
Submitted:
09 February 2024
Posted:
13 February 2024
You are already at the latest version
Abstract
Edible oils have commercial and nutritional value due to the presence of essential fatty acids. They can be consumed fresh in the form of capsules known as nutraceuticals. The quality of such products is of interest to the consumer. In this context, this study describes a method based on high resolution nuclear magnetic resonance (NMR) and Fourier transform mid-infrared spectroscopic analysis (FTIR), combined with statistical analyzes to differentiate different edible oils used as nutraceuticals in Brazil by fatty acid content. Through the analysis of 1H NMR spectra, the levels of saturated and unsaturated fatty acids in edible oils were characterized and quantified. Statistical analysis of the data confirmed the real distinction between nutraceutical raw materials, with emphasis on ω-9, ω-6 and ω-3 fatty acids. The analytical approach presented also demonstrated potential to identify the origin (animal or vegetable) of edible oils used as nutraceuticals.
Keywords:
lipid composition
; 1H-NMR
; chemometrics
; edible oils quality control
1. Introduction
Vegetable and animal edible oils have great economic relevance since they are lipid sources widely used as raw material in the processing industry (pharmaceutical, food, and chemical) and for the human diet. They can be present in diets in different forms, including the in natura encapsulated formula known as nutraceuticals [1,2]. This term was introduced in 1989 and refers to foods of plant or animal origin with pharmaceutical and nutritional activities [3,4]. Therefore, nutraceuticals have a functional food appeal.
The high commercial and nutritional value of these oils is closely related to the specific properties linked to their lipid composition, marked by triacylglycerides (TG) constituted by saturated (SFA), monounsaturated (MUFA), and polyunsaturated (PUFAs) fatty acids. Free fatty acids, tocopherols, tocotrienols, and vitamins A and E may also be present in smaller amounts [5]. A wide variety of edible oil-based nutraceuticals can be found in Brazil. The most common are the oils from soybean (Glycine max), sunflower (Helianthus annuus), garlic (Allium sativum), corn (Zea mays), almonds (Prunus dulcis), andiroba (Carapa guianensis), safflower (Carthamus tinctorius), Brazil nut (Bertholletia excelsa), coconut (Cocos nucifera), linseed (Linum usitatissimum), primrose (Oenothera biennis), borage (Borago officinalis), chia (Salvia hispanica), and palm oil (Elaeis guineensis) [5]. Nutraceuticals formulated based on fish oils, known to be rich in PUFAs, are also common [5,6,7].
The number of available nutraceuticals has continuously grown, reflecting market developments, research, and consumer interest. However, they are often met with skepticism due to efficacy and safety concerns, in part due to the well-documented lack of regulation and oversight in the sector [4]. Therefore, regulating quality, efficacy, mechanism of action, and safety requirements can benefit potential consumers and the industry. In this context, studies referring to the composition of different raw materials used in the production of nutraceuticals converge to determine the quality of the product in question.
Classically, the quality of edible oils used in nutraceutical manufacturing is evaluated by moisture, refraction index, viscosity, acidity, peroxide, iodine index, and saponification [2,8,9]. Although they are analytically robust and easy to perform, these conventional methods are time-consuming and only allow the simultaneous analysis of a few classes of compounds. On the other hand, modern analytical instrumentation, especially chromatographic and spectroscopic techniques, is more accurate and informative in evaluating the complex chemical profiles of these oils [1,10,11,12]. Among the spectroscopic techniques, nuclear magnetic resonance (NMR) and medium infrared with Fourier transform (FTIR) stand out in this analytical context. These methods allow the simultaneous collection of qualitative and quantitative chemical information without quantification standards, common in chromatographic analysis routines [13,14,15].
The non-selective and highly reproductive nature of the NMR allows the collection of molecular fingerprints without the need for elaborate separation methods. The NMR, as a result of the direct relationship between the signal area and the number of nuclei responsible for that signal, allows the quantification of many compounds in complex matrices concomitantly with qualitative analysis, which leads to a reduction in sample handling and exposure time [13,15,16,17,18]. Consequently, NMR can be applied in assessing the quality of edible oils since such investigations are based on the lipid composition and its relationship with the physicochemical and organoleptic characteristics of the matrix.
A suitable quantitative approach by NMR allows the simultaneous collection of information about the chemical profile as well as the contents of such components. This fact for an analytical context of edible oils represents a significant advantage since the time of exposure and manipulation of the sample can determine the onset of unwanted reactions such as lipid oxidation [15]. Quantification by NMR (qNMR) is possible due to the direct proportion between the intensity of a signal and the number of nuclei responsible for that signal. This information is translated by integrating the analyte NMR signal. Thus, the higher the concentration of a given substance, the greater the number of nuclei responsible for that signal and, therefore, the greater the area of the signal [18,19]. Commonly, quantification via NMR requires the use of internal standards that are inserted directly into the solution containing the analyte [18]. However, the choice of a quantification standard must meet requirements such as purity, chemical inertness towards the sample components, low volatility and solubility similar to the analyte, and, in the particular case of NMR, present relaxation times (which must be adequate to the time available for analyses) as well as its chemical structure, to avoid overlapping of standard x analyte signals [16,18]. Alternatively, Akoka et al. developed a computational protocol called Electronic Reference to access In-vivo Concentration (ERETIC), which consists of electronically synthesized reference signals from calibration experiments with known concentration solutions [19]. Such "synthetic" signals can be inserted in any region of the sample spectrum, thus eliminating possible effects of analyte versus internal standard interaction and signal overlap [18,19,20,21].
The use of NMR in studies of complex matrices (e.g., edible oils) generates a range of information that may not be readily interpretable. The simple comparative method may not recognize the grouping or separation tendencies between samples caused by possible processing errors or tampering [13,14,22]. In this context, chemometric treatment of the NMR and FTIR data can help identify and quantify potential authenticity biomarkers. The main chemometric protocols used in the aforementioned analytical approaches refer to exploratory analysis via Principal Component Analysis (PCA) and Hierarchical Class Analysis (HCA) [23]. In PCA, the multivariate dataset is projected into a new space with a reduced statistical dimension, with minimal damage to sample relationships. The new dimension, expressed by new variables called principal components (PCs), aims to highlight clustering or separation trends not previously identified in the spectra [17,24]. HCA, on the other hand, is a hierarchical process in which the reduction of the data matrix results in a two-dimensional dendrogram that emphasizes the clusters of samples by similarity. Thus, it is understood that neighboring samples are statistically and chemically similar. In contrast, distant samples, even from the same matrix, may indicate possible tampering processes since they were classified as statistically and chemically distinct [18,25,26,27].
In the context presented, our study describes an analytical protocol based on the synergy between 1H NMR and FTIR applied in the analysis of Brazilian edible oil-based nutraceuticals. The data, derived from the investigation of different matrices of edible oils, were submitted to unsupervised chemometric analyzes that allowed the distinction between the types of oils. The discrimination between them indicated the existence of different contents of saturated and unsaturated fatty acids, and this observation motivated the relative quantification of the cited fatty acids.
2. Materials and Methods
2.1. Sample Collection
The sampling comprised pure edible oils provided by Brazilian industries in Goiânia and Anápolis and commercial oils purchased in the same cities. Samples of garlic (Allium sativum), almonds (Prunus dulcis), andiroba (Carapa guianensis), sunflower (Helianthus annuus), safflower (Carthamus tinctorius), Brazil nut (Bertholletia excelsa), palm (Elaeis guineensis), coconut (Cocos nucifera), linseed (Linum usitatissimum), primrose (Oenothera biennis), chia (Salvia hispanica), and soybean (Glycine max) and fish oils pure and in mixtures, were used in this study.
2.2. 1H NMR Experiments
For each 1H NMR analysis, 100 μL of the oil sample was solubilized in 400 μL of deuterated chloroform (CDCl3). The NMR spectra were acquired on a Bruker Avance III 500 spectrometer (Bruker, Germany) operating at 11.75 Tesla, fitted with a three-channel broadband inverse (TBI) probe. The 1H NMR experiments were performed in triplicates, acquired with an accumulation of 256 spectra, 65,536 scanning points during acquisition and processing, the total acquisition time of 7.1 seconds, the spectral width was 16 ppm, receiver gain fixed at 11.3 and constant temperature of 25 °C during acquisition. The zg30 pulse sequence (Bruker) was used, with automatic pulse calibration and magnetic field homogeneity (shimming). An exponential correction factor was applied in processing to broaden the spectral line of 0.3 Hz. Baselines and phases were automatically corrected in the TopSpin working software (v 3.5, Bruker, Germany). All NMR spectra were given in ppm related to the TMS signal used as an internal reference at δ 0.00.
2.3. ERETIC Signal Calibration
The lipid composition of the oils was determined by relativizing the analyte signals versus the ERETIC signal. Therefore, it was necessary to calibrate the ERETIC signal by acquiring a 1H NMR spectrum under quantitative conditions using a standard solution of known concentration. A 2.0 mmol.L-1 caffeine solution in CDCl3 was used as a calibration standard. The spectral acquisition and processing parameters strictly followed the experimental protocol of the 1H NMR experiments.
2.4. Fourier-Transform Infrared Spectroscopy (FTIR)
FTIR spectra of edible oils were acquired on a Spectrum 400 FTIR spectrometer (PerkinElmer, USA). Samples were mixed with potassium bromide (KBr), and the pellets were analyzed in the range of 4000–400 cm-1 (resolution of 2 cm-1), with 12 scans recorded. All samples were analyzed in triplicate and measured at room temperature (25 °C) under identical conditions.
2.5. Exploratory Analysis by PCA and HCA
Data analysis by PCA was performed using the AMIX 3.9.15 software (Bruker BioSpin, Germany). The data matrix was obtained by the spectral bucketing procedure of the 1H NMR data, using the rectangular shape and optimized width of 0.05. The spectral regions referring to the residual signals to non-deuterated solvent at δ 7.0-7.5 (CHCl3) and the TMS at δ - 0.3-0.3 were excluded from the data matrix. The PCA was performed with a data matrix mean-centered and a 95.0% confidence interval and validated with the full-cross validation method. The HCA was performed from the data matrix constructed with each oil sample's average FTIR spectral data. The nearest neighbor method to create the Clusters and their correlations as the type of distance was used to construct the dendrogram.
3. Results and Discussion
3.1. Characterization of Lipid Profile by 1H NMR
Figure 1 shows 1H NMR spectrum of a linseed oil sample. The spectrum showed regions with broad signals, reflecting the cause-and-effect relationship between the low mobility of lipids in solution and the consequent short spin-spin relaxation times [28]. The spectral characterization was performed based on the literature [5,13,14,15,27,28,29,30]. Table 1 shows the assignment of the main signals of this spectrum, their multiplicities and coupling constants.
3.2. Statistical Analysis
Due to the extreme visual similarity between the 1H NMR spectra, previous exploratory analysis by PCA was performed to verify if the samples of edible oil-based nutraceuticals could be statistically differentiated. The PC1 x PC2 score chart indicated clear discrimination tendencies between the samples (Figure 2A), with the positive sense of PC1, the statistical region responsible for discriminating the most significant number of samples. In contrast, the negative PC1 discriminated the soy, linseed, and chia samples. The accumulated variance explained by the first two components used in the construction of the graph was 86.9%.
Analyzing the PCA loadings (Figure 2B), the principal chemical descriptors responsible for discriminating the samples presented in the score plot were identified. The positive scores of PC1, the statistical region where most of the sampling were discriminated, was strongly influenced by the signals of hydrogens with chemical shifts at δ 0.88, assigned to the hydrogens of terminal methyl groups of oleic (ω-9) and SFAs. On the other hand, the trend observed along with the negative PC1 scores, the statistical region populated by soybean, linseed, and chia samples, was strongly influenced by the signals at δ 5.38, 2.83, 2.08, and 0.98, assigned to vinylic, allylic, bis-allylic, and terminal methyl hydrogens of α-linolenic acid (ω-3), respectively.
Extrapolating the results from PCA, we can infer that the distinction between the oil-based nutraceuticals samples was strongly influenced by the different contents of MUFAs (ω-9) and PUFAs (ω-6 and ω-3) in addition to signals attributed to SFAs. Therefore, an adaptation between the equations described by Miyake et al. (1998) and the ERETIC method to calculate the relative percentages of the lipid descriptors (SFA, ω-9, ω-6, and ω-3) indicated as PCA discriminators for each nutraceutical sample evaluated in the present study [31]. It is worth noting that the application of NMR in the quantification of fatty acids relies on other protocols, such as those described by Martinez-Yusta et al. (2014) and Santos et al. (2018) [5,32]. The equations used in the aforementioned calculations, as well as the integrations of the signal areas, are shown in Figure 3.
Table 2 presents the results of the quantifications for each type of sample. Analyzing the percentages of ω-9 fatty acids and SFAs of the different matrices, it was found that nutraceuticals based on coconut, palm, andiroba, Brazil nut, and safflower oils, previously divided into positive PC1 scores (Figure 2A) had low percentages of ω-3 fatty acids. On the other hand, these samples showed the highest levels of SFAs and ω-9 fatty acids. This information is consistent with the analysis of PCA loadings (Figure 2B), which indicated as the main descriptor for the region, the signal in δ 0.88, previously assigned to terminal methyl groups of SFAs and ω-9 fatty acids.
The matrices with the highest percentages of ω-3 acids were the samples of chia and linseed. These samples were broken down into negative PC1 scores, as shown in Figure 2A. Again, the descriptors (δ 5.38, 2.83, 2.08, and 0.98) indicated in the loading plot (Figure 2B), previously assigned to hydrogens of the α-linolenic acid (ω-3) and others unsaturated chemical groups, support the observation. The large group in the center of the graph in Figure 2A, composed of oil-based nutraceuticals sunflower, fish, soy, primrose, garlic, copaiba, and almond samples, showed intermediary levels of saturated and unsaturated fatty acids when compared with the other samples. No apparent correlation between the percentages of saturated and unsaturated fatty acids and the descriptors indicated in the loading graph was observed for the large group of samples centered on the PCA score graph (Figure 2A). For comparative analytical purposes of the results from the NMR-PCA model presented, the profiles of oil-based nutraceuticals were also evaluated via the FTIR technique, which is recognized as a more accessible for the industry. Figure 4 shows the score plot for PC1 x PC2, with accumulated variance explained by the first two components equal to 72.5%.
The data dispersion was similar to that obtained by the ¹H NMR data. Along the positive PC1 scores, safflower, palm, garlic, andiroba, and copaiba samples were discriminated, and the statistical region was strongly influenced by signals with wave numbers equal to 1417 cm-1 (C=CH), 1654 cm-1 (C =C), and 967 cm-1 (HC=CH). These signals are characteristic of absorptions (folding and stretching) of PUFAs. The coconut samples were discriminated in the negative scores of PC1, influenced mainly by signals referring to the stretching of C-O and C=O bonds, typical of ω-6 and ω-9 fatty acids, highlighting again the contents of these acids, previously determined by 1H NMR. As in the NMR analyses, chia and linseed samples were discriminated similarly. However, now it was along the negative PC2 scores, with the C=C link (ν 722 cm-1) as the main descriptor.
Regarding the similarity between the edible oils, the multivariate analysis of the FTIR data via HCA highlighted the remarkable similarity between the chia and linseed samples (Figure 5), previously identified in the PCA treatment of the NMR data. The resulting dendrogram also indicated the existence of significant similarity between the samples of soybean, sunflower, and fish (pure and declared mixture). This similarity between the samples is the principal basis of the adulteration of fish oils, commonly practiced with these vegetable oils (soybean and sunflower) of lower market value. However, despite HCA presenting data in agreement with the PCA-NMR and PCA-FTIR models, the resulting dendrogram indicated a more remarkable similarity between copaiba and coconut oils, information not evidenced in the exploratory analyzes by PCA of NMR and FTIR data.
Although NMR allows the simultaneous obtaining of a qualitative (determination of constituents) and quantitative (relative lipid percentages) lipid screening, the FTIR technique showed concordant and rapid results, confirming analytical complementarity since similarities were observed in the discrimination of nutraceuticals by composition. The interpretation of the results can still be extrapolated in terms of clear distinctions between nutraceuticals regarding the origin of the oilseed matrices used, as well as peculiar results from the FTIR-HCA model that indicated the possibility of verifying the authenticity of the edible oils used as raw materials.
5. Conclusions
This study demonstrated the 1H NMR data allowed the qualitative (signal assignment) and quantitative (via relative signal integration) determination of the lipid profiles of different Brazilian edible oils commonly used to manufacture nutraceuticals. Additionally, the chemometric treatment (PCA) of the NMR data allowed the identification of discriminatory statistical trends between the analyzed lipid profiles. Such information was corroborated in the treatment of the data obtained by analyzing the oils by FTIR. The evaluation of PCA loadings indicated that the signals of SFAs, MUFAs (ω-9), and PUFAs (ω-6 and ω-3) showed great relevance for data dispersion. As the signal areas influence the intensities of the 1H NMR signals, the descriptors identified in the loadings were quantified, making it possible to build a database that can be used for future studies to authenticate the edible oils studied. The HCA-FTIR model evaluated the oil similarities, and it allowed the confirmation of the significant nearness of the principal adulterants (soybean and sunflower oils) of fish oils. Notably, the analytical protocol presented here can be a promising analytical alternative for regulatory and certifying bodies since the quality authentication of edible oils used as raw materials in the industry is a relevant issue for the economy and health of the final customer.
Author Contributions
Conceptualization, Igor Savioli Flores, Vinícius Silva Pinto and Luciano Morais Lião; methodology, Igor Savioli Flores, Vinícius Silva Pinto and Luciano Morais Lião; formal analysis, Igor Savioli Flores, Daniel Luiz Rodrigues da Annunciação and Vinícius Silva Pinto; investigation, Igor Savioli Flores and Vinícius Silva Pinto; data curation, Igor Savioli Flores, Daniel Luiz Rodrigues da Annunciação and Vinícius Silva Pinto; writing—Igor Savioli Flores and Vinícius Silva Pinto; writing—review and editing, Igor Savioli Flores, Vinícius Silva Pinto and Luciano Morais Lião; visualization, Luciano Morais Lião; supervision, Igor Savioli Flores and Luciano Morais Lião; project administration, Luciano Morais Lião; funding acquisition, Luciano Morais Lião. All authors have read and agreed to the published version of the manuscript.
Funding
No specific funding for the development of this project was approved. Meanwhile, in 2004 the Financier of Studies and Projects (FINEP) approved the purchase of NMR; the Foundation for Research Support of the State of Goiás (FAPEG) and the National Council for Scientific and Technological Development (CNPq) supported other projects, which indirectly bring resources to the Laboratory. Thus, they are in the Acknowledgments section.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Acknowledgments
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors. However, the authors would like to thank Financiadora de Estudos e Projetos – FINEP for the acquisition and constant contributions to the maintenance of the NMR instrument. The authors also thank Fundação de Amparo à Pesquisa do Estado de Goiás – FAPEG and Conselho Nacional de Desenvolvimento Científico e Tecnológico – CNPq for the resources approved for developing other projects, which indirectly supported this work.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Yadav, G.G.; Manasa, V.; Murthy, H.N.; Tumaney, A.W. Chemical composition and nutraceutical characterization of Balanites roxburghii seed oil. J. Food Compos. Anal. 2023, 115, 104952. [Google Scholar] [CrossRef]
- Santos, M.O.; Camilo, C.J.; Macedo, J.G.F.; de Lacerda, M.N.S.; Lopes, C.M.U.; Rodrigues, A.Y.F.; da Costa, J.G.M.; Souza, M.M.A. Copaifera langsdorffii Desf.: A chemical and pharmacological review. Biocatal. Agric. Biotechnol. 2022, 39, 102262. [Google Scholar] [CrossRef]
- Nagy, M.M.; Wang, S.; Farag, M. Quality analysis and authentication of nutraceuticals using near IR (NIR) spectroscopy: A comprehensive review of novel trends and applications. Trends Food Sci. Technol. 2022, 123, 290–309. [Google Scholar] [CrossRef]
- Pandey, S.N.; Singh, G.; Semwal, B.C.; Gupta, G.; Alharbi, K.S.; Almalki, W.H.; Albratty, M.; Najmi, A.; Meraya, A.M. Therapeutic approaches of nutraceuticals in the prevention of Alzheimer's disease. J. Food Biochem. 2022, 46, e14426. [Google Scholar] [CrossRef]
- Santos, J.S.; Escher, G.B.; Pereira, J.M.S.; Marinho, M.T.; Prado-Silva, L.; Sant’Ana, A.S.; Dutra, L.M.; Barison, A.; Granato, D. 1H NMR combined with chemometrics tools for rapid characterization of edible oils and their biological properties. Ind. Crops Prod. 2018, 116, 191–200. [Google Scholar] [CrossRef]
- Kozub, A.; Nicolaichuk, H.; Przykaza, K.; Tomaszewska-Gras, J.; Fornal, E. Lipidomic characteristics of three edible cold-pressed oils by LC/Q-TOF for simple quality and authenticity assurance. Food Chem. 2023, 415, 135761. [Google Scholar] [CrossRef] [PubMed]
- do Nascimento, T.A.; Lopes, T.I.B.; Nazario, C.E.D.; Oliveira, S.L.; Braz, G.A. Vegetable oils: Are they true? A point of view from ATR-FTIR, 1H NMR, and regiospecific analysis by 13C NMR. Food Res. Int. 2021, 144, 1–9. [Google Scholar] [CrossRef]
- Mitrea, L.; Teleky, B-E.; Leopold, L-F.; Nemes, S-A.; Plamada, D.; Dulf, F.V.; Pop, I-D.; Vodnar, D.C. The physicochemical properties of five vegetable oils exposed at high temperature for a short-time-interval. J Food Compos. Anal. 2022, 106, 104305. [Google Scholar] [CrossRef]
- Jamwal, R.; Kumari, S.; Sharma, S.; Kelly, S.; Cannavan, A.; Kumar, D. Vibrational Spectroscopy Recent trends in the use of FTIR spectroscopy integrated with chemometrics for the detection of edible oil adulteration. Vib. Spectrosc. 2021, 113, 103222. [Google Scholar] [CrossRef]
- Galvan, D.; Tanamati, A.A.C.; Casanova, F.; Danieli, E.; Bona, E.; Killner, M.H.M. Compact low-field NMR spectroscopy and chemometrics applied to the analysis of edible oils. Food Chem. 2021, 365, 130476. [Google Scholar] [CrossRef]
- Jia, Z.; Liang, C. Molecular Dynamics and Chain Length of Edible Oil Using Low-Field Nuclear Magnetic Resonance. Molecules. 2023, 28, 197. [Google Scholar] [CrossRef]
- Mota, M.F.S.; Waktola, H.D.; Nolvachai, Y.; Marriott, P.J. Gas chromatography ‒ mass spectrometry for characterization, assessment of quality and authentication of seed and vegetable oils. Trends Anal. Chem. 2021, 138, 116238. [Google Scholar] [CrossRef]
- Gibson, M.; Percival, B.C.; Edgar, M.; Grootveld, M. Low-Field Benchtop NMR Spectroscopy for Quantification of Aldehydic Lipid Oxidation Products in Culinary Oils during Shallow Frying Episodes. Foods. 2023, 12, 1254. [Google Scholar] [CrossRef]
- Cai, S.; Zhang, Y.; Xia, F.; Shen, G.; Feng, J. An expert system based on 1H NMR spectroscopy for quality evaluation and adulteration identification of edible oils. J Food Compos. Anal. 2019, 84, 103316. [Google Scholar] [CrossRef]
- Pinto, V.S.; dos Anjos, M.M.; Pinto, N.S.; Liao, L.L. Analysis of thermal degradation of Brazilian palm oil by quantitative 1H NMR and chemometrics. Food Control. 2021, 130, 1–9. [Google Scholar] [CrossRef]
- Huang, Z-M.; Xin, J-X.; Sun, S-S.; Li, Y.; Wei, D-X.; Zhu, J.; Wang, X-L.; Wang, J.; Yao, Y-F. Rapid Identification of Adulteration in Edible Vegetable Oils Based on Low-Field Nuclear Magnetic Resonance Relaxation Fingerprints. Foods. 2021, 10, 3068. [Google Scholar] [CrossRef] [PubMed]
- Cui, C.; Xia, M.; Chen, J.; Shi, B.; Peng, C.; Cai, H.; Jin, L.; Hou, R. 1H NMR-based metabolomics combined with chemometrics to detect edible oil adulteration in huajiao (Zanthoxylum bungeanum Maxim.). Food Chem. 2023, 43, 136305. [Google Scholar] [CrossRef] [PubMed]
- Giraudeau, P. Quantitative NMR spectroscopy of complex mixture. Chem. Commun. 2023, 59, 6627–6642. [Google Scholar] [CrossRef] [PubMed]
- Akoka, S.; Barantin, L.; Trierweiler, M. Concentration measurement by proton NMR using the ERETIC method. Anal. Chem. 1999, 71, 2554–255. [Google Scholar] [CrossRef] [PubMed]
- Saglam, M.; Paasch, N.; Horns, A.L.; Weidner, M.; Bachmann, R. 1H NMR metabolic profiling for the differentiation of fish species. Food Chem. 2023, 4, 100602. [Google Scholar] [CrossRef]
- Pinto, V.S.; Flores, I.S.; Ferri, P.H.; Lião, L.M. NMR Approach for Monitoring Caranha Fish Meat Alterations due to the Freezing-Thawing Cycles. Food Anal. Methods 2020, 13, 2330–2340. [Google Scholar] [CrossRef]
- Jin, H.; Wang, Y.; Lv, B.; Zhang, K.; Zhu, Z; Zhao, D.; Li, C. Rapid Detection of Avocado Oil Adulteration Using Low-Field Nuclear Magnetic Resonance. Foods. 2022, 11, 1134. [Google Scholar] [CrossRef]
- Kalogiouri, N.P.; Aalizadeh, R.; Dasenaki, M.E.; Thomaidis, N.S. Application of High Resolution Mass Spectrometric methods coupled with chemometric techniques in olive oil authenticity studies - A review. Anal. Chim. Acta 2020, 1134, 150–173. [Google Scholar] [CrossRef]
- Gunning, Y.; Taous, F.; Ghali, T.E.; Gibbon, J.D.; Wilson, E.; Brignall, R.M.; Kemsley, E.K. Mitigating instrument effects in 60 MHz 1H NMR spectroscopy for authenticity screening of edible oils. Food Chem. 2022, 370, 131333. [Google Scholar] [CrossRef] [PubMed]
- Dhaulaniya, A.S.; Balan, B.; Yadav, A.; Jamwal, R.; Kelly, S.; Cannavan, A.; Singh, D.K. Development of an FTIR based chemometric model for the qualitative and quantitative evaluation of cane sugar as an added sugar adulterant in apple fruit juices. Food Addit. Contam. Part A 2020, 37, 539–551. [Google Scholar] [CrossRef] [PubMed]
- Vieira, F.L.M.; Benedito, L.E.C.; Moreira, A.C.O.; Braga, J.W.B.; de Oliveira, A.L. Applicability of NMR in combination with chemometrics for the characterization and differentiation of oil-resin extracted from Copaifera langsdorffii and Copaifera spp. Microchem. J. 2024, 197, 109850. [Google Scholar] [CrossRef]
- Choze, R.; Alcantara, G.B.; Filho, E.G.A.; Silva, L.M.; Faria, J.C.; Lião, L.M. Distinction between a transgenic and a conventional common bean genotype by 1H HR-MAS NMR. Food Chem. 2013, 141, 2841–2847. [Google Scholar] [CrossRef] [PubMed]
- Claridge, T.D.W. High-Resolution NMR Techniques in Organic Chemistry, 3rd ed.; Elsevier: Amsterdam, Netherlands, 2016; pp. 11–59. [Google Scholar]
- Kupriyanova, G.; Smirnov, M.; Mershiev, I.; Maraşli, A.; Okay, C.; Mozzhukhin, G.; Rameev, B. Comparative analysis of vegetable oils by 1H NMR in low and high magnetic fields. J Food Compos. Anal. 2024, 126, 105877. [Google Scholar] [CrossRef]
- Hasanpour, M.; Rezaie, A.; Iranshahy, M.; Yousefi, M.; Saberi, S.; Iranshahi, M. 1H NMR-based metabolomics study of the lipid profile of omega-3 fatty acid supplements and some vegetable oils. J Pharm. Biomed. Anal. 2024, 238, 115848. [Google Scholar] [CrossRef]
- Martínez-Yusta, A.; Goicoechea, E.; Guillén, M.D. Food Lipids Studied by 1H NMR Spectroscopy: Influence of Degradative Conditions and Food Lipid Nature. Compr. Rev. Food Sci. Food Saf. 2014, 13, 839–85. [Google Scholar] [CrossRef]
- Miyake, Y.; Yokomizo, K.; Matsuzaki, N. Determination of unsaturated fatty acid composition by high-resolution nuclear magnetic resonance spectroscopy. J Am. Oil Chem. Soc. 1998, 75, 1091–1094. [Google Scholar] [CrossRef]
Figure 1.
1H NMR spectrum of a linseed oil sample (CDCl3, 500 MHz). Highlighted, expansions of spectral regions useful in the characterization of lipid profiles were presented.
Figure 1.
1H NMR spectrum of a linseed oil sample (CDCl3, 500 MHz). Highlighted, expansions of spectral regions useful in the characterization of lipid profiles were presented.
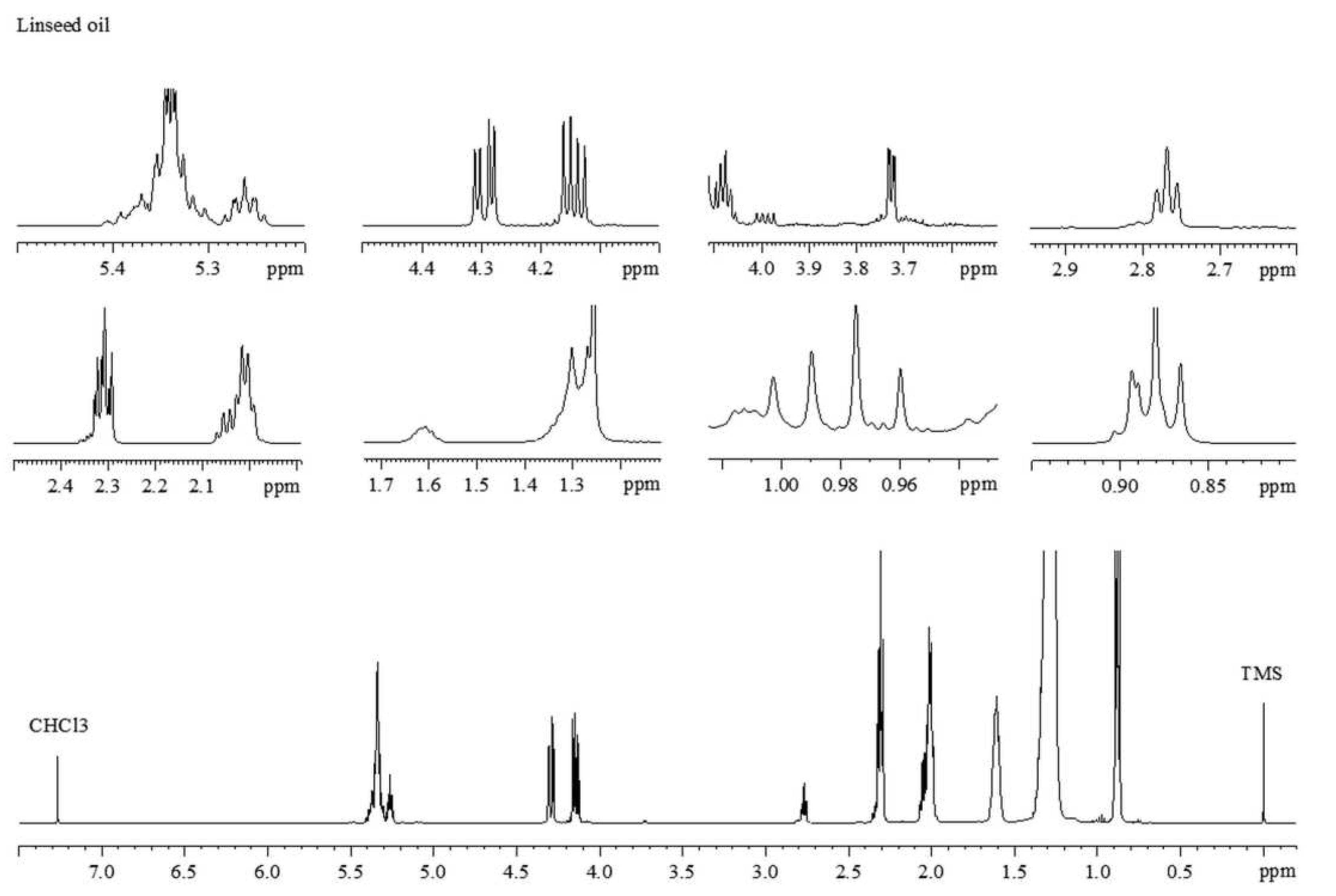
Figure 2.
Score plot (a) and loadings (b) of PC1 versus PC2 obtained from the 1H NMR data of Brazilian edible oil-based nutraceuticals.
Figure 2.
Score plot (a) and loadings (b) of PC1 versus PC2 obtained from the 1H NMR data of Brazilian edible oil-based nutraceuticals.
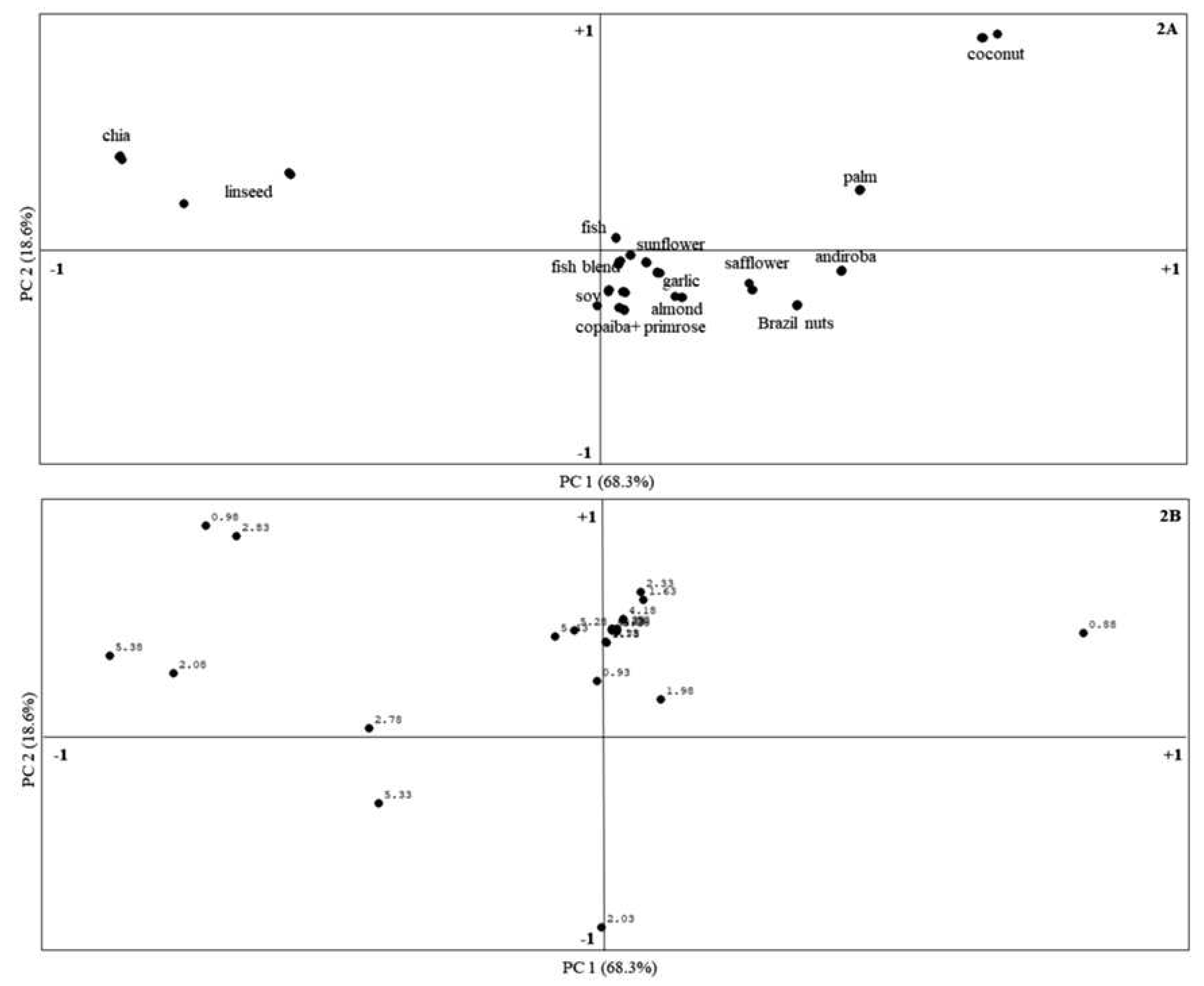
Figure 3.
1H NMR spectrum of soy oil-based nutraceutical. The integrations of the signals of the chemical groups were presented concerning the ERETIC signal, positioned at δ 5.00 ± 0.15 of precision related to the signal's center. Also highlighted were the expansions of the regions of interest for calculating the percentages of SFA, ω-9, ω-6, and ω-3, calculated from equations 1, 2, 3, and 4, positioned in the upper left portion.
Figure 3.
1H NMR spectrum of soy oil-based nutraceutical. The integrations of the signals of the chemical groups were presented concerning the ERETIC signal, positioned at δ 5.00 ± 0.15 of precision related to the signal's center. Also highlighted were the expansions of the regions of interest for calculating the percentages of SFA, ω-9, ω-6, and ω-3, calculated from equations 1, 2, 3, and 4, positioned in the upper left portion.
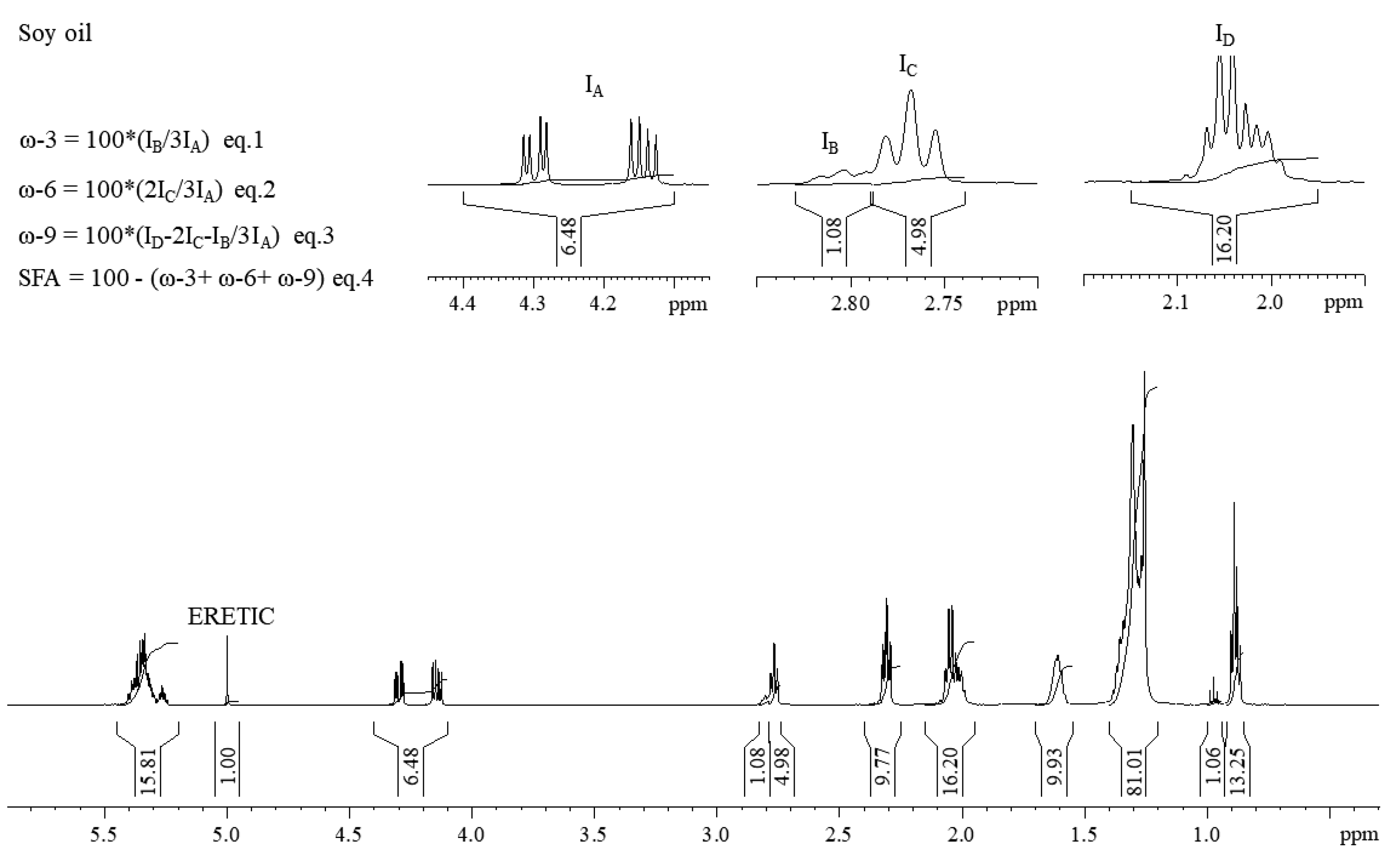
Figure 4.
Score plot of PC1 versus PC2 obtained from the FTIR data of Brazilian edible oil-based nutraceuticals. The main numbers of waves and chemical groups responsible for the observed discrimination were highlighted.
Figure 4.
Score plot of PC1 versus PC2 obtained from the FTIR data of Brazilian edible oil-based nutraceuticals. The main numbers of waves and chemical groups responsible for the observed discrimination were highlighted.
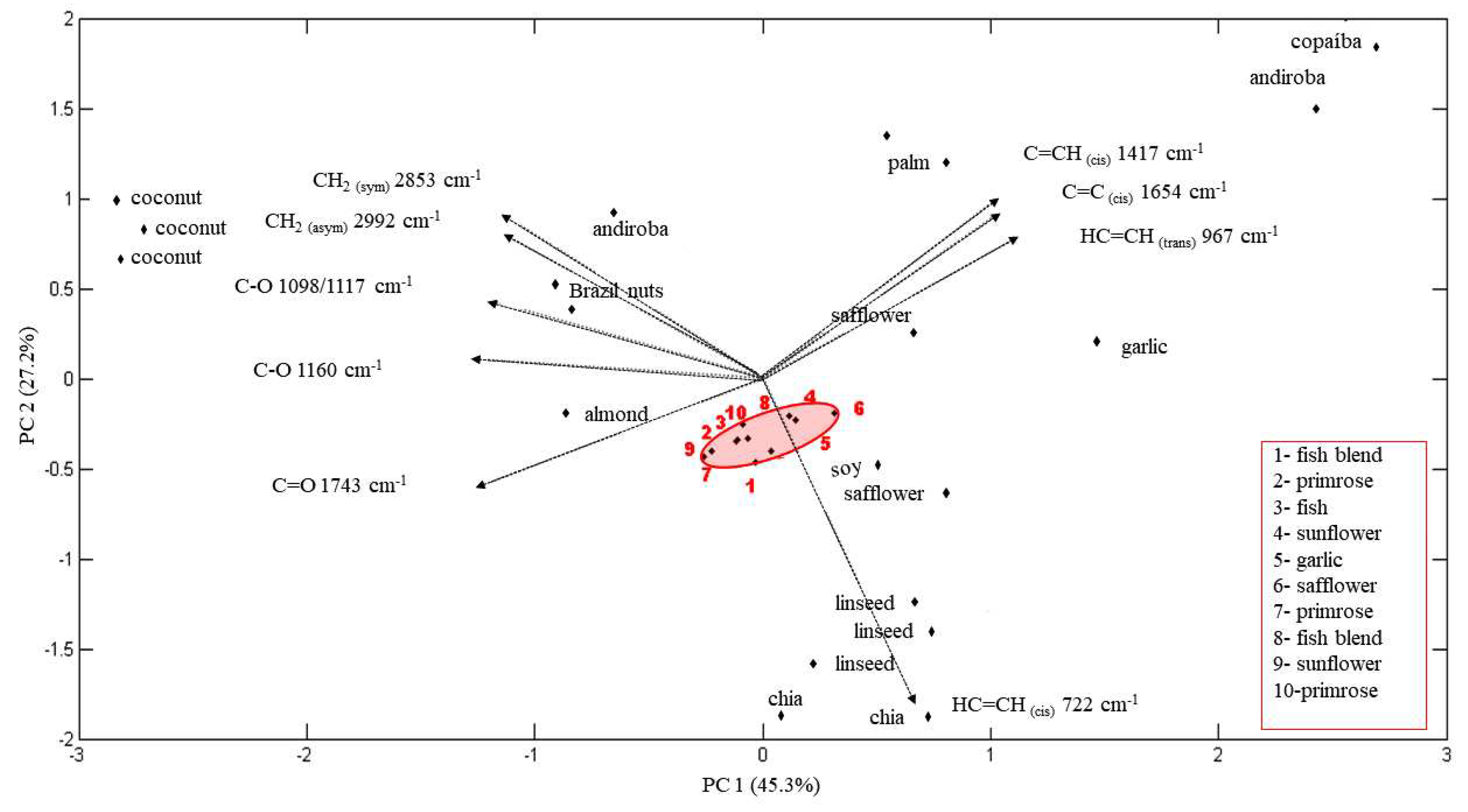
Figure 5.
Resulting dendrogram from the hierarchical classes analysis of FTIR analysis of oil-based nutraceuticals.
Figure 5.
Resulting dendrogram from the hierarchical classes analysis of FTIR analysis of oil-based nutraceuticals.
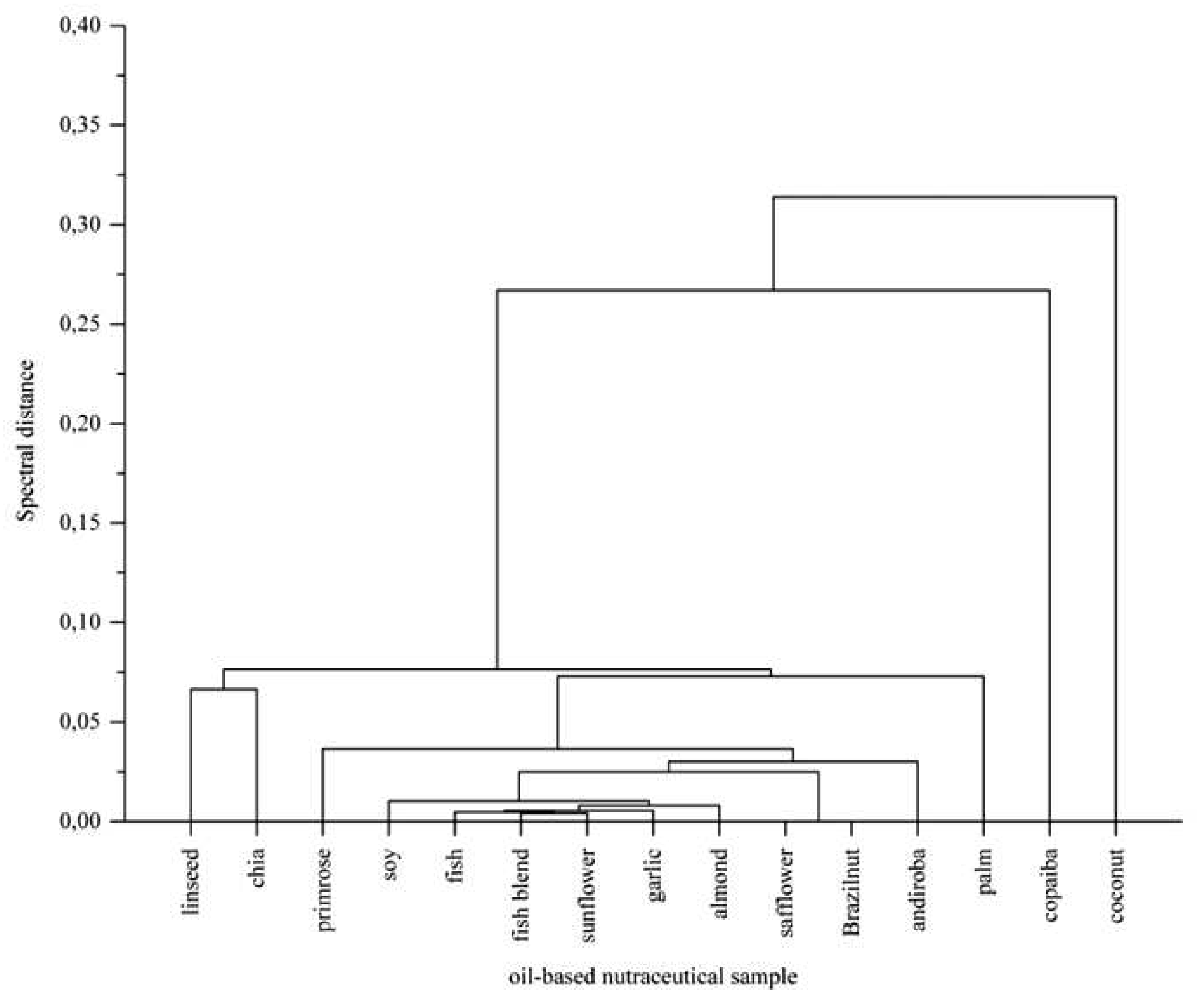

Table 1.
1H NMR spectral data assignment for the relevant signals observed in edible oils samples analyzed (CDCl3, 500 MHz).
Table 1.
1H NMR spectral data assignment for the relevant signals observed in edible oils samples analyzed (CDCl3, 500 MHz).
| δ 1H (ppm) | Multiplicities (J Hz) | Group | Assignment |
|---|---|---|---|
| 0.87 | t (6.7) | -CH3 | SFAs and MUFA (omega-9) acyl group |
| 0.89 | t (6.7) | -CH3 | linoleic acid (omega-6) acyl groups |
| 0.97 | t (7.5) | -CH3 | omega-3 acyl groups |
| 1.20-1.40 | m | -(CH2)n | acyl groups of all fatty acids |
| 1.55-1.65 | m | –CH2–CH2-COO- | PUFAs, except DHA |
| 1.95-2.10 | m | -CH2-CH=CH- | PUFAs, except for DHA |
| 2.30 | t (7.5) | –CH2-COO- | acyl group, except DHA |
| 2.33 | t (7.5) | –CH2-COO- | Free fatty acids |
| 2.43 | m | –CH2-COO- | DHA acyl group |
| 2.77 | t (6.5) | =HC-CH2-CH=- | bis-allylic hydrogen of omega-6 PUFAs |
| 2.80 | t (6.3) | =HC-CH2-CH=- | bis-allylic hydrogen of omega-3 PUFAs |
| 3.73 | dd (1.4, 4.9) | -CH2-OH | 1,2-diglycerides |
| 4.07 | m | -CH-OH | 1,3-diglycerides |
| 4.14 | dd (6.0, 11.8) | -CH2-OCOR- | glyceryl group of TG |
| 4.30 | dd (4.4,11.8) | -CH2-OCOR- | glyceryl group of TG |
| 5.26 | m | -CHOCOR | glyceryl group of TG |
| 5.34 | m | -CH=CH- | PUFAs acyl groups |
Multiplicities: d – doublet, dd – doublet of doublet, m – multiplet, t – triplet.
Table 2.
Percentages of saturated, ω-3, ω-6, and ω-9 fatty acids by 1H NMR data of edible oil-based nutraceutical samples used as nutraceuticals in Brazil.
Table 2.
Percentages of saturated, ω-3, ω-6, and ω-9 fatty acids by 1H NMR data of edible oil-based nutraceutical samples used as nutraceuticals in Brazil.
| Vegetable source | ||||
|---|---|---|---|---|
| Sample | SFA | PUFA (ω-3, %) | PUFA (ω-6, %) | MUFA (ω-9, %) |
| Almond | 45.3±1.0 | 4.8±1.5 | 10.7±0.7 | 39.1±0.9 |
| Andiroba | 57.5±0.6 | 3.4±0.3 | 12.3±1.1 | 26.8±0.7 |
| Brazil nut | 56.0±0.9 | 6.5±0.3 | 12.9±1.2 | 24.6±1.4 |
| Chia | 21.4±1.1 | 48.5±1.1 | 19.0±0.9 | 11.1±1.2 |
| Coconut | 68.8±0.4 | 3.7±0.5 | 2.0±0.2 | 30.5±0.5 |
| Copaiba | 39.8±0.8 | 6.4±0.5 | 29.6±1.0 | 24.2±1.1 |
| Garlic | 35.4±1.1 | 5.5±1.0 | 15.9±0.8 | 43.2±1.5 |
| linseed | 19.1±1.0 | 46.3±1.1 | 17.9±0.8 | 16.7±1.3 |
| Palm | 63.9±1.3 | 5.1±0.8 | 5.8±0.6 | 25.2±0.7 |
| Primrose | 21.6±0.5 | 50.9±0.5 | 4.2±0.4 | 12.8±0.8 |
| Safflower | 55.0±0.6 | 4.2±0.4 | 7.2±0.9 | 33.6±0.7 |
| Soy | 16.9±1.1 | 9.6±0.3 | 41.0±1.3 | 32.5±1.8 |
| Sunflower | 28.9±0.6 | 14.3±0.3 | 14.4±0.7 | 42.4±0.8 |
| Animal source | ||||
| Fish (blends) | 43.7±0.4 | 10.1±0.6 | 14.9±0.7 | 31.3±0.5 |
| Fish | 51.4±0.5 | 22.0±0.5 | 13.8±0.8 | 12.8±0.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



