Submitted:
19 August 2024
Posted:
20 August 2024
You are already at the latest version
Abstract
The paper presents theoretical notions with practical applications for establishing of one dental bur lifetime (durability and reliability based on the active part wear considering a series of statistical indicators. For the justification application of theoretical notions in practice, a conical-cylindrical dental bur was studied experimentally, to obtain a series of data in the work process, necessary for statistical calculation. The parameter taken into consideration in this paper is mass lost through the dental bur active part wear, tested. This is useful for the dental bur lifetime establishment and its extension or even optimization in operation. The loss of mass of the dental bur active part is analyzed in the work process by the results and experimental data obtained and validated by a numerical calculation statistical-mathematical. The numerical calculation approximates very well the mass lost through the wear at different rotation speeds and operation times, with those experimentally determined ones, based on which it was established lifetime. The results showed that the dental bur works with high yield in the first 20 hours of work, , after which it should be replaced with a new one.
Keywords:
Dental bur
; Lifetime
; Reliability
; Mass lost
; Wear
1. Introduction
The main requirement for the efficient and effective operation of a technical system is durability and reliability of the system According to refs. [1,2], durability represents the period as a technical system is kept in operation, in well-established conditions, and the materials, even and after the operation, keep their initial properties. Instead, reliability ensures the operation safety of the technical system, without breaking down over the working process time, according to the prescribed norms [2,3,4], thus being a quality characteristic. A modern description of durable and reliable technical systems is systemic presented in Figure 1.
Mathematically, the essential components that define the safety in the exploitation of the system, in known working conditions (of availability, reliability, and maintenance of the system), i.e. without failures, are presented.
Reliability, R(t), as a function of time (t – operation time, variable size), represents the operation probability, in a time range [0, t) [4], at predetermined parameters, failure-free and with values between 0 and 1.
Practically, the reliability is determined by calculation, (established during the product design [5,6]) followed by the verification in the laboratory, and in the system operation is confirmed the effective reliability. For each product/element of the technical system, can be determined the reliability of each element resulting from series production [7], with the start of the system's operation, also experimental. Therefore, reliability is the main component of total quality control.
This paper's theoretical notions refer only to the dental bur active part wear, which is verified through a practical application. Thus, the dental bur active part failure will be analyzed, also experimentally, together with its wear [6,7,8].
The active part is the element without restoration of a dental bur (loses working capacity due to failure or wears [6,7,8]), i.e. it is not repairable but replaced/changed. The defect, in the studied case, represents a deviation from the quality and it assumes the operation interruption in the set time range, or the inability to function at the parameters imposed by the designer, of the dental bur active part.
According to [8], defects are physical imperfections, material inconveniences, etc. that can appear during the execution phase, due to material, performer, equipment used, etc., and during operation, due to the working environment, wear, shocks, deformations, etc. Thus, by summing up the operation times of the system, the quantitative failures can be determined [6,9].
Dental burs being fine mechanics tools, made of expensive materials and used for delicate operations from a technical point of view, their rapid wear requires studies and research, to extend their lifetime or even optimize their operation. This involves a detailed analysis, in the working process, by wear calculation that limits the dental burs' lifetime (durability and reliability) [9,10].
The wear process of the dental burs’ active part is analyzed through the theoretical presentation of the methodology of analytical and practical statistical calculation for its wear and with the appropriate explanations. The justification by statistical calculation of dental burs' active part wear will be done through experimental tests with practical applications, regarding extending the lifetime, even optimizing operation; providing new ideas for constructive solutions, and establishing some criteria possible for replacement of used dental burs.
2. Materials and Methods
The phenomenon of friction-wear stands out, therefore, by its great complexity due to the multitude and interaction in the operation of all factors, external (load, speed, environment, etc.) and internal (the material of the friction couplings with the respective structure and hardness, roughness, temperature etc.). This perfectly objective situation, which is accentuated when moving from laboratory research on models to operational conditions, explains to some extent the difficulties and the current state of wear calculation.
The interaction of the friction-wear processes is represented schematically in Figure 2, where you can see an image of the interdependence of the complex processes that take place on the friction surfaces.
The mechanical processes, respectively of superficial interaction and friction, give rise to thermal processes of accumulation and heat transfer, which influence both the processes due to the action of the environment, chemical and tribochemical, as well as the processes of modifying the structure, with implications on the subsequent interaction processes superficial and final dimensional changes (wear).
The elements that justify the statistical calculation of wear are presented in detail in refs. [6,9,10,11] and can be synthesized in two main directions:
- the statistical nature of the friction-lubrication-wear process, namely: the random mode of production of real area contacts, the formation of wear particles, the variation of the surface structure and condition, the variation of external parameters, the mode of action of lubricants and additives, etc.);
- that the analytical calculation relationships include factors that can be constant and experimentally determined coefficients, they cannot separate the influence of the weight of the respective factors and cannot cover all types of wear that contribute to surface degradation.
The statistical calculation of wear has the advantage that the relationships obtained by statistical means - regression relationships - are relatively easy to obtain, starting from data and experimental results, which include the interaction of all factors [9,10].
However, knowing the error, with such relations a considerably larger volume of information can be obtained than that entered for their determination.
To be able to apply certain quantitative methods for extracting the desired information, it must be possible to find a (statistical) model of the studied phenomenon that incorporates its essential characteristics as realistic as possible. At the same time, the (statistical) model not to be too complicated for analytical handling [6,8]. Also, it is necessary that the phenomenon (process) studied statistically can be mathematically formalized conveniently. The solution to this problem (of finding the statistical-mathematical model) was the concept of a random variable whose value is a number determined by the event resulting from an experiment.
The failure-free operation time of a product (here the dental bur), and the hardness of certain assembly or working elements of the dental unit are examples of random variables. These random variables characterize the respective phenomena/processes. The behavior of random variables from a mathematical point of view is described by the failure function, F(x). Then, by experiment is defined as the practical verification of a phenomenon, process, or technical data by voluntarily causing the phenomenon or process to appear, by repeating it in the laboratory, or by following its development in the production process.
3. Results and Discussions
3.1. Theoretical aspects
The distribution law establishes the correspondence between the random values, xi, and the respective probabilities, pi using an analytical relationship, as follows: P(X = xi) = P(xi) = pi called probability function or distribution function, F(x), which it can be empirical or theoretical. If the probability of the phenomenon/process (X = xi), i.e. P(X = xi) is obtained through experience based on statistical observation data, then the statistical probability is a relative frequency, and the distribution is empirical. The failure function, F(x) is the most representative characteristic of a random variable and defines the probability of the phenomenon/process, that the variable value, X be less than the value of a given x:
If the random variables, X follow a continuous statistical distribution, the function, F(x) has the form:
where, f(x) - is the frequency function (probability distribution density), which is the derivative of the function, F(x), and R(x) – is the reliability function. The plot of the function, f(x) is illustrated in Figure 3.
The value of the quantity, f(x)dx represents the probability that the variable, x belongs to the elementary interval, dx. The function plot, F(x) from Figure 4 looks that:
that is, the area bounded by the function curve, f(x), and the abscissa axis is equal to unity.
When studying a quality characteristic, the experimenter has at his disposal observational data obtained by measurements of durability. This durability is a random variable. Even if its distribution is not known, certain indicators, and certain measures [7] of the trend of the considered variable are necessary.
An experimental distribution (obtained through observations), respectively empirical, shows that for any characteristic of the population, a variation tendency with two aspects is generally observed: localization around a certain value (position), respectively variation (scattering), Figure 5.
They are phenomena located around the same values, but they present different scatters (see Figure 5). It is noted that the distribution can be symmetrical or asymmetrical about the location area. There are several statistical indicators with which a quantitative analysis can be performed to compare trends in location and variation (dispersion), namely:
a) Location indicators - indicate the value where the actual data of the phenomenon/process tends to cluster. The main trend location indicator is the average [12] (arithmetic average, being the most important), M(X) and
b) Variation indicators - those indicators that represent the deviation of the values, x from their arithmetic mean and include:
- dispersion, D(X) or with σ2 (σ = ) – represents the square mean deviation), if it is defined about the mean value, and mathematically the relation is given:
The average squared deviation, σ calculated is a "guarantee" of the accuracy of the determinations and can only be calculated if there are at least three values [8]. On the other hand, the value of the mean square deviation, σ allows conclusions to be drawn only if it comes from at least 30 values and, at the same time, the calculation is made only if the distribution is normal (Gaussian) or almost Gaussian.
- quartile of the random variable, Xα defined as the equation root:
F(Xα) = α,
and is another reliability indicator, and α is defined as percentile
This indicator expresses the time at which a system or its component works with a certain probability (1 – F(x)).
The first collected data on the values of the investigated characteristic are presented as a disordered table. By ordering the collected (experimental) data, the statistical/statistical string (series) is obtained. Sorting is usually done in ascending order.
Data grouping is done on grouping intervals, the size of which is generally taken to be equal, except for extreme intervals, when different values can be used. The grouping intervals can be set as a number with the relation [7, 13, and 14]:
where, Z is the record data total number.
n = 1 + 3.322 lg Z,
The size (amplitude) of the interval (class) is:
where, xmax and xmin are the maximum and minimum values of the data string [7,8,14,15].
During the execution of tests and the collection of experimental data, values appear that are substantially different in size from the other values, they are much smaller or much larger than the rest of the respective statistical series. Because of this, it is natural to suspect these data as "outliers", i.e. they are not from the statistical/statistical string/series. These are due to specific random influencing factors, measurement errors due to devices, operators, data recording mistakes, or data coming from a phenomenon/process other than the one under study. Until now, no absolute criterion has been established for the instant recognition of the presence of outliers [8], which differ clearly (glaringly, visibly) from the other values of the statistical series.
There is a rich palette of tests (statistical criteria) to identify the presence of outliers. But to minimize "outlier" data/values, it is necessary to reach the state of stability (it does not mean, however, that all the causes generating outliers are canceled). This is possible, when the two parameters of the selection are known: the mean, , and the dispersion, D(X), respectively the mean square deviation, σ of the data. Because statistical tests are used when the values come from a normal (Gaussian) distribution, some of the main statistical parameters are checked.
For the analysis of a parameter, it can be estimated pointwise (as an isolated value) or with a confidence interval or significance threshold, if an interval is established that includes a probability, P, the true value of the estimated parameter (the degree of precision of the estimate or the probability of the estimate). Therefore, the probability value, P, implies a certain interval, (x1, x2), according to the relationship:
and to which the respective parameter belongs.
It is mentioned that there is a "risk" or the probability that the true value will fall outside the considered confidence interval.
Depending on how the risk is placed on the confidence interval, it can be:
- confidence interval with bilateral risk (symmetric or asymmetric - the risk is placed with equal values, (α/2) on either side of the extreme values of the interval, Figure 6).
Analyzing Figures 10 and 11 it can be seen that R(t) is monotonically decreasing, instead, F(t) is increasing. These functions take values in the range [0,1] because when t → ∞, R(t) = 0, F(t) = 1, and when t → 0, R(0) = 1, F(0) = 0 and f(t) verifies the relationship .
The dental burs' reliability can also be specified with the help of the numerical values of the indicators attached to the operating time, t (variable), until the first failure. These indicators (presented above) are: M(t), D(t), σ, and tα, etc.
The values, M(t) of the operation time without failure are determined with relation (4)and presented in Table 2. By integration of the function, M(t), was obtained t = 20,433 hours, in the working conditions at the rotation speed of 7000 rpm.
The system (the dental bur active part) is without reconditioning, then M(t) represents the average time without system failure, until the first failure. M(t) of the system, i.e. the average value of t, can be expressed either by function R(t) or function f(t) (see relation (4)).
The variation of the random variable, t, or the distribution variation, D2(t) is defined by relation (5) and is obtained D2(t) = 2.562 hours, and the mean square deviation, σ, of t, is the indicator that can often be used instead of the D2(t) and results from 1.600 hours.
D2(t) and σ show the degree of uniformity of system/product performance (here, dental burs of the same type) from the point of view of reliability, by their values. If the technological process of manufacturing the system/product is well established, then the D2(t) and σ values are relatively small and show us the degree of uniformity of the set of tested dental burs, in the present case.
The last important reliability indicator considered is the operating time quartile, tα, defined as the root of the equation:
what results from equation/relation (6) and α with values from 0.01...0.99, is defined as a percentile.
At a rotation speed of 7000 rpm and α = 0.99 was obtained tα = 21,502 hours. In the reliability theory, the value his tα is interpreted as a guaranteed time, i.e. the period when the defective elements proportion in a certain system/group does not exceed the value, α pre-set [4]. The value of tα = 21,502 hours is very close to t2 = 21,573 hours, calculated analytically, which justifies the correlation between the theoretical and experimental results.
As stated above, the first data collected regarding the values of the investigated parameter (the lost mass by the dental bur active part) is presented as a disordered mass, and by ordering (ascending) of the experimental data, the statistical series is obtained.
The grouping of the data is done on grouping intervals, whose number, n calculated with relation (7) is n = 5 (must be an integer and it was considered Z = 16 tested dental burs) and whose size is generally taken to be equal, except for the extreme intervals, when can use different values. The size (amplitude) of the interval is determined based on relation (8) and is A = (1.4 – 0.5)/5 = 0.18.
Another important role in the reliability theory has it too also the function, h(t) = f(t)/R(t), R(t) ≠ 0 that measures the intensity (rate) of failure (the instantaneous risk of failure), or the hazard of a system/component product, defined as the failure rate limit in the interval [t , t+Δt], Δt > 0 very small [4], whose variation is presented in Figure 12, was used.
It can be seen that the failure risk rate is around 10%, for 20 hours and increases approximately exponentially in the 21st hour of operation. This means that the dental bur active part is taken out of operation after 20 operation hours and is normal that it be replaced.
The evolution of function h(t) shows that there is no failure risk, in the range t Є (0, 14) hours, the variation being linear, with a very small slope. In the range t Є (14, 18), the wear phenomenon becomes visible because h(t) has a variation after a fast-growing curve, and the failure risk increases. Then, in the range t Є (18, 21) hours, the failure risk becomes inevitable, when the plot of h(t) increases, after an exponential curve, suddenly.
Therefore, it is confirmed the experimental results correlate, with the analytical ones for the researched dental burs, i.e. can work without major risk of failure for up to 18 hours. At the same time, this proves the closeness between the hours determined analytically based on the experimental results to those of operation without a major failure.
On the other hand, when measuring by weighing of mass lost through wear by the dental burs active part and presented in Table 2 obtained different random values, each value having several repetitions, so a frequency of its own. These values are located in an interval with two limit values (lower and upper).
The values distribution between the limit two ones of the range can vary (with their frequency) after a distribution law. It is mentioned that the variation range of a property/characteristic/parameter reflects the quality level of a product of industrial manufacturing.
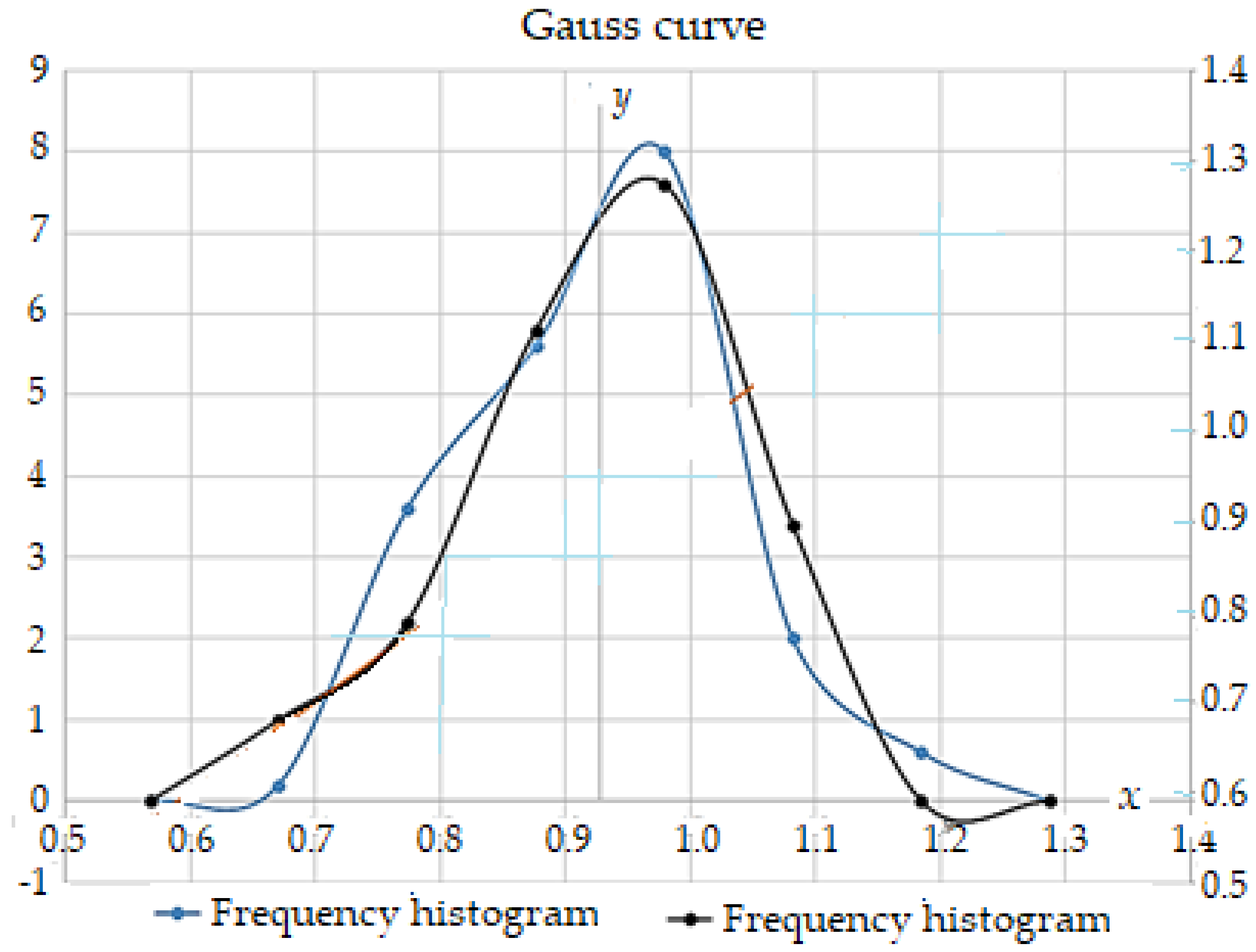
The lost mass values through effective wear (random variable) are distributed after the normal (Gaussian) distribution law because factors that determine their dispersion through wear are of the same order, accidental and independent, in large numbers and must be less than a given value what corresponds to a probability, p, i.e. of reliability, R(t)).
The normal distribution or Gaussian, represents the frequency function or probability distribution density, f(x), which is closest to a normal distribution function, of the shape:
whose variation over time is shown in Figure 13.
It is observed on the probability density function curves two inflection points, of abscissas 0.88 and 1.08, where the area bordered by these abscissas and curves represents about 58.33% of the entire surface.
This proves that the values of mass lost by wear of dental burs active part are the most distributed.
The curves present a maximum of approximately, y = 5.03 at x = 0.95 (blue curve) and y = 4.98 for the same x = 0.95 (curve black), the reliability obtained being approximately 97.42% of the entire area (i.e., limited by the curves and the abscissa axis, in the range (0.67, 1.18) - confidence range), so, a reliability excellent, and the intervals (-∞, 0.67) and (1.18, +∞) can be practically neglected.
Thus, the scattering/confidence range is (0.67, 1.18), with limit deviations of ± 0.25 compared to the values distribution center (cluster), and the critical range is (-∞, 0.67) U (1.18, +∞). Therefore, the lost mass values through wear have a Gaussian (normal) distribution, and the function, f(x) is a normal distribution function or the probability distribution density (the blue and black curves from Figure 13).
4. Conclusions
• The phenomenon of friction-wear is noticeable, due to the multitude and interaction in the operation of all factors, external (load, speed, environment, etc.) and internal (the material of the friction couplings with the respective structure and hardness, roughness, temperature, etc. ), a perfectly objective situation, which is accentuated when moving from laboratory research on models to operational conditions, explains to some extent the difficulties and the current state of wear calculation.
• The wear statistical calculation starts from the real situation reflected by experimental data, as the basis for the analytical calculation relations (regression relations), given the interaction of all influencing factors. It is justified, even from the statistical nature of the friction-wear process.
• It is necessary to find a (statistical-mathematical) model for the studied phenomenon/process (wear of the dental bur active part) in view quantitative extract of the desired information. At the same time, not to be too complicated for analytical handling, but to incorporate its essential characteristics as realistically as possible.
• The solution to this problem is the concept of a random variable - a quantity determined by the event resulting from the performance of an experiment, the case of establishing the operating time without failures (in this case), of the dental bur active part as an example of random variables. The distribution function is used to compare random variables.
• When the values come from a normal distribution, some of the main statistical parameters, average, dispersion, mean square deviation, etc. are determined and checked. If these checks do not lead to favorable conclusions regarding the normality of the data distribution, the measurement data from the statistical series will be checked more thoroughly.
• The results showed that the investigated dental burs may operate without failure major risk until 18 hours, very close to those determined experimental, which validates the correlation between analytical calculation and the experimental test results.
• The researched parameter of the analyzed dental burs was the mass lost through wear, determined by weighing, taking different random values, between two limits, each value repeating itself several times (having its frequency), and their scattering can be represented through a distribution law.
• Most experimental data of the mass lost by the wear of the dental bur active part are very close to the Gaussian normal distribution and the probability density (frequency function) is a normal distribution function, so Gaussian.
In perspective, it is envisaged to expand the analysis of wear behavior by statistical calculation, based on experimental data, and to other types of dental burs.
References
- Kapur K., Feng Q., Statistical Methods for Product and Process Improvement. In: Pham, H. (eds) Springer Handbook of Engineering Statistics. Springer Handbooks. Springer, London, 2006. [CrossRef]
- ***http://dexonline.net (accessible September 30, 2023).
- Liu T., Yu J., Wang H., Li H., Zhou B., Modified Method for Determination of Wear Coefficient of Reciprocating Sliding Wear and Experimental Comparative Study, Mar. Sci. Eng.2022, 10(8), 1014. [CrossRef]
- Burlacu G., Danet N., Bandrabur C., Duminica T., Reliability, Maintainability and Availability of Technical Systems (in Romanian), Matrimax Publishing House, 2005, Bucharest, Romania, ISBN: 973-685-891-X.
- Vodă V.Gh., Isaic-Maniu Al., Bârsan-Pipu N., Breakdown. Statistical models with applications (in Romanian), Economic Publishing House, 1999, Bucharest, Romania, ISBN 973-590-179-X.
- Pavelescu, D., Tribotehnica (in Romanian), Technical Publishing House, Bucharest, 1983.
- Laurent L., Pillet M., Conformity and statistical tolerancing, Int. J. Metrol. Qual. Eng.2018, 9 (1), 1-8. [CrossRef]
- Văleanu, I., Hâncu M., Elements of general statistics (Ph.D. Thesis in Romanian), Litera Publishing House, 1990, Bucharest, Romania.
- Ilie F., Saracin I.A., Establishing the Durability and Reliability of a Dental Bur Based on the Wear, Materials2023, 16(13), Number: 4660, https://www.mdpi.com/1996-1944/16/13/4660.
- Ilie F., Saracin I.A., Gh. Voicu, Study of Wear Phenomenon of a Dental Milling Cutter by Statistical–Mathematical Modeling Based on the Experimental Results, Materials 2022, 15, 1903. [CrossRef]
- Blau, P.J., Tribosystem analysis: A practical approach to the diagnosis of wear problems, 1st Edition, Publisher: CRC Press, Taylor & Francis Group, Boca Raton, 2016, Abingdon Oxfordshire, England. [CrossRef]
- Birolini A., Chapter 7: Statistical Quality Control and Reliability Tests. In: Reliability Engineering. Springer, Berlin, Heidelberg, Germany. [CrossRef]
- Queiroz T., Monteiro C., Carvalho L., Francois K., Interpretation of Statically Data: The Importance of Affective Expressions, Statistics Education Research Journal2017, 16(1), 163-180, http://iase-web.org/Publications.php?p.
- Li. J., Application of Statistical Process Control in Engineering Quality Management, IOP Conf. Series: Earth and Environmental Science2021, 831, 012073. [CrossRef]
- Tudor A., Prodan Gh., Muntean C., Motoiu R., Durability and reliability of mechanical transmissions (in Romanian), Technical Publishing House, 1988, Bucharest, Romania.
- Saracin I.A., Studies and research on the durability and realiability of dental milling cutters (in Romanian), Ph.D. Thesis, 2021, Bucharest, Romania.
- Cho J-H., Yoon H-I., Han J-S., Kim D-J., Trueness of the Inner Surface of Monolithic Crowns Fabricated by Milling of a Fully Sintered (Y, Nb)-TZP Block in Chairside CAD-CAM System for Single-visit Dentistry, Materials2019 12(19), 3253. [CrossRef]
- Fry R., McManus S., Smooth Bump Functions and Geometry of Banach Spaces, A Brief Survey, Expositiones Mathematicae2002, 20(2), 143-183. [CrossRef]
- https://mathworld.wolfram.com/BumpFunction.html (acces 12 October, 2023).
Figure 1.
General systemic description of a technical system.
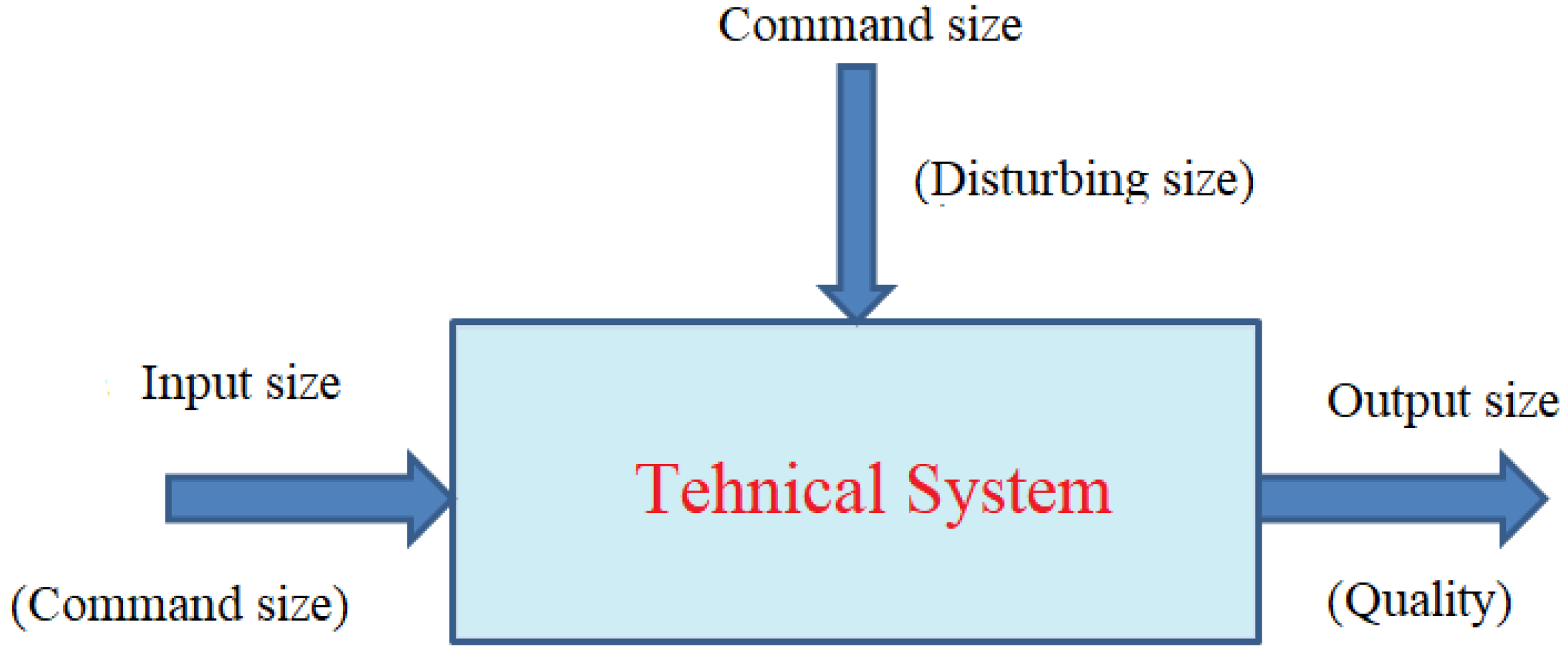
Figure 2.
Interaction diagram of friction-wear processes.
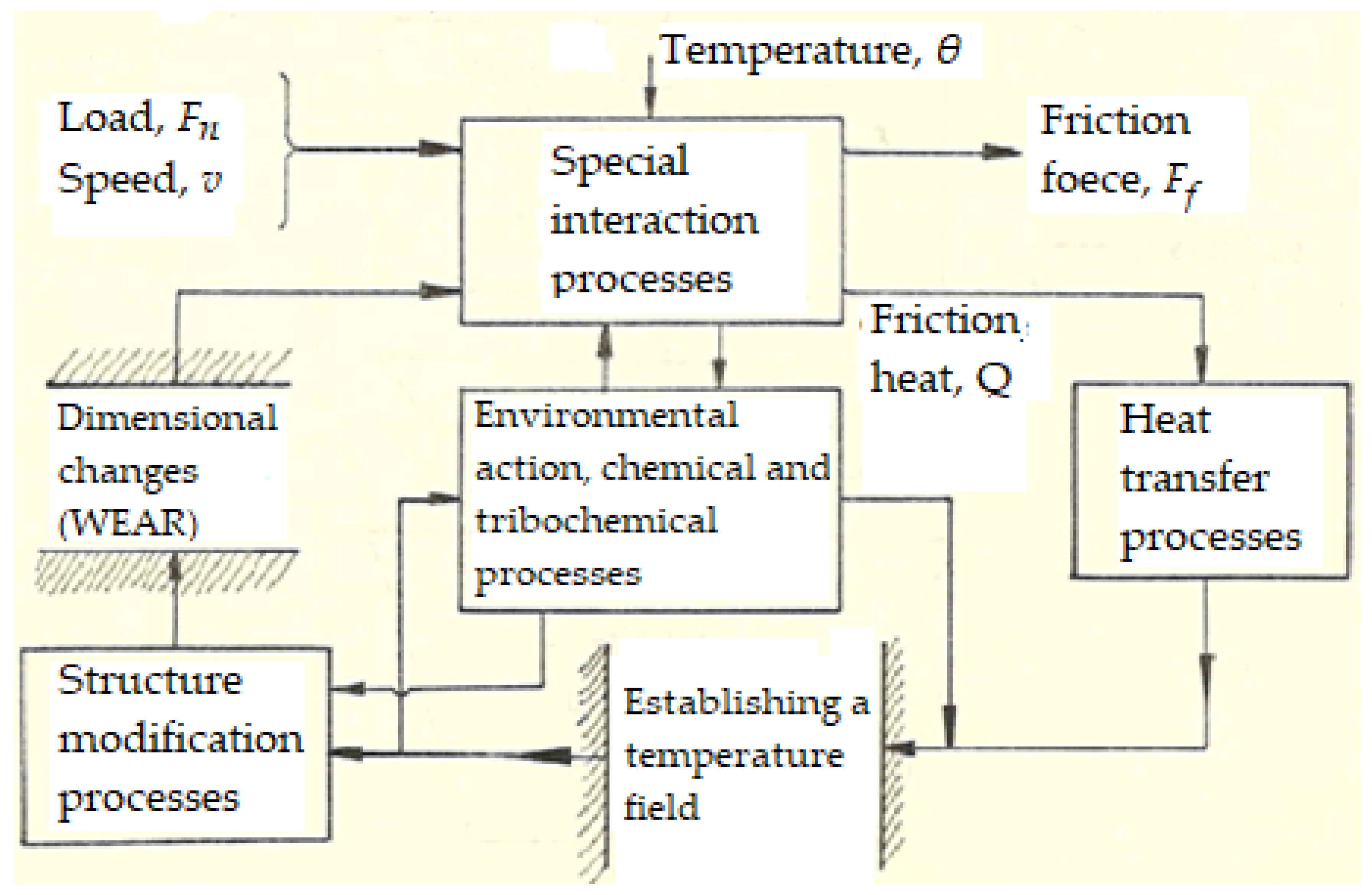
Figure 3.
Variation plot of the function, f(x), for continuous functions.
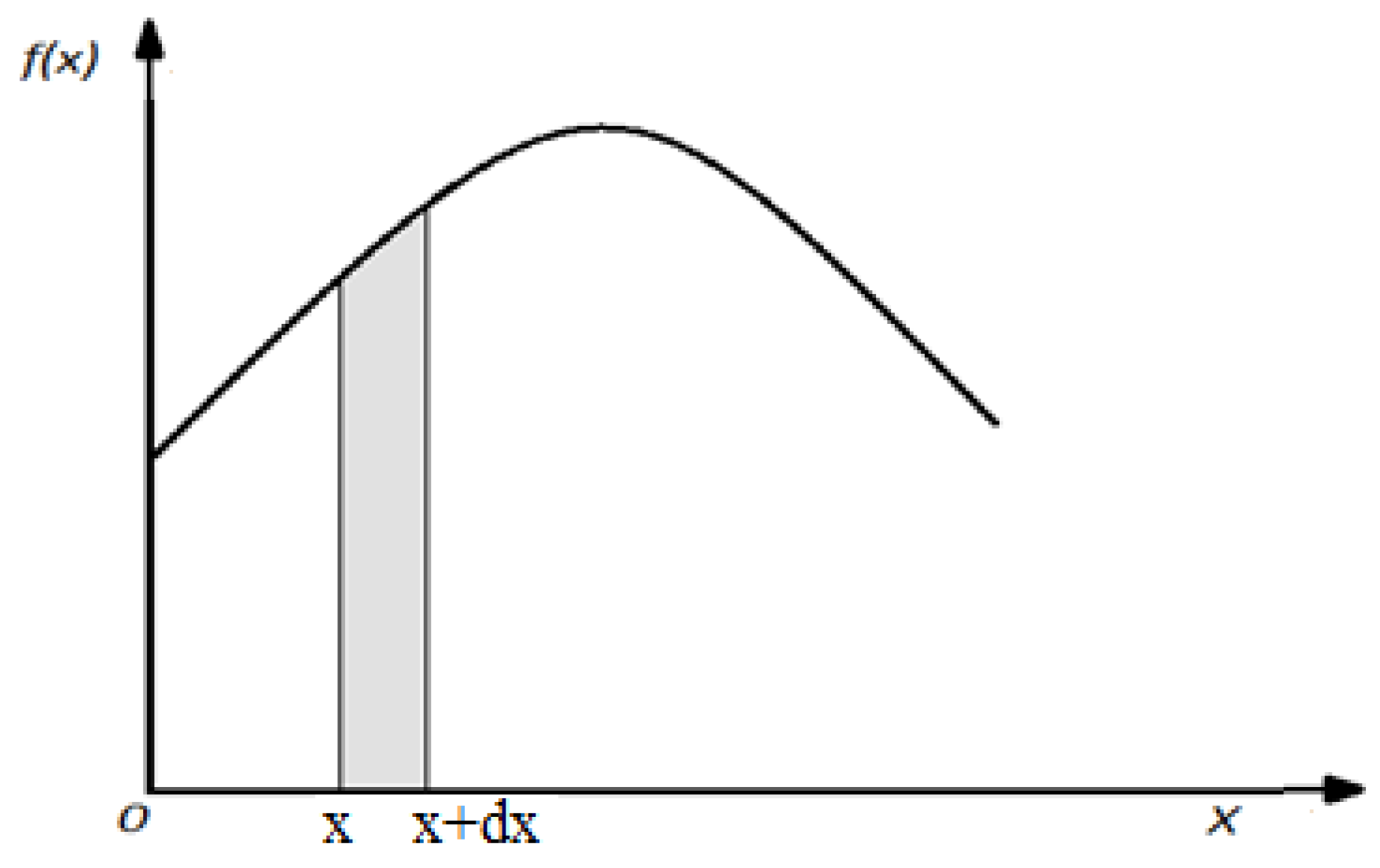
Figure 4.
Distribution function continuous, F(x).
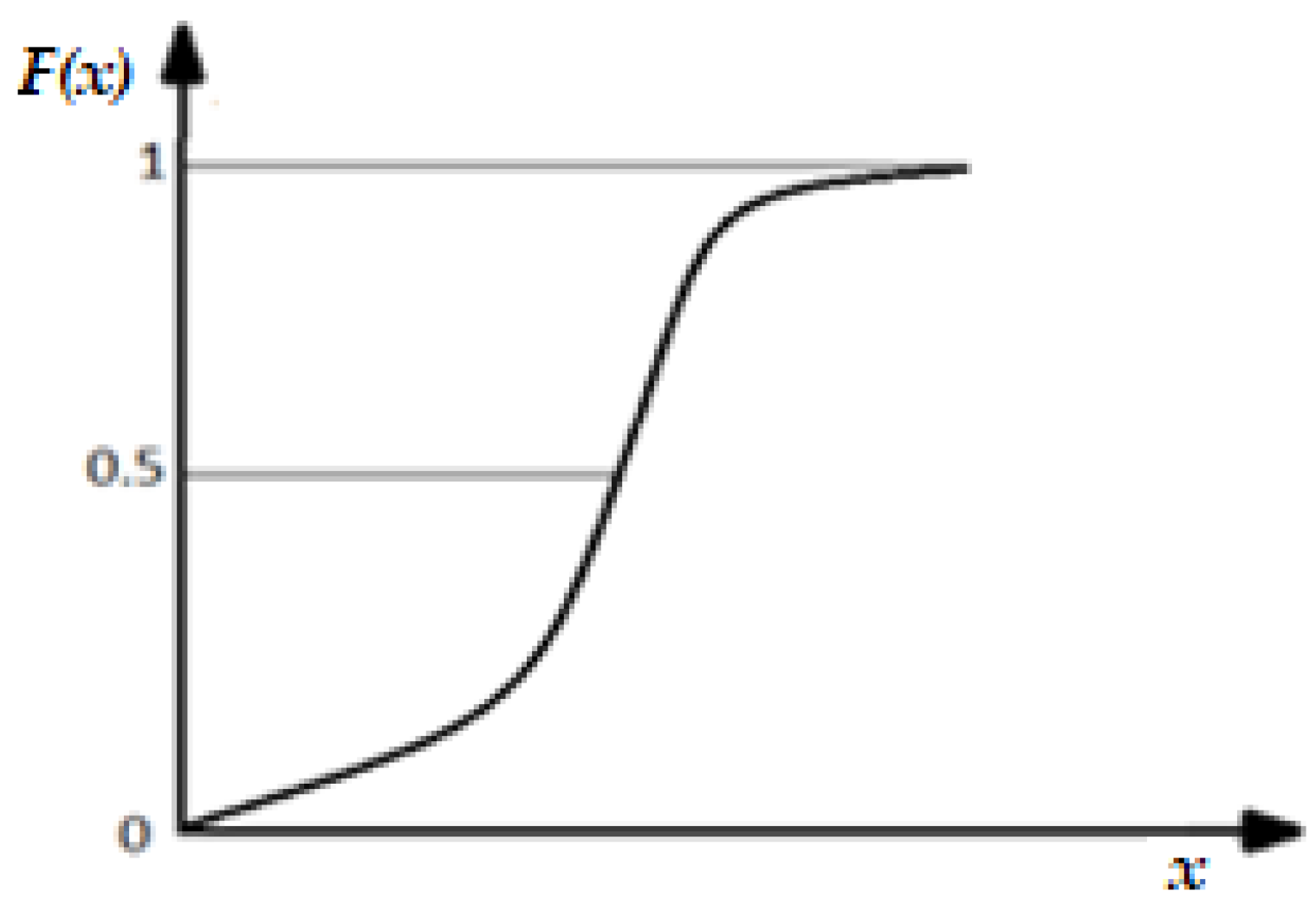
Figure 5.
Representation of distribution functions for phenomena/processes with different scatters.
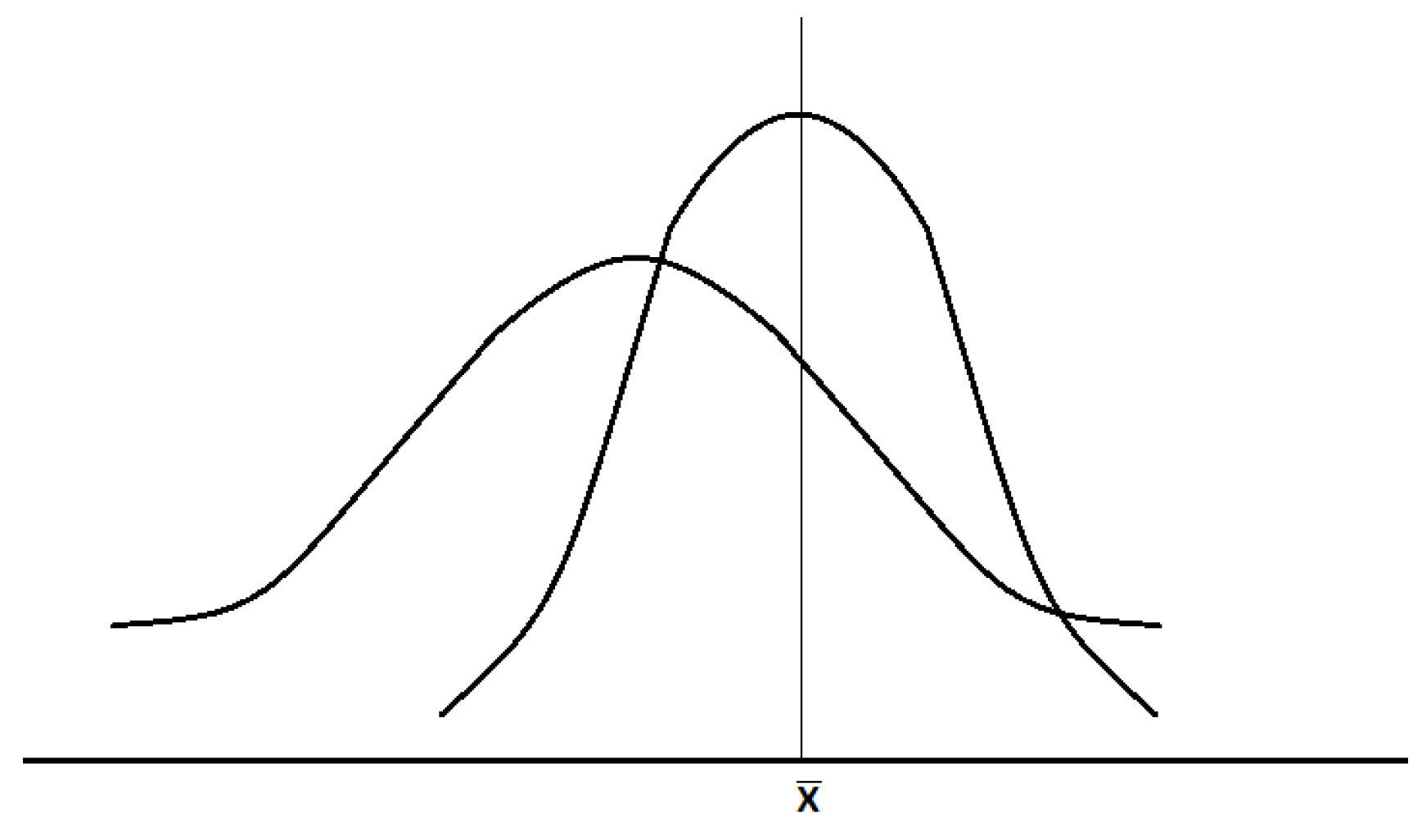
Figure 12.
Instantaneous risk (failure) function plot, h(t), for the investigated dental burs.
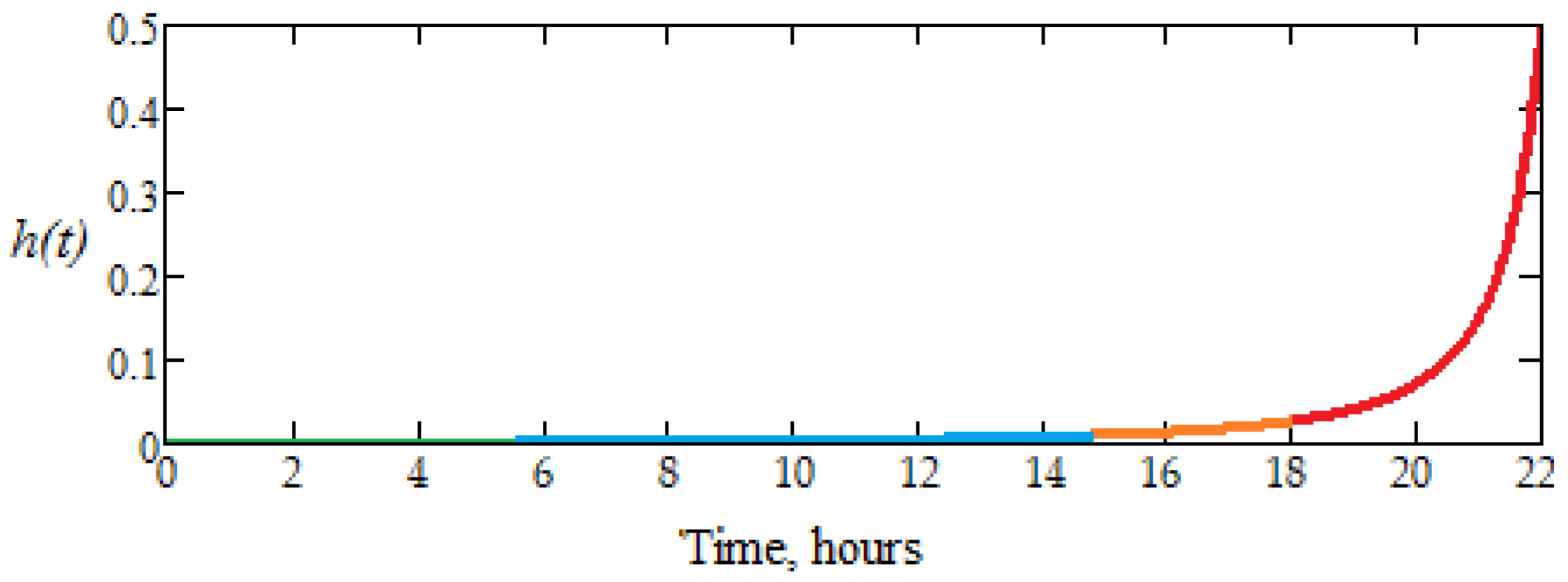
Figure 13.
Probability density plot for the Gaussian (normal) distribution law.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



