
Submitted:
06 March 2024
Posted:
07 March 2024
You are already at the latest version
Abstract
The research develops and validates new decomposition models for DNI estimations from Southern African data. The results demonstrated improved DNI estimation accuracy compared to the baseline models across all testing and validation datasets. These outcomes suggest that utilising a localised model can significantly enhance DNI estimations for Southern Africa and potentially for developing similar models in diverse geographic regions worldwide. Furthermore, clustered models highlighted the potential advantages of grouping data based on shared geographical and climatic attributes. This clustering approach could enhance decomposition model performance, particularly when local data is limited or data is available from multiple nearby stations. The Southern African decomposition model, which encompasses a wide spectrum of climatic regions and geographic locations, exhibited notable improvements over the baseline models despite occasional overestimation or underestimation. The overall metrics affirm the substantial advancement achieved with the Southern African model. This study focused on validating the model for hourly DNI in Southern Africa within a range of clearness index-intervals from 0.175 to 0.875. Implementing accurate decomposition models in developing countries can accelerate the adoption of renewable energy sources, diminishing reliance on coal and fossil fuels.
Keywords:
Decomposition Model
; Global Horizontal Irradiance
; Direct Normal Irradiance
; Solar Radiation Model
1. Introduction
Photovoltaic (PV) systems require accurate modelling and monitoring to ensure their profitability. The amount of irradiance at the site, the GPI, is the foundation of designing, modelling and monitoring PV systems. The global plane-of-array irradiance (GPI) comprises the plane-of-array’s (POA) direct beam, ground and diffuse irradiance components. GPI is used to model and monitor PV systems, as this shows the amount of generated solar power and, therefore, one of the most important contributing factors to designing a PV system. The global horizontal irradiance (GHI), direct normal irradiance (DNI) and diffuse horizontal irradiance (DHI) components are required to calculate these irradiance components.
Irradiance components with a transposition model calculate GPI () as
is the direct beam irradiance, is the ground-reflected irradiance, and is the diffuse irradiance component in the POA. GHI, DNI and DHI components are required to calculate , and . The sum of the DNI projected onto the horizontal surface using the cosine of the solar zenith angle , and DHI gives the GHI, shown in Figure 1, [1]:
GHI, DHI, and DNI units are in .
Most ground-based stations have at least measurements of GHI. Other measurements include radiometric data such as DNI, DHI and ultra-violet, and meteorologic data such as the temperature, pressure, rainfall, relative humidity, wind direction and wind speed. Pyranometers measure DHI and GHI, and the pyrheliometer measures DNI.
GHI is measured with a hemispherical view and is mounted horizontally. Similar in setup to other pyranometers, the DHI pyranometer includes the additional feature of being shaded from direct sunlight. The pyrheliometer has a narrow view that only measures the beam directly from the Sun and is usually a Sun tracker for increased accuracy [2]. The irradiance measurements are converted to and logged accordingly.
Calibrating the equipment to the ISO 9060:1990 standard is necessary, and it is advisable to undergo recalibration every two years to ensure the reliability of measurements. The maintenance required is to clean the domes and regularly check and replace the desiccant, which keeps the instruments dry internally.
GHI, DNI and DHI are interdependent; therefore, having only two irradiance measurements is sufficient to estimate the third using the decomposition models (also sometimes called separation models) [3]. If only the GHI is available, the DNI and DHI also are estimated using the decomposition models. The transposition models calculate GPI using the irradiance components. Therefore, GHI, DHI and DNI correlations are usually empirically expressed as a decomposition model [4].
Indices are relationships between different irradiance components. Decomposition and transposition models utilise these relationships.
The definition of the direct beam transmittance and diffuse transmittance is
Liu and Jordan defined the as
All K-values (, and ) are unitless.
The extraterrestrial irradiance on a normal surface depends on the day of the year
The Solar Constant is usually 1,367 .
Determining the horizontal extraterrestrial irradiance involves multiplying it by the cosine of as expressed in Equation (7):
Multipredictor decomposition models can improve accuracy compared to single predictor models [6]. However, the disadvantage is that multiple measurements must be available, which is not always the case for developing countries or brand-new sites of PV installations.
Boland et al. and Ridley et al. developed a logistical model to estimate solar diffuse radiation [7,8]. Soares et al., Talvitie et al., and Kalyanam and Hoffmann have proposed machine-learning-based models to predict solar diffuse and direct components [9,10,11]. Bessafi et al. have proposed a satellite-based decomposition model as an alternative to ground-based measurements [12], and Janjai et al. have proposed statistical models for estimating diffuse radiation [13].
Decomposition models have been developed by assessing previous models and improving the accuracy of these estimations. As more data and measurements become available, researchers have the opportunity to develop models for different climates and temporal resolutions. Most models predominantly use . Some of the variables used in the decomposition models are the solar altitude angle and dew point temperature . Using as the main predictor in decomposition models is popular because of its simplicity and applicability [6].
Orgill and Hollands developed a relationship between the and [14], and Erbs et al. extended the - relationship to latitudes from 31 to 42∘ North [15]. Louche et al. established a GHI and DNI relationship for a Mediterranean site to estimate using [16].
The Direct Insolation Simulation Code (DISC) was developed by Maxwell [17], and Perez et al. developed the Dirint model with the hopes of increasing the performance of the DISC model [18]. The Dirint model of Perez et al. has shown superior performance when estimating the DNI [19].
In Korea, Lee et al. developed a model using 6 Korean locations [20], and Lee et al. developed a new model using Maxwell’s DISC model by refitting the coefficients [3]. Skartveit and Olseth developed a DNI estimation model using the solar elevation angle for Norway based on hourly GHI and DHI records [21].
The main limitations of decomposition models are that some have limited climate scope, and the dataset’s temporal resolution affects the irradiance estimation accuracy. A decomposition model in a tropical climate may be unsuitable for a desert climate and vice versa. Intra-hourly-based models perform differently from daily- or monthly-based models, which is why many available decomposition models exist.
Several regions, such as Belgium [4], China [24], the USA [19], and North Africa [25], evaluated the accuracy of decomposition models.
Gueymard and Ruiz-Arias provided an extensive study of 140 available decomposition models. The authors state that the predicted DNI’s accuracy highly depends on the decomposition model. Validation studies exist but are limited to a few models and test stations, i.e. biased to a specific location or climate [26]. Research indicates that no decomposition model has been developed and validated for South Africa.
Laiti et al. state that, in general, decomposition models tend to overestimate DHI and underestimate DNI and typically, models tend to underestimate DHI in overcast periods and overestimate during clear-sky periods [19].
Higher resolution data include higher values, resulting in extreme overestimations of DNI. These hourly DNI estimates have higher accuracy than 1-minute DNI estimates. Subhourly estimations would be highly beneficial for real-time monitoring and forecasting of solar power [26].
Figure 2 visualises the testing and validation countries of common decomposition models in green of models such as Orgill and Hollands, Erbs et al., Louche et al., Reindl et al., DISC (Maxwell), Dirint (Perez et al.), Lee et al., Lee et al., Skartveit and Olseth and Lam and Li) [3,14,15,16,17,18,20,21,22,23].
The development of the decomposition model in South America includes Brazil [28], Argentina and Brazil [29]. Northern African models include Nigeria [30], Algeria [31] and Morocco [32].
Engerer developed a model for Australia and observed that the model only slightly outperformed the Dirint model [33]. The BRL model by Ridley et al. developed a method to construct multiple variable logistic models for the diffuse solar fraction, which includes Mozambique [8]. Figure 2 represents these discussed models [8,28,29,30,31,32,33] in red.
South African research on decomposition models includes the following: Tsubo and Walker published the only Southern African-based study on the relationship between radiation and [34]. However, this relationship is with photosynthetically active radiation related to agricultural practices, not PV systems. Clear-sky model assessments and validation studies have been performed by [35] and [36] for Southern African countries. Clear-sky models simplify atmospheric attenuation to estimate solar irradiance under clear-sky conditions and do not represent decomposition models and is not include these studies as comparison models, as they are irrelevant to the research.
Mahachi’s thesis assessed decomposition and transposition models in South Africa and showed that the models tend to overestimate the DHI but underestimate the DNI [37]. Furthermore, the DISC and Dirint decomposition models showed the most accurate estimations of the DNI and DHI for the South African climatic conditions [38].
As discussed, decomposition models are empirical relationships between GHI, DHI and DNI. All three irradiance components are required to estimate GPI. Decomposition models are useful as it reduces the measurement equipment by decomposing one irradiance component into two other; for example, use GHI to estimate DHI and DNI.
Most decomposition models are not universally applicable and localised to a specific climate, and the temporal resolution is not always transferable. There has not been extensive literature published representing the Southern African region in decomposition models, which this research article will attempt to address.
2. Model Development
The methodology to develop a novel decomposition model is based on selected data from the automated QC procedure and addresses three geographical models:
- a localised decomposition model, which is site-specific;
- a clustered decomposition model, which encapsulates several sites to group an area based on their geographical location;
- and a regional (Southern African) model, which encapsulates the data from the SAURAN network for developing a model specific to Southern Africa.
2.1. SAURAN Database
Table 1 summarises the SAURAN stations’ corresponding geographical information, such as latitude, longitude, and elevation above sea level.
Table 3 shows the data points available for the model development, taken from Table 2. Further, the data points assessed are between 0.175 and 0.875.
The data points are hourly measurements of the GHI, DNI and DHI. The split of the train-validation-test datasets is 50:25:25, with the exceptions of two datasets, ILA and MIN. The ILA and MIN have a 0:0:100 data split and are two unknown datasets as part of the test study.
Table 3 also shows each station’s mean GHI, DNI, and DHI determined after applying the QC procedure.

Table 2.
SAURAN database and dataset sizes from [39].
Table 2.
SAURAN database and dataset sizes from [39].
| Station | Dataset size | Start Date | End Date | |
|---|---|---|---|---|
| Before QC | After QC | |||
| CSIR | 46,434 | 26,539 | 11 March 2017 | 31 October 2022 |
| CUT | 28,077 | 14,619 | 24 October 2017 | 31 October 2022 |
| FRH | 40,895 | 22,233 | 7 February 2017 | 24 February 2022 |
| GRT | 18,541 | 9774 | 27 November 2013 | 24 January 2016 |
| HLO | 21,532 | 11,728 | 8 October 2015 | 27 October 2020 |
| ILA | 8832 | 4676 | 13 October 2021 | 31 October 2022 |
| KZH | 52,323 | 38,898 | 7 December 2015 | 07 August 2022 |
| KZW | 20,291 | 10,756 | 7 December 2015 | 12 December 2018 |
| MIN | 8185 | 4423 | 28 October 2021 | 31 October 2022 |
| MRB | 4201 | 2462 | 17 March 2017 | 22 October 2019 |
| NMU | 39,969 | 23,130 | 10 December 2015 | 30 September 2022 |
| NUST | 52,004 | 27,401 | 26 July 2016 | 31 October 2022 |
| PMB | 9773 | 5415 | 13 July 2021 | 31 October 2022 |
| RVD | 63,716 | 34,457 | 27 March 2014 | 28 July 2021 |
| SALT | 14,151 | 9908 | 21 July 2017 | 22 December 2020 |
| STA | 40,256 | 21,751 | 7 December 2015 | 19 April 2021 |
| SUN | 87,720 | 47,733 | 24 May 2010 | 31 October 2022 |
| SUT | 1715 | 902 | 8 February 2017 | 20 April 2017 |
| UBG | 38,917 | 20,646 | 26 November 2014 | 6 November 2020 |
| UFS | 31,665 | 17,152 | 16 January 2014 | 30 August 2017 |
| UNV | 59,100 | 33,144 | 23 April 2015 | 31 October 2022 |
| UNZ | 56,399 | 30,373 | 11 July 2014 | 31 October 2022 |
| UPR | 78,792 | 42,128 | 19 September 2013 | 31 October 2022 |
| VAN | 24,701 | 13,234 | 26 August 2016 | 10 July 2019 |
Table 3.
Model development stations indicating the mean GHI, DNI and GHI and sizes of training, validation and testing sets.
Table 3.
Model development stations indicating the mean GHI, DNI and GHI and sizes of training, validation and testing sets.
| Station | Mean1 | Dataset2 | Cluster Allocation | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| GHI [] | DNI [] | DHI [] | Total | Train | Validation | Test | ||||
| CSIR | 575 | 599 | 167 | 14,991 | 7,495 | 3,748 | 3,748 | 2 | ||
| CUT | 609 | 639 | 159 | 9,161 | 4,580 | 2,290 | 2,291 | 2 | ||
| FRH | 544 | 583 | 151 | 12,224 | 6,112 | 3,056 | 3,056 | 4 | ||
| GRT | 573 | 624 | 151 | 5,788 | 2,894 | 1,447 | 1,447 | 4 | ||
| HLO | 550 | 608 | 138 | 7,061 | 3,530 | 1,765 | 1,766 | 1 | ||
| ILA | 589 | 680 | 131 | 2,709 | 0 | 0 | 2,709 | 1 | ||
| KZH | 533 | 517 | 179 | 8,782 | 4,391 | 2,195 | 2,196 | 3 | ||
| KZW | 531 | 511 | 184 | 5,945 | 2,972 | 1,486 | 1,487 | 3 | ||
| NMU | 556 | 545 | 165 | 10,562 | 5,281 | 2,640 | 2,641 | 4 | ||
| NUST | 614 | 670 | 149 | 15,901 | 7,950 | 3,975 | 3,976 | 1 | ||
| MIN | 564 | 573 | 161 | 2,761 | 0 | 0 | 2,761 | 2 | ||
| RVD | 630 | 729 | 125 | 19,624 | 9,812 | 4,906 | 4,906 | 1 | ||
| SUN | 556 | 645 | 133 | 28,508 | 14,254 | 7,127 | 7,127 | 1 | ||
| UBG | 591 | 602 | 158 | 12,137 | 6,068 | 3,034 | 3,035 | 2 | ||
| UFS | 567 | 654 | 137 | 10,257 | 5,128 | 2,564 | 2,565 | 2 | ||
| UNV | 579 | 524 | 197 | 15,874 | 7,937 | 3,968 | 3,969 | 2 | ||
| UNZ | 530 | 528 | 176 | 10,055 | 5,027 | 2,514 | 2,514 | 3 | ||
| UPR | 568 | 609 | 163 | 28,089 | 14,044 | 7,022 | 7,023 | 2 | ||
| VAN | 597 | 683 | 126 | 7,860 | 3,930 | 1,965 | 1,965 | 1 | ||
1 Daylight average, 2 Dataset size after quality control as in [40] and
2.2. Comparison Metrics
The comparison metrics are the root mean square error (RMSE), mean absolute error (MAE) and mean bias error (MBE).
where is the measured value, and is the predicted value. A low RMSE and MAE indicate a good model, whereas an MBE should be closer to zero. RMSE indicates the concentration of data around the line of best fit. Therefore, a smaller RMSE is indicative of a more accurate model.
The Pearson correlation coefficient r indicates the correlation between data:
In Equation (9), and represent the individual points with index i and and represent the mean of the x and y sample set. An r closer to -1 has a negative correlation, meaning if one variable increases, the other decreases. In contrast, if r is closer to 1, it has a positive correlation, meaning if one variable increases, the other would also [41].
Statistical indicators used for the comparison metrics are the MBE, RMSE and MAE, all expressed as a percentage of the mean measured DNI [26] and . Further comparison metrics are two MAE -intervals: and .
The MBE indicates whether a model over or underestimates the DNI, and the RMSE indicates the deviation of the errors. A significant difference between MAE and RMSE indicates a larger variance in the data. Lower RMSE and MAE are ideal, whereas an MBE closer to zero is optimal. The MAE is an unbiased estimator and also evaluates the two intervals. Lower and higher indicate overcast and clear-sky conditions, respectively. Therefore, the two intervals assess the models under varying weather conditions.
2.3. Regression and Fitting
The relationship between two variables is quantified using statistical methods like regression. Regression techniques can be linear, multi-linear and non-linear.
The definition of a linear relationship is
where y is the response, x is the regressor, is the intercept, and is the slope. A regression analysis quantifies the strength of a relationship between y and x [41].
The least squares method estimates and so that the sum of the squares of the residuals is at a minimum. The residual sum of squares is denoted as and is the sum of squares of the errors about the regression line. Thus, the minimisation of
where denotes the predicted or fitted value.
The coefficient of determination, , indicates how good the fit of a model is and is a number between zero and one.
A higher -value indicates that the model explains the variation in the response variable around its mean, and the regression model fits the observation better [41].
Polynomial regression is the modelling of a dependent, y, as an -degree polynomial of x
Exponential regression is where the best fit of an equation is an exponential function, like
or
Multi-linear regression has multiple variables, which is the outcome of a response variable
2.4. Software Development Tools
2.5. Baseline Models
Three comparative models are used as a baseline to compare the new models. Based on the literature, the DISC and Dirint models performed well for Southern African climates [38,46].
The Dirint [18] and Lee [3] models are also used for comparison because their foundation is similar to the DISC model [17].
Maxwell’s DISC quasi-physical approach has three assumptions [3]:
- The relative air mass is the dominant parameter affecting the relationship between and ;
- The physical model used to calculate will provide a physically-based reference from which the changes in can be calculated (see Equation (20) below);
- Seasonal, annual and climate variations in the relationship between and are fully accounted for by parametric functions in that relate to , cloud cover and PW vapour.
is defined as [47]
The absolute AM () is the pressurised normalisation of AM, expressed as
where P refers to the atmospheric pressure at the test site, and is the atmospheric pressure at sea level.
The clear-sky limit is a polynomial in :
Two intervals determine the coefficients and : and .
For
For
Maxwell’s model possesses a different functional form because the quasi-physical approach is applied; therefore, it partially reflects the physics involved in the atmospheric transmission of solar radiation [3]. The , and parameters were fitted based on solar radiation data from Atlanta, Georgia, USA, 1981 [17]. Maxwell adopted the Bird clear-sky model for (see Equation (22)). The parameters , and , as described in Equations (23) and (24), were then fitted based on the dataset.
The DISC model, termed ‘quasi-physical’, combines a clear-sky model with experimental fits for other sky conditions. The model is a clear-sky irradiance attenuated by a function of . Maxwell derived the empirical regressions from 12 years of recorded radiation data at 70 stations [4,17].
The Dirint model is based on the DISC model and was developed by Perez et al. [18]. The goal was to improve the accuracy of the DISC model by Maxwell [17].
The Dirint model uses a clearness index variation parameter :
Furthermore, a stability index parameter :
considers the previous (), current (i) and next hourly () record. When the preceding or hourly record is missing, is
A low is a stable condition, whereas a high characterises unstable conditions, which allows the distinction between hazy and partly cloudy conditions. The is an adequate atmospheric PW estimator [18]. The Dirint model’s atmospheric PW (W) is estimated using:
The Dirint is a four-dimension conditional model, having the , , and W. Based on the four-dimensional model, the calculation of hourly DNI is
where
Coefficients and are from a complex lookup table.
Lee et al. created a new model for Korea with the same format as Maxwell’s DISC model.
For
or
The evaluation consists of comparing the localised, clustered and regional models against the three baseline models: DISC, Dirint and Lee. The DISC and Dirint models were selected based on their performance in estimating DNI for Southern African climates. The Lee and Dirint models have foundational similarities to the DISC model. These models consider whether the newly developed decomposition model improves the accuracy of hourly DNI estimations for Southern Africa. The accuracy evaluation uses the comparison metrics discussed in the next section.
2.6. Decomposition Model Development Methodology
The methodology builds on the DISC model. The DISC model stands out as one of the better-performing models for estimating DNI for South Africa [38]. Its simplicity is evident in its lack of need for a complex four-dimensional lookup table, unlike the Dirint model.
The original DISC model uses Equation (21), an exponential function. However, the regression model for an exponential function, as discussed in Section 2.3, showed difficulty in finding optimal a, b and c coefficients in all cases. Instead, a second-order polynomial function of
is a suitable substitute with similar regression results.
The training set then fits a, b and c for intervals and :
and the validation and testing sets evaluate the model’s accuracy.
Each model development undergoes the following initial processing steps:
- Empirical formulae estimate , , pressure, , and . From this, the assessment of available models aids in developing a new model;
- Data is split into intervals of 0.05 , starting from 0.175 to 0.875;
- is then modelled as Equation (34);
- The interval or intervals are then fitted against the function to determine Equation (34) to determine the a, b and c coefficients using a least squares regression analysis;
- From the -interval function, the -, - and - coefficients are fitted to a polynomial of Equation (35) with regards to ;
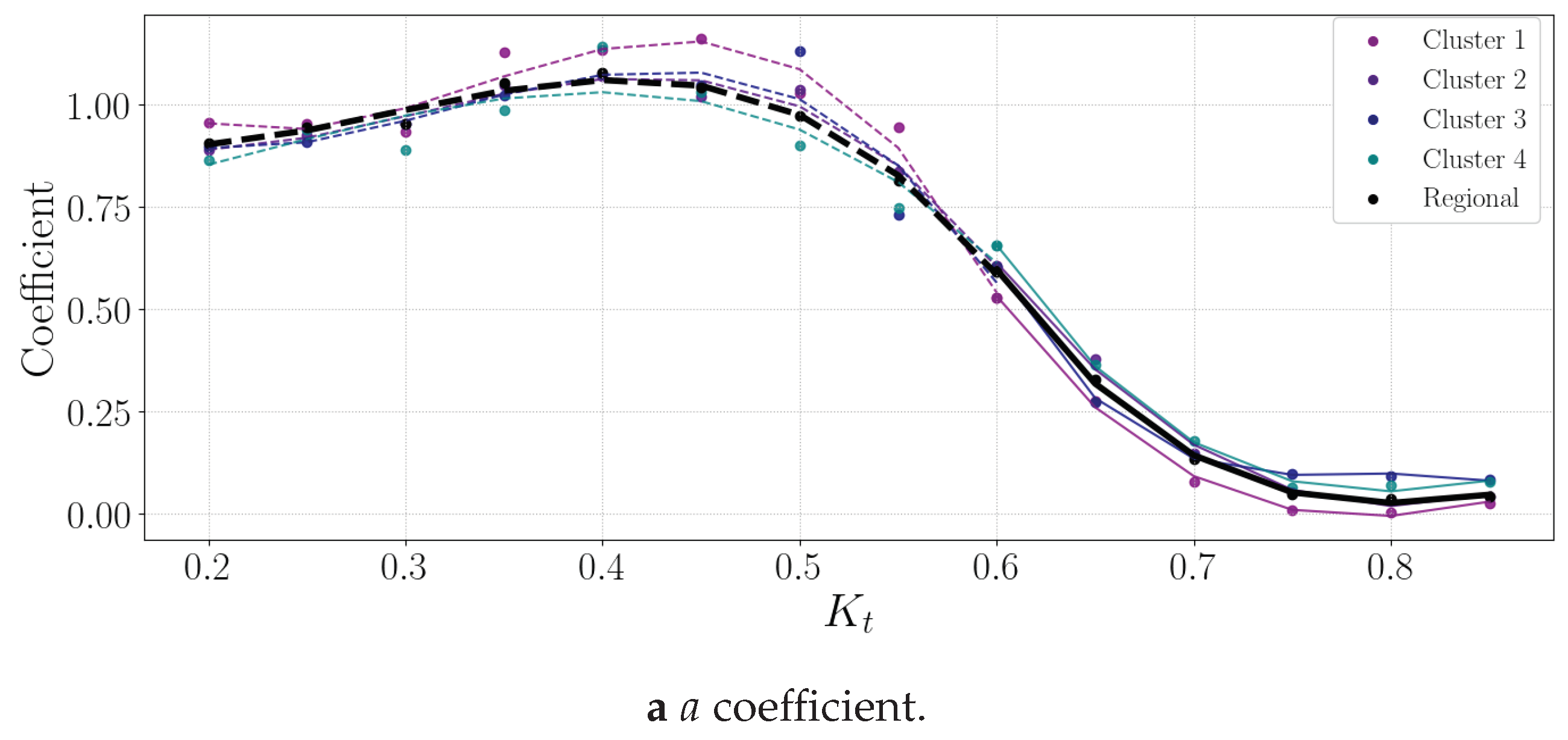
For each SAURAN station, a localised decomposition model is developed. A clustered decomposition model describes an area with similar irradiance patterns using the clustered areas discussed in [40]. Farmer and Rix first presented a two-cluster correlation map using the SAURAN database [48] and, by using this approach, this study formulated four clusters instead of two in Southern Africa, as shown in Figure 3a.
Figure 3a shows the clusters’ geographical location, and Figure 3b shows the penetration levels of GHI. Table 4 shows the different clusters’ training sets’ mean GHI, DNI and DHI.
Figure 3.
Clusters within the Southern African context.
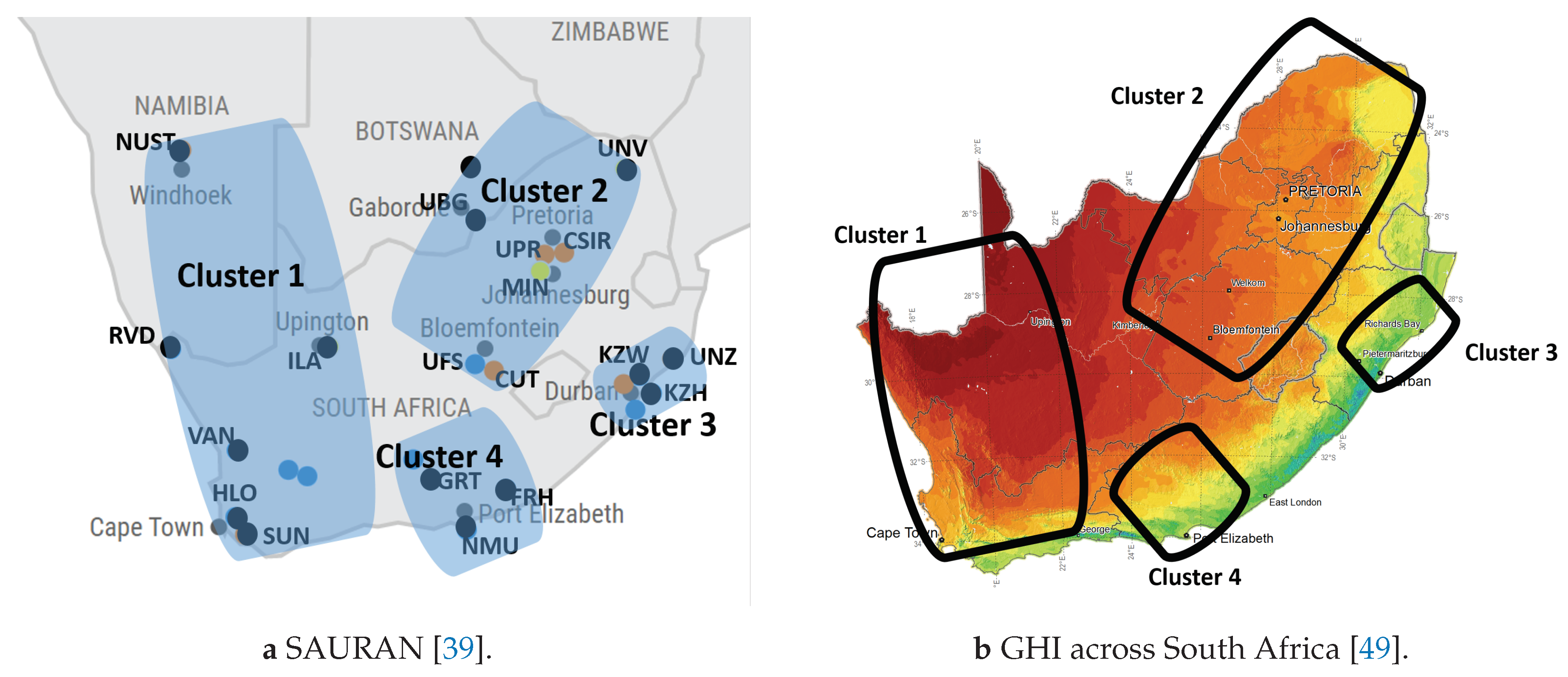
Cluster 1 receives the most GHI and DNI, and Cluster 3 receives the least, as evident from Figure fig:Clustersb. The different climates are also evident in these clusters: Cluster 3 is more humid and receives, on average, more DHI than Cluster 1.
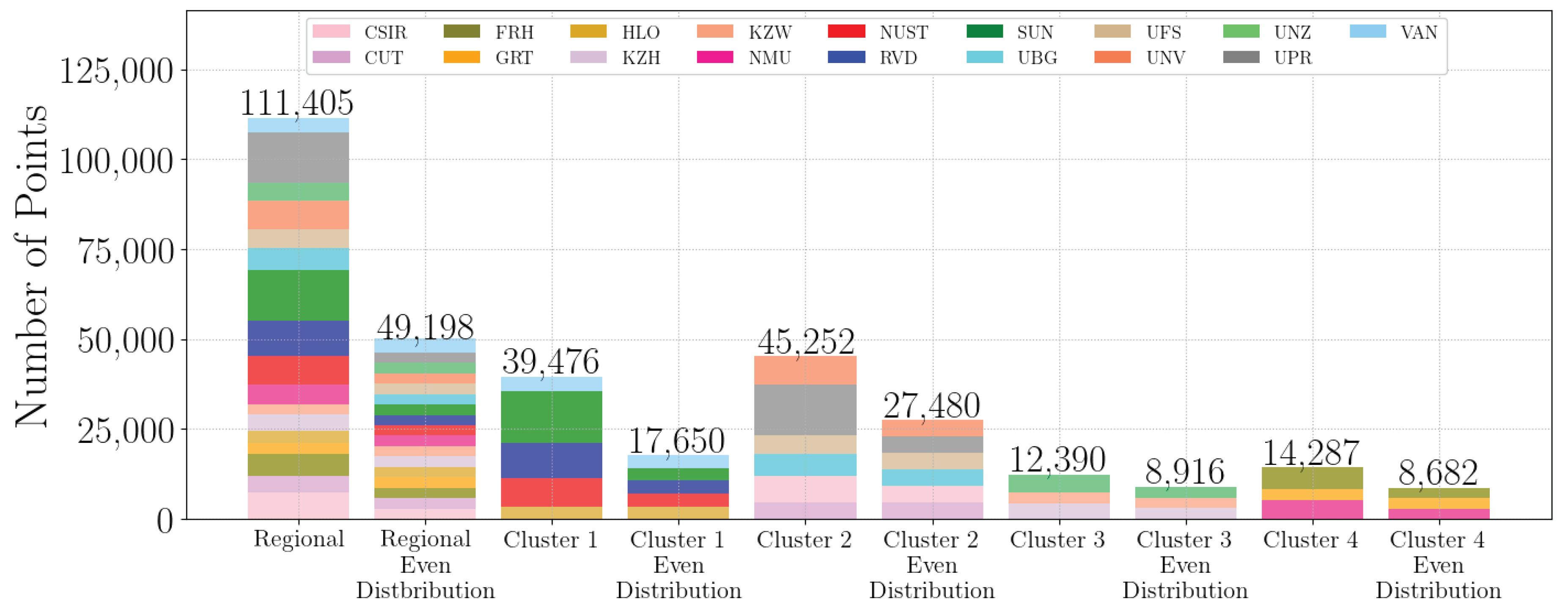
Figure 4 shows how the cluster data is combined. Each cluster and the regional (Southern African) model are combined with even distributions of datasets to avoid introducing a bias, as some stations are over-represented in the original data set. Some stations, such as the SUN, UPR and RVD stations, have considerably more data available as they are either older stations or have not been closed down.
The different stations have varying climates, and therefore, a larger representation of one station will result in a biased model towards that station. The advantage of the even distribution is that every station is sufficiently represented and will not cause a model bias, but this reduces the amount of available data.
Cluster 2’s stations have higher elevation and summer humidity due to its warm, rainy summers and dry, cold winters. The expected annual irradiance levels are lower, as seen in Figure 3b. The stations have higher humidity because of their location and higher DHI levels.
The two stations in Cluster 2, UPR and CSIR, are expected to have more diffuse particles due to the higher air pollution levels and, therefore, higher DHI levels. Cluster 2 has a large bias of the data from Pretoria, South Africa, from the CSIR and UPR datasets.
Cluster 4 has lower annual irradiance levels, as seen in Figure 3b, and FRH and NMU are closer to the coastline, whereas GRT is inland.
3. Development of New Decomposition Models
The section consists of three subsections:
- The localised decomposition models, developed using the training dataset of the SAURAN station;
- The clustered decomposition models, which are modelled on the training data of all the stations within the cluster, as discussed in Figure 4;
- And the regional model is modelled on all the stations’ training data (Table 3).
3.1. Localised Decomposition Models
The localised decomposition model equations for the a, b and c coefficients are presented in Appendix A.
3.2. Cluster Decomposition Models
Figure 5, Figure 6, Figure 7 and Figure 8 show the different corresponding clusters’ model coefficients.
3.2.1. Cluster 1
Figure 5 shows the Cluster 1 and five stations’ a, b and c coefficients. The discussion of the different stations is in Appendix A under Subsections A.5 (HLO), A.11 (NUST), A.12 (RVD), A.13 (SUN) and A.19 (VAN).
The RVD model is the only model showing difficulty fitting the coefficients with . Table 3 indicates that the RVD station has the highest mean DNI and GHI, with the lowest DHI measurements, compared to the rest of Cluster 1’s stations.
Figure 5.
Cluster 1 coefficients in .
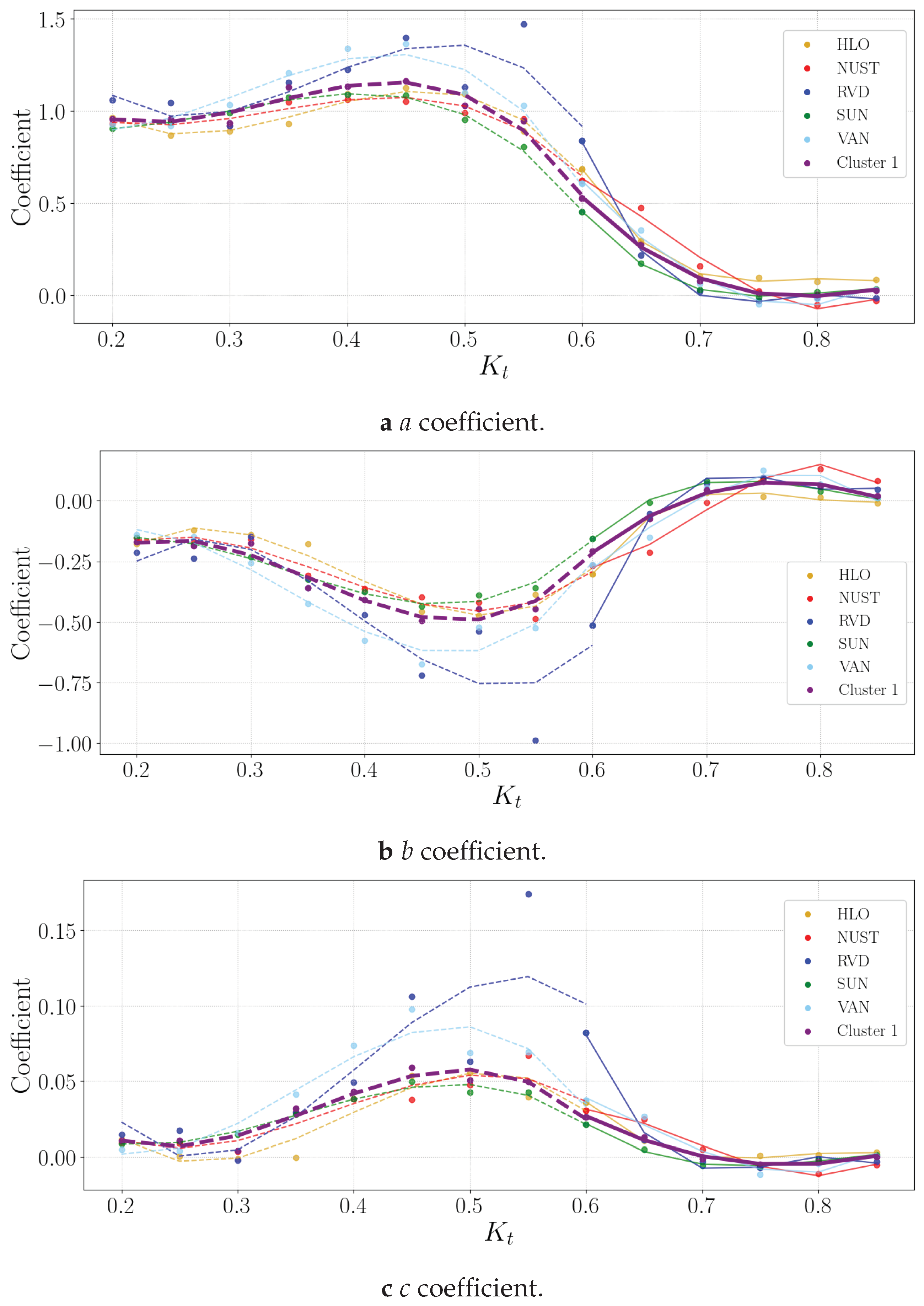
The coefficients for Cluster 1 are
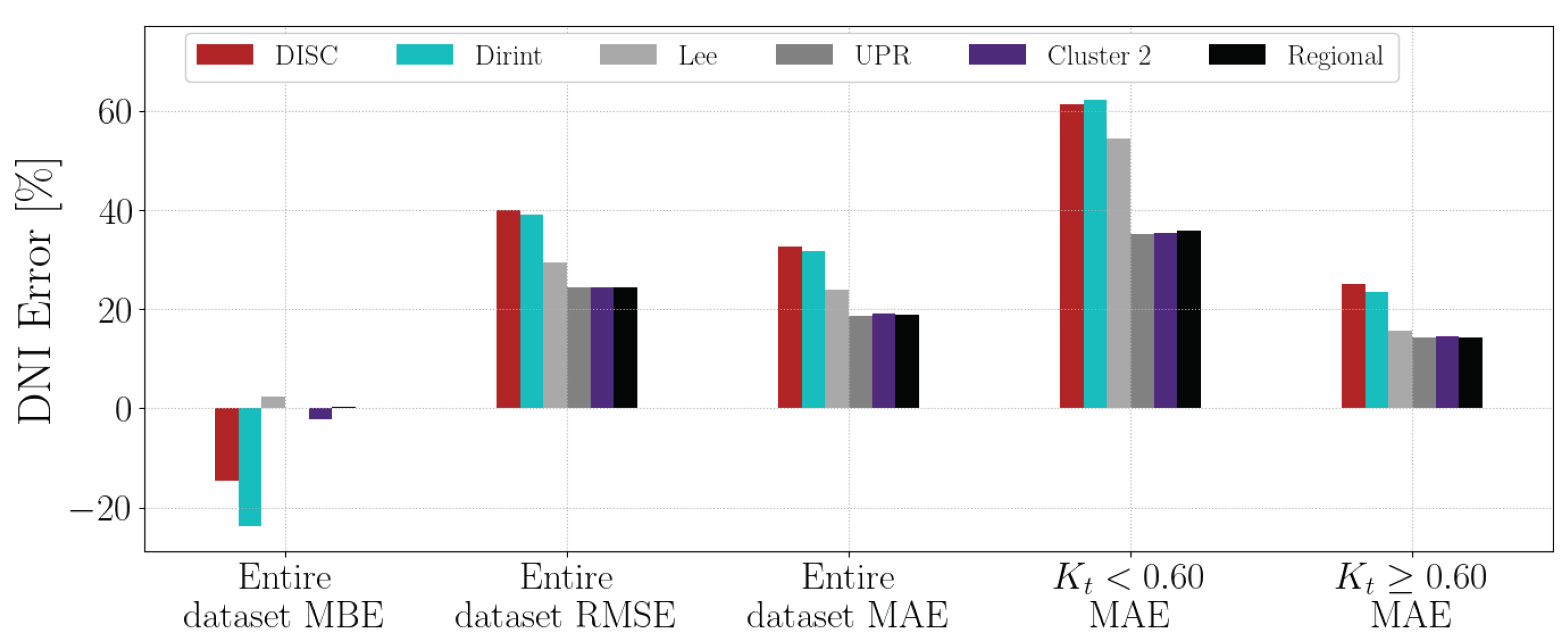
3.2.2. Cluster 2
Cluster 2 consists of the CSIR, CUT, UBG, UFS, UPR, and UNV datasets. Figure 6 shows the Cluster 2 and six stations’ a, b and c coefficients.
The discussion of the different stations are in Appendix A under Subsections A.1 (CSIR), A.2 (CUT), A.14 (UBG), A.15 (UFS), A.18 (UPR) and A.16 (UNV). The UFS have the greatest deviation from the Cluster 2 fit.
Figure 6.
Cluster 2 coefficients in .
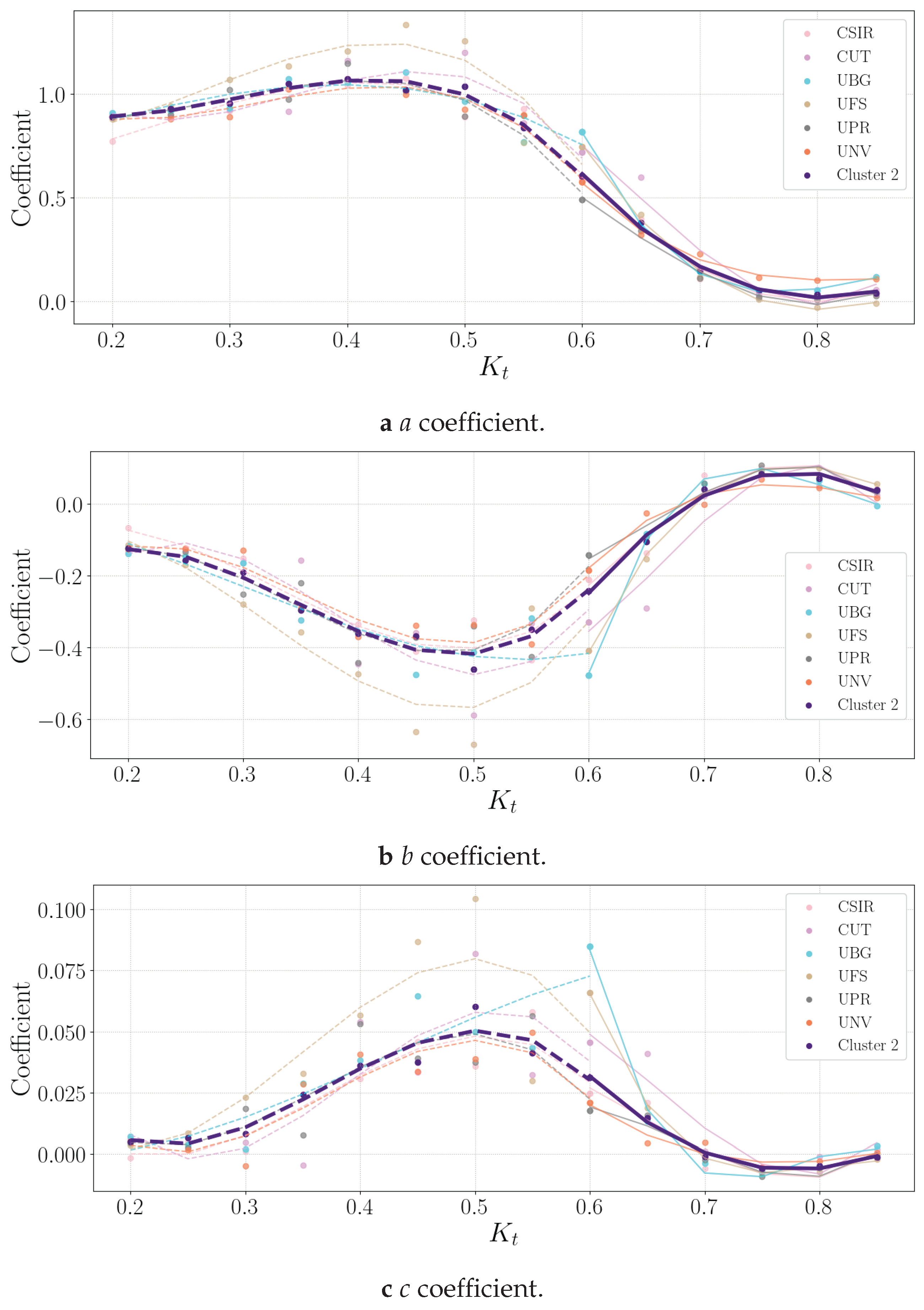
The coefficients for Cluster 2 are
3.2.3. Cluster 3
Cluster 3 consists of the KZH, KZW and UNZ datasets. Figure 7 shows the Cluster 3 and three stations’ a, b and c coefficients.
The discussion of the different stations is in Appendix A under Subsections A.7 (KZH), A.8 (KZW) and A.17 (UNZ). The three models fit quite well and are similar to Cluster 3.
Figure 7.
Cluster 3 coefficients in .
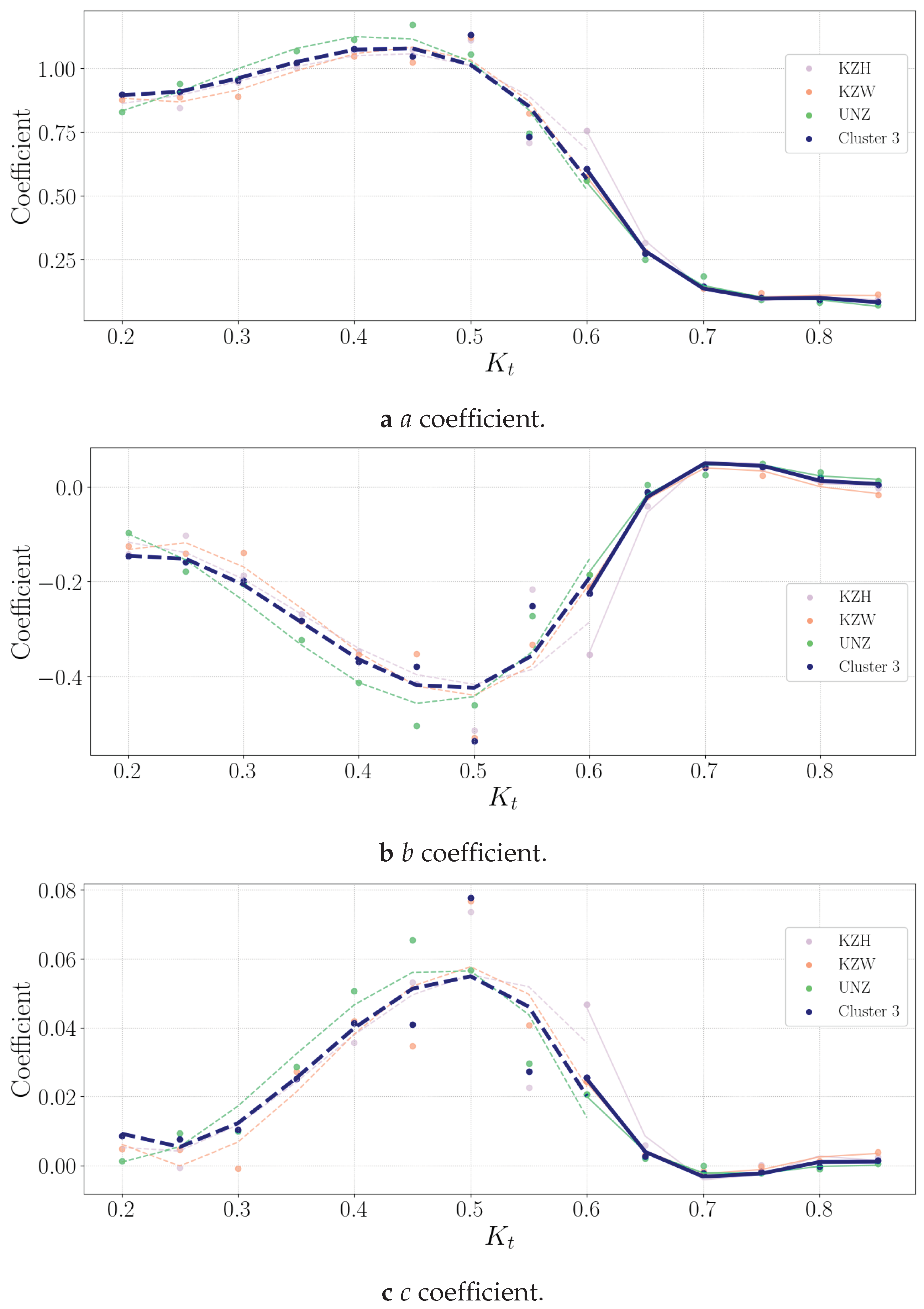
The coefficients for Cluster 3 are
3.2.4. Cluster 4
Cluster 4 consists of the NMU, FRH and GRT datasets. Figure 8 shows the Cluster 4 and three stations’ a, b and c coefficients.
The discussion of the different stations is in Appendix Avvvv under Subsections A.10 (NMU), A.3 (FRH) and A.4 (GRT). The GRT station’s c-coefficient does show difficulty in a fit determination.
Figure 8.
Cluster 4 coefficients in .
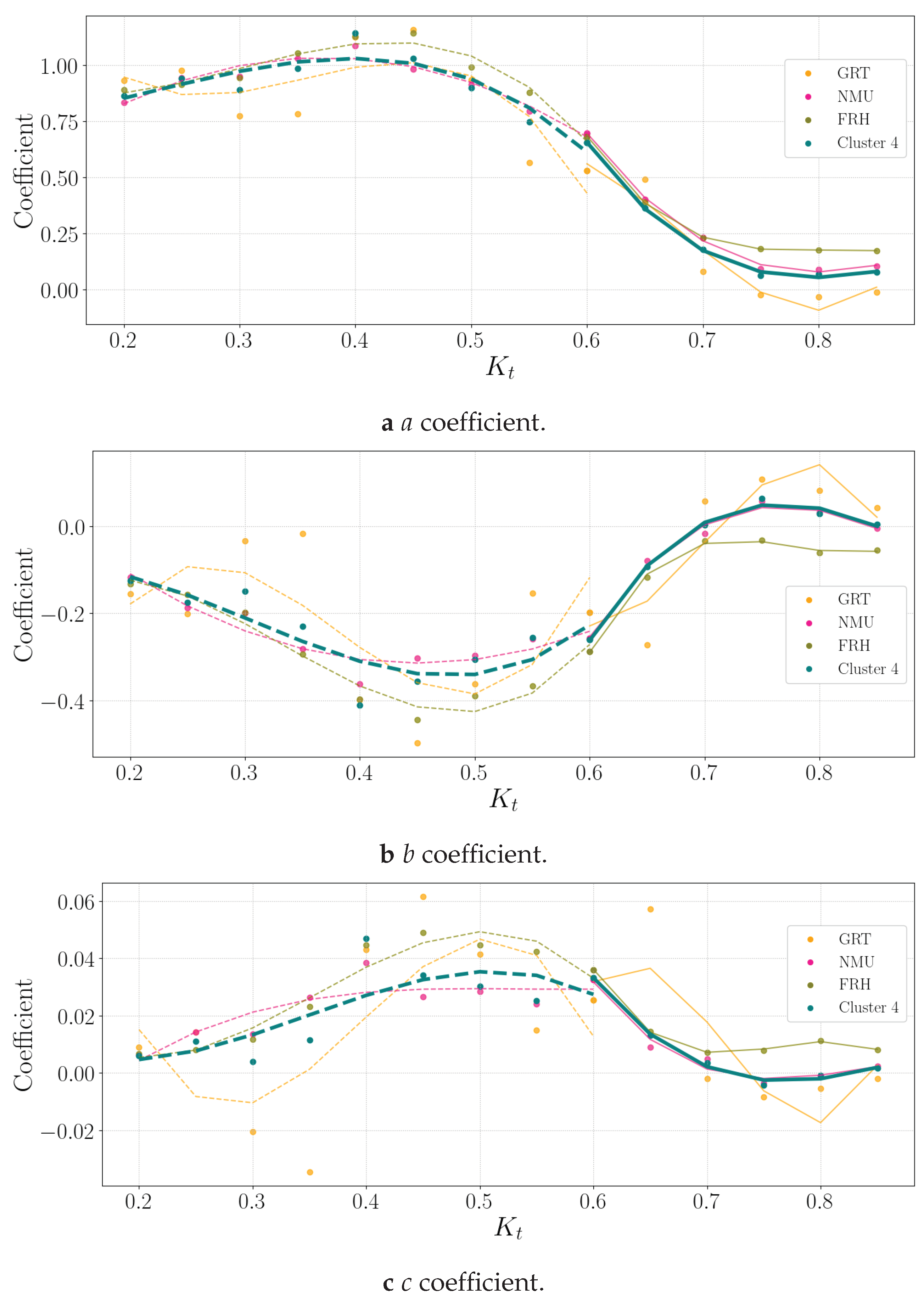
The coefficients for Cluster 4 are
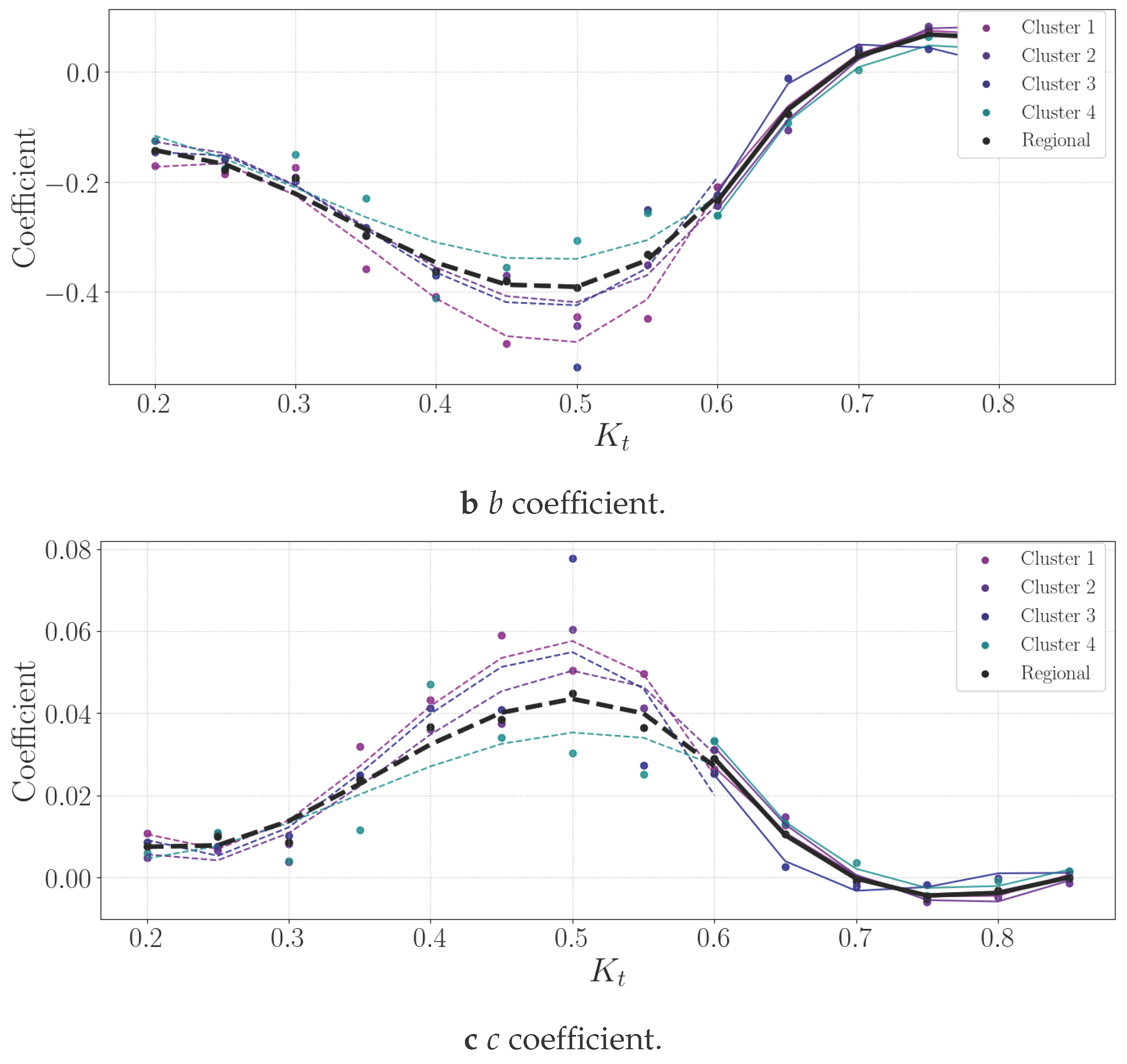
3.3. Regional Decomposition Model
The regional (Southern African) decomposition model data is an even distribution of the SAURAN stations regarding the number of data points used per station. Multiple climates, different elevations and pollution levels are represented within the dataset, leading to a better decomposition model for Southern Africa and a regional application.
The coefficients for the regional model are
Figure 9.
Regional model coefficients in .
4. Results
Each station is discussed individually by assessing the dataset’s comparison metrics: the -value, MBE, RMSE and MAE, and the MAE of two -intervals. The results compare the localised, clustered and regional (Southern African) models to the three baseline models, DISC, Dirint and Lee. The tables visualise the results for each station using red and green, with green denoting lower error and red denoting higher error.
Table 3 discusses the validation data. In the previous section, the localised, clustered, and regional models were empirically determined. Appendix A expands on the equations for the localised models.
Section 3.2 and Section 3.3 discussed the clustered and regional models. The test data also introduces two unknown datasets, the ILA and MIN datasets. These datasets assess the models with new data for the developed models. ILA and MIN have no localised model, but geographically, they fall within a cluster: ILA falls under Cluster 1 and MIN under Cluster 2.
4.1. Testing and Validation Results
4.1.1. CSIR
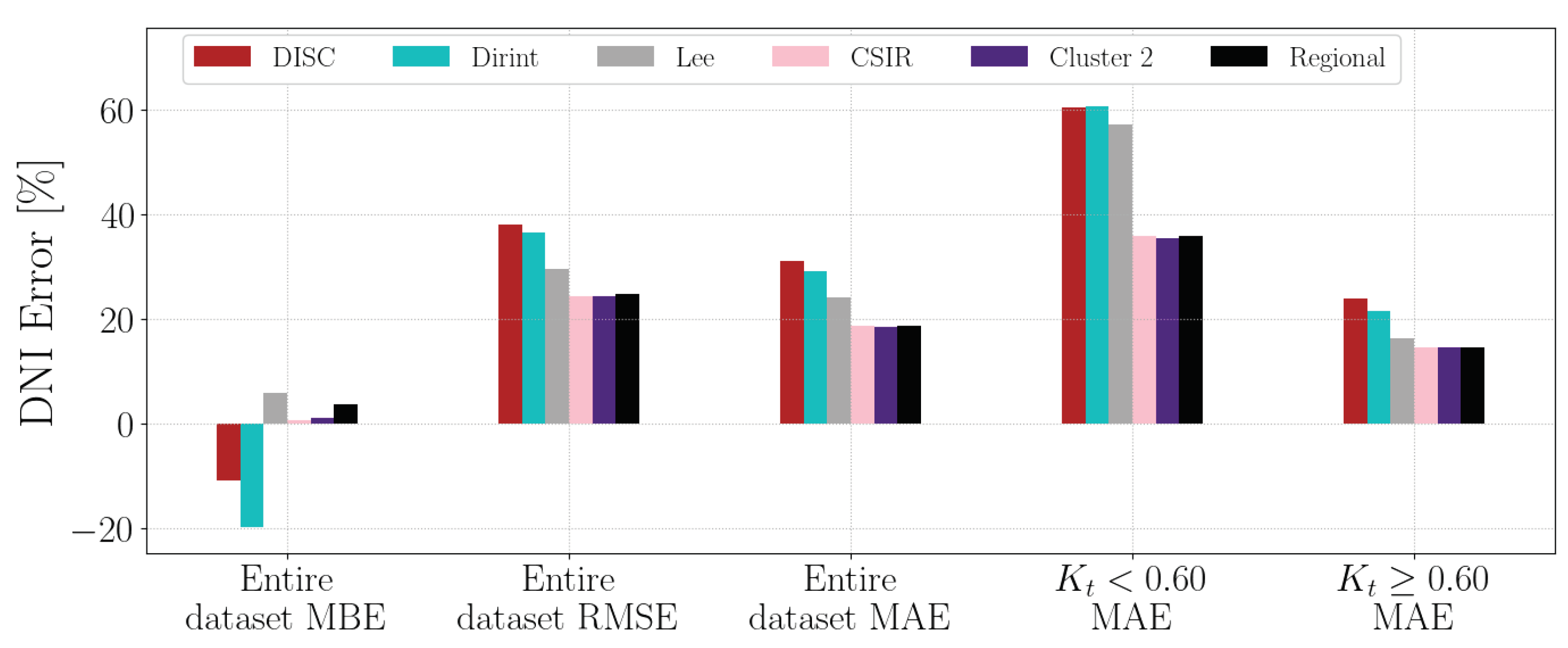
Section A.1 shows the decomposition model equations for the CSIR station. Table 5 shows the results of the CSIR station. The results show that the localised, Cluster 2 and regional models outperform the baseline models in all metrics. The localised model significantly improves for lower , reducing the MAE from around 60% to 36%.
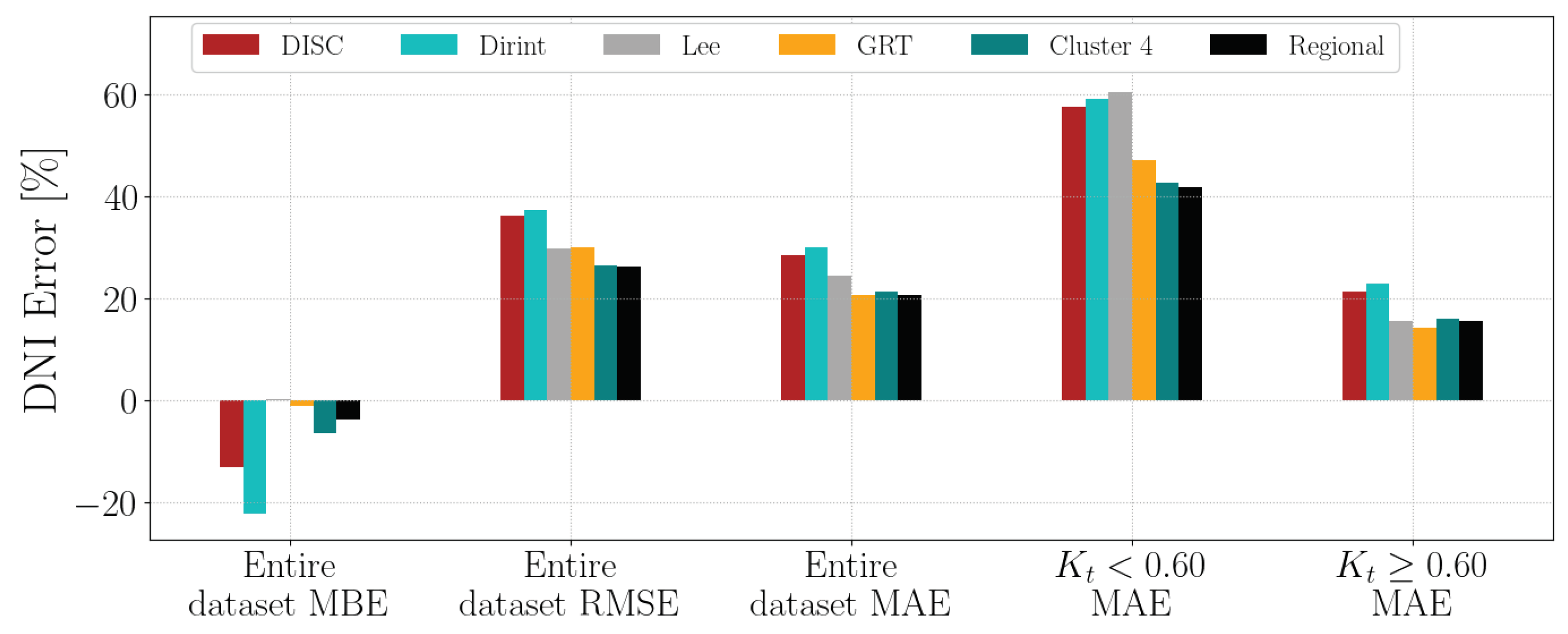
4.1.2. CUT
Section A.2 shows the decomposition model equations for the CUT station. Table 6 shows the CUT station results. The localised Cluster 2 and regional model significantly improve the comparison metrics over the three baseline models. The Lee model has a similar MBE to the regional model (±0.7) and has a higher -metric similar to Cluster 2. However, the Lee RMSE and MAE still do not outperform the new models.
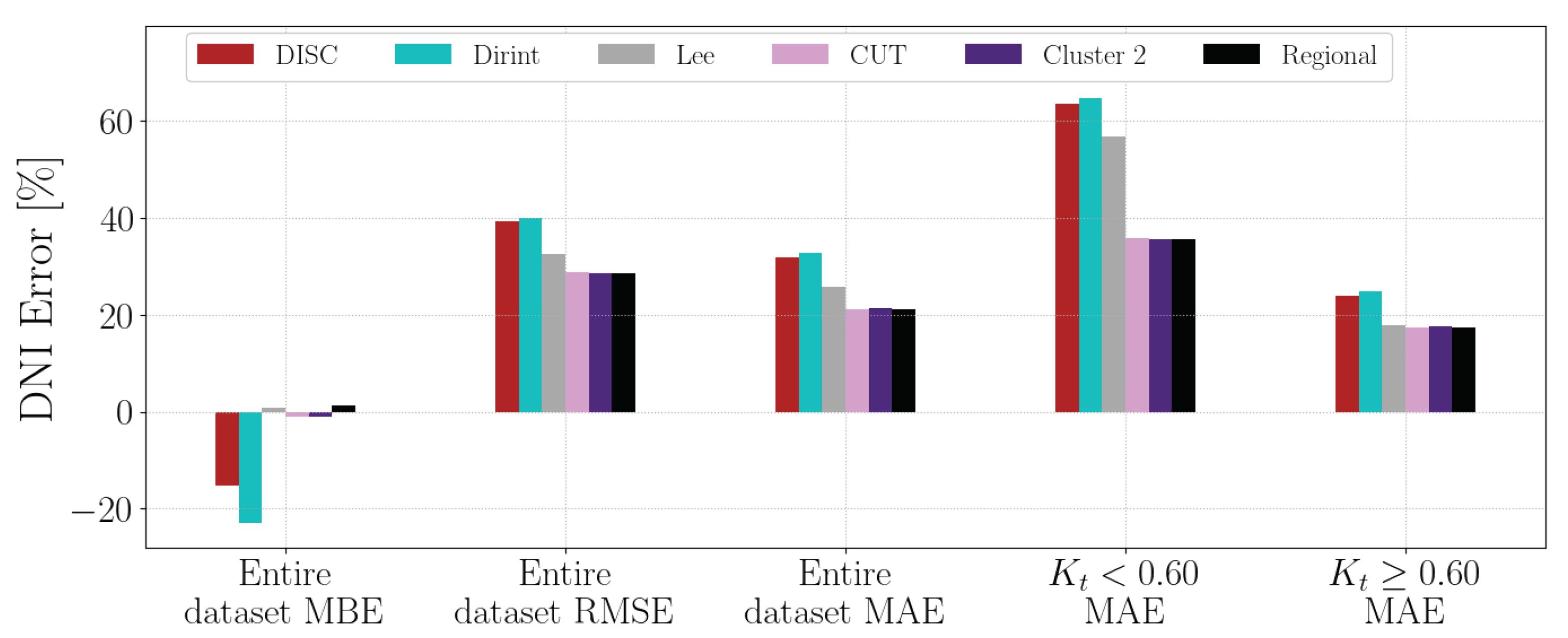
4.1.3. FRH
Section A.3 shows the decomposition model equations for the FRH station. Table 7 shows the results of the FRH station. The localised model outperforms the baseline models by improving and MBE and reducing MAE and RSME. The Lee model shows the lowest MAE for higher -values; however, it does show an overestimation for DNI with a higher MBE. For most metrics, the localised, Cluster 4 and regional model outperforms the baseline models.
4.1.4. GRT
Section A.4 shows the decomposition model equations for the GRT station. Table 8 shows the GRT station results. The localised model does show improvement over the DISC and Dirint model but does not significantly outperform the Lee model. The Lee model has a higher , lower MBE AND RMSE, whereas the localised model has a lower MAE for the entire dataset and the two intervals. The Cluster 4 and regional models perform better than the DISC and Dirint models but do not significantly outperform all the baseline models.
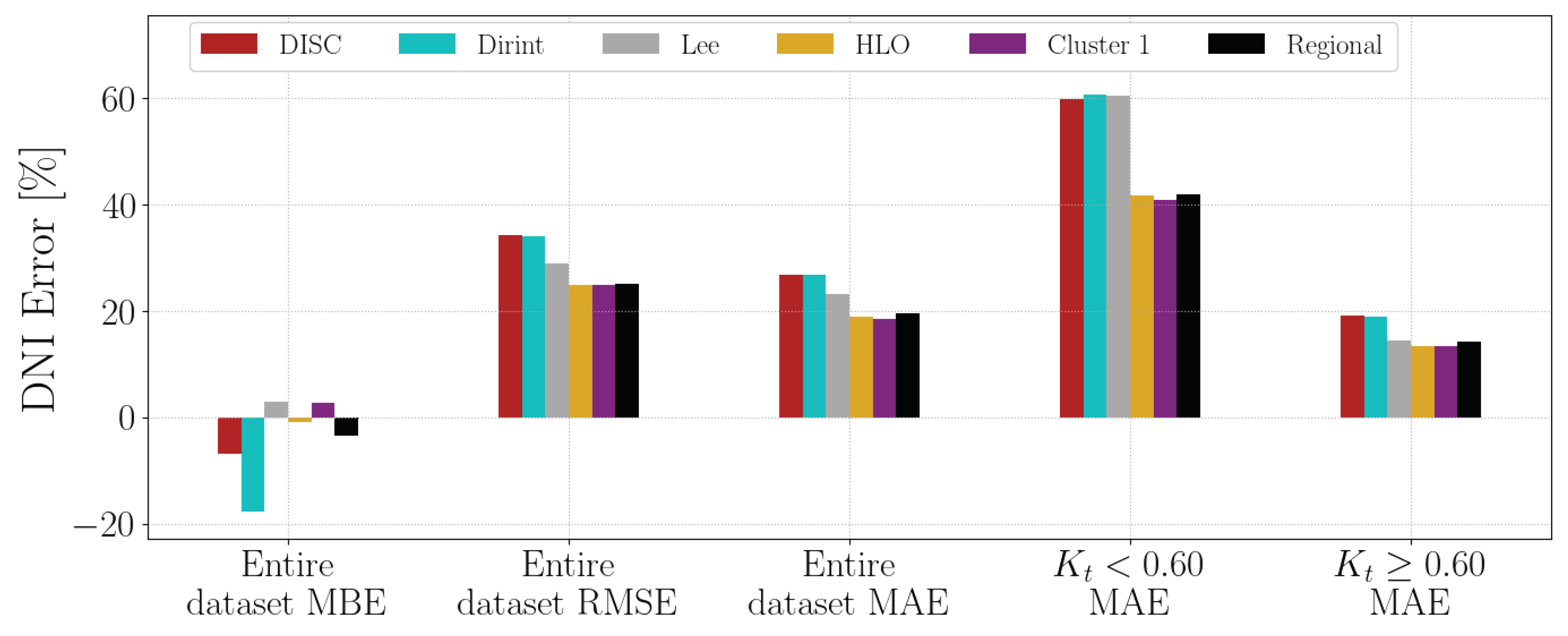
4.1.5. HLO
4.1.6. ILA
Figure A6 presents the test results of the ILA dataset. The ILA dataset has no localised decomposition model; therefore, the testing only assesses the Cluster 1 and regional models. The results show that the Cluster 1 and regional models outperform the baseline models. The results highlight the substitution of using a Cluster model when no localised model is available, subject to the geographical location within the Cluster area.
4.1.7. KZH
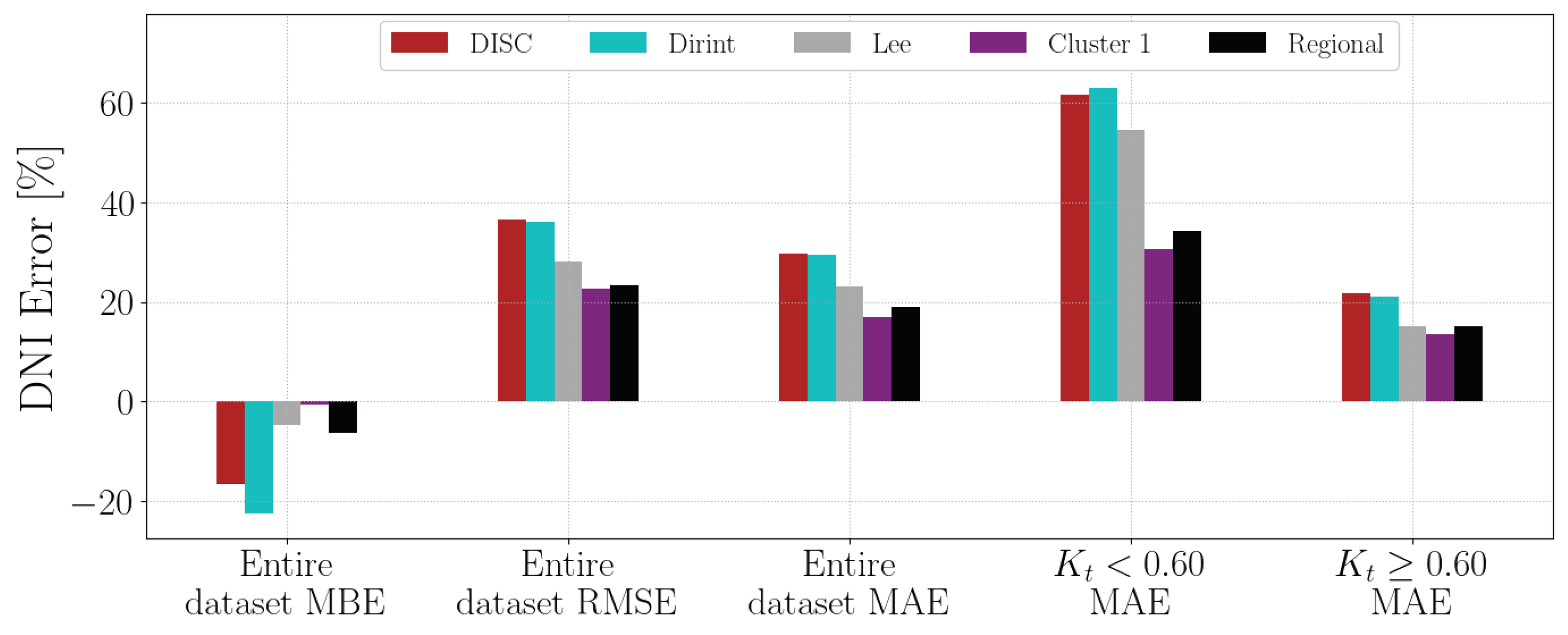
Section A.7 shows the decomposition model equations for the KZH station. Table 10 shows the results of the KZH station. The localised, Cluster 3 and regional models all show significant improvements in reducing the error over the baseline models. The DISC has a lower MBE than the regional model.
Figure A7 shows the test results of the KZH dataset. The localised, Cluster 3 and regional models all outperform the baseline models. The regional model does not outperform Cluster 3 or the localised model significantly.
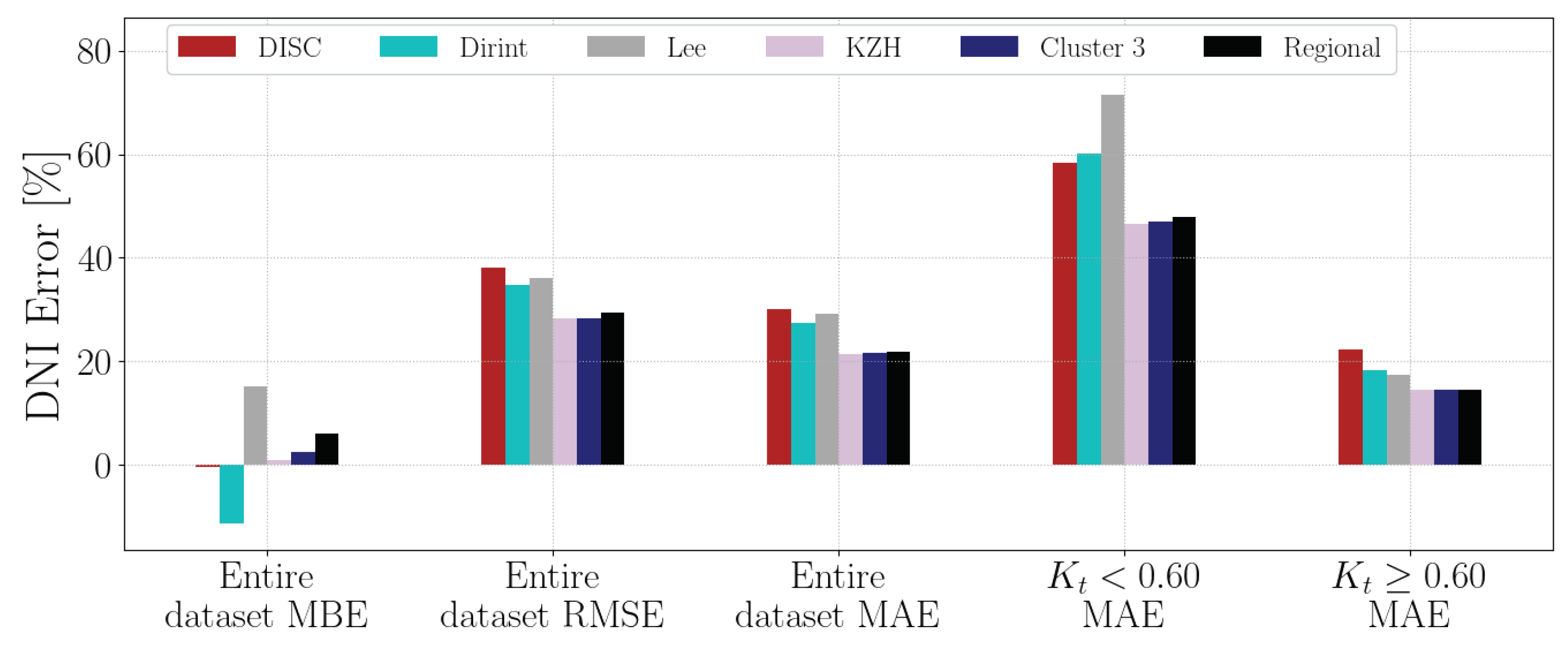
4.1.8. KZW
Section A.8 shows the decomposition model equations for the KZW station. Table 11 shows the results of the KZW station. The localised, clustered, and regional models show improvement over the baseline models with metrics that assess the entire data set.
Figure A8 shows the test results of the KZW dataset. The validation and testing results from Table 11 correspond.
MIN
The test results of the MIN dataset are presented in Figure A9. MIN has no localised decomposition model and falls geographically under Cluster 2. The cluster model and localised model show improvement over the baseline models. Much like the ILA dataset, the MIN dataset demonstrates how the clustered and regional models can serve as alternatives to enhance DNI estimations in Southern Africa.
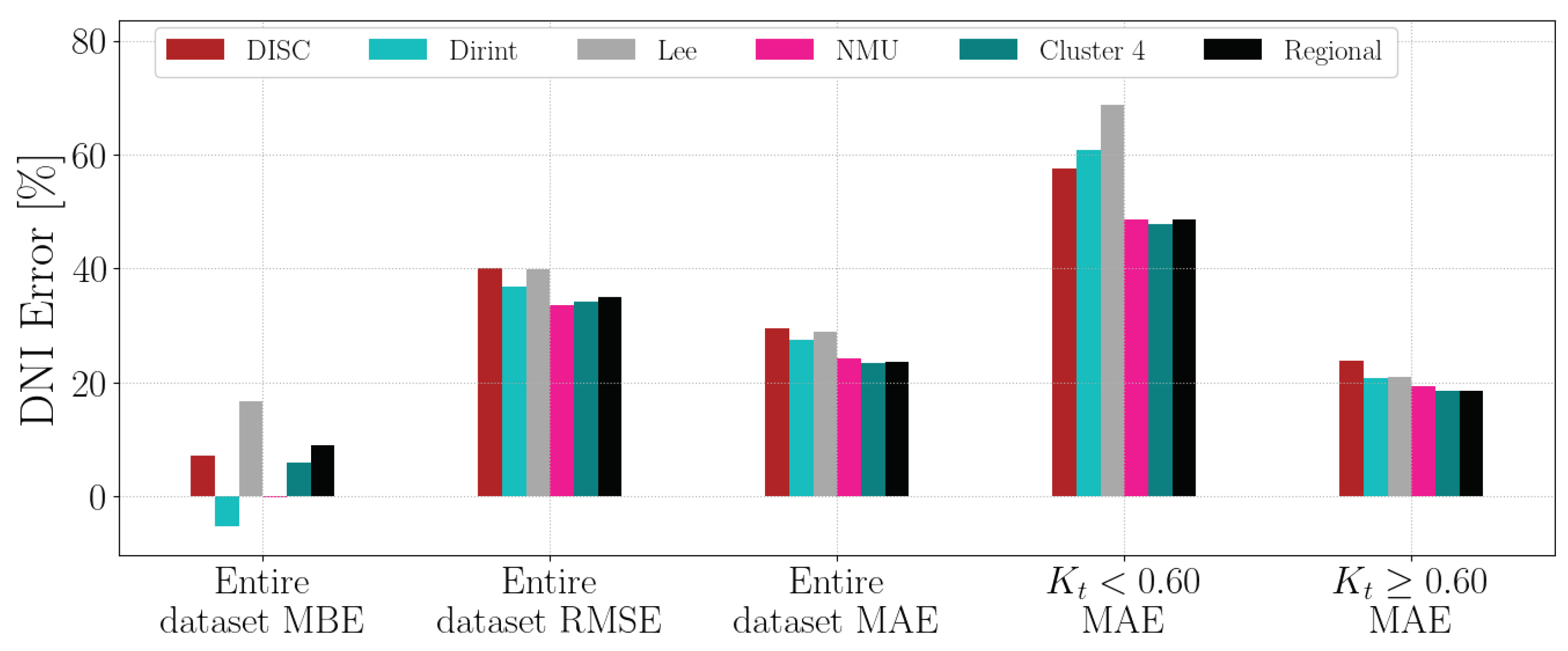
Ň Section A.10 shows the decomposition model equations for the NMU station. Table 12 shows the NMU station results. The localised, Cluster 4 and regional models show significant improvement in reducing the errors from the baseline models. Based on the higher MBE, the Cluster 4 and regional models overestimate the DNI more than the DISC and Dirint models.
The test results of the NMU dataset are presented in Figure A10. Localised and cluster models outperform baseline models, consistent with the results in Table 12.
4.1.9. NUST
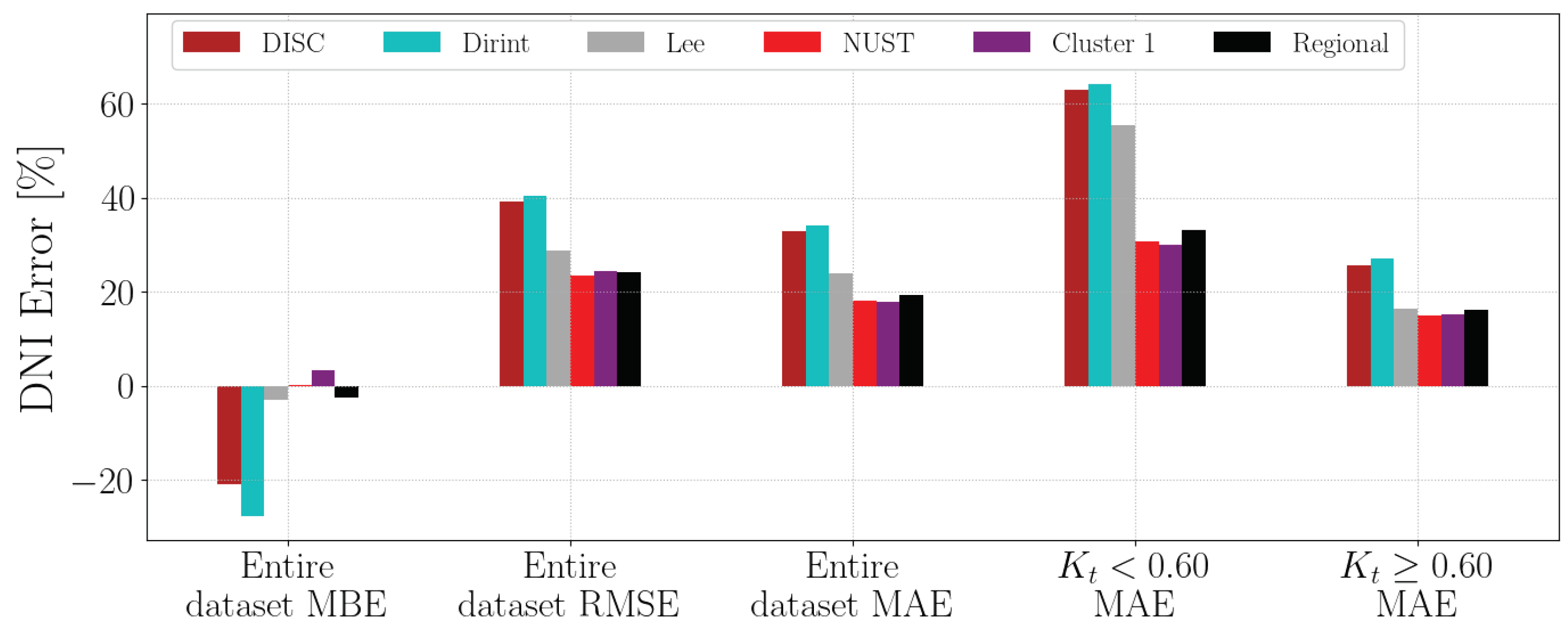
Section A.11 shows the decomposition model equations for the NUST station. Table 13 shows the results of the NUST station. The localised model shows superior performance over the baseline models, as well as the clustered and regional models. The metrics of the clustered model compared to the baselines indicate that the regional model slightly overestimates the DNI compared to the lowest baseline model (Lee), which slightly underestimates the DNI.
The test results of the NUST dataset are presented in Figure A11. Localised, clustered, and regional models outperform the baseline models, consistent with the validation results presented in Table 13. The regional model shows marginal underperformance compared to the localised and Cluster 1 model, but not significant enough to warrant it as unusable.
4.1.10. RVD
Section A.12 shows the decomposition model equations for the RVD station. Table 14 shows the RVD station results. The localised, clustered, and regional models outperform the baseline models. The Lee model performs better than the regional model but does not outperform the localised and cluster models. The RVD station receives more irradiance on average than other stations in the SAURAN database.
Figure A12 shows the test results of the RVD dataset. The results indicate that the localised, cluster and regional models outperform the baseline models, which is consistent with the validation results of the previous section in Table 14. The localised model’s RMSE is higher than the Lee model; however, the localised model does best in reducing the error for the other metrics. Though the regional model outperforms the baseline models, it does show the worst performance of the three newly developed models for RVD.
4.1.11. SUN
Section A.13 shows the decomposition model equations for the SUN station. Table 15 shows the SUN station results. The localised model outperforms the baseline models by improving and reducing the MBE, RMSE and MAE. The Cluster 1 and regional models show a slightly worse MBE than the Lee baseline model but otherwise outperform the baseline models. The Lee model also predicts higher points with a lower MAE than the regional model; however, the other metrics indicate that the regional model shows better results overall.
Figure A13 shows the test results of the SUN dataset. The results indicate that the localised, cluster and regional models outperform the baseline models, which is consistent with the testing results of the previous section in Table 15. As with the validation results, the regional model is the worst-performing new model but still outperforms the baseline models.
4.1.12. UBG
Section A.14 shows the decomposition model equations for the UBG station. Table 16 shows the UBG station results. The localised, clustered and regional models all outperform the baseline models. The Lee model has a lower MBE than the Cluster 1 and regional models. The Lee model also has a lower MAE for ; however, the other metrics indicate that the model does not improve the , RMSE, overall MAE and MAE.
Figure A14 shows the test results of the UBG dataset. The test results show that the localised, Cluster 1 and regional models outperform the baseline models. The Lee model has a lower MBE than the regional model, consistent with the validation results in Table 16.
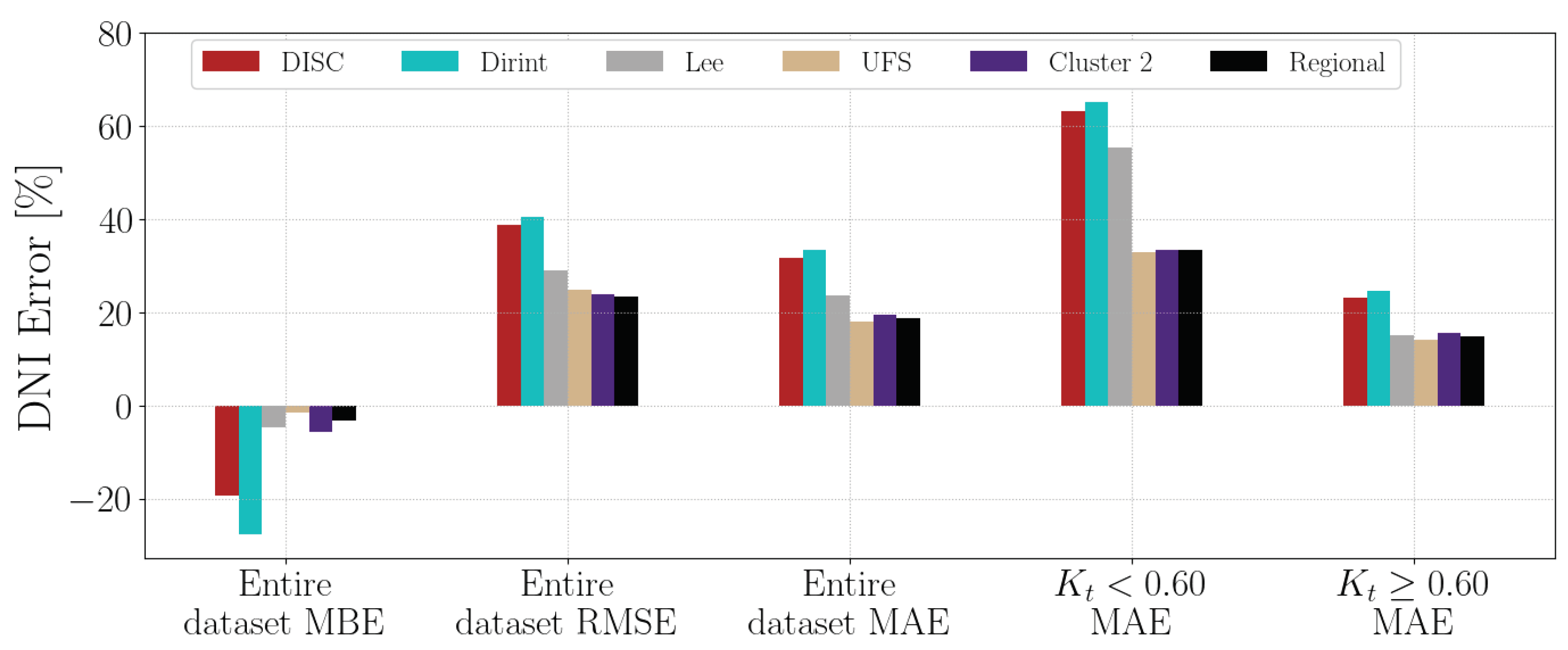
4.1.13. UFS
Section A.15 shows the decomposition model equations for the UFS station. Table 17 shows the UFS station results. The localised, Cluster 2 and regional models outperform the baseline models. The Lee model underestimates the DNI slightly better than the Cluster 2 model.
Figure A15 shows the test results of the UFS dataset. All three new decomposition models significantly improve the errors compared to the baseline models, consistent with the validation results in Table 17.
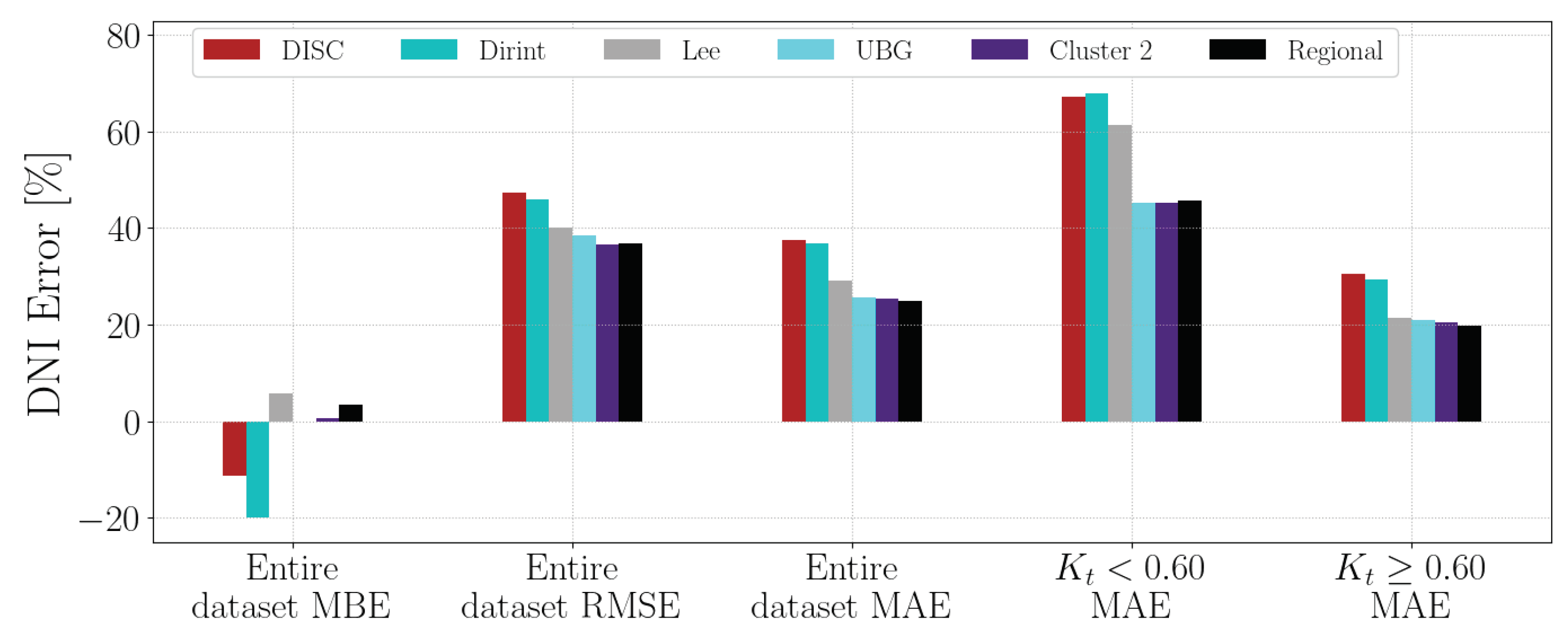
4.1.14. UNV
Section A.16 shows the decomposition model equations for the UNV station. Table 18 shows the UNV station results. The localised, Cluster 2 and regional models significantly improved over the baseline models. The Cluster 2 and regional model overestimates the DNI more than the DISC model, based on the MBE.
Figure A16 shows the test results of the UNV dataset. The test results correspond with the validation results in Table 18, where the localised, Cluster 2 and regional models outperform the baseline models. The only exception is the MBE, where the Cluster 2 and regional models perform worse than the DISC model. Considering all the metrics, the new models outperform the baselines in reducing the overall error of DNI estimations.
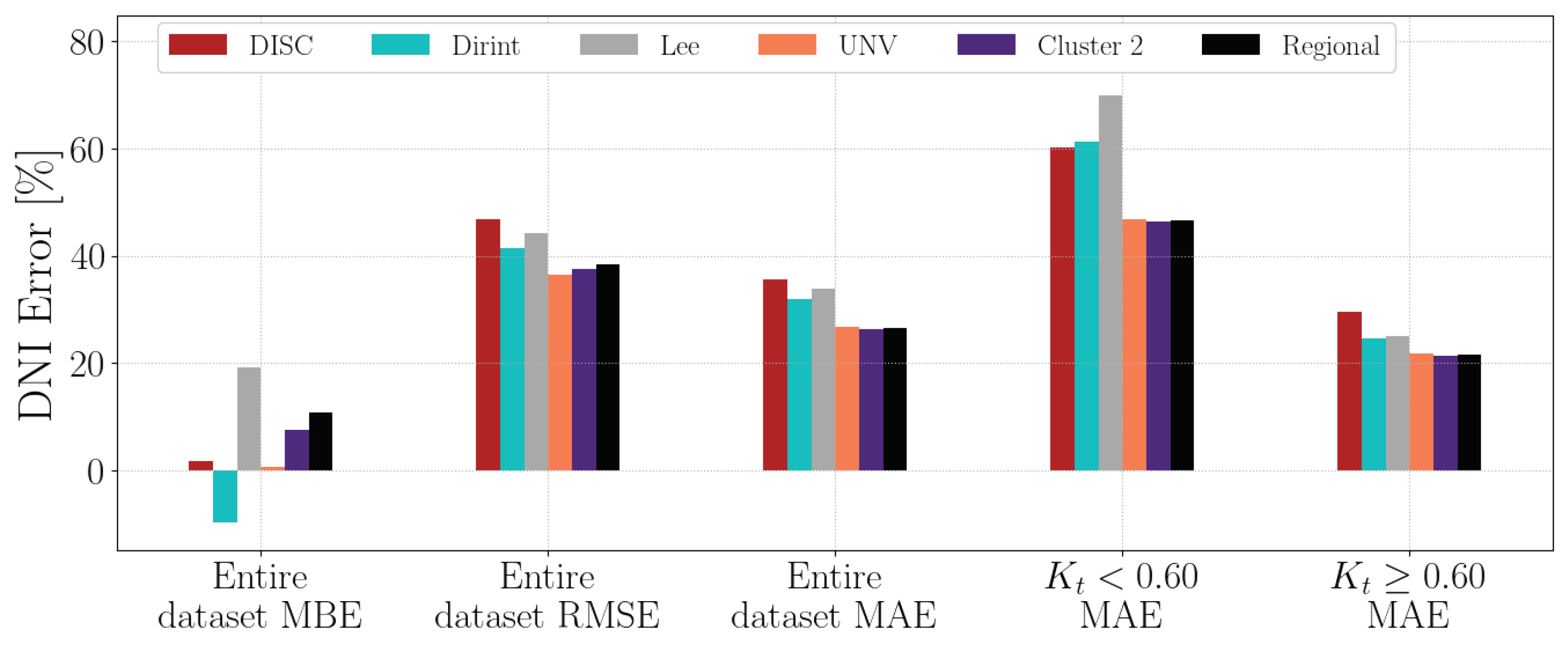
4.1.15. UNZ
Section A.17 shows the decomposition model equations for the UNZ station. Table 19 shows the results of the UNZ station. The localised, clustered and regional models all show improvement over the baselines. The Dirint model has a lower MBE than the regional model.
Figure A17 shows the test results of the UNZ dataset, which correspond with the validation results in Table 19.
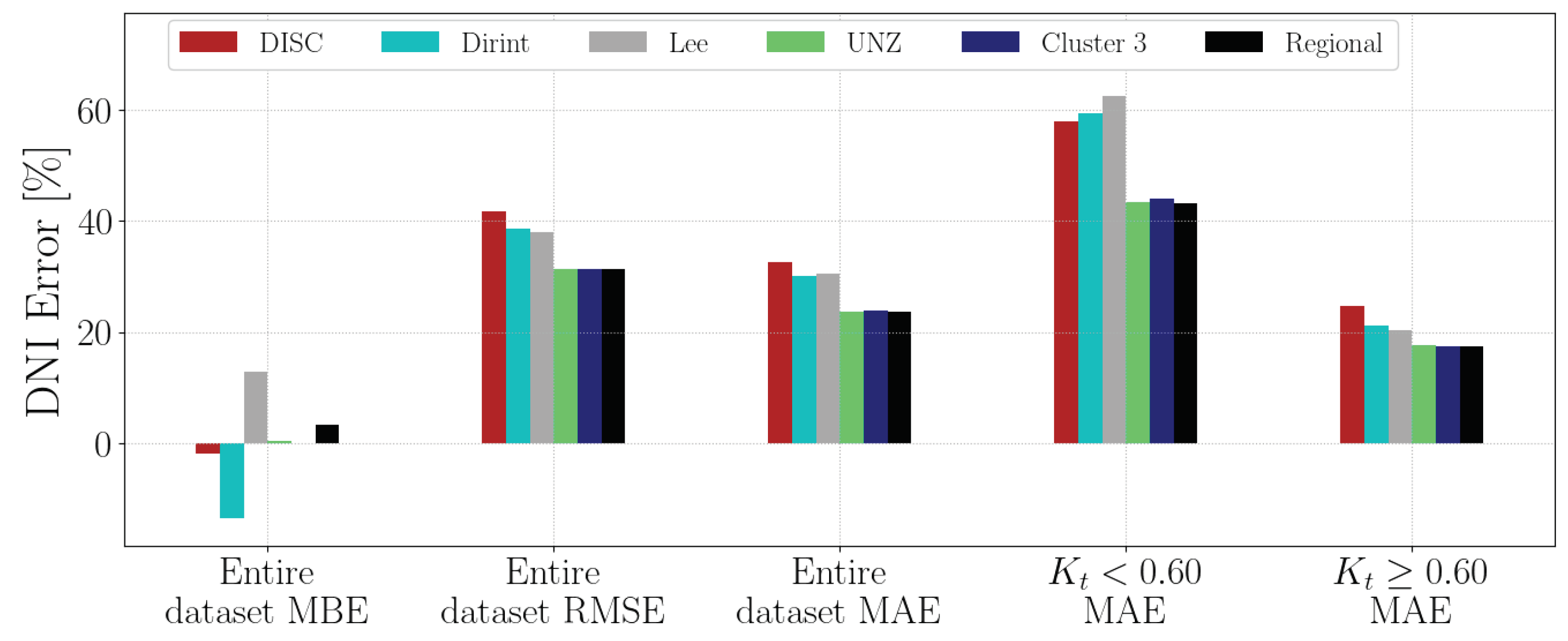
4.1.16. UPR
Section A.18 shows the decomposition model equations for the UPR station. Table 20 shows the UPR station results. The localised, cluster and regional models outperform the baseline models.
Figure A18 shows the test results of the UPR dataset. The comparison metrics of the entire dataset indicate that the localised, cluster and regional models outperform the baseline models, which is consistent with the results of the validation dataset in Table 20.
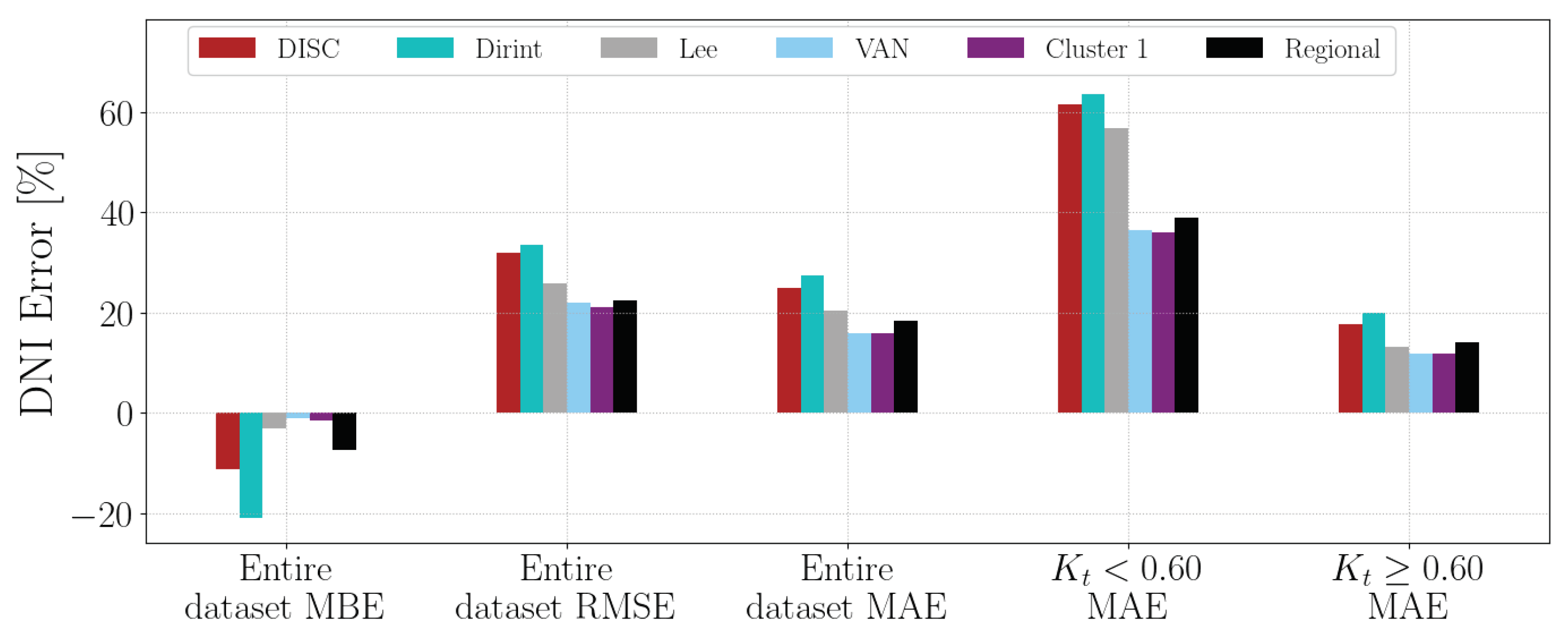
4.1.17. VAN
Section A.19 shows the decomposition model equations for the VAN station. Table 21 shows the results of the VAN station. The localised model outperforms the baseline models by improving and reducing the MBE, RMSE and MAE. The new models significantly reduce the MAE in the higher compared to the baseline models. Even when outperforming the baseline models, the regional model performs the worst of the new model. The VAN station receives a very high average DNI and DHI and lower DHI than the rest of the database’s stations. These results are similar to the RVD station, which has significantly higher irradiance levels than the other stations.
Figure A19 shows the test results of the VAN dataset. The new models all outperform the baseline models. The regional model shows the worst performance of the new models, even when outperforming the baseline models, similar to the RVD station that receives more irradiance on average compared to the other stations. These results are consistent with the validation results in Table 21.
4.2. Discussion
Table 22 summarises the performance of the localised, clustered and regional models for both the test and validation sets.
As expected, the localised models outperformed the baseline models for all station datasets because of the site-specific climatic training data. As discussed in the previous section, the cluster model combines multiple stations in a similar geographical area.
The clustered model will have significantly more data from which to train a model. A clustered model is ideal if a site has no data for localised model development using the discussed methodology. The regional (Southern African) model also shows improvement over the baseline models, indicating that this model may be appropriate for adoption as a new model for Southern Africa. The two models with no localised model (ILA and MIN) showed improvement using the clustered and regional model in the validation study.
5. Conclusion
This article presented the development of a new decomposition model of hourly DNI estimations for Southern Africa. The new models improved the DISC model [17] in developing new decomposition models localised for Southern African climates. The new decomposition models improved the DNI estimation errors over the baselines for all validation and test sets.
The results indicate that a localised model will improve the estimations of DNI. The proposed methodology can be helpful for the development of local decomposition models for other areas worldwide.
Clustered models also indicate that grouping data based on similar geographical and climatic properties can also improve the performance of decomposition models. This phenomenon could be helpful when using a clustered decomposition model if no local model or limited data is available but from two or more geographically close stations.
The overall model, the regional decomposition model, is encapsulated by different climatic regions and geographical locations. There are also some exceptions where the model over- or underestimates the DNI; however, the overall metrics indicate that the Southern African model significantly improves over the baseline models.
The study validates hourly irradiance data for -intervals between 0.175 and 0.875. Recommendations for future work include developing models for higher and lower values and models for higher temporal resolutions with increased accuracy, which is ideal for real-time monitoring and short-term forecasting of PV power.
Developing countries with an accurate decomposition model can open the path to expanding the use of renewable energy sources and reducing their dependence on coal and fossil fuels. Good-quality data is needed to ensure the progress of solar energy research and development. The next step is assessing the decomposition models with well-known transposition models to determine improved accuracy for PR estimations.
Author Contributions
Conceptualisation, F.D.; methodology, F.D.; software, F.D.; validation, F.D.; formal analysis, F.D.; investigation, F.D.; resources, F.D. and A.R.; data curation, F.D.; writing—original draft preparation, F.D.; writing—review and editing, F.D. and A.R.; visualisation, F.D.; supervision, A.R; project administration, F.D. and A.R; funding acquisition, F.D.and A.R. All authors have read and agreed to the published version of the manuscript.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Localised Decomposition Models
Appendix A.1. CSIR
The test results of the CSIR dataset are in Figure A1.
Figure A1.
Hourly test results of decomposition model development for CSIR.
Appendix A.2. CUT
The validation results of the CUT dataset are in Figure A2.
Figure A2.
Hourly test results of decomposition model development for CUT.
Appendix A.3. FRH
The test results of the FRH dataset are in Figure A3.
Figure A3.
Hourly test results of decomposition model development for FRH.
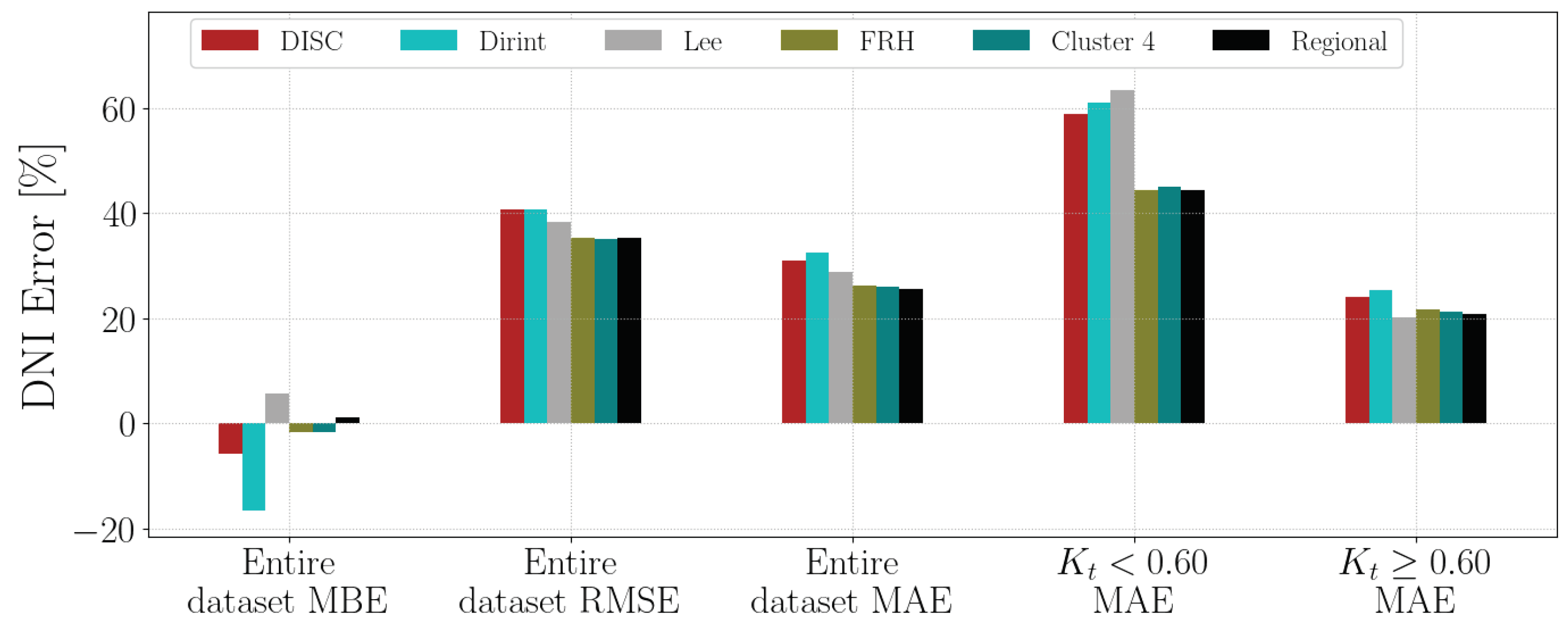
Appendix A.4. GRT
Figure A4 shows the test results of the GRT dataset.
Figure A4.
Hourly test results of decomposition model development for GRT.
Appendix A.5. HLO
Figure A5 shows the test results of the HLO dataset.
Figure A5.
Hourly test results of decomposition model development for HLO.
Appendix A.6. ILA
There is no decomposition model developed for the ILA station.
The test results of the ILA dataset are in Figure A6.
Figure A6.
Hourly test results of decomposition model development for ILA.
Appendix A.7. KZH
The test results of the KZH dataset are in Figure A7.
Figure A7.
Hourly test results of decomposition model development for KZH.
Appendix A.8. KZW
Figure A8 shows the test results of the KZW dataset.
Figure A8.
Hourly test results of decomposition model development for KZW.

Appendix A.9. MIN
There is no decomposition model developed for the MIN station.
The test results of the MIN dataset are in Figure A9.
Figure A9.
Hourly test results of decomposition model development for MIN.

Appendix A.10. NMU
The test results of the NMU dataset are in Figure A10.
Figure A10.
Hourly test results of decomposition model development for NMU.
Appendix A.11. NUST
The test results of the NUST dataset are in Figure A11.
Figure A11.
Hourly test results of decomposition model development for NUST.
Appendix A.12. RVD
The test results of the RVD dataset are in Figure A12.
Figure A12.
Hourly test results of decomposition model development for RVD.
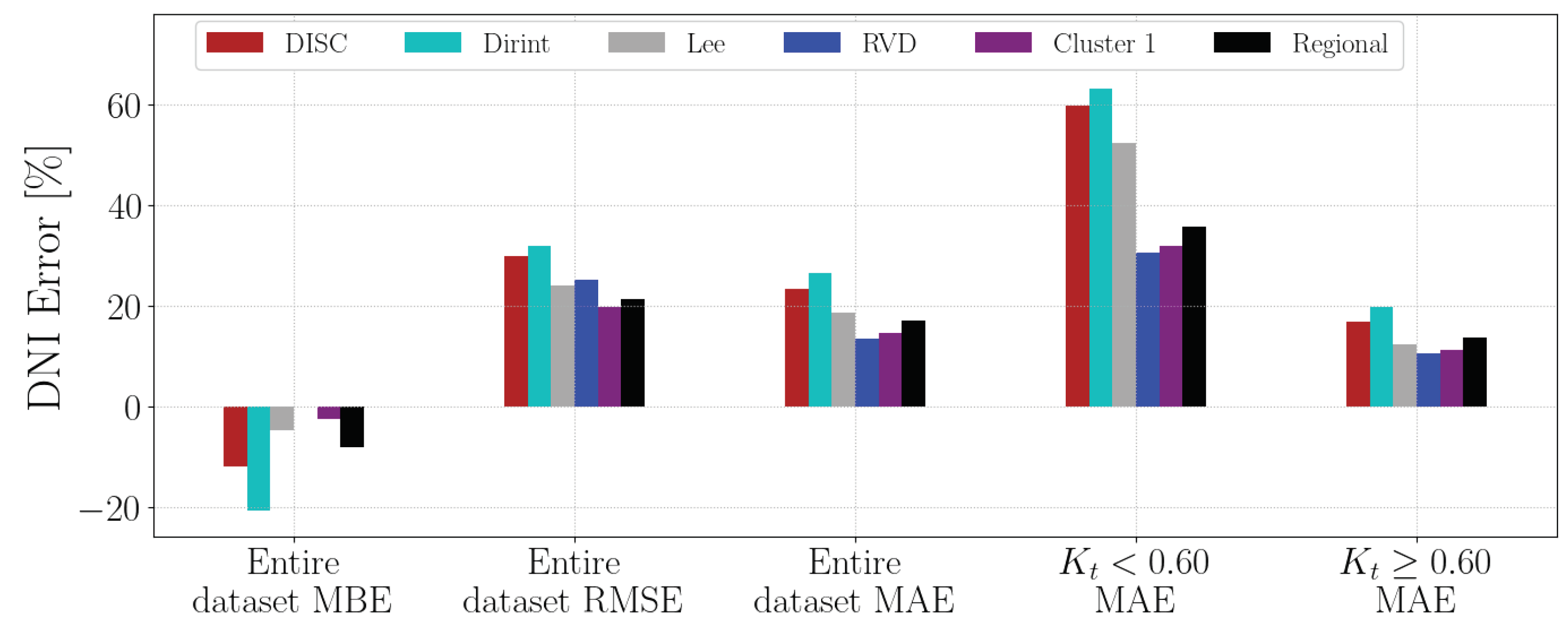
Appendix A.13. SUN
The test results of the SUN dataset are in Figure A13.
Figure A13.
Hourly test results of decomposition model development for SUN.
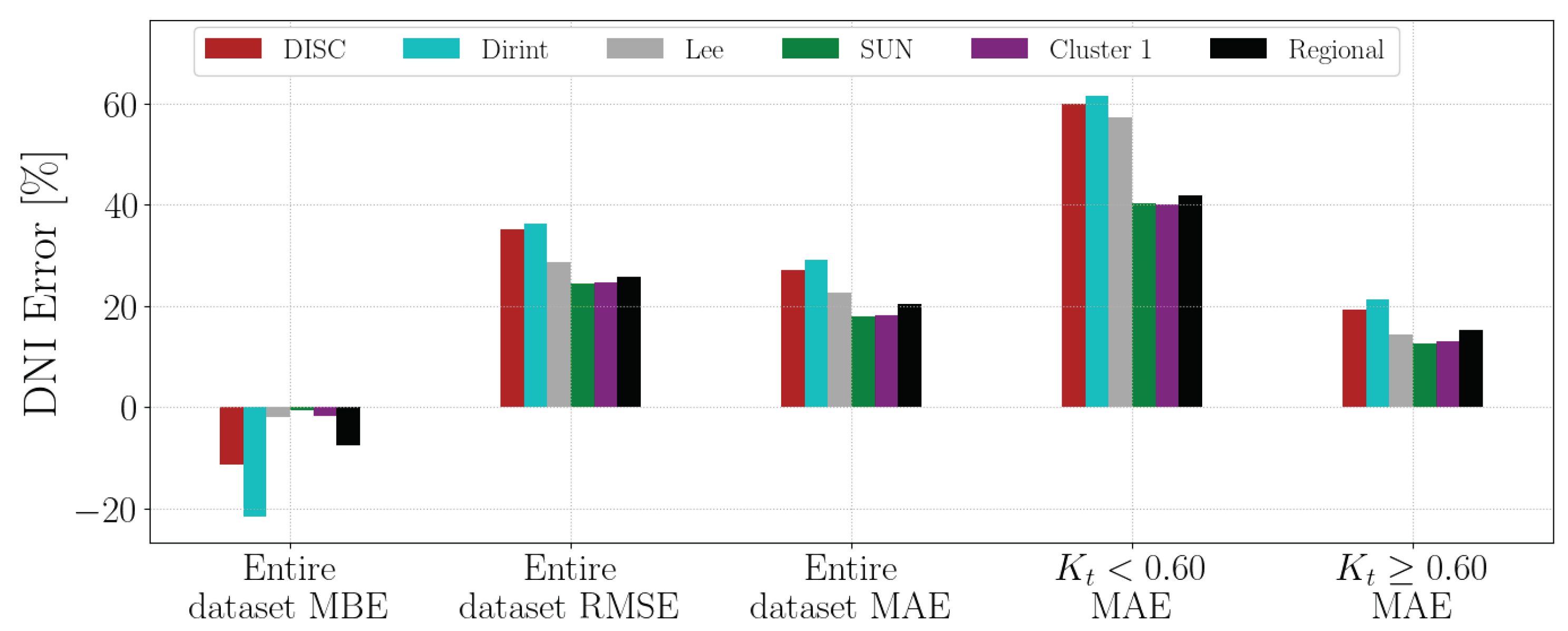
Appendix A.14. UBG
The test results of the SUN dataset are in Figure A14.
Figure A14.
Hourly test results of decomposition model development for UBG.
Appendix A.15. UFS
The test results of the SUN dataset are in Figure A15.
Figure A15.
Hourly test results of decomposition model development for UFS.
Appendix A.16. UNV
The test results of the UNV dataset are in Figure A16.
Figure A16.
Hourly test results of decomposition model development for UNV.
Appendix A.17. UNZ
The test results of the UNZ dataset are in Figure A17.
Figure A17.
Hourly test results of decomposition model development for UNZ.
Appendix A.18. UPR
The test results of the UPR dataset are in Figure A18.
Figure A18.
Hourly test results of decomposition model development for UPR.
Appendix A.19. VAN
Figure A19 shows the test results of the VAN dataset.
Figure A19.
Hourly test results of decomposition model development for VAN.
References
- Masters, G. Renewable and Efficient Electric Power Systems, 2 ed.; John Wiley and Sons, Inc.: Hoboken, New Jersey, 2013; pp. 186–245,316–398.
- Sengupta, M.; Habte, A.; Wilbert, S.; Gueymard, C.; Remund, J. Best Practices Handbook for the Collection and Use of Solar Resource Data for Solar Energy Applications: Third Edition 2021. [CrossRef]
- Lee, H.; Kim, S.Y.; Yun, C. Comparison of Solar Radiation Models to Estimate Direct Normal Irradiance for Korea. Energies 2017, 10, 594. [CrossRef]
- Bertrand, C.; Vanderveken, G.; Journée, M. Evaluation of decomposition models of various complexity to estimate the direct solar irradiance over Belgium. Renewable Energy 2015, 74, 618 – 626. [CrossRef]
- Liu, B.Y.; Jordan, R.C. The interrelationship and characteristic distribution of direct, diffuse and total solar radiation. Solar Energy 1960, 4, 1 – 19. [CrossRef]
- Yang, D.; Gueymard, C.A. Ensemble model output statistics for the separation of direct and diffuse components from 1-min global irradiance. Solar Energy 2020, 208, 591–603. [CrossRef]
- Boland, J.; Huang, J.; Ridley, B. Decomposing global solar radiation into its direct and diffuse components. Renewable and Sustainable Energy Reviews 2013, 28, 749–756. [CrossRef]
- Ridley, B.; Boland, J.; Lauret, P. Modelling of diffuse solar fraction with multiple predictors. Renewable Energy 2010, 35, 478–483. [CrossRef]
- Soares, J.; Oliveira, A.P.; Božnar, M.Z.; Mlakar, P.; Escobedo, J.F.; Machado, A.J. Modeling hourly diffuse solar-radiation in the city of São Paulo using a neural-network technique. Applied Energy 2004, 79, 201–214. [CrossRef]
- Talvitie, T.; Eldali, F.; Pinney, D. Predicting Solar Diffuse and Direct Components Using Deep Neural Networks. 2021 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT) 2021, pp. 1–5. [CrossRef]
- Kalyanam, R.; Hoffmann, S. A Novel Approach to Enhance the Generalization Capability of the Hourly Solar Diffuse Horizontal Irradiance Models on Diverse Climates. Energies 2020, 13. [CrossRef]
- Bessafi, M.; Oree, V.; Khoodaruth, A.; Chabriat, J.P. Impact of decomposition and kriging models on the solar irradiance downscaling accuracy in regions with complex topography. Renewable Energy 2020, 162, 1992–2003. [CrossRef]
- Janjai, S.; Phaprom, P.; Wattan, R.; Masiri, I. Statistical models for estimating hourly diffuse solar radiation in different regions of Thailand. Proceedings of the International Conference on Energy and Sustainable Development: Issues and Strategies (ESD 2010), 2010, pp. 1–6. [CrossRef]
- Orgill, J.; Hollands, K. Correlation equation for hourly diffuse radiation on a horizontal surface. Solar Energy 1977, 19, 357 – 359. [CrossRef]
- Erbs, D.; Klein, S.; Duffie, J. Estimation of the diffuse radiation fraction for hourly, daily and monthly-average global radiation. Solar Energy 1982, 28, 293 – 302. [CrossRef]
- Louche, A.; Notton, G.; Poggi, P.; Simonnot, G. Correlations for direct normal and global horizontal irradiation on a French Mediterranean site. Solar Energy (Journal of Solar Energy Science and Engineering); (USA) 1991, 46. [CrossRef]
- Maxwell, E. A quasi-physical model for converting hourly global horizontal to direct normal insolation. Technical report, Solar Energy Research Institute, 1987.
- Perez, R.; Ineichen, P.; Maxwell, E.; Seals, R.; Zelenka, A. Dynamic global-to-direct irradiance conversion models. ASHRAE Transactions 1992, 98, 354–369.
- Lave, M.; Hayes, W.; Pohl, A.; Hansen, C.W. Evaluation of Global Horizontal Irradiance to Plane-of-Array Irradiance Models at Locations Across the United States. IEEE Journal of Photovoltaics 2015, 5, 597–606. [CrossRef]
- Lee, K.; Yoo, H.; Levermore, G.J. Quality control and estimation hourly solar irradiation on inclined surfaces in South Korea. Renewable Energy 2013, 57, 190 – 199. [CrossRef]
- Skartveit, A.; Olseth, J.A. A model for the diffuse fraction of hourly global radiation. Solar Energy 1987, 38, 271 – 274. [CrossRef]
- Lam, J.C.; Li, D.H. Correlation between global solar radiation and its direct and diffuse components. Building and Environment 1996, 31, 527 – 535. [CrossRef]
- Reindl, D.; Beckman, W.; Duffie, J. Diffuse Fraction Correlations. Solar Energy 1990, 45, 1–7. [CrossRef]
- Yao, W.; Li, Z.; Xiu, T.; Lu, Y.; Li, X. New decomposition models to estimate hourly global solar radiation from the daily value. Solar Energy 2015, 120, 87–99. [CrossRef]
- Khalil, S.A.; Shaffie, A. A comparative study of total, direct and diffuse solar irradiance by using different models on horizontal and inclined surfaces for Cairo, Egypt. Renewable and Sustainable Energy Reviews 2013, 27, 853–863. [CrossRef]
- Gueymard, C.A.; Ruiz-Arias, J.A. Extensive worldwide validation and climate sensitivity analysis of direct irradiance predictions from 1-min global irradiance. Solar Energy 2016, 128, 1–30. Special issue: Progress in Solar Energy, . [CrossRef]
- Laiti, L.; Giovannini, L.; Zardi, D.; Belluardo, G.; Moser, D. Estimating Hourly Beam and Diffuse Solar Radiation in an Alpine Valley: A Critical Assessment of Decomposition Models. Atmosphere 2018, 9. [CrossRef]
- Oliveira, A.P.; Escobedo, J.; Machado, A.; Soares, J. Correlation models of diffuse solar-radiation applied to the city of São Paulo, Brazil. Applied Energy 2002, 71, 59–73. [CrossRef]
- Salazar, G.; Pedrosa Filho, M. Analysis of the Diffuse Fraction from Solar Radiation Values Measured in Argentina and Brazil Sites. 2020. [CrossRef]
- Chendo, M.; Maduekwe, A. Hourly global and diffuse radiation of Lagos, Nigeria—Correlation with some atmospheric parameters. Solar Energy 1994, 52, 247–251. [CrossRef]
- Chikh, M.; Mahrane, A.; Haddadi, M. Modeling the Diffuse Part of the Global Solar Radiation in Algeria. Energy Procedia 2012, 18, 1068–1075. Terragreen 2012: Clean Energy Solutions for Sustainable Environment (CESSE), . [CrossRef]
- Benchrifa, M.; Tadili, R.; Idrissi, A.; Essalhi, H.; Mechaqrane, A. Development of New Models for the Estimation of Hourly Components of Solar Radiation: Tests, Comparisons, and Application for the Generation of a Solar Database in Morocco. International Journal of Photoenergy 2021, 2021, 1–16. [CrossRef]
- Engerer, N. Minute resolution estimates of the diffuse fraction of global irradiance for southeastern Australia. Solar Energy 2015, 116, 215–237. [CrossRef]
- Tsubo, M.; Walker, S. Relationships between photosynthetically active radiation and clearness index at Bloemfontein, South Africa. Theoretical and Applied Climatology 2005, 80, 17–25. [CrossRef]
- Nijegorodov, N. Improved ashrae model to predict hourly and daily solar radiation components in Botswana, Namibia, and Zimbabwe. Renewable Energy 1996, 9, 1270–1273. World Renewable Energy Congress Renewable Energy, Energy Efficiency and the Environment, . [CrossRef]
- Mabasa, B.; Lysko, M.D.; Tazvinga, H.; Zwane, N.; Moloi, S.J. The Performance Assessment of Six Global Horizontal Irradiance Clear Sky Models in Six Climatological Regions in South Africa. Energies 2021, 14. [CrossRef]
- Mahachi, T. Energy yield analysis and evaluation of solar irradiance models for a utility scale solar PV plant in South Africa. Master’s thesis, University of Stellenbosch, South Africa, 2016. [CrossRef]
- Daniel, F.M.; Rix, A.J. The Evaluation of Decomposition Models Under Varying Weather Conditions for South Africa. Southern African Sustainable Energy Conference, 2021, pp. 207–213.
- SAURAN. https://sauran.ac.za/, 2022.
- Daniel-Durandt, F.M.; Rix, A.J. Automating Quality Control of Irradiance Data with a Comprehensive Analysis for Southern Africa. Solar 2023, 3, 596–617. [CrossRef]
- Walpole, R.; Myers, R.; Myers, S.; Ye, K. Probability & Statistics for Engineers & Scientists; Pearson Education Inc.: Boston, MA, 2012.
- Anaconda Software Distribution, 2020.
- Holmgren, W.; Hansen, C.; Mikofski, M. pvlib python: a python package for modeling solar energy systems. Journal of Open Source Software 2018, 3, 884. [CrossRef]
- McKinney, W.; others. Data structures for statistical computing in python. Proceedings of the 9th Python in Science Conference. Austin, TX, 2010, Vol. 445, pp. 51–56. [CrossRef]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Computing in Science & Engineering 2007, 9, 90–95. [CrossRef]
- Mahachi, T.; Rix, A. Evaluation of irradiance decomposition and transposition models for a region in South Africa Investigating the sensitivity of various diffuse radiation models. IECON 2016 - 42nd Annual Conference of the IEEE Industrial Electronics Society, 2016, pp. 3064–3069. [CrossRef]
- Kasten, F.; Young, A.T. Revised optical air mass tables and approximation formula. Appl. Opt. 1989, 28, 4735–4738. [CrossRef]
- Farmer, W.; Rix, A.J. Mapping the spatial perturbations seen by the power system network due to intermittent renewable energy sources. Southern African Sustainable Energy Conference, 2021, pp. 222–228.
- Solargis. https://solargis.com/maps-and-gis-data/download/south-africa, 2021.
Figure 1.
The irradiance relationships between GHI, DNI, DHI and .
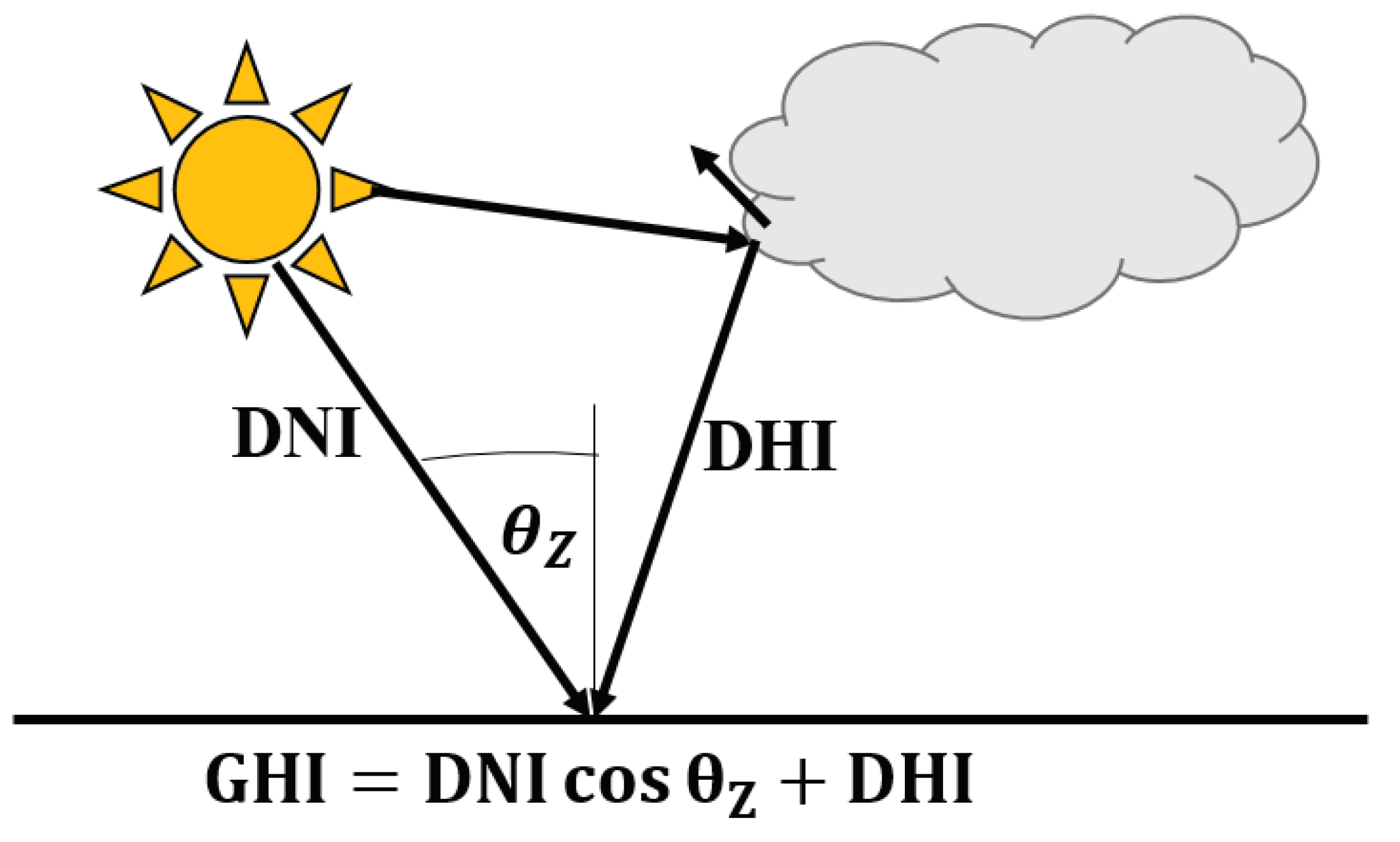
Figure 2.
Validation sites of discussed decomposition models.
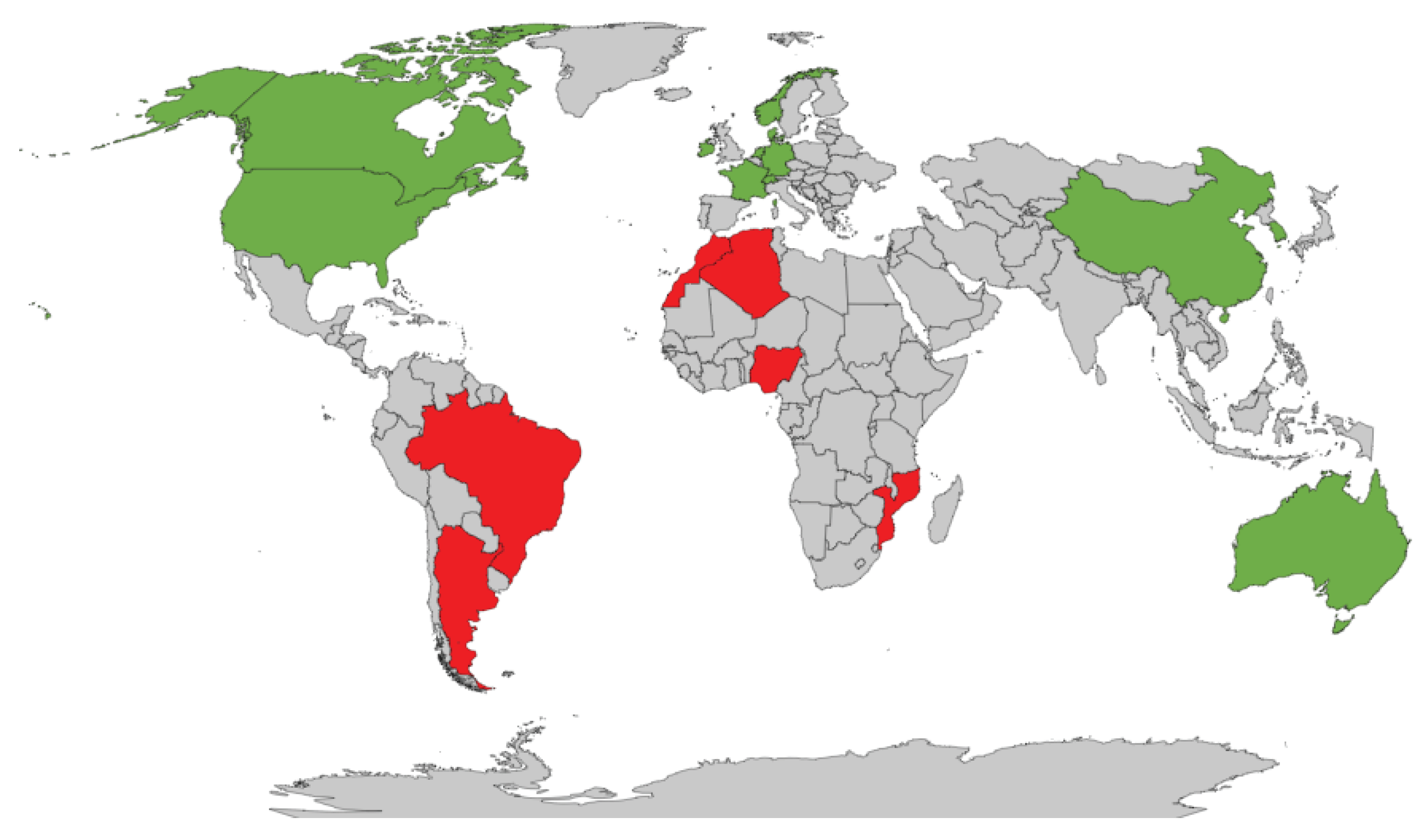
Figure 4.
Distribution of data within clusters.
| Name (Location) | Coordinates | Elevation | |
|---|---|---|---|
| (Lat (∘S), Long (∘E)) | (m) | ||
| CSIR | CSIR Energy Centre (Pretoria, South Africa) | 25.747, 28.279 | 1400 |
| CUT | Central University of Technology (Bloemfontein, South Africa) | 29.121, 26.216 | 1397 |
| FRH | University of Fort Hare (Alice, South Africa) | 32.785, 26.845 | 540 |
| GRT | Graaff-Reinet (Graaff-Reinet, South Africa) | 32.485, 24.586 | 660 |
| HLO | Mariendal (Mariendal, South Africa) | 33.854, 18.824 | 178 |
| ILA | Ilanga CSP Plant (Upington, South Africa) | 28.490, 21.520 | 884 |
| KZH | University of KwaZulu-Natal Howard College (Durban, South Africa) | 29.871, 30.977 | 150 |
| KZW | University of KwaZulu-Natal Westville (Durban, South Africa) | 29.817, 30.945 | 200 |
| MIN | CRSES Mintek (Johannesburg, South Africa) | 26.089, 27.978 | 1521 |
| NMU | Nelson Mandela University (Gqeberha, South Africa) | 34.009, 25.665 | 35 |
| NUST | Namibian University of Science and Technology (Windhoek, Namibia) | 22.565, 17.075 | 1683 |
| RVD | Richtersveld (Alexander Bay, South Africa) | 28.561, 16.761 | 141 |
| SUN | Stellenbosch University (Stellenbosch, South Africa) | 33.935, 18.867 | 119 |
| UBG | Gaborone (Gaborone, Botswana) | 24.661, 25.934 | 1014 |
| UFS | University of Free State (Bloemfontein, South Africa) | 29.111, 26.185 | 1491 |
| UNV | Venda (Vuwani, South Africa) | 23.131, 30.424 | 628 |
| UNZ | University of Zululand (KwaDlangezwa, South Africa) | 28.853, 31.852 | 90 |
| UPR | University of Pretoria (Pretoria, South Africa) | 25.753, 28.229 | 1410 |
| VAN | Vanrhynsdorp (Vanrhynsdorp, South Africa) | 31.617, 18.738 | 130 |
Table 4.
Clusters mean irradiances.
| Mean 4 | |||
|---|---|---|---|
| GHI | DNI | DHI | |
| [] | [] | [] | |
| Cluster 1 | 592 | 669 | 135 |
| Cluster 2 | 583 | 604 | 165 |
| Cluster 3 | 534 | 523 | 178 |
| Cluster 4 | 557 | 579 | 158 |
4 Mean values of training set
Table 5.
Hourly validation results of decomposition model development for CSIR.
| Model | Entire Dataset | |||||
|---|---|---|---|---|---|---|
| MBE [%] | RMSE [%] | MAE [%] | MAE [%] | MAE [%] | ||
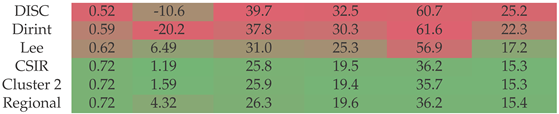 | ||||||
Table 6.
Hourly validation results of decomposition model development for CUT.
| Model | Entire Dataset | |||||
|---|---|---|---|---|---|---|
| MBE [%] | RMSE [%] | MAE [%] | MAE [%] | MAE [%] | ||
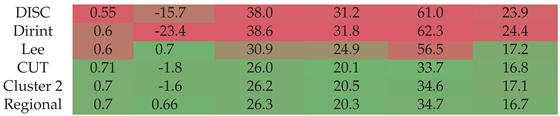 | ||||||
Table 7.
Hourly validation results of decomposition model development for FRH.
| Model | Entire Dataset | |||||
|---|---|---|---|---|---|---|
| MBE [%] | RMSE [%] | MAE [%] | MAE [%] | MAE [%] | ||
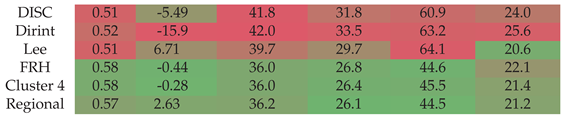 | ||||||
Table 8.
Hourly validation results of decomposition model development for GRT.
| Model | Entire Dataset | |||||
|---|---|---|---|---|---|---|
| MBE [%] | RMSE [%] | MAE [%] | MAE [%] | MAE [%] | ||
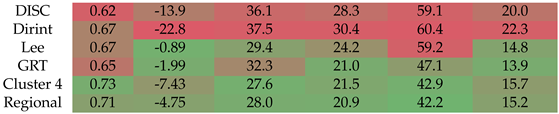 | ||||||
Table 9.
Hourly validation results of decomposition model development for HLO.
| Model | Entire Dataset | |||||
|---|---|---|---|---|---|---|
| MBE [%] | RMSE [%] | MAE [%] | MAE [%] | MAE [%] | ||
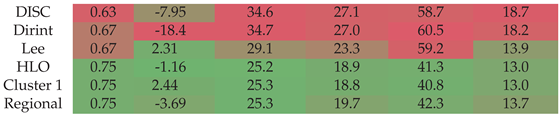 | ||||||
Table 10.
Hourly validation results of decomposition model development for KZH.
| Model | Entire Dataset | |||||
|---|---|---|---|---|---|---|
| MBE [%] | RMSE [%] | MAE [%] | MAE [%] | MAE [%] | ||
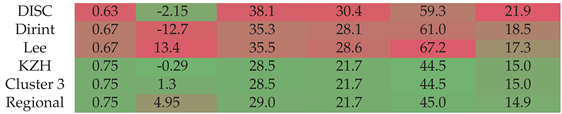 | ||||||
Table 11.
Hourly validation results of decomposition model development for KZW.
| Model | Entire Dataset | |||||
|---|---|---|---|---|---|---|
| MBE [%] | RMSE [%] | MAE [%] | MAE [%] | MAE [%] | ||
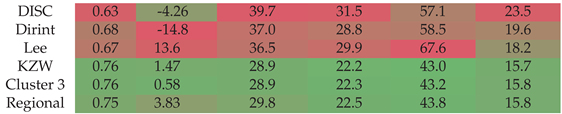 | ||||||
Table 12.
Hourly validation results of decomposition model development for NMU.
| Model | Entire Dataset | |||||
|---|---|---|---|---|---|---|
| MBE [%] | RMSE [%] | MAE [%] | MAE [%] | MAE [%] | ||
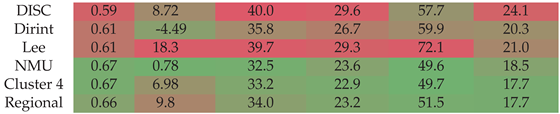 | ||||||
Table 13.
Hourly validation results of decomposition model development for NUST.
| Model | Entire Dataset | |||||
|---|---|---|---|---|---|---|
| MBE [%] | RMSE [%] | MAE [%] | MAE [%] | MAE [%] | ||
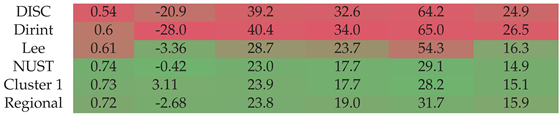 | ||||||
Table 14.
Hourly validation results of decomposition model development for RVD.
| Model | Entire Dataset | |||||
|---|---|---|---|---|---|---|
| MBE [%] | RMSE [%] | MAE [%] | MAE [%] | MAE [%] | ||
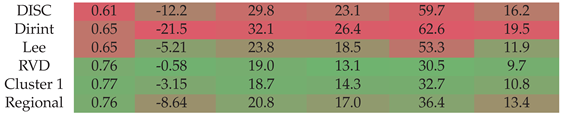 | ||||||
Table 15.
Hourly validation results of decomposition model development for SUN.
| Model | Entire Dataset | |||||
|---|---|---|---|---|---|---|
| MBE [%] | RMSE [%] | MAE [%] | MAE [%] | MAE [%] | ||
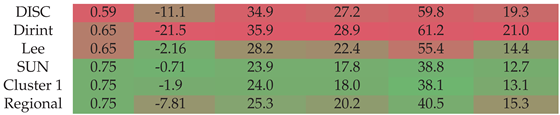 | ||||||
Table 16.
Hourly validation results of decomposition model development for UBG.
| Model | Entire Dataset | |||||
|---|---|---|---|---|---|---|
| MBE [%] | RMSE [%] | MAE [%] | MAE [%] | MAE [%] | ||
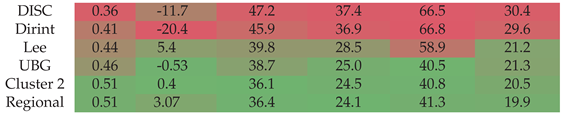 | ||||||
Table 17.
Hourly validation results of decomposition model development for UFS.
| Model | Entire Dataset | |||||
|---|---|---|---|---|---|---|
| MBE [%] | RMSE [%] | MAE [%] | MAE [%] | MAE [%] | ||
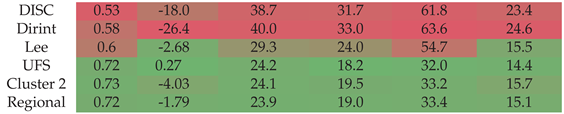 | ||||||
Table 18.
Hourly validation results of decomposition model development for UNV.
| Model | Entire Dataset | |||||
|---|---|---|---|---|---|---|
| MBE [%] | RMSE [%] | MAE [%] | MAE [%] | MAE [%] | ||
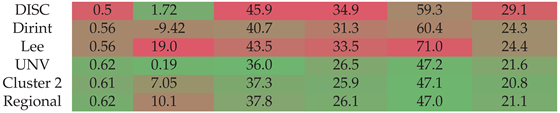 | ||||||
Table 19.
Hourly validation results of decomposition model development for UNZ.
| Model | Entire Dataset | |||||
|---|---|---|---|---|---|---|
| MBE [%] | RMSE [%] | MAE [%] | MAE [%] | MAE [%] | ||
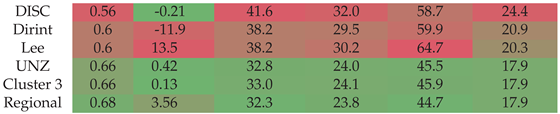 | ||||||
Table 20.
Hourly validation results of decomposition model development for UPR.
| Model | Entire Dataset | |||||
|---|---|---|---|---|---|---|
| MBE [%] | RMSE [%] | MAE [%] | MAE [%] | MAE [%] | ||
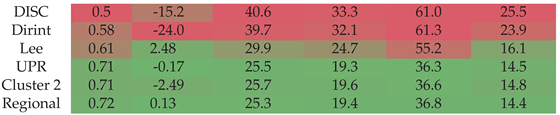 | ||||||
Table 21.
Hourly validation results of decomposition model development for VAN.
| Model | Entire Dataset | |||||
|---|---|---|---|---|---|---|
| MBE [%] | RMSE [%] | MAE [%] | MAE [%] | MAE [%] | ||
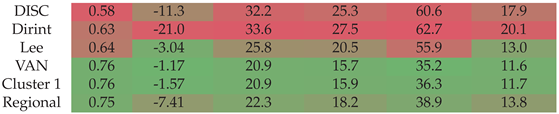 | ||||||
Table 22.
Summary of test and validation sets of stations outperforming baseline models.
| Dataset | Localised model | Cluster model | Regional model | |||||
|---|---|---|---|---|---|---|---|---|
| outperforms | outperforms | outperforms | ||||||
| baseline models | baseline models | baseline models | ||||||
| Test | Validation | Test | Validation | Test | Validation | |||
| CSIR | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| CUT | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| FRH | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| GRT | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| HLO | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| ILA | - | ✓ | - | ✓ | - | ✓ | ||
| KZH | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| KZW | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| MIN | - | ✓ | - | ✓ | - | ✓ | ||
| NMU | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| NUST | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| RVD | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| SUN | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| UBG | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| UFS | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| UNV | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| UNZ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| UPR | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| VAN | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



