Submitted:
12 March 2024
Posted:
12 March 2024
You are already at the latest version
Abstract
Recently, there has been considerable research on deepfake detection. However, most existing methods face challenges in adapting to the advancements in new generative models within unknown domains. In addition, the emergence of new generative models capable of producing and editing high-quality images, such as Diffusion, Consistency, and LCM, poses a challenge for traditional deepfake training models. These advancements highlight the need for adapting and evolving existing deepfake detection techniques to effectively counter the threats posed by sophisticated image manipulation technologies. In this paper, our objective is to detect deepfake videos in unknown domains using unlabeled data. Specifically, our proposed approach employs Meta Pseudo Labels (MPL) with Supervised Contrastive Learning, so-called SupCon-MPL, allowing the model to be trained on unlabeled images. MPL involves the simultaneous training of both a Teacher model and a Student model, where the Teacher model generates Pseudo Labels utilized to train the Student model. This method aims to enhance the adaptability and robustness of deepfake detection systems against emerging unknown domains. Supervised Contrastive Learning utilizes labels to compare samples within similar classes more intensively, while encouraging greater distinction from samples in dissimilar classes. This facilitates the learning of features in a diverse set of deepfake images by the model, consequently contributing to the performance of deepfake detection in unknown domains. When utilizing the ResNet50 model as the backbone, SupCon-MPL exhibited an improvement of 1.58% in accuracy compared to traditional MPL in known domain detection. Moreover, in the same generation of unknown domain detection, there was a 1.32% accuracy enhancement, while in the detection of post-generation unknown domains, there was an 8.74% increase in accuracy.
Keywords:
Deepfake Detection
; Deepfake Unknown Domain
; Meta Pseudo Labels
; Supervised Contrastive Learning
; Generative Misuse
1. Introduction
Recently, with the advancement of generative artificial intelligence models [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15], deepfakes have become increasingly similar to real images/videos, making them difficult to distinguish. Deepfakes can be broadly categorized into three generations based on the evolution of generative models. First-generation deepfake generative models[1,2,3,4,5] typically attempt to generate simple and low-resolution images/videos based on probability distributions or synthesize multiple images/videos by exploiting features in tasks such as Face2Face and FaceSwap. In particular, GAN-based models such as CGAN [2], WGAN [4], WGAN-GP [5], as well as AutoEncoder-based models like VAE [6], Conditional VAE [7], have enabled the generation of various deepfake images/videos. However, first-generation deepfakes often exhibit noticeable artifacts that can be discerned by the human eye. With the transition to second-generation deepfake generative models [6,7,8], there has been progress in generating high-resolution deepfake images that are more difficult to distinguish compared to first-generation ones, along with performance improvements in various tasks. In particular, second-generation deepfake generative models like StyleGAN, proposed by T. Karras et al. [8], produce deepfake images that are difficult for the human eye to distinguish, excluding some flaws such as artifacts in hair. Second-generation deepfakes can be generated using deepfake generation tools such as DeepfaceLab [10], DeepSwap [11], Synthesia [12] and others. Finally, third-generation deepfake generative models [9,13,14,15] produce images/videos that are even more flexible and difficult to distinguish than those generated by second-generation models, across various tasks. In particular, Stable Diffusion, proposed by R. Rombach et al. [13], is currently being used for the generation of various human and artwork images, raising concerns related to copyright and human rights issues. Furthermore, the Consistency model proposed by Y. Song et al. [15] has enabled state-of-the-art deepfake generative model training at a lower cost by reducing the extensive iteration process required by previous Diffusion models for restoring original images from noise. As deepfakes increasingly become difficult to distinguish from real images/videos, they are being utilized in various criminal activities.
To address issues caused by deepfakes, methods have been proposed to identify flaws in landmarks that occur when deepfake generative models create images, aiding in the detection of deepfakes [16,17,18,19]. Meanwhile, recent advancements in deepfake detection for single models have shown improvement in detecting deepfake videos and images. D.A. Coccomini et al. [20] enhanced the detection performance of deepfake videos and images by combining EfficientNet [21] and Vision Transformer [22] when training a single model. In other words, existing deepfake detection models [16,17,18,19,20,21,22,23] verify flaws in facial landmarks during the preprocessing stage and construct large models for flexible predictions.
Previous studies have primarily focused on the detection performance of labeled known domain (Known Domain) tasks in deepfake detection. However, deepfake generation models are rapidly evolving, and similar generations of deepfake generation models are also being developed diversely. Therefore, detecting deepfake images in unknown domains (Unknown Domain) is also crucial. A few studies have proposed generalized deepfake detection models using techniques such as Contrastive Learning, Meta Learning, and others [24,25,26,27,28,29,30,31,32,33,34,35,36].
In this paper, we propose SupCon-MPL, combination of the Meta Pseudo Labels (MPL) [37] with Supervised Contrastive Learning (SupCon) [38] to further train the model with unlabeled images/videos, simultaneously enhancing the model's generalization ability to distinguish deepfakes in unknown domains. The proposed SupCon-MPL utilizes the basic structure of MPL, where two models, namely teacher and student, are simultaneously trained. Each model influences the other during training. The teacher model constructs pseudo-labels for unlabeled images and transfers them to the student model. Through this approach, the student model learns from unlabeled data, providing the potential to train effectively with limited labeled data. Furthermore, during the training process, we apply the SupConLoss [38] to the encoder of each model, enabling Contrastive Representation Learning, thereby inducing generalized model training.
The performance evaluation experiments were conducted in two parts: model validation experiments and deepfake detection experiment based on scenario. In the model validation experiments, we utilized the data from five domains within FaceForensics++ [39]. We evaluated the detection performance in labeled Known Domains by combining the data in various ways and assessed the generalized detection performance in Unknown Domains. The deepfake detection experiment based on scenario involves training the model with first-generation’s deepfake datasets (FaceForensics++ [39], DFDC [40], Celeb-DF [41]) and evaluating the detection performance on first- and second-generation unknown deepfake datasets (StyleGAN [8], NeuralTextures [39]). The experimental results showed that SupCon-MPL achieved performance improvements of 1.58%, 1.32%, and 8.74% over the baseline MPL model in the proposed evaluation scenario, respectively.
2. Related Works
As deepfake generation models advance, various detection methods have also been researched. A common approach in deepfake detection is to explore flaws in facial images [16,17,18,19]. However, the continual development of new generative models has led to the problem of being unable to train detection models using data from all generative models. To address this problem, a few studies have explored training generalized deepfake detection models [24,25,26,27,28,29,30,31,32,33,34,35,36].
2.1. Generalized Deepfake Detection
The generalization of deepfake detection implies the ability to detect deepfake videos generated not only by the models used during training but also by unseen or new generative models. In other word, as generative models progress from GANs, VAEs to Diffusion and Consistency models, achieving the ability to detect deepfakes generated by various and new generative models simultaneously is the main goal of generalized deepfake detection techniques. Recently, research has been conducted on detecting deepfake videos that are unknown from both the data and training perspectives.
On the data perspective, SBL [29] and OST [30] enhanced the generalization of deepfake detection by synthesizing additional training data by combining original images from each generative model with various other images and selectively using them. On the training perspective, A. Jain et al. [25] utilized datasets from Google, Jigsaw, FaceForensics++ [39], Celeb-DF [41], Deepfake-TIMIT [42], and their own database DF-Mobio to train a generalized deepfake detection model using Contrastive Representation Learning across various domains. A. Nadimpalli et al. [26] proposed a hybrid learning technique combining supervised learning and reinforcement learning. In particular, during the training process, the reinforcement learning agent selects the top k augmentations that have the most significant impact on performance improvement when training through CNN and uses them for testing, enabling the training of a generalized deepfake detection model. We employed the meta-learning technique Meta Pseudo Labels in the deepfake training process, appling it after domain splitting for each data, resulting in training a model with higher performance in the same model training [24].
2.2. Contrastive Representation Learning in Deepfake Detection
Currently, research applying Contrastive Representation Learning (CRL) for training generalized deepfake detection models is conducted. CRL enables learning similar features in the feature space between a specific image and from the same domain (positive images), while also learning features that differentiate from different domain (negative images). H. Chih-Chung et al. [27] utilized Contrastive Loss [43] to train the encoder, following which they trained the classifier to generalize the discriminative performance on deepfake images generated by various GAN-based models. S. Fung et al. [36] trained the encoder using unsupervised CRL with image pairs that include random augmentation applied to the same image during the training process. Following this, they trained the classifier using labeled images to develop a generalized deepfake detection model. X. Ying et al. [35] addressed the issue of conventional CRL techniques not utilizing label information of deepfake images by applying Supervised Contrastive Learning (SupCon) [38], which use label information. However, CRL requires a large amount of data, especially a significant number of negative samples. In this paper, we performed CRL using SupCon [38], while simultaneously combining the SupCon model with meta-learning method, MPL [37]. This approach also allows for additional CRL training on unlabeled data, even when using the same labeled data, enabling the training of a more generalized deepfake detection model compared to conventional MPL.
2.3. Meta Pseudo Labels
Meta Pseudo Labels (MPL) [37] trains the model using unlabeled images, and when the same model is trained on an image classification task, it has shown improved performance compared to conventional models. MPL gained significant attention by achieving over 90% Top 1 score on the ImageNet [44] classification task, marking a significant milestone. Figure 1a shows the MPL facilitates the learning of the Teacher model through feedback from the Student model, thus enhancing the conventional learning techniques such as Knowledge Distillation [45] or Noisy Student[46], where the Teacher model passes on information to the Student model. This improvement addresses the issue of inadequate learning of the student model when the performance of the Teacher model is subpar. The training process of the MPL is shown in Figure 1b. The student model in MPL learns through the Pseudo Labels inferred by the Teacher model. Subsequently, it imparts the feedback value regarding the learning to the Teacher model. The Teacher model learns through the Labeled Loss from the labeled data, UDA Loss [47], feedback from the student model, and MPL Loss from the unlabeled data. But it consumes substantial computing resources due to the simultaneous training of the two models.
From the perspective of training a generalized deepfake detection model, MPL can enhance the performance of generalized deepfake detection by enabling additional learning through unlabeled data, compared to models trained solely with labeled data. In this paper, we experiment with the enhancement of detection capabilities for unknown domains and post-generation deepfakes, using both MPL [37] and SupCon [38].
3. Proposed SupCon-MPL Based Deepfake Detection
To detect deepfake videos in the Deepfake Unknown Domain, the proposed method introduces SupCon-MPL, a meta-learning model based on CRL, utilizing unlabeled Images from the Deepfake Known Domain.
3.1. Proposed Training Strategy
3.1.1. Known Domain and Unknown Domain in Deepfake
A deepfake domain can be defined as a collection of images and their features, generated from a "specific deepfake generative model". In this paper, we distinguish deepfake domains into known domain () and Unknown Domain (). Known domain () refers to a collection of deepfake images that are labeled when training models. The data in is labeled and therefore can be directly used for training. Meanwhile, unknown domain () refers to data created by unknown deepfake generative models. The data in is not labeled, hence it is not possible to determine whether the image is real or fake. Also, as they are created from various generative models, they can involve various features. Known domain can be defined as where is known deepfake generative model, and the deepfake dataset consists of a dataset composed with a set of deepfake images and labels generated by . On the other hand, unknown domain can be defined as where is unknown deepfake generative model, and the deepfake dataset consists of a dataset composed with a set of deepfake images generated by .
In this paper, to address , we first experiment by distinguishing into a labeled dataset () and an Unlabeled Dataset () as shown in Figure 2(a). Subsequently, to verify the influence of on the training process, we assume as and perform experiments as shown in Figure 2(b). In the deepfake training scenario, from the perspective of generative models by generation, both and constitute with first-generation , and evaluation is conducted using the first and second generation .
3.1.2. Training Strategy for Deepfake Unknown Domain Detection
The training process is employed based on a comparison between the base model and the student model of the MPL (SupCon-MPL). Upon completion of training the base model with the entire dataset , the model is subsequently employed as the Teacher model to train Student model. In other words, we aim to verify performance improvement when training the model under the same conditions. If performance enhancement is validated at this method, it suggests that superior performing models can be trained under identical learning conditions, even when employing larger or state-of-the-art (SOTA) models.
The training images are constructed considering the problems of existing deepfake detection. While deepfakes by known generative models exist in , deepfake images by unknown generative models also exist in . Therefore, during training phase, we enhance the deepfake detection performance in using labeled data and contribute to the generalization of the learning model by using data and from and as unlabeled data, respectively. Consistent with this approach, the data and are structured into , with images from dataset serving as .
In the proposed method, we combine data in three strategies to detect the Unknown Domain Dataset . The first strategy is to use the data from and as the same domain, aiming to verify whether unlabeled data from a specific contributes to the improvement of model performance. Figure 2a illustrates the training strategy of using as unlabeled data. The second strategy aims to solve the realistic deepfake problem by experimenting with the impact of unlabeled data on the detection performance of the corresponding domain. Figure 2b illustrates the feasibility of improving model performance by employing dataset as labeled data and dataset as unlabeled data . Finally, in the deepfake scenario experiment, after training the model using the first-generation deepfake dataset as and , the generalized deepfake detection model learning is assessed through the first-generation and the first and second-generation .
3.2. SupCon-MPL: Supervised Contrastive Learning with Meta-Pseudo Labels
In the proposed method, following the strategy in Figure 2b, the MPL model is trained for the detection of deepfakes in the Unknown Domain . SupCon-MPL allows supplementary training utilizing unlabeled videos, and with the aid of CRL, it enhances the deepfake detection in feature space. Furthermore, it affords the flexibility to employ diverse encoder models during the training phase and enables fine-tuning of the SupCon-MPL-trained model.
In particular, the limitations of deepfake detection with limited labeled data can be mitigated by using unlabeled data, and a generalized detection model can be trained through CRL. Another notable advantage lies in the capability to conduct concurrent learning via feedback from the student model, even if the performance of the teacher model is low. The details of the proposed method are elucidated in Figure 3. The most significant distinction from the conventional MPL and SupCon model training is that with learning through unlabeled data not only resolves the training issue of CRL due to limited data but also enhances detection capabilities in both and . Ultimately, the final goal is to enhance the detection capabilities of deepfakes in domains that are not targeted, especially in a situation where new deepfake models in continue to be developed.
The training of the SupCon-MPL is conducted by first having the student model use unlabeled data to perform CRL, followed by fine-tuning with labeled data. In this process, the teacher model 's classifier learns through the feedback from , while learns dependently on .
3.3. SupCon-MPL Loss Function
SupCon-MPL, as shown in Figure 3, is composed of a teacher model () and a student model (S), each of which consists of an encoder and a linear classifier. SupCon-MPL has two loss functions in order to sequentially train each model. One involves the Teacher model distilling knowledge to the student model , while the other entails the Teacher model training from the feedback factor provided by on the labeled data. The knowledge distilled by includes previously learned content about deepfakes.
In SupCon-MPL, let the parameters of classifier and classifier be , respectively, and denote the batch of images and labels on the labeled data as , and the batch of images on the unlabeled data as . The goal of SupCon-MPL is to minimize the parameters of the generalized deepfake detection model .
Hence, the objective function of SupCon-MPL is defined as follows.
For optimization, SupCon-MPL approximates by the learning rate , and then,
defines the final objective function as follows.
Both and consist of an encoder and a classifier, and are trained according to their respective loss functions. The loss function of , the encoder of , is composed of SupConLoss [38], and the loss function of , the classifier, is composed of Labeled Loss for the labeled data and MPL Loss reflecting the feedback from . First and foremost, the loss function of , receives image pairs as inputs that reflect different random augmentations on the same image and the label . Subsequently, the loss value is obtained by passing image pairs through SupConLoss [38]. At this juncture, given the similarity between the current training process and that of the original MPL's UDA Loss, the utilization of the UDA Loss is no more continued.
is promptly updated following the computation of the .
The Labeled Loss of , , measures the difference between and the label predicted by through Crossentropy Loss (CE Loss). Here, denotes the embedding value derived by passing the labeled data through .
The MPL Loss calculates the difference between the hard pseudo label , which is the maximum value extracted from the pseudo labels generated by through , and the logit. Here, denotes the embedding value derived by passing the labeled data through .
The feedback factor of was calculated in the same way as the original Meta Pseudo Labels [37], using Taylor Expansion to calculate the difference before and after the training of . In the proposed method, we approximated using the difference from the CE Loss value for the labeled data after was trained to the value before training. This allows the final loss value to converge as the training progresses.
The final loss function of , is composed of the sum of each loss function value.
is trained through unlabeled data. The loss function of student model’s encoder , denoted as , is trained utilizing SupConLoss [38], akin to . It leverages , comprising an unlabeled image paired with pseudo labels , generated by .
is also promptly updated following the computation of the
The loss function of is calculated using CE Loss for the Hard Pseudo Label of for and the prediction of . Here, denotes the embedding value derived by passing the labeled data through .
The SupConLoss in , on the Teacher model and Student model are as follows.
Here, is the index of the randomly augmented data, and is the set of indices for all positives in the batch (Since and are labels of images that have been randomly augmented from , they are the same as ). and are the embedding values of each randomly augmented image in passed through the encoder , and , and is the temperature parameter. In other words, the inner product between positive pairs ( and are the same class but different samples) is maximized through , and the inner product between negative pairs is minimized through , so that the SupConLoss is minimized.
The training process of the proposed SupCon-MPL model for deepfake detection is as shown in Figure 4.
4. Experiment
4.1. Experiment Setup
The experiments are conducted using NVIDIA Tesla V100 32 and NVIDIA RTX-3090. The single-domain experiment and the multi-domain experiment are existing outputs of the Meta Learning-based Deepfake Detection Project [24]. The Pretrained model, Meta Pseudo Labels model (MPL model), SupCon model, and SupCon-MPL model are experimented for their training performance under the same conditions and hyperparameters. The training dataset uses the videos of the Deepfakes(DF), Face2Face(F2F), FaceSwap(FS), NeuralTextures(NT), and Real videos in FaceForensics++ [39], with DFDC [40], and Celeb-DF [41]. In scenario evaluation, deepfake videos of first-generation’s unknown domain are NeuralTextures(NT)[39] with Real videos, and for post-generation’s unknown domain, we selected StyleGAN [8] images with CelebA [48] videos. We used MTCNN [49] to extract face images frame by frame of Each video.
In the single-domain experiment, 260,000 real and 340,000 fake data from each domain in the FaceForensics++ [39] are used. During training, the amount of validation data used is 20% of the training data, and the evaluation dataset uses 150,000 per each data domain. In the multi-domain experiment, 200,000 labeled data are randomly extracted from 4 domains, and 180,000 unlabeled data are extracted from a single domain for use.
The generational deepfake scenario trains using 170,000 each of the 1st generation known domain's FaceForensics++ (DF, F2F, FS, Real) [39], DFDC[40], Celeb-DF [41] data, and then evaluates using 51,200 each of 1st and 2nd generation Unknown Domain data. Backbone model in scenario evaluation, we used ResNet50 [50] due to lack of computational resources.
The hyperparameters used in the experiment are a learning rate of 1e-4, an image size of 64, and a batch size of 512. In the MPL, SupConMPL models, the batch sizes of labeled and unlabeled images are 64 and 448, respectively. Finally, the threshold is used at 0.95. The training models used were ResNet50 [50], ResNet101 [50], ResNext50 [51], EfficientNet-b5 [21], and WideResNet50 [52].
Experiment data and evaluation data use a mix of fake and real data. In the experiment in Section 4.2.1, video data from one domain is used as labeled and unlabeled data, and in the experiment in Section 4.2.2, videos from multiple domains are used as labeled data, and one domain is used as unlabeled data.
4.2. Single-domain Experiment
In the experiment using only one domain, as shown in Table 1, the performance of the known domain increased in most of situation. Furthermore, it was confirmed that the performance in unknown domains also increased in most of situation. Based on EfficientNet-b5 [21] in Table 1, ACC and AUC in K improved by an average of 4.47% and 4.53% respectively, and ACC in U improved by an average of 0.20%, but AUC decreased by an average of 0.13%. However, overall, out of a total of 64 ACC and AUC validations recorded in Table 1, Table 2, Table 3, Table 4, Table 5, Table 6, Table 7 and Table 8, 44 and 41 case improved, respectively. Through this, it was confirmed that when using the same data, the performance of the MPL model is higher than the pretrained model.
4.3. Multi-domain Experiment
In the multi-domain experiment, the combination of data is configured considering the actual deepfake situation. The situation is assumed to have deepfake data from multiple domains and data from . Afterwards, the evaluation is conducted through the data used as . Therefore, MPL trains with deepfake videos from multiple domains, and after training, MPL experiments the ability to detect unlabeled data using unlabeled data. As a result of the experiment, ACC and AUC increased by an average of 1.59%, 1.26% in 2 models in Table 9 and Table 10. Through this, it was confirmed that the MPL model improved the deepfake detection ability of the unknown model by learning with unlabeled data.
4.4. SupCon-MPL Experiment
The experiment uses the labeled data identically to the multi-domain experiment and evaluates according to each combination of known domain and unknown domain. At this time, Celeb-DF [41] is used as unlabeled data in the training of the SupCon-MPL model. As a result of the experiment, shown in Table 11, when evaluating FS data as an Unknown domain compared to the SupCon model [35], ACC and AUC decreased, but in other validations, the performance of the SupCon-MPL model was similar or higher than the performance of the two models being compared. This shows that the SupCon-MPL model has been trained as a generalized detection model compared to the existing deepfake detection model.
4.5. Deepfake Scenario Experiment
In this section, we construct a training scenario for a deepfake detection model in the real world and train the model. The scenario involves training a deepfake model with first-generation deepfake data, then experiment with the detection of first-generation deepfake (NT) that was not participated while training, and post-generation(second-generation) deepfakes (StyleGAN) that are newly developed and unknown. Table 12 shows the training results of various models according to the scenario. As a result of the experiment, among various models, the SupCon-MPL model achieved highest performance in all scenario evaluations compared to other models.
4.5. Limitations
The main goal of the SupCon-MPL is to enhance the deepfake detection performance in unknown domains using meta-learning. Therefore, in this paper, we conducted experiments by reconfiguring a limited deepfake dataset into scenarios.
The main limitation is related to computing resources. As the training in Section 4.3. and Section 4.4. was conducted using NVIDIA RTX-3090, only ResNet50 [50] could be used as the backbone model in SupCon-MPL, which uses two models. Subsequent experiments are needed with various backbone models and larger image sizes through more computing resources.
The next limitation is that we could not find a verified deepfake dataset for the third generation and higher. Further experiments are needed through the corresponding dataset in the future.
5. Conclusion
With the development of various deepfake generative models, it has become important to develop a generalized deepfake detection model that guarantees the detection performance of unknown domain deepfakes, not just the data of the domain used for training. The proposed SupCon-MPL improved all detection performances over other model's known and unknown domains in scenario evaluations by utilizing unlabeled deepfake images/videos and Contrastive Learning. Indeed, one of the significant features of SupCon-MPL is its ability to train models using a large amount of unlabeled data. This provides a method to enhance the model's performance utilizing the countless images and videos available on the internet and so on.
Future research will focus on improving the detection performance of higher generation deepfake images/videos using these methods. Additionally, studies on reducing the training cost of SupCon-MPL will be conducted. The goal is to develop a more efficient and economical deepfake detection model through these efforts.
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. Advances in neural information processing systems 2014, 27. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv Preprint, 1411. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J. W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18-23 June 2018; pp. 8789–8797. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In International conference on machine learning, Sydney, Australia, 6-; pp. 214-223. 11 August.
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. C. Improved training of wasserstein gans. Advances in neural information processing systems 2017, 30. [Google Scholar]
- Kingma, D. P.; Welling, M. Auto-encoding variational bayes. arXiv Preprint 2013, arXiv:1312.6114. [Google Scholar]
- Sohn, K.; Lee, H.; Yan, X. Learning structured output representation using deep conditional generative models. Advances in neural information processing systems 2015, 28. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 15-20 June 2019; pp. 4401–4410. [Google Scholar] [CrossRef]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the ICML 2021 Workshop on Unsupervised Reinforcement Learning, Virtual, 18-24 July 2021; pp. 8821–8831. [Google Scholar]
- DeepFaceLab. Available online: https://github.com/iperov/DeepFaceLab (accessed on 5 March 2024).
- Deepswap. Available online: https://www.deepswap.ai/ko (accessed on 5 March 2024).
- synthesia. Available online: https://www.synthesia.io (accessed on 5 March 2024).
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, New Orleans, LA, USA, 18-24 June 2022; pp. 10684–10695. [Google Scholar] [CrossRef]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E. L.; Norouzi, M. Photorealistic text-to-image diffusion models with deep language understanding. Advances in Neural Information Processing Systems 2022, 35, pp–36479. [Google Scholar]
- Song, Y.; Dhariwal, P.; Chen, M.; Sutskever, I. Consistency models. 2023.
- Li, Y.; Lyu, S. Exposing deepfake videos by detecting face warping artifacts. arXiv Preprint 2018, arXiv:1811.00656. [Google Scholar]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting visual artifacts to expose deepfakes and face manipulations. In 2019 IEEE Winter Applications of Computer Vision Workshops, Waikoloa, HI, USA, 7-11 Jan. 2019; pp. 83-92; [CrossRef]
- Li, Y.; Chang, M. C.; Lyu, S. In ictu oculi: Exposing ai generated fake face videos by detecting eye blinking. arXiv Preprint 2018, arXiv:1806.02877; [Google Scholar] [CrossRef]
- Ciftci, U. A.; Demir, I.; Yin, L. Fakecatcher: Detection of synthetic portrait videos using biological signals. IEEE transactions on pattern analysis and machine intelligence 2020. [Google Scholar] [CrossRef] [PubMed]
- Coccomini, D. A.; Messina, N.; Gennaro, C.; Falchi, F. Combining efficientnet and vision transformers for video deepfake detection. In International conference on image analysis and processing, Lecce, Italy, ; pp. 219-229; 23–27 May. [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning, Los Angeles County, California, United States, 9-15 Jan 2019; pp. 6105-6114.
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv Preprint 2020, arXiv:2010.11929. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21-26 July 2017; pp. 1251–1258. [Google Scholar] [CrossRef]
- Moon, K.-H.; Ok, S.-Y.; Seo, J.; Lee, S.-H. Meta Pseudo Labels Based Deepfake Video Detection. Journal of Korea Multimedia Society 2024, 27, pp–9. [Google Scholar] [CrossRef]
- Jain, A.; Korshunov, P.; Marcel, S. Improving generalization of deepfake detection by training for attribution. In 2021 IEEE 23rd International Workshop on Multimedia Signal Processing, Tampere, Finland, 6-; pp. 1-6; 8 October. [CrossRef]
- Nadimpalli, A. V.; Rattani, A. On improving cross-dataset generalization of deepfake detectors. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, New Orleans, LA, USA, 18-24 June 2022; pp. 91-99. [Google Scholar] [CrossRef]
- Hsu, C. C.; Lee, C. Y.; Zhuang, Y. X. Learning to detect fake face images in the wild. In 2018 international symposium on computer, consumer and control, Taichung, Taiwan, 6-; pp. 8 December. [CrossRef]
- Dong, F.; Zou, X.; Wang, J.; Liu, X. Contrastive learning-based general Deepfake detection with multi-scale RGB frequency clues. Journal of King Saud University-Computer and Information, 2023. [Google Scholar] [CrossRef]
- Shiohara, K.; Yamasaki, T. Detecting deepfakes with self-blended images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18-24 June 2022; pp. 18720-18729. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, Y.; Song, Y.; Wang, J.; Liu, L. Ost: Improving generalization of deepfake detection via one-shot test-time training. Advances in Neural Information Processing Systems 2022, 35, 24597–24610. [Google Scholar]
- Aneja, S.; Nießner, M. Generalized zero and few-shot transfer for facial forgery detection. arXiv Preprint 2020, arXiv:2006.11863. [Google Scholar]
- Kim, M.; Tariq, S.; Woo, S. S. Fretal: Generalizing deepfake detection using knowledge distillation and representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Nashville, TN, USA, 20-25 June 2021; pp. 1001-1012. [Google Scholar] [CrossRef]
- Qi, H.; Guo, Q.; Juefei-Xu, F.; Xie, X.; Ma, L.; Feng, W.; Zhao, J. Deeprhythm: Exposing deepfakes with attentional visual heartbeat rhythms. In Proceedings of the 28th ACM international conference on multimedia, Seattle, WA, USA, 12-16 October 2020; pp. 4318-4327. [Google Scholar] [CrossRef]
- Lee, S.; Tariq, S.; Kim, J.; Woo, S. S. Tar: Generalized forensic framework to detect deepfakes using weakly supervised learning. In IFIP International Conference on ICT Systems Security and Privacy Protection, Oslo, Norway, 22-; pp. 24 June. [CrossRef]
- Xu, Y.; Raja, K.; Pedersen, M. Supervised contrastive learning for generalizable and explainable deepfakes detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3-8 January 2022; pp. 379–389. [Google Scholar]
- Fung, S.; Lu, X.; Zhang, C.; Li, C.T. DeepfakeUCL: Deepfake Detection via Unsupervised Contrastive Learning. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Pham, H.; Dai, Z.; Xie, Q.; Le, Q. V. Meta pseudo labels. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Nashville, TN, USA, pp. 11557-11568, 20-25 June 2021. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Krishnan, D. Supervised contrastive learning. Advances in neural information processing systems 2020, 33, pp–18661. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Niessner, M. Faceforensics++: Learning to Detect Manipulated Facial Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October-2 November 2019; pp. 1-11. [Google Scholar] [CrossRef]
- Dolhansky, B.; Bitton, J.; Pflaum, B.; Lu, J.; Howes, R.; Wang, M.; Ferrer, C. C. The deepfake detection challenge (dfdc) dataset. arXiv Preprint 2020, arXiv:2006.07397. [Google Scholar]
- Li, Y.Z.; Yang, X.; Sun, P.; Qi, H.G.; Lyu, S. Celeb-DF: A Large-scale Challenging Dataset for DeepFake Forensics. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 14-19 June 2020; pp. 3207-3216. [Google Scholar] [CrossRef]
- Korshunov, P.; Marcel, S. Deepfakes: a new threat to face recognition? assessment and detection. arXiv Preprint 2018, arXiv:1812.08685. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality reduction by learning an invariant mapping. In 2006 IEEE computer society conference on computer vision and pattern recognition, New York, NY, USA, 17-, 2; pp. 2, 22 June. [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20-25 June 2009; pp. 248-255. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv Preprint 2015, arXiv:1503.02531. [Google Scholar]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13-19 June 2020; pp. 10687–10698. [Google Scholar] [CrossRef]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, T.; Le, Q. Unsupervised data augmentation for consistency training. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6-12 December 2020; pp. 6256–6268. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, pp–1499. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference On Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv Preprint 2016, arXiv:1605.07146. [Google Scholar]
Figure 1.
(a) Training Overview and (b) process with label/unlabeled datasets of Meta Pseudo Labels [37].
Figure 1.
(a) Training Overview and (b) process with label/unlabeled datasets of Meta Pseudo Labels [37].
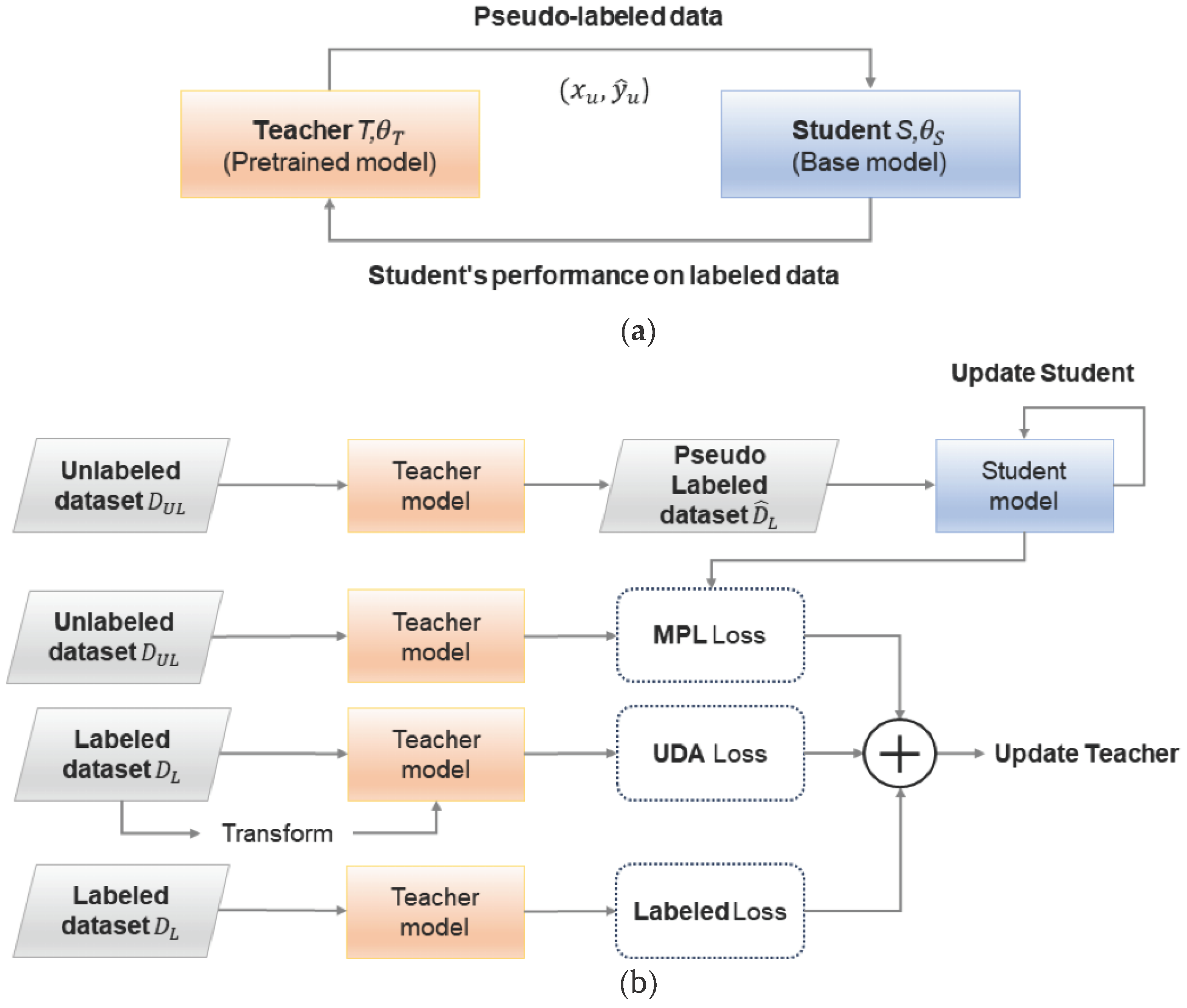
Figure 2.
Deepfake image discrimination strategy targeting for (a) known domain and (b) unknown domain.
Figure 2.
Deepfake image discrimination strategy targeting for (a) known domain and (b) unknown domain.
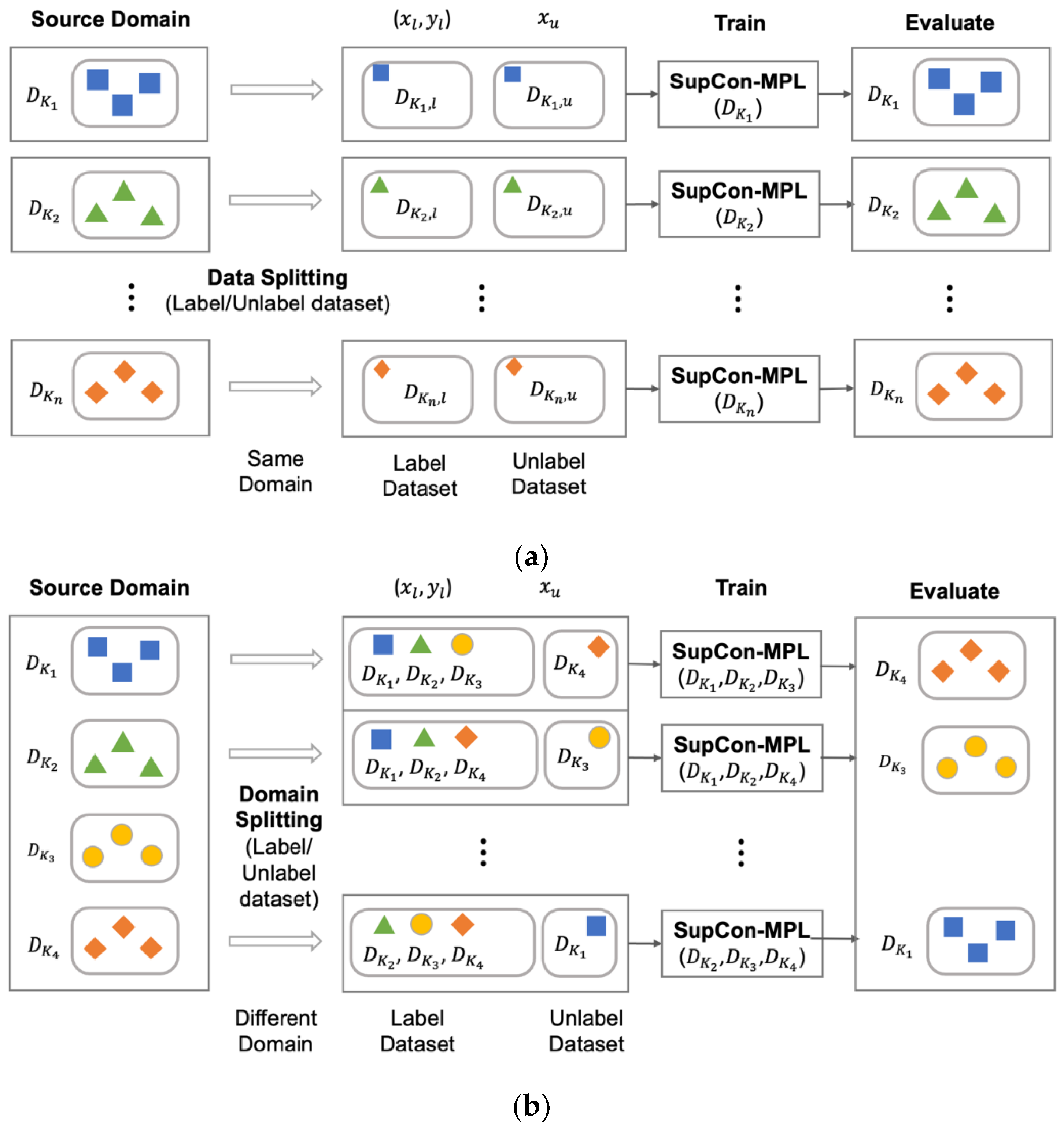
Figure 3.
Modified Meta Pseudo Labels and loss functions for Deepfake Detection.
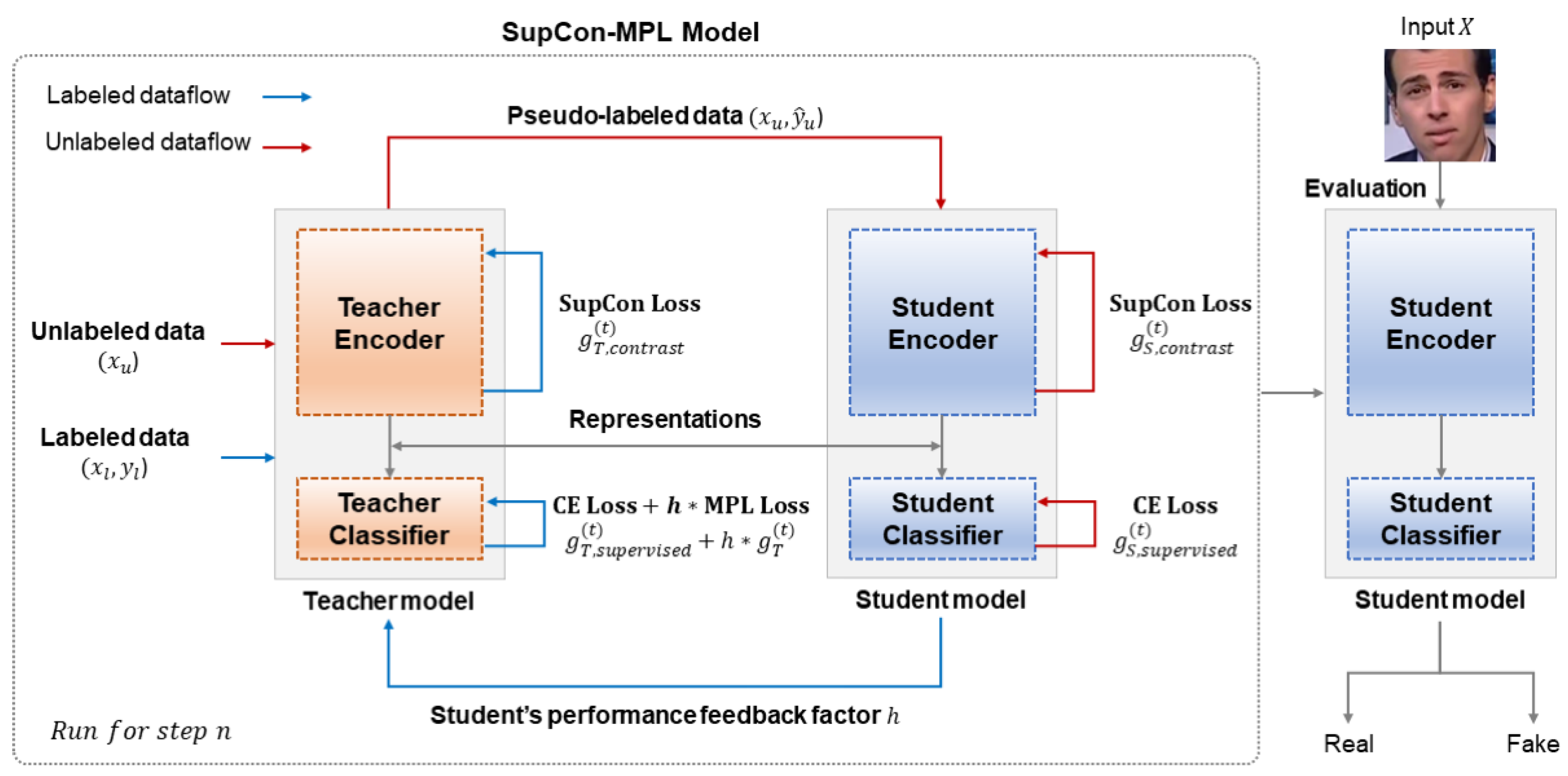
Figure 4.
Pseudo code of proposed SupCon-MPL.


Table 1.
The performance of pretrained and MPL model on known domain (EfficientNetb5[21]).
Table 1.
The performance of pretrained and MPL model on known domain (EfficientNetb5[21]).
| Baseline model | Train Dataset | Test Dataset | Pretrained model | MPL model | ||
|---|---|---|---|---|---|---|
| ACC | AUC | ACC | AUC | |||
| EfficientNetb5[21] | DF | DF | 89.35 | 89.35 | 90.08 | 90.08 |
| F2F | F2F | 77.21 | 77.21 | 80.35 | 80.35 | |
| FS | FS | 84.52 | 84.31 | 87.90 | 87.43 | |
| NT | NT | 64.13 | 63.33 | 74.79 | 74.47 | |
Table 2.
The performance of pretrained and MPL model on unknown domain (EfficientNetb5[21]).
Table 2.
The performance of pretrained and MPL model on unknown domain (EfficientNetb5[21]).
| Baseline model | Train Dataset | Test Dataset | Pretrained model | MPL model | ||
|---|---|---|---|---|---|---|
| ACC | AUC | ACC | AUC | |||
| EfficientNetb5[21] | DF | F2F | 51.59 | 51.60 | 51.70 | 51.70 |
| FS | 55.97 | 52.06 | 56.45 | 52.65 | ||
| NT | 55.37 | 51.26 | 55.41 | 51.37 | ||
| F2F | DF | 57.56 | 57.55 | 53.87 | 53.84 | |
| FS | 56.47 | 54.05 | 55.48 | 51.92 | ||
| NT | 54.63 | 51.91 | 54.76 | 50.99 | ||
| FS | DF | 57.25 | 57.22 | 57.61 | 57.88 | |
| F2F | 51.76 | 51.77 | 51.98 | 51.99 | ||
| NT | 53.79 | 49.89 | 54.32 | 49.80 | ||
| NT | DF | 58.72 | 58.71 | 61.03 | 61.00 | |
| F2F | 54.52 | 54.53 | 55.88 | 55.89 | ||
| FS | 51.65 | 49.42 | 53.29 | 49.34 | ||
Table 3.
The performance of pretrained and MPL model on known domain (ResNet50[50]).
Table 3.
The performance of pretrained and MPL model on known domain (ResNet50[50]).
| Baseline model | Train Dataset | Test Dataset | Pretrained model | MPL model | ||
|---|---|---|---|---|---|---|
| ACC | AUC | ACC | AUC | |||
| ResNet50[50] | DF | DF | 91.16 | 91.16 | 91.29 | 91.30 |
| F2F | F2F | 82.47 | 82.48 | 83.98 | 83.97 | |
| FS | FS | 87.55 | 87.21 | 88.31 | 88.09 | |
| NT | NT | 74.96 | 74.28 | 76.22 | 75.84 | |
Table 4.
The performance of pretrained and MPL model on unknown domain (ResNet50[50]).
Table 4.
The performance of pretrained and MPL model on unknown domain (ResNet50[50]).
| Baseline model | Train Dataset | Test Dataset | Pretrained model | MPL model | ||
|---|---|---|---|---|---|---|
| ACC | AUC | ACC | AUC | |||
| ResNet50[50] | DF | F2F | 52.91 | 52.89 | 51.92 | 51.86 |
| FS | 56.80 | 52.68 | 57.02 | 53.00 | ||
| NT | 55.91 | 51.77 | 55.45 | 51.33 | ||
| F2F | DF | 53.94 | 53.90 | 53.79 | 53.75 | |
| FS | 54.62 | 50.97 | 55.32 | 51.35 | ||
| NT | 54.76 | 51.20 | 54.96 | 51.04 | ||
| FS | DF | 56.34 | 56.30 | 59.57 | 59.53 | |
| F2F | 51.16 | 51.10 | 51.57 | 51.52 | ||
| NT | 53.67 | 49.44 | 53.81 | 49.61 | ||
| NT | DF | 60.45 | 60.43 | 60.17 | 60.15 | |
| F2F | 54.74 | 54.70 | 53.56 | 53.51 | ||
| FS | 51.59 | 48.15 | 51.84 | 48.51 | ||
Table 5.
The performance of pretrained and MPL model on known domain (ResNet101[50]).
Table 5.
The performance of pretrained and MPL model on known domain (ResNet101[50]).
| Baseline model | Train Dataset | Test Dataset | Pretrained model | MPL model | ||
|---|---|---|---|---|---|---|
| ACC | AUC | ACC | AUC | |||
| ResNet101[50] | DF | DF | 91.16 | 91.16 | 91.13 | 91.13 |
| F2F | F2F | 81.41 | 81.41 | 83.50 | 83.49 | |
| FS | FS | 87.59 | 87.37 | 87.75 | 87.66 | |
| NT | NT | 74.17 | 74.56 | 76.03 | 75.53 | |
Table 6.
The performance of pretrained and MPL model on unknown domain (ResNet101[50]).
Table 6.
The performance of pretrained and MPL model on unknown domain (ResNet101[50]).
| Baseline model | Train Dataset | Test Dataset | Pretrained model | MPL model | ||
|---|---|---|---|---|---|---|
| ACC | AUC | ACC | AUC | |||
| ResNet101[50] | DF | F2F | 52.69 | 52.63 | 51.26 | 51.20 |
| FS | 56.90 | 52.73 | 56.02 | 51.84 | ||
| NT | 55.93 | 51.74 | 54.93 | 50.73 | ||
| F2F | DF | 53.63 | 53.59 | 53.50 | 53.46 | |
| FS | 54.33 | 50.08 | 54.86 | 50.85 | ||
| NT | 54.62 | 51.01 | 55.17 | 51.28 | ||
| FS | DF | 57.04 | 57.70 | 59.55 | 59.51 | |
| F2F | 51.43 | 51.37 | 51.84 | 51.79 | ||
| NT | 53.66 | 49.55 | 53.61 | 49.59 | ||
| NT | DF | 62.66 | 62.65 | 60.16 | 60.14 | |
| F2F | 52.69 | 52.63 | 51.26 | 51.20 | ||
| FS | 56.90 | 52.73 | 56.02 | 51.84 | ||
Table 7.
The performance of pretrained and MPL model on known domain (ResNext50[51]).
Table 7.
The performance of pretrained and MPL model on known domain (ResNext50[51]).
| Baseline model | Train Dataset | Test Dataset | Pretrained model | MPL model | ||
|---|---|---|---|---|---|---|
| ACC | AUC | ACC | AUC | |||
| ResNext50[51] | DF | DF | 90.29 | 90.29 | 91.14 | 91.14 |
| F2F | F2F | 81.19 | 81.17 | 82.87 | 82.85 | |
| FS | FS | 87.04 | 86.77 | 87.36 | 87.36 | |
| NT | NT | 74.26 | 74.43 | 76.32 | 75.78 | |
Table 8.
The performance of pretrained and MPL model on unknown domain (ResNext50[51]).
Table 8.
The performance of pretrained and MPL model on unknown domain (ResNext50[51]).
| Baseline model | Train Dataset | Test Dataset | Pretrained model | MPL model | ||
|---|---|---|---|---|---|---|
| ACC | AUC | ACC | AUC | |||
| ResNext50[51] | DF | F2F | 51.83 | 51.73 | 51.66 | 51.56 |
| FS | 56.57 | 52.53 | 57.24 | 53.21 | ||
| NT | 55.25 | 51.57 | 54.72 | 50.50 | ||
| F2F | DF | 54.57 | 54.58 | 54.46 | 54.47 | |
| FS | 54.31 | 50.38 | 55.28 | 51.45 | ||
| NT | 54.67 | 50.89 | 54.80 | 51.02 | ||
| FS | DF | 59.23 | 59.23 | 60.33 | 60.33 | |
| F2F | 52.02 | 51.93 | 52.98 | 52.89 | ||
| NT | 53.31 | 49.22 | 53.41 | 49.55 | ||
| NT | DF | 60.58 | 60.58 | 58.50 | 58.51 | |
| F2F | 54.16 | 54.11 | 52.46 | 52.38 | ||
| FS | 49.17 | 46.78 | 51.26 | 47.80 | ||
Table 9.
The performance of pretrained and MPL model on known domain (ResNext50[51]).
Table 9.
The performance of pretrained and MPL model on known domain (ResNext50[51]).
| Baseline model | Train Dataset | Unlabeled Dataset |
Pretrained model | MPL model | ||
|---|---|---|---|---|---|---|
| ACC | AUC | ACC | AUC | |||
| ResNext50[51] | F2F, FS, NT | DF | 63.33 | 63.32 | 66.23 | 66.22 |
| DF, FS, NT | F2F | 57.35 | 57.39 | 58.04 | 58.08 | |
| DF, F2F, NT | FS | 50.69 | 50.53 | 51.81 | 51.54 | |
| DF, F2F, FS | NT | 53.63 | 53.05 | 53.89 | 53.06 | |
Table 10.
The performance of pretrained and MPL model on known domain (WideResNet50[52]).
Table 10.
The performance of pretrained and MPL model on known domain (WideResNet50[52]).
| Baseline model | Train Dataset | Unlabeled Dataset |
Pretrained model | MPL model | ||
|---|---|---|---|---|---|---|
| ACC | AUC | ACC | AUC | |||
| WideResNet50[52] | F2F, FS, NT | DF | 63.17 | 63.14 | 66.03 | 66.00 |
| DF, FS, NT | F2F | 56.86 | 56.87 | 57.60 | 57.60 | |
| DF, F2F, NT | FS | 48.37 | 47.74 | 52.86 | 51.13 | |
| DF, F2F, FS | NT | 54.22 | 53.43 | 53.92 | 51.96 | |
Table 11.
The performance of SupCon-MPL compared with baseline model and SupCon model [35].
Table 11.
The performance of SupCon-MPL compared with baseline model and SupCon model [35].
| Baseline model | Train Dataset |
Unlabeled Dataset |
Pretrained model |
SupCon model [35] |
SupCon-MPL(ours) model |
|||
|---|---|---|---|---|---|---|---|---|
| ACC | AUC | ACC | AUC | ACC | AUC | |||
| ResNet50 [50] | FF (without DF) | DF (unknown) | 64.24 | 64.27 | 62.88 | 62.84 | 64.60 | 64.55 |
| F2F+FS+NT (known) | 70.56 | 71.36 | 75.44 | 75.52 | 75.84 | 76.00 | ||
| FF (without F2F) | F2F (unknown) | 55.76 | 55.64 | 56.61 | 56.64 | 58.74 | 58.77 | |
| DF+FS+NT (known) | 77.26 | 76.89 | 75.54 | 75.54 | 78.11 | 78.28 | ||
| FF (without FS) | FS (unknown) | 54.47 | 52.07 | 55.75 | 53.68 | 55.72 | 53.41 | |
| DF+F2F+NT (known) | 75.99 | 75.87 | 76.02 | 75.88 | 77.22 | 77.12 | ||
| FF (without NT) | NT (unknown) | 56.71 | 54.95 | 56.58 | 54.31 | 56.76 | 54.02 | |
| DF+F2F+FS (known) | 77.39 | 77.41 | 79.09 | 79.26 | 81.22 | 81.32 | ||
Table 12.
The performance of SupCon-MPL compared with other deepfake detection methods.
| Model |
Scenario Deepfakes (Known) |
Current-Generation Deepfakes (Unknown) |
Post-Generation Deepfakes (Unknown) |
| Tar [34] | 52.40 | 44.62 | 49.96 |
| DDT [31] | 80.41 | 44.62 | 49.49 |
| MPL [24] | 79.82 | 56.53 | 43.16 |
| SupCon [35] | 79.01 | 56.66 | 47.77 |
| SupCon-MPL(ours) | 81.40 | 57.85 | 51.90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



