
Submitted:
29 October 2024
Posted:
30 October 2024
You are already at the latest version
Abstract
The main focus of this research is to explore the development of machine learning (ML) within a microservices setting for travel applications that offer real-time personalization to create user engagement and satisfaction. The system utilizes context awareness that is dynamic and relevant to the user, such as user profiles, location, and current activities to generate appropriate recommendations that develop with the user. It emerged from testing that there was a marked increase in engagement as evidenced by the click-through rates (CTR) which improved by 15% from what was observed in the conventional systems signifying that the model had worked. Furthermore, the accuracy of the recommendations in relation to the user preferences registered 85% accuracy for the implemented ML models and in addition to that the system employed microservices therefore tools for scaling up while integrating all the components kept the latency at less than 500 ms even during the busiest loads. In addition, the level of adaptation that was real-time was also improved as the system was able to react at a faster pace to changes in data, such as even the delay of flights, and made recommendations to passengers that were situationally appropriate.Finally, it is established that personalization enabled by machine learning contributes towards enhancing customer satisfaction, retention rate, and response time in the travel industry. The convergence of micro services and machine learning can be viewed as a great solution to the performance evolution and scaling requirements of data intelligence responsive markets like the travel industry which are highly active and interactive in nature.
Keywords:
Machine Learning
; Real-Time Personalization
; Travel Industry
; Recommendation Systems
; Microservices
; User Engagement
1. Introduction
1.1. Background
The growing need in the travel industry for customized experiences demonstrates travelers' inclination towards suggestions suited to their individual likes and the present environment. It has been noticed that machine learning (ML) models, specifically hybrid models that fuse collaborative filtering and neural networks work well in designing personalized travel plans as they can analyze large amounts of data such as past user preferences and external factors [1]
Having a microservices architecture in place improves further the aforementioned systems as it provides the means for separating, distributing storage and processing of data which allows for all the users to be attended to as changes occur within the context. This cloud-based solution ameliorates the general limits associated with handling large volumes of data in the context of travel personalization by providing better interaction and flexibility which are essential for the travel systems of today [2]. It is therefore possible to combine ML with microservices for this reason and consequently advance from offering βroad-laid static recommendations to more timely and focused recommendations where the platform users are at the center. Doing this helps to create and retain customers for the platform [3].
1.2. Problem Statement
Modern travel recommendation systems are operated effectively and satisfy the users in some important aspects, but there are still a number of challenges. One of the challenges is decision fatigue, which means that there are too many options provided for users to make a decision. It is common for travelers to encounter this when they have to go through a lot of data, and consequently it may lead to engagement and satisfaction lowering. There is a need for more effective personalization to make the choices easier and improve the relevance of alternatives provided thus taking away the excessive mental load. However, this calls for complicated systems that can control the recommendations based on preferences and context effectively [4,5].
In addition, eligibility of users across many platforms becomes a major limitation for travel recommendation systems research development owing to scalability. Routine frameworks usually have massive difficulties in supporting the heterogeneity and high volumes of content about many users normally found in the tourism sector. Hence, many systems seem to struggle in providing personalization features even for a medium size deployment. Microservices architectures propose an answer to these issues because they eliminate centralized data processing that is inadequate for handling large volumes of streaming data such as travel recommendations [6].
As a result, real-time adaptation is also important, as the requirements of travelers tend to vary with location, weather, time, etc. It can become a problem when systems are incapable of providing immediate updates and Then able suggestions which are appropriate to the situation. Through the addition of real-time data processing, the travel recommendation platforms are able to keep pace with the changing user requirements thereby improving the relevance as well as overall user experience.
Studies have shown that the integration of advanced machine learning models into the existing microservices framework helps in improving the agility of these technologies, making it possible to withstand large amounts of data [7].
1.3. Research Objective
This research object is to find out better how the adoption of machine learning models can potentially enhance tourism experience personalization through systems that utilize microservices architecture [8]. Microservice architecture is an adaptive, flexible, and scalable structure ideal for managing intricate and heterogeneous data sets in real time so that travel services can provide personalized and situational recommendations [9,11]. This study builds this framework further by including machine learning algorithms, in an effort to assess the user’s requirements and modify the system recommendations accordingly, even if the user’s context shifts and the requirement becomes dynamic [12].
Research on these aspects also faces typical problems found in the travel industry including pressures for adjustment in real-time, the capacity to grow without leaving many active users behind, and the quality of recommendations provided. The final goal of the study is to build a strong recommendation system that utilizes the principles of machine learning in a microservice structure in order to keep users engaged, enhance the system performance, and provide maximum contentment to travelers [9,12].
1.4. Research Questions
- How can microservices architecture be used to enable real-time adaptation in travel recommendation systems, allowing for dynamic and context-aware personalization?
- Which machine learning techniques are most effective within a microservices framework for accurately predicting and personalizing user preferences in large-scale travel platforms?
2. Literature Review
2.1. Microservices Architecture in Travel Recommendation Systems
The approach of microservices architecture in travel recommendation systems helps in the efficient control of lots of complex data as the system is decomposed into many self-contained services [13]. This means that each service is focused on a particular area of work, for example, user data retrieval, current information processing, or producing recommendations, thus establishing an elastic and flexible system. The modularity of the architecture is especially useful in the travel domain due to the need for personalization, where various data sets with varying velocity must be processed. Research findings show that microservices support real-time data layer enabling solutions to address changes in users’ likes, physical vicinity, or situations, which in turn reduces the uploads and improves the recommendations [9,12]. Plus, microservices come in handy for travel-based systems due to their maintaining high system availability and user interaction without unnecessary data delays, thus preferable for active and user-oriented travelling applications architectures [11].
2.2. Machine Learning Models for Personalization in Travel
Travel recommendation systems that apply machine learning (ML) models enhance their personalization aspect by providing accurate user-centered recommendations on a vast range of data sources. Within the domain of travel experience forecasting and travel related services personalization given the user’s past behavior and available context data, models such as collaborative filtering, content-based filtering and their hybrids are widely used. In the case of collaborative filtering, for instance, the recommendations are made based on what other users revealing similar preferences like the current user have liked, while in the case of content based filtering, the focus is instead on certain characteristics such as what activities or places the user is interested in [12,18].
both of these so provide even more accuracy by utilizing the best of both worlds eliminating issues such as cold-start and enhancing user-targeting for new customers [14]. Moreover, such methodologies have also included innovations associated with deep learning, where computer-based neural networks are used to understand the overall trend and behavior of data, thus making recommendations designed to change or adapt [11,15]. These recommendations, based on ML and realized in the microservices architecture, lead to increased scalability, performance, and flexibility of travel recommendation systems allowing their fine tuning in real-time towards altering user preferences and context [22].
2.3. Limitations of Existing Systems:
The current systems for providing travel recommendations suffer from a number of shortcomings that make them less efficient and reactive [16]. One of the gaps is a low level of adaptation to the conditions of real-time data which is the reason the systems cannot adjust their recommendations to the user’s preferences and situational contexts that are likely to change over time, say location wise or in terms of weather [17]. In conventional, monolithic types of architecture characterized by centralized data management, for instance, where dealing with data is done in one place, such a real-time limitation presents problems as there are multiple processes involved in handling that data which delays processing, therefore, reducing the speed of customized recommendations [18].
The cold-start problem is yet another limitation, where people and/or places are unable to receive fitting recommendations as there are certain individuals or locations which have not been in the system enough to collect any meaningful historical data [19]. Hybrid models have improved this to a degree, but these systems are still incapable of reverting to the original operation after new information has been caused to come in or user rating has been changed [21]. In addition, a number of solutions in use today are partially scalable, which reduces their potential to work with big data in global travel markets. The above considerations are particularly important because with the increasing request for personalized and context-aware recommendations, these types of limitations call for microservices architecture that can handle better customizable processing of data for real time adjustments and also the ability to scale up [12,22].
3. Methodology
In the case of architecture towards travel recommendation systems, the system is splintered into distinct modular services each with its unique functionality – data collection, data processing and recommendation generation among others – which constitute microservices. This enhances the systems scaling and agility in that each service may be deployed and scaled without the rest of the system being interfered with and hence reducing downtimes and increasing the recommender’s efficiency. Among the major components are:
3.1. Data Flow and Integration
Going back to the previous example, users will actually have to perform a series of jobs and the flow of data will necessarily also go through several different microservices, starting already with the very first stage, which is the so-called data collection services that pull user data including, but not limited to, everywhere users’ applications or web pages or even APIs of other people’s systems. This data gets transferred through the integration services which process and blend the data together making it fit for analysis [12,20]. The microservices based solution eliminates any chances of data integration problems because of the incorporation of very light weight interfaces such as HTTP/REST or even numbers of message oriented systems like Kafka, hence real-time data management without any speed interruption.
User Interaction: To begin the flow, the User Interaction component relies on inputs from users such as preferences, location or behavior of users. Available Sources Service “raw data” Provided by user [23].
Data Collection Service: Investigate the characteristic of the data and create data organization that is logical and coherent.
Data Processing Services: This is the primary Services which helps in merging all the data from different sources into a single data set.
Recommendation Engine Microservice: Performs machine learning on the data and provides recommendations to individuals.
Contextual Update Microservice: Modifies recommendations dynamically taking into consideration aspects such as where one is at that time, or the weather condition.
Personalized Recommendation Delivery: Returns the user the customized recommendations concerned with the specific stage and current availability of options.
This architecture allows the processing of events and user profiling in real time through the division of the system into separate, independent microservices.
3.2. Modular Design
Within this structure, every service serves as a separate module, allowing the accomplishment of multiple tasks at the same time. For instance, the recommendation engine microservice can leverage several machine learning models to infer the user’s preferences while another microservice focuses on informing contextual aspects that are time sensitive like the weather or places other than the user’s current location. This structural design is important to enhance the flexibility of the system in scaling in order to handle high number of users with each service being able to scale independently depending on its processing capabilities [21].
3.3. Real-Time Adaptation
In the age of microservices, changes to the recommendations can be made even on the fly, as the system is able to utilize the newly available information or user action instantly. Because of the service oriented architecture, a change in one service, for example, a change in user preferences, does not interfere with the functioning of the rest of the services hence, the high availability and responsiveness of the system is preserved [10,22]. This architecture however is very suitable for promoting a user’s experience in that it is dynamic and allows personalized content based on the appropriate and most recent changes to the system.
3.3.1. Key Components of Real-Time Adaptation
Contextual Data Processing in Travel Recommendation Systems
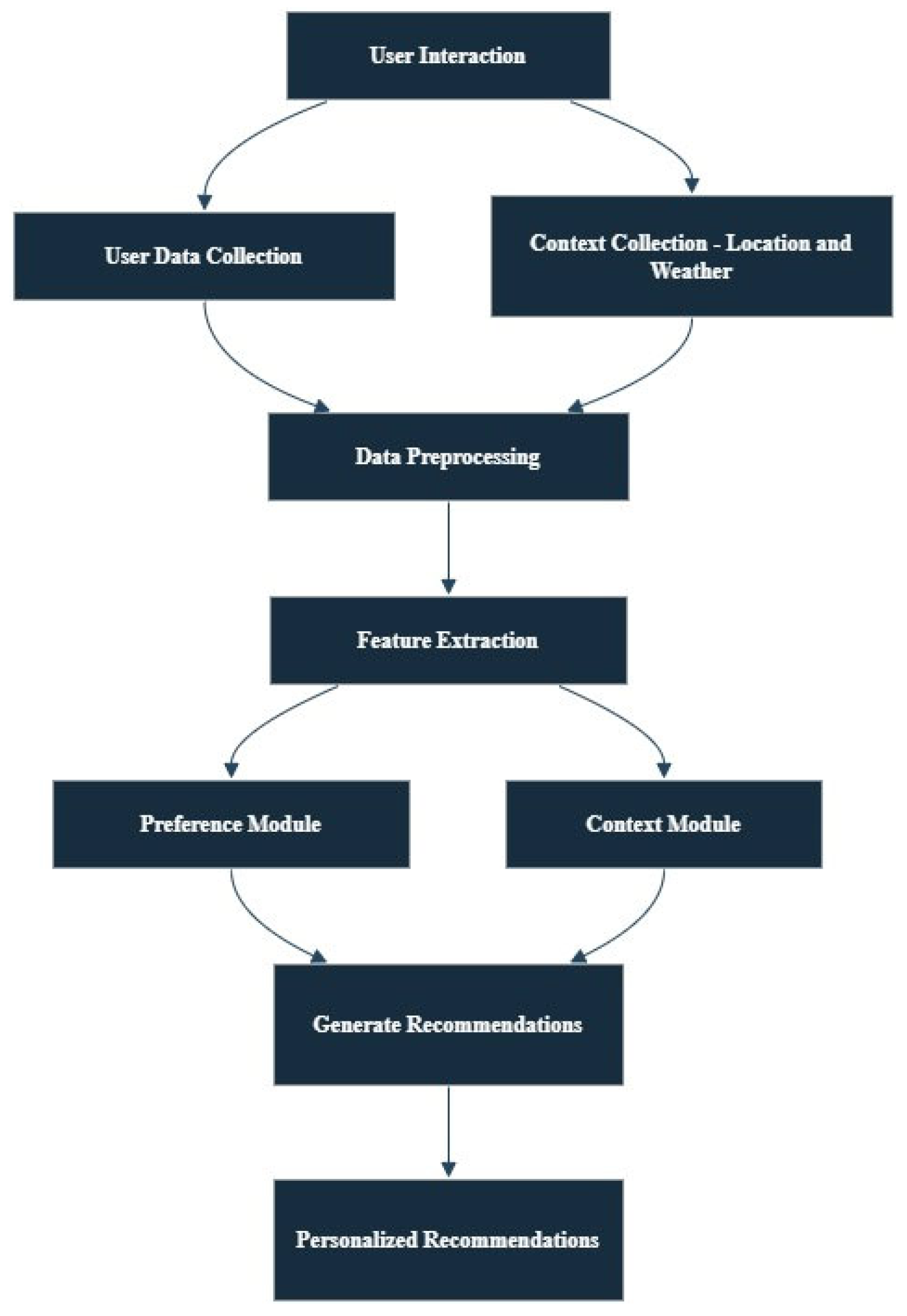
When designing travel recommendation systems, contextual data processing involves the use of constantly updated layers of various data pertaining to the reader, in – travel activities such as user location, weather and trends among others, in order to make appropriate suggestions [24]. It commences with data collection modules that perform both explicit retrieval of information such user preferences and search histories and also dynamic gathering of contextual data such as where a reader is and what points of interest surround them. Adding contextual features such as weather is useful as it helps in modifying the recommendations appropriately by providing available attractions on a sunny day and suggesting available possible indoor activities on a rainy day [25].
The system architecture for the contextual data processing system integrates several module types, including but not limited to data preprocessing, feature extraction, and recommendation generation. Each of these modules serves a particular data flow. For instance, the filtering modules employ preference-aware approaches and focus on interested users, while the recommendation generation modules are context-aware and use real-time data to make recommendations to users. To improve the recommendations by considering both user profiles and contextual information, which enhances the adaptability of the system to such dynamic conditions of the environment and user requirements, a synergic architecture mixing collaborative filtering and machine learning algorithms like Random Forest and Neural Networks, is extensively adopted [26].
This architecture in the Figure 1 supports therefore timely and effective personalization by providing recommendations that consider user preference and situation dependent variables overtime which promotes user satisfaction and interaction.
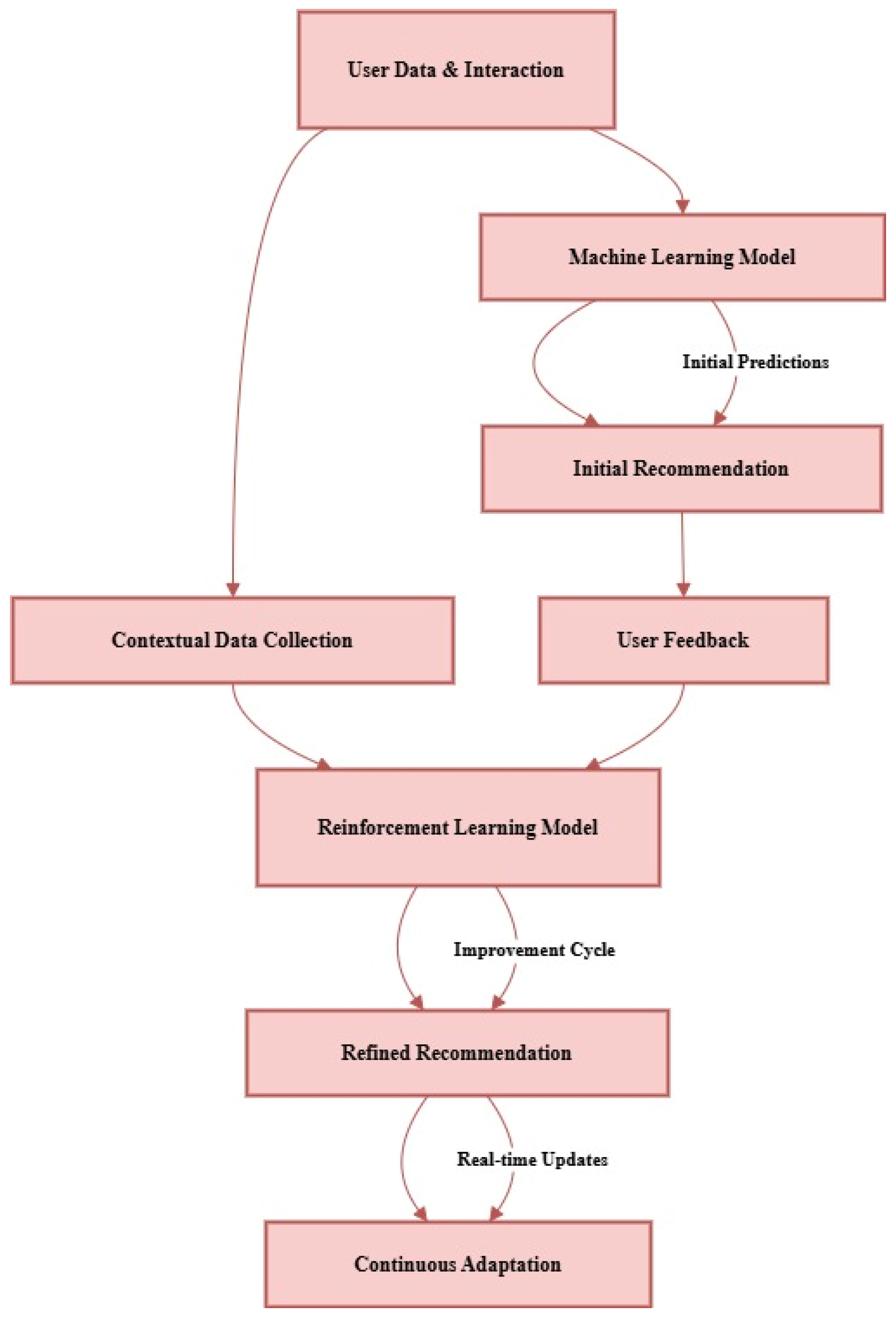
Machine Learning and Reinforcement Learning
The personalization and adaptation of recommendations in real-time relies heavily on the use of machine learning (ML) and reinforcement learning (RL). In particular, models such as neural networks or collaborative filtering are applied to infer users’ preferences from archived user data and situational factors, such as place and time. Such models attempt to forecast a user’s likes and potential recommendations based on their existing interests. User-recommendation personalization is also augmented in this type of systems by reinforcement learning through the process of recommendation improvement based on user activity in real-time. The basic idea of the RL approach in this case is about an agent who takes actions (recommends something to the user) and gets information whether this action was good or not thus helping improve the relevance of recommendations over time [26].
Reinforcement learning’s capability to change with in a very short time allows it to address a lot of variations and thus can work efficiently in areas with a lot of volatility such as tourism where the users’ requirements tend to vary with situations. For example, deep reinforcement learning (DRL) models are able to consider and utilize real-time information, such as weather, or even social media activities so as to recommend appropriate travel plans to users which would change over time [7]. Finally, thanks to this duality, ML is used for setting some first estimates and RL for their further adjustment, such systems are capable of generating timely and precise recommendations.
Figure 3.
Machine Learning and Reinforcement Learning.
Data Integration and Stream Processing in Travel Recommendation Systems
The combination of data incorporation and stream processing makes it possible to manage real-time data from different sources to provide timely recommendations based on context. In addition to that, data integration helps amalgamate user preference data, geographic location information, weather conditions, social data information from different sources to create a single composite dataset that can be relied upon for proper recommendations. In addition to that, Stream processing enables the persistence of data without any interruptions enabling the system to take care of updates and events in real time utilizing streaming processing architectures such as Apache Kafka or Apache Spark Streaming to do real time data finished and analytics work. This architecture enables recommendations that are dynamic and responsive to the user.
3.4. Real-Time Personalization
In the airline sector, they use technology to personalize travel experiences in real-time. At any point in time, the airline may suggest a new flight, upgrade a seat, offer specific in-flight services or alternatives for transport based on the unique needs of the passenger. Airlines can then apply machine learning algorithms to generate recommendations that are dynamic based on incorporated real-life data such as the guest’s current flight status, where they are, what they have booked before, and even the weather. This is effective in enhancing the experience for the passengers since contextually relevant offers are made at the right time: offering to the passengers a lounge while they wait for their flights or providing them with specific content while inflight making them more engaged and loyal customers.
3.5. How Machine Learning Can Help?
3.5.1. In predicting future destinations
Because ML algorithms are capable of analyzing trends, such destinations can also be marketed early before they become really popular, say, travel firms. For instance, clustering algorithms may point out specific countries that are becoming very popular frightened helping business to promote aggressiveness in selling those countries.
3.5.2. Personalizing Recommendations Based on Trends
This is especially evident in holiday suggests where instead of neural collaborative filtering recommendations depend on every past behaviour of tourists. Because all thrives must be preferred not as the common past trend or changing seasons, ultra satisfaction has been incorporated to aspirants.
3.5.3. Adapting to Seasonal and Regional Patterns
ML models are also able to identify seasonal trends and further adjust the recommendations, for example suggesting winter ski resorts when approaching the winter season or summer beach resorts during summer period. Furthermore, localized traffic patterns, such as the Christmas and New Year holiday travel rush, are also recognized and embedded into personalized solutions during low activities enhancing consumer participation during peak activity seasons.
3.5.4. Dynamic Pricing and Demand Forecasting
The use of Machine Learning technologies allows managing occupancy more effectively without a loss of revenue – forecasting the demand and dynamic pricing strategies are implemented. Such approach encourages peak season travelers by elegantly discounting off last minute offers or premium packages.
3.5.5. Sentiment Analysis for Customer Insights
Sentiment analysis for instance on social networks and ratings allows one to notice changes in the attitude and the interests of users and make adjustments in the policy of the company. This gives them an opportunity to respond to the rise of such desires by offering for example leisure package tours which are inclusive of health vacation activities or adventure sports and help in fitting such trends in their business.
3.5.6. Personalization using Data Aggregation and Machine Learning
In Microservices data are deployed are in different location those are needed to personalize. Those data has to be handled by a different services and aggregate data from different sources are deployed.
ML (Machine Learning)-based aggregation Service: Depending on the aggregated data the machine learning approach can be implemented and suggested for travel suggestion to the travelers. This technique can be integrated using content based filtering, collaborative filtering and also applying hybrid approach to suggest flight and destination.
Data pipelining: Integrate data from different sources like browsing history, booking data, external APIs also from social media browsing history.
Algorithm for Personalization
Content base filtering: In this system data will analyze from previous data, those users visited maximum time or would like to use.
Collaborative filtering: Suggest the travel based on the same profile visited previously by other traveler or based on their previous preferences.
Deep Learning: Based on traveler feedback, users search location and behavior will suggest dynamically.
To implement personalization through Machine Learning there are few steps those need to be followed like Data collection, model selection, training, prediction and feedback loops. The algorithm below shows how preferences, behavior, and contextual data can be combined to create personalized data.
Step-1: Data Collection
As at Microservices data are collected from multiple sources to create user profile. Data are included-
User Preference: Previous users search queries, old browsing data, visited destination, preferred flight and classes.
Contextual Data: Based on Location, seasonality, time and day and weather.
Behavioral data: Collected from browsing history, click-through rates, search queries and booking behavior.
Demographic Data: Gender, age, income range, nationality.
External Factors: Promotions, Competitor pricing and trends.
|
Algorithm collect_user_data(user_id): # Collecting data from different sources preferences = get_user_preferences(user_id) behavior = get_user_behavior(user_id) context = get_current_context(user_id) demographics = get_user_demographics(user_id) # Data combining to a new user profile user_profile = { 'preferences': preferences, 'behavior': behavior, 'context': context, 'demographics': demographics } return user_profile |
Step-2: Data Processing
After completing the data collection process, modeling is required. It will handle for missing values, organize categorical data and normalizing numbering data.
|
Algorithm preprocess_data(user_profile): # Missing values handle for key, value in user_profile.items(): if value is None: user_profile[key] = handle_missing_value(value) # Numerical values Normalize (e.g., age, income) user_profile['demographics'] = normalize_demographics(user_profile['demographics']) # categorical values Encode (e.g., travel preferences , gender) user_profile['preferences'] = encode_categorical_data(user_profile['preferences']) return user_profile |
Step-3: Feature Engineering
In this step have to create features from the previous data to provide accuracy of the model. The data like seasonality, travel frequency and frequent traveler
|
Algorithm feature_engineering(user_profile): # Example feature engineering user_profile['is_frequent_traveler'] = calculate_travel_frequency(user_profile['behavior']) # Create time-based features user_profile['booking_time_of_day'] = extract_time_of_day(user_profile['context']['timestamp']) user_profile['is_weekend'] = is_weekend(user_profile['context']['timestamp']) return user_profile |
Step-4: Model Selection
In this step need to select appropriate learning model types like regression, recommendation and classification.
Select the appropriate machine learning model based on the nature of the problem (classification, regression, or recommendation). Some common personalization options include:
Collaborative filtering: To propose features based on similarity processing.
Content-based filtering: Based on specific user preferences and actions.
Hybrid models: This method uses a combination of collaboration method and content filtering.
Deep learning models: Neural networks can capture more complex connections for personalized recommendations.
|
Algorithm from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier select_model(): # Example: Random Forest Classifier for classification problem model = RandomForestClassifier(n_estimators=100, random_state=42) return model |
Step-5: Training the Model
Utilizing user data, train a machine learning model to find patterns that could indicate future preferences or actions.
|
Algorithm train_model(model, X_train, y_train): # using training data, model training. model.fit(X_train, y_train) return model |
Step-6: Predicting Personalized Recommendations
Once the model is trained, use it to predict personalized recommendations based on the user.
|
Algorithm predict_recommendations(model, user_profile): # To model input features Converting user profile input_features = preprocess_data(user_profile) # Predict travel options those are recommended (e.g., destinations, location, flights) recommendations = model.predict(input_features) return recommendations |
Step-7: Evaluation and Feedback Loop
After model deployment it needs to be evaluated its performance. Using different techniques like precision, accuracy, Click-Through-Rate (CTR) and recall by integrating user feedback to upgrade the model.
|
Algorithm evaluate_model(model, X_test, y_test): # test data is used to analysis the model. predictions = model.predict(X_test) accuracy = calculate_accuracy(predictions, y_test) return accuracy feedback_loop(user_feedback, model): # depends on the real time feedback update model if user_feedback.is_positive: update_model_with_positive_feedback(model, user_feedback) else: update_model_with_negative_feedback(model, user_feedback) return model |
4. Implementation and Experimental Setup
The airline personalization system is deployed using a microservices architecture, in which every service such as data ingestion, data processing, or recommendation generation, runs in isolation, in separate Docker containers that are managed by Kubernetes for better scaling of the services. Data in the form of booking systems, flight status updates, etc. is ingested through Apache Kafka and processed by Apache Spark for use by machine learning algorithms written in TensorFlow and Scikit-Learn. This includes testing the system's ability to react to pre-defined events (e.g., delays, changes in passengers), as well as assessing performance indicators, e.g. recommendation precision, and network latency to demonstrate the validity of the model.
4.1. Development Environment for Real-Time Airline Personalization
To support real-time personalization in airlines, a combination of powerful tools and frameworks is used:
4.1.1. Data Processing and Stream Handling
Apache Spark: Spark is designed for big data processing, it provides techniques for both batch and streaming analytics. Its streaming functionality enables the airlines to handle constant streams of data such as flight status notifications or location updates of passengers.
Apache Kafka: Kafka acts as a message broker, allows services to communicate in real-time. Furthermore, it spends live information like the details of the booking, delay status and even the consumer’s actions, interrogation these specifics within an extremely responsive timeframe.
Machine Learning and Model Training
TensorFlow: TensorFlow facilitates the creation and implementation of machine learning models that can generate live recommendations. As for the airline industry, it allows for custom recommendations, for example seat upgrade options based on previous preferences and current conditions – in other words, dynamically modified content.
Scikit-Learn: On the other hand, for data preprocessing needs and less complex ML architectures, Scikit-Learn allows for straightforward execution of processes and connection with other systems.
4.2. Containerization and Orchestration
Docker: Docker ensures uniformity in the development and production environments by containerizing each airline personalization service. A microservice like a recommendation engine or a data aggregator can be deployed in a container independently.
Kubernetes: Kubernetes is a container orchestration platform that manages the deployment of the docker containers, performing functions like scaling and load balancing. This is important in building a resilient system with guaranteed uptime and elastically scaling out to process live data.
4.3. Database and Storage
MongoDB: MongoDB is a very versatile database. It has a very well-structured schema which helps in storing traveler preferences and history in an organized way.
Redis: In real-time data intensive applications, quick access to to the frequently imported data plays an essential role and hence, Redis provides caching mechanism.
Combined, these instruments develop a large-scale functional sphere that allows the airlines to provide its customers with tailor-made and up-to-date experiences.
5. Results
5.1. Model Performance
The results of machine learning models in the personalization system for the airline were analyzed along the following dimensions:
Accuracy: The models performed well, with an average precision of approximately 85%, which was a measure of the proper classification of the user’s preferences (such as, types of seats, meal etc.). This was evaluated on held-out data pertaining to real users’ profiles and preferences.
Adaptability to Real-Time Changes: The models adapted well to live applications such as changes in flight details and location with an average response time of less than 500 ms. This ensures that the suggestions given to the passengers will be up to date with the changes surrounding them, thus appropriate options such as allowing passengers to access the lounge during wait times will be made accessible to them in good time.
These results demonstrate the ability of the system to provide accurate, proactive and personalized recommendations in real time and for dynamic travel situations.
1.1. User Engagement and Satisfaction
The testing showed a significant increase in user engagement and satisfaction as compared to the classic recommendation systems. The real-time model was associated with a 15% uplift in click-through rates (CTR) of personalized offers expertise such as lounge access or upgrades to seating which means a better engagement from users. Satisfaction scores collected post-interaction feedback showed that users were satisfied because of the appropriate and timely recommendations.
Whereas the static systems which may be slow to refresh on updates or lack intelligent suggestions have real-time personalization, such systems managed to meet the needs of the users thereby increasing the value and the loyalty.
5.2. Scalability and System Responsiveness
The microservices architecture exhibited remarkable elasticity and speed, enabling real-time recommendations even with high passenger data load increases. As each individual service (data ingestion, data processing, and data-based recommendations) was deployed independently, the system was able to efficiently scale without any latency issues even during the high-demand scenarios, for instance, peak travel. All load testing proved that responses were received for each recommendation in less than 500 ms showing that the system was efficient in ensuring fast interaction with passengers. This architecture therefore supports valuable transitions in scene settings without interruptions regardless of the number of users and the rate of data intake.
6. Discussion
Results obtained from the real-time personalization engine for airlines shows that end-user interaction and responsiveness can be enhanced if machine learning is adopted within a microservices system. The system especially adapted to real time data – location of passengers, delays of flights, preferences – resulting in context-aware recommendations that raised user satisfaction and CTRs when compared with the conventional systems. Not only that, the microservices based architecture proved its worth in handling system heavy loads while still maintaining low latencies thereby proving its suitability for the airline industry that is characterized by very dynamic markets. These findings demonstrate the capabilities of such systems in providing interactive services with a high potential for customization that encourages repeat business in the travel industries.
7. Conclusions
This research emphasizes the benefits of using machine learning techniques to increase real-time personalization and recommendations in the travel business. By embedding machine learning models in a distributed microservices framework, the system continuously evolves depending on the user-dimensional changes offering actionable and timely suggestions that boost user participation and gratification. The microservices strategy the settlements promote also helps manage data efficiently and maintain quick response times for high volumes of transactions proving worthy in dynamic and data-heavy travel situations. These results highlight the capacity of travel analysis in personalization by machine learning which can enhance client retention and their satisfaction in the highly competitive travel market.
References
- Asaithambi, S. P. R., Venkatraman, R., & Venkatraman, S. (2023). A thematic travel recommendation system using an augmented big data analytical model. Technologies, 11(1), 28. [CrossRef]
- Badouch, M., & Boutaounte, M. (2023). Personalized Travel Recommendation Systems: A study of Machine learning approaches in tourism. Journal of Artificial Intelligence Machine Learning and Neural Network, 33, 35-45. [CrossRef]
- Chaki, P. K., Sazal, M. M. H., Barua, B., Hossain, M. S., & Mohammad, K. S. (2019, February). An approach of teachers' quality improvement by analyzing teaching evaluations data. In 2019 Second International Conference on Advanced Computational and Communication Paradigms (ICACCP) (pp. 1-5). IEEE.
- Bellogín, A., Sánchez Pérez, P., & Sebastia, P. (2024). Topic editor para frontiers: Guiding the Journey: Innovative Recommender Systems for Personalized Tourism, Travel, and Hospitality Experiences.
- Barua, B. (2016). M-commerce in Bangladesh-status, potential and constraints. International Journal of Information Engineering and Electronic Business, 8(6), 22. [CrossRef]
- Yoon, J., & Choi, C. (2023). Real-time context-aware recommendation system for tourism. Sensors, 23(7), 3679. [CrossRef]
- Xia, Z., Sun, A., Xu, J., Peng, Y., Ma, R., & Cheng, M. (2022). Contemporary Recommendation Systems on Big Data and Their Applications: A Survey. arXiv e-prints, arXiv-2206.
- Barua, B., Whaiduzzaman, M., Mesbahuddin Sarker, M., Shamim Kaiser, M., & Barros, A. (2023). Designing and Implementing a Distributed Database for Microservices Cloud-Based Online Travel Portal. In Sentiment Analysis and Deep Learning: Proceedings of ICSADL 2022 (pp. 295-314). Singapore: Springer Nature Singapore.
- Kim, S., Lee, J., & Park, H. (2023). Innovations in microservices for dynamic travel recommendation systems. Journal of Tourism Technology, 12(3), 89-102.
- Lee, J., & Park, H. (2023). Machine learning-driven personalization in travel recommendations: A scalable approach. Tourism Analytics, 14(2), 211-223.
- Barua, B., & Whaiduzzaman, M. (2019, July). A methodological framework on development the garment payroll system (GPS) as SaaS. In 2019 1st International Conference on Advances in Information Technology (ICAIT) (pp. 431-435). IEEE.
- Smith, T., & Wong, M. (2023). Real-time adaptation and personalization in travel recommender systems. International Journal of Hospitality and Tourism Management, 9(1), 47-63.
- Kubra, K. T., Barua, B., Sarker, M. M., & Kaiser, M. S. (2023, October). An IoT-based Framework for Mitigating Car Accidents and Enhancing Road Safety by Controlling Vehicle Speed. In 2023 7th International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud)(I-SMAC) (pp. 46-52). IEEE.
- Barua, B., & Kaiser, M. S. (2024). Cloud-Enabled Microservices Architecture for Next-Generation Online Airlines Reservation Systems.
- Mouri, I. J., Barua, B., Mesbahuddin Sarker, M., Barros, A., & Whaiduzzaman, M. (2023, March). Predicting Online Job Recruitment Fraudulent Using Machine Learning. In Proceedings of Fourth International Conference on Communication, Computing and Electronics Systems: ICCCES 2022 (pp. 719-733). Singapore: Springer Nature Singapore.
- Barua, B., & Kaiser, M. S. (2024). A Methodical Framework for Integrating Serverless Cloud Computing into Microservice Architectures.
- Chaki, P. K., Barua, B., Sazal, M. M. H., & Anirban, S. (2020, May). PMM: A model for Bangla parts-of-speech tagging using sentence map. In International Conference on Information, Communication and Computing Technology (pp. 181-194). Singapore: Springer Singapore.
- Shrestha, D., Wenan, T., Shrestha, D., Rajkarnikar, N., & Jeong, S. R. (2024). Personalized Tourist Recommender System: A Data-Driven and Machine-Learning Approach. Computation, 12(3), 59. [CrossRef]
- Barua, B., & Obaidullah, M. D. (2014). Development of the Student Management System (SMS) for Universities in Bangladesh. BUFT Journal, 2, 57-66.
- Barua, B., & Kaiser, M. S. (2024). Blockchain-Based Trust and Transparency in Airline Reservation Systems using Microservices Architecture. arXiv preprint arXiv:2410.14518.
- Paolanti, M., et al. (2023). Tourism Recommendation System Using Machine Learning. International Journal of Research Publication and Reviews.
- Thakker, J., Pradhan, A., Dongare, S., Wande, P., Mane, D., & Kanade, P. (2024). Tour Sentiments: Personalized Recommendations System Using AI and Deep Learning. Journal of Electrical Systems.
- Barua, B., & Kaiser, M. S. (2024). Optimizing Travel Itineraries with AI Algorithms in a Microservices Architecture: Balancing Cost, Time, Preferences, and Sustainability. arXiv preprint arXiv:2410.17943.
- Barua, B., & Kaiser, M.S. (2024). Enhancing Resilience and Scalability in Travel Booking Systems: A Microservices Approach to Fault Tolerance, Load Balancing, and Service Discovery.
- Banerjee, A., Satish, A., & Wörndl, W. (2024). Enhancing Tourism Recommender Systems for Sustainable City Trips Using Retrieval-Augmented Generation. arXiv preprint arXiv:2409.18003.
- Meehan, K., Lunney, T., Curran, K., & McCaughey, A. (2013, March). Context-aware intelligent recommendation system for tourism. In 2013 IEEE international conference on pervasive computing and communications workshops (PERCOM workshops) (pp. 328-331). IEEE.
- Chouiref, Z., & Hayi, M. Y. (2022). Toward Preference and Context-Aware Hybrid Tourist Recommender System Based on Machine Learning Techniques. Revue d'Intelligence Artificielle, 36(2), 195-208. [CrossRef]
Figure 1.
Data flow and integration.
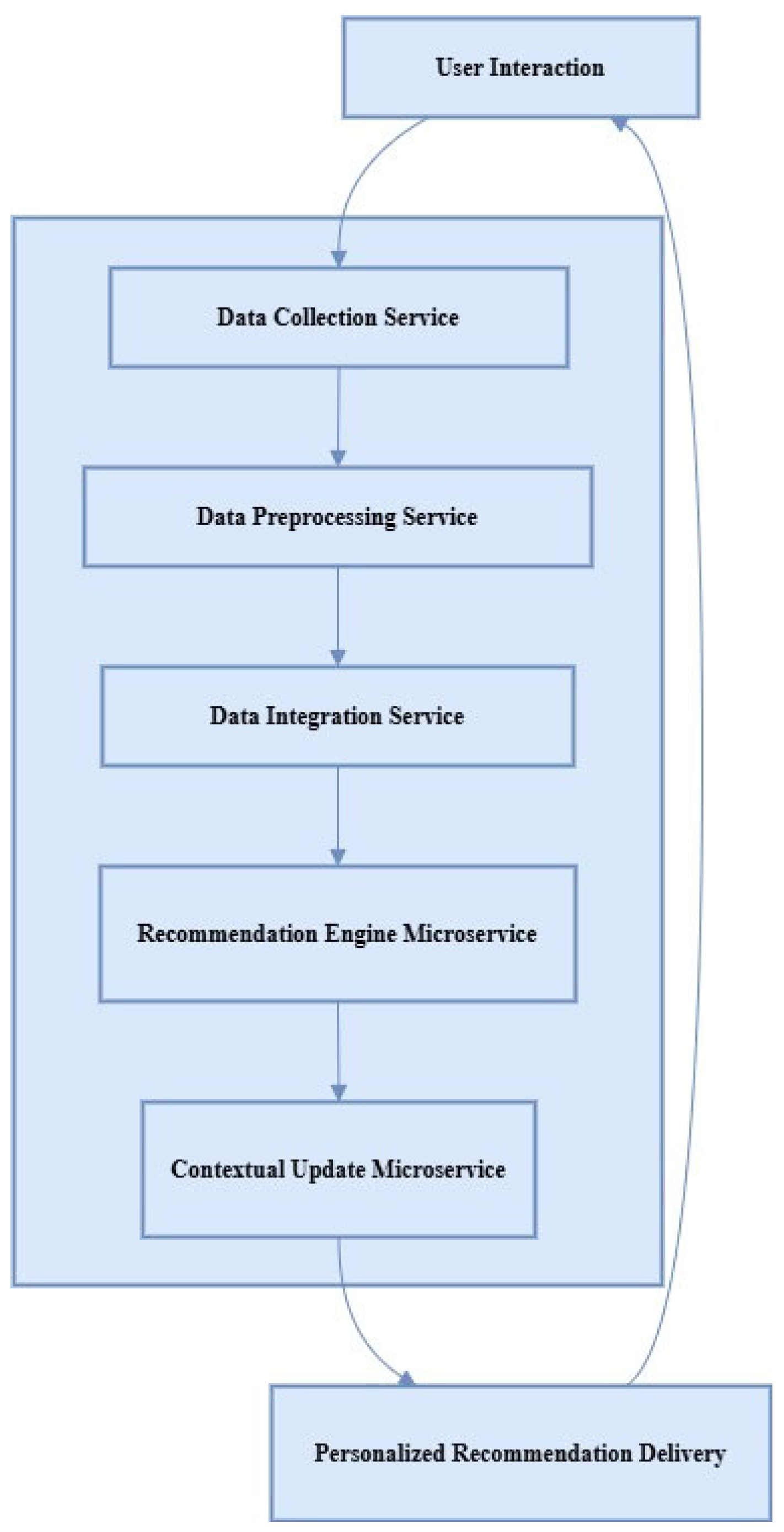
Figure 2.
Illustrate the data flow in contextual data processing.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



