
Submitted:
25 January 2024
Posted:
09 February 2024
You are already at the latest version
Abstract
Despite significant milestones in armed conflict research generally and climate security research specifically, methodologically tight explanation of naturally caused armed conflict still leaves much to be desired. In this article we unpack the black box of the climate-security nexus and advance causal modelling of armed conflict. To infer effects of natural causes on armed conflict outcomes, we apply recent advances in causal methods to conflict outcomes that have been non-experimentally observed across Iraqi municipalities. Retrieval of an entire empirical causal structure of climate-conflict pathways allows us to corroborate the existence of a cause-and-effect relationship between climatological, environmental, and demographic variables and armed conflict. We confirm that soil temperature, population density, and variability of latent energy cause an increase in fatalities, while rice production decreases fatalities. We discuss our findings, their limitations, and future research directions, and reflect on their relevance for policy interventions.
Keywords:
Causality
; Methodology
; Conflict modeling
; Non-experimental observations
1. Introduction
Since the founding of the Correlates of War Project in 1963 (Suzuki, Krause, and Singer 2002), armed conflict research has benefited from advances in the scientific method, including data collection (Raleigh et al. 2010; Sundberg and Melander 2013), modeling (Kress 2012) and prediction (Cederman and Weidmann 2017). However, in localities where no armed conflict has been historically observed, outbreak of armed conflict remains hard to predict. In effect, any attempt to predict armed conflict where none has occurred necessitates an explanation of conflict’s causes (Cederman and Weidmann 2017; Ward 2016). Whereas correlation does not imply causation, ethics and feasibility of scientific research preclude rigorous experimentation with armed conflict outbreak that might yield causal insights. Unsurprisingly, the outbreak of armed conflict still eludes methodologically rigorous explanation (Cederman and Weidmann 2017). These circumstances have led many authors in environmental security research to refrain from offering causal explanations altogether. For instance, one of the field’s founders, Homer Dixon, explicitly avoided “entangling himself in the metaphysical debate about the relative importance of causes of naturally caused armed conflict” (7, Homer-Dixon 2010).
Pathways that causally trace armed conflict to climatological variables have been studied since at least the 1990s (Deligiannis 2012; Homer-Dixon 1991; Homer-Dixon and Blitt 1998; Baechler 1998; Rodríguez-Labajos and Martinez-Alier 2015; Sakaguchi, Varughese, and Auld 2017). Occasionally, such studies corroborate that armed conflict can be naturally caused (Hsiang, Burke, and Miguel 2013; Hsiang and Burke 2013). Until now, however, the methodologically soundest scientific explanation of naturally caused armed conflict has been limited to natural experiments (Hsiang, Burke, and Miguel, 2013), and no exhaustive causal mechanism that links conflict with climate could be empirically confirmed (Hsiang, Burke, and Miguel, 2013; Sakaguchi, Varughese, and Auld 2017; Koubi 2019). Since rigorous experimentation does not apply to armed conflict, sufficiently strong evidence of such a mechanism is still in search of adequate methodology (Koubi 2019; Sakaguchi, Varughese, and Auld 2017). This leaves an important gap in the literature not just for scholarly reasons but also for policy purposes because policy interventions can only effectively address causes once such causes are identified and estimated. Unpacking the black-box of the climate-conflict nexus is instrumental therein.
In addressing this gap, our article describes a methodology to infer causality from non-experimental observations of armed conflict. We make use of recent advances in the theory and methods of causality (Pearl 2009). Building on these advances, we test commonly hypothesized climate-conflict linkages. Our cross-section consists of 294 non-experimental observations, one for each municipality in Iraq (i.e., subdistricts, Arabic: nawāḥī) as our unit of analysis. Our outcome variable is the count of conflict fatalities. Each observation is additionally described in terms of explanatory variables, including demographics, vital resources, environment, and climate. These observations were sampled from several geocoded maps (Raleigh et al. 2010; Running and Mu 2015; Muñoz-Sabater et al. 2021; McNally et al. 2017; Gridded Population of the World 2018; Huffman et al. 2009; Abatzoglou et al. 2018). From these observations, we retrieved an empirical causal mechanism of climate-conflict linkages. Represented as a causal graph, the mechanism shows causal pathways from climatological variables to armed conflict outcomes. The mechanism is also characterized by causal effects of these variables on the count of conflict fatalities wherever these effects could be identified and estimated. Our findings confirm that causal effects on conflict fatalities can be traced to their natural causes. An increase in soil temperature or an increase in variability of latent energy causes an increase in the count of conflict fatalities. An increase in rice production causes a decrease in the count of conflict fatalities, alleviating the effects of soil temperature and latent energy on the count of conflict fatalities. More densely populated municipalities are more susceptible to these effects.
Our study makes several new contributions to armed conflict research in general and environmental security research in particular. First and foremost, by retrieving an empirical causal structure, identifying causal paths, and estimating causal effects, we demonstrate how advances in causality can be leveraged in armed conflict research with non-experimental observations. Second, specifically to environmental security research, we corroborate the existence of cause-and-effect relationships between climatological and environmental variables and conflict. More specifically, we show that climatological processes are an environmentally and demographically mediated cause of conflict. Third, we show how causal frameworks can be used to inform more effective policy interventions.
The article is structured as follows: Section 2, demarcates the research gap in the existing environmental security and armed conflict literature. Sections 3-4 offer hypotheses and describe data and methods. Section 5 outlines results. Section 6 discusses key contributions, research limitations, future directions, and practical implications. Section 7 states the study’s conclusions.
2. The Research Gap: Naturally Caused Armed Conflict
One line of armed conflict research focused on prediction. Authors acknowledge that armed conflict prediction is hard (Hegre et al. 2012; Hegre, Nygård, and Landsverk 2021; Ward 2016). In fact, armed conflict prediction does not have to be possible, let alone useful, if that prediction is not both geographically and historically localized (Cederman and Weidmann, 2017). Armed conflict prediction is additionally challenging in localities where armed conflict is about to occur for the first time (Chadefaux 2017). To this end, grounding prediction in climatological variables has also been tried (Bhardwaj et al., 2021). Considering climate as a threat multiplier (Hayhoe 2020), this line of environmental security research has refrained from making causal assertions.
Attempting to overcome the challenges and pitfalls of armed conflict prediction, some advances in environmental security research have been made by focusing on causality of armed conflict. Studies investigated both connections that trace causes of violent organized conflict to scarce resources (e.g., Deligiannis 2012; Homer-Dixon 2010; Sakaguchi, Varughese, and Auld 2017) and causal typologies of environmental conflict (e.g., Deligiannis 2012; Baechler 1998; Rodríguez-Labajos and Martinez-Alier 2015). Causes of conflict have been attributed to environmental stress and scarcity (Homer-Dixon and Blitt 1998; Homer-Dixon 1991, 1994), allocation and management of scarce water resources (Yoffe, Wolf, and Giordano 2003; Dinar et al. 2015; Al-Muqdadi et al. 2016), including shocks in food production (Buhaug et al., 2015). Scarcity of vital resources also plays an important role in seven climate-related conflict pathways that have been recently proposed (Sweijs, de Haan, and van Manen 2022). Some evidence corroborates that natural, climatological conditions, e.g., deviations from precipitation and mild temperatures, cause armed conflict (Hsiang, Burke, and Miguel 2013; Hsiang and Burke 2013). Despite these advances, however, depending on the methodology, the empirical evidence for specific causal pathways, along which the specific climate–conflict linkages are active, remains weak, associative rather than causal, and inconclusive (ssBerghold and Lujala 2012; Sakaguchi, Varughese, and Auld 2017; Koubi 2019). Hence, whereas domain knowledge strongly suggests that climate has affected organized armed conflict within countries, specific causal mechanisms linking climate to armed conflict remain less understood. Exhaustive formal descriptions of such mechanisms are few and far in between, and their empirically validated counterparts are absent (Mach et al. 2019). This is the research gap that our study is intended to fill.
Finally, ascertaining the mechanisms of climate-conflict linkages is not only relevant for scientific reasons, but also policy purposes. Before the structural patterns of climate–conflict linkages are causally understood, not only will the prediction of armed conflict outbreak continue to suffer, but the effectiveness of targeted policy interventions will also not reach their full mitigatory potential.
3. Theory and Hypotheses
This section derives our causal hypotheses from relevant findings. Adapted from Sakaguchi, Varughese, and Auld (2017), Figure 1 outlines the basic mechanism of causal climate-conflict linkages, which has been extensively hypothesized in environmental security literature. The hypothetical linkages are rooted in climatological causes. The figure respectively distinguishes between direct and indirect linkages (i.e., paths A and B, respectively). The latter are indirect because environmental scarcity hypothetically plays a mediating role between climatological causes and armed conflict outcomes. This is the overall rationale behind our hypotheses.
Figure 1.
Hypothesized causal pathways originating from climate-conflict linkages.
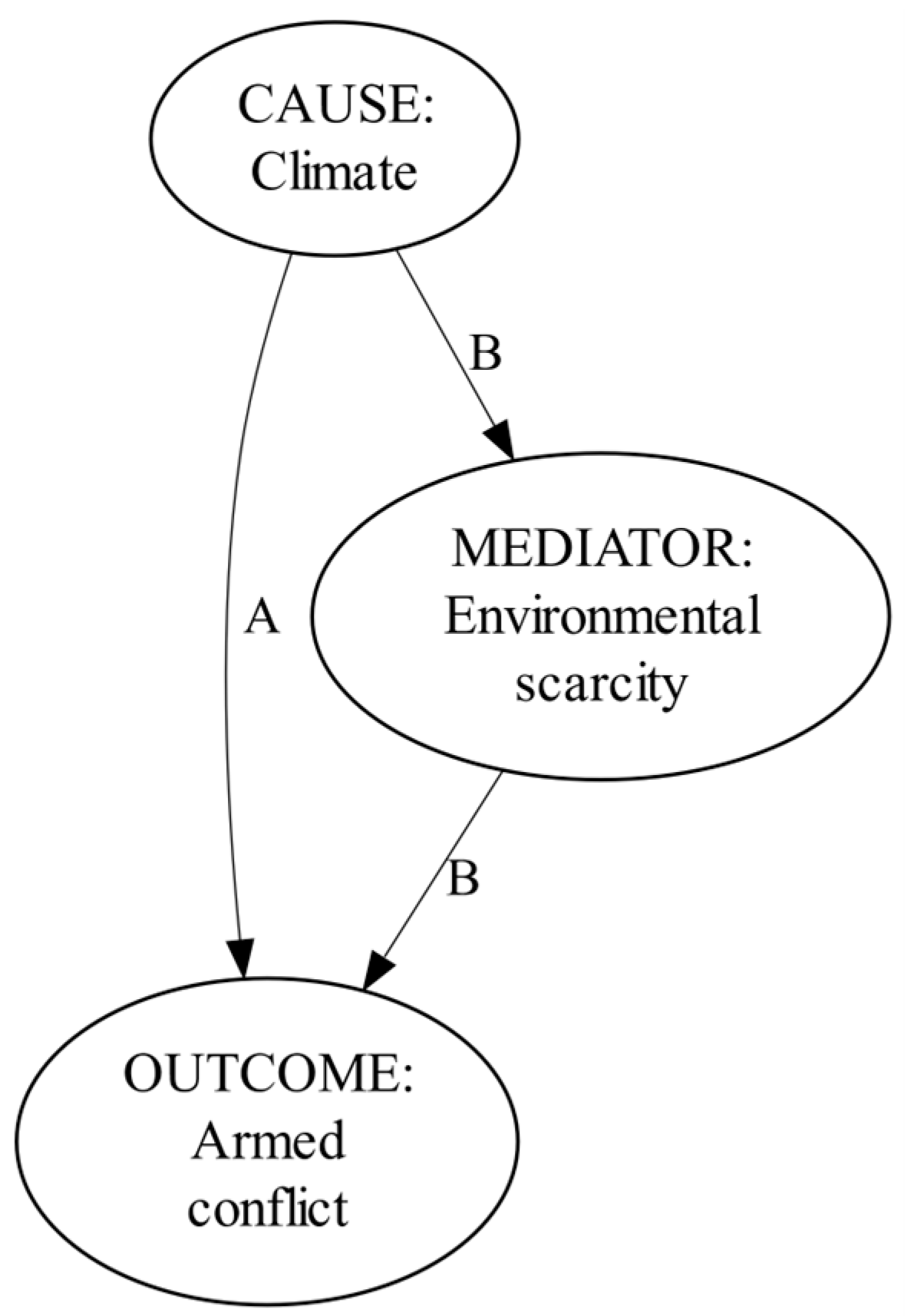
Climatological processes have been argued to cause armed conflict directly (Hsiang, Meng, and Cane 2011; Hsiang, Burke, and Miguel 2013; Slettebak 2012; Ghimire and Ferreira 2016, Bai and Kung, 2011). The direct causation between climate and armed conflict can play out through responsiveness of population to climatological processes. For instance, a specific climatological change adversely impacts livelihoods, while fragmented population mobilizes to preclude this impact. In the expectation of familiar climatological consequences, direct climatological effects on armed conflict can be caused by attempts of armed factions to preclude this adverse impact. Such effects can originate from precipitation, evaporation, temperature, or simply the fact that different physical surroundings absorb or release accumulated heat differently (i.e., also referred to as latent heat or energy) (Hsiang, Burke, and Miguel 2013; Sakaguchi, Varughese, and Auld, 2017). Therefore, we hypothesize that changes in precipitation, temperature, and latent energy directly cause changes in armed conflict activity (H1). Please refer to Figure 2 for the visualization.
Figure 2.
The first set of hypotheses: Direct causal effects.
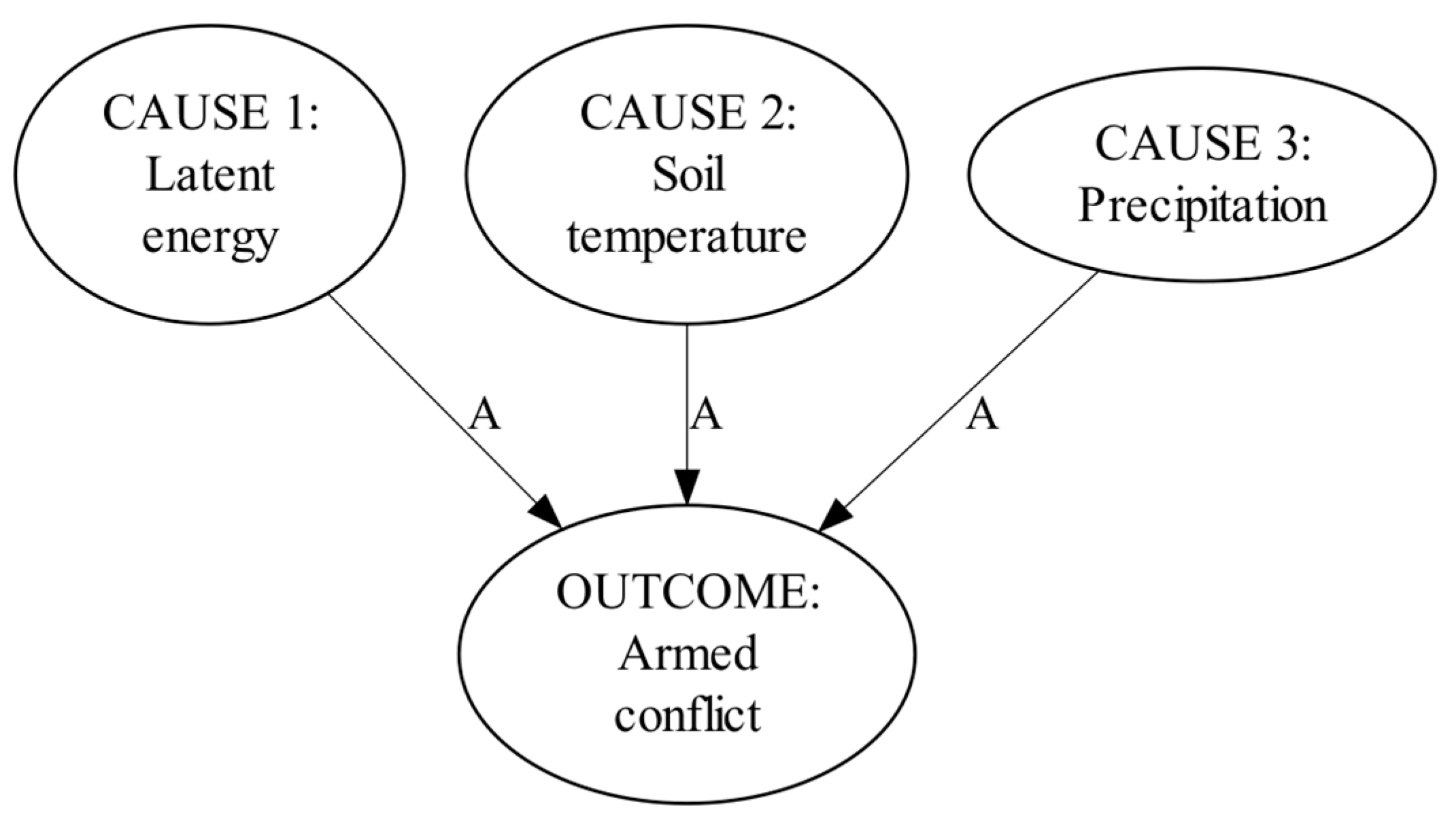
- H1 a): An increase in latent energy in the form of heat directly causes an increase in armed conflict activity.
- H1 b): An increase in soil temperature directly causes an increase in armed conflict activity.
- H1 c): An increase in precipitation (Heat is defined as the energy emanating from the physical surroundings (Glickman and Zenk 2000)) directly causes a decrease in the armed conflict activity.
Further, climatological processes have also been argued to cause armed conflict indirectly (Ash and Obradovich 2019; Sakaguchi, Varughese, and Auld 2017; Koubi et al., 2012). Causal mediation of climatological effects on armed conflict concerns primarily scarcity of vital resources, also referred to as environmental scarcity (Homer-Dixon 1991, 1994, 2010; Koren, 2019). Environmental scarcity has been argued to mediate the climatological effects on armed conflict (Sakaguchi, Varughese, and Auld, 2017; Homer-Dixon 2010). Whereas we elaborate causal mediation more specifically below, we can already hypothesize that the effects of climatological processes indirectly cause armed conflict.
- H2 a): An increase in latent energy indirectly causes an increase in armed conflict activity.
- H2 b): An increase in soil temperature indirectly causes an increase in armed conflict activity.
- H2 c): An increase in precipitation indirectly causes a decrease in armed conflict activity.
Adding specificity to the indirect causal paths, causal mediation can rest on specific causal conditions. Agricultural and pastoral conditions have been argued to shape social response to climate-induced migration (Xiao, Fang, and Ye 2013). Degradation and desertification of arable land and availability of water for agriculture have been argued to mediate the climatological effects on violent conflict (Hendrix and Glaser 2007; Fjelde and von Uexkull 2012; Ide et al. 2020). Rice production has been shown to mediate causal effects of temperature on the emergence of actual violence (Caruso, Petrarca, and Ricciuti 2016). Since rice is one of Iraq’s key crops (Encyclopaedia Britannica, 2022, “Iraq, Agriculture, forestry, and fishing”, accessed January 22, 2023, https://www.britannica.com/place/Iraq/Agriculture-forestry-and-fishing), we hypothesize that the climatological effects are also mediated by the production of agricultural resources, specifically rice production. Please refer to Figure 3 for the visualization.
Figure 3.
The third set of hypotheses: Specific causal mediation.
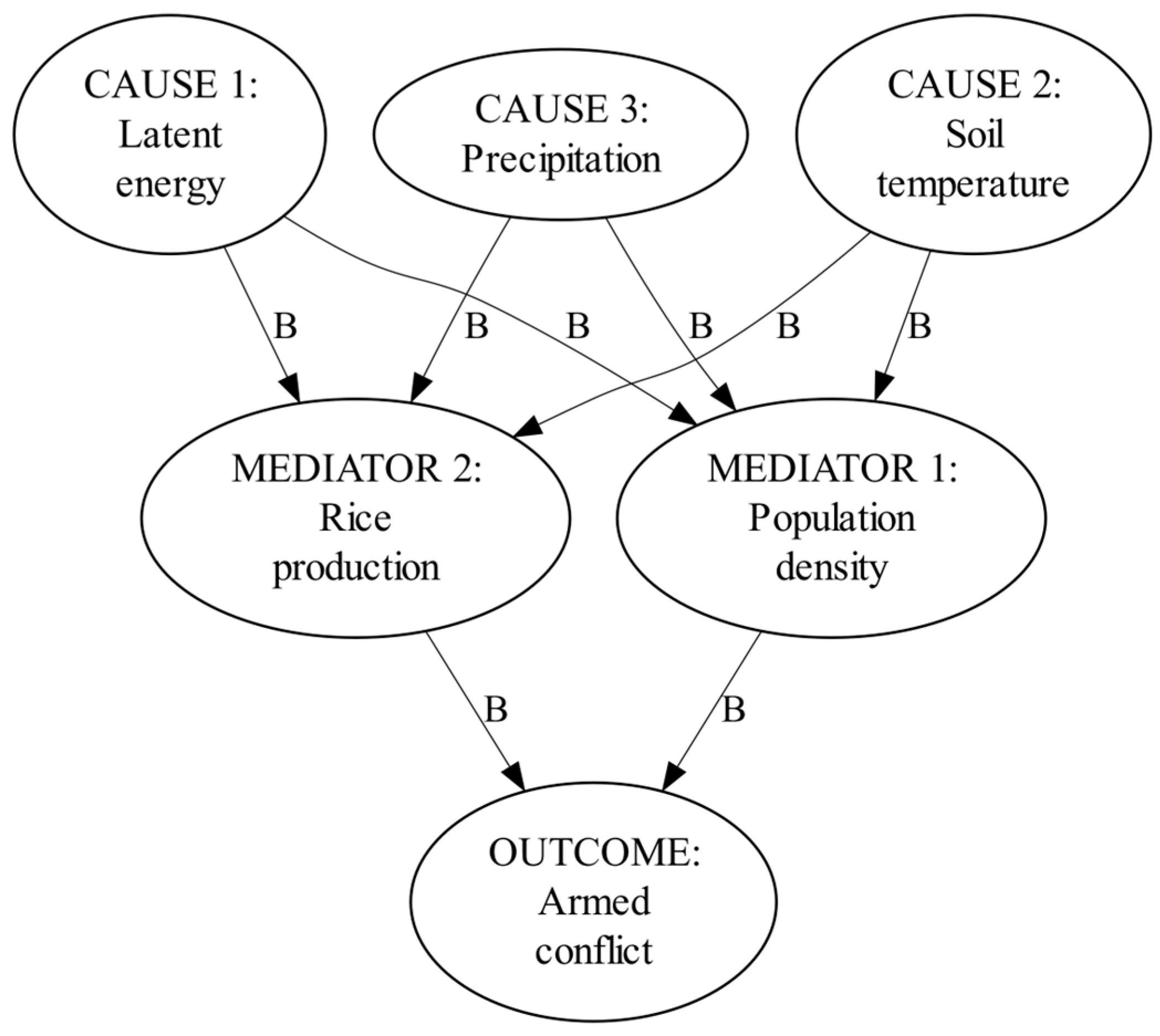
- H3 a): Given the indirect paths from the climatological processes to armed conflict activity, rice production causally mediates the indirect effects of climatological processes on armed conflict activity, by causing an additional decrease in armed conflict activity.
In line with the previous reasoning, because the association between conflict activity and either the size, growth, density, or migration of population has already been shown (Tir and Diehl 1998; Raleigh and Hegre 2009; Reuveny 2007), these variables may also naturally mediate effects of climatological causes on armed conflict outcomes. Specifically, the scarcity of vital resources matters more to denser populations than it does to less dense populations (Ash and Obradovich 2019; Acemoglu, Fergusson, and Johnson 2020). Intuitively, a denser population is likelier to cope with and mitigate tensions less effectively than a less dense population is. Everything else equal, the denser population is, therefore, likelier to succumb to organized violence caused by climatological processes. Thus, our next hypothesis, H3 a), is in line with this reasoning. Please refer to Figure 3 for the visualization.
- H3 b): Given the indirect paths from the climatological processes to armed conflict activity, population density causally mediates the indirect effects of climatological processes on armed conflict activity, by causing an additional increase in armed conflict activity.
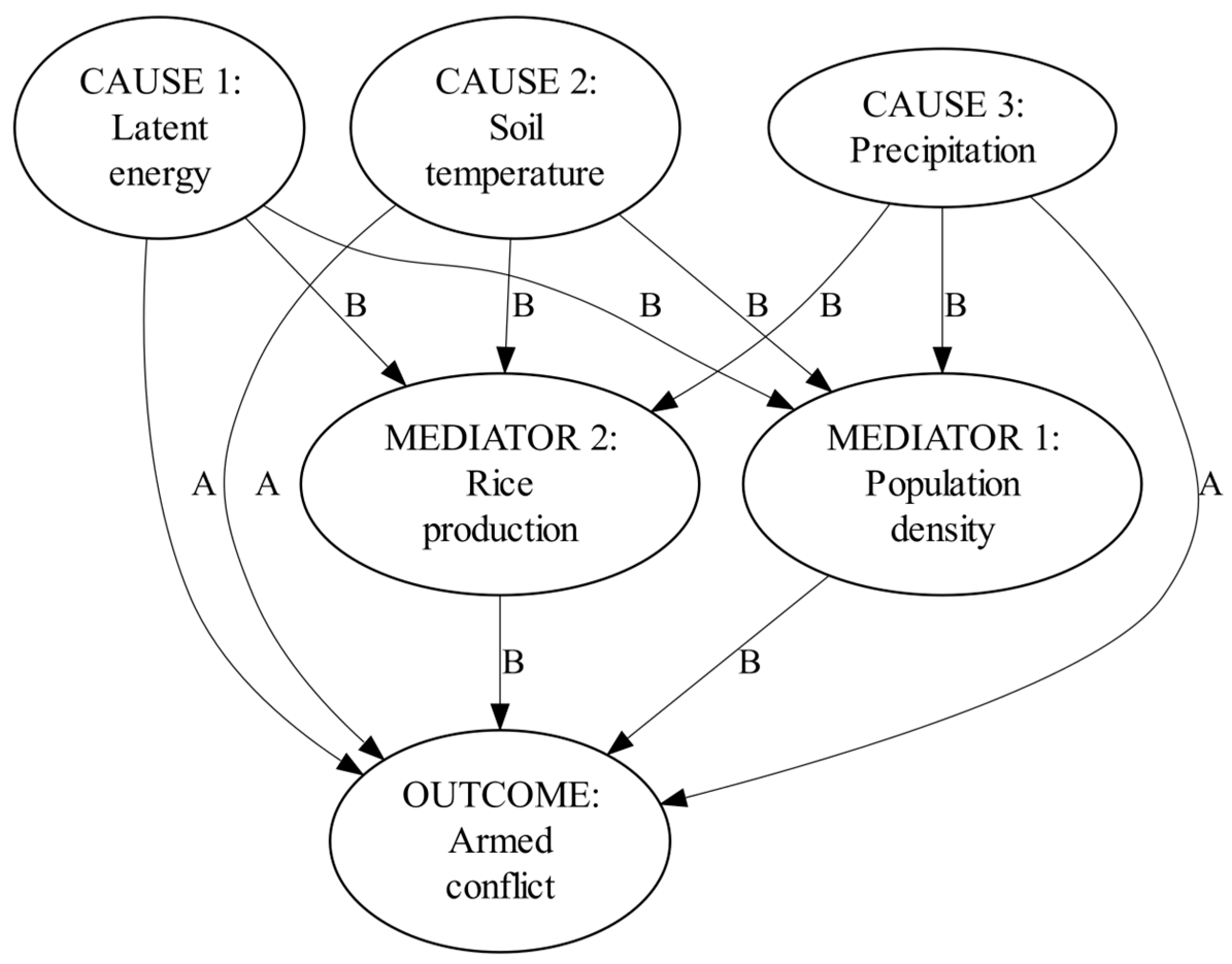
With these hypotheses, it is possible to compose the entire hypothetical causal structure of climate-conflict linkages, as shown in Figure 4. As can be seen in the figure, grounded in climatological processes, the scarcity of vital resources exposes population to existential stress. Both the density of population and scarcity of agricultural resources aggravate these effects.
Figure 4.
All the hypotheses combined: The hypothetical causal structure.
4. Data and Methods
4.1. Data Sources
The armed conflict activity variables were sourced from Armed Conflict Location and Event Data Program (Raleigh et al. 2010) (ACLED). We also retrieved geo-coded maps from the Humanitarian Data Exchange (Humanitarian Data Exchange, 2021, “Iraq - Subnational Administrative Boundaries,” accessed December 19, 2022, https://data.humdata.org/dataset/cod-ab-irq), European Centre for Medium-Range Weather Forecasts of Copernicus Climate Change Service (Muñoz-Sabater et al. 2021), NASA (Huffman et al. 2009; Running and Mu 2015; McNally et al., 2017), Center for International Earth Science Information Network of Columbia University (Gridded Population of the World 2018), and MapSPAM (International Food Policy Research Institute 2019). The latter maps geo-code explanatory variables as grids. Our unit of analysis is the Iraqi municipalities. Our sample size includes all the 294 Iraqi municipalities. Our time horizon was from January 1, 2020, to January 1, 2022. The observations across this time horizon were aggregated as a single cross-section. We specify aggregation methods below. The reason for this time horizon is the high availability of recent data. Whenever a grid was not available for the entire horizon, we respectively sourced a grid for the corresponding variable across the available time horizon.
Despite the rationale for the inclusion of other explanatory variables pertaining to the society and politics (Yin, 2020; Adano et al. 2012; Raleigh 2010), Iraq is a data scarce country, and such variables are generally unavailable for Iraq at an appropriate resolution. We discuss this unavailability in the context of our research limitations in the discussion section.
Conflict activity variables
We retrieved several armed conflict variables from ACLED (Raleigh et al. 2010). Geospatially associated with specific geographical coordinates on a geographical map, values of conflict activity variables are geo-coded as counts. As conflict types, ACLED specifies battles, explosions/remote violence, violence against civilians, protests, riots, and strategic developments. ACLED also reports fatalities (The reported fatalities should be understood in terms of ACLED’s additional qualifications (Raleigh et al., 2010)) for each such conflict type (Raleigh et al. 2010).
Conflict Fatalities: Sourced from ACLED, our outcome variable was the count of total conflict fatalities. We proxy the outcome variable as the sum of counted fatalities that are attributed to each of the specific conflict event types.
Civilian Fatalities: From ACLED, we also sourced the count of civilian fatalities. Violence against civilians is specified as deliberate infliction of violence on unarmed non-combatants by an organized armed faction (Raleigh et al. 2010). These events include sexual violence attacks, abductions, or acts of forced disappearance (Raleigh et al. 2010). We sourced this variable as the count of fatalities for the conflict event that is designated as acts of violence against civilians.
Conflict Events: From ACLED, we also sourced conflict events. To proxy the counted conflict events, we summed counts for each of the specific conflict event types (i.e., battles, explosions/remote violence, violence against civilians, protests, riots, and strategic developments).
Explanatory Variables
Climatological Processes
Climate is the long-term weather pattern characterizing an area. Climatological conditions pertain to weather. We specified the climatological variables in accordance with Sakaguchi, Varughese, and Auld (2017). Because temperature, precipitation, and heat have been already hypothesized and empirically shown to be associated with and cause violent conflict (Hsiang, Burke, and Miguel 2013), we selected these variables to describe the weather conditions in Iraq.
Soil Temperature: Temperature is a physical quantity that expresses how hot matter is (Glickman and Zenk 2000; Inventing Temperature: Measurement and Scientific Progress 2005). We selected soil temperature, because it should impact the growth and cultivation of agricultural resources, as well as availability of water. From European Centre for Medium-Range Weather Forecasts’ ERA5-Land dataset (Muñoz-Sabater et al. 2021), we sourced soil temperature at the 28-100 cm depth: Corresponding to the resolution of 11132 square meters, a pixel on the map shows a value of temperature in Kelvins.
Precipitation Index: Precipitation is condensed water vapor that falls from clouds as raindrops, pellets or needles of ice, hail, or snowflakes (Glickman and Zenk 2000). We sourced this variable from NASA and Japan Aerospace Exploration Agency’s Integrated Multi-Satellite Retrievals for Global Precipitation Measurement Data as the quality index (The notion of quality refers to the degree of confidence in the index (Huffman, 2019)) of precipitation for monthly data (Huffman 2019): A pixel on the geo-coded map shows a value of precipitation in millimeters per 11132 square meters (Huffman et al. 2009).
Latent Energy: Also referred to as latent heat, latent energy refers to energy released from the Earth’s surface to the atmosphere that is associated with evaporation or condensation of water vapor at the Earth’s surface (Glickman and Zenk 2000), and, therefore, shows the climatological process that goes beyond temperature and precipitation, but impacts the physical surroundings. We sourced average latent heat flux (Running and Mu 2015) from NASA and United States Geological Survey’s MODIS 006 MOD16A2 dataset, where the flux pertains to the average latent heat that passes through matter. Corresponding to the resolution of 500 square meters, a pixel on the map shows a value in Joules.
Environmental scarcity of vital resources
Environmental scarcity refers to scarcity of vital resources for which human communities directly and vitally depend on their physical surroundings. Since scarcity of agricultural resources can catalyze violent conflict (Sakaguchi, Varughese, and Auld 2017), the earlier findings on rice production informed our proxy of crops in Iraq (Caruso, Petrarca, and Ricciuti 2016).
Rice Production: From Global Spatially Disaggregated Crop Production Statistics Data for 2010 Version 2.0 of MapSPAM, we sourced the production of rice for rainfed portion of the crop (International Food Policy Research Institute 2019). Corresponding to the resolution of 10000 square meters, a pixel on the map shows a value in metric tons. Given the constrained time horizon of the dataset, this variable was for 2017 as the most recent observation.
Demographics
Population Density: Since density of population has been found relevant for armed conflict activity (Raleigh and Hegre 2009), we sourced population density from Gridded Population of the World Version 4.11 of Center for International Earth Science Information Network at Columbia University (Gridded Population of the World 2018). Corresponding to the resolution of 927.67 square meters, a pixel on the map shows the estimated number of people per 30 arc-second grid cells. Given the constrained time horizon of the dataset, this variable was sourced for 2020 as the most recent observation.
From geo-coded observations to municipal values
All the variables are geo-coded. On each geo-coded map, values of the corresponding variable are respectively associated with specific geographical coordinates. Since our unit of analysis is the Iraqi municipalities, a municipal value of a given variable must be an aggregate of geo-located values of that variable within that municipality. However, the geo-coded maps that store these variables do not contain the municipal borders. Thus, a shapefile with the municipal borders had to be inscribed into each such map if the any geographical aggregation of pixel values were to be conducted municipally. We sourced this shapefile from the UN OCHA Humanitarian Data Exchange. The shapefile stores the municipal borders as a geometry variable (i.e., a polygon). The 294 municipal borders are shown in Figure 7.
Figure 5.
Municipal borders in Iraq.
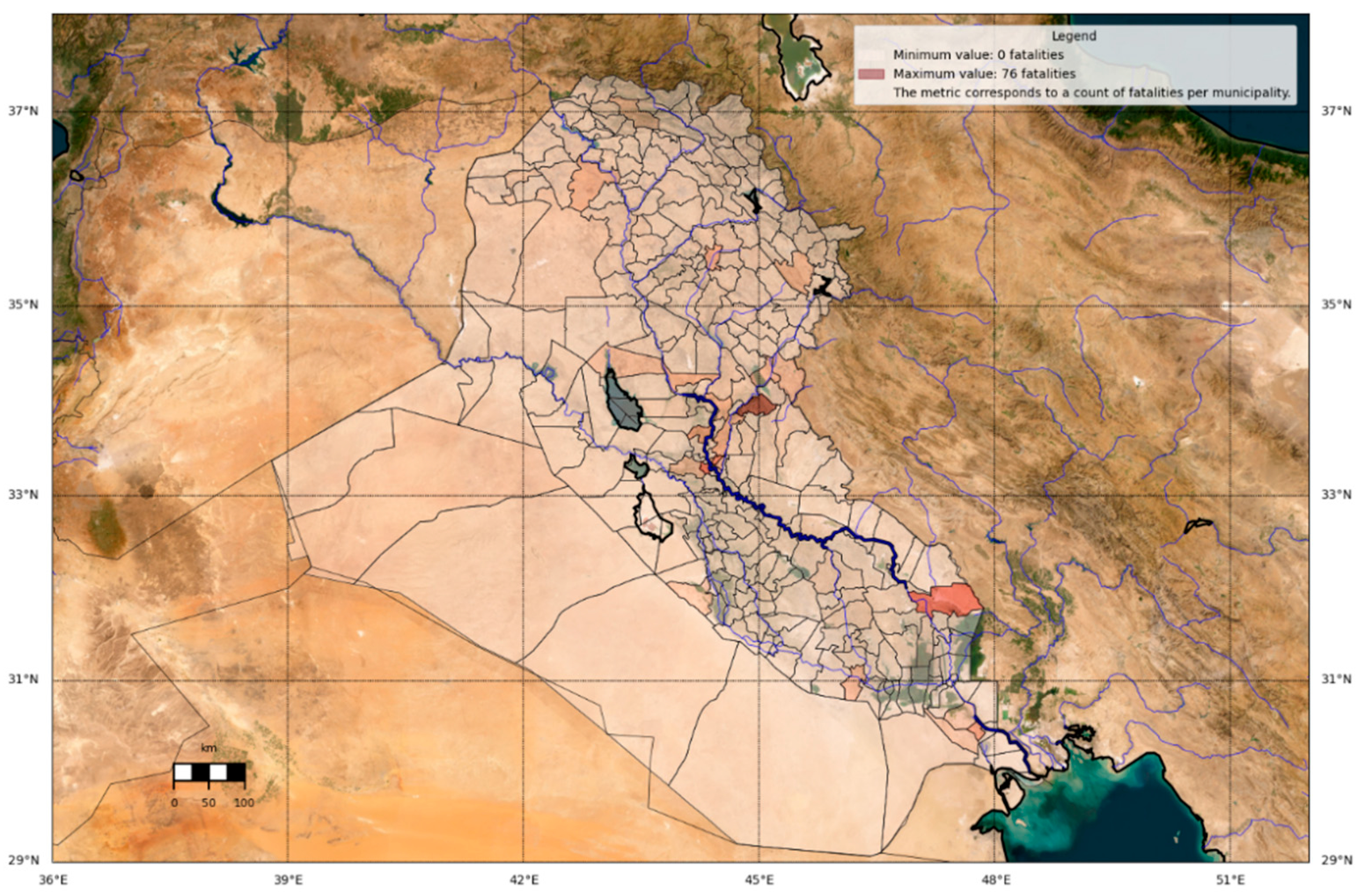
Furthermore, the conflict activity variables are geolocated. For each municipality, we counted geolocated values of conflict activity variable that were reported to have occurred within that municipality’s polygon. This procedure was applied to all the count of conflict events, civilian fatalities, and conflict fatalities. Figure 8 shows the count of conflict fatalities across the Iraqi municipalities.
Figure 6.
Civilian fatalities visualized across the Iraqi municipalities.
Finally, the available grids respectively store values of the explanatory variables as pixels. Each such pixel is associated with specific geographical coordinates. We respectively bounded the pixel values by the municipal polygons as in the previous case. Since the storage of explanatory variables was not sparse anymore, we aggregated the values of explanatory variables, so much so each aggregation emphasized extreme values of the observed explanatory variables, respectively. Specifically, pixel values of precipitation were aggregated geographically as pixel maxima and temporally as municipal maxima. Pixel values of soil temperature were aggregated geographically as pixel sums and temporally as municipal sums. Pixels values of average latent heat flux were aggregated geographically as pixel maxima and temporally as municipal standard deviations. Moreover, pixel values of rice production were aggregated geographically as pixel minima and temporally as municipal minima. Finally, pixels values of population density were aggregated geographically as pixel maxima for the year 2020, the most recent observation. Exemplifying the output, Figure 9 shows the resulting map for population density.
Figure 7.
Population density visualized across 294 municipalities in Iraq.
4.2. Methods
Causal methodology generally requires experimentation (Rubin 1974, 1978, 2005; Holland 1986). However, it is nowadays possible to infer and model causality even with non-experimental observations (Robins 1986; Spirtes, Glymour, and Schienes 1993; Hitchcock and Pearl 2001; Nichols 2007; Pearl 2009). Acknowledging the need for the non-experimental approach to environmental security, we argue that it is possible to unpack the black-box relationship at the core of climate-conflict nexus. By applying causal methodology to non-experimental observations, causal paths, and effects behind the causal mechanism of climate-conflict linkages can be respectively disentangled and quantified. This is done in three stages outlined in Table 1.

Table 1.
The Stages of Causal Inference.
| Causal Discovery | Causal Identification | Causal Estimation |
| Retrieval of a causal structure from non-experimental observations. | Verification if a causal query has a unique answer and, if so, formulation of a causal effect as a quantity that is yet to be estimated (i.e., causal estimand). | Calculation of a causal effect as a quantity that has been estimated (i.e., causal estimate), and testing that its probability is not due to randomness. |
The three subsections that follow explain in stages how causality is respectively discovered, identified, and inferred from non-experimental observations. The subsections exemplify response to a causal query: “What is the magnitude of causal effect of soil temperature on the count of conflict fatalities?”
Causal Discovery
The purpose of causal discovery is to retrieve a causal structure from available observations (Malinsky and Danks 2017). Such structures can be modeled graphically (Pearl 2009). Each directed edge of such causal graph represents causation between the node with an outgoing arrow and the node with an incoming arrow, respectively referred to as a cause and an effect (Pearl 2009). The graph on the left in Figure 8 contains a directed edge: Soil temperature → Conflict Fatalities, indicating that a change in soil temperature causes a change in conflict fatalities. The graph in the middle, however, contains a bidirected edge: Soil temperature ↔ Conflict Fatalities.
Figure 8.
Bidirected edges and causal cycle in a causal structure.
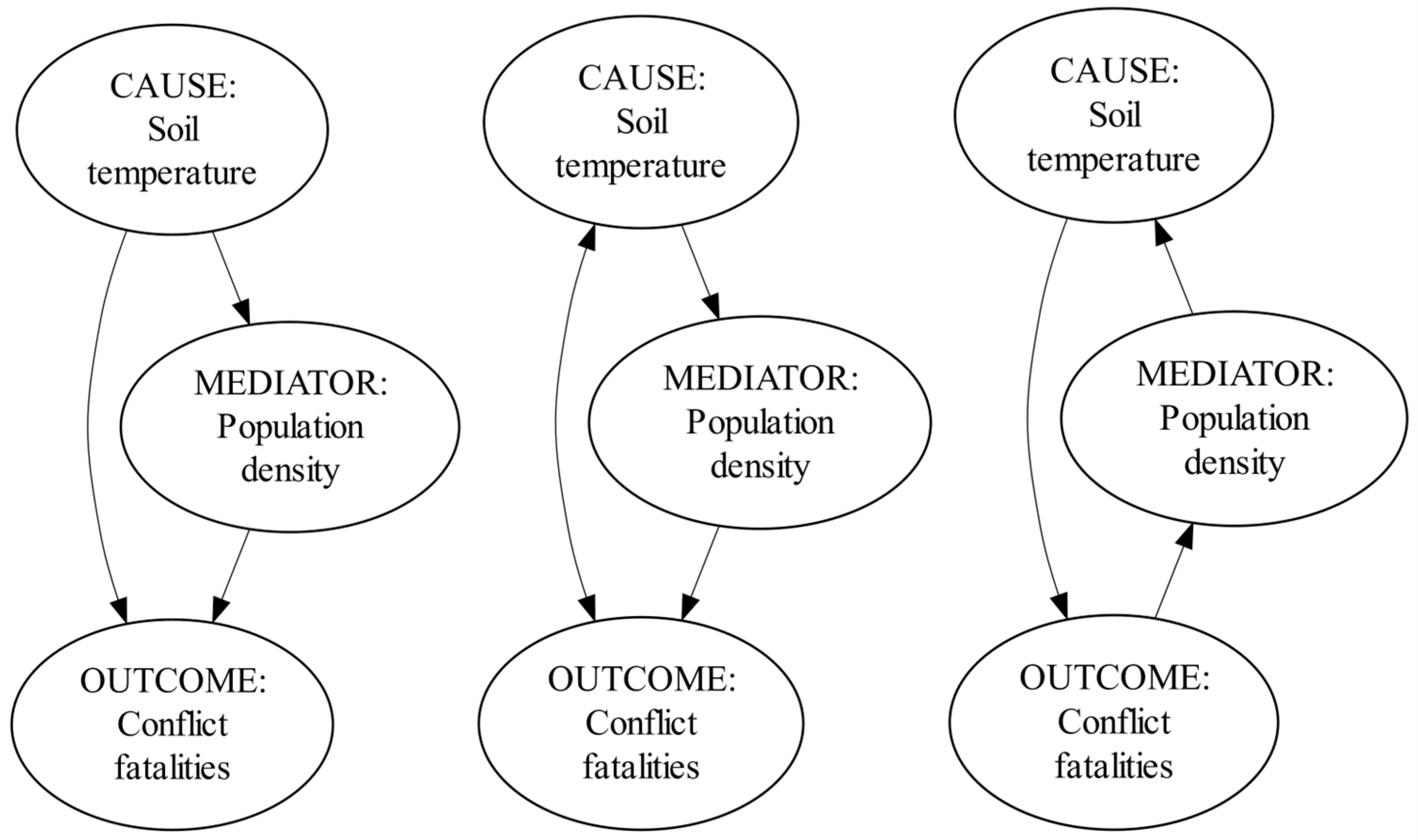
Each node in-between a node with only outgoing arrows (i.e., root cause) and node with only incoming arrows (i.e., effect, outcome) is a mediating node (for instance, Population Density). Further, the graph on the right in Figure 8 is characterized by a causal cycle: Soil Temperature → Conflict Fatalities → Population Density → Soil Temperature. Despite the recent theoretical advances (Bongers et al. 2021), the simplest conception of causality requires absence of bidirected edges and causal cycles from a causal graph, as they respectively point to hidden common causes or reverse causality; both of which can confound causal inference (Pearl 2009). Graphs without bidirected edges and cycles are referred to as directed acyclic graphs (DAG). The simplest conception of causality requires causal discovery to retrieve a DAG from available observations (Malinsky and Danks 2017).
Following this logic of causal discovery stage, we retrieved a DAG from our observations. Having applied Greedy Equivalence Search (GES) algorithm (Malinsky and Danks 2017), we retrieved the entire DAG from the available observations. The loss function we used was Bayesian Information Criterion. The output of the GES was the likeliest DAG, given our observations (Malinsky and Danks 2017). The nodes of the DAG correspond to our armed conflict activity and explanatory variables. The edges correspond to respective causal relationships between them (Malinsky and Danks 2017).
Causal Identification
The purpose of causal identification is to determine if, given a causal structure, the causal query has a unique answer (Shpitser and Pearl 2008). Otherwise, the query is unidentifiable. The identification also serves the purpose of formulating a quantity that is the unique answer to the query (Shpitser and Pearl 2008; Pearl 2009). A formula that enables quantification of that answer is referred to as an estimand (Lundberg, Johnson, and Stewart 2021).
Given the Soil temperature → Conflict Fatalities arrow in Figure 9, a node such as population density opens an alternative path from soil temperature to conflict fatalities. If such a node is not explicitly accounted for, it is referred to as a confounder (Pearl 2009). If it is possible to exhaustively account for confounders, it is also possible to identify a causal query.
Figure 9.
Presence of a confounder in causal identification.
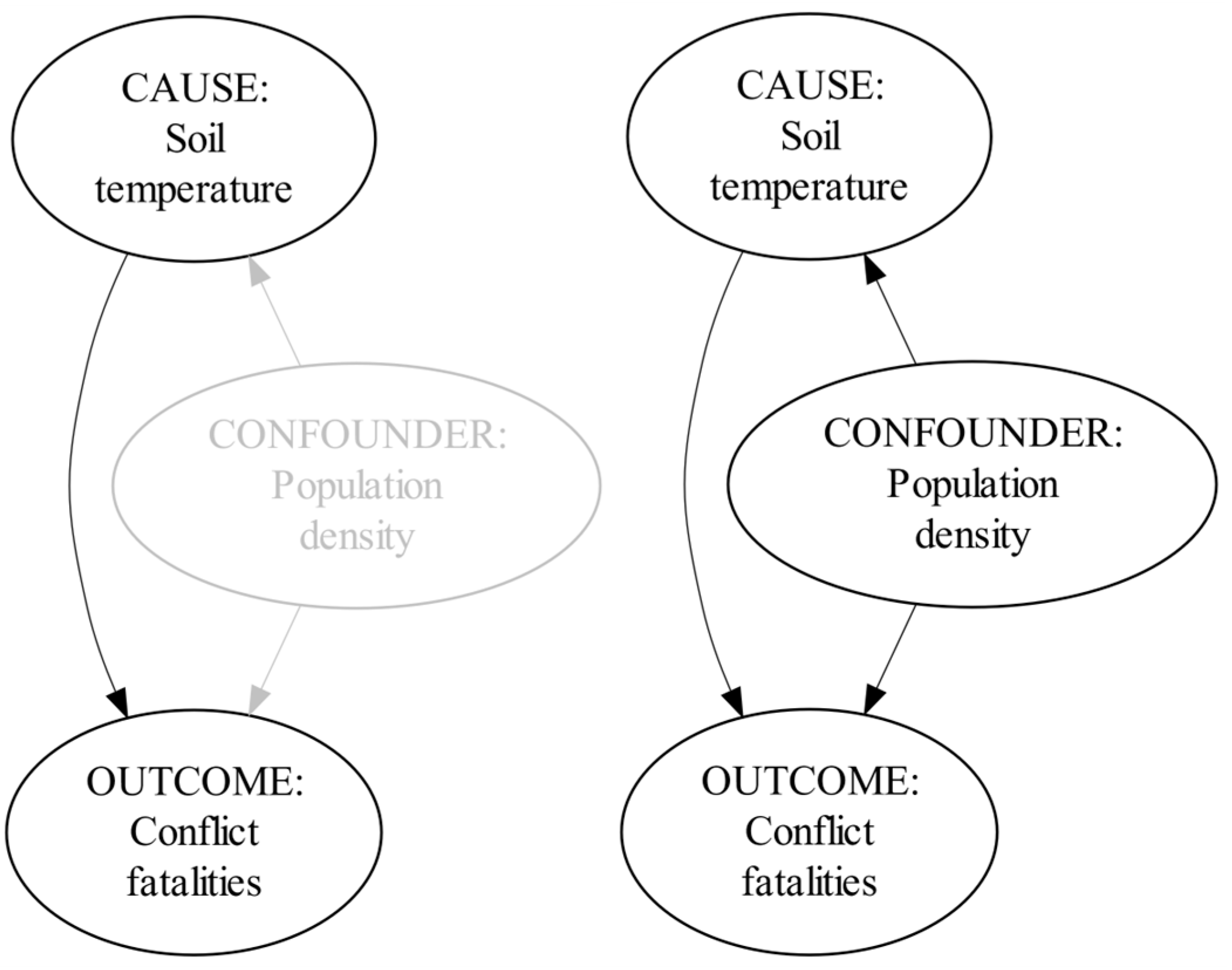
Given the probabilistic interpretation of causal graphs (Pearl 2009), let be a conditional probability distribution, let and respectively be the conflict fatalities, soil temperature, and population density variables, let , , and be the realized values of these variables respectively, and let be the operator that encodes interventions (Pearl 2012). If no variable were associated with soil temperature and conflict fatalities in Figure 9, then the unique answer to our causal query would have been . However, since population density opens an alternative causal path between these two variables, not accounting for population density may preclude the determination of unique answer to our causal query. Hence, the confounding effects of population density must be eliminated from the answer if our query is to be identified; the confounding effect must be marginalized. Thus, the causal graph in Figure 11 makes it possible to identify the unique answer to our causal query. Specifically, formulates the unique answer to the query.
This reasoning exemplifies an identification criterion known as backdoor criterion (Pearl 2009). For other identification methods, we refer the reader to Tian and Pearl (2002) and Shpitser and Pearl (2008). Having applied the above reasoning to the retrieved DAG, we respectively identified causal estimands of our explanatory variables, whenever access to our available variables made identification possible.
Causal Estimation and Hypothesis Testing
The last stage of causal inference includes estimation and hypothesis testing. In this stage, an estimator (i.e., a calculation method for estimation purposes), along with sampled observations, is applied to a causal estimand (Pearl 2009; Lundberg, Johnson, and Stewart 2021). This application results in an estimated causal quantity of causal effect, i.e., causal estimate. Eventually, an assessment is made if the estimate should be attributed to random error. Otherwise, the quantity is considered statistically significant.
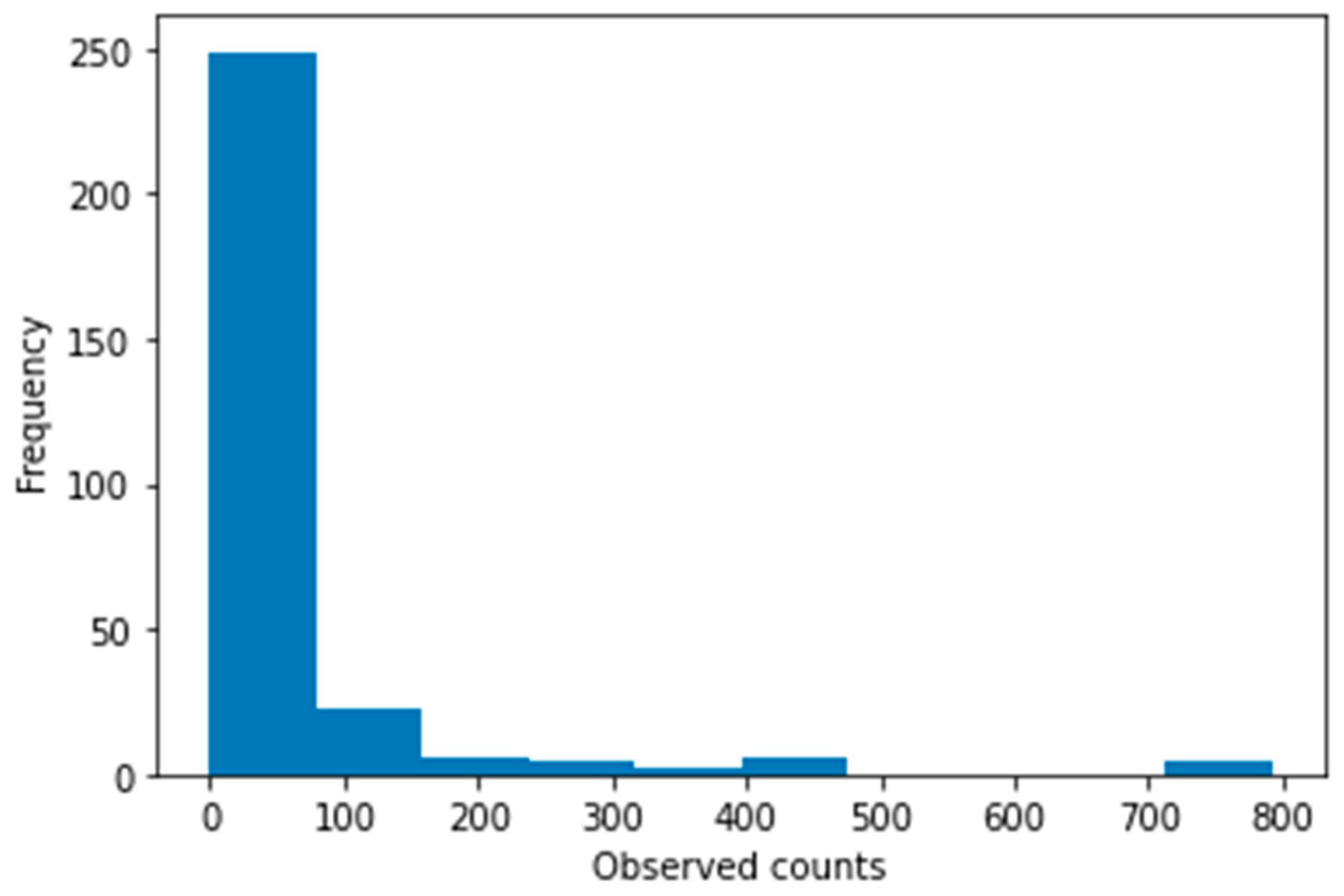
The histogram in Figure 10 suggest that fatality counts can be modeled with Poisson distribution, , where is the expected value of fatality counts, . The probability of an observed fatality count, , is then stated as , where is the basis of natural logarithm.
Figure 10.
Histogram of counted conflict fatalities.
Given the histogram in Figure 10, we can resort to Poisson regression to calculate causal estimates as Poisson regression coefficients. A Poisson coefficient is a value that applies to an outcome variable, stated as counts, given a change in a single explanatory variable, and holding all the other explanatory variables constant. If the two explanatory variables from Figure 11 can assumedly be linearly combined, then the expected value of fatality counts is stated as , where is the Poisson coefficient for soil temperature, is the Poisson coefficient for population density, and is a constant. In log terms, . The latter formula shows why commonly reported parameters of Poisson regression are stated in logs of expected counts.
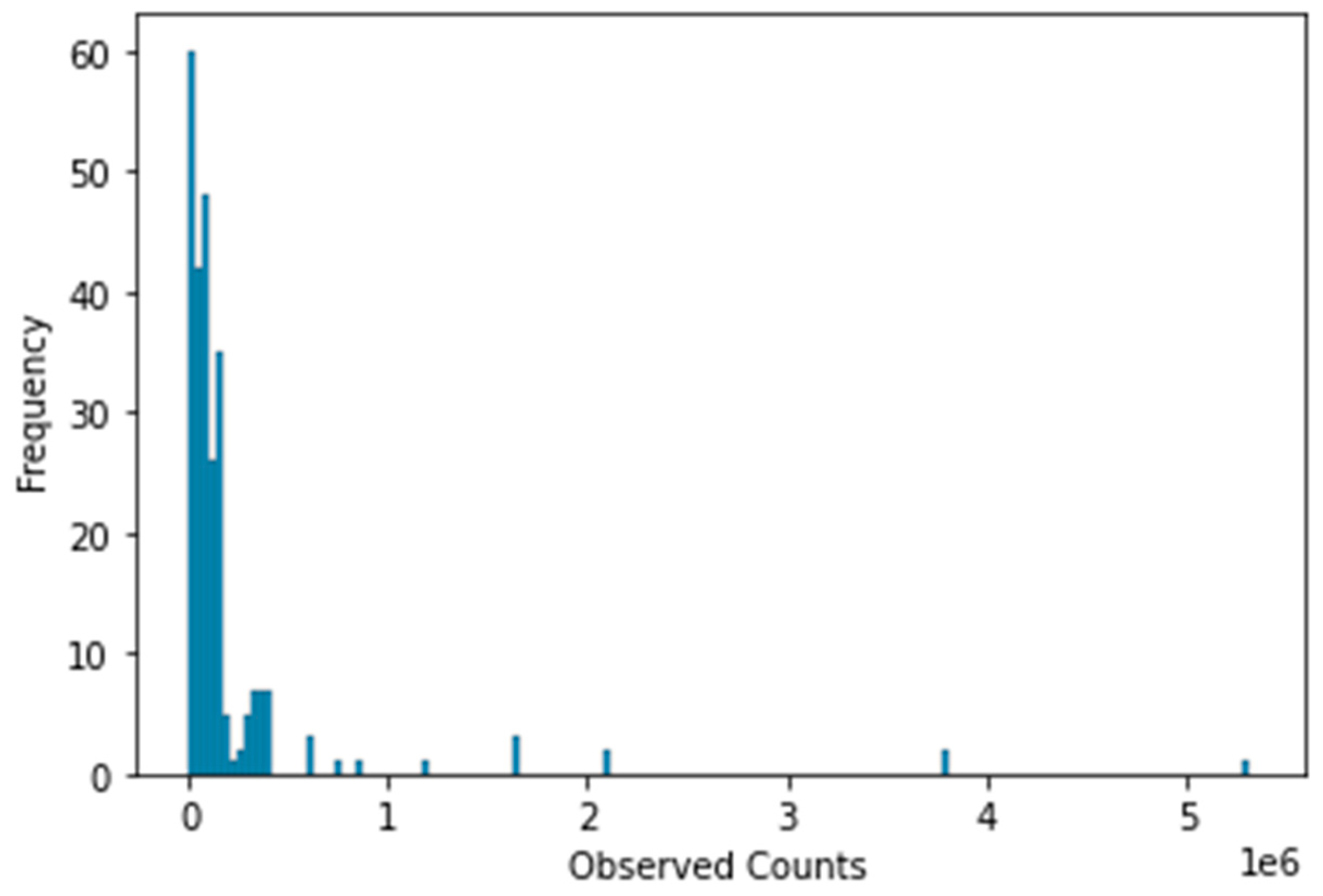
Given the observed soil temperature and population density variables, the conditional probability of single observed fatality count is stated as , where is the expected value of fatality counts. The previous subsection established that where is the probability of population density variable. The population density is equal to population count per pixel, where pixel is equal to 926.7 square meters (CIESIN - Columbia University, 2018). The histogram in Figure 13 shows that the population counts can also be modeled with Poisson distribution P(D) ∼ , where is the expected value of population counts. Assuming the latter, the probability distribution of an observed population count, is stated as .
Figure 11.
Histogram of population counts.
If we apply an intervention that sets the soil temperature variable to value , the probability of an observed fatality count, , is stated as Assuming independently and identically distributed observations of fatality counts the probability of an entire sample of such observations is stated as , where the intervention sets soil temperature to value across all the observations of fatality counts. The index is required for the calculation of probability of entire sample of independently and identically distributed observations of fatality counts, and is required for marginalizing population counts that could confound the calculation of estimate otherwise. To estimate the probability of the entire sample of observations, we resort to maximum likelihood estimation (Bertsimas and Nohadani 2019).
A Poisson coefficient is interpreted as a difference in logs of expected total conflict counts. Specifically, let and designate the expected count of fatalities for soil temperature that the intervention respectively sets to and . The difference between the subscripts and refers to one unit change in soil temperature . The Poisson coefficient for soil temperature is then stated as Moreover, under this intervention, only the coefficient for soil temperature is interpreted causally. One unit change in soil temperature is expected to cause the difference in the logs of expected fatality counts to change by the Poisson coefficient for soil temperature, given population density is held constant.
Furthermore, if the real effect is hypothesized not to exist (the null hypothesis), a significance level is the probability of incorrectly rejecting the null hypothesis (also referred to as the probability of Type I error). If the estimate’s probability (i.e., ) is smaller than the selected significance level (typically set at 5%, 1%, or 0.1%), then that estimate is too improbable for the null hypothesis to hold. Otherwise, the inference fails to reject the null hypothesis. Specifically, if the null hypothesis states that the causal effect of soil temperature does not exist, and the for the Poisson coefficient for soil temperature is less than, for instance, 1%, then the null hypothesis is rejected at the 1% level of statistical significance. It is in this case that the response to our query (“What is the magnitude of causal effect of soil temperature on the count of conflict fatalities?”) can be stated as the estimated quantity. Otherwise, the null hypothesis is not rejected, and the estimated quantity is zero.
Having formulated our causal estimands, rather than with Poisson distribution, we implemented our estimation as a generalized linear regression with negative-binomial distribution (Hilbe 2011). A generalization of Poisson distribution, negative-binomial distribution additionally allows to account for overdispersion of conflict fatalities, originating from conflict stickiness if the variance of conflict fatalities exceeds the mean of conflict fatalities. However, the interpretation of coefficients remains the same. By applying the maximum likelihood estimator (Bertsimas and Nohadani 2019) to our regression, we calculated the coefficients of our explanatory variables, those that yielded the maximum probability of our sample. We then tested their statistical significance. The estimation requires that our observations do not violate specific statistical and causal assumptions. We discuss these assumptions, their violations, and remedies in Section 6.
5. Results
Empirical Causal Structure
In the theory section, we proposed the hypothetical causal structure of climate-conflict linkages. Figure 12 shows the causal structure that we empirically retrieved from the available non-experimental observations.
Figure 12.
The empirical causal structure.
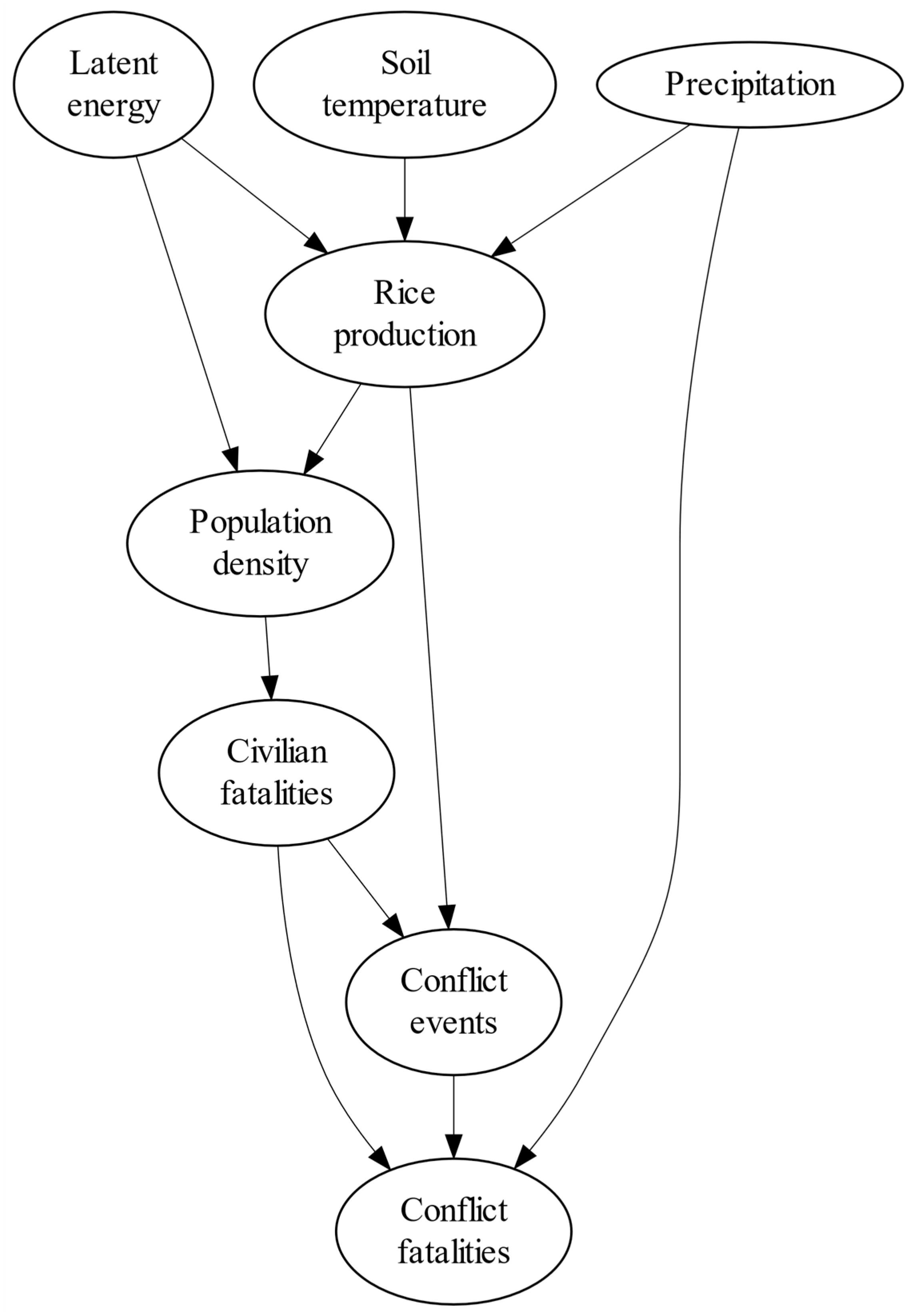
Albeit somewhat less expressive, the empirical causal structure largely corresponds with the hypothetical one in Figure 4. The conflict nodes cluster together. The only node with only incoming edges is conflict fatalities. Further, the structure is rooted in climatological processes. Apart from the direct causal path from the precipitation node, all the other paths from the climatological processes to conflict fatalities are indirect. Table 2 shows characteristics of these nodes in terms of several descriptive network properties that matter for the causal structure’s connectedness.
Table 2.
The empirical causal structure – Descriptive properties.
| Causal nodes: | Degree | Degree Centrality |
Betweenness Centrality |
Closeness Centrality |
| Soil Temperature |
1 |
0.125 |
0 |
0 |
| Precipitation | 2 | 0.25 | 0 | 0 |
| Latent energy | 3 | 0.25 | 0 | 0 |
| Rice Production | 5 | 0.625 | 0.152 | 0.375 |
| Population Density | 3 | 0.375 | 0.080 | 0.333 |
| Apart from degree metric which counts the number of edges per node, all the centrality metrics range from 0 to 1. 0 characterizes nodes on the periphery of empirical causal structure, and 1 characterizes the maximum centrality of node for the empirical causal structure. For more on centrality metrics, please refer to Hansen et al. (2020). | ||||
Because the population density and rice production nodes have the highest degrees and centrality measures, these nodes are pivotal to the connectedness of empirical causal structure. This lends credence to the causal mediation of climatological processes on the conflict outcomes. In fact, absence of population density and rice production would largely disconnect the climatological causes from these outcomes. Rather than accepting this evidence as conclusive, however, we further use the empirical structure to conduct the hypothesis testing.
Causal Hypotheses
The empirical causal structure can assist with validation of the causal hypotheses of naturally caused armed conflict. With this structure, we identified, formulated, and estimated causal effects of our explanatory variables on the count of conflict fatalities. For each causal estimate, a hypothesis test was conducted to discern whether to attribute the estimate to a random error or not. Table 3 lists the causal estimates, their standard errors, and asterisks, whenever an estimate was statistically significant at a standard level of statistical significance (5%: *; 1%: **; 0.1%: ***.). The parameter of the Negative Binomial distribution that describes stickiness of conflict fatalities has been estimated as α = 0.207. This points to the overdispersion of conflict.
Table 3.
The empirical causal structure - Causal effects on conflict fatalities.
| Intervention Variables: | |
| Soil Temperature | 1.201e+18*** (8.055e+24) |
| Precipitation | 88.764 (141.988) |
| Latent energy | 506.108* (7.2e+13) |
| Rice Production | -36.417*** (6.827) |
| Population Density | 138.097* (75.33) |
| The table shows standardized causal estimates. The estimation of causal effects was conducted with Generalized Linear Models and Negative-Binomial distribution. Reflecting the uncertainty of estimated causal effects, the corresponding standard errors are in the brackets. Statistical significance level: 5%: *; 1%: **; 0.1%: ***. | |
Our first set of hypotheses states that effects of climatological processes directly cause armed conflict outcomes. The changes in precipitation (H1 a), soil temperature (H1 b), and latent energy (H1 c) were hypothesized to cause a change in the count of conflict fatalities directly. The only climatological process with a direct causal path to conflict fatalities is precipitation. However, given the causal structure, the estimated causal effect of precipitation on the conflict fatalities is not statistically significant at any level of statistical significance. Since there is no evidence that warrants rejecting any of the null hypotheses relative to the first set of hypotheses, we do not accept the first set of hypotheses.
Further, our second set of hypotheses states that causal effects of the climatological processes on conflict fatalities are mediated. Precipitation was hypothesized to cause a decrease in the count of total conflicts indirectly (H2 a). Since the estimated effect of precipitation on the conflict fatalities is not statistically significant, there is no evidence to reject the null hypothesis relative to the H2 a) hypothesis. Furthermore, soil temperature (H2 b) and latent energy (H2 c) were hypothesized to cause an increase in the count of conflict fatalities indirectly. As there are no direct paths from these processes to conflict fatalities, their causal effects on conflict fatalities can only be indirect. Given the indirect paths from the climatological processes to armed conflict activity, ceteris paribus, a one unit increase in soil temperature causes a 1.201e+18 increase in the log of the ratio of counted conflict fatalities, at 0.1% statistical significance level. Given the indirect paths from the climatological processes to armed conflict activity, ceteris paribus, a one unit increase in variability of latent energy causes a 506.108 increase in the log of the ratio of counted conflict fatalities, at 5% statistical significance level. The respective standard errors, 8.055e+24 and 7.2e+13, make these estimates very uncertain. Nonetheless, this evidence warrants the rejection of null hypotheses relative to the latter two hypotheses, and we accept the H2 b) and H2 c) hypotheses.
Finally, our third set of hypotheses states that causal effects of climate on conflict fatalities are agriculturally and demographically mediated. Given the indirect paths from the climatological processes to armed conflict activity, whereas rice production causally mediates the indirect effects of climatological processes on armed conflict activity, by causing a decrease, population density causally mediates the indirect effects of climatological processes on armed conflict activity, by causing an increase in armed conflict activity. Whereas rice production was hypothesized to cause a decrease in the count of conflict fatalities (H3 a), population density was hypothesized to cause an increase (H3 b). Given the indirect paths from soil temperature and latent energy to armed conflict activity, ceteris paribus, a one unit increase in rice production causes a 36.417 decrease in the log of the ratio of counted conflict fatalities, at 0.1% statistical significance level. Given the indirect paths from soil temperature and latent energy to armed conflict activity, ceteris paribus, a one unit increase in population density causes a 138.097 increase in the log of the ratio of counted conflict fatalities, at 5% statistical significance level. This evidence leads us to reject the null hypotheses relative to the H3 a) and H3 b) hypotheses, and we accept the latter two hypotheses. In terms of causal mediation, we already saw that elimination of rice production and population density from the causal structure would disconnect soil temperature and latent energy from conflict fatalities. Our causal estimates corroborate these structural findings.
6. Discussion
6.1. Contributions
We make three contributions to armed conflict research. First, we demonstrate how advances in causal methodology can be leveraged in armed conflict research. Natural experiments with armed conflict are not common, and most observations of armed conflict are non-experimental (Hsiang, Burke, and Miguel, 2013). Nonetheless, causal assumptions can reconcile experimental and non-experimental armed conflict research. Tapping into causal methodology, we show how to retrieve an empirical causal structure, identify causal paths, and estimate causal effects with non-experimental observations of armed conflict. Beyond this, probability of distances between hypothesized and empirically discovered causal structures can be quantified and tested (Wills and Meyer 2020; Bollobás 2001) if domain knowledge guides causal discovery of naturally caused armed conflict. Otherwise, an empirical causal structure can be retrieved exploratorily, as exemplified by our study.
Second, specifically to environmental security research, we corroborate the existence of a cause-and-effect relationship between climatological, environmental, and demographic variables and armed conflict outcomes. We show that climatological processes are an agriculturally and demographically mediated cause of conflict. By disentangling the causal considerations at the core of naturally caused armed conflict, we respond to the research gap in the environmental security literature (Sakaguchi, Varughese, and Auld 2017; Koubi 2019; Mach et al. 2019). The early research refers to the metaphysical debate about relative importance of entangled natural causes of armed conflict (Homer-Dixon 2010). By retrieving the empirical causal structure from non-experimentally observed armed conflict, we ascertain the causal mechanism of climate–conflict linkages. The retrieved empirical causal structure shows that the climatological processes grounded in soil temperature, latent energy, and precipitation, are a root of naturally caused armed conflict. Furthermore, the empirical structure also points to the direct and indirect causal paths from these climatological causes to armed conflict outcomes. Our findings show that effects of these climatological causes on conflict fatalities are mediated by demographics and vital resources.
Third, we show how our causal findings can be used to inform the design of more effective policy interventions in armed conflict outcomes. Our findings ground policy designs that mitigate armed conflict. Acceptance of policy recommendations necessarily depends on the unpacking of black-box predictions (Cederman and Weidmann 2017). Because causality explains why things are the way they are, it satisfies a higher standard of interpretability than other approaches to interpretation do (Sagi and Rokach 2020). Causality also encodes policy relevance. For instance, mediators, such as population density and rice, are points where the indirect causal paths from the climatological roots to armed conflict outcomes lend themselves to strategic interventions. Causal frameworks allow for validation of other such points. Thus, causal explanation of naturally caused armed conflict can inform policy designs that mitigate armed conflict’s natural causes.
6.2. Research Caveats
Our first limitation pertains to our variables. Many vital resources depend on precipitation, temperature, energy, and availability of water (Hsiang, Burke, and Miguel, 2013; Hendrix and Salehyan 2012; Fjelde and von Uexkull 2012; Couttenier and Soubeyran 2014; Bernauer and Siegfried 2012), making it reasonable to choose rice, soil temperature, precipitation, and latent energy as the explanatory variables for our study. Population density has also been established as a reasonable choice (Tir and Diehl 1998; Urdal 2005, Raleigh and Hegre 2009). However, the causal sufficiency assumption states that any causally relevant ancestor between any pair of variables that is excluded from analysis can confound causal estimates (Malinsky and Danks 2017). This obviously applies to social and political variables in our case (e.g., political power-sharing arrangements, intergroup animosities, and horizontal inequality) (Yin, 2020; Adano et al. 2012; Raleigh 2010). Nonetheless, such variables are not available at an appropriate resolution for a data-scarce country like Iraq. Even if these variables had been available, however, their inclusion might not have been warranted, as it could have led to issues of reverse or cyclical causality, thereby confounding our estimates. Hence, acknowledging the trade-off between methodological rigor and domain knowledge remains part and parcel of causal modeling.
Our second limitation has to do with the fact that municipalities are geographical. The need to delimit conflict under study both geographically and historically (Cederman and Weidmann 2017) constrains the variability of our observations. The subtropical desert climate of Iraq certainly reduced the variability of observed climatological and environmental conditions. Eventually, this made it harder to arrive at statistically significant causal effects. This may also constrain the generalizability of our findings to other geographies. Thus, our findings are limited by the trade-off between the need to localize armed conflict temporally and geographically and sufficient variability of sampled observations of armed conflict under study. Moreover, because municipalities are geographical, it is not certain that the variables are independently and identically distributed. Neither the armed conflict activity nor explanatory variables necessarily abide by the municipal borders. Specifically, the tribal dynamics matters for armed conflict in Iraq, and the municipal and tribal boundaries do not always coincide (Water Peace and Security Report: Water challenges and conflict dynamics in Southern Iraq: An in-depth analysis of an under-researched crisis, 2022). Therefore, it is possible that any of the Iraqi municipalities received causal effects from any other Iraqi municipality (Bhattacharya, Malinsky, and Shpitser 2019; Hudgens and Halloran 2008; Al-Muqdadi et al. 2016): Whereas the spillover of causal effects across the municipalities should be investigated more closely, the data for this is presently unavailable.
Our third limitation has to do with the passage of time. Since a cause classically precedes its effect, temporality is a defining property of causation. However, because many of our data sources come with constrained availability, the quality of available time series was too low for the temporal modeling of naturally caused armed conflict to be possible. Thus, the temporality of causation remains implicit to our findings.
6.3. Future Directions
Several research directions can overcome the above limitations. Given the fact that we did not include social and political variables into our study, we should first investigate the need for their inclusion, by testing to what extent our causal findings remain robust relative to the assumed presence of hidden common causes (i.e., the relaxation of causal sufficiency). Causal frameworks for this purpose already exist (Bhattacharya, Nabi and Shpitser 2020; Bhattacharya et al. 2021; Lee et al. 2023).
Further, we should examine how to generalize our findings to other geographical localities. The smaller the size of locality, the less variable the observations. Consequently, the less likely it is that their variability suffices for statistical significance. Any reduction in size of locality can artificially make causal findings less likely to be statistically significant. However, it is possible to overcome the reduced variability of observations characteristic of small-sized localities by describing observations in informationally denser terms. This can be achieved by describing each locality with additional explanatory variables, while dimensionally reducing the number of explanatory variables to a smaller number of latent factors. One would then causally model armed conflict outcomes in terms of these latent factors. With this approach, we can investigate to what extent our findings can be generalized to other geographical localities.
Geography also matters for strategy. Natural resources are geolocated, as are competing factions. Claiming natural resources, competing factions can act strategically. Such dynamics rarely occur in socio-political and demographic vacuum. For instance, the already mentioned cross-municipal tribal networks can introduce both natural and strategic contingencies into armed conflict, as the latter has been observed across Iraqi municipalities. Obviously, because of geographical reasons, we should investigate naturally caused armed conflict for effects of natural causes that any Iraqi municipality may contract from any other Iraqi municipality. However, we should also investigate whether natural or strategic contingencies are at the root of such contagion. Causal frameworks to this end also exist (Bhattacharya, Malinsky, and Shpitser 2019; Hudgens and Halloran 2008).
Finally, our findings should be examined for temporal effects. Our empirical causal structure already points to the non-linearity of armed conflict outcomes (Wolfson, Puri and Martelli 1992). However, further research should investigate how to infer causal effects on armed conflict dynamics across time. Causality can be temporally represented with causal time-series graphs (Runge et al. 2019). These graphs can inform identification of time-varying causal paths and estimation of temporal causal effects. However, this would require not only time series data of sufficient quality, but also a plausibly hypothesized mechanism of temporal causal effects, which stands to go beyond our explanatory variables.
6.4. Policy Relevance
By explaining why things are the way they are, causality can yield more pragmatic utility for policymaking purposes than any other methodological approach can. It stands to reason that this warrants acceptance of our findings. This also encourages application of causal methodology to other policy domains that may benefit from causal evidence.
As far as environmental security is concerned, causality of climate-conflict nexus can inform conflict mitigation strategies. For instance, by targeting mediators along natural causal paths to conflict outcomes, policy interventions can be designed to disconnect these paths before aggravating causal effects reach conflict outcomes. Policies can be designed to mitigate conflict outcomes cost-effectively or even preempt them strategically. Sensible social and migration policies intended to reduce population density can disconnect some causal paths to conflict outcomes. Another example is development aid policies; these policies can achieve conflict mitigation similarly to social and migration policies, if they decrease latent heat and soil temperature, characteristic of the environment susceptible to armed conflict. By making specific vital resources less scarce, development aid policies can mitigate conflict by making food available to communities that might succumb to armed conflict otherwise. This can be achieved by anything from strategic investments into long-term hydrological infrastructure and agricultural technologies to short-term humanitarian relief operations (e.g., food assistance). Finally, our findings also allow for the assessment of Iraqi municipalities for vulnerability to any specific causal effects, before deciding how to implement proposed policies geographically.
7. Conclusion
Quasi-experimental approaches leave much to be desired, and natural experiments with armed conflict are rare. Further, ethics preclude rigorous experimentation with armed conflict. To the best of our knowledge, ours is the first study to apply the recent advances in the theory and methods of causality to naturally caused armed conflict. By resorting only to non-experimental observations, we discovered an empirical structure that corresponds to the mechanism of climate-conflict linkages. Given this structure, we exemplified how to infer effects of natural causes on armed conflict outcomes. Since our findings depend on specific assumptions, they can profit from additional validation. Thus, such validation, especially with interdisciplinary methods, is welcome.
References
- Abatzoglou, John T., Solomon Z. Dobrowski, Sean A. Parks, and Katherine C. Hegewisch. “TerraClimate, a High-Resolution Global Dataset of Monthly Climate and Climatic Water Balance from 1958–2015.” Scientific Data 5, no. 1 (January 9, 2018). [CrossRef]
- Al-Muqdadi, Sameh W., Mohammed F. Omer, Rudy Abo, and Alice Naghshineh. “Dispute over Water Resource Management—Iraq and Turkey.” Journal of Environmental Protection 07, no. 08 (January 1, 2016): 1096–1103. [CrossRef]
- Acemoglu, Daron, Leopoldo Fergusson, and Simon Johnson. “Population and Conflict.” The Review of Economic Studies 87, no. 4 (August 21, 2019): 1565–1604. [CrossRef]
- Adano, W.R., Ton Dietz, Karen Witsenburg, and Fred Zaal. “Climate Change, Violent Conflict and Local Institutions in Kenya’s Drylands.” Journal of Peace Research 49, no. 1 (January 1, 2012): 65–80. [CrossRef]
- Ash, Konstantin, and Nick Obradovich. “Climatic Stress, Internal Migration, and Syrian Civil War Onset.” Journal of Conflict Resolution 64, no. 1 (July 25, 2019): 3–31. [CrossRef]
- Baechler, Günther. Violence through Environmental Discrimination: Causes, Rwanda Arena, and Conflict Model, 1998. https://ci.nii.ac.jp/ncid/BA47069955.
- Bai, Ying, and James Kai-Sing Kung. “Climate Shocks and Sino-Nomadic Conflict.” The Review of Economics and Statistics 93, no. 3 (August 1, 2011): 970–81. [CrossRef]
- Bergholt, Drago, and Päivi Lujala. “Climate-Related Natural Disasters, Economic Growth, and Armed Civil Conflict.” Journal of Peace Research 49, no. 1 (January 1, 2012): 147–62. [CrossRef]
- Bernauer, Thomas, and Tobias Siegfried. “Climate Change and International Water Conflict in Central Asia.” Journal of Peace Research 49, no. 1 (January 1, 2012): 227–39. [CrossRef]
- Bertsimas, Dimitris, and Omid Nohadani. “Robust Maximum Likelihood Estimation.” Informs Journal on Computing 31, no. 3 (July 1, 2019): 445–58. [CrossRef]
- Bhardwaj, Jessica, Atifa Asghari, Isabella Aitkenhead, Madeleine Jackson, and Yuriy Kuleshov. “Climate Risk and Early Warning Systems: Adaptation Strategies for the Most Vulnerable Communities.” The Journal of Science Policy & Governance 18, no. 02 (June 21, 2021). [CrossRef]
- Bhattacharya, Rohit, Daniel Malinsky, and Ilya Shpitser. “Causal Inference Under Interference And Network Uncertainty.” PubMed 2019 (July 1, 2019). https://pubmed.ncbi.nlm.nih.gov/31885520.
- Bhattacharya, Rohit, Razieh Nabi, and Ilya Shpitser. “Semiparametric Inference For Causal Effects In Graphical Models With Hidden Variables.” ArXiv (Cornell University), March 27, 2020. arXiv:10.48550/arxiv.2003.12659.
- Bhattacharya, Rohit, Tushar Nagarajan, Daniel Malinsky, and Ilya Shpitser. “Differentiable Causal Discovery under Unmeasured Confounding.” ArXiv (Cornell University), March 18, 2021, 2314–22. arXiv:10.48550/arXiv.2010.06978.
- Bollobás, Béla. Random Graphs, 2001. [CrossRef]
- Bongers, Stephan, Patrick Forré, Jonas Peters, and Joris M. Mooij. “Foundations of Structural Causal Models with Cycles and Latent Variables.” Annals of Statistics 49, no. 5 (October 1, 2021). [CrossRef]
- Buhaug, Halvard, Tor A. Benjaminsen, Espen Sjaastad, and Ole Magnus Theisen. “Climate Variability, Food Production Shocks, and Violent Conflict in Sub-Saharan Africa.” Environmental Research Letters 10, no. 12 (December 1, 2015): 125015. [CrossRef]
- Caruso, Raul, Ilaria Petrarca, and Roberto Ricciuti. “Climate Change, Rice Crops and Violence. Evidence from Indonesia.” Social Science Research Network, January 1, 2014. [CrossRef]
- Cederman, Lars-Erik, and Nils B. Weidmann. “Predicting Armed Conflict: Time to Adjust Our Expectations?” Science 355, no. 6324 (February 3, 2017): 474–76. [CrossRef]
- Chadefaux, Thomas. “Conflict Forecasting and Its Limits.” Data Science 1, no. 1–2 (December 8, 2017): 7–17. [CrossRef]
- Couttenier, Mathieu, and Raphael Soubeyran. “Drought and Civil War in Sub-Saharan Africa.” The Economic Journal 124, no. 575 (July 16, 2013): 201–44. [CrossRef]
- Deligiannis, Tom. “The Evolution of Environment-Conflict Research: Toward a Livelihood Framework.” Global Environmental Politics 12, no. 1 (February 1, 2012): 78–100. [CrossRef]
- Dinar, Shlomi, David Katz, Lucia De Stefano, and Brian Blankespoor. “Climate Change, Conflict, and Cooperation: Global Analysis of the Effectiveness of International River Treaties in Addressing Water Variability.” Political Geography 45 (March 1, 2015): 55–66. [CrossRef]
- Fjelde, Hanne, and Nina von Uexkull. “Climate Triggers: Rainfall Anomalies, Vulnerability and Communal Conflict in Sub-Saharan Africa.” Political Geography 31, no. 7 (September 1, 2012): 444–53. [CrossRef]
- Ghimire, Ramesh, and Susana Ferreira. “Floods and Armed Conflict.” Environment and Development Economics 21, no. 1 (June 5, 2015): 23–52. [CrossRef]
- Glickman, Todd, and Walter Zenk. Glossary of Meteorology. American Meteorological Society EBooks, 2000. http://ci.nii.ac.jp/ncid/BA51955944.
- “Gridded Population of the World, Version 4 (GPWV4): Population Density.” Data set, January 1, 2018. https://catalog.data.gov/dataset/gridded-population-of-the-world-version-4-gpwv4-population-density.
- Hansen, Derek L., Ben Shneiderman, Marc A. Smith, and Itai Himelboim. “Calculating and Visualizing Network Metrics.” In Elsevier EBooks, 79–94, 2020. [CrossRef]
- Hayhoe, K. “Climate Change Is a Threat Multiplier.” AGU Fall Meeting Abstracts 2020 (December 1, 2020). http://ui.adsabs.harvard.edu/abs/2020AGUFMSY018..04H/abstract.
- Hegre, Håvard, Joakim Karlsen, Håvard Mokleiv Nygård, Håvard Strand, and Henrik Urdal. “Predicting Armed Conflict, 2010-20501.” International Studies Quarterly 57, no. 2 (December 6, 2012): 250–70. [CrossRef]
- Hegre, Håvard, Håvard Mokleiv Nygård, and Peder Landsverk. “Can We Predict Armed Conflict? How the First 9 Years of Published Forecasts Stand Up to Reality.” International Studies Quarterly 65, no. 3 (January 30, 2021): 660–68. [CrossRef]
- Hendrix, Cullen S., and Sarah M. Glaser. “Trends and Triggers: Climate, Climate Change and Civil Conflict in Sub-Saharan Africa.” Political Geography 26, no. 6 (August 1, 2007): 695–715. [CrossRef]
- Hendrix, Cullen S., and Idean Salehyan. “Climate Change, Rainfall, and Social Conflict in Africa.” Journal of Peace Research 49, no. 1 (January 1, 2012): 35–50. [CrossRef]
- Hilbe, Joseph M. Negative Binomial Regression, 2011. [CrossRef]
- Hitchcock, Christopher, and Judea Pearl. “Causality: Models, Reasoning and Inference.” The Philosophical Review 110, no. 4 (October 1, 2001): 639. [CrossRef]
- Holland, Paul W. “Statistics and Causal Inference.” Journal of the American Statistical Association 81, no. 396 (December 1, 1986): 945–60. [CrossRef]
- Homer-Dixon, Thomas. Environment, Scarcity, and Violence, 2010. [CrossRef]
- ———. “Environmental Scarcities and Violent Conflict: Evidence from Cases.” International Security 19, no. 1 (January 1, 1994): 5. [CrossRef]
- ———. “On the Threshold: Environmental Changes as Causes of Acute Conflict.” International Security 16, no. 2 (January 1, 1991): 76. [CrossRef]
- Homer-Dixon, Thomas, and Jessica Blitt. Ecoviolence : Links among Environment, Population and Security. Rowman & Littlefield EBooks, 1998. http://ci.nii.ac.jp/ncid/BA42666538.
- Hsiang, Solomon, and Marshall Burke. “Climate, Conflict, and Social Stability: What Does the Evidence Say?” Climatic Change 123, no. 1 (October 17, 2013): 39–55. [CrossRef]
- Hsiang, Solomon, Marshall Burke, and Edward Miguel. “Quantifying the Influence of Climate on Human Conflict.” Science 341, no. 6151 (September 13, 2013). [CrossRef]
- Hsiang, Solomon, Kyle C. Meng, and Mark A. Cane. “Civil Conflicts Are Associated with the Global Climate.” Nature 476, no. 7361 (August 1, 2011): 438–41. [CrossRef]
- Hudgens, Michael G., and M. Elizabeth Halloran. “Toward Causal Inference with Interference.” Journal of the American Statistical Association 103, no. 482 (June 1, 2008): 832–42. [CrossRef]
- Huffman, George. IMERG V06 Quality Index, NASA, 2019.
- Huffman, George J., Robert F. Adler, David T. Bolvin, and Eric Nelkin. “The TRMM Multi-Satellite Precipitation Analysis (TMPA).” In Springer EBooks, 3–22, 2009. [CrossRef]
- Ide, Tobias, Miguel Rodriguez Lopez, Christiane Fröhlich, and Jürgen Scheffran. “Pathways to Water Conflict during Drought in the MENA Region.” Journal of Peace Research 58, no. 3 (July 2, 2020): 568–82. [CrossRef]
- International Food Policy Research Institute, 2019, “Global Spatially-Disaggregated Crop Production Statistics Data for 2010 Version 2.0”, Harvard Dataverse, V4. [CrossRef]
- “Inventing Temperature: Measurement and Scientific Progress.” Choice Reviews Online 43, no. 01 (September 1, 2005): 43–0373. [CrossRef]
- Koren, Ore. “Food Resources and Strategic Conflict.” Journal of Conflict Resolution 63, no. 10 (March 11, 2019): 2236–61. [CrossRef]
- Koubi, Vally. “Climate Change and Conflict.” Annual Review of Political Science 22, no. 1 (May 11, 2019): 343–60. [CrossRef]
- Koubi, Vally, Thomas Bernauer, Anna Kalbhenn, and Gabriele Spilker. “Climate Variability, Economic Growth, and Civil Conflict.” Journal of Peace Research 49, no. 1 (January 1, 2012): 113–27. [CrossRef]
- Kress, Moshe. “Modeling Armed Conflicts.” Science 336, no. 6083 (May 18, 2012): 865–69. [CrossRef]
- Lee, Jaron J. R., Rohit Bhattacharya, Razieh Nabi, and Ilya Shpitser. “Ananke: A Python Package For Causal Inference Using Graphical Models.” ArXiv (Cornell University), January 26, 2023. arXiv:10.48550/arxiv.2301.11477.
- Lundberg, Ian, Rebecca A. Johnson, and Brandon Stewart. “What Is Your Estimand? Defining the Target Quantity Connects Statistical Evidence to Theory.” American Sociological Review 86, no. 3 (June 1, 2021): 532–65. [CrossRef]
- Mach, Katharine J., Caroline M. Kraan, W. Neil Adger, Halvard Buhaug, Marshall Burke, James D. Fearon, Christopher B. Field, et al. “Climate as a Risk Factor for Armed Conflict.” Nature 571, no. 7764 (June 12, 2019): 193–97. [CrossRef]
- Malinsky, Daniel, and David Danks. “Causal Discovery Algorithms: A Practical Guide.” Philosophy Compass 13, no. 1 (November 23, 2017): e12470. [CrossRef]
- McNally, Amy, Kristi R. Arsenault, Sujay V. Kumar, Shraddhanand Shukla, Peter Y. Peterson, Shugong Wang, Chris Funk, Christa D. Peters-Lidard, and J. P. Verdin. “A Land Data Assimilation System for Sub-Saharan Africa Food and Water Security Applications.” Scientific Data 4, no. 1 (February 14, 2017). [CrossRef]
- Muñoz-Sabater, Joaquín, Emanuel Dutra, Anna Agusti-Panareda, Clément Albergel, Gabriele Arduini, Gianpaolo Balsamo, Souhail Boussetta, et al. “ERA5-Land: A State-of-the-Art Global Reanalysis Dataset for Land Applications.” Earth System Science Data 13, no. 9 (September 7, 2021): 4349–83. [CrossRef]
- Nichols, Austin. “Causal Inference with Observational Data.” Stata Journal 7, no. 4 (December 1, 2007): 507–41. [CrossRef]
- Pearl, Judea. “Causal Inference in Statistics: An Overview.” Statistics Surveys 3, no. none (January 1, 2009). [CrossRef]
- ———. “The Do-Calculus Revisited.” ArXiv (Cornell University), October 16, 2012. arXiv:10.48550/arxiv.1210.4852.
- Raleigh, Clionadh. “Political Marginalization, Climate Change, and Conflict in African Sahel States.” International Studies Review 12, no. 1 (March 1, 2010): 69–86. [CrossRef]
- Raleigh, Clionadh, and Håvard Hegre. “Population Size, Concentration, and Civil War. A Geographically Disaggregated Analysis.” Political Geography 28, no. 4 (May 1, 2009): 224–38. [CrossRef]
- Raleigh, Clionadh, Andrew M. Linke, Håvard Hegre, and Joakim Karlsen. “Introducing ACLED: An Armed Conflict Location and Event Dataset.” Journal of Peace Research 47, no. 5 (September 1, 2010): 651–60. [CrossRef]
- Reuveny, Rafael. “Climate Change-Induced Migration and Violent Conflict.” Political Geography 26, no. 6 (August 1, 2007): 656–73. [CrossRef]
- Robins, James M. “A New Approach to Causal Inference in Mortality Studies with a Sustained Exposure Period—Application to Control of the Healthy Worker Survivor Effect.” Mathematical Modelling 7, no. 9–12 (January 1, 1986): 1393–1512. [CrossRef]
- Rodríguez-Labajos, Beatriz, and Joan Martinez-Alier. “Political Ecology of Water Conflicts.” Wiley Interdisciplinary Reviews: Water 2, no. 5 (June 3, 2015): 537–58. [CrossRef]
- Rubin, Donald B. “Bayesian Inference for Causal Effects: The Role of Randomization.” Annals of Statistics 6, no. 1 (January 1, 1978). [CrossRef]
- ———. “Causal Inference Using Potential Outcomes.” Journal of the American Statistical Association 100, no. 469 (March 1, 2005): 322–31. [CrossRef]
- ———. “Estimating Causal Effects of Treatments in Randomized and Nonrandomized Studies.” Journal of Educational Psychology 66, no. 5 (October 1, 1974): 688–701. [CrossRef]
- Runge, Jakob, Peer Nowack, Marlene Kretschmer, Seth Flaxman, and Dino Sejdinovic. “Detecting and Quantifying Causal Associations in Large Nonlinear Time Series Datasets.” Science Advances 5, no. 11 (November 1, 2019). [CrossRef]
- Running, Steve, Mu Qiaozhen. MOD16A2 MODIS/Terra Evapotranspiration 8-day L4 Global 500m SIN Grid. NASA LP DAAC. - University of Montana and MODAPS SIPS - NASA. (2015). http://doi.org/10.5067/MODIS/MOD16A2.006.
- Sagi, Omer, and Lior Rokach. “Explainable Decision Forest: Transforming a Decision Forest into an Interpretable Tree.” Information Fusion 61 (September 1, 2020): 124–38. [CrossRef]
- Sakaguchi, Kendra, Anil Varughese, and Graeme Auld. “Climate Wars? A Systematic Review of Empirical Analyses on the Links between Climate Change and Violent Conflict.” International Studies Review 19, no. 4 (October 5, 2017): 622–45. [CrossRef]
- Shpitser Ilya, and Judea Pearl. “Complete Identification Methods for the Causal Hierarchy.” Journal of Machine Learning Research, June 1, 2008. [CrossRef]
- Slettebak, Rune. “Don’t Blame the Weather! Climate-Related Natural Disasters and Civil Conflict.” Journal of Peace Research 49, no. 1 (January 1, 2012): 163–76. [CrossRef]
- Spirtes, Peter, Clark Glymour, and Richard Scheines. Causation, Prediction, and Search. Lecture Notes in Statistics, 1993. [CrossRef]
- Sundberg, Ralph, and Erik Melander. “Introducing the UCDP Georeferenced Event Dataset.” Journal of Peace Research 50, no. 4 (July 1, 2013): 523–32. [CrossRef]
- Suzuki, Susumu, Volker Krause, and J. David Singer. “The Correlates of War Project: A Bibliographic History of the Scientific Study of War and Peace, 1964-2000.” Conflict Management and Peace Science 19, no. 2 (September 1, 2002): 69–107. [CrossRef]
- Sweijs, Tim, Marlijn de Haan, Hugo van Manen. Unpacking the Climate Security Nexus Seven Pathologies Linking Climate Change to Violent Conflict, The Hague: The Hague Centre for Strategic Studies, 2022.
- Tian, Jin, and Judea Pearl. “A General Identification Condition for Causal Effects.” National Conference on Artificial Intelligence, July 28, 2002, 567–73. [CrossRef]
- Tir, Jaroslav, and Paul F. Diehl. “Demographic Pressure and Interstate Conflict: Linking Population Growth and Density to Militarized Disputes and Wars, 1930-89.” Journal of Peace Research 35, no. 3 (May 1, 1998): 319–39. [CrossRef]
- Urdal, Henrik. “People vs. Malthus: Population Pressure, Environmental Degradation, and Armed Conflict Revisited.” Journal of Peace Research 42, no. 4 (July 1, 2005): 417–34. [CrossRef]
- Ward, Michael D. “Can We Predict Politics? Toward What End?: Table 1.” Journal of Global Security Studies 1, no. 1 (February 1, 2016): 80–91. [CrossRef]
- Wills, Peter R., and François G. Meyer. “Metrics for Graph Comparison: A Practitioner’s Guide.” PLOS ONE 15, no. 2 (February 12, 2020): e0228728. [CrossRef]
- Wolfson, Murray, Anil Puri, and Mario Martelli. “The Nonlinear Dynamics of International Conflict.” Journal of Conflict Resolution 36, no. 1 (March 1, 1992): 119–49. [CrossRef]
- Xiao, Li-Ye, Xiaodong Fang, and Y. Ye. “Reclamation and Revolt: Social Responses in Eastern Inner Mongolia to Flood/Drought-Induced Refugees from the North China Plain 1644–1911.” Journal of Arid Environments 88 (January 1, 2013): 9–16. [CrossRef]
- Yin, Weiwen. “Climate Shocks, Political Institutions, and Nomadic Invasions in Early Modern East Asia.” Journal of Conflict Resolution 64, no. 6 (December 12, 2019): 1043–69. [CrossRef]
- Yoffe, Shira, Aaron T. Wolf, and Mark Giordano. “Conflict and Cooperation over International Freshwater Resources: Indicators of Basins at Risk.” Journal of the American Water Resources Association 39, no. 5 (October 1, 2003): 1109–26. [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



