Submitted:
31 January 2024
Posted:
01 February 2024
You are already at the latest version
Abstract
Semi-continuous data are very common in the social science and economics. In this paper, a Bayesian variable selection procedure is developed to assess the influence of exogenous factors including observed and unobserved on the semi-continuous data. Our formulation is based on the two-part latent variable model with polytomous response. We consider two schemes for the penalties of regression coefficients and factor loadings: the Bayesian spike and slab bimodal prior and the Bayesian lasso prior. Within the Bayesian framework, we implement Markov Chains Monte Carlo sampling method to conduct posterior inference. To facilitate posterior sampling, we recast the logistic model in part one as the norm-like mixture model. Gibbs sampler is designed to draw observations from the posterior. Our empirical results show that with suitable hyper-parameters, the spike and slab bimodal method slightly outperforms the Bayesian lasso in the current analysis. Finally, a real example related to the China household finance survey is analyzed to illustrate the application of the methodology.. .
Keywords:
Two-part latent variable model
; spike and slab prior
; Bayesian lasso
; MCMC sampling
; CHFS
MSC: 62H12; 62F15
1. Introduction
Semi-continuous data, characterized by excessive zeros, are very common in the fields of social science and economics. A typical example is given by [1] in the analysis of medical expenditures, in which the zeros correspond to a subpopulation of patients who do not use health services, while the positive values describe the actual levels of expenditures in use among users. In understanding such type of data structure, two-part model [2] is a widely appreciated statistical method. The basic assumption on two-part model is that the overall model is consisted of two processes: one binary process (Part one) and one continuous positive-valued process (Part two). The binary process, usually formulated within the logistic or probit regression model, is used to indicate whether the items are responded or not, while the continuous process, conditioning on the binary process, is used to describe what the actual levels of responses are (see, e.g., [3]). By combining two processes into one, two-part model provides a unified and flexible way in describing various relevance underlying semi-continuous data. Now, two-part model has been widely used in the health service [4,5,6], the medical expenditures [1,7,8,9], the household finance [10], the substance use study [11,12] and the genome analysis [13].
The traditional two-part model usually formulates the exogenous explanatory factors as fixed and observed. However, in the real applications especially in the social survey, many unobserved/latent and random factors also have important impacts on the outcome variable. This fact is revealed by [14] in the study of children’s aggressive behavior. [14] noted that two factors, the propensity to engage in aggressive behavior and the propensity to have high aggressive activity levels, had significant influence on the children’s aggressive behavior. They incorporated such two latent factors into analysis and established a two-component-two-part mixture model to identify the heterogeneity of population; [15] noticed that in China, the finance literacy of a family had a nonignorable influence on the desire to holding finance debts, and also affected the amount of finance debt being held. They suggested conducting a joint analysis of latent factor and observed covariates in two-part regression model. The latent factor is further manifested by multiple binary measurements via factor analysis model. [16] incorporated two-part regression model into the general latent variable model framework and analyzed the internal relationships between multiple factors longitudinally. These methods have brought significant attention to the two-part model in behavioral science, economics, psychology, and medicine in recent years, see for example, [13,17,18] and references therein for further developments of two-part model.
In the analysis of semi-continuous data, an important issue is to determine which explanatory factor is helpful in improving model fit. This issue is especially true when the number of exogenous factors is large since the commonly used forward and backward regression procedure is extremely time-consuming. Now, lasso and its extensions [19,20,21,22,23,24,25,26] have been the most commonly used methods for the feature extraction. A typical feature of these methods is to put some suitable penalties on the coefficients and shrink many coefficients to zero, thus performing variable selection. Recently, these penalization/regularizatio approaches have been applied widely for prediction and prognosis (see for example, [27,28]). Though more appealing, the lasso-type regularization also suffers some limitations. For example, most contributions are developed within the frequency framework and the performance heavily depends on the large sample theory. It also readily leads to computational difficulty in the analysis of mixed data. An alternative for the variable selection is conducted within the Bayesian framework. Statisticians have introduced hierarchical models with mixture spike-and-slab priors that can adaptively determine the amount of shrinkage [29,30]. The spike-and-slab prior is the fundamental basis for most Bayesian variable selection approaches, and has proved remarkably successful [29,30,31,32,33,34,35]. Recently, Bayesian spike-and-slab priors have been applied to predictive modeling and variable selection in large scale genomic studies, see [36] for a simple review. Nevertheless, model selection has never been considered in the two-part regression model with latent variables. In this study, we introduce spike and slab model and Bayesian lasso into two-part latent variable model, which is the first attempt for this model.
Our formulation is more along with the lines of spike and slab bimodal prior in [33] and Bayesian Lasso in [37]. We formulate the problem by specifying a normal distribution with mean zero to the regression coefficient or factor loading of interest. The probability of a related variable being excluded or included is governed by the variance. To model the shrinkage of coefficients properly, we consider two schemes for the variance parameter: one is the two-point mixture model with one component located at the point close to zero and the other component situated at the point far away zero. The proportion is governed by a beta-distribution with suitable hyperparameters. Another scheme is along with the Bayesian lasso in which the variance is specified via a gamma distribution scaled by the penalty parameters. Two schemes are unified into a hierarchical mixture model. Within the Bayes paradigm, we developed a fully Bayesian selection procedure for the two-part latent variable model. We resort to the Markov Chains Monte Carlo sampling method. Gibbs sampler is used to draw observations from the posterior. We obtained all full conditionals. Posterior analysis is carried out based on the simulated observations. We investigate the performance of the proposed methods via simulation study and a real example. Our empirical results show that two schemes results in similar results in the variable selection but SS with suitable hyperparameters slightly outperforms over BaLsso in the correct rate.
The remainder of this paper is organized as follows. Section 2 introduces the proposed model for the semi-continuous data with latent variables. Section 3 develops the MCMC algorithm for the proposed model. Bayesian inference procedures including parameters estimation and model assessment are also presented in this section. In Section 4, we present the results of simulation study to assess the performance of our proposed methodology and illustrate the practical value of our proposed model with household finance debt data. Section 5 concludes the paper with a discussion. Some technical details are given in the Appendix.
2. Model Description
In Section 2.1, a basic formulation for analyzing semi-continuous data with latent variables is presented. Section 2.2 presents a Bayesian procedure for the feature extraction.
2.1. Two-Part Latent Variable Model
Suppose that for , is a semicontinuous outcome variable which takes value in ; is a generic vector consisted of r fixed covariates representing the collection of observed explanatory factors of interest. We assume that each in is standardized in the sense and for . Moreover, we include m letent/unobserved variables into analysis to account for unobserved heterogeneity of responses.Conceptually,these latent variables can be the covariates that are not directly observed or the synthesization of some highly correlated explanatory items suffering from the noisy. Inclusion of latent variables can improve model fits and strengthen the power of model interpretation, see [38] for more discussions on the latent variables in a general setting. To deal with the spike of at zero, we follow the common routine in literature (see for example, [9,11]) and identify with two surrogate variables: and , where denotes the indicator function of set A and represents the positive part of a. That is, we separate the whole dataset into two parts: one part is the binary dataset which corresponds to the response-to-nonresponse indicators of subject and the other part is the logarithm of positive values. Our interest focuses on the exploration of effects of exogenous factors on two parts.
We assume that and satisfy the following sampling models:
in which and are the intercept parameters, and are the vectors of regression coefficients, and and are the vectors of factor loadings; is the scale and `T’ is the transpose operator of vector or matrix; For compactness, we write and and treat as the complete explanatory variables.
The involvement of latent variables apparently complicates the model. It readily results in model identification problem [39,40]. This is especially true when the dimension of is high. In this case, any auxiliary information is required to manifest further. Among various-easy-constructs, we consider latent variable (LV, [39,40]) approach. A basic assumption on LV approach is that there exist, say p manifestations , of which each may be continuous, counted or categorical, and assuming that they satisfy the following link equation
where F is a known and fixed link function, is the vector of errors used to identity the idiosyncratic part of that can not be explained by , and is the vector of unknown parameters used to quantify the uncertainty of model. The information about is manifested by via F. In this paper, in view of the real applications, we consider p ordered categorical variable , of which takes value in and satisfies the following link model:
where are the threshold parameters with and , and is the vector of latent responses satisfying the factor analytic model:
where is a p-dimensional intercept vector, is the -dimensional factor loading matrix, and is the identity matrix of order p. We assume that conditional upon , and are independent.
We refer to the model specified by (1), (2) and (4) associated with (5) as the two-part latent variable model with polytomous responses. It provides a unified framework to explore the dependence of binary, continuous and categorical data simultaneously. The dependence between them results from the share of common factors or latent variables. If is degenerated at zeros or the factor loadings are taken as zeros, the dependence among them disappears, and the overall model reduces to the traditional two-part model and ordinal regression model.
To facilitate the efficient calculation, motivated by the key identity in [41] (see squation (2) in their seminar paper), we express the logistics model (1) as the mixture model of form
where , and is the standard Pólya-Gamma probability density function. Assuming that we introduce auxiliary variables and augment them with , then equation (1) can be considered as the marginal density of the joint distribution
Note that the exponential part in the brackets is the kernel of normal density function with respect to . Hence, it admits conjugate full-conditional distributions for all regression coefficients, factor loadings and factor variables, leading to a straightforward Bayesian computation.
Let , ,and be the sets of observed variables; We write for the collect of factor variables, and write , , for the sets of latent response variables. The complete-data likelihood is given by
where is the set of indices, is the set of threshold parametes, and is the vector of unknown parameters. For the moment, we assume in all are free.
2.2. Bayesian Feature Selection
Generally speaking, regression variables and factor variables may not have impacts on the and simultaneously, and some redundant variables may exist. The presence of redundant variables not only decreases the model fit but also weakens the power of model interpretation. Therefore, it is necessary to determine which regression coefficient or factor loading is significantly away from zero. In the context of frequency statistics, this issue is generally tackled out via stepwise regression, in which each variable is decided to be exclude or included according to the model fit. However, the situation becomes complex when the number of independent variables is large. In this paper, we pursuit a Bayesian variable selection procedure. To this end, we follow [37] and assume
in which we use to represent a diagonal matrix with the diagonal element and let . That is, we assume that each in ( is similar) is centered at zero (or equivalently each is excluded from ) but with the probability governed by the variance . If is close to zero, then the probability of taking zero increases, and tends to be excluded; conversely, if is large, then the probability of being zero is small and tends to be maintained. As a result, the value of plays a key role in determining whether is relevant to be selected in Part one. With this in mind, a reasonable assumption on and is that:
where is the Dirac measure concentrated at point a, is the random weight used to measure the similarity between and , and is the hyperparameter used to represent how far is away from zero or slab; is a previously specified small positive value used to identity the `spike’ of at zero. In other words, every is assumed to be equal to with probability and equal to with probability . This is also true for , and . To model and properly, we assign the following beta distributions to them
where , , and are the hyperparameters used to control the shape of beta density, that is, to determine the magnitude of weights in . For example, if in equation (12) is small and is large, then equation (12) encourages to take small value with high probability. In contrast, it follows from that large and small encourage to take large value in . In the case that , equation (12) reduces to the uniform distributions on . In this case, every value in is possible for with the same probability. In the real applications, if no information can be available, one can assign the values to them to ensure the beta distribution to be inflated enough.
Finally, to measure the magnitudes of `slap’ in the distributions of and , we specify gamma distributions for and , or equivalently,
where `’ denotes the inverse-gamma distribution with mean for and variance for ; , , and are the hyperparameters which are treated to fixed and known. Similarly, one can assign values to them to ensure (13) to be dispered enough. For example, we can follow the routine in [33] in the ordinary regression analysis, and set and to obtain dispersed priors.
Note that equations (10) and (11) can be formulated as hierarchy as follows: for ,
where and are the latent binary variables respectively. Such a formulation aims to separate and from the distributions (10) and (11) to facilitate posterior sampling.
It is instructive to compare the proposed method to the Bayesian lasso [37], in which the variance parameters and in equation (9) are specified via exponential distributions as follows:
where and are the shrinkage/penality parameters used to control the amount of shrinkage of and toward zero.
Modeling and like equations (16) and (17) lead to marginal distributions of and as the laplace distributions with location zero and scale . The penalty parameters and are rather crucial in determining the amount of shrinkage of parameters. Figure 1 presents the plots of densities of Laplace distribution across various choices of . It can be seen that the larger the value of , the more kurtosis the density, indicating more penalties on the regression coefficient.
Due to their key role in equations (16) and (17), for and , we assign the following gamma priors to them, i.e.,
where `’ denotes the gamma distribution with mean . As the previous discussions, the values of , , and should be selected with care since they relate the shrinkages directly. Similar to that in (13), one can set , to enhance the robustness of inference. This routine is followed in our empirical study.
Let , , , , ,. We treat and as known hyperparameters. Note that and are totally determined by , and , . In the following, we abbreviate spike and slab bimodal prior to SS and Bayesian lasso to BaLsso.
3. Bayesian Inference
3.1. Prior Specification and MCMC Sampling
In view of the model complexity, we consider Bayesian inference. Some priors are required to specify for unknown parameters to complete Bayesian model specification. Based on the model convention, it is naturally to assume that the parameters involved in the different models are independent.
Firstly, for , and , we consider the following conjugate priors:
where `’ denotes the inverse Wishart distribution with degrees of freedom and scale matrix [42]; is the row vector of ; , , , , , and are the hyperparameters which are treated to be fixed and known.
Secondly, for , , in part one and two, we assume they are mutually independent and satisfy
where , , , and , are the fixed hyperparameters.
Lastly, for threshold parameter , without loss of generality, we assume that , the number of categories of , is invariant across the subscript j and equals to c. Moreover, we assume that , where is the row vector of . In the following, we suppress the subscript j in for notational simplicity and write for .
Let be any strictly monotonically increasing and differentiable function on with and . For example, one can take for some or student distribution with degrees of freedom , where is the standard normal distribution function. To specify a prior for , we follow [43] and let for . It is easily to show that the transformation is invertible with Jacobi determination unity. We first consider the following Dirichlet distribution for :
where is the multivariate beta function evaluated at , and . Then, by the formula of inverse transformation, the joint distribution of is given by
where is the derivative of with respect to x. We call (24) the transformed Dirichlet prior and use it as the prior of . An advantage of working with (24) is that conditional upon and , the transformed distribution of has the beta distribution given by
3.2. MCMC Sampling
With the prior given above, the inference about is based on the posterior , which has no closed form. Motivated by the key idea in [44], we treat latent quantities as the missing data and argument them to the observed data to form the complete data. The statistical inference is carried out based on the complete-data likelihood. For this end, apart from , and mentioned before, we further let be the collection of latent quantities involved in the specifications of and , i.e., , , , , , under SS and , under BaLsso. Rather than working with the posterior directly, we consider the following joint distribution
where can be considered as the marginal of . We use Markov chain Monte Carlo(MCMC, [45,46]) sampling method to simulate observations from this target distribution. In particular, Gibbs sampler is implemented to draw observations iteratively from the full conditional distributions as follows:
- draw from ,
- draw from ,
- draw from ,
- draw from , and
- draw from .
Upon convergence, the posterior is approximated by the empirical distribution of the simulated observations. The convergence of algorithm can be monitored by plotting the traces of estimates under different starting values or observing the values of EPSR [47] of unknown parameters. The technical details on implementing MCMC sampling are given in Appendix.
Simulated observations obtained from the blocked Gibbs sampler can be used for statistical inference via a straightforward analysis procedure. For example, the joint Bayesian estimates of unknown parameters can be obtained via sample averaging as follows:
where are the simulated observations from the posterior. The consistent estimates of covariance matrices of estimates can be obtained via sample covariance matrices.
The main purpose of introducing SS and BaLsso is to screen the variable in . Unlike that in the frequency statistics, Bayesian variable selection does not produce the estimates and exactly equal to zero, and hence it is necessary to determine which component can be treated as zero. This can accomplished via posterior confidence intervals (PCI) of and , given by
where is any previously specified value in . The calculation of PCI can be achieved via Monte Carlo method. For example, let be the K observations generated from the posterior distribution, then the PCI of with confidence level is given by ,, where is the order statistics.
Another choice for variable determination in SS is based on the posterior probability of and , which can be approximated by
where and are the k observations drawn from the posterior distribution via Gibbs sampler. The variable is selected in part one and two if and .
4. Simulation Study
In this section, a simulation study is conducted to assess the performance of the proposed method. The main objective is to assess the accuracy of estimates and the correct rate of variable selection. We consider one semi-continuous variable , two factor variables and , and six categorical variables . We assume that , and satisfy equations (1), (2) and (4) associated with (5), respectively, in which the number of fixed covariates is set at five. We generate and from the standard normal distribution, and from the binomial distribution with probability of success 0.3, and from the uniform distribution on . All covariates were standardize to unify the scales. For ordered categorical variables, we take , that is, each belongs to .
The true values of population parameters are set as follows: , , , , , , in which is a vector with elements being unity. The factor loading matrix and conviance matrix are taken as
in which ones and zeros in are treated as fixed to identify model; the thresholds are set as for , where the elements with an asterisk are treated as fixed for model identification. Based on these setups, we generate data by first drawing latent factors from , and then drawing latent responses from (5). The ordered categorical responses , the indicator responses and the intensity responses are sequentially generated from (5), (1) and (2). To investigate the effect of sample size on the estimates, we take and 1000, respectively, which represent small and large levels of sample size.
For Bayesian analysis, we consider the following inputs for hyperparameters: for the parameters involved in the measurement model, we take , and ; the elements in corresponding to the free parameters in are set at zero, and for ; , and ; for the threshold parameters , we take , which denotes the uniform distribution of p on the simplex in ; for intercept parameters , and in the two-part model, we set , , and ; the hyperparameters involved in the formulation of and are set as before. Note that these values can ensure the priors inflated enough, hence it could be expected to enhance the robust of inference. In addition, we set in equations (10) and (11) to guarantee and clumping at zero sufficiently .
The MCMC algorithm described in Section 3 is implemented to obtain the estimates of unknown parameters . Before formal implementation, a few test runs were conducted as pilots to monitor the convergence of the Gibbs sampler. We plot the values of EPSR of unknown parameters against the number of iterations under three different starting values. For SS, Figure 2 presents the plots of EPSR of unknown parameters under three different starting value with sample size .
It can be found that the convergence of estimates is fast and all values of EPSR are less than 1.2 in about 300 iterations. To be conservative, we remove the first 2000 observations as burn-in phrase and further collect 3000 observations for calculating the bias (BIAS), the root mean squares (RMS) and the standard deviation (SD) of the estimate across 100 replications. The BIAS and RMS of the j-th component in estimates are defined as follows:
where is the j-th element of population parameters . The summaries of estimates of main parameters under two scenarios are reported in Table 1 and Table 2, where the sums of SD and RMS across the estimates are presented in the last rows.
Examinations of Table 1 and Table 2 present the following findings: (i) Both methods produce satisfactory results and the performance of SS are slightly superior to that of BaLsso. For , the total RMS and SD are 1.870 and 1.975 respectively under SS, and amount to 2.016 and 2.035 respectively under BaLsso; (ii) As expected, increasing the sample size improves the accuracy of the estimates both for SS and BaLsso.
Another simulation is conducted to assess the performance of the proposed method in the variable selection when the covariates and latent variables are correlated. In this setting, we generate covariates and latent factors jointly from the multivariate normal distribution with mean zeros and covariance matrix with , where is the entry of . We consider three scenarios for : (i) , (ii) and (iii) , which represents respectively the weak, the mild and the strong dependence among them. The values of and are taken as and respectively, and the sample size is taken as . The other model setups are set as the same as before. We implement MCMC sampling and collect 3000 observations after removing first 2000 observations for posterior inference. We follow [48] and treat a regression coefficient to be zero if the absolute value of its estimate is less than 0.1. Table 3 gives the summary of variable selection across 100 replications.
Based on Table 3, it can be found that (i) for nonzero regression coefficients, two methods exhibit satisfactory performances, both with 100% correct rates across all situations; (ii) for zero regression coefficients, there exist difference between two methods, and SS are uniformly outperforms BaLsso. The underlying reason perhaps is that for SS, the variances of estimates are set to be small enough to ensure the coefficients close to zero while for BaLsso, the variance of estimates are controlled by the shrinkage parameters which may not be large enough to ensure this point; (iii) with the increase of the strength of dependence, the correct rates of two methods decreases.
5. China Household Finance Survey Data
To demonstrate the usefulness of the proposed methodology, in this section a small portion of Chinese household finance debt data is analyzed. The dataset is collected from the China household financial survey (CHFS), a non-profit institute organized by the Southeast University of Finance and Economics. The survey covers a series of questions which touch on the information about various aspects of the household’s financial situation. In this study, we only focus on the measurement `gross debts per household (DEB)’, the amount of the secured debt and unsecured debt of a household under investigation. We extracted them from the survey of Zhejiang Province in 2013. Due to some uncertain factors, some measurements in DEB are missing. The missing proportion is about 2.7%. We remove the subjects with missing entries and the ultimate sample size is 884. A preliminary data analysis shows that the measurements DEB contain excessive zeros and the proportion of zeros is about 72.58%. Naturally, we treat this variable as the outcome variable , and identify it with and . Figure 3 presents the histogram of DEB as well as the logarithms of positive values. It can be seen clearly that dataset illustrates strong heterogeneity. The skewness and kurtosis of DEB are 1.1042 and 2.3361, respectively, which indicates that single parametric model for DEB may be unappreciated.
We include the following measurements as the potential explanatory factors to interpret the variability in DEB: gender (), age (, marital status (), health condition(), educational experience (), employment status of the household head (), the number of family members (aged over 16, ), and the household annual income (). Table 4 gives the descriptive summary of the measurements under consideration. To unify the scale, all covariates were standardized.
Besides the observed factors mentioned above, we also include family culture , a latent factor into current analysis. It is well-known that China is an ancient civilization country with a long history, and Confucian culture has deeply rooted in the social development. Economic activity or social development can not be independent of cultural development. Hence, it is of practical interest to investigate how the family culture affect the behaviour of the household finance debt. Based on the design of the questionnaire, we select the following three measurements as manifestations for :(i) boys’s preference (BP,). This is a three-category measurement coded by 0, 1 and 2, which corresponds to the attitude `oppositive’, `does’t matter’ and `strongly support’; (ii) attitude toward to the single of children (SC), coded by 0, 1 and 2, according to the leve of support; (iii) importance of a household head in a family.This measurement is originally coded in point 0 to 5 according to the support level. However, in view of that the frequencies in the last three groups are small, we group them into three categories and recode them by 0 (does not matter), 1(important) and 2 (very important). In addition, due to that some manifestations are missing, we treat missing data as missing random and ignorable [49], and ignore the specific missing mechanic that results in missing data.
Let , , and , where is the collectionn of observed data and is the set of missing data. We formulate , and within equations (1), (2) and (5), and assume that . The inputs of hyperparameters in the priors are taken as follows: , and . The values of other hyperparameters are taken as the same as those in the simulation study. To implement MCMC sampling algorithm, we need to impute the missing data in . This is just to do by drawing from the conditional distribution , where and are the components of and respectively which corresponds to the missing entry in . In addition, to identify the model and scale the factor, we set . We also adopt the method in [50] in the context of latent variable model with polytomous data and fix at , where is the size of equal to 1, and is the observed frequency of 0 in . To assess the convergence of the algorithm, for SS, we plot the traces of estimates under three different initial values (see Figure 4). It can be seen that the algorithm converges at about 3000 iterations. To be conservative, we collect 6000 observations after deleting the initial 4000 observations for calculating the estimates and the standard deviations.
Table 6 gives the summary of the estimates of unknown parameters in two parts and factor loadings. Examinations of Table 6 show that most estimates are very close but there exists differences in the estimates of , , , , , and . For example, the estimates of , and under SS are , , with standard deviations , and respectively, while equal to , and with standard deviations , and under BaLsso. These differences reflect the fact that two methods impose different penalties on the regression coefficients in the variable selection.

Table 5.
Estimates and standard deviations estimates of unknown parameters under SS and BaLsso: CHFS data.
Table 5.
Estimates and standard deviations estimates of unknown parameters under SS and BaLsso: CHFS data.
| SS | BaLsso | SS | BaLsso | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Par | Est. | SD | Est. | SD | Par | Est. | SD | Est. | SD | |||
| -0.835 | 0.078 | -0.838 | 0.080 | 9.782 | 0.152 | 9.670 | 0.125 | |||||
| 0.050 | 0.063 | 0.076 | 0.070 | -0.137 | 0.103 | -0.107 | 0.088 | |||||
| -0.750 | 0.099 | -0.757 | 0.102 | -0.147 | 0.141 | -0.015 | 0.081 | |||||
| 0.107 | 0.085 | 0.147 | 0.088 | -0.022 | 0.065 | -0.006 | 0.075 | |||||
| 0.428 | 0.062 | 0.072 | 0.070 | -0.019 | 0.060 | -0.029 | 0.069 | |||||
| 0.577 | 0.070 | 0.082 | 0.081 | 0.259 | 0.123 | 0.322 | 0.107 | |||||
| 0.004 | 0.040 | 0.005 | 0.052 | 0.035 | 0.058 | 0.053 | 0.067 | |||||
| 0.118 | 0.079 | 0.130 | 0.079 | 0.043 | 0.072 | 0.281 | 0.113 | |||||
| 0.747 | 0.073 | 0.092 | 0.077 | 0.384 | 0.132 | 0.188 | 0.118 | |||||
| -0.059 | 0.112 | -0.039 | 0.092 | 1.205 | 0.106 | 1.910 | 0.104 | |||||
| 0.312 | 0.150 | 0.300 | 0.152 | |||||||||
| -0.791 | 0.062 | -0.714 | 0.057 | |||||||||
| -0.865 | 0.067 | -0.625 | 0.068 | |||||||||
To see more clearly, Table 4 gives the resulting selected variables according to SS and BaLsso. It can be seen that (i) for part one, both methods give the same results for the selection of factors `gender’, `age’, `material status’, `employment’, `number of adults’ and `family culture’. Two methods favor that `age’,`material status’, and `number of adults’ can be helpful in improving model fits while `gender’ and `family culture’ have less impacts on the probabilities of being held finance debt. However, there exist contradictory conclusion in selecting `health condition’, `education’ and `income’; (ii) for part two, except the factors `age’ and `number of adults’, two methods give the same results. In particular, both methods support that `family culture’ is relevant to the amount of household finance debts being held. This fact is also revealed by [17] in the analysis of CHFS by using two-part nonlinear latent variable model. The further interpretation is omitted for saving spaces.
6. Discussion
Two-part latent variable model can be considered as an extension of traditional two-part model to the situations where the latent variables are included to identify the unobserved heterogeneity of population resulting from the absence of the observed covariates. When analyzing such a model, an important issue is to determine which factor is relevant to the outcome variable. This is especially true when the number of exogenous factors is high because the usual model selection/comparison procedure is extremely time-consuming. In this paper, we restor to the Bayesian variable selection method and developed a fully Bayesian variable selection procedure for the semi-continuous data. Our formulation is along the lines with the spike and slab bimodal prior and recast the distribution of regression coefficients and factor loadings as hierarchy of priors over the parameter and model space. The selected variables is identified with high posterior probability of occurrence. We also consider a adaptive Bayesian lasso (BaLsso) for reference. To facilitate the computation, we recast the logistic regression model in part one as the flavor of normal mixture model by introducing latent Polya-gamma variables. which admits the conjugate conjugate full-conditional distributions for all regression coefficients, factor loadings and factor variables.
Although the Bayesian variable selection has its unique advantage, there are still some limitations that need to be considered with care. First, its computational complexity is high. Bayes SSL requires Monte Carlo sampling to estimate the posterior distribution, which can lead to slower calculation speed, especially when working with high-dimensional data sets. Secondly, the method is sensitive to hyperparameter and data distribution assumptions. The selection of the hyperparameters of the prior distribution, such as the ratio of spike to slab, lasso penalty parameters, and data distribution assumptions, will have a great impact on the results. When the data does not conform to the model convention, the performance of the model is poor. Therefore, these issues need to be carefully considered in practical application to ensure that the Bayesian SS method can be effectively applied to specific data sets.
Funding
This research was funded by National Nature Science Foundation of China (NNSF 11471161) and Natural Science Foundation of the Higher Education Institutions of Jiangsu Province (15KJB110010).
Acknowledgments
We are thankful to Professor Xin-Yuan Song, Department of Statistics, The Chinsese University of Hong Kong, Hong Kong, for providing us CHFS data.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| TPM | Two-part model |
| TPLVM | Two-part latent variable model |
| SS | Spike and slab bimodal prior |
| BaLsso | Bayesian lasso |
| MCMC | Markov Chains Monte Carlo |
| CHFS | China household finance survey |
Appendix A
In this section, we will present some technical details on the full conditionals in the MCMC sampling. For ease of exposition, for any scalar or vector x, we use to denote the conditional distribution of x given `⋯’. Note that under the scenarios SS and BaLsso, the full conditionals of , , and are exactly the same. The following derivations are mainly based on the Bayes theorem.
1. Full conditional of
Let , . By some algebra, it can be shown that
where
Hence, draw of can be obtained by simulating independently from the normal distribution (A1).
2. Full conditional of
Following the similar derivation in [41], it can be shown that given , and , is the entilted Polya-Gamma distribution given by
where . Drawing from this distribution can be achieved via rejection sampling, see [41] or [52] for more details on this issue.
3. Full of conditional of
Note that
Hence, given , the full conditional of only depends on , , and , and is given by
This is the truncated normal distribution and its draw can be obtained via inverse distribution sampling method, see for example, [53].
4. Full conditional of
Recall that is consisted of , , , , , , , and . Hence, draw of can be accomplished by (i) drawing from , (ii) drawing from , (iii) drawing from , (iv) drawing from , (v) drawing from , (vi) drawing from , (vii) drawing form , and (viii) drawing from sequentially. Note that given , and , the models (8), (2) and (5) reduce to the ordinary regression models, and hence most of full conditionals, similar to that of the regression coefficients and variance/covariance in the Bayesian regression analysis, are the standard distributions such as normal, gamma, inverse gamma and wishart distributions. As a matter of fact, by some tedious but non-trivial calculations, it can be shown that
in which
where is the matrix with the row , is the column of , and is the matrix with the row ; , . are the sample means of and and denotes the size of .
However, for , we note that
Hence, drawing can be obtained by drawing from independently. Moreover, under prior (24), it can be shown that
where is the vector of with removed. Let , . It follows from (25) that
where
As a result, we can draw by first generating a from the truncated beta distribution (A8) and then transform it to the via inverse-transformation by setting . A draw of truncated beta distribution can be obtained by implementing inverse-distribution sampling method.
4. Full conditional of
First of all, it is noted that is consisted of , , , , , and under SS, and formed by , , and under BaLsso. Similar to that of , we update by drawing observations from their full conditionals per component sequentially.
Firstly, it is noted that
which indicates that the components in the posteriors of and are independent. Further, it follows easily from (12) that
where
and is the standard normal probability density function.
Secondly, it is noted that
Hence,
where , as before, is the size of set A.
Lastly, it follows from
that
where
For BaLasso, we follow the practice in [37]) and can show
in which
where is the inverse-gaussian distribution with density [54].
Similarly,
in which
References
- Deb, P.; Munkin, M.K.; Trivedic, R.K. Bayesian analysis of the two-part model with endogeneity: Application to health care expenditure. J. Appl. Econ. 2006, 21, 1081–1099. [Google Scholar] [CrossRef]
- Cragg, J.G. Some statistical models for limited dependent variables with application to the demand for durable goods. Econometrica 2006, 39, 829–844. [Google Scholar] [CrossRef]
- Neelon, B.; Zhu, L.; Neelon, S.E.B. Bayesian two-part spatial models for semicontinuous data with application to emergency department expenditures. Biostatistics 2015, 16, 465–479. [Google Scholar] [CrossRef]
- Manning, W.G.; et al. (1981). A two-part model of the demand for medical Care: preliminary results from the health insurance experiment, in Health, Economics, and Health Economics, eds. van der Gaag, J. and Perlman, M., p. 103-104, Amsterdam: North-Holland.
- Su, L.; Tom, B.D.; Farewell, V.T. Bias in 2-part mixed models for longitudinal semi-continuous data. Biostatistics 2009, 10, 374–389. [Google Scholar] [CrossRef]
- Su, L.; Tom, B.D.; Farewell, V.T. A likelihood-based two-part marginal model for longitudinal semi-continuous data. Statiscal Methods in Medical Research 2015, 24, 194–205. [Google Scholar] [CrossRef]
- Liu, L.; Cowen, M.E.; Strawderman, R.L.; Shih, Y.C.T. A flexible two-part random effects model for correlated medical costs. Journal of Health Economics 2010, 29, 110–123. [Google Scholar] [CrossRef]
- Smith, V.A.; Neelon, B.; Preisser, J.S.; Maciejewski, L. A marginalized two-part model for semicontinuous data. Statistics in Medicine 2015, 33, 4891–4903. [Google Scholar] [CrossRef] [PubMed]
- Tooze, J.A.; Grunwald, J.K.; Jones, R.H. Analysis of repeated measures data with clumping at zero. Statistical Methods in Medical Research 2002, 11, 341–355. [Google Scholar] [CrossRef]
- Brown, R.A.; Monti, P.M.; Myers, M.G.; Martin, R.A.; Rivinus, T.; Dubreuil, M.E.T.; Rohsenow, D.J. Depression among cocaine abusers in treatment: Relation to cocaine and alcohol use and treatment outcome. American Journal of Psychiatry 1998, 155, 220–225. [Google Scholar] [CrossRef]
- Olsen, M.K.; Schafer, J.L. A two-part random-effects model for semicontinuous longitudinal data. Journal of the American Statistical Association 2001, 96, 730–745. [Google Scholar] [CrossRef]
- Xing, D.Y.; Huang, Y.X.; Chen, H.N.; Zhu, Y.L.; Dagen, G.A.; Baldwin, J. Bayesian inference for two-part mixed effects model using skew distributions, with application to longitudinal semi-continuous alcohol data. Statistical Methods in Medical Research 2017, 26, 1838–1853. [Google Scholar] [CrossRef]
- Chen, J.Y.; Zheng, L.Y.; Xia, Y.M. Bayesian analysis for two-part latent variable model with application to fractional data. Communications in Statistics - Theory and Methods 2023. [Google Scholar] [CrossRef]
- Kim, Y.; Muthén, B.O. Two-Part Factor Mixture Modeling: Application to an Aggressive Behavior Measurement Instrument. Structural Equation Modeling: A Multidisciplinary Journal 2009, 16, 602–624. [Google Scholar] [CrossRef]
- Feng, X.; Lu, B.; Song, X.; Ma, S. Financial literacy and household finances: A Bayesian two-part latent variable modeling approach. Journal of Empirical Finance 2019, 51, 119–137. [Google Scholar] [CrossRef]
- Xia, Y.M.; Tang, N.S. Bayesian analysis for mixture of latent variable hidden Markov models with multivariate longitudinal data. Computational Statistics & Data Analysis 2019, 132, 190–211. [Google Scholar]
- Gou, J.W.; Xia, Y.M.; Jiang, D.P. Bayesian analysis of two-part nonlinear latent variable model: Semiparametric method. Statistical Moddelling 2023, 23, 721–741. [Google Scholar] [CrossRef]
- Xiong, S.C.; Xia, Y.M.; Lu, B. Bayesian Analysis of Two-Part Latent Variable Model with Mixed Data. Communications in Mathematics and Statistics in press. 2023. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American Statistical Association 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Fu, W.J. Penalized regression: the bridge versus the lasso. Journal of computational and Graphical Statistics 1998, 7, 109–148. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements ofStatistical Learning; Springer-Verlag: New York, NY, 2009. [Google Scholar]
- Hastie, T. , Tibshirani, R. and Wainwright, M. (2015). Statistical Learning with Sparsity - The Lasso and Generalization, CRC Press: New York.
- Kuo, L.; Mallick, B.K. Variable selection for regression models. Sankhya, Ser. B 1998, 60, 65–81. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via theLasso. J. R. Stat. Soc. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selectionvia the elastic net. Zou, H., and Hastie, T. 2005, 67, 301–320. [Google Scholar]
- Zou, H. The adaptive Lasso and its oracle properties. Journal of the American statistical Association 2006, 101, 1418–1429. [Google Scholar] [CrossRef]
- Zhang, W.; Ota, T.; Shridhar, V.; Chien, J.; Wu, B.; et al. Networkbased survival analysis reveals subnetwork signatures for predicting outcomes of ovarian cancer treatment. PLOS Comput. Biol. 2013, 9, e1002975. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Q.; Shi, X.; Xie, Y.; Huang, J.; Shia, B.; et al. Combiningmultidimensional genomic measurements for predicting cancerprognosis: observations from TCGA.Brief. Bioinform 2014, 16, 291–303. [Google Scholar]
- George, E.I.; McCulloch, R.E. Variable selection via Gibbs sampling. Journal of the American Statistical Association 1993, 88, 881–889. [Google Scholar] [CrossRef]
- George, E.I.; McCulloch, R.E. Approaches for Bayesianvariable selection. Stat. Sin. 1997, 7, 339–373. [Google Scholar]
- Chipman, H.A. Bayesian variable selection with related predictors. Canad. J. Statist. 1996, 24, 17–36. [Google Scholar] [CrossRef]
- Ishwaran, H.; Rao, J.S. Spike and Slab gene selcetion for multigroup microarray data. Journal of the American Statistical Association 2005, 87, 371–390. [Google Scholar]
- Ishwaran, H.; Rao, J.S. Spike and Slab variable selection: frequentist and Bayesian strageies. The Annals of Statistics 2005, 33, 730–773. [Google Scholar] [CrossRef]
- Mitchell, T.J.; Beauchamp, J.J. Bayesian variable selection in linear regression. Journal of the American Statistical Association 1988, 83, 1023–1032. [Google Scholar] [CrossRef]
- Rockova, V.; George, E.I. EMVS: The EM approach toBayesian variable selection. Journal of the American Statistical Association 2014, 109, 828–846. [Google Scholar] [CrossRef]
- Tang, Z.X.; Shen, Y.P.; Xinyan Zhang, X.Y.; Nengjun Yi, N.J. The Spike-and-Slab Lasso Generalized Linear Modelsfor Prediction and Associated Genes Detection. Genetics 2017, 205, 77–88. [Google Scholar] [CrossRef]
- Park, T.; Casella, G. The Bayesian Lasso, Journal of the American Statistical Association 2008, 482, 681–686. [Google Scholar] [CrossRef]
- Skrondal, A.; Rabe-Hesketh, S. Generalized latent variable modelling: multilevel, longitudinal and structural equation models; Chapman & Hall/CRC: London.
- Bollen, K.A. Structural Equations with Latent Variables; John Wiley & Sons: New York, 1989. [Google Scholar]
- Lee, S. Y. (2007). Structural Equation Modeling: A Bayesian Approach, John Wiley & Sons: New York.
- Polson, N.G.; Scott, J.G.; Windle, J. Bayesian Inference for Logistic Models Using Polya-Gamma Latent Variables. Journal of the American Statistical Association 2013, 108, 1339–1349. [Google Scholar] [CrossRef]
- Anderson, T. W. (1984). An Introduction to Multivariate Statistical Analysis, John Wiley & Sons: New York.
- Sha, N.J.; Dechi, B.O. A Bayes inference for ordinal response with latent variable approach. Stats 2019, 2, 321–331. [Google Scholar] [CrossRef]
- Tanner, M.A.; Wong, W.H. The calculation of posterior distributions by data augmentation(with discussion). Journal of the American statistical Association 1987, 82, 528–550. [Google Scholar] [CrossRef]
- Gelfand, A.E.; Smith, A.F.M. Sampling-based approaches to calculating marginal densities. Journal of the American Statistical Association 1990, 85, 398–409. [Google Scholar] [CrossRef]
- Geman, S.; Geman, D. Stochastic relaxation, Gibbs distribution, and the Bayesian restoration of images. IEEE Transactions on Pattern Analysis and Machine Intelligence 1984, PAMI-6, 721–741. [Google Scholar] [CrossRef]
- Gelman, A.; Rubin, D.B. Inference from iterative simulation using multiple sequences (with discussion). Statistical Science 1992, 7, 457–511. [Google Scholar] [CrossRef]
- Feng, X.; Wang, Y.F.; Lu, B.; Song, X.Y. Bayesian regularized quantile structural equation models. Journal of Multivariate Analysis 2017, 154, 234–248. [Google Scholar] [CrossRef]
- Little, R.J.A.; Rubin, D.B. Statistical analysis with missing data, second Edition ed; John Wiley & Sons: New York, 2002. [Google Scholar]
- Song, X.Y.; Lee, S.Y. A tutorial on the Bayesian approach for analyzing structural equation models. Journal of Mathematical Psychology 2012, 56, 135–148. [Google Scholar] [CrossRef]
- Song, X.Y.; Xia, Y.M.; Zhu, H.T. Hidden Markov latent variable models with multivariate longitudinal data. Biometrics 2017, 73, 313–323. [Google Scholar] [CrossRef]
- Devroye, L. (1986). Non-Uniform Random Variate Generation, Springer-Verlag: New York.
- Ross, S. M. (1991). A Course in Simulation, MacMillan: New York.
- Chhikara, R. S. , and Folks, L. (1989). The Inverse Gaussian Distribution: Theory, Methodology, and Applications, Marcel Dekker: New York.
- Duan, N.; Manning, W.G.; Morris, C.N.; Newhouse, J.P. A Comparison of alternative models for the demand for medical Care. Journal of Business and Economic Statistics 1983, 1, 115–126. [Google Scholar] [CrossRef]
Figure 1.
Plot of the densities of Laplace distribution across different choices of .
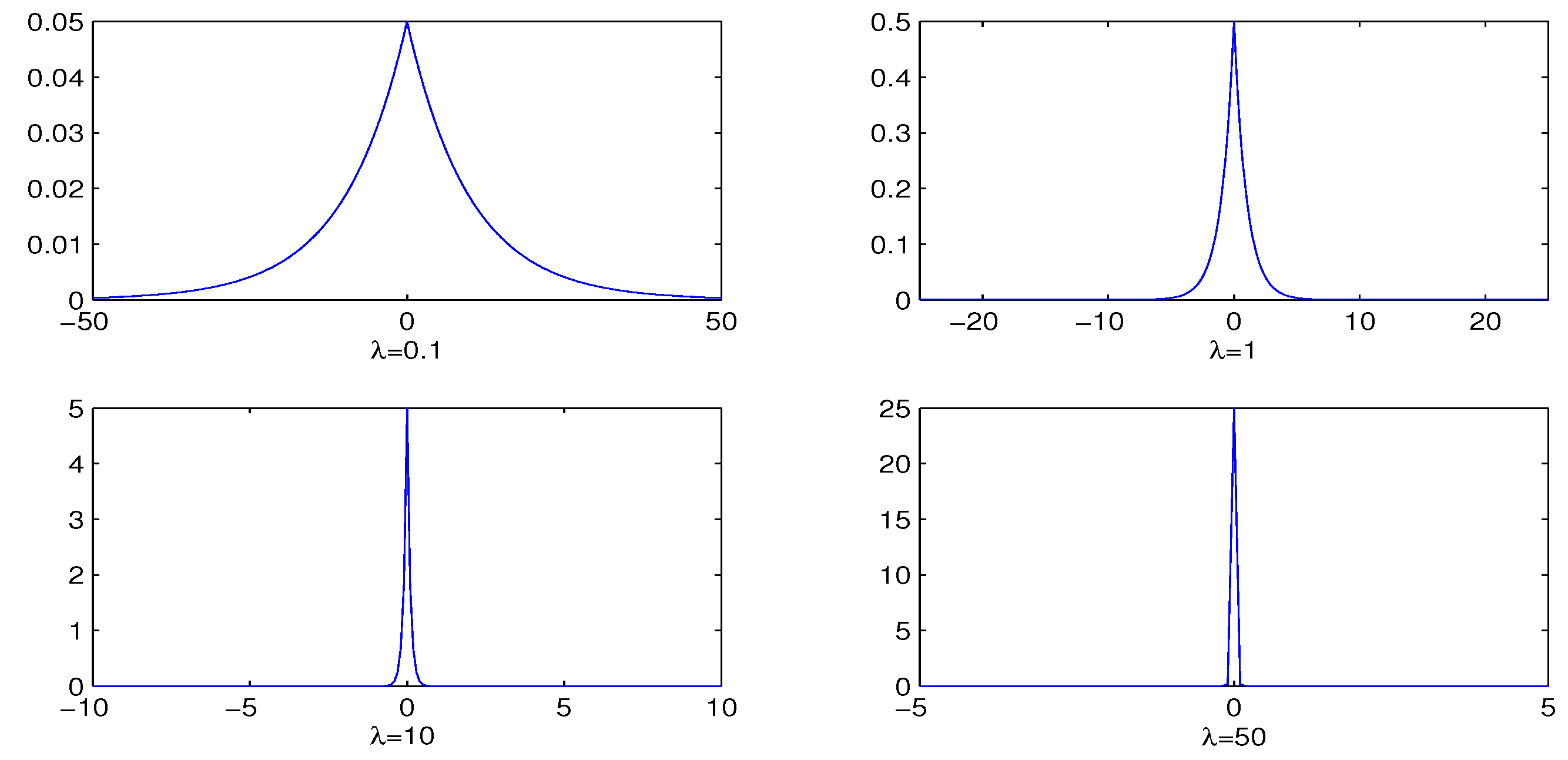
Figure 2.
Plot of the values of EPSR of unknown parameters under three different starting values: simulation study and .
Figure 2.
Plot of the values of EPSR of unknown parameters under three different starting values: simulation study and .
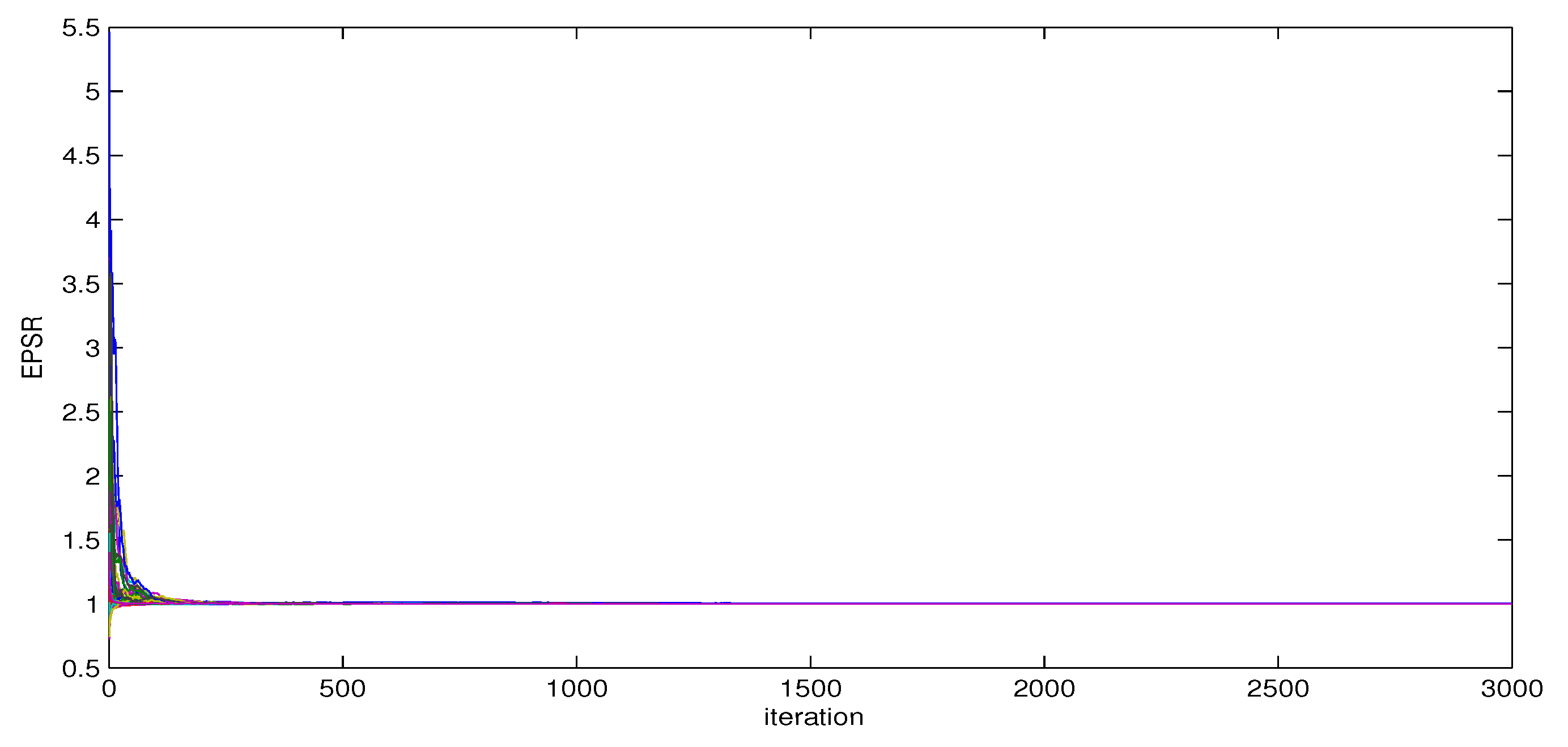
Figure 3.
Histograms of DEB and the logarithms of their positive values: China household finance survey data. Left panel corresponding the DEB and right panel corresponding to .
Figure 3.
Histograms of DEB and the logarithms of their positive values: China household finance survey data. Left panel corresponding the DEB and right panel corresponding to .
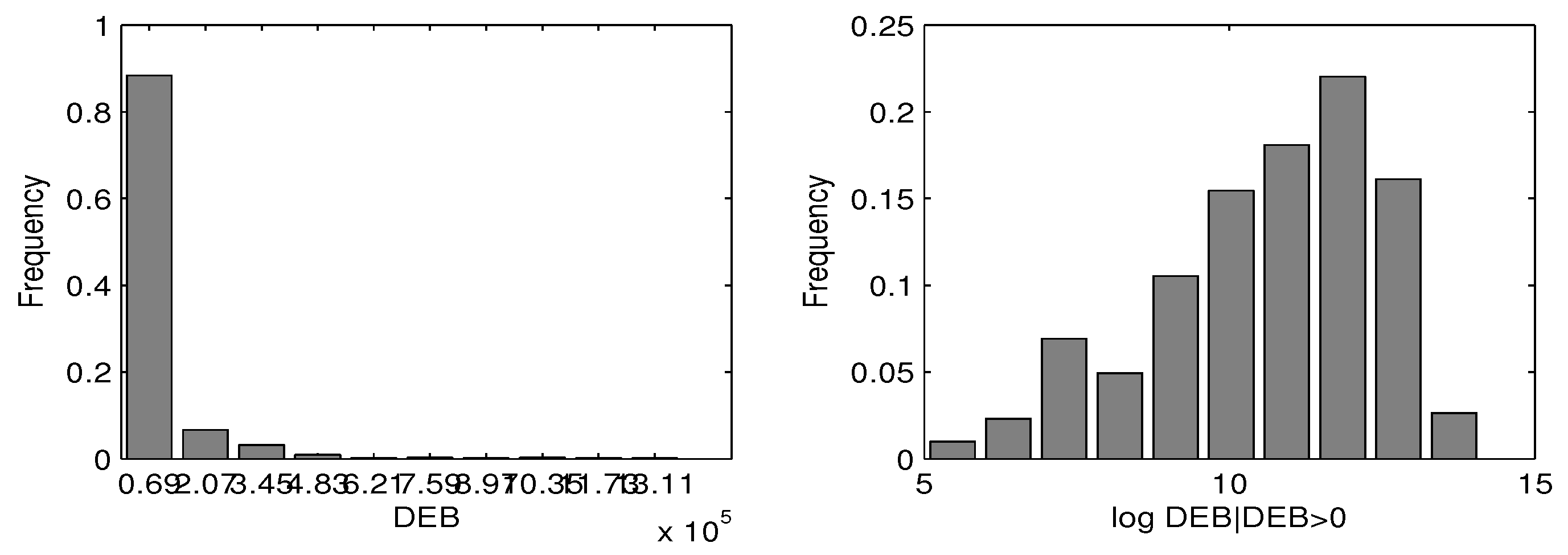
Figure 4.
Trace plots of the estimates of unknown parameters against the number of iteration under SS prior: CHFS data.
Figure 4.
Trace plots of the estimates of unknown parameters against the number of iteration under SS prior: CHFS data.
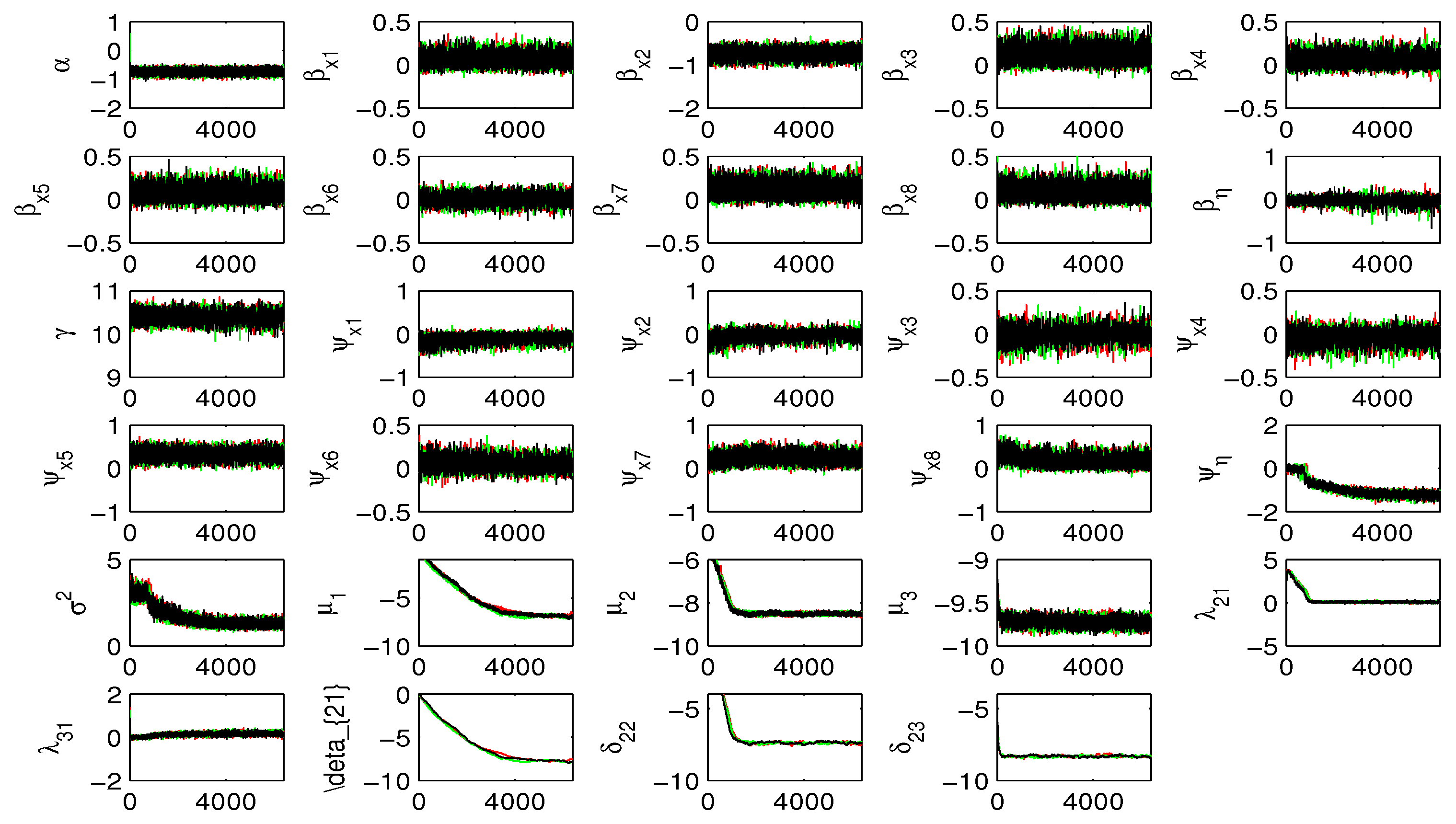
Table 1.
Summary of the estimates of unknown parameters under SS and BaLsso: simulation study and .
| SS | BaLsso | ||||||
|---|---|---|---|---|---|---|---|
| PAR | BIAS | RMS | SD | BIAS | RMS | SD | |
| -0.015 | 0.097 | 0.129 | 0.028 | 0.150 | 0.134 | ||
| -0.056 | 0.143 | 0.142 | -0.152 | 0.217 | 0.136 | ||
| -0.001 | 0.021 | 0.061 | -0.019 | 0.042 | 0.079 | ||
| -0.144 | 0.216 | 0.145 | -0.122 | 0.251 | 0.148 | ||
| 0.005 | 0.030 | 0.064 | -0.008 | 0.040 | 0.078 | ||
| -0.091 | 0.147 | 0.137 | -0.045 | 0.135 | 0.137 | ||
| 0.017 | 0.028 | 0.075 | 0.026 | 0.055 | 0.096 | ||
| -0.187 | 0.237 | 0.184 | -0.126 | 0.209 | 0.184 | ||
| 0.010 | 0.079 | 0.084 | 0.008 | 0.063 | 0.085 | ||
| -0.035 | 0.079 | 0.077 | -0.011 | 0.065 | 0.074 | ||
| 0.005 | 0.032 | 0.051 | -0.018 | 0.031 | 0.054 | ||
| -0.007 | 0.061 | 0.070 | -0.021 | 0.085 | 0.069 | ||
| -0.007 | 0.029 | 0.049 | -0.003 | 0.031 | 0.053 | ||
| -0.070 | 0.093 | 0.077 | -0.018 | 0.082 | 0.075 | ||
| -0.040 | 0.086 | 0.089 | -0.02 | 0.069 | 0.088 | ||
| -0.011 | 0.033 | 0.062 | 0.014 | 0.036 | 0.069 | ||
| 0.085 | 0.129 | 0.117 | 0.038 | 0.082 | 0.111 | ||
| 0.042 | 0.078 | 0.073 | 0.058 | 0.098 | 0.071 | ||
| 0.030 | 0.072 | 0.071 | 0.034 | 0.063 | 0.072 | ||
| 0.058 | 0.079 | 0.072 | 0.052 | 0.090 | 0.073 | ||
| 0.031 | 0.060 | 0.072 | 0.037 | 0.064 | 0.073 | ||
| 0.014 | 0.041 | 0.074 | 0.018 | 0.058 | 0.076 | ||
| Total | - | 1.870 | 1.975 | - | 2.016 | 2.035 | |
Table 2.
Summary of the estimates of unknown parameters under SS and BaLsso: simulation study and .
| SS | BaLsso | ||||||
|---|---|---|---|---|---|---|---|
| PAR | BIAS | RMS | SD | BIAS | RMS | SD | |
| 0.052 | 0.096 | 0.087 | 0.009 | 0.092 | 0.087 | ||
| 0.005 | 0.069 | 0.089 | 0.055 | 0.117 | 0.090 | ||
| 0.003 | 0.048 | 0.058 | 0.032 | 0.052 | 0.060 | ||
| 0.007 | 0.086 | 0.093 | -0.045 | 0.076 | 0.091 | ||
| 0.004 | 0.015 | 0.049 | -0.020 | 0.043 | 0.060 | ||
| 0.010 | 0.071 | 0.086 | 0.013 | 0.074 | 0.085 | ||
| -0.003 | 0.029 | 0.059 | 0.032 | 0.064 | 0.077 | ||
| 0.002 | 0.102 | 0.120 | -0.042 | 0.108 | 0.114 | ||
| 0.017 | 0.042 | 0.053 | 0.030 | 0.056 | 0.054 | ||
| -0.023 | 0.038 | 0.046 | -0.016 | 0.039 | 0.047 | ||
| -0.007 | 0.019 | 0.033 | -0.005 | 0.018 | 0.037 | ||
| -0.028 | 0.060 | 0.042 | -0.014 | 0.026 | 0.043 | ||
| -0.007 | 0.023 | 0.033 | 0.000 | 0.018 | 0.036 | ||
| -0.005 | 0.035 | 0.046 | 0.003 | 0.043 | 0.047 | ||
| -0.031 | 0.058 | 0.053 | -0.039 | 0.063 | 0.054 | ||
| -0.001 | 0.031 | 0.045 | -0.025 | 0.081 | 0.053 | ||
| 0.018 | 0.049 | 0.068 | 0.041 | 0.053 | 0.071 | ||
| 0.021 | 0.041 | 0.045 | 0.033 | 0.038 | 0.045 | ||
| 0.016 | 0.049 | 0.045 | 0.028 | 0.038 | 0.045 | ||
| 0.032 | 0.049 | 0.045 | 0.054 | 0.057 | 0.045 | ||
| 0.043 | 0.059 | 0.046 | 0.043 | 0.054 | 0.046 | ||
| 0.016 | 0.043 | 0.049 | 0.005 | 0.037 | 0.048 | ||
| Total | - | 1.112 | 1.29 | - | 1.247 | 1.335 | |
Table 3.
Number of correctly selected variables in the two-part model on the simulated data sets.
| SS | BaLsso | ||||||
|---|---|---|---|---|---|---|---|
| PAR | |||||||
| 100 | 100 | 100 | 100 | 100 | 100 | ||
| 98 | 96 | 85 | 88 | 86 | 76 | ||
| 100 | 100 | 100 | 100 | 100 | 100 | ||
| 96 | 95 | 86 | 93 | 93 | 85 | ||
| 100 | 100 | 100 | 100 | 100 | 100 | ||
| 96 | 94 | 93 | 97 | 92 | 87 | ||
| 100 | 100 | 100 | 100 | 100 | 100 | ||
| 99 | 100 | 100 | 100 | 100 | 100 | ||
| 100 | 99 | 95 | 100 | 98 | 93 | ||
| 100 | 100 | 100 | 100 | 100 | 100 | ||
| 100 | 100 | 97 | 98 | 100 | 91 | ||
| 100 | 100 | 100 | 100 | 100 | 100 | ||
| 100 | 100 | 100 | 100 | 100 | 100 | ||
| 100 | 98 | 97 | 97 | 96 | 96 | ||
Table 4.
Descriptive statistics of explanatory variables: CHFS data .
| Variable. | Description. | Mean. | Max. | Min. | SD |
| Gender () | =1, male; =0, otherwise | 0.756 | 1 | 0 | 0.430 |
| Age () | 51.81 | 91 | 19 | 14.931 | |
| Marital status () | =1, married; 0, otherwise | 0.863 | 1 | 0 | 0.344 |
| Health condition ( | =1, good; 0, otherwise | 0.833 | 1 | 0 | 0.373 |
| Education degree ( | =1, high school or above; | ||||
| =0, otherwise | 0.352 | 1 | 0 | 0.478 | |
| Employment () | =1, yes; 0, otherwise | 0.092 | 1 | 0 | 0.290 |
| No. of adults () | 3.002 | 3 | 0 | 1.301 | |
| Annual Income (CYN) | 0 |
* Note: Superscripts are used to indicate values raised to the power 10 (thus ).The measurement is taken as the middle value of the range in the questionnaire.
Table 6.
The selected variables in the CHFS data: 0: exclude and 1: included.
| Part one | Part two | |||||
|---|---|---|---|---|---|---|
| VAR | SS | BaLsso | SS | BaLsso | ||
| Gender | 0 | 0 | 1 | 1 | ||
| Age | 1 | 1 | 1 | 0 | ||
| Material status | 1 | 1 | 0 | 0 | ||
| Health condition | 1 | 0 | 0 | 0 | ||
| Education | 1 | 0 | 1 | 1 | ||
| Employment | 0 | 0 | 0 | 0 | ||
| No. of Adults | 1 | 1 | 0 | 1 | ||
| Income | 1 | 0 | 1 | 1 | ||
| Family culture | 0 | 0 | 1 | 1 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



