Submitted:
22 December 2023
Posted:
26 December 2023
You are already at the latest version
Abstract
In this paper, we will use the maximum likelihood estimation (MLE) and the Bayes methods to perform estimation procedures for the reliability of stress-strength ℜ=P[X>Y] based on independent adaptive progressive censored samples that were taken from the Chen distributions. An approximate confidence interval of ℜ is constructed using a variety of classical techniques, such as the normal approximation of the MLE, the normal approximation of the log-transformed MLE, and the percentile bootstrap (Boot-p) procedure. The Bayesian estimation of ℜ is obtained based on the balanced loss function, which comes in two versions here, the symmetric balanced squared error (BSE) loss function and the asymmetric balanced linear exponential (BLINEX) loss function. When estimating ℜ using the Bayesian approach, all the unknown parameters of the Chen distributions are assumed to be independently distributed and to have informative gamma priors. Further, a mixture of Gibbs sampling algorithm and Metropolis-Hastings algorithm is used to compute the Bayes estimate of ℜ and the associated highest posterior density credible interval. In the end, simulation research are used to assess the general overall performance of the proposed estimators and a real data set is provided to exemplify the theoretical results.
Keywords:
Chen distribution
; Stress-strength reliability
; Maximum likelihood estimator
; Delta method
; Bootstrap
; Bayes estimator
; Markov Chain Monte Carlo
; Adaptive progressive censored
MSC: 62N02; 62F10; 62F15
1. Introduction
Modern industrial systems are frequently created with exacting criteria of quality. There are many different methods used to improve system reliability. A redundant structure is a method for further developing system reliability. For instance, a cloud storage server typically has a minimum of one backup to assist users in protecting sensitive data. In the same vein, a commercial aircraft is equipped with a backup engine for use in the event of unexpected malfunctions. In many industrial products, such as production systems, pump systems, power generation systems, etc. The reliability of systems is impacted by a number of factors when they are added to be used within the actual environment, including operating environments, outdoor shocks, operators, and so on. One way to look at these factors is as stresses the system experiences while it is operating. In such situations, the stress-strength (S-S) model is normally used to evaluate the parallel machine’s reliability. The S-S version, first offered through Birnbaum and McCarty (1958), is one of the most widely used reliability fashions. For this model, it fails if its stress exceeds its strength. Therefore, device reliability can be described as the probability that the device’s strength exceeds its stress. That is expressed mathematically in the form , where X stands for the stress variable and Y for the system’s strength. Numerous statistical issues, including those involving quality control, engineering, clinical, and biostatistics, have found use for the S-S model. In the context of medical research, for instance, the variable ℜ quantifies the efficacy of a novel treatment in relation to its control; in this case, X and Y stand for the new treatment’s and the control’s respective effects. Similar to this, in engineering studies, ℜ stands for the likelihood that a system component’s strength (Y) will exceed the system’s external stress (X). An overview of all the techniques and consequences related to the S-S version is provided by Kotz et al. (2003).
Evaluating the reliability of the S-S model using different statistical techniques has been the focus of a lot of research lately. For example, Gittani et al. (2015) presented point and interval estimates of the reliability of the S-S model under a Lindley power distribution. They used maximum likelihood (ML) estimators as well as parametric and nonparametric bootstrapping techniques. Using recorded samples from two parameter generalized exponential distribution, Asgharzadeh et al. (2017) estimated the S-S model . The process of establishing a generalized inference on the S-S model based on the unknown parameters of the generalized exponential distribution was carried out by Wang et al. (2018). With the growing interest in this system and the importance of Chen distribution, which has become evident in the past two decades, in order to obtain point and interval estimates for a multicomponent ℜ of an S-out-of-j system, Kayal et al. (2020) used classical and Bayesian methods under the assumption that both the S-S variables follow a Chen distribution with a common shape parameter. The reliability estimation of ℜ when the failure times are progressively Type-II censored and both the latent strength and stress variables originate from the inverse exponential Rayleigh distribution was discussed by Ma et al. (2023). Moreover, Agiwal (2023) developed a Bayesian estimation method to estimate ℜ where X and Y are inverse Chen random variables. Recently, Sarhan and Tolba (2023) have given attention to the estimation of ℜ for step-stress partial acceleration life testing, when the stress and strength additives are independent random variables generated from Weibull distributions with specific shape and scale parameters.
To gather information about the lifetime and reliability characteristics of products, various units are typically used during life testing experiments. In actuality, it is sometimes not possible to finish experiments until all failures are noted due to time and financial constraints. To increase test efficiency in this regard, several censoring schemes and testing techniques are suggested. In practise, the most commonly used methods in the literature are type I and type II control. According to these methods, life tests terminate or stop after a specified time or a specified number of failures, respectively. Through various life testing experiments, there are many different challenges that experimenters face in order to be able to control the testing time as well as keep the experimental units intact, so stopping the experiment before all experimental units fail is one of the solutions to achieve these goals. This is done through the use of control structures that rely on deferring some active devices from the experiment. The progressive censoring system is considered one of the experimental designs commonly used in recent years, as through this system, survival units are arbitrarily removed from the test at any stage of the test. As a result, it is more adaptable and efficient than conventional censoring techniques. Over time, numerous models of progressive censorship have been discussed. According to this model, censoring has been divided into two parts: when the experiment ends after a specific time, this section is called progressive censoring of the first type, while the second part is progressive censoring of the second type, and in this section the experiment stops after a predetermined number of failures appear. Through both sections, experimenters will be able to freely remove test units during the experiment at non-terminal times. Whithin a type-II progressive censoring scheme, to test the life of units, the experimenter puts n units through the test at time zero, and only m units that fail completely are observed. With the primary failure, which may take the shape , is randomly eliminated from the final devices within the test. At the time of the second failure , the experimenter selects a random number of final units, let it be , and they are removed from the experiment. Finally, in the same sequence, at the time of the mth failure, the experimenter removes all remaining units from the experiment, where
When test units are highly reliable, the long testing time represents one of the main drawbacks of the progressive type-II censoring model. For this reason, Ng et al. (2009) suggested an improved model (see Figure 1) that allows for adjustments to the censoring scheme throughout the experiment. This improved model is known in the literature as the adaptive type-II progressive censoring model. The technique of this model can be explained as follows.
(1) First, the effective sample size m, the number of units to be tested n, the progressive censoring scheme () and the time point T must be determined in advance before the beginning of the experiment.
(2) As indicated by the preceding progressive censoring strategy, units are arbitrarily eliminated from the test at the moment of the first failure . units are also arbitrarily removed from the test at the moment of the second failure, , and so on.
(3) When the mth failure occurs before time T (i.e., ), the test ends at this point with the unchanged progressive censoring scheme (), and we will have the standard progressive type-II censoring. with the unchanged progressive censoring scheme (). Where
(4) In the event where , where and is the Jth failure time occur before the time T, then no surviving item will be removed from the test by placing , and at the time all remaining units are removed, where . Because of this, the progressive censoring scheme that is being used in this instance is ().
(5) After running the previously specified test, we may get the following adaptive progressive type-II censored observation data
More works presented on the adaptive type-II progressive censoring model, we referred to Almuqrin et al. (2023) and the references contained within it.
Many scientific and engineering applications use a variety of distributions, including gamma, exponential, Rayleigh, normal, Weibull, and others, to model the lifetime characteristic of products. Among the various probabilistic models, bathtub-shaped failure rate distributions have drawn a lot of attention. These models are highly helpful for studying complex systems or sub-systems and for making decisions, particularly when the target product’s entire life cycle needs to be modelled. Regarding this, numerous authors have proposed and discussed in literature a variety of probability models featuring bathtub-shaped failure rate functions. The bathtub-shaped hazard function offers a suitable conceptual model for the lifespan of humans as well as certain mechanical and electronic products. Xie and Lai (1995), Wang (2002), and Xie et al. (2002) are only a few of the writers whose articles contain references to the earlier comprehensive work on parametric probability distributions with bathtub-shaped failure rate function. The Chen distribution is considered one of the most important distributions that contain bathtub curves.
Chen (2000) introduced a distribution that is often called the Chen or bathtub-shaped distribution with two parameters in the literature. It is a significant probability model that is frequently applied to lifetime analysis. This probability model is truly crucial for studying physical events for which the hazard rate function predicts bathtub-shaped behavior. It gives complex systems whose failure rates vary over time a flexible way to be modelled. One of the primary features of the Chen distribution is its bathtub-shaped failure rate curve, which has three unique phases (decreasing, constant, and ascending) and may be used to describe a wide range of systems. This curve has a wide range of potential applications, including researching the efficacy of medications or therapies across various age groups. It can be helpful when analyzing mortality data as well. When modeling the reliability of items or systems that are prone to wear and tear, one might employ the Chen distribution. The following are the cumulative density function (CDF) and probability density function (PDF) for the Chen distribution:
and
Here, both and are known as shape parameters. As for the hazard rate function (HRF) for the Chen distribution, it is given in the following form
The Chen distribution’s HRF (3) has a bathtub form with a minimum at , when . It increases when . This distribution may be used to describe many kinds of failure-time data quite well since it is fairly adaptable. For example, if we select in (1), this distribution further transforms into a Gompertz distribution with parameters 1 and . When , the exponential power distribution results. If Chen() and we take , the distribution turns into a Weibull distribution with parameters and .
Compared to other two-parameter models, this distribution stands out due to a few key features, including a bathtub-shaped hazard rate function and closed-form joint confidence regions and shape parameter confidence intervals. As a result, researchers have paid close attention to this distribution in recent years due to its broad applicability in simulating a variety of real-life phenomena. For a brief review, Using progressive type-II censoring, Wu (2008) calculated the MLEs of the unknown parameters and approximated their intervals. Rastogi, Tripathi, and Wu (2012) achieved the Bayesian inference of this distribution against various symmetric and asymmetric loss functions. Using the likelihood and Bayes approaches, Sarhan et al. (2015) determined the reliability where X and Y are two independent r.v.s. with a two-parameter Chen distribution. Tarvirdizade and Ahmadpour (2016), and Raqab et al. (2018) have studied the estimation of the S-S reliability for the two-parameter Chen model based on upper record values. Using data that was progressively censored, Kayal et al. (2017) looked at the Bayesian one and two sample prediction. Ahmed et al. (2020) observed the Chen distribution for a competitive risk model with progressive type-II censored data. The S-S reliability of this lifespan distribution was investigated by Shoaee and Khorram (2015) using type-II progressively censored data. According to recent observations by Wang et al. (2022) the multicomponent system is reliable when both stress and strength follow Chen distribution.
One significant phenomenon in life testing studies that we mention is the S-S models. While there is a large body of literature on the inference processes of S-S models under full samples, little emphasis has been given to the case of censored data, specifically type II adaptive progressive censored data. From this, our objective became clear. This article’s primary goal is to use adaptive progressive type censored data to estimate the S-S Reliability ℜ, in the case when X and Y are Chen distributions’ independent variables.
The following describes the paper’s methodology: First, we’ll estimate ℜ using the ML technique. Next we will discuss the asymptotic confidence interval of ℜ. The delta approach is used to estimate the variance of the ℜ estimator in order to achieve the required interval. Second, the balanced loss function is taken into account in order to compute Bayesian estimates of ℜ, with special attention paid to the balanced square error (BLINEX) loss function (BSEL) and the balanced exponential loss function. In the last ten years, the Markov chain Monte Carlo technique has become a popular solution to the Bayesian approach to deal with the problem of many integrals arising in the posterior distribution. Using this technique, we calculate the Bayes estimates and credible intervals for ℜ. A comprehensive numerical comparison of the presented estimates with respect to means squared errors, coverage probabilities, and confidence lengths is carried out.
The structure of the paper is as follows after this introduction. Section 2: Here, we give the expression for ℜ of Chen distribution. The ML estimate of ℜ and the associated approximate confidence interval as will as boot-p confidence interval are also discussed. In Section 3, we derive the Bayesian estimate ℜ and the its credible interval using the Gibbs technique within Metropolis-Hastings. In Section 6 we present an examination of an actual data set. In Section 5, we do a Monte Carlo simulation analysis to compare the suggested values of ℜ. In Section 6, we finally bring the article to a close.
2. Maximum Likelihood Estimation of ℜ
Given independent strength and stress random variables X and Y that have parameters () and () correspondingly, according to Chen distributions, the reliability of the component is defined as
It is worth noting that the evaluation depends on whether this probability () is less than or greater than . The result is evaluated and interpreted as follows:
- The lifetime of the two products or any two units is equal if .
- If , the lifetime of Unit/Product 1 exceeds that of Unit/Product 2. For example, if , Unit/Product 1 is better than Unit/Product 2 with a probability of 70%.
- If ℜ < 0.5, the lifetime of Unit/Product 2 exceeds that of Unit/Product 1. For example, if , Unit/Product 2 is better than Unit/Product 1 with a probability (). The adaptive type-II censored sample is used in this part to determine the MLE of ℜ.Since ℜ is independent of the common shape parameter in this case, obtaining ℜ is a straightforward process using Equation (4) provided that the values of the parameters and are known or estimated using different estimation methods.
Suppose is an adaptive type-II progressive censored sample from Ch() with the scheme {} such that . Additionally, be an adaptive type-II progressive censored sample from Ch() under the scheme {} such that .
According to the two independent random samples X and Y, the likelihood function (LF) is provided by
where
and
Wu (2015) provides the likelihood function (5) for ℜ in the progressive censored sample case, which is produced in the situation . Moreover, the likelihood function for ℜ in the complete sample is reached when and , as reported by Sarhan et al. (2015).
The following may be used to represent the LF for the observed sample data, X and Y, using Equations (1), (2), and (5):
Ignoring the additive constants and , the log-LF, say = () is given by:
The first order derivatives of the log-likelihood function, with respect to , and are
and
From (8) and (9), we obtain
where,
and
In the case that the parameter is known, the MLE of and can be obtained directory from the Equation (11). But, when the all parameters are unknown, the parameter will be estimated by maximizing the profile log-likelihood function , with respect to by solving the following nonlinear equation:
where
and
This non-linear Equation (14) has a fixed point solution at , which may be found by using the following straightforward iterative method
Where, The kth iteration of is denoted by . The process of iteration ought to be terminated when | is small enough.
Equation (11) may now be used to get and as and , respectively, by using . An easy way to obtain MLE of ℜ is to use the invariant properties of MLEs. Afterwards, is obtained from (4) as follows:
2.1. Asymptotic Confidence Interval of ℜ
Here, we construct asymptotic confidence interval (ACI) of ℜ using the asymptotic distribution of MLE ℜ for which we also require asymptotic distribution of . In this regard, the Fisher information matrix is written as
and from the log-likelihood function (7), we have the second partial of with respect to , and which is illustrated in the following
and
The above expectation is not easily expressed precisely, as is evident. Consequently, instead of using expectation, the observed Fisher information matrix will be employed. Given an MLE of () as (), the observed Fisher information matrix may be expressed as follows:
In accordance with this, the following is an estimated approximate covariance matrix of ():
We must determine the variance of the ℜ in order to calculate the asymptotic confidence interval. Using the delta approach, we can determine the approximate estimate of the variance of ℜ. Confidence intervals for functions of MLEs may be calculated generally using this technique, see Greene (2000).
Let
where
Next, the approximation of Var() is provided, as follows:
where represents matrix transpose. Thus , and an approximate confidence interval for ℜ is obtained from these data and is provided by
where the percentile of the standard normal distribution with a right-tail probability (), as stated in the literature in many references, is represented by .
2.2. Bootstrap Confidence Interval of ℜ
A small sample size clearly degrades the performance of the confidence interval based on the asymptotic results. We create confidence interval for this purpose by utilizing the percentile parametric bootstrap approach; for more information, refer to Efron and Tibshirani (1994). The procedure to determine the percentile Boot-p confidence interval of ℜ is shown below.
- Step 1:
- The initial values are established for the following: , , , , , , , , , and progressive censoring schemes () and ().
- Step 2:
-
Using the previous initial inputs, independent samples () and () are generated from Ch() and Ch(), respectively. The procedures listed below are what we use to create the adaptive progressively type II censored data sets from Chen lifetimes (see to Kundu and Joarder (2010)).
- i)
- From a typical uniform distribution , generate independent and identical observations of size .
- ii)
- Establish for .
- iii)
- For each , evaluate . Thus, the progressive Type-II censored sample {} originates from the distribution.
- iv)
- To compute the sample data from () of the progressive type-II censoring scheme, given the starting values of and , one may set , where .
- v)
- Determine the value of , which satisfies , and remove the sample
- vi)
- Using the truncated distribution , get the first order statistics (), where the sample size is
- vii)
- Using steps i-vi, we generate two adaptive progressive type-II censoring data () and () from Ch(), Ch(), respectively.
- Step 3:
- The generated data is used to calculate the MLEs for , , , and then using Equation (19), the MLE for ℜ is estimated.
- Step 4:
- Bootstrap samples from Ch() and Ch() were created using the preceding stages. These samples may be expressed as () and ().
- Step 5:
- With the bootstrap samples provided, calculate bootstrap estimates , , and . Subsequently, compute the bootstrap estimate of ℜ, say
- Step 4:
- Steps 3 and 4 can be repeated times to provide numbers of ℜ’s bootstrap estimators, let it be , , 2, , .
- Step 5:
- After the preceding step, the bootstrap estimates of ℜ need to be ordered as follows: .
- Step 6:
- For the variable ℜ, the two-sided bootstrap confidence interval is provided
3. Bayes Estimation of ℜ
The Bayes estimator and associated credible interval of ℜ are constructed in this section.
3.1. Prior and Posterior Distributions
Because of its simplicity and ease of computation, the gamma prior is taken into consideration for the parameter in a variety of lifetime models as an informative prior. It is a distribution with a peak close to zero and a tail that extends to infinity. This means that we can actually simplify the solution to the posterior distribution. Consequently, it is believed that we have separate gamma priors for the unknown parameters , and . Mathematically, the independent prior distributions will take the following forms
In this case, the values of , , , , and are selected to represent past understanding of , and . It should be noted that if the hyper-parameters are taken to be zero (), the gamma prior reduces to non-informative form.
The joint prior distribution and the likelihood function are used in the Bayesian technique to create the posterior distribution of any parametric space (). Thus, the following joint posterior density of , and is derived from Eqs. (6), and (25)-(27)
where, and are given by (12) and (13), respectively. Below is the definition of the standardizing constant A:
In decision theory, defining a loss function is essential to determine the optimal estimator and utilize it to express the lowest statistical error (risk) connected to each potential estimate. To make the computations easier, a squared error loss function is used by several writers to generate Bayesian estimates. However, this loss function’s primary critique is that it gives equal weight to overestimation and underestimating, which is at odds with real-world practises. In the literature, a number of asymmetric loss functions have been put out to deal with this situation. We mention the linear exponential (LINEX) (Varian (1975) and generalized entropy (Calabria and and Pulcini (1996)) loss functions as some of the asymmetric loss functions that are used in the literature.
To calculate the posterior distribution of ℜ, we have the following transformation: . Then from (4), we have The posterior distribution of ℜ and Z can be calculated by the following formula:
In the above formula, J is called Jacobian and is calculated as follows
In the next subsection, we will focus on a more general loss function, which is the balanced loss function to estimate ℜ via Bayesian approach. It includes several symmetric and non-symmetric loss functions. Both the balanced LINEX (BLINEX) and balanced squared error (BSE) loss functions may be obtained from it.
3.2. Balanced Loss Function
A generalized loss function known as the balanced loss function (refer to Jozani (2012)) has the following form:
where represents an arbitrary loss function, a previously chosen "target" estimator of is , which can be determined by maximum likelihood estimator or any other estimator. The weight has values in the interval .
Selecting allowed (29) to be simplified to the balanced squared error (BSE) loss function, which Ahmadi et al. (2009) utilized in the following form:
and the associated Bayes estimate for the unidentified parameter is provided by
The loss function for balanced LINEX (BLINEX) with shape parameter c () may be derived by selecting ; (Zellner (1986)).
Thus, under the BLINEX loss function, the Bayes estimate of is provided by
Keep in mind that balanced loss functions are more widely applicable.; as special cases, they consist of the MLE and the symmetric and asymmetric Bayes estimates. Eq. (34) may be used to get the ML estimator for , as well as the squared error loss function (symmetric) when . Furthermore, the Bayes estimator under the BLINEX loss function in (35) reduces to MLE when , and when , it leads to the LINEX loss function (asymmetric) situation.
Based on the BSE loss function, the Bayes estimator for ℜ may be obtained from (34) by
and from (36), which yields the Bayes estimator for ℜ under the BLINEX loss function
It is well known that assuming BSE loss function, the Bayesian estimator of ℜ can be obtained also from (30) by
Additionally, the Bayesian estimator of ℜ under BLINEX loss function is given as follows:
is given by (30).
Since it is often difficult to discover the analytical solution, the Bayes estimators in Equations (37)–(40) require many integrations, for which computational and numerical approaches are required to confront the integrals. Therefore, Markov chain Monte Carlo (MCMC) approach considered to approximate these integrations. Metropolis-Hastings (M-H) algorithm will be implemented to compute the Bayes estimates and credible intervals width of ℜ under BSE and BLINEX loss functions. The section that follows goes into further depth about these techniques.
3.3. Bayes Estimation Via MCMC Approach
Sampling from the posterior is done directly for complex functions using the MCMC method, which was suggested by Robert and Casella (2004). Using the preceding value from the specified function, this creates a chain or sequence of random samples. Thus, sampling methodology is the foundation of this process in order to compute and encounter the high dimensional function. The Gibbs sampler and the Metropolis-Hastings (MH) algorithm are two main techniques utilized in this procedure. The Gibbs sampler, initially introduced by Casella and George (1992), is among the most precisely described MCMC sampling algorithms. Wherein the conditional posterior distribution, a lower dimension functional form, is obtained from the high dimensional parametric model. The algorithm known as Metropolis-Hastings (MH), which was created by Metropolis (1953) and then expanded upon by Hastings (1970), produces samples based on any given probability distribution function. It is more straightforward to use in high dimensions, applicable without an envelope, and has a normalizing effect compared to other iterative techniques. The Gibbs approach must decompose the joint posterior distribution into full conditional distributions for each parameter in the model. Computing Bayesian estimates of , as well as any function of , requires sampling from each of these conditional distributions.
Specifically, (28) shows that it is not possible to get explicit forms for the marginal posterior distributions for each parameter. It can be demonstrated that given , , and data, the conditional density of is given by
given , and data, the conditional density of is
and correspondingly, given , , and data, the conditional density of is
Evidently, samples of and using (41) and (42), respectively, are readily produced with any procedure for producing gamma. Unfortunately, standard techniques cannot sample the conditional posterior distribution of (Eq. (43)) directly since it cannot be analytically reduced to a known distribution. It seems like a normal distribution based on its plot. In order to get random numbers from this distribution, we employ the Metropolis-Hastings technique with a normal proposal distribution. So, to sample from (43) we first produced a proposal value from a normal distribution Var, where Var represents the variance of and is the current value of .
The following procedures illustrate how the Metropolis-Hastings algorithm functions within Gibbs sampling to simulate posterior samples:
- (1):
- For given begin with a first estimate (.
- (2):
- Assign j to 1.
- (3):
- Generate and from Gamma( and Gamma(, respectively.
- (4):
- With a normal proposal distribution, Var, create from using Metropolis-Hastings.
- (5):
- From (3), compute .
- (6):
- Place .
- (7):
- Go through steps 3–6 N times.
To ensure convergence and eliminate any bias in the initial value selection, the first M simulated variates are eliminated. Then, for sufficiently big N, the selected sample, , , creates an estimated posterior sample that may be utilized to construct the Bayesian inference of ℜ.
Using the BSE loss function provided by (37), the estimated Bayes estimate of ℜ is obtained as follows.
Also, the approximate Bayes estimate for ℜ, under BLINEX, from (38) is subsequently provided by
Additionally, the approximated/estimated credible intervals for ℜ are given by , which may be obtained by sorting , in ascending orders, see Chen and Shao (1999). The number in the burn-in phase is M here. In the same way, the Bayes estimator for ℜ can be found from relations (39) and (40).
The purpose of next section is to clarify how to apply the previously suggested approaches to actual occurrences that occur in the real world.
4. Carbon Fiber Data Application
Carbon fiber is composed of strong, thin crystalline carbon strands, which are effectively extended chains of carbon atoms joined by a bond. Since fibers are light, robust, and extremely durable, they are employed in several processes to create excellent structural materials. They are currently employed as steel and plastic substitutes. Therefore, we used actual carbon fiber data from Badr and Kahn (1982), which expresses the draw of impregnated carbon fibers at 1000 GPa (gigapascals) and the strength of single carbon fibers. Single fibers with gauge lengths of 20 mm (data set I) and 10 mm (data set II) underwent tension testing. The appropriate sample sizes are and , in that order. After deducting 0.75 from each of the data sets, Kundu and Gupta (2006) examined the changed data sets and fitted the Weibull models to each of them independently. Similarly, Çetinkaya and Genç (2019) fit the Power model for each data set independently after multiplying them by 1/3 and 1/5, respectively. Then, they used Bayesian and maximum likelihood techniques to investigate the ℜ estimation problem. The same data transformed by Çetinkaya and Genç (2019) will be used here. Table 1 and Table 2 present the transformed data sets, respectively, for gauge lengths of 20 mm and 10 mm.
The random variables that produce the strength measurements in Data Set I and the stress measurements in Data Set II are represented by the letters X and Y, respectively. We apply the maximum likelihood estimation process and fit the Chen distributions to these complete data sets. To avoid the problem of initial values when using the Newton-Raphson (N-R) method, we propose to use the fixed point iteration algorithm to obtain an initial value from (17). Then, we use (11) to find or . By using these procedures, the MLEs are and . Using complete data (X, Y) and Eq. (4), the ML estimate of ℜ is computed as . Based on the MLEs of , and, the data set X has a Simirnov test statistic of and a corresponding p-value of . For the data set Y, the corresponding values are and . As a result, the null hypothesis that the data sets originate from the Chen distribution cannot be rejected. Upon plotting the histograms of the two data sets, we discovered that the Chen density corresponds quite well with the histograms, as seen in Figure 2(i,iii). Furthermore supporting this are the Q-Q plots for the two data sets displayed in Figure 2(ii,iv). Additionally, Figure 3 shows the estimated/empirical CDFs of the Chen distributions using the whole data sets. The results indicate that, for both data 1 and 2, the fitted distribution functions closely resemble the respective empirical distribution functions.
From the complete carbon fiber data (), several adaptive type-II progressive censoring samples are generated with different choices of , , and censoring schemes R and S. Table 3 presents these samples. The different estimators for ℜ are computed using the previously described techniques based on these generated samples. After calculating the MLE of ℜ using the N-R procedure, we calculate Bayes estimates of ℜ under both BSE and BLINEX loss functions and the M-H approach. Here, a non-informative prior is employed in the Bayes estimates, where , because we lack previous knowledge about the parameters. The values of are initialized when samples from the posterior distribution are created using M-H. Where, and indicate the MLEs of the parameters and , respectively. From a total of samples produced by the posterior density, we then remove the first 1000 burn-in samples. Then, as specified by Eqs. (39) and (40), Bayes estimates of ℜ are obtained using various loss functions, such as BSE and BLINEX with and .
The convergence of the chains must be verified in accordance with the Bayesian technique. Thus, Figure 4(i) displays the MCMC trace plot with sample mean, and 95% HPD credible interval for ℜ. Also, using the Gaussian kernel, Figure 1(ii) displays the marginal posterior density estimate of ℜ and its histogram based on samples of size 20000. The graphic clearly shows how nearly symmetrical the marginal distribution is. So, these charts demonstrate how the sample data from the Chen model displays a suitable mixture for the Bayes estimate. Table 4 shows the estimated outcomes for ℜ based on ML’s approach. Table 4 also shows the results of Bayes estimates of ℜ with respect to the BSE and BLINEX loss functions, over a range of values of and a variable value of the LINEX parameter c. It is worth mentioning that, for deferent schemes, the bootstrap estimate of ℜ and its 95% confidence interval were generated using a bootstrap sample of size 1000. Furthermore, Table 5 displays the lower, higher, and lengths of confidence intervals for ℜ using the normal approximation interval, Log normal confidence interval, Boot p, and Bayes procedures. A 95% confidence level is used in this process.
Figure 2.
Data sets 1 and 2 histograms with Q-Q graph and an estimated model density.
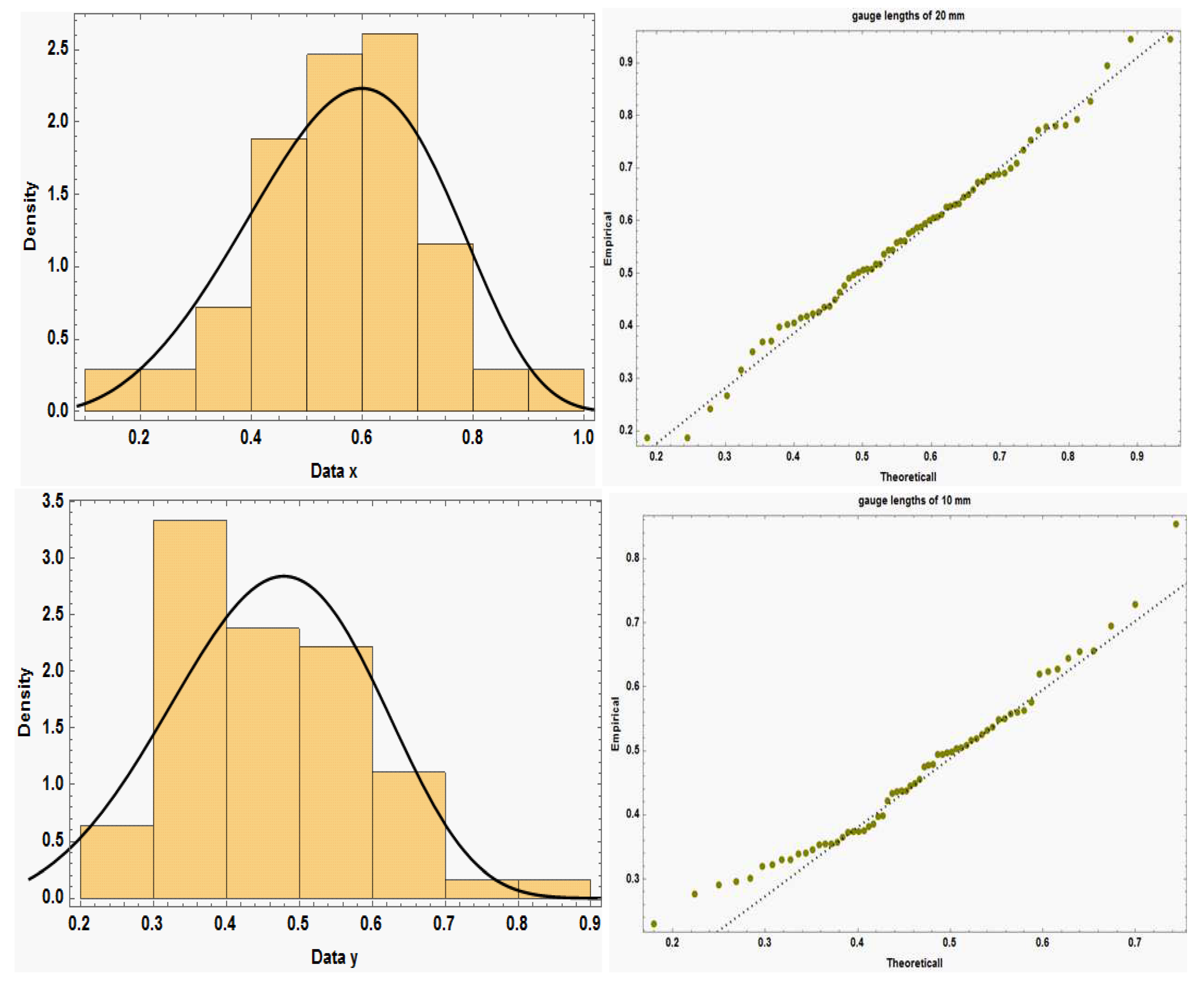
Figure 3.
The fitted distribution functions for data sets 1 and 2 as well as the empirical distribution functions.
Figure 3.
The fitted distribution functions for data sets 1 and 2 as well as the empirical distribution functions.
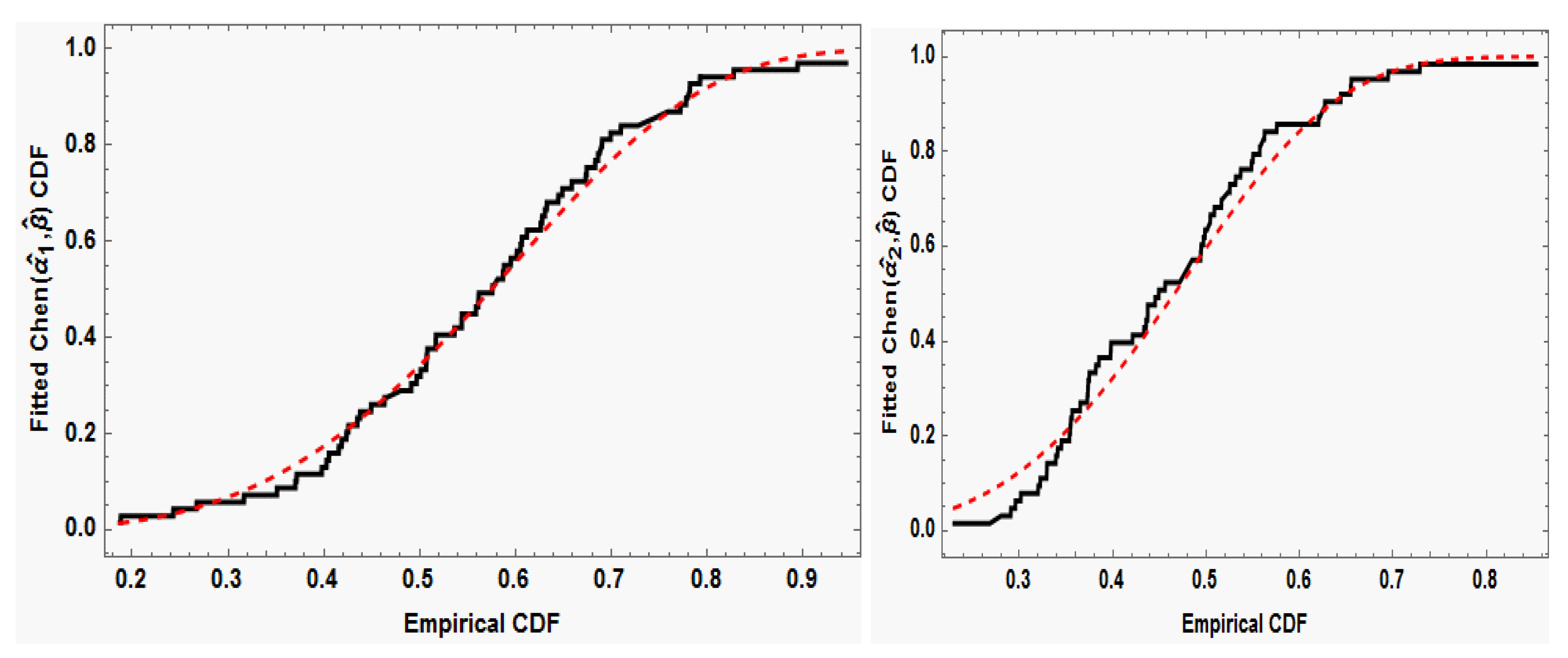

Table 3.
The generated adaptive type-II progressively censored samples for carbon fiber data.
| Scheme | Generated data | |
| I | Type-II censoring: | |
| , , , , and | ||
| x | 0.1873, 0.1880, 0.2430, 0.2673, 0.3167, 0.4053, 0.4157, 0.4187, 0.4237, 0.4257, 0.4913, 0.4967, | |
| 0.5010, 0.5067, 0.5073, 0.5440, 0.5587, 0.5613, 0.5617, 0.5760, 0.6053, 0.6067, 0.6120, 0.6263, | ||
| 0.6277, 0.6733, 0.6743, 0.6833, 0.6863, 0.6893,0.7723, 0.7780, 0.7800, 0.7820, 0.7927. | ||
| y | 0.2302, 0.2764, 0.2906, 0.2956, 0.3014, 0.3200, 0.3222, 0.3292, 0.3294, 0.3390, 0.3408, 0.3448, | |
| 0.3536, 0.3544, 0.3550, 0.3564, 0.3650, 0.3728, 0.3732, 0.3736, 0.3748, 0.3818, 0.3850, 0.3976, | ||
| 0.3980, 0.4212, 0.4334, 0.4356, 0.4374, 0.4374, | ||
| II | Censoring from the start: | |
| , , , , and | ||
| x | 0.1873, 0.1880, 0.3167, 0.3703, 0.3717, 0.4053, 0.4157, 0.4187, 0.4257, 0.4377, 0.4633, 0.5010, | |
| 0.5067, 0.5073, 0.5080, 0.5170, 0.5440, 0.5440, 0.5587, 0.5613, 0.5617, 0.5760, 0.5880, 0.6053, | ||
| 0.6277, 0.6307, 0.6447, 0.6490, 0.6587, 0.6863, 0.6903, 0.7780, 0.7820, 0.7927, 0.9450. | ||
| y | 0.2302, 0.2956, 0.3200, 0.3222, 0.3294, 0.3544, 0.3550, 0.3748, 0.3818, 0.4212, 0.4334, 0.4356, | |
| 0.4374, 0.4374, 0.4454, 0.4560, 0.4750, 0.4790, 0.4946, 0.4986, 0.5028, 0.5088, 0.5254, 0.5316, | ||
| 0.5370, 0.5486, 0.5502, 0.5756, 0.6204, 0.6272, 0.6442, 0.6548, 0.695. | ||
| III | Progressive type-II censoring: | |
| , , , , and | ||
| x | 0.1873, 0.1880, 0.2430, 0.2673, 0.3167, 0.3510, 0.4027, 0.4053, 0.4157, 0.4377, 0.4493, 0.4633, | |
| 0.4763, 0.5073, 0.5080, 0.5170, 0.5613, 0.5617, 0.5760, 0.5800, 0.5950, 0.6013, 0.6053, 0.6263, | ||
| 0.6733, 0.6743, 0.6893, 0.6903, 0.6993, 0.7100, 0.7347, 0.7723, 0.7780, 0.7800, 0.9450. | ||
| y | 0.2302, 0.2764, 0.2906, 0.2956, 0.3014, 0.3200, 0.3292, 0.3294, 0.3390, 0.3408, 0.3536, 0.3544, | |
| 0.3650, 0.3736, 0.3748, 0.3850, 0.3976, 0.4454, 0.4492, 0.4560, 0.4778, 0.4986, 0.5164, 0.5192, | ||
| 0.5370, 0.5486, 0.5574, 0.6204, 0.6242, 0.6272, 0.6442, 0.6548, 0.7290. | ||
| IV | Adaptive type-II progressive censoring: | |
| , , , , and | ||
| x | 0.1873, 0.1880, 0.2430, 0.2673, 0.3167, 0.3510, 0.3703, 0.3717, 0.3980, 0.4027, 0.4053, 0.4237, | |
| 0.4257, 0.4350, 0.4633, 0.4967, 0.5010, 0.5073, 0.5080, 0.5613, 0.5760, 0.5870, 0.5880, 0.6013, | ||
| 0.6067, 0.6120, 0.6307, 0.6587, 0.6833, 0.7100, 0.7723, 0.7780, 0.7820, 0.8277, 0.9450 | ||
| y | 0.2302, 0.2764, 0.2906, 0.2956, 0.3014, 0.3200, 0.3292, 0.3294, 0.3390, 0.3408, 0.3536, 0.3544, | |
| 0.3650, 0.3736, 0.3748, 0.3850, 0.3976, 0.4454, 0.4492, 0.4560, 0.4778, 0.4986, 0.5164, 0.5192, | ||
| 0.5370, 0.5486, 0.5574, 0.6204, 0.6242, 0.6272, 0.6442, 0.6548, 0.7290. | ||
Figure 4.
Data set histogram with Q-Q graphs and an estimated model density.
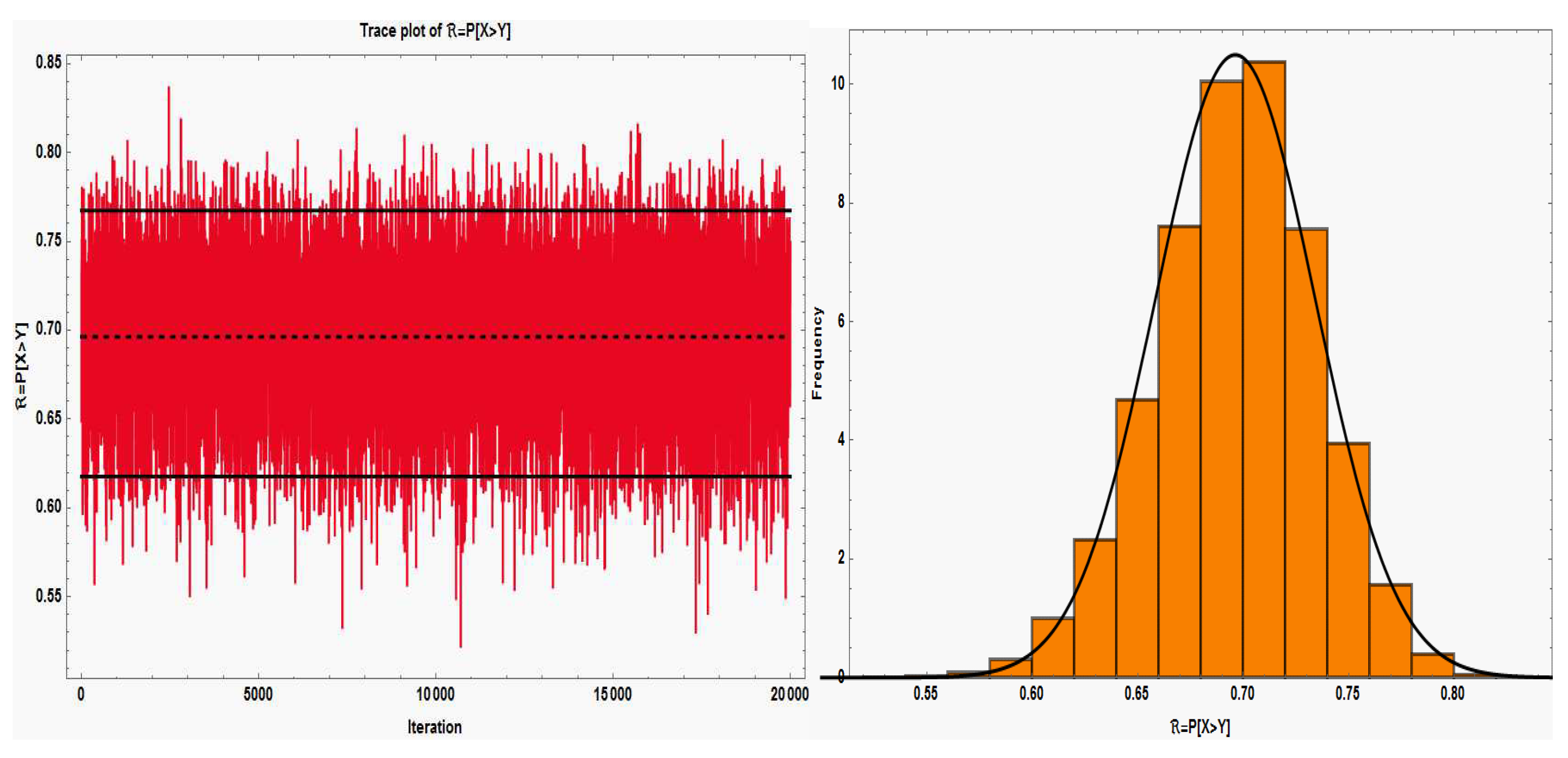
Table 4.
ML, bootstrap and Bayes point estimates of ℜ for carbon fiber data.
| Scheme | (, | MLEs | Boot-p | BSE | BLINEX | |||
| Complete data set | (, ) | 0.6986 | 0.6992 | 0 | 0.6963 | 0.6999 | 0.6960 | 0.6927 |
| 0.25 | 0.6969 | 0.6996 | 0.6966 | 0.6941 | ||||
| 0.50 | 0.6974 | 0.6992 | 0.6973 | 0.6956 | ||||
| 0.95 | 0.6985 | 0.6986 | 0.6984 | 0.6983 | ||||
| I | (, ) | 0.8774 | 0.8817 | 0 | 0.8683 | 0.8716 | 0.8679 | 0.8647 |
| 0.25 | 0.8706 | 0.8731 | 0.8703 | 0.8678 | ||||
| 0.50 | 0.8728 | 0.8745 | 0.8726 | 0.8709 | ||||
| 0.95 | 0.8769 | 0.8771 | 0.8769 | 0.8767 | ||||
| II | (, ) | 0.6909 | 0.6907 | 0 | 0.6848 | 0.6922 | 0.6841 | 0.6770 |
| 0.25 | 0.6864 | 0.6919 | 0.6858 | 0.6804 | ||||
| 0.50 | 0.6879 | 0.6916 | 0.6875 | 0.6838 | ||||
| 0.95 | 0.6906 | 0.6910 | 0.6906 | 0.6902 | ||||
| III | (, ) | 0.6986 | 0.7000 | 0 | 0.6961 | 0.6997 | 0.6957 | 0.6924 |
| 0.25 | 0.6967 | 0.6994 | 0.6964 | 0.6939 | ||||
| 0.50 | 0.6973 | 0.6991 | 0.6971 | 0.6954 | ||||
| 0.95 | 0.6984 | 0.6986 | 0.6984 | 0.6902 | ||||
| IV | (, ) | 0.6958 | 0.6947 | 0 | 0.6935 | 0.7006 | 0.6927 | 0.6861 |
| 0.25 | 0.6941 | 0.6994 | 0.6935 | 0.6885 | ||||
| 0.50 | 0.6946 | 0.6982 | 0.6943 | 0.6909 | ||||
| 0.95 | 0.6957 | 0.6961 | 0.6957 | 0.6953 | ||||
Table 5.
Different interval estimates of ℜ for carbon fiber data.
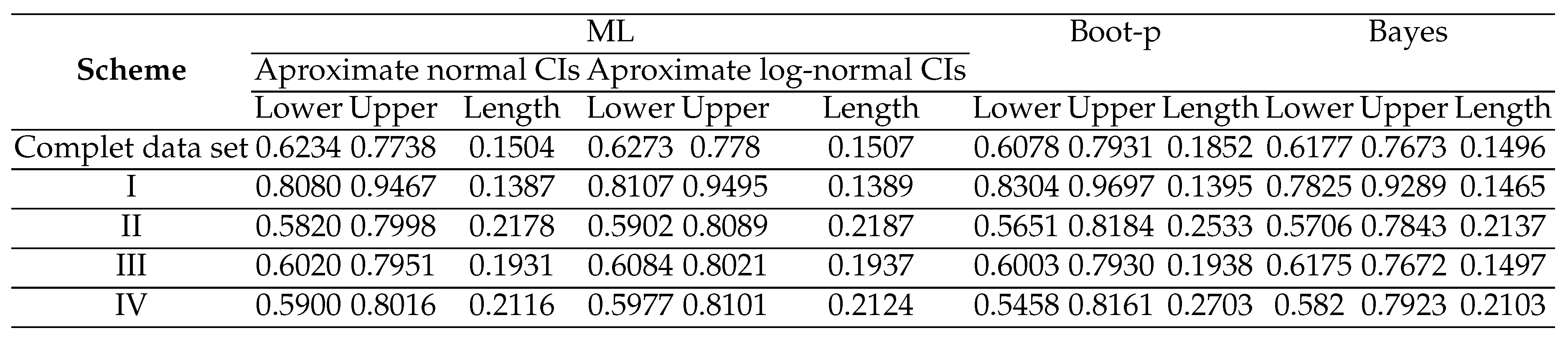
Analysis of an earlier real data set illustrates the significance and use of the adaptive type-II progressive censoring and the inferential methods based on it. It is demonstrated that the estimate of the S-S reliability model and the associated varied confidence intervals is highly dependent on the number of failures and a predefined number of inspection times. The performance of the various estimating techniques may also be observed to be rather similar to one another. Table 4’s numerical findings substantiate our understanding that, for ℜ, all Bayes estimation outcomes under the BSEL and BLINEX loss functions are equal to the respective MLEs as approaches unity. The results also show that the default estimators within the SE and LINEX loss functions, respectively, are derived from the default estimators based on both BSEL and BLINEX, when . Thus, it is evident to us how important it is to use balanced loss functions in the Bayes approach. Table 5 indicates that the Bayes estimator is the best based on the length of the confidence interval. The estimators of approximate normal and approximate log-normal are next in order of preference, and the bootstrap estimator is the last one. Additionally, the values of the lengths of the confidence intervals based on the interval estimators of approximate normal and approximate log-normal exhibit a substantial convergence.
In summary, the results of point estimates and interval estimates do not change significantly between different schemes. It is evident that, as predicted in Tables 4 and 5, the estimates produced using the type-II censored data are nearer to the estimates produced with the complete sample. Although the adaptive type-II progressive censoring scheme shortens the testing time, the accuracy cannot be determined from a single sample so for better comparison we will create a simulation study in the next section.
5. Simulation and Comparisons
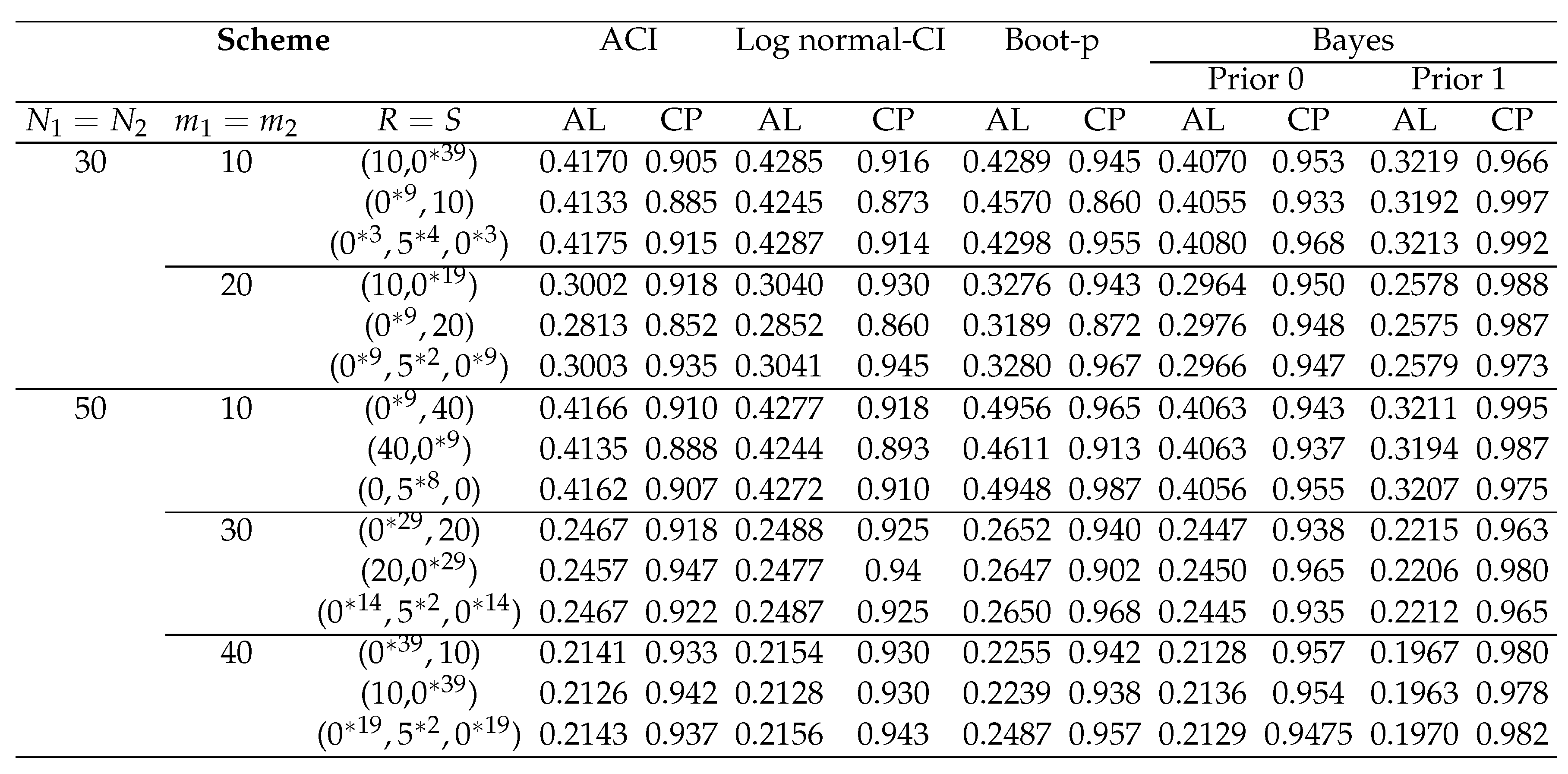
Numerous simulation tests are conducted to evaluate the accuracy of our estimations using Monte Carlo simulations. While the coverage percentage (CR) and interval mean length (IML) are used to evaluate interval estimation, the mean square error (MSE) and estimate value (VALUE) are used to evaluate point estimation. Smaller MSE and closer estimation value indicate better estimation performance for point estimation. Furthermore, in the context of interval estimation, better estimates are produced with greater coverage rates and shorter interval mean lengths.
First and foremost, the algorithm (Steps 2 and 3) provided in Subsection 2.2 must be used to construct adaptive type-II progressive censored data from an Chen distributions (, ). It is established that the real values of (, , ) are (). To facilitate comparison, we take into account , and () =()=, , , , and . Three separate censoring schemes (CS) are selected for each combination of sample sizes and times and . We simplify the censoring schemes by abbreviating them. For instance, () is the representation of (). Every scenario involves 1000 iterations of the simulation. Mathematica software may then be used to do Monte Carlo simulations in order to obtain the corresponding MSEs and VALUEs for the point estimate and the related mean lengths and coverage rates for the interval estimation of ℜ. Based on these repeated samples, the following formulae are used to calculate the estimators’ bias, MSE, and lower bound:
The solutions of likelihood equations for the MLE are found by applying the Newton-Raphson technique. Additionally, we calculate the predicted length and coverage probability (CP) for the log- normal interval (Log-NCI), the percentile bootstrap interval (Boot-p), and the asymptotic confidence interval (ACI). We utilize 1000 bootstrap iterations to generate the bootstrap confidence intervals. It is configured with as the significance threshold. Furthermore, two different prior types are taken into consideration to produce the Bayes estimates of ℜ: Prior 0 () represents the non-informative prior scenario, whereas Prior 1 values () represents the informative prior scenario, which are chosen such that the prior means match the original means. We have computed the Bayes estimates of ℜ under balanced (BSE, BLINEX) loss functions with different values of () and LINEX constant c (). The Bayes estimates and corresponding credible credible intervals are calculated using samples, and the first values are discarded as the burn-in phase. The simulation results are reported in Tables 6 and 7. Based on the simulation results, we can conclude that:
- According to the outcomes of our simulation, biases and MSEs are found to decrease with increasing sample sizes ().
- Overall, none of the three censoring schemes performs better than the others when compared, although the random scheme (Scheme 3 in Table 6) performs better when it comes to minimal MSEs than the other two schemes. In most cases shown in Table 6, in terms of minimal MSEs, scheme 3, scheme 1, and scheme 2 are the schemes that perform the best through worst. This is true in several m and N cases.
- The results indicate that the different estimations are successful since the estimated values are near to the actual values and the bias and mean square errors generally decrease as sample sizes () grow.
- The Bayes estimators seem to be sensitive to the assumed values of the prior parameters, based on the performance of the estimators based on Prior 0 and 1.
-
The Bayes estimate under LINEX with and provides better estimates for ℜ because of having the smallest MSEs.The interval average lengths (ALs) and coverage probabilities (CPs) are used in Table 7 to compare the suggested confidence intervals. The following conclusions are drawn from these tables:
- For various censoring schemes, in terms of interval length, the bootstrap interval is the largest, while the Bayesian credible intervals under both prior 0 and priors 1 are the smallest. Moreover, the asymptotic confidence intervals are the second-best ones.
- By expanding the sample size, the average lengths (ALs) and the CPs for ML, bootstrap and Bayesian approaches have improved.
- When comparing the confidence/credible interval lengths based on schemes 1 and 2 to those based on schemes 3, it is evident that the second scheme’s intervals in most cases for N and m have the shortest.
- When the sample size increases, the coverage probabilities approach , indicating that the asymptotic confidence intervals will get more accurate. Through a comparison of the various credible and confidence intervals, it is clear that, in the majority of cases that are taken into consideration, the Bayes intervals offer the highest coverage percentages. Based on the Prior 1, the Bayes credible interval performs best. Further, in the case of traditional asymptotic intervals, the CPs are less than 0.95 and always more than 0.95 under Prior 1, but for Bayesian intervals they remain close to 0.95 under Prior 0. While the bootstrap confidence intervals is bigger than the other confidence intervals, it performs well in terms of coverage probability.
Table 6.
Bias’s and MSE’s of the point estimations for ℜ when
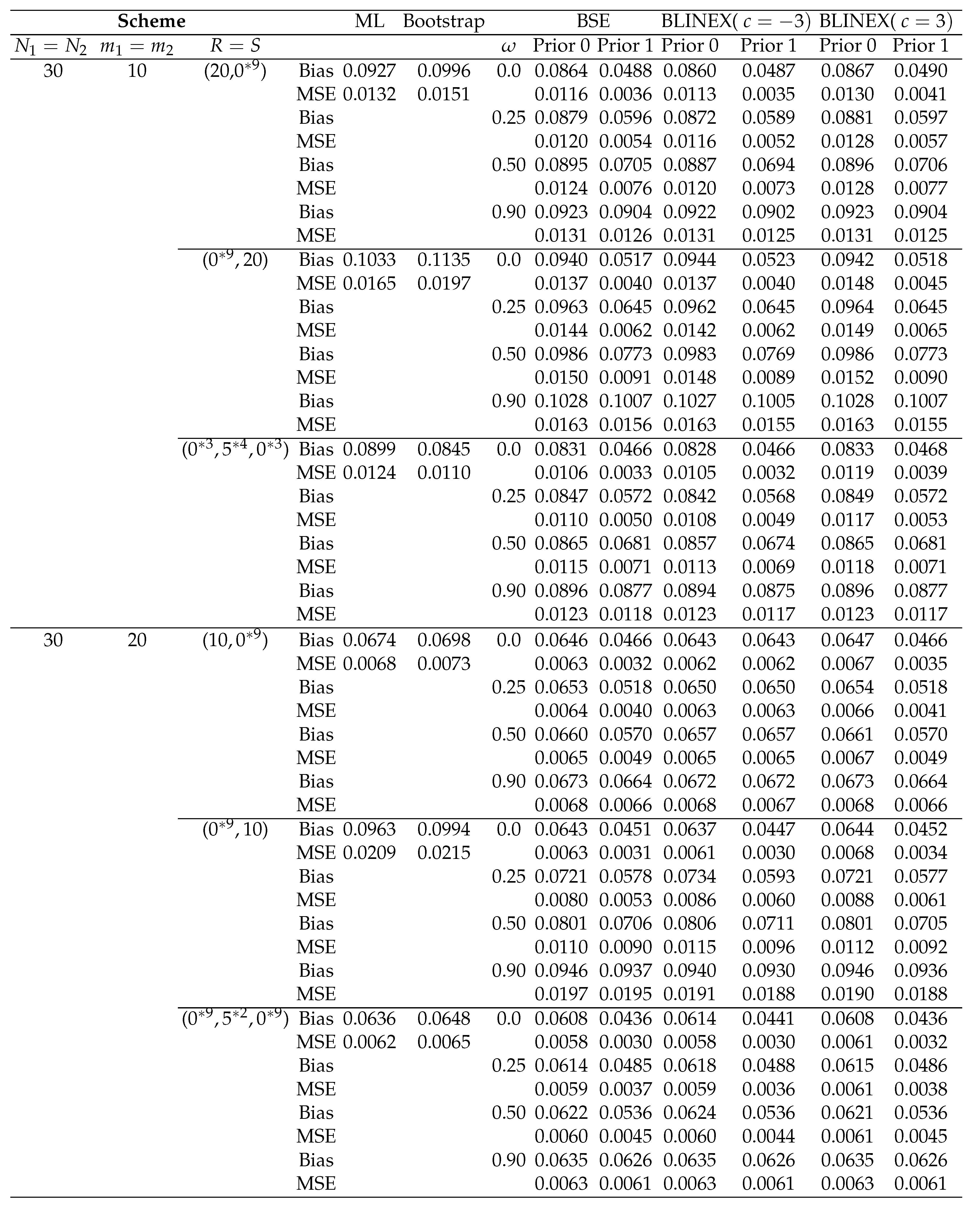
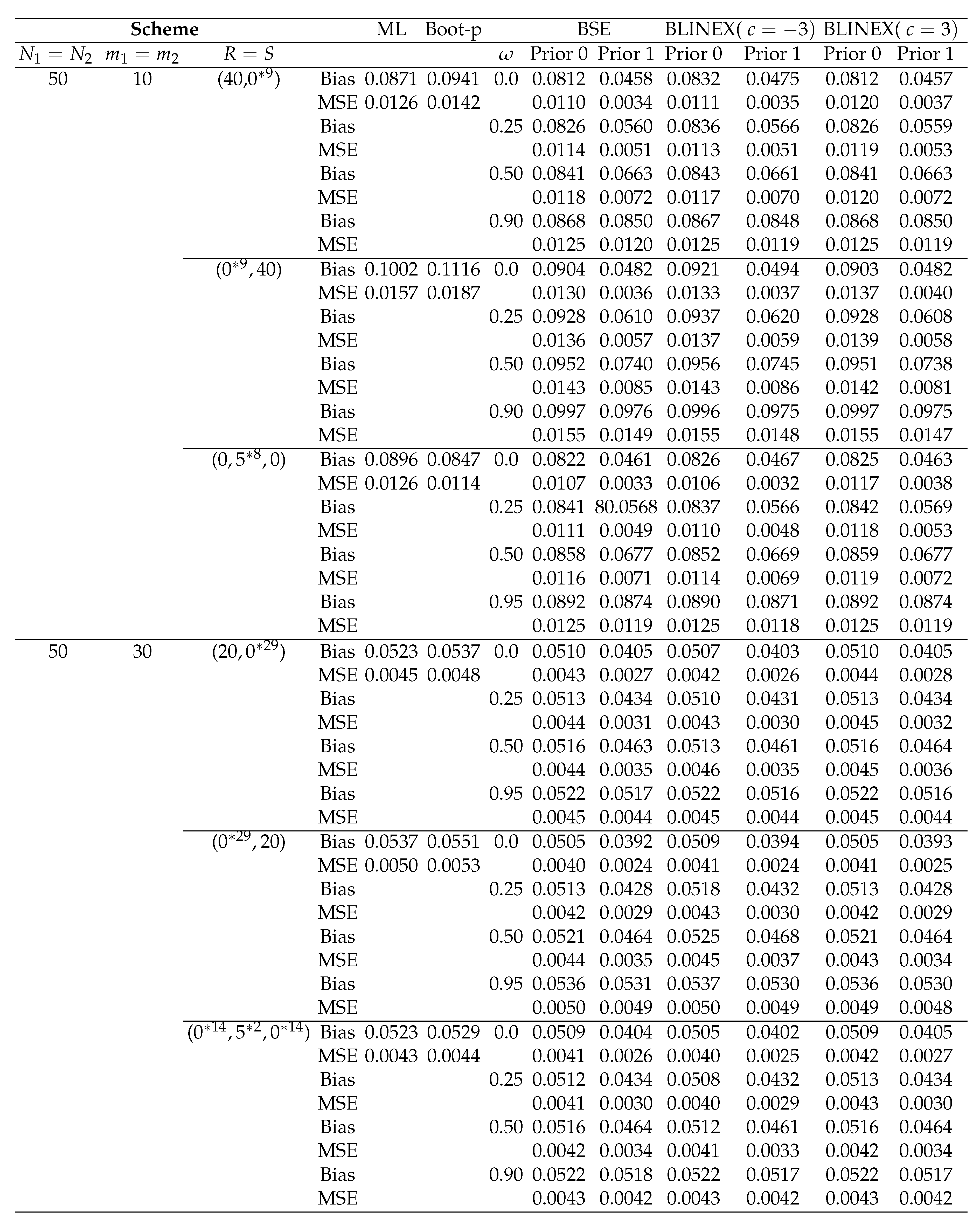
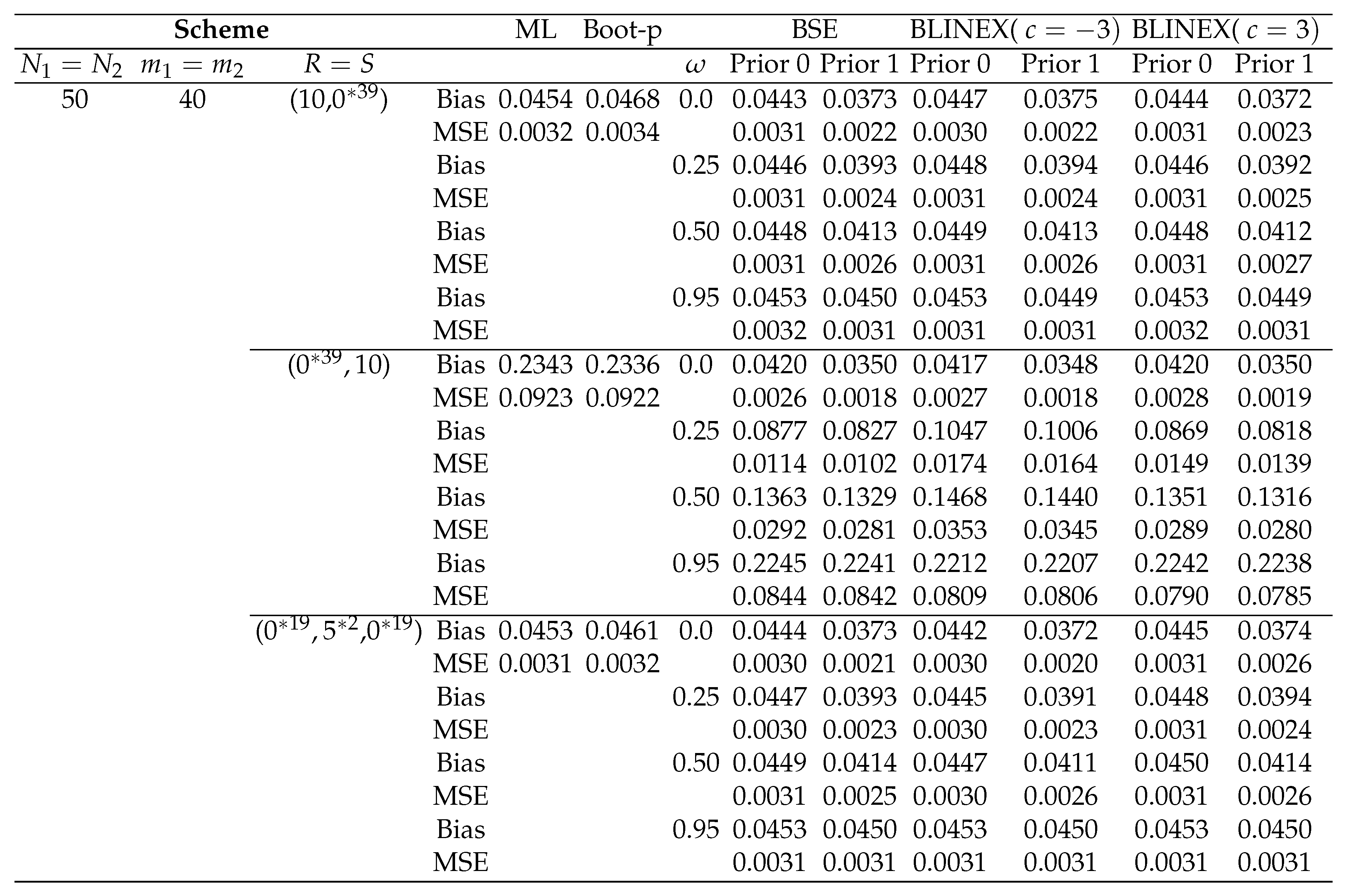
Table 7.
Average confidence/credible interval lengths (AL) with for coverage percentage (CP)
5.1. Conclusion
This study deals with the statistical inference of the stress-strength (S-S) reliability of Chen distribution under the assumption that the data are adaptive type-II progressively censored. The maximum likelihood approach is taken into consideration in order to determine the point as well as the interval estimates of the distribution’s S-S reliability. The parametric percentile bootstrap confidence interval and the approximated confidence intervals for the S-S reliability are derived. In order to obtain the approximate normal/log-normal intervals, the variance of the estimators of the S-S reliability is approximated using the delta method. We also revisit the gamma prior assumption-based Bayesian calculation of the stress-strength reliability. The Bayes estimates are derived by accounting for balanced squared error and balanced LINEX loss functions. We use the Markov chain Monte Carlo procedure to obtain the Bayes estimates and credible intervals for the highest posterior density. We compare the provided estimates in terms of their means squared error, confidence lengths, and coverage probabilities through an exhaustive numerical analysis. An application is examined to provide context for the recommended techniques. As can be seen from the numerical results, the Bayes estimates outperform estimates derived using the maximum likelihood approach. When utilising the asymmetric loss function in place of the symmetric loss, the Bayesian estimations yield more accurate estimates.
References
- Agiwal, V. Bayesian estimation of stress strength reliability from inverse Chen distribution with application on failure time data. Annals of Data Science 2023, 10, 317–347. [CrossRef]
- J. Ahmadi, M.J. Jozani, E. Marchand and A. Parsian, Bayes estimation based on k-record data from a general class of distributions under balanced type loss functions. Journal of Statistical Planning and Inference 2009, 139,1180–1189. [CrossRef]
- E. A. Ahmed, Z. Ali Alhussain, M. M. Salah, H. Haj Ahmed, and M. S. Eliwa, Inference of progressively type-II censored competing risks data from Chen distribution with an application. Journal of Applied Statistics 2020, 47, 2492–2524. [CrossRef]
- Almuqrin, M.A.; M. M.Salah, and E.A. Ahmed. Statistical Inference for Competing Risks Model with Adaptive Progressively Type-II Censored Gompertz Life Data Using Industrial and Medical Applications. Mathematics 2022, 10, 4274. [CrossRef]
- A. Asgharzadeh, R. Valiollahi and M. Z. Raqab, Estimation of Pr(Y<X) for the two parameter generalized exponential records, Communications in Statistics-Simulation and Computation, 46 (2017), 371–394.
- M. Bader, and A. Priest, Statistical Aspects of Fiber and Bundle Strength in Hybrid Composites. In: Hayashi, T., Kawata, S. and Umekawa, S., Eds., Progress in Science and Engineering Composites, ICCM-IV, Tokyo, (1982),1129-1136.
- Z.W. Birnbaum and R.C. McCarty. A distribution-free upper confidence bound for Pr(Y<X), based on independent samples of x and y Ann. Math. Stat., 29 (1958), 558-562.
- R. Calabria and G. Pulcini. Point estimation under asymmetric loss functions for left-truncated exponential samples. Commun. Statist. Theory Meth., 25:585–600,1996. [CrossRef]
- G. Casella and E.I. George, Explaining the Gibbs sampler. Am Stat 46(1992),167–74.
- Ç. Çetinkaya and A. I. Genç, Stress–strength reliability estimation under the standard two-sided power distribution. Applied Mathematical Modelling, 65 (2019), 72-88. [CrossRef]
- Z. Chen, A new two-parameter lifetime distribution with bathtub shape or increasing failure rate function, Stat. Probab. Lett. 49(2000), 155–161. [CrossRef]
- M. H. Chen, and Q. M. Shao, Monte Carlo estimation of Bayesian credible and HPD intervals. Journal of computational and Graphical Statistics, 8(1999), 69-92.
- B. Efron and R. J. Tibshirani, An introduction to the bootstrap. CRC press, (1994).
- W. H. Greene, Econometric Analysis, 4th Ed. New York: Prentice Hall, (2000).
- M.E. Ghitany, D.K. Al-Mutairi and S.M Aboukhamseen, Estimation of the reliability of a stress-strength system from power Lindley distributions. Commun. Stat.-Simul. Comput. 44 (2015), 118–136. [CrossRef]
- W.K. Hastings, Monte Carlo sampling methods using Markov chains and their applications. Biometrika 57(1970):97–109.
- T. Kayal, Y. M. Tripathi, S. Dey, and S. J. Wu, On estimating the reliability in a multicomponent stress-strength model based on Chen distribution. Communications in Statistics-Theory and Methods, 49(2020), 2429-2447. [CrossRef]
- T. Kayal, Y. M. Tripathi, D. P. Singh and M. K. Rastogi, Estimation and prediction for Chen distribution with bathtub shape under progressive censoring. Journal of Statistical Computation and Simulation, 87(2017), 348-366. [CrossRef]
- S. Kotz, M. Lumelskii and M. Pensky, The stress-strength model and its generalizations: theory and applications, World Scientific, New-York, (2003).
- D. Kundu, and R.D. Gupta, Estimation ofp(y < x) for weibull distributions. IEEE Trans. Reliability, 55(2006), 270-280.
- B.X. Wang, Geng, Y.and J.X Zhou, Inference for the generalized exponential stress-strength model. Appl. Math. Model, 53 (2018), 267–275.
- J. G. Ma, L. Wang, Y. M. Tripathi and M. K. Rastogi, Reliability inference for stress-strength model based on inverted exponential Rayleigh distribution under progressive Type-II censored data, Communications in Statistics-Simulation and Computation, 52 (2023), 2388-2407. [CrossRef]
- N. Metropolis, A.W. Rosenbluth, M.N, Rosenbluth, A.H. Teller, E. Teller, Equation of state calculations by fast computing machines. J Chem Phys 21(1953),1087–92. [CrossRef]
- H.K.T. Ng, D. Kundu, P.S. Chan, Statistical analysis of exponential lifetimes under an adaptive Type-II progressive censoring scheme. Naval Research Logistics (NRL). 2009; 56(8):687–698. [CrossRef]
- M. Z. Raqab, O. M. Bdair and F. M. Al-Aboud, Inference for the two-parameter bathtub-shaped distribution based on record data. Metrika, 81, 229-253. [CrossRef]
- M. K. Rastogi, Y. M. Tripathi and S.J. Wu, Estimating the parameters of a bathtub-shaped distribution under progressive type-II censoring, J. Appl. Statist. 39(2018), 2389–2411. [CrossRef]
- C.P. Robert and G. Casella, Monte Carlo statistical methods. Springer, New York, (2004). [CrossRef]
- A. M. Sarhan, and H. T. Ahlam, Stress-Strength Reliability Under Partially Accelerated Life Testing Using Weibull Model. Scientific African (2023): e01733.
- A. M. Sarhan, B. Smith, D.C. Hamilton, Estimation of P(Y < X) for a two-parameter bathtub shaped failure rate distribution. Int J Stat Probab 4(2015 ),33–45. [CrossRef]
- S. Shoaee and E. Khorram, Stress-strength reliability of a two-parameter bathtub-shaped lifetime distribution based on progressively censored samples. Communications in Statistics-Theory and Methods, 44(2015), 5306-5328. [CrossRef]
- B. Tarvirdizade and M. Ahmadpour, Estimation of the stress–strength reliability for the two-parameter bathtub-shaped lifetime distribution based on upper record values. Statistical Methodology, 31(2016), 58-72. [CrossRef]
- H.R. Varian, A Bayesian Approach to Real Estate Assessment, North-Holland, Amsterdam, (1975), 195-208.
- F.K. Wang, A new model with bathtub-shaped failure rate using an additive Burr XII distribution, Reliab. Eng. System Safety. 70(2000), 305–312. [CrossRef]
- L.Wang, K. Wu, Y. M. Tripathi and C. & Lodhi, Reliability analysis of multicomponent stress–strength reliability from a bathtub-shaped distribution. Journal of Applied Statistics, 49(2022), 122-142.
- S. J. Wu, Estimation of the two-parameter bathtub-shaped lifetime distribution with progressive censoring. Journal of Applied Statistics, 35(2008), 1139-1150. [CrossRef]
- M. Xie and C. D. Lai, Reliability analysis using an additive Weibull model with bathtub-shaped failure rate function, Reliability Engineeering and Systems Safety, 52(1995), 87-93. [CrossRef]
- M. Xie, Y. Tang, and T.N. Goh, A modified Weibull extension with bathtub-shaped failure rate function, Reliab. Eng. System Safety. 76(2002), 279–285. [CrossRef]
Figure 1.
Illustration of an adaptive type-II progressive censoring scheme.
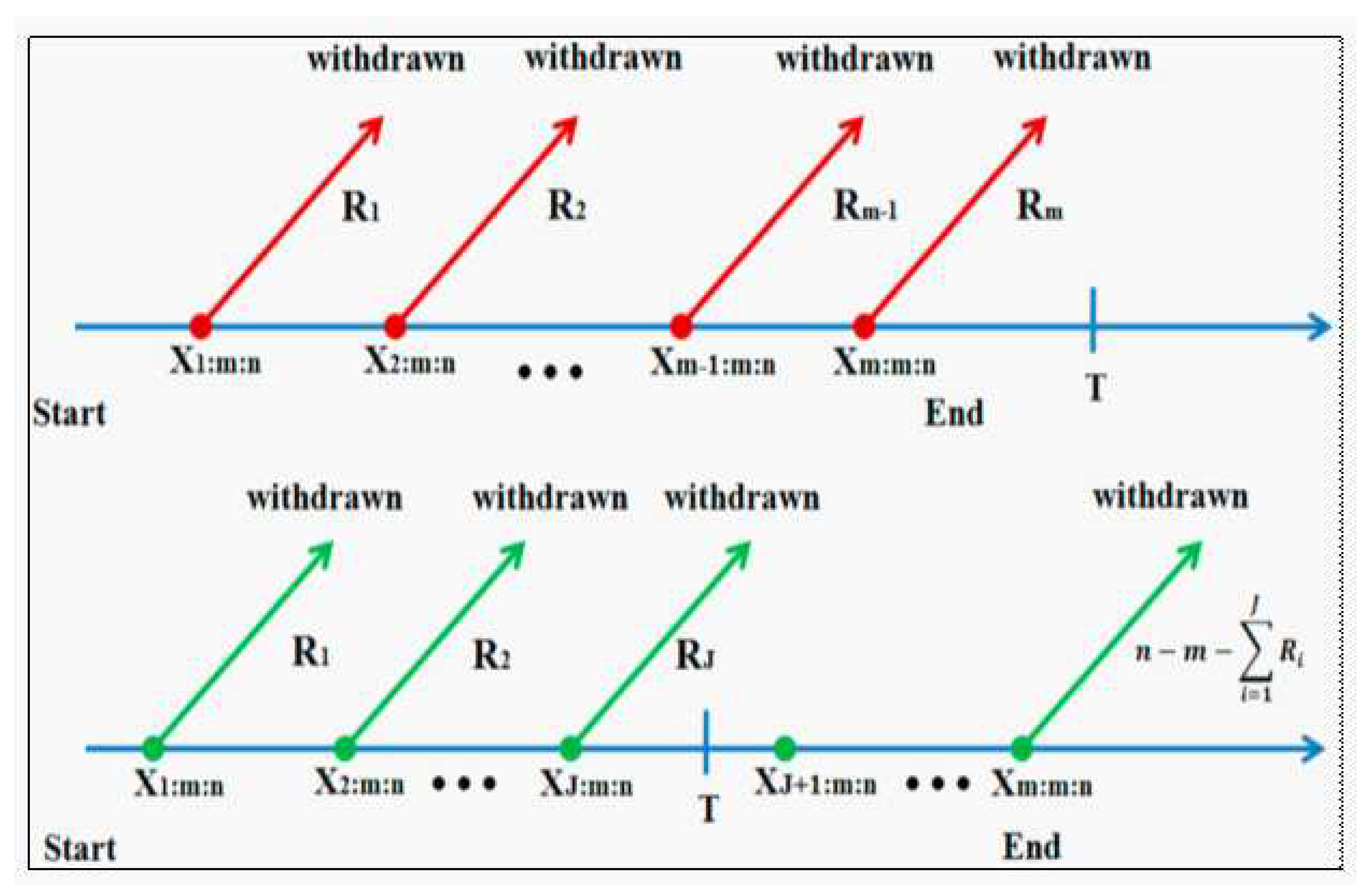
Table 1.
Transformed Data Set I (for gauge lengths of 20 mm) from Çetinkaya and Genç (2019).
| 0.1873 | 0.4053 | 0.4913 | 0.5440 | 0.6053 | 0.6733 | 0.7723 | 0.1880 | 0.4157 | 0.4967 | 0.5587 |
| 0.6067 | 0.6743 | 0.7780 | 0.2430 | 0.4187 | 0.5010 | 0.5613 | 0.6120 | 0.6833 | 0.7800 | 0.2673 |
| 0.4237 | 0.5067 | 0.5617 | 0.6263 | 0.6863 | 0.7820 | 0.3167 | 0.4257 | 0.5073 | 0.5760 | 0.6277 |
| 0.6893 | 0.7927 | 0.3510 | 0.4350 | 0.5080 | 0.5800 | 0.6307 | 0.6903 | 0.8277 | 0.3703 | 0.4377 |
| 0.5170 | 0.5870 | 0.6327 | 0.6993 | 0.8943 | 0.3717 | 0.4493 | 0.5170 | 0.5880 | 0.6447 | 0.7100 |
| 0.9450 | 0.3980 | 0.4633 | 0.5363 | 0.5950 | 0.6490 | 0.7347 | 0.9450 | 0.4027 | 0.4763 | 0.5440 |
| 0.6013 | 0.6587 | 0.7540 |
Table 2.
Transformed Data Set II (for gauge lengths of 10 mm) from Çetinkaya and Genç (2019).
| 0.2302 | 0.3408 | 0.3748 | 0.4454 | 0.5028 | 0.5574 | 0.6950 | 0.2764 | 0.3448 | 0.3818 | 0.4492 |
| 0.5044 | 0.5608 | 0.7290 | 0.2906 | 0.3536 | 0.3850 | 0.4560 | 0.5088 | 0.5624 | 0.8540 | 0.2956 |
| 0.3544 | 0.3976 | 0.4750 | 0.5164 | 0.5756 | 0.3014 | 0.3550 | 0.3980 | 0.4778 | 0.5192 | 0.6204 |
| 0.3200 | 0.3564 | 0.4212 | 0.4790 | 0.5254 | 0.6242 | 0.3222 | 0.3650 | 0.4334 | 0.4940 | 0.5316 |
| 0.6272 | 0.3292 | 0.3728 | 0.4356 | 0.4946 | 0.5370 | 0.6442 | 0.3294 | 0.3732 | 0.4374 | 0.4970 |
| 0.5486 | 0.6548 | 0.3390 | 0.3736 | 0.4374 | 0.4986 | 0.5502 | 0.6554 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



