
Submitted:
08 February 2024
Posted:
12 February 2024
You are already at the latest version
Abstract
The study investigated the usage of open data in public organizations, focusing on the motives, preferences, and governance ideals that determine their quality. The study shed light on how open data platforms are created and improved, as well as their influence on government operations. The primary goal was to understand the motivations behind the usage of open data, evaluate gov-ernance ideals, and examine institutions' efforts to standardize data formats. Hierarchical regres-sion analysis divides variables into core reasons and different preferences, demonstrating a need for "diversification" in order to use open data effectively. Efficiency, accountability, community impact, knowledge, and high-quality service delivery are all emphasized in governance value analysis. The institution's dedication to standardizing open data formats is evidenced by legislative measures and the integration of many technologies. The findings illustrate the institution's dual strategy of em-ploying traditional techniques and new technologies for effective data management. The report suggests increasing data openness and standardization, investing in ongoing training, upgrading alerting and awareness systems, and adopting specific regulations for open data use. Monitoring and feedback techniques are critical for adjusting and refining open data services to satisfy de-velopment needs. This study adds to the scientific knowledge of open data use by highlighting important motives, preferences, and governance ideals. The offered guidelines provide practical insights for public organizations looking to improve their open data platforms by promoting openness, efficiency, and community participation.
Keywords:
Improving use of open data
; data utilization
; data optimization
; enhancing data access
; open data impact
; open data government
; data transparency
; data-driven decision making
1. Introduction
The digital era is seen to have heralded an unprecedented time of data production, promoting the rise of worldwide open data projects. This has inspired open data, which is defined as publicly accessible and machine-readable structured information, to have enormous potential for revolutionizing decision-making processes while also increasing openness and creativity in both the public and commercial sector. Open data projects have increased openness, accountability and innovation, affecting government services, policy choices, and economic growth [1]. Challenges include worries about data quality, privacy, and the need for technical innovation. To solve these serious privacy problems, legal considerations and user-friendly interfaces are required. Data interoperability initiatives, as well as adherence to frameworks such as open data charters and the European data portal, are critical to realizing open data's revolutionary potential [1]. Open data has enormous potential for boosting openness, increasing accountability, and stimulating innovation, so impacting government services, policy choices, and public participation [2]. Its revolutionary influence on a more open and participatory society is acknowledged, but obstacles remain in a variety of areas. Apart from data quality difficulties [3]. and privacy and security concerns that must be addressed, strong procedures are deemed required [4]. Authors such as [5] advocate for user-friendly interfaces, while technology breakthroughs such as machine learning enable open data to reach its full potential. According to the authors [6] addressing data interoperability issues is critical, and initiatives such as the [1] and collaborative efforts European Data Portal, 2020 have provided significant frameworks for addressing challenges and achieving societal transformation through open data. The importance of open data in numerous areas, particularly in government, industry, and the public realm, has encouraged academics to investigate techniques for improving its usage [7]. Globally, there are open data projects motivated by the potential to enhance openness, innovation, and informed decision-making. Recent research, such as [7] highlight the importance of open data in urban sustainability and identify influential elements. Furthermore, writers such as [8] investigate data optimization strategies, focusing on ways that optimize the benefits of open data for decision makers. [9] investigate the effects of open data on geospatial applications, highlighting transformative roles. Similarly, [10] study the importance of open data on governmental openness and accountability. Furthermore, [11] emphasize the significance of data openness, whereas [12] investigate the use of open data in data-driven decision-making, notably in healthcare. These extensive studies give useful insights regarding open data's use, availability, impact, and transparency, laying the groundwork for a successful data-driven decision-making process in public institutions [2].
This research aims to increase the use of open data in public institutions by addressing problems and providing improvement measures. The key goals are to improve data usage, increase data access, and better assess the impact of open data on government. The study's goal is to give practical ideas and practices based on a thorough review of literature and research from a variety of areas. It helps public entities make more effective and transparent data-driven decisions.
2. Literature Review
Open Data - On a worldwide basis, open data efforts stand out for their potential to transform decision-making, transparency, and creativity. The revolutionary value of open data is generally acknowledged, particularly in terms of increasing openness, accountability, and creativity in both the public and corporate sectors. Author [2] stresses their importance in creating a more open and participatory society, which leads to increased government accountability and developments in public services. The quality of open data is a substantial concern, with variances in accuracy, timeliness, and completeness among open data sources [8]. Addressing these issues is critical to building trust and confidence. Meanwhile, maintaining open access while protecting data privacy is a difficult challenge that necessitates robust privacy and security safeguards, as well as a sophisticated knowledge of legal and ethical factors [4]. Because of the complexity and variety of open data, proper technologies and user-friendly interfaces are required [5]. It is thought that adopting innovations like machine learning and artificial intelligence expands the possibilities of open data. Data availability is acknowledged as a barrier, however initiatives such as data programs and data journalism are critical in resolving this issue [6]. Furthermore, best practices and initiatives, as described in the Open Data Charter (2015) and collaborative efforts (European Data Portal, 2020), are required to improve data quality, safeguard privacy, and ensure accessibility.
The Promise of Open Data - Open data has evolved as a disruptive force that promotes openness, accountability, and innovation. We use open data to dramatically improve government services, inform policy choices, and engage individuals in governance [13]. This organized and accessible knowledge fosters a more inclusive society. Open data has an influence on economic growth by empowering entrepreneurs and fostering innovation in a variety of areas [14]. However, difficulties such as changing data quality and privacy concerns must be addressed [15]. Additionally, user-friendly interfaces and technical breakthroughs, such as machine learning, are critical for realizing the full potential of open data [16]. Open data, with its transformational potential, improves government services and drives economic growth [17]. Data quality and privacy issues must be addressed in order for them to live up to their full potential.
Challenges in data quality While open data has many advantages, it confronts a significant challenge: data quality, which includes security concerns. Different levels of quality, timeliness, and completeness in open data sources create challenges for crucial decision-making processes. Authors such as [18] underline the importance of resolving these challenges in data quality, stating that dependability is critical for confidence and use [19]. The variety of open data sources, ranging from government databases to community contributions, complicates the task of maintaining data quality standards. Authors [20] emphasize the importance of resolving these concerns, stating that discrepancies in correctness and dependability harm the credibility and utility of open data. Realizing the full potential of open data necessitates a collaborative effort to solve the problem of data quality, establishing consistency, correctness, and dependability as prerequisites for informed decision-making in the public sector, business, and public services [21]. Collaboration between academics and practitioners is required to establish and execute high data quality standards. Addressing challenges of accuracy, consistency, and dependability is critical to realizing the full potential of open data [22]. This collaborative approach between researchers and data custodians is critical for defining and upholding standards that improve the integrity and usefulness of open data, resulting in better informed decision-making processes [23].
Data Privacy and Security – The issue of privacy and data security in open data presents significant issues, as writers such as [24] underline the importance of striking a careful balance and implementing adequate privacy and security safeguards when dealing with open data. Addressing legal and ethical concerns is critical to mitigating the risks connected with digitalization and the sharing of sensitive information [25]. Maintaining a balance between data openness, privacy, and security entails protecting personal data, commercial secrets, and government information [26]. The repeated use of processes and regulatory frameworks, such as the General Data Protection Regulation (GDPR), is critical for safeguarding sensitive data [27]. As cyber dangers grow, open data platforms must integrate encryption, access limitations, and routine security assessments [28]. According to [29] is critical for people, businesses, and governments to properly lead privacy and data security principles. Strong legislative frameworks, technical measures, and data efforts are required to realize open data's transformational potential while maintaining a balance between transparency and sensitive information protection [3].
Technological challenges - Because open data is ever-changing and complicated, adequate technologies and tools for integration, analysis, and visualization are required [30]. User-friendly systems and interfaces are also essential for greater accessibility [31]. Machine learning and artificial intelligence, according to [32] promise to unlock the full potential of open data through automated analysis. Despite its transformational potential, the open data movement confronts technological obstacles [33]. Different data sources, formats, and integration challenges impede smooth usage [34]. To realize the full promise of open data, these barriers must be overcome and future technologies accepted [35]. With the rapid advancement of technology, open data efforts must remain relevant by releasing regular updates and changes to ensure they are accessible and useful [36]. The growing number of cyber threats necessitates the use of strong cybersecurity measures such as encryption and access security restrictions [7]. Technological difficulties are long-standing, necessitating ongoing adaptation to advances and investments in data privacy and security [37].
Data Literacy and Expertise – A key hurdle to realizing the benefits of open data is a lack of data and knowledge among users, which include government agencies, businesses, and people. [12] underline the need of training and proper support for open data interpretation and successful utilization [38]. Collaboration with educational institutions, data journalism projects, and professional training are critical for bridging knowledge gaps and improving open data use [39]. Developing a competent and certified workforce is critical to fulfilling open data's revolutionary potential [40].
Best Practices and Strategies - Organizations and governments should follow best practices and strategies defined in frameworks such as the Open Data Charter 2015 and the European Data Portal 2020 to maximize the usage of open data. These principles serve as a road map for improving data quality, enhancing privacy protection, and making open data more accessible [41]. The European Data Portal 2020 emphasizes the use of data standards and interoperability as key principles for facilitating seamless data integration and exchange. Collaborative efforts are critical because open data projects frequently involve several stakeholders, which promotes knowledge exchange and resource sharing. User-friendly data portals, as advocated by the Open Data Charter, are required for efficient data sharing [42]. It is critical to ensure that data is easily accessible, downloadable, and machine-readable. population representation is critical; open data should be accessible and intelligible to the broader population [43]. Visualizations, interactive tools, and instructional materials improve data accessibility, encouraging better comprehension, and encouraging public participation in decision-making. Replicating these principles and initiatives is critical to unleashing open data's revolutionary potential for openness, accountabilit, and innovation.
3. Methods (Required)
The study technique is based on a mixed model, in which I provided concepts and studies connected to open data improvement and consequences via a literature review. Surveys, interviews, document analysis, and fieldwork have all been used as data extraction methods. Training sessions were held for ministry workers, and direct work on the Kosovo open data platform was done to improve and develop an adequate standard for open data. The first study instrument evaluated the existing situation of open data utilization, including involvement from a variety of individuals. The data were processed by factorial analysis. Regarding the interviews, data were processed utilizing the qualitative approach of first interpretation, and regression analysis was provided for standardization based on ministry officials. The program was attended by ministry officials, most of whom were IT maintenance workers or senior officials. The platform project involved the development of two data storage models in Excel and CSV formats. Currently, all ministries use these two formats to post their data on the platform. The research was carried out between April 2023 and January 15, 2024. The research concept is presented below:
Figure 1.
Concept of research. Source: Author.

The research's scientific significance is extensive, providing organizations with a true reflection on how to enhance the situation of open data consumption by public entities. This improves the quality and efficacy of their usage, controlling some areas of data security. All phases of the research were carried out with previous ministry consent, and the research was closely developed in consultation with all stakeholders involved, with the goal of enhancing the situation of open data. The research findings are expected to have a substantial scientific influence on improving the situation of open data in Kosovo.
Research questions:
R1. How can the effectiveness and impact of open data services on citizens be comprehensively assessed and improved, taking into account their usage patterns, preferences and feedback?
R2. How can collaboration with officials and IT inform the development of effective training to address identified needs in open data services?
R3. How can public institutions achieve effective standardization of formats for open data to enhance accessibility, interoperability, and usability?
R4. How can open data services be optimized to better serve diverse stakeholders, including citizens, businesses and NGOs?
4. Resutls
Step 1. Citizen research and measurement of usage level.
Figure 2.
Eigen value graph.
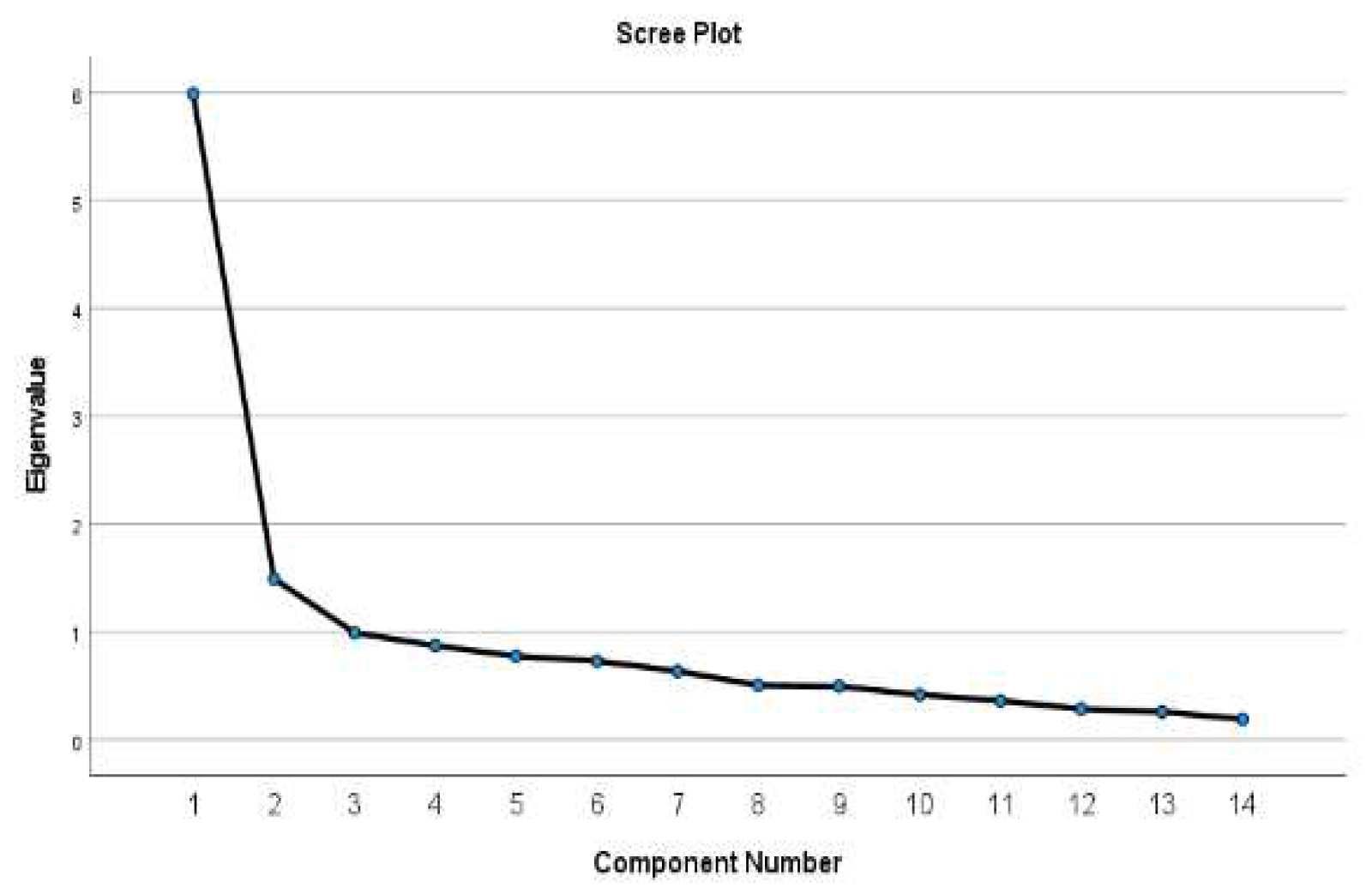
The reasons for the use of open data by citizens have been analyzed to ascertain usage factors and determine their significance. This has been accomplished through the application of factor analysis testing. From the results of the analysis, it is observed that the p-value of the test is 0.000, indicating that the data is reliable and can be interpreted with confidence. From the graph, it is understood that the data is classified into two main components, both of which have passed the eigenvalue of 1.

Table 1.
KMO and Bartlett's Test.
| Kaiser-Meyer-Olkin Measure of Sampling Adequacy. | .855 | |
| Bartlett's Test of Sphericity | Approx. Chi-Square | 610.083 |
| df | 91 | |
| Sig. | .000 | |
Source: Author.
In the first component, various variables were identified and separated into two categories based on their coefficients: over 0.70 and below 0.70. Initially, we are considering those values greater than 0.70 as relevant to investigating various incentives and triggers that push individuals to contribute to the open data landscape. Individuals participating in open data projects are driven by altruistic intentions to provide the groundwork for others to build on (0.785), highlighting the collaborative character of these endeavors. Contributors hope to be rewarded for important contributions, emphasizing the relevance of knowledge systems in open data platforms. The powerful engine of continuous learning (0.744) encourages contributors to broaden their abilities, remain relevant, and drive technical breakthroughs. Furthermore, the high enthusiasm to contribute to the creation of the semantic network and linked data (0.707) demonstrates a long-term commitment to defining the future of data integrity and accessibility. Understanding these motives is critical for building a cooperative and sustainable community of open data users, which may be referred to as motivation. In the second set of variables with coefficients less than 0.70, the preference for "Developing a unique website/service" (0.664) suggests a strong desire in developing a unique platform or service. At the same time, the interest in "Profit generation" (coefficient of 0.625) indicates a preference for making financial advantages. The value of 0.603 for "Curiosity" represents motivation based on curiosity and a desire to investigate. This group may be classified as "Diversification," representing a combination of artistic, economic, and spiritual aspirations.
Table 2.
Rotated Component Matrixa.
| Component | ||
| 1 | 2 | |
| Providing a platform for others to build on. | .785 | .265 |
| Being acknowledged as the creator of something helpful or smart. | .753 | .074 |
| Learning new skills | .744 | .139 |
| Developing the semantic web/linked data web | .707 | .260 |
| Developing a unique site/service | .664 | .349 |
| generating profit | .625 | .409 |
| Curiosity | .603 | .071 |
| Meeting the needs of a management or customer | .568 | .302 |
| Solving a specific difficulty. | .515 | .467 |
| Making the government more efficient. | .110 | .786 |
| Making the government more responsible. | .183 | .696 |
| Making a Difference in My Local Community | .174 | .692 |
| Developing a greater grasp of governance | .176 | .680 |
| Providing superior service to people or clients. | .377 | .639 |
| Extraction Method: Principal Component Analysis. Rotation Method: Varimax with Kaiser Normalization. | ||
| a. Rotation converged in 3 iterations. | ||
Source: Author.
In the second component, we give numerical values associated with each term that can be understood as individual survey replies or particular judgments of various elements of government activity. The higher the number, the greater the perceived importance or effectiveness of the given aim. "Optimizing government efficiency" received the highest score, 0.786, suggesting a strong emphasis on improving overall operations and functioning. Following closely are "Improving government accountability" (0.696) and "Influence on my local community" (0.692), indicating a strong desire for responsibility and community effect. "Developing deeper knowledge of governance" (0.680) indicates a willingness to understand and grasp governance concepts. Finally, the phrase "Providing excellent services to citizens or clients" (0.639) emphasizes the significance of providing quality services to the audience. Overall, these principles represent a shared commitment to efficiency, accountability, community impact, governance expertise, and the delivery of quality services in the context of government operations. This category might be described as the analysis of governance values.
Several variables are differentiated and classified into two primary categories based on the classification findings, with coefficients more than or less than 0.70 each. While variables with coefficients greater than 0.70 highlight motivations and stimuli for contributing to the field of open data, such as altruistic hopes, the need for knowledge, continuous learning, and long-term commitment, variables with coefficients less than 0.70 represent preferences such as creating a unique website, financial gain, or curiosity. The combination of these ideals results in a sense of "diversification." The examination of governance values reveals a collective focus on efficiency, accountability, community impact, governance knowledge, and the provision of outstanding services in the context of government operations, known as "Motivation and Diversification in Governance."
Step 2. Research with officials and IT, identification of needs, and development of training.
The model summary table shows the results of a hierarchical regression study using five consecutive models to determine their fit in predicting the quality of public institutions associated with open data platforms. As more predictors are added to each model, the correlation coefficient (R) rises from.874 to.982, indicating that the model is better able to explain the variance in the dependent variable.
Table 3.
Summary of regression.
| Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | |||||||||||||||||||||
| B | S.H | β | Sig. | B | S.H | β | Sig. | B | S.H | β | Sig. | B | S.H | β | Sig. | B | S.H | β | Sig. | ||||||
| Criteria and conditions of use | .773 | .01 | .874 | .000 | .450 | .023 | .509 | .000 | 1.487 | .035 | 1.682 | .000 | 1.496 | 0.28 | 1.691 | .000 | 1.592 | .026 | 1.800 | .000 | |||||
| Characteristics of open data | * | * | * | * | .362 | .021 | .448 | .000 | .642 | .016 | .794 | .000 | .670 | .019 | .829 | .000 | .573 | .014 | .709 | .000 | |||||
| Regulations on data usability | * | * | * | * | * | * | * | * | -1.145 | .035 | -1.501 | .000 | -1.122 | .028 | -1.471 | .000 | -1.228 | .027 | -1.610 | .000 | |||||
| Features of government data platforms | * | * | * | * | * | * | * | * | * | * | * | * | -.131 | .006 | -.179 | .000 | -.141 | .006 | -.193 | .000 | |||||
| Access format for open data | * | * | * | * | * | * | * | * | * | * | * | * | * | * | * | * | .190 | .015 | .182 | .000 | |||||
| R | ,874 | ,912 | ,964 | ,978 | ,982 | ||||||||||||||||||||
| R² | ,763 | ,831 | ,930 | ,957 | ,964 | ||||||||||||||||||||
| ANOVA (Sig.) | ,000 | ,000 | ,000 | ,000 | ,000 | ||||||||||||||||||||
| Dependent variable | Quality of public institucions of open data platforms | ||||||||||||||||||||||||
Soruce: Author.
The modified R Square likewise climbs steadily, reaching.964 in the final model, suggesting that the included variables account for nearly 96.4% of the variation in the quality of public institutions. The standardized coefficients and statistical significance of individual predictors at each stage shed light on their contributions to the model's predictive power. The F change statistics validate each model's overall significance, emphasizing the strength of the association between predictors and the quality of public institutions in the setting of open data platforms.
The coefficients table shows the unstandardized and standardized coefficients for each predictor in the hierarchical regression models that estimate the quality of public institutions using open data platforms. Model 1 has a constant term of 0.957 and a substantial positive influence from the predictor "Criteria and conditions of use" (B = 0.773, Beta = 0.874). Subsequent models include more predictors, and the coefficients show how each predictor affects the dependent variable. Particularly, in Model 3, "Regulations on data usability" has a negative effect (B = -1.145, Beta = -1.501), showing a considerable impact on the quality of government institutions. The final model (Model 5) adds "Access format for open data," which has a beneficial effect (B = 0.190, Beta = 0.182). All factors in each model had statistically significant impacts (p < 0.05), highlighting their significance in explaining the variance in the quality of public institutions using open data platforms.
The research demonstrated a constant improvement in model fit when more variables were added. The resulting model (Model 5) had a high R Square of.964, suggesting that the selected variables could explain nearly 96.4% of the variation in the quality of public institutions. Standardized coefficients revealed significant effects for all predictors (p < 0.05), indicating their relative importance. Several fundamental elements have a substantial impact on the quality of public institutions that use open data platforms. In particular, "Criteria and conditions of use," "Characteristics of open data," "Regulations on data usability," "Features of government data platforms," and "Access format for open data" all play an important role in explaining the observed variation in the quality of public institutions. Based on the findings, stakeholders should prioritize improving the criteria and circumstances for using open data, addressing open data features, and developing effective data usability rules. Furthermore, paying attention to the characteristics of government data platforms and making open data available in accessible formats might help to improve the quality of public institutions. Continuous monitoring and adaption of these aspects are critical for the ongoing development of open data platforms and their influence on public institutions.
Step 3. Standardization of formats for open data by public institutions.
Table 4.
Firts interpretation of interview.
| Quesitons | First interpretation | Answer of respodentes | Keywords |
| Is there an internal regulation for the use of data at the institution where you work? | The institution under discussion has implemented appropriate internal regulations for specific tasks and also has specific guidelines for the use of open data in this context. | R1.Yes, we have internal regulations that apply to our institution and are tailored to specific tasks. R2.Yes, we have regulations. R3.No, we do not have any regulations. R4.No. R5.Yes, we have. R6.Yes, in our institution, regulations have been created that specify the form of using open data. R7.No. |
Regulation Institution Creation |
| Which regulation is that? Could you provide a brief summary, and if possible, can we find the link to this regulation? If yes, please let us know! | The institution has implemented an appropriate law and operates based on it. The Law on Official Documents is applicable. The document establishes rules for public data, while there is no specific information regarding regulations. | R1.Yes, there is an appropriate law for the institution where they also work based on that law. R2.The Law on Official Documents. R3.No, we do not have. R4.No. R5.Yes, it is the Law on Official Documents. R6.The document for public data. R7.We do not have any specific regulations. |
Law Official Documents Public Data Regulation |
| How do you record your daily data? You can choose more than one option. | The use of traditional forms and Excel is the most common way of distributing information, while the institution has created a specific program. | R1.Through traditional forms, In the Excel program, In the program created by the Institution. R12.Through traditional forms, In the Excel program, In the program created by the Institution. R3.In the Excel program. R4.In the Excel program, In the program created by the Institution. R5.In the Excel program. R6.In the Excel program, In the program created by the Institution. R7.Through traditional forms, In the Excel program. |
Traditional Form Excel Program Institution Distribution |
| What other programs does your institution use? | The use of Microsoft Office and included applications such as Word, Outlook, and Chrome is the most common distribution. The use of the Microsoft Office suite includes a wide range of applications. | R1.Microsoft Office R2.Microsoft Word, Microsoft Outlook, Google R3.Chrome, Skype for Business. R4./ R5.Microsoft Office suite R6./ R7.SIMBNJ, DATABASE, |
Microsoft Office Word Outlook |
| Do you have any common data formats, for example, in the Excel program, where you store your data? | Rarely do they store data in the same formats, while often using different formats for information storage. | R1.Very rarely do we store them in the same formats. R2.Sometimes we store them in the same formats. R3.We never store them in the same formats. R4.Often, we store them in the same formats. R5./ R6.Sometimes we store them in the same formats. R7./ |
Rarely Format Information Different |
| What valid data, meaning non-sensitive data that does not touch upon the interests of your institution, can you share with us? So, could you list the data that you keep during the day in an Excel program or any other program, or in traditional form? |
The data includes expenses, planned projects, processes, and achievements, while specific information is in various programs and consultations for respective matters. |
R1. Data on expenses, planned projects, in progress, and completed, etc. R2. R3. In Excel but also in other programs. R4. R5. We are in consultation above this matter. R6. Data on the staff in MAPL, data on the number of legal acts, data on municipality gatherings, the examination of legality, data on trainings in municipalities, municipal performance, etc. MAPL |
Data Programs Consultations Information |
| Which datasets do you use within your department, specifically what datasets do you use? Please list only datasets that are classified as public data! | The data includes tables, PSO, and is available in Excel format. Currently, email data for officials is in the DKTI console. | R1. Tabular data, PSO, in Excel format, etc. R2./ R3./ R4./ R5./ R6. Currently, in DKTI, we have data on emails for officials of the Ministry in the console. R7./ |
Data Tabular PSO (Possession of State Origin) Excel |
| Which datasets are currently available to the public? | So far, only data requested based on the law for public documents and general reports of the institution have been made public. | R1. We don't have R2. / R3. / R4. So far, only what has been requested based on the law for access to public documents and the general reports published by the institution have been made public. R5. / R6. Perhaps the representation expenses of the Cabinet R7. We don't have |
Published Requested Laws Public documents |
Source: Author.
Step 4. Improving open data services for all stakeholders such as citizens, businesses, NGOs, etc.
Topic 1. Internal restrictions: Following the initial interpretation, institutions affirm the presence of internal data usage restrictions. The development of these laws demonstrates a dedication to the proper use of information in specified duties. Based on the application of internal regulations and a commitment to responsible data usage, I advocate increasing openness and adhering to best practices for data management.
Topic 2. Regulation Formats: Institutions have enacted legislation governing official papers and establishing norms for public data. There is no explicit information on rules, however they may be needed by law for official papers. Given the importance of openness and efficient information access, I urge that the institution adopt and publicize particular data usage policies, as well as user practices and recommendations.
Topic 3. Daily Data Registration: Data is updated by standard forms and Excel applications, while the institution has established a specific software for efficient information registration. These are the primary channels for distribution. For future improvements to the data registration process, I advocate investigating information technology options to increase efficiency and developing a dedicated platform for data registration and maintenance.
Topic 4. Open Data Formats: Institutions make substantial use of Microsoft Office, including Word and Outlook. I recommend looking at more tools on this platform to improve team interaction and productivity.
Topic 5. Data Validity: Many institutions do not keep data in standard formats. I advocate standardizing formats in order to increase information consistency and usability in the future. This will assist to streamline administrative operations.
Topic 6: Departmental Datasets: Institutions have maintained a variety of information, such as costs, initiatives, and accomplishments across programs. I advocate creating an integrated platform for publicly sharing mixed public information while protecting institutional interests, hence boosting openness and trustworthiness.
Topic 7. Currently Available Datasets: So far, the institution has only published data required by law for public publications and general reports. I advocate improving openness by sharing additional datasets to help raise public knowledge and involvement.
The results show a commitment to responsible data usage through internal policies and legal requirements for official documents. The use of conventional forms and Excel for data registration, as well as the execution of a specific program, demonstrate an effective combination of classic techniques and contemporary technology for information management. Recommendations for developing particular standards and standardized data formats highlight the need of future data openness and consistency. Additionally, a unified platform for datasets and an increase in available datasets would boost legitimacy and public engagement, increasing the relationship between the institution and the community.
5. Discussions
The analysis of the amount of open data utilization by categorizing variables into two groups underlines two important points. Variables with coefficients greater than 0.70 reflect fundamental motivations such as altruistic aspirations, the need for knowledge, and continuous learning, whereas variables with coefficients less than 0.70 indicate other preferences such as the creation of a unique website/service, financial gain, and curiosity. The combination of these ideals results in a sense of "diversification." Governance value analysis reveals a shared emphasis on efficiency, accountability, community impact, governance expertise, and the delivery of high-quality services. Finally, "Motivation and Diversification in Governance" are critical to the successful use of open data and the development of government operations.
The findings of hierarchical regression analysis, as shown in the model fit and coefficient table, give important insights into the factors that influence the quality of public institutions' open data platforms. The ongoing model adaption progress, as seen by the improved correlation coefficient and modified R Square, highlights the relevance of predictors in explaining the independent variable. "Usage Criteria and Conditions," "Characteristics of Open Data," "Regulations for Data Usage," "Attributes of Government Data Platforms," and "Accessible Formats for Open Data" all make an important contribution to the quality of public institutions. In the context of Step 2, this research informs suggestions by highlighting the need of improving open data usage criteria and circumstances, addressing their characteristics, and establishing effective data usage guidelines. This material should be utilized in official and IT training to ensure ongoing development of open data platforms and to improve the quality of public institutions.
The institution in issue has taken great measures to standardize open data formats. It has taken a legislative approach by enacting a statute for official records, which includes internal regulations and particular rules for open data usage. As a result of this habit, conventional forms and Excel have become the most popular methods of information sharing. However, the integration of Microsoft Office and associated apps, such as Word, Outlook, and Chrome, demonstrates a variety of techniques. Aside from exchanging tables, PSO, and other information in Excel format, the university has developed a tailored tool to meet unique requirements. The data comprises costs, projects, procedures, and accomplishments, with the usage of various formats for information storage making a distinction. So far, the disclosed data is mostly based on the legal obligations for public papers and the institution's general reports. These steps indicate this institution's efforts to standardize and transparently distribute open data.
The results show that the institution is clearly committed to using data appropriately in accordance with internal norms and the legislation for official documents. The use of old forms and Excel, as well as the installation of a specific software, suggests a concerted attempt to blend traditional approaches with cutting-edge information management technology. Recommendations for developing particular standards and standardizing data formats underline the need of future data openness and consistency. The usage of a single platform for datasets, as well as the inclusion of available datasets, will boost legitimacy and public engagement, helping to strengthen the institution's relationship with the community. These efforts highlight a sustainable path towards improving open data services for all users, including citizens, businesses, and civil society organizations.
6. Conclusions
The research of the amount of open data usage divided factors into two categories, with the first highlighting underlying reason and the second focusing diverse preferences. The combination of humanitarian intentions, a desire for information, and constant learning is consistent with the open data community's aims of "diversification". Governance value analysis reveals a shared emphasis on efficiency, accountability, community impact, governance expertise, and the delivery of high-quality services. In Step 2, expanding open data utilization based on demands and developing training activities demonstrate an attempt to strengthen the skills of authorities and IT staff. In this context, guidelines for standardized data usage criteria and circumstances highlight the importance of information uniformity and efficiency. The standardization of formats by public entities represents a step toward greater openness and efficiency in the sharing of open data. The institution's use of conventional methods as well as new technology demonstrates an integrated approach to data management. In conclusion, attempts to improve open data services reflect a comprehensive strategy that includes all user parties. On this route to change, "Motivation and Diversification in Governance" are critical for effective open data use and government activity enhancement.
7. Recommendations
Based on the study of the results and issues observed, numerous recommendations are made to increase the exploitation of open data and government activities:
- Improve Data Transparency and Standardization: Establish norms and procedures for using and sharing open data. Standardizing data formats and developing a single platform for datasets can improve consistency and dependability, making it easier for the public to access and participate.
- Continuously invest in training and skill development for authorities and IT departments. This mix of conventional expertise and modern technology will help to make better use of open data platforms and increase worker capacity.
- Improving Notification and Awareness systems: Establishing effective notification and awareness systems can increase community engagement. This may involve informative campaigns, public training sessions, and the establishment of an environment in which residents, corporations, and organizations may actively participate.
- Developing and enforcing explicit policies for open data use. This will assist to guarantee that users utilize data appropriately and ethically.
- Monitoring and Feedback: Institutions should maintain a sustainable monitoring strategy to track open data usage and user feedback. This will allow for the modification and improvement
References
- Charter, «International open data charter,» Open Data Charter, 2015.
- T. Davies, «Open data, democracy and public sector reform,» A look at open government data use from data. gov. uk, p. 1–47, 2010.
- Y. Zhang, C. Y. Zhang, C. Zhang dhe Y. Xu, «Effect of data privacy and security investment on the value of big data firms,» Decision Support Systems, vëll. i 146, p. 113543, 2021. [CrossRef]
- M. Janssen dhe J. van den Hoven, Big and Open Linked Data (BOLD) in government: A challenge to transparency and privacy?, vëll. i 32, Elsevier, 2015, p. 363–368. [CrossRef]
- R. Kitchin, «The Data Revolution: A critical analysis of big data, open data and data infrastructures,» The Data Revolution, p. 1–100, 2021.
- J. Gray, L. J. Gray, L. Bounegru, R. Rogers, T. Venturini, D. Ricci, A. Meunier, M. Mauri, S. Niederer, N. S. Querubı́n, M. Tuters dhe others, «Engaged research-led teaching: composing collective inquiry with digital methods and data,» Digital Culture & Education, vëll. i 14, p. 55–86, 2022.
- Q. Wang, M. Q. Wang, M. Su, M. Zhang dhe R. Li, «Integrating digital technologies and public health to fight Covid-19 pandemic: key technologies, applications, challenges and outlook of digital healthcare,» International Journal of Environmental Research and Public Health, vëll. i 18, p. 6053, 2021. [CrossRef]
- M. C. Andrade, R. O. d. M. C. Andrade, R. O. d. Cunha, J. Figueiredo dhe A. A. Baptista, «Do the european data portal datasets in the categories government and public sector, transport and education, culture and sport meet the data on the web best practices?,» Data, vëll. i 6, p. 94, 2021. [CrossRef]
- K. Janowicz, S. K. Janowicz, S. Gao, G. McKenzie, Y. Hu dhe B. Bhaduri, GeoAI: spatially explicit artificial intelligence techniques for geographic knowledge discovery and beyond, vëll. i 34, Taylor & Francis, 2020, p. 625–636. [CrossRef]
- T. Cahlikova dhe V. Mabillard, «Open data and transparency: Opportunities and challenges in the Swiss context,» Public Performance & Management Review, vëll. i 43, p. 662–686, 2020. [CrossRef]
- Nikiforova, Anastasija; McBride, Keegan, «Open government data portal usability: A user-centred usability analysis of 41 open government data portals,» Telematics and Informatics, vëll. i 58, p. 101539, 2021. [CrossRef]
- Fotopoulou, «Conceptualising critical data literacies for civil society organisations: agency, care, and social responsibility,» Information, Communication & Society, vëll. i 24, p. 1640–1657, 2021. [CrossRef]
- M. Kassen, «Open Data Governance in Finland: Understanding the Promise of Public-Private Partnerships,» në Open Data Governance and Its Actors: Theory and Practice, Springer, 2022, p. 65–96. [CrossRef]
- E. Ruijer dhe A. Meijer, «Open government data as an innovation process: Lessons from a living lab experiment,» Public Performance & Management Review, vëll. i 43, p. 613–635, 2020.10.1080/15309576.2019.1568884
- F. T. Neves, M. F. T. Neves, M. de Castro Neto dhe M. Aparicio, «The impacts of open data initiatives on smart cities: A framework for evaluation and monitoring,» Cities, vëll. i 106, p. 102860, 2020. [CrossRef]
- A. Vall, Y. Sabnis, J. Shi, R. Class, S. Hochreiter dhe G. Klambauer, «The promise of AI for DILI prediction,» Frontiers in Artificial Intelligence, vëll. i 4, p. 638410, 2021. [CrossRef]
- J. van Hoof, R. F. M. van den Hoven, M. Hess, W. H. van Staalduinen, L. M. T. Hulsebosch-Janssen dhe J. Dikken, «How older people experience the age-friendliness of The Hague: A quantitative study,» Cities, vëll. i 124, p. 103568, 2022. [CrossRef]
- A. Nikiforova, «Open Data Quality Evaluation: A comparative analysis of open data in Latvia,» arXiv preprint arXiv:2007.04697, 2020. [CrossRef]
- F. R. Schumacher, A. A. Al Olama, S. I. Berndt, S. Benlloch, M. Ahmed, E. J. Saunders, T. Dadaev, D. Leongamornlert, E. Anokian, C. Cieza-Borrella dhe others, «Association analyses of more than 140,000 men identify 63 new prostate cancer susceptibility loci,» Nature genetics, vëll. i 50, p. 928–936, 2018. [CrossRef]
- B. Šlibar, D. Oreški dhe N. Begičević Ređep, «Importance of the open data assessment: An insight into the (meta) data quality dimensions,» Sage Open, vëll. i 11, p. 21582440211023178, 2021. [CrossRef]
- J. Byabazaire, G. O’Hare dhe D. Delaney, «Data quality and trust: Review of challenges and opportunities for data sharing in iot,» Electronics, vëll. i 9, p. 2083, 2020. [CrossRef]
- A. A. Alwan, M. A. Ciupala, A. J. Brimicombe, S. A. Ghorashi, A. Baravalle dhe P. Falcarin, «Data quality challenges in large-scale cyber-physical systems: A systematic review,» Information Systems, vëll. i 105, p. 101951, 2022. [CrossRef]
- H. Kim, «Quality evaluation of the open standard data,» The Journal of the Korea Contents Association, vëll. i 20, p. 439–447, 2020. [CrossRef]
- T. Scassa dhe F. Perini, «Data for development: Exploring connections between open data, big data, and data privacy in the Global South,» The Future of Open Data, p. 179, 2022.
- J. Koo, G. Kang dhe Y.-G. Kim, «Security and privacy in big data life cycle: a survey and open challenges,» Sustainability, vëll. i 12, p. 10571, 2020. [CrossRef]
- G. McArdle dhe R. Kitchin, «Improving the veracity of open and real-time urban data,» Built Environment, vëll. i 42, p. 457–473, 2016. [CrossRef]
- S. Kasar dhe M. Kshirsagar, «Open challenges in smart cities: privacy and security,» Security and privacy applications for smart city development, p. 25–36, 2021.
- P. Runeson, T. Olsson dhe J. Linåker, «Open Data Ecosystems—An empirical investigation into an emerging industry collaboration concept,» Journal of Systems and Software, vëll. i 182, p. 111088, 2021. [CrossRef]
- C.-Y. Liu, W.-P. Li dhe Y.-P. Tu, «Privacy perils of open data and data sharing: A case study of Taiwan's open data policy and practices,» Wash. Int'l LJ, vëll. i 30, p. 545, 2020.
- S.-M. Park dhe Y.-G. Kim, «A metaverse: Taxonomy, components, applications, and open challenges,» IEEE access, vëll. i 10, p. 4209–4251, 2022. [CrossRef]
- A. Gupta, A. Anpalagan, L. Guan dhe A. S. Khwaja, «Deep learning for object detection and scene perception in self-driving cars: Survey, challenges, and open issues,» Array, vëll. i 10, p. 100057, 2021. [CrossRef]
- D. M. Botı́n-Sanabria, A.-S. Mihaita, R. E. Peimbert-Garcı́a, M. A. Ramı́rez-Moreno, R. A. Ramı́rez-Mendoza dhe J. d. J. Lozoya-Santos, «Digital twin technology challenges and applications: A comprehensive review,» Remote Sensing, vëll. i 14, p. 1335, 2022. [CrossRef]
- J. Zbontar, F. Knoll, A. Sriram, T. Murrell, Z. Huang, M. J. Muckley, A. Defazio, R. Stern, P. Johnson, M. Bruno dhe others, «fastMRI: An open dataset and benchmarks for accelerated MRI,» arXiv preprint arXiv:1811.08839, 2018. [CrossRef]
- I. Mergel, «Open innovation in the public sector: drivers and barriers for the adoption of Challenge. gov,» në Digital Government and Public Management, Routledge, 2021, p. 94–113. [CrossRef]
- A. Alam, «Platform utilising blockchain technology for eLearning and online education for open sharing of academic proficiency and progress records,» në Smart Data Intelligence: Proceedings of ICSMDI 2022, Springer, 2022, p. 307–320. [CrossRef]
- X. Huang, P. Wang, X. Cheng, D. Zhou, Q. Geng dhe R. Yang, «The apolloscape open dataset for autonomous driving and its application,» IEEE transactions on pattern analysis and machine intelligence, vëll. i 42, p. 2702–2719, 2019. [CrossRef]
- E. Fonseca, X. Favory, J. Pons, F. Font dhe X. Serra, «Fsd50k: an open dataset of human-labeled sound events,» IEEE/ACM Transactions on Audio, Speech, and Language Processing, vëll. i 30, p. 829–852, 2021. [CrossRef]
- R. Ramachandran, K. Bugbee dhe K. Murphy, «From open data to open science,» Earth and Space Science, vëll. i 8, p. e2020EA001562, 2021.10.1029/2020EA001562
- T. Coughlan, «The use of open data as a material for learning,» Educational Technology Research and Development, vëll. i 68, p. 383–411, 2020. [CrossRef]
- D. A. Adler, F. Wang, D. C. Mohr, D. Estrin, C. Livesey dhe T. Choudhury, «A call for open data to develop mental health digital biomarkers,» BJPsych Open, vëll. i 8, p. e58, 2022. [CrossRef]
- H. Aguinis, N. S. Hill dhe J. R. Bailey, «Best practices in data collection and preparation: Recommendations for reviewers, editors, and authors,» Organizational Research Methods, vëll. i 24, p. 678–693, 2021. [CrossRef]
- K. Bhattacharjee, A. Islam, J. Vaidya dhe A. Dasgupta, «PRIVEE: A visual analytic workflow for proactive privacy risk inspection of open data,» në 2022 IEEE Symposium on Visualization for Cyber Security (VizSec), 2022. [CrossRef]
- F. Z. Borgesius, J. Gray dhe M. Van Eechoud, «Open data, privacy, and fair information principles: Towards a balancing framework,» Berkeley Technology Law Journal, vëll. i 30, p. 2073–2131, 2015. [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



