Submitted:
23 October 2024
Posted:
24 October 2024
You are already at the latest version
Abstract
Since the seminal work of Kolmogorov, probability theory has been based on measure theory, where the central components are so-called probability measures, defined as measures with total mass equal to 1. In Kolmogorov’s theory, a probability measure is used to model an experiment with a single outcome that will belong to exactly one out of several disjoint sets. In this paper, we present a different basic model where an experiment results in a multiset, i.e. for each of the disjoint sets we get the number of observations in the set. This new framework is consistent with Kolmogorov’s theory, but the theory focuses on expected values rather than probabilities. We present examples from testing Goodness-of-Fit, Bayesian statistics, and quantum theory, where the shifted focus gives new insight or better performance. We also provide several new theorems that address some problems related to the change in focus.
Keywords:
Category
; double slit experiment
; expectation measure
; extended probabilistic power domain
; expected value
; Gaussian approximation
; information divergence
; monad
; point process
; Poisson distribution
; Poisson point process
; quantum information theory
; thinning
; valuation
MSC: 60A05, 60G55
1. Introduction
Throughout the history of probability theory, some mathematicians have focused on probabilities, and others have focused on expectations. In his seminal paper from 1933, Kolmogorov focused on probabilities [1], but in the present paper, we will develop expectation theory as an alternative to probability theory, focusing on expectations. Expectation theory has been developed to handle technical problems in several applications in information theory, statistics (both frequentist and Bayesian), quantum information theory, and probability theory itself. We will present the basic definitions of our theory and provide interpretations of the core concepts. Standard probability theory, as developed by Kolmogorov, can be embedded in the present theory. Similarly, our theory can be embedded into standard probability theory. The focus is on discrete measures to keep this paper at a moderate length. Since there is no inconsistency between the two theories, there are many cases where expectation theory, as developed here for discrete measures, can also be used for more general measures. Some readers may be more interested in theory, and others may be more interested in applications. The paper is written hoping that the different sections can be read quite independently.
1.1. Organization of the Paper
In Section 2 we point out some significant ideas related to the work of Kolmogorov and we will review some later developments that are important for our topic. The notion of a probability monad will be presented in Section 2.3. This approach allows us to focus on which basic operations are needed to define a well-behaved class of models.
The theoretical framework we will develop may be viewed as a part of the theory of point processes. Usually, the topic of point processes is considered an advanced part of probability theory. Still, we will consider some aspects of the theory of point processes as quite fundamental for modeling randomness. In Section 2.4 we will give a short overview of the relevant concepts of the theory of point processes. For readers familiar with the theory of point processes, it puts our contribution in a well-known context. It will also provide a framework to ensure the rest of the paper provides a consistent theory. In the subsequent sections, our discussions will often focus on finite samples, but the conclusions will also hold for more general samples, which is easy to see with some general knowledge of point processes.
In Section 3 we develop the theory of finite empirical measures. Such finite empirical measures are formally equivalent to multisets. Some basic properties of empirical measures are established. It is pointed out that many problems in information theory can be formulated for empirical measures without reference to randomness.
In Section 4 we introduce finite expectation measures. In Section 4.3 we introduce the Poisson interpretation that allows us to translate between results for expectation measures and results for Poisson point processes with probability measures. The cost of this translation is that the outcome space of the process is infinite, even if the expectation measure is finite. The Poisson interpretation enables us to give probabilistic interpretations of conditioning and independence for general measures, as discussed in Section 4.4 and Section 4.5. In [2] it was demonstrated that the reverse information projection of a probability distribution into a convex set of probability distributions may not be a probability distribution. This has been an important motivation for studying information divergence for general measures, as done in Section 4.6.
In Section 5, we will provide examples of how the present theory gives alternative interpretations and improved results to some familiar problems in decision theory, Bayesian statistics, Testing Goodness-of-Fit, and information theory.
We end the paper with a short conclusion, including a list of concepts in probability theory and the corresponding concepts in expectation theory.
1.2. Terminology
A measure with a total mass of 1 is usually called a probability measure or a normalized measure. We will deviate from this terminology and use the term unital measure for a measure with total mass 1. The term normalized measure will only be used when a unital measure is the result of dividing a finite measure by the total mass of the measure. We will reserve the word probability measure to situations where the weights of a unital measure are used to quantify uncertainty, and it is known that precisely one observation will be made and one can decide which event the observation belongs to in a system of mutually exclusive events that cover the whole outcome space. Similarly, we will talk about an expectation measure if our interpretation of its values are given in terms of expected values of some random variables. Other classes of measures are coding measures that are used in information theory and mixing measures that are unital measures used for barycentric decompositions of points in convex sets.
In standard probability theory, the probability measures lives on a space often called a sample space, but we will use the alternative term, an outcome space. The word sample will be used informally about the result of a sampling process. The result of a point process will be called an instance of the process.
2. Probability Theory Since Kolmogorov
2.1. Kolmogorov’s Contribution
The modern foundation of probability theory is due to Kolmogorov. He contributed in many ways, and here we shall only focus on the aspects that are most relevant for the present paper. His 1933 paper [1] was in line with two ideas earlier mathematicians developed.
The first idea is symbolic logic, as developed by G. Boole. In this approach to logic, the propositions form a Boolean algebra. A truth assignment function is a binary function that assigns one of the values 0 (false) and 1 (true) to any proposition consistently. In particular, if A is a proposition, either A is assigned the value 1 or is assigned the value 1. Kolmogorov’s work may be seen as an extension where statements are replaced by events, i.e., measurable sets, and the events A and are assigned probabilities in in such a way that . Thus, probability theory can be described as an extension of logic where the functions can take values in rather than values in . Such extensions have been formalized as monads to be discussed in Section 2.3, but the theory of monads was only developed much later as part of category theory. See [3,4] for a general discussion of probability monads.
Lebesgue’s theory of measures inspired the second main idea in Kolmogorov’s 1933 paper. Measure theory was used to extend the previous definitions of integrals. The basic idea is that a measure is defined on a set of measurable sets. Such a measure should be countable additive like the notion of an area. Measure theory has been beneficial for the theory of integration, and in particular, it leads to nice convergence theorems like Lebesgue’s theorem on dominated convergence. Kolmogorov used measure theory to allow similar general convergence results in probability theory.
Basic probability theory is defined on measurable spaces, but several essential theorems do not hold for all measurable spaces. Therefore, it is often assumed that the outcome space is a standard Borel space. Such a space emerges if the measurable sets are the Borel sets of a topology defined by a complete separable metric space. This assumption will cover most applications. A standard Borel space has a one-to-one measurable mapping from the outcome space to the unit interval equipped with the Borel -algebra.
The primary objects in Kolmogorov’s probability theory are the outcome space and a probability measure on the outcome space. All probabilities are with respect to this outcome space and this probability measure. This assumption leads to a consistent theory, but it is just assumed that an outcome space and a probability measure exist. Theorems like the Daniell-Kolmogorov consistency theorem (also called Kolmogorov’s extension theorem [[5] page 246, Theorem 1]) make it quite explicit that the existence of an outcome space is a consistency assumption. For a random process where we define the finite-dimensional distribution functions by
defined for all sets with . For the random the finite-dimensional distributions function satisfies the Chapman-Kolmogorov equations stated below.
where ∧ indicates an omitted coordinate
Theorem 1
(Kolmogorov’s Theorem on the existence of a process). Let , with , , be a given family of finite- dimensional distributions, satisfying the Chapman-Kolmogorov Equations (2). Then , there exists a probability space and a random process such that
Later, category theory was developed, and commutative diagrams in category theory are exactly a language for expressing this type of consistency.
2.2. Probabilities or Expectations?
To a large extent, the present paper may be viewed as an extension of the point of view presented by Wittle [6]. By identifying an event with its indicator function, his exposition is formally equivalent to Kolmogorov’s probability theory.
If is a measurable space, we may define as the set of bounded -measurable functions . For any unital measure on we may define the functional by
The functional satisfies that
Any functional that satisfies these two conditions may be identified with a unital measure.
To describe weak convergence, we are interested in the outcome space as a topological space rather than as a measurable space. A second countable space is also a Lindelöf space, i.e., any open covering has a countable sub-covering. If the measure is locally finite, then the whole space has a covering by open sets of finite measures. In particular, the measure is -finite.
If the space is a locally compact Hausdorff space, then a locally finite measure is the same as a finite measure on compact sets. For such spaces, the integral
is well-defined for any function f that is continuous with compact support. Radon measures can be identified with positive functionals on . With these conditions, the duality between Radon measures and continuous functions with compact support works perfectly without any pathological problems.
On a locally compact Hausdorff space, the finite measures can be identified with positive functionals on the continuous functions on the one-point compactification of the space.
2.3. Probability Theory and Category Theory
For the categorical treatment of probability theory, we first have to recall the definition of a transition kernel [[7] Chapter 1].
Definition 1.
Let and be two measurable spaces. A transition kernel from Ω to S is a function
such that:
-
For any fixed the mappingis measurable.
-
For every fixed , the mappingis a measure on .
Let denote the measures on . If , then a measure on is given by
Thus, a transition kernel may be identified with a mapping that we will call a transition operator.
If the measure is a unital measure for any , then the transition kernel is called a Markov kernel. The key observation for the categorical treatment of probability theory is that Markov kernels can be composed.
The first to put probability theory into the framework of category theory seems to be Lawvere [8]. He defined a category Pro that has measurable spaces as objects and Markov kernels as morphisms. The category Pro contains the singleton sets as initial objects. A probability measure on can then be identified with a morphism from an initial object to .
Later, the theory of monads was introduced in category theory, and monads have had a significant impact on functional programming [9]. The first to describe the category Pro in terms of monads was Giry [10]. First, we consider the category of measurable spaces Maes. It has measurable spaces as objects and measurable maps between measurable spaces as morphisms.
To the measurable space we associate the set of probability measures on X. The set is equipped with the smallest -algebra such that the maps are all measurable where . If g is a measurable map from to then a measurable map from to is defined by
which can also be written as . If f is the indicator function of the measurable set B and the functional is given by the probability measure , then we get
which is the usual definition of an induced probability measure. In this way is a functor from the category Maes to itself, i.e., an endofunctor.
The morphisms in the category Pro are Markov operators , but Markov operators are given by Markov kernels. It is useful to describe in detail how one can switch between Markov operators and Markov kernels. For this purpose, we introduce a natural transformation that translates Markov operators into Markov kernels, and and we introduce a natural transformation that translates Markov kernels into Markov operators.
A measurable space can be embedded into by mapping into the Dirac measure . In this way . Now may be considered as a measurable map, i.e., a morphism in the category Maes, and the following diagram commutes.
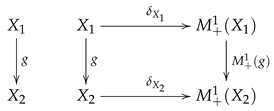 Thus, is a natural transformation from the identity functor in the category Maes to the functor . If is a Markov operator, then the corresponding Markov kernel is given by .
Thus, is a natural transformation from the identity functor in the category Maes to the functor . If is a Markov operator, then the corresponding Markov kernel is given by .
We will use to denote the functor . We have a measurable map from to that maps to
Then we have the following commutative diagram
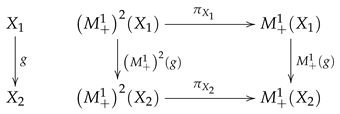 so that is a natural transformation from to . If is a Markov kernel, then the corresponding Markov operator is given by . Thus, the following diagram commutes.
so that is a natural transformation from to . If is a Markov kernel, then the corresponding Markov operator is given by . Thus, the following diagram commutes.
A Markov kernel from to may now be described as a measurable map from to . Composition of Markov kernels is given by
and we have the identities
The first two identities can be translated into the following commutative diagram
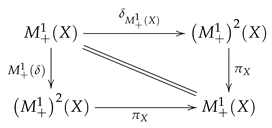 Whenever this diagram commutes, we say that acts as an identity. Associativity means that the following diagram commutes.
Whenever this diagram commutes, we say that acts as an identity. Associativity means that the following diagram commutes.
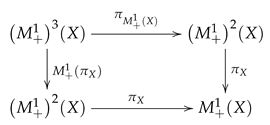 and we say that the functor is associative.
and we say that the functor is associative.
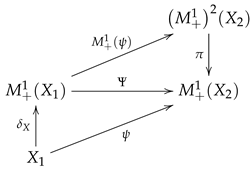
When an endofunctor together with two natural transformations and satisfies associativity and acts as the an identity, we say that forms a monad. For any monad, morphisms from X to can be composed by Equations (18) leading to the Kleisli composition of morphisms. For a category with a monad, the Kleisli category of the monad has the same objects as the original category, and as morphisms, it has the Kleisli morphisms. In this way, the category of Markov kernels can be identified with the Kleisli morphisms associated with the monad . The Kleisli category is equivalent to the category introduced by Lawvere. The equivalence is established by a functor that maps the object X into and maps Kleisli morphisms into their extensions.
2.4. Preliminaries on Point Processes
First, we will define a point process with points in S. Typically, S will be a d-dimensional Euclidean space, but S could, in principle, denote any complete separable metric space. Let denote the Borel -algebra on S. Let denote a probability space. A transition kernel from to is called a point process if
- For all the measure is locally finite.
- For all bounded sets the random variable is a count variable.
The interpretation is that if the outcome is then is a measure that counts how many points there are in various subsets of S, i.e., is the number of points in the set . Each measure will be called an instance of the point process. In the literature on point processes, one is often interested in simple point processes where when B is a singleton. However, point processes that are not simple are also crucial for the problems that will be discussed in this paper.
The definition of a point process follows the general structure of probability theory, where everything is based on a single underlying probability space. This will ensure consistency, but often this probability space has to be quite large if several point processes or many random variables are considered simultaneously.
The measure is called the expectation measure of the process if for any we have
The expectation measure gives the mean value of the number of points in the set B. Different point processes may have the same expectation measure.
A one-point process is a process that outputs precisely one point with probability 1. For a one-point process the expectation measure of the process is simply a probability measure on S. Thus, probability measures can be identified with one-point processes. It is possible to define a monad for point processes [12]. The monad defined in [12] is also related to the observation that the Giry monad is distributive over the multiset monad as discussed in [13]. These results are closely related to the results we will present in the following sections.
A point process can be thinned, meaning each point in an instance is kept or deleted according to some random procedure. We can do -thinning for by keeping a point in the sample with probability and deleting it from the sample with probability . This is done independently for each point in the sample. Thus is an -thinning of if
for any measurable set B. If is an -thinning of we write .
2.5. Poisson Distributions and Poisson Point Processes
For the Poisson distribution is the probability distribution on with point probabilities
The Poisson distribution may be viewed as a point process on a singleton set. The set of Poisson distributions is closed under addition and thinning.
For any locally finite measure on that has density with respect to the Lebesgue measure, can define a Poisson point process with intensity as a point process with expectation measure [[7] Chapter 3]. The following two properties characterize the Poisson point process.
- For all the random variable is Poisson distributed with mean value .
- If are disjoint, then the random variables and are independent.
The Equations (27) and (28) also hold if the numbers are replaced by measures. The following result was essentially proved by Rényi [14] and Kallenberg [15].
Theorem 2.
Let P be a unital measure and let be independent point processes with expectation measure . Then converges to in total variation.
2.6. Valuations
Until now, we have presented the results in terms of measure theory. For a more general theory, it is helpful to switch to from measures to valuations [16]. Any measure satisfies the following properties.
- Strictness
- .
- Monotonicity
- For all subsets , implies .
- Modularity
- For all subsets ,
For any lattice with a bottom element a valuation is defined as a function that satisfies strictness, monotony, and modularity. The notion of a valuation makes sense in any lattice with a bottom element.
We are mainly interested in valuations that are continuous in the following sense. The possible values of a valuation are lower reals in , which are elements in the set with a topology of lower bounded open intervals. Thus, a function into is continuous, if it is lower semicontinuous when the usual topology.
- Continuity
- for any directed net .
This notion of continuity captures both the inner regularity of a measure and it captures -additivity.
A Borel measure restricted to the open sets of a topological space is a valuation. On any complete separable metric space any continuous valuation on the open sets is the restriction of a Borel measure. It will not make any difference whether we speak of measures or valuations for the applications that we will discuss in Section 5
If X is a topological space, then denotes the set of continuous valuations on X. The set of valuations has a structure as a topological space, so that is an endofunctor in the category Top of topological spaces. The functor defines a monad that is called the extended probabilistic power domain [17]. It is defined in much the same way as the monads defined by Giry.
3. Observations
The outcome space plays a central role in Kolmogorov’s approach to probability. The basic experiment in his theory will result in a single point in the outcome space. The measurable subsets of the outcome space play the same role as the propositions play in a Boolean algebra in logic. The principle of excluded middle in logic states that any proposition is either true or false. Similarly, the basic experiment in Kolmogorov’s theory results in a single point, and these points exclude each other. In this paper, the result of a basic experiment will be a multiset rather than a single point.
3.1. Observations as Multiset Classifications
In computer science, we operate with different data types. A set is a collection of objects, where repetition and order are not relevant. A list is a collection of objects, where order and repetition are relevant. Multisets are unordered, but repetitions are relevant, so objects are counted with multiplicity. We shall discuss the relation between these data types in this subsection.
A review of the theory of multisets can be found in [18]. Monro [19] discusses two ways of defining a multiset, and the distinction between these definitions is important for the present work.
The following example is similar to what can be found in basic textbooks on statistics.
Example 1.
Consider a list of observations of five animals like . The list may be represented by a table with a number as a unique key that indicates the order in which we have made the observations. In the present example all the animals are different and if we are not interested in the order in which
we have made the observations, we may represent the observations by the set where the animals have been displayed in alphabetic order, but in a set the order does not matter.
| Key | Animal |
| 1 | cow |
| 2 | horse |
| 3 | bee |
| 4 | sheep |
| 5 | flie |
These animals can be classified as either mammals or insects, leading to the list of observations or, equivalently, to the table. Since the list contains repetitions, we cannot represent it by the set
. Instead, we may represent it by the multiset .
| Key | Animal |
| 1 | mammal |
| 2 | mammal |
| 3 | insect |
| 4 | mammal |
| 5 | insect |
According to the first definition of a multiset by Monro [19], a multiset is a set with an equivalence relation ≃. If denotes the set of equivalence classes, then we get a mapping . Alternatively, any mapping leads to equivalences classes on . Dedekind was the first to identify a multiset with a function [18]. To each equivalence class we assign the number of elements in the equivalence class. This is called the multiplicity of the equivalence class.
A category Mul with multisets as objects was defined by Monro [19]. An object in the category Mul is a set with an equivalence relation ≃. If and are objects in the category Mul, then a morphism from to is a mapping that respects the equivalence relations, i.e., if in then in . This category has been studied in more detail in [20].
An equivalence is often based on a partial preorder. Let ⪯ denote a partial preordering on . Then, an equivalence relation ≃ is defined by if and only and . If then ⪯ induces an ordering on , that we will also denote ⪯.
The downsets (hereditary sets) in form a distributive lattice with ∩ and ∪ as lattice operations. If the set is finite, then the lattice is finite, and if satisfies the decending chain condition (DCC) then so does the lattice of downsets. Any finite distributive lattice can be represented by a finite poset [[21] Thm. 9], and a distributive that satisfies DCC can be represented by a poset that satisfies DCC. There is a one-to-one correspondence between the elements of and the irreducible elements of the lattice. This construction can be viewed as a concept lattices [22] based on the partial ordering ⪯.
The partial preordering ⪯ is an equivalence relation if and only if the lattice generated is a Boolean lattice. Therefore, we get a lattice where one cannot form complements except if ⪯ is an equivalence relation. The shift from Boolean lattices to more general lattices corresponds to shifting from logic with a law of excluded middle to more general classification systems.
The set of downset in is closed under finite intersections and under arbitrary unions because any union is a finite union. Thus, the downsets in form a topology. The continuous functions for this topology are monotone functions for the ordering. Topological spaces and continuous functions form a category. If some of the equivalence classes in has more than one element, then the topology does not satisfy the separation condition , but the topology on equivalence classes always satisfies .
Multisets can also be described using -algebras as it is done in probability theory. A classification on given by an equivalence relation ≃ or by a partial preordering ⪯ leads to a topology on . This topology generates a Borel -algebra on . For any two outcomes we have if and only if for all Borel measurable sets B.
3.2. Observations as Empirical Measures
According to the second definition of a multiset discussed by Monro [19], a multiset is a mapping of a set into that gives the multiplicity of each of the elements. This corresponds to the data types in statistics that are called count data. Here, we will represent such multisets by finite empirical measures.
Example 2.
The list can be written as a multiset or, equivalently, we may represent the multiset by the measure . Alternatively, the multiset can be represented by a table of frequencies.
| Classification | Frequency |
| insect | 2 |
| mammal | 3 |
The mapping from lists to an empirical measure is called the accumulation map, and it is denoted .
Definition 2.
Let be a topological space. By afinite empirical measure, we understand a finite sum of Dirac measures on the Borel σ-algebra of . The set of finite empirical measures on will be denoted or for short.
With these definitions, is an endofunctor on the category Maes of measurable spaces.
When the notion of observation is based on an equivalence, there is an implicit assumption that any two elements each has its own identity, but at the same time, they are equivalent according to a classification. In quantum physics, particles may be indistinguishable in a way that one would not see in classical physics. The following example shows that there are data sets that the first definition of a multiset cannot handle.
Example 3.
Young’s experiment, also called the double slit experiment, was first used by Young as a strong argument for the wave-like nature of light. Nowadays, it is often taken as an illustration of how quantum physics fundamentally differs from classical physics. The observations are often described as a paradox, but at least part of the paradox is related to a wrong presentation of the observations.
In its modern form, the experiment uses monochromatic light from a laser. The laser beam is first sent through a slit in a screen. The electromagnetic wave spreads like concentric circles after passing through the first slit, as illustrated in Figure 1. The wave then hits a second screen with two slits. After passing the two slits we get two waves that spread like concentric circles until they hit a photographic film that will display an interference pattern created by the two waves.
Now follows a "paradox" as it is described in many textbooks. The electromagnetic wave is quantized into photons, so if the intensity of the light is low we will only get separate points on the photographic film, but we get the same interference pattern as before. This may be explained as interference between photons passing through the left and the right slit respectively. Now we lower the intensity so much that the photons arrive at the photographic film one by one. After a long time of exposure, we get the same interference pattern as before. This apparently gives a paradox because it is hard to understand how a single photon should pass through both slits and have interference with itself.
A problem with the above description is that the number of photons emitted from a laser is described by a Poisson point process. Even if the intensity is low, one cannot emit a single photon for sure. If the mean number of photons emitted is say 1 then there is still a probability that 0 or 2 (or more) photons are emitted and this will hold even if the intensity is very low. What we observe is a number of dots on the photographic film, which can be described as by a multiset if the photographic film is divided into regions. If we really want to send single photons, it could be done using a single-photon source. For a single-photon source there is no uncertainty in the number of photons emitted, but according to the time-energy uncertainty relation there will still be uncertainty in the energy. The energy E of a photon is given by
where h is Planck’s constant, f is the frequency, c is the speed of light, and λ is the wave length. Thus, uncertainty in the energy means uncertainty in frequency and wave length. Since the interference pattern observed on the photographic film depends on the wave length, one would not get the same interference pattern if a single-photon emitter was used instead of coherent light from a laser.
We see that the idea that the observation in terms of a multiset comes from observation of a large number of individual photons is simply wrong and leads to an inconsistent description of the experiment.
We can do the following operations with empirical measures.
- Addition.
- Restriction.
- Inducing.
The first operation we will look at is addition. Let and denote two lists of observations from the same alphabet , and let denote the concatenation of the lists. Then . Thus, the sum of two empirical measures has an interpretation via merging two datasets together. The corresponding operation for point processes is called superposition. Addition of empirical measures is a way of obtaining an empirical measure without using the accumulation map on a single list.
The next operation we will look at is restriction. If data is described by the empirical measure on and B is a subset of then the restriction of to subsets of B is an empirical measure on B that we will denote by . In probability theory all measures should be unital so we need the notion of conditional probability, but multisets cannot be normalized, and the concept simplifies to the notion of restriction.
Assume that is a continuous (or measurable) mapping. Then the induced measure is defined by
where is an empirical measure on and B is a measurable subset of . The measure is called the induced measure and is often denoted rather than .
One can easily prove that inducing is additive in the measure and similar basic results regarding the interaction between addition, restriction and creation of induced measures.
3.3. Categorical Properties of the Empirical Measures and Some Generalizations
Addition, restriction, and inducing can be described in the language of category theory. The existence of addition means that the category of multisets is commutative. Restriction can be characterized as a retraction that is additive. The existence of induced measures means that is a functor from topological spaces to measure spaces.
If is a topological space, then we equip with the smallest topology such that
are continuous for all continuous functions f. Here, the integral simplifies to a sum when . If we define then becomes an endofunctor in the category of topological spaces and a monad can be defined in exactly the same way as for the Giry monad. Kleisli morphisms map points in a topological space into empirical measures on the topological space. Empirical measures will often be denoted in order to emphasize that an empirical measure typically is the results of some sampling process.
One can generalize finite empirical measures on a topological space to continuous integer valued valuations on a topological space. These integer valued valuations form a sub-monad of the monad of all continuous valuations.
As we have seen in Section 3.1 classifications may lead to other lattices than Boolean lattices, so it is relevant to discuss integer-valued valuations on more general distributive lattices. We shall work out the theory for finite lattices in all details below. If is a finite topological space, then we can define an integer-valued valuation v on the topology by
where means the number of elements in the open set .
Lemma 1.
Let v be a continuous valuation on a topological space . Let be some element. Then the restriction given by is an integer valued valuation. If then given by is also an integer valued valuation and . If v is continuous, then and are continuous.
Proof.
The strictness of and are obvious. The monotonicity of is obvious. To see that is monotone, let be some elements in the lattice. Then
Modularity of is a simple calculation. Modularity of follows because . Continuity is obvious. □
Let v denote a valuation on a topological space . Then is called an atom of the valuation if implies that or . An atomic valuation is a valuation that is a sum of valuations for which L is an atom.
Proposition 1.
Any integer valued valuation on a topological space is atomic.
Proof.
The proof is by induction on . First, the results hold for the trivial valuation with . Assume that the result holds for any valuation with . Let v be a valuation with . If L is an atom, then v is atomic. If is not an atom, then there exists such that . Then and are atomic valuations and implying that v is atomic. □
Theorem 3.
Let denote a finite topological space. If the topology satisfies the separation condition , then for any integer valued valuation v on the lattice of open sets there exists a uniquely determined empirical measure μ on such that for any open set B we have
Proof.
We have to prove that if is an atom for the valuation v, then v is given by a uniquely determined Dirac valuation. Let A denote a minimal atom. Then
For let denote the smallest open set that contains a. Then there must exist such that , since, otherwise, one would have Hence we have , which implies that . Hence,
Assume that . Then, for all open sets B. Hence, if and only if . Since the topology satisfies , we must have . □
As a consequence of the theorem, any integer-valued valuation v on a finite distributive lattice can be represented by a finite set with a topology such that the multiset obtained by mapping to equivalence classes satisfies (33).
For applications in statistics, the main example of a lattice is the topology of a complete separable metric space.
Theorem 4.
Let μ denote an integer valued valuation on the topology of a complete separable metric space. Then μ is a simple valuation, i.e., there exists integers and letters such that
Proof.
Based on a result of Topsøe [[23] Thm. 3] Manilla has proved that any valuation on the topology of a metric space can be extended to a measure on the -algebra of Borel sets of the metric space [[24] Cor. 4.5]. When the metric space is separable and complete, we may, without loss of generality, assume that the metric space is and let denote the identity on . Then is increasing and integer-valued. Therefore, F is a staircase function with a finite number of steps. The measure P will have a point mass at each step and no mass in between. Hence, is simple. □
3.4. Lossless Compression of Data
Bayesian statistics focus on single outcomes of experiments and the frequentist interpretation focus on infinite i.i.d. sequences. Information theory takes a position in between. In information theory, the focus is on extendable sequences rather than on finite or infinite sequences [25]. In lossless source coding, we consider a sequence of observations in the source alphabet , i.e., an observation is an element in where n is some natural number. We want to encode the letters in the source alphabet by sequences of letters in an output alphabet of length . In lossless coding, the encoding should be uniquely decodable. Further, the encoding should be so that as concatenation of source letters is encoded as the corresponding concatenation of output letters. We require that not only is uniquely decodable, but any (finite) string in should be encoded into a string in in a unique way. If the code is uniquely decodable then it satisfies Kraft’s inequality
where denotes the length of the code word [[26] Thm. 5.2.1]. Instead of encoding single letters in into we may do it as block coding where a block in is mapped as a string via a mapping . The following theorem is a kind of reverse of Kraft’s inequality for block coding.
Theorem 5
Using this theorem, we can identify uniquely decodable codes with code length functions that satisfy Kraft’s inequality. There is a correspondence between codes and sub-unital measures given by
Now, the goal in lossless source coding is to code with a code-length that is as short as possible. If a code word has empirical measure and the function ℓ is used then the total code length is
Our goal is to minimize the total code length and this is achieved by the code length function
If a code with this code length function is used then the total code length will be where H denotes the Shannon entropy of a probability measure. We can define the entropy of any finite discrete measure by
With this definition one can easily prove that if is a measurable mapping and is a measure on then the following chain rule holds
The chain rule reflects that coding the result in can be done by first coding the result in and then code the result in restricted to subset of letters in that maps into the observed letter in .
One could proceed on exploring the correspondence between measures and codes as is done in the minimum description length (MDL) approach to statistics, and much of the content of Section 4 could be treated as using MDL. For instance, the number of source letters of length n is and it grows exponentially, but the number of different multisets of size n is upper bounded by and it grows like a polynomial in n. This fact has important consequences related to the maximum entropy principle and in the information theory literature [27] it is called the method of types where type is another word for multiset.
In order to emphasize the distinction between probability measures and expectation measures, we will not elaborate on this approach in the present exposition. Here we will just emphasize that Kraft’s inequality and Equations (46) are some of the few examples where a theorem states that unital measure play a special role beyond the fact that all finite measures can be normalized.
3.5. Lossy Compression of Data
If an information source is compressed to a rate below the entropy of the source letter cannot be reconstructed from the output letters. In this case one will experience a loss in description of the source and methods for minimizing the loss are handled by rate distortion theory. In rate distortion theory, we introduce a distortion function that quantified how much is lost if was sent, and it was reconstructed as . If then d may be a metric or a function of a metric. As demonstrated in the papers [28,29,30] many aspects of statistical analysis can be handled by rate distortion theory. This involves cluster analysis, outlier detection, testing Goodness-of-Fit, estimation, and regression. Important aspects of statistics can be treated using rate distortion theory, but in order to keep the focus on the distinction between probability measures and expectation measures, we will not go into further details regarding rate distortion theory.
4. Expectations
Multisets, empirical measures, and integer valued valuations are excellent for descriptive statistics, but these concepts neither describe randomness, sampling, nor expectations. In this section, we will discuss more general categories where these concepts are incorporated.
4.1. Simple Expectation Measures
Let denote a large outcome space and let denote the empirical measure on the set if the outcome is . The empirical measure can be described as a list of frequencies or as a multiset. Assume that the size of the multiset is . The measure may describe a sample from a population, but it may also describe the whole population, in which case the subscript is not needed. In modern statistics various resampling techniques play an important role, and for this reason we will keep the subscript in order both to describe sampling and resamling. Now we take a sample of size n from the population.
The simplest situation is when . If then is the probability that a randomly selected point from the multiset described by belongs to B. The unital measure is the empirical distribution. The empirical measure gives a table of frequencies and the empirical distribution gives a table of relative frequencies.
Next, consider the situation when we take a sample of size from the population. There are different ways of taking a sample of size n. One may sample with replacement or without replacement. These two basic sampling schemes are described by the multinomial distribution and by the multivariate hyper-geometric distribution respectively. For both sampling methods, the mean number of observations in a set B is given by . Thus, the expected values are described by the measure where . Here we have scaled the measure by a factor , and this leads to a measure that is not given by a multiset.
Consider a sample described by an empirical measure with sample size . For cross validation, we may randomly partition the sample into a number of subsamples. One may then check if a conclusion based on a statistical analysis of one of the subsamples is the same as if another subsample had been taken. If there are k random subsamples, then the expected number of observations in B is and the random subsample may be described by the measure where .
In bootstrap re-sampling one selects n objects from a sample of size n but this is done with replacement. If the sample is described by the measure , then the mean number of observations in B is . Thus, bootstrap re-sampling corresponds to the measure where . We see that although multiplying by 1 does not change the measure, it may reflect a non-trivial re-sampling procedure.
In general, we may perform -thinning of a multiset. This is done by keeping each point with probability and deleting it with probability . The preservation/deletion of observations is done independently for each observation. For values of in we can implement -thinning using a random number generator that gives a uniform distribution on a finite set. Such random numbers can be created by rolling a die, draw a card from a deck, or a similar physical procedure. The set is not complete, which is inconvenient for formulating various theorems. Therefore, we will also allow irrational values of so that can assume any value in .
We discussed addition of measures in the previous section. In particular, we may add n copies of the measure together to obtain the measure . Then we may sample from by thinning by some factor so that we obtain the measure . In this way, we may multiply a measure by any positive number. In general, there will be many different ways of implementing a multiplication by the positive number t:
- There are many ways of writing t as a product where and n is an integer.
- There are many different sampling schemes that will lead to a multiplication be .
- There are many ways of generating the randomness that is needed to perform the sampling.
Although there are many ways of implementing a multiplication of the measure by the number , it is often sufficient to know the resulting measure rather than details about how the multiplication is implemented. In Section 4.3 we will introduce a kind of default way of implementing the multiplication.
By allowing multiplication by positive numbers we can obtain any finite measure concentrated on a finite set, i.e., measures of the form
The set is defined as the finitely supported finite measures on . The finitely supported finite measures are related to the empirical measures in exactly the same way as probability measures are related to truth assignment functions in logic.
4.2. Categorical Properties of the Expectation Measures and Some Generalizations
We want to study a monad that allow us to work with both empirical measures and unital measures as done in probability theory. The set is defined as the finitely supported finite measures on . If is a probability measure and the outcome space is then is formally a point process with points in . The expectation measure of the point process is given by to by
By linearity the transformation defined by Equations (50) extends to a natural transformation from to .
As before, we let denote the natural transformation that maps into , i.e., the Dirac measure concentrated in a. It is straight forward to check that forms a monad. The Kleisli morphisms generated by this monad will generate a category that we will call the finite expectation category, and we will denote it by Fin.
Finite lattices can be represented by finite topological spaces, and for these spaces the theory is simple.
Theorem 6.
Let denote a finite topological space. If the topology satisfies the separation condition , then for any finite valuation v on τ there exists a finite expectation measure μ on the Borel σ-algebra such that for any open set B we have
Proof.
The proof is an almost a word by word repetition of the proof of Theorem 3. □
All finite expectation measures are continuous valuations on a topological space. The monad of continuous valuations on topological spaces is important because it includes all probability measures on complete separable metric spaces, that is the most used model in probability theory.
4.3. The Poisson Interpretation
Let denote a discrete measure such that
where . Then the Poisson point process given by the product
is a point process with expectation measure . Thus, any discrete measure has an interpretation as the expectation measure of a discrete Poisson point process (see Section 2.5). This interpretation will be called the Poisson interpretation, and it can be used to translate properties and results for (non-unital) expectation measure into properties and results for probability measures.
A. Rényi was the first to point out that a Poisson process has extreme properties related to information theory [31] and entropy for point processes were later studied by Mc Fadden [32]. Their results were formulated for simple point processes. Here we will look at some results for processes supported on a finite number of points. If we thin a one-point process, We will get a process given by the expectation measure where and is the void probability, i.e., the probability of getting no point. Here we shall just present two results that are generalizations of similar results in [33,34,35]. We say that a point process is a multinomial sum if it is a sum of independent thinned one point processes. Let denote the set of sums of independent thinned one-point processes with expectation measure and let denote the total variation closure of . As a consequence of Theorem 2 the distribution lies in . The following results can be proved in the same way as a corresponding result in [33] was proved.
Theorem 7.
The maximum entropy process in is the Poisson point process
The following result states that a homogeneous process has greater entropy than an inhomogeneous process with the same mean number of points. This is a point process version of the result that the uniform distribution is the distribution with maximal entropy on a finite set.
Theorem 8.
Let be a set with m elements. Then the Poisson point process that has maximum entropy under the condition that , is the process where for all .
Proof.
We note that
so it is sufficient to prove that the sum is Shur concave under the condition that
Let and let then
where means the binomial distribution with number parameter n and success probability p. For a fixed value of we have to maximize . The maximum is achieved when , i.e., . To see that is maximal for it is sufficient to note that is a concave function which follows from [36]. □
The Poisson interpretation does not only work for finite expectation measure. The following result is relevant for valuations on topological spaces.
Theorem 9.
Let μ denote a σ-finite measure on a complete separable metric space. Then μ is an expectation measure of a Poisson point process.
Proof.
Since the measure is -finite, it can be written as , where is a finite measure for all i. Each can be written as a sum of a discrete measure and a continuous measure. The discrete measure is the expectation measure of a discrete product of Poisson distributions. The continuous measure is the expectation measure of a Poisson point process. Each of these are examples of simple Poisson point processes. The result follows because a countable sum of Poisson point processes is a Poisson random process. □
It is also possible to construct Poisson point processes on finite topological spaces.
Theorem 10.
Let v denote a valuation on the topology of a finite set . Assume that the topology satisfies the separation condition . Then there exists an outcome space Ω with a probability measure P and a transition kernel from Ω to such that
- is Poisson distributed for any open set B.
- For any open sets the random variable is independent of the random variable given the random variable if and only if .
Further for any open set B we have
Proof.
First we determine the measure on such that for any open set B. Then we construct independent Poisson distributed random variables such that . Then, for any open set B, we define a random variable
With these definitions
The conditional independence follows from the construction. □
It is worth noting that for any lattice, the relation defines a separoid relation (abstract notion of independence) if and only the lattice is distributive. For a distributive lattice the relation can also be written as , and this relation is separoid if and only the lattice is modular (see [37] and [38] Cor. 2].
4.4. Normalization, Conditioning and Other Operations on Expectation Measures
Empirical measures can be added, one can take restrictions and one can find induced measures. Using the same formulas these operations can be performed on expectation measures, but we are not only interested in the formulas but also in probabilistic interpretations.
First we note that any -finite measure is the expectation measure of some point process. Assume that for some finite measures . Then
where are finite measures. Thus, is a probabilistic mixture of finite measures. Therefore, we just have to prove that any finite measure is the expectation measure of a point process. The normalized measure has an interpretation as a probability measure, which is the same as a one-point process. We may add n copies of this process to obtain a process with expectation measure . If , then this process can be thinned to get a process with expectation measure . The following proposition gives probabilistic interpretations of addition, restriction, and inducing for expectation measures via the same operations applied to empirical measures. These equations are proved by simple calculations.
Proposition 2.
Let be a probability space. Let and denote point processes with expectation measures μ and ν and with points in . Let A be a subset of and let be some mapping. Then
respectively.
If is an expectation measure on the set , then is a unital measure that we will call the normalized measure. Unital measures are normally called probability measures, and our aim is to give a probabilistic interpretation of the normalized measure by specifying an event that has probability equal to .
Theorem 11.
Let B be a subset of . Let P denote a probability measure on Ω and assume that is a Poisson point process with expectation measure μ. Then
Proof.
We take the mean of the empirical distribution with respect to P.
Now the random variable is Poisson distributed with mean and the random variable is Poisson distributed with mean and these two random variables are independent. When we condition on the distribution of is binomial with mean . Hence
□
The theorem states that is the probability of observing a point in B if one first observe a multiset of points as an instance of a point process and then randomly select one of the points from the multiset. This is not very different from random matrix theory, where one first calculate all eigenvalues of a random matrix and then randomly selected one of the eigenvalues. Wigner’s semicircular law states that such a randomly selected eigenvalue from a large random matrix has a distribution that approximately follows a semicircular law.
Proposition 2 holds for all point processes, but in Theorem 11 it is required that the point process is a Poisson point process. The following example shows there are point processes where Equations (63) does not hold.
Example 4.
The Poisson interpretation of normalized expectation measures carries over to conditional measures.
Corollary 1.
Let P denote a probability measure on Ω and assume that is a Poisson point process with expectation measure μ. Let A and B be subsets of with . Then
Proof.
A conditional measure is the normalization of an expectation measure restricted to a subset.
The corollary is proved by applying Theorem 11 to the measure . The condition will ensure that . □
Let be an expectation measure on and let g be a map from to . Then the induced measure is also an expectation measure. If then a Markov kernel from to is given by
With this Markov kernel the measure can be factored as
4.5. Independence
The notion of independence plays an important role in the theory of randomness, so we need to define this notion in the context of expectation measures.
Definition 3.
Assume that μ is a measure on . For let denote the mappings . Then we say that is independent of if does not depend on .
Theorem 12.
Let μ be a measure on with projections and . Then is independent of if and only if
where and are the marginal measures on and respectively.
Proof.
We have
Let denote the unital measure on given by . Then
□
Note that Equations (72) is the standard way of calculating expected counts in a contingency table under the assumption of independence. Note also that Equations (72) can be rewritten as
which is the well-known equation that states that for independent variables the joint probability is the product of the marginal probabilities.
4.6. Information Divergence for Expectation Measures
Let P and Q be discrete probability measures. Then Kullback-Leibler divergence is defined by
For arbitrary discrete measures and we define information divergence by extending Equations (78) via the following formula
With this definition information divergence becomes a Csiszár f-divergence, and it gives a continuous function from the cones of discrete measures to the lower reals .
Proposition 3.
Let μ and ν denote two finite measures. Then
Note that on the left-hand side is a KL-divergence for probability measures, while the right-hand side is an information divergence for expectation measures.
Proof.
First assume that the outcome space is a singleton so that and are elements in . Then
The results follows because KL-divergence is additive on product measures. □
Information divergence is a Csiszár f-divergence, but it is also a Bregman divergence defined on the cone of discrete measures, and except for a constant factor it is the only Bregman divergence that is also a Csiszár f-divergence. On an alphabet with at least three letters KL-divergence may (except for a constant factor) also be characterized as the only Bregman divergence that satisfies a data processing inequality for Markov kernels of unital measures, and there are a number of equivalent characterizations [39], if the alphabet has at least three letters. Here we focus on the convex cone of measures rather than the simplex of probability measures. Therefore it is interesting to note that information divergence has a characterization on a one letter alphabet as a Bregman divergence that satisfies the following property called 1-homogenuity.
Theorem 13.
Assume that is a function that satisfies the following conditions.
- with equality when
- is minimal when
- for all
Then there exists a positive constant c such that
Proof.
The first two conditions imply that d is a Bregman divergence [39] Proposition 4]so there exists a strictly convex function g such that According to property 3. we have
We differentiate with respect to y and get
This holds for all so for some constant
for some constant Hence
□
Theorem 14.
Let P be a Bernoulli sum on with expectation measure . Then
for .
Let denote a convex set of measures. Then is defined as . If and the measure satisfies then is called the information projection of on [40,41,42].
Proposition 4.
Let ν be a measure of a finite alphabet , and let be a convex set of measures on . If is the information projection of ν on then is the information projection of on the convex hull of the probability measures of the form where .
Proof.
The measure is the information projection of if and only if the following Pythagorean inequality
is satisfied for all [[42] Theorem 8]. Now we have
Since a Pythagorean inequality is satisfied for , it must be the information projection of on the convex hull of the distributions where . □
The reversed information projection is defined similar to the definition of the information projection [2,43,44,45]. If is a convex set, then is defined as . If then is said to be the reversed information projection of on if .
Proposition 5.
Let μ be a measure of a finite alphabet , and let be a convex set of measures on . Assume that and that Then the probability measure is the reverse information projection of on the convex hull of the set of probability measures .
Proof.
According to the so-called four point property by Csiszár and Tusnády [43] the measure is the reverse information projection of on if and only if
for all in . The probability measure has outcome space . For we will write as short for . We calculate
Therefore
for all . □
5. Applications
In this section we will present some examples of how expectation measures can be used to give a new way to handle some problems from statistics and probability theory.
5.1. Goodness-of-Fit Tests
Here we will take a new look at testing Good-of-Fit in one of the simplest possible setups. We will test if a coin is fair, and we perform an experiment where we count the number of heads and tails after tossing the coin a number of times. Let X denote the number of heads and let Y denote the number of tails. Our null hypothesis is that there is symmetry between heads and tails. Here we will analyze the case when we have observed and .
Typically, one will fix the number of tosses so that , and assume that X has a binomial distribution with success probability First we will look at an example where the null hypothesis states that and .
The maximum likelihood estimate of p is The divergence is
We introduce the signed log-likelihood as
so that
In [[46] Cor 7.2] it is proved that
where denotes the distribution function of a standard Gaussian distribution. A QQ plot with a Gaussian distribution on the first axis and the distribution of on the second axis one gets a staircase function with horizontal steps each intersecting the line corresponding to a perfect match between the distribution of and a standard Gaussian distribution as illustrated in Figure 2.
Instead of using the Gaussian approximation one could calculate tail probabilities exactly (Fisher’s exact test), but as we shall see below one can even do better.
In expectation theory, it is more natural to assume that X and Y are independent Poisson distributed random variables with mean values and respectively. In our analysis, the null hypothesis states that
Since the maximum likelihood estimate of is Hence the estimate of and are Here we define the random variable and We calculate the divergence
i.e., the same expression as in the classical analysis. Since X is binomial given that we have
Since the distribution of is close to a standard Gaussian distribution under the condition the same is true for when we take the mean value over the Poisson distributed variable Since each of the steps intersects the straight line near the mid-point of the step the effect of taking the mean value with respect to N is that the steps to a large extent cancel out as illustrated in Figure 3.
The only step that partly survive the randomization is the step . For the binomial distribution, the length of this step is determined by . If the sample size is Poisson distributed then the length of the step is determined as
which is about half of the value for the binomial distribution. The reason for this is that the probability that a Poisson distributed random variable is even is approximately . If we tested we would get a step of length about one third of the corresponding step for the binomial distribution. In a sense, testing gives the most significant deviation from a Gaussian distribution.
If we square , we get 2 times divergence, which is often called the -statistic. Due to symmetry between head and tail, the intersection property is also satisfied when the distribution of the -statistic is compared with a -distribution [47]. This is illustrated in Figure 4.
For statistical analysis, one should not fix the sample size before sampling. A better procedure is to sample for a specific time so that the sample size becomes a random variable. In practice, this is often how sampling takes place and if the sample size is really random, it may even be misleading to analyze data as if n was fixed.
5.2. Improper Prior Distributions
Prior distributions play a major role in Bayesian statistics. A detailed discussion about how prior distributions can be determined in various cases is beyond the topic of this article. We will refer to [49] for a review of the subject including a long list of references. See [50] for a more information theoretic treatment of prior distributions.
In Bayesian statistics, a justification of how posterior distributions are calculated is normally based on a probabilistic interpretation of the prior distribution. It is well-known that proportional prior distributions will lead to the same posterior distribution. For this reason the total weight of the prior distribution is not important as long as the total weight is finite. With a finite total weight the total weight can always be normalized in order to obtain a unital measure, and unital measures allow a probabilistic interpretation within Bayesian statistics. A significant problem in Bayesian statistics is the use of improper prior distributions, i.e., prior distributions described by measures with infinite total mass. Such a prior is problematic in that it does not allow a literal interpretation in Bayesian statistics. If we replace probability measures by expectation measures, this problem disappears. We will just give a simple example of how improper prior distributions can be given probabilistic interpretation using the Poisson interpretation of expectation measures.
Consider a statistical model where a random variable X has distribution given by the Markov kernel
We assume that the mean value parameter is integer valued. We choose the counting measure times on as an improper prior distribution for the mean value parameter. There are a number of ways or arguing in favor of this prior distribution. For instance the counting measure is invariant under integer translations. Except for a multiplicative constant translation invariance uniquely determines the prior measure as a Haar measure. Combining times the counting measure on with the Markov kernel (107) we get a joint measure on supported on the points illustrated in Figure 6.
Each point supporting the joint measure will have weight . The marginal measure on X is times the counting measure on as discussed in Section 4.4. Now the joint measure can be factored into times the counting measure on and a Markov kernel
The Markov kernel (108) can be considered as the posterior distribution of M given that
These calculations can be justified within a probabilistic setting via point processes. First, the prior is represented by a Poisson point process with times the counting measure on as expectation measure. If the Markov kernel (107) is applied to this process, then we obtain a Poisson point process on the points in illustrated in Figure 6 with times the counting measure as expectation measure. For an instance of this joint point process let denote the number of points with x as second coordinate. We will condition on so we will assume that Among these n points that all have second coordinate equal to x, we choose a random point according to a uniform distribution, i.e., each point is selected with probability The selected point has coordinates where We want to calculate the distribution of M for a given value of According to Corollary 1 we get and this is our posterior distribution.
This derivation works for any value of In particular we will get the same result if we thin the process by a factor i.e., if we replace by The derivation involves selecting 1 out of points under the condition that If we have
for Therefore, with high probability there will only be one point that has second coordinate x if the point process has been thinned with a small value of . Hence, the step, where we randomly select one of the points, becomes almost obsolete if we thinned the process sufficiently.
If the Poisson point process is a process in time, then there will be a first point for which and the probability of will be the probability that this first point satisfies . With a process in time, one can introduce a stopping time that stops the process when has been observed for the first time. This often simplifies the interpretation, but exactly this kind of reasoning goes wrong in many presentations of the double-slit experiment (Example 3). In this experiment, the point process is not a process in time because no arrival times for the photons are recorded. If one had precise records of time, the uncertainty for energy and frequency would destroy the interference pattern.
5.3. Markov Chains
The idea of randomizing the sample size has various consequences, and sometimes this leads to great simplifications. Let denote some Markov operator that generates a Markov chain. The time average is usually defined as
Many properties of such time averages are known, but what complicates the matter is that the composition of and is not a time average. If we instead define
then is a Markov operator and . The Markov operators generate a Markov process in continuous time, and this Markov process tend to have better properties than the original Markov chain. For instance, all recurrent states under get positive transition probabilities under . The same idea was also used in [51] to prove that if is an affine map of a convex body into itself, then converges to a retraction of the convex body to the set of fix points of the affine map . Many theorems in probability involving averages should be revisited to see what the consequences are if the usual average is replaced by taking a weighted average with Poisson distributed weights.
5.4. Inequalities for Information Projections
Let be a unital measure on a finite set and let C denote the convex set of unital measures such that the mean value of is . Then the information projection P of Q on C can be determined by using Lagrange multipliers.
The moment generating function is defined by and in order to get a unital measure we shall choose . Thus, P is element in the exponential family
The mean value is and should be chosen so that this equals .
If we drop the condition that the projection should be unital, we get simplified expressions. The Lagrange equation becomes
and the mean value of this measure is .
Theorem 15.
Let Q be a unital measure on a finite set and let X be a random variable such that
Then there exists such that
for all measures satisfying
Proof.
For a fixed value of the right-hand side is minimized for the distribution determined by (117), so it is sufficient to prove the inequality for . Thus, we have to prove that
for for some . We differentiate both side, and it is sufficient to prove that
because . We differentiate once more, and we have to prove that
Now we differentiate one more time, and we have to prove that
for but this holds by continuity because . □
Similar results hold for measures on infinite sets, but in these cases one should be careful to choose the parameters so that the information projection exists. In a number of important cases, the inequality above may be extended to all positive (or negative) values rather than positive (or negative) values in a neighborhood of zero. Some of these cases are mentioned below.
Hypergeometric distributions can be approximated by binomial distributions. A lower bound is given by the following inequality [52].
where is the second normalized Kravchuk polynomial. For hypergeometric distribution with this lower bound can be written as
As demonstrated in [52] this lower bound is tight for fixed values of n and p and large values of the parameters N and K.
Binomial distributions can be approximated by Poisson distributions. For any distribution P we have the following lower bound on information divergence.
where denotes the second normalized Poisson-Charlier polynomial [53]. If P is binomial and then we get the inequality
and this inequality is tight for fixed and n tending to infinity [35,54,55,56].
In the central limit theorem the rate of convergence is primarily determined by the skewness and if the skewness is zero it is primarily determined by the excess kurtosis. If the skewness is non-zero then lower bounds on divergence involve both skewness and kurtosis, so for simplicity we will only present the case where the skewness is zero and the excess kurtosis is negative. For all measures P for which the integral where denotes the fourth normalized Hermite polynomial, we have
If P is a unital measure with variance excess kurtosis then according to [[57] Theorem 7] this inequality reduces to
Lower bounds for the rate of convergence have been discussed in the papers [57,58,59,57] where this and similar inequalities were treated in great detail.
For all these inequalities, it gives simplifications if we do not require that the measures are unital. The hard part is to prove that the inequalities do not only hold in a neighborhood of zero, but that they hold for all values of interest. This hard part of the proofs is still hard without the assumption that the measures are unital, but it should be noted that the hard part is not relevant if we are only interested in lower bounds on the rate of convergence.
6. Discussion and Conclusions
Expectation theory may be considered an alternative to Kolmogorov’s theory of probability. Still, it may be better to view the two theories as two ways of describing the same situations using measure theory. The language of probability theory focuses on experiments where a single outcome is classified according to mutually exclusive classes. The language of expectation theory focuses on experiments where the results are given as tables of frequencies. There will be no inconsistency if the two languages are mixed. Expectation measures can be understood within probability theory, as is already the case in the theory of point processes. If our understanding of randomness is based on expectation measures, then an expectation measure can be interpreted as the expectation measure of a process in a larger outcome space.
In this paper we have only worked out the basic framework and interpretation of expectation theory. This opens up a lot of new research questions. For instance, it should be possible to justify the use of Haar measures as prior distributions rigorously in the same way as Haar probability measures on compact groups can be justified as being probability measures that maximize the rate-distortion function [60]. In expectation theory, it is natural to consider sampling with a randomized sample size. Since many results in probability theory are formulated for fixed sample sizes there is a lot of work to be done to generalize the results to cases with random sample sizes. Our present results suggest that simpler or stronger results can be obtained, but in many cases new techniques may be needed.
In this paper, we discussed finite expectation measures and valuations on topological spaces and downsets of posets that satisfy the DCC. The valuation approach is more general, but it is an open research question which category is most useful for further development of expectation theory.
Quantum information theory can be based on generalized probabilistic theories. In these theories a measurement is defined as something that maps a preparation into a probability measure. A state is defined as an equivalence classes of preparations that cannot be distinguished be any measurement. With a shift from probability measures to expectation measures one should similarly change the focus in quantum theory from states that are represented by density operators (positive operators with trace 1) to positive trace class operators. Thus, the focus should shift from the convex state space to the state cone. For applications in quantum information theory it is still too early to say what the impact will be, but shifting the focus away from mutually exclusive events may circumvent some of the paradoxes that have haunted the foundation of quantum theory for more than a century.
Below there is a list of concepts from probability theory and standard quantum information theory and how they relate to the concepts that have been introduced in the present paper.
| Probability theory | Expectation theory |
| Probability | Expected value |
| Outcome | Instance |
| Outcome space | Multiset monad |
| P-value | E-Value |
| Probability measure | Expectation measure |
| Binomial distribution | Poisson distribution |
| Density | Intensity |
| Bernoulli random variable | Count variable |
| Empirical distribution | Empirical measure |
| KL-divergence | Information divergence |
| Uniform distribution | Poisson point process |
| State space | State cone |
Funding
This research received no external funding.
Acknowledgments
I want to thank Peter Grünwald and Tyron Lardy for stimulating discussions related to this topic.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| bin | binomial distribution |
| DCC | decending chain condition |
| E-statistic | Evidence statistic |
| E-value | Observed value of an E-statistic |
| hyp | Hypergeometric distribution |
| IID | Independent identically distributed |
| KL-divergence | Information divergence restricted to probability measures |
| MDL | Minimum description length |
| Mset | Multiset |
| N | Gaussian distribution |
| PM | Probability measure |
| Po | Poisson distribution |
| mset | Multiset |
| Poset | Partially ordered set |
| Pr | Probability |
References
- Kolmogorov, A.N. Grundbegriffe der Wahrscheinlichkeitsrechnung; Springer: Berlin, 1933. [Google Scholar]
- Lardy, T.; Grünwald, P.; Harremoës, P. Reverse Information Projections and Optimal E-statistics. IEEE Transactions on Information Theory 2024. [Google Scholar] [CrossRef]
- Perrone, P. Categorical Probability and Stochastic Dominance in Metric Spaces. phdthesis, Max Planck, Institute for Mathematics in the Sciences. 2018. [Google Scholar]
- nLab authors. monads of probability, measures, and valuations. Revision 45. 2024. Available online: https://ncatlab.org/nlab/show/monads+of+probability%2C+measures%2C+and+valuations.
- Shiryaev, A.N. Probability; Springer: New York, 1996. [Google Scholar]
- Whittle, P. Probability via Expectation, 3 ed.; Springer texts in statistics; Springer Verlag: New York, 1992. [Google Scholar]
- Kallenberg, O. Random Measures; Springer: Schwitzerland, 2017. [Google Scholar] [CrossRef]
- Lawvere. The Category of Probabilistic Mappings. Lecture notes.
- Scibior, A.; Z..; Ghahramani.; Gordon, A.D. Practical probabilistic programming with monads. In Proceedings of the 2015 ACM SIGPLAN Symposium on Haskell; Association for Computing Machinery: New York, NY, USA, 2015; Haskell ’15; pp. 165–176. [Google Scholar] [CrossRef]
- Giry, M. A categorical approach to probability theory. Categorical Aspects of Topology and Analysis; Banaschewski, B., Ed.; Springer Berlin Heidelberg: Berlin, Heidelberg, 1982; pp. 68–85. [Google Scholar]
- Lieshout, M.V. Spatial Point Process Theory. In Handbook of Spatial Statistics; Handbooks of Modern Statistical Methods; Chapman and Hall, 2010; chapter 16. [Google Scholar]
- Dash, S.; Staton, S. A Monad for Probabilistic Point Processes; ACT, 2021. [Google Scholar]
- Jacobs, B. From Multisets over Distributions to Distributions over Multisets. Proceedings of the 36th Annual ACM/IEEE Symposium on Logic in Computer Science; Association for Computing Machinery: New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- Rényi, A. A characterization of Poisson processes. Magyar Tud. Akad. Mat. Kutaló Int. Közl. 1956, 1, 519–527. [Google Scholar]
- Kallenberg, O. Limits of Compound and Thinned Point Processes. Journal of Applied Probability 12, 269–278. [CrossRef]
- nLab authors. valuation (measure theory). 2024. Available online: https://ncatlab.org/nlab/show/valuation+%28measure+theory%29.
- Heckmann, R. Spaces of valuations. In Papers on General Topology and Applications; New York Academy of Sciences, 1996. [Google Scholar] [CrossRef]
- Blizard, W.D. The development of multiset theory. Modern Logic 1991, 1, 319–352. [Google Scholar]
- Monro, G.P. The Concept of Multiset. Mathematical Logic Quarterly 1987, 33, 171–178. [Google Scholar] [CrossRef]
- Isah, A.; Teella, Y. The Concept of Multiset Category. British Journal of Mathematics and Computer Science 2015, 9, 427–437. [Google Scholar] [CrossRef]
- Grätzer, G. Lattice Theory; Dover, 1971. [Google Scholar]
- Wille, R. Formal Concept Analysis as Mathematical Theory. In Formal Concept Analysis; Ganter, B., Stumme, G., Wille, R., Eds.; Number 3626 in Lecture Notes in Artificial Intelligence; Springer, 2005; pp. 1–33. [Google Scholar]
- Topsøe, F. Compactness in Space of Measures. Studia Mathematica 1970, 36, 195–212. [Google Scholar] [CrossRef]
- Alvarez-Manilla, M. Extension of valuations on locally compact sober spaces. Topology and its Applications 2002, 124, 397–433. [Google Scholar] [CrossRef]
- Harremoës, P. Extendable MDL. Proceedings ISIT 2013; IEEE Information Theory Society,, 2013; pp. 1516–1520. [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley, 1991. [Google Scholar]
- Csiszár, I. The Method of Types. IEEE Trans. Inform. Theory 1998, 44, 2505–2523. [Google Scholar] [CrossRef]
- Harremoës, P. Testing Goodness-of-Fit via Rate Distortion. Information Theory Workshop, Volos, Greece, 2009. IEEE Information Theory Society, 2009, pp. 17–21. [CrossRef]
- Harremoës, P. The Rate Distortion Test of Normality. Proceedings ISIT 2019. IEEE Information Theory Society, 2019, pp. 241–245. [CrossRef]
- Harremoës, P. Rate Distortion Theory for Descriptive Statistics. Entropy 25, 456. [CrossRef]
- Rényi, A. On an Extremal Property of the Poisson Process. Annals Inst. Stat. Math. 1964, 16, 129–133. [Google Scholar] [CrossRef]
- McFadden, J.A. The Entropy of a Point Process. J. Soc. Indst. Appl. Math. 1965, 13, 988–994. [Google Scholar] [CrossRef]
- Harremoës, P. Binomial and Poisson Distributions as Maximum Entropy Distributions. IEEE Trans. Inform. Theory 2001, 47, 2039–2041. [Google Scholar] [CrossRef]
- Harremoës, P.; Johnson, O.; Kontoyiannis, I. Thinning and Information Projection. 2008 IEEE International Symposium on Information Theory. IEEE, 2008, pp. 2644–2648.
- Harremoës, P.; Johnson, O.; Kontoyiannis, I. Thinning, Entropy and the Law of Thin Numbers. IEEE Trans. Inform Theory 2010, 56, 4228–4244. [Google Scholar] [CrossRef]
- Hillion, E.; Johnson, O. A proof oof the Shepp-Olkin entropy concavity conjecture. Bernoulli 2017, arXiv:1503.0157023, 3638–3649. [Google Scholar] [CrossRef]
- Dawid, A.P. Separoids: A mathematical framework for conditional independence and irrelevance. Ann. Math. Artif. Intell. 2001, 32, 335–372. [Google Scholar] [CrossRef]
- Harremoës, P. Entropy inequalities for Lattices. Entropy 2018, 20, 748. [Google Scholar] [CrossRef]
- Harremoës, P. Divergence and Sufficiency for Convex Optimization. Entropy 2017, arXiv:1701.0101019, 206. [Google Scholar] [CrossRef]
- Csiszár, I. I-Divergence Geometry of Probability Distributions and Minimization Problems. Ann. Probab. 1975, 3, 146–158. [Google Scholar] [CrossRef]
- Pfaffelhuber, E. Minimax Information Gain and Minimum Discrimination Principle. Topics in Information Theory; Csiszár, I.; Elias, P., Eds. János Bolyai Mathematical Society and North-Holland, 1977, Vol. 16, Colloquia Mathematica Societatis János Bolyai, pp. 493–519.
- Topsøe, F. Information Theoretical Optimization Techniques. Kybernetika 1979, 15, 8–27. [Google Scholar]
- Csiszár, I.; Tusnády, G. Information geometry and alternating minimization procedures. Statistics and Decisions 1984, (Supplementary Issue 1), 205.237. [Google Scholar]
- Li, J.Q. Estimation of Mixture Models. Ph.d. dissertation, Department of Statistics, Yale University,, 1999. [Google Scholar]
- Li, J.Q.; Barron, A.R. Mixture Density Estimation. Proceedings Conference on Neural Information Processing Systems: Natural and Synthetic;, 1999.
- Harremoës, P. Bounds on tail probabilities for negative binomial distributions. Kybernetika 2016, 52, 943–966. [Google Scholar] [CrossRef]
- Harremoës, P.; Tusnády, G. Information Divergence is more χ2-distributed than the χ2-statistic. 2012 IEEE International Symposium on Information Theory; IEEE,, 2012; pp. 538–543. [CrossRef]
- Györfi, L.; Harremoës, P.; Tusnády, T. Some Refinements of Large Deviation Tail Probabilities. arXiv:1205.1005.
- Kass, R.E.; Wasserman, L.A. The Selection of Prior Distributions by Formal Rules. Journal of the American Statistical Association 1996, 91, 1343–1370. [Google Scholar] [CrossRef]
- Grünwald, P. The Minimum Description Length principle; MIT Press, 2007. [Google Scholar]
- Harremoës, P. Entropy on Spin Factors. Information Geometry and Its Applications; Ay, N.; Gibilisco, P.; Matúš, F., Eds. Springer, 2018, Vol. 252, Springer Proceedings in Mathematics & Statistics, pp. 247–278, [arXiv:1707.03222]. arXiv:1707.03222].
- Harremoës, P.; Matúš, F. Bounds on the Information Divergence for Hypergeometric Distributions. Kybernetika 2020, 56, 1111–1132. [Google Scholar] [CrossRef]
- Harremoës, P.; Johnson, O.; Kontoyiannis, I. Thinning and Information Projections. arXiv:1601.04255.
- Harremoës, P. Convergence to the Poisson Distribution in Information Divergence. Preprint 2, Mathematical department, University of Copenhagen, 2003.
- Harremoës, P.; Ruzankin, P. Rate of Convergence to Poisson Law in Terms of Information Divergence. IEEE Trans. Inform Theory 2004, 50, 2145–2149. [Google Scholar] [CrossRef]
- Kontoyiannis, I.; Harremoës, P.; Johnson, O. Entropy and the Law of Small Numbers. IEEE Trans. Inform. Theory 2005, 51, 466–472. [Google Scholar] [CrossRef]
- Harremoës, P. Lower Bounds for Divergence in the Central Limit Theorem. In General Theory of Information Transfer and Combinatorics; Springer Berlin Heidelberg: Berlin, Heidelberg, 2006; pp. 578–594. [Google Scholar] [CrossRef]
- Harremoës, P. Lower bound on rate of convergence in information theoretic Central Limit Theorem. Book of Abstracts for the Seventh International Symposium on Orthogonal Polynomials, Special functions and Applications;, 2003; pp. 53–54.
- Harremoës, P. Lower Bounds on Divergence in Central Limit Theorem. Electronic Notes in Discrete Mathematics 2005, 21, 309–313. [Google Scholar] [CrossRef]
- Harremoës, P. Maximum Entropy on Compact groups. Entropy 2009, 11, 222–237. [Google Scholar] [CrossRef]
Figure 1.
When coherent light is sent through first a single slit in screen S1 and then through the two slits b and c on screen S2, then an interference pattern emerges at the photographic film F.
Figure 1.
When coherent light is sent through first a single slit in screen S1 and then through the two slits b and c on screen S2, then an interference pattern emerges at the photographic film F.
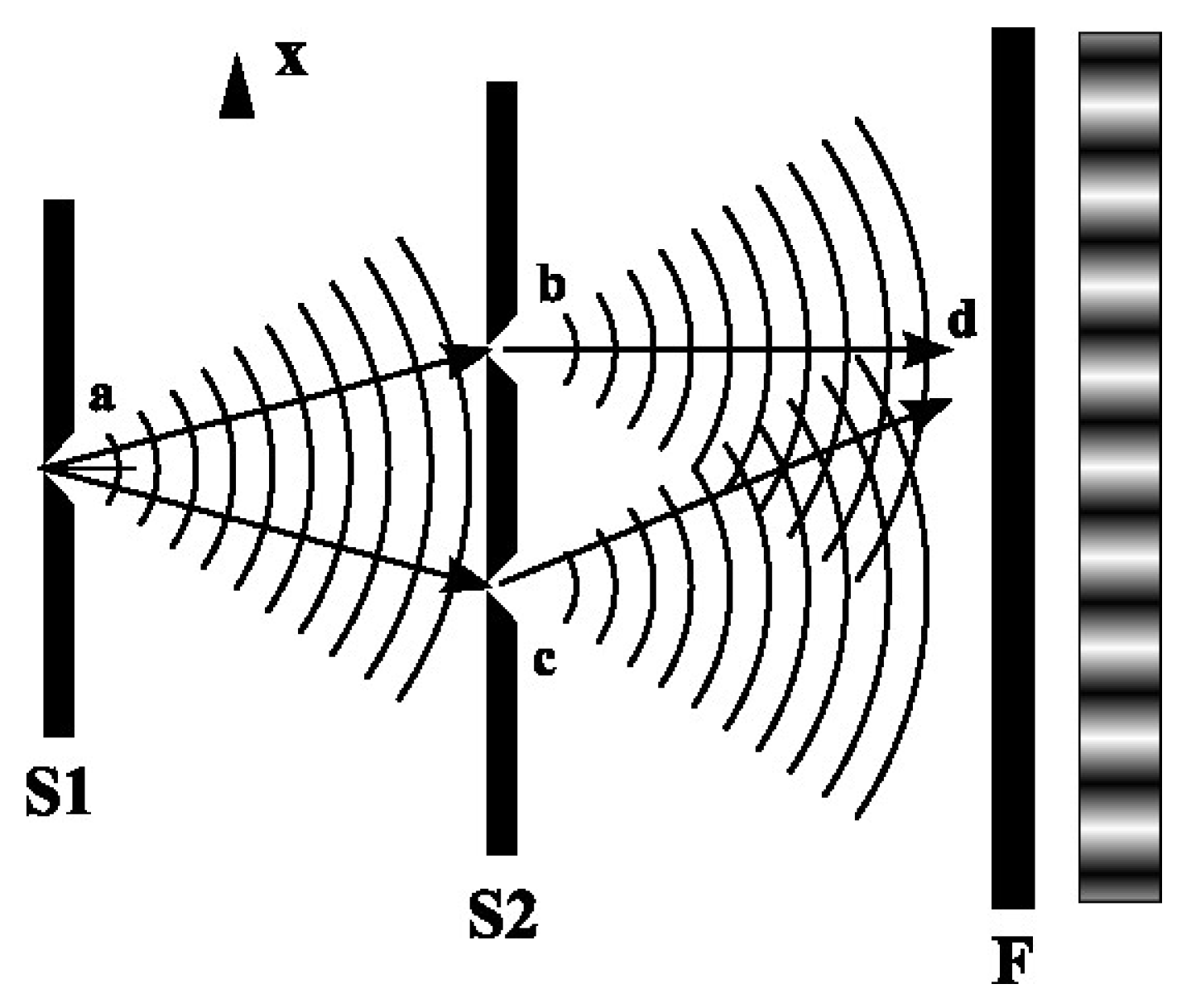
Figure 2.
QQ-plot of a standard Gaussian distribution against the distribution of where X has a binomial distribution with and
Figure 2.
QQ-plot of a standard Gaussian distribution against the distribution of where X has a binomial distribution with and
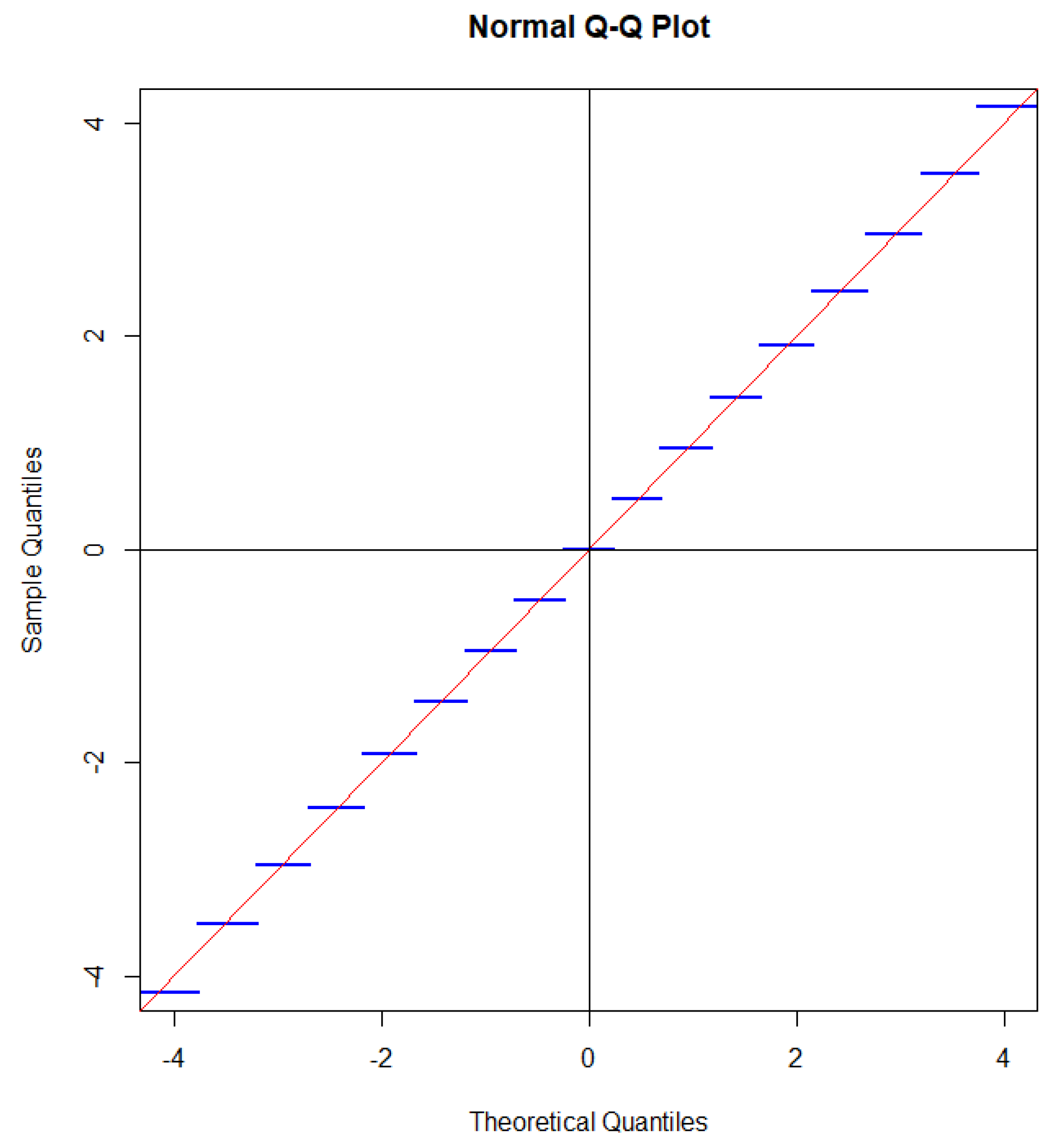
Figure 3.
QQ-plot of a standard Gaussian distribution against the distribution of where X has a Poisson distributed with mean and where Y is also Poisson distributed with mean 10 and Y is independent of X.
Figure 3.
QQ-plot of a standard Gaussian distribution against the distribution of where X has a Poisson distributed with mean and where Y is also Poisson distributed with mean 10 and Y is independent of X.
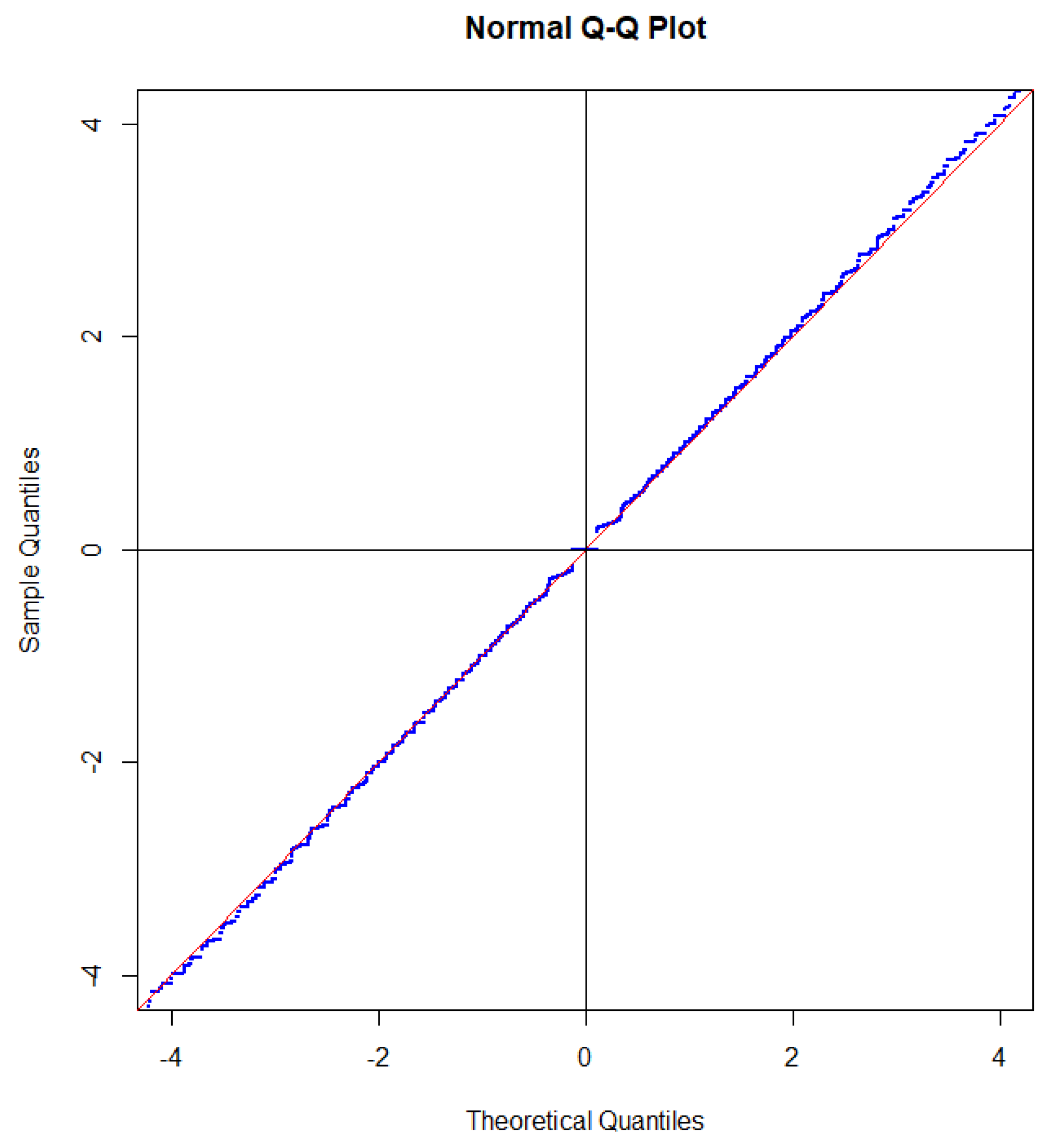
Figure 4.
QQ-plot of the -distribution with against the distribution of the -statistic for testing in .
Figure 4.
QQ-plot of the -distribution with against the distribution of the -statistic for testing in .
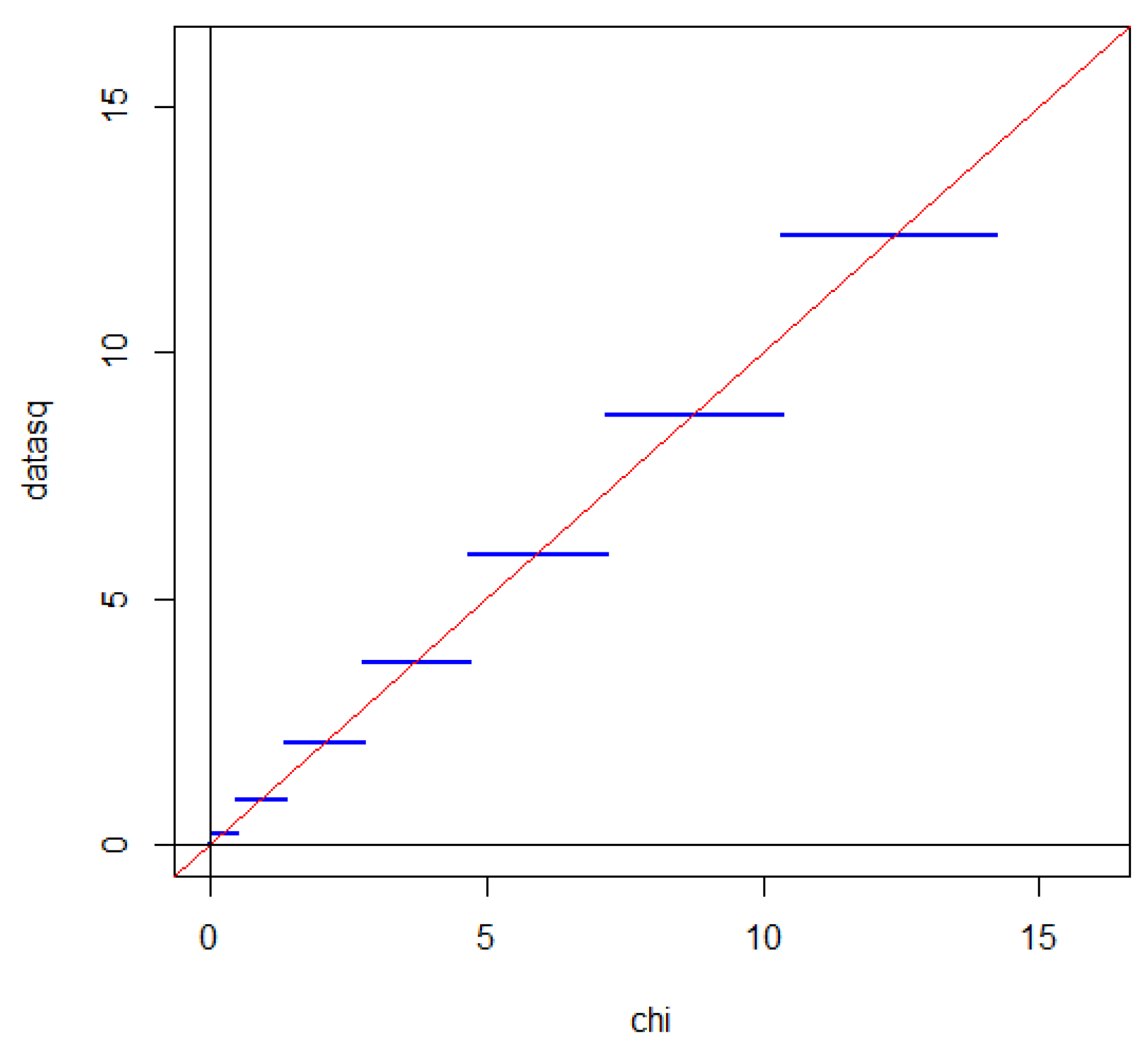
Figure 5.
QQ-plot of the -distribution with against the distribution of the -statistic for testing based on We see that there is a tiny but systematic deviation from the straight line in that the values of are a little larger than predicted by the -distribution. A continuity correction as described in [48] may handle this minor issue.
Figure 5.
QQ-plot of the -distribution with against the distribution of the -statistic for testing based on We see that there is a tiny but systematic deviation from the straight line in that the values of are a little larger than predicted by the -distribution. A continuity correction as described in [48] may handle this minor issue.
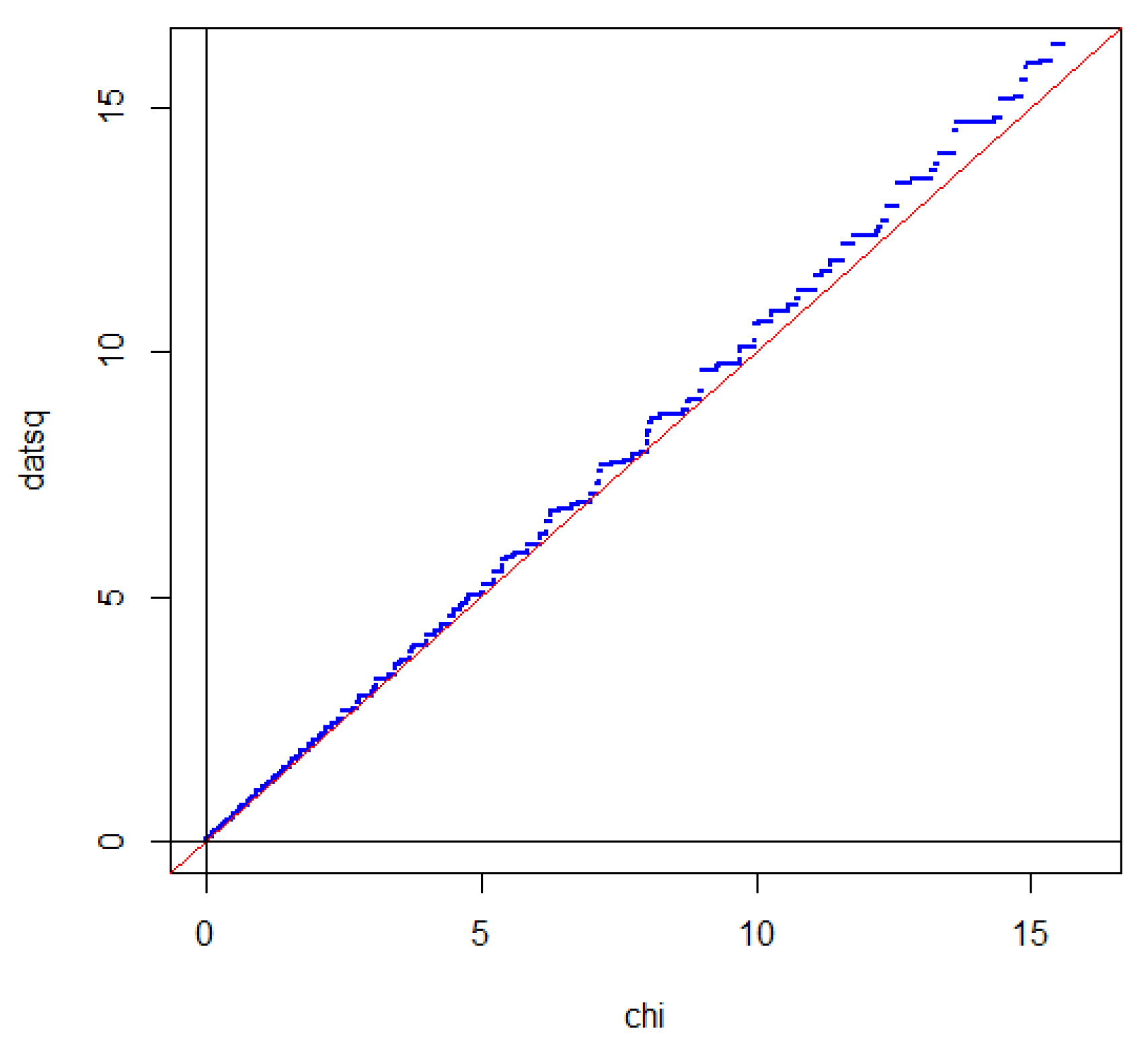
Figure 6.
Support of the joint measure.
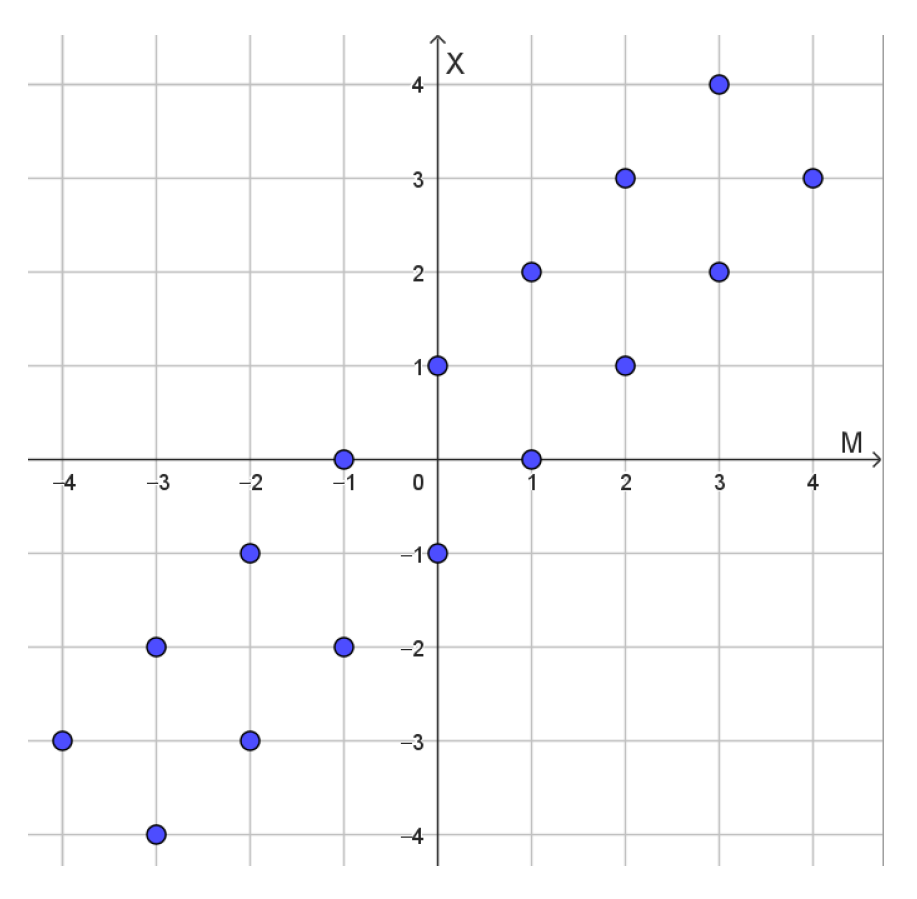
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



