
Submitted:
23 July 2024
Posted:
24 July 2024
You are already at the latest version
Abstract
For Sir Ronald Fisher, it is important to consistently obtain significant p-values to support an experimental hypothesis. So, replicating experiments to obtain independent p-values is a legitimate and desirable research practice. Several simple statistics have been proposed to meta-analyze p-values, all assuming that they are genuine, i.e. observations from independent standard Uniform random variables. But, as publication bias favors the studies that report "significant" p-values, when a p>0.05 is obtained for the outcome of an experiment, some researchers will "fall into temptation" and decide to replicate the experiment in the hope of getting a smaller second p-value, ideally a significant one. Consequently, if the smallest of two p-values is reported, this is a Beta(1,2) distributed "fake" p-value, not a uniformly distributed genuine p-value. This is an unacceptable scientific research practice, and moreover the detection of fake p-values is unpractical. Even when it is possible, the analytic results to accommodate their existence in combined tests are cumbersome. For an informed decision, inclusive when the presence of fake p-values in a sample of p-values to be meta-analyzed is probable, tables with simulated critical values for the usual combined testing are supplied. This will also allow comparisons to be made between several combined tests.
Keywords:
combined p-values
; fake p-values
; Mendel random variables
; meta-analysis
1. Introduction
The use of p-values, defined as the probability of obtaining a result equal to or more extreme than what was actually observed, under a null hypothesis of no effect or no difference, is generally credited to Pearson [1], although Kennedy-Shaffer [2] extensively lists its previous use, tracing it back to Arbuthnott [3].
Fisher [4,5] popularized the concept, which plays a central role in his theory of significance testing. According to Fisher [6], a p-value should function as an informal index to evaluate the discrepancy between the data and the hypothesis under investigation. This closely matches the meaning of significance of Edgeworth [7], who considered a difference to be "significant and not accidental" if it was unlikely to have resulted from chance alone. On the other hand, a p-value smaller than 0.05, considered by Fisher [4,5] to be a threshold for a significant value, only hints that the experiment should be repeated. If subsequent studies also generate significant p-values, then it is fair to conclude that the observed effects are unlikely to result from chance alone. In this regard, Fisher [8] states that “A scientific fact should be regarded as experimentally established only if a properly designed experiment rarely fails to give this[P=0.05]level of significance”. Therefore, a significant p-value just indicates that further experiments should be carried out.
Obtaining significant p-values raises the issue of reproducibility (cf. Utts [9], Greenwald et al. [10], or Colquhoun [11]), which in turn requires that the p-values obtained from the repeated experiments must be summarized into a combined p-value. Being well-aware of this, Fisher [6] was one of the first to meta-analyze p-values. Note, however, that a combined p-value is not, in general, a p-value in the strict sense of the definition (Vovk and Wang [12]).
Taking a different approach, Neyman and Pearson [13,14] developed a theory for hypothesis testing. Significance testing and hypothesis testing were in Fisher’s [15] and E. Pearson’s [16] points of view incompatible, but they have become so intertwined that they are regarded by most users as part of a single and coherent approach to statistical inference (Lehman [17]). The work of Cox et al. [18] is an excellent critical overview of significance testing, with stimulating discussions and reply.
Despite the original Neyman-Pearson standpoint that hypothesis testing limits the number of mistaken conclusions in the long run, the discomforting price of abandoning the ability to measure evidence and assess the truth from a single experiment was soon forgotten in favor of the methodology of using p-values. In other words, taking for granted that each study originates conclusions with certain error rates instead of adding evidence to that provided by other sources and other studies. This clearly generated plenty of bad science, raising doubts on many scientific papers, with p-values adding nothing to true scientific knowledge (Ioannidis [19,20]).
The editorials in The American Statistician vol. 70 (Wasserstein and Lazar [21]) and vol. 73 (Wasserstein et al. [22]), introducing issues discussing the dangers of abuse when using p-values and significance testing, summarize, to a certain extent, the fierce debate on the matter and have originated a warning on p-values in Nature (Baker [23]). To cite some highlights of the debate, while Goodman [24,25] and Kühberger et al. [26] warn on the fallacies and misconceptions of p-values, Benjamini [27] claims that the abuse is not the fault of the p-values, and Greenland [28] states that valid p-values behave exactly as they should. Critics of the p-values question why is it so hard to get rid of significance testing and p-values (Goodman [29]; Halsey [30]), or to put forward the need to complement p-values with effect size, sample size, or Bayes factors (Colquhoun [31]; Goodman et al. [32]; Rougier [33]), or even to recommend lowering the significance threshold to 0.005, cf. Di Leo and Sardanelli [34]. Murdoch et al. [35] emphasize that p-values are random variables and the innovating paper of Fraser [36] argues that the p-value function should be used instead of p-values.
The heart of the matter is that a single p-value should not be used as a sound basis for decision. As already mentioned, a low p-value is just an indication that the experiment should be repeated, and that only consistently obtaining low p-values uphold the conviction that the null hypothesis should be rejected, as both Fisher and Neyman and Pearson originally defended, although on opposite sides when it comes to statistical inference understanding. Therefore, replicating to obtain independent p-values in such contexts is legitimate, even desirable, and the resulting combined p-values are relevant for decision making under uncertainty.
The classical test statistics for combining p-values assume that the p-values are all genuine (or bona fide), i.e. that under a null hypothesis the ’s are independent and identically distributed standard Uniform random variables. The combination of genuine p-values either relies on algebraic properties of Uniform random variables (order statistics, sums, products), or on transformations of standard Uniform random variables. In Section 2, a preliminary discussion of combining genuine p-values is undertaken.
However, the assumption that all ’s are genuine can be false, namely since the bias that results from some publication policies is the source of selective reporting of scientific findings. The greater opportunity researchers have to publish significant results than non-significant ones originates a so-called file drawer problem, thus exacerbating the publication bias phenomenon, which is discussed in Section 3. In addition to censoring p-values above traditional thresholds, publication bias can increase the temptation to replicate experiments in the hope of obtaining significant results.
Such scientific malpractice originates the report of fake p-values, as described in Section 4, where Mendel random variables, inspired by the Mendel-Fisher controversy, discussed in Fisher [37], Franklin et al. [38], and Pires and Branco [39], are introduced. While it is acceptable to think that the replication of p-values may strengthen the confidence in the idea that observed effects are unlikely to result from chance alone, the replication of p-values with the sole purpose of keeping only the most favorable ones is methodologically wrong, even possibly fraud, as Fisher [37] hinted in his discussion of Mendel’s results. The new trend of retaining only the p-values less than some specified cut-off value (Zaykin [40]; Neuhäuser and Bretz [41]; Zhang et al. [42]), or to use the product of the most significant p-values (Dudbridge and Koeleman [43]), have a similar effect of favoring the rejection of an overall null hypothesis, which in our opinion biases the conclusions. An extension of Deng and George’s [44] contraction, considered in SubSection 4.1, leads to ways of testing independence versus correlated P-values, in SubSection 4.2. In SubSection 4.3, the combination of genuine and fake p-values is investigated. This is a simple issue using Tippett’s [45] minimum method, but the analytical results for other ways of combining p-values, exemplified in SubSection 4.3, are complex to work with, even in the simplest case of just one fake p-value being present, making them useless from a practical point of view.
In these complex settings, simulation is a good tool for obtaining estimates of critical values for combined tests. Tables are supplied as Supplementary Materials, and in Section 5 their usefulness for an overall informed decision is illustrated. Section 6 summarizes the main findings with a comparison of different scenarios.
2. Combining Genuine -Values
Let us assume that the p-values , , are known for testing versus , , in n independent studies on some common topic, and that the objective is to achieve a decision on the overall problem : all of the are true versus : some of the are true.
As there are many different ways in which can be false, selecting an appropriate test is in general unfeasible. On the other hand, combining the available ’s so that is the observed value of a random variable whose sampling distribution under is known is a simple issue, since under , is the observed value of a random vector with independent univariate margins, i.e. genuine p-values.
The classical statistics for combining independent genuine p-values use:
- —
- transformations of the random variables, namely , , where is the standard Gaussian cumulative distribution function, or (SubSection 2.1), or
- —
- sums, products and order statistics of , namely the Pythagorean harmonic, geometric and arithmetic means (SubSection 2.2).
Note, however, that there are good reasons to believe that not all ’s are genuine, either because some of the are true, or because there is truncation (Zaykin et al. [40]; Neuhäuser and Bretz [41]; Zhang et al. [42]) or censoring due to publication bias (two issues that will be addressed in Section 3), or even because of poor scientific methodology (possibly fraud) leading to the generation of fake p-values, as described in Section 4 in the context of the Mendel-Fisher controversy (Fisher [37]; Franklin et al. [38]; Pires and Branco [39]) and Mendel random variables.
2.1. Combining Transformed Genuine p-Values
In 1932, Fisher [6] (Section 21.1), from the fact that when , used the statistic
Thus, the overall hypothesis is rejected at a significance level if , where denotes the q-th quantile of the chi-square distribution with m degrees of freedom.
In what concerns the use of Gaussian transformed p-values, Stouffer et al. [46] used as a test statistic
As
is rejected at a significance level if , with denoting the q-th quantile of the standard Gaussian distribution.
Since , an alternative to Fisher’s method is to use the statistic
as observed in Chen [47]. Note that Liu et al. [48] and Cinar and Viechtbauer [49] prefer an inverse chi-square method, more precisely,
where is the inverse cumulative distribution function of the chi-square distribution with one degree of freedom.
Mudholkar and George [50] propose the use of the statistic
based on the logit transformation , and which combines together and .
Due to the approximation
is rejected at significance level if
where represents the q-th quantile of Student’s t-distribution with m degrees of freedom. Or alternatively, as
is rejected if .
2.2. Should You Mean It?
An interesting way of combining p-values is to consider an average-like function
where is a continuous strictly monotonic function (Kolmogorov [51]).
If in (1), , , this is the so-called mean of order r
with the understanding that the case is the limit as , i.e.
If , then (Theorem 16 in Hardy et al. [52]). The means of order r for combining p-values are invariant for any permutation of , which is a useful property for the simulations carried out to obtain the results in Section 5.
The most used means of order r, defined in (2), are the Pythagorean means, namely
- —
- Harmonic mean:
- —
- Geometric mean:
- —
- Arithmetic mean:
Other special cases are
and
From now on, we shall use the notations , and , due to their use in the combined tests of Tippett [45], Edgington [53] and Wilkinson [54], respectively.
Tippett [45] was the first one to meta-analyze p-values using the statistic
As , the decision is to reject at a significance level if the minimum observed p-value .
Tippett’s minimum method is a special case of Wilkinson’s method (Wilkinson [54]), which recommends the rejection of if some order statistic . As
the cut-of-point c to reject at a significance level is the solution of
Note that Tippett’s and Wilkinson’s methods use drastically restricted information, contrasting with the efficient way in which Fisher’s and Stouffer’s methods use all available information.
In 1933, Pearson [55] expressed the distribution of
as a function of the upper incomplete Beta function,
In fact, the product of n independent random variables verifies
where is a random variable with probability density function
with such that , cf. Brilhante et al. [56] and Brilhante and Pestana [57].
As , , we conclude that the geometric mean
of n independent is a random variable with probability density function
where is the Euler’s Gamma function, being the indicator function of A.
Therefore, the cumulative distribution function of is
where , , is the upper incomplete Gamma function. Critical quantiles for can easily be computed from the critical quantiles of , where , since .
Observe, however, that using products of standard uniform random variables, or adding their exponential logarithms, provides essentially the same information. Pearson [55] acknowledged that combining p-values using
is equivalent to Fisher’s [6] earlier combination method based on
as described in SubSection 2.1.
In 1934, Pearson [58] observed that in bilateral contexts it would be more adequate to combine and , namely using
As already observed, is equivalent to . Similarly, using Fisher’s transformation, defined in (3) is equivalent to
which clearly is not -distributed. Owen [59] used the Bonferroni’s correction
to establish lower and upper bounds.
Instead of (3), we suggest the use of the minimum of the geometric means,
Combining p-values through their sum (Edgington [53]), or arithmetic mean,
is also feasible, but much less appealing than Fisher’s chi-square transformation method, since has a very cumbersome probability density function,
where is the largest integer not greater than x. However, for moderately large values of n, an approximation based on the central limit theorem can be used to perform an overall test on versus . But this procedure is not consistent, in the sense that it can fail to reject the overall test’s null hypothesis, even though the results of some of the individual p-values are extremely significant.
Wilson [60] recommends the use of the harmonic mean for combining mutually exclusive tests, not necessarily independent, assuming that the p-values being combined are valid. It was shown that effectively controls the strong-sense familywise error rate, i.e. the probability of falsely rejecting a null hypothesis in favor of an alternative hypothesis in one or more of all tests performed. The harmonic mean of p-values, whose distribution is in the domain of attraction of the heavy-tailed Landau skewed additive (1,1)-stable law [61], is robust to positive dependency between p-values and also to the distribution of weights w used in its computation, being as well insensitive to the number of tests, aside from being mainly influenced by the smallest p-values. Based on recent developments in robust risk aggregation techniques, Vovk and Wang [12], without making any assumptions on the dependence structure of the p-values to be combined, extended those results to generalized means and showed that np-values can be combined by scaling up the harmonic mean by a factor .
2.3. Which Combining Rule Should Be Used?
To illustrate the application of different combined methods, Examples 1 and 2 are considered using data taken from Hartung et al. [62]. The tables in the Supplementary Materials, containing critical values for each combined method, are used (case , i.e. no fake p-values, compared with fake p-values) to decide whether the hypothesis should be rejected or not.
Example 1
(Table 3.1, [62], p. 31). For the meta-analysis of case-control studies on the risk of lung cancer in women in relation to exposure to environmental tobacco smoke the p-values are
The observed values for the above combined tests statistics are:
In this case, is rejected at the usual significance level using all combined tests, with the exception of Tippett’s method, as expected, since only 4 of the 19 p-values are smaller than . As can be noted, Tippett’s rule drastically discards most of the information and therefore should not be considered a reliable test to make an overall decision.
Example 2
(Table 13.1, [62], p. 172). For the meta-analysis of validity studies examining the correlation between ratings of the instructor and student achievement the p-values are:
The observed values for the combined tests statistics are:
The overall rejection of seems more consistent in this example. However, a closer look at the data shows that 9 out of 20 p-values are greater than the usual significance level , which is an exceptional case, since p-values greater than often lead to the non-publication of the studies, thus creating a phenomenon known as publication bias. Four of the p-values are much greater than , which causes the rejection of when using the combined tests based on the transformations of p-values , , and , whereas the rejection using the mean of order r tests , , , , and is due to the existence of some very small p-values.
Both previous examples raise some concern on the validity and efficiency of combined tests and on the question of which one should actually be used. A common understanding on this matter is that any rational combining procedure should be monotone, in the sense that if one set of p-values leads to the rejection of the overall null hypothesis , any set of componentwise smaller p-values , , must also lead to its rejection.
Birnbaum [63] has shown that every monotone combined test procedure is admissible, i.e. provides a most powerful test against some alternative hypothesis for combining some collection of tests, and therefore is optimal for some combined testing situation whose goal is to harmonize eventually conflicting evidence, or to pool inconclusive evidence. In the context of social sciences, Mosteller and Bush [64] recommend Stouffer et al.’s [46] method, which is also preferred by Whitlock [65], while Littell and Folks [66,67] have shown that, under mild conditions, Fisher’s method is optimal for combining independent tests. Owen [59], showing that Birnbaum’s statement on the inadmissibility of Pearson’s two-sided combined test was wrong, recommends Pearson’s two-sided combination rule, given in (4). Marden [68], using the concepts of sensitivity and sturdiness, orders from best to worst , warning that all statistics perform worse as n increases.
The thorough comparison performed by Loughin [69] concludes that the normal combining function has a good performance in problems where evidence against the combined null hypothesis is spread among more than a small fraction of the individual tests. Moreover, when the total evidence is weak, Fisher’s method is the best choice if the evidence is at least moderately strong and is concentrated in a relatively small fraction of the individual tests. The Mudholkar and George’s [50] logistic combination method provides a compromise between the two. When the total evidence against the combined null hypothesis is concentrated in one or in a very few of the tests to be combined, Tippett’s minimum function can be useful as well. See also Won et al. [70] on how to choose an optimal method to combine p-values.
Since there is no unanimity among researchers as to which procedure should be used, a reasonable approach is to compare the results for a variety of tests. For this purpose, tables with critical values for the combined test statistics discussed earlier are presented as Supplementary Materials.
For more details on the early developments of combining one-sided tests, see the first chapter of Oosterhoff [71]. In what regards recent advances on combining tests, namely in a dependence framework, or using e-values, defined by expectations, instead of p-values, defined by probabilities, see recent developments in Vovk and Wang [72], Vovk et al. [73], and Vuursteen et al. [74].
3. Publication Bias
Published results have in general significant p-values, typically less than 0.05, and this publication bias is one of the ill-resolved problems in the meta-analysis of p-values. In fact, many published studies deal with significant p-values, see for instance the insistence on in Zintaras et al. [75].
The influential International Committee of Medical Journal Editors (ICMJE) [76] in its Uniform Requirements for Manuscripts states that
“Editors should seriously consider for publication any carefully done study of an important question, relevant to their readers, whether the results for the primary or any additional outcome are statistically significant. Failure to submit or publish findings because of lack of statistical significance is an important cause of publication bias’’.
The Journal of Articles in Support of the Null Hypothesis [77] offers “an outlet for experiments that do not reach the traditional significance levels (p < .05)[...]reducing the file drawer problem, and reducing the bias”, considering that “without such a resource researchers could be wasting their time examining empirical questions that have already been examined”.
As with many other techniques used in meta-analysis, publication bias can easily lead to erroneous conclusions in combined testing (Pestana et al. [78]). Indeed, if the set of available p-values comes mainly from studies considered worthy of publication because the observed p-values are small, thus pointing out to significant results, then the rejection of can be due to publication bias. Often, the assumption that the ’s are observations of independent Uniform(0,1) random variables is questionable, since they are frequently a set of low order statistics, given that p-values greater than 0.05 are less published.
Example 3
(Table B1, p. 726 in van Aert et al. [79] assessment of meta-analysis) For the set of the p-values
the observed values for the combined test statistics are:
is rejected, as expected, whatever combined test is used. In fact, the meta-analysis of these p-values is a pointless exercise, since it is obvious that they cannot be a random sample from the standard Uniform distribution.
As a matter of fact, it seems reasonable to assume for the set of p-values in Example 3 that the distribution of the underlying ’s is a , where the right endpoint is the unbiased estimate . Consequently, dividing the values by 0.0718 we obtain a genuine standard Uniform sample, i.e. 0.6814, 0.9615, 0.1853, 0.5184, 0.2620, 0.6368, 0.4278, 0.5964, 0.4668, 0.3818, 0.0418, 0.7400, 0.4668, 0.3540, 0.3344, 0.0321, 0.3540, 0.3665, 0.5978, 0.2397, 0.5086, 0.3999, 0.2787, 0.6940, 0.1867, and the observed values of the combined tests statistics for these new values are:
So there is no reason to reject the hypothesis that the sample of expanded values is from the standard Uniform distribution.
It is worth noting that under the moment of order k of the geometric mean is
Hence,
the standard deviation decreases to zero, the skewness steadily decreases after a maximum 0.2645 for , and the kurtosis increases from (for ) towards 0. Observe that for , the expected value of is greater than 0.36 and the standard deviation is smaller than 0.1. Therefore, whenever is smaller than a threshold , the test based on will lead to the rejection of , as it happens with the data from van Aert et al. [79], but a smaller than a low threshold can just be a consequence of publication bias.
The assessment of publication bias is often performed computing the number of non-significant p-values that would be needed to reverse the decision to reject based on the available p-values, which is illustrated with Examples 4 and 5.
Example 4.
For the seven p-values in Fogacci et al. [80]from studies on the effect of vitamin D supplements administered to pregnant women with risk of preeclampsia incidents:
it follows that . As , is rejected. In this example, , , and are greater than , and the rejection of is caused by the very small and values, thus raising some doubts as to whether the p-values are truly genuine. According to Hartung et al. [62], p. 177, to reverse the decision to reject at the significance level , it is necessary to compute the number of non-significant additional p-values such that
where for simplicity it is assumed that . The solution of depends on the value of . For instance, if , then , if , then , and if , then .
Example 5.
The p-values in Table 2 of Zintaras et al.’s [75] investigation of heterogeneity-based genome search for preeclampsia are:
Since , is also rejected (). In this case, to observe , it will be needed if , if , and if . Even if , it will require .
In Zintaras et al.’s [75] example, the high number of non-significant studies needed to reverse the rejection of seems to indicate that the decision is the consequence of having consistently low p-values, or possibly moderate censoring of non-significant p-values (note that ). In Fogacci et al.’s [80] example, the rejection of was due to , although 4 out of 7 p-values are greater than 0.05, and the fact that is quite small, can be considered suspicious.
Begg and Mazumdar [81] and Egger et al. [82] devised tests to detect publication bias. Jin et al. [83] and Lin and Chu [84] present interesting overviews, and Givens et al. [85] provide a deep insight on publication bias in meta-analysis, namely using data-augmentation techniques.
It is also worth mentioning that Zaykin et al. [40], Neuhäuser and Bretz [41] and Zhang [42] advocate the use of a truncated product combination statistic of only those p-values smaller than some specified cut-off value, which in practice dismisses publication bias. Dudbridge and Koeleman [43] go even further, proposing the combination of the most significant p-values. This recommendation clearly favors the rejection of , therefore increasing the probability of false positive results, and contributing to the misconception that significance implies importance.
4. Mendel Random Variables — Combined Tests with Genuine and Fake -Values
The assumption , , is rather naive. In fact, the alternative hypothesis states that some of the are true, and so a meta-decision on implicitly assumes that some of the ’s may have non-uniform distribution, cf. Hartung et al. [62], pp. 81–84; Kulinskaya et al. [86], pp. 117–119. Thus, the uniformity of the ’s is solely the consequence of assuming that the null hypothesis is true, and this far-fetched assumption led Tsui and Weerahandi [87] to introduce the concept of generalized p-values. See also Weerahandi [88], Hung et al. [89] and Brilhante [90], and references therein, on the promising concepts of generalized and of random p-values. Moreover, a consequence of publication bias is that most of the published studies point out to the rejection of . Hence, instead of combining p-values, it would be more reasonable to combine either generalized p-values or random p-values. Assuming that the p-values being combined can come from a combination of null and alternative hypotheses, Dai and Charnigo [91] investigated a Beta mixture adjustment. For large exploratory studies, an extreme-value distribution adjustment for fixed numbers of combined evidence and a Beta distribution adjustment for the most significant evidence are accurate and efficient (Dudbridge and Koeleman [92]).
Moreover, when the result of an experiment leads to a p-value which is not highly significant or significant, there is the possibility of the researcher carrying out a new experiment, in the hope of obtaining a "better" p-value that favors the publication of his study.
Such malpractice of trying to obtain results more attuned with the researcher’s expectations (or wishes) is scientifically wrong, eventually fraud, leading to results “too good to be true”, as Fisher [37] observed in his appraisal of Mendel’s data: “the data of most, if not all, of the experiments have been falsified so as to agree closely with Mendel’s expectations”. For more details on the (in)famous Mendel-Fisher controversy, see Franklin et al. [38], and Pires and Branco [39].
If a reported is the "best" of ℓ observed p-values in ℓ independent repetitions of an experiment, such "fake p-value" comes from the minimum of ℓ independent Uniform(0,1) random variables, so that with probability density function
On the other hand, fake p-values demand substantial changes in the computation of combined p-values. For instance, with regard to Fisher’s method, for fake p-values , it implies that . Therefore, for , i.e. for genuine p-values , it follows that . Hence, the existence of fake p-values requires the following adjustment to Fisher’s combined test:
but the problem is that the values are actually unknown.
Using the integral transform theorem, , and as far as Stouffer et al.’s method is concerned,
while for Chen’s statistic,
In what concerns Mudholkar and George’s statistic, if , then the cumulative distribution function and probability density function of are, respectively,
The central limit theorem can be used to obtain an approximation of , as long as we know which of the p-values are the fake ones and their corresponding values.
In fact, the main problem here is that there is no information on whether some of the reported p-values are in fact fake p-values, and if so, how many and which ones are. In the classical framework, the number n of p-values to be combined is generally small, and if the overall null hypothesis is true, it seems reasonable to expect that the number of fake p-values with distribution, , to be much smaller than the number of genuine standard Uniform distributed p-values. For what follows, it is assumed that the proportion of fake p-values among the observed p-values being combined is , .
With regard to fake p-values, it is likely that in most cases , especially when the second experiment provides a smaller p-value that supports the researcher’s expectations. Actually, if the second p-value is again non-significant, there is a good chance that this would continue to happen with other similar experiments, which have a cost attached (at least they are time-consuming). In this situation, the researcher will most likely decide to give up carrying out further experiments and no p-value will be reported.
For what follows, it is also assumed that the model for the p-values to be combined is , with , i.e. is a genuine p-value if , or a fake one if . As it is unknown whether is genuine or fake, the distribution of is a mixture of the minimum of two independent Uniform(0,1) random variables and of a Uniform(0,1) random variable, with weights and , respectively.
Therefore, has probability density function
where denotes the minimum of two standard uniform random variables , and . In other words,
More generally, tilting the probability density function of with pole , for , we obtain the probability density function of a random variable given by
and thus we shall say that when .
Note that , is the minimum of two independent standard uniform random variables, and is the maximum of two independent standard uniform random variables. For intermediate values of , is a mixture of a standard uniform random variable, with weight , and a Beta(1,2) random variable, and for , it is a mixture of a standard uniform random variable and a Beta(2,1) random variable, i.e. with cumulative distribution function
where if and if , and and denote, respectively, the minimum and maximum of two independent standard uniform random variables.
4.1. Deng and George’s Contractions with Mendel Random Variables
Let X and Y be independent random variables with support . The support extension resulting from or [respectively ] followed by the contraction [respectively ], so that , restores the unit support. These contractions have been used by Deng and George [44], with — i.e. — to obtain a useful characterization of the standard Uniform distribution. Theorem 1 extends their results to , random variables.
Theorem 1.
If and Y, with support , are independent random variables, then
In particular, if and are independent, then
and the cumulative distribution function of
is
where and .
Proof.
The probability density function of is , so for , . If and , then , and . Therefore, for ,
and consequently,
In what regards the random variable defined in (5),
and hence , i.e. .
On the other hand, for ,
and therefore
with . □
4.2. Testing Independence
The extension of classical methods of combining independent p-values to a more general framework of combining correlated p-values is nowadays an active area of research, with far-reaching consequences in dealing with taxa and investigation in Genomics and, more generally, with Big Data. Therefore, testing the independence of a sequence of standard uniform random variables versus autoregressive Mendel processes is relevant in the context of meta-analyzing p-values.
Let , , be a sequence of replicas of independent Mendel random variables . For and , define
If , then the sequence , , is the initial one, but if , then there is serial correlation.
The inverse transformation , with and , leads to
where , , , and
Since
for all , this is equivalent to
The following cases are considered.
- —
-
:If , the sequence , , is the initial one, and so the joint probability density function of iswhich requires solving the equationwhere is a sequence of independent standard uniform random variables, and therefore
- —
-
, :If and , then , andwith , and so . On the other hand, is the maximum likelihood estimator of , which is also sufficient for . The likelihood function is . Therefore, the hypothesis of independence should be rejected if , with the power of the test being equal to if , or 1 otherwise.
- —
-
, :For a general , it follows from and thatand with the independence of the ’s implying thatAs , the cumulative distribution function ofis
4.3. Combined Tests with Genuine and Fake p-values — Some Analytic Results
4.3.1. Tippett’s
Provided the number of fake p-values is known, it is straightforward to obtain the exact distribution of Tippett’s combined test statistic: If there are fake Beta(1,2) p-values among the n available ’s to be combined, . Therefore, the decision rule is to reject at a significance level if the minimum observed p-value .
Tippett’s case is quite unique, since the analytical results for the test statistics of the other combination methods are cumbersome.
4.3.2. Pearson’s
The computation of the probability density function of Pearson’s statistic when all ’s are independent genuine p-values is a straightforward exercise of multiplicative algebra of random variables, since
To accommodate fake p-values in the analysis, the first step is to obtain the cumulative distribution function of when there exists just one fake p-value in the sample, and the remaining p-values are genuine ones (note that it is irrelevant to know which is actually the fake one).
- —
- Probability density function of , with independent and
Let , where , , and are independent random variables, and define . Therefore,
where and are independent random variables. Since the joint probability density function of the random pair is
for ,
Consequently, for ,
Noting that , where , , and in particular, , (cf. Abramowitz and Stegun [93], 6.5.1–6.5.3 and 6.5.13), we get
Therefore, substituting the above expression in (6), it follows that
Note that due to the contraction resulting from multiplying random variables with support ,
and therefore for all , . In other words, , the Dirac degenerate at 0 "density", and , i.e. the Heaviside function.
- —
- Probability density function of , with independent and
Let be independent random variables. The probability density function of is
and from which we easily obtain the probability density function of ,
Applying recursive methods, the probability density function of is
4.3.3. Fisher’s Statistic Sampling Distribution for Combining p-Values from a Mendel(m) Population
If are independent and identically distributed random variables with probability density function f, the probability density function of the sum is the n-fold convolution of f, denoted by , and defined as
with and . As for the n-fold convolution of a finite mixture of probability density functions , i.e. with probability density function where and , it is
(Sarabia et al. [94]), which is also a mixture.
Let be a random sample with , , , i.e. with probability density function
and define .
If , then since , . If , define , . Therefore, for , the probability density function of can be expressed as
Consequently, if , the distribution of is a convex mixture of two exponential distributions, more precisely,
where denotes an exponential random variable with scale parameter . On the other hand, if , then the distribution of is also a convex mixture since its probability density function can be expressed as
where W has probability density function .
Note that if (respectively, ), probability density function (8) (respectively, probability density function (9)) can be considered a general mixture. Hence, the probability density function of is the n-fold convolution of a finite mixture when .
Although Theorem 1 in Sarabia et al. [94] only deals with convex mixtures, it is extended in Theorem 2 to general finite mixtures, i.e. mixtures where some mixing weights are allowed to be negative.
Theorem 2.
Let , , be probability density functions and X a random variable with probability density function defined by
where are real constants subject to . The probability density function of the n-fold convolution of f is
Proof.
Denoting by the characteristic function of the probability density function , , the characteristic function of , the probability density function of the n-fold convolution of f, is
As is the characteristic function of the convolution , the probability density function of the n-fold convolution of f is
which is an immediate consequence of the inversion formula for characteristic functions. □
Therefore, from Theorem 2 it follows that is a finite mixture when .
Since probability density functions (8) and (9) are formally equivalent, for what follows, it suffices to work with probability density function (8). Thus applying (7), we get for ,
where and .
Noticing that is the m-convolution of an exponential probability density function with scale parameter j, in other words, is the probability density function of the sum of m independent and identically distributed exponential random variables with scale parameter j, , it follows that is the probability density function of the Gamma distribution with shape parameter m and scale parameter j, and therefore
Hence,
Using the formula
(cf. Gradshteyn and Ryzhik [95], 3.383.1), where , , is the Beta function and 1 the Kummer’s confluent hypergeometric function, we obtain
Therefore, for ,
For example, if and ,
which is a convex mixture, and if and ,
which is a general mixture.
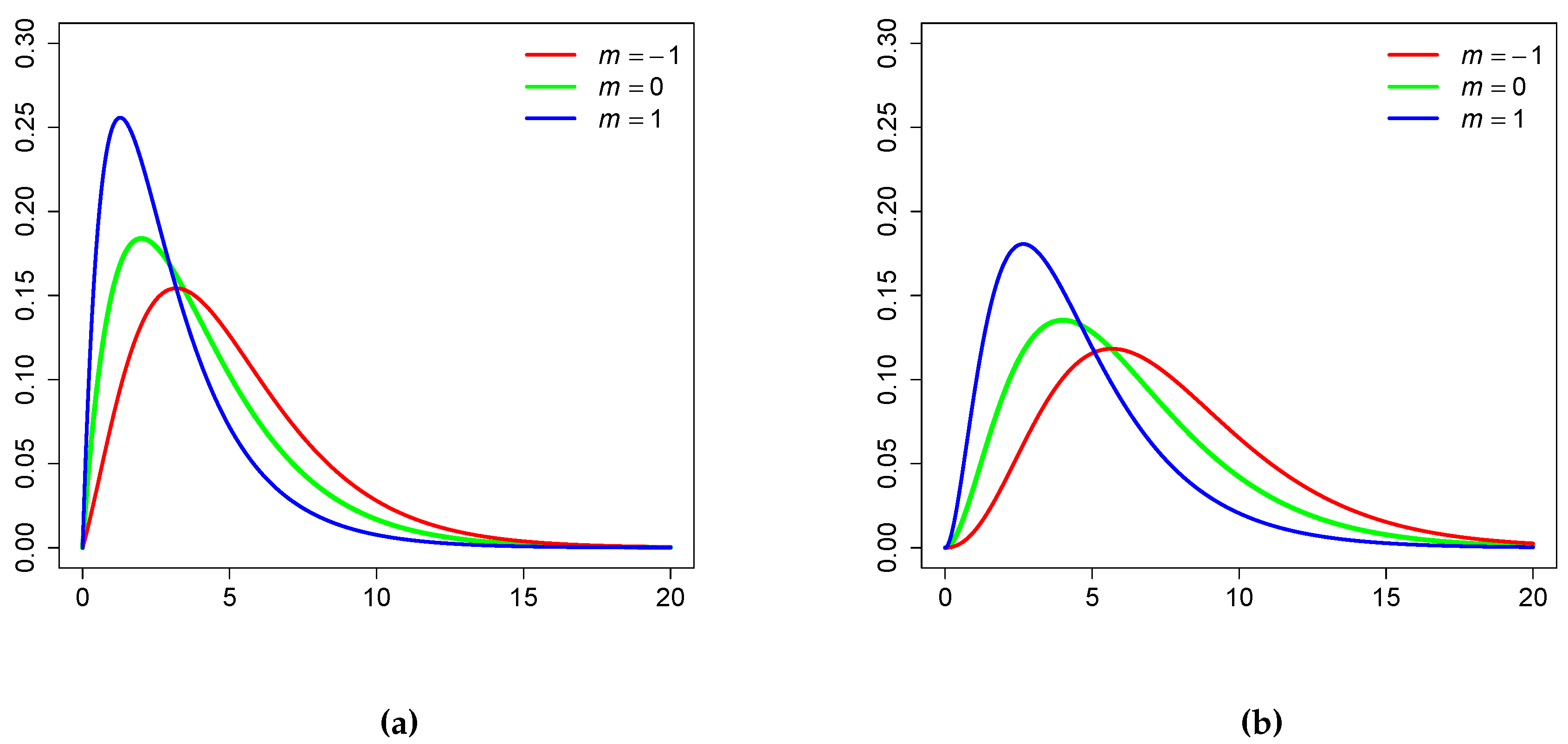
In Figure 1 we plot the probability density function of for and .
5. Discussion
With the exception of Tippett’s , the other combined test statistics mentioned in Section 2 have a distribution that does not allow a closed-form expression for the cumulative distribution function when there are fake p-values in the sample.
As already mentioned, it is in general impossible to know whether there exist or not fake p-values among the set of p-values to be combined. Therefore, a realistic approach is to examine possible scenarios and assess how the existence of fake p-values can affect the decision on the overall hypothesis .
For this purpose, a simple simulation was carried out with the software R (version 4.3.1), a language and environment for statistical computing (R Core Team 2023, [96]), to obtain quantile estimates of order q (q = 0.005,0.01,0.025,0.05,0.1,0.9,0.95,0.975,0.99,0.995) for the combined test statistics indicated in Section 2, and when some of the p-values in the sample are fake ones. The guidelines in Davison and Hinkley [97] on how to estimate quantiles (pp. 18-19) were followed here. The tables with the estimated quantiles (in a few cases some are exact) are supplied in the Supplementary Materials for sample sizes , and when there exists at most fake p-values. These tables are a useful tool to build up an overall picture, as is illustrated with Example 6.
Example 6.
For the set of fictional p-values:
the observed values for the combined test statistics are:
We reproduce below only the part for from the tables in the Supplementary Materials (without the standard errors), highlighting the critical quantiles that lead to the rejection of with an asterisk, as well as indicating the smallest significance level for which this happens.
• Fisher’s Statistic
| 0.900 | 0.950 | 0.975 | 0.990 | 0.995 | |||
| 18 | 0 | 0.025 | |||||
| 18 | 1 | 0.025 | |||||
| 18 | 2 | 0.025 | |||||
| 18 | 3 | 0.05 | |||||
| 18 | 4 | 0.05 | |||||
| 18 | 5 | 0.05 | |||||
| 18 | 6 | 0.10 |
• Stouffer’s Statistic
| 0.900 | 0.950 | 0.975 | 0.990 | 0.995 | |||
| 18 | 0 | 0.025 | |||||
| 18 | 1 | 0.025 | |||||
| 18 | 2 | 0.025 | |||||
| 18 | 3 | 0.01 | |||||
| 18 | 4 | — | |||||
| 18 | 5 | — | |||||
| 18 | 6 | — |
• Chen’s Statistic
| 0.900 | 0.950 | 0.975 | 0.990 | 0.995 | |||
| 18 | 0 | 0.10 | |||||
| 18 | 1 | 0.10 | |||||
| 18 | 2 | 0.10 | |||||
| 18 | 3 | 0.10 | |||||
| 18 | 4 | 0.10 | |||||
| 18 | 5 | 0.10 | |||||
| 18 | 6 | 0.10 |
• Mudholkar and George’s Statistic
| 0.900 | 0.950 | 0.975 | 0.990 | 0.995 | |||
| 18 | 0 | 0.025 | |||||
| 18 | 1 | 0.05 | |||||
| 18 | 2 | 0.05 | |||||
| 18 | 3 | 0.05 | |||||
| 18 | 4 | 0.10 | |||||
| 18 | 5 | 0.10 | |||||
| 18 | 6 | 0.10 |
• Geometric Mean
| 0.005 | 0.010 | 0.025 | 0.050 | 0.100 | |||
| 18 | 0 | 0.025 | |||||
| 18 | 1 | 0.025 | |||||
| 18 | 2 | 0.025 | |||||
| 18 | 3 | 0.05 | |||||
| 18 | 4 | 0.05 | |||||
| 18 | 5 | 0.05 | |||||
| 18 | 6 | 0.10 |
• Minimum of Geometric Means
| 0.005 | 0.010 | 0.025 | 0.050 | 0.100 | |||
| 18 | 0 | 0.05 | |||||
| 18 | 1 | 0.05 | |||||
| 18 | 2 | 0.05 | |||||
| 18 | 3 | 0.05 | |||||
| 18 | 4 | 0.05 | |||||
| 18 | 5 | 0.05 | |||||
| 18 | 6 | 0.10 |
• Harmonic Mean
| 0.005 | 0.010 | 0.025 | 0.050 | 0.100 | |||
| 18 | 0 | — | |||||
| 18 | 1 | — | |||||
| 18 | 2 | — | |||||
| 18 | 3 | — | |||||
| 18 | 4 | — | |||||
| 18 | 5 | — | |||||
| 18 | 6 | — |
• Arithmetic Mean
| 0.005 | 0.010 | 0.025 | 0.050 | 0.100 | |||
| 18 | 0 | 0.10 | |||||
| 18 | 1 | 0.10 | |||||
| 18 | 2 | — | |||||
| 18 | 3 | — | |||||
| 18 | 4 | — | |||||
| 18 | 5 | — | |||||
| 18 | 6 | — |
• Minimum
| 0.005 | 0.010 | 0.025 | 0.050 | 0.100 | |||
| 18 | 0 | — | |||||
| 18 | 1 | — | |||||
| 18 | 2 | — | |||||
| 18 | 3 | — | |||||
| 18 | 4 | — | |||||
| 18 | 5 | — | |||||
| 18 | 6 | — |
• Maximum
| 0.005 | 0.010 | 0.025 | 0.050 | 0.100 | |||
| 18 | 0 | 0.10 | |||||
| 18 | 1 | 0.10 | |||||
| 18 | 2 | 0.10 | |||||
| 18 | 3 | 0.10 | |||||
| 18 | 4 | — | |||||
| 18 | 5 | — | |||||
| 18 | 6 | — |
Note that the conclusions with and are the same, but it is obviously useful to supply both tables. The example has been constructed to have p-values in the range , some of them small and some large. This is a situation where and , which use both ’s and ’s, may be useful for an informed decision.
In fact, in this example, and perform almost as well as (or ) and better than . Moreover, the statistic seems to be less reliable than and , and except for the geometric () mean , the means of order , i.e. , , and , do not contribute effectively for a clearcut decision.
This example shows that the existence of fake p-values can influence the overall decision on , as expected, and the most recommended Fisher’s and Stouffer et al.’s methods are clearly affected by their existence. Aside from the number of fake p-values in the sample, their magnitude has also a bearing on the smallest level that leads to the rejection of .
6. Conclusions
Although significance testing and p-values have these days plenty of bad press and detractors, reporting low p-values still has a mythic standing and influences publication acceptance. Therefore, it is possible that research teams will try to obtain smaller p-values if the first ones obtained are not significant. In these unwanted situations, which were first pointed out by Fisher [37] when denouncing the possibility of fraud in Mendel’s theories (cf. also Franklin [38], and Pires and Branco [39]), the most realistic scenarios are:
- In the first experiment the p-value obtained was greater than 0.05 and the p-value obtained in the second experiment is smaller than 0.05. The first one is "hidden" and the second one is reported. However, the reported p-value is not genuine, it is the fake result of two P, and therefore it is Beta(1,2)-distributed.
- The p-values obtained in the first and second experiments were both greater than 0.05. This seems to indicate that there are no grounds to reject the null hypothesis and the most plausible consequence is the abandonment of the line of research, thus leading to no p-value being published. In fact, replicating experiments has costs, at least it is time consuming, and therefore discarding further experimentation seems to be a reasonable decision.
So, when meta-analyzing p-values via combining them, one must be aware that in the Brave New World of scientific achievements, where the underlying motto is "publish or perish", eventually some — but almost certainly very few — of the the ’s, , to be used in statistics are fake p-values, although in an honest world all p-values should be genuine values.
It is therefore reasonable to use tools such as the extensive tables supplied in the Supplementary Materials to compare the results of several combined tests, assuming that between the ’s there are fake p-values.
Supplementary Materials
The following supporting information can be downloaded at the website of this paper posted on Preprints.org.
Author Contributions
Conceptualization, M.F.B., M.I.G., S.M., D.P. and R.S.; Funding acquisition, M.I.G.; Investigation, M.F.B., M.I.G., S.M., D.P. and R.S.; Methodology, M.F.B., M.I.G., S.M., D.P. and R.S.; Project administration, M.F.B., D.P. and R.S.; Resources, M.F.B., M.I.G., and R.S.; Software, M.F.B. and R.S.; Supervision, M.F.B. and D.P.; Writing – original draft, M.F.B., M.I.G., S.M., D.P. and R.S.; Writing – review & editing, M.F.B., M.I.G., S.M., D.P. and R.S.. All authors have read and agreed to the published version of the manuscript.
Funding
Research partially supported by National Funds through FCT—Fundação para a Ciência e Tecnologia, project UIDB/00006/2020 (CEAUL). (https://doi.org/10.54499/UIDB/00006/2020)
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Pearson, K. On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling. Philosophical Magazine Series 5 1900, 50, 157–175. [Google Scholar] [CrossRef]
- Kennedy-Shaffer, L. Before p<0.05 to beyond p<0.05: Using History to contextualize p-values and significance testing. Amer. Stat. 2019, 73, 82–90. [Google Scholar] [CrossRef]
- Arbuthnott, J. An argument for divine providence, taken from the constant regularity observ’d in the births of both sexes. Philosophical Transactions of the Royal Society of London 1710, 27, 186–190. [Google Scholar] [CrossRef]
- Fisher, R.A. On the interpretation of χ2 from contingency tables, and the calculation of P. J. R. Stat. Soc. 1922, 85, 87–94. [Google Scholar] [CrossRef]
- Fisher, R.A. Statistical Methods for Research Workers; Oliver and Boyd: Edinburgh, UK, 1925. [Google Scholar]
- Fisher, R.A. Statistical Methods for Research Workers, 4th ed.; Oliver and Boyd: London, UK, 1932. [Google Scholar]
- Edgeworth, F.Y. The calculus of probabilities applied to psychical research, Part I. In Proceedings of the Society for Psychical Research; Society for Psychical Research, 1885; Vol. 3, pp. 190–199. [Google Scholar]
- Fisher, R.A. The arrangement of field experiments. Journal of the Ministry of Agriculture 1926, 33, 503–515. [Google Scholar]
- Utts, J. Replication and meta-analysis in parapsychology. Statist. Sci. 1991, 6, 363–378. [Google Scholar] [CrossRef]
- Greenwald, A.G.; Gonzalez, R.; Harris, R.J.; Guthrie, D. Effect sizes and p values: what should be reported and what should be replicated? Psychophysiology 1996, 33, 175–183. [Google Scholar] [CrossRef] [PubMed]
- Colquhoun, D. The reproducibility of research and the misinterpretation of p-values. R. Soc. Open Sci. 2017, 4, 171085. [Google Scholar] [CrossRef] [PubMed]
- Vovk, V.; Wang, R. Combining p-values via averaging. Biometrika 2020, 107, 791–808. [Google Scholar] [CrossRef]
- Neyman, J.; Pearson, E. On the use and interpretation of certain test criteria for purposes of statistical inference: Part I. Biometrika 1928, 20A, 175–240. [Google Scholar] [CrossRef]
- Neyman, J.; Pearson, E.S. On the problem of the most efficient tests of statistical hypotheses. Phil. Trans. R. Soc. Lond. Series A 1933, 231, 289–337. [Google Scholar] [CrossRef]
- Fisher, R. Statistical methods and scientific induction. J. R. Stat. Soc. Series B Stat. Methodol. 1955, 17, 69–78. [Google Scholar] [CrossRef]
- Pearson, E.S. Statistical concepts in the relation to reality. J. R. Stat. Soc. Series B 1955, 17, 204–207. [Google Scholar] [CrossRef]
- Lehmann, E.L. The Fisher, Neyman-Pearson theories of testing hypotheses: one theory or two? J. Amer. Stat. Assoc. 1993, 88, 1242–1249. [Google Scholar] [CrossRef]
- Cox, D.R.; Spjøtvoll, E.; Johansen, S.; van Zwet, W.R.; Bithell, J.F.; Barndorff-Nielsen, O.; Keuls, M. The role of significance tests [with discussion and reply]. Scandinavian Journal of Statistics 1977, 4, 49–70. [Google Scholar]
- Ioannidis, J.P.A. Why most published research findings are false. Chance 2005, 18, 40–47. [Google Scholar] [CrossRef]
- Ioannidis, J.P.A. What have we (not) learnt from millions of scientific papers with p values? Amer. Stat. 2019, 73, 20–25. [Google Scholar] [CrossRef]
- Wasserstein, R.L.; Lazar, N.A. The ASA statement on p-values: context process, and purpose. Amer. Stat. 2016, 70, 129–133. [Google Scholar] [CrossRef]
- Wasserstein, R.L.; Schirm, A.L.; Lazar, N.A. Moving to a world beyond "p<0.05". Amer. Stat. 2019, 73, 1–19. [Google Scholar] [CrossRef]
- Baker, M. Statisticians issue warning on P values. Nature 2016, 531, 151–151. [Google Scholar] [CrossRef]
- Goodman, S.N. Toward evidence-based medical statistics. 1: The P value fallacy. Ann. Intern. Med. 1999, 130, 995–1004. [Google Scholar] [CrossRef] [PubMed]
- Goodman, S. A dirty dozen: twelve p-value misconceptions. Seminars in Hematology 2008, 45, 135–140. [Google Scholar] [CrossRef] [PubMed]
- Kühberger, A.; Fritz, A.; Lermer, E.; Scherndl, T. The significance fallacy in inferential statistics. BMC Research Notes 2015, 8, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Benjamini, Y. It’s not the p-values’ fault. J. Amer. Stat. Assoc. 2016. Online Supplement to ASA Statement on P-values. [Google Scholar]
- Greenland, S. Valid p-values behave exactly as they should: Some misleading criticisms of p-values and their resolution with s-values. Amer. Stat. 2019, 73, 106–114. [Google Scholar] [CrossRef]
- Goodman, S.N. Why is getting rid of p-values so hard? Musings on science and statistics. Amer. Stat. 2019, 73, 26–30. [Google Scholar] [CrossRef]
- Halsey, L.G. The reign of the p-value is over: what alternative analyses could we employ to fill the power vacuum? Biol. Lett. 2019, 15, 20190174. [Google Scholar] [CrossRef] [PubMed]
- Colquhoun, D. The false positive risk a proposal concerning what to do about p-values. Amer. Stat. 2019, 73, 192–201. [Google Scholar] [CrossRef]
- Goodman, W.M.; Spruill, S.E.; Komaroff, E. A proposed hybrid effect size plus p-value criterion: empirical evidence supporting its use. Amer. Stat. 2019, 73, 168–185. [Google Scholar] [CrossRef]
- Rougier, J. p-Values, Bayes factors, and sufficiency. Amer. Stat. 2019, 73, 148–151. [Google Scholar] [CrossRef]
- Di Leo, G.; Sardanelli, F. Statistical significance: p value, 0.05 threshold, and applications to radiomics—reasons for a conservative approach. Eur. Radiol. Exp. 2020, 4, 1–8. [Google Scholar] [CrossRef]
- Murdoch, D.S.; Tsai, Y.L.; Adcock, J. P-values are random variables. Amer. Stat. 2008, 62, 242–245. [Google Scholar] [CrossRef]
- Fraser, D.A.S. The p-value function and statistical inference. Amer. Stat. 2019, 73, 135–147. [Google Scholar] [CrossRef]
- Fisher, R.A. Has Mendel’s work been rediscovered? Ann. Sci. 1936, 1, 115–137. [Google Scholar] [CrossRef]
- Franklin, A.; Edwards, A.W.; Fairbanks, D.J.; Hartl, D.L. Ending the Mendel-Fisher Controversy; University of Pittsburgh Press: Pittsburgh, USA, 2008. [Google Scholar] [CrossRef]
- Pires, A.M.; Branco, J.A. A statistical model to explain the Mendel-Fisher controversy. Stat. Sci. 2010, 25, 545–565. [Google Scholar] [CrossRef]
- Zaykin, D.V.; Zhivotovsky, L.A.; Westfall, P.H.; Weir, B.S. Truncated product method for combining P-values. Genetic Epidemiology 2002, 22, 170–185. [Google Scholar] [CrossRef]
- Neuhäuser, M.; Bretz, F. Adaptive designs based on the truncated product method. BMC Medical Research Methodology 2005, 5, 1–7. [Google Scholar] [CrossRef]
- Zhang, H.; Tong, T.; Landers, J.; Wu, Z. TFisher: A powerful truncation and weighting procedure for combining p-values. Ann. Appl. Stat. 2020, 14, 178–201. [Google Scholar] [CrossRef]
- Dudbridge, F.; Koeleman, B. Rank truncated product of P-values, with application to genomewide association scans. Genet. Epidemiol. 25, 360–366. [CrossRef]
- Deng, L.Y.; George, E.O. Some characterizations of the uniform distribution with applications to random number generation. Ann. Inst. Statist. Math. 1992, 44, 379–385. [Google Scholar] [CrossRef]
- Tippett, L.H.C. The Methods of Statistics; Williams & Norgate Ltd.: London, UK, 1931. [Google Scholar] [CrossRef]
- Stouffer, S.A.; Schuman, E.A.; DeVinney, L.C.; Star, S.; Williams, R.M. The American Soldier: Adjustment During Army Life; Vol. I, Princeton University Press: New Jersey, USA, 1949. [Google Scholar] [CrossRef]
- Chen, Z. Optimal tests for combining p-values. Appl. Sci. 2022, 12, 322–322. [Google Scholar] [CrossRef]
- Liu, J.Z.; Mcrae, A.F.; Nyholt, D.R.; Medland, S.E.; Wray, N.R.; Brown, K.M.; AMFS Investigators; Hayward, N.K.; Montgomery, G.W.; Vissher, P.M.; et al. A versatile gene-based test for genome-wide association studies. The American Journal of Human Genetics 2010, 87, 139–145. [Google Scholar] [CrossRef]
- Cinar, O.; Viechtbauer, W. The poolr package for combining independent and dependent p values. J. Stat. Softw. 2022, 101, 1–42. [Google Scholar] [CrossRef]
- Mudholkar, G.S.; George, E.O. The logit method for combining probabilities. In Symposium on Optimizing Methods in Statistics; Rustagi, J., Ed.; Academic Press: New York, USA, 1979; pp. 345–366. [Google Scholar]
- Kolmogorov, A.N. Sur la notion de la moyenne. Atti della Reale Accademia Nazionale dei Lincei. Classe di scienze fisiche, matematiche, e naturali. Rendiconti Serie VI 1930, 12, 388–391. [Google Scholar]
- Hardy, G.H.; Littlewood, J.E.; Pólya, G. Inequalities, 2nd ed.; Cambridge University Press: Cambridge, UK, 1952. [Google Scholar]
- Edgington, E.S. An additive method for combining probability values from independent experiments. J. Psychol. 1972, 80, 351–363. [Google Scholar] [CrossRef]
- Wilkinson, B. A statistical consideration in psychological research. Psychol. Bull. 1951, 48, 156–158. [Google Scholar] [CrossRef]
- Pearson, K. On a method of determining whether a sample of size n supposed to have been drawn from a parent population having a known probability integral has probably been drawn at random. Biometrika 1933, 25, 379–410. [Google Scholar] [CrossRef]
- Brilhante, M.F.; Gomes, M.I.; Mendonça, S.; Pestana, D.; Pestana, P. Generalized Beta models and population growth, so many routes to chaos. Fractal Fract 2023, 7. [Google Scholar] [CrossRef]
- Brilhante, M.F.; Pestana, D. BetaBoop function, BetaBoop random variables and extremal population growth. In International Encyclopedia of Statistical Science, 2nd ed.; Lovric, M., Ed.; Springer: Berlin, Germany, 2024. [Google Scholar]
- Pearson, K. On a new method of determining "goodness of fit". Biometrika 1934, 26, 425–442. [Google Scholar] [CrossRef]
- Owen, A.B. Karl Pearson’s meta-analysis revisited. Ann. Stat. 2009, 37, 3867–3892. [Google Scholar] [CrossRef] [PubMed]
- Wilson, D.J. The harmonic mean p-value for combining dependent tests. In Proceedings of the of the National Academy of Sciences, Vol. 116, USA; 2019; pp. 1195–1200. [Google Scholar] [CrossRef]
- Landau, L. On the energy loss of fast particles ionization. J. Phys. (USSR) 1944, 8, 201–205. [Google Scholar] [CrossRef]
- Hartung, J.; Knapp, G.; Sinha, B.K. Statistical Meta-Analysis with Applications; Wiley: New Jersey, USA, 2008. [Google Scholar] [CrossRef]
- Birnbaum, A. Combining independent tests of significance. J. Amer. Statist. Assoc. 1954, 49, 559–574. [Google Scholar] [CrossRef]
- Mosteller, F.; Bush, R. Selected quantitative techniques. In Handbook of Social Psychology: Theory and Methods; Lidsey, G., Ed.; Addison-Wesley: Cambridge MA, USA, 1954. [Google Scholar]
- Whitlock, M.C. Combining probability from independent tests: the weighted Z-method is superior to Fisher’s approach. J. Evol. Biol. 2005, 18, 1368–1373. [Google Scholar] [CrossRef]
- Littell, R.C.; Folks, L.J. Asymptotic optimality of Fisher’s method of combining independent tests, I. J. Amer. Statist. Assoc. 1971, 66, 802–806. [Google Scholar] [CrossRef]
- Littell, R.C.; Folks, L.J. Asymptotic optimality of Fisher’s method of combining independent tests, II. J. Amer. Statist. Assoc. 1973, 68, 193–194. [Google Scholar] [CrossRef]
- Marden, J.I. Sensitive and sturdy p-values. Ann. Stat. 1991, 19, 918–934. [Google Scholar] [CrossRef]
- Loughin, T.M. A systematic comparison of methods for combining p-values from independent tests. Comput. Stat. Data Anal. 2004, 47, 467–485. [Google Scholar] [CrossRef]
- Won, S.; Morris, N.; Lu, Q.; Elston, R.C. Choosing an optimal method to combine P-values. Stat. Med. 2009, 28, 1537–1553. [Google Scholar] [CrossRef]
- Oosterhoff, J. Combination of One-Sided Statistical Tests; Vol. 28, Mathematical Centre Tracts, Mathematical Centre Amsterdam: Amsterdam, Netherland, 1969. [Google Scholar]
- Vovk, V.; Wang, R. E-values: calibration, combination and applications. Ann. Statist. 2021, 49, 1736–1754. [Google Scholar] [CrossRef]
- Vovk, V.; Wang, B.; Wang, R. Admissible ways of merging p-values under arbitrary dependence. Ann. Stat. 2022, 50, 351–375. [Google Scholar] [CrossRef]
- Vuursteen, L.; Szabó, B.; van der Vaart, A.; van Zanten, H. Optimal testing using combined test statistics across independent studies. Advances in Neural Information Processing Systems 2023, 36. [Google Scholar] [CrossRef]
- Zintzaras, E.; Kitsios, G.; Harrison, G.A.; Laivuori, H.; Kivinen, K.; Kere, J.; Messinis, I.; Stefanidis, I.; Ioannidis, J.P.A. Heterogeneity-based genome search meta-analysis for preeclampsia. Hum Genet 2006, 120, 360–370. [Google Scholar] [CrossRef]
- ICMJE. Uniform Requirements for Manuscripts Submitted to Biomedical Journals. https://web.archive.org/web/20120716211637/http://www.icmje.org/publishing_1negative.html, 2024.
- JASNH. Welcome to the Journal of Articles in Support of the Null Hypothesis. https://www.jasnh.com/about.html.
- Pestana, D.; Rocha, M.L.; Vasconcelos, R.; Velosa, S. Publication Bias and Meta-Analytic Syntheses. In Advances in Regression, Survival Analysis, Extreme Values, Markov Processes and other Statistical Applications; Lita da Silva, J., Caeiro, F., Natário, I., Braumann, C., Eds.; Springer: Berlin, Germany, 2013; pp. 347–354. [Google Scholar] [CrossRef]
- van Aert, R.C.; Wicherts, J.M.; van Assen, M.A. Conducting Meta-Analyses Based on p Values: Reservations and Recommendations for Applying p-Uniform and p-Curve. Perspect. Psychol. Sci. 2016, 11, 713–729. [Google Scholar] [CrossRef]
- Fogacci, S.; Fogacci, F.; Banach, M.; Michos, E.D.; Hernandez, A.V.; Lip, G.Y.H.; Blaha, M.J.; Toth, P.P.; Borghi, C.; Cicero, A.F.G.; et al. Vitamin D supplementation and incident preeclampsia: A systematic review and meta-analysis of randomized clinical trials. Clin. Nutr. 2020, 39, 1742–1752. [Google Scholar] [CrossRef]
- Begg, C.B.; Mazumdar, M. Operating characteristics of a rank correlation test for publication bias. Biometrics 1994, 50, 1088–1101. [Google Scholar] [CrossRef]
- Egger, M.; Davey, S.G.; Schneider, M.; Minder, C. Bias in meta-analysis detected by a simple, graphical test. BMJ 1997, 315, 629–634. [Google Scholar] [CrossRef]
- Jin, Z.C.; Zhou, X.H.; He, J. Statistical methods for dealing with publication bias in meta-analysis. Stat. Med. 2015, 34, 343–360. [Google Scholar] [CrossRef]
- Lin, L.; Chu, H. Quantifying publication bias in meta-analysis. Biometrics 2018, 74, 785–794. [Google Scholar] [CrossRef]
- Givens, G.H.; Smith, D.D.; Tweedie, R.L. Publication bias in meta-analysis: a Bayesian data-augmentation approach to account for issues exemplified in the passive smoking debate. Stat. Sci. 1997, 12, 221–250. [Google Scholar] [CrossRef]
- Kulinskaya, E.; Morgenthaler, S.; Staudte, R.G. Meta Analysis. A Guide to Calibrating and Combining Statistical Evidence; Wiley: Chichester, UK, 2008. [Google Scholar] [CrossRef]
- Tsui, K.; Weerahandi, S. Generalized p-values in significance testing of hypothesis in the presence of nuisance parameters. J. Amer. Stat. Assoc. 1989, 84, 602–607. [Google Scholar] [CrossRef]
- Weerahandi, S. Exact Statistical Methods for Data Analysis; Springer: New York, USA, 1995. [Google Scholar] [CrossRef]
- Hung, H.; O’Neill, R.; Bauer, P.; Kohn, K. The behavior of the p-value when the alternative is true. Biometrics 1997, 53, 11–22. [Google Scholar] [CrossRef]
- Brilhante, M.F. Generalized p-values and random p-values when the alternative to uniformity is a mixture of a Beta(1,2) and uniform. In Recent Developments in Modeling and Applications in Statistics; Oliveira, P., Temido, M., Henriques, C., Vichi, M., Eds.; Springer: Heildelberg, Germany, 2013; pp. 159–167. [Google Scholar] [CrossRef]
- Dai, H.; Charnigo, R. Omnibus testing and gene filtration in microarray data analysis. J. Appl. Stat. 2008, 35, 31–47. [Google Scholar] [CrossRef]
- Dudbridge, F.; Koeleman, B.P.C. Efficient computation of significance levels for multiple associations in large studies of correlated data, including genomewide association studies. Am. J. Hum. Genet. 2004, 75, 424–435. [Google Scholar] [CrossRef]
- Abramowitz, M.; Stegun, I.A. Handbook of Mathematical Functions: with Formulas, Graphs, and Mathematical Tables, 8th ed.; Dover: New York, USA, 1972. [Google Scholar]
- Sarabia, J.M.; Prieto, F.; Trueba, C. The n-fold convolution of a finite mixture of densities. Appl. Math. Comput. 2012, 218, 9992–9996. [Google Scholar] [CrossRef]
- Gradshteyn, I.S.; Ryzhik, I.M. Table of Integrals, Series, and Products, 5th ed.; Academic Press: San Diego, USA, 1980. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2023. [Google Scholar]
- Davison, A.C.; Hinkley, D.V. Bootstrap Methods and their Application; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar] [CrossRef]
Figure 1.
Probability density function of for : (a) . (b) .
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



