
Submitted:
27 June 2024
Posted:
27 June 2024
You are already at the latest version
Abstract
From the various perspectives of Machine Learning (ML) and the multiple models used in this discipline, there is an approach aimed at training models for the Early Detection (ED) of anoma-lies. The early detection of anomalies is crucial in multiple areas of knowledge since identifying and classifying them allows for early decision-making and provides a better response to mitigate the negative effects caused by late detection in any system. This article presents a literature review to examine which machine learning models (MLM) operate with a focus on ED in a multidisci-plinary manner and specifically how these models work in the field of fraud detection. A variety of models were found, including Logistic Regression (LR), Support Vector Machines (SVM), De-cision Trees (DT), Random Forests (RF), Naive Bayesian Classifier (NB), K-Nearest Neighbors (KNN), Artificial Neural Networks (ANN), Extreme Gradient Boosting (XGB), among others. It was identified that MLMs operate as isolated models, categorized in this article as Single Base Models (SBM) and Stacking Ensemble Models (SEM). It was identified that MLMs for ED in multiple areas under SBM and SEM implementation achieved accuracies greater than 80% and 90%, respectively. n fraud detection, accuracies greater than 90% were reported by the authors. The article concludes that MLMs for ED in multiple applications, including fraud, offer a viable way to identify and classify anomalies robustly, with a high degree of accuracy and precision. MLMs for ED in fraud are useful as they can quickly process large amounts of data to detect and classify suspicious transactions or activities, helping to prevent financial losses.
Keywords:
Machine Learning Models
; Early Detection
; Data Analysis
; Fraud Detection
; Performance Metrics
; Stacking Ensemble
1. Introduction
Machine learning (ML) has become a discipline that automates repetitive and complex tasks through its algorithms, thereby increasing operational efficiency across various organizations. ML analyzes large amounts of data to identify patterns and trends, aiming to improve decision-making in different contexts [1,2,3,4,5,6,7]. This discipline of artificial intelligence trains models based on data analysis to make automatic predictions, allowing the models to deduce correct labels based on the learning acquired from historical data.
Although ML has advantages over classical methods used in multiple areas, each ML model is unique. Each model is trained with data of different characteristics that must be identified to make correct predictions with a high degree of accuracy and precision (e.g., numerical, alphanumeric, and discrete data). Additionally, ML training takes long time due to large volumes of data that the models require [3].
Another associated disadvantage is the interpretability of the data [8], which limits the understanding of the model to make high-quality predictions. There is also an ongoing need for high-quality data, which must be sufficiently reliable and that effectively allows expressing the problem statement. In addition to this, the need to have a sufficient amount of data to train the models can be costly and time-consuming to collect [9]. There is also the risk of bias. Poor data quality during the training, validation, and testing can lead the model to make inaccurate decisions [10].
In general, despite the multiple disadvantages mentioned earlier, ML continues to have advantages in automating processes, improving decision-making, and personalizing services by analyzing user preferences to enhance customer experience. ML can revolutionize businesses and society in general. Currently, ML is a trending tool that every organization must constantly monitor to remain relevant and increasingly competitive [11].
Early Detection (ED) is an important field in ML. The implementation of accurate predictive models for Early Detection (ED) improves outcomes by optimizing time and resources, enhancing problem prevention, and contributing to the improvement of policies for early decision-making [9]. ML-based Early Detection (ED) is currently actively used in socially impactful areas such as production processes, agronomy, energy efficiency, fraud detection, and medicine.
ML-based Early Detection (ED) in production processes can improve aspects such as quick intervention in automated processes, limiting negative impacts on operations, and preventing potential damages. It also allows cost savings by reducing downtime and cutting maintenance expenses. Additionally, it enables greater reliability in automated processes, ensuring consistent and accurate results, improving yields, and maximizing productivity and production [4,9].
ML-based Early Detection (ED) in agronomic processes is used to improve crop health, maximize resource management, increase yields, mitigate climate change, and promote sustainable agricultural practices. Farmers can ensure food security and environmental sustainability by proactively addressing challenges and making better decisions through the use of ML and new technologies [6,12].
In energy systems, ML-based Early Detection (ED) helps optimizing energy consumption, reducing costs, and improving sustainability in various sectors such as electric grids and microgrids. ML algorithms are used to detect faults or anomalies at an early stage, aiding in fault prevention, improving reliability, and prolonging the lifespan of critical assets, such as power transformers [13]. Additionally, ED through ML can enable the implementation of preventive and proactive maintenance strategies, leading to greater operational efficiency and minimizing downtime in industrial energy systems [3].
ML-based Early Detection (ED) in medicine is used in public health programs to reduce healthcare costs and improve procedures with the aim of achieving more satisfactory outcomes in patients [14,15,16]. ML-based Early Detection (ED) has shown promising results in the prediction and early identification of diseases such as diabetes [17,18,19,20], cardiovascular diseases [21], breast cancer [10,18,22,23,24] and dementia [25].
Currently, medical personnel can detect diseases in early stages, facilitating rapid interventions and the application of preventive measures more tailored to the symptoms of the diseases [26]. Additionally, improvements have been found in patient care, optimizing treatment plans [27] and achieving more accurate diagnoses. Continuously, ML promotes proactive healthcare management [15], which improves the sustainability of healthcare systems and contributes to health improvement initiatives.
Also, ML-based Early Detection (ED) in fraud detection is used for several reasons. It allows timely intervention, preventing further fraudulent activities and minimizing potential financial losses and damages [28]. It helps reduce negative impacts on organizations and financial systems by detecting fraudulent activities before they escalate into larger issues. Additionally, it allows for saving resources by preventing larger losses that may occur if fraud is detected at a later stage [29]. ML-based fraud ED helps maintain the integrity of data and financial records by restricting unauthorized access and manipulation of information [30]. ML-based ED provides valuable information about fraudulent patterns and trends to enhance fraud detection strategies. In general, ML-based ED allows for risk mitigation, asset protection, maintaining trust between entities, ensuring security and stability in financial organizations and government fiscal surveillance systems.
Given the importance of ML-based ED, this article aims to conduct a systematic literature review to identify the most commonly used ML models (MLMs) in ML-based ED in the aforementioned areas. As a second objective, this article aims to identify new methodologies for using these MLMs to improve classification or prediction in ED. This literature review is motivated by the exploration of MLMs currently used in ED for fraud detection. The intention of this article is to identify how ML-based ED models have impacted the field of fraud detection by analyzing their advantages and disadvantages, and to present a discussion on the benefits that the fraud domain can obtain as part of Fiscal Surveillance and Control.
This review aims to provide academics and professionals with guidance in their work, facilitating the quick identification of current algorithms and methodologies used in ML for the application of ED in the referenced areas and in the field of fraud. The main contributions of this article are as follows:
- Presentation of the most used MLMs for ED.
- Division of MLMs for ED into two main categories: Single Base Model (SBM) and Stacking Ensemble Model (SEM).
- Identification of SBM or SEM in ED for fraud.
- Discussion on how ML-based ED can improve processes in fraud.
The article is structured in the following sections: Section 2 describes the research article selection process for a systematic literature review on MLMs for ED. Section 3 gives an overview of data balancing and model validation metrics currently used in machine learning. Section 4 gives an overview of the machine learning models found and their performance in multiple applications and specifically in fraud detection. Section 5 discusses the performance of the machine learning models found for early detection in multiple areas and the importance of using these models in early fraud detection. Finally, conclusions are presented.
2. Article Selection Process
A systematic literature review is a research approach that examines information and findings regarding a research topic [31]. This approach aims to locate the largest possible number of relevant studies on the subject of study and, through referenced or proprietary methodologies, determine what can be confidently asserted from these studies [32,33]. This section provides an overview of the literature to help understand the MLMs for ED used in the present literature.
In this article, the process of searching and selecting articles consists of two stages, aiming to answer the following two questions:
- RQ1: Which MLMs are currently used in the literature for early detection in multiple areas?
- RQ2: How have these MLMs for ED been implemented in the context of fraud?
In stage 1, based on RQ1 and RQ2, Scopus was selected as the search engine, and the following keywords were used for the search equation: "machine learning model", "data analytics" or "data analysis", "early detection", and finally "fraud detection". These five keywords formed the first search equation within the time frame between 2018 and 2024. As a result of this search, a total of 55 scientific articles were obtained, included in electronic databases such as Springer Link, Elsevier, IEEE, MDPI, Taylor and Francis.
Figure 1 presents an analysis of the occurrence of words in the selected articles. The color map in Figure 1 illustrates the frequency of recurring concepts in the literature found. It is inferred, then, that models such as Logistic Regression (LR), Support Vector Machines (SVM), Decision Trees (DT), Data analytics (DA) and Random Forests (RF) are base models used in ED or early diagnosis.
Having reviewed the information from this preliminary search, in stage 2, it was identified that currently in ML, from a methodological aspect, with the aim of improving the prediction of base models, stacking ensemble has been implemented in recent years. This allowed extending the initial search equation by including the keyword "Stacking Ensemble" with a focus on ED. As a result, a total of 57 articles related to ML-based ED were obtained. Additionally, a search matrix was synthesized to identify the contribution of each article, the base MLMs (44 articles) and the ensemble MLMs (12 articles), and their application areas. Finally, the necessary information was extracted regarding applications and MLMs applied to ED in multiple areas (45 articles), particularly in fraud detection (11 articles).
3. MLM Data Balancing and Performance Metrics
In the literature review consulted, various procedures were evident for conducting proper validations of MLMs, such as data balancing and the application of performance metrics. Validating MLMs is crucial to ensure their reliability and effectiveness in decision-making. Validation allows for evaluating the predictive capacity of models, identifying potential issues like overfitting, and ensuring that the results obtained are generalizable and consistent with new data [34]. In model validation, it can be verified its performance, accuracy, and capability to handle different scenarios, which helps ensure that they are useful and reliable in real-world applications [17].
3.1. Data Balancing
Data balancing in MLMs addresses the problem of class imbalance. One class may have significantly more instances than another in a dataset. When classes are imbalanced, models tend to favor the class with more instances, which can lead to poor performance in predicting the class with fewer instances.
Using data balancing techniques in the preprocessing of information to train a ML model improves the model's ability to learn patterns from all classes equitably, resulting in more accurate, precise, and generalizable predictions. The purpose of balancing is to achieve an equilibrium where the detection of both minority and majority classes is of interest.
Data balancing can be achieved through techniques such as oversampling (duplicating instances of the minority class), undersampling (removing instances of the majority class), or more advanced methods like SMOTE (Synthetic Minority Over-sampling Technique) [35]. These techniques help improve the predictive capability of models by ensuring that all classes are treated equitably during training.
3.2. Performance Metrics
Performance metrics in ML are measures used to evaluate the performance and effectiveness of machine learning models in data prediction and classification. In the literature review consulted, metrics such as accuracy, precision, recall (sensitivity), specificity, F1-score, AU-ROC (Area under receiver operating characteristics curve), AU-PRC (Area under the precision-recall curve), MCC(Matthews correlation coefficient) and confusion matrix [34] are used. These metrics provide information about the predictive capability, accuracy, and overall effectiveness of MLMs. All the mentioned metrics are related to the confusion matrix. The confusion matrix (Figure 2) is a tool that allows visualizing the performance of a classification model by showing the number of true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN) that the model has produced on a test dataset [22]. Table 1 presents descriptions of the evaluation metrics.
The confusion matrix can also be extended to multiclass problems. It is not necessarily intended only for binary problems. In a multiclass classification context, the confusion matrix is expanded to include all classes present in the problem. Thus, its construction will have a length of N, corresponding to the number of classes.
4. Machine Learning Models for ED and Applications
According to the literature review, two methodologies for applying MLMs in multiple applications were identified. These methodologies describe the use of MLMs from the following perspectives.
Single Base Models (SBM). These base models serve as individual classifiers or regressors that make predictions based on input data. Among the most common base models are LR (Logistic Regression), SVM (Support Vector Machine), DT (Decision Tree), RF (Random Forest), NB (Naive Bayes), K-Nearest Neighbors (KNN), and Neural Networks (NN). When using a single model, the choice depends on the characteristics, distribution, and properties of the datasets [16]. SBMs are also used as a basis for ensemble methods and more complex stacking models [36]. Table 2 presents a brief description of SBMs.
Stacking Ensemble Model (SEM). They involve combining multiple base models to improve the predictive performance of SBM. These models use a two-level stacking approach; base models make predictions at the first level, and meta-learning combines these predictions at the second level [13,16]. The purpose of this ensemble methodology is to combine two or more models, each with its strengths and weaknesses, to construct a more robust model. Stacking ensemble models have proven to be promising in various applications by offering advantages such as improved accuracy, reduced overfitting, and enhanced performance compared to individual models [37]. SEM models use boosting, bagging, and stacking schemes [30]. Each SEM operates within its own domain space, showing varying levels of performance based on the aggregated selection of base models and the distribution, non-linearity, and class imbalance present in the dataset. Some of the most popular boosting algorithms are AdaBoost (Adaptive Boosting), Gradient Boosting, XGBoost, and LightGBM [13]. These algorithms have variations in how they adjust weights and combine weak models to form the final model, but they follow the general scheme of boosting. An example of bagging is RF, where multiple decision trees are trained on training datasets generated by bootstrap sampling (sampling with replacement), and predictions from individual trees are averaged to produce the final prediction.
Within the literature review, different types of SBMs and SEMs were found. Under the search parameters in the matrix of sintering literature review, for ED, different configurations of these models were obtained in areas such as Medicine (37 articles), fraud detection (11 articles), agronomy (2), energy efficiency (2 articles), industrial processes (2 articles), education (1 article), and telecommunications (1 article). Table 3 and Table 4 present the SBMs and SEMs, respectively, for multiple areas excluding articles related to fraud detection, which are analyzed later.
1Polynomial Regression; 2Gradient Boosting; 3AdaBoost; 4Gaussian naive bayes; 5Stochastic Gradient Descent; 6Gaussian process; 7Insolation Forest; 8DenseStream.
According to Table 3, the most used SBM for early detection, based on the reviewed literature, are Random Forest (RF), Support Vector Machine (SVM) and K-Nearest Neighbor (KNN). These models are applied in the medical field, achieving average performances above 80% according to the metrics reported by various authors. In other fields, RF also stands out as a frequently used model, with performance levels similarly approaching 80%.
On the other hand, in the SEMs presented in Table 4, it is identified that RF is the most commonly used base model, followed by DT, then LR, SVM, and KNN with the same frequency, followed by ANN and XGB also at the same level. NB is the least used base model for early detection in the literature studied. As the best Metalerner, LR is identified as the most used due to its simplicity in computation and inference for decision-making. It is also identified that the SEM methodology achieves performances in some cases exceeding 90%.
According to Table 4, SEM yields superior results compared with SBM. It is important to note that the SEM approaches found are implemented in the medical field, which is a critical area for decision-making, as a misdiagnosis can have severe repercussions in various health contexts. This justifies why most of the literature on SBM and SEM consulted focuses on the field of medicine, in comparison with other areas for early detection.
Hybrid models acting as MLM and SEM were also found. The selection of base, ensemble, or hybrid models will depend on the working context and the characteristics of the data.
4.1. Machine Learning Models for ED in Fraud Detection
MLMs are used in fraud detection to analyze patterns and behaviors in data in order to identify fraudulent activities. These models are important for early fraud detection (ED) as they can quickly process large amounts of data to detect and classify suspicious transactions or activities, helping to prevent financial losses.
ML-based models for ED offer several advantages over traditional fraud detection methods. MLMs have the ability to adapt and improve over time as more data is analyzed, thereby increasing their accuracy in fraud detection [64]. They can also analyze complex and diverse data sources, allowing them to detect sophisticated and evolving fraud schemes that may go unnoticed by traditional rule-based systems or human intervention [65]. Table 5 presents the MLMs found in the literature for ED for fraud detection.
Table 5 presents the MLMs found in the literature consulted for ED in fraud detection. Only the use of SBM was found for fraud detection. RF persists as the most frequently used model, followed by KNN. LR, SVM and XGB are used at the same level for fraud detection. RF continues to be the most used and reliable model for fraud detection according to Table 5, with two authors reporting better performance with this model. Although RF is based on bagging and XGB utilizes boosting, they are considered base models grounded in DT. Table 5 reflects that in most cases, each MLM achieved a high number of accurate fraud detections in real fraud cases, with authors reporting accuracy metrics exceeding 90%.
5. Discussion
ML algorithms are increasingly used in various fields due to their ability to adapt to new data and identify hidden patterns, enabling decision-making with a higher degree of reliability. Although most models found in the literature work as standalone base models, the use and experimentation with ensemble methodologies to improve the performance of base models is becoming increasingly common.
The information in Table 3 and Table 4 shows that base models are used diversely across multiple areas, unlike SEM. Specifically, Table 4 reports that SEMs work exclusively in the medical field. This is justified because SEMs, by gathering the various decisions from SBM, allow for a more robust acquisition of data variability and a better fit to the data. Consequently, the identification of the problem is more accurate and precise, whether in the context of regression or classification. The unification of these decisions constitutes a more solid knowledge base that serves as input to another model for final decision-making. This is particularly important in the medical field, where decision-making is critical for diagnosing a person, requiring a minimal margin of error.
Within the models in Table 5 for early fraud detection, it was found that the models found in the literature are SBM. Although the authors do not consider SEM models for early fraud detection, the SBM used achieved significant performance with good adaptability to emerging patterns, good training times, and good adaptation to data for fraud detection [1,65,66,68,69,70].
An important aspect to achieve satisfactory results in the training, validation, and testing of SEM and SBM in any context will be the associated data engineering analysis [71]. This refers to the effective selection of the data characteristics that would be supplied as information to the SBM. Additionally, analysis of data balancing techniques to balance major or minor classes [64], such as the SMOTE method [69].
This aspect for SEMs is not considered critical since the patterns of training, validation, and testing are responses from the SBM. However, in this case, cross-validation processes must be ensured to avoid overfitting issues, model selection bias, and errors in variance estimation. The use of SEM strictly must consider cross-validation methods such as K-Fold, Hold-Out, Leave-One-Out, Leave-P-Out, Monte Carlo, Stratified K-fold, and Repeated K-fold, Time Series Cross-Validation, and Nested Cross-Validation [25,52]. These methods provide a more reliable estimation of model performance on unseen data, reducing the risk of overfitting and enabling better hyperparameter tuning and model evaluation.
The use of MLMs in ED for fraud detection, whether as SBM or SEM, will continue to be the subject of study in areas such as corporate security, surveillance, and fiscal and financial control, due to its ability to process large amounts of data rapidly and adapt to new information over time.
A determining factor in MLMs training in fraud ED is the limitations in data collection for model training. Data collection for fraud ED is constrained by the availability of labeled data due to the lack of digitalization of this information. Without digitized data, the process of consolidating a labeled historical dataset is slow and costly, which restricts the applicability of MLMs in fraud ED, especially in cases such as tax fraud detection [29]. The lack of digitized data can hinder the effectiveness and accuracy of fraud ED processes, as manual data handling is time-consuming and error-prone. Moreover, the challenge of labeling transactions as fraudulent or non-fraudulent can be complex due to the difficulty in definitively asserting the fraudulent nature of transactions, leading to careful use of labeled examples and the need for verification by expert personnel to identify such specific fraud, which is also subject to ethical considerations [64].
It is important that in the field of fraud detection in ED, strategies for data balancing will be considered based on available information to reduce intrinsic bias that may include human manipulation or unwanted value judgments when labeling data.
Implementing SEM as MLMs for fraud ED offer several advantages over base models and traditional methods. Some of the advantages that this type of models can offer include:
- Improved prediction performance by maximizing fraud detection through effective identification of patterns and anomalies in the data, leading to better prediction performance. Using features based on SBM responses allows the analysis of behaviors that may not have been explored in traditional methods, thereby enhancing a more comprehensive analysis of fraud indicators. Additionally, the adaptability and robustness of SEM enable it to adjust to the strengths and weaknesses of multiple baseline models, improving overall detection performance and robustness in identifying fraudulent activities [16].
- Combining the predictive power of various models enables the identification of fraudulent behaviors at an early stage with greater accuracy, which allows for timely intervention and prevention of fraudulent activities [20].
- SEM provides a more reliable balance between precision and interpretability, making them operationally viable for fraud detection tasks, due to the adoption of features and operating dynamics of SBMs.
6. Conclusions
The literature review under the search equation allowed for the consolidation of two ways of using MLMs for ED: Single-base models (SBM) and Stacking Ensemble Model (SEM). The implementation of SBM was identified in different areas, whereas SEM models were implemented only in the field of medicine due to the high precision required in this area.
The implementation of SEM can favor and strengthen conventional fraud detection efficiently, allowing to improve prediction performance by leveraging the integration of features from different base models. SEM enables better adaptability to data and robust decision-making. Additionally, it provides more accurate early detections in scenarios with high data variability, reduces issues such as overfitting, and allowing handling biases in the data.
Both SBM and SEM have proven to be efficient in early detection across multiple areas, particularly in fraud, with accuracies in some cases exceeding 90%. For the use of MLMs, it will always be relevant to perform data engineering processes to select appropriate features for model training, and to pay special attention to data balancing to achieve adequate results in predictions.
From the analyzed information, it can be inferred that a challenging task in the field of fraud detection is the consolidation of reliable databases for training MLMs for ED, as well as the adoption of new models and cutting-edge methodologies such as Deep Learning.
Future research lines may be oriented to develop further advancements in techniques and technologies like Deep Learning Models as SBM and SEM to enhance the accuracy, efficiency, and scalability of fraud detection systems. Other potential research lines include: Enhanced Data Enrichment (the quality and quantity of data), Advanced Machine Learning Algorithms in fraud detection (Convolutional Neural Networks and ANN- Long Short-Term Memory), Real-time Fraud and Blockchain Technology for secure and transparent transaction verification and enhancing fraud detection capabilities through immutable and decentralized data storage.
Author Contributions
For research articles with several authors, a short paragraph specifying their individual contribu-tions must be provided. The following statements should be used “Conceptualization, O.Z.C., J.A.Z.C., M.D.A.S. and J.A.R.C..; methodology, O.Z.C., J.A.Z.C. and M.D.A.S; validation, J.A.Z.C, M.D.A.S and J.A.R.C.; formal analysis, O.Z.C., J.A.Z.C. and M.D.A.S.; investigation, O.Z.C., J.A.Z.C., M.D.A.S. and J.A.R.C; resources, M.D.A.S. and J.A.R.C.; writing—original draft prepa-ration, O.Z.C.; writing—review and editing, J.A.Z.C., M.D.A.S. and J.A.R.C.; supervision, J.A.Z.C., M.D.A.S. and J.A.R.C. All authors have read and agreed to the published version of the manu-script.”
Funding
This paper was funded by the project titled “Diseño e implementación de soluciones integrales para modernizar la infraestructura tecnológica que permita fortalecer los sistemas de información y analítica de datos de la Contraloria General de la República, with code H: 59943 of the Universidad Nacional de Colombia.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Saheed, Y.K.; Baba, U.A.; Raji, M.A. Big Data Analytics for Credit Card Fraud Detection Using Supervised Machine Learning Models. In Big Data Analytics in the Insurance Market; 2022; pp. 31–56 ISBN 978-1-80262-637-7.
- Prakash, S.; Mahapatra, S.; Nayak, M. Data Analysis in Clinical Decision Making—Prediction of Heart Attack. Smart Innov. Syst. Technol. 2023, 317, 339–347. [Google Scholar] [CrossRef]
- Darville, J.; Yavuz, A.; Runsewe, T.; Celik, N. Effective Sampling for Drift Mitigation in Machine Learning Using Scenario Selection: A Microgrid Case Study. Appl. Energy 2023, 341. [Google Scholar] [CrossRef]
- Baghbanpourasl, A.; Kirchberger, D.; Eitzinger, C. Failure Prediction through a Model-Driven Machine Learning Method.; 2021; pp. 527–531.
- Mollaoglu, A.; Baltaoglu, G.; Cakrr, E.; Aktas, M.S. Fraud Detection on Streaming Customer Behavior Data with Unsupervised Learning Methods.; 2021.
- Ollagnier, C.; Kasper, C.; Wallenbeck, A.; Keeling, L.; Bee, G.; Bigdeli, S.A. Machine Learning Algorithms Can Predict Tail Biting Outbreaks in Pigs Using Feeding Behaviour Records. PLoS ONE 2023, 18. [Google Scholar] [CrossRef] [PubMed]
- Ojajuni, O.; Ayeni, F.; Akodu, O.; Ekanoye, F.; Adewole, S.; Ayo, T.; Misra, S.; Mbarika, V. Predicting Student Academic Performance Using Machine Learning. Lect. Notes Comput. Sci. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinforma. 2021, 12957 LNCS, 481–491. [Google Scholar] [CrossRef]
- Yi, X.; Liu, Y.; Zhou, B.; Xiang, W.; Deng, A.; Fu, Y.; Zhao, Y.; Ouyang, Q.; Liu, Y.; Sun, Z.; et al. Incorporating SULF1 Polymorphisms in a Pretreatment CT-Based Radiomic Model for Predicting Platinum Resistance in Ovarian Cancer Treatment. Biomed. Pharmacother. 2021, 133. [Google Scholar] [CrossRef]
- Heistracher, C.; Casas, P.; Stricker, S.; Weissenfeld, A.; Schall, D.; Kemnitz, J. Should I Sample It or Not? Improving Quality Assurance Efficiency Through Smart Active Sampling.; 2023.
- Li, M.; Nanda, G.; Chhajedss, S.S.; Sundararajan, R. Machine Learning-Based Decision Support System for Early Detection of Breast Cancer. Indian J. Pharm. Educ. Res. 2020, 54, S705–S715. [Google Scholar] [CrossRef]
- Zaidi, M.A. Conceptual Modeling Interacts with Machine Learning – A Systematic Literature Review. Lect. Notes Comput. Sci. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinforma. 2021, 12957 LNCS, 522–532. [Google Scholar] [CrossRef]
- Carter, S.; van Rees, C.B.; Hand, B.K.; Muhlfeld, C.C.; Luikart, G.; Kimball, J.S. Testing a Generalizable Machine Learning Workflow for Aquatic Invasive Species on Rainbow Trout (Oncorhynchus Mykiss) in Northwest Montana. Front. Big Data 2021, 4. [Google Scholar] [CrossRef] [PubMed]
- Santamaria-Bonfil, G.; Arroyo-Figueroa, G.; Zuniga-Garcia, M.A.; Azcarraga Ramos, C.G.; Bassam, A. Power Transformer Fault Detection: A Comparison of Standard Machine Learning and autoML Approaches. Energies 2024, 17, 77. [Google Scholar] [CrossRef]
- Ghomrawi, H.M.K.; O’Brien, M.K.; Carter, M.; Macaluso, R.; Khazanchi, R.; Fanton, M.; DeBoer, C.; Linton, S.C.; Zeineddin, S.; Pitt, J.B.; et al. Applying Machine Learning to Consumer Wearable Data for the Early Detection of Complications after Pediatric Appendectomy. Npj Digit. Med. 2023, 6. [Google Scholar] [CrossRef]
- Damre, S.S.; Shendkar, B.D.; Kulkarni, N.; Chandre, P.R.; Deshmukh, S. Smart Healthcare Wearable Device for Early Disease Detection Using Machine Learning. Int. J. Intell. Syst. Appl. Eng. 2024, 12, 158–166. [Google Scholar]
- Ghasemieh, A.; Lloyed, A.; Bahrami, P.; Vajar, P.; Kashef, R. A Novel Machine Learning Model with Stacking Ensemble Learner for Predicting Emergency Readmission of Heart-Disease Patients. Decis. Anal. J. 2023, 7. [Google Scholar] [CrossRef]
- Iparraguirre-Villanueva, O.; Espinola-Linares, K.; Flores Castañeda, R.O.; Cabanillas-Carbonell, M. Application of Machine Learning Models for Early Detection and Accurate Classification of Type 2 Diabetes. Diagnostics 2023, 13. [Google Scholar] [CrossRef] [PubMed]
- Srivastava, A.; Samanta, S.; Mishra, S.; Alkhayyat, A.; Gupta, D.; Sharma, V. Medi-Assist: A Decision Tree Based Chronic Diseases Detection Model.; 2023.
- Anbananthen, K.S.M.; Busst, M.B.M.A.; Kannan, R.; Kannan, S. A Comparative Performance Analysis of Hybrid and Classical Machine Learning Method in Predicting Diabetes. Emerg. Sci. J. 2023, 7, 102–115. [Google Scholar] [CrossRef]
- Liu, J.; Fan, L.; Jia, Q.; Wen, L.; Shi, C. Early Diabetes Prediction Based on Stacking Ensemble Learning Model.; 2021; pp. 2687–2692.
- Tripathi, P.; Vishwakarma, K.; Sahu, S.; Vishwakarma, A.; Kori, D. Enhancing Cardiovascular Health: A Machine Learning Approach to Predicting Heart Disease.; 2023; pp. 238–242.
- Dhivya, P.; Bazilabanu, A.; Ponniah, T. Machine Learning Model for Breast Cancer Data Analysis Using Triplet Feature Selection Algorithm. IETE J. Res. 2023, 69, 1789–1799. [Google Scholar] [CrossRef]
- Kwon, H.; Park, J.; Lee, Y. Stacking Ensemble Technique for Classifying Breast Cancer. Healthc. Inform. Res. 2019, 25, 283–288. [Google Scholar] [CrossRef] [PubMed]
- Gupta, R.; Bhargava, R.; Jayabalan, M. Diagnosis of Breast Cancer on Imbalanced Dataset Using Various Sampling Techniques and Machine Learning Models.; 2021; Vol. 2021-December, pp. 162–167.
- Broman, S.; O’Hara, E.; Ali, M.L. A Machine Learning Approach for the Early Detection of Dementia.; 2022.
- Laganaro, F.; Mazza, M.; Marano, G.; Piuzzi, E.; Pallotti, A. Classification-Based Screening of Depressive Disorder Patients Through Graph, Handwriting and Voice Signals.; 2023; pp. 6–10.
- Chauhan, R.; Goel, A.; Alankar, B.; Kaur, H. Predictive Modeling and Web-Based Tool for Cervical Cancer Risk Assessment: A Comparative Study of Machine Learning Models. MethodsX 2024, 12. [Google Scholar] [CrossRef] [PubMed]
- Pachón Rodríguez, W.A.; Melo Martínez, C.E. Fraud Detection in Utilities Using Data Analytics and Geospatial Analysis. Int. J. Saf. Secur. Eng. 2023, 13, 457–467. [Google Scholar] [CrossRef]
- De Roux, D.; Pérez, B.; Moreno, A.; Del Pilar Villamil, M.; Figueroa, C. Tax Fraud Detection for Under-Reporting Declarations Using an Unsupervised Machine Learning Approach.; 2018; pp. 215–222.
- Rahul, K.; Seth, N.; Dinesh Kumar, U. Spotting Earnings Manipulation: Using Machine Learning for Financial Fraud Detection. Lect. Notes Comput. Sci. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinforma. 2018, 11311 LNAI, 343–356. [Google Scholar] [CrossRef]
- Deepa, N.; Pham, Q.-V.; Nguyen, D.C.; Bhattacharya, S.; Prabadevi, B.; Gadekallu, T.R.; Maddikunta, P.K.R.; Fang, F.; Pathirana, P.N. A Survey on Blockchain for Big Data: Approaches, Opportunities, and Future Directions. Future Gener. Comput. Syst. 2022, 131, 209–226. [Google Scholar] [CrossRef]
- Saggi, M.K.; Jain, S. A Survey towards an Integration of Big Data Analytics to Big Insights for Value-Creation. Inf. Process. Manag. 2018, 54, 758–790. [Google Scholar] [CrossRef]
- Naghib, A.; Jafari Navimipour, N.; Hosseinzadeh, M.; Sharifi, A. A Comprehensive and Systematic Literature Review on the Big Data Management Techniques in the Internet of Things. Wirel. Netw. 2023, 29, 1085–1144. [Google Scholar] [CrossRef]
- Santana-Mancilla, P.C.; Castrejón-Mejía, O.E.; Fajardo-Flores, S.B.; Anido-Rifón, L.E. Predicting Abnormal Respiratory Patterns in Older Adults Using Supervised Machine Learning on Internet of Medical Things Respiratory Frequency Data. Information 2023, 14, 625. [Google Scholar] [CrossRef]
- Ebrahimi, A.; Wiil, U.K.; Baskaran, R.; Peimankar, A.; Andersen, K.; Nielsen, A.S. AUD-DSS: A Decision Support System for Early Detection of Patients with Alcohol Use Disorder. BMC Bioinformatics 2023, 24. [Google Scholar] [CrossRef] [PubMed]
- Vijayakumar, J.; Kumar, H.S.; Kalyanasundaram, P.; Markkandeyan, S.; Sengottaiyan, N. An Intelligent Stacking Ensemble-Based Machine Learning Model for Heart Abnormality.; 2022.
- Appiahene, P.; Dogbe, S.S.D.; Kobina, E.E.Y.; Dartey, P.S.; Afrifa, S.; Donkoh, E.T.; Asare, J.W. Application of Ensemble Models Approach in Anemia Detection Using Images of the Palpable Palm. Med. Nov. Technol. Devices 2023, 20. [Google Scholar] [CrossRef]
- Tolles, J.; Meurer, W.J. Logistic Regression: Relating Patient Characteristics to Outcomes. JAMA - J. Am. Med. Assoc. 2016, 316, 533–534. [Google Scholar] [CrossRef]
- Kazemi, A.; Boostani, R.; Odeh, M.; AL-Mousa, M.R. Two-Layer SVM, Towards Deep Statistical Learning. In Proceedings of the 2022 International Engineering Conference on Electrical, Energy, and Artificial Intelligence (EICEEAI); November 2022; pp. 1–6. [Google Scholar]
- Rahmatillah, I.; Astuty, E.; Sudirman, I.D. An Improved Decision Tree Model for Forecasting Consumer Decision in a Medium Groceries Store. In Proceedings of the 2023 IEEE 17th International Conference on Industrial and Information Systems (ICIIS); IEEE: Peradeniya, Sri Lanka, August 25, 2023; pp. 245–250. [Google Scholar]
- Shen, T.; Mishra, C.S.; Sampson, J.; Kandemir, M.T.; Narayanan, V. An Efficient Edge–Cloud Partitioning of Random Forests for Distributed Sensor Networks. IEEE Embed. Syst. Lett. 2024, 16, 21–24. [Google Scholar] [CrossRef]
- Vijay, V.; Verma, P. Variants of Naïve Bayes Algorithm for Hate Speech Detection in Text Documents. In Proceedings of the 2023 International Conference on Artificial Intelligence and Smart Communication (AISC); IEEE: Greater Noida, India, January 27, 2023; pp. 18–21. [Google Scholar]
- Kaur, M.; Thacker, C.; Goswami, L.; Tr, T.; Abdulrahman, I.S.; Raj, A.S. Alzheimer’s Disease Detection Using Weighted KNN Classifier in Comparison with Medium KNN Classifier with Improved Accuracy. In Proceedings of the 2023 3rd International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE); IEEE: Greater Noida, India, May 12, 2023; pp. 715–718. [Google Scholar]
- Shivaji Rao, S.S.; Gangadhara Rao, K. Diagnosis of Liver Disease Using ANN and ML Algorithms with Hyperparameter Tuning. In Proceedings of the 2024 2nd International Conference on Intelligent Data Communication Technologies and Internet of Things (IDCIoT); IEEE: Bengaluru, India, January 4, 2024; pp. 629–634. [Google Scholar]
- Cengiz, K.; Lipsa, S.; Dash, R.K.; Ivković, N.; Konecki, M. A Novel Intrusion Detection System Based on Artificial Neural Network and Genetic Algorithm With a New Dimensionality Reduction Technique for UAV Communication. IEEE Access 2024, 12, 4925–4937. [Google Scholar] [CrossRef]
- Raj, S.P.; Sudha, I. A Novel Logistic Regression in Coronary Artery Disease Prediction and Comparison of XGBoost Classifier for Improved Accuracy. In Proceedings of the 2023 Intelligent Computing and Control for Engineering and Business Systems (ICCEBS); IEEE: Chennai, India, December 14, 2023; pp. 1–4. [Google Scholar]
- Garg, K.; Gill, K.S.; Malhotra, S.; Devliyal, S.; Sunil, G. Implementing the XGBOOST Classifier for Bankruptcy Detection and Smote Analysis for Balancing Its Data. In Proceedings of the 2024 2nd International Conference on Computer, Communication and Control (IC4); IEEE: Indore, India, February 8 2024; pp. 1–5. [Google Scholar]
- Varma, B.S.S.; Kalyani, G.; Asish, K.; Bai, M.I. Early Detection of Alzheimer’s Disease Using SVM, Random Forest & FNN Algorithms.; 2023.
- Selvi, S.S.; Barkur, P.; Agarwal, N.; Kumar, A.; Mishra, Y. Time Series Based Models for Corona Data Analytics.; 2022.
- Kim, M.; Kim, J.; Qu, J.; Huang, H.; Long, Q.; Sohn, K.-A.; Kim, D.; Shen, L. Interpretable Temporal Graph Neural Network for Prognostic Prediction of Alzheimer’s Disease Using Longitudinal Neuroimaging Data.; 2021; pp. 1381–1384.
- Chen, R.; Stewart, W.F.; Sun, J.; Ng, K.; Yan, X. Recurrent Neural Networks for Early Detection of Heart Failure from Longitudinal Electronic Health Record Data: Implications for Temporal Modeling with Respect to Time before Diagnosis, Data Density, Data Quantity, and Data Type. Circ. Cardiovasc. Qual. Outcomes 2019, 12. [Google Scholar] [CrossRef]
- Kaliappan, J.; Bagepalli, A.R.; Almal, S.; Mishra, R.; Hu, Y.-C.; Srinivasan, K. Impact of Cross-Validation on Machine Learning Models for Early Detection of Intrauterine Fetal Demise. Diagnostics 2023, 13. [Google Scholar] [CrossRef]
- Singh, L.K. ; Pooja; Garg, H. ; Khanna, M. An IoT Based Predictive Modeling for Glaucoma Detection in Optical Coherence Tomography Images Using Hybrid Genetic Algorithm. Multimed. Tools Appl. 2022, 81, 37203–37242. [Google Scholar] [CrossRef]
- Di Martino, F.; Delmastro, F.; Dolciotti, C. Malnutrition Risk Assessment in Frail Older Adults Using M-Health and Machine Learning.; 2021.
- Nasim, S.; Almutairi, M.S.; Munir, K.; Raza, A.; Younas, F. A Novel Approach for Polycystic Ovary Syndrome Prediction Using Machine Learning in Bioinformatics. IEEE Access 2022, 10, 97610–97624. [Google Scholar] [CrossRef]
- Ain Nazir, N.U.; Shaukat, M.H.; Luo, R.; Abbas, S.R. Novel Breath Biomarkers Identification for Early Detection of Hepatocellular Carcinoma and Cirrhosis Using ML Tools and GCMS. PLoS ONE 2023, 18. [Google Scholar] [CrossRef] [PubMed]
- Oladimeji, O.O.; Oladimeji, A.; Olayanju, O. Machine Learning Models for Diagnostic Classification of Hepatitis C Tests. Front. Health Inform. 2021, 10. [Google Scholar] [CrossRef]
- Lambay, M.A.; Mohideen, S.P. Applying Data Science Approach to Predicting Diseases and Recommending Drugs in Healthcare Using Machine Learning Models – A Cardio Disease Case Study. Multimed. Tools Appl. 2024. [CrossRef]
- Chen, Y.-M.; Chen, P.-C.; Lin, W.-C.; Hung, K.-C.; Chen, Y.-C.B.; Hung, C.-F.; Wang, L.-J.; Wu, C.-N.; Hsu, C.-W.; Kao, H.-Y. Predicting New-Onset Post-Stroke Depression from Real-World Data Using Machine Learning Algorithm. Front. Psychiatry 2023, 14. [Google Scholar] [CrossRef] [PubMed]
- Mathis, M.R.; Engoren, M.C.; Joo, H.; Maile, M.D.; Aaronson, K.D.; Burns, M.L.; Sjoding, M.W.; Douville, N.J.; Janda, A.M.; Hu, Y.; et al. Early Detection of Heart Failure With Reduced Ejection Fraction Using Perioperative Data Among Noncardiac Surgical Patients: A Machine-Learning Approach. Anesth. Analg. 2020, 130, 1188–1200. [Google Scholar] [CrossRef] [PubMed]
- Kumar, R.; Maheshwari, S.; Sharma, A.; Linda, S.; Kumar, S.; Chatterjee, I. Ensemble Learning-Based Early Detection of Influenza Disease. Multimed. Tools Appl. 2024, 83, 5723–5743. [Google Scholar] [CrossRef] [PubMed]
- Islam, J.; Zhang, Y. Brain MRI Analysis for Alzheimer’s Disease Diagnosis Using an Ensemble System of Deep Convolutional Neural Networks. Brain Inform. 2018, 5. [Google Scholar] [CrossRef]
- Gupta, R.; Krishna, T.A.; Adeeb, M. Cough Sound Based COVID-19 Detection with Stacked Ensemble Model.; 2022; pp. 1391–1395.
- Nesvijevskaia, A.; Ouillade, S.; Guilmin, P.; Zucker, J.-D. The Accuracy versus Interpretability Trade-off in Fraud Detection Model. Data Policy 2021, 3. [Google Scholar] [CrossRef]
- Tadesse, T. Combining Control Rules, Machine Learning Models, and Community Detection Algorithms for Effective Fraud Detection.; 2022; pp. 42–46.
- Hao, Y.; Qiu, F. Research on the Application of DM Technology with RF in Enterprise Financial Audit. Mob. Inf. Syst. 2022, 2022, e4051469. [Google Scholar] [CrossRef]
- Agrawal, N.; Panigrahi, S. A Comparative Analysis of Fraud Detection in Healthcare Using Data Balancing & Machine Learning Techniques.; 2023.
- Aggarwal, R.; Sarangi, P.K.; Sahoo, A.K. Credit Card Fraud Detection: Analyzing the Performance of Four Machine Learning Models.; 2023; pp. 650–654.
- El Barakaz, F.; Boutkhoum, O.; Hanine, M.; El Moutaouakkil, A.; Rustam, F.; Din, S.; Ashraf, I. Optimization of Imbalanced and Multidimensional Learning Under Bayes Minimum Risk and Savings Measure. Big Data 2022, 10, 425–439. [Google Scholar] [CrossRef] [PubMed]
- Soleh, M.; Djuwitaningrum, E.R.; Ramli, M.; Indriasari, M. Feature Engineering Strategies Based on a One-Point Crossover for Fraud Detection on Big Data Analytics.; 2020; Vol. 1566.
- Kumari, P.; Mittal, S. Fraud Detection System for Financial System Using Machine Learning Techniques: A Review.; 2024.
Figure 1.
Bibliometric analysis.
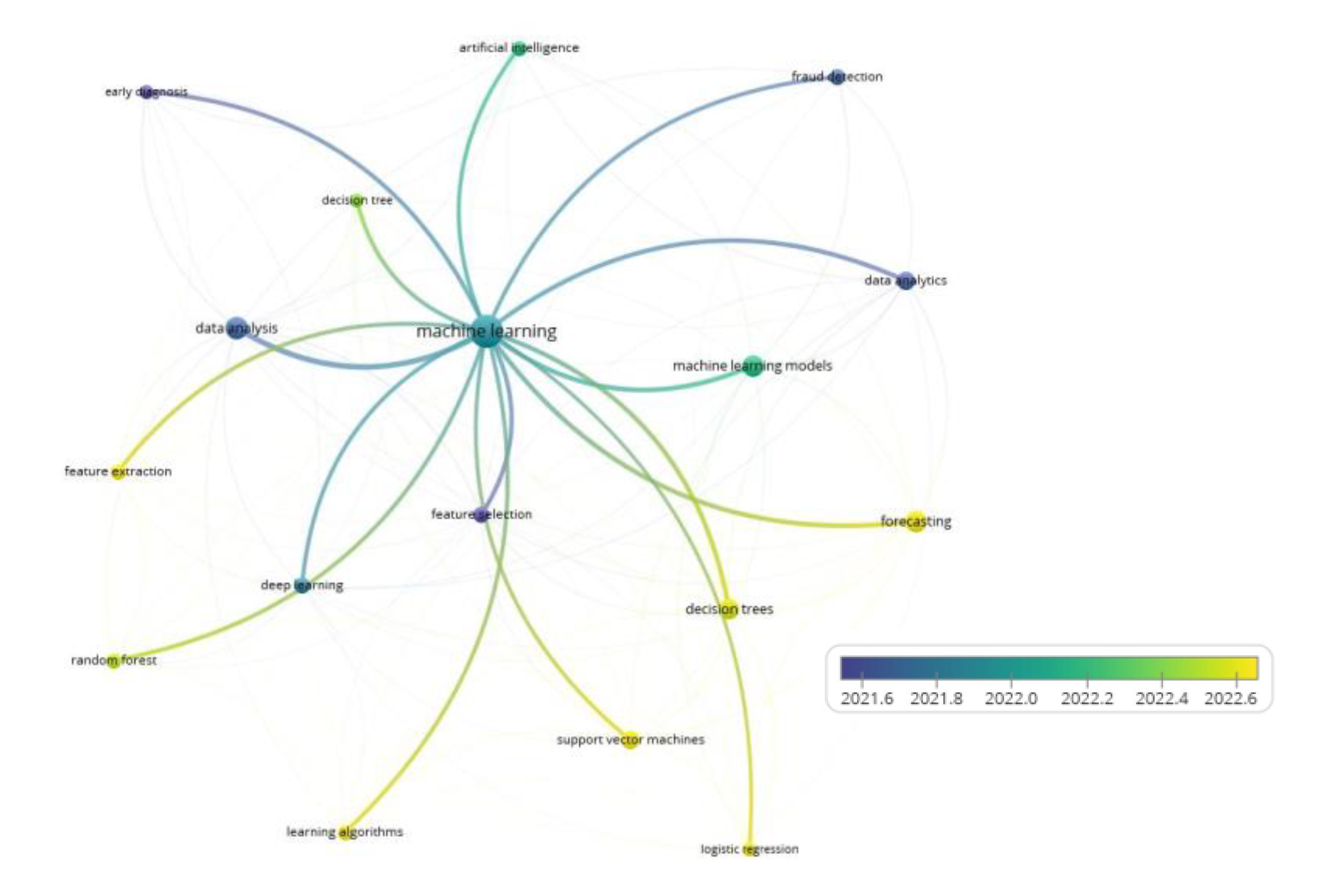
Figure 2.
Confusion matrix for a binary problem.


Table 1.
Descriptions of the evaluation metrics.
| Metric | Description | Formulation |
|---|---|---|
| Accuracy | Proportion of correct predictions out of the total predictions made by the model. | |
| Precision | Proportion of true positives (TP) over the sum of true positives and false positives (FP). | |
| Recall (Sensitivity) | Proportion of true positives to the sum of true positives and false negatives (FN). | |
| Specificity | Proportion of true negatives (TN) over the sum of true negatives and false positives (FP). | |
| F1-Score | It is the harmonic mean of precision and recall. | |
| AU-ROC | ROC chart represents the true positive rate (TPR) versus the false positive rate (FPR) at various thresholds. A higher AU-ROC indicates better model performance. | (TPR) Vs (FPR) |
| AU-PRC | PRC chart shows the relationship between precision (P) and recall (R) for different classification thresholds of the model. A higher AU-PRC indicates better model performance. | (P) Vs (R) |
| MCC | Correlation between true classes and predicted labels. |
Table 2.
Description of SBM and XGBoost of SEM
| Model | Description |
|---|---|
| LR[38] | A statistical model used to analyze the relationship between a dependent variable (binary outcome) and one or more independent variables. It is commonly used for binary classification tasks where the outcome variable is categorical with two possible outcomes. Logistic regression estimates the probability that a given input belongs to a specific category by fitting the data to a logistic function, which transforms the outcome into an interval between 0 and 1. |
| SVM[39] | A supervised machine learning algorithm used for classification and regression tasks. SVM works by finding the optimal hyperplane that best separates data points into different classes in a high-dimensional space. Its goal is to maximize the margin between the classes, making it effective for both linear and non-linear classification problems. SVM can handle high-dimensional data and is known for its ability to generalize well to unseen new data. |
| DT[40] | A machine learning algorithm used for classification and regression tasks. It is a tree-shaped model where internal nodes represent features, branches represent decisions based on those features, and leaf nodes represent the outcome or decision. The algorithm recursively splits the data based on the most significant feature at each node, aiming to create homogeneous subsets. Decision trees are easy to interpret and visualize, making them valuable for understanding the decision-making process in a model. It can handle both numerical and categorical data, making them versatile for various types of datasets. |
| RF[41] | A machine learning algorithm composed of multiple decision trees. Each tree is built using bootstrapping and random feature selection to create an ensemble of uncorrelated trees, resulting in more accurate predictions than individual trees. The algorithm leverages the concept of collective knowledge, where the forest of decision trees works together to make predictions, and the final prediction is based on the majority vote of the trees. |
| NB[42] | A probabilistic classifier based on the application of Bayes' theorem. It assumes that the presence of a particular feature in a class is not related to the presence of any other feature. Despite their simplicity, Naive Bayes classifiers are known for their efficiency and effectiveness in various classification tasks, especially in text classification and spam filtering. |
| KNN[43] | A machine learning algorithm used for classification and regression tasks. In KNN, the class or value of a data point is determined by the majority class or the mean value of its nearest neighbors in the feature space. The algorithm calculates the distance between data points and classifies them based on the majority class of the nearest k data points. |
| ANN[44,45] | A computational model inspired by the structure and functioning of the neural networks in the human brain. ANNs consist of interconnected nodes, known as artificial neurons, that process information and learn patterns from data. These networks are used in machine learning and deep learning to solve complex problems such as pattern recognition, classification, and regression, among others. |
| XGBoost[46,47] | A model that uses gradient boosting to optimize the loss function and handle complex patterns in data. XGBoost is widely used for classification, regression, and ranking tasks due to its speed, accuracy, and ability to handle large datasets efficiently. It uses decision trees as base models and trains them sequentially. XGBoost in some cases is considered a base model grounded in DT. |
Table 3.
Multidisciplinary MLM-SBM for early detection
| Ref. | Application | *: Best Model - +: Other Models | Evaluation Metric | Area | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LR | SVM | DT | RF | NB | KNN | ANN | XGB | + | ||||
| [48] | Alzheimer’s disease Detection | x | x | *x | ACC:88% | Medicine | ||||||
| [49] | Forecasting coronavirus | x | x | *x | 1PR | RMSE:78 | ||||||
| [50] | Prognostic prediction of Alzheimer's disease | x | x | *x | ACC:53.5% | |||||||
| [51] | Predict the early onset of heart failure | x | x | *x | AUC:77% | |||||||
| [18] | breast cancer, heart disease, and diabetes detection | x | x | *x | x | ACC > 90% | ||||||
| [52] | Intrauterine Fetal Demise detection | x | x | x | x | x | x | *2GB | ACC:99% | |||
| [34] | Predicting Abnormal Respiratory Patterns in Older Adults | x | x | *2GB | ACC:100% | |||||||
| [17] | Detection and Accurate Classification of Type 2 Diabetes | x | x | x | x | *x | ACC:79.6% | |||||
| [26] | Classification-based screening of Depressive Disorder patients through graph, handwriting and voice signals | x | *x | ACC:78.13% | ||||||||
| [53] | Glaucoma recognition | x | x | *x | x | ACC:99% | ||||||
| [22] | Early detection of breast cancer | *x | x | x | x | x | x | ACC:95.4% | ||||
| [54] | Malnutrition Risk Assessment in Frail Older Adults | *x | x | x | x | 3AB | ACC > 90% | |||||
| [55] | Polycystic Ovary Syndrome Prediction | x | x | x | x | x | *4GNB,2,5 | ACC:100% | ||||
| [25] | Early Detection of Dementia | x | *x | x | x | ACC:100% | ||||||
| [14] | early detection of complications after pediatric appendectomy | x | x | *x | x | x | x | 2,3,5 | AUCROC:80% | |||
| [56] | Early detection of hepatocellular carcinoma and cirrhosis | *x | ACC:80% | |||||||||
| [21] | Predicting Heart Disease | x | x | *x | x | ACC:94.15% | ||||||
| [57] | diagnostic classification of hepatitis C tests | x | x | *x | x | x | ACC:98.9% | |||||
| [58] | Prediction of diseases and recommending drugs in healthcare | x | x | *x | x | 5,2 | ACC:96.26% | |||||
| [2] | Prediction of Heart Attack | *x | x | x | ACC:85% | |||||||
| [8] | Prediction of platinum resistance in ovarian cancer treatment | *x | x | AUC>96% | ||||||||
| [59] | Prediction of post-stroke depression | *x | ACC>81% | |||||||||
| [60] | Early Detection of Heart Failure | x | x | *x | ACC:80.82% | |||||||
| [27] | Early detection of cervical cancer | x | x | x | x | *x | 3 | AUCROC:91.2% | ||||
| [3] | Prediction of stochastic Climate factors | *x | RMSE:7.029 | Energy | ||||||||
| [13] | Power Transformer Fault Detection | x | x | x | x | x | x | *6GP | ACC>80% | |||
| [6] | Tail biting outbreaks predictions in pigs using feeding behaviors records | x | x | *x | x | ACC:96% | Agronomy | |||||
| [12] | Prediction of biological species invasion | x | x | *x | x | x | 2 | ACC:89% | ||||
| [9] | Production line sampling prediction | *x | ACC:84% | Industry | ||||||||
| [4] | Predict failures in the production line. | *7IF | TPR:66.7% | |||||||||
| [5] | Fraud Detection on Streaming Customer Behavior Data | *8DS | ACC:99% | Telecom | ||||||||
| [7] | Predict student academic performance | x | x | x | x | *x | 3,5 | ACC:97.12% | academy | |||
| FREQUENCY MODEL | 13 | 18 | 14 | 19 | 8 | 18 | 11 | 9 | ||||
| FREQUENCY AS BEST MODEL | 2 | 2 | 1 | 8 | 1 | 4 | 4 | 4 | ||||
Table 4.
Multidisciplinary MLM-SEM for Early Detection
| Ref. | Application | Base Learners | Best Meta Learner | Evaluation Metric | Area | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LR | SVM | DT | RF | NB | KNN | ANN | XGB | + | |||||
| [61] | Detection of infuenza disease | x | x | x | x | x | 9 | SVM | ACC:84.7% | Medicine | |||
| [10] | Early Detection of Breast Cancer | x | x | x | x | 10 | 11DSS | ACC:96.2% | |||||
| [23] | Classification of Breast Cancer | x | x | 2,12GLM | GLM | ACC:97.34% | |||||||
| [62] | Brain MRI analysis for Alzheimer’s disease diagnosis | x | ANN | ACC:93% | |||||||||
| [37] | Detection using images of the palpable palm | x | x | x | x | x | NB | ACC:99.73% | |||||
| [16] | predicting emergency readmission of heart-disease patients | x | x | x | x | x | x | XGB | ACC:88% | ||||
| [35] | early detection of patients with alcohol use disorder | x | x | x | x | x | 13LIR | ACC:98% | |||||
| [19] | Diabetes prediction | x | 3,13GBT | GBT | ACC:83.9% | ||||||||
| [36] | Heart abnormality detection | x | x | x | x | 15CB | LR | AUCROC:92% | |||||
| [63] | Cough Sound based COVID-19 Detection | x | x | x | LR | ACC:79.86% | |||||||
| [20] | Early Diabetes Prediction | x | 3,14 | LR | ACC:96% | ||||||||
| [24] | Diagnosis of Breast Cancer | x | x | x | LR | AUC>72% | |||||||
| FREQUENCY MODEL | 5 | 5 | 6 | 9 | 2 | 5 | 4 | 4 | |||||
1Polynomial Regression; 2Gradient Boosting; 3AdaBoost; 4Gaussian naive bayes; 5Stochastic Gradient Descent; 6Gaussian process; 7Insolation Forest; 8DenseStream; 9Boosting Trees; 10Lasso Regression; 11Decision Support System; 12Generalized Linear Model; 13Linear Regression; 14Gradient Boosted Tree; 15CatBoost.
Table 5.
MLM for Early Detection in Fraud
| Ref. | Application | *: Best Model - +: Other Models | Evaluation Metric | Area | ||||||||
| LR | SVM | DT | RF | NB | KNN | ANN | XGB | + | ||||
| [28] | Fraud detection in utility companies | x | *x | x | x | x | x | x | 16CART | ACC:62.3% | Fraud | |
| [66] | Enterprise Financial Audit | x | *x | x | ACC:84.35% | |||||||
| [67] | Analysis of Fraud Detection in Healthcare | x | x | x | *x | ACC:74.8% | ||||||
| [68] | Credit Card Fraud Detection | x | x | *x | x | ACC:100% | ||||||
| [69] | Fraud detection problem in credit cards | x | x | x | *15 | ACC>90% | ||||||
| [1] | Big Data Analytics for Credit Card Fraud Detection | x | *x | 2,3 | ACC:96.29% | |||||||
| [65] | Fraud in financial institutions | x | *x | x | 5 | ACC:98% | ||||||
| [64] | Fraud detection in financial and banking systems | x | x | x | x | x | x | *x | 13 | ACC:6.7% | ||
| [70] | Fraud Detection in Credit card and Transactions | x | x | x | *16 | ACC:96% | ||||||
| [29] | Detection of under-declarations in tax payments | *17SC | ACC:58% | |||||||||
| [30] | Detection in earnings manipulation in financial firms | x | x | *3 | AUCROC: 74.4% | |||||||
| FREQUENCY MODEL | 5 | 5 | 3 | 8 | 3 | 6 | 3 | 5 | ||||
| FREQUENCY AS BEST MODEL | 0 | 1 | 1 | 2 | 0 | 1 | 0 | 2 | ||||
1Polynomial Regression; 2Gradient Boosting; 3AdaBoost; 4Gaussian naive bayes; 5Stochastic Gradient Descent; 6Gaussian process; 7Insolation Forest; 8DenseStream; 9Boosting Trees; 10Lasso Regression; 11Decision Support System; 12Generalized Linear Model; 13Linear Regression; 14Gradient Boosted Tree; 15CatBoost, 16Classification and regression tree,17Spectral Clustering.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



