Submitted:
03 January 2024
Posted:
05 January 2024
You are already at the latest version
Abstract
Currently, Pythagorean fuzzy sets (PFSs) have been widely applied in various fields due to their substantial advantages in expressing and dealing with uncertainty. However, measuring the similarity and difference between PFSs effectively remains an unresolved issue. Inspired by Tanimoto similarity, we propose a novel set of similarity and distance measures for PFSs. We delve into the theoretical properties of the proposed measures and compare it with existing PFSs measures. Numerous numerical examples validate their rationality and effectiveness. Furthermore, our experimental findings suggest that in contrast to existing measures, the introduced measures successfully circumvent various counter-intuitive issues encountered by current measures, and yield more pronounced outcomes in the discrimination of different fuzzy sets. This enhances the uniqueness and superiority of our measures. Finally, we developed two decision models based on the proposed measures and validated their applicability in three applications.
Keywords:
Pythagorean fuzzy sets
; Tanimoto similarity measure
; distance measure
; pattern recognition
; medical diagnosis
; multi-attribute decision-making
1. Introduction
Decision-making is a common behavior. Ideally, the data required for decision-making would be precise and comprehensive; unfortunately, in reality, the majority of the information we have for decision-making is either uncertain or incomplete, implying the presence of uncertainty [1,2]. Uncertainty is the primary factor impeding correct decision-making, and it has become increasingly pervasive in various fields because of the complexity of practical issuses and the natural bounds of understanding. This ambiguity always manifests itself randomly and in uncertain manners, which leads to the difficulties of accurate depiction and decision-making process. Therefore, how to accurately describe uncertainty has become a paramount challenge [3,4]. Currently, numerous innovative theories and techniques have been suggested for depicting uncertainty in real-world scenarios, including fuzzy sets [5], Intuitionistic fuzzy sets (IFSs) [6], evidence theory [7,8], rough sets [9,10,11] and R-numbers [12]. Among the array of theories, the IFSs stands out for its proficiency in capturing ambiguity and indeterminacy through the delineation of membership and nonmembership intervals for elements. This distinctive characteristic has rendered IFSs an indispensable instrument across various disciplines for grappling with uncertainties [13,14,15]. However, in some cases, the condition that the sum of the membership degree and nonmembership degree required by the International Federations must be less than or equal to 1 may be violated. Inspired by this, Yager [16] first introduced Pythagorean fuzzy sets (PFSs) as an evolution of IFSs in 2013. The hallmark of this model is its employment of the Pythagorean membership function, which introduces a degree of hesitation into the parameters of IFSs, including their membership degree, nonmembership degree and indeterminacy degree. PFSs stipulate that the sum of squares of membership and nonmembership is not more than 1, making it more effective in representing uncertain information. Subsequently, Zhang and Xu [17] introduced the concept of Pythagorean fuzzy numbers (PFNs) and subsequently proposed the PF-TOPSIS method for multi-attribute decision-making (MADM) problems. Wei and Gao [18,19] developed the Pythagorean fuzzy interactive aggregation operator based on arithmetic and topological measures. As a means of simplifying supplier selection, Li [20] proposed a fuzzy Hamy mean operator. Gao [21] proposed a Pythagorean fuzzy Hamacher priority aggregation operator for MADM based on existing priority aggregation operators [22]. Wei and Lu [23] developed a Pythagorean fuzzy Maclaurin symmetric mean operator, which enabled the capture of relationships between multiple parameters.
A similarity measure is a mathematical function that assesses the degree of resemblance between two objects. In the context of fuzzy sets, similarity measures are of utmost importance in solving clustering, classification and decision-making problems [24,25,26]. At present, various similarity measures have been proposed for Pythagorean fuzzy sets:
- Wei [27] proposed some similarity measures between PFSs based on cosine function. To address the problem of MADM, Garg [28] developed a PFSs-based correlation measure and Wang [29] proposed a generalized Dice similarity measure. Zhang [30] introduced exponential functions and proposed several new similarity measures for Pythagorean fuzzy sets. Li [31] proposed a new similarity measure for PFSs based on spherical arc distance from a geometric perspective and constructed a MADM method in a Pythagorean fuzzy environment. Hussian and Yang [32] proposed new similarity measures for PFSs based on the Hausdorff measures and applied them to solve MADM problems. Li and Lu [33] proposed new similarity measures by extending the Hamming distance and Hausdorff distance. Zeng, Li and Yin [34] developed a novel similarity measure for PFSs and applied it to analyzing decision makers’ preferences. Zhang [35] presented a similarity measure and proposed a method for approximately calculating experts’ weights when their weights are entirely unknown. In addition, for more similarity measures for PFSs, please refer to the papers[36,37,38].
The concept of a similarity measure is used to express the degree of resemblance between individuals, while a distance measure represents the degree of divergence between individuals:
- Hussian and Yang [32] developed a measure to calculate the distance between PFSs using the Hasudorff measures. Li and Lu [33] proposed some novel distance while Xu [17] proposed a Hamming distance measure. Moreover, Ren, Xu and Gou [39] proposed a novel distance measure that builds upon the Euclidean distance model. Chen [40] has developed a novel method based on VIKOR for multi-criteria decision-making tasks involving Pythagorean fuzzy information. Simultaneously, Li and Zeng [41] proposed multiple distance measures after considering the four parameters of PFSs. Zeng, Li and Yin [34] proposed a series of modified distance measures by taking into account the importance of incorporating ambiguity into the equation. In addition, Chen [42] defined a novel generalized distance measure and devised a distance-based compromise method for decision analysis based on multiple criteria. There are more existing distance measures for PFSs [43,44,45].
In many cases, similarity and distance measures are used interchangeably, with distance being seen as the inverse of similarity, and vice versa. In practical applications, for distance calculations, the shortest distance is observed between the closest observation points, while for similarity calculations, the highest level of similarity is observed between the closest observation points.
Currently, the utilization of PFSs is exceedingly well-received [46,47,48,49,50,51,52], yet the existing similarity and distance measures may yield counter-intuitive outcomes in certain situations. Therefore, the exploration and utilization of similarity and distance measures for PFSs is a highly valuable area of inquiry. This paper proposes several novel similarity measures and distance measures for PFSs, inspired by Tanimoto similarity [53]. Our examples illustrate the properties of these measures. As well, a pair of models is also proposed for using these measures in patterns recognition, medical diagnosis, and MADM issues in Pythagorean fuzzy environments. As part of our experiment, we compared our proposed measures with a number of existing ones. In addition to overcoming numerous counter-intuitive scenarios in existing measures, our measures provide more differentiated measurement results when distinguishing between PFSs. These qualities exemplify the superior nature of our proposed measures.
The main contributions of this paper are as follows:
(1) We propose several similarity and distance measures for PFSs based on the Tanimoto similarity measure and prove their basic properties;
(2) Two models based on the Tanimoto measures are proposed and applied to pattern recognition, medical diagnosis and MADM problems to verify their effectiveness;
(3) Several experiments demonstrate that the proposed measures overcome counter-intuitive limitations of existing measures for PFSs and tend to produce more significant results when distinguishing PFSs.
Section 2 provides a brief review of the basic ideas and mathematical foundations of fuzzy sets. Several new similarity and distance measures for fuzzy sets are introduced in Section 3 and their mathematical properties are established. Section 4 presents two models based on the proposed measures to address pattern recognition, medical diagnosis and MADM problems, respectively. Section 5 draws conclusions and provides future research directions.
2. Preliminaries
In this section, some basic concepts related to fuzzy sets, Tanimoto measure and several existing measures for PFSs will be given.
2.1. Intuitionistic Fuzzy Sets
Definition 1
([6]). We utilize the symbol Z to denote a finite set. An Intuitionistic fuzzy set I is given by:
where signifies the membership degree of z, and expresses the nonmembership degree of z. , and satisfy:
, the indeterminacy degree of z is:
2.2. Pythagorean fuzzy sets
2.3. Tanimoto measure
Definition 3
3. Some novel tanimoto similarity and distance measures for PFSs
This section presents the Pythagorean fuzzy version of the Tanimoto measure, which includes both similarity and distance measures. Furthermore, we demonstrate several outstanding properties satisfied by the proposed measures. Comparative experiments with existing measures are conducted to verify their effectiveness and superiority.
3.1. Novel similarity measures
Definition 4.
For two PFSs, and , where , the Tanimoto similarity measure for them can be given by:
Theorem 1.
For any two PFSs F and G, the satisfies:
- 1.
- ;
- 2.
- ;
- 3.
- , if .
Proof of Theorem 1.
Therefore, we have finished the proofs. □
If we consider the weights of , a weighted Tanimoto similarity measure between PFSs F and G is proposed as fllows:
Definition 5.
For , take the weight . The weighted Tanimoto measure is described as:
Similar to the Proof of Theorem 1, we can get:
Theorem 2.
For any two PFSs F and G, the satisfies:
- 1.
- ;
- 2.
- ;
- 3.
- , if .
For , taking the indeterminacy degree , we can get:
3.2. Novel distance measures
Definition 6.
For two PFSs, and , where , the Tanimoto distance measure for them can be given by:
The larger the is, the greater the difference between two PFSs.
Theorem 3.
For any two PFSs F and G, the satisfies the conditions:
- 1.
- ;
- 2.
- ;
- 3.
- , if .
If we consider the weights of , a weighted Tanimoto distance measure between PFSs F and G is proposed as fllows:
Definition 7.
For , take the weight . The weighted Tanimoto measure is described as:
Theorem 4.
For any two PFSs F and G, the satisfies the conditions:
- 1.
- ;
- 2.
- ;
- 3.
- , if .
Taking the the indeterminacy degree into consideration, then:
3.3. Numerical experiments
Example 1.
Let be three PFSs in , which are expressed as:
Based on the equations presented before, the Tanimoto measures have been computed and shown in Table 2 and Table 3.
Taking the weights , the weighted Tanimoto measures between PFSs , and are shown in Table 4 and Table 5.
According to the results above, it is discernible that when , the Tanimoto measures between , and , which satisfies the Property 3 in Definition 4 and Property 3 in Definition 6. Besides, and , which satisfy the Property 2 in Definition 4 and Property 2 in Definition 6.
Example 2.
and are two PFSs in z, where
. In this example, Figure 1 illustrates the distribution of the proposed similarity measure under changes in both membership degree and nonmembership degree. As shown in Figure 1 (c) and Figure 1 (d), with variations in ρ and σ, the value of remains within the range of . Additionally, when ρ equals σ, the similarity measure between and achieves its maximum value of 1, and when ρ equals 1 and σ equals 0 or when ρ equals 0 and σ equals 1, it reaches its minimum value of 0. This confirms that the Tanimoto measure satisfies Property 1 as defined in Definition 4.
Example 3.
F and G are two PFSs under different cases in and shown in Table 6.
As Table 6 indicates, the F of 1 is equivalent to the F of 2, while their Gs differ. Hence, the similarity between F and G in 1 ought to differ from that of F and G in 2. Similar observations hold for other cases. Table 7 presents the outcomes of employing diverse similarity measures to assess the similarity between F and G across different cases. In each case group, we employed distinct colors to highlight the counter-intuitive outcomes generated by each measure. Specifically, red denotes counter-intuitive results obtained in 1 and 2, blue represents those in 3 and 4, and green indicates the counter-intuitive results observed in 5 and 6. Notably, most similarity measures yield counter-intuitive measure outcomes. Specifically, , , , and produce counter-intuitive outcomes on 1 and 2; , and yield counter-intuitive outcomes on 3 and 4; and, , , and yield counter-intuitive outcomes on 5 and 6. However, the proposed Tanimoto similarity measures perform correctly in all cases, demonstrating the superiority of our measures.
Example 4.
Similar to Example 3, we apply the proposed Tanimoto distance measures to the counter-intuitive cases of existing distance measures. As shown in Table 8, F and G are two PFSs under different cases, and Table 9 presents the measurement results. In each case group, we use different colors to highlight the counter-intuitive results generated by each measures. Specifically, produce counter-intuitive outcomes on 1 and 2; yield counter-intuitive outcomes on 3 and 4; and, and yield counter-intuitive outcomes on 5 and 6. However, the proposed Tanimoto distance measures perform correctly in all cases, demonstrating the superiority of our measures.
Example 5.
A, B and C are three random PFSs. We employ the proposed similarity measure to assess their similarity and subtract the minimum value from the maximum Tanimoto similarity value to obtain . We have conducted 100 such experiments and computed the average of the final results to get the average distance between the maximum and minimum values of similarity results in these 100 experiments (). Similarly, we will compare s obtained using other measures, as shown in Figure 3.
The findings in Figure 3 suggest that the Tanimoto similarity measure exhibits the maximum , indicating that the proposed similarity measure tends to assign more differentiated similarity values when distinguishing between different fuzzy sets. This attribute endows it with greater discriminatory power to discern different levels of similarity and enhances its performance in distinguishing PFSs with high similarity. A wider range of similarity values assigned to different PFSs may enhance the credibility of PFSs classification and foster more confident decision-making. On the other hand, has the smallest , which means that it is more likely to classify highly similar PFSs into the same category or exhibit more hesitation in selecting between different samples. This characteristic will be detrimental to high-precision decision-making. These results indicate that our proposed measures are superior to the existing measures. These characteristics will be further validated in the subsequent examples.
4. Applications
In this section, we introduce two models that utilize the proposed measures in pattern recognition, medical diagnosis and MADM problems. Furthermore, we conducted a series of experiments and compared our models with existing measures to demonstrate their effectiveness and superiority.
4.1. A model for pattern recognition and medical diagnosis
There are some known patterns , denoted by PFSs represented by a finite universe of discourse . There are some samples of unknown categories , denoted by . Our goal is to classify into the given patterns . The recognition process is described in detail below:
- Step 1
- Calculate the Tanimoto similarity(or distance) between and .
- Step 2
- Step 3
-
If any pattern has the highest Tanimoto similarity between , then, and belong to the same category:If distance measure is used as the standard of measure, then the following form would be applied:The pseudo code description of the model is as Algorithm 1.
| Algorithm 1 Algorithm for pattern recognition and medical diagnosis |
 |
Example 6.
This example is centered on the recognition of patterns. It leverages PFSs for the delineation of three instances whose categories have been confirmed, denoted as , as well as a solitary sample from an as yet unrecognized category, labeled S. The parameters that govern these samples are detailed in Table 10.
In order to ascertain the categorical ascription of the unknown sample S, we employed the Tanimoto similarity measures as delineated in our methodological framework:
- Step 1
- Step 2
- Step 3
- According to the principle of maximum similarity and minimum distance, the pattern recognition result of S are as follows:
Furthermore, the measurement results derived from the extant methods are detailed in Table 13.
Utilizing the data shown in Table 13, we can identify that S and demonstrate the highest degree of similarity. This finding is consistently confirmed across the Tanimoto similarity measures before, validating the effectiveness of the proposed similarity measures. It is noteworthy that the similarity scores derived from the Tanimoto measures exhibit significant variability. We computed the Tanimoto similarity values for all PFSs with respect to S and subtracted the second highest value from the maximum one, denoted as , and a similar analysis was conducted for other measures, as depicted in Figure 4. We can find that the Tanimoto similarity measure yields the highest and ranks third in terms of indeterminacy. The similarity scores between S and as determined by our proposed metrics are substantially different from those between S and other PFSs. Consequently, we can assert with confidence that is a more suitable pattern. However, the similarity scores between S and the known samples derived from other measures are more closely aligned. Hence, relying on these measures for decision-making may result in greater hesitation. These findings align with the conclusions drawn in Example 5, suggesting that our proposed measures are superior in distinguishing between samples.
Example 7.
In this example, the aim is to recognize mineral categories through pattern recognition. Specifically, we consider six common mixtures of minerals that are represented by PFSs , with each mixture consisting of six fundamental minerals which collectively form the universe of discourse . Our primary goal is to employ the proposed measure in order to determine the category to which an unknown mixed mineral S pertains. Table 14 displays the known PFSs and the unidentified mineral S, whereas Table 15 summarizes the resulting outcomes.
Table 15 displays the similarity measures for mineral S and , with the Tanimoto measure producing the highest similarity score. This result confirms that mineral S belongs to , which is consistent with findings from other studies that have used various similarity measures. Likewise, Figure 5 illustrates the among different measures, and the Tanimoto similarity measures rank the first and the second among the measures shown in the figure.
Example 8
([55]). Assuming the presence of four patients, namely Ragu, Mathi, Velu and Karthi, denoted by , and exhibiting symptoms including Headache, Acidity, Burning eyes, Back pain and Depression, represented as . The set of possible diagnoses is denoted by , and includes: : Stress; : Ulcer; : Vision problem; : Spinal problem; : Blood pressure. The Pythagorean fuzzy relation is expressed by PFS, as shown in Table 16, while the Pythagorean fuzzy relation is represented by PFSs and listed in Table 17. Every entry in both tables is defined by the PFS, with the values indicating membership degree and nonmembership degree, respectively. The proposed similarity and distance measures are employed to evaluate the similarity and distance between each patient and potential diagnosis. Based on the principle of maximum similarity or minimum distance, each patient is diagnosed accordingly. Table 18 and Table 19 present the similarity measure outcomes and distance measure outcomes of each patient I towards each diagnosis D, alongside the ultimate diagnosis results.
Based on the findings presented in Table 18 and Table 19, it is observed that exhibits the highest Tanimoto similarity measure and the lowest Tanimoto distance measure towards ; displays the highest Tanimoto similarity measure and the lowest Tanimoto distance measure towards ; demonstrates the highest Tanimoto similarity measure and the lowest Tanimoto distance measure towards ; and showcases the highest Tanimoto similarity measure and the lowest Tanimoto distance measure towards . Thus, we can conclude that Ragu is diagnosed with stress, Mathi with spinal problems, Velu with vision problems and Karthi with stress.
In order to validate the effectiveness of our proposed measures, a comparison was conducted against other methods, and the outcomes have been summarized in Table 20. It is observed from Table 20 that our proposed measures provide diagnostic outcomes that are consistent with those obtained using methods proposed by Xiao and Ding [55], Zhou [56] and Deng [57]. The experimental results lend support to the practicability of our proposed similarity and distance measures.
4.2. The model for MADM
Suppose that is a discrete set of alternatives, and is the set of attributes, is the weighting vector of the attribute , where , . is the experts evaluate, representing the type of each attribute, where 1 represents the benefit type and 0 represents the cost type. Suppose that is the Pythagorean fuzzy matrix, where indicates the degree that the alternative satisfies the attribute and indicates the degree that the alternative does not satisfy the attribute , , , , , . The proposed model is described below:
- Step 1
-
Defining the Pythagorean fuzzy positive ideal solution :The equation for correction is as follows:
- Step 2
-
Calculating the weighted Tanimoto similarity measure between and as follows:If the standard of measure is distance, then additional distance measures must be calculated in the following way:
- Step 3
- Step 4
-
If any alternative has the highest Tanimoto similarity between , then, is the most important alternative:If distance measure is used as the standard of measure, then the following form would be applied:The pseudo code description of the model is as Algorithm 2.
| Algorithm 1 Algorithm for MADM |
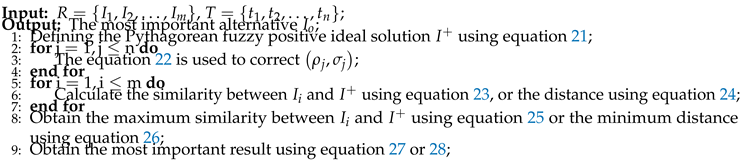 |
Example 9.
A company is planning to purchase a batch of computers, with six alternative model schemes to choose from, and has selected five attributes as selection criteria, including the materials used, reputation, response time, service life and price . The weights of these attributes are denoted by , where . After expert evaluation, all attribute types are provided: . Forming a Pythagorean fuzzy decision matrix :
We will utilize the proposed MADM model to select the most appropriate solution.
- Step 1
- Defining the Pythagorean fuzzy positive ideal solution . As we want the response time and price to be as low as possible, these two attributes are defined as cost types and set to :
- Step 2
- Step 3
- Step 4
Furthermore, we have obtained congruent outcomes by employing the MADM models proposed by Wang [29] and Zhang [30], respectively, which proves the effectiveness of the proposed model. The corresponding calculation outcomes have been delineated in Table 23 and Table 24, respectively. The parameter α is a positive constant and represents the positive ideal solution, which are calculated using Wang’s method.
5. Conclusions
In this study, we propose a set of innovative similarity and distance measures for PFSs, drawing inspiration from the Tanimoto coefficient. The experiment demonstrated that the proposed measures possess two outstanding characteristics: (1) avoiding numerous counter-intuitive outcomes caused by existing measures; and (2) providing more differentiated measurement results when distinguishing between different PFSs. Therefore, decision-making based on this measure can yield more confident results. Compared to some existing PFSs measures, the proposed measures are more effective and superior. We also designed two decision models based on the proposed measures and applied them to problems such as pattern recognition, medical diagnosis and multi-attribute decision-making to demonstrate their effectiveness. Future research will apply the various measures proposed to a wider range of scenario problems to confirm the potential of our measures and PFSs.
Funding
This work was supported by National Natural Science Foundation of China under grant No. 62102235 and Natural Science Foundation of Shandong Province under grant No. ZR2020QF029.
Data Availability Statement
The analyzed data used to support the findings of this study are included within the article.
Conflicts of Interest
The authors declare that there is no conflict of interest regarding the publication of this paper.
References
- Keith, A.J.; Ahner, D.K. A survey of decision making and optimization under uncertainty. Annals of Operations Research 2021, 300, 319–353. [Google Scholar] [CrossRef]
- Hariri, R.H.; Fredericks, E.M.; Bowers, K.M. Uncertainty in big data analytics: survey, opportunities, and challenges. Journal of Big Data 2019, 6, 1–16. [Google Scholar] [CrossRef]
- Yager, R.R. On using the Shapley value to approximate the Choquet integral in cases of uncertain arguments. IEEE Transactions on Fuzzy Systems 2017, 26, 1303–1310. [Google Scholar] [CrossRef]
- Wang, X.; Song, Y. Uncertainty measure in evidence theory with its applications. Applied Intelligence 2018, 48, 1672–1688. [Google Scholar] [CrossRef]
- Huang, B.; Li, H.; Feng, G.; Guo, C. Intuitionistic fuzzy β-covering-based rough sets. Artificial Intelligence Review 2020, 53, 2841–2873. [Google Scholar] [CrossRef]
- Atanassov, K.T. Intuitionistic fuzzy sets. Fuzzy Sets & Systems 1986, 20, 87–96. [Google Scholar]
- Yager, R.R. Generalized dempster–shafer structures. IEEE Transactions on Fuzzy Systems 2018, 27, 428–435. [Google Scholar] [CrossRef]
- Deng, Y. Uncertainty measure in evidence theory. Science China Information Sciences 2020, 63, 210201. [Google Scholar] [CrossRef]
- Ma, X.; Zhan, J.; Sun, B.; Alcantud, J.C.R. Novel classes of coverings based multigranulation fuzzy rough sets and corresponding applications to multiple attribute group decision-making. Artificial Intelligence Review 2020, 53, 6197–6256. [Google Scholar] [CrossRef]
- Aggarwal, M. Rough information set and its applications in decision making. IEEE Transactions on Fuzzy Systems 2017, 25, 265–276. [Google Scholar] [CrossRef]
- Wei, W.; Liang, J. Information fusion in rough set theory: An overview. Information Fusion 2019, 48, 107–118. [Google Scholar] [CrossRef]
- Seiti, H.; Hafezalkotob, A.; Martínez, L. R-sets, comprehensive fuzzy sets risk modeling for risk-based information fusion and decision-making. IEEE Transactions on Fuzzy Systems 2019, 29, 385–399. [Google Scholar] [CrossRef]
- Gulzar, M.; Alghazzawi, D.; Mateen, M.H.; Kausar, N. A certain class of t-intuitionistic fuzzy subgroups. IEEE Access 2020, 8, 163260–163268. [Google Scholar] [CrossRef]
- Aruna Kumar, S.; Harish, B. A modified intuitionistic fuzzy clustering algorithm for medical image segmentation. Journal of Intelligent Systems 2018, 27, 593–607. [Google Scholar] [CrossRef]
- Ngan, R.T.; Ali, M.; Fujita, H.; Abdel-Basset, M.; Giang, N.L.; Manogaran, G.; Priyan, M.; others. A new representation of intuitionistic fuzzy systems and their applications in critical decision making. IEEE Intelligent Systems 2019, 35, 6–17. [Google Scholar]
- Yager, R.R. Pythagorean membership grades in multicriteria decision making. IEEE Transactions on Fuzzy Systems 2013, 22, 958–965. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, Z. Extension of TOPSIS to multiple criteria decision making with Pythagorean fuzzy sets. International journal of intelligent systems 2014, 29, 1061–1078. [Google Scholar] [CrossRef]
- Wei, G. Pythagorean fuzzy interaction aggregation operators and their application to multiple attribute decision making. Journal of Intelligent & Fuzzy Systems 2017, 33, 2119–2132. [Google Scholar]
- Wei, G.; Wei, C.; Gao, H. Multiple attribute decision making with interval-valued bipolar fuzzy information and their application to emerging technology commercialization evaluation. IEEE Access 2018, 6, 60930–60955. [Google Scholar] [CrossRef]
- Li, Z.; Wei, G.; Lu, M. Pythagorean fuzzy hamy mean operators in multiple attribute group decision making and their application to supplier selection. Symmetry 2018, 10, 505. [Google Scholar] [CrossRef]
- Hui, G. Pythagorean fuzzy Hamacher Prioritized aggregation operators in multiple attribute decision making. Journal of Intelligent and Fuzzy Systems 2018, 35, 2229–2245. [Google Scholar]
- Wei, G.; Wei, Y. Some single-valued neutrosophic dombi prioritized weighted aggregation operators in multiple attribute decision making. Journal of Intelligent & Fuzzy Systems 2018, 35, 2001–2013. [Google Scholar]
- Wei, G.; Lu, M. Pythagorean fuzzy Maclaurin symmetric mean operators in multiple attribute decision making. International Journal of Intelligent Systems 2018, 33, 1043–1070. [Google Scholar] [CrossRef]
- Wang, H.; Peng, M.j.; Yu, Y.; Saeed, H.; Hao, C.m.; Liu, Y.k. Fault identification and diagnosis based on KPCA and similarity clustering for nuclear power plants. Annals of Nuclear Energy 2021, 150, 107786. [Google Scholar] [CrossRef]
- Singh, S.; Ganie, A.H. Applications of picture fuzzy similarity measures in pattern recognition, clustering, and MADM. Expert Systems with Applications 2021, 168, 114264. [Google Scholar] [CrossRef]
- Marins, M.A.; Ribeiro, F.M.; Netto, S.L.; Da Silva, E.A. Improved similarity-based modeling for the classification of rotating-machine failures. Journal of the Franklin Institute 2018, 355, 1913–1930. [Google Scholar] [CrossRef]
- Wei, G.; Wei, Y. Similarity measures of Pythagorean fuzzy sets based on the cosine function and their applications. International Journal of Intelligent Systems 2018, 33, 634–652. [Google Scholar] [CrossRef]
- Garg, H. A novel correlation coefficients between Pythagorean fuzzy sets and its applications to decision-making processes. International Journal of Intelligent Systems 2016, 31, 1234–1252. [Google Scholar] [CrossRef]
- Wang, J.; Gao, H.; Wei, G. The generalized Dice similarity measures for Pythagorean fuzzy multiple attribute group decision making. International Journal of Intelligent Systems 2019, 34, 1158–1183. [Google Scholar] [CrossRef]
- Zhang, Q.; Hu, J.; Feng, J.; Liu, A.; Li, Y. New similarity measures of Pythagorean fuzzy sets and their applications. IEEE Access 2019, 7, 138192–138202. [Google Scholar] [CrossRef]
- Li, J.; Wen, L.; Wei, G.; Wu, J.; Wei, C. New similarity and distance measures of Pythagorean fuzzy sets and its application to selection of advertising platforms. Journal of Intelligent & Fuzzy Systems 2021, 40, 5403–5419. [Google Scholar]
- Hussian, Z.; Yang, M.S. Distance and similarity measures of Pythagorean fuzzy sets based on the Hausdorff metric with application to fuzzy TOPSIS. International Journal of Intelligent Systems 2019, 34, 2633–2654. [Google Scholar] [CrossRef]
- Li, Z.; Lu, M. Some novel similarity and distance measures of pythagorean fuzzy sets and their applications. Journal of Intelligent & Fuzzy Systems 2019, 37, 1781–1799. [Google Scholar]
- Zeng, W.; Li, D.; Yin, Q. Distance and similarity measures of Pythagorean fuzzy sets and their applications to multiple criteria group decision making. International Journal of Intelligent Systems 2018, 33, 2236–2254. [Google Scholar] [CrossRef]
- Zhang, X. A novel approach based on similarity measure for Pythagorean fuzzy multiple criteria group decision making. International Journal of Intelligent Systems 2016, 31, 593–611. [Google Scholar] [CrossRef]
- Pan, L.; Gao, X.; Deng, Y.; Cheong, K.H. Constrained Pythagorean fuzzy sets and its similarity measure. IEEE Transactions on Fuzzy Systems 2021, 30, 1102–1113. [Google Scholar] [CrossRef]
- Athira, T.; John, S.J.; Garg, H. A novel entropy measure of Pythagorean fuzzy soft sets. AIMS Mathematics 2020, 5, 1050–1061. [Google Scholar] [CrossRef]
- Habib, A.; Akram, M.; Kahraman, C. Minimum spanning tree hierarchical clustering algorithm: a new Pythagorean fuzzy similarity measure for the analysis of functional brain networks. Expert Systems with Applications 2022, 201, 117016. [Google Scholar] [CrossRef]
- Ren, P.; Xu, Z.; Gou, X. Pythagorean fuzzy TODIM approach to multi-criteria decision making. Applied soft computing 2016, 42, 246–259. [Google Scholar] [CrossRef]
- Chen, T.Y. Remoteness index-based Pythagorean fuzzy VIKOR methods with a generalized distance measure for multiple criteria decision analysis. Information Fusion 2018, 41, 129–150. [Google Scholar] [CrossRef]
- Li, D.; Zeng, W. Distance measure of Pythagorean fuzzy sets. International Journal of Intelligent Systems 2018, 33, 348–361. [Google Scholar] [CrossRef]
- Chen, T.Y. Novel generalized distance measure of pythagorean fuzzy sets and a compromise approach for multiple criteria decision analysis under uncertainty. Ieee Access 2019, 7, 58168–58185. [Google Scholar] [CrossRef]
- Ullah, K.; Mahmood, T.; Ali, Z.; Jan, N. On some distance measures of complex Pythagorean fuzzy sets and their applications in pattern recognition. Complex & Intelligent Systems 2020, 6, 15–27. [Google Scholar]
- Mahanta, J.; Panda, S. Distance measure for Pythagorean fuzzy sets with varied applications. Neural Computing and Applications 2021, 33, 17161–17171. [Google Scholar] [CrossRef] [PubMed]
- Zhou, F.; Chen, T.Y. A novel distance measure for pythagorean fuzzy sets and its applications to the technique for order preference by similarity to ideal solutions. International Journal of Computational Intelligence Systems 2019, 12, 955–969. [Google Scholar] [CrossRef]
- Deveci, M.; Eriskin, L.; Karatas, M. A survey on recent applications of pythagorean fuzzy sets: A state-of-the-art between 2013 and 2020. Pythagorean Fuzzy Sets: Theory and Applications 2021, 3–38. [Google Scholar] [CrossRef]
- Farhadinia, B. Similarity-based multi-criteria decision making technique of pythagorean fuzzy sets. Artificial Intelligence Review 2022, 55, 2103–2148. [Google Scholar] [CrossRef]
- Verma, R.; Mittal, A. Multiple attribute group decision-making based on novel probabilistic ordered weighted cosine similarity operators with Pythagorean fuzzy information. Granular Computing 2023, 8, 111–129. [Google Scholar] [CrossRef]
- Premalatha, R.; Dhanalakshmi, P. Enhancement and segmentation of medical images through pythagorean fuzzy sets-An innovative approach. Neural Computing and Applications 2022, 34, 11553–11569. [Google Scholar] [CrossRef] [PubMed]
- Riaz, M.; Naeem, K.; Peng, X.; Afzal, D. Pythagorean fuzzy multisets and their applications to therapeutic analysis and pattern recognition. Punjab University Journal of Mathematics 2020, 52. [Google Scholar]
- Lin, M.; Huang, C.; Chen, R.; Fujita, H.; Wang, X. Directional correlation coefficient measures for Pythagorean fuzzy sets: their applications to medical diagnosis and cluster analysis. Complex & Intelligent Systems 2021, 7, 1025–1043. [Google Scholar]
- Peng, X.; Garg, H. Multiparametric similarity measures on Pythagorean fuzzy sets with applications to pattern recognition. Applied Intelligence 2019, 49, 4058–4096. [Google Scholar] [CrossRef]
- Lipkus, A.H. A proof of the triangle inequality for the Tanimoto distance. Journal of Mathematical Chemistry 1999, 26, 263–265. [Google Scholar] [CrossRef]
- Ejegwa, P.; Awolola, J. Novel distance measures for Pythagorean fuzzy sets with applications to pattern recognition problems. Granular Computing 2021, 6, 181–189. [Google Scholar] [CrossRef]
- Xiao, F.; Ding, W. Divergence measure of Pythagorean fuzzy sets and its application in medical diagnosis. Applied Soft Computing 2019, 79, 254–267. [Google Scholar] [CrossRef]
- Zhou, Q.; Mo, H.; Deng, Y. A new divergence measure of pythagorean fuzzy sets based on belief function and its application in medical diagnosis. Mathematics 2020, 8, 142. [Google Scholar] [CrossRef]
- Deng, Z.; Wang, J. New distance measure for Fermatean fuzzy sets and its application. International Journal of Intelligent Systems 2022, 37, 1903–1930. [Google Scholar] [CrossRef]
Figure 1.
The value of Tanimoto similarity varying with and in example 2.

Figure 2.
The value of Tanimoto distance varying with and in example 2.
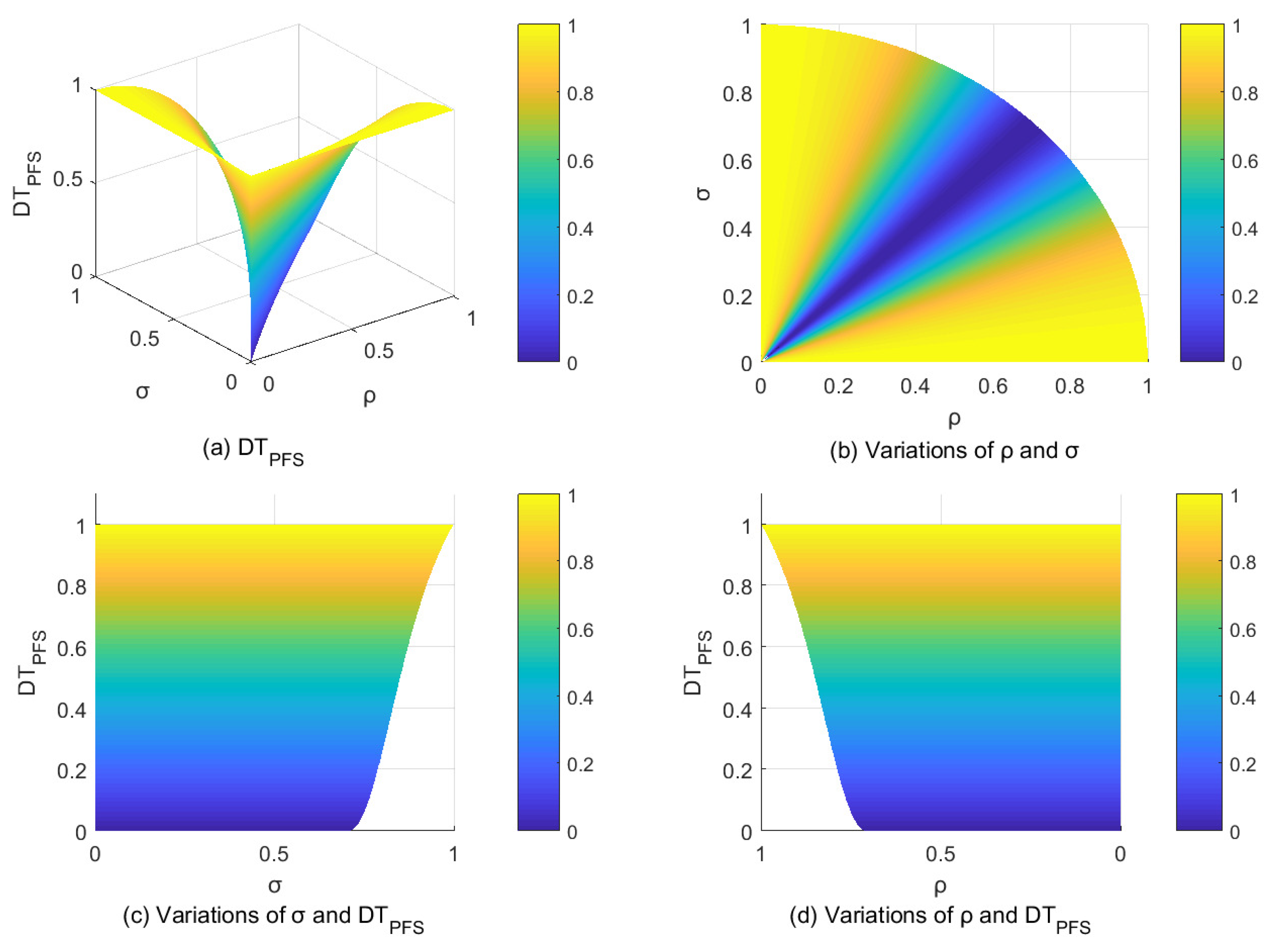
Figure 3.
Difference between the highest and lowest values obtained by different measures in Example 5.
Figure 3.
Difference between the highest and lowest values obtained by different measures in Example 5.
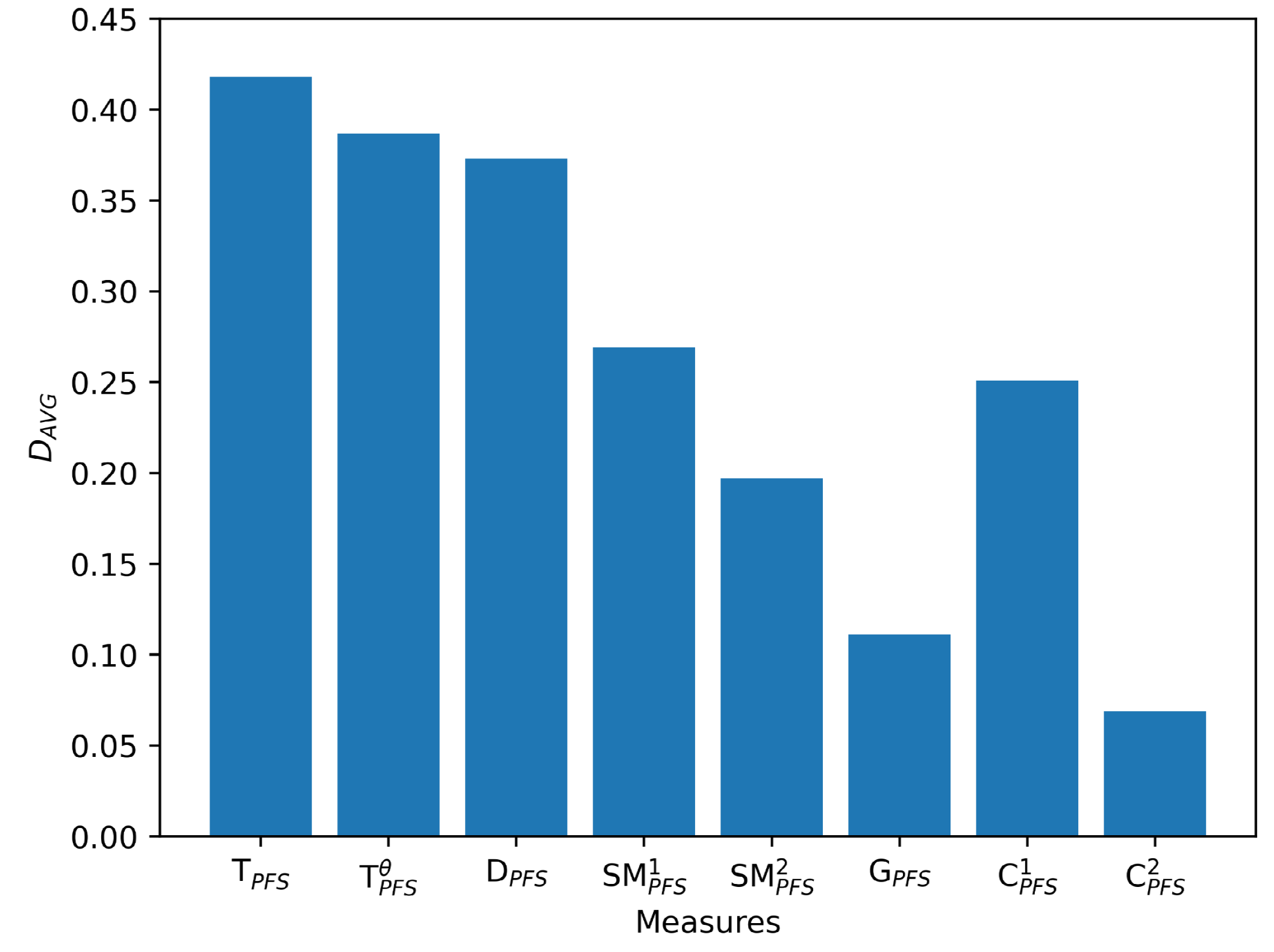
Figure 4.
Difference between the highest and second-highest values obtained by different measures in Example 6 .
Figure 4.
Difference between the highest and second-highest values obtained by different measures in Example 6 .
Figure 5.
Difference between the highest and second-highest values obtained by different measures in Example 7 .
Figure 5.
Difference between the highest and second-highest values obtained by different measures in Example 7 .
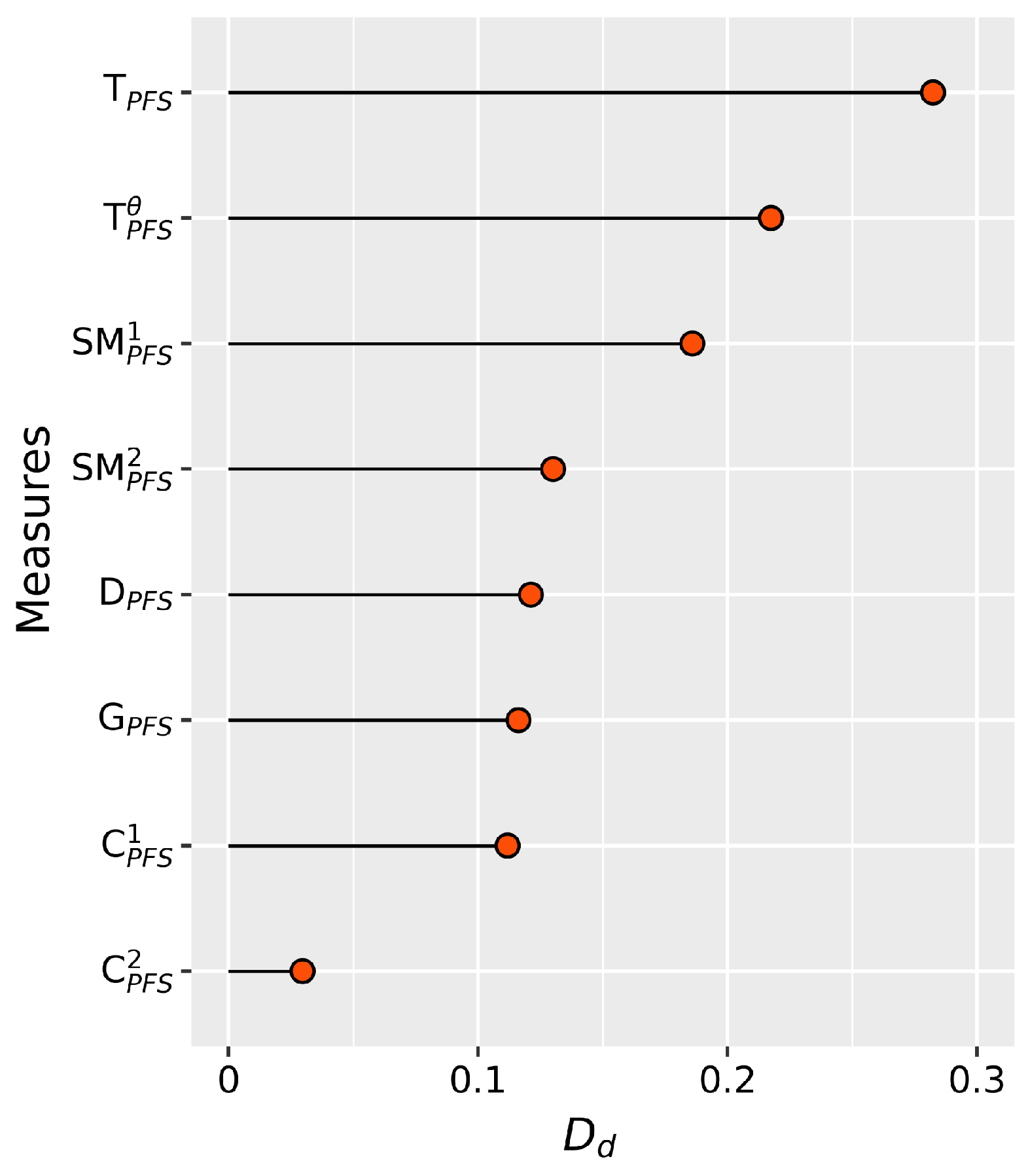

Table 1.
Exiting similarity and distance measures for PFSs.
| Zhang [30] | |
| Zhang [30] | |
| Wang [29] | |
| Li [31] | |
| Wei [27] | |
| Wei [27] | |
| Li [31] | ; ; ; ; |
| Ejegwa [54] |
Table 2.
The outcomes using Tanimoto similarity measures in Example 1
| Measures | |||
|---|---|---|---|
| 1.0000 | 0.4266 | 0.4266 | |
| 1.0000 | 0.6732 | 0.6732 |
Table 3.
The outcomes using Tanimoto distance measures in Example 1
| Measures | |||
|---|---|---|---|
| 0.0000 | 0.5734 | 0.5734 | |
| 0.0000 | 0.3268 | 0.3268 |
Table 4.
The outcomes using weighted Tanimoto similarity measures in Example 1
| Measures | |||
|---|---|---|---|
| 1.0000 | 0.4204 | 0.4204 | |
| 1.0000 | 0.9133 | 0.9133 |
Table 5.
The outcomes using weighted Tanimoto distance measures in Example 1
| Measures | |||
|---|---|---|---|
| 0.0000 | 0.5796 | 0.5796 | |
| 0.0000 | 0.0867 | 0.0867 |
Table 6.
PFSs F and G under different cases in Example 3
| PFSs | ||
|---|---|---|
| F | ||
| G | ||
| PFSs | ||
| F | ||
| G | ||
| PFSs | ||
| F | ||
| G |
Table 7.
The results of different similarity measures in Example 3
| Measures | ||||||
|---|---|---|---|---|---|---|
| 0.573 | 0.639 | 0.912 | 0.905 | 0.579 | 0.713 | |
| 0.697 | 0.909 | 0.935 | 0.917 | 0.592 | 0.722 | |
| 0.719 | 0.770 | 0.806 | 0.791 | 0.617 | 0.617 | |
| 0.840 | 0.840 | 0.875 | 0.875 | 0.774 | 0.693 | |
| 0.746 | 0.746 | 0.884 | 0.884 | 0.697 | 0.799 | |
| 0.800 | 0.800 | 0.879 | 0.879 | 0.765 | 0.765 | |
| 0.887 | 0.887 | 0.972 | 0.965 | 0.894 | 0.894 | |
| 0.971 | 0.971 | 0.993 | 0.991 | 0.973 | 0.973 |
Table 8.
PFSs F and G under different cases in Example 4
| PFSs | ||
|---|---|---|
| F | ||
| G | ||
| PFSs | ||
| F | ||
| G | ||
| PFSs | ||
| F | ||
| G |
Table 9.
The results of different distance measures in Example 4
| Measures | ||||||
|---|---|---|---|---|---|---|
| 0.939 | 0.805 | 0.970 | 0.892 | 0.592 | 0.801 | |
| 0.578 | 0.555 | 0.724 | 0.528 | 0.587 | 0.523 | |
| 0.269 | 0.269 | 0.445 | 0.321 | 0.283 | 0.283 | |
| 0.258 | 0.187 | 0.362 | 0.362 | 0.178 | 0.178 |
Table 10.
Known PFSs and a simple S in Example 6
| S |
Table 11.
The results of Tanimoto similarity measures in Example 6
| Measures | |||
|---|---|---|---|
| 0.403 | 0.804 | 0.364 | |
| 0.387 | 0.713 | 0.373 |
Table 12.
The results of Tanimoto distance measures in Example 6
| Measures | |||
|---|---|---|---|
| 0.597 | 0.196 | 0.636 | |
| 0.613 | 0.287 | 0.627 |
Table 13.
The results of different similarity measures in Example 6
| Measures | |||
|---|---|---|---|
| 0.560 | 0.886 | 0.555 | |
| 0.540 | 0.689 | 0.536 | |
| 0.648 | 0.779 | 0.659 | |
| 0.798 | 0.878 | 0.807 | |
| 0.719 | 0.859 | 0.707 | |
| 0.926 | 0.964 | 0.922 |
Table 14.
Known PFSs and a simple S in Example 7
| S |
Table 15.
Results of different similarity measures in Example 7
| Measures | ||||||
|---|---|---|---|---|---|---|
| 0.294 | 0.194 | 0.207 | 0.603 | 0.321 | 0.144 | |
| 0.310 | 0.233 | 0.315 | 0.613 | 0.395 | 0.198 | |
| 0.452 | 0.303 | 0.462 | 0.591 | 0.470 | 0.304 | |
| 0.383 | 0.400 | 0.441 | 0.627 | 0.436 | 0.314 | |
| 0.518 | 0.518 | 0.573 | 0.703 | 0.546 | 0.495 | |
| 0.775 | 0.746 | 0.759 | 0.848 | 0.790 | 0.733 | |
| 0.638 | 0.610 | 0.566 | 0.811 | 0.699 | 0.541 | |
| 0.904 | 0.895 | 0.880 | 0.951 | 0.921 | 0.875 |
Table 16.
Symptomatic characteristic of the patient in Example 8
Table 17.
Symptomatic characteristic of the diagnosis in Example 8
Table 18.
Diagnostic results of the Tanimoto similarity measure in Example 8
| Classification | ||||||
|---|---|---|---|---|---|---|
| 0.564 | 0.432 | 0.450 | 0.132 | 0.169 | ||
| 0.142 | 0.233 | 0.236 | 0.530 | 0.446 | ||
| 0.317 | 0.256 | 0.617 | 0.127 | 0.222 | ||
| 0.676 | 0.363 | 0.281 | 0.150 | 0.145 |
Table 19.
Diagnostic results of the Tanimoto distance measure in Example 8
| Classification | ||||||
|---|---|---|---|---|---|---|
| 0.436 | 0.568 | 0.550 | 0.868 | 0.831 | ||
| 0.858 | 0.767 | 0.764 | 0.470 | 0.554 | ||
| 0.683 | 0.744 | 0.383 | 0.873 | 0.778 | ||
| 0.324 | 0.637 | 0.719 | 0.850 | 0.855 |
Table 20.
Comparisons of different methods in Example 8
| Methods | ||||
|---|---|---|---|---|
| Stress | Spinal problem | Vision problem | Stress | |
| Xiao and Ding | Stress | Spinal problem | Vision problem | Stress |
| Zhou | Stress | Spinal problem | Vision problem | Stress |
| Deng | Stress | Spinal problem | Vision problem | Stress |
Table 21.
The results of Tanimoto similarity measures in Example 9
| Measures | ||||||
|---|---|---|---|---|---|---|
| 0.747 | 0.913 | 0.019 | 0.699 | 0.381 | 0.474 | |
| 0.696 | 0.870 | 0.014 | 0.642 | 0.337 | 0.337 |
Table 22.
The results of Tanimoto distance measures in Example 9
| Measures | ||||||
|---|---|---|---|---|---|---|
| 0.253 | 0.087 | 0.981 | 0.301 | 0.619 | 0.526 | |
| 0.304 | 0.130 | 0.986 | 0.358 | 0.663 | 0.663 |
Table 23.
The results of Dice similarity measure in Example 9
| 0.654 | 0.822 | 0.021 | 0.557 | 0.345 | 0.379 | |
| 0.762 | 0.897 | 0.028 | 0.691 | 0.445 | 0.503 | |
| 0.975 | 1.020 | 0.053 | 1.017 | 0.726 | 0.893 | |
| 1.234 | 1.138 | 0.162 | 1.573 | 1.381 | 2.136 |
Table 24.
The results of Exponential similarity measure in Example 9
| Measures | ||||||
|---|---|---|---|---|---|---|
| 0.366 | 0.479 | 0.122 | 0.357 | 0.185 | 0.273 | |
| 0.450 | 0.629 | 0.326 | 0.505 | 0.398 | 0.486 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



