
Submitted:
22 October 2024
Posted:
23 October 2024
You are already at the latest version
Abstract
This paper presents a comprehensive review of the You Only Look Once (YOLO) framework, a transformative one-stage object detection algorithm renowned for its remarkable balance between speed and accuracy. Since its inception, YOLO has evolved significantly, with versions spanning from YOLOv1 to the most recent YOLOv11, each introducing pivotal innovations in feature extraction, bounding box prediction, and optimization techniques. These advancements, particularly in the backbone, neck, and head components, have positioned YOLO as a leading solution for real-time object detection across a variety of domains. In this review, we explore YOLO's diverse applications, including its critical role in medical imaging for COVID-19 detection, breast cancer identification, and tumor localization, where it has significantly enhanced diagnostic efficiency. YOLO's robust performance in autonomous vehicles is also highlighted, as it excels in challenging conditions like fog, rain, and low-light environments, thereby contributing to improved road safety and autonomous driving systems. In the agricultural sector, YOLO has transformed precision farming by enabling early detection of pests, diseases, and crop health issues, promoting more sustainable farming practices. Additionally, we provide an in-depth performance analysis of YOLO models—such as YOLOv9, YOLO-NAS, YOLOv10, and YOLOv11—across multiple benchmark datasets. This analysis compares their suitability for a range of applications, from lightweight embedded systems to high-resolution, complex object detection tasks. The paper also addresses YOLO's challenges, such as occlusion, small object detection, and dataset biases, while discussing recent advancements that aim to mitigate these limitations. Moreover, we examine the ethical implications of YOLO's deployment, particularly in surveillance and monitoring applications, raising concerns about privacy, algorithmic biases, and the potential to perpetuate societal inequities. These ethical considerations are critical in domains like law enforcement, where biased object detection models can have serious repercussions. Through this detailed review of YOLO's technical advancements, applications, performance, and ethical challenges, this paper serves as a valuable resource for researchers, developers, and policymakers looking to understand YOLO’s current capabilities and future directions in the evolving field of object detection.
Keywords:
YOLO
; single stage detection
; object detection
; performance evaluation
; deep neural network
; real-time object detection
1. Introduction
Object detection, a core task in computer vision, has seen remarkable advancements in recent years due to the ongoing development of more efficient and accurate algorithms [1,2]. One of the most significant breakthroughs in this field is the You Only Look Once (YOLO) framework, a pioneering one-stage object detection algorithm that has drawn widespread attention for its ability to achieve real-time detection with high precision [3,4]. YOLO’s approach—simultaneously predicting bounding boxes and class probabilities in a single forward pass—sets it apart from traditional multi-stage detection methods [5,6,7]. This capability makes YOLO exceptionally well-suited for applications requiring rapid decision-making, such as autonomous driving, medical diagnostics, and surveillance systems[8,9]. The evolution of object detection methods has paved the way for YOLO, offering a novel solution to the longstanding challenge of balancing speed and accuracy in detection tasks [10,11]. Its real-time performance, coupled with its flexibility across a wide range of domains, has cemented YOLO as a leading algorithm in both academic research and practical applications. As object detection continues to evolve, a deeper understanding of YOLO’s architecture and its extensive applicability becomes increasingly important, particularly as newer versions introduce significant architectural improvements and optimizations [12].
This review provides a comprehensive exploration of the YOLO framework, beginning with an overview of the historical development of object detection algorithms, leading to the emergence of YOLO [13]. The subsequent sections delve into the technical details of YOLO’s architecture, focusing on its core components—the backbone, neck, and head—and how these elements work in unison to optimize the detection process. By examining these components, we highlight the key innovations that enable YOLO to outperform many of its counterparts in real-time detection scenarios. A central theme of this review is the versatility of YOLO across diverse application domains. From detecting COVID-19 in X-ray images to enhancing road safety under adverse weather conditions [14], YOLO has demonstrated its ability to address complex challenges across fields such as medical imaging, autonomous vehicles, and agriculture. In each of these domains, YOLO’s ability to process high-resolution images quickly and accurately has driven substantial improvements in detection efficiency and accuracy.
Throughout this review, we address several key research questions, including the major applications of YOLO, its performance compared to other object detection algorithms, and the specific advantages and limitations of its various versions. We also consider the ethical implications of using YOLO in sensitive applications, particularly regarding privacy concerns, dataset biases, and broader societal impacts. As YOLO continues to be deployed in applications such as surveillance and law enforcement, these ethical considerations become increasingly critical to responsible AI development. Therefore, this review synthesizes insights from various domains to provide a holistic understanding of the YOLO framework’s contributions to the field of object detection. By highlighting both the strengths and limitations of YOLO, this paper offers a foundation for future research directions, particularly in optimizing YOLO for emerging challenges in the ever-evolving landscape of computer vision.
2. Literature Search Strategy
Conducting a comprehensive literature review on the YOLO framework, requires a systematic and methodologically rigorous approach. This study employed a well-structured strategy to navigate the extensive and multidisciplinary body of literature on YOLO, ensuring a thorough and representative selection of the most relevant and impactful studies.
2.1. Search Methodology
To ensure an exhaustive review, we focused on reputable and high-impact sources such as IEEE Xplore, SpringerLink, and key conference proceedings, including CVPR, ICCV, and ECCV. In addition, we utilized search engines like Google Scholar and academic databases, leveraging Boolean search operators to construct detailed queries with phrases such as “object detection,” “YOLO,” “deep learning,” and “neural networks.” This approach allowed us to capture the latest research and most significant papers across disciplines related to computer vision and machine learning.
The search covered an array of top-tier publications, including but not limited to:
- IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
- Computer Vision and Image Understanding (CVIU)
- Journal of Machine Learning Research (JMLR)
- International Journal of Computer Vision (IJCV)
- Journal of Artificial Intelligence Research (JAIR)
The search results yielded an initial pool of 53,200 articles. To manage this large collection, a two-step screening process was applied:
- Title Screening: The titles were reviewed to eliminate papers not directly related to YOLO or object detection methodologies.
- Abstract Screening: Abstracts were thoroughly examined to assess the relevance of each article in terms of its focus on YOLO’s architectural innovations, applications, or comparative analysis.
2.2. Selection Criteria
We applied stringent inclusion and exclusion criteria to refine the literature pool:
-
Inclusion Criteria:
- ▪
- Studies providing in-depth analysis of YOLO architecture and methodologies.
- ▪
- High-impact and widely cited papers.
- ▪
- Research papers offering empirical results from YOLO-based applications in various domains.
- ▪
- Articles that address both the strengths and limitations of YOLO.
-
Exclusion Criteria:
- ▪
- Articles that merely mention YOLO without exploring its methodologies or applications.
- ▪
- Research papers lacking substantive contributions to the development or application.
- ▪
- Duplicate or redundant publications across multiple conferences or journals.
This process refined the literature pool to 72 articles, which were selected for a full-text review. The chosen articles span a wide range of topics, including YOLO’s architectural developments, training and optimization strategies, and its application across diverse domains such as medical imaging, autonomous vehicles, and agriculture.
2.3. Coding and Classification
The selected articles were further categorized based on specific features of the YOLO framework. Each article was coded according to the following dimensions:
- Architectural Innovations: Backbone, neck, and head components, and innovations across YOLO versions (e.g., YOLOv3, YOLOv4, YOLOv5, YOLOv9).
- Training Strategies: Data augmentation, transfer learning, and optimization techniques.
- Performance Metrics: Evaluation metrics such as mAP (mean Average Precision), FPS (Frames Per Second), and computational cost (FLOPs).
- Applications: Medical imaging, autonomous driving, agriculture, industrial applications, and more.
Table 1 provides a detailed breakdown of the different versions of YOLO, their architectural innovations, and methodological approaches. For each version, we analyzed training strategies, loss functions, post-processing techniques, and optimization methods. This systematic classification allows for a nuanced understanding of YOLO’s progression and its practical applications.
3. Single Stage Object Detectors
3.1. Understanding Single-Stage Detectors in Object Detection: Concepts, Architecture, and Applications
Single-stage object detectors represent a class of models designed to detect objects in an image through a single forward pass of the neural network [10]. Unlike two-stage detectors, which involve separate steps for region proposal and object classification, single-stage detectors perform both tasks simultaneously, streamlining the detection process [8]. This approach has gained popularity due to its simplicity, computational efficiency, and real-time processing capabilities, making it particularly well-suited for applications that demand quick inference, such as autonomous vehicles and surveillance systems [15].
A typical single-stage detector directly predicts object class probabilities and bounding boxes without the need for a region proposal network (RPN) [4,16]. Several key concepts define single-stage object detectors:
- Unified Architecture: These detectors employ a unified neural network architecture that predicts bounding boxes and class probabilities simultaneously, eliminating the need for a separate region proposal phase [17].
- Anchor Boxes or Default Boxes: To accommodate varying object scales and aspect ratios, single-stage detectors use anchor boxes (also referred to as default boxes) [18]. These predefined boxes allow the network to make adjustments to better fit objects of different shapes and sizes.
- Regression and Classification Head: Single-stage detectors consist of two main components: a regression head for predicting bounding box coordinates and a classification head for determining object classes. Both heads operate on the feature maps extracted from the input image [19].
- Loss Function: The model's training objective involves minimizing a combination of three losses: localization loss (for accurate bounding box predictions), confidence loss (for object presence or absence), and classification loss (for class label accuracy) [20].
- Efficiency and Real-time Processing: One of the primary advantages of single-stage detectors is their computational efficiency, making them suitable for real-time processing. The absence of a separate region proposal step reduces computational overhead, allowing for rapid detection [23].
- Applications: Single-stage detectors find applications in various domains, including autonomous vehicles, surveillance, robotics, and object recognition in images and videos. Their speed and simplicity make them particularly well-suited for scenarios where real-time detection is crucial. These applications are supported by numerous studies that highlight the efficiency and effectiveness of single-stage detectors in dynamic environments, especially in autonomous driving and pedestrian detection scenarios [24,25,26,27]. The effectiveness of single-stage detectors in surveillance systems enables continuous monitoring and quick response, which is essential for security applications [25]. In robotics, these detectors assist in real-time object recognition, facilitating navigation and interaction with the environment [28,29]. Therefore, the versatility and performance of single-stage detectors have made them a critical component in various modern technology applications.
These characteristics make single-stage detectors a critical tool in object detection, providing a balance between speed and accuracy while supporting a wide range of real-world applications. The flowchart of a single-stage detector's operation is depicted in Figure 1.
3.2. Typical Single-Stage Object Detectors
Several single-stage detectors have been developed over the years, each with unique innovations and optimizations. Below is an overview of key single-stage detectors, their architectures, and contributions to the field of object detection:
3.2.1. SSD (Single Shot Detectors)
Introduced by Liu et al. in 2016 [30], the Single Shot MultiBox Detector (SSD) leverages a Convolutional Neural Network (CNN) as its backbone for feature extraction. SSD utilizes multiple layers from the base network to generate multi-scale feature maps, allowing it to detect objects at various scales. For each feature map scale, SSD assigns anchor boxes with different aspect ratios and sizes, simultaneously predicting object class scores and bounding box offsets. After predictions are made, non-maximum suppression is applied to remove duplicate bounding boxes and retain the most confident detections. The architecture of SSD is illustrated in Figure 2.
3.2.2. DenseBox
DenseBox[31], developed by Huang et al., integrates object localization and classification within a single framework. Unlike other models that rely on sparse anchor boxes, DenseBox densely predicts bounding boxes across the entire image, improving localization accuracy. The model employs a deep CNN for feature extraction, followed by non-maximum suppression to refine object detections. DenseBox’s dense prediction mechanism allows for enhanced performance in detecting small and closely packed objects. Figure 3 shows the detailed architecture of DenseBox.
3.2.3. RetinaNet
RetinaNet [32], introduced by Lin et al., addresses the issue of class imbalance commonly found in object detection tasks. The architecture incorporates a Feature Pyramid Network (FPN) for multi-scale feature extraction and employs a novel focal loss function to give higher priority to harder-to-detect objects during training. This loss function helps mitigate the imbalance between foreground and background classes, making RetinaNet particularly effective in scenarios with sparse object occurrences. The workflow of RetinaNet is shown in Figure 4.
3.2.4. RFB Net
The RFB Net (RefineNet with Anchor Boxes) [33], developed by Niu and Zhang, builds upon the basic RefineNet architecture. RFB Net introduces anchor boxes of varying sizes and aspect ratios to improve detection performance, particularly for small objects. This model applies a series of refinement stages that iteratively enhance both localization accuracy and classification confidence. The architecture of RFB Net is shown in Figure 5.
3.2.5. Efficient Det
EfficientDet[34], proposed by Tan and Le, introduces a compound scaling approach to simultaneously increase network depth, width, and resolution while maintaining computational efficiency. EfficientDet uses a BiFPN (Bidirectional Feature Pyramid Network) for efficient multi-scale feature fusion, balancing model size and performance. This design achieves state-of-the-art object detection results with reduced computational complexity, making it ideal for resource-constrained applications. The architecture of EfficientDet is shown in Figure 6.
3.2.6. YOLO
The YOLO framework, pioneered by Joseph Redmon, revolutionized real-time object detection by introducing a grid-based approach to predict bounding boxes and class probabilities simultaneously [35]. This innovative design facilitates a highly efficient detection process, making YOLO particularly suitable for applications needing real-time performance.
Since its inception, the YOLO architecture has undergone continuous evolution, with each version—from YOLOv1 through to the latest YOLOv9—introducing enhancements in accuracy, speed, and efficiency [36]. Significant advancements include the introduction of anchor boxes, which improve the model's ability to detect objects of varying shapes and sizes, as well as new loss functions aimed at optimizing performance. Additionally, each YOLO iteration features optimized backbones that contribute to faster processing times and better detection capabilities.
The evolution of the YOLO framework from 2015 to 2023 showcases the iterative enhancements made in response to emerging challenges in object detection [37]. Each revision has made strides in minimizing latency while maximizing detection accuracy—central goals in the continuing development of real-time object detection technologies. Figure 7 illustrates the timeline of YOLO’s evolution from 2015 to 2023.
To quickly and accurately identify objects, YOLO divides an image into a grid and predicts both bounding boxes and class probabilities simultaneously. Bounding box coordinates and class probabilities are generated by convolutional layers, following feature extraction by a deep Convolutional Neural Network (CNN). YOLO improves the detection of objects at varying sizes through the use of anchor boxes at multiple scales. The final detections are refined using Non-Maximum Suppression (NMS), which filters out redundant and low-confidence predictions, making YOLO a highly efficient and reliable method for object detection.
Each YOLO variant introduces distinct innovations aimed at optimizing both speed and accuracy. For example, YOLOv4 and YOLOv5 integrated advanced backbones and loss functions such as Complete Intersection over Union (CIoU) to improve object localization. Table 2 below provides an overview of the loss functions used across various YOLO models, highlighting their contributions to classification and bounding box regression.
3.3. The YOLO Architecture: Backbone, Neck, and Head
The three primary components of the YOLO architecture—backbone, neck, and head—undergo significant modifications across its variants to enhance performance:
- Backbone: Responsible for extracting features from input data[38], the backbone is typically a CNN pre-trained on large datasets such as ImageNet. Common backbones in YOLO variants include ResNet50, ResNet101, and CSPDarkNet53.
- Neck: The neck further processes and refines the feature maps generated by the backbone. It often employs techniques like Feature Pyramid Networks (FPN) and Spatial Attention Modules (SAM) [39] to improve feature representation.
- Head: The head processes fused features from the neck to predict bounding boxes and class probabilities. YOLO's head typically uses multi-scale anchor boxes, ensuring effective detection of objects at different scales [40].
Table 3 provides a comparison of the strengths and weaknesses of various YOLO variants, showcasing the trade-offs between speed, accuracy, and complexity.
4. Investigation, Evaluation with Benchmark
We conducted an in-depth investigation into the performance of YOLO models across various application domains by thoroughly analyzing the architectures implemented by different researchers and their corresponding results. YOLO models are particularly popular in real-time applications due to their single-shot detection framework, which enables both speed and efficiency. In our comprehensive comparison study, we examined how YOLO models perform in key domains such as medical imaging, autonomous vehicles, and agriculture. Additionally, we provided an overview of the suitability of these models based on evaluation metrics such as accuracy, speed, and resource efficiency, highlighting their effectiveness across a diverse range of fields.
4.1. Medicine
The YOLO framework has revolutionized medical image analysis with its ability to efficiently and accurately detect, classify, and segment medical images across a range of applications[41]. The core principles behind YOLO’s success in medical image analysis can be divided into three main categories: object detection and classification, segmentation and localization, and compression and enhancement. Each of these frameworks offers unique capabilities to address specific challenges in medical imaging.
4.1.1. Object Detection and Classification Frameworks
YOLO’s object detection and classification frameworks focus on the accurate identification and categorization of objects within medical images. These applications streamline the detection of key features, abnormalities, and pathologies, reducing the time required for manual analysis and minimizing the risk of human error. By automating object classification, YOLO enables quicker and more precise medical diagnoses.
Breast Cancer Detection in Mammograms: YOLOv3 has been successfully implemented to detect breast abnormalities in mammograms, using fusion models to enhance the accuracy of classification. This model provides reliable detection of early-stage breast cancer, significantly aiding radiologists in making timely and accurate diagnoses [42].
Face Mask Detection in Medical Settings: YOLOv2 has been adapted to detect face masks in hospital and clinical environments, achieving an mAP of 81%[43]. This application was particularly important during the COVID-19 pandemic, ensuring that healthcare facilities maintained proper protective measures [44].
Gallstone Detection and Classification: YOLOv3 has demonstrated high accuracy (92.7%) in detecting and classifying gallstones in CT scans, making it a valuable tool in radiology for diagnosing gallbladder diseases quickly and accurately[45].
4.1.2. Segmentation and Localization Frameworks
Segmentation and localization frameworks extend YOLO’s capabilities beyond object detection to identifying specific regions of interest, such as tumors, and delineating their boundaries. This is particularly useful for medical image analysis, where precise localization of pathologies is critical for treatment planning [49].
Ovarian Cancer Segmentation for Real-Time Use: YOLOv5 has been applied for the segmentation of ovarian cancer, providing accurate identification of tumor boundaries [50]. The model's real-time capabilities allow it to be used during surgical procedures, giving doctors valuable information to guide their interventions [51].
Multi-Modality Medical Image Segmentation: YOLOv8, when combined with the Segment Anything Model (SAM), has shown strong results across multiple modalities, including X-ray, ultrasound, and CT scan images [52]. This integration enables more precise segmentation and classification, enhancing the diagnostic capabilities of radiologists and surgeons.
Brain Tumor Localization Using Data Augmentation: YOLOv3, paired with data augmentation techniques like 180° and 90° rotations, has proven effective in brain tumor detection and segmentation. The use of data augmentation strengthens the model’s ability to identify tumors in complex orientations, leading to better treatment planning [53,54].
4.1.3. Compression, Enhancement, and Reconstruction Frameworks
YOLO’s application in medical image compression and enhancement helps address challenges in transmitting, storing, and reconstructing high-quality medical data. In telemedicine and secure medical data sharing, preserving image fidelity is critical for ensuring accurate diagnoses. YOLO’s capabilities in this area provide efficient solutions for compressing medical images without compromising their quality.
Medical Image Compression and Encryption: YOLOv7 has been utilized to compress medical images while maintaining high-quality reconstructions during transmission [55]. In one notable application, liver tumor 3D scans were encrypted and reconstructed with a PSNR of 30.42 and SSIM of 0.94, ensuring that sensitive medical information remains secure and accurate during remote consultations or telemedicine applications [56].
Secure Medical Data Transmission and Image Reconstruction: YOLOv7 has also been applied to enhance the transmission and reconstruction of encrypted medical data, which is especially useful for maintaining data integrity in telemedicine. The chaos and encoding methods used in YOLOv7 ensure that high-quality images are transmitted securely across networks.
4.2. Autonomous Vehicles
The application of YOLO models in the field of autonomous vehicles has proven transformative, particularly for enhancing real-time object detection capabilities[67]. As self-driving technology advances and autonomous vehicles become more prevalent, there is an increasing demand for robust computer vision systems capable of accurately detecting and classifying objects in diverse and often challenging environmental conditions [71]. This capability is essential to ensure the safety and reliability of autonomous driving systems.
4.2.1. Challenges in Real-Time Object Detection for Autonomous Vehicles
One of the primary challenges faced by autonomous vehicles is maintaining accurate object detection under various weather conditions, such as fog, snow, and rain. These adverse conditions can distort images and interfere with navigation, making it difficult for the vehicle to accurately discern critical environmental factors like road signs, pedestrians, and other vehicles. The ultimate objective of integrating YOLO models into autonomous vehicle systems is to develop a reliable detection framework that ensures safe and efficient operation, regardless of external conditions.
YOLO’s single-shot detection framework, known for its rapid inference time, makes it particularly well-suited for real-time applications. This is critical for autonomous vehicles, which must make quick decisions in dynamic environments. Moreover, advancements in YOLO’s architecture, such as improvements in attention mechanisms, backbone networks, and feature fusion techniques, have further increased its accuracy and speed, allowing it to detect objects of varying sizes—even smaller objects like pedestrians and distant vehicles [81].
4.2.2. YOLO's Advancements for Harsh Weather Conditions
Real-time object detection in harsh weather is one of the most critical areas of research in autonomous vehicle systems. Weather conditions like snow, fog, and heavy rain can obscure visibility, making object detection challenging [67]. YOLO’s rapid processing capabilities have been enhanced with architectural improvements to handle these conditions effectively. For instance, a study using YOLOv8 applied transfer learning to datasets captured under adverse weather conditions, including fog and snow. The model achieved promising results, with mAP scores of 0.672 and 0.704, demonstrating YOLO’s adaptability to real-world challenges and making it a strong candidate for deployment in autonomous driving systems.
4.2.3. Small Object Detection in Autonomous Driving
Detecting small objects at various distances is another significant challenge for autonomous vehicle systems [67]. Small objects, such as pedestrians, cyclists, or road debris, can often be difficult to detect, but they are critical for safe driving. Enhanced versions of YOLO models, particularly YOLOv5, have introduced techniques like structural re-parameterization and the addition of small object detection layers to improve performance. These improvements have been shown to significantly increase the mAP for detecting smaller objects, especially in urban environments where small, fast-moving objects are common.
For example, WOG-YOLO, a variant of YOLOv5, exhibited significant improvements in detecting pedestrians and bikers, increasing the mAP for each by 2.6% and 2.3%, respectively. This focus on small object detection makes YOLO models particularly suitable for urban driving scenarios, where vehicles must detect various obstacles quickly and accurately to ensure safe navigation.
4.2.4. Efficiency and Speed Optimizations for Autonomous Vehicles
In addition to improved accuracy, YOLO models have been optimized for speed and efficiency, making them ideal for edge computing applications in autonomous vehicles, where computational resources are often limited. Lightweight versions of YOLO, such as YOLOv7 and YOLOv5, have incorporated various architectural optimizations—such as lightweight backbones, neural architecture search (NAS), and attention mechanisms—to improve inference time without sacrificing accuracy.
For instance, YOLOv7 has been enhanced with a hybrid attention mechanism (ACmix) and the Res3Unit backbone, significantly improving its performance, achieving an AP score of 89.2% on road traffic data [67]. These optimizations ensure that YOLO models can deliver real-time performance in dynamic environments, a key requirement for autonomous vehicles operating in various conditions.
4.2.5. YOLO's Performance Across Different Lighting Conditions
Another critical challenge in autonomous vehicle systems is detecting objects under varying lighting conditions, such as nighttime driving. YOLO models, particularly YOLOv8x, have demonstrated strong performance in low-light environments, utilizing advanced feature extraction and segmentation techniques to improve object detection accuracy.
In one study, YOLOv8x outperformed other YOLOv8 variants, achieving precision, recall, and F-score metrics of 0.90, 0.83, and 0.87, respectively, on video data captured during both day and night. This capability ensures that autonomous vehicles can operate safely across different lighting conditions, a vital feature for real-world deployment[68,69].
The table below (Table 5) provides a summary of key studies that highlight YOLO’s effectiveness in autonomous vehicle applications. Various YOLO versions, including YOLOv5, YOLOv7, and YOLOv8, have been employed to enhance object detection performance across different datasets and conditions, showcasing YOLO’s flexibility and adaptability to the unique challenges of autonomous driving.
4.3. Agriculture
YOLO has transformed agricultural practices by enabling fast, accurate detection of crops, pests, and environmental factors affecting crop health. One of its most significant applications is crop monitoring, where YOLO’s real-time object detection helps identify issues such as pests, diseases, and nutrient deficiencies early, enabling timely interventions that improve yields. In precision farming, YOLO helps distinguish crops from weeds, allowing selective herbicide application. This reduces chemical usage, lowers costs, and minimizes environmental impact, supporting sustainable agriculture. YOLO's integration with UAVs further enhances its utility, providing large-scale monitoring and detailed insights that would be difficult and time-consuming to gather manually. Beyond crop monitoring, YOLO is applied to tasks such as fire detection, livestock management, and environmental monitoring. By automating these processes, YOLO contributes to efficient farm management and improved resource use.
Table 6 summarizes notable applications of YOLO in agriculture:
4.3.1. Crop Health Monitoring and UAV Integration
One of the most critical applications of YOLO in agriculture is the continuous monitoring of crop health [91]. With the integration of YOLO models and UAV systems, farmers can now scan large-scale agricultural areas, detecting early signs of pest infestations, diseases, or nutrient deficiencies. This proactive approach helps prevent crop loss and optimize farm productivity.
A noteworthy study employed YOLOv5 integrated into UAVs for detecting forest degradation. The model performed impressively, identifying damaged trees even in challenging conditions such as snow[92]. This advancement has far-reaching implications, allowing farmers and environmental researchers to monitor vast landscapes, particularly in remote or difficult-to-access areas, with unprecedented accuracy and speed [93].
4.3.2. Precision Agriculture and Weed Management
YOLO plays a pivotal role in precision agriculture by facilitating accurate crop and weed differentiation. In precision farming, herbicides can be applied selectively to target weeds without affecting crops[94,95]. This method not only reduces the use of chemicals, lowering the cost of farming, but also minimizes environmental damage, leading to more sustainable agricultural practices.
A modified version of YOLOv3 was deployed to monitor apple orchards, achieving an F1-score of 0.817 [96]. The model utilized DenseNet for improved feature extraction and performed exceptionally well at detecting apples at various developmental stages. This level of precision is invaluable for farmers managing orchards, as it enables better decision-making regarding harvesting and pest control[97].
4.3.3. Real-Time Environmental Monitoring and Fire Detection
YOLO has also been applied to monitor environmental hazards, such as forest fires[98,99]. In a study using an ensemble of YOLOv5 and other detection models like DeepLab and LightYOLO, researchers developed a real-time fire detection system mounted on UAVs. The system outperformed conventional models, achieving an F1-score of 93% and mAP of 85.8%. This real-time capability is crucial in mitigating the spread of fires and protecting valuable forest and agricultural resources[100].
4.3.4. Application in Livestock Management and Other Areas
While YOLO’s application in crop monitoring remains a primary focus, it has also been applied to livestock management [101]. UAVs equipped with YOLO models can monitor livestock across large grazing areas, providing real-time updates on animal health and location. This technology is instrumental in reducing the risk of disease outbreaks and improving overall farm management [102].
Furthermore, YOLO’s flexibility extends to various agricultural operations. A notable example is Ag-YOLO, a lightweight version of YOLO developed for Intel Neural Compute Stick 2 (NCS2) hardware, which was designed for crop and spray monitoring. Ag-YOLO achieved an F1-score of 0.9205, proving to be an efficient, cost-effective solution for farmers operating in resource-constrained environments [90].
4.4. Industry
In industrial applications, YOLO (You Only Look Once) has become one of the most widely used real-time object detection models due to its high-speed processing and efficient object identification capabilities. The single-stage architecture of YOLO allows it to detect and classify objects in a single pass through the neural network, making it particularly suitable for environments that require rapid decision-making, such as production lines, automated quality control, and anomaly detection. Its adaptability to a wide range of tasks across different industries, from food processing to construction, has made YOLO a versatile tool.
In manufacturing and production, YOLO is used to improve the accuracy and efficiency of automated systems. Whether it's detecting defects in products or monitoring safety in real-time, YOLO contributes to higher-quality outcomes and reduced operational costs [103]. For instance, in food processing, YOLO can be employed to ensure quality control by detecting defects in packaged goods, while in construction, it can help identify safety issues, such as the use of protective gear like helmets [104].
YOLO’s implementation in logistics and warehousing has also streamlined processes such as package tracking, inventory management, and equipment monitoring. Robotic systems using YOLO for object detection and identification can automate repetitive tasks, improve safety, and increase production throughput. Despite certain challenges, such as lower accuracy when detecting. Table 7 summarizes various industrial applications of YOLO, showcasing its versatility and effectiveness across different tasks.
4.4.1. Applications of YOLO in Industrial Manufacturing
One of the most impactful uses of YOLO in industry is in manufacturing, where its real-time detection capabilities are leveraged for automated quality control, defect detection, and production optimization. YOLO’s speed and accuracy allow manufacturers to identify issues on the production line quickly, reducing downtime and minimizing faulty outputs [114].
Surface Defect Detection: YOLOv5, combined with transformers, was used to detect small defects on surfaces in grayscale imagery, improving detection efficiency. The bidirectional feature pyramid network proposed in this study significantly enhanced the model’s ability to identify minor defects, achieving an mAP of 75.2% [115].
Wheel Welding Defect Detection: YOLOv3 was applied to the specific task of detecting weld defects in vehicle wheels, achieving impressive results with mAP scores of 98.25% and 84.36% at different thresholds. While this model was highly effective in its target environment, it was noted that it may not generalize well to other real-time detection tasks without further adaptation [116].
Workpiece Detection and Localization: Another notable application is workpiece detection on production lines, where YOLOv5 was enhanced with lightweight deep convolution layers to improve detection accuracy. The model showed significant improvements, increasing mAP by 2.4% on the COCO dataset and 4.2% on custom industrial datasets [117].
4.4.2. Applications in Automated Quality Control and Safety
YOLO’s role in quality control systems is crucial for maintaining the consistency and safety of products in industries like packaging, construction, and electronics. By automatically identifying defects or inconsistencies in real-time, YOLO allows manufacturers to catch problems early in the production process.
Real-Time Packaging Defect Detection: In one study, YOLO was used to develop a deep learning-based system for detecting packaging defects in real-time. The model automatically classified product quality by detecting defects in boxed goods, achieving a precision of 81.8%, accuracy of 82.5%, and mAP of 78.6%. Such systems can be deployed to monitor quality across high-speed production lines, reducing the risk of shipping faulty products to customers [118].
Safety-Helmet Detection in Construction: Safety in construction is another critical area where YOLO has proven its worth. A lightweight version of YOLOv5, known as PG-YOLO, was specifically developed for edge devices in IoT networks, improving inference speed while maintaining accuracy. The model achieved an mAP of 93.3% for detecting workers wearing safety helmets in construction sites, helping ensure compliance with safety regulations [119].
4.4.3. Industrial Robotics and Automation
In logistics and warehouse management, YOLO’s ability to detect and identify objects in real-time is a key asset for automating routine tasks, improving both safety and efficiency. YOLO is integrated into robotic systems that handle object detection for sorting, transporting, and monitoring inventory.
Production Line Equipment Monitoring: YOLOv5s was enhanced with a channel attention module, Slim-Neck, Decoupled Head, and GSConv lightweight convolution to improve real-time identification and localization of production line equipment, such as robotic arms and AGV carts. This system achieved precision rates of 93.6% and mAP scores of 91.8%, showcasing its effectiveness in automating production line processes [111].
Power Line Insulator Detection: In another study, YOLOD was developed to address uncertainty in object detection by placing Gaussian priors in front of the YOLOX detection heads. This model was applied to power line insulator detection, improving the robustness of object detection by using calculated uncertainty scores to refine bounding box predictions. YOLOD achieved an AP of 73.9% [120].
5. Evolution and Benchmark-Based Discussion
5.1. Evolution
The YOLO family has undergone considerable evolution, with each new iteration addressing specific limitations of its predecessors while introducing innovations that improve its performance in real-time object detection. YOLOv6, YOLOv7, and YOLOv8 represent key advancements in the early evolution of this framework, each contributing significantly to the landscape of object detection in terms of speed, accuracy, and computational efficiency.
YOLOv6: Enhanced Speed and Practicality. YOLOv6 was designed with a focus on speed and practicality, particularly for real-world applications requiring fast and efficient object detection. It introduced modifications in network structure that enabled faster processing while maintaining a decent level of accuracy. YOLOv6 was particularly impactful for lightweight deployment on edge devices, which have limited computing power, making it an attractive option for applications in fields such as surveillance, robotics, and automated inspection systems. However, while YOLOv6 improved efficiency, it faced challenges in complex scenarios involving small or overlapping objects, leading to the need for more advanced versions.
YOLOv7: Improving Accuracy and Feature Extraction. YOLOv7 introduced significant architectural changes that enhanced accuracy and feature extraction capabilities. One of the key advancements in YOLOv7 was the integration of cross-stage partial networks (CSPNet), which improved the model’s ability to reuse gradients across different stages, allowing for better feature propagation and reducing the model's overall complexity. This improvement translated into better performance in detecting smaller objects or objects within cluttered environments. YOLOv7 also introduced the concept of extended path aggregation, which helped in merging features from different layers to provide a more detailed and robust representation of the input image. These advancements made YOLOv7 more suitable for applications in industries like medical imaging, autonomous driving, and aerial surveillance, where high accuracy in challenging environments is paramount. However, even with these improvements, YOLOv7 was not immune to the problem of vanishing gradients—a common issue in deeper neural networks that leads to poor training outcomes due to the weakening of signal propagation as it moves through multiple layers. This was particularly problematic in cases where high-resolution image data required more sophisticated feature extraction.
YOLOv8: Streamlining for Resource Efficiency.YOLOv8 further refined the architecture, focusing on achieving better resource efficiency without sacrificing accuracy. One of the most notable advancements in YOLOv8 was its ability to scale efficiently across different hardware configurations, making it a flexible tool for both low-power devices and high-performance computing environments. YOLOv8 streamlined the training process and introduced optimizations that improved its ability to generalize across a wide range of object detection tasks. YOLOv8 also enhanced the handling of multi-object detection scenarios, where multiple objects of different sizes and shapes appear in a single frame. Despite these improvements, YOLOv8 faced challenges in deeper architectures, particularly with convergence issues. These issues arose from the model's struggle to balance the computational complexity required for deeper networks with the need for real-time inference. As a result, YOLOv8’s performance on complex datasets, especially those involving small, overlapping, or occluded objects, was not always consistent.
Addressing Limitations: The Road to YOLO-NAS and YOLOv9. The limitations observed in YOLOv6 through YOLOv8—such as vanishing gradients and convergence problems—were the catalysts for the development of more sophisticated models like YOLO-NAS and YOLOv9. These models aimed to not only enhance speed and accuracy but also tackle the deeper challenges inherent to neural network architectures, such as gradient management and efficient feature extraction.
5.1.1. YOLO-NAS: A Major Turning Point
Before the introduction of YOLOv9, YOLO-NAS developed by Deci AI marked a significant shift in the evolution of the YOLO framework. As object detection models became more widely deployed in real-world applications, there was a growing need for solutions that could balance accuracy with computational efficiency, especially on edge devices that have limited processing power. YOLO-NAS answered this call by incorporating Post-Training Quantization (PTQ), a technique designed to reduce the size and complexity of the model after training. This allowed YOLO-NAS to maintain high levels of accuracy while reducing its computational footprint, making it ideal for resource-constrained environments like mobile devices, embedded systems, and IoT applications.
PTQ enabled YOLO-NAS to deliver minimal latency, which is a crucial factor for real-time object detection, where every millisecond counts. By optimizing the model post-training, PTQ made YOLO-NAS one of the most efficient object detection models for real-time applications, especially in industries where computational resources are scarce, such as autonomous vehicles, robotics, and smart cameras for security systems. The ability to reduce inference time without sacrificing performance positioned YOLO-NAS as a go-to model for developers looking to deploy sophisticated object detection systems on low-power devices.
YOLO-NAS introduced two significant architectural innovations that set it apart from previous models in the YOLO family:
- Quantization and Sparsity Aware Split-Attention (QSP): The QSP block was designed to enhance the model’s ability to handle quantization while still maintaining high accuracy. Quantization often leads to a degradation of model precision because the model is forced to operate with reduced numerical precision (e.g., moving from floating-point to integer operations). QSP mitigated this accuracy drop by using sparsity-aware mechanisms that allowed the model to be more selective in how it used and stored information across different layers. This helped preserve important features, even in a quantized environment.
- Quantization and Channel-Wise Interactions (QCI): The QCI block further refined the process of quantization by focusing on channel-wise interactions. It enhanced the way features were extracted and processed in the network, ensuring that key information wasn’t lost during the quantization process. By intelligently adjusting how information is passed between channels, QCI ensured that YOLO-NAS could maintain high precision in its predictions, even when the model was reduced to a lightweight architecture. This made it particularly useful for edge applications that require smaller model sizes but cannot afford to lose accuracy.
These innovations were inspired by frameworks like RepVGG and aimed to address the common challenges associated with post-training quantization, specifically the loss of accuracy that typically accompanies such optimization techniques [121]. The combination of QSP and QCI allowed YOLO-NAS to achieve a high level of precision while retaining a small model size, making it an efficient tool for real-time object detection on constrained hardware.
Despite the impressive advancements introduced in YOLO-NAS, the model did face challenges in handling high-complexity image detection tasks. In scenarios where objects were occluded or had intricate patterns, YOLO-NAS struggled to maintain the same level of accuracy as it did in simpler object detection tasks. For example, applications in agriculture, where leaves and crops often occlude one another, or in medical imaging, where subtle variations in texture and shape are critical, highlighted the limitations of YOLO-NAS. The model's performance often dipped when faced with these complex visual environments, underscoring the need for further architectural improvements.
While YOLO-NAS was an excellent solution for resource-efficient detection in straightforward real-time applications, it required additional improvements to handle the nuances of more complex datasets. These limitations laid the groundwork for the development of future models like YOLOv9, which aimed to address these issues through more advanced gradient handling, better feature extraction, and the use of more sophisticated network architectures.
5.1.2. YOLOv9: Groundbreaking Innovations
In response to the challenges encountered by earlier models, YOLOv9 introduced several groundbreaking techniques designed to improve gradient flow, handle error accumulation, and facilitate better convergence during training. These innovations allowed YOLOv9 to extend its applicability to a broader range of real-world object detection tasks.
The key innovations in YOLOv9 include:
- Programmable Gradient Information (PGI): PGI was designed to tackle the issue of vanishing gradients by enhancing the flow of gradients throughout the model. YOLOv9's PGI ensured smoother backpropagation across multiple prediction branches, significantly improving convergence and overall detection accuracy. PGI is composed of three key components: (a) Main Branch: Responsible for inference tasks. (b) Auxiliary Branch: Manages gradient flow and updates the network parameters. (c) Multi-level Auxiliary Branch: Handles error accumulation and ensures that the gradients propagate effectively across all layers. By addressing gradient backpropagation across complex prediction branches, PGI allowed YOLOv9 to achieve better performance, particularly in detecting multiple objects in challenging environments.
- Generalized Efficient Layer Aggregation Network (GELAN): The GELAN module was another major innovation in YOLOv9. By drawing from CSPNet [122] and ELAN [123], GELAN provided flexibility in integrating different computational blocks, such as convolutional layers and attention mechanisms. This adaptability allowed YOLOv9 to be fine-tuned for specific detection tasks, from simple object recognition to complex multi-object detection, making it a versatile tool for a wide array of real-time detection applications.
- Reversible Functions: To ensure information preservation throughout the network, YOLOv9 utilized reversible functions. The formula used for this is: , represents the transformation of input data through a reversible function, and vζ applies an inverse transformation to recover the original input. These reversible layers allowed YOLOv9 to reconstruct input data perfectly, minimizing information loss during forward and backward passes. The reversible functions allowed for more precise detection and localization of objects, especially in high-dimensional and complex datasets.
5.1.3. Evolution to YOLOv10 and YOLOv11
Following YOLOv9, YOLOv10 and YOLOv11 brought further refinements to the YOLO framework, making significant strides in both speed and accuracy.
YOLOv10 introduced groundbreaking innovations that enhanced performance and efficiency, building on the strengths of its predecessors while pushing the boundaries of real-time object detection. A key advancement in YOLOv10 was the introduction of the C3k2 block, an innovative feature that greatly improved feature aggregation while reducing computational overhead. This allowed YOLOv10 to maintain high accuracy even in resource-constrained environments, making it ideal for deployment on edge devices. Additionally, the model's improved attention mechanisms enabled better detection of small and occluded objects, allowing YOLOv10 to outperform previous versions in tasks such as facemask detection and autonomous vehicle applications. Its ability to balance computational efficiency with detection precision set a new standard, with a final mAP50 of 0.944 in benchmark tests.
YOLOv11 further advanced the framework with the introduction of C2PSA (Cross-Stage Partial with Spatial Attention) blocks, which significantly enhanced spatial awareness by enabling the model to focus more effectively on critical regions within an image. This innovation proved especially beneficial in complex scenarios, such as shellfish monitoring and healthcare applications, where precision and accuracy are crucial. YOLOv11 also featured a restructured backbone with smaller kernel sizes and optimized layers, which improved processing speed without sacrificing performance. The inclusion of Spatial Pyramid Pooling-Fast (SPPF) enabled even faster feature aggregation, solidifying YOLOv11 as the most efficient and accurate YOLO model to date. It achieved a final mAP50 of 0.958 across multiple benchmarks, making YOLOv11 a leading choice for real-time object detection tasks across industries ranging from healthcare to autonomous systems.
5.2. Benchmarks
With the introduction of YOLOv9, the benchmarks for performance have shifted. We conducted a comprehensive evaluation of YOLOv9, YOLO-NAS, YOLOv8, YOLOv10, and YOLOv11 using well-established datasets like Roboflow 100 [124], Object365[125], and COCO[126]. These datasets offer diverse real-world challenges, allowing us to assess the models’ strengths and weaknesses under different conditions.
5.2.1. Benchmark Findings
Our results consistently showed that YOLOv9 outperformed both YOLO-NAS and YOLOv8, particularly in complex image detection tasks where objects are occluded or exhibit detailed patterns. However, with the introduction of YOLOv10 and YOLOv11, the benchmark shifted even further. YOLOv10 introduced new feature aggregation techniques, and YOLOv11’s spatial attention mechanisms greatly improved object detection, especially in challenging datasets.
For instance:
- Shellfish Monitoring: In tasks such as shellfish monitoring, which involve complex patterns and occlusions, YOLO-NAS and YOLOv8 struggled to maintain accuracy. While YOLOv9 demonstrated greater adaptability, handling the intricate challenges more effectively, YOLOv10 and YOLOv11 pushed the performance further with their superior spatial attention and feature extraction capabilities. YOLOv11 achieved a final mAP50 of 0.563, the highest among the tested models.
- Medical Image Analysis: On medical image datasets, particularly for tasks such as blood cell detection, YOLOv9 outperformed YOLO-NAS and YOLOv8. However, the architectural advancements in YOLOv10 and YOLOv11 resulted in even better performance, with YOLOv11 achieving an mAP50 of 0.958. This demonstrates its superior capability to detect small and detailed features within cluttered or noisy data, which is critical for applications in medical diagnostics.
These results are summarized in Table 8, highlighting the mAP50 (mean Average Precision at 50% Intersection over Union) scores across several datasets.
5.2.2. Performance Insights
Facemask Detection: All models performed well on this dataset, with YOLOv11 dominating, achieving an mAP50 of 0.962. The improved spatial attention mechanisms in YOLOv11 allowed it to detect subtle variations in facemask patterns, making it the best-performing model in this domain. YOLOv10 also showed improvements over YOLOv9, reaching an mAP50 of 0.950.
Shellfish Monitoring: This dataset presented complex challenges with occluded and overlapping objects. Both YOLO-NAS and YOLOv8 struggled, achieving relatively low mAP50 scores of 0.469 and 0.466, respectively. YOLOv9 demonstrated better adaptability with 0.534, while YOLOv10 and YOLOv11 further improved on these results, reaching 0.542 and 0.563, respectively, thanks to their advanced spatial attention mechanisms.
Forest Smoke Detection: YOLOv8 performed particularly well in detecting smoke patterns, achieving an mAP50 of 0.911, while YOLOv9 closely followed with 0.865. However, YOLOv10 and YOLOv11 both improved on this with scores of 0.925 and 0.945, respectively. The improvements in feature extraction and attention mechanisms in YOLOv11 gave it a slight edge over previous versions in detecting subtle smoke patterns.
Human Detection: For human detection, YOLOv9 outperformed YOLO-NAS but was only marginally better than YOLOv8. YOLOv10 reached 0.829, and YOLOv11 achieved the highest mAP50 at 0.854, benefiting from its optimized backbone and better handling of occlusions in complex scenes.
Pothole Detection: YOLOv9 demonstrated superior performance in detecting potholes on road surfaces, achieving an mAP50 of 0.780. However, YOLOv10 and YOLOv11 demonstrated further advancements, reaching 0.793 and 0.815, respectively, making them more reliable for this specific detection task.
Blood Cell Detection: In medical image analysis, YOLOv9 showed great precision with an mAP50 of 0.933. However, YOLOv10 and YOLOv11 set a new standard for this dataset, achieving 0.944 and 0.958, respectively. The enhanced gradient flow and feature extraction capabilities in these models contributed to their superior performance in detecting minute and complex patterns, crucial in medical diagnostics.
5.2.3. Training Considerations: Extended Epochs for Model Optimization
In our benchmark study, the YOLO models (YOLOv9, YOLO-NAS, YOLOv8, YOLOv10, and YOLOv11) were trained for 20 epochs, providing a baseline for performance evaluation. However, it is evident that this limited number of training cycles does not fully tap into the models' potential. Extended training, involving more epochs, would likely result in smoother learning curves and allow the models to achieve even higher levels of accuracy, especially in tasks that involve complex datasets and intricate object patterns.
Extended training is essential for performance improvement across several aspects of object detection models:
- Refined Feature Extraction: Each epoch allows the model to update and refine its internal feature representations. Models like YOLO-NAS, which are optimized for resource efficiency, benefit from longer training cycles, as this gives the model more opportunities to fine-tune its performance on challenging examples like occluded objects or those with non-standard shapes. YOLOv10, with its enhanced feature aggregation blocks, could further refine its detection capabilities with extended epochs, improving accuracy in both resource-constrained environments and complex scenarios.
- Improved Convergence: While 20 epochs are sufficient for initial insights into performance, convergence—when a model reaches its lowest possible error rate—often requires more iterations. YOLOv9, YOLOv10, and YOLOv11, featuring more intricate architectures, benefit from prolonged training to reach optimal convergence. Specifically, YOLOv9’s use of Programmable Gradient Information (PGI) and Generalized Efficient Layer Aggregation Networks (GELAN) would see further improvements with more epochs, helping the model stabilize gradient flow and improve detection accuracy in environments with occluded or complex objects. YOLOv11, with its C2PSA blocks, would also benefit from more iterations, as this would allow better spatial awareness and feature extraction for difficult detection tasks.
- Avoiding Overfitting: One concern with prolonged training is overfitting, where the model becomes too tuned to the training data, losing its generalization ability. However, this risk can be mitigated by using early stopping techniques or cross-validation. For models like YOLO-NAS and YOLOv8, incorporating regularization methods such as dropout layers or weight decay would allow them to benefit from extended training epochs without falling prey to overfitting. YOLOv11, with its spatial attention mechanisms, could particularly benefit from extended training, as more iterations would enhance its ability to focus on the most critical regions of the image.
- Fine-Tuning for Specialized Tasks: In applications like medical imaging, autonomous driving, or industrial automation, where precision is critical, additional training epochs combined with fine-tuning can make a noticeable difference in model performance. YOLOv10, with its enhanced feature aggregation techniques, could greatly benefit from fine-tuning to optimize its performance in specific tasks such as pothole detection or shellfish monitoring. YOLOv11, with its cutting-edge spatial attention blocks, would further improve in complex, specialized tasks like forest smoke detection or health monitoring, where accurate object localization is paramount.
- Learning Rate Scheduling: As the number of epochs increases, adjusting the learning rate becomes essential. Models like YOLOv9, YOLOv10, and YOLOv11 would benefit from learning rate schedulers that gradually decrease the learning rate during training, ensuring stable convergence and preventing the model from overshooting its optimal parameter values. Adaptive optimization techniques, such as AdamW or RMSProp, could further enhance training performance in extended epochs, particularly in models with complex architectures like YOLOv10 and YOLOv11.
The Specific Impacts on YOLO-NAS, YOLOv9, YOLOv10, and YOLOv11 are as follows:
- YOLO-NAS: Given that YOLO-NAS uses Post-Training Quantization (PTQ), additional epochs would help solidify its quantization strategy, improving performance on both low-resource and high-complexity tasks. The Quantization and Sparsity Aware Split-Attention (QSP) and Quantization and Channel-Wise Interactions (QCI) blocks would benefit from extended training, leading to better feature selection and processing even with quantization. Longer training would also help the model adapt to complex detection tasks that require precision, like health monitoring or industrial automation.
- YOLOv9: YOLOv9’s architectural advancements, such as PGI and GELAN, would see improved performance with more training epochs, especially in scenarios involving multiple prediction branches. Extended training would stabilize its gradient flow and error management, improving performance in complex environments like forest smoke detection or medical imaging. Additionally, YOLOv9’s reversible functions could further benefit from extended epochs, ensuring that input reconstruction becomes more robust, ultimately enhancing detection precision in real-time applications.
- YOLOv10: As a major advancement over previous versions, YOLOv10 introduced the C3k2 block for more efficient feature aggregation. Extended training would refine its ability to balance computational efficiency and detection precision, particularly for resource-constrained tasks on edge devices. Additional epochs would enable YOLOv10 to improve its performance on specialized tasks like pothole detection and autonomous vehicle applications, achieving better convergence and stability.
- YOLOv11: The most recent and advanced YOLO model, YOLOv11, introduced the Cross-Stage Partial with Spatial Attention (C2PSA) blocks, greatly enhancing spatial awareness. Prolonged training would allow the model to fine-tune these blocks for better detection of small or occluded objects, especially in complex tasks such as shellfish monitoring or industrial safety detection. The use of Spatial Pyramid Pooling-Fast (SPPF) for feature aggregation would also improve with more epochs, enabling YOLOv11 to excel in real-time detection tasks with a final mAP50 score that sets it apart from earlier models.
As we look toward further optimizing the YOLO family models, a comprehensive training regimen that includes extended epochs, dynamic learning rates, and fine-tuning techniques will be crucial in extracting the best performance from these models. Expanding the datasets to include even more diverse real-world scenarios will allow the models to generalize better across different applications, ensuring they maintain top-tier performance in both simple and complex detection tasks.
While our 20-epoch benchmark provided valuable performance insights, longer training cycles—combined with the right optimization techniques—would likely unlock even greater accuracy and generalization potential for YOLOv9, YOLO-NAS, YOLOv8, YOLOv10, and YOLOv11, particularly in challenging real-time object detection tasks.
5.2.4. Performance Analysis of YOLO Variants on Benchmark Datasets
The mAP50 charts in Figure 8 illustrate how YOLOv11, YOLOv10, YOLOv9, YOLO-NAS, and YOLOv8 perform across a range of benchmark datasets. These plots provide an in-depth comparison of the models over 20 training epochs, offering key insights into how each model handles different detection tasks. The inclusion of YOLOv10 and YOLOv11 further emphasizes the advancements made in real-time object detection, particularly in complex datasets that challenge earlier models.
-
YOLOv11 and YOLOv10 take the lead: Across almost all benchmarks, YOLOv11 consistently outperforms its predecessors, demonstrating the effectiveness of its C2PSA (Cross-Stage Partial with Spatial Attention) blocks, which allow the model to focus more accurately on important regions within the image. YOLOv10 follows closely behind, benefiting from its C3k2 blocks that optimize feature aggregation and balance computational efficiency with accuracy.
- ▪
- Blood cell detection: YOLOv11 achieved the highest mAP50 of 0.958, followed by YOLOv10 at 0.944. Both models surpass YOLOv9 (0.933), YOLO-NAS (0.9041), and YOLOv8 (0.93). The C2PSA and C3k2 blocks in YOLOv11 and YOLOv10 allowed these models to detect intricate patterns, such as those found in medical imaging, more effectively than previous iterations.
- ▪
- Facemask detection: YOLOv11 also dominated the facemask detection dataset, achieving a mAP50 of 0.962, compared to YOLOv10's 0.950. This was higher than YOLOv9 (0.941), YOLOv8 (0.924), and YOLO-NAS (0.9199), indicating that the newer models are better suited for precise feature extraction in tasks with clear object boundaries, such as facemask detection.
- ▪
- Human Detection: In human detection, YOLOv11 scored a mAP50 of 0.854, with YOLOv10 at 0.829. Although YOLOv9 closely followed at 0.812, YOLOv11 and YOLOv10 demonstrated more stability across the 20 training epochs, thanks to their ability to handle occlusions and dynamic backgrounds.
- Real-Time Applications and Edge Device Suitability
While YOLO-NAS is known for its efficiency in real-time applications, it was outperformed by YOLOv11 and YOLOv10 in tasks requiring more intricate feature extraction. However, YOLO-NAS’s architecture still proves effective for simpler tasks, such as facemask detection, where it recorded a mAP50 of 0.9199. YOLOv10 and YOLOv11 offer a strong balance between accuracy and computational efficiency, making them suitable for deployment on edge devices that require fast, resource-efficient models.
- Performance on Autonomous Vehicle and Industrial Tasks
In tasks like pothole detection, which are critical for autonomous vehicles, YOLOv11 again led the models with a mAP50 of 0.815, followed by YOLOv10 at 0.793 and YOLOv9 at 0.78. The newer YOLO models consistently improved over time, showing that their architectures are more adaptable to dynamic, real-time environments. This is crucial in applications such as road safety, where detecting subtle features like potholes in various lighting and weather conditions is essential.
- Handling Complex Data: Shellfish and Smoke Detection
Complex datasets, such as shellfish monitoring and smoke detection, present unique challenges due to the overlapping and occluded objects within the images. YOLOv11 stood out in these tasks, with a mAP50 of 0.563 in shellfish monitoring and 0.945 in smoke detection. YOLOv10 also performed well, with scores of 0.542 and 0.925, respectively. In contrast, YOLOv9, YOLO-NAS, and YOLOv8 struggled more with these datasets, particularly in shellfish monitoring, where YOLOv9 only achieved a mAP50 of 0.534, and YOLO-NAS fell behind at 0.469.
In smoke detection, YOLOv8 initially performed better than YOLOv9, with a mAP50 of 0.911 compared to YOLOv9’s 0.865. However, YOLOv11 surpassed both models, making it the top performer by the end of the training epochs. YOLO-NAS, while still competitive, recorded a mAP50 of 0.7811, highlighting its limitations in handling more dynamic tasks that require detailed motion analysis and fine-grained object detection.
- Training Epochs: The Importance of Extended Training
As illustrated in the mAP50 charts, extending the training epochs beyond 20 could further enhance the performance of all models, particularly YOLOv10 and YOLOv11. Both models showed a strong upward trajectory throughout the 20 epochs, suggesting that additional training could further improve their ability to handle complex object detection tasks. YOLO-NAS, while designed for efficiency, exhibited earlier flattening in its performance, indicating that its architectural limitations may prevent it from reaching the same level of accuracy in high-complexity tasks.
Therefore, the addition of YOLOv10 and YOLOv11 has shifted the performance standards in real-time object detection. While YOLO-NAS remains a strong candidate for resource-constrained environments, and YOLOv8 continues to deliver adaptable performance, YOLOv11 has emerged as the most versatile and accurate model across a range of challenging datasets. Whether in medical imaging, autonomous driving, or industrial monitoring, YOLOv11’s ability to handle complex patterns, occlusions, and dynamic environments makes it the preferred choice for tasks requiring high precision and model stability.
In Table 9 we present the results of testing various YOLO models on a facemask dataset. The objective was to evaluate the performance of older YOLO versions (YOLOv5, YOLOv6, and YOLOv7) to understand their capabilities in handling relatively simple image classification tasks like facemask detection.
YOLOv7 achieved the highest mAP50 (mean Average Precision at 50% Intersection over Union threshold) score of 0.927, outperforming both YOLOv6 and YOLOv5. This higher score suggests that YOLOv7 is particularly well-suited for simple object detection tasks involving clear and distinguishable objects. YOLOv7’s efficiency and architectural simplicity enabled it to outperform even newer models like YOLO-NAS in tasks with fewer complexities, where lighter architectures excel.
- YOLOv7's performance highlights its capability to handle real-time detection while balancing precision, making it suitable for applications such as facemask detection.
- On the other hand, YOLOv6 and YOLOv5 underperformed relative to YOLOv7, with mAP50 scores of 0.6771 and 0.791 respectively. YOLOv6 and YOLOv5, while capable of decent performance in general object detection, require further optimization, including additional epochs of training and fine-tuning of model parameters to improve their accuracy in specialized tasks like facemask detection.
The results show that older models like YOLOv5 and YOLOv6 could still be relevant with appropriate adjustments, but for tasks that prioritize high speed and accuracy on relatively simple datasets, YOLOv7 stands out as the optimal choice.
These results underscore the importance of selecting models based on the complexity of the dataset and task. While newer models may offer advanced features for handling complex image detection, older, simpler architectures can still perform optimally when the task at hand involves more straightforward detection.
6. Ethical Considerations in the Deployment of YOLO: A Deeper Examination
The YOLO (You Only Look Once) framework, with its transformative real-time object detection capabilities, has significantly reshaped a broad range of industries. Its efficiency and speed have enabled breakthroughs in fields such as healthcare, autonomous driving, agriculture, and industrial automation. However, as with any disruptive technology, the widespread use of YOLO raises profound ethical questions. These issues extend beyond basic concerns of privacy or fairness and tap into deeper societal, philosophical, and environmental considerations. To responsibly harness YOLO’s potential, we must delve into these ethical challenges with a nuanced understanding.
6.1. The Erosion of Privacy and the Threat of Surveillance Dystopias
As YOLO continues to enhance surveillance capabilities, we face the risk of creating a society where individuals are constantly monitored without their consent. Beyond the simple argument of privacy violations, YOLO-enabled systems threaten to embed a culture of surveillance into the fabric of daily life. The rapid pace of technological innovation is outpacing legislative and ethical frameworks, leading to a world where the omnipresent eye of cameras, drones, and smart devices can track and analyze human behavior in granular detail.
The ethical challenge here is not just about balancing security and privacy; it is about safeguarding the very concept of autonomy and freedom. In an environment where every action is logged and analyzed by real-time object detection systems, individuals may begin to self-censor or alter their behavior to avoid suspicion. This normalization of constant surveillance can lead to a dystopian future where free expression and individuality are compromised, and dissenting voices are stifled.
6.2. Bias and the Reinforcement of Social Inequalities
YOLO models, like many AI technologies, are only as fair as the data on which they are trained. However, the bias problem runs deeper than simple data misrepresentation. The use of YOLO in critical systems—such as predictive policing, healthcare diagnostics, or hiring processes—can reinforce systemic inequalities. By automating decision-making processes, we risk entrenching the biases present in historical data and perpetuating discriminatory practices.
In healthcare, for example, biased YOLO models could lead to unequal diagnostic outcomes across different racial or socioeconomic groups, where misdiagnosis or delayed detection could be life-threatening. In law enforcement, biased models might disproportionately target certain communities, leading to over-policing and further marginalization. The ethical dilemma lies in how we reconcile the tension between technological advancement and social justice. It is not enough to train YOLO on more diverse datasets; we must rigorously interrogate how the algorithms themselves make decisions, ensuring that they do not replicate or amplify existing biases.
6.3. Accountability in an Age of Automated Decision-Making
One of the most complex ethical issues surrounding YOLO’s deployment is accountability. As these systems become increasingly autonomous, the line between human and machine responsibility blurs. When a YOLO-powered system makes a wrong decision—whether in diagnosing a disease, misidentifying a pedestrian, or flagging an innocent person as a security threat—who is accountable for the consequences?
The issue of accountability goes beyond merely ensuring transparency in the development of YOLO models. It extends into legal and moral territory, where developers, deployers, and users must navigate an intricate web of responsibility. If a YOLO-powered autonomous vehicle is involved in an accident, who should be held responsible—the developer who designed the model, the organization that deployed it, or the user who trusted it? As we integrate YOLO into critical decision-making systems, we must establish clear ethical and legal frameworks for accountability, ensuring that responsibility is distributed appropriately across all stakeholders.
6.4. The Ethical Dilemmas in Medical and Life-Critical Applications
YOLO’s application in healthcare—particularly in diagnostics, surgery, and patient monitoring—holds immense promise, but it also raises high-stakes ethical questions. Errors in object detection in these domains can have life-or-death consequences. A misdiagnosis caused by an incorrect detection of a tumor or a missed abnormality in a critical scan can lead to delayed treatments or improper medical interventions.
This challenges the trust between healthcare professionals and AI systems. While YOLO can assist in increasing the accuracy of medical assessments, it should not undermine the authority and expertise of healthcare professionals. Ensuring that YOLO remains a tool that complements human judgment, rather than replaces it, is vital. The ethical debate extends to questions about the humanization of care—how much reliance on automated systems is acceptable before the personal touch of medical practitioners is lost?
6.5. Environmental Sustainability and the Hidden Cost of Automation
One of the overlooked ethical issues with YOLO is its environmental impact. The growing demand for AI and machine learning models has led to significant increases in energy consumption, particularly in training and deploying large-scale YOLO models. While the technology itself is seen as cutting-edge, the infrastructure required to support its deployment is resource-intensive, contributing to the carbon footprint of AI technologies.
This ethical concern goes beyond efficiency in training and into the realm of sustainability. As YOLO models are integrated into a broader range of industries, the need for high-performance computing resources grows. Data centers, GPUs, and cloud computing infrastructures—essential for training large-scale models—consume vast amounts of energy. Therefore, it is essential that we focus on developing greener AI technologies and optimizing YOLO variants for energy efficiency. This includes prioritizing lightweight models that maintain performance while minimizing environmental harm, as well as exploring renewable energy sources for data centers.
6.6. The Social Impact of YOLO and the Displacement of Human Labor
The automation potential of YOLO extends beyond its technical capabilities and into societal concerns. As industries adopt YOLO for object detection and automation, particularly in manufacturing, agriculture, and logistics, the displacement of human labor becomes a significant ethical concern. The technology that drives efficiency in industrial settings often comes at the cost of jobs, particularly in sectors reliant on manual labor for tasks such as quality control and monitoring.
The ethical challenge here is twofold. First, there is a need to address the potential economic disruption caused by widespread automation. Policymakers, businesses, and technology developers must collaborate to create strategies for retraining and upskilling displaced workers. Second, there is the broader philosophical question about the value of human labor in an automated society. As machines take over more tasks, how do we ensure that humans are not rendered obsolete? A society that over-automates without regard for the social consequences risks creating deep divides between those who benefit from automation and those who are left behind.
6.7. Ethical Frameworks for Responsible YOLO Deployment
The rapid pace of YOLO’s evolution demands the parallel development of ethical frameworks that guide its responsible use. These frameworks should prioritize human dignity, fairness, privacy, and sustainability. At the core of this endeavor is the commitment to responsible AI development, where transparency, accountability, and inclusivity are foundational principles.
Developers and organizations must adopt stringent ethical guidelines for training, deploying, and monitoring YOLO-powered systems. These guidelines should include considerations of data fairness, model interpretability, privacy protections, and energy efficiency. By embedding ethical principles into the development lifecycle, we can ensure that YOLO is deployed in ways that benefit society without compromising fundamental rights or causing harm.
7. Conclusion
This paper has examined the remarkable evolution of the YOLO (You Only Look Once) family of object detection models, from earlier versions like YOLOv6, YOLOv7, and YOLOv8, through to groundbreaking innovations such as YOLO-NAS, YOLOv9, and the most recent releases, YOLOv10 and YOLOv11. Each iteration has brought advancements in speed, accuracy, and computational efficiency, solidifying YOLO's role as a dominant framework in real-time object detection. YOLO's single-stage detection architecture has enabled rapid, efficient object identification across diverse and time-sensitive fields, such as healthcare, autonomous driving, agriculture, and industrial automation.
YOLO-NAS introduced a key innovation with Post-Training Quantization (PTQ), optimizing the model for resource-constrained environments without compromising accuracy. YOLOv9 further enhanced performance by introducing features like Programmable Gradient Information (PGI) and Generalized Efficient Layer Aggregation Networks (GELAN), allowing the model to tackle more complex detection tasks, including those with occlusions and intricate patterns.
The recent developments in YOLOv10 and YOLOv11 have further pushed the boundaries of performance. YOLOv10’s C3k2 blocks and YOLOv11’s Cross-Stage Partial with Spatial Attention (C2PSA) blocks significantly improved the models' ability to detect small and occluded objects while maintaining computational efficiency. In particular, YOLOv11 emerged as the most accurate and efficient model in benchmark tests, outperforming previous versions in tasks such as facemask detection, blood cell analysis, and autonomous vehicle applications.
Comprehensive benchmarks across datasets like Roboflow 100, Object365, and COCO have demonstrated the distinct advantages of YOLOv9, YOLOv10, and YOLOv11, particularly in complex object detection scenarios. Among these, YOLOv11 consistently achieved the highest performance, confirming its status as the current gold standard for real-time detection tasks in applications that require high precision, such as healthcare, environmental monitoring, and autonomous systems.
However, with these technological advancements come important ethical considerations. YOLO's ability to enable real-time object tracking and identification raises concerns about privacy and the potential for intrusive surveillance, which could threaten individual freedoms and civil liberties. Additionally, the automation of tasks previously performed by humans, especially in industries such as manufacturing and agriculture, could lead to job displacement. Therefore, the need for stringent ethical frameworks and guidelines becomes crucial to ensure that YOLO’s powerful capabilities are used responsibly and for the benefit of society.
Therefore, YOLO has demonstrated itself as a highly adaptable and powerful tool for real-time object detection across multiple domains. As research continues to refine its performance, particularly through the development of lightweight and energy-efficient models, YOLO will undoubtedly remain at the forefront of object detection technology. However, ensuring its responsible and ethical deployment will be essential in maximizing its potential while safeguarding societal values.
References
- Diwan, T. , Anirudh, G., & Tembhurne, J. Object detection using YOLO: Challenges, architectural successors, datasets and applications. Multimedia Tools and Applications 2023, 82, 9243–927. [Google Scholar] [PubMed]
- Vijayakumar, A. , & Vairavasundaram, S. Yolo-based object detection models: A review and its applications. Multimedia Tools and Applications.
- Wang, X. , Li, H., Yue, X., & Meng, L. A comprehensive survey on object detection YOLO. Proceedings, p. 0073, 2023. Available online: http://ceur-ws.org/Vol-1613/.
- Soviany, P. and Ionescu, R. T., 2018. Optimizing the trade-off between single-stage and two-stage deep object detectors using image difficulty prediction. In Proceedings of the 2018 20th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC) (pp. 209-214). IEEE. [Google Scholar]
- Chandana, R.K. and Ramachandra, A.C. Real time object detection system with YOLO and CNN models: A review. arXiv, arXiv:2208.773.
- Kaur, R. and Singh, S. A comprehensive review of object detection with deep learning. Digital Signal Processing 2023, 132, 103812. [Google Scholar] [CrossRef]
- Zhao, X. , Ni, Y. & Jia, H. Modified Object detection method based on YOLO. In Proceedings of Chinese Conference on Computer Vision, Tianjin, China, 11-14 October 2017. [Google Scholar]
- Zhao, Z.Q. , Zheng, P., Xu, S.T. and Wu, X. Object detection with deep learning: A review. IEEE transactions on neural networks and learning systems 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Ragab, M.G. , Abdulkader, S.J., Muneer, A., Alqushaibi, A., Sumiea, E.H., Qureshi, R., Al-Selwi, S.M. and Alhussian, H., 2024. A Comprehensive Systematic Review of YOLO for Medical Object Detection (2018 to 2023). IEEE Access.
- Shetty, A.K. , Saha, I., Sanghvi, R.M., Save, S.A. and Patel, Y.J., 2021. A review: Object detection models. In 2021 6th International Conference for Convergence in Technology (I2CT) (pp. 1-8). IEEE.
- Du, J. , 2018. Understanding of object detection based on CNN family and YOLO. In Journal of Physics: Conference Series (Vol. 1004, p. 012029). IOP Publishing.
- Zou, X. A Review of Object Detection Techniques," Proceedings of International Conference on Smart Grid and Electrical Automation, Xiangtan, China, 10-. 11 August.
- Sanchez, S.A. , Romero, H.J. and Morales, A.D., 2020. A review: Comparison of performance metrics of pretrained models for object detection using the TensorFlow framework. In IOP conference series: materials science and engineering (Vol. 844, No. 1, p. 012024). IOP Publishing.
- Ashraf, I. , Hur, S., Kim, G., & Park, Y. Analyzing Performance of YOLOx for Detecting Vehicles in Bad Weather Conditions. Sensors (Basel) 2024, 24, 1–19. [Google Scholar]
- Yasmine, G. , Maha, G. and Hicham, M., 2023. Overview of single-stage object detection models: From YOLOV1 to Yolov7. In 2023 International Wireless Communications and Mobile Computing (IWCMC) (pp. 1579-1584). IEEE.
- Ren, S. , He, K., Girshick, R. & Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv arXiv:1506.01497, 2016.
- Deng, J. , Xuan, X., Wang, W., Li, Z., Yao, H. and Wang, Z., 2020. A review of research on object detection based on deep learning. In Journal of Physics: Conference Series (Vol. 1684, No. 1, p. 012028). IOP Publishing.
- Zhong, Y. , Wang, J., Peng, J. & Zhang, L. Anchor box optimization for Object detection. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Colorado, CO, USA, 1-. 5 March.
- Wu, S. , Li, X. & W, X. IoU-aware single-stage object detector for accurate localization. Image and Vision Computing 2020, 97, 1–9. [Google Scholar]
- Luo, S. , Dai, H. , Shao, L. and Ding, Y., 2021. M3dssd: Monocular 3d single stage object detector. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 6145-6154). [Google Scholar]
- Devi, S. , Thopalli, K., Malarvezhi, P. and Thiagarajan, J.J. Improving single-stage object detectors for nighttime pedestrian detection. International Journal of Pattern Recognition and Artificial Intelligence 2022, 36, 2250034. [Google Scholar] [CrossRef]
- Hosang, J. , Benensom, R. & Schiele, B. Learning Non-Maximum Supression. arXiv, arXiv:1707.02950.
- Yang, Z. , Sun, Y. , Liu, S. and Jia, J., 2020. 3dssd: Point-based 3d single stage object detector. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 11040-11048). [Google Scholar]
- Wang, L. , Hua, S., Zhang, C., Yang, G., Ren, J. and Li, J. YOLOdrive: A Lightweight Autonomous Driving Single-Stage Target Detection Approach. IEEE Internet of Things Journal.
- Dai, X. HybridNet: A fast vehicle detection system for autonomous driving. Signal Processing: Image Communication 2019, 70, 79–88. [Google Scholar] [CrossRef]
- Balasubramaniam, A. and Pasricha, S. Object detection in autonomous vehicles: Status and open challenges. arXiv, arXiv:2201.07706.
- Ortiz Castello, V. , del Tejo Catalá, O., Salvador Igual, I. and Perez-Cortes, J.C. Real-time on-board pedestrian detection using generic single-stage algorithms and on-road databases. International Journal of Advanced Robotic Systems 2020, 17, 1729881420929175. [Google Scholar] [CrossRef]
- Ren, J. , Chen, X. Accurate single stage detector using recurrent rolling convolution. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 5420–5428.
- Lu, Z, V Rathod, and R Votel. “Retinatrack: Online Single Stage Joint Detection and Tracking,. , 2020. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 1 January 1466.
- Liu, W. , Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y., & Berg, A. C., 2016. SSD: Single Shot MultiBox Detector. In Lecture Notes in Computer Science, Springer International, pp. 21–37.
- Huang, L. , Yang, Y., Deng, Y., & Yu, Y. DenseBox: Unifying Landmark Localization with End-to-End Object Detection. arXiv arXiv:1509.04874, 2015.
- Yi, T. , Goyal, P., Girshick, R., He, K. & Dollar, P. Focal Loss for Dense Object Detection. Focal Loss for Dense Object Detection. arXiv arXiv:1708.02002, 2017.
- Liu. S., Huang, D. & Wang, Y. Receptive Field Block Net for Accurate and Fast Object Detection. Receptive Field Block Net for Accurate and Fast Object Detection. arXiv arXiv:1711.07767, 2018.
- Tan, M. , Pang, R. & Le, Q. V. EfficientDet: Scalable and Efficient Object Detection. arXiv, arXiv:1911.09070.
- Jiang, Z. , Zhao, L., Li, S. and Jia, Y. Real-time object detection method based on improved YOLOv4-tiny. arXiv arXiv:2011.04244, 2020.
- Kumar, C. and Punitha, R., 2020. Yolov3 and yolov4: Multiple object detection for surveillance applications. In 2020 Third international conference on smart systems and inventive technology (ICSSIT) (pp. 1316-1321). IEEE.
- Das, A. , Nandi, A. and Deb, I., 2024. Recent Advances in Object Detection Based on YOLO-V4 and Faster RCNN: A Review. Mathematical Modeling for Computer Applications, pp.405-417.
- Mahasin, M. & Dewi, I. A. Comparison of CSPDarkNet53, CSPResNeXt-50, and EfficientNet-B0 Backbones on YOLO V4 as Object Detector. International Journal of Engineering, Science and Information Technology 2022, 2, 1–9. [Google Scholar]
- Chen, H. , Chen, Z., & Yu, H. Enhanced YOLOv5: An Efficient Road Object Detection Method. Sensors 2023, 23, 1–21. [Google Scholar]
- Li, R. , Zeng, X., Yang, S., Yan, Q. L. A. & Li, D. ABYOLOv4: improved YOLOv4 human object detection based on enhanced multi-scale feature fusion. EURASIP Journal on Advances in Signal Processing 2024, 6, 1–16. [Google Scholar]
- Jaykumaran, R. , 2023. Revolutionizing Medical Imaging with YOLO: Detecting Bone Fractures in X-rays using Computer Vision. Medium.
- Prinzi, F. , Insalaco, M., Orlando, A., Gaglio, S. and Vitabile, S. A yolo-based model for breast cancer detection in mammograms. Cognitive Computation 2024, 16, 07–120. [Google Scholar] [CrossRef]
- Han, Z. , Huang, H., Fan, Q., Li, Y., Li, Y. and Chen, X. SMD-YOLO: An efficient and lightweight detection method for mask wearing status during the COVID-19 pandemic. Computer methods and programs in biomedicine 2022, 221, 106888. [Google Scholar] [CrossRef]
- Vibhuti, Jindal, N. , Singh, H. and Rana, P.S. Face mask detection in COVID-19: a strategic review. Multimedia Tools and Applications 2022, 81, 40013–40042. [Google Scholar] [CrossRef]
- Yu, C.J. , Yeh, H.J., Chang, C.C., Tang, J.H., Kao, W.Y., Chen, W.C., Huang, Y.J., Li, C.H., Chang, W.H., Lin, Y.T. and Sufriyana, H. Lightweight deep neural networks for cholelithiasis and cholecystitis detection by point-of-care ultrasound. Computer Methods and Programs in Biomedicine 2021, 211, 106382. [Google Scholar] [CrossRef] [PubMed]
- Monemian, M. and Rabbani, H. Detecting red-lesions from retinal fundus images using unique morphological features. Scientific Reports 2023, 13, 3487. [Google Scholar] [CrossRef] [PubMed]
- Alyoubi, W.L. , Abulkhair, M.F. and Shalash, W.M. Diabetic retinopathy fundus image classification and lesions localization system using deep learning. Sensors 2021, 21, 3704. [Google Scholar] [CrossRef] [PubMed]
- Farahat, Z. , Zrira, N., Souissi, N., Benamar, S., Belmekki, M., Ngote, M.N. and Megdiche, K. Application of Deep Learning Methods in a Moroccan Ophthalmic Center: Analysis and Discussion. Diagnostics 2023, 13, 1694. [Google Scholar] [CrossRef]
- Sobek, J. , Medina Inojosa, J.R., Medina Inojosa, B.J., Rassoulinejad-Mousavi, S.M., Conte, G.M., Lopez-Jimenez, F. and Erickson, B.J., 2024. MedYOLO: A Medical Image Object Detection Framework. Journal of Imaging Informatics in Medicine, pp.1-9.
- Vasker, N. , Sowrov, A.R.A., Hasan, M., Ali, M.S., Rashid, M.R.A. and Islam, M.M., 2023. Unmasking Ovary Tumors: Real-Time Detection with YOLOv5. In 2023 4th International Conference on Big Data Analytics and Practices (IBDAP) (pp. 1-6). IEEE.
- Sadeghi, M.H. , Sina, S., Omidi, H., Farshchitabrizi, A.H. and Alavi, M. Deep learning in ovarian cancer diagnosis: a comprehensive review of various imaging modalities. Polish Journal of Radiology 2024, 89, e30. [Google Scholar] [CrossRef]
- Zhang, S. , Wang, K., Zhang, H., Wang, T., Gao, X., Song, Y. and Wang, F. An improved YOLOv8 for fiber bundle segmentation in X-ray computed tomography images of 2.5 D composites to build the finite element model. Composites Part A: Applied Science and Manufacturing 2024, 185, 108337. [Google Scholar] [CrossRef]
- Hossain, A. , Islam, M.T., Islam, M.S., Chowdhury, M.E., Almutairi, A.F., Razouqi, Q.A. and Misran, N. A YOLOv3 deep neural network model to detect brain tumor in portable electromagnetic imaging system. IEEE Access 2021, 9, 82647–82660. [Google Scholar] [CrossRef]
- Chen, A. , Lin, D. and Gao, Q. Enhancing brain tumor detection in MRI images using YOLO-NeuroBoost model. Frontiers in Neurology 2024, 15, 1445882. [Google Scholar] [CrossRef]
- Sara, U. , Akter, M. and Uddin, M.S. Image quality assessment through FSIM, SSIM, MSE and PSNR—a comparative study. Journal of Computer and Communications 2019, 7, 8–18. [Google Scholar] [CrossRef]
- Amin, J. , Anjum, M.A., Sharif, M., Kadry, S., Nadeem, A. and Ahmad, S.F. Liver tumor localization based on YOLOv3 and 3D-semantic segmentation using deep neural networks. Diagnostics 2022, 12, 823. [Google Scholar] [CrossRef]
- Sapitri, A. I. , Nurmaini, S., Rachmatullah, M. N., Tutuko, B., Darmawahyuni, A., Firdaus, F., Rini, D. P. & Islami, A. Deep learning-based real-time detection for cardiac objects with fetal ultrasound video. Informatics in Medicine Unlocked 2023, 36, 1–8. [Google Scholar]
- Baccouche, A. , Zapirain, G. B., Zheng, Y. & Elmaghraby, A. S. Early detection and classification of abnormality in prior mammograms using image-to-image translation and YOLO techniques. Computer Methods and Programs in Biomedicine 2022, 221, 1–17. [Google Scholar]
- Loey, M. , Manogaran, G., Hamed, M. & Khalifa, N. Fighting against COVID-19: A novel deep learning model based on YOLO-v2 with ResNet-50 for medical face mask detection. Sustainable Cities and Society, Sustainable Cities and Society 2021, 65, 1–8. [Google Scholar]
- Pang, S. , Ding, T., Qiao, S., Meng, F., Wang, S., Li, P. & Wang, X. A novel YOLOv3-arch model for identifying cholelithiasis and classifying gallstones on CT images. PL0S One 2019, 14, 1–11. [Google Scholar]
- Wang, X. , Li, H. & Zheng, P., 2022. Automatic Detection and Segmentation of Ovarian Cancer Using a Multitask Model in Pelvic CT Images. Oxidative Medicine and Cellular Longevity, Vol.
- Safdar, M. F. , Alkobaisi, S. S. & Zahra, F. T. A Comparative Analysis of Data Augmentation Approaches for Magnetic Resonance Imaging (MRI) Scan Images of Brain Tumor. Journal of the Society for Medical Informatics of Bosnia & Herzegovina 2020, 28, 29–36. [Google Scholar]
- Li, S. , Li, Y., Yao, J., Chen, B., Song, J., Xue, Q. & Yang, X. Label-free classification of dead and live colonic adenocarcinoma cells based on 2D light scattering and deep learning analysis. Cytometry. Journal of the International Society for Analytical Cytology 2021, 99, 1134–1142. [Google Scholar]
- Pandey, S. , Chen, K. F. & Dam, E. B. Comprehensive Multimodal Segmentation in Medical Imaging: Combining YOLOv8 with SAM and HQ-SAM Models. Proceedings of IEEE/CVF International Conference on Computer Vision Workshops, Paris, France, 2-. 6 October.
- Pal, P. , Kundu, S. & Dhara, A. K. Detection of red lesions in retinal fundus images using YOLO V3. Journal of Ophthalmic Research Group 2020, 7, 49–53. [Google Scholar]
- Priyanks, Baranwal, N. , Singh, K. N. & Singh, A. K. YOLO-based ROI selection for joint encryption and compression of medical images with reconstruction through super-resolution network. Future Generation Computer Systems 2024, 150, 1–9. [Google Scholar]
- Haimer, Z. , Mateur, K., Farhan, Y. and Madi, A.A., 2023. Yolo algorithms performance comparison for object detection in adverse weather conditions. In 2023 3rd International Conference on Innovative Research in Applied Science, Engineering and Technology (IRASET) (pp. 1-7). IEEE.
- Verbytska, O. , Gregorutti, B. and Valiere, M., 2024. Endometriosis detection on ultrasound videos. In Joint DFH/UFA workshop on AI in Medicine: Optimised Trials with Machine Learning.
- Elesawy, A. , Mohammed Abdelkader, E. and Osman, H. A Detailed Comparative Analysis of You Only Look Once-Based Architectures for the Detection of Personal Protective Equipment on Construction Sites. Eng 2024, 5, 347–366. [Google Scholar] [CrossRef]
- Zhang, Y. , Sun, Y., Wang, Z. & Jiang, Y. YOLOv7-RAR for Urban Vehicle Detection. Sensors 2023, 23, 1–20. [Google Scholar]
- Jia, X. , Tong, Y., Qiao, H., Li, M., Tong, J., & Liang, B. Fast and accurate object detector for autonomous driving based on improved YOLOv5. Scientific reports 2023, 13, 1–13. [Google Scholar]
- Dazlee, N. M. A. A. , Khalil, S. A., Abdul-Rahman, S. & Mutalib, S. Object Detection for Autonomous Vehicles with Sensor-based Technology Using YOLO. International Journal of Intelligent Systems and Applications in Engineering 2022, 10, 129–124. [Google Scholar]
- Xu, L. , Yan, W. & Ji, J. The research of a novel WOG-YOLO algorithm for autonomous driving object detection. Scientific Reports 2023, 13, 1–13. [Google Scholar]
- Aloufi, N. , Alnori, A., Thayananthan, V. & Basuhail, A. Object Detection Performance Evaluation for Autonomous Vehicles in Sandy Weather Environments. Applied Science 2023, 13, 1–22. [Google Scholar]
- Li, Y. , Wang, J., Huang, J. & Li, Y. Research on Deep Learning Automatic Vehicle Recognition Algorithm Based on RES-YOLO Model. Sensors 2022, 22, 1–24. [Google Scholar]
- Kumar, D. & Muhammad, N, Object Detection in Adverse Weather for Autonomous Driving through Data Merging and YOLOv8. Sensors 2023, 23, 1–29. [Google Scholar]
- Afdal, A. , Saddami, K., Sugiarto, S., Fudai, Z. & Nasaruddin, N. Real-Time Object Detection Performance of YOLOv8 Models for Self-Driving Cars in a Mixed Traffic Environment. Proceedings of 2nd International conference on Computer Systems, Information Technology, and Electrical Engineering, Banda Aceh, Indonesia, 2-. 3 August.
- Al Mudawi, N. , Qureshi, A. M., Abdelhaq, M., Alshahrani, A., Alazeb, A., Alonazi, M. & Algarni, A. Vehicle Detection and Classification via YOLOv8 and Deep Belief Network over Aerial Image Sequences. Sustainability 2023, 15, 1–19. [Google Scholar]
- Azevedo, P. & Santos, V. Comparative analysis of multiple YOLO-based target detectors and trackers for ADAS in edge devices. Robotics and Autonomous Systems 2024, 171, 1–9. [Google Scholar]
- He, Q. , Xu, A., Ye, Z., Zhou, W. & Cai, T. Object Detection Based on Lightweight YOLOX for Autonomous Driving. Sensors 2023, 23, 1–20. [Google Scholar]
- Sarda, A. , Dixit, S. & Bhan, A. Object Detection for Autonomous Driving using YOLO [You Only Look Once] algorithm. Proceedings of the 3rd International Conference on Intelligent Communication Technologies and Virtual Mobile Networks, Tirunelveli, India, 4-. 6 February.
- Puliti, S. & Astrup, R. Automatic detection of snow breakage at single tree level using YOLOv5 applied to UAV imagery. International Journal of Applied Earth Observation and Geoinformation 2022, 112, 1–11. [Google Scholar]
- Jemma, H. , Bouahir, W., Leblon, B. & Bouguila, N. Computer vision system for detecting orchard trees from UAV images. Proceedings of the International archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences Congress, Nice, France, 6-. 11 June.
- Idrissi, M. , Hussain, A., Barua, B., Osman, A., Abozariba, R., Aneiba, A. & Asyhari, T. Evaluating the Forest Ecosystem through a Semi-Autonomous Quadruped Robot and a Hexacopter UAV. Sensors 2022, 22, 1–25. [Google Scholar]
- Tian, Y. , Yang, G., Wang, Z., Wang, H., Li E. & Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Computers and Electronics in Agriculture 2019, 157, 417–426. [Google Scholar]
- Bahhar, C. , Ksibi, A., Ayadi, M., Jamjoom, M. M., Ullah, Z., Soufiene, B.O. & Sakli, H. Wildfire and Smoke Detection Using Staged YOLO Model and Ensemble CNN. Electronics 2023, 12, 1–15. [Google Scholar]
- Hong, S. J. , Han, Y., Kim, S. Y., Lee, A. Y., & Kim, G. Application of Deep-Learning Methods to Bird Detection Using Unmanned Aerial Vehicle Imagery. Sensors 2019, 19, 1–16. [Google Scholar]
- Gai, R. , Chen, N. & Yuan, H. A detection algorithm for cherry fruits based on the improved YOLO-v4 model. Special issue on IoT-based Health Monitoring System.
- Yang, G. , Wang, J., Nie, Z., Yang, H. & Yu, S. A Lightweight YOLOv8 Tomato Detection Algorithm Combining Feature Enhancement and Attention. Agronomy 2023, 13, 1–14. [Google Scholar]
- Qin, Z. , Wang, W., Dammer, K. H., Guo, L. & Cao, Z. Ag-YOLO: A Real-Time Low-Cost Detector for Precise Spraying with Case Study of Palms. Frontiers in Plant Science 2021, 12, 1–14. [Google Scholar]
- Zhang, W. , Huang, H., Sun, Y. and Wu, X. AgriPest-YOLO: A rapid light-trap agricultural pest detection method based on deep learning. Frontiers in Plant Science 2022, 13, 1079384. [Google Scholar] [CrossRef]
- Liu, D. , Lv, F., Guo, J., Zhang, H. and Zhu, L. Detection of forestry pests based on improved YOLOv5 and transfer learning. Forests 2023, 14, 1484. [Google Scholar] [CrossRef]
- Jayagopal, P. , Purushothaman Janaki, K., Mohan, P., Kondapaneni, U.B., Periyasamy, J., Mathivanan, S.K. and Dalu, G.T. A modified generative adversarial networks with Yolov5 for automated forest health diagnosis from aerial imagery and Tabu search algorithm. Scientific Reports 2024, 14, 4814. [Google Scholar] [CrossRef]
- Dandekar, Y. , Shinde, K., Gangan, J., Firdausi, S. and Bharne, S., 2022. Weed plant detection from agricultural field images using yolov3 algorithm. In 2022 6th International Conference On Computing, Communication, Control And Automation (ICCUBEA (pp. 1-4). IEEE.
- Dang, F. , Chen, D., Lu, Y. and Li, Z. YOLOWeeds: A novel benchmark of YOLO object detectors for multi-class weed detection in cotton production systems. Computers and Electronics in Agriculture 2023, 205, 107655. [Google Scholar] [CrossRef]
- MacEachern, C.B. , Esau, T.J., Schumann, A.W., Hennessy, P.J. and Zaman, Q.U. Detection of fruit maturity stage and yield estimation in wild blueberry using deep learning convolutional neural networks. Smart Agricultural Technology 2023, 3, 100099. [Google Scholar] [CrossRef]
- Rai, N. , Zhang, Y., Ram, B.G., Schumacher, L., Yellavajjala, R.K., Bajwa, S. and Sun, X. Applications of deep learning in precision weed management: A review. Computers and Electronics in Agriculture 2023, 206, 107698. [Google Scholar] [CrossRef]
- Zhou, M. , Wu, L., Liu, S. and Li, J. UAV forest fire detection based on lightweight YOLOv5 model. Multimedia Tools and Applications 2024, 83, 61777–61788. [Google Scholar] [CrossRef]
- Wu, Z. , Xue, R. and Li, H. Real-time video fire detection via modified YOLOv5 network model. Fire Technology 2022, 58, 2377–2403. [Google Scholar] [CrossRef]
- Miao, J. , Zhao, G., Gao, Y. and Wen, Y., 2021. Fire detection algorithm based on improved yolov5. In 2021 International Conference on Control, Automation and Information Sciences (ICCAIS) (pp. 776-781). IEEE.
- Badgujar, C.M. , Poulose, A. and Gan, H. Agricultural object detection with You Only Look Once (YOLO) Algorithm: A bibliometric and systematic literature review. Computers and Electronics in Agriculture 2024, 223, 109090. [Google Scholar] [CrossRef]
- Kaiyu, T. , Lei, N., Bozedan, G., Congsheng, J., Yuanmeng, F., Liang, T., Zhongling, H., Xiang, J. and Kun, J., 2023. Application of Yolo Algorithm in Livestock Counting and Identificatiom System. In 2023 20th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP) (pp. 1-6). IEEE.
- Zhu, L. , Zhang, J. and Jia, C., 2022. An improved YOLOv5-based method for surface defect detection of steel plate. In 2022 China Automation Congress (CAC) (pp. 2233-2238). IEEE.
- Wang, B. , Wang, M., Yang, J. and Luo, H. YOLOv5-CD: Strip steel surface defect detection method based on coordinate attention and a decoupled head. Measurement: Sensors 2023, 30, 100909. [Google Scholar]
- Guo, Z. , Wang, C., Yang, G., Huang, Z., & Li, G. MSFT-YOLO: Improved YOLOv5 Based on Transformer for Detecting Defects of Steel Surface. Sensors 2022, 22, 1–15. [Google Scholar]
- Dong, C. , Pang, C., Li, Z., Zeng, X. & Hu, X. PG-YOLO: A Novel Lightweight Object Detection Method for Edge Devices in Industrial Internet of Things. IEEE Access 2022, 10, 123736–123745. [Google Scholar]
- Tianjiao, L. & Hong, B. In A optimized YOLO method for object detection. In Proceedings of the 16th International Conference on Computational Intelligence and Security, Guangxi, China, 27-30 November 2020. [Google Scholar]
- Wang, J. , Dai, H., Chen, T., Liu, H., Zhang, X., Zhong, Q. & Lu, R. Toward surface defect detection in electronics manufacturing by an accurate and lightweight YOLO-style object detector. Scientic Reports 2023, 13, 1–12. [Google Scholar]
- Schneidereit, S. , Mansouri, Y, A., Schneidereit, T., Breuß, M., & Gebauer, M. YOLO-based Object Detection in Industry 4.0 Fischertechnik Model Environment. arXiv, arXiv:2301.12827.
- Vu, T. T. H. , Pham, D. L. & Chang, T. W. A YOLO-based Real-time Packaging Defect Detection System. Procedia Computer Science 2023, 217, 886–894. [Google Scholar]
- Yu, M. , Wan, Q., Tian, S., Hou, Y., Wang, Y. & Zhao, J. Equipment Identification and Localization Method Based on Improved YOLOv5s Model for Production Line. Sensors 2022, 22, 1–23. [Google Scholar]
- Liu, Z. & Lv, H. YOLO_Bolt: a lightweight network model for bolt detection. Scientific Reports 2023, 14, 1–13. [Google Scholar]
- Dai, Z. Uncertainty-aware accurate insulator fault detection based on an improved YOLOX model. Energy Reports 2022, 8, 12809–12821. [Google Scholar] [CrossRef]
- Zendehdel, N. , Chen, H. and Leu, M.C. Real-time tool detection in smart manufacturing using You-Only-Look-Once (YOLO) v5. Manufacturing Letters 2023, 35, 1052–1059. [Google Scholar] [CrossRef]
- Le, H.F. , Zhang, L.J. and Liu, Y.X. Surface defect detection of industrial parts based on YOLOv5. IEEE Access 2022, 10, 130784–130794. [Google Scholar] [CrossRef]
- Cong, P. , Lv, K., Feng, H. and Zhou, J. Improved yolov3 model for workpiece stud leakage detection. Electronics 2022, 11, 3430. [Google Scholar] [CrossRef]
- Xu, X. , Zhang, X. and Zhang, T. Lite-yolov5: A lightweight deep learning detector for on-board ship detection in large-scene sentinel-1 sar images. Remote Sensing 2022, 14, 1018. [Google Scholar] [CrossRef]
- Nishant, B. , Gill, S.S. and Raj, B., 2023. August. Improving Quality Assurance: Automated Defect Detection in Soap Bar Packaging Using YOLO-V5. In 2023 International Conference on Electrical, Electronics, Communication and Computers (ELEXCOM) (pp. 1-6). IEEE.
- Tran, V.T. , T.S., Nguyen, T.N. and Tran, T.D. Safety helmet detection at construction sites using YOLOv5 and YOLOR. In International Conference on Intelligence of Things; Springer International Publishing: Cham, Switzerland, 2022; pp. 339–347. [Google Scholar]
- Chen, Y. , Liu, H., Chen, J., Hu, J. and Zheng, E. Insu-YOLO: an insulator defect detection algorithm based on multiscale feature fusion. Electronics 2023, 12, 3210. [Google Scholar] [CrossRef]
- Chu, X. , Li, L. & Zhang, B. Make RepVGG Greater Again: A Quantization-aware Approach. arXiv, arXiv:2212.01593.
- Wang, C. Y. , Liao, H. Y. M., Yeh, I. H., Wu, Y. H., Chen, P. Y., & Hsieh, J. W. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. arXiv arXiv:1911.11929, 2019.
- Zhang, X. , Zeng, H., Guo, S., & Zhang, L. Efficient Long-Range Attention Network for Image Super-resolution. arXiv, 2203. [Google Scholar]
- Ciaglia, F. , Zuppichini, F., S., Guerrie, P., McQuade, M. & Solawetz, J. Roboflow 100: A Rich, Multi-Domain Object Detection Benchmark. arXiv, arXiv:2211.13523.
- Shao, S. , Li, Z. , Zhang, T., Peng, C., Yu, G., Zhang, X., Li, J. & Sun, J., High-Quality Dataset for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, South Korea, 27 October–2 November 2019., 2029. Objects365: A Large-Scale. [Google Scholar]
- Lin, T. Y. , Marie, M., Belongie, S., Bourdev, L., Girshick, R., Hays, J., Pernora,P., Ramanan, D., Zitnick, C. L. & Dollar, P. Microsoft COCO: Common Objects in Context. arXiv, arXiv:1405.0312.
Figure 1.
Single-stage detectors flow-chart.
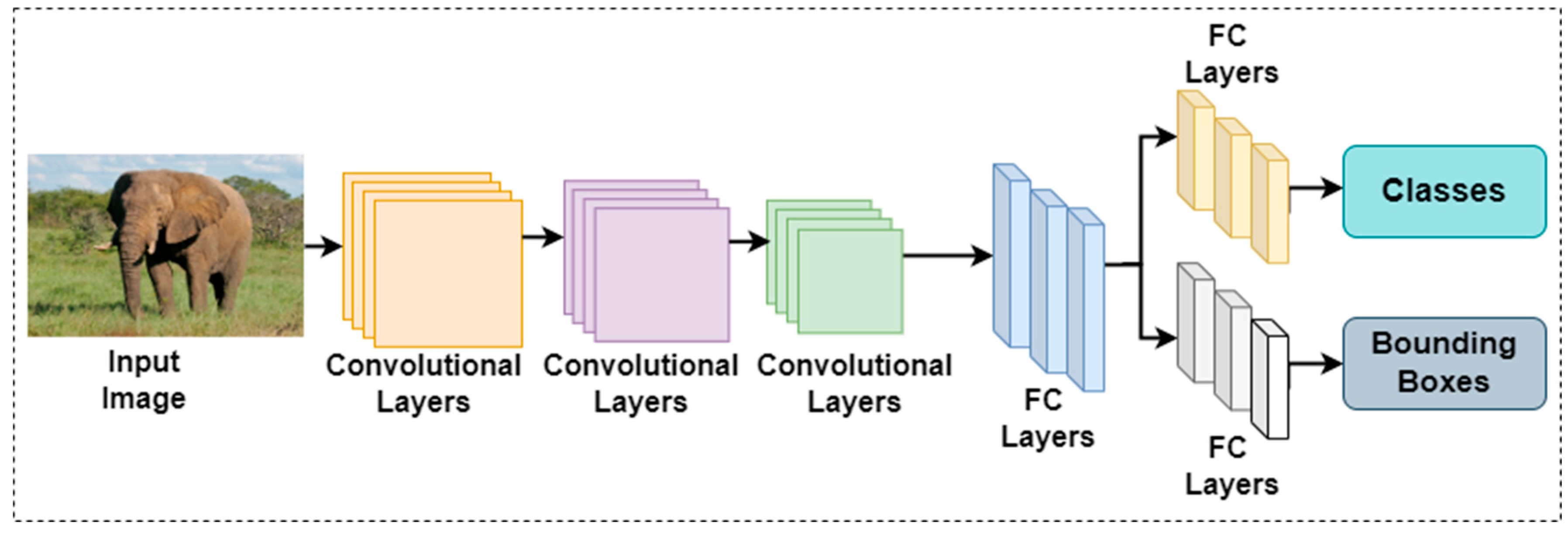
Figure 2.
Flow diagram of SSD architecture.
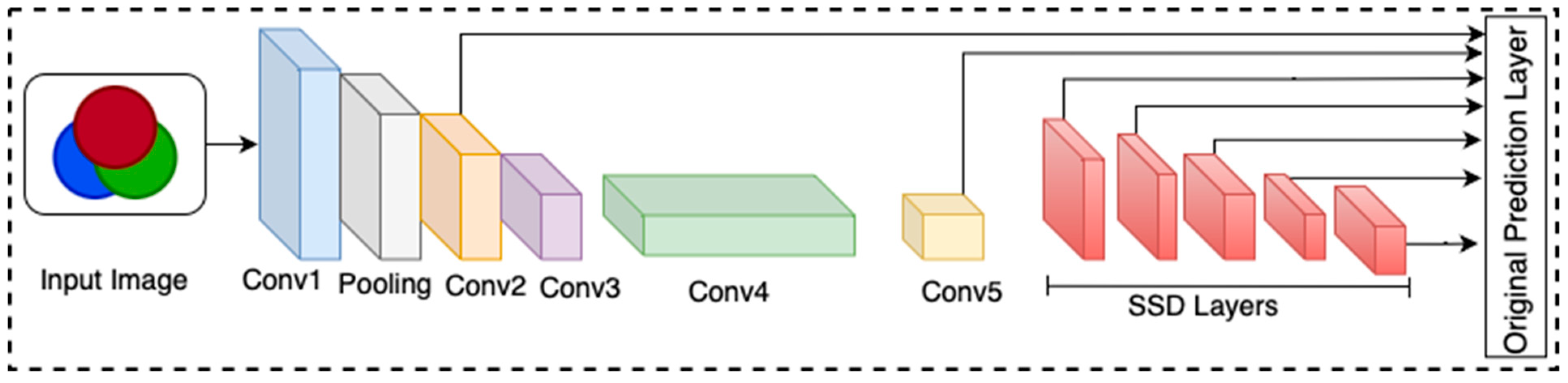
Figure 3.
Detailed architecture of DenseBox.
Figure 4.
Detailed workflow of RetinaNet.
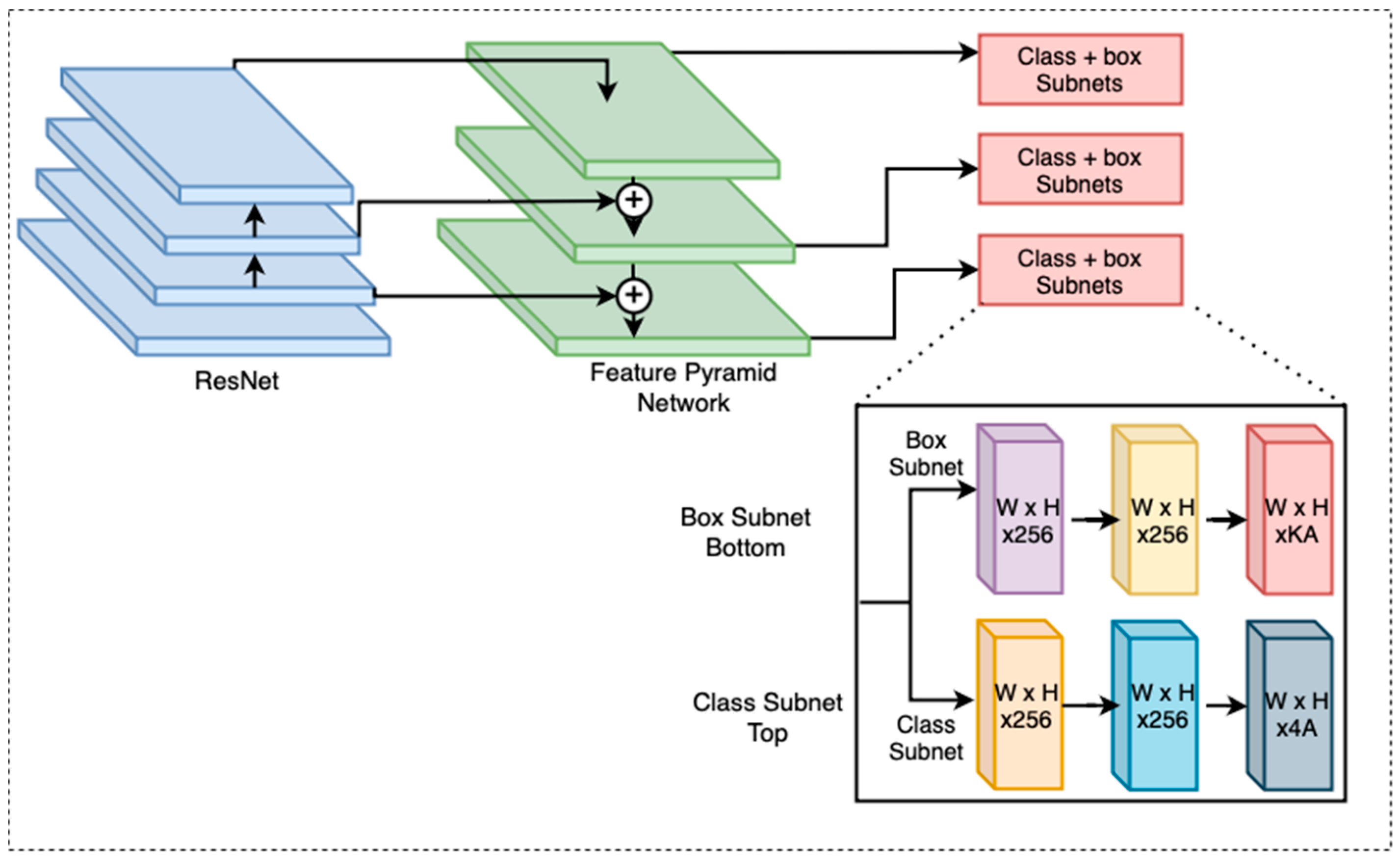
Figure 5.
The workflow diagram of RFB Net.
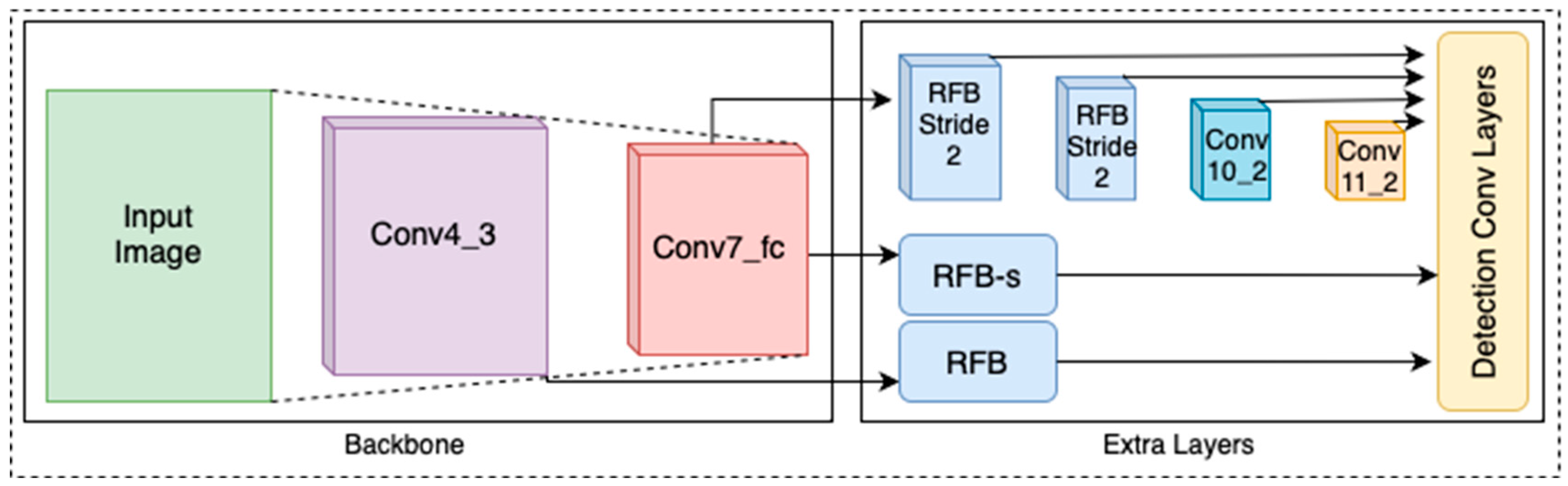
Figure 6.
The architectural overview of Efficient Det.
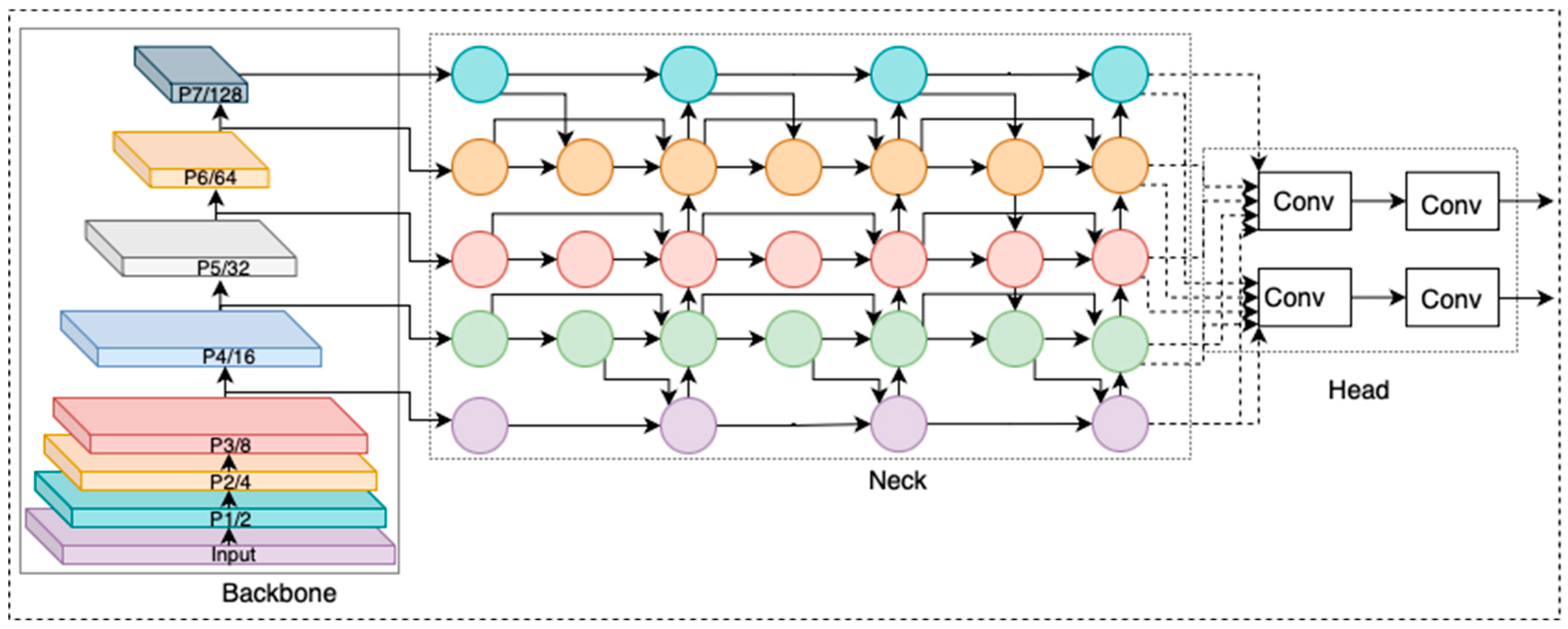
Figure 7.
Timeline of YOLO models starting from 2015 to 2023.
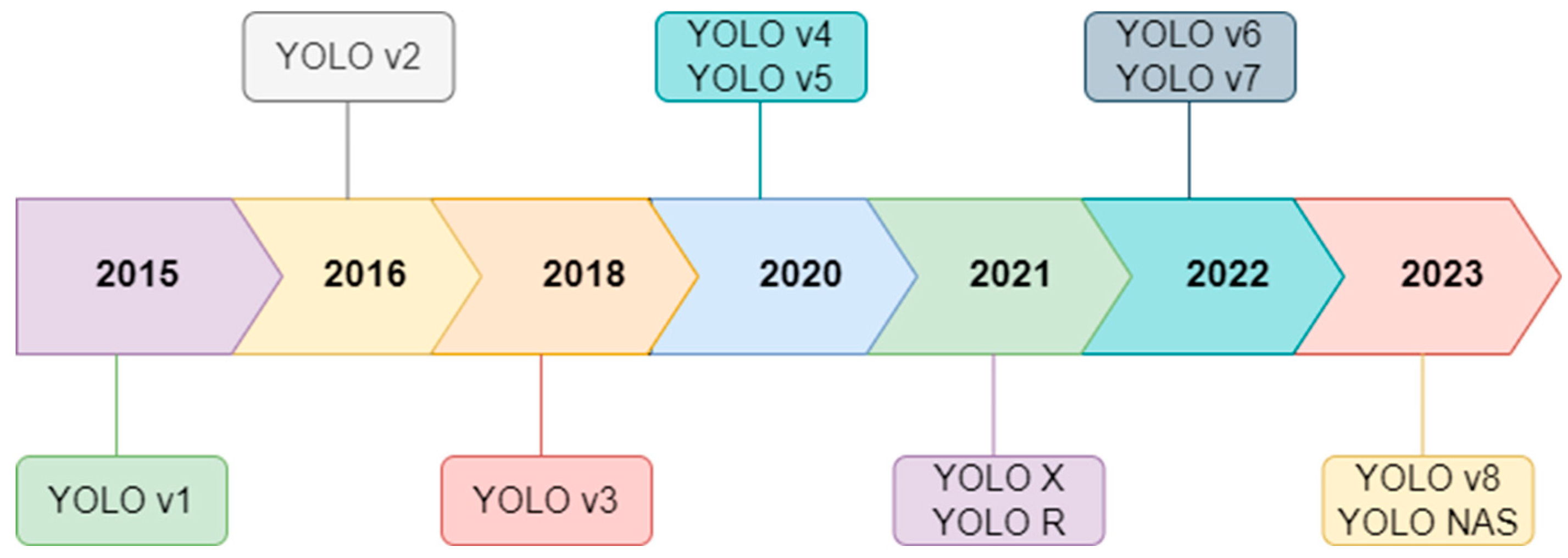
Figure 8.
mAP50 plots of YOLO11, YOLO10, YOLOv9. YOLO-NAS and YOLOv8 on benchmark datasets.
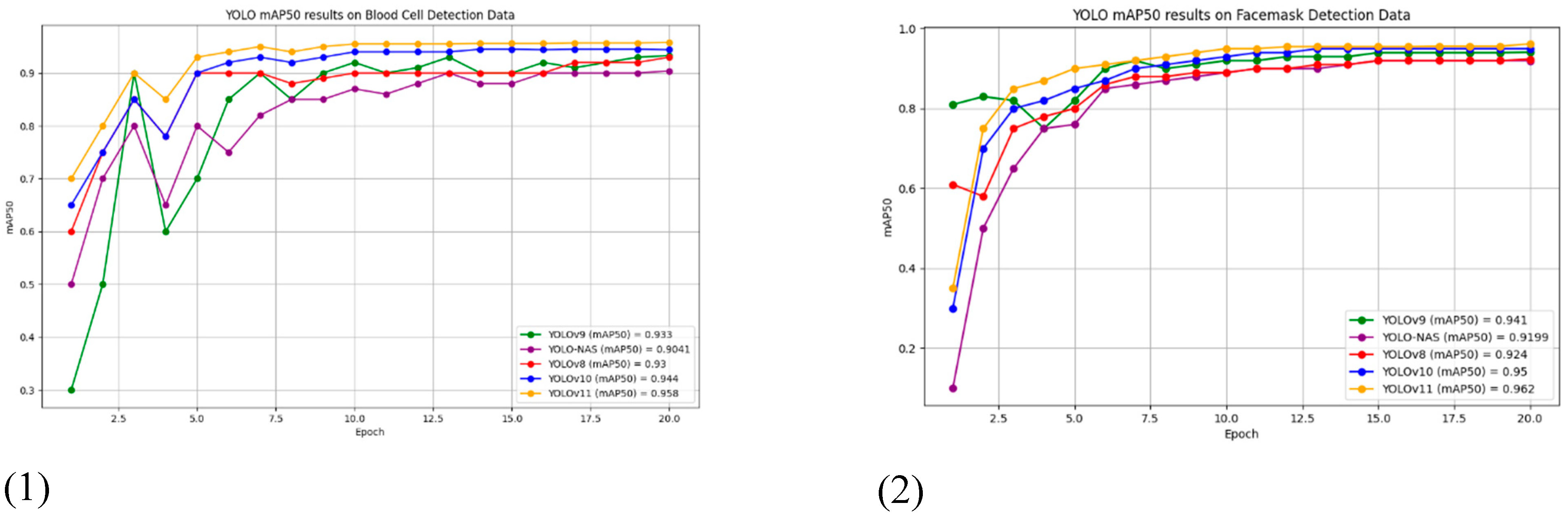
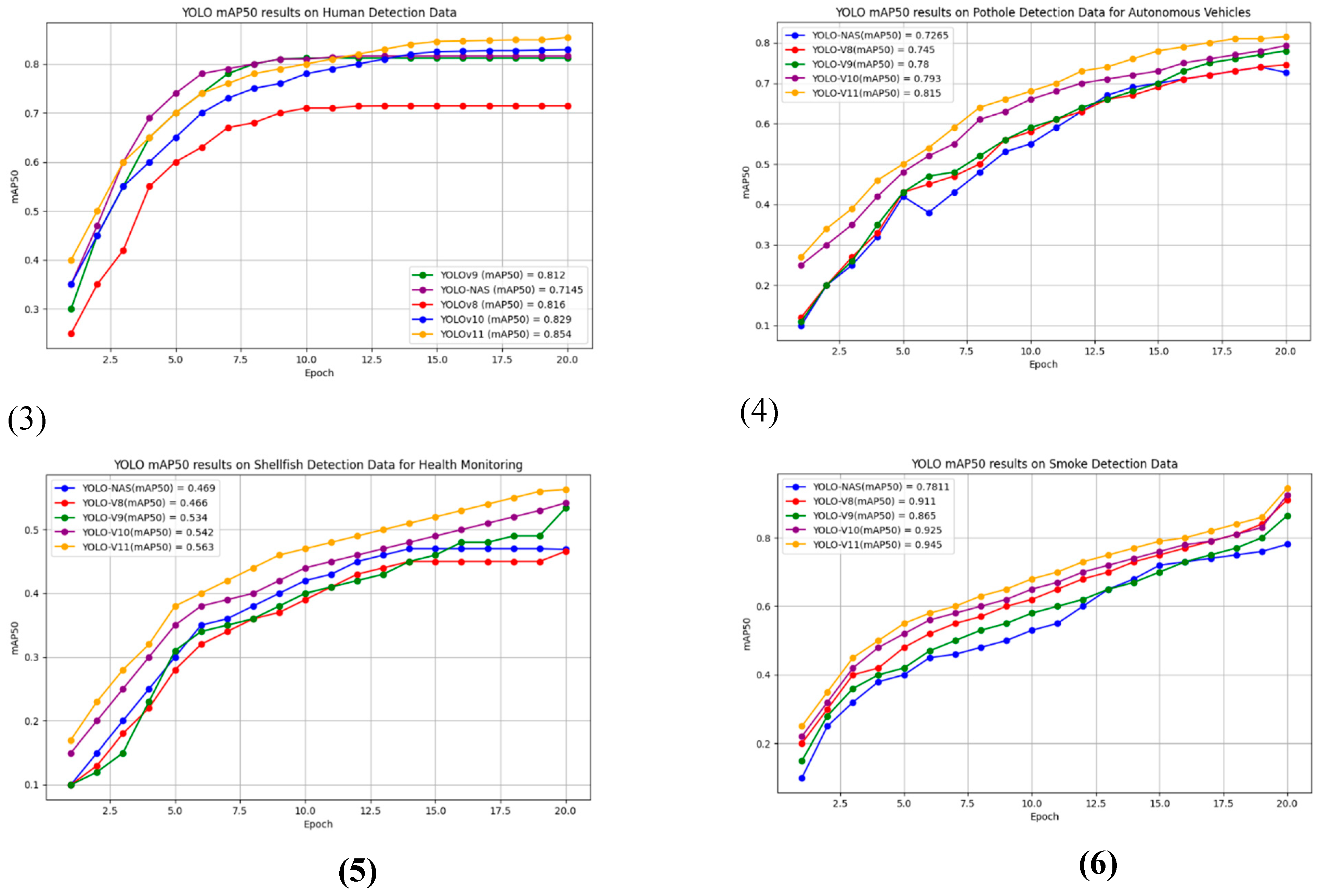

Table 1.
YOLO framework version and research methodologies.
| YOLO Version | Architectural Innovations | Training Strategies | Optimization Techniques |
|---|---|---|---|
| YOLOv1 | Simplified CNN backbone, basic bounding box prediction | Geometric transformations, hue jitter | Stochastic Gradient Descent, Non-Maximum Suppression (NMS) |
| YOLOv2 | DarkNet-19 backbone, K-means clustering for anchor box refinement | Fine-tuning, pre-trained weights | SGD with momentum, hyperparameter tuning, Adam optimizer |
| YOLOv3 | DarkNet-53, multi-scale detection, residual connections | Mix-up, data augmentation, noise | Non-Maximum Suppression, thresholding, multi-scale object detection |
| YOLOv4 | CSPDarkNet-53, PANet, mosaic data augmentation | Transfer learning, knowledge distillation | Generalized IoU, focal loss, dynamic quantization |
| YOLOv5 | CSPNet, dynamic anchor refinement, lightweight architecture | Mosaic, CutMix, early stopping | Post-Training Quantization, filter pruning, low-rank approximation |
| YOLOv6 | PANet, CSPDarkNet53 | Adversarial training, domain-specific augmentation | IoU loss, confidence thresholding, multi-scale fusion |
| YOLOv7 | EfficientRep backbone, dynamic label assignment | Fine-tuning, adversarial patch detection | NAS, quantization, gradient clipping |
| YOLOv8 | Path Aggregation Network, Dynamic Kernel Attention | Adversarial training, data augmentation | Momentum and Adam optimizer, post-training quantization |
| YOLOv9 | Multi-level auxiliary feature extraction | Fine-tuning, domain-specific augmentation | GELAN module, deep supervision for resource-constrained systems |
Table 2.
Overview of Loss function in various YOLO models.
| Model | Bounding Box Regression | Classification |
|---|---|---|
| YOLOv1 | Mean Squared Error (MSE) | Binary Cross Entropy (BCE) |
| YOLOv2 | Sum Squared Error | BCE |
| YOLOv3 | GIoU / DIoU | Cross Entropy (CE) |
| YOLOv4 | CIoU | BCE / Focal Loss |
| YOLOv5 | CIoU | Focal Loss |
| YOLOv6 | CIoU / DFL | VariFocal Loss |
| YOLOv7 | CIoU | BCE |
| YOLOv8 | CIoU / DFL | CE |
| YOLO-NAS | DFL | - |
| YOLOv9 | L1 Loss | BCE |
Note: Mean Squared Error (MSE), Generalized Intersection over Union (GIoU), Distance based Intersection over Union (DIoU), Binary Cross Entropy (BCE), Cross Entropy (CE), Complete Intersection over Union (CIoU), Distributed Focal Loss (DFL).
Table 3.
Strengths and weakness comparisons of various YOLO models.
| Model | Strengths | Weaknesses |
|---|---|---|
| YOLOv1 | Fast performance, real-time detection | Lower accuracy compared to two-stage detectors |
| YOLOv2 | Better performance with anchor boxes | Still suffers from accuracy issues |
| YOLOv3 | Improved accuracy with Darknet-53 backbone | Increased complexity, slower than earlier versions |
| YOLOv4 | Adaptable with various heads and backbones | Less user-friendly |
| YOLOv5 | Faster training and more accurate than YOLOv3 | Less adaptable than YOLOv4 |
| YOLOv6 | Fewer computations and parameters | Less research and resource availability |
| YOLOv7 | Accuracy and speed improvements over YOLOv6 | Higher complexity, risk of overfitting |
| YOLOv8 | Lighter and faster compared to YOLOv7 | Case-specific optimizations |
| YOLO-NAS | Good balance of accuracy and speed | Less widely adopted |
| YOLOv9 | Reduced model size, ideal for real-time applications | Focuses too much on specific objects, ignoring the rest |
Table 4.
Applications of YOLO in medical image analysis.
| YOLO Version | Performance Metrics | Observations/Results | Image Domain |
|---|---|---|---|
| YOLO v7[57] | mAP | Proposed a unique 2D to 3D bounding box adaptation method using NMS for 3D image analysis. Achieved mAP of 82.10%. | Ultrasound Videos |
| YOLO v3[58] | F1-Score, Accuracy, Precision, AUC, Recall | Fusion model accurately identified and categorized breast abnormalities in mammograms. | Breast Cancer |
| YOLO v2[59] | mAP | Achieved 81% mAP for medical face mask detection. | Face Mask |
| YOLO v3[60] | Recall, Precision, Accuracy | Detected and classified gallstones with an average accuracy of 92.7%. | Radiology |
| YOLO v5[61] | Dice Score, F1-Score, Precision, Sensitivity, Specificity | Accurate identification and segmentation of ovarian cancers for real-time applications. | Ovarian Cancer |
| YOLO v3[62] | mAP | Best performance in medical imaging with data augmentation techniques, 180° and 90° rotations. | Brain Tumor |
| YOLO v3[63] | Accuracy, Specificity, Sensitivity | Introduced a label-free method for cellular analysis using 2D light scattering and neural networks. | Oncology |
| YOLO v8[64] | Dice Score, Precision, Recall, F1-Score | YOLO v8 combined with SAM achieved high scores on X-ray, ultrasound, and CT scan data. | X-Ray, Ultrasound, CT-Scan |
| YOLOv3[65] | Average Precision | In the proposed work, they used YOLOv3 to detect red lesion in images and predicts bounding boxes and does classification using logistic regression. They achieved an average precision of 83.3%. | RGB Fundus Images |
| YOLOv7[66] | Peak-signal-to-noise-ratio (PSNR), structural similarity index (SSIM) | They did image compression using YOLOv7 while preserving information in the images. They used chaos and encoding to encrypt the input images and performed reconstruction at the receiver. They achieved PSNR of 30.42 and SSIM of 0.94 | Liver Tumor 3D scans |
Table 5.
Application of YOLO in the field of autonomous vehicles.
| YOLO Version | Performance Metrics | Observations | Image Domain |
|---|---|---|---|
| YOLOv7[70] | AP | Proposed modifications including ACmix for hybrid attention, RFLA for feature fusion, and Res3Unit backbone, achieving 89.2% AP. | Road traffic data |
| YOLOv5[71] | mAP | Added structural re-parameterization and small object detection layers, achieving 96.1% mAP. | KITTI Dataset (8 classes) |
| YOLOv2, YOLOv3[72] | mAP, Precision, Recall | Complex YOLO outperformed Tiny-YOLO with a mean Average Precision of 0.217. | KITTI Dataset |
| YOLOv5[73] | mAP | WOG-YOLO showed improvements in detecting small objects, increasing mAP by 2.6% for pedestrians and 2.3% for bikers. | Self-built dataset |
| YOLOv5, YOLOv7[74] | mAP | Evaluated on different activation functions. YOLOv7 with SiLU achieved an mAP of 94%, while YOLOv5 with LeakyReLU reached 88%. | Sandy weather data |
| YOLOv3[75] | Accuracy, Recall | The RES-YOLO network improved vehicle detection accuracy and reduced background noise. | Vehicle dataset |
| YOLOv8[76] | mAP | Transfer learning applied to hard weather datasets improved object detection, achieving mAP scores of 0.672 and 0.704. | Fog, snow, and hard weather datasets |
| YOLOv8[77] | Precision, Recall, F-score | YOLOv8x outperformed other variants, with precision, recall, and F-score of 0.90, 0.83, and 0.87, respectively. | Video road data for day and night |
| YOLOv8[78] | Accuracy | A five-stage model using YOLOv8 for detection and Deep Belief Network for classification achieved 95.6% accuracy. | Aerial imagery dataset |
| YOLOv8, YOLOv7, YOLOv5, YOLOv4[79] | mAP | YOLOv7 performed the best with mAP50 scores when deployed on edge devices for real-time inference. | Road dataset |
| YOLOX[80] | mAP | Combined ShuffDet backbone and attention mechanism to achieve 92.20% mAP while reducing parameters by 34%. | KITTI dataset for road traffic |
| YOLOv4[81] | mAP, F1-score, Recall | YOLOv4 was trained on a custom dataset for object detection, achieving an mAP of 74.6%, F1-score of 0.70, and recall of 0.81. | Custom vehicle dataset |
Table 6.
Application of YOLO in agriculture.
| YOLO Version | Performance Metrics | Observations | Image Domain |
|---|---|---|---|
| YOLOv5[82] | Precision, Recall | UAV-based detection system for forest degradation, effective even in snowy conditions. | UAV imagery of trees |
| YOLOv5[83] | Precision, F1-Score, mAP, Recall | DeepForest with YOLO, mAP of 82%, outperformed other models. | Apple trees in UAV RGB images |
| YOLOv5s, YOLOv5x[84] | IoU, Recall, Precision, mAP | Lightweight YOLOv5s ideal for embedded systems. | RGB forest images |
| YOLOv3[85] | F1-Score | Modified YOLOv3, F1-score of 0.817, used for apple detection. | Apple images from orchards |
| YOLOv5[86] | F1-Score, mAP | YOLOv5 ensemble technique for real-time forest fire detection, F1-score of 93%. | FLAME dataset from UAVs |
| YOLOv3[87] | IoU | YOLOv3 achieved 91.80% average precision for bird detection. | UAV aerial images |
| YOLOv4[88] | mAP | YOLOv4 for cherry ripeness detection, increased mAP by 0.5%. | Cherry ripeness detection |
| YOLOv8s[89] | mAP | Lightweight YOLOv8s model with mAP of 93.4%, suitable for small devices. | Tomato image data |
| Ag-YOLO[90] | F1-Score | Ag-YOLO for crop monitoring and spraying, F1-score of 0.9205. | UAV imagery of palm trees |
Table 7.
Applications of YOLO in industry.
| YOLO Version | Performance Metrics | Observations | Image Domain |
|---|---|---|---|
| YOLOv5[105] | mAP | Combined YOLO with transformers to detect small-scale objects and defects. Proposed a bidirectional feature pyramid network, achieving an mAP of 75.2%. | Grayscale imagery of surface defects |
| YOLOv5[106] | mAP | PG-YOLO was developed as a lightweight version for edge devices in IoT networks. Improved inference speed without sacrificing accuracy, achieving an mAP of 93.3%. | RGB images of safety-helmet wearing (SHWD) |
| YOLOv3[107] | mAP | For detecting weld defects in vehicle wheels, this model achieved an mAP of 98.25% and 84.36% on AP 75 and AP 50, respectively. Environment-specific model. | RGB images of vehicle wheel welding |
| YOLOv5[108] | mAP, GFLOPS | ATT-YOLO, inspired by transformers, performed well on surface detection tasks in electronic manufacturing, achieving an mAP of 49.9% with 21.8 GFLOPS. | Laptop surface images |
| YOLOv3, YOLOv5[109] | mAP | YOLO models used for process flow tracking in Industry 4.0. Models were applied to datasets with distortions and achieved final mAP scores of 80% (YOLOv3) and 70% (YOLOv5). | Colorful objects in industry setting |
| YOLO[110] | Precision, Accuracy, mAP | Introduced a deep learning-based system for real-time packaging defect detection. The system achieved 81.8% precision, 82.5% accuracy, and an mAP of 78.6%. | Images of damaged and intact boxes |
| YOLOv5s[111] | Precision, Recall, mAP | An upgraded YOLOv5s model used for real-time identification and localization of production line equipment, including robotic arms and AGV carts. Achieved precision of 93.6%, recall of 85.6%, and mAP of 91.8%. | Real-time data from simulated production line |
| YOLOv5[112] | mAP | Enhanced YOLOv5 for detecting workpieces on production lines. Improved mAP on COCO dataset by 2.4% and on custom data by 4.2% using ghost bottleneck lightweight deep convolution. | Images of bolts |
| YOLOD[113] | Average Precision | YOLOD, a unique model addressing uncertainty in object detection, used Gaussian priors in front of YOLOX detection heads. Improved bounding box regression and achieved an AP of 73.9%. | Power line insulator images |
Table 8.
Performance of YOLOv11, YOLOv10, YOLOv9, YOLO-NAS and YOLOv8 on multiple datasets.
| Datasets | YOLOv9 | YOLO-NAS | YOLOv8 | YOLOv10 | YOLOv11 |
|---|---|---|---|---|---|
| Facemask Detection | 0.941 | 0.9199 | 0.924 | 0.950 | 0.962 |
| Shellfish Monitoring | 0.534 | 0.469 | 0.466 | 0.542 | 0.563 |
| Forest Smoke Detection | 0.865 | 0.7811 | 0.911 | 0.925 | 0.945 |
| Human Detection | 0.812 | 0.7145 | 0.816 | 0.829 | 0.854 |
| Pothole Detection | 0.78 | 0.7265 | 0.745 | 0.793 | 0.815 |
| Blood Cell Detection | 0.933 | 0.9041 | 0.93 | 0.944 | 0.958 |
Table 9.
Results of different YOLO variants on facemask data.
| Model Type | mAP50 |
|---|---|
| YOLOv7 | 0.927 |
| YOLOv6 | 0.6771 |
| YOLOv5 | 0.791 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



