Submitted:
26 April 2024
Posted:
28 April 2024
You are already at the latest version
Abstract
Our paper deals with an advanced statistical tool for the volatility prediction problem in financial (crypto) markets. Firstly, we consider the conventional GARCH involved volatility models. We next extend the corresponding GARCH based forecasting and calculate a specific probability associated with the predicted volatility levels. Since the probability evaluation is based on a stochastic model, we next develop an additional data-driven estimation of this probability. The proposed advanced statistical estimation uses real (historical) market data. The obtained theoretic results for the statistical probability of levels are also discussed in the framework of the integrated volatility concept. A possible application of the established probability estimation to the volatility clustering problem is also mentioned. Our paper includes a concrete practical implementation of the resulting (combined) volatility prediction tool and considers a novel module for trading and volatility estimation in crypto markets recently developed by 1ex Trading Board group in collaboration with the GoldenGate Venture. Moreover, we discuss shortly a possible using of the proposed model based and data-driven volatility prediction methodology in the financial risk management.
Keywords:
technical analysis
; formal volatility models
; volatility prediction
; statistical probability of levels
; trading algorithms
1. Introduction and Motivation
In financial engineering, volatility is usually defined as the dispersion of a return series and is computed by taking the (sample) standard deviation (see, e.g., [11,19,32]). Volatility is the most important parameter in the pricing of crypto derivatives, and the trading volume has drastically increased in recent years. To price an option, one needs to know (or estimate) the volatility of the underlying asset from the real-time instant until the option expires. Note that the probability distributions of financial returns are characterized by high volatility persistence and thick tails (see, e.g., [1,12]). In the realm of modern crypto markets, the manifestation of volatility constitutes a very important indicator of the inherent fluctuations in the main market characteristics [13,32,36]. It gives crucial information to crypto traders and constitutes a pivotal element of many effective cryptocurrency trading strategies. Volatility information is very important for assessing risk and pricing derivative products, as well as for developing trading strategies.
The volatility prediction problem is an important topic in the technical analysis of financial markets (see [9,10,20,32,37,40,41], and the references therein). It is common knowledge that various time-series models are widely used for handling the data of highly volatile financial markets. For example, the relatively simple generalized autoregressive conditional heteroskedasticity (GARCH) models can effectively be applied to the volatility forecasting problem (see [9,10,16,22,38,39,41]). On the other hand, the majority of the existing time-series techniques for volatility prediction involve the celebrated quasi-maximum likelihood (QML) estimation approach [7,10,17,18,33]. One can use this conventional estimation methodology for necessary parameter identification in a selected GARCH (p,q) model. We refer to [2,28,33] for the general identification theory.
However, the conventional QML estimation approach mentioned above was initially designed under the classic normality assumption [17,32,33,39]. Thus, it is inefficient if the volatility proxies are non-Gaussian (see [14]). Otherwise, there are several specific features of financial market volatility that are well-documented. These "stylized facts" include the fat-tailed distributions of asset returns, volatility clustering, asymmetry, and mean reversion. It is well-known that the QML method is non-robust in the presence of outliers, even with fat-tailed and skewed distributions. Therefore, the classic (Gaussian) QML method for the GARCH parameter identification problem needs to be improved and extended with some additional analytical tools.
Although the development of mathematical models for crypto markets and new trading algorithms has been a major topic of research, forecasting financial market volatility is more difficult. Surprisingly, although high volatility can pose a considerable menace to shareholders, it can also be a source of significant financial returns. Even when stock markets oscillate, fall, or skyrocket, there is always a possibility to profit if market volatility is exploited.
In this paper, we extend the existing GARCH volatility prediction technique using an additional useful tool. We introduce predicted volatility levels and calculate the probability that financial market volatility will not fall below these (predicted) levels. This formal mathematical technique involves the well-known stochastic volatility model (see, e.g., [32]). Additionally, we use real market data and develop a constructive lower estimation for the probability evaluation mentioned above. This data-driven estimation of the probability of volatility levels integrates the model parameters and real market data. The advanced statistical analysis we propose can be considered for integrated volatility frameworks. It can also be useful in the context of the volatility clustering problem [29,30]. Our paper includes a short presentation of a practically oriented volatility analysis module, recently developed by the 1ex Trading Board group in collaboration with GoldenGate Venture. This novel tool includes the volatility prediction methodology discussed in this paper and some related trading algorithms.
Let us also note that robust volatility forecasting plays an important role in financial risk management [25,36,42]. Various hedge funds, banks, financial groups, and trading houses use the well-known value-at-risk (VaR) indicators. Modern VaR estimators essentially use some volatility predictors. Moreover, a credible volatility prediction scheme can also be applied to optimize the design of novel profitable trading algorithms for crypto markets [3–6,15]. It is well-known that the highly fluctuating crypto exchange prices and the corresponding highly frequent changes in the main market indicators make accurate price forecasting nearly impossible. In this situation, consistent volatility prediction can essentially improve concrete trading strategies.
The remainder of our paper is organized as follows: Section 2 contains the formal volatility prediction problem formulation in the framework of the general GARCH model. We also examine concrete GARCH abstractions, discuss some useful mathematical and financial facts, and introduce the concept of the predicted volatility levels. Section 3 includes a critical consideration of the conventional QLM technique for model (parameter) identification in a general GARCH model. We focus our attention on the conceptual difficulties of this widely used methodology in the case of non-Gaussian stochastic errors. The criticism in this section helps in understanding the necessity of some additional and novel predictive tools. Section 4 is devoted to the development of a novel probabilistic tool for volatility prediction. We use the well-known stochastic volatility model for this purpose. The application of an advanced mathematical technique makes it possible to calculate the characteristic probability associated with the predicted volatility levels. Concretely, we evaluate the exact probability of financial market volatility not falling below a prescribed (predicted) level. In Section 5, we perform a statistical analysis of financial market data and derive a novel, lower estimation of the probability associated with predicted volatility. This data-driven version of the probability estimation is a formal consequence of the stochastic volatility model studied in the previous section. Section 6 contains a short description of the practically oriented volatility estimation module "AI NEWS," recently developed by the 1ex Trading Board group in collaboration with GoldenGate Venture. Section 7 summarizes our paper.
2. Volatility Prediction in Financial Markets Using GARCH Models
Consider a series of prices of an asset at time points and introduce the corresponding logarithmic return (log return):
Using the obtained data set, , we now define the (sample) volatility, , for the given time period:
Here,
is a sample mean return. Evidently, (1) constitutes a method of moment unbiased estimation of the second moment (i.e., variance of return) for the observable series of returns, . Here, we do not assume the covariance stationarity of . The complete time period can be interpreted as a full time frame associated with a complete series of historical prices.
Note that there are a number of theoretical and practical advantages to using log returns in finance (see, e.g., [11,19]). In financial engineering, volatility is often defined as the square root of (1) (the sample standard deviation); however, the square root of in (1) constitutes a biased estimation of the corresponding standard deviation (see, e.g., [33,39] for details).
As mentioned in the introduction, there are various methods for estimating the volatility in (1). Next, we focus our attention on a simple but effective volatility forecasting procedure that uses a relatively simple GARCH model (see [16,19], and the references therein). Recall that the generic GARCH(p,q) abstraction has the following formal expression:
Here,
is a conditional mean and is a sigma-algebra generated by the data that are available up to the time instant . Moreover, the possibly non-normal random variables, , are assumed to be independent and identically distributed with
We also assume that the GARCH(p,q) coefficients
in (2) are known for every . The deterministic value, , in model (2) is sometimes called an intercept. Note that we consider a general non-stationary GARCH model here. Evidently, the above non-stationary abstractions constitute an adequate modeling framework for modern, highly volatile crypto markets.
As the statistical properties of the sample mean, , in (1) make it a very inaccurate approximation of a true mean, taking the necessary deviations around zero instead of , as in formulae (1), increases the accuracy of the volatility prediction. Therefore, we next assume that for all in (2).
The conditional variance in the GARCH(p,q) model (2) constitutes a specific model-based volatility estimation. The main idea of the proposed GARCH model is that the conditional variance of returns has an autoregressive structure and is positively correlated to its own recent past. Note that this model also generates the volatility clustering effect.
In the case of a GARCH (1,1), we obtain
From (3), next, we derive the model-based unconditional variance estimation, , of the return :
The resulting volatility prediction expression (4) has a recursive nature. In the stationary case, namely, for
we evidently have the explicit time-invariant volatility prediction:
The so-called volatility persistence is given here by .
Let us also present the resulting formulae for the estimated volatility, , of return associated with a stationary GARCH (2,2) predictive model
The corresponding volatility prediction in that case can be expressed as follows:
We refer to [16] for the necessary mathematical formalism. Recall that the covariance-stationarity condition for the general GARCH(p,q) process (2) has the generic form:
Next, using a "predicted volatility level," we denote the value , calculated using one of the above formulae (4), (5), or (7). In parallel with the common volatility definition, we also consider the well-known "integrated volatility" concept over the period t to :
The integrated volatility concept (8) is of central importance in the pricing of crypto derivatives (see, e.g., [29] for details). Let us also refer to [32] for some existing integrated volatility estimators. Evidently, the GARCH-based predicted volatility levels mentioned above naturally imply the corresponding levels of integrated volatility in (8). For example, the combination of the simple trapezoidal rule and (4) implies the following estimation
of .
Note that the integrated volatility, , can also be estimated using the return samplings for a time interval of the sufficiently frequent returns (see, e.g., [1])
Here, n is the sampling frequency, denotes a compound return, and is the probability associated with the exchange prices (exchange rates) under consideration. The basic relation (10) also involves a useful concept from modern financial engineering; namely, the so-called "realized volatility" (see [20,32] and the references therein). Similar to the forecasting technique for the predicted volatility discussed above, one can also estimate some of the additional important statistical characteristics of return. For example, the GARCH models presented in this section provide a consistent analytic basis for an adequate estimation of the corresponding kurtosis coefficients (see, e.g., [27] for details).
3. On the Critical Analysis of the QML Method for Parameter Identification
The general GARCH-based volatility model (2), as well as the concrete predictive relations (4), (5), (7), and (9), are derived under the assumption of the known model parameters (coefficients)
and
However, practical application of these approaches involves a necessary identification procedure for defining the GARCH parameters mentioned above. Moreover, one also needs to estimate (identify) the standardized errors, , in model (2).
The quasi-maximum likelihood (QML) method is widely used for the identification of the GARCH(p,q) models (2). We refer to [7,10,17,18,33] for some mathematical details and concrete applications of the QML techniques. Under the standard normality assumptions, this method provides consistent and asymptotically normal estimations in the case of strictly stationary GARCH processes. Recall that the conventional QML involves maximizing the Gaussian log-likelihood, and the resulting solution constitutes an adequate estimation of a parameter vector under the normality assumptions.
However, it is common knowledge that financial time-series (for example, the crypto exchange rates) have the characteristics of being leptokurtotic and fat-tailed with skewness. Moreover, these series usually involve the so-called volatility clustering effect. The "stylized facts" about the financial market volatility mentioned above also include asymmetry and mean reversion. Note that these properties of the volatility dynamics are now well documented (see, e.g., [12,32]).
The non-regular behavior of the modern financial markets and the corresponding stylized facts about volatility make it impossible to consider the classical Gaussian assumption for the stochastic errors in the GARCH(p,q) models. Note that the generic normal probability distributions do not involve outliers and are incompatible with the fat-tailed and skewness effects mentioned above. On the other side, it is well-known that the QML method is non-robust in the presence of data outliers generated by fat-tailed and skewed distributions. It is remarkable that in some professional publications and also in practical trading manuals, one still follows inconsistent normality assumptions. As a result, this simplified Gaussian-based modeling approach involves a deficient description and faulty forecasting of the real (crypto) market dynamics.
The above problem of an adequate modeling framework for the stochastic errors in the general GARCH(p,q) model (2) is crucially important for the resulting model-based volatility prediction. The basic QML estimation is inefficient if the volatility proxies are non-Gaussian (see, e.g., [32] and the references therein). As a consequence, one will obtain a possible inconsequential estimation, , for the parameters of the basic GARCH volatility model under consideration.
In this situation, one can consider some concrete fat-tailed and skewed probability distribution in order to examine and simulate the more realistic case studies of the modeled volatility dynamics. For example, one can use the "contaminated" and skewed normal distribution, skewed Student distribution, skewed generalized error distribution, and many others. These non-regular probability distributions generate various types of realistic additive and innovative outliers for the time-series-based modeling of financial time-series. We refer to [2,14,23] for the corresponding research and simulation results.
Let us note that the fat-tailed and skewed distributions constitute an adequate modeling framework in the case of cryptocurrency time-series (see [12]). On the other hand, we usually have no information about a concrete real probability distribution associated with these specific financial series. The same is also true with respect to the series of returns. That means that the concrete non-Gaussian (fat-tailed and skewed) probability distributions of the stochastic errors in the GARCH model (2) are generally unknown.
The above fact constitutes the main motivation for the necessary methodological extension of the existing model-based techniques for volatility prediction and for developing some additional data-driven statistical tools. Next, we propose a novel statistical metric that can be used as an auxiliary analytic tool for the GARCH-based prediction of the volatility levels. This metric involves real market data and constitutes a quantitative method for seeing how well the model-based volatility prediction would have done. The novel methodology we introduce in the next sections can also be implemented as a part of the common backtesting procedures for the design and verification of new algorithmic trading strategies.
4. Exact Probability Calculation for the Predicted Volatility Levels
This section presents a useful result that can be applied to the formal probabilistic analysis of the predicted volatility levels. By taking into consideration the conceptual difficulties of the OML method discussed in Section 3, we propose an auxiliary statistical-based predictive metric.
Consider the well-known stochastic volatility model (see, e.g., [32] and the references therein):
where is an average, is the speed of the volatility process, and is called "volatility of volatility". Using , we denote a Wiener process with
The above stochastic volatility model is usually considered in combination with the price dynamics:
Similar to (11), we are dealing with an associated Wiener process here:
Using in (12), we denote the mean. Many useful mathematical models of financial markets include the generic abstraction (12). Let us mention the classic Samuelson pricing model and the celebrated Black-Scholes theory (see [8,35]).
Note that the price and the volatility models (11)–(12) constitute an interconnected system of equations. This natural interconnection can be described by a specific correlation between and . The fundamental system (11)–(12) can also be used for modeling the crypto markets. This model also generates some stylized facts about the volatility mentioned in the previous sections; namely, the Black–Scholes volatility smile and volatility clustering. We refer to [8] for further technical details.
We now consider the GARCH(1,1) and GARCH(2,2) models from Section 2 and the corresponding predicted volatility levels (4), (5), and (7). Let be a required volatility level that is associated with the corresponding GARCH-based predictions. Roughly speaking, we have here the non-stationary level such that
for (4), and the stationary level
in the case of (5) and (7). The required probability associated with the predicted volatility level, , can now be defined as follows:
where . Recall that denotes the probability measure associated with the exchange prices, (see Section 2). Note that the above diffusion Markov processes—namely, processes (11) and (12)—are assumed to be defined in the same probability space.
The proposed definition (13) expresses a probability that the volatility does not fall below a specific level (a level of ) for . This constitutes a kind of "consistency" for the model-based volatility prediction concept determined by GARCH(1,1) or GARCH(2,2). Note that in (13), we are dealing with a conditional probability and assuming that the initial volatility, , is higher than . We now calculate the required probability determined by (13) using only the stochastic volatility abstraction discussed above. Note that this calculation does not involve the GARCH(p,q) volatility model.
In parallel with the characteristic probability (13), we introduce the formal complement:
where the stochastic dynamics of are given by (11). This complement expresses the probability of the following "complementary" event
for . The complementary probability given by (14) can now be evaluated. From the abstract result of [31], it follows that function in (14) satisfies the following boundary value problem:
where is a solution of (11). From [31], we also deduce that the auxiliary function
satisfies the boundary value problem for the conventional heat equation:
The solution of the boundary value problem (16) can be written as follows (see, e.g., [26]):
Here, we use the following notation for the auxiliary function:
where
We now consider the definition (17) of the auxiliary function and obtain an explicit expression for the original function in problem (15). This expression implies the corresponding formal result for the desired probability in (13):
where .
A direct verification shows that the obtained complementary to (18)—namely, the probability —satisfies the boundary value problem (15). Moreover, for the function and for the desired probability in (18), we can verify the natural condition
for .
We now conclude that the probability of the GARCH-based predicted volatility level, , is explicitly given by the resulting relation (18). It expresses the probability of the event
for , assuming that the initial volatility (for ) satisfies the inequality condition
Finally, let us note that the exact probability calculus developed in this section is based on the generic stochastic modeling approach (11) for volatility dynamics.
5. Statistics of the Predicted Volatility Levels
The probabilistic analysis of the predicted volatility levels performed in the previous section is based on an abstract mathematical model; namely, on the stochastic equation (11). Next, we consider this obtained theoretical technique and use it for an applied, data-driven statistical analysis of the GARCH-based estimations of volatility levels.
Consider the resulting formulae (18) from Section 4 and put . Our aim is to derive a lower estimation of the probability expressed in (18). We examine it for the constant predicted volatility levels, , in (5) (GARCH(1,1) model) and (7) (GARCH(2,2) model). For a constant volatility level, , with
we obtain
Here, .
We now examine the limit value of the probability expression in (19) for . We next interpret the resulting as a probability that in the "foreseeable future", the volatility does not fall below the prescribed (constant) level, . As
we obtain
Coming back to a real financial (crypto) market data, we introduce the number , defined as follows:
where is the real market volatility. Function in (21) is a generic indicator function
for the discrete time . Roughly speaking, the number indicates how many times the real market volatility is higher as a given constant level, . Using (20) and the basic properties of the exponential function, we deduce our final lower estimation of the limiting probability, :
Recall that the value in (22) is determined by the stationary GARCH (1,1) predictive model (formulae (5)) or by the stationary GARCH(2,2) predictive model (formulae (7)).
The obtained final probability estimation (22) constitutes a data-driven (statistical) estimation of the probability that the volatility does not fall below a prescribed level . The number M (determined above) describes the real behavior of the market volatility, . This number can be obtained from a concrete historical market data set. The same data set can also be used for the identification of the necessary parameters , , and of the stochastic volatility model (11).
Consider now a simple example. In the simplified case
we obtain the following illustrative version of the general estimation (22):
Note that there is no loss of generality in example (23), due to the parametric scalability of the obtained lower estimation (22).
The historical market data set used above for the evaluation of estimation (22) can also be applied to the so-called in-sample forecasting technique. This in-sample method can now be combined with the complementary out-of-sample testing. This approach is methodologically similar to the main idea of the celebrated Monte Carlo method (see [4,21,33,34] and the references therein).
The exact probability evaluation (18) from Section 4 as well as the corresponding data-driven statistical estimations (22) and (23) can also be performed in the context of the integrated volatility (8). One can use the exact value of the integrated volatility in (8) or the simple approximate formulae (9) for and define the exact probability or the corresponding statistical estimation similar to (18) or (22), respectively. As many modern financial risk indicators, for example, the well-known value-at-risk (VaR) indicators, use volatility predictors, the probabilistic analysis of the predicted volatility levels presented in Section 4 and Section 5 can also be applied to modern risk management.
6. Some Practical Implementations
We now discuss a concrete practical implementation of the statistical analysis for the volatility forecasting methodology developed in our paper. Concretely, we present the volatility prediction module for crypto markets recently developed by the 1ex Trading Board group (see https://1ex.com/) in collaboration with GoldenGate Venture. This novel analytic tool, called "AI NEWS," has an interconnected structure that includes a generic GARCH(2,2) model and the associated statistical probability estimation (22) developed in the previous section.
The conceptual block diagram of the 1ex Trading Board volatility forecasting algorithm for the AI NEWS module mentioned above is given in Figure 1. Note that the three grouped sub-modules in Figure 1 represent a statistical block which complements the conventional GARCH-based volatility analysis and constitutes the main contribution of our paper.
This block diagram represents the necessary data and information flows, as well as the system inputs, outputs, and the operational sub-modules. The given sub-modules are necessary for the calculation of the predicted volatility levels and for the evaluation of the statistical estimation (22). The output of the presented block diagram constitutes a final trading decision. The current market data, as well as the involved volatility prediction and statistical probability of the levels, can be visualized by the designed module.
We now use the AI NEWS methodology mentioned above and depict (Figure 2) the market dynamics, the volatility prediction profile, and the corresponding statistical probability level for the concrete crypto trading pair BTC/USDT (date: 10 April 2024).
As one can see, the estimated statistical probability associated with the selected volatility level in that example is equal to 0.98.
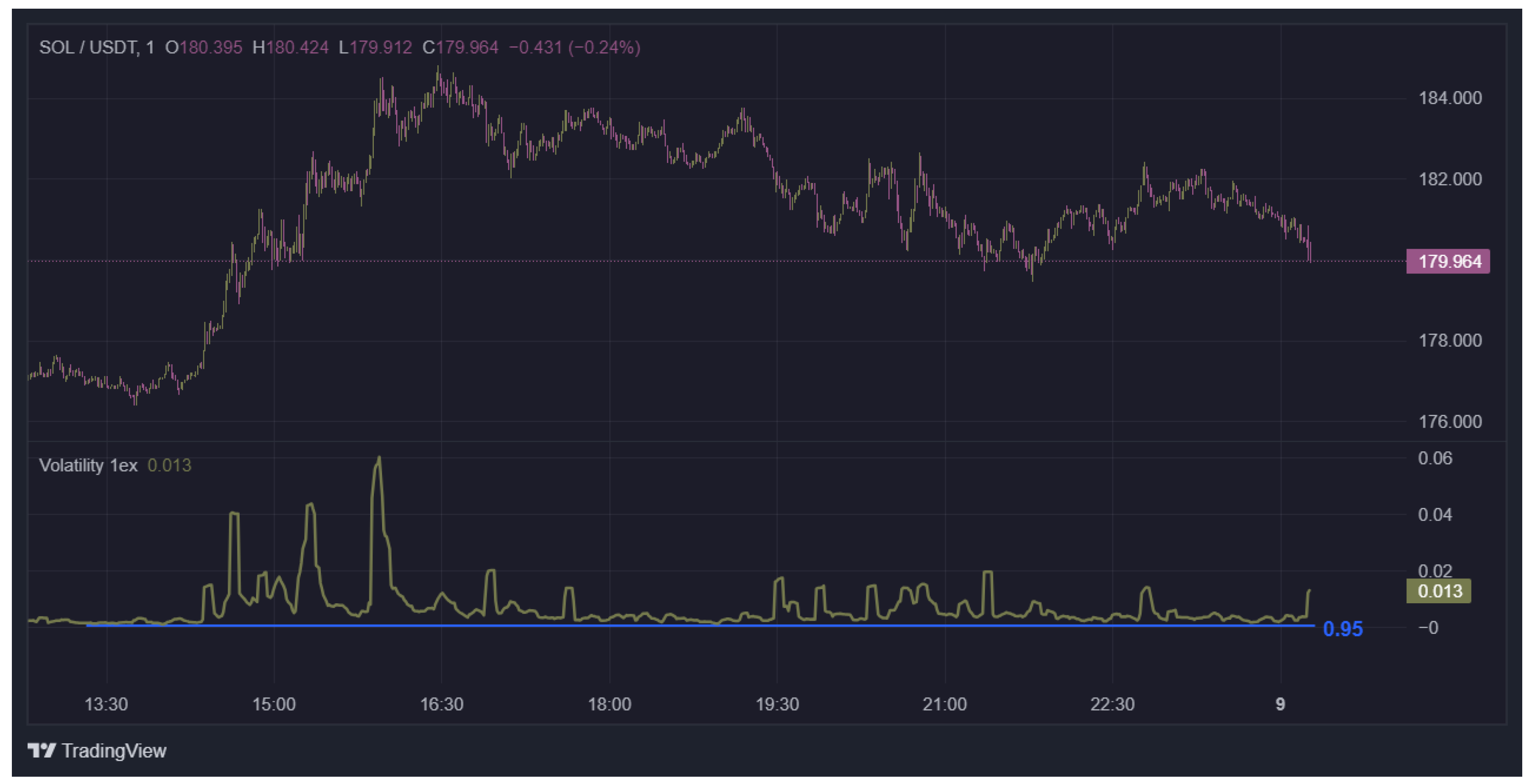
Let us also apply the developed predictive statistical analysis to an alternative example; namely, to the trading pair SOL/USDT (date 09/04/2024). The corresponding market dynamics, volatility prediction profile and the calculated statistical probability level for this pair are shown in Figure 3.
The statistical analysis of the predicted volatility levels studied in this section has a potential to be applied to the risk management. The 1ex volatility tool mentioned above helps investors and portfolio managers to fix certain levels of risk which they can bear. An adequate forecast of the market volatility of asset prices over the investment holding period constitutes a very useful initial information for assessing the investment risk.
Finally note that many modern profitable cryptocurrency trading algorithms involve the adequate volatility prediction schemes. Let us refer here to the class of feedback type trading algorithms and also to the widely used family of pullback and drawdown trading strategies (see [3,4,5,6]). The novel methodology of the predicted volatility levels developed in this paper can also be used in the celebrated Avellaneda-Stoikov market making strategy.
7. Concluding Remarks
In this paper, we developed a complementary probabilistic tool for the conventional GARCH-based volatility predictor. The classic GARCH abstractions naturally generate some stationary or non-stationary predicted volatility levels. As mentioned in Introduction, the real probability distributions of financial returns involve high volatility persistence, fat tails, and some additional effects. On the other hand, the widely used QLM parameter estimation methodology is closely related to the (non-realistic) normality assumption and the robust versions of this technique involve some restrictive technical assumptions.
The deficiency of the QLM method mentioned above, as well as the general methodological difficulties of the classic parameter identification approaches, have motivated the development of some additional (complementary) volatility forecasting techniques. From a formal point of view, a GARCH-based volatility predictor constitutes a model-based approach. The main idea of the approach proposed in this paper consists of using a novel data-driven volatility prediction metric that has an auxiliary character for the basic GARCH predictor. In this study, we developed a new additional predictive metric by applying some advanced probabilistic and statistical tools. Roughly speaking, for a model-based predicted volatility level we propose to calculate a statistical probability that the financial market volatility does not fall below this level. We call it the "probability of predicted volatility levels."
As the exact result of computation of the above probability is given by a sophisticated (theoretical) expression, we next extended the proposed approach and calculate a constructive lower estimate of the "probability of predicted volatility levels." The obtained lower estimate involves the necessary real market data and constitutes an implementable robust version of the prediction metric mentioned above. In fact, we finally proposed a combined prediction approach that contains the model-based and the data-driven elements. Moreover, this approach is compatible with some techniques of the celebrated Monte Carlo methodology, in view of the given (historical) data set.
The developed data-driven volatility prediction approach can be used as an auxiliary tool in many analytical concepts of modern financial engineering; for example, it can be studied in the context of the general time-series forecasting. Robust and credible volatility prediction is also an part of many modern cryptocurrency trading algorithms. Moreover, the proposed estimation technique can be applied to the advanced characterization of the integrated volatility and to the important problem of volatility clustering in crypto markets. A robust volatility prediction technique plays a crucial role in modern financial risk management.
Let us also note that the proposed formal calculation of the statistical probability associated with the predicted volatility levels can be implemented not only for the concrete GARCH-based models studied in this paper, as the developed technique is fully compatible with some alternative volatility forecasting approaches. Moreover, the proposed probabilistic and statistical techniques have a general analytic nature and do not depend on some specific financial data or market conditions.
The probabilistic analysis studied in our paper constitutes an initial theoretical development. In our study, we concentrated on some rigorous mathematical details of the proposed prediction schemes. However, these analytical techniques were implemented in a concrete module for the crypto market volatility forecasting developed by the 1ex Trading Board group in collaboration with GoldenGate Venture. We discussed this practical tool briefly in our paper. The paper does not compare the proposed statistical approach to the existing volatility prediction methods. Due to a very large number of modern theoretical and applied results related to the predicted volatility, we consider a necessary comparative analysis as a future work. The detailed comparative analysis constitutes an important and self-contained topic of a future paper.
Finally, note that the auxiliary statistical analysis of the predicted volatility levels developed in this study can also be considered in the context of novel forecasting approaches based on modern machine learning methodologies [24,37]. It seems to be possible to extend the proposed concepts of volatility levels and the corresponding statistical analysis developed in our paper to volatility forecasting schemes involving deep learning approaches.
Conflicts of Interest
The authors declare no conflict of interest.
References
- T.G. Andersen, T. Bollerslev, F.X. Diebold, H. Ebens, The distribution of realized stockr return volatility, Journal of Financial Economics vol. 61, 2001, pp. 43 –- 76. [CrossRef]
- V. Azhmyakov, J. Pereira Arango, M. Bonilla, R. Juarez del Torro and St. Pickl, Robust state estimations in controlled ARMA processes with the non-Gaussian noises: applications to the delayed dynamics, IFAC PapersOnline, vol. 54, 2021, pp. 334 – 339. [CrossRef]
- V. Azhmyakov, I. Shirokov, L. A. Guzman Trujillo, Application of a switched PIDD control strategy to the model-free algorithmic trading, IFAC PapersOnline, vol. 55, 2022, pp. 145 – 150. [CrossRef]
- V. Azhmyakov, I. Shirokov, Yu Dernov, L. A. Guzman Trujillo On a data-driven optimization approach to the PID-based algorithmic trading, Journal of Risk and Financial Management, vol. 16, 2023, pp. 1 – 18. [CrossRef]
- B. R. Barmish and J. A. Primbs, On a new paradigm for stock trading via a model-free feedback controller, IEEE Transactions on Automatic Control, vol. 61, 2016, pp. 662 -– 676.
- M. H. Baumann, On stock trading via feedback control when underlying stock returns are discontinuous, IEEE Transactions on Automatic Control, vol. 62, 2017, pp. 2987 -– 2992.
- J.R. Birge, F. Louveaux, Introduction to Stochastic Programming, Springer, New York, USA, 2011.
- F. Black and M. Scholes, The pricing of options and corporate liabilities, Journal of Political Economy, vol. 81, 1973, pp. 637 –- 659. [CrossRef]
- T. Bollerslev, Generalized autoregressive conditional heteroskedasticity, Journal of Econometrics, vol. 31, 1986, pp. 307 – 327. [CrossRef]
- T. Bollerslev, T. Wooldridge, Quasi-maximum likelihood estimation and inference in dynamic models with time-varying covariances, Econometric Reviews, vol. 11, 1992, pp. 143 – 172. [CrossRef]
- C. Brooks, Introductory Econometcs for Finance, Cambridge University Press, Glasgow, UK, 2015.
- R. Cont, Empirical properties of asset returns: stylized facts and statistical issues, Quantitative Finance vol. 1, 2001, pp. 223 –- 236. [CrossRef]
- J. Danielsson, M. Valenzuela, I. Zer, Learning from history: volatility and financial crises, Review of Finance, vol. 21, 2018, pp. 2774 –- 2805. [CrossRef]
- J. Fan, L. Qi, D. Xiu, Quasi-maximum likelihood estimation of GARCH models with heavy-tailed likelihoods, Journal of Business and Economic Statistics, vol. 32, 2014, pp. 178 –- 191. [CrossRef]
- S. Formentin, F. Previdi, G. Maroni and C. Cantaro, Stock trading via feedback control: an extremum seeking approach, in: Proceedings of the Mediterranean Conference on Control and Automation, Zadar, Croatia, 2018, pp. 523 – 528.
- C. Francq, J. Zakoian, GARCH Models, Wiley, Wiltshire, UK, 2010.
- P. Franses, H. Ghijsels, Additive outliers, GARCH and forecasting volatility, International Journal of Forecasting , vol. 15, 1999, pp. 1 – 9. [CrossRef]
- R.G. Gallager, Stochastic Processes, Cambridge University Press, NY, USA, 2013.
- H. Greene, Econometric Analysis, Pearson, UK, 2011.
- M.G. Haas, J.P. Franziska, Implementing intraday model-free implied volatility for individual equities to analyze the return–volatility relationship, Journal of Risk and Financial Management, vol. 17, 2024, pp. 2 – 19. [CrossRef]
- C. Hammel and W. B. Paul, Monte Carlo simulations of a trader-based market model, Physica A, vol. 313, 2002, pp. 640 – 650. [CrossRef]
- D. Huang, H. Wang, Q. Yao, Estimating GARCH models: when to use what?, Econometric Journal , vol. 11, 2008, pp. 27 – 38. [CrossRef]
- P.J. Huber, E.M. Ronchetti, Robust Statistics, Wiley, New York, USA, 2005.
- St. Jansen, Machine Learning for Algorithmic Trading, Packt, Birmingham, UK, 2020.
- D. Kahneman, A. Tversky, Prospect theory: An analysis of decision under risk, in: Handbook of the Fundamentals of Financial Decision Making, World Scientific Publishing, Singapore, 2013.
- J. Kevorkian, Partial Differential Equations: Analytical Solution Techniques. Texts in Applied Mathematics, USA, New York, Springer, 2000.
- T.-H. Kim, H. White, On more robust estimation of skewness and kurtosis, Finance Research Letters, vol. 1, 2004, pp. 56 –- 73. [CrossRef]
- F. L. Lewis, Optimal Estimation, Wiley, New York, USA, 1986.
- T. Lux, M. Marchesi, Volatility clustering in financial markets: a microsimulation of interacting agents, International Journal of Theoretical and Applied Finance, 2000, vol. 3, 2000, pp. 675 -– 702. [CrossRef]
- V. Nikolova, J.E. Trinidad Segovia, M. Fernández-Martínez. M.A. Sánchez-Granero A novel methodology to calculate the probability of volatility clusters in financial series: an application to cryptocurrency markets, Mathematics, vol. 8, 2020. pp. [CrossRef]
- L.S. Pontryagin, A.A. Andronov, and A.A. Vitt, On statistical analysis of dinamical systems, Zhurnal Eksperimental’noi i Teoreticheskoi Fiziki, vol. 3, 1933, pp. 165 – 180.
- S.-H. Poon, C.W.J. Granger, Forecasting volatility in financial markets: a review, 2003, pp. 478 – 539.
- A. Poznyak, Advanced Mathematical Tools for Automatic Control Engineers: Stochastic Tools, Elsevier, NY, USA, 2009.
- R.Y. Rubinstein, Simulation and the Monte Carlo Method, John Wiley Inc., New York, USA, 1981. 1981).
- P.A. Samuelson, Rational theory of warrant pricing, Industrial Management Review, vol. 6, 1965, pp. 13 – 31.
- W.G. Schwert, Stock volatility and crash of 87, Review of Financial studies, 1990, pp. 77 – 102.
- D. Shah, W. Campbell, F H. Zulkernin, A comparative study of LSTM and DNN for stock market forecasting, in: Proceedings of the IEEE International Conference on Big Data, Seattle, USA, 2018, pp 4148 – 4155.
- J. Sen, S. Mehtab, A. Dutta Volatility modeling of stocks from selected sectors of the Indian economy using GARCH, in: Proceedings of the Asian Conference of Innovation in Technology, Pune, India, 2021, pp. 1 – 9.
- S. Taylor, Modeling Financial Time Series, Wiley, Chichester, UK, 1986.
- P.B. Verhoeven, B. Pilgram, M. McAleer, A. Mees, Non-linear modelling and forecasting of S & P 500 volatility, Mathematics and Computers in Simulation, vol. 59, 2002. pp. 233 – 241.
- L. Wang, F. Ma, J. Liu, L. Yang, Forecasting stock price volatility: new evidence from the GARCH-MIDAS model, International Journal of Forecasting, vol 36, 2020, pp. 684 – 694.
- W.T. Ziemba, R.G. Vickson, Stochastic Optimization Models in Finance, Academic Press, New York, USA, 1975.
Figure 1.
The conceptual block diagram of the 1ex Trading Board volatility prediction module.
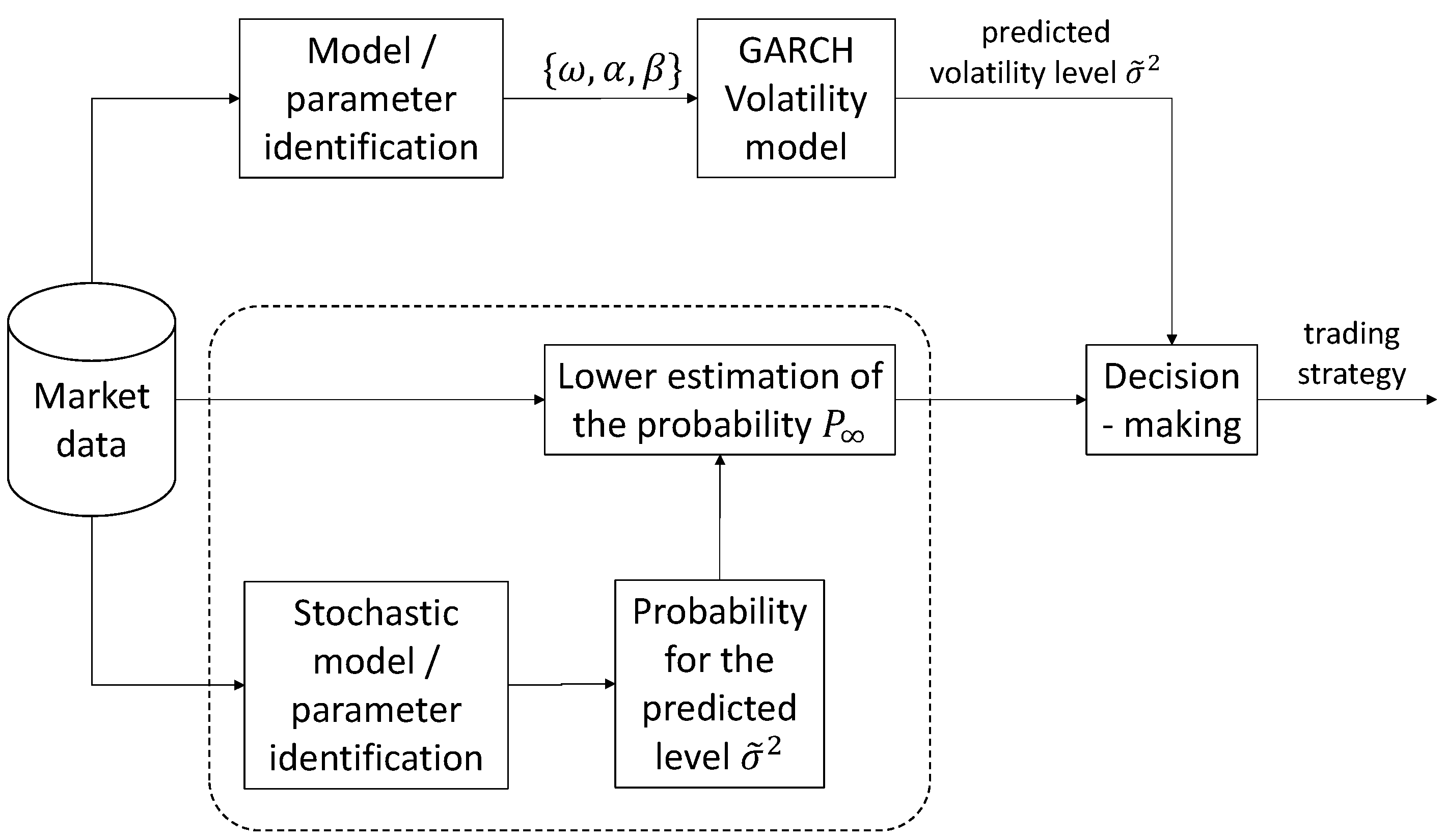
Figure 2.
The 1ex Trading Board volatility prediction module: BTC/USDT.
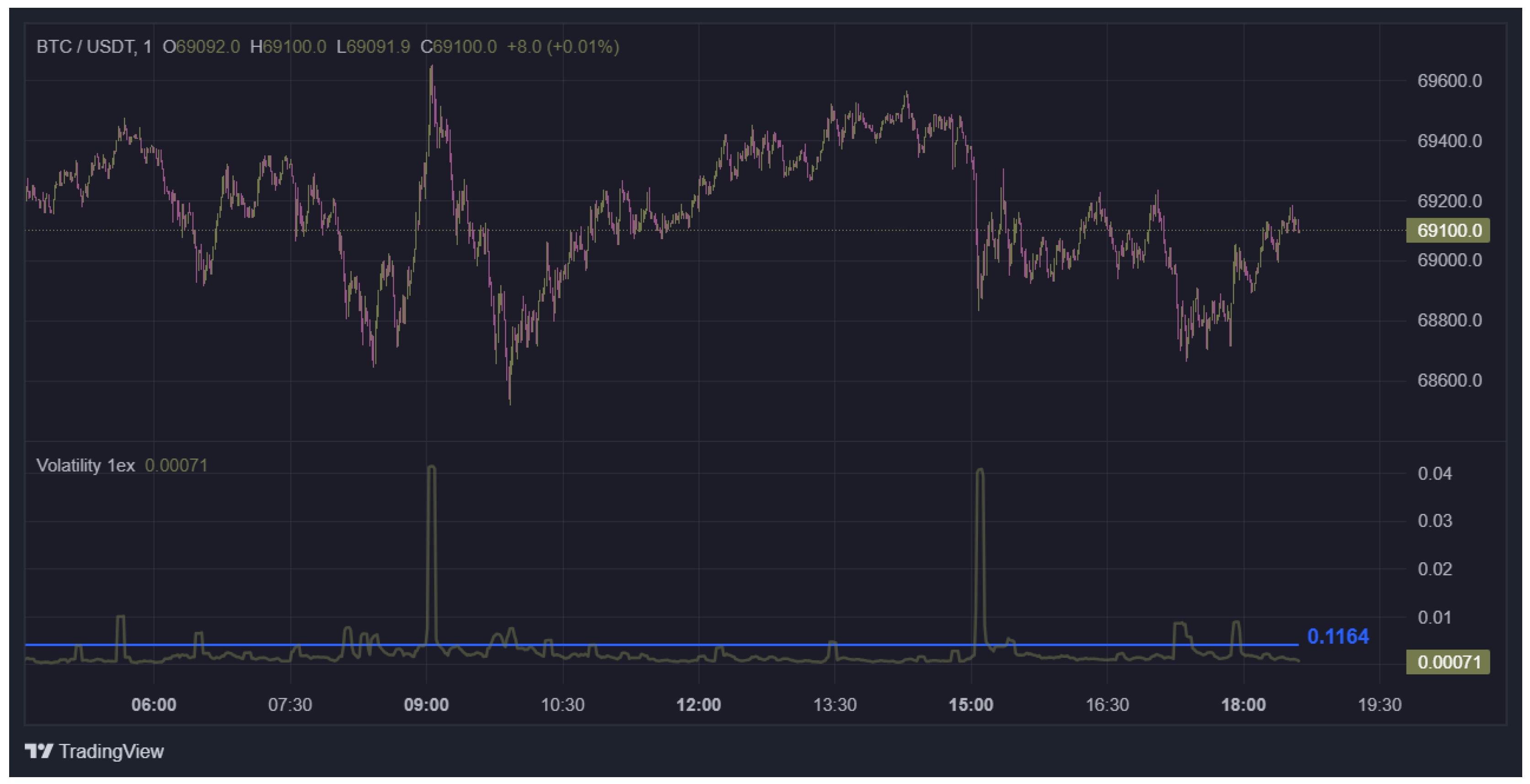
Figure 3.
The 1ex Trading Board volatility prediction module: SOL/USDT.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



