
Submitted:
12 June 2024
Posted:
13 June 2024
You are already at the latest version
Abstract
It has been argued that the historical nature of evolution makes it a highly path-dependent process. Under this view, the outcome of evolutionary dynamics could have resulted in organisms with different forms and functions. At the same time, there is ample evidence that convergence and constraints strongly limit the domain of the potential design principles that evolution can achieve. Are these limitations relevant in shaping the fabric of the possible? Here, we argue that fundamental constraints are associated with the logic of living matter. We illustrate this idea by considering the thermodynamic properties of living systems, the linear nature of molecular information, the cellular nature of the building blocks of life, multicellularity and development, the threshold nature of computations in cognitive systems, and the discrete nature of the architecture of ecosystems. In all these examples, we present available evidence and suggest potential avenues towards a well-defined theoretical formulation.
Keywords:
contingency
; convergence
; constraints
; information
; evolution
; thermodynamics
1. Introduction
Imagine that a space probe lands on a distant planet. The probe has sophisticated instruments that detect life on different scales. These instruments might detect a network structure of chemical reactions in the atmosphere or identify molecular biosignatures consistent with living systems [1,2,3,4,5,6]. The probe can also scan its surroundings, capturing morphological biosignatures and other instruments might analyse the chemical network of the atmosphere and measure its topological and molecular complexity [2,7,8,9].
How different would such an alternative biosphere be? How dependent would an alternative life form be on the environmental context? Are there physical or chemical preconditions required for life to emerge? These questions can be extended beyond evolutionary biology [10] and astrobiology [11] and affect our potential to design (using synthetic biology and bioengineering) novel life forms [12,13,14,15]. More generally, we can capture the essence of the previous questions by asking whether we can predict what kind of (possible) living forms of organisation exist beyond what we know from our biosphere (the actual).
One established view sees the evolution of life as highly path-dependent [16,17,18]. In the words of Jacques Monod ([16], pp. 42-43),
... the biosphere does not contain a predictable class of objects or events but constitutes a particular occurrence, compatible with first principles but not deducible from these principles, and therefore essentially unpredictable.
François Jacob, in turn, discussing tinkering in evolution and the problems associated with levels of complexity, concludes that [19]:
There are always some constraints imposed by stability and thermodynamics. But as complexity increases, additional constraints appear (...). Consequently, there cannot be any general law of evolution.
Here, Jacob acknowledges the limitations of predicting the properties at one scale based on the properties of the components at lower scales, which is nowadays understood using the concept of emergent properties [20,21]
Stephen J. Gould developed the most famous (and controversial) approach to these questions. He argued that because of its historical nature, “re-running the tape of evolution” would lead to entirely different outcomes [17]. Much of the argument was based on the Cambrian Explosion event, which took place 550 Ma agoa and involved the rise of all animal body plans [22,23]. Gould’s work triggered a renewed interest in the Cambrian event and, more generally, in the problem of evolutionary contingency.
The contingency scenario depicted by Gould has been reanalyzed and put in a more general context [24,25]. However, the essential message is still relevant within evolutionary dynamics and astrobiology studies. The evidence for convergent evolution has challenged the idea that an alternative biosphere would look alien to ours [10,26,27]. In contrast to Monod and Gould’s views, Conway Morris points out that
organisms are under constant scrutiny of natural selection and are also subject to the constraints of the physical and chemical factors that severely limit the action of all inhabitants of the biosphere. Put simply, convergence shows that in the real world, not all things are possible.
The presence of constraints, particularly in the evolution of developmental programs, was emphasised in the pioneering work of Pere Alberch, who suggested the concept of “The logic of monsters”: even when dealing with theratologies, whose phenotypic traits have no selective value, we can organise the diversity of forms under a logic taxonomy, suggesting that organismal complexity is strongly limited [28]:
...monsters are a good system to study the internal properties of generative rules. They represent forms which lack adaptative function while preserving structural order. There is an internal logic to the genesis and transformation of morphologies and in that logic we may learn about the constraints on the normal.
In this structuralist (or internalist) perspective, gene expression can only be seen as a necessary condition for morphogenetic dynamics, but it is insufficient. As a result of feedback between gene expression patterns and cell-cell interactions, very little of either the structure or the variation in developmental paths is explained by linear mappings from gene labelsb.
The notion of fundamental constraints is also present in a geometric concept proposed by David Raup: the morphospace, i.e., a multidimensional space representing different morphological or structural characteristics of a given class of entities (from cells to networks) [30]. An important lesson from the distribution of living entities across the morphospace is that some parts are densely occupied while others are voids, associated with unobserved possibilities. This uneven occupation is strongly related to the role played by constraints and the presence of convergent solutions. This concept has been extended across disciplines, from network topology to language [31,32] and also applies to ecological systems [28,33]. Like morphospaces, species-interaction networks partition the environmental parameter space into a discrete set of possible biotic configurations, where some partitions can be larger than others [34,35]. This robustness (compatibility with a larger set of environmental conditions) can be a target of evolution, as argued by Waddington and others [36,37,38].
Finally, there is an argument by Stuart Kauffman and collaborators concerning the intrinsic unpredictability of evolutionary dynamics due to the “non-ergodic”c character of biology [39]. In their own words [40,41]:
The chemical and physical properties of the different complex molecules are different, and in biology, the functional properties of these tens of thousands of different molecules in cells are also different. The universe is not ergodic because it will not make all the possible different complex molecules on timescales very much longer than the lifetime of the universe. It is true that most complex things will never “get to exist”.
The authors use “non-ergodic” here in the sense that not every part of the configuration space can be explored. In a nutshell, the size of sequence space associated with a biological polymer of length L built from a molecular alphabet of size would be:
Thus, the space of possible proteins with a length of 1000 amino acids is , a space so large that it could never be explored in our universe [42]. The space of possible molecular configurations of molecules within an organism is yet astronomically larger. How can we then talk about universal life features in this scenario?
Nonetheless, there are several major reasons to expect convergence. First, all evolutionary trajectories occur under certain generic selective constraints, such as the laws of mathematics, physics, and chemistry, and these should lead to some universal features [43,44]. Second, many of these spaces are not explored randomly. For example, analyses of the nature of the genotype spaces show that network structures are far from uniform [45]. This is particularly relevant when dealing with the emergence of molecular functions, where the genotype space is highly redundant [46], meaning that a huge number of genotypes are consistent with the same phenotype [47]. The percolating nature of these genotype spaces strongly favours the potential for success in evolutionary search [48]. Quoting Susanna Manrubia, these properties further ensure that different functions may await just a few mutations apart [46,49,50]. Moreover, some intrinsic properties of chemical and physical nature can deeply constrain the possible repertoires of molecular structures, as exemplified by the fact that only a small fraction of protein folds are realizable even looking at the full sequence diversity [51,52,53,54]. Finally, evolutionary trajectories happen within a certain system: Darwinian evolution will act on populations of entities. Entities within the system emerge within assembly spaces [2,55,56]. They are constructed from components over evolutionary timescales. These shape evolution and shift the way one should think about sequence search conditioned on the past, where the logic of assembly spaces may lead to certain types of universal convergence [56].
Here, we discuss some of the fundamental constraints that limit the space of evolutionary outcomes. We focus on areas that are most well-studied and most likely to be universal, involving several case studies that reveal deep constraints associated with the logic of the organisation of living systems. Specifically, we start with some core thermodynamic constraints and then discuss the logic underlying molecular information carriers, cellular reproduction, multicellularity, cognitive architectures, and ecosystem organisation. Finally, we consider the concept of phase transitions as a paradigm for the emergence of living complexity. A recurrent theme in the following sections concerns predictions about biological complexity made before empirical evidence came in. In our view, such predictions strongly hint at some kind of universality. Such universality fits within the broader goal of finding general theories of life that transcend the specifics of life on Earth [44,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71].
2. Living Systems as Thermodynamic Engines
Every organism on Earth operates as a thermodynamic engine in the sense that it acquires free energy from the environment and uses it to drive essential biological functions. The ubiquitous nature of thermodynamic constraints suggests that a certain kind of thermodynamic logic is a universal feature of living systems.
Any form of life is expected to be an embodied and differentiated structure that performs healing, self-repair, and error correction. Such processes reduce the system’s entropy by mapping a large set of “incorrect” (damaged) states to a much smaller set of “correct” (viable) states. Entropy reduction also comes by growth: the synthesis of organised biological machinery from simpler, disconnected components — for example, as done by the ribosome during the synthesis of proteins — involves a large reduction in entropy [72].
The second law of thermodynamics states that a physical processes must generate an overall increase of the entropy of a system () and its environment ():
Therefore, living systems can only perform processes that reduce entropy internally if, at the same time, they produce an even greater increase of entropy in the environment. Thus, the universal thermodynamic logic of life is that low-entropy input (“resource”) is turned into high-entropy output (“waste”), which can be expressed asd:
This suggests that all life forms face the the problem of maintaining a low internal entropy in a race against the second law. This thermodynamic perspective on biology is closely associated with Schrödinger’s well-known 1944 book What is life? [74], and the much less well known articulation by Boltzmann in 1886 [75].
We may add a few important details and questions to the abovementioned general picture. First, for a system coupled to a thermal reservoir at temperature T, such as an atmosphere or an ocean, the entropy production in the environment is related to the amount of heat released Q,
where is Boltzmann’s constant. In fact, for almost all life on Earth, thermodynamic driving is accomplished by acquiring energy from the environment and releasing it as heat. Important examples of heat generation include the absorption of visible photons and radiation of lower-frequency infrared, the breakdown of high-energy biotically produced molecules (within trophic ecosystems), and the exchange of electrons between environmentally provided donors and acceptors [76]. Although in principle entropy production can also occur due to exchanges of other quantities besides energy [77,78], heat flow is a fundamental and ubiquitous energy-exchange channel, suggesting it should have a primary role in the thermodynamics of life on other planets.
Biological heat generation recapitulates the pattern observed at the planetary scale. Late-stage planets are essentially closed to exchanges of matter with their environments but open to energy exchange via incoming solar flux and outgoing thermal radiation [79,80]. Notably, the other source of thermodynamic driving available to chemotrophic life — the gradual oxidation of mantle minerals — needs to be coupled to hydrogen escape to maintain more oxidising surface conditions than the interior in an era without photosynthetic production of oxidants [81]. However, on a planet with oxygenic photosynthesis, even that process can be maintained while conserving matter, as long as the burial of organic carbon can compensate for the liberation of oxygen — a large-scale geological rearrangement driven by sunlight but mediated by life. To summarise, it is very likely that heat generation serves as a primary thermodynamic driving force for life anywhere. To the extent that life does not completely replace geological processes with novel ones [82], but rather partially conserves geologically facile processes [81], the sharing of major thermodynamic properties by the two becomes even more expected.
A second important point is that the second law is obeyed not only globally — that is, at the level of the entire organisms — but also locally at the level of each individual reaction. For this reason, each entropy-reducing reaction must be locally coupled to a free-energy source. In biology, a collection of energy intermediates are used to drive many biotically essential transitions that otherwise would not occur spontaneously [83,84]. These intermediates include first and foremost the phosphate-bearing cofactors (ATP and the other nucleoside triphosphates, and others [85]) that can drive dehydrating reactions by phosphoryl group transfers, a variety of electron-transfer cofactors (such as NAD, NADP and a variety of others [86]), and membranes that act as capacitors for the exchange of protons. Energy intermediates remove the need for internal processes to be in direct contact with environmental sources of free energy, thus achieving a kind of thermodynamic autonomy [87]. In addition, the fact that many core reactions coupled to these intermediates can be run bidirectionally [88,89] allows life to store energy, e.g., in molecules like glycogen, thereby buffering against stochastic and deterministic (e.g., day/night) environmental fluctuations and achieving a further kind of thermodynamic autonomy [87].
As a third point, it is interesting to consider what can be added to the picture using results from nonequilibrium thermodynamics, such as Onsager’s principle of detailed balance [91]. One important insight made by Morowitz is that any nonequilibrium chemical system in steady-state must exhibit cycles [92], as illustrated in Figure 1. That is, it must exhibit sequences of transformations that leave the system’s state invariant, while exchanging energy and/or matter with the environment. Today we recognise metabolic cycles, such as the citric acid cycle [93,94], as some of the most fundamental and universal organising principles of metabolism. Morowitz’s insight was that such metabolic cycles must be present in any living system (see Figure 1b).
To illustrate this concept formally, we may consider a simplified model involving N metabolites, denoted by the vector . Suppose that the concentration of each metabolite can be influenced by the reactions converting it from and to other metabolites,
where is the net flux of the reaction that converts metabolite j to i. In a steady state, all concentrations are constant, so for all i. The key point is that outside of the trivial (equilibrium) steady-state where all fluxes vanish (), steady-state fluxes must necessarily exhibit one or more cycles [92,95]. An example is provided by a cycle such as that corresponds to positive fluxes . This cycle involves the creation and destruction of metabolites , so its net effect leaves the concentrations invariant.
While living systems must meet the constraints of energy, it should be noted that more proximal constraints from kinetics, from limits of chemical mechanism, or from robust paths for construction and degradation may impose tighter constraints that obscure ultimate roles from thermodynamics. The complexity of identifying the relative importance of ultimate versus proximal constraints is a chief source of difficulty in interpret based on idealised reversible assembly [96]. However, how key a constraint energy is to living systems can be tested by assessing how close organisms have come to the possibility frontier. Efforts to assess the conversion efficiency in heterotrophs from food to new biomass have been made [97], including a very early effort by Morowitz to tie these explicitly to entropy [98]. More recent work has sought to include the more subtle entropies of sequence information [72] within estimates of efficiency for biological assembly. Other arguments related to metabolic scaling indicate that energy is a key consideration in the evolutionary optimisation of organisms [43,44,99,100].
A final note to properly frame the extent of thermodynamic constraints is needed: Many abiotic systems exhibit some of the properties mentioned above. For example, hurricanes, Bénard cells (Fig. Figure 1a), and other naturally occurring “dissipative structures” [101] also couple local entropy reduction to external entropy production and also exhibit ongoing cycles, yet they are not alive. However, apart from biosynthetic networks in organisms and a few engineered synthetic chemical systems, there are no known dissipative structures whose cycles drive the chemical assembly of complex molecules rather than the mechanical formation of physical structures (such as vortices). Another difference is that abiotic dissipative structures depend entirely on the presence of appropriate boundary conditions for their existence. This is unlike living systems, which construct organismal boundaries and maintain internal energy stores in order to attain a degree of thermodynamic autonomy from immediate environmental conditions.
3. Linear Information Carriers
Information plays a central role in living systems beyond energy and matter and the thermodynamic considerations described in the previous section. Previous work has suggested that some of the most universal characteristics of life are related to its informational, algorithmic, and computational properties [44,62,70,102].
Here, we consider one aspect of this story, motivated by the fact that all lifeforms seem to require physical information carriers that provide the means by which phenotype properties can be transmitted across generations or time. Two properties of information carriers are important. First, they can reliably code for a large number of phenotypic states. Second, that information can be replicated. Without the emergence of a shared information carrier, any evolved feature also has to evolve a method of transmission of that feature — almost like a new origin of life. What are the fundamental constraints associated with biological information carriers?
Of course, the best known information carrier in biology is the DNA molecule. Two remarkable insights into the nature of the genetic information were advanced before molecular biology and the unveiling of DNA structure in 1953. The first has to be found in the writings of Nikolai Koltsov, who, as early as 1927 concluded that the basis of heritability at the molecular and cellular level had to be found in some class of giant, double-stranded molecules able to self-replicate in a semiconservative way [103,104]. Koltsov’s conjecture was that the genetic material replication should be explained in terms of linear copolymers, with each strand to be used as a template [105]. Seventeen years later, another suggestion was found in Schrödinger’s book What is life?, where he suggested that the information-coding molecule (the gene, pp. 60-61 in [74]) should on the one hand, be a regular structure (like a “crystal”) while, on the other, allow for an intrinsic “disorder” compatible with “atoms playing an individual role”.
Koltsov and Schrödinger’s visions, based on reflections turned out to be strikingly accurate once Watson, Crick and Franklin uncovered the structure of DNA [107,108]. Their work revealed a right-handed helix composed of two antiparallel strands twisted around each other, forming a helical backbone of sugar-phosphate groups with nitrogenous bases paired in the core. As predicted by Koltsov, the discovery elucidated the mechanism of heredity based on semiconservative replication and laid the foundation for understanding how genetic information is stored and transmitted in living organisms. Here, DNA molecules are copied thanks to DNA polymerases, which can “read” single-stranded DNA chainse that act as the “tape”. This also includes a proofreading mechanism: the DNA polymerase can detect errors in the base pairing and remove the mismatched nucleotides. Moreover, linear tapes and their reading machines are also at work at the levels of transcription (RNA synthesis from DNA, Figure 2a) and translation (protein synthesis from RNA, Figure 2b). These systems can be classified as biocomputing machines within a hierarchy [109,110].
Beyond DNA, life, in general, uses three types of polymers: polynucleotides, polypeptides and polysaccharides [111]. Because of their particular chemical features, information and functional (enzymatic and structural) machinery are associated with the first two, while the third group is responsible for energy storage and recognition. The mapping between polymer class and its role is tightly related to their folding, assembly and complementarity properties. Folding allows for the formation of low entropy states that become stable thanks to self-interactions, whereas in polynucleotides, monomers do not engage in attractive interactions and display energy degeneracy, i.e., each sequence is energetically about equal. Sugar-based polymers, on the other hand, are branched structures made of the same class of monomers.
The widespread use of long, linear polymers for biological information processing is striking. Is there anything special about one-dimensional linear polymers that leads them to be a universal solution to the information-carrying problem? Are higher-dimensional information carriers possible? Three main arguments support the idea that the linear polymer is the expected option, based on constraints associated with (a) evolvability, (b) computation and (c) thermodynamics. Several authors have discussed the first, which concerns the enormous advantages of some kinds of linear polymers. As pointed out by Howard Pattee [112] (see also [113,114,115,116,117]):
There is an enormously larger class of natural structures that have nearly equal probabilities of formation because they are one-dimensional and have nearly equivalent energies. They are linear copolymers, like polynucleotides and polypeptides. Life and evolution depend on this class of copolymer that forms an unbounded sequence space, undetermined by laws. (...) This unbounded sequence space is the first component of the freedom from laws necessary for evolution.
At the same time, not all information-carrying and information-processing systems are one-dimensional in molecular biology. For instance, the folded DNA molecule exhibits a rich three-dimensional spatial organisation, much of which has important functional roles in regulating gene expression. At a more abstract level, cells display a tangled web of molecular interactions connecting different (genetic, metabolic and signalling) networks, which are appropriately conceptualised in high-dimensional space. Nonetheless, much of this complex organisation emerges from the capabilities enabled by underlying one-dimensional molecules. This view is partly supported by the observation that higher-dimensional forms of information processing (whether in physical space as with chromatin or abstract space of gene regulatory networks) appear to play a smaller role in more primitive lifeforms, such as prokaryotes.
Beyond the specific solutions found in modern cells, let us consider the following question: what would be the expected logic of a minimal information-processing molecule? This is a relevant problem, since any early life capable of evolution should have been able to store and propagate information. Given our current knowledge of molecular cell biology, we might be biased while answering the previous question. In modern cells, linear chains made of discrete units from a given alphabet store information and are scanned by another given molecule that can read the message. However, such a picture was already in place before molecular biology, which Alan Turing introduced in 1936.
The so-called Turing machine is a mathematical model of computation, and its definition will sound very familiar. It consists of an infinite tape divided into cells, a read/write head that moves left or right along the tape and has a finite set of states. Each tape cell contains a symbol from a finite alphabet (Fig. Figure 2c). The machine operates based on a set of transition rules: given the current state and symbol under the head, the machine can write a new symbol, move the head left or right, and transition to a new state. The Turing machine represents a foundational concept in the theory of computation, defining a simple computational mechanism capable of performing any algorithmic computation — thereby, it is universal and established the basis for understanding the limits and possibilities of algorithmic processes. While building such a general framework, Turing’s ideas (perhaps inspired by some of the technology of his time, such as tapes and machines reading them) surprisingly match the molecular computational devices resulting from evolution.
Chemically speaking, some linear polymers seem the simplest and most reliable choices if we need to store bits on a molecular structure. For obvious reasons, a homopolymer (i.e., made of identical monomers) would carry no information. Instead, a heteropolymer, formed by a chain of different kinds of monomers, would provide the substrate of many possible strings of symbols while allowing evolution to occur. Additionally, a molecular system able to scan this string would be strongly constrained by the one-dimensional nature of the heteropolymer. In this context, we could imagine an alternative molecular machinery where a given information substrate is based on some heterogeneous two-dimensional set of monomers and such potential is illustrated by the remarkable advances in DNA engineering as a material [118,119]. Beyond these nanostructure assembly processesf, it has been shown that two-dimensional monolayers can be obtained from mixtures of adenine and uracil [120,121] leading to aperiodic structures, although under contrived physical conditions. In this context, despite the potential information that can be stored in these monolayers and the relevance of surfaces to facilitate polymerization [122], polymers can eventually end up strongly bound to the surface, becoming an evolutionary dead end. Beyond these possibilities, it is not difficult to imagine the challenges imposed by creating, reading and replicating such kind of molecular information in predictable ways.
Our central interest here has been to go beyond the specific to the universal. What can be said of information processing systems in general? One fundamental constraint is the energy required to perform information copying operations. Landauer’s bound [124] gives us the minimal energy required to perform an abstract computation and many string writing operations, including copies and transformations of it [125]. Copying a DNA strand or producing a protein from a ribosome can be cast as writing a specific string from a set of unordered letters (e.g. nucleotides or amino acids). Under this framework, it is possible to calculate the minimal energy required to write a string, and amazingly, it has been shown that the energy usage of the ribosome is only one or two orders of magnitude above this bound [126].
This is an interesting case where fundamental physical limits are relevant to a very general process, and they also help us to understand cellular physiology. For example, how should we assess whether the energy flux of an environment is sufficient to support a living system? One extreme possibility is to ask if the available energy is sufficient for string copying and processing operations for a very small amount of stored information. One can easily connect the fundamental bounds of information to metabolism via Landauer’s bound, by calculating the minimal metabolic rate W needed to replicate genetic information given a genome length and desired cellular growth rate [126]. Landauer’s bound states that [124]
where Q is the heat released to a bath at temperature T, is Boltzmann’s constant, and are the initial and final system entropy, respectively. This is nothing more than the expression of the second law of thermodynamics, Eqs. (1) and (3), where . For the case of writing a specific string from a set of unordered letters, we have that and
n is the number of unique elements, or letters, in the informational system and L is the length of information (the string length), that is being copied. We can convert this into a metabolic rate by considering how fast the information is copied. Given a time to divide in seconds, the minimal metabolic rate of copying is
We illustrate this result in Figure 3 for an alphabet of elements for various L and . This is the minimal metabolic rate for copying alone and doesn’t account for other functions of an organism. We reference the typical bacterial metabolism (TBM) and the typical genome length (TGL) of bacteria. For typical division times, the minimal genome copying cost is many orders of magnitude smaller than known metabolic rates. However, as shown in the figure, the costs increase with larger genomes and shorter division times.
4. Cells as Minimal Units of Life
All living entities in our current biosphere can be classified as cellular life forms and virus-like elements [128]. Cell division involves, on the one hand, copying the information contained in the cell to its daughter cells, and on the other reproduction of its embodied architecture by using this informationg of its embodied architecture; each copy must define a compartment and a set of metabolic components necessary to start a new cell cycle. More abstractly, both genomes and their vessels require constructive processes. For the genome, the constructive partitioning and assembly occurring in most genotypes’ life cycles operate over the more basic copying dynamics, as Watson, Crick, and Franklin recognised. The term “construction dynamics” has been introduced [129,130] to study specific structural factors, ranging from reproduction to ecology and niche construction [131], that place universal constraints or requirements on the dynamics of evolving populations.
In our biosphere, the copying of genomes ultimately depends on the reproduction life cycle bound of metabolising cells. In that sense, even if they are not singular or even “minimal” by any unambiguous measure, they are essential to the realisation of living states on Earth. Even the simplest cells exhibit an extraordinary and diverse molecular complexity and common design principles. As far as we know, no alternative building blocks exist in our biosphere. Is the logic of cellular organisation an inevitable outcome of the evolution of life? Here, we consider three critical constraints that might impose some fundamental limits to what such a living autonomous agent might be. These include three main concepts: (a) the logic of self-replicating machines, (b) the physicochemical logic of minimal autonomous agents (cells) that become differentiated from their external environment, and (c) the thermodynamic limitations associated with reliable reproduction.
The algorithmic basis of self-replication was approached by von Neumann using a very abstract (but also general) view, thus ignoring the exact nature of the physical components and the specific functions carried out by the replicator. Von Neumann understood the importance of information and its relevance in providing the instructions necessary to reproduce the entire system while also copying the instructions themselvesh. To some extent, von Neumann’s so-called Universal Constructor (UC) was inspired by the steps followed in a factory to build machines in an assembly line, where each component has to be available in space for assembly. Formally, it was defined in terms of a “machine” that is implemented using operations on a lattice. The machine includes four primary components: the Constructor, the Instructions, the Duplicator, and the Controller (Fig. Figure 4a). The Constructor (A) builds the new machine out of components from the surrounding environment. The Instructions (I) contain information on how A will operate and effectively define an input tape (as in Turing machines). The Duplicator (B) reads the instructions and duplicates them. Finally, the Controller (C) regulates the whole process, which has to unfold in a given sequence. As defined, the tape plays two markedly different roles. First, the information on the tape provides instructions to be interpreted and allows the construction of a machine. On the other hand, the information on the tape is also treated as uninterpreted data, which must be copied and attached to the new machine.
Von Neumann’s insight went a crucial step beyond Schrödinger’s conceptualisation of information by showing that a self-replicating agent must contain a sufficient description of itself [134,135]. As happened with our previous case study, the components of von Neumann’s construction mirror those of self-replication found in cellular biology. Although the biological reality is significantly more complex and multifaceted, we find close similarities between the Duplicator and the information storage mechanism in cells (DNA, perhaps RNA in early protocells), the Controller’s role in interpreting and executing instructions resembling cellular control mechanisms, the Constructor’s function in manufacturing new components akin to cellular machinery (as executed by RNA polymerase and the ribosome, see Figure 4b), and the Instructions reflecting the genetic information directing cellular self-replication. These striking similarities suggest a fundamental logic determining the critical components required for a self-replicating system. Once again, von Neumann’s theoretical insight came years ahead of discovering the relevant structures in molecular biology. No less important, von Neumann’s insight went beyond the problem of self-replication and is deeply engrained with the problem of open-ended evolution, which has been a central problem within the field of artificial life [136,137,138,139] by pointing to the minimal conditions for complexity to be able to grow.
The search for other formal systems able to self-replicate, usually defined on a two-dimensional lattice, has shown simpler examples with a much small number of parts as those proposed initially by von Neumann [64,140]. However, there is a rather crucial problem when mapping the original cellular automaton approach to the UC into the real world: all these systems share a high brittleness. Due to the deterministic, spatially dependent nature of the rules required to implement replication, even a slight error (or mutation) typically destroys the whole pattern. Initial conditions must also be fixed in some predetermined way; otherwise, the system will not follow adequate paths towards reliable copying.
How can we solve it? The qualitative theory put in terms of the UC design is agnostic as to how you implement it, and one answer to our question comes from the dominant role played by self-organisation of soft matter [141,142] and the requirements to obtain a system displaying agency. Here, chemical and physical constraints play a crucial role. In looking for them, we will also see that alternatives lacking information (a set of instructions) can exist, defining a compartment-metabolism system. More importantly, understanding these phenomena and the potential presence of constraints is essential to understanding the transition from non-living to living matter and the design of artificial cells [143,144,145,146,147,148].
The first constraint for a system to be able to replicate itself is very basic: molecular components need to be available. This is achieved when there is phase separation from the environment [151,152] that makes it possible to concentrate the needed substrates within a given domain. In practical terms, this requires a closed compartment defining an inside and an outside and the subsequent flows of energy and matter that occur across the boundary. Interestingly, a rather limited set of structures are the most plausible candidates. In a water-solvent world, one robust path to creating a compartment that separates the inside from the outside environment is provided by amphiphiles, which spontaneously self-organise in space to form well-defined structures. They are polar molecules with a well-defined hydrophilic head group (attraction to water) and a tail group showing hydrophobicity. Due to this conflicting relation towards water molecules, amphiphiles can self-assemble into compact bilayers that define the system’s boundaries. Along with this polar nature, the shape of one molecule largely decides the curvature of the self-organised assembly. The bending energy associated to a given closed configuration is given by
where is the bending modulus and is the mean curvature of the vesicle surface at . Energy minimisation, as defined from the solutions of , provides a wide range of possible shapes, from highly stable (spheres, for example, with only positive curvature) to others displaying metastable states that imply the presence of local negative curvature (required when cell division occurs) [149,153].
Although most models of cell origins ignore the physical embodiment defined by interacting amphiphiles, any future development will require this component to explain how evolution allowed the reproduction of early cells. However, physical models already show that there are plenty of opportunities. When membrane growth and permeability are coupled to bending energy, a rich space of great morphological diversity is found [154]. Some toy models also include information (Fig. Figure 4c) coupled to metabolism and compartment growth [155]. But models have also shown that such a possibility exists in an information-free context where only metabolism and compartment are present, both in amphiphile-based vesicles [156,157,158]) and micelles [149,159]. Two examples are displayed in Figure 5. In both cases, cell division occurs through growth and instability. The first example, simulated explicitly using dissipative particle dynamics [149], displays no evolution. In the second case, each protocellular assembly carries a different set of molecules, and the division rate depends on the compositional information associated with the specific combination of surfactants, so this information indirectly modulates the division process that is driven by the relative free energy difference between the mother aggregate and the resulting daughter aggregates.
None of these information-free examples has been observed in our current biosphere. Why? Although the self-organising properties of information-free soft matter could provide a source of reliable self-replication, that is not present in von Neumann’s formulation, the potential for adaptation and open-ended evolution associated with information-carrying protocells would be difficult to overcome [160]. Thus, we can conjecture that some kind of UC equipped with linear information carriers and exploiting the robustness of self-assembly might have been the expected, perhaps unique solution.
5. Multicellularity and Development: on Growth, Form and Life Cycles
As we mentioned above, the early literature on constraints in development supported the concept that there are limits to the possible in terms of forms and developmental paths [47]. Regarding morphological diversity, multicellular life forms exhibit an enormously rich repertoire of structures. Darwin described this with the famous quote: “from so simple a beginning endless forms most beautiful and most wonderful have been, and are being, evolved." [161]. For a naturalist, this diversity strikes as the most obvious view of the generative potential of life [162]. But is there a truly endless universe of multicellular form, or is the universe of what is actually observed limited due to fundamental constraints affecting the evolution of complex life?
In this section, we address this question by considering three different problems that include different types of constraints, namely: (a) the transitions to individuality within the context of the emergence of multicellularity and the emergence of life cycles; (b) the nature of the complexity classes in pattern-forming dynamics and (c) the existence of a physico-genetic toolkit that pervades the emergence of metazoan complexity.
Evidence suggests that the emergence of cells naturally leads to the potential evolution of multicellularity (MC). MC has emerged independently at least a dozen times on Earth, possibly more, though many lineages have been lost to history [166,167,168]. Laboratory experiments [169,170] and engineered multicellular systems [171,172] suggest that simple MCi is relatively easy to obtain. This is an evolutionary transition in individuality. It occurs when replicators, such as cells, form groups that evolve into independent reproducers themselves, causing some loss of autonomy among their parts [173,174,175] (see also [176,177,178]). The universal principle is the loss of autonomy in cell-like replicators due to selection acting on groups, favouring traits that enhance group fitness. There is a range of possible MC levels of complexity between strict unicellularity and bona fide multicellular organisms [179]. Crucially, understanding the possible paths to MC requires considering the logic of life cycles [180]. A working definition of MC that encapsulates these features involves two properties: (1) Existence. There must be a stage during the organism’s life cycle where a group state is clearly recognisable. (2) Evolution. Groups must be able to multiply and share heritable information with newly created groups [175]. We note that this definition does not explicitly require groups to be formed of the same species, and indeed, there is a vast array of possible multicellular forms involving multiple species [181,182,183].
What kind of universal logic can be defined here? The first answer to this question comes from the dynamical logic of the problem, which requires the fulfilment of a general principle of biological construction: to create a group, individual units must come together within a finite physical domain and, importantly, deal with the emergence of cheaters [184,185]. In this context, two generic classes of MC can be defined (Fig. Figure 6a-b). In the first, MC develops from a single cell that generates a clonal assembly through cell division (), whereas in the second, there is an aggregation of individual cells from a set that form a cluster that can be defined by a graph defined by the cell locations and their local interactions. These examples illustrate the two dynamical processes that can generate MC groups: (a) stay together (ST) when, as new units are generated, they keep in close connection with the rest, and (b) come together (CT) which occurs when the units move towards each other. Using these basic mechanisms, it is possible to build a taxonomy of cell cycles [180], three of which are indicated in Figure 6b, as well as mathematical models that allow exploration of the evolutionary principles [186]. These models reveal that ST can favour the division of labour while CT allows the exploitation of a combination of units with different properties. Both can be found at every level of biological construction, and their dynamical features define constraints to the possible.
There is another general problem associated to MC: the potential for cheaters to emerge. Parasitic entities are a universal property of evolved complexity (see Section VII), and parasitic entities can threaten the cooperative nature of MC. The problem is illustrated by groups of microbes that produce some common good (such as a metabolite) that helps the group grow faster than others lacking it. However, within groups, free-riding cheats that do not produce the good usually grow fastest of all [187]. The problem arises from the asymmetry in time scales of growth: MC systems evolve slowly compared to the cells within them, which makes them vulnerable to cellular innovations, as occurs with cancer [188]. How can this problem be solved? One solution to stabilising multicellularity against cheaters is the evolution of traits that increase cell-level fitness in a group context but come at a cost to free-living fitness. This is enabled by “ratcheting” processes where cells acquire traits that commit them to a group lifestyle. This stabilises the group and may serve as a universal mechanism that propelled multicellular complexity [189,190]. Developmental ratchets would effectively define an arrow of evolutionary time, allowing increases in developmental complexity.
Early forms of multicellularity are typically quite simple and a far cry from the endless forms that so entranced Darwin. Our last consideration here is tied to pattern-forming mechanisms and the emergence of developmental programs. The rise of complex animals at the Cambrian boundary brought the question of the creative potential of development and the contributions of chance and necessity. In this context, although many components of the MC toolkit were already in place in the unicellular ancestors [191], black swan events might have also predated the origins of animals [192]. An important consequence of the emergence of gene regulation is the possibility of pattern-forming processes across scales, from cells to organisms [193]. The most famous is the Turing instability associated with reaction-diffusion mechanisms [194,195], which exemplifies the role of self-organisation as a mechanism to generate spatial order through symmetry breaking instabilities [196]. These self-organising phenomena typically involve the interaction between local amplification (due to reaction dynamics) and long-range communication due to diffusion-like processes. This classic picture has been completed with contributions that incorporate mechanochemical interactions [197,198,198]. Symmetry breaking is partly responsible for the differentiation paths that allow the generation of specialised cell types [165], often represented as dynamical paths on a Waddington epigenetic landscape (Fig. Figure 6c) [199]. On the other hand, the combinatorial power of gene regulatory networks would also suggest that many (perhaps infinite) potential body plans are possible. To address this problem, one needs to consider the nature of the genotype-phenotype mapping, i.e., the map
that can be understood as how a given genotype is connected with a given phenotype . The genotype can, for example, be described by the wiring diagram connecting genes, whereas the phenotype could be the observed spatial distribution of cell states. This formal approach has been used in very different contexts to study shape spaces, including RNA folds [200,200], pattern-forming gene networks [201,202,203,204] and circuits [205]. They all share a remarkable universal pattern of organisation, including neutrality, characterised by flat regions where different genotypes have the same fitness [29] (see also [206]). They show high redundancy, with many genotypes corresponding to the same phenotype (thus ensuring stability against mutations) and forming interconnected networks. These properties help explain how genetic variation sustains phenotypic stability and drives evolutionary dynamics while, once again, imposing limits to the space of possibilities [202].
The problem of physical constraints to biological form has been addressed historically [207], in particular by D’Arcy Thompson, who proposed the idea that physical analogies between tissues and foams or liquids could help understand the mechanics of biological form and its changes [208,209]. Despite its limitations [210], new theories inspired in physics have validated many of those intuitions [211,212,213]. In particular, it has been proposed that metazoan complexity can be generated out of a core set of physico-genetic modules affecting well-defined physical properties such as cohesion, viscoelasticity, diffusion or polarity [214,215]. An example is illustrated by the classical work on cell sorting (Fig. Figure 6d), where a randomly mixed cell population displaying two or more cell types experiences a global arrangement due to differential adhesion energies [216,217]. As an example, we consider three cell types: (external medium), (white) and (black). Cells attach to neighbours more if it lowers the energy per unit area [218]. The energy at position is:
where indicates the coordinates of the set of eight nearest neighbours (Moore neighbourhood) and indicates the adhesion energy between cell types and .
The dynamics is easily defined: choose one cell located in the coordinate and see if swapping with a neighbour at will or not reduce the energy (thus defining spontaneous transitions). If is the increase of energy in going from the initial to the final state, the probability of swapping is:
where T is an effective temperature that controls noise. If we iterate this simple probabilistic rule, the system evolves towards a final configuration that can match (in space and time) the observed self-organisation towards a stable macroscopic pattern (Fig. Figure 6e-f). Single and combinatorial actions of these modules constitute a “pattern language” capable of generating all metazoan body plans and organs, supporting the view that there are strong bounds to the endless formsj.
A final word is in force regarding the collective properties of aggregates of cells: through developmental stages, large-scale but precise deformations are possible thanks to the collective action of cells [222]. Indeed, even the material properties of single cells may live in the continuum; these individual properties are projected at the collective level — for example, the tissue — in a highly non-trivial way [223,224]. Surprisingly, the continuum of cell material properties is projected to the tissue level as a finite amount of different material phases. This result can be theoretically explained, for example, using a slight variation of the energy function proposed in Equation (8) [224]. Therefore, multicellularity implies collective behaviour and new ways of regulating biological processes across scales. In Section 8, we will return to the connection between different scales and how this gives rise to the phenomenon of phase transitions.
6. Cognitive Networks, Thresholds and Brains
Storing and accessing information is necessary for the emergence of cognitive agents [225,226]. However, decision-making and learning were required for higher cognitive complexity and predictive abilities. In other words, living systems evolved mechanisms that could reduce the uncertainty of the environment [227,228,229]. Moreover, the emergence of multicellular organisms close to the Cambrian explosion precipitated goal-directed movement and behaviours that required enhanced environmental perception and memory [230].
A general feature of many cognitive systems is the presence of mechanisms that transform analog signals into digital responses. The need for signal discrimination and the fact that analog computation is more prone to noise might be two crucial constraints on the evolution of cognition [231,232,233,234]. Neurons present a prototypical example of digital information processing and its advantages. Although behavioural patterns existed before neurons, the rapid expansion of neural components enabled novel complex behaviours.
The evolution of neurons [235] and neural circuits [236] allowed life to overcome the limitations imposed by diffusion-limited communication [237]. In both neural and aneural agents, all-or-none behavioural decisions are made using a standard design principle: integrating different inputs is weighted, leading to a threshold-mediated response. This also seems to occur within organisms as well as within cells. Is this a universal design principle?
During the mid-20th century, a new wave of computing machines created a technological environment for emulating logic elements akin to those in nervous systems. Pioneering theoretical contributions in mathematical biology by Warren McCulloch and Walter Pitts yielded a groundbreaking revelation: the ability to conceptualise units of cognition (referred to as “neurons”) within a logical framework [238,239]. These formal neurons were characterised as threshold units, drawing significant inspiration from the cutting-edge understanding of neural circuits. Unsurprisingly, the McCulloch-Pitts model revolved around the threshold nature of neuron responses and their mathematical depiction [240].
The illustrative depiction of the McCulloch-Pitts model’s conceptual framework is outlined in Figure 7a-b. The presented “formal neuron” (Fig. Figure 7b) operates as a simple Boolean system, with its state assuming one of two values: (an equivalent description of neurons as spins, , is sometimes employed when studying neural circuits using techniques from statistical physics). These two states typically correspond to neurons at rest (inactive) or in the act of firing (sending signals to other neurons). In response to incoming signals from a set of N presynaptic units, formal neurons exhibit sudden activation if the weighted sum of inputs surpasses a threshold [241,242].
While activation follows an all-or-nothing principle, the weights, denoted as , are continuous and indicate the impact of the state of presynaptic neuron j on postsynaptic neuron i, thereby modelling the strength of connections. These weights can be either positive or negative, allowing for the implementation of excitation and inhibition. In the McCulloch-Pitts approach, the integration of incoming signals by the postsynaptic neuron is expressed as:
where the additional parameter, , establishes the neuron’s threshold. The non-linear step function yields a value of 1 if its argument is positive and 0 otherwise. Consequently, neuron fires when the weighted sum of presynaptic inputs surpasses its threshold. The introduced non-linearity through enforces the all-or-none neural responsek.
McCulloch and Pitts demonstrated a pivotal insight: combinations of formal threshold neurons can be used to construct any logic Boolean circuit. This implies that, at least in their Boolean representation, brains could execute the same logic operations as computers. The McCulloch-Pitts model and its descendants have influenced the further development of Artificial Neural Networks. Beyond the single-unit design discussed here, artificial neural networks were inspired by another seemingly universal design principle associated with cortical architecture [243]: the presence of multiple processing layers (such as those found in the visual cortex). Are there alternative approaches to designing cognitive networks that do not rely on threshold-like units?
Interestingly, the basic McCulloch-Pitts design is common to many other living systems, including gene regulatory networks [244,245,246,247], immune networks [248,249,250], collective intelligence [251,252,253,254,255] or some aneural systems, such as quorum-sensing decisions in microbial communities, where an explicit equivalence has been defined [256]. These examples share an essential feature that departs from standard neural networks: they are “liquid’, meaning that the parts (proteins, bacteria or ants) move in space and that there is no stable, hardwired connectivity among pairs of individuals [257,258]. Do these systems follow a different logic scheme from the integration-threshold motif?
We illustrate this equivalence by considering gene regulatory networks, one of the best-studied examples. In this case, expression levels of transcription factors (TF), to be indicated as (intracellular concentration) of different TF ( in Figure 7d) change following a dynamical model [259]:
where is the degradation rate, and is a threshold-like function that is a consequence of the order of the molecular nature of interactions between DNA and TF. More precisely, because TF typically forms dimers, the nonlinearity associated with dimerisation automatically implies cooperative, threshold-like responses [260,261]. Here, the weights encapsulate diverse factors influencing the binding of TF.
What are the consequences of employing polarised, threshold-like elements in line with McCulloch-Pitt’s logic? This approach may facilitate the early development of multilayer processing structures, including interneurons as a crucial innovation, re-entrant closed loops and memory circuits capable of learning [262,263]. Are loops and multilayer architectures a convergent evolutionary design? A positive answer is suggested by the comparative study of neural networks in invertebrates and vertebrates [264,265]. Despite evolving along separate branches, these groups exhibit similar network topologies. This resemblance is observed in layered neural networks described by Ramon y Cajal for insect and cephalopod visual systems [266,267]. It has also been suggested that neural circuits with re-entrant loops are crucial for complex cognitive tasks [268]. One implication of these shared architectures is the potential for convergent minds shaped by evolution [269,270,271,272].
7. Ecology: Inevitable Parasites and Functional Trees
As the ecologist Ramon Margalef said [276], there is a “baroque of nature": there are so many species that an inevitable question is “why so many?”. Presumably, an alternative, much simpler prokaryotic biosphere could fulfil all biogeochemical functions of ecosystems [277]. In Margalef’s view, even though physical limits bind the organisation of ecosystems, there is plenty of room for the possible within these limits. The emergence of variations and the feedback between species and their environments might explain communities’ regularities and diversity. And yet, here again, the ecological literature is full of examples of systems where continuous features can be effectively discretised into a small number of categories.
Two basic components of this discretisation are involved. First, there is a well-known classification of the interactions between two species into combinations of neutral, positive or negative exchanges [278]. From this set, , different pairs can be derived,
with each pair mapping neutralism, competition, predation or parasitism, among other possibilitiesl. Despite other features affecting each species at play, further classification within each class reveals again a discrete repertoirem. Such an approach has been made, for example, within parasites, showing that, despite the enormous diversity of habitats, hosts, sizes or shapes, their diversity of strategies largely transcends phylogenetic boundaries [281].
Are there alternatives to these ecological network architectures? Would ecological webs in other planets (with different energy flows and chemical diversity), display different structural patterns? [282,283,284]. All these interactions occur (unless under controlled conditions) in a given environmental context where limited resources are availablen.
Here enters the second component of discretisation because the stability properties of these networks largely determine the separation between what is possible and what is not [286,287]. Due to these stability constraints, we can predict that some communities are impossible to observe (cannot be realised). Moreover, despite the enormous variation of climate and resource conditions, ecosystems display essentially the same properties, from Antarctica to the Sahel [288]. We can also reconstruct fossil ecosystems, the so-called “paleo food webs” [289,290] (Fig. Figure 8a,b), and again find universal patterns shared with modern ecological networks [291].
By avoiding the actual embodiment of biological agents and going down to their algorithmic description, in silico experiments support the presence of constraints in the logic of possible ecosystems. The first historical attempt to simulate an evolving digital ecology was made in the 1950s by Niles Barricelli, using the MANIAC computer at Los Alamos National Laboratory, as a digital environment [292,293], who wanted to test the theory of simbiogenesis [294]. These simulations were based on a grid of cells, each representing an individual organism. The organisms, defined as binary strings could reproduce, mutate, and compete. Complex interactions emerged but with an important characteristic: parasites rapidly evolved, jeopardising the potential for creating diversity and evolving complexity. As with natural systems, they were a seemingly inevitable component.
Barricelli’s ideas were forgotten until the days of Artificial Life in the 1980s [295,296,297]. Two crucial developments attracted renewed attention to the evolution of virtual agents: (a) the formalisation and propagation of computer viruses and (b) the creation of computer ecologies. Computer viruses can be seen as an inevitable outcome of computer networks interacting with data storage and transmission processes. Fifty years after Kleene’s theorem, self-replicating infectious programs were designed to infect local network servers. From a meagre presence in 1990, DOS-based computer viruses skyrocketed to over 10,000 by 1996. This surge prompted an arms race between new viruses and programmers [298], and their spread was shown to follow the epidemic nature of their real counterparts [299]. This is a perfect illustration of a convergent pattern that is shared between living and artificial systems. What about other ecological interactions?
Ecologist Tom Ray designed the program Tierra on a laptop, creating a virtual architecture in the host computer’s memory with its instructions and memory space [300,301] (also see [302]). Each digital organism has a genetic code that dictates its behaviour and features. Replication introduces mutation through faulty "genetic code" copying, while selection happens via competition for memory and CPU resources. Tierra unexpectedly displayed diverse ecological interactions due to the digital selection process. After the growth of shorter, faster-replicating programs, parasites emerged, needing other programs for reproduction. Hyper-parasites and immunisation mechanisms followed. Recombination (primitive sex) emerged in response to threats, leading to social behaviour through program cooperation. Other simulations of evolving ecosystems confirm the generative potential of artificial life systems [273,303,304,305,306]. Despite differences, the convergence in interaction classes suggests that the discrete set of possible interactions is standard in both digital and natural worlds. Some artificial life models use game-theoretic approaches with coded strategies in a digital genome. Complex patterns emerge, including coevolution, extinction (punctuated equilibrium [307]), cooperation [308], and ecological networks involving trophic levels [274] (Fig. Figure 8d).
These patterns can also be explored using dynamical models that have been used traditionally within the context of artificial chemistries [310,311] and deterministic chemical reaction dynamics [312]. The latter involves systems of coupled differential equations with higher-order nonlinear terms. One standard formulation is:
where is the population of type i, is the concentrations vector representing s different types, and each sum includes the different potential reaction events leading to the production of type k, i.e., the bimolecular reactions
along with their associated rates . These are kinetic models grounded in reactions assuming random molecule collisions. The term stands for a dilution flux that keeps the condition of constant populationo.
How can we introduce evolutionary rules and a context where functionalities are represented? Some particular formulations of these models describe Darwinian dynamics in molecular reaction networks [313] (see also [314]). This occurs when mutations are introduced as one specific reaction class, whereas mean replication is a fitness measure. A finite set of resources provides the source of selection.
The different types of entities whose evolution is described by equations such as Eq. (12) do not need to be restricted to chemical species. An algorithmic reaction system can be built using abstract symbols, binary strings, numbers or even proofs [275,311]. In Fontana’s Alchemy (for Algorithmic Chemistry), the emergence of novelties is possible by assigning to object interactions the formal properties of functions operating on data [315,316]. In this case, objects act based on symbol binding and -calculus rules, where one object functions on another as an argument, resulting in a new object. For two objects , an interaction leads to a composed object , creating a new object . Interactions define a mapping: , representing any computable function, with constraints from underlying semantics. If (power set of ), an additional mapping describes the allowable “collisions.” In the resulting Turing gas model, dynamics enable the compositional generation of new objects and the formation of complex interacting object networks, including hypercycles [317,318,319]. This kind of algorithmic chemistries can lead to complex networks of interactions (starting from catalytic cycles) that also contain parasites (Fig. Figure 8e).
The widespread presence of parasites in both artificial and natural communities suggests that they are a universal outcome of the evolution of complex adaptive systems [320]. In silico coevolution models have shown that parasites actively promote diversity and evolvability [309,321], as illustrated by the phylogenetic trees in (Fig. Figure 9a-b). Here, the presence (a) or absence (b) of parasites dramatically alters species richness, consistently with their role in natural communities [322]. A construct that we term functional evolutionary trees can be introduced to provide a unified picture of these case studies. Consider a given evolving biosphere (living or artificial) where novel forms of interactions among agents emerge. Some forms result from adaptations offered by available energy pockets (such as occurs with parasites), while major innovations mediate others. We could build an evolutionary tree (Fig. Figure 9c,d) where we cluster together those species that share a common set of defining ecological behaviours.
Results from artificial life models, as discussed above, suggest that there is a finite set of possible classes of interactions, namely a set , where each contains species sharing the same qualitative attributes. Initially, we start from a set of species containing a single homogeneous population of individuals of a single class (such as Ray’s initial set of programs). Due to evolutionary branching, new classes emerge up to a given time where several clusters (classes) are found in , where the diversity of each class is likely to depend on environmental variables . We conjecture as a result of evolutionary dynamics, the classes form a partition of the final set of species , so that
Commonalities across different runs would reflect the convergent dynamics of our evolving systems. Specifically, how trees branch over evolutionary time would be somewhat path-dependent (the kinds of parasites might differ, Figure 9e,f). Still, the final structure of ecological networks would include the same set of ecological roles.
Another perspective on ecology follows by considering observed regularities and what they might tell us about life [43,44,323,324]. One of the most powerful recent approaches to ecology connects allometric scaling laws with fundamental physical constraints [43,99,325]. Recently, such approaches to ecology have been extended to create novel biosignatures [323] and to suggest that the logic of cellular metabolism may be universal [324].
8. Phase Transitions and Critical States
Some of our previous case studies are deeply connected with the emergence of major innovations in evolution. These so-called major evolutionary transitions [326] refer to critical points in the history of life on Earth where new levels of biological organisation (cells, multicellularity or language, to cite a few) and complexity emerged. It has been suggested that these transitions, which imply a marked shift from a given qualitative level of organisation to a new one, can be mapped into the concept of phase transitions from statistical physics [13,58,327,328,329]. Because of the nature of these transitions, they are likely to be relevant in our understanding of macroevolutionary processes, ranging from punctuated equilibrium [307] to the hierarchical nature of evolutionary change [330,331] and the role that constraints play in setting transition points [100,332,333].
The theory of phase transitions was developed within physics over roughly 90 years spanning most of the 20th century [334,335,336,337,338,339,340], delivering a fully formalised and consistent theory of phases and the transitions separating them. The results have strongly influenced efforts to build a “systems science” approach to complexity in this area [341,342]. As discussed in the Introduction, the historical nature of living matter seems to play a secondary role when looking at the fundamental logic of its organisation. How much of physics constrains the possible, and what is the relative role of contingency? Interestingly, the two components are not exclusive. This is known as symmetry breaking [343,344].
We can illustrate this concept using one particularly successful and influential model: the so-called two-dimensional Ising model [345,346,347]. It is a discrete model with simple rules to explain phase transitions in ferromagnetic materials (see Figure 10a). In this model, a two-dimensional lattice represents a magnet with units () having two possible states (spins): up () and down (). Quantum mechanics suggests the lowest energy state occurs when adjacent atoms share the same spin. The global magnetisation depends on the difference between the total number of up and down spins ( and ). Spins align at low temperatures (), resulting in ordered states in what is known as the ferromagnetic phase, where . Since two possible, completely symmetric ways of alignment are at work, the symmetry must be “broken". Above , disorder prevails, with . Here, the temperature T is the control parameter, whereas the magnetisation M is the so-called order parameter. As T is tuned, two distinct phases with marked macroscopic properties are observable, separated by a well-defined critical point .
The Ising model considers an energy function , based on the microscopic interactions between magnet units
The coupling constant J defines the strength of the interaction between nearest neighbours within the lattice of magnets. Dynamical changes in the orientation of the magnets are introduced using transition probabilities that depend on temperature and neighbour spins. The transition probability is defined using a temperature-dependent function:
where is the energy change associated with a spin flip.
The Ising model has been shown to predict experimental observations of magnetic systems near with high accuracy. This is an important fact since the model ignores most of the microscopic details of the real system, keeping only the symmetry of the interactions, demonstrating universality in critical phenomena theory. Multiple extensions have been proposed, and the number of applications is huge, even considering simple, mean-field versions of the modelp.
Indeed, beyond ferromagnetism, the 2d Ising model and its extensions have been used in many contexts within complex systems. This includes its equivalence to Eigen’s quasispecies model, thus allowing mapping the error threshold as a phase transition [351,352,353], cell membrane responses [354], multicellular assemblies [355,356], spatiotemporal changes in rainforests [357], universal models of complexity [358] or large-scale functional brain dynamics [359]. We mention this disparate set of examples because, in all cases, it was possible to understand complex phenomena on a qualitative and quantitative basis accurately.
In turn, several well-known examples of evolutionary innovations seem to be associated with a symmetry-breaking event. These include, for example, the transition from “prevolution” to evolution [360], natural selection [361], the universality of intermediate metabolism [81,93] as well as the origin of chirality (Fig. Figure 10b) [362,363,364] as a mechanism to favour one of the two possible (symmetric) solutions through an amplification phenomenon: the final choice would be a historical accident. Other transitions involve the jump to novel properties associated with increased network connectivity. This would be the case of the emergence of autocatalytic cycles out of random chemical reactions (Fig. Figure 10c) once the number of possible reactions crosses the percolation threshold (a nonequilibrium phase transition) [365,366,367,368]. Similarly, the collective evolution of the genetic code might have also resulted from a phase transition (Fig. Figure 10d). In this case, the combination of threshold conditions for forming phases and their subsequent robustness in supporting the selection of higher-order organisations was invoked to explain the assignment of amino acids to codons in the genetic code [369]. The insight of this argument, first articulated by Woese in 1967 [370], was that although a highly reliable code could function adequately with codon assignments that were a frozen accident as Crick suggested [371], the actual genetic code implemented in molecular machinery is subject to errors even in extant, highly-evolved life, and must have been much more error-prone in the earliest eras of ribosomal translation and genome replication and transcription.
Along with the potential connection between evolutionary innovations and phase transitions, critical points play another role. While the previous examples deal with crossing the boundaries from one phase to another, some innovations are tied to the evolution towards critical states. Criticality (sometimes also called “the edge of chaos”) usually refers to the state where the system is poised between two phases: an ordered phase (high order parameter) and a disordered phase (vanishing order parameter). For instance, criticality occurs in the two-dimensional Ising model when . The idea that criticality might have several desirable properties has been advanced by different scholars within the context of nonlinearity and chaos [372], computation [373], genetic codes [374], virus evolution [375], virus-immune system coevolution [376], neuroscience [377,378] or ecology [379,380]. There are several good reasons for critical states playing a key role in living systems: information transfer becomes optimal at criticality [381,382] and sensitivity to external signals is maximised [383].
One hallmark of these transitions and their macroscopic emergent phases is their significantly lowerq range of variation compared to the microscopic configurations that produce them. While the possible microscopic configurations can increase combinatorially with system size, the self-reinforcing patterns that emerge can take far fewer forms, sometimes only finitely many, leading to a substantial reduction in the degrees of freedom for the system’s potential states [386]. From a developmental perspective — as we already outlined in Section 5 — the existence of material phases at the tissue scale defines a low-dimensional scenario of potential tissue properties and structures with obvious regulatory advantages [387,388,389]. For example, it has been reported that the embryonic tissue in early stages lies close to the fluidisation critical point, enabling the tissue to melt and thus induce a strong deformation to solidify again, to fix the morphogenetic changes [390]. This discrete nature comes hand in hand with side effects: cancer progression, in some stages, is more efficient thanks to the fluidisation/rigidification of the involved tissues [391]. In addition, huge fluctuations due to the proximity to the critical point may represent a serious drawback for the precision of tissue development [390]. From an evolutionary perspective, these robust properties can be seen differently: phase transitions define a clear boundary separating two qualitative behaviours, with each phase characterised by a few fundamental parameters. Despite their differences, systems that undergo these transitions will exhibit some fundamental common laws of organisation. This phenomenon is known as convergence.
One final point is related to the nature of the possible laws that could drive the increasing complexity of living entities. By default, it is assumed that natural selection is the dominant process at work, although alternative scenarios based on persistence-level selection (lacking replication) need some consideration [393]. On the other hand, our previous examples suggest that self-organisation and emergent phenomena are as relevant as selection [366]. Is that the case? Could other types of dynamical processes also account for the generation of complexity? Manfred Eigen proposed that natural selection is a phase transition in itself [361], and some authors suggest that this is likely to be a universal principle [392].
This section concludes with an idea suggested by several previous works [61,360]: deep constraints also limit the possible kinds of evolutionary laws ruling the biosphere. These would include (along with the thermodynamic laws discussed in section II): (a) an inevitable requirement for autocatalysis as a mechanism for population amplification, (b) the emergence of molecular heterogeneity as a precondition for population dynamics and (c) the phase transition to evolution from a non-Darwinian to Darwinian biosphere once some given interaction thresholds are achieved. Future work should consider how a theoretical framework can be defined to prove the uniqueness of natural selection as the expected generative force that drives biological complexity.
9. Discussion
Are there multiple alternative ways to generate living complexity? Predicting potential universal features of living systems, such as those resulting from constraints in the examples discussed in this paper, poses several significant challenges. Given the lack of multiple alternative scenarios, how can we address the logic of life? This question makes particular sense under a view of evolutionary dynamics as a highly path-dependent process. If life (however defined) can unfold in highly dimensional spaces that cannot be fully explored, there seems to be plenty of room for divergent designs. However, the existence of constraints in those spaces of the possible might profoundly change this view. The implications have been discussed in the context of possible life, from chemical constraints to phenotypic convergence in an alternative biosphere, but are likely to be relevant in understanding the limits of bioengineering design. In this context, many of the questions raised in this paper have been the target of dedicated efforts within the field of Artificial Life [273,393,394,395]. The “surprising creativity” of digital evolution has been an extraordinary source of inspiration and understanding [396].
In this paper, we conjecture that there are constraints that limit the logic of life across scales. To this goal, we provide a set of arguments suggesting that computational, physical and dynamical constraints profoundly limit the design space of possible living systems. The examples presented here have been supported by different but complementary arguments (computational, ecological, chemical, etc.). Our list (which by no means is intended to be exhaustive) includes:
- Internal entropy-reducing processes characterise the thermodynamic logic of living systems. Such processes are enabled by coupling processes that produce greater entropy in the environment, likely in the form of generated heat. Life is also expected to store and employ energy intermediates to drive internal processes and to decouple from environmental conditions, thereby attaining a degree of thermodynamic autonomy. Finally, the internal metabolic process will be organized around cyclic transformations.
- Linear heteropolymers formed by sets of units (symbols) having near-equivalent energies are the expected substrate for carrying molecular information. They allow the exploration of vast combinatorial spaces, and the physical constraints associated with linearity might pose severe limitations to the repertoire of possible monomer candidates.
- Closed cell compartments equipped with a von Neumann replication logic are needed for self-reproducing living forms capable of evolution. The compartment allows the concentration of required molecules and defines a boundary between internal and external environments connected through a membrane that can play a part in the constructor roles by exploiting physical instabilities. Such a closed container can be achieved using a specific class of molecules (the amphiphiles) and is thus constrained to a subset of chemical candidates.
- Multicellularity allows the emergence of new kinds of organisation out of simpler units. One universal precondition for this innovation is the presence of some physically embodied process that guarantees the closeness of cells. While the group provides mechanisms of efficient collective reproduction, these new units of selection (from cell clusters to organisms) need to deal with cheaters through ratcheting. The potential diversity of basic morphological designs might be strongly constrained by a finite number of physico-genetic motifs, whose combinations might generate the whole repertoire of basic developmental programs sharing deep common morphological motifs.
- Beyond information coding on coded strings, cognitive systems require threshold-like units that allow reliable integration and decision-making. Complex cognition has been unfolding by evolving different (but formally equivalent) circuits based on threshold functions that integrate surrounding signals. In multicellular systems, this means evolving cells that display polarisation and provide the means for rapid sensing and propagation of information. Because of these features, complex cognition might have been constrained to evolve towards multilayer systems.
- Ecosystem architectures are deeply constrained within a finite set of possible classes of ecological interactions. Current and past ecosystems reveal such a discrete repertoire of possibilities, and in silico models of evolving ecologies support this constrained repertoire. Among other regularities, the widespread presence of parasites suggests that they are an inevitable outcome of complex adaptive systems.
Each particular case questions us about different aspects of the evolutionary logic of biocomplexity. Each of the conjectures requires a rigorous formulation of the hypotheses and, in most cases, the consideration of diverse fields of analysis, from information theory and statistical physics to astrobiology and evolutionary biology. Solutions may require the development of new conceptual frameworks beyond the boundaries associated with each field. Furthermore, the problems under consideration are part of a hierarchy in which certain properties at one scale can affect (or be affected) by those at the next scale.
Does the notion of fundamental constraints for life eliminate the potential for surprises? Certainly not. Concentrating on logical structures ignores an essential aspect of multicellular life: the diversity of morphological, anatomical, and physiological adaptations in response to environmental factors. However, if our proposed constraints are universal, the logic of life elsewhere is likely to be quite familiar.
Acknowledgments
This paper was facilitated by the coincidental confluence of many of the authors at the Santa Fe Institute, and we thank the SFI for the general environment that brings such people together. RS thanks Luis Seoane, Luis Rocha, Jordi Delgado, Pedro Marquez-Zacarias, Marti Sanchez-Fibla, Clement Moulin-Frier and Kepa Ruiz-Mirazo for comments on the first version of the manuscript, the members of the Complex Systems Lab for so many discussions and the support of an AGAUR FI-SDUR 2020 grant. MDD acknowledges partial financial support from the Human Frontier Science Program Organization (HFSP Ref. RGY0064/2022). BCM thanks Adrián Aguirre-Tamaral for insightful comments on earlier versions of the manuscript and acknowledges the support of the field of excellence `Complexity of life in basic research and innovation’ of the University of Graz and the joint FWF/DFG Weave project I 6533-B. AK received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie Grant Agreement No. 101068029. EL thanks the Swedish Research Council for financial support and the interdisciplinary centres IceLab and the Santa Fe Institute for their creative research environments. ES is supported by the Earth-Life Science Institute at the Tokyo Institute of Technology, the Center for the Origin of Life at Georgia Institute of Technology, and the Wisconsin Institute for Discovery at the University of Wisconsin at Madison, and thanks to the Santa Fe Institute for its generous hospitality during writing. DHW thanks the Santa Fe Institute for its support.
| a | Those estimates are based on evidence from the fossil record that reveals a sharp transition, whereas molecular clock studies (where divergence times are obtained from sequence comparison) locate the origin of animals at about 780 Ma. See [22] and references therein. |
| b | The mapping between genes and phenotypes is poorly captured by the linear connection. The nature of the genotype-phenotype mapping [29] is highly compositional and algorithmic, reflecting the inevitable and essential interdependence of the molecular components that constitute organisms and enact their physiology and development. |
| c |
In statistical physics, an ergodic system is one which, over sufficiently long timescales, explores all possible microstates that are consistent with its macroscopic properties. Mathematically, for any physical observable , where is the microstate that specifies all of the system’s coordinates, the long-time average of converges to the ensemble average, so
In intuitive terms, an ergodic system explores (over time) all possible ways it can exist. It suggests that, given enough time, the system will visit all the available configurations or states.
|
| d | In nonequilibrium thermodynamics [73], the rate of entropy production per time can be expressed as an integral
|
| e | Once helicases unwind the double-stranded DNA helix. |
| f | To a large extent, the complementary nature of DNA is what allows the enormous flexibility in building structures and machines. A given strand will match only its complement and weakly interact with other sequences. In this way, many components can be assembled together in two or three dimensions while keeping the control on interaction strengths between every pair of elements. |
| g | A distinction needs to be made between replicators and reproducers. As suggested by E. Szathmáry, reproduction of a cell implies making a copy of the whole that is not limited to the genome, in contrast with viral particles or other putative “naked” molecular replicators in early life. |
| h | Some crucial insights into this problem were advanced within the context of Turing machines. If Universal Turing Machines can have access to its own code (a form of self-description), it is possible to show that one can re-write any program so that it will print out a copy of itself before it starts running. In formal terms, for any Turing machine , there exists a such that prints out a description of on its tape and then behaves in the same way as . Conceptually, this is reminiscent of the UC, which makes a copy of the Instructions and then carries out the Instructions. The mathematician Stephen Kleene first developed these ideas in his second recursion theorem [132,133]. |
| i | Simple MC (SMC) refers to a form of multicellular organisation where cells form clusters or colonies with limited differentiation and coordination. Unlike complex multicellularity, where cells exhibit specialised functions and are organised into distinct tissues and organs, SMC involves groups of similar or identical cells working together, often with minimal communication or structural integration. |
| j | In some cases, as it occurs with fractal branching patterns in plants [219] or growing corals [220], there is a set of generative rules (that sometimes can be expressed in terms of grammar) that successfully reproduce the whole repertoire of forms, which can often be classified within a parameter space in terms of seperated phases. For intriguing arguments that fractal growth with environmentally regulated parameters governed the Ediacaran fauna that may have been a transition stage to non-self-similar development, see [221] |
| k | Alternative implementations may employ smooth step functions, such as
|
| l | Three of these combinations, and are subdivided when applied to real cases. Predation and parasitism, for example, share the pair, but the kind of interaction and associated life cycles are different. |
| m | It is worth mentioning that there is a branch of theoretical ecology that deals with the qualitative stability of communities as derived from the sign matrix of pairwise interactions [279,280]. This indicates that much can be inferred solely based on the qualitative effects of member species on each other. |
| n | Importantly, thermodynamic arguments based on the Maximum Entropy formalism also reveal the power of constraints when dealing with the overal statistical patterns of ecosystem organization (instead of the internal logic) such as species– area relationships or abundance distributions in macroecology [285]. |
| o | In this case, by making the summation over k we obtain as the associated dilution term. |
| p | Ignoring spatial effects, a mean-field approximation can be made for the average magnetisation, which follows the differential equation . It is easy to show that three fixed points exist, associated with a symmetry-breaking (pitchfork) bifurcation [350]. A potential function (as defined in one-dimensional dynamical systems, see [351]) can be derived from , i.e., from , which in this case, gives a fourth-order expression that is a symmetric function, i. e. . For , the only stable state is , whereas for , the zero state is unstable, whereas two possible, completely symmetric solutions exist, namely . These potential functions are displayed as insets in Figure 10a. |
| q |
References
- Summons, R.E.; Albrecht, P.; McDonald, G.; Moldowan, J.M. Molecular biosignatures. <italic>Strategies of Life Detection</italic> <bold>2008</bold>, pp. 133–159.
- Marshall, S.M.; Mathis, C.; Carrick, E.; Keenan, G.; Cooper, G.J.; Graham, H.; Craven, M.; Gromski, P.S.; Moore, D.G.; Walker, S.I.; others. Identifying molecules as biosignatures with assembly theory and mass spectrometry. Nature communications 2021, 12, 3033. [Google Scholar] [CrossRef]
- Chan, M.A.; Hinman, N.W.; Potter-McIntyre, S.L.; Schubert, K.E.; Gillams, R.J.; Awramik, S.M.; Boston, P.J.; Bower, D.M.; Des Marais, D.J.; Farmer, J.D.; others. Deciphering biosignatures in planetary contexts. Astrobiology 2019, 19, 1075–1102. [Google Scholar] [CrossRef]
- Seager, S.; Bains, W.; Petkowski, J. Toward a list of molecules as potential biosignature gases for the search for life on exoplanets and applications to terrestrial biochemistry. Astrobiology 2016, 16, 465–485. [Google Scholar] [CrossRef]
- Johnson, S.S.; Anslyn, E.V.; Graham, H.V.; Mahaffy, P.R.; Ellington, A.D. Fingerprinting non-terran biosignatures. Astrobiology 2018, 18, 915–922. [Google Scholar] [CrossRef]
- Cleaves, H.J.; Hystad, G.; Prabhu, A.; Wong, M.L.; Cody, G.D.; Economon, S.; Hazen, R.M. A robust, agnostic molecular biosignature based on machine learning. Proceedings of the National Academy of Sciences 2023, 120, e2307149120. [Google Scholar] [CrossRef]
- Solé, R.V.; Munteanu, A. The large-scale organization of chemical reaction networks in astrophysics. Europhysics Letters 2004, 68, 170. [Google Scholar] [CrossRef]
- Estrada, E. Returnability as a criterion of disequilibrium in atmospheric reactions networks. Journal of Mathematical Chemistry 2012, 50, 1363–1372. [Google Scholar] [CrossRef]
- Bartlett, S.; Li, J.; Gu, L.; Sinapayen, L.; Fan, S.; Natraj, V.; Jiang, J.H.; Crisp, D.; Yung, Y.L. Assessing planetary complexity and potential agnostic biosignatures using epsilon machines. Nature Astronomy 2022, 6, 387–392. [Google Scholar] [CrossRef]
- McGhee, G.R. <italic>Convergent evolution: limited forms most beautiful</italic>; MIT press, 2011.
- Grefenstette, N.; Chou, L.; Colón-Santos, S.; Fisher, T.M.; Mierzejewski, V.; Nural, C.; Sinhadc, P.; Vidaurri, M.; Vincent, L.; Weng, M.M. Chapter 9: Life as We Don’t Know It. Astrobiology 2024, 24, S–186. [Google Scholar] [CrossRef]
- Church, G.M.; Regis, E. <italic>Regenesis: how synthetic biology will reinvent nature and ourselves</italic>; Basic Books, 2014.
- Solé, R. Synthetic transitions: towards a new synthesis. Philosophical Transactions of the Royal Society B: Biological Sciences 2016, 371, 20150438. [Google Scholar] [CrossRef]
- Ebrahimkhani, M.R.; Levin, M. Synthetic living machines: A new window on life. Iscience 2021, 24. [Google Scholar] [CrossRef]
- Davies, J.; Levin, M. Synthetic morphology with agential materials. Nature Reviews Bioengineering 2023, 1, 46–59. [Google Scholar] [CrossRef]
- Monod, J. <italic>On chance and necessity</italic>; Springer, 1974.
- Gould, S.J. <italic>Wonderful life: the Burgess Shale and the nature of history</italic>; WW Norton & Company, 1989.
- Carroll, S.B. <italic>A series of fortunate events: chance and the making of the planet, life, and you</italic>; Princeton University Press, 2020.
- Jacob, F. Evolution and tinkering. Science 1977, 196, 1161–1166. [Google Scholar] [CrossRef]
- Anderson, P.W. More Is Different: Broken symmetry and the nature of the hierarchical structure of science. Science 1972, 177, 393–396. [Google Scholar] [CrossRef]
- Artime, O.; De Domenico, M. From the origin of life to pandemics: Emergent phenomena in complex systems, 2022.
- Erwin, D.H.; Valentine, J.W. The cambrian explosion. <italic>Genwodd Village, Colorado: Roberts and Company</italic> <bold>2013</bold>.
- Carroll, S.B. Chance and necessity: the evolution of morphological complexity and diversity. Nature 2001, 409, 1102–1109. [Google Scholar] [CrossRef]
- Erwin, D.H. Was the Ediacaran–Cambrian radiation a unique evolutionary event? Paleobiology 2015, 41, 1–15. [Google Scholar] [CrossRef]
- Blount, Z.D.; Lenski, R.E.; Losos, J.B. Contingency and determinism in evolution: Replaying life’s tape. Science 2018, 362, eaam5979. [Google Scholar] [CrossRef]
- Morris, S.C. <italic>Life’s solution: inevitable humans in a lonely universe</italic>; Cambridge university press, 2003.
- Solé, R.V.; Valverde, S.; Rodriguez-Caso, C. Convergent evolutionary paths in biological and technological networks. Evolution: Education and Outreach 2011, 4, 415–426. [Google Scholar] [CrossRef]
- Alberch, P. The logic of monsters: Evidence for internal constraint in development and evolution. Geobios 1989, 22, 21–57. [Google Scholar] [CrossRef]
- Manrubia, S.; Cuesta, J.A.; Aguirre, J.; Ahnert, S.E.; Altenberg, L.; Cano, A.V.; Catalán, P.; Diaz-Uriarte, R.; Elena, S.F.; García-Martín, J.A.; others. From genotypes to organisms: State-of-the-art and perspectives of a cornerstone in evolutionary dynamics. Physics of Life Reviews 2021, 38, 55–106. [Google Scholar] [CrossRef]
- Raup, D.M. Geometric analysis of shell coiling: general problems. Journal of paleontology 1966, 1178–1190. [Google Scholar]
- Corominas-Murtra, B.; Goñi, J.; Solé, R.V.; Rodríguez-Caso, C. On the origins of hierarchy in complex networks. Proceedings of the National Academy of Sciences 2013, 110, 13316–13321. [Google Scholar] [CrossRef]
- Avena-Koenigsberger, A.; Goni, J.; Solé, R.; Sporns, O. Network morphospace. Journal of the Royal Society Interface 2015, 12, 20140881. [Google Scholar] [CrossRef]
- Saavedra, S.; Rohr, R.P.; Bascompte, J.; Godoy, O.; Kraft, N.J.; Levine, J.M. A structural approach for understanding multispecies coexistence. Ecological Monographs 2017, 87, 470–486. [Google Scholar] [CrossRef]
- Long, C.; Deng, J.; Nguyen, J.; Liu, Y.Y.; Alm, E.J.; Solé, R.; Saavedra, S. Structured community transitions explain the switching capacity of microbial systems. Proc. Natl. Acad. Sci. USA 2024, 121. [Google Scholar] [CrossRef]
- Deng, J.; Taylor, W.; Saavedra, S. Understanding the impact of third-party species on pairwise coexistence. PLoS Comput. Biol. 2022, 18, e1010630. [Google Scholar] [CrossRef]
- Waddington, C.H. Canalization of development and the inheritance of acquired characters. Nature 1942, 150, 563–565. [Google Scholar] [CrossRef]
- Wagner, A. Robustness and Evolvability in Living Systems; Princeton Univ. Press: NJ, 2007. [Google Scholar]
- Medeiros, L.P.; Boege, K.; del Val, E.; Zaldivar-Riverón, A.; Saavedra, S. Observed ecological communities are formed by species combinations that are among the most likely to persist under changing environments. The American Naturalist 2021, 197, E17–E29. [Google Scholar] [CrossRef]
- Kauffman. <italic>Investigations</italic>; Oxford University Press, 2000.
- Kauffman, S.A.; Roli, A. A third transition in science? Interface Focus 2023, 13, 20220063. [Google Scholar] [CrossRef]
- Kauffman, S.A. Prolegomenon to patterns in evolution. Biosystems 2014, 123, 3–8. [Google Scholar] [CrossRef]
- Dryden, D.T.; Thomson, A.R.; White, J.H. How much of protein sequence space has been explored by life on Earth? Journal of The Royal Society Interface 2008, 5, 953–956. [Google Scholar] [CrossRef]
- Kempes, C.P.; Koehl, M.; West, G.B. The scales that limit: the physical boundaries of evolution. Frontiers in Ecology and Evolution 2019, 7, 242. [Google Scholar] [CrossRef]
- Kempes, C.P.; Krakauer, D.C. The multiple paths to multiple life. Journal of molecular evolution 2021, 89, 415–426. [Google Scholar] [CrossRef]
- Aguirre, J.; Catalán, P.; Cuesta, J.A.; Manrubia, S. On the networked architecture of genotype spaces and its critical effects on molecular evolution. Open biology 2018, 8, 180069. [Google Scholar] [CrossRef]
- Manrubia, S. The simple emergence of complex molecular function. Philosophical Transactions of the Royal Society A 2022, 380, 20200422. [Google Scholar] [CrossRef]
- Alberch, P. From genes to phenotype: dynamical systems and evolvability. Genetica 1991, 84, 5–11. [Google Scholar] [CrossRef]
- Gavrilets, S.; Gravner, J. Percolation on the fitness hypercube and the evolution of reproductive isolation. Journal of theoretical biology 1997, 184, 51–64. [Google Scholar] [CrossRef]
- Fontana, W. Modelling ‘evo-devo’with RNA. BioEssays 2002, 24, 1164–1177. [Google Scholar] [CrossRef]
- Schultes, E.A.; Bartel, D.P. One sequence, two ribozymes: implications for the emergence of new ribozyme folds. Science 2000, 289, 448–452. [Google Scholar] [CrossRef]
- Li, H.; Helling, R.; Tang, C.; Wingreen, N. Emergence of preferred structures in a simple model of protein folding. Science 1996, 273, 666–669. [Google Scholar] [CrossRef]
- Li, H.; Tang, C.; Wingreen, N. Are protein folds atypical? Proc. Nat. Acad. Sci. USA 1998, 95, 4987–4990. [Google Scholar] [CrossRef]
- Denton, M. The Protein Folds as Platonic Forms: New Support for the Pre-Darwinian Conception of Evolution by Natural Law. J. Theor. Biol. 2002, 219, 325–342. [Google Scholar] [CrossRef]
- Banavar, J.R.; Maritan, A. Colloquium: Geometrical approach to protein folding: a tube picture. Reviews of Modern Physics 2003, 75, 23. [Google Scholar] [CrossRef]
- Ahnert, S.E.; Johnston, I.G.; Fink, T.M.; Doye, J.P.; Louis, A.A. Self-assembly, modularity, and physical complexity. Physical Review E 2010, 82, 026117. [Google Scholar] [CrossRef]
- Sharma, A.; Czégel, D.; Lachmann, M.; Kempes, C.P.; Walker, S.I.; Cronin, L. Assembly theory explains and quantifies selection and evolution. Nature 2023, 622, 321–328. [Google Scholar] [CrossRef]
- Cleland, C.E. <italic>The Quest for a Universal Theory of Life: Searching for Life as we don’t know it</italic>; Vol. 11, Cambridge University Press, 2019.
- Goldenfeld, N.; Woese, C. Life is physics: evolution as a collective phenomenon far from equilibrium. Annu. Rev. Condens. Matter Phys. 2011, 2, 375–399. [Google Scholar] [CrossRef]
- Goldenfeld, N.; Biancalani, T.; Jafarpour, F. Universal biology and the statistical mechanics of early life. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 2017, 375, 20160341. [Google Scholar] [CrossRef]
- Walker, S.I.; Packard, N.; Cody, G. Re-conceptualizing the origins of life. Philosophical transactions. Series A, Mathematical, physical, and engineering sciences 2017, 375. [Google Scholar] [CrossRef]
- Walker, S.I. Origins of life: a problem for physics, a key issues review. Reports on Progress in Physics 2017, 80, 092601. [Google Scholar] [CrossRef]
- Davies, P.C.; Walker, S.I. The hidden simplicity of biology. Reports on Progress in Physics 2016, 79, 102601. [Google Scholar] [CrossRef]
- Walker, S.I.; Bains, W.; Cronin, L.; DasSarma, S.; Danielache, S.; Domagal-Goldman, S.; Kacar, B.; Kiang, N.Y.; Lenardic, A.; Reinhard, C.T.; others. Exoplanet biosignatures: future directions. Astrobiology 2018, 18, 779–824. [Google Scholar] [CrossRef]
- Langton, C.G. Self-reproduction in cellular automata. Physica D: Nonlinear Phenomena 1984, 10, 135–144. [Google Scholar] [CrossRef]
- von Neumann, John; Ed. Burks, A. <italic>Theory of self-reproducing automata</italic>; University of IIlinois Press, Illinois, 1966.
- Langton, C.G.; Taylor, C.; Farmer, J.D.; Rasmussen, S. <italic>Artificial Life II: Santa Fe Institute Studies in the Sciences of Complexity, Proceedings Vol. 10</italic>; Addison-Wesley Redwood City, CA, 1992.
- Langton, C.G.; Taylor, C.; Farmer, J.D.; Rasmussen, S. <italic>Artificial Life III, Santa Fe Institute Studies in the Science of Complexity</italic>; Addison-Wesley Redwood City, CA, 1994.
- Küppers, B.O. <italic>Information and the Origin of Life</italic>; MIT Press, 1990.
- Yockey, H.P. Information theory, evolution, and the origin of life; Cambridge University Press, 2005.
- Walker, S.I.; Davies, P.C. The algorithmic origins of life. Journal of the Royal Society Interface 2013, 10, 20120869. [Google Scholar] [CrossRef]
- Flack, Jessica; Eds. Walker, S.I.; Davies, P.C.; Ellis, G.F., From Matter to Life: Information and Causality; Cambridge University Press, 2017; chapter Life’s Information Hierarchy, p. 283.
- Kempes, C.P.; Wolpert, D.; Cohen, Z.; Pérez-Mercader, J. The thermodynamic efficiency of computations made in cells across the range of life. Phil. Trans. Roy. Soc. A 2017, arXiv:1706.05043v1 [q-bio.OT]375, 20160343–arXiv:1706. [Google Scholar] [CrossRef]
- Glansdorff, P.; Prigogine, I. On a general evolution criterion in macroscopic physics. Physica 1964, 30, 351–374. [Google Scholar] [CrossRef]
- Schrödinger, E. <italic>What is life? The physical aspect of the living cell and mind</italic>; Cambridge university press, 1944.
- Boltzmann, L. The second law of thermodynamics, Populare Schriften, Essay no. 3, address to the Imperial Academy of Sciences 1886. In <italic>Theoretical Physics and Philosophical Problems, Selected Writings of L. Boltzmann</italic>; D. Reidel, 1974; pp. 13–32.
- Lengeler, J.W.; Drews, G.; Schlegel, H.G. Biology of the Prokaryotes; Blackwell Science: New York, 1999. [Google Scholar]
- Liu, J.; Marison, I.W.; Von Stockar, U. Microbial growth by a net heat up-take: A calorimetric and thermodynamic study on acetotrophic methanogenesis by Methanosarcina barkeri. Biotechnology and Bioengineering 2001, 75, 170–180. [Google Scholar] [CrossRef]
- Heijnen, J.J.; Van Dijken, J.P. In search of a thermodynamic description of biomass yields for the chemotrophic growth of microorganisms. Biotechnology and Bioengineering 1992, 39, 833–858. [Google Scholar] [CrossRef]
- Barlow, C.; Volk, T. Open systems living in a closed biosphere: a new paradox for the Gaia debate. BioSystems 1990, 23, 371–384. [Google Scholar] [CrossRef]
- Budyko, M.I. <italic>The evolution of the biosphere</italic>; Vol. 9, Springer Science & Business Media, 2012.
- Smith, E.; Morowitz, H.J. The origin and nature of life on Earth: the emergence of the fourth geosphere; Cambridge U. Press: London, 2016; ISBN 9781316348772. [Google Scholar]
- Benner, S.A.; Ellington, A.D.; Tauer, A. Modern metabolism as a palimpsest of the RNA world <bold>1989</bold>. <italic>18</italic>, 7054–7058.
- Branscomb, E.; Russell, M.J. Turnstiles and bifurcators: the disequilibrium converting engines that put metabolism on the road. Biochim. Biophys. Acta 2013, 1827, 62–78. [Google Scholar] [CrossRef]
- mechanisms, E.; the conversion of disequilibria; the engines of creation. Branscomb, E. and Biancalani, T. and Goldenfeld, N. and Russell, M. Phys. Rep. 2017, 677, 1–60. [Google Scholar]
- Pasek, M.A.; Kee, T.P. On the Origin of Phosphorylated Biomolecules. In Origins of Life: The Primal Self-Organization; Egel, R., Lankenau, D.H., Mulkidjanian, A.Y., Eds.; Springer-Verlag: Berlin, 2011; pp. 57–84. [Google Scholar]
- Braakman, R.; Smith, E. The compositional and evolutionary logic of metabolism. Physical Biology 2013, 10, 011001. [Google Scholar] [CrossRef] [PubMed]
- Moreno Bergareche, A.; Ruiz-Mirazo, K. Metabolism and the problem of its universalization. BioSystems 1999, 49, 45–61. [Google Scholar] [CrossRef]
- Braakman, R.; Smith, E. The emergence and early evolution of biological carbon fixation. PLoS Comp. Biol. 2012, 8, e1002455. [Google Scholar] [CrossRef] [PubMed]
- Nunoura, T.; Chikaraishi, Y.; Izaki, R.; Suwa, T.; Sato, T.; Harada, T.; Mori, K.; Kato, Y.; Miyazaki, M.; Shimamura, S.; Yanagawa, K.; Shuto, A.; Ohkouchi, N.; Fujita, N.; Takaki, Y.; Atomi, H.; Takai, K. A primordial and reversible TCA cycle in a facultatively chemolithoautotrophic thermophile. Science 2018, 359, 559–563. [Google Scholar] [CrossRef]
- Koschmieder, E.; Pallas, S. Heat transfer through a shallow, horizontal convecting fluid layer. International Journal of Heat and Mass Transfer 1974, 17, 991–1002. [Google Scholar] [CrossRef]
- Onsager, L. Reciprocal Relations in Irreversible Processes. I. Physical Review 1931, 37, 405–426. [Google Scholar] [CrossRef]
- Morowitz, H.J. Physical background of cycles in biological systems. Journal of Theoretical Biology 1966, 13, 60–62. [Google Scholar] [CrossRef]
- Smith, E.; Morowitz, H.J. Universality in intermediary metabolism. Proc. Nat. Acad. Sci. USA 2004, 101, 13168–13173. [Google Scholar] [CrossRef] [PubMed]
- Morowitz, H.; Smith, E. Energy flow and the organization of life. Complexity 2007, 13, 51–59. [Google Scholar] [CrossRef]
- Schnakenberg, J. Network theory of microscopic and macroscopic behavior of master equation systems. Reviews of Modern physics 1976, 48, 571. [Google Scholar] [CrossRef]
- England, J.L. Statistical physics of self-replication. J. Chem. Phys. 2013, 139, 121923. [Google Scholar] [CrossRef]
- Calow, P. Conversion efficiencies in heterotrophic organisms. Biol. Rev. 1977, 52, 385–409. [Google Scholar] [CrossRef]
- Morowitz, H.J. Some Order-Disorder Considerations in Living Systems. Bull. Math. Biophys. 1955, 17, 81–86. [Google Scholar] [CrossRef]
- West, G.B.; Brown, J.H.; Enquist, B.J. A general model for the origin of allometric scaling laws in biology. Science 1997, 276, 122–126. [Google Scholar] [CrossRef]
- Kempes, C.P.; Dutkiewicz, S.; Follows, M.J. Growth, metabolic partitioning, and the size of microorganisms. Proceedings of the National Academy of Sciences 2012, 109, 495–500. [Google Scholar] [CrossRef]
- Prigogine, I.; Nicolis, G. Biological order, structure and instabilities. Quarterly Reviews of Biophysics 1971, 4, 107–148. [Google Scholar] [CrossRef]
- Cronin, L.; Krasnogor, N.; Davis, B.G.; Alexander, C.; Robertson, N.; Steinke, J.H.; Schroeder, S.L.; Khlobystov, A.N.; Cooper, G.; Gardner, P.M.; others. The imitation game - a computational chemical approach to recognizing life. Nature biotechnology 2006, 24, 1203–1206. [Google Scholar] [CrossRef]
- Koltsov, N. Physical-chemical fundamentals of morphology. Prog Exp Biol 1927, 3–31. [Google Scholar]
- Koltsov, N. Hereditary molecules. Sci. Life 1935, 5, 4–314. [Google Scholar]
- Soyfer, V.N. The consequences of political dictatorship for Russian science. Nature Reviews Genetics 2001, 2, 723–729. [Google Scholar] [CrossRef]
- Hopcroft, J.E. Turing machines. Scientific American 1984, 250, 86–E9. [Google Scholar] [CrossRef]
- Watson, J.D.; Crick, F.H. Molecular structure of nucleic acids: a structure for deoxyribose nucleic acid. Nature 1953, 171, 737–738. [Google Scholar] [CrossRef]
- Franklin, R.E.; Gosling, R.G. Evidence for 2-chain helix in crystalline structure of sodium deoxyribonucleate. Nature 1953, 172, 156–157. [Google Scholar] [CrossRef]
- Amos, M. <italic>Cellular computing</italic>; Systems Biology, 2004.
- Al-Hashimi, H.M. Turing, von Neumann, and the computational architecture of biological machines. Proceedings of the National Academy of Sciences 2023, 120, e2220022120. [Google Scholar] [CrossRef]
- Runnels, C.; Lanier, K.A.; Williams, J.K.; Bowman, J.C.; Petrov, A.S.; Hud, N.V.; Williams, L.D. Folding, Assembly, and Persistence: The Essential Nature and Origins of Biopolymers. J. Mol. Evol. 2018, 86, 598–610. [Google Scholar] [CrossRef]
- Pattee, H. How does a molecule become a message? Communication in Development, Anton L (ed) Developmental Biology Supplement, 1969.
- Kull, K. A sign is not alive—a text is. Σημειωτκη´-Sign Systems Studies 2002, 30, 327–336. [Google Scholar] [CrossRef]
- Barbieri, M. <italic>The organic codes: an introduction to semantic biology</italic>; Cambridge University Press, 2003.
- Pattee, H.H. Physical and functional conditions for symbols, codes, and languages. Biosemiotics 2008, 1, 147–168. [Google Scholar] [CrossRef]
- Rocha, L.M.; Hordijk, W. Material representations: From the genetic code to the evolution of cellular automata. Artificial life 2005, 11, 189–214. [Google Scholar] [CrossRef]
- Goodwin, B. Biology and meaning. Towards a Theoretical Biology (Edinburgh: Edinburgh University Press, 1972) 2017, 4, 259–275. [Google Scholar]
- Seeman, N.C. DNA in a material world. Nature 2003, 421, 427–431. [Google Scholar] [CrossRef]
- Ramezani, H.; Dietz, H. Building machines with DNA molecules. Nature Reviews Genetics 2020, 21, 5–26. [Google Scholar] [CrossRef]
- Sowerby, S.J.; Stockwell, P.A.; Heckl, W.M.; Petersen, G.B. Self-programmable, self-assembling two-dimensional genetic matter. Origins of Life and Evolution of the Biosphere 2000, 30, 81–99. [Google Scholar] [CrossRef]
- Sowerby, S.J.; Holm, N.G.; Petersen, G.B. Origins of life: a route to nanotechnology. Biosystems 2001, 61, 69–78. [Google Scholar] [CrossRef]
- Cairns-Smith, A.G. The chemistry of materials for artificial Darwinian systems. International Reviews in Physical Chemistry 1988, 7, 209–250. [Google Scholar] [CrossRef]
- Milo, R.; Phillips, R. <italic>Cell Biology by the Numbers</italic>; 2015.
- Landauer, R. Irreversibility and heat generation in the computing process. IBM journal of research and development 1961, 5, 183–191. [Google Scholar] [CrossRef]
- Kolchinsky, A.; Corominas-Murtra, B. Decomposing information into copying versus transformation. Journal of the Royal Society Interface 2020, 17, 20190623. [Google Scholar] [CrossRef]
- Kempes, C.P.; Wolpert, D.; Cohen, Z.; Pérez-Mercader, J. The thermodynamic efficiency of computations made in cells across the range of life. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 2017, 375, 20160343. [Google Scholar] [CrossRef]
- Munteanu, A.; Attolini, C.S.O.; Rasmussen, S.; Ziock, H.; Solé, R.V. Generic Darwinian selection in catalytic protocell assemblies. Philosophical Transactions of the Royal Society B: Biological Sciences 2007, 362, 1847–1855. [Google Scholar] [CrossRef]
- Koonin, E.V. The origins of cellular life. Antonie Van Leeuwenhoek 2014, 106, 27–41. [Google Scholar] [CrossRef]
- Flack, J.C. Multiple time-scales and the developmental dynamics of social systems. Phil. Trans. R. Soc. B 2012, 367, 1802–1810. [Google Scholar] [CrossRef]
- Flack, J.C.; Erwin, D.; Elliot, T.; Krakauer, D.C. Timescales, symmetry, and uncertainty reduction in the origins of hierarchy in biological systems. In Evolution Cooperation and Complexity; Sterelny, K., Joyce, R., Calcott, B., Fraser, B., Eds.; MIT Press: Cambridge, MA, 2013; pp. 45–74. [Google Scholar]
- Odling-Smee, F.J.; Laland, K.N.; Feldman, M.W. Niche Construction: The Neglected Process in Evolution; Princeton U. Press: Princeton, N. J, 2003. [Google Scholar]
- Kleene, S.C. On notation for ordinal numbers. The Journal of Symbolic Logic 1938, 3, 150–155. [Google Scholar] [CrossRef]
- Marion, J.Y. From Turing machines to computer viruses. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 2012, 370, 3319–3339. [Google Scholar] [CrossRef]
- Pattee, H.H. Dynamic and linguistic modes of complex systems. International Journal Of General System 1977, 3, 259–266. [Google Scholar] [CrossRef]
- Rocha, L.M. Evolution with material symbol systems. Biosystems 2001, 60, 95–121. [Google Scholar] [CrossRef]
- McMullin, B. John von Neumann and the evolutionary growth of complexity: Looking backward, looking forward. Artificial life 2000, 6, 347–361. [Google Scholar] [CrossRef]
- Ruiz-Mirazo, K.; Umerez, J.; Moreno, A. Enabling conditions for ‘open-ended evolution’. Biology & Philosophy 2008, 23, 67–85. [Google Scholar]
- Ruiz-Mirazo, K.; Peretó, J.; Moreno, A. A universal definition of life: autonomy and open-ended evolution. Origins of Life and Evolution of the Biosphere 2004, 34, 323–346. [Google Scholar] [CrossRef]
- Packard, N.; Bedau, M.A.; Channon, A.; Ikegami, T.; Rasmussen, S.; Stanley, K.O.; Taylor, T. An overview of open-ended evolution: Editorial introduction to the open-ended evolution ii special issue. Artificial life 2019, 25, 93–103. [Google Scholar] [CrossRef]
- Sipper, M. Fifty years of research on self-replication: An overview. Artificial life 1998, 4, 237–257. [Google Scholar] [CrossRef]
- Mouritsen, O.G. <italic>Life-as a matter of fat</italic>; Vol. 538, Springer, 2005.
- Hamley, I.W. <italic>Introduction to soft matter: synthetic and biological self-assembling materials</italic>; John Wiley & Sons, 2007.
- Rasmussen, S.; Chen, L.; Deamer, D.; Krakauer, D.C.; Packard, N.H.; Stadler, P.F.; Bedau, M.A. Transitions from nonliving to living matter. Science 2004, 303, 963–965. [Google Scholar] [CrossRef]
- Stano, P.; Luisi, P.L. Achievements and open questions in the self-reproduction of vesicles and synthetic minimal cells. Chemical Communications 2010, 46, 3639–3653. [Google Scholar] [CrossRef]
- Ruiz-Mirazo, K.; Briones, C.; de la Escosura, A. Prebiotic systems chemistry: new perspectives for the origins of life. Chemical reviews 2014, 114, 285–366. [Google Scholar] [CrossRef]
- Luisi, P.L. <italic>The emergence of life: from chemical origins to synthetic biology</italic>; Cambridge University Press, 2016.
- Serra, R.; Villani, M.; others. <italic>Modelling protocells</italic>; Springer, 2017.
- Rasmussen, S.; Bedau, M.A.; McCaskill, J.S.; Packard, N.H. A roadmap to protocells. Protocells: bridging nonliving and living matter. MIT Press, Cambridge.
- Sole, R.V. Evolution and self-assembly of protocells. The international journal of biochemistry & cell biology 2009, 41, 274–284. [Google Scholar]
- Kahana, A.; Lancet, D. Self-reproducing catalytic micelles as nanoscopic protocell precursors. Nature Reviews Chemistry 2021, 5, 870–878. [Google Scholar] [CrossRef]
- Morowitz, H.J.; Heinz, B.; Deamer, D.W. The chemical logic of a minimum protocell. Origins of Life and Evolution of the Biosphere 1988, 18, 281–287. [Google Scholar] [CrossRef]
- Deamer, D. <italic>First life: Discovering the connections between stars, cells, and how life began</italic>; Univ of California Press, 2011.
- Solé, R.V.; Munteanu, A.; Rodriguez-Caso, C.; Macía, J. Synthetic protocell biology: from reproduction to computation. Philosophical Transactions of the Royal Society B: Biological Sciences 2007, 362, 1727–1739. [Google Scholar] [CrossRef]
- Ruiz-Herrero, T.; Fai, T.G.; Mahadevan, L. Dynamics of growth and form in prebiotic vesicles. Physical review letters 2019, 123, 038102. [Google Scholar] [CrossRef]
- Fellermann, H.; Rasmussen, S.; Ziock, H.J.; Solé, R.V. Life cycle of a minimal protocell—a dissipative particle dynamics study. Artificial Life 2007, 13, 319–345. [Google Scholar] [CrossRef]
- Macía, J.; Solé, R.V. Protocell self-reproduction in a spatially extended metabolism–vesicle system. Journal of theoretical biology 2007, 245, 400–410. [Google Scholar] [CrossRef]
- Macia, J.; Solé, R.V. Synthetic Turing protocells: vesicle self-reproduction through symmetry-breaking instabilities. Philosophical Transactions of the Royal Society B: Biological Sciences 2007, 362, 1821–1829. [Google Scholar] [CrossRef]
- Corominas-Murtra, B. Thermodynamics of Duplication Thresholds in Synthetic Protocell Systems. Life 2019, 9(1), 9. [Google Scholar] [CrossRef]
- Fellermann, H.; Solé, R.V. Minimal model of self-replicating nanocells: a physically embodied information-free scenario. Philosophical Transactions of the Royal Society B: Biological Sciences 2007, 362, 1803–1811. [Google Scholar] [CrossRef]
- Vasas, V.; Szathmáry, E.; Santos, M. Lack of evolvability in self-sustaining autocatalytic networks constraints metabolism-first scenarios for the origin of life. Proceedings of the National Academy of Sciences 2010, 107, 1470–1475. [Google Scholar] [CrossRef]
- Darwin, C. On the Origin of Species; John Murray: London, 1859. [Google Scholar]
- Wilson, E.O. <italic>The diversity of life</italic>; WW Norton & Company, 1999.
- Mombach, J.C.; Glazier, J.A.; Raphael, R.C.; Zajac, M. Quantitative comparison between differential adhesion models and cell sorting in the presence and absence of fluctuations. Physical Review Letters 1995, 75, 2244. [Google Scholar] [CrossRef]
- Ollé-Vila, A.; Duran-Nebreda, S.; Conde-Pueyo, N.; Montañez, R.; Solé, R. A morphospace for synthetic organs and organoids: the possible and the actual. Integrative Biology 2016, 8, 485–503. [Google Scholar] [CrossRef]
- Márquez-Zacarías, P.; Pineau, R.M.; Gomez, M.; Veliz-Cuba, A.; Murrugarra, D.; Ratcliff, W.C.; Niklas, K.J. Evolution of cellular differentiation: from hypotheses to models. Trends in Ecology & Evolution 2021, 36, 49–60. [Google Scholar]
- Grosberg, R.K.; Strathmann, R.R. The evolution of multicellularity: a minor major transition? Annu. Rev. Ecol. Evol. Syst. 2007, 38, 621–654. [Google Scholar] [CrossRef]
- Bonner, J.T. <italic>First signals: the evolution of multicellular development</italic>; Princeton University Press, 2009.
- Knoll, A.H. The multiple origins of complex multicellularity. Annual Review of Earth and Planetary Sciences 2011, 39, 217–239. [Google Scholar] [CrossRef]
- Ratcliff, W.C.; Denison, R.F.; Borrello, M.; Travisano, M. Experimental evolution of multicellularity. Proceedings of the National Academy of Sciences 2012, 109, 1595–1600. [Google Scholar] [CrossRef]
- Ratcliff, W.C.; Fankhauser, J.D.; Rogers, D.W.; Greig, D.; Travisano, M. Origins of multicellular evolvability in snowflake yeast. Nature communications 2015, 6, 6102. [Google Scholar] [CrossRef]
- Solé, R.; Ollé-Vila, A.; Vidiella, B.; Duran-Nebreda, S.; Conde-Pueyo, N. The road to synthetic multicellularity. Current Opinion in Systems Biology 2018, 7, 60–67. [Google Scholar] [CrossRef]
- Toda, S.; Blauch, L.R.; Tang, S.K.; Morsut, L.; Lim, W.A. Programming self-organizing multicellular structures with synthetic cell-cell signaling. Science 2018, 361, 156–162. [Google Scholar] [CrossRef]
- Michod, R.E. Evolution of individuality during the transition from unicellular to multicellular life. Proceedings of the National Academy of Sciences 2007, 104, 8613–8618. [Google Scholar] [CrossRef]
- West, S.A.; Fisher, R.M.; Gardner, A.; Kiers, E.T. Major evolutionary transitions in individuality. Proceedings of the National Academy of Sciences 2015, 112, 10112–10119. [Google Scholar] [CrossRef]
- Libby, E.; Rainey, P.B. A conceptual framework for the evolutionary origins of multicellularity. Physical biology 2013, 10, 035001. [Google Scholar] [CrossRef]
- Carmel, Y. Human societal development: is it an evolutionary transition in individuality? Philosophical Transactions of the Royal Society B 2023, 378, 20210409. [Google Scholar] [CrossRef]
- Rainey, P.B. Major evolutionary transitions in individuality between humans and AI. Philosophical Transactions of the Royal Society B 2023, 378, 20210408. [Google Scholar] [CrossRef]
- Krakauer, D.; Bertschinger, N.; Olbrich, E.; Flack, J.C.; Ay, N. The information theory of individuality. Theory in Biosciences 2020, 139, 209–223. [Google Scholar] [CrossRef]
- Queller, D.C.; Strassmann, J.E. Beyond society: the evolution of organismality. Philosophical Transactions of the Royal Society B: Biological Sciences 2009, 364, 3143–3155. [Google Scholar] [CrossRef]
- Van Gestel, J.; Tarnita, C.E. On the origin of biological construction, with a focus on multicellularity. Proceedings of the National Academy of Sciences 2017, 114, 11018–11026. [Google Scholar] [CrossRef]
- Queller, D.C. Relatedness and the fraternal major transitions. Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences 2000, 355, 1647–1655. [Google Scholar] [CrossRef]
- Libby, E.; Ratcliff, W.C. Lichens and microbial syntrophies offer models for an interdependent route to multicellularity. The Lichenologist 2021, 53, 283–290. [Google Scholar] [CrossRef]
- Andersson, R.; Isaksson, H.; Libby, E. Multi-species multicellular life cycles. In <italic>The Evolution of Multicellularity</italic>; CRC Press, 2022; pp. 343–356.
- Aktipis, C.A.; Boddy, A.M.; Jansen, G.; Hibner, U.; Hochberg, M.E.; Maley, C.C.; Wilkinson, G.S. Cancer across the tree of life: cooperation and cheating in multicellularity. Philosophical Transactions of the Royal Society B: Biological Sciences 2015, 370, 20140219. [Google Scholar] [CrossRef]
- Márquez-Zacarías, P.; Conlin, P.L.; Tong, K.; Pentz, J.T.; Ratcliff, W.C. Why have aggregative multicellular organisms stayed simple? Current Genetics 2021, 67, 871–876. [Google Scholar] [CrossRef]
- Tarnita, C.E.; Taubes, C.H.; Nowak, M.A. Evolutionary construction by staying together and coming together. Journal of theoretical biology 2013, 320, 10–22. [Google Scholar] [CrossRef]
- Sandoz, K.M.; Mitzimberg, S.M.; Schuster, M. Social cheating in Pseudomonas aeruginosa quorum sensing. Proceedings of the National Academy of Sciences 2007, 104, 15876–15881. [Google Scholar] [CrossRef]
- Aktipis, A.; Maley, C.C. Cooperation and cheating as innovation: insights from cellular societies. Philosophical Transactions of the Royal Society B: Biological Sciences 2017, 372, 20160421. [Google Scholar] [CrossRef]
- Libby, E.; Conlin, P.L.; Kerr, B.; Ratcliff, W.C. Stabilizing multicellularity through ratcheting. Philosophical Transactions of the Royal Society B: Biological Sciences 2016, 371, 20150444. [Google Scholar] [CrossRef]
- Libby, E.; Ratcliff, W.C. Ratcheting the evolution of multicellularity. Science 2014, 346, 426–427. [Google Scholar] [CrossRef]
- Sebé-Pedrós, A.; Degnan, B.M.; Ruiz-Trillo, I. The origin of Metazoa: a unicellular perspective. Nature Reviews Genetics 2017, 18, 498–512. [Google Scholar] [CrossRef]
- Ruiz-Trillo, I.; Kin, K.; Casacuberta, E. The origin of metazoan multicellularity: a potential microbial black swan event. Annual Review of Microbiology 2023, 77, 499–516. [Google Scholar] [CrossRef]
- Murray, J.D.; Murray, J.D. <italic>Mathematical biology: II: spatial models and biomedical applications</italic>; Vol. 18, Springer, 2003.
- Turing, A.M. The chemical basis of morphogenesis. Bulletin of mathematical biology 1990, 52, 153–197. [Google Scholar] [CrossRef]
- Marcon, L.; Sharpe, J. Turing patterns in development: what about the horse part? Current opinion in genetics & development 2012, 22, 578–584. [Google Scholar]
- Prigogine, I.; Nicolis, G. On symmetry-breaking instabilities in dissipative systems. The Journal of Chemical Physics 1967, 46, 3542–3550. [Google Scholar] [CrossRef]
- Odell, G.; Oster, G.; Burnside, B.; Alberch, P. A mechanical model for epithelial morphogenesis. Journal of mathematical biology 1980, 9, 291–295. [Google Scholar] [CrossRef]
- Collinet, C.; Lecuit, T. Programmed and self-organized flow of information during morphogenesis. Nature Reviews Molecular Cell Biology 2021, 22, 245–265. [Google Scholar] [CrossRef]
- Waddington, C.H. <italic>The strategy of the genes</italic>; Routledge, 2014.
- Fontana, W.; Schuster, P. Shaping space: the possible and the attainable in RNA genotype–phenotype mapping. Journal of Theoretical Biology 1998, 194, 491–515. [Google Scholar] [CrossRef]
- Solé, R.V.; Fernández, P.; Kauffman, S.A. Adaptive walks in a gene network model of morphogenesis: insights into the Cambrian explosion. <italic>arXiv preprint q-bio/0311013</italic> <bold>2003</bold>.
- Borenstein, E.; Krakauer, D.C. An end to endless forms: epistasis, phenotype distribution bias, and nonuniform evolution. PLoS computational biology 2008, 4, e1000202. [Google Scholar] [CrossRef]
- Munteanu, A.; Sole, R.V. Neutrality and robustness in evo-devo: emergence of lateral inhibition. PLoS computational biology 2008, 4, e1000226. [Google Scholar] [CrossRef]
- Cotterell, J.; Sharpe, J. An atlas of gene regulatory networks reveals multiple three-gene mechanisms for interpreting morphogen gradients. Molecular systems biology 2010, 6, 425. [Google Scholar] [CrossRef]
- Fernández, P.; Solé, R.V. Neutral fitness landscapes in signalling networks. Journal of The Royal Society Interface 2007, 4, 41–47. [Google Scholar] [CrossRef]
- Catalán, P.; Arias, C.F.; Cuesta, J.A.; Manrubia, S. Adaptive multiscapes: an up-to-date metaphor to visualize molecular adaptation. Biology Direct 2017, 12, 1–15. [Google Scholar] [CrossRef]
- Deutsch, A.; Dormann, S. <italic>Mathematical modeling of biological pattern formation</italic>; Springer, 2005.
- Thomson, J.A. On growth and form, 1917.
- Ball, P. The self-made tapestry: pattern formation in nature <bold>1999</bold>.
- Graner, F.; Riveline, D. ‘The Forms of Tissues, or Cell-aggregates’: D’Arcy Thompson’s influence and its limits. Development 2017, 144, 4226–4237. [Google Scholar] [CrossRef]
- Forgacs, G.; Newman, S.A. <italic>Biological physics of the developing embryo</italic>; Cambridge University Press, 2005.
- Stolarska, M.A.; Kim, Y.; Othmer, H.G. Multi-scale models of cell and tissue dynamics. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 2009, 367, 3525–3553. [Google Scholar] [CrossRef]
- Lenne, P.F.; Trivedi, V. Sculpting tissues by phase transitions. Nature Communications 2022, 13, 664. [Google Scholar] [CrossRef]
- Newman, S.A.; Bhat, R. Dynamical patterning modules: a" pattern language" for development and evolution of multicellular form. International Journal of Developmental Biology 2009, 53, 693. [Google Scholar] [CrossRef]
- Newman, S.A. Physico-genetic determinants in the evolution of development. Science 2012, 338, 217–219. [Google Scholar] [CrossRef]
- Graner, F.; Glazier, J.A. Simulation of biological cell sorting using a two-dimensional extended Potts model. Physical review letters 1992, 69, 2013. [Google Scholar] [CrossRef]
- Brodland, G.W. Computational modeling of cell sorting, tissue engulfment, and related phenomena: A review. Appl. Mech. Rev. 2004, 57, 47–76. [Google Scholar] [CrossRef]
- Steinberg, M.S. Adhesion-guided multicellular assembly. Journal of theoretical biology 1975, 55, 431–443. [Google Scholar] [CrossRef]
- Prusinkiewicz, P.; Lindenmayer, A. <italic>The algorithmic beauty of plants</italic>; Springer Science & Business Media, 2012.
- Kaandorp, J.A. <italic>Fractal Modelling: Growth and Form in Biology</italic>; Springer Science & Business Media, 1994.
- Hoyal Cuthill, J.F.; Conway Morris, S. Fractal branching organizations of Ediacaranrangeomorph fronds reveal a lost Proterozoicbody plan <bold>2014</bold>. <italic>111</italic>, 13122–13126.
- Wolpert, L. <italic>Principles of Development</italic>; Oxford University Press, 2015.
- Staple, D.; Farhadifar, R.; Röper, J.C.; Aigouy, B.; Eaton, S.; Jülicher, F. Mechanics and remodelling of cell packings in epithelia. The European physical journal. E, Soft matter 2010, 33, 117–27. [Google Scholar] [CrossRef]
- Bi, D.; Lopez, J.; Schwarz, J.; Manning, M.L. A density-independent glass transition in biological tissues. Nature Physics 2014, 11. [Google Scholar] [CrossRef]
- Jablonka, E.; Lamb, M.J. The evolution of information in the major transitions. Journal of theoretical biology 2006, 239, 236–246. [Google Scholar] [CrossRef]
- Lyon, P.; Keijzer, F.; Arendt, D.; Levin, M. Reframing cognition: getting down to biological basics, 2021.
- Wagensberg, J. Complexity versus uncertainty: The question of staying alive. Biology and philosophy 2000, 15, 493–508. [Google Scholar] [CrossRef]
- Llinás, R.R. <italic>I of the vortex: From neurons to self</italic>; MIT press, 2002.
- Seoane, L.F.; Solé, R.V. Information theory, predictability and the emergence of complex life. Royal Society open science 2018, 5, 172221. [Google Scholar] [CrossRef]
- Paulin, M.G.; Cahill-Lane, J. Events in early nervous system evolution. Topics in Cognitive Science 2021, 13, 25–44. [Google Scholar] [CrossRef]
- Sarpeshkar, R. Analog versus digital: extrapolating from electronics to neurobiology. Neural computation 1998, 10, 1601–1638. [Google Scholar] [CrossRef]
- Sjöström, P.J.; Turrigiano, G.G.; Nelson, S.B. Rate, timing, and cooperativity jointly determine cortical synaptic plasticity. Neuron 2001, 32, 1149–1164. [Google Scholar] [CrossRef]
- Shagrir, O. <italic>The nature of physical computation</italic>; Oxford University Press, 2022.
- Maley, C.J. Analogue computation and representation. The British Journal for the Philosophy of Science 2023, 74, 739–769. [Google Scholar] [CrossRef]
- Kristan, W.B. Early evolution of neurons. Current Biology 2016, 26, R949–R954. [Google Scholar] [CrossRef]
- Jékely, G. Origin and early evolution of neural circuits for the control of ciliary locomotion. Proceedings of the Royal Society B: Biological Sciences 2011, 278, 914–922. [Google Scholar] [CrossRef]
- Jékely, G. The chemical brain hypothesis for the origin of nervous systems. Philosophical Transactions of the Royal Society B 2021, 376, 20190761. [Google Scholar] [CrossRef]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. The bulletin of mathematical biophysics 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Cowan, J.D. Discussion: McCulloch-Pitts and related neural nets from 1943 to 1989. Bulletin of mathematical biology 1990, 52, 73–97. [Google Scholar] [CrossRef]
- Anderson, J.A.; Rosenfeld, E. <italic>Talking nets: An oral history of neural networks</italic>; MiT Press, 2000.
- Churchland, P.S.; Sejnowski, T.J. <italic>The computational brain</italic>; MIT press, 1992.
- Rojas, R. <italic>Neural networks: a systematic introduction</italic>; Springer Science & Business Media, 2013.
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological cybernetics 1980, 36, 193–202. [Google Scholar] [CrossRef]
- Glass, L.; Kauffman, S.A. The logical analysis of continuous, non-linear biochemical control networks. Journal of theoretical Biology 1973, 39, 103–129. [Google Scholar] [CrossRef]
- Kurten, K. Correspondence between neural threshold networks and Kauffman Boolean cellular automata. Journal of Physics A: Mathematical and General 1988, 21, L615. [Google Scholar] [CrossRef]
- Luque, B.; Solé, R.V. Phase transitions in random networks: Simple analytic determination of critical points. Physical Review E 1997, 55, 257. [Google Scholar] [CrossRef]
- Bornholdt, S. Boolean network models of cellular regulation: prospects and limitations. Journal of the Royal Society Interface 2008, 5, S85–S94. [Google Scholar] [CrossRef]
- Parisi, G. A simple model for the immune network. Proceedings of the National Academy of Sciences 1990, 87, 429–433. [Google Scholar] [CrossRef]
- Perelson, A.S.; Weisbuch, G. Immunology for physicists. Reviews of modern physics 1997, 69, 1219. [Google Scholar] [CrossRef]
- Agliari, E.; Barra, A.; Del Ferraro, G.; Guerra, F.; Tantari, D. Anergy in self-directed B lymphocytes: a statistical mechanics perspective. Journal of theoretical biology 2015, 375, 21–31. [Google Scholar] [CrossRef]
- Deneubourg, J.L.; Goss, S.; Franks, N.; Sendova-Franks, A.; Detrain, C.; Chrétien, L. The dynamics of collective sorting robot-like ants and ant-like robots. From animals to animats: proceedings of the first international conference on simulation of adaptive behavior, 1991, pp. 356–365.
- Solé, R.V.; Miramontes, O.; Goodwin, B.C. Oscillations and chaos in ant societies. Journal of theoretical Biology 1993, 161, 343–357. [Google Scholar] [CrossRef]
- Theraulaz, G.; Bonabeau, E.; Nicolis, S.C.; Solé, R.V.; Fourcassié, V.; Blanco, S.; Fournier, R.; Joly, J.L.; Fernández, P.; Grimal, A.; others. Spatial patterns in ant colonies. Proceedings of the National Academy of Sciences 2002, 99, 9645–9649. [Google Scholar] [CrossRef]
- Couzin, I.D. Collective cognition in animal groups. Trends in cognitive sciences 2009, 13, 36–43. [Google Scholar] [CrossRef]
- McMillen, P.; Levin, M. Collective intelligence: A unifying concept for integrating biology across scales and substrates. Communications Biology 2024, 7, 378. [Google Scholar] [CrossRef]
- Yusufaly, T.I.; Boedicker, J.Q. Mapping quorum sensing onto neural networks to understand collective decision making in heterogeneous microbial communities. Physical biology 2017, 14, 046002. [Google Scholar] [CrossRef]
- Solé, R.; Moses, M.; Forrest, S. Liquid brains, solid brains, 2019.
- Piñero, J.; Solé, R. Statistical physics of liquid brains. Philosophical Transactions of the Royal Society B 2019, 374, 20180376. [Google Scholar] [CrossRef]
- Mjolsness, E.; Sharp, D.H.; Reinitz, J. A connectionist model of development. Journal of theoretical Biology 1991, 152, 429–453. [Google Scholar] [CrossRef]
- Alon, U. <italic>An introduction to systems biology: design principles of biological circuits</italic>; CRC press, 2019.
- Sneppen, K. <italic>Models of life</italic>; Cambridge University Press, 2014.
- Ginsburg, S.; Jablonka, E. The evolution of associative learning: A factor in the Cambrian explosion. Journal of theoretical biology 2010, 266, 11–20. [Google Scholar] [CrossRef]
- Piccinini, G. The First computational theory of mind and brain: a close look at mcculloch and pitts’s “logical calculus of ideas immanent in nervous activity”. Synthese 2004, 141, 175–215. [Google Scholar] [CrossRef]
- Shigeno, S. Brain evolution as an information flow designer: The ground architecture for biological and artificial general intelligence. <italic>Brain Evolution by Design: From Neural Origin to Cognitive Architecture</italic> <bold>2017</bold>, pp. 415–438.
- Shigeno, S.; Andrews, P.L.; Ponte, G.; Fiorito, G. Cephalopod brains: an overview of current knowledge to facilitate comparison with vertebrates. Frontiers in Physiology 2018, 952. [Google Scholar] [CrossRef]
- Garcia-Lopez, P.; Garcia-Marin, V.; Freire, M. The histological slides and drawings of Cajal. Frontiers in neuroanatomy 2010, 4, 1156. [Google Scholar] [CrossRef]
- North, G.; Greenspan, R.J. Invertebrate neurobiology. <italic>(No Title)</italic> <bold>2007</bold>.
- Seth, A.K.; Bayne, T. Theories of consciousness. Nature Reviews Neuroscience 2022, 23, 439–452. [Google Scholar] [CrossRef]
- Dennett, D.C. <italic>Kinds of minds: Toward an understanding of consciousness</italic>; Basic Books, 2008.
- Powell, R.; Mikhalevich, I.; Logan, C.; Clayton, N.S. Convergent minds: the evolution of cognitive complexity in nature, 2017.
- Dennett, D.C. <italic>From bacteria to Bach and back: The evolution of minds</italic>; WW Norton & Company, 2017.
- Solé, R.; Seoane, L.F. Evolution of brains and computers: the roads not taken. Entropy 2022, 24, 665. [Google Scholar] [CrossRef]
- Adami, C. <italic>Introduction to artificial life</italic>; Springer Science & Business Media, 1998.
- Kristian, L.; Nordahl, M.G. Artificial Food Webs. <italic>ARTIFICIAL LIFE III, Santa Fe Institute, Addison-Wesley</italic> <bold>1994</bold>.
- Banzhaf, W. Self-organisation in a system of binary strings <bold>1994</bold>.
- Margalef, R. Our biosphere. <italic>(No Title)</italic> <bold>1997</bold>.
- Ghilarov, A.M. Ecosystem functioning and intrinsic value of biodiversity. Oikos 2000, 90, 408–412. [Google Scholar] [CrossRef]
- Odum, E.P.; Barrett, G.W.; others. <italic>Fundamentals of ecology</italic>; Vol. 3, Saunders Philadelphia, 1971.
- May, R.M. Qualitative stability in model ecosystems. Ecology 1973, 54, 638–641. [Google Scholar] [CrossRef]
- Marzloff, M.P.; Dambacher, J.M.; Johnson, C.R.; Little, L.R.; Frusher, S.D. Exploring alternative states in ecological systems with a qualitative analysis of community feedback. Ecological Modelling 2011, 222, 2651–2662. [Google Scholar] [CrossRef]
- Poulin, R. <italic>Evolutionary ecology of parasites</italic>; Princeton university press, 2011.
- Sasselov, D.D.; Grotzinger, J.P.; Sutherland, J.D. The origin of life as a planetary phenomenon. Sci. Adv. 2020, 6, eaax3419. [Google Scholar] [CrossRef]
- Batalha, N.M. Exploring exoplanet populations with NASA’s Kepler Mission <bold>2014</bold>. <italic>111</italic>, 12647–12654.
- McKay, C.P. Requirements and limits for life in the context of exoplanets. Proc. Nat. Acad. Sci. USA 2014, 111, 12628–12633. [Google Scholar] [CrossRef]
- Harte, J.; Newman, E.A. Maximum information entropy: a foundation for ecological theory. Trends in ecology & evolution 2014, 29, 384–389. [Google Scholar]
- Gause, G.F. Experimental studies on the struggle for existence. Journal of Experimental Biology 1932, 9, 389–402. [Google Scholar] [CrossRef]
- May, R.M. Will a large complex system be stable? Nature 1972, 238, 413–414. [Google Scholar] [CrossRef]
- Pimm, S.L. <italic>The balance of nature?: ecological issues in the conservation of species and communities</italic>; University of Chicago Press, 1991.
- Roopnarine, P.D. Extinction cascades and catastrophe in ancient food webs. Paleobiology 2006, 32, 1–19. [Google Scholar] [CrossRef]
- Mitchell, J.S.; Roopnarine, P.D.; Angielczyk, K.D. Late Cretaceous restructuring of terrestrial communities facilitated the end-Cretaceous mass extinction in North America. Proceedings of the National Academy of Sciences 2012, 109, 18857–18861. [Google Scholar] [CrossRef]
- Dunne, J.A.; Williams, R.J.; Martinez, N.D.; Wood, R.A.; Erwin, D.H. Compilation and network analyses of Cambrian food webs. PLoS biology 2008, 6, e102. [Google Scholar] [CrossRef]
- Barricelli, N.A. Numerical testing of evolution theories: part I theoretical introduction and basic tests. Acta Biotheoretica 1962, 16, 69–98. [Google Scholar] [CrossRef]
- Barricelli, N.A. Numerical testing of evolution theories: Part II preliminary tests of performance. symbiogenesis and terrestrial life. Acta Biotheoretica 1963, 16, 99–126. [Google Scholar] [CrossRef]
- Dyson, G. <italic>Turing’s cathedral: the origins of the digital universe</italic>; Vintage, 2012.
- Langton, C.G. Studying artificial life with cellular automata. Physica D: Nonlinear Phenomena 1986, 22, 120–149. [Google Scholar] [CrossRef]
- Rocha, L. Evolutionary systems and artificial life. <italic>Lecture Notes, Los Alamos National Laboratory</italic> <bold>1997</bold>.
- Rasmussen, S.; Knudsen, C.; Feldberg, R.; Hindsholm, M. The coreworld: Emergence and evolution of cooperative structures in a computational chemistry. Physica D: Nonlinear Phenomena 1990, 42, 111–134. [Google Scholar] [CrossRef]
- Solé, R.; Elena, S.F. <italic>Viruses as complex adaptive systems</italic>; Vol. 15, Princeton University Press, 2018.
- Lloyd, A.L.; May, R.M. How viruses spread among computers and people. Science 2001, 292, 1316–1317. [Google Scholar] [CrossRef]
- Ray, T.S. An Approach to the Synthesis of Life, Artificial Life II. Santa Fe Institute Studies in the Sciences of Complexity, Proc. Addison-Wesley, 1991, pp. 371–408.
- Ray, T.S. Evolution, complexity, entropy and artificial reality. Physica D: Nonlinear Phenomena 1994, 75, 239–263. [Google Scholar] [CrossRef]
- Lachman, M. Origins of Evolution <bold>1991</bold>.
- Hillis, W.D. Co-evolving parasites improve simulated evolution as an optimization procedure. Physica D: Nonlinear Phenomena 1990, 42, 228–234. [Google Scholar] [CrossRef]
- Dennett, D.C. <italic>Darwin’s dangerous idea</italic>; Allen Press, 1995.
- Wilke, C.O.; Adami, C. The biology of digital organisms. TRENDS in ecology & evolution 2002, 17, 528–532. [Google Scholar]
- Solé, R.V.; Valverde, S. Macroevolution in silico: scales, constraints and universals. Palaeontology 2013, 56, 1327–1340. [Google Scholar] [CrossRef]
- Eldredge, N.; Gould, S.J. Punctuated equilibria: an alternative to phyletic gradualism. Models in paleobiology 1972, 1972, 82–115. [Google Scholar]
- Lindgren, K. Evolutionary phenomena in simple dynamics. Artificial life II 1991, 10, 295–312. [Google Scholar]
- Zaman, L.; Meyer, J.R.; Devangam, S.; Bryson, D.M.; Lenski, R.E.; Ofria, C. Coevolution drives the emergence of complex traits and promotes evolvability. PLoS Biology 2014, 12, e1002023. [Google Scholar] [CrossRef]
- Dittrich, P.; Ziegler, J.; Banzhaf, W. Artificial chemistries—a review. Artificial life 2001, 7, 225–275. [Google Scholar] [CrossRef]
- Banzhaf, W.; Yamamoto, L. <italic>Artificial chemistries</italic>; MIT Press, 2015.
- Stadler, P.F.; Fontana, W.; Miller, J.H. Random catalytic reaction networks. Physica D: Nonlinear Phenomena 1993, 63, 378–392. [Google Scholar] [CrossRef]
- Eigen, M. <italic>From strange simplicity to complex familiarity: a treatise on matter, information, life and thought</italic>; OUP Oxford, 2013.
- Smith, E.; Krishnamurthy, S. Symmetry and Collective Fluctuations in Evolutionary Games; IOP Press: Bristol, 2015. [Google Scholar]
- Fontana, W.; Wagner, G.; Buss, L.W. Beyond Digital Naturalism. Artificial Life 1994, 1, 211–227. [Google Scholar] [CrossRef]
- Fontana, W.; Buss, L.W. The barrier of objects: From dynamical systems to bounded organizations. In Boundaries and Barriers; Casti, J., Karlqvist, A., Eds.; Addison-Wesley: New York, 1996; pp. 56–116. [Google Scholar]
- Eigen, M. Selforganization of Matter and the Evolution of Biological Macromolecules. Naturwissenschaften 1971, 33, 465–522. [Google Scholar] [CrossRef]
- Eigen, M.; Schuster, P. The hypercycle, Part A: The emergence of the hypercycle. Naturwissenschaften 1977, 64, 541–565. [Google Scholar] [CrossRef]
- Eigen, M.; Schuster, P. The hypercycle, Part C: The realistic hypercycle. Naturwissenschaften 1978, 65, 341–369. [Google Scholar] [CrossRef]
- Hickinbotham, S.J.; Stepney, S.; Hogeweg, P. Nothing in evolution makes sense except in the light of parasitism: evolution of complex replication strategies. Royal Society Open Science 2021, 8, 210441. [Google Scholar] [CrossRef]
- Seoane, L.F.; Solé, R. How Turing parasites expand the computational landscape of digital life. Physical Review E 2023, 108, 044407. [Google Scholar] [CrossRef]
- Hudson, P.J.; Dobson, A.P.; Lafferty, K.D. Is a healthy ecosystem one that is rich in parasites? Trends in ecology & evolution 2006, 21, 381–385. [Google Scholar]
- Kempes, C.P.; Follows, M.J.; Smith, H.; Graham, H.; House, C.H.; Levin, S.A. Generalized stoichiometry and biogeochemistry for astrobiological applications. Bulletin of Mathematical Biology 2021, 83, 73. [Google Scholar] [CrossRef]
- Gagler, D.C.; Karas, B.; Kempes, C.P.; Malloy, J.; Mierzejewski, V.; Goldman, A.D.; Kim, H.; Walker, S.I. Scaling laws in enzyme function reveal a new kind of biochemical universality. Proceedings of the National Academy of Sciences 2022, 119, e2106655119. [Google Scholar] [CrossRef]
- Brown, J.H.; Gillooly, J.F.; Allen, A.P.; Savage, V.M.; West, G.B. Toward a metabolic theory of ecology. Ecology 2004, 85, 1771–1789. [Google Scholar] [CrossRef]
- Szathmáry, E.; Smith, J.M. The major evolutionary transitions. Nature 1995, 374, 227–232. [Google Scholar] [CrossRef]
- Szathmáry, E. Toward major evolutionary transitions theory 2.0. Proceedings of the National Academy of Sciences 2015, 112, 10104–10111. [Google Scholar] [CrossRef]
- Walker, S.I. Origins of life: a problem for physics,a key issues review. Rep. Prof. Phys. 2017, 80, 092601. [Google Scholar] [CrossRef]
- Wolf, Y.I.; Katsnelson, M.I.; Koonin, E.V. Physical foundations of biological complexity. Proceedings of the National Academy of Sciences 2018, 115, E8678–E8687. [Google Scholar] [CrossRef]
- Eldredge, N. <italic>Unfinished synthesis: biological hierarchies and modern evolutionary thought</italic>; Oxford University Press, USA, 1985.
- Tëmkin, I.; Eldredge, N. Networks and hierarchies: Approaching complexity in evolutionary theory. <italic>Macroevolution: Explanation, interpretation and evidence</italic> <bold>2015</bold>, pp. 183–226.
- DeLong, J.P.; Okie, J.G.; Moses, M.E.; Sibly, R.M.; Brown, J.H. Shifts in metabolic scaling, production, and efficiency across major evolutionary transitions of life. Proceedings of the National Academy of Sciences 2010, 107, 12941–12945. [Google Scholar] [CrossRef]
- Kempes, C.P.; Wang, L.; Amend, J.P.; Doyle, J.; Hoehler, T. Evolutionary tradeoffs in cellular composition across diverse bacteria. The ISME journal 2016, 10, 2145–2157. [Google Scholar] [CrossRef]
- Foëx, G.; Weiss, P. Le magnétisme; Armand Colin: Paris, 1926. [Google Scholar]
- Kochmański, M.; Paszkiewicz, T.; Wolski, S. Curie-Weiss magnet – a simple model of phase transition. Eur. J. Phys. 2013, 34, 1555–1573. [Google Scholar] [CrossRef]
- Landau, L.D. Theory of phase transformations. Zh. Eksp. Teor. Fiz. 1937, 7, 19–32. [Google Scholar]
- Gell-Mann, M.; Low, F.E. Quantum electrodynamics at small distances. Phys. Rev. 1954, 95, 1300–1312. [Google Scholar] [CrossRef]
- Wilson, K.G.; Kogut, J. The renormalization group and the ε expansion. Phys. Rep., Phys. Lett. 1974, 12C, 75–200. [Google Scholar] [CrossRef]
- Weinberg, S. Phenomenological Lagrangians. Physica A 1979, 96, 327–340. [Google Scholar] [CrossRef]
- Polchinski, J.G. Renormalization group and effective lagrangians. Nuclear Physics B 1984, 231, 269–295. [Google Scholar] [CrossRef]
- Wiener, N. Cybernetics: Or the Control and Communication in the Animal and the Machine, second ed.; MIT Press: Cambridge, MA, 1965. [Google Scholar]
- Haken, H. Synergetics: Introduction and Advanced Topics, first ed.; Springer Verlag: New York, 2010. [Google Scholar]
- Li, R.; Bowerman, B. Symmetry breaking in biology. Cold Spring Harbor perspectives in biology 2010, 2, a003475. [Google Scholar] [CrossRef]
- Krakauer, D.C. Symmetry–simplicity, broken symmetry–complexity. Interface Focus 2023, 13, 20220075. [Google Scholar] [CrossRef]
- Wilson, K.G. Problems in physics with many scales of length. Scientific American 1979, 241, 158–179. [Google Scholar] [CrossRef]
- Yeomans, J.M. <italic>Statistical mechanics of phase transitions</italic>; Clarendon Press, 1992.
- Hughes, R.I. The Ising model, computer simulation, and universal physics. Ideas In Context 1999, 52, 97–145. [Google Scholar]
- Wikipedia. Chirality (chemistry) — Wikipedia, The Free Encyclopedia, 2024.
- Farmer, J.D.; Kauffman, S.A.; Packard, N.H. Autocatalytic replication of polymers. Physica D: Nonlinear Phenomena 1986, 22, 50–67. [Google Scholar] [CrossRef]
- Solé, R. <italic>Phase transitions</italic>; Princeton University Press, 2011.
- Leuthäusser, I. An exact correspondence between Eigen’s evolution model and a two-dimensional Ising system. The Journal of chemical physics 1986, 84, 1884–1885. [Google Scholar] [CrossRef]
- Leuthäusser, I. Statistical mechanics of Eigen’s evolution model. Journal of statistical physics 1987, 48, 343–360. [Google Scholar] [CrossRef]
- Tarazona, P. Error thresholds for molecular quasispecies as phase transitions: From simple landscapes to spin-glass models. Physical Review A 1992, 45, 6038. [Google Scholar] [CrossRef]
- Duke, T.; Bray, D. Heightened sensitivity of a lattice of membrane receptors. Proceedings of the National Academy of Sciences 1999, 96, 10104–10108. [Google Scholar] [CrossRef]
- Weber, M.; Buceta, J. The cellular Ising model: a framework for phase transitions in multicellular environments. Journal of The Royal Society Interface 2016, 13, 20151092. [Google Scholar] [CrossRef]
- Simpson, K.; L’Homme, A.; Keymer, J.; Federici, F. Spatial biology of Ising-like synthetic genetic networks. BMC biology 2023, 21, 185. [Google Scholar] [CrossRef]
- Schlicht, R.; Iwasa, Y. Forest gap dynamics and the Ising model. Journal of theoretical Biology 2004, 230, 65–75. [Google Scholar] [CrossRef]
- De las Cuevas, G.; Cubitt, T.S. Simple universal models capture all classical spin physics. Science 2016, 351, 1180–1183. [Google Scholar] [CrossRef]
- Fraiman, D.; Balenzuela, P.; Foss, J.; Chialvo, D.R. Ising-like dynamics in large-scale functional brain networks. Physical Review E 2009, 79, 061922. [Google Scholar] [CrossRef]
- Nowak, M.A.; Ohtsuki, H. Prevolutionary dynamics and the origin of evolution. Proc. Nat. Acad. Sci. USA 2008, 105, 14924–14927. [Google Scholar] [CrossRef]
- Eigen, M. Natural selection: a phase transition? Biophysical chemistry 2000, 85, 101–123. [Google Scholar] [CrossRef]
- Saito, Y.; Hyuga, H. Colloquium: Homochirality: Symmetry breaking in systems driven far from equilibrium. Reviews of Modern Physics 2013, 85, 603. [Google Scholar] [CrossRef]
- Jafarpour, F.; Biancalani, T.; Goldenfeld, N. Noise-induced mechanism for biological homochirality of early life self-replicators. Physical review letters 2015, 115, 158101. [Google Scholar] [CrossRef]
- Ribó, J.M.; Hochberg, D.; Crusats, J.; El-Hachemi, Z.; Moyano, A. Spontaneous mirror symmetry breaking and origin of biological homochirality. Journal of The Royal Society Interface 2017, 14, 20170699. [Google Scholar] [CrossRef]
- Kauffman, S.A. Autocatalytic sets of proteins. Journal of theoretical biology 1986, 119, 1–24. [Google Scholar] [CrossRef]
- Kauffman. The Origins of Order: Self-Organization and Selection in Evolution <bold>1993</bold>.
- Hanel, R.; Kauffman, S.A.; Thurner, S. Phase transition in random catalytic networks. Physical Review E 2005, 72, 036117. [Google Scholar] [CrossRef]
- Xavier, J.C.; Hordijk, W.; Kauffman, S.; Steel, M.; Martin, W.F. Autocatalytic chemical networks at the origin of metabolism. Proceedings of the Royal Society B 2020, 287, 20192377. [Google Scholar] [CrossRef]
- Vetsigian, K.; Woese, C.; Goldenfeld, N. Collective evolution and the genetic code. Proc. Nat. Acad. Sci. USA 2006, 103, 10696–10701. [Google Scholar] [CrossRef]
- Woese, C.R. The Genetic Code: The Molecular Basis for Genetic Expression; Harper and Row: New York, 1967. [Google Scholar]
- Crick, F.H.C. The origin of the genetic code. J. Mol. Biol. 1968, 38, 367–379. [Google Scholar] [CrossRef]
- Crutchfield, J.P. Between order and chaos. Nature Physics 2012, 8, 17–24. [Google Scholar] [CrossRef]
- Langton, C.G. Computation at the edge of chaos: Phase transitions and emergent computation. Physica D: nonlinear phenomena 1990, 42, 12–37. [Google Scholar] [CrossRef]
- Tlusty, T. A model for the emergence of the genetic code as a transition in a noisy information channel. Journal of theoretical biology 2007, 249, 331–342. [Google Scholar] [CrossRef]
- Schuster, P. Genotypes with phenotypes: Adventures in an RNA toy world. Biophysical chemistry 1997, 66, 75–110. [Google Scholar] [CrossRef]
- Kamp, C.; Bornholdt, S. Coevolution of quasispecies: B-cell mutation rates maximize viral error catastrophes. Physical Review Letters 2002, 88, 068104. [Google Scholar] [CrossRef]
- Chialvo, D.R. Emergent complex neural dynamics. Nature physics 2010, 6, 744–750. [Google Scholar] [CrossRef]
- Schuster, H.G. <italic>Criticality in neural systems</italic>; John Wiley & Sons, 2014.
- Solé, R.V.; Alonso, D.; McKane, A. Self–organized instability in complex ecosystems. Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences 2002, 357, 667–681. [Google Scholar] [CrossRef]
- Biroli, G.; Bunin, G.; Cammarota, C. Marginally stable equilibria in critical ecosystems. New Journal of Physics 2018, 20, 083051. [Google Scholar] [CrossRef]
- Beggs, J.M. The criticality hypothesis: how local cortical networks might optimize information processing. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 2008, 366, 329–343. [Google Scholar] [CrossRef]
- Shew, W.L.; Plenz, D. The functional benefits of criticality in the cortex. The neuroscientist 2013, 19, 88–100. [Google Scholar] [CrossRef]
- Mora, T.; Bialek, W. Are biological systems poised at criticality? Journal of Statistical Physics 2011, 144, 268–302. [Google Scholar] [CrossRef]
- Touchette, H. The large deviation approach to statistical mechanics. Phys. Rep. 2009, 478, 1–69. [Google Scholar] [CrossRef]
- Smith, E. Emergent order in processes: the interplay of complexity, robustness, correlation, and hierarchy in the biosphere. Complexity and the Arrow of Time; Lineweaver, C., Davies, P., Ruse, M., Eds.; Cambridge U. Press: Cambridge, MA, 2013. [Google Scholar]
- Batterman, R.W. The Devil in the Details: Asymptotic Reasoning in Explanation, Reduction, and Emergence; Oxford University Press: New York, 2002. [Google Scholar]
- Lawson-Keister, E.; Manning, M.L. Jamming and arrest of cell motion in biological tissues. Current Opinion in Cell Biology 2021, 72, 146–155. [Google Scholar] [CrossRef]
- Hannezo, E.; Heisenberg, C.P. Rigidity transitions in development and disease. Trends in Cell Biology 2022, 32, 433–444. [Google Scholar] [CrossRef]
- Corominas-Murtra, B.; Petridou, N. Viscoelastic Networks: Forming Cells and Tissues. Frontiers in Physics 2021, 9. [Google Scholar] [CrossRef]
- Petridou, N.I.; Corominas-Murtra, B.; Heisenberg, C.P.; Hannezo, E. Rigidity percolation uncovers a structural basis for embryonic tissue phase transitions. Cell 2021, 184, 1914–1928. [Google Scholar] [CrossRef]
- Kim, J.H.; Pegoraro, A.F.; Das, A.; Koehler, S.A.; Ujwary, S.A.; Lan, B.; Mitchel, J.A.; Atia, L.; He, S.; Wang, K.; Bi, D.; Zaman, M.H.; Park, J.A.; Butler, J.P.; Lee, K.H.; Starr, J.R.; Fredberg, J.J. Unjamming and collective migration in MCF10A breast cancer cell lines. Biochemical and Biophysical Research Communications 2020, 521, 706–715. [Google Scholar] [CrossRef]
- Levin, S.R.; Scott, T.W.; Cooper, H.S.; West, S.A. Darwin’s aliens. International Journal of Astrobiology 2019, 18, 1–9. [Google Scholar] [CrossRef]
- Langton, C.G. Artificial life. In <italic>Artificial life</italic>; Routledge, 1989; pp. 1–47.
- Bedau, M.A.; McCaskill, J.S.; Packard, N.H.; Rasmussen, S.; Adami, C.; Green, D.G.; Ikegami, T.; Kaneko, K.; Ray, T.S. Open problems in artificial life. Artificial life 2000, 6, 363–376. [Google Scholar] [CrossRef]
- Bedau, M.A. Artificial life. In <italic>Philosophy of biology</italic>; Elsevier, 2007; pp. 585–603.
- Lehman, J.; Clune, J.; Misevic, D. The surprising creativity of digital evolution. Artificial Life Conference Proceedings. MIT Press One Rogers Street, Cambridge, MA 02142-1209, USA journals-info …, 2018, pp. 55–56.
Figure 1.
Cyclic structures characterise dissipative systems that reach nonequilibrium steady states due to external driving. In an abiotic system like a Bénard cell (a), a temperature gradient leads to the formation of cells that transport heat by cyclic convection (image adapted from [90]). In living systems, chemical energy drives metabolic cycles such as the citric acid cycle (b), which plays a crucial role in energy production and biosynthesis. Such metabolic cycles consume resource molecules and synthesise energetic intermediates and building blocks while releasing heat. In the figure, both the intermediate metabolites of the cycle and the enzymes are indicated (image from David Goodsell).
Figure 1.
Cyclic structures characterise dissipative systems that reach nonequilibrium steady states due to external driving. In an abiotic system like a Bénard cell (a), a temperature gradient leads to the formation of cells that transport heat by cyclic convection (image adapted from [90]). In living systems, chemical energy drives metabolic cycles such as the citric acid cycle (b), which plays a crucial role in energy production and biosynthesis. Such metabolic cycles consume resource molecules and synthesise energetic intermediates and building blocks while releasing heat. In the figure, both the intermediate metabolites of the cycle and the enzymes are indicated (image from David Goodsell).

Figure 2.
Linear polymers, information and computation. Several molecular events involve information storage and processing, such as DNA replication (a) or transcription (b) or the RNA → DNA reverse transcription in viruses (c). All these examples involve linear polymers that are “read” but special nanomachines (DNA and RNA polymerases or the reverse transcriptase). Here RNApol is RNA polymerase, DNApol is DNA polymerase, ssDNA is single-stranded DNA, dsDNA is double-stranded DNA nd vRNA for viral RNA. The classical model of computation defined by Turing (d) involves a machine with internal states that scans a linear string of symbols (here made of zeros and ones) and changes its internal states as computation proceeds. Images (a) and (b) are adapted from David Goodsell. Image (c) adapted from [106].
Figure 2.
Linear polymers, information and computation. Several molecular events involve information storage and processing, such as DNA replication (a) or transcription (b) or the RNA → DNA reverse transcription in viruses (c). All these examples involve linear polymers that are “read” but special nanomachines (DNA and RNA polymerases or the reverse transcriptase). Here RNApol is RNA polymerase, DNApol is DNA polymerase, ssDNA is single-stranded DNA, dsDNA is double-stranded DNA nd vRNA for viral RNA. The classical model of computation defined by Turing (d) involves a machine with internal states that scans a linear string of symbols (here made of zeros and ones) and changes its internal states as computation proceeds. Images (a) and (b) are adapted from David Goodsell. Image (c) adapted from [106].
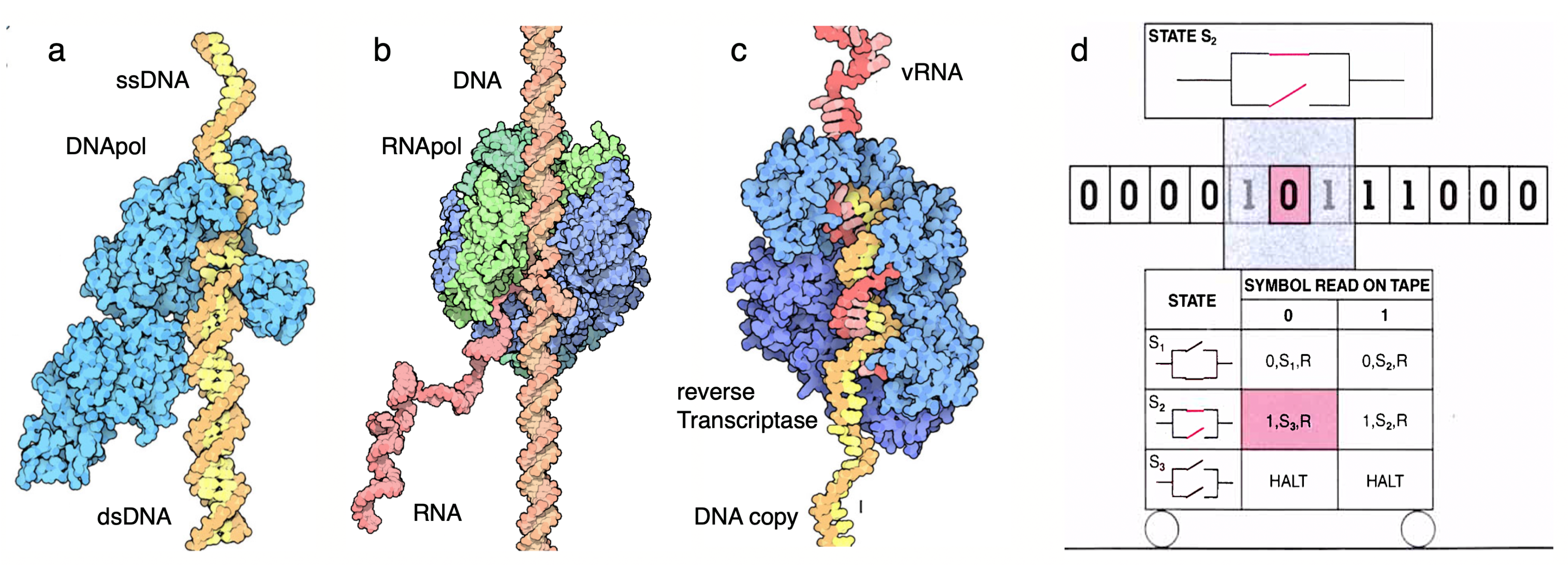
Figure 3.
Required metabolic rate for information copying alone, as calculated by Eq. (6). The key parameters are the number of letters in the informational alphabet (n), the length of the genome (L), and the time to copy the information (). We show the minimal metabolic rate for at various division times , from 1 s to s. Dashed lines indicate a typical bacterial metabolic rate (TBM) of J/s [123], typical genome length (TGL) of bases, with typical division time s.
Figure 3.
Required metabolic rate for information copying alone, as calculated by Eq. (6). The key parameters are the number of letters in the informational alphabet (n), the length of the genome (L), and the time to copy the information (). We show the minimal metabolic rate for at various division times , from 1 s to s. Dashed lines indicate a typical bacterial metabolic rate (TBM) of J/s [123], typical genome length (TGL) of bases, with typical division time s.
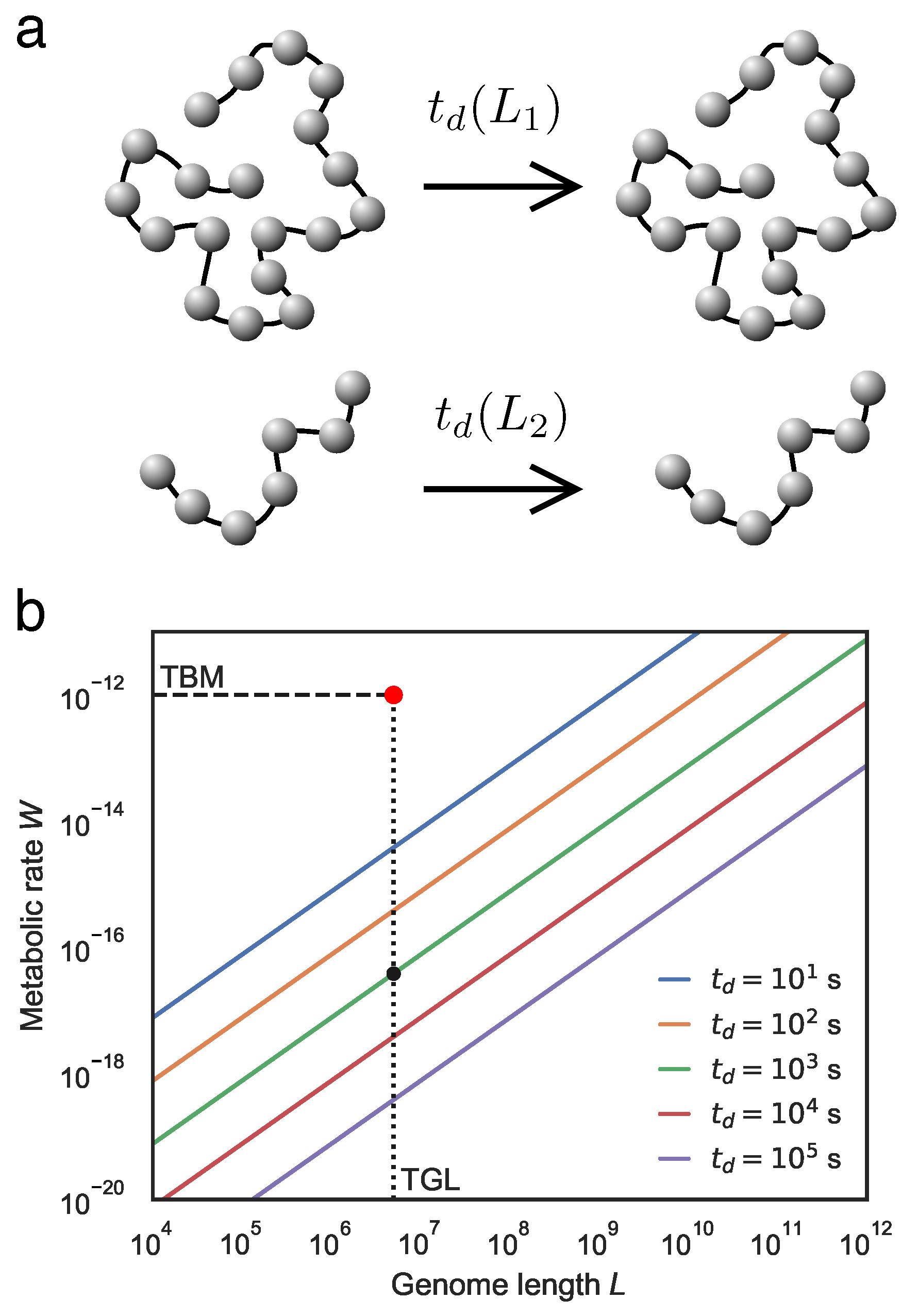
Figure 4.
The logic of self-replicating living “machines”. Cells reproduce through a complex process that uses DNA as a set of instructions but requires also DNA to be replicated. In von Neumann’s theory (a), a formal machine capable of copying itself would require a set of instructions to guide the construction of a new machine under some controlled states such that instructions also get replicated. In biology, one crucial component of the cellular translation machinery is the ribosome (b), made of two subunits (RibLU and RibSU) that “read” RNA strings to synthesise proteins, playing the role of the Constructor. In a molecular, embodied implementation of cell reproduction, self-organised interactions between a compartment, metabolism and information must interact. An example of a simple implementation is shown in (c) for a synthetic cell involving a compartment coupled to double-stranded polymers and a minimal metabolism (adapted from [127]). Here, a precursor is transformed into lipids (L) that allow membrane growth until some instability triggers division.
Figure 4.
The logic of self-replicating living “machines”. Cells reproduce through a complex process that uses DNA as a set of instructions but requires also DNA to be replicated. In von Neumann’s theory (a), a formal machine capable of copying itself would require a set of instructions to guide the construction of a new machine under some controlled states such that instructions also get replicated. In biology, one crucial component of the cellular translation machinery is the ribosome (b), made of two subunits (RibLU and RibSU) that “read” RNA strings to synthesise proteins, playing the role of the Constructor. In a molecular, embodied implementation of cell reproduction, self-organised interactions between a compartment, metabolism and information must interact. An example of a simple implementation is shown in (c) for a synthetic cell involving a compartment coupled to double-stranded polymers and a minimal metabolism (adapted from [127]). Here, a precursor is transformed into lipids (L) that allow membrane growth until some instability triggers division.
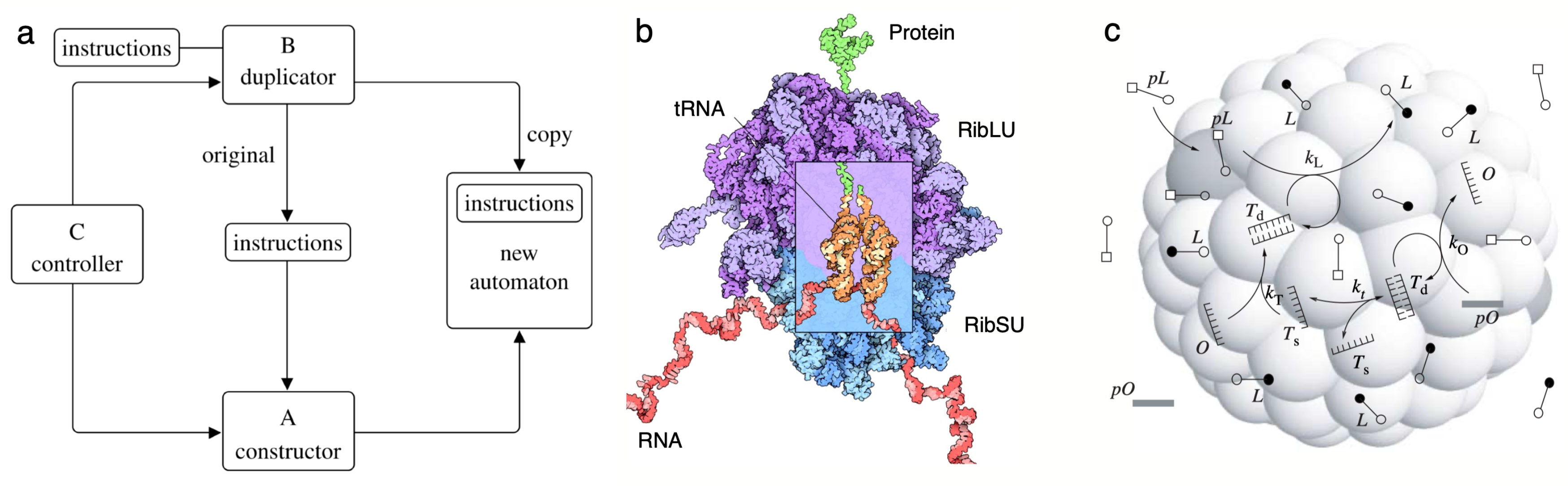
Figure 5.
Information-free protocell division. In these two examples, a possible reproduction cycle involving growth (G) and division (D) occurs on micelles composed of lipid molecules constantly fed from the environment. In (a), these are hydrophobic precursors (indicated as T-T) that react to become a polar amphiphile (H-T) thanks to some reaction (figure adapted from [149]). In (b), a similar scenario involves a diverse feeding of lipid molecules forming a heterogeneous aggregate where the recruitment of a particular lipid into the aggregate depends on the compositional information of the aggregate; which lipids already make up the aggregate. In this lipid world scenario, the two resulting daughter cells are different (adapted from [150]).
Figure 5.
Information-free protocell division. In these two examples, a possible reproduction cycle involving growth (G) and division (D) occurs on micelles composed of lipid molecules constantly fed from the environment. In (a), these are hydrophobic precursors (indicated as T-T) that react to become a polar amphiphile (H-T) thanks to some reaction (figure adapted from [149]). In (b), a similar scenario involves a diverse feeding of lipid molecules forming a heterogeneous aggregate where the recruitment of a particular lipid into the aggregate depends on the compositional information of the aggregate; which lipids already make up the aggregate. In this lipid world scenario, the two resulting daughter cells are different (adapted from [150]).
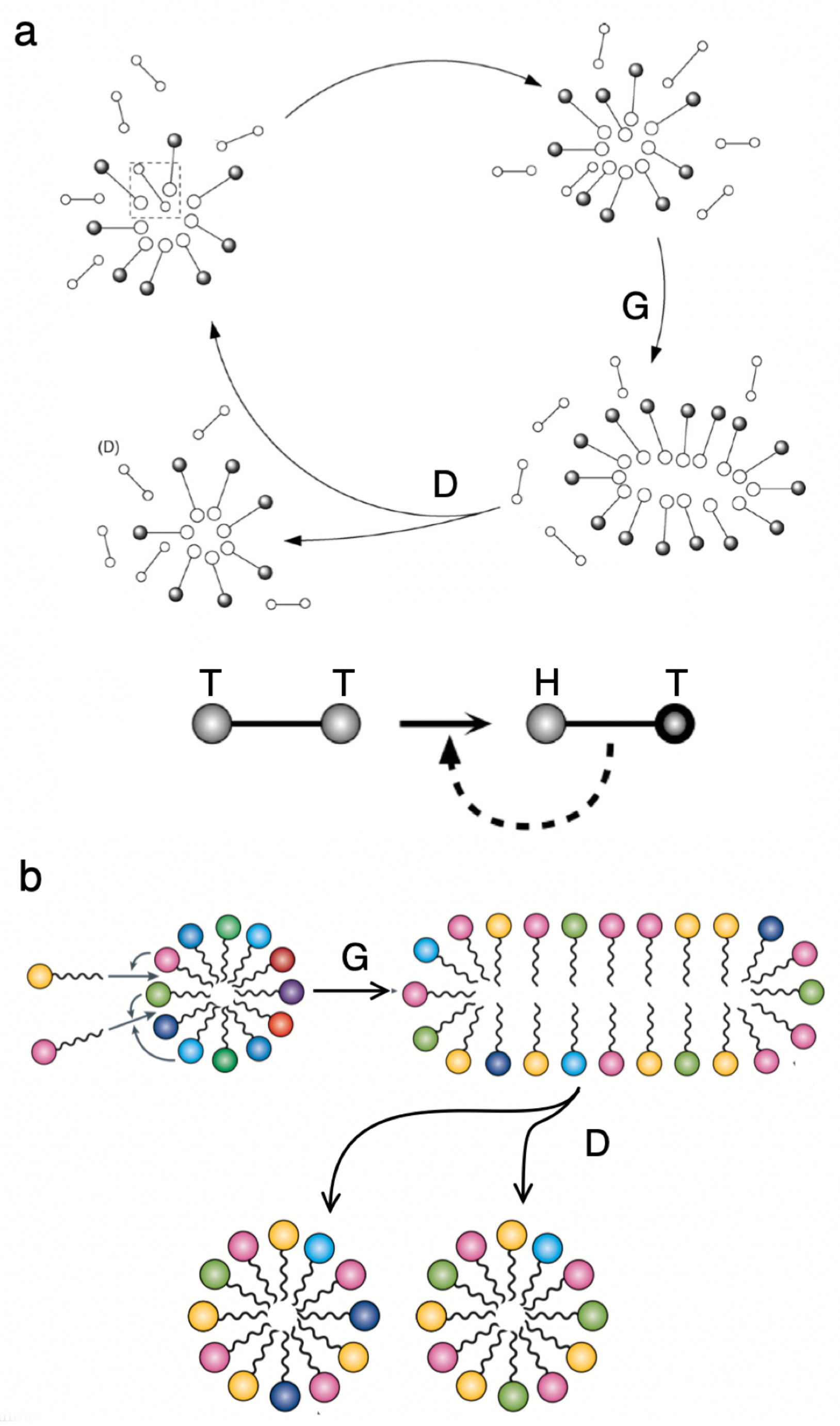
Figure 6.
The logic of multicellularity and development. (a) At the simplest description level, MC organisms can be assigned to two groups: clonal (upper plot) versus aggregative MC. In the former, a transition occurs after repeated cell divisions with the final population forming a cluster. In the second, the transition is from a set of cells towards another set (which might contain the same cells and where their states might or might not remain the same) where some interaction matrix between cell pairs can be defined. (b) MC life cycles can be classified within a well-defined taxonomy where transitions to individuality can be described as graphs connecting (grey arrows) single units (S) and aggregates that can be generated by coming together (CT) or staying together (ST) mechanisms, or even the coexistence of both. Shown, from top to bottom, are the life cycles of Dictyostelium discoideum (image by David Scharf), Caspaspora owczarzaki (from the Multigenome Lab) and Bacillus subtilis (image by Arnaud Bridier). (c) Within MC organisms, cell differentiation increases organismal complexity and can be described by a succession of symmetry-breaking events on a Waddington landscape. Here, marbles indicate cell types (either transient or final). In (d) we show an example of the predictable tissue sorting emerging from a completely disordered cell assembly (adapted from [163]). This can be explained through a simple differential adhesion model (e,f) based on cell sorting dynamics [164]. Here the two cell types are indicated by open and filled circles. Adhesion forces are present, and cells can switch their locations in space if the adhesion energy decreases. Figures (a) and (c) adapted from [165].
Figure 6.
The logic of multicellularity and development. (a) At the simplest description level, MC organisms can be assigned to two groups: clonal (upper plot) versus aggregative MC. In the former, a transition occurs after repeated cell divisions with the final population forming a cluster. In the second, the transition is from a set of cells towards another set (which might contain the same cells and where their states might or might not remain the same) where some interaction matrix between cell pairs can be defined. (b) MC life cycles can be classified within a well-defined taxonomy where transitions to individuality can be described as graphs connecting (grey arrows) single units (S) and aggregates that can be generated by coming together (CT) or staying together (ST) mechanisms, or even the coexistence of both. Shown, from top to bottom, are the life cycles of Dictyostelium discoideum (image by David Scharf), Caspaspora owczarzaki (from the Multigenome Lab) and Bacillus subtilis (image by Arnaud Bridier). (c) Within MC organisms, cell differentiation increases organismal complexity and can be described by a succession of symmetry-breaking events on a Waddington landscape. Here, marbles indicate cell types (either transient or final). In (d) we show an example of the predictable tissue sorting emerging from a completely disordered cell assembly (adapted from [163]). This can be explained through a simple differential adhesion model (e,f) based on cell sorting dynamics [164]. Here the two cell types are indicated by open and filled circles. Adhesion forces are present, and cells can switch their locations in space if the adhesion energy decreases. Figures (a) and (c) adapted from [165].
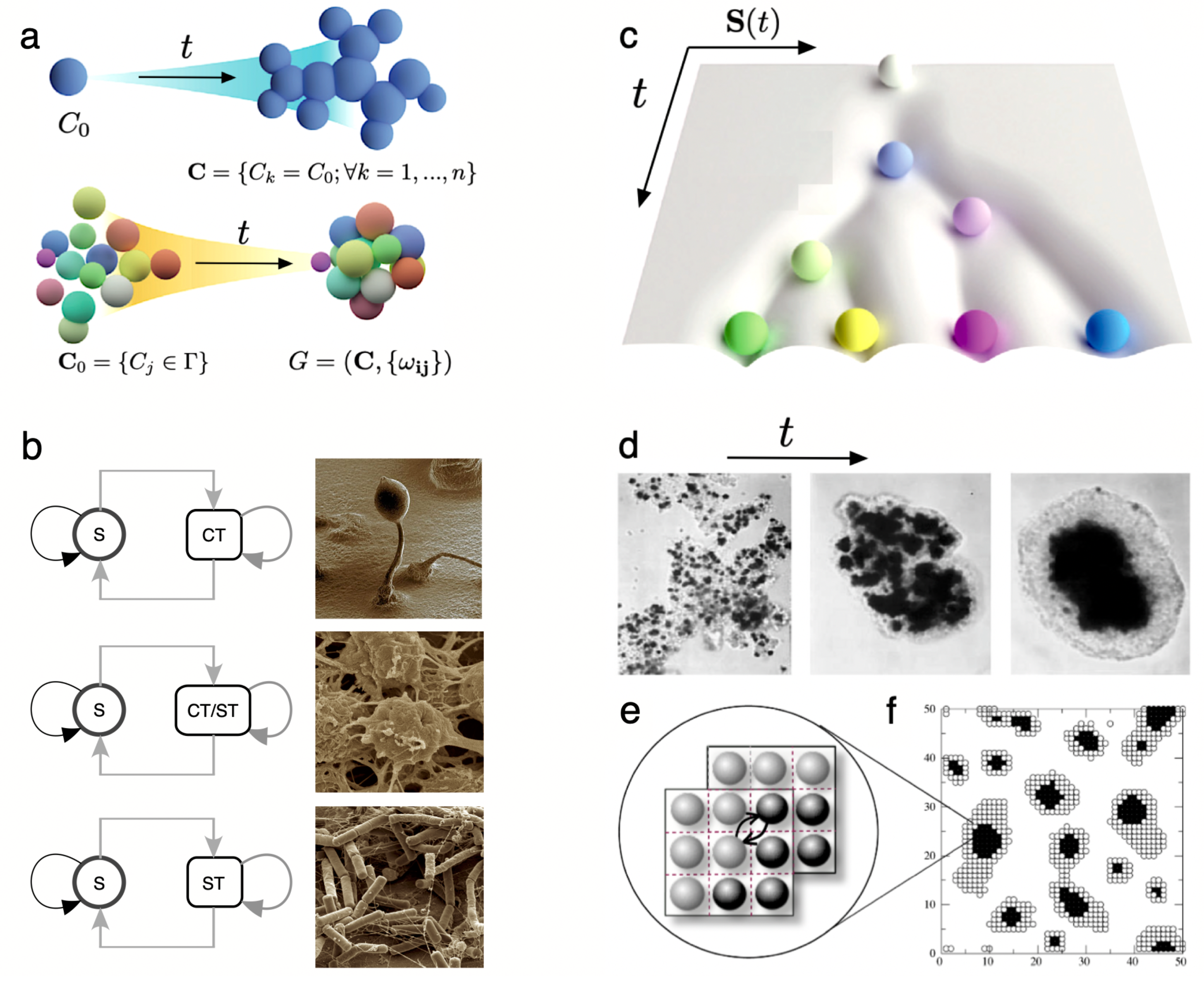
Figure 7.
Cognitive networks may exhibit a unique logic of nonlinear response functions. Neurons (a) are specialised cells that gather and propagate information in a threshold-like manner. They have a well-defined polarity connected with the input-output signal transmission. The standard McCulloch-Pitts model of a formal neuron (b) captures the essence of this transmission in terms of a weighted threshold function, which in its simplest form can be represented as a binary on-or-off response (c). Other information transmission systems, like genetic networks, are usually modelled similarly (d-e). For example, transcription factors () are proteins expressed by some genes that bind to DNA (d, image by David Goodsell) and regulate the expression of other genes. The input-output diagram in (e) is analogous to the neural counterpart, and the corresponding response functions are also highly nonlinear threshold functions. The outcome of these interactions can modify the expression of a given protein (f) or set of proteins.
Figure 7.
Cognitive networks may exhibit a unique logic of nonlinear response functions. Neurons (a) are specialised cells that gather and propagate information in a threshold-like manner. They have a well-defined polarity connected with the input-output signal transmission. The standard McCulloch-Pitts model of a formal neuron (b) captures the essence of this transmission in terms of a weighted threshold function, which in its simplest form can be represented as a binary on-or-off response (c). Other information transmission systems, like genetic networks, are usually modelled similarly (d-e). For example, transcription factors () are proteins expressed by some genes that bind to DNA (d, image by David Goodsell) and regulate the expression of other genes. The input-output diagram in (e) is analogous to the neural counterpart, and the corresponding response functions are also highly nonlinear threshold functions. The outcome of these interactions can modify the expression of a given protein (f) or set of proteins.
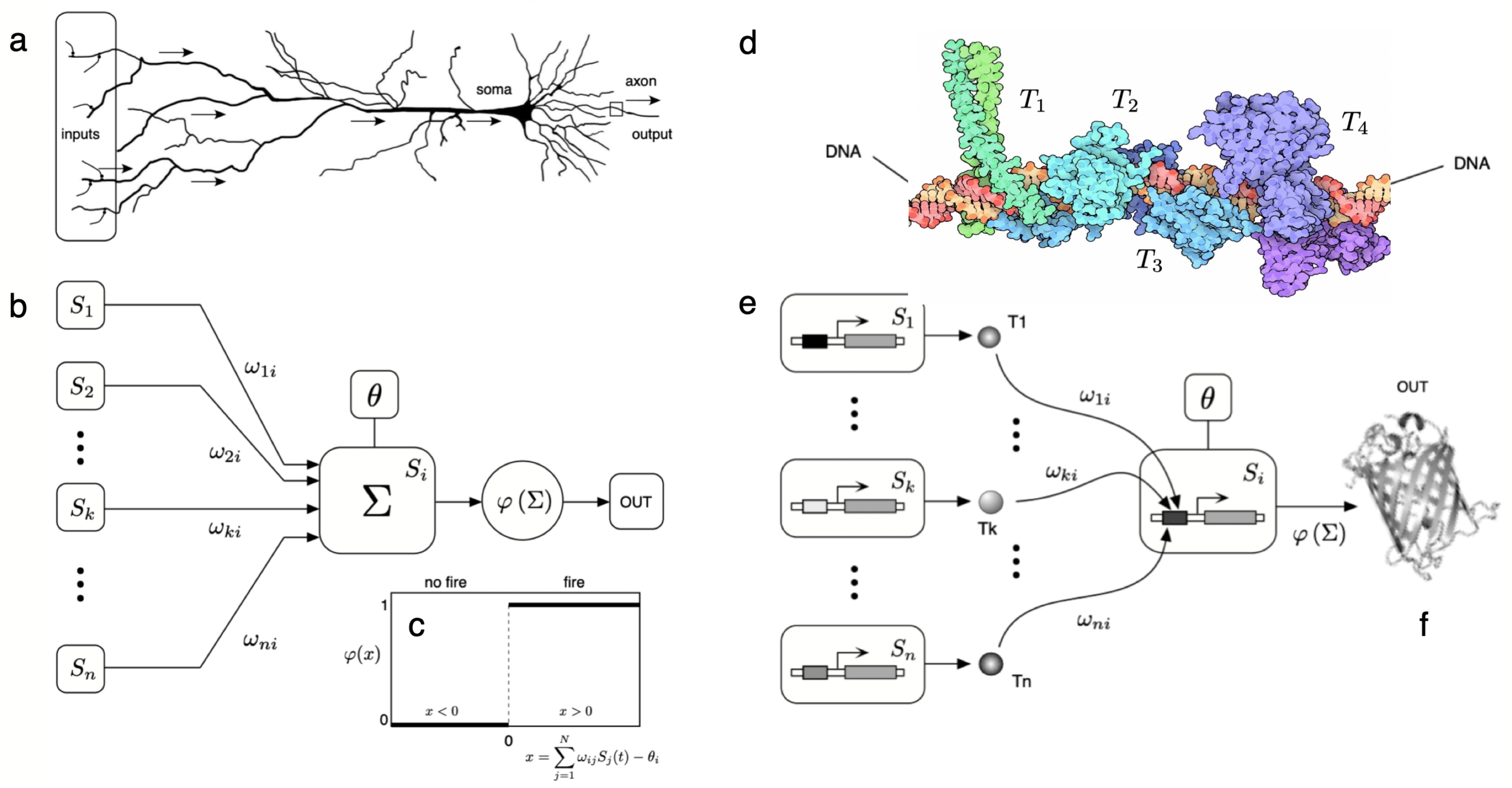
Figure 8.
Universal patterns in ecosystems and digital ecologies. Despite their huge diversity, ecosystem architectures are identified in current and fossil communities (a) and the ecological network (so-called “paleo food webs”) reconstructed, as shown in (b) for a fossil ecosystem before the K-T extinction. One approach to the evolution of these ecological networks relies on digital versions of species and their interactions. An example is shown in (c), where the virtual CPU of the Tierra system is summarised (adapted from [273]). Here, S and R stand for the Slicer and Reaper queues, which introduce rewards and ageing. It is possible to evolve food webs (d) with a discrete number of layers using evolutionary dynamics on bit strings encoding game-theoretic models (adapted from [274]). Algorithmic reactors allow evolving interaction networks and see sequences of increase in complexity, as illustrated in (e), where different “species” are indicated as filled nodes, where interactions can happen directly (continuous arrows) or through an intermediate operator rule (adapted from [275]). The evolved networks always include parasitic interactions.
Figure 8.
Universal patterns in ecosystems and digital ecologies. Despite their huge diversity, ecosystem architectures are identified in current and fossil communities (a) and the ecological network (so-called “paleo food webs”) reconstructed, as shown in (b) for a fossil ecosystem before the K-T extinction. One approach to the evolution of these ecological networks relies on digital versions of species and their interactions. An example is shown in (c), where the virtual CPU of the Tierra system is summarised (adapted from [273]). Here, S and R stand for the Slicer and Reaper queues, which introduce rewards and ageing. It is possible to evolve food webs (d) with a discrete number of layers using evolutionary dynamics on bit strings encoding game-theoretic models (adapted from [274]). Algorithmic reactors allow evolving interaction networks and see sequences of increase in complexity, as illustrated in (e), where different “species” are indicated as filled nodes, where interactions can happen directly (continuous arrows) or through an intermediate operator rule (adapted from [275]). The evolved networks always include parasitic interactions.
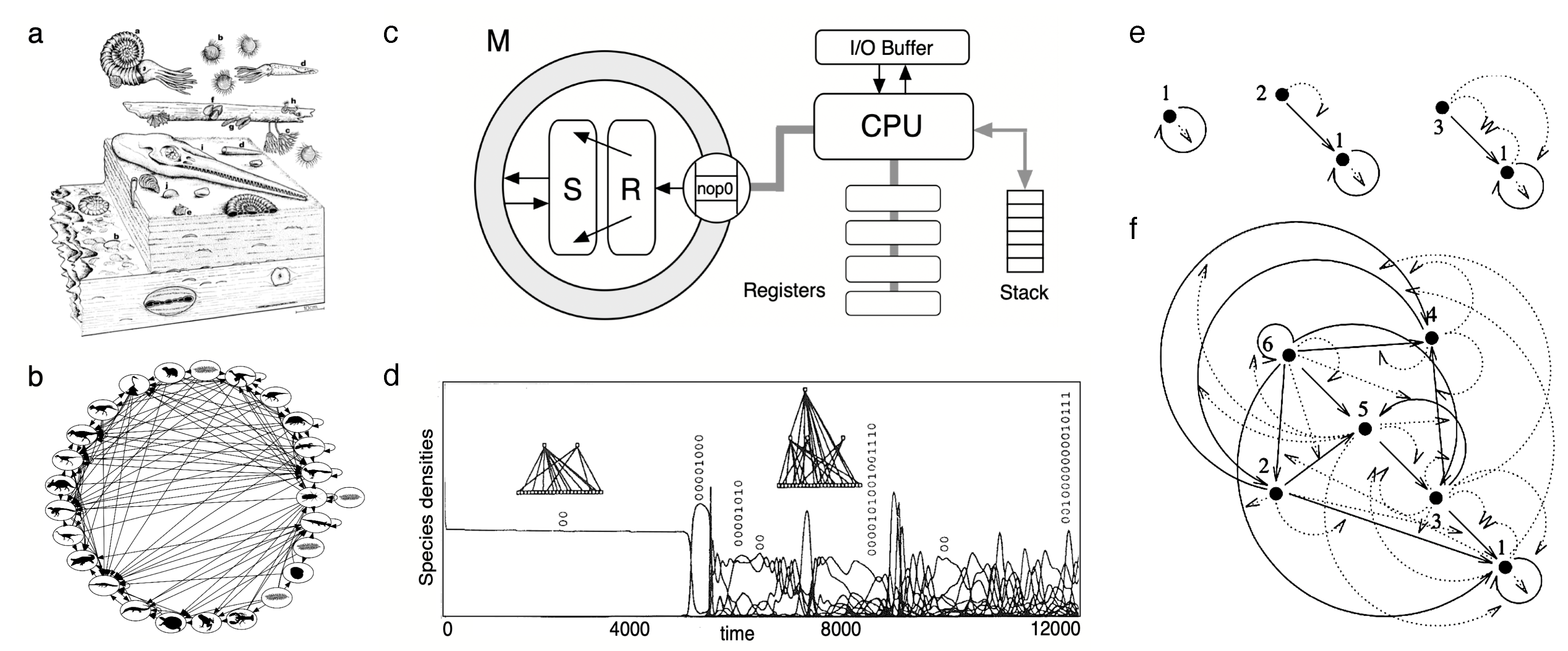
Figure 9.
Parasites and functional evolutionary trees. Digital ecologies generate well-defined, qualitative classes of agents that we can identify as parasites, predators, or natural counterparts associated with a discrete set of constraints in the repertoire of potential functional roles. In (a) and (b), we display the evolutionary trees of an artificial life implementation using Avida, where parasites are present (a) or suppressed (b). The resulting phylogenies indicate that parasites promote diversity (adapted from [309]). The convergent patterns exhibited by ecosystems are illustrated using a diagrammatic representation of two “runs” (c,d) of an abstract world, starting from an initial set of species and looking at a final set of species . Branches appear each time a new functional class emerges. Although the branching patterns might differ, we conjecture that functional trees will branch into the same qualitative, discrete classes . A thick branch associated with parasites will always be present in both cases, with diverse (but common) solutions indicated on the right using examples from extant viruses (e,f). Each time viruses emerge, they will influence the dynamics and even the emergence of new branches, as sketched by the wiggled lines.
Figure 9.
Parasites and functional evolutionary trees. Digital ecologies generate well-defined, qualitative classes of agents that we can identify as parasites, predators, or natural counterparts associated with a discrete set of constraints in the repertoire of potential functional roles. In (a) and (b), we display the evolutionary trees of an artificial life implementation using Avida, where parasites are present (a) or suppressed (b). The resulting phylogenies indicate that parasites promote diversity (adapted from [309]). The convergent patterns exhibited by ecosystems are illustrated using a diagrammatic representation of two “runs” (c,d) of an abstract world, starting from an initial set of species and looking at a final set of species . Branches appear each time a new functional class emerges. Although the branching patterns might differ, we conjecture that functional trees will branch into the same qualitative, discrete classes . A thick branch associated with parasites will always be present in both cases, with diverse (but common) solutions indicated on the right using examples from extant viruses (e,f). Each time viruses emerge, they will influence the dynamics and even the emergence of new branches, as sketched by the wiggled lines.
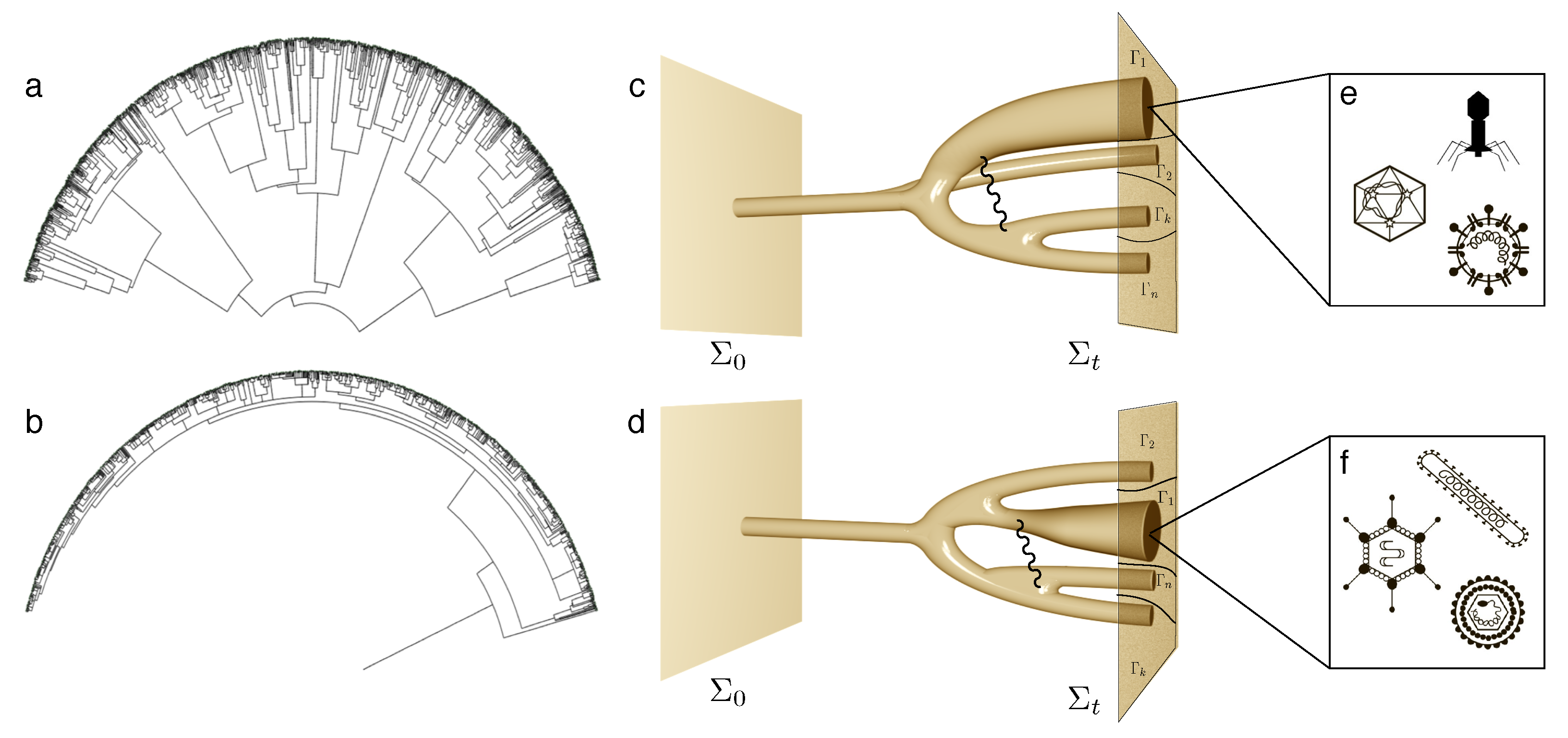
Figure 10.
Phase transition in physics versus evolutionary transitions. In (a), the phase transition associated with the two-dimensional Ising model is shown, displaying the average magnetisation (the order parameter) (i.e. a sum over all spins ) against the temperature (the control parameter). The snapshots are obtained by indicating “up” (+1) and “down” (-1) spins as black and white squares, respectively. Two possible ordered configurations are obtained for temperatures lower than the critical , associated with a symmetry-breaking phenomenon. For , a disordered phase is present, with an essentially random arrangement of spins, lacking spatial correlations. A critical point separates these two phases. The inset curves represent the macroscopic potential function derived from a mean field approximation. Open and filled circles stand for unstable and stable states, respectively. In (b-c), we display three examples of models of evolutionary innovations that exhibit some phase transition, along with some of their underlying mathematical descriptions. These are (b) the emergence of homochirality (figure from [348]), (c) the emergence of autocatalytic cycles out of random chemistry of reacting species (figure redrawn from from [349]) (d) the collective evolution of genomes as described by the transition from horizontal to vertical genetic transition (figure from [59]).
Figure 10.
Phase transition in physics versus evolutionary transitions. In (a), the phase transition associated with the two-dimensional Ising model is shown, displaying the average magnetisation (the order parameter) (i.e. a sum over all spins ) against the temperature (the control parameter). The snapshots are obtained by indicating “up” (+1) and “down” (-1) spins as black and white squares, respectively. Two possible ordered configurations are obtained for temperatures lower than the critical , associated with a symmetry-breaking phenomenon. For , a disordered phase is present, with an essentially random arrangement of spins, lacking spatial correlations. A critical point separates these two phases. The inset curves represent the macroscopic potential function derived from a mean field approximation. Open and filled circles stand for unstable and stable states, respectively. In (b-c), we display three examples of models of evolutionary innovations that exhibit some phase transition, along with some of their underlying mathematical descriptions. These are (b) the emergence of homochirality (figure from [348]), (c) the emergence of autocatalytic cycles out of random chemistry of reacting species (figure redrawn from from [349]) (d) the collective evolution of genomes as described by the transition from horizontal to vertical genetic transition (figure from [59]).
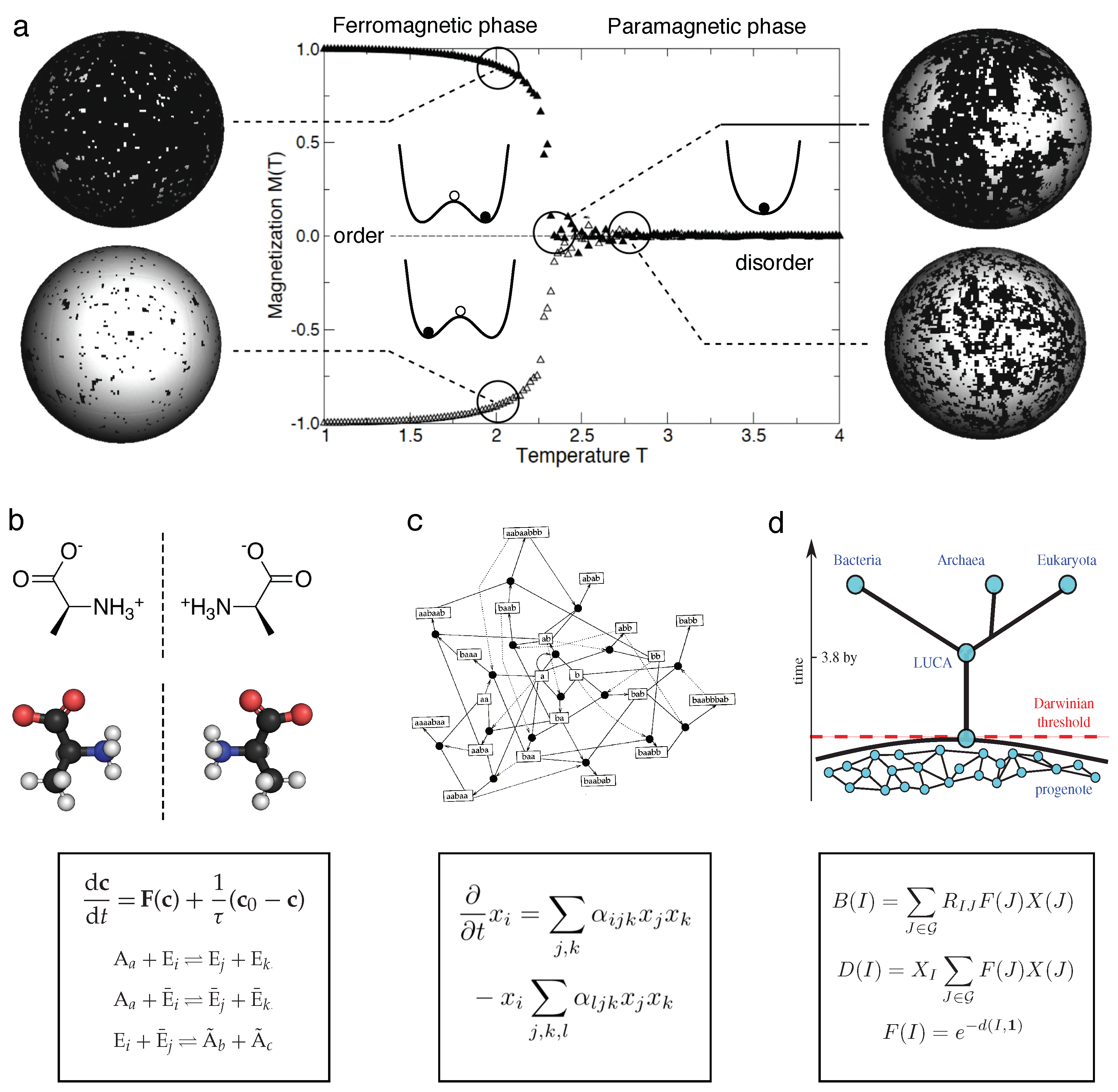
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



