
Submitted:
17 January 2024
Posted:
17 January 2024
You are already at the latest version
Abstract
All sensing systems have some inherent error. Often, these errors are systematic, and observations taken within a similar region of space and time can have correlated error structure. However, the data from these systems are frequently assumed to have completely independent and uncorrelated error. This work introduces a correlated error model for GNSS-reflectometry (GNSS-R) using observations from NASA’s Cyclone Global Navigation Satellite System (CYGNSS). We validate our model against near-simultaneous observations between two CYGNSS satellites, and double difference our results with modeled observables to extract the correlated error structure due to the observing system itself. Our results are useful to catalogue for future GNSS-R missions and can be applied to construct an error covariance matrix for weather data assimilation.
Keywords:
GNSS
; reflectometry
; observation error
; correlated error
1. Introduction
Launched in 2016, the Cyclone Global Navigation Satellite System (CYGNSS) mission provides a suite of land and ocean surface sensing products through a technique known as Global Navigation Satellite System reflectometry (GNSS-R). With GNSS-R, the eight CYGNSS satellites act as receivers in a bistatic radar system, where GPS satellites are the transmitters, and the Earth surface is the target of interest.
The CYGNSS mission aims to improve tropical cyclone prediction by measuring ocean surface wind speeds over the tropics [1]. Other satellite observations are impaired by difficulty in collecting windspeeds underneath thick cloud layers in tropical cyclones, and in-situ measurements often are challenging and dangerous to collect due to extreme conditions within tropical cyclones. By exploiting GPS broadcasts in the L-band where there is limited attenuation from thick rain and cloud layers, CYGNSS can collect observations through mature tropical cyclones.
With eight satellites in equatorial low-Earth orbit, CYGNSS can collect global observations with a median revisit time of 3.8 hours. However, the sampling characteristics of CYGNSS differ from many other space-based weather observations. Instead of imaging, CYGNSS data are comprised of tracks of specular points that streak across the Earth surface. Images are reconstructed from composites of multiple satellites. This unique sampling mechanism poses challenges for assimilation into numerical weather prediction (NWP) models.
Data assimilation (DA) is the component of a NWP system that incorporates observations with evolving forecast models. A common data DA technique poses the problem as variational equation that minimizes a cost function [2]:
where represents the cost function, is the variational argument, is the background model state of dimension n, is the n-by-n background error covariance matrix, is the observation vector of dimension p, is the forward model operator for transforming from model space to observation space, and is the p-by-p observation error covariance matrix.
In practice, a great deal of focus is placed on estimating B [3,4] because incorrectly specified B can have significant impacts to the performance of the model. Famously, introducing perfect observations to a perfect model can still lead to forecast degradations if B is poorly constructed [5].
On the other hand, is comparatively overlooked. NWP data assimilation (DA) schemes often assume each observation error is completely uncorrelated [6,7,8]. This is performed for three main reasons: to simplify the assumptions needed for minimizing the cost function in Equation 1 and reduce the computational resources required to solve the forecast problem; to reduce the data handling and storage requirements for observation data at low latencies; and because frequently the information required to specify correlated observation errors was unavailable or difficult to ascertain.
There are some major recent advancements on this front. Discussions of correlated instrument errors are generally limited to explorations for interchannel correlated errors in infrared [9,10] and microwave [11] sounders, with some physical models of correlation proposed [12]. Spatial observation error correlation is discussed in [11,13] but generally restricted to estimates of total observation error correlation as estimated from a weather model [14]. More recently, instrument error inventories for microwave sounders have been established [15].
Nevertheless, the assumption that observation errors are independent and uncorrelated is not valid for any observatory. In practice, observation error correlations are minimized by thinning the dataset or ‘super-obbed’ samples, which improves overall model skill by mitigating the effects of correlated error, which may be interpreted by the model as a real signal [16,17,18].
The premise of not fully exploiting observation data is unappealing, considering that the process of acquiring these data usually requires the considerable capital expense of building and flying remote sensing satellites. The highest utility of dense observations in space and time occurs when the application (i.e., the model) resolution matches the observation resolution. For many imagers and sounders, there may be a reasonable case that thinning is an appropriate way to scale dense observation data to match model gridding.
For CYGNSS, however, thinning the data is an especially unpalatable solution, as the peak utility of CYGNSS data is during the relatively uncommon occurrence that a specular point passes through the eyewall of a tropical cyclone. Thinning may miss this observation or misrepresent the structure of the storm in the model. By a similar token, ‘super-obbing’ is not a practicable remedy, because tracks are one dimensional and collocated observations are potentially hours apart. Blending data from a wide temporal window risks misrepresenting the dynamics of the tropical cyclone and negates the fast-revisit utility of the observatory.
Estimating the correlated error structure for observations can improve model skill in NWP [6,13,19,20,21]. A number of methods have been demonstrated to estimate the observation error correlation matrix [22,23], most notably Desroziers’ diagnostic [24].
Our work does not estimate the full observation error correlation matrix that is typical of these prior works. Instead, we provide a first-principles, bottoms-up, tunable engineering model for how the CYGNSS instrumentation itself can cause observations to contain correlated errors. This correlation model is validated and tuned against empirical observation data during a period when two CYGNSS assets were in a specific orbital geometry where observations nearly coincided in space in time. We further discuss the challenges and opportunities that result from this correlated error model, as well as highlight potential for applicability to future assimilation investigations.
2. Materials and Methods
2.1. The CYGNSS Observatory
The CYGNSS main observable is normalized bistatic radar cross section (NBRCS), . This is derived from the radar range equation [25]:
where is the calibrated power received by the nadir science antenna; are the losses due to attenuation in the atmosphere; is the power of the transmitter, which in this case is a GPS satellite; is the antenna gain of the GPS satellite in the direction of the Earth specular point; is the wavelength of the GPS signal, which for CYGNSS is the GPS L1 signal at 1575 MHz; is the gain of the CYGNSS nadir science antenna in the direction of the Earth specular point; is the total range loss of the transmission via the Earth specular point; and is the effective scattering area of the specular point.
NBRCS is directly related to the mean square slope (MSS) of ocean wave spectra via [25,26]:
where is the angle of incidence of the scattering geometry and is the Fresnel electric field reflection coefficient for the ocean surface at the specular point. CYGNSS retrieves windspeed from via an empirical Geophysical Model Function (GMF) [27] that is processed operationally via a stored look-up table (LUT).
In practice, un-normalized bistatic radar cross section is calculated for every delay and Doppler, the native coordinates of the delay-Doppler Mapping Instrument (DDMI). is calculated from the average of over a 3-by-5 bin window centered at the specular point, and divided by the effective area corresponding to the surface area bounded by the 3-by-5 window [].
After launch of the CYGNSS mission, it became clear that uncertainty in the GPS effective isotropic radiated power (EIRP) would significantly impact calibration quality, [28,29,30]. The EIRP is simply the product from Equation 2. Errors are present in both terms: not only is there general uncertainty with the actual (versus published) transmit power of GPS satellites, newer generations of the constellation operate with a flexible power mode and dynamically change transmit power levels across their respective orbits [31]. Further, only a subset of the GPS antenna patterns were published [32] and they were not sufficiently detailed to constrain the error in EIRP for CYGNSS calibration.
To remedy this, Wang et. al. developed a novel calibration technique that utilizes the onboard zenith CYGNSS antenna and empirically derived relationship from measured GPS antenna patterns to estimate GPS EIRP in the direction of the Earth specular point at the time of observation [33]. This new technique has been adopted in the CYGNSS Level 1 calibration algorithm since version 3.0, and modifies the radar equation to become the following [34]:
where all the terms are the same as in Equation 2, with the additions of , the transmission range loss from the GPS source to the CYGNSS zenith antenna (written as a loss in the numerator to distinguish from the range losses); the CYGNSS zenith antenna gain in the direction of the GPS satellite; the power received from the CYGNSS zenith receiver ; and the specular-zenith ratio for the GPS EIRP as described in [33].
Each of the terms in Equation 4 can potentially be a source of correlated error, but for practical reasons this study only evaluates those sources with the largest error magnitude and therefore the largest potential utility for future data assimilation users. The five largest sources of error are explored as shown in Table 1, representing a 1-sigma error magnitude for a reference windspeed at 10 m/s. The following sections evaluate each of these terms in depth.
2.2. The Bottoms-up Correlated Error Model
The CYGNSS Level 1 correlated error model is constructed to represent the major error sources based on the physical and operational characteristics of the CYGNSS observatories. These errors are correlated over both space and time, and depend on several variables relating to the operation of the CYGNSS constellation.
Construction of the error model is intended to be realistic enough to represent measurable and plausible correlated errors, yet flexible enough to allow for tuning and parameterization. The general modeled structure of correlated error takes the form:
where is the normalized correlated error between any two samples and with a domain . There are component terms that are added together, and each of the th term corresponds to a unique source of error. represents the error covariance between any two samples and for a specific component . is a normalization constant to ensure that the diagonal terms of the matrix is 1.
Each of the terms can be further generalized as:
where represents the magnitude of each error component as calculated in [33,34,36], and can be thought of as the variance of the error; and is a derived function with a domain that represents the correlation in error between samples and for each component .
Each function depends on different arguments, depending on the nature of the error source. The individual errors are explored in depth in the following sections. Further, several tuning parameters have been added to assist with validation. The initial values of the tuning parameters are 1 and essentially leave the model output unmodified. However, this model assumes that the relative magnitude of the error components.
2.2.1. Model Assumptions
Several assumptions are made regarding the overall model and each individual term. The first is that the decorrelation scales of interest are on the order of seconds to minutes. This restricts the problem to errors that decorrelate on timescales that would be of relevance to numerical weather prediction users. CYGNSS observations may have correlated error structure that evolves at longer timescales, say, daily or seasonally. However, this structure would probably be better resolved via other calibration and processing techniques and would not add significant value to a correlated error matrix. As a result, all errors between CYGNSS samples and are assumed to be 100% uncorrelated if there is more than 10 minutes of separation in observation time. This corresponds to roughly 4500 km of distance, where observations could reasonably be treated as wholly uncorrelated.
Further, all error terms are assumed to be uncorrelated with each other. This assumption simplifies the implementation and calculation of the model, but is less supported theoretically. There are a number of plausible rationales for why many of these error sources are correlated. However, this model hopes to correct for these empirically with the implementation of tuning parameters.
Finally, there is a general assumption throughout that all the error sources in the model exhibit wide-sense stationarity during the timescales of interest. Therefore, the error magnitude values are treated as constants. In practice, the magnitude of errors and their correlation time and space scale sizes may well vary, e.g. seasonally and regionally. A fully operational implementation of the methodology developed here would take these dependencies into account, e.g. by an appropriate parameterization of the properties of the errors. Here, we only consider stationary error properties in order to illustrate how they are determined and how they would be combined to be used by a DA scheme.
2.2.1. The Full Correlated Error Model
Considering the terms in Table 1 and applying Equation 5, the Level 1 correlated error model is constructed:
where is the correlated error component from the calibrated nadir receiver power and discussed in Appendix B; is the correlated error component from the zenith receiver and discussed in Appendix C; and are the correlated error components from the nadir and zenith CYGNSS antenna patterns, respectively, and discussed in Appendix D; and is the correlated error component due to the zenith-specular ratio used for dynamic EIRP estimation and discussed in Appendix E.
2.3. Verification Techniques
One of the primary challenges in constructing the CYGNSS Level 1 correlated error model is identifying a plausible validation scenario. In practice, it can be difficult to disentangle the various sources of correlated observation error structure, e.g. those caused by the inherent behavior and calibration of the instrument and, by the geophysical retrieval and inversion process, and by the representativity errors imposed when observations are gridded and ingested into models. Further, the choice of ground truth may impose an additional source of correlated error, such as when using reanalysis data or another observation source.
In an effort to disentangle these correlated errors and isolate only those due to instrumental sources, this work validates the correlated error structure by matching up near- simultaneous collocated observations made by two different observatories at nearly identical geometries, generating modeled NBRCS from reanalysis data, and single- and double-differencing the results.
2.3.1. Curating Matchup Observations
As a constellation of eight small satellites in the same orbital plane, CYGNSS is generally unable to collect collocated, near-simultaneous observations from different satellites. If the CYGNSS observatories were equally distributed across the orbital plane, each asset would follow the next at approximately a 10 minute lag. However, in that time both of the uniquely defining features of the CYGNSS observation changes: (1) the surface of the Earth rotates underneath the observatories, changing the ground track, and (2) the GPS satellites that serve as the source of radar signal advance in their orbit. Therefore in 10 minutes, it can be quite challenging to develop 1-to-1 matchup conditions suitable for investigating the correlated error structure at timescales of seconds to minutes.
CYGNSS has no onboard thrusters, and orbit phasing is controlled solely through differental drag. At several junctures during the CYGNSS mission, one of the observatories has advanced within the plane to be nearly overlapping with another, yet at a slightly different altitude. Generally, the greater the altitude difference between the observatories, the faster the relative precession within the orbit plane.
An exhaustive review of each observatory’s ephemerides for the life of the mission identified a few matchup opportunities. Matchups near the beginning of the mission were preferred, as the orbit planes of the satellites tend to drift apart over the lifetime of the mission. After further filtering by operational status of each observatory to ensure they were in similar attitude configurations and operating in similar science modes, a 24 hour period starting 0Z on 11 SEP 2019 was chosen, where FM1 and FM5 were in a nearly identical orbital phase for a sustained period. A representation of the ground sampling during this period is shown in Figure 1.
Each “track” of observations (when a series of observations are made in close succession sharing a CYGNSS receiver and GPS transmitter) was matched sample-for-sample between FM1 and FM5 by first minimizing the distance between observations, and then quality controlling for several factors:
- Matched tracks must both have greater than 300 samples;
- Individual sample matchups are valid if samples are within 0.5 degrees (great circle distance);
- Individual samples are screened to ensure no quality control flags apply;
- The matched track is only valid if 60% of the data remains after all other matchup criteria applies.
The resulting matchup conditions produced 103 matched tracks within the 24 hour period of near-simultaneous observations.
2.3.2. Generating Model NBRCS
A forward model for the CYGNSS observatory (generating from wind data) can be challenging. Operationally, CYGNSS uses a GMF LUT that maps between the two quantities. However, for the purposes of this analysis, we prefer to use a physically-representative forward operator that represents the physical dynamics of the roughening of the ocean surface due to locally driven winds.
For each sample matched up, is generated by computing a spectrally-corrected ocean surface MSS from an ERA5-forced [37] WaveWatch III wave model as described in [38]. Because the resolution of ERA5 is much coarser than CYGNSS Level 1 observations in both space and time, the is matched up with via a tri-linear interpolation across three dimensions (latitude, longitude, and time).
Therefore, for every track of data, there are observations from two different CYGNSS observatories, and two modeled NBRCS from reanalysis data.
2.3.3. Estimating Total Correlated Error
Single- and double-differencing are common techniques to calibrate remote sensing instruments, especially radiometers [39,40] and radars [41]. Both are useful for quantifying the correlated error structures in CYGNSS observations.
For each track of data, there are two single-differenced datasets,
where is the single-differenced data from the two matched-up observations from FM1 and FM5, and is the single-differenced data of the model-generated NBRCS for the specific coordinates of FM1 and FM5. The double-difference is computed by differencing these two quantities:
Both the SDs and DD are useful for our analysis. The term represents the difference in measured by two different CYGNSS satellites. Despite the strict matchup conditions, these assets are still measuring different fields of view at different times. These differences may result in some residual correlated structure. In addition, any correlated structure in may not reveal structure imposed from fundamental properties of the earth system. Therefore, allows us to identify the correlated structure of any systematic differences in observation target. An example of the utility of these differencing techniques is shown in Figure 2.
Since we are primarily interested in correlated error, and not absolute error, our primary investigative tool is the autocorrelation function. The correlated error for each track can be computed by autocorrelating the DD using the standard formulation:
where is the lag, is the total number of lags observed, is the value of timeseries at time , is the mean of timeseries , and the standard deviation is formulated as normal, .
Because the error correlation behavior can vary from track-to-track, we also construct a bulk autocorrelation which approximates the autocorrelation behavior for all tracks sampled. For this we consolidate tracks, the bulk autocorrelation is:
where , is the index for track number, and the standard deviation and mean are calculated as before, but with the consolidated track series .
2.3.4. Model Tuning
The constructed correlated error model is designed to estimate the correlated error between arbitrary samples and . Validating the correlated error with empirical matches is challenging since the empirical error correlation can only be estimated in a broader, statistical sense. To create an appropriate comparison, we introduce the modeled error autocorrelation , which is a function of lag :
where is calculated in Equation 7, is the lag, is the total number of lags observed. The quantity is reasonably comparable to the autocorrelation of observed error for a single track of samples. A similar analog can be made for bulk modeled error autocorrelation , which will estimate the autocorrelation behavior of the error model across M tracks:
where is the modeled autocorrelation for track at lag .
A parametrized version of is constructed of the form
where
- represents the relative magnitude of the white noise component of the error, which decorrelates at ;
- represents the relative magnitude long-decay pedestal, or any residual correlated errors at the edge of our timescales of interest;
- represents the relative magnitude of the correlated caused by terms and , which exhibit smooth decay as samples spread apart when projected through the nadir and zenith antenna coordinates, respectively [see Appendix D for an in-depth discussion]; and
- represents the relative decorrelation roll-off in terms and .
With an appropriate benchmark, the tuning parameters , , , and are iterated such that matches a target signal. The tuning parameters are applied such that they can be modified to change specific characteristics of the modeled behavior:
The parameters modify directly and are described in depth in Appendix B, Appendix C,Appendix D and Appendix E. The target for matching the modeled autocorrelation is the bulk autocorrelation of the double differenced data DD:
Because this is an under-determined system, there is no unique solution to optimizing the tuning parameters. Further, these parameters all relate to one another, and changing one will impact the others. Instead, is tuned heuristically such that the modeled behavior matches the empirical data at key points: to match the white noise component at lag ; to match the rolloff at lags and ; and to match the endpoint behavior at lag .
3. Results
3.1. Bulk Behavior
The constructed model is first tuned to match the overall behavior of as described in Section 2.3.4. With the appropriate tuning parameters, the bulk modeled autocorrelation closely resembles in most important aspects, including relative magnitude of white noise component, relative rate of decorrelation roll-off, and endpoint behavior at large lags. The final tuned is shown in Figure 3 with , , and .
The behavior in Figure 3 is worth discussing in detail. The single-differenced model generated decays at a much slower rate than the single-differenced observations and double-differenced data suggests that the errors of the slight mismatch in observation location and time are generating errors on a fundamentally different scale than the instrument errors. Further, the fact that the double-differenced decorrelation is almost identical to the observation single-differencing suggests that single-differencing near-simultaneous observations are a reasonable approximation for bulk error correlation.
Evaluating the double difference trace in Figure 3 also reveals important qualities about the CYGNSS error correlation structure. First, the uncorrelated error component accounts for roughly 5% of the total system error. Therefore, assumptions that samples be treated as independent with uncorrelated error are empirically refuted. Further the error decorrelation rolloff is swift: about 50% of the error has decorrelated within 7 seconds of observation. Using a flat-plane approximation of Earth, this corresponds to a distance of approximately 50 km, which is generally the scale of the gridding of modern global weather models, but much coarser than the resolution of state-of-the-art regional models. Finally, the endpoint behavior at large lag times suggest a small, positive correlated error (~2%) at larger timescales. The statistical properties of the lag correlation become less stable at larger lags, but the existence of a long-timescale correlation is not surprising, considering all observations from a single receiver share a common electronics and processing chain.
The fact that our tuned model can approximate bulk error correlation structure with similar features as validates the assumption that the overall instrument correlated error can be modeled from the fundamental components of the instrument observable, in our case, the radar-range equation (Equation 2). Further, that can be generated between arbitrary samples suggests that an observation error correlation matrix R can be generated dynamically from first-principles given appropriate knowledge about the instrument and retrieval.
The value of the chosen tuning parameters is also worth investigating. The untuned model is defined by having parameters . Figure 3 demonstrates that the modification of tuning parameters can change the overall model behavior significantly to match observed behavior. Figure 3 further suggests that the untuned generally overestimates both the relative magnitudes of uncorrelated error (i.e., white noise, tuned by ) and totally-correlated error (i.e., endpoint correlation, tuned by ). The chosen parameters for tuning are shown in Table 2.
The tuning parameter is used to vary the relative magnitude of the near-sample correlated error roll-off. In our tuned model, this parameter remains at 1. The tuning parameter is used to enhance or reduce the steepness of the rolloff in correlation, caused by two observations moving farther apart in the nadir and zenith coordinate systems. If , it enhances the steepness of decay. The fact that our optimized tuning maintains suggests that the filtering theory discussed in Lemma C2 is a reasonable model of decay.
3.2. Single-Track Comparisons
The tuned model can be compared to single track autocorrelations of matched-sample double differences via the modeled error autocorrelation as described in Equation 12. We compare three exemplar tracks in Figure 4.
The single-track autocorrelation behavior shown in Figure 4 is also revealing of the limitations of this work. The single-track error autocorrelation for double-differenced data is highly variable. This may be due to both artifacts in the data (processing, quality control, insufficient data) as well as real behavior of the observation. It is worth articulating that autocorrelation of data is generally less stable with smaller datasets and at longer lags. With our quality control parameters, we flag out significant quantities of data, which decreases the stability of autocorrelations from track to track. We further note the difficulty in exploring the dynamics of this behavior in a statistical sense: our aperture of observation where two CYGNSS assets are in a near-overlap condition is quite rare, and as the mission progresses, the orbit planes of the satellites have drifted, making further matchup scenarios less representative. These behaviors may evolve differently day-to-day or as a function of observed windspeed, but the paucity of data in this configuration makes it challenging to establish sufficient baselines to test for significance.
3.3. Dynamic Correlated Error Estimation and Impact of Tuning
The model can produce plausible dynamics suggesting broader importance of a realistic dynamic correlated error model. Figure 5 plots two nearby tracks captured nearly simultaneously by the same receiver (but different GPS transmitters).
Because correlated error can be generated for any arbitrary observation using the bottoms-up model, the dynamics of how instrument errors decorrelate can be explored. If the observations were treated as completely independent without any correlated error, the matrix in Figure 5a would contain non-zero elements exclusively along the main diagonal. However, we observe several structural elements. The ‘pixelation’ pattern is largely a result of the term and originates from the coarse mapping of the estimated GPS antenna gain pattern as a function of scattering incidence . This phenomenon is explored in depth in Appendix D. The smooth decorrelation roll-off is from the and components of the model, and represent the direct and reflected signals moving about the nadir and zenith the antenna patterns in CYGNSS receivers as the observation is collected along the track. We note that the model allows for cross-track correlation where the two different tracks share a CYGNSS receiver but have a different GPS transmitter. In both the untuned and tuned cases, these tracks appear to have uncorrelated cross-track error. There are residual correlations between the tracks when the scattering geometry is such that the two tracks share similar incidence angles or are near similar antenna coordinates, in addition to the shared receiver noise at lag .
We can also determine for our matchup tracks where CYGNSS observes similar track geometries with the same GPS transmitter but with two different receivers. The correlated structure for one of the tracks in the previous example (but matched by difference receivers) is shown in Figure 6.
The model allows for correlated error between two different receivers that share a GPS transmitter. We note that observations sharing the same GPS transmitter may contain correlated error due to correlated misestimation of GPS transmit power. This may be an incomplete articulation of the full cross-receiver error correlation. For example, CYGNSS assets in similar orbital regimes may experience similar thermal and environmental conditions that cause correlated errors during our timescales of interest. We assume that correlated error due to misestimation of GPS transmit power is nearly constant for the timescales of interest.
As demonstrated in Figure 6, the cross-track correlation virtually disappears after tuning the model . Taken with the data presented in Figure 5, there appears to be negligible cross-track error correlation, either from when two tracks share a CYGNSS receiver or when two tracks share a GPS transmitter. This is a novel result, but challenging to validate in practice, as the double-differencing may eliminate any shared error correlation between two tracks.
4. Discussion and Conclusions
This work produces a first-principles estimate of correlated instrument error with results that approximate observed statistical behavior. The correlated error model exhibits complex dynamics that are generally plausible, but difficult to validate outside of the large-scale statistical estimation discussed in Section 3.1. Nevertheless, we believe that this model presents a significant advancement in the estimation of the spatial and temporal correlation structure of instrument error for remote sensing systems, and in particular, for the unique considerations of GNSS-R measurements by CYGNSS.
In essence, this work answers a theoretical exercise for enumerating the plausible engineering reasons why two data points from the same observing constellation can share correlated sources of error. The instrument-originating sources of correlated error is likely to be a small component of the overall correlated structures of observation error. A companion work will explore how the retrieval that maps from NBRCS to windspeed produces correlated error structures in space and time.
The correlated error model is designed to compute the estimated correlated error from arbitrary CYGNSS samples, but in practice, this may prove burdensome to implement. It is likely that a given sufficient assumptions about the stationarity of the instrument correlated error, and the overall magnitude of the instrument-originating sources of correlated error, this information can be conveyed as a static LUT.
The fact that the bulk statistical behavior between the estimated autocorrelation model averaged over all tracks is consistent with the observed double difference autocorrelation (c.f. Figure 3) is reassuring, but the disparity between the individual track model estimated autocorrelations and the single-track double difference estimations (c.f. Figure 4) suggests that either the model is insufficient at capturing the dynamics track-to-track or that the correlated error may not be as stationary as assumed.
Further, the fact that the single-differenced observations generally drive the double-differenced autocorrelation behavior suggests that Powell et. al.’s metric of simultaneity and collocation [42] generally applies for CYGNSS when satellites are in a near overlap condition. This interesting result suggests that double-differencing may not be required for statistical estimations of GNSS-R errors given a sufficiently large dataset of observations that nearly overlap.
The specific values of the tuning parameters recovered suggest that the correlated error model overestimates both the uncorrelated and highly-correlated components of instrument error. This is useful information for future studies, because as an opportunistic measurement, GNSS-R has limited insight to the error structures in the source signals from GPS. The fact that the error correlation decays relatively rapidly provides evidence that nearby samples in space and time can add significant new information to a forecast. Further, the fact that the tuning parameters and suggest that the overall structure of the error correlation decay is consistent with theory posited in Appendix D (that the primary source of error correlation is from the application of smoothing filters in the production of antenna gain patterns) and that the application of the Filtering Lemma (Lemma D2) is reasonable.
Author Contributions
Conceptualization, C.E.P. and C.S.R.; methodology, C.E.P..; software, C.E.P, D.S.M., T.W., and A.R..; validation, C.E.P.; formal analysis, C.E.P.; investigation, C.E.P.; resources, C.S.R.; data curation, C.E.P and A.R.; writing—original draft preparation, C.E.P..; writing—review and editing, all authors; visualization, C.E.P.; supervision, C.S.R..; project administration, C.E.P. and C.S.R.; funding acquisition, C.S.R. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Aeronautics and Space Administration Science Mission Directorate under Contract NNL13AQ00C with the University of Michigan.
Data Availability Statement
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
The construction of makes a few important assumptions that are worth examining in depth. First, we will describe the general mathematical framework. In general, if and are random vectors of length , then the covariance matrices of and are constructed:
where and are the -by- covariance matrices of and , respectively; the bracket operator denotes the expectation operation, and the superscript denotes the transpose vector. Notably, the covariance matrix is symmetric and positive semi-definite. The covariance matrices can also be constructed in the following manner:
Where is a diagonal -by- matrix with the standard deviations of :
and is the correlation matrix with correlation coefficients :
As standard, , and the diagonals all must equal 1. The cross-covariance matrices can also be defined in a similar fashion:
where and are the cross-correlation matrices and are not generally symmetric. The error magnitudes in Table XX are calculated using a standard error propagation technique as highlighted in Gleason et. al [25]:
is the error magnitude of term , is the estimated one-sigma dynamic range of and is an arbitrary function. We can propagate these errors as the sums of covariance matrices with the derivation below, inspired from Chapter 9 in Taylor [45].
For an arbitrary function with random vector arguments X and Y, , where and Y , we can approximate F by its first order Taylor Series expansion about the mean value, assuming that the errors are generally small compared to the arguments:
Noting that , and using , then,
and expanding using Equations A5, A7, and A8,
Substituting from Equation A6,
The construction of in Equation 7 ignores the cross-correlation between component terms, i.e., we assert . This is for two main reasons:
- The terms as described in Appendix B, Appendix C, Appendix D and Appendix E are not constructed from random variables, but rather through analytic specification to emulate the expected correlated behavior. We generally have insufficient knowledge to measure or estimate the cross correlation between error components. Instead, this model simply estimates the cross-correlation of error within individual components, which then add independently.
- Any residual cross-correlation between error components can be tuned per our tuning parameters.
As we further assume that that each component term of the error comes from a wide-sense stationary distribution where the error magnitudes are treated as constants. This means that for each component of , and noting Equation A2,
For our error correlation model , we simply construct analytically for each term, for which we adopt the nomenclature Ecorr to emphasize that that it is an error correlation function. Therefore, from Equation 5 (reproduced here),
where .
For this model, F is drawn from Equation 4 (reproduced here)
where we use the parameters of with the largest error magnitude, . The relevant partial derivatives from Equation A10 become:
To estimate as shown in Table 1, these partial derivatives are evaluated at the one-sigma value for a reference 10 m/s windspeed using Equation A6. The total error model becomes:
where is described in Appendix B, is described in Appendix C, and are described in Appendix D, and is described in Appendix E. is a normalization constant that forces to behave like a correlation such that , and can be thought of as an estimate for the rolled-up variance. Because this model has tunable parameters, it is not necessarily representative of the true variance of , but rather of the modeled variance from our bottoms-up model construction.
Appendix B
The term represents calibrated received power from GPS signals reflected from Earth’s surface. is calibrated both from pre-launch characterizations as well as on on-orbit blackbody at known temperature, which as of 2022 takes a reading every 10 minutes to re-compute gain that may have changed due to the dynamic thermal environment in orbit [35].
For CYGNSS, is computed by the Level 1A algorithm:
where is the raw counts at delay-Doppler bins where a scattered signal is present and is the measured parameter for an observation, is an estimate of the background noise without any scattered signal, and is the receiver gain in units of counts/watt. In current processing, is an average of the raw counts at in the delay-Doppler map at coordinates at lower delay values than the specular point [25]. Further, gain is measured on-orbit by performing reading from an onboard blackbody at known temperature, and calibrated via
is the counts measured while looking at the blackbody, is the power in watts from the blackbody as estimated from a thermocouple located near the receiver’s low noise amplifier, and is the receiver noise power in watts estimated from a pre-launch parameterization. Equations B1 and B2 can be combined:
The magnitude of the errors for the components calculating is displayed in Table B1 and have a similar calculation as before.

Table B1.
The magnitudes of 1-sigma errors for each term in Equation B3. The shaded rows indicate that the absolute magnitude is negligible compared to the dominant error terms, and are neglected in the construction of the error model in this work.
Table B1.
The magnitudes of 1-sigma errors for each term in Equation B3. The shaded rows indicate that the absolute magnitude is negligible compared to the dominant error terms, and are neglected in the construction of the error model in this work.
| Error Term | Error Magnitude [dB] |
|---|---|
| 0.14 [36] | |
| 0.14 [36] | |
| 0.10 [36] | |
| 0.07 [35] | |
| ~0.04 [36] |
, , and all vary with temperature, and the instrument gain will fluctuate as the satellite enters different thermal conditions in orbit. The most significant errors will occur just as the satellite crosses the terminator. At that point, CYGNSS will go from a nearly steady-state thermal environment, such as approximately half an orbit of illumination or eclipse, and then quickly enter the opposite state. The fraction of orbit spent illuminated is determined by the orbit beta angle, which varies on scales of weeks to months.
The dominant error term in the Level 1A algorithm is , which also varies with temperature. The calibration sequence is designed to correct for this, and we assume that the errors vary slowly with the timescales of interest, which is defined to be on scales of seconds to minutes. Therefore, all errors from are assumed to be 100% correlated in time within a given track of CYGNSS observations, i.e., during when series of samples adjacent in space and time share a GPS transmitter and a CYGNSS receiver. is also very sensitive to radio-frequency interference (RFI), which will present as non-physical signals above the specular point in a delay-Doppler map. We do not aim to model the complex phenomenologies of RFI in this work and assume there are no correlated error structures from RFI.
Errors in occur because of a variety of reasons. The low noise amplifiers were all characterized on the ground prior to launch to establish the relationship of the noise figure with respect to temperature. The values of this relationship were stored in a look-up table (LUT) for processing science data. However, as the amplifiers age, the noise floor characteristics may have evolved, producing errors in this mapping. Further, the thermal environment of the thermocouple may not be exactly same that is experienced by the amplifier itself. For the purposes of this model, we assume all errors due to incomplete or erroneous knowledge of the true receiver noise power are 100% correlated with each other for a given track, as we assume that the errors evolve slowly compared to the timescales of interest.
Therefore, the error correlation terms for and for any arbitrary CYGNSS samples and are the following:
The conditions that must be met are the following: and must share a CYGNSS receiver, a GPS transmitter, and be observed within 10 minutes of each other.
is the measured parameter, the raw counts of power from a science observation near the region of the specular point. The analog-to-digital processing chain is the primary source of errors, such as quantization errors and non-common-mode interference. We assume these error terms are 100% uncorrelated with each other, that is for every sample, it can be treated as white noise. The error correlation term for is then:
The error term for counts measured during a blackbody sample is a source of analytically-defined correlated error. Every 10 minutes (earlier in the mission, every 1 minute), the receiver is switched from the nadir science antenna to look at the onboard blackbody source for a period of 4-6 seconds. Science observation processing linearly interpolates the counts between the nearest blackbody looks. When errors are made in estimating , those errors are correlated linearly with all adjacent samples due to this interpolation. Correlation due to linear interpolation has an analytical form. Assuming a blackbody look happens at timesteps 0 and , then the correlation between any two samples and at arbitrary timesteps and where is:
where and . The actual values of the sampled blackbodies do not matter, as the correlated error is simply a function of how far the samples are from the blackbody looks in time.
Errors in are due to misestimations in of the blackbody’s true noise power, which may be because the thermocouple is measuring incorrectly. We assume that the errors of this nature not only are slowly varying compared to the timescales of interest, but because of the marginal absolute magnitude, factor a negligible and unmeasurable amount in the overall correlated error structure. As such the model ignores this term.
The rolled-up correlated error model from the sources in between any arbitrary samples and can be expressed as follows:
Because this model estimates the correlated error in each term that calculates , this contribution to the overall correlated is not multiplied by the error . As such, we do not normalize this construction, as it will be normalized when combined with the other constituent terms in . contains two tuning parameters: is used to size uncorrelated white-noise error, and is used to size the magnitude of totally-correlated errors.
Appendix C
The zenith receiver on CYGNSS works much the same way as the nadir science receiver. However, the zenith receiver does not have an onboard calibration system, and data are processed from pre-flight characterizations of the electronics. The counts of the receiver are converted to watts via a quadratic regression. Because the satellite is subject to the same thermal dynamics as the nadir receiver, one can expect that the zenith power estimate contains errors due to thermally-driven gain variations. We model the similarly to the nadir receiver, but with some important distinctions. Because the zenith receiver operates without an onboard blackbody to calibrate against, a number of simplifying assumptions are made. Errors are broken up into just two components, correlated and uncorrelated . We further assume that correlated error due to the absence of an onboard blackbody are outside the timescale of interest. The correlated error term is assumed to be totally correlated provided that the matching conditions are met:
The conditions for are that samples and are made with the same CYGNSS observatory and within 10 minutes of each other. In addition, an uncorrelated component is allowed:
The rolled-up correlated error model from the sources in between any arbitrary samples and can be expressed as follows:
with the same tuning parameters and as in Appendix A. Note that we assume dB as suggested in [33]. is estimated directly from a 24 hours of CYGNSS data as approximately 1% of the magnitude of the signal , therefore this model assumes dB.
Appendix D
The CYGNSS observatory has three antennas, one zenith antenna that is used for direct GPS-to-CYGNSS signal tracking, as well as two nadir science antennas that are used to capture the scattered signal from Earth’s surface. Each of the eight spacecraft had all three antennas characterized pre-launch, and values were stored in a lookup table for science processing.
Errors in the antenna gain pattern can arise for a variety of reasons. First, the measurement equipment on the ground is essentially a receiver, but in controlled conditions. This means that while systematic and correlated errors are likely well-constrained, uncorrelated speckle-type error can still occur. To produce realistic antenna gain patterns, the results of the ground characterization were smoothed with various filters and techniques.
Another source of error is the fact that CYGNSS antennas were not characterized while integrated with the spacecraft. This was a cost-saving measure decided by the mission management team. However, the electromagnetic properties of the antenna couple in some fashion with the spacecraft bus, and that will inevitably change the gain patterns.
Initial analysis of CYGNSS data shortly after launch showed significant retrieval performance dependence on the observation azimuthal angle with respect to the CYGNSS body frame, which was later hypothesized to originate in errors in the CYGNSS antenna patterns. To compensate for this deviation from measured patterns, the CYGNSS antenna patterns have been updated at several instances over the mission life via empirical calibration. The nadir antenna patterns are updated by comparing a climatology of CYGNSS measurements of (> 2 years) with model-generate and plotting a scaling factor in the antenna reference coordinate system. is generated by using modeled reanalysis winds to generate mean-squared slope with the L-band spectrum extension model as described in [38]. However, during the generation of these updated patterns, a number of smoothing filters are applied.
This prompts discussion of a conjecture used extensively for this section:
Conjecture D1.
Uncorrelated errors can become correlated by post-processing with averaging and filters.
This insight drives much of this section’s analysis. Smoothing and filtering will necessarily impose a correlation in error between previously uncorrelated error. For white noise, that implies that the choice of filter will add color and structure to the noise.
In particular, a handy lemma allows us to demonstrate that for white noise, the information required to capture correlated error structure is the filtering kernel itself. We will explore this behavior for a one dimensional case, but it is generalizable to higher dimensions in our application, as the two-dimensional filters used for antenna smoothing are separable by construction.
Lemma D2.
For a filtered signal , where is a filtering kernel and is an arbitrary data signal, the autocorrelation is the convolution of the autocorrelated kernel and the autocorrelated signal .
Proof of Lemma D2.
Assume convolution and cross-correlation have the standard definitions for two real-valued timeseries and , that is,
and
where is the convolution operator, is the cross-correlation operator, and is the lag argument. Observe that convolution operations is commutative, and further, that the cross correlation can be written as a convolution by exploiting its symmetry:
Therefore, to evaluate the correlated error imposed by kernel ,
If the arbitrary signal happens to be white noise, it is completely uncorrelated, and its autocorrelation collapses to a Dirac delta function centered at . Therefore, the entire structure of the correlated error is from the filter itself:
For the purposes of this work’s error model, we have no knowledge of the potential correlated structure in the actual errors in the gain pattern. The nadir antenna patterns are updated after applying a 6-degree boxcar averaging filter in both the azimuthal and elevation in the spacecraft coordinate frame, and then an additional 10-degree two-dimensional smoothing window. We assume that zenith antenna patterns use a similar post-processing technique during their generation.
These filtering kernels act like low-pass filters. All correlated structure on scales ~5 degrees and smaller and uncorrelated error will be strongly influenced by the filtering process and the correlated structure can be estimated from the Filter Lemma. This model assumes that there is no residual larger-scale structure in correlated error in the antenna gain patterns.
The generated filter kernel, which applies to both the nadir and zenith antenna patterns, can be shown in Figure D1. The correlated error is a function of how close any two observations are with respect to the relevant antenna gain pattern coordinates.
Figure D1.
The filtering kernel used to smooth nadir and zenith antenna gain patterns. This kernel imposes correlated error structure onto the antenna gain patterns. The coordinate system should be read in the relevant antenna reference frame. Therefore, if two observations are nearby in the antenna pattern, they will have strongly correlated error. However, if two observations are far apart in the pattern, the correlated structure decays.
Figure D1.
The filtering kernel used to smooth nadir and zenith antenna gain patterns. This kernel imposes correlated error structure onto the antenna gain patterns. The coordinate system should be read in the relevant antenna reference frame. Therefore, if two observations are nearby in the antenna pattern, they will have strongly correlated error. However, if two observations are far apart in the pattern, the correlated structure decays.
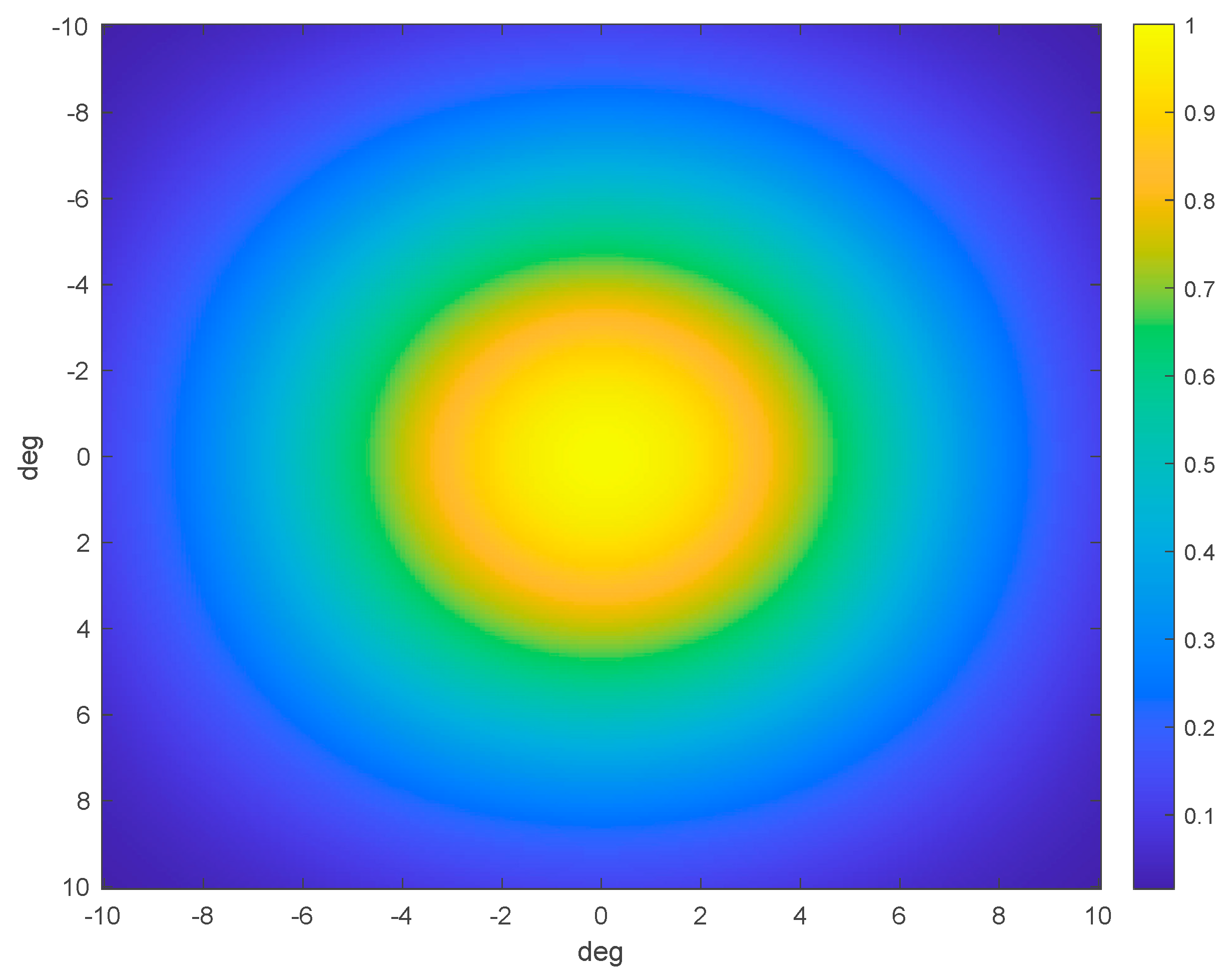
For any arbitrary samples and , we compute the gain pattern coordinates and in the relevant antenna reference frame. To retrieve how correlated the error is, we compute the distance between the two observations in the reference frame:
The error correlation function is computed via a LUT of the filter kernel K:
This error correlation holds if the samples and share the same antenna and are on the same spacecraft. If they are on separate antennas or spacecraft, the correlated error is zero. The rolled-up correlated errors for the gain patterns can be expressed as:
where two new tuning parameters have been introduced. is used to the tune the overall magnitude of the correlated error from these components, and is used to scale the decorrelation roll-off rate as the samples spread in antenna coordinates.
Appendix E
Errors in zenith-specular ratio are defined as a function of specular incidence angle , which is a function of the geometry of a given GPS transmitter, a CYGNSS receiver at any given sample time.
is used to estimate GPS EIRP and is a derived via as described in [46]:
where the angles are defined in the GPS reference frame. For specular geometries, the azimuthal angles in the zenith direction are nearly identical to the specular direction, so . In addition, the elevation angles in the GPS antenna reference frame and can be estimated from the angle of incidence of specular reflection from Earth :
As a result, can be expressed as a function of specular incidence angle and azimuthal angle in the GPS antenna reference frame. While GPS antenna patterns are known to exhibit azimuthal dependence, this variation is less significant than the elevation angle and CYGNSS uses the azimuthal average for its EIRP estimate:
The estimated correlated error in however come two steps of this processing. First is the mapping of Earth scattering incidence angle to GPS antenna elevation angles and in Equations E2a and E2b. This particular mapping is coarse, as even the high fidelity derived GPS antenna maps are plotted to 0.5 degree increments. Because the dynamic range of only extends to about 15 degrees, that only leaves ~30 data points to map the full dynamic range of scattering incidence angles.
The second aspect has to do with the way in which is processed and generated and invokes the same logic as in the Filter Lemma. For every GPS satellite, a LUT is generated as a function of observation incidence angle . To minimize discontinuities, a fourth-order power series is fit. We argue that this smoothing is predominant source of correlated error structure. An example of this is demonstrated in Figure E1.
Figure E1.
This figure illustrates a calculated zenith-specular ratio as a function of observation incidence angle . The blue trace is interpolated from raw observations over a two-year period at each of the elevation gridpoints in the GPS antenna pattern for a single azimuthal cut of PRN 2. The red trace is a generated smoothed zenith-specular ratio that would be similar to ones used in the operational LUTs using a 4th-order power series fit. Note that at large incidence angles, i.e., grazing observations, there is a great deal of uncertainty in because there are few valid observations in those regions. In practice, only data at incidence angles < 60 degrees constrain error in .
Figure E1.
This figure illustrates a calculated zenith-specular ratio as a function of observation incidence angle . The blue trace is interpolated from raw observations over a two-year period at each of the elevation gridpoints in the GPS antenna pattern for a single azimuthal cut of PRN 2. The red trace is a generated smoothed zenith-specular ratio that would be similar to ones used in the operational LUTs using a 4th-order power series fit. Note that at large incidence angles, i.e., grazing observations, there is a great deal of uncertainty in because there are few valid observations in those regions. In practice, only data at incidence angles < 60 degrees constrain error in .
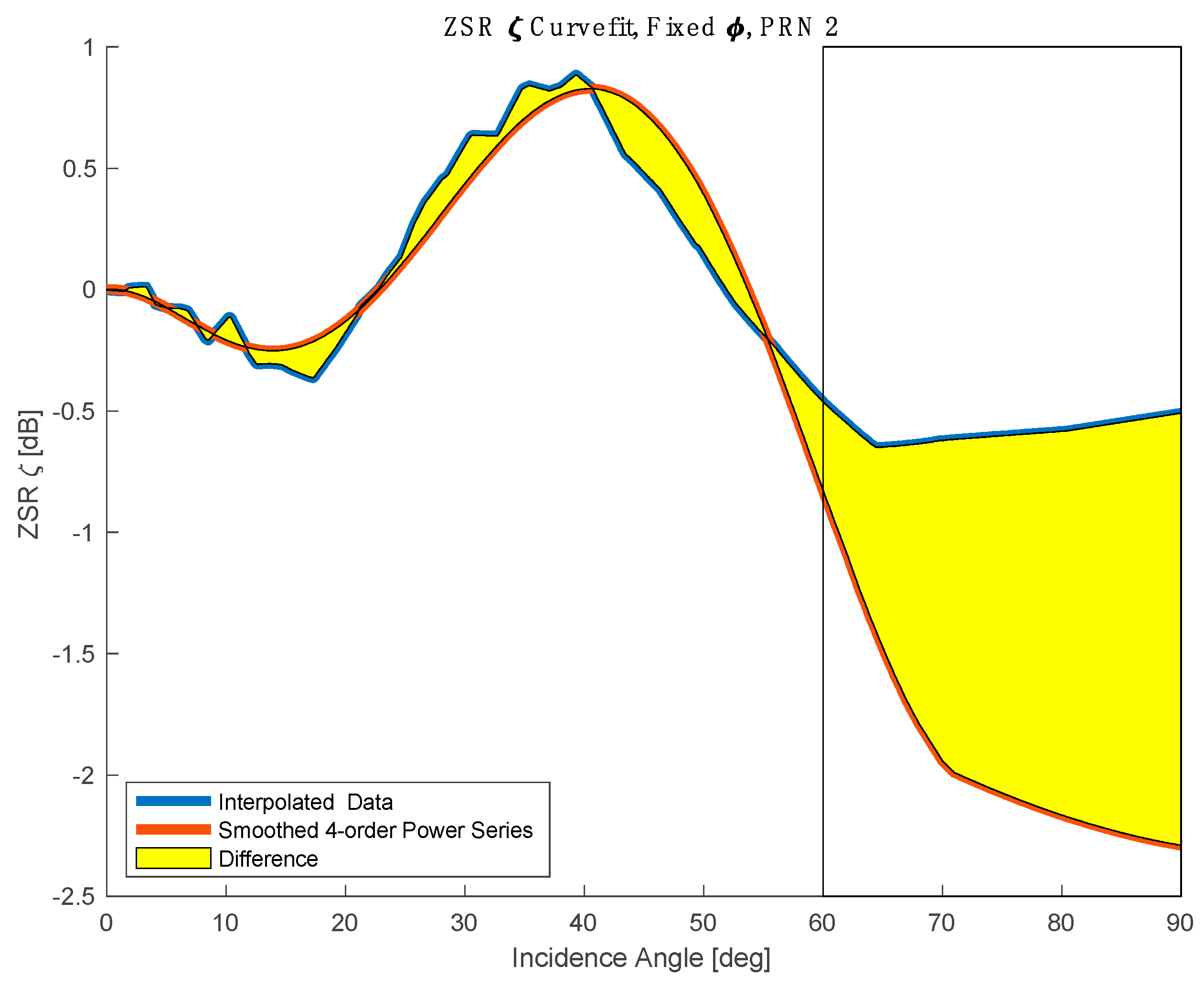
While linear interpolation itself imparts some degree of error structure, we believe it is the most representative way to express “raw” data in a continuous series for the purposes of exploring correlated error due to the power series smoothing. For each GPS PRN, we calculate the difference between these estimates:
Then, the error correlation is simply:
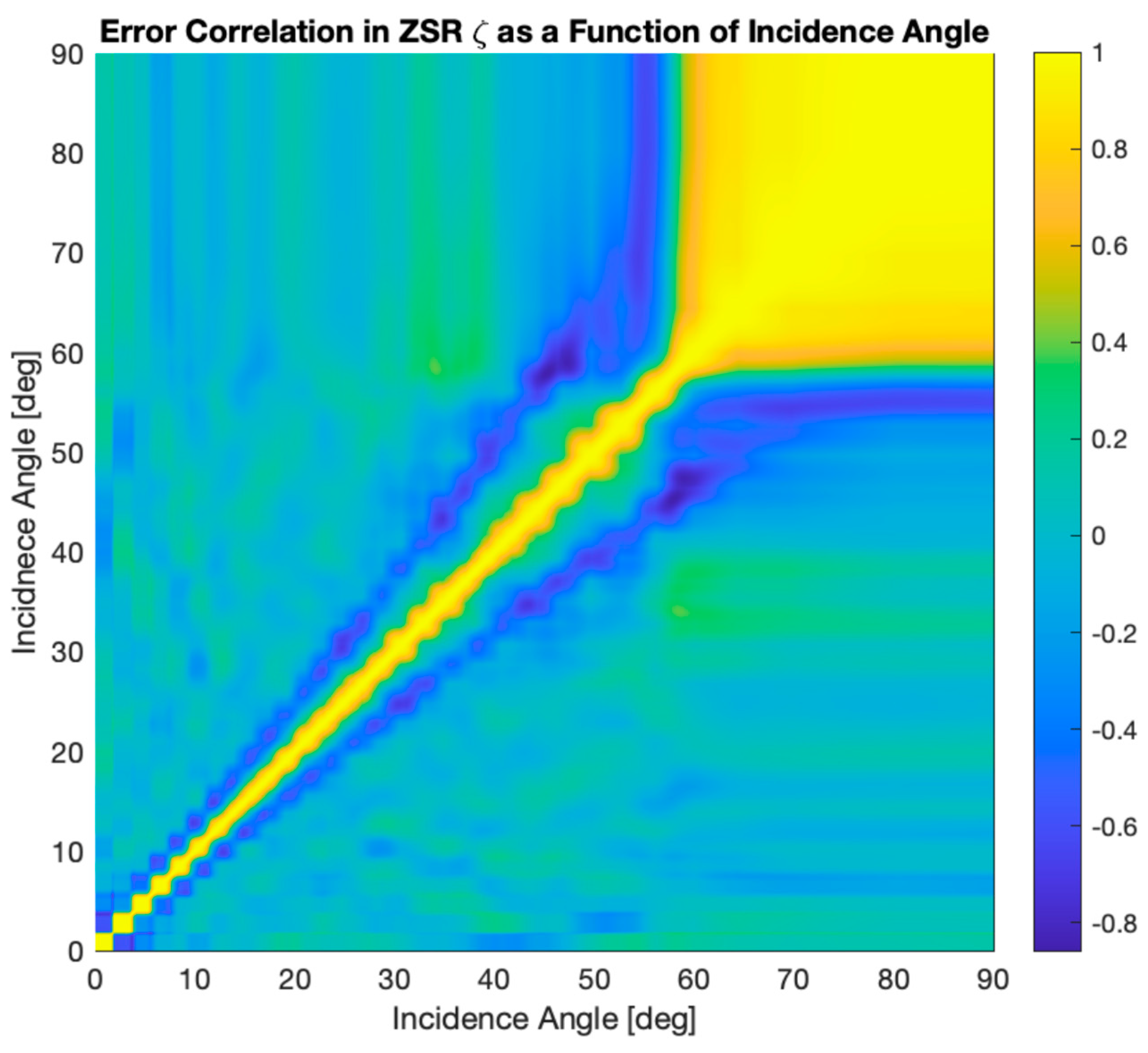
where is incidence angle of the observation at sample and is incidence angle of the observation at sample . In practice, the correlation is computed by utilizing each azimuthal cut as an instance, and building a LUT of correlation as a function of incidence angles for samples and . An example of this LUT for GPS PRN 2 is shown in Figure D2. The rolled-up correlated error for can then be expressed as:
with the same tuning parameter as introduced in Appendix B.
Figure E2.
This correlation matrix is used to produce . Note that the mapping from coordinates in GPS elevation angle and to Earth scattering incidence angle is coarse and produces the checkerboard-like pattern near the diagonal. A single error in the measurement of in the GPS antenna pattern is will highly correlate within a range of incidence angles in as mapped. At high incidence angles, errors are strongly correlated as the powerseries fit is likely to be wrong in the same direction.
Figure E2.
This correlation matrix is used to produce . Note that the mapping from coordinates in GPS elevation angle and to Earth scattering incidence angle is coarse and produces the checkerboard-like pattern near the diagonal. A single error in the measurement of in the GPS antenna pattern is will highly correlate within a range of incidence angles in as mapped. At high incidence angles, errors are strongly correlated as the powerseries fit is likely to be wrong in the same direction.
References
- Ruf, C.S.; Chew, C.; Lang, T.; Morris, M.G.; Nave, K.; Ridley, A.; Balasubramaniam, R. A New Paradigm in Earth Environmental Monitoring with the CYGNSS Small Satellite Constellation. Scientific Reports 2018, 8. [Google Scholar] [CrossRef]
- Lorenc, A.C.; Ballard, S.P.; Bell, R.S.; Ingleby, N.B.; Andrews, P.L.F.; Barker, D.M.; Bray, J.R.; Clayton, A.M.; Dalby, T.; Li, D.; et al. The Met. Office Global Three-dimensional Variational Data Assimilation Scheme. Quart J Royal Meteoro Soc 2000, 126, 2991–3012. [Google Scholar] [CrossRef]
- Bannister, R.N. A Review of Forecast Error Covariance Statistics in Atmospheric Variational Data Assimilation. I: Characteristics and Measurements of Forecast Error Covariances. Quart J Royal Meteoro Soc 2008, 134, 1951–1970. [Google Scholar] [CrossRef]
- Bannister, R.N. A Review of Forecast Error Covariance Statistics in Atmospheric Variational Data Assimilation. II: Modelling the Forecast Error Covariance Statistics. Quart J Royal Meteoro Soc 2008, 134, 1971–1996. [Google Scholar] [CrossRef]
- Morss, R.E.; Emanuel, K.A. Influence of Added Observations on Analysis and Forecast Errors: Results from Idealized Systems. Quart J Royal Meteoro Soc 2002, 128, 285–321. [Google Scholar] [CrossRef]
- Stewart, L.M.; Dance, S.L.; Nichols, N.K. Data Assimilation with Correlated Observation Errors: Experiments with a 1-D Shallow Water Model. Tellus A: Dynamic Meteorology and Oceanography 2013, 65, 19546. [Google Scholar] [CrossRef]
- Fowler, A.M.; Dance, S.L.; Waller, J.A. On the Interaction of Observation and Prior Error Correlations in Data Assimilation. Quarterly Journal of the Royal Meteorological Society 2018, 144, 48–62. [Google Scholar] [CrossRef]
- Liu, Z.Q.; Rabier, F. The Interaction between Model Resolution, Observation Resolution and Observation Density in Data Assimilation: A One-Dimensional Study. Quarterly Journal of the Royal Meteorological Society 2002, 128, 1367–1386. [Google Scholar] [CrossRef]
- Stewart, L.M.; Dance, S.L.; Nichols, N.K.; Eyre, J.R.; Cameron, J. Estimating Interchannel Observation-error Correlations for IASI Radiance Data in the Met Office System. Quart J Royal Meteoro Soc 2014, 140, 1236–1244. [Google Scholar] [CrossRef]
- Bormann, N.; Bonavita, M.; Dragani, R.; Eresmaa, R.; Matricardi, M.; McNally, A. Enhancing the Impact of IASI Observations through an Updated Observation-error Covariance Matrix. Quart J Royal Meteoro Soc 2016, 142, 1767–1780. [Google Scholar] [CrossRef]
- Bormann, N.; Bauer, P. Estimates of Spatial and Interchannel Observation-Error Characteristics for Current Sounder Radiances for Numerical Weather Prediction. I: Methods and Application to ATOVS Data. Q.J.R. Meteorol. Soc. 2010, 136, 1036–1050. [Google Scholar] [CrossRef]
- Liu, Y.-A.; Li, Z.; Huang, M. Towards a Data-Derived Observation Error Covariance Matrix for Satellite Measurements. Remote Sensing 2019, 11, 1770. [Google Scholar] [CrossRef]
- Simonin, D.; Waller, J.A.; Ballard, S.P.; Dance, S.L.; Nichols, N.K. A Pragmatic Strategy for Implementing Spatially Correlated Observation Errors in an Operational System: An Application to Doppler Radial Winds. Quart J Royal Meteoro Soc 2019, 145, 2772–2790. [Google Scholar] [CrossRef]
- Waller, J.A.; Dance, S.L.; Nichols, N.K. On Diagnosing Observation-error Statistics with Local Ensemble Data Assimilation. Quart J Royal Meteoro Soc 2017, 143, 2677–2686. [Google Scholar] [CrossRef]
- Yang, J.X.; You, Y.; Blackwell, W.; Da, C.; Kalnay, E.; Grassotti, C.; Liu, Q. (Mark); Ferraro, R.; Meng, H.; Zou, C.-Z.; et al. SatERR: A Community Error Inventory for Satellite Microwave Observation Error Representation and Uncertainty Quantification. Bulletin of the American Meteorological Society 2023. [CrossRef]
- Bauer, P.; Buizza, R.; Cardinali, C.; Noël Thépaut, J. Impact of Singular-Vector-Based Satellite Data Thinning on NWP. Quarterly Journal of the Royal Meteorological Society 2011, 137, 286–302. [Google Scholar] [CrossRef]
- Gao, Y.; Xiao, H.; Jiang, D.; Wan, Q.; Chan, P.W.; Hon, K.K.; Deng, G. Impacts of Thinning Aircraft Observations on Data Assimilation and Its Prediction during Typhoon Nida (2016). Atmosphere 2019, 10, 754. [Google Scholar] [CrossRef]
- Hoffman, R.N. The Effect of Thinning and Superobservations in a Simple One-Dimensional Data Analysis with Mischaracterized Error. Monthly Weather Review 2018, 146, 1181–1195. [Google Scholar] [CrossRef]
- Rainwater, S.; Bishop, C.H.; Campbell, W.F. The Benefits of Correlated Observation Errors for Small Scales. Quart J Royal Meteoro Soc 2015, 141, 3439–3445. [Google Scholar] [CrossRef]
- Stewart, L.M.; Dance, S.L.; Nichols, N.K. Correlated Observation Errors in Data Assimilation. Numerical Methods in Fluids 2008, 56, 1521–1527. [Google Scholar] [CrossRef]
- Daley, R. The Effect of Serially Correlated Observation and Model Error on Atmospheric Data Assimilation. Mon. Wea. Rev. 1992, 120, 164–177. [Google Scholar] [CrossRef]
- Waller, J.A.; Dance, S.L.; Nichols, N.K. Theoretical Insight into Diagnosing Observation Error Correlations Using Observation-minus-background and Observation-minus-analysis Statistics. Quart J Royal Meteoro Soc 2016, 142, 418–431. [Google Scholar] [CrossRef]
- Dee, D.P.; Da Silva, A.M. Maximum-Likelihood Estimation of Forecast and Observation Error Covariance Parameters. Part I: Methodology. Mon. Wea. Rev. 1999, 127, 1822–1834. [Google Scholar] [CrossRef]
- Desroziers, G.; Berre, L.; Chapnik, B.; Poli, P. Diagnosis of Observation, Background and Analysis-error Statistics in Observation Space. Quart J Royal Meteoro Soc 2005, 131, 3385–3396. [Google Scholar] [CrossRef]
- Ruf, C.; McKague, D.; Posselt, D.J.; Gleason, S.; Clarizia, M.P.; Zavorotny, V.U.; Butler, T.; Redfern, J.; Wells, W.; Morris, M.; et al. CYGNSS Handbook; 2nd ed.; Michigan Publishing Services, 2022; ISBN 978-1-60785-787-7.
- Clarizia, M.P.; Ruf, C.S. Wind Speed Retrieval Algorithm for the Cyclone Global Navigation Satellite System (CYGNSS) Mission. IEEE Transactions on Geoscience and Remote Sensing 2016, 54, 4419–4432. [Google Scholar] [CrossRef]
- Ruf, C.S.; Balasubramaniam, R. Development of the CYGNSS Geophysical Model Function for Wind Speed. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 2019, 12, 66–77. [Google Scholar] [CrossRef]
- Gleason, S.; Ruf, C.S.; Orbrien, A.J.; McKague, D.S. The CYGNSS Level 1 Calibration Algorithm and Error Analysis Based on On-Orbit Measurements. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 2019, 12, 37–49. [Google Scholar] [CrossRef]
- Wang, T.; Ruf, C.; McKague, D.; Russel, A.; O’Brien, A.; Gleason, S. The Important Role of Antenna Pattern Characterization in the Absolute Calibration of GNSS-R Measurements. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS; IEEE: Brussels, Belgium, July 11 2021; pp. 144–146.
- Wang, T.; Ruf, C.; Gleason, S.; McKague, D.; O’Brien, A.; Block, B. Monitoring GPS Eirp for Cygnss Level 1 Calibration. In Proceedings of the IGARSS 2020 - 2020 IEEE International Geoscience and Remote Sensing Symposium; IEEE: Waikoloa, HI, USA, September 26 2020; pp. 6293–6296.
- Steigenberger, P.; Thölert, S.; Montenbruck, O. Flex Power on GPS Block IIR-M and IIF. GPS Solutions 2019, 23, 1–12. [Google Scholar] [CrossRef]
- Marquis, W.A.; Reigh, D.L. The GPS Block IIR and IIR-M Broadcast L-Band Antenna Panel: Its Pattern and Performance: GPS Block IIR and IIR-M L-Band Antenna Panel Pattern. J Inst Navig 2015, 62, 329–347. [Google Scholar] [CrossRef]
- Wang, T.; Ruf, C.S.; Gleason, S.; O’Brien, A.J.; McKague, D.S.; Block, B.P.; Russel, A. Dynamic Calibration of GPS Effective Isotropic Radiated Power for GNSS-Reflectometry Earth Remote Sensing. IEEE Transactions on Geoscience and Remote Sensing 2021, 1–12. [Google Scholar] [CrossRef]
- Gleason, S. Level 1B DDM Calibration Algorithm Theoritical Basis Document (Rev. 3); University of Michigan, 2020;
- Powell, C.E.; Ruf, C.S.; Russel, A. An Improved Blackbody Calibration Cadence for CYGNSS. IEEE Trans. Geosci. Remote Sensing 2022, 60, 1–7. [Google Scholar] [CrossRef]
- Gleason, S. Level 1A DDM Calibration Algorithm Theoretical Basis Document (Rev. 2); University of Michigan, 2018;
- Hersbach, H.; Bell, B.; Berrisford, P.; Hirahara, S.; Horányi, A.; Muñoz-Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Schepers, D.; et al. The ERA5 Global Reanalysis. Quarterly Journal of the Royal Meteorological Society 2020, 146, 1999–2049. [Google Scholar] [CrossRef]
- Wang, T.; Zavorotny, V.U.; Johnson, J.; Yi, Y.; Ruf, C. Integration of Cygnss Wind and Wave Observations with the Wavewatch III Numerical Model. In Proceedings of the IGARSS 2019 - 2019 IEEE International Geoscience and Remote Sensing Symposium; IEEE, July 2019; pp. 8350–8353. [Google Scholar]
- Berg, W.; Brown, S.T.; Lim, B.H.; Reising, S.C.; Goncharenko, Y.; Kummerow, C.D.; Gaier, T.C.; Padmanabhan, S. Calibration and Validation of the TEMPEST-D CubeSat Radiometer. IEEE Trans. Geosci. Remote Sensing 2021, 59, 4904–4914. [Google Scholar] [CrossRef]
- Kroodsma, R.A.; McKague, D.S.; Ruf, C.S. Inter-Calibration of Microwave Radiometers Using the Vicarious Cold Calibration Double Difference Method. IEEE J. Sel. Top. Appl. Earth Observations Remote Sensing 2012, 5, 1006–1013. [Google Scholar] [CrossRef]
- Zec, J.; Jones, W.; Alsabah, R.; Al-Sabbagh, A. RapidScat Cross-Calibration Using the Double Difference Technique. Remote Sensing 2017, 9, 1160. [Google Scholar] [CrossRef]
- Powell, C.E.; Ruf, C.S.; Gleason, S.; Rafkin, S.C.R. Sampled Together: Assessing the Value of Simultaneous Co-Located Measurements for Optimal Satellite Configurations. Bull. Amer. Meteor. Soc. [Accepted, Publication Pending]. [CrossRef]
- CYGNSS CYGNSS Level 1 Science Data Record Version 3. 1 2021.
- Hersbach, H.; Bell, B.; Berrisford, P.; Biavati, G.; Horányi, A.; Muñoz Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Razum, I.; et al. ERA5 Hourly Data on Single Levels from 1940 to Present 2023.
- Taylor, J.R. An Introduction to Error Analysis: The Study of Uncertainties in Physical Measurements; 2nd ed.; University Science Books: Sausalito, Calif, 1997; ISBN 978-0-935702-42-2.
- Wang, T.; Ruf, C.S.; Gleason, S.; O’Brien, A.J.; McKague, D.S.; Block, B.P.; Russel, A. Dynamic Calibration of GPS Effective Isotropic Radiated Power for GNSS-Reflectometry Earth Remote Sensing. IEEE Transactions on Geoscience and Remote Sensing 2021, 1–12. [Google Scholar] [CrossRef]
Figure 1.
Comparison of FM1 and FM5 observations for 11 SEP 2019. (a) Rendering of the ground samples captured during the 24-hour period in the near-overlap condition; (b) A single track of samples for both FM1 and FM5 that has been matched sample-for-sample to facilitate one-to-one comparisons of the observations. The samples from each observatory are no more than 0.5 deg apart in distance and were acquired approximately 3 seconds apart in time.
Figure 1.
Comparison of FM1 and FM5 observations for 11 SEP 2019. (a) Rendering of the ground samples captured during the 24-hour period in the near-overlap condition; (b) A single track of samples for both FM1 and FM5 that has been matched sample-for-sample to facilitate one-to-one comparisons of the observations. The samples from each observatory are no more than 0.5 deg apart in distance and were acquired approximately 3 seconds apart in time.
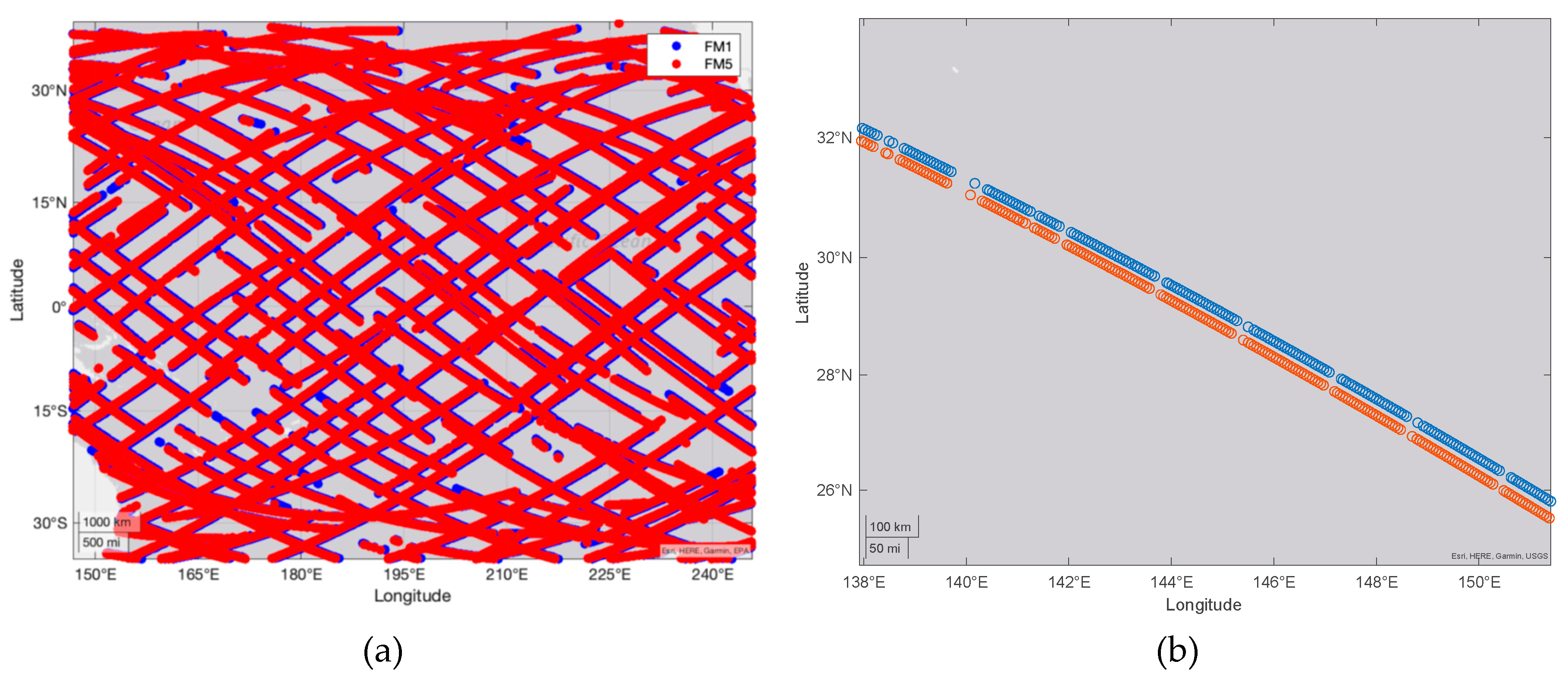
Figure 2.
A display of model (blue) and observed (green) single-differenced matchup data for a single CYGNSS track, with the double-differenced data (red) overlaid. Note that both the model and observed single differences are similarly high early in the track, suggesting that the differences in the observations may be because the samples are observing fundamentally different targets, captured in . The double difference accounts for these types of errors, and for the entire track, the double difference is quite stable. The sparsity of data is caused by quality control parameters, such as when the CYGNSS observatory is performing its onboard calibration procedure, which occurs once every minute. Because the two matched observatories do not have synchronized calibration clocks, the matched dataset typically flags out two of these cadences for every minute of sampling.
Figure 2.
A display of model (blue) and observed (green) single-differenced matchup data for a single CYGNSS track, with the double-differenced data (red) overlaid. Note that both the model and observed single differences are similarly high early in the track, suggesting that the differences in the observations may be because the samples are observing fundamentally different targets, captured in . The double difference accounts for these types of errors, and for the entire track, the double difference is quite stable. The sparsity of data is caused by quality control parameters, such as when the CYGNSS observatory is performing its onboard calibration procedure, which occurs once every minute. Because the two matched observatories do not have synchronized calibration clocks, the matched dataset typically flags out two of these cadences for every minute of sampling.
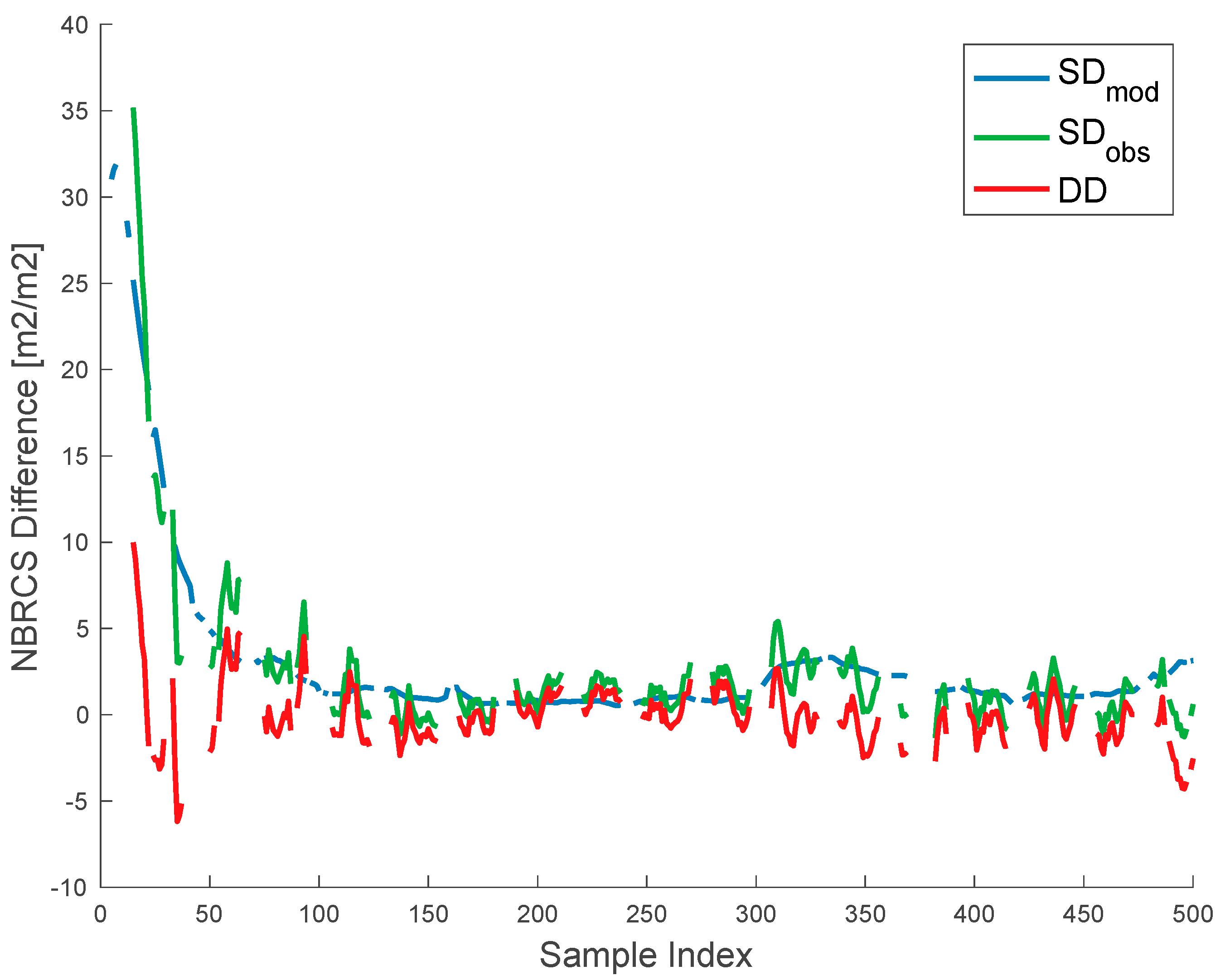
Figure 3.
Comparison of the bulk error autocorrelation behavior for all matched tracks. Shown is the single difference of modeled (blue), the single difference of observed (green), the double-difference DD (purple), the untuned bulk model error correlation (dotted red), and the final tuned bulk model error correlation (orange). The lags are computed in seconds, which correspond to single samples at 1 Hz sampling for the CYGNSS observatory. Note that DD generally follows the trace, suggesting that single-differencing for this particular use case may be a reasonable representation of bulk error correlation behavior.
Figure 3.
Comparison of the bulk error autocorrelation behavior for all matched tracks. Shown is the single difference of modeled (blue), the single difference of observed (green), the double-difference DD (purple), the untuned bulk model error correlation (dotted red), and the final tuned bulk model error correlation (orange). The lags are computed in seconds, which correspond to single samples at 1 Hz sampling for the CYGNSS observatory. Note that DD generally follows the trace, suggesting that single-differencing for this particular use case may be a reasonable representation of bulk error correlation behavior.
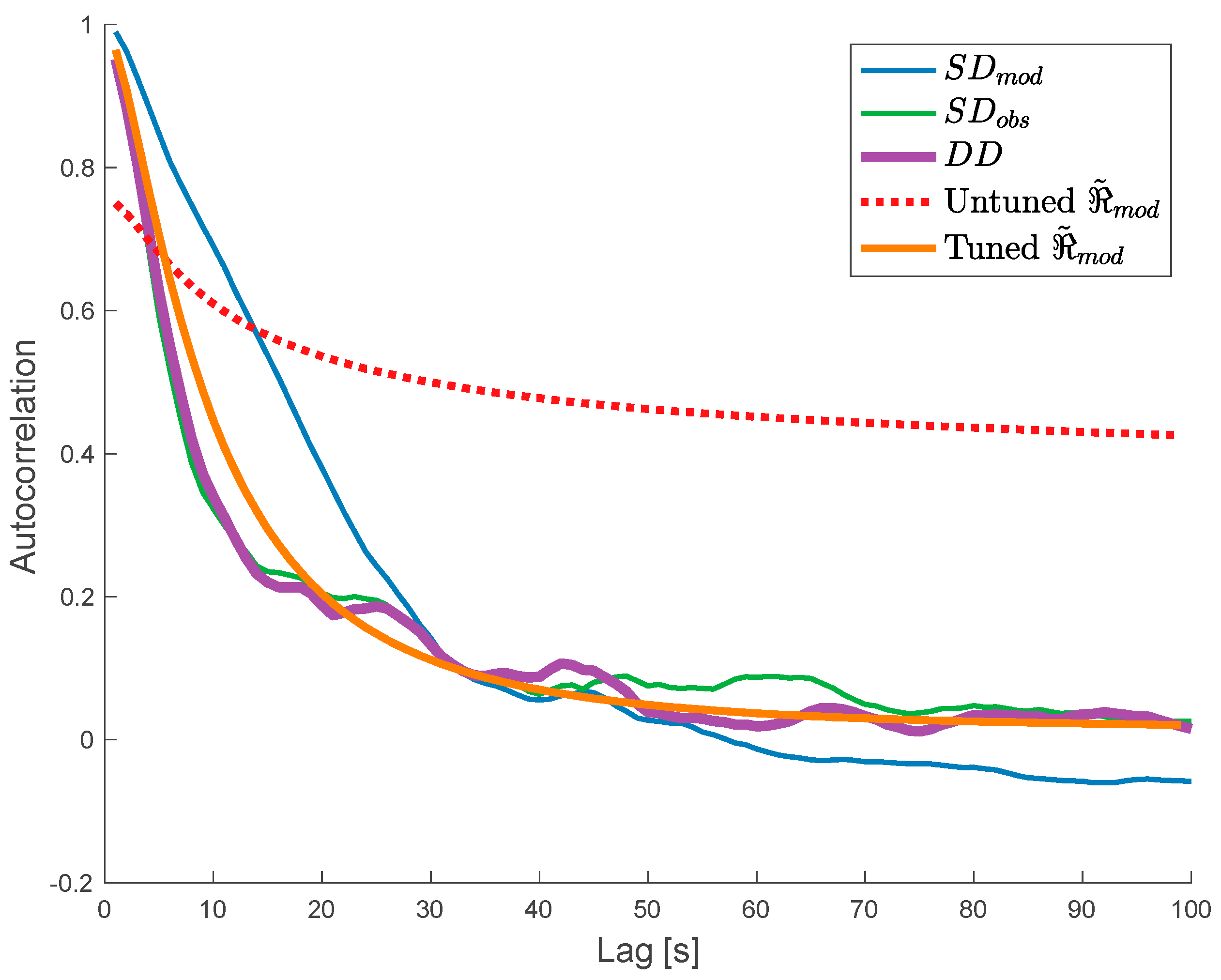
Figure 4.
Comparison of the single-track error autocorrelation behavior three selected tracks. Shown is the autocorrelation of the NBRCS double difference (solid lines), untuned modeled error correlation , and tuned modeled error autocorrelation (dashed lines) for each of the three tracks. Each track is painted a different color. This figure demonstrates the wide variability of single-track autocorrelations of double differences, arising from the variability of the observable, the limited amount of data in a single track, and the challenges in quality-controlling sufficient observation data. It is possible that the correlated error does vary this much from track-to-track. In contrast, both the tuned and untuned modeled error autocorrelation is much more stable from track-to-track.
Figure 4.
Comparison of the single-track error autocorrelation behavior three selected tracks. Shown is the autocorrelation of the NBRCS double difference (solid lines), untuned modeled error correlation , and tuned modeled error autocorrelation (dashed lines) for each of the three tracks. Each track is painted a different color. This figure demonstrates the wide variability of single-track autocorrelations of double differences, arising from the variability of the observable, the limited amount of data in a single track, and the challenges in quality-controlling sufficient observation data. It is possible that the correlated error does vary this much from track-to-track. In contrast, both the tuned and untuned modeled error autocorrelation is much more stable from track-to-track.
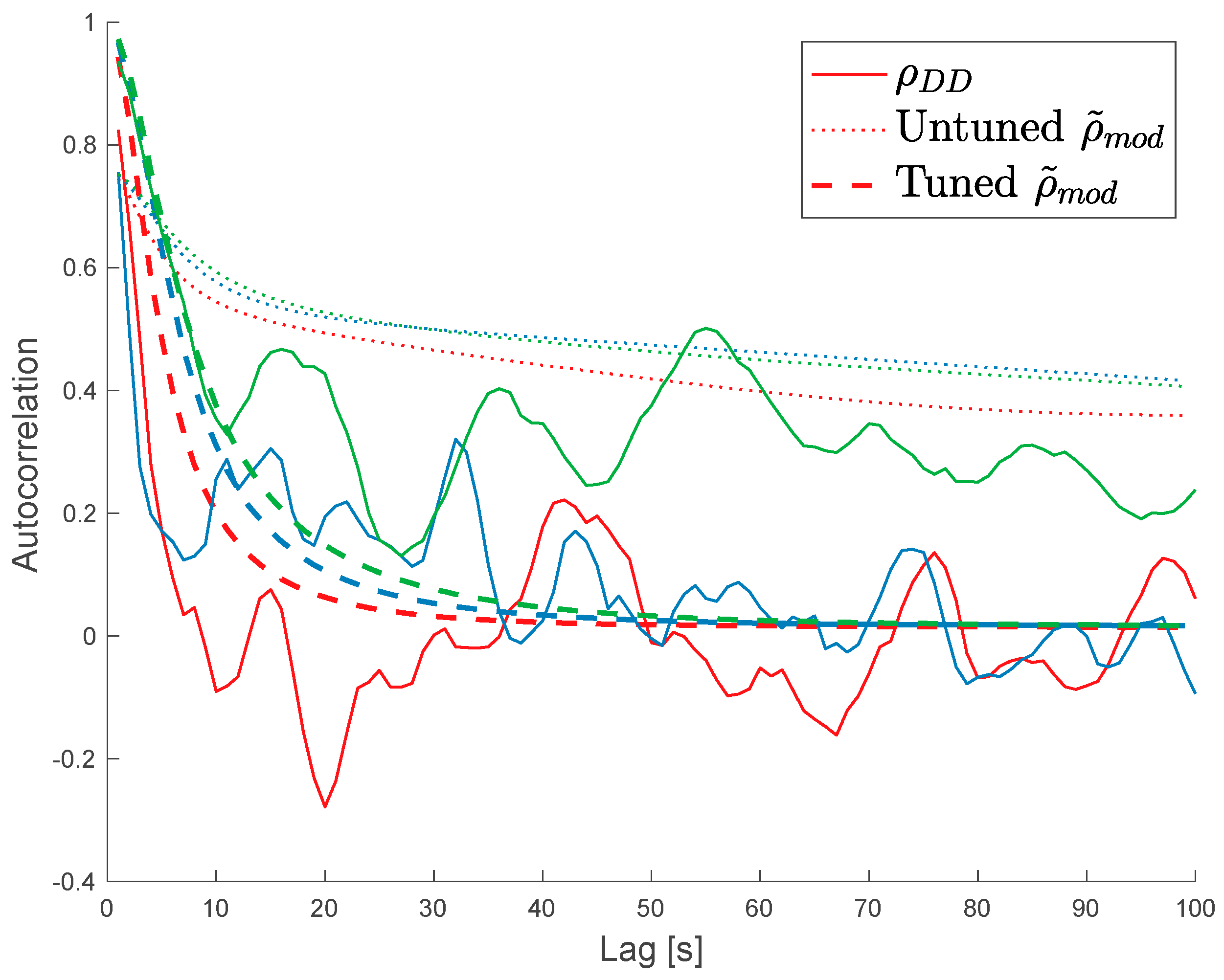
Figure 5.
Generated untuned and tuned for two nearby tracks captured by the same CYGNSS receiver, each with three different representations. (a) Untuned as represented by sample index. The two tracks are concatenated in a vector, and modeled error correlation is calculated for each combination of indices. The green vertical line represents an exemplar index (i=129) along the track where correlated error is estimated for every other observation in the neighborhood. (b) Untuned for the same exemplar index as represented by the physical location of sample acquisition. (c) Untuned for the same exemplar index represented by time of acquisition. The traces for the two different tracks are plotted as different colors. The error correlation along the same track is in blue, while the error correlation for the adjacent track is in red. (d) Tuned as represented by sample index for the same two tracks as in (a). (e) Tuned for the same tracks represented in physical location. (e) Tuned for the same exemplar index represented by time of acquisition. Note that for both the untuned and tuned cases, the correlated error for the adjacent track is nonzero, but generally very small compared to the error correlation along the track.
Figure 5.
Generated untuned and tuned for two nearby tracks captured by the same CYGNSS receiver, each with three different representations. (a) Untuned as represented by sample index. The two tracks are concatenated in a vector, and modeled error correlation is calculated for each combination of indices. The green vertical line represents an exemplar index (i=129) along the track where correlated error is estimated for every other observation in the neighborhood. (b) Untuned for the same exemplar index as represented by the physical location of sample acquisition. (c) Untuned for the same exemplar index represented by time of acquisition. The traces for the two different tracks are plotted as different colors. The error correlation along the same track is in blue, while the error correlation for the adjacent track is in red. (d) Tuned as represented by sample index for the same two tracks as in (a). (e) Tuned for the same tracks represented in physical location. (e) Tuned for the same exemplar index represented by time of acquisition. Note that for both the untuned and tuned cases, the correlated error for the adjacent track is nonzero, but generally very small compared to the error correlation along the track.
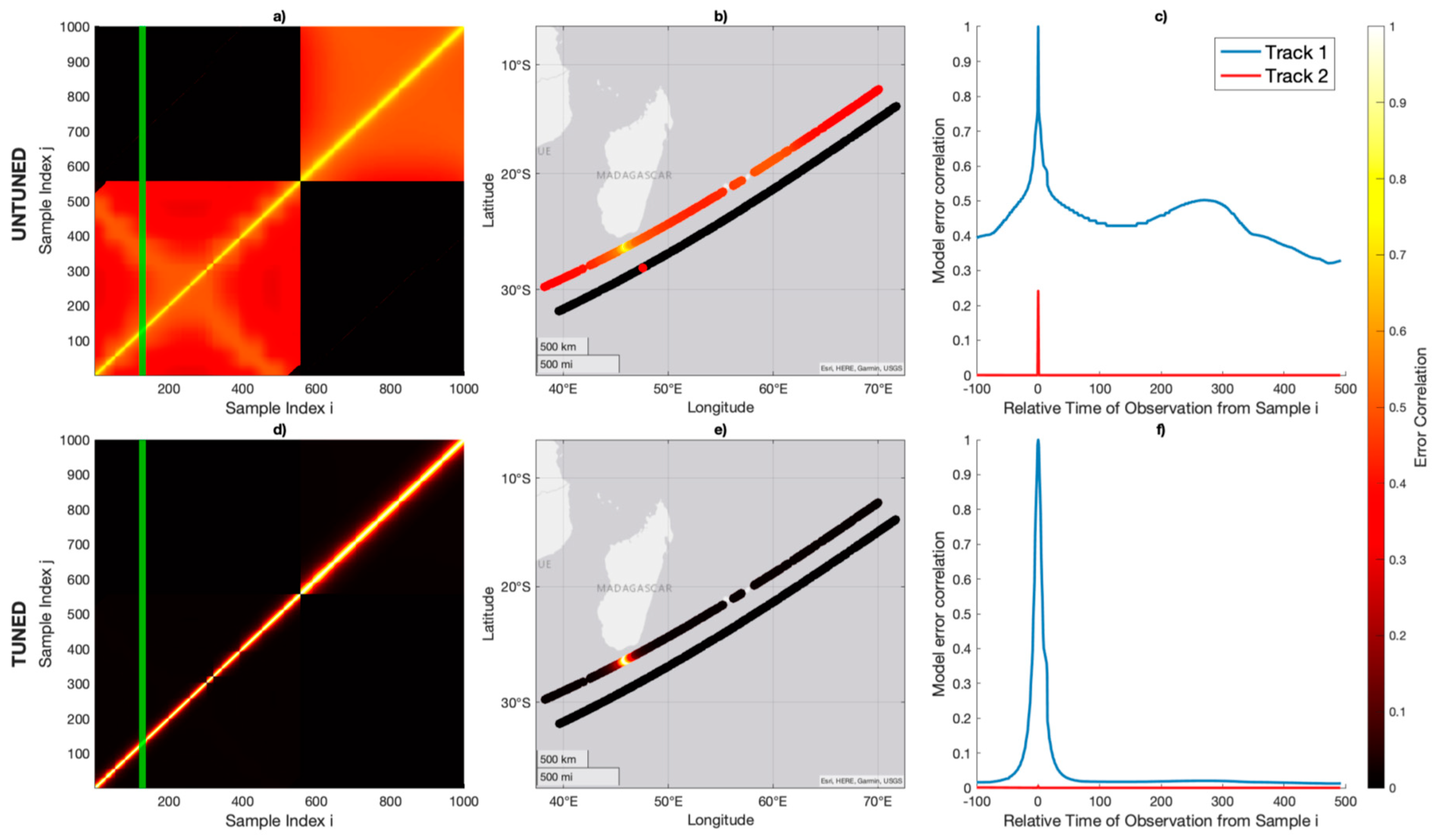
Figure 6.
Generated untuned and tuned for two nearby tracks captured by two different CYGNSS receivers during the overlap period, each with three different representations. (a) Untuned as represented by sample index. The two tracks are concatenated in a vector, and modeled error correlation is calculated for each combination of indices. The green vertical line represents an exemplar index (i=129) along the track where correlated error is estimated for every other observation in the neighborhood. The correlated error model allows for correlated error across receivers. (b) Untuned for the same exemplar index as represented by the physical location of sample acquisition. (c) Untuned for the same exemplar index represented by time of acquisition. The traces for the two different tracks are plotted as different colors. The error correlation along the same track is in blue, while the error correlation for the adjacent track is in red. (d) Tuned as represented by sample index for the same two tracks as in (a). (e) Tuned for the same tracks represented in physical location. (e) Tuned for the same exemplar index represented by time of acquisition. Note that the tuning has virtually eliminated cross-track error correlation.
Figure 6.
Generated untuned and tuned for two nearby tracks captured by two different CYGNSS receivers during the overlap period, each with three different representations. (a) Untuned as represented by sample index. The two tracks are concatenated in a vector, and modeled error correlation is calculated for each combination of indices. The green vertical line represents an exemplar index (i=129) along the track where correlated error is estimated for every other observation in the neighborhood. The correlated error model allows for correlated error across receivers. (b) Untuned for the same exemplar index as represented by the physical location of sample acquisition. (c) Untuned for the same exemplar index represented by time of acquisition. The traces for the two different tracks are plotted as different colors. The error correlation along the same track is in blue, while the error correlation for the adjacent track is in red. (d) Tuned as represented by sample index for the same two tracks as in (a). (e) Tuned for the same tracks represented in physical location. (e) Tuned for the same exemplar index represented by time of acquisition. Note that the tuning has virtually eliminated cross-track error correlation.
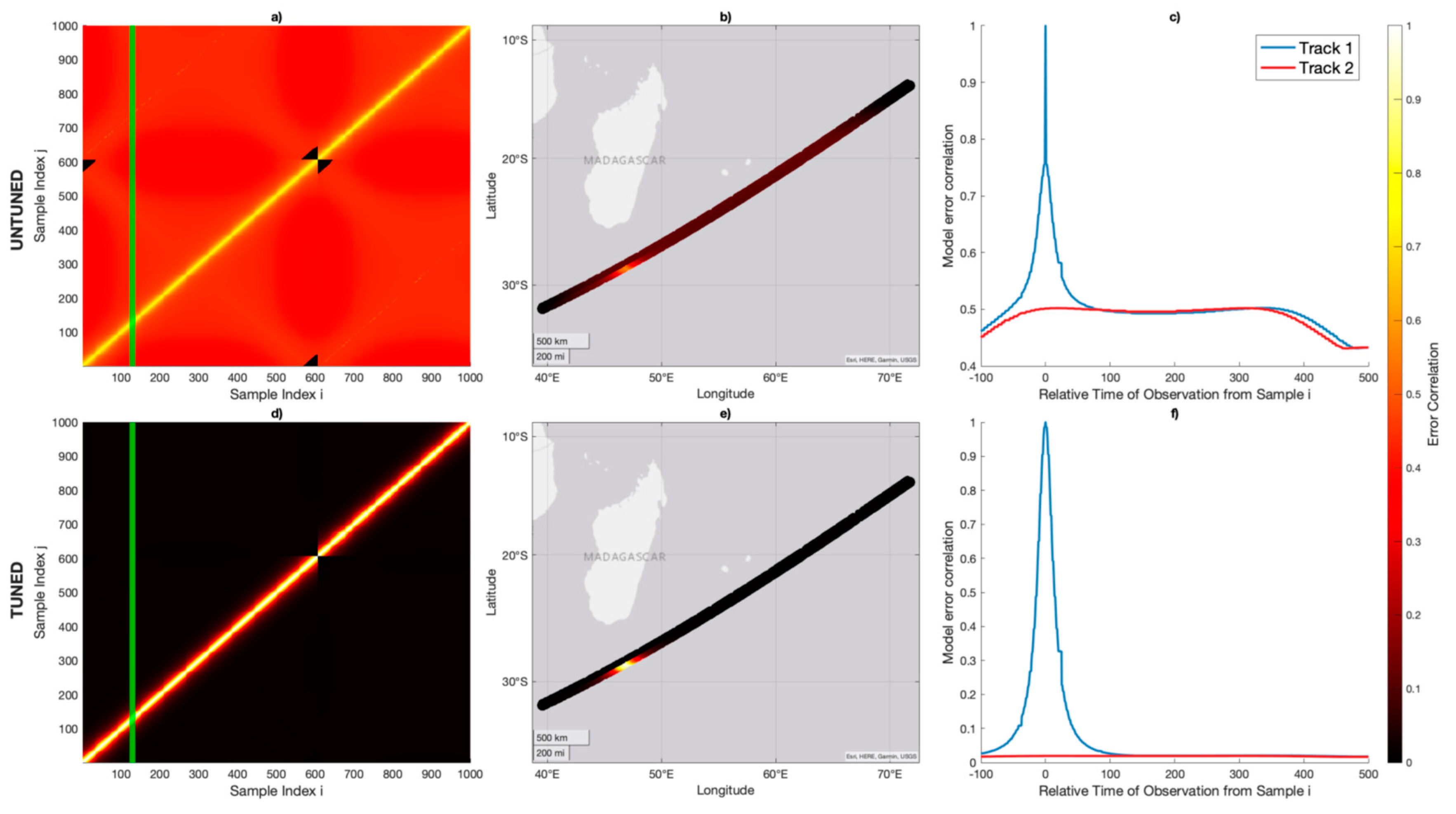
Table 1.
The magnitudes of 1-sigma errors for each term in Equation 4. The shaded rows indicate that the absolute magnitude is negligible compared to the dominant error terms, and are neglected in the construction of the error model in this work.
Table 1.
The magnitudes of 1-sigma errors for each term in Equation 4. The shaded rows indicate that the absolute magnitude is negligible compared to the dominant error terms, and are neglected in the construction of the error model in this work.
| Error Term | Error Magnitude [dB] |
|---|---|
| 0.43 [25] | |
| 0.23 [35] | |
| 0.20 [33] | |
| 0.18 [33] | |
| 0.15 [33] | |
| 0.05 [34] | |
| 0.04 [34] | |
| <0.01 [34] | |
| <0.01 (assumed ~ ) |
Table 2.
The chosen magnitudes of model tuning parameters for .
| Tuning Parameter | Magnitude | Function |
|---|---|---|
| 0.005 | Relative magnitude of uncorrelated error | |
| 0.01 | Relative magnitude of endpoint correlated error | |
| 1 | Relative magnitude of nearby roll-off | |
| 1 | Steepness of roll-off component |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



