
Submitted:
10 January 2024
Posted:
11 January 2024
You are already at the latest version
Abstract
It is unavoidable that the characteristics of the robot system alter inexactly or cannot be correctly determined during movement and are impacted by external disturbances. There are many adaptive control methods, such as sliding control or neural control, to improve the quality of trajectory tracking for robot motion systems. Still, those methods require a large amount of computation related to solving the problem of constrained nonlinear optimization problem. The article presents some techniques for determining an intelligent controller's online learning function parameters, including two circuits: the inner circuit is a state feedback linearized controller, and the outer course is an Interactive learning controller and does not use the robot's mathematical mode with function parameters online optimal learning and intelligent online learning closely following the joint model to stabilize the robot system. Finally, the 2-DOF planar robot simulation is performed on Matlab software R2022b. The findings indicate that outstanding tracking performance is achievable.
Keywords:
Interactive learning control (ILC)
; estimated according to the Taylor series
; intelligent feedback
1. Introduction
Robots have been widely used in many industrial fields, so countless robot control methods have been researched and applied, helping robots achieve accurate trajectory tracking. However, these methods are all built based on the mathematical model describing the robot, and they are classified depending on the level of accuracy of that mathematical model. The Euler - Lagrange model is a form of mathematical model often used for developing and synthesizing controllers, and it is impacted by external input noise d(t) as follows:
In which is the vector of joint variables; is the vector of uncertain parameters; is the inertia matrix that is always positive definite symmetry; is the vector of Coriolis and centrifugal components; describes the effect of friction; is the vector gravity; is the noise vector in the actuator and you is the control signal.
With the matching variables equal to the number of input signals, such a robot system has enough actuators. The robot control task is to build a feedback controller so that the output is the joint variables that follow the desired trajectory and the tracking quality does not depend on uncertain parameters and components and external noise. Over time, due to many objective factors, such as equipment wear and tear from environmental impacts, the initially set design quality is no longer guaranteed. In this case, it is common to rebuild the controller. As we know, to design an industrial robot motion control system using the traditional method, one thing that cannot be changed is to always clearly understand the control object, which means the control object must be controlled and expressed in modeling in the form of some mathematical model that accurately describes the object, which here can be a transfer function and can also be a state model in the form of a system of differential equations-highest classification. At the same time, when building and designing a motion control system, it is necessary to anticipate objective factors that will not impact the system as expected, such as external interference, etc., leading to damage to the system. The control is no longer as effective as before, and one must redefine the mathematical model of the control object, re-evaluate the rules of unwanted effects, bring objectivity into the system, Rebuild the controller, or at least redefine the parameters for the controller. There have been many control methods to solve the above problem, for example, the exact linearization method [1]. If the external noise component passes, but the indeterminate constant parameter still exists, we have the inverse control method of the model [2]. In cases where both external noise components and uncertain constant parameters exist, there is a sliding control method [3]. However, the disadvantage of the sliding control method is the phenomenon of chattering when the system slides on the sliding surface at a high frequency. To improve this vibration phenomenon, there is also a high-order sliding control method [4], but it still requires an estimated value of the maximum standard deviation of the model caused by andand cannot eliminate it. Due to vibration, there is still a risk of premature failure of robot mechanical equipment components. To overcome the above disadvantages, intelligent control methods can be used, such as the control trend of not using the robot's dynamic model (1), so the control quality is not affected. by components ) and .The intelligent control method mainly applied to robots mentioned in the article is the iterative learning method [5]. This integrated control method with cyclic working systems requires the same state. At the same time, the parameters ) and are also required to be periodic and have the exact change period as the working cycle of industrial robots. The primary iterative learning control method is only sometimes applied to meet the desired control quality. There have been many improvements to iterative learning to improve control quality and expand the scope of practical applications. The first improvement is the improvement of combining iterative learning with traditional control methods, often called indirect iterative learning or direct transmission iterative learning. These improvements include [6] when the friction component alone cannot be determined, [7] when that is not possible, or [8] when the learning function parameters cannot be found, as well as when the learning function parameters need to be changed. Change during work cycles. A control trend for a class of robotic systems is model matching control, including [9]. This control method requires the mathematical model (1), which will encounter problems and disadvantages of previous traditional control methods. The next improvement is to use model-based control but almost entirely not use the mathematical model (1) of the robot, applicable to both cases where ) and are dependent. It depends on time and does not require periodicity, so it can be considered an intelligent model-matching control method. This method is based on theoretical results on optimal control of each segment on the time axis available in [10] and applying disturbance estimation to control self-balancing two-wheeled vehicles [11].
The main content of the article is to analyze and evaluate additional improvements to essential iterative learning to improve the quality of motion control of robot systems and expand the scope of practical applications, specifically, Intelligent control based on model matching (model matching) almost wholly does not need to use the mathematical model of the robot system, applicable to the case where ) and depends on time, no need for circulation for the robot system. The content of the article includes six parts. Part 1 is the problem of researching iterative learning for robot systems. Part 2 presents the results of the 2-DOF robot dynamic equation; Part 3 presents two robot control structures using iterative learning; Part 4: The first structure controls the robot using iterative learning; Part 5 and part 6: The second structure controls the robot using iterative learning; Part 7 is conclusions and future research directions.
2. Robot planar dynamic model
A 2-DOF planar robot arm is shown in Figure 1, where are respectively.
The dynamic equations for this system can be found using the Lagrange Euler formulation [1]. The dynamic model of the two-DOF:
with the following results:
Problems that arise in working in real-time, factors that cannot be ignored include the impact of interference on the system and unwanted changes to model parameters. The control problem is the signal tracking control for the industrial robot motion system. The most comprehensive solution would be the method of using iterative learning control. This method can be added to a traditional control system to compensate for system errors, or it can also be applied immediately to robots without a conventional controller. The content of the article proposes 02 solutions to control industrial robots by iterative learning using innovative online learning parameters presented explicitly in sections 4, 5, and section 6.
3. Two structure diagrams for robot control using iterative learning method
The content of the article proposes 02 solutions to control industrial robots by iterative learning using innovative online learning parameters Figure 2 and Figure 3.
These two solutions are different because we need to add an intermediate controller in the inner loop with the first solution, but we do not with the second solution. The task of this medium inner-loop controller is to make the industrial robot system adapt to the iterative learning control principle later because the iterative learning controller often requires the control object to be stable (possibly no need for asymptotic stabilization). We need the mathematical model (1) of the industrial robot system to design an intermediate controller as a stable system. In the second solution, the uncertainty estimation block, in addition to the pure task of estimating the function uncertainty components to perform input compensation, must also carry out the additional function of making a stable system. If we apply the "smart" estimation principle introduced in part 5 to design the uncertainty estimation block, then with the second solution, we do not need the industrial robot system's mathematical model (1). However, the price for this is that the processing speed of the second solution will be much slower than the first solution. According to the simulation results obtained, it's about 140 times slower. In addition, since both of these solutions use an uncertainty estimation block for compensation control, they will be applicable for adaptive control of industrial robot systems with additional noise in the input, i.e., applying the method described by (4), (15). This is also a difference from the original model (1) because interference in the actuators is unavoidable. Furthermore, it is possible to assume that this input disturbance can contain matched model uncertainties. In that case, both control solutions are adaptive to the trouble and robustness of model bias.
4. Structure the first diagram for robot control the iterative learning method
4.1. Algorithm content according to the first control diagram
The mathematical model (1) and assume that is undetermined. Then we have:
With the sum of all the functional uncertainty components of the model:
It can be seen immediately that when used:
With being two properly chosen matrices, the system becomes:
where is an uncertain component of system (7).
The model (7) will have the canonical form:
In addition, for system (9) to be stable, that is, to have a Hurwitz matrix A, we must choose two matrices so that the eigenvalues of A given in (7) lie to the left of the imaginary axis. The simplest way is to choose them according to the method of assigning pole points using Matlab's place(.) command, and these pole points should be selected as accurate (negative) numbers to eliminate fluctuations during transitions.
And then the system output:
Follow the given periodic pattern trajectory
Now we use notation: Give the input and output of systems (9) (10), respectively at the time in the k test, with being the sample extraction cycle. Then the P-type learning function, standard to all update time i at the k time, will be:
Where:
K is the matrix of learning functions that must be chosen so that the learning function converges.
The uncertainty component of the system, in general, can be estimated and explicitly compensated as follows: First, we must approximate model (9) at time i in the k time, then when paid by , becomes:
Hence, In which: So from , we have the estimated valuefor the next offset at time i+1 as:
The structure of the intelligent control system for industrial robots is shown in Figure 2.
Below is the algorithm describing the steps to calculate an iterative learning controller, combined with identifying and compensating uncertain components (no need repetitive) for industrial robots after accurate linearization; several tries k is continuous along with the control process and only ends when the control stops.
Algorithm 1: structure the first for robot control the iterative learning method is with function parameters smart online learning
| 1 | Assign Choose ; Calcutate . Choose K; Assign small value . |
| 2 | while continue the control do |
| 3 | fordo |
| 4 | Send to into uncertain control (9) and determine . |
| 5 | Calcutate . |
| 6 | Establish and calcutate . |
| 7 | end for |
| 8 | Set up the sum vector. từ , theo (11) |
| 9 | Update vector from its existing value according to (10) that is, calculate the values., |
| 10 | Set |
| 11 | end while |
4.2. Applied to robot control
For the simulation, there are assigned:
The orbits are set as two periodic functions of period T as follows:
The simulation results in Figure 4 and Figure 5 show that, when combined with the identification and noise compensation stages of the traditional controller (13), the iterative learning controller (11) has achieved good signal tracking quality. The preset error with tracking error after 60 trials is small enough and acceptable: . The residual error in the simulation results is due to the non-smooth trapezoidal signal set at . It also affects the tracking error due to channel interleaving in the system.
5. The structure of the second iterative learning controller with model-free determination of optimal learning parameters for industrial robot
To stabilize the system without using traditional control methods. This makes it possible to apply iterative learning control to even unstable systems without using a mathematical model of the system.
Tool: Estimate the derivative using Taylor series analysis.
5.1. Algorithm content according to the first control diagram
where are two arbitrarity chosen matrices and
From (15) we see that the route cost calculation of model (1) is contained in this vector. Based on the equivalent model (14), the proposed intelligent controller for the robot is as follows:
First, the estimation errors of the new unknown function vector will be adjusted, as shown below.
With the estimation of bias as (17) system (14) will become linear:
and , are square matrices with zero
Secondly, control the compensation system in equation (17) so that its output will converge to a desired reference value .
5.2. Feedback linearization for internal loop control using model-free disturbance compensation
Returning to the compensator in equation (16) and designating as the present working period i.e. with then (17) is rewritten as:
The automatic mode – free feedback linearization block (Figure 2) aims to estimate from the measured values of at two times and for each corresponding value. With being an arbitrarily chosen constant small value, then we expand the Taylor function of the function around as follows,
Where
Assuming the last term of expression (20) is very small and can be ignored, the expression will be used to approximate equation (19) by replacing the signs “”and in (10) with "=" and
Then, calculate
which yields
Theorem 1: The value calculated in equation (23) causes the approximation error of expression (22) to decrease.
Proof: Error in expression (22) will be calculated:
where
And the estimated value will also be calculated according to expression (22) as follows:
The optimization problem would then be written:
has a unique solution
which coincides with given in (23).
From (23) we see that the estimation tool created to compensate for noise and uncertainty in the vector model does not use the mathematical model (1). Therefore, the noise compensator (16) with obtained from expression (23) will be model–free.
5.3. Outer loop control is by iterative learning controller design.
Expression (17) describes the system (14) that becomes LTI by compensating the synthetic disturbances in (15) by the compensator (16), and it is rewritten in ILC language for iterative learning systems as after:
where
The control objective at this point is to choose the proper learning parameter K for the update rule P-Type, assuming we have identified two matrices that make the matrix A provided in equation (6).
In order to satisfy the required convergence for all i , or at least as close as possible to the orgin.
The value given by ILC (26) is partially constant, so the discrete time model in equation (24) obtained is equivalent to the continuous time model in equation (17). In expression (24), no information about the system model (1) is used either. Therefore (24) can be applied to all robot controllers. From (24), it is obtained with the assumption .
This results from (24) and the clear demonstration of repeatable ability
Hence,
Where
Theorem 2: For the scenario, all requirementsfor allwill only be satisfied if and when the P-Type learning parameter K is selected in a way that makes the value supplied in (16) Schur.
Proof: For the autonomous system (27) the proof is comprehensive as it is clear that it is stable if and only if it is Schur.
5.4. Control algorithm and performance of closed – loop system
The following algorithm is established to implement the proposed model-free controller (16) where the and values are obtained from expressions (26) and (13), respectively. In this control algorithm, the working time T of the robots is repeatedly tested by each While loop.
In fig. 2 illustrates the output tracking performance of the closed-loop system with the output scenario .
Theorem 3:The proposed mode-free control framework in Fig. 1 (which includes the feedback linearization block via disturbance compensator (16), (23) and the ILC block (26), drives the robot manipulators' (1) output tracking errorto adependent neighborhoodof origin if d is limited and continuous. If a smaller is selected, a smallerwill be.
Proof: Because noiseis continuous and bounded, the total noiseand componentare also continuous and bounded. The upper limit ofisand this limit can be reduced arbitrarily by reducingaccording to theorem 1
The validity of Theorem 2 was confirmed by
The subtraction (29) from (17) yields
Lyapaunov equation with optional positive definite matrix Q we always have positive definite P because A is Hurwitz. From the positive definite function we have the result:
with is is the maximum value of the Q matrix.
Since as long as
The orbital error vector tends to the origin
This control algorithm contains all the necessary calculations and has the following structure:
Algroithm 2: The structure of the second iterative learning controller with model-free determination of optimal learning parameters for industrial robot
| 1 | Choose two matrices ,, given in (25) become Hurwitz . Determine given in (25) and given in (28). Choose . Calculate . Determine given in (23) Choose learning and tracking error . Assign . Choose learning parameter K so that Φ of (16) becomes Schur. |
| 2 | while continue the control do |
| 3 | fordo |
| 4 | Send to robot for a whilr of . measure , . |
| 5 | calculate . |
| 6 | end for |
| 7 | establish . |
| 8 | calculate and |
| 9 | end while |
Thus, each while - do loop represents one working cycle (one attempt) in this algorithm. In addition, it can be seen that the above control algorithm does not use model (1) of the robot at all, so it is also an intelligent algorithm.
5.5. Applied to robot control
The robot is repetitive with and disturbed by:
The parameters are random. The robot is assumed to have an period cycle: ; The control signal update time is selected: . A robot with 2 degrees of freedom has the following parameters (Fig 1):Assigned:
These visual tracking results demonstrate the convergence of both joint variables to the required references. Over the course of the working day, the highest tracking error value is around 250 for the first joint variable and for the second joint variable, respectively. Furthermore, they confirmed that the tracking error will decrease with the number of trials conducted. Therefore, these simulation findings fully validate all of the above-mentioned theoretical claims.
6. The structure of the second iterative learning controller with model-free determination of online learning parameters for industrial robot
The structure of two control loop circuits is still used, as shown in Figure 3.
6.1. Control the inner loop
Next is the inner loop. This loop uses Taylor series analysis to estimate at time , the previously measured value of with This estimation formula is given in (35).
The remarkable thing is that while the iterative learning controller works in a cyclic cycle T, the inner loop controller is not cyclic. In other words, the internal loop controller also estimates the non-periodic functional uncertainty component. It can be seen that neither control loop uses the mathematical model (1) of the robot at all, and that is their intelligent feature.
6.2. Outer loop control is by iterative learning controller design.
This is a loop circuit that uses cybernetics P-style iteration with diagonal learning function parameter matrix
The number of elements equals the number of joint variables (output) and the input variable because robot (1) is a sufficient actuator. Each elementis determined according to:
This loop generates the control signal.
where choose two matrices ,in (6), which become Hurwitz and a sufficiently small constant , is obtained from the iterative learning controller piecewise constant form, i.e.
when with and with The remaining component m in (3.39) is the estimated value of m given in (3.18), including input uncertainty and model bias, i.e
at time . The inner loop controller determines it.
To facilitate installation, the following algorithm summarizes the calculations for implementing the controller (16) proposed above.
Algroithm 3: the structure of the second iterative learning controller with model-free determination of online learning parameters for industrial robot
| 1 | Choose two matrices ,, in (6), which become Hurwitz and a sufficiently small constant . Calculate . Determine Choose learning and tracking error . Assign the robot's initial state and initial output to the outer loop controller (iterative learning controller) |
| 2 | while keeping the controls in place |
| 3 | for do |
| 4 | send to robot for a while of . measure and . determine . |
| 5 | Calculate . |
| 6 | end for |
| 7 | establish . |
| 8 | Calculate or and |
| 9 | end while |
6.3. Applied to robot control
Evaluate and verify the quality of the control algorithm for a two-DOF planar robot with the following data:
Friction components:
With input noise assumed as follows:
Instead of using the controller design, the parameters (20) and disturbances (21) will be employed to simulate the robot dynamics as in model (1). The parameter is chosen randomly.
A robot with 2 degrees of freedom has the following parameters:
The robot is assumed to have a duty cycle . The time to update the control signal (and also to measure the output) is chosen as . The signal given to the two channels is two periodic functions of period T as follows:
We obtain the simulation results in Figures 10, 11,12, 13, 14,15,16 and Fig 17.
Comment:Figure 10 and Figure 11 are the results of two output channels, respectively, after 20 and 300 trials when the controller learns iteratively using the formula.
Figure 13.
Meets the position of the second joint when used (40).
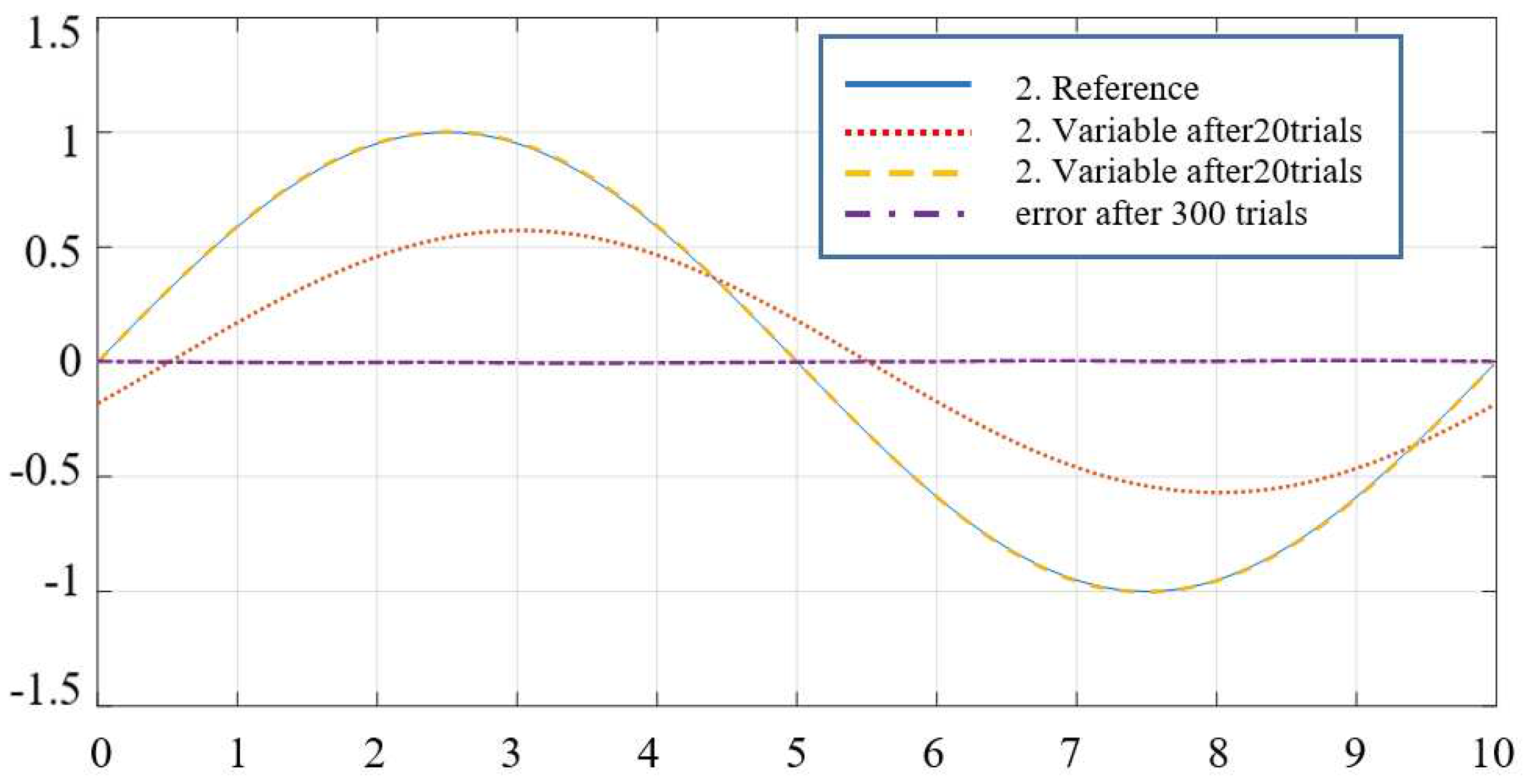
For "Smart" determination, the learning function parameter is the input/output signal pair index . This result shows that the controller has provided the required tracking quality, and after 300 trials, the output signal has tracked the password set in both channels.
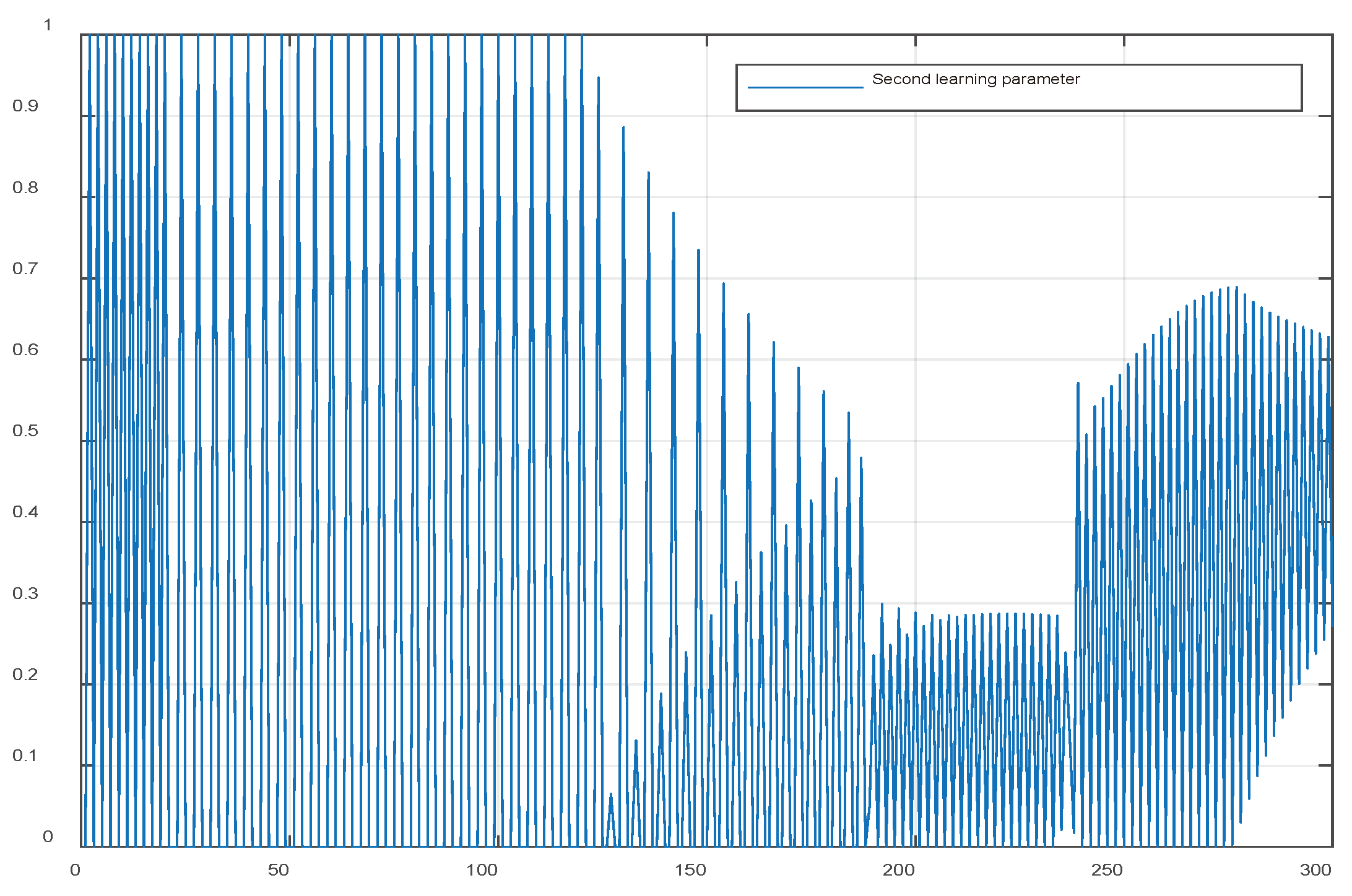
When using formula (40) to determine the intelligent learning parameter in the iterative learning controller instead of (39), the quality of tracking the set signal is unchanged. The difference now is only the appropriate change. The results of the two learning parameters are shown in Figure 14, Figure 15, Figure 16, and Figure 17.
7. Conclusions
Propose a two-loop control structure for the robot, in which the inner loop is an uncertain function component estimator to compensate for the robot's input, and the outer circle is an iterative learning controller (Figure 2). The Taylor series analysis method was used to create an inner loop controller. This method does not necessitate the creation of a mathematical model of the robot. For estimating, it simply takes measured signal values from previous systems. Develop two options for installing an iterative learning controller in the outer loop. The difference between these two options lies in the online determination of learning function parameters. The two proposed control circuits have been installed into the control algorithm and simulated with the planar robot to evaluate the quality. The correctness of the above-mentioned solutions has been demonstrated by theory and validated by simulation - Create a control algorithm based on the concepts above for controlling two items that work in batch processes in industry robots. These control algorithms are all distinguished because they do not (or only very infrequently) employ the mathematical model of the control object. The quality of these control algorithms has also been verified through a 2-DOF robot simulation. However, there are still disadvantages when building methods to determine convergence parameter sets for nonlinear learning functions with known structures. The problem of constrained control by iterative learning still needs to be solved. These will be the following research directions.
References
- L.Lewis, D.M. L.Lewis, D.M. Dawson and C.T.Abdallah, “ Robot manipulator control theory and practice”, Marcel Dekker, 2004.
- W. Spong, S. W. Spong, S. Hutchinson, and M. Vidyasagar,” Rovot modeling and control”, New York, Wiley, 2006.
- Z. S. Jiang, F. Z. S. Jiang, F. Xei, X. Wang anf Z. Li, “Adaptive dynamic sliding mode control for space manipulator with external disturbance”, Journal of Control and, 2019.
- Goel, A Swarup, “MIMO uncertain nonlinear system control via adaptive hight-order super twisting sliding mode and its application to robotic manipulator”, Journal Control Autom. Electr. Syst., 28, 36-49, 2017.
- Wang, Y et.al.; “Servy on iterative leaning control, repetitive control and run to run control. Journal of process control”, 19, (10), 589-1600, 2009.
- R. Lee, L. R. Lee, L. Sun, Z. Wang, M.Tomizuka,” AdaptivebILCcontrol of robot manipulators for friction compensation”. IFAC PapersOnline 52 (15), 175-180, 2019.
- F. Boiakrif, D. F. Boiakrif, D.Boukhetala and F.Boudjema Velocity observer-based ILCcontrol for robot manipulators. F Bouakrif, D Boukhetala, F Boudjema. International Journal of Systems Science 44 (2), 214,222, 2013.
- Nguyen, P.D.; Nguyen, N.H. Adaptive control for nonlinear non-autonomous systems with unknown input disturbance. Int. J. Control. 2021, 95, 3416–3426. [Google Scholar] [CrossRef]
- Jeyasenthil, R.; Choi, S.-B. A Robust Controller for Multivariable Model Matching System Utilizing a Quantitative Feedback Theory: Application to Magnetic Levitation. Appl. Sci. 2019, 9, 1753. [Google Scholar] [CrossRef]
- Nguyen, P.D.; Nguyen, N.H. Adaptive control for nonlinear non-autonomous systems with unknown input disturbance. Int. J. Control. 2021, 95, 3416–3426. [Google Scholar] [CrossRef]
- K. G. Tran, N. H. K. G. Tran, N. H. Nguyen, P. D. Nguyen “Observer based controller two - wheeled inverted robots with unknown input disturbance and model uncertainty”, Journal of Control Science and Engineering, 1-12, 2020.
- Husnain, S.; Abdulkader, R. Fractional Order Modeling and Control of an Articulated Robotic Arm. Eng. Technol. Appl. Sci. Res. 2023, 13, 12026–12032. [Google Scholar] [CrossRef]
- Zouari, L.; Chtourou, S.; Ben Ayed, M.; Alshaya, S.A. A Comparative Study of Computer-Aided Engineering Techniques for Robot Arm Applications. Eng. Technol. Appl. Sci. Res. 2020, 10, 6526–6532. [Google Scholar] [CrossRef]
- Ben Ayed, M.; Zouari, L.; Abid, M. Software In the Loop Simulation for Robot Manipulators. Eng. Technol. Appl. Sci. Res. 2017, 7, 2017–2021. [Google Scholar] [CrossRef]
- Duc, D.M.; Tuy, T.X.; Phuoc, P.D. A Study on the Response of the Rehabilitation Lower Device using Sliding Mode Controller. Eng. Technol. Appl. Sci. Res. 2021, 11, 7446–7451. [Google Scholar] [CrossRef]
Figure 1.
Two -DOF planar robot arm.
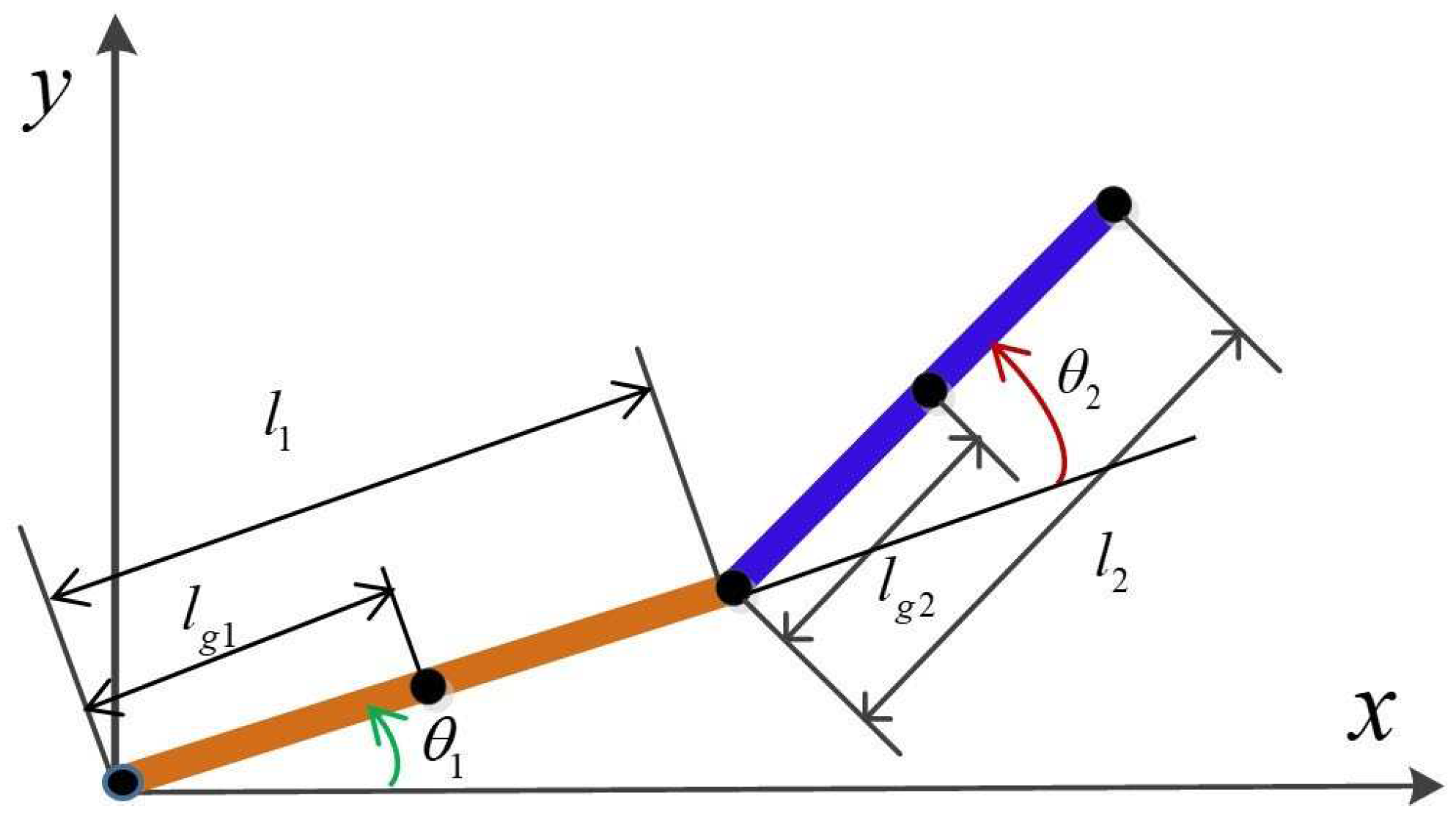
Figure 2.
Structure the first diagram for robot control using the iterative learning method.
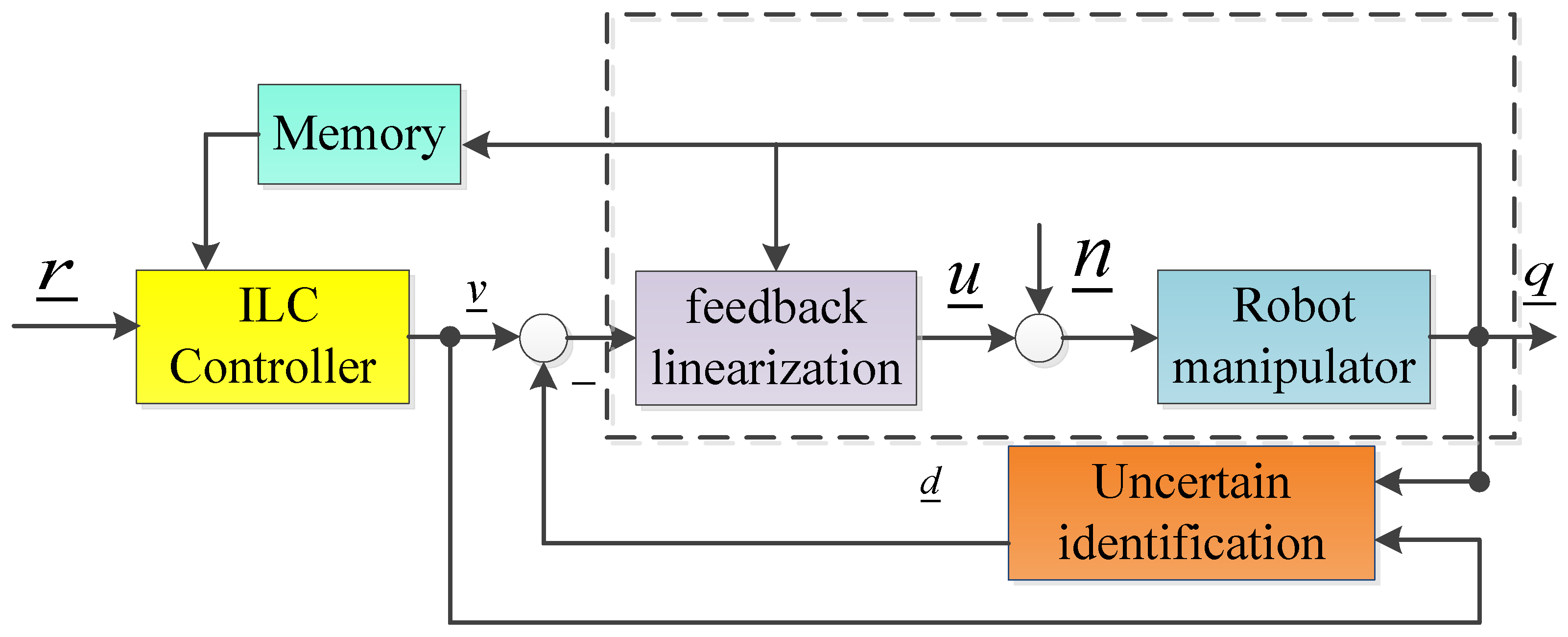
Figure 3.
Structure the second diagram for robot control using the iterative learning method.
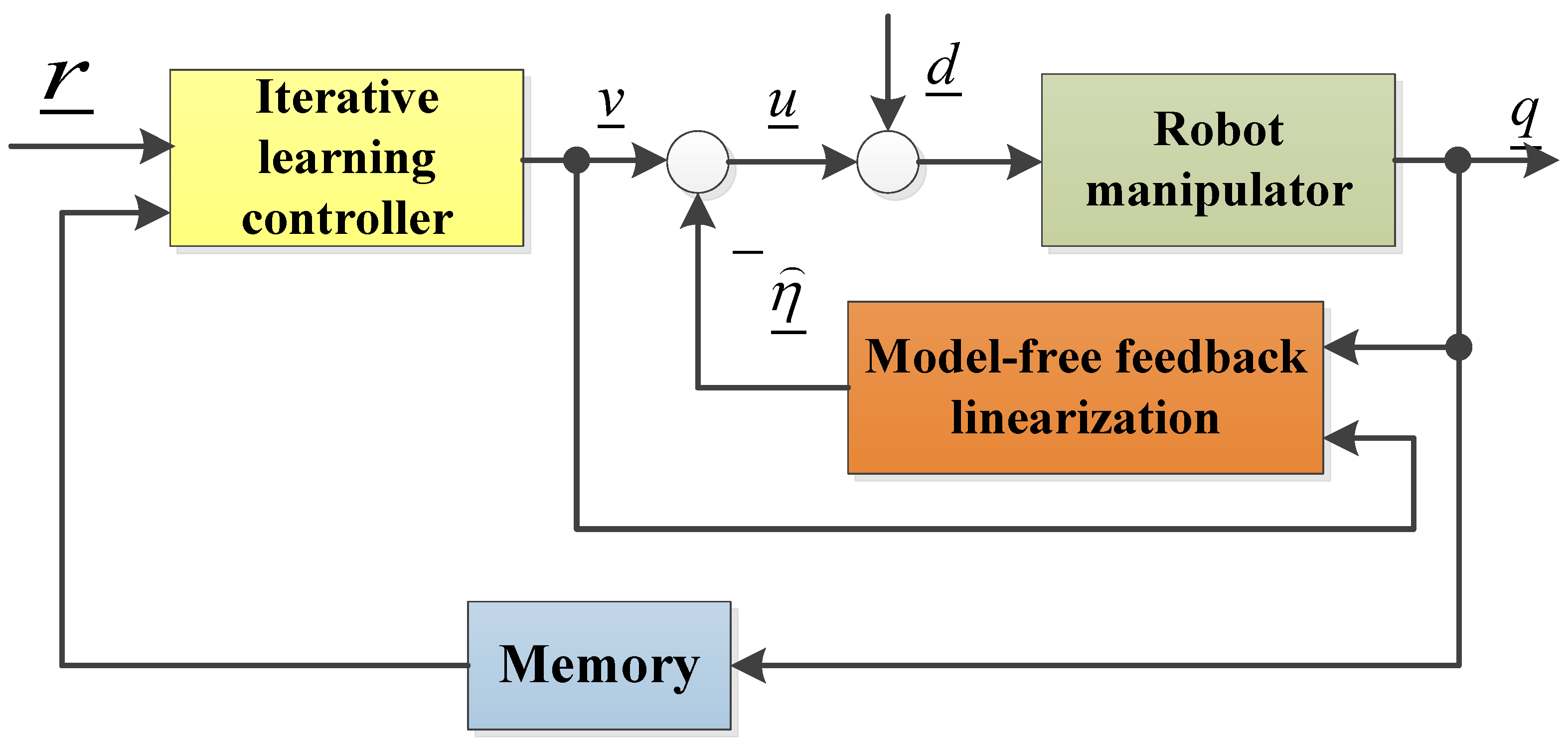
Figure 4.
Output tracking results after 20 trials of the first joint.
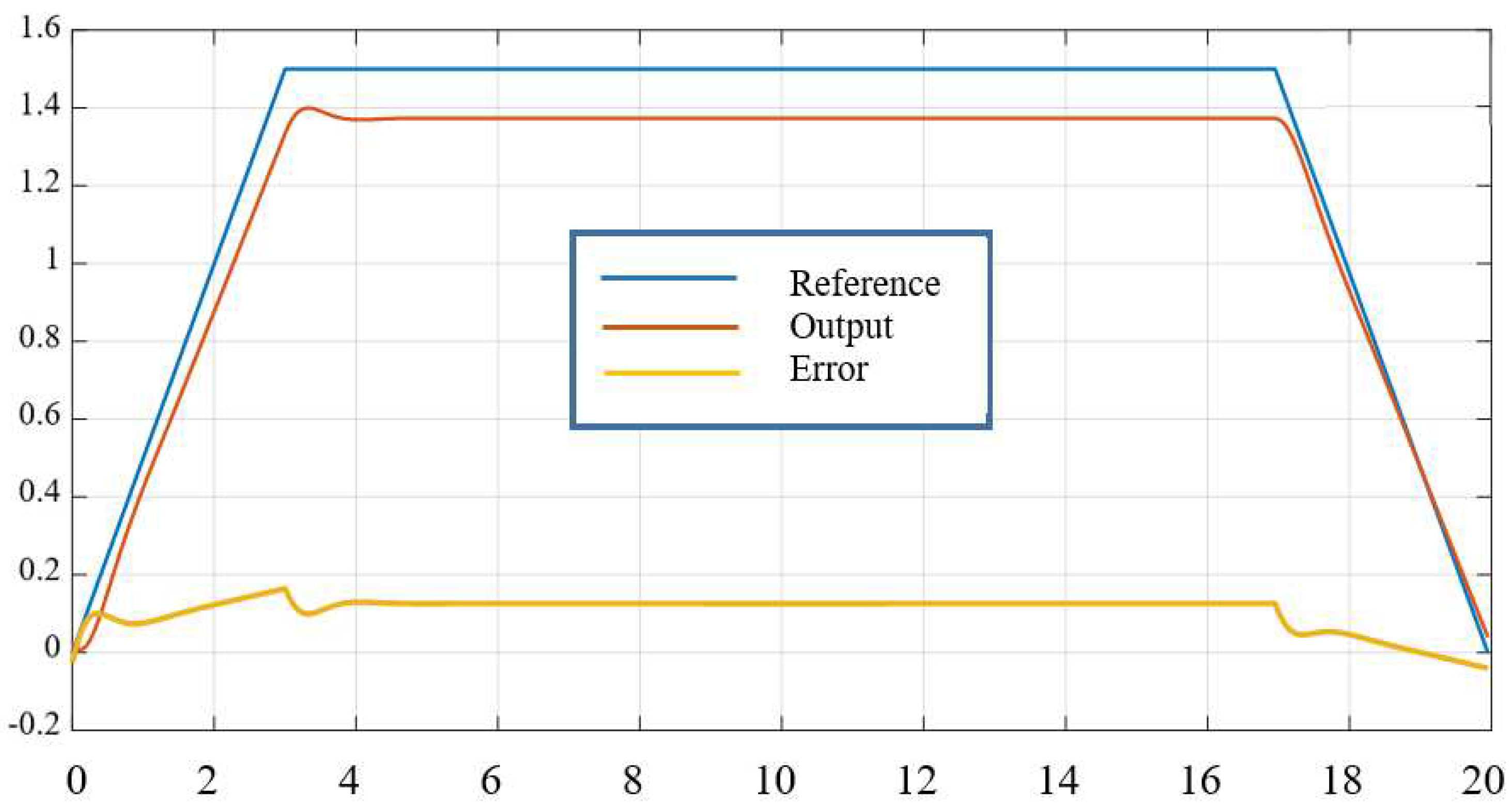
Figure 5.
Output tracking results after 20 trials of the second joint.
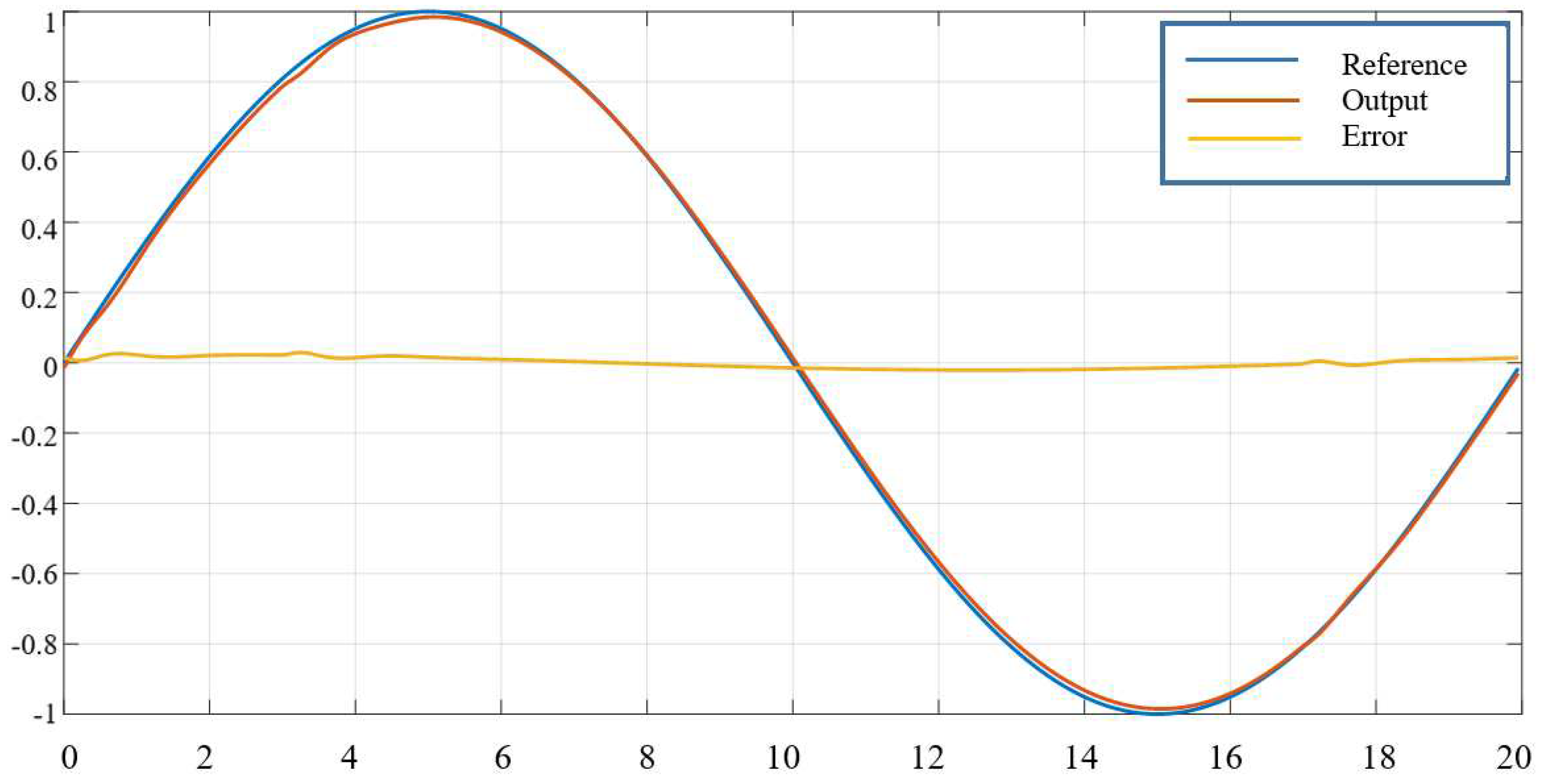
Figure 6.
Output tracking results after 60 trials of the first joint.
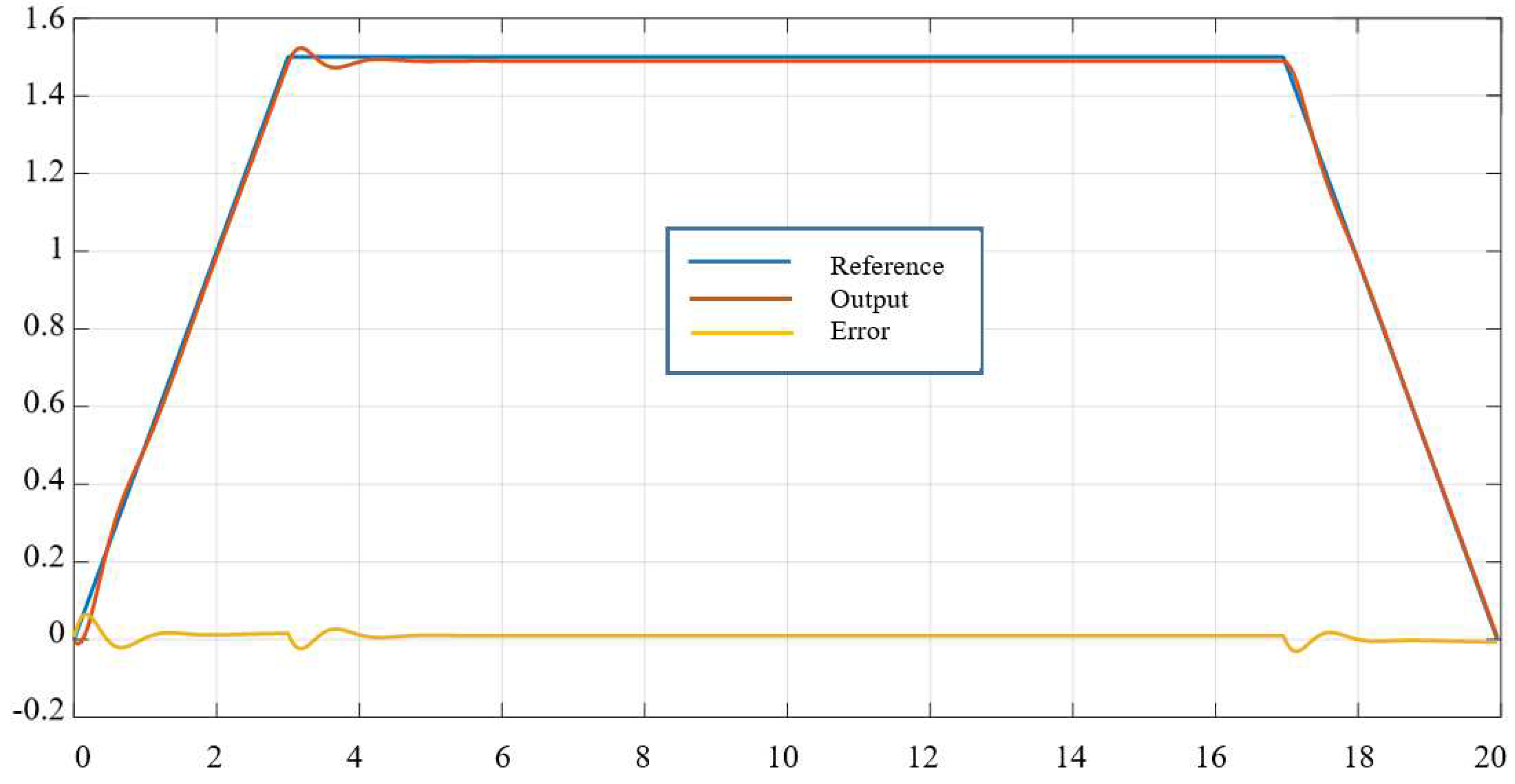
Figure 7.
Output tracking results after 60 trials of the second joint.
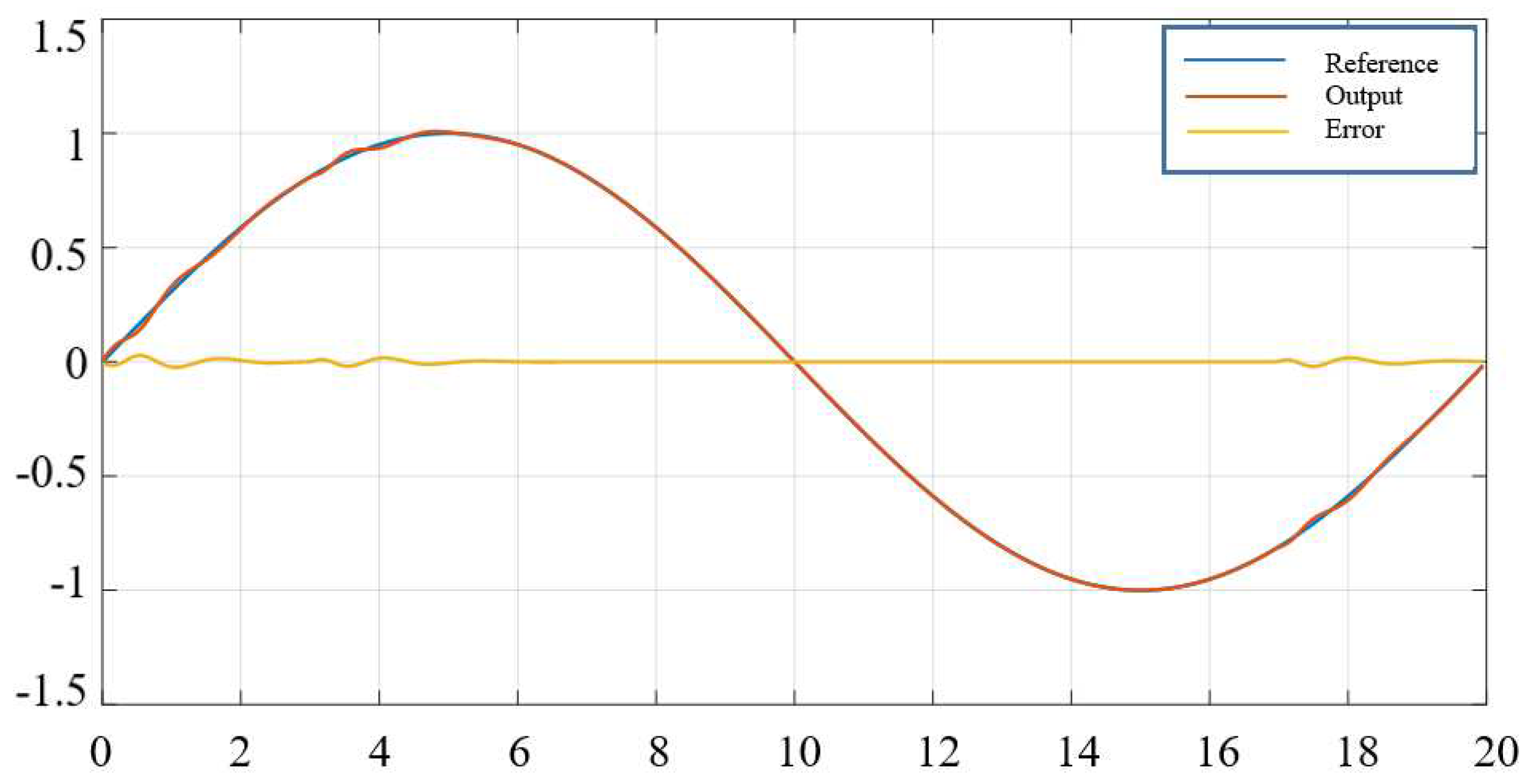
Figure 8.
The output response of the first common variable after trying 15 and 250 times.
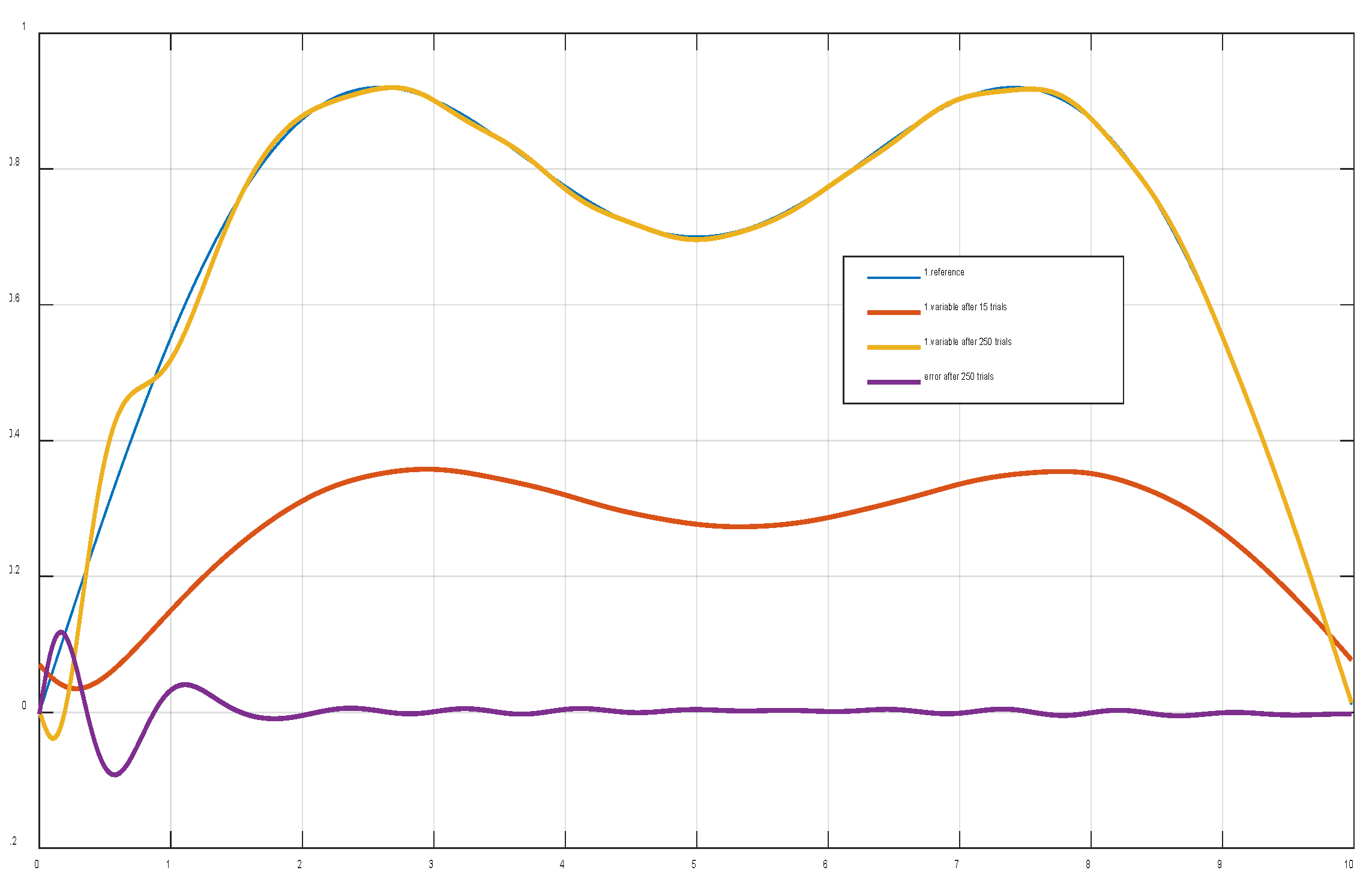
Figure 9.
The output response of the second common variable after trying 15 and 250 times.
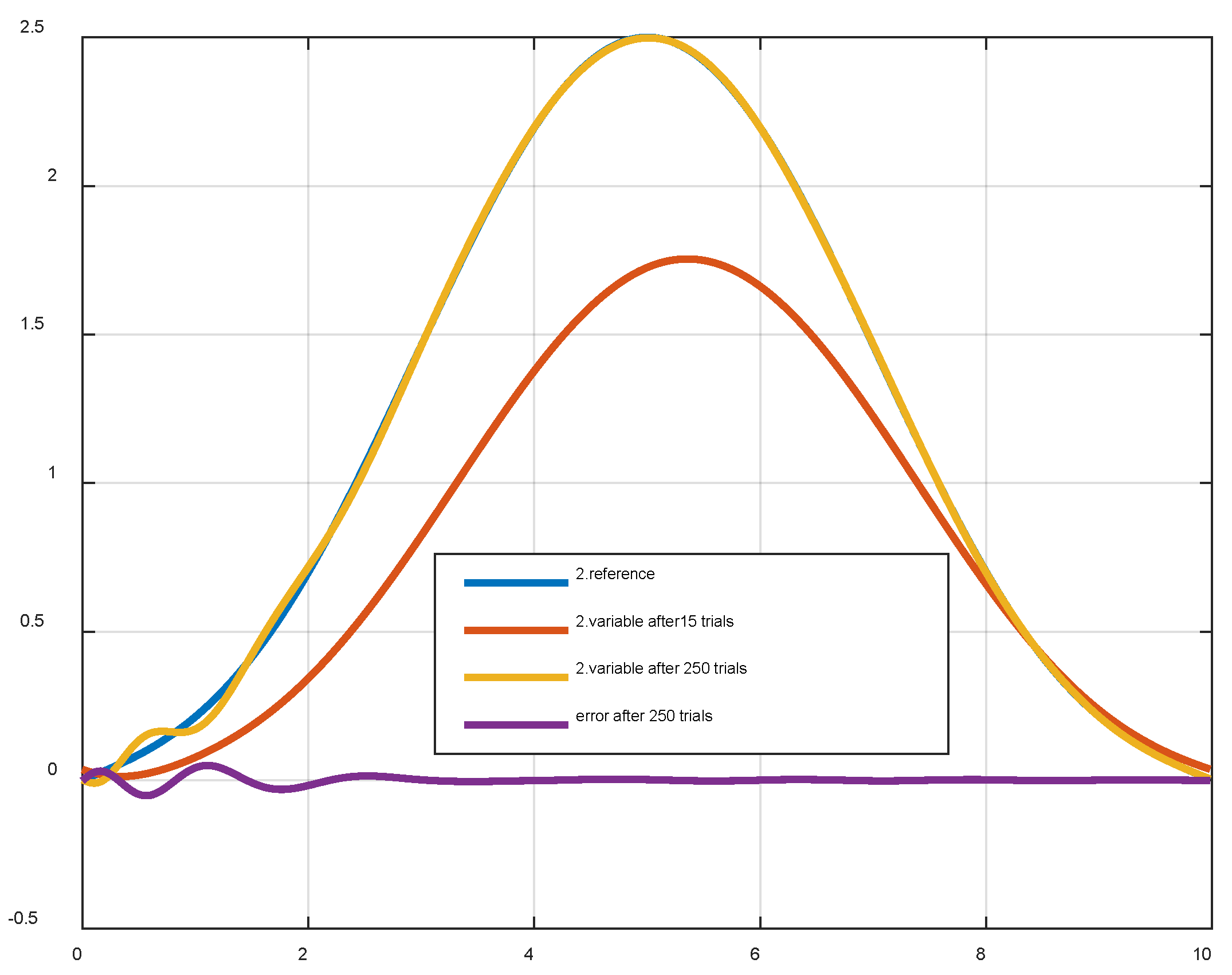
Figure 10.
Meets the position of the first joint when used (39).
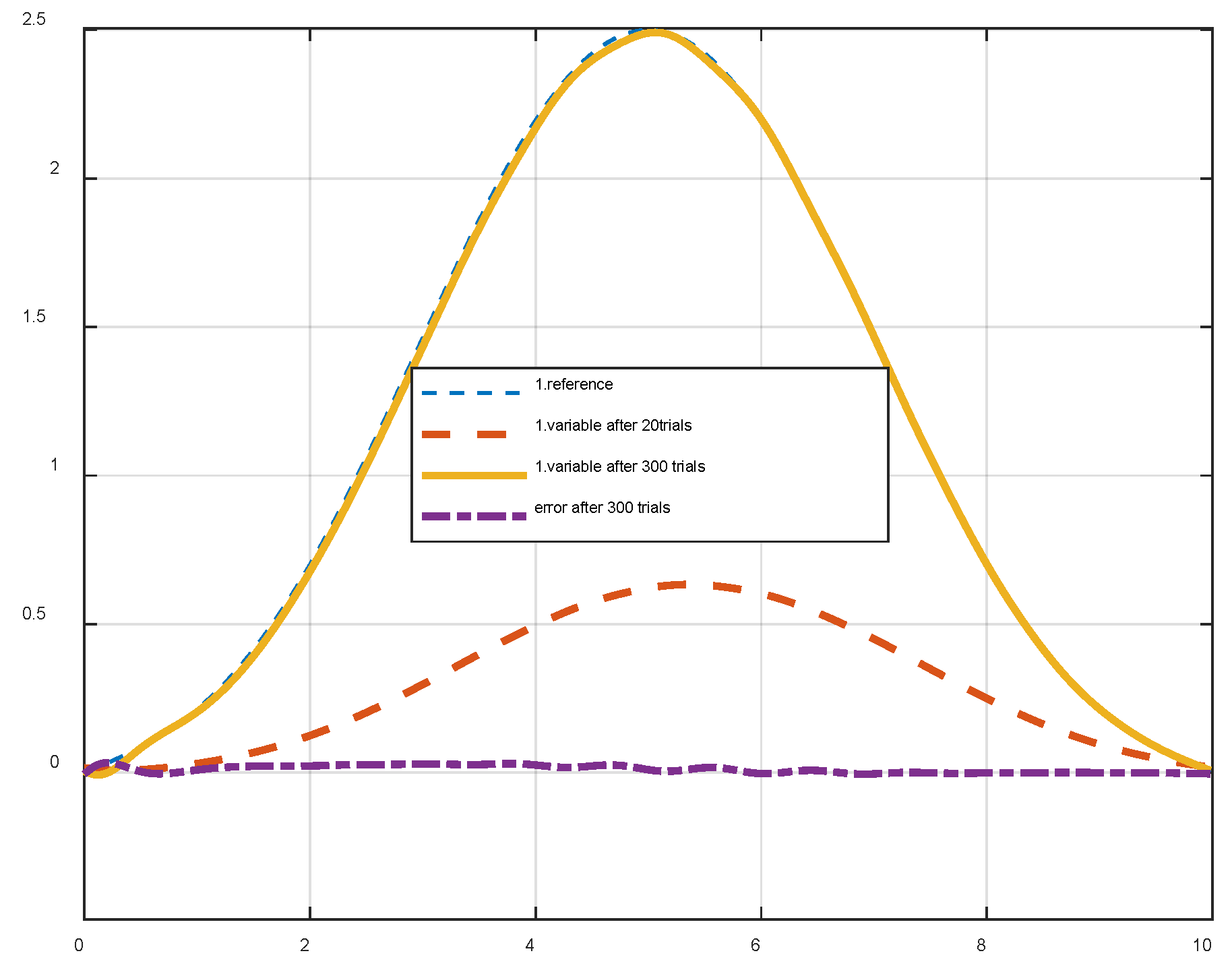
Figure 11.
Meets the position of the second joint when used (39).
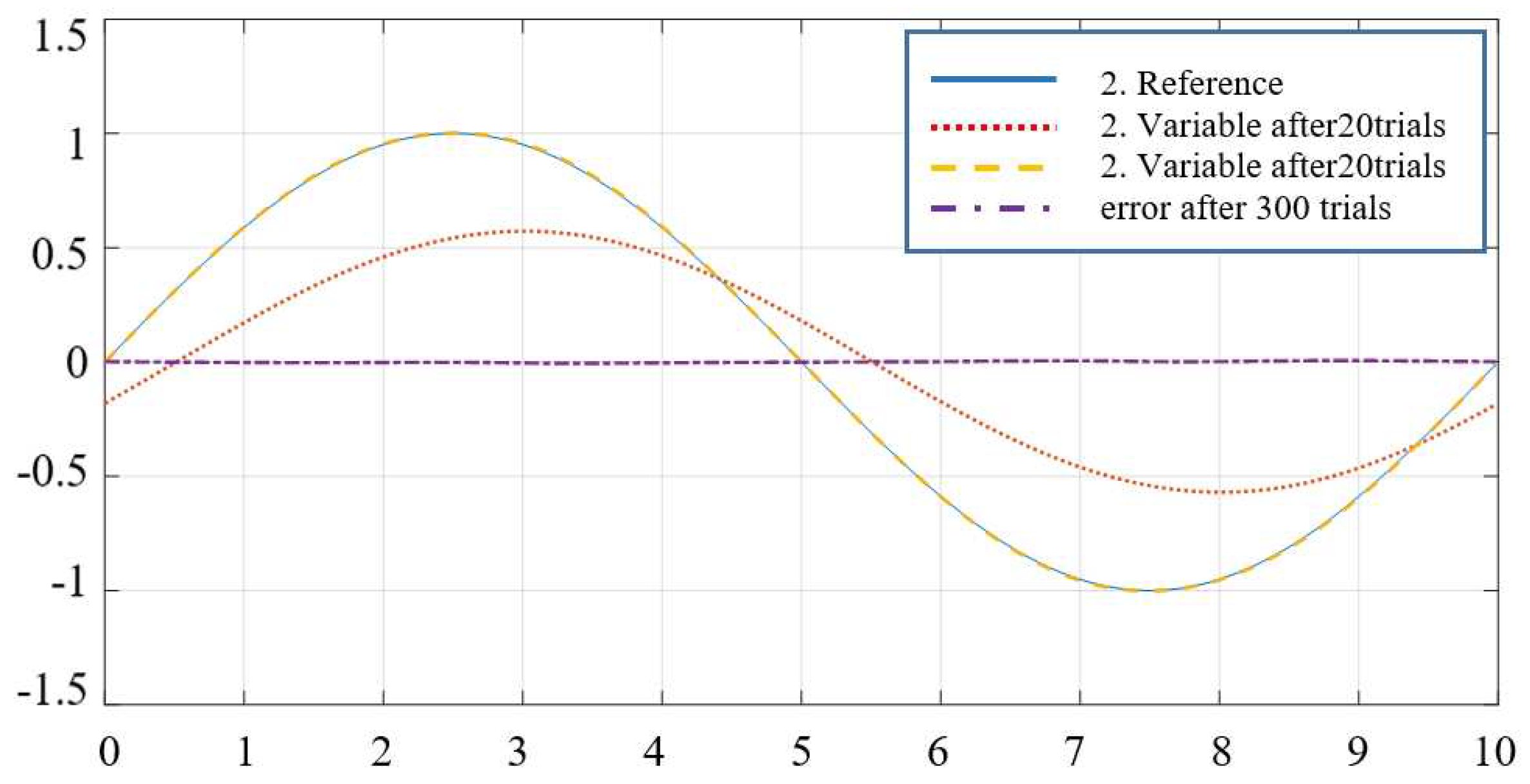
Figure 12.
Meets the position of the first joint when used (40).
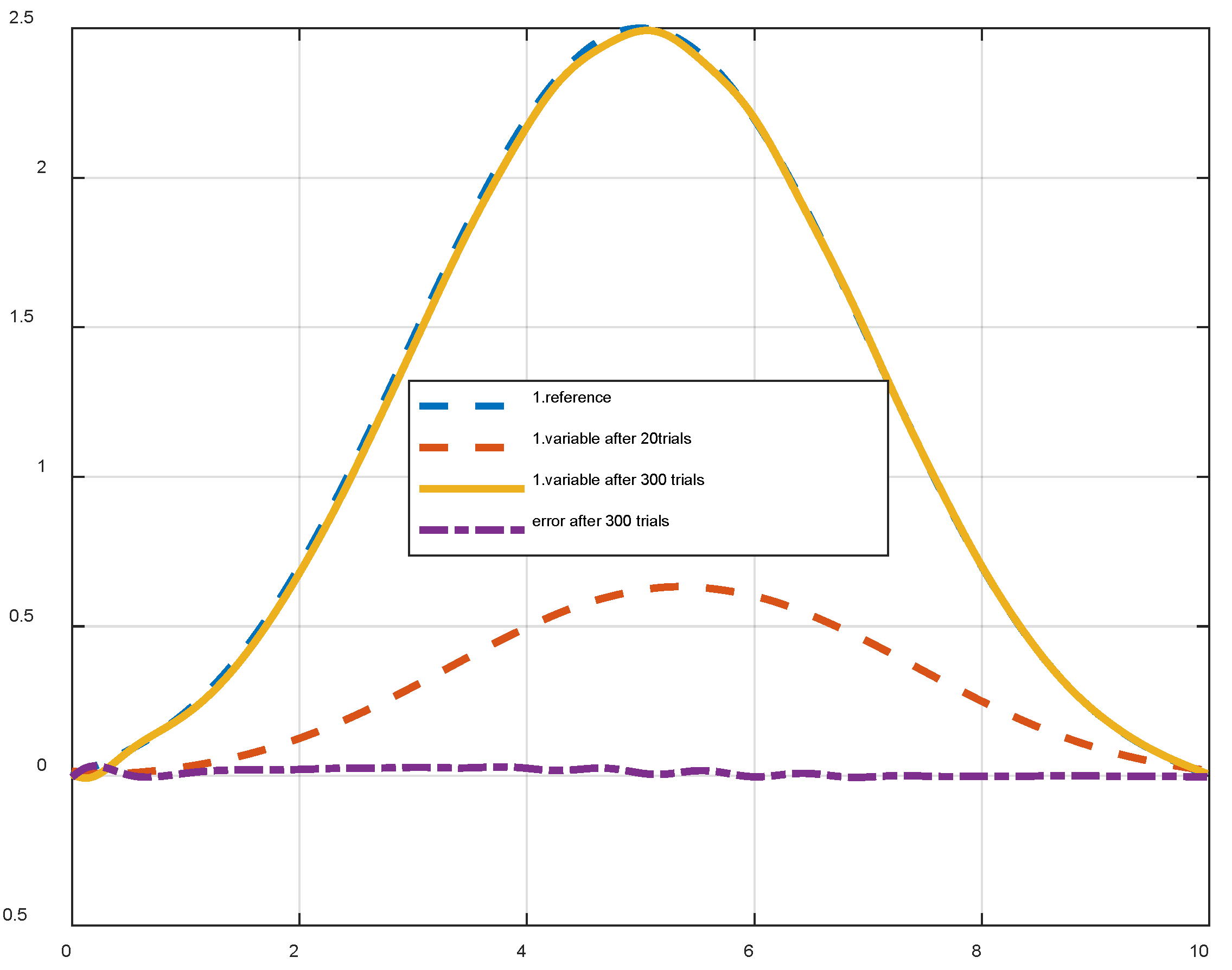
Figure 14.
Change in the first learning function parameter when using (39).
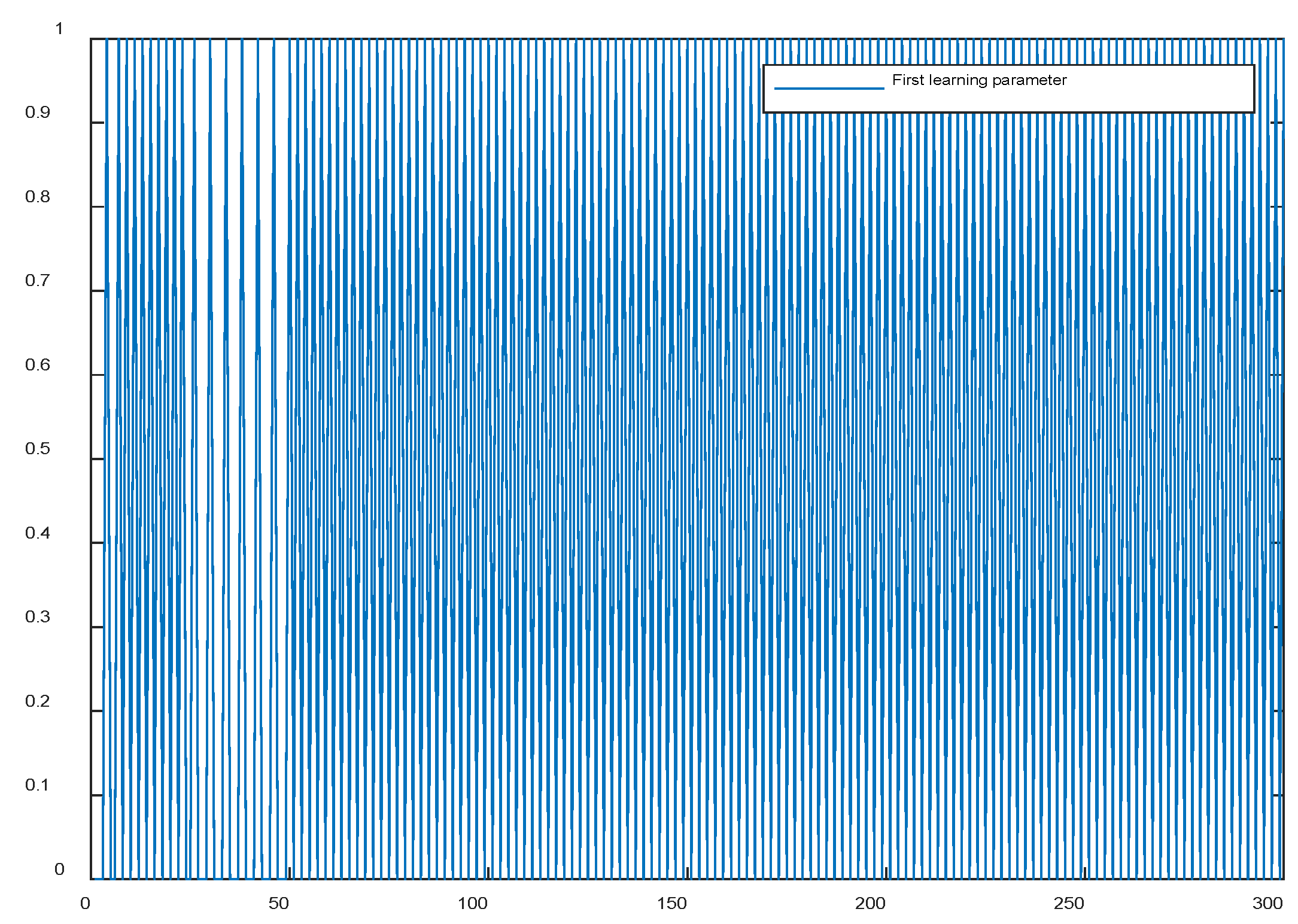
Figure 15.
Change in the second learning function parameter when using (39).
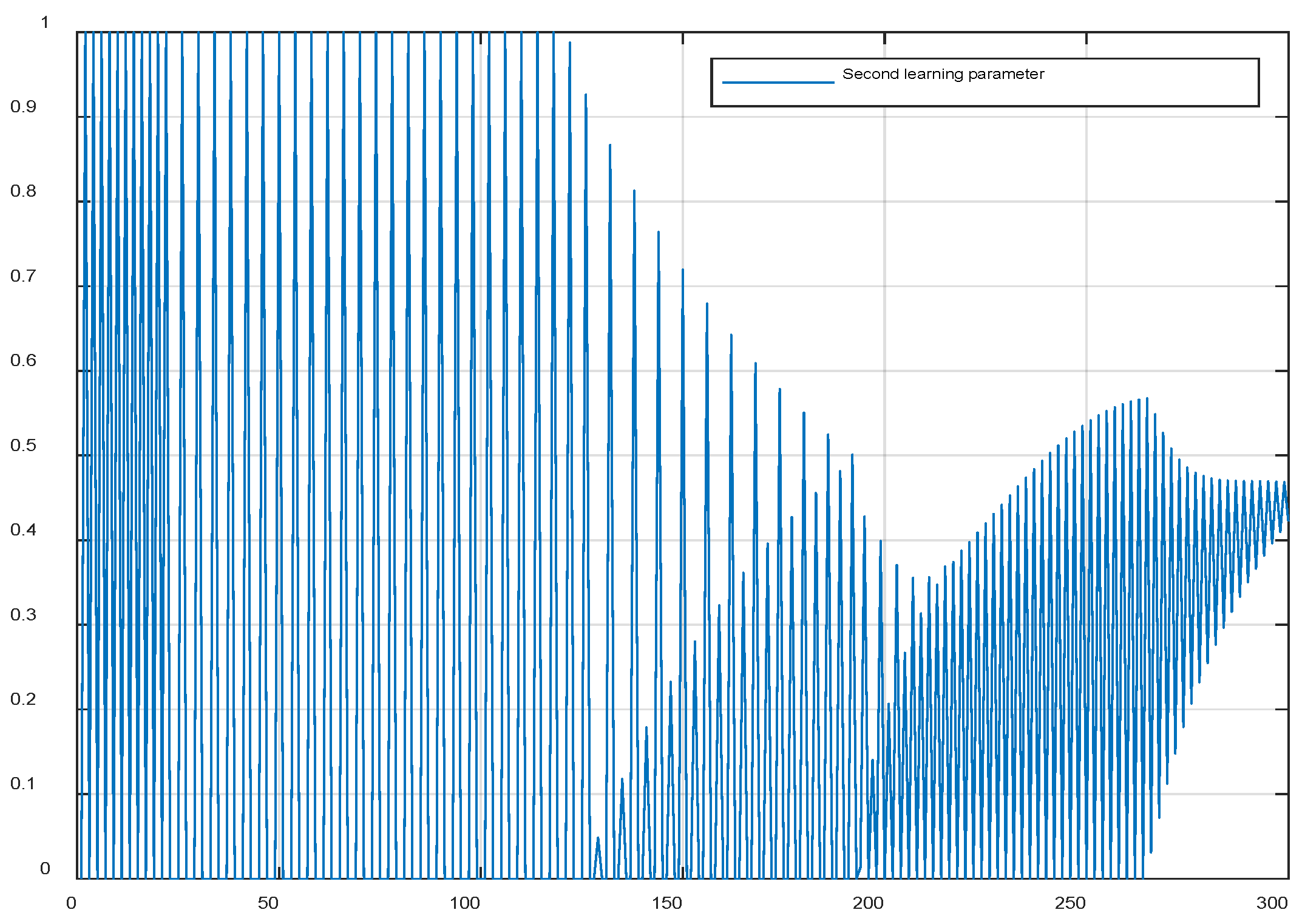
Figure 16.
Change in the first learning function parameter when using (40).
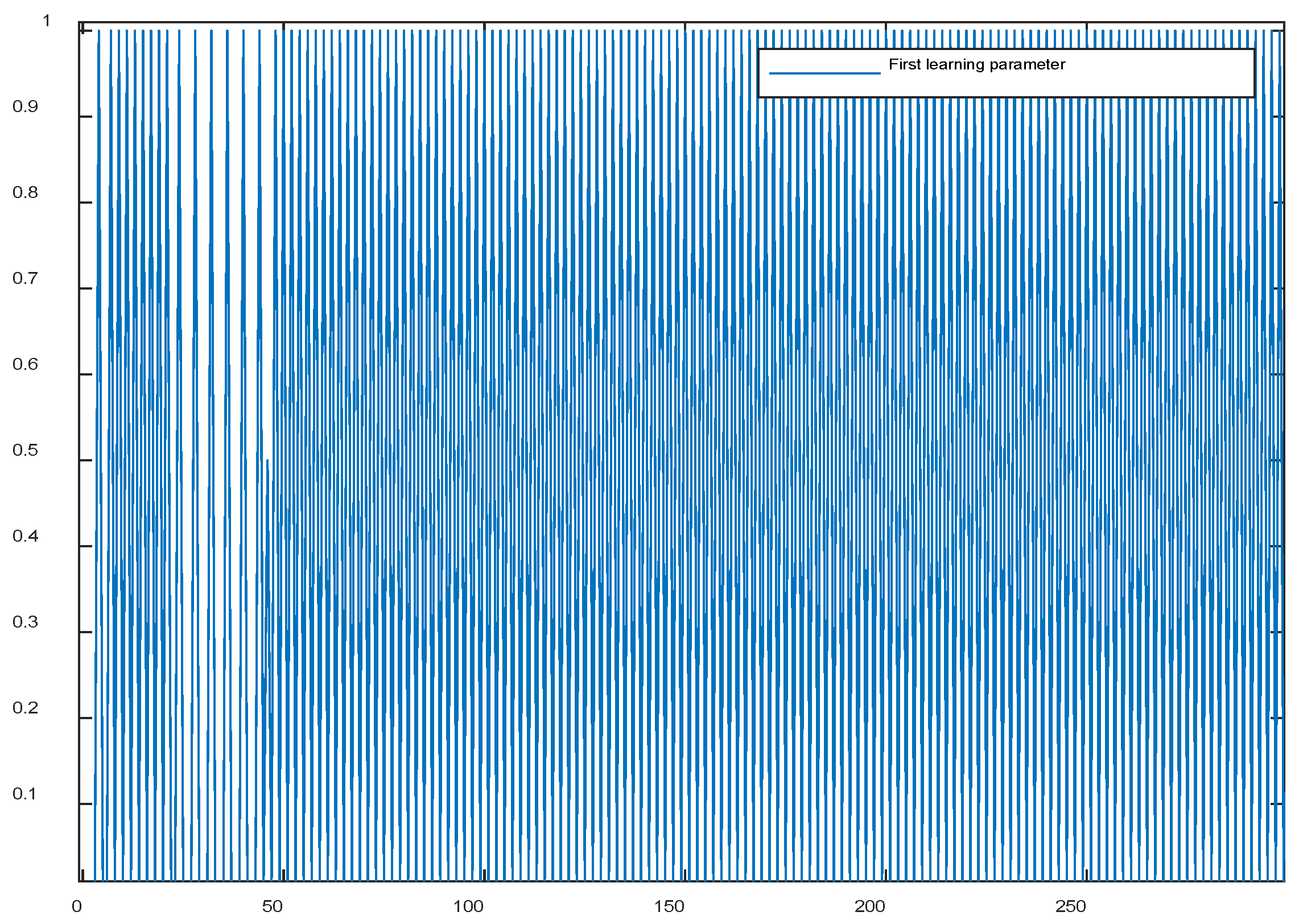
Figure 17.
Figure 17. Change in the second learning function parameter when using (40).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



