
Submitted:
19 November 2024
Posted:
21 November 2024
You are already at the latest version
Abstract
Laissez-faire interpretation of what constitutes a digital twin may catalyze a broader diffusion of the principles (ideas) and perhaps even accelerate adoption of digital representations of physical entities, albeit in select parts of the affluent world (nations with significant amount of disposable income, per capita). The limits of efficiency and efficacy of digital proxies will affect the value of actionable (bidirectional) information which may be extracted/shared/exchanged from data and analytics (contextually connected causal relationships, Figure 33). Applications are easier in the mechanical context (manufacturing, automotive, buildings). Digital duplicates of natural systems (environment, health, agriculture) are beguiling. Representation in the form of “twins” suggests exact/identical twining (of data) which may be difficult to duplicate between the physical and digital. Hence, digital cousins of tiny sub-segments of systems may be useful if we grasp the science of the data and avoid the less understood cognitive processes (cognition refers to mental action or process of acquiring knowledge and understanding through thought, experience, and the senses). If parameters are well understood (e.g., causality), if the acquired data is rigorous, mathematically robust (e.g., proportionality, rate, ratio) and informative (e.g., blood glucose levels and type II diabetes mellitus), then digital cousins may be less irrational as an aspirational goal. Directly or indirectly, knowingly or unknowingly, in astronomical events or in infinitesimal instances, all tools, technologies and techniques (e.g., statistical, operations research [OR], mathematical) converge to catalyze our need to be data-informed, to make sense of data before the value of the data perishes, and extract actionable information (e.g., process optimization in OR). At the core of almost any system with a popular “buzz” (digital twins, internet of things, cyberphysical systems, cloud, machine learning, smart cities, “big data”, “DL”, “AI”, “Industry X.O”) we commence with data to extract meaningful information of value. Relevant semantics or “meaning” must arise from the anastomosis of causality with context as well as metrics and measurements. Value is related to “performance” depending on the context and actions (feed-back, feed-forward) which could become a highly complex decision process (e.g., explosion of state space when synthesizing or analyzing data from percepts, environment, actuators, and sensors, referred to as PEAS, the superset of the OODA loop: the cycle of observe-orient-decide-act). The underlying glue that permeates the fabric of continuum between meaning and value is causality. Almost every “thing” (made of atoms) or processes or systems we dissect, deconstruct and reconstruct, is made significant when and if associated with data (bits). The continuum of meaning and value is in dynamic interaction with the continuum between atoms to bits. The constructs of this multi-string, multi-dimensional continuum are connectivity, data, analytics and context (ACDC). In this chapter, we explore examples of this “electricity” which powers the engines of science, decision science, and data-informed systems across a broad and diverse spectrum of verticals and applications. However, economics of technology could make or break digital representation. It may remain prohibitive for decades, if not centuries, in resource constrained communities, which comprises ~80% of the global population of ~8 billion. Therefore, one begs to ask how suitable are digital twins?
Keywords:
Digital Twins
; Digital Cousins
; Data Analytics
; AI
; Artificial Intelligence
; ML
; Machine Learning
; MU
; Machine Usefulness
; Medical Devices
; Remote Monitoring
; Ventilator
; Scratch
; Thunkable
; Nitrogen Cycle
; Cardiovascular Systems
; BNP
; Statistics
; Bootstrapping
; Winsorization
; Halicin
; Drug Repurposing
; Chemistry
; Small Molecules
; Time Series
; Econometrics
; GARCH
; ARCH
Background
Astronautics, space exploration and NASA have been using mechanical twins followed by digital representations of electro-mechanical systems since 1950’s [1] and other attempts may reach as far back as the dawn of the 20th century. Basic twining was essential to space programs where physical duplicates on ground had to match system performance in space. Physical and digital duplicates (cyberphysical systems [2], virtual twins, digital twins) were key to NASA’s finest hour [3] in assessing/simulating mechanical scenarios to save the astronauts on Apollo 13.
The return of the astronauts aboard Apollo 13 boosted the idea of virtual proxies and digital duplicates as a “sandbox” for monitoring, testing, and analyses. Digital twins, therefore, is a digital by design metaphor, not a technology. Marketing of the term “digital twins” was not an epiphany [4] or an invention or a flash of clarity, it was progressive reasoning. This progression [5] of insight was “adjusted” to be sensational (outlined in [6] “history of digital twin technology”). The diffusion of digital twins and its adoption in our vernacular is due to centuries of scientific exploration [7] and foresight which empowered scientists and engineers to extract insight from experimental duplication of conditions when working with alternate forms of representation, to capture data and/or observe events/instances depending on the context and based on science.
Digital twins are an alternate (cyber, virtual) form of representation of physical objects and mechanical systems. Digital twins, therefore, are cyberphysical systems [8] (CPS) which are expected to inform operational behavior in order to enable humans and/or other decision systems to better optimize system performance. The latter may be loosely analogous to studying prions, viruses and uni-cellular bacteria to better understand molecular complementarity as the basic and underlying mechanism of structure and function, which may be extrapolated to test models of biological processes in multi-cellular eukaryotes, including plants, animals and humans.
In a previous essay on the emergence of digital twins [9] we discussed far-ranging issues. Grasping the context of digital representation is far broader than idea of digital twins as a tool or marketable technology or instant transparency-enabler for (bi-directional) flow of data and information. Digital twins are immersed in an immense chaos of concepts ranging from ethics to education and everything in between. Making sense of each contributing strand or part and its relationship to the ever-changing “whole” is a task for hordes of brilliant people for centuries. Despite the quagmire, let us try to re-focus and attempt to scratch the surface of a few issues which remain unaddressed, unanswered and unexplored. Why?
First, digital twin is not a technology, it is a concept, a design metaphor using the cyber medium to connect physical entities with their digital representations to facilitate transparency (bi-directional) between data of systems in the context of the networked physical world. To the chagrin of scientists, marketing efforts exacerbated the problems of digital transformation by leaning toward hyperbole [10] which nudged the science out of its place. Hence, digital twins are now part of corporate campaigns where digital representation and/or digital transformation is akin to “hammers in search of nails”. Delusional projections [11] aren’t synonymous with reality.
The second reason is that science and engineering principles in the implementation of digital twins suffers from an abundance of unknown unknowns when transforming vision into reality. Patchwork of systems integration varies dramatically and influences rational outcomes.
The third reason is the sluggish pace of change and adoption as well as resistance to new tools to remove barriers created by conventional wisdom and the dead weight of old technology. The efficiency and efficacy of digital representations are still being debated in many “brown-field” industries and cautious investment is partly due to deep mistrust [12]. If digital transformation is not about technology [13] then why are some groups peddling prosperity [14] by disguising non-existent demand for unproven [15] technologies?
The fourth reason is the lack of standards [16], interoperability between standards, inability to merge/distribute data and lack of incisive logic in expert systems to make sense of data (which respects the tenets of ACDC). Value (Datta et al., 2003) of information [17] is a complicated metric yet it is the only relevant key performance indicator (KPI) for ROI (return on investment).
Digital duplicates, digital proxies, digital twins, digital cousins may be useful depending on the context of the application. The terms are synonymous and semantic differences may be significant but scenario-specificity and data-centricity are equally important. Digital twin is an umbrella term within the universal set of digital transformation where “twining” is a quagmire of amorphous metaphors applicable at various levels of sophistication (see Figure 1a, 1b and 1c).
Introduction
Enhanced diffusion of the digital-by-design metaphor may lift many boats including that of digital twins, cyberphysical systems [21] (CPS) and internet of things (IoT) in the networked [22] physical world system. These terms have evolved asynchronoulsy when engineering excellence spawned new ideas. On closer analysis [23] common grounds, relationships and interdependencies were identified between these systems (terms). What appears to get lost is the fact that these and other related ideas are “new improvizations” based on a bedrock of just a few core elements.
The foundation for all these systems and categories of systems are built on the pillars of connectivity, data, and analytics. Irrespective of how we view the organization of the cyber and physical components, all of these systems and sub-systems are inextricably linked with network of bridges built on a trinity of pillars (connectivity, data, analytics). The quintessential glue that binds these elements is the anastomosis of context and causality [24]. Without context of causal relationship, these pillars and bridges will collapse because dependencies (not correlations) are salient to making sense from (uncorrupted) data. Semantics is germane to extracting information from data and it is at the core of analytics even if and even when, things start to think [25].
Figure 2.
The hubris of so-called “big data” was exposed when Google got flu wrong [26] (but it was not a single event in 2013). Google Flu Trend (GFT) was quite consistently wrong since 2008-2009 [27] but wasn’t corrected. Small data, good data [28], contextual data are crucibles for credible outcomes when causality is respected. Corrupting or amplifying data [29] without understanding the causal context may generate papers but hurts practitioners. In reality these tools and techniques could compromise patient safety [30], morbidity and mortality. Very slight changes in data due to data selection and data sampling errors may have cumulative effects (time series data) when aggregated (corrupted?) data is used at a different point or instance of use to generate incorrect decision or improper diagnosis (please see Figure 28 and Figure 29), for example using and depending on uncertain artificial intelligence (AI) assisted tools (e.g., for cancer screening).
Figure 2.
The hubris of so-called “big data” was exposed when Google got flu wrong [26] (but it was not a single event in 2013). Google Flu Trend (GFT) was quite consistently wrong since 2008-2009 [27] but wasn’t corrected. Small data, good data [28], contextual data are crucibles for credible outcomes when causality is respected. Corrupting or amplifying data [29] without understanding the causal context may generate papers but hurts practitioners. In reality these tools and techniques could compromise patient safety [30], morbidity and mortality. Very slight changes in data due to data selection and data sampling errors may have cumulative effects (time series data) when aggregated (corrupted?) data is used at a different point or instance of use to generate incorrect decision or improper diagnosis (please see Figure 28 and Figure 29), for example using and depending on uncertain artificial intelligence (AI) assisted tools (e.g., for cancer screening).
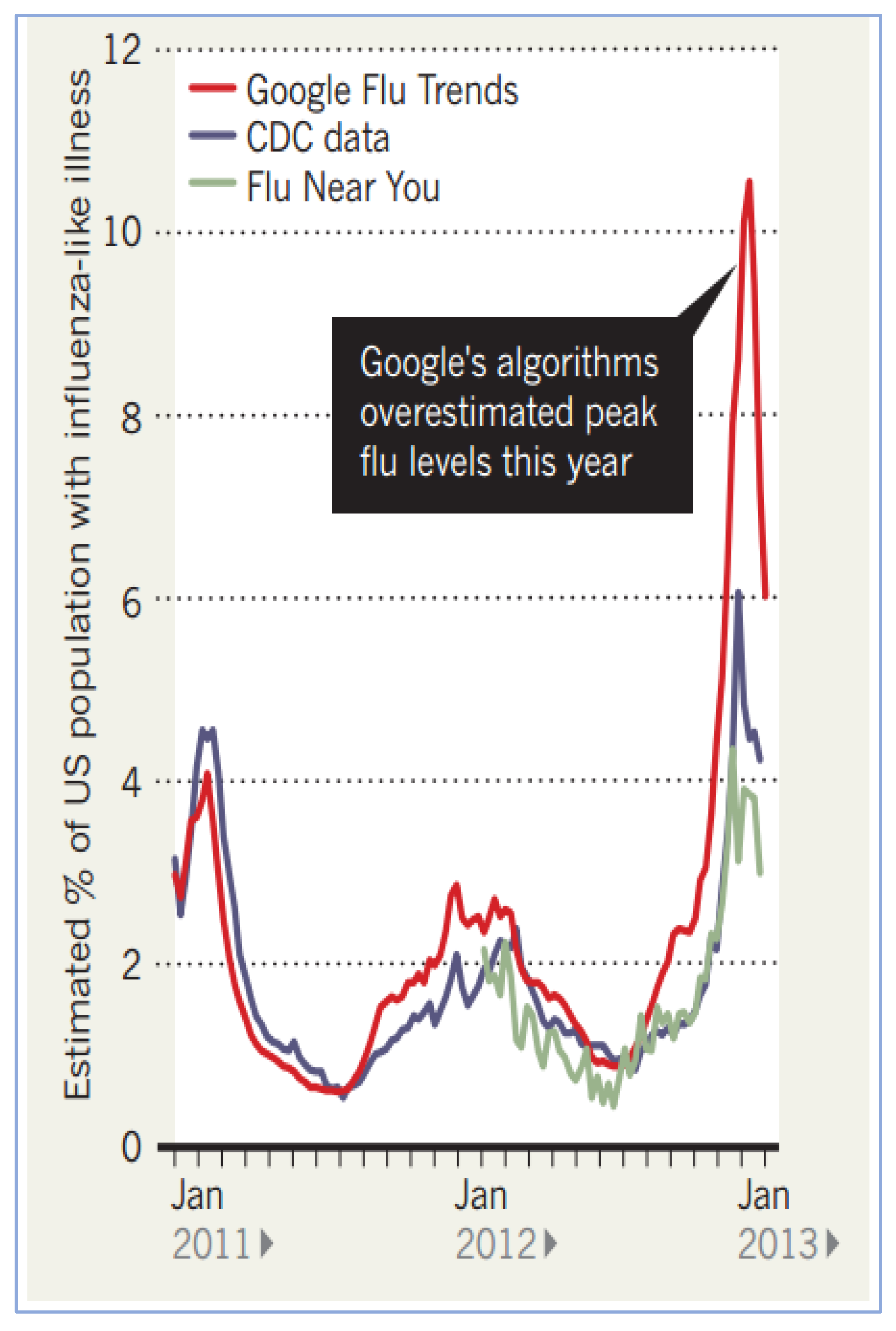
Figure 3.
a: Causality: Photo [31] featuring Annie Boots (Felis catus [32]) implying correlation is not causation (lack of correlation need not imply lack of causality [33]). Many users are failing to assimilate the central role of causality with respect to data. The use of AI lacking intelligence [34] conceals the fact that programming is devoid of causality [35] and cognition [36]. Exploring [37] thoughts [38] and ideas [39] about cognition is essential. But, irrational exuberance (“reverse” engineer [40] “the brain to understand the mind”) may not be credible. Artificial intelligence (AI) models, especially AI language models are notorious [41] bullshitters [42] (quote from Heikkilä, 2023) presenting falsehoods as facts. They are excellent at predicting the next word in a sentence because they use nearest neighbor search (which dates back to the 11th Century [43]). AI models have no knowledge of what the sentence actually means (semantics). The failure [44] to launch the semantic web [45] shows how difficult it is to represent semantics through programming languages because knowledge representation [46] with ontologies is a profound challenge which remains sorely [47] unaccomplished [48] due to the fact that real entities (as used by humans) resists mapping onto mathematically-sound hierarchies [49] (for binary systems, which runs computation). AI code [50] and AI models are totally devoid of causality, cognition, and semantics. AI could be weirdly [51] entertaining if browsing with an AI-fueled search engine what to watch on streaming media. But, it is too dangerous to be trusted as a tool, in instances where combining logic and search is essential to obtain unvarnished facts, e.g., point-of-care emergency nurse or doctor or a mission critical operator (for power generation infrastructure or energy distribution). The call to pause [52] certain forms of AI use and research may be too little, too late and too feeble. Cognition: Is the cognitive [53] layer in the cartoon (center) representative of cognition, in its scientific perspective? Amorphous convergence of six august [54] disciplines [55] (right) may be involved in cognitive science. Cognitive patterns in the mind [56] are difficult to distill in discrete units for cognitive engines in any tool, software or agent based system, at the current level of our knowledge. Cognition in our vernacular oozes out of marketing [57] where brand imagery [58] (for all visual thinkers), allusion and possession are “goals” set by the sales department. Cognition in any tool is just akin to instructions but simple words aren’t sufficientlt sensational. Taking advantage of the general ignorance about the meaning of cognition, the word (cognition) is used in PR to convey an aura, tangential to science but with an opulence of allure. It may be similar to marketing “intelligence” in AI (artificial intelligence) which bears little semblance to what constitutes the scientific nature of intelligence (still an enigma). DNA is an acronym which make scientists squirm with agony when it is used [59] for marketing. Every mention of timeless [60] beauty, time travel [61] and time [62] frozen on the ladder of life are decorative expressions devoid of physics or science of time (a certain corporation claimed to have reversed time [63] but no, they did not [64]). Capturing cognition in logic layers using “if this, then that” type of reasoning (values) is as far as the practice of cognition may proceed but including the science of cognition is still aspirational.
Figure 3.
a: Causality: Photo [31] featuring Annie Boots (Felis catus [32]) implying correlation is not causation (lack of correlation need not imply lack of causality [33]). Many users are failing to assimilate the central role of causality with respect to data. The use of AI lacking intelligence [34] conceals the fact that programming is devoid of causality [35] and cognition [36]. Exploring [37] thoughts [38] and ideas [39] about cognition is essential. But, irrational exuberance (“reverse” engineer [40] “the brain to understand the mind”) may not be credible. Artificial intelligence (AI) models, especially AI language models are notorious [41] bullshitters [42] (quote from Heikkilä, 2023) presenting falsehoods as facts. They are excellent at predicting the next word in a sentence because they use nearest neighbor search (which dates back to the 11th Century [43]). AI models have no knowledge of what the sentence actually means (semantics). The failure [44] to launch the semantic web [45] shows how difficult it is to represent semantics through programming languages because knowledge representation [46] with ontologies is a profound challenge which remains sorely [47] unaccomplished [48] due to the fact that real entities (as used by humans) resists mapping onto mathematically-sound hierarchies [49] (for binary systems, which runs computation). AI code [50] and AI models are totally devoid of causality, cognition, and semantics. AI could be weirdly [51] entertaining if browsing with an AI-fueled search engine what to watch on streaming media. But, it is too dangerous to be trusted as a tool, in instances where combining logic and search is essential to obtain unvarnished facts, e.g., point-of-care emergency nurse or doctor or a mission critical operator (for power generation infrastructure or energy distribution). The call to pause [52] certain forms of AI use and research may be too little, too late and too feeble. Cognition: Is the cognitive [53] layer in the cartoon (center) representative of cognition, in its scientific perspective? Amorphous convergence of six august [54] disciplines [55] (right) may be involved in cognitive science. Cognitive patterns in the mind [56] are difficult to distill in discrete units for cognitive engines in any tool, software or agent based system, at the current level of our knowledge. Cognition in our vernacular oozes out of marketing [57] where brand imagery [58] (for all visual thinkers), allusion and possession are “goals” set by the sales department. Cognition in any tool is just akin to instructions but simple words aren’t sufficientlt sensational. Taking advantage of the general ignorance about the meaning of cognition, the word (cognition) is used in PR to convey an aura, tangential to science but with an opulence of allure. It may be similar to marketing “intelligence” in AI (artificial intelligence) which bears little semblance to what constitutes the scientific nature of intelligence (still an enigma). DNA is an acronym which make scientists squirm with agony when it is used [59] for marketing. Every mention of timeless [60] beauty, time travel [61] and time [62] frozen on the ladder of life are decorative expressions devoid of physics or science of time (a certain corporation claimed to have reversed time [63] but no, they did not [64]). Capturing cognition in logic layers using “if this, then that” type of reasoning (values) is as far as the practice of cognition may proceed but including the science of cognition is still aspirational.

Sources of Data
The digital twin umbrella (CPS [65], IoT [66], industrial IoT [67], interplanetary IoT [68]) and other emerging proxy systems are scientific/engineetring manifestations of case-specific contextual interpretations aspiring to understand/unleash/reveal the meaning/value of operational data [69] [see ref 73 A-D]. The latter guides connectivity (what must be connected), identity of data nodes or sources and what information of value (i.e., actionable?) can be extracted from data analytics, either alone or by combining different results (data fusion informed by causality, not cognition). Connectivity, data and analytics with respect to context are primordial layers for almost any decision science. A fitting analogy may be the geology of the base layer [70] of the Grand Canyon referred to as Brahma, Vishnu and Rama schist [71] (mythological creators of the universe).
Almost all aspects of being digital [72] and the digital by design metaphor is governed by connectivity, data, analytics and context (ACDC). The contextual/causal digital thread runs through the fabric of digital transformation, as data, from various events/instances in/of the networked physical world. Relational semantics between data and information is still far from formulation but context is not optional in transforming data into information. The processes are human designed, human coded, human implemented, with little left for artificial intelligence [73].
Acquisition of data or percepts (P) from systems, environments (E) and operations are possible, if connected. Sources of data include a plethora of monitoring tools e.g., sensors (S). Making sense of data and extracting information of value from data (if there is information in the data) is the performance driver for the “response” phase which includes information-informed (or data-informed) decision support (for humans-in-the-loop) or may involve autonomous and/or semi-autonomous actuation (A). Data from the post-actuation cycle (i.e., “feedback” [74] or “feed-forward” [75] controls [76]) may be pivotal for dynamic systems seeking to re-inform, re-optimize and re-evaluate the nature/quality/timing of the next response (albeit in an “ideal” scenario).
PEAS [77] is a mnemonic borrowed from agent-based systems which aims to address systems performance through convergence of percepts, environment, actuators, sensors. It may share common grounds with the OODA [78] loop (observe, orient, decide, act). PEAS and OODA contribute to advance DIKW (data, information, knowledge, wisdom), which begins with the core elements (ACDC) and may include data fusion [79] if contextually relevant and if causal.
Taken together, ACDC plus versions of case-specific PEAS and OODA appears to be a smörgåsbord of interlocking and/or shared principles, which when titrated, may better inform the common practice of constrained optimization (but not always).
Optimization may influence the outcome or performance or prediction of anticipated performance. Productivity may depend on performance. Economies depend on productivity. Pursuit of globalization and development depends on the economy. By association, it follows that ethical progress of civilization may be ultimately guided by connected data (i.e., ACDC).
The causal significance of the trinity of connectivity, data and analytics in ACDC may be compared with the philosophical trinity represented by Brahma, Vishnu and Rama schists at the base of the Grand Canyon. This mythological [80] analogy of fundamentals are quintessential layers relevant to any context of digital transformation including digital twins. (It is unnecessary to understand this analogy in order to grasp the significance of ACDC with respect to causality.)
Published literature (Jones, D. et al., 2020) and a review of various types of digital twins [81] [85a-85i] reveal a set of existing tools and technologies, integrated, re-configured and labelled as digital twins. Most models (“are wrong but a few may be useful”, reference 760) of “digital twin technologies” are in engineering textbooks without any new “technology” that is distinct for digital twins (Table 1). These approaches face problems due to lack or non-compliance with standards and challenges due to lack of interoperability between data and distributed data as well as information (databases) in multi-dimensional decision systems (e.g., service automation).
Deployment of digital twins ignores science and pursues existing systems integration tools and technologies based on established engineering principles. IoT and CPS are “A2B” (atoms [96] to bits [97]) design metaphors connecting atoms and/or bits with other atoms and/or bits. Implementation of IoT (not a scientific endeavor) is connectivity in context of causality, if it asks the correct questions (a difficult task) to guide data acquisition (data of/from objects, processes). The quality of the acquired data and analytics are essential to answer the (correct?) questions.
The business of digital twins is deeply rooted in monetization of data where analytics is key. Creative analytics or innovative tools may make this space valuable, if the analytical platform can make better sense of data and provide information in the semantic context of the use case (in real-time or near real-time before the value of the data/information perishes).
The context of deploying digital twins may be the nexus where science can also inform strategy rather than performance, alone. It is obvious but bears emphasis that science is necessary at every step since engineering is science-informed and technology is engineering-informed. By extension, almost every endeavor is based on or linked to science. However, selective myopia may prevent science from infecting business strategy and exclude scientists from the discussions.
Scientists on the other hand may make digital twins sound pompous to justify high-brow academic exercises by introducing complex models [98] with respect to performance optimization and predictive analytics. Enterprises may be averse to science infiltrating their daily dose of ERP, e.g., dealing with manufacturing executions systems (MES), product lifecycle management (PLM), and supply chain management (SCM).
The push-pull between principles and practice may be better served with some degree of mutual porosity between the two cultures. Creating industry-university partnerships (PPP, public private partnerships) are occasionally productive by informing scientists about the pragmatic needs of the corporate world and informing practitioners about science / engineering principles which may be amenable for pragmatic adoption in the business milieu.
Despite polarized perspectives, there is little doubt that uncorrupted contextual data from causal relationship is the most important lowest common denominator at the heart of any digital transformation, including digital twins, IoT, CPS. Acquisition of data is the central driver of the digital thread that runs through and connects almost all forms of digital transformation. What types of data (parameters) are a part of the design for pragmatic applications of digital twins? What is the source of the data or the nature of causality between data sources?
Sensors are data sources for changes (time series data) in environments (temperature, vibration, lumens). In addition, data is acquired from automatic identification tools (for example, radio frequency identification, RFID) and positioning systems (local positioning systems, LPS and global positioning systems, GPS). From an engineering perspective, the field of sensors [99] in general and biosensors [100], in particular (see ref 721), include electrochemical [101], thermal, piezoelectric, fiber optic, magnetic, pressure sensors, etc. Sensor engineering is focused on material science tools to capture and transmit the signal. Signal capture depends on the material of the sensor which reacts to or senses the stimuli and generates the signal for transduction.
Science Behind the Data (Not Data Science)
Different sensors are based on distinct target units of activity and set of basic behaviors which are indicators of the “signal” from actions/reactions. If sensor data is deconstructed into its elemental form or sufficiently reduced, we observe patterns in signals based on units or models. Combinations of these models/units/patterns/elements can generate an almost unlimited variety of system behaviors (what we aim to sense and the signal we attempt to capture and then acquire in the form of sensor data from signal transduction).
In scientific terms, the observed manifestations are due to a few or a relatively small group of fundamental or universal ‘truths’ which are referred to as models, units, rules, logic, patterns, elements or behaviors (see Figure 2 in Datta et al., 2021 [102]). These “truths” are not random behaviors whose entropy fluctuates with the degree of chaos. In physical sciences [103], large scale system behaviors can be reduced and mapped to simple models [104]. Combination of simple models, with widely different microscopic details, applies to, and generates, large set of possible system behaviors [105]. The perception of non-deterministic behavior (chaos) in human scales [106] may be explained by deterministic patterns of behavior in universal scales [107].
Sensor data in run-of-the-mill digital twins are often generated from waveform data (continuous streaming data) which are “sampled” as discrete data by human-specified time intervals in middleware (Figure 28 and Figure 29). Continuous waveform data (raw data) may be computationally expensive to transmit (energy constraints, power consumption), collect, store and analyze. Streaming raw data may be plagued by errors introduced due to lack of suitable bandwidth, latency and jitter (inherent in telecommunications). Hence, continuous waveform data is converted to discrete data “points” and transmitted. The latter is the data “source” for the bulk of digital transformation scenarios which continues to evolve [108] as in-network [109] processing functions proceed from traditional (power, query, logic optimization [110]) to virtual machines [111]. The granularity of this time series data is adjusted by industry and businesses based on business logic which often disregards science and engineering principles. Is this level of data acquisition acceptable for business applications? Are accuracy and precision “relative” terms?
The physics of waveform data make sensors amenable for continuous sensing or monitoring. This is crucial from an engineering perspective due to data flow, life cycle of the data stream and the physics of hysteresis [112] in devices (for example, thermostats for digital twins of buildings) where sensor reusability is key to performance optimization (e.g., digital twins for energy conservation). Waveforms are part of the natural radio frequency spectrum which are harnessed for applications by humans. The interruption, change (frequency, amplitude, phase), reflection, refraction in the radio frequency can be captured by a detector as a “variation from normal” due to “sensing” the phenomena we are trying to monitor (e.g., reflected radio frequency [113] to monitor heart rate, respiratory rate). The captured waveform [114] (raw) data may be compressed [115] as a discrete data [116] point for data analytics tools. The transition of waveform data to discrete point data may influence data integrity or include harmful errors when data is stored.
Digital twins which are able to source continuous waveform data are more reliable in terms of the digital representation of the parameter at the required level of granularity. For example, temperature, pressure, light sensors detect waveforms and the primary data is in terms of waveform changes. The medium of data is true continuous waveform.
But for electrochemical sensors, as the name implies, the waveform medium is an indirect engineering tool created to capture and report data from a different medium which is the primary trigger. In this case a chemical medium may be the source of the data. Changes triggered in the chemical medium where the primary activity occurs [117] induces a secondary change in the electrical circuit (conductance, capacitance, admittance) which is the waveform data captured by an electrochemical sensor (e.g., electrical impedance spectroscopy).
Electrochemistry may be viewed as a bridge between physics where waves are ubiquitous for transmission (radio frequency) vs biology (life) where molecules (particles) may be the dominant signal transducer (think de Broglie wave-particle duality [118] of the electron).
If digital twins can capture and represent this bridge between waves and molecules in terms of data, then, the efficiency of digital transformation may improve. Is the key to that quantum leap rooted in sensing and sensors? In anything that is biological (living) binding of molecules act as a trigger and that data is vital to understanding function in biological systems. Once bound, molecules may be reluctant to dissociate. Lack of dissociation, or a very reduced dissociation rate, makes the sensor unusable for continuous monitoring purposes (contrast with motion sensors). Most sensors in this category may be for a single-use unless there is a scheme to regenerate the sensor (material / molecule for binding) and re-establish ground state (baseline).
The difficulty in capturing that binding is rooted in the definition of binding. When two molecules bind, it is a natural law that the binding is sufficiently stable for a time period, t, for an action/reaction to occur, as a part of the reaction kinetics. We need to identify molecular binding events with precision, specificity and duration (i.e., kinetics, in chemical terms of time). Identity, precision, specificity and kinetics must be measured. The “measure” of the molecular parameters must be transmitted. Without data transmission (signal transduction) there cannot be any digital representation. The latter makes waves pivotal for acquisition of data from molecules. Interaction between molecules (between atoms) generates data (bits) as a record of that event. Cumulative data over time provides rate of reactions which is dependent on time. Metric for kinetics as time series data is crucial to detect pattern(s) as signatures of change which we aim to detect (sense).
Connecting atoms to bits [119] is not a frivolous public relations vignette but the essence of Being Digital (Negroponte, 1999) and the Holy Grail of digital transformation, manufacturing [120] and digital twins. Connecting atoms to bits is not the end game, making sense of data is key to understanding the meaning of change over time. The value lies in analytics. Delivery of value to the end user in the form of actionable information (in time) is the key to profit from data (e.g., information as a service). Digital twins/cousins must embrace bidirectional optimization based on science and extract/acquire data from interactions at the nexus of physics, chemistry, biology and medicine which underlies/determines planetary [121] health, one health [122] and global safety.
Data-Deforming Statistical Tools Embedded in Digital Twins?
If connected data is the bedrock for advancing civilization, then the treatment of data and analysis must refrain from using techniques which tampers with the meaning and value of data. It is reasonable to assume that responsible and ethical scientists and data enthusiasts are unlikely to indulge in deliberate data manipulation using specific statistical tools to change, obfuscate, mask or modify the meaning of the data or subject it to statistical treatment in order to selectively “fit” pre-conceived models (“all models are approximations, and no model form can ever represent the truth absolutely” [123]) or a priori interpretations which are biased or conceals bias. Assumption of good faith may be patently incorrect if data is ingested by and subjected to machine learning tools where opaque “black box” operations are as much as a mystery as are cosmic blackholes. Even more damaging are the assumptions made by machine learning (ML) itself and the bias these assumptions may introduce. The most debilitating of all assumptions is the one which assumes that all data (each data point) is an independent value (discussed in the section “Trouble with the Uncertain Science of Artificial Intelligence”). The condition may hold true for some mechanical systems (power generation [124] vs emissions [125]) but almost always false for biological systems (where proportionality, dependencies, inter-relationships between events are the norm).
Uncompromising transparency about the treatment of raw data must be forthcoming from every nook and cranny (of the data network). Statistical tools are often implicated in “lying with statistics” (Huff, 1954) and over-fitting to models are often blamed (Box & Jenkins, 1970). But, this discussion should not be viewed as a criticism or denigration of statistics, rather a clarion call for informed judgement, ample caution and to seek wisdom (untainted by profitability) when perusing data, if one or more data-deforming statistical tools are implicated in the analysis.
The immense value [126] of statistics in data analysis [127] and statistical interpretations [128] cannot be over-emphasized. In the context of data science, the milestones over the past 50 years starts with Box-Jenkins ARMA/ARIMA (Box and Jenkins, 1970), fitting time-series model to lagged values in ARCH/GARCH [129] error-correction applied to econometrics [130] (but not limited to econometrics [131]). 1970’s also witnessed Stonebraker’s insightful [132] INGRES [133] and later the post-INGRES (POSTGRES [134]). The trinity of ARMA/ARIMA, ARCH/GARCH, and relational INGRES/POSTGRES forms the foundational underpinning with respect to dealing with data [135].
Analysis of large volumes of data is not “new” as implied by “big data” [136] and AI tools (ANN, DL) are almost a century old [137]. Any tool can be valuable in “some” context or possess a statistically credible merit. For this discussion the usual suspects for potential data-deforming statistical techniques (some more, some less) include, but are not limited to, the following:
[i] Clustering
[ii] Bootstrapping (reinventing resampling to manufacture fake, synthetic data)
[iii] Winsorizing
[iv] Imputation
[v] Interpolation
[i] Clustering
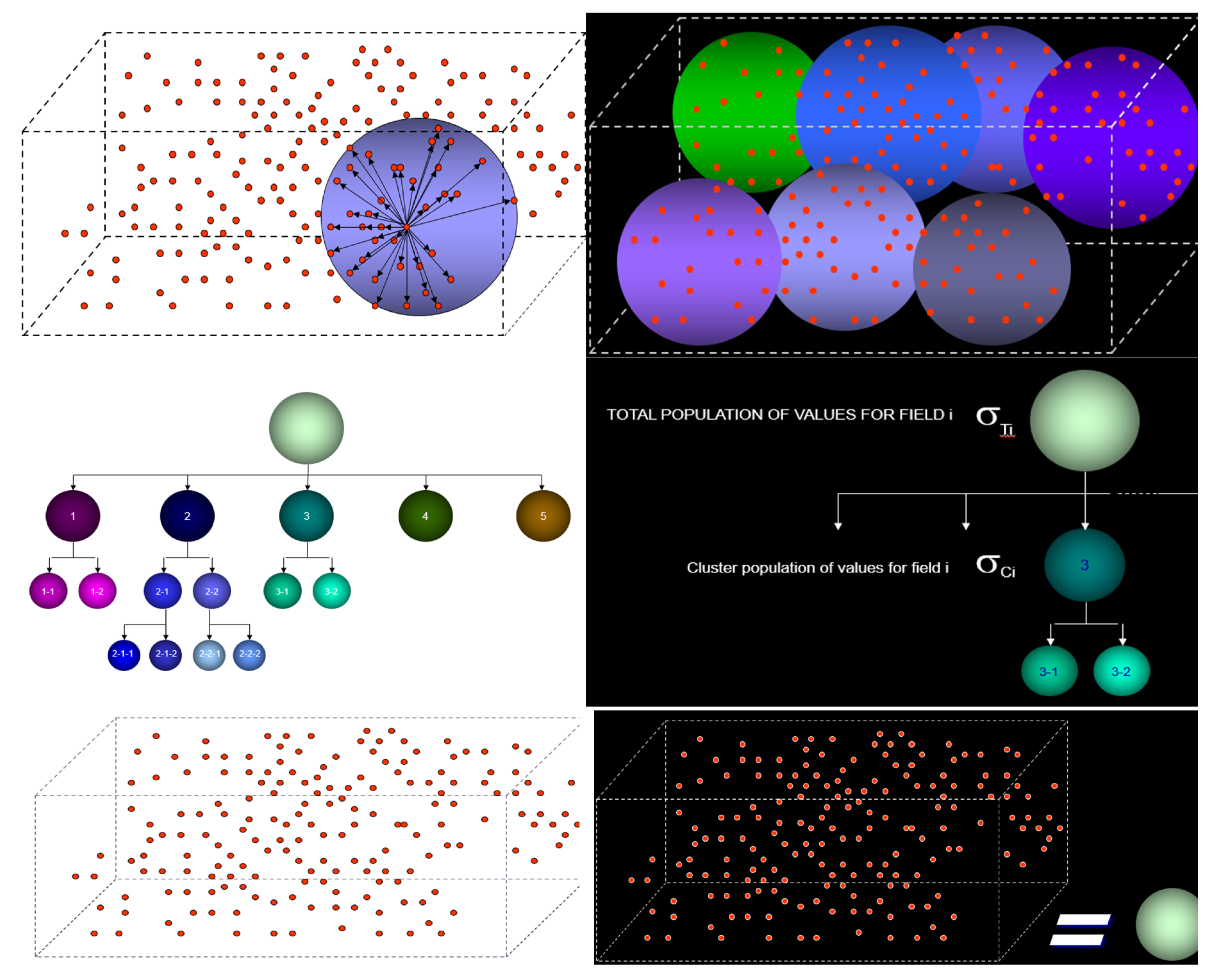
Cartoon 1. a: Acquired raw data (bottom, L) is stripped of its characteristics, attributes, values and even meaning after clustering reduces it to a point value or field value (green circle; bottom, R). b: Arbitrary measures in data software corrupts data, creates errors, generates artifacts. The trend is to bend data to fit normal distribution (bottom, left) but in reality it could be skewed with vastly different error terms and distribution of error (which may be farthest from “normal”). Data wrangling ignores/expunges subtle and not-so-subtle significance often cryptic in raw data to make data handling [138] easier (bottom, right) but may remain oblivious of potential “signature” points in occasional outliers which are often forerunners of events or antecedent instances.
Clustering is often mandatory for software packages ingesting high volume of raw data. Data or patterns of data are plotted in ‘n’ dimensional space. Each point in cartoon 1a (bottom, left panel) may represent multiple (n) pieces of information (data, patterns, dimensions, etc.). To begin the clustering process, distances are calculated to determine similarity (top, left panel). The choice of “distance” from a focal point may be entirely arbitrary. It follows that the cluster (top, left panel) is, therefore, an arbitrary grouping. The “family” of clusters (top, right) may contain a spread of data or data patterns, which loses its (individual) value due to this reductionist technique. The hierarchy of clustering (middle section, left panel) is an indication of granularity. The standard deviation ratio (calculated by dividing sigma Ci by sigma Ti) indicates how much a field (i) in a particular cluster varies in comparison to all clusters (middle section, right panel). If the standard deviation (sigma) ratio for a field is small (an arbitrary measure), the “field” value represents the cluster. The entire data set or pattern set may be denuded of its signal, significance and meaning by substituting the representative value for field “i” (green circle, bottom right) for the entire set.
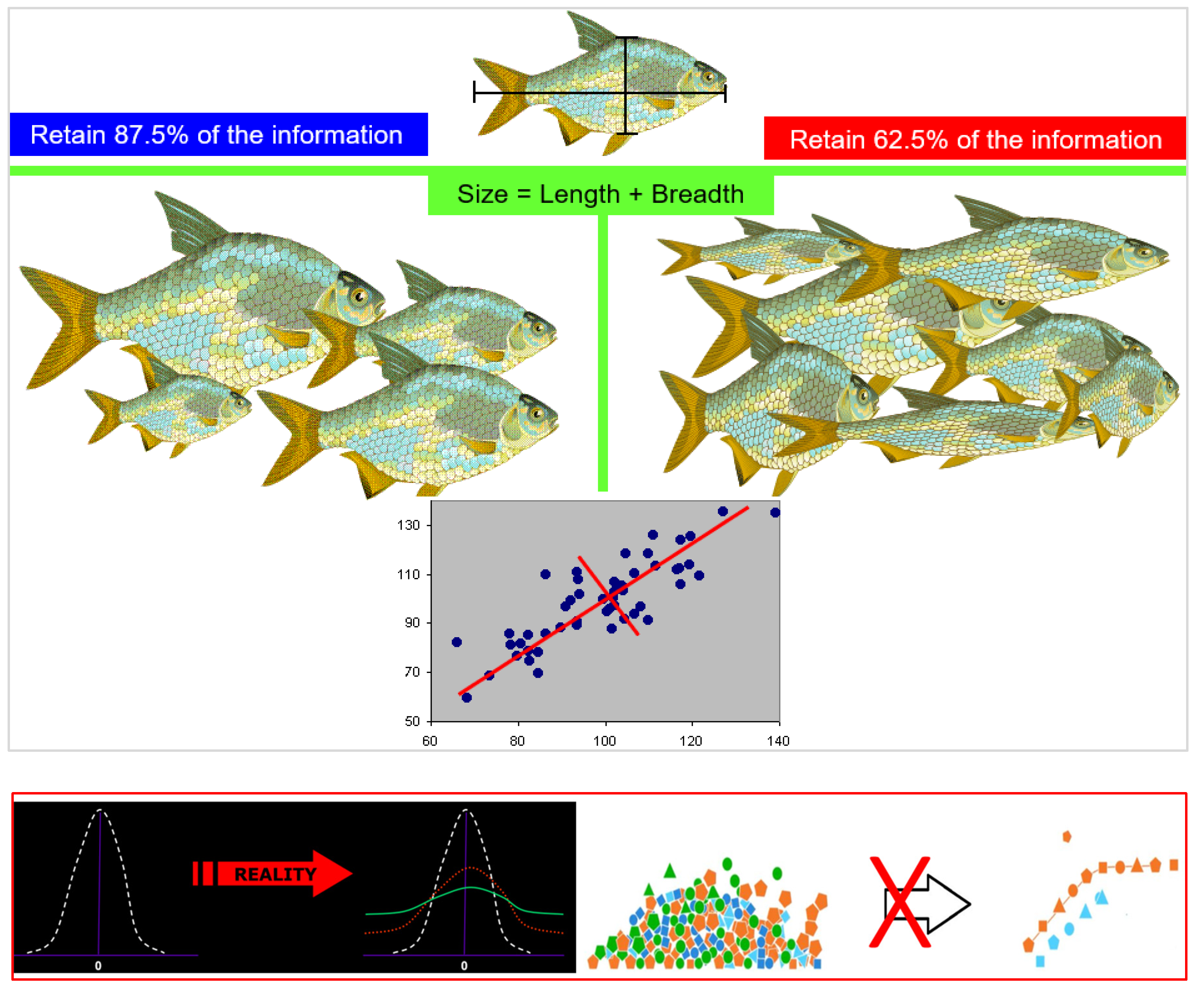
There is no one-size-fits-all in reality but off-the-shelf data analytics software may often use simple templates (e.g., size = length + breadth) to deal with data deluge, irrespective of the features in the data. These processing steps erase information from data and ignore outliers. The latter may help to predict emerging or imminent change. Lost information significantly decreases the expected value from analytics, potentially may result in decreasing profitability and may be dangerous if the data is linked to or indirectly feeds mission-critical decision systems. Traditional homoscedastic data distribution may be far from reality. Heteroscedasticity may be the norm.
[ii] Bootstrapping—Reinventing Resampling to Manufacturing Fake, Synthetic Data
“As raw materials became scarce, synthetics were developed” is scarce, by definition. When data was scarce (low volume), bootstrapping was created as a resampling [139] tool which copied segments of data and then replicated the copies (similar to block printing) to generate the illusion of high volume data (by repeating the process 1,000 or 10,000 times). Resampling was reinvented to manufacture fake data which is euphemistically marketed as “synthetic” data. The latter appears to have originated from the financial sector (derivatives pricing [140]).

Bootstrapped fake synthetic data are copies (not real) of data, which ignores two cardinal assumptions [a] data is independent and [b] identically distributed (IID). What happens when we analyze data over time? Data collected over time, time series data, is serially correlated and is not (cannot be) independent and identically distributed due to its very nature (i.e., data at time t1,n is dependent on data at time t0,n-1). The bootstrappers alternative to making “fakes” for time series data adds insult to injury by creating moving block bootstrap (MBB) and circular block bootstrap (CBB) tools to further advance fake data synthesis which hides the process through obfuscation.
Fake synthetic data is used to train models, e.g., machine learning (ML) models, so-called artificial intelligence models (using artificial neural networks [ANN], convolutional neural networks [CNN], recurrent neural networks [RNN], very shallow deep learning [DL] models).
Imagine the outcome/performance of testing these models? When using a subset of the fake training data as a test or challenge, the performance/outcome is, of course, absolutely stellar. In the real world, the performance of bootstrapped synthetic data trained systems cannot be trusted except for trivial tasks, for example, returning the correct amount of change in a grocery store (if stores accept cash and if customers are using cash). In the face of complex challenges or cyber-attacks the “deep fake” systems are likely to perish. GAN (general adversarial network) created images [141] (see below, from Zhou et al., 2021) could fool the models trained on synthetic data.

[iii] Winsorizing
Censoring data by limiting extreme values or outliers (winsorization [142]) has a role in statistical treatment in certain fields but probably not in others, e.g., healthcare. In the latter, outliers are often potential signals for prognosis. A winsorized estimator could be a source of error because extreme values are replaced by certain percentiles (intentional? introduction of artifacts and/or bias). Even worse is trimming or truncation, where extreme values are discarded.
[iv] Imputation
Replacing missing data [143] with substituted values [144] invites errors and data selection bias. Yet it appears to be in robust use [145] in different [146] domains with interesting outcomes [147] despite usual concerns about integrity of data as well as ethics in data handling.
[v] Interpolation
It is a type of estimation or approximation (replete with mathematical rigor [148] which dates back to the 7th century [149]). Interpolation aims to find new data (points) based on the range of a discrete set of known data points (finding data points outside the range of known data points is known as extrapolation, which is error prone and is an art rather than science or statistics).
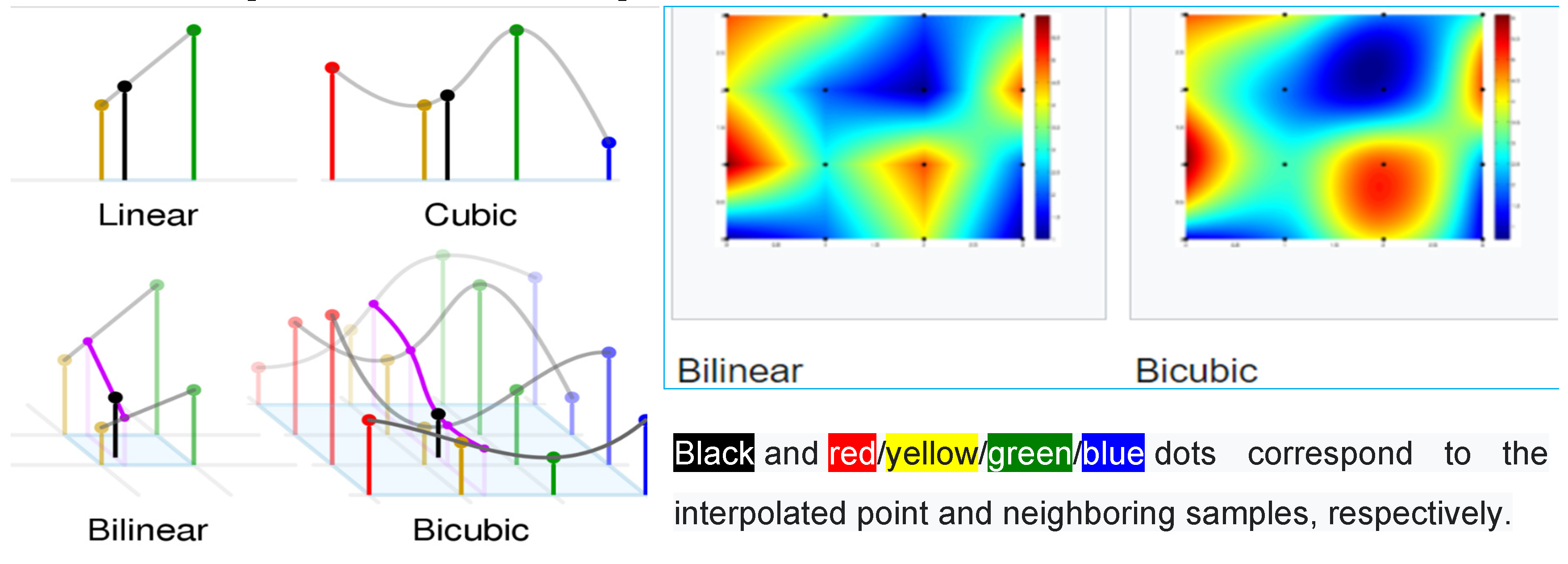
Cartoon 2. Multivariate Interpolation [150] of Waveform Data (for example, electrocardiography): Is it a concern? If digital filtering techniques are applied to waveform data during digital signal processing (DSP), could it involve bilinear and/or bicubic interpolation? Are the apparent differences between the bilinear and bicubic representations (right panel) in any shape or form influence the sampled data? Can it affect interpretation of the electrocardiograph waveform data?
Data from gun violence in the US [151] suggests that living is a dying art, especially without any penal consequences for the perpetrators and their protagonists. In the anti-parallel world of corporate sponsored ChatGPT [152], data fabrication makes lying a living art but with preventable consequences (“if we knew ahead of time, we could have tried to prevent it from happening” [153]).
Science of Causality Eroded by the Tsunami of Data
Ubiquity of sensors (among other things) is increasing data volume but what about information in the data? Is it boosting productivity? A plethora of sensor types [154] (not only electrochemical sensors) and sensor engineering based on specificity of the context (application environment) may offer insight and/or novel perspectives and opportunities. It is also fraught with major challenges, for example, when analytics ignored causal relationships, which remained unresolved during the design phase of process engineering with respect to data acquisition.
Transmitting data from sensors (wired or wireless) may depend on telecommunication protocols, global standards, software and hardware already in commercial use. But just because sensors are available and/or data can be transmitted does not mean that data or digital twins are a panacea [155] or that it can be used for anything and everything [156].
In the 20th century the design of data acquisition and analysis commenced by asking the “correct” questions, first. Brainstorming sessions reviewed the questions and deconstructed-reconstructed the analysis as a series of questions. Then teams debated the data necessary (to be collected or acquired or sourced) to prove/disprove the content of the questions based on causal relationships in context of the primary problem(s). Data design was rationally informed by contributing mathematicians and statisticians operating within scientific principles of causality. Data analysis was mathematically rigorous but also used statistical techniques [157] followed by visualization [158]. Design of data acquisition paid attention to veracity and integrity of data.
In the 21st century with the advent of mass media “data” we now collect/store/source polluted and corrupted, as well as irrational, unethical and worthless data in the name of “big data” in data lakes, swamps and dumps. Making sense of the khichuri (by “data scientists”) does not start with questions (forget the concept of “correct” questions, first) but how to fit the data to models or “cook-up” models from data for pecuniary reasons (Figure 2) to amplify sales of artificial [159] stupidity [160]. In data science, today, correct questions may be just an after-thought.
Stupidity [161] in science and research is valuable but can we extend it to data science, too? The few good ideas in digital twins must not be lost in this quagmire or in our attempt to provide definitions or create taxonomies. Digital twins will benefit from thoughtful granularity of data informed by design embracing causality but on the other hand it may also flourish as a laissez-faire term for digital representations of physical entities. It may remain agnostic of how much more [162] or less [163] sophisticated it is, as long as it delivers quantitative/measurable value to facilitate near-real time bi-directional optimization. Caution may be prudent (Figure 3) in interpretation of data and analysis based on context and causality. For example, primordial versions of digital dashboards for building management and energy efficiency came into existence since SCADA [164] appeared in practice and gained popularity over the past 25 years. Attempts to extrapolate these experiences to urban planning and indulging in the amorphous notion of “smart cities” is disquieting [165] but perhaps better than other deadly indulgences [166]. Science and its application [167] to human dignity [168] and social values “must always form the chief interest of all technical endeavors.” We should not forget this even in the climate of this era, overflowing with debate, dissent, disagreement, comments, criticisms, “diagrams & equations”.
Diabetes: Blood Glucose Data Through the Lens of Causality
Causality in mechanical systems may be established by independence of data and data points, but not in living systems. In other parallel worlds, data mining and/or pattern recognition (without ? causality) may reveal facts/artefacts of value. For example, non-obvious relationship awareness (NORA) evolved from risk [169] analysis, was applied to vulnerable systems [170] and proved to be useful as a methodological framework for tracking and intelligence collection for counter-terrorism [171] and analyses of terrorist networks [172].
Causality in biological systems cannot guarantee independence of data and/or data points. Living systems are system of systems which are inextricably intertwined, share dependencies and a complex pattern of multi-level inter-relationships. The heart of this multi-dimensional push-pull balance is germane to the conscious and subconscious maintenance of homeostasis. Isolating an independent variable and an independent data point is reasonably implausible.
With this context, we begin our discussion on diabetes and its economic [173] as well as productivity impact from the global epidemic of type II diabetes mellitus [174]. The mortality and morbidity from undiagnosed type II diabetes mellitus (T2DM) includes 277,000 premature deaths attributed to diabetes in 2017 in US (cost of diagnosed diabetes was US$327 billion in 2017 in the US, alone). Hence, it may be worth exploring whether digital monitoring (individuals at risk due to diabetes) may help to improve quality of life and reduce healthcare costs. In other words, architecting a bidirectional (?) digital cousin equivalent for monitoring/treating diabetes.
The biotech industry reports executed by paid agents and for-profit consultants (carefully disguised as “scientific” papers) ooze with malfeasance, if probed beyond the title and if the list of authors and their affiliations are compared. These reports claim one commercial blood glucose monitoring system at a cost of EUR 50,000 to be “cost-effective” (in France [175], UK [176] and Australia [177]). This is an action comparable to the US sugar industry offering bribes [178] to Harvard scientists to publish lies about the risks of sugar consumption on heart disease [179].
To be worthy of our consideration, the digital monitoring digital twin/cousin equivalent for diabetes (may include type I and type II) must be feasible for home use in Asia and Africa, for example, in India and Nigeria [180]. US-centric views of healthcare digital twins are a definitive path to bankruptcy (62.1% of all US bankruptcies in 2007 were due to medical expenses [181]).
Science reveals that blood glucose concentration (milligrams per deciliter, mg/dl) is generally a good indicator of the status of diabetes (type I and II). The causal relationship between blood glucose level and the “status of diabetes” is well [182] documented. Elevated levels of blood glucose levels may be recorded after intake of sugar/carbohydrate-rich food but levels should return to 80-120 mg/dl for non-diabetic adults within 2 hours. The persistence of blood glucose values above this range (hyperglycemia) is viewed as diabetes. The status of diabetes (not the etiology of diabetes), therefore, may be extrapolated with mild confidence from the data obtained by monitoring blood glucose concentration. This data is based on causal relationship. The use of this data in a digital twin/cousin for diabetes (or other forms of digital representation) may offer value for healthcare monitoring and precision treatment to improve quality of life.
It is critical to recognize that data from blood glucose level may be linked to several different etiologies [183] but the outcome of most etiological conditions converge to increase or decrease [184] only one parameter: blood glucose concentration. The change in the value of this data (range 80-120 mg/dl) is indicative of hypo- (<80 mg/dl) or hyper-glycemia (>120 mg/dl). Hence, this parameter (blood glucose concentration) has a causal relationship and the veracity of this data, if reliable, is of diagnostic value as well as an indicator for action/treatment.
The idea of a digital twin/cousin for diabetes (DtDc) is supported by causality with respect to the data (acquired to inform the medical status of the individual). Diffusion of DtDc may be a boon for society but may face political suppression by “big” pharma because it may reduce sales [185] of diabetes medication. Transparency from continuous monitoring of blood glucose concentration will expose the march of unreason [186] to justify over-medication. Sales of medication is the commercial [187] reason to lower [188] the range to “create” more “diabetic” (label) individuals. Physicians, legally, must prescribe medication based on blood tests (e.g., HbA1c [189]). Digital monitoring and digital representation may unleash the individual’s time series data to enable precision medication, adjusted for individual need, to better alleviate health conditions.
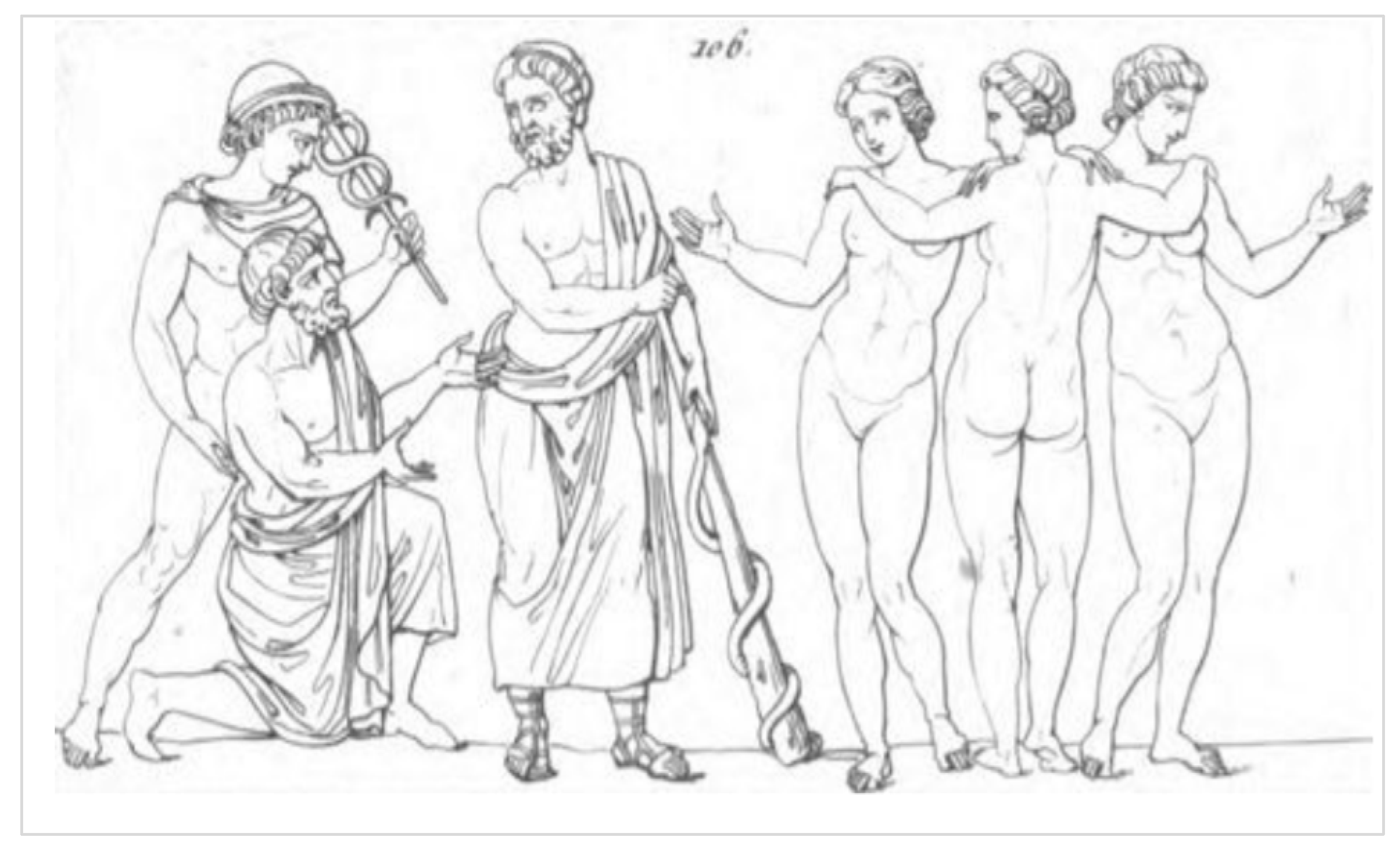
Figure 4.
Asclepius, the god of healing and his three daughters, Meditrina (medicine), Hygieia (hygiene), and Panacea (healing). The staff and single snake of Asclepius should not be confused with the twin snakes and caduceus of Hermes, the deified trickster and god of commerce, who is viewed with disdain (Figure 1.1 [190]). Plate from Aubin L. Millin, Galerie Mythologique (1811) [191].
Figure 4.
Asclepius, the god of healing and his three daughters, Meditrina (medicine), Hygieia (hygiene), and Panacea (healing). The staff and single snake of Asclepius should not be confused with the twin snakes and caduceus of Hermes, the deified trickster and god of commerce, who is viewed with disdain (Figure 1.1 [190]). Plate from Aubin L. Millin, Galerie Mythologique (1811) [191].
The “diabetes pandemic” has moved ahead of the silent epidemic [192] phase and more catastrophic [193] in the long run compared to upheaval due to CoVID-19 pandemic [194]. Estimating blood glucose concentration, over time (time series data) may be helpful in analysis of the pre-diabetic state in individuals and control of diabetes in patients, at rural and urban communities.
In the 21st century, there is nothing to crow about a digital representation in software (DtDc) with non-invasive [195] blood glucose [196] data monitoring [197]. Health data collection profile may also include oxygenation (pulse oximetry SpO2) and data from photoplethysmography [198] including hemoglobin [199] and blood pressure [200]. These few parameters along with body mass index (BMI) and other health history may suffice to offer individuals remote guidance, e.g., with respect to diabetes (without the cost of visiting a clinic). This simplified scenario of mobile retail health is applicable to countries with national health systems and where health is not a wealth creation platform for salesmen, retail outlets and medical insurance behemoths. This suggestion (Figure 5) in lieu of digital twins may be useful worldwide but excludes USA [201] and India. The latter appears to be aggressively pursuing [202] for-profit healthcare business.
Digital Twins for Complex Events: Cardiovascular Diseases (CVD)
Cardiovascular disease (CVD) risk factors include hypertension, hypercholesterolemia [211], dyslipidemia, atherosclerosis, obesity, tobacco use, and elevated hemoglobin A1c (diabetes). Independently, or in combination, they contribute to stroke [212] and other CVD including [213] congestive heart failure (CHF [214]), myocardial infarction (MI), stroke, pulmonary embolism, cardiopulmonary arrest (cardiac arrest), peripheral artery disease (PAD), atrial fibrillation, and angina pectoris [215] (chest pain). Taken together, cardiovascular dysfunction is the number one cause of death (~18 million deaths in 2017, almost one-third of all deaths, globally [216]).
Post-SARS-CoV-2 [217] infection (CoVID-19 pandemic) patients (some with pre-existing CVD) experienced acute respiratory distress syndrome (ARDS), venous thromboembolism (VTE), acute myocardial infarction (AMI), and acute heart failure (AHF). In addition, with or without pre-existing co-morbidities, few patients also experienced SARS-CoV-2 induced [218] myocarditis [219] (inflammation of heart muscle) and pericarditis (inflammation of outer lining of the heart) which presented symptoms of (but not limited to) angina (chest pain), tachycardia and/or arrhythmia (heart palpitations) and dyspnea (shortness of breath).
If pursued, stratified molecular epidemiological analysis (using stored donor blood from blood banks) in the post-CoVID-19 era may reveal an even greater share of deaths directly or indirectly due to CVD or complications resulting from CVD (e.g., chronic kidney disease and increased mortality due to ESRD, end-stage renal disease [220]). Multi-factorial complications may be confounded by factors based on genetics, immunological functions, nutritional status and other known (drug use [221], contra-indications from prescribed medications, basal metabolic rate, body mass index [222], diet, stress, lifestyle [223]) or unknown / unidentified determinants.
There is a need for additional focus on CVD at a granular level to detect changes before they reach levels where it becomes an acute care or emergency medicine statistic. Figure 6 indicates the cross-linked complexity due to viral myocarditis without accounting for pre-existing co-morbidities or patient-specific genomic/metabolomic constitution or behaviors [226].
Even before the pandemic, groups were keen to propose digital twins for cardiovascular health (for example, very poor attempt at detection of stroke [227] due to silent ischemia). The urge is to model precision cardiology [228] for digital twins using AI to solve precision human-specific problems. Is it an example of FOMO (fear of missing out [229])? In an utopian world, where data, information and knowledge about CVD is complete and computable, it may be worthwhile to consider designing a sub-segment of CVD using digital representation of data from electro-physiology and bio-markers for individual-specific CVD digital twins, with humans in the loop.
The array of known [231] biomarkers (Table 2) for only a couple (myocardial infarction and heart failure) of the many dysfunctions that constitute cardiovascular diseases should drive home the tortuous complexity of cardiac physiology and biochemistry in CVD. Establishing causality with clarity in the context of known dependencies between these bio-markers (and their networks of biological activities) may not be taken lightly. “Cardio digital twins” in the context of CVD may be comparable to a kindergarten science fair exhibit (Martinez-Velazquez, 2019).
It may be decades to biochemically ascertain how the profile of these and other bio-markers may change in individuals infected by SARS-CoV-2. Massive epidemiological studies may be required given that half the global population [232] are infected (hence, blood bank data).
For example, B-type natriuretic peptide (brain natriuretic peptide, BNP) in patients with acute myocardial infarction (Table 2) showed statistically [233] significant [234] (p< 0.001) elevation (elevated BNP of 462.875 picogram per milliliter) compared to controls (BNP concentration of 35.356 pg/ml). Because viral myocarditis can cause acute myocardial infarction and acute heart failure, we may re-think medical decision [235] making and re-establish diagnostic criteria [236] for levels of BNP (bio-marker concentration) in the post-CoVID population.
In terms of data for digital representation or digital twins, are we certain what levels of BNP bio-marker may be suitable for prognosticating? In terms of the data, are we clear about the ranges we should choose to indicate “normal” level? In terms of data, should we use the same range in our analysis of BNP data from individuals who were, versus, who were not, infected by SARS-CoV-2? In terms of data, what error correction may be necessary if the analytical tool for BNP data analysis is used for individuals from sub-Saharan Africa (highest infection rate of 79.3%, that is, 79·3 per 100 were infected with SARS-CoV-2) versus individuals from Asia (southeast Asia, east Asia, and Oceania had the lowest infection rate of 13%, that is, 13 per 100 population was infected with SARS-CoV-2)?
More than 30 years after the discovery of BNP [237] and recognition of the significance of this vasoactive peptide (32 amino acids) in myocardial infarction (MI), only recently [238] we have started creating sensors [239] for hBNP-32. BNP is an excellent indicator as a bio-marker for MI because it is produced [240] in response to pressure overload in ventricles and increased stress on ventricular walls (the main etiology of myocardial infarction is a lack of oxygen supply causing acute ischemia of cardiac tissue). BNP under 100pg/ml is “normal” for all ages but >450pg/ml, >900pg/ml and >1800pg/ml indicates acute heart failure for 50 years and older, 50-75 years and over 75 years, respectively. Detection and sensing is clouded by the short circulation time of BNP (about 20 minutes). Rapid release and diffusion of hBNP-32 from injured cardiac tissue to blood increases the signature bio-marker level (but rarely exceeds 2ng/ml during acute heart failure). Pre-pro-BNP (108 amino acids) undergoes proteolytic cleavage to generate human BNP32 (77-108 residues, 32 amino acid vasoactive peptide [241]) and the amino terminal fragment NT-pro-BNP (residues 1-76 amino acids, lacks biological activity). NT-pro-BNP circulation time is ~1-2 hours and serves as the target for most clinical tests. NT-pro-BNP levels <125 pg/mL (under 74 years) and <450 pg/mL (over 75 years) are normal. NT-pro-BNP >450 pg/mL (under 50 years) and >900 pg/mL (over 50 years) may be an indicator of serious cardiac problems.
In terms of causality, hBNP-32 and NT-pro-BNP data is closely aligned with myocardial infarction (without other confounding factors, according to published reports). The narrow time windows makes “after the fact” data useless (highly perishable value of data). The detection level of pg/ml makes it a difficult metric for traditional sensors (LoD, limit of detection).
In response to stretch, atrial cardiocytes also synthesize and release (secreted from the right atrium) atrial natriuretic peptide (ANP [242]) but this 28 amino acid vasoactive hormone with a half-life of 2-5 minutes is not regarded as a general bio-marker in MI, CHF or other CVD. ANP has vasodilating properties [243] both in arteries and veins which improves hemodynamics in heart failure and alleviates hypertension. Non-competitive immunoradiometric assay (IRMA) or competitive immunoradiometric assay (radiometric immunoassay, RIA) are usual laboratory [244] procedures to estimate plasma levels of ANP (16.1 +/- 8.6 ng/l, 5.2 +/- 2.8 pmol/l) and BNP (8.6 +/- 8.2 ng/l, 2.5 +/- 2.4 pmol/l) to better inform clinical treatment of patients with MI/CHF/CVD.
Table 2 row 1 refers to high-sensitivity troponin [245] (hs-cTn) i.e., cardiac troponin I (cTnI inhibits interaction with myosin heads in the absence of sufficient calcium ions) and cardiac troponin T (cTnT attaches the troponin complex to the actin filament) are two of three proteins that form the troponin complex (ITC includes troponin C which acts as the calcium binding site and involved in regulation of contraction of skeletal muscles but also synthesized by cardiac muscles). Cardiac-specific isoform troponins I and T (produced only by cardiac muscles with a plasma half-life of ~2 hours) are established bio-markers of cardiomyocyte injury. Data from cTnI and cTnT must be included in any CVD clinical profile, must be analyzed to inform treatment, both in reality and virtually (e.g., for aspirational “cardio” flavored digital cousins).
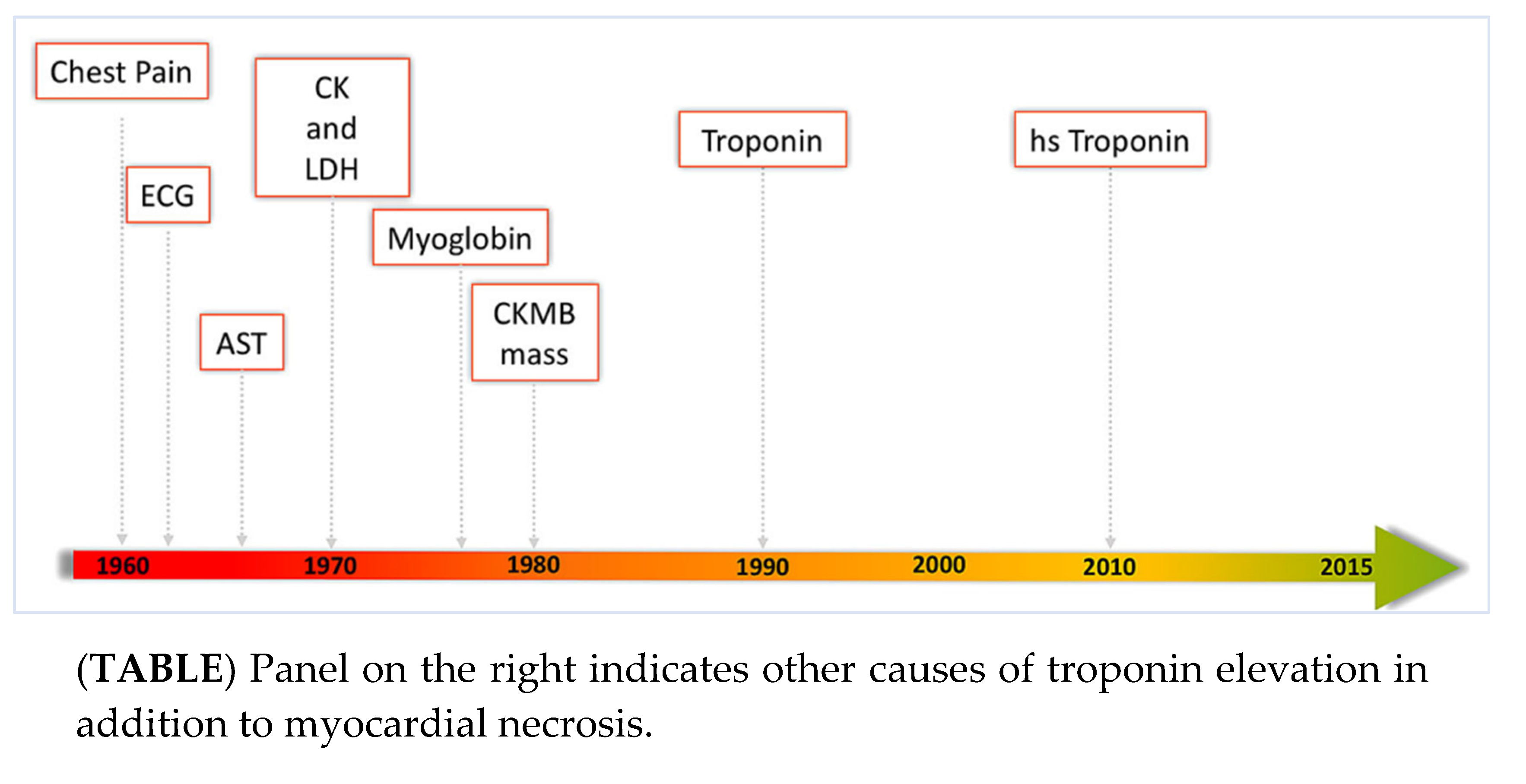
Figure 7.
A: Is there anything new [246]? Timeline of Troponin as a cardiac bio-marker for acute myocardial infarction [247]. ECG—ElectroCardioGram; AST—Aspartate Transaminase; CK—Creatine Kinase; LDH—Lactate DeHydrogenase; CKMB [248]—Creatine Kinase Myocardial Band; hs—high sensitivity. B: Is high-sensitivity cardiac troponin a reliable quantitative marker for AMI? (TOP) AMI acute myocardial infarction, CAD coronary artery disease, CHF congestive heart failure, HI healthy individual, LVH left ventricular hypertrophy, PE pulmonary embolus, SAB Staphylococcus aureus bacteremia. The lower the level of hs-cTn, the higher the negative predictive value (NPV) for the presence of AMI. The higher the level of hs-cTn, the higher the PPV (positive predictive value) for the presence of AMI. Levels just above the 99th percentile have a low PPV for AMI.
Figure 7.
A: Is there anything new [246]? Timeline of Troponin as a cardiac bio-marker for acute myocardial infarction [247]. ECG—ElectroCardioGram; AST—Aspartate Transaminase; CK—Creatine Kinase; LDH—Lactate DeHydrogenase; CKMB [248]—Creatine Kinase Myocardial Band; hs—high sensitivity. B: Is high-sensitivity cardiac troponin a reliable quantitative marker for AMI? (TOP) AMI acute myocardial infarction, CAD coronary artery disease, CHF congestive heart failure, HI healthy individual, LVH left ventricular hypertrophy, PE pulmonary embolus, SAB Staphylococcus aureus bacteremia. The lower the level of hs-cTn, the higher the negative predictive value (NPV) for the presence of AMI. The higher the level of hs-cTn, the higher the PPV (positive predictive value) for the presence of AMI. Levels just above the 99th percentile have a low PPV for AMI.

The table in Figure 7B begs to ask whether elevated levels of hs-cTn may necessarily reflect heart failure or acute myocardial infarction, by definition? (Myocardial [249] infarction defines acute myocardial infarction (AMI) as evidence of myocardial necrosis in a patient with the clinical features of acute myocardial ischemia). Elevation of cTn may indicate myocardial injury but there are myriad of diseases, inflammation, systemic dysfunctions (Table in Figure 7B) and infections [250] which releases troponin. Elevated cTn data is not exclusively causal for AMI and calls for differential diagnosis [251], correlation with BNP [252] and non-ischemic [253] cases [254].
How does the science of causality with respect to the data resonate with the design of “cardio” (Corral-Acero et al., 2020) digital twins? CVD signatures may not rely exclusively on electrical signals (waves) because the cardiovascular system (most physiological systems) is an electro-chemical juggernaut where signals (waves) are influenced by molecules (particles) and are rarely mutually exclusive without dependencies between networks and circuits of affiliated functions. Physiology is an inextricably linked system of systems which has evolved through synergistic integration of innumerable sub-systems acted on and guided by homeostasis [255].
If compared with even a tiny sub-system in physiology or medicine, the most advanced mechanical systems of today (e.g., Mars Rover [256]) may be akin to motion pictures in the late 19th century or TV [257] in the 1930’s: goofy, grainy, snowy and a drizzly experience in entertainment. The silver lining in the latter is what makes mechanical systems more suitable for digital twins. However, digital representation to monitor (diabetes-linked [258]) silent [259] myocardial ischemia [260] may save lives. Hence, is it worth exploring cardio digital cousins, no matter how crude it is?
Can Digital Twins Cope with Complexity? Cancer? Agriculture?
In the very distant future, science and sensor engineering inventions in health monitoring may help the idea of digital twins for patients with respect to patient-specific metabolomic data, if there is verifiable causality. In our current approach, KPI (Figure 5) may be viewed as case-specific digital representations (individual, patient) by integrating waveform time series data with medical records (EHR, EMR) and providing visualization (mobile phones, tablets, etc.).
The example of CVD illustrates the value of continuously monitoring bio-markers to predict risk of disease. Currently in the in utero stage of digital twins, the ability to track and trace bio-markers or other metabolomic targets is possible at a substantial cost, in clinics/labs. Testing non-invasive [263] bio-markers [264] for certain types of cancer [265] may reveal clues [266] and/or predict treatment (prevention), even years (decades) before the appearance of clinical symptoms.
Figure 9.
The futility of attempting to create biological digital twins may be appreciated by understanding the outline of the information packaged in this one cartoon [267]. Analysis of whole genomes [268] of 3,949 patients in 19 cancer types detected 61.2 million somatic mutations. An average of 7.5 events per cancer type were in protein-coding regions (meaning: these mutations can change the proteins synthesized by these genes). In the noncoding genome, 3.7 events per cancer type were detected proximal to certain genes in certain tissue types (meaning; we have very little clue as to how and why mutations in the noncoding region can/will affect gene expression, transcription or translation and/or how it may affect biological function/outcomes). In regulatory region of genes, 3.8 noncoding events per cancer type involved cancer-relevant genes (meaning: these mutations can up/down/stop expression of these genes). Perhaps, in a few centuries, we may shed some light on the functional role or significance of these 61.2 million somatic mutations. Long range interactions in genomes may share similarities with long range and allosteric [269] interactions [270] between proteins and between/within protein binding domains [271]. When can we expect this type of data to be a part of digital twins? More importantly, is it really necessary or will it be at all necessary if prevention of cancer by vaccines [272] gain momentum?
Figure 9.
The futility of attempting to create biological digital twins may be appreciated by understanding the outline of the information packaged in this one cartoon [267]. Analysis of whole genomes [268] of 3,949 patients in 19 cancer types detected 61.2 million somatic mutations. An average of 7.5 events per cancer type were in protein-coding regions (meaning: these mutations can change the proteins synthesized by these genes). In the noncoding genome, 3.7 events per cancer type were detected proximal to certain genes in certain tissue types (meaning; we have very little clue as to how and why mutations in the noncoding region can/will affect gene expression, transcription or translation and/or how it may affect biological function/outcomes). In regulatory region of genes, 3.8 noncoding events per cancer type involved cancer-relevant genes (meaning: these mutations can up/down/stop expression of these genes). Perhaps, in a few centuries, we may shed some light on the functional role or significance of these 61.2 million somatic mutations. Long range interactions in genomes may share similarities with long range and allosteric [269] interactions [270] between proteins and between/within protein binding domains [271]. When can we expect this type of data to be a part of digital twins? More importantly, is it really necessary or will it be at all necessary if prevention of cancer by vaccines [272] gain momentum?
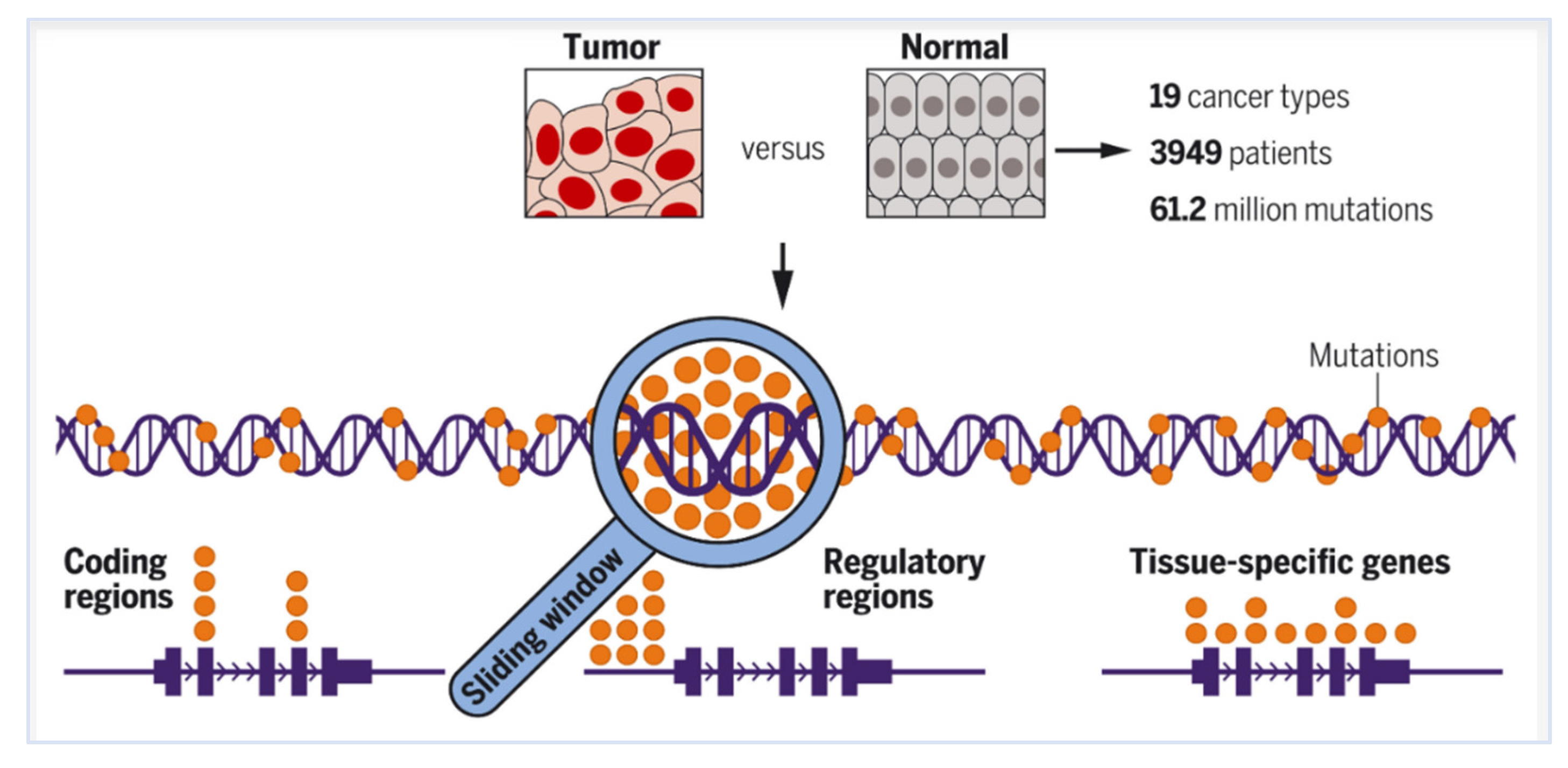
Figure 10.
Interactions [273] of soil organisms (microbiome). Root chemicals (orange—antagonists against plants; blue—mutualists). The chemistry between soil organisms (symbionts, pathogens, herbivores) is differentiated over a vertical gradient in the rhizosphere. Interaction continuum between roots and soil biota are closely related to the gradient of root chemical traits. Most of the insect herbivores are present in the top horizon of soils and interact with taproots (defended by chemicals against herbivores and pathogens. Plant pathogenic nematodes and microbes generally infect fine roots (physically most vulnerable). Root exudates are actively released from root tips and contain various chemicals. Beneficial microbes, such as mycorrhizal fungi rhizobia, and plant growth-promoting bacteria, also interact mostly with fine roots (attracted by the release of chemicals). Except for names of the microbiota, and parts of the plants, there is an almost total absence of molecular understanding of chemical, biochemical and growth processes. In the absence of relevant data how could we even begin to think in terms of digital twins for the plant or the soil or the microbiome? But, it appears science and evidence from data may be irrelevant for some proponents [274] of digital twins where the mantra of “publish first” trumps credibility.
Figure 10.
Interactions [273] of soil organisms (microbiome). Root chemicals (orange—antagonists against plants; blue—mutualists). The chemistry between soil organisms (symbionts, pathogens, herbivores) is differentiated over a vertical gradient in the rhizosphere. Interaction continuum between roots and soil biota are closely related to the gradient of root chemical traits. Most of the insect herbivores are present in the top horizon of soils and interact with taproots (defended by chemicals against herbivores and pathogens. Plant pathogenic nematodes and microbes generally infect fine roots (physically most vulnerable). Root exudates are actively released from root tips and contain various chemicals. Beneficial microbes, such as mycorrhizal fungi rhizobia, and plant growth-promoting bacteria, also interact mostly with fine roots (attracted by the release of chemicals). Except for names of the microbiota, and parts of the plants, there is an almost total absence of molecular understanding of chemical, biochemical and growth processes. In the absence of relevant data how could we even begin to think in terms of digital twins for the plant or the soil or the microbiome? But, it appears science and evidence from data may be irrelevant for some proponents [274] of digital twins where the mantra of “publish first” trumps credibility.
Is It up to Scratch? Data-Informed Digital Services (DIDS)
At the core of ACDC (analytics, connectivity, and data the context of causality), is the need for diffusion of data, which can inform decisions in a manner that non-expert end-users may access (actionable) information. For providers, value from digital twin translates to profit. Intuitive or user-friendly features are crucial for mass adoption of tools, especially mobile tools.
We will avoid business school [275] strategies and focus on debating data-informed digital services (DIDS) as an umbrella for digital representation to deliver services (see Figure 5 for resource constrained environments). DIDS may be an alternative digital twin-esque or cousin-esque approach for mission-critical applications and life-saving devices, such as the ventilator. This device is currently a part of the global vernacular due to its quintessential role in saving millions of lives at the peak of CoVID-19 pandemic.
We begin with an alphabet soup at the bottom of the pyramid in Figure 11(top). It begins with “atoms to bits” and adds connectivity to catalyze decision making, that is, ABCD (Atoms to Bits Connectivity in Decisions). ABCD is a data acquisition layer where sensors, tags, manual input and other sources feed raw data. The internet of things (IoT) is the canonical data layer for objects and things which feed on the granularity of the common denominator (ABCD). CPS combines data from atoms (physical objects) with instructions (bits) from commands, processes and procedures which directs/determines actions/reactions in the networked physical world [276].
The user may benefit from the synthesis of these layers (blurred boundaries) through DIDS where distributed data may be curated for quality control, analyzed with mathematical model(s) and/or statistical technique(s), perhaps even fused with other internal or external data.
The outcome of this data processing is information which “informs” the user (humans in the loop) how to make better decisions. The “edge” interactions may be immobile contexts (control tower, office, factory [277]) or real-time dynamic interactions where outcomes (data, information) may influence the user, instantly (via mobile platforms, smartphone, tablets) or users may wish to subscribe to information updates (publish/subscribe) for decision support.
The mark of interrogation at the tip of the pyramid offers further room for imagination, invention, innovation and interpretation of the collective path, which data may take to arrive at information, which users can synergize/integrate to improve/profit from their decisions/actions. This ability in the [ ? ] segment on top of the pyramid is suggestive of an “always on” real-time digital representation with DIDS-integrated decision support for systems (farm, factory, flying saucers), mission critical applications and even for life-saving ventilators or security devices.
This ability in the [ ? ] segment on top of the pyramid (Figure 11) may be erroneously evangelized as “digital twins” to enhance the marketing panache of what may be, in some/many instances, simply a vanilla aggregation of data and analytics in a dumb digital duplicate, which may, in appropriate circumstances, provide useful data, information and collective system status.
Humans are ill-equipped, non-linear, irrational [280] systems and immersed in artefacts of complex systems. Most rational and natural actions are governed by a set of immutable scientific principles based on thermodynamics (mathematics, physics, chemistry, biology). The journey from individual molecule to individuality is a natural outcome. The former (molecules) may not behave unnaturally but the latter (individuals) are prone to irrational behaviors. Therefore, data from systems guided by natural laws (machines guided by physics and engineering) generally generate data from deterministic events. Humans-in-the-loop systems (e.g., manual healthcare data acquisition / entry; economic data) are sources of uncertainty, corrupt data, altered artefacts and data due to spurious events (fake big data [281]), uninformed models or biased frameworks.
Frameworks are workhorses for science. The over-arching importance of understanding, creating and implementing robust frameworks may be best exemplified by the theory of quantum mechanics [282]. The latter is less of a theory and more of a foundational framework [283] where physical theory fits or must be fitted (?). A lesser known but another highly relevant framework is the theory of quantum chromodynamics [284] (QCD) based on the discovery of quarks and gluons. Unlike the theory of quantum mechanics where physical theories “fit” (? nicely [285]) in case of QCD the “fit” is constrained due to lack of mathematical tools (open research topic).
The underlying mathematical infrastructure at the heart of frameworks is referred to as schema, a common conceptual feature in complex adaptive systems (e.g., epidemiology). The granularity of such schemas makes it possible for highly modular mathematical expressions (e.g., equations for rates/flows) to be “mixed and matched” (from repertoire of model schemas) to generate different sub-frameworks depending on the desired outcome (i.e., what the complex adaptive system expects to create, modify or represent). Modular mathematical expressions that constitute frameworks or schemas may be viewed as scaffolds for data. An equation for rate or flow in a complex adaptive system is alive when it acquires data or is involved in information arbitrage (e.g., data or information from environment or interaction with/within the environment of the system which is referred to as the “percept” from the “environment”). The source of data (data acquisition system) may be human or data harvesting tool, such as sensors. This (sensor) data represents actions in the real world which feeds schemas (rates, flows, weights) and the feedback (in a closed loop system) influences the schema(s) to change/modify actions/behaviors (actuate/automate) to improve/optimize system performance.
Multiple arrays of schemas may have multiple data feeds (may switch between data feeds depending on tasks or desired systems-level outcome). Individual outcomes must be synthesized and/or synergized as a whole for the most relevant semantic interpretation which is of value for the whole or “performance” based on PEAS framework (percepts, environments, actuators and sensors, discussed earlier). DIDS offers clues as to how frameworks, performance and PEAS may influence decision support. Unbeknownst to solution providers in the real world, they are trying to create (?) systemic solutions and/or predictive [286] tools for “profitable problems” by using this rubric, translating these concepts for (pragmatic?) implementations, e.g., digital twins. Data, dependencies, relationships and ratios are granularities which influences and/or informs weights, rates, flows to enable contextual titration/optimization of system outcome/performance.
In an ideal situation data-informed feedback from humans-in-the-loop may combine concepts (ACDC, ABCD, DIDS, PEAS, OODA). Tuning or adapting outcomes to a desired level is often valuable for end-users and triggers adoption of concepts/tools (digital twins/cousins). Pre-setting desired outcomes are common in certain systems e.g., fuel-dependent optimization of turbines to limit release of greenhouse gases (GHG) to a pre-specified level. The retrosynthetic [287] approach is a form of “backward planning and optimization” if system attributes are identifiable (parts, components, characteristics) and if each are associated with rigorous performance metrics.
What if we create mathematical models, frameworks or schemas for parts or components of the system? Each schema is then subjected to PEAS-like treatment and the components (think individual gears) are brought back together (inside a clock) to deliver the “whole” performance. But, complexity of complex adaptive systems may be rate-limiting for retrosynthesis because the ability to deconstruct the end point (performance) may be influenced by too many “synthons” (e.g., state space explosion in an optimization problem [lemma] with too many dependencies).
A crucial question is whether these schema or mathematical expressions can be created as modular entities which can be stored in a “library” or a repertoire of modular units (e.g., weights, rates, flows) which can be re-used as granular entity level models when probing other systems or optimizing performance? Simulated 3D concurrent engineering [288] workbenches [289] may be an analogy where functions and components may be sourced from a repertoire (“drag & drop” from a menu of choices) to modify/re-construct/re-configure engineering design for diverse objects.
A highly analytical, deeply incisive and very significant mathematical framework which embraces some of these ideas (discussed in the last eight paragraphs) was recently published [290] to highlight a brilliant convergence of epidemiology and economic factors from the perspective of disease modelling in plants. Perusal of this paper reveals the importance of parameters which could be equivalent to features (in our hypothetical model and a potential general mathematical framework) linked to data (data feeding the feature or the feature/parameter as a higher level data node). Murray-Watson et al. effectively uses “switching terms” with values (0, 1) indicating portability of parameters in an equation based model, EBM (add/delete depending on context). This attribute lends itself to integrating EBM with agent based models (ABM) where inclusion or exclusion of the (software) agent (data tool) makes the framework modular, agile, adaptable and dynamic, to the address the specificity in queries (questions from non-expert end users, farmers).
Translating this mathematical structure of the infrastructure into frameworks (ASIM, application specific integrated models) and simulation tools may converge with the old idea [291] of tangible user interface [292] (TUI [293]). Computationally constrained users [294] may experiment (e.g., strategic planning) by changing values, parameters and variables to explore deterministic what-if scenarios (not only for managers or executives but a training tool for new entrants, workforce development, and high school students vocational training). The next few paragraphs (grasp the depth of Figure 12) may add further clarity to this “value added” thinking if non-experts are empowered to change/modify equation based models using “drag and drop” tools linked to a menu of features/parameters/variables with a sliding scale (e.g., values high to low) which the user can manipulate/control/command/limit/extend (when necessary, on-demand, in real-time).
Convergence of epidemiology and economic factors in Murray-Watson et al. are poised to add error correction tools (models are, naturally, error prone), e.g., generalized autoregressive conditional heteroskedasticity (GARCH; Datta and Granger, 2006). GARCH is a representative error correction technique from financial econometrics, which is useful in view of volatility and veracity of high volume data, which introduces, amplifies and accumulates error in equation based models (GARCH models the variance of the error). A simulation tool or TUI which enables users to change the error rate will be immensely helpful to observe ranges of errors and their impact on suggestive, predictive and prescriptive analytics (see Figure 13 and Figure 14 for potential applications / use cases). The simulation will help establish acceptable boundaries of error limits depending on the desired level of tolerance or acceptable degree of system risk.
Libraries of practical use-case models (mathematical frameworks) must contain examples of use cases in demand (domain specific). For example, water supply [295], water quality and water requirement [296] calculations [297] are central for crop production. Water use, water treatment and irrigation practices are under threat from climate change as well as limits on fresh water versus brown water, etc. The gradient of the arable land, soil moisture determinants (type of soil, soil microbes, etc.) and chemicals (fertilizers, pesticides, herbicides) are a few of the parameters (vectors, vector spaces) generally taken into account (integrated with experience) by growers, when making decisions to support their target goals (crops, produce, cattle). These parameters (features/vectors) are linked with tier-1, tier-2 or even tier-3, dependencies. The base of this “pyramid” (Figure 11) consists of events/instances which may generate time series data (scalar). Specific sensors (if deployed) can collect data to provide information (related to vectors and if there is information in the data) to better equip decision support systems to assist humans-in-the-loop (unable to mine/capture “experience” which can computationally substitute for a human).
A mathematical representation of this model, its network of dependencies and range of values (scalar) for each feature/sub-feature (vectors) may serve as an embedded logic engine behind an user interface. Non-expert users can benefit from such tools using drag and drop objects or changing levers or selecting tools to optimize their expectations of performance. Tools are less useful if data or information is unidirectional. In order to re-tune, re-set, re-calibrate system performance at the edge, the features [298] must be familiar to users. We must simplify [299] the “Lego Mindstorms” approach [300] by dragging and dropping icons and “joining” (the subject and the predicate, conjunction) to reflect the intended “meaning” (semantics) using (Boolean logic) embedded operators (designed as connections). At the points of use, it may serve as a mobile distributed sense and response system which may partially actuate (sense, analyze, respond, actuate, SARA [301]) with semi-autonomy for non-mission critical systems with high fault tolerance. The foundation of such a system, now available as SCRATCH [302] (created 20 years ago by Elisabeth Sylvan [303]). MIT spin-off Thunkable [304] and Lego [305] Mindstorms [306] uses this idea. Scratch-esque tools for real-world edge applications/scenarios are the bridge to the next billion users in manufacturing, energy, logistics, agriculture, smart homes, healthcare, & cybersecurity.
Figure 12.
a: Sylvan (2007) described “tools to build online communities” where almost any user capable of articulating the task in natural language (English) may create command sets to instruct computation without the need to “code” the syntax of the instruction in a programming language. “Drag & drop” icons (embedded code) deliver user’s task description to configure instructions. MIT “Scratch” (top) shows list of features/instructions which can be combined on a design board (bottom, right) to deliver an outcome that non-experts can construct. MIT spin-off “Thunkable” (bottom, left) appears to be a “digital copy” (for-profit commercial version) of MIT Scratch.
Figure 12.
a: Sylvan (2007) described “tools to build online communities” where almost any user capable of articulating the task in natural language (English) may create command sets to instruct computation without the need to “code” the syntax of the instruction in a programming language. “Drag & drop” icons (embedded code) deliver user’s task description to configure instructions. MIT “Scratch” (top) shows list of features/instructions which can be combined on a design board (bottom, right) to deliver an outcome that non-experts can construct. MIT spin-off “Thunkable” (bottom, left) appears to be a “digital copy” (for-profit commercial version) of MIT Scratch.
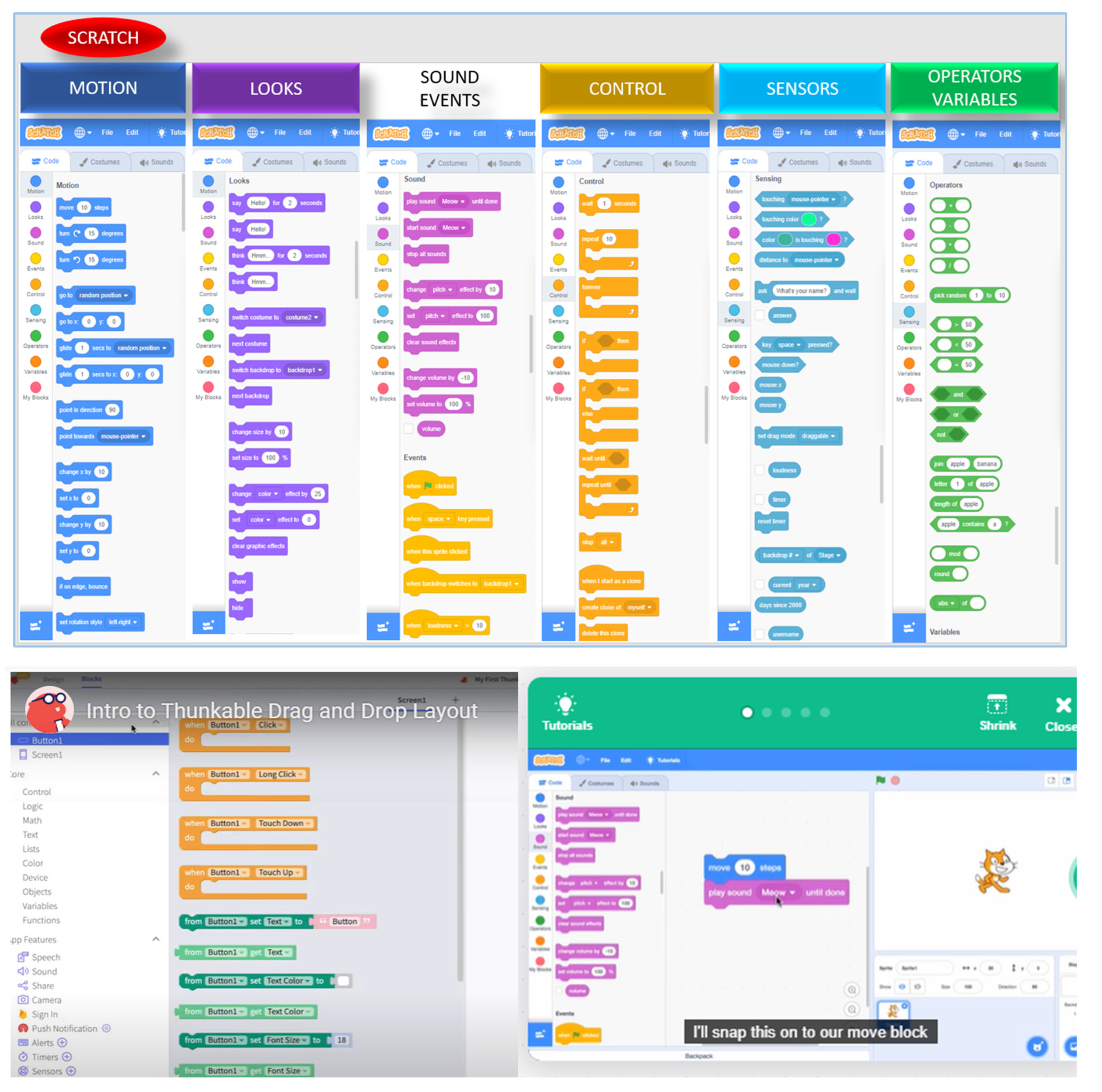
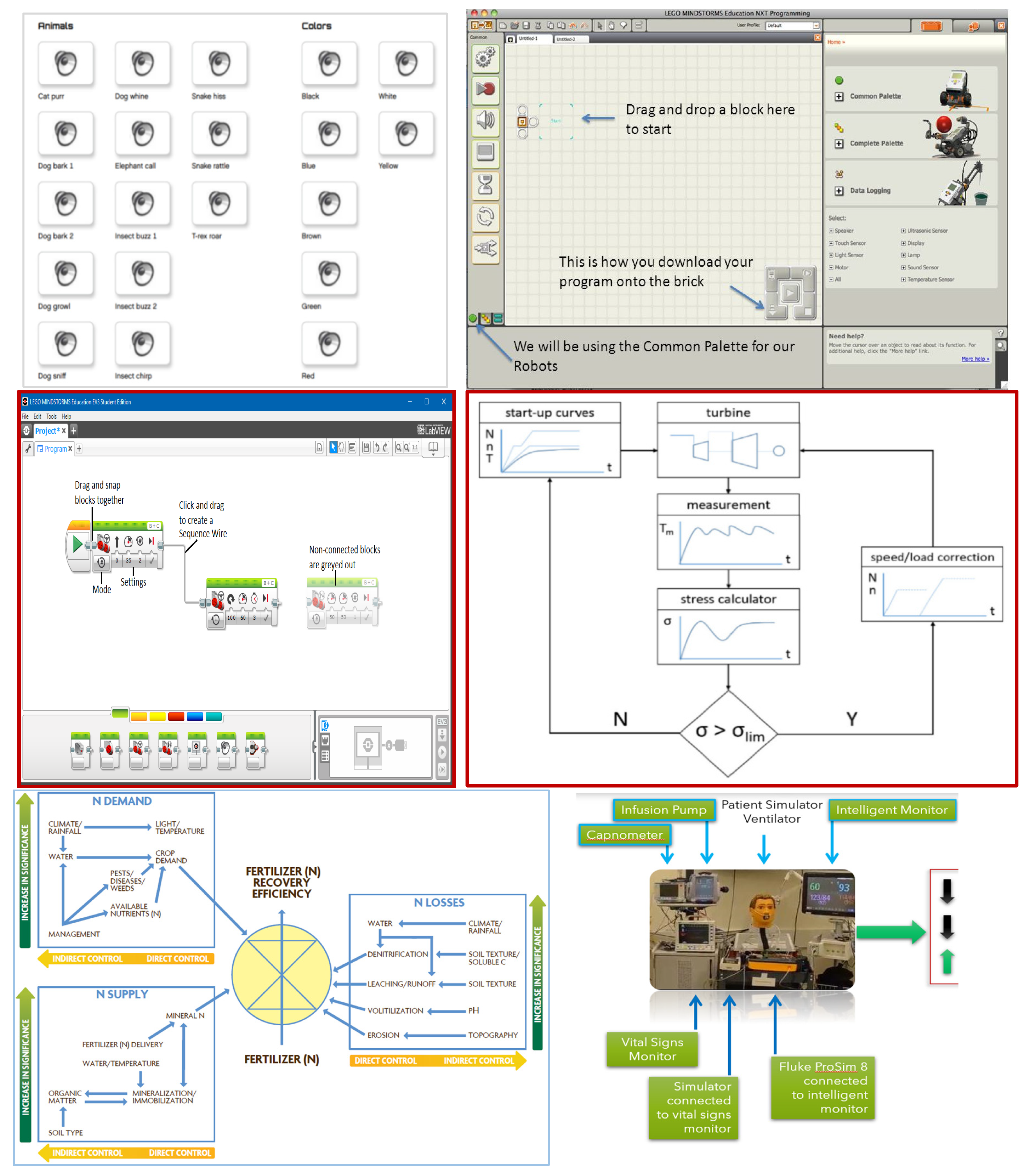
Figure 12. b: Diffusion of ubiquitous computing at the edge may be transformed from vision to reality, partially, using tools with embedded code (Sylvan, 2007). Non-experts may create new tasks, or sense, analyze, respond and even actuate (SARA) to adapt or optimize key performance indicators based on need, events, feedback. Can we transform these principles into practice?
The common denominator emphasized in Figure 12 are tasks which can be performed by non-expert users without programming (each time, for each instance). If it is up to Scratch, can we use a common platform with a workbench [307] containing a palette of tools with embedded code? The tools must be application-specific but the principle of embedded code may be applied, universally. Non-expert users can choose user interfaces optimized for mobile computing as long as scenario-specific tools are available and adequately addresses the user’s need/purpose.
In the Lego Mindstorms palette of tools for animal calls/colors (Figure 12b, top, left), children may create “robo-dog” using an user interface on the workbench (Figure 12b, top, right). The “digital twin” robo-dog may look like a black and white spotted Dalmatian but may purr like a cat if the user inserts “cat purr” as the animal call instead of dog sound (whine, bark, etc). The middle panel (Figure 12b, burgundy outline) extends the idea (Lego workbench, left) to energy generation, specifically, turbine optimization [308] for energy plants (Figure 12b, middle, right). Non-technical users may program an optimization routine/step without knowledge of programming or code. Users choose icons with pre-determined functions/values and connects in a manner which produces a desired outcome. Users must understand functions related to turbine start parameters (domain knowledge) and the palette of tools must have embedded code in modules/connectors that is relevant to the scenario (in this example, turbine start optimization for power generation).
Mobile device interfaces for applications in agriculture [309] (left, bottom, Figure 12b) and healthcare [310] (Figure 12b, bottom, right) may use Scratch-type GUI, workbenches and palette of tools supporting case-specific configurations for users to modify/optimize/explore. A “triage” dashboard may display a simulated outcome, before live deployment of modifications, to allow users to observe the results and impact of their modifications. For example, what if the scenario selected by user includes a nitrate value too low or too high? It may be informative to review how the user’s nitrate value may impact the outcome as well as its relationship to global issues, for example, nitrogen availability in terrestrial ecosystems [311] (or phosphorous [312] pollution [313]).
Scratch at the edge for non-expert users is in sharp contrast to the traditional notion of centralized control exercised by experts. It resembles a decentralized distributed decision-making model which is not a mirage and thematically lends support to the idea of data democratization without the illusion of digital twins. In the context of complexity of nitrogen (Figure 12b, bottom, left) and post-surgical PCA (patient-controlled analgesia, Figure 12b: bottom, right), can we apply retrosynthetic principles to explore how to optimize behaviors for complex adaptive systems?
Using “crowd-informed” Scratch-esque tools in the hands of mobile users (non-experts), can we release the “joystick” of retrosynthetic analysis for the masses? In many scenarios, the “outcome” is community-specific and driven by economics. One shoe may not fit all. If a global model needs modification to fit the local need then who is better equipped to modify the model than the local end-user with a targeted outcome in mind? For example, a model of Nitrogen as a fertilizer may be best made useful by the local farmer for local use. Scratch may enable users to better control decentralized data and information to optimize services for micro-environments.
Mathematical Models: All Models Are Wrong (Some Are Useful)
All models are wrong [314], but however incorrect, some models may offer a guiding hand to inform the structure of the infrastructure, which may serve as a “perch” (scaffold) for data, on the journey to make sense of data (analytics). While some models are useful, only a few survive unscathed, in practice, because models are either too simplistic or attempt to reach, capture, and encapsulate granularities beyond their grasp. Digital twins lack granularity because proponents may choose to ignore the necessary minutiae either due to their lack of depth or the cost to delve into details. Canonical “quick & dirty”, “fast & cheap”, “shoddy & second grade” commercial endeavors cringe at science, depth, and detail, as factors that lengthen their ‘time to market’ metric. Hence, the over-simplified pedestrian ‘digital twins’ (cardio, soil microbiome, earth).
On the other extreme is our fantasy of contemplating but never taking that quantum leap from quantum mechanics and quantum chromodynamics to explore the pragmatism of our lofty ideas (some of which were discussed in the preceding section, following Figure 11). But, is there any benefit from our elusive quest for the middle ground between the race for profit [315] and gluttony [316] versus the penchant for illumination, plight to be complete and ill-treating good [317] as the enemy of perfect? What if the twins are archenemies [318]? The chasm between the two cultures [319] is not about science but a revealing social cleavage between reason and power, or between self-interest and societal good, or between haphazard realities and moral hazard.
Our discussion following Figure 11 and the next section (models of life) is an attempt to sketch a few examples from agriculture and healthcare. For better or for worse, for the richer and for the poorer, in sickness and in health, the progress of civilization depends on agriculture and health in addition to three other essentials: energy, water and sanitation, collectively referred to as FEWSH (food, energy, water, sanitation, health). The intricately intertwined interactions within FEWSH fuels life and living, agnostic of affluence. It is braggadocious to claim that we are “delving in details” when we haven’t even scratched the surface. It is hubris if we claim “we know” because practically we almost know nothing either about science or about science and human values [320]. In this spartan landscape of our limited knowledge, we continue to return to what we can reasonably count on: analytics, connectivity, data in the context of causality (ACDC). All that which counts but cannot be counted [321] is left to the imagination of the readers.
In agriculture, healthcare and other living systems, can we create a repertoire of models or schemas? Mathematical models may serve as “engines” in backend applications ingesting contextually relevant data. Users can interact through Scratch-type tools on mobile UI (phones). From the miniscule arsenal of our knowledge, even the known factors which may affect the efficiency of nitrogen use in agriculture are far too numerous to design an adequate “efficiency” metric or target outcome using the retrosynthetic approach (where we first create a target or a metric as the goal). If we could find that target, we could work backwards to determine how to arrive at that targeted outcome by adjusting the “levers” within the interconnected systems. The latter may “sound” like the (flawed) back propagation algorithm but it is not. Is it the tried and true concept similar to the retrosynthetic approach (ref 287) by Elias J. Corey?
Figure 13.
Crop, Environmental and Management Factors Affecting Nitrogen Use Efficiency: Conceptual model depicting the three main controlling processes (nitrogen demand, supply and loss), major mechanisms and factors regulating fertilizer (Nitrogen) use efficiency. The “control” in the center, influences the flow of fertilizer (N) into the crop (Balasubramanian et al., 2004 [322]).
Figure 13.
Crop, Environmental and Management Factors Affecting Nitrogen Use Efficiency: Conceptual model depicting the three main controlling processes (nitrogen demand, supply and loss), major mechanisms and factors regulating fertilizer (Nitrogen) use efficiency. The “control” in the center, influences the flow of fertilizer (N) into the crop (Balasubramanian et al., 2004 [322]).
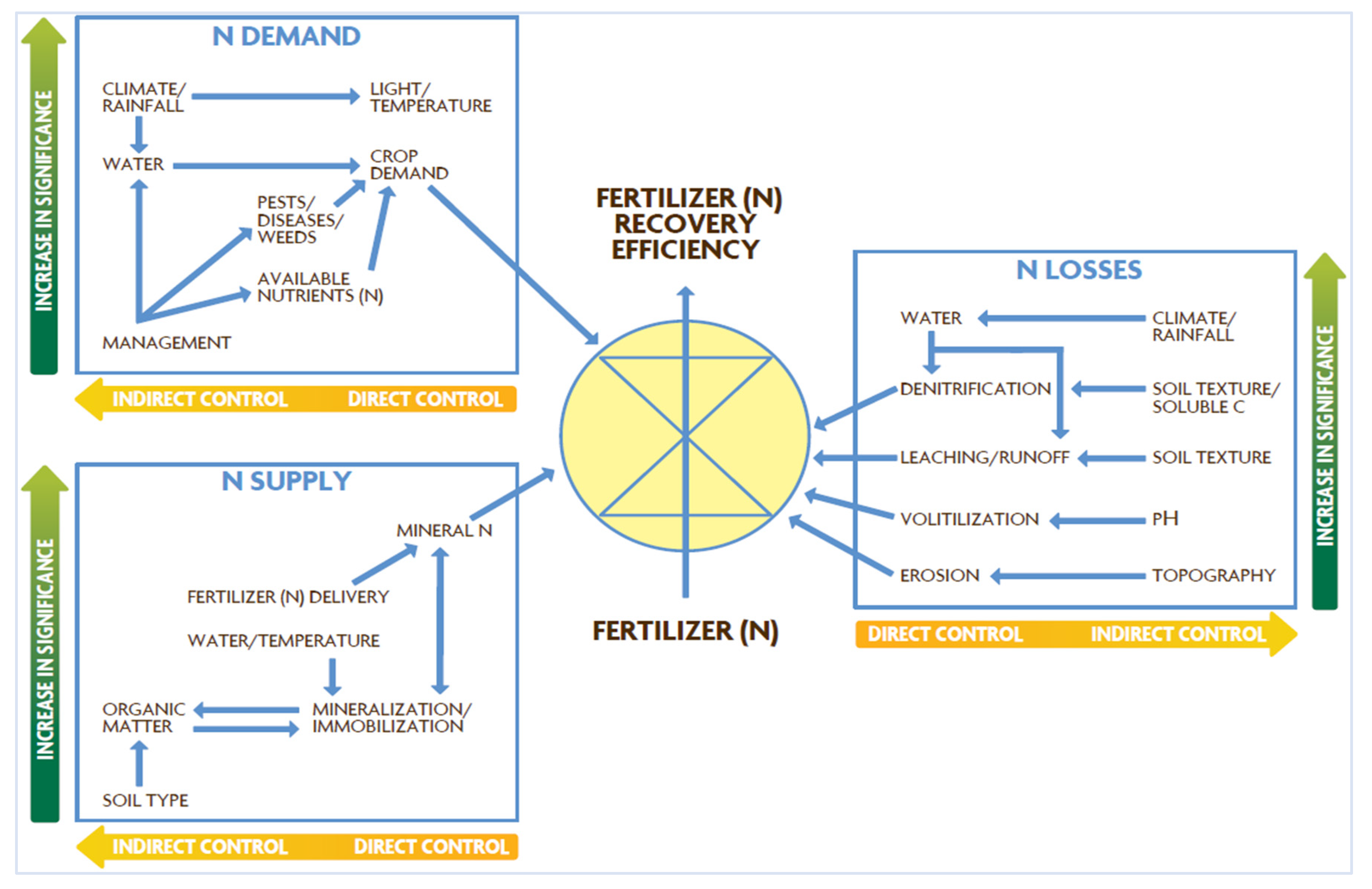
Dissecting the problem (previous section) reveals that water and temperature are common elements in three sub-domains. Can we focus on these two data-revealing (measurable) granular elements in this complex adaptive system? What we uncover/interpret may be extrapolated [323] beyond our grasp of the granularities, their causal factors, meaning and contextual significance.
Although error-prone, we may proceed to build mathematical models assuming that ‘water’ measurements and quantification will generate data for “water models” within the “universal” model of nitrogen efficiency. The sub-library of water models must be searchable using “discovery” tools and search engines. The models are expected to become increasingly complex depending on the plethora of features associated with water. Search engine optimization tools using keywords may be a failing strategy. The use of graph databases to contextualize water data in terms of relationships in specific instances of data (with other causes, if any) may be useful. Time series data integrated with causal context in a time-stamped graph database of water data may be valuable for analytics, in any context, including digital twin representations.
Discovery of model repertoires increases value through re-usability of pre-created models in a library. Teams working on related agricultural topics (e.g., carbon cycle, phosphorous cycle) may search, find and use “water” models from Nitrogen efficiency. Models may be imported (inserted/integrated) using common APIs (application programming interfaces) or modified after import to adapt to user-specific tasks (but only if the pre-coded model language is interoperable with the programming language of the task at hand). This “newly” modified model may be also uploaded back to the source library and designated “water model x.y” to enrich the searchable repertoire. Crowdsourcing may gather “best practices” from “distributed science” [324] and increase diversity and granularity of models to amplify the range of explored scenarios.
Generally speaking, connectivity, data and analytics (ACDC) with respect to each factor in each sub-domain, is immersed in dependencies, relationships and dynamic ratios with one or more factor or network of factors. Hence, sub-domain models may need further reductionism to sub-component models and more drilling down to define weights, rates and flows (associated data). In the sub-domain “N Demand” (Figure 13: top, left) we need sub-component models of “light” and “temperature” which are key elements used in multiple applications and may not be limited only to nitrogen efficiency in agriculture.
Thus, granular elements, such as, light, temperature, water, etc., are basal parameters which are parts of complex and comprehensive models stored in libraries. Context-dependent “drag and drop” actions by non-expert users may “pull-down” one or more of these models depending on the “match” with use-case, using Scratch-type tools. For example, “water” related models ought to be different for different cycles, e.g., “water” related to N cycle, “water” related to P cycle and “water” related to C cycle but stored under “water” within sub-folders water.N, water.P, and water.C (there may be many more versions of water.N if more “crowd-sourced” users work with the Nitrogen cycle and fewer individuals work with phosphorous or carbon). Cycle-specific and application-specific maintenance of models (“water” “light” “temperature”) requires data feeds (from sensors?) where ingestion of data and analytical outcome, if any, must be auto-updated, but of course, humans in the loop may be involved to update/upload/verify data.
Streaming sensor data from pre-selected sources may be dynamically added/deleted. The source description of sensor data and its API for ingestion should be kept “open” with modifiable user exists to add/delete different sources or offer ad hoc access to specific data sources (real-time access to [wireless] sensor networks not usually integrated with data acquisition). The latter is a systems and data interoperability issue which can become rate-limiting, reduce efficiency and productivity, if proprietary interfaces inhibit advances or are stymied by humans. Non-compliance between sensor data source, sensor database and data distribution standards [325] are reasons why data synchronization, analytical output and decision support systems are in a chronic state of underwhelming performance even after massive investments in technology [326]. It is unfortunate [327] that standards [328] may also suffer from problems in terms of interoperability [329].
Often, manufacturers [330] coerce [331] customers and non-technical users to eschew call for common standards and open APIs. One goal is to peddle proprietary [332] software (closed data dictionaries) to amplify sales. Aspirational leaps of progress are often frozen on the ladder between the aggressive for-profit-only [333] chants and the open-source democratization mantra.
Still pursuing nitrogen [N], we observe N in model cropping system (Figure 14) can be quite different. Thus, mathematical frameworks become increasingly formidable even for small sub-segments. Enthusiasm for model building may be curtailed because discrete mathematical functions may fail to capture the intrinsic non-linearity of complex adaptive systems which are continuous (analog systems [334]) and are incomplete when transformed to discrete signals (digital representation, digital twins). Values, weights, data and information operate within ranges and create a “push-pull” dynamic scenario which leads to the outcome, perhaps not as optimal or as precise as mathematicians desire but a rational “approximation” in a “zone” where >80% of the problems may be addressed/solved rather than fitting >95% or >99% of the cases. Outcome of mathematical models, the frameworks they create, and the schemas which act as scaffolds for data, must act in concert to harmonize dynamic re-optimization for continuous complex systems.
Figure 14.
Hypothetical nitrogen [N] stocks and flows for a model cropping system [335] with high (top panel) reliance on mineral N inputs and low (bottom panel) reliance on mineral N fertilizer.
Figure 14.
Hypothetical nitrogen [N] stocks and flows for a model cropping system [335] with high (top panel) reliance on mineral N inputs and low (bottom panel) reliance on mineral N fertilizer.
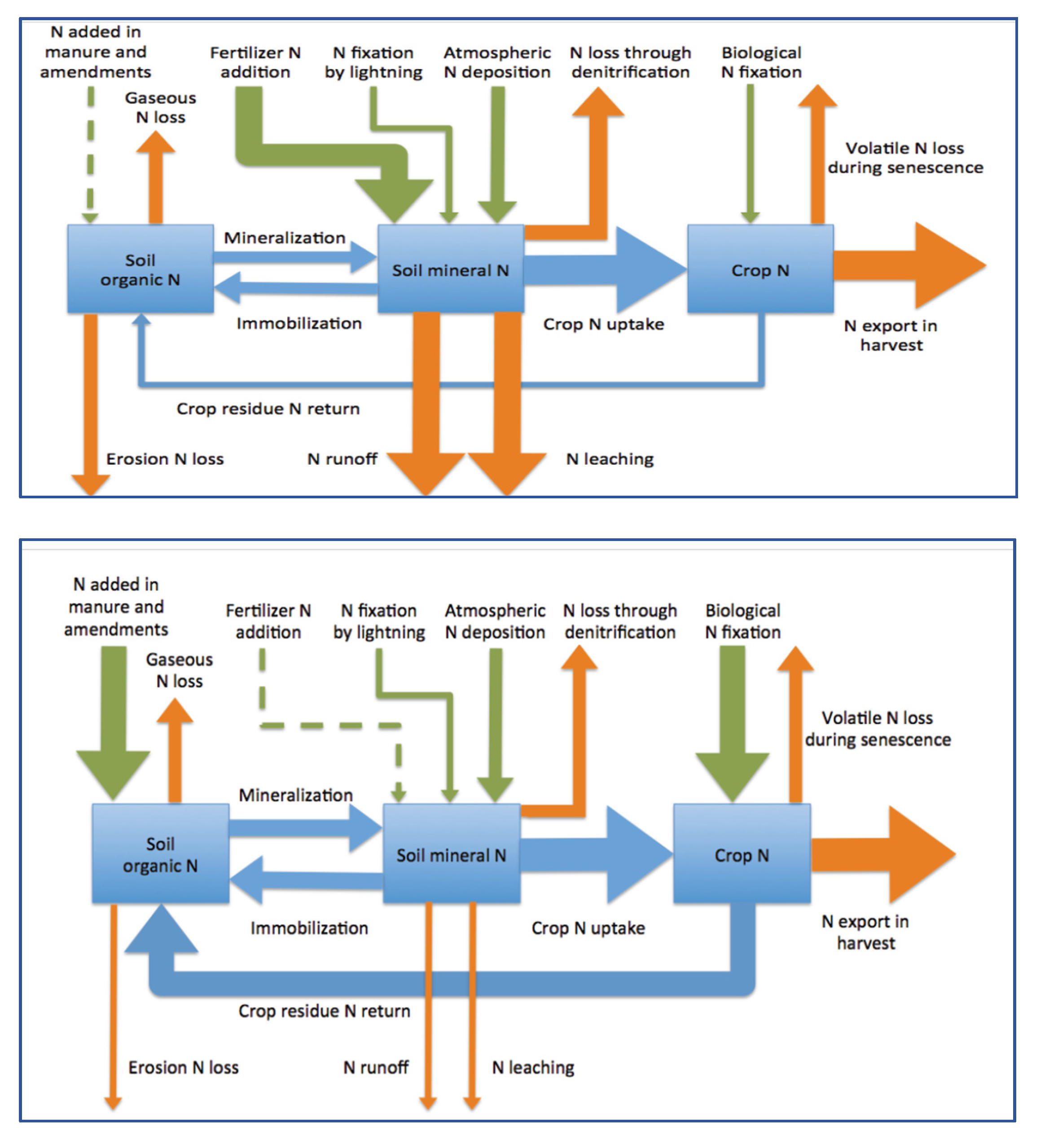
Models of Systems: Living vs Non-Living (Mechanical Systems)
Having encouraged the creation of mathematical models it will be remiss not to point out that rigid frameworks and complex adaptive systems are not synonymous. Mathematical models must be based on causality, context, connectivity, data and analytics (ACDC). Data sources and models within sub-components of components (sub-system and sub-domain) may contribute in a hierarchical fashion, to system performance. Systems level performance of complex systems (Nitrogen in agriculture or PCA in hospitals) are not “points” in terms of performance but fabrics with flexibility, ranges, and tolerances which represents asynchronous continuum of adaptation and homeostasis, the hallmarks of complex push-pull characteristic of adaptive living systems.
Living systems must accommodate volatility. The latter is uncommon in mathematical models. Frameworks must allow its operation to deal with fluctuating levels of fault tolerance in order for a schema to be a relevant contributor to systems performance. Data, information, value and action (DIVA) with respect to ACDC are connected and related but weighted differently because of their semantic distances [336] (semantic relatedness measure [337]) which may be subject to change based on specificity of use, application type, or the precision needed by the end-user.
Hence, mathematical models of value must be evaluated through the combined lens of DIVA and ACDC. Therefore, are equation based models (EBM) of mathematical frameworks copacetic as schemas for adaptive system performance? The rigidity of EBM versus flexibility of software agent based models (ABM) may have to co-exist, unequally, to accommodate dynamic push-pull which is a central feature of living systems. Can EBM and ABM co-exist in a model? Are models suitable for the molecular dynamics of the “continuum” of adaptations that complex systems must achieve to attain homeostasis, survive, and evolve?
For example, in a specific instance of glucose metabolism, the equation based model may be the only model required to account for the outcome from hydrolysis of disaccharides, sucrose and lactose. The kinetics of enzymatic hydrolysis of each molecule of sucrose produces exactly one molecule of glucose and one molecule of fructose. With the same mathematical precision, one molecule of lactose, hydrolyzed, will generate one molecule each of galactose and glucose. In this scenario EBM = 1 and ABM = 0. In another instance, the concentration of glucose in the blood (of humans) can vary from 60mg/dl to 600mg/dl. Extreme values will present a series of (fabric of) pathophysiological dysfunctions but as a whole for the human (systems performance) the outcome is unlikely to be death, at least, not immediately. In this scenario the inflexibility of mathematical frameworks makes their rigidity almost useless for any decision support system (requires humans in the loop). In this scenario, EBM = 0 and ABM = 1.
Mathematical models are not a panacea but could be an essential element in our quest for systems-level optimization. By definition, optimization may be an incorrect descriptor because unequal coalition of many sub-parts may lead to a sub-optimal level which addresses >80% of the system needs/attributes (rather than attempting 95% optimization of one system, at a great cost to another). The inclusion and balanced execution of these factors through a digital twin or digital cousin is utopian. Label-less, limited, digital representation may suffice in these contexts.
In our next example, the post-operative scenario of patient-controlled analgesia (PCA) is an infinitesimally tiny slice of hospital healthcare paraphernalia with remediable options to mitigate risk from mortalities [338] due to overdose of analgesics. PCA enables patients to self-administer morphine to reduce post-operative/-obstetric pain, in patients with low pain threshold.
PCA highlights the vital need for interoperability between and portability of models from one system or application to another (via open APIs). The idea of “mobile” models (frameworks, schemas created by humans) is an example of biomimicry. Transposons [339] and tycheposons [340] are mobile genetic elements [341] enabling genes to move between genomes. The discovery [342] challenged the conventional wisdom that genes [343] were static elements. Bio-mobile tools [344] for genetic modifications [345] may also confer immunity [346] even between species [347]. One example is the “shuttling of defense cargo” where plants [348] transmit nucleic acids (small RNA) to silence virulence in a pathogen. It is a disease control [349] model [350] worth exploring if we can delineate the molecular genetics [351] of virulence [352] and in addition to other [353] models.
In the PCA cartoon (below, right) 3 parameters are indicated: blood oxygen saturation (SpO2), respiratory rate (RR) and end-tidal carbon dioxide (etCO2). These three are just the tip of the iceberg. A plethora of other factors and sub-factors (underlying co-morbidities) may be critical in determining patient-specific PCA attributes in post-surgical care. For management of pain, the whole patient must be monitored using integrated information platforms.
Figure 15.
US opioid crisis (>100,000 deaths [354] in 2021) attributed to opioids, include heroin, codeine, hydrocodone, oxycodone, and morphine. We may need to re-evaluate approved patient safety protocols and medical device operations (false alerts?) to reduce mortality from patient-controlled analgesia (PCA) which uses morphine infusion for post-operative patients in hospitals.
Figure 15.
US opioid crisis (>100,000 deaths [354] in 2021) attributed to opioids, include heroin, codeine, hydrocodone, oxycodone, and morphine. We may need to re-evaluate approved patient safety protocols and medical device operations (false alerts?) to reduce mortality from patient-controlled analgesia (PCA) which uses morphine infusion for post-operative patients in hospitals.
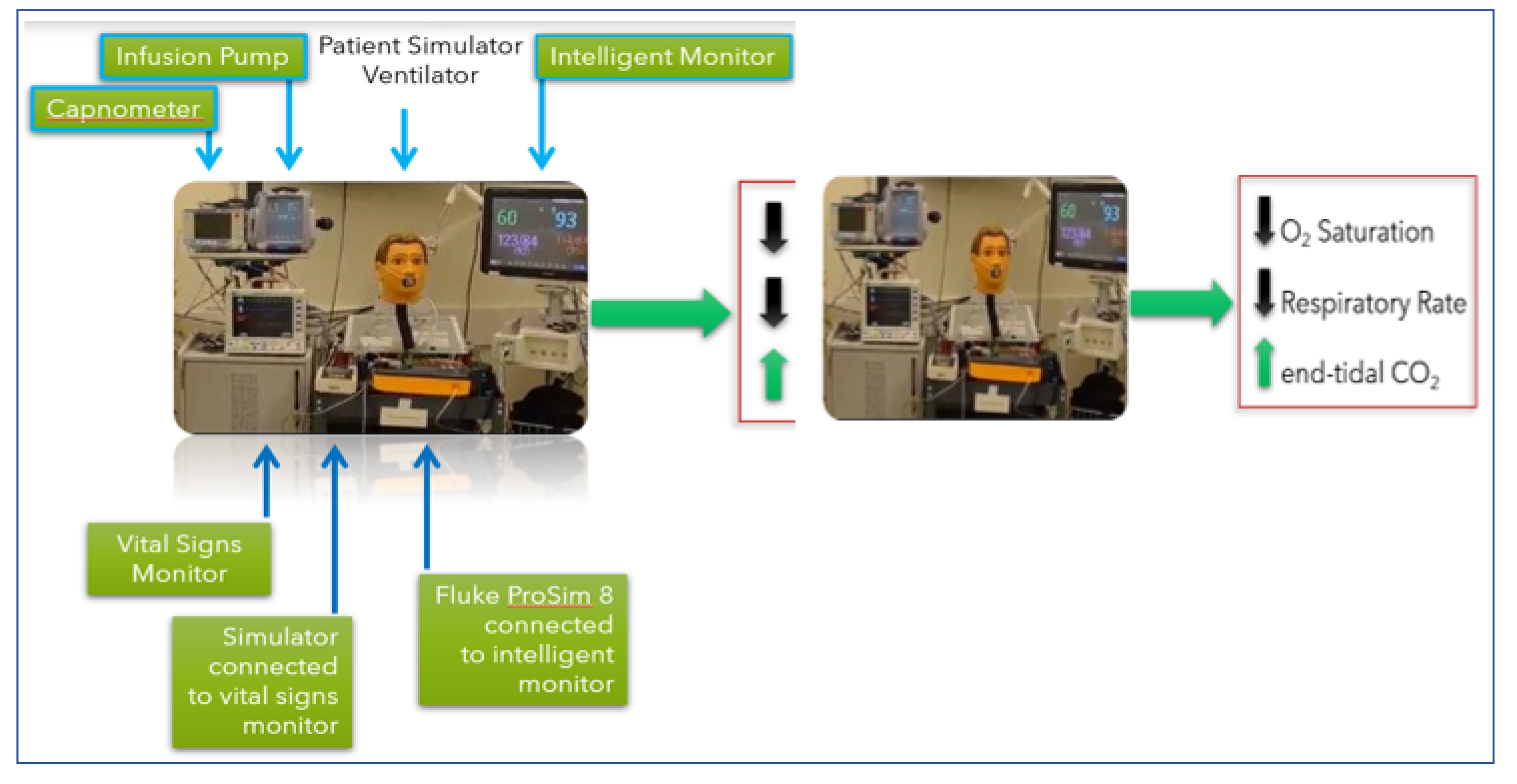
Opioid-induced episodes of bradypnea (abnormally slow breathing rate: adult respiratory rate (RR) is 12-20 breaths per minute) and desaturation (lowering of blood oxygen saturation) can escalate to respiratory depression (RD). Low RR (RD) may require rescue (ROSC, return of spontaneous circulation [355]) but in-hospital cardiopulmonary resuscitation [356] is successful in fewer than one in five patients. Hence, careful planning to administer PCA based on patient history and stringent synergistic integration of medical devices and device data are necessary (only if aggregated data from integrated systems enables real-time “whole” patient monitoring).
Reducing risks due to false alarms (spurred by ad hoc addition of medical devices) may reduce mortalities/morbidities (Makary et al., 2016) contributed by the lack of medical device interoperability. Medical devices involved in the PCA scenario include [a] CPOX or continuous pulse oximeters [357] for oxygen saturation [b] respiratory rate [358] measurements have evolved from the pneumotachometer [359] to spirometry for standard [360] pulmonary function testing in a clinical setting to continuous measurements which may be reliable (in near future) using sensors [361] and [c] capnography [362] instrumentation to measure end-tidal [363] carbon dioxide [364] (pressure in mm Hg). Instrument manufacturers ignore data integration needs for patient safety platforms, e.g., to avoid anoxic brain injury from unrecognized post-operative respiratory depression (PORD [365]).
One problem is with the embedded middleware. In general, outsourced software used by device manufacturers are built in remote locations responding to “spec sheets” without process feedback or synergy with hardware. Middleware is often a “blackbox” which holds a number of so-called workflows which are linked to “model fitting [366] functions” in software which selects or processes data based on its “fit” with the embedded model. The lack of harmonization between hardware and software OEMs (lower tier suppliers in the device supply chain [367]) is a very thorny problem. Usually the “first world” brand controls the IP, marketing, sales and profit. The brand uploads a device-specific bill of materials (BOM) to a portal (e.g., Alibaba) to source hardware, assemble (Wuxi, China) and ship from a warehouse (Kaohsiung, Taiwan) to customers using labels from the (US/EU) brand owners. Somewhere in between, software files from Bangalore, India or Mexico City, Mexico are downloaded. What often costs less than $50 to procure is sold for $50,000 plus additional annual cost of service contracts for device maintenance/upgrades.
Medical professionals are clueless about supply chain business models. But ignorance is not bliss when errors can kill patients. Limitations of “model fitting” arising from, for example, the dependence on limited number of training sets may lead to extrapolations (“how to fit” and “what to fit”) which introduces errors [368], corrupts data and ushers bias (Sjoding et al., 2020). Various sources of discrepancy makes it unreliable to trust the scientific authenticity of output from the device or find confidence [369] in the result (outcome). These minutiae only matters if the investigators are sufficiently astute. Usually, automated [370] output from devices are viewed as sacrosanct, which is not the case if the raw data (inaccessible to medical professionals due to proprietary lock on device data ports) can be deconstructed. Emerging [371] tools [372] are increasingly relying on calculations based on shrink-wrapped algorithms and “apps” allowing plenty of room for post-market errors and artefacts to thrive, unchecked, unregulated and unsecured.
The extrapolation from relationships between data from individuals to model fitting of individual data to generic models based on aggregated training sets, is disconcerting. Depending on the acuity, automated decision support or prediction analytics based on “learning” models can easily go awry and even prove to be fatal. Unsupervised processes are a minefield for healthcare information arbitrage. Data processing via stand-alone apps may become grotesquely thorny.
Figure 16.
“App” after death [373]? Tsunami of apps (MDApp [374]) generates value for commerce. Its contribution to healthcare is not without merit, either, but exercising plenty of caution is prudent.
The reductionist approach to make “bite” size things fit for “apps” is a profitable modus operandi for grocery store design teams aiming to please the mobile smartphone user in quest of rapid retail therapy. In healthcare, the risk of apps pandering to the lowest common denominator may not be without consequences. Equations are essential in mathematical models which are at the heart of the “fitting” engines that run in the background of many apps which ingests data to provide data-driven outcome. Often, if not always, the data-driven outcome is of a poorer quality and less dependable if compared to data-informed information.
For example, in the case of PCA, what happens in the alveoli of the lungs due to opioids (morphine in PCA) is of particular concern with respect to respiratory depression and potential for fatal consequences if PORD continues. Thus, accurate composition and partial pressures of alveolar [375] air is critical. It is pivotal to recognize that the alveolar air is unlikely to be in a state of equilibrium (see Figure 17) in a post-operative or post-obstetric patient. Metrics of diffusion and exchange of inhaled/exhaled breathing gases (air) at the alveolar-capillary unit interface may not fit model values in an app because of physiological changes which are PCA user-specific.
This distinction can become critical when PCA data are evaluated using frameworks, models, apps based on data (mass balance [376], steady-state equilibrium) from normal individuals where values (normal range) of parameters may be drawn from equilibrium phase of gaseous exchange. The cheaper and quicker point-of-care “easy-to-use” app may transmogrify to become diabolical and deadly due incorrect interpretation and extrapolation, for some PCA users.
Figure 17.
Pulmonary physiology at the heart of PCA depends on the alveolar gas equation [377] (oxygen equation) and the alveolar ventilation equation (carbon dioxide equation). Derivation of these equations [378] (top cartoon) are not trivial. The apps in Figure 18 use standard equations and normal ranges. The principle of mass balance relevant to physiology of multiple organ systems, is also applicable to pulmonary physiology. Relative rates with which substances (chemicals, air, gases, water) enter and exit these systems are subject to multiple conditions which can vary between individuals. Steady-state equilibrium occurs when the rates of entry and exit are equal under “normal” conditions. If existing tools are computed based on mass balance then one must question whether steady state equilibrium is applicable during opioid administration in PCA.
Figure 17.
Pulmonary physiology at the heart of PCA depends on the alveolar gas equation [377] (oxygen equation) and the alveolar ventilation equation (carbon dioxide equation). Derivation of these equations [378] (top cartoon) are not trivial. The apps in Figure 18 use standard equations and normal ranges. The principle of mass balance relevant to physiology of multiple organ systems, is also applicable to pulmonary physiology. Relative rates with which substances (chemicals, air, gases, water) enter and exit these systems are subject to multiple conditions which can vary between individuals. Steady-state equilibrium occurs when the rates of entry and exit are equal under “normal” conditions. If existing tools are computed based on mass balance then one must question whether steady state equilibrium is applicable during opioid administration in PCA.
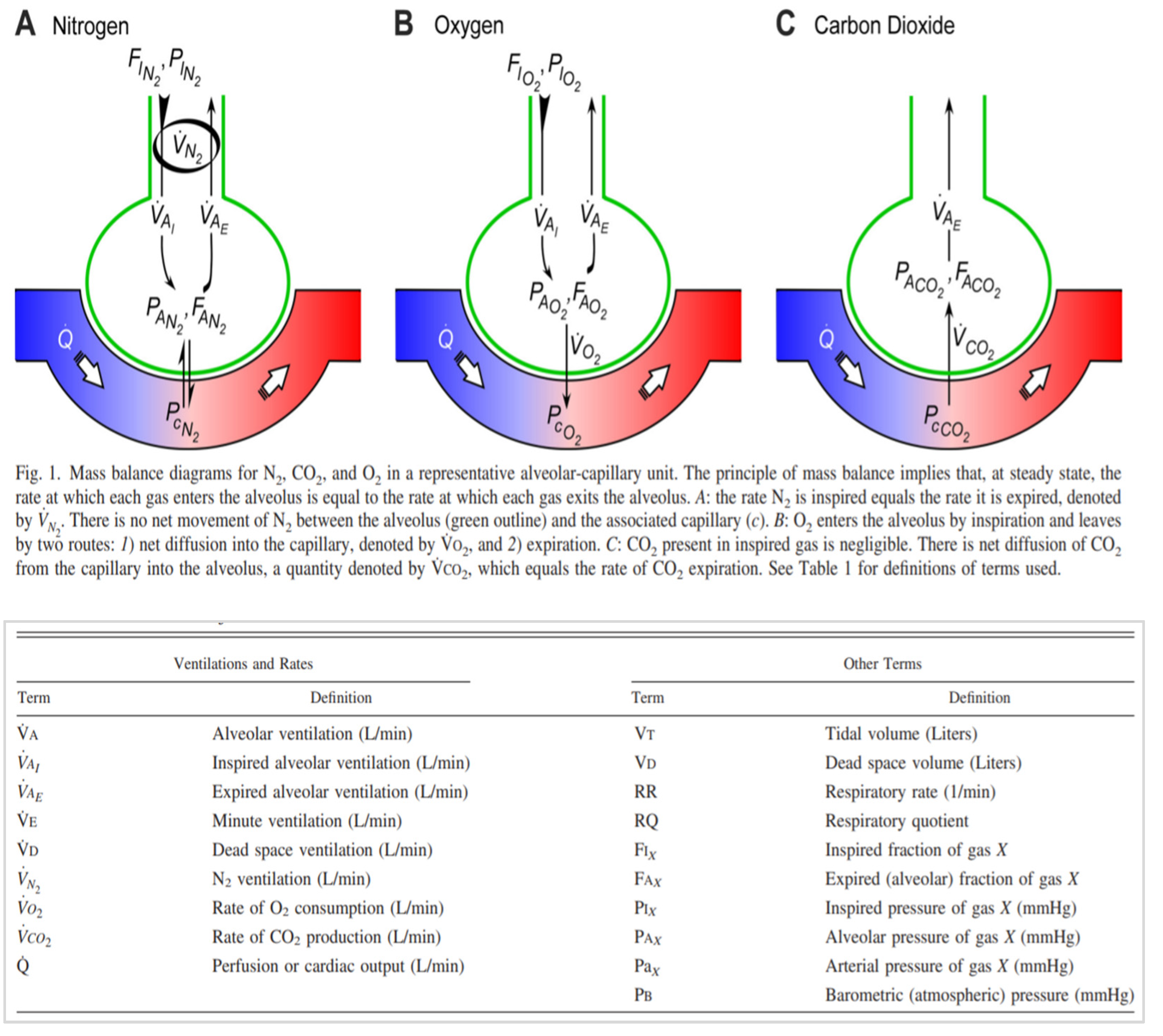
Figure 18.
The holy grail of physiology is the maintenance of homeostasis. For pulmonary physiology it means the parameters for steady state equilibrium must optimize and maintain gaseous exchange within ranges suitable for normal functions and states of activity. Gas exchange in the alveoli is a sub-part of the recorded gas exchange in the lungs because conducting airways (connecting air passages) do not have gas exchange potential and referred to as “dead” space volume (“wasted” breath) denoted by VD. VD was calculated via ‘ideal’ alveolar equations, whereas PaCO2 or VD models were based on end-tidal CO2 tension (PETCO2), tidal volume (VT), and/or weight. Breathing faster or deeper enhances gas exchange while rapid shallow breathing tends to be less efficient at gas exchange. In PCA, standard “models” of breathing may not apply due to post-operative respiratory depression (PORD). Destruction of alveolar walls in patients with pre-existing chronic obstructive pulmonary disease (COPD) can result in coalescing of multiple alveoli, giving rise to enlarged air spaces that are poorly perfused (e.g., emphysema). In this instance the physiological dead space volume in PCA patients with COPD are a sum of VD due to connecting air passages (dead space without gas exchange potential) and VD due to alveolar air that no longer participates in normal alveolar respiratory gas exchange. Thus, the true value of VD must be taken into account for PCA. Is this granularity of data in the context of PCA likely to be a part of the status quo middleware in the app? Similar scenarios may be presented due to pulmonary embolism which may block perfusion to entire alveolar capillary units and will significantly alter the alveolar gas equations [379]. Medical vigilance of digital representation can make the difference between life and (app-driven) death.
Figure 18.
The holy grail of physiology is the maintenance of homeostasis. For pulmonary physiology it means the parameters for steady state equilibrium must optimize and maintain gaseous exchange within ranges suitable for normal functions and states of activity. Gas exchange in the alveoli is a sub-part of the recorded gas exchange in the lungs because conducting airways (connecting air passages) do not have gas exchange potential and referred to as “dead” space volume (“wasted” breath) denoted by VD. VD was calculated via ‘ideal’ alveolar equations, whereas PaCO2 or VD models were based on end-tidal CO2 tension (PETCO2), tidal volume (VT), and/or weight. Breathing faster or deeper enhances gas exchange while rapid shallow breathing tends to be less efficient at gas exchange. In PCA, standard “models” of breathing may not apply due to post-operative respiratory depression (PORD). Destruction of alveolar walls in patients with pre-existing chronic obstructive pulmonary disease (COPD) can result in coalescing of multiple alveoli, giving rise to enlarged air spaces that are poorly perfused (e.g., emphysema). In this instance the physiological dead space volume in PCA patients with COPD are a sum of VD due to connecting air passages (dead space without gas exchange potential) and VD due to alveolar air that no longer participates in normal alveolar respiratory gas exchange. Thus, the true value of VD must be taken into account for PCA. Is this granularity of data in the context of PCA likely to be a part of the status quo middleware in the app? Similar scenarios may be presented due to pulmonary embolism which may block perfusion to entire alveolar capillary units and will significantly alter the alveolar gas equations [379]. Medical vigilance of digital representation can make the difference between life and (app-driven) death.
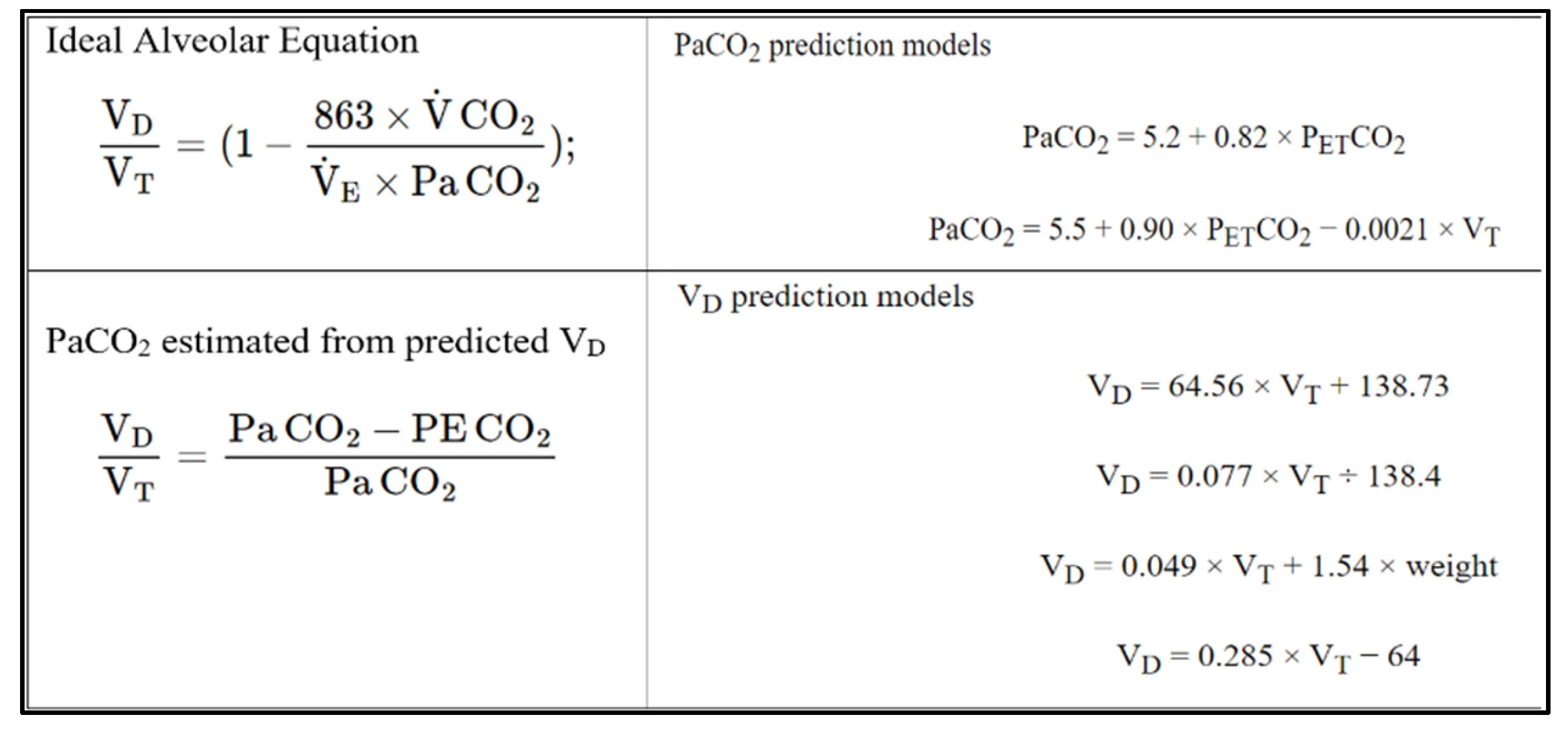
The ability to adapt mathematical models and frameworks for specific scenarios (unlikely for apps) may deliver benefits for precision medicine but not in the hands of “brain-less” digital twins. We are practicing imprecision medicine if we choose to remain ignorant about software, middleware and apps-running-on-models incapable of changing or adapting the “fit” to fit patient needs. Fitting the equation to the patient is highly recommended and desirable but not an easy task. The “fitting” to patient will require patient-specific data for multiple parameters which may be difficult to obtain and configure the app, specifically, for individual post-operative patients.
Theoretically, if we had workbenches or user interfaces with each parameter provided in a menu of choices, then an expert may be able to partially adjust/adapt the values. Will these tools and effort improve point-of-care services, patient safety, quality of care and efficiency? Can DIDS help in this context? DIDS may include SCRATCH-friendly UIs, Lego Mindstorm approaches and Ansys-esque [380] workbenches. These are grand challenges waiting for tools which must be orchestrated to be adapted for meaningful use relative to specific domains/users.
The future workforce of millennials growing up on a diet of short-cuts, videos and apps tend to gravitate to user-friendly user interfaces. Such habits accelerate through undergraduate years and spillover into medical school, residency and fellowships. Digital representations in healthcare are beneficial but knowledge must be combined with wisdom to know when to avoid digital interpretations in favor of extracting wisdom from Nature (e.g., allosteric [381] machines [382]).
The immutability of mathematical constructs and the adaptive complexity inherent in biological flexibility indicates that there are “transforming principles” which are practiced by Nature, unbeknownst to humans. For example, the mathematics and physics of temperature (heat and cold) are biologically rendered and interpreted by the nervous system, when we perceive heat (ion channel TRPV1 [383]) or cold (ion channel TRPM8 [384]). Research [385] encourages us to build mathematical models because we recognize that bridges exist to ferry between mathematically rigorous laws of physics and (often laissez-faire) biological systems. Uncovering mechanisms to enable application-specific balance between immutability and flexibility may be one way to build knowledge bridges. Some bridges may lead to point solutions [386] while others may connect to swarms [387] with the bulk of the reality somewhere in between, which could address/solve about 80% of the problems, following the 80/20 Pareto Principle.
The principles and practice of DIDS is a call to harness the power of mathematical rigidity in the service of society through case-specific interpretations. Any branch of decision science, for example DIDS, which involves humans, must find tools and technologies to dissect, curate and synthesize the convergence of rational rules within the scope of irrational use/users. While immersed in the quagmire of rules and tools, one must remain creatively cognizant of the fact that the inevitable irrational (non-deterministic?) accompanies the rational (deterministic?) not only by chance but also by choice, e.g., irrational [388] choices [389], made by human design.
Immunizing Digital Twins and Cousins from Cybersecurity Risks
Being cognizant about device/instrument security/cybersecurity in mission-critical applications is a mandatory dimension in the 21st century. Billions or trillions of devices connect with apps which may not possess any provision for cybersecurity even when used in critical applications, for example, in energy, infrastructure, healthcare. For unprotected devices in the post-market phase, the science [390] of cybersecurity must find ways to deliver threat-proportionate dose of cybersecurity to uphold the key tenets of availability, integrity, and confidentiality [391] for information and data (ACDC) in any digital representation (IoT, IIoT, CPS, digital twins, etc.).
Cybersecurity must be addressed with equal zest for digital representation of physical objects (including medical devices). We will focus on life saving ventilators, we have heard so much about during the pandemic. Even though we will discuss only a few details of ventilator function, the cybersecurity component is not specific for the ventilator but for medical devices (a hypothetical device-agnostic science of cybersecurity is discussed in Datta, 2022, unpublished).
Figure 15 indicates that integrating ad hoc objects/devices may be a necessity. Devices and apps added to geospatially networked system introduces risks by violating trust boundaries. Poor attention to cybersecurity safety by design, complexity and lack of standards influence device manufacturing in healthcare and other sectors (e.g., energy, infrastructure, transportation). Pre-market and post-market gaps in cybersecurity amplify vulnerabilities for attacks. The usual cybersecurity approach to mitigating risks when dealing with connected devices (e.g., IoT, CPS, digital twins) uses threat models as a guide to track and analyze suspected cyber intrusions.
The spread of ransomware in healthcare [392] and hospitals [393] has kept pace [394] with the pandemic which has resulted in an epidemic [395] of cyberattacks. Response from agencies [396] indicate [397] that models (e.g., ATT&CK [398]) are necessary [399] but thinking beyond conventional [400] culture [401] will save lives since lives [402] are increasingly inextricably linked with the networked physical world [403] system (Engels et al., 2002). Ubiquitous [404] computing may include trillions of devices [405] manufactured by millions of companies, with geographically dispersed global supply chains which vary significantly in their competencies. It is difficult for regulatory agencies [406] to provide oversight [407] for these devices which connect to and communicate via the internet.
Systems integration of devices, including IoT-type cyberphysical systems (CPS) and the emergence of digital twins/cousins will add value to systems performance. But, cybersecurity risks [408] after systems integration must be re-evaluated [409] and mitigation strategies updated if systems integration violates the trust boundaries created during pre-market system design. Cybersecurity risks/threats introduced into systems due to integrating external devices may be dynamic, cryptic or volatile. Examples include sensors [410] in vehicles [411], digital diagnostics [412], medical devices [413], control-valve actuators in power plants [414] and photovoltaics in distributed energy resource optimization (micro-grids). Connectivity between these physical entities and their digital representations over the open internet increases the risks due to cybersecurity.
Cybersecurity “safety by design” is a bumper sticker “goal” due to lack of good security abstractions [415] as a guide. For device manufacturers the incorporation of cybersecurity is neither a core competency nor a business priority. Supply chain network planners relegate procurement functions to OEMs (original equipment manufacturers) mostly located in low-cost geographies who are less aware, ill-equipped and resource constrained even to consider cybersecurity in their design. Trillions of sub-systems, sub-components or spare parts are percolating globally without any form of place-holder protection from cybersecurity attacks or cybersecurity awareness.
Most businesses lack transparency, visibility and accountability with respect to supply chain assurance from their network of supply chain partners (Sarbanes-Oxley Act [416] of 2002). These actors source goods and services from sub-layers of the value network but businesses may be unaware of cryptology-based markers for supply-chain assurance. Hence, cybersecurity by design may be a delusional expectation for products with multi-tier supply chains extending into small and medium enterprises. The elusive quest to “build secure” during the pre-market phase is worthy in principle but may remain an illusion for cybersecurity protagonists who are irrationally optimistic in their expectation about the notion of global diffusion of cybersecurity, in practice.
Guidance for manufacturers [417] promotes the “build secure” adage but the glacial pace of change reflects how manufacturers may view or resist cybersecurity unless mandated, regulated, enforced or incentivized to better optimize specific outcomes, for example, end-point security [418]. Risks due to gaps [419] between principles (FDA guidance) and practice (implementation at point of use) in mission critical operations (energy, power grid, infrastructure, healthcare) could be fatal. Lack of cybersecurity increases risk (exponentially?) in healthcare [420], hospitals, telemedicine [421] for war fighters and medical devices for home health (remote monitoring). Programs to mitigate cybersecurity risks due to vulnerabilities arising from systems integration of devices may be an unsurmountable/unmanageable problem of gigantic proportions if a device-specific [422] approach was the only modus operandi. There is no panacea solution for device-level cybersecurity in the post-market phase, as evident from a recent FDA [423] guidance.
In terms of digital twins, one example of edge-dependent dynamic variant reconfiguration incorporates digital twins as a “mirage” for apps running Shadow Figment [424] where intruders are tracked [425] via honeypots [426] using a “digital shadow” (fake digital duplicate / digital twin) of the actual operation (which stays protected/secured). Digital twins can change, depending on the application running the honey pot-esque project [427] “Shadow Figment” created by PNNL [428]. It is an innovative application of digital representation to boost cybersecurity and conceptually may converge with hardware and software executing Agent-driven tasks [429].
To find new horizons, convergence may be key and history may be a good guide. Insights from 1945 [430] partially captured the concept of ubiquitous [431] computing in the 1990s. Progress [432] over a century created computing which can sense, predict, plan, process data, execute complex applications and continuously compute across distributed systems for performance optimization, load-balancing, fault tolerance as well as other functions, but not without a few problems [433].
From the IC (integrated circuits) to the ICU (intensive care units) computing today is a complex orchestration of CPUs (central processing unit), GPUs (graphics pu) and NPUs (neural pu). Cybersecurity for devices on land (mobile edge devices) communicating with data centers under the sea [434] or cloud computing on MARS via the interplanetary internet [435] (interplanetary internet of things) must expect the unexpected. If the questions are correct, we are likely to uncover data to inform our knowledge-armed defensive and offensive approach to security.
For the current discussion, the device-agnostic platform approach to device cybersecurity will focus on the ventilator, a medical device used in intensive care units (SICU, NICU, surgical, neonatal), emergency departments as well as for home health [436]. Microprocessor (IC) controlled mechanical ventilators [437] have rudimentary computational needs but saves lives. These devices are regulated by a handful of variables (Table 3 & Table 4) with pre-loaded instructions (algorithms). Medical professionals can change parameters based on patient-centric variables and available resources. The “digital twin” equivalent of a hospital ventilator via a mobile phone app provides near real-time connectivity with the patient’s data, analytical tools and point-of-use knowledge. It is unlikely to be feasible as a global model but in affluent nations such a digital twin may not be a distant idea, if the model can be successfully controlled and can capture key functions/data.
Ventilators, like most devices, are potentially at risk from malicious events (unauthorized users/intruders). Vulnerabilities in design may become fatal without cybersecurity provisions because ventilators are not only a device for data acquisition but also a device that performs semi-autonomous or autonomous data-informed actuation in cases of acute respiratory care to maintain breathing functions. Monitoring the amount of oxygen (fraction of inspired oxygen, Fi [438]) delivered to the patient (FiO2) is a critical data [439] element which must be secured to avoid hyperoxia or hypoxia. There is a glut of ventilator designs from engineers [440] and enthusiasts [441] in response to the pandemic in affluent nations [442] as well as low-cost ventilators [443] for resource-limited [444] settings. Cybersecurity by design does not appear to play a part in any proposal.
Malicious tampering with ventilators may induce oxygen toxicity [445] or poisoning [446] leading to cessation of breathing (respiratory arrest/failure). Hypoxemia, hypercapnia and hypoxia may result in brain injury [447] within 3-4 minutes. Severe brain damage and/or coma may lead to brain death [448] followed by clinical death (after cessation of breathing the case/patient-centric time to death varies [449] widely).
Cybersecurity of acute care medical devices is a life and death matter, in a span of a few minutes. In hospitals, ventilators can be monitored by professionals who are in proximity to the device but home health users may request remote changes to the device (ventilator) depending on the physiological status. Cybersecurity for remote monitoring require additional stringency with respect to endpoint identity [450], device user identification and internet protocol (IP) security. Using IP-based identification [451] with security and routing [452] controls are necessary for trust in asset management, authentication, authorization, and remote maintenance/activities.
Traditionally, one or more passwords may be used to authenticate the patient receiving services at home and the medical professional authorized to deliver the services. In an open networking environment, beyond firewalls, a tool such as MIT-Kerberos [453] authentication [454] server uses a coded format of passwords which are compared to a time-stamped code string but the actual passwords are never sent across open networks. After authentication is complete only then traditional IP transport layer security (TLS [455]) is established.
Ventilators assist with improving pulmonary perfusion which requires certain design criteria and performance indicators (Table 3 and Table 4). For patients who are unable to breathe on their own it provides mechanical “lung assist” and delivers a mixture of oxygen to improve perfusion. Ventilators [456] provide different types of assisted breathing functions [457] (volume assist/control; pressure assist/control; pressure support ventilation; volume SIMV [synchronized intermittent mandatory ventilation]; and pressure SIMV). From a cybersecurity perspective the microprocessor is involved in the execution of a set of algorithms for machine trigger variables and machine cycle variables as well as some compensatory mechanisms (SIMV) for respiratory optimization (Figure 19, Table 3).
Direct (through device) or indirect (e.g., digital twin) cybersecurity attacks may disrupt mechanical assistance or oxygen concentration, which, if undetected, may lead to severe brain damage, coma and/or clinal death (e.g., lack of brain-stem responses). Simple “bit dribbling” by malicious intruders can slightly increase or decrease the range of values (low/high) to induce cessation of assisted breathing or alter the gaseous composition of inhaled breath leading to brain death and congestive heart failure (CHF).
In the context of medical devices, a “by-product” is the proliferation of device-specific (status) alarms [458] triggered when values (data/measurement/metrics) falls above or below the threshold/range (pre-set, hard-coded). Altering values may perturb thresholds/ranges and trigger automatic alarms. Cybersecurity attacks could trigger tens or hundreds of alarms in a hospital to deliberately sow debilitating confusion. Reduction [459] of alarm events [460] is a thorny issue. What if it was a false positive or what if the alarm caused a fatal distraction?
Performance of alarms and the criteria governing their on/off status are complex legal issues at the heart of patient safety. Table 3 indicates “disconnect alarm” is a required “safety feature” but in contrast Table 4 emphasizes need for alarm. Alarms are linked to a network of physiological variables (Table 3, bottom panel) which are measured and communicated in near real-time to determine the status of the patient. Addressing this tug-of-war requires continuous data analyses by combining data from different devices (different device manufacturers). The analysis of data instructs embedded/coded routines for triggering safety protocols, including alarms, which are essential elements of patient safety. Alarms in the context of patient safety should be secured and cannot be selectively turned on/off without medical authorization. Breach of cybersecurity in any device with an alarm may be as simple as to turn-on or turn-off the alarm (why “on-off” state machine security is not trivial and the consequences may be fatal).

Table 3.
Desired design features for ventilators (right). Performance criteria/indicators [461] to maintain physiological breathing in adults (bold, panel).
Table 3.
Desired design features for ventilators (right). Performance criteria/indicators [461] to maintain physiological breathing in adults (bold, panel).
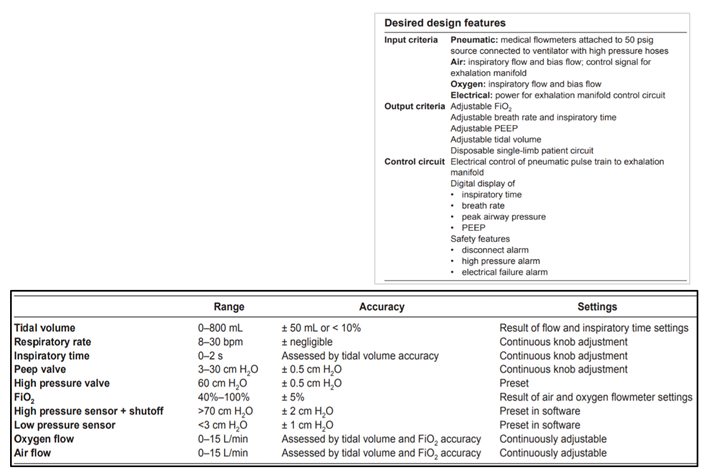 |
Table 4.
Nodes of control in ventilators which, if altered, may affect mortality and morbidity. Ventilator settings and values are obtained from MGH [462] ICUs (CoVID-19 patients).
Table 4.
Nodes of control in ventilators which, if altered, may affect mortality and morbidity. Ventilator settings and values are obtained from MGH [462] ICUs (CoVID-19 patients).
| Ventilator Variables | What happens/comments if changed/altered. Nodes where cybersecurity may be essential. |
|
Respiratory Rate (RR) (breaths per minute) between 6—40 (normal). I/E Ratio (inspiratory/expiration time ratio) recommended start 1:2; range of 1:1–1:4. Assist Control is based on a Trigger Sensitivity (trigger variables, see Figure 2). When a patient tries to inspire, they can cause a dip (2 to 7 cm H2O) with respect to PEEP pressure (not necessarily equal to atmospheric pressure). Airway pressure must be monitored continually (units in cm H2O) Maximum pressure: 40 Plateau pressure: 30 Passive mechanical blow-off valve: 40 PEEP* 5–15 cm (required) Patient-centric need 10–15 *Positive end-expiratory pressure (PEEP) is a value set up in patients receiving invasive or non-invasive mechanical ventilation. Tidal Volume (TV) (air volume pushed into lung) between 200–800 mL (patient-centric, based on patient weight) etCO2 (end-tidal CO2 is the amount of carbon dioxide in exhaled air) assesses ventilation (35-45 mmHg or 4.0-5.7kPa, kiloPascals) and perfusion (gaseous exchange in the lungs). High etCO2 signals good ventilation, while low etCO2 signals hypoventilation. |
Respiratory Rate (RR) of 6-9 are applicable to Assist Control. Failure conditions must result in an alarm and permit conversion to manual clinician override. If automatic ventilation fails, the conversion to manual ventilation must be immediate. Capnometric data (partial pressure of CO2 in exhaled air, etCO2, generated as waveform data—capnograph) is the fastest indicator to assess if ventilation is compromised. Immediate action is recommended without waiting for pulse oximetry data which may be subject to some degree of phase equilibration since pulse oximetry assesses the amount of oxygen bound to RBC (red blood cells). |
Figure 19.
Decision tree for ventilators (Chatburn, 2016) are guided by patient data & feedback.
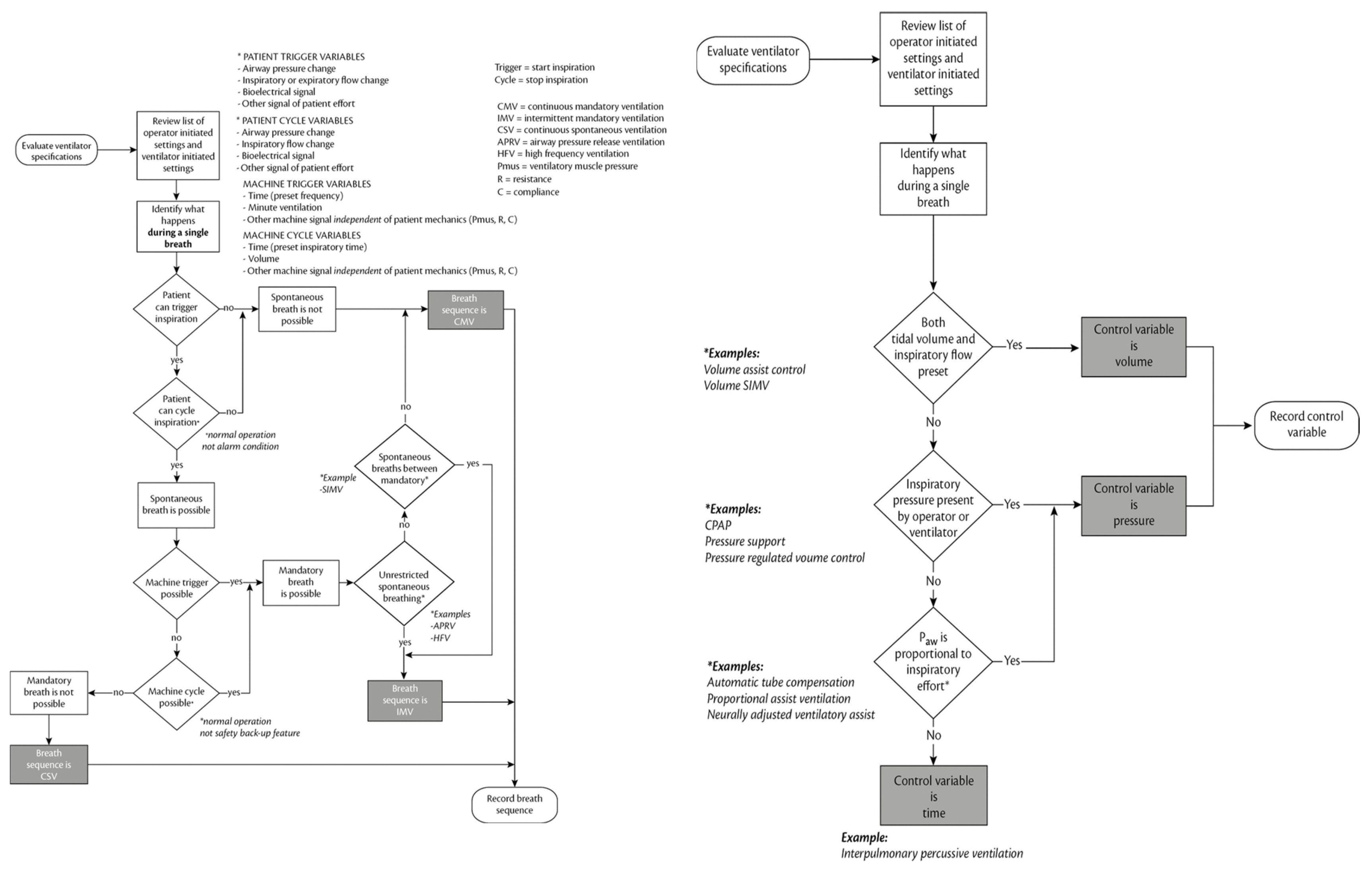
Data analysis, feedback and decision support at point-of-use may have cyber components linked with the ecosystem of the physical medical instrument or device. The supply chain of this closed loop cyberphysical system [463] (CPS [464]) must be secured. The weakest link is a penetration point to corrupt data or exfiltrate data and information. Corrupt data, if stored (EHR/EMR) and analyzed, may lead to harmful decisions, including death (Figure 20 and Figure 21).
Lateral persistence and lateral movement of intruders exploiting the gaps in cyberdefense may be catastrophic. Intruders “tunnel” from edge devices to storage devices, e.g., perhaps from the ventilator’s digital twin to the electronic health records or electronic medical records (EHR, EMR). Tunneling through routers (wired/wireless networks) to access devices and gain special privileges to data stores are a part of the ecosystem where the reality of threats from ransomware could become deadly. Ransomware at the device level is annoying (devices can be replaced) but databases are the Achilles heel for systems, unless dynamic redundancy is a daily/hourly ritual.
In an ecosystem-centric view, if the network is compromised, device cyber-security becomes exponentially significant to prevent data tampering at the point-of-use. Can sensor devices store data (data persistence?) rather than transmitting the data if the network is not secure? Ubiquity of sensors makes this a serious problem with life and death consequences in certain cases. For example, oxygen sensors [465] in ventilators are vital to prevent hyperoxia or hypoxia by using FiO2 data (Figure 19, left) to adjust the composition of the inhaled gaseous mix.
Low cost sensors without cybersecurity characteristics may introduce higher risks (the cost savings appears to be penny wise but pound foolish). It is an open question whether low cost sensors without “local cache” or tiny databases are suitable for mission critical operations. It is useful to revisit DARPA Smart Dust [466] with respect to sensor networks (tinyOS [467], tinyDB [468]), cybersecurity of data, data acquisition from devices [469] in hospitals, industry and the edge e.g., IoT-type wearable photoplethysmography [470] (see related suggestion in Figure 5).
Devices which generate/collect continuous waveform data [471] are vulnerable to minor changes (see Figure 20 and Figure 21). Intermittent sampling periods for continuous variables (gaps in time series data [472]) could change the data profile and alter the data-informed analytical outcome. Storage [473] of waveform data “samples” (sampling time) in patient records (EHR [474]) introduces sampling errors which could be detrimental for diagnosis, prognosis, treatment and medication. Deliberate artefacts [475] introduced [476] into data under the guise of efficacy [477] further degrades the data and legitimizes corrupt data storage in electronic health / medical records (EHR, EMR).
Errors also arise due to proprietary restrictions in data handling enforced by device manufacturers and software vendors (EHR, EMR) who ruthlessly maintain inaccessible data dictionaries (Epic [478] Systems [479]) which prevents interoperability and data distribution between different software and middleware in clinics/hospitals. Vendor-Implemented Legal Exclusion (VILE) deliberately obstructs data distribution using open data distribution standards (DDS) and prevents data interoperability. VILE has contributed to make medical errors the 3rd leading cause of death [480] in the US. Patient safety [481] is a vicious task even without cybersecurity risks and new classes of threats from low performing and unsecure digital twins/cousins at home and hospital.
Data Representation: Primum Non Nocere [482] (First, Do no Harm [483])
Stupidity (Schwartz, 2008) in scientific research is an asset if it induces one to imagine and think thoughts to advance science and even better if such science can serve society. There is a profound need to inculcate reasonable stupidity and the publication of negative results to ignite the ability to think differently, creatively. Knowledge of negative results and confidence to be stupid are desired audacities for creativity. The exception that proves the latter is one report of a digital twin [484] for a human disease (multiple sclerosis, MS) without regard to what causes [485] MS and absence of data related to various causal factors [486]. The latter is an example why digital twins for any living entity or system may be far beyond the grasp of those who are still living.
Digital representation related to living systems may not be abandoned (by obsequious readers) but digital twins for human disease (Voigt et al., 2021) is an example of mindless drivel. Granularity in ACDC in the causal context of the target/problem is key. Incremental advances in the candle industry did not result in the electric light bulb. What was untrue for the electric light bulb may be true for digital twins for living systems. Small steps and incremental advances may result in tiny but meaningful digital representation of living systems (plants, animals, humans).
Figure 20.
Error prone data is stored due to sampling time choices (sample points show 1-minute period). Which value will be recorded by the electronic health record (EHR) database? Data from pulse oximetry shows blood oxygen levels via an oxygen saturation measurement called peripheral capillary oxygen saturation, or SpO2 (percentage of oxygen in blood). Sampling point data vulnerabilities (sampling frequency, time between samples) may introduce egregious errors in cumulative time series data which can be device-centric or patient-specific. Maintaining data integrity for digital twins (cybersecurity for confidentiality) requires the context of the raw data to make sense of analytics [487] for micro-decisions (patient-specific, precision medicine) as well as gaining a macro-understanding i.e., the value network (see page 63 of 94 in DATA [488]).
Figure 20.
Error prone data is stored due to sampling time choices (sample points show 1-minute period). Which value will be recorded by the electronic health record (EHR) database? Data from pulse oximetry shows blood oxygen levels via an oxygen saturation measurement called peripheral capillary oxygen saturation, or SpO2 (percentage of oxygen in blood). Sampling point data vulnerabilities (sampling frequency, time between samples) may introduce egregious errors in cumulative time series data which can be device-centric or patient-specific. Maintaining data integrity for digital twins (cybersecurity for confidentiality) requires the context of the raw data to make sense of analytics [487] for micro-decisions (patient-specific, precision medicine) as well as gaining a macro-understanding i.e., the value network (see page 63 of 94 in DATA [488]).
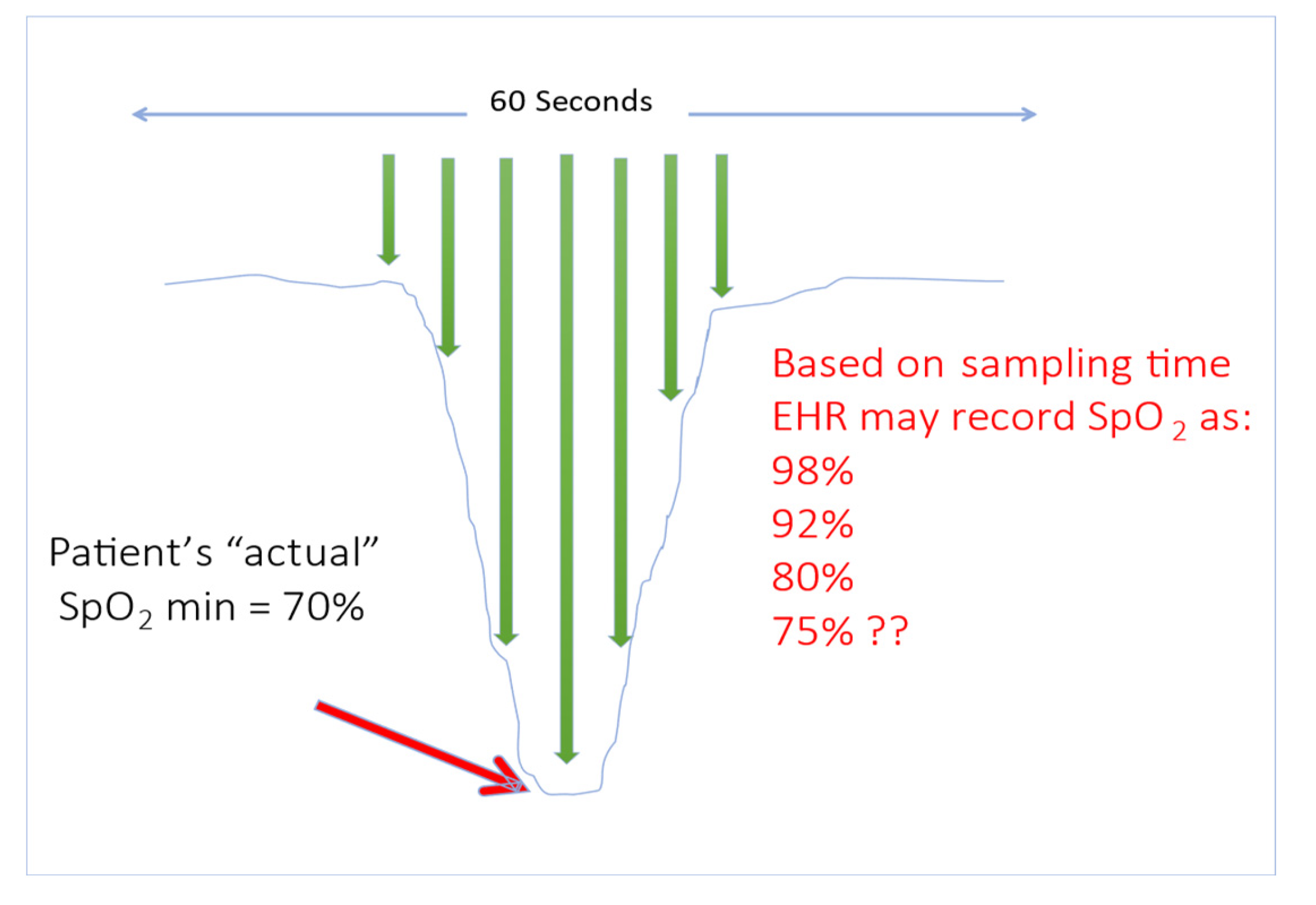
Figure 21.
ECG waveform data (top) shows atrial fibrillation with rapid ventricular rate [489]. Waveform data is “sampled” for storage [490] in electronic health records (EHR). Depending on sampling time interval, patient-specific time series data may be corrupted (bottom: A,B) before it is stored (see page 77 of 94 in “DATA”, see reference number in Figure 20). In the future misdiagnosis is likely based on A/B which differs from raw waveform data (top). Data integrity of the waveform is crucial patient-specific time series data for any representative tool. One might think that this is a likely candidate for digital twins [491] if one is sufficiently gullible [492].
Figure 21.
ECG waveform data (top) shows atrial fibrillation with rapid ventricular rate [489]. Waveform data is “sampled” for storage [490] in electronic health records (EHR). Depending on sampling time interval, patient-specific time series data may be corrupted (bottom: A,B) before it is stored (see page 77 of 94 in “DATA”, see reference number in Figure 20). In the future misdiagnosis is likely based on A/B which differs from raw waveform data (top). Data integrity of the waveform is crucial patient-specific time series data for any representative tool. One might think that this is a likely candidate for digital twins [491] if one is sufficiently gullible [492].
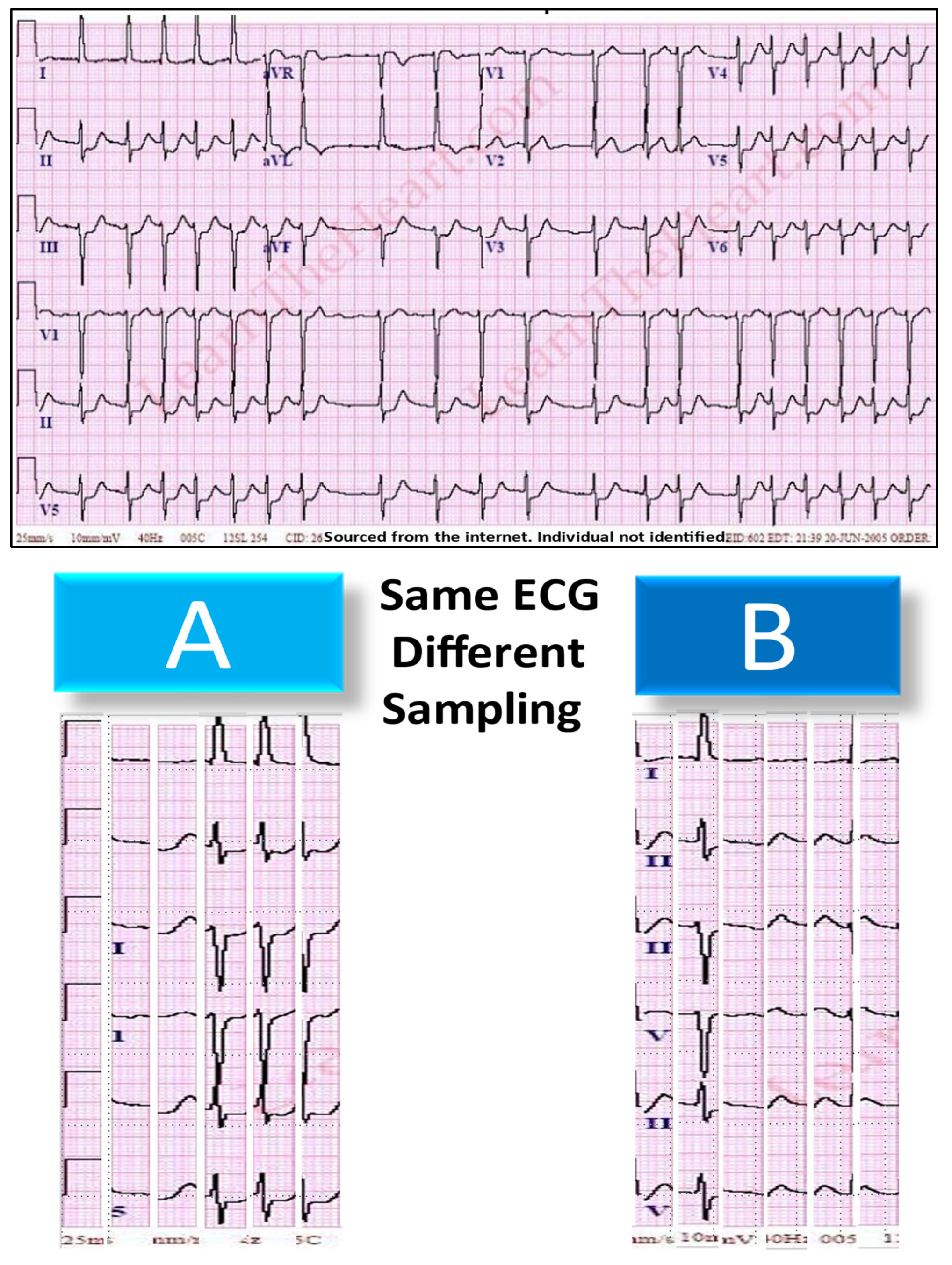
Non-living entities with a known number of components (e.g., cars ~30,000 parts, planes ~6 million parts, submarines ~10 million parts) may be eventually amenable to some form of twining, albeit at the sub-system or sub-component level. Digital representation will continue to advance in parallel with advances in the use of data. It is not simple. Few will venture to claim that we know what to do with respect to veracity of data (not synthetic data [493]) in digital twins.
In mechanical systems, no matter how detailed, the digital representation may be precise with respect to number of dependencies/interrelationships and accurate descriptions or values of characteristics and attributes. There is perhaps nothing non-deterministic (except if the physical entity explodes). Humans know how each of the thousands or millions of parts were designed, manufactured, and integrated as a system. Thus, digital twin of a sub-system may be a college project. It is unnecessary to revive digital twins as the tulipmania [494] of the 21st century.
In humans, data represented erroneously may increase mortality and morbidity, illustrated in Figure 20 and Figure 21 (cartoons of actual examples). In humans, we have very little idea about the networks and circuits that we collectively refer to as physiology. In the tiny “real estate” of a human body we may have 30-40 trillion human cells [495] (each cell has 6 billion base pairs of DNA per diploid genome [496]) interacting between cell-types [497] and some of them probably also interacting with 30-40 trillion bacteria [498] (each bacteria have ~4 million base pairs [499] of DNA per haploid genome). Roughly, each human body has ~2.4x1026 base pairs of DNA which may be interacting in ways mostly unknown [500]. DNA (base pairs per human) outshines the number of observable stars in the Universe (7x1022) and far exceeds the total number of grains of sand [501] on Earth (7x1018). DNA controls genetics. Single cell RNA sequencing reveals that cell type specific expression may vary widely within the same individual under physiological stress, infection, or dysfunction. What will happen [502] to precision public health if population genetics meets single cell sequencing? It may not be unreasonable to conclude that one may be wise to avoid using the terms “digital twins” and “living systems” in the same sentence, in the same century. Digital cousins [503] may be the shoddy and hapless alternative for the foreseeable future.
The hypothetical suggestion in Figure 5 and the reality of the emergence, growth, and obsolescence of the video cassette recorder in the 20th century (Tellis and Golder, 1996) offers profound lessons and parallels. In the 20th century, when man was landing on the Moon, here on Earth, cardiac defibrillators were limited to sophisticated hospitals. In the 21st century, roadside defibrillators are an increasingly common fixture (Figure 22). Mobile phones for the wealthy had to be carried by a valet (in a box) but now they dangle from ear lobes of women in Argentina, Belgium and Cameroon. Computers which occupied football fields are now the “palm pilots” (smartphones have more computing power [504] than what was available for NASA’s Apollo mission to the Moon). Data-informed reservations about the value of digital representation is clear. It is not a matter of time or technology but trust. When will trusted digital representations become digital twins or cousins? Depending on the complexity of the target, the unit t3 (“time to trust”) may be in decades or perhaps, centuries, or perhaps, never.
Data from the Garbage Can? A Killer App for Digital Twins
If we are what we eat [508] then it follows that we are what we excrete [509] (excrements). This centuries-old observation was scientifically [510] substantiated [511] in the 1960’s yet the principles are still not a part of science [512] or education [513] in schools. Public health [514] practices lack systemic implementation and dissemination of this crucial information was lacking from public discourse, until recently [515]. However, it was knee-jerk reaction from the great awakening catalyzed by the global catastrophe from the CoVID-19 pandemic due to SARS-CoV-2.
Figure 23.
Wastewater-based epidemiology is crucial to monitor disease outbreaks and other public health threats (e.g., illicit [516] drugs [517]) yet it remains just an idea. Half-truths seeded by consulting companies [518] has resulted in trillions of dollars of waste due to digital transformation (ZoBell, 2018). This photo from UC Davis (Safford et al. 2022) is one indication how corporate belligerence about “digital transformation” has starved investments for public good. Flying taxis [519] are worth “guiding” and the press [520] is coy while cooing about investments flying high and celebrating deception [521]. In the century which has witnessed the Mars Rover [522] it is hard to fathom why public health surveillance [523] must rely on people literally going down the drain for sample collection, while the nefarious lot are peddling drones [524] and sales of home [525] robots?
Figure 23.
Wastewater-based epidemiology is crucial to monitor disease outbreaks and other public health threats (e.g., illicit [516] drugs [517]) yet it remains just an idea. Half-truths seeded by consulting companies [518] has resulted in trillions of dollars of waste due to digital transformation (ZoBell, 2018). This photo from UC Davis (Safford et al. 2022) is one indication how corporate belligerence about “digital transformation” has starved investments for public good. Flying taxis [519] are worth “guiding” and the press [520] is coy while cooing about investments flying high and celebrating deception [521]. In the century which has witnessed the Mars Rover [522] it is hard to fathom why public health surveillance [523] must rely on people literally going down the drain for sample collection, while the nefarious lot are peddling drones [524] and sales of home [525] robots?

Figure 24.
Water contamination [526] is a health [527] risk and chronic [528] Arsenic [529] toxicity [530] affects millions in Bangladesh [531] (top panel: symptoms [532] of Arsenic poisoning [533]). Sensing [534] (bottom, right) Arsenic in surface water [535] can save lives [536] if the feasible systemic solution may venture beyond measuring [537] and alerts—bottom, left (van Geen et al., 2006). Digital representation of Arsenic concentration (parts per million) in drinking water (GIS map) may mimic the experiment (Nokia UI, bottom, left) and disseminate the geo-tagged data. What is the value of science [538] or data, for a very thirsty child, who is without a mobile phone, but standing in front of the tube well [539] expecting to drink water? Should she drink the Arsenic-laced water from the tube well?
Figure 24.
Water contamination [526] is a health [527] risk and chronic [528] Arsenic [529] toxicity [530] affects millions in Bangladesh [531] (top panel: symptoms [532] of Arsenic poisoning [533]). Sensing [534] (bottom, right) Arsenic in surface water [535] can save lives [536] if the feasible systemic solution may venture beyond measuring [537] and alerts—bottom, left (van Geen et al., 2006). Digital representation of Arsenic concentration (parts per million) in drinking water (GIS map) may mimic the experiment (Nokia UI, bottom, left) and disseminate the geo-tagged data. What is the value of science [538] or data, for a very thirsty child, who is without a mobile phone, but standing in front of the tube well [539] expecting to drink water? Should she drink the Arsenic-laced water from the tube well?

Figure 25.
Cartoon of data from Biobot [540] network of wastewater treatment plants: is there any information in the data [541]? At least for affluent nations [542] if the digital economics [543] of digital twins of wastewater surveillance for public health is feasible, it may provide value. This may be a ‘B2B’ business with a twist. Businesses creating tools for surveillance will sell to municipal customers (for sewers). Business to government sales is not new but public health surveillance involves people, directly, in a manner analogous to domains touched by FDA and CDC. Will public health surveillance businesses still focus on shareholder value or deliver science for society? Will it fashion itself as an ethical social business or run after 501(c)n [544] exemptions?
Figure 25.
Cartoon of data from Biobot [540] network of wastewater treatment plants: is there any information in the data [541]? At least for affluent nations [542] if the digital economics [543] of digital twins of wastewater surveillance for public health is feasible, it may provide value. This may be a ‘B2B’ business with a twist. Businesses creating tools for surveillance will sell to municipal customers (for sewers). Business to government sales is not new but public health surveillance involves people, directly, in a manner analogous to domains touched by FDA and CDC. Will public health surveillance businesses still focus on shareholder value or deliver science for society? Will it fashion itself as an ethical social business or run after 501(c)n [544] exemptions?
However paradoxical it may seem, it may be only a tiny bit of an exaggeration to state that sewer systems may become the new paradigm for global health and an indicator of public wellness. Data from sewers may inform molecular epidemiology of communities, local and global. To acquire a better handle on quality of life should we consider digital representations and digital twins for sewer systems? Epidemiologists armed with time series data can mine patterns of activity in sewer systems and perhaps predict emergence of potential pathogens before they can reach critical mass or exceed thresholds to become public emergencies. These thinking suits nations where managed sewer systems are the norm and sanitation services are under municipal supervision (open defecation [545] continues [546] to be a problem in many nations).
Sewer digital twins is a digital representation of data from sewers. Geo-tagged sensor data from the sewer wireless sensor network (SWSN), can be uploaded through a gateway to the internet and accessed by any digital device. Sensors in the sewer [547] (SITS) may be the “new age” 21st century equivalent of the 19th century practice of canaries in the coal mine [548] (CITcom).
The science of the data from SWSN will be influenced by [1] the molecular science of the target (what do we wish to detect from the sewer) and [2] sensor engineering with respect to signal acquisition and signal transduction. Without science, we do not know what it is that we are detecting and without engineering we lack connectivity, hence, the data to analyze, whether we detected our target (ACDC in practice). If we solve the science and engineering issues, is that success in principle or success in practice? If we succeed, can we implement a physical SWSN and design a digital representation of SWSN?
Figure 26.
Success in principle is not success in practice. Solving science and engineering issues does not guarantee implementation and adoption unless the economics of technology [549] are favorable. Cartoon shows business pillars which must be viable to uphold SWSN as a tool. TCE [550] (Transaction cost economics), KPI [551] (Key Performance Indicators), ROI (Return on Investment) & Public Private Partnerships (PPP) are key. Interrelationships between these factors are illustrated as agents [552] in a cube-of-cubes [553]. Can SWSN and ethical profitability co-exist? Can entrepreneurial innovation seed SWSN as a social business with the potential to be a catalyst for local/global economic growth?
Figure 26.
Success in principle is not success in practice. Solving science and engineering issues does not guarantee implementation and adoption unless the economics of technology [549] are favorable. Cartoon shows business pillars which must be viable to uphold SWSN as a tool. TCE [550] (Transaction cost economics), KPI [551] (Key Performance Indicators), ROI (Return on Investment) & Public Private Partnerships (PPP) are key. Interrelationships between these factors are illustrated as agents [552] in a cube-of-cubes [553]. Can SWSN and ethical profitability co-exist? Can entrepreneurial innovation seed SWSN as a social business with the potential to be a catalyst for local/global economic growth?
|
SEND Sensor is installed inside the sewer → sensor Detects target molecule(s) → data transmitted to gateway and uploaded to internet → users auto download data from internet to device. |
SAMD Sample of sewer fluid is extracted →sample is tested to Detect target molecule(s) at a testing facility → data uploaded to internet → users auto download data from internet (for Figure 20 and Figure 22). |
| The difference between the two lies with the science of SEND vs the engineering of SAMD. | |
The science of data with respect to SWSN for public health epidemiology may be significantly different depending on the sequence of events: SEND or SAMD (above). In the section “science behind the data” we discussed why and how the bio-recognition elements of the sensor must bind the target molecule we wish to detect. If detection is due to the binding then the sensor transduces the data after the binding, but the sensor material stays bound to the target molecule. Binding triggers signal transduction and data is transmitted but the sensor is used up (“consumed”). The sensor is no longer available to bind another target molecule. Unless the sensor is replaced, target molecules may be still in the sample but there will be no new data from the sensor which is no longer available to bind, again.
If the target we wish to detect was light, motion or temperature, then light sensors, motion sensors and temperature sensors continuously sense, using waveforms for detection. The sensor is not “consumed” and keeps detecting the target wave as long as the sensor has adequate energy (battery life of sensor). In the wave scenario, by eliminating the “binding” of molecules or particles, we have improved the usability of the sensor system which does not need frequent replenishment to continue sensing (and subsequent generation of data, over time).
Due to our very limited knowledge, the ability to detect molecules using waves or reflection/refraction of waves is currently an open research question. At less than 100 nanometer (nm) range (virions, proteins, our targets for detection) the wavelength of visible white light (374-749nm, “white” light) is unlikely to detect changes in a complex colloidal soup (sewer sample, wastewater) between the absence or presence of very small molecules.
Waveform detection without binding may help to install sensors inside sewers. One option involves Terahertz (THz) radiation but the road to a THz solution may need quite a few inventions and research to explore unknown unknowns.
Terahertz (THz, 1 trillion Hertz or 1012 Hertz) occupies the spectrum range 0.3 -3.0 THz or 0.3x1012–3x1012 Hertz (Hz) to the left (Figure 27) of visible light (400x1012–800x1012 Hertz or 4x1014 to 8x1014 cycles per second or Hertz). Terahertz has the potential for applications in communication [554], sensing, spectroscopy and imaging due to its non-ionizing photon energy, ability to penetrate optically opaque materials (abundant in sewers, wastewater, soil), unique spectral signatures for macro-molecules and chemicals (most desirable properties for sensors in the sewer, wastewater and soil).
The combination of sensing (spectral signature [555] from molecular dynamics [556] of folded proteins [557]) and communication (data transmission) on a THz chip [558] may unleash the flood of sensors for sewers which can continuously detect without binding and transmit data when it detects the target (analogous to light, motion, temperature sensors). Submillimeter range THz spectroscopy is expected to yield macromolecular motions as protein signatures in aqueous environments [559] but calculation of the absorption spectra may suffer uncertain (?) absorption of THz by water (attenuated by the presence of water). Probing the science of this problem may uncover solutions which may lead to some form of standardization of spectral signatures for proteins. If a THz spectral signature for SARS-CoV-2 Spike protein is a reality and if we have a THz sensor in the sewer which elicits this spectral signature, then the data will reveal that the THz sensor detected SARS-CoV-2 [560] in the sewer (sewer sample, wastewater). If and when we have a THz sensor for continuous monitoring in sewer systems for SARS-CoV-2, the cost may be $50,000 per sensor. If the sensitivity and specificity of the sensor is reliable and reproducible then we have a robust product ($50,000 per sensor). After decades of innovation, reduction in transaction cost and economies of scale, an improved sensor using Terahertz spectroscopy may be ubiquitous in sewer systems and may cost even less than $1 per sensor.
The discussion about wave, e.g., Terahertz radiation, as the sensing medium is due our search for reusable sensors for continuous monitoring with no or ultra-low hysteresis [565]. Sensors which bind molecules exhibit very high hysteresis, that is, sensor characteristics are permanently changed. The failure to return to baseline criteria (default factory specifications) makes the sensor useless or highly error-prone, after initial binding. Changing sensors in the sewer after each binding event makes such sensors a non-starter for SWSN (sewer wireless sensor network).
The science of waveform sensing using Terahertz spectroscopy is not hypothetical. But, can we create an implementable sensor product required to detect viruses and bacteria in sewers or in the agricultural industry for food safety? It may not be impossible to create a working prototype in a lab but installation in sewers will require idiot-proofing to withstand manhandling.
Figure 28.
Science behind the data: wastewater monitoring in sewer systems must address the science of hysteresis (vastly reduce or eliminate hysteresis) in order to repeatedly reuse sensors to continuously monitor and transmit data from SWSN (may be digitally represented as a digital twin). Since we are immersed in natural spectrum of waves, objects in motion will collide with waves and reflect waves (pebble in a pond). Reflected radiofrequency (RF) waves indicate direction of motion (top, left corner). ISAR [566] (inverse synthetic aperture radar [567]) is an old technique used for mapping surfaces of Earth and other planets. ISAR uses movement of a target to emulate an antenna array (see [a], top, left corner) to locate an object by steering its beam spatially. In [b] the moving object itself emulates an antenna array and acts as an inverse synthetic aperture. Wi-Fi Vision [568] (Wi-Vi) leverages this principle (Adib & Katabi, 2013) in order to beamform the received signal in time (rather than in space) and locate the moving object. Wi-Vi can signal movement (humans [569], animals [570]) but in sewers locating the movement of nanometer (viruses) or micrometer (bacteria) sized particles or molecules (3,4-Methylenedioxymethamphetamine [571] metabolites [572]) is a challenge for new “eyes” and new thinking.
Figure 28.
Science behind the data: wastewater monitoring in sewer systems must address the science of hysteresis (vastly reduce or eliminate hysteresis) in order to repeatedly reuse sensors to continuously monitor and transmit data from SWSN (may be digitally represented as a digital twin). Since we are immersed in natural spectrum of waves, objects in motion will collide with waves and reflect waves (pebble in a pond). Reflected radiofrequency (RF) waves indicate direction of motion (top, left corner). ISAR [566] (inverse synthetic aperture radar [567]) is an old technique used for mapping surfaces of Earth and other planets. ISAR uses movement of a target to emulate an antenna array (see [a], top, left corner) to locate an object by steering its beam spatially. In [b] the moving object itself emulates an antenna array and acts as an inverse synthetic aperture. Wi-Fi Vision [568] (Wi-Vi) leverages this principle (Adib & Katabi, 2013) in order to beamform the received signal in time (rather than in space) and locate the moving object. Wi-Vi can signal movement (humans [569], animals [570]) but in sewers locating the movement of nanometer (viruses) or micrometer (bacteria) sized particles or molecules (3,4-Methylenedioxymethamphetamine [571] metabolites [572]) is a challenge for new “eyes” and new thinking.
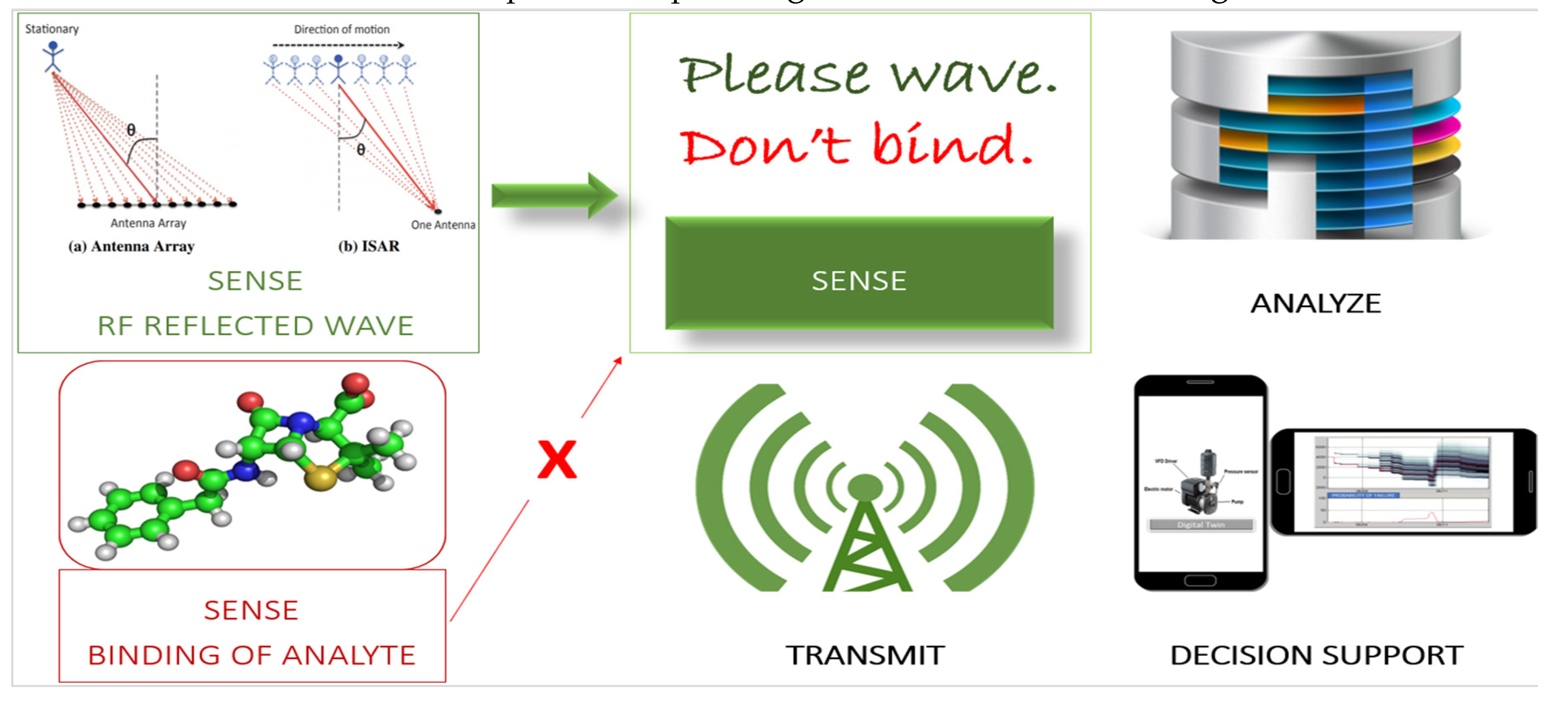
Figure 29.
Hypothetical cartoons by PowerPoint enables diffusion of ideas. For tools, in this cartoon, to reach the less affluent world (80% of population) the power from economies of scale (next billion users) must be harvested. The disconnect between science and human values erupts from the grave discord between advances in usable technologies vs the economics of technology in the context of applications and sustainable operations [574]. Democratization of data enabled by the explosion of software defined services has catalyzed convergence of science, engineering, and technology to reach the masses, albeit unequally [575]. Peddling prosperity for the affluent few (less than 20% of the global population) excludes thinking and designing tools and technology to help farmers, sewer workers and laborers (who aren’t invited to Davos) to contribute to poor [576] economics, participate in global economic growth, and pursue development as freedom [577].
Figure 29.
Hypothetical cartoons by PowerPoint enables diffusion of ideas. For tools, in this cartoon, to reach the less affluent world (80% of population) the power from economies of scale (next billion users) must be harvested. The disconnect between science and human values erupts from the grave discord between advances in usable technologies vs the economics of technology in the context of applications and sustainable operations [574]. Democratization of data enabled by the explosion of software defined services has catalyzed convergence of science, engineering, and technology to reach the masses, albeit unequally [575]. Peddling prosperity for the affluent few (less than 20% of the global population) excludes thinking and designing tools and technology to help farmers, sewer workers and laborers (who aren’t invited to Davos) to contribute to poor [576] economics, participate in global economic growth, and pursue development as freedom [577].
In the SAMD option, a sample is collected from the sewer for testing. Such tests may not need sophisticated waveform sensing, even if it is available and feasible. However, there must be a better way to sample wastewater from sewers compared to the operation shown in Figure 23. A drone-mounted robotic collection arm using specified outlet/exhaust sewer pipe (as a location to access wastewater) may be an engineering task for school students inspired by robotics [573].
Ethics: Please Don’t Leave Home Without It
Human life is at the center of our discussion on healthcare, medicine, and social welfare, in general. Ethics is at the functional core of healthcare and its relation to science-based medical care of people through detection (diagnosis [578]), prevention (prophylaxis [579]) and treatment [580] (therapy) of their physical and mental illnesses. Medical ethics deals with values and norms that individuals, groups, and organizations use as a basis for their engagement and justification [581] of health related practices [582]. The principle of patient beneficence is of importance in relation to healthcare technologies. Can we improve quality of patient care by embracing the idea of digital twins and the promise of digital representation to optimize operations through data transparency?
Do humans have the knowledge to optimize human systems with digital tools? Physical functions and mental characteristics (consciousness, attitudes, behaviors) of humans are complex (more than cars, aircrafts, submarines). Mars Rover, mass spectrometry and mining operations for rare earth metals, at a systems engineering level, pales by comparison to viruses which are measured in nanometers but can change the future of human healthcare with unpredictable severity for decades/centuries (e.g., SARS-CoV-2, Ebola). Isn’t the thought of even a skeletal digital twin or digital cousin for healthcare [583] a ludicrous tempest in a teacup or in a closet?
Figure 30.
a: Perhaps unpredictable [584] consequences of fluctuating severity may unfold in the 22nd century due to viral antigenic drift (e.g., SARS-CoV-2 evolution [585]). This is in addition to all the viruses [586] predicted to possess pandemic potential [587] and millions of other [588] unknown pathogens. Discoveries [589] and ethics, combined, will determine the fate of planetary [590] health. b: Unethical takes a whole new meaning in this phantasmagoric horror show starring JUUL e-cigarettes designed [591] to be disguised [592] and especially marketed [593] to school students, teens, and young adults. Alert from CDC [594] did not discourage shark tanks from swimming [595] along with this deception. In this shocking moral hazard, the investors and the manufacturers are risk-free with respect to the social cost of long term healthcare effects due to mortality and morbidity, teens and young adults may experience in the future due to induction by JUUL to develop nicotine addiction. Health problems due to vaping [596] may lead to cancer, too. It took years for the judicial system to address these health atrocities and issue a gentle reprove [597].
Figure 30.
a: Perhaps unpredictable [584] consequences of fluctuating severity may unfold in the 22nd century due to viral antigenic drift (e.g., SARS-CoV-2 evolution [585]). This is in addition to all the viruses [586] predicted to possess pandemic potential [587] and millions of other [588] unknown pathogens. Discoveries [589] and ethics, combined, will determine the fate of planetary [590] health. b: Unethical takes a whole new meaning in this phantasmagoric horror show starring JUUL e-cigarettes designed [591] to be disguised [592] and especially marketed [593] to school students, teens, and young adults. Alert from CDC [594] did not discourage shark tanks from swimming [595] along with this deception. In this shocking moral hazard, the investors and the manufacturers are risk-free with respect to the social cost of long term healthcare effects due to mortality and morbidity, teens and young adults may experience in the future due to induction by JUUL to develop nicotine addiction. Health problems due to vaping [596] may lead to cancer, too. It took years for the judicial system to address these health atrocities and issue a gentle reprove [597].

Ethics demand protection of patient interests. Patient care, patient safety and advocacy for the patient (welfare) should take precedence agnostic of the socio-economic milieu. Maximization of the interests of economic stakeholders is unethical if it reduces the patient’s quality of life index.
Figure 30. c: Unethical practices in healthcare enforced by medical associations in collusion with big pharma with support from politicians is a heinous form of socially metastatic carcinomatosis. The march of unreason continues even after medical experts [598] exposed unscientific [599] claims.
Almost two decades ago, by lowering the range of fasting blood glucose level the ADA (America Diabetes Association) committed scientific fraud. The ADA’s actions opened the flood gates for sales of medication, “potions” and home monitoring kits after every meal, irrespective of the diabetic status of the person. Retailers for grocery items (coffee, dairy, sugar substitute) besieged the Food and Drug Administration (FDA) to label products as items which prevent diabetes. Life coaches and fitness gurus came out of the woodwork to pamper starlets in the “real housewives of Beverly Hills” and the wailing men from Wall Street since ADA tied body mass index with pre-diabetes. The latter is not untrue but using the labels from ADA and CDC the disreputable market practices became disproportionately amplified from lifestyle suggestions to fear-mongering “medical treatment” for prevention of pre-diabetes. The result was a viciously unstoppable transmutation of disingenuous tabloid fodder to veritable truth catalyzed by pseudo-science hacks, social gurus, and glib PR campaigns to drum up “pre-diabetes” patients by the millions, as sacrificial lambs for retail health [600], healthcare organizations and the biomedical industrial complex [601]. These activities are rationalized using data based on criteria [602] (slide 26) promoted by supposedly responsible and venerable organizations such as the ADA and CDC. In 2012, the pre-diabetes market was $44 billion and total cost of diabetes was $245 billion in the US. The cost of diabetes in 2017 was $327 billion according to the ADA [603]. In a five year span (2012-2017) the ADA helped to funnel almost $100 billion to the supply chain partners who are the beneficiaries of ADA’s lowered standards: medically, morally, and ethically.
Education: Mountains Beyond Mountains
Synthetic lab-grown diamonds are a gem but its consumption [604] as a commercial entity is a problem in search of a solution. The idea of representation as a twin was transformative in the mechanical context when it was instrumental in rescuing the astronauts aboard Apollo 13.
The social view of (even) life-saving ideas (Figure 22) are often slow to be recognized, slower to be adopted and often ridiculed [605] by erudite colleagues [606]. Robert Langer’s method to use nanoparticles and lipid molecules to encase drugs and nucleic acids for sustained delivery in vivo was met with derision by the elite scientific community because it was “too” innovative for 1976 [607] but saved more than 20 million [608] lives in 185 countries when used as the medium of delivery for the mRNA vaccine for CoVID-19.
On the other hand, at least in the US, ill-informed people who remain resistant to science constitute the unvaccinated population, directly exacerbating the population public health crisis due to the ongoing pandemic. Irrational hesitation or refusal to be vaccinated against COVID-19 may have resulted in >1 million preventable deaths in the US, at a cost in excess of $13 billion [609] (which is a conservative estimate in view of the $4 trillion [610] lost by the economic ecosystem). Through the “bean counting” lens, in terms of broader societal impact, perhaps it is fitting to indulge in introspection with respect to the adage the educated customer is our best consumer.
Future vaccine sales and sales of “digital twins” products/services depend on the degree to which the public is aware, educated, and cognizant about the value due to vaccines and digital twins. Vaccines and digital twins are farthest apart from any perspective but both are completely dependent on education in science, technology, engineering, medicine, & mathematics (STEM).
There are no known quick fixes for science and mathematics [611] education (STEM). The home-grown supply chain of talent which is central to commerce [612] and economy [613] to preserve democracy [614] and freedom [615] is dwindling. Digital twins are an advanced tool which needs a plethora of converging science and engineering principles to even begin to start crawling. Its success depends on K-12 education. The success of K-12 education starts with good teachers.
The knee-jerk reaction is to bemoan inadequate funding for education in technology for professional development of teachers [616]. Carefully crafted technology initiatives are nudging computer science (digital twins are not about computer science) while ignoring other subjects specifically mentioned in the call for CS [617] by the “coder-in-chief” (a pathetic moniker designed to grovel for attention from TV news and media). The message was re-shaped in a form which blatantly pandered for publicity and peddled prosperity for a sub-sector of technology, in the name of helping STEM.
Vaccine, digital twins and STEM are synonymous but they are not synonymous with technology, alone. STEM is not synonymous with technology, alone. It should not be framed by corporate and/or political shenanigans for the sake of corporate profitability and political expediency. Technology should not be glorified at the expense of science, engineering, and mathematics.
Mathematics is hard and news cycles are short, hence the “faster” approach of “coding” is the Holy Grail for funding agencies to provide glitter and glamour. It is certainly far better than doing nothing but computer science (CS) deserves equal and essential complementarity by improving diffusion of and rigor in mathematics (among other things) and the understanding that coding is only a very tiny part of CS. Coding is not CS.
Mathematics and science has taken a back seat in K-16 education where “tools” are celebrated but the “fundamentals” are left in the cold, as boring, and hard. This is the “new delusion” brought on by the scientific illiteracy of politicians and political illiteracy of scientists. It will be remiss to avoid this discussion for sake of “pleasantries” or to make things “palatable” to readers because educating the consumer is key to global development.
As a basic scientist, one may be intrinsically biased toward science (physics, chemistry, biology), medicine and mathematics. However, analytically, there is nothing wrong with promoting computer science and/or programming (coding) even though there is an immense chasm of difference between computer science as a scientific/engineering discipline vs coding, which is a tool, similar to a recipe.
Some of those who create recipes are indeed gifted researchers who are also deeply grounded in the fundamentals of science [618] even though the outcome or external “impact” surfaces merely as a recipe in a cookbook or an online “pop-up” when e-shopping for grocery delivery using a smartphone. If one delves deeper into this line of reasoning, it may be awe-inspiring to observe that the simple process of browning [619] bread (regulated during the process of baking bread), if used in a Montessori [620] approach in school projects (project-based [621] or case-based or problem-based learning, PBL [622]), could enable students to learn about convergence of trans-disciplinarity in the real world. Browning of bread can teach chemistry, biology, food, nutrition, physiology, cardiovascular disease, diabetes and related [623] aspects (engineering, software, data analytics, physics of instrumentation) as well as mathematical [624] rigor essential for quantitative analyses and metrics embedded in each sub-topic. Chemistry can be made thrilling and interesting just by asking students if they like chocolate [625] or what is in their paintbox [626] or discussing restoration of old paintings [627]. Lithium-ion battery [628] and learning redox [629] will keep children engaged, while the chemistry of shaving [630] may generate pre-pubertal guffaws. It could be thrilling to discuss chemistry of wood [631] and most students may be amazed to learn how wood can be made to become stronger than steel. The launch of a satellite made of wood [632] is a segue for things in space, space geo-bio-chemistry and telecommunications. The wireless TV remote is perfect for a project-based understanding of convergence in telecommunications.
These discussions can teach almost entire science and mathematics curricula. However, it is difficult to execute such multi-disciplinary complementarity in the K-16 curriculum because teachers may not have the grasp over various overlapping disciplines (or the ability to conduct assessment of learning). The reason for outlining this granularity of STEM is related to the fact that programming may be embedded in most of the items mentioned above, which is ignored when “coding” is just learning by rote. Coding is a sauce, not an entrée.
Programs for coding in schools and colleges (e.g., Girls Who Code) often dive into programming specific languages [633] for the express purpose of writing “lines of” code as the index of success. There is value in this tool. Examples of economic growth from rural India is evidence. However, the socio-economic turmoil from India, headache and pennies as payment rarely makes it to the Wall Street Journal or BBC or ZDF. Is this distorted view of “affluence” the reason for US public education to push for “coding” as if it is a panacea, a solipsistic bliss?
Figure 31.
Lacking from K-12 Educational Initiatives: Philosophies of Software Languages [634].
Figure 31.
Lacking from K-12 Educational Initiatives: Philosophies of Software Languages [634].
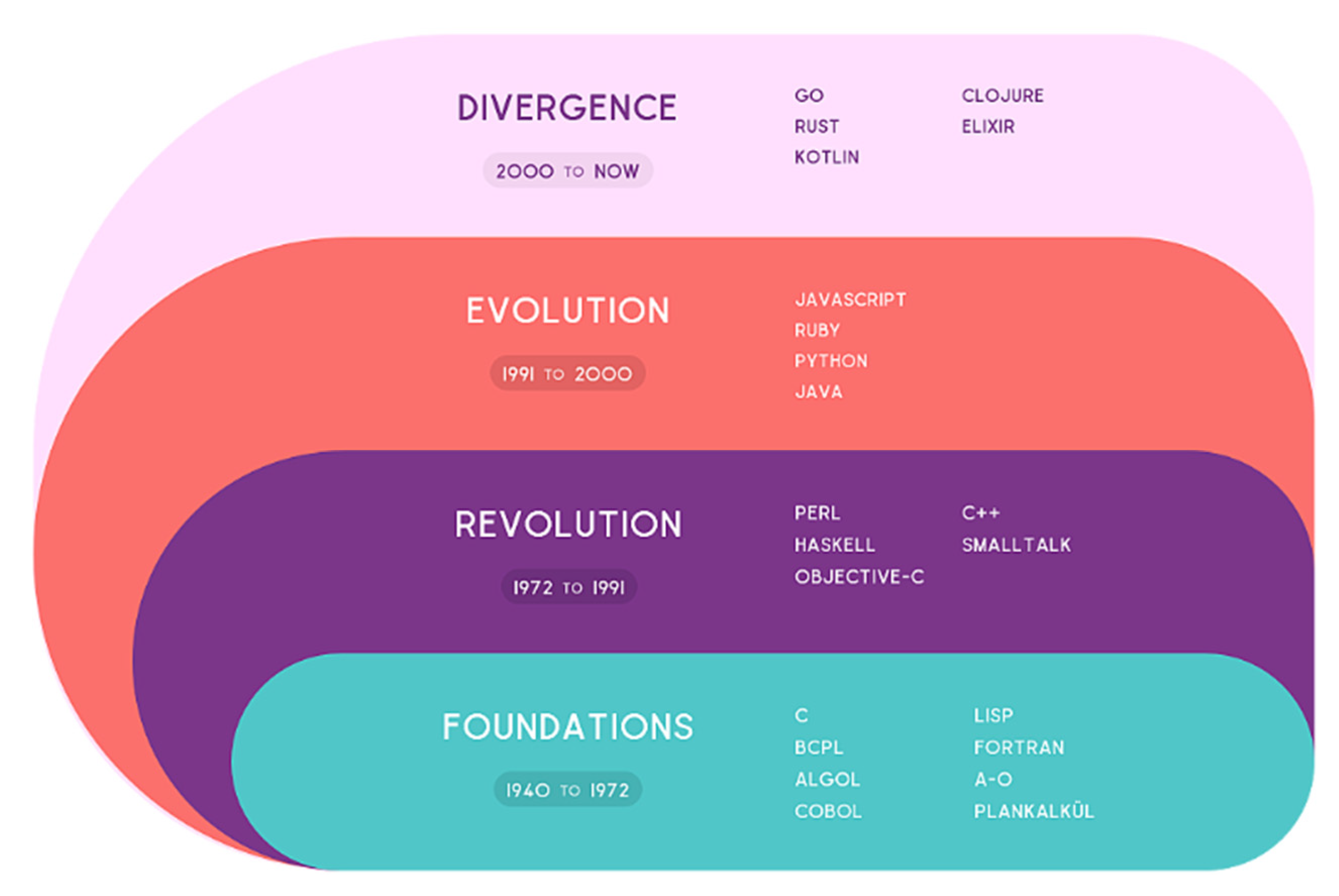
Dissecting the extraordinarily rich trans-disciplinarity of programming (coding) and the foundations of languages may illustrate a few salient issues. Programming “language” is an outcome which tries to capture and learn from the attributes of natural languages, e.g., grammar (noun, pronoun, verb, adverb, conjunction, preposition), syntax [635] (descriptive content, subject, predicate) and semantics [636] (meaning). Programming and software is lost when it meets with lexical semantics and clueless when dealing with cognition (contrary to absurd claims by the media, which corporations create for marketing purposes, where a lie can travel half-way round the world even before truth can put on its trousers [637]). Linguistics and study of the language infrastructure are critical foundations which informs the logic structure that generated the initial series of programming languages (code) during the middle of the last century (20th century). The combination of data and code through object oriented programming (OOP) was the “revolution” in the last few decades of the last century. The origin of this “revolution” may be traced back to “patterns” arising from architecture, designing and planning [638] cities and buildings. The 21st century evolution and differentiation is linked to predecessors, e.g., Julia [639] is a “modern” and improved language compared to Python, which was once considered progressive. Rust is even more linked to C++ and appears to resemble C, if C were to be developed in the 21st century.
Figure 32.
Data, Structure, Relations, Syntax, Semantics—cryptic when translated to binary code. Linguistics, cognition, grammar and patterns in our mind during language development are influencers of programming [640] (coding) yet students (and teachers) are in the dark about the inextricable link between learning languages and coding. In this example, neither “RecordDate” nor “DateofRecord” are real words but programmers synthesize arbitrary syntax, intending to capture the same outcome, i.e., meaning (semantics). The syntax is created in the brain of a human, not in the computer. Code cannot capture causality (see Figure 3a). Programming (coding) and resultant software used by computers are semantically challenged (i.e., dumb). Syntax, as shown in this HTML example, is only good for the specific use case. Hence, this code in the software is incapable of merging data (for example, from different phone logs) because hard-coded syntax produced by different programmers are unlikely to be exactly identical.
Figure 32.
Data, Structure, Relations, Syntax, Semantics—cryptic when translated to binary code. Linguistics, cognition, grammar and patterns in our mind during language development are influencers of programming [640] (coding) yet students (and teachers) are in the dark about the inextricable link between learning languages and coding. In this example, neither “RecordDate” nor “DateofRecord” are real words but programmers synthesize arbitrary syntax, intending to capture the same outcome, i.e., meaning (semantics). The syntax is created in the brain of a human, not in the computer. Code cannot capture causality (see Figure 3a). Programming (coding) and resultant software used by computers are semantically challenged (i.e., dumb). Syntax, as shown in this HTML example, is only good for the specific use case. Hence, this code in the software is incapable of merging data (for example, from different phone logs) because hard-coded syntax produced by different programmers are unlikely to be exactly identical.
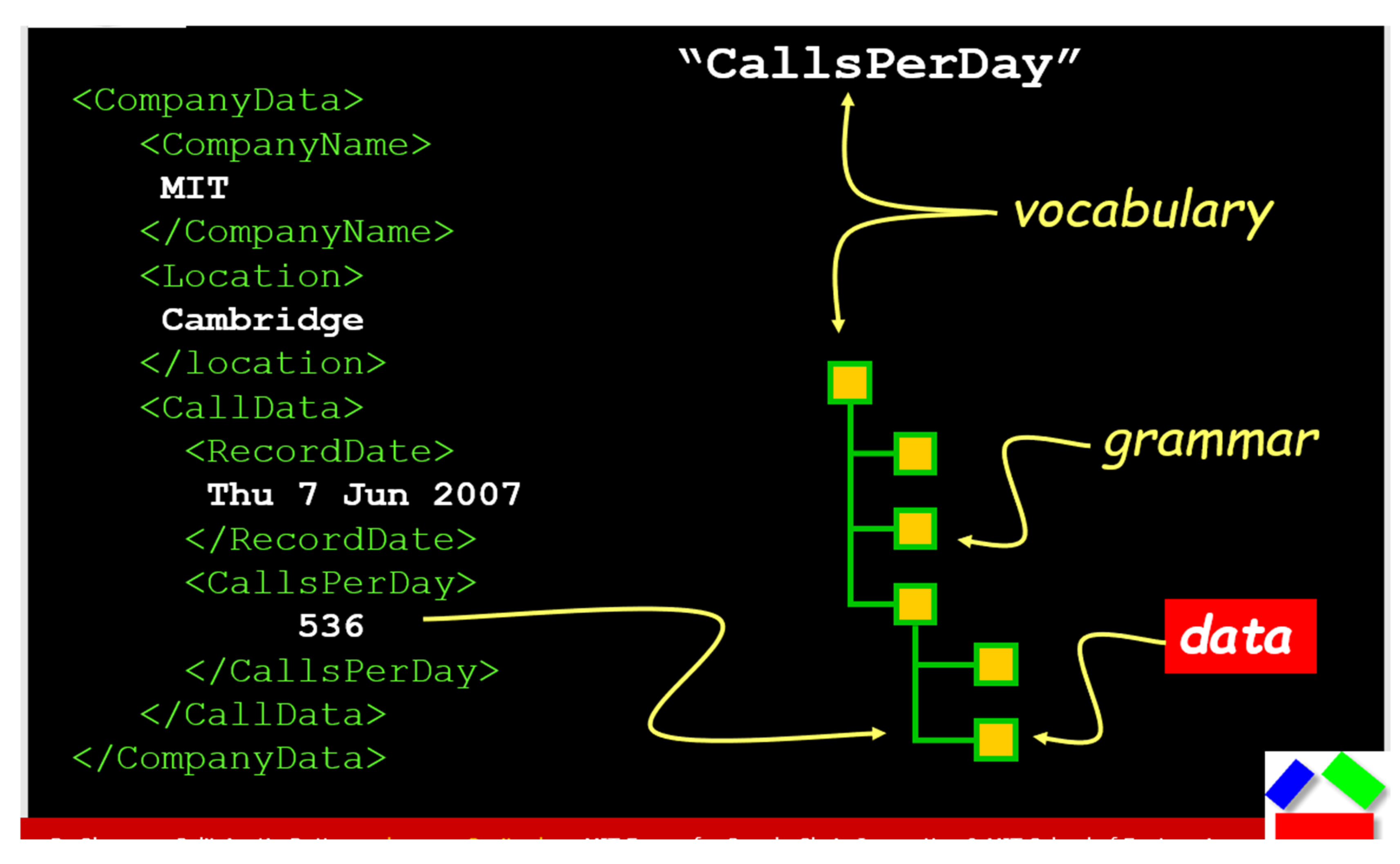
If one can grasp the foundational tenets, then such an individual may be better suited to adapt, un-learn and re-learn whatever may follow in the market of programming languages (revolution, evolution, differentiation, divergence, convergence). Job insecurity due to changes in programming technology (code) may become less of a thorny socio-economic problem if students were acquainted with the modus operandi which is at the heart of change. Technology drifts every few years much to the chagrin of employees who may prefer job stability, regular paychecks, and peace of mind. Preparing students to deal with inevitable challenges due to the dynamics of technology may help them to be fortified when they are the adults in the workforce.
The foundations of programming languages are inherited from the foundations of natural languages which are built on the structure [641] of linguistic infrastructures [642] we are exploring [643]. We are clueless how knowledge representation can mathematically fit with binary computation (see Figure 3a). We have been unable to distill into programming languages the binary form of semantics and cognition which occurs during language acquisition and pattern development in the mind [644]. It is the key reason for our complete failure to include causality through code and binary execution for computation. Linguistics are at the core of programming languages. Syntax is language derived from and based on natural language [645] of the programmer (varies immensely with the mother tongue of the programmer, e.g., English, Chinese or Spanish). Individuals may choose to describe the same content (things, objects, processes) in different forms of syntax. The choice of words is based on the linguistic proficiency of transforming thoughts into spoken words based on vocabulary. Programming instructors in K-16 are unlikely to discuss these facts.
These problems are further exacerbated when programming extends into ill-understood (unknown) domains, e.g., artificial neural networks [646] (ANN). The vain attempt to generate “intelligent” software (mostly through marketing propaganda of “artificial intelligence”) is plagued with inconsistencies of extrapolation and mimicry of biological functions (for example, neural networks) in human-designed programs or software processes. The basic circuitry of a neural network is regulated by electro-chemical signals which are extremely difficult (if not impossible) to reproducibly quantify in humans and higher animals. The claim that an “artificial” neural network may represent the logic patterns in our brains is infinitely cherubic, if one is familiar with the basic science of neurology and is aware of the granularity of details for even a simple (mono-synaptic) neural signal communication. Mimicry of artificial neural networks using patterns even from worms (Caenorhabditis elegans [647]) may be too complex with too many dependencies and/or interrelationships, some of which may be latent.
Let us assume that one has created a rudimentary Boolean [648] logic structure from some form of so-called artificial neural network with programming (coding) to perform operations. What are the operatives and what are the mathematical basis of the tools deployed/necessary for the operation? Can we transform the outcome to become information [649] which can offer value to users? Is making an app [650] the Holy Grail? Computation and programming is better suited to deal with the tsunami of data (humans cannot process large volumes of data). Logic, computer and programs (code) are only as good as rule based [651] expert [652] systems [653] which depend on the code and data provided. If it is not provided by humans, it does not exist in the computer. Computers cannot answer why (e.g., what causes the automobile to stop at a red light? what is the reason?).
Programs cannot think but excellent in performing binary operations based on pre-programmed logic, rules and embedded structure/procedures/protocols. Mimicry of neural signals and quantification of signal strengths (“weights”) are arbitrary and devoid of contributing any mode of “new” thought, which depends on causality. Thus, we have a high performing logic tool (e.g., AI) which depends on code to enable computation at speeds unattainable by humans.
The trinity of mathematics, biology and languages, form the invisible part of the iceberg where coding or programming is the visible tip of computation. Our penchant for quick results and gratification may be fueling our desire to polish the chrome (coding) and kick the can of hard facts (mathematics, biology, language) down the road for somebody else to tune the engine. We are immersed in system of systems (akin to “mountains beyond mountains”) which requires the ability to think in layers of thoughts and understand complexity by assimilating analyses.
We can make things entertaining (e.g., “gaming”) and perhaps easy for students to feel accomplished, now, but only to observe social discontent, later. Is the design of information technology tools in public education skewed to statistically amplify the positives in our elusive quest for rapid rewards? Are we in denial about the nature of science education necessary to create the vaccines of the future to serve society and manufacture/program digital twins/cousins as commercial products? Are we still a nation [654] at risk?
Figure 33.
How to think about analytical thinking? It is difficult to grasp the significance of the DIKW pyramid or attempt to explain how data, information, knowledge and wisdom (DIKW [655]) may be inter-dependent as a “building” process, over time. Analytical thinking is key to progress yet poorly taught or understood. An easier approach is to catalyze students to ask “why” (that is, the concept of cause or causality). Cause and effect is not an abstraction but offers an abundance of instances from daily life, e.g., epidemiology of diseases [656] (7 layers, LEFT). The “build” concept in analytical thinking can be made relevant to students by referring to the ubiquitous mobile phone, and the incessant war of “apps” which could cease in an instant if the flow of 0’s and 1’s are affected. The latter may segue to explain OSI (Open Systems Interconnection) information engineering reference model [657] (7 layers, RIGHT). Students must be prompted at each stage to ask “why” and extend that “why” each time a computer command generates a response. “Why” did the computer perform in that manner? The why will eventually lead students to grasp that the performance of the computer is strictly linked to what was coded and pre-programmed into the computer by humans. Computers cannot answer why unless a human has programmed it with the value/data/information a priori. Computers cannot think.
Figure 33.
How to think about analytical thinking? It is difficult to grasp the significance of the DIKW pyramid or attempt to explain how data, information, knowledge and wisdom (DIKW [655]) may be inter-dependent as a “building” process, over time. Analytical thinking is key to progress yet poorly taught or understood. An easier approach is to catalyze students to ask “why” (that is, the concept of cause or causality). Cause and effect is not an abstraction but offers an abundance of instances from daily life, e.g., epidemiology of diseases [656] (7 layers, LEFT). The “build” concept in analytical thinking can be made relevant to students by referring to the ubiquitous mobile phone, and the incessant war of “apps” which could cease in an instant if the flow of 0’s and 1’s are affected. The latter may segue to explain OSI (Open Systems Interconnection) information engineering reference model [657] (7 layers, RIGHT). Students must be prompted at each stage to ask “why” and extend that “why” each time a computer command generates a response. “Why” did the computer perform in that manner? The why will eventually lead students to grasp that the performance of the computer is strictly linked to what was coded and pre-programmed into the computer by humans. Computers cannot answer why unless a human has programmed it with the value/data/information a priori. Computers cannot think.
Expectation: Quest for Silver Linings?
The 21st Century Ig Nobel [658] Prize for the category “Jargon-unum” (perhaps inspired by Jargonium [659]) may be awarded to AI for creating “data fuel” which can ignite a global inferno if used by disenfranchised individuals, corporations, and organizations. In the 20th Century, other fuels capable of global mayhem were rewarded with several Nobel Prizes beginning with the 1901 inaugural Nobel Prize. Are there common elements between these two events?
The 1901 inaugural Nobel Prize in Physics recognized Wilhelm Conrad Röntgen, who produced and detected electromagnetic radiation in the wavelength range referred to as X-rays or Röntgen rays (8 November 1895). The following year, the celebration of “radiation” ignored [660] Claude Félix Abel Niépce de Saint-Victor (1805-1870) but applauded Henri Becquerel’s re-discovery that uranium salts emitted radiation (March 2, 1896 [661]) similar to Röntgen’s X-rays. Radiation reached a crescendo (1898) when Marie Skłodowska Curie and Pierre Curie reported “strange uranium rays” from pitch blende (Polonium, Thorium, Radium). Marie Curie coined the term “radioactivity” to describe the spontaneous transmutation of elements.
Henri Becquerel, Marie Skłodowska Curie, and Pierre Curie received the 1903 Nobel Prize in Physics for radioactivity. Leo Szilard, in 1933, conceived and patented the idea of fission to release nuclear energy [662]. In 1938, Otto Hahn submits a paper demonstrating fission (showing production of radioactive barium from neutron irradiated uranium). Within days, Otto Frisch and Lise Meitner correctly interpret Otto Hahn’s results as evidence that the uranium nucleus had split in two (nuclear fission was predicted by Irene Curie and Frederic Joliot-Curie, 1934 [663]). In 3 days [664] (Aug 6-9, 1945) radiation from atomic explosions annihilated ~250,00 people [665] in Japan. In 2021, nuclear power plants supplied 2653 TWh of electricity (10% of global production [666]). The silver lining in “radiation” is that controlled fission is sustainable [667] form of energy for global development. Much to the chagrin of scientists, benefits of nuclear energy are being disfigured by anti-science [668] propaganda and political [669] correctness [670] gone awry. The unjust “atomic” wrapper on everything “nuclear” is a manufactured perception fictitiously conceived by non-scientists lacking knowledge in nuclear science, economics and the factors affecting the oscillation of global population (growth and decline [671] before 22nd Century).
In this context we compare the massive misinformation campaign in the name of AI (artificial intelligence) and its detrimental effect is a plague on society. The silver lining for “nuclear” is energy security. Can we find a silver lining for AI and its use?
The potential for human carnage from radiation pales by comparison to the diabolical economic catastrophe from the irrational exuberance of using AI for everything, even when AI tools generate mountains of egregious errors [672]. Indiscriminate use of AI (e.g., unregulated use in healthcare [673]) can explode into widespread discontent. The failure of “intelligence” in AI is due to its flawed infrastructure (ANN) and its inability to integrate causality (Figures 3a, 3b and 33). Digital twins and other buzz words describing information technology tools are vehicles which has the potential to corrupt data and pollute information arbitrage, when relying on AI analytics.
If viewed objectively, “mistakes” could be valuable and as important as “stupidity” in science, but only for learning and un-learning purposes to generate fresh embers of wonder and uncover new paths for exploratory re-learning. But, mistakes and stupidity, if allowed to infect the lives of people, may and will cause harm, which can be irreversible. It is illogical to think that mistakes will never cause harm [674] but the insidious underbelly could explode if mistakes are swept “under the rug” in a manner that is conniving [675] and manipulates the truth [676] to peddle hysteria about AI. Our ability to be error-prone (to err is human [677]) and our capacity to make mistakes, some more inspired than others [678], propels us forward, often, but not always.
We should resist the inclination to deprive the attribute of infallibility from experiments and certainly preserve it when experimenting with AI, because it is quintessential for learning. The error is not in making errors but in concealing the incorrect results due to errors (by not publishing the mistakes, errors, and incorrect interpretations). It is the latter which makes AI untrustworthy, biased and a strenuously deadly tool of unknown potential to seed chaos/havoc.
Perpetuating the myth that there is “intelligence” in artificial intelligence makes a grand mockery of the human race. For example, claiming AlphaGo [679] is better at games is as naïve as a dumb doorknob or an excellent demonstration that computers can indeed compute. AlphaGo uses reinforcement learning (RL) algorithms [680] combined with a variety of neural networks and MCTS [681] (Monte Carlo tree search). The semantics of “intelligence” is non-existent in these tools. AlphaGo may be occasionally better at games because human competitors may not be able to compute all the known permutations and combinations to determine all the possible outcomes in a specific move, in an instant (high performance computation, i.e., speed). Human dexterity may not perform, instantly, to map the patterns of complex interrelationships which may emerge in the 2nd or 3rd or n-th tier of the game, as a result of that initial move or some previous move in the game. Games created by humans are a series of sequences, albeit complex, but not causal or mired in unknowns. It is suited to the type of performance mapping we expect of computers where “volume” and the need for speed can overwhelm humans. It is not about intelligence but a series of operations, too fast and too numerous for most humans. AI marketing counts on this inability of the masses to grasp and understand the analytical difference between volume of operations vs human intelligence necessaryfor the operation. The gullibility [682] of the masses is exploited by the media to create propaganda machines to preach that the AlphaGo computer is more “intelligent” than the human and “intelligence” in “AI” is now in hand (when, in fact, these tools have nothing to do with intelligence, or AI but are logic rules working in tools, on steroid).
However, blaming corporate gulosity for unethical globalization of AI is incomplete. The skeleton in the closet is the lack of K-12 science (STEM) education and the dilution of rigor in mathematics and science in public schools to cater to the lowest common denominators. The incompetence of systemic public education is one key purveyor of this social developmental deformity which allows cumulative ossification of artefacts to become embedded in the social anatomy. Organizations exploit this metaphorical osteoporosis to usurp the social fabric which lacks critical thinking skills and unethically accelerates unstoppable misrepresentations.
Figure 34.
Transmutation of tabloid fodder to veritable truth catalyzed by pseudo-science hacks producing draconian freak shows [683]. Glib marketers and smug lobbyists inflate quasi-scientists [684] into “celebrities” and seek unscrupulous pockets within media companies to fuel sensationalism.
Figure 34.
Transmutation of tabloid fodder to veritable truth catalyzed by pseudo-science hacks producing draconian freak shows [683]. Glib marketers and smug lobbyists inflate quasi-scientists [684] into “celebrities” and seek unscrupulous pockets within media companies to fuel sensationalism.
The incorrigible shadow from AlphaGo falls on AlphaFold [685] which claims it can solve protein structures using AI by harvesting information from molecular physics [686] and other tools, e.g., PDB (Protein Data Bank [687] added the first 100,000 structures in ~40 years [1971-2011] but the next 100,000 in eight years) designed and curated by humans (CASP13 [688], CASP14 [689]).
For basic scientists, the “aroma” emanating from AI-fueled hubris of AlphaFold exceeds that of putrescine (butane-1,4-diamine) and cadaverine (pentane-1,5-diamine). AlphaFold appears to convey the impression (immensely debilitating for science, young students, and scientists) that it “knows” or has the “intelligence” in its system to know all there is to know about solving protein structure and that it has “learned” enough to predict protein structure [690] without additional [691] discoveries from protein chemistry [692], biophysics [693], crystallography [694] and scanning electron cryo-microscopy [695] (cryoSEM, cryoEM). The reason to celebrate AlphaFold as an impressive computer-assisted tool is lost in its braggadocios claim which implies it can do better than the past 100+ years of erudition (since 1913 [696]) which established scientific principles and practices for determining protein structure, functionally relevant and biologically validated.
Audacity is essential to break new grounds but the leap of audacity may not be bereft of substance or cloaked in half-truths or ignore the gaps that knowledge inherits in every step of progress. Under the epidermis of AI-AlphaFold we find good suggestive tools which may predict tertiary protein structure from primary structure [697] (amino acid sequence) of proteins. We should forgive AI-AlphaFold for lacking the “wisdom” that protein structure is adapted for biological function and quaternary structure is often necessary. Quaternary [698] structure of a protein is the association of several protein chains (often containing domains [699]) or subunits into a closely packed arrangement. Each subunit may have its own primary, secondary, and tertiary structure. The subunits are held together by hydrogen bonds and van der Waals forces between nonpolar side chains. Tertiary structure of individual strands often change or modify to accommodate or “fit” quaternary structures or may lend itself to “induced fit” to optimize biological function.
AI predicted protein structure may have less in common with the in vivo structure of the protein with respect to its function, a fact revealed during decades of research into the tertiary protein structure of the alpha and beta strands of hemoglobin (Hb). Viewed independent of the heme-containing moiety (i.e., quaternary structure of functional hemoglobin), they appear different (independent tertiary structures). If one “solves” the structure of alpha-Hb and beta-Hb then you have protein structure but not the protein structure of Hemoglobin (2 alpha + 2 beta).
It may be true that it may not be possible to grasp the semantic externalism cryptic between the structural folds in proteins when viewed independently (secondary structure, tertiary structure) versus structure as a functional unit (quaternary structure optimized by evolutionary processes for biological function). But, not all proteins have quaternary structure. The fervent of anti-intellectualism and over-hyped tools, e.g., AI, makes it appear that science happens on the computer. Breakthroughs happen in science laboratories through hands and minds of people whose work is “incalculably diffusive” [700] for the “growing good of the world” but often without fame. These scientists and engineers, after having lived a quiet but tremendously productive life, rest in “unvisited tombs” or unmarked graves, unbeknownst to the AI activists.
Semantic externalism is over-shadowed by the arrogance of the “AI-on-ALL” crowd yet validated, in the case of AI-AlphaFold, by Koshland’s “induced fit” [701] theory. Corroborating scientific evidence has made “induced fit” the de facto modus operandi for many (all?) proteins which act as enzymes (biological catalysts). Induced fit suggests that the structure of enzymes may not be static. The meaning of the structure depends on the external (in vivo) environment.
Proteins may change their structure, especially around its active site, to better fit with the substrate or ligand, in an effort to optimize (regulate) its in vivo function. This “active” structure is crucial in pharmaceutical interactions between the active protein and small molecules (ligands and inhibitors). Synthetic molecules (organic chemistry) or natural products (from plants) can change the function of proteins leading to healthcare benefits (e.g., remission of cancer, control of hypertension, antibiotics, etc.) or self-harm (adverse effects of Δ-9-tetrahydrocannabinol).
Benefits from suggestive abilities of AI-AlphaFold are as innumerable as its limitations. It is a suggestive tool for in silico secondary structure, for a known primary structure (sequence of amino acids, starting from the N-terminal). There will be instances when the suggestions are nearly correct because the primary pattern recognition depends on harvested data from structural motif repositories (Protein Data Banks) curated by scientists based on crystallographic [702] data and biological studies of structure with functional validation, over decades.
The assumptions made by AI-AlphaFold, coupled with the gargantuan amount of science of protein folding which we do not know, makes it very difficult to inculcate credibility of the outcome when using any AI-tool. If the outcome is placed in the numerator and the claim goes beyond “suggestion” (toward “fact”) then the value of the quotient may approach “fiction” if the assumptions and uncertainties as well as their confidence levels are in the denominator.
Let us analyze assumptions about water molecules associated with amino acid side chains in protein structure. The molecular arrangement of bulk water undergoes change near the protein surface. The surface of proteins contain hydrophilic and hydrophobic residues which can change depending on the hydration state of the protein and due to the zwitterionic [703] (affected by pH) nature of amino acids. The behavior of water in the hydration [704] shell (solvation [705] shell) of the protein has profound implications for the physical structure of the protein as well as its stability and range of potential biological function or efficacy. The structural order of protein hydration water also influences van der Waals [706] interactions (dispersion forces) and hydrogen bonding [707], all of which affects protein structure and function.
The contribution of hydration to protein folding thermodynamics (enthalpy [708], entropy [709]) makes it crucial to understand assumptions about water molecules when determining the impact of hydration on protein structure. Assumptions about molecular water (in the AI-AlphaFold logic layers) may need new learning and may be re-visited because water is not what it seems to be [710] as in traditional H2O. The formula is an oversimplification which needs understanding in the context of chemical phenomena (e.g., hydration in protein structure).
Microstructural essentialism points out that there are dozens [711] of different arrangements of H2O (microstructures) which differs in their dynamic interactions (transforming back and forth between H3O+ and OH-) depending on thermodynamic conditions. The presence of protein surfaces and zwitterionic amino acid side chains are influencers which can affect variations of microstructures. In turn, the microstructures of water (preferred varieties?) can influence the nature of hydration of proteins, affecting its structure, stability, and biological function. H2O, therefore, is no longer what it used to be. According to semantic externalism, the meaning of H2O will be determined based on the microstructures in the external (water) environment. What are the assumptions about the meaning of water in AlphaFold? Irrespective of the assumptions, AlphaFold is a good suggestive tool for protein structure, albeit in the unintelligent [712] category.
The dysfunction due to generative AI (ChatGPT and its variations) has resulted in fitting actions [713] and polarized communities. To resurrect AI, let us discuss “silver linings” that AI tools can accomplish, without any need for any human level intelligence in AI. The umbrella of tools referred to as AI (includes machine learning, ML, deep learning, DL) are expert systems based on knowledge bases and pre-programmed logic but devoid of semantics (Datta, 2007; ref 53).
What do we have in hand which is pre-determined logic and pre-programmed in detail? Programming, coding. Anybody can use a book, e.g., Python for Dummies [714] and learn how to write lines of code and become a programmer by following the logic rules. Can AI accomplish this “robotic” coding/programming task if we can find a way for AI tools to understand the question? “Understanding” is the great uncertainty but possible for limited use.
How difficult can it be to functionalize a software GUI (graphic user interface) where, for example, a mockup of a website design can be implemented by dragging and dropping shapes on an active interface? It can be accomplished (see Figure 12a & Figure 12b, top, left). Building websites can be an AI “silver lining” by automating software code, for the webpage, using “AI”. Writing code is a formula which expert systems can execute with precision. AI can serve as a co-pilot [715] in automating code. The latter idea (intent to write code) took shape in the last century but formalized by Charles Simonyi [716], the entrepreneur behind “intentional” software [717].
Imagine the profound impact of democratization of programming. What if a physician can dictate characteristics (sensor [718] data) and features she wants (symptoms) in a point-of-use app for a patient-specific treatment? What if an AI service can auto-generate code to create that app to improve patient-specific precision care/safety to augment the patient’s quality of life?
This may be the “silver lining” for AI. It is within the reach of science to serve society and be data-informed and information-informed. When AI can aspire for such august tasks, it begs to ask why AI is made to spout such mindless drivel [719]? Expert systems with embedded logic rules can help to make sense of data with accuracy and precision, if data is uncorrupted.
Calling any tool “AI” could be a deadly sin [720] and for logical people it may be akin to finding sand in a salad. But, for the sake of greater good, perhaps we should tolerate (overlook? bury?) this semantic oxymoronism and acquiesce to be thankful for many other benefits we enjoy due to progress in information technology. What’s in a name [721]?
Dubious Data Tools
The compelling reason why we may seek to create digital duplicates of physical entities to mimic operational processes (in the form of digital proxies or digital twins, digital cousins) is to improve efficiency and performance, for mechanical systems. Processing and analytics of operational data, therefore, is key to uncovering opportunities to adjust/adapt parameters/values for performance push-pull optimization. In other words, data-informed decisions are central in performance optimization. Hence, data and tools for data analytics are crucial to the discussion and debate because it directly influences the outcome expected from data tools and analytics.
What is under the “bonnet” of decision support engines are of paramount importance. The criteria for using these tools, implicit and explicit assumptions made by tools, the methods or processes used in the treatment of raw data and the veracity of the data, are salient elements. It is good that decision support systems have moved away from nomograms [722] but brushing almost everything unabashedly with AI is unacceptable if we value the uncompromising principle of causality and causal data in context of questions, scenario simulations [723] and data analytics.
We return to reiterate the reasons why AI tools may be detrimental for data analytics performed by decision systems including digital proxies and digital twins (which are a form of optimization tool aimed at improving the outcome of decision systems).
The back and forth discussion of data, data tools and deep frustration with “AI” as an imprecise tool (e.g., large language models [724] or LLMs) under the hood of digital twins is about recognizing that AI can regurgitate or “recite” [725] (pre-determined logic based expert system) but it cannot “reason” (i.e., devoid of rational de novo deductions). However, the unfortunate use of LLM/AI tools to create fake [726] data to support scientific hypothesis [727] in clinical trials could be the flatline, literally. It is shocking [728] individuals are supporting this system and helping to create tools like LLM GPT-4 ADA (large language model generative pretrained transformer advanced data analysis) which glorifies data contamination [729] by LLMs (“leak, cheat, repeat”).
In other words, in simple terms, there is no truth in AI because causality based cognition cannot (yet) be mathematically mapped for knowledge representation in binary or any other form useful for computational architecture (& software), with respect to relational semantics. Software in AI uses variations of artificial neural networks (ANNs) for “learning” and “training” ANNs to recognize “model” syntax based on selected material (language models) and imagery (pictures). There is nothing new in these models or processes (“learning”, “training”) to enable the software or ANNs to ask “why” and explain the causality behind the logic or action it delivers (outcome of ANNs). Irrespective of the hubris of LLM/AI ChatGPT tools, models or processes, it is still incapable of suggesting an outcome that is not already present (fed) in the system. Vast amounts of data, information and design are uploaded to large language models (LLM) but the system still does not “understand” semantics, that is, the “meaning” or impact of its outcome, despite the claims made by GPT-4 (generative pretrained transformer version 4 of ChatGPT).
The lack of understanding and the inability of computational systems to access machine-readable semantics (mathematical and/or binary representation of meaning in the digital world) is one reason why the semantic web dwindled [730] into oblivion. Digital ontology, ontological maps and numerically connecting their trans-disciplinary cross pollination of natural language are beyond the capabilities of science and current humans. Creating a database of information (Cyc [731], 1984) proved to be insufficient for knowledge representation [732] and failed to capture the context of data. Absence of numerical mapping of causal relationships between context of the problem and the context of the data, was the reason for the lack of “value-add” from Cyc [733].
So, what is new? Not ANN from almost 100 years ago but the even older NN, from 1,000 years ago is the new “new” under the “hood” of GPT-4 [734] and generative AI. We find principles of NN—nearest neighbor—analysis (k-nearest neighbor algorithms are used in data mining) as the “intelligence” in generative AI / ChatGPT. Nearest neighbor (NN) classification appears in Alhazen’s Book of Optics and it is due to Al-Khalili’s work [735] (circa 1011A.D. to 1021A.D.).
Why the irrational pursuit to re-invent intelligence in AI? Why do we need AI to think like Maria Göppert Mayer [736], Linda Buck [737] or Barbara Liskov [738] or engage with the cerebrum or the corpus callosum [739] through an implanted chip under our skull? Callous use of AI by corporations could spell disaster. We suggest an abundance of caution with hardware-in-the-loop and humans-in-the-loop to remain cognizant that data/information in complex systems [740] are immersed in knotty dependencies with respect to making sense of data (if contextual data and information arbitrage is expected to offer value).
AI was coined as a marketing term by John McCarthy (summer of 1955 [741]) to be used instead of and to replace cybernetics. McCarthy had an aversion for Norbert Weiner [742] who used the word “cybernetics” (McCarthy and Minsky preferred but could not use [743]). Thus, AI was an accidental syntax, a misnomer borne out of poor choice but sensationalized the media by adding panache to the ganache on top of the crepe cake of ANN. We have no clue as to what is and what constitutes intelligence. How do we propose to create a tool (AI) that exhibits intelligence?

Trouble with the Uncertain Science of Artificial Intelligence
A freshman keen on pursuing a STEM career, a PhD student in computer science and a government employee with executive oversight over R&D which includes AI, berated (SD) for skirting the basic issues as to why AI and its manifestations are risky tools. The flawed logic is capable of harm if artificial intelligence (AI) is unchecked and used as a decision support tool in autonomous systems because it can be fatal at a personal level as well as a population level. One wonders if disenfranchised people may find ways to deploy it as a weapon of mass destruction.
Let us attempt to summarize the scientific reasons why AI and its foundations are based on assumptions which may be false for ML/AI if used in most systems or complex applications. Although Ada Lovelace [744] first thought about artificial intelligence in the 19th century, we start this discussion in the 20th century with difference engines as sketched by Minsky (in ref 649).
The illustration in Figure 35 introduces bio-inspired “neurality” to the general problem solving approach which followed from logic-based information processing system (1956, logic theory machine [745]). Perhaps the latter was influenced by the enigmatic code-breaking saga [746] (1940) which culminated in “machine intelligence” (1950 [747]) but stopped short of “AI” which was not coined until 1955 [748]. A century later, we haven’t moved beyond logic-based information processing (expert systems) but the “climate of the era” [749] has changed due to low cost of high speed computation, negligible cost of data storage and tools for acquisition of high volume of data (but the data may not be useful contextual data or data may be polluted or corrupted).
The 1950’s witnessed a convergence of ideas starting with neurophysiologist Warren McCulloch and mathematician Walter Pitts (1943 [753]) who modeled a simple neural network using electrical circuits. Hebb (1949 [754]) strengthened the idea and Rosenblatt (1958 [755]) proposed the “perceptron” concept to usher in artificial neural networks (ANN). The ANN model is an useful crude approximation and oversimplified extrapolation of how neurons may work in the brain. These are the origins of the sketches by Minsky in Society of Mind (reference 646).
ANN (in a myriad of forms) can be a valuable tool in non-mission critical applications for secondary decision support suggestions for humans-in-the-loop (HIL). In the 21st century the ANN concept occupies the heart of the disinformation spewed by AI protagonists. The grave discontent is the illegitimate attempt to make ANNs synonymous with “intelligence” where the “brain is a computer” (false) and neural networks are the “computing machinery” for brains to function (false). Hence, artificial neural networks (which is far cry from physiological neural networks) fuels the myth that ANN enhances our ability to generate artificial intelligence (AI) by “mimicking” our brain. The latter is farthest from the truth. We know very little about the brain and its biological operations (Figure 36) are far more enigmatic than the ENIGMA machine.
We are incapable of capturing and mathematically representing our crude knowledge, the connections and their set of dependencies (Figure 36) in a binary (computational) context, where syntax and semantics is sufficiently numerical to be amenable for use by binary logic operators.
The nature of data acquisition and processing of data and information by neural networks in the brain are largely unknown. What influences these operations are even less known. What we know about neural transmission is that there are at least two dimensions referred to as the electrochemical gradient. It combines an electrical impulse involving neural components (axon, dendron) with release of chemical messengers in the synapse [756]. How do we even begin to “model” this system? How can ANNs be a legitimate model of this complex process?
ANN as a model, therefore, falls in the category that “all models are wrong [758], but some are useful” (within reason). Biological mimicry is useful as a guiding principle or template but may be immensely difficult to capture. In the case of ANN, the model fails miserably to capture the electrochemical gradient which is the foundation of neural communication (i.e., transmission of data/information) in biological systems. It is audacious to capture and model the synaptic environment (Figure 37, above) which is inextricably linked with the electrical component of neural information arbitrage. The electro-chemical complementarity of neural systems behavior is still too difficult to model. Does ANN capture even an ill-informed version of this reality?
This oversimplification and cherubic approximation of neural circuitry, which we refer to as ANN, is assumed to be sacrosanct as the “model” building block in the context of AI. In many cases, models are quintessential for science to progress, in the reductionist approach. Without the bacteria (experimental model) we may not have dissected the principles of feedback regulation (induction/repression [759]), which is central to evolution, physiology and homeostasis, in almost all organisms, spanning the entire gamut from plants, viruses, bacteria, animals and humans.
How did we represent the electrochemical gradient (in ANN) which is salient to the process by which x (input data) informs the output y (decision) in the information processing cascade? The evolutionary and biological development of the electrochemical complimentarity is central to neural communication. In ANN, it is reduced to an arbitrary numerical point as weight, w (Figure 38) and assigned heuristic values (ill-defined values obtained through trial and error). The intensely error-prone method of assigning w (weights) is neither a secret (see text in lower panel in Figure 39) nor capable of taking into account the dependencies between features which influences the “weight” i.e., the value assigned (see text in the upper panel in Figure 39).
The structure of every unit in ANN’s infrastructure, is based on gross approximations of processes stripped of their elements in neural information arbitrage. These processes (x, input) are coupled with error-laden arbitrary weights to further accumulate error in every step of the operational sequence, resulting in an outcome (y, output) which may be a farce. Compounding layers of ANN’s in certain tools (e.g., CNN, DNN, MPNN, PNN, RNN) amplifies errors to produce outcomes which may be wrong, harmful or fatal (e.g., in healthcare and medicine).
It may not be unclear that, first, [1] the structure of the infrastructure of ANNs (Figure 38) is based on ‘drawings’ of neural connectivity completely stripped of its richness as a template for information arbitrage. What is left of the “neural” inspired theme, is an A-B type ball-and-spoke model borrowed from FedEx [763]. Secondly, [2] evolution-driven electro-chemical wealth of contextual data-informed closed-loop homeostatic information exchange was replaced with “w” (heuristic weights) irrelevant to the neural system it is supposed to mimic. Weights (w) are arbitrary numbers assigned by the user, without any standard, any definition, any consensus index or a consistent (shared) baseline to similar problems. The electro-chemical duality central to the evolutionary complementarity of information processing in neural systems was impossible to capture through knowledge representation [764]. Weights (w) was the nice concept of “feature weighing” introduced by Frank Rosenblatt in 1958 (ref 755). The latter was deemed inadequate and insufficient by Papert and Minsky (ref 760) due to its inability to account for dependencies which influences the weights of features (Figure 39). These “weighted evidence” (evidence of what?) was adopted by AI/ML folks. The march of biological implausibility amplified the shallow-ness of “w” (risk [765]) in deep learning [766] (~75 year old idea of CNN [767] also used in the neocognitron [768] inspired by Hubel [769] and Wiesel [770]). On the other hand, SGD (stochastic gradient descent [771]) exploded [772] as the back propagation algorithm (BPA).
Figure 41.
In 1989, egregious errors due to biological implausibility exploded in the name of “Back Propagation Algorithm” (learning representations by back-propagating errors [773]). BPA (SGD) fueled the stampede of unreason contributing to the deadly sins [774] of AI. The trial and error method to “fit” weights “w” was inadequate (1969, ref 759) and arbitrary to reach a desired output (right, cartoon [775]). BPA is analogous to retrosynthetic chemistry in organic synthesis. It was published by Corey in 1964, for which he was awarded the 1990 Nobel Prize in Chemistry (ref 287). Did BPA copy the retrosynthetic principle in another name? Corporations and hordes of academics latched on to this tsunami of unreason for the fear of missing out, created wealth from disingenuous solutions in the name AI-autonomy to replace humans (to increase corporate profit). To add injury to insult, AI promises precision analytics to improve performance without humans (e.g., digital twins) even in medicine [776]. AI disinformation specialists ignore science, disregard evidence, disrespect ethics and more illogical, compared to anti-vaxxers [777].
Figure 41.
In 1989, egregious errors due to biological implausibility exploded in the name of “Back Propagation Algorithm” (learning representations by back-propagating errors [773]). BPA (SGD) fueled the stampede of unreason contributing to the deadly sins [774] of AI. The trial and error method to “fit” weights “w” was inadequate (1969, ref 759) and arbitrary to reach a desired output (right, cartoon [775]). BPA is analogous to retrosynthetic chemistry in organic synthesis. It was published by Corey in 1964, for which he was awarded the 1990 Nobel Prize in Chemistry (ref 287). Did BPA copy the retrosynthetic principle in another name? Corporations and hordes of academics latched on to this tsunami of unreason for the fear of missing out, created wealth from disingenuous solutions in the name AI-autonomy to replace humans (to increase corporate profit). To add injury to insult, AI promises precision analytics to improve performance without humans (e.g., digital twins) even in medicine [776]. AI disinformation specialists ignore science, disregard evidence, disrespect ethics and more illogical, compared to anti-vaxxers [777].

AI puffery related to “back propagation algorithm” claimed to create new wealth while BPA, in reality, appears analogous to backward scheduling practiced in logistics [778] and supply chain management. The history of hype in AI [779] and the deliberate bias in AI is still an academic exercise [780] or a footnote (in this case, an endnote, [781]). Bias in AI continues to create suffering [782] for those qualified to challenge the content even when faced with resistance from corporations [783] who are loathe to abide by ethics. When BPA stoked suspicion [784] (~30 years later), the chief salesman of BPA admitted that it is not [785] his work [786] and he is afraid [787] of dangers [788] arising out of its application. Scientifically impossible and biologically implausible application of back propagation algorithm continues [789]. Is BPA a fraud? The science community in the 20th century recognized that cartoons of ANN and weights based on feature machines were vastly inadequate schemes to capture the complexity of bio-inspired themes (neural networks, memory, learning, semantic context, language, brain). The NN alternative as expert systems [790] understood that intelligence, however artificial, was a mirage. The AI winters of the past [791] and future [792] indicates we know very little about biological systems.
Figure 42.
Cartoon on page 196 (of 336) from ref 646 (Marvin Minsky [1986] Society of Mind).
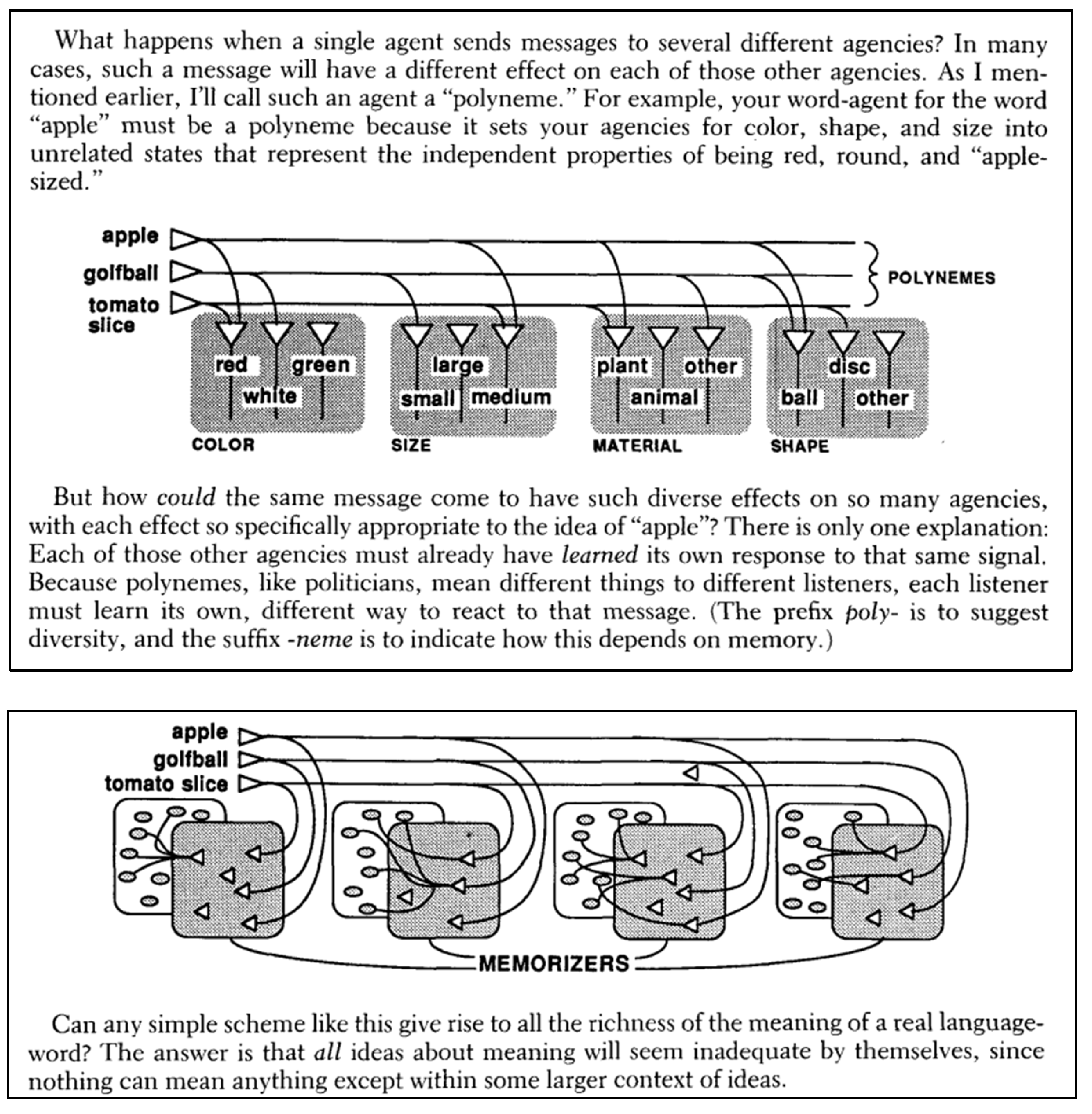
The imperfection of ANN as a model in AI may have been overlooked if the model was useful. The nail on the coffin of ANN-based ML/AI stems from mathematical/statistical issues which cannot be undone unless one can undo the philosophy, principles and practice of basic mathematics and statistics.

In other words, the above < response > is dependent on a prior event. In Figure 38, (see McCullogh-Pitts model of the structure of the infrastructure of ANN) the model input x is the canonical “independent” variable. In Figure 42, input “apple” is x, the independent variable. But is it independent? Mathematically, the input “apple” is NOT an independent variable because its “states” (color, shape, size) are unrelated features. Being an “apple” depends on (dependent variable) the “independent properties of being red, round and apple-sized” (the independent variables, in this example, with respect to the McCullough-Pitts model).
Therefore, in the ANN unit (Figure 38) and all ANNs based on “independent x variable” (including the infamous back propagation algorithm ANN cartoon in Figure 41), the disturbing question is—is the assumption of x, as the independent variable, mathematically incorrect? In small mechanical systems or very small system of systems, the assumption may be correct or nearly-correct. Does that hold true for complex systems? Biological systems? Medical systems?
In mathematical calculations following model building (see inset circle in Figure 38), the values of “x” are assumed to be a set of independent values. The latter will generate a value for y, the dependent variable (i.e., the outcome y is expected to depend on independent inputs, x). If there are scenarios (such as the one sketched in Figure 42, as “apple”) where the input values of x are not independent then it violates the fundamental mathematics of the equation-based model (and all aspects of time series data) to generate error-filled outcome (erroneous output, y).
If tens, hundreds or thousands of “hidden” layers of ANN (BPA—back propagation algorithms, DNN—deep neural networks, CNN—convolutional neural networks, RNN—recurrent neural networks) are performing operations using input values based on the imperfect assumption of x as an independent variable, then we are accumulating 10’s, 100’s, 1000’s of error-filled outcomes (output, y) which, when aggregated (summation), may generate massive gobbledygook (ref 51), nonsense or output lacking credibility or value for decision support.
In biological, medical and healthcare systems there is nothing that is an independent variable. Living systems are closed-loop homeostatic system of systems where the fundamental thrust of life and living is to optimize the physiological parameters of the system through a series of push-pull equilibriums. If everything is a dependent variable then the entire core mathematical construct of ANN or related ML/AI is false, no matter how one sugar coats the truth/facts.
The resistance (inability?) of the community to comprehend the granularity of dependent vs independent variable (in the mathematical operation in any equation-based model of ANN) is at the heart of the problem. If (patient) data is collected over time, it is time series data, it is serially correlated and not (cannot be) independent and identically distributed due to its very nature (i.e., data at time t1,n is dependent on data at time t0,n-1). For any industry, this myopia or inability to grasp this mathematical irrationality (falsehood), has the potential to trigger global economic catastrophe, mortality and morbidity, if any critical decision support is left to AI.
However, these tools are useful (necessary) when sorting through very high volume of data at speeds which will never be matched by humans on any reasonable scale. The dexterity of so-called ANN-ML/AI tools are useful to gather suggestions through secondary support systems linked to mobile, hardware and humans in the loop (HIL). But, ANN-ML/AI tools may never be considered to be anything more than a source of suggestive analytics (e.g., in healthcare).
Lack of understanding in defining the network of dependencies associated with ANN mathematical operators may not enable robust risk mitigation strategies in low fault tolerance scenarios. Hence, ANN-ML/AI tools may not execute any comprehensive operation with the possible exception of highly differentiated events (e.g., turn off PCA, due to PORD; alert HIL) which offers an approved, verified, tested and credible binary (yes/no) outcome which can/may prevent (reduce risk with minimal harm) immediate mortality or long term morbidity.
Perhaps propelled by pecuniary interests, decision makers may wish to remain oblivious of the difference between an independent variable with confounding factors and a dependent variable. The mathematical heart of this problem extends to all complex systems including large mechanical systems (prime area for deployment of digital twins) such as turbines (in energy generation, in airplanes), cities (utilities, transportation, emergency response systems are vast networks of inter-dependent cascades [793]) and natural disasters (weather, wildfires, earthquakes).

The abundance of caution necessary in implementing embedded ANN-ML/AI tools in software, middleware and hardware, cannot be overemphasized. A solution for the mathematical problem inherent in the construct of ANN-ML/AI tools may not surface from any rapid-fix or error-correction algorithm (Shannon, 1948 [794]) or protocol (Kalman, 1960 [795]). The root of the problem is our lack of understanding (knowledge) of the range of dependencies associated with each variable, which can affect its performance. For healthcare [796], knowledge grows only if we invest in basic science research. For mechanical systems it may be necessary to better understand the physics, chemistry and material science related issues of the engineered system. The caution is critical for healthcare, transportation and emergency response systems, where tiny errors could lead to cascading catastrophes. Leaders and decision makers, many with more degrees than a thermometer, must prioritize safety and purpose over profit. These decisions are about ethics and science in the service of society, to lift quality of life and living, locally and globally.
Refraining from the use of ANN-ML/AI tools must not be the knee-jerk reaction. Greater focus on analysis of outcome (suggestive analytics) and oversight of implementations are the cautious and optimistic path. However crude, ANNs may enable scanning of very large volumes of data for patterns. There are problems with quality of raw data but that is a different discussion. Using ANN-ML/AI tools for pattern recognition could inform suggestive/predictive analytics. The credibility of patterns will improve if verified using large volume of data (plural of anecdote is not data). Errors due to confounding factors (unknown dependencies and unknown unknowns about dependencies) are inevitably going to seed doubts with respect to the outcomes because we are using a crude/imperfect model but we may no longer have to bundle the errors, arbitrarily.
Granger [797] and Engle’s [798] seminal research in financial econometrics (also in SCM [799], supply chain management) used lagged values of error terms to model the variance of the error [800] (for each variable) to determine the skedasticity of the error. In earlier techniques, aggregated error terms were assigned an arbitrary “normal” distribution (perhaps analogous to arbitrary weights in ANNs). In reality, error distribution may be skewed depending on the variable (or features of a variable). Hetero-skedasticity may be the reality and not the assumption of homo-skedasticity. The latter was the key inadequacy in tools that existed prior to the 1980’s for analysis of high volume time series data (e.g., what we may source from EKG, EEG, CBC).
ARCH/GARCH error correction models [801] based on high volume of time series data [802] may creatively converge with ANN-ML/AI tools to reveal patterns cryptic in data. For example, [a] metal stress in engine systems of an airplane in flight, to analyze PLM MTBF [803] (mean time between failure) for parts, [b] patient specific PQRST trends [804] (intervals) from ECG waveform data stored in EHR/EMR, [c] routing data and traffic patterns to optimize logistics of delivery and distribution in network planning for better supply chain management. ANN-ML/AI tools can help to build dynamic simulations (e.g., congestion pricing) which can ingest large volumes of data from a broad spectrum of variables to simulate what-if scenarios by including/excluding variables (negatively/positively) to model profit/probabilities and risk [805].
Case Study: Halicin—Hard Work in Chemistry Lab (Not a Gift of AI)
Despite severe shortcomings of ANN-ML/AI, the value of suggestive analytics from ANN-ML/AI may not be trivial, as long as we verify the outcome through research (i.e., verify if the suggestions from ANN-ML/AI are functional/viable/applicable, e.g., in biology).
In this case study [806] we analyze an application of ANN-ML/AI in bio-chemistry and molecular biology to identify an old (known) molecule and repurpose it as a new antibiotic. The case demonstrates the critical need for curated contextual data in training any ANN model (even to extract suggestions based on high volume data via the principles of pattern recognition).
Occasional over-fitting [807] is often applied when training ANN using tools such as RFA (recursive feature addition [808]) and is a form of “force-fitting” (for example, force fitting of RDF in healthcare applications [809]). Perusal of research [810] reveals the minutiae with respect to the nature of the domain specific data and the context of data curation (sections 3, 4) that is critical as preparatory work based on broad spectrum [811] of knowledge (the domain specificity of this example is at the molecular [atomic and/or sub-atomic] scale).
Figure 43.
After extensive training using precision data enriched for features using RFA, it is not surprising when gross errors are found in the outcome (see Figure 7, page 13981, ref 810, Nandy et al.). This is one example how artificial neural networks (ANN) used in machine learning (ML) exercises and analytics generate erroneous results. ΔEg data (left column) shows ANN error (0.09 eV) with respect to DFT (density functional theory [812]) in a singlet [Co(NH2CH3)6]3+ transition metal complex. Data from right column (table) shows large ANN error (−4.91 eV) with respect to DFT for a quintet [Mn(HNNH)6]3+ transition metal complex. The quintet [Mn(HNNH)6]3+ complex highest occupied molecular orbital level is underestimated by 4.9 eV, which is almost double the mean absolute error. This ANN was specifically trained using ΔEg data models on a set of 64 octahedral homoleptic complexes (OH64). The discrepancy (ANN error) is significant because frontier molecular orbital energetics provide essential insight into chemical reactivity and dictate optical and electronic properties. Small errors could make an immense difference in terms of chemistry of the transition metal complex. In this illustration, the metals are shown as spheres and coordinating atoms as sticks (C atoms, gray; N atoms, blue; H atoms, white). In healthcare, can we trust error-prone ANN? Should we use the poor quality of EHR data to inform an even poorly performing ANN?
Figure 43.
After extensive training using precision data enriched for features using RFA, it is not surprising when gross errors are found in the outcome (see Figure 7, page 13981, ref 810, Nandy et al.). This is one example how artificial neural networks (ANN) used in machine learning (ML) exercises and analytics generate erroneous results. ΔEg data (left column) shows ANN error (0.09 eV) with respect to DFT (density functional theory [812]) in a singlet [Co(NH2CH3)6]3+ transition metal complex. Data from right column (table) shows large ANN error (−4.91 eV) with respect to DFT for a quintet [Mn(HNNH)6]3+ transition metal complex. The quintet [Mn(HNNH)6]3+ complex highest occupied molecular orbital level is underestimated by 4.9 eV, which is almost double the mean absolute error. This ANN was specifically trained using ΔEg data models on a set of 64 octahedral homoleptic complexes (OH64). The discrepancy (ANN error) is significant because frontier molecular orbital energetics provide essential insight into chemical reactivity and dictate optical and electronic properties. Small errors could make an immense difference in terms of chemistry of the transition metal complex. In this illustration, the metals are shown as spheres and coordinating atoms as sticks (C atoms, gray; N atoms, blue; H atoms, white). In healthcare, can we trust error-prone ANN? Should we use the poor quality of EHR data to inform an even poorly performing ANN?
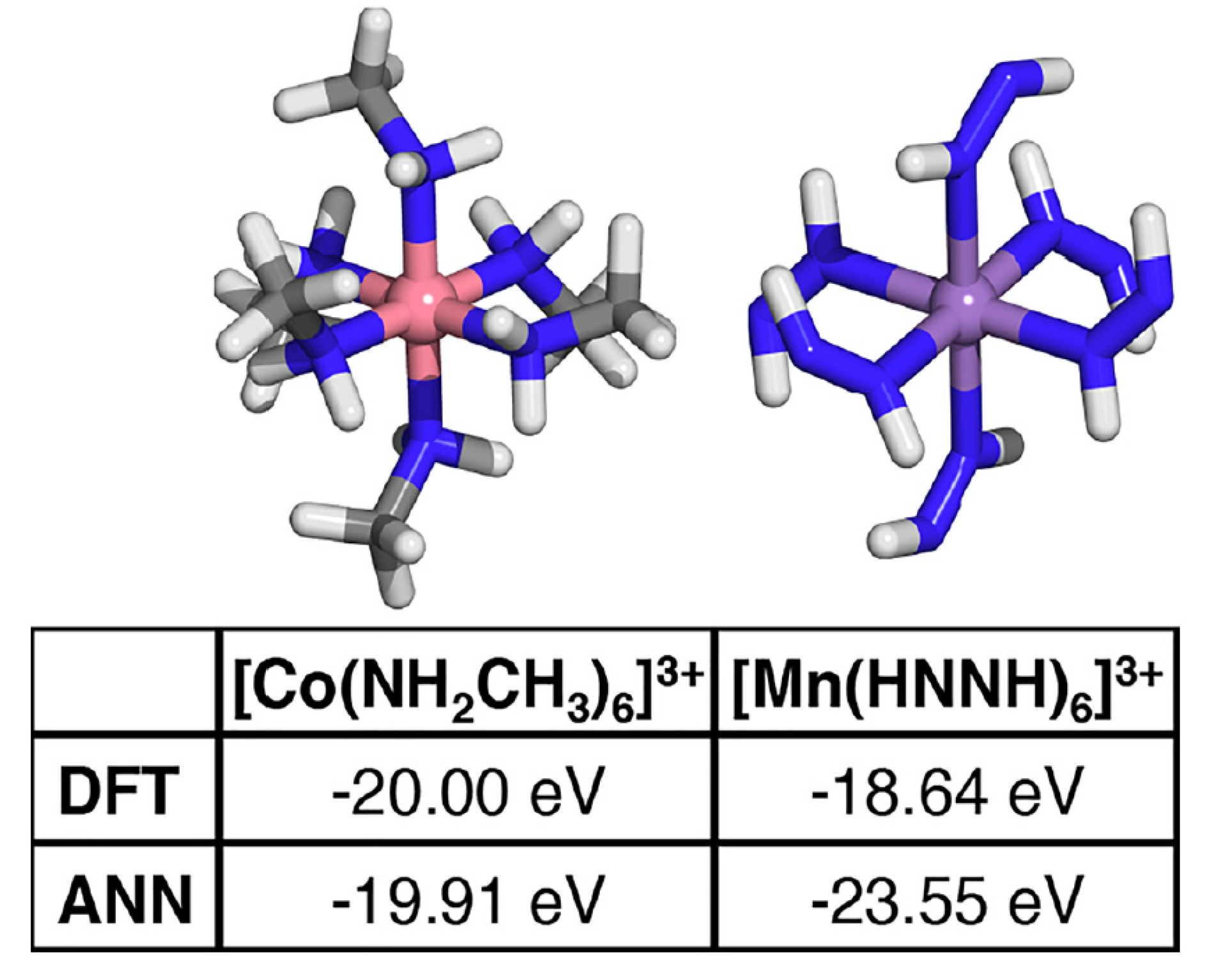
Neural network [813] known as MPNN [814] (message passing neural network) for molecules [815] is a tool [816] to unleash data [817] for health and medicine. This example centers on uncovering and repurposing a previously known molecule as an antibiotic (Halicin) using a plethora of tools including MPNN/DNN (DL). Stokes [818] et al., Tshitoyan [819] et al. and Nandy et al. (ref 810) emphasize data curation and learning, without mentioning the term AI or “artificial intelligence” in their papers (unfortunately, the marketing at MIT news [820], as expected, did not shy away from promoting fake sensationalism to bolster the false appeal of AI).
The learning that generated the antibiotic (Halicin), is elegant in its detail and the training (MPNN) was structured with precision, optimized and re-optimized (using hyperparameter [821] optimization). The old idea of ensembling [822] was applied to improve outcomes in silico but predictions were biologicallytested through rigorous experiments. Even after repeated steps to minimize errors, the authors were acutely cognizant of the pitfalls of ML:
“It is important to emphasize that machine learning is imperfect. Therefore, the success of deep neural network (DNN) model-guided antibiotic discovery rests heavily on coupling the approaches to appropriate testing and experimental designs.”
[ Stokes et al., page 698; ref. 818; there was no mention of “AI” in the published paper in Cell ]
Figure 44.
Training a neural network (ANN) to recognize molecules relies on the fact that every molecule may be represented as a graph (or a collage of connected graphs, eliciting the idea of a knowledge graph). The water molecule may be viewed as a graph with oxygen (O) as the node (vertex). Bonds between oxygen and hydrogen (O–H) serves as “side” or edge. Most molecules (within reason) may be transformed into a molecular graph and is at the heart of MPNN training to recognize different types of molecules. Then, the trained neural network, MPNN, is used to search for similar or dissimilar molecules in a data repository (assumption: data repository contains legitimate, correct and curated data).
Figure 44.
Training a neural network (ANN) to recognize molecules relies on the fact that every molecule may be represented as a graph (or a collage of connected graphs, eliciting the idea of a knowledge graph). The water molecule may be viewed as a graph with oxygen (O) as the node (vertex). Bonds between oxygen and hydrogen (O–H) serves as “side” or edge. Most molecules (within reason) may be transformed into a molecular graph and is at the heart of MPNN training to recognize different types of molecules. Then, the trained neural network, MPNN, is used to search for similar or dissimilar molecules in a data repository (assumption: data repository contains legitimate, correct and curated data).
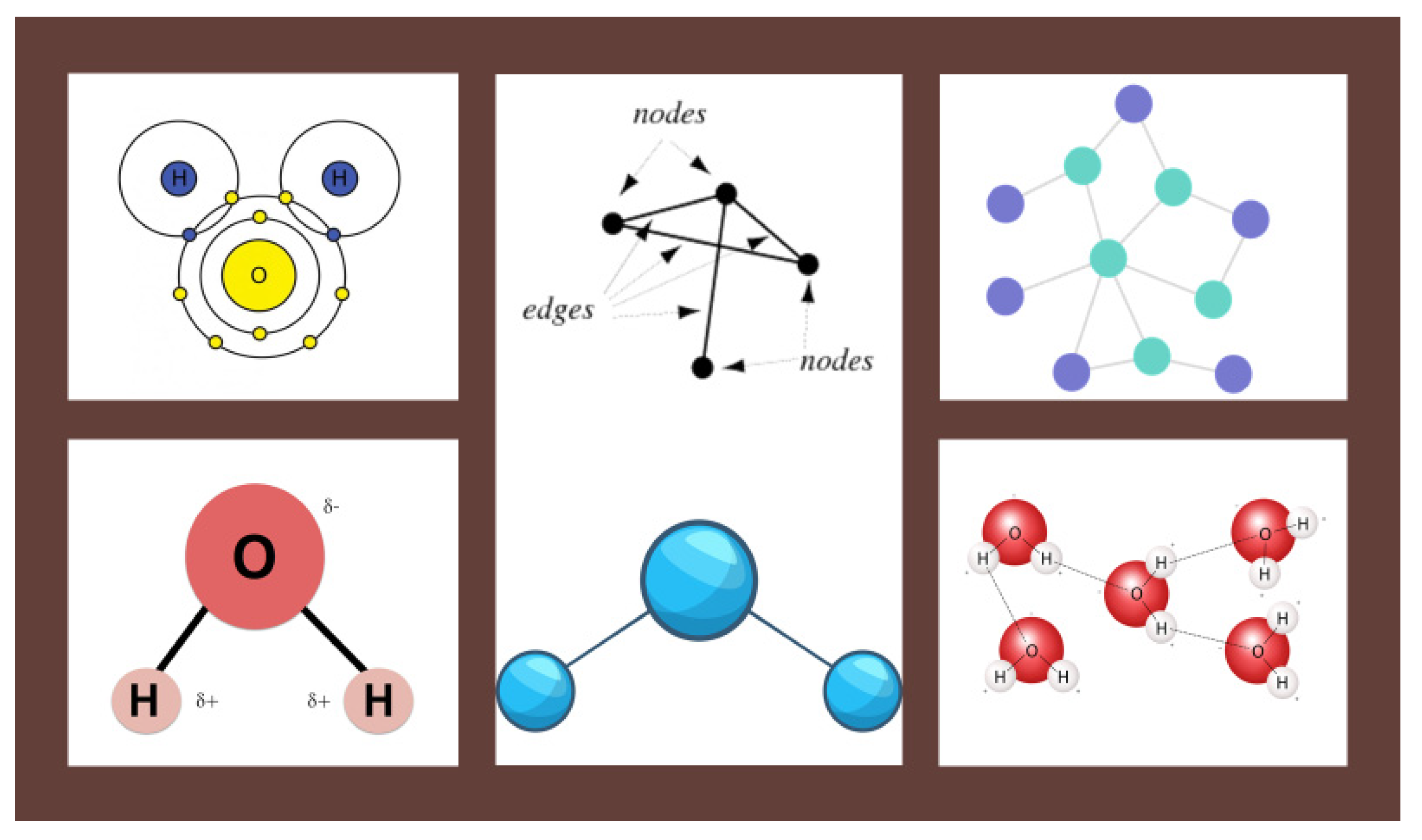
Let us review the actual numbers. A curated set of 2335 molecules were used as the MPNN training set for new antibiotic molecules. The 2335 training data set included a FDA library of 1,760 molecules pre-selected (biologically curated) based on their ability to inhibit microbial (E. coli BW25113) growth. In other words, molecules with structure and function known to possess anti-microbial activity. Training MPNN with this data set enables the neural network to learn the structures in order to select similar (or dissimilar) structures from a large library of structures. The expectation is that when a “challenge” library is presented to the MPNN, the degree of similarity or dissimilarity, in terms of the output from the MPNN, can be tuned by modifying selection parameters. For example, using prediction scores (PS) to categorize molecules from a larger library (in this case, the ZINC database with ~1.5 billion molecules). By selecting higher PS value (>0.7, >0.8, >0.9), the outcome is “context enriched” and a sub-set of molecules (in this case, 107,347,223, i.e., reductionism at work) is further subjected to other selection criteria, for example, nearest neighbor analysis (Tanimoto score). Finally, potential molecules (in this case, 23) are biologically screened (microbial assay) to identify the “new” antibiotic candidate(s). 1 (one) such candidate is Halicin (Stokes et al.), previously identified as the c-Jun N-terminal kinase inhibitor SU3327 and re-discovered as a broad-spectrum antibiotic, re-named Halicin, but still the same molecule as SU3227, albeit repurposed, based on function.
Figure 45.
Candidates (MPNN suggestive analytics: 8 molecules, left) from ZINC database (1.5 billion molecules) were scored using nearest neighbor (NN) analysis (yellow circles, bottom right). NN is based on principles established ~1,000 years ago [823] (circa 1030). Data is curated at successive steps by enriching for context (selecting higher prediction scores, PS, top right).
Figure 45.
Candidates (MPNN suggestive analytics: 8 molecules, left) from ZINC database (1.5 billion molecules) were scored using nearest neighbor (NN) analysis (yellow circles, bottom right). NN is based on principles established ~1,000 years ago [823] (circa 1030). Data is curated at successive steps by enriching for context (selecting higher prediction scores, PS, top right).
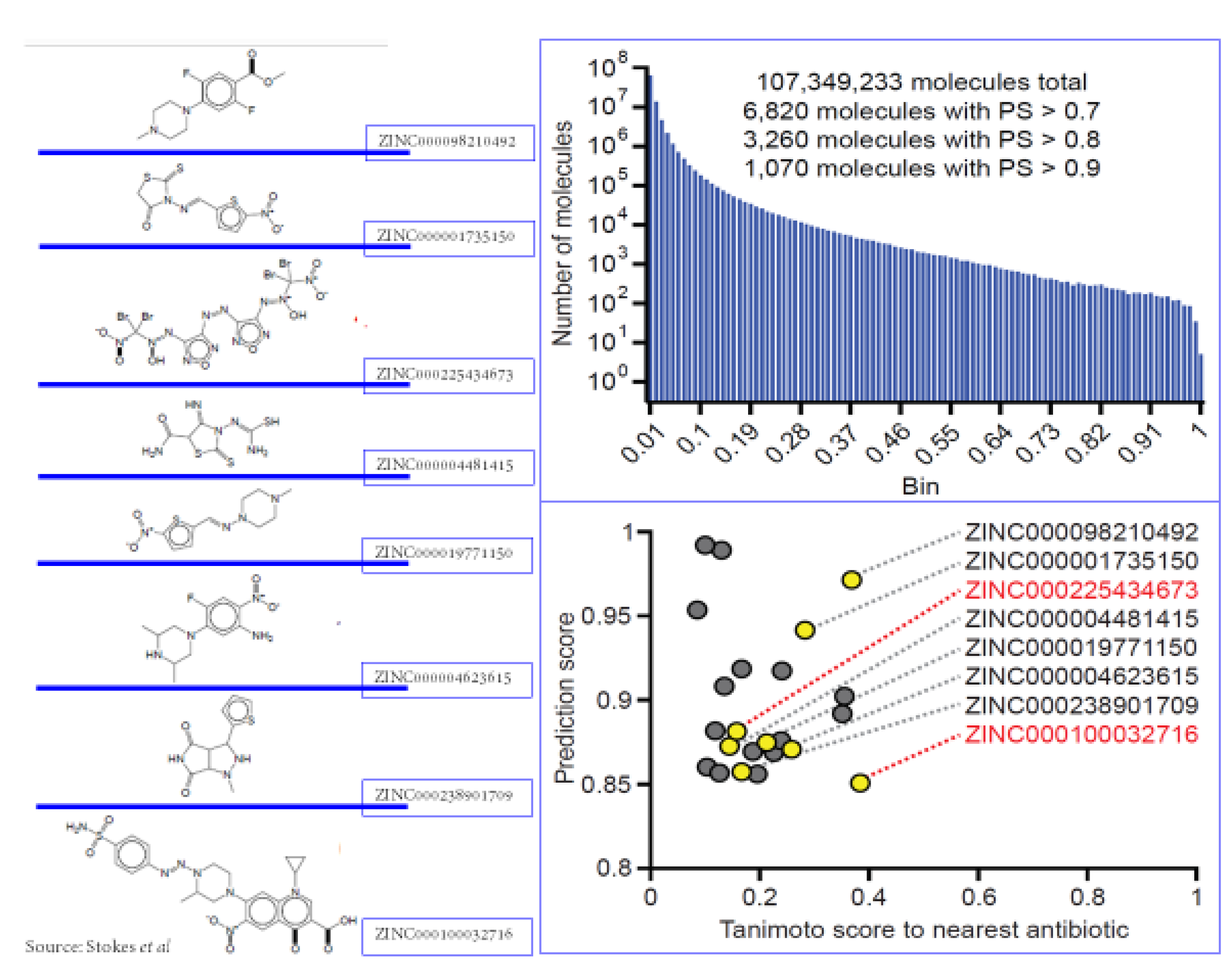
Summary
Without even mentioning AI, the research to repurpose molecule SU3227 as a new antibiotic, Halicin, is a stellar example how unintelligent but useful ANN/ML tools were used to rapidly identify 1 molecule by scanning ~1.5 billion molecules. The “intelligence” was in the work of scientists involved in using the ANN/ML tools to perform steps designed by humans (human intelligence) to execute searches/matches/patterns to extract suggestions from operating the “dumb” tools. The “dumb” tools did an expected, ordinary but excellent job of following human instructions/commands in line with exactly how they were “trained” by intelligent humans. Halicin was identified/verified by its function as an antibiotic in a microbial assay. Halicin is not a product of any computational process but it was aided by computational tools. The computer as a tool did exactly what it was supposed to do when it was first conceived, designed, debated and structured (but not constructed) in the early 19th century (1820’s/1830’s) by Ada Lovelace and Charles Babbage. Computation is a tool, is still un-intelligent and dumb as a doorknob, but outstanding in its ability to follow/execute human commands to perform dull, dreary and even dangerous jobs, rapidly, especially when there are too many.
Rapidly is the key word where ANN/ML tools shine brilliantly. It is the key reason for continuing [824] to use ANN/ML tools, when appropriate, with human supervision at each step. Significant time compression (25-50%) during the various steps [825] in drug discovery also generates significant challenges [826]. An abundance of scientific scrutiny, reality check [827] and regulatory [828] caution cannot be overemphasized because profit [829] trumps purpose, almost always, in the name of innovation [830]. Can we trust a big pharma and a consulting group, jointly involved in peddling “AI” prosperity [831] which could spell and smell like collusion?
Disclaimer
No “AI” subjects or “twins” or “cousins” or “bootstrapped synthetic (fake) data” were involved, used or hurt, in the process of identifying Halicin, a broad spectrum antibiotic.
Figure 46.
Is there an absence of “labs” in this cartoon between the computer and vial of drugs? Is this the perspective of machine learning in drug discovery [832]? (Cartoon from reference 826).
Figure 46.
Is there an absence of “labs” in this cartoon between the computer and vial of drugs? Is this the perspective of machine learning in drug discovery [832]? (Cartoon from reference 826).
Biological Assumptions Made by ML Are Incorrect
To reiterate, the mathematics of commonly used machine learning models and cross-validation depends upon the assumption of independence, i.e., the value of one example is not dependent on another example. In biology, nothing is independent. Hence, all ML outcomes are dubious (e.g., repeated draws from a card deck without replacing the drawn card are dependent, because the probability of the next card depends on what has already been drawn).
In genomics [833], dependence is the fundamental theme (of inheritance), it is ubiquitous, it is pervasive yet it appears to be ignored by individuals trained in data handling but oblivious of the principles which are germane to the context of the data. For predicting protein–protein [834] interactions, protein pairs are represented in a dataset with unique identifiers and they may appear to be independent, but all pairs that share a given protein are correlated with each other. Other examples of biological dependencies are inextricably linked in the context of enhancer–promoter, regulator–gene and drug–protein interactions.
The fundamentals of ML in biomedical sciences are false because the central assumption of independence is incorrect. Almost everything in biology is a system of systems immersed in variably weighted dependencies, which is almost impossible to capture in binary knowledge representation. Biological or physiological outcomes are not point solutions but constrained optimization of network effects aimed at maintaining or restoring homeostasis (not necessarily a state of equilibrium but an individual state of acceptable physiological tolerance).
Figure 47.
Dependency (Top) arises when biological groups exhibit similar feature–outcome relationships, such as correlated functions of proteins from the same family or complex. (Bottom) Confounding variables are unobserved variables that alter dependence structures between the observed variables. Unmeasured ancestry of individuals is a confounder of relationship between genetic variants and gene expression (left, bottom). Expression is higher for individuals from one ancestry group, A4 (right, bottom). Cartoon from reference 833.
Figure 47.
Dependency (Top) arises when biological groups exhibit similar feature–outcome relationships, such as correlated functions of proteins from the same family or complex. (Bottom) Confounding variables are unobserved variables that alter dependence structures between the observed variables. Unmeasured ancestry of individuals is a confounder of relationship between genetic variants and gene expression (left, bottom). Expression is higher for individuals from one ancestry group, A4 (right, bottom). Cartoon from reference 833.
Need More Proof? Artificial Intelligence Meets Natural Stupidity [835], Again [836].
You may not train AI/ML on DNA (A, T, G. C) and search [837] for DNA/RNA (A, T, G, C, U) unless the sequences are so unique (so long) and the probability of finding exact matches are so low that the result / outcome may seem plausible as a suggestion for biological verification. This is what happens [838] when dumb and un-intelligent tools (AI/ML/ANN) are used by people [839] who may not be trained in the context of the content and performs training using “data” (lacking context, curation) oblivious (perhaps) about the science behind the search, not cognizant about the pitfalls of the logic, and fails to ask the correct question (i.e., garbage in / garbage out).
Figure 48.
(Top) Retraction of data based on AI/ML. (Bottom) Published in 1976 (ref 835), McDermott refers to AI creating imaginary anthropomorphic language as “wishful mnemonics” (terminology introduced with the hope that the metaphors would eventually become reality).
Figure 48.
(Top) Retraction of data based on AI/ML. (Bottom) Published in 1976 (ref 835), McDermott refers to AI creating imaginary anthropomorphic language as “wishful mnemonics” (terminology introduced with the hope that the metaphors would eventually become reality).

The chasm is deeper than Challenger Deep [840] when it comes to the chemical, neuro-biological and medical illiteracy (usually) of computer scientists, binary specialists and AI (ANN/ML) programmers (e.g., none of the authors of this essay are academically trained in both domains). Neither educational strategies [841] nor the much-ballyhooed trans-/multi-disciplinarity or even the mundane garden variety “collaboration” has offered any solutions that can stand the test of time. Intellectual progress suffers because there are few minds (humans) where chemistry, neurobiology and medicine (e.g., MD) co-inhabits the brain with computer science (logic), and programming (e.g., Ph.D. in EECS). A MD collaborating with a PhD or a programmer is clearly not a solution as evident from half-baked, flawed, and retracted outcomes. Knowledge transfer is far more difficult than generally assumed. We need a supply chain of MD-PhD talent (PhD in EECS) in the design of ANN/ML-AI applications in chemical, biological and medical domains, if we wish to obtain modest outcomes which we can trust in terms of actionable information (guaranteed to do no harm to the user or the patient). This scenario is similar to the status quo observed in the sluggish pace of science bills as it advances through the political system and appropriations (committees). Science is held hostage (often, viciously [842]) by the political illiteracy of scientists and scientific illiteracy of politicians [843].
The call and need for trans-/multi-disciplinary co-habitation in our meninges may be supported by the mathematical treatment of SGD (stochastic gradient descent) by Poggio (ref 775). The biological implausibility of the elegant mathematical treatment (McCulloch-Pitts neuron model unit of ANN, see Figure 38) may survive the bio-inspired “model” phase but may fall apart in the context of real world applications, if humans are involved.
This situation is analogous to atoms and very small molecules which behave in strict deference to the natural philosophy of science and mathematics. But, when these atoms are combined into what we call a human, the unit model of atoms and its very strict adherence to mathematical laws are completely at the mercy of human choices [844], however irrational [845] it may be, from a supposedly rational [846] perspective.
Therefore, it begs to ask whether ANN (core of ML/AI) based on the McCulloch-Pitts neuron model (unit ANN) is a rational model of an irrational human or an irrational model from the perspective of a rational human who chooses [847] to be irrational? Can we use this succinct but oversimplified “sketch” as a representative rational unit model for ANN (which is triggering a million mutinies and a global mayhem) if it is based on humans who are collectively chronic cases exhibiting irrational behavior [848]?
Undoubtedly, the historical (1948) neuron-inspired McCulloch-Pitts model unit in ANN, therefore, is reasonably an unreasonable choice as a basic unit (building block) of a so-called revolution, which is grossly ill-informed and driven by actually incorrect artificial intelligence (AI). The scientific illiteracy of AI may be better conveyed to the masses if we use an example from literature [849] (“a poor player, That struts and frets his hour upon the stage, And then is heard no more. It is a tale Told by an idiot, full of sound and fury, Signifying nothing.”).
Through the lens of history, it is not uncommon to find the plight of humans attempting to copy or replicate nature or natural processes (e.g., birds in respect to flying, mechanical life as a copy of biological life, artificial intelligence without respect to human intelligence). In the 21st century, the US tech companies and their consulting partners may have perfected the art of riding roughshod over society to boost shareholder value by using words (origins in academia) which were re-designed to serve as buzz words for profit. This list includes the fuzzy and the buzzy [850] which were/are part of the business vernacular. E.g., big data, data lakes, agile, IoT, AI.
Figure 49.
Michael Stonebraker at CSAIL, MIT (personal photo) a few weeks after winning the Turing Award [851] (2015) for his seminal work (INGRES [852], POSTGRES [853]) which forms the bedrock of data analyses. Corporations & consultants usurped his work as “big data” just for “new revenue streams” but “big data” is finally dead [854].
Figure 49.
Michael Stonebraker at CSAIL, MIT (personal photo) a few weeks after winning the Turing Award [851] (2015) for his seminal work (INGRES [852], POSTGRES [853]) which forms the bedrock of data analyses. Corporations & consultants usurped his work as “big data” just for “new revenue streams” but “big data” is finally dead [854].

The blindness to facts in our elusive quest to find intelligence in AI is not without a parallel. From 10th century BC to the 18th century AD (see Table V), anecdotes and evidence [855] suggests an innate zeal to instill “life” even through mechanical automatons [856].
Figure 50.
The elusive quest to find “life” through the mechanical Duck [857] in the 18th century resembles the penchant to unleash “intelligence” in artificial intelligence (AI) in the 21st century.
Figure 50.
The elusive quest to find “life” through the mechanical Duck [857] in the 18th century resembles the penchant to unleash “intelligence” in artificial intelligence (AI) in the 21st century.

Table 5.
Being “life-like” was a fascination long before AI punctuated the 21st century dinner table conversations. ~3,000 years ago, mechanical automation enthusiasts were keen to replicate or duplicate human life through mechanical twins (reference 856). The ability to create a mechanical twin with precision and accuracy saved the lives of 3 astronauts aboard Apollo 13. How feasible is it to expect that digital twins may save lives, too?
Table 5.
Being “life-like” was a fascination long before AI punctuated the 21st century dinner table conversations. ~3,000 years ago, mechanical automation enthusiasts were keen to replicate or duplicate human life through mechanical twins (reference 856). The ability to create a mechanical twin with precision and accuracy saved the lives of 3 astronauts aboard Apollo 13. How feasible is it to expect that digital twins may save lives, too?
 |
Figure 51.
Evidence [858] indicates that AI models “spew nonsense” [859], cheat [860] and lie [861].

Temporary Concluding Commentary—Reasoning and Usefulness.
Halicin sets the “gold standard” for use of un-intelligent dumb tools (e.g., ANN/ML) to extract suggestive analytics based on human-designed reasoning, training and learning. The success of Halicin is a clarion call to dispense with the hubris of AI (and AI politics). However, it is impossible not to take note that AI politics is not a domain where evidence plays any role.

Unlike law (interpretation “will be influenced by the climate of the era”), in science neither “weather of the day” nor “climate of the era” may influence evidence. So-called “deep learning” (convolutional neural network) is inspired by the work of Hubel and Weisel (1962) while exploring the neural architecture of the cat’s visual cortex (ref 770). The evidence from Halicin and the pitfalls of ML indicates that pompous [862] AI shenanigans are unnecessary.
Because jet engines and healthcare are more than just poles apart [863], it is unclear if digital twins can be trusted for any health system [864]. Simple “twins”/“cousins” may be feasible, if the value proposition is compelling. In calculating the risk to reward ratio, it will be rewarding if the denominator may be larger than the numerator. Socially beneficial examples may include blood glucose monitoring in diabetes and its control. Will any digital twin for diabetes become globally feasible? Biological systems are unsuitable because we know even less, with even more research, e.g., regulatory [865] protein FOXP3 [866] binds to regions of human DNA discarded by the sequence analysis programs because they were considered non-functional (TnG repeats).
Figure 51. Are these candidates for digital twins? FOXP3 protein binds to DNA (the importance of disorder [867]). 25 years after the human genome was sequenced, we do not yet know what DNA actually does in certain parts! Multi‐layer systems as digital twins? Simple bi‐directional data and information arbitrage seems to be complex for an ordinary sensor Q and A (reference 718).
Discussion about digital proxies/twins/cousins is inextricably linked to data analysis because digital duplicates are essentially software architectures created for data, analytics and performance optimization of the physical entity using data-informed decision systems. The rush to use AI in data analysis makes it impossible to ignore the potential for deleterious effect of AI with respect to the anticipated data-informed improvements in the physical components.
The ill-informed use of or reliance on AI without grasping the nature of the operation (“black box”) appears to have moved from AI being a scientific tool to a state where use of AI represents status, ego, and marketing due to the “fear of missing out” rather than rational need. The recently cultivated hubris of AI has smarmed the glib and smug proponents of AI into a corner where acknowledging the “deadly sins of AI” (Rodney Brooks) is deeply embarrassing. To admit that AI is a marketing term invented by John McCarthy should be a cathartic release.
There is a non-zero probability this discussion is not unbiased but the science of AI tools (ANN, ML, RNN, CNN, MPNN, GNN, Liquid Time-Constant (LTC) Neural Networks [868], Liquid Foundation Models [869], Fluid [870] Interfaces [871], DLL [872]) could be useful and even appropriate if viewed and used as ART (artificial reasoning tool [873]) or just RT.
The reason why we seek to optimize performance is based on the fact that data informs our reasoning to adjust/adapt (values of) variables/attributes in quest of “better” outcomes. The holy grail of operations research (e.g., OR in supply chain operations management) was/is the fine-tuning of optimization which may depend on the number of variables which can affect the outcome (weights, dependencies). With increasing number of variables, the optimization system state space may explode [874] and solutions become untenable. Taming the state space explosion problem [875] may use reasoning tools, e.g., artificial neural networks/machine learning (ANN/ML) which can accommodate thousands of layers of nodes/networks (deep learning algorithms).
Hence, AI tools are helpful in the reasoning process by its ability to collect, converge and compute contextual data and human-derived/pre-coded logic, in volumes only possible due to the power, speed and low cost of computation (but humanly impossible). Our inability to let go of the misnomer AI is a human foible and has nothing to do with actual intelligence in AI. On the other hand, there is immense value in the reasoning power of these tools if the fundamentals are curated [876] by trustworthy [877] humans, bias-free (?) logic designs are pre-coded and contextual uncorrupted data is available for analysis by artificial reasoning tools (ART, RT). Reasoning, not intelligence, is a rational expectation from data-informed analytics performed by software systems conceived by humans, programmed by humans and created based on human knowledge. There is nothing artificial about human-coded reasoning/logic. Artificial monikers (AI, ART) are unnecessary if we create robust reasoning tools (RT) to help data-informed digital proxies or any analytics platform to optimize systems and performance.
Reasoning is necessary for analyzing gargantuan data streams to detect patterns or predict trends (even prescriptive) and could be meaningful for optimization of performance, economy and society. Hence, machine usefulness (MU) could be a “game changer” if we can make better sense of data. Making sense of data started ~50 years ago with Michael Stonebraker’s INGRES followed by POSTGRES [878] (see legend in Figure 49). Machines which can unleash value of data contributes to “machine usefulness” which improves the portfolio of reasoning tools. MU, RT and automation [879] could be catalytic for global economic growth [880], if such tools are empowered to be distributed (not centralized), shared (not proprietary) and accessible for progress [881].
Figure 52.
Machine Usefulness [882] as a Reasoning Tool? Testimony [883] presented to the Senate Committee on Homeland Security and Governmental Affairs by Daron Acemoglu [884], MIT. It is as if a seer had foretold that the global economy will pay a hefty penalty for the AI myth [885] and society will pay an untold price when the AI bubble [886] bursts.
Figure 52.
Machine Usefulness [882] as a Reasoning Tool? Testimony [883] presented to the Senate Committee on Homeland Security and Governmental Affairs by Daron Acemoglu [884], MIT. It is as if a seer had foretold that the global economy will pay a hefty penalty for the AI myth [885] and society will pay an untold price when the AI bubble [886] bursts.
Machines do not learn de novo but follow human-created workflow based on pre-coded logic/instructions/commands. Machine learning is a misnomer because the “learning” is a set of deterministic transactions based on (fancifully referred to as “trained”) human-provided data, pre-programmed logic and sets of values/ranges with associated weights (relevance to case), probabilities, dependencies, categories, predictive boundaries, groups, patterns, prescriptive thresholds/suggestions, and other case-specific attributes for designated tasks.
Therefore, it reasons that if ML is a tool under the umbrella of AI, then by association, the lack of learning and absence of intelligence in ML is propagated to AI applications. The global public is immersed in the delusion that there is intelligence in AI because the abbreviation includes it as a word! That’s where it should end but unfortunately the collusion to reward [887] this delusion will, eventually, extract its toll on the health of the economy and fragile social cohesion.
Figure 53.
The extent of the lack of intelligence in AI and the global AI delusion is evident in the Google manufactured (“noble” intentions?) software AlphaFold which aims to predict structure of proteins. Please note the 3 bundles (G,B,U). AlphaFold model [888] of human insulin bears no relation to the scientifically proven structure of insulin (in the protein database, PDB) which was determined using protein biochemistry, X-ray crystallography and human brains contributed by Dorothy Crowfoot Hodgkin (Nobel Prize in Chemistry, 1964 [889]). Should any credible medical professional pay any attention to insulin structure variations if delusional AlphaFold [890] was used to alter/modify/re-engineer the insulin molecule or the process which makes human insulin available to ~200 million [891] diabetics who depend on their daily (weekly [892]) dose of insulin?
Figure 53.
The extent of the lack of intelligence in AI and the global AI delusion is evident in the Google manufactured (“noble” intentions?) software AlphaFold which aims to predict structure of proteins. Please note the 3 bundles (G,B,U). AlphaFold model [888] of human insulin bears no relation to the scientifically proven structure of insulin (in the protein database, PDB) which was determined using protein biochemistry, X-ray crystallography and human brains contributed by Dorothy Crowfoot Hodgkin (Nobel Prize in Chemistry, 1964 [889]). Should any credible medical professional pay any attention to insulin structure variations if delusional AlphaFold [890] was used to alter/modify/re-engineer the insulin molecule or the process which makes human insulin available to ~200 million [891] diabetics who depend on their daily (weekly [892]) dose of insulin?
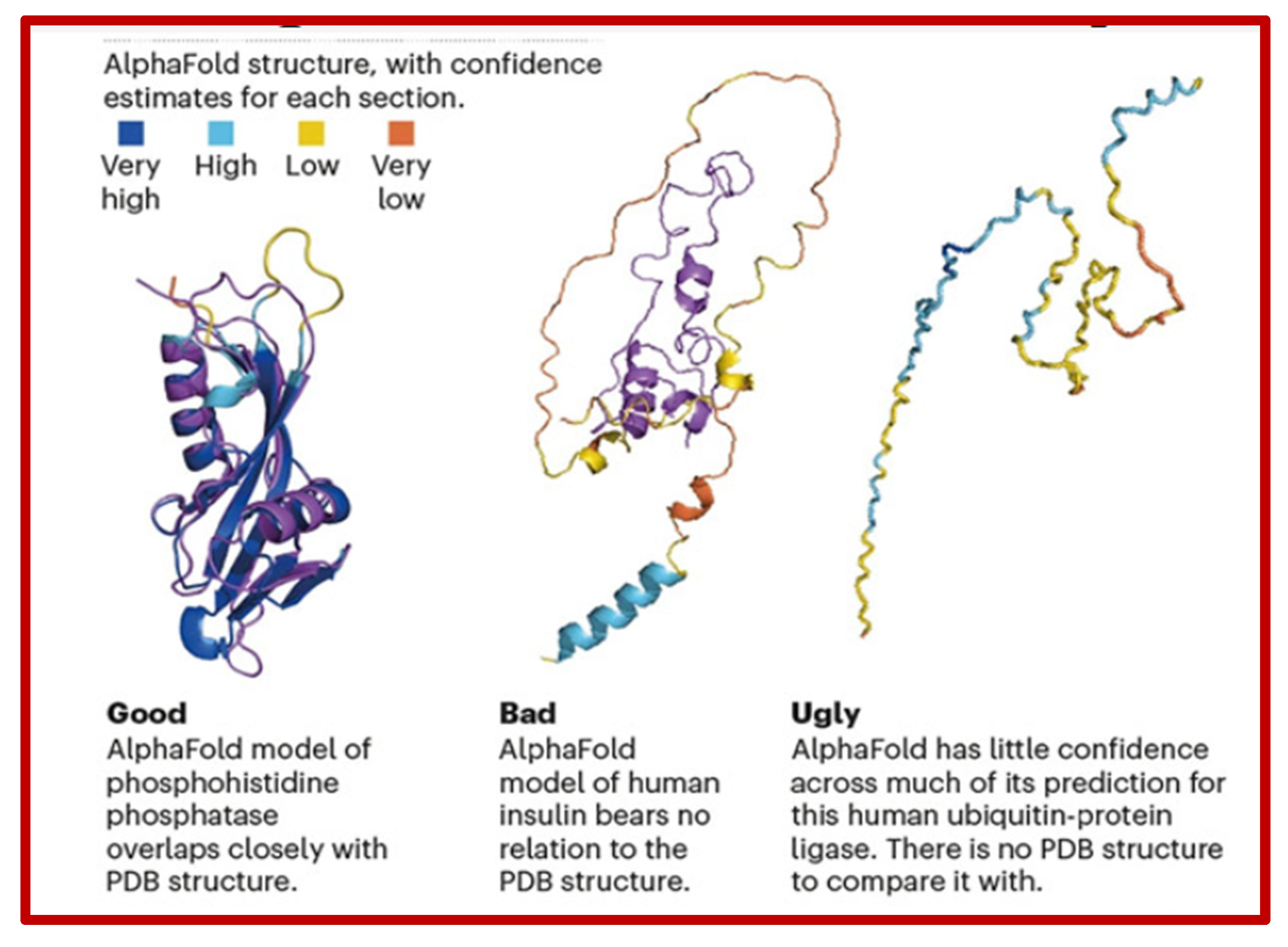
If a human presents a state of fever (pyrexia, febrile state), the etiology of the fever is key for diagnosis and treatment. Table VI lists ~1,000 different mix-match potential (causes) related to variables [893] (10 x 6 x 13) which could be causal for the fever. In the patient’s digital twin (if it exists) the data from the table must be analyzed and accessible at the point of care. This is where machine usefulness and reasoning tools can be of meaningful assistance. AI or ML is just over-hyped jargon because medical (not artificial) knowledge of the variables are central to science.
Table 6.
The human febrile state (fever) may present metabolic effects (one or more from at least ten potential effects) which may affect one or more organs (one or more of at least six separate systems may be involved) and calls for diagnostic testing to provide several data points (may be more than a dozen different type of tests, in addition to case-specific testing).
Table 6.
The human febrile state (fever) may present metabolic effects (one or more from at least ten potential effects) which may affect one or more organs (one or more of at least six separate systems may be involved) and calls for diagnostic testing to provide several data points (may be more than a dozen different type of tests, in addition to case-specific testing).
| Metabolic Effects | Organ Systems Affected | ||||||
| Brain | Cardiovascular | Gastrointestinal | Liver | Kidney | Hemostasis | ||
| 1 | |||||||
| 2 | |||||||
| 3 | |||||||
| 4 | |||||||
| 5 | |||||||
| 6 | |||||||
| 7 | |||||||
| 8 | |||||||
| 9 | |||||||
| 10 | |||||||
| Diagnostic approach to fever/hyperthermia includes the following Diagnostic Testing data: | |||||||
| TEST | DATA | ||||||
| 1 | •ESR and CRP | ||||||
| 2 | •Procalcitonin (elevated in certain bacterial infections) | ||||||
| 3 | •Tuberculin skin test | ||||||
| 4 | •HIV | ||||||
| 5 | •Serum LDH | ||||||
| 6 | •Routine blood cultures | ||||||
| 7 | •RF, ANA, heterophile antibody (children & young adults) | ||||||
| 8 | •CPK | ||||||
| 9 | •Serum protein electrophoresis | ||||||
| 10 | •Imaging studies (based on medical history) | ||||||
| 11 | •CNS signs should prompt lumbar puncture and CSF tests | ||||||
| 12 | •If in malaria-endemic regions: thick/thin peripheral smears. | ||||||
| 13 | •Thrombophlebitis & infective endocarditis (IV drug abuse) | ||||||
Data analytics in complex system of systems (e.g., optimizing NOx emissions from jet engines) will find some common ground with “fever” and the layers of complexity associated with determining causality. The latter must be skillfully and rapidly extracted from the plethora of potential cryptic reasons behind the symptoms of fever (elevation of core body temperature above an evolutionary ‘set-point’ regulated by the thermoregulatory center in the hypothalamus).
Any RN, PA or MD will attest to the fact that rapid determination of causality (etiology) in a stressful medical environment may be partially alleviated by a “physician’s friend” in the form of a bi-directional digital tool with a Florence Nightingale [894] app which may be able to:
[1] rapidly ingest and process the input (understanding of symptoms and related semantics),
[3] cross-check patient’s medical history (connecting to other EMR/EHR may be an epic failure). Taken together, the descriptive, predictive, and prescriptive contributions to diagnostic analysis at the point of care could be served by reasoning tools using machine usefulness. The key is to synthesize the data (informed/selective data fusion) from multiple domains (including multiple bibliometric [895] repositories) into actionable information which can optimize patient care and improve patient safety at the point of care, in near real-time (even for remote home healthcare).
Garden variety fever is successfully diagnosed, treated and “cured” every day in millions of locations and in clinics in poor nations, serving billions of people, without MU, RT or apps. But, the mix-match features (Table VI) linked to the causality of fever symptoms may become critical if/when “fever” is a “cover up” for something which may be physiologically sinister. For jet engines and fever, the “normal” is usually within defined SOP. But, exception management is where we require machines/tools to explore/search/connect massive amounts of data from a variety of seemingly unlinked events (non-obvious) in widely distributed repositories to identify threads or clues to mitigate risks from ominous events or dangerous instances lurking in plain sight or the ability to “sense” signals to thwart off potential mortality and morbidities.
Machines using reasoning tools can probe the world of non-obvious relationships (NORA [896], non-obvious relationship analysis). It helps if the “world models” are robust and not near-fakes [897]. NORA may be traced back to its evolution from a short story [898], a hundred years ago. The “network” idea from the 1929 short story graduated in 1961 as a MIT PhD thesis [899], grew into the concept of information sharing in small networks [900] with strong and weak ties [901]. NORA was innovatively applied by Jeff Jonas [902] (c. 1983) to use information as a tool (weapon [903]) to detect [904] bank fraud [905]. Also, networks are the foundation of the world wide web [906]. NORA’s relationship elements popped up in a popular book [907] and the topic [908] is of considerable research (graph networks) interest. The social impact of NORA, relationships and networks, were creatively used in well-crafted TV series, in a 2012 episode [909] (Figure 54).
Figure 54.
From post-9/11 use by NSA … NORA captured creative minds in a 2012 TV series.

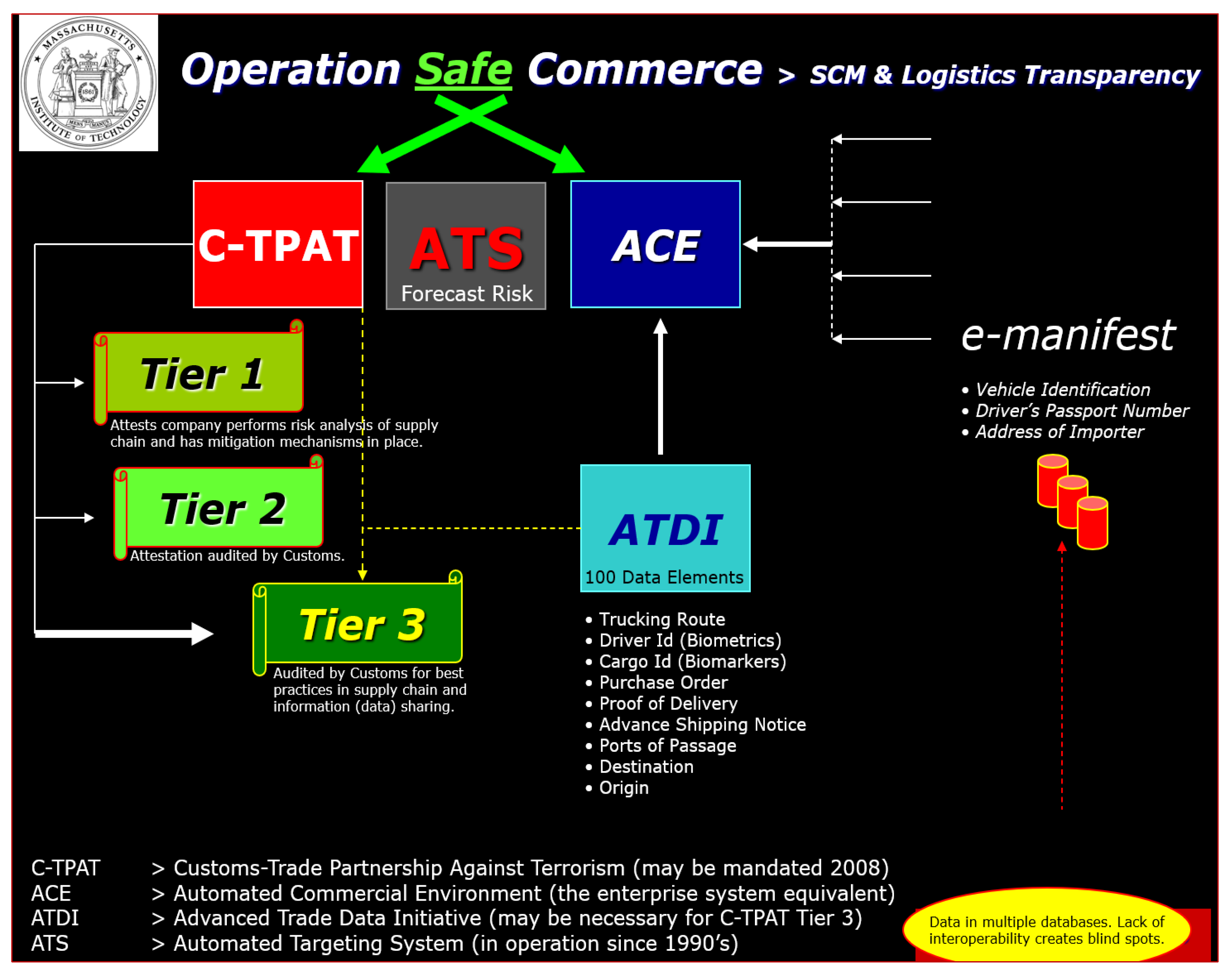
Trade provides a plethora of opportunities to breach security. The mammoth scale of US operations [912] include ~11 million maritime containers at US seaports, another 11 million arrive by truck and 2.7 million by rail. The Port of Los Angeles [913] handles ~10 million TEUs (annual container counts measured in Twenty-Foot Equivalent Units, abbreviated as TEUs). There is no doubt that machine usefulness is quintessential in conjunction with NORA and other RT tools to comb through the millions of data nodes and sources (select examples in Figure 55) with the highly time-critical need to identify potential threat disguised as or contained within the cargo, before the cargo reaches the shore, hopefully. It is impossible to inspect all incoming cargo.
For all incoming goods and services, it was necessary not to wait for the risk to arrive in the US but to extend risk management beyond the US shores into the financial and physical supply chain operations at the source countries and overseas suppliers. The exponential amplification of the risk after 9/11 created the need for The Sarbanes-Oxley Act [914] (SOX) to determine unsavory actions associated with the cargo prior to or during its transit to the US. The use of NORA and associated tools are the mainstay of supply chain transparency in order to gain some form of visibility within the network of networks involved in products arriving in the US. Machine usefulness and reasoning tools shine in cases where NORA is required. The extraction and convergence of threads are rooted in pattern recognition. Just like the causality of fever, there may be an unending number of factors/actors which may need continuous updating, checking and cross-checking to uncover cargo related threats in a time-sensitive/critical manner.
Imagine how beneficial it may be if digital twins of energy plants (electricity/gas producers) used NORA to detect a priori operational threats (both physical and cyberphysical threats). Digital twins which can respond in time (perishable information) are of immense value if the granularity of uncorrupted data and performance of the data analytics system is integrated with the exceptional capabilities expected from (e.g., NORA) reasoning tools (RT) under the banner of machine usefulness (MU). Understanding the context and semantics of the variables and data (values) could become complicated for computers (due to syntax-based programming, see Figure 32). Semantics (at least, semantic baffles) are central to optimizing contextually relevant performance in any data-informed decision system (DIDS, see Figure 11).
In most non-biological and mechanical systems, relationships are guided by natural laws (e.g., physics). The events in machines and systems are deterministic with discrete values or categorical variables (categorical distribution) which may be independent (the assumption: each data point is independent, i.e., no other confounding factors are influencing the outcome/data). In biological systems almost all event values are from continuous variables, with many levels of tortuously non-linear dependencies with variable degrees of relevance to systems and network of sub-systems, which are inextricably connected to a broader and distributed coalition of system of systems, governed by natural laws of chemistry, thermodynamics, homeostasis and evolution.
Epilogue
Is time the only independent variable? Organisms inhabit the earth only for a time being, therefore, we are—time beings—dependent on time. Monetization of time is commerce [915]. In ancient times, time was monetized via barter. With the ascent of money [916] in medieval times, money included trust [917]. The steam age [918] introduced the value of data as a business model for monetization of time over time [919] in the form of time [920] series [921] data (in forecasting). Now, data integrity is challenged by unscrupulous data corruption, unethical promotion of tools for fake analytics, growth of unbiased institutions, smug organizations, and greedy corporations.
Figure 56.
Once a science magazine, now just a pedestrian corporate pecuniary tool? [922].
Figure 56.
Once a science magazine, now just a pedestrian corporate pecuniary tool? [922].

Figure 57.
Published by Nature on 13 March 2019 & proven wrong on 14 March 2019. [923].
Figure 57.
Published by Nature on 13 March 2019 & proven wrong on 14 March 2019. [923].

Acknowledgements
Lt. Col. Greg H. Parlier’s [924] invitation to present a talk [925] (which didn’t happen) was one reason for continuing these thoughts about data, analytics and digital transformation Thoughts about “being digital” (Negroponte, 1999) dates back to the author’s role in connecting public schools to the internet (NetDay [926] 1996, San Francisco Bay Area, CA). The first part of “digital twin” (Datta, 2016; ref 9) were broader in scope and more abstract. This chapter is about data in digital transformation. One limitation of digital twins is due to questionable data analytic tools. The acerbic commentary in this discussion is due to the author and does not represent the views of affiliated institutions. I added my 2 cents to the field [927] with respect to the facts, figures, challenges [928] and opportunities. To combine and converge thoughts to highlight the art of the possible/impossible, uncover broad spectrum of uncomfortable problems (e.g., fake prosperity peddled by AI [929]) and point out a few positives where the anastomosis of history of science with human values may uphold our plight to employ the fruits of science as a service to society. If knowledge is credible, it builds more credible knowledge, and may even create Einstein [930]). We are clueless if Didymos [931] will ever meet Didymium, or if they are fit to undertake the strenuous climb of the steep path, to ascend the luminous summit. A tryst with destiny? They may, or may not, survive the winding space through the digital cacophony from unending clouds of uncertain context and causality, mist of bidirectionality and dense fog of unknown unknowns. If one is not offended by the infrequent sardonicism and chooses to explore, then the list of references may help to re-think with “new eyes” toward trans-disciplinary convergence as a catalyst for fresh embers of wonder. Thoughts and patterns [932] with respect to context which are sparked by our causal brain may (will) remain unmatched by a computational instantiation of a context. How do we start thinking about things that has never been thought? What happens to thoughts when we no longer think about them? References represent a haphazard reality of pre-existing thoughts which may ignite re-thinking, re-search and re-assembly through new “eyes”. A far bigger, knotty, and complex socio-academic problem with respect to the amorphous supply chain of talent is briefly explored in the section mountains beyond mountains [933] (because we need robust pillars to build bridges). The borrowed title of this chapter plucks out a few vestigial relics from the Periodic Table and combines two published works, one just a smidgen more stellar [934] than the other (ref 833), one may be a drop in the ocean and the other, perhaps, is a pebble in the pond, one without second is emptiness, the other makes it true.
Appendix A
The #NobelPrizeinPhysics2024 for Hopfield & Hinton rewards plagiarism and incorrect attribution in computer science. It’s mostly about Amari’s “Hopfield network” and the “Boltzmann Machine.”
The Lenz-Ising recurrent architecture with neuron-like elements was published in 1925. In 1972, Shun-Ichi Amari made it adaptive such that it could learn to associate input patterns with output patterns by changing its connection weights. However, Amari is only briefly cited in the “Scientific Background to the Nobel Prize in Physics 2024.” Unfortunately, Amari’s net was later called the “Hopfield network.” Hopfield republished it 10 years later, without citing Amari, not even in later papers. The related Boltzmann Machine paper by Ackley, Hinton, and Sejnowski (1985) was about learning internal representations in hidden units of neural networks (NNs). It didn’t cite the first working algorithm for deep learning of internal representations by Ivakhnenko & Lapa (1965). It didn’t cite Amari’s separate work (1967-8) on learning internal representations in deep NNs end-to-end through stochastic gradient descent (SGD). Not even the later surveys by the authors nor the “Scientific Background to the Nobel Prize in Physics 2024” mention these origins of deep learning. (Did not cite relevant prior work by Sherrington & Kirkpatrick [SK75] & Glauber). The Nobel Committee also lauds Hinton et al.‘s 2006 method for layer-wise pretraining of deep NNs (2006). However, this work neither cited the original layer-wise training of deep NNs by Ivakhnenko & Lapa (1965) nor the original work on unsupervised pretraining of deep NNs (1991). The “Popular information” says: “At the end of the 1960s, some discouraging theoretical results caused many researchers to suspect that these neural networks would never be of any real use.” However, deep learning research was obviously alive and kicking in the 1960s-70s, especially outside of the Anglosphere. Many additional cases of plagiarism and incorrect attribution can be found in the following reference, which also contains the other references above. One can start with J. Schmidhuber (2023). How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23, Swiss AI Lab IDSIA, 14 Dec 2023. https://people.idsia.ch/~juergen/ai-priority-disputes.html See also: J. Schmidhuber (2022). Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, IDSIA, Lugano, Switzerland, 2022. Preprint arXiv:2212.11279. https://people.idsia.ch/~juergen/deep-learning-history.html (This extends the 2015 survey https://people.idsia.ch/~juergen/deep-learning-overview.html).


In Praise of Imperfection ?


Rodney Brooks is the Panasonic Professor of Robotics (emeritus) at MIT, currently working on his Magnum Opus book--don’t hold your breath! He is a robotics entrepreneur and is currently the CTO and co-founder of Robust AI. Before that he was Founder, Chairman and CTO of Rethink Robotics (it ran from September 1st, 2008, through October 3rd, 2018, and was originally called Heartland Robotics). He is also a Founder, former Board Member (1990–2011) and former CTO (1990–2008) of iRobot Corp (Nasdaq: IRBT). Dr. Brooks is the former Director (1997–2007) of the MIT Artificial Intelligence Laboratory and then the MIT Computer Science & Artificial Intelligence Laboratory (CSAIL). He received degrees in pure mathematics from the Flinders University of South Australia and a Ph.D. in Computer Science from Stanford University in 1981. He held research positions at Carnegie Mellon University and MIT, and a faculty position at Stanford before joining the faculty of MIT in 1984. He has published many papers in computer vision, artificial intelligence, robotics, and artificial life. Dr. Brooks served for many years as a member of the International Scientific Advisory Group (ISAG) of National Information and Communication Technology Australia (NICTA), and on the Global Innovation and Technology Advisory Council of John Deere & Co. He was an Xconomist at Xconomy and a regular contributor to the Edge. From June 2014 until May 2020 he was a member of the Visiting Committee on Advanced Technology, VCAT, at the National Institute of Standards and Technology, NIST. Since June 2015 he has been an external member of GE’s Robotics Advisory Council. From January 2016 until mid 2019 he was Deputy Chairman of the Advisory Board of Toyota Research Institute. From February 2019 until January 2021 he was “Luminary” at Bell Labs. In the past he has been a member of the external advisory group to LG Electronics. Dr. Brooks is a Member of the National Academy of Engineering (NAE), a Founding Fellow of the Association for the Advancement of Artificial Intelligence (AAAI), a Fellow of the American Academy of Arts & Sciences (AAAS), a Fellow of the American Association for the Advancement of Science (the other AAAS), a Fellow of the Association for Computing Machinery (ACM), a Fellow of the Institute of Electrical and Electronics Engineers (IEEE), a Corresponding Member of the Australian Academy of Science (AAS) and a Foreign Fellow of the Australian Academy of Technological Sciences and Engineering (ATSE). He won the Computers and Thought Award at the 1991 IJCAI (International Joint Conference on Artificial Intelligence). In 2008 he won the IEEE Inaba Technical Award for Innovation Leading to Production. In 2014 he won the Robotics Industry Association’s Engelberger Robotics Award for Leadership. He won the 2015 IEEE Robotics and Automation Award. In 2021 he won the Group B NEC C& C Foundation Prize. He won the IEEE Founders Medal in 2023. He received the Computer History Museum Fellow Award in 2023. He was awarded honorary Doctor of Science degrees from Flinders University in 2016, and Worcester Polytechnic Institute in 2017, and a Doctor of the University degree from the Queensland University of Technology, in December 2017. He has been the Cray lecturer at the University of Minnesota, the Mellon lecturer at Dartmouth College, and the Forsythe lecturer at Stanford University. He was co-founding editor of the International Journal of Computer Vision and is a member of the editorial boards of various journals including Adaptive Behavior, Artificial Life, Applied Artificial Intelligence, Autonomous Robots, New Generation Computing.
FR Daron Acemoglu
ON 10-15-2024 [To] Shoumen Datta
References
- Sylvia Doughty Fries (1991) NASA Engineers and the Age of Apollo. .pdf.
- Lee, Edward A. (2015) The Past, Present and Future of CPS. Sensors National Aeronautics and Space Administration (NASA). ISBN 0-16-036174-5 https://history.nasa.gov/SP-410415 4837-4869 http://www.mdpi.com/1424-8220/15/3/4837.
- Granath, Bob. (2015) “Members of Apollo 13 Team Reflect on ‘NASA’s Finest Hour.’” NASA, 17 April 2015. http://www.nasa.gov/content/members-of-apollo-13-team-reflect-on-nasas-finest-hour.
- M. Grieves and J. Vickers (2017) Digital Twin: Mitigating Unpredictable, Undesirable Emergent Behavior in Complex Systems in: Transdisciplinary Perspectives in Complex Systems Springer International Publishing, Cham, 2017: pp. 85–113. [CrossRef]
- E.H. Glaessgen, D.S. E.H. Glaessgen, D.S. Stargel (2012) The digital twin paradigm for future NASA and U.S. Air force vehicles. Collect. Tech. Pap.—AIAA/ASME/ASCE/AHS/ASC Struct. Struct. Dyn. Mater. Conf. (2012) 1–14. [CrossRef]
- IBM. What is a Digital Twin? https://www.ibm.com/topics/what-is-a-digital-twin.
- Kuhn, Thomas S. (1962). The structure of scientific revolutions. University of Chicago Press. ISBN-13 9780226458083 https://www.lri.fr/~mbl/Stanford/CS477/papers/Kuhn-SSR-2ndEd.pdf.
- E.A. Lee and S.A. Seshia (2016) Introduction to Embedded Systems, A Cyber-Physical Systems Approach. MIT Press, Cambridge, Massachusetts. http://leeseshia.
- Datta, Shoumen (2016) Emergence of Digital Twins https://arxiv.org/ftp/arxiv/papers/1610/1610.06467.pdf Letter in Journal of Innovation Management 5, 3 (2017) 14-33 ISSN 2183-0606 http://hdl.handle.net/10216/107952.
- Aashish Mehra “Digital Twin Market worth $48.2 billion USD by 2026” https://www.marketsandmarkets.com/PressReleases/digital-twin.asp.
- Markets, Research. Global Digital Twins Markets Report 2021-2026—Emphasis on Reducing Project Costs to Drive Uptake of Digital Twin Technology. https://www.prnewswire.com/news-releases/global-digital-twins-markets-report-2021-2026---emphasis-on-reducing-project-costs-to-drive-uptake-of-digital-twin-technology-301466731.html.
- ZoBell, Steven (2018) “Council Post: Why Digital Transformations Fail: Closing The $900 Billion Hole In Enterprise Strategy.” Forbes. https://www.forbes.com/sites/forbestechcouncil/2018/03/13/why-digital-transformations-fail-closing-the-900-billion-hole-in-enterprise-strategy/.
- Tabrizi, Behnam et al. (2019) “Digital Transformation Is Not About Technology.” Harvard Business Review. https://hbr.org/2019/03/digital-transformation-is-not-about-technology.
- “Digital Transformation Investments to Top $6.8 Trillion Globally as Businesses & Governments Prepare for the Next Normal.” IDC. https://www.idc.com/getdoc.jsp?containerId=prMETA47037520.
- Erik Brynjolfsson, Daniel Rock and Chad Syverson (2017) Artificial Intelligence And The Modern Productivity Paradox: A Clash Of Expectations And Statistics in The Economics of Artificial Intelligence: An Agenda, eds. Ajay Agrawal, Joshua Gans and Avi Goldfarb (2019) Working Paper 24001 http://www.nber.org/papers/w24001 https://www.nber.org/system/files/working_papers/w24001/w24001.pdf.
- K.E. Harper, C. Ganz, S. Malakuti (2019) Digital Twin Architecture and Standards. J. of Innovation, Industrial Internet Consortium (19) pages 0–12 https://www.iiconsortium.org/news/joi-articles/2019-November-JoI-Digital-Twin-Architecture-and-Standards.pdf.
- Özer, Özalp, and Wei Wei. “Inventory Control with Limited Capacity and Advance Demand Information.” Operations Research, vol. 52, no. 6, 2004, pp. 988–1000. https://doi.org/10.1287/opre.1040.0126 and http://www.jstor.org/stable/30036647.
- Geoffrey, Cann (2021) A Digital Twin Is More than Just a Clone. 19 April 2021. https://geoffreycann.com/a-digital-twin-is-more-than-just-a-clone.
- Waldemar Walczak https://twitter.com/streetphotofdn/status/1497890783000731649.
- “How Digital Twin Technology Is Helping Build a Smart Railway System in Italy.” The Forecast By Nutanix. https://www.nutanix.com/theforecastbynutanix/industry/how-digital-twin-technology-is-helping-build-a-smart-railway-system-in-italy.
- Gürdür Broo, D and Boman, U and Törngren, M (2020) Cyber-physical systems research and education in 2030: Scenarios and strategies. December 2020. Journal of Industrial Information Integration 22(3). ISSN 2452-414X http://publications.eng.cam.ac.uk/1257295/. [CrossRef]
- Datta, S. (2015) L’Internet des Objets : la troisième révolution industrielle. Logistique and Management 23 n°3 29-33 (Translation available https://dspace.mit.edu/handle/1721.1/111021) http://www.tandfonline.com/doi/abs/10.1080/12507970.2015.11742760.
- Datta, S. (2015) Dynamic Socio-Economic Disequilibrium. J. Innovation Management 3 3 4-9 http://feupedicoes.fe.up.pt/journals/index.php/IJMAI/article/view/190/133.
- Jones, D. , Snider, C., Nassehi, A., Yon, J. and Hicks, B. (2020). Characterising the Digital Twin: A systematic literature review. CIRP Journal of Manufacturing Science and Technology. [CrossRef]
- Granger, Clive W. J. (1969) Investigating Causal Relations by Econometric Models and Cross-spectral Methods. Econometrica, 37 (3), 424–438.
- https://doi.org/10.2307/1912791 & https://www.jstor.org/stable/1912791?seq=1.
- http://jeti.uni-freiburg.de/studenten_seminar/stud_sem_SS_09/grangercausality.pdf.
- Gershenfeld, Neil A. (1999) When things start to think. Henry Holt, NY. 978-0805058741.
- Butler, D. (2013) When Google got flu wrong. Nature. 2013 February 14; 494 (7436):155-156. [CrossRef]
- Lazer D, Kennedy R, King G, Vespignani A. (2014) Big data. The parable of Google Flu: traps in big data analysis. Science. 2014 March 14; 343 (6176):1203-1205. [CrossRef]
- Fung, Kaiser (2014) “Google Flu Trends’ Failure Shows Good Data > Big Data.” Harvard Business Review, 2014.
- https://hbr.org/2014/03/google-flu-trends-failure-shows-good-data-big-data.
- Edmond Adib, Fatemeh Afghah and John J. Prevost et al. “Arrhythmia Classification Using CGAN-Augmented ECG Signals.” ArXiv:2202.00569 January 2022 http://arxiv.org/abs/2202.00569 and https://arxiv.org/pdf/2202.00569.pdf.
- Ross, Casey and Data analysis by Adam Yala, Janice Yang and Ludvig Karstens (2022) Jameel Clinic, Massachusetts Institute of Technology “AI Gone Astray: How Subtle Shifts in Patient Data Send Popular Algorithms Reeling, Undermining Patient Safety.” STAT 2/28/2022 https://www.statnews.com/2022/02/28/sepsis-hospital-algorithms-data-shift/.
- www.reddit.com/r/funny/comments/7uvjpu/how_to_spot_a_dragon_using_an_illusion_spell/.
- Loudon, J. W. (1850). The Entertaining Naturalist. Henry G. Bohn, York Street, Covent Garden, London. https://play.google.com/store/books/details?id=_7tGAQAAMAAJ&rdid=book-_7tGAQAAMAAJ&rdot=1.
- Buchanan, M. (2012) Cause and correlation. Nature Phys 8 852 (2012). [CrossRef]
- Datta, Shoumen. (2016) Intelligence in Artificial Intelligence. October 2016. https://arxiv.org/abs/1610.07862 and https://arxiv.org/ftp/arxiv/papers/1610/1610.07862.pdf.
- Sgaier, S. K., Huang, V. and Charles, G. (2020). The Case for Causal AI. Stanford Social Innovation Review. 18 (3) 50–55. [CrossRef]
- Wilson, R. A. and Keil, F. C. (1999) MIT Encyclopedia of the Cognitive Sciences. MIT Press.
- http://web.mit.edu/morrishalle/pubworks/papers/1999_Halle_MIT_Encyclopedia_Cognitive_Sciences-paper.pdf.
- Evelina Fedorenko, Anna Ivanova, Riva Dhamala and Marina Umaschi Bers (2019) The language of programming: a cognitive perspective. Massachusetts Institute of Technology. https://neuranna.mit.edu/sites/default/files/documents/Fedorenko%20et%20al%20Programming%20S&S%20author%20version.pdf.
- Fabian Fagerholm, Michael Felderer, Davide Fucci, Michael Unterkalmsteiner, Bogdan Marculescu, Markus Martini, Lars Göran Wallgren Tengberg, Robert Feldt, Bettina Lehtelä, Balázs Nagyváradi and Jehan Khattak (2022) Cognition in Software Engineering: A Taxonomy and Survey of a Half-Century of Research https://arxiv.org/pdf/2201.05551.pdf.
- Anna Ivanova, Martin Schrimpf, Stefano Anzellotti, Noga Zaslavsky, Evelina Fedorenko and Leyla Isik (2021) Beyond linear regression: mapping models in cognitive neuroscience should align with research goals. bioRxiv 2021.04.02.438248. [CrossRef]
- https://www.biorxiv.org/content/10.1101/2021.04.02.438248v2.full.pdf.
- Brain and Cognitive Sciences https://bcs.mit.edu/.
- Melissa Heikkilä (02.13.2023) The Algorithm. MIT Technology Review.
- Will Douglas Heaven (2022) “Why Meta’s Latest Large Language Model Survived Only Three Days Online.” MIT Technology Review (November 18, 2022) https://www.technologyreview.com/2022/11/18/1063487/meta-large-language-model-ai-only-survived-three-days-gpt-3-science/.
- NOTE: “History of nearest neighbor classification and its appearance in Alhazen’s Book of Optics is given by Pelillo (2014). Al-Khalili (2015) dates the work 1011 to 1021, coinciding with much of Alhazen’s decade of imprisonment in Cairo. Smith (2001) claims a completion time between 1028 and 1038, closer to Alhazen’s death circa 1040.” Source: George H. Chen and Devavrat Shah (2018), “Explaining the Success of Nearest Neighbor Methods in Prediction”, Foundations and Trends in Machine Learning. Vol. 10: No. 5-6, pp 337-588. [CrossRef]
- https://devavrat.mit.edu/wp-content/uploads/2018/03/nn_survey.pdf.
- What happened to the semantic web? (2018) https://news.ycombinator.com/item?id=16806657.
- Berners-Lee, Tim, James Hendler, and Ora Lassila (2001) “THE SEMANTIC WEB.” Scientific American 284, no. 5 p. 34-43 www.scientificamerican.com/article/the-semantic-web/ https://www-sop.inria.fr/acacia/cours/essi2006/Scientific%20American_%20Feature%20Article_%20The%20Semantic%20Web_%20May%202001.pdf.
- Sowa, John F. and Alexander Borgida, eds. Principles of Semantic Networks: Explorations in the Representation of Knowledge. Morgan Kaufmann Series in Representation and Reasoning, 1991. San Mateo, CA. ISBN 978-1558600881 http://www.jfsowa.com/pubs/semnet.pdf.
- Ramesh S Patil, Richard E Fikes, Peter F Patel-Schneider, Don Mckay, Tim Finin, Thomas Gruber and Robert Neches (1992) DARPA Knowledge Sharing Effort: Progress Report 1992 https://redirect.cs.umbc.edu/~finin/papers/kr92/kr92-ksharing.pdf.
- Tim Berners-Lee (1999) Weaving the Web: The Original Design and Ultimate Destiny of the World Wide Web by Its Inventor. Harper, San Francisco. 1999. ISBN-13 978-0062515865.
- https://www.w3.org/People/Berners-Lee/Weaving/Overview.html.
- Datta, Shoumen (2007) Unified Theory of Relativistic Identification of Information in a Systems Age: Proposed Convergence of Unique Identification with Syntax and Semantics through Internet Protocol version 6. Massachusetts Institute of Technology Engineering Systems Division (ESD) Working Paper Series (WP), 2007. (ESD-WP-2007-17) Datta, Shoumen (2012) Unified Theory of Relativistic Identification of Information in a Systems Age: Convergence of Unique Identification with Syntax and Semantics through Internet Protocol version 6 (IPv6). International Journal of Advanced Logistics 1 66-82 http://dspace.mit.edu/handle/1721.1/41902 & http://dspace.mit.edu/handle/1721.1/41910.
- Hendler, James (2023) Understanding the Limits of AI coding. Science. 2023 ; 379(6632): 548. [CrossRef] [PubMed]
- Shane, Janelle (2019) You Look like a Thing and I Love You: How Artificial Intelligence Works and Why It’s Making the World a Weirder Place. New York: Voracious, an imprint of Little, Brown and Company, a division of Hachette Book Group. ISBN-13 978-0316525244 https://www.janelleshane.com/book-you-look-like-a-thing.
- Future of Life Institute (2023) Pause Giant AI Experiments: An Open Letter https://futureoflife.org/open-letter/pause-giant-ai-experiments/.
- Joshua Eric Siegel (2016) Data Proxies, the Cognitive Layer, and Application Locality: Enablers of Cloud-Connected Vehicles and Next-Generation Internet of Things. Submitted to the Department of Mechanical Engineering in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Mechanical Engineering, Massachusetts Institute of Technology, Cambridge, Massachusetts, USA. https://dspace.mit.edu/handle/1721.1/104456.
- Chomsky, Noam (1959). “Review of Verbal behavior”. Language. 35 (1): 26–58. https://doi.org/10.2307/411334. ISSN 0097-8507 https://www.worldcat.org/issn/0097-8507 https://www.ugr.es/~fmanjon/A%20Review%20of%20B%20%20F%20%20Skinner%27s%20Verbal%20Behavior%20by%20Noam%20Chomsky.pdf. [CrossRef]
- Miller, George A (2003). “The cognitive revolution in a historical perspective”. Trends in Cognitive Sciences 7. https://www.cs.princeton.edu/~rit/geo/Miller.pdf.
- Ray Jackendoff (1994) Patterns In The Mind. Basic Books. .
- https://vdoc.pub/download/patterns-in-the-mind-language-and-human-nature-3evkhnr99v2g.
- White, Irving S. (1959) “The functions of advertising in our culture.” J. Marketing 24.1 p. 8-14 https://www.proquest.com/docview/209291580/fulltextPDF/BD3A3616D8F54250PQ/1?accountid=130362.
- Mead, G. and Morris, C. (1934) Mind, self & society from the standpoint of a social behaviorist. University of Chicago Press, 1934. http://tankona.free.fr/mead1934.pdf.
- Simon McLain and Jonathan Copulsky (2012) Making the Most of your Marketing DNA. Deloitte Review 10 https://www2.deloitte.com/content/dam/insights/us/articles/making-the-most-of-your-marketing-dna/US_deloittereview_Making_the_Most_of_Your_Marketing_DNA_Jan12.pdf.
- Miss World 1994 Aishwarya Rai—by Longines-Watches Brand (2011) http://missbrasildotcom.blogspot.com/2011/07/miss-world-1994-aishwarya-rai-by.html.
- Back to the Future (1985) https://www.imdb.com/title/tt0088763/.
- Elton John and George Michael (1974) Don’t Let the Sun Go Down on Me https://www.lyrics.com/lyric/7407325/Elton+John/Don%27t+Let+the+Sun+Go+Down+on+Me.
- Lesovik GB, Sadovskyy IA, Suslov MV, Lebedev AV, Vinokur VM. (2019) Arrow of time and its reversal on the IBM quantum computer. NATURE Sci. Rep. 2019 March 13; 9(1): 4396. [CrossRef]
- K. Kakaes (2019) No, scientists didn’t just “reverse time” with a quantum computer: Amazing headlines about time machines are a long way off the mark, sadly. MIT Technology Review (March 14, 2019) https://www.technologyreview.com/2019/03/14/103311/no-ibm-didnt-just-reverse-time-with-a-quantum-computer/.
- Gill, Helen (2008) From vision to reality: cyber-physical systems. In HCSS national workshop on new research directions for high confidence transportation CPS: automotive, aviation, and rail (pp. 1-29). https://research.ece.cmu.edu/electriconf/2008/PDFs/Gill%20-CMU%20Electrical%20Power%202008%20-%20%20Cyber-Physical%20Systems%20-%20A%20Progress%20Report.pdf.
- Neil Gershenfeld, Raffi Krikorian and Danny Cohen (2004) The Internet of Things. Scientific American. Vol. 291, No. 4 (Oct 2004), pp. 76-81 https://www.jstor.org/stable/10.2307/26060727 https://www.scientificamerican.com/article/the-internet-of-things/.
- Neil Gershenfeld and JP Vasseur (2014) As Objects Go, Online; The Promise (and Pitfalls) of <i>the Internet of Things. </i>Foreign Affairs 93, no. Neil Gershenfeld and JP Vasseur (2014) As Objects Go Online; The Promise (and Pitfalls) of the Internet of Things. Foreign Affairs 93, no. 2 (March/14): 60-67 https://heinonline.org/HOL/LandingPage?handle=hein.
- Muralidharan, Shapna and Ko, Heedong (2019). An InterPlanetary file system (IPFS) based IoT framework. In 2019 IEEE international conference on consumer electronics (ICCE) (1-2). https://ieeexplore.ieee.org/document/8662002.
- [69-A] Didem Gürdür Broo, M. Bravo-Haro and J. Schooling (2022) Design and implementation of a smart infrastructure digital twi. Autom. Constr. 136 (2022) 104171. [CrossRef]
- [69-B] Didem Gürdür Broo, K. Lamb, R. Juvenile Ehwi, E. Anneli Pärn, A. Koronaki, C. and Makri, T. Zomer, Four Futures (2020) One Choice: Options for the Digital Built Britain of 2040. Cambridge University, Cambridge, UK, 2020. https://www.researchgate.net/publication/346963286.
- [69-C] Didem Gürdür Broo and, J. Schooling (2021 Digital twins in infrastructure: definitions, current practices, challenges and strategies, Int. J. Constr. Manag. 21 (2021) 1–10. [CrossRef]
- [69-D] Didem Gürdür Broo and, J. Schooling (2021) A Framework for Using Data as an Engineering Tool for Sustainable Cyber-Physical Systems. IEEE Access. 9 (2021) 22876–22882. [CrossRef]
- Powell, J.W. (1876) Report on the geology of the eastern portion of the Uinta Mountains and a region of country adjacent thereto. U.S. Geological Survey of the Territories (Powell), 7:21. [CrossRef]
- Bonnie Bloeser (1985) Melanocyrillium, a New Genus of Structurally Complex Late Proterozoic Microfossils from the Kwagunt Formation (Chuar Group), Grand Canyon, Arizona. Journal of Paleontology, Vol. 59, No. 3 (May, 1985), pp. 741-765. SEPM Society for Sedimentary Geology https://www.jstor.org/stable/1304994 and https://www.researchgate.net/profile/Bonnie-Bloeser/publication/292268785_Melanocyrillium_a_new_genus_of_structurally_complex_late_Proterozoic_microfossils_from_the_Kwagunt_Formation_Chuar_Group_Grand_Canyon_Arizona/links/5cb78546a6fdcc1d499c49e7/Melanocyrillium-a-new-genus-of-structurally-complex-late-Proterozoic-microfossils-from-the-Kwagunt-Formation-Chuar-Group-Grand-Canyon-Arizona.pdf.
- The Vishnu Schist. https://utahgeology.com/the-vishnu-schist-of-the-grand-canyon.
- Negroponte, Nicholas. 1995. Being digital. Knopf, NY. ISBN-13 : 978-0679762904.
- http://governance40.com/wp-content/uploads/2018/12/Nicholas-Negroponte-Being-Digital-Vintage-1996.pdf.
- McCarthy, J. (2004) What is AI? http://jmc.stanford.edu/articles/whatisai/whatisai.pdf.
- Maeda RS, Cluff T, Gribble PL, Pruszynski JA. (208) Feedforward and Feedback Control Share an Internal Model of the Arm’s Dynamics. J Neurosci. 2018 ; 38(49):10505-10514. [CrossRef]
- Iosa M, Gizzi L, Tamburella F, Dominici N. (2015) Neuro-motor control and feed-forward models of locomotion in humans. Frontiers in Human Neuroscience 2015 ; 9:306. [CrossRef]
- Pisotta I, Molinari M. (2014) Cerebellar contribution to feedforward control of locomotion. Front Hum Neurosci. 2014 ; 8:475. [CrossRef]
- Artificial Intelligence—Intelligent Agents (2017) https://courses.edx.org/asset-v1:ColumbiaX+CSMM.101x+1T2017+type@asset+block@AI_edx_intelligent_agents_new__1_.pdf.
- William, S. Angerman (2004) Coming Full Circle With Boyd’s OODA Loop Ideas: An Analysis Of Innovation Diffusion And Evolution (Thesis). https://apps.dtic.mil/dtic/tr/fulltext/u2/a425228.pdf.
- Castanedo, Federico (2013) “Review of Data Fusion Techniques.” Scientific World Journal, 2013. [CrossRef]
- Donnamarie Romano (2001) Philosophy of Religion in Chapter 2 Section 2 of Philip A. Pecorino “Philosophy of Religion” www.qcc.cuny.edu/socialsciences/ppecorino/phil_of_religion_text/chapter_2_religions/hinduism.htm and https://www.qcc.cuny.edu/socialsciences/ppecorino/phil_of_religion_text/default.htm.
- [81a through 81i].
- [81a], F. Tao, H. Zhang, A. Liu and A. Y. C. Nee (2019) Digital Twin in Industry: State-of-the-Art in IEEE Transactions on Industrial Informatics, vol. 15, no. 4, pp. 2405-2415, 19. [CrossRef]
- [81b] Qi, Qinglin, et al. (2021) “Enabling Technologies and Tools for Digital Twin.” Journal of Manufacturing Systems, vol. 58, Jan. 2021, pp. [CrossRef]
- [81c] Jorge Corral-Acero, Francesca Margara, Maciej Marciniak, Cristobal Rodero, Filip Loncaric, Yingjing Feng, Andrew Gilbert, Joao F Fernandes, Hassaan A Bukhari, Ali Wajdan, Manuel Villegas Martinez, Mariana Sousa Santos, Mehrdad Shamohammdi, Hongxing Luo, Philip Westphal, Paul Leeson, Paolo DiAchille, Viatcheslav Gurev, Manuel Mayr, Liesbet Geris, Pras Pathmanathan, Tina Morrison, Richard Cornelussen, Frits Prinzen, Tammo Delhaas, Ada Doltra, Marta Sitges, Edward J Vigmond, Ernesto Zacur, Vicente Grau, Blanca Rodriguez, Espen W Remme, Steven Niederer, Peter Mortier, Kristin McLeod, Mark Potse, Esther Pueyo, Alfonso Bueno-Orovio, Pablo Lamata (2020) The ‘Digital Twin’ to enable the vision of precision cardiology. European Heart Journal, Vol. 41, Issue 48, 21 December 2020, pages 4556–4564. [CrossRef]
- [81d] S Boschert, C Heinrich and R Rosen (2018) Next generation digital twin.Proceedings of the 12th International Symposium on Tools and Methods of Competitive Engineering (TMCE, May 7-11, 2018, Las Palmas de Gran Canaria, Spain). Edited by: I. Horváth, J.P. Suárez Rivero and P.M. Hernández Castellano ISBN 978-94-6186-910-4 https://www.researchgate.net/profile/Stefan-Boschert/publication/325119950_Next_Generation_Digital_Twin/links/5af952ca0f7e9b026bf6e553/Next-Generation-Digital-Twin.pdf.
- [81e] Fei Tao, Fangyuan Sui, Ang Liu, Qinglin Qi, Meng Zhang, Boyang Song, Zirong Guo, Stephen C.-Y. Lu and A. Y. C. Nee (2019) Digital twin-driven product design framework. International Journal of Production Research 57:12, 3935-3953. [CrossRef]
- [81f] L Zhang, L Zhou and BKP Horn (2021) “Building a Right Digital Twin with Model Engineering.” Journal of Manufacturing Systems, vol. 59, 21, pp. [CrossRef]
- [81g] R Parmar, A Leiponen and LDW Thomas (2020) “Building an Organizational Digital Twin.” Business Horizons, vol. 63, no. 6, 20, pp. 725–736. [CrossRef]
- [81h] Ma, J. , Chen, H., Zhang, Y., Guo, H., Ren, Y., Mo, R and Luyang, L (2020) A digital twin-driven production management system for production workshop. Int J Adv Manufacturing Technology 110 1385–1397 (2020). [CrossRef]
- [81i] Y Pan and L Zhang (2021) BIM-data mining integrated digital twin framework for advanced project management. Automation in Construction 124 (2021) 103564 ISSN 0926-5805. . [CrossRef]
- Didem Gürdür Broo and, J. Schooling (2020) Towards Data-centric Decision Making for Smart Infrastructure: Data and Its Challenges. IFAC-PapersOnLine. 53 (2020) 90–94. [CrossRef]
- Didem Gürdür Broo, A. Vulgarakis Feljan, J. El-Khoury, S. Kumar Mohalik, R. Badrinath, A. Pradeep Mujumdar, E. Fersman, (2018) Knowledge Representation of Cyber-physical Systems for Monitoring Purpose in: Procedia CIRP, 2018. [CrossRef]
- Zhang, H.; Liu, Q.; Chen, X.; Zhang, D.; Leng, J. (2017) A Digital Twin-Based Approach for Designing and Multi-Objective Optimization of Hollow Glass Production Line, IEEE Access. 5 (2017) 26901–26911. [CrossRef]
- Jeffrey Voas, Peter Mell an Vartan Piroumian (2021) Considerations for Digital Twin 2 3 Technology and Emerging Standards. National Institute of Standards and Technology, US Department of Commerce. https://dooi.org/10.6028/NIST.IR.8356-draft https://nvlpubs.nist.gov/nistpubs/ir/2021/NIST.IR.8356-draft.pdf.
- Leng, J.; Jiang, P. (2017) Granular computing–based development of service process reference models in social manufacturing contexts. Concurrent Engineering 25 (2017) 95–107. [CrossRef]
- Souza, V.; Cruz, R.; Silva, W.; Lins, S.; Lucena, V. (2019) Digital Twin Architecture Based on the Industrial Internet of Things Technologies. 2019 IEEE Int. Conf. Consum. Electron. 2019. [Google Scholar] [CrossRef]
- Alam, K.M.; El Saddik, A. (2017) C2PS: A digital twin architecture reference model for the cloud-based cyber-physical systems. IEEE Access. 5 (2017) 2050–2062. [CrossRef]
- Boschert, S.; Rosen, R. (2016) Digital Twin—The Simulation Aspect in: Mechatron. Futur., Springer International, Cham, 2016, pp. [CrossRef]
- Aheleroff, S.; Xu, X.; Zhong, R.Y.; Lu, Y. (2021) “Digital Twin as a Service (DTaaS) in Industry 4.0: An Architecture Reference Model.” Advanced Engineering Informatics, vol. 47, 21, p. 101225. [CrossRef]
- Redelinghuys, A.J.H.; Basson, A.H.; Kruger, K. (2020) A six-layer architecture for the digital twin: a manufacturing case study implementation J. Intelligent Manuf. 31 (2020) 1383–1402. [CrossRef]
- Lee, J.; Bagheri, B.; Kao, H.A. (2015) Cyber-Physical Systems architecture for Industry 4.0-based manufacturing systems, Manuf. Lett. 2015. [Google Scholar] [CrossRef]
- Alam, K.M.; Sopena, A.; El Saddik, A. (2015) Design and Development of a Cloud Based Cyber-Physical Architecture for the Internet-of-Things Proc. 2015 IEEE Int. Symp. Multimedia, ISM 2015. 2016. [Google Scholar] [CrossRef]
- Didem Gürdür Broo, K. Raizer, J. El-Khoury (2018) Data Visualization Support for Complex Logistics Operations and Cyber-Physical Systems in Proc. 13th Int. Jt. Conf. Comput. Vision, Imaging Comput. Graph. Theory Appl. SCITEPRESS—Science and Technology Publications, Phoenix, 2018: pp. [CrossRef]
- Haße, H.; Li, B.; Weißenberg, N.; Cirullies, J.; Otto, B. (2019) Digital Twin for Real-Time Data Processing in Logistics. Artif. Intell. Digit. Transform. Supply Chain Manag. (Proceedings Hambg. Int. Conf. Logist. (HICL) 27 (2019) 0–1. [CrossRef]
- Ishii, H. (1997) Tangible Bits: Towards Seamless Interfaces between People, Bits, and Atoms in Proceedings of Computer-Human Interactions (CHI), SIGCHI ACM, March 1997 http://tangible.media.mit.edu/person/hiroshi-ishii/.
- Datta, Shoumen (2018) Atoms To Bits—Why It May Not Be Enough ? Iot Is A Design Metaphor For Digital Transformation X.0 https://dspace.mit.edu/handle/1721.1/111021.
- San, Omar (2021) The digital twin revolution. Nat Comput Sci, 2021. [CrossRef]
- Vetelino, J. and Reghu, A. (Eds.). (2011) Introduction to Sensors (1st ed.). CRC Press.
- Eric, S. McLamore, Evangelyn Alocilja, Carmen Gomes, Sundaram Gunasekaran, Daniel Jenkins, Shoumen.P.A. Datta, Yanbin Li, Yu (Jessie) Mao, Sam R. Nugen, José I. Reyes-De-Corcuera, Paul Takhistov, Olga Tsyusko, Jarad P. Cochran, Tzuen-Rong (Jeremy) Tzeng, Jeong-Yeol Yoon, Chenxu Yu and Anhong Zhou (2021) FEAST of Biosensors: Food, Environmental and Agricultural Sensing Technologies (FEAST) in North America. Biosensors and Bioelectronics. 2021, 113011. [CrossRef]
- Moreira G, Casso-Hartmann L, Datta SPA, Dean D, McLamore E, Vanegas D. (2022) Development of a Biosensor Based on Angiotensin-Converting Enzyme II (ACE2) for Severe Acute Respiratory Syndrome Coronavirus 2 (SARS-CoV-2) Detection in Human Saliva. Front Sensors (Lausanne). 2022; 3:917380. [CrossRef]
- Datta, Shoumen Palit Austin, Tausifa Jan Saleem, Molood Barati, María Victoria López López, Marie-Laure Furgala, Diana C. Vanegas, Gérald Santucci, Pramod P. Khargonekar and Eric S. McLamore (, 2021) Data, Analytics and Interoperability between Systems (IoT) is Incongruous with the Economics of Technology: Evolution of Porous Pareto Partition (P3). Chapter 2 in “Big Data Analytics for Internet of Things” 1st ed. Editors Tausifa Jan Saleem and Mohammad Ahsan Chishti. Wiley. ISBN: 9781119740759. [CrossRef]
- https://onlinelibrary.wiley.com/doi/abs/10.1002/9781119740780.ch2.
- Nobel Prize in Physics 2021 www.nobelprize.org/prizes/physics/2021/press-release/.
- Ravishankara AR, Randall DA, Hurrell JW. Complex and yet predictable: The message of the 2021 Nobel Prize in Physics. Proc Natl Acad Sci USA. 2022 ; 119(2): e2120669119. [CrossRef]
- Universality. New England Complex Systems Institute. https://necsi.edu/14-universality.
- Manabe, S.; Wetherald, R.T. (1975) The effects of doubling the CO2 concentration on the climate of a general circulation model. J. Atmos. Sci. 32 3–15 (1975). https://journals.ametsoc.org/downloadpdf/journals/atsc/32/1/1520-0469_1975_032_0003_teodtc_2_0_co_2.xml.
- Manabe, S.; Wetherald, R.T. (1967) Thermal equilibrium of the atmosphere with a given distribution of relative humidity. J. Atmos. Sci. 24 241–259 (1967). https://climate-dynamics.org/wp-content/uploads/2016/06/manabe67.pdf.
- Samuel Madden, Michael J. Franklin, Joseph M. Hellerstein and Wei Hong (2002) TAG: a Tiny AGgregation Service for Ad-Hoc Sensor Networks. 5th Annual Symposium on Operating Systems Design and Implementation (OSDI). December, 2002. UC Berkeley Intel Research Lab https://web.stanford.edu/class/cs240e/papers/madden_tag.pdf.
- Farhad Firoozi, Vladimir I. Zadorozhny and Frank Y. Li (2018) Subjective Logic-Based In-Network Data Processing for Trust Management in Collocated and Distributed Wireless Sensor Networks IEEE Sensors Journal, vol. 18, no. 15. , 2018 pages 6446-6460. [CrossRef]
- Jonathan Beaver, Mohamed A. Sharaf, Alexandros Labrinidis, Panos K. Chrysanthis (2003) Power-Aware In-Network Query Processing for Sensor Data extended version of the paper “TiNA: A Scheme for Temporal Coherency-Aware in-Network Aggregation” Proceedings of the 3rd ACM MobiDE Workshop (03, MobiCom) http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.82.
- Bowen Liang, Jianye Tian, and Yi Zhu (2023) An In-Network Computing Service Placement Mechanism for NUMA-based Software Router in Quan, Wei eds., Emerging Networking Architecture and Technologies: First International Conference, ICENAT 2022, Shenzhen, China, -17, 2022, Proceedings. Springer Nature, 2023. ISBN 978-981-19-9697-9 https://link.springer.com/book/10.1007/978-981-19-9697-9.
- Brokate, Martin, and Avner Friedman. “Optimal Design for Heat Conduction Problems with Hysteresis.” SIAM Journal on Control and Optimization, vol. 27, no. 4, 89, pp 697-717. [CrossRef]
- Adib, Fadel, and Katabi, Dina (2013) “See through Walls with WiFi!” ACM SIGCOMM Computer Communication Review, vol. 43, no. 4, 13, pp. 75–86. [CrossRef]
- http://people.csail.mit.edu/fadel/wivi/index.html.
- Winslow RL, Granite S, Jurado C (2016) WaveformECG: A Platform for Visualizing, Annotating, and Analyzing ECG Data. Comput Sci Eng. 2016 September-October; 18(5): 36-46. [CrossRef]
- Andrews, C.A.; Davies, J.M.; Schwarz, G.R. (1967) Adaptive data compression in Proceedings of the IEEE, vol. 55, no. 3, pp. 267-277, March 1967. [CrossRef]
- Weinstein, S.; Ebert, P. (1971) “Data Transmission by Frequency-Division Multiplexing Using the Discrete Fourier Transform,” in IEEE Transactions on Communication Technology, vol. 19, no. 5, pp. 628-634, 71. [CrossRef]
- Li R, Qi H, Ma Y, Deng Y, Liu S, Jie Y, Jing J, He J, Zhang X, Wheatley L, Huang C, Sheng X, Zhang M, Yin L. (2020) A flexible and physically transient electrochemical sensor for real-time wireless nitric oxide monitoring. Nature Communications 2020 ; 11(1):3207. [CrossRef]
- [a] Louis de Broglie (1923) Ondes et quanta. Séance du 10 September 1923. Acad. Sci. Paris 177 (1923) 507–510 http://cds.cern.ch/record/263873 https://www.academie-sciences.fr/pdf/dossiers/Broglie/Broglie_pdf/CR1923_p507.pdf.
- [b] Louis de Broglie (1923) Quanta de lumière, diffraction et interferences. Séance du 24 September 1923. Acad. Sci. Paris 177 (1923) 548–551 https://www.academie-sciences.fr/pdf/dossiers/Broglie/Broglie_pdf/CR1923_p548.pdf.
- [c] Louis de Broglie (1923) Les quanta, la théorie cinétique des gaz et le principe de Fermat. Séance du 8 October 1923. Acad. Sci. Paris 177 (1923) 630–632 https://www.academie-sciences.fr/pdf/dossiers/Broglie/Broglie_pdf/CR1923_p630.pdf.
- [d] Louis de Broglie (1924) Recherches sur la théorie des Quanta. Physique. Migration—université en cours d’affectation, 1924. Français. fftel-00006807f (Louis de Broglie, PhD Thesis) https://tel.archives-ouvertes.fr/tel-00006807/document.
- [e] Louis de Broglie, Nobel Lecture 1929 https://www.nobelprize.org/uploads/2016/04/broglie-lecture.pdf.
- Gershenfeld, Neil (2005) Bits and atoms. In NIP & Digital Fabrication Conference (Vol. 2005, No. 3, pp. 2-2). Society for Imaging Science and Technology. ISSN 2169-4451 (Print).
- Neil Gershenfeld and Jim Euchner (2015) Atoms and Bits: Rethinking Manufacturing. Research-Technology Management, 58:5, pp. [CrossRef]
- The Lancet Planetary Health (2022) Editorial: Climate risks laid bare. The Lancet. Vol. 6, issue 4, E292, , 2022. [CrossRef]
- https://www.thelancet.com/pdfs/journals/lanplh/PIIS2542-5196(22)00075-4.pdf.
- Curtin, Leah (2021) “Pandemics and ‘One Health’: The intertwining of nature, wildlife, and humans increases the risk of disease spread.” American Nurse Journal, vol. 16, no. 6, June 2021, p. 48. https://www.myamericannurse.com/wp-content/uploads/2021/05/an6-Curtin-513.pdf.
- Box, George E. P., and Gwilym M. Jenkins. (1970) Time Series Analysis; Forecasting and Control. San Francisco: Holden-Day, 1970. ISBN-13 9780816210947 https://download.e-bookshelf.de/download/0003/8810/69/L-G-0003881069-0007953902.pdf.
- Nicholson, Scott, David Keyser, Marissa Walter, Greg Avery, and Garvin Heath (2021) “Chapter 8: Greenhouse Gas Emissions.” In The Los Angeles 100% Renewable Energy Study, edited by Jaquelin Cochran and Paul Denholm. Golden, CO: National Renewable Energy Laboratory. NREL/TP-6A20-79444-8. https://www.nrel.gov/docs/fy21osti/79444-8.pdf.
- Steen, M. (2000) Greenhouse Gas Emissions From Fossil Fuel Fired Power Generation Systems. European Commission Joint Research Centre (DG-JRC) Institute For Advanced Materials, Energy Technology Observatory (ETO), Institute for Advanced Materials https://publications.jrc.ec.europa.eu/repository/bitstream/JRC21207/EUR%2019754%20EN.pdf.
- Ali Z, Bhaskar SB. (2016) Basic statistical tools in research and data analysis. Indian Journal of Anaesthesiology 2016 September; 60(9): p. 662-669. [CrossRef]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5037948/pdf/IJA-60-662.pdf.
- Mishra P, Pandey CM, Singh U, Keshri A, Sabaretnam M. (2019) Selection of appropriate statistical methods for data analysis. Ann Card Anaesth. 2019 July-September; 22(3):297-301. [CrossRef]
- Centers for Disease Control and Prevention (2013) Analyzing and Interpreting Large Datasets. CDC https://www.cdc.gov/globalhealth/healthprotection/fetp/training_modules/11/large-data-sets_pw_final_09252013.pdf.
- Engle, Robert. 2001. “GARCH 101: The Use of ARCH/GARCH Models in Applied Econometrics.” Journal of Economic Perspectives. 15 (4): 157-168. [CrossRef]
- Robert, F. Engle and Clive W. J. Granger (2003) “The Sveriges Riksbank Prize in Economic Sciences in Memory of Alfred Nobel 2003” www.nobelprize.org/prizes/economic-sciences/2003.
- Datta, Shoumen and Granger, Clive W. J. (2006) Improvements in Forecasting Massachusetts Institute of Technology (MIT) Engineering Systems Division (ESD) Working Paper (WP) Series (ESD-WP-2006-11) https://dspace.mit.edu/handle/1721.1/102799 Datta, S., Granger, Clive W. J., Barari, M. and Gibbs, T. (2007) Management of Supply Chain: an alternative modeling technique for forecasting. J Operational Research Society 58 1459-1469 http://dspace.mit.edu/handle/1721.1/41906 http://www.tandfonline.com/doi/full/10.1057/palgrave.jors.2602419.
- Conner-Simons, Adam (2015) “Michael Stonebraker Wins $1 Million Turing Award.” MIT News (2015) https://news.mit.edu/2015/michael-stonebraker-wins-turing-award-0325.
- Stonebraker, Michael, Gerald Held, Eugene Wong, and Peter Kreps. (1976) “The Design and Implementation of INGRES.” ACM Transactions on Database Systems 1, no. 3 (Sept 1976): pages 189–222. [CrossRef]
- Michael Stonebraker and Lawrence, A. Rowe (1986) The design of POSTGRES. In Proceedings of the 1986 ACM SIGMOD international conference on Management of data (SIGMOD ‘86). Association for Computing Machinery (ACM), New York, NY. pp. 340–355. [CrossRef]
- E. F. Codd (1970) A relational model of data for large shared data banks. Communications of the ACM 13, 6 (70), p. 377–387. [CrossRef]
- Fortune (2021) “Andrew Ng:, A.I. Needs to Get Past the Idea of Big Data.” https://fortune.com/2021/07/30/ai-adoption-big-data-andrew-ng-consumer-internet/.
- Hardesty, Larry (April 14, 2017) Explained: Neural Networks. MIT News. https://www.csail.mit.edu/news/explained-neural-networks.
- Data Wrangling https://commons.wikimedia.org/w/index.php?curid=97533273.
- Simon, Julian L. (1999) Resampling: The New Statistics. 2nd ed. Arlington, VA. https://web.archive.org/web/20051223034539/http://www.resample.com/content/text/index.shtml.
- Kevin, Sheppard; et al. (2022). bashtage/arch: Release 5.3.1 (v5.3.1). Zenodo. [CrossRef]
- Zhou Q, Zuley M, Guo Y, Yang L, Nair B, Vargo A, Ghannam S, Arefan D, Wu S. (2021) A machine and human reader study on AI diagnosis model safety under attacks of adversarial images. Nat Commun. 2021 ; 12(1): 7281. [CrossRef]
- Cecil Hastings, Jr. , Frederick Mosteller, John W. Tukey, Charles P. Winsor (1947) “Low Moments for Small Samples: A Comparative Study of Order Statistics,” The Annals of Mathematical Statistics 18(3), pages 413-426 (September, 1947) https://projecteuclid.org/journalArticle/Download?urlId=10.1214%2Faoms%2F1177730388.
- Barnard J, Meng XL. (1999) Applications of multiple imputation in medical studies: from AIDS to NHANES. Statistical Methods in Medical Research. 1999 March; 8(1): pages17-36. [CrossRef]
- https://journals.sagepub.com/doi/pdf/10.1177/096228029900800103.
- Scheet P, Stephens M. (2006) A fast and flexible statistical model for large-scale population genotype data: applications to inferring missing genotypes and haplotypic phase. Am J Human Genetics. 2006 April; 78(4): pages 629-44. [CrossRef]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1424677/pdf/AJHGv78p629.pdf.
- 1000 Genomes Project Consortium; Abecasis GR, Altshuler D, Auton A, Brooks LD, Durbin RM, Gibbs RA, Hurles ME, McVean GA. A map of human genome variation from population-scale sequencing. Nature. 2010 October 28; 467(7319): pp.1061-1073. [CrossRef]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3042601/pdf/ukmss-34220.pdf.
- Johnson, Charles R. (1990). “Matrix completion problems: a survey”. Matrix Theory and Applications. Proceedings of Symposia in Applied Mathematics vol. 40 pages 171–198. ISBN 9780821801543. [CrossRef]
- The Netflix Prize https://en.wikipedia.org/wiki/Netflix_Prize.
- Waring Edward (1779) Problems concerning interpolations. Philosophical Transactions of the Royal Society. [CrossRef]
- Brahmagupta’s Interpolation Formula https://en.wikipedia.org/wiki/Brahmagupta%27s_interpolation_formula.
- Interpolation https://en.wikipedia.org/wiki/Interpolation.
- Gun Violence Archive https://www.gunviolencearchive.org/.
- Will Douglas Heaven (2023) “ChatGPT Is Everywhere. Here’s Where It Came from.” MIT Technology Review. https://www.technologyreview.
- National Commission on Terrorist Attacks Upon the United States (2004) THE 9/11 COMMISSION REPORT. Final Report of the National Commission on Terrorist Attacks Upon the United States http://govinfo.library.unt.edu/911/report/911Report.pdf and https://govinfo.library.unt.edu/911/report/911Report_Exec.htm.
- Lee H, Choi TK, Lee YB, Cho HR, Ghaffari R, Wang L, Choi HJ, Chung TD, Lu N, Hyeon T, Choi SH, Kim DH. (2016) A graphene-based electrochemical device with thermoresponsive microneedles for diabetes monitoring and therapy. Nat Nanotechnol. 2016 June; 11(6): 566-572. [CrossRef]
- Apte, Pushkar P. and Costas J. Spanos. (2021) “The Digital Twin Opportunity.” MIT Sloan Management Review 63 (1) (Fall): 15-17.
- Voosen, Paul (2020). Europe Builds ‘Digital Twin’ of Earth to Hone Climate Forecasts. Science, 2020; 370, 16–17. [CrossRef]
- Huff, Darrell (1954) How to Lie With Statistics. [1st ed] Norton, NY. www.horace.org/blog/wp-content/uploads/2012/05/How-to-Lie-With-Statistics-1954-Huff.pdf.
- Tufte, Edward R. (2001) The Visual Display of Quantitative Information. 2nd ed. Graphics Press, CT. http://faculty.salisbury.edu/~jtanderson/teaching/cosc311/fa21/files/tufte.pdf ISBN-13 978-1930824133 https://www.edwardtufte.com/tufte/books_vdqi.
- Michael Falk (2007) Artificial Stupidity https://arxiv.org/ftp/arxiv/papers/2007/2007.03616.pdf.
- (2019) Artificial Stupidity. William & Mary Law Review 61 1187 (2020) BYU Law Research Paper No. 20-03 https://ssrn.com/abstract=3399170.
- https://scholarship.law.wm.edu/cgi/viewcontent.cgi?article=3857&context=wmlr.
- Schwartz, M. A. (2008) The importance of stupidity in scientific research. J. of Cell Science 2008 June 1; 121(11):1771. [CrossRef]
- Mollie, B. LeBlanc (2020) Digital Twin Technology for Enhanced Upstream Capability in Oil and Gas. Submitted to the system design and management (SDM) program in partial fulfillment of the requirements for the degree of Master of Science in Engineering and Management at the Massachusetts Institute of Technology (September 2020) https://dspace.mit.edu/bitstream/handle/1721.1/132840/1263186138-MIT.pdf?sequence=1&isAllowed=y.
- Eric, S. McLamore, R. Huffaker, Matthew Shupler, Katelyn Ward, Shoumen Palit Austin Datta, M. Katherine Banks, Giorgio Casaburi, Joany Babilonia, Jamie S. Foster (2019) Digital Proxy of a Bio-Reactor (DIYBOT) Combines Sensor Data and Data Analytics for Wastewater Treatment and Wastewater Management Systems. Nature Science Reports 10 8015 (2020) www.nature.com/articles/s41598-020-64789-5.pdf.
- Daneels and, W. Salter (1999) What is SCADA? Switzerland International Conference on Accelerator and Large Experimental Physics Control Systems, 1999, Trieste, Italy https://cds.cern.ch/record/532624/files/mc1i01.pdf.
- Batty, M. (2018) Digital twins. Environment and Planning B: Urban Analytics and City Science. 2018; 45(5): 817-820. [CrossRef]
- Scott, G. Weiner, Michelle A. Hendricks, Sanae El Ibrahimi, Grant A. Ritter, Sara E. Hallvik, Christi Hildebran, Roger D. Weiss, Edward W. Boyer, Diana P. Flores, Lewis S. Nelson, Peter W. Kreiner, Michael A. Fischer (2022) Opioid-related overdose and chronic use following an initial prescription of hydrocodone versus oxycodone. PLoS ONE 17(4): e0266561. [CrossRef]
- The New York Times (1931) “Einstein Sees Lack In Applying Science; Man Has ‘Not Yet Learned To Make Sensible Use Of It,’ He Asserts. Cites War And Machinery. He Urges California Students To Seek To Put Knowledge To Good Of The Race.,” , 1931. https://www.nytimes.com/1931/02/17/archives/einstein-sees-lack-in-applying-science-man-has-not-yet-learned-to.html.
- Bronowski, Jacob (1956) “SCIENCE AND HUMAN VALUES: 3. The Sense of Human Dignity.” Higher Education Quarterly 11, no. 1 (Nov 1956) p. 26-42. [CrossRef]
- Kaplan, S. , Garrick, J.B. (1981) On the quantitative definition of risk. J. of Risk Analysis, 1(1): 11-27. https://www.nrc.gov/docs/ML1216/ML12167A133.pdf.
- Sarda, Priya, and James H. Lambert (2004) “Risk-based model for tracking complexity in system vulnerability analysis.” In Proceedings of the 2004 IEEE Systems and Information Engineering Design Symposium. 2004, pp. 65-70. IEEE, 2004.
- Horowitz, B.M., & Haimes, Y.Y. (2003). Risk-based methodology for scenario tracking, intelligence gathering, and analysis for countering terrorism. Sys Eng vol. 6., no.3, pp. 152-169 https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.130.3698&rep=rep1&type=pdf.
- Berzinji, Ala (2011) Detecting key players in terrorist networks. https://www.diva-portal.org/smash/get/diva2:442516/FULLTEXT01.pdf.
- American Diabetes Association. Economic Costs of Diabetes in the U.S. in 2017. Diabetes Care. 2018 May; 41(5): 917-928. [CrossRef]
- Lin X, Xu Y, Pan X, Xu J, Ding Y, Sun X, Song X, Ren Y, Shan PF. (2020) Global, regional, and national burden and trend of diabetes in 195 countries and territories: an analysis from 1990 to 2025. Science Reports 2020 September 8; 10(1): 14790. [CrossRef]
- Roze S, Isitt JJ, Smith-Palmer J, Lynch P, Klinkenbijl B, Zammit G, Benhamou PY. (2021) Long-Term Cost-Effectiveness the Dexcom G6 Real-Time Continuous Glucose Monitoring System Compared with Self-Monitoring of Blood Glucose in People with Type 1 Diabetes in France. Diabetes Therapy 2021 January; 12(1): 235-246. [CrossRef]
- Roze S, Isitt J, Smith-Palmer J, Javanbakht M, Lynch P. (2020) Long-term Cost-Effectiveness of Dexcom G6 Real-time Continuous Glucose Monitoring Versus Self-Monitoring of Blood Glucose in Patients With Type 1 Diabetes in the U.K. Diabetes Care. 2020 Oct; 43(10): pages 2411-2417 https://diabetesjournals.org/care/article-pdf/43/10/2411/629953/dc192213.pdf.
- Isitt JJ, Roze S, Tilden D, Arora N, Palmer AJ, Jones T, Rentoul D, Lynch P. (2022) Long-term cost-effectiveness of Dexcom G6 real-time continuous glucose monitoring system in people with type 1 diabetes in Australia. Diabet Med. 2022 : e14831. [CrossRef]
- The Logical Indian (2016) How The Sugar Industry Paid Harvard Scientists & Shifted Blame Of Heart Diseases To Fat. 17 Sep 2016. https://thelogicalindian.com/story-feed/awareness/how-the-sugar-industry-paid-harvard-scientists-shifted-blame-of-heart-diseases-to-fat/.
- Kearns CE, Schmidt LA, Glantz SA. (2016) Sugar Industry and Coronary Heart Disease Research: A Historical Analysis of Internal Industry Documents. JAMA Internal Medicine 2016 ; 176(11): 1680-1685. [CrossRef]
- The Lancet (2022) Diabetes Nigeria. Vol. 339, issus 10330, pp. 1155-1200 , 2022 https://www.thelancet.com/action/showPdf?
- Lancet Nigeria Commission: Investing in health and the future of the nation (March 15, 2022). [CrossRef]
- Himmelstein DU, Thorne D, Warren E, Woolhandler S. (2007) Medical bankruptcy in the United States, 2007: results of a national study. Am J Med. 2009 August; 122(8):741-746.
- https://www.amjmed.com/action/showPdf?pii=S0002-9343%2809%2900404-5.
- Mandal, Ananya (2009) “History of Diabetes.” News-Medical.Net. 3 December 2009. https://www.news-medical.net/health/History-of-Diabetes.aspx.
- NIDDK “Symptoms & Causes of Diabetes. National Institute of Diabetes and Digestive and Kidney Diseases www.niddk.nih.gov/health-information/diabetes/overview/symptoms-causes.
- Censi S, Mian C, Betterle C. (2018) Insulin autoimmune syndrome: from diagnosis to clinical management. Ann Transl Med. 2018 September; 6(17):335. [CrossRef]
- Taylor, SI. (2020) The High Cost of Diabetes Drugs: Disparate Impact on the Most Vulnerable Patients. Diabetes Care. 2020 October; 43(10): 2330-2332. [CrossRef]
- Garber, Judith (2021) “How a Pharma-Led Campaign to Lower a Diabetes Treatment Target Put Seniors at Risk.” Lown Institute, 19 November 2021. https://lowninstitute.org/how-a-pharma-led-campaign-to-lower-a-diabetes-treatment-target-put-seniors-at-risk/.
- Angell, Marcia (2004). The truth about the drug companies: how they deceive us and what to do about it. Random House, NY. ISBN-13 978-0375760945.
- Piller, Charles (2019) The War on ‘prediabetes’ Could Be a Boon for Pharma—but Is It Good Medicine? Science. [CrossRef]
- CDC (2018) “All About Your A1C.” Centers for Disease Control and Prevention, 21 August, 2018. https://www.cdc.gov/diabetes/managing/managing-blood-sugar/a1c.html.
- Ian, B. Wilkinson, Tim Raine, Kate Wiles, Anna Goodhart, Catriona Hall and Harriet O’Neill (2017) Thinking about medicine, Chapter 1 in Oxford Handbook of Clinical Medicine (10 ed.
- DOI: 10.1093/med/9780199689903.003.0001 https://oxfordmedicine.com/view/10.1093/med/9780199689903.001.0001/med-9780199689903-chapter-1.
- https://oxfordmedicine.com/view/10.1093/med/9780199689903.001.0001/med-9780199689903-chapter-1?print=pdf.
- https://medbooksvn.org/oxford-handbook-of-clinical-medicine-10th-edition-pdf-free-download/.
- Millin, Aubin-Louis (1811) Galerie mythologique: recueil de monuments pour servir à l’étude de la mythologie, de l’histoire de l’art, de l’antiquité figurée, et du langage allégorique des anciens. Soyer, Paris, 1811. https://wellcomecollection.org/works/zh8smpa2.
- Economist Intelligence Unit (2007) The silent epidemic: An economic study of diabetes in developed and developing countries (Sponsored by Novo Nordisk, manufacturer of diabetes related medication and diagnostics tools) http://graphics.eiu.com/upload/portal/diabetes_web.pdf.
- Tabish SA (2007) Is Diabetes Becoming the Biggest Epidemic of the Twenty-first Century? Int J Health Sci (Qassim). 2007 July; 1(2): V-VIII https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3068646/pdf/ijhs-1-2-005a.pdf.
- Francesco Bianchi, Giada Bianchi and Dongho Song (2020) Long-Term Impact Of The Covid-19 Unemployment Shock On Life Expectancy And Mortality Rates. National Bureau of Economic Research (NBER), Cambridge, Massachusetts. NBER Working Paper 28304 http://www.nber.org/papers/w28304 https://www.nber.org/system/files/working_papers/w28304/w28304.pdf.
- Kakkar, T.; Richards, B.; Jha, A.; Saha, S.; Ajjan, R.; Grant, P.; Jose, G. (2015) Glucosense: Photonic Chip Based Non-Invasive Glucose Monitor. Diabetes Tech & Therapeutics 17(S1) A82-A83. 8th International Conference on Advanced Technologies & Treatments for Diabetes, Paris, France (February 18–21, 2015). [CrossRef]
- Lanzola G, Losiouk E, Del Favero S, Facchinetti A, Galderisi A, Quaglini S, Magni L, Cobelli C. (2016) Remote Blood Glucose Monitoring in mHealth Scenarios: A Review. Sensors (Basel). 2016 ; 16(12):1983. [CrossRef]
- Tang L, Chang SJ, Chen CJ, Liu JT (2020) Non-Invasive Blood Glucose Monitoring Technology: A Review. Sensors (Basel) 2020 ; 20(23): 6925. [CrossRef]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7731259/pdf/sensors-20-06925.pdf https://arxiv.org/pdf/2101.08996.pdf.
- Tamura, T. (2019) Current progress of photoplethysmography and SPO2 for health monitoring. Biomed Eng Lett. 2019 ; 9(1): 21-36. [CrossRef]
- Hasan MK, Aziz MH, Zarif MII, Hasan M, Hashem M, Guha S, Love RR, Ahamed S (2021) Noninvasive Hemoglobin Level Prediction in a Mobile Phone Environment: State of the Art Review and Recommendations. JMIR Mhealth Uhealth. 2021 ; 9(4): e16806. [CrossRef]
- Yang S, Morgan SP, Cho SY, Correia R, Wen L, Zhang Y. (2021) Non-invasive cuff-less blood pressure machine learning algorithm using photoplethysmography and prior physiological data. Blood Press Monit. 2021 ; 26(4): 312-320. [CrossRef]
- Bill Moyers Journal (2009) The Human Toll of America’s Health Disaster http://www.pbs.org/moyers/journal/blog/2009/08/the_human_toll_of_americas_hea.html.
- “Private Healthcare in India: Boons and Banes.” Institut Montaigne https://www.institutmontaigne.org/en/blog/private-healthcare-india-boons-and-banes.
- US Customs and Border Protection (CBP) Global Entry: Trusted Traveler Program https://www.cbp.gov/travel/trusted-traveler-programs/global-entry.
- Rene Millman (2006) “Heathrow Trials New Biometric Scheme.” IT PRO https://www.itpro.co.uk/99563/heathrow-trials-new-biometric-scheme.
- Allen, J. (2007) Photoplethysmography and its application in clinical physiological measurement. Physiol Meas. 2007 March; 28(3): R1-39. [CrossRef]
- Nilsson L, Johansson A, Kalman S. (2005) Respiration can be monitored by photoplethysmography with high sensitivity and specificity regardless of anaesthesia and ventilatory mode. Acta Anaesthesiol Scand. 2005 September; 49(8): 1157-1162. [CrossRef]
- Saquib, N.; Papon, M.T.I.; Ahmad, I.; Rahman, A. (2015) “Measurement of heart rate using photoplethysmography” 2015 International Conference on Networking Systems and Security (NSysS), 2015, pp. 1-6. [CrossRef]
- Seeman E and Martin, TJ. (1989) Non-invasive techniques for the measurement of bone mineral. Baillieres Clin Endo Metab. 1989 May; 3(1): 1-33. [CrossRef]
- Berger, A. (2002) Bone mineral density scans. BMJ. 2002 ; 325(7362): 484. [CrossRef]
- Negishi T, Abe S, Matsui T, Liu H, Kurosawa M, Kirimoto T, Sun G. (2020) Contactless Vital Signs Measurement System Using RGB-Thermal Image Sensors and Its Clinical Screening Test on Patients with Seasonal Influenza. Sensors (Basel). 2020 ; 20(8): 2171. [CrossRef]
- Goldstein JL, Brown MS. (1973) Familial hypercholesterolemia: identification of a defect in the regulation of 3-hydroxy-3-methylglutaryl coenzyme A reductase activity associated with overproduction of cholesterol. Proc Natl Acad Sci USA 1973 October; 70(10): 2804-2808. [CrossRef]
- Bonita R, Beaglehole R, Asplund K. (1994) The worldwide problem of stroke. Curr Opin Neurol. 1994 February; 7(1): 5-10. [CrossRef]
- Jameson JL, Fauci AS, Kasper DL, Hauser SL, Longo DL, Loscalzo J, eds. Harrison’s Principles of Internal Medicine. 21st ed. McGraw Hill, 2022. ISBN-13 : 978-1264268504 https://accessmedicine.mhmedical.com/book.aspx?bookid=3095.
- Bui AL, Horwich TB, Fonarow GC. (2011) Epidemiology and risk profile of heart failure. Nat Rev Cardiol. 2011 January; 8(1): 30-41. [CrossRef]
- Heberden, William (1772) Some account of a disorder of the breast.
- Medical Transactions. The Royal College of Physicians of London. 2: 59-67, 1772.
- Silverman, ME (1987) William Heberden and Some Account of a Disorder of the Breast. Clinical Cardiology 1987 March; 10(3): 211-213. [CrossRef]
- Vashista, Shivani (2019) History of medicine—William Heberden. J Pract Cardiovasc Science 2019 5:164-165. [CrossRef]
- Saglietto A, Manfredi R, Elia E, D’Ascenzo F, DE Ferrari GM, Biondi-Zoccai G, Munzel T (2021) Cardiovascular disease burden: Italian and global perspectives. Minerva Cardiol Angiol. 2021 June; 69(3): 231-240. [CrossRef]
- Datta, Shoumen (2020) Aptamers for Detection and Diagnostics (ADD): Can mobile systems process optical data from aptamer sensors to identify molecules indicating presence of SARS-CoV-2 virus? Should healthcare explore aptamers as drugs for prevention as well as its use as adjuvants with antibodies and vaccines? (unpublished manuscript) PDF “Part 2: SARS-CoV-2” MIT Library https://dspace.mit.edu/handle/1721.1/145774.
- Schultz JC, Hilliard AA, Cooper LT Jr, Rihal CS. (2009) Diagnosis and treatment of viral myocarditis. Mayo Clin. 2009 November; 84(11):1001-9. [CrossRef]
- Michael Kang and Jason An (2022) Viral Myocarditis. [Updated 2022 Jan 5]. StatPearls Publishing. https://www.ncbi.nlm.nih.gov/books/NBK459259.
- Liu M, Li XC, Lu L, Cao Y, Sun RR, Chen S, Zhang PY. (2014) Cardiovascular disease and its relationship with chronic kidney disease. Eur Rev Med Pharmacol Sci. 2014 October; 18(19): 2918-2926 https://www.europeanreview.org/wp/wp-content/uploads/2918-2926.
- Bade, Richard, et al. (2022) “A Taste for New Psychoactive Substances: Wastewater Analysis Study of 10 Countries.” Environ Sci & Tech Letters, vol. 9, no. 1, 22, pp. 57-63. [CrossRef]
- Krauser DG, Lloyd-Jones DM, Chae CU, Cameron R, Anwaruddin S, Baggish AL, Chen A, Tung R, Januzzi JL Jr. (2005) Effect of body mass index on natriuretic peptide levels in patients with acute congestive heart failure: a ProBNP Investigation of Dyspnea in the Emergency Department (PRIDE) substudy. Am Heart J. 2005 April; 149(4): 744-750. [CrossRef]
- Djoussé L, Driver JA, Gaziano JM. (2009) Relation Between Modifiable Lifestyle Factors and Lifetime Risk of Heart Failure. JAMA. 2009; 302(4): 394–400. [CrossRef]
- Andrew Abboud and James, L. Januzzi, Jr. (2020) “Heart Failure Biomarkers in COVID-19.” American College of Cardiology. July 27, 2020. https://www.acc.org/latest-in-cardiology/articles/2020/07/27/09/25/heart-failure-biomarkers-in-covid-19.
- COVID-19 Cumulative Infection Collaborators (2022) Estimating global, regional, and national daily and cumulative infections with SARS-CoV-2 through November 14, 2021: a statistical analysis. LANCET (April 8, 2022). [CrossRef]
- https://www.thelancet.com/action/showPdf?pii=S0140-6736%2822%2900484-6.
- Castiglioni S, Salgueiro-González N, Bijlsma L, Celma A, Gracia-Lor E, Beldean-Galea MS, Mackuľak T, Emke E, Heath E, Kasprzyk-Hordern B, Petkovic A, Poretti F, Rangelov J, Santos MM, Sremački M, Styszko K, Hernández F, Zuccato E. (2021) New psychoactive substances in several European populations assessed by wastewater-based epidemiology. Water Res. 2021 ; 195: 116983. [CrossRef]
- Martinez-Velazquez, R.; Gamez, R.; El Saddik, A. (2019) “Cardio Twin: A Digital Twin of the human heart running on the edge” 2019 IEEE International Symposium on Medical Measurements and Applications 2019, pp. 1-6. [CrossRef]
- Corral-Acero J, Margara F, Marciniak M, Rodero C, Loncaric F, Feng Y, Gilbert A, Fernandes JF, Bukhari HA, Wajdan A, Martinez MV, Santos MS, Shamohammdi M, Luo H, Westphal P, Leeson P, DiAchille P, Gurev V, Mayr M, Geris L, Pathmanathan P, Morrison T, Cornelussen R, Prinzen F, Delhaas T, Doltra A, Sitges M, Vigmond EJ, Zacur E, Grau V, Rodriguez B, Remme EW, Niederer S, Mortier P, McLeod K, Potse M, Pueyo E, Bueno-Orovio A, Lamata P. (2020) The ‘Digital Twin’ to enable the vision of precision cardiology. Eur Heart J. 2020 ; 41(48): 4556-4564. [CrossRef]
- Gupta M and Sharma, A. (2021) Fear of missing out: A brief overview of origin, theoretical underpinnings and relationship with mental health. World J Clin Cases. 2021 ; 9(19): 4881-4889. [CrossRef]
- Wang XY, Zhang F, Zhang C, Zheng LR, Yang J. (2020) Biomarkers for Acute Myocardial Infarction and Heart Failure. Biomed Res Int. 2020 ; 2020:2018035 https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6988690/pdf/BMRI2020-2018035.
- Jaffe AS, Babuin L, Apple FS. (2006) Biomarkers in acute cardiac disease: the present and the future. J Am Coll Cardiol. 2006 ; 48(1):1-11. [CrossRef]
- Shioda K, Lopman B. (2022) How to interpret the total number of SARS-CoV-2 infections. Lancet. 2022 : S0140-6736(22)00629-8. [CrossRef]
- Bleile, MaryLena (2021) Theoretical Justification of the Bi Error Method. ArXiv:2009.12453 [Stat], vol. 284, 2021, pp. 196–209. [CrossRef]
- Bleile, M. (2021). Youden’s J and the Bi Error Method. In: Arai, K. (eds) Intelligent Computing. Lecture Notes in Networks and Systems, vol 284. Springer, Cham. [CrossRef]
- Felder, S., Mayrhofer, T. (2022). Basic Tools in Medical Decision Making in Medical Decision Making. Springer, Berlin, Heidelberg. [CrossRef]
- Youden, WJ. (1950) Index for rating diagnostic tests. Cancer. 1950 January; 3(1): 32-35.
- Sudoh T, Kangawa K, Minamino N, Matsuo H. (1988) A new natriuretic peptide in porcine brain. Nature. 1988 ; 332(6159): 78-81. [CrossRef]
- https://www.nature.com/articles/332078a0.pdf.
- Maalouf R, Bailey S. (2016) A review on B-type natriuretic peptide monitoring: assays and biosensors. Heart Fail Rev. 2016 September; 21(5): 567-578. [CrossRef]
- Grabowska I, Sharma N, Vasilescu A, Iancu M, Badea G, Boukherroub R, Ogale S, Szunerits S. (2018) Electrochemical Aptamer-Based Biosensors for the Detection of Cardiac Biomarkers. ACS Omega. 2018 ; 3(9):12010-12018. [CrossRef]
- Durak-Nalbantić A, Džubur A, Dilić M, Pozderac Z, Mujanović-Narančić A, Kulić M, Hodžić E, Resić N, Brdjanović S, Zvizdić F. (20212) Brain natriuretic peptide release in acute myocardial infarction. Bosnian Journal of Basic Medical Science 2012 August; 12(3): 164-168 https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4362425/pdf/BJBMS-12-164.pdf.
- Gorenjak, M. Natriuretic Peptides in Assessment of Ventricular Dysfunction. EJIFCC. 2003 Jul 3;14(2):89-91. PMCID: PMC6169139. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6169139/pdf/ejifcc-14-089. [PubMed]
- de Bold AJ, Borenstein HB, Veress AT, Sonnenberg H. (1981) A rapid and potent natriuretic response to intravenous injection of atrial myocardial extract in rats. Life Sci. 1981 ; 28(1): 89-94. [CrossRef]
- Sandefur CC, Jialal I. (2021) Atrial Natriuretic Peptide. StatPearls Publishing, 2022. https://www.ncbi.nlm.nih.gov/books/NBK562257/.
- Clerico A, Iervasi G, Del Chicca MG, Emdin M, Maffei S, Nannipieri M, Sabatino L, Forini F, Manfredi C, Donato L. (1998) Circulating levels of cardiac natriuretic peptides (ANP and BNP) measured by highly sensitive and specific immunoradiometric assays in normal subjects and in patients with different degrees of heart failure. J Endocrinol Invest. 1998 March; 21(3): 170-179. [CrossRef]
- Bailey, K. (1946) Tropomyosin: a new asymmetric protein component of muscle. Nature, 1946 ; 157:368. [CrossRef]
- Jaffe AS, Babuin L, Apple FS. 2006) Biomarkers in acute cardiac disease: the present and the future. J Am Coll Cardiol. 2006 ; 48(1): 1-11. [CrossRef]
- Garg P, Morris P, Fazlanie AL, Vijayan S, Dancso B, Dastidar AG, Plein S, Mueller C, Haaf P. (2017) Cardiac biomarkers of acute coronary syndrome: from history to high-sensitivity cardiac troponin. Intern Emerg Med. 2017 March; 12(2): 147-155. [CrossRef]
- Apple, F.S. (1989) Diagnostic use of CK-MM and CK-MB isoforms for detecting myocardial infarction. Clin Lab Med. 1989 December; 9(4): 643-654.
- Thygesen K, Alpert JS, Jaffe AS, Chaitman BR, Bax JJ, Morrow DA, White HD; Executive Group on behalf of the Joint European Society of Cardiology (ESC)/American College of Cardiology (ACC)/American Heart Association (AHA)/World Heart Federation (2018) Task Force for the Universal Definition of Myocardial Infarction. Fourth Universal Definition of Myocardial Infarction (2018). Circulation. 2018 ; 138(20): e618-e651. [CrossRef]
- Mueller C, Giannitsis E, Jaffe AS, Huber K, Mair J, Cullen L, Hammarsten O, Mills NL, Möckel M, Krychtiuk K, Thygesen K, Lindahl B; ESC Study Group on Biomarkers in Cardiology of the Acute Cardiovascular Care Association. (2021) Cardiovascular biomarkers in patients with COVID-19. Eur Heart J Acute Cardiovasc Care. 2021 ; 10(3): 310-319. [CrossRef]
- Korff S, Katus HA, Giannitsis E. (2006) Differential diagnosis of elevated troponins. Heart. 2006 July; 92(7): 987-993. [CrossRef]
- Islam MN, Alam MF, Debnath RC, Aditya GP, Ali MH, Hossain MA, Siddique SR. (2016) Correlation between Troponin-I and B-Type Natriuretic Peptide Level in Acute Myocardial Infarction Patients with Heart Failure. Mymensingh Med J. 2016 April; 25(2): 226-231.
- Schwuchow-Thonke S, Göbel S, Emrich T, Schmitt VH, Fueting F, Klank C, Escher F, Schultheiss HP, Münzel T, Keller K, Wenzel P. (2021) Increased C reactive protein, cardiac troponin I and GLS are associated with myocardial inflammation in patients with non-ischemic heart failure. Science Rep. 2021 ; 11(1): 3008. [CrossRef]
- Patterson CC, Blankenberg S, Ben-Shlomo Y, Heslop L, Bayer A, Lowe G, Zeller T, Gallacher J, Young I, Yarnell JWG. (2018) Troponin and BNP are markers for subsequent non-ischaemic congestive heart failure: the Caerphilly Prospective Study (CaPS). Open Heart. 2018 ; 5(1): e000692. [CrossRef]
- Billman, GE. (2020) Homeostasis: The Underappreciated and Far Too Often Ignored Central Organizing Principle of Physiology. Front Physiol. 2020 ; 11: 200. [CrossRef]
- NASA—Mars Exploration Program https://mars.nasa.gov.
- Ken Robichaux (2021) The Picture Show Man https://pictureshowman.com/what-and-when-was-the-first-movie-shown-on-television/.
- Langer A, Freeman MR, Josse RG, Steiner G, Armstrong PW. (1991) Detection of silent myocardial ischemia in diabetes mellitus. Am J Cardiol. 1991 ; 67(13): 1073-1078. [CrossRef]
- Gul Z, Makaryus Amgad. (2021) Silent Myocardial Ischemia. StatPearls Publishing, 2022. https://www.ncbi.nlm.nih.gov/books/NBK536915.
- Nesto RW, Watson FS, Kowalchuk GJ, Zarich SW, Hill T, Lewis SM, Lane SE. (1990) Silent myocardial ischemia and infarction in diabetics with peripheral vascular disease: assessment by dipyridamole thallium-201 scintigraphy. Am Heart J. 1990 November; 120(5): 1073-1077. [CrossRef]
- Gutterman, David (2013) Silent Myocardial Ischemia https://www.escardio.org/static-file/Escardio/education/live-events/courses/education-resource/Fri-11-SMI-Gutterman.pdf.
- Williams SA, Ostroff R, Hinterberg MA, Coresh J, Ballantyne CM, Matsushita K, Mueller CE, Walter J, Jonasson C, Holman RR, Shah SH, Sattar N, Taylor R, Lean ME, Kato S, Shimokawa H, Sakata Y, Nochioka K, Parikh CR, Coca SG, Omland T, Chadwick J, Astling D, Hagar Y, Kureshi N, Loupy K, Paterson C, Primus J, Simpson M, Trujillo NP, Ganz P. (2022) A proteomic surrogate for cardiovascular outcomes that is sensitive to multiple mechanisms of change in risk. Sci Trans Med 2022 Apr 6; 14(639):eabj9625. [CrossRef]
- Wang X, Kaczor-Urbanowicz KE, Wong DT. (2017) Salivary biomarkers in cancer detection. Medical Oncology 2017 January; 34(1): 7. [CrossRef]
- Henry NL and Hayes, DF. (2012) Cancer biomarkers. Molecular Oncology 2012 April; 6(2):140-146. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5528374/pdf/MOL2-6-140.pdf.
- National Cancer Institute (NCI, NIH) Biomarker Testing for Cancer Treatment (2021) https://www.cancer.gov/about-cancer/treatment/types/biomarker-testing-cancer-treatment.
- Costa PA, Saul EE, Paul Y, Iyer S, da Silva LL, Tamariz L, Lopes G. (2021) Prevalence of Targetable Mutations in Black Patients With Lung Cancer: A Systematic Review and Meta-Analysis. JCO Oncol Pract. 2021 May; 17(5): e629-e636. [CrossRef]
- Dietlein F, Wang AB, Fagre C, Tang A, Besselink NJM, Cuppen E, Li C, Sunyaev SR, Neal JT, Van Allen EM. (2022) Genome-wide analysis of somatic noncoding mutation patterns in cancer. Science. 2022 ; 376(6589) www.science.org/doi/10.1126/science.abg5601.
- Nurk S, Koren S, Rhie A, Rautiainen M, Bzikadze AV, Mikheenko A, Vollger MR, Altemose N, Uralsky L, Gershman A, Aganezov S, Hoyt SJ, Diekhans M, Logsdon GA, Alonge M, Antonarakis SE, Borchers M, Bouffard GG, Brooks SY, Caldas GV, Chen NC, Cheng H, Chin CS, Chow W, de Lima LG, Dishuck PC, Durbin R, Dvorkina T, Fiddes IT, Formenti G, Fulton RS, Fungtammasan A, Garrison E, Grady PGS, Graves-Lindsay TA, Hall IM, Hansen NF, Hartley GA, Haukness M, Howe K, Hunkapiller MW, Jain C, Jain M, Jarvis ED, Kerpedjiev P, Kirsche M, Kolmogorov M, Korlach J, Kremitzki M, Li H, Maduro VV, Marschall T, McCartney AM, McDaniel J, Miller DE, Mullikin JC, Myers EW, Olson ND, Paten B, Peluso P, Pevzner PA, Porubsky D, Potapova T, Rogaev EI, Rosenfeld JA, Salzberg SL, Schneider VA, Sedlazeck FJ, Shafin K, Shew CJ, Shumate A, Sims Y, Smit AFA, Soto DC, Sović I, Storer JM, Streets A, Sullivan BA, Thibaud-Nissen F, Torrance J, Wagner J, Walenz BP, Wenger A, Wood JMD, Xiao C, Yan SM, Young AC, Zarate S, Surti U, McCoy RC, Dennis MY, Alexandrov IA, Gerton JL, O’Neill RJ, Timp W, Zook JM, Schatz MC, Eichler EE, Miga KH, Phillippy AM. (2022) The complete sequence of a human genome. Science. 2022 April; 376(6588): 44-53. [CrossRef]
- [a] Monod J, Changeux JP and Jacob F. (1963) Allosteric proteins and cellular control systems. J Mol Biol. 1963 April; 6: 306-329. [CrossRef]
- [b] Monod J, Wyman J, Changeux JP (1965) On The Nature Of Allosteric Transitions: A Plausible Model. J Mol Biol. 1965 May; 12: 88-118. [CrossRef]
- Changeux, JP. (2013) 50 years of allosteric interactions: the twists and turns of the models. Nat Rev Mol Cell Biol. 2013 December; 14(12): 819-829. [CrossRef]
- Andre, J. Faure, Júlia Domingo, Jörn M. Schmiedel, Cristina Hidalgo-Carcedo, Guillaume Diss and Ben Lehner (2022) Mapping the energetic and allosteric landscapes of protein binding domains. Nature, 2022. [Google Scholar] [CrossRef]
- https://www.nature.com/articles/s41586-022-04586-4.pdf.
- Jocelyn Kaiser (2022) New Generation of Cancer-Preventing Vaccines Could Wipe out Tumors before They Form. Science (, 2022). [CrossRef]
- Tsunoda, Tomonori, Krosse, Sebastian and van Dam, Nicole M. (2017) “Root and Shoot Glucosinolate Allocation Patterns Follow Optimal Defence Allocation Theory.” Journal of Ecology, edited by Kenneth Whitney, vol. 105, no. 5, 17, pp. 1256–1266. [CrossRef]
- Mukhtar, Hussnain, Rainer F. Wunderlich, and Yu-Pin Lin. (2022) “Digital Twins of the Soil Microbiome for Climate Mitigation” Environments 9, no. 3: 34. [CrossRef]
- Parker, Martin. (2018) Shut down the Business School: What’s Wrong with Management Education. Pluto Press, 2018. https://www.theguardian.com/news/2018/apr/27/bulldoze-the-business-school.
- Daniel, W. Engels, Sanjay E. Sarma, Laxmiprasad Putta, David Brock (2022) The Networked Physical World System. International Conference WWW/Internet 2002 (ICWI): pages 104-111.
- https://www.researchgate.net/profile/Daniel-Engels-2/publication/220969017_The_Networked_Physical_World_System/links/0c96052aba0920de0e000000/The-Networked-Physical-World-System.pdf.
- Anandaraj, S.P. , Poornima S., Vignesh R., Ravi V. (2022) Industrial Automation of IoT in 5G Era. In: Velliangiri S., Gunasekaran M., Karthikeyan P. (eds) Secure Communication for 5G and IoT Networks. EAI/Springer Innovations in Communication and Computing. Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-030-79766-9_6.
- John Godfrey Saxe (1816-1887) The Blind Men and the Elephant.
- https://allpoetry.com/The-Blind-Man-And-The-Elephant https://www.extension.iastate.edu/4h/files/page/files/The%20Blind%20Men%20and%20the%20Elephant.pdf.
- http://realityraiders.com/fringewalker/belief-systems/the-blind-men-and-the-elephant/.
- Kahneman, D. (2011). Thinking, fast and slow. Farrar, Straus and Giroux. 978-0374533557.
- http://dspace.vnbrims.org:13000/jspui/bitstream/123456789/2224/1/Daniel-Kahneman-Thinking-Fast-and-Slow-.pdf.
- Eliza Strickland (2022) “Andrew Ng: Farewell, Big Data.” IEEE Spectrum, 9 February 2022. https://spectrum.ieee.org/andrew-ng-data-centric-ai.
- Max Born (1924) “Über Quantenmechanik”, Z. Phys. 26, 379–395 in Sources of Quantum Mechanics, edited by B. L. van der Waerden Dover, New York, 1968.
- Dirac, P.A.M. (1925) “The fundamental equations of quantum mechanics” Proceedings of the Royal Society of London, Series A 109, 642–653 1925 https://www.informationphilosopher.com/solutions/scientists/dirac/Fund_QM_1925.pdf.
- Wilczek, Frank (2000) “QCD made simple.” Phys. Today 53.8 (2000): 22-28. DOI S-0031-9228-0008-010-8 https://frankwilczek.com/Wilczek_Easy_Pieces/298_QCD_Made_Simple.pdf https://cerncourier.com/a/the-history-of-qcd/ and https://cds.cern.ch/record/943008/files/p55.pdf.
- Aaltonen, T.; et al. (2022) High-precision measurement of the WW boson mass with the CDF II detector. Science 376 (2006) 6589, 170-176. April 8, 2022. [CrossRef]
- Anish Agarwal, Abdullah Alomar, Devavrat Shah (2022) On Multivariate Singular Spectrum Analysis and its Variants. [CrossRef]
- Corey, E.J. , Ohno, Masaji, Mitra, Rajat B., and Vatakencherry, Paul A. (1964) Total Synthesis of Longifolene. Journal of the American Chemical Society 1964, 86, 3, 478–485. [Google Scholar]
- https://doi.org/10.1021/ja01057a039 & www.nobelprize.org/prizes/chemistry/1990/summary/.
- Ansys Motion Multibody Dynamics Simulation Software.
- https://www.ansys.com/products/structures/ansys-motion.
- Alawadhi, E.M. (2010). Finite Element Simulations Using ANSYS (1st ed.). [CrossRef]
- Murray-Watson Rachel, E. and Cunniffe Nik J. (2022) How the epidemiology of disease-resistant and disease-tolerant varieties affects grower behaviour. Journal of the Royal Society Interface. 19: 20220517. [CrossRef]
- Hiroshi Ishii (1990) TeamWorkStation: towards a seamless shared workspace. In Proceedings of the 1990 ACM conference on Computer-supported cooperative work (CSCW ‘90). ACM (NY, USA) 13-26. [CrossRef]
- Brygg Ullmer. (1997) Models and Mechanisms for Tangible User Interfaces. Thesis (M.S.)--Massachusetts Institute of Technology, Program in Media Arts & Sciences, 1997. https://trackr-media.tangiblemedia.org/publishedmedia/Papers/324-Models%20and%20Mechanisms%20for/Published/PDF.
- Ullmer, B. and Ishii, H. (2000) Emerging frameworks for tangible user interfaces. IBM Syst. J. 39, 3-4 (00), 915-931.https://trackr-media.tangiblemedia.org/publishedmedia/Papers/295-Emerging%20Frameworks%20for%20Tangible/Published/PDF.
- MIT Museum (September 20, 2022) SandScape: Tangible User Interface Exhibition.
- https://tangible.media.mit.edu/event/187/ and www.media.mit.edu/projects/sandscape/overview.
- Proctor, J. , Rigden, A., Chan, D. and Huybers, P. (2022) More accurate specification of water supply shows its importance for global crop production. Natre Food, 2022. [Google Scholar] [CrossRef]
- Nechifor V, Winning M. (2019) Global crop output and irrigation water requirements under a changing climate. Heliyon. 2019 ; 5(3):e01266. [CrossRef]
- Ammar ME, Davies EGR. (2019) On the accuracy of crop production and water requirement calculations: Process-based crop modeling at daily, semi-weekly, and weekly time steps for integrated assessments. Journal of Environmental Management. 2019 ; 238:460-472. [CrossRef]
- MIT App Inventor—Lego Mindstorms https://appinventor.mit.edu/explore/content/legoMindstorms.html.
- Joe Olayvar and Evelyn Lindberg (2016) LEGO Mindstorms EV3 Programming Basics https://www.sos.wa.gov/_assets/library/libraries/projects/youthservices/legoMindstormsev3programmingbasics.pdf.
- Lego Mindstorms—User Guide https://www.lego.com/cdn/cs/set/assets/bltbef4d6ce0f40363c/LMSUser_Guide_LEGO_MINDSTORMS_EV3_11_Tablet_ENUS.pdf.
- Giacobassi, C.A.; Oliveira, D.A.; Pola, C.C.; Xiang, D.; Tang, Y.; Datta, S.P.A.; McLamore, E.S.; Gomes, C.L. (2021) Sense–Analyze–Respond–Actuate (SARA) Paradigm: Proof of Concept System Spanning Nanoscale and Macroscale Actuation for Detection of Escherichia coli in Aqueous Media. Actuators 2021, 10, 2. [Google Scholar] [CrossRef]
- MIT SCRATCH https://scratch.mit.edu/projects/editor/?tutorial=getStarted.
- Elisabeth Sylvan (2007) The sharing of wonderful ideas : influence and interaction in Online Communities of Creators. PhD Thesis. Massachusetts Institute of Technology, School of Architecture and Planning, Program in Media Arts and Sciences, February 2008. https://dspace.mit.edu/handle/1721.1/42404 https://dspace.mit.edu/bitstream/handle/1721.1/42404/237183488-MIT.pdf?sequence=2&isAllowed=y.
- https://thunkable.com/.
- Margaret Evans and Resnick, Mitchel (2016) “Member Collaboration: LEGO Mindstorms.” MIT Media Lab, Massachusetts Institute of Technology, Cambridge, MA https://www.media.mit.edu/posts/member-collaboration-lego-s-Mindstorms/.
- Papert, Seymour (1980) Mindstorms: Children, Computers, and Powerful Ideas. 1st edition. New York: Basic Books, 1980. https://dl.acm.org/doi/pdf/10.5555/1095592.
- Ansys Materials Data for Simulation.
- https://www.ansys.com/products/materials/materials-data-for-simulation.
- Nowak, Grzegorz, et al. (2020) “Improving the Power Unit Operation Flexibility by the Turbine Start-up Optimization.” Energy, vol. 198, 20, p. 117303. [CrossRef]
- Drinkwater, Laurie E. (2016) Systems Research for Agriculture: Innovative Solutions to Complex Challenges. Sustainable Agriculture Research and Education (SARE) Program, NIFA (National Institute of Food and Agriculture), U.S. Department of Agriculture (USDA) 2016.
- https://www.sare.org/wp-content/uploads/Systems-Research-for-Agriculture.pdf.
- Datta, S. and Goldman, J.M. (2017) Healthcare—Digital Transformation of the Healthcare Value Chain: Emergence of Medical Internet of Things (MIoT) may need an Integrated Clinical Environment https://arxiv.org/abs/1703.04524 & https://dspace.mit.edu/handle/1721.1/107893 https://arxiv.org/ftp/arxiv/papers/1703/1703.04524.pdf.
- Mason RE, Craine JM, Lany NK, Jonard M, Ollinger SV, Groffman PM, Fulweiler RW, Angerer J, Read QD, Reich PB, Templer PH, Elmore AJ. (2022) Evidence, causes, and consequences of declining nitrogen availability in terrestrial ecosystems. Science. 2022 ; 376(6590):eabh3767. [CrossRef]
- National Research Council (US) Committee on the Ocean’s Role in Human Health. (1999) From Monsoons to Microbes: Understanding the Ocean’s Role in Human Health. Washington (DC): National Academies Press (US); 1999. 3, Harmful Algal Blooms. https://www.ncbi.nlm.nih.gov/books/NBK230692/ https://www.ncbi.nlm.nih.gov/books/NBK230696/pdf/Bookshelf_NBK230696.pdf.
- Sharpley, A. and Beegle, D. (2001) Managing Phosphorous for Agriculture and the Environment. Pennsylvania State University (Penn State) College of Agricultural Sciences, Agricultural Research and Cooperative Extension https://extension.psu.edu/downloadable/download/sample/sample_id/20723/.
- Box, George E. P. (1976) “Science and statistics” Journal of the American Statistical Association, 71 (356): 791–799. [CrossRef]
- National Public Radio (2016) Hidden History Of Koch Brothers Traces Their Childhood And Political Rise. NPR, 19 January 2016. https://www.npr.org/2016/01/19/463565987/hidden-history-of-koch-brothers-traces-their-childhood-and-political-rise.
- Xiao R, Ross JS, Gross CP, Dusetzina SB, McWilliams JM, Sethi RKV, Rathi VK. (2022) Hospital-Administered Cancer Therapy Prices for Patients With Private Health Insurance. JAMA Intern Med. 2022. [CrossRef]
- Don’t Let ‘Perfect’ Be the Enemy of Good. Harvard Business Review, 14 February 2020. https://hbr.org/tip/2020/02/dont-let-perfect-be-the-enemy-of-good.
- Elizabeth, Sifa. (2019) “Book Review: ARCHENEMIES by Marissa Meyer.” Sifa Elizabeth Reads, 19 April 2019. https://sifaelizabethreads.wordpress.com/2019/04/19/book-review-archenemies-by-marissa-meyer/.
- Snow, Charles Percy (1959) The Two Cultures. London: Cambridge University Press. ISBN 978-0-521-45730-9 http://sciencepolicy.colorado.edu/students/envs_5110/snow_1959.pdf https://apps.weber.edu/wsuimages/michaelwutz/6510.Trio/Rede-lecture-2-cultures.pdf.
- Snow, Charles Percy (1963). The Two Cultures: And a Second Look: An Expanded Version of The Two Cultures and the Scientific Revolution. Cambridge University Press http://www.christs.cam.ac.uk/cms_misc/media/Publications_Christs_Magazine_2010_web.pdf.
- Jacob Bronowski (1956) Science and Human Value. Lectures at MIT, 1953. Julian Messner, Inc., New York. .
- https://sciencepolicy.colorado.edu/students/envs_5110/bronowski_1956.pdf (1956 edition) https://books.google.com/books/about/Science_and_Human_Values.html?id=aE35f348ztIC Science and Human Values. Nature 179 221–222 (1957). [CrossRef]
- Toye, F. (2015) ‘Not everything that can be counted counts and not everything that counts can be counted’ (attributed to Albert Einstein). The British Pain Society. British Journal of Pain. 2015 February; 9(1):7. [CrossRef]
- Balasubramanian, V., B. Alves, M. Aulakh, M. Bekunda, Z. Cai, L. Drinkwater, D. Mugendi, C. van Kessel, and O. Oenema. (2004) Crop, Environmental, and Management Factors Affecting Nitrogen Use Efficiency in Agriculture and the Nitrogen Cycle: Assessing the Impacts of Fertilizer Use on Food Production and the Environment, ed A.R. Mosier, K. Syers, and J.R. Freney. pp. 19–33 The Scientific Committee on Problems of the Environment (SCOPE), Island Press: Washington, DC. https://www.researchgate.net/profile/Milkha-Aulakh/publication/40120929_Crop_environmental_and_management_factors_affecting_nitrogen_use_efficiency/links/5b71c0faa6fdcc87df744597/Crop-environmental-and-management-factors-affecting-nitrogen-use-efficiency.pdf.
- Yousefzadeh, R.; Cao, X. (2022) To what extent should we trust AI models when they extrapolate? https://doi.org/10.48550/arXiv.2201.11260 & https://arxiv.org/pdf/2201.11260.pdf.
- Andreasson JOL, Gotrik MR, Wu MJ, Wayment-Steele HK, Kladwang W, Portela F, Wellington-Oguri R; Eterna Participants, Das R, Greenleaf WJ. (2022) Crowdsourced RNA design discovers diverse, reversible, efficient, self-contained molecular switches. Proc Natl Acad Sci USA 2022 ; 119(18):e2112979119. [CrossRef]
- Data Distribution Service (DDS) Standard https://www.omg.org/omg-dds-portal/.
- Zobell, Steven (2018) “Why Digital Transformations Fail: Closing The $900 Billion Hole In Enterprise Strategy.” Forbes.https://www.forbes.com/sites/forbestechcouncil/2018/03/13/why-digital-transformations-fail-closing-the-900-billion-hole-in-enterprise-strategy/.
- Bert Farabaugh (2018) 11 Myths About the DDS Standard https://www.electronicdesign.com/technologies/embedded-revolution/article/21807399/11-myths-about-the-dds-standard.
- Angelo Corsaro and Douglas, C. Schmidt (2020) The Data Distribution Service: The Communication Middleware Fabric for Scalable and Extensible Systems-of-Systems https://www.dre.vanderbilt.edu/~schmidt/PDF/dds-sos.pdf.
- Datta, S, Lyu, J. and Chen, P-S. (2007) Decision Support and Systems Interoperability in Global Business Management. International J of Electronic Business Management 5 255-265 http://dspace.mit.edu/handle/1721.1/41917.
- David, W. Johnson (2020) Healthcare’s Epic Problem https://www.4sighthealth.com/wp-content/uploads/2020/02/4sightHealth-Healthcares-Epic-Problem.MCC_.2-4-20.pdf.
- Epic CEO Judy Faulkner Asks Hospitals to Oppose HHS’ Interoperability Rule. https://www.beckershospitalreview.com/ehrs/epic-ceo-judy-faulkner-asks-hospitals-to-oppose-hhs-interoperability-rule.html.
- Caldwell, Patrick (2015) “We’ve Spent Billions to Fix Our Medical Records, and They’re Still a Mess. Here’s Why.” Mother Jones. https://www.motherjones.com/politics/2015/10/epic-systems-judith-faulkner-hitech-ehr-interoperability.
- Jennings, Katie (2021) “The Billionaire Who Controls Your Medical Records.” Forbes. https://www.forbes.com/sites/katiejennings/2021/04/08/billionaire-judy-faulkner-epic-systems.
- Analog versus Digital Comparison Chart https://www.ccri.edu/faculty_staff/engt/jbernardini/JB-Website/ENGR1020/1020-016-Fall/10-Analog-Digital-Compare.pdf.
- Framework for Assessing Effects of the Food System (2015). National Academies Press. http://nap.edu/18846 (Figures 7-A-4 and 7-A-5).
- Rips, Lance J., Edward J. Shoben and Edward J. Smith (1973) “Semantic Distance and the Verification of Semantic Relations.” Journal of Verbal Learning and Verbal Behavior, vol. 12, no. 1, Feb. 1973, pp. 1–20. [CrossRef]
- http://arkiv.inf.ku.dk/KoLifeboat/CONCEPTS/semantic_distance.htm.
- Saif Mohammad and Graeme Hirst (2005) Distributional Measures of Semantic Distance: A Survey. [CrossRef]
- Death by PCA https://psnet.ahrq.gov/web-mm/death-pca.
- McClintock Barbara (1950) The origin and behavior of mutable loci in maize. Proc Natl Acad Sci USA 1950 June; 36(6): 344-355. [CrossRef]
- Hackl T, Laurenceau R, Ankenbrand MJ, Bliem C, Cariani Z, Thomas E, Dooley KD, Arellano AA, Hogle SL, Berube P, Leventhal GE, Luo E, Eppley JM, Zayed AA, Beaulaurier J, Stepanauskas R, Sullivan MB, DeLong EF, Biller SJ, Chisholm SW. (2023) Novel integrative elements and genomic plasticity in ocean ecosystems. Cell. 2023 ;186(1):47-62.e16. [CrossRef]
- Koonin EV, Makarova KS. (2017) Mobile Genetic Elements and Evolution of CRISPR-Cas Systems: All the Way There and Back. Genome Biol Evol. 2017 ; 9(10): 2812-2825. [CrossRef]
- Barbara McClintock (1983) The Nobel Prize in Physiology or Medicine https://www.nobelprize.org/prizes/medicine/1983/mcclintock/facts/.
- Morgan, T. H. (1922) Croonian Lecture: On the Mechanism of Heredity. Proceedings of the Royal Society of London. Series B, Containing Papers of a Biological Character, 94 (659). pp. 162-197.
- https://resolver.caltech.edu/CaltechAUTHORS:20141216-130147953 https://www.jstor.org/stable/pdf/80899.pdf?refreqid=excelsior%3Af0504abc13b5ce5276c02cb539dcd3fb&ab_segments=&origin=.
- Altae-Tran H, Kannan S, Demircioglu FE, Oshiro R, Nety SP, McKay LJ, Dlakić M, Inskeep WP, Makarova KS, Macrae RK, Koonin EV, Zhang F. (2021) The widespread IS200/IS605 transposon family encodes diverse programmable RNA-guided endonucleases. Science. 2021 October; 374(6563): 57-65. [CrossRef]
- Damon Lisch (2008) Epigenetic Regulation of Transposable Elements in Plants. Annual Review of Plant Biology (2009) 60:1, 43-66. [CrossRef]
- Mandadi KK, Scholthof KB. (2013) Plant immune responses against viruses: how does a virus cause disease? Plant Cell. 2013 May; 25(5): 1489-1505. [CrossRef]
- Zhao P, Yao X, Cai C, Li R, Du J, Sun Y, Wang M, Zou Z, Wang Q, Kliebenstein DJ, Liu SS, Fang RX, Ye J. (2019) Viruses mobilize plant immunity to deter nonvector insect herbivores. Sci Adv. 2019 ; 5(8): eaav9801. [CrossRef]
- Cai Q, Qiao L, Wang M, He B, Lin FM, Palmquist J, Huang SD, Jin H. (2018) Plants send small RNAs in extracellular vesicles to fungal pathogen to silence virulence genes. Science. 2018 ; 360(6393): 1126-1129. [CrossRef]
- Cai Q, He B, Weiberg A, Buck AH, Jin H. (2019) Small RNAs and extracellular vesicles: New mechanisms of cross-species communication and innovative tools for disease control. PLoS Pathog. 2019 ; 15(12): e1008090. [CrossRef]
- Cai Q, He B, Wang S, Fletcher S, Niu D, Mitter N, Birch PRJ, Jin H. (2021) Message in a Bubble: Shuttling Small RNAs and Proteins Between Cells and Interacting Organisms Using Extracellular Vesicles. Annual Review Plant Biology 2021 ; 72: 497-524. [CrossRef]
- Lomniczi B, Watanabe S, Ben-Porat T, Kaplan AS. (1984) Genetic basis of the neurovirulence of pseudorabies virus. J Virol. 1984 October; 52(1): 198-205. [CrossRef]
- Bernard, N. Fields and Karen Byers (1983) The Genetic Basis of Viral Virulence. Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences. Vol. 303, No. 1114, The Determinants of Bacterial and Viral Pathogenicity (1983), pp. 209-218 https://www.jstor.org/stable/3030132.
- Kreitz J, Friedrich MJ, Guru A, Lash B, Saito M, Macrae RK, Zhang F. (2023) Programmable protein delivery with a bacterial contractile injection system. Nature. 2023. [CrossRef] [PubMed]
- https://www.nature.com/articles/s41586-023-05870-7.pdf.
- CDC Center for Health Statistics (2022). Vital Statistics Rapid Release—Provisional Drug Overdose Data. (5 April 2022) https://www.cdc.gov/nchs/nvss/vsrr/drug-overdose-data.htm.
- Yagi T, Nagao K, Kawamorita T, Soga T, Ishii M, Chiba N, Watanabe K, Tani S, Yoshino A, Hirayama A, Sakatani K. (2016) Detection of ROSC in Patients with Cardiac Arrest During Chest Compression Using NIRS: A Pilot Study. Adv Exp Med Biol. 2016; 876: 151-157. [CrossRef]
- Schneider AP Nelson DJ, Brown DD. (1993) In-hospital cardiopulmonary resuscitation: a 30-year review. J Am Board Family Practice 1993 March–April; 6(2): 91-101.
- Sjoding MW, Dickson RP, Iwashyna TJ, Gay SE, Valley TS. (2020) Racial Bias in Pulse Oximetry Measurement. N Engl J Med. 2020 ; 383(25): 2477-2478. Erratum in: N Engl J Med. 2021 December 23; 385(26): 2496. [CrossRef]
- https://www.fda.gov/medical-devices/safety-communications/pulse-oximeter-accuracy-and-limitations-fda-safety-communication.
- Ginsburg AS, Lenahan JL, Izadnegahdar R, Ansermino JM. (2018) A Systematic Review of Tools to Measure Respiratory Rate in Order to Identify Childhood Pneumonia. Am J Respir Crit Care Med. 2018 ; 197(9): 1116-1127. [CrossRef]
- Nisbet, W. (1956) An instrument for measuring respiratory rates and volumes. Journal of Scientific Instruments No. 4. Volume 33 154 https://iopscience.iop.org/article/10.1088/0950-7671/33/4/308/pdf.
- Miller MR, Hankinson J, Brusasco V, Burgos F, Casaburi R, Coates A, Crapo R, Enright P, van der Grinten CP, Gustafsson P, Jensen R, Johnson DC, MacIntyre N, McKay R, Navajas D, Pedersen OF, Pellegrino R, Viegi G, Wanger J; ATS/ERS Task Force. (2005) Standardisation of spirometry. Eur Respir J. 2005 August; 26(2): 319-338. [CrossRef]
- Chu M, Nguyen T, Pandey V, Zhou Y, Pham HN, Bar-Yoseph R, Radom-Aizik S, Jain R, Cooper DM, Khine M. (2019) Respiration rate and volume measurements using wearable strain sensors. NPJ Digit Med. 2019 ; 2: 8. [CrossRef]
- Richardson M, Moulton K, Rabb D, Kindopp S, Pishe T, Yan C, Akpinar I, Tsoi B, Chuck A. (2016 March) Capnography for Monitoring End-Tidal CO2 in Hospital and Pre-hospital Settings: A Health Technology Assessment Canadian Agency for Drugs & Technologies in Health, Ottawa. v.
- Sanders AB, Kern KB, Otto CW, Milander MM, Ewy GA. (1989) End-tidal carbon dioxide monitoring during cardiopulmonary resuscitation. A prognostic indicator for survival. JAMA. 1989 September 8; 262(10): 1347-1351.
- Selby ST, Abramo T, Hobart-Porter N. (2018) An Update on End-Tidal CO2 Monitoring. Pediatr Emerg Care. 2018 December; 34(12): 888-892. [CrossRef]
- Lam T, Nagappa M, Wong J, Singh M, Wong D, Chung F. (2017) Continuous Pulse Oximetry and Capnography Monitoring for Postoperative Respiratory Depression and Adverse Events: A Systematic Review and Meta-analysis. Anesth Analg. 2017 December; 125(6): 2019-2029. [CrossRef]
- Celmins, A. (1987). Least squares model fitting to fuzzy data vector. Fuzzy Sets Syst, 22(3), 245-269. http://sa-ijas.stat.unipd.it/sites/sa-ijas.stat.unipd.it/files/81-94.pdf.
- Shoumen Datta, Bob Betts, Mark Dinning, Feryal Erhun, Tom Gibbs, Pinar Keskinocak, Hui Li, Mike Li, and Micah Samuels (2003) Adaptive Value Network. Chapter 1 (pages 3-67). In Evolution of Supply Chain Management: Symbiosis of Adaptive Value Networks and ICT. Chang, Yoon Seok, Makatsoris, Harris C., and Richards, Howard D., eds. ISBN 978-1-4020-7812-5 (2004) Kluwer Academic Publishers, Boston.
- https://doi.org/10.1007/b110025 & https://link.springer.com/book/10.1007/b110025.
- http://eprints.stiperdharmawacana.ac.id/68/1/%5BYoon_Seok_Chang%2C_Harris_C._Makatsoris%2C_Howard_D._%28BookFi%29.pdf.
- Imtiaz SA, Mardell J, Saremi-Yarahmadi S, Rodriguez-Villegas E. (2016) ECG artefact identification and removal in mHealth systems for continuous patient monitoring. Healthcare Technol Lett. 2016 ; 3(3): 171-176. [CrossRef]
- Bashar SK, Ding E, Walkey AJ, McManus DD, Chon KH. (2019) Noise Detection in Electrocardiogram Signals for Intensive Care Unit Patients. IEEE Access. 2019; 7: 88357-88368. [CrossRef]
- Ansari S, Farzaneh N, Duda M, Horan K, Andersson HB, Goldberger ZD, Nallamothu BK, Najarian K. (2017) A Review of Automated Methods for Detection of Myocardial Ischemia and Infarction Using Electrocardiogram and Electronic Health Records. IEEE Rev Biomed Eng. 2017; 10:264-298. [CrossRef]
- Powell MP, Anso J, Gilron R, Provenza NR, Allawala AB, Sliva DD, Bijanki KR, Oswalt D, Adkinson J, Pouratian N, Sheth SA, Goodman WK, Jones SR, Starr PA, Borton DA. (2021) NeuroDAC: an open-source arbitrary biosignal waveform generator. J Neural Eng. 2021 ; 18(1): 10.1088/1741-2552/abc7f0. [CrossRef]
- Hinrichs, H. , Scholz, M., Baum, A.K. et al. (2020) Comparison between a wireless dry electrode EEG system with a conventional wired wet electrode EEG system for clinical applications. Sci Rep, 2020; 10, 5218. [Google Scholar] [CrossRef]
- Steve Jobs at the Heavenly Gates—There’s an App for That. https://www.cbsnews.com/news/steve-jobs-at-the-heavenly-gates-theres-an-app-for-that/.
- MDApp www.mdapp.co.
- Fenn Wo, Rahn H, Otis AB. (1946) A theoretical study of the composition of the alveolar air at altitude. Am J Physiol. 1946 August; 146: 637-653. [CrossRef]
- Wang MC, Corbridge TC, McCrimmon DR, Walter JM. (2020) Teaching an intuitive derivation of the clinical alveolar equations: mass balance as a fundamental physiological principle. Adv Physiol Educ. 2020 ; 44(2): 145-152. [CrossRef]
- Sharma S, Hashmi MF, Burns B. (2021) Alveolar Gas Equation. StatPearls Publishing, 2022. https://www.ncbi.nlm.nih.gov/books/NBK482268/.
- Van Iterson EH, Olson TP. (2018) Use of ‘ideal’ alveolar air equations and corrected end-tidal PCO2 to estimate arterial PCO2 and physiological dead space during exercise in patients with heart failure. Int J Cardiol 2018 ; 250: 176-182. [CrossRef]
- Chambers, D. , Huang, C., & Matthews, G. (2015). Alveolar gas equation. In Basic Physiology for Anaesthetists (pp. 77-79) Cambridge University Press. [CrossRef]
- Ansys Workbench https://www.ansys.com/products/ansys-workbench.
- Monod J, Wyman J, Changeux JP (1965) On The Nature Of Allosteric Transitions: A Plausible Model. J Mol Biol. 1965 May; 12: 88-118. [CrossRef]
- Changeux, JP. (2018) The nicotinic acetylcholine receptor: a typical ‘allosteric machine’. Philosophical Transactions of the Royal Society of London, Series B (Biological Sciences) 2018 ; 373(1749): 20170174. [CrossRef]
- Caterina MJ, Schumacher MA, Tominaga M, Rosen TA, Levine JD, Julius D. (1997) The capsaicin receptor: a heat-activated ion channel in the pain pathway. Nature. 1997 ; 389(6653): 816-824. [CrossRef]
- [a] McKemy DD, Neuhausser WM, Julius D. (2002) Identification of a cold receptor reveals a general role for TRP channels in thermosensation. Nature. 2002 ; 416(6876): 52-58. [CrossRef]
- [b] Peier, Andrea M., et al. “A TRP Channel That Senses Cold Stimuli and Menthol.” Cell 108 (5) March 2002, pp. 705–715. [CrossRef]
- Julius, D.; Patapoutian, A. (2021) www.nobelprize.org/prizes/medicine/2021/summary/.
- McLamore, E.S. P.A. Datta, V. Morgan, N. Cavallaro, G. Kiker, D.M. Jenkins, Y. Rong, C. Gomes, J. Claussen, D. Vanegas, E.C. Alocilja (2019) SNAPS: Sensor Analytics Point Solutions for Detection and Decision Support. Sensors, vol. 19 no. 22 November 2019 p. 4935 www.mdpi.com/1424-8220/19/22/4935/pdf.
- Bonabeau, Eric, et al. (1999) Swarm Intelligence: From Natural to Artificial Systems. Oxford, 1999. ISBN-13 978-0195131598 http://docshare04.docshare.tips/files/20663/206639475.pdf.
- Ali, Mohsin and Manoranjan, Branavan (2013) On Vaccines and Irrationality. McMaster University, Canada. https://journals.mcmaster.ca/meducator/article/view/827/794.
- Pollitt, Katha. (2021) The Age of Irrationality. The Nation, 21. https://www.thenation.com/article/society/covid-denial-irrational/.
- Datta, Shoumen (2022) Cybersecurity. https://dspace.mit.edu/handle/1721.1/140303.
- Harris, Shon, and Fernando Maymí. (2018) CISSP Exam Guide. Eighth edition, McGraw-Hill Education, 2018. ISBN-13: 978-1260142655.
- The State of Ransomware in Healthcare 2021. SOPHOS Whitepaper. https://www.sophos.com/en-us/medialibrary/pdfs/whitepaper/sophos-state-of-ransomware-in-healthcare-2021-wp.pdf.
- Ransomware in Hospitals 2022 https://www.cybertalk.org/2021/08/10/best-practices-to-avoid-ransomware-attacks-on-hospitals-in-2022/.
- Cybersecurity and Infrastructure Security Agency (CISA), the Federal Bureau of Investigation (FBI), and the Department of Health and Human Services (HHS). Joint Cybersecurity Advisory. Ransomware Activity Targeting the Healthcare and Public Health Sector, October 28, 2020. https://www.cisa.gov/uscert/sites/default/files/publications/AA20-302A_Ransomware%20_Activity_Targeting_the_Healthcare_and_Public_Health_Sector.pdf.
- 4000 Attacks a Day Since CoVID-19 Pandemic. August 11, 2020.
- https://www.prnewswire.com/news-releases/top-cyber-security-experts-report-4-000-cyber-attacks-a-day-since-covid-19-pandemic-301110157.html.
- Cybercrime: CoVID-19 Impact. INTERPOL, 2020 (Lyon, France) https://www.interpol.int/en/content/download/15526/file/COVID-19%20Cybercrime%20Analysis%20Report-%20August%202020.pdf.
- Federal Bureau of Investigation, Cyber Division(February 4, 2022) Flash CU-000162-MW Indicators of Compromise Associated with LockBit 2.0 Ransomware https://www.ic3.gov/Media/News/2022/220204.pdf.
- MITRE ATT&CK vs Cyber Kill Chain vs Diamond Model https://medium.com/cycraft/cycraft-classroom-mitre-att-ck-vs-cyber-kill-chain-vs-diamond-model-1cc8fa49a20f.
- Nickels, Katie and and Ryan, Kovar (2019) MITRE ATT&CK: The Play at Home Edition 2.0 https://i.blackhat.com/webcasts/2019/11-21-black-hat-webcast-mitre-attack-by-k-nickels-and-r-kovar.pdf.
- National Academies of Sciences, Engineering, and Medicine (2017) Additional Observations on Foundational Cybersecurity Research: Improving Science, Engineering, and Institutions: An Annex: Unclassified Abbreviated Version of a Classified Report. National Academies Press, Washington, DC. [CrossRef]
- Georgiadou, A. , Mouzakitis, S., Askounis, D. Assessing MITRE ATT&CK Risk Using a Cyber-Security Culture Framework. Sensors 2021, 21, 3267. [Google Scholar] [CrossRef]
- Thomasian, Nicole M., and Eli Y. Adashi. “Cybersecurity in the Internet of Medical Things.” Health Policy and Technology, vol. 10, no. 3, Sept. 2021, p. 100549. [CrossRef]
- Sanjay Sarma, David Brock and Kevin Ashton (1999) “The Networked Physical World—Proposals for Engineering the Next Generation of Computing, Commerce, and Automatic-Identification,” MIT Auto-ID Center White Paper. MIT-AUTOID-WH001, 1999. https://autoid.mit.edu/publications-0 https://pdfs.semanticscholar.org/88b4/a255082d91b3c88261976c85a24f2f92c5c3.pdf.
- Max Mühlhäuser and Iryna Gurevych (2008) Introduction to Ubiquitous Computing. IGI Global. https://pdfs.semanticscholar.org/ab0e/b44c7c81a1af3fc2d23fa03f8f04f9e4ca2d.pdf.
- Anandaraj, S.P. , Poornima S., Vignesh R., Ravi V. (2022) Industrial Automation of IoT in 5G Era. In: Velliangiri S., Gunasekaran M., Karthikeyan P. (eds) Secure Communication for 5G and IoT Networks. EAI/Springer Innovations in Communication and Computing. Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-030-79766-9_6.
- Murrin, Suzanne (2018) FDA Should Further Integrate Its Review of Cybersecurity Into the Premarket Review Process for Medical Devices (OEI-09- 16-00220) 18. Office of the Inspector General (OIG), US Department of Health and Human Services, Washington, DC. https://oig.hhs.gov/oei/reports/oei-09-16-00220.
- Medicare Lacks Consistent Oversight of Cybersecurity for Networked Medical Devices in Hospitals (2021) US Department of Health & Human Services Office of Inspector General. Issue Brief 21, OEI-01-20-00220 www.oig.hhs.gov/oei/reports/OEI-01-20-00220.pdf.
- Elaine Bochniewicz, Melissa Chase, Steve Christey Coley, Kyle Wallace, Matt Weir and Margie Zuk (2020) Playbook for Threat Modeling Medical Devices. THE MITRE CORPORATION and the Medical Device Innovation Consortium (MDIC) https://www.mitre.org/sites/default/files/publications/Playbook-for-Threat-Modeling-Medical-Devices.pdf.
- Committee on Cyber Resilience Workshop Series, et al.(2019) Beyond Spectre: Confronting New Technical and Policy Challenges: Proceedings of a Workshop. Edited by Anne Johnson and Lynette I. Millett, National Academies Press, 2019. [CrossRef]
- El-Rewini, Z.; Sadatsharan, K.; Sugunaraj, N.; Selvaraj, D.F.; Plathottam, S.J.; Ranganathan, P. (2020) “Cybersecurity Attacks in Vehicular Sensors,” in IEEE Sensors Journal, vol. 20, no. 22, pp. 13752-13767, November 15, 2020. [CrossRef]
- Sun, X.; Yu, F.R.; Zhang, P. (2021) “A Survey on Cyber-Security of Connected and Autonomous Vehicles (CAVs),” in IEEE Transactions on Intelligent Transportation Systems. [CrossRef]
- World Health Organization (, 2020) Guidance for post-market surveillance and market surveillance of medical devices, including in-vitro-diagnostics. https://www.who.int/docs/default-source/essential-medicines/in-vitro-diagnostics/draft-public-pmsdevices.pdf?
- US Food and Drug Administration (, 2021) Cybersecurity Alert: Fresenius Kabi Agilia Connect Infusion System https://www.fda.gov/medical-devices/digital-health-center-excellence/cybersecurity.
- Hossein Motlagh N, Mohammadrezaei M, Hunt J, Zakeri B. (2020) Internet of Things (IoT) and the Energy Sector. Energies. 2020; 13(2):494. [CrossRef]
- US Department of Defense (2018) Summary of the National Defense Strategy: Sharpening American Military’s Competitive Edge https://dod.defense.gov/Portals/1/Documents/pubs/2018-National-Defense-Strategy-Summary.pdf.
- US Senate and House of Representatives of the United States of America in Congress [H.R.3763, July 30, 2002] Sarbanes-Oxley Act of 2002. Public Law 107–204 107th Congress https://pcaobus.org/About/History/Documents/PDFs/Sarbanes_Oxley_Act_of_2002.pdf Amendment https://www.govinfo.gov/content/pkg/COMPS-1883/pdf/COMPS-1883.pdf Study https://www.sec.gov/news/studies/2009/sox-404_study.pdf.
- Murugiah Souppaya Karen Scarfone Donna Dodson (22) Secure Software Development Framework (SSDF) Version 1.1: Recommendations for Mitigating the Risk of Software Vulnerabilities. Computer Security Division, Information Technology Laboratory, National Institute of Standards and Technology (NIST), US Department of Commerce. [CrossRef]
- Karayi, Sumir (, 2020) 3 Ways to Get Endpoint Security Back Under Control in the New Remote World of Work https://www.securitymagazine.com/articles/92362-ways-to-get-endpoint-security-back-under-control-in-the-new-remote-world-of-work.
- Adam Pennington, Andy Applebaum, Katie Nickels, Tim Schulz, Blake Strom and John Wunder (2019) Getting Started with ATT&CK. MITRE Corporation (attack.mitre.org) www.mitre.org/sites/default/files/publications/mitre-getting-started-with-attack-october-2019.pdf.
- Newman, Lily Hay (July 16, 2019) These Hackers Made an App That Kills to Prove a Point:.
- Medtronic and the FDA left an insulin pump with a potentially deadly vulnerability on the market—until researchers who found the flaw showed how bad it could be.WIRED.
- https://www.wired.com/story/medtronic-insulin-pump-hack-app.
- U.S. Army Telemedicine & Advanced Technology Research Center (TATRC, 2019) OpTMed Lab Conducts 4th Annual Field Evaluations at Communications-Electronics Research, Development and Engineering Center (CERDEC) Ground Activity. 2019. https://www.tatrc.org/www/docs/news/16_9_OpTMedVisitors.pdf.
- Burke G, Saxena N. (2021) Cyber Risks Prediction and Analysis in Medical Emergency Equipment for Situational Awareness. Sensors. 2021 ; 21(16):5325. [CrossRef]
- FDA (, 2023) Cybersecurity in Medical Devices: Refuse to Accept Policy for Cyber Devices and Related Systems (Under Section 524B of the FD&C Act) Guidance for Industry and Food and Drug Administration Staff (Document issued on , 2023) https://www.fda.gov/media/166614/download and https://www.fda.gov/medical-devices/digital-health-center-excellence/cybersecurity.
- Thomas, W. Edgar (2020) SHADOW FIGMENT—Model Driven Deception for Cyber-Physical System Defense. Pacific Northwest National Lab (PNNL.gov) https://apps.dtic.mil/sti/pdfs/AD1128044.pdf.
- Stoll, Clifford. (1989) The Cuckoo’s Egg: Tracking a Spy through the Maze of Computer Espionage. Doubleday, 1989 http://bayrampasamakina.com/tr/pdf_stoll_4_1.pdf.
- Lance Spitzner (, 2002) Honeypots: Tracking Hackers. Addison-Wesley ISBN: 0-321-10895-7 http://www.it-docs.net/ddata/792.pdf.
- Spitzner, Lance (2003) “The Honeynet Project: trapping the hackers”. IEEE Security & Privacy 1 (2): 15–23. [CrossRef]
- Shadow Figment (Battelle Number 31305) https://www.pnnl.gov/available-technologies/shadow-figment-model-driven-cyber-defense-control-systems.
- Datta, Shoumen (2016) Cybersecurity: Personal Security Agents as Modular Models representing People, Process, Atoms and Bits. European Union (EU) Agenda. https://euagenda.eu/upload/publications/cybersecurity.pdf.
- Bush, Vannevar “As We May Think.” The Atlantic. , 1945. https://www.theatlantic.com/magazine/archive/1945/07/as-we-may-think/303881/.
- Weiser, M. (1991) The Computer for the 21st Century. Scientific American, 265, 94-104. [CrossRef]
- Helena Parmask, Christina Jaegering, Maarja Pärnpuu. The History of Ubiquitous Computing https://www.sutori.com/en/story/the-history-of-ubiquitous-computing--SMuA4RazAxWSKRXHENnAGSx2.
- Leonardo, B. Oliveira, Fernando Magno Quintão Pereira, Rafael Misoczki, Diego F. Aranha, Fábio Borges, Michele Nogueira, Michelle Wangham, Min Wu and Jie Liu (2018) The computer for the 21st century: present security & privacy challenges. Journal of Internet Services and Applications. [CrossRef]
- Roach, John (2018) Under the sea, Microsoft tests a datacenter that’s quick to deploy, could provide internet connectivity for years. MICROSOFT https://natick.research.microsoft.com/.
- Burleigh S, Cerf V, Durst R, Fall K, Hooke A, Scott K, Weiss H. (2003) The Interplanetary Internet: a communications infrastructure for Mars exploration. Acta Astronaut. 2003 August-(4-10): 365-373. [CrossRef]
- [a] Ambrosino N, Pierucci P. (2021) Using Telemedicine to Monitor the Patient with Chronic Respiratory Failure. Life (Basel). 2021 ; 11(11):1113. [CrossRef]
- [b] Farré R, Navajas D, Prats E, Marti S, Guell R, Montserrat JM, Tebe C, Escarrabill J. (2006) Performance of mechanical ventilators at the patient’s home: a multicentre quality control study. Thorax. 2006 May; 61(5):400-404. [CrossRef]
- [c] Bassett, M R. (1994) Passive ventilators in New Zealand homes. Part 1: Numerical studies and Part 2: Experimental trials. UK, 1994 https://www.osti.gov/etdeweb/biblio/80807.
- Sanborn, WG. Microprocessor-based mechanical ventilation. Respiratory Care. 1993 January; 38(1):72-109.
- Fuentes S, Chowdhury YS. (2021) Fraction of Inspired Oxygen. StatPearls Publishing. https://www.ncbi.nlm.nih.gov/books/NBK560867.
- Balasamy, K. , Krishnaraj, N., Ramprasath, J. and Ramprakash, P. (2022). A Secure Framework for Protecting Clinical Data in Medical IoT Environment. [CrossRef]
- Massachusetts Institute of Technology (2020) MIT Emergency Ventilator Design Toolbox.
- https://e-vent.mit.edu/mechanical/.
- Tischer, Eric (2020) Open source DIY Ventilator PLC control system http://etischer.com/ventilator/ https://e-vent.mit.edu/user/etischer/?profiletab=main.
- El-Hadj A, Kezrane M, Ahmad H, Ameur H, Bin Abd Rahim SZ, Younsi A, Abu-Zinadah H. (2021) Design and simulation of mechanical ventilators. Chaos Solitons Fractals. 2021 September; 150:111169. [CrossRef]
- DeBoer B, Barari A, Nonoyama M, Dubrowski A, Zaccagnini M, Hosseini A. (2021) Preliminary Design and Development of a Mechanical Ventilator Using Industrial Automation Components for Rapid Deployment During the COVID-19 Pandemic. Cureus. 2021 ; 13(12):e20386. [CrossRef]
- https://assets.cureus.com/uploads/technical_report/pdf/75218/20220112-32222-oo35ov.pdf.
- Madekurozwa M, Bonneuil WV, Frattolin J, Watson DJ, Moore AC, Stevens MM, Moore J Jr, Mathiszig-Lee J, van Batenburg-Sherwood J. (2021) A Novel Ventilator Design for COVID-19 and Resource-Limited Settings. Frontiers in Medical Technology. 2021 ; 3:707826. [CrossRef]
- Chawla A, Lavania AK. (2011) Oxygen Toxicity. Medical Journal of the Armed Forces India. 2001 April; 57(2):131-3. [CrossRef]
- Donald, K.W. (1947) Oxygen poisoning in man; signs and symptoms of oxygen poisoning. British Medical Journal 1947 ; 1(4507):712-7. [CrossRef]
- Moll, Vanessa (2021) Overview of Respiratory Arrest in Critical Care Medicine, Merck Manual Professional Edition https://www.merckmanuals.com/professional/critical-care-medicine/respiratory-arrest/overview-of-respiratory-arrest.
- A definition of irreversible coma. Report of the Ad Hoc Committee of the Harvard Medical School to Examine the Definition of Brain Death. JAMA. 1968 August 5; 205(6):337-340 https://jamanetwork.com/journals/jama/article-abstract/340177.
- Cooke CR, Hotchkin DL, Engelberg RA, Rubinson L, Curtis JR. (2010) Predictors of time to death after terminal withdrawal of mechanical ventilation in the ICU. Chest. 2010 August; 138(2):289-297. [CrossRef]
- Skopik, Florian, Max Landauer, and Markus Wurzenberger. (2022) “Blind Spots of Security Monitoring in Enterprise Infrastructures: A Survey.” IEEE Security & Privacy, 2022, pp. 2–10. [CrossRef]
- Cheekiralla, Sivaram, and Daniel W. Engels (2006) “An IPv6-Based Identification Scheme.” 2006 IEEE International Conference on Communications, vol. 1, 2006, pp. 281-286. [CrossRef]
- Datta, Shoumen (2007) Unified Theory of Relativistic Identification of Information in a Systems Age: Proposed Convergence of Unique Identification with Syntax and Semantics through Internet Protocol version 6 (MIT Engineering Systems Working Paper Series 2007 ESD-WP-2007-17, School of Engineering, Massachusetts Institute of Technology, Cambridge) International Journal of Advanced Logistics 1 66-82 http://dspace.mit.edu/handle/1721.1/41902.
- Massachusetts Institute of Technology. Creating and Using Your MIT Kerberos Identity. MIT Information Systems and Technology (IST). https://ist.mit.edu/start/kerberos.
- Thomas Hardjono (2014) Kerberos for Internet-of-Things. MIT Kerberos and Internet Trust Consortium https://kit.mit.edu/sites/default/files/documents/Kerberos_Internet_of%20Things.pdf.
- Rescorla, E. (2018) Transport Layer Security (TLS) Protocol Version 1.3 ISSN: 2070-1721 https://datatracker.ietf.org/doc/html/rfc8446.
- Chatburn, Robert L., and Eduardo Mireles-Cabodevila. Design and Function of Mechanical Ventilators. In Oxford Textbook of Critical Care (2 ed.). Oxford University Press, 2016. [CrossRef]
- Lei, Yuan (2017). Ventilator System Concept. In Medical Ventilator System Basics: A clinical guide. Oxford University Press, Oxford, UK. July 2017. ISBN-13 9780198784975. [CrossRef]
- https://oxfordmedicine.com/view/10.1093/med/9780198784975.001.0001/med-9780198784975.
- https://oxfordmedicine.com/view/10.1093/med/9780198784975.001.0001/med-9780198784975-chapter-4.
- Borowski M, Görges M, Fried R, Such O, Wrede C, Imhoff M. (2011) Medical device alarms. Biomed Tech (Berlin) 2011 April; 56(2):73-83. [CrossRef]
- Koomen E, Webster CS, Konrad D, van der Hoeven JG, Best T, Kesecioglu J, Gommers DA, de Vries WB, Kappen TH. (2021) Reducing medical device alarms by an order of magnitude: A human factors approach. Anaesth Intensive Care. 2021 January; 49(1):52-61. [CrossRef]
- Chambrin, MC. (2001) Alarms in the intensive care unit: how can the number of false alarms be reduced? Crit Care. 2001 August; 5(4):184-8. [CrossRef]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC137277/pdf/cc1021.pdf).
- Knorr JM, Sheehan MM, Santana DC, Samorezov S, Sammour I, Deblock M, Kuban B, Chaisson N, Chatburn RL. (2020) Design and performance testing of a novel emergency ventilator for in-hospital use. Canadian Journal of Respiratory Therapy 2020 ; 56:42-51. [CrossRef]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7521602/pdf/cjrt-2020-023.pdf.
- Massachusetts General Hospital, Harvard Medical School https://hms.harvard.edu/affiliates/massachusetts-general-hospital.
- Yaacoub JA, Salman O, Noura HN, Kaaniche N, Chehab A, Malli M. (2020) Cyber-physical systems security: Limitations, issues and future trends. Microprocessors and Microsystems, 2020 September; 77:103201. [CrossRef]
- NIST Framework for Cyber-Physical Systems.
- Volume 1 https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.1500-201.pdf.
- Volume 2 https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.1500-202.pdf.
- Draeger Oxygen Sensor 6850645.
- https://www.draeger.com/Products/Content/sensors-oxygen-flow-pi-9071248-en-us.pdf.
- Pister, Kris. SMART DUST: Autonomous sensing and communication in a cubic millimeter. https://people.eecs.berkeley.edu/~pister/SmartDust/.
- Jason Hill, Robert Szewczyk, Alec Woo, Seth Hollar, David Culler, Kristofer Pister (2000) System Architecture Directions for Networked Sensors. In Proceedings of the 9th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS IX) ACM Cambridge MA https://pdos.csail.mit.edu/archive/6.097/readings/tinyos.pdf.
- Sam Madden, Joe Hellerstein, and Wei Hong (2003) TinyDB: In-Network Query Processing in TinyOS Version 0.4 September, 2003 http://telegraph.cs.berkeley.edu/tinydb/tinydb.pdf.
- Samuel, R. Madden, Michael J. Franklin, Joseph M. Hellerstein, and Wei Hong (2005) TinyDB: an acquisitional query processing system for sensor networks. ACM Transactions on Database Systems 30, 1 (March 2005), 122–173. [CrossRef]
- Castaneda D, Esparza A, Ghamari M, Soltanpur C, Nazeran H. A review on wearable photoplethysmography sensors and their potential future applications in health care. Int J Biosens Bioelectron. 2018; 4(4):195-202. 1. [CrossRef]
- Goodwin AJ, Eytan D, Greer RW, Mazwi M, Thommandram A, Goodfellow SD, Assadi A, Jegatheeswaran A, Laussen PC. (2020) A practical approach to storage and retrieval of high-frequency physiological signals. Physiological Measurement 2020 ; 41(3):035008. [CrossRef]
- Blalock, Davis, Madden, Samuel and Guttag, John (2018) “Sprintz: Time Series Compression for the Internet of Things.” Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 2, no. 3, Sep 2018, pp. 1–23. [CrossRef]
- https://dl.acm.org/doi/pdf/10.1145/3264903 and https://arxiv.org/pdf/1808.02515.pdf.
- Brinkmann BH, Bower MR, Stengel KA, Worrell GA, Stead M. (2009) Large-scale electrophysiology: acquisition, compression, encryption, and storage of big data. J Neurosci Methods. 2009 ; 180(1):185-92. [CrossRef]
- Charlton PH, Villarroel M, Salguiero F. (2016) Waveform Analysis to Estimate Respiratory Rate. 2016 . In: MIT Critical Data, editor. Secondary Analysis of Electronic Health Records [Internet]. Cham (CH): Springer; 2016. Chapter 26 https://www.ncbi.nlm.nih.gov/books/NBK543644/ https://www.ncbi.nlm.nih.gov/books/NBK543644/pdf/Bookshelf_NBK543644.pdf https://www.ncbi.nlm.nih.gov/books/NBK543630/pdf/Bookshelf_NBK543630.pdf.
- Edinburgh T, Smielewski P, Czosnyka M, Cabeleira M, Eglen SJ, Ercole A. (2021) DeepClean: Self-Supervised Artefact Rejection for Intensive Care Waveform Data Using Deep Generative Learning. Acta Neuro Suppl 2021;131:235-241. [CrossRef]
- Silva P, Luz E, Silva G, Moreira G, Wanner E, Vidal F, Menotti D. (2020) Towards better heartbeat segmentation with deep learning classification. Science Rep. 2020 ; 10(1):20701. [CrossRef]
- Bizzego A, Gabrieli G, Neoh MJY, Esposito G. (2021) Improving the Efficacy of Deep-Learning Models for Heartbeat Detection on Heterogeneous Datasets. Bioengineering. 2021 ; 8(12):193. [CrossRef]
- Skerrett, Patrick (2020) “Epic’s Call to Block a Proposed Data Rule Is Wrong for Many Reasons.” STAT. Jan 27, 2020. www.statnews.com/2020/01/27/epic-block-proposed-data-rule.
- Caldwell, Patrick (2015) “We’ve Spent Billions to Fix Our Medical Records, and They’re Still a Mess. Here’s Why.” Mother Jones. November/15 https://www.motherjones.com/politics/2015/10/epic-systems-judith-faulkner-hitech-ehr-interoperability/.
- Makary MA, Daniel M. (2016) Medical error-the third leading cause of death in the US. British Medical Journal, 2016 May 3; 353:i2139. [CrossRef]
- Luke Slawomirski, Ane Auraaen and Niek Klazinga (2017) The Economics Of Patient Safety: Strengthening a value-based approach to reducing patient harm at national level. Organisation for Economic Co-operation and Development (OECD), Health Division. https://www.oecd.org/els/health-systems/The-economics-of-patient-safety-March-2017.pdf.
- Spyros Retsas () Rapid Response: “First Do No Harm: The Impossible Oath.” BMJ (British Medical Journal) https://www.bmj.com/content/366/bmj.l4734/rr-2.
- Abbasi, Kamran. “First Do No Harm: The Impossible Oath.” BMJ, , 2019, l4734. [CrossRef]
- Voigt I, Inojosa H, Dillenseger A, Haase R, Akgün K, Ziemssen T. (2021) Digital Twins for Multiple Sclerosis. Front Immunol. 2021 ; 12: 669811. [CrossRef]
- Bjornevik K, Cortese M, Healy BC, Kuhle J, Mina MJ, Leng Y, Elledge SJ, Niebuhr DW, Scher AI, Munger KL, Ascherio A. (2022) Longitudinal analysis reveals high prevalence of Epstein-Barr virus associated with multiple sclerosis. Science. 2022 ; 375(6578): 296-301. [CrossRef]
- Bronge M, Högelin KA, Thomas OG, Ruhrmann S, Carvalho-Queiroz C, Nilsson OB, Kaiser A, Zeitelhofer M, Holmgren E, Linnerbauer M, Adzemovic MZ, Hellström C, Jelcic I, Liu H, Nilsson P, Hillert J, Brundin L, Fink K, Kockum I, Tengvall K, Martin R, Tegel H, Gräslund T, Al Nimer F, Guerreiro-Cacais AO, Khademi M, Gafvelin G, Olsson T, Grönlund H. Identification of four novel T cell autoantigens and personal autoreactive profiles in multiple sclerosis. (2022) Science Advances 2022 ; 8(17): eabn1823. [CrossRef]
- Datta, Shoumen and Granger, Clive (2006) Advances in Supply Chain Management: Potential to Improve Forecasting. MIT Engineering Systems Division, Working Paper ESD-WP-2006-11 https://dspace.mit.edu/handle/1721.1/102799.
- Published Version: Datta, Shoumen, Granger, Clive W. J., Barari, M. and Gibbs, T. (2007) Management of Supply Chain: an alternative modeling technique for forecasting. Journal of the Operational Research Society 58 1459-1469 http://www.tandfonline.com/doi/full/10.1057/palgrave.jors.2602419.
- http://dspace.mit.edu/handle/1721.1/41906.
- Datta, S. (2018) “DATA” (unpublished) MIT https://dspace.mit.edu/handle/1721.1/140303.
- Shettigar, UR. (1994) Management of rapid ventricular rate in acute atrial fibrillation. International Journal of Clinical Pharmacology and Therapeutics 1994 May; 32(5) pp. 240-245.
- Moskowitz A, Chen KP, Cooper AZ, Chahin A, Ghassemi MM, Celi LA. (2017) Management of Atrial Fibrillation with Rapid Ventricular Response in the Intensive Care Unit: A Secondary Analysis of Electronic Health Record Data. Shock. 2017 October; 48(4) p. 436-440. [CrossRef]
- Industrial Internet Consortium (IIC) Journal of Innovation 12th Edition (13 November 2019) https://newsstand.joomag.com/en/iic-journal-of-innovation-12th-edition/0994713001573661267.
- Marr, Bernard (2017) “What Is Digital Twin Technology—And Why Is It So Important?” Forbes https://www.forbes.com/sites/bernardmarr/2017/03/06/what-is-digital-twin-technology-and-why-is-it-so-important.
- Eliza Strickland (November 8, 2019) “The Blogger Behind ‘AI Weirdness’ Thinks Today’s AI Is Dumb and Dangerous.” IEEE Spectrum, . https://spectrum.ieee.org/blogger-behind-ai-weirdness-thinks-todays-ai-is-dumb-and-dangerous.
- Tulipmania https://penelope.uchicago.edu/~grout/encyclopaedia_romana/aconite/tulipomania.html.
- Bianconi E, Piovesan A, Facchin F, Beraudi A, Casadei R, Frabetti F, Vitale L, Pelleri MC, Tassani S, Piva F, Perez-Amodio S, Strippoli P, Canaider S. (2013) An estimation of the number of cells in the human body. Ann Hum Biol. 2013 November—December; 40(6): 463-471. [CrossRef]
- National Research Council (US) Committee on Mapping and Sequencing the Human Genome. Mapping and Sequencing the Human Genome. Washington (DC): National Academies Press (US); 1988. https://www.ncbi.nlm.nih.gov/books/NBK218247/ https://www.ncbi.nlm.nih.gov/books/NBK218252/pdf/Bookshelf_NBK218252.pdf.
- Perez RK, Gordon MG, Subramaniam M, Kim MC, Hartoularos GC, Targ S, Sun Y, Ogorodnikov A, Bueno R, Lu A, Thompson M, Rappoport N, Dahl A, Lanata CM, Matloubian M, Maliskova L, Kwek SS, Li T, Slyper M, Waldman J, Dionne D, Rozenblatt-Rosen O, Fong L, Dall’Era M, Balliu B, Regev A, Yazdany J, Criswell LA, Zaitlen N, Ye CJ. (2022) Single-cell RNA-seq reveals cell type-specific molecular and genetic associations to lupus. Science. 2022 ; 376(6589): eabf1970. [CrossRef]
- Sender R, Fuchs S, Milo R. (2016) Revised Estimates for the Number of Human and Bacteria Cells in the Body. PLoS Biol. 2016 Aug 19; 14(8): e1002533. [CrossRef]
- Verma SC, Qian Z, Adhya SL. (2019) Architecture of the Escherichia coli nucleoid. PLoS Genetics 2019 ; 15(12): e1008456. Erratum in: PLoS Genetics 2020 October 21; 16(10): e1009148. [CrossRef]
- Ofengeim D, Giagtzoglou N, Huh D, Zou C, Yuan J. (2017) Single-Cell RNA Sequencing: Unraveling the Brain One Cell at a Time. Trends Mol Med. 2017 June; 23(6): 563-576. [CrossRef]
- Krulwich, Robert. “Which Is Greater, The Number Of Sand Grains On Earth Or Stars In The Sky?” NPR, National Public Radio (NPR) https://www.npr.org/sections/krulwich/2012/09/17/161096233/which-is-greater-the-number-of-sand-grains-on-earth-or-stars-in-the-sky.
- Sumida TS, Hafler DA. (2022) Population genetics meets single-cell sequencing. Science. 2022 ; 376(6589): 134-135. [CrossRef]
- Inman, Phillip (2017) “Why Bitcoin and Its Digital Cousins Are under Increasing Scrutiny.” The Guardian, 31 July 2017. The Guardian. https://www.theguardian.com/technology/2017/jul/31/cryptocurrencies-more-investment-way-pay-bitcoin-regulation.
- Madrigal, Alexis C. (2019) “Your Smart Toaster Can’t Hold a Candle to the Apollo Computer.” The Atlantic, 16 July 2019. https://www.theatlantic.com/science/archive/2019/07/underappreciated-power-apollo-computer/594121/.
- Bernard Lown (June 7, 1921–February 16, 2021) Lown Institute https://lowninstitute.org/.
- https://lowninstitute.org/about/dr-bernard-lown/.
- Cakulev I, Efimov IR, Waldo AL. (2009) Cardioversion: past, present, and future. Circulation. 2009 Oct 20; 120(16):1623-1632. [CrossRef]
- Bernard Lown, Aamarasingham R, and Neuman J. (1962) New method for terminating cardiac arrhythmias. Use of synchronized capacitor discharge. JAMA 1962 ; 182:548-555. [CrossRef]
- Cizza G, Rother KI. (2011) Was Feuerbach right: are we what we eat? J Clin Invest. 2011 August; 121(8): 2969-2971. [CrossRef]
- Rose C, Parker A, Jefferson B, Cartmell E. (2015) The Characterization of Feces and Urine: A Review of the Literature to Inform Advanced Treatment Technology. Crit Rev Environ Sci Technol. 2015 ; 45(17): 1827-1879. [CrossRef]
- Berg Gerald (1966) Virus transmission by the water vehicle. I. Viruses. Health Lab Sci. 1966 April; 3(2):86-89.
- Berg, Gerald (1967). Transmission of viruses by the water route. [CrossRef]
- Datta, Shoumen (2022) Nation in Progress (unpublished essay) MIT Library https://dspace.mit.edu/handle/1721.1/146640.
- Champagne, Audrey E. and Klopfer, Leopold E. (1978) Cumulative Index to Science Education, 1916-1976, Volumes 1 through 60 (1916-1976). ERIC Information Analysis Center for Science, Mathematics, and Environmental Education, Columbus, OH, USA. Wiley-Interscience, John Wiley & Sons, Inc., 605 Third Avenue, New York, NY 10016. https://files.eric.ed.gov/fulltext/ED174481.pdf.
- Safford HR, Shapiro K, Bischel HN. (2022) Opinion: Wastewater analysis can be a powerful public health tool-if it’s done sensibly. Proc Natl Acad Sci USA 2022 Febryary 8; 119(6): e2119600119. [CrossRef]
- How Sewage Surveillance Could Aid Public Health beyond COVID.” PBS NewsHour, https://www.pbs.org/newshour/health/how-sewage-surveillance-could-aid-public-health-beyond-covid.
- Haalck I, Löffler P, Baduel C, Wiberg K, Ahrens L, Lai FY. (2021) Mining chemical information in Swedish wastewaters for simultaneous assessment of population consumption, treatment efficiency and environmental discharge of illicit drugs. Science Reports 2021 ; 11(1): 13510. [CrossRef]
- Huizer M, Ter Laak TL, de Voogt P, van Wezel AP. (2021) Wastewater-based epidemiology for illicit drugs: A critical review on global data. Water Res. 2021 ; 207: 117789. [CrossRef]
- Venkat Atluri, Aamer Baig and Satya Rao (2018) Tech-Enabled Transformation: The Trillion-Dollar Opportunity for Industrials. McKinsey & Company https://www.mckinsey.com/business-functions/mckinsey-digital/our-insights/tech-enabled-transformation https://www.mckinsey.com/~/media/mckinsey/business%20functions/mckinsey%20digital/our%20insights/tech%20enabled%20transformation/tech-enabled-transformation-the-trillion-dollar-opportunity-for-industrials.pdf.
- Sindreu, Jon (2021) “As Electric Air Taxis Land on Stock Markets, Investors Need a Flight Guide.” Wall Street Journal, https://www.wsj.com/articles/as-electric-air-taxis-land-on-stock-markets-investors-need-a-flight-guide-11628950018.
- Hepher, Tim (2022) “Boeing Invests $450 Mln in Flying Taxi Developer Wisk.” Reuters, https://www.reuters.com/business/aerospace-defense/boeing-invests-450-mln-flying-taxi-developer-wisk-2022-01-24/.
- Nast, Condé (2017) “Silicon Valley’s Favorite $400 Juicer Is Based on a Lie.” Vanity Fair.
- Jennifer Chu (, 2011) “3Q: The next Mars Rover’s Destination.” MIT News, Massachusetts Institute of Technology https://news.mit.edu/2011/mars-rover-0725.
- Celia Henry Arnaud (2020) Mariana Matus means to combat the opioid epidemic with chemical data. Chemical & Engineering News, American Chemical Society. https://cen.acs.org/environment/water/Mariana-Matus-means-to-combat-the-opioid-epidemic-with-chemical-data/98/i9.
- Theo Wayt (August 3, 2021) “Amazon’s Drone Delivery Team ‘Collapsing,’ Losing over 100 Workers: Report.” New York Post, https://nypost.com/2021/08/03/amazons-drone-delivery-team-collapsing-losing-over-100-workers/.
- 15 Robots You’ll Want to Bring Home in 2022 https://www.schlage.com/blog/categories/2022/01/robots-for-home.html.
- Butler, Lindsey J., Madeleine K. Scammell, and Eugene B. Benson. (2016) “The Flint, Michigan, water crisis: A case study in regulatory failure and environmental injustice.” Environmental Justice 9.4 (2016): 93-97. https://www.liebertpub.com/doi/pdfplus/10.1089/env.2016.0014?casa_token=pMM-A2tKI0UAAAAA:j6iBzQpnKIO4rWql9ygaDCzdbzN2l1o5osOtn714srJ5yhRoDGsKVEXTrBIboO6iom0Z8VsBzvdy4w.
- Bellinger, David C. (2016) “Lead contamination in Flint—an abject failure to protect public health.” New England Journal of Medicine 374.12 (2016): 1101-1103. https://www.nejm.org/doi/pdf/10.1056/NEJMp1601013?articleTools=true.
- Ratnaike RN (2003) Acute and chronic arsenic toxicity. Postgraduate Medical J. 2003; 79:391-396 https://pmj.bmj.com/content/postgradmedj/79/933/391.full.pdf.
- Yunus FM, Khan S, Chowdhury P, Milton AH, Hussain S, Rahman M. (2016) A Review of Groundwater Arsenic Contamination in Bangladesh: Millennium Development Goal Era and Beyond. Int J Env Res Public Health. 2016 ;13(2): 215. [CrossRef]
- Campbell JP and Alvarez, JA. (1989) Acute arsenic intoxication. Am Fam Physician. 1989 December; 40(6): 93-97.
- McLellan, F. (2002) Arsenic contamination affects millions in Bangladesh. Lancet. 2002 ; 359(9312): 1127. [CrossRef]
- Allan H Smith, Elena O Lingas and Mahfuzar Rahman (2000) Contamination of drinking-water by arsenic in Bangladesh: a public health emergency.
- http://www.sos-arsenic.net/english/contamin/smith.html.
- Mudur, G. (2000) Half of Bangladesh population at risk of arsenic poisoning. BMJ. 2000 ; 320(7238): 822B www.ncbi.nlm.nih.gov/pmc/articles/PMC1127187/pdf/822a.pdf.
- MOBOSENS https://ece.illinois.edu/newsroom/news/3092.
- de Villiers CA, Lapsley MC, Hall EA. (2015) A step towards mobile arsenic measurement for surface waters. Analyst. 2015 ; 140(8): 2644-2655. [CrossRef]
- Haley Dunning (, 2018) Simple Arsenic Sensor Could Save Lives. Imperial College, London. https://www.imperial.ac.uk/news/185132/simple-arsenic-sensor-could-save-lives/.
- van Geen A, Trevisani M, Immel J, Jakariya M, Osman N, Cheng Z, Gelman A, Ahmed KM. (2006) Targeting low-arsenic groundwater with mobile-phone technology in Araihazar, Bangladesh. J Health Popul Nutr. 2006 September; 24(3): 282-297. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3013249/pdf/jhpn0024-0282.pdf.
- Rong, Y.; Padrona, A.V.; Hagerty, K.J.; Nelson, N.; Chic, S.; Keyhani, N.O.; Katz, J.; Datta, S.P.A.; Gomes, C.; McLamore, E.S. (2018) Post Hoc Support Vector Machine Learning for Impedimetric Biosensors Based on Weak Protein–Ligand Interactions. The Analyst, 2018; 143, 2066–2075. [Google Scholar] [CrossRef]
- KTH Royal Institute of Technology (2014) Methods Will Reverse Arsenic Danger in Bangladesh Water Supply. https://medicalxpress.com/news/2014-10-methods-reverse-arsenic-danger-bangladesh.html.
- Biobot Network of Wastewater Treatment Plants https://biobot.io/data/.
- Aura Carreño Rosas (, 2022) Hamilton to Make Wastewater Data Related to COVID-19. https://www.cbc.ca/news/canada/hamilton/wastewater-data-available-1.6381105. 6381.
- Don Mitchell (, 2021) “Hamilton Joins Province’s $12M Initiative to Detect COVID-19 in Wastewater.” https://globalnews.ca/news/7706355/hamilton-covid-19-wastewater-testing/.
- Avi Goldfarb & Catherine Tucker (2019) Digital Economics. Journal of Economic Literature, vol 57(1), pages 3-43 WP 23684. [CrossRef]
- US IRS section 501(c) Organization https://en.wikipedia.org/wiki/501(c)_organization.
- The World Bank. WHO/UNICEF Joint Monitoring Programme ( JMP ) for Water Supply, Sanitation and Hygiene (2020) People practicing open defecation: India (14.93 % of the total population). https://data.worldbank.org/indicator/SH.STA.ODFC.ZS?locations=IN.
- Ahmad Adil (, 2021) Experts draw attention to India’s open defecation problem. https://www.aa.com.tr/en/asia-pacific/experts-draw-attention-to-indias-open-defecation-problem/2424082.
- Datta, Shoumen (2020) CITCOM: An Incomplete Review of Ideas and Facts about SARS-CoV-2. (unpublished manuscript) MIT Library https://dspace.mit.edu/handle/1721.1/128017.
- Kat Eschner (, 2016) The Story of the Real Canary in the Coal Mine. Smithsonian Magazine.
- https://www.smithsonianmag.com/smart-news/story-real-canary-coal-mine-180961570/.
- David, Paul A. “The Dynamo and the Computer: An Historical Perspective on the Modern Productivity Paradox.” The American Economic Review 80, no. 2 (1990): 355-361. www.jstor.org/stable/2006600. https://pdfs.semanticscholar.org/dff7/9b2f28cbb79da91becaab803667f30394233.pdf?_ga=2.215911511.1520557695.1570682035-1238830782.1562127126) http://bit.ly/Economics-of-Technology.
- Ronald, H. Coase (1937) The Nature of the Firm. Economica Vol. 4, No. 16, 37, pp. 386-405. [CrossRef]
- https://onlinelibrary.wiley.com/doi/epdf/10.1111/j.1468-0335.1937.tb00002.x.
- https://www.nobelprize.org/prizes/economic-sciences/1991/coase/facts/.
- Hinley DS, Reiblein S. (1970) A goal-oriented approach for managing software process change. WIT Transactions on Information and Communication Technologies. 1970 January 1; 13. https://www.witpress.com/Secure/elibrary/papers/SQM95/SQM95024FU.pdf.
- Muco, M. (2015) The Society of Mind https://courses.media.mit.edu/2016spring/mass63/wp-content/uploads/sites/40/2015/09/Society-of-Mind.pdf.
- Minsky, Marvin. L. (1988) The Society of Mind. Simon & Schuster, NY. ISBN: 978-0-671-65713-0 http://www.acad.bg/ebook/ml/Society%20of%20Mind.pdf.
- Osaka University. (2021, February 3). Terahertz accelerates beyond 5G towards 6G. ScienceDaily. www.sciencedaily.com/releases/2021/02/210203162302.htm.
- Xu J, Plaxco KW, Allen SJ. 2006) Collective dynamics of lysozyme in water: terahertz absorption spectroscopy and comparison with theory. J Phys Chem B. 2006 ; 110(47):24255-9. [CrossRef]
- Karplus, Martin (2006) Spinach on the ceiling: a theoretical chemist’s return to biology. Annual Review of Biophysics and Biomolecular Structure 2006; 35:1-47. [CrossRef]
- McCammon JA, Gelin BR, Karplus M. (1977) Dynamics of folded proteins. Nature, 1977 ; 267(5612): 585-90. https://www.nature.com/articles/267585a0.pdf.
- Wu, X. , Lu, H. & Sengupta, K. (2019) Programmable terahertz chip-scale sensing interface with direct digital reconfiguration at sub-wavelength scales. Nature Commun 10, 2722. [CrossRef]
- Xu J, Plaxco KW, Allen SJ. (2006) Probing the collective vibrational dynamics of a protein in liquid water by terahertz absorption spectroscopy. Protein Sci. 2006 May; 15(5): 1175-1181. [CrossRef]
- Geisianny Moreira, Lisseth Casso-Hartmann, Shoumen Datta, Delphine Dean, Eric McLamore and Diana Vanegas (22) Development of a hACE2-biosensor for SARS-CoV-2 detection in human saliva (in press) Draft “SARS-CoV-2 Sensor” available from MIT Library https://dspace.mit.edu/handle/1721.1/123983.
- Claus Heinrich and Bob Betts (2003) Adapt or Die: Transforming Your Supply Chain into an Adaptive Business Network. John Wiley & Sons, 2003. ISBN-13: 978-0471265436.
- Tellis GJ and Golder, PN. (1996) First to market first to Fail? Real causes of enduring market leadership. MIT Sloan Management Review 1996; 37(2): 65-75. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=906021.
- Victoria Morgan, Lisseth Casso-Hartman, David Bahamon-Pinzon, Kelli McCourt, Robert G. Hjort, Sahar Bahramzadeh, Irene Velez-Torres, Eric McLamore, Carmen Gomes, Evangelyn C. Alocilja, Shoumen Palit Austin Datta and Diana C. Vanegas (2019) Sensor-as-a-Service: Convergence of Sensor Analytic Point Solutions (SNAPS) and Pay-A-Penny-Per-Use (PAPPU) Paradigm as a Catalyst for Democratization of Healthcare in Underserved Communities. Diagnostics 2020, 10 (1), 22. [CrossRef]
- Fukuyama, Francis (1995). Trust : the social virtues and the creation of prosperity. Free Press, NY. .
- Oh J, Kim JO, Kim Y, Choi HB, Yang JC, Lee S, Pyatykh M, Kim J, Sim JY, Park S. (2019) Highly Uniform and Low Hysteresis Piezoresistive Pressure Sensors Based on Chemical Grafting of Polypyrrole on Elastomer Template with Uniform Pore Size. Small. 2019 August; 15(33): e1901744. [CrossRef]
- Vehmas R, Neuberger N. (2021) Inverse Synthetic Aperture Radar Imaging: A Historical Perspective and State-of-the-Art Survey. IEEE Access. 2021. [CrossRef]
- Hardange, Jean-Philippe (1992) “Inverse Synthetic Aperture Radar.” Advisory Group for Aerospace Research and Development (AGARD, France). August, 1992.
- Fadel Adib and Dina Katabi (2013) See Through Walls with Wi-Fi. SIGCOMM’13, –16, 2013. https://people.csail.mit.edu/fadel/papers/wivi-paper.pdf https://www.ijcseonline.org/pub_paper/142-IJCSE-05991.pdf.
- https://people.csail.mit.edu/fadel/wivi/project.html.
- Fadel Adib, Hongzi Mao, Zachary Kabelac, Dina Katabi, and Robert C. Miller (2015) Smart Homes that Monitor Breathing and Heart Rate. https://dspace.mit.edu/handle/1721.1/116277.
- Yusheng Hao, Jincheng Li, Weilan Wang, and Qiang Lin (2019) An Animal Respiration Monitoring System Based on Channel State Information of Wi-Fi Network. In Proceedings of the 7th International Conference on Information Technology: IoT and Smart City, 2019. [CrossRef]
- Freudenmann RW, Oxler F, Bernschneider-Reif S. (2006) The origin of MDMA (ecstasy) revisited: the true story reconstructed from the original documents. Addiction. 2006 September; 101(9): 1241-5. [CrossRef]
- de la Torre R, Farré M, Roset PN, Pizarro N, Abanades S, Segura M, Segura J, Camí J. (2004) Human pharmacology of MDMA: pharmacokinetics, metabolism, and disposition. Ther Drug Monit. 2004 April; 26(2): 137-144. [CrossRef]
- First Robotics https://www.firstinspires.org/robotics/frc.
- Hartzband P, Groopman J. (2016) Medical Taylorism. N Engl J Med. 2016 ; 374(2): 106-108 https://www.nejm.org/doi/pdf/10.1056/NEJMp1512402.
- Zhang Y, Zheng X, Jiang D, Luo H, Guo K, Song X, Wang C. (2022) The perceived effectiveness and hidden inequity of postpandemic fiscal stimuli. Proc Natl Acad Sci USA 2022 ; 119(18): e2105006119. [CrossRef]
- Abhijit Banerjee and Esther Duflo (2012) <i>Poor Economics</i>. PublicAffairs, NY. Abhijit Banerjee and Esther Duflo (2012) Poor Economics. PublicAffairs, NY. ISBN-13 978-1610390934https://www.nobelprize.org/prizes/economic-sciences/2019/summary/.
- Sen, Amartya (1999) Development as Freedom. Alfred Knopf, New York, 1999. https://www.nobelprize.org/prizes/economic-sciences/1998/sen/facts/.
- McLamore ES, Moreira G, Vanegas DC, Datta Shoumen (2022). Context-Aware Diagnostic Specificity (CADS). Biosensors (Basel). 2022 February 7;12(2):101. https://doi.org/10.3390/bios12020101 https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8869940/pdf/biosensors-12-00101.pdf. [CrossRef]
- Self-amplifying COVID-19 mRNA Vaccine Candidate ARCT-154 Meets Primary Efficacy Endpoint in Phase 3 Study (April 20, 2022) https://ir.arcturusrx.com/node/11271/pdf.
- Wei J, Alfajaro MM, DeWeirdt PC, Hanna RE, Lu-Culligan WJ, Cai WL, Strine MS, Zhang SM, Graziano VR, Schmitz CO, Chen JS, Mankowski MC, Filler RB, Ravindra NG, Gasque V, de Miguel FJ, Patil A, Chen H, Oguntuyo KY, Abriola L, Surovtseva YV, Orchard RC, Lee B, Lindenbach BD, Politi K, van Dijk D, Kadoch C, Simon MD, Yan Q, Doench JG, Wilen CB. (2021) Genome-wide CRISPR Screens Reveal Host Factors Critical for SARS-CoV-2 Infection. Cell. 2021 ; 184(1): 76-91.e13. [CrossRef]
- Brusselaers, N. , Steadson, D., Bjorklund, K. et al. (2022) Evaluation of science advice during the COVID-19 pandemic in Sweden. Humanit Soc Sci Commun. [CrossRef]
- https://www.nature.com/articles/s41599-022-01097-5.pdf.
- Biller-Andorno, Nikola; Monteverde, Settimio; Krones, Tanja; Eichinger, Tobias (2021) Medizinethik. Springer Fachmedien Wiesbaden, 2021.
- https://doi.org/10.1007/978-3-658-27696-6.
- https://link.springer.com/book/10.1007/978-3-658-27696-6.
- Bruynseels K, Santoni de Sio F, van den Hoven J. (2018) Digital Twins in Health Care: Ethical Implications of an Emerging Engineering Paradigm. Front Genet. 2018 ; 9:31. [CrossRef]
- Markov PV, Katzourakis A, Stilianakis NI. (2022) Antigenic evolution will lead to new SARS-CoV-2 variants with unpredictable severity. Nat Rev Microbiol. 2022 May; 20(5): 251-252. [CrossRef]
- Yewdell, JW. (2021) Antigenic drift: Understanding COVID-19. Immunity. 2021 ; 54(12): 2681-2687. [CrossRef]
- Wille M and Barr IG (2022) Resurgence of avian influenza virus. Science. 2022 : eabo1232. [CrossRef]
- Graham, Barney S. and Sullivan, Nancy J. (2017) Emerging viral diseases from a vaccinology perspective: preparing for the next pandemic. Nature Immunology, 2018. [CrossRef]
- Simões EAF, Center KJ, Tita ATN, Swanson KA, Radley D, Houghton J, McGrory SB, Gomme E, Anderson M, Roberts JP, Scott DA, Jansen KU, Gruber WC, Dormitzer PR, Gurtman AC. (2022) Prefusion F Protein-Based Respiratory Syncytial Virus Immunization in Pregnancy. N Engl J Med. 2022 ; 386(17):1615-1626. [CrossRef]
- Hong J, Kwon HJ, Cachau R, Chen CZ, Butay KJ, Duan Z, Li D, Ren H, Liang T, Zhu J, Dandey VP, Martin NP, Esposito D, Ortega-Rodriguez U, Xu M, Borgnia MJ, Xie H, Ho M. Dromedary camel nanobodies broadly neutralize SARS-CoV-2 variants. (2022) Proc Natl Acad Sci USA 2022 ; 119(18): e2201433119. [CrossRef]
- Horton R, Beaglehole R, Bonita R, Raeburn J, McKee M, Wall S. (2014) From public to planetary health: a manifesto. Lancet 2014 ; 383(9920): 847. [CrossRef]
- JUUL Labs 73 Percent Market Share and $15 Billion Valuation Has Come With a ‘Rapid Proliferation’ of Copycat Products. The Fashion Law, 5 October 2018. https://www.thefashionlaw.com/juul-labs-73-percent-market-share-has-come-with-a-rapid-proliferation-of-copycat-products/.
- Nancy Schimelpfening (April 26, 2020) Six Vaping Products Disguised as Everyday Items. https://www.healthline.com/health-news/teens-and-disguised-vaping-devices#Knowing-the-risks.
- “Vaping Device That Looks like USB Drive Popular with Teens.” The Atlanta Journal-Constitution (December 8, 2017) https://www.ajc.com/news/national/vaping-device-that-looks-like-usb-drive-popular-with-teens/0oSeHqNrORZRcIdvofAw1N/.
- CDC “Teacher and Parents: That USB Stick Might Be an E-cigarette” https://www.cdc.gov/tobacco/basic_information/e-cigarettes/teacher-parent/pdfs/parent-teacher-ecig-p.pdf.
- Levy, Ari (2017) “E-Cigarette Maker Juul Is Raising $150 Million after Spinning out of Vaping Company.” CNBC . https://www.cnbc.com/2017/12/19/juul-labs-raising-150-million-in-debt-after-spinning-out-of-pax.html.
- Austin-Datta, Rebecca Jane, Chaudhari, P. V., Cheng, T. D., Klarenberg, G., Striley, C. W. and Cottler, L. B. (2022). Electronic Nicotine Delivery Systems (ENDS) use Among Members of a Community Engagement Program. Journal of Community Health. [CrossRef]
- Kaplan, Sheila (2021) Juul to Pay $40 Million to Settle N.C. Vaping Case. New York Times, . www.nytimes.com/2021/06/28/health/juul-vaping-settlement-north-carolina.html.
- International Expert Committee (2009) International Expert Committee report on the role of the A1C assay in the diagnosis of diabetes. Diabetes Care. 2009 July; 32(7): 1327-1334. [CrossRef]
- David M. Nathan, on behalf of the International Expert Committee; International Expert Committee (2009) Report on the Role of the A1C Assay in the Diagnosis of Diabetes: Response to Kilpatrick, Bloomgarden, and Zimmet. Diabetes Care 1 December 2009; 32 (12): e160. December. [CrossRef]
- Walmart (2022) “Walmart Health Introduces Telehealth Diabetes Program To Help Businesses Support Employees Through Education and Behavioral Care.” https://corporate.walmart.com/newsroom/2022/04/28/walmart-health-introduces-telehealth-diabetes-program-to-help-businesses-support-employees-through-education-and-behavioral-care.
- David Johnson (2018) Eisenhower’s Prophecy: The Healthcare Industrial Complex.
- https://www.4sighthealth.com/eisenhowers-prophecy-the-healthcare-industrial-complex/.
- https://www.4sighthealth.com/wp-content/uploads/2018/12/4sightHealth.EisenhowersProphecy.MCC_.12-19-18.pdf.
- American Diabetes Association (2022) Classification and Diagnosis of Diabetes: Standards of Medical Care in Diabetes—2022. Diabetes Care 2022; 45(Suppl. 1):S17-S38.
- https://www.diabetes.org/newsroom/press-releases/2020/ADA-releases-2021-standards-of-medical-care-in-diabetes https://professional.diabetes.org/content-page/slide-deck Slide 26 in https://professional.diabetes.org/sites/professional.diabetes.org/files/media/2022_soc_slide_deck_3.pptx.
- American Diabetes Association (ADA) The Cost of Diabetes. https://www.diabetes.org/about-us/statistics/cost-diabetes.
- Davidson, Annie (2023) “Best Places To Buy Stunning Lab-Created Diamonds.” Forbes. https://www.forbes.com/sites/forbes-personal-shopper/article/best-lab-grown-diamonds/.
- Tan, Lucas. (2023) “Prof Who Went on to Co-Found Moderna Was Told to ‘Find Another Job’ after Pitching Drug Delivery Idea.” The Straits Times. , 2023. https://www.straitstimes.com/singapore/moderna-co-founder-told-to-find-another-job-after-pitching-vaccine-delivery-idea.
- Mihai, Andrei (2022) Quasicrystal Debate. Lindau Nobel Laureate Meetings. June 28, 2022. https://www.lindau-nobel.org/blog-adversity-quasicrystals-and-a-nobel-the-forbidden-fivefold-symmetry-that-was/.
- Langer, Robert and Folkman, Judah (1976) Polymers for the sustained release of proteins and other macromolecules. Nature. 1976 ; 263(5580): p. 797-800. [CrossRef]
- Watson OJ, Barnsley G, Toor J, Hogan AB, Winskill P, Ghani AC. (2022) Global impact of the first year of COVID-19 vaccination: a mathematical modelling study. Lancet Infect Dis. 2022 September; 22(9): p. 1293-1302. [CrossRef]
- Farrenkopf PM (2022) Cost of Ignoring Vaccines. Yale J Biol Med. 2022 Jun 30; 95(2):265-9 https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9235251/pdf/yjbm_95_2_265.pdf.
- Kalemli-Ozcan, Sebnem. “The $4 Trillion Economic Cost of Not Vaccinating the Entire World.” The Conversation. http://theconversation.com/the-4-trillion-economic-cost-of-not-vaccinating-the-entire-world-154786.
- Azerbayev, Zhangir, Bartosz Piotrowski, Hailey Schoelkopf, Edward W. Ayers, Dragomir Radev, and Jeremy Avigad (2023) “ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics.” arXiv, , 2023. https://arxiv.org/abs/2302.12433 https://doi.org/10.48550/arXiv.2302.12433 and https://arxiv.org/pdf/2302.12433.pdf.
- Ferguson, Niall (2009) The Ascent of Money: A Financial History of the World. Penguin 2009 https://www.academia.edu/25856541/THE_ASCENT_OF_MONEY_A_FINANCIAL_HISTORY_of_THE_WORLD.
- Smith, Adam (1776). An Inquiry Into The Nature And Causes Of The Wealth Of Nations. W. Strahan and T. Cadell, London. March 9, 1776. https://www.ibiblio.org/ml/libri/s/SmithA_WealthNations_p.pdf.
- Tocqueville, Alexis de (1838) Democracy in America. G. Dearborn & Co. NY (1838) https://www.gutenberg.org/files/815/815-h/815-h.htm.
- Sen, Amartya (1999) Development as Freedom. New York: Alfred Knopf; 1999. ISBN-13 978-0385720274 https://scholar.harvard.edu/sen/publications/development-freedom.
- Kanaga Rajan (2022) $2 Million Grant Supports Expansion of SF State Computer Science.
- https://news.sfsu.edu/news/2-million-grant-supports-expansion-sf-state-computer-science-all-program.
- Megan Smith (, 2016) Computer Science for All. Executive Office of the President, The White House. https://obamawhitehouse.archives.
- Sorangel Rodriguez-Velazquez (2016) Chemistry of Cooking. LibreTexts. https://chem.libretexts.org/Bookshelves/Biological_Chemistry/Chemistry_of_Cooking_(Rodriguez-Velazquez).
- Hodge, J.E. (1953) “Dehydrated foods: chemistry of browning reactions in model systems,” Journal of Agricultural and Food Chemistry, vol. 1, no. 15, pp. 928–943, 1953.
- https://pubs.acs.org/doi/pdf/10.1021/jf60015a004.
- Qais Faryadi (2007) The Montessori Paradigm of Learning: So What? https://files.eric.ed.gov/fulltext/ED496081.pdf.
- Brigid J., S. Barron, Schwartz, D. L., Vye, N. J., Moore, A., Petrosino, A., Zech, L., Bransford, J. D., & The Cognition and Technology Group at Vanderbilt. (1998). Doing with Understanding: Lessons from Research on Problem- and Project-Based Learning. Journal of the Learning Sciences, 7(3/4), 271–311. http://www.jstor.org/stable/1466789 http://web.mit.edu/monicaru/Public/old%20stuff/For%20Dava/Grad%20Library.Data/PDF/Brigid_1998DoingwithUnderstanding-LessonsfromResearchonProblem-andProject-BasedLearning-1896588801/Brigid_1998DoingwithUnderstanding-LessonsfromResearchonProblem-andProject-BasedLearning.pdf.
- Servant-Miklos, Virginie. “Problem-Oriented Project Work and Problem-Based Learning: ‘Mind the Gap!’” Interdisciplinary Journal of Problem-Based Learning, vol. 14, no. 1, March 2020. [CrossRef]
- Tamanna N, Mahmood N. (2015) Food Processing and Maillard Reaction Products: Effect on Human Health and Nutrition. Int J Food Science. [CrossRef]
- Boaler, J. (2002). Learning from Teaching: Exploring the Relationship between Reform Curriculum and Equity. Journal for Research in Mathematics Education. [CrossRef]
- Mitch Jacoby (2017) What’s chocolate, and how does its chemistry inspire such cravings?
- , 2017. Chemical and Engineering News, vol. 95, issue 7.
- https://cen.acs.org/articles/95/i7/whats-chocolate-and-how-does-its-chemistry-inspire-such-cravings.html.
- [i] Cooper, R. , & Deakin, J.J. (2016). Botanical Miracles: Chemistry of Plants That Changed the World (1st ed.). CRC Press. [CrossRef]
- [ii] Sequin-Frey, Margareta (1981) “The Chemistry of Plant and Animal Dyes.” Journal of Chemical Education 58, no. 4 (81): 301. [CrossRef]
- [iii] Lambourne, R., and T. A. Strivens. (1999) Paint and Surface Coatings: Theory and Practice. 2nd ed. Cambridge, UK. Woodhead Publishing. 1999.
- [iv] https://docs.google.com/document/d/1H6SonjJYn_qSA4Kia-4r2g2EPEqkvUaG/edit.
- Rachel Brazil (, 2014) “Modern Chemistry Techniques Save Ancient Art.” Scientific American www.scientificamerican.com/article/modern-chemistry-techniques-save-ancient-art/.
- Castelvecchi, Davide (2021) “Electric Cars and Batteries: How Will the World Produce Enough?” Nature 596, no. 7872 (, 2021): pages 336-339. [CrossRef]
- Abruña, Héctor D., Yasuyuki Kiya, and Jay C. Henderson (2008) “Batteries and Electrochemical Capacitors.” Physics Today 61, no. 12 (08): 43–47. [CrossRef]
- [i] Jennifer Chu (2020) “Why Shaving Dulls Even the Sharpest of Razors.” Massachusetts Institute of Technology. https://news.mit.edu/2020/why-shaving-dulls-razors-0806.
- [ii] Theresa Machemer (2020) “The Scientific Reason Why Razors Don’t Stay Sharp for Long.” Smithsonian Magazine. https://www.smithsonianmag.com/smart-news/why-razors-are-dull-within-weeks-according-science-180975534/.
- Chaoji Chen, Yudi Kuang, Shuze Zhu, Ingo Burgert, Tobias Keplinger, Amy Gong, Teng Li, Lars Berglund, Stephen J. Eichhorn and Liangbing Hu (2020) Structure–property–function relationships of natural and engineered wood. Nature Review Materials 5, 642–666 (2020). [CrossRef]
- Akemi Kanda (2021) Japanese scientists plan to launch wooden satellite in 2023.
- The Asahi Shimbun (September 13, 2021) https://www.asahi.com/ajw/articles/14439277.
- https://www.japantimes.co.jp/news/2021/12/31/national/japan-wooden-satellite/.
- http://www.arrl.org/news/launch-of-a-wooden-satellite-still-pending.
- https://www.esa.int/Enabling_Support/Space_Engineering_Technology/ESA_flying_payloads_on_wooden_satellite.
- Paul Barry (2017). Head First: Python (2nd ed). O’Reilly.
- The Philosophies of Languages, from Smalltalk to Perl (, 2019) https://www.welcometothejungle.com/en/articles/philosophies-programming-languages.
- Chomsky, Noam. Aspects of the Theory of Syntax. 50th Anniversary Ed., MIT Press, 2015.
- . Semantics and Cognition. MIT Press, 1985.
- The quote is a so-called “Churchillian Drift” from the Latin “fama, malum qua non aliud velocius ullum” by Publius Vergilius Maro (Poet Virgil, , 70 BC–September 21, 19 BC) in Aeneid (book IV, line 174) https://www.poetryintranslation.com/inc/unzip/unzip.php?filename=Virgilaeneidpdf.zip.
- Alexander, C., Ishikawa, S.,, Silverstein, M. (1977). A Pattern Language: Towns, Buildings, Construction. Oxford University Press, NY. ISBN-13 978-0195019193 https://campus.burg-halle.de/id-neuwerk/wp-content/uploads/2018/07/A_Pattern_Language.pdf.
- Adam Conner-Simons (, 2018 ) CSAIL’s Julia Programming Language Launches Version 1.0. Computer Science and Artificial Intelligence Laboratory (CSAIL), MIT https://www.csail.mit.edu/news/csails-julia-programming-language-launches-version-10.
- This slide is from the author’s teaching presentation at MIT (author co-founded MIT Data Center, 2003, in an attempt to explore an infrastructure language—M Language) http://web.mit.edu/edmund_w/www/DATACENTERpeople.htm.
- Chomsky, Noam. Syntactic Structures. De Gruyter, 1957. [CrossRef]
- Chomsky, Noam. Language and Mind. 3rd ed, Cambridge University Press, 2006. https://www.ugr.es/~fmanjon/Language%20and%20Mind.pdf.
- Rajpopat, Rishi Atul (2021). In Pāṇini We Trust: Discovering the Algorithm for Rule Conflict Resolution in the Aṣṭādhyāyī (Doctoral thesis). [CrossRef]
- Jackendoff, R. (1994). Patterns in the mind : language and human nature. Basic Books, NY. https://www.academia.edu/29111910/Jackendoff_1994_Patterns_in_the_Mind_Language_and_human_nature_pdf.
- Language Exchange, Harvard University. https://languageexchange.fas.harvard.edu/.
- Minsky, Marvin. The Society of Mind. Simon and Schuster, 1986. http://www.acad.bg/ebook/ml/Society%20of%20Mind.pdf.
- WORMS, LIFE AND DEATH. Nobel Lecture, , 2002. H. ROBERT HORVITZ, Massachusetts Institute of Technology. https://www.nobelprize.org/uploads/2018/06/horvitz-lecture.pdf.
- Boole, G. (1847). The Mathematical Analysis of Logic : being an essay towards calculus of deductive reasoning. Macmillan Barclay & Macmillan. https://www.gutenberg.org/files/36884/36884-pdf.pdf.
- Robert Gallager Claude Shannon and George Boole, Enablers of the Information Age. Massachusetts Institute of Technology. www.rle.mit.edu/rgallager/documents/BooleShannon.pdf.
- MIT App Inventor. https://appinventor.mit.edu/.
- Bruce, G. Buchanan and Edward H. Shortliffe (June 1, 1984). Rule Based Expert Systems: The Mycin Experiments of the Stanford Heuristic Programming Project (The Addison-Wesley series in artificial intelligence). Addison-Wesley Longman Publishing Co., Inc., USA. ISBN: 978-0-201-10172-0 http://www.shortliffe.net/Buchanan-Shortliffe-1984/MYCIN Book.htm.
- Rose, J. (1988). Application of Expert Systems, edited by J. Ross Quinlan, Turing Institute Press, Glasgow, Scotland, and Addison-Wesley Publishing Company, Sydney, Australia. Robotica 6 (4), 347-347. [CrossRef]
- Peter Jackson (December 1, 1998). Introduction to Expert Systems (3rd. ed.). Addison-Wesley Longman ISBN-13 978-0-201-87686-4 https://www.cs.ox.ac.uk/files/3425/PRG95.pdf. /.
- US Department of Education, United States National Commission on Excellence in Education (1983) A Nation at Risk : The Imperative for Educational Reform. A Report to the Nation and the Secretary of Education, United States Department of Education. Washington, D.C. National Commission on Excellence in Education, 1983.
- https://edreform.com/wp-content/uploads/2013/02/A_Nation_At_Risk_1983.pdf.
- Russell.L. Ackoff, (1989) “From Data to Wisdom,” Journal of Applied Systems Analysis 16 (1989): pages 3-9. https://softwarezen.me/wp-content/uploads/2018/01/datawisdom.pdf NOTE: The poet T.S. Eliot alluded to the “DIKW hierarchy” (in 1934) in “The Rock” [Where is the wisdom we have lost in knowledge? Where is the knowledge we have lost in information?
- Bhopal, Raj S. (2016) Concepts of Epidemiology: Integrating the Ideas, Theories, Principles, and Methods of Epidemiology. Third edition. New York: Oxford University Press, 2016. ISBN 978–0–19–873968–5 https://www.accord.edu.so/course/material/epidemiology-432/pdf_content.
- ISO (1994) Open Systems Interconnection (OSI) Basic Reference Model https://www.iso.org/obp/ui/#iso:std:iso-iec:7498:-1:ed-1:v2:en.
- Ig Nobel Prize https://en.wikipedia.org/wiki/Ig_Nobel_Prize.
- Jargonium https://www.jargonium.com/ and https://www.jargonium.com/who-are-we.
- Claude Félix Abel Niépce de Saint-Victor https://en.wikipedia.org/wiki/Abel_Ni%C3%A9pce_de_Saint-Victor.
- American Physical Society (08) This Month in Physics History https://www.aps.org/publications/apsnews/200803/physicshistory.cfm.
- Carey Sublette () Chronology For The Origin Of Atomic Weapons (Section 10) Version 2.13 https://nuclearweaponarchive.org/Nwfaq/Nfaq10.html.
- Bertrand Goldschmidt. Frances Contribution To The Discovery Of The Chain Reaction. https://www.iaea.org/sites/default/files/publications/magazines/bulletin/bull4-0/04004782124su.pdf.
- The National Museum of Nuclear Science and History. Timeline. Atomic Heritage Foundation https://ahf.nuclearmuseum.org/ahf/nuc-history/timeline/.
- Radiation Effects Research Foundation (A Cooperative Japan-US Research Organization, Hiroshima, Japan and Nagasaki, Japan) https://www.rerf.or.jp/en/.
- World Nuclear Association—Nuclear Power Today | Nuclear Energy https://world-nuclear.org/information-library/current-and-future-generation/nuclear-power-in-the-world-today.aspx.
- Brook, Barry W., and Corey J. A. Bradshaw (2015) “Key Role for Nuclear Energy in Global Biodiversity Conservation: Biodiversity and Sustainable Energy.” Conservation Biology 29, no. 3 (15) pages 702–712. [CrossRef]
- Taverne, Dick (2005) The March of Unreason: Science, Democracy, and the New Fundamentalism. New York: Oxford University Press, 2005. ISBN-13 978-0199205622 Watts G (2005) The March of Unreason: Science, Democracy, and the New Fundamentalism. British Medical Journal. 2005 May 21; 330(7501):1214. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC558032/pdf/bmj33001214.pdf.
- https://www.scienceinschool.org/wp-content/uploads/2014/11/issue6_unreason.pdf.
- https://library.wur.nl/WebQuery/file/cogem/cogem_t48ff36bf_001.pdf.
- Friedman, Jonathan (2019) PC Worlds: Political Correctness and Rising Elites at the End of Hegemony. 1st ed., vol. 2. Berghahn Books, 2019. [CrossRef]
- Spirlet, Thibault (2023) “Swedes Ditching Scandinavia in Droves over Political Correctness.” Express.co.uk (, 2023) https://www.express.co.uk/news/world/1738801/swedes-scandinavia-political-correctness-sweden-portugal-southern-europe.
- National Academies of Sciences, Engineering, and Medicine (2022) Operationalizing Sustainable Development to Benefit People and the Planet. Washington, DC: The National Academies Press. [CrossRef]
- Shane, Janelle (2019) You Look like a Thing and I Love You: How Artificial Intelligence Works and Why It’s Making the World a Weirder Place. First edition. New York: Voracious/Little, Brown and Company, 2019. https://www.aiweirdness.com/.
- Broussard, Meredith (, 2023) More than a Glitch: Confronting Race, Gender, and Ability Bias in Tech. The MIT Press, 2023. Cambridge, MA. ISBN-13 9780262373067 https://mitpress.mit.edu/9780262047654/more-than-a-glitch/.
- Gogh, Vincent van, Leo Jansen, Hans Luijten, and Nienke Bakker. Vincent van Gogh: Ever Yours: The Essential Letters. New Haven: Yale University Press, 2014 ISBN-13 9780300209471 https://www.worldcat.org/title/881612492.
- Ten references: from 675-01 through 675-10.
- [675-01] David Freedman (, 2017) A Reality Check for IBM’s AI Ambitions. MIT Tech Rev. www.technologyreview.com/2017/06/27/4462/a-reality-check-for-ibms-ai-ambitions/.
- [675-02] Paul van der Laken (, 2017) IBM’s Watson for Oncology: A Biased and Unproven Recommendation System in Cancer Treatment?paulvanderlaken.com https://paulvanderlaken.com/2017/09/12/ibms-watson-for-oncology-a-biased-and-unproven-recommendation-system-in-cancer-treatment/.
- [675-03] Casey Ross and Ike Swetlitz (, 2018) IBM’s Watson supercomputer recommended ‘unsafe and incorrect’ cancer treatments, internal documents show. STAT. https://www.statnews.com/wp-content/uploads/2018/09/IBMs-Watson-recommended-unsafe-and-incorrect-cancer-treatments-STAT.pdf.
- [675-04] Angela Chen (, 2018) IBM’s Watson gave unsafe recommendations for treating cancer. The Verge. https://www.theverge.com/2018/7/26/17619382/ibms-watson-cancer-ai-healthcare-science.
- [675-05] Advisory Board (, 2018) IBM’s Watson recommended ‘unsafe and incorrect’ treatments for cancer patients, investigation. www.advisory.com/daily-briefing/2018/07/27/ibm.
- [675-06] Eliza Strickland (, 2019) How IBM Watson Overpromised and Underdelivered on AI Health Care. IEEE Spectrum. https://spectrum.ieee.org/how-ibm-watson-overpromised-and-underdelivered-on-ai-health-care.
- [675-07] Growing Life (, 2019) IBM Halting Sales of Watson AI for Cancer & Drug Disc.
- www.gowinglife.com/ibm-halting-sales-of-watson-ai-tool-for-cancer-and-drug-discovery/.
- [675-08] Dark Daily (, 2019) Artificial Intelligence Systems, Like IBM’s Watson, Continue to Underperform When Compared to Oncologists and Anatomic Pathologists. https://www.darkdaily.com/2019/08/21/artificial-intelligence-systems-like-ibms-watson-continue-to-underperform-when-compared-to-oncologists-and-anatomic-pathologists/.
- [675-09] Steve Lohr (, 2021) What Ever Happened to IBM’s Watson? IBM’s artificial intelligence was supposed to transform industries and generate riches for the company. Neither has panned out. Now, IBM has settled on a humbler vision for Watson. NYT (July 17, 2021).
- https://www.nytimes.com/2021/07/16/technology/what-happened-ibm-watson.html.
- [675-10] Lizzie O’Leary (, 2022) How IBM’s Watson Went From the Future of Health Care to Sold Off for Parts. Slate. https://slate.com/technology/2022/01/ibm-watson-health-failure-artificial-intelligence.html.
- Three references: 676-A through 676-C.
- [676-A] Growing Life (July 12, 2019) IBM Halting Sales of Watson AI tool for Cancer and Drug Discovery.
- https://www.gowinglife.com/ibm-halting-sales-of-watson-ai-tool-for-cancer-and-drug-discovery/.
- [676-B] Matteo Manica and Joris Cadow (, 2019) Novel AI tools to accelerate cancer research. IBM Research. www.ibm.com/blogs/research/2019/07/ai-tools-for-cancer-research/. .
- [676-C] Emani S, Rui A, Rocha HAL, Rizvi RF, Juaçaba SF, Jackson GP, Bates DW. (2022) Physicians’ Perceptions of and Satisfaction With Artificial Intelligence in Cancer Treatment: A Clinical Decision Support System Experience and Implications for Low-Middle-Income Countries. Journal of Medical Internet Research Cancer. 2022 ; 8(2):e31461. [CrossRef]
- Latin proverb: errare humanum est https://en.wikipedia.org/wiki/List_of_Latin_phrases_(E)#errare_humanum_est.
- Donaldson, M.S. , Corrigan, J.M. and Kohn, L.T. eds. (2000) To err is human: building a safer health system. National Academies Press, Washington, DC. Full Report from NAP Press is here: https://nap.nationalacademies.org/catalog/9728/to-err-is-human-building-a-safer-health-system.
- Brief https://nap.nationalacademies.org/resource/9728/To-Err-is-Human-1999--report-brief.pdf.
- Gainty, Caitjan (, 2023) “From a ‘deranged’ Provocateur to IBM’s Failed AI Superproject: The Controversial Story of How Data Has Transformed Healthcare.” The Conversation, , 2023.
- https://theconversation.com/from-a-deranged-provocateur-to-ibms-failed-ai-superproject-the-controversial-story-of-how-data-has-transformed-healthcare-189362.
- “Google’s AlphaGo Defeats South Korean Go Master Lee Sedol” (, 2016) The Center for Brains, Minds & Machines, MIT. https://cbmm.mit.edu/news-events/news/googles-alphago-defeats-south-korean-go-master-lee-sedol.
- Lu M, Shahn Z, Sow D, Doshi-Velez F, Lehman LH. (2021) Is Deep Reinforcement Learning Ready for Practical Applications in Healthcare? A Sensitivity Analysis of Duel-DDQN for Hemodynamic Management in Sepsis Patients. AMIA Annu Symp Proc. 2021 ; 2020:773-782 https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8075511/pdf/112_3410310.
- Gu, Bonwoo, and Yunsick Sung (2021) “Enhanced Reinforcement Learning Method Combining One-Hot Encoding-Based Vectors for CNN-Based Alternative High-Level Decisions” Applied Sciences 11, no. 3: 1291.
- https://doi.org/10.3390/app11031291.
- https://www.mdpi.com/2076-3417/11/3/1291.
- https://www.mdpi.com/2076-3417/11/3/1291/pdf?version=1612146566.
- Hofstadter, Douglas R. (1980) Gödel, Escher, Bach: An Eternal Golden Braid. Vintage.
- ISBN-13 9780394745022 https://www.physixfan.com/wp-content/files/GEBen.pdf.
- Sam Farahzad (, 2016) Watch: By 2020 We Will Be Able to Produce a Brain In a Box. Futurism. https://futurism.com/videos/watch-2020-will-able-produce-brain-box.
- IBM’s, Dr. Dharmendra S. Modha “My Work and Thoughts” https://modha.org/.
- IBM’s, Dr. Dharmendra Modha—Advances Towards Building an Artificial Brain (, 2017) UC Berkeley https://www.youtube.com/watch?v=SQ9l7vmSROU.
- Jumper J, Evans R, Pritzel A, Green T, Figurnov M, Ronneberger O, Tunyasuvunakool K, Bates R, Žídek A, Potapenko A, Bridgland A, Meyer C, Kohl SAA, Ballard AJ, Cowie A, Romera-Paredes B, Nikolov S, Jain R, Adler J, Back T, Petersen S, Reiman D, Clancy E, Zielinski M, Steinegger M, Pacholska M, Berghammer T, Bodenstein S, Silver D, Vinyals O, Senior AW, Kavukcuoglu K, Kohli P, Hassabis D. (2021) Highly accurate protein structure prediction with AlphaFold. Nature. 2021 August; 596(7873): 583-589. DOI 10.1038/s41586-021-03819-2. Epub 2021 . https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8371605/pdf/41586_2021_Article_3819. [PubMed]
- Brini E, Simmerling C, Dill K. (2020) Protein storytelling through physics. Science. 2020 ; 370(6520):eaaz3041. [CrossRef]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7945008/pdf/nihms-1676765.pdf.
- Crystallography: Protein Data Bank (1971) Nature New Biology 233, 223 (1971). [CrossRef]
- Strasser, Bruno J (2019) Collecting Experiments: Making Big Data Biology. University of Chicago Press, 2019. ISBN-13 978-0226634999 https://press.uchicago.edu/ucp/books/book/chicago/C/bo38870755.html.
- PDB History www.rcsb.org/pages/about-us/history; www.ebi.ac.uk/pdbe/docs/nobel/nobels.html.
- Abriata LA, Tamò GE, Dal Peraro M. (2019) A further leap of improvement in tertiary structure prediction in CASP13 prompts new routes for future assessments. Proteins. 2019 December; 87(12):1100-1112. [CrossRef] [PubMed]
- Moult, J. , Fidelis, K., Kryshtafovych, A., Schwede, T. & Topf, M. (2020) Critical assessment of techniques for protein structure prediction, fourteenth round. CASP 14 Abstract Book https://www.predictioncenter.org/casp14/doc/CASP14_Abstracts.pdf.
- Dauter Z, Wlodawer A. (2016) Progress in protein crystallography. Protein Peptide Letters 2016; 23(3):201-210. [CrossRef] [PubMed]
- Brereton AE, Karplus PA. (2015) Native proteins trap high-energy transit conformations. Sci Adv. 2015 ; 1(9):e1501188. [CrossRef] [PubMed]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4646835/pdf/1501188.pdf.
- Ramachandran GN, Ramakrishnan C, Sasisekharan V. (1963) Stereochemistry of polypeptide chain configurations. J Mol Biol. 1963 July; 7: 95-99. [CrossRef]
- Pearson, Karl (1892) Grammar of Science. p. 470 http://sarkoups.free.fr/pearson1911.pdf.
- The Nobel Prize in Chemistry 1962. Max Ferdinand Perutz and John Cowdery Kendrew. https://www.nobelprize.org/prizes/chemistry/1962/summary/.
- The Nobel Prize in Chemistry 2017. Jacques Dubochet, Joachim Frank and Richard Henderson. https://www.nobelprize.org/prizes/chemistry/2017/summary/.
- Cressey, D. Cressey, D., Callaway, E. (2017) Cryo-electron microscopy wins chemistry Nobel. Nature 550, 167 (2017). [CrossRef]
- Bragg, W. H.; Bragg, W. L. (1913). “The Reflexion of X-rays by Crystals”. Proc. R. Soc. Lond. A. 88 (605): 428–38. Bibcode:1913RSPSA..88..428B. [CrossRef]
- https://www.nobelprize.org/prizes/physics/1915/summary/.
- Abriata LA, Tamò GE, Dal Peraro M. (2019) A further leap of improvement in tertiary structure prediction in CASP13 prompts new routes for future assessments. Proteins. 2019 December; 87(12):1100-1112. [CrossRef] [PubMed]
- Christine Slingsby, Paul Barnes, John Finney, Vincent Casey (2021) John Desmond Bernal: his contributions to crystallography. International Union of Crystallography Newsletter. Vol. 29. No. 3. https://www.iucr.org/news/newsletter/volume-29/number-3/John-Desmond-Bernal-his-contributions-to-crystallography.
- Yu X, Wang C, Li Y. (2006) Classification of protein quaternary structure by functional domain composition. BMC Bioinformatics. 2006 ;7:187. [CrossRef]
- Mary Anne Evans (George Eliot) Middlemarch (1871-1872) www.bl.uk/people/george-eliot.
- https://www.bl.uk/collection-items/middlemarch-book-i.
- https://www.bl.uk/romantics-and-victorians/articles/middlemarch-reform-and-change.
- [701-I] Koshland, DE. (1958) Application of a Theory of Enzyme Specificity to Protein Synthesis. Proc Natl Acad Sci U S A. 1958 February; 44(2):98-104. [CrossRef] [PubMed]
- [701-II] Thoma, J.A. & Koshland, D.E. (1960) Competitive Inhibition by Substrate During Enzyme Action Evidence for the Induced-Fit Theory. Journal of the American Chemical Society 82, 3329–3333 (1960). [CrossRef]
- [701-III] Daniel, E. Koshland, Jr. (1998) Conformational changes: How small is big enough? Nature Medicine, Volume 4, Number 10, pages 1112-1114.
- https://laskerfoundation.org/wp-content/uploads/2021/01/1998_koshland.pdf.
- The Nobel Prize in Chemistry 1964. Dorothy Crowfoot Hodgkin. https://www.nobelprize.org/prizes/chemistry/1964/summary/.
- https://oumnh.ox.ac.uk/learn-dorothy-crowfoot-hodgkin.
- https://doi.org/10.1038/204922b0.
- Magdolna Hargittai and Istvan Hargittai (2021) Images of Dorothy Hodgkin. International Union of Crystallography Newsletter. Vol. 29. No. 3. https://www.iucr.org/news/newsletter/volume-29/number-3/John-Desmond-Bernal-his-contributions-to-crystallography.
- Harris LJ, Birch TW. (1930) Zwitterions: Proof of the zwitterion constitution of the amino-acid molecule. II. Amino-acids, polypeptides, etc., and proteins as zwitterions, with instances of non-zwitterion ampholytes. Biochem J. 1930; 24(4):1080-97. [CrossRef]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1254608/pdf/biochemj01125-0233.pdf.
- Schoenborn BP, Garcia A, Knott R. (1995) Hydration in protein crystallography. Progress in Biophysics and Molecular Biology 1995; 64(2-3):105-19. [CrossRef]
- Czapiewski D, Zielkiewicz J. (2010) Structural properties of hydration shell around various conformations of simple polypeptides. J Phys Chem B. 2010 ;114(13):4536-50. [CrossRef] [PubMed]
- Roth CM, Neal BL, Lenhoff AM. (1996) Van der Waals interactions involving proteins. Biophys J. 1996 Feb; 70(2):977-87. [CrossRef] [PubMed]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1224998/pdf/biophysj00053-0401.pdf.
- Derewenda ZS, Lee L, Derewenda U. (1995) The occurrence of C-H...O hydrogen bonds in proteins. J Mol Biol. 1995 ;252(2):248-62. [CrossRef]
- Makhatadze GI, Privalov PL. (1993) Contribution of hydration to protein folding thermodynamics. I. The enthalpy of hydration. J Mol Biol. 1993 ; 232(2):639-659. [CrossRef] [PubMed]
- Privalov PL, Makhatadze GI. (1993) Contribution of hydration to protein folding thermodynamics. II. The entropy and Gibbs energy of hydration. J Mol Biol. 1993 ; 232(2):660-679. [CrossRef] [PubMed]
- Bernal, J.D. , Barnes, P., Cherry, I.A, J.L. Finney (1969) “Anomalous” Water. Nature 224, 393–394 (1969). [CrossRef]
- Rosu-Finsen A, Davies MB, Amon A, Wu H, Sella A, Michaelides A, Salzmann CG.(2023) Medium-density amorphous ice. Science. 2023 February 3; 379(6631):474-478.
- doi: 10.1126/science.abq2105. Epub 2023 February 2. PMID: 36730416.
- Broussard, Meredith (, 2019) Artificial Unintelligence: How Computers Misunderstand the World. MIT Press, Cambridge, MA. ISBN-13 9780262537018 https://mitpress.mit.edu/9780262537018/artificial-unintelligence/.
- Satariano, Adam. “ChatGPT Is Banned in Italy Over Privacy Concerns.” The New York Times, , 2023. https://www.nytimes.com/2023/03/31/technology/chatgpt-italy-ban.html.
- Maruch, Stef, and Aahz Maruch.(2006) Python for Dummies. Wiley, 2006. 978-0471778646.
- Dakhel, Arghavan Moradi, Vahid Majdinasab, Amin Nikanjam, Foutse Khomh, Michel C. Desmarais, Zhen Ming, and Jiang. (2022) “GitHub Copilot AI Pair Programmer: Asset or Liability?” arXiv, , 2022. [CrossRef]
- Simonyi, Charles; Christerson, Magnus; Clifford, Shane (2006). “Intentional Software”. Proceedings of the 21st Annual ACM SIGPLAN Conference on Object-oriented Programming Systems, Languages, and Applications. OOPSLA 2006. New York, NY, USA. ACM: 451–464. [CrossRef]
- Intentional Software https://en.wikipedia.org/wiki/Intentional_Software.
- McLamore, Eric S. and Datta, Shoumen P.A. (2023) A Connected World: System-Level Support through Biosensors. Annual Reviews in Analytical Chemistry (Palo Alto, California). 2023 ; 16(1):285-309. [CrossRef] [PubMed]
- Fortune. “‘You’re Married, but You’re Not Happy’: Microsoft’s Bing Bot Declares Its Love for a Human User.” https://fortune.com/2023/02/17/microsoft-chatgpt-bing-romantic-love/.
- Brooks, Rodney (2017) “The Seven Deadly Sins of AI Predictions.” MIT Technology Review https://www.technologyreview.com/2017/10/06/241837/the-seven-deadly-sins-of-ai-predictions/.
- Shakespeare, William (1597) Romeo and Juliet. ISBN-13 9780199535897.
- https://global.oup.com/academic/product/romeo-and-juliet-the-oxford-shakespeare-9780199535897.
- https://www.thesparkmill.com/blog-posts/2022/6/27/lc4qnp6s3s3tk9a9mngi0brnfma627.
- Samuel Gessner, Ulf Hashagen, Jeanne Pfeiffer, Dominique Tournès (1950) Mathematical Instruments between Material Artifacts and Ideal Machines: Their Scientific and Social Role before 1950. Oberwolfach Rep. 14 (2017), no. 4, pp. 3471–3560. [CrossRef]
- Alomar, Abdullah, Pouya Hamadanian, Arash Nasr-Esfahany, Anish Agarwal, Mohammad Alizadeh, and Devavrat Shah (2023) “CausalSim: A Causal Framework for Unbiased Trace-Driven Simulation.” arXiv, , 2023.
- https://doi.org/10.48550/arXiv.2201.01811 and https://arxiv.org/pdf/2201.01811.pdf.
- Arash Nasr-Esfahany (2022) Thesis submitted to the Department of Electrical Engineering and Computer Science in partial fulfillment of the requirements for the degree of Master of Science in Computer Science and Engineering at the Massachusetts Institute of Technology (Feb 2022) MIT Library (thesis) https://dspace.mit.edu/handle/1721.1/143352.
- Liu, Nelson F., Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. “Lost in the Middle: How Language Models Use Long Contexts,” 2023. [CrossRef]
- Wu, Zhaofeng, Linlu Qiu, Alexis Ross, Ekin Akyürek, Boyuan Chen, Bailin Wang, Najoung Kim, Jacob Andreas, and Yoon Kim. “Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks,” 2023. [CrossRef]
- Taloni A, Scorcia V, Giannaccare G. (2023) Large Language Model Advanced Data Analysis Abuse to Create a Fake Data Set in Medical Research. JAMA Ophthalmology. Published online November 09, 2023. [CrossRef]
- Naddaf, Miryam (2023) “ChatGPT Generates Fake Data Set to Support Scientific Hypothesis.” Nature, November 22, 2023. [CrossRef]
- https://www.nature.com/articles/d41586-023-03635-w.
- Berber Jin and Keach Hagey (2023) “The Contradictions of Sam Altman, AI Crusader.” WSJ, , 2023. https://news.ycombinator.com/item?id=35392288&p=2.
- https://www.wsj.com/tech/ai/chatgpt-sam-altman-artificial-intelligence-openai-b0e1c8c9.
- Balloccu, Simone and Schmidtová, Patrícia and Lango, Mateusz and Dušek, Ondřej (2024) Leak, Cheat, Repeat: Data Contamination and Evaluation Malpractices in Closed-Source LLMs. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (EACL) vol. 1, pages 67-73 https://arxiv.org/abs/2402.03927 https://aclanthology.org/2024.eacl-long.5.pdf https://leak-llm.github.io and https://arxiv.org/pdf/2402.03927.
- Bernstein, Abraham, James Hendler, and Natalya Noy (2016) “A New Look at the Semantic Web.” Communications of the ACM 59, no. 9 (, 2016): 35–37. [CrossRef]
- Lenat, Douglas B., and R. V. Guha. (1989) Building Large Knowledge-Based Systems: Representation and Inference in the Cyc Project. Reading, Massachusetts. 1989.
- John Sowa (1993) D., B. Lenat and R. V. Guha, Building Large Knowledge-Based Systems: Representation and Inference in the Cyc Project. 93 Artificial Intelligence 61:95-104 https://www.researchgate.net/publication/220545983.
- Cyc https://cyc.com/publications/.
- Martínez, Eric (2023) Re-Evaluating GPT-4’s Bar Exam Performance (May 8, 2023). [CrossRef]
- George, H. Chen and Devavrat Shah (2018) “Explaining the Success of Nearest Neighbor Methods in Prediction” (, 2018) Foundations and Trends in Machine Learning. ISBN 978-1680834543 https://devavrat.mit.edu/wp-content/uploads/2018/03/nn_survey.pdf.
- Maria Göppert Mayer https://www.nobelprize.org/prizes/physics/1963/mayer/biographical/.
- Linda Buck https://www.nobelprize.org/prizes/medicine/2004/buck/facts/.
- Barbara Liskov https://amturing.acm.org/award_winners/liskov_1108679.cfm.
- Sandrone, S. (2022) Roger W. Sperry (1913-1994). Journal of Neurology 2022 September; 269(9):5194-5195. [CrossRef]
- Salvo, Joseph J. (2023). Welcome to the Complex Systems Age: Digital Twins in Action. In: Crespi, N., Drobot, A.T., Minerva, R. (eds) The Digital Twin. Springer, Cham. [CrossRef]
- Massachusetts Institute of Technology (MIT) Computer Science and Artificial Intelligence (CSAIL) Laboratory. Early Artificial Intelligence Projects (MIT CSAIL).
- Hill, Doug (2014) “The Eccentric Genius Whose Time May Have Finally Come (Again).” The Atlantic, June 11, 2014. https://mitpress.mit.edu/author/norbert-wiener-8216/.
- https://www.theatlantic.com/technology/archive/2014/06/norbert-wiener-the-eccentric-genius-whose-time-may-have-finally-come-again/372607/.
- The Question of Artificial Intelligence (Routledge Library Editions: Artificial Intelligence) 1st Edition by Brian P. Bloomfield (Editor) ISBN 978-1138585348. Published , 2020. Book Review http://jmc.stanford.edu/artificial-intelligence/reviews/bloomfield.pdf.
- Baldwin, Sarah (26 July 2018) “Ada Lovelace and the Analytical Engine.” Ada Lovelace. https://blogs.bodleian.ox.ac.uk/adalovelace/2018/07/26/ada-lovelace-and-the-analytical-engine.
- Newell, A. and Simon, H. A. (1956) The Logic Theory Machine: A Complex Information Processing System. P-868. , 1956. http://shelf1.library.cmu.edu/IMLS/MindModels/logictheorymachine.pdf.
- Gladwin, Lee (1997) Alan Turing, ENIGMA and the Breaking of German Machine Ciphers in World War II. US National Archives https://www.archives.gov/files/publications/prologue/1997/fall/turing.pdf.
- Turing, M. (1950) Computing Machinery and Intelligence. Mind 49: 433-460 https://redirect.cs.umbc.edu/courses/471/papers/turing.pdf.
- McCarthy, J. , Minsky, M. L., Rochester, N., & Shannon, C. E. (1955) A Proposal for the Dartmouth Summer Research Project on Artificial Intelligence, August 31, 1955. AI Magazine. [CrossRef]
- https://ojs.aaai.org/aimagazine/index. 1904.
- Breyer, Stephen G. (, 2024) Reading the Constitution: Why I Chose Pragmatism, Not Textualism. First edition, Simon & Schuster, 2024.
- https://hls.harvard.edu/today/stephen-breyer-for-the-defense/.
- https://constitutioncenter.org/media/files/Justice-Stephen-Breyer-on-Reading-the-Constitution-transcript-LANCC.pdf.
- Newell, A., Shaw, J. C., and Simon, H. A. (1958) Elements of a theory of human problem solving. Psychological Review, 65(3), 151–166. [CrossRef]
- https://iiif.library.cmu.edu/file/Simon_box00064_fld04878_bdl0001_doc0001/Simon_box00064_fld04878_bdl0001_doc0001.pdf.
- The RAND Corporation, P-1584. 30 December 1958. Revised 9 February 1959 http://bitsavers.informatik.uni-stuttgart.de/pdf/rand/ipl/P-1584_Report_On_A_General_Problem-Solving_Program_Feb59.pdf.
- Newell, Allen (1963) A Guide to the General Problem Solver Program GPS-2-2 (RM-3337-PR) 63. United States Air Force under Project RAND contract No AF 49 (638)-700. Rand Corporation, Santa Monica, CA https://stacks.stanford.edu/file/druid:zk239tp3547/zk239tp3547.pdf.
- McCulloch, W.S. , Pitts, W. (1943) A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical Biophysics 5, 115–133 (1943). [CrossRef]
- https://www.cs.cmu.edu/~epxing/Class/10715/reading/McCulloch.and.Pitts.pdf.
- Hebb, D.O. (1949) The Organization of Behavior. A Neuropsychological Theory. Wiley & Sons, NY. https://pure.mpg.de/rest/items/item_2346268_3/component/file_2346267/content.
- Rosenblatt, F. (1958). The perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65(6), 386–408. [CrossRef]
- Südhof TC and Malenka RC (2008). Understanding synapses: past, present, and future. Neuron. 2008 November 6; 60(3):469-76. https://doi.org/10.1016/j.neuron.2008.10.011. PMID: 18995821; https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3243741/pdf/nihms342894.pdf. [CrossRef] [PubMed]
- Südhof, TC. (2021) The cell biology of synapse formation. J Cell Biol. 2021 ; 220(7):e202103052. [CrossRef] [PubMed]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8186004/pdf/JCB_202103052.pdf.
- Box, George E. P and Norman R. Draper (1987). Empirical Model-Building and Response Surfaces, p. 424, Wiley. ISBN 0471810339. https://typeset.io/pdf/empirical-model-building-and-response-surfaces-2cz2q2bdbg.pdf.
- Jacob F and Monod, J. (1961) Genetic regulatory mechanisms in the synthesis of proteins. Journal Mol Biol. 1961 June; 3:318-56. [CrossRef] [PubMed]
- Minsky, Marvin and Papert, Seymour. Perceptrons: An Introduction to Computational Geometry, 1969. [CrossRef]
- Wolfram, Stephen (2012) Overcoming Artificial Stupidity. https://blog.wolframalpha. https://blog.wolframalpha.com/2012/04/17/overcoming-artificial-stupidity/. 2012.
- Wolfram, Stephen (2015) Wolfram Language Artificial Intelligence: The Image Identification Project https://writings.stephenwolfram.com/2015/05/wolfram-language-artificial-intelligence-the-image-identification-project/.
- Frederick Smith—Founder & Chairman, FedEx (Federal Express Corporation) https://achievement.org/achiever/frederick-w-smith/.
- John, F. Sowa (1999) Knowledge Representation: Logical, Philosophical, and Computational Foundations, Brooks Cole Publishing Co., Pacific Grove, CA. www.jfsowa.com/krbook/ https://archive.org/details/knowledgereprese00sowa_0.
- T. Poggio and Liao, Q. T. Poggio and Liao, Q., “Theory II: Landscape of the Empirical Risk in Deep Learning”. 2017. MIT Center for Brains, Minds and Machines. https://cbmm.mit.edu/ https://cbmm.mit.edu/sites/default/files/publications/CBMM%20Memo%20066_1703.09833v2.pdf.
- LeCun, Y. , Bengio, Y. & Hinton, G. Deep learning. Nature. [CrossRef]
- Hardesty, Larry (2017) “Explained: Neural Networks.” MIT News. . https://news.mit.edu/2017/explained-neural-networks-deep-learning-0414.
- Fukushima, K. (1980) Neocognitron: A Self-Organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position. Biological Cybernetics, 36, 193-202. [CrossRef]
- David Hubel (1926-2013) https://www.nobelprize.org/prizes/medicine/1981/hubel/facts/ https://www.nei.nih.gov/about/news-and-events/news/remembering-visionary-neuroscientist-david-hubel.
- Hubel, David and Wiesel, Torsten (1962) Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. J Physiol. 1962 January; 160(1):106-154. [CrossRef] [PubMed]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1359523/pdf/jphysiol01247-0121.pdf.
- C. Zhang, Liao, Q., Rakhlin, A., Sridharan, K., Miranda, B., Golowich, N., and Poggio, T. (2017) “Musings on Deep Learning: Properties of SGD”. 2017. MIT Center for Brains, Minds and Machines. https://cbmm.mit.edu/ https://cbmm.mit.edu/sites/default/files/publications/CBMM-Memo-067.pdf https://cbmm.mit.edu/sites/default/files/publications/CBMM-Memo-067-v3.pdf https://cbmm.mit.edu/sites/default/files/publications/CBMM-Memo-067-v4.pdf.
- Geoffrey, E. Hinton https://www.cs.toronto.edu/~hinton/.
- Rumelhart, D. , Hinton, G. & Williams, R. Learning representations by back-propagating errors. Nature, 1986. [Google Scholar] [CrossRef]
- Brooks, Rodney (2017) The Seven Deadly Sins of AI Predictions. MIT Technology Review. https://www.technologyreview.com/2017/10/06/241837/the-seven-deadly-sins-of-ai-predictions/ https://rodneybrooks.com/the-seven-deadly-sins-of-predicting-the-future-of-ai/.
- Back Propagation https://www.techopedia.com/definition/17833/backpropagation.
- Ted A James (2023) How Artificial Intelligence is Disrupting Medicine and What it Means for Physicians. https://postgraduateeducation.hms.harvard.edu/trends-medicine/how-artificial-intelligence-disrupting-medicine-what-means-physicians.
- Miyazaki K, Uchiba T, Tanaka K, Sasahara K. (2022) Aggressive behaviour of anti-vaxxers and their toxic replies in English and Japanese. Humanit Soc Sci Commun. 2022; 9(1):229. [CrossRef] [PubMed]
- Julian Bramel and David Simchi-Levi. The Logic of Logistics: Theory, Algorithms, and Applications for Logistics and Supply Chain Management. 2nd ed, Springer, 2005. ISBN 978-0387221991 https://industri.fatek.unpatti.ac.id/wp-content/uploads/2019/03/008-The-Logic-of-Logistics-Theory-Algorithms-and-Application-for-Logistics-Management-Julian-Bramel-David-Simchi-Levi-Edisi-1-1997.pdf.
- Villani, Tom (2024) AI Hype Cycles: Lessons from the Past to Sustain Progress. https://www.njii.com/2024/05/ai-hype-cycles-lessons-from-the-past-to-sustain-progress/.
- Buolamwini Joy and Gebru Timnit (2018) Gender shades: intersectional accuracy disparities in commercial gender classification. Proceedings of Machine Learning Research 81:1–15, 2018. Proceedings of the Conference on Fairness, Accountability and Transparency; Feb 23–24, 2018 https://www.ajl.org/about.
- https://www.media.mit.edu/people/joyab/overview/.
- http://proceedings.mlr.press/v81/buolamwini18a.html.
- https://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf.
- https://news.mit.edu/2018/study-finds-gender-skin-type-bias-artificial-intelligence-systems-0212.
- Reva Schwartz, Apostol Vassilev, Kristen K. Greene, Lori Perine, Andrew Burt, Patrick Hall.
- (2022) Towards a Standard for Identifying and Managing Bias in Artificial Intelligence. National Institute of Standards and Technology (NIST). 1270. [CrossRef]
- Karen Hao (2020) We read the paper that forced Timnit Gebru out of Google. Here’s what it says. MIT Technology Review https://scholar.google.com/citations?user=lemnAcwAAAAJ&hl=en https://www.technologyreview.com/2020/12/04/1013294/google-ai-ethics-research-paper-forced-out-timnit-gebru/ https://www.wired.com/story/google-timnit-gebru-ai-what-really-happened/.
- https://www.washingtonpost.com/technology/2020/12/23/google-timnit-gebru-ai-ethics/.
- https://time.com/6132399/timnit-gebru-ai-google/.
- https://www.theglobeandmail.com/business/article-the-downside-of-ai-former-google-scientist-timnit-gebru-warns-of-the/.
- https://www.npr.org/2020/12/17/947719354/ousted-black-google-researcher-they-wanted-to-have-my-presence-but-not-me-exactl.
- Lauren Goode and Louise Matsakis (2020) Amazon Doubles Down on Ring Partnerships With Law Enforcement. WIRED. , 2020. https://www.wired.com/story/ces-2020-amazon-defends-ring-police-partnerships/.
- Perez, Carlos E. (2017) “Why We Should Be Deeply Suspicious of BackPropagation.” Intuition Machine, . https://medium.com/intuitionmachine/the-deeply-suspicious-nature-of-backpropagation-9bed5e2b085e.
- Backpropagation evolved from the work of Henry Kelley (1960), Seppo Linnainmaa (1970).
- Henry, J. Kelley (1960) Gradient Theory of Optimal Flight Paths. ARS Journal, Vol. 30, No. 10, pp. 947-954. https://gwern.net/doc/statistics/decision/1960-kelley.pdf.
- Seppo Linnainmaa (1970). The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors. Master’s Thesis (in Finnish), University of Helsinki. https://people.idsia.ch/~juergen/linnainmaa1970thesis.pdf.
- Seppo Linnainmaa (1976) Taylor expansion of the accumulated rounding error. BIT, 1976. [CrossRef]
- Juergen Schmidhuber (AI Blog, 2014; updated 2023). Who invented backpropagation? https://people.idsia.ch/~juergen/who-invented-backpropagation.html https://people.idsia.ch/~juergen/.
- “Who Invented Backpropagation? Hinton Says He Didn’t, but His Work Made It Popular.” Synced Review, . https://medium.com/syncedreview/who-invented-backpropagation-hinton-says-he-didnt-but-his-work-made-it-popular-e0854504d6d1.
- Will Douglas Heaven (2023) “Geoffrey Hinton Tells Us Why He’s Now Scared of the Tech He Helped Build.” MIT Technology Review. https://www.technologyreview.com/2023/05/02/1072528/geoffrey-hinton-google-why-scared-ai/.
- Sara Brown (2023) Why Neural Net Pioneer Geoffrey Hinton Is Sounding the Alarm on AI. Massachusetts Institute of Technology Sloan School of Management https://mitsloan.mit.edu/ideas-made-to-matter/why-neural-net-pioneer-geoffrey-hinton-sounding-alarm-ai.
- Wright LG, Onodera T, Stein MM, Wang T, Schachter DT, Hu Z, McMahon PL. (2022) Deep physical neural networks trained with backpropagation. Nature. 2022 January; 601(7894):549-555. [CrossRef] [PubMed]
- Gallant, Stephen I.(1993) Neural Network Learning and Expert Systems. MIT Press, 1993. ISBN 9780262527897 https://mitpress.mit.edu/9780262527897/neural-network-learning-and-expert-systems/ https://www.gbv.de/dms/ohb-opac/111089174.pdf.
- AI Winter https://en.wikipedia.org/wiki/AI_winter.
- AI Winter (future) https://www.iflscience.com/the-ai-winter-is-coming-in-2024-a-top-scientist-predicts-72352.
- Buldyrev SV, Parshani R, Paul G, Stanley HE, Havlin S. (2010) Catastrophic cascade of failures in interdependent networks. Nature. 2010 ; 464(7291):1025-8. [CrossRef] [PubMed]
- Claude, E. Shannon (1948) A Mathematical Theory of Communication. The Bell System Technical Journal, Vol. 27, pp. 379–423, 623–656, July, October, 1948. https://people.math.harvard.edu/~ctm/home/text/others/shannon/entropy/entropy.pdf.
- Kalman RE (1960) "A new approach to linear filtering and prediction problems".
- Journal of Basic Engineering, vol. 82, pp. 35–45, 60. https://www.cs.unc.edu/~welch/kalman/media/pdf/Kalman1960.pdf.
- Panesar, S.S. , Kliot, M., Parrish, R., Fernandez-Miranda, J., Cagle, Y., Britz, G.W. (2019) Promises and Perils of Artificial Intelligence in Neurosurgery. Neurosurgery. [CrossRef]
- Granger, C. W. J. & Newbold, Paul (1986) “Forecasting Economic Time Series” Elsevier Monographs, Elsevier, 2nd ed. ISBN 9780122951831 https://econpapers.repec.org/bookchap/eeemonogr/9780122951831.htm.
- Engle, R.F. (1982) Autoregressive Conditional Heteroskedasticity with Estimates of the Variance of U.K. Inflation. 1008; 50. [Google Scholar] [CrossRef]
- Datta, S. P. A. and Granger, C. W. J. (2006) Potential to Improve Forecasting Accuracy: Advances in Supply Chain Management. Working Paper in MIT Engineering Systems Division. 2006—MIT Library https://dspace.mit.edu/handle/1721.1/41905.
- 2007—MIT Library https://dspace.mit.edu/handle/1721.1/41906.
- Datta, S.; Granger, C.W.J.; Barari, M.; Gibbs, T. (2007) “Management of supply chain: an alternative modelling technique for forecasting” Journal of the Operational Research Society, vol. 58(11), pages 1459-1469, 07. https://ideas.repec.org/a/pal/jorsoc/v58y2007i11d10.1057_palgrave.jors.2602419.html.
- Engle, Robert F. and C. W. J. Granger (1987) “Co-Integration and Error Correction: Representation, Estimation, and Testing.” Econometrica 55, no. 2 (1987): 251-276. [CrossRef]
- Engle, Robert. GARCH 101: An Introduction to the Use of ARCH/GARCH models in Applied Econometrics. https://web-static.stern.nyu.edu/rengle/GARCH101.PDF.
- Granger, Clive W. J. (2003) Time Series Analysis, Cointegration, and Applications. Nobel Lecture https://www.nobelprize.org/uploads/2018/06/granger-lecture.pdf.
- MTBF (Mean Time Between Failures): A Metric in PLM (Product Lifecycle Management) https://www.mingosmartfactory.com/mtbf-mean-time-between-failure-manufacturing-explained/.
- Levine ME, Albers DJ, Hripcsak G. (2017) Comparing lagged linear correlation, lagged regression, Granger causality, and vector autoregression for uncovering associations in EHR data. AMIA Annu Symp Proc. 2017 ; 2016:779-788. PMID: 28269874 https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5333294/pdf/2499084.
- Engle, Robert F. (2003) Risk and Volatility: Econometric Models and Financial Practice. Nobel Lecture https://www.nobelprize.org/uploads/2018/06/engle-lecture.pdf.
- Datta, Shoumen Palit Austin, Tausifa Jan Saleem, Molood Barati, María Victoria López López, Marie-Laure Furgala, Diana C. Vanegas, Gérald Santucci, Pramod P. Khargonekar and Eric S. McLamore (2021) Data, Analytics and Interoperability between Systems (IoT) is Incongruous with the Economics of Technology: Evolution of Porous Pareto Partition (P3). Chapter 2 in “Big Data Analytics for Internet of Things” ed. Tausifa Jan Saleem and Md. Ahsan Chishti. WILEY. [CrossRef]
- Babyak, M. A. (2004) “What You See May Not Be What You Get: A Brief, Nontechnical Introduction to Overfitting in Regression-Type Models.” Psychosomatic Med, vol. 66, no. 3, 04, pp 411-21. [CrossRef]
- Tarfa Hamed (2017) Recursive Feature Addition: A Novel Feature Selection Technique, Including a Proof of Concept in Network Security. PhD thesis, University of Guelph, Canada. https://atrium.lib.uoguelph.ca/xmlui/bitstream/handle/10214/10315/Hamed_Tarfa_201704_PhD.pdf?sequence=1&isAllowed=y.
- Shi, Longxiang, et al. "Semantic Health Knowledge Graph: Semantic Integration of Heterogeneous Medical Knowledge and Services." BioMed Research International, vol. 2017, 2017, pp. 1–12. [CrossRef]
- Aditya Nandy, Chenru Duan, Jon Paul Janet, Stefan Gugler, and Heather J. Kulik (2018).
- “Strategies and Software for Machine Learning Accelerated Discovery in Transition Metal Chemistry.” Industrial and Engineering Chemistry Research, volume 57, number 42, Oct 2018, pages 13973-13986 https://pubs.acs.org/doi/pdf/10.1021/acs.iecr.8b04015.
- Virshup, Aaron M., et al. “Stochastic Voyages into Uncharted Chemical Space Produce a Representative Library of All Possible Drug-Like Compounds.” Journal of the American Chemical Society, vol. 135, no. 19, 13, pages 7296-7303. [CrossRef]
- Sam Lemonick (2019) As DFT Matures, Will It Become a Push-Button Technology? Chemical & Engineering News, volume 97, issue 35 https://cen.acs.org/physical-chemistry/computational-chemistry/DFT-matures-become-push-button/97/i35.
- Joan Bruna, Wojciech Zaremba, Arthur Szlam & Yann LeCun (2014) “Spectral Networks and Locally Connected Networks on Graphs” https://arxiv.org/pdf/1312.6203.pdf.
- Justin Gilmer, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals and George E. Dahl (2017) Neural Message Passing for Quantum Chemistry. https://arxiv.org/pdf/1704.01212.pdf.
- Kyle Swanson (2019) Message Passing Neural Networks for Molecular Property Prediction. Master’s Thesis. EECS, Massachusetts Institute of Technology. https://dspace.mit.edu/bitstream/handle/1721.1/123133/1128814048-MIT.pdf?sequence=1&isAllowed=y.
- Heid E, Greenman KP, Chung Y, Li SC, Graff DE, Vermeire FH, Wu H, Green WH, McGill CJ. (2023) Chemprop: A Machine Learning Package for Chemical Property Prediction. J Chem Inf Model. 2024 ; 64(1):9-17. [CrossRef] [PubMed]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10777403/pdf/ci3c01250.pdf.
- Lars Ruddigkeit, Ruud van Deursen, Lorenz C. Blum and Jean-Louis Reymond (2012) “Enumeration of 166 Billion Organic Small Molecules in the Chemical Universe Database GDB-17.” J of Chemical Information and Modeling, vol. 52, no. 11, 12, pp. 2864–2875. [CrossRef]
- Jonathan, M. Stokes, Kevin Yang, Kyle Swanson, Wengong Jin, Andres Cubillos-Ruiz, Nina M. Donghia, Craig R. MacNair, Shawn French, Lindsey A. Carfrae, Zohar Bloom-Ackerman, Victoria M. Tran, Anush Chiappino-Pepe, Ahmed H. Badran, Ian W. Andrews, Emma J. Chory, George M. Church, Eric D. Brown, Tommi S. Jaakkola, Regina Barzilay and James J. Collins (2020) “A Deep Learning Approach to Antibiotic Discovery.” Cell, vol. 180, no. 4, 20, pp. 688-702.e13. [CrossRef]
- Vahe Tshitoyan, John Dagdelen, Leigh Weston, Alexander Dunn, Ziqin Rong, Olga Kononova, Kristin A. Persson, Gerbrand Ceder and Anubhav Jain (2019) Unsupervised word embeddings capture latent knowledge from materials science literature. 2019. [CrossRef]
- Trafton, Anne (2020) “Artificial Intelligence Yields New Antibiotic.” MIT News | Massachusetts Institute of Technology, https://news.mit.edu/2020/artificial-intelligence-identifies-new-antibiotic-0220.
- Zhang, Xiang, et al. (2019) “Deep Neural Network Hyperparameter Optimization with Orthogonal Array Tuning.” 19 https://arxiv.org/pdf/1907.13359.pdf.
- Zhang, Yang, et al. (2022) "CrowdOptim: A Crowd-Driven Neural Network Hyperparameter Optimization Approach to AI-Based Smart Urban Sensing." Proceedings of the ACM on Human-Computer Interaction, vol. 6, no. CSCW2, November 2022, pages 1–27. [CrossRef]
- Lars Kai Hansen and Peter Salamon (1990) Neural Network Ensembles. IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 12, No. 10, 90. https://pdfs.semanticscholar.org/257d/c8ae2a8353bb2e86c1b7186e7d989fb433d3.pdf.
- Marcello Pelillo (2014) “Alhazen and the nearest neighbor rule.” Pattern Recognition Letters 38 (2014) 34–37. [CrossRef]
- Niazi, SK. The Coming of Age of AI/ML in Drug Discovery, Development, Clinical Testing, and Manufacturing: The FDA Perspectives. Drug Design Development Ther. 2023 ; 17:2691-2725. [CrossRef] [PubMed]
- Dara S, Dhamercherla S, Jadav SS, Babu CM, Ahsan MJ. Machine Learning in Drug Discovery: A Review. Artificial Intelligence Review 2022; 55(3):1947-1999. [CrossRef] [PubMed]
- U. S. Government Accountability Office (GAO). Artificial Intelligence in Health Care: Benefits and Challenges of Machine Learning in Drug Development [Reissued with Revisions on Jan. 31, 2020.] | U.S. GAO. https://www.gao.gov/products/gao-20-215sp and https://www.gao.gov/assets/gao-20-215sp.pdf.
- Editorial “AI’s Potential to Accelerate Drug Discovery Needs a Reality Check.” Nature, vol. 622, no. 7982, 23, pp. [CrossRef]
- US Food & Drug Administration (FDA) Using Artificial Intelligence and Machine Learning in the Development of Drug and Biological Products. 2024.
- 2024 https://www.fda.gov/media/167973/download?attachment.
- 2023 https://www.fda.gov/media/165743/download?attachment.
- Insilico Medicine—From Start to Phase 1 in 30 Months AI-discovered and AI-designed Anti-fibrotic Drug Enters Phase I Clinical Trial https://insilico.com/phase1.
- ElZarrad MK, Lee AY, Purcell R, Steele SJ. Advancing an agile regulatory ecosystem to respond to the rapid development of innovative technologies. Clinical Translational Science 2022 June; 15(6):1332-1339. [CrossRef] [PubMed]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9199874/pdf/CTS-15-1332.pdf.
- Wellcome Trust (Pharmaceutical Corporation) and Boston Consulting Group (BCG) Unlocking the Potential of AI in Drug Discovery. “This report and its findings were produced and co-authored by Wellcome and BCG.” https://cms.wellcome.org/sites/default/files/2023-06/unlocking-the-potential-of-AI-in-drug-discovery_report.pdf.
- Vamathevan J, Clark D, Czodrowski P, Dunham I, Ferran E, Lee G, Li B, Madabhushi A, Shah P, Spitzer M, Zhao S. Applications of machine learning in drug discovery and development. Nat Rev Drug Discov. 2019 June; 18(6):463-477. [CrossRef] [PubMed]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6552674/pdf/nihms-1029624.pdf.
- Whalen S, Schreiber J, Noble WS, Pollard KS. (2022) Navigating the pitfalls of applying machine learning in genomics. Nature Review Genetics 2022 March; 23(3):169-181. [CrossRef] [PubMed]
- Lannelongue L, Inouye M. (2024) Pitfalls of machine learning models for protein-protein interaction networks. Bioinformatics. 2024 Februay 1;40(2):btae012. [CrossRef] [PubMed]
- Drew McDermott (1976) Artificial intelligence meets natural stupidity. MIT Computer Science and Artificial Intelligence Laboratory, Massachusetts Institute of Technology. [CrossRef]
- Gihawi A, Ge Y, Lu J, Puiu D, Xu A, Cooper CS, Brewer DS, Pertea M, Salzberg SL. Major data analysis errors invalidate cancer microbiome findings. mBio. 2023 Oct 31;14(5):e0160723. [CrossRef] [PubMed]
- Poore, G.D. , Kopylova, E., Zhu, Q. et al. RETRACTED ARTICLE: Microbiome analyses of blood and tissues suggest cancer diagnostic approach. Nature 579, 567–574 (2020). [CrossRef]
- Ajami, Nadim J., and Jennifer A. Wargo. “AI Finds Microbial Signatures in Tumours and Blood across Cancer Types.” Nature, vol. 579, no. 7800, Mar. 2020, pp. 502–503. Retracted on , 2024. [CrossRef]
- Catherine Offord (, 2024) Journal retracts influential cancer microbiome paper. https://www.science.org/content/article/journal-retracts-influential-cancer-microbiome-paper.
- Schrope, Mark. “James Cameron Heads into the Abyss.” Nature, Mar. 2012, p. nature.2012.10246. DOI.org (Crossref). [CrossRef]
- Kolodner, Janet L. Case-Based Reasoning. Morgan Kaufmann Publishers, 1993.
- Fauci Defends Himself against Republican Attacks over COVID Origins. https://ny1.com/nyc/all-boroughs/news/2024/06/03/fauci-republicans-house-covid-origins.
- Fox, Jeremy. “Who Are the Most Accomplished Scientist-Politicians in History?” Dynamic Ecology, . https://dynamicecology.wordpress.com/2020/02/10/who-are-the-most-accomplished-scientist-politicians-in-history.
- Arrow, Kenneth J. (1959) “Rational Choice Functions and Orderings.” Economica 26, no. 102 (1959): 121–27. [CrossRef]
- https://www.nobelprize.org/prizes/economic-sciences/1972/arrow/facts/.
- Kahneman, Daniel (2011) Thinking, Fast and Slow. Farrar, Straus and Giroux, 2011.
- http://dspace.vnbrims.org:13000/jspui/bitstream/123456789/2224/1/Daniel-Kahneman-Thinking-Fast-and-Slow-.pdf.
- https://www.nobelprize.org/prizes/economic-sciences/2002/kahneman/facts/.
- “Rational Order from ‘Irrational’ Actions.” Yale Insights, 19 October 2020. https://insights.som.yale.edu/insights/rational-order-from-irrational-actions.
- Sen, Amartya. “Internal Consistency of Choice.” Econometrica 61, no. 3 (1993): 495–521. [CrossRef]
- https://www.nobelprize.org/prizes/economic-sciences/1998/sen/facts/.
- Akerlof, George A., and Janet L. Yellen. “Rational Models of Irrational Behavior.” The American Economic Review 77, no. 2 (1987): 137–42. http://www.jstor.org/stable/1805441.
- https://www.economicswebinstitute.org/essays/akerlofyellen.pdf.
- https://www.nobelprize.org/prizes/economic-sciences/2001/akerlof/facts/.
- Shakespeare, William (1623) Macbeth. Wordsworth Classics. Ware, England: Wordsworth Edition 1992. https://archive.org/details/macbethwordswort00will/mode/2up.
- Pratt, Mary (2015) 15 Most Misused Buzzwords in IT.” CIO Magazine https://www.cio.com/article/191262/most-misused-buzzwords-in-information-technology.html.
- “Michael Stonebraker Wins $1 Million Turing Award.” Massachusetts Institute of Technology, . https://amturing.acm.org/award_winners/stonebraker_1172121.cfm.
- https://news.mit.edu/2015/michael-stonebraker-wins-turing-award-0325.
- MICHAEL STONEBRAKER, EUGENE WONG, PETER KREPS and GERALD HELD (1976) The Design and Implementation of INGRES. ACM Transactions on Database Systems, Vol. 1, No. 3, 76, pages 189-222. https://www.cs.cmu.edu/~natassa/courses/15-721/papers/p189-stonebraker.pdf.
- Michael Stonebraker and Lawrence, A. Rowe. Rowe. 1986. The design of POSTGRES. In Proceedings of the 1986 ACM SIGMOD international conference on Management of data (SIGMOD ‘86). Association for Computing Machinery, New York, NY, USA, 340–355. [CrossRef]
- On the Death of Big Data (2014) https://adtmag.com/blogs/dev-watch/2014/09/death-of-big-data.aspx.
- ibn al-Razzaz al-Jazari (1136-1206) Kitab fi Ma’rifat al-Hiyal al-Handasiyya (The Book of Knowledge of Ingenious Mechanical Devices) ISBN-13 978-9027703293 https://archive.org/details/cover_20200113_2057 Complete Book https://ia902803.us.archive.org/23/items/cover_20200113_2057/Content.pdf.
- Wood, Gaby (2002) Living Dolls: A Magical History of the Quest for Mechanical Life. Paperback edition, Faber and Faber, 2003.
- Wood, Gaby (2003) Edison’s Eve : a magical history of the quest for mechanical life. Anchor Books, NY. https://archive.org/details/edisonsevemagica0000wood_n8o7.
- Digesting Duck. https://en.wikipedia.org/wiki/Digesting_Duck.
- Shumailov, Ilia, et al. “AI Models Collapse When Trained on Recursively Generated Data.” Nature, vol. 631, no. 8022, 24, pp. 755–759. [CrossRef]
- Gibney, Elizabeth. “AI Models Fed AI-Generated Data Quickly Spew Nonsense.” Nature, 24. [CrossRef]
- [1] Balloccu, Simone; Schmidtová, Patrícia; Lango, Mateusz and Dušek, Ondřej (2024) Leak, Cheat, Repeat: Data Contamination and Evaluation Malpractices in Closed-Source LLMs. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics. https://aclanthology.org/2024.eacl-long.5.pdf ; https://leak-llm.github.io ; https://arxiv.org/abs/2402.03927 ; https://arxiv.org/pdf/2402.03927.
- Zhou L, Schellaert W, Martínez-Plumed F, Moros-Daval Y, Ferri C, Hernández-Orallo J. Larger and more instructable language models become less reliable. Nature. 2024 Sep 25. [CrossRef] [PubMed]
- Stanford University (2014) "One Hundred Year Study on Artificial Intelligence (AI100)" https://ai100.stanford.edu/.
- 2016 https://ai100.stanford.edu/sites/g/files/sbiybj18871/files/media/file/ai100report10032016fnl_singles.pdf.
- 2021.
- https://ai100.stanford.edu/sites/g/files/sbiybj18871/files/media/file/AI100Report_MT_10.pdf.
- Tarassenko L, Topol EJ. (2018) Monitoring Jet Engines and the Health of People. JAMA. 2018 ; 320(22):2309-2310. [CrossRef] [PubMed]
- Rahul Mangharam et al. (June 21, 2024) CyberCardia: Multi-scale Cardiac Digital Twins for surgical guidance and in-silico clinical trials (in press).
- Coorey G, Figtree GA, Fletcher DF, Snelson VJ, Vernon ST, Winlaw D, Grieve SM, McEwan A, Yang JYH, Qian P, O’Brien K, Orchard J, Kim J, Patel S, Redfern J. The health digital twin to tackle cardiovascular disease-a review of an emerging interdisciplinary field. NPJ Digit Med. 2022 Aug 26;5(1):126. [CrossRef] [PubMed]
- Rudra D, deRoos P, Chaudhry A, Niec RE, Arvey A, Samstein RM, Leslie C, Shaffer SA, Goodlett DR, Rudensky AY. (2012) Transcription factor Foxp3 and its protein partners form a complex regulatory network. Nat Immunol. 2012 October; 13(10): 1010-1019. [CrossRef] [PubMed]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3448012/pdf/nihms395152.pdf.
- Zhang W, Leng F, Wang X, Ramirez RN, Park J, Benoist C, Hur S. (2023) FOXP3 recognizes microsatellites and bridges DNA through multimerization. Nature. 2023 December; 624(7991): 433-441. [CrossRef] [PubMed]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10719092/pdf/41586_2023_Article_6793.pdf.
- Liu Z, Zheng Y. (2023) An immune-cell transcription factor tethers DNA together. Nature. 2023 December; 624(7991): 255-256. [CrossRef] [PubMed]
- Liquid Neural Networks (LTC) https://cbmm.mit.edu/video/liquid-neural-networks.
- Liquid Foundation Models (LFM). Liquid AI https://www.liquid.ai/liquid-foundation-models.
- Hofstadter, Douglas (1994) Fluid Concepts and Creative Analogies: Computer Models of the Fundamental Mechanisms of Thought. 1994. Basic Books, NY. ISBN 0-465-05154-5 Bulletin of Science, Technology and Society, 15(1) 58-58. [CrossRef]
- Pattie Maes. Fluid Interfaces https://www.media.mit.edu/groups/fluid-interfaces/overview/ https://www.media.mit.edu/people/pattie/overview/.
- Wicht, Baptiste, et al. (2018) DLL: A Blazing Fast Deep Neural Network Library. arXiv, 2018. [CrossRef]
- McLamore ES, Palit Austin Datta S, Morgan V, Cavallaro N, Kiker G, Jenkins DM, Rong Y, Gomes C, Claussen J, Vanegas D, Alocilja EC. (2019) SNAPS: Sensor Analytics Point Solutions for Detection and Decision Support Systems. Sensors (Basel). 2019 ;19(22):4935. [CrossRef] [PubMed]
- Clarke, E.M. , Klieber, W., Nováček, M., Zuliani, P. (2012) Model Checking and the State Explosion Problem. In: Meyer, B., Nordio, M. (eds) Tools for Practical Software Verification. LASER 2011. Lecture Notes in Computer Science, vol 7682. Springer, Berlin, Heidelberg. [CrossRef]
- João Bastos, Jeroen Voeten, Sander Stuijk, Ramon Schiffelers, and Henk Corporaal. 2021. Taming the State-space Explosion in the Makespan Optimization of Flexible Manufacturing Systems. ACM Trans. [CrossRef]
- Rose L, Bewley S, Payne M,Colquhoun D, Perry S. (2024) Using artificial intelligence (AI) to assess the prevalence of false or misleading health-related claims. Royal Society OpenSci. 11: 240698. [CrossRef]
- Májovský M, Černý M, Kasal M, Komarc M, Netuka D. (2023) Artificial Intelligence Can Generate Fraudulent but Authentic-Looking Scientific Medical Articles: Pandora’s Box Has Been Opened. J Med Internet Res. 2023 ; 25:e46924. [CrossRef] [PubMed]
- History of INGRES and POSTGRES https://en.wikipedia.org/wiki/PostgreSQL.
- Acemoglu, Daron, and Pascual Restrepo (2018) Artificial Intelligence, Automation and Work. Working Paper 24196, National Bureau of Economic Research, January 2018. National Bureau of Economic Research. [CrossRef]
- Acemoglu, Daron, and Pascual Restrepo (2018) “The Race between Man and Machine: Implications of Technology for Growth, Factor Shares, and Employment.” American Economic Review, vol. 108, no. 6, 18, pp. [CrossRef]
- Acemoglu, Daron, and Simon Johnson (2023) Power and Progress: Our Thousand-Year Struggle over Technology and Prosperity. 1st edition, Public Affairs, 2023. 9781541702530 https://mitpressbookstore.mit.edu/book/9781541702530.
- https://shapingwork.mit.edu/wp-content/uploads/2023/08/PandP_Acemoglu-Johnson_July2023.pdf.
- https://www.cepr.net/we-can-do-better-with-a-thousand-years-review-of-power-and-progress-by-daron-acemoglu-and-simon-johnson/.
- https://www.cato.org/commentary/book-review-power-progress-our-thousand-year-struggle-over-technology-prosperity.
- “Who Will Benefit from AI?” MIT News | Massachusetts Institute of Technology, . https://news.mit.edu/2023/who-will-benefit-ai-machine-usefulness-0929.
- Daron Acemoglu (2023) Written Testimony: Hearing on “The Philosophy of AI: Learning from History, Shaping Our Future” US Senate Committee on Homeland Security and Governmental Affairs. Daron Acemoglu, Institute Professor, MIT (, 2023) https://www.hsgac.senate.gov/wp-content/uploads/Testimony-Acemoglu-2023-11-08.pdf.
- Daron Acemoglu—2024 Nobel Prize in Economics https://www.nobelprize.org/prizes/economic-sciences/2024/acemoglu/facts/.
- https://news.mit.edu/2024/mit-economists-daron-acemoglu-simon-johnson-nobel-prize-economics-1014.
- Acemoglu, Daron (2024 ) Opinion: America Is Sleepwalking Into an Economic Storm. New York Times. https://www.nytimes.com/2024/10/17/opinion/economy-us-aging-work-force-ai.html.
- Funk, Jeffrey and Smith, Gary ((20240 Opinion: The AI bubble is looking worse than the dot-com bubble. Here’s why. (, 2024) https://www.marketwatch.com/story/the-ai-bubble-is-looking-worse-than-the-dot-com-bubble-heres-why-f688e11d.
- Jürgen Schmidhuber (2024) The #NobelPrizeinPhysics2024 for Hopfield & Hinton rewards plagiarism and incorrect attribution in computer science. (Please see APPENDIX 1, page 222) Jürgen Schmidhuber’s AI Blog https://people.idsia.ch/~juergen/blog.html.
- Thornton JM, Laskowski RA, Borkakoti N. (2021) AlphaFold heralds a data-driven revolution in biology and medicine. Nat Med. 2021 October; 27(10):1666-1669. [CrossRef] [PubMed]
- https://www.nature.com/articles/s41591-021-01533-0.pdf.
- Insulin Structure by Dorothy Crowfoot Hodgkin (1964) https://www.nobelprize.org/prizes/chemistry/1964/hodgkin/facts/.
- AlphaFold Delusion https://www.nature.com/articles/d41586-024-03214-7 https://www.nature.com/articles/d41586-022-00997-5.
- Buse JB, Davies MJ, Frier BM, Philis-Tsimikas A. (2021) 100 years on: the impact of the discovery of insulin on clinical outcomes. BMJ Open Diabetes Res Care. 2021 August; 9(1):e002373. [CrossRef] [PubMed]
- Wysham C, Bajaj HS, Del Prato S, Franco DR, Kiyosue A, Dahl D, Zhou C, Carr MC, Case M, Firmino Gonçalves L; (2024) QWINT-2 Investigators. Insulin Efsitora versus Degludec in Type 2 Diabetes without Previous Insulin Treatment. N Engl J Med. 2024. [CrossRef] [PubMed]
- Balli S, Shumway KR, Sharan S. Physiology, Fever. [Updated 2023 ]. In: StatPearls [Internet] 2024 January https://www.ncbi.nlm.nih.gov/books/NBK562334/.
- Karimi H, Masoudi Alavi N. (2015) Florence Nightingale: The Mother of Nursing. Nurs Midwifery Stud. 2015 June; 4(2):e29475. [CrossRef] [PubMed]
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4557413/pdf/nms-04-29475.pdf.
- Hung CC, Tu MY, Chien TW, Lin CY, Chow JC, Chou W. (2023) The model of descriptive, diagnostic, predictive, and prescriptive analytics on 100 top-cited articles of nasopharyngeal carcinoma from 2013 to 2022: Bibliometric analysis. Medicine (Baltimore). 2023 ; 102(6):e32824. [CrossRef] [PubMed]
- P. M. Kogge and D. A. Bayliss (2013) “Comparative performance analysis of a Big Data NORA problem on a variety of architectures,” 2013 International Conference on Collaboration Technologies and Systems, San Diego, CA, 2013, pp. 22-34. [CrossRef]
- Keyon Vafa, Justin Y. Chen, Jon Kleinberg, Sendhil Mullainathan, and Ashesh Rambachan (2024) Evaluating the World Model Implicit in a Generative Model. arXiv:2406. [CrossRef]
- Frigyes Karinthy (1929) CHAIN-LINKS http://vadeker.net/articles/Karinthy-Chain-Links_1929.pdf.
- Gurevich, Michael (1961) The Social Structure of Acquaintanceship Networks (1961), PhD Thesis, MIT. https://dspace.mit.edu/handle/1721.1/11312.
- Milgram, Stanley (1967) The Small World Problem. Psychology Today 2, 60–67 (1967) https://snap.stanford.edu/class/cs224w-readings/milgram67smallworld.pdf.
- Granovetter, Mark S. (1973) “The Strength of Weak Ties.” American Journal of Sociology, vol. 78, no. 6, 1973, pp. 1360–1380 http://www.jstor.org/stable/2776392 https://www.cs.cmu.edu/~jure/pub/papers/granovetter73ties.pdf.
- Jeff Jonas.
- https://soif.org.uk/speakers/jeff-jonas/.
- https://jeffjonas.typepad.com/ & https://jeffjonas.typepad.com/jeff_jonas/2012/06/index.html.
- Wiseman, C. and MacMillan, I.C. (1984) “CREATING COMPETITIVE WEAPONS FROM INFORMATION SYSTEMS”, Journal of Business Strategy, Vol. 5 No. 2, pp. 42-49. [CrossRef]
- Bourgeois, D. (2014) Non-Obvious Relationship Awareness. In D. Bourgeois, Information Systems for Business and Beyond. USA: Saylor Academy. https://resources.saylor.org/wwwresources/archived/site/textbooks/Information%20Systems%20for%20Business%20and%20Beyond.pdf.
- Jong, Yannick de (2018) Non-Obvious Relationship Awareness (NORA)—IThappens. https://www.ithappens.nu/non-obvious-relationship-awareness-nora/.
- Barabási, Albert-László, Réka Albert, and Hawoong Jeong. "Scale-free characteristics of random networks: the topology of the world-wide web."Physica A: statistical mechanics and its applications 281.1-4 (2000): 69-77.
- C. Fass, B. C. Fass, B. Turtle, and M. Ginelli, Six Degrees of Kevin Bacon. Penguin Books, 1996. https://books.google.com/books/about/Six_Degrees_of_Kevin_Bacon.html?id=op5ZltZSHf4C.
- Computation, Radius (2014) "On the Solvability of the Six Degrees of Kevin Bacon Game." https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=882b6be0dae3ca487720c14249bd2029fe3f6371.
- Person of Interest (2011-2016) https://www.imdb.com/title/tt1839578/.
- WCO—World Customs Organization, Brussels https://www.wcoomd.org/en Disclosure: The cartoon in Figure 55 was created by corresponding author (Shoumen Datta) for discussions at the US Department of Homeland Security (7th Sep 2005). Part of the material was also used in discussions with and within WCO and WTO (World Trade Organization, Brussels) as well as teaching/lectures at MIT Sloan School of Management (Cambridge, MA) and KEDGE Business School (Bordeaux, France). Versions of this cartoon were used in talks, worldwide. During the period 2004-2007, Shoumen Datta served as an Advisor to Michel Danet, Secretary General of WCO, Brussels and engaged in customs security related activities with many foreign government members of the WCO as well as the US Department of Homeland Security, Washington, D.C.
- Sarbanes-Oxley Act of 2002—H.R.3763—107th Congress (2001-2002) https://www.congress.gov/bill/107th-congress/house-bill/3763.
- US Department of Homeland Security—Cargo Security and Examinations https://www.cbp.gov/border-security/ports-entry/cargo-security.
- The Port of Los Angeles—Container Statistics https://www.portoflosangeles.org/business/statistics/container-statistics.
- The Sarbanes-Oxley Act of 2002—https://sarbanes-oxley-act.com/.
- Tang, Y.X. (2019) Big Data Analytics of Taxi Operations in New York City. American Journal of Operations Research, 9, 192-199. [CrossRef]
- Ferguson, Niall (2009) The Ascent of Money: A Financial History of the World. Penguin, NY. https://www.academia.edu/25856541/THE_ASCENT_OF_MONEY_A_FINANCIAL_HISTORY_of_THE_WORLD Reference class.
- Fukuyama, Francis (1995) Trust: the social virtues and the creation of prosperity. Free Press, NY. https://ciaotest.cc.columbia.edu/journals/scs/v1i1/f_0026836_22565.pdf.
- Herbert Simon (1987) The Steam Engine and the Computer: What Makes Technology Revolutionary. EDUCOM Bulletin Vol. 22, no. 1 (Spring 1987) pp. 2-5. https://er.educause.edu/-/media/files/article-downloads/erm0132.pdf https://stacks.stanford.edu/file/druid:kx071kb0607/kx071kb0607.pdf https://direct.mit.edu/books/monograph/4286/chapter/182849/The-Steam-Engine-and-the-Computer-What-Makes Herbert Simon—Nobel Prize—www.nobelprize.org/prizes/economic-sciences/1978/simon/facts.
- B.C. Time-stamped data collection recorded as documentation of Sunspots (China). Zhentao, X. (1989). The Basic Forms of Ancient Chinese Sunspot Records. Chinese Science, 9, 19–28. http://www.jstor.org/stable/43290440 https://chandra.harvard.edu/edu/formal/icecore/The_Historical_Sunspot_Record.pdf.
- Udny Yule (1927) On a Method of Investigating Periodicities in Disturbed Series, with Special Reference to Wolfer’s Sunspot Numbers. Philosophical Transactions of the Royal Society of London. Series A, Papers of a Mathematical or Physical Character, Vol. 226 (1927) 267-298. https://www.jstor.org/stable/91170 and https://federico-ramponi.unibs.it/ddsm/yule.pdf Biographical https://www.cambridgescholars.com/resources/pdfs/978-1-4438-5067-4-sample.pdf.
- Cini, Andrea, et al. (2023) Graph Deep Learning for Time Series Forecasting. arXiv, 2023. [CrossRef]
- Lesovik, G.B. , Sadovskyy, I.A., Suslov, M.V. et al. Arrow of time and its reversal on the IBM quantum computer. Nature Science Reports. [CrossRef]
- Konstantin Kakaes () “No, Scientists Didn’t Just ‘Reverse Time’ with a Quantum Computer.” MIT Technology Review. https://www.technologyreview.com/2019/03/14/103311/no-ibm-didnt-just-reverse-time-with-a-quantum-computer.
- Parlier, Greg H. (, 2011) Transforming U.S. Army Supply Chains: Strategies for Management Innovation. Business Expert Press, NY.
- ICORES 2024. 13th International Conference on Operations Research and Enterprise Systems https://icores.scitevents.org/KeynoteSpeakers.aspx.
- NetDay https://en.wikipedia.org/wiki/NetDay.
- Zhan, Y. , Tan, X., Wang, M., Wang, T., Zheng, Q., Shi, Q. (2023) Implementation and Deployment of Digital Twin in Cloud-Native Network. In: Quan, W. (eds) Emerging Networking Architecture and Technologies. ICENAT 2022. Com in Computer and Information Sci, vol 1696. Springer, Singapore. [CrossRef]
- Xiaochen Zheng, Jinzhi Lu & Dimitris Kiritsis (2022) The emergence of cognitive digital twin: vision, challenges and opportunities, International Journal of Production Research, 60: 24, pages 7610-7632. [CrossRef]
- US VC Valuations Report Q2 (, 2024) https://pitchbook.com/news/reports/q2-2024-us-vc-valuations-report & https://pitchbook.com/news/reports/q2-2024-us-vc-valuations-report & https://twitter.com/rodneyabrooks/status/1825944530929201605.
- Hanoch Gutfreund and Jürgen Renn (2023) The Einsteinian Revolution: The Historical Roots of His Breakthroughs. Princeton University Press. ISBN 978069116.
- https://doi.org/10.2307/jj.3876688 & https://press.princeton.edu/our-authors/renn-jurgen https://ui.adsabs.harvard.edu/abs/2023erhr.book.....R/abstract ISBN 9780691256498.
- Didymos & Dimorphos—NASA Science https://science.nasa.gov/solar-system/asteroids/didymos/.
- Bongard, Mikhail Moiseevich (1970) Pattern Recognition. Edited by Joseph K. Hawkins. Translated by Theodore Cheron. Published, 1970 (Rochelle Park, NJ; Hayden Book Company, Spartan Books) https://archive.org/details/patternrecogniti00bong https://www.journals.uchicago.edu/doi/10.1086/407078.
- Kidder, Tracy (2003) Mountains Beyond Mountains: The Quest of Dr. Paul Farmer, A Man Who Would Cure the World. Random House, NY. ISBN-13: 978-0812973013.
- Wilczek, Frank (2005) Nobel Lecture: Asymptotic freedom: From paradox to paradigm. Reviews of Modern Physics 77(3) p.857 https://arxiv.org/pdf/hep-ph/0502113.pdf https://journals.aps.org/rmp/pdf/10.1103/RevModPhys.77.857 https://www.nobelprize.org/prizes/physics/2004/wilczek/facts/.
- Rabindranath Tagore (1928) Fireflies. https://www.best-poems.net/poem/fireflies-by-rabindranath-tagore.html & https://www.nobelprize.org/prizes/literature/1913/summary/ https://www.nobelprize.org/prizes/literature/1913/tagore/facts/.
Figure 1.
a: Ideas and degrees of “twining” may vary but by reducing conceptual barriers we may be able to accelerate the adoption cycle, at least in principle. Both cartoons are “twins” of some sort but cartoon on the left [18] illustrates the canonical idea of digital twins. The cartoon on the right [19] highlights the pain inflicted due to unethical globalization, aggression and war crimes. b: In some instances it may appear that certain practices are loosely based on the idea or principle of digital twins but without the moniker. The “digital” representation of the turkey in the oven is delivering the on-demand functionality, i.e., the temperature of the turkey in the oven. c: Real vs virtual representation [20] of the train is devoid of new technology. It is a GUI illustrating the wireframe of an actual object to display data from hardware, using software.
Figure 1.
a: Ideas and degrees of “twining” may vary but by reducing conceptual barriers we may be able to accelerate the adoption cycle, at least in principle. Both cartoons are “twins” of some sort but cartoon on the left [18] illustrates the canonical idea of digital twins. The cartoon on the right [19] highlights the pain inflicted due to unethical globalization, aggression and war crimes. b: In some instances it may appear that certain practices are loosely based on the idea or principle of digital twins but without the moniker. The “digital” representation of the turkey in the oven is delivering the on-demand functionality, i.e., the temperature of the turkey in the oven. c: Real vs virtual representation [20] of the train is devoid of new technology. It is a GUI illustrating the wireframe of an actual object to display data from hardware, using software.

Figure 5.
Palm [203] or finger [204] biometric photoplethysmography [205] in retail shops, grocery stores, shopping malls, petrol pumps, etc., can record blood glucose levels, SpO2, hemoglobin, blood pressure, respiratory rate [206], heart rate [207] (pulse), body temperature and bone density [208] (with additional [209] tools) for a compendium of vital [210] signs (key physiological indicators, KPI). The biometric id and time stamped individualized time series data is sent to the user’s mobile phone, designated physicians, hospitals and any authorized entity (family). Children in schools, students in universities, employees in work-places and customers in restaurants can choose to record their vital data. Instruments placed in kiosks, community centers, primary care or convenience stores can serve citizens. Granular time series data is a digital treasure trove for personalized medicine, if uncorrupted. Anonymized data collected by health groups can map zip codes where help is necessary. Data-informed evidence-based policies can improve local and national governance. Data from sewers (wastewater, sanitation) may be integrated with crowd-sourced medical data to begin to build epidemiologic profile to aid precision public health for prevention and control.
Figure 5.
Palm [203] or finger [204] biometric photoplethysmography [205] in retail shops, grocery stores, shopping malls, petrol pumps, etc., can record blood glucose levels, SpO2, hemoglobin, blood pressure, respiratory rate [206], heart rate [207] (pulse), body temperature and bone density [208] (with additional [209] tools) for a compendium of vital [210] signs (key physiological indicators, KPI). The biometric id and time stamped individualized time series data is sent to the user’s mobile phone, designated physicians, hospitals and any authorized entity (family). Children in schools, students in universities, employees in work-places and customers in restaurants can choose to record their vital data. Instruments placed in kiosks, community centers, primary care or convenience stores can serve citizens. Granular time series data is a digital treasure trove for personalized medicine, if uncorrupted. Anonymized data collected by health groups can map zip codes where help is necessary. Data-informed evidence-based policies can improve local and national governance. Data from sewers (wastewater, sanitation) may be integrated with crowd-sourced medical data to begin to build epidemiologic profile to aid precision public health for prevention and control.

Figure 6.
Post-pandemic incidents of CVD are increasing due to multi-factorial confounding [224] reasons which makes it difficult to make predictions of risk based on bio-markers. More than 3 billion [225] (of the 8 billion global population) were infected with SARS-CoV-2 (2020-2021). .
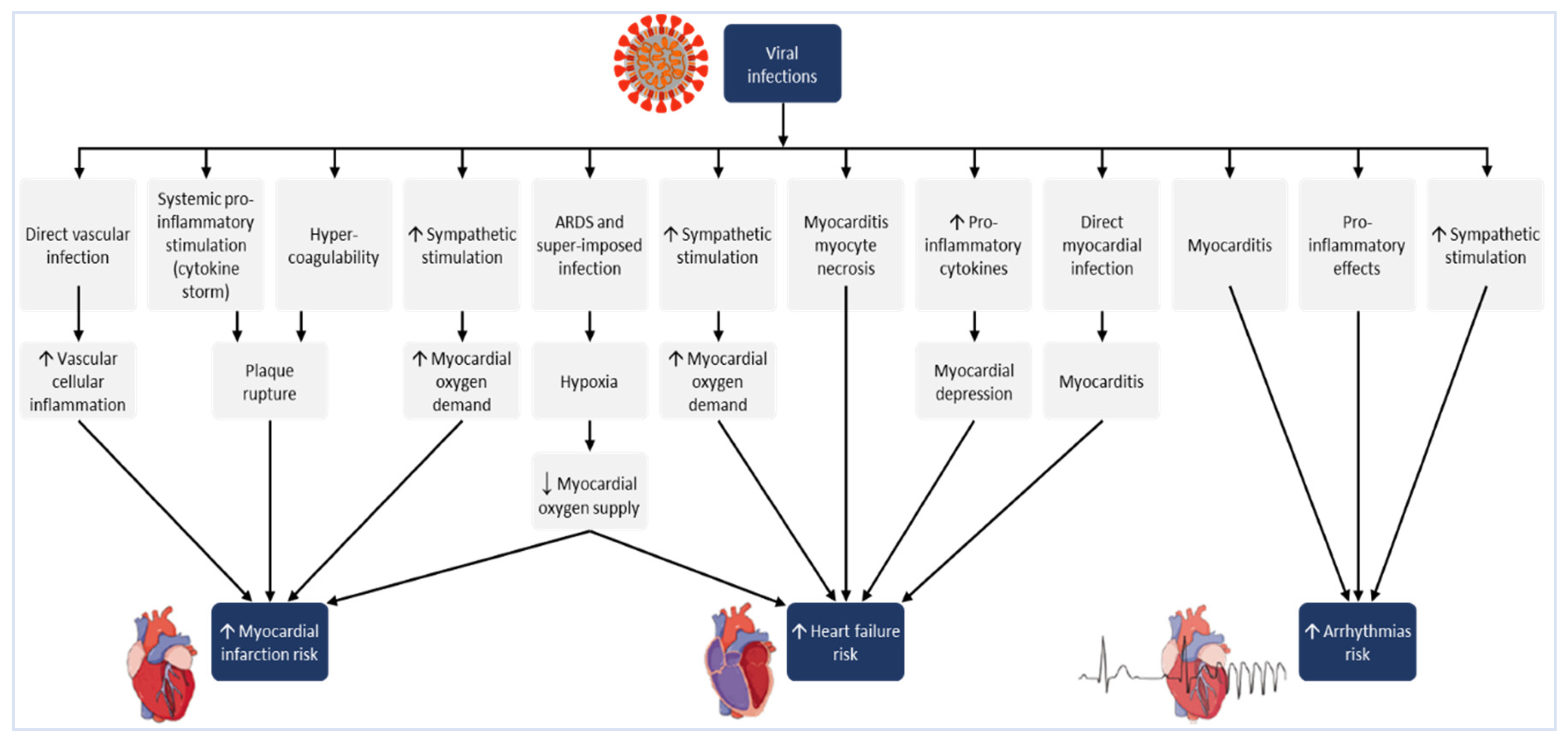
Figure 11.
Pyramid (top) suggests the importance of integrated systems thinking to synergize the trinity of analytics, connectivity, data in the context of causality (ACDC). An analogy is that of 6 (blind) men from Indostan [278] (India) touching parts of an elephant [279] and claiming the “elephant is a tree” (man who touched the leg), “it is like a rope” said the blind man who touched the tail. “Like a snake” (man who touched the trunk). “It is like a big hand fan” (man who touched the ear). “Like a huge wall” said the man who touched the belly of the elephant. “Like a spear” said the blind man who touched the tusk. By focusing on parts, they missed the far greater value from the sum of the parts. Misguided by solely focusing on the part (sub-system? silo?) their data, understanding and decision was incorrect. As a consequence, their interpretation lacks actionable value in the context of the “whole” animal (integrated system, system of systems, ecosystem).
Figure 11.
Pyramid (top) suggests the importance of integrated systems thinking to synergize the trinity of analytics, connectivity, data in the context of causality (ACDC). An analogy is that of 6 (blind) men from Indostan [278] (India) touching parts of an elephant [279] and claiming the “elephant is a tree” (man who touched the leg), “it is like a rope” said the blind man who touched the tail. “Like a snake” (man who touched the trunk). “It is like a big hand fan” (man who touched the ear). “Like a huge wall” said the man who touched the belly of the elephant. “Like a spear” said the blind man who touched the tusk. By focusing on parts, they missed the far greater value from the sum of the parts. Misguided by solely focusing on the part (sub-system? silo?) their data, understanding and decision was incorrect. As a consequence, their interpretation lacks actionable value in the context of the “whole” animal (integrated system, system of systems, ecosystem).


Figure 22.
Bernard Lown [505] (1961) of Brigham and Women’s Hospital, Harvard Medical School, is credited in the Western world with initiating the modern era of cardioversion [506]. He combined direct current defibrillation and cardioversion with portability and safety [507]. The obsolescence of landline phones in UK vacated the iconic phone boxes, which now houses AED (defibrillators). Roadside defibrillator in the village of Marsh Green (below), near Town of Edenbridge, Kent.
Figure 22.
Bernard Lown [505] (1961) of Brigham and Women’s Hospital, Harvard Medical School, is credited in the Western world with initiating the modern era of cardioversion [506]. He combined direct current defibrillation and cardioversion with portability and safety [507]. The obsolescence of landline phones in UK vacated the iconic phone boxes, which now houses AED (defibrillators). Roadside defibrillator in the village of Marsh Green (below), near Town of Edenbridge, Kent.
Figure 27.
The economics of technology and value proposition will determine if THz sensors in the sewers may fly, adapt or die [561]. Let us explore Ampex, they pioneered the video recorder market in 1956. Each VCR unit was priced at $50,000. Masaru Ibuka, co-founder of Sony and Yuma Shiraishi at JVC, set out to produce VCRs that would cost 1% of Ampex’s price. In the 1980’s, VCR sales went from $17 million to $2 billion at Sony, $2 million to $2 billion at JVC, $6 million to $3 billion at Matsushita [562]. By 2000’s VCR’s were ~$50 and VHS tapes were ~$1. Millennials don’t even know about VCRs. What about microprocessors, memory, storage? To develop a low-cost sensor for resource constrained [563] communities the initial “sticker” shock (high cost) may be the price of excellence and the recognition that the next billion users deserve effective tools, trusted [564] systems and knowledge to build a better compass, to create new roads (not just a road map, to merely find pre-existing roads).
Figure 27.
The economics of technology and value proposition will determine if THz sensors in the sewers may fly, adapt or die [561]. Let us explore Ampex, they pioneered the video recorder market in 1956. Each VCR unit was priced at $50,000. Masaru Ibuka, co-founder of Sony and Yuma Shiraishi at JVC, set out to produce VCRs that would cost 1% of Ampex’s price. In the 1980’s, VCR sales went from $17 million to $2 billion at Sony, $2 million to $2 billion at JVC, $6 million to $3 billion at Matsushita [562]. By 2000’s VCR’s were ~$50 and VHS tapes were ~$1. Millennials don’t even know about VCRs. What about microprocessors, memory, storage? To develop a low-cost sensor for resource constrained [563] communities the initial “sticker” shock (high cost) may be the price of excellence and the recognition that the next billion users deserve effective tools, trusted [564] systems and knowledge to build a better compass, to create new roads (not just a road map, to merely find pre-existing roads).
Figure 35.
Cartoon from page 74, ref 649 (Minsky, M. [1986] Society of Mind) is a “neuralized” problem solving approach from Newell, Shaw & Simon (1958 [750], 1959 [751], 1963 [752]).
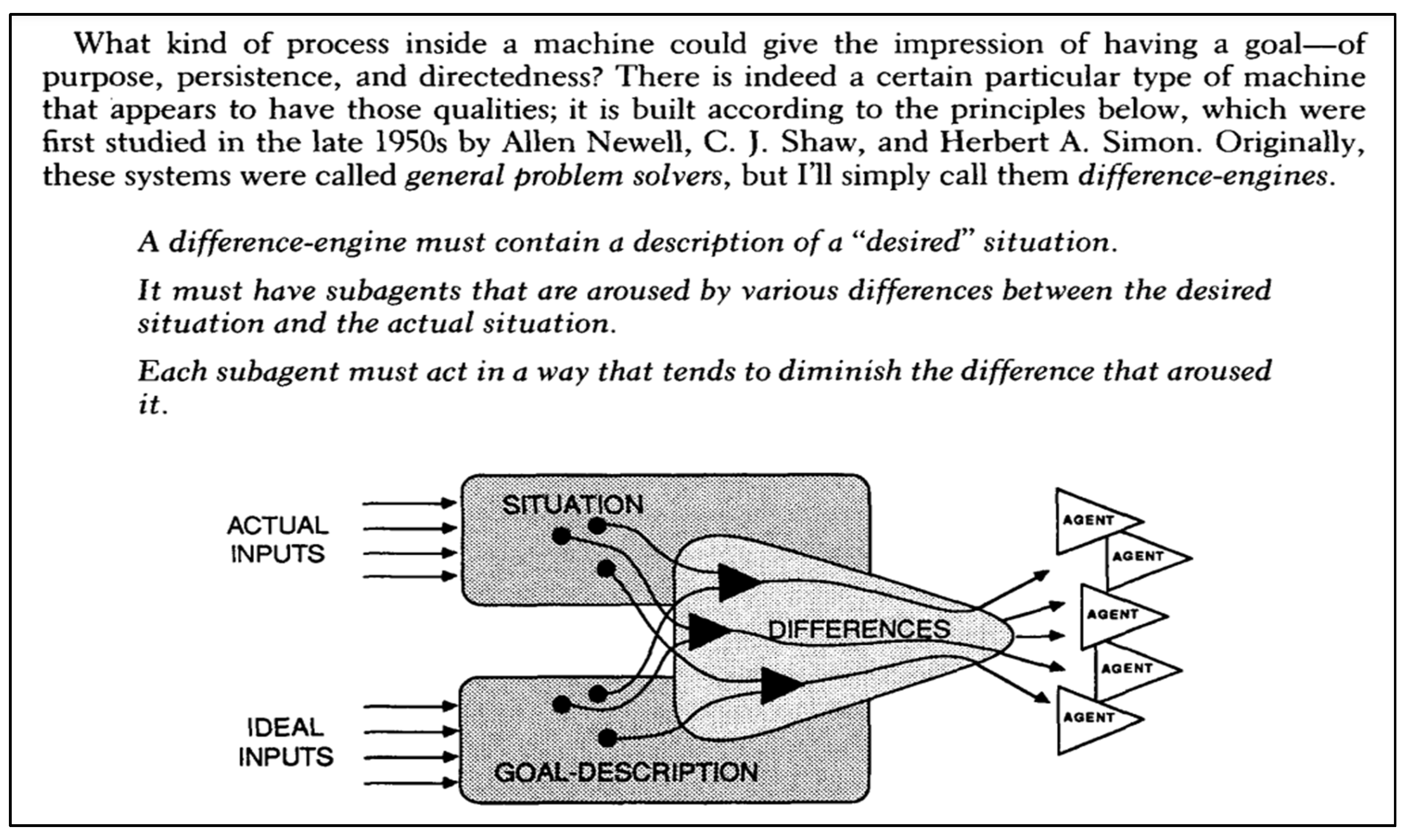
Figure 36.
Cartoon from pg. 154 (of 336) from ref 646 (Marvin Minsky [1986] Society of Mind).
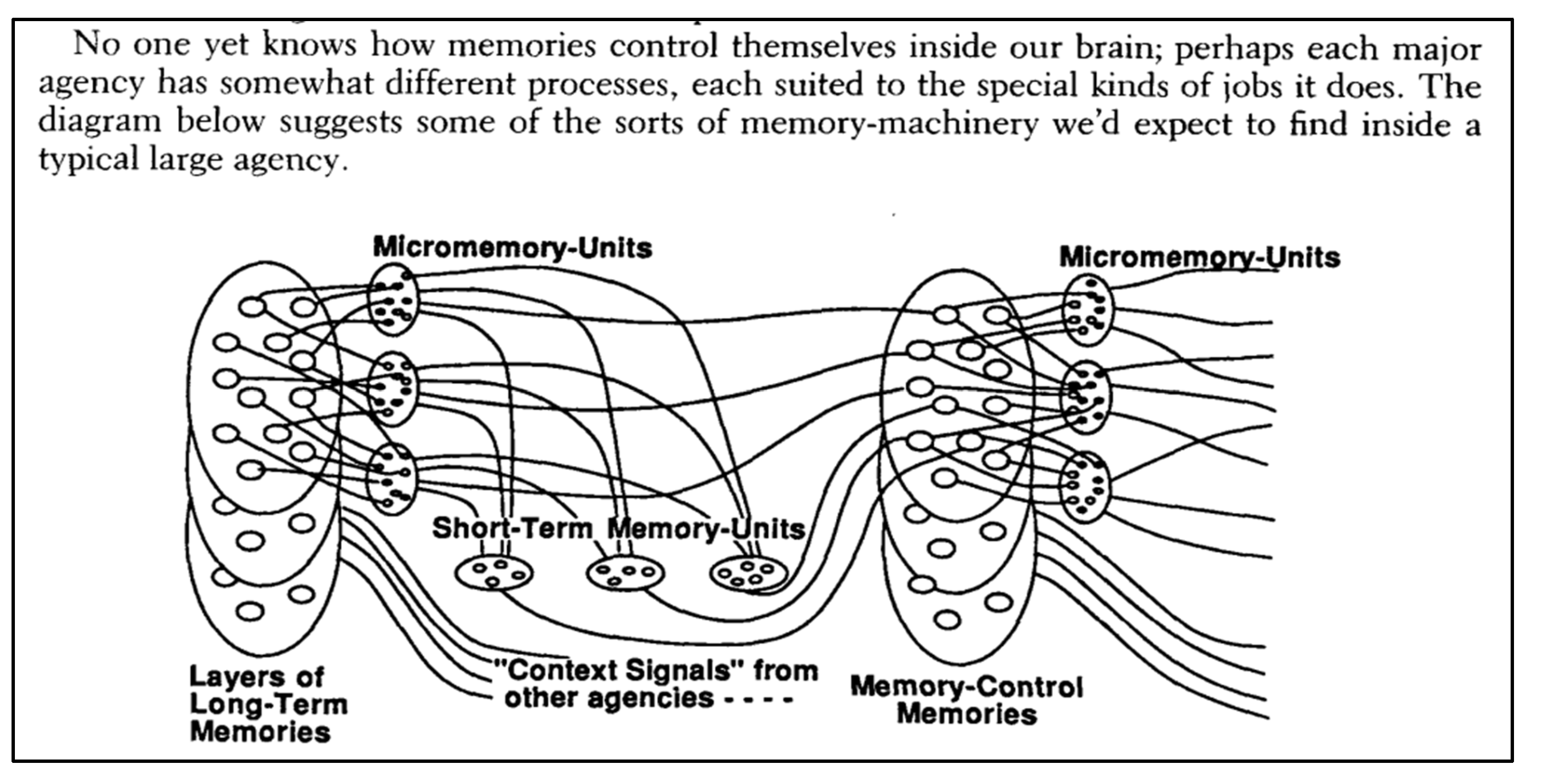
Figure 37.
Synapses [757] are composed of presynaptic specializations containing canonical neurotransmitter release machinery and postsynaptic specializations constructed of diverse receptors and postsynaptic densities.
Figure 37.
Synapses [757] are composed of presynaptic specializations containing canonical neurotransmitter release machinery and postsynaptic specializations constructed of diverse receptors and postsynaptic densities.
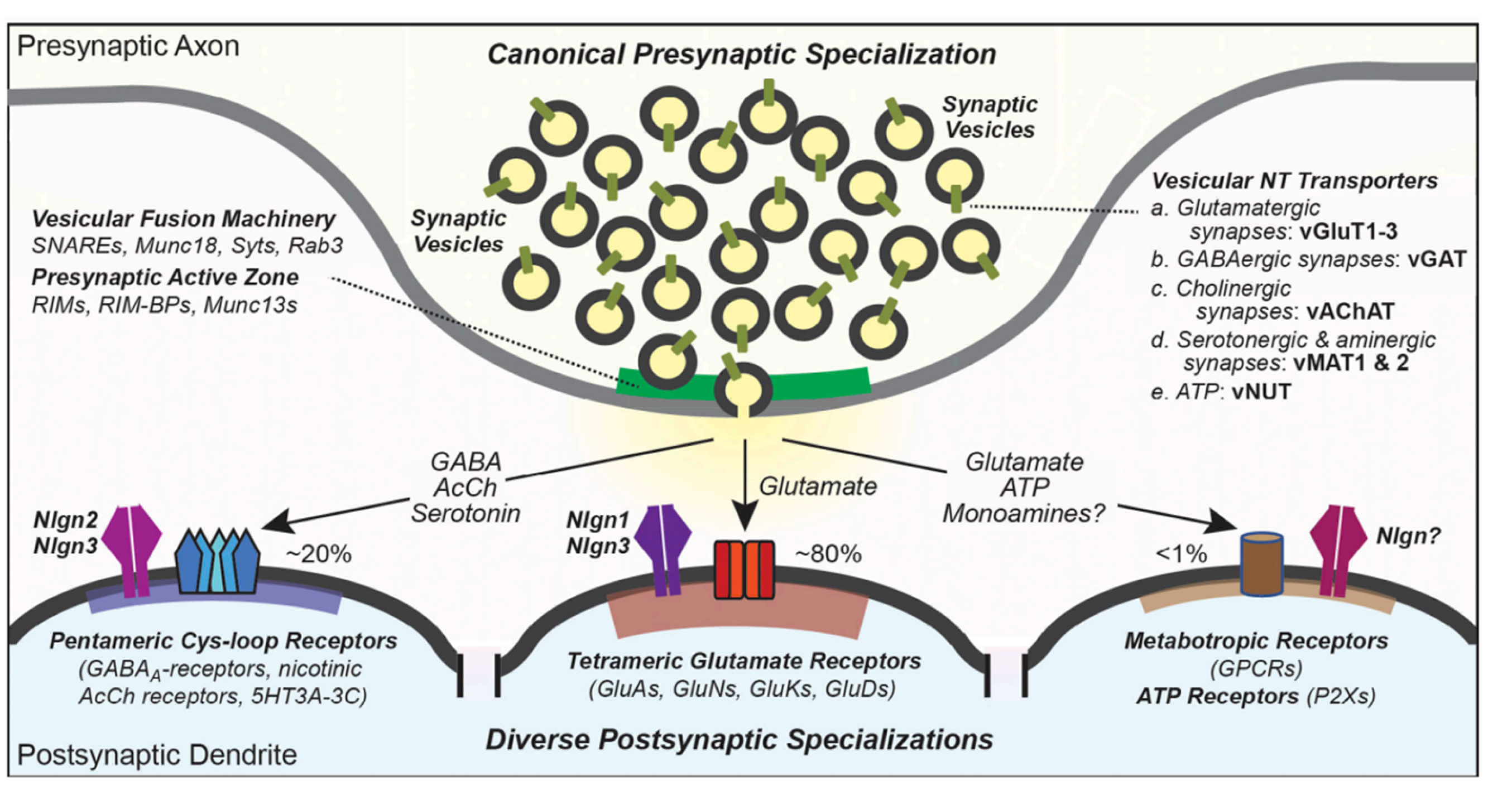
Figure 38.
Unable to model the complexity in Figure 36-37, we have reduced/excluded most features to create an unit model for ANN. The input is denoted by x (independent variable) and the processing (see circle) is followed by the output y (dependent variable). This is ANN.
Figure 38.
Unable to model the complexity in Figure 36-37, we have reduced/excluded most features to create an unit model for ANN. The input is denoted by x (independent variable) and the processing (see circle) is followed by the output y (dependent variable). This is ANN.
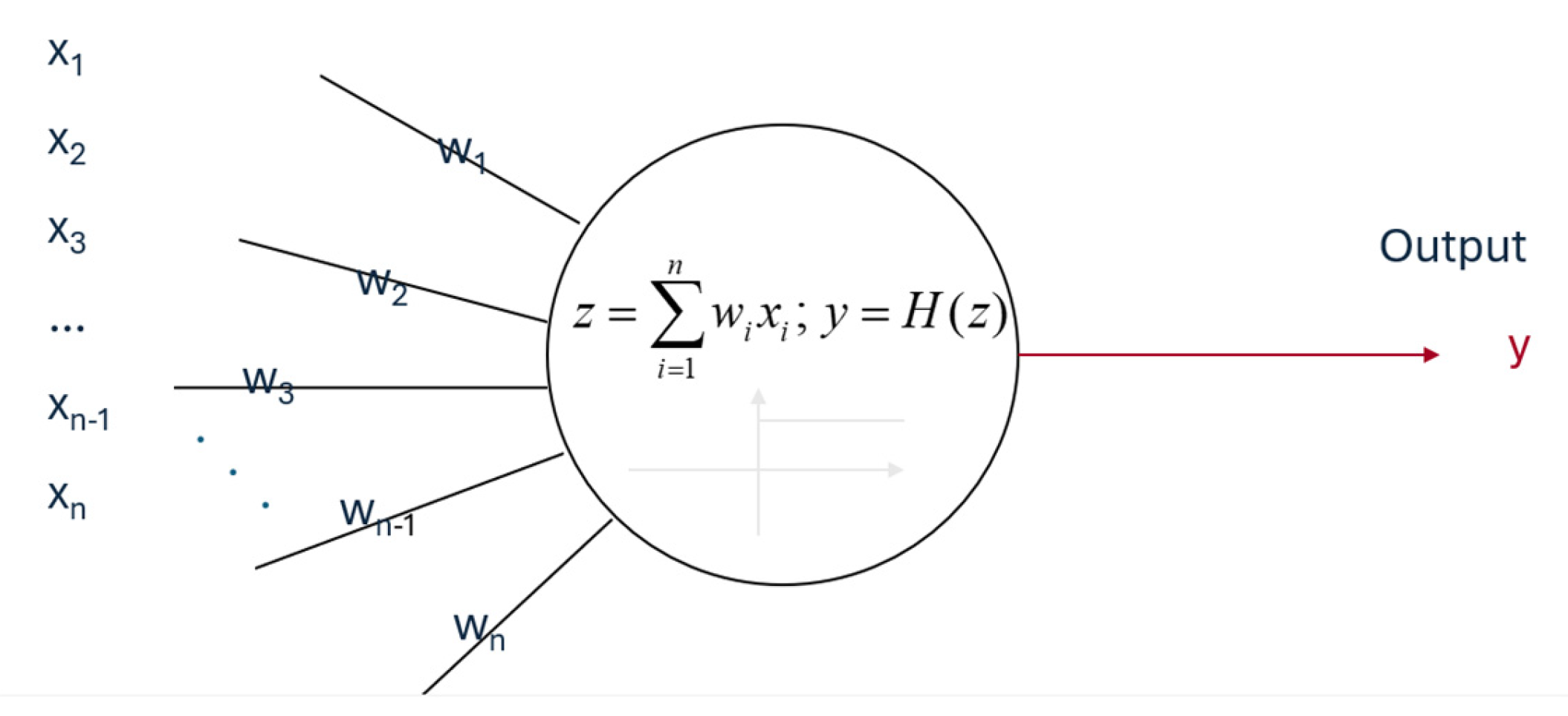
Figure 39.
Cartoon on page 198 (of 336) from reference 646 (text refers to Perceptrons [760]).
Figure 39.
Cartoon on page 198 (of 336) from reference 646 (text refers to Perceptrons [760]).
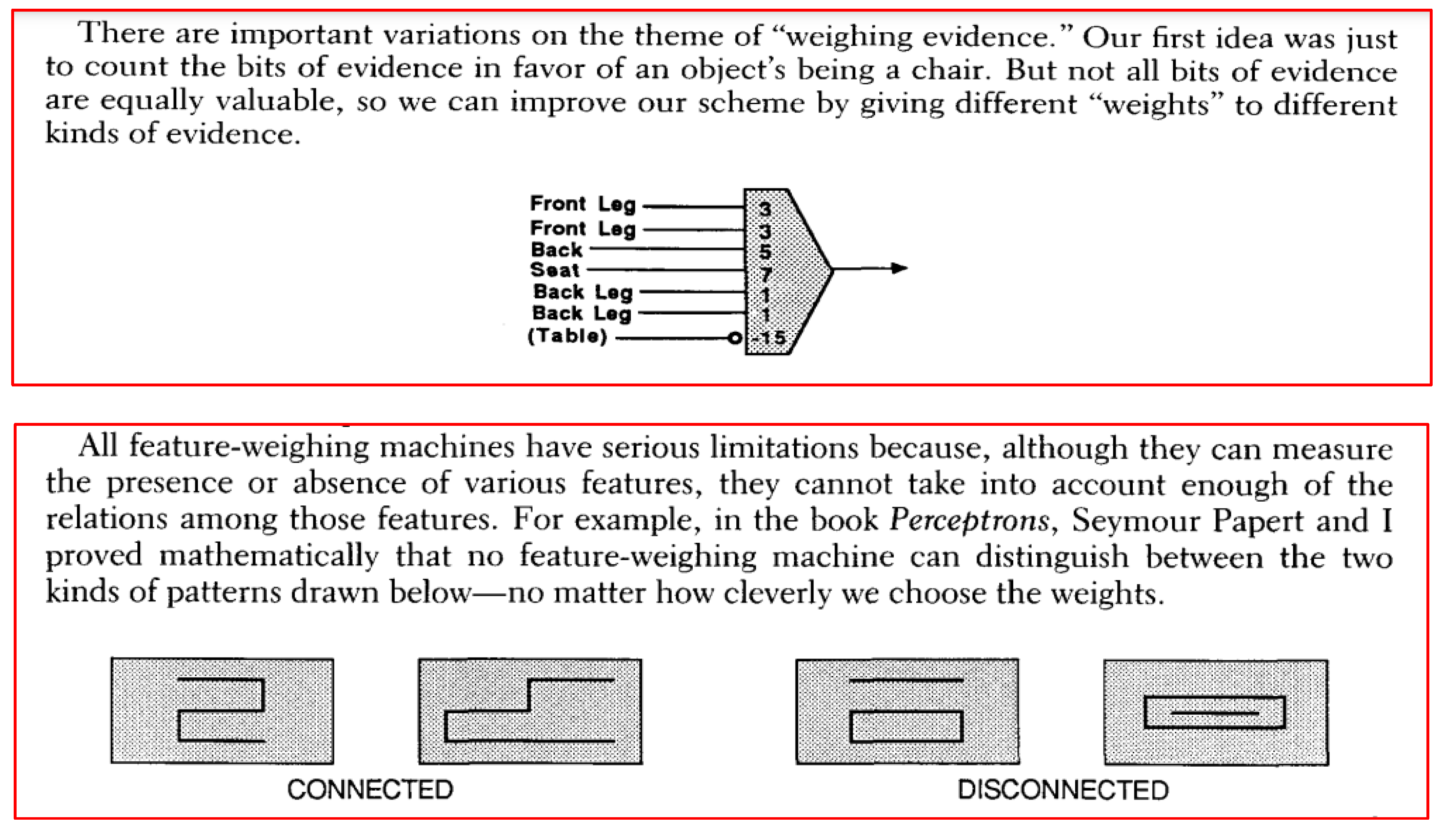
Figure 40.
The rise of artificial stupidity appears to show no signs of decline [761]. The Image Identification Project [762] indicates the potential of AI in creating slapstick humor for the entertainment industry or a killer app for children.

Table 1.
Parameters that define the operation of digital twins are central to its design in terms of data acquisition (connectivity), integrity of the data and analytics performed on the data to obtain information. Publications appear to focus on models and architectures, which may be useful for development of standards. Systems integration is the commercial thrust. What is lacking from the discussion is the nature of the parameters (measurable factors) and the science of causality with respect to data. Data acquisition tools for systems integration aren’t smart (usually dumb as door-knobs). If the logic layer lacks the causal rational, can we trust the value of information?
Table 1.
Parameters that define the operation of digital twins are central to its design in terms of data acquisition (connectivity), integrity of the data and analytics performed on the data to obtain information. Publications appear to focus on models and architectures, which may be useful for development of standards. Systems integration is the commercial thrust. What is lacking from the discussion is the nature of the parameters (measurable factors) and the science of causality with respect to data. Data acquisition tools for systems integration aren’t smart (usually dumb as door-knobs). If the logic layer lacks the causal rational, can we trust the value of information?
| Digital Twins—focus, characteristics, approaches, tools and use of common technologies |
| Data-centricity [82] |
| Knowledge representation [83] |
| Physics-based system modelling and distributed real-time process data to generate a digital design of the system at the pre-production phase (engineering analysis capabilities) [84] |
| Standards [85] |
| Reference models [86] |
| Architecture [87] |
| Architecture (reference model for cloud-based cyber-physical systems) [88] |
| Architecture (data and simulation model for digital town) [89] |
| Architecture (Industry 4.0 services) [90] |
| Architecture (6-layer production system [91], 5-level CPS architecture [92] & L6 for simulation) |
| Sensing-as-a-Service [93] |
| Data architecture (for logistics [94] system) |
| Integrate real-time data processing ( for logistics [95] system). Three component architecture: data acquisition, data processing, data visualization. Data acquisition: sensors, micro-controller, beacons (WLAN integrated with data processing). Data processing: SMACK (Spark, Mesos, Akka, Cassandra, Kafka) for distributed streaming big data. MQTT data broker Mosquitto and Java Spring Boot Framework for backend support. Components communicate with backend via representational state transfer (REST) API. Data visualization: KPIs & digital descriptions of physical objects on frontend e.g., Angular, component-based UI |
Table 2.
Acute MI and heart failure (CHF, AHF) bio-markers [230]: Prognostic [P]; Diagnostic [D]; Risk Stratification [RS]; Therapeutic Guidance [TG]; Therapeutic Target [TT]. BNP: B-type natriuretic peptide; cMyC: cardiac myosin-binding protein C; CRP: C-reactive protein; cys-C: cystatin C; ESM-1: endothelial cell-specific molecule 1; Gal-3: galectin-3; GDF-15: growth-differentiation factor-15; hFABP: heart-type fatty acid binding protein; hs-cTn: high-sensitivity troponin; IL-6: interleukin-6; lncRNA: long noncoding RNA; miRNA: microRNA; MPV: mean platelet volume; NT-proBNP: N-terminal pro-brain natriuretic peptide; PAPP-A: pregnancy-associated plasma protein-A; sCD40L: soluble CD40 ligand; SIRT: sirtuin; ST-2: suppression of tumorigenicity 2; TREML: triggering receptor expressed on myeloid cells.
Table 2.
Acute MI and heart failure (CHF, AHF) bio-markers [230]: Prognostic [P]; Diagnostic [D]; Risk Stratification [RS]; Therapeutic Guidance [TG]; Therapeutic Target [TT]. BNP: B-type natriuretic peptide; cMyC: cardiac myosin-binding protein C; CRP: C-reactive protein; cys-C: cystatin C; ESM-1: endothelial cell-specific molecule 1; Gal-3: galectin-3; GDF-15: growth-differentiation factor-15; hFABP: heart-type fatty acid binding protein; hs-cTn: high-sensitivity troponin; IL-6: interleukin-6; lncRNA: long noncoding RNA; miRNA: microRNA; MPV: mean platelet volume; NT-proBNP: N-terminal pro-brain natriuretic peptide; PAPP-A: pregnancy-associated plasma protein-A; sCD40L: soluble CD40 ligand; SIRT: sirtuin; ST-2: suppression of tumorigenicity 2; TREML: triggering receptor expressed on myeloid cells.
| Bio-markers | Pathophysiology (AMI, AHF, CHF) | Clinical Value |
|---|---|---|
| hs-cTn | Myocardial injury | P—D—RS—TG |
| BNP/NT-proBNP | Myocyte stretch Inflammation, Oxidative stress |
P—D—RS—TG—TT |
| Copeptin | Inflammation, Oxidative Stress | P—D |
| CRP, sCD40L | Inflammation | P |
| IL-6 | Inflammation, Hypertrophy/fibrosis | P—D—RS |
| Gal-3 | Hypertrophy/fibrosis, Myocardial injury | P—TG |
| ESM-1 | Endothelial dysfunction, Hypertrophy/fibrosis | P—RS |
| cMyC | Endothelial dysfunction | D |
| hFABP | Myocardial injury | D |
| ST-2 | Myocardial injury | P—TG—RS |
| TREML, PAPP-A | Myocardial injury | P |
| miRNA | Oxidative stress | P—D |
| lncRNA | Inflammation | P |
| SIRT, GDF-15 | Apoptosis | P |
| MPV, cys-C | P |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



