
Submitted:
30 May 2024
Posted:
30 May 2024
You are already at the latest version
Abstract
Beans are the most widely used protein source in the world and their productivity is directly linked to nitrogen (N). The short crop cycle imposes the need for fast methodologies for N quantification. In this work, we evaluated the performance of four machine learning algorithms in nitrogen prediction using NIR spectroscopy. Increasing doses of nitrogen were applied to the plants and leaf reflectance was collected. Weka software was used to test the algorithms. The selection of the most effective spectral zones was made with the VIP. Considering predictions with the whole NIR, the best results were achieved with RF (R2 = 0,84 and RMSE = 2,69 g kg-1) and KNN (R2 = 0,77 and RMSE = 3,86 g kg-1). The intervals of 700-740 nm and 983-995 nm were considered the most important for the study of N. More efficient predictions were verified when only spectral regions screened by VIP were included, increasing the accuracy of the RF, KNN and M5 models by 6%, 4% and 8%, respectively. The efficiency of N prediction based on NIR reflectance combined with machine learning was verified. This approach can optimize the management of nitrogen fertilization, serving as an important tool in precision agriculture.
Keywords:
Algorithms
; Reflectance
; Precision Agriculture.
1. Introduction
Beans (Phaseolus vulgaris L.) are an essential staple food and one of the most produced agricultural crops worldwide, especially in Central and South America, being the main source of vegetable protein and the most important legume for direct human consumption [1,3]. In addition, it is used for other purposes, as a biological nitrogen-fixing agent in soil and animal feed [4]. Brazil stands out in the world for being one of the largest producers and consumers of common beans (Phaseolus Vulgaris L.), with a total area of 2,613,086 hectares harvested in 2021 [5,6].
Nitrogen (N) is considered an essential element to obtain high yields, with a significant influence on common bean growth, due to its strong link with plant photosynthesis, vegetative growth and grain yield [7]. Within the context of precision agriculture, it is extremely important to quantify the leaf N content to establish the amount to be applied to the soil, considering the phenological stage of the crop. Meanwhile, the excessive supply of N can result in plants that are more susceptible to attack by pests and diseases, promote exaggerated vegetative development, delay the reproductive phase of plants, favor the indiscriminate growth of weeds in the cultivation area, cause contamination in soil and water, and significantly increase the cost of production.
Conventional chemical analyses for the quantification of leaf N in plants are destructive, laborious, time-consuming, and require specific equipment and inputs [8,9]. Due to the fast cycle (60 to 80 days) of the bean crop, the development of fast and in situ methodologies for N prediction are of great importance and highly anticipated in the smart agriculture scenario. Management to match the supply of N with the needs of the crop is a viable alternative to achieve high yield and reduce environmental impact, making the application more efficient [10].
In this context, spectroscopy has shown potential as a fast and non-invasive approach to observe plant characteristics, making it possible to monitor and optimize nitrogen fertilization through reflectance data, for example [11,12]. This method is based on the detection of biochemical changes that affect the photosynthetic activity, structure and stability of chemical bonds, which promotes changes in reflectance [13]. Recently, near-infrared spectroscopy (NIRS) has been extensively studied as an innovative and economically viable technique, being successfully employed in the estimation of nutrients in plants [14,15]. Near-infrared (NIR) reflectance has been shown to be positively correlated with chlorophyll content in leaves, and is useful for studying N [8].
Among the most widely used techniques to deal with hyperspectre data, partial least squares regression (PLSR) stands out as the most popular model [16,17]. However, this model presents some difficulty in capturing nonlinear connections in spectroscopic data [18]. This context increases the demand for other alternative methods capable of dealing with nonlinear connections present in datasets obtained by spectroscopy. Because hyperespectral measurements produce high and complex amounts of data, one type of approach that could ideally handle this is machine learning [19]. Machine learning algorithms such as trees, rules, support vector machines, and artificial neural networks are advantageous when compared to linear methods in treating nonlinear problems [20]. In recent years, machine learning has advanced towards building predictive models focused on quantifying plant characteristics using spectra [21]. Despite this, the use of other machine learning models for leaf N estimation is still incipient; To the best of our knowledge, this study is the first to evaluate and compare the potential of four machine learning algorithms in the prediction of leaf N in bean crop. The use of machine learning algorithms can promote a rapid estimation of N in plants, contributing to the management of nitrogen fertilization as an important tool in the context of precision agriculture.
The main objective of this work was to evaluate and compare the performance of four machine learning algorithms (Random Forest - RF, K-nearest neighbors - KNN, Artificial Neural Network - RNA and M5Rules - M5) in the prediction of leaf nitrogen of common bean crop by means of hyperspectral data in the NIR range (700 to 1300nm). The specific objectives of this research also include: (1) To establish which NIR spectral zones are most appropriate for leaf nitrogen estimation; (2) To compare the predictive performance of the algorithms with the full spectrum and considering only the specific intervals selected by the VIP index.
2. Materials and Methods
Detailed information addressing the location of the experimental area and experimental design (Section 2.1.), leaf sampling, leaf reading with spectroradiometer and analysis of leaf nitrogen content (Section 2.2.), configuration of machine learning models and performance evaluation metrics (Section 2.3.) were presented in this section.
2.1. Study Place and Experimental Design
The experiment was carried out in a greenhouse at the School of Animal Science and Food Engineering of the University of São Paulo (Faculdade de Zootecnia e Engenharia de Alimentos da Universidade de São Paulo - FZEA-USP), Campus Pirassununga/SP - Brazil. The geographic location is depicted in Figure 1. According to the Köppen classification, the climate in the study area is humid subtropical (Cw) with an average annual temperature of 20.6°C and an average annual rainfall of 1238 mm [22].
The substrate used for sowing was composed of three parts of soil (Quartzarenic Neosol), 2 parts of tanned cattle manure and 2 parts of crushed sugarcane straw, aiming at maintaining the soil uncompacted and aerated. The physicochemical properties of each substrate component are described in detail in Table 1.
A completely randomized design was used with four treatments (0, 50, 100 and 150 kg N ha-1) and 8 replications. The seeds of the BRS FC104 cultivar were donated by the Brazilian Agricultural Research Corporation (Empresa Brasileira de Pesquisa Agropecuária - EMBRAPA), the unit responsible for the improvement of the common bean plant, headquartered in the city of Santo Antônio de Goiás, Goiás/Brazil. Start-up fertilization (40, 140 and 140 kg ha-1 of N, P2O5 and k2O, respectively) and nitrogen fertilization were based on the technical recommendations of the fertilization manual of the Agronomic Institute of Campinas (Instituto Agronômico de Campinas - IAC) for an expected yield of more than 5000 kg ha-1, using Urea (45% of N) as nitrogen fertilizer [23]. The nitrogen doses stipulated for each treatment were applied when the plants were in the V4 phenological stage, characterized by the complete development of the first trifoliate leaf.
5L plastic containers, 18 cm wide and 21 cm in diameter were used for sowing beans, fully filled with the substrate to the brim, in which 4 seeds were deposited for germination in each of them on 05/01/2023. 15 days after sowing - DAS, only the two plants with the best vegetative vigor per pot were maintained. The spacing between plants was 10 cm and between rows of pots 40 cm, equivalent to a population density of 250,000 plants per hectare.
The water supply of the plants was carried out manually with the use of a graduated beaker, and a daily depth of 5 mm of water was applied. Temperature and humidity data (average, maximum and minimum daily) were collected daily using a digital thermo-hygrometer, as shown in Figure 2.
2.2. Foliar Collection, Hyperespectral Data Acquisition and Quantification of Leaf Nitrogen
In the V4 phenological phase at 32 Days After Sowing (DAS), when the third trifoliate leaf was completely open and flat, 21 leaflets from 6 plants were sampled for each treatment. Immediately after collection, the leaflets were packed in sealed plastic bags that were inserted into a 20L thermal box containing ice to maintain the turgidity of the leaf material and transported to the geoprocessing laboratory for spectral reading. For this purpose, a proximal spectroradiometer, model ASD FieldSpec FR Spectroradiometer® (ASD - Analytical Spectral Devices Inc., Boulder, CO, USA) was used, operating in the spectral range of 350 - 2500 nm with spectral resolution of 1.4 nm from 350 to 1050 and 2 nm from 1050 to 2500 nm interval of 1 nm. The sensor was calibrated every 5 minutes, using a barium sulfate plate for the white pattern (100% reflectance) and a black surface for the black pattern (0% reflectance). Spectral ranges between 350 and 449 nm were discarded due to the high noise level. After reading, the leaflets were placed in paper bags and dried in an oven with forced ventilation at a constant temperature of 65°C up to constant weight. The dry leaf material was crushed to form a fine powder and sent for quantification of nitrogen content. The chemical quantification of the N content was based on the Kjeldahl method [24].
2.3. Model Description and Performance Analysis
The models were implemented in the Environment for Knowledge Analysis (WEKA) software, version 3.8.6. WEKA is an innovative, open-source tool for all research communities working on supervised and unsupervised learning methodologies and was developed at the University of Waikato, New Zealand [25].
Random Forest (RF) was proposed by Breiman (2001) and is a nonlinear ensemble decision tree-based algorithm, which deals with high-dimensional input datasets by constructing and averaging some random decision trees for regression or classification [26]. Among the important tuning parameters for this machine learning algorithm, 2 stand out: 1) number of trees to grow; and 2) number of variables per node [27]. RF was implemented with cross-validation of 10 folds, batchsize of 100 and 100 interactions.
KNN is an algorithm that can be used in regression and classification problems, and is considered one of the simplest. This model adopts the concept of nearest neighbors with an initial value of 'K' to find the similarity between the data points and then forwards the new data point to the category with the closest similarity [28]. Similarity is measured by calculating the Euclidean distance (EDx,y), as shown in equation 1. In this work, the algorithm was implemented with 5k nearest neighbors and cross-validation with 10 folds.
M5P is a powerful implementation of Quinlan's M5 algorithm, having as a rule to recursively partition the data space and fit a prediction model within each partition [29,30]. M5 was configured according to Weka's standard, being batchsize 100 and cross-validation with 10 folds.
Artificial neural networks have gained significant attention due to their ability to mimic the functioning of the human brain and their effectiveness in solving complex problems [31]. The Multi-Layer Perceptron-based RNA model is a supervised learning algorithm and consists of multiple layers of interconnected nodes, with each node performing a simple calculation using a weighted sum of its inputs and an activation function [32]. The standard Weka parameters were maintained with a learning rate of 0.3, a batchsize of 100 and cross-validation with 10 folds.
The performance of the machine learning models was calculated with all reflectance data (700 - 1300nm) and with the selection of the spectral zones most correlated with the actual nitrogen content obtained in the laboratory, adopting as a metric the importance index of the variable in the projection (VIPi), mathematically described by equation 2. VIP was calculated using partial least squares regression with 15 components and thresh=1 in Matlab R2022b software. VIP scores for each wavelength were extracted and processed in OriginPro 2024 software. The VIP classifies the independent variables according to their explanatory power, making possible a more efficient evaluation of the problem of multiple collinearity between variables [33]. In our study, we were rigorous, adopting the 1.0 value as the cut-off value to select the most responsive wavelengths in the prediction of N.
where Wik is the value of the weight for the variable i, SSYk is the sum of the squares of the variance for the k-th (k-ésimo), I is the number of independent variables, SSYTotal is the sum total of the squares given by the variables, and L is the total number of components.
The coefficient of determination (R2) and the root mean squared error (RMSE) were used as the main metrics used to measure the amount of explained variance and, consequently, the performance of the models used in this study in the estimation of N. The stability of the models was evaluated by comparing the difference in the values of R2 and RMSE. The R2 expresses the fit between the values estimated by the model and the actual nitrogen value, corresponding to that measured in the laboratory. The R2 can range from 0 to 1; the closer the value is to 1, the more accurate the model is in predicting. The RMSE represents the deviation (error) between the estimated value and the measured value. In this case, the predictive accuracy of the model is improved proportionately as RMSE values are reduced. Equations 3 and 4 were used to calculate the metrics.
where Pi represents the predicted value of the regression model, y represents the mean value of the measured value, yi represents the measured value, and n represents the sample size.
3. Results
3.1. Foliar Nitrogen Content
The descriptive analysis of the nitrogen content present in common bean leaves submitted to four levels of nitrogen fertilization is shown in Figure 3. In general, the arithmetic mean of the leaf N content increased as a function of the applied doses, reaching values of 37.02, 46.68, 51.72 and 58.9 g kg-1 for T1 (0 kg ha-1 N), T2 (50kg ha-1 N), T3 (100 kg ha-1 N) and T4 (150 kg ha-1 N), respectively.
The leaf N content obtained in this study is in agreement with those obtained by [34] who studied 16 varieties of common bean submitted to two doses of N (0 e 100kg ha-1) and found a mean leaf N content of 37.6 51.7 g kg-1 in BRS amethyst and 36.1 51.7 g kg-1 in Dama TAA in the absence of N. Regarding the dose of 100 kg ha-1, our mean result, 51.7 g kg-1, was slightly higher than the value observed by the authors, 41.8 g kg-1, for cultivar IAC millennium (IAC milênio).
3.2. Leaf Spectral Analysis
The mean reflectance curves of the cultivar BRS FC104, comprised in the near-infrared range - NIR (700 to 1300nm) and resulting from the application of the four nitrogen treatments (Figure 3), are shown in Figure 4. The spectral behavior of leaves with different concentrations of N showed little variation in reflectance, being between 0.45 and 0.55 on the y-axis, where the two smallest reflectance curves (green and blue lines) represent the concentrations of 60.6 and 51.7 g kg-1 of N, respectively.
Near-infrared wavelengths (between 720 and 1300 nm) refer to the scattering of light along the mesophyll under the influence of internal leaf structures such as cell wall width, intercellular air spaces, and the amount of mesophyll per unit leaf area within the mesophyll [35,36]. Reflectances around 0.5 obtained in healthy bean plants were measured by [37] in the NIR region, showing satisfactory vegetative vigor of the crop at 25 DAS. When fertility is adequate, plants are more photosynthetically active, which characterizes greater absorption of electromagnetic energy in the visible region and greater reflectance in the red border and near-infrared regions [38]. Other plant species also express similar spectral behavior with respect to reflectance. Assessing the hyperspectral response of species Megathyrsus maximus, Pennisetum purpureum Schumach, Philodendron sp. Tradescantia pallida cv. purpurea, Cordyline fruticosa (L.) and Cordyline fruticosa (L.), in the near-infrared region (700 - 1300 nm), reflectance of approximately 50% with progressive decreases up to 1058 nm were observed by [35].
Two spectral zones most correlated with leaf nitrogen content were identified using the VIP index across the NIR spectrum, as shown in Figure 5. The first is located in the range of 700 to 740nm, with the highest VIP (4.1) observed at the 708nm wavelength - blue dotted line. In the second, VIP scores higher than 1 occurred only at wavelengths 983, 994 and 995nm, and the value verified at 988nm was observed at wavelength 708nm.
Several studies have proven the efficiency of the interval between 700 - 740 nm in the study of leaf N in several plant species. Evaluating the importance of spectral bands in the prediction of N in sugarcane crops, Silva et al., (2023) observed VIP ranging from 1 to 1.5 for sugarcane. The accuracy of reflectance spectroscopy is further refined by selecting the most responsive wavelengths for analysis, as different plant features are more discernible at specific wavelengths [39,40]. This selection process is critical to generating reliable and actionable data [40].
RF stood out as the most accurate model in the prediction of N when the entire NIR spectrum (700 - 1300 nm) was used, expressing an excellent coefficient of determination (R2 = 0.84) and lower error (RMSE = 2.69) between observed and predicted values (Figure 6 - A). The scatter plots showing the performance of the KNN and M5Rules models reveal reduced capacity when compared to RF, but efficient in the estimation of N, both with R2≥0.7 and errors lower than 4 g kg-1 (Figure 6-B and D). ANN was the least appropriate model to deal with estimation of N from NIR reflectance, expressing the largest error.
These results reflect the robustness of the RF model applied to the prediction of leaf N in the bean crop. One explanation for this is the fact that this algorithm is composed of multiple trees trained through bagging and a random variable selection process, having excellent capability against noise and outliers in the database [41,42]. RF demonstrates aptitude for data with nonlinearity inherent in the relationship between spectral variables and biophysical or biochemical parameters. Applied to predictions of nitrogen and leaf chlorophyll in maize crops, Random Forest outperformed the ANN, M5P, REPT, SVM and ZR algorithms, using hyperspectral data as input [43]. Evaluating models based on in-situ hyperspectral data to predict nitrogen concentration in three legumes (soybean, teparian bean, moth bean) with four machine learning algorithms, Flynn et al., (2023) found the superiority of RF (R2 = 0.72) compared to KNN, PLS, and SVM.
On the other hand, the ANN model has a high capacity for nonlinear approximation and excellent generalization [44]. However, in this study, ANN did not obtain satisfactory performance when compared to the other models. This fact may have occurred due to the need for successive modifications in the hyperparameters of the network for optimization in the prediction [45].
The selection of the most significant wavelengths by VIP for N prediction, located in the spectral ranges between 700 - 740 nm and 983 - 995 nm, (Figure 5) increased the R2 of the RF, KNN and M5 algorithms by 6%, 4% and 8%, respectively, improving the predictive capacity (Figure 7). On the other hand, RNA's performance was reduced by 3% when the two spectral intervals obtained by VIP were used.
These results are similar to those obtained in the literature. Fiorio et al., (2024b) obtained more efficient predictions of leaf nitrogen content in sugarcane from hyperspectral reflectance data using PLSR, considering only spectral ranges obtained by VIP. The research conducted by Azadnia et al., (2023), studied the prediction of N, phosphorus (P) and potassium (K) in apple trees with spectroscopy data and also proved the performance gain of machine learning algorithms as a function of the choice of the most effective intervals using VIP [46].
Comparing the performance results of KNN dealing with raw spectral data and only with the wavelengths selected by VIP, a 25% reduction in error is observed, from 3.86 g kg-1 to 2.89 g kg-1. This considerable difference may have occurred because the KNN algorithm is more sensitive to data quality than other algorithms, and the choice of more relevant variables increases its capacity for generalization, interpretability, and computational efficiency [47,48].
4. Conclusions
For predictions using the spectral range between 700 – 1300nm NIR, the best results were achieved with RF (R2 = 0.84 and RMSE = 2.69 g kg-1) and KNN (R2 = 0.77 and RMSE = 3.86 g kg-1). The intervals of 700 - 740 nm and 983 - 995 nm were obtained by VIP and considered the most important for the study of N in bean culture from NIR spectroscopy. The use of the two spectral bands selected by VIP resulted in more efficient predictions, increasing the performance of the RF (R2 = 0.84 and RMSE = 2.69 g kg-1), KNN (R2 = 0.84 and RMSE = 2.69 g kg-1) and M5 (R2 = 0.84 and RMSE = 2.69 g kg-1) models by 6%, 4% and 8%, respectively. The findings of this work prove the efficiency of prediction of leaf N content in the bean crop based on NIR reflectance data combined with machine learning algorithms. This approach can optimize the management of nitrogen fertilization, serving as an important tool in the context of precision agriculture. Finally, further studies under field conditions, including with other agricultural crops, are recommended to consolidate the use of machine learning in the prediction of N considering NIR spectroscopy.
Author Contributions
Conceptualization, M.S.T., and C.A.A.C.S.; methodology, M.S.T., E.J.S.S., and T.L.S.; software, J.R.R., T.L.S., M.S.T., and E.J.S.S.; validation, M.S.T., J.R.R., T.L.S. and M.M.B; formal analysis, P.R.F., M.S.T. and C.A.A.C.S; resources, J.R.R..; data curation, T.L.S., M.S.T. and E.J.S.S.; writing—original draft preparation., J.R.R., and M.S.T.
Funding
This research was funded by Coordination for the Improvement of Higher Education Personnel (Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - CAPES) - Brazil (Funding Code 001) and the Luiz de Queiroz Agricultural Studies Foundation (Fundação de Estudos Agrários Luiz de Queiroz - FEALQ).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Antolin, L. A. S.; Heinemann, A. B.; Marin, F. R. Impact Assessment of Common Bean Availability in Brazil under Climate Change Scenarios. Agric Syst 2021, 191, 103174. [Google Scholar] [CrossRef]
- Heinemann, A. B.; Costa-Neto, G.; Fritsche-Neto, R.; da Matta, D. H.; Fernandes, I. K. Enviromic Prediction Is Useful to Define the Limits of Climate Adaptation: A Case Study of Common Bean in Brazil. Field Crops Res 2022, 286, 108628. [Google Scholar] [CrossRef]
- FAO. FAOSTAT Statistical Database. Rome: Food and Agriculture Organisation of the United Nations. 2020.
- Shumi, D. Response of Common Bean (Phaseolus Vulgaris L.) Varieties to Rates of Blended NPS Fertilizer in Adola District, Southern Ethiopia. African Journal of Plant Science 2018, 12(8), 164–179. [Google Scholar] [CrossRef]
- Araujo Robusti, E.; Godoy Androcioli, H.; Ventura, M. U.; Hata, F. T.; Soares Júnior, D.; Menezes Júnior, A. de O. Integrated Pest Management versus Conventional System in the Common Bean Crop in Brazil: Insecticide Reduction and Financial Maximization. Int J Pest Manag 2023, 1–11. [CrossRef]
- da Silva Borges, M. P.; Trezzi, M. M.; Mendes, K. F.; Fuzinatto, E.; Pilatti, G.; da Silva, A. A. Tolerance of Brazilian Bean Cultivars to S-Metolachlor and Poaceae Weed Control in Two Agricultural Soils. Agronomy 2023, 13 (12), 2919. [CrossRef]
- Xie, K.; Ren, Y.; Chen, A.; Yang, C.; Zheng, Q.; Chen, J.; Wang, D.; Li, Y.; Hu, S.; Xu, G. Plant Nitrogen Nutrition: The Roles of Arbuscular Mycorrhizal Fungi. J Plant Physiol 2022, 269, 153591. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Jia, X.; Hu, M.; Zhou, M.; Li, D.; Liu, W.; Wang, R.; Zhang, J.; Xie, C.; Liu, L.; Wang, F.; Chen, H.; Chen, T.; Hu, H. An Effective Data Augmentation Strategy for CNN-Based Pest Localization and Recognition in the Field. IEEE Access 2019, 7, 160274–160283. [Google Scholar] [CrossRef]
- Silva, B. C. da; Prado, R. de M.; Baio, F. H. R.; Campos, C. N. S.; Teodoro, L. P. R.; Teodoro, P. E.; Santana, D. C.; Fernandes, T. F. S.; Silva Junior, C. A. da; Loureiro, E. de S. New Approach for Predicting Nitrogen and Pigments in Maize from Hyperspectral Data and Machine Learning Models. Remote Sens Appl 2024, 33, 101110. [CrossRef]
- Fu, Y.; Yang, G.; Pu, R.; Li, Z.; Li, H.; Xu, X.; Song, X.; Yang, X.; Zhao, C. An Overview of Crop Nitrogen Status Assessment Using Hyperspectral Remote Sensing: Current Status and Perspectives. European Journal of Agronomy 2021, 124, 126241. [Google Scholar] [CrossRef]
- Acosta, M.; Quiñones, A.; Munera, S.; de Paz, J. M.; Blasco, J. Rapid Prediction of Nutrient Concentration in Citrus Leaves Using Vis-NIR Spectroscopy. Sensors 2023, 23(14), 6530. [Google Scholar] [CrossRef]
- Fiorio, P. R.; Silva, C. A. A. C.; Rizzo, R.; Demattê, J. A. M.; Luciano, A. C. dos S.; Silva, M. A. da. Prediction of Leaf Nitrogen in Sugarcane (Saccharum Spp.) by Vis-NIR-SWIR Spectroradiometry. Heliyon 2024, 10(5), e26819. [CrossRef]
- Sanaeifar, A.; Yang, C.; de la Guardia, M.; Zhang, W.; Li, X.; He, Y. Proximal Hyperspectral Sensing of Abiotic Stresses in Plants. Science of The Total Environment 2023, 861, 160652. [Google Scholar] [CrossRef]
- Azadnia, R.; Rajabipour, A.; Jamshidi, B.; Omid, M. New Approach for Rapid Estimation of Leaf Nitrogen, Phosphorus, and Potassium Contents in Apple-Trees Using Vis/NIR Spectroscopy Based on Wavelength Selection Coupled with Machine Learning. Comput Electron Agric 2023, 207, 107746. [Google Scholar] [CrossRef]
- Amaral, J. B. C.; Lopes, F. B.; Magalhães, A. C. M. de; Kujawa, S.; Taniguchi, C. A. K.; Teixeira, A. dos S.; Lacerda, C. F. de; Queiroz, T. R. G.; Andrade, E. M. de; Araújo, I. C. da S.; Niedbała, G. Quantifying Nutrient Content in the Leaves of Cowpea Using Remote Sensing. Applied Sciences 2022, 12(1), 458. [CrossRef]
- Ji, F.; Li, F.; Hao, D.; Shiklomanov, A. N.; Yang, X.; Townsend, P. A.; Dashti, H.; Nakaji, T.; Kovach, K. R.; Liu, H.; Luo, M.; Chen, M. Unveiling the Transferability of <scp>PLSR</Scp> Models for Leaf Trait Estimation: Lessons from a Comprehensive Analysis with a Novel Global Dataset. New Phytologist 2024. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.; Lu, X.; Yu, S.; Gu, S.; Huang, G.; Guo, X.; Zhao, C. The Application of Machine Learning Models Based on Leaf Spectral Reflectance for Estimating the Nitrogen Nutrient Index in Maize. Agriculture 2022, 12(11), 1839. [Google Scholar] [CrossRef]
- Mustaqimah; Devianti; Munawar, A. A.; Sufardi, S. Capability of Short Vis-NIR Band Tandem with Machine Learning to Rapidly Predict NPK Content in Tropical Farmland: A Case Study of Aceh Province Agricultural Soil Dry Land, Indonesia. Case Studies in Chemical and Environmental Engineering 2024, 9, 100711. [CrossRef]
- Osco, L. P.; Ramos, A. P. M.; Faita Pinheiro, M. M.; Moriya, É. A. S.; Imai, N. N.; Estrabis, N.; Ianczyk, F.; Araújo, F. F. de; Liesenberg, V.; Jorge, L. A. de C.; Li, J.; Ma, L.; Gonçalves, W. N.; Marcato Junior, J.; Eduardo Creste, J. A Machine Learning Framework to Predict Nutrient Content in Valencia-Orange Leaf Hyperspectral Measurements. Remote Sens (Basel) 2020, 12(6), 906. [CrossRef]
- Barcala, V.; Rozemeijer, J.; Ouwerkerk, K.; Gerner, L.; Osté, L. Value and Limitations of Machine Learning in High-Frequency Nutrient Data for Gap-Filling, Forecasting, and Transport Process Interpretation. Environ Monit Assess 2023, 195(7), 892. [Google Scholar] [CrossRef] [PubMed]
- Li, D.; Hu, Q.; Ruan, S.; Liu, J.; Zhang, J.; Hu, C.; Liu, Y.; Dian, Y.; Zhou, J. Utilizing Hyperspectral Reflectance and Machine Learning Algorithms for Non-Destructive Estimation of Chlorophyll Content in Citrus Leaves. Remote Sens (Basel) 2023, 15(20), 4934. [CrossRef]
- Alvares, C. A.; Stape, J. L.; Sentelhas, P. C.; de Moraes Gonçalves, J. L.; Sparovek, G. Köppen’s Climate Classification Map for Brazil. Meteorologische Zeitschrift 2013, 22(6), 711–728. [Google Scholar] [CrossRef] [PubMed]
- Cantarella, H.; Quaggio, J. A.; Júnior, D. M.; Boaretto, R. M.; Raij, B. van. Boletim 100: Recomendações de Adubação e Calagem Para o Estado de São Paulo; 2022.
- Lynch, J. M.; Barbano, D. M. Kjeldahl Nitrogen Analysis as a Reference Method for Protein Determination in Dairy Products. J AOAC Int 1999, 82(6), 1389–1398. [Google Scholar] [CrossRef]
- Bakthavatchalam, K.; Karthik, B.; Thiruvengadam, V.; Muthal, S.; Jose, D.; Kotecha, K.; Varadarajan, V. IoT Framework for Measurement and Precision Agriculture: Predicting the Crop Using Machine Learning Algorithms. Technologies (Basel) 2022, 10(1), 13. [Google Scholar] [CrossRef]
- Shi, M.; Hu, W.; Li, M.; Zhang, J.; Song, X.; Sun, W. Ensemble Regression Based on Polynomial Regression-Based Decision Tree and Its Application in the in-Situ Data of Tunnel Boring Machine. Mech Syst Signal Process 2023, 188, 110022. [Google Scholar] [CrossRef]
- Azadnia, R.; Rajabipour, A.; Jamshidi, B.; Omid, M. New Approach for Rapid Estimation of Leaf Nitrogen, Phosphorus, and Potassium Contents in Apple-Trees Using Vis/NIR Spectroscopy Based on Wavelength Selection Coupled with Machine Learning. Comput Electron Agric 2023, 207, 107746. [Google Scholar] [CrossRef]
- Roopashree, S.; Anitha, J.; Mahesh, T. R.; Vinoth Kumar, V.; Viriyasitavat, W.; Kaur, A. An IoT Based Authentication System for Therapeutic Herbs Measured by Local Descriptors Using Machine Learning Approach. Measurement 2022, 200, 111484. [Google Scholar] [CrossRef]
- Wang, Y.; Ian, H. Induzindo Árvores Modelo Para Classes Contínuas. In Induzindo árvores modelo para classes contínuas; 9a Conferência Europeia sobre Aprendizado de Máquina, 1997.
- Thai, T. H.; Omari, R. A.; Barkusky, D.; Bellingrath-Kimura, S. D. Statistical Analysis versus the M5P Machine Learning Algorithm to Analyze the Yield of Winter Wheat in a Long-Term Fertilizer Experiment. Agronomy 2020, 10(11), 1779. [Google Scholar] [CrossRef]
- Afzal, S.; Ziapour, B. M.; Shokri, A.; Shakibi, H.; Sobhani, B. Building Energy Consumption Prediction Using Multilayer Perceptron Neural Network-Assisted Models; Comparison of Different Optimization Algorithms. Energy 2023, 282, 128446. [Google Scholar] [CrossRef]
- Harsányi, E.; Bashir, B.; Arshad, S.; Ocwa, A.; Vad, A.; Alsalman, A.; Bácskai, I.; Rátonyi, T.; Hijazi, O.; Széles, A.; Mohammed, S. Data Mining and Machine Learning Algorithms for Optimizing Maize Yield Forecasting in Central Europe. Agronomy 2023, 13(5), 1297. [Google Scholar] [CrossRef]
- Zovko, M.; Žibrat, U.; Knapič, M.; Kovačić, M. B.; Romić, D. Hyperspectral Remote Sensing of Grapevine Drought Stress. Precis Agric 2019, 20(2), 335–347. [Google Scholar] [CrossRef]
- Nunes, H. D.; Leal, F. T.; Mingotte, F. L. C.; Damião, V. D.; Junior, P. A. C.; Lemos, L. B. Agronomic Performance, Quality and Nitrogen Use Efficiency by Common Bean Cultivars. J Plant Nutr 2021, 44(7), 995–1009. [Google Scholar] [CrossRef]
- Falcioni, R.; Moriwaki, T.; Pattaro, M.; Herrig Furlanetto, R.; Nanni, M. R.; Camargos Antunes, W. High Resolution Leaf Spectral Signature as a Tool for Foliar Pigment Estimation Displaying Potential for Species Differentiation. J Plant Physiol 2020, 249, 153161. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, S.; Zhang, B. Evaluation of Hyperspectral Indices for Retrieval of Canopy Equivalent Water Thickness and Gravimetric Water Content. Int J Remote Sens 2016, 37(14), 3384–3399. [Google Scholar] [CrossRef]
- Machado, M. L.; Pinto, F. de A. C.; Paula Junior, T. J. de; Queiroz, D. M. de; Cerqueira, O. de A. T. White Mold Detection in Common Beans through Leaf Reflectance Spectroscopy. Engenharia Agrícola 2015, 35(6), 1117–1126. [Google Scholar] [CrossRef]
- Liang, L.; Qin, Z.; Zhao, S.; Di, L.; Zhang, C.; Deng, M.; Lin, H.; Zhang, L.; Wang, L.; Liu, Z. Estimating Crop Chlorophyll Content with Hyperspectral Vegetation Indices and the Hybrid Inversion Method. Int J Remote Sens 2016, 37(13), 2923–2949. [Google Scholar] [CrossRef]
- Crusiol, L. G. T.; Sun, L.; Sun, Z.; Chen, R.; Wu, Y.; Ma, J.; Song, C. In-Season Monitoring of Maize Leaf Water Content Using Ground-Based and UAV-Based Hyperspectral Data. Sustainability 2022, 14(15), 9039. [CrossRef]
- Falcioni, R.; Antunes, W. C.; Demattê, J. A. M.; Nanni, M. R. Biophysical, Biochemical, and Photochemical Analyses Using Reflectance Hyperspectroscopy and Chlorophyll a Fluorescence Kinetics in Variegated Leaves. Biology (Basel) 2023, 12(5), 704. [Google Scholar] [CrossRef] [PubMed]
- Maimaitijiang, M.; Sagan, V.; Sidike, P.; Daloye, A. M.; Erkbol, H.; Fritschi, F. B. Crop Monitoring Using Satellite/UAV Data Fusion and Machine Learning. Remote Sens (Basel) 2020, 12(9), 1357. [Google Scholar] [CrossRef]
- Li, D.; Hu, Q.; Ruan, S.; Liu, J.; Zhang, J.; Hu, C.; Liu, Y.; Dian, Y.; Zhou, J. Utilizing Hyperspectral Reflectance and Machine Learning Algorithms for Non-Destructive Estimation of Chlorophyll Content in Citrus Leaves. Remote Sens (Basel) 2023, 15(20), 4934. [Google Scholar] [CrossRef]
- Silva, B. C. da; Prado, R. de M.; Baio, F. H. R.; Campos, C. N. S.; Teodoro, L. P. R.; Teodoro, P. E.; Santana, D. C.; Fernandes, T. F. S.; Silva Junior, C. A. da; Loureiro, E. de S. New Approach for Predicting Nitrogen and Pigments in Maize from Hyperspectral Data and Machine Learning Models. Remote Sens Appl 2024, 33, 101110. [CrossRef]
- Khan, M.; Ullah, Z.; Mašek, O.; Raza Naqvi, S.; Nouman Aslam Khan, M. Artificial Neural Networks for the Prediction of Biochar Yield: A Comparative Study of Metaheuristic Algorithms. Bioresour Technol 2022, 355, 127215. [Google Scholar] [CrossRef]
- Sreedhara, B. M.; Rao, M.; Mandal, S. Application of an Evolutionary Technique (PSO–SVM) and ANFIS in Clear-Water Scour Depth Prediction around Bridge Piers. Neural Comput Appl 2019, 31(11), 7335–7349. [Google Scholar] [CrossRef]
- Azadnia, R.; Rajabipour, A.; Jamshidi, B.; Omid, M. New Approach for Rapid Estimation of Leaf Nitrogen, Phosphorus, and Potassium Contents in Apple-Trees Using Vis/NIR Spectroscopy Based on Wavelength Selection Coupled with Machine Learning. Comput Electron Agric 2023, 207, 107746. [Google Scholar] [CrossRef]
- Narmilan, A.; Gonzalez, F.; Salgadoe, A. S. A.; Kumarasiri, U. W. L. M.; Weerasinghe, H. A. S.; Kulasekara, B. R. Predicting Canopy Chlorophyll Content in Sugarcane Crops Using Machine Learning Algorithms and Spectral Vegetation Indices Derived from UAV Multispectral Imagery. Remote Sens (Basel) 2022, 14(5), 1140. [Google Scholar] [CrossRef]
- Yoosefzadeh-Najafabadi, M.; Earl, H. J.; Tulpan, D.; Sulik, J.; Eskandari, M. Application of Machine Learning Algorithms in Plant Breeding: Predicting Yield From Hyperspectral Reflectance in Soybean. Front Plant Sci 2021, 11. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Detailed map of the location of the experimental area.
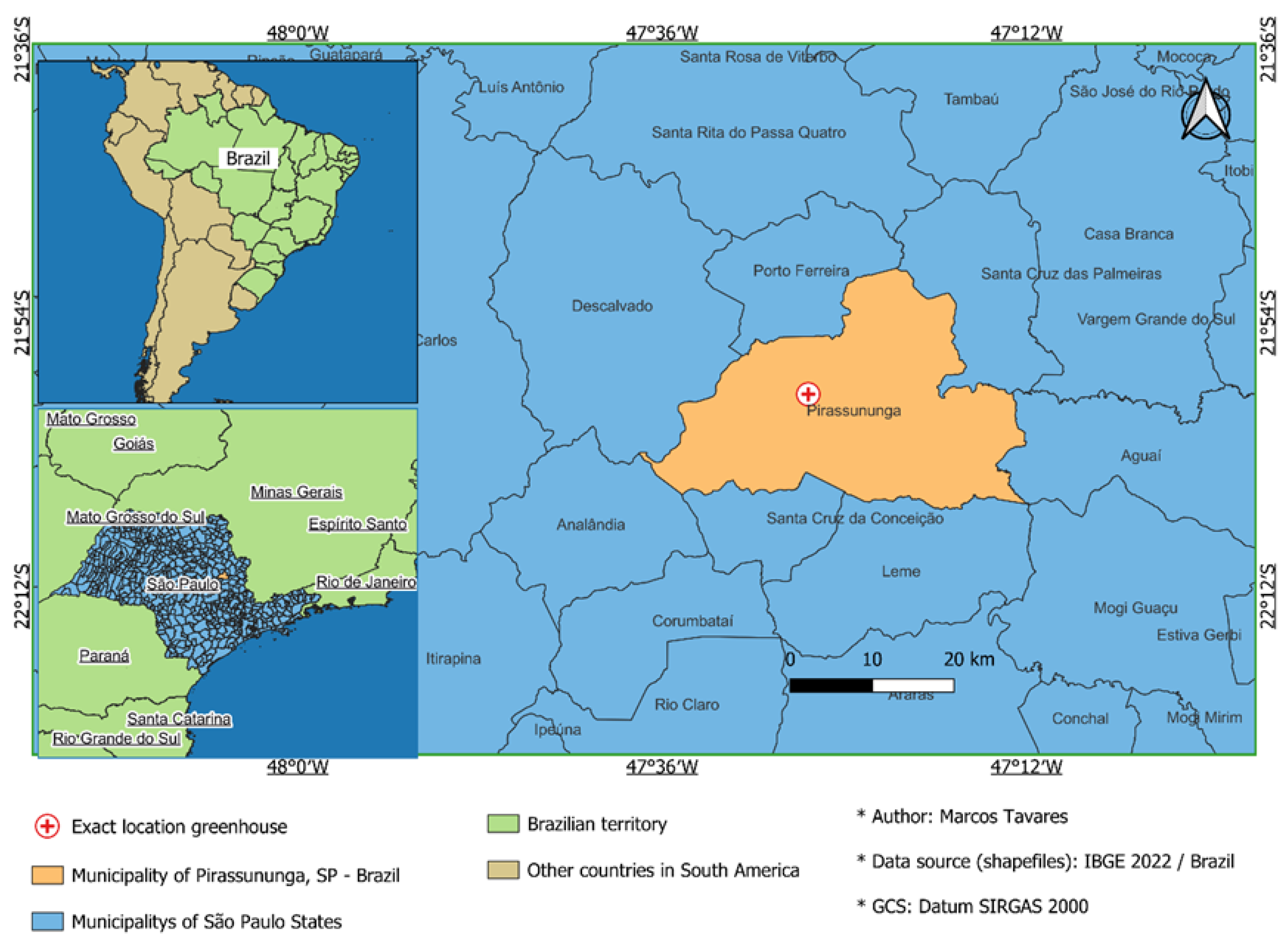
Figure 2.
Temperature and humidity data collected during the experimental period.
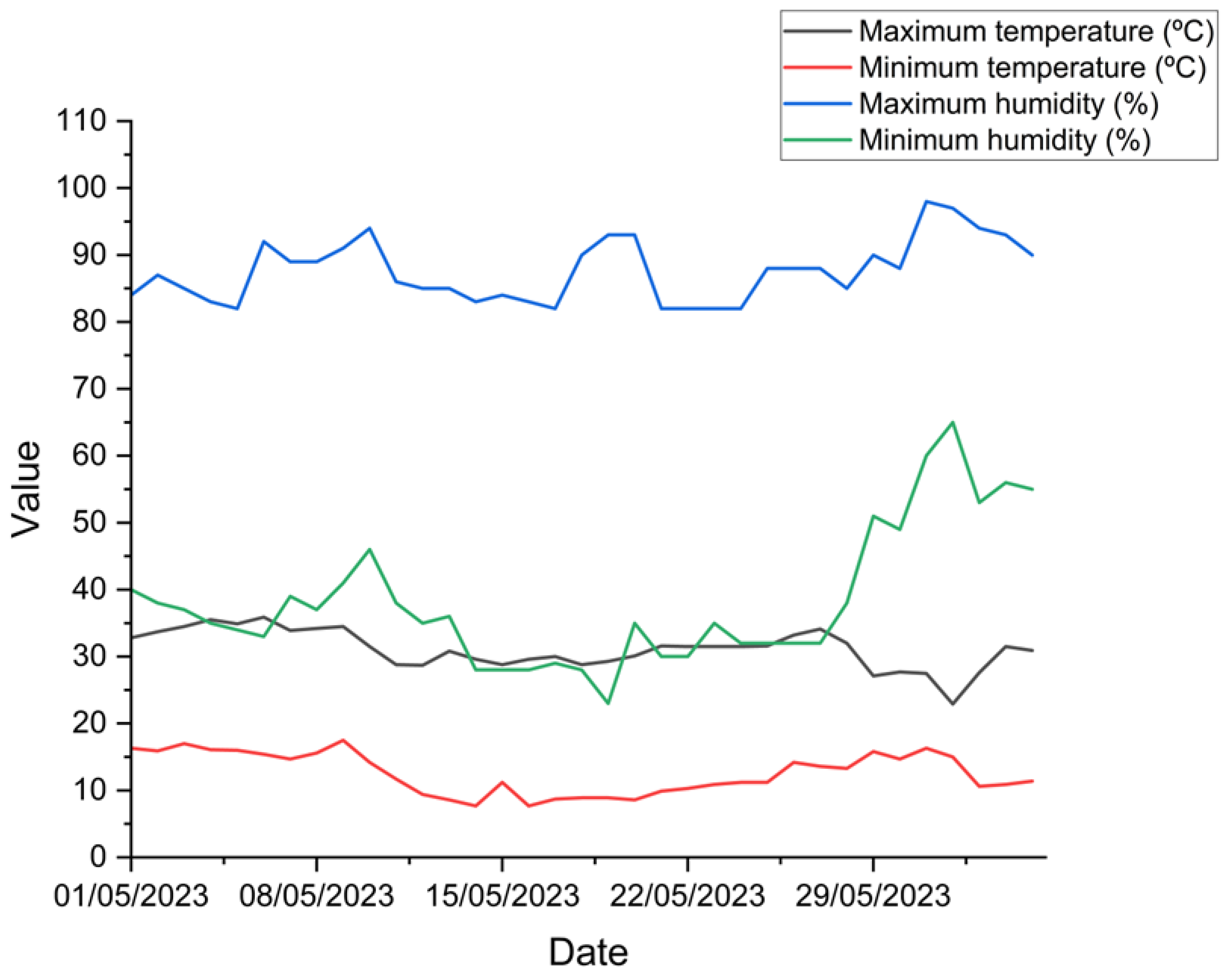
Figure 3.
Average values of nitrogen content in common bean leaves submitted to nitrogen application. T1: 0 kg ha-1 N, T2: 50 kg ha-1, T3: 100 kg ha-1, T4: 150 kg ha-1.
Figure 3.
Average values of nitrogen content in common bean leaves submitted to nitrogen application. T1: 0 kg ha-1 N, T2: 50 kg ha-1, T3: 100 kg ha-1, T4: 150 kg ha-1.
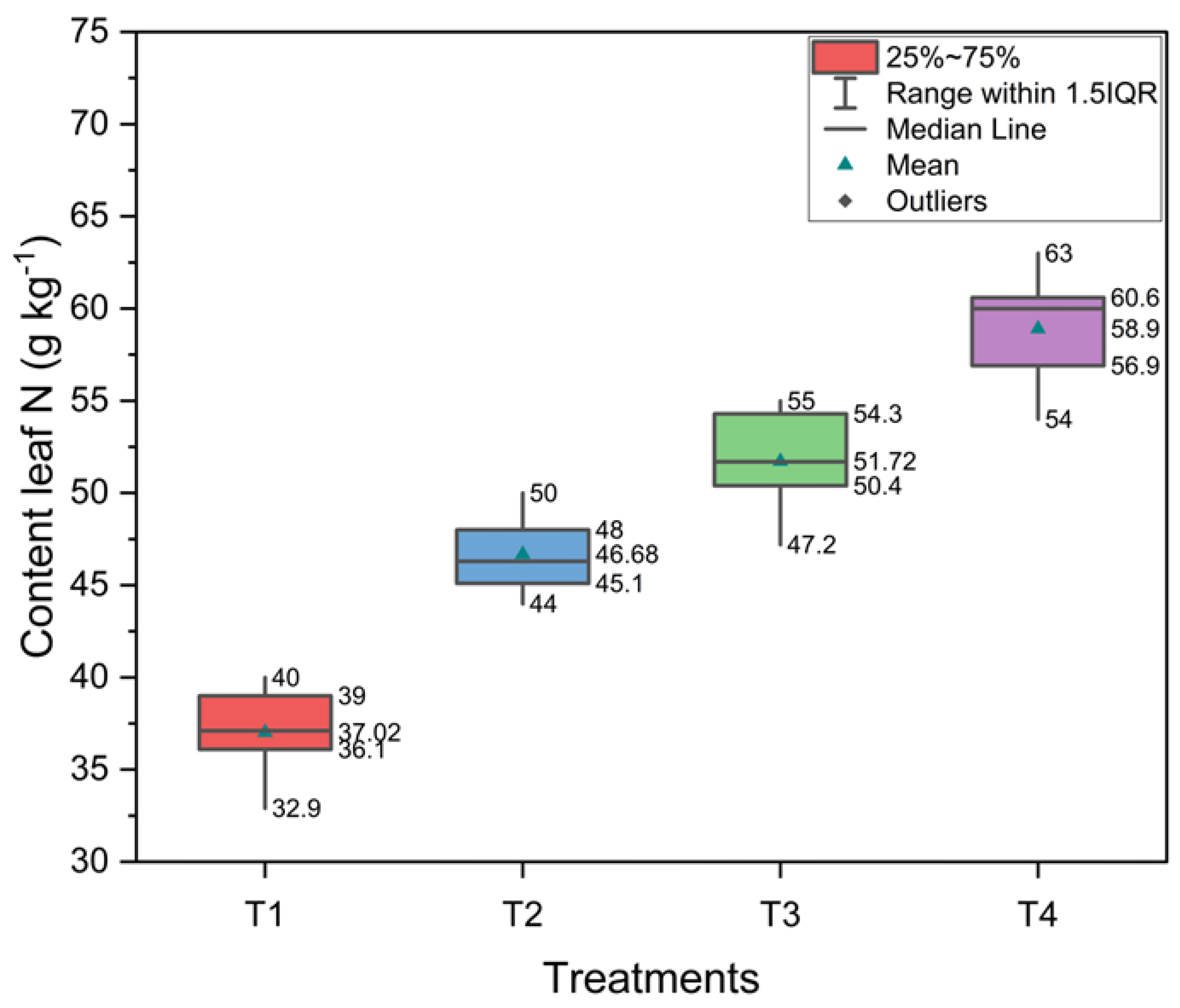
Figure 4.
Spectral curve of medium reflectance (700 to 1300 nm) in BRS FC104 bean leaves grown in a greenhouse and submitted to 4 levels of nitrogen fertilization.
Figure 4.
Spectral curve of medium reflectance (700 to 1300 nm) in BRS FC104 bean leaves grown in a greenhouse and submitted to 4 levels of nitrogen fertilization.
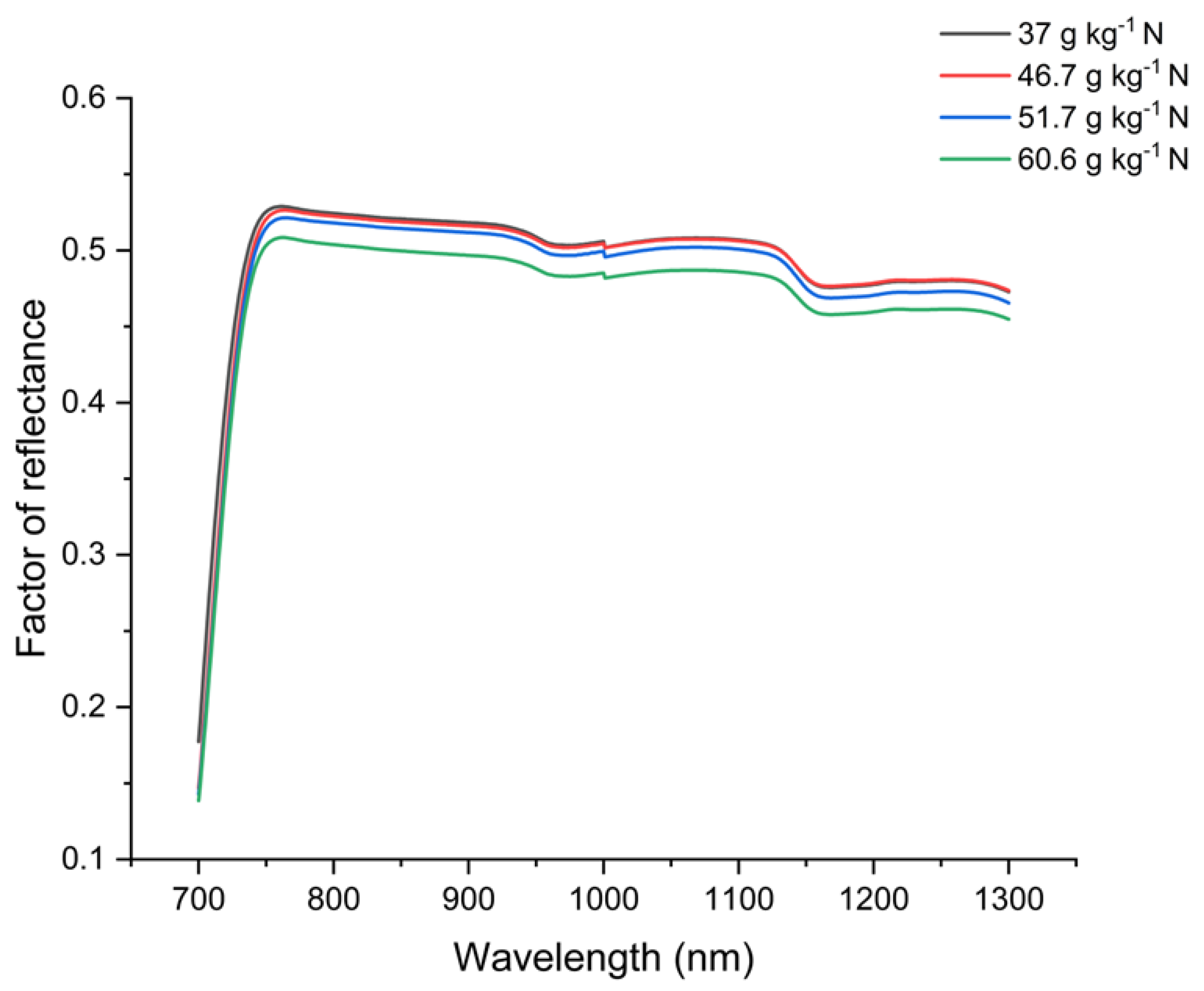
Figure 5.
Selection of the most effective wavelengths for N prediction based on VIP scores, showing two spectral zones highlighted in yellow.
Figure 5.
Selection of the most effective wavelengths for N prediction based on VIP scores, showing two spectral zones highlighted in yellow.
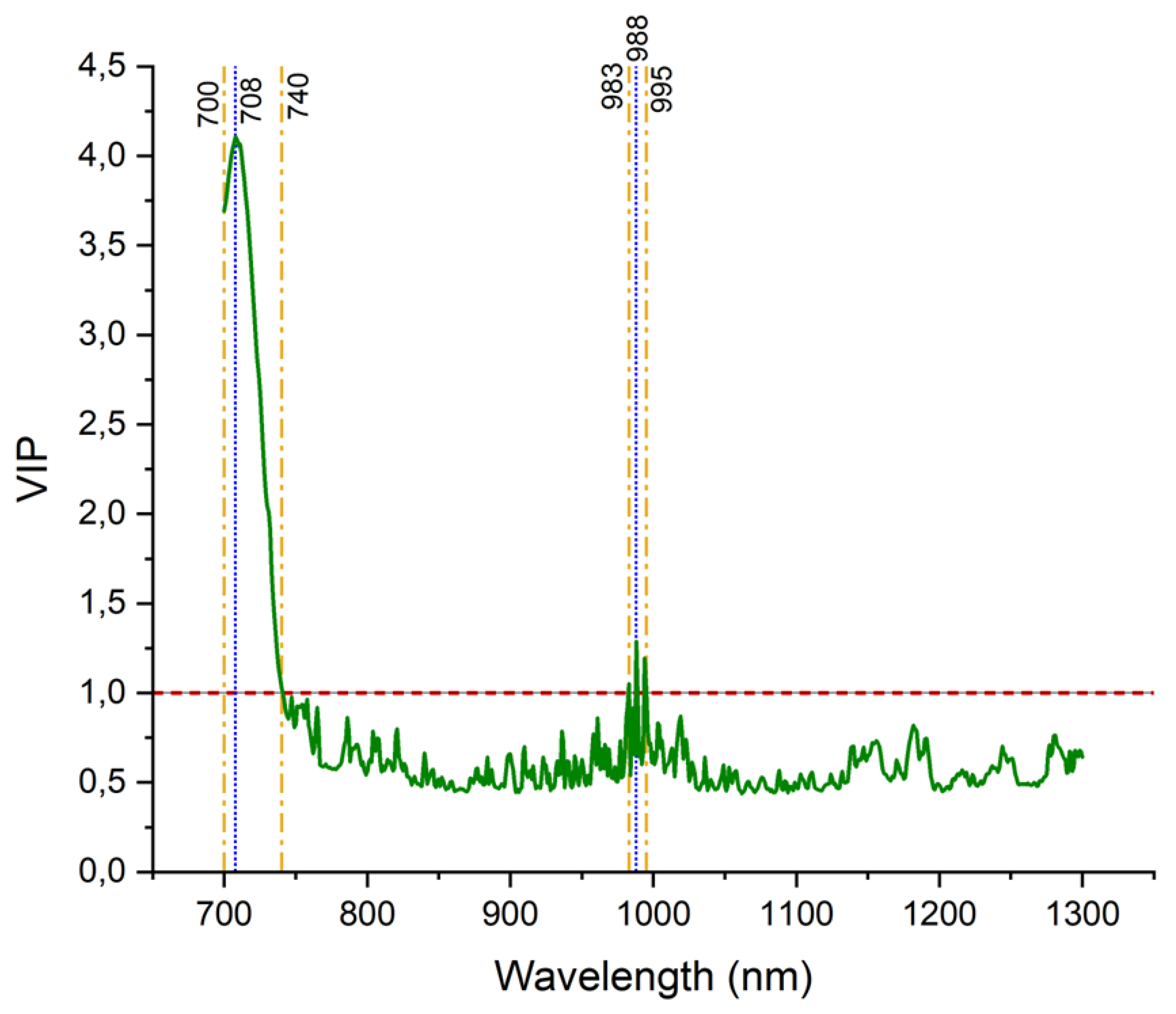
Figure 6.
Performance of machine learning models in predicting N using raw NIR reflectance data in the spectral range of 700 to 1300 nm. A - Random Forest (RF); B - K nearest neighbors (KNN); C - Artificial Neural Network (ANN); D - M5Rules (M5).
Figure 6.
Performance of machine learning models in predicting N using raw NIR reflectance data in the spectral range of 700 to 1300 nm. A - Random Forest (RF); B - K nearest neighbors (KNN); C - Artificial Neural Network (ANN); D - M5Rules (M5).
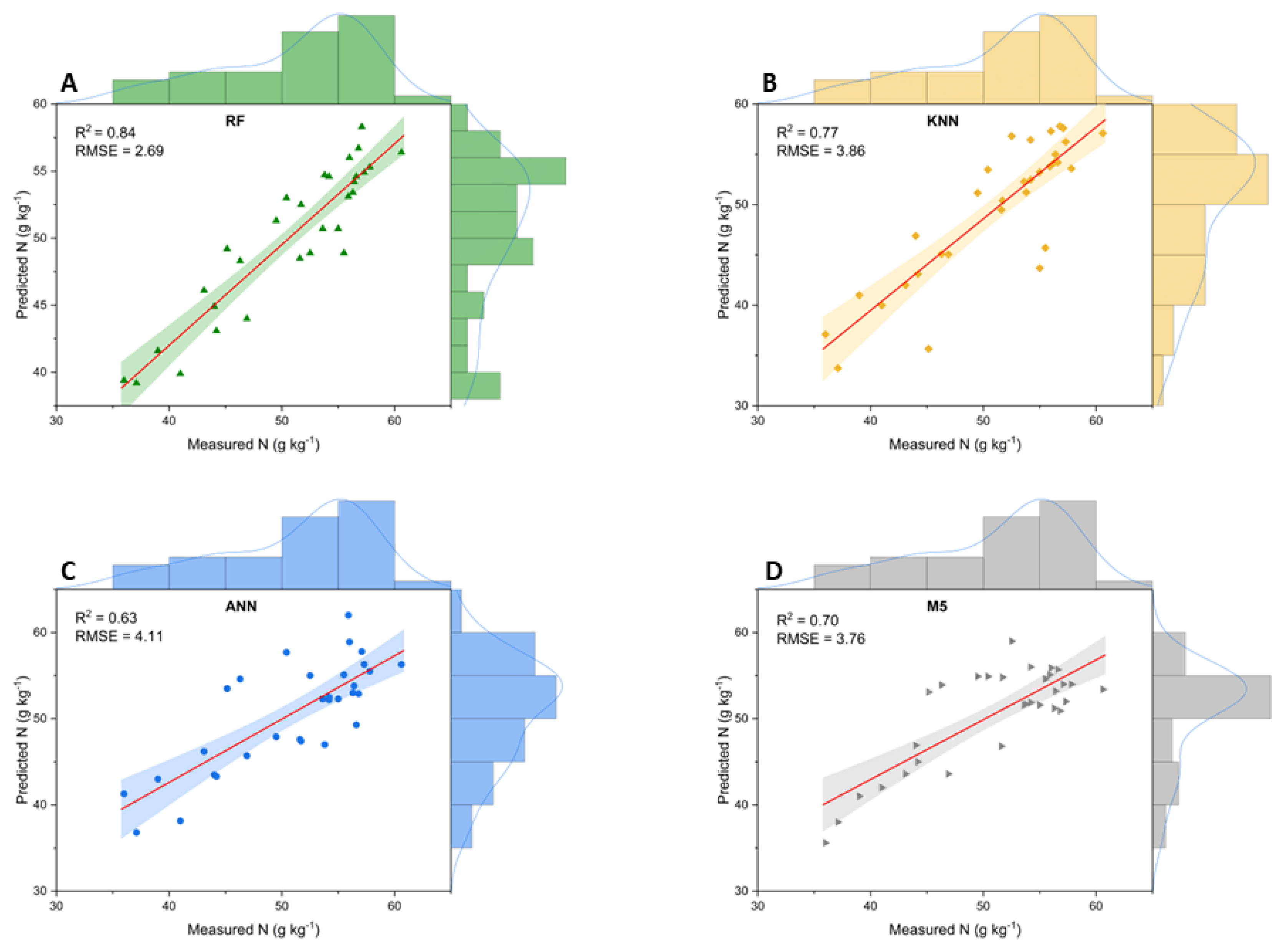
Figure 7.
Performance of machine learning models in estimating N using only the two most effective spectral regions (700 - 740 nm and 983 - 995 nm) for N prediction selected by VIP. A - Random Forest (RF); B - K nearest neighbors (KNN); C - Artificial Neural Network (ANN); D - M5Rules (M5).
Figure 7.
Performance of machine learning models in estimating N using only the two most effective spectral regions (700 - 740 nm and 983 - 995 nm) for N prediction selected by VIP. A - Random Forest (RF); B - K nearest neighbors (KNN); C - Artificial Neural Network (ANN); D - M5Rules (M5).
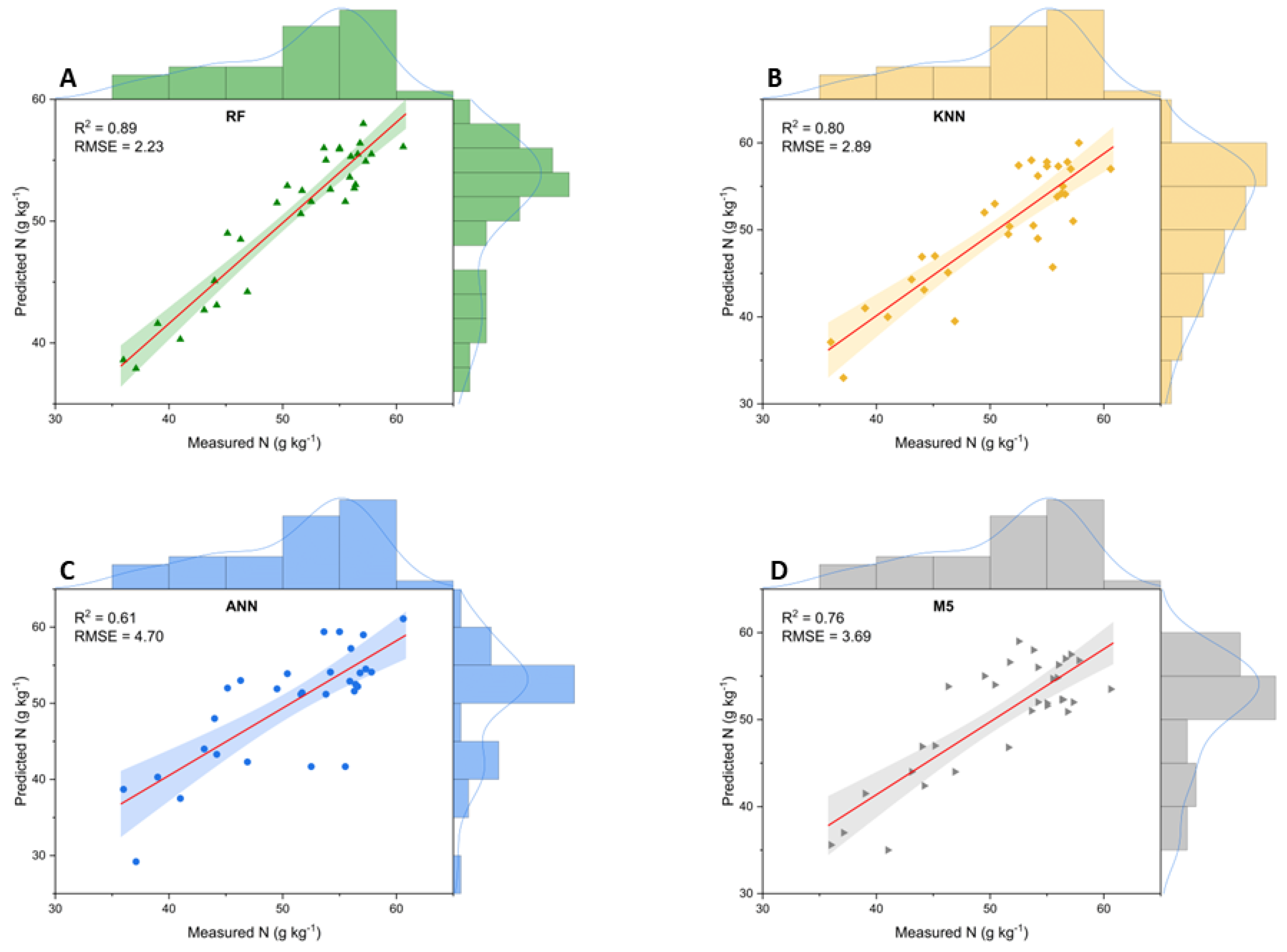

Table 1.
Physicochemical properties of the materials used for substrate composition.
| Soil (Quartzarenic Neosol): 0-20 cm | |||||||||
| pH (CaCl2) | P (res) mg . dm-3 | S (PPM) | K (res) mmolc . dm-3 | Ca | Mg | Al | H + Al | M.O. | C.T. |
| 4,4 | 8 | 4 | 0,3 | 16 | 4 | 4,1 | 30 | 16 | 9,3 |
| Complementary Results | |||||||||
| SB | CTC | V | m | Relationships between bases (CTC) % | Relationships between bases | ||||
| mmolc . dm-3 | ------------ % ------------ | Ca/CT | Mg/CT | K/CTC | (H+Al)/CTC | Ca/Mg | Ca/K | ||
| 20 | 50 | 41 | 17 | 32 | 8 | 1 | 60 | 4 | 53,3 |
| Micronutrients | Textural Analysis | Mg/K | (Ca+Mg)/K | ||||||
| ------------------ mg . dm-3 (PPM) ------------------ | --------------- % --------------- | 13,3 | 66,7 | ||||||
| B | Cu | Fe | Mn | Zn | Sand total |
Clay | Silt | ||
| 0,12 | 1,6 | 51 | 4,6 | 2,9 | 90 | 8 | 2 | ||
| Tanned Cattle Manure | |||||||||
| pH | MS total | M.O | Gray | C total |
C org | N | P2O5 | K2O | |
| 6,6 | ----------------------------------%--------------------------------- | --------------------g/kg-------------------- | |||||||
| 63,5 | 17,6 | 80 | 10,2 | 6,8 | 10,2 | 5,9 | 3,8 | ||
| S | CaO | MgO | B | Cu | Zn | Mn | Relation C/N | ||
| ------------------g/kg---------------- | ------------------------------- mg/kg ------------------------- | 10:1 | |||||||
| 0,4 | 7,7 | 9,6 | 3,1 | 230 | 217,2 | 1100 | |||
| Crushed Sugarcane Straw | |||||||||
| pH | MS total | M.O | Gray | C total |
C org | N | P2O5 | K2O | |
| 4,9 | ---------------------------------- % ---------------------------------- | --------------------g/kg-------------------- | |||||||
| 7,6 | 50,6 | 28,4 | 29,4 | 12,8 | 9,1 | 4,8 | 2 | ||
| S | CaO | MgO | B | Cu | Zn | Mn | Relation C/N | ||
| -------------- g/kg --------------- | ------------------------------ mg/kg ----------------------------- | 32:1 | |||||||
| 0,3 | 5,9 | 6,2 | 2,1 | 77,8 | 121 | 454,5 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



