
Submitted:
02 October 2024
Posted:
03 October 2024
You are already at the latest version
Abstract
The saguaro cactus (Carnegiea gigantea) plays a pivotal role in desert ecosystems, making its population monitoring essential. Traditional census methods used by the United States Forestry Service are resource-intensive, prompting a need for more cost-effective alternatives. Automated detection methods using advanced object detection models applied to drone imagery present a promising solution. In a proof-of-concept study, 244 drone images of saguaros were captured from a top-down perspective over an undeveloped hill adjacent to Sun Ray Park, Phoenix, Arizona (33.3188° N, 111.9980° W), from altitudes of 486, 507, and 519 meters above mean sea level (AMSL). We employed the Mask R-CNN model from the Detectron2 framework for model training. The images were divided into training, validation, and test sets in an approximate 8:1:1 ratio, with the sets separated by their physical locations within the park: training data was centralized, validation data was positioned to the east, and test data was located in the west. The Mask R-CNN achieved an average precision of 89.8% and an average F1 score of 90.3% in identifying saguaros across 27 test images from 486/507 m AMSL, demonstrating the model's effectiveness in accurately identifying saguaro cacti. Despite the limited sample size, the model's adaptability to diverse scenarios underscores its potential for practical applications in ecological conservation. This research contributes to the field of automated monitoring by offering a viable alternative to labor-intensive methods, thus supporting the sustainability of saguaro in their native habitat.
Keywords:
Saguaro cactus
; population monitoring
; image recognition
; drone imagery
; Mask R-CNN
; Detectron2
1. Introduction
As the guardian of the Sonoran Desert, the saguaro cactus (Carnegiea gigantea) plays a vital role as a source of sustenance and shelter for a diverse range of desert wildlife, while holding profound significance within the rich cultural heritage of the Tohono O’odham people [1]. The saguaro stands as the tallest presence within the local ecosystem, typically reaching heights of 14 m and as high as 23 m [2]. Sagurao provides shelter for numerous species seeking to evade predators or hunt for prey [3]. Several avian species, including Harris’s and red-tailed hawks [4], choose to nest on its sturdy branches or drill cavities (e.g., gilded flicker and Gila woodpeckers) inside the saguaro’s pulpy flesh [5]. Despite the presence of oxalates, certain creatures like pack rats, jackrabbits, mule deer, and bighorn sheep consume the flesh directly from a standing saguaro, especially during periods of food and water scarcity [6]. Beyond its critical ecological role, the saguaro is intricately intertwined with the religions, ceremonies, cultures, and livelihoods of indigenous peoples such as the Papago (Tohono O’odham) and Pima nations, who have inhabited the region for millennia [5].
Consequently, the saguaro stands as a reliable bioindicator of ecological well-being in the Sonoran Desert, underscoring the imperative of accurate population monitoring for this keystone species in conservation management efforts [1]. The United States Forestry Service has been conducting extensive manual censuses in Saguaro National Park (SNP) every ten years since 1990 to study the saguaro cactus [7]. This vital endeavor requires a significant commitment of time, resources, and labor. In this regard, an impressive 500 individual volunteers dedicated an astounding 750 person-days and over 3,500 hours to map 24,000 saguaros at Saguaro National Park in 2020 [8].
An emerging trend is to use affordable unmanned aerial vehicles, commonly known as drones, to monitor agricultural and other natural resources, as an alternative to extensive in situ surveying techniques [9]. This innovative approach holds the promise of significantly diminishing the time and labor demands associated with conventional population assessments [10]. A study used aerial imagery collected by Pima Association Governments at the spatial resolution of 15.24 cm/pixel [10]. However, it employed shadow features rather than the actual pixels of saguaros, likely due to insufficient resolution of saguaro images. Thus, this method can only detect mature saguaros that cast a sufficiently distinct shadow, which affects the accuracy depending on the prominence and orientation of the shadows as well as effects from local vegetation, geology, and topographic relief [10]. The authors indicated that identification of saguaros within the obtained images presented a challenging task, reporting an overall accuracy of their technique 58% [10].
Recent advances in artificial intelligence (AI) techniques, particularly automatic object detection from images, provide unprecedented opportunities to provide solutions to this problem set [11,12]. Object detection primarily revolves around two key tasks: object localization or segmentation, which predicts the precise position of an object within an image, and object classification, which determines the category (i.e., class) to which an object belongs [13]. In a classification task, the input is typically an image containing a single object, and the output is a corresponding class label. Conversely, localization methods discern patterns from images that contain one or more objects, each annotated with a bounding box or precise boundary. By seamlessly integrating these two tasks, it becomes feasible to both locate and classify each instance of an object within an image. Nevertheless, accurately determining the positions of bounding boxes, masks, or boundaries (i.e., precise outline) for each object is a critical step in this process [14,15]. If too many candidates of bounding boxes or boundaries are proposed, it can lead to a computationally burdensome training process, while an insufficient number of candidates may result in the identification of “unsatisfactory regions” [13]. Of note, even general object recognition algorithms, such as DALLE-3 [16], cannot achieve adequate performance for recognizing a large population of saguaros in a single picture. It performs particularly poorly from top-views, due to insufficient saguaros representation in the training datasets. Thus, application of the latest AI techniques to high-resolution top-view images requires further development.
The R-CNN (Regions with Convolutional Neural Network Features) algorithm [17] introduced a novel approach to object detection by combining CNN features with region proposals, leading to substantial improvements in accuracy, object localization, and the overall object detection pipeline [10]. This innovative approach mitigated the requirement for handling an excessive number of candidates by harnessing a selective search algorithm to generate candidates judiciously. Nonetheless, it did exhibit certain limitations, such as slow inference speed due to the need to propose and process each region independently. To address these issues, the fast R-CNN algorithm was introduced [18], which effectively classifies object proposals using deep convolutional networks. This approach enhances both training and testing speeds while simultaneously improving detection accuracy. The successor to Fast R-CNN, Faster R-CNN [19], enhances its predecessor by incorporating a Region Proposal Network (RPN) that shares full-image convolutional features with the detection network. This integration allows for an almost cost-free generation of region proposals [17]. After that, Mask R-CNN [20] was developed on top of Faster R-CNN by adding an output branch in parallel for predicting an object mask (Region of Interest) along with the branch for bounding box recognition [18]. Mask R-CNN has been used in various applications such as medical image analysis, autonomous driving, and robotics [21,22]. The model is trained end-to-end using a multi-task loss function that combines classification, localization, and mask prediction losses. Mask R-CNN has several advantages over its predecessors, including higher detection rate, improved instance segmentation performance, the ability to generalize to other tasks, and the potential to estimate the size of the saguaros.
2. Materials and Methods
2.1. Data Collection and Preprocessing
Drone images were collected with a DJI Phantom 4 Pro quadcopter between 3 and 4 pm near Sun Ray Park in Phoenix, Arizona (approximately 33.3188° north, 111.9980° west) on March 3, 2022. The aircraft operated at three low altitudes ranging from 381 m to 421 m above mean sea level (AMSL): 486 m (west of the park), 519 m (most in the east of the park), and 507 m (covering the entire park). These flights were designed to test the reproducibility across a range of altitudes and the adaptability of the algorithm, with the first two flights adjusting for altitude differences between the peak and the ground, while the last flight used an unadjusted altitude, as an alternative data collection method. The aircraft traversed horizontally at its nominal flight altitude with the camera pointed directly below the aircraft (i.e., nadir), or 90 degrees from the direction of travel, to capture imagery.
The images were uploaded to and annotated by the Datatorch [24] and Roboflow platforms [25]. Each image was assigned to a team member for manual annotation and another for verification. The cacti were annotated into three classes: “saguaro” (mature saguaro with arms), “spear” (young saguaro without arms), and “barrel”(which may produce buds that bloom at the top in April) [26]. The creation of the “spear” class was to focus on training cacti with arms since barrel cacti and young saguaros are very similar, both of which comprise a small proportion in the full dataset. We focus on modeling the distinct morphology of mature saguaros with arms and recommend that the discrimination between the other two classes be focus of future studies.
To facilitate model training, various image preprocessing steps were explored, including auto-orientation, horizontal and vertical flip augmentations, resizing, tiling, and auto-contrast filtering.
After annotation and preprocessing, the resulting dataset was exported into Common Objects in Context (COCO) JSON format [27] for modeling.
2.2. Model Training and Evaluation
To detect saguaros from the images, we utilized the Detectron2 package [23], one of the state-of-the-art object detection packages that does not require a very large sample size. Detectron2 is built on the Torch deep learning library [25] and implemented with various R-CNN models and evaluation tools, including Mask R-CNN [20].
The Mask R-CNN (Region-based Convolutional Neural Network) was chosen as the base model for object detection for its capability to model on pixel level, speed, performance, and compatibility with various libraries and platforms. Additionally, the model offered robust documentation, which made it preferable over other alternatives, such as YOLOv5 [28].
The model was trained, validated, and tested using the processed dataset of altitude 486/519 m AMSL, with approximated sample ratios of 8:1:1, respectively. Training, validation, and independent test sets were separated by their geographical location to minimize image overlap of saguaros between training, validation, and testing datasets. Default training parameters were used initially with Mask R-CNN. Various parameters were tuned, such as learning rate, maximum iterations, and Intersection over Union (IoU) threshold [17,29]. Default values were used for other parameters. The results of the model were evaluated, to achieve the maximal mean average precision (mAP) [30] from the validation set under various combinations of parameters.
The final model performance was evaluated on the independent test datasets that were not utilized during the training and validation. The mAP, sensitivity (recall), precision, and F1 scores, which combine sensitivity and precision, were selected as metrics of accuracy for model recognition of saguaros in the images. Following convention, sensitivity was defined as the percentage of correctly predicted saguaros among total annotated saguaros in the test set with precision being referring to the percentage of correctly predicted saguaros among total predicted saguaros. During the evaluation of the testing dataset, we treated the same saguaros from different images as unique samples or observations, as they were likely collected from different altitudes, aircraft headings, or camera geometry.
Our code was extended from a preexisting Google Colab notebook [31] that can directly work with the Roboflow platform, specifically created for training models in the Detectron2 ecosystem with customized datasets. It was revised to work within Jupyter Notebooks on a GPU server. Specifically, the Nvidia RTX 4090 GPU was used for the training and testing.
To recap, our methodology encompassed data collection, pre-processing, model selection, choice of hardware and training environment, selection of an object detection library, code execution, data export, model training, evaluation, and post-training analysis to achieve the desired results.
3. Results
3.1. Collected Data and Its Geospatial Distribution
Data was collected from Sun Ray Park, Phoenix, Arizona on March 3, 2022. A total of 87 images were captured from the east side of the park between 3:00 pm to 3:15 pm at an altitude of 519 m above mean sea level (AMSL), and 72 images were taken from the relatively lower part of the park between 3:30 pm and 3:41 pm from 486 m AMSL. The two flights corresponded to 98 to 136 m, and 65 to 101 m above the ground level (Figure 1, image number 1-159), respectively. Additionally, 85 images were captured across the park between 3:47 pm and 3:53 pm at 507 m AMSL (Figure 1, image number 160-244), corresponding to 86 to 122 m above the ground level. Figure 1 depicts the geographical locations of the aerial images captured by a DJI Phantom 4 Pro drone. Each point represents a distinct image acquisition point above the ground, color-coded according to its breakdown to training, validation, or test sets. The white points indicate the image locations, each labeled with an identifier. The training data is centered within the park (green), while the validation data is located to the east (orange), and the test data covers the western region from 486m and 507 m AMSL altitudes (blue).
3.3. Test Results
The average precision from [21] independent test images was 89.8% and 67.7% for boxes and masks respectively when using 0.5 as the IoU cutoff across various recall cutoffs. Examining the model’s performance using the key metrics of Recall, Precision, and F1 scores across the images (shown in Table 1) suggested a similar performance. Specifically, we achieved an average F1 score of 91.4% across 27 independent test images taken at 486/507 m, underscoring the robustness of our model in accurately identifying Saguaro instances. Those results include scenarios where images lacked any Saguaro, and where duplicated predictions were counted as false positives, which compromised precision and the average F1 score. This metric provides insight into the model’s ability to generalize to diverse scenarios, including those without the target object.
Figure 2 presents exemplary results showcasing the robust performance of our Saguaro detection model. In this scenario, the model achieved a remarkable 100% recall, precision, and F1 score for this image, accurately identifying all instances of Saguaro in images captured at altitudes of 95 m above the ground. These results exemplify the model’s effectiveness in successful Saguaro detection, demonstrating its reliability and accuracy in a variety of scenarios (e.g., shapes and angles)
Figure 3 sheds light on specific challenges encountered by our Saguaro detection model, emphasizing instances where the model mistakenly identified spears or barrels as Saguaro. The model erroneously detected a saguaro instance from the bottom right of an image at an altitude of 101 m above the ground, showcasing a potential limitation in its discernment, particularly when faced with intricate patterns in dense vegetation areas, such as a young saguaro under the shape of a big tree or bush. Of note, the color patterns between armed saguaros and unarmed saguaros or barrels are expected to be very similar. This example highlights the need for continued refinement and consideration of such complex scenarios in future iterations of the model, such as collecting more spears and barrels and training the model to distinguish armed saguaros from unarmed ones.
4. Discussion
Our study aimed to enhance saguaro (Carnegiea gigantea) cacti population monitoring using an advanced object detection model, Mask R-CNN, applied to drone images. The saguaro, with its ecological significance and cultural importance, serves as a bioindicator in the Sonoran Desert, emphasizing the need for accurate population assessments. The traditional method of manual censuses, undertaken by the United States Forestry Service, is resource-intensive. In comparison with another population research on saguaros that developed an automated shadow detection method for mapping mature saguaros and correctly identified 58% of mature saguaros [10], our approach leverages more affordable automated object detection technologies and higher resolution nadir images, representing a promising avenue for optimizing population monitoring. Our model achieved an average F1 score of 90.3% across all independent test images taken from a distance ranging from 65 to 136 m above the ground level, despite being trained on a limited number of training samples.
The integration of Mask R-CNN into our methodology yielded compelling results with a limited set of images. The model demonstrated exceptional recall, precision, and F1 scores, achieving a notable average F1 score of 90.3% across independent test images. This robust performance signifies the model’s proficiency in accurately identifying saguaro instances, thereby streamlining the monitoring process. Importantly, our model showcased adaptability in scenarios without saguaros. It yielded an average false positive rate of 16.4%, implying future improvement. Versatility is critical for its application in diverse ecological contexts, contributing to its reliability as a monitoring tool.
However, our study also highlighted challenges, particularly in Figure 3, where the model incorrectly identified spears and barrels as saguaros. We also experienced challenges in handling partial saguaros located at the edge of an image. This underscores the importance of ongoing refinement, considering intricacies in the landscape like saguaros spread on the mountains over 100 meters, and addressing complex scenarios where false positives can occur. Notably, we tested with a small number of sample and trained with a much larger training set. Performance is expected to increase with additional training samples. Additionally, our images were taken from a nadir view using drones, making pattern recognition more challenging compared to front-view images or those with shadows. In such cases, inexperienced annotators often struggle to distinguish spear saguaro cacti from barrel cacti when image resolution is insufficient. Future studies should focus on capturing more data to improve the model’s capability to discern subtle differences in dense vegetation areas, ensuring greater accuracy in challenging environments. With larger data, other AI models such as transformer-based ones will become applicable.
5. Conclusions
In conclusion, our study successfully applied the Mask R-CNN model to drone images for saguaro detection, achieving notable accuracy in population monitoring. The model demonstrated exceptional performance with test images taken from 486 or 507 m AMSL, highlighting its robustness in identifying unique features of saguaros. This capability optimizes the monitoring process, showing adaptability across diverse scenarios, including images without saguaros. Such versatility underscores its potential for practical deployment in ecological conservation efforts. Although challenges remain, particularly in discerning intricate patterns, ongoing refinements will further improve the model’s accuracy. This technique presents a viable alternative to labor-intensive manual censuses. Future studies will aim to collect more data and apply more advanced modeling techniques to enhance automated population monitoring and broaden their applications in ecological conservation. As stewards of the Sonoran Desert, the integration of advanced technologies into conservation practices ensures a sustainable future for the saguaro cactus and the delicate ecosystem to which it belongs.
Author Contributions
Conceptualization, Don Swann, Kamel Didan and Haiquan Li; Data curation, Wenting Luo, Breeze Scott, Jacky Cadogan and Truman Combs; Formal analysis, Wenting Luo and Haiquan Li; Funding acquisition, Haiquan Li; Investigation, Kamel Didan and Haiquan Li; Methodology, Breeze Scott, Jacky Cadogan and Haiquan Li; Project administration, Haiquan Li; Resources, Truman Combs and Kamel Didan; Software, Wenting Luo, Breeze Scott and Jacky Cadogan; Supervision, Kamel Didan and Haiquan Li; Validation, Haiquan Li; Visualization, Wenting Luo; Writing – original draft, Wenting Luo, Breeze Scott and Jacky Cadogan; Writing – review & editing, Truman Combs and Haiquan Li. All authors will be informed about each step of manuscript processing including submission, revision, revision reminder, etc. via emails from our system or assigned Assistant Editor.
Funding
This research was funded by a start-up fund from the College of Agriculture and Life Sciences at the University of Arizona.
Data Availability Statement
Code and images will be shared on GitHub upon publication.
Acknowledgments
The authors appreciate Jennica Li for her annotations of saguaros from the drone images.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Biel, A.W. Saguaro Cactus: Sentinel of the Southwest. 2009; Available from: https://www.nps.gov/articles/saguaro-cactus-facts.htm.
- Service, U.S.N.P. Cacti. Available from: https://www.nps.gov/orpi/learn/nature/cacti.htm.
- Yetman, D.; et al. The saguaro cactus: a natural history. 2020: University of Arizona Press.
- Tomoff, C.S. Avian species diversity in desert scrub. Ecology 1974, 55, 396–403. [Google Scholar] [CrossRef]
- Drezner, T.D. The keystone saguaro (Carnegiea gigantea, Cactaceae): a review of its ecology, associations, reproduction, limits, and demographics. Plant Ecology, 2014, 215, 581–595. [Google Scholar] [CrossRef]
- U.S. National Park Services. The Saguaro Cactus. April 11, 2024 [cited 2024; Available from: https://www.nps.gov/sagu/learn/nature/saguaro.htm. /.
- Saguaro National Park Arizona. Long-term Saguaro Monitoring. [cited 2024; Available from: https://www.nps.gov/sagu/learn/nature/long-term-monitoring.htm.
- O’Brien, K.; Swann, D. Three decades of ecological change: the 2020 saguaro census. Part I: changes in the saguaro population 1990-2020. Unpublished report to Western National Parks Association, Tucson, 2021.
- Hassanalian, M.; Abdelkefi, A. Classifications, applications, and design challenges of drones: A review. Progress in Aerospace sciences 2017, 91, 99–131. [Google Scholar] [CrossRef]
- Carter, F.; van Leeuwen, W.J. Mapping saguaro cacti using digital aerial imagery in Saguaro National Park. Journal of Applied Remote Sensing 2018, 12, 036016–036016. [Google Scholar] [CrossRef]
- James, K.; Bradshaw, K. Detecting plant species in the field with deep learning and drone technology. Methods in Ecology and Evolution 2020, 11, 1509–1519. [Google Scholar] [CrossRef]
- Tian, Y. Artificial intelligence image recognition method based on convolutional neural network algorithm. Ieee Access 2020, 8, 125731–125744. [Google Scholar] [CrossRef]
- Zhao, Z.-Q.; et al. Object detection with deep learning: A review. IEEE transactions on neural networks and learning systems, 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Chen, L.; et al. Review of image classification algorithms based on convolutional neural networks. Remote Sensing 2021, 13, 4712. [Google Scholar] [CrossRef]
- Kaur, J.; Singh, W. Tools, techniques, datasets and application areas for object detection in an image: a review. Multimedia Tools and Applications 2022, 81, 38297–38351. [Google Scholar] [CrossRef]
- OpenAI, DALL·E 3 System Card. 2023.
- Girshick, R.; et al. Rich feature hierarchies for accurate object detection and semantic segmentation. in Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
- Girshick, R. Fast r-cnn. in Proceedings of the IEEE international conference on computer vision. 2015.
- Ren, S.; et al. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems 2015, 28. [Google Scholar] [CrossRef]
- He, K.; et al. Mask r-cnn. in Proceedings of the IEEE international conference on computer vision. 2017.
- Hsia, C.-H.; et al. Mask R-CNN with new data augmentation features for smart detection of retail products. Applied Sciences 2022, 12, 2902. [Google Scholar] [CrossRef]
- Sahin, M.E.; et al. Detection and classification of COVID-19 by using faster R-CNN and mask R-CNN on CT images. Neural Computing and Applications 2023, 35, 13597–13611. [Google Scholar] [CrossRef]
- Wu, Y.; et al. Detectron2. 2019: Github.
- DataTorch Inc. DataTorch (Version 0.1.1) [Software]. [cited 2024; Available from: https://datatorch.io/ and https://github.com/datatorch/python.
- Dwyer, B.; et al. Roboflow (Version 1.0) [Software]. Available from: https://roboflow.com/.
- Torre, D. Cactus. 2017: Reaktion Books.
- Lin, T.-Y.; et al. Microsoft coco: Common objects in context. Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6–12, 2014. Proceedings, Part 2014, 13, 740–755. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: better, faster, stronger. in Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv, 2016; arXiv:1609.04747. [Google Scholar]
- Henderson, P.; Ferrari, V. End-to-end training of object class detectors for mean average precision. in Computer Vision–ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, November 20-24, 2016, Revised Selected Papers, Part V 13. 2017. Springer.
- Bisong, E.; Bisong, E. Google colaboratory. Building machine learning and deep learning models on google cloud platform: a comprehensive guide for beginners, 2019: p. 59-64.
Figure 1.
Geospatial Distribution of Aerial Image in Sun Ray Park: Pictures taken from 519 m (images 1 to 87), 486 m (images 88-159), and 507m (images 160-244) above mean sea level. Residential areas have been masked to ensure privacy.
Figure 1.
Geospatial Distribution of Aerial Image in Sun Ray Park: Pictures taken from 519 m (images 1 to 87), 486 m (images 88-159), and 507m (images 160-244) above mean sea level. Residential areas have been masked to ensure privacy.
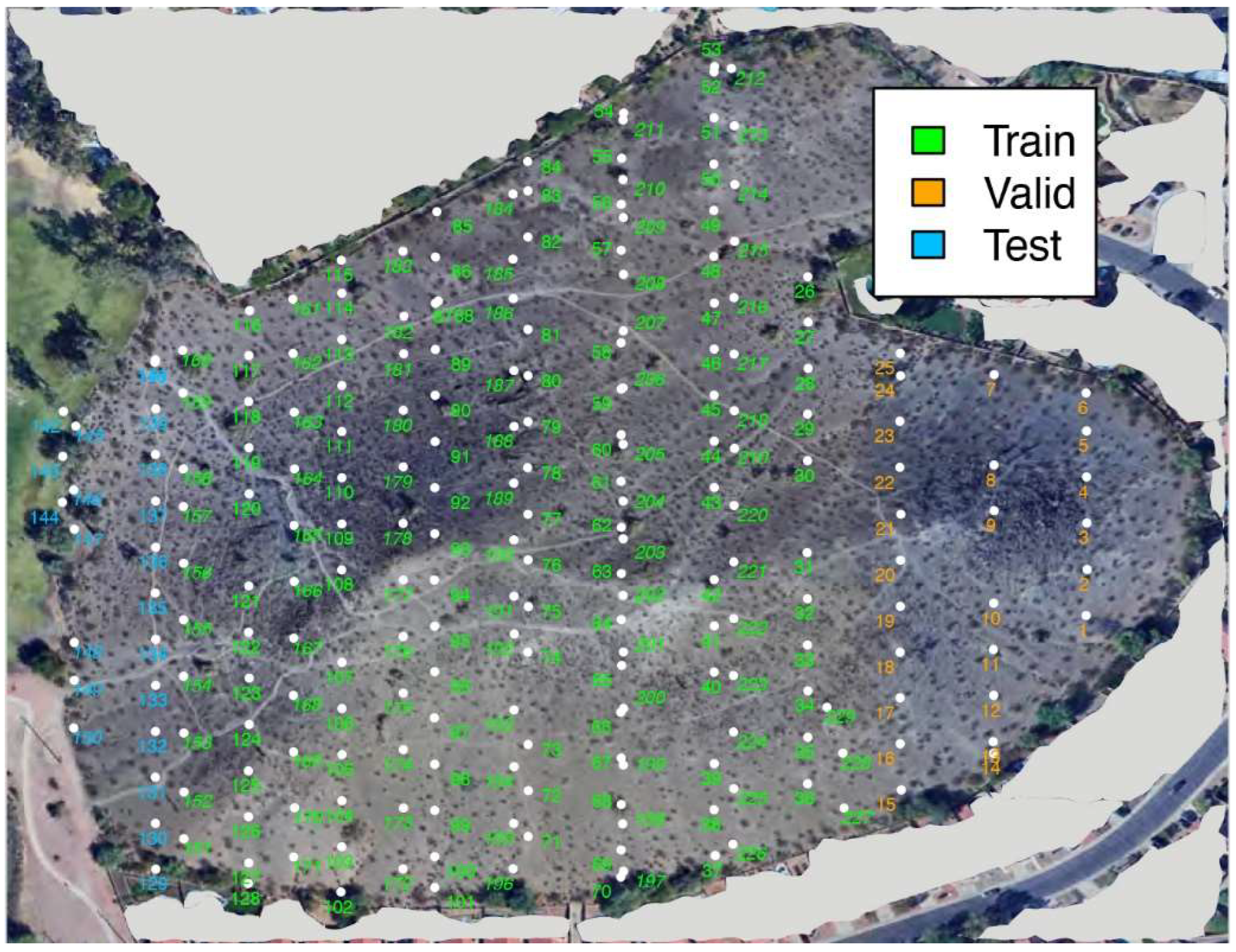
Figure 2.
A Perfect Example of Saguaro Detection.

Figure 3.
A Case Study of False Positives.


Table 1.
Performance Evaluation of the Saguaro Detection Model.
| Metrics | Test pictures taken from 486/507m AMSL |
| Recall | 98.1% |
| Precision | 83.6% |
| Overall F1 | 90.3% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



