Model (3.2) can be expressed as
Now we extend the above classical single-valued model to interval-valued case.
Definition 3.1 If is the n-dimensional vector of interval-valued observations, is the single point valued design matrix, is a p-dimensional interval-valued parameter vector, then model (3.3), is called interval-valued space error model.
Next, we give the algorithm for multiplication of the matrix and interval values.
Definition 3.2 Let be the interval in , the interval value vector is multiplied by any dimensional matrix , the algorithm is defined as follows:
For the general single-valued linear model, the idea of the least squares estimation method is to minimize the sum of the squares of the residuals. We shall use the same mathematical idea here. For interval-valued spatial error model, the least square estimation of interval-valued unknown parameter is to minimize under the definition of distance
where and represent the center and radius of interval value m respectively. The above formula is the quadratic function of and , and , so there is a minimum value.
Next, calculate the partial derivatives of and respectively
that is,
The regular equation is:
where . The parameter estimation of the interval-valued spatial error model can be obtained by solving the regular equation. The following is the result about the rank of .
Lemma 3.3 If , then .
Proof Since
and
it has
The result is proved. □
Based on Lemma 3.3, suppose , then the estimator of interval-valued spatial error model can be obtained by solving the regular equation, which is shown in the following theorem.
Theorem 3.3 Under the condition of Lemma 3.3, the least squares estimation of interval-valued spatial error model is unique, which is denoted as
After obtaining the estimation form of unknown parameter , we then discuss the properties. First, consider the unbiasedness of .
Theorem 3.4 The least squares estimate is an unbiased estimate of .
Proof By Theorem 3.3,
The result is proved. □
For the interval-valued spatial error model, when , the covariance of can be obtained, as shown in the following result.
Theorem 3.5 If , , , then the covariance matrix of is
(1) ,
(2) ,
where represent the ith and jth element of respectively, and represent the ith, jth rows of matrix A respectively.
Proof For the ith and jth element of , if , it has
When , it has
The result is proved. □
Next we discuss the estimation of error and error variance. We mainly consider the expectation and covariance of interval-valued error estimation.
Theorem 3.6 The error estimator can be obtained from , and its expectation and variance are as follows:
(1)
(2),
where .
Proof
(1) Since
it has
(2) On the other hand,
Then the ith element of is
Thus when ,
where respectively represent the ith and jth rows of matrix A. When ,
The result is proved. □
Next, we consider the estimation of and . Denote .
Theorem 3.7 and are unbiased estimators of and respectively.
Proof Since is an idempotent matrix, it has
So
Then the estimator of is gived as
So
Since is an idempotent matrix, so
Furthermore
The estimator of is given as
So
The result is proved. □
In the following, we discuss the independence of and .
Theorem 3.8 and are independent, and are independent.
Proof Since
it can be seen that is the quadratic form of , is the linear form of , and
According to the independence theorem of quadratic form and linear form of normal variables, it is necessary to prove that they are independent of each other, that is, the product of linear part, variance part and quadratic part of normal variables is 0. Then
Similarly, is the quadratic form of , is the linear form of , and then
Thus and are independent, and are independent. □
Theorem 3.9 In the sense of distance, the sufficient condition for the strong consistentancy of for estimating is:
where, ,
Proof According to Theorem 3.4, is an unbiased estimate of , namely,
Moreover,
From it has
Thus
Therefore, in the sense of metric, is a strong consistent estimate of . □
4. Numerical simulation
In this part, the parameter estimation process of interval-valued spatial error model is further explored by numerical simulation. Based on the distance of the interval value, mean square error of the estimator is calculated to measure the goodness of the estimation.
Based on Equation 3.3, the interval-valued spatial error model in matrix form is expanded as follows:
where
is the unit matrix of dimension n, is the spatial autocorrelation coefficient. and W as the spatial weight matrix. Using the first-order adjacency method, assuming that n samples are arranged in one font, the spatial weight matrix can be written as follows:
The true values of the given interval value parameters are respectively. Then,
where, the error term follows the normal distribution, that is
First, take , the explanatory variable X is generated according to the rules of , and a set of values will be obtained in each simulation experiment.
The scatter point in Figure 1 is the data generated by a simulation experiment, and the two fitting lines are the corresponding interval value spatial error model function:
Repeat the above process for 500 times to obtain the average value of as follows:
Next, the mean square error MSE of the parameter estimation obtained by the model is calculated as one of the criteria to measure the goodness of the estimation. The calculation method is based on interval value distance:
By calculation, the MSE of samples are 0.0165 and 0.0006 respectively.
Similarly, set , repeat the above simulation process for 500 times respectively, and obtain the average value of and the sample mean square error MSE respectively. The specific simulation results are summarized in Table 1 and Table 2.
It can be seen from the simulation results that when , the obtained parameter estimation is very close to the real value. With the increase of sample size, the obtained estimation is closer to the real value, and the sample mean square error MSE is smaller and smaller.
5. Empirical analysis
5.1 Data preparation
In this paper, we select the index data of 31 cities from 31 provinces and autonomous regions in China (not considered temporarily due to geographical factors, Hong Kong, Macao and Taiwan) to illustrate the application of interval-valued spatial error model in practice. This section mainly studies factors such as latitude, maximum and minimum temperatures and temperature difference. Due to the vast territory of China, the temperature and latitude of different cities in a region are different. Therefore, the provincial capital cities in various regions are selected as the research object. The temperature data is the minimum and maximum temperature on July 8, 2021. The temperature data comes from Baidu weather forecast, and the latitude data comes from convenient query website( https://jingweidu.bmcx.com/ ), the data indicators are summarized in Table 3.
Before modeling and analysis, spatial autocorrelation test is carried out for the data. First, the spatial autocorrelation test is based on the spatial weight matrix. In this paper, the distance based representation is selected for the selection of the spatial weight matrix. The spatial weight matrix is obtained by the open source software geoda. After obtaining the spatial weight matrix, the matrix is standardized. Of course, there are many representation methods of spatial weight matrix, and distance representation can also be selected, which will not be repeated here. Spatial autocorrelation is based on the explained variable. The explained variable in this paper consists of the interval value of the lowest temperature and the highest temperature. Therefore, in the spatial autocorrelation test, the general linear model can be used to model the upper and lower endpoints of interval values respectively, and the center values of the highest and lowest temperatures can be used for spatial autocorrelation test.
One of the main methods of spatial autocorrelation test is to conduct global or local Moran’s I test. As can be seen from the table below, the global Moran’s I indexes are 0.4193 and 0.3013 respectively, and the tested p values are less than the significant level of 0.05. Therefore, the original hypothesis is rejected and it is considered that the maximum and minimum temperatures of 31 provinces, cities and autonomous regions in China have a certain spatial autocorrelation.
5.2 Parameter estimation of interval-valued spatial error model
After data preparation and spatial autocorrelation test, the interval-value spatial error model is established. Among them, the dependent variable is air temperature, the interval value data is composed of the lowest and highest air temperatures, and the explanatory variable is latitude. The parameter estimation is carried out by the parameter estimation method of interval-value spatial error model in Section 3. It is assumed that the air temperature and latitude conform to the interval-valued linear model, that is:
As the method mentioned in Section 4, by the minimum temperature and the maximum temperature we can obtained () respectively. Then take the average value as the () of the interval-valued spatial error model. GeoDa software is used to obtain the spatial weight matrix of 31 regions. Take the inverse square of the matrix elements, and then standardize to obtain the final spatial weight matrix..
The parameter estimation results are shown in Table 5, which shows that:
The final interval-valued spatial error model is:
In Figure 4, the abscissa and ordinate are latitude and temperature (maximum temperature and minimum temperature) respectively, it can be seen that the temperature and latitude of the 31 cities in China are negatively correlated. With the increasing of latitude, the temperature has a certain downward trend. At the same time, it can also be seen that the temperature difference (the difference between the maximum temperature and the minimum temperature) tends to expand with the increase of latitude, which is also consistent with the large diurnal temperature difference in northwest and northeast of China. And small temperature difference between day and night in central region of China, southeast and southwest of China.
Acknowledgments
This work is supported by the National Social Science Fund of China No.19BTJ017.
References
- Aumann R J. Integrals of set-valued functions[J]. Journal of Mathematical Analysis and Applications, 1965, 12(1): 1-12.
- Blanco Fernandez A, Corral N, Gonzalez-Redriguez G, Lubiano M A. Some properties of the dk-variance for interval-valued sets[J]. 2008,D.Dubois et al. (Eds.): Soft Methods for Hand. Var. And Imprecision,ASC48:331-337.
- Billard L, Diday E. Regression analysis for interval-valued data. Conference of the International Federation of Classifification Societies[C]. Springer-Verlag, 2000: 369-374.
- Billard L, Diday E. Symbolic regression analysis[J]. Studies in Classification Data Analysis and Knowledge Organization, 2002, 281- 288.
- Hess C. On multivalued martingales whose values may be unbounded: martingale selectors and Mosco convergence[J]. Journal of Multivariate Analysis, 1991, 39: 175-201. [CrossRef]
- Hiai F, Umegaki H. Integrals, conditional expectations, and martingales of multivalued functions[J]. Journal of Multivariate Analysis, 1977, 7(1): 149-182. [CrossRef]
- Li S, Li J, Li X. Stochastic integral with respect to set-valued square integrable martingales [J]. Journal of Mathematical Analysis and Applications, 2010, 370: 659-671. [CrossRef]
- Li S, Ogura Y. Convergence of set valued sub- and supermartingales in the KuratowskiMosco sense[J]. The Annuals of Probability, 1998, 26: 1384-1402.
- Li S, Ogura Y. Convergence of set-valued and fuzzy-valued martingales[J]. Fuzzy sets and systems, 1999, 101: 453-461. [CrossRef]
- Li S, Ogura Y, Kreinovich V. Limit Theorems and Applications of Set-Valued Random Variables[M]. Netherlands: Kluwer academic publishers(Springer), 2002.
- Lyashenko N N. Limit theorems for sums of independent compact random subsets of a Euclidean space[J]. Journal of Mathematical Sciences, 1982, 20(3): 2187-2196. [CrossRef]
- Lyashenko N N. Statistics of random compacts in Euclidean space[J]. Journal of Mathematical Sciences, 1983, 21(1): 76-92. [CrossRef]
- Molchanov I S. Theory of Random Sets[M](Springer), 2005.
- al Papageorgiou N S. On the theory of Banach space valued multifunction. 2. set valued martingales and set valued measures[J]. Journal of Multivariate Analysis, 1985, 17: 207- 227. [CrossRef]
- Papageorgiou N S.On the conditional expectation and convergence properties of random sets[J]. Transactions of the American Mathematical Society, 1995, 347: 2495-2515.
- Vitale R. Lp metrics for compact, convex sets[J]. Journal of Approximation Theory, 1985, 45(3): 280-287.
- Yang X, Li S. The Dp-metric space of set-valued random variables and its application to covariances[J]. International Journal of Innovative Computing, Information and Control, 2005, 1: 73-82.
- Zhang Wenxiu, Li Shoumei, Wang Zhenpeng, Gao Yong. Introduction to set-valued stochastic processes[M].Beijing: Science Press,2007.
- Lima Neto E, de Carvalho F, Centre and range method for fitting a linear regression model to symbolic interval data[J].Computational Statistics and Data Analysis,2008:52, 1500-1515. [CrossRef]
- Lima Neto E, de Carvalho F, Constrained linear regression models for symbolic interval-valued variables[J], Computational Statistics and Data Analysis, 2010:54,333-347. [CrossRef]
- Tang Nana. Linear regression and autoregressive time series models with constraints [D], Beijing University of technology,2017.
- Wang H, Guan R, Wu J. Linear regression of interval-valued data based on complete information in hypercubes[J]. Journal of systems science and systems engineering (English Edition),2012, 21(4): 422-442. [CrossRef]
- Souza L, Souza R, Amaral G, Filho T. A parametrized approach for linear regression of interval data[J]. Knowledge-Based Systems, 2017, 131: 149-159. [CrossRef]
- Wang X, Li S, Denoeux T. Interval-valued linear model[J]. International journal of computational intelligence systems, 2015, 8(1): 114-127.
- Yildirim V, Kantar Y M. Robust estimation approach for spatial error model[J]. Journal of Statistical Computation and Simulation, 2020, 90(3):1-21. [CrossRef]
- Anselin L. Spatial Econometrics: Methods and Models [M],1988.
- Prucha K I R. A generalized moments estimator for the autoregressive parameter in a spatial model[J]. International Economic Review, 2010, 40(2):509-533. [CrossRef]
Figure 1.
numerical simulation of interval valued spatial error model
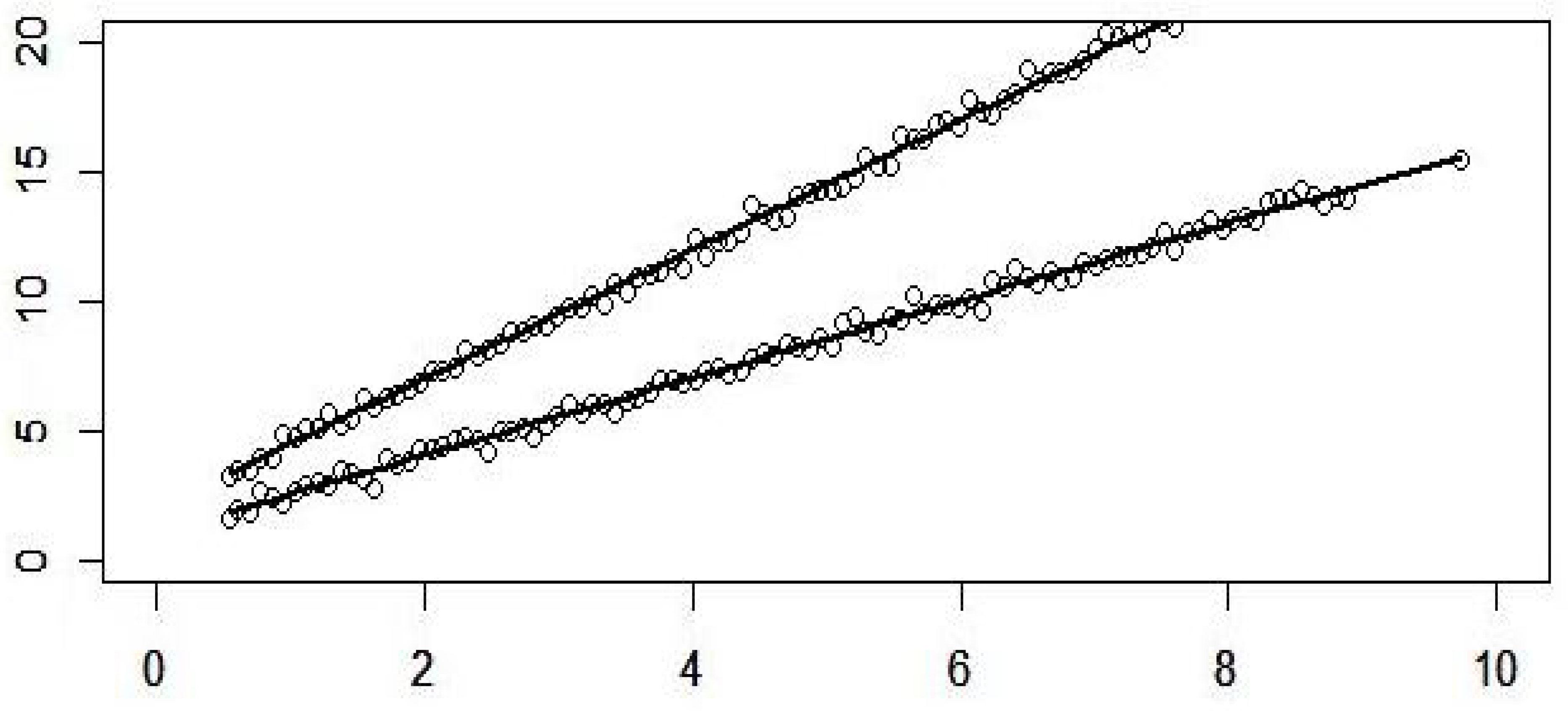
Figure 2.
Scatter plot of global Moran’s I coefficient of minimum temperature
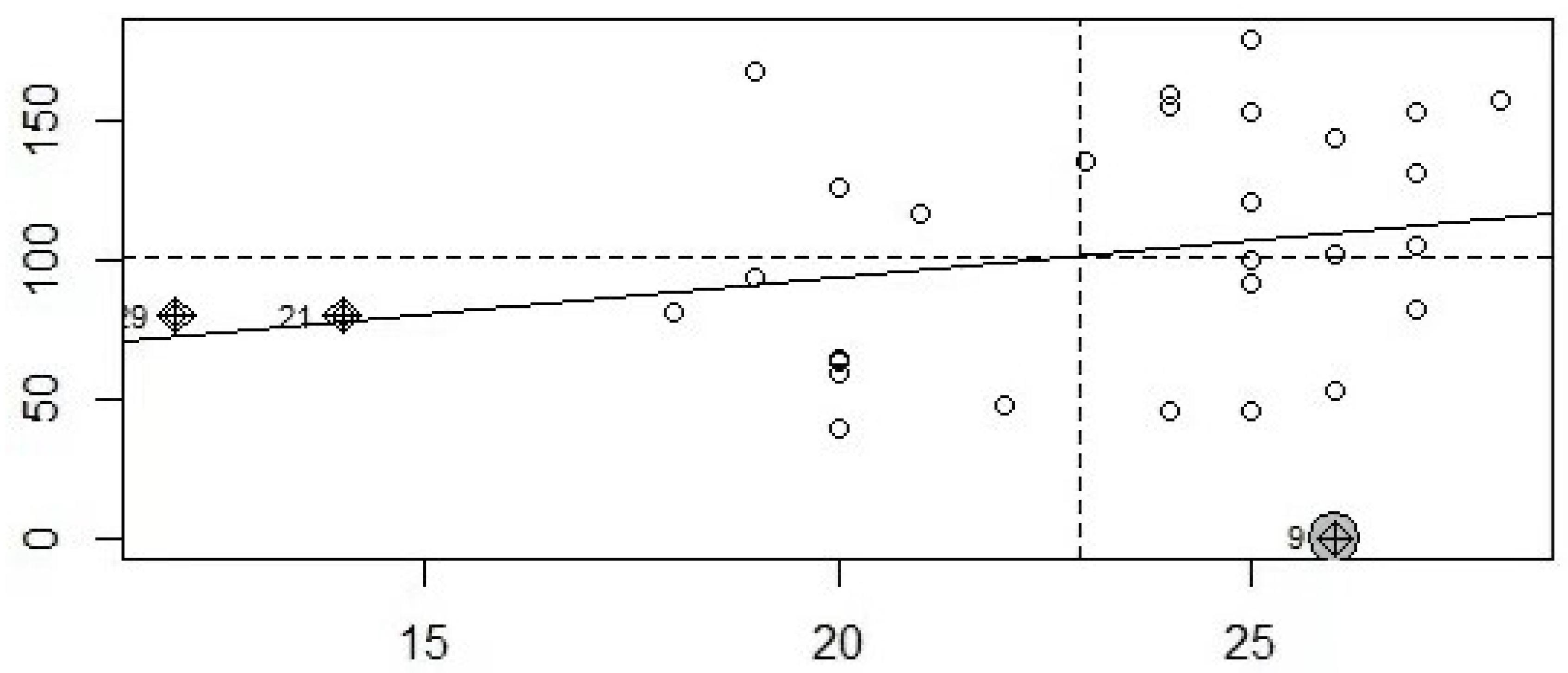
Figure 3.
Scatter plot of global Moran’s I coefficient of maximum temperature
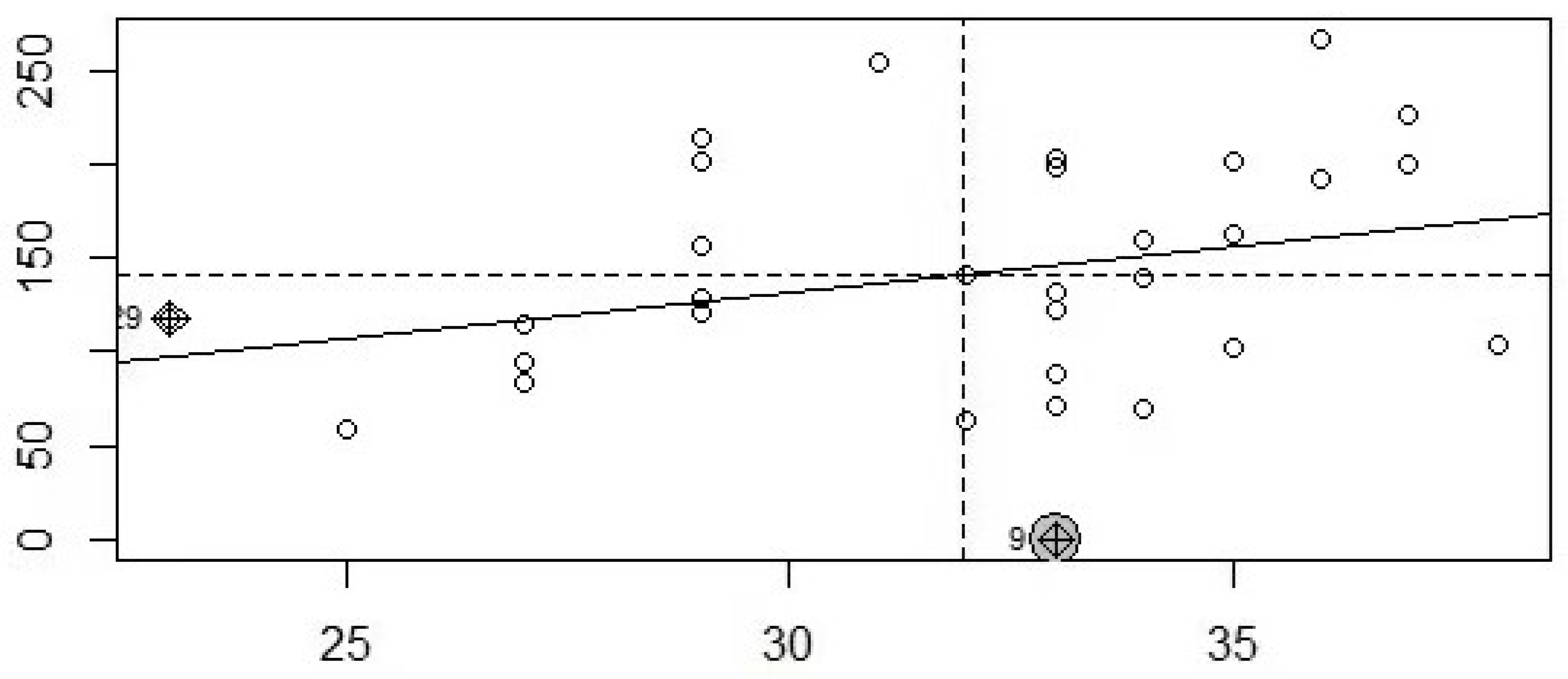
Figure 4.
Interval value spatial error model of temperature and latitude
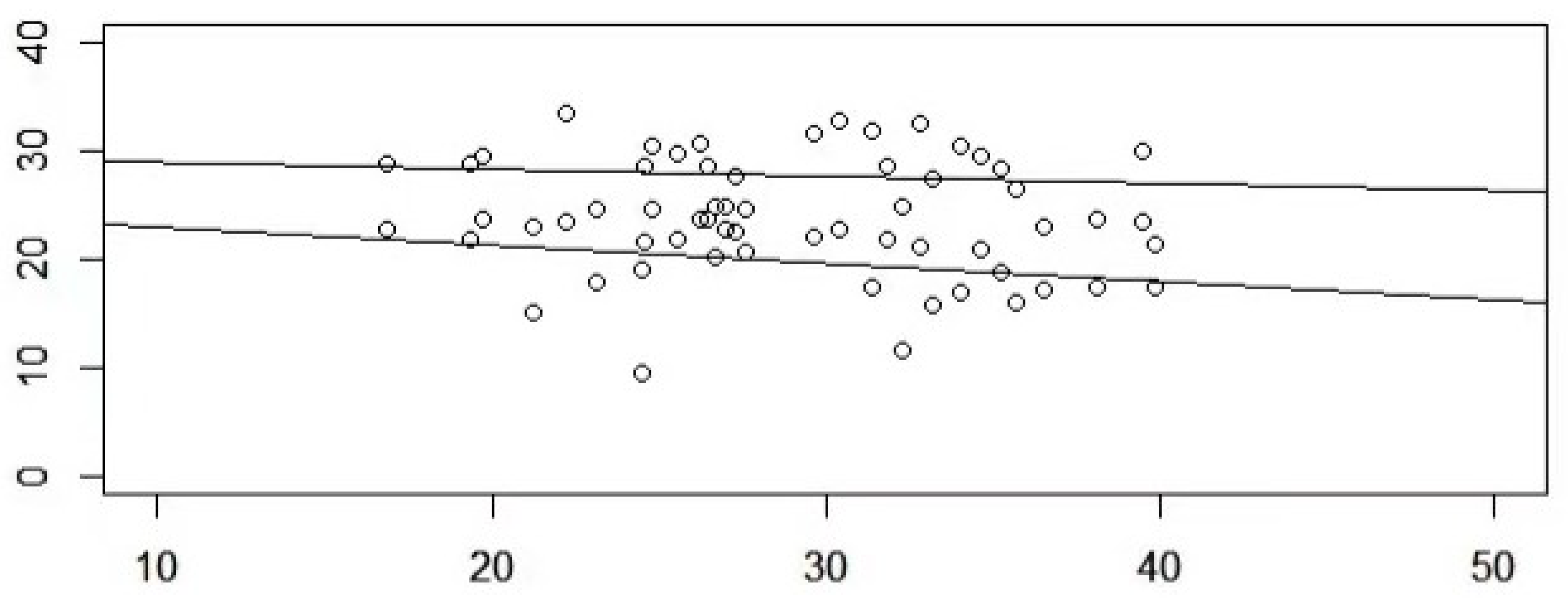

Table 1.
Average of
| n=100 | n=200 | n=300 | |
| [1.0004,2.0019] | [1.0023,1.9991] | [0.9988,2.0032] | |
| [1.4999,2.4999] | [1.4998,2.5002] | [1.5001,2.4999] |
Table 2.
Sample mean square error MSE
| n=100 | n=200 | n=300 | |
| 0.01651 | 0.00723 | 0.00462 | |
| 0.00060 | 0.00007 | 0.00002 |
Table 3.
Data and indicators
| Region | Minimum temperature | Maximum temperature | Latitude |
| Hefei | 24 | 29 | 31.79 |
| Beijing | 22 | 33 | 40.22 |
| Chongqing | 25 | 34 | 29.4 |
| Fuzhou | 27 | 38 | 26.05 |
| Lanzhou | 20 | 36 | 36.1 |
| Guangzhou | 27 | 34 | 23.16 |
| Nanning | 25 | 33 | 22.78 |
| Guiyang | 21 | 29 | 26.68 |
| Haikou | 26 | 33 | 20.02 |
| Shijiazhuang | 24 | 37 | 38.04 |
| Haerbin | 20 | 25 | 45.55 |
| Zhengzhou | 26 | 37 | 34.72 |
| Wuhan | 27 | 33 | 30.58 |
| Changsha | 25 | 33 | 28.26 |
| Nanjing | 26 | 29 | 31.33 |
| Nanchang | 28 | 35 | 28.55 |
| Changchun | 20 | 27 | 43.83 |
| Shenyang | 20 | 27 | 41.81 |
| Huhehaote | 19 | 31 | 40.81 |
| Yinchuan | 20 | 35 | 38.47 |
| Xining | 14 | 29 | 36.65 |
| Xian | 25 | 36 | 34.23 |
| Jinan | 25 | 33 | 36.55 |
| Shanghai | 26 | 32 | 31.41 |
| Taiyuan | 19 | 32 | 37.94 |
| Chengdu | 23 | 29 | 30.66 |
| Tianjin | 24 | 34 | 39.72 |
| Wulumuqi | 25 | 33 | 43.36 |
| Lasa | 12 | 23 | 29.65 |
| Kunming | 18 | 27 | 24.89 |
| Hangzhou | 27 | 35 | 30.21 |
Table 4.
Global Moran’s I test results
| Statistic | Minimum temperature | Maximum temperature |
| Moran’s I | 0.4193 | 0.3013 |
| p-value | 0.000014 | 0.000985 |
Table 5.
Interval valued parameter estimation results
| [24.7501,29.5478] | [-0.1681,-0.0619] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



