
Submitted:
24 October 2024
Posted:
25 October 2024
You are already at the latest version
Abstract
Satellite-derived high-resolution soil moisture and precipitation data have become widely adopted in natural hazard and climate change research. Landslide susceptibility mapping, which often relies on static predisposing factors, faces challenges in accounting for temporal changes, limiting its efficacy in accurately identifying potential locations for landslide occurrences. A key challenge is the lack of sufficient ground-based monitoring networks for soil moisture and precipitation, especially in remote areas with limited access to rain gauge data. This study addresses these limitations by integrating static landslide conditioning factors—such as topography, geology, and landscape features—with high-resolution dynamic satellite data, including soil moisture and precipitation. Using machine learning techniques, particularly the Random Forest (RF) algorithm, the approach enables the generation of dynamic landslide susceptibility maps that incorporate both spatial and temporal variations.
The work validates the method by analyzing two major landslide events and their relationship to hydrological factors, occurred during two rainfall events in 2019 in Italy. The results successfully identified high-probability landslide areas by accounting for multiple hydrogeological factors and capturing the unique patterns of rainfall and soil moisture distribution and intensity. The findings emphasize the need for further research to refine the use of high-resolution satellite precipitation and soil moisture data, particularly in identifying the optimal temporal and spatial resolutions for landslide susceptibility mapping.
Keywords:
Landslide Susceptibility Map
; High-Resolution Precipitation and Soil Moisture
; Machine Learning Algorithm
1. Introduction
Climate variables and their changes affect landslide activity [1,2,3] leading to an increase in rainfall-induced landslides in many areas of the world. The threat of shallow landslides on people, environment, structures and infrastructures is becoming more severe. A reliable landslide susceptibility prediction has to account for these types of landslides [4]. Landslide susceptibility assessment is an effective way to manage and evaluate landslides by predicting and demonstrating the probability and distribution of possible landslides in a certain area [5,6,7]. The spatial distribution of landslides occurrence at the regional scale [8,9] provides a scientific basis for landslide disaster prevention and regional development planning [10].
To predict “where” landslides are likely to occur, several methods have been proposed [9]. Geomorphological mapping, analysis of landslide inventories, heuristic terrain and susceptibility zoning, physically-based numerical modeling, and statistically-based classification methods are just some of the proposed approaches [11,12,13,14,15,16,17].
In addition to the traditional models, multifarious machine learning models have been developed and used to map landslide susceptibility [18,19,20,21].
In recent years, due to the rapid development of computer technology there has been a notable shift towards exploring advanced modeling architectures capable of delivering superior predictive performance. Techniques such as deep learning [22,23], ensemble modeling [24], and hybrid approaches [25,26] have gained prominence, and showed the power of machine learning algorithms to predict landslide susceptibility [26,27,28]. Among these techniques, the Random Forest (RF) machine learning algorithm is particularly promising. This model operates by constructing an ensemble of decision trees from randomly selected subsets of the input data, combining their predictions to derive a final output. RF demonstrated effectiveness in addressing both classification and regression tasks [29,30]. The strength of RF model lies in its ability to use the combined knowledge of individual trees while mitigating the risk of overfitting [31].
In addition, the RF model is particularly advantageous in the landslide susceptibility assessment, due to its capacity to include different types of data [32]. Both numerical and categorical variables, covering factors such as slope angle, lithology, and land use, can be seamlessly integrated without forcing strict distributional assumptions. This flexibility makes the RF model well-suited for analyzing the complex interaction of factors contributing to landslides occurrence.
The main factors that induce shallow landslides are divided into two categories: static and dynamic. Static factors, also known as conditioning factors, include topographic features, geological conditions, and land cover. Dynamic factors, also known as triggering factors, are the rainfall and soil moisture conditions.
The assessment of triggering factors is important for the reliability of susceptibility maps. Landslide susceptibility modeling has tipically focused on static information [33,34,35], while the dynamic influence of rainfall and soil moisture have often been ignored [36,37]. Recent advancements in data-driven solutions allowed for the incorporation of spatiotemporal variations of these variables, leading to more accurate and comprehensive landslide hazard assessments [38]. By incorporating explanatory variables that reflect spatiotemporal variations, such as rainfall and soil moisture parameters, the models can capture the complex interactions between environmental factors and landslide triggering mechanisms [39,40].
The evolution of data-driven landslide susceptibility models has been marked by an increasing sophistication in methodological approaches and a growing recognition of the importance of spatiotemporal dynamics [28,32,41,42,43,44,45].
The space-time solution approaches explicitly account for the temporal dimension of landslide occurrences, incorporating dynamic variables like rainfall and antecedent hydrological conditions to capture the evolving nature of landslide hazards [46]. These methodologies allow for the simultaneous assessment of landslide risk across both geographic space and time, enabling a more comprehensive understanding of the dynamic nature of land-slide occurrences [47].
High-resolution soil moisture and precipitation data have become essential in understanding and predicting landslide events, especially in regions prone to rainfall-induced landslides [48,49,50,51].
Soil moisture and precipitation data can be derived from in situ measurements, but they have limitations. For example, the accuracy of both rainfall intensity-duration and cumulative rainfall-duration (E-D) models are influenced by various factors, such as the resolution of rainfall and geohazard data, the spatial relationship between rain gauges and landslide locations, and the criteria used to define threshold limits [52,53]. These approaches typically involve calculating rainfall parameters for each landslide event based on data from relevant rain gauges [54]. The selection of appropriate rain gauges remains a challenge, with no universally accepted methodology [55]. In addition, the spatial limitations of rain gauges hinder the accurate assessment of rainfall and soil moisture conditions in close proximity to landslide sites.
A promising solution to overcome these limitations is offered by satellite-derived data. By leveraging remote sensing technologies, researchers can obtain comprehensive, high-resolution rainfall and soil moisture data over large areas, providing a more accurate and spatially continuous representation of the environmental conditions that influence landslide occurrence [56,57,58,59]. The integration of these satellite-derived data into landslide prediction models has the potential to improve the accuracy and reliability of landslide forecasts, thereby enhancing the ability to mitigate the risks associated with these natural hazards.
In this study, the limitations of raingauge-based susceptibility models are addressed by integrating high-resolution satellite derived soil moisture and precipitation data with advanced machine learning techniques. By combining these powerful tools, a more sophisticated model that captures the intricate relationships between the various factors is developed, leading to a deeper understanding of the critical conditions under which landslides are triggered.
The document is organized as follows: Section 2 provides a detailed description of the study area, defining the main geological and climatic features. An overview of the static and dynamic factors considered in the study is reported in Section 3. Section 4 describes the machine learning method used, and Section 5 presents the results of the application of the model to a selected study area and the discussion related to the 2019 severe weather events which triggered a significant number of landslides in the area.
2. Study Area
2.1. Geological and Geomorphological Setting
The studied area extends for 9,500 km² between Piemonte, Lombardia, Liguria, and Emilia Romagna regions (Figure 1 A). The area is characterized by a high susceptibility to landslides and many phenomena occurred in the past (red dots in Figure 1 B). For landslide events, a detailed inventory is available and the date and location of each event occurrence is detailed. From January 2016 to December 2021, 410 phenomena were recorded in the area.
The geology of the area consists of the alluvial, lacustrine and marine deposits in the central part of the area while an extensive area of bedrock is located in the northern zone [60] (see Figure 2). The northwest is primarily covered by unconsolidated clastic rock, comprising loosely arranged and uncemented materials of all grain sizes with a heterogeneous origin, such as clay soil, sand, and conglomerate.
The southern sectors are dominated by hilly reliefs composed of carbonate-rich sedimentary rocks (limestone, dolomite, and marl) and chaotic terrains with a clay matrix. In contrast, the southwest is characterized by marlstone and Schistose metamorphic rocks, encompassing a wider variety of rock types.
The digital elevation model (with a 20 m resolution) reveals that the territory shows different morphology, ranging from flat areas such as the AA traversed by the Po River, to peaks surpassing 1,700 m (the highest peak being Falterona Mount at 1,655 m a.s.l.).
2.2. Climatic Features
The study area is located in the Po River basin. It is influenced by the Alps, which protect the Po Valley from cold winds from north Europe and by the Apennines limit which mitigate the action of the sea [61]. The lowest temperatures are recorded in January, followed by a rise until July when the peak is reached, and then a decline from September to December, with values similar to those in January. Winter (December to February) is the coldest season, while summer (June to August) is the warmest. Autumn (September to November) tends to have slightly higher temperatures compared to spring (March to May).
According to the Po River Basin Authority [25], the average annual precipitation over the Po River basin is approximately 1200 mm at the Pontelagoscuro closure section. Of this total, about two-thirds flows to the Adriatic Sea as discharge, while the remaining one-third is believed to be lost due to evaporation and/or vegetation interception.
Analyzing rainfall since 1980 shows that rainfall events are more intense but less frequent, resulting in a 20% reduction in total annual rainfall [62].
Seasonally, rainfall events are reduced by up to 50% in spring and summer, while they have varied little in autumn.
3. Materials
Data acquisition for landslide susceptibility analysis begins with the collection of raw data from various sources, including digital terrain models (DTMs), geological maps, Landsat 7 satellite images, and satellite-based rainfall and soil moisture products records. Ten static conditioning factors are selected and derived from the collected data: elevation, slope angle, aspect, plan curvature, profile curvature, geology, land cover, normalized difference vegetation index (NVDI), distance to road, and distance to river. These static factors have been commonly used by previous researchers in studying landslides see e.g. [63,64].
In addition to the static conditioning factors, daily rainfall and daily soil moisture data, along with two antecedent cumulative rainfall parameters (7 days and 15 days before the events), are selected to characterize soil moisture and rainfall conditions that trigger landslides during rainstorms.
3.1. Static Conditioning Factors
Landslide occurrence is directly impacted by the angle of the slope, a crucial factor contributing to shear stress and subsequent terrain instability. The digital terrain model (DTM) provides insights into regional topography and geomorphology, reflecting the influence of slope’s geographical features on landslide evolution. For this reason, five widely used slope characteristics – elevation, slope angle, aspect, plan curvature, and profile curvature – are calculated correspondingly. For instance,aspect indicates the direction a slope faces (represents the compass direction 0° to 360°), influencing sunlight exposure, moisture content, vegetation growth, and erosion rates. Slopes with certain aspects may retain more moisture, have less vegetation, or experience rapid snowmelt and freeze-thaw cycles.
Plan curvature and profile curvature represent the effects of topographic gradient on flow rate and water flow patterns, respectively. Curvature, generally, describes a surface’s deviation from flatness [65].
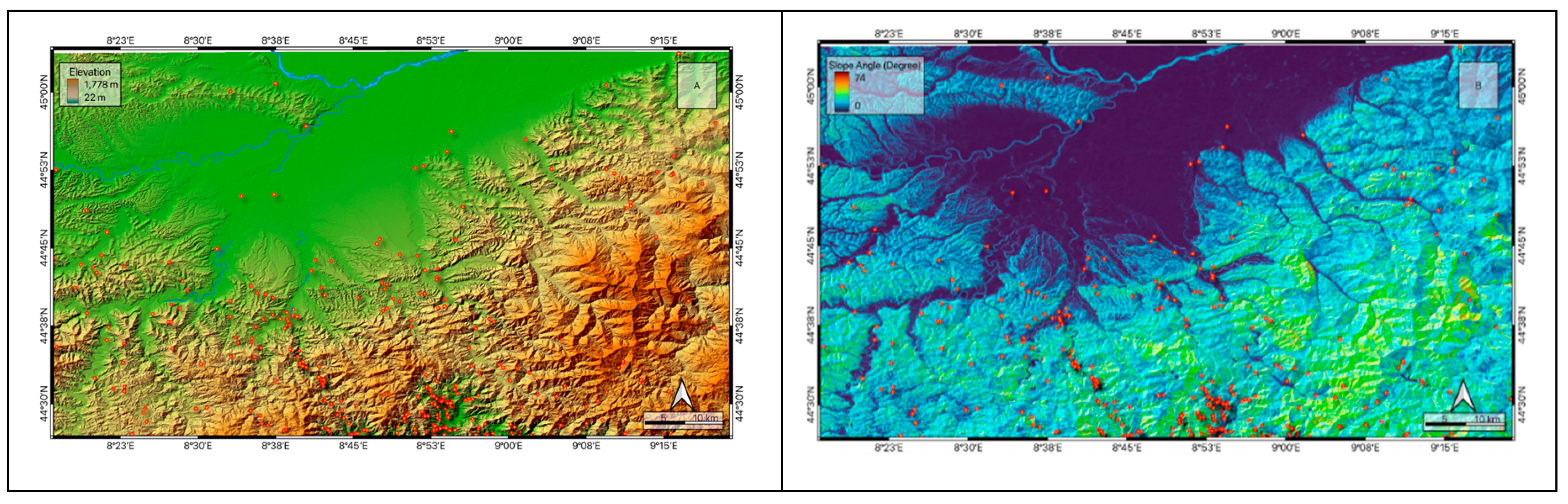
QGIS software, utilizing three-dimensional analysis and data management tools, calculates and maps topographic and geomorphological factors to predict landslide susceptibility. Figure 4 illustrates the distribution of elevation (Figure 3 A) and slope angle (Figure 3 B) across the study area.
Figure 3.
Elevation distribution in the study area (A) and slope distribution (B). Red dots show the occurred landslides in the study area.
Figure 3.
Elevation distribution in the study area (A) and slope distribution (B). Red dots show the occurred landslides in the study area.
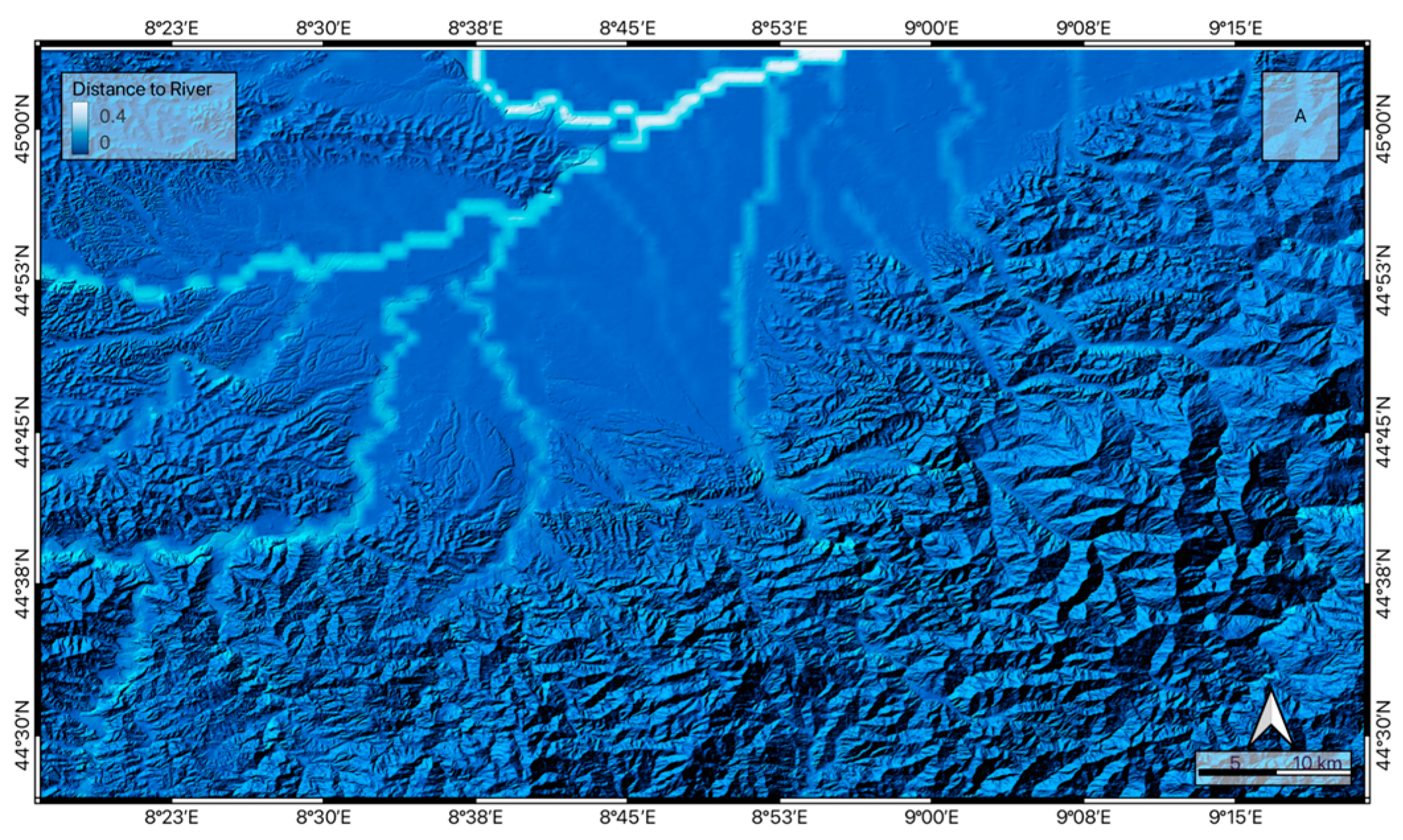
To define the lithology distribution the classification proposed by Bucci et al. 2022 [60] was adopted (Figure 2). The hydrological environment was obtained by considering the distance to the nearest river for each point within the study area (Figure 4).
Figure 4.
Spatial distribution of the distance to river parameter in the study area.
Land cover, particularly vegetation, provides both hydrological and mechanical effects on slope stability. Land cover is an important conditioning factor for the rainfall-triggered landslides [66,67] due to its effect on the soil mechanical behavior and soil moisture (Figure 5 A). In this study, the normalized difference vegetation index (NDVI), derived from remote-sensing data, is used to indicate the growth condition of vegetation. NDVI values close to or less than zero and decreasing negative values indicate non-vegetated features, such as rock and bare soil surfaces, water, and artificial structures. Higher positive values represent denser green vegetation, such as grass and forest (Figure 5 B).
3.2. Dynamic Conditioning Factors
Rainfall and soil saturation conditions at the onset of a storm event are two of main triggering factors for landslides activation. Despite the study area is densely instrumented, localized events as well as local features may impact the rainfall and soil saturation observed fields. Moreover, over the study area, soil moisture monitoring networks are not present and modeled estimates could be impacted by the quality of the input rainfall. The use of hydrometeorological variables obtained through remotely sensed information could mitigate such limitations. To this end, in this study soil saturation and rainfall obtained through remotely sensed information has been used to train the proposed model. Rainfall data are obtained through the integration of multiple datasets in order to achieve a more reliable and more resolute field. More in details, the state-of-the-art Integrated Multi-satellitE Retrievals for GPM Late Run product [68], the Climate Prediction Center Global Unified Gauge-Based Analysis of Daily Precipitation [69] and the soil moisture-derived rainfall through SM2RAIN algorithm [70] are integrated and then downscaled a 1 km of spatial resolution. Table 1 summarizes the main features of the parent products.
For more details about the integration and the downscaling procedures, the readers are referred to Filippucci et al., 2022 [71]. The soil moisture data have been obtained through the GLEAM model [69].
GLEAM is a modelling framework dedicated to the estimation of evaporation over land through satellite data. The model estimates the different components of evapotranspiration, i.e. transpiration, bare-soil evaporation, interception loss, open-water evaporation and sublimation along with surface and root-zone soil saturation conditions. More in details, soil moisture is obtained by taking advantages of a multi-layer balance model that can assimilates satellite observations. The estimates used in the current study are those obtained by forcing the model with the same product used for retrieving the rainfall conditions, guaranteeing the same temporal and spatial resolutions.
The static and dynamic factors considered in this study for the landslide susceptibility assessment are listed in Table 2 along with the data sources.
4. Method
To evaluate the landslide susceptibility of the area the Random Forest model (RF) has been used.
Evaluation of the RF model typically involves partitioning the dataset into training and testing subsets. The training data are employed for the construction of the decision tree ensemble, while the testing data are used to assess the model’s predictive performance.
4.1. Machine Learning
The RF model was implemented using the ‘randomForest’ package in the R 4.6.0 statistical software environment [29]. The process began with input data from approximately 400 landslide locations and 400 non-landslide locations, utilizing features such as slope angle, lithology type, elevation, and rainfall. Multiple decision trees were built by the RF algorithm, each with different nodes based on these features. For example, slope angle might be used as the root in one tree, while lithology type could be the next node; in another tree, elevation might be the starting point followed by rainfall. This variety in tree construction allows different patterns in the data to be identified by the model.
Once the trees were built, new data points could be evaluated to assess the probability of a landslide occurring at those locations. The features of the new points—such as slope angle, lithology, elevation, and rainfall—were processed by each tree in the forest to provide a binary output, either “yes” (indicating a landslide is likely) or “no” (indicating it is not). The final output was determined by calculating the percentage of trees that predicted “yes.” For instance, if 70 out of 100 trees predicted “yes,” a probability of 0.7 (or 70%) for a landslide was assigned by the model. Selecting the optimal train/test split ratio is crucial for improving model performance. A well-defined split ratio reduces the risk of overfitting and enhances the model’s ability to perform effectively on unseen data. To ensure balanced data, 410 non-landslide samples, equal to the number of landslide samples, were utilized in the study. The proportion of training data varied from 0.5 to 0.9, which resulted in an increase in the number of landslide samples considered for model training from 200 to 360.
The classification accuracy of the RF model on the testing dataset, evaluated at different train/test split ratios, is shown in Figure 6 A. It was observed that as the training subset ratio increased, the model’s classification accuracy on the testing dataset also improved, peaking at a 0.7 (70/30) split. This finding aligns with the recommendations of Gholamy et al. (2018) [72], who advocate for a 70/30 split as optimal for model training and testing in similar contexts.
To minimize the out-of-bag error rate of bootstrap samples, the hyperparameters ‘ntree’ (number of trees) and ‘mtry’ (number of predictor variables considered at each split) were fine-tuned and optimized for each dataset using the model’s tuning function, as illustrated in Figure 6 B and Figure 6 C.
Four key performance indicators are used to evaluate the performance of RF in this study (Figure 6 D): accuracy, recall, precision, and the receiver operating characteristic (ROC) curve. To understand these metrics, we first define the four prediction types in binary classification for landslide prediction:
True Positive (TP): Correctly predicts a landslide where one occurred.
False Positive (FP): Incorrectly predicts a landslide when none occurred.
True Negative (TN): Correctly predicts no landslide when none occurred.
False Negative (FN): Incorrectly predicts no landslide when one occurred.
The performance indicators are:
Accuracy: The ratio of correct predictions (TP + TN) to all predictions (TP + FP + TN + FN).
Recall: The model’s ability to identify actual landslides (TP) out of all true cases (TP + FN).
Precision: The reliability of predicting landslides, representing true positives (TP) among all predicted positives (TP + FP).
4.2. Relative Importance
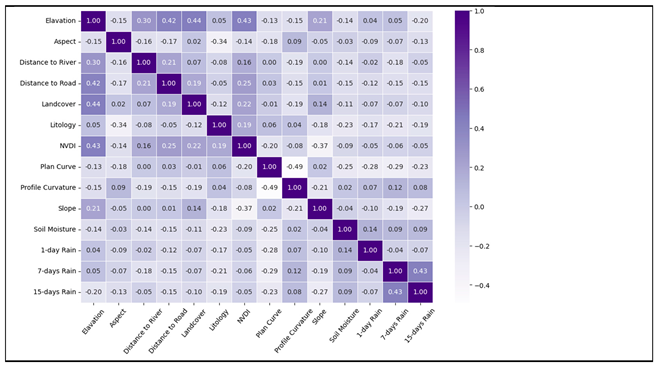
In the second part of evaluating the performance of the RF, the statistical relationships between independent variables were assessed to determine potential correlation issues, prior to the conditioning factors importance analysis being investigated. Spearman’s correlation matrix [73] was employed for this purpose (Table 3), due to its suitability for both continuous and ordinal data [74] being recognized. Multicollinearity, indicated by a high degree of relationship between variables, was identified by Spearman correlation values exceeding 0.7. Table 3 reveals strong correlations among daily and antecedent rainfall factors (e.g., 7-day and 15-day antecedent rain). Such correlations have been shown to have minimal impact on the predictive performance of machine learning models [75], they were still taken into consideration.
RF model assessed the relative importance of conditioning factors for landslide susceptibility prediction using mean decrease accuracy (MDA) and mean decrease GINI (MDG). MDA quantifies the reduction in model accuracy when a factor is excluded, while MDG measures a factor’s contribution to node purity. Higher values of MDA and MDG indicate greater importance for a given factor (Figure 7).
All selected conditioning factors were observed to have positive values for landslide prediction model learning, although their degree of contribution differed. Specifically, among static topographic factors, slope angle was noted to be of the highest importance, followed by elevation, profile and plan curvature. Surface cover materials, indicated by land cover and NDVI, were found to play a more significant role than subsurface materials when compared to geological factors.
Regarding dynamic rainfall conditions, daily rainfall was identified as more important than antecedent rainfall factors (i.e., 7-day and 15-day). This is consistent with the understanding that most landslides in Italy are classified as shallow, primarily triggered by short, intense rainstorms. Within these factors, soil moisture was determined to have a relatively greater influence than antecedent conditions.
Distance to road and geology were found to be the least significant among the 14 selected conditioning factors. However, it should be noted that the determined importance of road distribution in the model predictions may have been affected by the exclusion of human-made landslide triggering events from the input landslide dataset. The geological features were not found to be as helpful in predicting landslides as other factors. This could be because landslides were observed in areas with very different types of rocks and soil, making it difficult to find a single geological cause. It was suggested that separating the geology data into smaller groups and considering the effects of weathering might make the predictions better.
Although the removal of conditioning factors with null predictive value has been suggested in some studies [76,77], all 14 landslide conditioning factors in this study were found to have positive predictive capability. Furthermore, it has been indicated in literature (see e.g. [78]) that the importance of a single conditioning factor like slope angle can be site-specific and dependent on the scale of analysis and selection method. Therefore, all 14 conditioning factors were utilized in the analysis for the development of the model.
5. Results and Discussion
5.1. Rainfall Events
To evaluate the susceptibility map two major rain storms with the highest number of induced landslides were selected for analysis.
The rainfall hydrogram, obtained from the procedures developed by CNR-IRPI in Perugia, is shown in Figure 8.
The first event (R1), occurred in October 2019, brought intense rainfall and subsequent landslides to northwestern Italy, causing widespread disruption and displacement. Locations such as San Bartolomeo del Bosco, Osigli, and areas surrounding Genoa were particularly affected. The consequences included road closures, isolated communities, evacuations, and disruptions to public transportation. Infrastructure damage was also reported, with a bridge collapsing in Capriata d’Orba. In total, this rainstorm resulted in 39 natural terrain landslides and 2 fatalities, with a maximum reported rainfall of 73 millimeters. Figure 9, besides showing the values of maximum daily rainfall, illustrates the average daily rainfall in the studied area and the antecedent 15-day cumulative average rainfall over the study area between October and late January.
The second event (R2), on 23 November 2019, impacted a broader range of areas from the northeast to the south of the studied region. This event led to significant financial and human losses, particularly in the Liguria area, resulting in 45 natural terrain landslides and directly affecting more than 120 people. As shown in Figure 8, the maximum rainfall amounts in both events were similar, reaching close to 70 millimeters, but the cumulative average rainfall on 23 November reached higher values compared to the event in October.
5.2. Modeling Results
Using the collected data, which includes conditioning factors in the study area as well as values extracted from satellite data (including daily rainfall, soil moisture, 7 and 15 days cumulative rainfall at each point), two landslide susceptibility maps were created for the two events under review using the optimized RF model. Figure 10 D and Figure 11 D respectively show the predicted landslide susceptibility results for these two events. The locations of landslides triggered by each rainfall event are indicated in both figures. From the predicted landslide susceptibility and the spatial distribution of rainfall and soil moisture parameters for the two events (Figure 9 and Figure 10), some interesting results can be identified:
In the October event, the concentration of rainfall in the northern and central sectors of the area can be clearly observed in Figure 9 A, and to better understand this, the points where landslides occurred on that day are marked. By comparing daily rainfall and examining the 15-day cumulative rainfall, a spatial shift in rainfall concentration from the central areas to the western and southern parts of the study area (Figure 9 B) can be observed. This 15-day rainfall concentration in the central areas could have a very interesting correlation with the spatial distribution of soil moisture values on the day of the event (Figure 9 C). By examining the predicted landslide susceptibility results for October 2019, a meaningful correlation can be observed where both predicted high-risk landslide zones and the concentration of the 15-day rainfall and soil moisture values are located. Soil moisture and rainfall conditions play an important role in spatially identifying landslides and can vary significantly with different rainfall events. This difference can be observed in the spatial distribution of maximum rainfall on this day and the location of landslides. On this day, the maximum rainfall was 70 mm, which occurred in the northern part of the study area, but the landslides occurred in the central areas. These results clearly emphasize the importance of considering rainfall and soil moisture factors in accurately understanding and identifying high-risk areas.
As shown in Figure 10, on 23 November, the intensity of rainfall was almost the same as on 20 October, with both experiencing approximately 70 mm of rainfall. However, on 23 November, the spatial distribution of rainfall was concentrated in the western and southwestern regions and also affected a larger area from north to south. This difference can also be observed in the average daily rainfall presented in Figure 8 for these two events. On this day, the average rainfall across the entire area was nearly twice the reported average rainfall for 20 October. By examining the distribution of landslides that occurred on 23 November and the spatial distribution of soil moisture and rainfall on that day, the accuracy of the model in predicting high-susceptibility areas can be recognized. Similarly, the maximum predicted susceptibility index on 23 November is higher than on 20 October (0.93). Although these calculated susceptibility values may not be quantitatively accurate, it has been proven that the proposed model can correctly consider various intensities of soil moisture and rainfall-related parameters. For 23 November, the high-susceptibility area predicted was not concentrated in a specific region but was able to identify points that were in the eastern part of the study area, where the spatial distribution of soil moisture and intense rainfall was accurately the location of landslides. The proposed spatiotemporal landslide prediction model can satisfactorily respond to rainfalls with distinct spatial distributions, which was not reported in the previous case study.
5.3. Reliability Results
To gain a better understanding of the performance of the presented model, it is essential to investigate the model’s ability to differentiate and assess the impact of hydrological factors on the predicted values of landslide susceptibility. To this end, the susceptibility difference values for each pixel in two events (Figure 13), along with the difference values of daily rainfall (Figure 11 A),15-day cumulative rainfall (Figure 11 B), and soil moisture (Figure 12), were extracted and presented.
In the eastern part of the study area, higher daily and 15-day cumulative rainfall values were observed in November compared to the October 20 event, leading to an increase in areas with a high probability of landslides (red dots) in the eastern regions. Additionally, an examination of the obtained soil moisture values for this event compared to the previous one indicates higher soil moisture in the second event, thus increasing the probability of landslides in this area. As reported in the landslide database, four landslides occurred in these areas on this day, all of which were correctly classified by the model as very high risk.
However, a noteworthy point in this area is that in high-altitude regions like Monte Carmo, located in the southeast, the measured moisture values at the peak were higher in the first event than in the second event, yet the susceptibility values measured in this area were higher in the second event. To investigate the causes of this phenomenon, Figure 11, which respectively show the daily (Figure 11 A) and 15-day cumulative rainfall (Figure 11 B) in this area, can be examined. It can be observed that the cumulative rainfall in this area was approximately 240 mm higher in the second event than in the corresponding 15-day period of the first event. This demonstrates the model’s ability to consider multiple hydrological factors simultaneously in identifying areas with a high probability of landslides. However, upon examining the susceptibility values of these two events in these areas, it is noted that although the differences in susceptibility values seem significant, Figure 13 reveals that these areas, due to their specific landscape characteristics, have a low probability of landslides.
Figure 12.
For each pixel in the study area and in relation to R1 and R2 events, the figure shows the soil moisture difference.
Figure 12.
For each pixel in the study area and in relation to R1 and R2 events, the figure shows the soil moisture difference.
Furthermore, on October 20, an analysis of the central and southern parts of the study area reveals that soil moisture values (Figure 12) were more concentrated in the central areas compared to the second event (purple figure).
Additionally, by examining the reported landslides on this day and analyzing the cumulative rainfall and spatial distribution pattern of daily rainfall in this area, it can be concluded that the model was able to identify the high-probability areas in this region (yellow dots in Figure 13).
Figure 13.
Spatial distribution of susceptibility difference evaluated in relation to the two rainfall events R1 and R2 for each pixel of study area.
Figure 13.
Spatial distribution of susceptibility difference evaluated in relation to the two rainfall events R1 and R2 for each pixel of study area.
This is a noteworthy point, as if only daily rainfall values were considered for the October 20 event, the maximum rainfall would have occurred in the northern and central regions, and without the model’s utilization of other dynamic parameters like soil moisture and 15-day cumulative rainfall, it would not have been able to produce meaningful results.
On November 23, a large number of landslides occurred in the western part of the study area. Examination of the daily rainfall distribution on this day reveals a concentration of rainfall in the western and southern parts of the study area. The extracted soil moisture values for this region also show higher values in the landslide-prone areas compared to the first event. In this region, there is a wider distribution of areas with a high probability of landslides compared to the October 20 event, indicating the successful performance of the model in identifying high-risk areas considering rainfall and moisture scenarios.
In the northwestern part of the study area, a higher probability of landslides was predicted for the November 23 event compared to October 20, despite lower soil moisture values on this day compared to October 20. This can be well explained by examining the daily rainfall distribution in this area, which shows higher rainfall values on November 23. Considering this, the model was able to predict areas with a higher risk class for this day. It is also worth mentioning that the 15-day cumulative rainfall values were higher in the second event compared to the first event.
5.4. Conclusions
Since the 1980s, hundreds of studies have contributed to the understanding of landslide susceptibility across various geological, climatic, and geographical settings. A variety of methods, both direct and indirect, have been employed, incorporating both qualitative and quantitative approaches.
In this study, a method for predicting landslide probability using the RF algorithm was presented. Significant improvements in predictive accuracy were achieved by integrating static landslide conditioning factors with high-resolution dynamic variables, such as soil moisture and both daily and cumulative rainfall derived from satellite data. A part of Po River region in Italy was analyzed, and the model, validated using two rainstorm events from 2019, successfully identified areas with a high probability of landslides by considering multiple hydrogeological factors and effectively captured the distinct characteristics of rainfall and soil moisture distribution and intensity. The predicted high probable zones are closely aligned with the observed spatial distribution of landslides, particularly during severe rainstorms.
While a general methodology for spatial and temporal landslide prediction was introduced, the results are site-specific. It is recommended that the method be recalibrated for other applications to identify the optimal configuration of parameters, especially when considering different types of landslides or dynamic variables.Future work could focus on examining the relationship between the time series of dynamic variables—rainfall and soil moisture—and landslide occurrences within specified time windows.
Acknowledgments
This work was supported by the European Space Agency “4DMed-Hydrology” project (contract n. 4000136272/21/I-EF).
References
- F. Ardizzone, S.L. Gariano, E. Volpe, L. Antronico, R. Coscarelli, M. Manunta, A.C. Mondini, A Procedure for the Quantitative Comparison of Rainfall and DInSAR-Based Surface Displacement Time Series in Slow-Moving Landslides: A Case Study in Southern Italy, Remote Sensing 2023, 15, 320. [CrossRef]
- D. Salciarini, L. Brocca, S. Camici, L. Ciabatta, E. Volpe, R. Massini, C. Tamagnini, Physically based approach for rainfall-induced landslide projections in a changing climate, Proceedings of the Institution of Civil Engineers - Geotechnical Engineering 2019, 172, 481–495. [CrossRef]
- E. Volpe, S.L. Gariano, L. Ciabatta, Y. Peiro, E. Cattoni, Expected Changes in Rainfall-Induced Landslide Activity in an Italian Archaeological Area, Geosciences 2023, 13, 270. [CrossRef]
- E. Volpe, L. Ciabatta, D. Salciarini, S. Camici, E. Cattoni, L. Brocca, The Impact of Probability Density Functions Assessment on Model Performance for Slope Stability Analysis, Geosciences 2021, 11, 322. [CrossRef]
- D.S. Mwakapesa, X. Lan, Y. Mao, Landslide susceptibility assessment using deep learning considering unbalanced samples distribution, Heliyon 2024, 10, e30107. [CrossRef]
- G. Duan, J. Zhang, S. Zhang, Assessment of Landslide Susceptibility Based on Multiresolution Image Segmentation and Geological Factor Ratings, IJERPH 2020, 17, 7863. [CrossRef]
- J. Gao, X. Shi, L. Li, Z. Zhou, J. Wang, Assessment of Landslide Susceptibility Using Different Machine Learning Methods in Longnan City, China, Sustainability 2022, 14, 16716. [CrossRef]
- A. Trigila, C. Iadanza, C. Esposito, G. Scarascia-Mugnozza, Comparison of Logistic Regression and Random Forests techniques for shallow landslide susceptibility assessment in Giampilieri (NE Sicily, Italy), Geomorphology 2015, 249, 119–136. [CrossRef]
- W. Chen, W. Li, H. Chai, E. Hou, X. Li, X. Ding, GIS-based landslide susceptibility mapping using analytical hierarchy process (AHP) and certainty factor (CF) models for the Baozhong region of Baoji City, China, Environ Earth Sci 2016, 75, 63. [CrossRef]
- J. Dou, A.P. Yunus, D. Tien Bui, A. Merghadi, M. Sahana, Z. Zhu, C.-W. Chen, K. Khosravi, Y. Yang, B.T. Pham, Assessment of advanced random forest and decision tree algorithms for modeling rainfall-induced landslide susceptibility in the Izu-Oshima Volcanic Island, Japan, Science of The Total Environment 2019, 662, 332–346. [CrossRef]
- P. Aleotti, R. Chowdhury, Landslide hazard assessment: summary review and new perspectives, Bull Eng Geol Env 1999, 58, 21–44. [CrossRef]
- F. Guzzetti, A. Carrara, M. Cardinali, P. Reichenbach, Landslide hazard evaluation: a review of current techniques and their application in a multi-scale study, Central Italy, Geomorphology 1999, 31, 181–216. [CrossRef]
- A. Carrara, Multivariate models for landslide hazard evaluation, Mathematical Geology 1983, 15, 403–426. [CrossRef]
- D. Salciarini, R. Morbidelli, E. Cattoni, E. Volpe, Physical and numerical modelling of the response of slopes under different rainfalls, inclinations and vegetation conditions, RIG-2022-1-1 2022, 1229, 47–61. [CrossRef]
- D. Salciarini, E. Volpe, E. Cattoni, Probabilistic vs. Deterministic Approach in Landslide Triggering Prediction at Large–scale, in: F. Calvetti, F. Cotecchia, A. Galli, C. Jommi (Eds.), Geotechnical Research for Land Protection and Development, Springer International Publishing, Cham, 2020: pp. 62–70. [CrossRef]
- D. Salciarini, A. Lupattelli, F. Cecinato, E. Cattoni, E. Volpe, Static and seismic numerical analysis of a shallow landslide located in a vulnerable area, RIG-2022-2-2 2022, 1236, 5–23. [CrossRef]
- A. Johari, Y. Peiro, Determination of stochastic shear strength parameters of a real landslide by back analysis, IJRRS 2021, 4, 7–16. [CrossRef]
- A. Merghadi, A.P. Yunus, J. Dou, J. Whiteley, B. ThaiPham, D.T. Bui, R. Avtar, B. Abderrahmane, Machine learning methods for landslide susceptibility studies: A comparative overview of algorithm performance, Earth-Science Reviews 2020, 207, 103225. [CrossRef]
- J.N. Goetz, A. Brenning, H. Petschko, P. Leopold, Evaluating machine learning and statistical prediction techniques for landslide susceptibility modeling, Computers & Geosciences 2015, 81, 1–11. [CrossRef]
- A.M. Youssef, B.A. El-Haddad, H.D. Skilodimou, G.D. Bathrellos, F. Golkar, H.R. Pourghasemi, Landslide susceptibility, ensemble machine learning, and accuracy methods in the southern Sinai Peninsula, Egypt: Assessment and Mapping, Nat Hazards (2024). [CrossRef]
- N. Sharma, M. Saharia, G.V. Ramana, High resolution landslide susceptibility mapping using ensemble machine learning and geospatial big data, CATENA 2024, 235, 107653. [CrossRef]
- F. Huang, J. Zhang, C. Zhou, Y. Wang, J. Huang, L. Zhu, A deep learning algorithm using a fully connected sparse autoencoder neural network for landslide susceptibility prediction, Landslides 2020, 17, 217–229. [CrossRef]
- J. Yao, S. Qin, S. Qiao, W. Che, Y. Chen, G. Su, Q. Miao, Assessment of Landslide Susceptibility Combining Deep Learning with Semi-Supervised Learning in Jiaohe County, Jilin Province, China, Applied Sciences 2020, 10, 5640. [CrossRef]
- D. Tien Bui, A. Shirzadi, H. Shahabi, M. Geertsema, E. Omidvar, J. Clague, B. Thai Pham, J. Dou, D. Talebpour Asl, B. Bin Ahmad, S. Lee, New Ensemble Models for Shallow Landslide Susceptibility Modeling in a Semi-Arid Watershed, Forests 2019, 10, 743. [CrossRef]
- B.T. Pham, I. Prakash, J. Dou, S.K. Singh, P.T. Trinh, H.T. Tran, T.M. Le, T. Van Phong, D.K. Khoi, A. Shirzadi, D.T. Bui, A novel hybrid approach of landslide susceptibility modelling using rotation forest ensemble and different base classifiers, Geocarto International 2020, 35, 1267–1292. [CrossRef]
- C. Wang, H. Jia, S. Zhang, Z. Ma, X. Wang, A dynamic evaluation method for slope safety with monitoring information based on a hybrid intelligence algorithm, Computers and Geotechnics 2023, 164, 105772. [CrossRef]
- M.D. Ferentinou, M.G. Sakellariou, Computational intelligence tools for the prediction of slope performance, Computers and Geotechnics 2007, 34, 362–384. [CrossRef]
- N. Wang, H. Zhang, A. Dahal, W. Cheng, M. Zhao, L. Lombardo, On the use of explainable AI for susceptibility modeling: Examining the spatial pattern of SHAP values, Geoscience Frontiers 2024, 15, 101800. [CrossRef]
- L. Breiman, No title found., Machine Learning 2001, 45, 5–32. [CrossRef]
- K. Xu, Z. Zhao, W. Chen, J. Ma, F. Liu, Y. Zhang, Z. Ren, Comparative study on landslide susceptibility mapping based on different ratios of training samples and testing samples by using RF and FR-RF models, Natural Hazards Research 2024, 4, 62–74. [CrossRef]
- D.R. Cutler, T.C. Edwards, K.H. Beard, A. Cutler, K.T. Hess, J. Gibson, J.J. Lawler, RANDOM FORESTS FOR CLASSIFICATION IN ECOLOGY, Ecology 2007, 88, 2783–2792. [CrossRef]
- W. Chen, X. Xie, J. Wang, B. Pradhan, H. Hong, D.T. Bui, Z. Duan, J. Ma, A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility, CATENA 2017, 151, 147–160. [CrossRef]
- P. Reichenbach, M. Rossi, B.D. Malamud, M. Mihir, F. Guzzetti, A review of statistically-based landslide susceptibility models, Earth-Science Reviews 2018, 180, 60–91. [CrossRef]
- P. Vorpahl, H. Elsenbeer, M. Märker, B. Schröder, How can statistical models help to determine driving factors of landslides?, Ecological Modelling 2012, 239, 27–39. [CrossRef]
- A. Brenning, Spatial prediction models for landslide hazards: review, comparison and evaluation, Nat. Hazards Earth Syst. Sci. 2005, 5, 853–862. [CrossRef]
- P. Reichenbach, M. Rossi, B.D. Malamud, M. Mihir, F. Guzzetti, A review of statistically-based landslide susceptibility models, Earth-Science Reviews 2018, 180, 60–91. [CrossRef]
- F. Guzzetti, P. Reichenbach, M. Cardinali, M. Galli, F. Ardizzone, Probabilistic landslide hazard assessment at the basin scale, Geomorphology 2005, 72, 272–299. [CrossRef]
- M. Di Napoli, H. Tanyas, D. Castro-Camilo, D. Calcaterra, A. Cevasco, D. Di Martire, G. Pepe, P. Brandolini, L. Lombardo, On the estimation of landslide intensity, hazard and density via data-driven models, Nat Hazards 2023, 119, 1513–1530. [CrossRef]
- N. Wang, H. Zhang, A. Dahal, W. Cheng, M. Zhao, L. Lombardo, On the use of explainable AI for susceptibility modeling: Examining the spatial pattern of SHAP values, Geoscience Frontiers 2024, 15, 101800. [CrossRef]
- S. Steger, M. Moreno, A. Crespi, S. Luigi Gariano, M. Teresa Brunetti, M. Melillo, S. Peruccacci, F. Marra, L. De Vugt, T. Zieher, M. Rutzinger, V. Mair, M. Pittore, Adopting the margin of stability for space–time landslide prediction – A data-driven approach for generating spatial dynamic thresholds, Geoscience Frontiers 2024, 15, 101822. [CrossRef]
- P. Magliulo, A. Di Lisio, F. Russo, Comparison of GIS-based methodologies for the landslide susceptibility assessment, Geoinformatica 2009, 13, 253–265. [CrossRef]
- L. Shano, T.K. Raghuvanshi, M. Meten, Landslide susceptibility evaluation and hazard zonation techniques – a review, Geoenviron Disasters 2020, 7, 18. [CrossRef]
- P. Lima, S. Steger, T. Glade, F.G. Murillo-García, Literature review and bibliometric analysis on data-driven assessment of landslide susceptibility, J. Mt. Sci. 2022, 19, 1670–1698. [CrossRef]
- N. Nocentini, A. Rosi, S. Segoni, R. Fanti, Towards landslide space-time forecasting through machine learning: the influence of rainfall parameters and model setting, Front. Earth Sci. 2023, 11, 1152130. [CrossRef]
- A. Dahal, H. Tanyas, C. Van Westen, M. Van Der Meijde, P.M. Mai, R. Huser, L. Lombardo, Space–time landslide hazard modeling via Ensemble Neural Networks, Nat. Hazards Earth Syst. Sci. 2024, 24, 823–845. [CrossRef]
- J.-J. Lee, M.-S. Song, H.-S. Yun, S.-G. Yum, Dynamic landslide susceptibility analysis that combines rainfall period, accumulated rainfall, and geospatial information, Sci Rep 2022, 12, 18429. [CrossRef]
- M. Ahmed, H. Tanyas, R. Huser, A. Dahal, G. Titti, L. Borgatti, M. Francioni, L. Lombardo, Dynamic rainfall-induced landslide susceptibility: a step towards a unified forecasting system, (2023). [CrossRef]
- T. Halter, P. Lehmann, A. Wicki, J. Aaron, M. Stähli, Optimising landslide initiation modelling with high-resolution saturation prediction based on soil moisture monitoring data, Landslides (2024). [CrossRef]
- P. Marino, D.J. Peres, A. Cancelliere, R. Greco, T.A. Bogaard, Soil moisture information can improve shallow landslide forecasting using the hydrometeorological threshold approach, Landslides 2020, 17, 2041–2054. [CrossRef]
- L. Schilirò, G.M. Marmoni, M. Fiorucci, M. Pecci, G.S. Mugnozza, Preliminary insights from hydrological field monitoring for the evaluation of landslide triggering conditions over large areas, Nat Hazards 2023, 118, 1401–1426. [CrossRef]
- Y. Peiro, L. Y. Peiro, L. Ciabatta, E. Volpe, E. Cattoni, Spatiotemporal Modelling of Landslide Susceptibility Using Satellite Rainfall and Soil Moisture Products through Machine Learning Techniques, (2024). [CrossRef]
- Y. Sun, D. Wendi, D.E. Kim, S.-Y. Liong, Deriving intensity–duration–frequency (IDF) curves using downscaled in situ rainfall assimilated with remote sensing data, Geosci. Lett. 2019, 6, 17. [CrossRef]
- V. Basumatary, B. Sil, Generation of Rainfall Intensity-Duration-Frequency curves for the Barak River Basin, Meteorol. Hydrol. Water Manage. (2017). [CrossRef]
- A.C. Mondini, F. Guzzetti, M. Melillo, Deep learning forecast of rainfall-induced shallow landslides, Nat Commun 2023, 14, 2466. [CrossRef]
- M.C. Levy, A. Cohn, A.V. Lopes, S.E. Thompson, Addressing rainfall data selection uncertainty using connections between rainfall and streamflow, Sci Rep 2017, 7, 219. [CrossRef]
- M.T. Brunetti, M. Melillo, S.L. Gariano, L. Ciabatta, L. Brocca, G. Amarnath, S. Peruccacci, Satellite rainfall products outperform ground observations for landslide prediction in India, Hydrol. Earth Syst. Sci. 2021, 25, 3267–3279. [CrossRef]
- T. Pellarin, C. Román-Cascón, C. Baron, R. Bindlish, L. Brocca, P. Camberlin, D. Fernández-Prieto, Y.H. Kerr, C. Massari, G. Panthou, B. Perrimond, N. Philippon, G. Quantin, The Precipitation Inferred from Soil Moisture (PrISM) Near Real-Time Rainfall Product: Evaluation and Comparison, Remote Sensing 2020, 12, 481. [CrossRef]
- H. Yang, K. Hu, S. Zhang, S. Liu, Feasibility of satellite-based rainfall and soil moisture data in determining the triggering conditions of debris flow: The Jiangjia Gully (China) case study, Engineering Geology 2023, 315, 107041. [CrossRef]
- Y. Hong, R. Adler, G. Huffman, Evaluation of the potential of NASA multi-satellite precipitation analysis in global landslide hazard assessment, Geophysical Research Letters 2006, 33, 2006GL028010. [CrossRef]
- F. Bucci, M. Santangelo, L. Fongo, M. Alvioli, M. Cardinali, L. Melelli, I. Marchesini, A new digital lithological map of Italy at the 1:100 000 scale for geomechanical modelling, Earth Syst. Sci. Data 2022, 14, 4129–4151. [CrossRef]
- Po River Basin Authority, 2006., Caratteristiche del bacino del fiume Po e primo esame dell’ impatto ambientale delle attivitá umane sulle risorse idriche (Characteristics of Po River catchment and first investigation of the impact of human activities on water resources), (n.d.).
- R. Vezzoli, P. Mercogliano, S. Pecora, A.L. Zollo, C. Cacciamani, Hydrological simulation of Po River (North Italy) discharge under climate change scenarios using the RCM COSMO-CLM, Science of The Total Environment 2015, 521–522, 346–358. [CrossRef]
- Y. Achour, H.R. Pourghasemi, How do machine learning techniques help in increasing accuracy of landslide susceptibility maps?, Geoscience Frontiers 2020, 11, 871–883. [CrossRef]
- X. Chen, W. Chen, GIS-based landslide susceptibility assessment using optimized hybrid machine learning methods, CATENA 2021, 196, 104833. [CrossRef]
- I. Cantarino, M.A. Carrion, F. Goerlich, V. Martinez Ibañez, A ROC analysis-based classification method for landslide susceptibility maps, Landslides 2019, 16, 265–282. [CrossRef]
- E. Volpe, S.L. Gariano, F. Ardizzone, F. Fiorucci, D. Salciarini, A Heuristic Method to Evaluate the Effect of Soil Tillage on Slope Stability: A Pilot Case in Central Italy, Land 2022, 11, 912. [CrossRef]
- D. Salciarini, E. Volpe, L. Di Pietro, E. Cattoni, A Case-Study of Sustainable Countermeasures against Shallow Landslides in Central Italy, Geosciences 2020, 10, 130. [CrossRef]
- G.J. Huffman, D.T. Bolvin, D. Braithwaite, K.-L. Hsu, R.J. Joyce, C. Kidd, E.J. Nelkin, S. Sorooshian, E.F. Stocker, J. Tan, D.B. Wolff, P. Xie, Integrated Multi-satellite Retrievals for the Global Precipitation Measurement (GPM) Mission (IMERG), in: V. Levizzani, C. Kidd, D.B. Kirschbaum, C.D. Kummerow, K. Nakamura, F.J. Turk (Eds.), Satellite Precipitation Measurement, Springer International Publishing, Cham, 2020: pp. 343–353. [CrossRef]
- P. Xie, M. Chen, S. Yang, A. Yatagai, T. Hayasaka, Y. Fukushima, C. Liu, A Gauge-Based Analysis of Daily Precipitation over East Asia, Journal of Hydrometeorology 2007, 8, 607–626. [CrossRef]
- L. Brocca, L. Ciabatta, C. Massari, T. Moramarco, S. Hahn, S. Hasenauer, R. Kidd, W. Dorigo, W. Wagner, V. Levizzani, Soil as a natural rain gauge: Estimating global rainfall from satellite soil moisture data, JGR Atmospheres 2014, 119, 5128–5141. [CrossRef]
- P. Filippucci, High-resolution remote sensing for rainfall and river discharge estimation, 2022.
- H. Gholami, A. Mohammadifar, Novel deep learning hybrid models (CNN-GRU and DLDL-RF) for the susceptibility classification of dust sources in the Middle East: a global source, Sci Rep 2022, 12, 19342. [CrossRef]
- Corder, Gregory W and Foreman, Dale I, Nonparametric statistics: A step-by-step approach, John Wiley \& Sons, 2014.
- Jan Hauke, Tomasz Kossowski, COMPARISON OF VALUES OF PEARSON’S AND SPEARMAN’S CORRELATION COEFFICIENTS ON THE SAME SETS OF DATA, (2011).
- A. Garg, K. Tai, Comparison of statistical and machine learning methods in modelling of data with multicollinearity, IJMIC 2013, 18, 295. [CrossRef]
- N.-D. Hoang, D. Tien Bui, A Novel Relevance Vector Machine Classifier with Cuckoo Search Optimization for Spatial Prediction of Landslides, J. Comput. Civ. Eng. 2016, 30, 04016001. [CrossRef]
- H. Hong, W. Chen, C. Xu, A.M. Youssef, B. Pradhan, D. Tien Bui, Rainfall-induced landslide susceptibility assessment at the Chongren area (China) using frequency ratio, certainty factor, and index of entropy, Geocarto International 2016, 1–16. [CrossRef]
- W. Chen, X. Xie, J. Wang, B. Pradhan, H. Hong, D.T. Bui, Z. Duan, J. Ma, A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility, CATENA 2017, 151, 147–160. [CrossRef]
Figure 1.
(A) Localization of the study area (in orange) within Italy; (B) Spatial distributions of landslides (red dots) in the study area [2017–2022].
Figure 1.
(A) Localization of the study area (in orange) within Italy; (B) Spatial distributions of landslides (red dots) in the study area [2017–2022].
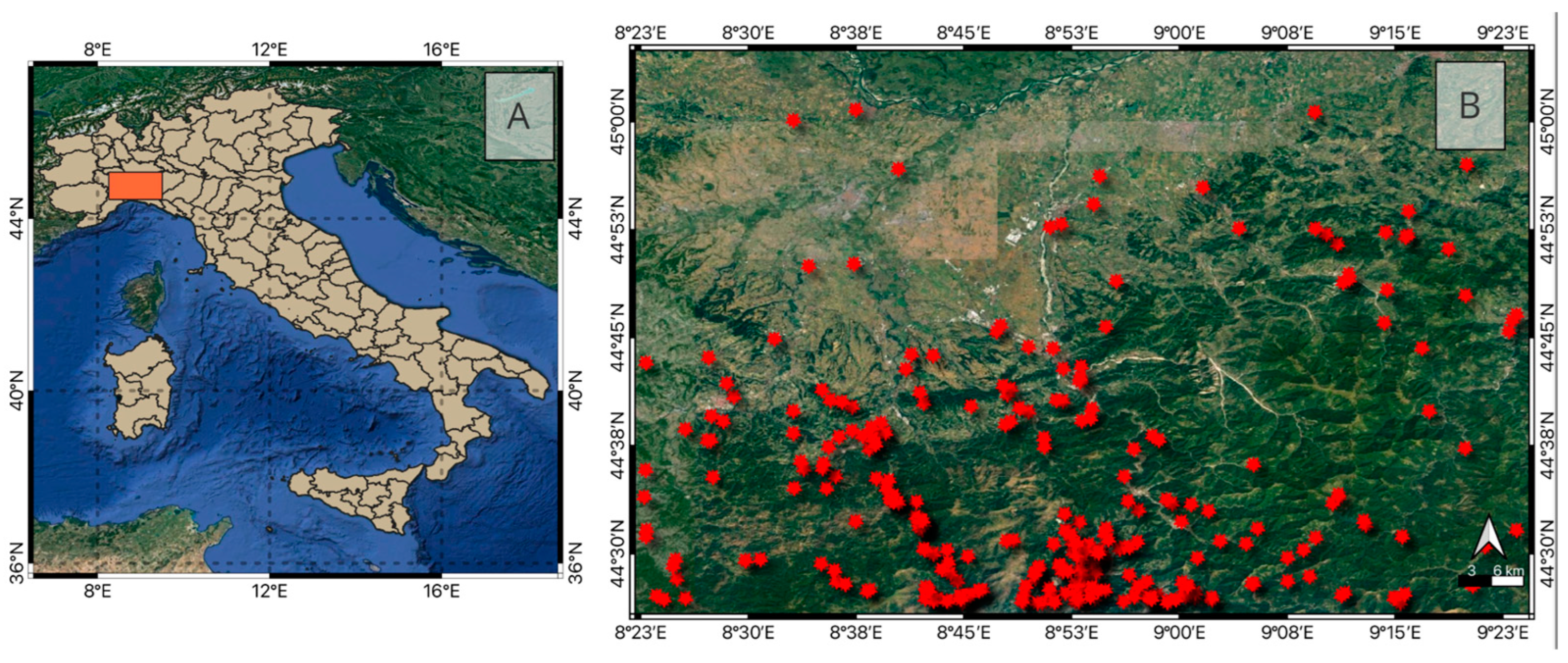
Figure 2.
Lithology distribution in the study area [60].
Figure 2.
Lithology distribution in the study area [60].
Figure 5.
Distribution of land cover (A) and the spatial distribution of NDVI (B).
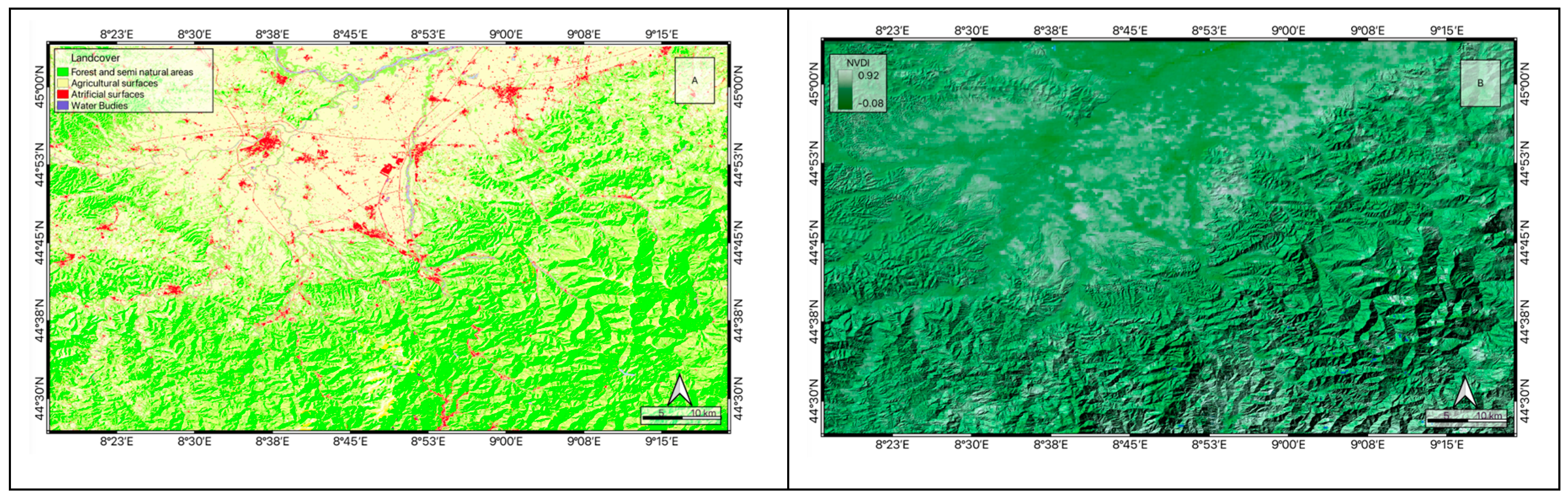
Figure 6.
RF model accuracy for different train/test split ratios (Figure 6 A); model’s tuning function (Figure 6 B and Figure 6 C); model’s performance (Figure 6 D).
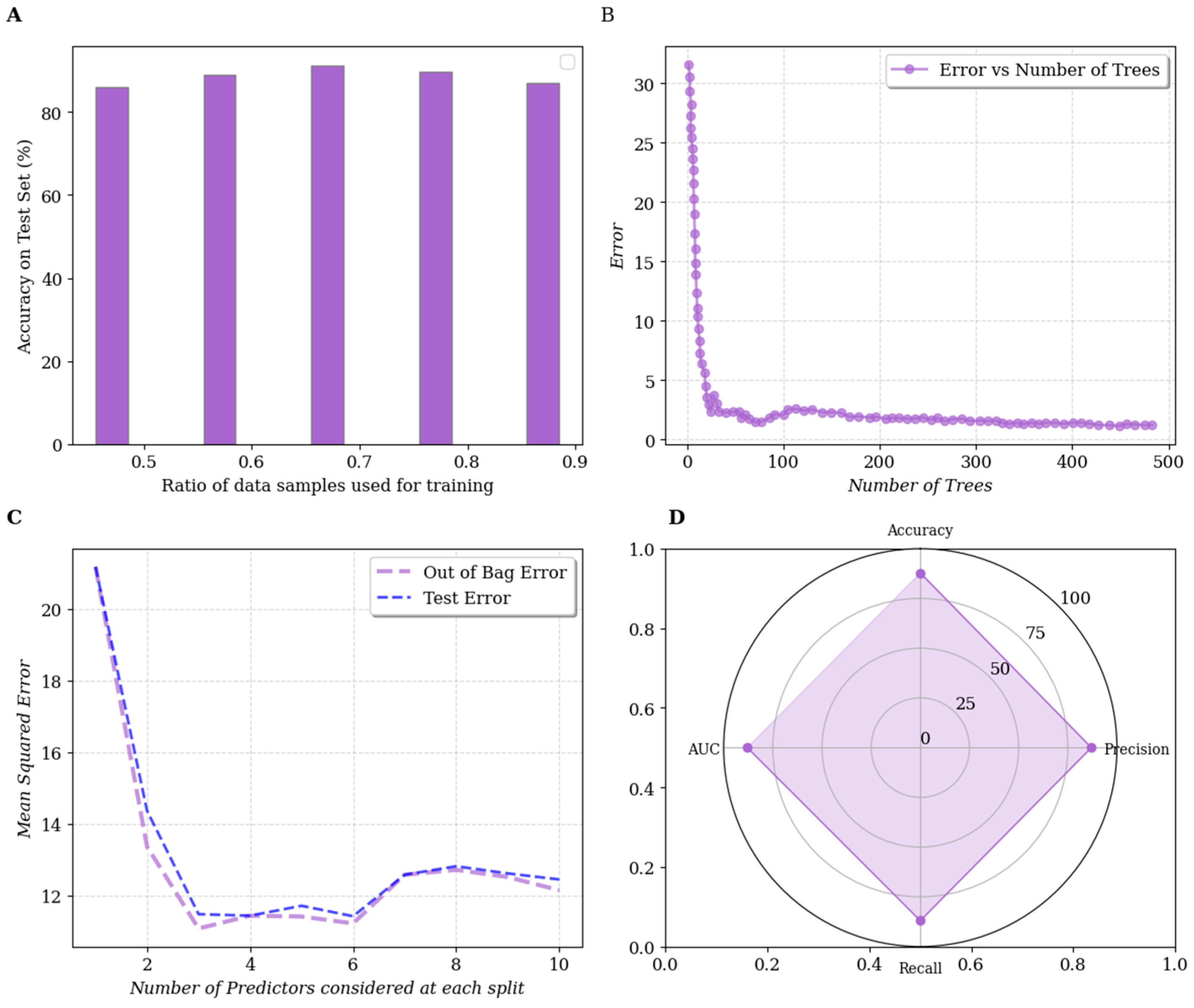
Figure 7.
Ranking of condition factors importance.
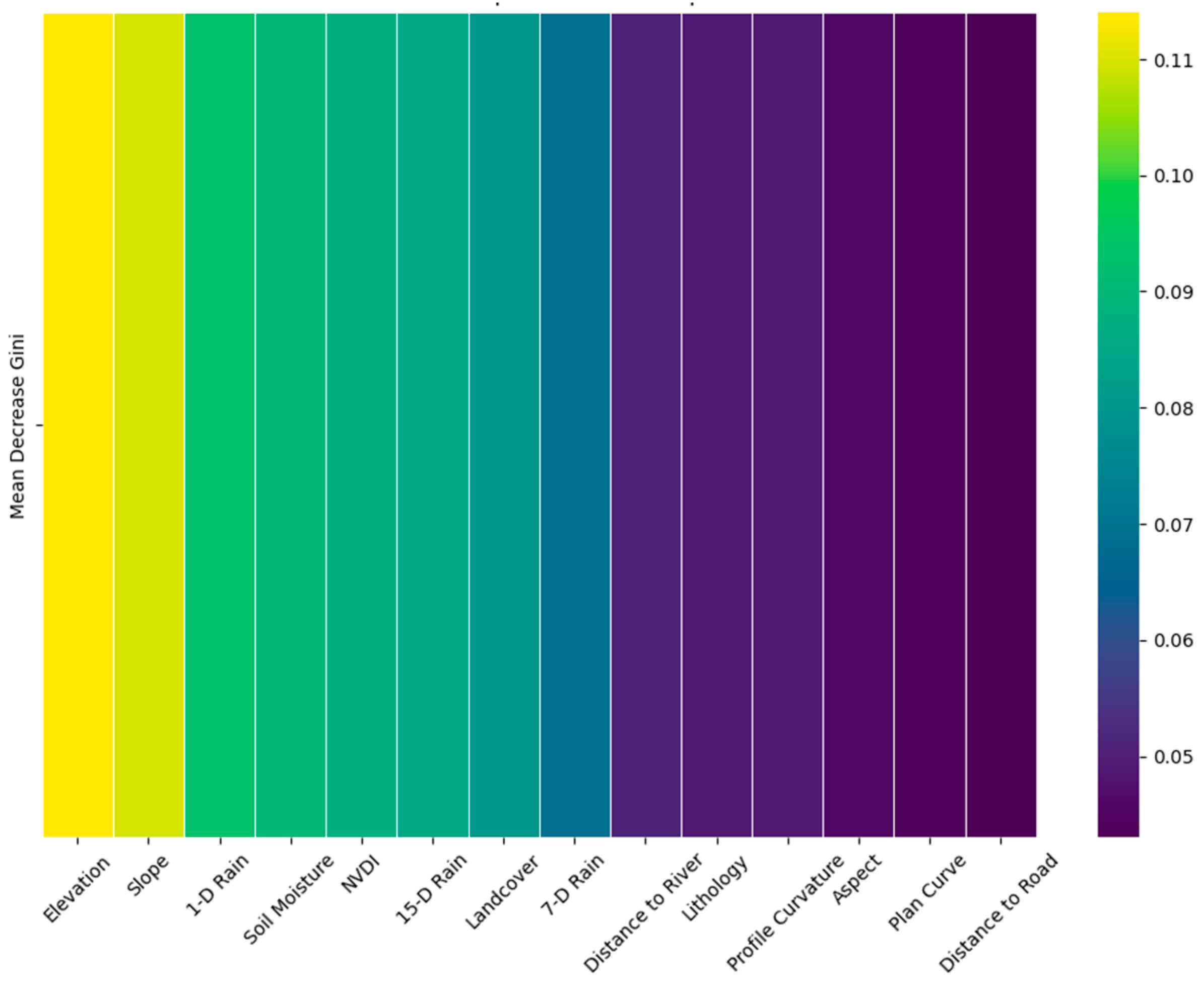
Figure 8.
Bar chart showing, for each day the maximum rainfall (red lines), the average rainfall (blue line). Pink bars show the cumulative 15-D rainfall and daily rainfall, in the studied period. The blue stars in the figure mark the two events chosen.
Figure 8.
Bar chart showing, for each day the maximum rainfall (red lines), the average rainfall (blue line). Pink bars show the cumulative 15-D rainfall and daily rainfall, in the studied period. The blue stars in the figure mark the two events chosen.
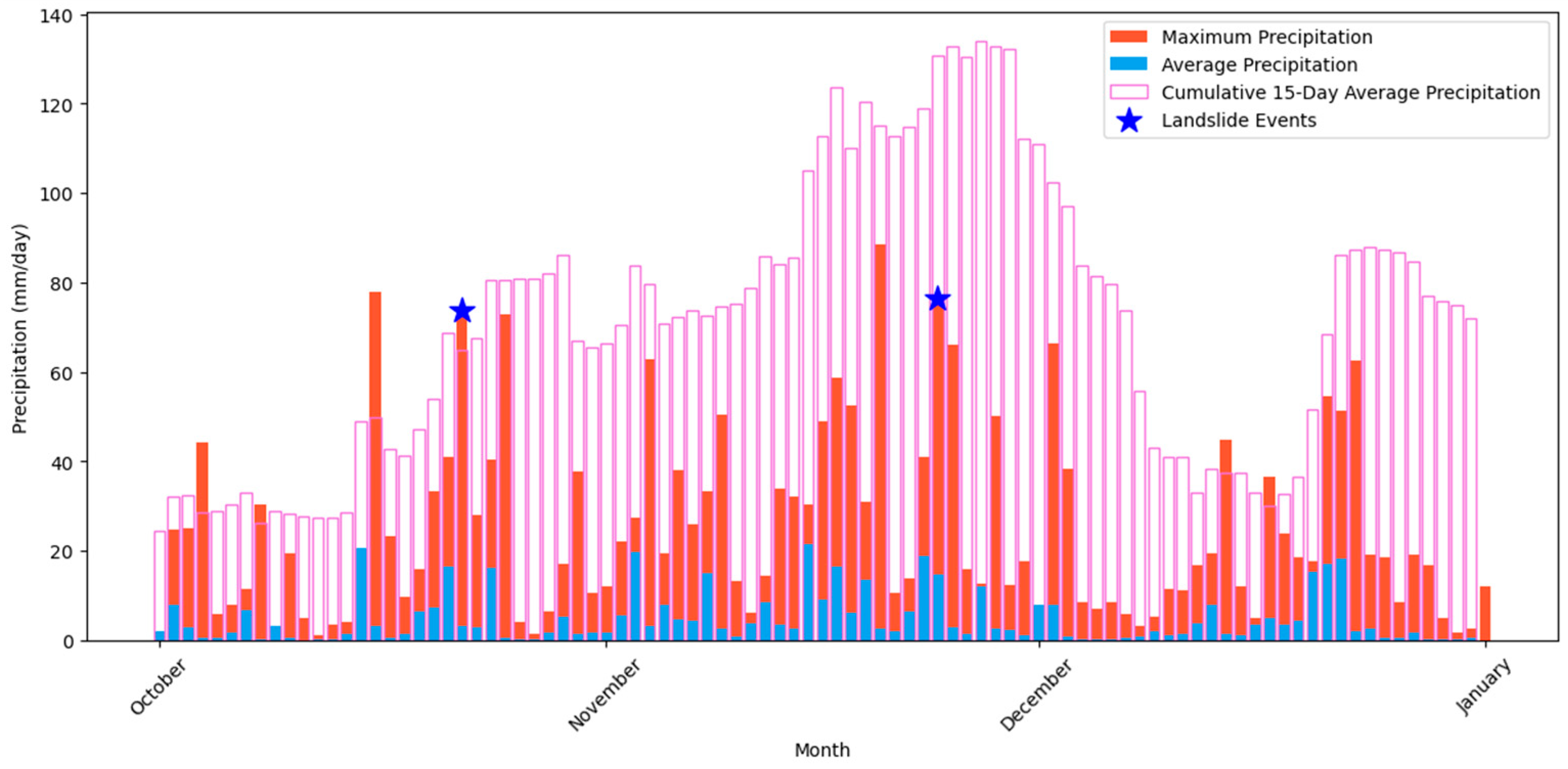
Figure 9.
In relation to the R1 rainfall event, the images show the spatial distribution of: i) average daily rainfall (A), the cumulative 15-D rainfall (B), soil moisture (C), Landslide susceptibility (D). The yellow stars symbolize the occurred landslides.
Figure 9.
In relation to the R1 rainfall event, the images show the spatial distribution of: i) average daily rainfall (A), the cumulative 15-D rainfall (B), soil moisture (C), Landslide susceptibility (D). The yellow stars symbolize the occurred landslides.
Figure 10.
In relation to the R2 rainfall event, the images show the spatial distribution of: i) average daily rainfall (A), the cumulative 15-D rainfall (B), soil moisture (C), Landslide susceptibility (D). The yellow stars symbolize the occurred landslides.
Figure 10.
In relation to the R2 rainfall event, the images show the spatial distribution of: i) average daily rainfall (A), the cumulative 15-D rainfall (B), soil moisture (C), Landslide susceptibility (D). The yellow stars symbolize the occurred landslides.
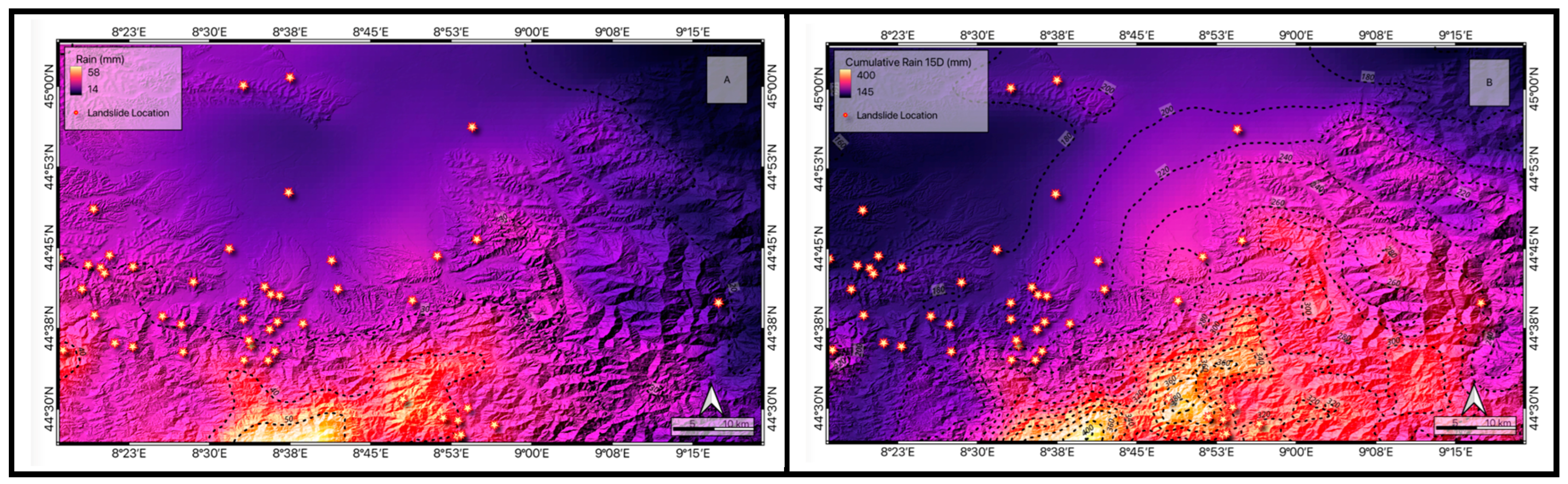
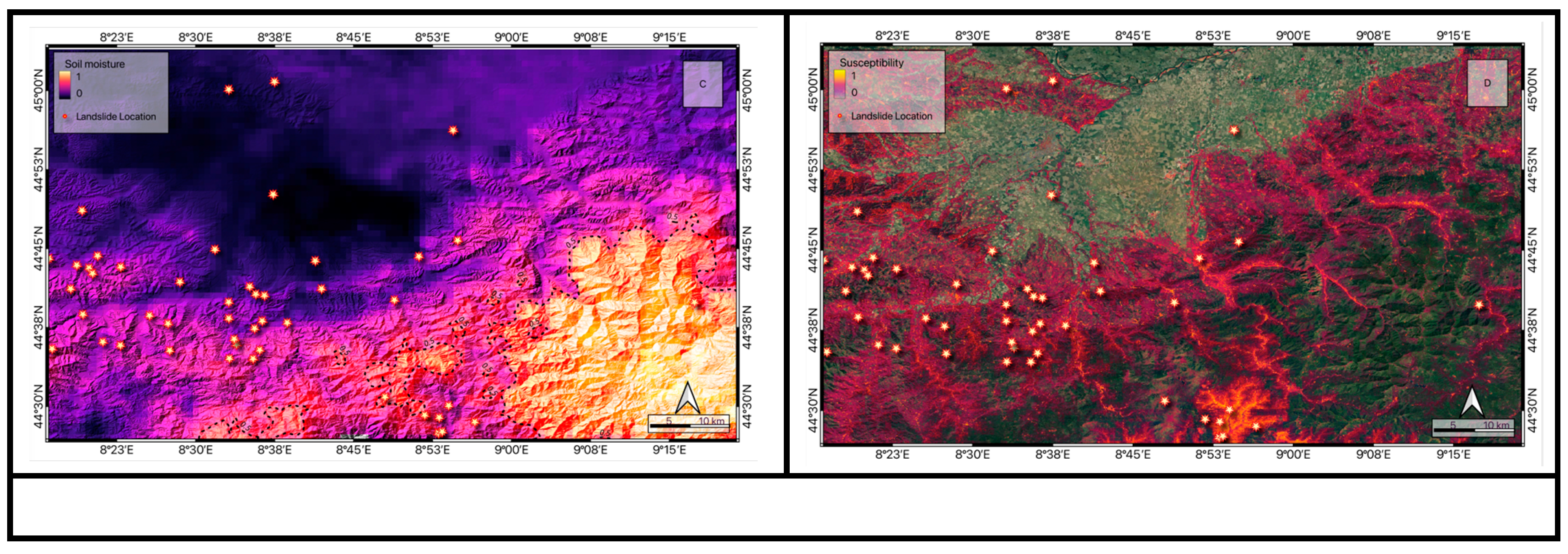
Figure 11.
For each pixel in the study area, the figures show: the difference of daily rain (A) and the difference of cumulative 15-D rain (B) related to R1 and R2.
Figure 11.
For each pixel in the study area, the figures show: the difference of daily rain (A) and the difference of cumulative 15-D rain (B) related to R1 and R2.
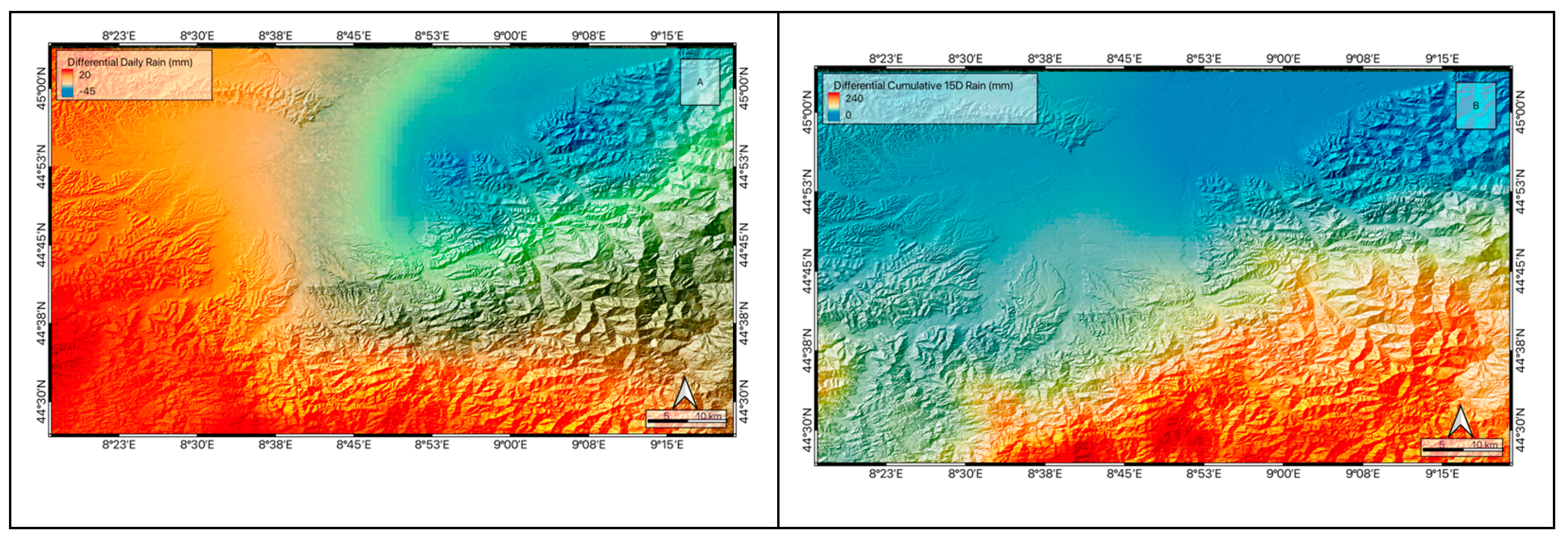

Table 1.
main characteristics of the products considered.
| Product | Spatial Resolution | Temporal Resolution | Temporal coverage | Source |
| IMERG-LR | 0.1° | 0.5 hour | 2002 – to date | NASA |
| CPC | 0.5° | Daily | 1981 – to date | NOAA |
| SM2RAIN | 1 km | Daily | 2017 – 2022 | TUWIEN |
Table 2.
Static and dynamic triggering factors considered in the analyses.
| Factor | Description | Surce,scale/resolution |
| Elevation | Digital elevation of the terrain surface | DTM, 10m |
| Slope angle | Angle of the slope inclination | DTM, 10m |
| Aspect | Compass direction of the slope exposure | DTM, 10m |
| Plan curvature | Curvature perpendicular to the slope, indicating concave or convex surface | DTM, 10m |
| Profile Curvature | Curvature parallel to the slope, indicating concave or convex surfaces | DTM, 10m |
| Geology | Lithology of the surface material | Geo-Map 1:100 000 |
| land cover | physical material on the surface of the Earth | CORINE Land Cover (CLC), 100 m |
| NVDI | An index to quantify the growth of green vegetation on land cover | Landsat 7, 10m |
| Distance to river | Distance to river | HyrdoSHED(SRTM),10m |
| Distance to road | Distance to road | CIESIN,10m |
| Soil Moisture | Amount of soil water content | GLEAM 4DMED, 1Km |
| 1-Day Rain | Amount of cumulative 1-d antecedent rainfall | 4DMED, 1Km |
| 7-Day Rain | Amount of cumulative 7-d antecedent rainfall | 4DMED, 1Km |
| 15-Day Rain | Amount of cumulative 15-d antecedent rainfall | 4DMED, 1Km |
Table 3.
Spearman’s correlation between pairs of fifteen condition factors.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



