Submitted:
09 October 2024
Posted:
09 October 2024
You are already at the latest version
Abstract
With the gradual development and integration of artificial intelligence into various industries, there is also a great range of integration in the financial industry. Therefore, this article focuses on the trend prediction model and financial risk management problems of deep reinforcement learning (DRL), one of the largest branches of artificial intelligence, in the cryptocurrency market. In addition, in the experimental part of this paper, the artificial intelligence machine learning Long short-term memory network (LSTM) model is used to make effective time series prediction and analysis on the relevant data of the cryptocurrency market, so as to make a large-scale analysis to improve the accuracy of market trend prediction and the effectiveness of risk management. In addition, in this experiment, technology-related indicators, emotional states of financial market customers and other content related to large language models are combined. While optimizing investment strategy by using deep reinforcement learning algorithm, machine learning prediction model is also used to capture the time dependence of financial market. The experimental results also show that the predicted results are consistent with the actual value. Therefore, the model has high practical application value in predicting the time series price trend of cryptocurrency in the financial market and indicates that the integrated DRL model framework can further optimize and manage the price and trading strategy of the financial market. Future research should focus on improving the LSTM model and incorporating more features to improve prediction accuracy and adapt to market changes.
Keywords:
Deep reinforcement learning (DRL)
; Long short-term memory Network (LSTM)
; The cryptocurrency market
; Risk management time series forecasting
1. Introduction
For more than half a century, the volume of transactions in financial markets and the factors that influence them have been extensively studied, especially in exploring the relationship between volume and market returns. Although the relationship between trading volume and stock price may be inconsistent under the hypothesis of weak market efficiency, the study on this relationship is still attracting more and more attention from researchers and investors [1,2,3]. Many people believe that accurately grasping the trading point can significantly improve returns, but in reality, how to choose the right time to trade is not easy. Traders and financial experts typically face three scenarios: buy, sell, or hold until the best time comes. The goal of an optimized trading system is to maximize profits through some kind of theory or equation.
In recent years, scientists in the field of economics have conducted in-depth studies on the fluctuations and influencing factors of the cryptocurrency market and have proposed several techniques and strategies to help traders time their trades more effectively [4]. The following are several trading strategies commonly used in financial markets: double cross, day trading, swing trading, scalping, and long trading [5]. Each of these strategies has its own characteristics. Among them, the double cross strategy judges the market trend by the cross signal of the long-term and short-term moving average. Day trading emphasizes completing all trades in a single trading day to avoid risk; Swing trading aims to profit from price movements; Scalping trades make a difference by making small price changes; Position trading focuses on long-term holdings and reduces the focus on short-term fluctuations [6].
However, in our research, the application of these strategies has not always resulted in satisfactory trading results for the cryptocurrency market during certain periods. While some strategies are effective at achieving profits, in some cases they lead to losses. This is partly because it is extremely rare for all participants in the market to maintain temporary positions. In actual trading, traders may encounter situations where they are unable to buy or sell the target asset [7,8,9,10,11]. In addition, some traders may follow the "random walk theory", which holds that stock price movements are random and unpredictable, a theory proposed by Burton McKerr in 1973, which argues that market price movements cannot predict future movements through historical data [12,13,14]. Therefore, this study aims to use deep reinforcement learning techniques to evaluate trends in the cryptocurrency market and optimize risk management, with a view to improving the accuracy and efficiency of trading decisions.
2. Related Work
2.1. Research of Cryptocurrency Market Trend
In the research of cryptocurrency market trend prediction and risk management, deep reinforcement learning (DRL) has become an important research direction. Huang et al. studied the predictability of cryptocurrency returns by building a tree-based return prediction model and training it with 124 technical indicators. Their research shows that machine learning models, especially technical data analysis, are effective in improving predictive power, thus providing new evidence for cryptocurrency market predictions based on technical indicators. Guarino et al. compared the performance of algorithmic trading agents, which use technical analysis to construct trading strategies, with DRL agents, which are more adaptable and autonomous, on cryptocurrency markets and other financial assets. They found that DRL agents showed higher efficiency when trading using technical indicators. However, their study ignores the impact of commission costs, while pointing out that DRL agents have deficiencies in interpretability that limit their application in real investments.
Satarov et al. applied the Deep Q Network (DQN)algorithm to identify favorable trading points. In the study, DRL agents were rewarded only when they sold and penalized for consecutive actions to avoid holding or selling multiple times. The experimental results show that the DRL method has superior performance compared with the three traditional technology strategies after considering the transaction cost of 0.15%. Mahayana et al. used near-end Strategy Optimization (PPO) to automate trading in BTC, using 1-minute candlestick data and 18 technical indicators. The reward function they designed considers not only the location of the agent, but also the penalty for each holding time step. Although their experiment did not consider transaction costs, the results showed that the PPO strategy did not significantly improve profitability compared to the buy-and-hold strategy.
Schnaubelt applied PPO to Bitcoin limit order data to study the optimal limit order placement strategy. The PPO agent achieved a 36.93% cost reduction by reducing total transaction costs and showed superior performance in comparison to other DRL algorithms such as DQN and dual DQN. The study delves into execution techniques but ignores commission cost considerations in trading strategies. Li et al. propose a deep reinforcement learning architecture for high-frequency trading (HFT) that combines a long sequence representation extractor (LSRE) and a cross-asset attention network (CAAN). The architecture reduces the time complexity of the model by improving the transformer encoder and demonstrates better profitability and risk control on four encrypted datasets. However, the complexity of the system and the neglect of external factors limit its practical application.
In addition, Lucarelli and Borotti employ a multi-agent framework for local DRL training, where each cryptocurrency asset (such as Bitcoin, Ethereum, Litecoin, and Ripple) is managed by a local agent designed to maximize the global reward signal for optimized portfolio management. Their research yielded promising results, but completely ignored the impact of trading commissions. Cui et al. trained PPO agents based on market data to build low-risk cryptocurrency trading systems using conditional value at risk (CVaR) as a reward function. Their system effectively captures the compounding effects of tail-risk in financial markets, but it also ignores transaction costs.
In conclusion, most DRL methods in the existing literature focus on agent training in unsupervised learning and low commission environments and give priority to finding strategies to maximize profits with a small amount of work. Our research aims to improve existing methods by combining data from technical and social indicators, applying high-performance deep reinforcement learning algorithms and new risk-adjusted reward functions, while introducing layers of safety mechanisms to optimize trading behavior and improve portfolio performance metrics.
3. Cryptocurrency Market Trend Assessment Strategy
3.1. Methodology
The main goal of this study is to process and model time series of cryptocurrency market data using Long short-term Memory network (LSTM) models to improve the accuracy of market trend prediction and effectively manage the associated financial risks. Specifically, we aim to capture the hidden time dependencies in the cryptocurrency market through LSTM models, thereby improving the accuracy of forecasts, and integrate this predictive power into a deep reinforcement learning (DRL) framework to optimize investment strategies and enable better risk management.
3.2. Prediction Model Construction
In the existing cryptocurrency market trend forecast, how to effectively model the time series of market data is still an important research question [15]. Traditional models often struggle to deal with the complex dynamic characteristics and nonlinear relationships in the cryptocurrency market. To this end, the LSTM model is proposed in this study because it has significant advantages in processing time series data and is able to capture long-term dependencies and short-term fluctuations in the data.
In addition, combining the prediction results of the LSTM model with the DRL algorithm will provide a new perspective for optimizing investment strategy and risk management. Key research questions include: How can LSTM models be constructed and trained to accurately predict market trends? How can LSTM-generated time series forecast data be effectively integrated into the DRL framework to optimize trading strategies and reduce risk? These issues will be addressed through detailed experiments and evaluations to verify the effectiveness and practical application potential of LSTM combined with DRL.
3.3. Data Preparation and Preprocessing
In this study, we used data sets from multiple cryptocurrencies for time series analysis and modeling. This includes market data for cryptocurrencies such as Bitcoin, Dogecoin, Ethereum and Cardano. These datasets contain historical price information from 2015 to 2021, covering key metrics such as Open, High, Low, Close, adjusted Close and Volume.

Table 1.
data sets from multiple cryptocurrencies for time series analysis and modeling.
| Date | Open | High | Low | Close | Adj Close | Volume | |
| 0 | 2015/9/13 | 235.242004 | 235.934998 | 229.332001 | 230.511993 | 230.511993 | 18478800 |
| 1 | 2015/9/14 | 230.608994 | 232.440002 | 227.960999 | 230.643997 | 230.643997 | 20997800 |
| 2 | 2015/9/15 | 230.492004 | 259.182007 | 229.822006 | 230.304001 | 230.304001 | 19177800 |
| 3 | 2015/9/16 | 230.25 | 231.214996 | 227.401993 | 229.091003 | 229.091003 | 20144200 |
| 4 | 2015/9/17 | 229.076004 | 230.285004 | 228.925995 | 229.809998 | 229.809998 | 18935400 |
Data reading and preliminary examination: We first read the data files of each cryptocurrency through the pandas library and conduct a preliminary examination of the data structure. For example, Bitcoin's dataset (df_bitcoin) has a total of 2193 records and 7 fields. The data check revealed a small number of missing values in all fields, with the percentage of missing values in each field being about 0.182%.
Missing value processing: Missing value processing is necessary for every data set. We found that all the fields involved in the dataset (such as Open, High, Low, Close, Adj Close, and Volume) had a small number of missing values. Although the proportion of these missing values is relatively small, in order to ensure the stability and accuracy of the model, we will interpolate or delete the missing values in the subsequent processing steps.
Technical indicators calculation: In order to enrich the input data of the model, we calculate some common technical indicators and add them to the data set. These indicators include moving averages (SMA), Relative Strength Index (RSI), and others. The calculation code is as follows:
import ta
# Calculate technical indicators
df['SMA_20'] = ta.trend.sma_indicator(df['Close'], window=20)
df['RSI'] = ta. momentum. RSIIndicator(df['Close']). rsi ()
df['MACD'] = ta. trend. macd(df['Close'])
df['ATR'] = ta. volatility. average_true_range(df['High'], df['Low'], df['Close'])
Data consolidation and standardization: When dealing with multiple cryptocurrency data, we need to consolidate and standardize the data in order to train the model. The normalization step includes data normalization, using the MinMaxScaler to scale the data to the range [0, 1]. This helps to improve the training of the model, especially when using deep learning algorithms. The standardized code is as follows:
from sklearn. preprocessing import MinMaxScaler
# Data standardization
scaler = MinMaxScaler ()
df [['Open', 'High', 'Low', 'Close', 'Volume', 'SMA_20', 'RSI', 'MACD', 'ATR']] = scaler.fit_transform (df [['Open’, ‘High', 'Low', 'Close', 'Volume', 'SMA_20', 'RSI', 'MACD', 'ATR']])
Data Integration: To further enrich the data set, we combined market sentiment data and macroeconomic data into the main data set. The code example for the merge is as follows:
sentiment_df = pd. read_csv('sentiment_data.csv')
macro_df = pd. read_csv('macro_data.csv')
# Merge market sentiment data
df = df. merge (sentiment_df, on='Date', how='left')
# Merge macroeconomic data
df = df. merge (macro_df, on='Date', how='left')
Data partitioning: To evaluate model performance, we divide the data set into a training set and a test set. The training set is used for model training, while the test set is used for model evaluation and validation. The train_test_split function was used to divide the data set, ensuring that the model could make valid predictions about previously unseen data. The partition code is as follows:
from sklearn. model_selection import train_test_split
# Data division
train_df, test_df = train_test_split (df, test_size=0.2, shuffle=False)
3.4. LSTM Model Construction and Training
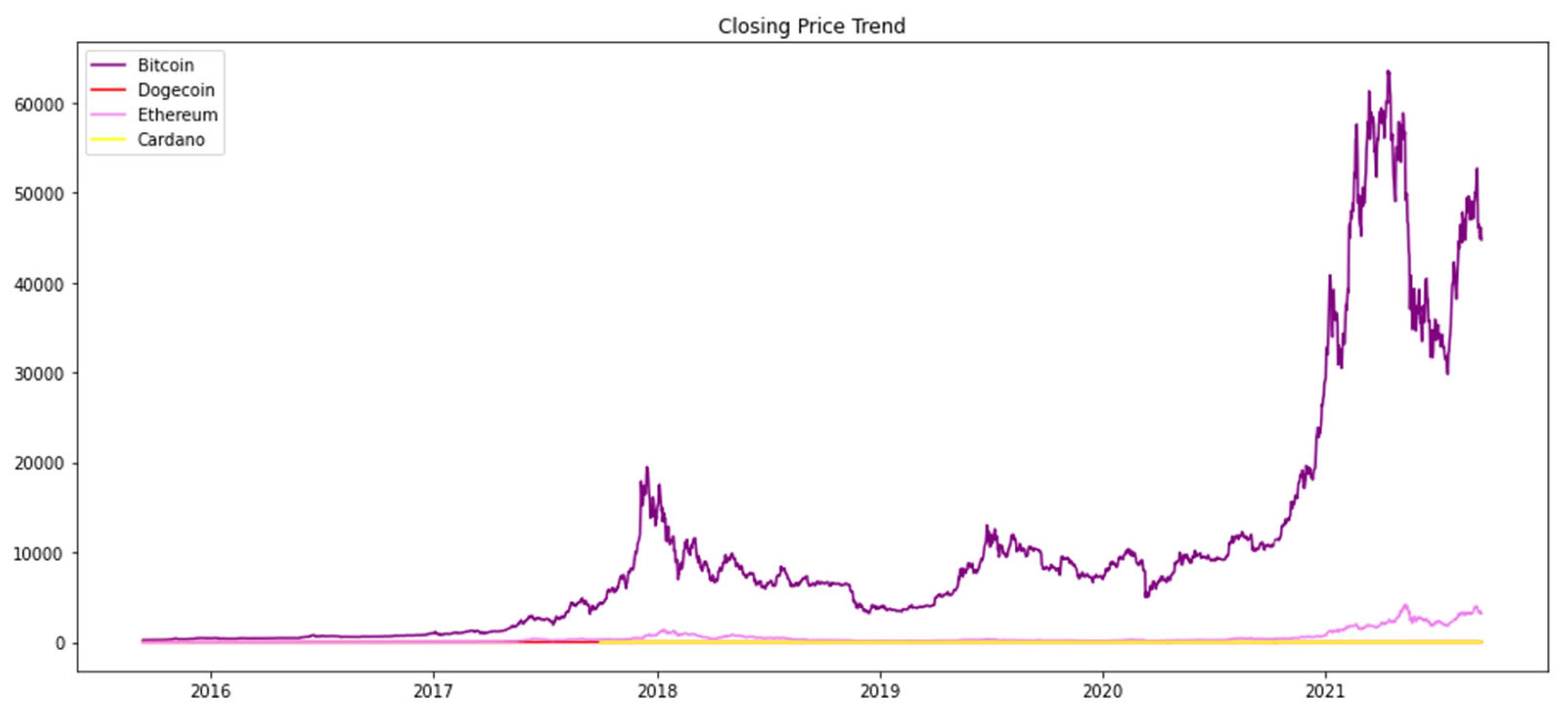
The Long Short-term Memory (LSTM) model We will use to analyze and predict the time series data of the cryptocurrency market. The day model is very important in the time series prediction because it is excellent in dealing with long-term relationships in the series data. The steps are as follows: First, the date column in the data set is converted to the date-time format. Ensure that the time series data can be processed smoothly, so as to enable subsequent analysis and correct understanding of the practical information before constructing the LSTM model, we visualize the market fluctuation by plotting the closing price trend of each cryptocurrency, and the closing price changes of Bitcoin Ether and Cardano can be visually observed. The trend change in the price of each cryptocurrency provides valuable background information for subsequent modeling. The following diagram shows the trend of closing prices of various cryptocurrencies:
Figure 1.
The Closing Price Trend for the four cryptocurrencies.
Building and training LSTM model After completing data processing and preparation, we move to the next step of the LSTM model long short-term memory neural network is a kind of especially suitable for processing time series, because it can effectively capture long-term dependencies, in order to train the model to plan to process this step is mainly in a reasonable range, so as to improve the model. Next, we divide the data into training, collection testing and training, and the actual training of the language model. Through learning these data, the model will gradually master the law of market price changes, while testing and the verification and adjustment of the language model [16].
Through these data, we can understand the prediction accuracy of the model and make necessary adjustments according to the test results. In order to improve the predictive performance and reliability of the model in the training process, we will constantly monitor and adjust the forecast of the model according to the training results, the market price trend course parameters may also involve the selection of the most appropriate training strategy and algorithm optimization methods, and finally through this way is to effectively predict the future market price for investment decisions
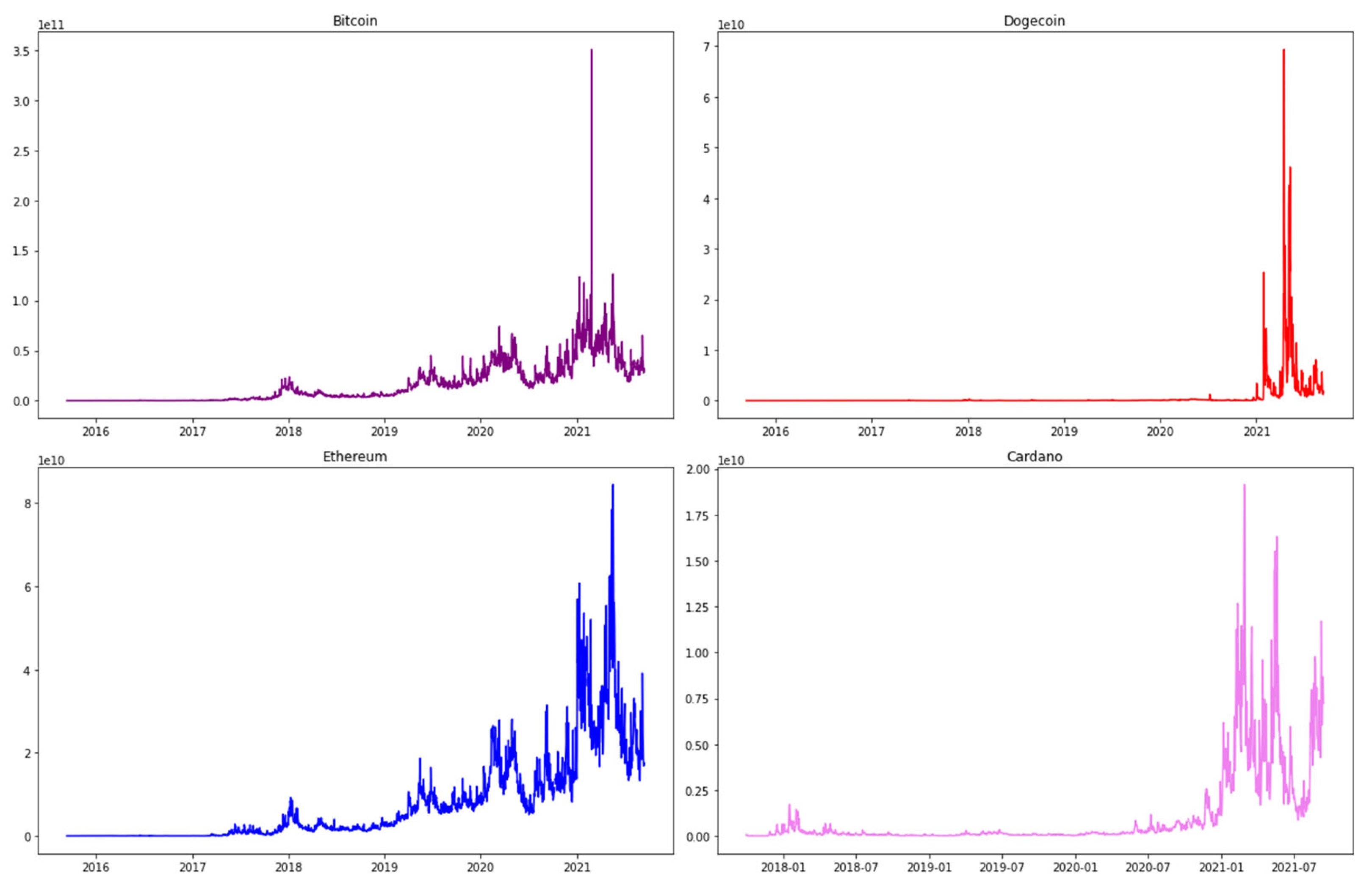
Figure 2.
A multi-subgraph chart of the Volume trends of four cryptocurrencies.
3.5. Cryptocurrency Closing Price Trend Forecast
This section provides a time series analysis of the closing prices of four major cryptocurrencies (Bitcoin, Dogecoin, Ethereum, and Cardano) over the past two years.
By sifting through data since September 2019 and plotting closing price trends, the study aims to reveal the market performance of these cryptocurrencies and their dynamics over a specified time period. The chart shows the price trend of each currency and clearly identifies the volatility characteristics of each currency through different colored lines.
Figure 3.
Closing Price over 2 years for four cryptocurrencies.
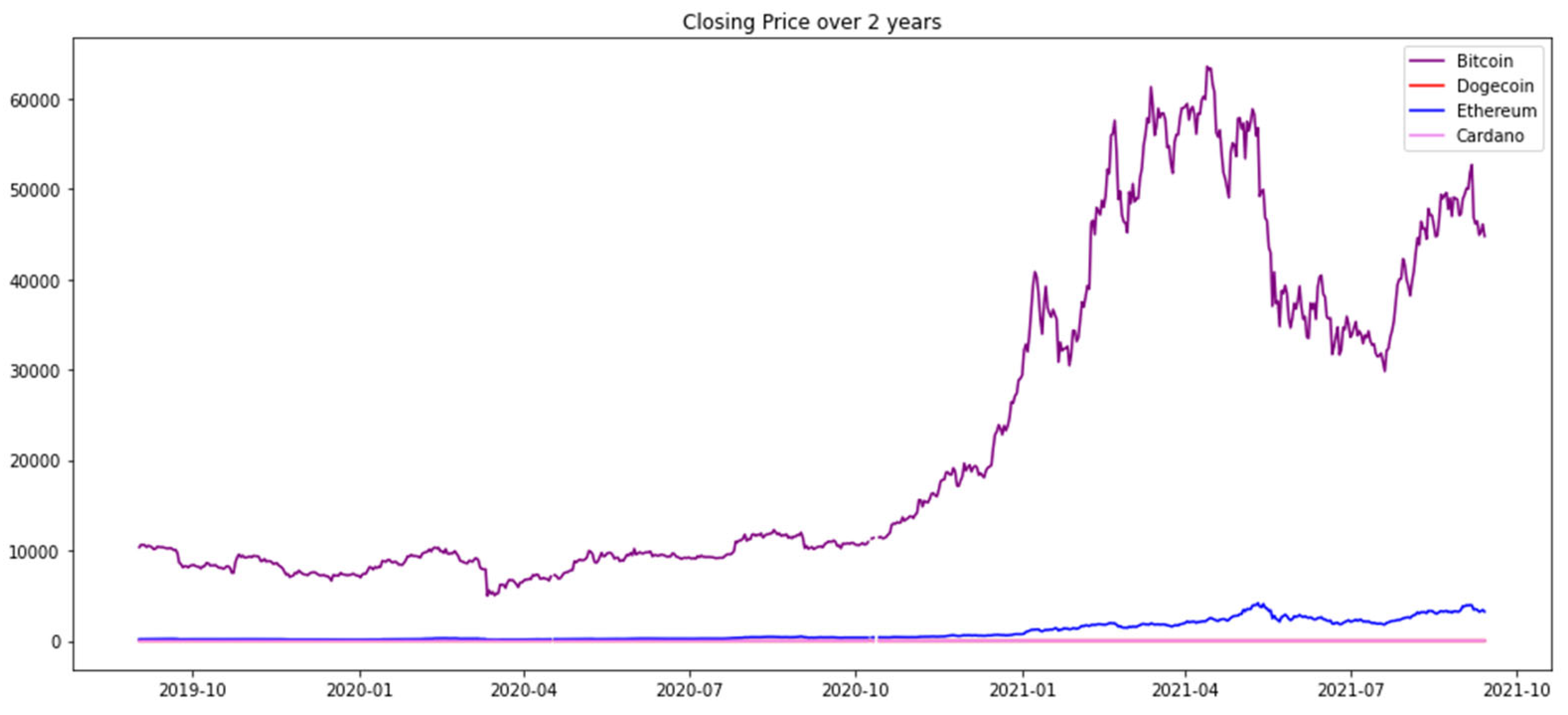
The core significance of this analysis is to provide an in-depth insight into the cryptocurrency market. By comparing the price changes of different cryptocurrencies over the same time frame, it is possible to identify their price fluctuation patterns and trends. This not only helps to understand market behavior, but also provides data support for investment decisions and helps to develop investment strategies based on historical performance.
3.6. Cryptocurrency Trading Volume and Price
In this section, we run a series of analyses on the trading volumes and prices of four major cryptocurrencies (Bitcoin, Dogecoin, Ethereum, and Cardano) over the past two years. First, by visualizing the trading volume trends over this time period, we can observe the changes in market activity for each cryptocurrency. Then, by comparing the opening and closing prices, we further explore the price volatility characteristics of these currencies. This comparison reveals the dynamics of daily prices and provides a basis for in-depth analysis. In addition, we calculated the density distribution of daily returns to understand the volatility of returns across different cryptocurrencies.
To make time series predictions, we built an LSTM model using the closing price data of Bitcoin. Data processing involves standardizing closing price data and creating training sets. The training data is formatted to fit the LSTM model in order to predict future price movements. This process provides sufficient preparation for the establishment of a predictive model, which helps to further analyze and predict the future trend of the Bitcoin market.
3.7. LSTM Model Predicted Price
In this part of the experiment, we combine the closing price of the cryptocurrency transaction data and the cool city unit in the model system by predicting the price trend of the Long short-term memory (LSTM) neural network, that is, there is no first stm-etage 128 cells and there is seriensequenzzeitabhangige datenausrichtung allowed further stm-ebene on 64 other cells. The model is trained using an Adam optimization knife and a quadratic troubleshooting function. Losses during training create a relatively good impression of the quality of training data.
Table 2.
Effective data sets for predictive training.
| Close | |
|---|---|
| Date | |
| 2020/9/2 | 11414.03418 |
| 2020/9/3 | 10245.29688 |
| 2020/9/4 | 10511.81348 |
| 2020/9/5 | 10169.56738 |
| 2020/9/6 | 10280.35156 |
| ... | ... |
| 2021/6/27 | 34649.64453 |
| 2021/6/28 | 34434.33594 |
| 2021/6/29 | 35867.77734 |
| 2021/6/30 | 35040.83594 |
| 2021/7/1 | 33572.11719 |
In order to obtain more accurate data in this experiment and test the performance of the model, it is necessary to test the integrity of the data set through data scaling and reshaping training in the process of experimental testing. Therefore, the model prediction should be transformed repeatedly and compared with the actual price. And the data of these predictions and tests are concentrated in the actual closing price for a certain comparison, so that not only can we get more accurate evaluation model data, but also bring better results in the accuracy and effectiveness of the machine learning prediction model in the price trend of cryptocurrency. This comparison method is in the verification of the model's prediction ability and prediction death. More intelligent and clear management decisions can be made in the price process.
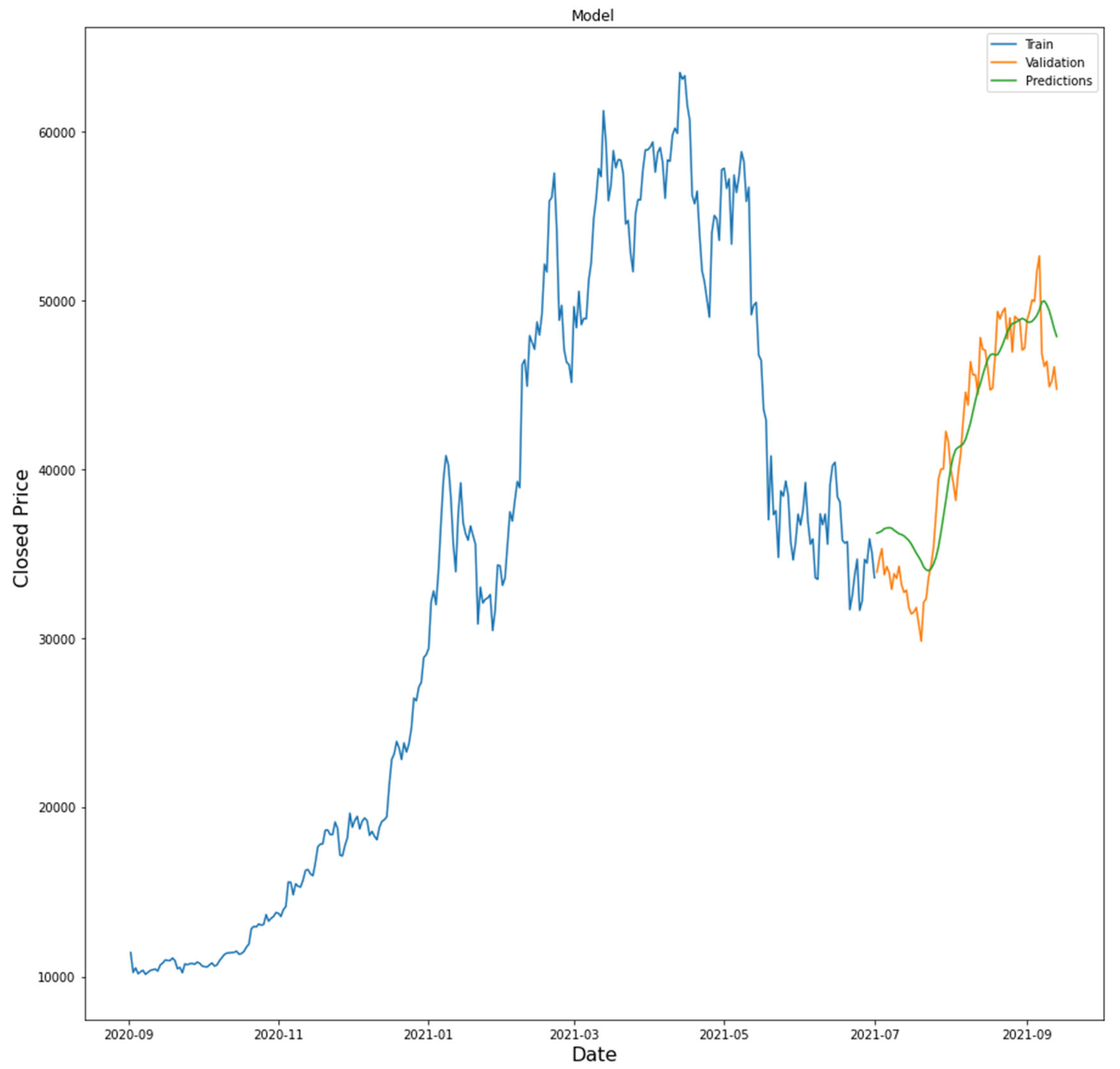
Figure 4.
Prediction results of cryptocurrency under the LSTM model.
3.8. Conclusion and Discussion
The study used a long short-term memory (LSTM) model to predict Bitcoin's closing price, focusing primarily on its performance in capturing the temporal dependence of cryptocurrency market data. In the experiment, we carried out detailed data preparation, including normalization and processing of missing values, to ensure the stability of the model [17]. This LSTM model has two LSTM layers and two fully connected layers, and can be trained to learn from historical price data and predict future price movements. After training, the loss value of the model is 0.0305, and the fit between the training data is quite good.
In the testing phase, we prepare the test data set and compare the predicted results with the actual closing price using the trained model. This evaluation proved that the model can provide accurate predictions, and also confirmed its usefulness in predicting Bitcoin price trends. In addition, the visualization of the predicted and actual prices further illustrates that the model does a good job of capturing market trends and volatility.
The results of this experiment show that in the process of LSTM time series forecasting, it can be seen that the network has a high potential to improve the prediction of market trends and guide investment decisions. By combining these machine learning predictions with a deep reinforcement learning (DRL) framework in Waiting's experiments, trading strategies and risk management can be further optimized. Therefore, future financial market forecasting efforts should explore improving the LSTM model and incorporating other features to improve forecasting accuracy and adaptability to market changes.
4. Conclusions
Since the birth of cryptocurrencies, the development of the cryptocurrency market has brought rapid changes to the financial market and has become one of the important components of the financial market. As one of the highly volatile currencies in the global financial market, the algorithmic trading of the cryptocurrency market is also one of the great risk mechanisms. Compared with the traditional financial market, the cryptocurrency market has great extreme volatility, diversification and arbitrage opportunity of cross-platform price difference. Therefore, it has become one of the effective strategies of the financial market [18]. Try to take advantage of price differences between different exchanges, or differences and correlations between different currencies in the same trade. In recent years, with the continuous progress of artificial intelligence machines, learning and other technologies, more and more research and applications have begun to analyze how artificial intelligence machine learning algorithms are integrated with financial markets and financial trading markets, so as to develop smarter, more efficient and more risk-resistant trading strategies.
The impact of artificial intelligence on the cryptocurrency market and cryptocurrency trading market is very obvious, and the intelligent algorithm of artificial intelligence can quickly process a large amount of transaction data in the financial market, and can identify greater security risks, so as to achieve the trend of cryptocurrency prices with the highest accuracy and security, by using the transaction history data of the financial market, Continue to gain artificial intelligence systems from the behavior of the market, and try to optimize seven financial trading strategies. Therefore, this ability to continue allows traders to make clearer and more rational decisions in the market, thereby minimizing risk while realizing some potential profitability. Elon Musk has commented on the impact of artificial intelligence on the cryptocurrency space. He noted that AI could be a major game-changer for several industries, including finance and cryptocurrencies. In addition, Musk also said that AI has the potential to improve efficiency and create new opportunities, which will revolutionize the automotive industry. In an interview with Business Insider in 2023, for example, he discussed the role of AI in fast-changing industries and hinted at its potential applications in finance, including cryptocurrencies.
Artificial intelligence is also one of the great advantages of all-weather trading, it is different from traditional human traders, artificial intelligence algorithms can immediately execute transactions while trading monitoring, and the fastest and most accurate speed can detect the trend of trading prices. The persistence and vigilance of this artificial intelligence can ensure that every trading opportunity and the best execution time of the trade are seized during the financial transaction process. Of course, artificial intelligence is not only able to trend and predict the advantages of trading, but artificial intelligence systems can also improve the efficiency of trading by eliminating some impulsive decisions and emotional biases that may lead to the trading process, such as greed and impulsiveness, etc. Artificial intelligence follows the pre-established guidance direction and strategy at the same time. Able to have a more systematic and structured approach to trading on the general direction. And good at a large number of quasi-data analysis, forecasting, retracement, high-speed management and adaptation to a variety of market data and strategies, reduce transaction costs, and minimize human error, so as to improve trading performance.
In the financial market, the development of more complex algorithms may provide higher accuracy and adaptability, thus further improving the ability of traders. Therefore, the rise of artificial intelligence is not only related to automated intelligence, but also can change the nature of trading strategies, which is that they can get rapid response and efficiency in the fast-paced and unpredictable financial market. Artificial intelligence is changing the trading industry of the cryptocurrency market by introducing machine intelligence algorithms to improve the transaction production efficiency, accuracy and judgment of the financial market. Artificial intelligence systems completely change the traditional trading model through the fact data analysis trend prediction and 24-hour transaction execution capability. And with the continuous development of artificial intelligence, this technology is expected to change the trading scene of other currencies in the future, providing traders in the financial market with more powerful trading tools and helping them to get higher interests.
References
- Jiang, Z., & Liang, J. (2017, September). Cryptocurrency portfolio management with deep reinforcement learning. In 2017 Intelligent systems conference (IntelliSys) (pp. 905-913). IEEE. [CrossRef]
- Lucarelli, G., & Borrotti, M. (2019). A deep reinforcement learning approach for automated cryptocurrency trading. In Artificial Intelligence Applications and Innovations: 15th IFIP WG 12.5 International Conference, AIAI 2019, Hersonissos, Crete, Greece, May 24–26, 2019, Proceedings 15 (pp. 247-258). Springer International Publishing. [CrossRef]
- Xu, Y., Liu, Y., Xu, H., & Tan, H. (2024). AI-Driven UX/UI Design: Empirical Research and Applications in FinTech. International Journal of Innovative Research in Computer Science & Technology, 12(4), 99-109. [CrossRef]
- Liu, Y., Xu, Y., & Song, R. (2024). Transforming User Experience (UX) through Artificial Intelligence (AI) in interactive media design. Engineering Science & Technology Journal, 5(7), 2273-2283. [CrossRef]
- Li, H., Wang, S. X., Shang, F., Niu, K., & Song, R. (2024). Applications of Large Language Models in Cloud Computing: An Empirical Study Using Real-world Data. International Journal of Innovative Research in Computer Science & Technology, 12(4), 59-69. [CrossRef]
- Ping, G., Wang, S. X., Zhao, F., Wang, Z., & Zhang, X. (2024). Blockchain Based Reverse Logistics Data Tracking: An Innovative Approach to Enhance E-Waste Recycling Efficiency. [CrossRef]
- Schnaubelt, M. (2022). Deep reinforcement learning for the optimal placement of cryptocurrency limit orders. European Journal of Operational Research, 296(3), 993-1006. [CrossRef]
- Lei, H., Wang, B., Shui, Z., Yang, P., & Liang, P. (2024). Automated Lane Change Behavior Prediction and Environmental Perception Based on SLAM Technology. arXiv preprint arXiv:2404.04492. [CrossRef]
- Wang, B., Zheng, H., Qian, K., Zhan, X., & Wang, J. (2024). Edge computing and AI-driven intelligent traffic monitoring and optimization. Applied and Computational Engineering, 77, 225-230. [CrossRef]
- Xu, H., Niu, K., Lu, T., & Li, S. (2024). Leveraging artificial intelligence for enhanced risk management in financial services: Current applications and future prospects. Engineering Science & Technology Journal, 5(8), 2402-2426. [CrossRef]
- Shi, Y., Shang, F., Xu, Z., & Zhou, S. (2024). Emotion-Driven Deep Learning Recommendation Systems: Mining Preferences from User Reviews and Predicting Scores. Journal of Artificial Intelligence and Development, 3(1), 40-46.
- Wang, Shikai, Kangming Xu, and Zhipeng Ling. "Deep Learning-Based Chip Power Prediction and Optimization: An Intelligent EDA Approach." International Journal of Innovative Research in Computer Science & Technology 12.4 (2024): 77-87. [CrossRef]
- Ping, G., Zhu, M., Ling, Z., & Niu, K. (2024). Research on Optimizing Logistics Transportation Routes Using AI Large Models. Applied Science and Engineering Journal for Advanced Research, 3(4), 14-27. [CrossRef]
- Shang, F., Shi, J., Shi, Y., & Zhou, S. (2024). Enhancing E-Commerce Recommendation Systems with Deep Learning-based Sentiment Analysis of User Reviews. International Journal of Engineering and Management Research, 14(4), 19-34. [CrossRef]
- Kochliaridis, V., Kouloumpris, E., & Vlahavas, I. (2023). Combining deep reinforcement learning with technical analysis and trend monitoring on cryptocurrency markets. Neural Computing and Applications, 35(29), 21445-21462. [CrossRef]
- Betancourt, Carlos, and Wen-Hui Chen. "Reinforcement learning with self-attention networks for cryptocurrency trading." Applied Sciences 11.16 (2021): 7377. [CrossRef]
- Yang, M., Huang, D., Zhang, H., & Zheng, W. (2024). AI-Enabled Precision Medicine: Optimizing Treatment Strategies Through Genomic Data Analysis. Journal of Computer Technology and Applied Mathematics, 1(3), 73-84. [CrossRef]
- Wen, X., Shen, Q., Zheng, W., & Zhang, H. (2024). AI-Driven Solar Energy Generation and Smart Grid Integration A Holistic Approach to Enhancing Renewable Energy Efficiency. International Journal of Innovative Research in Engineering and Management, 11(4), 55-55. [CrossRef]
- Li, J., Wang, Y., Xu, C., Liu, S., Dai, J., & Lan, K. (2024). Bioplastic derived from corn stover: Life cycle assessment and artificial intelligence-based analysis of uncertainty and variability. Science of The Total Environment, 174349. [CrossRef]
- Xiao, J., Wang, J., Bao, W., Deng, T., & Bi, S. (2024). Application progress of natural language processing technology in financial research. Financial Engineering and Risk Management, 7(3), 155-161. [CrossRef]
- Wang, S., Zhu, Y., Lou, Q., & Wei, M. (2024). Utilizing Artificial Intelligence for Financial Risk Monitoring in Asset Management. Academic Journal of Sociology and Management, 2(5), 11-19. [CrossRef]
- Shen, Q., Wen, X., Xia, S., Zhou, S., & Zhang, H. (2024). AI-Based Analysis and Prediction of Synergistic Development Trends in US Photovoltaic and Energy Storage Systems. International Journal of Innovative Research in Computer Science & Technology, 12(5), 36-46. [CrossRef]
- Zhu, Y., Yu, K., Wei, M., Pu, Y., & Wang, Z. (2024). AI-Enhanced Administrative Prosecutorial Supervision in Financial Big Data: New Concepts and Functions for the Digital Era. Social Science Journal for Advanced Research, 4(5), 40-54. [CrossRef]
- Li, H., Zhou, S., Yuan, B., & Zhang, M. (2024). OPTIMIZING INTELLIGENT EDGE COMPUTING RESOURCE SCHEDULING BASED ON FEDERATED LEARNING. Journal of Knowledge Learning and Science Technology ISSN: 2959-6386 (online), 3(3), 235-260. [CrossRef]
- Pu, Y., Zhu, Y., Xu, H., Wang, Z., & Wei, M. (2024). LSTM-Based Financial Statement Fraud Prediction Model for Listed Companies. Academic Journal of Sociology and Management, 2(5), 20-31. [CrossRef]
- Yang, M., Huang, D., Zhang, H., & Zheng, W. (2024). AI-Enabled Precision Medicine: Optimizing Treatment Strategies Through Genomic Data Analysis. Journal of Computer Technology and Applied Mathematics, 1(3), 73-84. [CrossRef]
- Wen, X., Shen, Q., Zheng, W., & Zhang, H. (2024). AI-Driven Solar Energy Generation and Smart Grid Integration A Holistic Approach to Enhancing Renewable Energy Efficiency. International Journal of Innovative Research in Engineering and Management, 11(4), 55-55. [CrossRef]
- Lou, Q. (2024). New Development of Administrative Prosecutorial Supervision with Chinese Characteristics in the New Era. Journal of Economic Theory and Business Management, 1(4), 79-88. [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



