
Submitted:
13 March 2024
Posted:
14 March 2024
You are already at the latest version
Abstract
Coenzyme Q (CoQ) is a lipidic compound widely distributed in nature with crucial functions in metabolism, protection against oxidative damage and ferroptosis, and other processes. CoQ biosynthesis is a conserved and complex pathway involving several proteins. COQ2 is a member of the UbiA family of transmembrane prenyltransferases that catalyzes the condensation of the head and tail precursors of CoQ, a key step in the process because its product is the first intermediate that will be modified in the head by the next component of the synthesis process. Mutations in this protein have been linked to primary CoQ deficiency in humans, a rare disease predominantly affecting organs with a high energy demand. The reaction catalyzed by COQ2 and its mechanism are still unknown. Here we aimed at clarifying COQ2 reaction by exploring possible substrate binding sites using a strategy based on homology, comprising the identification of ligand-bound homologs with solved structures available in the Protein Data Bank (PDB) and their subsequent structural superposition to the AlphaFold predicted model for COQ2. The results highlight some residues located on the central cavity or the matrix loops that may be involved in substrate interaction, some of them mutated in primary CoQ deficiency patients. Furthermore, we analyze the structural modifications introduced by the pathogenic mutations found in humans. These findings shed new light on the understanding of COQ2 function and, thus, CoQ biosynthesis and pathogenicity of primary CoQ deficiency.
Keywords:
coenzyme Q
; ubiquinol
; mitochondria
; rare disease
; antioxidant
1. Introduction
Coenzyme Q, (CoQ, ubiquinone), is a lipidic molecule present in the three domains of life. From a biochemical point of view, it is formed by a highly hydrophobic polyisoprenoid tail with a variable number of isoprene units depending on the species (10 in humans, thus called CoQ10) attached to a benzoquinone head with redox properties [1]. CoQ is of paramount importance because of its universal role in the respiratory chain as an electron carrier. However, additional functions have been proposed [1,2,3,4]. In bacteria, it has been associated with other processes such as response to oxidative stress, formation of disulphide bonds and regulation of gene expression [5,6], whereas in eukaryotes a plethora of both mitochondrial and extramitochondrial functions have been identified.
For instance, CoQ accepts electrons from dehydrogenases enzymes located in the mitochondria, hence it is involved in multiple metabolic pathways, including biosynthesis of pyrimidines, sulphide detoxification and oxidation of fatty acids, proline and branched chain amino acids [7]. It also regulates the mitochondrial permeability transition pore (mPTP) and uncoupling proteins (UCPs) [2]. In all cell membranes also including mitochondria and plasma lipoproteins, it functions as an antioxidant, protecting against lipid peroxidation and reducing other antioxidants, such as vitamin E and ascorbate [8,9]. Additionally, CoQ promotes membrane stability and protects against ferroptosis [10,11].
CoQ biosynthesis is a highly conserved process that takes place in the inner mitochondrial membrane in eukaryotes and the cytosol in prokaryotes [12]. Despite the early discovery of CoQ in the 50s [13,14], there is still a limited understanding of its biosynthesis process which includes several transmembrane and peripheral membrane proteins, hydrophobic intermediates, unidentified components and, at least in yeasts and mammals, the existence of a biosynthetic complex known as CoQ-synthome or complex Q. The proteins involved in CoQ biosynthesis are generally known as Ubi proteins in prokaryotes and COQ proteins in eukaryotes [1,3,15]. Thirteen proteins encoded in the nucleus genome take part in this pathway in humans: COQ2, COQ3, COQ4, COQ5, COQ6, COQ7, COQ8A (ADCK3), COQ8B (ADCK4), COQ9, COQ10A, COQ10B, PDSS1 (DPS1) and PDSS2 (DLP1) [4]. Mutations in some of these proteins (COQ2, COQ4, COQ6, COQ7, COQ8A, COQ8B, PDSS1 and PDSS2) have been related to primary CoQ deficiency in humans that encompasses rare autosomal recessive diseases characterized by a wide heterogeneity of symptoms, severity and age of onset, mainly affecting organs with high energy needs, such as brain, inner ear, muscles, heart and kidneys [1,3].
COQ2 protein or 4-hydroxybenzoate polyprenyltransferase (EC 2.5.1.39) is a transmembrane protein inserted in the inner mitochondrial membrane that participates in the second step in CoQ synthesis that is the condensation of the benzoquinone head and the polyisoprenoid tail [1,3,16,17]. Finally, the head undergoes a series of modifications: three hydroxylations catalyzed in humans by COQ6 (C5 hydroxylation), COQ7 (C6 hydroxylation) and COQ4 (C1 hydroxylation); three methylations performed by COQ3 (C5 and C6 O-methylations) and COQ5 (C2 methylation); and a decarboxylation recently associated with COQ4 (C1 decarboxylation). All these enzymes are peripheral membrane proteins located in the matrix side of the inner mitochondrial membrane [1,3,18].
In humans, the CoQ-synthome is thought to be constituted by the enzymes involved in head modification (COQ3, COQ4, COQ5, COQ6 and COQ7), together with other COQ proteins (COQ8A, COQ8B and COQ9), lipids (CoQ intermediates and phospholipids), cofactors and metal ions. It seems that this organization permits that CoQ intermediates are channelled from one enzyme to the next, reducing the risk of leakage. However, it is still unknown how CoQ-synthome, constituted mainly by peripherally-associated proteins, comes into contact with the membrane-embedded intermediates, tightly located into the inner mitochondrial membrane [3]. COQ2 could function as an anchor site for CoQ-synthome as proposed in yeast by Tran & Clarke (2007) [19], making the substrates accessible to the head-modifying enzymes and, thus, solving potential transport problems associated with the hydrophobic nature of CoQ intermediates [3]. Nevertheless, no experimental 3D structure of human COQ2 is available to date, which hinders progress in understanding the function of this protein. Structural data on COQ2 and determining the position and structural effect of pathological mutations would, therefore, provide a valuable insight into CoQ biosynthesis and pathogenicity of primary CoQ deficiency.
Taking advantage of the AlphaFold Protein Structure Database [20], our aim was to use a human COQ2 structural model in order to predict potential binding sites for its substrates, para-hydroxybenzoate (PHB) and decaprenyl diphosphate (DPP), in a homology-based manner, searching for significant homologs in the Protein Data Bank (PDB) that contain ligands structurally similar to these molecules. Further, we determined the location of the human missense single nucleotide mutations leading to one amino acid substitutions affecting COQ2 activity and generating mitochondrial disease, and their effect on COQ2 structure.
2. Materials and Methods
2.1. HHpred Search
Human COQ2 (Q96H96) amino acid sequence was downloaded from the UniProt database [21] and used as input for homology search performed by HHpred, available at the MPI Bioinformatics Toolkit website [22,23], with default parameters. PDB_mmCIF70 was used as database to select homologs with experimentally solved structures. In contrast to other popular homolog detection tools such as BLAST or PSI-BLAST, HHpred provides a higher sensitivity so that more distant homology relationships can be traced, aligning the query protein with homologs, creating a profile hidden Markov model (HMM) from the resulting multiple sequence alignment and comparing it to the profiles HMMs from the target database [24].
2.2. File Parsing
In-house Python 3.8.5 scripts were used and edited in Spyder IDE 5.4.0. First, the PDB Chemical Component Dictionary, featuring all ligands included in PDB structures and detailed information about these molecules, was downloaded as a plain text file (available at https://www.wwpdb.org/data/ccd) and parsed using in-house scripts. For each ligand, the name and the structure represented as a Simplified Molecular-Input Line-Entry System (SMILES) string was extracted. The HHpred output was also downloaded as a text file and processed: hits with a probability score higher than 50% and containing ligands were selected.
2.3. Molecular Similarity
Similarity between ligands and molecules PHB and undecaprenyl phosphate (UP) was determined using a Python script based on a tutorial available at the TeachOpenCADD platform [25]. UP was used instead of the actual substrate, DPP, because the latter is not present in the PDB Chemical Component Dictionary. The 3-letter codes identifying PHB and UP in the dictionary were PHB and 5TR, respectively. To determine the degree of similarity between a ligand and query molecule, we obtained their Molecular ACCess System (MACCS) fingerprint, that shows the predefined chemical features that are present. Then, the fingerprints were compared, and the molecular similarity was computed in terms of Tanimoto coefficient, with values ranging from 0 (lowest similarity) to 1 (highest similarity) [25,26]. Ligands with a Tanimoto coefficient bigger than 0.3 were selected for further studies.
2.4. Multiple Sequence Alignment (MSA)
A BLAST (Basic Local Alignment Search Tool) [27] search with human COQ2 as query and UniProtKB/SwissProt as database was performed to retrieve homologs from different organisms. Other homologous sequences were obtained from the UniProtKB database [21]. All sequences were aligned in SeaView 5.0.5 [28], using MUSCLE (MUltiple Sequence Comparison by Log- Expectation) [29]. The MSA was manually edited in Jalview 2.11.2.7 [30].
2.5. 2D Structure Prediction
2.6. AlphaFold2 Prediction Model
Structure prediction model for COQ2 was retrieved from the AlphaFold Protein Structure Database [20], and subsequently visualised and customised in PyMOL (The PyMOL Molecular Graphics System, Version 2.0 Schrödinger, LLC.).
2.7. Variant Structure Prediction
2.8. Structure Superposition
Homologs with potentially interesting ligands were superposed to the AlphaFold prediction model of COQ2 using the PyMOL “super” command, while the predicted structures containing mutations were superposed to the COQ2 model with PyMOL “align” command. The first one is appropriate for proteins that share 30% or less sequence identity, whereas the second works for sequences with more than 30% identity [36,37].
3. Results
3.1. Homology Search
Homology search by HHpred with human COQ2 (Q96H96) as query revealed 22 hits with structures available in the PDB, some of them referring to the same homolog that aligned with more than one region. The hit with the highest score was 4OD4_A, a homolog of UbiA in the archaea Aeropyrum pernix K1 (ApUbiA) but this homolog contain no ligand. Six other structures had at least one hit with a probability score higher than 50%. Five of them contained ligands: 6M31_B, 8DJM_B, 4TQ3_B, 7Q21_f and 7E1V_H. Results were manually curated to check for contact with the correct PDB chain. Structures without ligands bound to the correct chain, or ligands associated with different chains, were disregarded (e.g. 7E1V_H and 7Q21_f). In addition, even though the hit with the highest score (4OD4_A) did not contain any ligands, a structure of the same protein with different ligands can be found on the PDB with identifier 4OD5_A [38], and was included in our analysis.
Five structures containing ligands were selected for further analysis: 4OD5_A, the structure of ApUbiA; 6M31_B, a digeranylgeranylglyceryl phosphate synthase from the archaea Methanocaldococcus jannaschii DSM 2661 (MjDGGGPase); 8DJM_B, UbiA prenyltransferase domain-containing protein 1, another member of the UbiA family, from the chinese hamster, Cricetulus griseus (CgUBIAD1); 4TQ3_B, a homolog of UbiA from the archaea Archaeoglobus fulgidus DSM 4304 (AfUbiA); and 7Q21_f, cytochrome c oxidase polypeptide 4, component of the respiratory supercomplex in the Gram-positive bacteria Corynebacterium glutamicum ATCC 13032. From these, 4OD5_A, 6M31_B and 4TQ3_B were solved by X-ray diffraction (resolutions 3.56, 2.30 and 2.41 Å, respectively), while the method used for 8DJM_B and 7Q21_f was electron microscopy (resolutions 3.23 and 2.90 Å, respectively). The list of ligands associated with these structures can be found on Table 1.
3.2. Ligand Similarity
The molecular similarity between the ligands bound to the selected structures and PHB or a similar molecule to DPP, 5TR, was determined. PHB is present in 4OD5_A, but no similar ligand was found in any other selected structure. The most similar molecule to 5TR was geranyl diphosphate (GPP), bound to 4TQ3_B, with a Tanimoto coefficient of 0.92. The second molecule with a highest Tanimoto coefficient (0.81) was geranyl S-thiolodiphosphate (GST), present in 4OD5_A. Other ligands with a coefficient value higher than 0.3 were: phosphatidic acid (7PH) and cardiolipin (CDL) from 7Q21_f; cholesterol hemisuccinate (Y01) and digitonin (AJP) from 8DJM_B; and [(Z)-octadec-9-enyl] (2R)-2,3-bis(oxidanyl)propanoate (MPG), lauryl dimethylamine-n-oxide (LDA) and phosphate ion (PO4) from 6M31_B (Figure 1).
3.3. Residues Potentially Involved in Substrate Binding
ApUbiA (4OD5_A) was used as a template to identify residues potentially involved in substrate binding in human COQ2 (hCOQ2). Several residues, all of them conserved in hCOQ2 (Figure 2), were proposed to be important for protein-substrate interaction in ApUbiA structure. When the corresponding residues in EcUbiA were mutated, the activity was abolished or reduced [38].
Based on structural proximity, ApUbiA residues Asp54, Asp58, Arg63, Arg67, Tyr115, Lys119, Asp182 and Asp186 may interact with the pyrophosphate (PPi) group of the tail precursor and two Mg2+ ions required as cofactors by UbiA family prenyltransferases. The equivalent residues in hCOQ2 are Asp134, Asp138, Arg143, Arg147, Tyr195, Lys199, Asp255 and Asp259. Additionally, residues Asn50, Asp175 and Tyr178 (Asn130, Asp248 and Tyr251 in hCOQ2) are located in the proximity of the C1 atom of the tail precursor, and Arg43 is close to ligand PHB’s carboxyl group in ApUbiA structure, which corresponds to Arg123 in hCOQ2 [38].
3.4. COQ2 Structural Model
According to MEMSAT, hCOQ2 is predicted to contain 9 transmembrane regions, called S1-S9. The N-terminal (which bears the signal peptide) and the loops connecting S2-S3, S4-S5, S6-S7 and S8-S9 face the matrix side of the inner mitochondrial membrane, whereas the C-terminal and the loops between S1-S2, S3-S4, S5-S6 and S7-S8 lie on the intermembrane space (Figure 3).
The predicted structure of hCOQ2 (Q96H96) is available at the AlphaFold Protein Structure Database (Figure 4) [20]. This model shows that hCOQ2 is an all-helical protein, which is in line with the results of the secondary structure prediction by PSIPRED (Figure 5). It is constituted by several α-helices connected by short loops and arranged in a channel-like structure, containing what appears to be a central cavity. The confidence level, measured as a per-residue confidence score (pLDDT), is generally very high (pLDDT > 90, dark blue), except for the N- and C-terminus, which were predicted to be disordered by DISOPRED (Figure 5). The first one has a very low confidence (pLDDT < 50, orange) in positions 1-57, whereas the second mostly shows a low confidence (70 > pLDDT > 50, yellow) from residue 356 to the end of the protein, in agreement with the disorder prediction related to the pLDDT score [39,40]. Regions with a pLDDT value lower than 90 were removed in this analysis for clarity, so the final model used in subsequent analysis is composed of residues 60-354 (Figure 6).
To date, twelve-point mutations in hCOQ2 have been associated with primary CoQ deficiency, most of them pathogenic according to SIFT (Sorting Intolerant From Tolerant) (Table 2) [1]. Mutated residues were represented as spheres in the model (Figure 6). From these, five are in predicted transmembrane regions, mostly facing the putative inner surface of the channel. The rest of them can be found on loop regions, five on the matrix side and two facing the intermembrane space.
Additionally, interesting regions were highlighted in the COQ2 model (Figure 6), in particular, two conserved Asp-rich motifs ranging from positions 134-138 (Asp134XXXAsp138) and 255-259 (Asp255XXXAsp259), an additional motif in positions 195-199 (Tyr195XXXLys199) and a lateral opening delimited by S1 and S9. The Asp-rich motifs are a signature of the UbiA family members that could be important for activity or substrate interaction, located on the loop regions connecting S2-S3 and S6-S7, whereas the third motif is found on the loop between S4-S5, all of them on the matrix side. The lateral opening has been described in some UbiA homologs such as ApUbiA, AfUbiA and MjDGGGPase [17,38,41,42].
3.5. Structural Superposition of Homologous Structures to COQ2
When superposed to the hCOQ2 model, the most similar structure, i.e., the one with the lower root-mean square deviation (RMSD), was 4TQ3_B (2.901 Å), followed by 4OD5_A (3.477 Å), 6M31_B (4.516 Å), 8DJM_B (4.992 Å) and, lastly, 7Q21_f (18.917 Å). Given the high RMSD value, 7Q21_f was excluded from further analysis.
In the 4TQ3_B structure (AfUbiA), the GPP is located inside the central cavity, with the PPi group looking at the matrix side. The above indicated conserved motifs and two Mg2+ ions are in the proximity of the PPi group. Three residues mutated in CoQ primary deficiency patients are close to GPP: Arg123, Arg147 and Ala252, all of them predicted as pathogenic (Figure 7a).
In 4OD5_A (ApUbiA), both the GST and the PHB can be found inside the central cavity. The PPi group from GST is facing the matrix, with two Mg2+ ions, the Asp-rich motifs, the Tyr195XXXLys199 motif and residue Arg147 in the proximity, whereas pHB is close to Arg123. Ala252 is close to one of the Mg2+ ions (Figure 7b). This suggest that the Mg2+ ions play an important role in the binding of the reactive end of GST with pHB.
In 6M31_B (MjDGGGPase), several MPG and LDA molecules are located inside the cavity, in the lateral portal and around the protein. In the central cavity, three mutated residues (Arg123, Tyr247 and Gly340) are close to the ligands. A Mg2+ ion is bound to the structure, on the matrix side and near the mutated residue Arg123, but in a more peripheral position compared to 4TQ3_B and 4OD5_A (Figure 7c).
In 8DJM_B (CgUBIAD1), the Y01 and AJP are situated around the protein. AJP is found in the proximity of Cys228, a residue mutated in primary CoQ deficiency patients (Figure 7d).
3.6. Effects of Mutations in COQ2 Structure
The structures of the twelve variants with mutations associated to primary CoQ deficiency were predicted and then superposed to the COQ2 model. A list of the variants and the RMSD values obtained, in order from lowest to highest (i.e., from more similar to the wild type to more divergent) can be found on Table 3. There does not seem to be a correlation between the pathogenicity of the mutation and the structural similarity of the variants to the wild type. As expected, point mutations do not produce great global impact on the whole structure of the protein, with RMSD values below 0.3 for all the variants. However, locally, some of them cause small alterations in the loop between S6 and S7 on the matrix side, as well as the N-terminal region, even when the modification takes place elsewhere in the protein (Figure 8). These small modifications could be related with the loss of interaction with the rest of the members of the CoQ-synthome, explaining their high pathogenic effect.
4. Discussion
The tertiary structure prediction from aminoacidic sequence has always been a major challenge in bioinformatics, but recent advances in artificial intelligence have brought about a revolution in this field [43]. AlphaFold2 is a machine learning method that not only predicts protein structures with high accuracy using both evolutionary and geometric information, but also associates a confidence value on a residue level. This is possible thanks to an innovative architecture based on artificial neural networks [39,40]. This technology was applied to all known sequences and the AlphaFold Protein Structure Database currently holds more than 200 million predicted structures [20], including hCOQ2.
Our goal was to leverage the homologous relationship of hCOQ2 to other members of the UbiA family with ligand containing experimentally solved structures, including UbiA homologs from the thermophilic archaea A. pernix (ApUbiA) and A. fulgidus (AfUbiA), a DGGGPase enzyme from another archaeum, M. jannaschii (MjDGGGPase), and a UBIAD1 homolog from the chinese hamster, C. griseus (CgUBIAD1). Proteins from the UbiA family are integral prenyltransferases responsible for the synthesis of a wide range of molecules: CoQ and other quinones such as menaquinone and plastoquinone, vitamin E, chlorophyll, heme, secondary metabolites, components of the cell wall in mycobacteria and membrane lipids in archaea [17,44,45].
hCOQ2 is predicted to contain nine transmembrane regions connected by loops, with the N-terminus facing the matrix side and the C-terminus the intermembrane space. This topology was previously reported by Desbats et al. (2016), except that a different isoform of the protein was used in their analysis [46]. The hCOQ2 gene has four possible start codons and the isoform obtained from the transcript generated from the most downstream ATG (called ATG4), used in the present study, is the most common one, with 371 amino acids [1,46]. Moreover, the AlphaFold model for hCOQ2 shows with a high confidence that it is an all-helical protein organized in a channel-like structure with a central cavity, which is consistent with the PDB structures of the homologous proteins ApUbiA, AfUbiA, MjDGGGPase and CgUBIAD1: 4OD5_A, 4TQ3_B, 6M31_A and 8DJM_B, respectively [17,38,41,42]. When the AlphaFold model is superposed to these structures, the RMSD values are generally globally good, despite the low similarity in their sequences. On the contrary, the highest RMSD value by far is obtained, as expected, with 7Q21_f, structure of the cytochrome c oxidase subunit from C. glutamicum, because it is the only selected homolog that does not belong to the UbiA family.
It is noteworthy that the superposition of UbiA homologs from archaea to hCOQ2 provides lower RMSD values than the homolog from the only mammal, the chinese hamster. In this case the technique used for structure determination must be taken into consideration. The structure of the archaeal proteins was determined by X-ray crystallography, which usually yields a higher resolution than electron microscopy, used for 8DJM_B. The exception is 4OD5_A, solved by X-ray diffraction, but with the worst resolution among all the selected structures. This could explain why 4TQ3_B (AfUbiA) provides the lowest RMSD value instead of 4OD5_A (ApUbiA), even when the second one is closer, in sequence, to hCOQ2 [44]. It is also interesting that, according to previous phylogenetic and clustering studies, the UbiA/COQ2 cluster is more distant to MenA/UBIAD1 than to AfUbiA or MjDGGGPase [17,44], suggesting an earlier divergence of UbiA/COQ2 and MenA/UBIAD1.
Another important observation is that the HHpred output includes 4OD4_A, the apo-state structure of ApUbiA, but not 4OD5_A, the same structure but bound to ligands, because it only takes into consideration the most similar structure for a given protein, the representative, to avoid redundancy. In future approaches, the relationship between the structure and the nature of the ligands would help to discover the binding motives of other representative of the CoQ-synthome. Another problem is that a small number of significant homologs with solved structures was identified and, therefore, the information obtained from them is limited, which is not surprising given that transmembrane structure determination is a challenging matter [47].
The members of the UbiA family catalyse the transfer of hydrophobic chains derived from isoprene or phytol to other compounds that act as acceptors, generally aromatic molecules, providing hydrophobicity [48]. hCOQ2 is responsible for the addition of an isoprenoid chain (DPP in humans) to PHB, which is the precursor of CoQ’s redox-active head. The search for similar ligands bound to the selected structures yielded nine molecules with a Tanimoto coefficient of at least 0.3 when compared to 5TR, a molecule resembling the substrate DPP. The most similar ligands are GPP, precursor of DPP that can be used in vitro by EcUbiA [38,49], and GST, a non-metabolizable analogue of GPP [38], followed by other molecules with long linear chains and an artificial derivative of cholesterol, among others.
When the structures 4TQ3_B (AfUbiA) and 4OD5_A (ApUbiA), containing GPP and GST, respectively, are superposed to hCOQ2, these ligands are found inside the central cavity, with the PPi group positioned towards the matrix side and two Mg2+ ions nearby, in the proximity of the motifs located on the matrix loops and two residues mutated in primary CoQ deficiency patients (Arg147 and Ala252). It has been proposed that the motifs found in the matrix loops play an important role in substrate binding and/or activity, probably involving the coordination of the Mg2+ ions that bridge the CoQ tail precursor with the Asp residues in the motifs and are necessary for the reaction with PHB [17,38,41,42]. We speculate that these residues are essential for the stability of the interaction with the isoprenoid tail explaining why these mutations are incompatible with the life [50].
On the contrary, mutations affecting residues Arg147 and Ala252 [46], located on the matrix side of hCOQ2, are found in CoQ-deficient patients [1]. The equivalent residue of Arg147 in ApUbiA is predicted to be involved in recognition of the PPi group in the polyisoprenoid chain and mutating its counterpart in EcUbiA causes a drastic reduction in the enzymatic activity. Meanwhile, Ala252 is next to residue Tyr251, whose counterpart in ApUbiA is thought to be close to the C1 atom of the isoprenoid chain [38]. Furthermore, pathogenic variants p.Arg147His and p.Ala252Val were previously proposed to disrupt the interaction with the PPi group and one of the Mg2+ ions, respectively [44]. p.Arg147His was found in heterozygosis together with another mutation, p.Asn178Ser, in a 2-year-old boy who suffered steroid-resistant nephrotic syndrome (SRNS) [51], while p.Ala252Val was present in twins with a wide range of symptoms that died a few months after their births [52].
6M31_B provides information related to ligands around the lateral portal defined by transmembrane regions S1 and S9. This opening may be responsible for product release into the inner mitochondrial membrane in eukaryotes or the plasma membrane in prokaryotes [17,38,41]. If hCOQ2 really acts as an anchor site for the CoQ-synthome in humans, it is possible that the product of this protein is not released immediately to the inner mitochondrial membrane and instead stays inside the cavity, being the redox head further modified by the other COQ polypeptides until the last product, CoQ10, is finally released through the lateral portal. The lateral portal has been observed in ApUbiA, AfUbiA and MjDGGGPase, in accordance with the idea proposed by Chen et al. (2022) that binding of the substrate induces the opening of the portal [41].
Conversely, none of the ligands bound to the selected structures were similar to the aromatic substrate, PHB, which could indicate that proteins of the UbiA family display a higher specificity for linear substrates. It is also worth noting that some alternative aromatic substrates have been suggested in different organisms, including para-aminobenzoic acid in yeast and phenolic compounds such as kaempferol, resveratrol and p-coumaric acid in mammals [12]. Taken into consideration that different substrates of the aromatic head can successfully bind to isoprene tail, the specificity for the aromatic substrate seems to be less strong than for the isoprene tail. This allows for different head substrates to have been considered in the treatment of CoQ10 deficiency due to dysfunction of head-modifier CoQ-synthome members [1,53]. Further, this interaction must occur in the matrix side of hCOQ2 permitting the interaction of this part of the molecule with the head-modifying enzymes in the CoQ-synthome. This is consistent with the hypothesis that hCOQ2 functions as an anchor site for the CoQ-synthome and with docking studies published by Herebian et al. (2017) [50], but does not agree with the putative binding site of this ligand in 4OD5_A (ApUbiA) [38], a residue located in a central position inside the cavity that is equivalent to one of the amino acids mutated in primary CoQ deficiency patients, Arg123 [1]. Mutating the counterpart of this residue in EcUbiA has a negative impact on both the enzymatic activity and the interaction with PHB. However, our results reveal that the lateral chain of Arg123 clashes with PHB when 4OD5_A is superposed to the AlphaFold model of hCOQ2, which is in line with the ideas of Huang et al. (2014), who concluded that the structure of AfUbiA does not support this binding site for the aromatic substrate because it lies too close to the polyprenyl chain [42]. There are also ligands in the proximity of Arg123 in structure 6M31_B. This residue, therefore, could interact instead with the linear substrate, which may explain its importance, whereas the pHB binding site could lie elsewhere. For instance, Herebian et al. (2017) have proposed alternative binding sites for this ligand in different positions of the central cavity [50]. Alternatively, it could simply mean that there are differences between members of the UbiA family concerning the binding site of the aromatic substrate and explaining the different aromatic substrates able to be used by hCOQ2.
Interestingly, the different mutations studied did not produce great changes in the structure of the protein. Some of them produced small alterations in the loop between S6 and S7 and the N-terminal region, both on the matrix side. Taken into consideration their pathogenic effect due by the disruption of the activity of hCOQ2, these small modifications can be associated with a loss of interaction with the rest of the members of the CoQ-synthome. Further experiments in this sense must be performed since, to date, the whole structure of the CoQ-synthome has been elusive.
5. Conclusions
Taken together, our results help to improve the understanding of hCOQ2, providing an updated schematic representation of the topology, identifying possible substrate binding sites and interpreting some of the pathogenic mutations related to primary CoQ deficiency. It is important, nevertheless, to note that they are mainly based on predictions. AlphaFold, albeit highly useful, also has limitations. For instance, it is not able to predict ligands [54], justifying why it was combined with an homology-based approach here, with all the associated limitations. Thus, it would be of interest to solve the structure of hCOQ2 and other members of the UbiA family both in the apo and substrate-bound state, as well as to study possible protein-protein interactions involving hCOQ2, especially with other COQ proteins that are thought to be part of the CoQ-synthome, with the purpose of demonstrating the anchor site hypothesis.
Author Contributions
All the authors have contributed significantly to this study. In resume “Conceptualization, D.P.D and G.L.L; methodology, D.P.D.; software, M.A.V.P. and D.P.D; validation, all the authors; formal analysis, all the authors; investigation, all the authors.; writing—original draft preparation, all the authors; writing—review and editing, all the authors. All authors have read and agreed to the published version of the manuscript.”
Funding
“This research received no external funding”.
Acknowledgments
In this section, you can acknowledge any support given which is not covered by the author contribution or funding sections. This may include administrative and technical support, or donations in kind (e.g., materials used for experiments).
Conflicts of Interest
The authors declare no conflicts of interest
References
- Alcazar-Fabra, M.; Rodriguez-Sanchez, F.; Trevisson, E.; Brea-Calvo, G. Primary Coenzyme Q deficiencies: A literature review and online platform of clinical features to uncover genotype-phenotype correlations. Free Radic Biol Med 2021, 167, 141-180. [CrossRef]
- Hernandez-Camacho, J.D.; Garcia-Corzo, L.; Fernandez-Ayala, D.J.M.; Navas, P.; Lopez-Lluch, G. Coenzyme Q at the Hinge of Health and Metabolic Diseases. Antioxidants (Basel) 2021, 10. [CrossRef]
- Stefely, J.A.; Pagliarini, D.J. Biochemistry of Mitochondrial Coenzyme Q Biosynthesis. Trends Biochem Sci 2017, 42, 824-843. [CrossRef]
- Wang, S.; Jain, A.; Novales, N.A.; Nashner, A.N.; Tran, F.; Clarke, C.F. Predicting and Understanding the Pathology of Single Nucleotide Variants in Human COQ Genes. Antioxidants (Basel) 2022, 11. [CrossRef]
- Aussel, L.; Pierrel, F.; Loiseau, L.; Lombard, M.; Fontecave, M.; Barras, F. Biosynthesis and physiology of coenzyme Q in bacteria. Biochim Biophys Acta 2014, 1837, 1004-1011. [CrossRef]
- Kawamukai, M. Biosynthesis of coenzyme Q in eukaryotes. Biosci Biotechnol Biochem 2016, 80, 23-33. [CrossRef]
- Crane, F.L. Discovery of ubiquinone (coenzyme Q) and an overview of function. Mitochondrion 2007, 7 Suppl, S2-7. [CrossRef]
- Barroso, M.P.; Gomez-Diaz, C.; Lopez-Lluch, G.; Malagon, M.M.; Crane, F.L.; Navas, P. Ascorbate and alpha-tocopherol prevent apoptosis induced by serum removal independent of Bcl-2. Arch Biochem Biophys 1997, 343, 243-248. [CrossRef]
- Barroso, M.P.; Gomez-Diaz, C.; Villalba, J.M.; Buron, M.I.; Lopez-Lluch, G.; Navas, P. Plasma membrane ubiquinone controls ceramide production and prevents cell death induced by serum withdrawal. J Bioenerg Biomembr 1997, 29, 259-267. [CrossRef]
- Hadian, K. Ferroptosis Suppressor Protein 1 (FSP1) and Coenzyme Q(10) Cooperatively Suppress Ferroptosis. Biochemistry 2020, 59, 637-638. [CrossRef]
- Kagan, V.E.; Straub, A.C.; Tyurina, Y.Y.; Kapralov, A.A.; Hall, R.; Wenzel, S.E.; Mallampalli, R.K.; Bayir, H. Vitamin E/Coenzyme Q-Dependent "Free Radical Reductases": Redox Regulators in Ferroptosis. Antioxid Redox Signal 2023. [CrossRef]
- Fernandez-Del-Rio, L.; Clarke, C.F. Coenzyme Q Biosynthesis: An Update on the Origins of the Benzenoid Ring and Discovery of New Ring Precursors. Metabolites 2021, 11. [CrossRef]
- Crane, F.L.; Hatefi, Y.; Lester, R.L.; Widmer, C. Isolation of a quinone from beef heart mitochondria. Biochim Biophys Acta 1957, 25, 220-221. [CrossRef]
- Morton, R.A. Ubiquinone. Nature 1958, 182, 1764-1767. [CrossRef]
- Awad, A.M.; Bradley, M.C.; Fernandez-Del-Rio, L.; Nag, A.; Tsui, H.S.; Clarke, C.F. Coenzyme Q(10) deficiencies: Pathways in yeast and humans. Essays Biochem 2018, 62, 361-376. [CrossRef]
- Desbats, M.A.; Lunardi, G.; Doimo, M.; Trevisson, E.; Salviati, L. Genetic bases and clinical manifestations of coenzyme Q10 (CoQ 10) deficiency. J Inherit Metab Dis 2015, 38, 145-156. [CrossRef]
- Ren, S.; de Kok, N.A.W.; Gu, Y.; Yan, W.; Sun, Q.; Chen, Y.; He, J.; Tian, L.; Andringa, R.L.H.; Zhu, X.; et al. Structural and Functional Insights into an Archaeal Lipid Synthase. Cell Rep 2020, 33, 108294. [CrossRef]
- Pelosi, L.; Morbiato, L.; Burgardt, A.; Tonello, F.; Bartlett, A.K.; Guerra, R.M.; Ferizhendi, K.K.; Desbats, M.A.; Rascalou, B.; Marchi, M.; et al. COQ4 is required for the oxidative decarboxylation of the C1 carbon of coenzyme Q in eukaryotic cells. Molecular Cell 2024. [CrossRef]
- Tran, U.C.; Clarke, C.F. Endogenous synthesis of coenzyme Q in eukaryotes. Mitochondrion 2007, 7 Suppl, S62-71. [CrossRef]
- Varadi, M.; Anyango, S.; Deshpande, M.; Nair, S.; Natassia, C.; Yordanova, G.; Yuan, D.; Stroe, O.; Wood, G.; Laydon, A.; et al. AlphaFold Protein Structure Database: Massively expanding the structural coverage of protein-sequence space with high-accuracy models. Nucleic Acids Res 2022, 50, D439-D444. [CrossRef]
- UniProt, C. UniProt: The Universal Protein Knowledgebase in 2023. Nucleic Acids Res 2023, 51, D523-D531. [CrossRef]
- Gabler, F.; Nam, S.Z.; Till, S.; Mirdita, M.; Steinegger, M.; Soding, J.; Lupas, A.N.; Alva, V. Protein Sequence Analysis Using the MPI Bioinformatics Toolkit. Curr Protoc Bioinformatics 2020, 72, e108. [CrossRef]
- Zimmermann, L.; Stephens, A.; Nam, S.Z.; Rau, D.; Kubler, J.; Lozajic, M.; Gabler, F.; Soding, J.; Lupas, A.N.; Alva, V. A Completely Reimplemented MPI Bioinformatics Toolkit with a New HHpred Server at its Core. J Mol Biol 2018, 430, 2237-2243. [CrossRef]
- Soding, J.; Biegert, A.; Lupas, A.N. The HHpred interactive server for protein homology detection and structure prediction. Nucleic Acids Res 2005, 33, W244-248. [CrossRef]
- Sydow, D.; Morger, A.; Driller, M.; Volkamer, A. TeachOpenCADD: A teaching platform for computer-aided drug design using open source packages and data. J Cheminform 2019, 11, 29. [CrossRef]
- Kuwahara, H.; Gao, X. Analysis of the effects of related fingerprints on molecular similarity using an eigenvalue entropy approach. J Cheminform 2021, 13, 27. [CrossRef]
- Altschul, S.F.; Gish, W.; Miller, W.; Myers, E.W.; Lipman, D.J. Basic local alignment search tool. J Mol Biol 1990, 215, 403-410. [CrossRef]
- Gouy, M.; Guindon, S.; Gascuel, O. SeaView version 4: A multiplatform graphical user interface for sequence alignment and phylogenetic tree building. Mol Biol Evol 2010, 27, 221-224. [CrossRef]
- Edgar, R.C. MUSCLE: A multiple sequence alignment method with reduced time and space complexity. BMC Bioinformatics 2004, 5, 113. [CrossRef]
- Waterhouse, A.M.; Procter, J.B.; Martin, D.M.; Clamp, M.; Barton, G.J. Jalview Version 2--a multiple sequence alignment editor and analysis workbench. Bioinformatics 2009, 25, 1189-1191. [CrossRef]
- Jones, D.T. Protein secondary structure prediction based on position-specific scoring matrices. J Mol Biol 1999, 292, 195-202. [CrossRef]
- Jones, D.T.; Cozzetto, D. DISOPRED3: Precise disordered region predictions with annotated protein-binding activity. Bioinformatics 2015, 31, 857-863. [CrossRef]
- Buchan, D.W.A.; Jones, D.T. The PSIPRED Protein Analysis Workbench: 20 years on. Nucleic Acids Res 2019, 47, W402-W407. [CrossRef]
- Pettersen, E.F.; Goddard, T.D.; Huang, C.C.; Meng, E.C.; Couch, G.S.; Croll, T.I.; Morris, J.H.; Ferrin, T.E. UCSF ChimeraX: Structure visualization for researchers, educators, and developers. Protein Sci 2021, 30, 70-82. [CrossRef]
- Mirdita, M.; Schutze, K.; Moriwaki, Y.; Heo, L.; Ovchinnikov, S.; Steinegger, M. ColabFold: Making protein folding accessible to all. Nat Methods 2022, 19, 679-682. [CrossRef]
- Align. In PyMolWiki. Available online: (accessed on September 2023).
- Super. In PyMolWiki. Available online: (accessed on September 2023).
- Cheng, W.; Li, W. Structural insights into ubiquinone biosynthesis in membranes. Science 2014, 343, 878-881. [CrossRef]
- Bertoline, L.M.F.; Lima, A.N.; Krieger, J.E.; Teixeira, S.K. Before and after AlphaFold2: An overview of protein structure prediction. Front Bioinform 2023, 3, 1120370. [CrossRef]
- Jumper, J.; Evans, R.; Pritzel, A.; Green, T.; Figurnov, M.; Ronneberger, O.; Tunyasuvunakool, K.; Bates, R.; Zidek, A.; Potapenko, A.; et al. Highly accurate protein structure prediction with AlphaFold. Nature 2021, 596, 583-589. [CrossRef]
- Chen, H.; Qi, X.; Faulkner, R.A.; Schumacher, M.M.; Donnelly, L.M.; DeBose-Boyd, R.A.; Li, X. Regulated degradation of HMG CoA reductase requires conformational changes in sterol-sensing domain. Nat Commun 2022, 13, 4273. [CrossRef]
- Huang, H.; Levin, E.J.; Liu, S.; Bai, Y.; Lockless, S.W.; Zhou, M. Structure of a membrane-embedded prenyltransferase homologous to UBIAD1. PLoS Biol 2014, 12, e1001911. [CrossRef]
- Kuhlman, B.; Bradley, P. Advances in protein structure prediction and design. Nat Rev Mol Cell Biol 2019, 20, 681-697. [CrossRef]
- Li, W. Bringing Bioactive Compounds into Membranes: The UbiA Superfamily of Intramembrane Aromatic Prenyltransferases. Trends Biochem Sci 2016, 41, 356-370. [CrossRef]
- Mugoni, V.; Postel, R.; Catanzaro, V.; De Luca, E.; Turco, E.; Digilio, G.; Silengo, L.; Murphy, M.P.; Medana, C.; Stainier, D.Y.; et al. Ubiad1 is an antioxidant enzyme that regulates eNOS activity by CoQ10 synthesis. Cell 2013, 152, 504-518. [CrossRef]
- Desbats, M.A.; Morbidoni, V.; Silic-Benussi, M.; Doimo, M.; Ciminale, V.; Cassina, M.; Sacconi, S.; Hirano, M.; Basso, G.; Pierrel, F.; et al. The COQ2 genotype predicts the severity of coenzyme Q10 deficiency. Hum Mol Genet 2016, 25, 4256-4265. [CrossRef]
- Yeh, V.; Goode, A.; Bonev, B.B. Membrane Protein Structure Determination and Characterisation by Solution and Solid-State NMR. Biology (Basel) 2020, 9. [CrossRef]
- Yang, Y.; Ke, N.; Liu, S.; Li, W. Methods for Structural and Functional Analyses of Intramembrane Prenyltransferases in the UbiA Superfamily. Methods Enzymol 2017, 584, 309-347. [CrossRef]
- Melzer, M.; Heide, L. Characterization of polyprenyldiphosphate: 4-hydroxybenzoate polyprenyltransferase from Escherichia coli. Biochim Biophys Acta 1994, 1212, 93-102. [CrossRef]
- Herebian, D.; Seibt, A.; Smits, S.H.J.; Bunning, G.; Freyer, C.; Prokisch, H.; Karall, D.; Wredenberg, A.; Wedell, A.; Lopez, L.C.; et al. Detection of 6-demethoxyubiquinone in CoQ(10) deficiency disorders: Insights into enzyme interactions and identification of potential therapeutics. Mol Genet Metab 2017, 121, 216-223. [CrossRef]
- Diomedi-Camassei, F.; Di Giandomenico, S.; Santorelli, F.M.; Caridi, G.; Piemonte, F.; Montini, G.; Ghiggeri, G.M.; Murer, L.; Barisoni, L.; Pastore, A.; et al. COQ2 nephropathy: A newly described inherited mitochondriopathy with primary renal involvement. J Am Soc Nephrol 2007, 18, 2773-2780. [CrossRef]
- Jakobs, B.S.; van den Heuvel, L.P.; Smeets, R.J.; de Vries, M.C.; Hien, S.; Schaible, T.; Smeitink, J.A.; Wevers, R.A.; Wortmann, S.B.; Rodenburg, R.J. A novel mutation in COQ2 leading to fatal infantile multisystem disease. J Neurol Sci 2013, 326, 24-28. [CrossRef]
- Santos-Ocana, C.; Cascajo, M.V.; Alcazar-Fabra, M.; Staiano, C.; Lopez-Lluch, G.; Brea-Calvo, G.; Navas, P. Cellular Models for Primary CoQ Deficiency Pathogenesis Study. Int J Mol Sci 2021, 22. [CrossRef]
- Perrakis, A.; Sixma, T.K. AI revolutions in biology: The joys and perils of AlphaFold. EMBO Rep 2021, 22, e54046. [CrossRef]
Figure 1.
Ligands with a Tanimoto coefficient bigger than 0.3 when compared to 5TR. The chemical structure, the component identifier in the PDB Component Dictionary and the value of the Tanimoto coefficient for each ligand are displayed.
Figure 1.
Ligands with a Tanimoto coefficient bigger than 0.3 when compared to 5TR. The chemical structure, the component identifier in the PDB Component Dictionary and the value of the Tanimoto coefficient for each ligand are displayed.
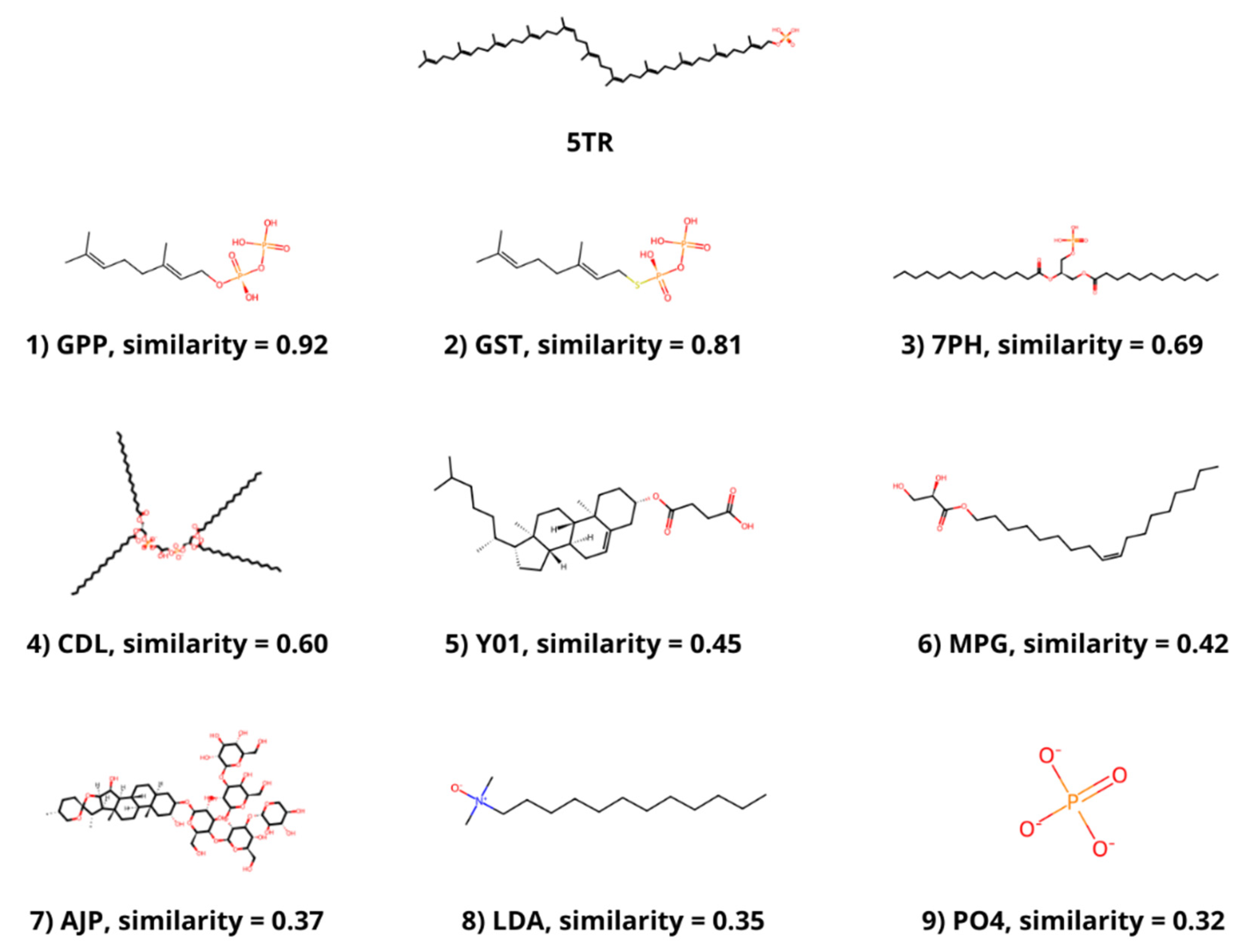
Figure 2.
Multiple sequence alignment of human COQ2 (hCOQ2) and some homologs from different organisms, including UbiA from E. coli (EcUbiA), UbiA homolog from A. pernix (ApUbiA), UbiA homolog from A. fulgidus (AfUbiA), DGGGPase from M. jannaschii (MjDGGGPase), UBIAD1 homolog from C. griseus (CgUBIAD1), COQ2 from Pan troglodytes (PtCOQ2), COQ2 from Mus musculus (MmCOQ2), COQ2 from Danio rerio (DrCOQ2), COQ2 from Drosophila melanogaster (DmCOQ2), COQ2 from Caenorhabditis elegans (CeCOQ2), PPT1 from Arabidopsis thaliana (AtPPT1) and COQ2 from Saccharomyces cerevisiae (ScCOQ2). The degree of sequence conservation is indicated in shades of blue: dark (> 80%), medium (> 60%) and light (> 40%). Conserved motifs are represented in pink boxes. Residues located in the proximity of the PPi group and the C1 atom of the tail precursor are denoted by green and purple dots, respectively. The residue associated with PHB binding is depicted with an orange dot.
Figure 2.
Multiple sequence alignment of human COQ2 (hCOQ2) and some homologs from different organisms, including UbiA from E. coli (EcUbiA), UbiA homolog from A. pernix (ApUbiA), UbiA homolog from A. fulgidus (AfUbiA), DGGGPase from M. jannaschii (MjDGGGPase), UBIAD1 homolog from C. griseus (CgUBIAD1), COQ2 from Pan troglodytes (PtCOQ2), COQ2 from Mus musculus (MmCOQ2), COQ2 from Danio rerio (DrCOQ2), COQ2 from Drosophila melanogaster (DmCOQ2), COQ2 from Caenorhabditis elegans (CeCOQ2), PPT1 from Arabidopsis thaliana (AtPPT1) and COQ2 from Saccharomyces cerevisiae (ScCOQ2). The degree of sequence conservation is indicated in shades of blue: dark (> 80%), medium (> 60%) and light (> 40%). Conserved motifs are represented in pink boxes. Residues located in the proximity of the PPi group and the C1 atom of the tail precursor are denoted by green and purple dots, respectively. The residue associated with PHB binding is depicted with an orange dot.
Figure 3.
Topology of COQ2. Transmembrane helices predicted by MEMSAT are represented by pink boxes.
Figure 3.
Topology of COQ2. Transmembrane helices predicted by MEMSAT are represented by pink boxes.
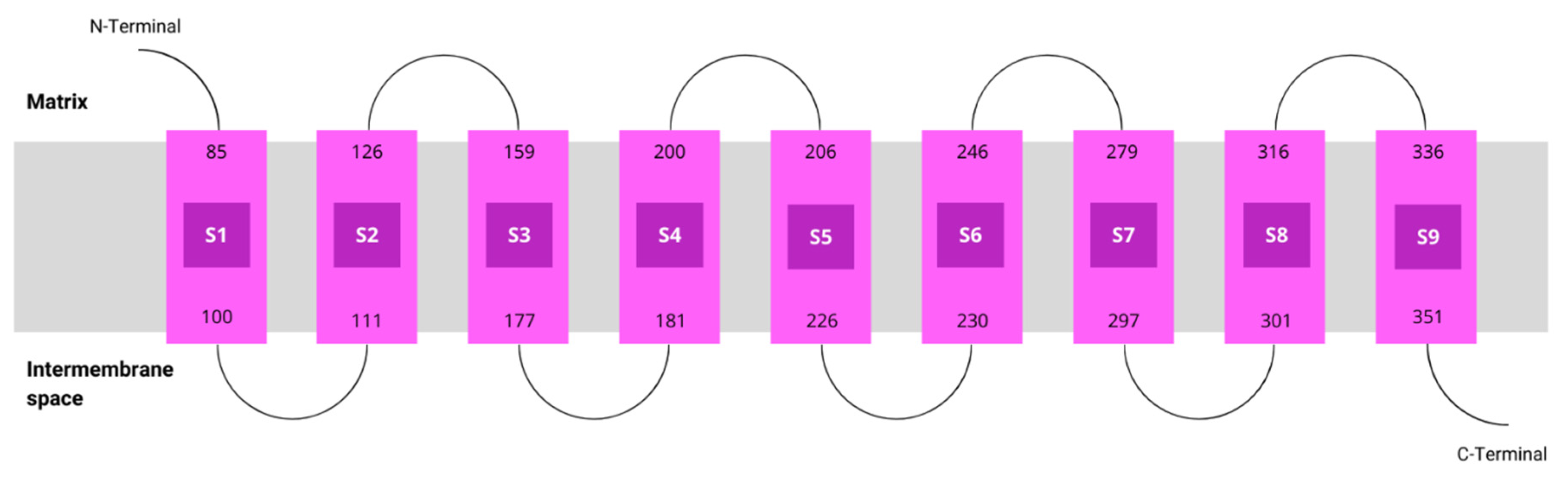
Figure 4.
AlphaFold prediction model for COQ2. The colours represent the per-residue confidence score for the prediction: dark blue (very high, pLDDT > 90), light blue (confident, 90 > pLDDT > 70), yellow (low, 70 > pLDDT > 50) and orange (very low, pLDDT < 50). Figure taken from the AlphaFold Protein Structure Database [20].
Figure 4.
AlphaFold prediction model for COQ2. The colours represent the per-residue confidence score for the prediction: dark blue (very high, pLDDT > 90), light blue (confident, 90 > pLDDT > 70), yellow (low, 70 > pLDDT > 50) and orange (very low, pLDDT < 50). Figure taken from the AlphaFold Protein Structure Database [20].
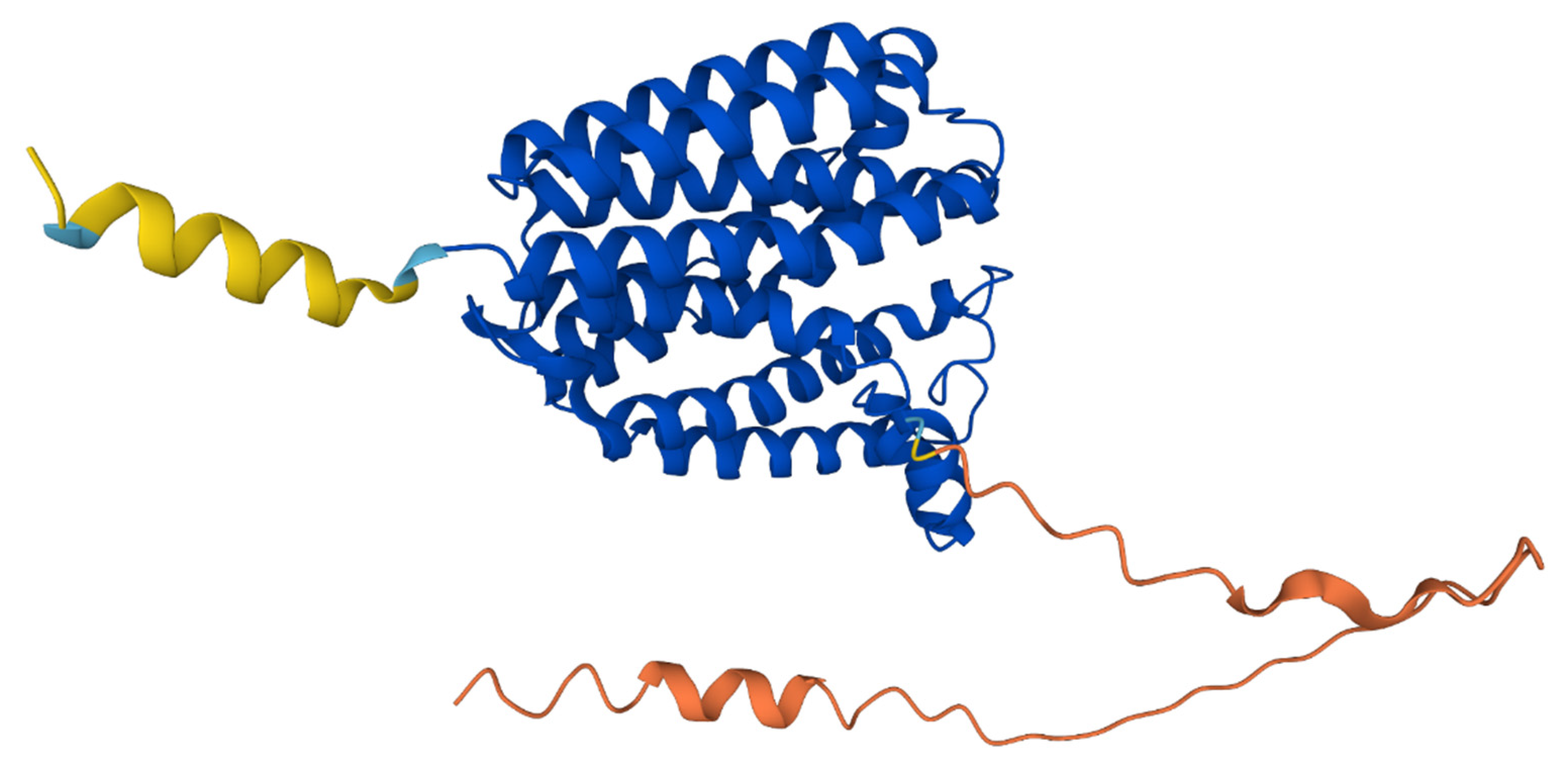
Figure 5.
Secondary structure and disordered regions prediction for COQ2. Helices predicted by PSIPRED are indicated in pink. Putative disordered regions according to DISOPRED are depicted by blue or green boxes.
Figure 5.
Secondary structure and disordered regions prediction for COQ2. Helices predicted by PSIPRED are indicated in pink. Putative disordered regions according to DISOPRED are depicted by blue or green boxes.
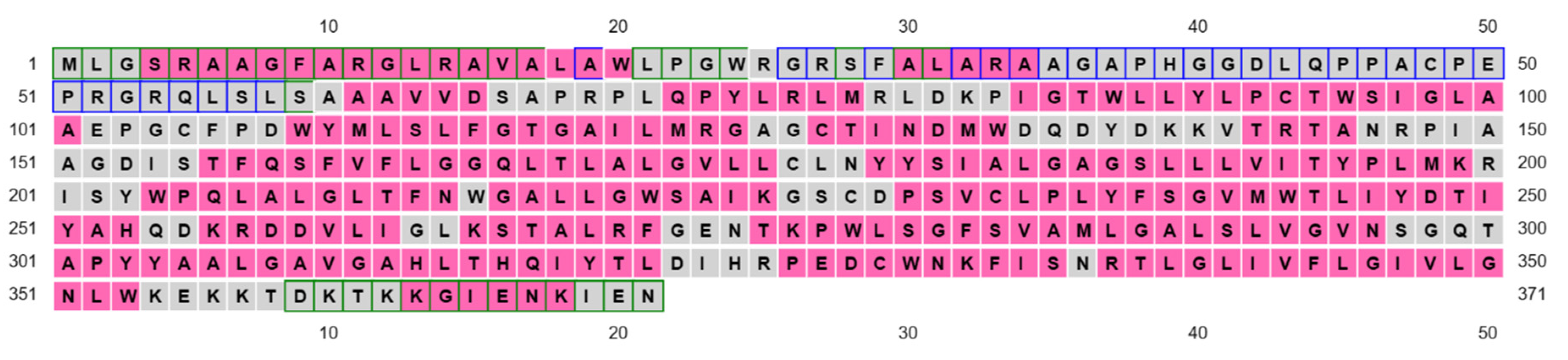
Figure 6.
COQ2 structural model (positions 60-354). Residues mutated in primary CoQ deficiency patients are represented as spheres and labelled in black. Conserved motifs are coloured in pink. Transmembrane helices S1 and S9, delimiting the putative lateral portal, are indicated in sky blue.
Figure 6.
COQ2 structural model (positions 60-354). Residues mutated in primary CoQ deficiency patients are represented as spheres and labelled in black. Conserved motifs are coloured in pink. Transmembrane helices S1 and S9, delimiting the putative lateral portal, are indicated in sky blue.
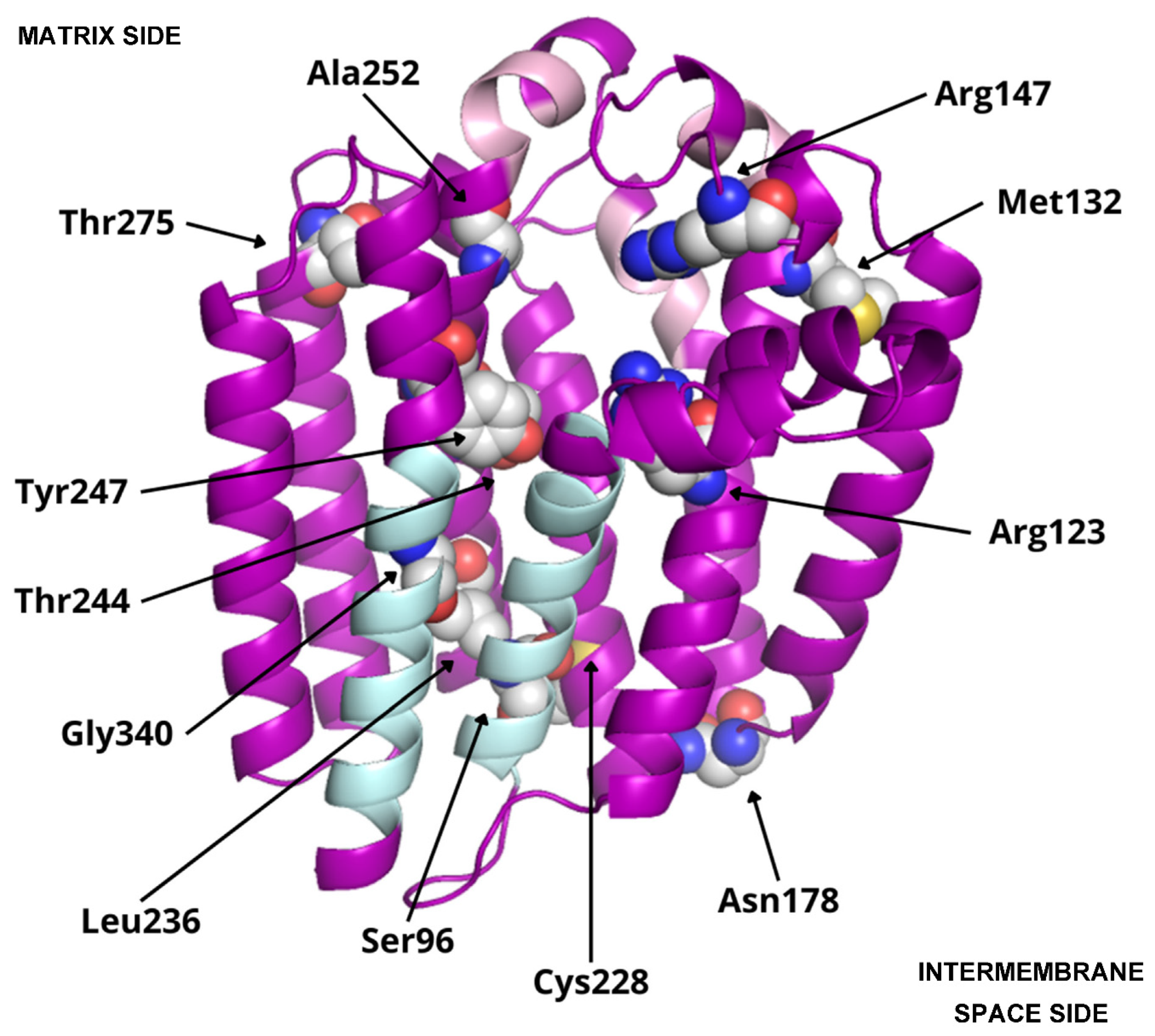
Figure 7.
Potentially interesting ligands modelled into the COQ2 structural model. The conserved motifs and the lateral portal are depicted in pink and sky blue, respectively, while residues associated with primary CoQ deficiency are shown as spheres. The mutated residues that lie close to a potentially interesting ligand are labelled in black. The superposed structures of the homologous proteins were removed for clarity. (a) GPP in cyan and two Mg2+ ions in green from 4TQ3_B. (b) GST and pHB in yellow and two Mg2+ ions in green from 4OD5_A. (c) MPG and LDA in blue and a Mg2+ ion in green from 6M31_B. (d) Y01 and AJP in green from 8DJM_B.
Figure 7.
Potentially interesting ligands modelled into the COQ2 structural model. The conserved motifs and the lateral portal are depicted in pink and sky blue, respectively, while residues associated with primary CoQ deficiency are shown as spheres. The mutated residues that lie close to a potentially interesting ligand are labelled in black. The superposed structures of the homologous proteins were removed for clarity. (a) GPP in cyan and two Mg2+ ions in green from 4TQ3_B. (b) GST and pHB in yellow and two Mg2+ ions in green from 4OD5_A. (c) MPG and LDA in blue and a Mg2+ ion in green from 6M31_B. (d) Y01 and AJP in green from 8DJM_B.
Figure 8.
Structural superposition of variants associated with primary CoQ deficiency to the COQ2 model. Each structure is represented in a different colour: p.Ser96Asn (yellow), p.Arg123His (pink), p.Met132Arg (grey), p.Arg147His (cyan), p.Asn178Ser (blue), p.Cys228Arg (red), p.Leu236Phe (green), p.Thr244Ile (teal), p.Tyr247Cys (magenta), p.Ala252Val (orange), p.Thr275Ala (wheat), p.Gly340Ala (light blue) and wild type (purple).
Figure 8.
Structural superposition of variants associated with primary CoQ deficiency to the COQ2 model. Each structure is represented in a different colour: p.Ser96Asn (yellow), p.Arg123His (pink), p.Met132Arg (grey), p.Arg147His (cyan), p.Asn178Ser (blue), p.Cys228Arg (red), p.Leu236Phe (green), p.Thr244Ile (teal), p.Tyr247Cys (magenta), p.Ala252Val (orange), p.Thr275Ala (wheat), p.Gly340Ala (light blue) and wild type (purple).


Table 1.
List of significant HHpred hits with ligands. The PDB identifier and a description of the protein are displayed. For each ligand, the name and identifier in the PDB Chemical Component Dictionary are included.
Table 1.
List of significant HHpred hits with ligands. The PDB identifier and a description of the protein are displayed. For each ligand, the name and identifier in the PDB Chemical Component Dictionary are included.
| PDB ID | Protein | Ligands |
|---|---|---|
| 4OD5_A | UbiA homolog from Aeropyrum pernix K1 |
p-hydroxybenzoic acid (PHB) |
| Geranyl S-thiolodiphosphate (GST) | ||
| Magnesium ion (MG) | ||
| 6M31_B | Digeranylgeranylglyceryl phosphate synthase from Methanocaldococcus jannaschii DSM 2661 | [(Z)-octadec-9-enyl] (2R)-2,3-bis(oxidanyl)propanoate (MPG) |
| Lauryl dimethylamine-n-oxide (LDA) | ||
| Phosphate ion (PO4) | ||
| Magnesium ion (MG) | ||
| 8DJM_B | UbiA prenyltransferase domain-containing protein from Cricetulus griseus | Cholesterol hemisuccinate (Y01) |
| Digitonin (AJP) | ||
| 4TQ3_B | UbiA homolog from Archaeoglobus fulgidus DSM 4304 | Geranyl diphosphate (GPP) |
| Magnesium ion (MG) | ||
| 7Q21_f | Cytochrome c oxidase polypeptide 4 from Corynebacterium glutamicum ATCC 13032 | Phosphatidic acid (7PH) |
| Cardiolipin (CDL) | ||
| Tridecane (TRD) |
Table 2.
List of pathogenic and tolerated mutations associated with primary CoQ deficiency and their location in the protein.
Table 2.
List of pathogenic and tolerated mutations associated with primary CoQ deficiency and their location in the protein.
| Amino acid modification | Location | SIFT prediction |
|---|---|---|
| Ser96Asn | Transmembrane helix S1 | Pathogenic |
| Arg123His | Transmembrane helix S2 | Pathogenic |
| Met132Arg | Loop between S2-S3 (matrix side) | Pathogenic |
| Arg147His | Loop between S2-S3 (matrix side) | Pathogenic |
| Asn178Ser | Loop between S3-S4 (intermembrane space side) |
Tolerated |
| Cys228Arg | Loop between S5-S6 (intermembrane space side) |
Pathogenic |
| Leu236Phe | Transmembrane helix S6 | Pathogenic |
| Thr244Ile | Transmembrane helix S6 | Tolerated |
| Tyr247Cys | Loop between S6-S7 (matrix side) | Pathogenic |
| Ala252Val | Loop between S6-S7 (matrix side) | Pathogenic |
| Thr275Ala | Loop between S6-S7 (matrix side) | Tolerated |
| Gly340Ala | Transmembrane helix S9 | Pathogenic |
Table 3.
List of RMSD values obtained by the superposition of the structures containing pathogenic or tolerated mutations related to primary CoQ deficiency to the COQ2 model.
Table 3.
List of RMSD values obtained by the superposition of the structures containing pathogenic or tolerated mutations related to primary CoQ deficiency to the COQ2 model.
| Variant | SIFT prediction | RMSD (Å) |
|---|---|---|
| p.Ser96Asn | Pathogenic | 0.183 |
| p.Met132Arg | Pathogenic | 0.199 |
| p.Leu236Phe | Pathogenic | 0.207 |
| p.Arg147His | Pathogenic | 0.210 |
| p.Asn178Ser | Tolerated | 0.225 |
| p.Gly340Ala | Pathogenic | 0.237 |
| p.Tyr247Cys | Pathogenic | 0.246 |
| p.Cys228Arg | Pathogenic | 0.247 |
| p.Thr244Ile | Tolerated | 0.247 |
| p.Arg123His | Pathogenic | 0.256 |
| p.Thr275Ala | Tolerated | 0.257 |
| p.Ala252Val | Pathogenic | 0.268 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



