
Submitted:
17 June 2024
Posted:
17 June 2024
You are already at the latest version
Abstract
Microscopic and ultra-microscopic vascular sutures are indispensable in the surgical procedures such as arm transplantation and finger reattachment. The state of the blood vessels after suturing, such as vascular patency, narrow, and blocked, determines the success rate of the operation. If we can grasp the golden window period after blood vessel suture and before muscle tissue suture to achieve accurate and objective assessment of blood vessel status, it can not only reduce medical costs but also improve social benefits. Doppler optical coherence tomography enables high-speed, high-resolution imaging of biological tissues, especially microscopic and ultra-microscopic blood vessels. Using Doppler optical coherence tomography to image the sutured blood vessels, not only the three-dimensional structure of the blood vessels, but also the blood flow information can be obtained. By extracting the contour of blood vessel wall and the contour of blood flow area, the three-dimensional shape of blood vessel can be reconstructed in three dimensions, which provides parameter support for the assessment of blood vessel status. In this work, we propose a neural network-based multi-classification deep learning model that can simultaneously and automatically extract blood vessel boundaries from Doppler OCT vessel intensity images and the contours of blood flow regions from corresponding Doppler OCT vessel phase images. Compared with the traditional random walk segmentation algorithm and cascade neural network method, the proposed model has better performance. This method is easier to realize system integration and has great potential for clinical evaluation. It is expected to be applied to the evaluation of microscopic and ultra-microscopic vascular status in microvascular anastomosis.
Keywords:
Optical coherence tomography
; Image segmentation
; Deep learning
; Microvascular anastomosis
1. Introduction
Microscopic and ultra-microscopic vascular anastomosis is extremely challenging, which is the basis of plastic surgery and organ grafting [1]. The intraoperative vascular status assessment is of great importance. It can provide effective evaluation parameters such as thrombus formation, lumen restoration for potential early re-intervention [2]. The early intervention can not only improve the success rate of the surgery, but also reduce the expense of patients. The Doppler optical coherence tomography (DOCT) is a high-resolution non-invasive 3D imaging modality. As an assisting tool, it has demonstrated its special advantages in surgical evaluation [3,4].
Boundary segmentation of vessel wall from Doppler OCT intensity image and the segmentation of the inner lumen contour from Doppler OCT phase image are essential for the 3D morphology reconstruction of the vessel. Due to the strong scattering of red blood cells and other medium in vessel, the images suffer from low contrast and blurred boundary especially at the greater depth of the vessel. And the OCT images contain severely speckle noise and random noise, which increases the complexity of the boundary segmentation. Therefore, the algorithms for accurate boundary segmentation are demanded, which should be robust to the OCT noise and very good at the weak boundary segmentation.
There exist many boundary segmentation approaches for OCT vessel images. Earlier studies usually focus on pixel intensity changes, gradient information, Chan-Vese model, graph-based method. The pixel intensity changes along the A-Scan contour were used to achieve image segmentation [5,6,7,8], while most segmentation methods using intensity information are based on intensity changes of backscattered signals [9,10,11,12,13,14]. Gasca et al. [15] extracted the boundary in intensity images, but it was generally difficult to extract the weak boundary accurately. Sihan et al. [16] used Canny filter for edge detection, and then used link step for segmentation. However, due to the fixed threshold, this method has poor segmentation effect on noisy images. Yang et al. [17] proposed a segmentation algorithm based on dual-scale gradient information, which simultaneously uses the global gradient information and local gradient information to complement each other. And it adopts the shortest path search algorithm to optimize the edge in combination with the local Canny edge detection method, which has high accuracy and repeatability for the segmentation of 3D OCT volume data. However, this method is not robust to noise. Guimaraes et al. [18] used intensity images to achieve retinal segmentation, and divided different thresholds according to different tissues to achieve retinal layer segmentation. The computational efficiency of this method is very high. But due to the influence of the intensity variation in the layer, the intensity inconsistency causes artifacts in the blood vessels during the imaging process. Most of the segmentation methods based on image intensity information are used for eye image segmentation, which the extraction ability of weak boundary is insufficient. Chan-Vese (C-V) model is a classical region-based geometric active contour model, which can segment images without obvious edges well. The method based on C-V model first needs to set up an initial contour curve, and use the gradient information to get the optimal result. In 2006, Grady applied the random walk method to the field of image segmentation [19], introducing regularization into the segmentation process. This method can extract the weak boundary of images, but in the weak boundary extraction process of OCT images, the staircase effect will appear, resulting in incorrect segmentation. Roy et al. [20] used the random walk algorithm and signal attenuation model of OCT imaging process to track the maximum optical backscatter of each A-scan. And then used global gray scale statistics to optimize and achieve image segmentation. Huang et al. [21] used the Laplacian operator to perform iterative calculation by changing the calculation operator of the random walk, which showed good robustness to the weak boundary of OCT images. The graph-based approach is used to achieve segmentation of retinal in time domain OCT images [22,23,24] and OCT coronary vessel images [25]. Garvin et al. [26,27] also extended this method to spectral OCT images, adding flexible and diverse constraints and greatly improving segmentation accuracy. Nabila et al. [28] segmented retinal vessels of OCTA with generalized Gauss-Markov-Gibbs random field model and Markov-Gibbs random field model. Ruchir et al. [29] used the method of 3D map cutting to segment the skin surface layer. In 2022, Mittal et al. proposed to use random walk and interframe flattening algorithm to process OCT images. They used N-ret layer segmentation method to simplify OCT image segmentation and improve the accuracy of OCT image segmentation [30].Traditional vascular segmentation methods often rely on shallow image features, such as image gray scale and texture features, which have low representativeness and are easy to be disturbed by noise. Moreover, such features rely on designers’ experience and knowledge accumulation to design extraction algorithms. Practice has proved that the deep features are more representative. Machine learning techniques can extract deep features from massive data. In different application scenarios, more representative features can be extracted from the training data and applied to the blood vessel segmentation task, which can not only improve the accuracy of blood vessel segmentation, but also improve the segmentation efficiency. . The sparse representation and discriminant dictionary learning methods were used to vascular segmentation. According to the feature vector of pixels, each pixel is classified into blood vessels and non-blood vessels, so as to achieve the segmentation and extraction of retinal blood vessels [31,32,33]. In recent years, the powerful segmentation ability of deep learning has gradually been widely applied to the segmentation field of medical images. Roy et al. [34] proposed RelayNet for end-to-end segmentation of retinal layers and fluid masses in ocular OCT images. Fan et al. [35] used a multi-channel FCN to automatically segment coronary arteries from angiographic images. Hamwood et al. [36] studied the impact of batch size and network structure on retinal segmentation results. Girish et al. [37] applied the FCN model to the segmentation of the inner retinal capsule membrane. This plays an important role in ophthalmic diagnosis and quantification of retinal abnormalities. In recent years, many scholars have combined traditional methods with deep learning methods to achieve image segmentation. Fang et al. [38] combined deep learning with Graph Search to propose a Convolutional Neural Networks-Graph search (CNN-GS) architecture for automated segmentation of 9-layer boundaries of retinal OCT images. Zhang et al. [39] combined convolutional neural networks with random walk algorithms to segment plaques in OCT coronary artery images. The CFANet method proposed by MaFei et al. has achieved high accuracy in the segmentation of OCTA optic disc and macular region [40]. Yazan et al. [41] used SegNet in combination with conditional random fields to segment the lumen and calcified area of OCT coronary arteries, helping to determine the placement of stents during coronary interventional therapy. Ronneberger et al. [42] proposed full convolutional neural network U-net for the segmentation of neuron structure under electron microscope and the segmentation and extraction of cell contour under light microscope. More recent studies commonly use its variants for layer-wise retina segmentation [43,44,45]. The cascaded U-net architecture was proposed to segment the vessel intensity image and its corresponding phase image for the vessel wall and the blood flow area boundary, respectively [46]. It contains two U-nets, which means that the second segmentation results rely on the first segmentation results. The limitation of this method is that two models are trained and optimized separately, which takes more time to obtain the optimized models. Besides, when integrating the models into the system for online application, it is more complicated to call two models than one.
Due to the strong scattering of blood in the blood vessels, with the increase of imaging depth, the sensitivity of the OCT system decreases. And the signal-to-noise ratio of the images decreases, resulting in the blurring of the lower edge of the blood vessels. At the same time, OCT images contain noise, and noise levels in phase images are generally higher than in intensity images, increasing the difficulty and complexity of accurately segmenting the contour of blood vessel edges. The accurate extraction of the contour of blood vessel wall and blood flow region is particularly crucial for the reconstruction of the three-dimensional structure of blood vessel and the three-dimensional morphology of thrombus.
In this work, we proposed a multi-classification deep learning model to extract the vessel boundary from Doppler OCT intensity images and the lumen area contour from corresponding Doppler OCT phase images simultaneously and automatically. There are two reasons for using the U-net structure in this study. Firstly, the principle of OCT is a fiber optic Michelson interferometer. The interference occurs when the optical path difference between the reference light returned by the mirror and the backscattered light of the measured sample is within the coherence length of the light source. The detector output signal reflects the backscattering intensity of the medium. While the shallow and deep layers of U-Net acquire high-frequency and low-frequency information from the image, respectively, and the information of each level is well preserved through skip connections. Secondly, the scanning mirror can record its spatial position so that the reference light interferes with backscattered light from different depths within the medium. According to the position of the mirror and the corresponding interference signal intensity, the measurement data of different depths (z direction) of the sample can be obtained. U-Net can reconstruct the spatial structure with self-similarity and use the handcrafted image and the structure of the known part to interpolate the unknown region [48].
The pair of intensity image and phase image are preprocessed into one 512×512 grayscale image as the input of the model. The pixel categories of the input image are divided into three categories: background, vessel region and inner lumen area. The average Dice Coefficient (DC) adopted for the quantitative analysis of the segmentation results reaches 96.7%. Based on 250 in-vivo mouse femoral artery images segmentation results, 3D thrombosis morphology and lumen area analysis were adopted for quantitative outcome evaluation.
2. Methods
In this work, we regard two binary classification problems as a multi-classification issue. First, we preprocessed the intensity image and phase image as one grayscale image as shown in Figure 1(a). Then, the corresponding label is as shown in Figure 1(b). The background area is regarded as the zero category. The vessel region in intensity image belongs to the first category and the inner lumen area in phase image is classified into the second category.
2.1. Model Architecture
Our architecture is derived from the U-Net architecture described in [42], which is a classical network. Since the U-Net structure was proposed, it has gained widespread attention in the field of OCT vessel imaging. The deep layer contains semantic information of the features and the shallow layer contains high-resolution information of the fine features of the image [47]. We modify and extend the U-net architecture, which works with very few training images and yields more precise segmentation results, as shown in Figure 2. The input is a 512×512-pixel image. The output is the predicted probability map obtained by the SoftMax. We adopted convolutional layers with 3×3 filters. The batch normalization layer is added before each convolutional layer, which is helpful to prevent the gradient explosion and gradient disappearance. The Batch Normalization (BN) effectively normalizes each batch of inputs by re-centering and scaling to alleviate the problem of internal covariate shift and, in some cases, eliminates the need for dropout [49]. The convolutional layers are followed by the rectified linear unit (ReLU) activation function. The convolutional layers followed a pooling layer can extract deeper features in the encoder. The upsampling layers followed convolutional layers in the decoder. The max pooling layers and upsampling layers use 2×2 filters. The number of layers and the feature maps used in each convolution layer are illustrated in Figure 2.
2.2. Dataset and Implementation
The mouse artery was imaged with a Sensemos-OCT-840-70-U3 handheld probe (Suzhou Sensemos Technology Co., LTD ). The system was with each frame size of 512 (lateral)×512 (axial) pixels using a source with a central wavelength of 840 nm and tuning range from 820 nm to 860 nm. In brief, these data were obtained from the exposed femoral artery after anastomosis on six to eight-week-old male BALB/C mice. A 3D volume data of the anastomosed vessel site was acquired covering a volume range of 1.5 mm✕1.5 mm ✕5mm (lateral X lateral Y axial Z). The 3D dataset consists of 250 B-frames. Each B-frame image consisted of 1000 A-scans. All the experiments were performed on a workstation with one NVIDIA GeForce RTX4080 graphics processing units (GPU) and 128GB of RAM. The models were implemented with Python based on Keras deep learning library.The vascular Doppler OCT intensity images and corresponding phase images were first sampled into one 512×512 pixels grayscale images to fit the model. We crop the image by MATLAB software and only select the part with blood vessels. The size of image captured is 512*256. Then we merge the intensity image and phase image. The intensity image is placed on the left and the phase image is placed on the right. So, the size of CNN input image is 512*512. Then image pairs were manually delineated by specialists to form the gold standards of vessel wall boundary and inner blood flowing lumen area contour. The capability of Doppler OCT imaging for detection of thrombosis has been investigated and validated by gold standard histology analysis in previous publication [1]. That’ s the foundation of our drawing on the formation of gold standard. The training dataset consists of 250 images. To teach the network with desired invariance and robustness properties, data augmentation was applied to the training set and their corresponding segmentation labels 20-fold to obtain 5000 pairs of data sets as training inputs for the network. , which was by translation (the coefficient of width, height and zoom set as 0.07, 0.03, 0.05, respectively), rotation (coefficient sets 0.3), shear (coefficient sets 0.1) and flipping.
3. Results
3.1. Training Procedure
The training dataset and corresponding ground truth were delivered into the networks. The categorical Cross-entropy loss and Adam optimizer and learning rate of 0.0001 were adopted in training process. The learning rate is decreased by a fraction of 0.1 if the loss does not decrease for seven consecutive epochs. We used the dropout ratio 0.2 during the training procedure to reduce overfitting. The loss value was altered with the weights map of the convolutional layers. When the loss function value no longer decreases as the training epochs increases, the loss function tends to converge and the optimal classification model can be obtained. An early stopping mechanism is also employed to stop the training process if the loss value does not decrease for 5 consecutive epochs. The proposed architecture is trained for 100 epochs. In Figure 3, the convergence of the learning curves is illustrated over the epochs. The red curves represent the train accuracy and train loss while the black curves stand for the validation accuracy and validation loss. The loss values decreased quickly in the first several epochs and became steady.
3.2. Quantitative Evaluation
The metrics like Area Under the Curve (AUC) is used to evaluate the performance of the proposed network, which are defined as below [51]:
Where represents True Positives, FP represents False Positives, and FN represents False Negatives. The Dice Coefficient (DC) was also applied to evaluate both the segmentation and classification performance. We computed the average of the test dataset to get the final results. The DC is defined as below [39]:
Where and represent the segmented area and the corresponding ground truth. The range of DC value is 0-1. The closer the DC value is to 1, the better the performance of the networks.
3.3. Segmentation Results
To verify the validity of the proposed method, we segmented an 3D volume data contained 250 OCT artery images with the trained model. The several segmentation results are shown in Figure 4 and Table 1. The intensity images with vessel wall marked out with blue curves and the phase images with blood flowing lumen area boundary marked out by red curves. There is different degree of thrombosis occlusion in Figure 4(b-1), (d-1), (e-1), (f-1), (g-1) and (h-1) while no thrombosis is in Figure 4(a-1) and (c-1). We can see that the boundaries were successfully segmented, which demonstrates the effectiveness of the proposed method. Table 1 summarizes the performance metrics for (a-1) - (h-1) frame OCT images from 250 frame OCT images correspondingly. We can see that the precision is above 0.94 and the recall is above 0.96. In addition, the F1Score and the Dice are above 0.95.
We performed registration with subpixel image registration algorithm and 3D reconstruction of 250 segmentation results to visually display vascular morphology, as shown in Figure 5 [51,52]. In order to observe the internal structure of the blood vessel, we divided the blood vessel into two halves according to the blood vessel center line. We can see two clots in the blood vessels. At the location of thrombus 1, it caused a narrowing of the blood vessels to some extent.
4. Discussion
Quantitative analysis of the vessel was performed, which is essential to the objective assessment of the surgical successful rate. We calculated the blood flow region and blood vessel radius along the blood flow direction with 250 segmentation results, which contains a physical range of 1.5mm. We make the comparison with the traditional random walk algorithm and the cascaded U-net architecture. Figure 6(a) shows the blood flowing region variation along the vessel flow axis. It clearly shows that the lumen area becomes narrower at the thrombosis position, which points out by black circle. The average radius of one cross-sectional image in 10 angular directions with their stand deviations is shown in Figure 6(b), which is consistent with the segmentation results in [21,46]. The average radius of the vessel gets smaller at the thrombus point, which is easier to result in turbulence and contribute to the thrombosis formation.
Table 2 shows the performance of the proposed method compared to the traditional random walk method [21] and CU-Net method [46] in terms of the dice coefficient and consuming time. These three methods have high segmentation accuracy for Doppler OCT intensity map and phase map. The segmentation results of phase image with random walk and CU-Net method are slightly lower than that of intensity image. The CU-Net method and proposed method, these two algorithms based on deep learning have greater advantages in time compared with the traditional random walk method. The proposed method took an average time consumption of 0.63s to segment one intensity image and phase image pairs. And it took 157.5s to get all segmentation results, which is faster than the CU-Net method. Compared with the random walk method, the proposed method has a slight improvement in accuracy and a great improvement in time. Compared with the method based on cascaded U-net, the accuracy of the method based on the proposed method is slightly increased. The call of single network is more convenient, and the training of single network is simpler and more efficient in the process of network training. Besides, one model is much simpler and faster than two models for further incorporation into online OCT system for the segmentation process.
5. Conclusions
We proposed a method based on deep learning for Doppler OCT images segmentation. It can obtain the vessel boundary from the intensity image and the lumen area boundary from the corresponding phase image simultaneously, which achieve an average testing segmentation accuracy of 0.967 and an average time consumption of 0.63s. The 3D thrombosis morphology and quantitative analysis of the vessel condition were performed. The proposed method can extract the boundaries obtaining the morphology of vessel for accurate quantitative evaluation. In the future, we will develop a real-time online segmentation algorithm platform for OCT images. It is expected to realize real-time clinical segmentation and provide technical support for intraoperative evaluation, which could promote the application of OCT in clinical analysis assisting the doctors in making decisions.
Author Contributions
Conceptualization, Z.W.; Methodology, C.W.; Software, P.X, 3D rendering, W.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Basic research project of Shanxi Provincial Science and Technology Department (grant number, 20210302123208, 202203021212159, 202203021222038).
Conflicts of Interest
The authors declare no potential conflicts of interest with respect to the research, authorship, and publication of this article.
References
- Huang, Y., Ibrahim, Z., Tong, D., Zhu, S., Mao, Q., Pang, J., ... & Kang, J. U. Microvascular anastomosis guidance and evaluation using real-time three-dimensional Fourier-domain Doppler optical coherence tomography. Journal of biomedical optics. 2013, 18(11), 111404-111404. [CrossRef]
- Wang, Y., Bower, B. A., Izatt, J. A., Tan, O., & Huang, D. Retinal blood flow measurement by circumpapillary Fourier domain Doppler optical coherence tomography. J. Biomed. Opt. 2008, 13(6), 064003-064003. [CrossRef]
- Arevalillo-Herráez, M., Villatoro, F. R., & Gdeisat, M. A. A robust and simple measure for quality-guided 2D phase unwrapping algorithms. IEEE Trans. Image Process. 2016, 25(6), 2601-2609. [CrossRef]
- Dong, J., Chen, F., Zhou, D., Liu, T., Yu, Z., & Wang, Y. Phase unwrapping with graph cuts optimization and dual decomposition acceleration for 3D high-resolution MRI data. Magn. Reson. Med. 2017, 77(3), 1353-1358. [CrossRef]
- Koozekanani D, Boyer K, Roberts C. Retinal thickness measurements from optical coherence tomography using a Markov boundary model[J]. IEEE Transactions on Medical Imaging, 2001, 20(9): 900-916. [CrossRef]
- Ishikawa H, Stein D M, Wollstein G, et al. Macular segmentation with optical coherence tomography[J]. Investigative Ophthalmology & Visual Science, 2005, 46(6): 2012-2017. [CrossRef]
- Cabrera F D, Salinas H M, Puliafito C A. Automated detection of retinal layer structures on optical coherence tomography images[J]. Optics Express, 2005, 13(25): 10200-10216. [CrossRef]
- Ahlers C, Simader C, Geitzenauer W, et al. Automatic segmentation in three-dimensional analysis of fibrovascular pigmentepithelial detachment using high-definition optical coherence tomography[J]. British Journal of Ophthalmology, 2008, 92(2): 197-203. [CrossRef]
- Koozekanani D, Boyer K, Roberts C. Retinal thickness measurements from optical coherence tomography using a Markov boundary model[J]. IEEE Transactions on Medical Imaging, 2001, 20(9): 900-916. [CrossRef]
- Ishikawa H, Stein D M, Wollstein G, et al. Macular segmentation with optical coherence tomography[J]. Investigative Ophthalmology & Visual Science, 2005, 46(6): 2012-2017. [CrossRef]
- Mujat M, Chan R C, Cense B, et al. Retinal nerve fiber layer thickness map determined from optical coherence tomography images[J]. Optics Express, 2005, 13(23): 9480-9491. [CrossRef]
- Szkulmowski M, Wojtkowski M, Sikorski B, et al. Analysis of posterior retinal layers in spectral optical coherence tomography images of the normal retina and retinal pathologies[J]. Journal of Biomedical Optics, 2007, 12(4): 041207. [CrossRef]
- Fernandez D C, Salinas H M, Puliafito C A. Automated detection of retinal layer structures on optical coherence tomography images[J]. Optics Express, 2005, 13(25): 10200-10216. [CrossRef]
- Baroni M, Fortunato P, Torre A L. Towards quantitative analysis of retinal features in optical coherence tomography[J]. Medical Engineering & Physics, 2007, 29(4): 432-441. [CrossRef]
- Gasca F, Ramrath L, Huettmann G, et al. Automated segmentation of tissue structures in optical coherence tomography data[J]. Journal of Biomedical Optics, 2009, 14(3): 034046. [CrossRef]
- Sihan K, Botha C, Post F, et al. Fully automatic three-dimensional quantitative analysis of intracoronary optical coherence tomography: method and validation[J]. Catheterization and Cardiovascular Interventions, 2009, 74(7): 1058-1065. [CrossRef]
- Yang Q, Reisman C A, Wang Z, et al. Automated layer segmentation of macular OCT images using dual-scale gradient information[J]. Optics Express, 2010, 18(20): 21293-21307. [CrossRef]
- Guimarães P, Rodrigues P, Celorico D, et al. Three-dimensional segmentation and reconstruction of the retinal vasculature from spectral-domain optical coherence tomography[J]. Journal of Biomedical Optics, 2015, 20(1): 016006. [CrossRef]
- Grady L. Random walks for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28(11): 1768-1783. [CrossRef]
- Guha R A, Conjeti S, Carlier S G, et al. Lumen segmentation in intravascular optical coherence tomography using backscattering tracked and initialized random walks[J]. IEEE Journal of Biomedical Health Information, 2016, 20(2): 606-614. [CrossRef]
- Huang, Y., Wu, C., Xia, S., Liu, L., Chen, S., Tong, D. Ai D., Yang J. and Wang, Y. Boundary segmentation based on modified random walks for vascular Doppler optical coherence tomography images. Chinese Optics Letters, 2019, 17(5), 051001. [CrossRef]
- Haeker M, Abràmoff M D, Wu X, et al. Use of varying constraints in optimal 3-D graph search for segmentation of macular optical coherence tomography images[J]. Medical Image Computing and Computer-Assisted Intervention, 2007, 10(1): 244-251. [CrossRef]
- Haeker M, Sonka M, Kardon R, et al. Automated segmentation of intraretinal layers from macular optical coherence tomography images[C]. Medical Imaging 2007: Image Processing. SPIE, 2007, 6512: 385-395.
- Haeker M, Abrmoff M, Kardon R, et al. Segmentation of the surfaces of the retinal layer from OCT images[J]. Medical Image Computing and Computer-Assisted Intervention, 2006, 9(1): 800-807. [CrossRef]
- Zhang H, Essa E, Xie X. Automatic vessel lumen segmentation in optical coherence tomography (OCT) images[J]. Applied Soft Computing, 2020, 88: 106042. [CrossRef]
- Garvin M K, Abràmoff M D, Wu X, et al. Automated 3D intraretinal layer segmentation of macular spectral-domain optical coherence tomography images[J]. IEEE Transations on Medical Imaging, 2009, 28(9): 1436-1447. [CrossRef]
- Garvin M, Abramoff M, Kardon R, et al. Intraretinal layer segmentation of macular optical coherence tomography images using optimal 3-D graph search[J]. IEEE Transactions on Medical Imaging, 2008, 27(10): 1495-1505. [CrossRef]
- Eladawi N, Elmogy M, Helmy O, et al. Automatic blood vessels segmentation based on different retinal maps from OCTA scans[J]. Computers in Biology and Medicine, 2017, 89: 150-161. [CrossRef]
- Srivastava R, Yow A P, Cheng J, et al. Three-dimensional graph-based skin layer segmentation in optical coherence tomography images for roughness estimation[J]. Biomedical Optics Express, 2018, 9(8): 3590-3606. [CrossRef]
- Praveen M ,Charul B .Effectual Accuracy of OCT Image Retinal Segmentation with the Aid of Speckle Noise Reduction and Boundary Edge Detection Strategy.[J].Journal of microscopy,2022,289(3):164-179. [CrossRef]
- Malihe J, Hamid-Reza P, Ahad H. Vessel segmentation and microaneurysm detection using discriminative dictionary learning and sparse representation[J]. Computer methods and Programs in Biomedicine, 2017, 139: 93-108. [CrossRef]
- Soares J V, Leandro J J, Cesar R M Jr, et al. Retinal vessel segmentation using the 2D Gabor wavelet and supervised classification[J]. IEEE Transactions on Medical Imaging, 2006, 25(9): 1214-1222. [CrossRef]
- Wang Y, Ji G, Lin P, et al. Retinal vessel segmentation using multiwavelet kernels and multiscale hierarchical decomposition[J]. Pattern Recognition, 2013, 46(8): 2117-2133. [CrossRef]
- Roy A G, Conjeti S, Karri S P K, et al. ReLayNet: retinal layer and fluid segmentation of macular optical coherence tomography using fully convolutional networks[J]. Biomedical Optics Express, 2017, 8(8): 3627-3642.
- Fan J, Yang J, Wang Y, et al. Multichannel fully convolutional network for coronary artery segmentation in X-ray angiograms[J]. IEEE Access, 2018, 6(99): 44635-44643. [CrossRef]
- Hamwood J, Alonso C D, Read S A, et al. Effect of patch size and network architecture on a convolutional neural network approach for automatic segmentation of OCT retinal layers[J]. Biomedical Optics Express, 2018, 9(7): 3049-3066.
- Girish G N, Bibhash T, Sohini R, et al. Segmentation of intra-retinal cysts from optical coherence tomography images using a fully convolutional neural network model[J]. IEEE Journal of Biomedical and Health Informatics, 2019, 23(1): 296-304.
- Fang L, Cunefare D, Wang C, et al. Automatic segmentation of nine retinal layer boundaries in OCT images of non-exudative AMD patients using deep learning and graph search[J]. Biomedical Optics Express, 2017, 8(5): 2732-2744. [CrossRef]
- Zhang H, Wang G, Li Y, et al. Automatic plaque segmentation in coronary optical coherence tomography images[J]. International Journal of Pattern Recognition and Artificial Intelligence, 2019, 33(14): 1954035. [CrossRef]
- Fei M ,Sien L ,Shengbo W , et al. Deep-learning segmentation method for optical coherence tomography in ophthalmology.[J].Journal of biophotonics,2023,e202300321-e202300321.
- Gharaibeh Y, Prabhu D, Kolluru C, et al. Coronary calcification segmentation in intravascular OCT images using deep learning: application to calcification scoring[J]. Journal of Medical Imaging, 2019, 6(4): 045002. [CrossRef]
- Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]. International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015: 234-241.
- F. Isensee, P. F. Jaeger, S. A. A. Kohl, J. Petersen, and K. H. Maier-Hein,“nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation,” Nature Methods, vol. 18, no. 2, pp. 203–211, 2021.
- B. N. Anoop et al., “A cascaded convolutional neural network architecture for despeckling OCT images,” Biomed. Signal Process. Control, vol. 66, 2021, Art. no. 102463. [CrossRef]
- B. Hassan et al., “CDC-Net: Cascaded decoupled convolutional network for lesion-assisted detection and grading of retinopathy using optical coherence tomography (OCT) scans,” Biomed. Signal Process. Control, vol. 70, 2021, Art. no. 103030. [CrossRef]
- Wu, C., Xie, Y., Shao, L., Yang, J., Ai, D., Song, H., ... & Huang, Y. Automatic boundary segmentation of vascular Doppler optical coherence tomography images based on cascaded U-net architecture. OSA Continuum, 2019, 2(3), 677-689. [CrossRef]
- Zeiler, M. D., & Fergus, R. Visualizing and understanding convolutional networks. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6-12 September 2014.
- Ulyanov, D., Vedaldi, A., & Lempitsky, V. Deep image prior. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18-23 June 2018.
- Ioffe, S., & Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, Guangzhou China,12-15 July 2015.
- Yi F., Moon I., Javidi B. Automated red blood cells extraction from holographic images using fully convolutional neural networks. Biomed. Opt. Express, 2017, 8(10), 4466-4479.
- Geetha P. P., Sreekar T., Krishna T., Birendra B. EANet: Multiscale autoencoder based edge attention network for fluid segmentation from SD-OCT images. Int J Imaging Syst Technol, 2023, 33: 909-927. [CrossRef]
- Guizar-Sicairos M., Thurman S. T., Fienup J. R. Efficient subpixel image registration algorithms. Opt. letters, 2008, 33(2): 156-158. [CrossRef]
Figure 1.
The input and corresponding label of the architecture. (a) the input of the architecture, (b) the corresponding label, 0 represents back ground,1 represents vessel region, 2 represents inner lumen area. (Scale bar: 500 μm).
Figure 1.
The input and corresponding label of the architecture. (a) the input of the architecture, (b) the corresponding label, 0 represents back ground,1 represents vessel region, 2 represents inner lumen area. (Scale bar: 500 μm).
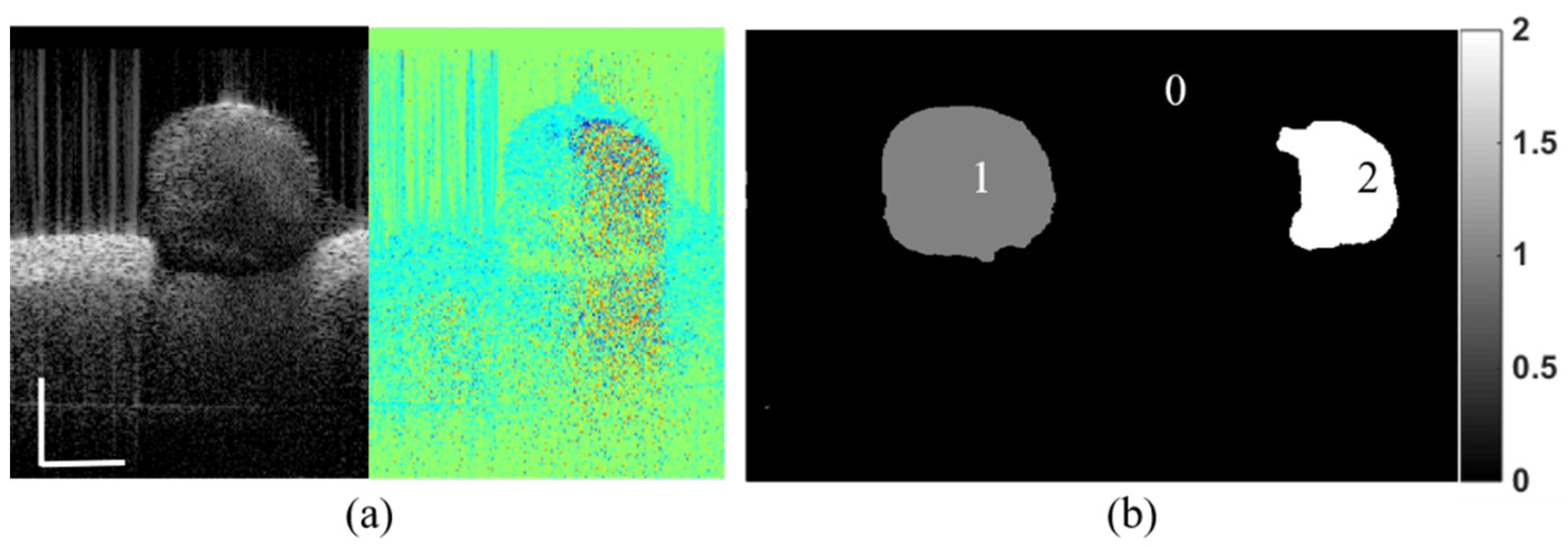
Figure 2.
Proposed convolutional neural network (CNN) model based on U-Net. The number written above each layer indicates the number of convolution kernels (channels).
Figure 2.
Proposed convolutional neural network (CNN) model based on U-Net. The number written above each layer indicates the number of convolution kernels (channels).
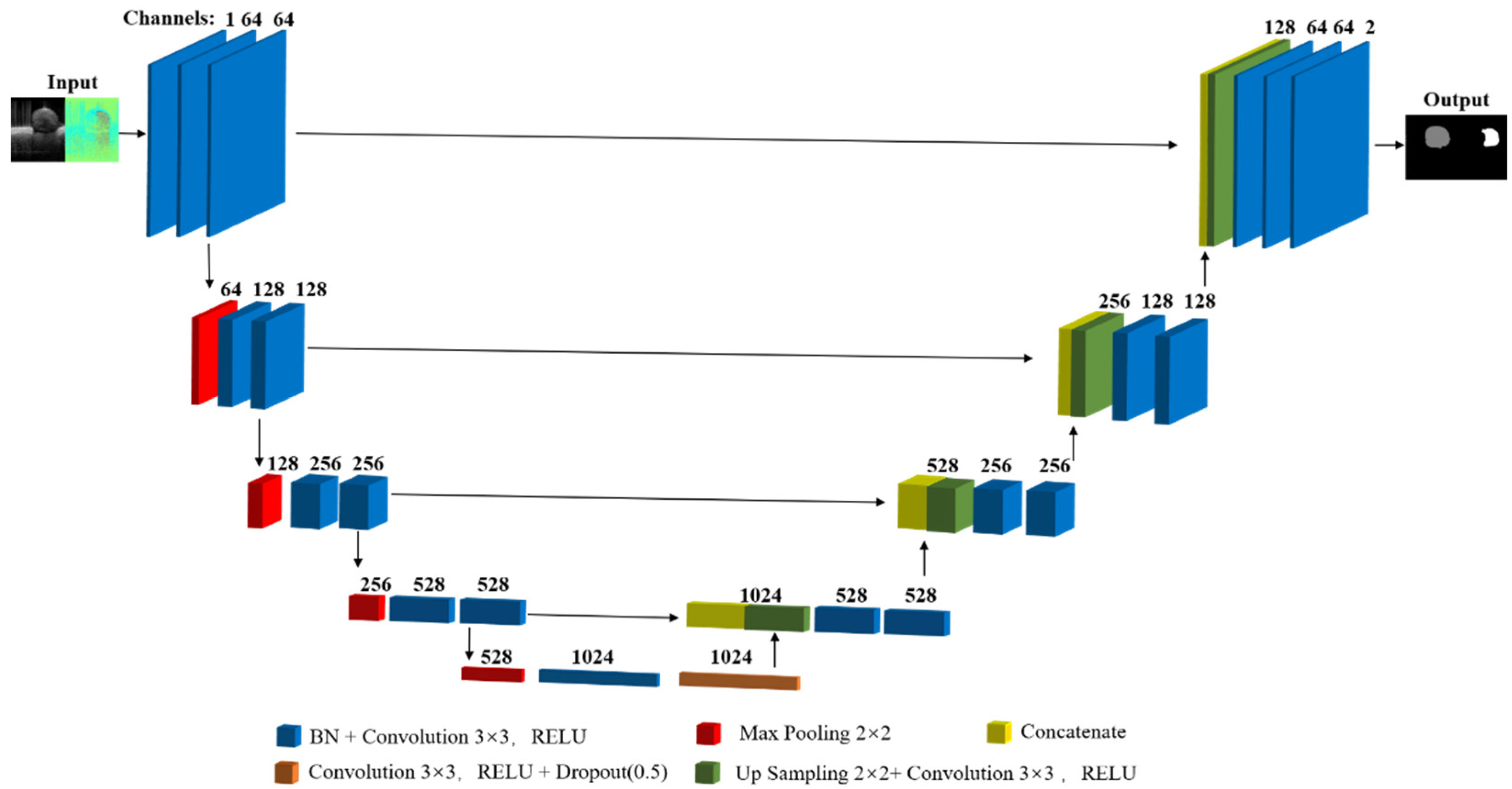
Figure 3.
Learning curves during the training of the model architecture.
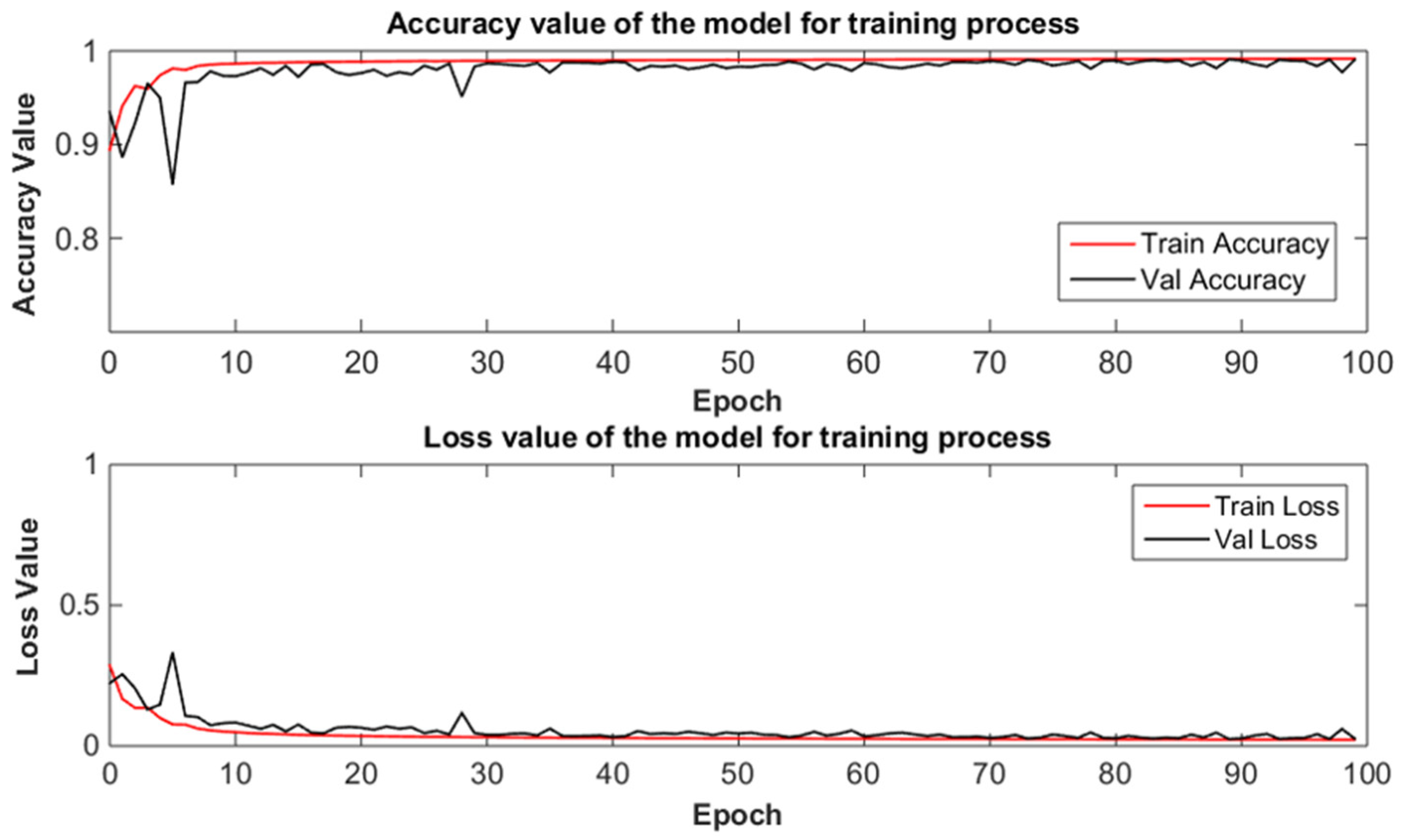
Figure 4.
Segmentation results of eight selective Doppler OCT image pairs using the proposed CNN model. (The blue boundary represents vessel wall, the red boundary represents blood flowing lumen area. Scale bar: 500 μm).
Figure 4.
Segmentation results of eight selective Doppler OCT image pairs using the proposed CNN model. (The blue boundary represents vessel wall, the red boundary represents blood flowing lumen area. Scale bar: 500 μm).
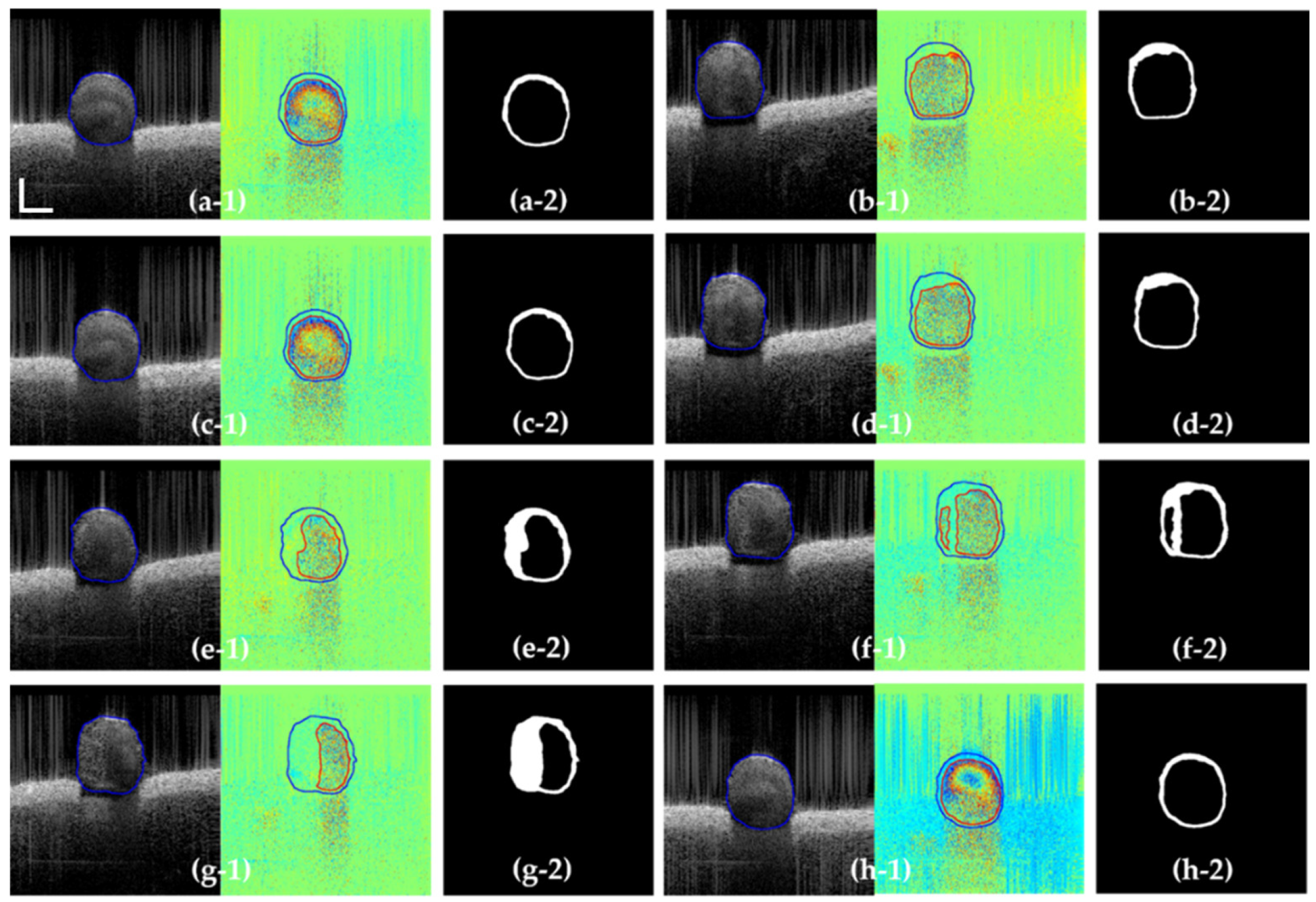
Figure 5.
3D reconstruction of the vessel. (a)The upper part of the blood vessel. (b)The bottom part of the blood vessel. The arrows 1 and 2 point at the thrombosis position. (Scale bar: 500 μm).
Figure 5.
3D reconstruction of the vessel. (a)The upper part of the blood vessel. (b)The bottom part of the blood vessel. The arrows 1 and 2 point at the thrombosis position. (Scale bar: 500 μm).
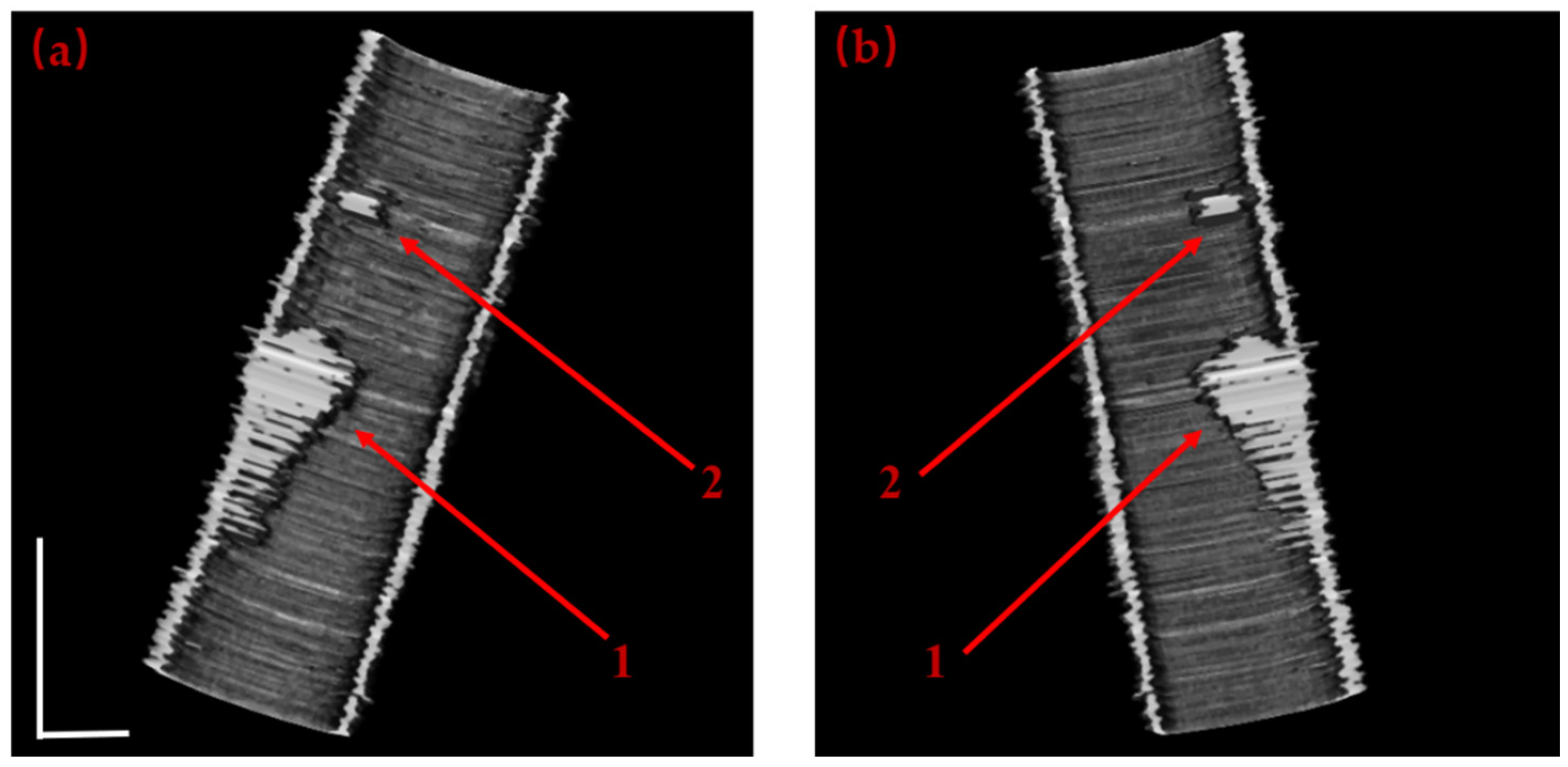
Figure 6.
(a) the blood flowing lumen area and (b) the average blood flowing lumen area radius and its variation along the blood flow axis.
Figure 6.
(a) the blood flowing lumen area and (b) the average blood flowing lumen area radius and its variation along the blood flow axis.
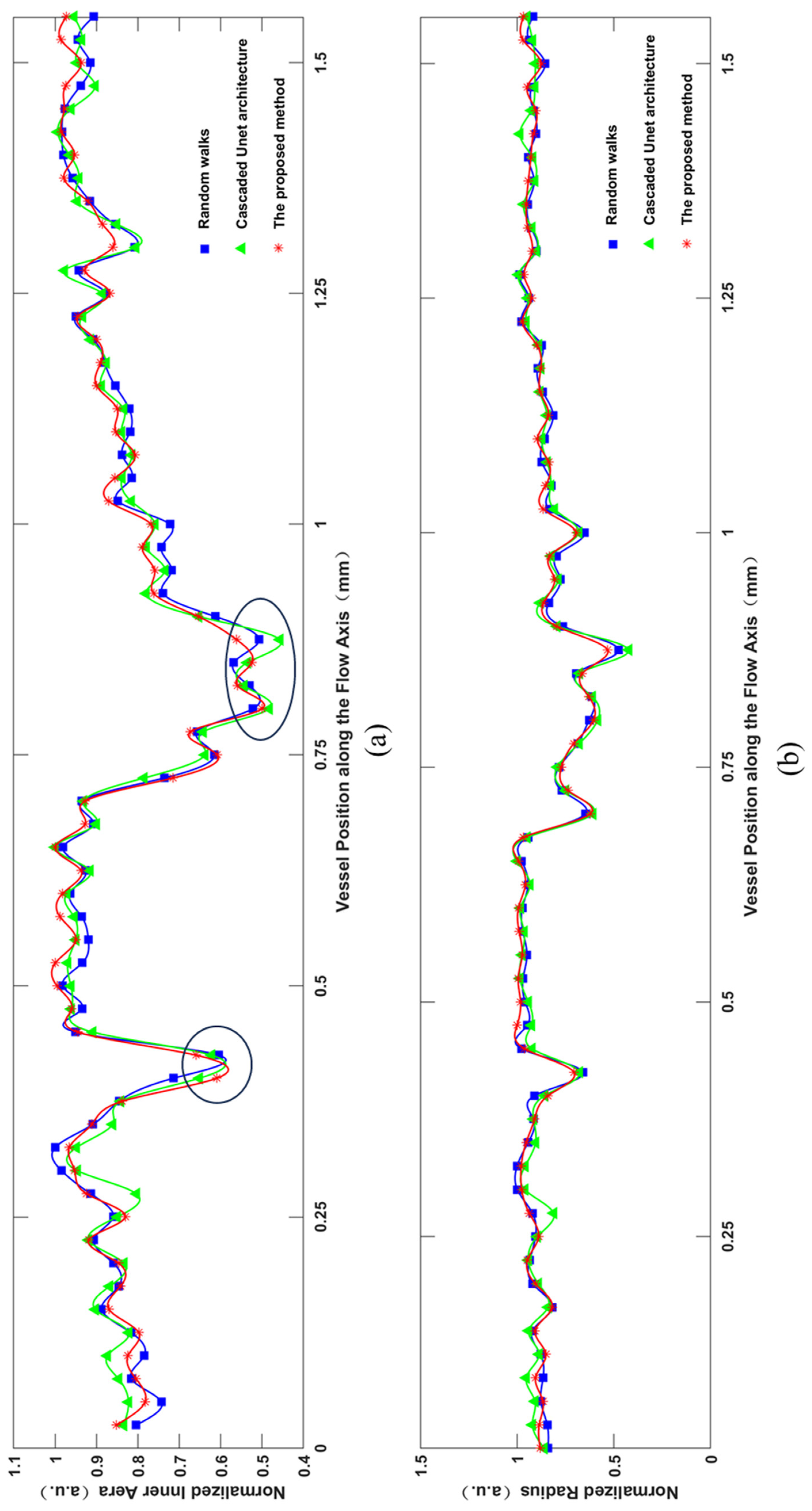

Table 1.
The evaluation of segmentation results with proposed method.
| Frame from Test Dataset | (a-1) | (b-1) | (c-1) | (d-1) |
| Precision | 0.977 | 0.964 | 0.971 | 0.947 |
| Recall | 0.985 | 0.979 | 0.982 | 0.962 |
| F1 | 0.963 | 0.958 | 0.965 | 0.953 |
| Dice | 0.968 | 0.965 | 0.976 | 0.954 |
| Frame from Test Dataset | (e-1) | (f-1) | (g-1) | (h-1) |
| Precision | 0.967 | 0.954 | 0.963 | 0.977 |
| Recall | 0.975 | 0.969 | 0.983 | 0.982 |
| F1 | 0.968 | 0.945 | 0.965 | 0.978 |
| Dice | 0.964 | 0.960 | 0.966 | 0.974 |
Table 2.
The Comparison of segmentation results with random walks algorithm and cascaded U-net architecture.
Table 2.
The Comparison of segmentation results with random walks algorithm and cascaded U-net architecture.
| Frame from Test Dataset | Random Walks | CU-Net | The proposed method | ||
|---|---|---|---|---|---|
| Intensity | Phase | Intensity | Phase | ||
| Dice | 0.966 | 0.945 | 0.954 | 0.948 | 0.967 |
| Time(s) | 19.08 | 19.03 | 0.31 | 0.37 | 0.63 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



