
Submitted:
07 June 2024
Posted:
11 June 2024
You are already at the latest version
Abstract
For the first time to optimize the creation of new neuroprotective agents based on bioflavonoids, we applied information technologies - docking analysis to calculate the binding of candidate molecules to the pharmacological target protein transthyretin, as well as the program of virtual screening of NO scavengers. As a result of this approach, the substance catechin was isolated from candidate molecules - quercetin, catechin, Epicatechin gallate, Epicatechin, Procyanidin B1, Procyanidin B2, Procyanidin B3, Catechin-3-gallate according to docking analysis. As a result of virtual screening, catechin was identified as a potential NO scavenger (55.15% prediction). The results of the prediction were confirmed by in vitro experiments. Course administration of catechin to animals with experimental multiple sclerosis (MS) against the background of methylprednisolone administration completely eliminated lethal cases, reduced the number of diseased animals by 20%, as well as prevented the development of severe neurological symptoms by 20% (compared to the methylprednisolone group) and by 60% compared to the control group. Course administration of catechin with methylprednisolone leads to decrease of neurodegradation markers in the cytosol of rats with EAE: NSE by 37%, and S-100 - by 54.8%. The combined administration of methylprednisolone significantly exceeds the combination of methylprednisolone with the reference drug mexidol by the degree of NSE reduction. The obtained results indicate a significant neuroprotective effect of ocular combinations of methylprednisolone and catechin. The above-mentioned confirms the correctness of bioflavonoid selection with the help of virtual screening program.
Keywords:
informational technologies
; multiple sclerosis
; virtual screening
; bioflavonoids
; neuroprotection
1. Introduction
Multiple sclerosis (MS) is a progressive autoimmune disease of the central nervous system (CNS). A key aspect of MS pathology is the infiltration of brain tissue by T cells that cross the blood-brain barrier, leading to characteristic inflammation and demyelination [1]. This perivascular infiltration of inflammatory cells into the CNS is facilitated by their adhesion to endothelial cells and subsequent migration across the blood-brain barrier [2]. Proinflammatory cytokines synthesized by T cells, including interleukin-2, lymphotoxin, γ-interferon, and tumor necrosis factor-alpha (TNF-α), contribute to a prolonged increase in blood-brain barrier permeability [3]. Additionally, these cytokines trigger the activation of microglial cells, macrophages, and astrocytes. In response, microglial cells secrete inflammatory cytokines and increased amounts of free radicals, promoting cell necrosis, membrane lysis, and significant damage to myelin and oligodendrocytes. [4,5].
Conformational changes in human proteins also play a role in the pathogenesis of multiple sclerosis (MS). While the nature of these conformational changes is largely unknown, some lead to the formation of amyloid fibrils. These amyloid fibrils accumulate in the extracellular space of tissues, causing organ dysfunction [6,7]. MS is characterized by four main pathological features: firstly, immunological changes in MS are considered to be due to an increase in the infiltration of proinflammatory cells, which consist of CD4+ T cells with T helper 1 (Th1)/Th17 phenotypes, B cells, monocytes, macrophages, natural killer (NK) cells. There is also a decrease in the number of CD8+ T cells, CD4+ CD25+ forkhead box P3 (FoxP3+) Treg cells and Treg 3 dysfunction; secondly, the inflammatory process destroys the myelin sheath or cell body of the oligodendrocyte, which leads to demyelination; third, inflammation also causes damage and loss of axons; fourth, the astrocytic response to inflammation-induced neuronal damage, the so-called “gliosis” [6,7]. The myelin sheath of the CNS (gray and white matter) is the main target in multiple sclerosis, the release of pro-inflammatory cytokines such as interleukin 17 (IL-17), IL-4, IL-10, IL-12, IL-23, TNF-α, as well as activation of macrophages and microglia damage the myelin sheath of neurons through the secretion of toxic substances such as reactive oxygen species (ROS), reactive nitrogen species (RNS), and glutamate [8,9].
Inducible NOS (iNOS) is known to be associated with the development of a number of autoimmune diseases. iNOS is induced on monocytes, cells that play a key role in the initiation and development of the immune response. The induction of the enzyme is influenced by pro-inflammatory cytokines, immunomodulatory peptides, and even beta-endorphin through a mechanism involving an increase in cAMP [10,11,12,13]. Excessive nitric oxide (NO) production is associated with lesions observed in multiple sclerosis (MS). Transthyretin (TTR) is a plasma protein implicated in three amyloid diseases: familial amyloidotic polyneuropathy, familial amyloid cardiomyopathy, and senile systemic amyloidosis [14,15]. The latter involves conformational changes in the wild-type protein, while the other two are caused by gene mutations.
The crystal structures of wild-type TTR and many of its disease-causing mutants have been determined and observed in patients with MS. There is evidence that certain natural antioxidants affect transthyretin expression [8,9,16,17,18,19,20,21]. The main classes of these antioxidants include phenolic acids, flavonoids, stilbenes, and lignans. These natural compounds have strong antioxidant properties, which are often associated with their neuroprotective effects against various neurodegenerative diseases, such as Alzheimer's disease, Parkinson's disease, Huntington's disease, amyotrophic lateral sclerosis, and multiple sclerosis. [22,23].
Various studies have shown that certain polyphenols can inhibit the self-assembly of specific peptides and proteins associated with amyloid diseases. The aggregation of amyloid fibrils is involved in some degenerative human pathologies, where the protein begins to form dimers and small oligomers, stimulating the growth of protofibrils and fibrils that are abnormally deposited in tissues and organs. Hundreds of small chemical molecules that bind to TTR have been discovered. All natural and chemical ligands belonging to different chemical classes capable of stabilizing the TTR tetramer have been investigated, identifying structural modifications that led to either an improvement or a decrease in their activity and/or selectivity. Since then, several other natural compounds have been investigated for their ability to inhibit TTR fibril formation and have been crystallized together with TTR, expanding the knowledge of their interactions and affinity binding.
Flavonoids, a class of natural antioxidant compounds, have also been investigated in recent years for their neuroprotective effects against various neurodegenerative diseases. Numerous studies have shown that flavonoids have different capacities to bind to the two thyroxine binding sites of TTR (T4-BS) and inhibit TTR amyloidogenesis by stabilizing the TTR tetramer. [24]. Several crystal structures of wild-type transthyretin (wt-TTR) in complex with these flavonoids have been reported in the literature, allowing researchers to study both the interactions of TTR with these flavonoids and the effect of the number and position of hydroxyl groups on ligand affinity. The most notable flavonoid is epigallocatechin gallate (EGCG), the main polyphenolic component of green tea. EGCG has multiple biological functions, including antioxidant and anti-inflammatory effects. In vitro experiments have also shown that EGCG is a potent anti-cancer agent. EGCG is considered a viable therapeutic candidate for preventing the progression of neurodegenerative diseases such as Alzheimer's disease, amyotrophic lateral sclerosis, multiple sclerosis, and Parkinson's disease. [26].
Flavonoids are a group of natural compounds used, for example, in the treatment of vascular endothelial damage. They are known as excellent scavengers of free oxygen radicals. Since the nitric oxide radical (NO) likely plays a role in this pathology, the ability of flavonoids to scavenge NO has been determined. Flavonoids were found to be very potent scavengers of NO. Anthocyanidins were identified as more efficient scavengers than hydroxyethylrutosides, which correlates with their therapeutic activity [26]. The values of their scavenging rate constants are only 30 times less active than those of the highly powerful endogenous hemoglobin scavenger of NO. It is assumed that NO removal contributes to the therapeutic effect of flavonoids [27]. The results obtained from crystal structure analysis are often combined with various physicochemical assessments in vitro or in vivo, making flavonoids very promising for the development of neuroprotective MS treatments.
The aim of the study. To identify the most active bioflavonoid with the properties of a TTR inhibitor and NO scavenger and to evaluate its effect in vitro and in a model of multiple sclerosis using modern information technologies (docking analysis, virtual screening program).
2. Materials and Methods
2.1. Docking Analysis
The first step was the docking analysis. The study was conducted using flexible molecular docking as an approach to finding molecules that have affinity for a specific biological target. Macromolecules from the Protein Data Bank (PDB) were used as a biological target, namely human transthyretin in complex with thyroxine (T4) (PDB ID - 1ICT) [Protein Data Bank. http://www.rcsb.org/pdb/home/home.-do. As of September 6, 2021].
Ligand preparation. Substances were drawn using MarvinSketch 20.20.0 and saved in mol format [MarvinSketch version 20.20.0, ChemAxon http://www.chemaxon.com]. After initial preparation, the ligands were optimized using Chem3D with the molecular mechanics algorithm MM2 and saved as pdb files. Molecular mechanics was employed to obtain more realistic geometric values for most organic molecules due to its high parameterization. Using AutoDockTools-1.5.6, the pdb files were converted to PDBQT format, with the number of active torsions set to default.
Protein Preparation: Protein structures were downloaded from the Protein Data Bank. Discovery Studio v19.1.0.18287 was used to remove water molecules and ligands from the protein structures, which were then saved as pdb files [Discovery Studio Visualizer v19.1.0.18287, Accelrys Software Inc., https://www.3dsbiovia.com]. In AutoDockTools 1.5.6, polar hydrogen atoms were added to the protein structures, which were then saved as PDBQT files. The grid field was set as follows: center_x = -1.750, center_y = -44.944, center_z = 33.278, size_x = 25, size_y = 25, size_z = 25 for the receptor (PDB ID - 1ICT). Vina was used for docking. Discovery Studio v 19.1.0.18287 was used for visualization.
2.2. The Virtual Screening Program.
The following machine learning models can be used for a virtual screening program:
- Linear Regression
Linear Regression is a machine learning method that uses a linear model to predict numerical values. It finds a linear relationship between input data and output values that allows you to make a prediction for new data.
- 2.
- Support Vector Machine Regression
Support Vector Machine Regression is a machine learning method used for regression tasks. It finds the hyperplane in the input space that separates the values of the output variable the most. The new input data can then be used to predict the output value.
- 3.
- Random Forest Regression
Random Forest Regression is a machine learning method used for regression tasks. It creates several different random forest trees, each of which predicts the value of the output variable. The predictions of each tree are then combined to get the final result.
- 4.
- Gradient Boosting Regression
Gradient Boosting Regression is a machine learning method used for regression tasks. It creates successive models, each of which corrects the errors of the previous model. The predictions of each model are then combined to produce the final result.
- 5.
- K-Nearest Neighbors Regression
The K-Nearest Neighbors (KNN) method is one of the machine learning algorithms used for classification and regression. This method searches for the k-nearest points (neighbors) to the point under study in the input data space and uses their values to predict the output variable for the point under study.
Feature scaling
Before building the models, we need to scale the features. While linear regression and random forest algorithms do not require this procedure, other methods, such as k-nearest neighbors, do, as they rely on the calculation of Euclidean distance.
For our purposes, we will use the MinMaxScaler.
# Create the scaler object with a range of 0-1
scaler = MinMaxScaler(feature_range=(0, 1))
# Fit on the training data
scaler.fit(train_features)
# Transform both the training and testing data
train_features = scaler.transform(train_features)
test_features = scaler.transform(test_features)
Evaluation of different models
We will prepare a number of auxiliary functions for running models and evaluating them
# Function to calculate mean absolute error
def mae(true_labels, predicted_labels):
return mean_absolute_error(true_labels, predicted_labels)
# Takes in a model, trains the model, and evaluates the model on the test set
def fit_and_evaluate(model, train_features, train_labels, test_features, test_labels):
# Train the model
model.fit(train_features, train_labels)
# Make predictions and evalute
model_test_pred = model.predict(test_features)
model_train_pred = model.predict(train_features)
model_test_mae = mae(test_labels, model_test_pred)
model_train_mae = mae(train_labels, model_train_pred)
# Return the performance metric
return model_test_mae, model_train_mae
2.2.1. Linear Regression Model
The result of this model is an error of 20% on the test sample and 16% on the training sample, respectively
lr = LinearRegression()
lr_mae_test, lr_mae_train = fit_and_evaluate(lr, train_features, train_labels, test_features, test_labels)
print('Linear Regression Performance on the test set: MAE = %0.4f' % lr_mae_test)
print('Linear Regression Performance on the train set: MAE = %0.4f' % lr_mae_train)
Linear Regression Performance on the test set: MAE = 20.0076
Linear Regression Performance on the train set: MAE = 16.0950
2.2.2. Regression Model Using the Support Vector Method
The result of this model is an error of 18.97% on the test sample and 17.47% on the training sample, respectively
svm = SVR()
svm_mae_test, svm_mae_train = fit_and_evaluate(svm, train_features, train_labels, test_features, test_labels)
print('Support Vector Machine Regression Performance on the test set:
MAE = %0.4f' % svm_mae_test)
print('Support Vector Machine Regression Performance on the train set:
MAE = %0.4f' % svm_mae_train)
Support Vector Machine Regression Performance on the test set: MAE = 18.9718
Support Vector Machine Regression Performance on the train set: MAE = 17.4767
2.2.3. Random Forest Model
The result of this model is an error of 23.72% on the test sample and 6.94% on the training sample, respectively
random_forest = RandomForestRegressor(random_state=0)
random_forest_mae_test, random_forest_mae_train = fit_and_evaluate(random_forest, train_features, train_labels, test_features, test_labels)
print('Random Forest Regression Performance on the test set: MAE = %0.4f' % random_forest_mae_test)
print('Random Forest Regression Performance on the train set: MAE = %0.4f' % random_forest_mae_train)
Random Forest Regression Performance on the test set: MAE = 23.7254
Random Forest Regression Performance on the train set: MAE = 6.9407
2.2.4. Graded Boosting Model
The result of this model is an error of 21.98% on the test sample and 3.6% on the training sample, respectively
gradient_boosted = GradientBoostingRegressor(random_state=0)
gradient_boosted_mae_test, gradient_boosted_mae_train = fit_and_evaluate(gradient_boosted, train_features, train_labels, test_features, test_labels)
print('Gradient Boosted Regression Performance on the test set: MAE = %0.4f' % gradient_boosted_mae_test)
print('Gradient Boosted Regression Performance on the train set: MAE = %0.4f' % gradient_boosted_mae_train)
Gradient Boosted Regression Performance on the test set: MAE = 21.9783
Gradient Boosted Regression Performance on the train set: MAE = 3.5952
2.2.5. K-Nearest Neighbors Model
The result of this model is an error of 18.78% on the test sample and 14.21% on the training sample, respectively.
knn = KNeighborsRegressor()
knn_mae_test, knn_mae_train = fit_and_evaluate(knn, train_features, train_labels, test_features, test_labels)
print('K-Nearest Neighbors Regression Performance on the test set: MAE = %0.4f' % knn_mae_test)
print('K-Nearest Neighbors Regression Performance on the train set:
MAE = %0.4f' % knn_mae_train)
K-Nearest Neighbors Regression Performance on the test set: MAE = 18.7883
K-Nearest Neighbors Regression Performance on the train set: MAE = 14.2183
The graph below demonstrates that the support vector and k-nearest neighbors models show similar results on the test sample and demonstrate the smallest error (about 18%).
plt.style.use('fivethirtyeight')
# Dataframe to hold the results
model_comparison = pd.DataFrame({'model': ['Linear Regression', 'Support Vector Machine',
'Random Forest', 'Gradient Boosted',
'K-Nearest Neighbors'],
'mae_test': [lr_mae_test, svm_mae_test, random_forest_mae_test,
gradient_boosted_mae_test, knn_mae_test],
'mae_diff': [lr_mae_test - lr_mae_train, svm_mae_test - svm_mae_train, random_forest_mae_test - random_forest_mae_train,
gradient_boosted_mae_test - gradient_boosted_mae_train, knn_mae_test - knn_mae_train]
})
# Horizontal bar chart of test mae
model_comparison.sort_values('mae_test', ascending = False).plot(x = 'model', y = 'mae_test', kind = 'barh',
color = 'red', edgecolor = 'black')
# Plot formatting
plt.ylabel(''); plt.yticks(size = 14); plt.xlabel('Mean Absolute Error'); plt.xticks(size = 14)
plt.title('Model Comparison on Test MAE', size = 20);
Upon comparing the error differences between training and test samples, we observe that the "support vectors" model exhibits the greatest generalization ability, while both the "random forest" and "graded boosting method" models display clear signs of overfitting (Figure 1 and Figure 2).
# Horizontal bar chart of test mae
model_comparison.sort_values('mae_test', ascending = False).plot(x = 'model',
y = ‘mae_diff’, kind = ‘barh’,
color = ‘blue’, edgecolor = ‘black’)
# Plot formatting
Plt.ylabel(‘’); plt.yticks(size = 14); plt.xlabel(‘Mean Absolute Error’);
plt.xticks(size = 14)
plt.title('Model Comparison on Difference between Test MAE and Train MAE', size = 20);
Following this, we proceed to optimize the models and visualize their performance:
Support vector method
The optimization of the model resulted in an enhancement of prediction accuracy on the training set. However, this improvement was accompanied by a decrease in performance on the test set (Figure 3.).
Random forest model
The optimization of the model resulted in a notable enhancement of generalization ability and effectively eliminated overfitting (Figure 4.). The error rate on the training set was 14.77%, and on the test set - 17.69%.
This section may be divided by subheadings. It should provide a concise and precise description of the experimental results, their interpretation, as well as the experimental conclusions that can be drawn.
K-nearest neighbors model
Optimization of the model led to overtraining of the model and loss of generalization properties (Figure 5).
Gradient boosting model
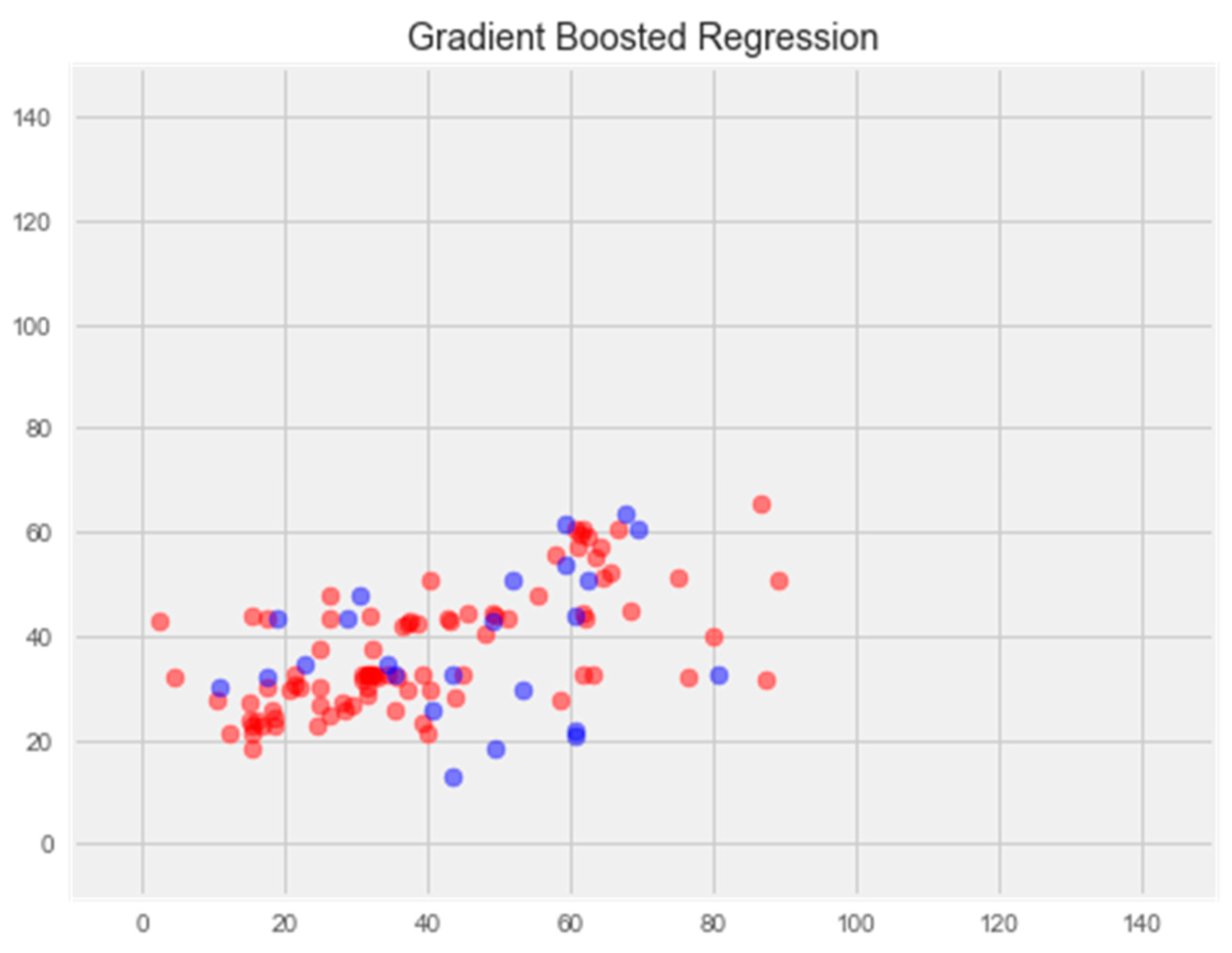
Optimization of this model led to a significant improvement in the generalization ability and eliminated overfitting (Figure 6). The error rate on the training sample was 11.81%, and on the test sample - 16.65%, which is the best indicator among all models.
Following our analysis, we tested several models for solving regression problems. The models that performed best without optimization were the support vector machines (SVM) and k-nearest neighbors (KNN) models.
After optimizing the models, the gradient boosting model demonstrated the best generalizing ability, achieving an error rate of 16%. This optimized model can be used to predict antioxidant activity based on quantum chemical parameters.
Furthermore, using the electronic topological approach, the Department of Medical and Pharmaceutical Informatics and New Technologies at ZSMPU developed a virtual screening program.
Figure 7.
The interface of the virtual screening program.
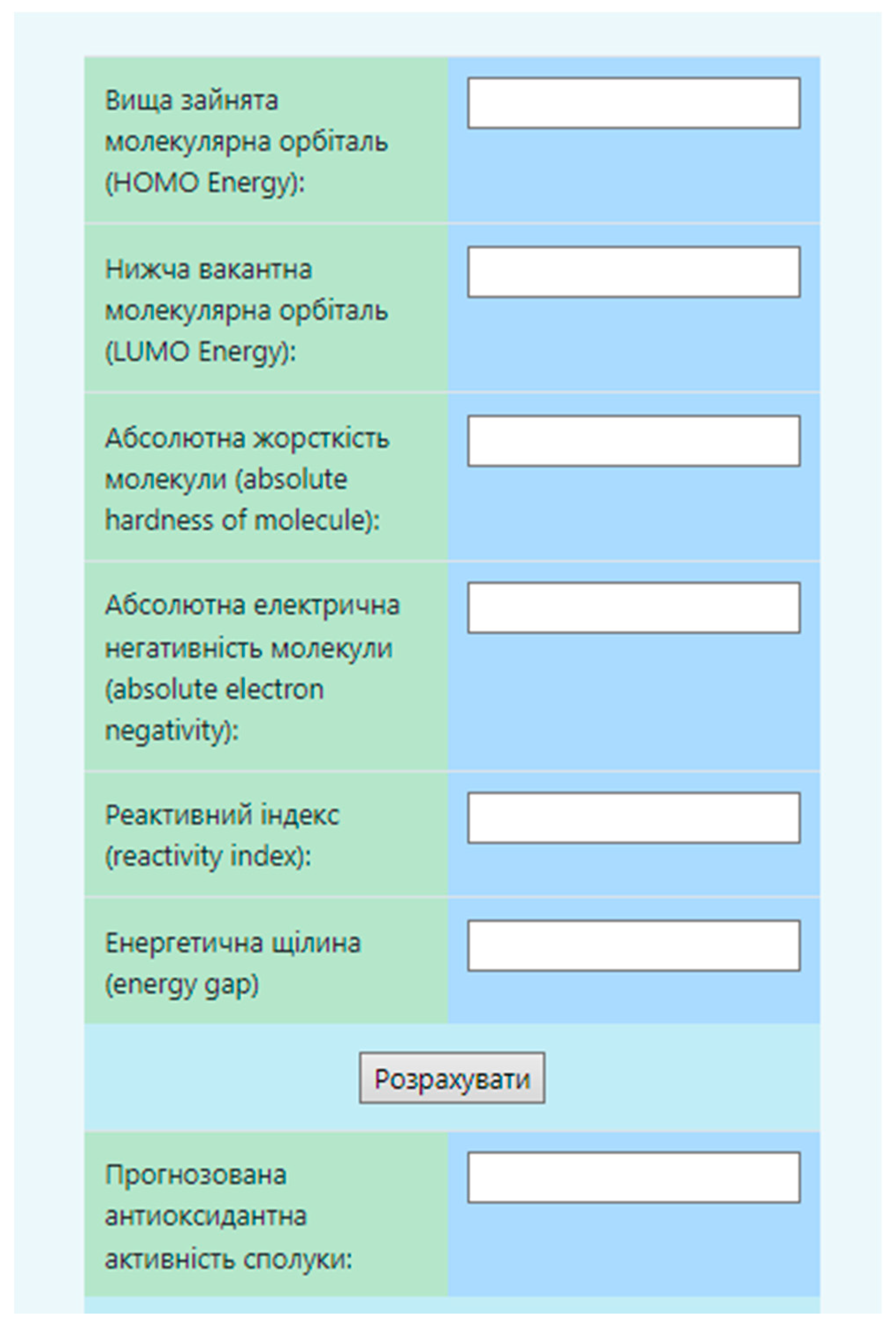
2.3. In Vitro Studies.
The second step was to conduct spectrophotometric studies on the degree of displacement of T4 flavonoids from the complex with proteins [28]. The experiments were performed on a Libra S 32 PC spectrophotometer (United Kingdom). Binding experiments were performed in a solution containing 50 mM phosphate buffer, pH 7.4 at 25°C. The interaction of T4 + transthyretin complexes with bioflavonoids was analyzed by observing the increase in optical density at 225 nm. Test samples and protein were dissolved in phosphate buffer. The final concentration in the sample was 10-7 M. The protein complex was also dissolved in phosphate buffer (0.1 μM). The test sample was added to the incubation sample, the volume was brought to 1.0 ml with phosphate buffer, and the optical density was recorded at 37° for 25 minutes.
The antioxidant activity (AOA) of bioflavonoids was also evaluated by inhibition of NO radical [18]. A 0.08% ascorbic acid solution and a 0.6% sodium nitroprusside solution were prepared extemporaneously. To 2 ml of sodium nitroprusside solution was added 1 ml of ascorbic acid and 0.5 ml of the test sample (10-6 M). After stirring, the reaction was started by immersion from a 300 W light source with λ = 425 nm for 30 min. AOA was estimated by the retention of ascorbic acid concentration, which was determined at λ = 265 nm.
2.4. Experimental Model of Multiple Sclerosis
The experiments were performed on 50 white outbred rats, weighing 220-260 g, of both sexes, obtained from the nursery of the Institute of Pharmacology and Toxicology of the National Academy of Medical Sciences of Ukraine. The quarantine (acclimatization) period for all animals was 14 days. During the quarantine, each animal was examined daily for behavior and general condition, and the animals were monitored twice a day in cages for morbidity and mortality. Before the start of the study, animals that met the criteria for inclusion in the experiment were divided into groups using the randomization method. Animals that did not meet the criteria were excluded from the study during quarantine. Cages with animals were placed in separate rooms. The light regime was 12 hours of light and 12 hours of darkness. The air temperature was maintained between 19-25°C, and relative humidity was 50-70%. Air temperature and humidity were recorded daily. A ventilation regime was established that provided about 15 volumes of air per hour. The experimental animals were kept on the same diet under normal vivarium conditions. Rats were housed in standard cages, with five animals per cage, while rabbits were housed one per cage. The diet consisted of fodder grain, bread, and root vegetables (beets and carrots).
Experimental allergic encephalomyelitis (EAE) was induced by a single subcutaneous injection of an encephalitogenic mixture (EMS) in complete Freund's adjuvant (CFA). The injection mixture per animal contained 100 mg of homologous spinal cord homogenate, 0.2 ml of CFA (5 mg/ml of killed mycobacteria), and 0.2 ml of saline. EMS was injected at the base of the tail under light ether anesthesia in a volume of 0.4 ml. The formation of EAE in animals was assessed by the development of neurological disorders, determined by the clinical and cumulative EAE index. The clinical index was determined by the following scale: muscle weakness of one limb - ½ point, paresis - 1 point, paralysis - 1 ½ points. If multiple limbs were involved, the scores were summed. The absence of disorders was scored as 0 points, and death was scored as 6 points. Animals with a clinical index of ½ - 2 ½ points were considered to have a mild form of EAE, while scores of 3 - 6 points corresponded to a severe course of EAE [29].
2.5. Drugs and Doses.
In vitro and in vivo studies included test samples of bioflavonoids: quercetin, catechin, epicatechin gallate, epicatechin, procyanidin B1, procyanidin B2, procyanidin B3, and catechin-3-gallate (Sigma, USA).
In the invivo experiments, there were five groups of animals:
1) Intact (10 rats)
2) Control - untreated with EAE, received physiological saline (10 rats)
3) Animals with EAE receiving baseline treatment - methylprednisolone (MP), 3.4 mg/kg, administered intraperitoneally slowly in saline (10 rats)
4) Animals with EAE receiving MP + catechin, 10 mg/kg, administered intragastrically (10 rats)
5) Animals with EAE receiving MP + antioxidant mexidol, 250 mg/kg, administered intragastrically (10 rats)
The drugs were administered 2 days after the induction of EAE: methylprednisolone for 7 days, and catechin and mexidol for 14 days (latent phase + clinical phase until the end of the peak of the disease). Control and intact rats received intraperitoneal and intragastric saline in similar volumes throughout the treatment course. All studies were performed on day 17 of the experiment.
Animal Euthanasia. At the end of the experiment, the animals were euthanized under thiopental sodium anesthesia (40 mg/kg).
2.6. Preparation of Biological Material
Blood was rapidly removed from the brain, and the brain was separated from the dura mater. The brain pieces under study were placed in liquid nitrogen, ground to a powdered state, and homogenized in a 10-fold volume of medium at 2°C containing (in mmol): sucrose - 250, Tris-HCl buffer - 20, EDTA - 1 (pH 7.4). At a temperature of +4°C, the mitochondrial fraction was isolated by differential centrifugation using a Sigma 3-30k refrigerated centrifuge (Germany). To purify the mitochondrial fraction from large cellular fragments, the homogenate was first centrifuged for 7 minutes at 1000g, and then the supernatant was centrifuged again for 20 minutes at 17000g. The supernatant was decanted and stored at -80°C.
2.7. Enzyme-Linked Immunosorbent Assay.
The cerebral cytosol was used to determine neurodegeneration markers, such as neuron-specific enolase (NSE) and protein S100 (S100), which reflect neuroglial activity as a natural response to massive neuronal destruction. NSE activity (ng/ml) and S100 content (ng/ml) were determined by enzyme-linked immunosorbent assay (ELISA) using the NSE ELISA KIT #MBS2024030 (MyBioSource, Inc., USA) and S-100 ELISA KIT #LS-F25201 (LifeSpan Biosciences, Inc., USA).
IL-1β was determined as an inflammatory marker involved in the mechanisms of secondary brain damage. The significance of this marker was confirmed by studies that revealed a correlation between increased IL-1β levels, the severity of neurological disorders, and growth factor deficiency (BDNF, IGF-1, PDGF). IL-1β was determined in the retinal homogenate by ELISA using the IL-1β ELISA KIT #KE10003 (Proteintech, USA).
As a marker of oxidative stress and to assess the antioxidant effect of the studied drugs, nitrotyrosine was determined by solid-phase enzyme immunoassay using the NITROTYROSINE ELISA KIT #HK501 (HycultBiotech, USA). The study was carried out using a Sirio-S microplate immunoassay reader (Seac Radim Company, Italy).
2.8. Statistical Methods of the Study
The results of the study were calculated using the standard statistical package of the licensed program “STATISTICA® for Windows 6.0” (StatSoft Inc., №AXXR712D833214FAN5), as well as “SPSS 16.0” and “Microsoft Office Excel 2003”. The normality of the distribution was assessed by the Shapiro-Wilk test. Data are presented as the mean value. The reliability of differences between the mean values was determined by the Student's t-test for normal distribution. In the case of a non-normal distribution or analysis of ordinal variables, the Mann-Whitney U test was used. To compare independent variables in more than two samples, analysis of variance (ANOVA) was used for normal distribution or the Kruskal-Wallis test for non-normal distribution. For all types of analysis, differences with p < 0.05 (95%) were considered statistically significant.
Quantum chemical calculations. In the course of the study, quantum chemical calculations of the descriptors HOMOEnergy (highest occupied molecular orbital) and LUMOEnergy (lowest vacant molecular orbital) were performed using the WinMopac software package (v. 7.2). The structure was optimized using the semi-empirical AM1 method with the following parameters: Calculation = SinglePoint, WaveFunction = ClosedShell (RHF).
3. Results and Discussion
As can be seen from the docking analysis data presented in Table 1, Table 2, Table 3, Table 4, Table 5 and Table 6, L-thyroxine has a binding energy of -6.4 cal/mol for the specific binding sites of human transthyretin. Quercetin and catechin are comparable to L-thyroxine in terms of binding energy and amount to -6.7 cal/mol. According to the docking analysis, the test samples - Epicatechin gallate, Epicatechin, Procyanidin B1, Procyanidin B2, Procyanidin B3, Catechin-3-gallate - have a binding energy to specific sites of human transthyretin in the range of 7-8 kcal/mol. The obtained results theoretically and mathematically substantiate the prospects for further in vitro studies of catechin.
In vitro experiments have shown that the addition of catechin to the incubation mixture leads to its binding to the protein transthyretin and displacement of thyroxine from the Transthyretin-L-thyroxine complex. This fact was evidenced by an increase in the optical density at 280 nm (formation of the catechin-transthyretin complex) and an increase in the optical density at 225 nm (displacement of -L-thyroxine from the complex and the appearance of its concentration in the incubation mixture). The results fully confirm the data of the docking analysis and indicate a high binding energy of this test sample with specific transthyretin binding sites.

Table 1.
Results of UV spectrophotometry of Transthyretin + Thyroxine samples after addition of flavonoid samples and incubation for 25 min. at 370С.
Table 1.
Results of UV spectrophotometry of Transthyretin + Thyroxine samples after addition of flavonoid samples and incubation for 25 min. at 370С.
| Experimental groups | 280 nm (protein binding) |
225 nm (level of displaced thyroxine) |
|---|---|---|
| indicators | ∆ | ∆ |
| control | 0±0 | 0±0 |
| catechin | 0,063±0,0001 | 0,082±0,0002 |
Table 2.
Molecular docking analysis of the affinity of the test samples and reference products for human transthyretin (TTR).
Table 2.
Molecular docking analysis of the affinity of the test samples and reference products for human transthyretin (TTR).
| Compound | Affinity (kcal/mol) to human transthyretin |
Docking 2D visualization |
|---|---|---|
| Thyroxin | -6.4 | 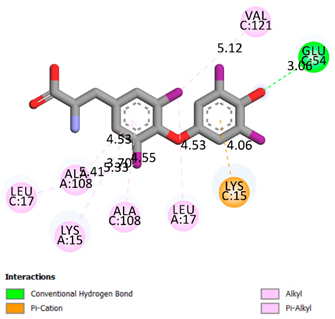 |
| Quercetin | -6.7 | 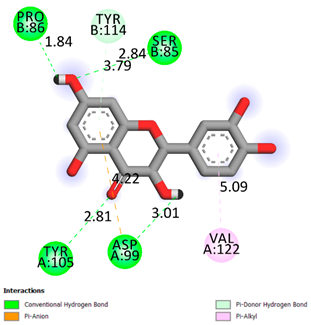 |
| Catechin | -6.2 |
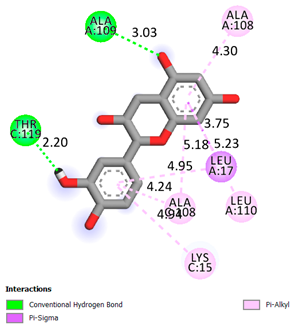 |
Table 2.
Molecular docking analysis of the affinity of the test samples and reference products for human transthyretin (TTR).
Table 2.
Molecular docking analysis of the affinity of the test samples and reference products for human transthyretin (TTR).
| Compound | Affinity (kcal/mol) to human transthyretin |
Docking 2D visualization |
|---|---|---|
| Epicatechin | -7.2 | 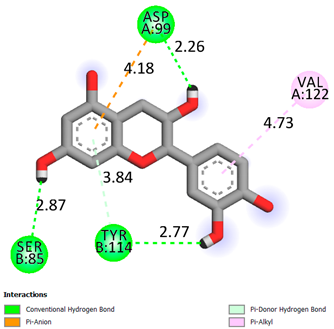 |
| Catechin-3-gallate | -7.6 | 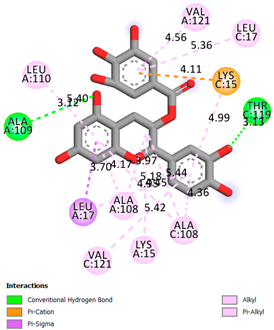 |
| Epicatechin-3-gallate | -7.3 | 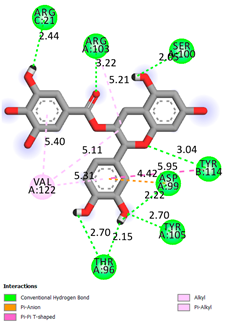 |
| Compound |
Affinity (kcal/mol) to human transthyretin |
Docking 2D visualization |
| Epigallocatechin 3-O-Gallate | -7.7 | 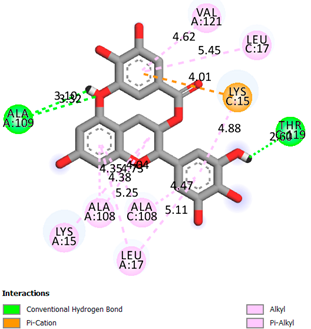 |
| Gallocatechin-3-gallate | -7.5 | 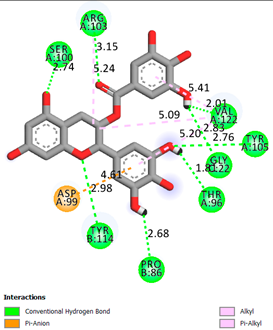 |
| Kaempferol | -7.2 | 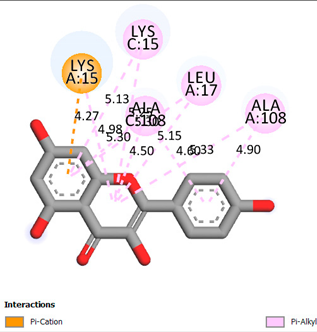 |
| Compound |
Affinity (kcal/mol) to human transthyretin |
Docking 2D visualization |
| Luteolin | -8.0 | 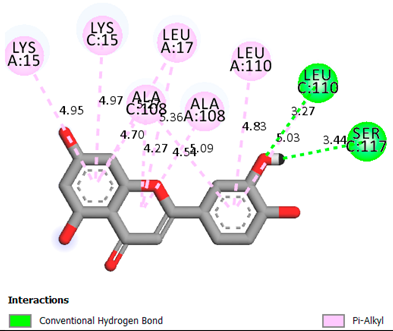 |
| Procyanidin B1 | -7.4 | 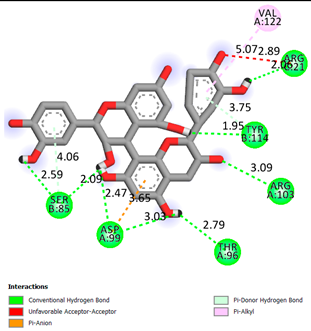 |
| Procyanidin B2 | -8.6 | 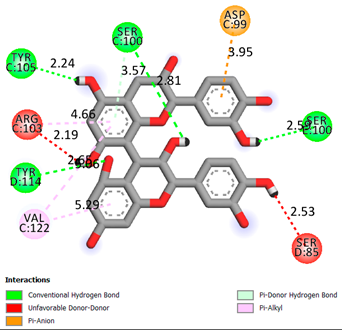 |
| Compound |
Affinity (kcal/mol) to human transthyretin |
Docking 2D visualization |
| Procyanidin B3 | -8.7 | 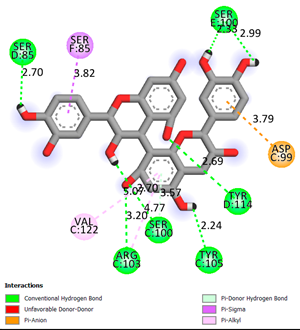 |
Table 3.
Results of UV spectrophotometry of Transthyretin + Thyroxine samples after addition of flavonoid samples and incubation for 25 min. at 370С.
Table 3.
Results of UV spectrophotometry of Transthyretin + Thyroxine samples after addition of flavonoid samples and incubation for 25 min. at 370С.
| Code | AOA results at 10-6 M | AOA prediction, %. | |
| E, M±m | % | 55.15 | |
| Catechin | 1.625±0.001 | 43.67 | |
| Control | 1.131±0.002 | - | |
Table 4.
Effect of catechin on the course of EAE in the setting of baseline methylprednisolone therapy.
Table 4.
Effect of catechin on the course of EAE in the setting of baseline methylprednisolone therapy.
| Indicators | Groups of animals | |||
|---|---|---|---|---|
| Control, EAE (n=10) |
MP (n=10) |
Catechin + MP (n=10) | Mexidol + MP (n=10) |
|
| % of sick animals (total/severe) | 100/70 | 80/30 | 80/10*1 | 80/20* |
| Average clinic index at the peak of EAE, points | 2.6+0.5 | 1.80+0.5 | 0.9+0.5*1 | 1.65+0.152 |
| Average cumulative index, points | 27.2+ 1.5 | 9.4+0.4* | 6.2+0.4*1 | 7.5+0.6* |
| Duration of EAE, days (Student's test) | 16.0 + 1.2 | 8.4 + 0.7* | 6.4 + 0.2*1 | 7.2 + 0.8* |
Notes. * - p ≤ 0.05 in relation to the control values. 1 - p ≤ 0.05 compared to methylprednisolone
Table 5.
Concentration of neurodegradation markers - neuron-specific enolase (NSE) and protein S-100 in the cytosol of rats with EAE after experimental therapy.
Table 5.
Concentration of neurodegradation markers - neuron-specific enolase (NSE) and protein S-100 in the cytosol of rats with EAE after experimental therapy.
| Experimental groups | NSE, ng/ml | S-100, ng/ml |
|---|---|---|
| Intact (n=10) | 0.223±0.015 | 0.088±0.002 |
| EAE (control) (n=10) | 9.11±0.151 | 0.97±0.0151 |
| MP (n=10) | 9.15±0.141 | 0.92±0.0331 |
| MP+ Mexidol (n=10) | 7.11±0.21*1,2 | 0.65±0.042*1,2 |
| MP+ catechin (n=10) | 5.74±0.11*1,2,3 | 0.438±0.014*1,2,3 |
Note: * - p < 0.05 compared to the control group. 1 - p < 0.05 in relation to the intact group. 2 - p < 0.05 in relation to the MP group. 3 - p < 0.05 in relation to the mexidol group.
Table 6.
Concentration of inflammatory markers IL-1b and oxidative stress nitrotyrosine in the cytosol of brain homogenate of rats with EAE and experimental therapy.
Table 6.
Concentration of inflammatory markers IL-1b and oxidative stress nitrotyrosine in the cytosol of brain homogenate of rats with EAE and experimental therapy.
| Experimental groups | Nitrotyrosine, ng/ml | IL-1b, ng/ml |
|---|---|---|
| Intact (n=10) | 0.88±0.042 | 0.31±0.018 |
| EAE (control) (n=10) | 9.89±0.331* | 3.88±0.0551 |
| MP (n=10) | 8.11±0.401 | 1.44±0.022*1 |
| MP+ Mexidol (n=10) | 5.32±0.32*1,2, | 1.39±0.033*1, |
| MP+ catechin (n=10) | 4.11±0.07*1,2,3 | 1.00±0.02*2,3 |
Note: * - p < 0.05 compared to the control group. 1 - p < 0.05 in relation to the intact group. 2 - p < 0.05 in relation to the MP group. 3 - p < 0.05 in relation to the mexidol group.
Our results do not contradict the data of other researchers who have conducted a detailed analysis of ligand interactions for complexes with human TTR. There are two known thyroxine binding sites of TTR (TBS) located in the dimer-dimer interface between the inner sheets of two TTR dimers [30]. These sites have a funnel-shaped morphology with polar residues placed at the entrance and at the bottom and a hydrophobic core located at the center. Three small depressions in the TTR sites were found, which are responsible for the placement of T4. TTR sites can work with several classes of chemicals, including hormones and hormone analogs. There is evidence of flavonoid binding to TTR sites [31].
Our data provide experimental support for further study of catechin.
When testing the structure of catechin using a virtual screening program, a result was obtained that predicted catechin's ability to bind NO at 55.15%. Further testing of catechin in in vitro experiments within the system of photoinduced auto-oxidation of sodium nitroprusside and NO release revealed that at a concentration of 10-6 M, catechin inhibits the formation of radicals by 43.67%. Reactive nitrogen species (RNS) and reactive oxygen species (ROS), collectively known as reactive oxygen and nitrogen species (RONS), are products of normal cellular metabolism. They interact with several vital biomolecules, including nucleic acids, proteins, and membrane lipids, irreversibly changing their function, potentially leading to cell death. Oxidative stress plays a significant role in the pathogenesis of cognitive impairment and the development and progression of neural damage. Increased production of nitric oxide (NO) occurs in numerous pathological conditions such as neurodegenerative diseases, inflammation, and ischemia, which coincide with heightened nitrosative/oxidative stress. The enzyme nitric oxide synthase (NOS) is responsible for NO production in various cells by converting L-arginine to L-citrulline [10].
Thus, the NO signaling pathway represents a viable therapeutic target. Naturally occurring polyphenols affect the NO signaling pathway, which may be important in the field of neurodegeneration and related complications. There are several important roles of NO in the peripheral and central nervous system. It plays a role in both neuroprotection and neurotoxicity. The presence of eNOS has been detected in the vascular endothelium, which is involved in the regulation of blood flow, reduction of neuronal apoptosis and platelet aggregation. Numerous studies, including only a few from human brain autopsies, have demonstrated the significant involvement of NO in neurodegenerative diseases. Decreased endothelial NO levels play a key role in increasing Aβ expression and modulating amyloid precursor protein (APP) in brain vessels [10]. Widespread nitration of Lewy bodies and Lewy nitrite has been demonstrated in autopsy cortex of patients with Lewy bodies and Alzheimer's disease. In addition, in patients with neurodegeneration with iron accumulation in the brain, nitration of α-synucleins in glial cells of the exposed white matter of the cerebellum, in patients with multiple systemic atrophy, as well as nitration of Lewy bodies and neuroaxonal spheroids in autopsy pale globe type 1 were detected [32].
A widespread prevalence of nitrated tau proteins in autopsy of the brains of MS patients has been demonstrated. The involvement of NO and its reaction product (with superoxide radicals), peroxynitrite, in MS pathology has also been reported in postmortem brain studies, as exceptionally elevated levels of protein nitration were found in the hippocampus of MS patients compared to age-matched controls [10]. Several studies based on animal models of MS have shown that NOS inhibition slows the progression of disease pathology. The involvement of NO and peroxynitrite has also been reported in postmortem studies of MS-affected brains, where increased nitration of tyrosine residues in degenerating neurons of the compact part of the substantia nigra was reported [10]. In addition, nitration of protein tyrosine residues has become a crucial factor in the pathogenesis of a wide range of neurodegenerative diseases [33].
It is also interesting to note that most NO-mediated neurodegenerative pathogenesis occurs through nitration. Therefore, utilizing new information technologies, we have identified catechin from a vast array of bioflavonoids. According to the results of docking analysis, catechin can form complexes with transthyretin, a protein involved in the pathogenesis of multiple sclerosis (MS). Additionally, it can serve as a potential scavenger of NO, which also contributes to the pathogenesis of MS. Consequently, a computer program for virtual screening yielded a 55% prediction. In vitro studies have subsequently confirmed the high potential of catechin as a neuroprotective agent for the treatment of MS.
The results of the studies indicate that during the induction of EAE in animals of the control group, the development of neurological disorders of varying severity was recorded. Thus, a death was recorded in 2 rats (20% mortality). Inflammatory reactions were recorded at the injection site, which were observed throughout the experiment. It was recorded that after the formation of EAE in experimental animals, the appearance of persistent neurological disorders was noticeable on day 9. The maximum neurological disorders were recorded on day 14 of the experiment. The duration of the maximum effect was 4 days. The duration of EAE was 16 days. The average cumulative index was 27 points. At the peak of clinical manifestations of pathology, the number of animals with a clinical index of 0.5-2.5 points was 30% of rats (mild degree of pathology). In 70% of rats, the clinical index was from 3 to 6 points (severe pathology). The administration of methylprednisolone increased the survival rate of rats with EAE to 100% and reduced the number of animals with severe symptoms by 18%. When methylprednisolone was administered, the neurological disorders of EAE “at the peak” were shorter (p<0.05) and in a milder form (p<0.05).
The administration of catechin alongside methylprednisolone resulted in the complete elimination of fatalities, a 20% reduction in the number of sick animals, and prevented the development of severe neurological symptoms by 20% (in comparison to the methylprednisolone group) and by 60% compared to the control group. Additionally, neurological symptoms of experimental autoimmune encephalomyelitis (EAE) were shorter (p<0.05) and manifested in mild or moderate forms with the administration of additional catechin. The clinical index at the peak of the disease decreased (p<0.05), as did the cumulative index (p<0.05). Therefore, due to its properties of binding to transthyretin and inhibiting NO production, catechin enhances the effect of methylprednisolone in EAE.
Similarly, the administration of the reference antioxidant drug Mexidol alongside methylprednisolone also resulted in the elimination of fatalities in rats with citicoline-induced EAE, along with the prevention of severe neurological disorders by 10% compared to the methylprednisolone group and by 50% compared to the control group. At the same time, the neurological symptoms of experimental autoimmune encephalomyelitis (EAE) were shorter (p<0.05) and manifested in mild or moderate-severe form. Both the clinical index at the peak of the disease and the cumulative index decreased significantly (p<0.05) compared with the control group. However, the additional administration of Mexidol with methylprednisolone did not lead to a significant increase in the therapeutic effect of methylprednisolone. Thus, unlike Mexidol, catechin is capable of significantly enhancing the effectiveness of methylprednisolone in EAE, which serves as an experimental equivalent of multiple sclerosis (MS).
As can be seen from the data presented in Table 5, the modeling resulted in significant neurodegenerative damage to the rat brain. After modeling the pathology, the activity of the neuronal membrane integrity marker NSE in the control group significantly increased by 40 times compared to intact values, indicating the development of significant neuronal destruction and the prevalence of necrotic death.
By the end of the experiment, the level of another marker, S 100 protein, which reflects the activity of astrocytic glia, a change in which is a natural response of nervous tissue to necrotic and necrobiotic processes, increased 11-fold compared to intact values. The data obtained indicate a significant primary lesion of the neuronal array and intensification of neuroglial proliferative processes in the modeling of EAE.
Course administration of methylprednisolone to rats with EAE did not affect the level of neurospecific markers. Co-administration of methylprednisolone with mexidol led to a significant decrease in NSE by 22% and S-100 by 29.3% compared to the control group. It is worth noting that in the group of EAE rats treated with methylprednisolone with mexidol, the levels of NSE and S-100 were significantly lower than in the group treated with methylprednisolone alone.
Course administration of catechin with methylprednisolone leads to a decrease in neurodegradation markers in the cytosol of rats with EAE: NSE by 37% and S-100 by 54.8%. In terms of the degree of NSE reduction, the combined administration of methylprednisolone significantly outperforms the combination of methylprednisolone with the reference drug mexidol. The results obtained indicate a significant neuroprotective effect of the ocular combination of methylprednisolone and catechin. The above confirms the correctness of the choice of bioflavonoid using a virtual screening program.
As can be seen from Table 6, the modeling of EAE significantly activates oxidative stress reactions by the end of the experiment, as evidenced by an 11.25-fold increase in nitrotyrosine in the rat brain cytosol. Also, modeling of EAE leads to a significant surge in neuroinflammatory reactions in response to the development of significant neurodegeneration and neuronal death by necrosis. Thus, we have noted a 12.5-fold increase in the proinflammatory cytokine IL-1b in the cytosol of the brain homogenate of rats with EAE. IL-1b is produced by microglia, participates in the local inflammatory response around the necrosis “core” zone and plays an important role in the mechanisms of secondary neuronal damage. During the interaction of IL-1b with receptors, nuclear transcription factors AP-1 and NF-kB are activated, which change the behavior of target cells and lead to the development of an acute-phase cellular response, expression of other proinflammatory factors, stimulation of iNOS and cytotoxic NO derivatives by astrocytes, increased mitochondrial pore permeability, and initiation of neuroapoptosis [34].
Course administration of methylprednisolone significantly reduced the level of nitrotyrosine and had no significant effect on the level of oxidative stress marker nitrotyrosine by 18% and inflammatory marker IL-1b by 63%. The addition of mexidol to methylprednisolone therapy leads to a significant increase in the antioxidant effect - a 46.2% decrease in nitrotyrosine compared to control and a 34% decrease in nitrotyrosine compared to the group receiving methylprednisolone alone. At the same time, the combination of methylprednisolone with mexidol did not affect the increase in anti-inflammatory effect. The level of IL-1b did not differ in both groups. The course administration of methylprednisolone with catechin to rats with EAE significantly increases both the antioxidant and anti-inflammatory effects of methylprednisolone.
Thus, in the cytosol of the brain homogenate of rats with EAE treated with a combination of catechin, the level of nitrtyrosine was 58.4% lower than the control value, and IL-1b - 74.2%. The values of these markers in the group receiving the combination with catechin were significantly lower than in the group with methylprednisolone monotherapy and methylprednisolone and the reference drug mexidol. This can be explained from the standpoint of the antioxidant mechanism of catechin action, which regulates the level of reactive oxygen species (ROS) and, thus, is able to regulate the expression of proinflammatory cytokines [35]. This can also be explained from the point of view that catechin is able to inhibit the formation of NO. This is evidenced by both the results of the virtual screening program and the results of in vitro experiments on inhibition of photoinduced NO formation. The reduction of IL-1b under the influence of catechin and the enhancement of this effect when it is administered together with methylprednisolone can be explained by its binding to transthyretin, which plays an important role in the development of neuroinflammation [10].
4. Conclusions
As a result of using new information technologies, we have selected a catechin from a large number of bioflavonoids, which, according to the results of docking analysis, can form complexes with transthyretin, a protein involved in the pathogenesis of MS, and can also be a potential scavenger of NO, which is also involved in the pathogenesis of MS. Thus, a computer program for virtual screening showed a 55% prediction. In vitro studies have confirmed the high potential of catechin as a neuroprotective treatment for MS.
Author Contributions
Conceptualization, I.B., V.R., O.P., N.B., N.G., V.O., and O.K..; methodology, I.B., V.R., O.P., N.B., N.G.; software, I.B., V.R., V.O., O.K..; validation, I.B., V.R., O.P., N.B., N.G., V.O., and O.K..; writing—original draft preparation, I.B., V.R., O.P., N.B.; writing—review and editing N.G., V.O., and O.K..; visualization, I.B., V.R., O.P., V.O., and O.K..; supervision I.B., V.R., O.P., N.B., N.G., V.O., and O.K..; All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All the data generated during this research are included in the manuscript.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Papiri, G.; D'Andreamatteo, G.; Cacchiò, G. , Alia, S.; Silvestrini, M.; Paci, C.; Luzzi, S.; Vignini, A. Multiple Sclerosis: Inflammatory and Neuroglial Aspects. Curr Issues Mol Biol. 2023, 45, 1443–1470. [Google Scholar] [CrossRef] [PubMed]
- Balasa, R.; Barcutean, L.; Mosora, O.; Manu, D. Reviewing the Significance of Blood–Brain Barrier Disruption in Multiple Sclerosis Pathology and Treatment. Int J Mol Sci. 2021, 22, 8370. [Google Scholar] [CrossRef] [PubMed]
- Bierhansl, L.; Hartung, H.P.; Aktas, O.; Ruck, T.; Roden, M.; Meuth, S.G. Thinking outside the box: non- canonical targets in multiple sclerosis. Nat Rev Drug Discov. 2022, 21, 578–600. [Google Scholar] [CrossRef] [PubMed]
- Kölliker-Frers, R.; Udovin, L.; Otero-Losada, M.; Kobiec, T.; Herrera, M.I.; Palacios, J.; Razzitte, G.; Capani, F. Neuroinflammation: An Integrating Overview of Reactive-Neuroimmune Cell Interactions in Health and Disease. Mediators Inflamm. 2021, 2021, 9999146. [Google Scholar] [CrossRef] [PubMed]
- Isik, S.; Kiyak, B.Y.; Akbayir, R.; Seyhali, R.; Arpaci, T. Microglia Mediated Neuroinflammation in Parkinson’s Disease. Cells. 2023, 12, 1012. [Google Scholar] [CrossRef] [PubMed]
- Alraawi, Z.; Banerjee, N.; Mohanty, S.; Kumar, T.K.S. Amyloidogenesis: What Do We Know So Far? Int J Mol Sci. 2022, 23, 13970. [Google Scholar] [CrossRef]
- Fagla, B.M.; Buhimschi, I.A. Protein Misfolding in Pregnancy: Current Insights, Potential Mechanisms, and Implications for the Pathogenesis of Preeclampsia. Molecules. 2024, 29, 610. [Google Scholar] [CrossRef] [PubMed]
- Hadjiagapiou, M.S.; Krashias, G.; Deeba, E.; Christodoulou, C.; Pantzaris, M.; Lambrianides, A. A Preclinical Investigation on the Role of IgG Antibodies against Coagulant Components in Multiple Sclerosis. Biomedicines. 2023, 11, 906. [Google Scholar] [CrossRef]
- Singh, M.K.; Shin, Y.; Ju, S.; Han, S.; Choe, W.; Yoon, K.S.; Kim, S.S.; Kang, I. Heat Shock Response and Heat Shock Proteins: Current Understanding and Future Opportunities in Human Diseases. Int J Mol Sci. 2024, 25, 4209. [Google Scholar] [CrossRef]
- Belenichev, I.; Popazova, O.; Bukhtiyarova, N.; Savchenko, D.; Oksenych, V.; Kamyshnyi, O. Modulating Nitric Oxide: Implications for Cytotoxicity and Cytoprotection. Antioxidants. 2024, 13, 504. [Google Scholar] [CrossRef]
- Coutinho Costa, V.G.; Araújo, S.E.-S.; Alves-Leon, S.V.; Gomes, F.C.A. Central nervous system demyelinating diseases: glial cells at the hub of pathology. Front. Immunol. 2023, 14, 1135540. [Google Scholar] [CrossRef] [PubMed]
- Hullsiek, R.; Li, Y.; Snyder, K.M.; Wang, S.; Di, D.; Borgatti, A.; Lee, C.; Moore, P.F.; Zhu, C.; Fattori, C.; Modiano, J.F.; Wu,J. and Walcheck, B. Examination of IgG Fc Receptor CD16A and CD64 Expression by Canine Leukocytes and Their ADCC Activity in Engineered NK Cells. Front. Immunol. 2022, 13, 841859. [Google Scholar] [CrossRef] [PubMed]
- Ramírez-Mendoza, A.A.; Mendoza-Magaña, M.L.; Ramírez-Herrera, M.A.; Hernández-Nazara, Z.H.; Domínguez-Rosales, J.A. Nitrooxidative Stress and Neuroinflammation Caused by Air Pollutants Are Associated with the Biological Markers of Neurodegenerative Diseases. Antioxidants. 2024, 13, 326. [Google Scholar] [CrossRef] [PubMed]
- Park, G.Y.; Jamerlan, A.; Shim, K.H.; An, S.S.A. Diagnostic and Treatment Approaches Involving Transthyretin in Amyloidogenic Diseases. Int J Mol Sci. 2019, 20, 2982. [Google Scholar] [CrossRef] [PubMed]
- Sanguinetti, C.; Minniti, M.; Susini, V.; Caponi, L.; Panichella, G.; Castiglione, V.; Aimo, A.; Emdin, M.; Vergaro, G.; Franzini, M. The Journey of Human Transthyretin: Synthesis, Structure Stability, and Catabolism. Biomedicines. 2022, 10, 1906. [Google Scholar] [CrossRef] [PubMed]
- Wieczorek, E.; Ożyhar, A. Transthyretin: From Structural Stability to Osteoarticular and Cardiovascular Diseases. Cells. 2021, 10, 1768. [Google Scholar] [CrossRef] [PubMed]
- Radwan, A.A.; Alanazi, F.K.; Raish, M. (2023) Design and synthesis of multi-functional small-molecule based inhibitors of amyloid-β aggregation: Molecular modeling and in vitro evaluation. PLoS ONE. 2023, 18, e0286195. [Google Scholar] [CrossRef] [PubMed]
- Rinauro, D.J.; Chiti, F.; Vendruscolo, M. Misfolded protein oligomers: mechanisms of formation, cytotoxic effects, and pharmacological approaches against protein misfolding diseases. Mol Neurodegeneration. 2024, 19, 20. [Google Scholar] [CrossRef] [PubMed]
- Stroo, E.; Koopman, M.; Nollen, E.A.; Mata-Cabana, A. Cellular Regulation of Amyloid Formation in Aging and Disease. Front Neurosci. 2017, 11, 64. [Google Scholar] [CrossRef]
- Li, J.; Guo, M.; Chen, L.; Chen, Z.; Fu, Y.; Chenet, Y. p53 amyloid aggregation in cancer: function, mechanism, and therapy. Exp Hematol Oncol. 2022, 11, 66. [Google Scholar] [CrossRef]
- Dakterzada, F.; Jové, M.; Cantero, J.L.; Pamplona, R.; Piñoll-Ripoll, G. Plasma and cerebrospinal fluid nonenzymatic protein damage is sustained in Alzheimer's disease. Redox Biol. 2023, 64, 102772. [Google Scholar] [CrossRef] [PubMed]
- Mutha, R.E.; Tatiya, A.U.; Surana, S.J. Flavonoids as natural phenolic compounds and their role in therapeutics: an overview. Futur J Pharm Sci. 2021, 7, 25. [Google Scholar] [CrossRef] [PubMed]
- Barber, K.; Mendonca, P.; Soliman, K.F.A. The Neuroprotective Effects and Therapeutic Potential of the Chalcone Cardamonin for Alzheimer's Disease. Brain Sci. 2023, 13, 145. [Google Scholar] [CrossRef] [PubMed]
- Ciccone, L.; Tonali, N.; Fruchart-Gaillard, C.; Barlettani, L.; Rossello, A.; Braca, A.; Orlandini, E.; Nencetti, S. Antioxidant Quercetin 3-O-Glycosylated Plant Flavonols Contribute to Transthyretin Stabilization. Crystals. 2022, 12, 638. [Google Scholar] [CrossRef]
- Mokra, D.; Adamcakova, J.; Mokry, J. Green Tea Polyphenol (-)-Epigallocatechin-3-Gallate (EGCG): A Time for a New Player in the Treatment of Respiratory Diseases? Antioxidants (Basel). 2022, 11, 1566. [Google Scholar] [CrossRef] [PubMed]
- Al-Khayri, J.M.; Sahana, G.R.; Nagella, P.; Joseph, B.V.; Alessa, F.M.; Al-Mssallem, M.Q. Flavonoids as Potential Anti-Inflammatory Molecules: A Review. Molecules. 2022, 27, 2901. [Google Scholar] [CrossRef] [PubMed]
- Ngoc, T.D.; Le, T.N.; Nguyen, T.V.A.; Mechler. A.; Hoa, N.T.; Nam, N.L.; Vo, Q.V. Mechanistic and Kinetic Studies of the Radical Scavenging Activity of 5-O-Methylnorbergenin: Theoretical and Experimental Insights. The J Phys Chem B. 2022, 126, 702–707. [Google Scholar] [CrossRef] [PubMed]
- Florio, P.; Folli, C.; Cianci, M.; Del Rio, D.; Zanotti, G.; Berni, R. Transthyretin Binding Heterogeneity and Anti-amyloidogenic Activity of Natural Polyphenols and Their Metabolites. J Biol Chem. 2015, 290, 29769–80. [Google Scholar] [CrossRef] [PubMed]
- Nefodov, O.O.; Belenichev, I.F.; Fedchenko, M.P.; Popazova, O.O.; Ryzhenko, V.P.; Morozova, O.V. Evaluation of methods of modeling and formation of experimental allergic encephalomyelitis. Research Results in Pharmacology. 2022, 8, 37–48. [Google Scholar] [CrossRef]
- Saldaño, T.E.; Zanotti, G.; Parisi, G.; Fernandez-Alberti, S. Evaluating the effect of mutations and ligand binding on transthyretin homotetramer dynamics. PLoS One. 2017, 12, e0181019. [Google Scholar] [CrossRef]
- Cody, V.; Truong, J.Q.; Holdsworth, B.A.; Holien, J.K.; Richardson, S.J.; Chalmers, D.K.; Craik, D.J. Structural Analysis of the Complex of Human Transthyretin with 3',5'-Dichlorophenylanthranilic Acid at 1.5 Å Resolution. Molecules. 2022, 27, 7206. [Google Scholar] [CrossRef] [PubMed]
- Forloni, G. Alpha Synuclein: Neurodegeneration and Inflammation. Int J Mol Sci. 2023, 24, 5914. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Shi, Q.; Zheng, Y.; Liu, Q.; He, Z.; Gao, Z.; Liu, Q. Insights Into the Mechanism of Tyrosine Nitration in Preventing β-Amyloid Aggregation in Alzheimer’s Disease. Front. Mol. Neurosci. 2021, 14, 619836. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Saeed, A.F.U.H.; Liu, Q.; Jiang, Q.; Xu, H.; Xiao, G.G.; Rao, L.; Duo, Y. Macrophages in immunoregulation and therapeutics. Signal Transduct Target Ther. 2023, 8, 207. [Google Scholar] [CrossRef]
- Wen, L.; Wu, D.; Tan, X.; Zhong, M.; Xing, J.; Li, W.; Li, D.; Cao, F. The Role of Catechins in Regulating Diabetes: An Update Review. Nutrients. 2022, 14, 4681. [Google Scholar] [CrossRef]
Figure 1.
Comparison of models on the test set.
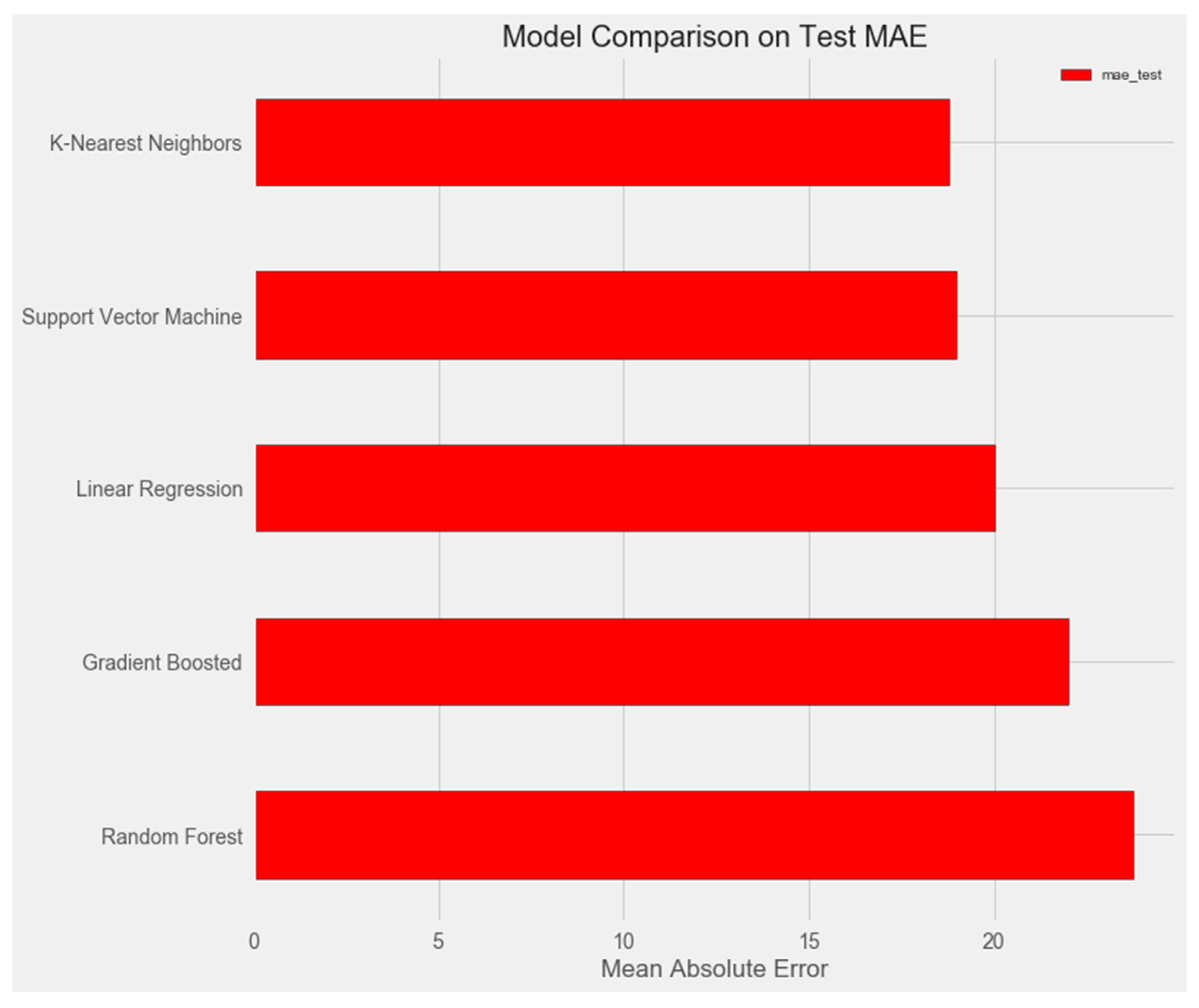
Figure 2.
Comparison of models on the training set.
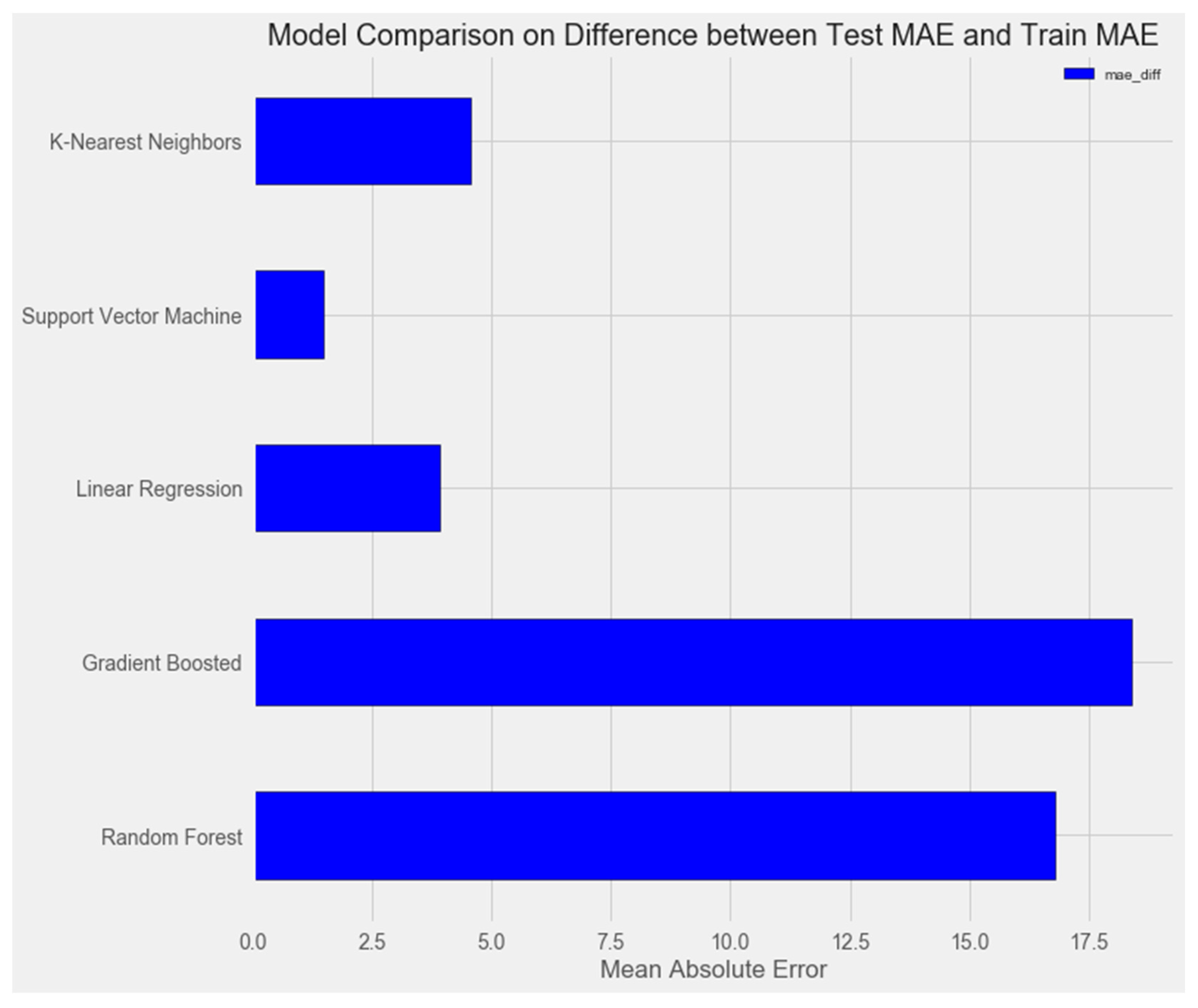
Figure 3.
Optimization of the support vector model.
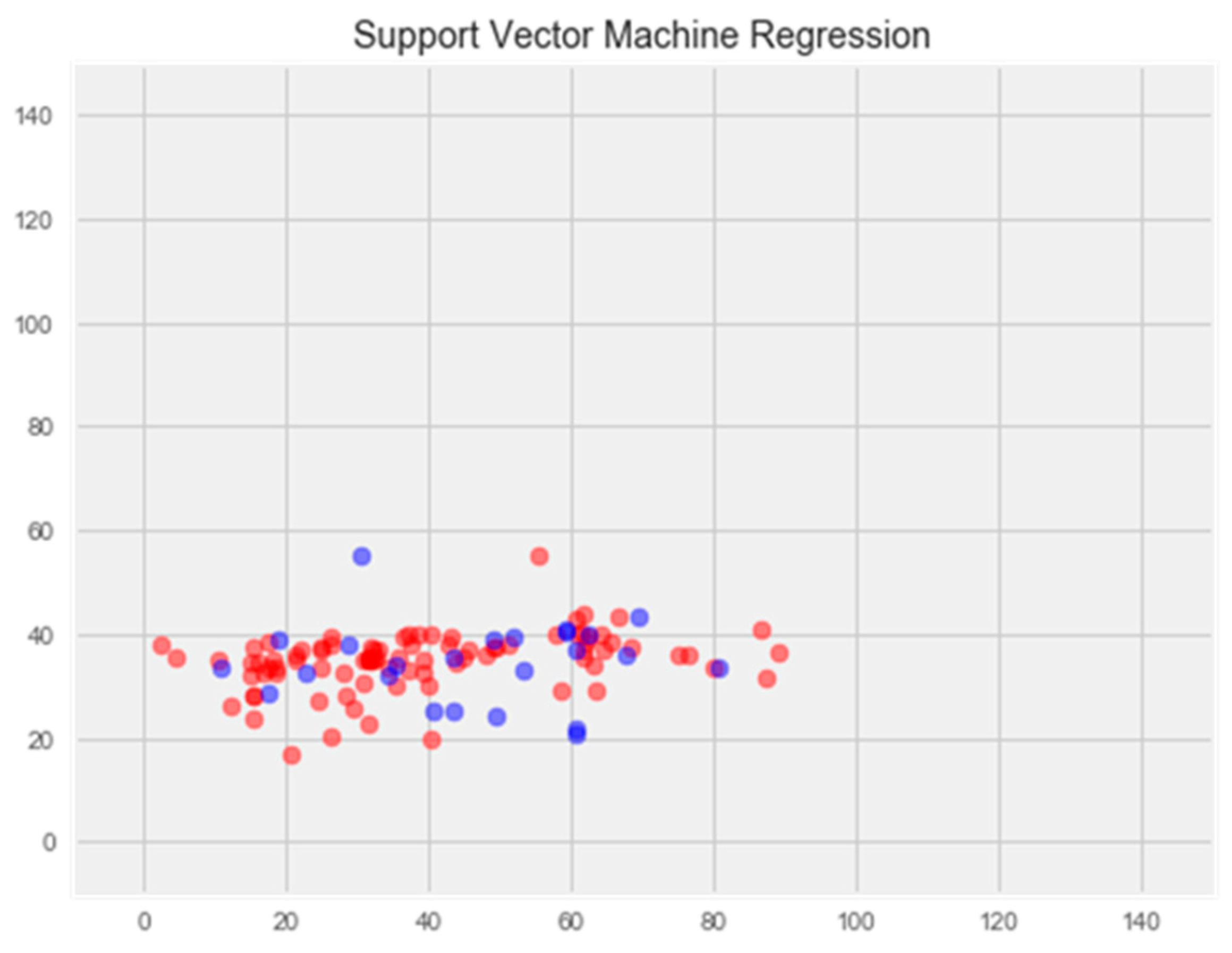
Figure 4.
Optimization of the random forest model.
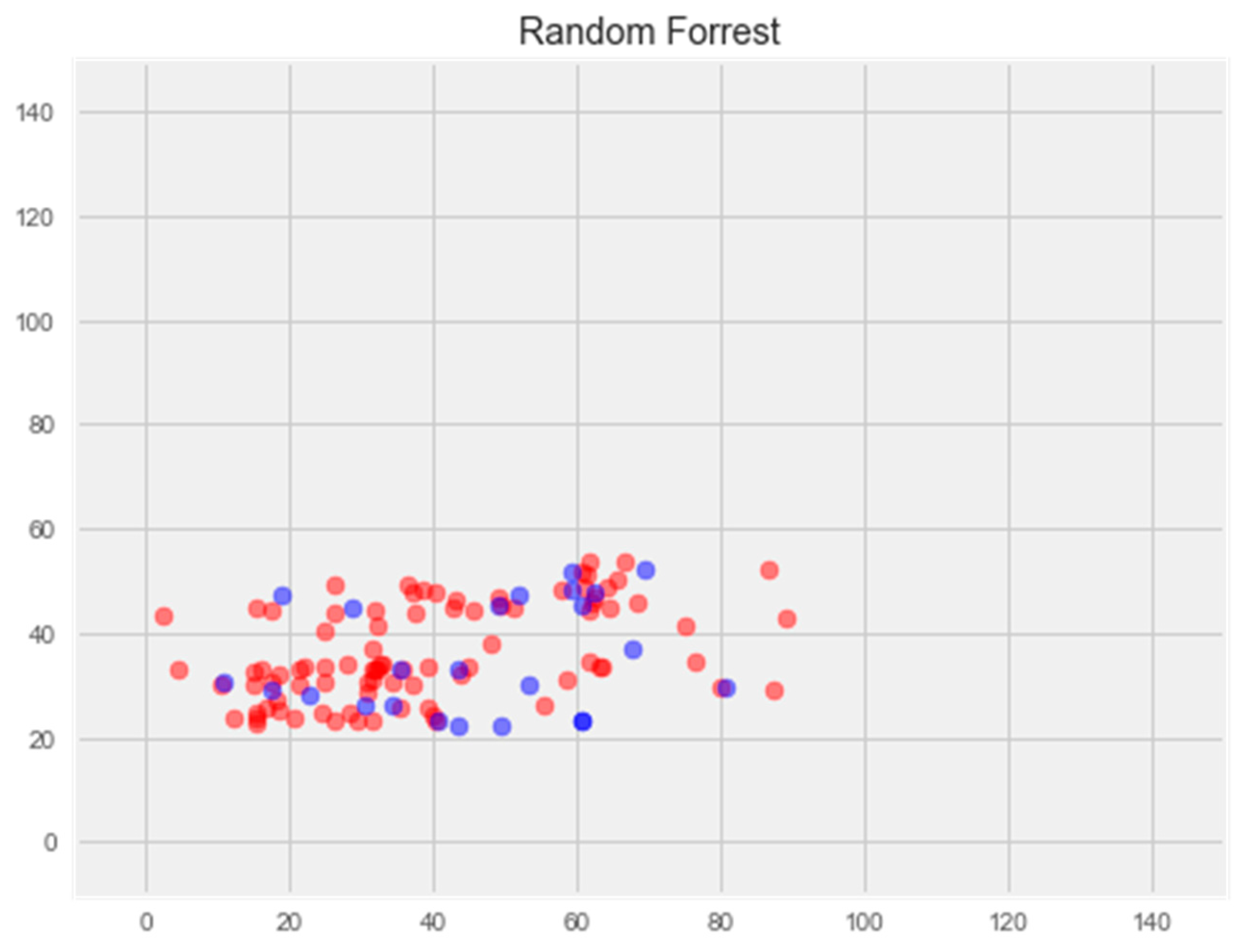
Figure 5.
Optimization of the k-nearest neighbors model.
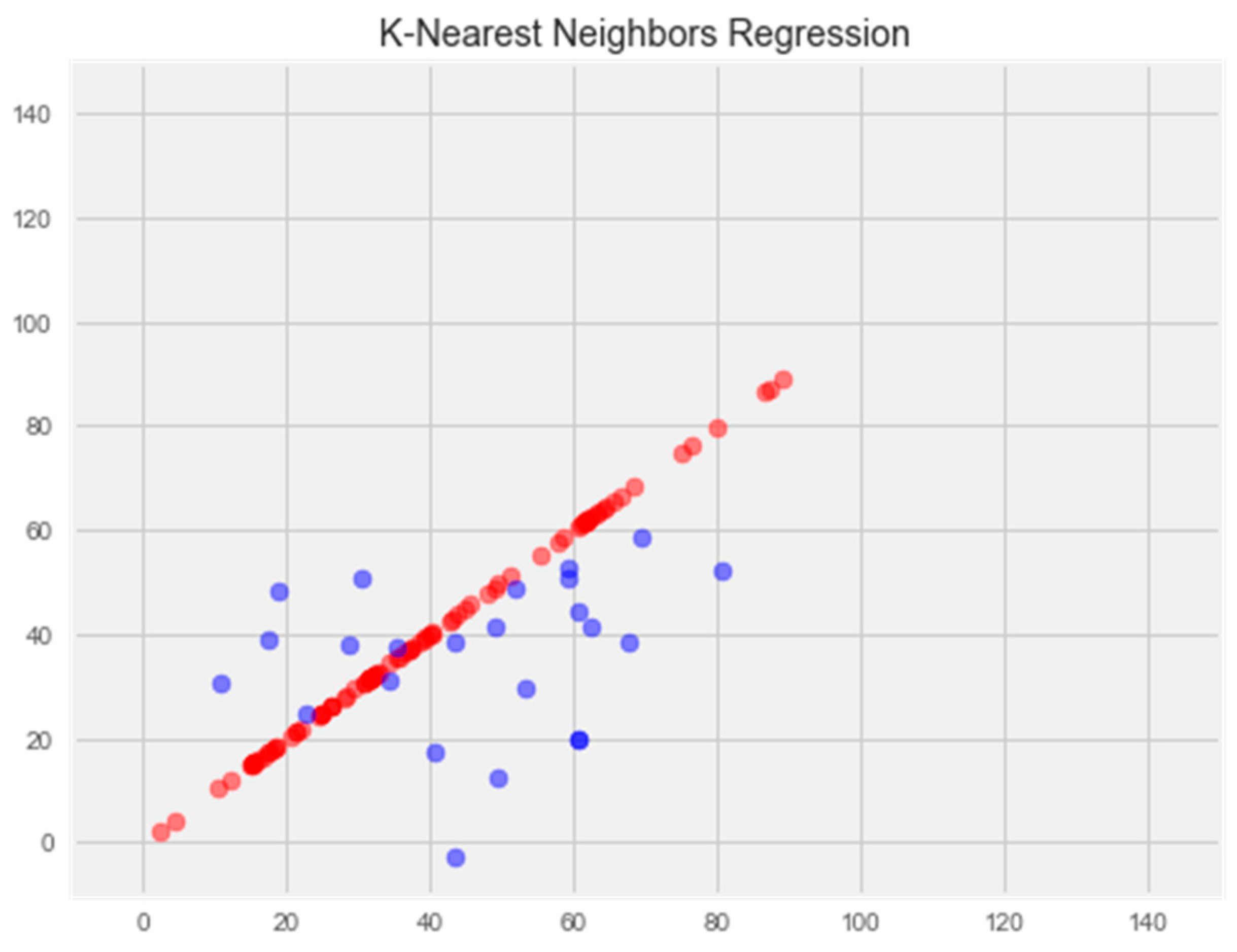
Figure 6.
Optimization of the gradient boosting model.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



