
Submitted:
15 May 2024
Posted:
16 May 2024
You are already at the latest version
Abstract
Recent advancements in computer vision, especially deep learning models, have shown considerable promise in tasks related to plant image object detection. However, the efficiency of these deep learning models heavily relies on input image quality, with low-resolution images significantly hindering model performance. Therefore, reconstructing high-quality images through specific techniques will help extract features from plant images, thus improve model performance. In this study, we explored the value of super-resolution technology for improving object detection model performance on plant images. Firstly, we built a comprehensive dataset comprising 1030 high-resolution plant images, named the PlantSR dataset. Subsequently, we developed a super-resolution model using the PlantSR dataset and benchmarked it against several state-or-the-art models designed for general image super-resolution tasks. Our proposed model demonstrated superior performance on the PlantSR dataset, indicating its efficacy in enhancing the super-resolution of plant images. Furthermore, we explored the effect of super-resolution on two specific object detection tasks: apple counting and soybean seed counting. By incorporating super-resolution as a pre-processing step, we observed a significant reduction in mean absolute error. Specifically, on the YOLOv7 model employed for apple counting, the mean absolute error decreased from 13.085 to 5.71. Similarly, on the P2PNet-Soy model utilized for soybean seed counting, the mean absolute error decreased from 19.159 to 15.085. These findings underscore the substantial potential of super-resolution technology in improving the performance of object detection models for accurately detecting and counting specific plants from images. The source codes and associated datasets are available at https://github.com/SkyCol/PlantSR.
Keywords:
super resolution
; object detection
; image reconstruction
; image processing
; deep learning
; plant phenotypes
1. Introduction
Plant images play an important role in understanding the intricate structures and characteristics of various plant species [1,2], and are often used for automatic analysis and extract useful information. However, images of plants often suffer from low-resolution and blurriness. Even in cases where the overall image possesses high resolution, certain objects within the image may exhibit low-resolution characteristics. These limitations in image resolution and quality impede the accurate extraction of features from images, consequently restricting the performance of deep learning models created for plant image object detection tasks.
Recent advancements in computer vision, particularly deep learning models, have garnered significant attention and shown promising results in the plant image object detection tasks, such as soybean seed counting [3,4] and wheat head detection [5,6,7]. Despite these successes, the effectiveness of these deep learning models heavily depends on the quality of input images [8]. Alterations in image resolution notably affect model accuracy, with low-resolution images impairing model performance during both training and inference phases [9,10,11]. Specifically, low-resolution images offer less informative content during the training phase compared to high-resolution counterparts, potentially undermining model effectiveness. Moreover, during inference phase, images with lower resolution than training data due to capturing targets at longer distances or camera resolution limitations can also diminish model performance.
Super resolution (SR) is an image processing technique aimed at enhancing spatial resolution by reconstructing high-resolution details from low-resolution images. Deep learning-based methods have emerged as the most effective solution in the field of super-resolution [12,13,14,15]. By reconstructing high-resolution details of plant images, super-resolution technology holds the potential to empower deep learning models to effectively learn and extract intricate features from images during training phase, and improve model performance when predicting on low-resolution images during inference phase.
Several studies have successfully applied SR techniques to plant images, enhancing the performance of deep learning models in specific tasks. For instance, Yamamoto K et al. [16] deployed super-resolution of plant disease images for the acceleration of image-based phenotyping and vigor diagnosis in agriculture. Maqsood M H et al. [17] applied super-resolution generative adversarial networks [18] for upsampling the images before using them, to train deep learning models for the detection of wheat yellow rust. Cap Q H et al. [19] proposed an effective super-resolution method called LASSR, for Plant disease diagnosis. Albert P et al. [20] transferred knowledge learned on ground-level images to raw drone images and estimated dry herbage biomass by applying super-resolution technology to raw drone images. These successes demonstrate the significant application value of super-resolution in plant image-related tasks.
While numerous dataset and models already exist in the classical field of SR [21,22,23,24] , specialized SR datasets and models tailored for plant image reconstruction remains absent. In this study, we built a dedicated SR dataset solely comprising plant images (PlantSR Dataset), which serves as a fundamental dataset for comparing the performance of super-resolution models on plant images. Leveraging the PlantSR dataset, we compared the performance of some established deep learning models in the classical field of SR and introduced a novel SR architecture specifically tailored for plant images (PlantSR Model). Our experimental results highlight that our model achieves state-of-art reconstruction performance on plant images while maintaining a reasonable model size and inference speed.
Next, we explored the improvement effects of our super-resolution model on apple counting and soybean seed counting tasks. For the apple counting task, applying the PlantSR model to test images led to a significant decrease in mean absolute error, reducing it from 13.085 to 5.71. Similarly, for the soybean seed counting task, applying the PlantSR model to both training and test images resulted in a decrease in mean absolute error, reducing it from 19.159 to 15.085. These findings underscore the potential of super-resolution technology in improving the performance of deep learning models for plant image-related tasks.
2. Materials and Methods
2.1. PlantSR Dataset
The PlantSR Dataset (Figure 1) comprises a total of 1030 plant images, categorized into four primary botanical groups: 25 images of Bryophytes [25], 115 images of Ferns [26], 440 images of Gymnosperms [27], and 450 images of Angiosperms [28]. The uneven distribution of plant images in the dataset reflects the biological reality of plant species diversity in nature. Being consistent with biological taxonomy, Angiosperms and Gymnosperms are typically more abundant in natural ecosystems compared to Ferns and Bryophytes. Therefore, the intentional allocation of a larger number of images to Angiosperms and Gymnosperms in the dataset is justified by their biological prevalence, as well as economic and ecological importance. All the images were meticulously selected to ensure high resolution and were sourced from Plants of the World Online [29]. These images was meticulously divided, with 830 images designated for the training dataset and 200 images for the test dataset. This dataset could be used as a fundamental dataset to compare the performance of super-resolution models on plant images for future studies. Sample images of four categorizes in the dataset are shown in Figure 2
2.2. Architecture of PlantSR Model
As shown in Figure 3. Our PlantSR model consists of four modules: shallow feature extraction, deep feature extraction and high-resolution (HR) image reconstruction.
Given a low resolution (LR) image as input , we first use a 3 × 3 convolutional layer to extract feature
where denotes a 3 × 3 convolutional layer, which is defined as the first component of the shallow feature extraction module. Then we use the second component of the shallow feature extraction module to extract shallow feature from , and use deep feature extraction module to extract deep feature from
where denotes the second component of the shallow feature extraction module, denotes the deep feature extraction module, these two modules consists of m and n residual groups (RG) respectively. Each RG is composed of four Residual SE-attention Blocks (RSEB) and a residual connection from input to output features. Within each RSEB, an SE-attention layer [30] is applied sequentially after a convolutional layer, a rectified linear unit (ReLU) layer, and another convolutional layer. Once got feature maps from deep feature extraction module, the HR image reconstruction module is performed to get SR image
where denotes HR image reconstruction module, which initiates by enhancing the feature map channels through a convolutional layer. Following this, the module scales up the feature maps using a PixelShuffle layer, and in the concluding step, reconstructs the feature maps to the RGB channel through another convolutional layer.
Throughout the training phase, we optimize the parameters by minimizing the L1 pixel loss.
where is obtained by taking LR image as the input of PlantSR, and is the corresponding ground-truth HR image. We opted for the L1 loss, as it has demonstrated superior performance in image restoration tasks [31]. The loss function was optimized using the Adam optimization algorithm.
2.3. Super-Resolution Effects on Apple Counting Task
As YOLOv7 is one of the most popular models in the field of object detection, we selected it to analysis our super-resolution model effects on counting apples [32]. For training and evaluating the apple counting model, we sourced 1000 images from the internet to form the training dataset. Additionally, we utilized 200 images of harvest-ready apples provided by the 2023 Asia and Pacific Mathematical Contest in Modeling competition as our test dataset. Each image in the test dataset was relatively small, all measuring 270 * 180 pixels.
After training the YOLOv7 model using 1000 images in the training dataset, we conducted tests with and without applying super-resolution to the test images. Super-resolution was achieved using the PlantSR (x3) model. To ensure optimal performance in processing apple images, we fine-tuned a PlantSR model using a curated collection of 100 high-resolution close-up apple images gathered from the internet, leveraging these images to train a model based on the original pre-trained model.
2.4. Super-Resolution Effects on Soybean Seed Counting Task
As an improvement to the P2PNet [33], Zhao J et al. proposed an automated soybean seed counting tool called P2PNet-Soy [34]. Thanks to their efforts, the accuracy of soybean seed counting in the field witnessed a significant improvement. P2PNet-Soy incorporates an unsupervised clustering algorithm, the k-d tree [35], as post-processing to find the centers of closely located predictions, thereby enhancing the final prediction accuracy. Additionally, P2PNet-Soy made some adjustments to the architecture of P2PNet to maximize model performance in seed counting and localization. We downloaded their open dataset, which consists of 126 images of soybean captured from one side as the training dataset, and 132 images of soybean taken from opposite as the evaluation dataset [36].
Expanding on the open dataset, we incorporated 60 soybean seed images from SDAU Technology Park and reorganized the dataset as follows: 126 images from P2PNet-Soy training dataset plus 30 additional images as the training dataset, 50 images from P2PNet-Soy evaluation dataset plus 10 additional images as the validation dataset, and 82 images from P2PNet-Soy evaluation dataset as the test dataset.
To explore the effects of super-resolution on the task of soybean seed counting, we trained and evaluated P2PNet-Soy with images in four different situations: (1) Original images across training, validation, and test Sets: All images used for training, validation, and testing purposes remained in their original resolution. (2) Original training and validation images with downsampling of test images: The training and validation images retained in their original resolution, while the test images underwent downsampling by a factor of two using bilinear interpolation. (3) Original training and validation images with downsampling and PlantSR (x2) upscaling of test images: Similar to the previous setup, the training and validation images remained in their original resolutions. However, for the test set, images underwent downsampling followed by upscaling using a PlantSR (x2) model. (4) PlantSR (x2) upscaled images across training, validation, and test sets: All images used for training, validation, and testing underwent upscaling by a PlantSR (x2) model.
Specially, in the fourth case, we proposed the application of PlantSR model as pre-processing step to P2PNet-Soy (Figure 4). Here's a detailed description of this setup: Before employing images for training, validation, and testing in P2PNet-Soy, all images underwent upscaling by a PlantSR (×2) model. To train a specific PlantSR model on soybean seed images, we collected 89 high-resolution close-up images of soybeans from laboratory settings. These images, possessing a higher pixel density than those in the original dataset, were used for transfer learning to train the specific PlantSR (×2) model on soybean seed images. During training phase, P2PNet-Soy randomly crop 224*224 patches from origin images. Considering the upscale by a factor of two, the resolution of these patches was adjusted to 448×448. Moreover, P2PNet-Soy used k-d tree to filter prediction results. In the implementation of the k-d tree, the parameter cutoff is set to find all points within the distance “r” from each point. Since the pixel density of the images was tripled, the parameter cutoff was also doubled in our experiment.
2.5. Training and Evaluation Settings
To assess the performance of various Super-Resolution (SR) models, including our PlantSR model, consistent training and evaluation settings were applied. All models were trained and evaluated on the PlantSR dataset and shared identical configurations for training. In each training batch, 32 patches sized 64×64 (for scale=2, scale=4) or 63x63 (for scale=3) were extracted from training images, followed by horizontal data augmentation. A total of 38997 batches constituted one epoch. Each model was trained for multiple epochs, and their evaluation metrics on the test dataset were recorded. The model that performs best in multiple epochs will be saved for final comparison. We used Adam [37] as the optimizer, the initial leaning rate was set to. All the SR models were trained on a NVIDIA RTX A5000 24G GPU.
To explore the effects of PlantSR model on the task of apple counting, we trained and evaluated YOLOv7 with test images with or without applying super-resolution to the test images. The input size of YOLOv7 was set to 640. A series of data argumentations (mosaic, mixup, random crop, random angle) were applied throughout the training phase. Training of YOLOv7 was conducted on an NVIDIA RTX A5000 24G GPU.
To explore the effects of PlantSR model on the task of soybean seed counting, we trained and evaluated P2PNet-Soy with images in four different cases. In all four cases, a series of data argumentations (random scale, random crop, random flipping, random change brightness) were applied throughout the training phase, mirroring the approach used in the original P2PNet-Soy. We used Adam as the optimizer, the initial leaning rate was set to and subsequently halved every 100 epochs. Training of P2PNet-Soy was conducted on an NVIDIA A100 40G Tensor Core GPU.
2.6. Evaluation Metrics
To compare the performance of several SR methods, we used two common metrics of image quality, including peak-to-peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM) [38]. Both the higher the PSNR and SSIM, the higher similarity between predicted images and high-resolution images, the better the model performance. The computation of these metrics is as follows:
where MAX represents the maximum possible pixel value in the image, which is 255 here. MSE denotes the mean squared error, indicating the average of squared differences between corresponding pixels in the original and predicted images.
where and are the means of images x and y, respectively. and are the variances of images x and y, respectively. represents the covariance between x and y. and equals to and , where is the dynamic range of pixel values, which is 255 here.
We used mean absolute error (MAE) and Root Mean Square Error (RMSE) to evaluate the performance of the soybean seed counting model and apple counting model. The closer the MAE and RMSE are to 0, the smaller the error in counting:
where n represents the number of images used for testing, represents the ground truth number of target object within each image, and represents the number of target object predicted by the model.
3. Results
Our experimental results are presented in three sections: (1) SR model compression. Based on the PlantSR dataset, we conducted a benchmarking of our PlantSR model against five well-established Super-Resolution (SR) models in the classic field of SR, alongside a traditional method, bicubic interpolation. (2) Super-Resolution effects on apple counting task. In this second section, we trained and evaluated the YOLOv7 model with test images with or without applying PlantSR model to achieve super-resolution. (3) Super-Resolution effects on soybean seed counting task. In this third section, we delved into the impact of our PlantSR model on the soybean seed counting task. Here, we meticulously trained and evaluated the P2PNet-Soy model with images in four different cases.
3.1. SR Model Compression
In this section, we rigorously benchmarked our proposed PlantSR network against a traditional method, bicubic interpolation, and five state-of-the-art Super-Resolution (SR) deep learning models: SRCNN [39], VDSR [40], EDSR [41], RCAN [42], and SwinIR [43]. Among the five SR deep learning models, SRCNN and VDSR employ interpolation to the Low-Resolution (LR) image as a preliminary step, subsequently learning to reconstruct the High-Resolution (HR) image from these interpolated images. This approach is commonly referred to as Pre-upsampling SR. Conversely, EDSR, RCAN, and SwinIR first extract features from LR images and then apply the upsampling module at the end of the network. This methodology is commonly referred to as Post-upsampling SR. Notably, our PlantSR model also belongs to the Post-upsampling SR category.
Table 1 presents the quantitative results, where the number of parameters is expressed in millions, frames per second (FPS) are denoted in frames, and the input size is specified in the number of pixels. During the training process, patches of sizes 64x64 (for scale=2, scale=4) or 63x63 (for scale=3) were utilized as High-Resolution (HR) images, subsequently downsampled by a factor of scale as Low-Resolution (LR) images. The models learned the transformation process from LR to HR. It is noteworthy that the reported FPS results, although averaged across multiple experimental outcomes, should be considered as reference points due to inherent variations.
Results demonstrate that our PlantSR model achieves exceptional SR performance on plant images while maintaining a reasonable model size and inference speed. Among the compared models, it was observed that SwinIR, which uses Swin Transformer [44] as its backbone network, exhibited satisfactory performance. However, it exhibited comparatively slower inference speeds and higher computational expenses. Visual comparison results of SR (×4) are illustrated in Figure 5.
3.2. Super-Resolution Effects on Apple Counting Task
In this section, we trained a YOLOv7 model using 1000 images collected from internet, and evaluated the model on test images with or without using PlantSR (x3) to achieve super-resolution. Before evaluation, we collected some high-resolution close-up images of apples to train a specialized PlantSR (x3) model which has superior performance in upscaling apple images. We used the PlantSR (x3) model pretrained on the PlantSR dataset as the initialization model and conducted further training on these high-resolution apple images, obtain the specialized PlantSR (x3) model for processing apple images. Next, we processed test images using this model, and test the YOLOv7 model on the test images after super-resolution.
Before applying PlantSR model to achieve super-resolution, the mean absolute error of the apple counting model on test images was 13.085. Notably, a significant portion of the images exhibited under-detection of apples, with predicted values falling below the ground truth values. However, post-application of super-resolution to the test images, the mean absolute error notably decreased to 5.71, which shows a great improvement on the model performance (Figure 6).
3.3. Super-Resolution Effects on Soybean Seed Counting Task
In this section, we trained and evaluated P2PNet-Soy with images in four different cases (Figure 7): (1) Original images across training, validation, and test sets. (2) Original training and validation images with downsampling of test images. (3) Original training and validation images while test images underwent downsampling followed by upscaling using a PlantSR (x2) model. (4) PlantSR (x2) upscaled images across training, validation, and test sets.
For the third and fourth cases, we used a PlantSR (x2) model for processing images. Despite the availability of previous trained models for resolution enhancement, we aimed to train a specialized PlantSR (x2) model with superior performance in upscaling these soybean seed images. To achieve this, we curated a collection of high-resolution close-up images of soybeans from laboratory settings, characterized by a higher pixel density compared to the soybean seed images used in training and evaluating P2PNet-Soy. We used the PlantSR (x2) model pretrained on the PlantSR dataset as the initialization model and conducted further training on these high-resolution soybean images, obtain the specialized PlantSR (x2) model for processing soybean seed images.
Table 2 shows the test results of P2PNet-Soy with different cases of images. Comparing the case where all images remained in their original resolution (Case 1) with the case where all images were upscaled using a PlantSR (x2) model (Case 4), we observed a reduction in MAE from 19.16 to 15.09. However, when evaluating the model trained on original images using downscaled test images (Case 2), the MAE increased significantly to 59.23. Notably, implementing a PlantSR (x2) model on these downscaled test images (Case 3) led to a noteworthy reduction in MAE, successfully minimizing it to 19.82, a value close to that achieved in Case 1.
4. Discussion
Plant image is often used for automatic analysis and extract useful information. Due to some limitations, the objects in these images may suffer from low-resolution. For instance, when counting soybean seeds through deep neural networks, we usually take images that includes the entire soybean plant. Although the entire images are high-resolution, the soybean seeds in the images can still be low-resolution. Another instance is that when using drones to capture images, it is difficult to obtain high-resolution images of the targets on the ground because of the flying altitude of the drone, which results in a longer shooting distance. These limitations of the object resolution may lead to insufficient information, resulting in a decrease in the performance of computer vision models.
The foundation of our approach rested on the creation of the PlantSR dataset, comprised exclusively of high-resolution plant images. This dataset not only facilitated the evaluation of SR models but also served as a valuable resource for benchmarking their performance. By ensuring the quality and diversity of images in this dataset, we aimed to provide a robust platform for comparing various SR methodologies.
Through extensive experimentation, we built the PlantSR model as the most effective solution for restoring high-resolution plant images from their low-resolution counterparts. Notably, we deliberately avoided transformer-based architectures in favor of alternative methodologies optimized for efficient inference in plant imagery [45,46,47]. This decision was driven by the need for practical inference speed and compelling performance gains, as evidenced by achieving the highest Peak Signal-to-Noise Ratio (PSNR) across all scaling factors (2, 3, and 4) on the PlantSR dataset.
Furthermore, we conducted experiments to explore the effects of super-resolution on two object detection task: apple counting and soybean seed counting. Our results demonstrated significant improvements in counting performance when applying the PlantSR model, particularly when images were initially low-resolution or downsampled. In the soybean seed counting task. Compare with the case where all images remained in their original resolution, applying a PlantSR (x2) model to upscale all images successfully reduced the MAE of P2PNet-Soy from 19.16 to 15.09. This enhancement in counting performance can be attributed to several factors: Firstly, the increased pixel density on the soybean seeds facilitated by the SR model enabled the counting model to discern and learn more intricate features. Secondly, by processing all images using the same SR model, a higher level of similarity among the images was achieved, potentially adapting the domain between the training and test images [48]. However, it was observed that downsampling test images led to a substantial decline in model performance, underlining the significant influence of image resolution on model performance. Notably, implementing a PlantSR (x2) model on these downsampled test images resulted in a remarkable reduction in MAE, minimizing it from 59.23 to 19.89. The apple counting task got similar results, applying PlantSR (x3) model on the low-resolution test images decreased the MAE from 13.085 to 5.71.
Besides these successes, certain limitations are inherent in our current methodology. Firstly, the PlantSR model, tailored specifically for plant image super-resolution, might not perform optimally for some other tasks in image reconstruction such as artifact reduction and denoising. Secondly, our focus was predominantly on the application of super-resolution to RGB images. Nonetheless, beyond RGB images, some other data types captured by various sensors exist, including images from multiple layers of channels taken by multispectral cameras, depth maps obtained by depth cameras, and three-dimensional point clouds acquired through lidar scanning. Super-resolution for these diverse data types remains an invaluable and challenging endeavor. Thirdly, enhancing the resolution of input images is likely to result in a slowdown in both the training and inference speed of deep learning models. This is particularly notable given the increased computational cost during the training phase.
In conclusion, our study underscores the potential of super-resolution technology in improving the performance of object detection models in plant image analysis. The development of specialized SR models, exemplified by the PlantSR model, holds immense promise in restoring high-resolution plant images and thereby enhancing the capabilities of computer vision models reliant on such images. Future research directions may involve delving into a generalized model capable of addressing multiple subtasks of image reconstruction for plant images, and propose more extensive models capable of handling a broader range of data types.
Author Contributions
Q.Y. and T.J. conceptualized and designed this study. M.S. participated in the data collection. T.J. and Y.Z. performed the analyses. All authors wrote and edited the manuscript.
Funding
This work was supported by National Key Research and Development Program of China (2021YFF1001100).
Data Availability Statement
The source code is available at https://github.com/SkyCol/PlantSR. The PlantSR dataset is available at figshare [49]. The High-Resolution soybean seed images is available at figshare [50].
Acknowledgments
We would like to thank Dr. Dajian Zhang at Shandong Agricultural University for technical support of soybean data.
Conflicts of Interest
The authors declare that they have no competing interests.
References
- Walter A, Liebisch F, Hund A. Plant phenotyping: from bean weighing to image analysis. Plant methods, 2015; 11(1): 1-11.
- Das Choudhury S, Samal A, Awada T. Leveraging image analysis for high-throughput plant phenotyping. Frontiers in plant science, 2019; 10: 508.
- Li Y, Jia J, Zhang L, Khattak AM, Sun S, Gao W, Wang M. Soybean seed counting based on pod image using two-column convolution neural network. Ieee Access, 2019; 7: 64177-64185.
- Wang Y, Li Y, Wu T, Sun S. Fast Counting Method of Soybean Seeds Based on Density Estimation and VGG-Two. Smart Agriculture 2021; 3(4): 111.
- Khaki S, Saeed N, Pham H, Wang L. WheatNet: A lightweight convolutional neural network for high-throughput image-based wheat head detection and counting. Neurocomputing. 2022; 489: 78-89.
- David E, Madec S, Sadeghi-Tehran P, Aasen H, Zheng B, Liu S, Kirchgessner N, Ishikawa G, Nagasawa K, Badhon MA, et al. Global Wheat Head Detection (GWHD) dataset: a large and diverse dataset of high-resolution RGB-labelled images to develop and benchmark wheat head detection methods. Plant Phenomics, 2020.
- David E, Serouart M, Smith D, Madec S, Velumani K, Liu S, Wang X, Pinto F, Shafiee S, Tahir I. S. A. et al. Global wheat head detection 2021: An improved dataset for benchmarking wheat head detection methods. Plant Phenomics, 2021.
- Koziarski M, Cyganek B. Impact of low resolution on image recognition with deep neural networks: An experimental study. International Journal of Applied Mathematics and Computer Science. 2018; 28(4): 735-744.
- Luke J, Joseph R, Balaji M. Impact of image size on accuracy and generalization of convolutional neural networks. Int. J. Res. Anal. Rev.(IJRAR), 2019; 6(1): 70-80.
- Sabottke C F, Spieler B M. The effect of image resolution on deep learning in radiography. Radiology: Artificial Intelligence, 2020; 2(1): e190015.
- Shermeyer J, Van Etten A. The effects of super-resolution on object detection performance in satellite imagery. Paper presented at: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2019: 0-0.
- Bashir, Syed MA, Wang Y, Khan M, Niu Y. A comprehensive review of deep learning-based single image super-resolution. PeerJ Computer Science. 2021; 7: e621.
- Gendy G, He G, Sabor N. Lightweight image super-resolution based on deep learning: State-of-the-art and future directions. Information Fusion. 2023; 94: 284-310.
- Lepcha D C, Goyal B, Dogra A, Goyal V. Image super-resolution: A comprehensive review, recent trends, challenges and applications. Information Fusion, 2023; 91: 230-260.
- Wang Z, Chen J, Hoi S C H. Deep learning for image super-resolution: A survey. IEEE transactions on pattern analysis and machine intelligence, 2020, 43(10): 3365-3387.
- Yamamoto K, Togami T, Yamaguchi N. Super-Resolution of Plant Disease Images for the Acceleration of Image-based Phenotyping and Vigor Diagnosis in Agriculture. Sensors. 2017; 17(11):2557.
- Ledig C, Theis L, Huszár F, Caballero J, Cunningham A, Acosta A, Aitken A, Tejani A, Totz J, Wang Z,et al. Photo-realistic single image super-resolution using a generative adversarial network. Paper presented at: Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. 4681-4690.
- Maqsood M H, Mumtaz R, Haq I U, Shafi U, Zaidi S, Hafeez M. Super resolution generative adversarial network (Srgans) for wheat stripe rust classification. Sensors. 2021. 21(23): 7903.
- Cap QH, Tani H, Kagiwada S, Uga H, Iyatomi H. LASSR: Effective super-resolution method for plant disease diagnosis. Computers and Electronics in Agriculture, 2021; 187: 106271.22.
- Albert P, Saadeldin M, Narayanan B, Fernandez J, Mac Namee B, Hennessey D, O'Connor NE, McGuinness K. Unsupervised domain adaptation and super resolution on drone images for autonomous dry herbage biomass estimation. Paper presented at: Proceedings of the IEEE conference on computer vision and pattern recognition. 2022: 1636-1646.
- Martin D, Fowlkes C, Tal D,Malik J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. Paper presented at: Proceedings Eighth IEEE International Conference on Computer Vision. IEEE, 2001; 2: 416-423.
- Timofte R, Agustsson E, Gool L, Yang MH, Zhang L, Lim B, Son S, Kim H, Nah S, Lee KM, et al. Ntire 2017 challenge on single image super-resolution: Methods and results. Paper presented at: Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 2017. 114-125.
- Li Z, Liu Y, Wang X, Liu X, Zhang B, Liu J. Blueprint separable residual network for efficient image super-resolution. Paper presented at: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2022. 833-843.
- Zhang Y, Tian Y, Kong Y, Zhong B, Fu Y. Residual dense network for image super-resolution. Paper presented at: Proceedings of the IEEE conference on computer vision and pattern recognition. 2018. 2472-2481.
- Zechmeister HG, Grodzińska K, Szarek-Łukaszewska G. Bryophytes. Trace Metals and other Contaminants in the Environment. Vol. 6. Elsevier, 2003; 329-375.
- Smith AR, Pryer KM, Schuettpelz E, Korall P, Schneider H, Wolf PG. A classification for extant ferns. Taxon, 2006, 55(3), 705-731.
- Hutchinson KRS,House H. The morphology of gymnosperms. Scientific Publishers, 2015.
- Bahadur B, Rajam MV, Sahijram L, Krishnamurthy KV. Angiosperms: An overview. Plant Biology and Biotechnology: Volume I: Plant Diversity, Organization, Function and Improvement. 2015; 361-383.
- POWO (2024). Plants of the World Online. Facilitated by the Royal Botanic Gardens, Kew. http://www.plantsoftheworldonline.org/.
- Hu J, Shen L, Sun G. Squeeze-and-excitation networks. Paper presented at: Proceedings of the IEEE conference on computer vision and pattern recognition 2018 (pp. 7132-7141).
- Zhao H, Gallo O, Frosio I, Kautz J. Loss functions for image restoration with neural networks. IEEE Transactions on computational imaging, 2016, 3(1): 47-57.
- Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2023: 7464-7475.
- Song Q, Wang C, Jiang Z, Wang Y, Tai Y, Wang C, Li J, Huang F, Wu Y. Rethinking counting and localization in crowds: A purely point-based framework. Paper presented at: Proceedings of the IEEE International Conference on Computer Vision. 2021: 3365-3374.
- Zhao J, Kaga A, Yamada T, Komatsu K, Hirata K, Kikuchi A, Hirafuji M, Ninomiya S, Guo W. Improved field-based soybean seed counting and localization with feature level considered. Plant Phenomics, 2023; 5: 0026.
- Pharr M, Jakob W, Humphreys G. Physically based rendering: From theory to implementation. Morgan Kaufmann; 2016.
- P2PNet-Soy project. https://github.com/UTokyo-FieldPhenomics-Lab/P2PNet-Soy.
- Kingma DP, Ba J. Adam: A method for stochastic optimization. arXiv (2014). arXiv:1412.6980.
- Wang Z, Bovik AC, Sheikh HR, Simoncelli EP. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 2004; 13(4): 600-612.
- Dong C, Loy CC, He K, Tang X. Image super-resolution using deep convolutional networks. IEEE transactions on pattern analysis and machine intelligence, 2015; 38(2): 295-307.
- Kim J, Lee JK, Lee KM. Accurate image super-resolution using very deep convolutional networks. Paper presented at: Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 1646-1654.
- Lim B, Son S, Kim H, Nah S, Lee KM. Enhanced deep residual networks for single image super-resolution. Paper presented at: Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 2017: 136-144.
- Zhang Y, Li K, Li K, Wang L,Zhong B, Fu Y. Image super-resolution using very deep residual channel attention networks. Paper presented at: Proceedings of the European conference on computer vision (ECCV). 2018: 286-301.
- Liang J, Cao J, Sun G, Zhang K, Gool LV, Timofte R. Swinir: Image restoration using swin transformer. Paper presented at: Proceedings of the IEEE international conference on computer vision. 2021: 1833-1844.
- Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, Lin S, Guo B, Wei Y. Swin transformer: Hierarchical vision transformer using shifted windows. Paper presented at: Proceedings of the IEEE international conference on computer vision. 2021: 10012-10022.
- Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I. Attention is all you need. Advances in neural information processing systems. 2017. 30.
- Bi J, Zhu Z, Meng Q. Transformer in computer vision. Paper presented at: 2021 IEEE International Conference on Computer Science, Electronic Information Engineering and Intelligent Control Technology (CEI). IEEE, 2021; 178-188.
- Lepcha DC, Goyal B, Dogra A, Goyal V. Image super-resolution: A comprehensive review, recent trends, challenges and applications. Information Fusion. 2023; 91: 230-260.
- Csurka G. Domain adaptation for visual applications: A comprehensive survey. arXiv preprint arXiv:1702.05374, 2017.
- PlantSR Dataset. figshare. Dataset. [CrossRef]
- HR_Soybean. figshare. Dataset. [CrossRef]
Figure 1.
PlantSR dataset. PlantSR Dataset contains 25 images of Bryophytes, 115 images of Ferns, 440 images of Gymnosperms, and 450 images of Angiosperms. These data was divided into 830 images as training dataset and 200 images as test dataset.
Figure 1.
PlantSR dataset. PlantSR Dataset contains 25 images of Bryophytes, 115 images of Ferns, 440 images of Gymnosperms, and 450 images of Angiosperms. These data was divided into 830 images as training dataset and 200 images as test dataset.
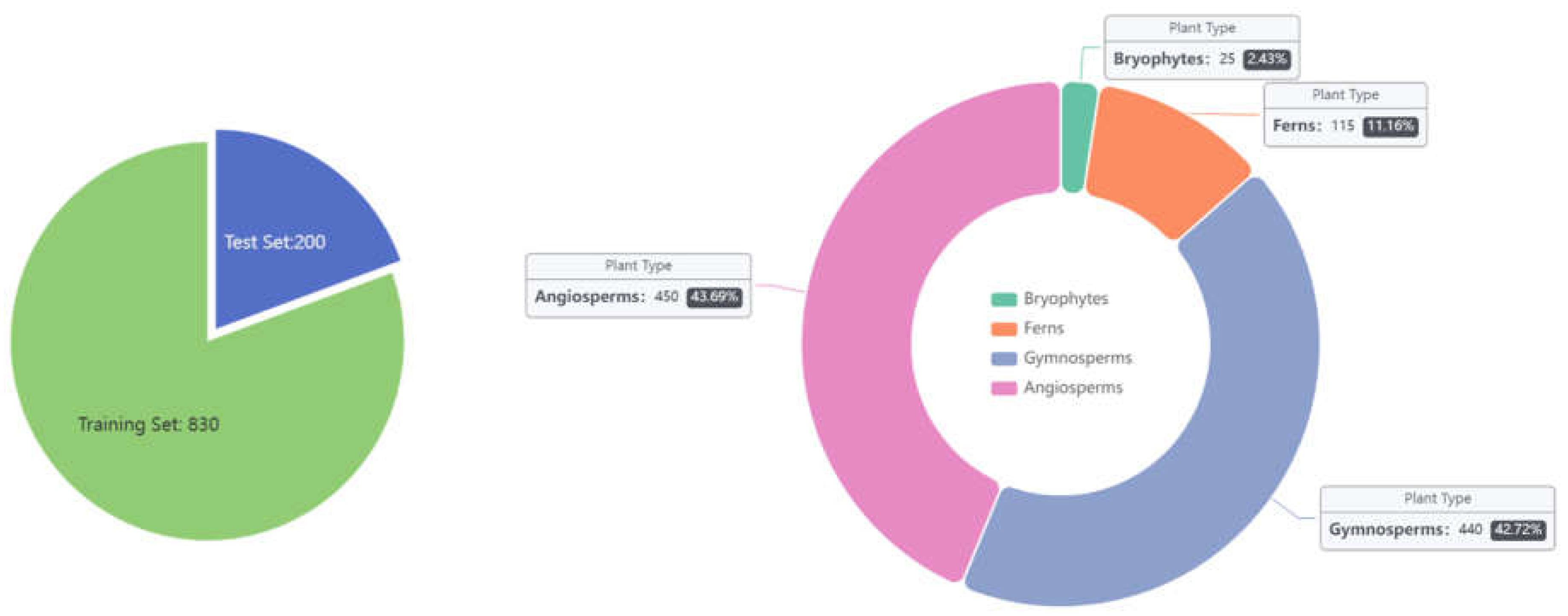
Figure 2.
Sample images of four categorizes in PlantSR dataset. (A) Sample image of Angiosperms. (B) Sample image of Gymnosperms. (C) Sample image of Ferns. (D) Sample image of Bryophytes.
Figure 2.
Sample images of four categorizes in PlantSR dataset. (A) Sample image of Angiosperms. (B) Sample image of Gymnosperms. (C) Sample image of Ferns. (D) Sample image of Bryophytes.

Figure 3.
Architecture of PlantSR Model. The model consists of a shallow feature extraction module, a deep feature extraction module and a high-resolution images reconstruction module.
Figure 3.
Architecture of PlantSR Model. The model consists of a shallow feature extraction module, a deep feature extraction module and a high-resolution images reconstruction module.
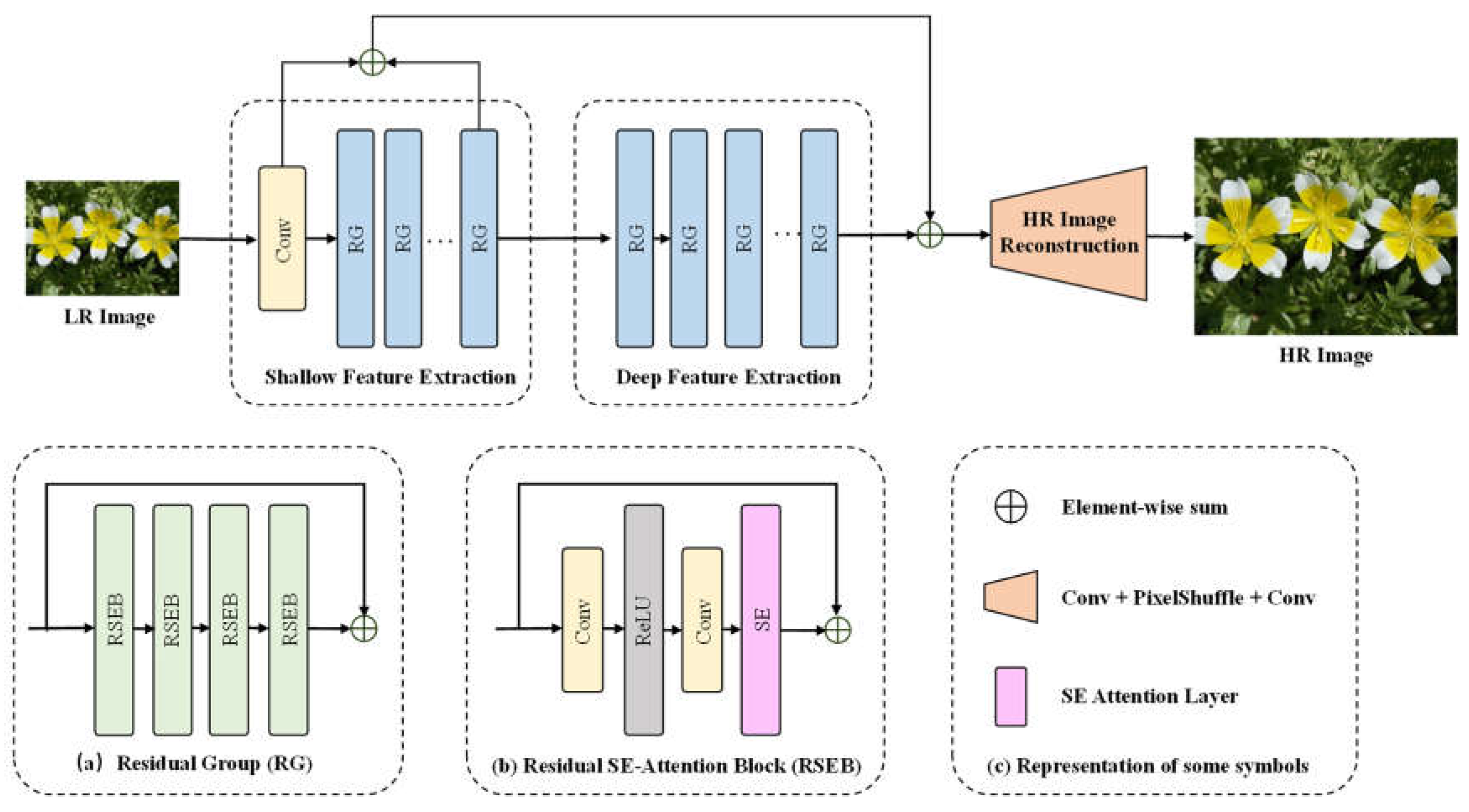
Figure 4.
Architecture of the P2PNet-Soy after applying PlantSR model as a pre-processing step.
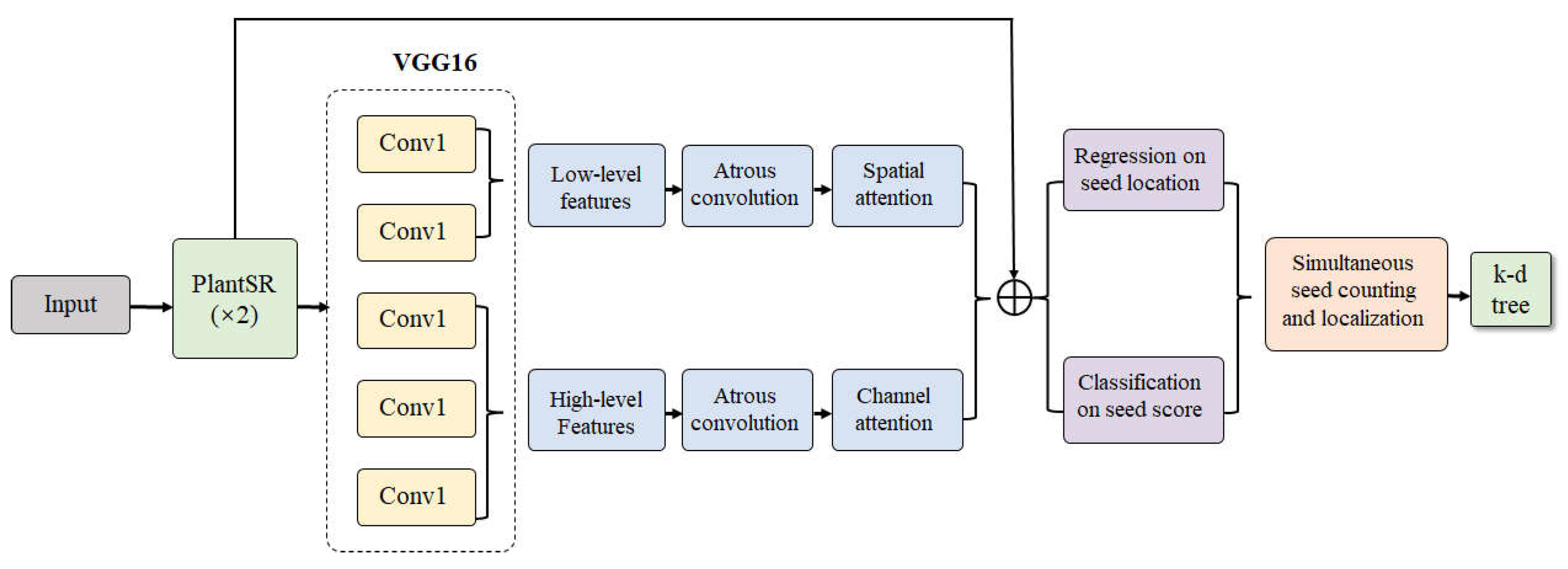
Figure 5.
Visual comparison results of image SR (×4) methods. The patches for comparison are marked with yellow boxes in the original images (left).
Figure 5.
Visual comparison results of image SR (×4) methods. The patches for comparison are marked with yellow boxes in the original images (left).

Figure 6.
Test results of YOLOv7 with different cases of test images.
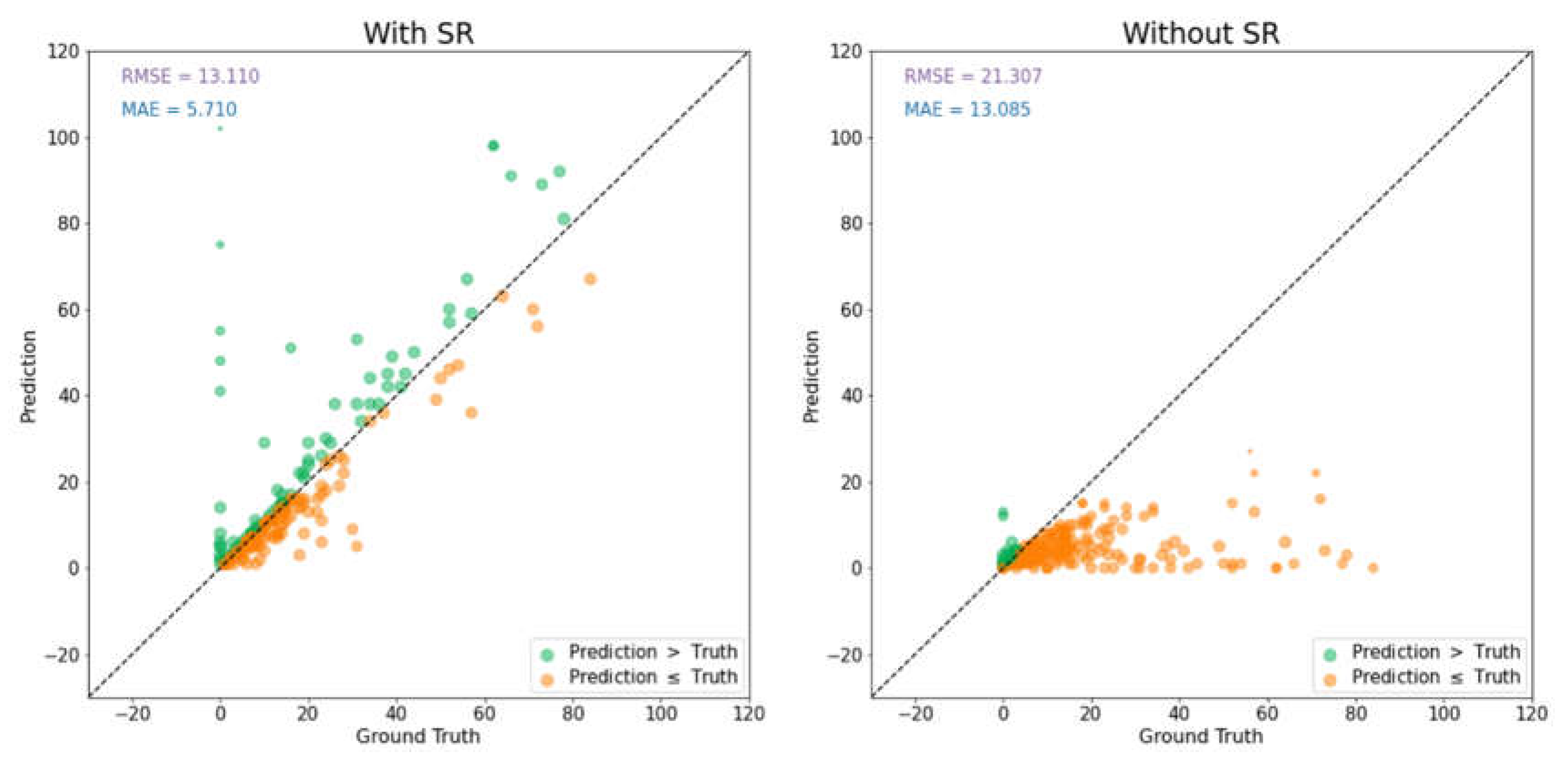
Figure 7.
Training, validation and test images of P2PNet-Soy in four different cases.
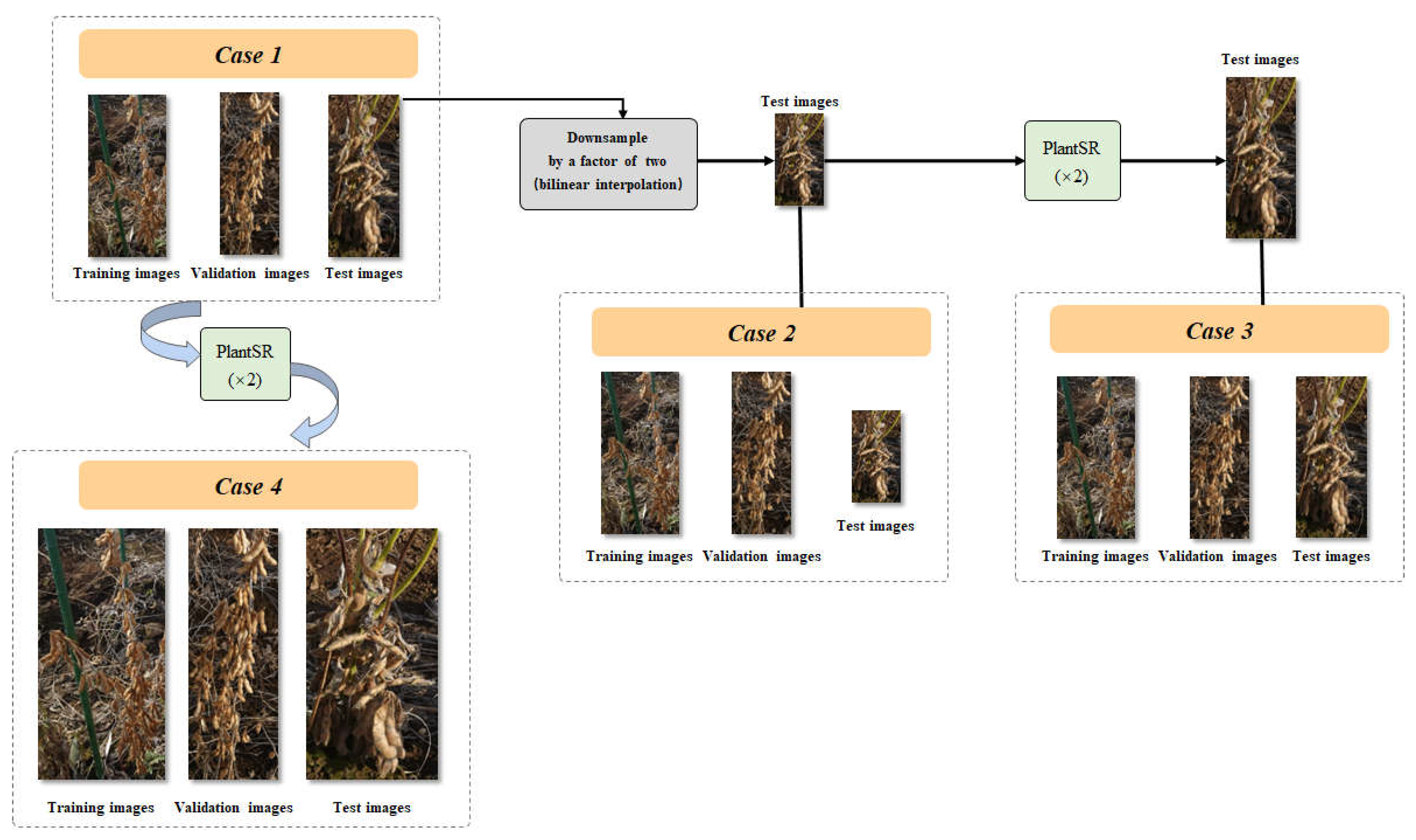

Table 1.
Compression results of SR methods.
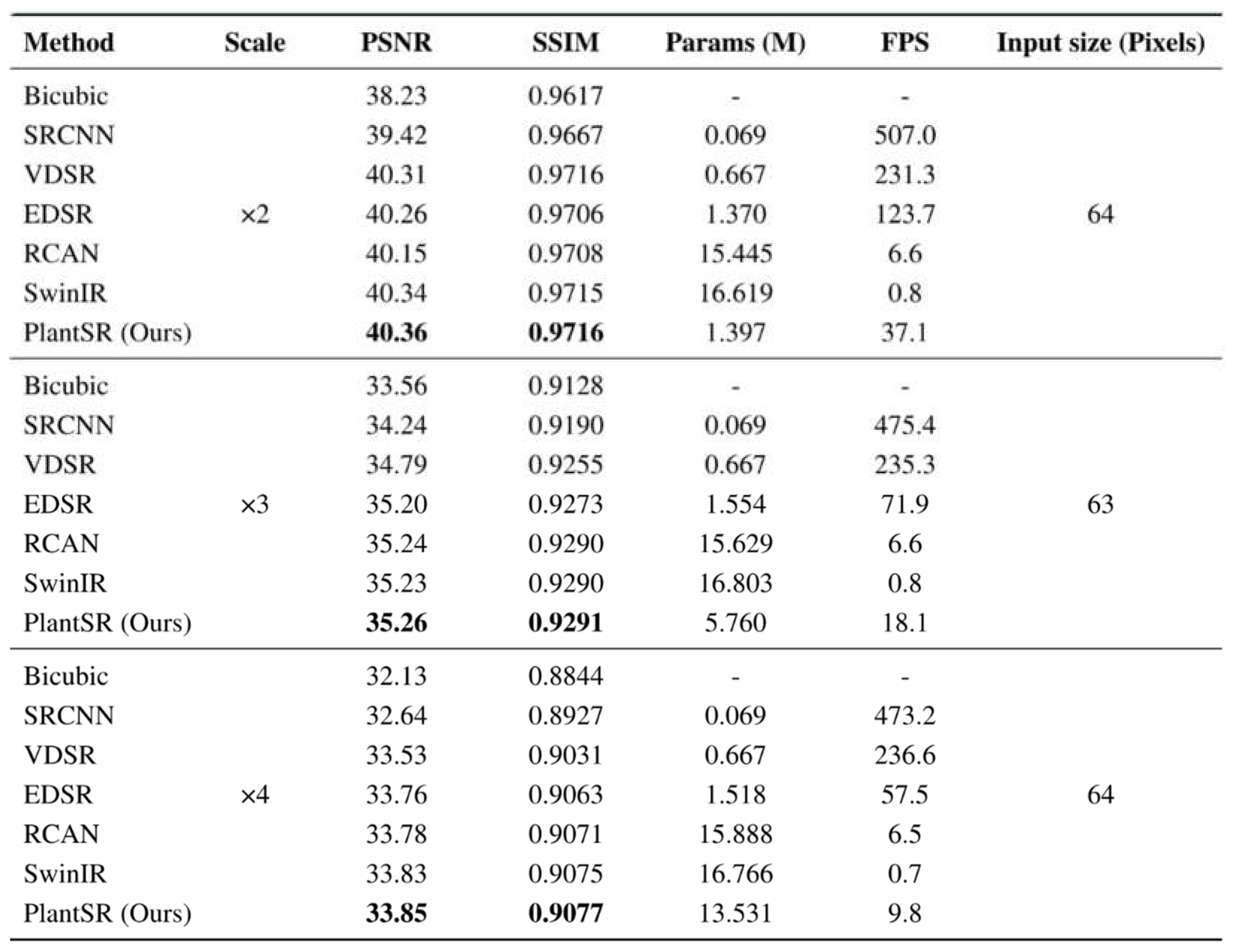
Table 2.
Train and evaluate P2PNet-Soy with images in four different cases.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



