
Submitted:
17 February 2024
Posted:
20 February 2024
You are already at the latest version
Abstract
This study focuses on examining various approaches for Tensor Decompositions (TDs) and their potential applications in satellite imaging (SI) and deep learning (DL). The research highlights how these decompositions can contribute to the advancement of SI and DL, providing valuable insights for future utilization of TDs in research. It explores how these techniques contribute to the advancement of SI and DL methods, providing insights into their potential applications and suggesting future research directions. The study aims to enhance the use of TDs techniques to further advance research efforts in these fields. More importantly, the current investigation offers a thorough analysis of the potential advantages and reasons for employing TDs techniques in different domains, including satellite imaging and deep learning. The aim is to enhance research outcomes by utilizing TDs. The review also identifies unresolved issues and proposes future directions for further investigation in this field. Fundamentally, these proposed open problems will open new grounds to the research community to articulate, innovate, and provide more real-life applications to improve the current state of the art by delving into a wider vision for a higher-level performance of both satellite imaging (SI) and deep learning (DL). Looking at the bigger scenario, this also suggests that TDs could be potentially employed to revolutionize existing machine learning technologies as well as the current space AI industry.
Keywords:
Tensor Decompositions (TDs)
; Satellite Imaging (SI)
; Deep Learning (DL)
; Tensor Train Networks (TTNs)
; Tucker decomposition (TUD)
; canonical polyadic decomposition (CPD)
; polyadic decomposition (PD)
; Roll
; Pitch
; and Yaw (RPY)
Introduction
In principle, this current work supplies a complementary part of the research conducted (c.f., [1]). As the author now feels the task completion and demonstration with both analytic expressions as well as illustrative data to interpret the newly devised research results. Existing super-resolution research focuses mostly on two-dimensional pictures [2]. There are well-known techniques for super-resolution. The methods employ interpolation techniques [3,4,5].
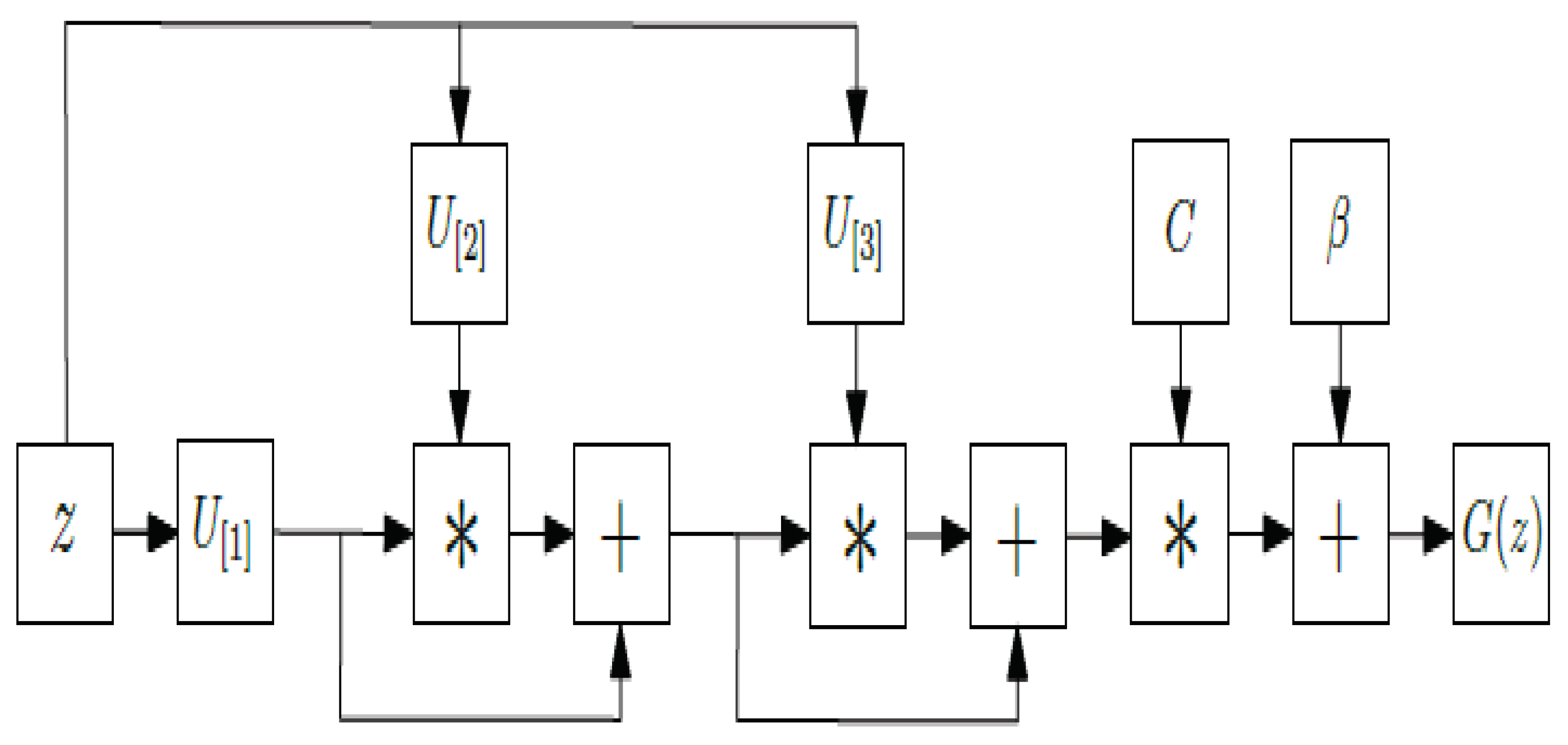
[1] provided an outline of the TD strategies used to solve electromagnetic problems. Integral Equation solvers' use of TDs to reduce CPU and memory use was specifically explored. The TDs used in surrogate modelling for estimating uncertainty in electromagnetic research were also examined. The discussion of TDs' function in enhancing energy works is more engaging. TDs approaches have received a lot of interest from researchers in various domains of computer science and engineering [2,3,4,5]. Figure 1 depicts TTNs.
TT, TUD and CPD are required for these approaches. Furthermore, the optimal performance for each of the decompositions is determined by certain factors. For example, the TUD [5] is effective at compressing low-dimensional arrays [7,8,9,10,11,12] containing Green's function samples and associated integrals. However, due to the curse of dimensionality, it performs badly for compressed high-dimensional data[13,14]. When great precision is desired, TTN is commonly employed instead of classic PD. Figure 2 depicts a three-way CPD array.
Tucker Representation (TR)
defines a three-dimensional array, , namely . Thus, this array’s TR has a core tensor of low rank combined with a set of factor matrices , . These rewrite to the form
Notably, and serve as mode matrix-tensor multiplication and multilinear rank pertaining to dimension respectively. More interestingly, is defined to be highly compressible if
and (c.f., (1), (2)) are calculated by singular value decomposition (SVD) approach [4,15,16] for a given tolerance, tol.
This paper’s road map is. Section 1 overviews the short paper upon which this current paper is aimed to be an extension of it. Section two deals with methodology. In section three, results and discussion are provided. Some influential emerging open problems from this paper are given in section combined with concluding remarks and the next phase of research are given in section four.
Methodology
Both panchromatic (PAN) and multispectral (MS) images are collected by remote sensing platforms [17], with PAN bands having a higher spatial resolution and a higher spectral richness than MS images. To create better images, these pictures are fused together using image fusion techniques; this process results in "pan-sharpening" whenever MS and PAN images of the same scene are fused together. Three types of pan-sharpening techniques—pixel, feature, and decision level techniques—are classified based on how the input images are merged.
Figure 3.
Visualization of the quality of different methods for processing multispectral (MS) images [17].
Figure 3.
Visualization of the quality of different methods for processing multispectral (MS) images [17].

To produce a high-resolution colour image, pan-sharpening algorithms [18,19] combine high-resolution panchromatic (PAN) and lower-resolution multispectral (MS) data. Similarly, it is challenging to preserve the excellent spatial and spectral quality of the input images during this procedure. Certain techniques could compromise one element for the other, leading to a compromise between spectral and spatial performances, as seen in Figure 4(c.f., [19]).
Imaging systems such as cameras are employed in aeronautical video surveillance, SI, and remote sensing applications [21] to produce three-dimensional models, panoramic mosaics, and detect changes in regions of interest. Moreover, in aerial imaging [21], imaging is collected from various positions and camera orientations, and the orientation of the camera must be calculated to align them appropriately, as illustrated in figure 5A (c, f., [21]). The RPY convention [21] is used to define the orientation of a camera relative to an aircraft. For more illustration, (see, Figure 5 (c.f., [21]).
An extensive analysis [22] of the evolution of deep learning models over time, starting with the early neural networks influenced by brain research and going all the way up to the prevalent models of today such as recurrent neural networks, convolutional neural networks, and deep belief networks. In addition, the paper looks at the models' beginnings, original construction, and evolution over time, providing important context for current and upcoming deep learning research. More specifically[22] focusing on three major families: deep generative models, convolutional neural networks, and recurrent neural networks. The paper aims to achieve two goals: documenting significant milestones in the history of deep learning that have influenced its current development and providing insights into how these remarkable works have emerged among numerous contemporaneous publications. Additionally, the authors briefly summarize three common directions pursued by these milestones, including simplicity in implementation, solving unique problems, and drawing inspiration from domains outside of machine learning and statistics.
Occam's razor [22] is a principle that suggests simpler models are often preferred over complex ones in deep learning. Dropout, for example, is widely recognized not only for its performance but also for its simplicity in implementation. Additionally, being ambitious in proposing models with more parameters can be remarkable if they solve problems that others cannot, such as Long- Short Term Memory (LSTM) bypassing the vanishing gradient problem.
Many DL models are inspired by domain knowledge outside of machine learning, like how convolutional neural networks draw inspiration from the human visual cortex. These directions can help readers have a greater impact on society, and more directions can be explored through revisiting these milestones. DL[23] has revolutionized pattern recognition by achieving superior accuracy in recognizing patterns in spatial and temporal data compared to humans. DL has expanded the capabilities of traditional machine learning algorithms and has gained popularity among practitioners dealing with diverse data types. In addition to covering important DL architectures, automatic architecture optimisation protocols, fault detection and mitigation through DL, this overview also looks at several domains where DL has made notable strides, including financial forecasting, fraud detection, medical image processing, power systems research, and recommender systems. The goal of the paper is to serve as a resource for academics who are considering using deep learning (DL) for pattern recognition tasks due to its remarkable ability to learn and scale with data.
During the backpropagation process in recurrent neural networks (RNNs), the issue of vanishing and exploding gradients can occur, which can be addressed by using LSTM networks. LSTMs utilize gates, such as the 'forget' gate and 'input' gate, to control the retention of information from previous time steps and update the candidate values accordingly. LSTM networks can also be enhanced with peephole connections or variations like Gated Recurrent Units (GRUs) for improved performance in tasks like acoustic modeling, handwriting recognition, sentence embedding, and part-of-speech tagging. A recurring module in LSTM networks, or a sort of recurrent neural network (RNN) that addresses the issue of vanishing and exploding gradients in RNNs by including specialized gates to regulate the flow of input over time, is shown in Figure 6.
The repeating module in an LSTM is made up of several parts, including forget gates, input gates, and output gates, that allow the network to store and update data from earlier time steps, making it suited for jobs involving sequential data.
Results and Discussion
The authors of [24] discussed the challenges of analysing large and complex datasets that deviate from standard statistical assumptions. A novel online algorithm for decomposing low-rank, Poisson-distributed tensors, which arise in various applications such as traffic engineering, genomics, and SI was proposed [24].
The authors [24] applied their proposed algorithm for Poisson TD and imputation to a real solar flare video that was corrupted by Poisson noise. The video had a resolution of 50 x 50 and 300 frames, and the algorithm was able to reconstruct the video with few samples, with rank for testing , and model parameter = 0.01, as demonstrated by Figure 7(c.f., [24]). Notably, serves as a parameter for the Bernoulli distribution.
To address the challenges of storing and transmitting large amounts of remote sensing data, as well as the use of super-resolution methods to improve the spatial resolution of low-resolution images, the authors [25] proposed a tensor-based approach for compressing and recovering multi-spectral image data, as well as a robust algorithm for super-resolving SIs, followed by an experimentally validated convolutional neural network for classification.
More specifically,[25] discussed the challenges of storing and transmitting large amounts of remote sensing data, particularly multispectral and hyperspectral images as seen in Figure 8 (c.f., [25]). Due to limitations in equipment and bandwidth, images are often compressed, which can negatively impact subsequent processing and classification tasks. Quantization, a process of mapping input values to output values, is used to reduce data size, but it also introduces challenges in data acquisition,
Using the sparse representations learning framework, the suggested approach for super-resolution [25,26] synthesizes high-spatial resolution hypercubes from low-resolution ones. For more illustration, see Figure 9(c.f.,[25]).
[26] discussed a method for compressing object detection models based on Tucker decomposition, which can reduce the storage and computing complexity of CNN-based models deployed onboard satellites.
TDs are widely used in machine learning (ML), especially when compressing massive amounts of data for deep learning. A framework for balancing the amount of model parameters and predictive accuracy is provided by tensor networks, such as tensor factorization, which enables the compression of neural models. This method has been effectively used with several DL architectures, including convolutional networks and restricted Boltzmann machines, either by compressing the entire design or by applying TDs to specific layers. The integration of TDs [27] with DL models, specifically focusing on modifying input aggregation functions using tensors within artificial neurons would explain how this approach can capture higher-order relationships in structured data, such as tree structures, and highlights using TDs as a trade-off between simplicity and complexity in neural aggregation.
Notably, the use of TDs in DL models[27] is an emerging research area that shows promise. While tensor factorization is a well-established method for multi-way data analysis, tensor decompositions are also being explored for the enhancement of the expressiveness of neural representations. This research direction is still in its early stages but holds potential for advancing DL models.
The research themes [27] present intriguing challenges that can enhance the performance of DL models and provide deeper insights into their functioning. The question of whether tensorization should only have an impact on the forward phase of neural models (i.e., computing neural activity) or if it also has significant implications for the backward phase (i.e., learning) is one such difficult open problem brought about using tensorized neural layers. By investigating this issue, we can increase our knowledge and the efficiency of DL models.
The popularity of image decomposition and natural language processing in the context of DL[28] has increased the demand for effective storage and support of the numerous parameters needed by deep learning algorithms. One solution to this problem is to employ sparse representation methods to compress the parameter matrix and lower storage pressure, such as tensor decomposition and matrix decomposition. Vectors can benefit from the compression capabilities of matrix-TDs’ reshaping and unfolding techniques, and an analysis is done to find the ideal compress ratio by reshaping. In DL[28], the input vector is reshaped into a three-way tensor, and the output tensor is unfolded into a vector. This reshaping and unfolding process reduces the number of parameters through tensor decomposition. However, the choice of reshaping into two-way, three-way, or N-way tensor affects the compressed ratio and representation power, which depend on the structure of the input data. The paper focuses on finding the best reshaping and unfolding strategy to achieve the optimal parameter compressed ratio. This is illustrated by Figure 10.
The authors[26] used a vector as the input for a Tensor-Factorized Neural Network (TFNN) to restructure it into a matrix or tensor to manage the number of parameters and increase training efficiency in deep learning. It remains an open challenge to find a better tensor shape to maintain representation power while compressing parameters.
TDs [27] are fundamental components in modern DL architectures, serving as the building blocks for various operations like convolution and attention. By incorporating tensor decompositions, deep neural networks can reduce the number of parameters, making them more efficient, robust, and capable of preserving the underlying structure in the data. Tensor analysis also helps in understanding the success of neural networks, including their approximation capabilities and the biases they leverage in computer vision.
In modern deep neural networks[27], each layer produces an activation tensor. This allows for obtaining a low-dimensional representation of the activation tensor, maintaining its structural properties within the network.
By using TDs and expressing the higher-order polynomial as a product of simpler functions, the expansion order can be increased without significantly increasing the network's complexity. This is illustrated by Figure 11.
Conclusions
An explanation is given to confirm the influential role of TDs in developing and revolutionizing SI. The current paper has several emerging open problems.
Open Problem One
Following [24], is it feasible to undertake their approach much further to other object detection models and mobile device with other rank selection to be involved. This is a potentially challenging problem.
Open Problem Two
According to [24], the authors did not prove either the convergency or the optimality for their proposed algorithm, so it is a real challenging open problem to mathematically validate their undertaken algorithm.
Open Problem Three
Rank selection [29] is a significant challenge in tensor methods, as determining the rank of a tensor is generally a computationally complex task. In practice, heuristics are often used to estimate the rank, such as selecting a rank that preserves around 90% of the parameters and gradually reducing it through compression. Using a penalty to the loss function to automatically set some components to zero is another method, as is applying Bayesian matrix factorization.
Open Problem Four
In tensor methods[29,30], the choice of decomposition is a significant consideration. Heuristics and experimental work can guide the selection, but there is no definitive method. In general, the Tensor-Train decomposition works well for obtaining large compression ratios, the CP decomposition is helpful for interpretable latent components, and the Tucker decomposition is appropriate for subspace learning. Further concerns come into play in DL, where the Tucker convolution provides flexibility with distinct ranks for each mode and the CP factorization is comparable to a MobileNet-v2 block. Higher-order convolutional LSTM learning has also proven to be successful using convolutional tensor-train decompositions.
Open Problem Five
Choosing the right TDs [29,30] and its rank based on the tensor structure is a continuous issue because of the interaction between tensor decomposition and convolutional kernels in deep learning models and the lack of theory to guide optimal selections. It also tackles the numerical challenges encountered in training tensorized deep neural networks, such gradient vanishing or exploding and instability, and offers solutions such as automatic mixed-precision and improved normalisation approaches.
Open Problem Six
In financial markets[23], trading in real-time poses a significant challenge as previously trained models may perform poorly when the dataset dynamics change. To address this, repetitive training of algorithms is necessary, but DL mechanism is more time- resources based. However, the application of deep learning with faster incremental learning in the financial market, particularly for automated trading, can help investors rely on deep learning models and avoid missing out on profitable trades. Additionally, Progressive Neural Networks can continually learn and transfer knowledge to new domains, making them effective in reinforcement learning tasks such as playing games like Atari and 3D maze games.
Open Problem Seven
DL architectures have the potential to overcome major industrial difficulties due to the growing availability [23] of data and sophisticated computing units. However, learning abstractions without explicit verbal explanations is less effective with typical deep learning algorithms because they mainly rely on big data sets. Techniques including data augmentation, transfer learning, recursive classification, synthetic data creation, and one-shot learning are being investigated to get around this restriction and work with less datasets. These techniques enable deep learning models to learn from sparse or fewer data representations.
Open Problem Eight
Sensor fusion [23] has led to a significant increase in data availability, which can provide more training examples for machine learning. However, the challenge lies in distinguishing useful data from irrelevant or erroneous instances. This requires further research to develop techniques for filtering out bad data, such as missing or incorrect values, and ensuring data quality for effective training.
More interesting, the next research phase includes finding solutions to the provided open problems.
References
- A. Mageed, et al, A review of potential applications of Tensor Decompositions to Electromagnetics and energy works.”, In 2022 IEEE Global Energy Conference (GEC),(2022). [CrossRef]
- N. K.Bose, et al, Advances in super resolution using L-curve[C]//ISCAS 2001, The 2001 IEEE International Symposium on Circuits and Systems (Cat. No. 01CH37196), (2001) 433–436. [CrossRef]
- H. S.Hou, et al, Cubic spline for image interpolation and digital filtering, IEEE Trans. Signal Process, (1978) 508–517. [CrossRef]
- S. Dai, et al, Soft edge smoothness prior for alpha channel super resolution, in Proc. IEEE Conf. Comput. Vis. Pattern Class., (2007) 1–8. [CrossRef]
- J. Sun, et al, Image super-resolution using gradient profile prior, in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., (2008)1–8. [CrossRef]
- X. Liu, et al, Image interpolation via regularized local linear regression[J], IEEE Trans. Image Process. (2011) 3455–3469. [CrossRef]
- I. Giannakopoulos, et al, Compression of volume-surface integral equation matrices via Tucker decomposition for magnetic resonance applications, IEEE Trans. Antennas Propag., (2022) 459-471. [CrossRef]
- I. Giannakopoulos, et al, Memory footprint reduction for the FFT- based volume integral equation method via tensor decompositions, IEEE Trans. Antennas Propag., (2019)7476-7486. [CrossRef]
- G. Polimeridis, J. K. White, On the compression of system tensors arising in FFT-VIE solvers, presented at the Proc IEEE Int. Symp. Antennas Propagat., (2014). [CrossRef]
- M. Wang, SuperVoxHenry: Tucker-enhanced and FFT-accelerated inductance extraction for voxelized superconducting structures, IEEE Trans. Appl. Supercond., (2021)1- 11. [CrossRef]
- M. Wang, VoxCap: FFT-accelerated and Tucker-enhanced capacitance extraction simulator for voxelized structures, IEEE Trans. Microw. Theory Techn.,(2020) 5154-5168. [CrossRef]
- M. Wang, A. C. Yucel, FFT-accelerated and Tucker-enhanced impedance extraction for voxelized structures, presented at the Proc. IEEE Int. Symp. Antennas Propagat., Singapore, (2021). [CrossRef]
- Qian, A. C. Yucel, On the compression of translation operator tensors in FMM-FFT-accelerated SIE simulators via tensor decompositions, IEEE Trans. Antennas Propag., (2021) 3359- 3370. [CrossRef]
- T. G. Kolda, B. W. Bader, Tensor decompositions and Applications, SIAM Rev., (2009) 455– 500. [CrossRef]
- I. Giannakopoulos, 3D cross-Tucker approximation in FFT based volume integral equation methods, presented at the Proc IEEE Int. Symp. Antennas Propagat. & CNC-USNC/URSI National Radio Sci. Meet. (2018). [CrossRef]
- S. Ahmadi-asl, et al, Randomized Algorithms for Computation of Tucker Decomposition and Higher Order SVD (HOSVD), IEEE Access, (2021) 28684-28706. [CrossRef]
- F. D. Javan, et al, A review of image fusion techniques for pan-sharpening of high-resolution satellite imagery. ISPRS journal of photogrammetry and remote sensing, (2021)101-117. [CrossRef]
- G. Vivone, et al, A critical comparison among pan sharpening algorithms, IEEE Trans. Geosci. Remote Sens, (2014)2565–2586. [CrossRef]
- G. Snehmani, et al, A comparative analysis of pan sharpening techniques on QuickBird and WorldView-3 images, Geocarto Int. 322017, (2017)1268–1284. [CrossRef]
- G. Dehghanpoor, et al, A Tensor Decomposition Method for Unsupervised Feature Learning on Satellite Imagery, In IGARSS 2020 IEEE International Geoscience and Remote Sensing Symposium, (2020) 1679-1682. [CrossRef]
- Zingoni, et al, Tutorial: Dealing with rotation matrices and translation vectors in image-based applications: A tutorial, IEEE Aerospace and Electronic Systems Magazine, (2019) 38-53. [CrossRef]
- Ye, G. Mateos, Online tensor decomposition and imputation for count data, In 2019 IEEE Data Science Workshop (DSW), (2019)17-21. [CrossRef]
- H. Wang, B. Raj, On the origin of deep learning, (2017), arXiv preprint arXiv:1702.07800. arXiv:1702.07800. [CrossRef]
- S. Sengupta, et al, A review of deep learning with special emphasis on architectures, applications and recent trends, Knowledge-Based Systems, (2020) 105596. [CrossRef]
- Aldini, et al, Hyperspectral image compression and super-resolution using tensor decomposition learning, In 2019 53rd IEEE Asilomar Conference on Signals, Systems, and Computers, (2019)1369-1373. [CrossRef]
- K. Fotiadou, et al, Spectral super resolution of hyperspectral images via coupled dictionary learning, IEEE Transactions on Geoscience and Remote Sensing, (2018) 2777–2797. [CrossRef]
- L. Huyan, Remote Sensing Imagery Object Detection Model Compression via Tucker Decomposition, Mathematics, (2023) 856. [CrossRef]
- D. Bacciu, D.P. Mandic, Tensor decompositions in deep learning, (2020), arXiv preprint arXiv:2002.11835. arXiv:2002.11835. [CrossRef]
- S. He, et al, Parameters Compressing in Deep Learning. Computers, Materials & Continua, (2020).
- Y. Panagakis, et al, “ Tensor methods in computer vision and deep learning, Proceedings of the IEEE,(2021) 863-890. [CrossRef]
Figure 1.
A schematic of TTNs [4].
Figure 1.
A schematic of TTNs [4].

Figure 2.
A three-way array’s CP decomposition [14].
Figure 2.
A three-way array’s CP decomposition [14].
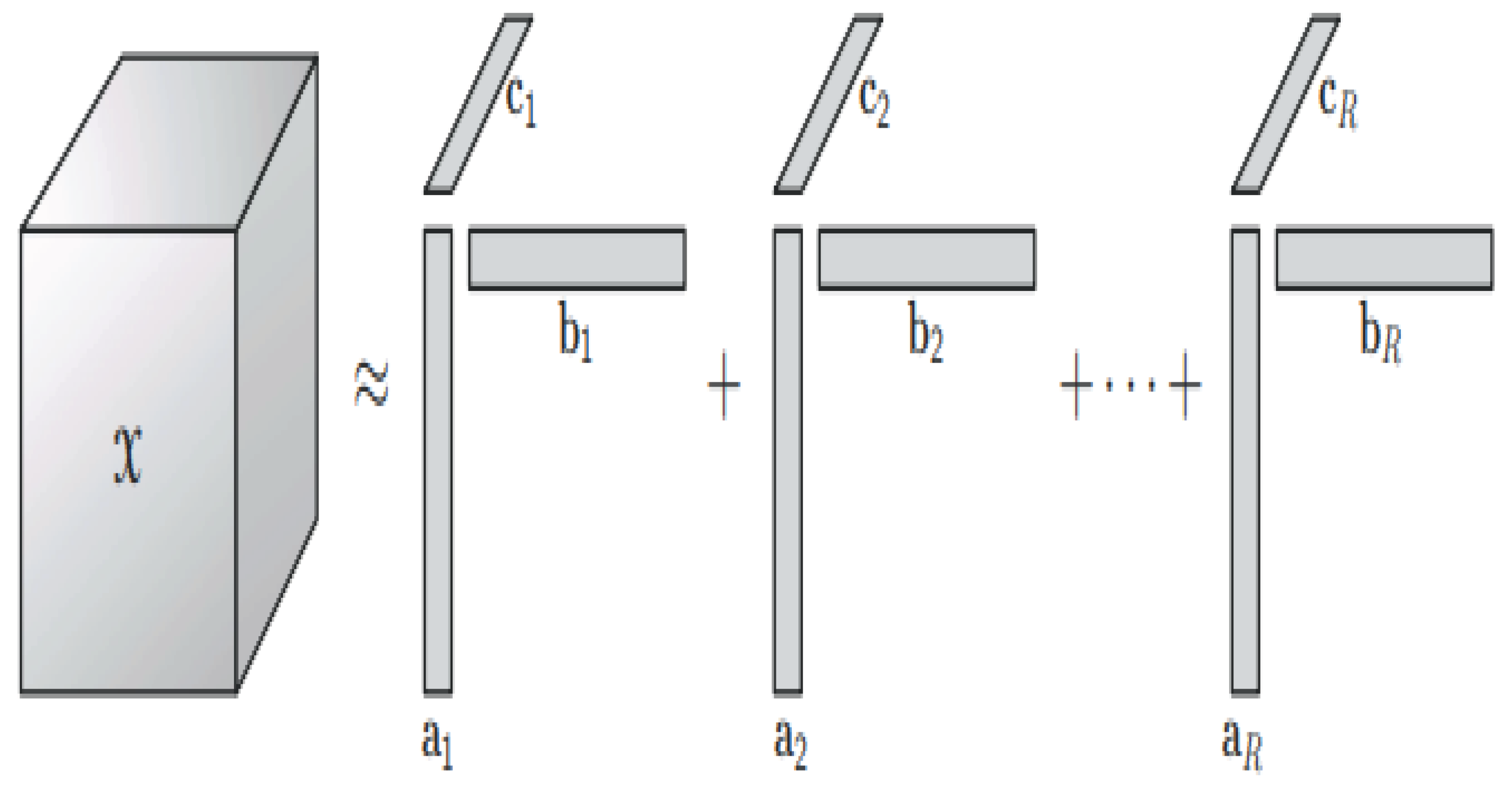
Figure 4.
The methods in the upper-right quadrant of the plot are considered to have the best overall quality, while those in the lower-left quadrant have the worst quality. Some methods prioritize spectral quality over spatial quality, while others prioritize spatial quality over spectral quality, and the choice of method may depend on the specific application and computational speed.
Figure 4.
The methods in the upper-right quadrant of the plot are considered to have the best overall quality, while those in the lower-left quadrant have the worst quality. Some methods prioritize spectral quality over spatial quality, while others prioritize spatial quality over spectral quality, and the choice of method may depend on the specific application and computational speed.
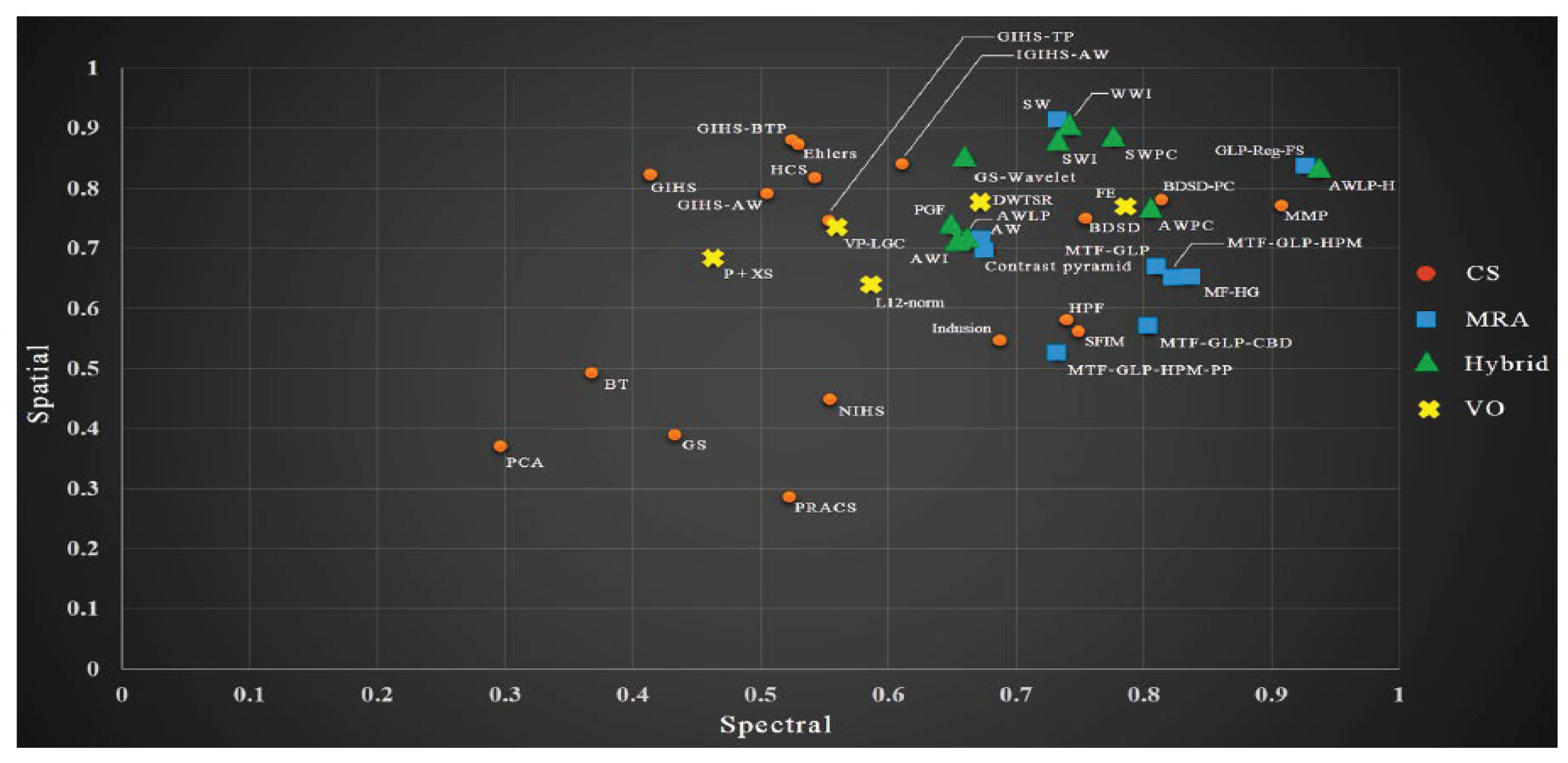
Figure 5.
RPY convention is a way of describing the orientation of an aircraft or camera in three-dimensional space.
Figure 5.
RPY convention is a way of describing the orientation of an aircraft or camera in three-dimensional space.
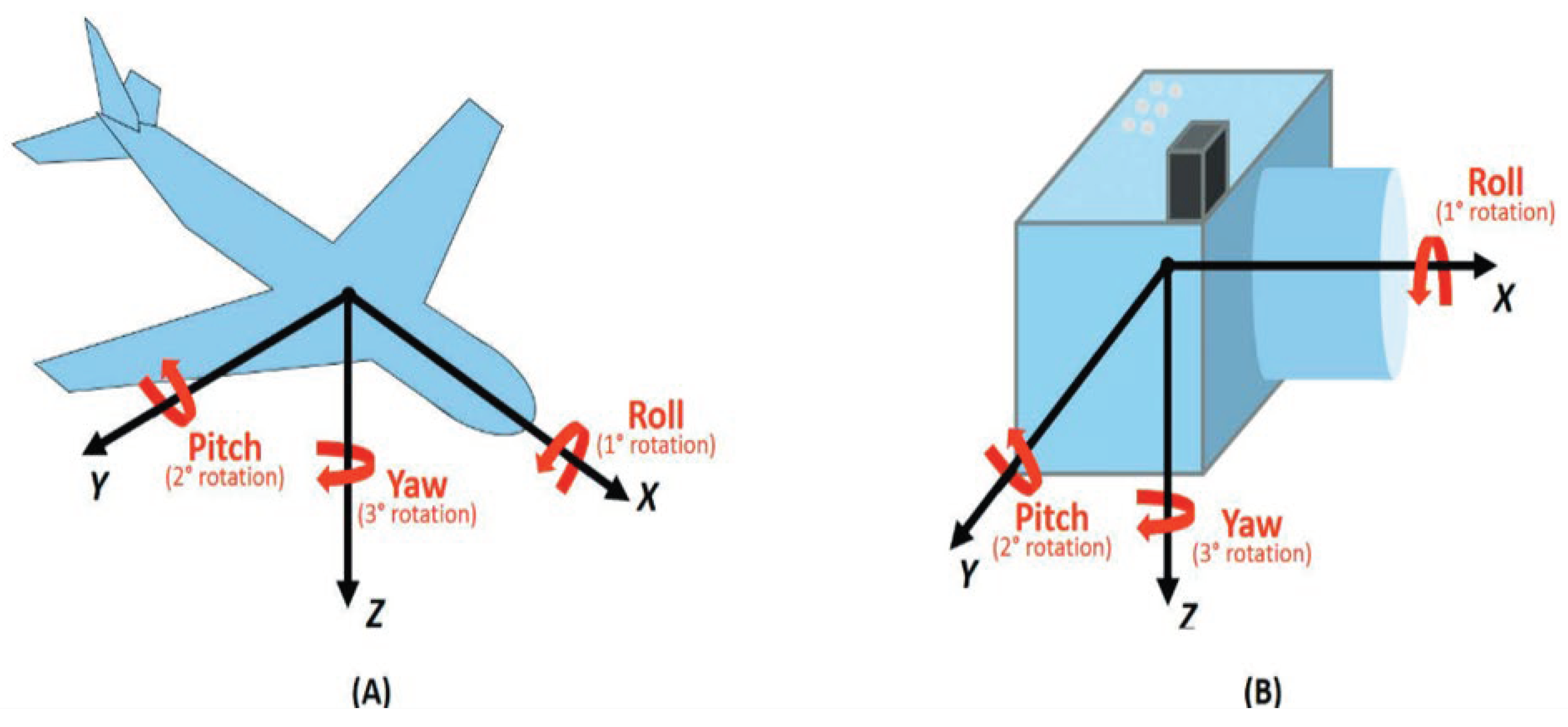
Figure 6.
An illustration of repeating module in LSTM[23].
Figure 6.
An illustration of repeating module in LSTM[23].
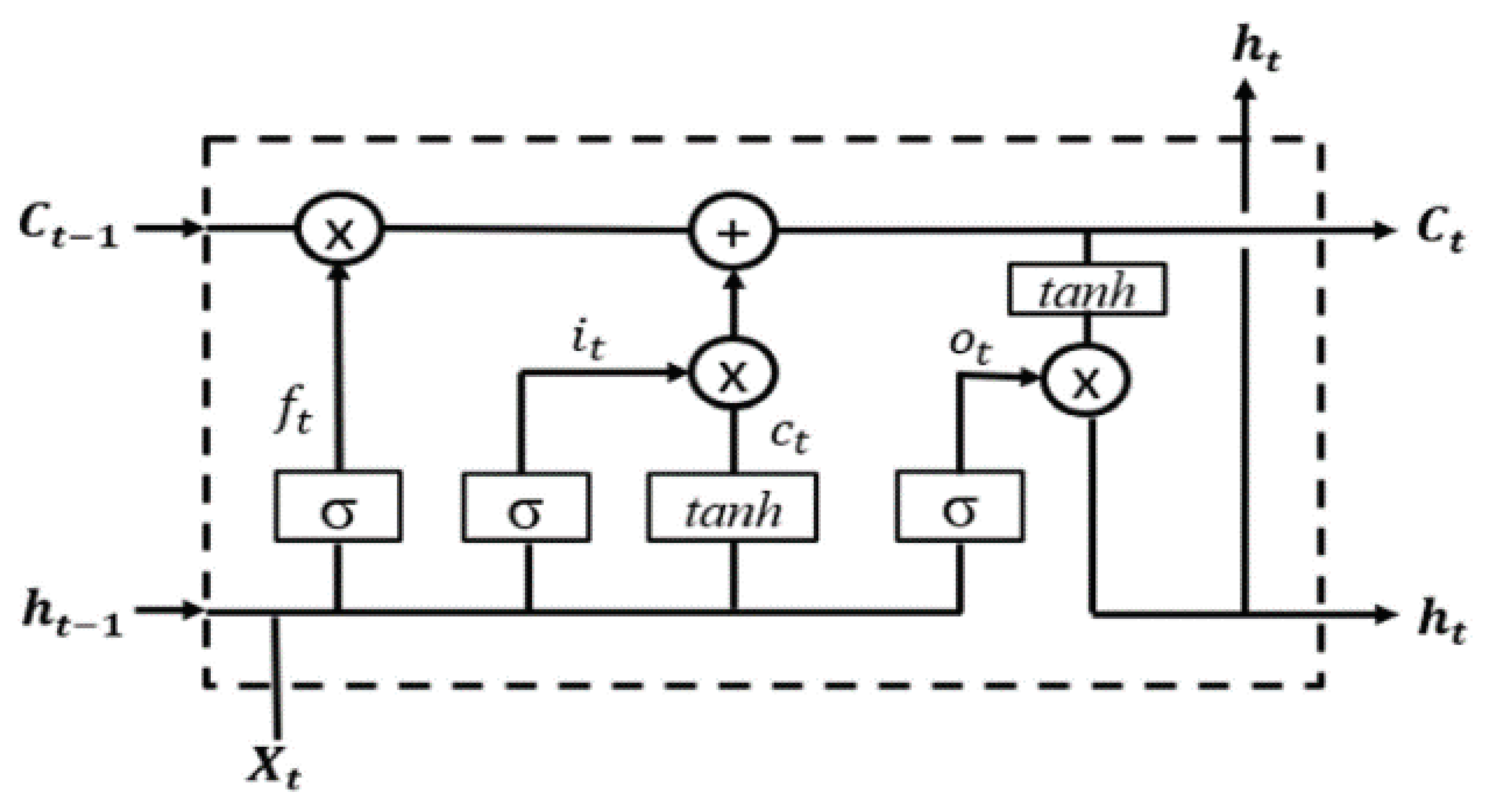
Figure 7.
Visualization of findings of the proposed algorithm (c.f., [24]).
Figure 7.
Visualization of findings of the proposed algorithm (c.f., [24]).
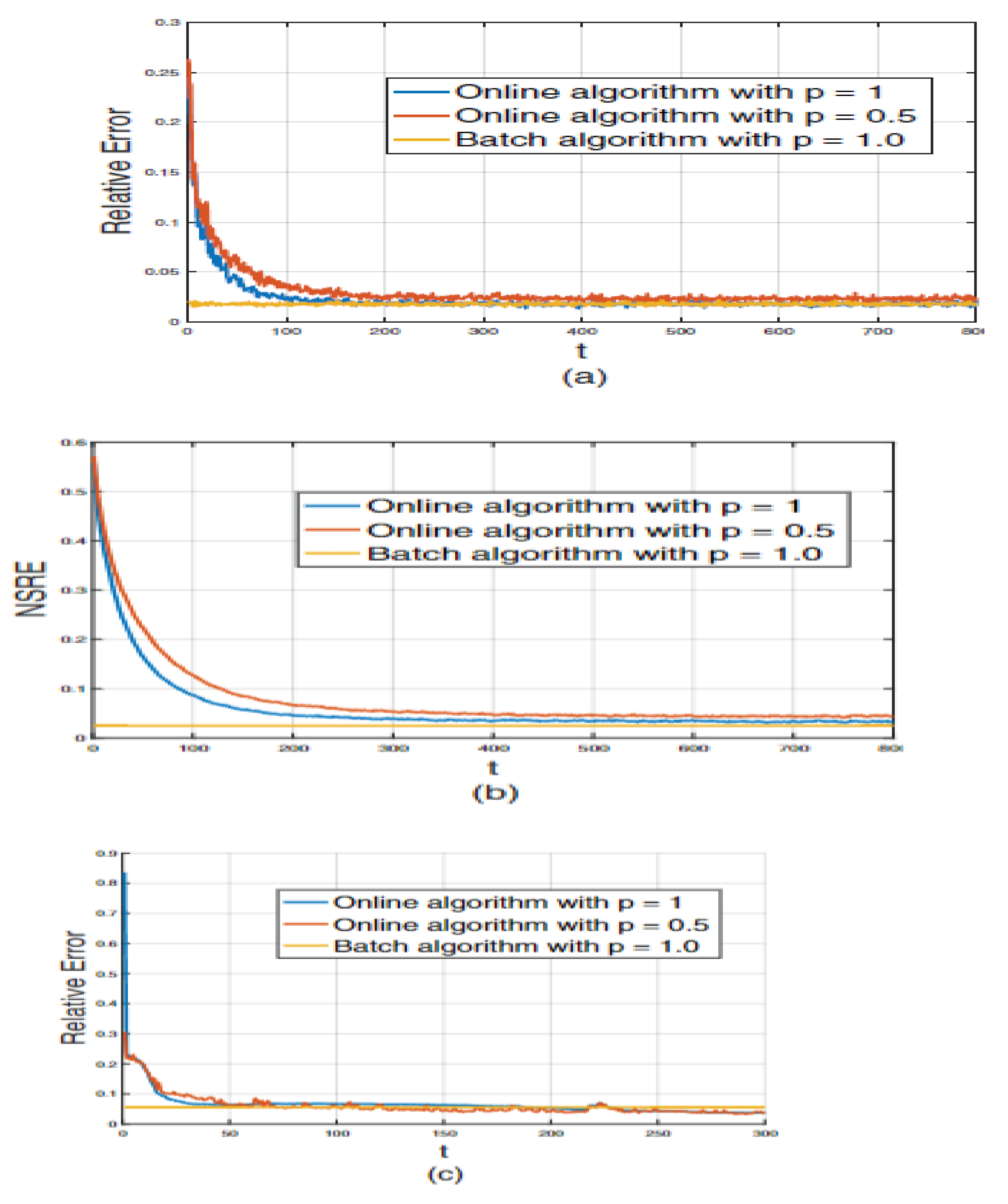
Figure 8.
A pipeline is suggested to categorize MS images of compressed low resolution[25].
Figure 8.
A pipeline is suggested to categorize MS images of compressed low resolution[25].
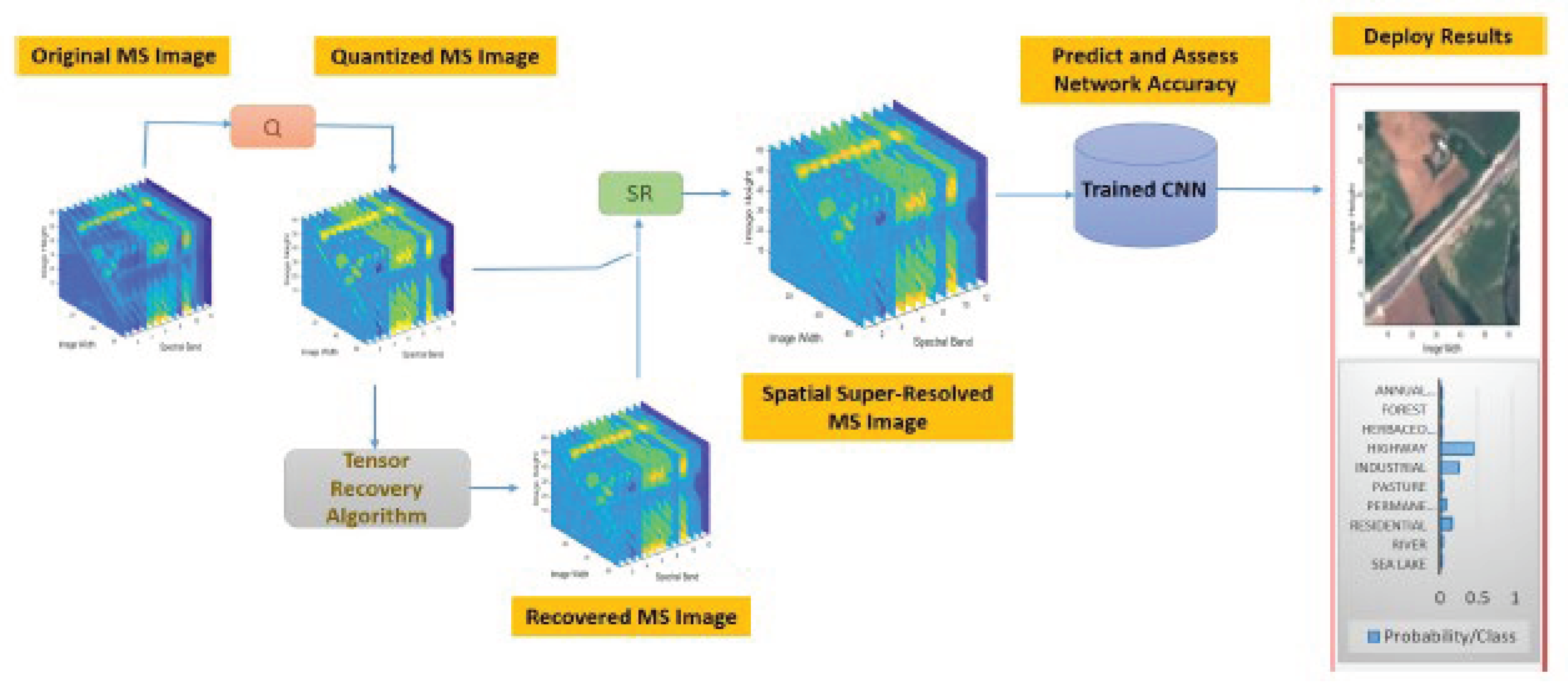
Figure 9.
Proposed-Method-Super-Resolution [25].
Figure 9.
Proposed-Method-Super-Resolution [25].
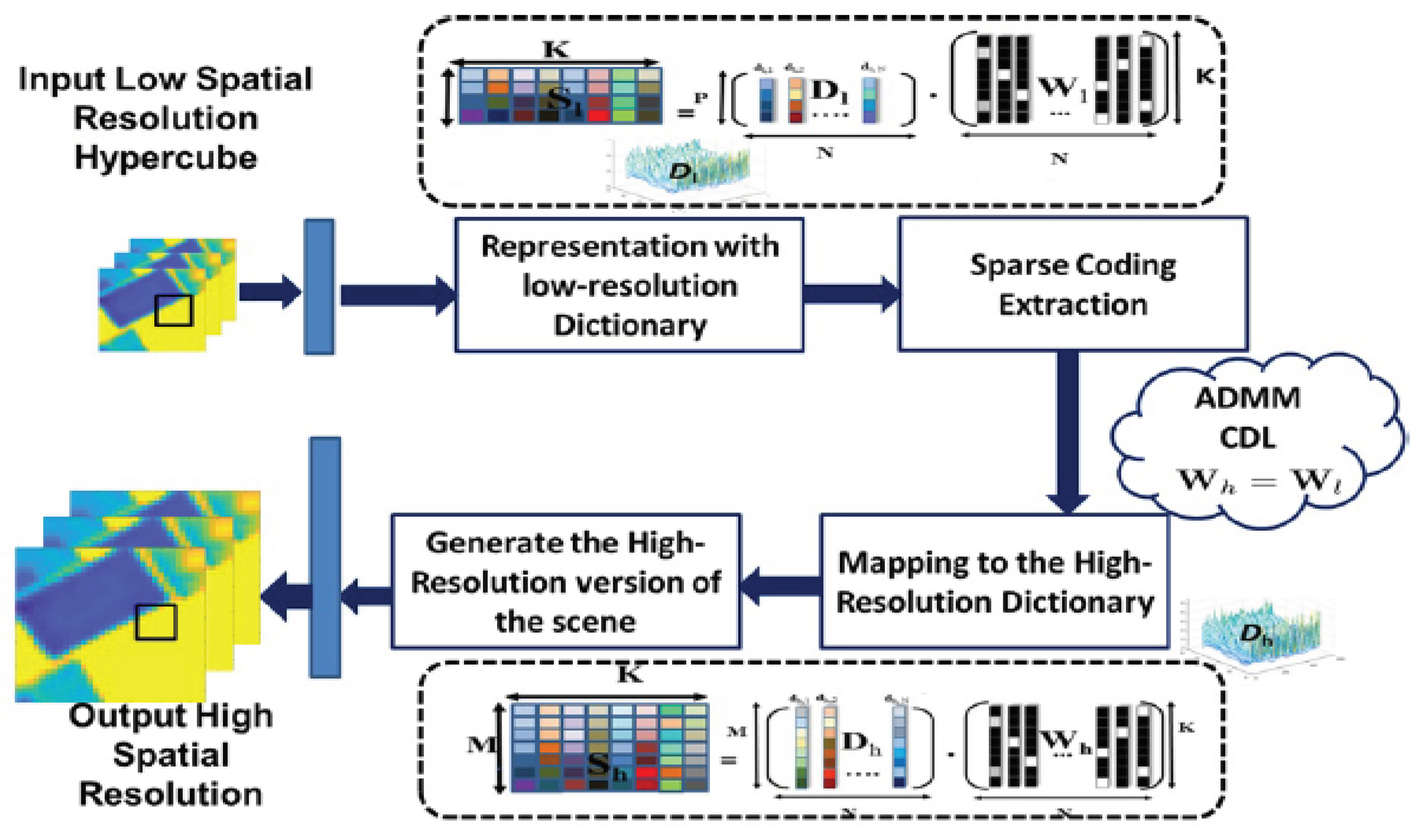
Figure 10.
The input vectors can be reshaped into an N-way tensor, while the output tensor of the compressed neural network is also N-way. The goal is to minimize the compressed network’s number of parameters, which can be formulated as an optimization problem[28].
Figure 10.
The input vectors can be reshaped into an N-way tensor, while the output tensor of the compressed neural network is also N-way. The goal is to minimize the compressed network’s number of parameters, which can be formulated as an optimization problem[28].
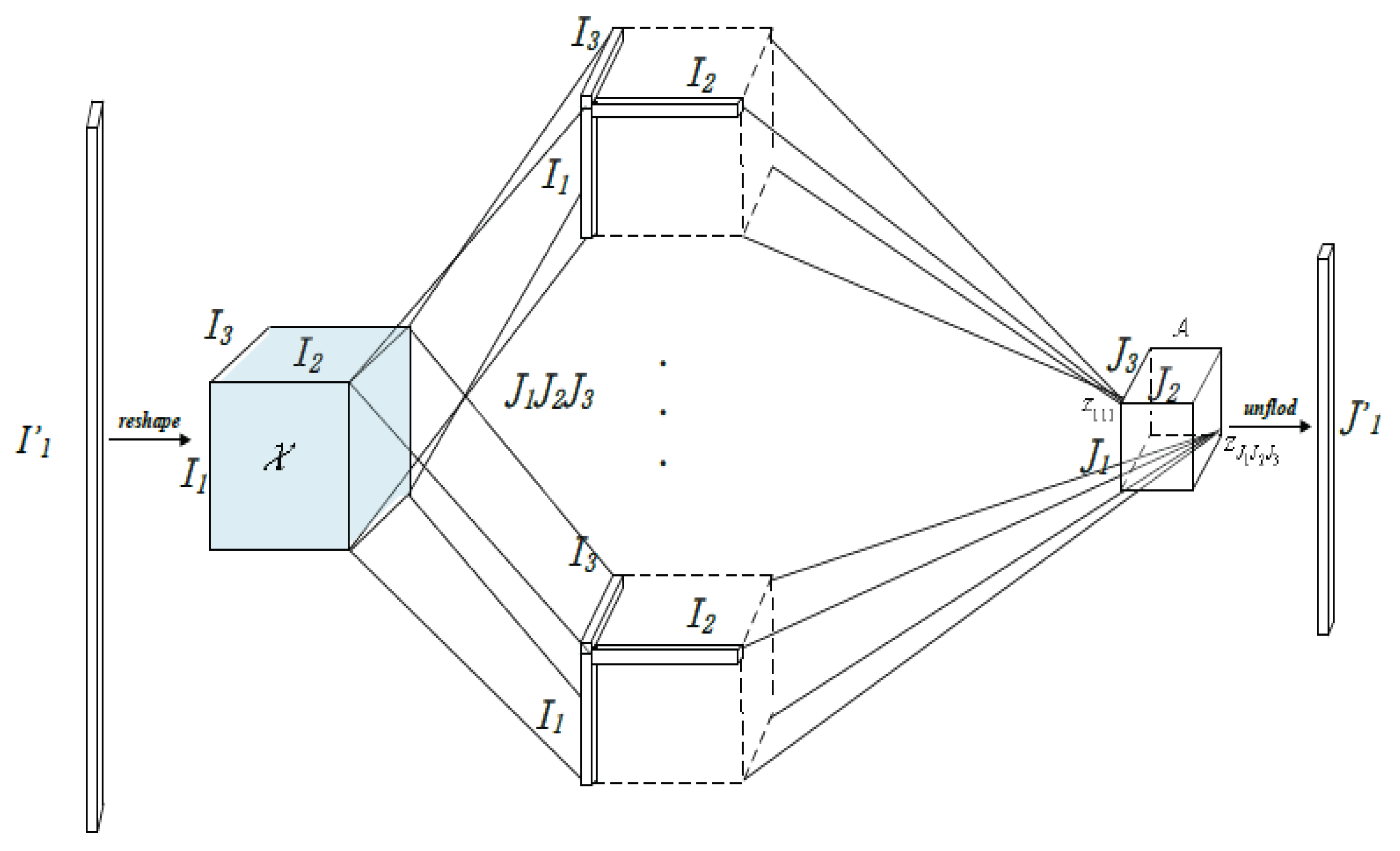
Figure 11.
This diagram visually represents the concept of expanding a polynomial function to the third order, which involves using low-order polynomials and their products to approximate a higher-order polynomial. This approach allows for variable separability and increases the expansion order without significantly increasing the number of layers in the neural network[29].
Figure 11.
This diagram visually represents the concept of expanding a polynomial function to the third order, which involves using low-order polynomials and their products to approximate a higher-order polynomial. This approach allows for variable separability and increases the expansion order without significantly increasing the number of layers in the neural network[29].
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



