
Submitted:
18 July 2024
Posted:
18 July 2024
You are already at the latest version
Abstract
Functional partially linear regression model, contains a functional linear part and a non-parametric part, in which testing the linear relationship between the response and the functional predictor is of fundamental importance. When functional data cannot be approximated with a few principal components, based on a pseudo estimate for the unknown non-parametric component, we develop a U-statistic of order-two in this paper. Under some regularity conditions, we use the martingale central limit theorem to prove that the proposed test statistic is asymptotically normal. The finite sample performance with simulation studies and real data application are assessed to verify the proposed test procedure.
Keywords:
Asymptotic normality
; Functional partially linear regression model
; Nadaraya-Watson estimate
; U-statistic
1. Introduction
In the past few decades, functional data analysis has been widely developed and applied in various fields, such as medicine, biology, economics, environmetrics, chemistry (see [1,2,3,4,5]). An important model in functional data analysis is partial functional linear model, which includes the parametric linear part and the functional linear part. To make the relationships between variables more flexible, the parametric linear part is usually replaced by the non-parametric part. This model is known as functional partially model, which has been studied in [6,7,8]. The functional partially linear regression model is defined as follows:
where Y is response variable, is functional predictor with mean and covariance operator . The slope function is an unknown function. is a general continuous function defined on a compact support . is a random error with mean zero and finite variance , and is independent of the predictor . When the is constant, the model (1) becomes a functional linear model. See [9,10,11]. When is parametric linear part, the model (1) becomes a partially functional linear model, which has been studied in [12,13,14].
Hypothesis testing plays a critical role in statistical inference. For testing the linear relationship between the response and the functional predictor in functional linear model, functional principal component analysis (FPCA) of the functional predictor in the literature is a major idea to construct test statistic. See [9,10,15]. Taking into account the flexibility of non-parametric functions, [6] introduced the functional partially linear regression model. [7] and [8] constructed the estimators of the slope functions based on spline and FPCA respectively, and the estimate of non-parametric components in their papers adopted B-spline. When the predictors are measured with additive error, [16] studied the estimators of slope function and non-parametric function by FPCA and kernel smoothing techniques. [17] established the estimators of slope function, non-parametric component and mean of response variable when existing missing responses at random.
However, testing the relationship between the response variable and the functional predictor in functional partially linear regression model has been rarely considered so far. In this paper, the following hypothesis testing for model (1) will be considered:
where is an assigned function. Without loss of generality, let . For testing (2), [18] constructed a chi-square test using FPCA when the functional data can be approximated with a few principal components. In particular, when the functional data cannot be approximated with a few principal components, only several researches have considerated this situation in functional data analysis. [19] constructed a FLUTE test based on order-four U-statistic for the testing in functional linear model, which can be computationally very costly. In order to save calculation time, [20] developed a faster test using a order-two U-statistic. Motivated by this, we propose a non-parametric U-statistic that combines the functional data analysis with the classical kernel method for testing (2).
The paper is organized as follows. In Section 2, we construct a new test procedure for testing in functional partially linear regression model. The theoretical properties of the proposed test statistic under some regularity conditions will be considered in Section 3. Simulation study is conducted in Section 4 to assess the finite sample performance of our proposed test procedure. Section 5 reports the testing result for spectrometric data. All the proofs of main theoretical results are presented in Appendix.
2. Test statistic
Suppose that Y and U are real-valued random variables. is a stochastic process with sample paths in , which is the set of all square integrable functions defined on . Let , represent the inner product and norm in , respectively. {} is a random sample from model (1),
For any given , we move to the left,
Then model (4) becomes classical non-parametric model. A pseudo kernel estimate of the non-parametric function using Nadaraya-Watson regression method can be constructed as follows:
where with being a preselected kernel function and h being the bandwidth whose optimal value can be determined by some data-driven methods such as the cross-validation methods. Here we estimate non-parametric without ith sample.
Let
where . So the pseudo estimate (5) of non-parametric function can be rewritten in matrix as
If we replace by in the model (3), we have
where , . If we denote , where “≜” stand for “defined as”. Then can be estimator of the conditional expectation for any .
For an arbitrary orthonormal basis in , the predictor and the slope function have following expansions. Denote the number of truncated basis function by p,
where , . Let , the model (7) can be rewritten as follows:
Denote , which has mean and covariance matrix . Let
For model (3), we define the approximation error as
To analyze the effect of the approximation error, we impose following condition on functional predictors and regression function.
(C1) Functional predictors and regression function satisfy:
(i) Functional predictors belongs to a Sobolev ellipsoid of order-two, then there exists a universal constant C, such that
(ii) Regression function satisfies where K is a constant.
Using Cauchy-Schwarz inequality, we have
Then the approximation error can be ignored as . Model (7) becomes:
which is a high-dimensional partial linear model. Since
can be used as an effective measure of the distance between and 0 when testing (2). Motivated by [21], we construct following test statistic by estimating (11).
where
where and are sample means of and . By some calculations, we can get , . The test statistic can served as a measurement of distance between and 0 under null hypothesis. Large values of test statistic are in favor of alternative hypothesis and leads to rejection of null hypothesis.
3. Asymptotic theory
To achieve the asymptotic properties of the proposed test, we first suppose following conditions based on [19] and [21]. Denote
A condition on the dimension of matrix is:
(C2) As , ; , .
(C3) There exists a m-dimensional random vector for a constant so that Here satisfies , , and for any , is a matrix such that . Each random vector is assumed to have finite 4th moments and for some constant . Furthermore, we assume
for and , where d is a positive integer.
(C4) , and .
(C5) The error term satisfies .
(C6) The random variable U has a compact support , and its density function has continuous second order derivative and bounded away from 0 on its support. The kernel function is a symmetric probability density function with a compact support. Also, it is Lipschitz continuous.
(C7) and are Lipschitz continuous, and have continuous second order derivatives.
(C8) The sample size n and the smoothing parameter h are assumed to satisfy .
(C9) The truncated number p and the sample size n are assumed to satisfy .
Condition (C2) has been adopted in many studies about high-dimensional data (see [21,22,23]). Condition (C3) resembles a factor model. To analyze the local power, we also impose the condition (C4) on the coefficient vector . In fact, (C4) can be served as the local alternatives as its distance measurement between and 0. This local alternative can be also found in [21]. (C5) is the typical assumptions for the error term . Conditions (C6-C8) are very common in non-parametric smoothing. (C9) is a technical condition which is needed to derive the theorems.
We will show the asymptotic theory of our proposed test statistic under the null hypothesis and the local alternative (C4) in the following two theorems.
Theorem 1.
Suppose that the conditions (C1), and (C3-C9) hold, then we have
where , and it can be regarded as the covariance operator of random variable .
Theorem 2.
Suppose that the conditions (C1-C3) and (C5-C9) hold, then under the null hypothesis or the local alternative (C4), we have
where represents convergence in distribution.
Theorem 2 indicates that under the local alternative hypothesis (C4), the proposed test statistic has the following asymptotic local power for the nominal level ,
where is the cumulative distribution function of the standard normal distribution, and denotes its upper quantile. Let , and this quantity can be viewed as a signal-to-noise ratio. When the term , the power converges to , then the power converge to 1 if it has a high order of . This implies that the proposed test is consistent. Our proposed test statistic also process the identical asymptotic local power. The performance of the power will be shown by simulation in Section 4.
By Theorem 2, the proposed test statistic rejects at a signification level if
where and are consistent estimators of and , respectively. We use the similar method as in [24] to estimate the trace. That is,
where , , with . And the simple estimator is used, which is consistent under the null hypothesis testing.
4. Simulation study
In this section, to evaluate the finite sample performance of the proposed test, some simulation studies are conducted. We generate 1,000 Monte Carlo samples in each simulation. For basis expansion and FPCA, we use the implementation in the R package fda.
Here we compare the proposed test with the chi-square test constructed by [18]. The cumulative percentage of total variance (CPV) method is used to estimate the number of principal components in . Define CPV explained by the first m empirical functional principal components as
where is the estimate of the eigenvalue of covariance operator. The minimal m for which CPV(m) exceeds a desired level, 95% is chosen in this section. We denote p as the number of basis functions used to fit curves. The simulated data is generated from the following model:
where or , and is independently generated from the uniform distribution . To analyze the impact of different error distributions, the following four distributions will be selected: (1) , (2) , (3) , (4) . All results about are presented in supplementary materials.
We next report the simulation results for two data structures of the predictor . Because fitting curves with several basis functions are not reasonable for functional data that cannot be approximated by a few principal components, the performance of and will be compared based on the change in the number of basis functions used in the fitting curves, and the performance of the proposed test when the number of basis functions used to fit curves is large enough (at this point, the value of cannot be calculated) will be presented.
1. The predictor , where follows a normal distribution with mean zero and variance , for . The slope function with c varying from 0 to 0.2. corresponds to the null hypothesis. The number of basis functions used to fit curves and the sample size are taken as: , . Under different error distributions, Table 1 and Table 2 evaluate the empirical size and power of both tests for different non-parametric functions when the nominal level is .
From Table 1 and Table 2, it can be seen that, (i) For different error distributions and different non-parametric functions, the performance of both tests is stable; (ii) Due to the asymptotic distribution of is for functional data that cannot be approximated by a few principal components, the power of proposed test is slightly lower than that of . (iii) As the sample size n increases, the power increases, while the power does not increase or decrease significantly as the value of p increases. In fact, for this data structure of the predictor, no matter how many basis functions are selected to fit the function curves, the number of principal components we finally select is very small.
2. The functional predictor is generated based on the expansion (8), where ’s are Fourier basis functions on [0,1] defined as , , , , . The first p of these basis functions will be used to generate the prediction function and slope function. Let , , where , , the coefficient of slope function with and c varying from 0 to 1. corresponds to the case in which is true. The coefficients of predictor follow the moving average model:
where the constant T controls the range of dependence between the components of predictor . are independently generated from the normal distribution with . The element at position of the covariance matrix for coefficient vector is where is independently generated from the uniform distribution on [0,1].
The Epanechnikov kernel is adopted in estimating non-parametric part . we select the bandwidth with cross validation (CV). When the significant level is 0.05, Table 3 and Table 4 show the empirical size and power of both tests for different non-parametric functions with different error distributions.
From Table 3 and Table 4, the number of basis functions used for fitting functions has a very important impact on the test. Specifically, (i) Under different error distributions, with the increase of p, the empirical size of test is much greater than the nominal level, while our proposed test has a stable performance; (ii) As the sample size n increases, the power increases, while the power decreases as the value of p increase. In fact, for this data structure of the predictor, the number of selected principal components is too large to make the test statistics based on FPCA perform well. Instead, the proposed test has great advantages(see bold numbers in Table 3 and Table 4).
Furthermore, to verify the asymptotic theory of our proposed test, when , Figure 1 and Figure 2 draw the null distributions and the q-q plots of for and , respectively. The null distributions are represented by the dashed lines, while the solid lines are density function curves of standard normal distributions. For different , Figure 3 and Figure 4 respectively show the empirical power functions of the proposed test statistics under four different error distribution functions when the non-parametric function is a linear function and a trigonometric function. When , the empirical power functions of the proposed test are represented by solid lines, dashed lines and dotted lines respectively. It can be seen that from Figure 3 and Figure 4, the power increases rapidly as long as c increases slightly. As the sample size n increases, the power increases, while the power decreases as p increases. The proposed test is stable under different error distributions. These are consistent with the conclusions in Table 3 and Table 4 (i.e.).
5. Application
This section applies the proposed test to the spectral data, which has been described and analyzed in the literature (see [25,26]). This dataset can be obtained on the following platforms: http://lib.stat.cmu.edu/datasets/tecator. There are 215 meat samples. Each sample contains chopped pure meat, which contains different absorption spectra and fat, protein and water contents. The observations of the spectral measurement are some curves, denoted by , which corresponds to the absorbance measured on the grid with 100 wavelengths ranging from 850nm to 1050nm in step. Fat, protein and water content (in percentage) are measured by chemical analysis method. Denote the fat contents as response variable , the protein contents as , and the moisture content as . Similar to [27], the following two models will be used to assume the relationship between them:
Here we mainly study the test in models (14) and (15): . The number of basis functions used for fitting function curves p is selected as 129. Figure 5 shows the estimation of slope function in models (14) and (15).
6. Conclusion
In this paper, we constructed a U-statistic of order-two for testing linearity between the functional predictor and the response variable in functional partially linear regression model. The proposed test procedure didn’t depend on the estimate of covariance operator of predictor function. The asymptotic distribution of proposed test statistic is normal under a null hypothesis and a local alternative assumption. Furthermore, numerical simulations show that our proposed test performs well when functional data cannot be approximated by a few principal components. Finally, the real data has applied to our proposed test to verify its feasibility.
Author Contributions
Conceptualization, F.Z. and B.Z.; methodology, B.Z.; software, F.Z.; validation, B.Z.; formal analysis, F.Z.; investigation, F.Z.; resources, F.Z.; data curation, F.Z.; writing—original draft preparation, F.Z.; writing—review and editing, B.Z.; visualization, B.Z.; supervision, B.Z.; project administration, B.Z.; funding acquisition, F.Z. and B.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (Nos.12271370,
Data Availability Statement
Not applicable.
Acknowledgments
The authors are grateful to the editor, associate editor, and referees for reviewing this manuscript, and hope to receive constructive comments and suggestions.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
We present some lemmas in order to complete the proofs of Theorem 1 and Theorem 2. Without loss of generality, we assume that and and in the sequel. Let . With reference to the asymptotic theory of non-parametric estimation, the pseudo estimation of non-parametric function satisfies . Denote for . Similarly as the lemmas in [21], it is easy to derive the following lemmas.
Lemma A1.
If (C1), (C3) and (C4) hold, for any square matrix M,it can be shown that
Lemma A2.
If (C1-C3) and (C5-C9) hold, then we have
Lemma A3.
If (C1-C9) hold, we can get
where , represent the sample means of and without ith and jth samples, for . That is
Proof. Proof of Theorem 1. Write
where
then the expectation of test statistic is:
To prove the conclusion (i) in Theorem 1, it needs to be calculated one by one for . Because of the similarity of calculation in different cases of , here we mainly consider the case where ,
where
For the above six items, we will analyze them one by one. Firstly, we consider the first term. Since
then holds. For the second term, we have
Combined with (C1),(C3) and (C9), holds. The error term with mean zero is independent of the predictor, hence it is easy to see that both the third term and the sixth term are zero. For the other two cross terms and ,we need to prove that they are high-order infinitesimals of . In fact,
Finally, for , we have
Using (C3) and the following fact , we obtained , i.e. . Then, it can be seen that
For the rest, refer to calculation of the above mean and the proof of Theorem 1 in [21]. The proof of the conclusion (i) in Theorem 1 is completed. The conclusion (ii) of Theorem 1 can be found in the proof of Theorem 2, here we omit it. □
Proof. Proof of Theorem 2
By the Throrem 1, we have the fact
then we only need to prove that
Denote , where . Then we have
In order to obtain the asymptotic properties of above equation, we will find the asymptotic order of all terms . These items are divided into the following two groups according to the treatment methods.
- Group 1: , , , , , , , , , .
- Group 2: , , , , , .
Since the methods are similar, the cases of and will be considered respectively in detail in each group. Firstly, for , we can rewrite
where
To prove (A3), We shall prove
where .
It is easy to see that the means of 9 items in the right equation of (A4) are all zero. Then in order to calculate their asymptotic order, it is necessary to prove their second moment. Due to the similarity of calculation of the first 8 items, we use the first item as an example to consider.
where
Let’s calculate and .
where , .
Using the Cauchy-Schwarz inequality and Lemma A.2, we can get
For and ,
So we can have . Apply similar methods to the , the terms are all equal to . For , rewrite
where
Since the means of above four formulas are zero, in order to prove that (A5) is true, it is necessary to verify the second moments of are the high-order infinitesimal of quantity . In fact,
Then the equation (A5) holds. Similarly, for Group 2, that is, when , , , , , , there is a similar proof process for the asymptotic behavior of each item in the group, here we only consider . By careful calculation,
Using the fact we have
In addition, by a simple calculation,
Combined (A6), (A7) with Cauchy-Schwarz inequality, we have
Denote , by condition (C1), we only need to consider . Then, by Slutsky’s theorem, if the following conclusion can be obtained, Theorem 2 will be proved.
By some simple calculations, we have . Let , , , where is a -algebra produced by , . It is easy to check , and is a martingale with mean 0. The martingale central limit theorem follows if we can check
Note that
Then we define
where
It is easy to check , and
By (C2), we have . Similarly, we can obtain , and
Combined with , then we have . Thus, equation (A8) holds. Finally, we only need to prove (A9). Therefore, using the law of large numbers, and the fact we only need to show that . By simple calculation, we can get
Combined (C2) and Lemma 2, equation (A9) holds. Thus, the proof of Theorem 2 completed. □
References
- Crainiceanu, C.M.; Staicu, A.M.; Di, C.Z. Generalized multilevel functional regression. Journal of the American Statistical Association 2009, 104, 1550–1561. [Google Scholar] [CrossRef] [PubMed]
- Leng, X. Müller, H.G. Time ordering of gene co-expression. Biostatistics 2006, 7, 569–584. [Google Scholar] [CrossRef] [PubMed]
- Kokoszka, P.; Miao, H.; Zhang, X. Functional Dynamic Factor Model for Intraday Price Curves. Journal of Financial Econometrics 2014, 13, 456–477. [Google Scholar] [CrossRef]
- Ignaccolo, R. and Ghigo, S. and Giovenali, E. Analysis of air quality monitoring networks by functional clustering. Environmetrics 2008, 19, 672–686. [Google Scholar] [CrossRef]
- Yao, F.; Müller, H.G. Functional quadratic regression. Biometrika 2010, 97, 49–64. [Google Scholar] [CrossRef]
- Lian, H. Functional partial linear model. Journal of Nonparametric Statistics 2011, 23, 115–128. [Google Scholar] [CrossRef]
- Zhou, J.; Chen, M. Spline estimators for semi-functional linear model. Statistics & Probability Letters 2012, 82, 505–513. [Google Scholar] [CrossRef]
- Tang, Q. Estimation for semi-functional linear regression. Statistics 2015, 49, 1262–1278. [Google Scholar] [CrossRef]
- Cardot, H.; Ferraty, F.; Mas, A.; Sarda, P. Testing hypotheses in the functional linear model. Scandinavian Journal of Statistics 2003, 30, 241–255. [Google Scholar] [CrossRef]
- Kokoszka, P.; Maslova, I.; Sojka, J.; Zhu, L. Testing for lack of dependence in the functional linear model. Canadian Journal of Statistics 2008, 36, 207–222. [Google Scholar] [CrossRef]
- James, G.M.; Wang, J.; and Zhu, J. Functional linear regression that’s interpretable. The Annals of Statistics 2009, 37, 2083–2108. [Google Scholar] [CrossRef]
- Shin, H. Partial functional linear regression. Journal of Statistical Planning and Inference 2009, 139, 3405–3418. [Google Scholar] [CrossRef]
- Yu, P.; Zhang, Z.; Du, J. A test of linearity in partial functional linear regression. Metrika 2016, 79, 953–969. [Google Scholar] [CrossRef]
- hu, H.; Zhang, R.; Yu, Z.; Lian, H,; Liu, Y. Estimation and testing for partially functional linear errors-in-variables models. Journal of Multivariate Analysis 2019, 170, 296–314. [Google Scholar] [CrossRef]
- Cardot, H.; Goia, A.; Sarda, P. Testing for no effect in functional linear regression models, some computational approaches. Communications in Statistics-Simulation and Computation 2004, 33, 179–199. [Google Scholar] [CrossRef]
- Zhu, H.; Zhang, R.; Li, H. Estimation on semi-functional linear errors-in-variables models. Communications in Statistics-Theory and Methods 2019, 48, 4380–4393. [Google Scholar] [CrossRef]
- Zhou, J,; Peng, Q. Estimation for functional partial linear models with missing responses. Statistics & Probability Letters 2020, 156, 108598. [Google Scholar] [CrossRef]
- Zhao, F.; Zhang, B. Testing Linearity in Functional Partially Linear Models. Acta Mathematicae Applicatae Sinica, English Series 2024, 40, 875–886. [Google Scholar] [CrossRef]
- Hu, W.; and Lin, N.; Zhang, B. Nonparametric testing of lack of dependence in functional linear models. PLoS ONE 2020, 15, e0234094. [Google Scholar] [CrossRef]
- Zhao, F.; Lin, N.; Hu, W.; Zhang, B. A faster U-statistic for testing independence in the functional linear models. Journal of Statistical Planning and Inference 2022, 217, 188–203. [Google Scholar] [CrossRef]
- Zhao, F.; Lin, N.; Zhang, B. A new test for high-dimensional regression coefficients in partially linear models. Canadian Journal of Statistics 2023, 51, 5–18. [Google Scholar] [CrossRef]
- Cui, H.; Guo, W.; Zhong, W. Test for high-dimensional regression coefficients using refitted cross-validation variance estimation. The Annals of Statistics 2018, 46, 958–988. [Google Scholar] [CrossRef]
- Zhong, P.; Chen, S. Tests for High-Dimensional Regression Coefficients With Factorial Designs. Journal of the American Statistical Association 2011, 106, 260–274. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, L.; Zhong, P. Tests for high-dimensional covariance matrices. Journal of the American Statistical Association 2010, 105, 810–819. [Google Scholar] [CrossRef]
- Ferraty, F.; c and Vieu, P. Nonparametric functional data analysis: theory and practice; Springer: New York, USA, 2006. [Google Scholar]
- Shang, H.L. Bayesian bandwidth estimation for a semi-functional partial linear regression model with unknown error density. Computational Statistics 2014, 29, 829–848. [Google Scholar] [CrossRef]
- Yu, P.; Zhang, Z.; Du, J. Estimation in functional partial linear composite quantile regression model. Chinese Journal of Applied Probability and Statistics 2017, 33, 170–190. [Google Scholar] [CrossRef]
Figure 1.
The null distributions and the q-q plots of our proposed test when .
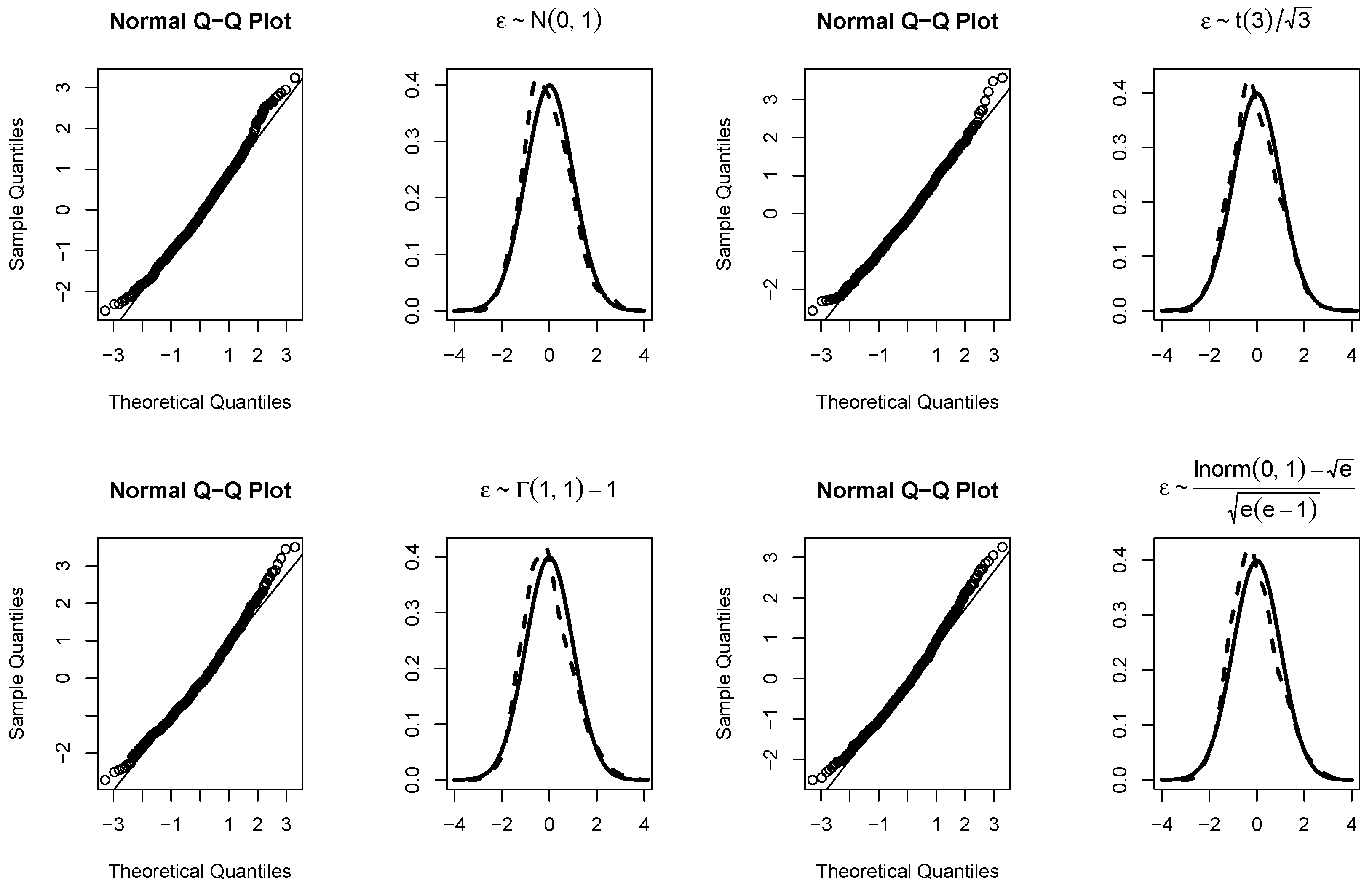
Figure 2.
The null distributions and the q-q plots of our proposed test when .
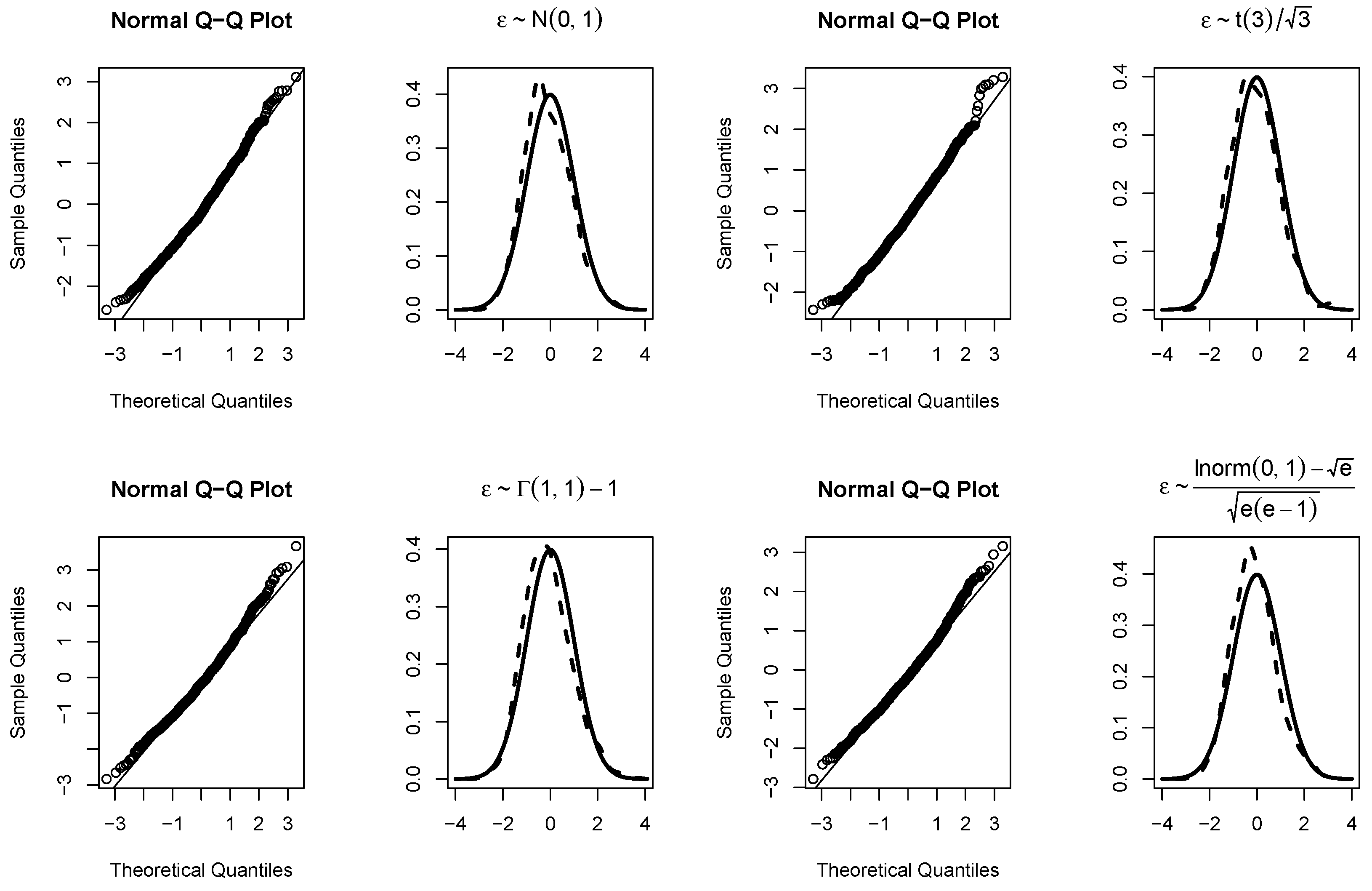
Figure 3.
Empirical power functions of our proposed test when .
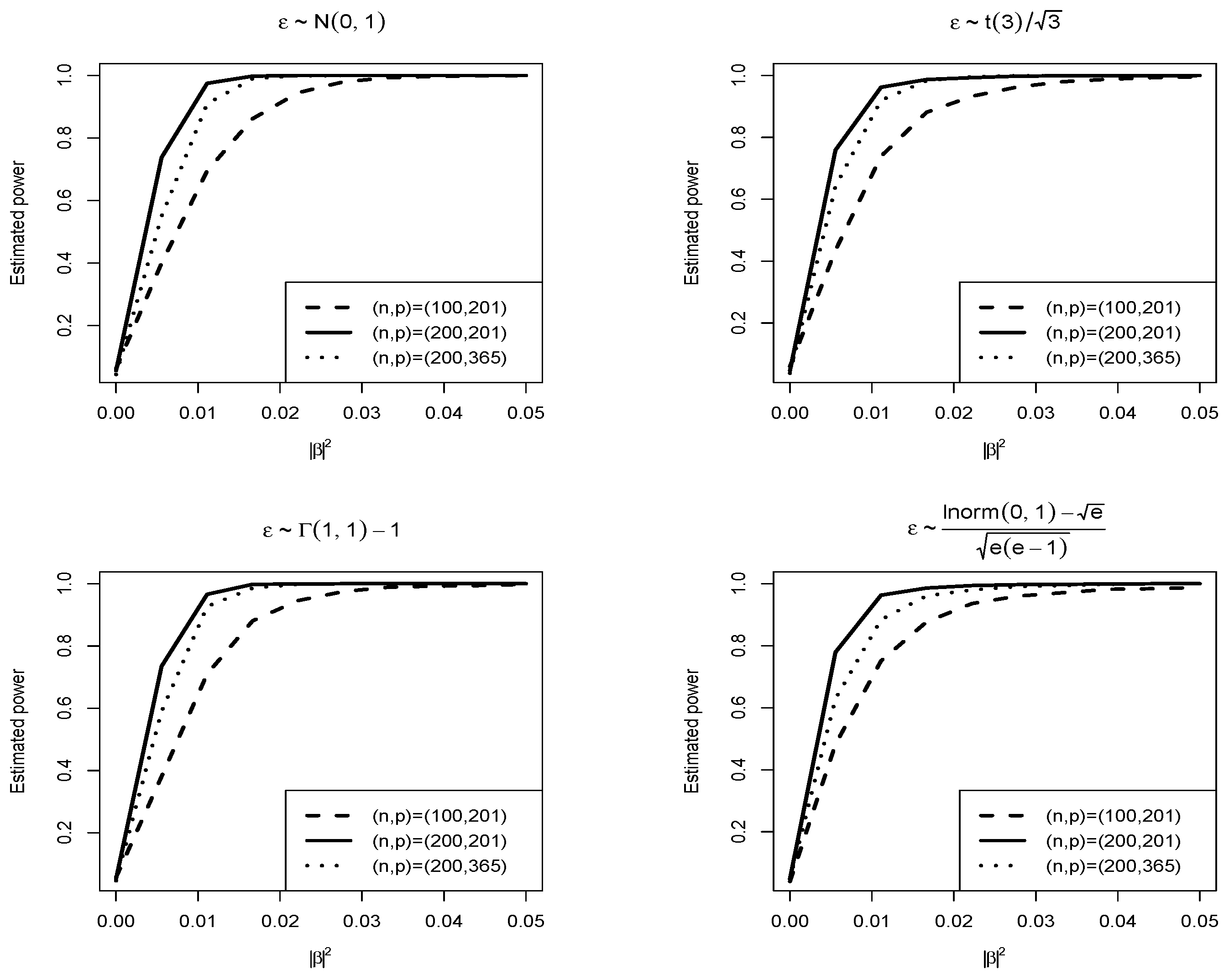
Figure 4.
Empirical power functions of our proposed test when .
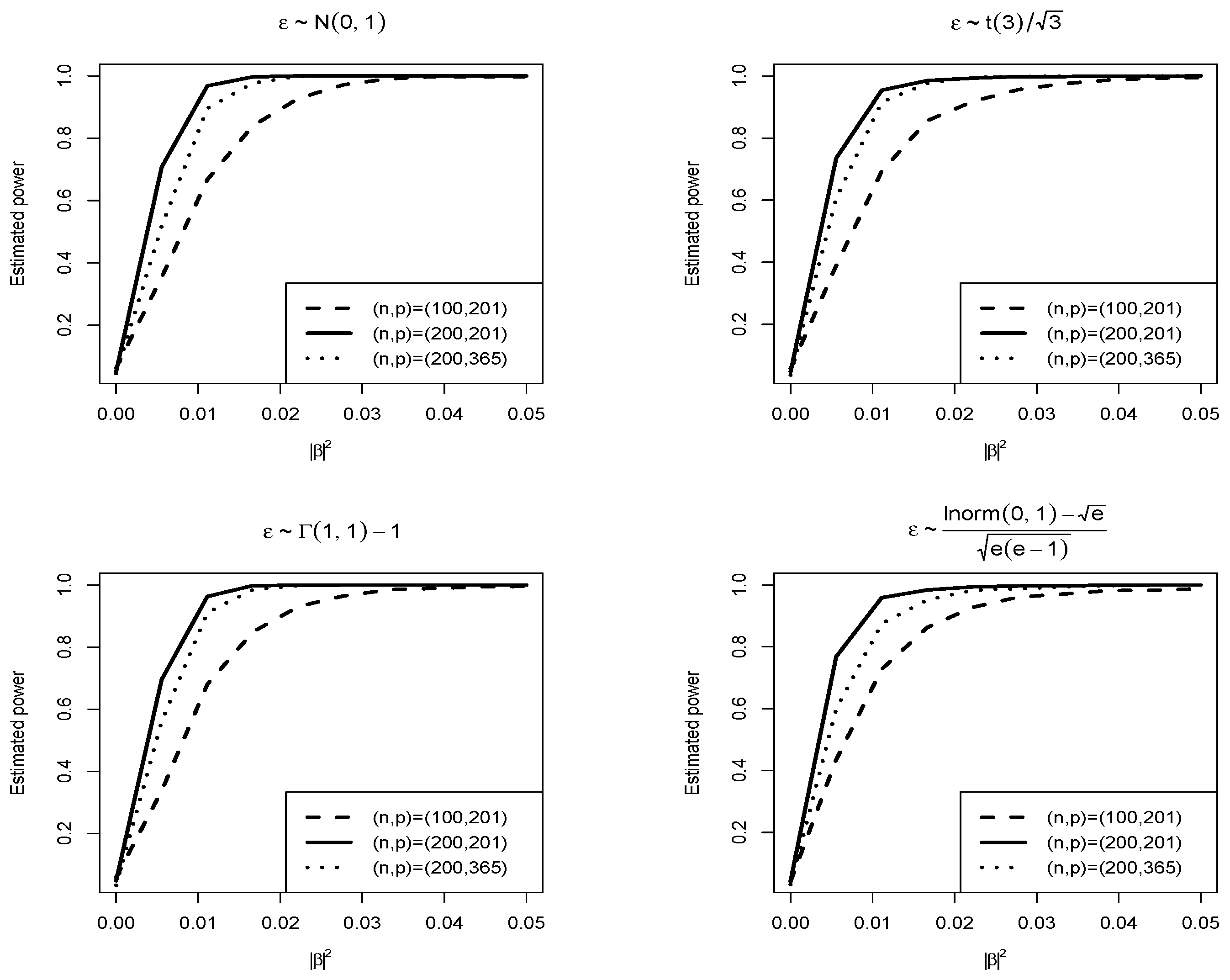
Figure 5.
(a) The estimator of the slope function in model (14); (b) The estimator of the slope function in model (15)
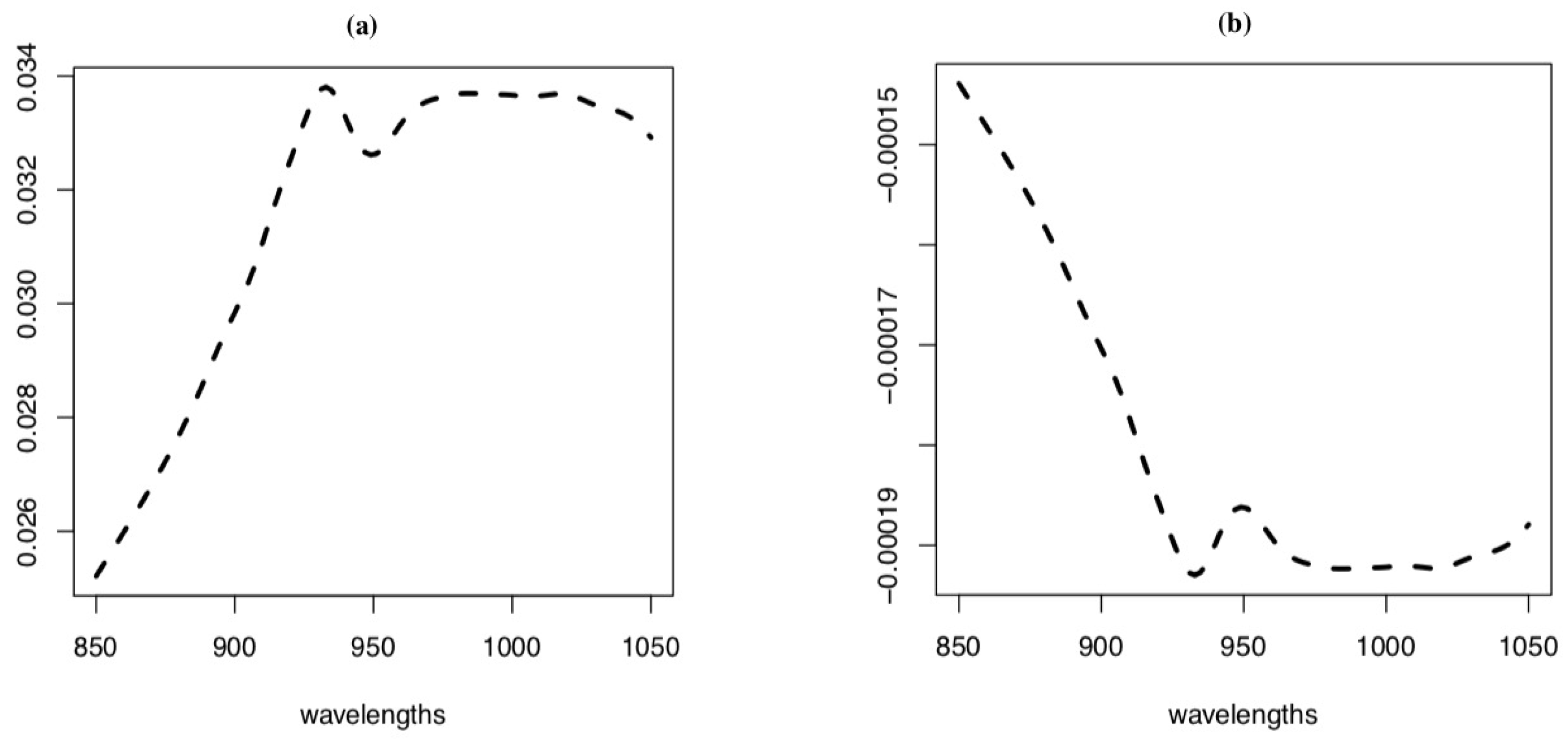

Table 1.
Empirical size and power when for two tests.
| c | N(0,1) | t(3) | lnorm(0,1) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| (50,11) | 0 | 0.069 | 0.060 | 0.074 | 0.077 | 0.071 | 0.071 | 0.084 | 0.053 |
| 0.05 | 0.097 | 0.101 | 0.133 | 0.102 | 0.135 | 0.107 | 0.148 | 0.111 | |
| 0.1 | 0.250 | 0.211 | 0.292 | 0.244 | 0.269 | 0.225 | 0.337 | 0.283 | |
| 0.15 | 0.474 | 0.383 | 0.555 | 0.448 | 0.494 | 0.415 | 0.576 | 0.470 | |
| 0.2 | 0.713 | 0.584 | 0.761 | 0.631 | 0.738 | 0.602 | 0.755 | 0.656 | |
| (100,11) | 0 | 0.049 | 0.052 | 0.055 | 0.052 | 0.058 | 0.059 | 0.049 | 0.052 |
| 0.05 | 0.233 | 0.195 | 0.275 | 0.225 | 0.217 | 0.195 | 0.312 | 0.268 | |
| 0.1 | 0.689 | 0.603 | 0.746 | 0.660 | 0.715 | 0.618 | 0.743 | 0.652 | |
| 0.15 | 0.961 | 0.877 | 0.956 | 0.913 | 0.963 | 0.899 | 0.931 | 0.884 | |
| 0.2 | 0.998 | 0.984 | 0.986 | 0.975 | 0.995 | 0.975 | 0.978 | 0.965 | |
| (100,49) | 0 | 0.057 | 0.060 | 0.050 | 0.061 | 0.051 | 0.049 | 0.055 | 0.047 |
| 0.05 | 0.224 | 0.203 | 0.282 | 0.255 | 0.236 | 0.225 | 0.305 | 0.288 | |
| 0.1 | 0.741 | 0.607 | 0.757 | 0.665 | 0.718 | 0.615 | 0.747 | 0.659 | |
| 0.15 | 0.962 | 0.900 | 0.947 | 0.871 | 0.950 | 0.884 | 0.938 | 0.886 | |
| 0.2 | 0.998 | 0.981 | 0.987 | 0.977 | 0.997 | 0.978 | 0.988 | 0.969 | |
Table 2.
Empirical size and power when for two tests.
| c | N(0,1) | t(3) | lnorm(0,1) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| (50,11) | 0 | 0.062 | 0.064 | 0.072 | 0.069 | 0.071 | 0.072 | 0.060 | 0.054 |
| 0.05 | 0.087 | 0.091 | 0.109 | 0.096 | 0.112 | 0.103 | 0.117 | 0.106 | |
| 0.1 | 0.235 | 0.197 | 0.250 | 0.219 | 0.241 | 0.208 | 0.293 | 0.249 | |
| 0.15 | 0.420 | 0.359 | 0.502 | 0.419 | 0.449 | 0.389 | 0.506 | 0.449 | |
| 0.2 | 0.658 | 0.545 | 0.724 | 0.605 | 0.694 | 0.573 | 0.735 | 0.638 | |
| (100,11) | 0 | 0.062 | 0.062 | 0.050 | 0.046 | 0.063 | 0.060 | 0.054 | 0.060 |
| 0.05 | 0.217 | 0.205 | 0.239 | 0.219 | 0.235 | 0.208 | 0.255 | 0.240 | |
| 0.1 | 0.668 | 0.568 | 0.714 | 0.617 | 0.696 | 0.605 | 0.748 | 0.644 | |
| 0.15 | 0.946 | 0.874 | 0.947 | 0.883 | 0.946 | 0.852 | 0.927 | 0.873 | |
| 0.2 | 0.996 | 0.980 | 0.993 | 0.972 | 1.000 | 0.979 | 0.987 | 0.964 | |
| (100,49) | 0 | 0.050 | 0.062 | 0.056 | 0.063 | 0.047 | 0.067 | 0.060 | 0.056 |
| 0.05 | 0.226 | 0.216 | 0.249 | 0.202 | 0.209 | 0.199 | 0.277 | 0.256 | |
| 0.1 | 0.674 | 0.562 | 0.734 | 0.611 | 0.692 | 0.582 | 0.733 | 0.639 | |
| 0.15 | 0.943 | 0.873 | 0.943 | 0.890 | 0.941 | 0.855 | 0.925 | 0.889 | |
| 0.2 | 0.997 | 0.976 | 0.994 | 0.981 | 0.998 | 0.980 | 0.982 | 0.955 | |
Table 3.
Empirical size and power when for two tests.
| c | N(0,1) | t(3) | lnorm(0,1) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| (50,11) | 0 | 0.097 | 0.066 | 0.088 | 0.076 | 0.096 | 0.074 | 0.104 | 0.059 |
| 0.25 | 0.378 | 0.454 | 0.442 | 0.518 | 0.389 | 0.443 | 0.487 | 0.572 | |
| 0.5 | 0.589 | 0.695 | 0.669 | 0.749 | 0.610 | 0.702 | 0.725 | 0.783 | |
| 0.75 | 0.765 | 0.832 | 0.811 | 0.861 | 0.769 | 0.847 | 0.832 | 0.882 | |
| 1 | 0.865 | 0.917 | 0.883 | 0.925 | 0.867 | 0.912 | 0.889 | 0.922 | |
| (100,11) | 0 | 0.060 | 0.067 | 0.086 | 0.064 | 0.072 | 0.058 | 0.062 | 0.049 |
| 0.25 | 0.511 | 0.711 | 0.582 | 0.738 | 0.569 | 0.739 | 0.618 | 0.760 | |
| 0.5 | 0.820 | 0.932 | 0.857 | 0.932 | 0.846 | 0.922 | 0.841 | 0.924 | |
| 0.75 | 0.949 | 0.984 | 0.943 | 0.975 | 0.935 | 0.973 | 0.917 | 0.967 | |
| 1 | 0.982 | 0.998 | 0.971 | 0.986 | 0.971 | 0.989 | 0.958 | 0.984 | |
| (100,49) | 0 | 0.245 | 0.064 | 0.224 | 0.058 | 0.236 | 0.058 | 0.202 | 0.048 |
| 0.25 | 0.541 | 0.498 | 0.570 | 0.543 | 0.534 | 0.501 | 0.563 | 0.564 | |
| 0.5 | 0.754 | 0.771 | 0.804 | 0.807 | 0.767 | 0.776 | 0.769 | 0.798 | |
| 0.75 | 0.884 | 0.910 | 0.899 | 0.936 | 0.899 | 0.904 | 0.879 | 0.887 | |
| 1 | 0.957 | 0.966 | 0.949 | 0.968 | 0.956 | 0.964 | 0.928 | 0.934 | |
Table 4.
Empirical size and power when for two tests.
| c | N(0,1) | t(3) | lnorm(0,1) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| (50,11) | 0 | 0.099 | 0.069 | 0.087 | 0.075 | 0.086 | 0.063 | 0.101 | 0.064 |
| 0.25 | 0.353 | 0.420 | 0.423 | 0.484 | 0.383 | 0.434 | 0.482 | 0.538 | |
| 0.5 | 0.574 | 0.661 | 0.640 | 0.714 | 0.602 | 0.677 | 0.695 | 0.758 | |
| 0.75 | 0.751 | 0.806 | 0.783 | 0.849 | 0.750 | 0.814 | 0.804 | 0.860 | |
| 1 | 0.841 | 0.893 | 0.869 | 0.913 | 0.842 | 0.897 | 0.874 | 0.913 | |
| (100,11) | 0 | 0.067 | 0.058 | 0.060 | 0.054 | 0.065 | 0.055 | 0.072 | 0.059 |
| 0.25 | 0.486 | 0.662 | 0.545 | 0.713 | 0.537 | 0.697 | 0.591 | 0.742 | |
| 0.5 | 0.783 | 0.901 | 0.819 | 0.906 | 0.814 | 0.907 | 0.832 | 0.916 | |
| 0.75 | 0.930 | 0.983 | 0.918 | 0.966 | 0.930 | 0.980 | 0.915 | 0.955 | |
| 1 | 0.976 | 0.996 | 0.959 | 0.983 | 0.977 | 0.994 | 0.954 | 0.972 | |
| (100,49) | 0 | 0.236 | 0.066 | 0.212 | 0.066 | 0.218 | 0.061 | 0.243 | 0.065 |
| 0.25 | 0.543 | 0.475 | 0.540 | 0.506 | 0.526 | 0.480 | 0.658 | 0.612 | |
| 0.5 | 0.744 | 0.745 | 0.781 | 0.791 | 0.747 | 0.750 | 0.835 | 0.815 | |
| 0.75 | 0.885 | 0.892 | 0.890 | 0.911 | 0.875 | 0.891 | 0.913 | 0.913 | |
| 1 | 0.948 | 0.964 | 0.937 | 0.956 | 0.938 | 0.955 | 0.947 | 0.956 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



