
Submitted:
21 August 2024
Posted:
21 August 2024
You are already at the latest version
Abstract
This paper presents an innovative methodology for enhancing museum visitor experiences through personalized content delivery using a combination of explicit and implicit visitor profiling. The approach integrates Bluetooth Low Energy (BLE) smart badges to collect telemetry data, enabling precise visitor localization and dynamic group formation based on real-time proximity and shared interests. Initial profiling begins with OAuth registration and brief surveys, which is then refined through continuous tracking of exhibit interactions and time spent at each exhibit. An AI-driven system delivers content to individual and group profiles, fostering both personalized learning and social interaction. This methodology addresses the limitations of traditional profiling by adapting to visitor behaviors in real-time while maintaining a strong focus on data privacy and ethical considerations. The proposed system not only enhances engagement and satisfaction but also sets the stage for future advancements in personalized cultural experiences.
Keywords:
visitor profiling
; smart museums
; smart badges
; content personalization
1. Introduction
In recent years, museums have transitioned from traditional repositories of artifacts to dynamic institutions providing immersive and educational experiences [1]. This transformation has been significantly influenced by advancements in technology, which have enabled museums to engage visitors through innovative methods. Personalization has become a critical element in optimizing visitor engagement, as it allows for the personalization of experiences based on individual interests, preferences, and learning styles [2].
Traditional museum experiences typically adhere to a one-size-fits-all model [3], which can lead to varying degrees of visitor satisfaction and engagement. Static exhibits and generalized information often fail to accommodate the diverse interests and backgrounds of contemporary visitors. Consequently, there is a growing demand for content delivery systems that can dynamically adapt to individual visitor preferences in real-time.
Personalization strategies have shown promise in enhancing visitor experiences across various domains, including entertainment and education [4]. For museums, the ability to deliver tailored content that aligns with individual preferences can significantly improve visitor satisfaction and engagement [5]. Personalized experiences not only make visits more enjoyable but also enhance learning outcomes by presenting information that is relevant and accessible to each visitor.
User profiling plays a vital role in delivering personalized content, as it enables systems to understand and anticipate individual user preferences and behaviors. By constructing detailed user representations based on data and multi-behavioral patterns, personalized systems can tailor content to address specific needs, thereby enhancing user satisfaction and engagement. Purificato et al. [6] provide an in-depth examination of user profiling, tracing its evolution from early stereotype models to advanced deep learning techniques. The research underscores the importance of creating precise user representations through implicit data collection and multi-behavior modeling, incorporating sophisticated approaches like graph data structures. The authors also emphasize the significance of privacy-preserving methods, explainability, and fairness in user profiling.
Visitor profiling methods, such as pre-visit surveys and basic demographic data collection, often fall short in capturing the dynamic nature of visitor preferences and behaviors [7,8]. These traditional methods, while useful for initial information, do not fully account for the nuances of how visitors interact with exhibits in real time. Consequently, there is a growing demand for sophisticated methods and technologies capable of dynamically responding to the evolving interests of visitors throughout their museum experience.
Technological advancements have enabled the collection and analysis of visitor data, facilitating the creation of personalized experiences [9,10]. Artificial Intelligence (AI) plays a crucial role in this personalized approach [11]. AI-driven systems, including museum-specific trained ChatGPT models, can generate tailored content by utilizing visitor profiles and real-time data. This ensures that the information provided is relevant, engaging, and appropriate for diverse audiences, including children, students, adults, and individuals with disabilities.
This paper aims to enhance the museum experience by addressing the limitations of traditional user profiling methods and leveraging modern technology. We propose a comprehensive personalization approach that begins with coarse visitor segmentation using OAuth user registration, which categorizes visitors into broad groups. These profiles are refined through short surveys administered during the museum tour and through implicit profiling that tracks visitor movements and interactions with exhibits. Additionally, dynamic group formation based on real-time telemetry data collected from Bluetooth Low Energy (BLE) smart badges is introduced. These innovations aim to enhance visitor engagement, provide tailored experiences, and improve overall satisfaction in museum settings.
2. Related Work
2.1. User Profiling Methods
User profiling methods are typically categorized into explicit, implicit, and hybrid approaches, each with distinct techniques for data collection and analysis. Purificato et al. [6] introduce a novel category termed pseudo-explicit profiling.
Explicit profiling, often referred to as static profiling, relies on user participation to gather data through online forms, questionnaires, or direct input of preferences. Although these techniques leverage extensive user-generated data, they are often insufficient for capturing the dynamic nature of visitor behavior and interests during museum visits.
Pseudo-explicit user profiling offers a new approach by utilizing publicly shared data from sources such as social media accounts, travel platforms, and other online services to create user profiles without requiring explicit input from users [12]. This method leverages the richness of openly shared data to generate accurate and comprehensive user profiles, enabling personalized services and recommendations while addressing challenges such as the cold start problem.
Implicit profiling, also known as dynamic profiling, gathers data based on user behavior and interactions without requiring direct input. This method includes tracking browsing history, click patterns, and time spent on activities, which offers a more detailed view of user preferences. In a museum context, implicit profiling can examine patterns like the sequence of rooms visited, the time spent at each exhibit, and other behavioral data, offering a deeper understanding of visitor interests. Implicit profiling systems, which track visitor movements, dwell times, and interaction patterns within museum spaces, have shown significant potential in enhancing visitor engagement. For instance, Yoshimura et al. [13] examine visitor mobility patterns within the Louvre Museum using a random walk model, providing important findings on crowd dynamics and offering guidance for improving visitor flow management. Similarly, Centorrino et al. [14] employed a Lagrangian IoT-based tracking system to accurately reconstruct visitor trajectories in crowded museums, enabling better management of visitor flow and enhancing the overall experience. Behavioral analytics greatly improve visitor engagement by revealing how various visitor segments interact with exhibits.
Hybrid profiling combines explicit and implicit methods to leverage the strengths of both approaches. This technique provides a comprehensive view of users by integrating direct input with behavioral data.
Traditional methods of visitor profiling in museums, such as demographic surveys and pre-visit questionnaires, have been extensively used to categorize visitors and predict their preferences [15,16]. These approaches involve collecting data such as age, gender, educational background, and cultural interests to understand visitor demographics and tailor the museum experience accordingly [17]. However, despite the usefulness of these methods, they are often constrained by their dependence on self-reported data, which can be prone to biases and inaccuracies.
In recent years, the field of visitor profiling has seen significant advancements with the integration of explicit and implicit profiling techniques. Implicit profiling involves the direct collection of visitor information through interactive systems such as mobile apps, which can ask visitors to create profiles, state their preferences, and provide feedback in real-time [18]. This method not only enriches the visitor database but also allows for dynamic customization of the museum experience based on individual profiles.
2.2. Technologies
Modern technologies are essential for implementing effective visitor profiling methods in museums [19,20].
Bluetooth Low Energy (BLE) beacons, for example, enable indoor positioning and tracking of visitor movements, providing valuable data on visitor flow and exhibit engagement [21]. This technology enables museums to understand how visitors engage with their environments and adapt their offerings accordingly. The integration of BLE beacons in museums has proven particularly effective in enabling location-based services, such as guiding visitors through personalized tour routes and offering real-time updates about exhibit events. Spachos and Plataniotis [22] explore the use of BLE beacons for indoor localization in smart museums, demonstrating how these beacons can deliver context-aware content related to artworks as visitors move through the museum. BLE beacons, combined with Internet of Things (IoT) technologies, offer a powerful means to track, localize, and interact with visitors, thereby enhancing their overall experience.
The IoT has further enhanced visitor experiences by creating interactive and personalized exhibits. Chianese and Piccialli [23] explore how IoT can be integrated into museums to connect cultural heritage artifacts with digital applications, enabling features like augmented reality to provide dynamic and engaging educational experiences. Mohamed et al. [24] propose a system that leverages IoT devices to collect data on customer behavior and preferences, enabling the creation of detailed customer profiles. Arvaniti-Bofili et al. [25] discuss a system designed to provide personalized recommendations within a museum setting by utilizing historical localization data and user interests to cluster similar users.
The use of Augmented Reality (AR), Virtual Reality (VR), and Artificial Intelligence (AI) has been transformative for museums, enabling them to create interactive and personalized experiences that bridge the gap between real and virtual environments. Augmented reality further enhances visitor experiences by overlaying digital information onto physical exhibits, contributing to visitor profiling by capturing interaction data [26]. Sepe and Marzullo [27] discuss how these technologies can enhance operational efficiency and visitor engagement by creating dynamic, interactive spaces that offer enriched educational and storytelling experiences. AI-assisted VR experiences at the MARTA Museum have shown positive results in user engagement and educational efficacy, encouraging further development of integrated VR and AI systems for cultural heritage education [28].
Machine learning (ML) algorithms are instrumental in analyzing data pertaining to visitor profiles by detecting patterns in visitor behavior, preferences, and engagement levels [29]. This data is subsequently utilized by AI systems to provide personalized recommendations and adaptive content delivery, thereby improving both operational efficiency and visitor satisfaction [30]. The adoption of these advanced technologies enables museums to develop comprehensive and dynamic visitor profiles, significantly enriching the overall visitor experience.
By integrating BLE beacons, AR, VR, AI, and IoT technologies, museums can offer tailored and immersive experiences that significantly improve visitor satisfaction and educational outcomes. These technologies not only enhance the visitor experience but also enable museums to operate more efficiently, ultimately contributing to their long-term sustainability and success.
2.3. Visitor Groups
Visitor group formation in museums significantly enhances social interaction by fostering engagement, shared experiences, and collaborative learning [31]. It plays a crucial role in enhancing the educational and social experiences in museums [32,33]. Visitors with shared interests are more likely to engage in meaningful discussions, exchange ideas, and strengthen social connections. This not only enriches the educational value of the visit but also increases overall satisfaction by creating a more interactive and enjoyable experience. The article by Fosh et al. [34] explores designing mobile museum guides that prioritize social interactions alongside personalization. The authors propose a design approach that integrates social aspects from the outset, allowing visitors to create and share personalized interpretations of exhibits with their friends and family.
In traditional museums, groups are typically formed through pre-arranged programs and guided tours led by museum staff. These guides provide context, engage visitors, and enhance the experience using their expertise. Groups are often organized based on demographic information and pre-visit questionnaires, with data gathered from surveys or registration forms. During the visit, guides assess interests through interactions and observations, directing groups to relevant exhibits, such as educational displays for school groups or specialized collections for art enthusiasts. This approach relies on the staff’s experience and intuition to optimize the visitor experience.
In a smart museum environment, advanced technologies and data analytics enable the dynamic formation of visitor groups with similar interests. These groups can be adjusted in real-time based on visitor preferences and behaviors, with apps offering personalized tours or facilitating self-guided exploration. Massarani et al. [35] found that during visits to the Museum of the Universe in Rio de Janeiro, family members primarily engage with each other and the exhibits, discussing scientific topics like astronomy, which enhances learning and group awareness. Tsiropoulou et al. [36] explore the concept of self-organizing museum visitor communities through a participatory action research approach. The study emphasizes the importance of engaging visitors actively in the museum experience, allowing them to form communities based on shared interests and interactions.
2.4. Smart Badges
Smart badges use real-time data like location and interaction history to dynamically group visitors. Equipped with sensors and communication technology, these badges track movements and behaviors, enabling the system to organize visitors into groups based on proximity or shared interests, enhancing the experience and improving crowd management. Typically, smart badges incorporate Radio Frequency Identification (RFID) or Near Field Communications (NFC) for secure access control and tracking, BLE for real-time location tracking and proximity sensing, and sensors for environmental or health monitoring.
Currently, only a few companies focus on developing smart badges, and there is limited literature on their development and applications. This suggests that the technology is still emerging and not yet widely adopted or deeply explored within the industry. Vocera Smart Badges [37] are advanced communication devices used in healthcare settings to enable hands-free, real-time communication among medical staff. They integrate seamlessly with hospital systems, allowing staff to make secure voice calls, send messages, and access critical patient information efficiently. Abeeway Smart Badges [38] are portable multi-mode trackers in an ID card format that incorporate embedded sensors. These badges combine GPS, Wi-Fi sniffing, BLE, and LoRaWAN TDoA geolocation technologies to support accurate and continuous outdoor and indoor tracking. Kontakt.io Smart Badges [39] are sophisticated devices designed for versatile tracking and access control applications. Leveraging BLE technology, these badges offer features such as contactless access control, real-time location tracking, and environmental monitoring. When integrated with Kio cloud platform, these smart badges enhance security, streamline visitor management, and improve asset tracking.
Caneschi and Ammendola [40] propose the use of the Pin—a Bluetooth beacon equipped with a unique identification code. In the context of the Museo Marino Marini, these Pins are detected by gateways distributed throughout the museum. The collected data is utilized to construct a journey profile for each Pin, documenting visitor presence in various areas, rooms, or in proximity to specific artworks. The Pin system has not yet been fully prototyped or validated. Park et al. [41] examine how interactive feedback from sociometric badges affects the creativity of group members. The study assesses whether smart technology can boost individual creativity during group discussions. Sociometric badges, which provide real-time feedback, were employed to monitor and influence participants’ interactions. The research revealed that participants who received real-time interactive feedback through these smart badges exhibited greater creativity compared to those who did not receive such feedback. De Jode et al. [42] explored the creation and application of digital empathy badges utilizing infrared transceiver technology. These badges were designed to promote mutual support and foster empathy among wearers. In a small pilot study, participants wore the badges to investigate how this technology could enhance social interactions and emotional support within groups. Su et al. [43] presents the development of a smart badge using LoRa wireless technology. This badge is designed to improve the experience of museum visitors by enabling personalized, location-based interactions. The badge allows visitors to receive relevant information and content as they move through different exhibits, enhancing their engagement and learning experience.
3. System Design
The proposed user profiling methodology and service represents an advanced iteration of the ExhibitXplorer museum visitor segmentation module [44]. ExhibitXplorer is designed to deliver personalized content using contextual geofencing and artificial intelligence. This updated system incorporates innovative hardware and software components to enhance visitor profiling.
3.1. Architecture
The proposed system utilizes the Kio Cloud platform by Kontakt.io Inc., which combines BLE devices, signal processing, and cloud-based analytics for precise real-time indoor location tracking. The Kontakt.io Location Engine Reference Architecture, an AI-based framework, provides accurate location data for both people and objects. Machine learning improves the platform by refining signal data to minimize noise and increase accuracy. It also enables predictive analytics for forecasting user movements, identifying security anomalies, and providing context to optimize space usage and facility management.
The summarized architecture of the system is shown in Figure 1.
From an infrastructure perspective, the system relies on fixed-position devices: (1) Anchor Beacon installed in museum rooms and corridors, provide location reference points; (2) Beam Mini BLE devices, used for room-level localization, emit the room’s ID via an Infrared (IR) transmitter; (3) Portal Light BLE-to-Wi-Fi gateways. These gateways aggregate data from the BLE devices and transmit it to the Kio Cloud for processing and analysis.
The system employs Smart Badges as tags, which are devices that transmit telemetry data using BLE technology and are typically worn by individuals. These Smart Badges are also equipped with an infrared receiver to receive signals from Beam Mini devices, enabling accurate room-level localization.
3.2. Methodology
The proposed methodology for dynamic visitor profiling and group formation in museums utilizes a combination of explicit and implicit profiling techniques, and smart badge technology. The methodology starts with coarse-grained profiling through OAuth registration, where visitors share basic information like age, gender, interests, etc. This profile is further refined through brief surveys conducted via a mobile app, collecting more detailed information about visitor interests and expectations.
Fine-grained profiling is achieved by monitoring how visitors interact with exhibits. This includes tracking the sequence of rooms visited and the time spent at each exhibit, offering a deeper analysis of visitor preferences and engagement. Visitors wear smart badges, which transmit telemetry data such as location and accelerometer readings, allowing for precise localization and movement tracking within the museum.
Dynamic group formation is achieved using smart visitor badges. When a visitor starts the process, the system detects nearby visitors based on badge signal strength (RSSI). Those interested in joining the group can accept the invitation by pressing a button on their badge. Once the group is formed, a composite profile is created from the common segments of individual profiles, which is then used to tailor content to the group’s shared interests. This approach enhances the social aspect of the museum experience by enabling visitors with similar interests to connect and explore together with personalized recommendations. Additionally, the museum can provide specialized tours and experiences tailored to these groups, enriching the visitor experience further.
All collected data—from OAuth registration, mobile app surveys, tracking movements, and smart badge interactions—is integrated into a visitor profile database. This data integration and analysis process enables the museum to deliver highly personalized content and recommendations to each visitor.
The museum visitor profiling service integrates several subsystems within a distributed architecture to provide a personalized and seamless experience. Central to the system is a mobile app that handles visitor registration, authorization, and profiling through brief surveys. This app communicates with the Kio Cloud via an SDK for Android and iOS, enabling real-time data transmission. The system’s architecture ensures interoperability, scalability, and security, facilitating smooth data flow and safeguarding visitor information.
By integrating these components, the proposed methodology provides a comprehensive solution for enhancing visitor experiences through personalized content delivery and dynamic group interactions. This approach not only improves engagement but also promotes social interaction, thereby enriching the overall museum visit.
3.3. Database Design
To support hybrid museum visitor profiling, the service requires a flexible database architecture. This database captures and manages extensive data on both physical and digital visitor interactions, including individual profiles, visit histories, and engagement metrics with exhibits. The service uses a MongoDB database, well-suited for this purpose due to its flexible schema design, scalability, and robust data-handling capabilities. MongoDB’s document-oriented architecture efficiently manages complex and evolving data structures, making it ideal for handling the dynamic data.
The database consists of eleven collections. The Entity Relationship (ER) diagram of the database is shown in Figure 2.
The Visitors collection is a core element of the museum database, designed to hold critical information about individual visitors. Its primary properties, „profile“ and „preferences“, are derived from a combination of OAuth-based pseudo-explicit registration data and explicit visitor profiling using short surveys conducted during museum visits. The „profile“ property includes data obtained from the OAuth registration process, while „preferences“ reflect data collected from visitor surveys and implicit profiling. This collection is essential for tracking visitor segments, enabling targeted personalization, and facilitating in-depth analysis. It includes average viewing time (e.g., 5 minutes), pace of visit (e.g., moderate), etc. Additionally, it records their engagement with technology, use of museum apps, preferred language, and viewing habits such as time spent (e.g., Long), and group preferences (e.g., Any). It also includes information on any specific impairment types the visitor may have, which aids in accommodating their needs and enhancing their overall experience.
The Authorizations collection manages OAuth authentication details for visitors, containing key data related to their login credentials and provider information. This collection includes the following main data:
- visitor_id: A unique identifier for the visitor within the database, ensuring that authorization details are correctly associated with the visitor’s profile regardless of the social network used for authentication.
- auth: An array of objects, each representing authentication details for a specific OAuth provider. Each object includes the provider, which specifies the OAuth service provider used for authentication, such as „facebook” or „google.” The „provider_id” contains the unique identifier assigned by the provider, linking the visitor’s account to the external service. The „email” field stores the visitor’s email address associated with the specific provider, ensuring accurate identification across different platforms. The „access_token” field holds the encrypted access token provided by the OAuth service, used for authenticating the visitor. The „user_data” field stores user information obtained from the OAuth provider.
The „user_data” field encapsulates supplementary user information obtained from the OAuth provider during the authentication process. For example, when using OAuth registration through Facebook, this field can include detailed attributes such as public_profile, email, user_hometown, user_birthday, user_age_range, user_gender, user_link, user_friends, user_location, user_likes, user_photos, user_videos, and user_posts, depending on the permissions granted. This data facilitates the delivery of contextually relevant content and allows for the customization of interactions and communication based on the visitor’s personal attributes, preferences, and demographic information.
The Visits collection documents individual instances of museum visits. It tracks the total duration of each visit, the number of exhibits viewed, and the rooms visited. Each entry in this collection is associated with a specific visitor and badge, and it also records the groups to which the visitor belonged during the visit. This collection is crucial for maintaining a historical record of museum visits, enabling the analysis of visit patterns, durations, and group dynamics over time.
The Rooms collection maintains data about the museum’s physical spaces, including details for each room such as its name, capacity, floor number, and the building in which it is situated. It also tracks the IDs of exhibits present in each room, providing a clear association between rooms and their contained exhibits. This collection is essential for spatial analysis of visitor behavior, supporting effective museum layout planning, and optimizing space utilization.
The Room Movements collection monitors visitor movements between different rooms or areas within the museum. It records entry and exit times for each room visit, associates these visits with specific visitor trips and groups. This data is crucial for analyzing visitor flow and congestion within the museum, revealing which rooms or areas are most frequently visited.
The Exhibits collection catalogs detailed information about each exhibit within the museum. It includes data such as the exhibit’s name, artist, creation year, description, and multimedia content. Additionally, it records the exhibit’s location within the museum through a designated room ID and specific grid coordinates. The collection also tracks a popularity score for each exhibit, reflecting visitor engagement and interest. This repository is pivotal for referencing and analyzing exhibit characteristics, and it facilitates the correlation between exhibit details and visitor interactions.
The Exhibit Interactions collection records data on how visitors engage with specific exhibits. It tracks the duration and type of interaction each visitor has with an exhibit, linking these interactions to particular visits and groups. The collection also includes timestamp data, enabling temporal analysis of visitor behavior. This information is essential for assessing exhibit popularity and effectiveness, and for analyzing how different visitor segments or groups engage with exhibits.
The Badges collection oversees the physical badges issued to visitors for tracking purposes. It monitors the status of each badge (active or inactive), links badges to current visitors and their groups, and records the usage history for each badge. This collection is crucial for the proximity-based group formation feature, aiding in the management of the museum’s badge inventory and analyzing usage patterns.
The Visitor Groups collection tracks the formation and dissolution of visitor groups within the museum. It records essential details about each group, including associated visitors, badges, segments, and their current location. This collection is vital for analyzing social dynamics, such as how various group compositions interact with exhibits and each other. It shows how group size and composition impact museum experiences and helps in creating features and activities designed for groups. Understanding group behaviors, movement patterns, and exhibit preferences helps design spaces that foster social interaction and collaborative learning.
The Feedback collection is essential for refining visitor profiling and enhancing museum experiences. It records detailed input from visitors, linking feedback to specific individuals, visits, and, optionally, particular exhibits. Each entry includes qualitative comments, a quantitative satisfaction rating, and a timestamp.
The Segments collection categorizes visitors into one or more of 18 predefined segments based on their preferences and behaviors, enabling museums to deliver personalized content and experiences. This segmentation approach helps museums tailor their exhibits and interactions to meet diverse audience needs, enhancing overall visitor satisfaction and engagement.
The segment names are chosen to be easily understood by ChatGPT. The following segments are currently used:
- Quick Visitors: Quick Visitors spend approximately 1-2 minutes per exhibit. They move quickly through the museum, focusing on key highlights and major attractions. They prefer quick highlights and brief overviews, favoring concise, impactful presentations. These visitors move rapidly through exhibits, focusing on the main attractions rather than in-depth exploration.
- Moderate Explorers: Moderate Movers spend about 3-5 minutes per exhibit. They enjoy a balanced experience that includes both quick highlights and more detailed content. Their pace is moderate, allowing them to engage with a mix of brief and moderately detailed exhibits.
- Leisurely Movers: Leisurely Movers spend approximately 6-10 minutes per exhibit. They engage more deeply with each exhibit, taking their time to explore detailed information and absorb the content. Their slower pace indicates a preference for thorough examination and contemplation of exhibits.
- In-Depth Movers: In-Depth Movers spend more than 10 minutes per exhibit. They immerse themselves extensively in the details, often revisiting exhibits and taking significant time to fully engage with and understand the content. Their extended viewing time reflects a desire for a comprehensive and immersive museum experience.
- Interactive Kids: This group consists of children aged 6 to 12 who are particularly attracted to interactive exhibits. Their visits tend to be brief, and the system should prioritize delivering content in the form of images, audio, and video to effectively engage this audience.
- Teen Trendsetters: Teen Trendsetters are teenagers aged 13-17 years who are interested in technology and interactive media. They engage with multimedia and social features and tend to move quickly through exhibits, focusing on the latest trends and interactive elements.
- Young Professionals: Young Professionals are individuals aged 18-30 years who are attracted to contemporary art, innovative exhibits, and social media. They prefer fast-paced exploration of trending exhibits and are often interested in the intersection of technology and art.
- Midlife Explorers: Midlife Explorers are adults aged 31-50 who are deeply engaged with historical artifacts, detailed exhibitions, and educational content. They seek meaningful and in-depth experiences that reflect their mature perspective and extensive life experience.
- Senior Art Connoisseurs: Senior Art Connoisseurs are visitors aged 51 and older who appreciate classic art, historical narratives, and in-depth stories. They enjoy leisurely visits with detailed explanations, taking their time to fully understand and reflect on the exhibits.
- Mobility-Friendly Visitors: Mobility-Friendly Visitors are individuals with mobility impairments who need accessible routes and interactive aids. They are interested in exhibits with accessibility features and may prefer guided tours that accommodate their needs.
- Sensory-Sensitive Visitors: This group includes individuals with sensory sensitivities, such as visual or hearing impairments. Visitors with visual impairments should be provided with audio content tailored to their needs. In contrast, visitors with hearing impairments should primarily receive visual content to ensure an accessible and engaging experience.
- Language-Specific Aficionados: Language-Specific Aficionados are visitors who prefer or require exhibits in specific languages. They seek out exhibits with multilingual information or content available in their native or preferred language. They are interested in ensuring that their museum experience is accessible and comprehensible in their chosen language.
- Group Collaborators: Group Collaborators are visitors who are willing to form a group. They enjoy collaborative and group-oriented exhibits and activities, valuing interactive and social experiences that allow them to engage with others.
- Family Visitors: Family Visitors include groups consisting of parents and children or extended family members. They are interested in exhibits that are engaging for all age groups and may seek out interactive, educational, and family-friendly activities. They prefer exhibits that offer something for everyone and provide opportunities for family interaction and learning.
- Solo Navigators: Solo Navigators prefer visiting the museum alone. They are interested in self-guided tours and personal reflection exhibits. These visitors value independence and personal space during their museum experience.
- Art and Cultural Enthusiasts: Art and Cultural Enthusiasts are deeply interested in art history, cultural exhibits, and historical artifacts. They engage thoroughly with exhibits related to art and culture, seeking detailed narratives and rich historical context.
- First-Time Explorers: First-Time Explorers are new visitors to the museum who seek a broad introduction to its offerings. They are interested in general overviews and introductory exhibits and may look for guidance or highlights to help them get acquainted with the museum.
- Frequent Visitors: Frequent Visitors are regular patrons of the museum who come often to see new and changing exhibits, explore special collections, and access behind-the-scenes content. They appreciate the opportunity to engage with fresh displays and exclusive material.
3.4. Software Architecture
The Museum Visitor Profiling module within ExhibitXplorer service employs a microservice-based architecture to ensure scalability, flexibility, and maintainability. This architecture is designed to handle visitor data efficiently while providing a seamless and personalized museum experience.
Figure 3 shows a summary diagram of the microservices used that are directly or indirectly related to museum visitor profiling.
Visitors interact with the museum’s services through a mobile application. This app interfaces with the backend infrastructure through an API Gateway.
The API Gateway serves as the main entry point for all client interactions. It is responsible for routing incoming requests to the appropriate microservices, handling load balancing, and managing security aspects such as authentication and rate limiting. This centralized access point ensures that external communications are streamlined and secure.
The Service Mesh orchestrates communication between microservices within the system. A service mesh is an architectural layer that manages communication between microservices in a distributed application. It provides a dedicated infrastructure for handling service-to-service interactions, which allows developers to focus on business logic without having to manage communication concerns directly. The service mesh ensures these services communicate efficiently and securely, while also providing tools for monitoring and managing their interactions. Within this mesh, several modules operate.
Core Modules are essential components for the system’s operation, encompassing the following microservices:
- The Auth Service plays a critical role by managing user access, ensuring that only authorized individuals can interact with the system. It handles tasks such as registration, login, permission checks, and security protocols.
- The Visitor Profile microservice maintains profiles for each visitor. This service manages the core visitor data, including the VISITORS, SEGMENTS, and VISITOR_GROUPS collections. It’s responsible for handling visitor profiles, implementing visitor segmentation, and managing visitor groups. The service also maintains two mapping collections: VISITOR_SEGMENT_MAPPING (V-S MAP) and VISITOR_GROUP_MAPPING (V-G MAP). In a microservice architecture, „mapping collections” refer to database collections specifically designed to manage the relationships or associations between different entities. These collections are essential when different services need to know about relationships without directly accessing each other’s primary data collections. They store references to the IDs of the entities they link, providing a way to look up connections efficiently. In our case mapping collections allow for flexible associations between visitors and their segments or groups without tightly coupling the data.
- The Content Personalization Service utilizes visitor profile data to customize recommendations and content for individual visitors. Functioning as both an aggregator and analyzer, this microservice integrates data from various other microservices to create tailored content suggestions. The service uses a Chatbot service from ExhibitExplorer to interact with ChatGPT. It transmits requests to the Chatbot service that encompass detailed information about all current visitor segments. By using these information, ChatGPT delivers highly relevant and personalized exhibit recommendations, precisely aligned with each visitor’s specific interests and preferences.
Tracking Modules are designed to capture and analyze data related to visitor behavior and interactions within the museum:
- The Visit Tracking microservice monitors and records how visitors engage with exhibits and navigate through the museum. It tracks movements, interactions, and other visit-related activities to enhance visitor experiences and optimize exhibit placements. It manages the VISITS, EXHIBIT_INTERACTIONS, and ROOM_MOVEMENTS collections. To maintain relationships between visits and specific interactions or movements, it also includes two mapping collections: VISIT_EXHIBIT_MAPPING (V-E MAP) and VISIT_ROOM_MAPPING (V-R MAP). These mapping collections allow the service to efficiently record and query a visitor’s journey through the museum, including which exhibits they interacted with and how they moved between rooms.
Support Modules provide additional functionalities that support and enhance the core services:
- The Badge Service manages visitor badges, which are used for access control and personalized experiences. It handles badge issuance, tracking, and associated data. It maintains the BADGES collection and includes a BADGE_VISITOR_MAPPING (B-V MAP) collection. This mapping collection is crucial for implementing proximity-based group formation, as it allows the service to quickly determine which visitors are associated with which badges at any given time. The Badge Service provides API for assigning badges to visitors and querying badge-visitor associations.
- The Exhibit Service maintains detailed information about museum exhibits, including their descriptions and attributes, ensuring that accurate and up-to-date information is available. It maintains the EXHIBITS collection, storing details about each exhibit such as its description, location, and any multimedia content associated with it. The Exhibit Service provides API for retrieving exhibit information.
- The Room Service manages data related to the museum’s physical layout, including room configurations and features. It maintains the ROOMS collection. The Room Service offers API for querying room information, which can be used in conjunction with the Visit Tracking Service to analyze visitor movement patterns.
- The Feedback Service collects and processes visitor feedback, which is crucial for assessing visitor satisfaction and making improvements to exhibits and services. It maintains the FEEDBACK collection, storing comments, ratings, and other forms of feedback provided by visitors. The Feedback Service offers APIs for submitting new feedback and retrieving existing feedback, which can be used to improve the museum experience and contribute to visitor profiling.
Together, these modules form a system that facilitates efficient visitor profiling.
3.5. Methods
3.5.1. Group Profiling
This subsection describes the implementation of the visitor group profiling algorithm. This algorithm aims to categorize each newly formed group into relevant segments. When a new group is created or an existing visitor profile is updated, the Visitor Profile microservice activates the algorithm to analyze the segments within the group’s profiles. The group profile is then generated by aggregating segments that appear more frequently than a predefined threshold, which is set as an environmental variable.
To implement the visitor group profiling algorithm, we use the aggregation capabilities of MongoDB.
Figure 4 shows an example aggregation pipeline that is used to obtain segment statistics - how many times segments occur in the profiles of visitors from a selected group. The pipeline starts by filtering documents that match the given „group_id” (operator $match). It then deconstructs the segments array in each document, creating separate documents for each segment ($unwind). Next, it groups these segments by their value and counts how often each segment appears ($group). The pipeline then sorts the segments by their count in descending order ($sort). Subsequently, pipeline re-groups all segments into a single array, where each entry contains the segment’s ID and its count ($group). Finally, the pipeline projects the result, outputting only the segments array without the „_id” field ($project).
Possible methods for setting a threshold for segment selection include absolute value thresholds, percentage-based thresholds, percentile-based thresholds, and statistical techniques. Absolute value thresholds involve setting a fixed numerical value, such as retaining only segments with counts exceeding a specific number. This method is straightforward but does not consider the variability within the data. Percentage-based thresholds use a proportion of the total count or maximum value, such as retaining segments that account for at least 20% of the total. While this method scales with the dataset, it can still be somewhat arbitrary. Percentile-based thresholds use statistical percentiles, such as the 75th percentile, to determine the cutoff for segment selection. This approach considers the relative position of segments within the distribution, ensuring that only those above a certain rank are kept. On the other hand, statistical techniques like Z-scores standardize data by converting counts into a common scale where the mean is 0 and the standard deviation is 1:
where is segment count; is mean; and is standard deviation. By calculating Z-scores, the number of standard deviations a segment’s count deviates from the mean can be quantified. For instance, retaining segments with Z-scores greater than 1 involves selecting those that deviate significantly from the average, providing a statistically rigorous approach for identifying meaningful deviations.
When there are only a few visitors in a group, it is possible that no segments will have a Z-score greater than 1. In such cases, the algorithm aggregates the segments of all visitors. However, four segments are always prioritized when delivering content due to their significance: „Mobility-Friendly Visitors,” „Sensory-Sensitive Visitors,” „Language-Specific Aficionados,” and „Interactive Kids.” These segments are consistently considered when delivering content, regardless of whether the visitor is part of a group or visiting alone.
3.5.2. Visitor Similarity Estimates
Delivering personalized content using ChatGPT requires significant time and resources. To reduce requests to the Chatbot microservice, Redis is used as a content caching server. When a request for custom content is made, the system checks if the desired information is already cached. This involves searching the cache for data related to the exhibit that was obtained for visitors with similar profiles. Jaccard’s algorithm will be used for this purpose. The Jaccard similarity measures the similarity between two sets by calculating the proportion of shared elements relative to the total number of distinct elements in both sets. It is calculated by dividing the size of the intersection of the two sets by the size of their union:
where is the set containing the segments for visitor with identifier , and is the probability that visitor and visitor have similar profiling. The similarity coefficient is a number in the interval [0, 1].
The Jaccard algorithm is highly efficient when comparing sets that are relatively small to medium-sized. The time complexity of computing the Jaccard similarity between two sets is where and are the sizes of the sets. Given that the sets in our case have a maximum size of 18 segments, the Jaccard algorithm is inherently efficient due to the small size of the sets, making the intersection and union operations computationally lightweight. To further optimize performance, particularly when managing frequent queries or larger data volumes, MongoDB’s built-in operators, such as set intersection and set union, are utilized. These operators allow to perform set operations directly within the database, reducing the need to transfer data to the application layer. This approach ensures that the similarity calculations are both fast and scalable, maintaining high efficiency even as the application grows.
There are two distinct strategies for retrieving cached content, each with its own approach to leveraging stored information:
- Exhibit-Centric Strategy: This strategy starts by querying the cache to check for content related to the desired exhibit. If cached content is available, the system retrieves the identifiers of the visitors for whom this content was created. It then compares the visitor’s segments with those of the cached visitors to assess similarity. If a visitor with a sufficiently similar profile is found, the corresponding cached content is retrieved. If no similar profile is found or no cached content exists, the system will generate new content using ChatGPT.
- Profile-Centric Strategy: This strategy begins by identifying visitors in the database whose profiles resemble that of the current visitor. Once similar profiles are identified, the system checks the cache for any content related to the desired exhibit that was generated for these visitors. If relevant cached content is found, it is retrieved. If no suitable cached content is available, the system defaults to generating new content using ChatGPT.
In this development, the Profile-Centric Strategy is employed. This approach is favored due to its efficiency; it significantly reduces the time required to retrieve the desired information. Specifically, by identifying similar visitor profiles before querying the cache, the system effectively reduces the search space and minimizes redundant operations. As a result, extracting the required content using the Profile-Centric Strategy is accomplished in approximately half the time compared to the Exhibit-Centric Strategy, thereby optimizing the overall performance and responsiveness of the content retrieval process.
Figure 5 illustrates an example aggregation pipeline employed to implement the Jaccard algorithm in this process. This MongoDB aggregation pipeline identifies visitors whose segment data closely matches a target visitor’s segments. It first excludes the target visitor („target_visitor_id”) from the results with the $match stage. Then, it performs a $lookup to find other visitors who share any segments with the target visitor, creating a list of matched visitors. The pipeline then computes the intersection and union sizes between the target visitor’s segments („target_segments”) and each matched visitor’s segments using $setIntersection and $setUnion, respectively. The Jaccard similarity, representing the proportion of shared segments, is calculated by dividing the intersection size by the union size. Finally, it filters out the results to include only those visitors whose similarity score exceeds a predefined threshold („SIMILARITY_TH”).
4. Results
This section details the results of implementing advanced visitor profiling through smart badges in a museum setting. The findings focus on the system’s effectiveness in tracking visitor behavior from check-in to check-out and identifying distinct behavioral patterns. Metrics analyzed include dwell time—the duration visitors spend viewing exhibits—and their movement patterns within the museum.
4.1. Mobile Application
To access the Profiling Service and deliver personalized content, museum visitors must install a mobile app that implements: (1) The user interface; (2) Communication with business logic deployed in a cloud infrastructure; (3) Access to beacon and smart badge data via the Kio Cloud SDK; and (4) Receive push notifications. The mobile app can be installed after scanning a QR code placed in visible locations at the museum entrances. At this stage, the app works with Android devices.
4.2. Visitor Registration and Login
The system uses OAuth 2.0 for visitor registration and authorization. OAuth 2.0 is a widely adopted framework that allows users to grant third-party applications access to their resources on other platforms without exposing their credentials [45]. For user registration and login, OAuth 2.0 enables authentication through social networks. Users are redirected to the authorization server of the chosen service, where they authenticate with their existing credentials. After successful authentication, users grant the application specific permissions, such as access to their basic profile information. The application then receives an access token to retrieve the authorized data and complete the registration or login process.
The mobile app allows visitors to register through a variety of social media such as Google, Facebook, LinkedIn, X, Instagram, and GitHub. To integrate OAuth 2.0 for user authentication with social media platforms, developers must create and configure applications specific to each platform. This process involves registering the application with the social media platform, which is a necessary step to obtain the credentials required for OAuth 2.0 authorization flows.
In our scenario, the visitor has registered using their Facebook account. By default, Facebook provides access to the user’s ID and name. To obtain additional information, a request must be made through a specially designed Facebook application. For example, this additional data from Facebook can include the user’s email address, location (country and city), gender, birthday, age range, friends, likes, posts, and other relevant details.
Figure 6 shows the „Authorizations” collection document that was generated after the visitor registered. Since this is a new user to the service, a unique identifier is generated for this user. User data is limited to the visitor’s name, email address, gender and location. This information will form the basis of visitor profiling. A new document is created in the Visitors collection for the new user. Next, the fields of the „profile” property are initialized with the data obtained during registration. At this point, the service assigns the visitor to the „First-Time Explorers” and „Midlife Explorers” segments.
A new document is created within the Visits collection to comprehensively detail all aspects of the current visit and the associated visitor. This document captures the start and end times of the visit, the sequence of rooms entered, the order of exhibits viewed, and the dwell time at each exhibit.
4.3. Smart Badge
Upon successful registration, the visitor receives a smart badge, which they then associate with their account. The use of the smart badge is crucial for implicit visitor profiling. If the visitor opts not to use the smart badge, tracking becomes less precise, and the visitor will be excluded from participating in group activities.
The Smart Badge from Kontakt.io is designed for precise localization within rooms, matching the size of an ISO identification card (see Figure 7a). It features an infrared receiver, which is particularly useful for accurate indoor positioning since infrared signals do not penetrate walls, unlike BLE signals. This property helps in minimizing interference and improving localization accuracy. The badge also includes two programmable buttons—red and blue—that facilitate communication with the mobile app and serve emergency functions. This design allows for real-time tracking of user locations, effective group formation, and streamlined access control within the museum environment.
To link the badge to their account, visitors need to choose the „Badge Association” option from the mobile app menu. The app then scans for Bluetooth Low Energy (BLE) packets emitted by nearby Smart Badges, displaying the badges based on the received signal strength indicator (RSSI). Visitors are shown a list of detected badges, each including its ID and MAC address. To complete the association, the visitor must press the blue button on their badge, which causes the corresponding badge in the app to be highlighted with a blue background. After this, the visitor selects the highlighted badge on the app and taps the „Associate” button (see Figure 7b). This action updates the Visits collection document to record the badge association, linking it with the visitor’s account.
Figure 8 illustrates the data available in the Telemetry, Secure Profile, and Location packets for the BLE Anchor Beacon (Figure 8a) and the Smart Badge (Figure 8b). For visitor profiling, the key information is found in the Telemetry and Location packets, including the badge ID, button status, accelerometer data, and room ID.
The configuration of smart badges is managed by the museum’s IT department and is essential for both the service’s functionality and the badges’ battery life. The most effective configuration is carried out through the Kio Cloud console. Smart badges can broadcast various types of BLE packets, including iBeacon, Eddystone, Telemetry, Location, and Secure Profile. Table 1 provides details on the configuration parameters of smart badges and their recommended values.
Battery consumption is reduced by extending the transmission intervals for telemetry and location packets to 1500 milliseconds. Disabling unused packet types such as Secute Profile, iBeacon and Eddystone also conserves energy. Lowering the TX power level to -4 dBm reduces the energy required for signal transmission. Additionally, limiting badge activity to working hours further helps to extend battery life.
4.4. Static Profiling
In our scenario, the information collected during visitor registration is inadequate for detailed visitor profiling. To address this limitation, static profiling is conducted through surveys administered via the mobile application. These surveys are customized for each visitor to fill in specific gaps in their profile information. The Visitor Profile microservice supports polling by sending short surveys to visitors via push notifications. The questions are designed to be direct and concise, with follow-up questions used only when necessary to refine categorization. This approach ensures that the survey remains user-friendly while effectively collecting the information needed to assign visitors to the appropriate segments.
For the analyzed visitor, the segments „Art and Cultural Enthusiasts,” and „Family Visitors,” were added following static profiling. While visitors cannot directly select which segments to associate with, they can view the list of current segments and remove any from their profile.
4.5. Dinymic Profiling
Dynamic profiling is continuously active while a visitor is within the museum, utilizing Kio Cloud Real-time Locating Systems (RTLS) to track their real-time location. Data on visitor movement at the room level is stored in the Room Movements collection. Visitor behavior within specific rooms is predicted by analyzing data from reference BLE beacons, which are deployed and configured according to the specific layout of each museum. Kio Cloud Smart Location facilitates the creation of building floor plans and the positioning of beacons and other hardware. Information on exhibit interactions is recorded in the „Exhibit Interactions” collection. The sequence of rooms visited and exhibits viewed is recorded in the „Visits Collection.” Following dynamic profiling, the visitor is categorized into the „Leisurely Movers” segment.
4.6. Group Profiling
The visitor has formed a group with her husband. At the time of this group formation, the husband was categorized into the following segments: „First-Time Explorers,” „Midlife Explorers,” „Family Visitors,” „Language-Specific Aficionados,” and „Leisurely Viewers.” Among these, three segments are common to both visitors, while three are unique to each individual. As no Z-score exceeds 1, it is assumed that the group will include all segments from both visitors.
5. Discussion
The implementation of advanced visitor profiling using telemetry-driven smart badges in museums offers several benefits but also presents challenges that warrant further exploration. This discussion will address the key findings, potential limitations, ethical considerations, and implications for future research.
5.1. Key Findings
The proposed system enhances the acquisition of museum visitors’ preferences through a combination of explicit and implicit profiling methods, delivering dynamically personalized content. Smart badges and BLE beacons facilitate real-time tracking of visitor movements and interactions, allowing the system to continuously refine visitor profiles. This represents a significant advancement over traditional methods, which rely on static data and fail to adapt to changing visitor interests. By integrating AI-driven content personalization, the system adjusts exhibits to suit the preferences of both individual visitors and dynamically formed groups, creating a more engaging and educational experience.
The badge association method in this solution is highly effective due to its simplicity and reliability. The mobile app uses BLE scanning to detect nearby badges and displays them based on signal strength, creating an intuitive and user-friendly process. Visitors can easily identify their badge by pressing the blue button, which highlights their badge in blue on the app. This visual confirmation reduces errors and ensures accurate badge selection. The process is quick, requires minimal user input, and offers immediate feedback, making it an efficient and reliable method for associating a badge with a user profile.
Another key contribution of this research is its innovative approach to group formation. Unlike conventional methods that pre-organize groups based on demographics or pre-visit questionnaires, the proposed system dynamically forms groups based on real-time proximity and shared interests. This approach enhances social interaction among visitors and allows the museum to offer more relevant and meaningful experiences tailored to these dynamically formed groups.
The microservice architecture further enhances the system’s robustness by allowing for independent development, deployment, and scaling of individual components. This modularity ensures that the system can efficiently manage increased demand, whether through adding more visitors, expanding museum content, or integrating additional data sources. The architecture supports seamless updates and maintenance, minimizing downtime and ensuring a consistently high-quality visitor experience.
5.2. Limitations and Challenges
Preliminary experiments indicate that the profiling system shows potential for improving visitor engagement and satisfaction. Nevertheless, several limitations must be addressed. The accuracy of tracking using BLE beacons and smart badges can be compromised by physical obstructions, signal interference, and large crowds, which may affect the quality of personalized content. Currently, the system depends on Kio Cloud’s AI-based localization algorithms, which necessitates the strategic deployment of beacons in various rooms and hallways. Beacons can be placed at specific points of interest, such as exhibits, to minimize the number of required devices, although this approach may result in reduced accuracy. Conversely, establishing a grid of beacons can enhance accuracy to within two meters but involves higher infrastructure costs.
A challenge arises when a museum visitor’s smart badge inadvertently rotates, causing the IR sensor to face the visitor’s body. This misalignment obstructs the IR sensor from receiving room identifier signals from ceiling-mounted IR emitters (beam mini), leading to inaccuracies or failures in location tracking at the room level. Given that the badge may be worn either vertically or horizontally, it is essential to ensure the IR sensor remains correctly oriented and unobstructed by the visitor’s body to maintain accurate tracking. To mitigate this issue, the badge should be securely affixed to the visitor’s clothing to reduce the likelihood of accidental flipping or rotation. Furthermore, the embedded accelerometer within the badge can be utilized for real-time orientation monitoring. By analyzing acceleration data along the x, y, and z axes, the system can detect improper orientation. Specifically, if the acceleration along the z-axis becomes negative, indicating that the IR sensor is facing the visitor’s body, the mobile application can issue an audible alert to prompt the visitor to adjust the badge. This method helps ensure reliable location tracking within the museum environment.
The collection and utilization of personal data for visitor profiling entail substantial ethical considerations concerning privacy and consent. Visitors may express concerns about continuous tracking and behavior analysis, despite the intended benefits for enhancing their experience. Upon registration, visitors are informed that their navigation and interactions with exhibits will be stored and analyzed within a cloud infrastructure. Additionally, visitors are given the choice to decline participation in implicit profiling and the use of smart badges. For those who opt out, personalized content will be created using explicit and pseudo-explicit profiling methods.
5.3. Future Research
The implementation of advanced visitor profiling using telemetry-driven smart badges in museums presents several opportunities for future research.
5.3.1. Enhancing Localization Accuracy
Future research should focus on enhancing the accuracy of visitor localization technologies. Kio Cloud offers a streaming API for real-time data transmission from infrastructure devices and tags to third-party streaming platforms. This functionality supports integration with services such as AWS Kinesis, Azure Event Hub, and IBM Watson.
Future initiatives are anticipated to concentrate on Azure Event Hub, an advanced real-time data streaming and processing platform designed to handle millions of events per second with minimal latency. Its compatibility with Apache Kafka further enhances its function as a message broker, optimizing Kafka workloads for improved performance and cost efficiency. Streaming data to these platforms will facilitate the development and deployment of advanced algorithms for processing telemetry and location data.
Future research should assess the cost efficiency and operational management of Azure Event Hub relative to other streaming services. This evaluation should include a detailed analysis of the financial implications related to data processing, storage, and bandwidth usage. Additionally, it is crucial to investigate operational aspects such as setup complexity, maintenance requirements, and scalability to fully understand the platform’s value proposition. Research should also explore strategies to optimize costs while maintaining high performance and reliability.
5.3.2. Data Privacy and Security
With the integration of real-time streaming data platforms, addressing data privacy and security concerns becomes increasingly important. Research should focus on developing secure data transmission and storage practices, ensuring compliance with privacy regulations, and implementing robust encryption methods.
5.3.3. Assessing the Impact on Visitor Experience
Evaluating the long-term impact of telemetry-driven smart badges on visitor experience and museum operations is another critical area for future research. This includes assessing how personalized content affects visitor engagement, learning outcomes, and overall satisfaction. Additionally, research should explore the operational implications for museums, such as the integration of these technologies with existing systems, the potential for increased operational costs, and the training requirements for museum staff. Understanding these factors will help museums make informed decisions about adopting and scaling such technologies.
6. Conclusions
The integration of advanced telemetry-driven smart badges in museums, along with real-time data streaming via platforms like Kio Cloud, marks a substantial advancement in visitor engagement and experience enhancement. Capturing and analyzing real-time telemetry and location data provides unparalleled opportunities for delivering personalized and dynamically adaptive content. This method exceeds traditional static profiling techniques by continuously updating visitor profiles based on actual interactions and preferences.
Key findings underscore the significant advantages of employing smart badges and real-time streaming technologies, including enhanced accuracy in visitor profiling, increased engagement through personalized content, and the potential for more meaningful social interactions via dynamically formed groups. However, the implementation of these technologies also presents several challenges. Addressing issues such as signal interference, badge orientation, and privacy concerns is crucial for ensuring system effectiveness and maintaining visitor trust. Ongoing research and development in these areas will drive innovation and contribute to the creation of more engaging, personalized, and efficient museum environments.
Funding
This research was funded by the Bulgarian Ministry of Education and Science, Project № 2409Е.
Data Availability Statement
The data are not publicly available due to research data ownership issues.
Acknowledgments
The author would like to thank the Centre of Competence “Intelligent Mechatronic, Eco and Energy Saving Systems and Technologies”, Project BG05M2OP001-1.002-0023, for technical support.
Conflicts of Interest
No conflicts of interest exist in the submission of this manuscript.
References
- Ye, B.H.; Ye, H.; Law, R. Systematic Review of Smart Tourism Research. Sustainability 2020, 12, 3401.
- Rodney, S. The Personalization of the Museum Visit. Art Museums, Discourse, and Visitors; Routledge: London, UK, 2019.
- Fogli, D.; Arenghi, A. “Design for All” versus “One-Size-Fits-All”: The Case of Cultural Heritage. In Proceedings of the CEUR Workshop Proceedings; 2018; Vol. 2101, pp. 89–96.
- Ifraheem, S.; Rasheed, M.; Siddiqui, A. Transforming education through artificial intelligence: Personalization, engagement, and predictive analytics. J. Adv. Distrib. Syst. 2024, 13, 22. [CrossRef]
- Fernández-Hernández, R.; Vacas-Guerrero, T.; García-Muiña, F.E. Online Reputation and User Engagement as Strategic Resources of Museums. Mus. Manag. Curatorship 2021, 36, 553–568. [CrossRef]
- Purificato, E.; Boratto, L., De Luca, E. W. User Modeling and User Profiling: A Comprehensive Survey. arXiv 2024, arXiv:2402.09660.
- Eke, C.I.; Norman, A.A.; Shuib, L.; Nweke, H.F. A Survey of User Profiling: State-of-the-Art, Challenges, and Solutions. IEEE Access 2019, 7, 144907–144924. [CrossRef]
- Mokatren, M.; Wecker, A.; Bogina, V.; Kuflik, T. A Museum Visitors Classification Based on Behavioral and Demographic Features. In Proceedings of the ACM UMAP 2019 Adjunct - Adjunct Publication of the 27th Conference on User Modeling, Adaptation and Personalization; 2019; pp. 383–386.
- Hijazi, A.N.; Baharin, H. The Effectiveness of Digital Technologies Used for the Visitor’s Experience in Digital Museums. A Systematic Literature Review from the Last Two Decades. Int. J. Interact. Mob. Technol. 2022, 16, 142–159. [CrossRef]
- Li, J.; Wider, W.; Ochiai, Y.; Fauzi, M.A. A Bibliometric Analysis of Immersive Technology in Museum Exhibitions: Exploring User Experience. Front. Virtual Real. 2023, 4. [CrossRef]
- Saihood, G. S. W.; Haddad, A. T. H.; & Eyada, F. Personalized experiences within heritage buildings: Leveraging AI for enhanced visitor engagement. In Proceedings of the 2023 International Conference on Data Science and Engineering (DeSE); 2023; 10468984. [CrossRef]
- Wu, W., Ghazali, M., & Huspi, S. H. A Review of User Profiling Based on Social Networks. IEEE Access 2024. [CrossRef]
- Yoshimura, Y.; Sinatra, R.; Krebs, A.; Ratti, C. Analysis of Visitors’ Mobility Patterns through Random Walk in the Louvre Museum. J. Ambient Intell. Humaniz. Comput. 2024, 15, 1643–1658. [CrossRef]
- Centorrino, P.; Corbetta, A.; Cristiani, E.; Onofri, E. Managing Crowded Museums: Visitors Flow Measurement, Analysis, Modeling, and Optimization. J. Comput. Sci. 2021, 53. [CrossRef]
- Brida, J.G.; Meleddu, M.; Pulina, M. Understanding Museum Visitors’ Experience: A Comparative Study. J. Cult. Herit. Manag. Sustain. Dev. 2016, 6, 47–71. [CrossRef]
- Gupta, R.; Dubey, A. K. ANALYSING DEMOGRAPHIC TRENDS AND VISITORS’ SATISFACTION AT THE NATIONAL MUSEUM, DELHI. PUSA J. Hosp. Appl. Sci. 2024, 10, 8–18.
- Kuflik, T.; Wecker, A.J.; Lanir, J.; Stock, O. An Integrative Framework for Extending the Boundaries of the Museum Visit Experience: Linking the Pre, during and Post Visit Phases. Inf. Technol. Tour. 2015, 15, 17–47. [CrossRef]
- Antoniou, A.; Katifori, A.; Roussou, M.; Vayanou, M.; Karvounis, M.; Kyriakidi, M.; Pujol-Tost, L. Capturing the Visitor Profile for a Personalized Mobile Museum Experience: An Indirect Approach. In Proceedings of the CEUR Workshop Proceedings; 2016.
- Gargiulo, R.; Carignani, F. Novel Approaches in Profiling in Museums. In Handbook of Research on Museum Management in the Digital Era; 2022; pp. 228–247.
- Taormina, F.; Baraldi, S.B. Museums and Digital Technology: A Literature Review on Organizational Issues. In Rethinking Culture and Creativity in the Digital Transformation; 2023; pp. 69–87.
- Verde, D.; Romero, L.; Faria, P.M.; Paiva, S. Indoor Content Delivery Solution for a Museum Based on BLE Beacons. Sensors 2023, 23. [CrossRef]
- Spachos, P.; Plataniotis, K.N. BLE Beacons for Indoor Positioning at an Interactive IoT-Based Smart Museum. IEEE Syst. J. 2020, 14, 3483–3493; [CrossRef]
- Chianese, A.; Piccialli, F. Designing a Smart Museum: When Cultural Heritage Joins IoT. In Proceedings of the Proceedings - 2014 8th International Conference on Next Generation Mobile Applications, Services and Technologies, NGMAST 2014; 2014; pp. 300–306.
- Mohamed, S.; Sethom, K.; Namoun, A.; Tufail, A.; Kim, K.H.; Almoamari, H. Customer Profiling Using Internet of Things Based Recommendations. Sustainability 2022, 14. [CrossRef]
- Arvaniti-Bofili, M.; Gkouskos, S.; Kalampokis, K.; Papaioannou, G.; Gogolos, G.; Chaldeakis, I.; Petridis, K.; Magoutis, K. Towards Personalized Recommendations in an IoT-Driven Tour Guide Platform. In Proceedings of the Communications in Computer and Information Science; 2020; Vol. 1310, pp. 3–11.
- Ronco, F. Smart technologies in the museum environment: AR experiments on physical models at the Museum of Oriental Art in Turin. In Proceedings of the 2024 Conference on Human-Computer Interaction in Museums; 2024; 17472.
- Sepe, F.; Marzullo, M. Making Smarter Museums Through New Technologies. In Handbook of Research on Museum Management in the Digital Era; 2022; pp. 75–98.
- Carolis, B. D., Macchiarulo, N., Bochicchio, M. A. AI-assisted virtual reality for cultural heritage education: The experience of the MARTA Museum. In Proceedings of the 2023 IEEE Conference on Experimental Technology and Digital Humanities; 2023.
- Ferrato, A.; Limongelli, C.; Mezzini, M.; Sansonetti, G. Using Deep Learning for Collecting Data about Museum Visitor Behavior. Appl. Sci. 2022, 12. [CrossRef]
- Yan, T. Research and application of AI-based interactive exhibits in Wuhan Museum of Science and Technology. J. Educ. Res. Appl. 2024, 8, 6091.
- Blud, L.M. Social Interaction and Learning among Family Groups Visiting a Museum. Mus. Manag. Curatorship 1990, 9, 43–51. [CrossRef]
- Tolmie, P.; Benford, S.; Greenhalgh, C.; Rodden, T.; Reeves, S. Supporting Group Interaction in Museum Visiting. In Proceedings of the Proceedings of the ACM Conference on Computer Supported Cooperative Work, CSCW; 2014; pp. 1049–1059.
- Shaby, N.; Assaraf, O.B.Z.; Koch, N.P. Students’ Interactions During Laboratory Group Activity in a Science Museum. Int. J. Sci. Math. Educ. 2024, 22, 703–720. [CrossRef]
- Fosh, L.; Lorenz, K.; Benford, S.; Koleva, B. Personal and social? Designing personalized experiences for groups in museums. MW2015: Museums and the Web 2015. MW2015: Museums and the Web 2015, Chicago, IL.
- Massarani, L.; Norberto Rocha, J.; Scalfi, G.; Silveira, Y.; Cruz, W.; Lage dos Santos Guedes, L. Families Visit the Museum: A Study on Family Interactions and Conversations at the Museum of the Universe – Rio de Janeiro (Brazil). Front. Educ. 2021, 6. [CrossRef]
- Tsiropoulou, E.E.; Thanou, A.; Paruchuri, S.T.; Papavassiliou, S. Self-Organizing Museum Visitor Communities: A Participatory Action Research Based Approach. In Proceedings of the Proceedings - 12th International Workshop on Semantic and Social Media Adaptation and Personalization, SMAP 2017; 2017; pp. 101–105.
- Stryker Co., Vocera V-Series Smartbadge User Guide, Available online: https://pubs.vocera.com/device/vseries/production/docs/vseries_v5000_user_guide.pdf (accessed on 14 August 2024).
- Abeeway Co., Datasheet DEABE3XX v1.7, Available online: https://www.abeeway.com/wp-content/uploads/2021/03/Abeeway_Badge-data-sheet_14.pdf (accessed on 14 August 2024).
- Kontakt.io Inc., Smart Badge technical specification, Available online: https://kontakt.io/app/uploads/2023/11/Technical-Specifications-Smart-Badge.pdf (accessed on 14 August 2024).
- Caneschi, F.; Ammendola, G. Pin: A smart wearable badge to track and augment your museum experience. Museo Marino Marini; 2019, pp. 1–16.
- Park, G.; Oh, H.; Lim, B.C.; Khoo, B.L.Z. Can Smart Technology Make Group Members More Creative? The Effect of Interactive Feedback Using Sociometric Badges on Members’ Creativity. Behav. Inf. Technol. 2023, 42, 2452–2466. [CrossRef]
- De Jode, M.; Hudson-Smith, A.; Mavros, P.; Coulton, P.; Huck, J.; Roberts, J.; Powell, P. Showing Mutual Support through Digital Empathy Badges. In Proceedings of the UbiComp and ISWC 2015 - Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing and the Proceedings of the 2015 ACM International Symposium on Wearable Computers; 2015; pp. 1–4.
- Su, C.M.; Shi, C.Y.; Wu, Y.L.; Lee, H.C. Demo Abstract: A LoRa Wireless Smart Badge for Enhancing Museum Visitors’ Experience. In Proceedings of the Proceedings - 2017 16th ACM/IEEE International Conference on Information Processing in Sensor Networks, IPSN 2017; 2017; pp. 261–262.
- Ivanov, R. ExhibitXplorer: Enabling Personalized Content Delivery in Museums Using Contextual Geofencing and Artificial Intelligence. ISPRS Int. J. Geo-Inf. 2023, 12. [CrossRef]
- Harisha, A.; Salian, L.; Yermal, A.; Shastry, C.G.A. Open Standard Authorization Protocol: OAuth 2.0 Defenses and Working Using Digital Signatures. In Advancements in Cybercrime Investigation and Digital Forensics; 2023; pp. 319–344 ISBN 9781000840834.
Figure 1.
System architecture.
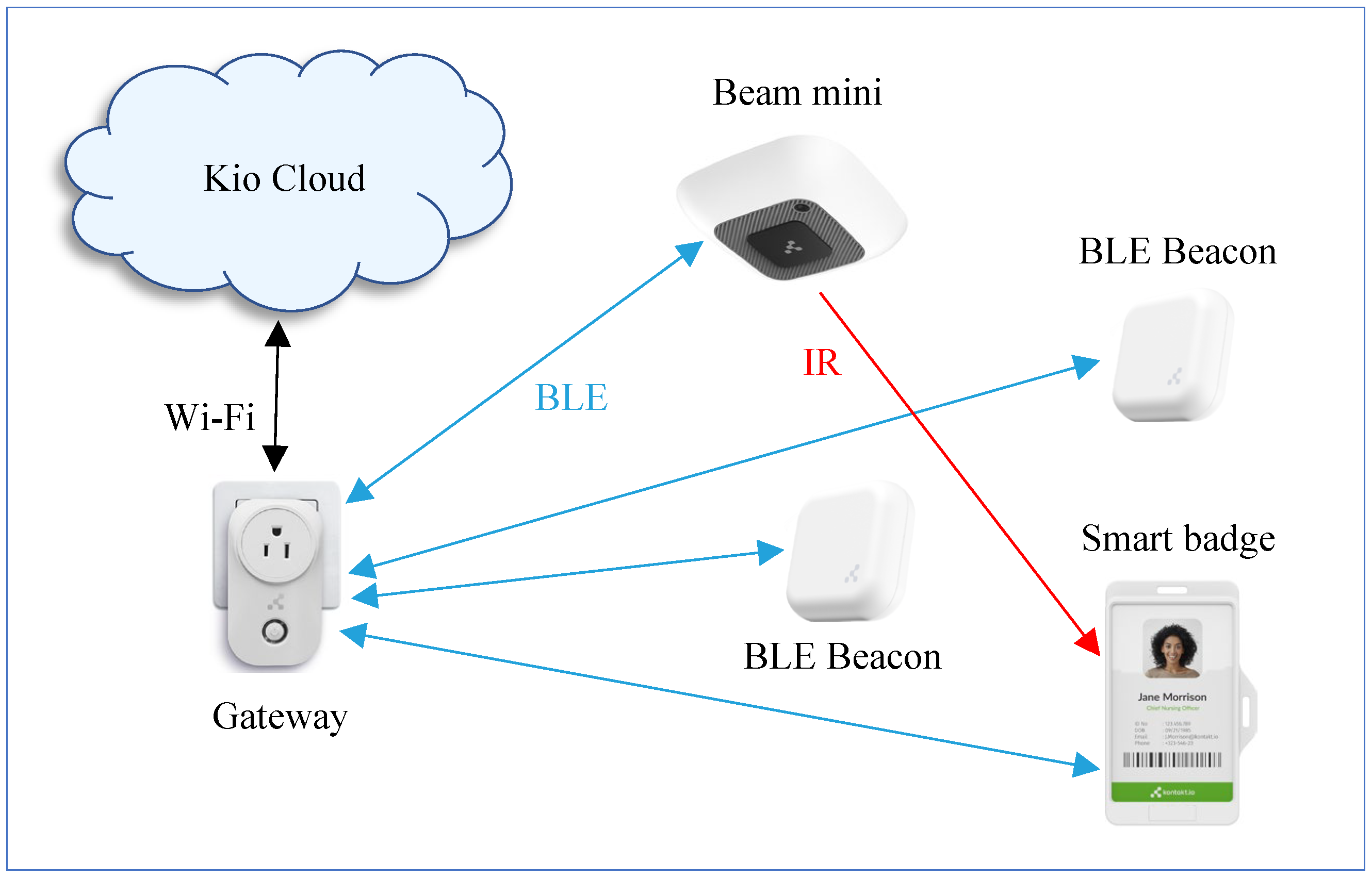
Figure 2.
ER database diagram.
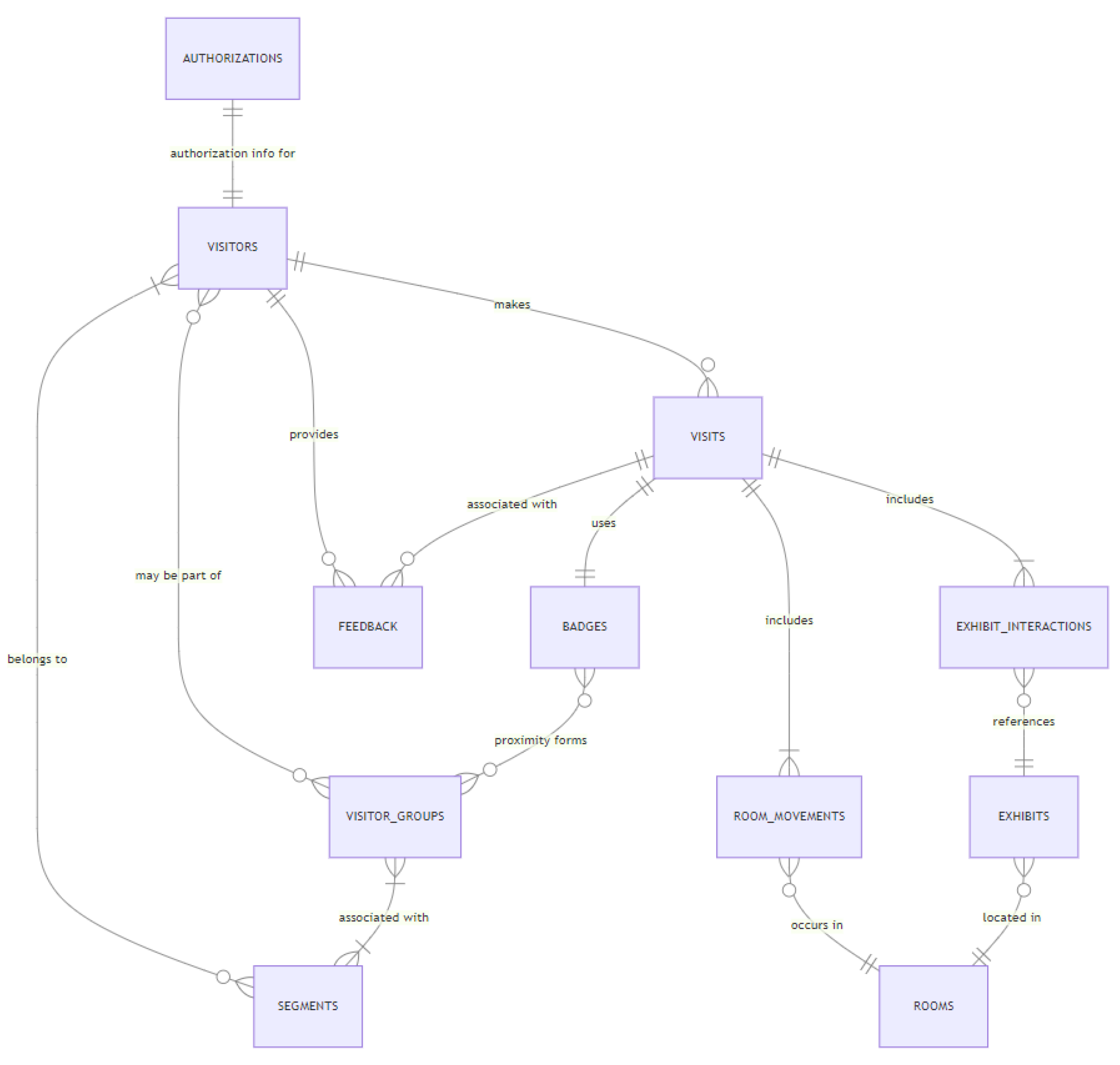
Figure 3.
Software architecture.
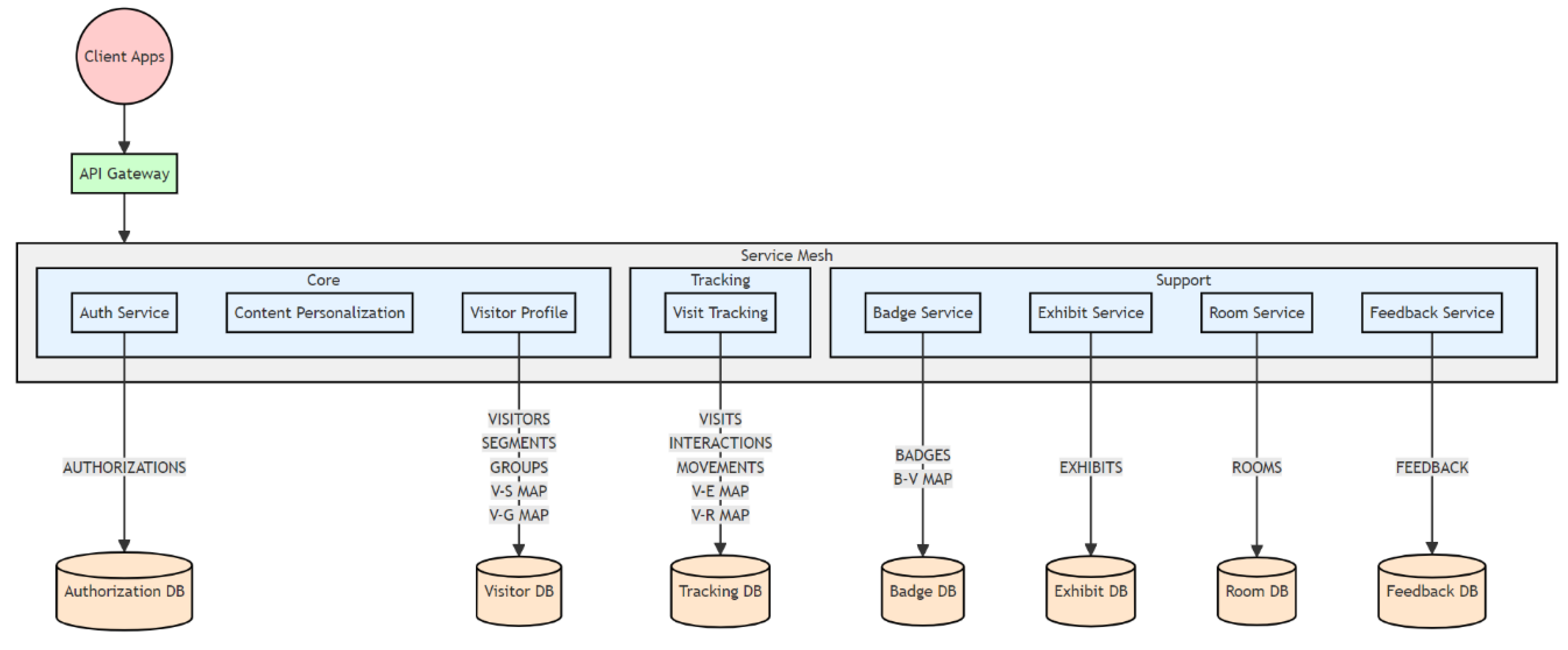
Figure 4.
Segment statistics - aggregation pipeline.

Figure 5.
Jaccard algorithm - aggregation pipeline.

Figure 6.
Visitor authorization document.

Figure 7.
Smart badges from Kontakt.io: (a) Front and back view; (b) Association.

Figure 8.
Data in packets: (a) Anchor Beacon; (b) Smart Badge.


Table 1.
Smart Badges configuration.
| Config parameter | Management |
|---|---|
| Telemetry packets | Enabled, Interval=1500ms |
| Location packets | Enabled, Interval=1500ms |
| Secure Profile packet | Disabled |
| TX Power Level for all packets | 5 (-4dBm) |
| iBeacon packets | Disabled |
| Eddystone packets (all types) | Disabled |
| Smart Badge Power on/off | Enabled |
| Power Saving Mode | Enabled, Working Hours |
| Button Events | Enabled |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



