
Submitted:
08 March 2024
Posted:
14 March 2024
Read the latest preprint version here
Abstract
In the dynamic landscape of the telecommunications industry, understanding and mitigating customer churn is paramount for maintaining competitive advantage and sustaining revenue streams. This comprehensive literature review delves into the intricacies of customer churn prediction, a crucial aspect in fortifying the bond between telecom businesses and their customers. The review methodically analyzes 11 articles published between 2000 and March 2024, spotlighting the strategic role of Customer Relationship Management and the prevalence of high churn rates that necessitate a shift from customer acquisition to retention strategies. Furthermore, the review navigates through the challenges inherent in churn prediction, including the complexities of managing large, imbalanced, and noisy datasets and the intricacies involved in model selection and optimization. Despite these challenges, the paper highlights the superior capability of machine learning techniques in handling complex datasets to provide accurate predictions, albeit acknowledging their practical complexities. The main aim of the study is to provide an overview, serving as a knowledge base for researchers interested in machine learning techniques within the realm of telecommunications.
Keywords:
Customer churn prediction
; machine learning
; telecommunication industry
; literature review
; imbalanced data
; sampling techniques
; classification techniques
; random forest
; XGBoost
; gradient boosting
; ensemble techniques
I. Introduction
Customer Relationship Management (CRM) represents a strategic approach aimed at strengthening the bond between businesses and their clientele. It is an essential instrument for delving into the intricacies of consumer behavior and preferences, with the goal of nurturing stronger, more impactful relationships. This, in turn, leads to the cultivation of a devoted and enduring customer base. The significance of CRM resonates across various sectors, notably in banking, insurance, and telecommunications. Within the telecommunications industry, a critical contributor to global revenue and social-economic development, the competition is fierce. Companies operating in this domain are not only intent on enlarging their customer base but also place a significant emphasis on retaining their existing customers, mindful of the substantial costs tied to the acquisition of new ones. Hence, in the telecom sector, customer retention emerges as a pivotal strategy for augmenting revenue and curtailing marketing expenses.
Customer churn is defined as the tendency of customers to abandon a service provider. Predicting customer churn involves the process of identifying customers who are likely to leave or switch from their current service provider for various reasons. This concept has been explored by various researchers.
II. Purpose of the Study
The foremost goal of churn prediction models is to identify at-risk customers, allowing companies to implement targeted retention strategies to maintain their customer base and maximize overall revenue. Customer churn prediction is an issue that spans across multiple sectors, including telecommunications, credit card services, internet service provision, e-commerce, retail marketing, newspaper publishing, banking, and financial services. The telecommunications industry, in particular, contends with especially high annual churn rates, often between 20% to 40%, underscoring the critical financial importance of retention over acquisition [1].
Data mining, a key discipline within computer science, seeks to uncover hidden patterns within large datasets through the application of statistical, mathematical, artificial intelligence, and machine learning techniques. Despite organizations having access to vast data reserves, the primary challenge resides in distilling this data into actionable insights, a task that data mining tools are well-equipped to tackle [2].
This literature review paper encompasses research from 2000 to March 2024, centring on churn prediction within the telecom sector. It outlines the research methodology, delivers a thorough analysis across three dimensions, evaluates and interprets findings, and discusses the prevalent challenges and limitations encountered by researchers. The concluding remarks are reserved for the final section of the paper.
The telecom industry, recognized as one of the most rapidly expanding global sectors, now reaches 95% of the world's population [3]. In this competitive field, customer retention is pivotal for sustaining revenue streams [4]. High churn rates exert considerable pressure on the industry, further emphasizing the value of customer retention over new customer acquisition due to the associated cost disparity.
In response to the churn challenge, companies are now concentrating more on customer retention than on acquisition. Establishing strong customer relationships has become a priority for businesses [5], and it is widely recognized that the best marketing strategy is one that ensures the retention of existing customers; thereby, reducing churn is a key aspect to achieving this goal [6,7]. To this end, machine learning techniques have been acknowledged as effective instruments in curbing the rising trend of customer churn rates.
III. Customer Churn in the Telecom Industry
This section delves into a collection of notable studies that have applied Machine Learning (ML) algorithms, with a particular focus on ensemble learning models, to tackle the Customer Churn Prediction (CCP) issue in the telecommunications sector. It also highlights research leveraging optimization algorithms to refine their proposed methodologies.
Mozer et al. [8] investigated customer churn prediction using ML models such as Decision Trees (DT), Artificial Neural Networks (ANN), Logistic Regression (LR), and ensemble learning models emphasizing boosting techniques. The research analysed data from 47,000 local mobile phone subscribers, incorporating variables like consumption history, billing, and credit, among others. The study's results showcased the superior performance of the ANN model over DT and LR in forecasting subscriber churn.
Hadden et al. [9] performed an extensive evaluation of feature selection methods to enhance CCP solutions. The study scrutinized prevalent ML models, including DT, regression analysis, and ANN. It revealed three primary benefits of feature selection: enhanced classification accuracy through the selection of pertinent features, reduced computational time, and compatibility with lower-dimensional datasets, which is particularly beneficial for neural networks. The researchers also underlined the importance of optimization techniques, like genetic algorithms, in augmenting CCP performance and suggested future exploration into Naïve Bayes and fuzzy inference systems for churn prediction.
Coussement et al. [10] presented an in-depth examination of Support Vector Machine (SVM) models in CCP, comparing cross-validation and grid-search for optimal parameter tuning. The study compared SVM models against LR and Random Forest (RF) methods regarding prediction accuracy. The findings underscored SVM's robustness against noisy data and its superior performance over LR when parameters were optimally tuned, although RF outperformed SVM.
Burez and Van Den [11] addressed the issue of class imbalance in CCP datasets by analysing various dataset balancing strategies, including random and sophisticated under-sampling techniques. The study implemented weighted RF and gradient boosting models, assessing outcomes through metrics like AUC and Lift. The results indicated that advanced under-sampling techniques outperformed random ones.
Pendharkar [12] introduced two ANN models employing Genetic Algorithm (GA) to fine-tune churn prediction accuracy among telecom subscribers. The models, one based on a cross-entropy criterion for CCP and the other leveraging GA to directly enhance churn prediction accuracy, exhibited superior performance metrics such as accuracy, lift decile above 10%, and AUC when applied to real-world cellular service datasets. The study also found that medium-sized neural networks yielded the best results, and the cross-entropy-based model showed higher resilience to overfitting.
Idris et al. [13] demonstrated that ensemble models, particularly those comprising DTs and utilizing boosting methods, can achieve superior outcomes in resolving the CCP issue. Nevertheless, the large size, imbalanced nature, and extensive feature sets of churn datasets pose challenges. To counter these, the study proposed a combined approach of genetic programming and the Adaboost model, which showed superior prediction accuracy compared to KNN and RF methods.
Vafeiadis et al. [14] conducted a detailed comparative analysis of ML methods for CCP in the telecom sector. The study applied and assessed common ML models, including DT, ANN, Naïve Bayes, SVM, and LR, using cross-validation on a public dataset. The research also explored the performance enhancement afforded by employing ensemble learning with boosting techniques.
Idris and Khan [15] introduced the FW-ECP, an intelligent forecasting system combining wrapper and filter feature selection methods with ensemble learning techniques. The system employed the Particle Swarm Optimization (PSO) algorithm for dataset balancing, the mRMR technique for feature selection, and the GA for eliminating irrelevant and redundant features. Two ensemble learning-based predictors were suggested and tested on two public datasets, showing superior performance due to the meta-heuristic algorithms' ability to manage imbalanced and large-scale training sets.
Imani and Arabnia [16] conducted a comprehensive evaluation of seven classifiers, including ANN, DT, SVM, RF, LR, XGBoost, LightGBM, and CatBoost, alongside three different sampling techniques to address the CCP issue. The study explored the efficacy of sampling techniques and hyperparameter tuning on telecom datasets across four evaluation metrics. The results indicated that regarding the F1-score, CatBoost outshines its counterparts in machine learning, delivering an impressive 93% after Optuna hyperparameter optimization is applied. When evaluating the ROC AUC metric, XGBoost, and CatBoost both stand out, each securing an impressive 91%. XGBoost's success is realized following the integration of SMOTE with Tomek Links, whereas CatBoost accomplishes this high-performance mark upon the implementation of Optuna hyperparameter optimization.
Imani et al. [17] investigated the efficacy of machine learning models in predicting telecom churn. Employing a public dataset, it focuses on algorithms like Random Forests, XGBoost, LightGBM, and CatBoost, and evaluates their performance with metrics such as Accuracy, Precision, Recall, F1-score, and ROC AUC. The research highlights the effectiveness of the SMOTE and ADASYN upsampling techniques in dealing with dataset imbalance, with ADASYN slightly edging out SMOTE in performance improvement. Notably, LightGBM stands out post-ADASYN, achieving an F1-score of 89% and ROC AUC of 95%, showcasing the value of advanced boosting algorithms and strategic upsampling in addressing the challenges of customer churn prediction.
Beeharry and Fokone [18] introduced a two-layer soft voting model to address the CCP challenge, analysing its performance on balanced and imbalanced public telecom datasets. The model, comprising conventional ML algorithms in the first layer and ensemble classifiers in the second, demonstrated a significant increase in the F1-score, especially on balanced datasets, outshining all base learners.
IV. Search Process
Acknowledging the high credibility of journals as research sources, the initial step involved consulting prominent online journal databases for a thorough academic review. The databases explored include:
IEEE Explore
Elsevier
ScienceDirect
MDPI
SpringerLink
ACM Digital Library
Utilizing specific search strings tailored to each database's syntax yielded 738 articles initially. The subsequent phase involved refining this pool to articles directly relevant to the topic. The inclusion and exclusion criteria were as follows:
- Articles must contain keywords from the search string. The search string was "customer churn prediction."
- Selection was limited to articles published in notable journals or conferences. Formats such as newsletters, lecture notes, books, doctoral dissertations, and unpublished works were excluded.
- The timeframe of the search was confined from the year 2000 to 2024.
- Only articles pertinent to the telecommunications sector were considered.
V. Article's Distribution
In this study, 11 articles were meticulously selected and analyzed across three distinct dimensions:
- ❖
- Distribution of articles by Techniques
- ❖
- Distribution of articles by Journals
- ❖
- Distribution of articles by Publication Year
A. Distribution of Articles by Year of Publication:
The distribution of articles based on the year of publication is illustrated in Table 1, which covers the years 2000 up to 2024. From this depiction, it is noticeable that the years 2007 to 2009 stand out as periods during which the telecommunications sector received a substantial volume of research material specifically focused on churn analysis.
B. Distribution of Articles by Journals:
This section provides insights into the distribution of articles by journals, as detailed in Table 2. A comprehensive exploration was conducted across eight journals and one conference proceeding to gather articles pertinent to churn prediction in the telecommunications sector. The journal "Expert System with Applications" alongside "IEEE" are at the forefront, each contributing three articles to the field and addressing the context of customer churn prediction. This distribution highlights the leading sources of scholarly information and research within the niche of churn prediction in telecommunications.
C. Distribution of articles by Techniques:
This section delves into the distribution of journal articles based on the techniques employed for model building, as outlined in Table 3. A total of 13 different techniques have been utilized across 11 articles, with some articles incorporating multiple techniques.
In the articles reviewed, the techniques that stand out due to their frequent use include the Artificial Neural Network, Decision Tree, Random Forest, and Logistic Regression. The ranking list of the machine learning techniques based on their frequency of use in the papers is as follows:
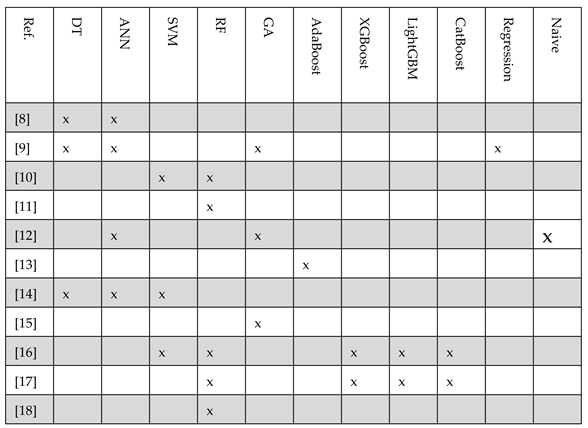
The classification reveals that Artificial Neural Networks (ANN), Decision Trees (DT), Logistic Regression (LR), and Random Forest (RF) are the most recurrent techniques cited in the reviewed papers, while methodologies such as XGBoost, LightGBM, and CatBoost are brought up less often. One reason for the infrequent mention of gradient boosting methods is the span of the research, which ranges from 2000 to 2024; these techniques have gained prominence more recently and are on their way to becoming standard for customer churn prediction. Additionally, the limited frequency of gradient boosting references may also be due to the relatively small number of papers analysed in this study, which could restrict the representation of the full spectrum of techniques currently in use.
The top four techniques are further explained briefly with insights from academic literature:
- Random forest:
The Random Forest (RF) technique is recognized for its robust performance in classifying nonlinear data. It constructs multiple decision trees, each from a randomly selected subset of predictor attributes, and aggregates their outcomes, typically through weighted averages, to make predictions. Its unique strength lies in its ability to handle datasets with correlated features effectively [19,20,21].
- 2.
- Logistic Regression:
Logistic Regression (LR) employs the logistic function to model probabilities instead of fitting data linearly. This function generates probabilities from a weighted sum, which are then optimized using a maximum-likelihood estimator. The estimator iteratively refines its predictions to enhance the model's accuracy by minimizing the error across the training dataset [19,20,22].
- 3.
- Decision Tree:
This technique is favored for predicting future trends and modeling based on interrelated decisions [23,24]. The Decision Tree (DT) model is incrementally built as a tree structure, expanding nodes along branches until terminal nodes are reached. Each node signifies a test on an attribute, branching out to represent all possible outcomes of that attribute. Noteworthy for their resilience to noise and ease of interpretation, decision trees have been a preferred choice in recent churn prediction research [19,25,26,31,32].
- 4.
- Neural Networks:
The Artificial Neural Network (ANN) is a frequently used method for tackling intricate challenges, including the task of predicting customer churn. Structured in a manner similar to the human brain, ANNs consist of a network of interlinked nodes. These networks are adaptable to different learning algorithms, thereby improving the machine learning procedure, and can be implemented in both hardware and software configurations. Among the various models, the Multi-Layer Perceptron stands out as particularly prevalent, and it is commonly trained through the Back-Propagation Network (BPN) algorithm [27,28].
VI. Challenges
This section addresses the various challenges researchers encounter in developing churn prediction models, particularly in the telecommunications sector:
- Incomplete or Missing Datasets: A significant challenge is the lack of complete datasets in the telecom industry field. On the other hand, some telecom companies provide datasets that are so large that they become cumbersome to manage, often compounded by issues of noisy data.
- Imbalanced Data: Another major hurdle is the imbalanced nature of the data, where the ratio of regular customers to churners is uneven. Often, churners' data constitute only about 10% to 20% of the total data, creating challenges in terms of the reliability of the predictive model.
These challenges underline the complexity of churn prediction in the telecommunications sector and emphasize the need for advanced methodologies and robust data management practices.
VII. Limitations
This section acknowledges the inherent limitations of the research despite efforts to bolster its reliability through robust references. The study's constraints include:
- Scope of Articles Reviewed: The review is confined to 11 articles published between 2000 and 2024. Increasing the number of research papers could enrich the study's findings.
- Keyword Constraints in the Search String: The research employed a search string incorporating key terms such as "customer churn prediction" and "telecommunication." However, this approach may have inadvertently excluded relevant articles that address churn prediction in telecom but do not feature these specific keywords.
- Limitation to Specific Online Publishers: The study was limited to sourcing articles from only six online publishers. Expanding the search to include additional academic journals could provide a more comprehensive understanding and possibly unveil additional insights.
These limitations highlight the necessity for a broader scope in future research to ensure a more comprehensive and nuanced understanding of churn prediction in the telecommunications sector.
VIII. Findings
This section outlines the findings from the research, acknowledging the limitations but also highlighting key implications:
- Popularity of Decision Tree Technique: The Decision Tree emerges as the most prevalent technique used for churn prediction, indicating its widespread acceptance and utility in the field.
- Data Quality Challenges: Researchers face major challenges in terms of data quality, particularly due to the unavailability of complete datasets or the presence of overly large datasets with noisy information.
- High Dimensionality and Data Imbalance: The high dimensionality and imbalanced nature of data are identified as significant obstacles, complicating the development of precise and reliable prediction models.
- Limitations of Classification Techniques: While classification techniques are effective for analyzing qualitative and continuous data, they fall short in ensuring the desired accuracy of prediction models, especially for highly dimensional, non-linear, or time series datasets.
IX. Conclusions
This section concludes the paper by reiterating the significant challenge of customer churn faced by the telecommunications industry today. This issue not only undermines customer loyalty but also leads to substantial revenue losses. The paper emphasizes that the effective solution lies in retaining current customers through the use of customer churn prediction models. Machine Learning techniques are highlighted as instrumental in this regard, as they enable the identification of at-risk customers, allowing for targeted retention strategies.
The paper begins by underscoring the severe threat of customer churn to telecom companies, supported by statistical evidence. It provides an extensive review of the customer churn problem, both in a broad context and then more specifically within the telecommunications sector.
A thorough comparison of selected articles is then presented across three deliberate dimensions: the year of publication, the techniques used, and the journals where the articles were published. In total, 11 articles were meticulously reviewed. The research findings contribute valuable insights to the field of customer churn predictive modeling in telecommunications. By doing so, the paper delineates a clear pathway for researchers, offering an overview and accumulating trends about machine learning applications in the telecommunication sector. This not only aids in understanding the current landscape but also guides future research endeavors in this critical area.
References
- Ahna, Jae-Hyeon, Sang-Pil Hana, and Yung-Seop Lee. "Customer churn analysis: Churn determinants and mediation effects of partial defection in the Korean mobile telecommunications service industry." Telecommunications Policy, vol. 30, no. 10-11, 2006, pp. 552–568. [CrossRef]
- Shu, Xiaoling, and Yiwan Ye. "Knowledge Discovery: Methods from data mining and machine learning." Social Science Research, vol. 110, 2023, p. 102817. [CrossRef]
- "FF23 Mobile Network Coverage." International Telecommunication Union, 10 Oct. 2023, www.itu.int/itu-d/reports/statistics/2023/10/10/ff23-mobile-network-coverage/.
- Idris, Adnan, Muhammad Rizwan, and Asifullah Khan. "Churn prediction in telecom using Random Forest and PSO based data balancing in combination with various feature selection strategies." Journal of Computers and Electrical Engineering, vol. 38, 2012, pp. 1808–1819. [CrossRef]
- Chen, Zhen-Yu, Zhi-Ping Fan, and Minghe Sun. "A hierarchical multiple kernel support vector machine for customer churn prediction using longitudinal behavioral data." European Journal of Operational Research, vol. 223, 2012, pp. 461–472. [CrossRef]
- Gordini, Niccolo, and Valerio Veglio. "Customers churn prediction and marketing retention strategies. An application of support vector machines based on the AUC parameter-selection technique in B2B e-commerce industry." Industrial Marketing Management, vol. 62, 2017, pp. 100–107. [CrossRef]
- Lemmens, Aurélie, and Sunil Gupta. "Managing churn to maximize profits." Marketing Science, vol. 39, no. 5, 2020, pp. 956–973. [CrossRef]
- Mozer, M. C., et al. "Predicting subscriber dissatisfaction and improving retention in the wireless telecommunications industry." IEEE Transactions on Neural Networks, vol. 11, 2000, pp. 690–696. [CrossRef]
- Hadden, J., et al. "Computer assisted customer churn management: State-of-the-art and future trends." Computers & Operations Research, vol. 34, 2007, pp. 2902–2917. [CrossRef]
- Coussement, K., and D. Van den Poel. "Churn prediction in subscription services: An application of support vector machines while comparing two parameter-selection techniques." Expert Systems with Applications, vol. 34, 2008, pp. 313–327. [CrossRef]
- Burez, J., and D. Van den Poel. "Handling class imbalance in customer churn prediction." Expert Systems with Applications, vol. 36, 2009, pp. 4626–4636. [CrossRef]
- Pendharkar, P. C. "Genetic algorithm based neural network approaches for predicting churn in cellular wireless network services." Expert Systems with Applications, vol. 36, 2009, pp. 6714–6720. [CrossRef]
- Idris, A., et al. "Genetic programming and adaboosting based churn prediction for telecom." IEEE International Conference on Systems, Man, and Cybernetics (SMC), 2012, pp. 1328–1332.
- Vafeiadis, T., et al. "A comparison of machine learning techniques for customer churn prediction." Simulation Modelling Practice and Theory, vol. 55, 2015, pp. 1–9. [CrossRef]
- Idris, A., and A. Khan. "Churn prediction system for telecom using filter–wrapper and ensemble classification." The Computer Journal, vol. 60, 2017, pp. 410–430. [CrossRef]
- Imani, M., and H. R. Arabnia. "Hyperparameter Optimization and Combined Data Sampling Techniques in Machine Learning for Customer Churn Prediction: A Comparative Analysis." Technologies, vol. 11, no. 6, 2023, p. 167. [CrossRef]
- Imani, M.; Ghaderpour, Z.; Joudaki, M. The Impact of SMOTE and ADASYN on Random Forests and Advanced Gradient Boosting Techniques in Telecom Customer Churn Prediction. Preprints 2024, 2024030213. [CrossRef]
- Beeharry, Y., and R. Tsokizep Fokone. "Hybrid approach using machine learning algorithms for customers' churn prediction in the telecommunications industry." Concurrency and Computation: Practice and Experience, vol. 34, 2022, e6627. [CrossRef]
- K, Jolly. Machine Learning with Scikit-Learn Quick Start Guide: Classification, Regression, and Clustering Techniques in Python. Packt Publishing Ltd, 2018.
- Usman-Hamza, Fatima Enehezei, et al. "Intelligent decision forest models for customer churn prediction." Applied Sciences 12.16 (2022): 8270. [CrossRef]
- Ullah, I., et al. "A churn prediction model using random forest: analysis of machine learning techniques for churn prediction and factor identification in telecom sector." IEEE Access, vol. 7, 2019, pp. 60134–60149. [CrossRef]
- Fujo, Wael S., et al. "Customer churn prediction in telecommunication industry using deep learning." Information Sciences Letters, vol. 11, no. 1, 2022, pp. 24.
- Chu, B. H., et al. "Towards a hybrid data mining model for customer retention." Knowledge-Based Systems, vol. 20, 2007, pp. 703–718. [CrossRef]
- Berry, M. J. A., and G. S. Linoff. Data Mining Techniques Second Edition – for Marketing, Sales, and Customer Relationship Management. 2004.
- Liu, R., et al. "An intelligent hybrid scheme for customer churn prediction integrating clustering and classification algorithms." Applied Sciences, vol. 12, no. 18, 2022, p. 9355. [CrossRef]
- Fathian, M., et al. "Offering a hybrid approach of data mining to predict the customer churn based on bagging and boosting methods." Kybernetes, 2016. [CrossRef]
- Tsai, Chih-Fong, and Yu-Hsin Lu. "Customer churn prediction by hybrid neural networks." Expert System with Applications, vol. 36, 2009, pp. 12547–12553. [CrossRef]
- Song, H. S., et al. "A personalized defection detection and prevention procedure based on the self-organizing map and association rule mining: Applied to online game site." Artificial Intelligence Review, vol. 21, 2004, pp. 161–184. [CrossRef]
- Bhambri, Vivek. "Data Mining as a Tool to Predict Churn Behaviour of Customers." GE-International Journal of Management Research (IJMR), April 2013, pp. 59-69.
- Idris, Adnan, Muhammad Rizwan, and Asifullah Khan. "Churn prediction in telecom using Random Forest and PSO based data balancing in combination with various feature selection strategies." Journal of Computers and Electrical Engineering, vol. 38, 2012, pp. 1808–1819. [CrossRef]
- Mazhari, N., et al. "An overview of the classification and its algorithm." 3rd Data Mining Conference (IDMC'09): Tehran . 2009.
- Joudaki, Majid, et al. "Presenting a New Approach for Predicting and Preventing Active/Deliberate Customer Churn in Telecommunication Industry." Proceedings of the International Conference on Security and Management (SAM). The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp), 2011.

Table 1.
THE DISTRIBUTION OF ARTICLES BASED ON THE YEAR OF PUBLICATION.
| Ref. | Journal/Publication |
|---|---|
| [8] | IEEE Transactions on Neural Networks |
| [9] | Computers & Operations Research |
| [10] | Expert Systems with Applications |
| [11] | Expert Systems with Applications |
| [12] | Expert Systems with Applications |
| [13] | IEEE International Conference on Systems, Man, and Cybernetics (SMC) |
| [14] | Simulation Modelling Practice and Theory |
| [15] | The Computer Journal |
| [16] | MDPI, Technologies |
| [17] | IEEE |
| [18] | Concurrency and Computation: Practice and Experience |
Table 2.
THE DISTRIBUTION OF ARTICLES BASED ON JOURNALS/PUBLICATION.
| Ref. | Journal/Publication |
|---|---|
| [8] | IEEE Transactions on Neural Networks |
| [9] | Computers & Operations Research |
| [10] | Expert Systems with Applications |
| [11] | Expert Systems with Applications |
| [12] | Expert Systems with Applications |
| [13] | IEEE International Conference on Systems, Man, and Cybernetics (SMC) |
| [14] | Simulation Modelling Practice and Theory |
| [15] | The Computer Journal |
| [16] | MDPI, Technologies |
| [17] | IEEE |
| [18] | Concurrency and Computation: Practice and Experience |
Table 3.
THE DISTRIBUTION OF ARTICLES BASED ON THE TECHNIQUES USED.
| Ref. | Techniques Used |
|---|---|
| [8] | Decision Trees (DT), Artificial Neural Networks (ANN), Logistic Regression (LR), Ensemble Learning Models with Boosting Techniques |
| [9] | Decision Trees (DT), Regression Analysis, Artificial Neural Networks (ANN), Feature Selection Techniques, Genetic Algorithms |
| [10] | Support Vector Machine (SVM), Cross-Validation, Grid-Search, Logistic Regression (LR), Random Forest (RF) |
| [11] | Weighted Random Forest (RF), Gradient Boosting Models, Under-sampling Techniques |
| [12] | Artificial Neural Networks (ANN) with Genetic Algorithm (GA) |
| [13] | Ensemble Models with Decision Trees (DT), Boosting Methods, Genetic Programming, AdaBoost |
| [14] | Decision Trees (DT), Artificial Neural Networks (ANN), Naïve Bayes, Support Vector Machine (SVM), Logistic Regression (LR), Ensemble Learning with Boosting Techniques |
| [15] | Filter–Wrapper Feature Selection, Ensemble Classification, Particle Swarm Optimization (PSO), Genetic Algorithm (GA) |
| [16] | Artificial Neural Networks, Decision Trees, Support Vector Machines, Random Forests, Logistic Regression, XGBoost, LightGBM, CatBoost, Sampling Techniques, Hyperparameter Optimization |
| [17] | Random Forest (RF), XGboost, CatBoost, LightGBM, SMOTE, ADASYN |
| [18] | Two-Layer Soft Voting Model, Conventional Machine Learning Algorithms, Ensemble Classifiers |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



