
Submitted:
03 March 2024
Posted:
04 March 2024
You are already at the latest version
Abstract
A handheld NIR spectrophotometric method was developed, validated and applied for determination of tadalafil in tablets. The aim of our work was to develop analytical methods based on vibrational techniques and using low-cost portable equipment. Based on different chemometric modeling, we attempt to validate the method, that gave encouraging results from the principal component analysis (PCA), DD-SIMCA and PLS modeling. Then came optimization using an appropriate experiment plan. For validation, we used the total error approach with acceptance limits set at ±10% with a risk level of 5%. The method showed that it was possible to perform both qualitative and quantitative analysis of pharmaceutical products using low-cost portable NIR systems with chemometric tools. The developed approach enabled to cross the first step in implementing a NIR method for quality control of Tadalafil-based drugs in the DRC.
Validation difficulties of PLS method resulted from the lack of information about inter-days serial variations of spectral responses. This would be interesting to extend the study to a larger calibration interval in order to correct uncertainties that may result from the variability observed under different conditions, and to verify robustness. These are the limitations of this work, but the results are nevertheless very encouraging.
Keywords:
Substandard and falsified medicines
; Handheld NIR
; Chemometric tools
; Development
; Validation
Introduction
Globally, Substandard and falsified medicines pose a serious risk to public health. Pharmaceutical falsification affects wealthy countries such as the United States, European countries, Australia, Japan, and others ; as well as developing countries where falsified medicines are frequently distributed. According to the World Health Organization (WHO), any medication that has been fraudulently and purposefully mislabeled regarding its identity or source is considered falsified. Both branded and generic products are subject to falsification; examples of falsified products include those with the proper or incorrect active ingredients, no active ingredients, insufficient active ingredients, or phony packaging [1]. Phosphodiesterase (PDE) 5 inhibitors for erectile dysfunction, such as astadalafil (Cialis), sildenafil (Viagra), and vardenafil (Levitra), are among the most popular categories of personal-import medications. In Japan, reports from 2011 and 2012 indicated that tadalafil that had been fabricated posed health risks. Compared to 2005, the quantity of counterfeit medications that failed customs inspection surged one hundredfold in 2015, with PDE 5 inhibitors accounting for a large portion of such medications. 40% of the test samples in a collaborative 2016 survey conducted by four producers and distributors of erectile dysfunction medications were fabricated. There have also been reports of tadalafil that isn’t real from the US, Canada, and Australia [2]. These medications are frequently made in unregulated street labs without adhering to good manufacturing practices. The effectiveness and safety of falsified medicines is extremely unreliable since their source in unknown and no quality control is carried out. Ingredients can range from harmless components to toxic and dangerous elements. The number of medications that require testing has increased due to growing concerns about falsified products, which emphasizes the need for quick and low-cost preliminary screening techniques. The problem of fake medications makes it abundantly evident that analytical methods are required in order to identify these false products and differentiate them from real medications. Several analytical methods have already been documented in the literature and can be broadly categorized into two categories: spectroscopic and chromatographic methods. Large quantities of these products arrive on the European market, which requires the development of simple and rapid methods to help customs officers detect them ; this is the case with the near-infrared technique [1,2,3].
In their Roadmap for Supply Chain Security, the Asia Pacific Economic Cooperation stated that it is critical to create strategies and procedures for identifying and stopping the production of falsified products. But the advancement of detection techniques has been sluggish, and no trustworthy technique has surfaced. Pharmaceutical analysis has traditionally relied on high-performance liquid chromatography (HPLC) and thin-layer chromatography (TLC), which are capable of precisely identifying and measuring active pharmaceutical ingredients (API). Because they produce consistent results, chromatographic techniques, particularly liquid chromatography coupled with mass spectrometry (LC-MS, HPLC-MS, UPLC-MS) are widely used. Nevertheless, there are a number of disadvantages to their use, such as the time-consuming nature of sample preparation and analysis, the high cost of the equipment, and the requirement for a skilled analyst. Furthermore, chromatography-based techniques may be harmful to the environment, primarily because solvents are used in the sample preparation and chromatographic separation processes [4]. Thus, several alternative method are used to verify the identity of batches of starting materials in accordance with the Pharmaceutical Inspection Convention and Pharmaceutical Inspection Co-operation Scheme, such as portable spectroscopic analyzers that are being developed. Spectroscopic analyses, including near-IR (NIR), Fourier transform IR, NMR, and Raman spectroscopy, have been developed as a quick, nondestructive method of analysis. The main non-destructive technique used in the pharmaceutical industry that doesn’t require sample preparation is NIR spectroscopy [5,6]. Among the many disadvantages of analytical techniques are their time-consuming nature, sample preparation requirements, reagent and instrumentation costs, and the requirement for skilled personnel. One such technique is gas chromatography–mass spectrometry (GC–MS). Additionally, they cause destruction [7]. The number of medications that require testing has increased due to growing concerns about counterfeit goods, which emphasizes the need for quick and low-cost preliminary screening techniques. Since longer wavelengths of fluorescence are generally acknowledged to result in lower levels of external interference, attempts to alter the fluorescence structure (such as by creating probes with near-infrared emission) may be successful. Furthermore, ratiometric pattern, which simultaneously monitors the fluorescence intensity of two wavelengths, can effectively eliminate external interference and improve detection sensitivity. However, Vibrational spectroscopy is a preferred detection and quantification technology in the crops industry and can address some of the limitations of the aforementioned methods when combined with multivariate statistical analysis techniques (chemometrics). In particular, near-infrared (NIR) spectroscopy showed that it could accurately quantify a wide range of elements and compounds [2,8,9]. Infrared spectroscopy has showed potential as tool for the control in different environments [10], and it also demonstrated benefits for non-invasive and immediate detection, which allowed the technique to gain acceptance and a wide range of use in industries, including biomedicine and more. It also performs well when applied to other tasks such as adulteration detection, drug forgery identification, crop quality testing, etc. Miniaturized NIR spectrometers are becoming more and more common due to advancements in electronic technologies and microelectromechanical systems; portable models have been commercialized up to this point. Portable NIR spectrometers are very popular because of their portability and flexibility, and their range of uses has grown from traditional laboratory settings to spot inspection [11]. Combined with chemometric tools, this technique can be more performant in evaluating products from any matrix, with possible online analytical applications. One of its advantages being the greater penetration of radiation in the sample, this makes it possible to analyse thicker solid sample by reflectance to obtain more representative information [12].
Several measurement modes can be used depending on the sample shape: reflection, transmission or transflection [13]. It is important to emphasize that the development of NIR methods for the quantification of solid dosage forms (tablets) presents major advantages in that they allow measurements to be carried out with little or no prior treatment of the samples. However, these methods present several challenges due to the influence of physical properties on the spectra. Additionnally, the presence of a variety of excipients and dosage forms, these generally require the analyst to develop specific predictive models for each formulation. In order to solve this problem, this is a continuation of the work of P.H. Ciza et al. [13,14], except that here for the first time we tested a non-soluble compound and used another solvent than water.
Therefore, this research aimed to develop and validate an analytical method by Near infrared for qualitative and quantitative determination of tadalafil marketed in Kinshasa and for it market surveillance in D.R. Congo with the use of chemometric tools combining PCA application and data pretreating. After development, the PLS method was validated and applied for quantitative application.
Materials and Methods
Materials
Two NIR spectrophotometric devices were used along our research, both dispersive portable NIR spectrophotometer systems namely NIR-S-G1, Innospectra Corp branded and NIR-M-T1, Innospectra Corp branded. Measurements were conducted in two modes (réflexion and transmission modes). We also use eppendofs (5 and 50 ml), volumetric pipette (1 ml), Analytical balance SV gram precision branded, Beaker, Bowl, gloves and paper towel.
Chemicals
To conduct this work, we used Tadalafil (Standard, 99,3%) from ZM Technologies Limited-liverpool, England, Methanol from Kim pharma-Kinshasa, D.R. congo, distilled water, Acetone from Merck KGaA-Germany, Magnesium stearate, Monohydrate lactose, cellulose microcristalline, cross carmelose and tadalafil samples from Kim Pharma, Kinshasa, D.R. Congo.
Methods
Tadalafil Tablets Sampling
This study was conducted on Tadalafil tablets, and for reasons of confidentiality, the brand names are not given but coded MCC, MMP, MXX and MTT, and the solvent used is Methanol.
- 1
- Brand MCC
Dark yellow, biconvex, diamond-shaped, film-coated tablets in rectangular blister packs, each containing two tablets. Each blister is packaged in a yellow, green and white cardboard box, with two blister packs in the latter. Each box also includes a leaflet containing composition, pharmacological properties, indication, contraindication, warnings, dosage, side effects, drug interactions, overdose, presentation and storage.
Dosage: 20 mg
Manufacturer: Eli lilly
Peremption date: june 2025
Batch number: 09968
- 2
- Brand MTT
Dark pink, rounded lozenge-shaped, film-coated tablet, contained in a rectangular blister pack. Each blister pack contains four tablets. Each blister is packaged in a blue-gold cardboard box containing a leaflet with composition, pharmacological properties, indication, contraindication, warning, dosage, side effects, drug interactions, overdose, presentation and storage.
Dosage: 20 mg
Manufacturer: Lincoln Pharmaceuticals Ltd.
Peremption date: january 2024
Batch number: NX 1001
- 3
- Brand MXX
Dosage: 20 mg
Manufacturer: Kim Pharma
Peremption date: july 2025
Batch number: XT-11
- 4
- Brand MMP
Pink, biconvex, diamond-shaped, film-coated tablet, contained in a rectangular blister pack. Each blister pack contains two tablets. Each blister is packaged in a black, yellow cardboard box containing a leaflet with composition, pharmacological properties, indication, contraindication, warning, dosage, side effects, drug interactions, overdose, presentation and storage.
Dosage: 10 mg
Manufacturer: Paloma
Peremption date: September 2025
Batch number: M-03
Solutions Preparation
Calibration and Validation Standards
Calibration and validation samples were prepared by dissolving reference tadalafil in methanol. Tadalafil standards were prepared in the presence of a sufficient quantity of mixing excipients to mimic tablets using gravimetric data as a reference. Three independent sample runs were performed for calibration and validation purposes with five concentration levels (5, 7.5, 10, 12.5 and 15 mg/mL tadalafil) in which the target concentration for the samples was 10 mg/mL.
Before analysis, tadalafil standard solutions containing excipients were shaken by hand for a maximum of 5 min, then left to settle for 10 min. The supernatant was finally filtered through a 4.5 μm filter.All calibration and validation solutions were prepared in triplicate for each concentration level and measured three times. For validation calculations, the three predictions were averaged per sample.
For qualitative model validation, solutions containing different brands of Tadalafil tablets were prepared at the target concentration of 10 mg/ml. In addition, a placebo solution was prepared with the excipient mixture at the target level.
Sample Preparation
Test solutions were prepared by simple dissolution or dilution of the unit dosage form with methanol to obtain a final solution of 1% w/v of the declared strength. The suspensions obtained from the tablet test sample were then shaken by hand for a maximum of 5 min, then allowed to stand for 10 min before passing through a 4.5 μm filter as for Tadalafil standards.
Results and Discussion
Data Acquisition and Chemiometric Pretreating
Chemometric calculations and analyses were performed in MATLAB (R2018a) (The Mathworks, Inc., Natick, MA, USA). For PLS models, the PLS Toolbox v.4.11 (EigenvectorResearch, Inc., Wenatchee, WA, USA) was used.
To reduce variability and improve chemical spectral characteristics, the raw NIR spectra were pre-processed.
Tadalafil spectra recorded with the NIR-S-G1 device in reflection (solid state) and with NIR-M-T1 in transmission (dissolved in methanol) are shown in Figure 1 and Figure 2 respectively. Specific spectral features of Tadalafil are present in the spectral range where the absorption of O-H bonds in methanol is low (between 1500 and 1640 nm). For the spectrum of tadalafil in methanol, no difference is observable to the naked eye. However, chemometric techniques can detect very small differences in absorption.
Figure 1.
Tadalafil spectra recorded with the NIR-S-G1 device in reflection.
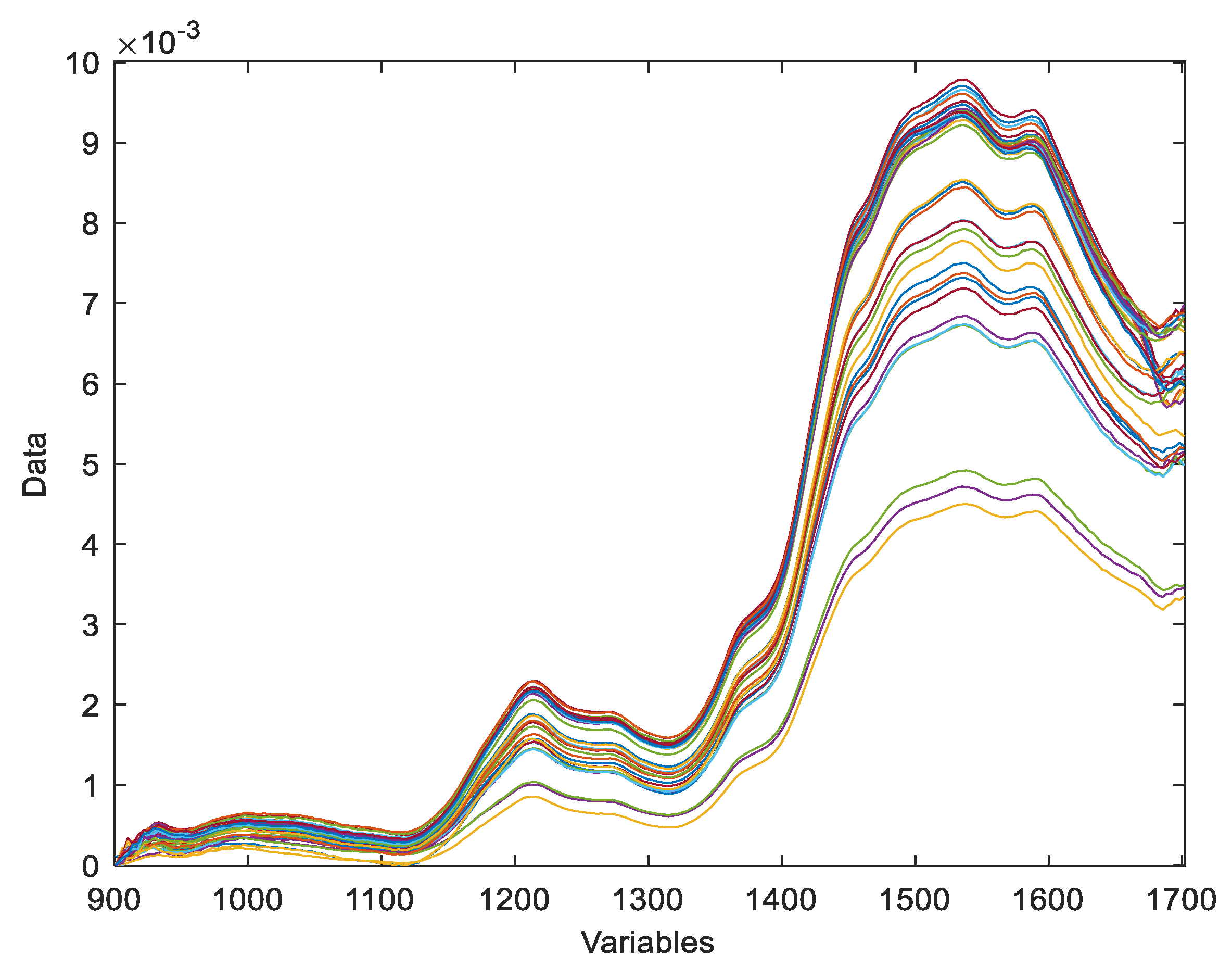
Figure 2.
Transmission spectra of NIR-M-T1 recorded Tadalafil.
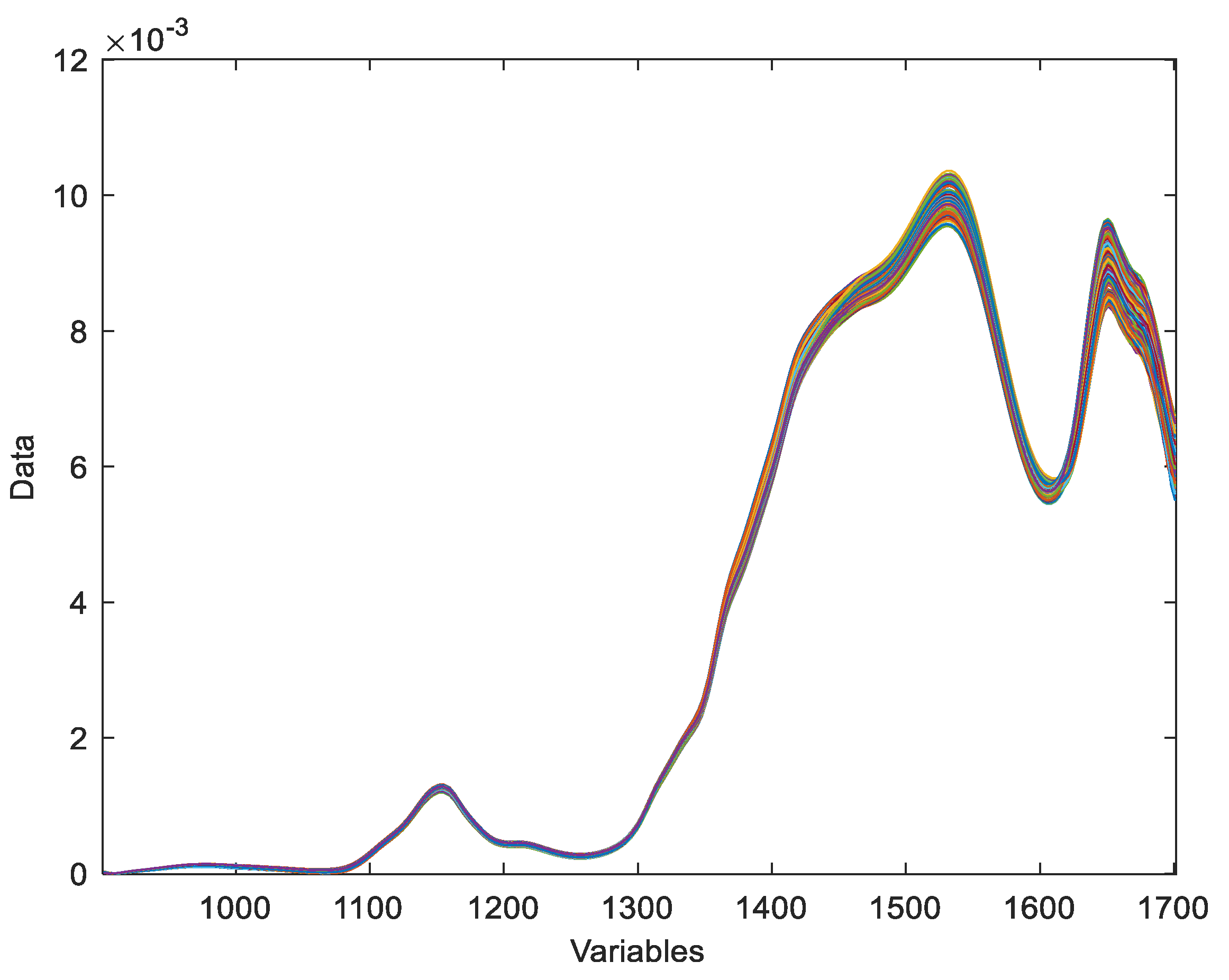
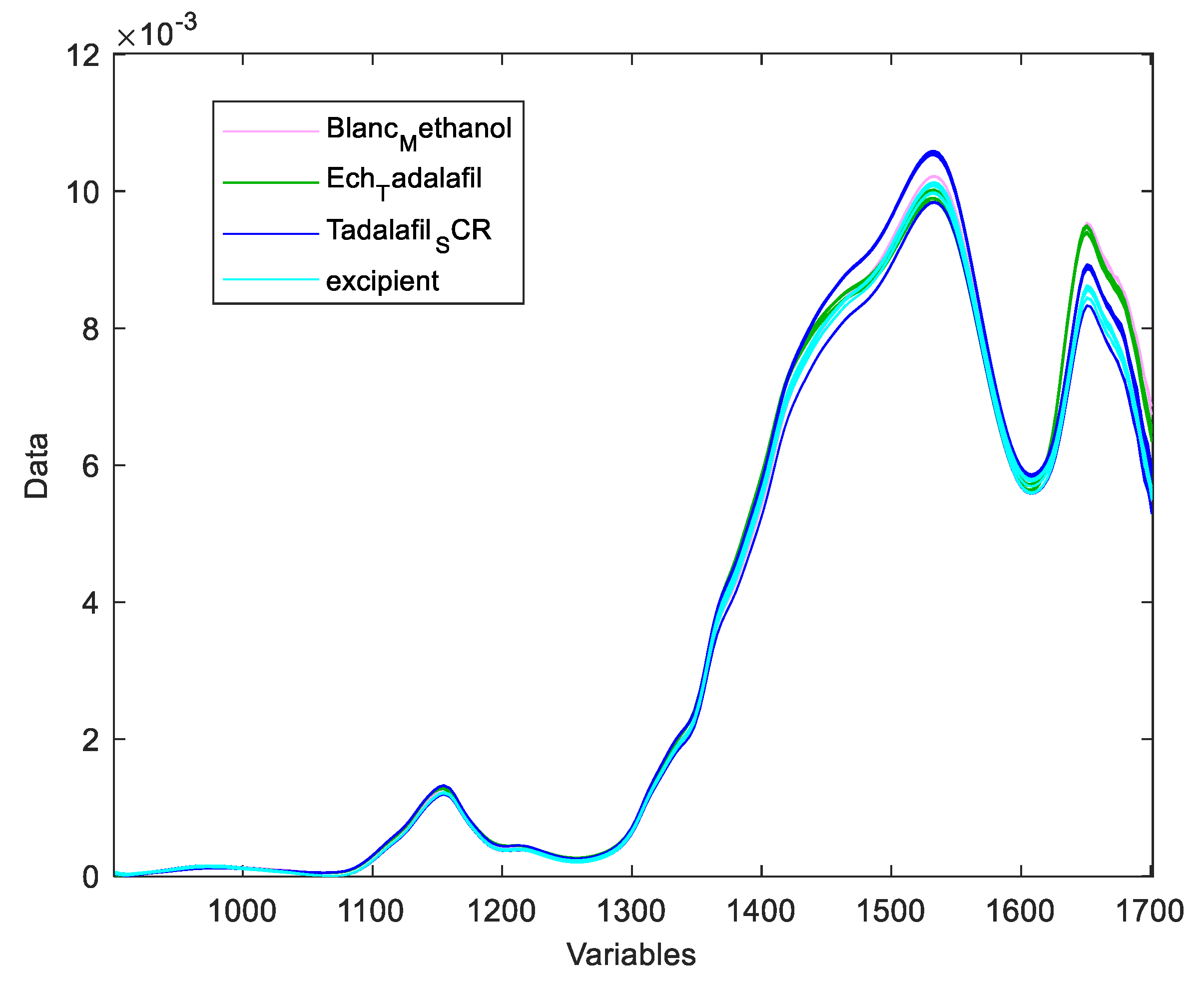
Figure 3.
Spectra of detadalafil tablet samples, matrix (excipient mixture),blank (methanol) and tadalafil SCR recorded NIR-M-T1 in transmission.
Figure 3.
Spectra of detadalafil tablet samples, matrix (excipient mixture),blank (methanol) and tadalafil SCR recorded NIR-M-T1 in transmission.
Chemiometric Data Analysis
- 1
- PCA models (principal component analysis)
As can be seen in Figure 4, there is considerable variability between tadalafil tablet samples (green) and tadalafil standard samples (blue). What’s more, when the results are compared between the different samples, there is a significant difference in terms of spectral signature.
- 2
- DD-SIMCA models
Due to the nature of NIR spectra (large, highly overlapping bands), it is recommended to use a qualitative model before the PLS regression model.
In this study, data-driven SIMCA (DD-SIMCA) was used to build qualitative identification models. DD-SIMCA is based on the construction of a principal component analysis (PCA) model of the target class, which in our case corresponds to the calibration spectra. In this way, the score distance (SD) and orthogonal distance (OD) can be calculated for each future spectrum, making it possible to determine, at a given confidence level, the acceptance zone for authentication of a specific brand. In our case, DD-SIMCA models were also used to distinguish X-1 Cialis from related (tadalafil-based) formulations but with different matrices.
A placebo solution (excipient and blank) was also projected onto the DD-SIMCA model to ensure that X-1’s excipients did not interfere with the qualitative models.
Sensitivity was assessed using the new set (tadalafil validation set) on the DD-SIMCA models, using the following formula:
As a first validation criterion, the specificity of the method must be demonstrated. It is generally good practice to build a qualitative model before the quantitative one. This ensures that only spectra similar to those used for calibration are projected onto the regression model.
As can be seen, visual spectral correlation cannot be a reliable method of selectivity. Due to the very small differences between spectra, pre-processing methods using Savitzky-Golay derivatives improve spectral characteristics and facilitate discrimination of different APIs in SIMCA models. In addition, chemometric methods were used to help detect spectral dissimilarities between these samples. A single-class classification model was developed using the DD-SIMCA approach. The model parameters selected are listed in Table I, together with the associated sensitivity and specificity.

Table I.
Marketing Autorisation.
| Applicant | Product name | Manufacturer | Origin country | Authorization N° | Registration N° | Validity(yr) | Peremption |
|---|---|---|---|---|---|---|---|
| KIM PHARMA | X-1 20mg, capsule, bxe of 2. | ETS KIM PHARMA | DR.Congo | MS.1253/10/05/DGM/0108/2016 | May 2016 | 5 | May 2021 |
| ELI LILLY NEDERLAND | Cialis20mg | Eli lilly Nederland | Netherland | EU/1/02/237/006 | Nov 2012 | 10 | Nov 2022 |
| Mon plaisir | - | - | - | - | - | - | |
| Tadalanique | - | - | - | - | - | - |
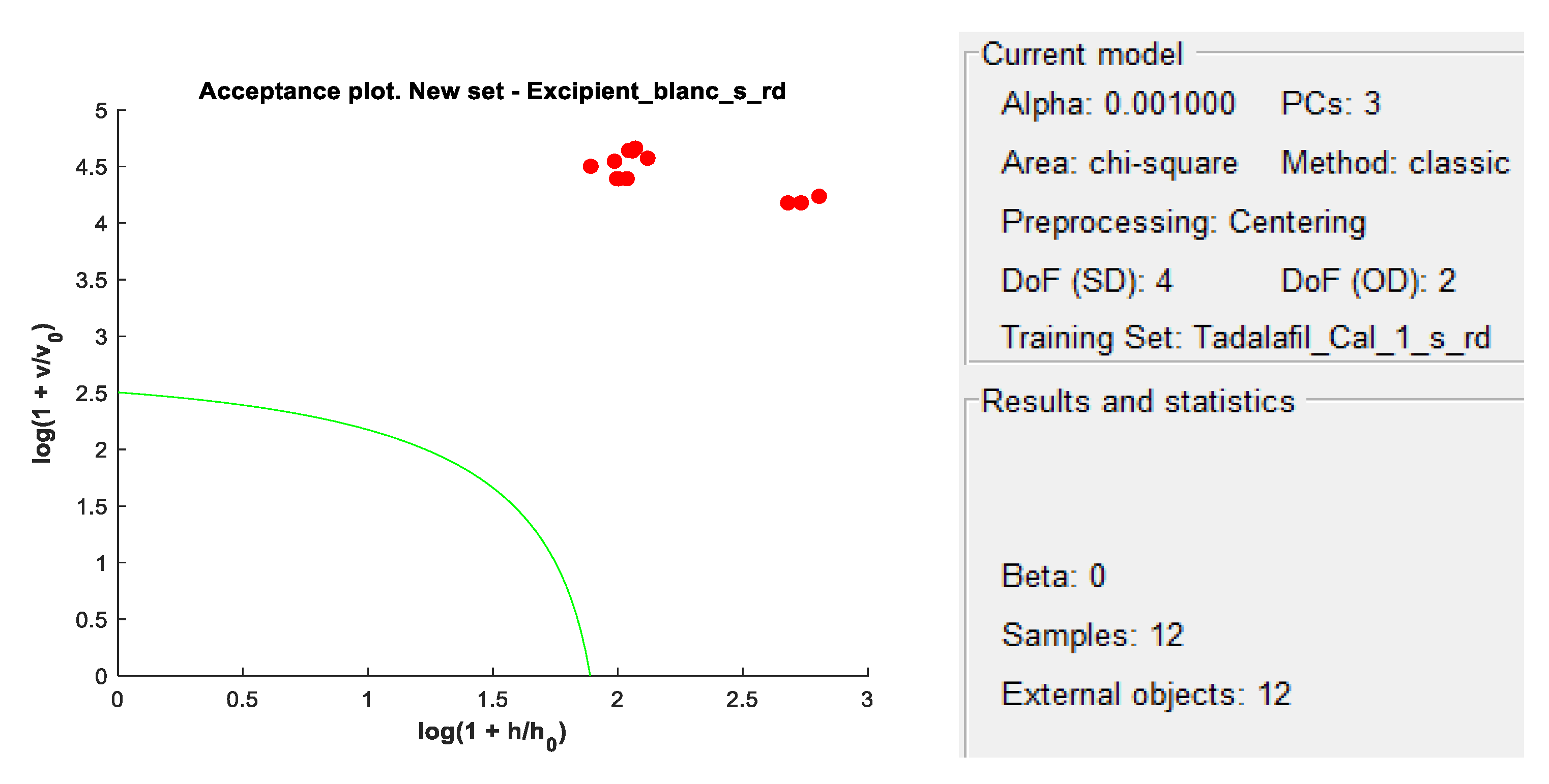
DD-SIMCA acceptance plots for calibration and validation data are shown in Figure 5 and Figure 6, while Figure 7 and Figure 8 show DD-SIMCA acceptance plots for X-1 and Cialis tablet data. The DD-SIMCA models applied to NIR data enabled perfect recognition of X-1 samples and perfect discrimination of placebo and, in part, Cialis samples. This confirms its applicability to systematically reject non-X-1 Tadalafil samples prior to quantitative analysis.
Nevertheless, performance showed a sensitivity of 97.7% for tadalafil validation samples; a specificity of 100% for matrix and a specificity of 33.3% for Cialis.
Table II.
Selected model parameters.
| Metric | NIR-M-T1 |
|---|---|
| Spectral range | 1530-1642 nm |
| Preprocessing | SG(1,2,15) + SNV + MC |
| # PC | 3 |
| A | 0.001 |
| Sn (VAL)% | 97.7 |
| Sp (Cialis)% | 33.3 |
| Sp (placebo)% | 100.0 |
SG: Savitzky-Golay (derivative, polynomial order, window size)
MC: Mean centering
SNV: Standard Normal Variable
Sn: Sensitivity
Sp: Specificity
PLS Analysis
Several PLS models have been built using different preprocessing methods, combinations of them and taking into account different numbers of latent variables.
Selecting an appropriate number of latent variables avoids under- or over-fitting the model.
A preselection of spectral ranges, preprocessing and number of latent variables was carried out with the PLS Toolbox model optimizer, using RMSEP as a quality criterion. The last few models selected were compared on the basis of accuracy profiles reflecting current use of the method.
Figure 10.
Graph showing the characteristics of the PLS calibration model for NIR data.
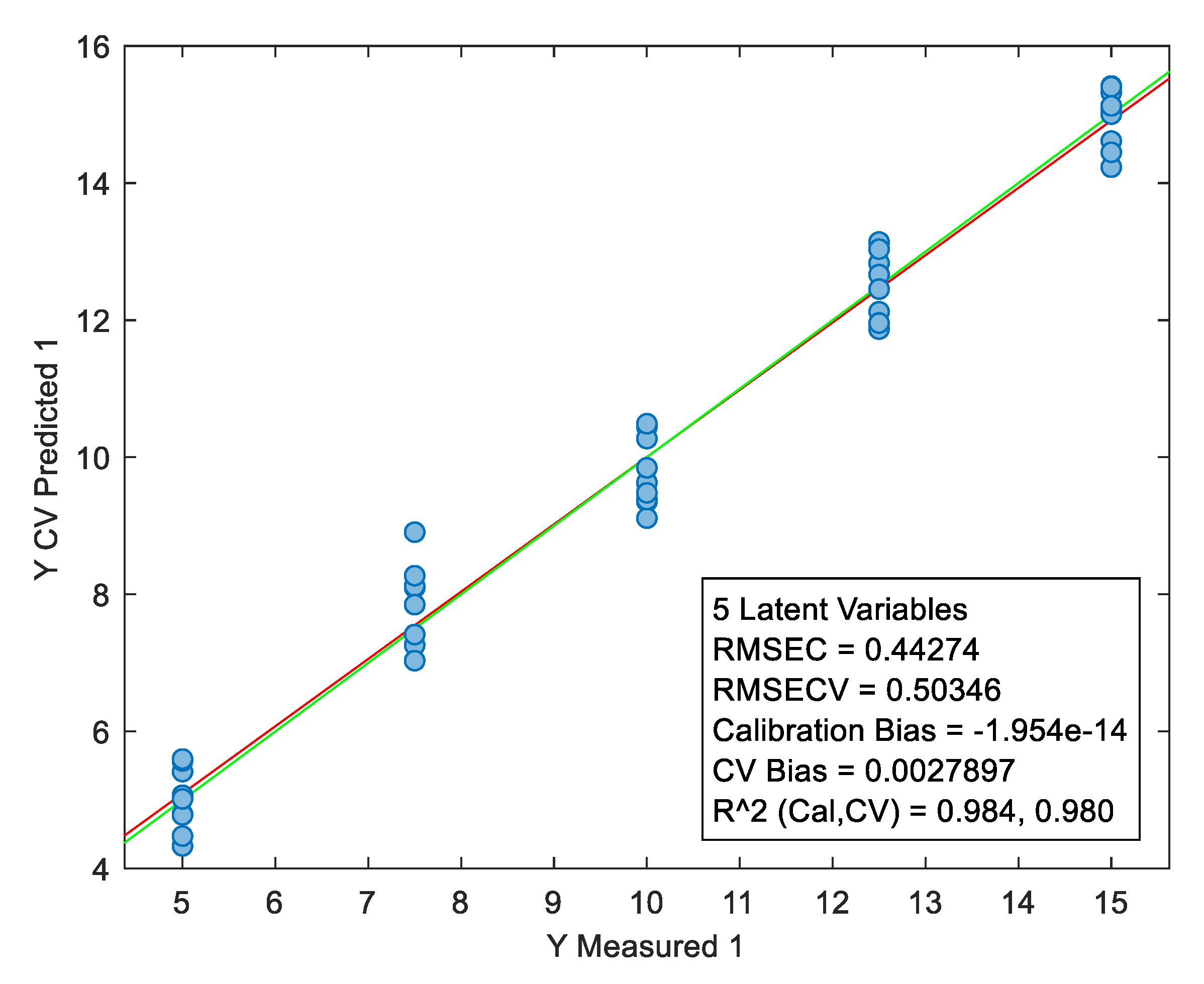
The wide dispersion of the relative error of different concentration levels can be explained by the fact that the matrix used contained excipients that could pass into the methanolic solution (due to the higher excipient/API ratio). This has a random impact on the amount of tadalafil present in the solution after the filtration step.After being developed, the PLS model was tested for its predictive ability on spectral data taken under multi-source environmental conditions (change in temperature and relative humidity). Unfortunately, a bias was observed when the developed model was used to predict validation samples measured under different conditions (see Figure 6).
Table III.
Summary of spectral acquisition parameters.

Figure 11.
Graph showing the characteristics of the PLS calibration model developed for the prediction of validation data.
Figure 11.
Graph showing the characteristics of the PLS calibration model developed for the prediction of validation data.
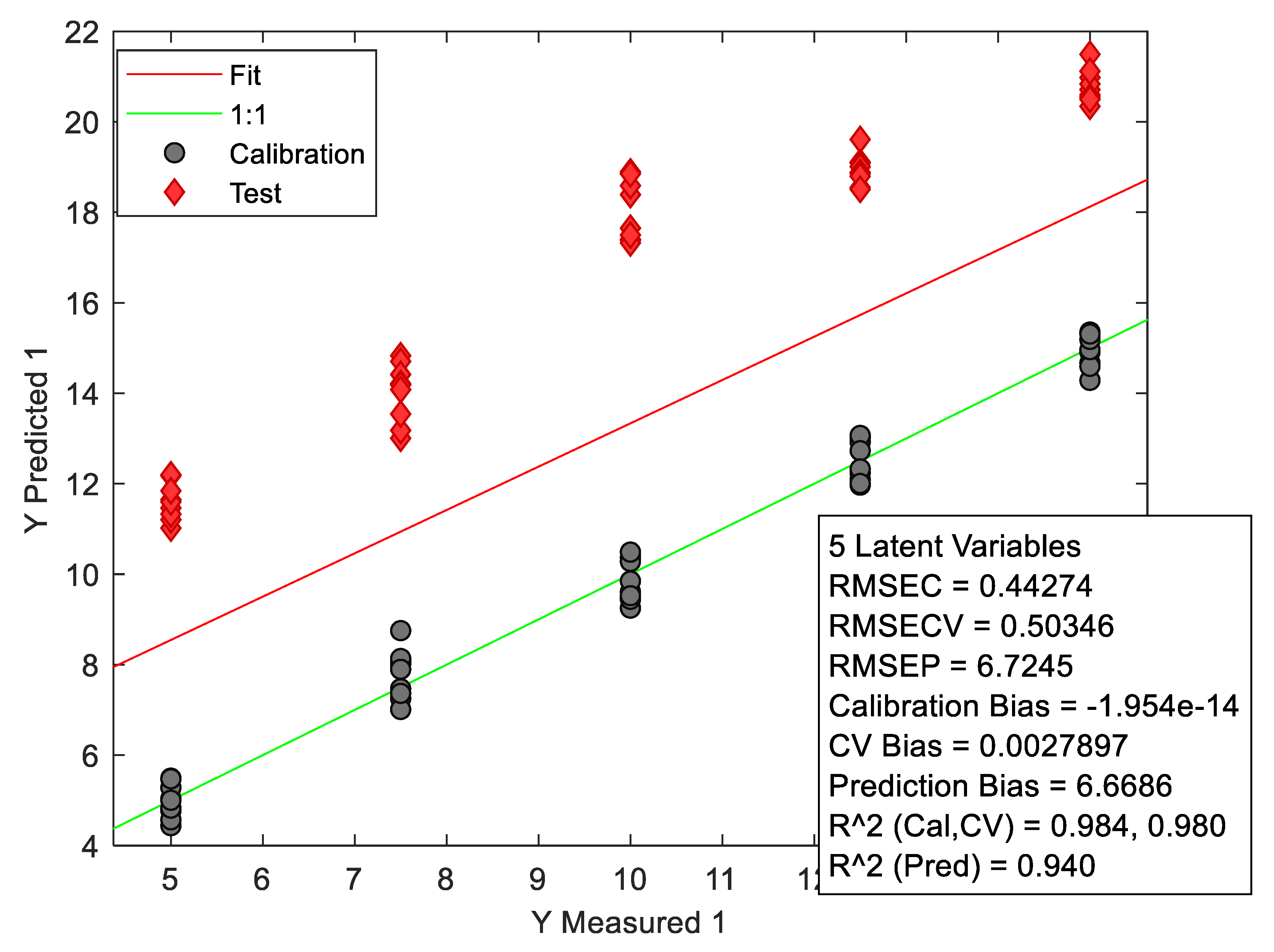
What’s more, when looking at the score graphs, the validation data are considered to be outliers in relation to the model, and unfortunately cannot be analyzed directly without correction.
The slope-bias correction SBC performed a linear-univariate model study between the predicted data and the standard data; then the linear model (taking into account the slope and y-intercept) was used to correct the predicted data using the following equation:
In some cases, this may be one of the alternative solutions for compensating for NIR spectral variations that may result from instrumental or environmental variability; for example, when samples and/or spectral measurements are significantly affected by changes in temperature, relative humidity or instrumental variability. What’s more, NIR-M-T1 portable instruments are still in the development phase, and do not have waterproof shells to protect the system from temperature and/or humidity variations. As a result, particular attention needs to be paid to their use in tropical zones, where there are strong seasonal variations in temperature and relative humidity.
Figure 12.
Characteristics of the linear Y model.
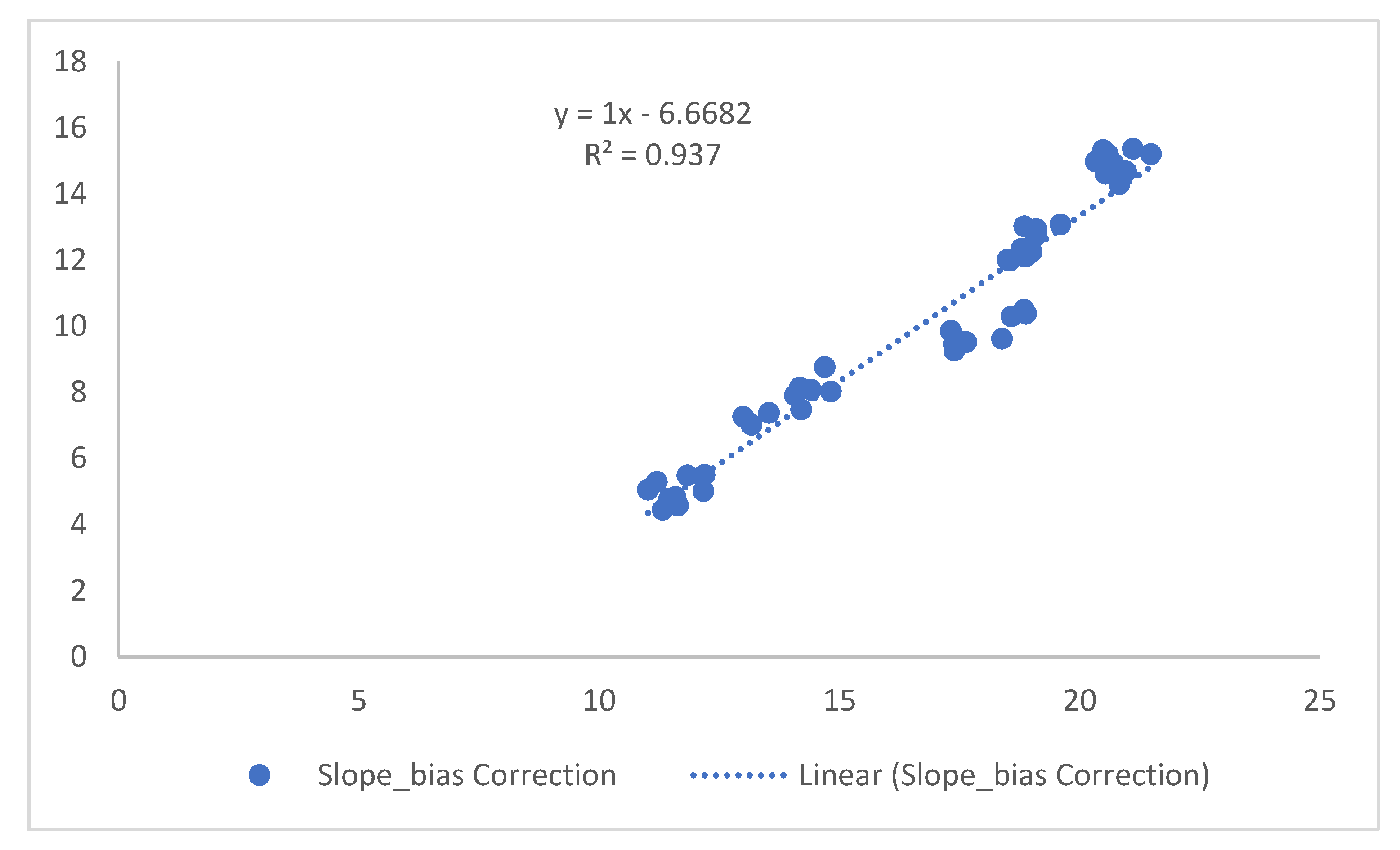
For SBC, the values of R2 (coefficient of determination), (the slope of the linear fit) and y-intercept, using predicted versus calibration data, are presented in the linear equations in Figure 8. The SBC corrected the bias observed when predicting standard tadalafil samples measured under different environmental conditions. The corrected predicted data enabled the model to be successfully validated in the tadalafil concentration range.
However, it would be interesting to test under different environmental conditions and check when a convergence is reached indicating the optimal condition to include in the overall modeling. Another approach could be the global modeling. This approach consists in adding the new variability resulting from the new data taken under different environmental conditions to the calibration set.
Validation
The NIR predictive model was validated using the total error approach with acceptance limits of ± 10% and a risk level of 5%.
All validation calculations were performed with E-noval 4.0b (PharmalexBelgium, Mont-saint-Guibert, Belgium).
Experiment plan
Validation standards are samples reconstituted in the matrix containing a known concentration and whose value is considered true by consensus.
Table IV shows the number of validation standards per concentration level, the concentration levels considered and the different series performed.
Table IV.
Experiment plan.
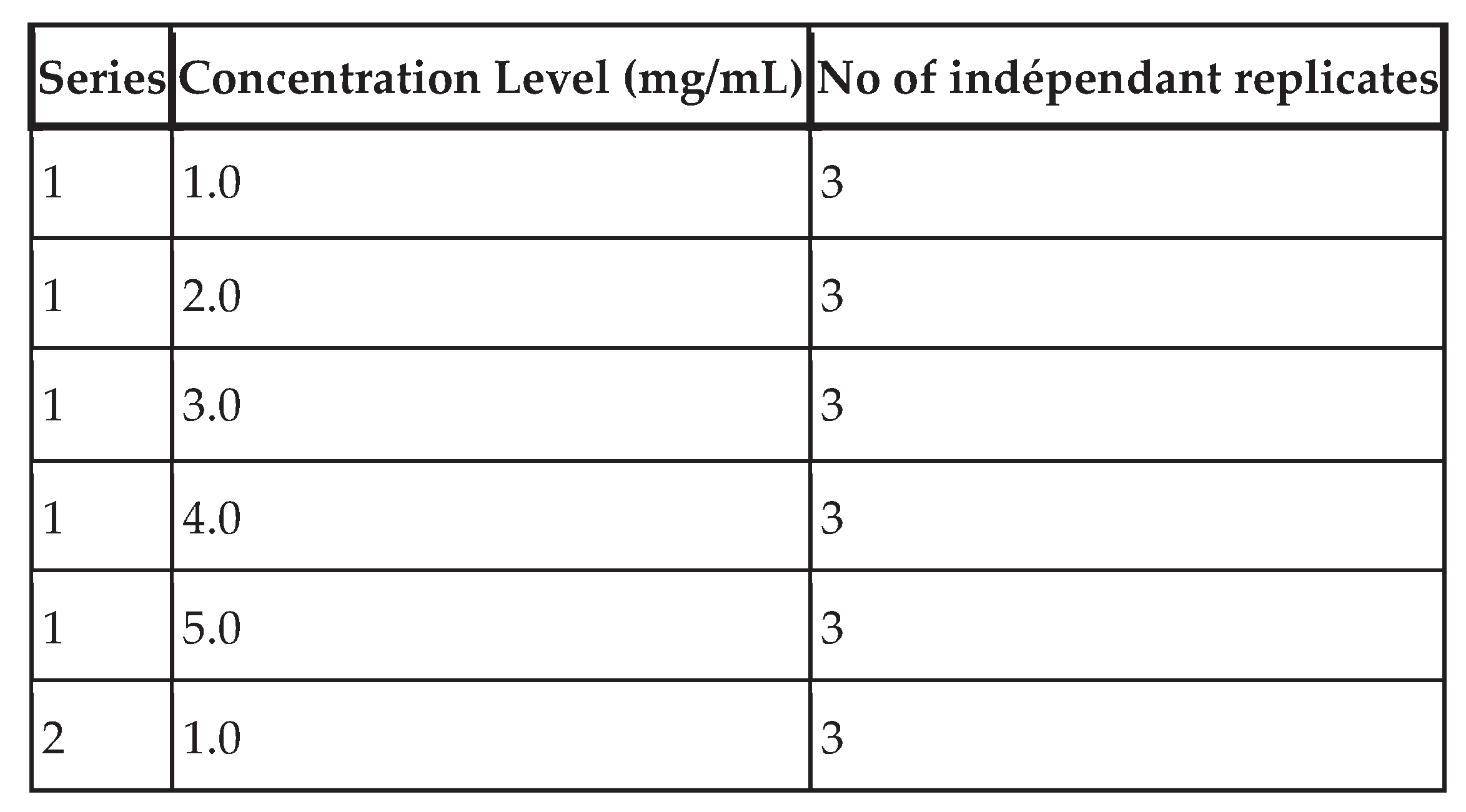
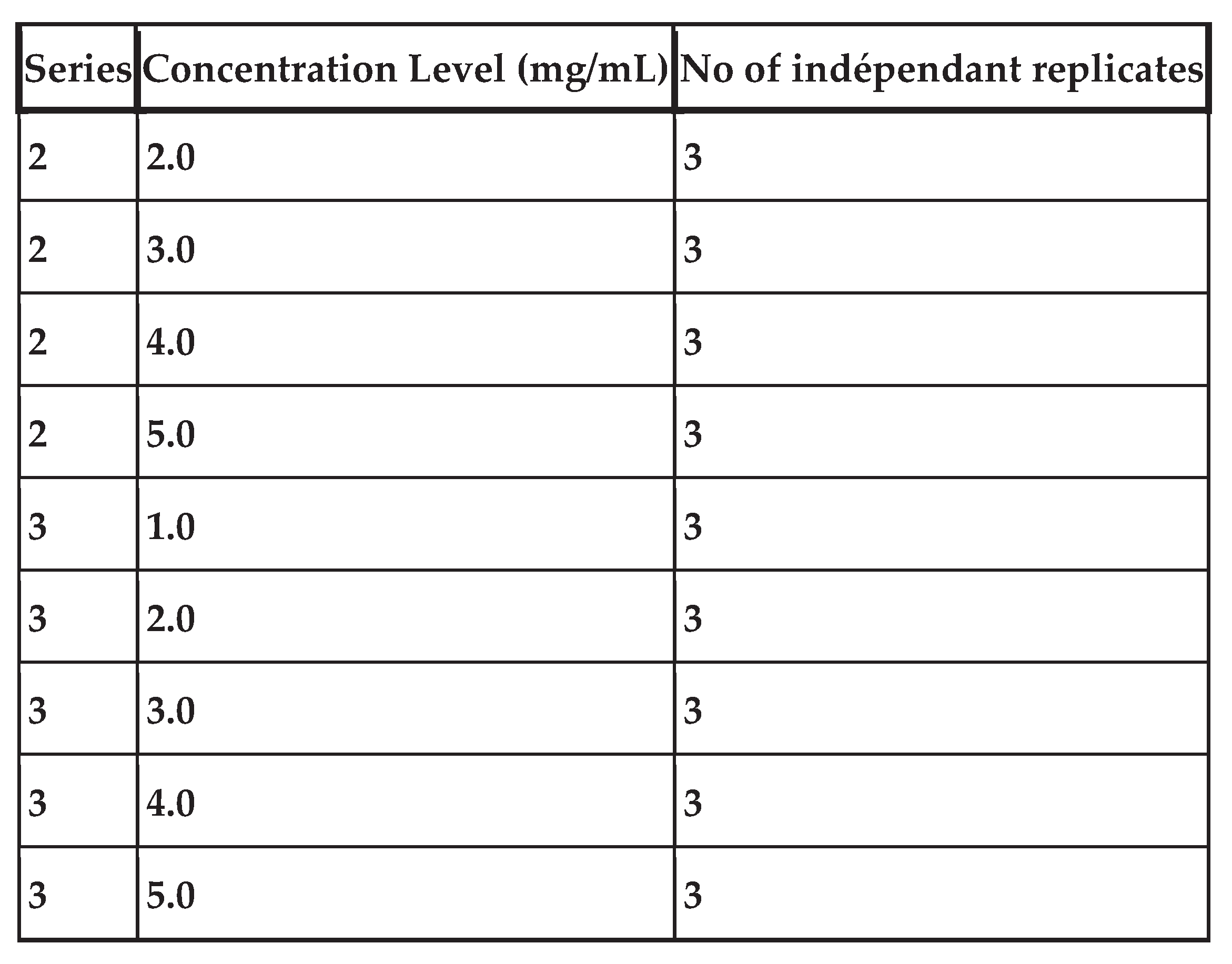
Total number of observations: 45
Validation criteria study
Trueness
Trueness expresses the closeness of agreement between the mean value obtained from a large series of test results and an accepted reference value. Trueness gives an indication of systematic errors.
As shown in Table V, trueness is expressed in terms of absolute bias (mg/mL), relative bias (%) or recovery rate (%) for each concentration level of the validation standards.
Table V.
The trueness.

Precision
Precision expresses the closeness of agreement between a series of measurements taken from multiple replicates of the same homogeneous sample under prescribed conditions. It provides information on random error and is assessed at two levels: repeatability and intermediate precision.
As shown in Table VI, precision (repeatability and intermediate precision) can be expressed in terms of standard deviation (SD) and coefficient of variation (CV).
Table VI.
Repeatability and relative intermediate precision.
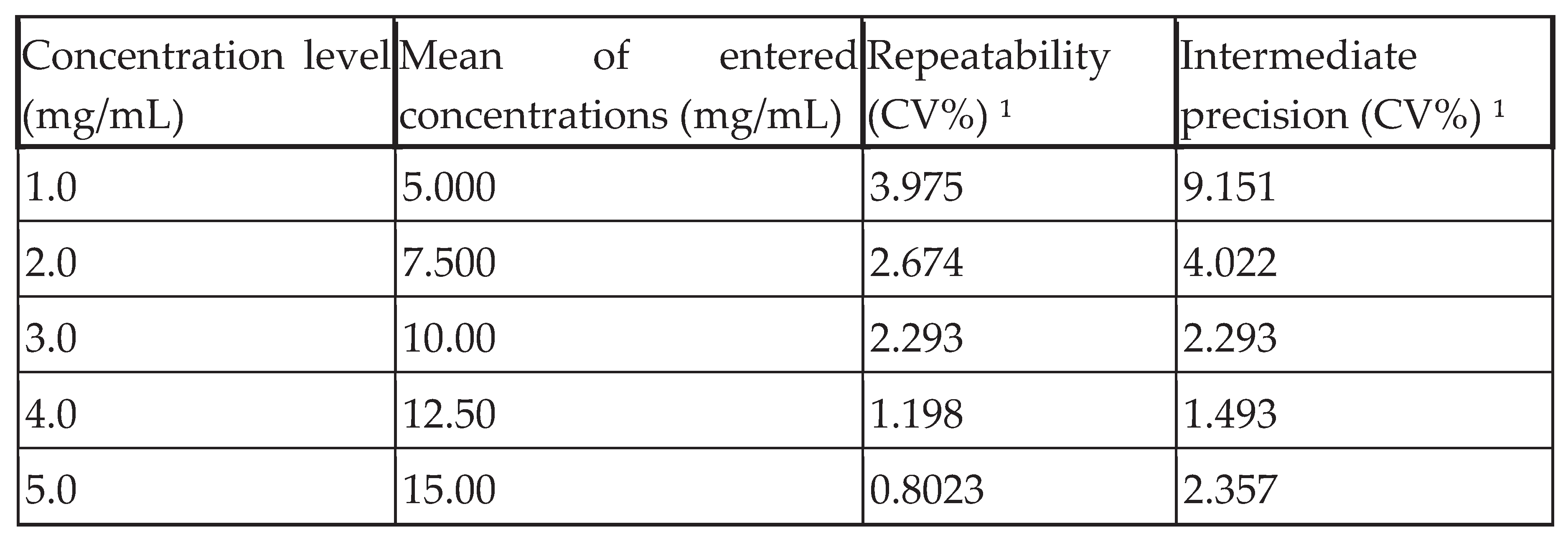
CVs in % of Repeatability and Intermediate precision were obtained by dividing the standard deviation (SD) obtained by the corresponding mean of the introduced concentrations.
The precision of this method was assessed at two levels: repeatability and intermediate precision. The coefficient of variation (CV) was used as an expression of this precision.
For good method fidelity, the percentage CV must not exceed 2.000 at all concentration levels studied. This explains the good precision only at levels 4.0 and 5.0; repeatability and intra-day intermediate precision are very good considering only these two levels.
Accuracy
Accuracy expresses the closeness of agreement between the test result and the reference value accepted as such, also known as the “conventionally true value”. Accuracy takes into account the total error, i.e., the systematic error and the random error associated with the result. Consequently, accuracy is the sum of trueness and precision. It is estimated from the accuracy profile shown in Figure 13.
Acceptance limits have been set at ± 10%, in line with the objective of the analytical procedure (USP).
Figure 13.
Accuracy profile.
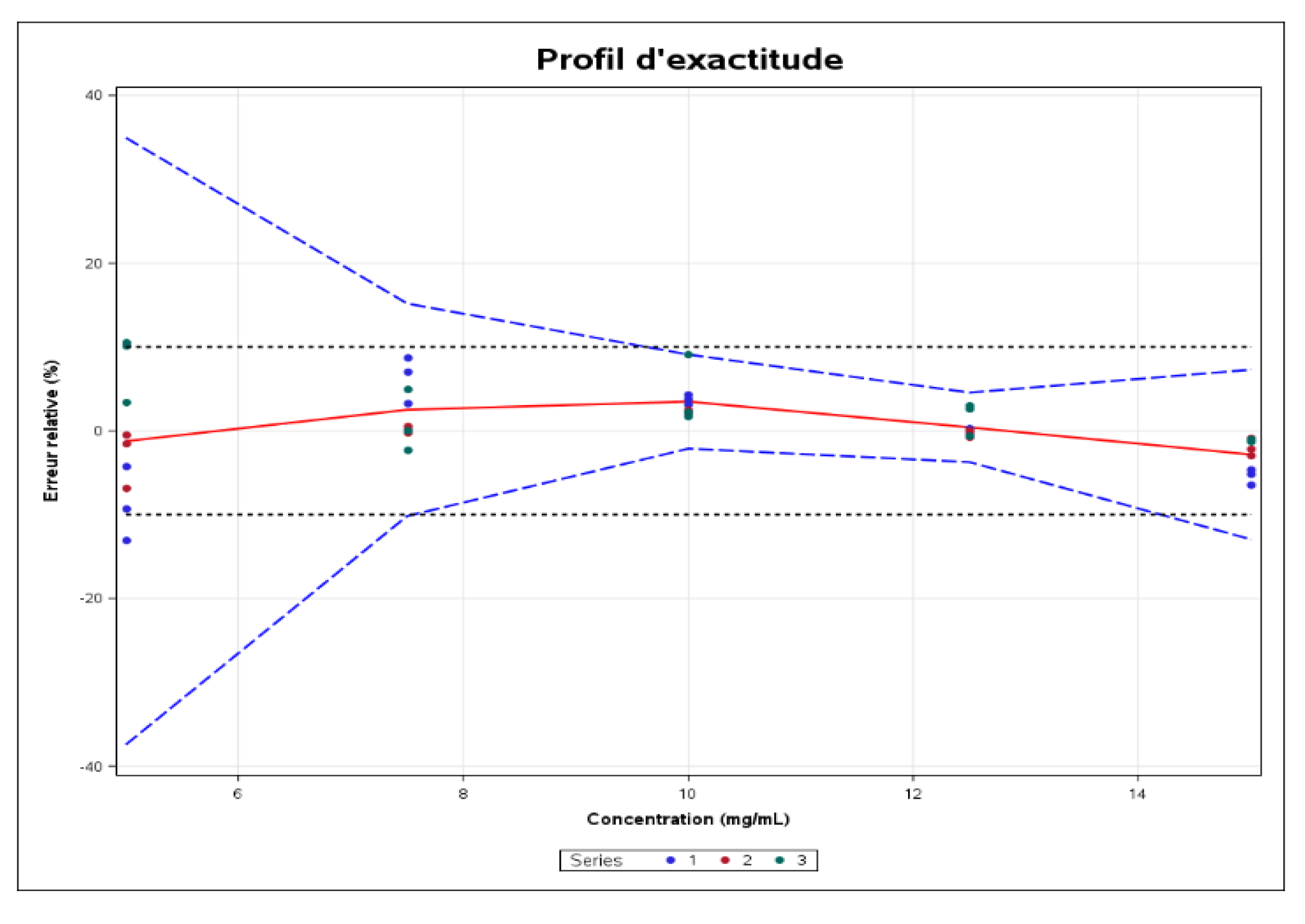
The solid red line represents the relative bias, the dashed blue lines define the limits of the tolerance interval expected at beta level, and the dashed black lines are the acceptance limits. The dots represent the relative error of the results and are plotted against their target concentrations.
Linearity
The linearity of an analytical method is its ability, within a certain assay interval, to obtain results directly proportional to the analyte concentration in the sample. A linear regression model (see Figure 7:1) was fitted to the results calculated as a function of the concentrations introduced, in order to obtain the following equation:
Y = 0.3650 + 0.9655 X
Where Y = results (mg/mL)
And X = concentrations introduced (mg/mL)
The coefficient of determination (r2) is 0.9890.
The correlation coefficient (r) is 0.9945.
Figure 14.
Relationship between introduced concentrations and results.
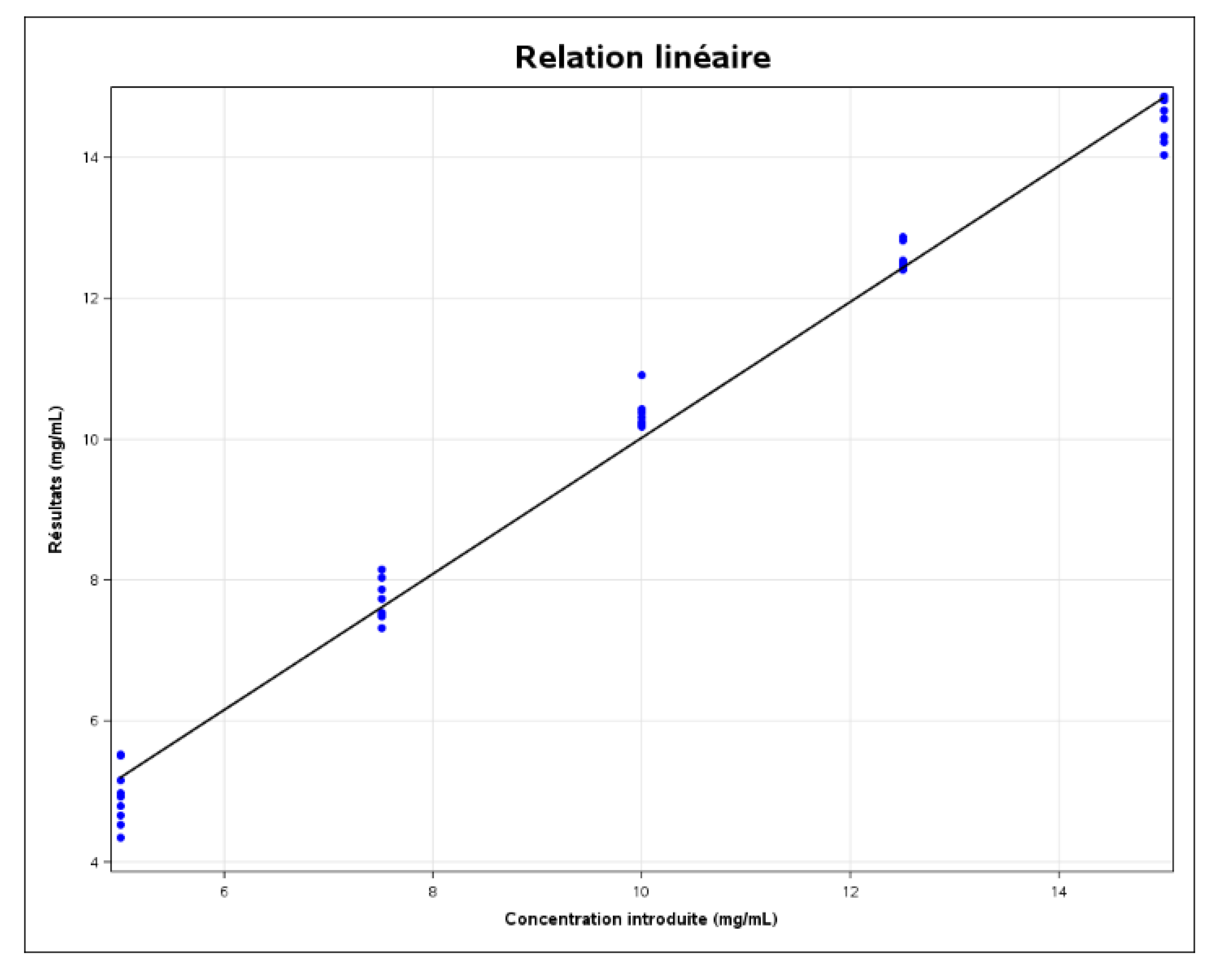
Figure 15.
linearity graph.
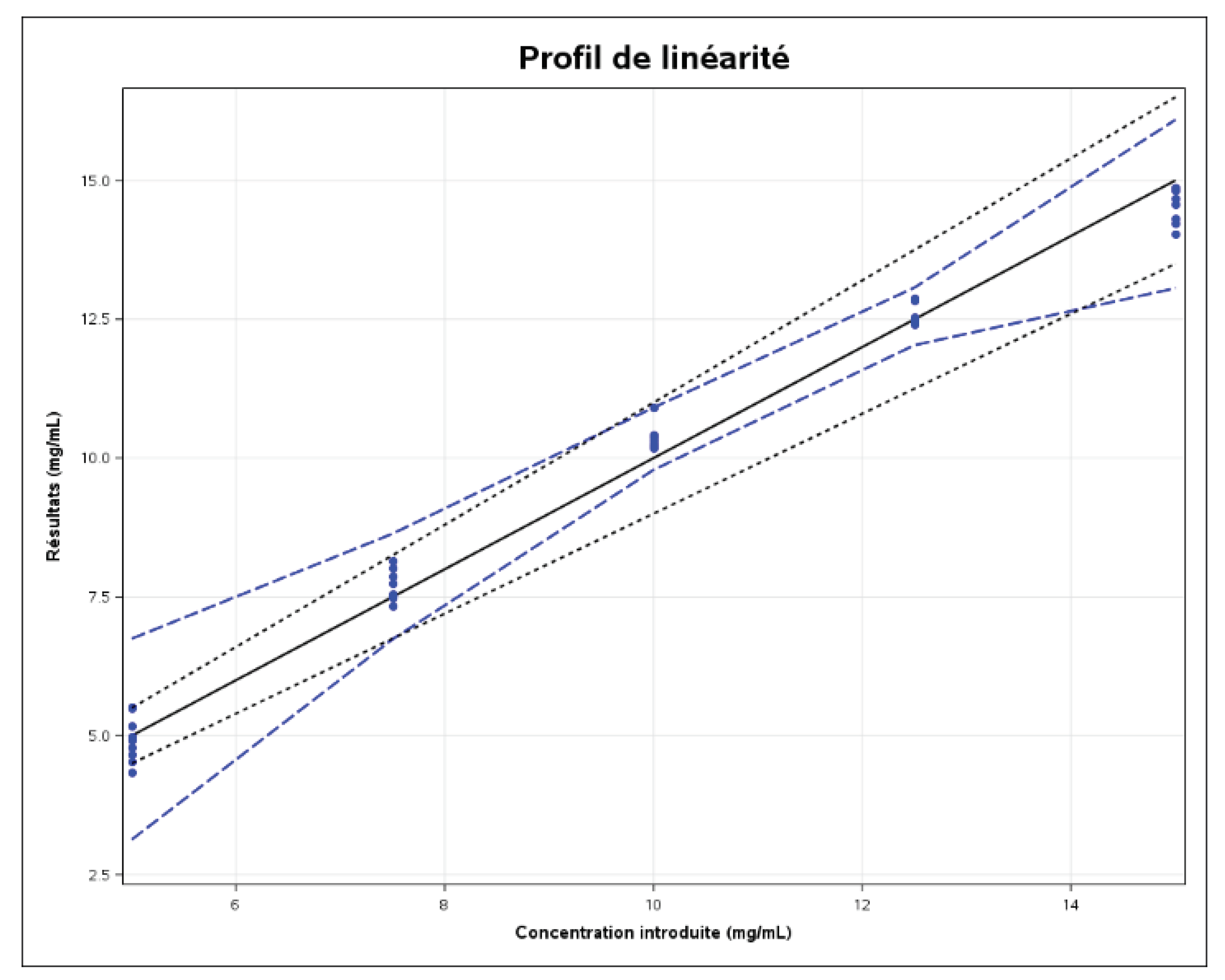
The solid black line is the identity line (Y=X). The limits represented by the dashed blue lines on the graph correspond to the accuracy profile, i.e., the “beta-expectation” tolerance limits expressed in absolute values.
In order to demonstrate the linearity of the method, the approach based on the expected tolerance interval at beta level, expressed as an absolute value, can be used and is illustrated in the previous figure. As the figure shows, the linearity of the method is not exactly valid. This is due to the fact that R2 (0.989) is not close to 1. In this case, we say that there is no good agreement between the concentrations introduced and the concentrations calculated for certain levels.
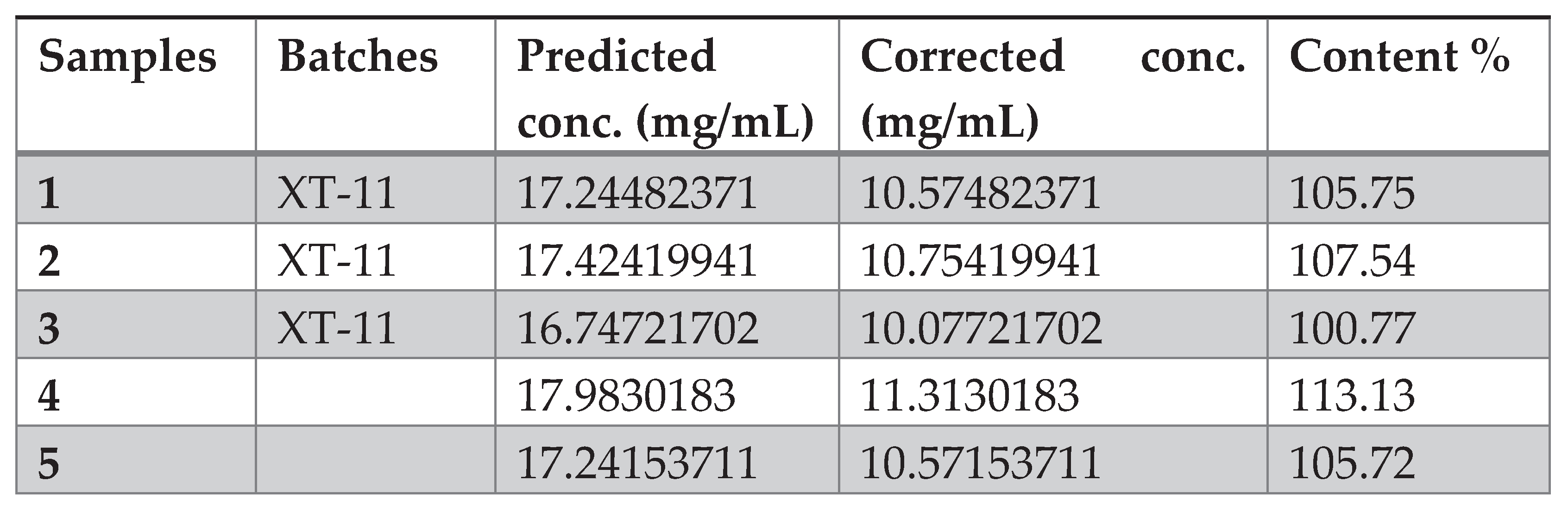
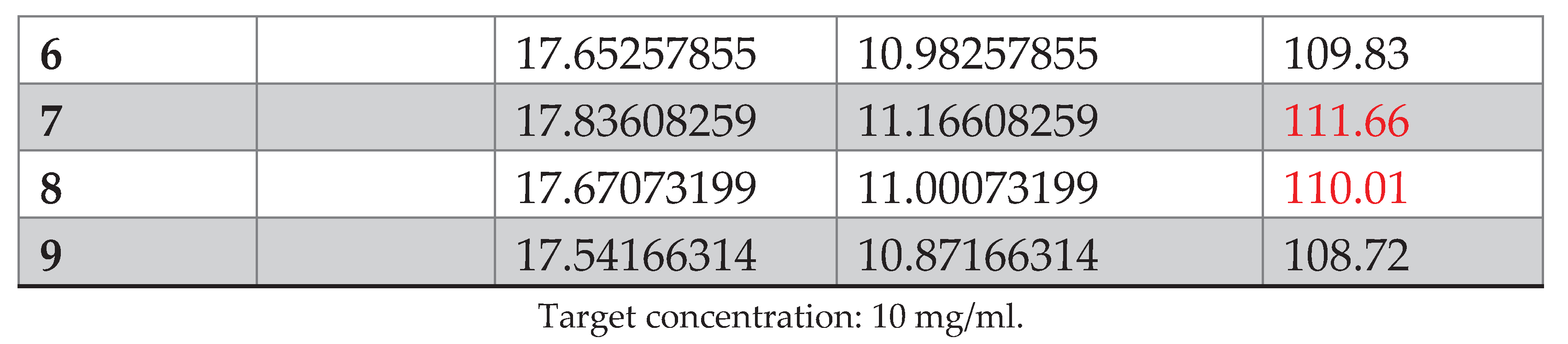
Method Application to the Drug Determination
It is important to remember that routine application is the final phase in the life cycle of an analytical procedure. As the developed method is not validated, it is important to cover all environmental variability and revalidate the method before considering its routine use. Nevertheless, a preliminary test was carried out on samples of X-1 tablets (Tadalafil 20 mg.) Test solutions were prepared by simply dissolving the unit dosage form with aqueous methanol solution to obtain a final solution of 1% w/v of the declared content. The resulting test tablet sample suspensions were then shaken by hand for a maximum of 5 min, then allowed to stand for 10 min before passing through a 4.5 μm filter as for the tadalafil standards.
Table VII.
Analytical results.
Conclusion
Hand-held spectrophotometers have now become essential tools for quality control of pharmaceutical products, particularly for the field detection of substandard and/or falsified drugs. The aim of our work was to contribute to the development of analytical methods based on vibrational techniques and using low-cost portable equipment. Based on the results of our research, we can conclude that the developed method have shown that it is possible to perform both qualitative and quantitative analysis of pharmaceutical products using low-cost portable PIR systems combined with chemometric tools.
Difficulties in validating the PLS method were encountered due to the lack of information on variations in spectral responses between the different series prepared on different days. However, it would be interesting to extend this study to a larger number of calibration data in order to correct measurement uncertainties that may result from the variability observed under different environmental conditions, and to verify robustness. These are the limitations of this work, but the results are nevertheless very encouraging.
References
- Campos, M.I.; Deban, L.; Antolin, G.; Pardo, R. A quantitative on-line analysis of salt in cured han by near-infrared spectroscopy and chemometrics. Meat Sci. 2023, 200, 109167. [Google Scholar] [CrossRef] [PubMed]
- Caramês, E.T.d.S.; Piacentini, K.C.; Almeida, N.A.; Pereira, V.L.; Pallone, J.A.L.; Rocha, L.d.O. Rapid assessment of enniatins in barley grains using near infrared spectroscopy and chemometric tools. Food Res. Int. 2022, 161, 111759. [Google Scholar] [CrossRef]
- Custers, D.; Krakowska, B.; De Beer, J.; Courselle, P.; Daszykowski, M.; Apers, S.; Deconinck, E. Chromatographic impurity fingerprinting of genuine and counterfeit Cialis® as a means to compare the discriminating ability of PDA and MS detection. Talanta 2016, 146, 540–548. [Google Scholar] [CrossRef]
- Custers, D.; Vandemoortele, S.; Bothy, J.; De Beer, J.O.; Courselle, P.; Apers, S.; Deconinck, E. Physical profiling and IR spectroscopy: simple and effective methods to discriminate between genuine and counterfeit samples of Viagra® and Cialis®. Drug Test. Anal. 2015, 8, 378–387. [Google Scholar] [CrossRef] [PubMed]
- Sanada, T.; Yoshida, N.; Matsushita, R.; Kimura, K.; Tsuboi, H. Falsified tadalafil tablets distributed in Japan via the internet. Forensic Sci. Int. 2020, 307, 110143. [Google Scholar] [CrossRef] [PubMed]
- Román, S.M.; Fernández-Novales, J.; Cebrián-Tarancón, C.; Sánchez-Gómez, R.; Diago, M.P.; Garde-Cerdán, T. Application of near-infrared spectroscopy for the estimation of volatile compounds in Tempranillo Blanco grape berries during ripening. J. Sci. Food Agric. 2023, 103, 6317–6329. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; Jia, Y. Near-Infrared data classification at phone terminal based on the combination of PCA and CS-RBFSVC algorithms. Spectrochim. Acta Part A: Mol. Biomol. Spectrosc. 2023, 287, 122080. [Google Scholar] [CrossRef] [PubMed]
- Sanada, T.; Yoshida, N.; Kimura, K.; Tsuboi, H. Detection Method of Falsified Medicines by Using a Low-Cost Raman Scattering Spectrometer Combined with Soft Independent Modeling of Class Analogy and Partial Least Squares Discriminant Analysis. Biol. Pharm. Bull. 2021, 44, 691–700. [Google Scholar] [CrossRef] [PubMed]
- Sanada, T.; Yoshida, N.; Kimura, K.; Tsuboi, H. Discrimination of Falsified Erectile Dysfunction Medicines by Use of an Ultra-Compact Raman Scattering Spectrometer. Pharmacy 2020, 9, 3. [Google Scholar] [CrossRef] [PubMed]
- Yao, S.; Ball, C.; Miyagusuku-Cruzado, G.; Giusti, M.M.; Aykas, D.P.; Rodriguez-Saona, L.E. A novel handheld FT-NIR spectroscopic approach for real-time screening of major cannabinoids content in hemp. Talanta 2022, 247, 123559. [Google Scholar] [CrossRef] [PubMed]
- Yuan, W.; Wan, C.; Zhang, J.; Li, Q.; Zhang, P.; Zheng, K.; Zhang, Q.; Ding, C. Near-infrared ratiometric fluorescent strategy for butyrylcholinesterase activity and its application in the detection of pesticide residue in food samples and biological imaging. Spectrochim. Acta Part A: Mol. Biomol. Spectrosc. 2023, 297, 122719. [Google Scholar] [CrossRef] [PubMed]
- Ciza, P.; Sacre, P.-Y.; Kanyonyo, M.; Waffo, C.; Borive, M.; Coïc, L.; Mbinze, J.; Hubert, P.; Ziemons, E.; Marini, R. Application of NIR handheld transmission spectroscopy and chemometrics to assess the quality of locally produced antimalarial medicines in the Democratic Republic of Congo. Talanta Open 2021, 3, 100025. [Google Scholar] [CrossRef]
- Ciza, P.; Sacre, P.-Y.; Waffo, C.; Kimbeni, T.; Masereel, B.; Hubert, P.; Ziemons, E.; Marini, R. Comparison of several strategies for the deployment of a multivariate regression model on several handheld NIR instruments. Application to the quality control of medicines. J. Pharm. Biomed. Anal. 2022, 215, 114755. [Google Scholar] [CrossRef] [PubMed]
- Silva, F.S.R.; da Silva, Y.J.A.B.; Maia, A.J.; Biondi, C.M.; Araújo, P.R.M.; Barbosa, R.S.; Silva, C.M.C.A.C.; Luiz, T.C.S.; Araújo, A.F.V. Prediction of heavy metals in polluted mangrove soils in Brazil with the highest reported levels of mercury using near-infrared spectroscopy. Environ. Geochem. Heal. 2023, 45, 1–16. [Google Scholar] [CrossRef] [PubMed]
Figure 4.
Principal component analysis of spectral data obtained with different acquisition parameters. Score diagram representing the variability between different samples.
Figure 4.
Principal component analysis of spectral data obtained with different acquisition parameters. Score diagram representing the variability between different samples.
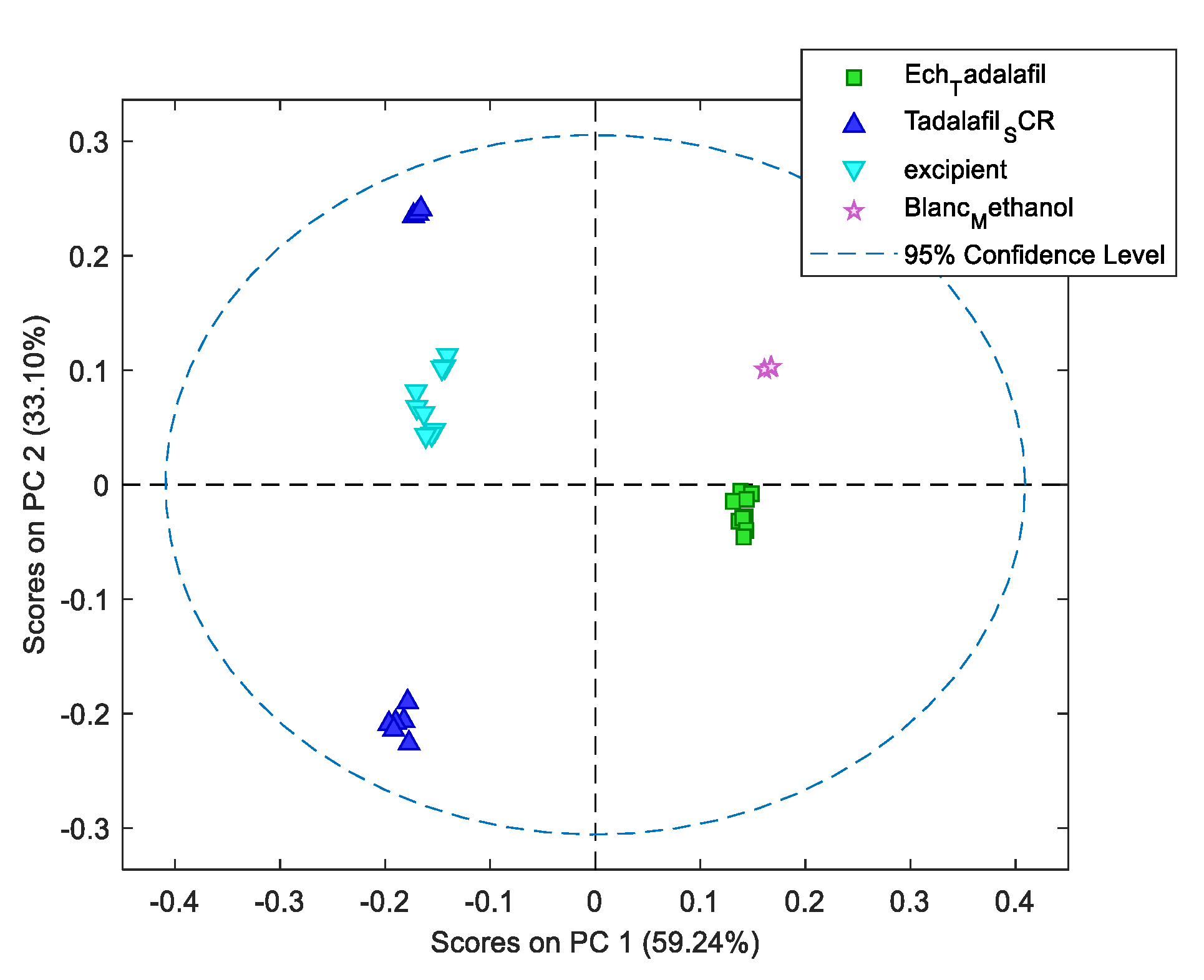
Figure 5.
DD-SIMCA acceptance diagram for calibration samples. Samples below threshold (green color) are considered as standards of the target class and were used to build the model.
Figure 5.
DD-SIMCA acceptance diagram for calibration samples. Samples below threshold (green color) are considered as standards of the target class and were used to build the model.
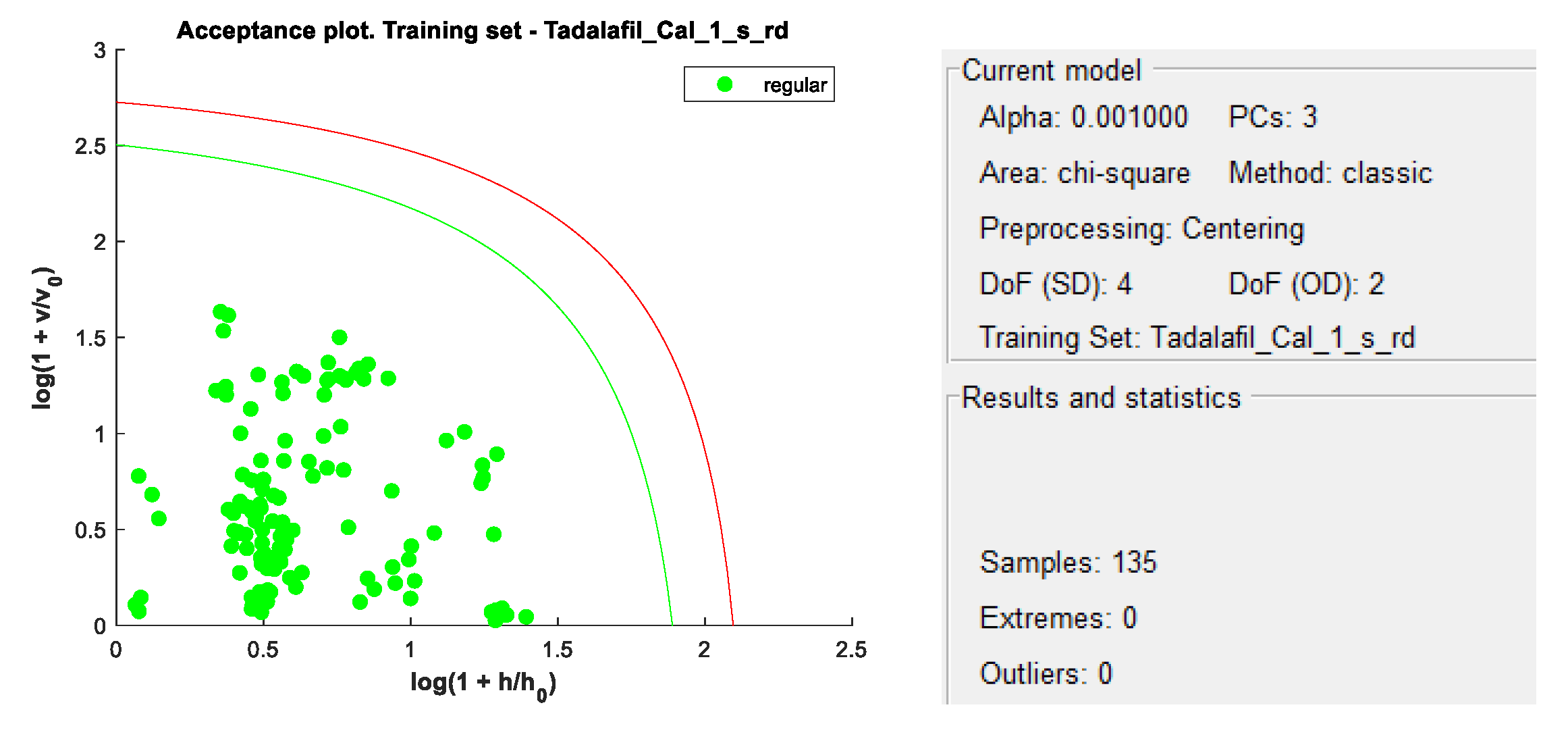
Figure 6.
DD-SIMCA acceptance diagram for validation samples. Samples below the threshold (green) are considered as belonging to the target class. Samples above the threshold (red) are considered outliers.
Figure 6.
DD-SIMCA acceptance diagram for validation samples. Samples below the threshold (green) are considered as belonging to the target class. Samples above the threshold (red) are considered outliers.
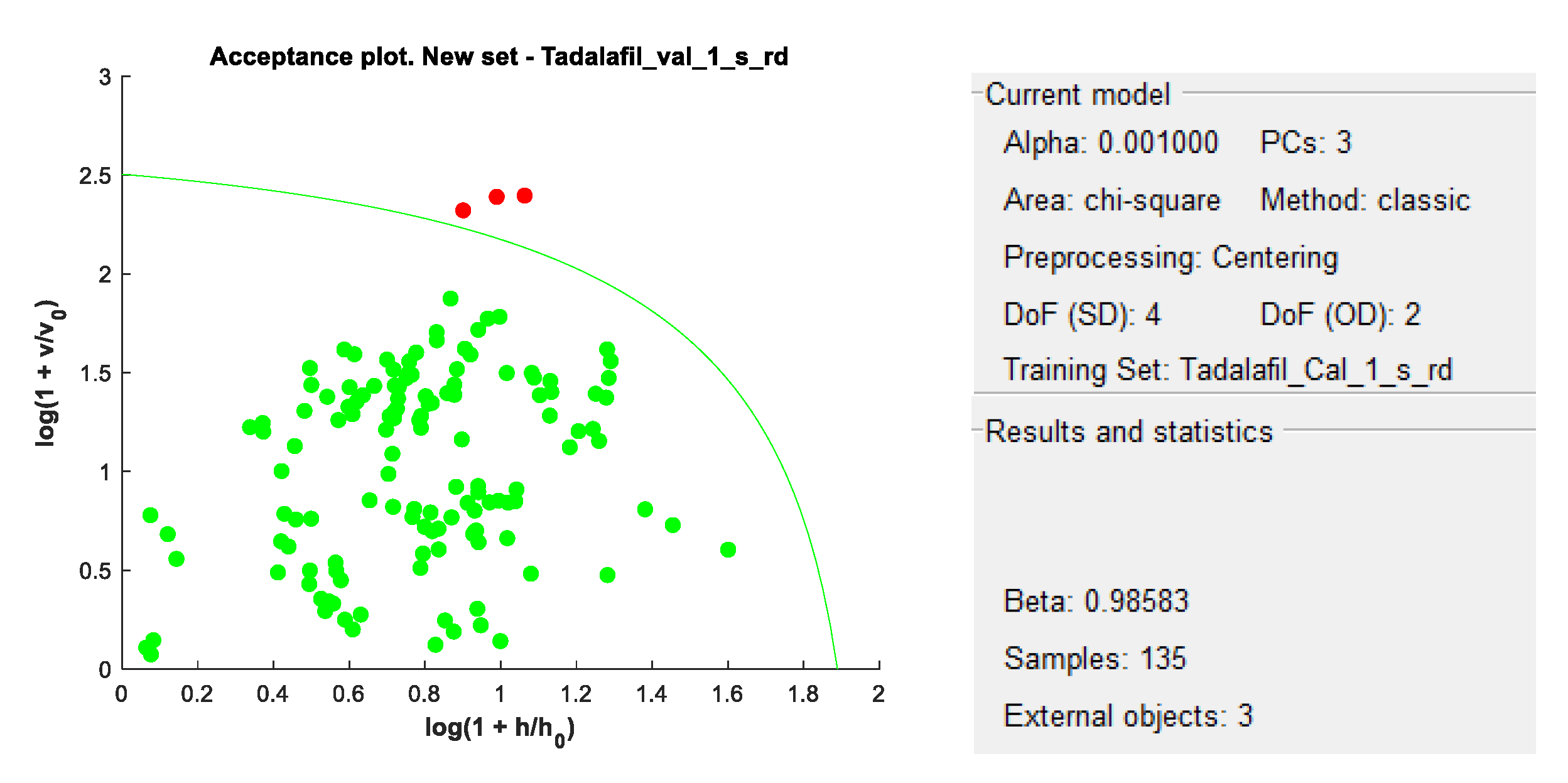
Figure 7.
DD-SIMCA acceptance diagram for X-1 samples. All samples below the threshold (green color) are considered authentic.
Figure 7.
DD-SIMCA acceptance diagram for X-1 samples. All samples below the threshold (green color) are considered authentic.
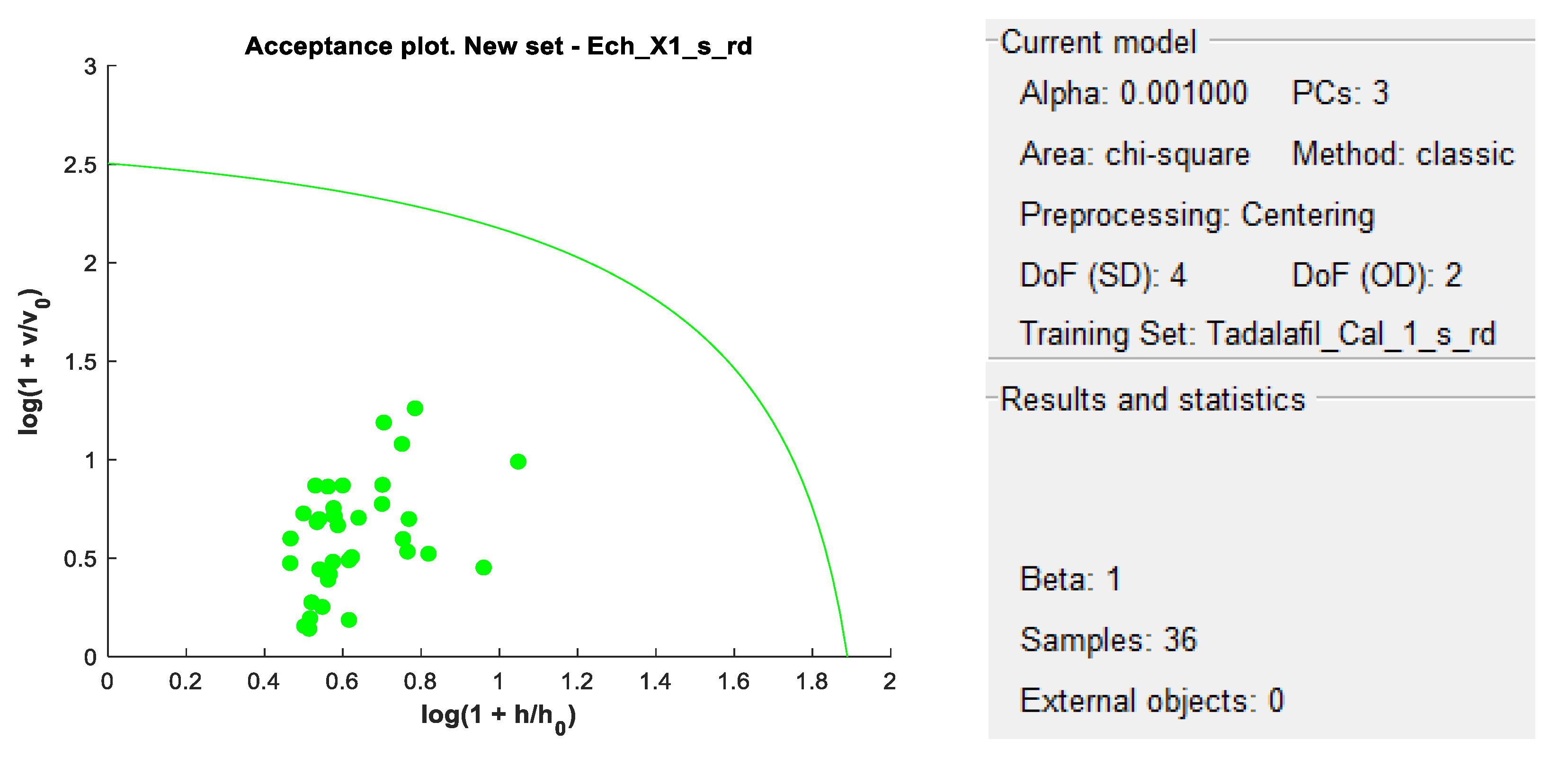
Figure 8.
DD-SIMCA acceptance chart for Cialis samples. Only a third of samples below the threshold (green color) are considered authentic.
Figure 8.
DD-SIMCA acceptance chart for Cialis samples. Only a third of samples below the threshold (green color) are considered authentic.
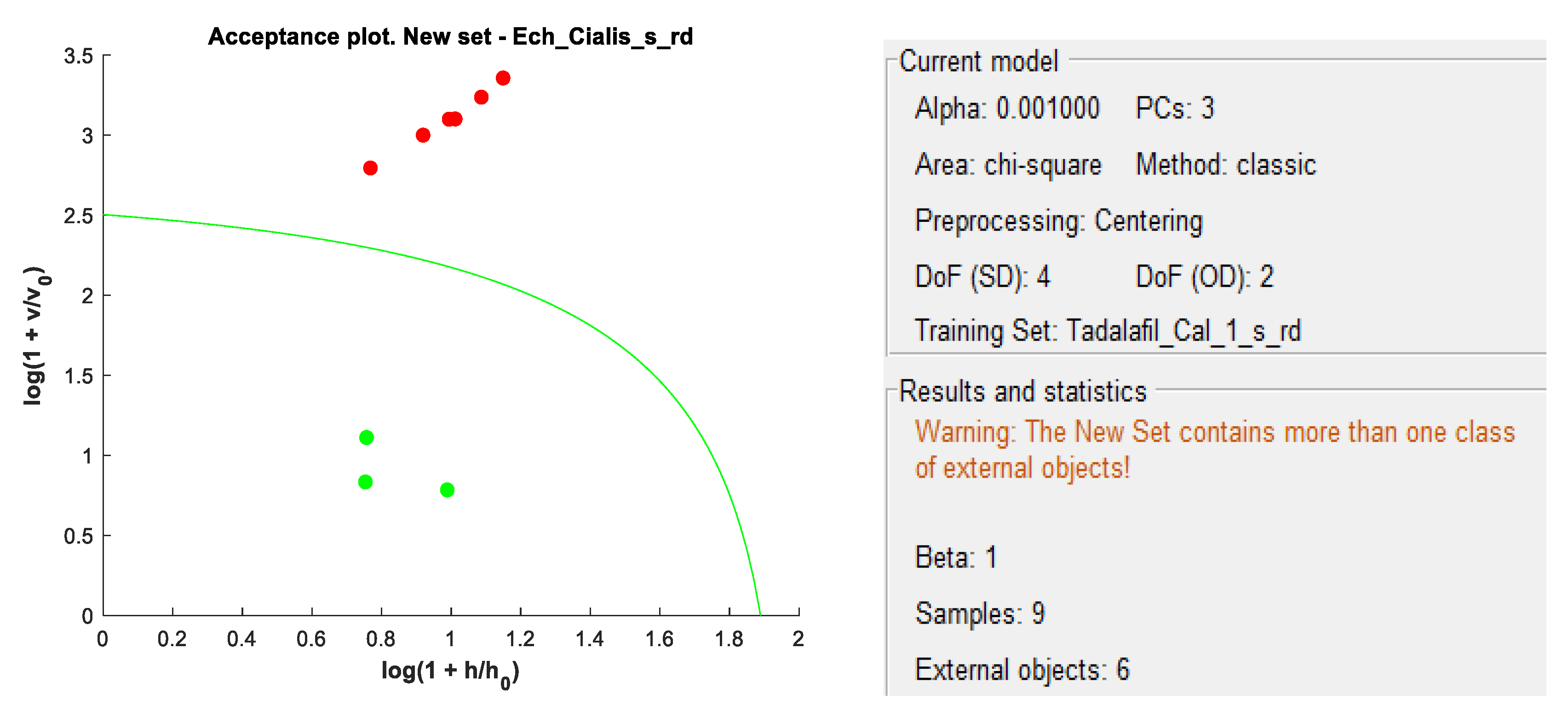
Figure 9.
DD-SIMCA acceptance diagram for matrix and blank. All samples above threshold (red color) are considered outliers.
Figure 9.
DD-SIMCA acceptance diagram for matrix and blank. All samples above threshold (red color) are considered outliers.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



